لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 10/06/21 في كل الموقع
-
لدي تطبيق يعمل على قاعدة بيانات mongo db وأنا أريد شرح لكيفية ضبط وتهئىة قاعدة البيانات هذه.2 نقاط
-
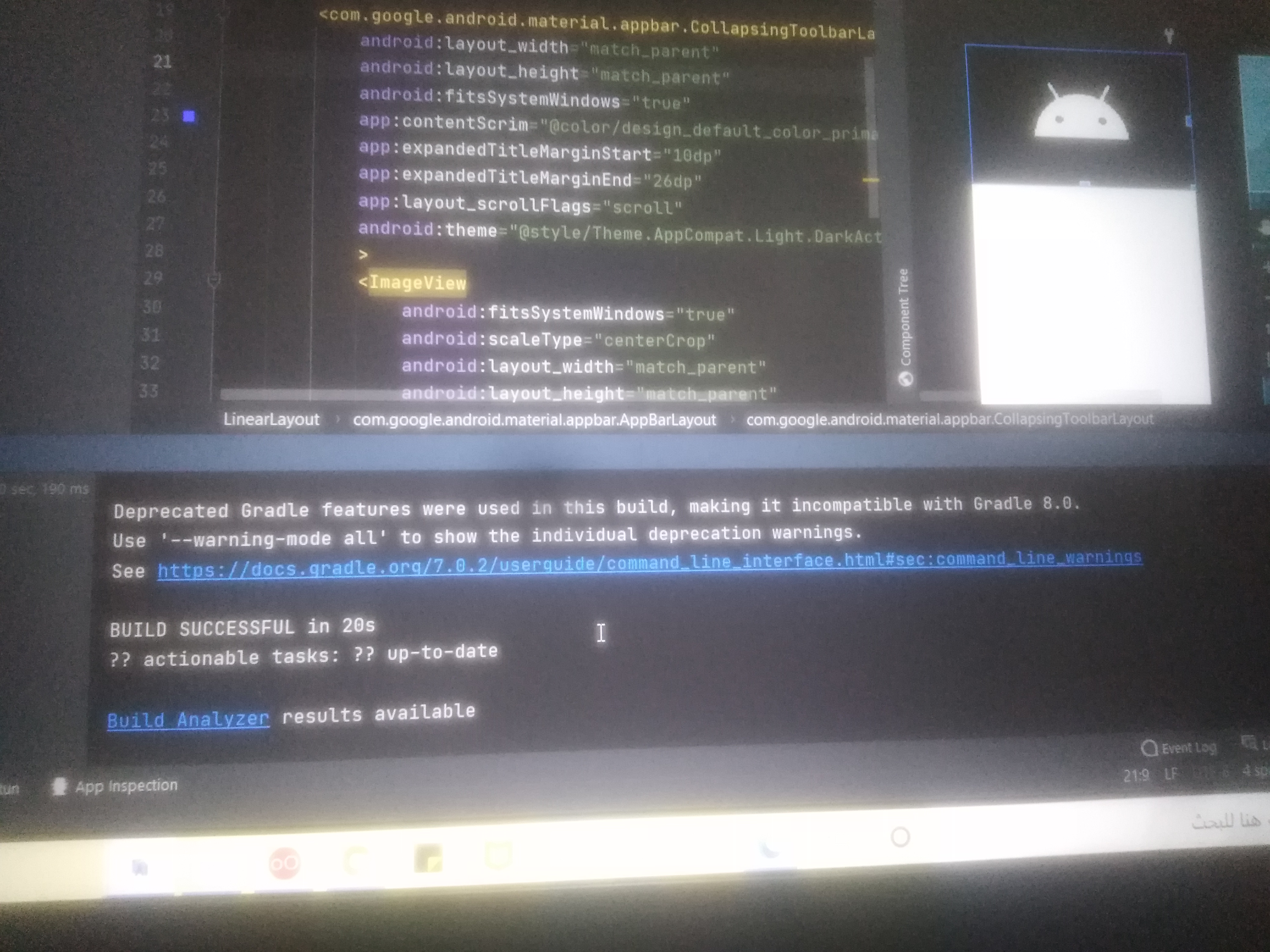
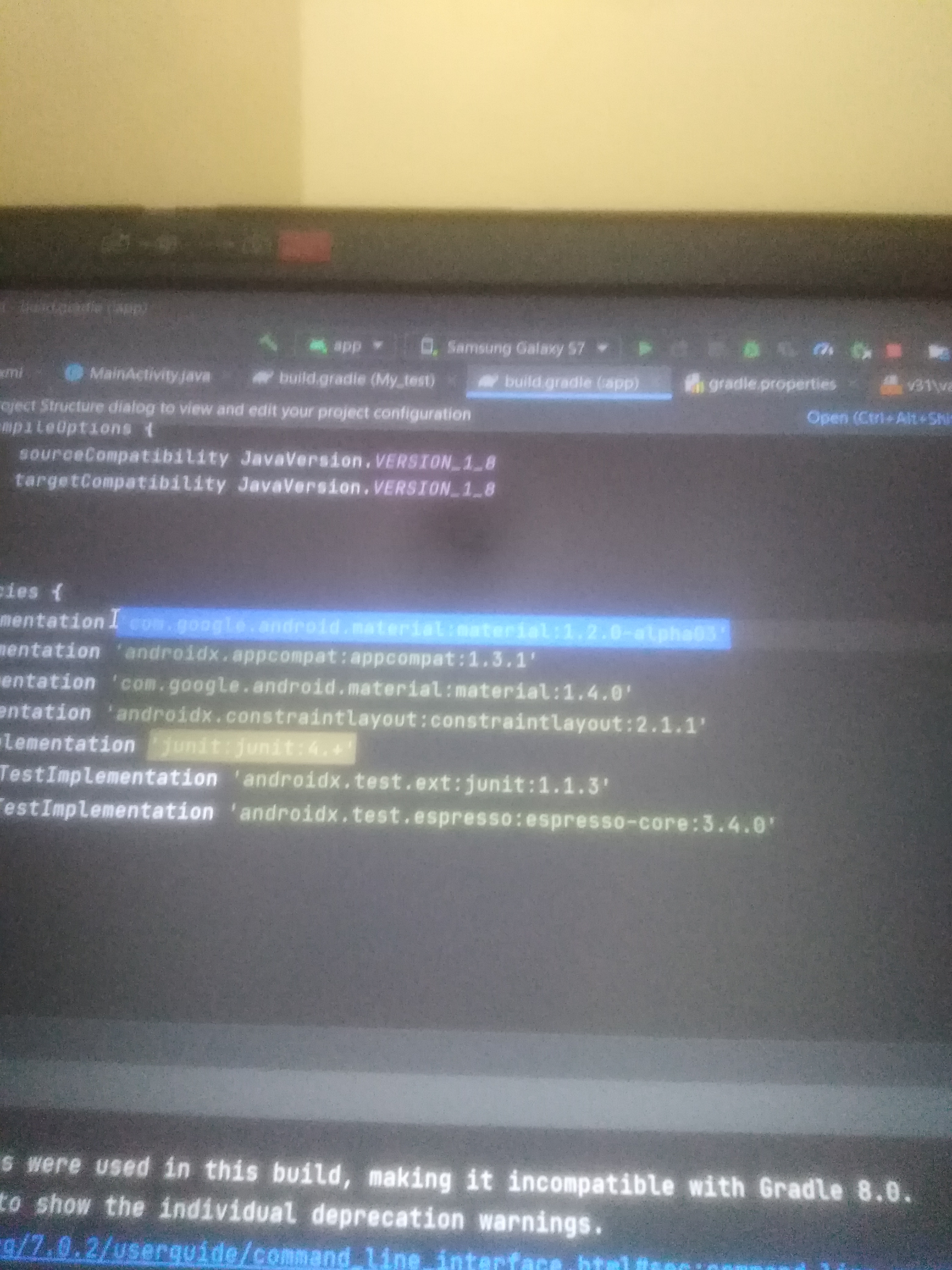
لماذا استخدم next/image بدل ال <img> العادية الخاصة بhtml ?2 نقاط
-
المكون next/image مبني فوق الوسم img في HTML ويضيف فوقه مزايا تخص تحسين الأداء تخديم الصور بصيغة Webp التي تدعم القياسات المتعددة ليختار المتصفح منها اصغر القياس المناسب تحسين أحجام الصور تلقائيا (عند الطلب) وبالتالي التوفير في مساحة المستخدمة على الخادم تأخير تحميل الصور في الموقع Lazy Loading مما يجعل تحميل الصفحة أسرع تصيير الصور دون التأثير على العناصر المجاورة أو ما يسمى Cumulative Layout Shift، أي يتم حجز مساحة مسبقة للصورة قبل تحميلها لكي تصير هيكلية الموقع كما تم تصميمها ولا تقفز العناصر عند تحميل الصور2 نقاط
-
مُكون الصور (Image Component) في next.js له عدد من المميزات مما يجعل له حلٌ لمشاكل الأداء(performance issues) حيث يقوم ذلك المُكون بتقديم عدد من المزايا مثل صيغة الصور: حيث ﻻ يقوم ذلك المُكون بتقديم الصور بصيغ قديمة مثل الjpeg, png وإنما يقوم بضغط الصور وتقديمها بصيغ مثل WebP, AVIF مما يجعل حجم الصور أقل بنسبة تُقدر ب20% إلى 30% تحميل الصور: حيث ﻻ يقوم ذلك المُكون بتحميل