

مرحبًا بكم مجددًا في هذا الدليل الذي يستكشف عالم بوت المحادثة الثوري ChatGPT المعتمِد على الذكاء الاصطناعي لإنشاء محادثات شبيهة بالإنسان.
لقد تناولنا بالمقال السابق مواضيع مختلفة، مثل: ما هو ChatGPT وكيف بدأ، ومراحل تطويره، وفوائده ومميزاته، ومقارنته بغيره من بوتات المحادثة المزودة بالذكاء الاصطناعي؛ كما تناولنا مختلف تطبيقات استخدام ChatGPT، والقيود والتحديات التي تواجهه، وكيفية الوصول إليه واستخدامه.
أما في هذا المقال، سنغوص أكثر في عملية تدريب بوت المحادثة ChatGPT والتقنيات المختلفة المستخدمة في تطويره، وسنستكشف المفاهيم الأساسية التي تُمكِّن البوت من الحفاظ على محادثات طبيعية وبديهية مع البشر، كما سنتناول التقنيات وخوارزميات التعلم الآلي التي تُستخدم لتدريب ChatGPT، ومجموعات البيانات التي تمكنه من فهم تفاصيل لغة الإنسان. وسنستكشف أيضًا دور التعلم غير الخاضع للإشراف الذي يسمح لـ ChatGPT بالتعلم والتحسين من خلال الخبرات، مما يجعله أداةً مفيدةً لمختلف الصناعات.
لذا، ودون إطالة، ندعوك لمواصلة قراءة هذه المقالة حتى النهاية حتى تعرف كيف تمكَّن ChatGPT من إجراء محادثات طبيعية مع البشر، ولنتعرف هنا أولًا، سنتعرف على التقنيات وخوارزميات التعلم الآلي ومجموعات البيانات المستخدمة في تدريب ChatGPT، ثم نتعمق في خطوات تدريب هذا البوت!
تقنية التدريب المسبق Pre-Training
فيما يلي سوف نناقش تقنيةً تسمى التدريب المُسْبَق لبوت المحادثة ChatGPT، وهي خطوة حاسمة في تعليم البوت كيفية إجراء محادثات طبيعية وبديهية مع البشر.
تعريف وأهمية التدريب المسبق
التدريب المسبق في ChatGPT هو عملية تعليم بوت المحادثة كيفية فهم اللغة البشرية قبل أن يبدأ في التحدث إلى الناس، وهذا الإجراء مهم جدًا، نظرًا لكون لغة البشر معقدةً للغاية، إذ هناك العديد من الطرائق المختلفة لقول نفس الشيء، لذلك من خلال عملية التدريب المسبق لـ ChatGPT، يمكنها مساعدته على فهم الفروق الدقيقة في اللغة البشرية وتحسين قدرته على إجراء محادثات هادفة مع الناس.
على سبيل المثال، تخيل أنك تحاول تعليم صديق لك كيفية لعب لعبة جديدة عليه، بالتالي إذا بدأت للتو في لعب اللعبة معه دون شرح لأي من قواعدها، فمن المحتمل أن يشعر بالارتباك والإحباط، لكن إذا استغرقت بعض الوقت لتعليمه القواعد وشرح كيفية اللعب له، فسيكون لديه فهمًا أفضل للعبة وسيكون قادرًا على الاستمتاع بها أكثر.
كذلك الأمر مع بوت المحادثة ChatGPT، إذ تشبه عملية تعليمه اللغة البشرية قواعد تعلم "لعبة جديدة".
خوارزميات تقنية التدريب المسبق
هناك العديد من خوارزميات التعلم الآلي المستخدمة في تقنية التدريب المسبق على بوت ChatGPT، بما في ذلك التعلم غير الخاضع للإشراف unsupervised learning، ونقل التعلم transfer learning، والتعلم تحت الإشراف الذاتي self-supervised learning. تساعد هذه الخوارزميات ChatGPT على التعلم وتحسين فهمه للغة من خلال أنواع مختلفة من بيانات التدريب.
التعلم غير الخاضع للإشراف
يتشابه هذا النوع من التعلم مع التعلم عن طريق الملاحظة. تخيل أنك جالس في حديقة تشاهد الناس يلعبون الطبق الطائر، وليس لديك مدرب يخبرك بما يجب عليك أن تفعله، ولكن لا يزال بإمكانك التعلم من خلال مشاهدة الأنماط والعلاقات بين اللاعبين وتعلم اللعب.
يُدرب ChatGPT في التعلم غير الخاضع للإشراف على البيانات دون أي تسميات أو إرشادات محددة، مما يسمح له بالتعلم من الأنماط والعلاقات داخل البيانات نفسها.
نقل التعلم
يشبه استخدام المعرفة من مهمة واحدة لمساعدتك في تعلم مهمة أخرى، فعلى سبيل المثال: إذا كنت تتعلم كيفية لعب الشطرنج فيمكنك البدء بتعلم الحركات والاستراتيجيات الأساسية، وبمجرد إتقان اللعبة يمكنك استخدام هذه المعرفة لمساعدتك في تعلم ألعاب الطاولة الأخرى.
في نقل التعلم يأخذ ChatGPT المعرفة المكتسبة من مهمة واحدة ويطبقها على مهمة أخرى، مما يساعده على التعلم بسرعة وأكثر كفاءة.
التعلم تحت الإشراف الذاتي
في التعلم تحت الإشراف الذاتي يُدرب ChatGPT على مهمة لا تتطلب أي تسميات أو إرشادات محددة، مثل التنبؤ بالكلمات المفقودة في الجملة، وهذا يساعده على تحسين قدرته في فهم اللغة.
ولشرح هذا النوع من التعلم أكثر، تخيل أنك تحاول تعلم كيفية ركوب الدراجة، وأنت في هذه الحالة لست بحاجة إلى شخص يخبرك بما يجب عليك أن تفعله، بل ما عليك سوى التدرب والتعلم من أخطائك.
فوائد التدريب المسبق في ChatGPT
تتمتع تقنية التدريب المسبق بالعديد من الفوائد، بما في ذلك تحسين قدرة ChatGPT على فهم الفروق الدقيقة في لغة الإنسان، وزيادة قدراته في المحادثة، والسماح له بالتعلم والتكيف مع المهام والمجالات الجديدة بسهولة أكبر، فمن خلال التدريب المسبق يمكننا التأكد من أن لديه أساسًا قويًا من المعرفة والفهم، مما يُمكن أن يساعده في أن يصبح أداةً أكثر فائدةً وفعاليةً في مختلف الصناعات والتطبيقات.
