

ترسل برامج التطبيقات رسائلًا إلى بعضها بعضًا، وكلٌّ من هذه الرسائل هي مجرد سلسلة غير مفسّرة من البايتات من منظور الشبكة، لكن هذه الرسائل تحتوي على أنواعٍ مختلفة من البيانات من منظور التطبيق، مثل مصفوفاتٍ من الأعداد الصحيحة وإطارات الفيديو وأسطر النص والصور الرقمية وما إلى ذلك، أي أن هذه البايتات لها معنى.
نأخذ الآن في الحسبان مشكلةَ أفضل طريقةٍ لتشفير الأنواع المختلفة من البيانات التي تريد برامج التطبيقات تبادلها ضمن سلاسل البايت، وهذا يشبه في كثيرٍ من النواحي مشكلة تشفير سلاسل البايتات ضمن إشاراتٍ كهرومغناطيسية التي رأيناها سابقًا.
هناك شكلان أساسيان للتشفير، أولهما يكون فيه المستقبِل قادرًا على استخراج نفس الرسالة من الإشارة التي أرسلها المرسل، وهذه هي مشكلة التأطير framing، والثاني هو جعل التشفير فعالًا قدر الإمكان. كلٌّ من هذه المخاوف موجودةٌ أيضًا عند تشفير بيانات التطبيق ضمن رسائل الشبكة.
لكي يتمكن المستقبل من استخراج الرسالة التي أرسلها المرسل، سيحتاج الطرفان إلى الموافقة على صيغة الرسالة المُسماة غالبًا صيغة العرض presentation format؛ فمثلًا إذا أراد المرسل إرسال مصفوفةٍ من الأعداد الصحيحة إلى المستقبِل، فيجب على الجانبين الاتفاق على شكل كلِّ عدد صحيح من ناحية عدد البتات، وكيفية ترتيب البايتات، وما إذا كان البايت الأعلى أهمية يأتي أولًا أو أخيرًا على سبيل المثال، وعدد العناصر الموجودة في المصفوفة.
يصف القسم الأول ترميزات مختلفة لبيانات الحاسوب التقليدية مثل الأعداد الصحيحة والأعداد العشرية وسلاسل الأحرف والمصفوفات والبنى. توجد أيضًا صيغٌ لبيانات الوسائط المتعددة، حيث يُنقل الفيديو في العادة مثلًا بإحدى الصيغ التي أنشأتها مجموعة خبراء الصور المتحركة Moving Picture Experts Group أو اختصارًا MPEG، وتُرسَل الصور الثابتة بصيغة المجموعة المشتركة لخبراء التصوير Joint Photographic Experts Group أو اختصارًا JPEG. نناقش المشاكل الخاصة التي تنشأ في تشفير بيانات الوسائط المتعددة لاحقًا.
تتطلب أنواع بيانات الوسائط المتعددة منا التفكير في كلٍ من العرض presentation والضغط compression، وتتعامل الصيغ المعروفة لنقل وتخزين الصوت والفيديو مع هاتين المسألتين من خلال التأكد من أن الذي جرى تسجيله أو تصويره أو سماعه لدى المرسل يمكن أن يفسّره المستقبل بصورةٍ صحيحة، وفعل ذلك بطريقةٍ تؤدي إلى عدم إغراق الشبكة بكمياتٍ هائلة من بيانات الوسائط المتعددة.
للضغط و لكفاءة التشفير تاريخٌ غني يعود إلى ابتكار شانون في نظرية المعلومات في فترة الأربعينات، فهناك قوتان متعارضتان تعملان هنا، وقد ترغب في الحصول على أكبر قدرٍ ممكن من التكرار في البيانات حتى يتمكن المستقبل من استخراج البيانات الصحيحة، حتى إذا أُدخلت أخطاءٌ في الرسالة. تضيف شيفرات اكتشاف الأخطاء وتصحيحها التي رأيناها في فصلٍ سابق معلومات زائدة إلى الرسائل لهذا الغرض، لكن نود إزالة أكبر قدرٍ ممكن من التكرار من البيانات حتى نتمكن من ترميزها في أقل عددٍ ممكن من البتات. توفّر بيانات الوسائط المتعددة ثروةً من الفرص للضغط بسبب الطريقة التي تعالج بها حواسنا وأدمغتنا الإشارات المرئية والسمعية، حيث أننا لا نسمع الترددات العالية وكذلك الترددات المنخفضة، ولا نلاحظ التفاصيل الدقيقة مثل الصورة الأكبر في الصورة، خاصةً إذا كانت الصورة تتحرك.
يُعَد الضغط مهمًا لمصممي الشبكات لعدة أسباب، ليس فقط لأننا نادرًا ما نجد وفرةً في حيز النطاق التراسلي bandwidth في كل مكانٍ في الشبكة، حيث تؤثر الطريقة التي نصمم بها خوارزمية ضغطٍ على حساسيتنا للبيانات المفقودة أو المتأخرة على سبيل المثال، وبالتالي قد تؤثر على تصميم آليات تخصيص الموارد وبروتوكولات طرفٍ إلى طرف. وبالمقابل إذا كانت الشبكة الأساسية غير قادرةٍ على ضمان مقدارٍ ثابت من حيز النطاق التراسلي طوال مدة مؤتمر الفيديو، فقد نختار تصميم خوارزميات ضغط متكيّفة مع ظروف الشبكة المتغيرة.
أخيرًا، تتمثل أحد الجوانب المهمة لكلٍ من صيغة العرض وضغط البيانات في أنهما يتطلبان من مضيفَي الإرسال والاستقبال معالجة كل بايتٍ من البيانات في الرسالة، ولهذا السبب يُطلق أحيانًا على تنسيق العرض وضغطه اسم وظيفتي معالجة البيانات data manipulation، وهذا على عكس معظم البروتوكولات المشروحة سابقًا، والتي تعالج الرسالة دون النظر إلى محتوياتها مطلقًا. وتؤثر معالجة البيانات على معدل النقل من طرفٍ إلى طرف عبر الشبكة بسبب تلك الحاجة إلى قراءة كل بايت من البيانات في رسالة وحسابها وكتابتها، حيث يمكن أن تكون هذه المعالَجات هي العامل المحدد في بعض الحالات.
