


Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 تحدث أحمد عن Subscript notation و update() و * operator ، يمكنك أيضاً استخدام __setitem__ لإضافة زوج (قيمة-مفتاح) إلى قاموسك: dict = {'key1':'Ali', 'key2':'Ahmad'} # __setitem__ استخدام الدالة dict.__setitem__('Key', 'Value') print(dict) # {'key1': 'Ali', 'key2': 'Ahmad', 'Key': 'Value'} أو الدالة setdefault كالتالي: dict = {'key1':'Ali', 'key2':'Ahmad'} # setdefault استخدام الدالة dict.setdefault('Key', "Value") print(dict) # {'key1': 'Ali', 'key2': 'Ahmad', 'Key': 'Value'}
تحدث أحمد عن Subscript notation و update() و * operator ، يمكنك أيضاً استخدام __setitem__ لإضافة زوج (قيمة-مفتاح) إلى قاموسك: dict = {'key1':'Ali', 'key2':'Ahmad'} # __setitem__ استخدام الدالة dict.__setitem__('Key', 'Value') print(dict) # {'key1': 'Ali', 'key2': 'Ahmad', 'Key': 'Value'} أو الدالة setdefault كالتالي: dict = {'key1':'Ali', 'key2':'Ahmad'} # setdefault استخدام الدالة dict.setdefault('Key', "Value") print(dict) # {'key1': 'Ali', 'key2': 'Ahmad', 'Key': 'Value'} -
بشكل عام لا يمكن فرز القواميس، ولكن يمكنك إنشاء قائمة مرتبة منهم.. إضافةً لما قدمه أحمد يمكنك استخدام الدالة sorted بالشكل التالي: sorted(dic.items(), key=lambda z: z[1]) سيؤدي هذا إلى فرز القاموس حسب قيم كل إدخال داخل القاموس من الأصغر إلى الأكبر. لفرزها بترتيب تنازلي فقط أضف rever1se = T1rue: sorted(dic.items(), key=lambda z: z[1], reverse=True) انظر للمثال التالي: dic = {'one':1,'three':3,'five':5,'two':2,'four':4} dic = sorted(dic.items(), key=lambda z: z[1]) dic # [('one', 1), ('two', 2), ('three', 3), ('four', 4), ('five', 5)] أو يمكنك استخدام القواميس المرتّبة OrderedDict وهي مطابقة للقواميس العادية باستثناء أنّها تتذكر ترتيب العناصر لحظة إدراجها فيها، بمعنى أنّه عند إضافة العناصر إلى قاموس مرتب، تعاد العناصر حسب ترتيب مفاتيحها عند إضافتها أول مرّة.: >>> # قاموس عادي غير مرتب >>> d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2} >>> # قاموس مرتب حسب المفاتيح >>> OrderedDict(sorted(d.items(), key=lambda t: t[0])) OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1)]) >>> # قاموس مرتب حسب القيم >>> OrderedDict(sorted(d.items(), key=lambda t: t[1])) OrderedDict([('pear', 1), ('orange', 2), ('banana', 3), ('apple', 4)]) >>> # قاموس مرتب حسب طول السلسلة النصية في المفاتيح >>> OrderedDict(sorted(d.items(), key=lambda t: len(t[0]))) OrderedDict([('pear', 1), ('apple', 4), ('orange', 2), ('banana', 3)]) تحافظ القواميس المرتّبة الجديدة على ترتيبها عند حذف العناصر منها، ولكن تُلحق المفاتيح الجديدة المضافة إلى نهاية القاموس مع المحافظة على ترتيب العناصر الباقية. حل مشكلتك: dic = {'one':1,'three':3,'five':5,'two':2,'four':4} from collections import OrderedDict OrderedDict(sorted(d.items(), key=lambda x: x[1])) """ OrderedDict([('one', 1), ('two', 2), ('three', 3), ('four', 4), ('five', 5)]) """
-
يمكنك استخدام مكتبة Vpython لكن أولاً قم بتثبيتها: pip install vpython حيث تمكنك هذه المكتبة من رسم أشكال ومجسمات ثلاثية الأبعاد وهي ثرية بالعديد من أنواع المجسمات مثل sphere, box, cylinder, ring, helix, curve, arrow, cone, text, pyramid وغيرها من shapes و paths.. لذا يمكنك الذهاب لتوثيق المكتبة وتعلم تصميم الأشكال منها وهي ليست صعبة أبداً وسلسلة.. أمثلة: حلقة: from vpython import * ring(pos=vector(1,1,1),axis=vector(0,1,0),radius=0.5,thickness=0.1) هرم: pyramid (pos=vector(5,2,0),size=vector(12,6,4),color=color.blue) جسم كروي: sphere (pos=vector(1,2,1),radius=0.5,color=color.blue) وهكذا.. ملاحظة: الرسم 3D يتطلب GPU قوية جداً.
-
أنت بحاجة إلى إصدار 64 بت من Python وفي حالتك تستخدم إصدار 32 بت. اعتباراً من الآن ، يدعم Tensorflow إصدارات 64 بت من Python 3.5.x و 3.8.x على Windows. لحل مشكلتك: في حال كنت تستخدم Windows (8, 8.1, 10) قم بتثبيتها كالتالي: python3 -m pip install --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.12.0-py3-none-any.whl بالنسبة ل mac ولينوكس قم بتبديل python3 إلى python حسب التكوين الخاص بك، وقم بتغيير py3 إلى py2 في عنوان url إذا كنت تستخدم Python 2.x.
- 1 جواب
-
- 2
-

-
الأمر كله يتعلق بال CPU، أولاُ يجب أن تعلم أن لكل معالج مجموعة تعليمات منخفضة المستوى Low-Level هذه التعليمات نسميها ISA، مجموعة التعليمات هذه هي قائمة بجميع الأوامر المتاحة بمختلف أشكالها التي يمكن لمعالج ما تنفيذها، وتتضمن هذه التعليمات: تعليمات حسابية ومنطقية مثل الجمع المنطقي والضرب المنطقي والنفي المنطقي ووووو.. طريقة تعريف هذه التعليمات وتحقيقها يلعب دوراً كبيراً جداً في سرعة المعالج وأدائه. هناك مجموعات تعليمات أساسية تدعمها كل المعالجات الحديثة وهناك توسعات كثيرة لها "Instruction Set Extensions" مثل SSE2, SSE4, AVX 2,AVX ..إلخ هذه التوسعات أو الإضافات أو الامتدادات تعطي الحاسب سرعة وأداء إضافي كبيرة. إن هذه الرسالة التي تظهر لك مفادها أن معالجك يدعم مجموعة تعليمات AVX لكن تنسرفلو لاتستفيد منها، هذه التعليمات تنفذ عمليات تسمى fused multiply-accumulate (FMA) وفائدتها في أنها تسرع من تنفيذ عمليات الجبر الخطي وضرب المصفوفات والجداء النقطي "dot-product" وعمليات الالتفاف على المصفوفات "convolution"، وكما نعرف جميعنا فإن هذه العمليات هي 90% من العمليات الداخلية التي تنفذ في التعلم الآلي. وبالتالي فإن تسريع حسابها يزيد سرعة الأداء بشكل كبير جداً بنسبة تصل ل 300٪. حسناً لماذا لاتستفيد منها وتستخدمها؟ السبب هو أن التوزيع الافتراضي لـ tensorflow تم إنشاؤه بدون امتدادات وحدة المعالجة المركزية ، مثل SSE4.1 و SSE4.2 و AVX و AVX2 و FMA وما إلى ذلك ، حيث أن التصميمات الافتراضية تهدف إلى أن تكون متوافقة مع أكبر عدد ممكن من وحدات المعالجة المركزية. سبب آخر هو أنه حتى مع هذه الإضافات ، تعد وحدة المعالجة المركزية أبطأ بكثير من وحدة معالجة الرسومات GPU ، ومن المتوقع أن يتم تنفيذ تدريب التعلم الآلي على نطاق متوسط وكبير على وحدة معالجة الرسومات GPU. إذاً ما الحل؟ إذا كان لديك GPU ، فلا يجب أن تهتم بدعم AVX ، وبالتالي يمكنك ببساطة تجاهل هذا التحذير عن طريق (منعه من الظهور): import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' أو إذا أردت استخدام تعليمات AVX فهناك تحديثات خاصة لتنسرفلو لكي تدعم هذه التعليمات بأنواعها المختلفة SSE4.1 و SSE4.2 و AVX و AVX2 و FMA إلخ.، وهي موجودة على gitHub في الرابط التالي: https://reposhub.com/python/deep-learning/lakshayg-tensorflow-build.html بعد أن تقوم بتحميل النسخة التي تريدها فقط ادخل لل cmd: pip install --ignore-installed --upgrade /path/to/binary.whl --user حيث تمرر له المسار الذي يتواجد فيه الملف الذي تم تنزيلها، أو يمكنك تحميلها مباشرة من gitHub: pip install --ignore-installed --upgrade "Download URL" --user حيث فقط تمرر له رابط النسخة التي نريدها (هناك عشرين نسخة أو أكثر وكل منها لنظام مختلف وتوسعات مختلفة). هذا كل شيئ..