على سبيل المثال، تخيل أنك تحاول استخدام ChatGPT للإجابة على أسئلة خدمة العملاء لمتجر عبر الإنترنت، وهنا إذا لم يكن ChatGPT مُدَرَّبًا مسبقًا، فقد لا يفهم الطرائق المختلفة التي قد يَطرح بها العملاء نفس السؤال، مثل "أين طلبي؟"، مقابل سؤال "متى ستصل شحنتي؟"؛ ولكن إذا دُرِّب مسبقًا على مجموعة متنوعة من أسئلة ومحادثات خدمة العملاء، فسيكون مجهزًا بطريقة أفضل لفهم استفسارات العملاء والرد عليها.
تقنية الصقل Fine-Tuning
فيما يلي سوف نناقش تقنيةً تسمى الصقل لبوت المحادثة ChatGPT، وهي خطوة حاسمة في تحسين أدائه في تنفيذ مهام محددة.
تعريف وأهمية الصقل Fine-Tuning
الصقل Fine-Tuning في ChatGPT هو عملية يُدرب من خلالها النموذج ChatGPT -الذي دُرِّب مسبقًا- على مهمة أو مجال معين، مثل: الإجابة على أسئلة خدمة العملاء أو إنشاء كلمات الأغاني، وهذا مهم لأنه على الرغم من أن ChatGPT قد دُرِّب مسبقًا على مجموعة واسعة من المهام اللغوية، إلا أنه لا يزال بحاجة إلى صقله لتحقيق أداء جيد في مهام أو مجالات محددة.
ولكي نفهم هذا بصورة أوضح، دعنا نستخدم مثال تعلم العزف على آلة العود. إذا كان لديك فهم عام لنظرية الموسيقى وكيفية العزف على الأوتار الأساسية، فهذا أمرٌ رائع! ومع ذلك لكي تعزف لحنًا معينًا، ستحتاج إلى ممارسة ذلك اللحن مرارًا وتكرارًا حتى تتقن لحنه بطريقة صحيحة.
يتشابه الصقل في ChatGPT مع عزف لحن معين على آلة العود، إذ يمنح النموذج المدرَّب مسبقًا ChatGPT فهمًا جيدًا للغة، لكن صقله لأداء مهمة معينة يساعده في أن يصبح خبيرًا في هذا المجال.
خوارزميات تقنية الصقل
هناك العديد من خوارزميات التعلم الآلي المستخدمة في الصقل لبوت ChatGPT، بما في ذلك التعلم الخاضع للإشراف supervised learning، ونقل التعلم، والتعلم من الصفر أو البداية learning from scratch.
يتضمن التعلم الخاضع للإشراف تزويد ChatGPT بالبيانات المصنفة، مثل: أمثلة الأسئلة والأجوبة، حتى يتمكن من تعلم كيفية إنشاء إجابات دقيقة، ويتضمن نقل التعلم أخذ المعرفة المكتسبة من مهمة واحدة وتطبيقها على مهمة أخرى، مما يسمح لـ ChatGPT بالتعلم بطريقة أسرع وأكثر كفاءة، ويتضمن التعلم من البداية أو من نقطة الصفر تدريب ChatGPT على مهمة أو مجال معين دون استخدام أي معرفة موجودة مسبقًا.
دعنا نواصل مع مثال العزف على آلة العود لفهم هذه الأساليب بصورة أوضح، يشبه التعلم الخاضع للإشراف وجود مدرس موسيقى يوضح لك كيفية عزف لحن معين خطوةً بخطوة، ويشبه التعلم بالنقل تعلم العزف على لحن جديد باستخدام تقنيات ومعرفة من اللحن الذي تعلمته بالفعل؛ أما التعلم من الصفر فيشبه محاولة تعلم لحن جديدة لكن بمفردك دون أي توجيه من المدرس أو معرفة مسبقة لديك.
فوائد الصقل في ChatGPT
هناك العديد من الفوائد لتقنية الصقل في ChatGPT، بما في ذلك تحسين أدائه في تنفيذ مهام محددة، وتقليل كمية البيانات اللازمة للتدريب، وزيادة دقته وكفاءته، وتسمح تقنية الصقل أيضًا لـ ChatGPT بالتكيف مع المهام والمجالات الجديدة بسهولة أكبر، مما يجعله أداة أكثر تنوعًا وإفادة.
وبالاستمرار مع مثال آلة العود، يمكن القول إن فوائد تقنية الصقل تشبه فوائد ممارسة لحن معين، فمن خلال التدرب على لحن معين تصبح أفضل في عزف هذا اللحن، لكنك تُحَسِّن أيضًا مهاراتك العامة في العزف على آلة العود.
وبالمثل، فمن خلال ضبط ChatGPT لمهمة أو مجال معين، يصبح أفضل في تنفيذ هذه المهمة، بالإضافة إلى التحسن في فهم اللغة وقدرات المحادثة بوجه عام.
مجموعات البيانات المستخدمة للتدريب Datasets
عندما يُدرب بوت المحادثة ChatGPT سيحتاج إلى تزويده بالعديد من الأمثلة على النص حتى يتمكن من تعلم الأنماط والعلاقات في اللغة، وتسمى هذه الأمثلة بـ "مجموعات البيانات Datasets".
أهمية مجموعات البيانات في تدريب ChatGPT
تُعَد مجموعات البيانات ضروريةً لتدريب ChatGPT لأنها توفر الأمثلة التي يحتاجها بوت المحادثة لتعلم كيفية فهم وإنشاء نص شبيه بالبشر، فبدون مجموعات البيانات لن يتمكن ChatGPT من تعلم كيفية إجراء محادثات طبيعية مع الناس.
نظرة عامة على مجموعات البيانات المستخدمة لتدريب ChatGPT
هناك العديد من مجموعات البيانات التي تستخدم عادةً لتدريب ChatGPT، وأحد مجموعات البيانات هذه يُطلق عليه Common Crawl وهو أحد أكبر وأكثر مجموعات البيانات شيوعًا، فهو يتضمن مجموعةً كبيرةً من النصوص من الإنترنت. وهناك مجموعة بيانات أخرى مستخدمة تسمى BooksCorpus، والتي تتضمن مجموعةً كبيرةً من الكتب في مختلف الأنواع.
أما مجموعة بيانات WebText فهي مجموعة بيانات أخرى شائعة الاستخدام وتتضمن نصًا من مواقع ويب مختلفة، وتُختار مجموعات البيانات هذه بعناية لتوفير مجموعة واسعة من الأمثلة النصية لـ ChatGPT للتعلم منها.