صيغة العرض
إحدى أكثر عمليات تحويل بيانات الشبكة شيوعًا هو التحويل من التمثيل الذي يستخدمه برنامج التطبيق إلى نموذجٍ مناسبٍ للإرسال عبر الشبكة والعكس صحيح، ويسمى هذا التحويل عادةً صيغة العرض presentation formatting، حيث يترجم برنامج الإرسال البيانات التي يريد نقلها من التمثيل الذي يستخدمه داخليًا إلى رسالةٍ يمكن إرسالها عبر الشبكة كما هو موضحٌ في الشكل الآتي؛ أي أن البيانات مشفرةٌ encoded في رسالة، ثم يترجم التطبيق هذه الرسالة القادمة على الجانب المستقبل إلى تمثيلٍ يمكنه بعد ذلك معالجته؛ وهذا يعني أنه فُك تشفير decoded الرسالة. تُسمى هذه العملية أحيانًا تنظيم الوسطاء argument marshalling أو التسلسل serialization، وتأتي هذه المصطلحات من عالم استدعاء الإجراء البعيد Remote Procedure Call أو اختصارًا RPC، حيث يعتقد العميل أنه يستدعي إجراءً مع مجموعة من الوسطاء، ولكن يجري بعد ذلك تجميع هذه الوسطاء وترتيبها بطريقةٍ مناسبة وفعالة لتشكيل رسالة شبكة.
.png.4fc69e6f06dd7e5c966ce130095be70c.png)
قد تسأل ما الذي يجعل هذه المشكلة صعبة، فأحد الأسباب هو تمثيل الحواسيب للبيانات بطرقٍ مختلفة، فقد تمثّل بعض الحواسيب الأعداد العشرية بصيغة معيار IEEE القياسي 754 على سبيل المثال، بينما لا تزال بعض الأجهزة القديمة تستخدم الصيغة غير القياسية الخاصة بها. تستخدم المعماريات المختلفة أحجامًا مختلفةً حتى بالنسبة لشيءٍ بسيط مثل الأعداد الصحيحة، مثل 16 بت و32 بت و64 بت. تُمثَّل الأعداد الصحيحة في بعض الأجهزة بصيغة big-endian أي أن البت الأعلى أهميةً من الكلمة هو ضمن البايت ذو العنوان الأعلى (أي تخزين البتات الأقل أهمية أولًا)، بينما تُمثَّل الأعداد الصحيحة في الأجهزة الأخرى بصيغة little-endian أي أن البت الأعلى أهميةً هو ضمن البايت ذو العنوان الأدنى (أي تخزين البتات الأكثر أهمية أولًا). تُعَد معالجات PowerPC على سبيل المثال من الآلات التي تتبع نمط big-endian، وتُعَد عائلة Intel x86 ذات معمارية little-endian. تدعم اليوم العديد من المعماريات كلا التمثيلين وتسمى bi-endian، ولكن النقطة المهمة هي أنه لا يمكنك أبدًا التأكد من كيفية تخزين المضيف الذي تتواصل معه للأعداد الصحيحة. يعرض الشكل التالي تمثيلات big-endian وlittle-endian للعدد الصحيح 34677374:

السبب الآخر الذي يجعل التنظيم صعبًا هو أن برامج التطبيق مكتوبة بلغات مختلفة، وحتى عندما تستخدم لغةً واحدةً فقد يكون هناك أكثر من مصرّفٍ compiler واحد، حيث تملك المصرّفات مقدارًا لا بأس به من المجالات في كيفية تخطيط البُنى (السجلات) في الذاكرة، مثل مقدار الحاشية padding التي تُوضَع بين الحقول التي تتكون منها البنية، وبالتالي لا يمكنك ببساطة نقل بنيةٍ من جهازٍ إلى آخر حتى لو كان كلا الجهازين لهما نفس المعمارية وكان البرنامج مكتوبًا بنفس اللغة، لأن المصرّف على الجهاز الوجهة قد يصف الحقول في البنية بصورةٍ مختلفة.
التصنيف
على الرغم من أن تنظيم الوسطاء ليس علمًا صعبًا للغاية، ولكن هناك عددٌ كبير من خيارات التصميم التي يجب عليك معالجتها. نبدأ بإعطاء تصنيفٍ بسيط لأنظمة تنظيم الوسطاء. ليس التصنيف التالي الوحيد القابل للتطبيق، ولكنه كافٍ لتغطية معظم البدائل المهمة.
أنواع البيانات
السؤال الأول هو ما هي أنواع البيانات التي سيدعمها النظام؟ هنا يمكننا تصنيف الأنواع التي تدعمها آلية تنظيم الوسطاء ضمن ثلاثة مستويات، حيث يعقّد كل مستوى المهمة التي يواجهها نظام التنظيم.
يعمل نهج التنظيم على مجموعةٍ معينة من الأنواع القاعدية base types في أدنى مستوى، حيث تتضمن الأنواع القاعدية الأعداد الصحيحة والأعداد العشرية والأحرف، وقد يدعم أيضًا الأنواع الترتيبية ordinal types والبوليانية Booleans. إن المعنى الضمني لمجموعة الأنواع القاعدية هو أن عملية التشفير يجب أن تكون قادرةً على تحويل كل نوعٍ قاعدي من تمثيلٍ إلى آخر، مثل تحويل عددٍ صحيح من النمط big-endian إلى النمط little-endian.
توجد أنواعٌ مسطحة flat types في المستوى التالي مثل البنى structures والمصفوفات. قد لا تبدو الأنواع المسطحة للوهلة الأولى أنها تعقّد تنظيم الوسطاء، ولكنها بالحقيقة تفعل ذلك. تكمن المشكلة في أن المصرّفات المستخدمة في تصريف برامج التطبيقات تدخل أحيانًا حاشيةً بين الحقول التي تشكّل البنية وذلك لصفِّ هذه الحقول على حدود الكلمات. ويحزم نهج التنظيم البنى بحيث لا تحتوي على حاشية.
قد يتعين على نهج التنظيم التعامل مع الأنواع المعقدة complex types ضمن أعلى مستوى، وهي الأنواع المُنشأة باستخدام المؤشرات pointers، أي أن بنية البيانات التي يريد أحد البرامج إرسالها إلى برنامجٍ آخر قد لا تكون متضمنةً في بنيةٍ واحدة، ولكنها قد تتضمن بدلًا من ذلك مؤشراتٍ من بنية إلى بنيةٍ أخرى. تُعد الشجرة مثالًا جيدًا لنوعٍ معقد يتضمن مؤشرات، ومن الواضح أن مشفر البيانات يجب أن يُعِد بنية البيانات للإرسال عبر الشبكة لأن عناوين الذاكرة تطبّق المؤشرات، ولا يعني مجرد وجود بنيةٍ ما في عنوان ذاكرةٍ معين على جهازٍ ما أنها ستكون بنفس العنوان على جهازٍ آخر، أي يجب أن يسلسل serialize (يسوّي) نهج التنظيم بنية البيانات المعقدة.