- 1 جواب
-
- 2
-
-
input_shape يمثل شكل البيانات التي ستدخل إلى طبقة معينة من نموذجك وبالتالي يجب أن تكون متوافقة مع حجم بياناتك، حيث أن كل طبقة من طبقات النموذج ستتلقى دخلأ بأبعاد معينة، لكننا لانحتاج لتحديد ذلك سوى لأول طبقة (لأن الطبقات التالية يتم استنتاج الأبعاد فيها لأنها تنتج من اختزال أبعاد الدخل على حجم الخلايا في الطبقة). وبما أن أول طبقة هي Dense فهي تتوقع منك مصفوفة (أو بمعنى أدق tensor) ثنائية الأبعاد تمثل حجم الباتش وعدد الفيتشرز features: model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(keras.layers.LayerNormalization()) input_shape=(10000,) تعني أن الدخل سيكون لديه 10 آلاف features (ال axis=0 لانحدده وبالتالي سيتم قبول أي قيمة لحجم الباتش).
- 1 جواب
-
- 2
-
-
يظهر هذا الخطأ عندما تكون بيانات التدريب والاختبار غير متوافقة، أقصد بذلك عندما تكون الأبعاد غير متوافقة، أي بمعنى أوضح إذا كانت:: # في حالة كانت بياناتك هي بيانات تصنيف ثنائي # x أبعاد الدخل shape : (samples,features) #سمها كما شئت y أو label أو ال target فيجب أن تكون أبعاد بيانات الهدف Shape: (samples,) # أي مثلاً X_Shape:(1000,521) --> يجب أن يكون --> y_shape:(1000,) #label أي بمعنى آخر يجب أن يكون لكل عينة من بياناتك قيمة تمثل الهدف أو # في حالة كانت بياناتك بيانات تصنيف متعدد X_Shape : (samples,features) y_shape: (samples,عدد الفئات) # أي في مثالك فإن أبعاد الدخل هي X_Shape : 7982, 10000) # ولدينا 46 فئة وبالتالي أبعاد الهدف تكون (7982, 46) وهنا يخبرك كيراس أن عدد ال samples في بياناتك هو 7982 بينما ال label هو 8982 لذا يظهر خطأ. الحل: x_val = x_train[:1000] partial_x_train = x_train[1000:] # هنا y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:] # الآن: partial_x_train.shape # (7982, 10000) partial_y_train.shape # (7982, 46) ... ... . . #fit تدريب النموذج من خلال الدالة history = model.fit(tf.convert_to_tensor(partial_x_train, np.float32), partial_y_train, epochs=6, batch_size=512, validation_data=(x_val, y_val),max_queue_size=10) حيث أنك قمت باقتطاع جزء من بيانات التدريب لديك لتكون بيانات validation لكنك نسيت أن تقوم باقتطاع بيانات الهدف أيضاً.
- 1 جواب
-
- 2
-
-
حسناً هناك عدة طرق، لكن يجب علينا أن نفرق بين قراءة الصورة وتحويلها إلى مصفوفة نمباي، الآن أول طريقة هي استخدام الدالة asarray بعد قراءة المصفوفة باستخدام مكتبة PIL لكن أولاً يجب تثبيتها: pip install Pillow الآن يمكنك استخدام PIL: from PIL import Image import requests #url ٍسأقرأ صورة من عنوان im = Image.open(requests.get(url, stream=True).raw) # طباعة معلومات الصورة print(im.format) print(im.size) print(im.mode) """ JPEG (1920, 1200) RGB """ # الآن تحويلها لمصفوفة نمباي numpydata = np.asarray(im) # <class 'numpy.ndarray'> print(type(numpydata)) # shape: (1200, 1920, 3) print(numpydata.shape) الطريقة الثانية استخدام numpy.array بنفس الطريقة: from PIL import Image import requests #url ٍسأقرأ صورة من عنوان im = Image.open(requests.get(url, stream=True).raw) # طباعة معلومات الصورة print(im.format) print(im.size) print(im.mode) """ JPEG (1920, 1200) RGB """ numpy_Arr = np.array(im) # <class 'numpy.ndarray'> print(type(numpy_Arr)) # shape: (1200, 1920, 3) print(numpy_Arr.shape) # ولاستعادة الصورة لشكلها الأصلي # Image.fromarray Image.fromarray(numpy_Arr) الطريقة الثالثة هي استخدام الدالة img_to_array من keras حيث نقوم في البداية بقراءتها من خلال الدالة load_img من كيراس أيضاً: # pip install keras # pip install tensorflow from keras.preprocessing.image import load_img mg = load_img('image1.png') im.mode # RGB type(mg) # <class 'PIL.PngImagePlugin.PngImageFile'> im.format # PNG im.size # (400, 200) # الآن تحويلها from keras.preprocessing.image import img_to_array numpy_array = img_to_array(img numpy_array.shape # (200, 400, 3) type(numpy_array) # <class 'numpy.ndarray'> numpy_array.dtype # type: float32 # ولاستعادة الصورة من مصفوفة نمباي from keras.preprocessing.image import array_to_img array_to_img(numpy_array) وأيضاً من خلال مكتبة OpenCV لكن أيضاً يجب تحميلها: # pip install opencv-contrib-python import cv2 as cv im = cv.imread('Sample.png') image = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) # لحفظها cv.imwrite('i.png', image) type(img) # <class 'numpy.ndarray'> حيث تقوم بقراءة الصورة كمصفوفة نمباي مباشرةً. وهذا كان كل شيئ.