مزايا وقيود كل مجموعة بيانات
كل مجموعة بيانات مستخدمة لتدريب ChatGPT لها مزاياها وقيودها؛ فمجموعة بيانات Common Crawl مثلَا، مفيدة لأنها تحتوي على قدر هائل من النصوص من مصادر مختلفة، مما يسمح لـ ChatGPT بالتعلم من مجموعة متنوعة من أنماط اللغة، ومع ذلك فإن أحد قيود مجموعة بيانات Common Crawl هو أنه يشتمل على الكثير من المحتوى، مثل: البريد العشوائي أو النص منخفض الجودة، مما قد يمثل تحديًا لـ ChatGPT للتعلم منه.
من ناحية أخرى، تُعَد مجموعة بيانات BooksCorpus مفيدةً لأنها تتضمن نصوصًا من تصنيفات مختلفة، مما يسمح لـ ChatGPT بالتعلم من مجموعة متنوعة من أنماط اللغة، ومع ذلك فإن أحد القيود هو أنها قد لا تكون مثاليةً في استخدام اللغة الحديثة، مثل مجموعات البيانات الأخرى، لأنها تتضمن في الغالب الكتب القديمة.
تُعَد مجموعة بيانات WebText مفيدةً لأنها تتضمن نصوصًا من مواقع ويب مختلفة، مما يسمح لـ ChatGPT بالتعلم من مجموعة متنوعة من أنماط اللغة المستندة إلى الويب؛ ومع ذلك فإن أحد القيود المفروضة هنا هو أنها قد تتضمن لغةً أكثر رسمية أو أقل تنظيمًا من مجموعات البيانات الأخرى، مما قد يجعل من الصعب على ChatGPT التعلم منها.
نماذج اللغات الكبيرة LLMs
كما ذكرنا في المقال السابق، ينتمي بوت المحادثة ChatGPT إلى مجموعة من النماذج تسمى: "نماذج اللغات الكبيرة Large Language Models" والمعروفة اختصارًا بـ LLMs، وهي نماذج يمكنها استيعاب وتحليل كميات هائلة من البيانات النصية، وأصبح استخدام هذه النماذج أكثر شيوعًا في السنوات الأخيرة بفضل قدرات وقوة أجهزة الحاسوب، وكلما زاد عدد البيانات والمعلِّمات التي تمتلكها نماذج LLMs، أصبح فهم اللغة أفضل.
وتشير "المعلمات" في نماذج اللغات الكبيرة LLMs إلى المتغيرات أو الإعدادات التي يستخدمها النموذج لعمل تنبؤات وإنشاء نص، حيث تتشابه هذه المعلمات مع التعليمات التي تخبر النموذج بكيفية معالجة اللغة وفهمها، وكلما زاد عدد المعلمات التي يمتلكها النموذج، أصبح أكثر مرونةً وقوةً في فهم اللغة وتوليدها.
فعلى سبيل المثال، لنفترض أن النموذج يحتوي على معلمة تسمى "المفردات"، حيث تخبر هذه المعلمة النموذج بكل الكلمات التي يعرفها ومعانيها، وكلما زاد عدد الكلمات التي يعرفها النموذج، كان بإمكانه فهم واستخدام مجموعة كبيرة من المفردات بطريقة أفضل عند التحدث إليك.
من ناحية أخرى، يمكن أن تكون المعلمة الأخرى هي "القواعد النحوية". تساعد هذه المعلمة النموذج في معرفة كيفية بناء الجُمَل بطريقة صحيحة، حيث فإذا تعلم النموذج الكثير من القواعد النحوية، فيمكنه التأكد من أن ردوده منطقية وتتبع الهيكل المناسب للجملة.
ومع ذلك، من المهم ملاحظة أن وجود عدد كبير من المعلمات لا يعني بالضرورة أن النموذج سيفهم اللغة تمامًا أو يؤدي أداءً لا تشوبه شائبة، في حين أن المزيد من المعلمات يمكن أن يُحسن الأداء إلى حد معين إلا أن هناك عوامل أخرى يجب مراعاتها، مثل: جودة وتنوع بيانات التدريب، وهيكل النموذج، وعملية التدريب نفسها، وهي عوامل تلعب أيضًا أدوارًا مهمة في مدى فهم النموذج للغة.
عادةً ما تُدرب نماذج LLMs على التنبؤ بالكلمة التالية في الجملة Next-token-prediction وذلك بناءً على الكلمات التي تسبقها. فعلى سبيل المثال: إذا كانت الجملة هي "تجلس القطة على ____" ، فإن نماذج LLMs سوف تتوقع أن الكلمة التالية هي "الكرسي" أو "السجادة" أو أي كلمة أخرى ذات صلة، وهذا ما يسمى بالتنبؤ بالرمز التالي.
هناك طريقة أخرى يمكن من خلالها تدريب نماذج LLMs وهي من خلال نمذجة اللغة المُقَنَّعة Masked-Language Modeling، وفي هذه الطريقة تُستبدل بعض الكلمات في الجملة بمسافات فارغة، وعلى النموذج أن يتنبأ بالكلمات المفقودة. فعلى سبيل المثال: إذا كانت الجملة هي "____أكلت الفأر"، فيجب أن تتنبأ نماذج LLMs بأن الكلمة المفقودة هي "القطة"، وغالبا هذا التنبوء يكون من خلال نموذج "الذاكرة طويلة قصيرة المدى Long-Short-Term-Memory" والمعروف اختصارًا بـ LSTM، حيث يملأ هذا النموذج الفراغ بالكلمة المحتملة الأنسب بالنظر إلى السياق المحيط.