بناءً على مدى تعقيد نظام الأنواع، تتضمن مهمة تنظيم الوسطاء تحويل الأنواع القاعدية، وحزم البنيات، وتخطيط بنيات البيانات المعقدة لتشكيل رسالةٍ متجاورة يمكن نقلها عبر الشبكة. يوضح الشكل التالي هذه المهمة.
.png.1aa71140c9399955b9065ee13ba3eec9.png)
استراتيجية التحويل
إن المشكلة التالية لإنشاء نظام الأنواع هي استراتيجية التحويل Conversion Strategy والتي سيستخدمها منظّم الوسطاء، وهناك خياران عامان، هما نموذج الوسيط المتعارف عليه canonical intermediate، ونموذج المستقبِل يفعل الصواب receiver-makes-right.
تتمثل فكرة نموذج الوسيط المتعارف عليه في الاستقرار على تمثيلٍ خارجي لكل نوع، حيث يترجم المضيف المرسل من تمثيله الداخلي إلى هذا التمثيل الخارجي قبل إرسال البيانات، ويترجم المستقبل من هذا التمثيل الخارجي إلى تمثيله المحلي عند تلقي البيانات. ولتوضيح الفكرة بصورةٍ أكبر، ضع في الحسبان بيانات الأعداد الصحيحة مع التأكيد على أن التعامل مع الأنواع الأخرى يجري بطريقةٍ مماثلة، فقد تصرّح بأنك ستستخدَم صيغة big-endian على أنها تمثيل خارجي للأعداد الصحيحة، وبالتالي يجب أن يترجم مضيف الإرسال كل عددٍ صحيح يرسله إلى شكل big-endian، كما يجب على المضيف المستقبل ترجمة الأعداد الصحيحة ذات صيغة big-endian إلى أي تمثيلٍ يستخدمه، وهذا ما يجري في الإنترنت على ترويسات البروتوكولات، وقد يستخدم مضيفٌ معين بالفعل نموذج big-endian، فلا يلزم في هذه الحالة التحويل.
الخيار البديل هو نموذج المستقبل يفعل الصواب، حيث يرسل المرسل بياناته بالتنسيق المحلي الداخلي الخاص به، أي لا يحوّل المرسل الأنواع الرئيسية، ولكنه يضطر إلى حزم وتسوية بنيات البيانات الأعقد، ثم يصبح المستقبل مسؤولًا عن ترجمة البيانات من صيغة المرسل إلى صيغته المحلية الخاصة. تكمن مشكلة هذه الاستراتيجية في أن كل مضيفٍ يجب أن يكون مستعدًا لتحويل البيانات من جميع بنيات الآلة الأخرى ويُعرف ذلك في الشبكات باسم حل N-by-N، حيث يجب أن تكون كل معماريةٍ من بين N معمارية آلة قادرةً على التعامل مع كل المعماريات N الأخرى؛ بينما في نظام يستخدم نموذج الوسيط المتعارف عليه، فيحتاج كل مضيفٍ إلى معرفة كيفية التحويل بين تمثيله الخاص وتمثيلٍ آخر فقط، الذي هو التمثيل الخارجي.
من الواضح أن استخدام صيغة خارجية مشتركة هو الشيء الصحيح الواجب فعله، وقد كانت هذه بالتأكيد الحكمة التقليدية في مجتمع الشبكات لأكثر من 30 عامًا، ولكن اتضح أنه لا توجد العديد من التمثيلات المختلفة للأصناف القاعدية المختلفة، أي أن N ليست كبيرةً كفاية. إن الحالة الأكثر شيوعًا هي أن تتواصل آلتان من نفس النوع مع بعضهما بعضًا، حيث تبدو ترجمة البيانات من تمثيل تلك المعمارية إلى تمثيلٍ خارجيٍ غريب في هذه الحالة أمرًا ساذجًا، وبالتالي فكل ما يتوجب على المستقبل هو إعادة ترجمة البيانات إلى تمثيل نفس المعمارية على المستقبل.
أما الخيار الثالث وعلى الرغم من عدم معرفتنا أي نظام موجودٍ يستغله، فهو يستخدم نموذج المستقبل يفعل الصواب receiver-makes-right إذا كان المرسل يعلم أن الوجهة لها نفس المعمارية، بينما سيستخدم المرسل صيغة الوسيط المتعارف عليه إذا كان الجهازان يستخدمان معمارياتٍ مختلفة، لكن كيف سيتعلم المرسل معمارية المستقبل؟ يمكن أن يتعلم هذه المعلومات إما من خادم أسماء name server أو عن طريق استخدام حالة اختبار بسيطة أولًا لمعرفة ما إذا كانت النتيجة المناسبة قد حدثت.
الوسوم
تكمن المشكلة الثالثة في تنظيم الوسطاء في كيفية معرفة المستقبل لنوع البيانات الموجودة في الرسالة التي يتلقاها. وهناك طريقتان شائعتان هما البيانات الموسومة tagged والبيانات غير الموسومة untagged. وهنا تُعَد طريقة البيانات الموسومة أسهل، لذلك سنشرحها أولًا.
الوسم tag هو أية معلوماتٍ إضافية مدرجةٍ في الرسالة، حيث تتجاوز التمثيل الملموس للأنواع القاعدية وتساعد المستقبل في فك تشفير الرسالة، وهناك العديد من الوسوم المحتملة الممكن تضمينها في الرسالة، فقد يُعزّز كل عنصر بيانات مع وسم نوع type tag على سبيل المثال، والذي يشير إلى أن القيمة التالية هي عددٌ صحيح، أو عددٌ عشري، أو أيًا كان؛ أما المثال الآخر فهو وسم الطول length tag المُستخدَم للإشارة إلى عدد العناصر في المصفوفة أو حجم عدد صحيح؛ بينما المثال الثالث فهو وسم المعمارية architecture tag الممكن استخدامه مع استراتيجية المستقبل يفعل الصواب لتحديد المعمارية التي أُنشِئت البيانات الموجودة في الرسالة بناءً عليها. يوضح الشكل التالي كيفية تشفير عددٍ صحيحٍ بسيط مؤلفٍ من 32 بت في رسالة موسومة.