-
تقوم هذه الدالة يتدريب نموذجك (تدريب الأوزان على المشكلة المعطاة)، ولها الشكل التالي: Model.fit( x=None, y=None, batch_size=None, epochs=1, verbose="auto", callbacks=None, validation_split=0.0, validation_data=None, shuffle=True, class_weight=None, sample_weight=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None, validation_batch_size=None, validation_freq=1, max_queue_size=10, workers=1, use_multiprocessing=False, ) 1. أول وسيط يشير إلى بيانات الدخل، ويجب أن يكون مصفوفة نمباي (أو نوع آخر يشابهها)، أو قائمة من المصفوفات "list of arrays" (في حالة كان نموذجك متعدد الدخل multiple inputs). أو يمكن أن تكون مصفوفة تنسر "TensorFlow tensor" أو قائمة من التنسر "list of tensors" (في حالة كان نموذجك متعدد الدخل multiple inputs). أو قاموس يربط اسم بمصفوفة أو تنسر في حال كان لمصفوفات الدخل أسماء. أو tf.data مجموعة بيانات مكونة من خلال تنسرفلو، بحيث تكون من الشكل (inputs, targets) أو (inputs, targets, sample_weights).أو مولد generator أو تسلسل keras.utils.Sequence بحيث يعيد (inputs, targets) أو (inputs, targets, sample_weights). 2. ثاني وسيطة هي بيانات الهدف أو ال Target أو ال label، وبشكل مشابه لبيانات الدخل x يجب أن تكون Numpy array(s) أو TensorFlow tensor(s)، ويجب أن تكوم متسقة مع x، أي بمعنى إذا كانت x تحوي 400 عينة فهذا يعني أنه يجب أن يكون لدينا 400 target، و لايجب أن يكون x نمباي و y تنسر أو العكس. وفي حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence فلا تقم بتمرير قيم ال y لأنهم يحصلون علبها بشكل تلقائي من خلال x. 3. الوسيط الثالث هو ال batch_size وهو يمثل حجم دفعة البيانات، وهو عدد صحيح يشير إلى عدد العيانات التي سيتم تطبيق خوارزمية الانتشار الأمامي والخلفي عليها في المرة الواحدة. أي مثلاً لو كان لديل 100 عينة وكان حجم الباتش 10 هذا يعني أن هسيكون لديك 10 باتشات وكل باتش يحوي 10 عينات وبالتالي سيتم تطبيق خوارزمية الانتشار الأمامي ثم الخلفي (تحديث الأوزان) على أول باتش ثم ينتقل للباتش الثاني وهكذا.. أيضاً في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence فلاتقم بتحديد هذا الوسيط لأنهم في الأساس يقومون بتوليد باتشات. وأيضاً في حالة لم تقوم بتعيين قيمة للباتش "None" فسأخذ القيمة الافتراضية 32. 4. الوسيط الرابع epochs عدد الحقب التي تريدها لتدريب النموذج، كل حقبة تقابل مرور على كامل مجموعة البيانات. 5. الوسيط الخامس هو ال verbose لعرض تفاصيل عملية التدريب في حال ضبطه على 0 لن يظهر لك تفاصيل عملية التدريب "أي الوضع الصامت"، أما في حالة ضبطه على 1 فهذا يعني أنك تريد أن تظهر لك تفاصيل التديب (الكل يريد هذا طبعاً). 6. الوسيط السادس callbacks قائمة من keras.callbacks.Callback وهي قائمة الاسترجاعات المطلوب تقديمها أثناء التدريب. 7. الوسيط السابع validation_split هو عدد حقيقي بين 0 و ال 1، يحدد نسبة يتم اقتطاعها من بيانات التدريب ليتم استخدامها كعينات تطوير Validaton set، وهذه الخاصية غير مدعومة في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence. 8. الوسيط الثامن validation_data هو البيانات التي تريد استخدامها كعينات تطوير Validaton set أي لن يستخدمها في عملية التدريب وإنما سيختبر عليها دقة النموذج بعد كل حقبة (تماماً كما في الوسيط السابق)، ويجب أن تكون tuble من الشكل (x_val, y_val) كما يجب أن تكون من نمط البيانات tensors أو مصفوفات نمباي، أو tf.data.Dataset أو generator أو keras.utils.Sequence تعيد (inputs, targets) أو (inputs, targets, sample_weights). 9. الوسيط التاسع shuffle يأخذ قيمة بوليانية لتحديد فيما إذا كنت تريد القيام بعملية خلط للبيانات قبل كل حقبة أو يأخذ str في حالة كنت تريد الخلط قبل كل باتش ونمرر له في هذه الحالة "batch". وفي حالة كانت بياناتك هي مولدات أو tf.data.Dataset سيتم تجاهل هذا الوسيط. ملاحظة: "batch" هي خيار خاص للتعامل مع قيود بيانات HDF5، يخلط في أجزاء chunks بحجم الدُفعة batch-sized chunks. ويكون له تأثير عندما تكون None= steps_per_epoch . أما الوسيط العاشر 10. فهو ال class_weight وهي عبارة عن قاموس (اختياري) يربط فهارس الفئة (أعداد صحيحة) بوزن (قيمة float) لتوزين دالة التكلفة (خلال فترة التدريب فقط) ويكون استخدامه مفيداً لإخبار النموذج "بإيلاء المزيد من الاهتمام" لفئات الأقلية في حال كانت البيانات غير متوازنة (مثلاً عدد صور القطط 1000 وعدد صور الكلب 4000). 11. الوسيط sample_weight هو مصفوفة أوزان (اختياري) لعينات التدريب وتستخدم أيضاً لتوزين دالة التكلفة.ويمكنك إما تمرير مصفوفة Numpy مسطحة (1D) بنفس طول عينات الإدخال (ربط 1: 1 بين الأوزان والعينات). أو في حالة البيانات الزمنية ، يمكنك تمرير مصفوفة ثنائية الأبعاد ذات شكل (عينات ، طول التسلسل) ، لتطبيق وزن مختلف لكل خطوة زمنية لكل عينة. وهذه الخاصية غير مدعومة في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence.. الوسيط 12. هو initial_epoch عدد صحيح. الحقبة التي تبدأ فيها التدريب (مفيدة لاستئناف دورة تدريبية سابقة). 13. steps_per_epoch عدد صحيح أو None إجمالي عدد الخطوات (مجموعات العينات) قبل الإعلان عن انتهاء حقبة واحدة وبدء المرحلة التالية. عند التدريب باستخدام موترات الإدخال مثل TensorFlow data tensors ، فإن القيمة الافتراضيةNone تساوي عدد العينات في مجموعة البيانات الخاصة بك مقسوماً على حجم الباتش، أو 1 إذا تعذر تحديد ذلك. إذا كانت x عبارة عن tf.data ، وكانت "steps_per_epoch=" None ، فسيتم تشغيل الحقبة حتى يتم استنفاد مجموعة بيانات الإدخال. وهذه الوسيطة غير مدعومة عندما تكون مدخلاتك هي مصفوفات. 14. validation_steps: تعمل فقط إذا تم توفير validation_data وكانت عبارة عن tf.data. وهي إجمالي عدد الخطوات (باتش من العينات batches of samples) المطلوب سحبها قبل التوقف عند إجراء ال validation في نهاية كل حقبة. إذا كانت "validation_steps" هي None ، فسيتم تشغيل ال validation حتى يتم استنفاد مجموعة بيانات validation_data. أما إذا تم تحديد "Validation_steps" فسيتم استخدام جزء فقط من مجموعة البيانات ، وسيبدأ التقييم من بداية مجموعة البيانات في كل حقبة. وهذا يعني استخدام نفس عينات التحقق في كل مرة. 15. validation_batch_size: عدد العينات لكل دفعة validation. إذا لم يتم تحديدها ، فسيتم تعيينها افتراضياً إلى batch_size. لا تحدد validation_batch_size إذا كانت بياناتك في شكل dataset, generator, أو keras.utils.Sequence.. (لأنها تولد باتشات). 