الصور فور دخول المُستخدم إلى الصفحة وإنما يقوم بتحميل الصور التي فقط يحتاجها المُستخدم ويقوم بعمل scroll إليها خاصية التحميل المُسبق: حيث يمكنك تحديد صورة ما بخاصية التحميل المسبق وتجعلها تحمل للمستخدم مبكراً قبل تحميل باقي الصفحة بالإضافة لمميزات أخرى يُقدمها هذا المُكون تُسهل من التعامل مع الصُور وتسهل عملية إضافة العديد من الخصائص عبر توفيرها2 نقاط
-
أحتاج إلى قيمة href افتراضية لـ Next / Link ، كما نفعل في لغة html العادية كما هو موضح أدناه <a href='#' ></a> لقد جربت هذا الارتباط ولكن ينتج خطأ بسبب السمة المطلوبة <Link href='#'></Link>2 نقاط
-
 إن العنصر الرابع من عناصر البرمجة هو الوحدات، ومع أنك تستطيع كتابة بعض البرامج الرائعة بما تعلمته من بداية هذه الدروس إلى الآن دون تعلم الوحدات، إلا أن تتبع ما يحدث في البرامج -مع زيادة حجمها- يصبح صعبًا جدًا، وسنحتاج إلى طريقة لاستخلاص بعض التفاصيل لنستطيع التفكير في المشكلات التي تواجهنا ونريد حلها، بدلًا من صرف الجهد والوقت في التفاصيل الدقيقة المتعلقة بكيفية عمل الحاسوب. توفر بايثون وجافاسكربت وVBScript ذلك إلى حد ما بما فيها من إمكانيات مضمّنة تلقائيًا، فهي تجنبنا التعامل مع عتاد الحواسيب والنظر في كيفية قراءة كل مفتاح على لوحة المفاتيح على حدة، وغير ذلك من الأمور التي تستنزف موارد المبرمجين. وتعتمد فكرة البرمجة باستخدام الوحدات على السماح للمبرمج بتوسيع الإمكانيات