البديل بالطبع هو عدم استخدام الوسوم، لكن كيف يعرف المستقبل كيفية فك تشفير البيانات في هذه الحالة؟ إنه يعرف لأنه كان مبرمَجًا على ذلك، فإذا استدعيتَ إجراءً بعيدًا يأخذ عددين صحيحين وعددًا عشريًا على أنهم وسطاء، فلا داعي لأن يفحص الإجراءُ البعيد الوسومَ لمعرفة ما استلمه للتو، حيث يفترض ببساطةٍ أن الرسالة تحتوي على عددين صحيحين وعددٍ عشري ويفك تشفيرها وفقًا لذلك. لاحظ أنه بينما يعمل هذا في معظم الحالات بصورةٍ جيدة، ولكن المكان الوحيد الذي ينهار فيه هو عند إرسال مصفوفات متغيرة الطول، حيث يُستخدم وسم الطول بصورةٍ شائعة للإشارة إلى طول المصفوفة في هذه الحالة.
من الجدير بالذكر أيضًا أن النهج غير الموسوم يعني أن صيغة العرض هي حقًا طرفٌ إلى طرف؛ حيث لا يمكن لبعض الوكلاء الوسيطين تفسير الرسالة دون وضع وسومٍ على البيانات. قد تسأل لماذا يحتاج الوكيل الوسيط إلى تفسير رسالة؟ الجواب هنا هو أنه بسبب حدوث أشياءٍ غريبة ناتجة في الغالب عن حلولٍ مخصصة ad hoc لمشاكلٍ غير متوقعة، لم يُصمَّم النظام للتعامل معها، ولكن التصميم السيئ للشبكة خارج نطاق هذا الكتاب.
الجذوع
الجذع Stub هو جزءٌ من الشيفرة التي تنفَّذ تنظيم الوسطاء، حيث تُستخدم الجذوع عادةً لدعم آلية RPC. ينظّم الجذعُ وسطاءَ الإجراء على جانب العميل في رسالةٍ يمكن إرسالها عن طريق بروتوكول آلية RPC، ويحوِّل الجذع على جانب الخادم الرسالةَ مرةً أخرى إلى مجموعةٍ من المتغيرات المُمكن استخدامها، مثل وسطاء من أجل استدعاء الإجراء البعيد. يمكن تفسير الجذع أو تصريفه.
يحتوي كل إجراء على جذع عميل وجذع خادم مخصَّصَين في النهج القائم على التصريف، ويمكن كتابة الجذع يدويًا، إلا أنه يُنشَأ عادةً بواسطة مصرّف الجذع بناءً على وصف واجهة الإجراء، وهذا الموقف موضحٌ في الشكل الآتي. بما أن الجذع يمكن تصريفه، فهو عادة فعالٌ للغاية، إذ يوفر النظام جذوع عميل وجذوع خادم عامةً في النهج القائم على التفسير، ويضبط وصف واجهة الإجراء معاملات هذه الجذوع. تغيير هذا الوصف أمرٌ سهل، لذلك تتميز الجذوع المُفسَّرة بأنها مرنة، وتُعَد الجذوع المصرَّفة Compiled stubs أكثر شيوعًا عمليًا.

أمثلة عن تمثيلات البيانات XDR وASN.1 وNDR وProtoBufs
نصف الآن بإيجاز أربعة تمثيلات بيانات شبكة شائعة من حيث هذا التصنيف. نستخدم النوع الأساسي للعدد الصحيح لتوضيح كيفية عمل كل نظام.
تمثيل XDR
تمثيل البيانات الخارجية External Data Representation أو اختصارًا XDR هو الصيغة الشبكية المُستخدمة مع SunRPC، حيث يكون XDR مسؤولًا عن المهام التالية:
- دعم نظام النوع C الكامل باستثناء المؤشرات الوظيفية.
- تحديد صيغة الوسيط المتعارف عليه.
- لا يستخدم الوسوم باستثناء الإشارة إلى أطوال المصفوفة.
- يستخدم جذعًا مُصرَّفًا.
تمثيل XDR للعدد الصحيح هو عنصر بيانات مؤلَّف من 32 بتًا يشفِّر عددًا صحيحًا من النوع C، ويُمثَّل في صيغة المكمل الثنائي twos’ complement من خلال وضع البايت الأعلى أهميةً من العدد الصحيح C في البايت الأول من العدد الصحيح XDR، ووضع البايت الأقل أهميةً من العدد الصحيح C في البايت الرابع من العدد الصحيح XDR، أي أن XDR تستخدم صيغة big-endian للأعداد الصحيحة. يدعم XDR كلًا من الأعداد الصحيحة ذات الإشارة والتي بدون إشارة، تمامًا كما يفعل النوع C.
يمثِّل XDR المصفوفات متغيرة الطول من خلال تحديد عددٍ صحيح بدون إشارة وبحجم 4 بايت يعطي عدد العناصر في المصفوفة، متبوعًا بالعديد من العناصر من النوع المناسب، ويرمِّز XDR مكونات البنية بترتيب تصريحها في البنية، كما يمثَّل حجم كل عنصرٍ أو مكونٍ بمضاعفات 4 بايتات لكلٍ من المصفوفات والبنى، وتُحشى أنواع البيانات الأصغر حجمًا حتى 4 بايتات باستخدام أصفار. استُثنيت الأحرف من قاعدة " الحشو حتى 4 بايتات pad to 4 bytes" التي تُشفَّر بحرفٍ لكل بايت.
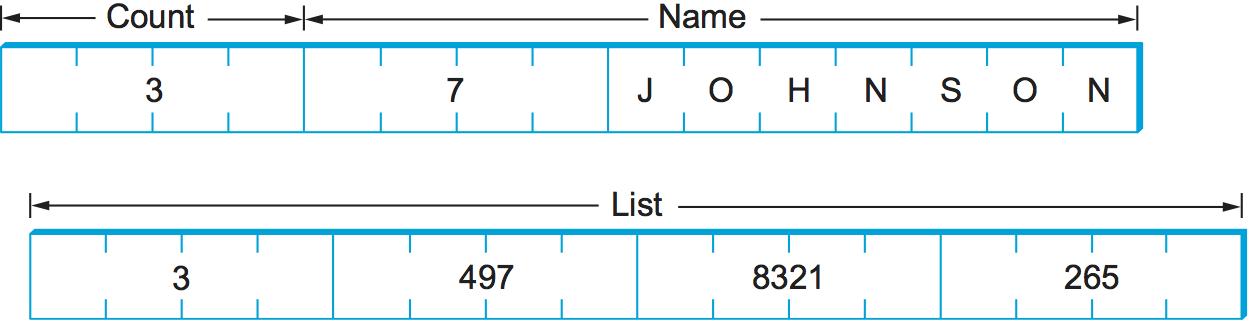
يعطي جزء الشيفرة التالي مثالًا على بنية C وهي item، وإجراء XDR الذي يشفِّر / يفك تشفير هذه البنية وهو xdr_item. حيث يبين الشكل السابق تخطيطًا لتمثيل XDR على السلك لهذه البنية عندما يكون الحقل name مكونًا من سبعة أحرف والمصفوفة list تحتوي على ثلاث قيم.