16. validation_freq: تعمل فقط إذا تم توفير validation_data وهي عبارة عن عدد صحيح أو collections.abc.Container (مثل list ، tuple ، إلخ). إذا كان عدداً صحيحاً ، فإنه يحدد عدد حقب التدريب التي سيتم تشغيلها قبل إجراء عملية تحقق جديدة، على سبيل المثال validation_freq = 2 يتم تشغيل ال validation كل حقبتين. إذا كانت Container ، فإنها تحدد الحفب التي سيتم فيها تشغيل ال validation ، على سبيل المثال Validation_freq = [1 ، 2 ، 10] أي تشغيل ال validation في نهاية الحقبة الأولى والثانية والعاشرة. 17. max_queue_size: عدد صحيح ، و يستخدم للمولد generator أو keras.utils.Sequence فقط. ويمثل الحجم الأقصى لرتل المولد. إذا لم يتم تحديدها ، فسيتم تعيين max_queue_size افتراضياً على 10. 18. use_multiprocessing: قيمة بوليانية لتحديد فيما إذا كنت تريد استخدام المعالجة المتعددة أم لا وهو مدعوم فقط في حالة generator أو keras.utils.Sequence. الآن سأعطيك مثال لاستخدامه في تدريب نموذج: from keras.datasets import reuters import keras import tensorflow as tf (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=10000) import numpy as np def vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) x_val = x_train[:1000] partial_x_train = x_train[1000:] y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:] from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(keras.layers.LayerNormalization()) model.add(layers.Dense(64, activation='relu')) model.add(keras.layers.LayerNormalization()) model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['CategoricalAccuracy']) #fit تدريب النموذج من خلال الدالة history = model.fit(tf.convert_to_tensor(partial_x_train, np.float32), partial_y_train, epochs=6, batch_size=512, validation_data=(x_val, y_val)) """ Epoch 1/6 16/16 [==============================] - 2s 75ms/step - loss: 1.7822 - categorical_accuracy: 0.6134 - val_loss: 1.1558 - val_categorical_accuracy: 0.7510 ... ... Epoch 6/6 16/16 [==============================] - 1s 56ms/step - loss: 0.1659 - categorical_accuracy: 0.9535 - val_loss: 0.9125 - val_categorical_accuracy: 0.8080 """ كما وترد هذه الدالة كائن History يحوي قيم ال loss وال accuracy لنموذجك في كل حقبة "epoch". حيث يمكننا الوصول إليهم من خلال الواصفة history من هذا الكائن أي كالتالي History.history: history.history """ {'categorical_accuracy': [0.6207717657089233, 0.8475319743156433, 0.9155600070953369, 0.9433726072311401, 0.9516412019729614, 0.9551491141319275], 'loss': [1.70294189453125, 0.7281545996665955, 0.43800199031829834, 0.2743467688560486, 0.2031983882188797, 0.1586201786994934], 'val_categorical_accuracy': [0.753000020980835, 0.7839999794960022, 0.7940000295639038, 0.796999990940094, 0.7900000214576721, 0.7860000133514404], 'val_loss': [1.115304946899414, 0.9754453897476196, 0.9541780948638916, 0.9103594422340393, 0.9673216342926025, 0.9509721994400024]} """
- 1 جواب
-
- 2
-
-
المصفوفة المتجاورة هي مصفوفة مخزنة في كتلة غير متقطعة في الذاكرة أي قيمها مخزنة بشكل متجاور، وبالتالي للوصول إلى العنصر التالي من المصفوفة، ننتقل فقط إلى عنوان الذاكرة التالي. ويشار لذلك بأن المصفوف C-order أي "C contiguous". import numpy as np # لنفرض لدينا المصفوفة التالية arr = np.arange(8).reshape(4,2) arr # سيكون شكلها كالتالي """ array([[0, 1], [2, 3], [4, 5], [6, 7]]) """ # وفي الذاكرة ستكون مخزنة بالشكل التالي # [0, 1, 2, 3, 4, 5, 6, 7] # أي أن هذه المصفوفة هي مصفوفة متجاورة حيث أن الأسطر الخاصة بالمصفوفة مخزنة على شكل كتل متجاورة وليس منفصلة وبالتالي # يحتوي عنوان الذاكرة التالي على قيمة الصف التالي في هذا الصف # مثلاً إذا أردنا التحرك لأسفل، فنحن نحتاج فقط إلى القفز فوق كتلة واحدة # أي مثلاً للانتقال من 0 ل 2 نحتاج فقط للقفز فوق القيمة 1 # أما منقول المصفوفة باستخدام array.T يؤدي إلى فقدان هذا التجاور بالنسبة للأسطر. ومع ذلك ، فإن arr.T هو Fortran متجاور لأن الأعمدة أصبحت موجودة في كتل متجاورة من الذاكرة. ومن ناحية الأداء، فغالباً ما يكون الوصول إلى عناوين الذاكرة المجاورة لبعضها البعض أسرع من الوصول إلى العناوين المتناثرة فقد يستلزم جلب قيمة من ذاكرة الوصول العشوائي عددًا من العناوين المجاورة التي يتم جلبها وتخزينها مؤقتًا لوحدة المعالجة المركزية. يعني أن العمليات عبر المصفوفات المتجاورة ستكون غالباً أسرع. ونتيجة لذلك فدوماً مانجد أن العمليات على الأسطر أسرع من العمليات على الأعمدة في المصفوفات. وبالمثل، ستكون العمليات على الأعمدة أسرع قليلاً بالنسبة لمصفوفات Fortran المتجاورة. أيضاً يجب أن تعلم أننا لا يمكننا تسطيح مصفوفة Fortran المتجاورة من خلال تعيين shape جديد أي: import numpy as np # لنفرض لدينا المصفوفة التالية arr = np.arange(8).reshape(4,2) arr array=arr.T array.shape=8 """ --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-17-a71f03f19106> in <module>() 4 arr 5 array=arr.T ----> 6 array.shape=8 AttributeError: Incompatible shape for in-place modification. Use `.reshape()` to make a copy with the desired shape. """ ولكي يكون هذا ممكناً ، يجب على NumPy وضع صفوف array.T معاً أي يجب أن يكون ترتيبهم في الذاكرة: [0, 2, 4, 6,1, 3, 5, 7] حيث أن بايثون يفترض عند تعيين shape جديد للمصفوفة أن المصفوفة تتبع C-order أي يحاول NumPy تنفيذ العملية على مستوى الصف. وبالتال هذا مستحيل القيام به. لأي محور، يحتاج NumPy إلى طول خطوة ثابت (عدد البايتات المراد نقلها) للوصول إلى العنصر التالي من المصفوفة. وبالتالي سيتطلب التسطيح بهذه الطريقة التخطي للأمام وللخلف في الذاكرة لاسترداد القيم المتتالية للمصفوفة. والحل الوحيد هو استخدام reshape(8) حيث يقوم NumPy بنسخ قيم array في كتلة جديدة من الذاكرة لأنه لا يمكنه إرجاع طريقة عرض view إلى البيانات الأصلية لهذا الشكل.