قيود نماذج LLMs
على الرغم من قدرات نماذج اللغات الكبيرة في معالجة اللغة الطبيعية، إلا أن لديها بعض القيود، وهي كما يلي:
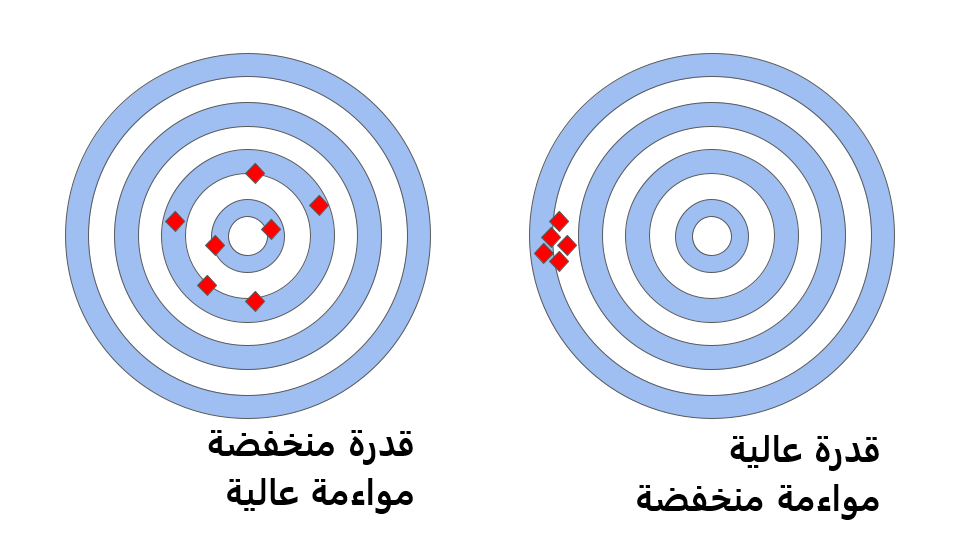
- أولًا، القدرة Capability مقابل المواءمة Alignment. يشير مفهوم القدرة Capability إلى ما يستطيع نموذج اللغة الكبير تنفيذه، فعلى سبيل المثال: هل يمكنه ترجمة اللغات أو الإجابة عن الأسئلة أو إنشاء كتابة إبداعية؟ أما مفهوم المواءمة Alignment فيشير إلى ما إذا كان نموذج اللغة الكبير يتماشى مع القيم والأهداف الإنسانية، وهذا يعني أنه يجب تصميم النموذج لإعطاء الأولوية لأشياء مثل الإنصاف والأمان والخصوصية.
والسبب الذي يجعل القدرة مقابل المواءمة قضيةً مهمة هو أنه نظرًا لأن هذه النماذج اللغوية الكبيرة تصبح أكثر قوةً وتُستخدم على نطاق أوسع، فإنها بذلك تصبح أكثر تأثيرًا في حياتنا، فعلى سبيل المثال: إذا استُخدم نموذج لغوي لاتخاذ قرارات بشأن من سيُعَيَّن لوظيفة أو من سيُوافَق عليه للحصول على قرض، فمن المهم أن يتماشى النموذج مع القيم الإنسانية لمنع التحيز والتمييز.
لنأخذ مثالًا أوضح. تخيل أن لديك صديقًا يحب لعب ألعاب الفيديو، وفي أحد الأيام يخبرك صديقك أنه يلعب لعبةً جديدةً ذات مؤثرات بصرية عالية قريبة إلى حدٍ كبيرٍ للطبيعية، لكن هذه اللعبة تعلمه أن يكون لئيمًا مع الناس وتكافئه لكونه عدوانيًا ولا تشجعه على أن يكون طيبًا. يشير هذا المثال إلى اختلال المواءمة لعدم توافق قيم وأهداف اللعبة (الفوز بأي ثمن) مع القيم الإنسانية (أن تكون طيبًا وعادلًا).
وبالمثل، فإن نموذج اللغة الكبير الذي يتمتع بقدرات كبيرة ولكن هذه القدرات لا تتماشى مع القيم الإنسانية، يمكن أن يتسبب أيضًا في حدوث ضرر. فعلى سبيل المثال، إذا استُخدم نموذج لغوي لكتابة مقالات إخبارية ولكن هذا النموذج تدرب على بيانات متحيزة أو غير دقيقة، فقد ينتهي به الأمر إلى نشر معلومات مضللة أو إدامة الصور النمطية الضارة.
-
ثانيًا، لا يمكنها إعطاء وزن أكبر لبعض الكلمات دون الأخرى، وذلك حتى لو كانت بعض الكلمات أكثر أهميةً في سياق الجملة. فعلى سبيل المثال، إذا كانت الجملة هي "زيد ____ القراءة" فالكلمة الأكثر احتمالًا للتنبؤ بالنسبة للنموذج ستكون "يكره" استنادًا إلى أن غالبية الناس تكره القراءة حسب ما ورد بقاعدة البيانات، لكن ماذا لو كان زيد على العكس من ذلك ويحب القراءة؟
-
ثالثًا، بالإضافة إلى ما سبق، يمكن لنماذج LLMs فقط معالجة المدخلات الفردية بالتتابع وليس ككل، وهذا يَحُد من قدرتها على فهم العلاقات المعقدة بين الكلمات والمعاني. ولمعالجة هذه القيود قَدَّم فريق Google Brain نوعًا جديدًا من النماذج يسمى المحولات Transformers في عام 2017، حيث تختلف المحولات عن نماذج LLMs في أنها تستطيع معالجة جميع بيانات الإدخال في وقت واحد وليس بالتسلسل، مستخدمةً في ذلك آلية الانتباه الذاتي self-attention لإعطاء وزن أكبر لأجزاء معينة من بيانات الإدخال فيما يتعلق بتسلسل اللغة، وهذا يسمح للمحولات بفهم العلاقات بين الكلمات والمعاني بطريقة أفضل، ثم معالجة مجموعات البيانات الأكبر.
بعبارات أبسط، تخيل أنك تحاول قراءة كتاب وفهمه، هنا سوف تقرأ نماذج LLMs صفحةً واحدةً فقط في كل مرة، وقد لا تتمكن من فهم الروابط الأعمق بين أجزاء مختلفة من الكتاب، بينما المحولات ستكون قادرةً على قراءة الكتاب بأكمله مرةً واحدة، مع فهم كيفية ارتباط جميع الأجزاء المختلفة ببعضها بعضًا.
GPT وآلية الانتباه الذاتي
هل سبق لك أن استخدمت تطبيق ترجمة لغة لترجمة كلمة أو جملة من لغة إلى أخرى؟ حسنًا، ماذا عن GPT والتي تعني Generative Pre-training Transformer أو المحولات التوليدية المدربة مسبقًا؟ يُعَد GPT نسخةً متقدمةً من مترجم اللغة! فهو يساعد أجهزة الحاسوب على فهم وترجمة لغة الإنسان حتى نتمكن من التحدث إلى أجهزة الحاسوب ويمكنهم الرد علينا.
تحصل نماذج GPT على بعض المعلومات من خلال (الإدخالات) التي ينفذها المستخدم، ثم يستخدم النموذج تلك المعلومات أو الإدخالات لإنشاء (الاستجابة) أو الرد. وتنفذ نماذج GPT ذلك باستخدام آلية خاصة تسمى الانتباه الذاتي التي تسمح لنموذج GPT، وهذا بالتركيز على أجزاء مختلفة من نص الإدخال لفهم المعنى والسياق بطريقة أفضل، ثم إعطاء استجابة صحيحة، تمامًا مثلما تقرأ قصةً عن قطة، فقد تولي مزيدًا من الاهتمام للأجزاء التي تصف القطة، واهتمامًا أقل للأجزاء التي تصف المشهد.