في هذا المثال، تُعَد كل من xdr_array وxdr_int وxdr_string ثلاث دوالٍ بدائية يوفِّرها XDR لتشفير المصفوفات والأعداد الصحيحة وسلاسل الأحرف وفك تشفيرها على التوالي، حيث يُعَد الوسيط xdrs متغير سياق يستخدمه XDR لتتبع مكانه في الرسالة التي يجري معالجتها، ويتضمن رايةً تشير إلى ما إذا كان هذا الإجراء مُستخدَمٌ لتشفير أو فك تشفير الرسالة، أي تُستخدَم إجراءات مثل xdr_item على كلٍ من العميل والخادم. لاحظ أنه يمكن لمبرمج التطبيق إما كتابة الإجراء xdr_item يدويًا أو استخدام مصرّف جذع يُسمَى rpcgen، وهو غير موضحٍٍ هنا لإنشاء إجراء التشفير / فك التشفير، ويأخذ rpcgen في الحالة الأخيرة الإجراء البعيد الذي يعرّف بنية البيانات item على أنها دخلٌ وخرجٌ للجذع المقابل.
#define MAXNAME 256; #define MAXLIST 100; struct item { int count; char name[MAXNAME]; int list[MAXLIST]; }; bool_t xdr_item(XDR *xdrs, struct item *ptr) { return(xdr_int(xdrs, &ptr->count) && xdr_string(xdrs, &ptr->name, MAXNAME) && xdr_array(xdrs, &ptr->list, &ptr->count, MAXLIST, sizeof(int), xdr_int)); }
تعتمد كيفية أداء XDR بالضبط على مدى تعقيد البيانات، فمن أجل حالةٍ بسيطة من مصفوفة من الأعداد الصحيحة والتي يجب تحويل كل عددٍ صحيح فيها من ترتيب بايتٍ واحد إلى آخر، سيتطلب الأمر ثلاث تعليمات لكل بايت وسطيًا، مما يعني أن تحويل المصفوفة بأكملها من المحتمل أن يكون مقيدًا بحيّز نطاق ذاكرة الجهاز. وستكون التحويلات الأعقد التي تتطلب مزيدًا من التعليمات لكل بايت محدودةً بوحدة المعالجة المركزية CPU، وبالتالي ستعمل بمعدل بيانات أقل من حيز نطاق الذاكرة التراسلي.
تمثيل ASN.1
يُعد تمثيل السياق المجرد الأول Abstract Syntax Notation One أو اختصارًا ASN.1 إحدى معايير ISO التي تحدد تمثيل البيانات المرسلة عبر الشبكة إضافةً إلى عدة أشياءٍ أخرى. ويُسمى الجزء الخاص بالتمثيل من ASN.1 بقواعد التشفير الأساسية Basic Encoding Rules أو اختصارًا BER.
تدعم ASN.1 نظام النوع C بدون مؤشرات دالةٍ، وتحدد النموذج الوسيط المتعارف عليه، كما تستخدم وسوم النوع، ويمكن تفسير أو تصريف جذوعها. إن أحد ادعاءات شهرة ASN.1 BER هو استخدامها بواسطة بروتوكول إدارة الشبكة البسيط Simple Network Management Protocol أو اختصارًا SNMP القياسي عبر الإنترنت.
تُمثِّل ASN.1 كل عنصر بيانات بثلاثيةٍ وفق النموذج التالي:
(tag, length, value)
يكون الوسم tag حقلًا ذا 8 بتات، على الرغم من أن ASN.1 يسمح بتعريف وسوم متعددة البايتات. يحدِّد حقل الطول length عدد البايتات التي تشكل القيمة value، وسنناقش حقل الطول length بصورةٍ أكثر أدناه. يمكن إنشاء أنواع بيانات مركبة مثل البنى structures عن طريق تداخل الأنواع البدائية، كما هو موضح في الشكل التالي.

إذا كانت القيمة value هي 127 بايت أو أقل، فسيُحدَّد الطول length في بايتٍ واحد، وبالتالي يُشفَّر عددًا صحيحََا مؤلفًا على سبيل المثال من 32 بتًا على الشكل التالي: نوع type مؤلفٌ من 1 بايت، وطول length مؤلف من 1 بايت، و4 بايتات تشفِّر العدد الصحيح، كما هو موضحٌ في الشكل الآتي. تُمثَّل القيمة value نفسها في حالة عدد صحيح، في صيغة مكملٍ ثنائي وشكل big-endian، تمامًا كما في XDR. ضع في الحسبان أنه على الرغم من تمثيل قيمة value العدد الصحيح بالطريقة نفسها تمامًا في كلٍ من XDR وASN.1، ولكن لا يحتوي تمثيل XDR على وسوم النوع type والطول length المرتبطة بهذا العدد الصحيح. يشغل هذان الوسمان حيزًا في الرسالة، والأهم من ذلك أنهما يتطلبان معالجةً أثناء التنظيم وإلغاء التنظيم، وهذا هو أحد الأسباب التي تجعل ASN.1 غير فعالٍ مثل XDR؛ أما السبب الآخر فهو حقيقة أن كل قيمة بيانات مسبوقة بحقل طول length تعني أنه من غير المحتمل أن تقع قيمة البيانات على حد بايتٍ طبيعي، مثل عدد صحيح يبدأ عند حد كلمة، وهذا يعقّد عملية التشفير / فك التشفير.