-
إضافة إلى الطرق المذكورة أعلاه، فإن الحل الأسهل هو استخدام الدالة asarray : import pandas as pd import numpy as np df=pd.DataFrame({"A": [1, 2], "B": [3, 4]}) np.asarray(df) """ array([[1, 3], [2, 4]]) """ أو من خلال np.array وبسهولة: import pandas as pd import six import numpy as np df=pd.DataFrame({"A": [1, 2], "B": [3, 4]}) np.array(df) """ array([[1, 3], [2, 4]]) """ ,وهنا مقارنة بين الثلاث طرق الرئيسية للتحويل: %time np.array(df) %time df.to_numpy() %time np.asarray(df) """ CPU times: user 105 µs, sys: 7 µs, total: 112 µs Wall time: 117 µs CPU times: user 59 µs, sys: 0 ns, total: 59 µs Wall time: 62.2 µs CPU times: user 79 µs, sys: 0 ns, total: 79 µs Wall time: 84.4 µs """
-
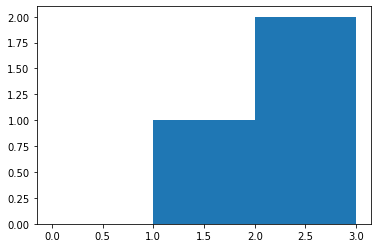
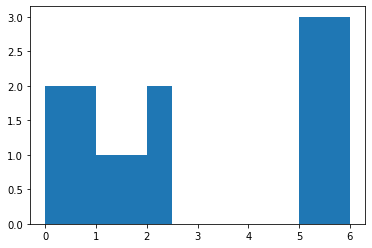
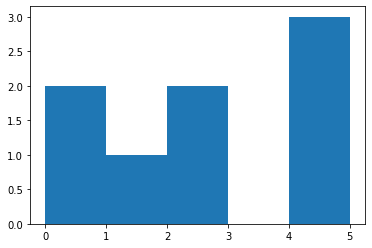
bin هو مجال يمثل عرض bar (شريط) واحد من الهستوغرام على طول المحور الأفقي X. كما يمكن أن نسميه بالفاصل الزمني. يقوم هذا التابع بحساب عدد مرات ظهور عناصر من مصفوفة الدخل ضمن مجال معين "bar"، ستفهم أكثر من خلال المثال التالي، لكن سأعطيك مثال من خلال دالة تكافئ هذه الدالة لأن هذه الدالة لاتقوم بالرسم: import matplotlib.pyplot as plt plt.hist([1, 2, 2], bins=[0, 1, 2, 3]) plt.show() # bins=[0, 1, 2, 3] تعني أنه سيتم تقسيم المحور الأفقي إلى أريع مجالات تبعاً لهذه القيم # [1, 2, 2] هي الثائمة التي نريد حساب هستوغرامها # وبالتالي هذا التابع يحسب لنا عدد مرات ظهور عناصر من بيانات الدخل ضمن مجال معين # لاحظ أنه ضمن المجال من 0 إلى 1 لايوجد أي عناصر في بيانات الدخل ولهذا لم يظهر لنا البار # ضمن المجال من 1 ل 2 يوجد قيمة وحيدة وهي 1 # لاحظ أن 2 لاتحتسب ضمن المجال وإنما الأصغر تماماً من 2 # الآن ضمن المجال من 2 ل 3 يوجد قيمتين في بيانات الدخل وهما 2 و 2 لذا كانت قمة البار تقابل القيمة 2 على المحور الأفقي مثال آخر: plt.hist([0,0,1, 2, 2,5,5,5], bins=[0, 1, 2, 3,4,5]) plt.show() # لاحظ أنه ضمن المجال من 3 ل4 لاتوجد أي قيمة في بيانات الدخل لذا كان طول البار يساوي 0 ضمن هذا المجال # كما نلاحظ أن طول البار يساوي 3 ضمن المجال من 4 ل 5 لوجود 3 قيم في بيانات الدخل ضمن هذا المجال # لاحظ أيضاً أنه بالرغم من أن 5 ليست أصغر تماماً لكنها احتسبت ضمن المجال وهذه حالة خاصة لأنها آخر مجال لاحظ هنا عند إضافة مجال آخر ستحتسب القيمة 5 ضمن المجال الجديد: # هنا سنعبث بالمجالات plt.hist([0,0,1, 2, 2,5,5,5], bins=[0, 1, 2,2.5,5,6]) plt.show() # أو مجال من 0 ل1 والثاني من 1 ل2والثالث من 2 ل 2.5 ويوجد ضمنه قيمتين وهكذا دالة np.histogram تعمل بشكل مكافئ تماماً، لكنها لاتقوم بالرسم. # أمثلة np.histogram([1, 2, 1], bins=[0, 1, 2, 3]) #(array([0, 2, 1]), array([0, 1, 2, 3])) np.histogram(np.arange(4), bins=np.arange(5), density=True) #(array([0.25, 0.25, 0.25, 0.25]), array([0, 1, 2, 3, 4])) np.histogram([[1, 2, 1], [1, 0, 1]], bins=[0,1,2,3]) #(array([1, 4, 1]), array([0, 1, 2, 3])) ونستخدمها في الأمور الإحصائية أو في مهام معالجة الصور حيث أن حساب هستوغرام صورة يخبرنا بالعديد من المعلومات عن الصورة.
- 1 جواب
-
- 1
-
-
أولاً هذه الطبقة تمكننا من إضافة دالة التنشيط التي نريدها إلى نموذجنا تماماً كما في الشكل الذي أضفته، أما بالنسبة للفرق بين الطريقتين فلايوجد فرق من حيث المبدأ لكن الفرق يكون من حيث الاستخدام والهدف، فعندما تريد مثلاً تطبيق ال Bachnormlaization أو ال Layer Normlaization على قيم z فهنا أنت بحاجة لفصل التنشيط عن قيم ال z التي تنتجها الخلايا، لاحظ المثال التالي: model = models.Sequential() model.add(layers.Dense(64,input_shape=(10000,))) model.add(keras.layers.LayerNormalization()) model.add(layers.Activation("relu")) model.add(layers.Dense(64)) model.add(keras.layers.LayerNormalization()) model.add(layers.Activation("relu")) model.add(layers.Dense(46, activation='softmax')) وهنا أيضاً: AlexNet.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='same')) AlexNet.add(BatchNormalization()) # هنا AlexNet.add(Activation('relu')) AlexNet.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'))
- 1 جواب
-
- 2
-
-
فقط قم بالمرور على مصفوفة المنقول وتمريرها : import numpy as np array = np.array([[1, 2, 7],[4,3,1]]) array """ array([[1, 2, 7], [4, 3, 1]]) """ # الآن نريد تمرير الأعمدة للتابع for column in array.T: print (column) """ [1 4] [2 3] [7 1] """ # وبالتالي for column in array.T: fun (column) أو من خلال np.hsplit: for column in np.hsplit(array, array.shape[1]): print(column) # أي سيتم تمريرهم بالشكل """ [[1] [4]] [[2] [3]] [[7] [1]] """ # وبالتالي for column in np.hsplit(array, array.shape[1]): fun(column)
- 2 اجابة
-
- 1
-
-
يمكننا استخدام np.argmax لمعرفة الفهرس الذي توجد فيه أكبر قيمة في المصفوفة كاملةً أو أكبر قيمة في كل عمود أو سطر من المصفوفة، وكل ماعلينا فعله هو تغيير المحور كما يلي: import numpy as np array = np.array([[1,2,3],[4,3,1]]) print("Original array:") print(array) """ [[1 2 3] [4 3 1]] """ # فهرس أكبر قيمة للمصفوقة كاملةً # لكنه هنا يقوم بتسطيح المصفوفة وبالتالي فهرس القيمة 4 هو 3 np.argmax(array,axis=None) #3 # لكل عمود np.argmax(array,axis=0) # array([1, 1, 0]) # لكل سطر np.argmax(array,axis=1) # array([2, 0]) كما ويمكننا استخدام التابع np.max: import numpy as np array = np.array([[1,2,3],[4,3,1]]) print("Original array:") print(array) """ [[1 2 3] [4 3 1]] """ # كامل المصفوفة np.max(array, axis=None, keepdims=True) # array([[4]]) # الأعمدة np.max(array, axis=0, keepdims=True) # array([[4, 3, 3]]) # الأسطر np.max(array, axis=1, keepdims=True) """ array([[3], [4]]) """ الآن لاحظ أن فهرس القيم العظمى التي حصلت عليها باستخدام argmax ليست الفهارس الحقيقية بالنسبة لكامل المصفوفة وإنما هي الفهرس بالنسبة للسطر أو العمود، أما إذا أردت الفهرس الحقيقي أي (عمود,سطر) تابع معي: import numpy as np array = np.array([[1, 2, 7],[4,3,1]]) print("Original array:") print(array) result = np.where(array == np.max(array,0)) print('Tuple of arrays returned : ', result) print('List of coordinates of maximum value in Numpy array : ') # zip the 2 arrays to get the exact coordinates listOfCordinates = list(zip(result[0], result[1])) for cord in listOfCordinates: print(cord) """ Original array: [[1 2 7] [4 3 1]] Tuple of arrays returned : (array([0, 1, 1]), array([2, 0, 1])) List of coordinates of maximum value in Numpy array : (0, 2) == 7 (1, 0) == 4 (1, 1) == 3 """ كما يمكنك استخدام التابع amax بنفس الطريقة التي استخدمنا فيها max.