ولتنفيذ ذلك يمر النموذج بأربع خطوات كما يلي:
- أولًا، يُنشئ النموذج ثلاثة أرقام مختلفة لكل كلمة أو عبارة تسمى "المتجهات"، الأول متجه "استعلام" والثاني متجه "مفتاح" والثالث متجه "قيمة"، فإن متجهات الاستعلام والمفتاح والقيمة تشبه المقصورات أو الأقسام المختلفة، يطرح الاستعلام سؤالاً، ويقدم المفتاح أدلة لهذا السؤال، وتعطي القيمة الإجابات على هذا السؤال، ويتعلم النموذج من العديد من الجُمل لتعيين قيم لهذه المتجهات واستخدامها لفهم وتوليد استجابات ذات مغزى.
- ثانيًا، يقارن متجه "الاستعلام" كل كلمة أو عبارة مع متجه "المفتاح" لكل كلمة أو عبارة أخرى في الجملة، ويساعد هذا الإجراء النموذج في معرفة الكلمات أو العبارات الأكثر أهمية لفهم الجملة بأكملها.
- ثالثًا، يأخذ النموذج نتائج هذه المقارنة ويحولها إلى مجموعة من الأرقام تسمى "أوزان" توضح مدى أهمية كل كلمة أو عبارة للجملة.
- رابعًا، بضرب النموذج هذه الأوزان في متجه "القيمة" لكل كلمة أو عبارة للحصول على رقم يسمى "متجه نهائي" يمثل مدى أهمية هذه الكلمة أو العبارة لمعنى الجملة بأكملها.
آلية الانتباه الذاتي متعدد الرؤوس
تُعد آلية الانتباه متعدد الرؤوس أو Multi-head attention امتدادًا للانتباه الذاتي الذي يسمح لنموذج GPT بفهم العلاقات والمعاني الفرعية الأكثر تعقيدًا بطريقة أفضل داخل نص الإدخال؛ فعلى سبيل المثال، تشبه آلية الانتباه متعدد الرؤوس وجود مجموعة من الأصدقاء تساعدك على قراءة قصة، بحيث يركز كل صديق على جزء مختلف من القصة، مما يساعدك على فهمها بطريقة أفضل، كذلك الأمر لدى هذه الآلية، فهي تساعد نموذج GPT على فهم العلاقات الأكثر تعقيدًا داخل النص.
وينفذ نموذج GPT مع آلية الانتباه الذاتي متعدد الرؤوس نفس الخطوات التي ينفذها من آلية الانتباه الذاتي، إلا أن آلية الانتباه الذاتي متعدد الرؤوس تكرر الخطوات الأربع التي ذكرناها للتو بالتوازي عدة مرات، وفي كل مرة يولد إسقاطًا خطيًا جديدًا لمتجهات الاستعلام والمفتاح والقيمة، ومن خلال توسيع الانتباه الذاتي بهذه الطريقة يكون النموذج قادرًا على استيعاب المعاني الفرعية والعلاقات الأكثر تعقيدًا داخل بيانات الإدخال.
وعلى الرغم من أن نماذج GPT-1 و GPT-2 و GPT-3 قدموا تطورات ملحوظة في معالجة اللغة الطبيعية، إلا أنهم يعانون من بعض القيود، فقد يُنتج نموذج GPT-3 مخرجات مثل:
- الافتقار إلى المساعدة، مما يعني أن النموذج لا يتبع تعليمات المستخدم الصريحة.
- استجابة تحتوي على الهلوسة، مما يعكس حقائق غير موجودة أو غير صحيحة.
- عدم القدرة على التفسير، مما يجعل من الصعب على البشر فهم كيفية وصول النموذج إلى قرار أو تنبؤ معين.
- تضمين محتوى سامًا أو متحيزًا أو ضارًا أو مسيئًا، مما يتسبب في نشر معلومات مضللة.
لذلك طُرحت منهجيات تدريب مبتكرة في ChatGPT المبني على نموذج GPT-3.5 وفي ChatGPT المبني على النموذج الأحدث GPT-4 لمواجهة بعض هذه القضايا المتأصلة في نماذج اللغات الكبيرة LLMs.
تدريب ChatGPT المبني على نموذج GPT-3.5
يُعَد ChatGPT المبني على نموذج GPT-3.5 نسخةً معدلةً من InstructGPT، لكن ما يميز ChatGPT هو أنه يستطيع التعامل مع طلبات واستجابات متعددة مع الحفاظ على سياق المحادثة؛ أما InstructGPT فيستطيع التعامل مع طلب واحد ثم تقديم استجابة واحدة لهذا الطلب في كل مرة استخدام.

يعود الفضل إلى InstructGPT الذي حل بعض القيود التي تواجه نماذج اللغات الكبيرة، فقد قدم نهجًا جديدًا في تدريب النماذج يدمج فيها تعليقات الإنسان في عملية التدريب لتحسين توافق نتائج النموذج مع نوايا المستخدم؛ ويُعرف هذا النهج باسم "التعلم المعزز من التقييمات البشرية Reinforcement Learning from Human Feedback"، والمعروفة اختصارًا بـ RLHF، ثم اعتمدت شركة OpenAI هذا النهج في تدريب نموذج GPT-3.5.
ويتكون هذا النهج من ثلاث خطوات أساسية كما يلي:
- أولاً، خطوة نموذج الصقل الخاضع للإشراف SFT.
- ثانيًا، خطوة نموذج المكافأة RM.
- ثالثًا، خطوة نموذج تحسين السياسة القريبة PPO.
تُنفذ الخطوة الأولى مرةً واحدةً فقط، بينما يمكن تكرار الخطوتين الثانية والثالثة باستمرار لجمع المزيد من بيانات المقارنة للوصول إلى أفضل سياسة تدريب، دعونا نغوص الآن في تفاصيل كل خطوة!