.png.65fdd9b91bf1fd286e6d7a3d4e84745a.png)
إذا كانت القيمة value هي 128 بايت أو أكثر، فسيجري استخدام عدة بايتات لتحديد طولها length، لكن قد تسأل لماذا يمكن للبايت تحديد طول يصل إلى 127 بايت بدلًا من 256 بايت؟ إن السبب في ذلك هو استخدام بتٍ واحدٍ لحقل الطول length للإشارة إلى طول حقل الطول length. يشير الرقم 0 في البت الثامن إلى حقل الطول length المؤلف من 1 بايت. لتحديد طول length أطول، يُضبَط البت الثامن على القيمة 1، وتشير البتات السبعة الأخرى إلى عدد البايتات الإضافية التي تشكِّل حقل الطول length. يوضح الشكل التالي حقل طول length بسيط يبلغ 1 بايت وطولًا length متعدد البايتات.
.png.8b68edab854550d290658c1271445006.png)
تمثيل NDR
تمثيل بيانات الشبكة Network Data Representation أو اختصارًا NDR هو معيار تشفير البيانات المُستخدَم في بيئة الحوسبة الموزعة Distributed Computing Environment أو اختصارًا DCE. ويستخدم NDR نموذج المستقبل الذي يفعل الصواب receiver-makes-right على عكس XDR وASN.1، ويحدث ذلك عن طريق إدخال وسم معمارية في مقدمة كل رسالة، وتكون عناصر البيانات بدون وسوم، ويستخدم NDR مصرّفًا لتوليد الجذوع. يأخذ هذا المصرّف وصفًا لبرنامج مكتوبٍ بلغة تعريف الواجهة Interface Definition Language أو اختصارًا IDL، ويولّد الجذوع اللازمة. يشبه IDL إلى حدٍ كبير C، ولذا فهو يدعم بصورةٍ أساسية نظام النوع C.

يوضح الشكل السابق وسم تعريف معمارية مؤلف من 4 بايتات مضمَّن في مقدمة كل رسالةٍ مشفرة بواسطة NDR. يحتوي البايت الأول على حقلين مؤلفين من 4 بتات. ويحدد الحقل الأول IntegrRep صيغة جميع الأعداد الصحيحة الموجودة في الرسالة، كما يشير الرقم 0 في هذا الحقل إلى الأعداد الصحيحة big-endian، ويشير الرقم 1 إلى الأعداد الصحيحة little-endian.
يشير حقل CharRep إلى صيغة الأحرف المستخدمة، حيث 0 يعني ASCII أي الشيفرة القياسية الأمريكية لتبادل المعلومات American Standard Code for Information Interchange، و1 يعني EBCDIC وهو بديلٌ أقدم من ASCII تحدده شركة IBM. ثم يحدد بايت FloatRep تمثيل الأعداد العشرية المستخدم، حيث 0 تعني IEEE 754 و1 تعني VAX و2 تعني Cray و3 تعني IBM، والبايتان الأخيران محجوزان للاستخدام المستقبلي. لاحظ أنه في الحالات البسيطة مثل مصفوفات الأعداد الصحيحة، يجري NDR نفس مقدار العمل الذي يجريه XDR، وبالتالي فهو قادرٌ على تحقيق نفس الأداء.
تمثيل ProtoBufs
توفّر مخازن البروتوكول المؤقتة Protocol Buffers أو اختصارًا Protobufs طريقة لغة محايدة ومنصةً محايدةً لتسلسل البيانات ذات البنى، وهي شائعة الاستخدام مع gRPC. تستخدم Protobufs استراتيجيةً ذات وسوم مع نموذجٍ وسيطٍ متعارف عليه، حيث يُنشَأ الجذع على كلا الجانبين من ملف .proto مُشارك، وتَستخدم هذه المواصفات صيغةً بسيطةً تشبه لغة C، كما يوضح المثال التالي.
message Person { required string name = 1; required int32 id = 2; optional string email = 3; enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; } message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; } required PhoneNumber phone = 4; }
حيث يمكن تفسير الرسالة message تقريبًا على أنها مكافئة لبنية typedef struct في لغة C، ويُعَد باقي المثال بديهيًا إلى حد ما، باستثناء إعطاء كل حقل معرفًا رقميًا لضمان التفرُّد في حالة تغيير المواصفات بمرور الوقت، ويمكن الإشارة لكل حقلٍ على أنه إما إجباري required أو اختياري optional.
طريقة تشفير Protobufs للأعداد الصحيحة جديدة، حيث تستخدم تقنيةً تسمى varints اختصارًا للأعداد الصحيحة ذات الطول المتغير variable length integers، حيث يستخدم كلُّ بايت مؤلف من 8 بتات البتَ الأعلى أهمية للإشارة فيما إذا كان هناك عددٌ أكبر من البايتات في العدد الصحيح، وتُستخدم البتات السبعة الأقل أهميةً لتشفير تمثيل المكمل الثنائي لمجموعة السبعة بتات في القيمة، وتكون المجموعة الأقل أهميةً هي الأولى في التسلسل.
هذا يعني أنه يمكن تشفير عددٍ صحيح صغيرٍ أي أقل من 128 في بايتٍ واحد، مثل تشفير العدد الصحيح 2 بالشيفرة 0000 0010، بينما يلزم المزيد من البايتات بالنسبة لعدد صحيح أكبر من 128، مثل تشفير العدد 365 كما يلي:
1110 1101 0000 0010
لتحقيق ذلك، أسقِط أولًا البت الأعلى أهمية من كل بايت، لأنه موجودٌ لإخبارنا فيما إذا كنا قد وصلنا إلى نهاية العدد الصحيح. يشير الرقم 1 في البت الأعلى أهميةً في البايت الأول في هذا المثال إلى وجود أكثر من بايتٍ واحد في varint:
1110 1101 0000 0010 → 110 1101 000 0010
بما أن طرق varint -وهي طرق لسَلسَلة الأعداد الصحيحة باستخدام بايتٍ واحد أو أكثر، حيث تأخذ الأعداد الأصغر عددًا أقل من البايتات- تخزِّن الأعداد ذات المجموعة الأقل أهمية أولًا، فإنك تعكس بعد ذلك المجموعتين المكونتين من سبع بتات، ثم تجمّعها للحصول على القيمة النهائية.