- 2 اجابة
-
- 1
-
-
السبب في قيامك بالخلط مابين Keras API و tensorflow.keras، فهما منفصلتين، فالأولى هي إطار العمل كيراس أما الثانية فهي كيراس نفسها لكن بعد أن تم دمجها كموديول في تنسرفلو عملية الدمج هذه قد تنتج أخطاءاً تتعلق بالتوافق في بعض الأحيان عندما تقوم باستخدامهما في نموذجك معاً، حيث قمت هنا بتهيئة معمارية sequential من tensorflow.keras وإضافة طبقات لها من Keras API لذا استخدم إما Keras API أو tensorflow.keras. وبالتالي يكون : from tensorflow.keras.layers import Conv2D,MaxPooling2D from tensorflow.keras.datasets import mnist from tensorflow.keras.models import Sequential import tensorflow.keras from tensorflow.keras.layers import Dense, Dropout, Flatten model = Sequential() model.add(Conv2D(30,(3,3),padding="valid",kernel_initializer="glorot_uniform", activation="tanh", input_shape=(28, 28, 1) )) model.add(Conv2D(30,(3,3), activation="tanh")) model.add(MaxPooling2D((2,2)) model.add(Dropout(0.4)) model.add(Flatten()) model.add(Dense(100, activation='relu')) model.add(Dropout(0.4)) model.add(Dense(10, activation='softmax'))
- 1 جواب
-
- 2
-
-
إذا لم تكن على دراية بهذا المفهوم فيجب أولاً أن تقوم بقراءة الإجابة عن هذا السؤال، فهو مرتبط به تماماً، حيث أن ال Layer Normalization هي تعديل على ال batch normalization: في batch normalization كنا نقوم بحساب المتوسط mean وال variance اعتماداً على حجم ال batch أما هنا فنقوم بحسابه اعتماداً على عدد الخلايا في الطبقة أي أن هذه المعملات الإحصائية يتم حسابها بشكل مستقل عن الباتش. وهذا هو الفرق بينهما. وسبب ظهورها هو أن ال batch normalization لاينفع مع مع شبكات RNNs (وهذا هو السبب الرئيسي). حيث أنه في هذا النوع من الشبكات يكون لدينا بيانات متسلسلة "sequential data" فالجمل تكون بأطوال مختلفة وبالتالي الاعتماد على الاحصائيات التي نحصل عليها بالنسبة لحجم الباتش يكون أمراً غير دقيق بالمرة. لذا أتت هذه الفكرة وهي حساب هذه المعاملات الإحصائية بالنبسة لكل عينة من البيانات أي عملياً (لكل جملة في حالة ال sequential data). في كيراس له الشكل التالي: tf.keras.layers.LayerNormalization( axis=-1, epsilon=0.001, center=True, scale=True, beta_initializer="zeros", gamma_initializer="ones", beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None, ) هذه الوسطاء هي نفسها في ال batch normlaization (يمكنك العودة إلى الرابط الذي قدمته في الأعلى). وفي المثال التالي أبين لك كيف يمكنك استخدامه مع الشبكة العصبية (بشكل مشابه لل batch norm): model = tf.keras.models.Sequential([ tf.keras.layers.Reshape((28,28,1), input_shape=(28,28)), tf.keras.layers.Conv2D(filters=16, kernel_size=(3,3),data_format="channels_last"), # LayerNorm Layer لإضافة طبة tf.keras.layers.LayerNormalization(axis=3 , center=True , scale=True), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) حيث قمنا بتطبيق Layernormalization بعد طبقة Conv2D واستخدام مقياس وعامل إزاحة. مثال آخر لاستخدامه مع نموذج لتحليل مراجعات الأفلام IMDB: from keras.datasets import reuters import keras (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=10000) import numpy as np def vectorize_sequences(sequences, dimension=10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1. return results x_train = vectorize_sequences(train_data) x_test = vectorize_sequences(test_data) from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) x_val = x_train[:1000] partial_x_train = x_train[1000:] y_val = one_hot_train_labels[:1000] partial_y_train = one_hot_train_labels[1000:] from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,))) model.add(keras.layers.LayerNormalization()) model.add(layers.Dense(64, activation='relu')) model.add(keras.layers.LayerNormalization()) model.add(layers.Dense(46, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['CategoricalAccuracy']) history = model.fit(partial_x_train, partial_y_train, epochs=6, batch_size=512, validation_data=(x_val, y_val)) ########################## أو يمكنك تطبيقها قبل استخدام دالة التنشيط ######################### model = models.Sequential() model.add(layers.Dense(64,input_shape=(10000,))) model.add(keras.layers.LayerNormalization()) model.add(layers.Activation("relu")) model.add(layers.Dense(64)) model.add(keras.layers.LayerNormalization()) model.add(layers.Activation("relu")) model.add(layers.Dense(46, activation='softmax'))
- 1 جواب
-
- 2
-
-
يمكنك حفظها من خلال الدالة save في نمباي، كملف من نوع NPY: from numpy import asarray from numpy import save import numpy as np # define data data = np.arange(200).reshape((4,5,10)) # save save('data.npy', data) # load from numpy import load # load array data = load('myarray.npy') # طباعة جزء منها print(data[0]) """ [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]] """ ويمكنك حفظها كملف مضغوط من خلال الدالة savez_compressed كملف من نوع NPZ: from numpy import savez_compressed # define data data = np.arange(200).reshape((4,5,10)) # save to npy file savez_compressed('array.npz', data) إن هذه الدالة تدعم عملية حفظ عدة مصفوفات ضمن ملف واحد، الآن إذا أردنا تحميلها فيمكننا القيام بذلك من خلال الدالة load أيضاً، لكن هنا سيتم تحميلها كقاموس لأنه كما قلنا هذه الدالة تدعم تخزين عدة مصفوفات وبالتالي قد تقوم load بتحميل عدة مصفوفات، ولهذا السبب تقوم هذه الدالة بتحميلها ك قاموس مفاتيحه arr_0 لأول مصفوفة، وفي حال تواجد مصفوفة أخرى arr_1 وهكذا.. هنا قمنا بحفظ مصفوفة واحدة أي سنجدها في arr_0 (ولايوجد غيرها: # تحميلها من الملف from numpy import load # تحميلها كقاموس data = load('array.npz') # استخراج أول مصفوفة subarray = data['arr_0'] # عرض جزء منها print(subarray[0]) """ [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49]] """ لكن في الطريقتين السابقتين، لا يمكننا فحص محتويات الملف المحفوظ باستخدام محرر نصوص لأن تنسيق الملف ثنائي. الآن إذا أردت استخدام savetext من أجل أن تكون قادراً على قراءة محتوياته مثلاً من محرر النصوص، فسنلجأ لأحد الحلول وهو تقسيم المصفوفة ثلاثية الأبعاد (أو أكبر) إلى شرائح ثنائية الأبعاد. على سبيل المثال: from numpy import savez_compressed import scipy.io # define