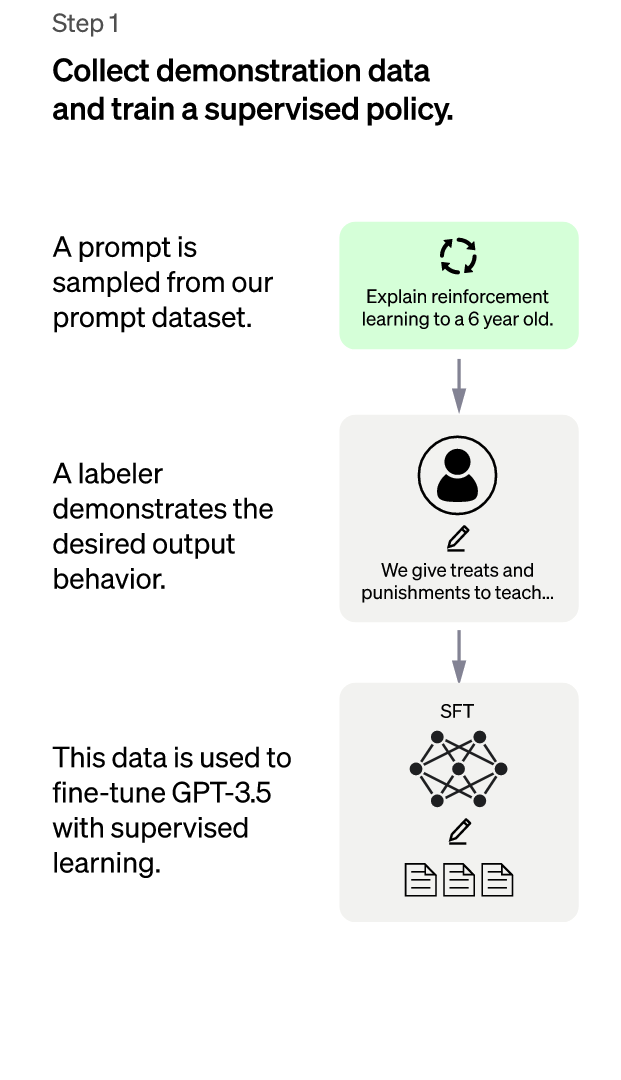
الخطوة الأولى: نموذج الصقل الخاضع للإشراف SFT
تُسمى الخطوة الأولى من نهج RLHF بنموذج "الصقل الخاضع للإشراف Supervised Fine-Tuning" والمعروف اختصارًا بـ SFT. تدور هذه الخطوة حول تعليم النموذج كيفية فهم لغة الإنسان وتوليد استجابات منطقية.
تخيل أنك تحاول تعليم روبوت كيفية فهم تعليماتك وتنفيذها، يمكنك البدء بإعطاء الروبوت مجموعة من التعليمات ثم مطالبته بأداء مهمة بناءً على تلك التعليمات. قد لا ينفذ الروبوت ما تريده منه بالضبط في البداية، ولكن مع الملاحظات والتعديلات التي سوف تقدمها له، سيكون في إمكانه بالنهاية تعلم تنفيذ تلك التعليمات بطريقة أفضل.
يعمل نموذج SFT بطريقة مماثلة، حيث يُعطى النموذج اللغوي المُدرَّب مسبقًا مجموعةً صغيرةً من التعليمات النموذجية، تسمى هذه التعليمات بـ "بيانات العرض التوضيحي" التي نُسقت بواسطة أشخاص مدَرَّبين على إنشاء مجموعة بيانات تتضمن أمثلةً على المدخلات (المطالبات) والمخرجات (الاستجابات) الصحيحة المقابلة لها، ثم "يُصقل" نموذج اللغة على هذه البيانات، مما يعني أنه قد دُرِّب لتوليد استجابات تتماشى مع المطالبات، ليصبح نموذج SFT الناتج هو بمثابة خط أساس لفهم الروبوت لكيفية اتباع التعليمات.
دعونا نجعل هذا الأمر أكثر واقعية! تخيل أن التعليمات هي "صنع شطيرة زبدة الفول السوداني والهلام"، قد تتضمن بيانات العرض التوضيحي أمثلة مثل "افرد زبدة الفول السوداني على شريحة واحدة من الخبز، ثم افرد الهلام على الشريحة الأخرى، ثم ضع الشريحتين معًا، ثم اقطع الشطيرة إلى نصفين"؛ وبذلك يكون نموذج SFT قد تدرب على إنشاء استجابات تتبع هذه الخطوات.
لكن حتى الآن نموذج SFT ليس مثاليًا، الأمر مشابه تمامًا للروبوت، فقد لا يصنع الشطيرة بطريقة صحيحة من المرة الأولى، فقد يولد نموذج SFT استجابات ليست تمامًا ما يتوقعه الإنسان، لكن على الرغم من ذلك يُعد هذا أمرًا جيدًا، فبالإمكان استخدام ردود الفعل من البشر لمساعدة النموذج على التحسن، وهو ما تدور حوله الخطوة التالية من نهج RLHF في تدريب نماذج اللغات الكبيرة.
الخطوة الثانية: نموذج المكافأة RM
في الخطوة الثانية من نهج RLHF، نريد تحسين نموذج SFT الذي أنشأناه في الخطوة الأولى باستخدام ردود الفعل من البشر، نطلق على هذه التعليقات اسم "المكافآت" لأنها تعطي مكافأةً لنموذج SFT عندما يولد استجابة جيدة تتوافق مع التوقعات البشرية.
ولجمع هذه المكافآت نطلب من البشر التصويت على عدد كبير من الردود الناتجة عن نموذج SFT. فعلى سبيل المثال، تخيل أننا نطلب من مجموعة من الأشخاص تقييم مدى استجابة نموذج SFT للتعليمات "اصنع شطيرة زبدة الفول السوداني والهلام"، فقد يصنفون الردود على مقياس من 1 إلى 4، حيث يمثل الرقم 4 أفضل استجابة تتوافق تمامًا مع توقعاتهم.
بعد ذلك، تُستخدم التقييمات من البشر لإنشاء مجموعة بيانات جديدة من "بيانات المقارنة"، وتتضمن بيانات المقارنة هذه أزواجًا من الردود التي أُنشأت بواسطة نموذج SFT جنبًا إلى جنب مع التقييمات المقدمة من البشر، ثم تُستخدم مجموعة البيانات هذه لتدريب نموذجًا جديدًا يسمى "نموذج المكافأة Reward Model" والمعروف اختصارًا بـ RM.
يُدرب نموذج المكافأة على التنبؤ بالتقييم الذي سوف يعطيه الإنسان لاستجابة معينة أُنشأت بواسطة نموذج SFT، على سبيل المثال: إذا كان نموذج SFT يولد استجابة لتعليمات "صنع شطيرة زبدة الفول السوداني والهلام"، فإن نموذج RM سوف يتنبأ بمدى تقييم الإنسان لتلك الاستجابة على مقياس من 1 إلى 4.
دعونا نجعل هذا الأمر أكثر واقعية، تخيل أن لديك إنسانًا آليًا يمكنه صنع الشطائر، لكنك تريده أن يصنع الشطائر التي تحبها. ولتنفيذ ذلك يمكنك تذوق الشطائر وتقديم ملاحظات إلى الروبوت حول ما أعجبك وما لم يعجبك، ثم يستخدم الروبوت هذه التقييمات لتحسين مهاراته في صنع الشطائر.