000 0010 110 1101 → 000 0010 || 110 1101 → 101101101 → 256 + 64 + 32 + 8 + 4 + 1 = 365
يمكنك التفكير في تدفق البايت المتسلسل على أنه مجموعةٌ من أزواج مفتاح / قيمة key/value بالنسبة لمواصفات الرسالة الأكبر، حيث يحتوي المفتاح أي الوسم على جزأين فرعيين هما المعرف الفريد للحقل أي تلك الأرقام الإضافية في مثال ملف proto.، ونوع السلك wire type للقيمة مثل Varint وهو أحد أمثلة نوع السلك التي رأيناها حتى الآن. تتضمن أنواع الأسلاك المدعومة الأخرى 32-bit و64-bit للأعداد الصحيحة ذات الطول الثابت، ومحددة الطول length-delimited للسلاسل والرسائل المُضمنة. تخبرك محدّدة الطول بعدد بايتات الرسالة المضمنة (البنية)، ولكنها وصفٌ آخر للرسالة في ملف proto. الذي يخبرك بكيفية تفسير تلك البايتات.
اللغات التوصيفية مثل XML
نناقش مشكلة صيغة العرض من منظور RPC، أي كيفية تشفير أنواع البيانات الأولية وبنية البيانات المُركبة، بحيث يمكن إرسالها من برنامج عميلٍ إلى برنامج خادم، ولكن تحدث نفس المشكلة الأساسية في إعداداتٍ أخرى، مثل كيفية وصف خادم الويب صفحة ويب بحيث يعرف أي عددٍ من المتصفحات المختلفة ما الذي يجب عرضه على الشاشة، وتكون الإجابة في هذه الحالة المحددة هي لغة توصيف النص التشعبي HyperText Markup Language أو اختصارًا HTML، والتي تشير إلى وجوب عرض سلاسل أحرفٍ معينة بخطٍ غامق أو مائل، ونوع الخط الذي يجب استخدامه وحجمه، ومكان وضع الصور.
أدى توفر جميع أنواع تطبيقات الويب والبيانات أيضًا إلى خلق موقفٍ تحتاج فيه تطبيقات الويب المختلفة إلى التواصل مع بعضها بعضًا وفهم بيانات بعضها البعض. قد يحتاج موقع التجارة الإلكترونية مثلًا إلى التحدُّث إلى موقع شركة الشحن على الويب للسماح للعميل بتتبع الطرد دون مغادرة موقع التجارة الإلكترونية على الإطلاق. ويبدأ هذا بسرعة في الظهور بصورةٍ كبيرة مثل RPC، ويستند النهج المتبع في الويب اليوم لتمكين مثل هذا الاتصال بين خوادم الويب على لغة التوصيف الموسعة Extensible Markup Language أو اختصارًا XML، وهي طريقةٌ لوصف البيانات المتبادلة بين تطبيقات الويب.
تأخذ لغات التوصيف -والتي تُعَد كلٌ من HTML وXML مثالين عنها-، نهج البيانات الموسومة إلى أقصى الحدود. تُمثل البيانات على هيئة نص وتتداخل وسوم النص المعروفة باسم markup مع نص البيانات للتعبير عن معلوماتٍ حول البيانات. تشير markup في حالة HTML إلى كيفية عرض النص، حيث يمكن للغات التوصيف الأخرى مثل XML التعبير عن نوع وبنية البيانات.
لغة XML هي في الواقع إطار عملٍ لتعريف لغات التوصيف المختلفة لأنواعٍ مختلفة من البيانات. لقد استخدمت لغة XML على سبيل المثال لتحديد لغة توصيفٍ مكافئة تقريبًا للغة HTML تُسمى Extensible HyperText Markup Language أو اختصارًا XHTML، ويعرّف XML صيغةً أساسيةً لخلط الترميز مع نص البيانات، لكن على مصمم لغة ترميزٍ معينة تسمية وتحديد الترميز الخاص بها، ومن الشائع الإشارة إلى اللغات الفردية القائمة على XML ببساطة باسم XML، لكننا سنؤكد على التمييز بينها هنا.
تشبه صياغة XML صياغة HTML، فقد يبدو سجل الموظف على سبيل المثال بلغةٍ افتراضيةٍ قائمةٍ على XML مثل مستند XML الآتي، والذي قد يُخزَّن في ملف باسم employee.xml، ويشير السطر الأول إلى إصدار XML المُستخدَم، كما تمثل الأسطر المتبقية أربعة حقولٍ تشكل سجل الموظف، ويحتوي آخرها hiredate على ثلاثة حقولٍ فرعية؛ أي توفِّر صياغة XML بنيةً متداخلةً لأزواج الوسم / القيمة tag/value، والتي تعادل بنية شجرة للبيانات الممثلة، حيث يكون employee هو الجذر. يُعَد هذا مشابهًا لقدرة XDR وASN.1 وNDR على تمثيل الأنواع المركبة، ولكن بصيغةٍ يمكن معالجتها بواسطة البرامج وقراءتها بواسطة البشر، ويمكن استخدام برامجٍ مثل المحللات اللغوية parsers على لغاتٍ مختلفة تستند إلى لغة XML، لأن تعريفات هذه اللغات يُعبَّر عنها على أنها بيانات قابلة للقراءة آليًا ويمكن إدخالها إلى البرامج.
<?xml version="1.0"?> <employee> <name>John Doe</name> <title>Head Bottle Washer</title> <id>123456789</id> <hiredate> <day>5</day> <month>June</month> <year>1986</year> </hiredate> </employee>
على الرغم من أن التوصيف والبيانات الواردة في هذا المستند توحي بشدة بإمكانية قراءتها للإنسان، إلا أن تعريف لغة تسجيل الموظف هو الذي يحدد في الواقع الوسوم المسموح بها وما تعنيه هذه الوسوم وأنواع البيانات التي تشير إليها. لا يمكن للقارئ البشري أو الحاسوب معرفة ما إذا كان عام 1986 الموجود في حقل العام year هو سلسلةٌ أو عددٌ صحيح أو عددٌ صحيح بدون إشارة، أو عدد عشري مثلًا بدون تعريفٍ رسميٍ للوسوم.
يُعطى تعريفُ لغةٍ معينة قائمةٍ على XML من خلال مخطط schema، وهو مصطلح قاعدة بيانات لتحديد كيفية تفسير مجموعةٍ من البيانات. لقد جرى تعريف العديد من لغات المخطط للغة XML، حيث سنركز هنا على المعيار الرائد والمعروف باسم مخطط XML الذي لا يثير الدهشة. يُعرَف المخطط الافرادي المُعرَّف باستخدام مخطط XML باسم مستند مخطط XML أو XML Schema Document واختصارًا XSD، يمثل ما يلي إحدى طرق توصيف XSD لهذا المثال، حيث يحدّد اللغة التي يتوافق معها نموذج المستند، وقد يُخزَّن في ملفٍ يسمى employee.xsd.