data data = np.arange(200).reshape((4,5,10)) with open('test.txt', 'w') as outfile: for slice_2d in data: np.savetxt(outfile, slice_2d) لكن هدفك هو أن تكون قابلة للقراءة بشكل واضح، لذا يمكننا أن نكون أكثر دقة قليلاً وأن نلجأ لخدعة، عن طريق تفريق الشرائح باستخدام أسطر التعليقات #. بشكل افتراضي، سيتجاهل numpy.loadtxt أي سطور تبدأ بـ # (أو أي حرف يتم تحديده بواسطة kwarg التعليقات): import numpy as np # بياناتنا data = np.arange(200).reshape((4,5,10)) # حفظ المصفوفة كملف with open('data.txt', 'w') as f: # سنضيف ترويسة من أجل سهولة القراءة f.write('# Array shape: {0}\n'.format(data.shape)) # كما قلنا سيتم تجاهل أي سطر يبدأ ب # نقوم بإنتاج الشرائح عن طريق المرور على المصفوفة for slic1e in data: np.savetxt(f, slic1e, fmt='%-7.2f') # طبعاة الشريحة وطباعة عبارة تشير للانتقال لشريحة أخرى f.write('# New slice\n') الآن لإعادة تحميلها: # طبعاً المصفوفة التي ستقرأ هي ثنائية arr = np.loadtxt('test.txt') # لذا نعود للثلاثية البعد بسهولة arr = arr.reshape((4,5,10)) arr """ array([[[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.], [ 10., 11., 12., 13., 14., 15., 16., 17., 18., 19.], [ 20., 21., 22., 23., 24., 25., 26., 27., 28., 29.], [ 30., 31., 32., 33., 34., 35., 36., 37., 38., 39.], [ 40., 41., 42., 43., 44., 45., 46., 47., 48., 49.]], ... ... ... """
- 3 اجابة
-
- 1
-
-
الطريقتين السابقتين تعتمدان على إنشاء مايسمى view لكن ماهو هذا ال view وكيف ينتج.. دعنا نفهم ذلك؟ ال view أو المشهد هو عرض جديد للمصفوفة مع نفس البيانات. أو بمعنى أوضح فكما يقول اسمها، إنها ببساطة طريقة أخرى لعرض بيانات المصفوفة. من الناحية الفنية ، هذا يعني أنه تتم مشاركة بيانات كلا الكائنين. هذا العرض الجديد للمصفوفة ينتج في حالتين الأولى عند قيامك بتطبيق مفهوم ال slicing (مثلاً عرض جزء من المصفوفة أو كاملها)، أو تغيير نمط البيانات (أو كليهما). وفيما يلي توضيح أكبر. وله الشكل التالي في بايثون: ndarray.view([dtype][, type]) # الوسيط الأول هو نمط البيانات الذي تريده # الوسيط الثاني نوع العرض الذي سيتم إرجاعه أمثلة، أولاُ سنعطي مثال لكيفية إنتاج مشهد للمصفوفة من خلال مفهوم التشريح أو slicing: # Slice views أخذ شرائح من المصفوفة أو أقسام محددة منها # المصفوفة الناتجة تكون عبارة عن مشهد من المصفوفة الأصلية بحيث تتم مشاركة البيانات import numpy as np arr = np.arange(8) arr # array([0, 1, 2, 3, 4, 5, 6, 7]) # الآن سنطبق مفهوم الشرائح ve = arr[1:2] ve # array([1]) # سنعدل قيمة في المصفوفة الأصلية لنرى فيما إذا كان حقاً قد تم تشارك البيانات arr[1] = 2 # لاحظ كيف تغيرت هي أيضاً ve # array([2]) # مثال آخر ve1 = arr[1::3] ve1 # array([1, 4, 10]) arr[7] = 10 ve1 #array([1, 4, 7]) الآن الطريقة الأخرى لإنتاج مشهد وهي تغيير نمط البيانات (حل مشكلتك): # Dtype views import numpy as np arr = np.arange(8, dtype='int32') arr # array([0, 1, 2, 3, 4, 5, 6, 7], dtype=int32) v = arr.view('float32') v """ array([0.e+00, 1.e-45, 3.e-45, 4.e-45, 6.e-45, 7.e-45, 8.e-45, 1.e-44], dtype=float32) """ # حسناً هنا صحيح أنهما تشاركا البيانات لكن حصل تشويه وهذ منطقي جداً لاختلاف حجم البايت بين النمطين (أنت تحاول تغيير النمط في نفس المكان) للقيم لذا يمكننا أن نعود بعد ذلك لفكرة التشريح # نقوم بإسناد قيم المصفوفة الأصلية ذات النمط الصحيح إلى المشهد ذو القيم الحقيقية v[:]=arr v[:] # array([0., 1., 2., 3., 4., 5., 6., 7.], dtype=float32) #وبالتالي هنا نكون حصلنا على مانريده # الآن لو نظرنا لقيم المصفوفة الأصلية arr """ array([ 0, 1065353216, 1073741824, 1077936128, 1082130432, 1084227584, 1086324736, 1088421888], dtype=int32) """ # ولو قمنا بتعديل أي قيمة فيها arr[2]=0 v # array([0., 1., 0., 3., 4., 5., 6., 7.], dtype=float32) # نلاحظ أن التعديل أنتقل إلى المصفوفة هذا يعني أنهما يتشاركان البيانات ########################################################################### #false مع تحديد النسخ على Astype بالنسبة لاستخدام #view فلا أظنها ترجع # كما أنني لم ارى ذلك في التوثيق # انظر للمثال التالي import numpy as np arr = np.arange(8, dtype='int32') arr # array([0, 1, 2, 3, 4, 5, 6, 7], dtype=int32) vv = arr.astype(np.float32, copy=False) vv # array([0., 1., 2., 3., 4., 5., 6., 7.], dtype=float32) arr[0]=5 arr # array([5, 1, 2, 3, 4, 5, 6, 7], dtype=int32) vv # array([0., 1., 2., 3., 4., 5., 6., 7.], dtype=float32) # لاحظ أنه لم يحدث أي تغيير لذا لاأظنها حلاً لمشكلتك
- 3 اجابة
-
- 3
-
-
قد ينتح هذا الخطأ في كثير من السيناريوهات أيضاً. بالنسبة لحالتك فإن المعامل not يطبق لنفي قيمة لكن لايمكنك تطبيقه لنفي عدة قيم في نفس اللحظة، وبالتالي عندما تمرر له مصفوفة سيعتبر أن ماقدمته له هو شيء غامض ولايستطيع التعامل معه لأنه يحوي عدة قيم، وبالتالي يقترح عليك أن تستخدم التابعين a.all() أو a.any() حسب ماتحتاج. الآن أنت تريد أن تعرف فيما إذا كانت مصفوفتك هي None أم لا وبالتالي تحاول استخدام not وكما نعرف فإن not None يعطي True وهذا جيد. الآن فكرتك هي أنه عندما تطبق not على مصفوفة سيعطيك False لأنه تحوي قيم (أي أنها تعتبر True)، أو حسب الكود الخاص بك لايعطي شيئ. ولكن هذا لن ينجح وسيعطيك الخطأ المذكور، وبالتالي لحل المشكلة سنستخدم التابعين اللذين اقترحهما بايثون، لكن في حالتنا فإن التابع الذي نحتاجه هو any، لكن قبل ذلك دعني أشرح لك مبدأ عمل هذا التابع، حيث أنه يقبل وسيط من أي نوع ويختبر فيما إذا كانت أي قيمة من قيمه على الأقل هي True فإذا وجد true يرد true وإلا false وهذا مانحتاجه، انظر للأمثلة: # لإرضاً نريد معرفة فيما إذا كان هنا عنصر واحد على الأقل من المصفوفة يحقق شرط معين # أي مثلاً هل يوجد أي قيمة أكبر من 0 arr = np.array([1,2]) arr>0 # array([ True, True]) np.any(arr>0) #true بالتالي سيعطي true هنا سيجد قيمة #true تمرير قيمة وحيدة سيعتبرها np.any(5) #true # لكن لو مررت 0 فسيعطي فالس لأن ال0 تقابل الفالس في بايثون np.any(0) # false # هنا سيرد none np.any(None) #False هنا سيرد np.any(False) وبالتالي يصبح الكود: import numpy as np def check(x): if not np.any(arr): print("It's None") else: print ("It's an array") arr = None check(arr) # It's None arr = np.array([1,2]) check(arr) # It's an array كما ويمكنك استخدام is None كما أشار الأستاذ محمد. كما ويمكننا استخدام فكرة نمط المصفوفة، فكما نعلم بأن المصفوفات في نمباي هي من النمط np.ndarray وبالتالي فيمكنك اختبار فيما إذا كانت الوسيط الممرر للتابع هو من هذا النمط أم لا من خلال التابع isinstance: import numpy as np def check(x): if isinstance(x, np.ndarray): print ("it's not") else: print("It's None") arr = None check(arr) # It's None arr = np.array([1,2]) check(arr) # It's an array