بالطريقة نفسها يأخذ نموذج المكافأة المخرجات الناتجة عن نموذج SFT ويقدمها إلى مجموعة من الأشخاص الذين يقدمون ملاحظات حول المخرجات التي يفضلونها، وبناءً على هذه التعليقات يتعرف نموذج المكافأة على نوع الإخراج المفضل ويولد مجموعة جديدة من بيانات التدريب التي يمكن أن يستخدمها نموذج SFT لتحسين أدائه.

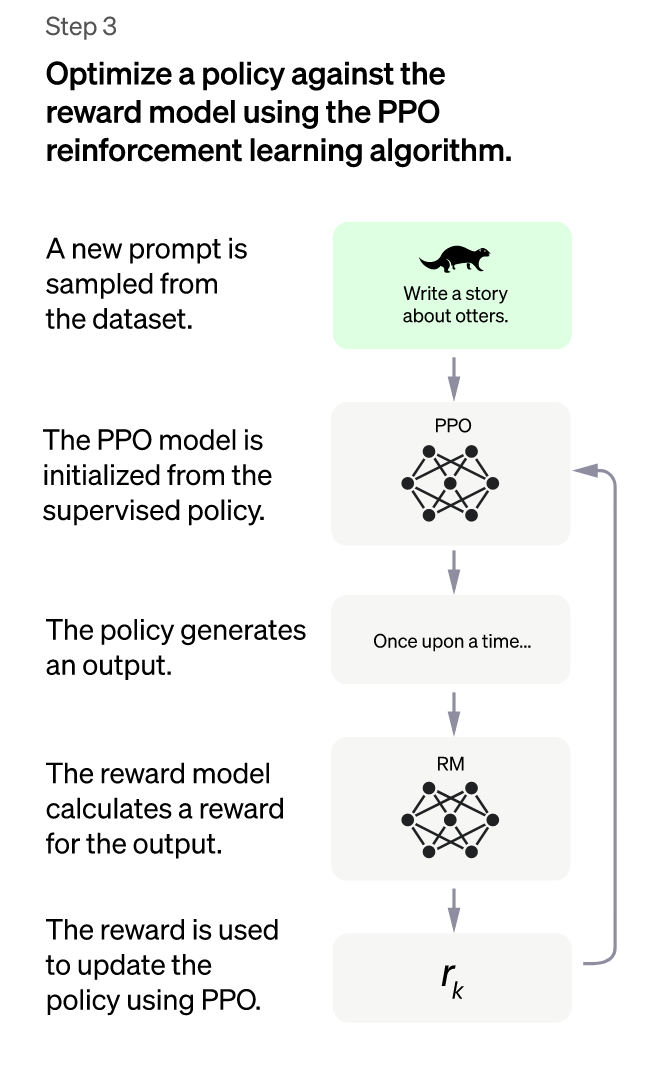
الخطوة الثالثة: نموذج تحسين السياسة القريبة PPO
الآن بعد أن أصبح لدينا نموذج مكافأة RM والذي يمكننا استخدامه لتحسين نموذج الصقل الخاضع للإشراف SFT وذلك من خلال استخدام أحد خوارزميات التعلم المعزز يُطلق عليها "تحسين السياسة القريبة Proximal Policy Optimization" والمعروفة اختصارًا بـ PPO، والتي تساعد النموذج على تعلم كيفية اتخاذ قرارات أفضل من خلال التعلم من التجربة والخطأ، ثم التحسين التدريجي لقواعد اتخاذ القرار أو "السياسة".
دعونا نجعل هذا الأمر أكثر واقعية، ولنفترض أنك تُعلم أحد أصدقائك كيفية لعب لعبة فيديو جديدة، وفي كل مرة يتخذ فيها صديقك إجراءً في اللعبة يحصل على ملاحظات منك "إذا فعلت شيئًا جيدًا مثل جمع عملة معدنية، فإنك تحصل على المزيد من النقاط، وإذا فعلت شيئًا سيئًا مثل الضرب من قِبَل عدو، فإنك تفقد نقاطًا"، والهدف من هذه الملاحظات هو كيفية حصول صديقك على أعلى درجة ممكنة باللعبة.
كذلك يساعد نموذج PPO نماذج اللغات الكبيرة وهو في حالتنا GPT-3.5 على التعلم من خلال التجربة والخطأ، ثم تحسين قواعد اتخاذ القرار تدريجيًا خطوةً واحدةً في كل مرة، وذلك من خلال إجراء تغييرات صغيرة على قواعد اتخاذ القرار في النموذج، وتحسينها تدريجيًا بمرور الوقت، مما يساعد على منع النموذج من ارتكاب أخطاء كبيرة أو الوقوع في نمط اتخاذ قرار سيئ.
وتختلف خوارزمية PPO عن خوارزميات تعليم النماذج الأخرى في أنها تحدث سياسة النموذج أثناء تنفيذه للمهمة، بدلًا من الانتظار حتى انتهائه من المهمة، وهذا يجعل النموذج أكثر قابليةً للتكيف والقدرة على التعلم من الأخطاء بسرعة، كما تستخدم خوارزمية PPO دالة القيمة لمساعدتها على معرفة مدى نجاحها، فتحدد دالة القيمة مقدار المكافأة التي سيحصل عليها النموذج مقابل تنفيذ عمل معين في موقف معين، مما يساعد هذا الإجراء النموذج على اتخاذ قرارات أكثر ذكاءً بشأن ما يجب فعله بعد ذلك.
ولمنع النموذج من الانحراف بعيدًا جدًا عن سياسته والإفراط في تحسين نموذج المكافأة وإفساد كل شيء، تضع خوارزمية PPO بعض القيود على مدى إمكانية تغييرها سياسة النموذج مرةً واحدة، وذلك من خلال استخدام عقوبة Kullback–Leibler لكل رمز، ويشبه هذا الإجراء القاعدة التي تنص على أن استجابات النموذج لا يمكن أن تكون مختلفةً جدًا عما قد يقوله الإنسان، مما يساعد النموذج على البقاء في المسار الصحيح والاستمرار في التعلم من المدخلات البشرية.
تقييم نموذج GPT-3.5
عندما نتحدث عن تقييم نموذج لغوي مثل GPT-3.5 الذي طورته OpenAI اعتمادًا على نموذج GPT-3 ليكون أكثر قوة ودقة، مما يجعله صالحًا للاستخدام في مجموعة واسعة من التطبيقات، مثل: إنشاء النصوص والإجابة على الأسئلة وترجمة اللغة، فإننا بذلك نحاول تقييم مدى قوة أدائه في المهام المختلفة، أو بعبارة أخرى نريد أن نعرف مدى دقته و موثوقيته إذا كنا سنستخدم النموذج لتطبيقات العالم الحقيقي.