<?xml version="1.0"?> <schema xmlns="http://www.w3.org/2001/XMLSchema"> <element name="employee"> <complexType> <sequence> <element name="name" type="string"/> <element name="title" type="string"/> <element name="id" type="string"/> <element name="hiredate"> <complexType> <sequence> <element name="day" type="integer"/> <element name="month" type="string"/> <element name="year" type="integer"/> </sequence> </complexType> </element> </sequence> </complexType> </element> </schema>
يشبه ملف XSD هذا مثالنا في المستند employee.xml، ولسببٍ وجيه هو أن مخطط XML بحد ذاته لغةٌ قائمة على لغةXML. توجد علاقةٌ واضحةٌ بين ملف XSD هذا والوثيقة أعلاه، حيث يشير السطر التالي إلى أن القيمة الموضوعة بين قوسين title يجب تفسيرها على أنها سلسلة string:
<element name="title" type="string"/>
كما يشير تسلسل هذا السطر وتداخله في XSD إلى أن الحقل title يجب أن يكون العنصر الثاني في سجل الموظف employee record.
يوفّر مخطط XML على عكس بعض لغات المخطط أنواع بيانات مثل السلسلة والعدد الصحيح والعدد العشري والبولياني، ويسمح بدمج أنواع البيانات تسلسليًا أو بصورةٍ متداخلة كما هو الحال في employee.xsd لإنشاء أنواع بياناتٍ مركبة. لذا فإن XSD يحدد أكثر من صيغة، كما يحدد نموذجَ البيانات المجُرّد الخاص به. يمثل المستند الذي يتوافق مع XSD مجموعةً من البيانات التي تتوافق مع نموذج البيانات.
تكمن أهمية XSD في تحديد نموذج بياناتٍ مجردة وليس مجرد صيغةٍ في إمكانية وجود طرقٍ أخرى إلى جانب XML لتمثيل البيانات التي تتوافق مع النموذج. إن XML به بعض أوجه النقص عند التمثيلٍ على طول السلك on-the-wire، فهو ليس مضغوطًا مثل تمثيلات البيانات الأخرى، كما أنه بطيء نسبيًا في التحليل. هناك عددٌ من التمثيلات البديلة الموصوفة المُستخدمة مثل التمثيل الثنائي.
نشرت منظمة المعايير الدولية ISO تمثيلًا يُدعى Fast Infoset، في حين أنتجت World Wide Web Consortium أو اختصارًا W3C مقترح تبادل XML الفعال Efficient XML Interchange أو اختصارًا EXI. تضحي التمثيلات الثنائية بإمكانية القراءة البشرية من أجل زيادة الكثافة والتحليل الأسرع.
حيز أسماء XML
يجب أن تحل XML مشكلةً شائعةً وهي مشكلة تعارض الأسماء، حيث تظهر هذه المشكلة لأن لغات المخطط مثل مخطط XML تدعم جزئية إمكانية إعادة استخدام المخطط على أنه جزءٌ من مخططٍ آخر. افترض تعريف اثنين من XSD بصورةٍ مستقلة عن بعضهما، وكلاهما يعرّف اسم العلامة على أنها idNumber. ربما يستخدم XSD هذا الاسم لتحديد موظفي الشركة، ويستخدمه XSD آخر لتحديد الحواسيب المحمولة المملوكة للشركة. قد نرغب في إعادة استخدام هاتين XSDs في XSD ثالث لوصف الأصول المرتبطة بالموظفين، ولكننا نحتاج لفعل هذا إلى بعض الآليات للتمييز بين أرقام معرّفات idNumbers الموظفين وأرقام معرّفات idNumbers الحواسيب المحمولة.
يُدعى حلُّ XML لهذه المشكلة حيز أسماء namespaces XML وهو مجموعةٌ من الأسماء، حيث يُحدَّد كل حيز أسماء XML بواسطة معرّف الموارد الموحد Uniform Resource Identifier أو اختصارًا URI.
سنشرح URIs بشيء من التفصيل في فصلٍ لاحق؛ لكن كل ما تحتاج إلى معرفته حقًا في الوقت الحالي هو أن URIs هي شكل من أشكال المعرّف الفريد عالميًا، وعنوان HTTP URL هو نوعٌ خاص من UNI. يمكن إضافة اسم رمزٍ بسيط مثل idNumber إلى حيز الأسماء طالما أنه فريد داخله، وبما أن حيز الأسماء فريد عالميًا والاسم البسيط فريدٌ داخل حيز الأسماء، فإن الجمع بين الاثنين هو اسمٌ مؤهلٌ qualified name فريد عالميًا لا يمكن أن يتعارض مع أي شيءٍ آخر.
يحدد XSD حيز أسماء الهدف من خلال السطر التالي:
targetNamespace="http://www.example.com/employee"
وهو معرف مواردٍ موحدٍ يحدد حيز الأسماء. ستنتمي جميع الرموز الجديدة المحددة في XSD إلى حيّز الأسماء هذا.
إذا أراد XSD الإشارة إلى الأسماء المعرّفة في XSDs أخرى، فيمكنه ذلك عن طريق تأهيل هذه الأسماء ببادئة حيز الأسماء؛ وهذه البادئة هي اختصارٌ قصيرٌ لـ URI الكامل الذي يعرِّف بالفعل حيز الأسماء. يسند السطر التالي مثلًا emp إلى بادئة حيز أسماء الموظف:
xmlns:emp="http://www.example.com/employee"
وسيجري تأهيل أي رمزٍ من حيز الأسماء هذا عن طريق وضع :emp قبله، كما هو الحال في السطر التالي:
<emp:title>Head Bottle Washer</emp:title>
أي أن emp: title هو اسمٌ مؤهل، ولن يتعارض مع الاسم title من حيز أسماءٍ آخر.
من اللافت للنظر كيفية استخدام XML على نطاقٍ واسع الآن في التطبيقات التي تتراوح من الاتصال بأسلوب RPC بين الخدمات المستندة إلى الويب إلى أدوات الإنتاجية المكتبية وإلى المراسلة الفورية. إنه بالتأكيد أحد البروتوكولات الأساسية التي تعتمد عليها الآن الطبقات العليا للإنترنت.
ترجمة -وبتصرّف- للقسم Presentation Formatting من فصل End-to-End Data من كتاب Computer Networks: A Systems Approach











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.