- 2 اجابة
-
- 2
-
-
كما هو معروف فإن البيانات تقسم إلى ٣ أقسام . بيانات تدريب training set وبيانات نقيس عليها تقدمنا خلال عملية التدريب validation set وبيانات نختبر عليها النموذج النهائي test set. وكما نعلم فإن بيانات التدريب هي بيانات مرئية أي أن النموذج يتدرب عليها ويعرف نتيجة كل عينة من البيانات. أما بيانات التحقق وبيانات الاختبار فلايعرف النموذج نتائجها أي أنها بيانات غير مرئية. والهدف من كونها غير مرئية هو قياس كفاءة النموذج الحقيقية. الآن دعنا نعود إلى بيانات ال Validation ... عندما نقوم بتدريب نموذج في التعلم الآلي (مثلاً نموذج لتصنيف الصور) فإن أهم شيئ نحتاجه هو تحديد بروتوكول لقياس عملية التقدم خلال عملية التدربب (تحديد طريقة تمكننا من معرفة سلوك عملية التدريب بغية تجنب ال overfitting وبغية ضبط معاملات النموذج العليا مثل عدد الطبقات أو الخلايا أو نوع الطبقات أو حجم الباتش ..الخ). وهناك عدة بروتوكولات أشهرها ال Cross Validation وتعتمد على أخذ عينة جزئية من بيانات التدريب وقياس دقة النموذج accuracy عليها بعد كل فترة (epoch) من عملية التدريب وهذه القيمة هي مايشار لها ب val_acc أما ال acc فهي دقة النموذج على بيانات التدريب. نحن بحاجة دوما لمراقبة هاتين القيمتين خلال تدريب النموذج ؟ لماذا؟ كما قلت لكي نقيس سلامة التقدم.. فخلال التدريب فإن الشيئ المؤكد دوماً هو أن ال acc ستزداد وتتحسن وهذا يكون إشارة إلى أن النموذج يتعلم من البيانات. لكن هذا قد يجعل النموذج يقع في ال OF وهذا ما لانريده بالطبع ..حسناً إذن كيف سنعرف متى يحدث ال OF منأجل أن نوقف علية التدريب؟ الجواب هو من خلال ال val_acc فطالما أنها تزداد مع ازدياد ال acc فهذا يعني أن النموذج مازال يتعلم ويسلك سلوك صحيح أي أن النموذج قادر على تعميم Generlaization ماتعلمه على بيانات جيدة لم يراها من قبل. أما عندما يستمر ال acc بالتحسن وتبدأ ال val_acc بالانهيار (بالانخفاض) فهذا يعني أن نموذجك لم يعد قادراً على التعلم أكثر من البيانات وبدأ يحفظها (حالة OF ) وهنا ينبغي أن نوقف عملية التدريب لأن النموذج لن يكون قادرا على تعميم مايتعلمه. ولهذا السبب نحن بحاجة لها. أما بابنسبة لل loss فهي قيمة التكلفة على بيانات التدربب و المحسوبة من دالة التكلفة التي حددتها للنموذج. أما val_loss فهي الخاصة ببيانات ال validation.
- 2 اجابة
-
- 3
-
-
من خلال np.isnan يمكنك معرفة ذلك، كل شيئ موضح في الكود التالي: import numpy as np a=np.array([[ 1. , 2.],[ 3. ,np.nan]]) a """ array([[ 1., 2.], [ 3., nan]]) """ # isnan #nan في مكان تواجد قيمة true هذا التابع يرد مصفوفة بوليانية بحيث تضع np.isnan(a) """ array([[False, False], [False, True]]) """ #وبالتالي nan أصغر قيمة هي دوماً np.min(a) #nan ترد np.isnan(np.min(a)) # True #لجمع عناصر مصفوفة تحوي قيم غير معرفة سيعطي نتيجة غير معرفة sum استخدام np.sum(a) # nan # وبالتالي np.isnan(np.sum(a)) # True ومن ناحية الأداء فاستخدام sum أفضل: a = np.random.rand(100000) %timeit np.isnan(np.min(a)) """ 10000 loops, best of 3: 153 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.9 us per loop """ # سأضع قيمة نان لإحدى الخلايا a[2000] = np.nan %timeit np.isnan(np.min(a)) """ 1000 loops, best of 3: 239 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.8 us per loop """ a[0] = np.nan %timeit np.isnan(np.min(a)) """ 1000 loops, best of 3: 326 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.9 us per loop """ نلاحظ أن min يكون أبطأ في وجود NaN أما في غيابها أسرع. أيضا يصبح أبطأ مع اقتراب NaN من بداية المصفوفة. من ناحية أخرى ، sum تبدو ثابتة بغض النظر عما إذا كانت هناك NaNs أو لا.
- 2 اجابة
-
- 3
-
-
يمكن استخدام الدالة numpy.multiply كالتلي: import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) np.multiply(a,b) """ array([[ 5, 12], [21, 32]]) """ كما ويمكنك استخدام المعامل *: import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[5,6],[7,8]]) a*b """ array([[ 5, 12], [21, 32]]) """
- 1 جواب
-
- 2
-
-
حسناً أنت لديك قائمة من المصفوفات، لذا للقيام بذلك هناك عدة طرق، أولها استخدام الدالة stack حيث تقوم هذه الدالة بتكديس المصفوفات على المحور المحدد لها (طبعاً يجب أن تكون المصفوفات متجانسة في الأبعاد بالنسبة للمحور المحدد لكي يتم التكديس): import numpy li = [numpy.array([ 3, 5]),numpy.array([ 3, 5])] # [array([3, 5]), array([3, 5])] numpy.stack( li, axis=0 ) # التكديس على المحور العمودي """ array([[3, 5], [3, 5]]) """ numpy.stack( li, axis=1 ) ألأفقي """ array([[3, 3], [5, 5]]) """ أما بالنسبة للدالة concatenate فلايمكنك استخدامها في حالتك مباشرةً، حيث أن هذه الدالة تتطلب أن تكون المصفوفات متجانسة الأبعاد أي يجب أن تكون كل المصفوفات ثنائية البعد حتى تعمل، في الرابط التالي كل شيئ تحتاجه لمعرفة كيفية عملها: أما إذا أردت تطبيقها على مثالك فلن ينجح ذلك لأن np.array([1, 2, 3]) تمثل شعاع أي ببعد واحد أما np.array([[4, 5, 6],[7, 8, 9]]) تمثل مصفوفة ثنائية وبالتالي لايمكن استخدام هذه الدالة لربطهما بالشكل الذي تريده. وسيعطي خطأ انظر: import numpy as np lst = [np.array([1, 2, 3]), np.array([[4, 5, 6],[7, 8, 9]])] np.concatenate(lst, axis=0 ) """ ValueError: all the input arrays must have same number of dimensions... لذا يجب عليك توسيع أبعاد المصفوفة الأولى قبل أن تستخدمها ولكن هذا سيكون مكلف، لذا فإن أفضل حل هو استخدام Stack. أو vstack : import numpy as np lst = [np.array([1, 2, 3]), np.array([[4, 5, 6],[7, 8, 9]])] np.vstack( lst ) """ array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) """ كما يمكنك استخدام row_stack: import numpy as np lst = [np.array([1, 2, 3]), np.array([[4, 5, 6],[7, 8, 9]])] np.row_stack( lst ) """ array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) """
- 2 اجابة
-
- 2
-
-
في النسخ الأحدث من كيراس تم نقلها إلى الموديول keras.layers.convolutional لذا يجب أن تستوردها بالشكل: from keras.layers.convolutional import Conv2D أو من خلال تنسرفلو فهي من الموديول tensorflow.keras.layers: from tensorflow.keras.layers import Conv2D
- 1 جواب
-
- 1
-