إذًا، السؤال الذي يطرح نفسه الآن، هو: كيف نقيم نموذج لغة مثل GPT-3.5؟
حسنًا، تتضمن عملية التقييم عادةً اختبار النموذج على مجموعة من المهام أو مجموعات البيانات المصممة لقياس أدائه، على سبيل المثال: قد نختبر النموذج في مهمة تتضمن إنشاء فقرة متماسكة من النص بناءً على عملية إدخال معينة، ولتقييم أداء النموذج في هذه المهام تُستخدم مجموعة من المقاييس:
- الدقة: هي أحد المقاييس الشائعة في التقييم، فهي تخبرنا عن عدد المرات التي ينتج فيها النموذج المخرجات الصحيحة.
- الارتباك: يقيس الارتباك مدى قدرة النموذج على التنبؤ بالكلمة التالية في تسلسل نصي بناءً على الكلمات السابقة في التسلسل، فتشير درجات الحيرة المنخفضة إلى أن النموذج أفضل في التنبؤ بالكلمة التالية، مما يعني أن النموذج لديه فهمًا أفضل للغة.
- التماسك: يقيس التماسك مدى جودة قراءة النص الذي أُنشأ بواسطة النموذج كما لو أنه كتبه إنسان، مع وجود روابط منطقية بين الأفكار والاستخدام المناسب للقواعد.
- الطلاقة: يقيس الطلاقة مدى قدرة النموذج على إنشاء نصًا صحيحًا نحويًا وخاليًا من الأخطاء.
يمكن أن تعطينا هذه المقاييس فكرةً جيدةً عن مدى جودة أداء النموذج، والأماكن التي قد تحتاج إلى تحسين. فعلى سبيل المثال، إذا كان النموذج يُنشئ نصًا غير دقيق أو مربك، فقد نحتاج إلى تعديل بيانات التدريب الخاصة به أو معلماته لتحسين أدائه.
سؤال آخر يطرح نفسه الآن، وهو: لماذا التقييم مهم في تطوير ChatGPT؟
حسنًا، كما ذكرنا سابقًا نحتاج إلى التأكد من أن النموذج ينتج نتائج دقيقةً وموثوقةً إذا كنا سنستخدمه في تطبيقات العالم الحقيقي، لذلك يساعدنا التقييم على تحديد أي نقاط ضعف في النموذج وإدخال تحسينات عليه. بالإضافة إلى ذلك، يساعدنا التقييم على مقارنة النماذج المختلفة ومعرفة أيها يعمل بطريقة أفضل، كما يمكن أن يكون التقييم مفيدًا أكثر للباحثين الذين يحاولون تطوير نماذج لغوية جديدة وأفضل.
تدريب نموذج GPT-4
كانت OpenAI حذرةً بشأن إصدار التفاصيل الفنية لنموذج GPT-4، حيث امتنع التقرير الفني صراحةً عن تحديد حجم النموذج أو البنية أو الأجهزة المستخدمة أثناء التدريب، في حين وصف التقرير أن النموذج دُرِّب باستخدام نهج "التعلم المعزز من التقييمات البشرية Reinforcement Learning from Human Feedback"، إلا أنه لم يقدم تفاصيل عن التدريب، بما في ذلك العملية التي أجريت من خلالها بناء مجموعة بيانات التدريب، أو قوة الحوسبة المطلوبة، أو أي معلمات فائقة مثل معدل التعلم، عدد الحقبة، أو المحسنات المستخدمة.
وادعى التقرير أن "المشهد التنافسي والآثار المترتبة على السلامة لنماذج اللغات الكبيرة" كانت من العوامل التي أثرت على هذا القرار.
خاتمة
في ختام هذه المقالة، نستطيع القول بأن تدريب ChatGPT يمثل إنجازًا هائلًا في مجال تعلم الآلة ومعالجة اللغة الطبيعية، فبفضل تقنيات التدريب المسبق والصقل، تمكنت ChatGPT من توليد نصوص ذات جودة عالية وشديدة الاقتران بالواقع، وهو ما يفتح الأبواب أمام استخدامات عدة في مجالات الذكاء الاصطناعي والتكنولوجيا الحديثة.
وعلى الرغم من أن تدريب ChatGPT يُعَد إنجازًا هائلًا، إلا أن هذا لا يعني أن الطريق أمامه مفروشًا بالزهور، فما زال هناك الكثير من التحديات التي تواجه هذا المجال، وخاصةً فيما يتعلق بمجموعات البيانات المستخدمة، ولكن بفضل الابتكارات الحالية والعمل الجاد للباحثين والمهندسين، يمكننا الأمل في مزيد من التحسن والتطور في هذا المجال.
وبناءً على ذلك، يجدر بنا التذكير بأن تطوير ChatGPT هو جزء من مسيرة طويلة نحو تحسين قدرات الآلة على التفاعل الذكي مع البشر، وهو ما يمثل تحديًا حقيقيًا يتطلب الكثير من الجهد والعمل الشاق، وبفضل هذه الجهود المتواصلة نأمل في أن نصل إلى مستويات جديدة من الذكاء الاصطناعي تُسهم في تحقيق المزيد من الاكتشافات الرائعة في هذا المجال.
وإلى هنا نكون قد وصلنا إلى نهاية هذا المقال الذي نتمنى أن يكون قد أضاف لكم معلومات جديدة ومفيدة، وفي حالة وجود أي استفسارات لا تترددوا في ذكرها لنا في التعليقات.
المصادر
- Training language models to follow instructions with human feedback
- Introducing ChatGPT
- openai.gpt-4
- GPT-4 wikipedia
- ChatGPT Statistics and Facts You Need to Know 50
- Behind ChatGPT’s Wisdom: 300 Bn Words, 570 GB Data
- Hacker News
اقرأ أيضًا
- تعرف على بوت المحادثة الذكي شات جي بي تي ChatGPT
- برمجة تطبيق 'ألهمني' لعرض النصائح والحكم المفيدة باستخدام ChatGPT في Node.js
- برمجة تطبيق 'لخصلي' لتلخيص المقالات باستخدام ChatGPT ولارافل
- تطوير تطبيق 'وصفة' لاقتراح الوجبات باستخدام ChatGPT و DALL-E في PHP
- تطوير تطبيق 'اختبرني' باستخدام ChatGPT ولغة جافاسكربت مع Node.js











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.