الموجودة في لغة البرمجة، عبر تجميع أجزاء من البرنامج في وحدات يمكن توصيلها ببرامجنا، وقد كانت الصورة الأولى للوحدات هي البرامج الفرعية subroutines التي تمثل كتلةً من الشيفرة نستطيع القفز إليها، بدلًا من استخدام GOTO التي ذكرناها في المقال السابق، لكنها تقفز عند تمام الكتلة عائدةً إلى المكان الذي استدعيت منه، ويُعرف هذا الأسلوب من الوحدات بالإجراء procedure أو الدالة function، بل إن مفهوم الوحدة module نفسه يتغير في بعض اللغات مثل بايثون، ليأخذ معنىً أكثر دقة. استخدام الدوال لننظر أولًا في كيفية استخدام الدوال functions الكثيرة التي تأتي في أي لغة برمجة، حيث تسمى مجموعة الدوال القياسية المضمّنة في اللغة باسم المكتبة القياسية، وقد رأينا استخدام بعض الدوال، وذكرناه في قسم العوامل في مقال البيانات وأنواعها؛ أما الآن فسننظر في الأمور المشتركة بينها، وكيف يمكن أن نستخدمها في برامجنا. للدالة الهيكل الأساسي التالي: aValue = someFunction ( anArgument, another, etc... ) يأخذ المتغير aValue القيمة التي نحصل عليها باستدعاء الدالة someFunction، والتي تقبل عدة وسطاء arguments بين القوسين -وقد لا يوجد أي وسيط-، وتعاملها على أنها متغيرات داخلية، وتستطيع الدوال أن تستدعي دوالًا أخرى داخلها. تفرض بعض اللغات وضع القوسين للدالة عند استدعائها حتى لو لم يكن لها وسطاء، وقد ذكرنا أنه يفضل تعويد النفس على استخدام الأقواس حتى في لغات مثل VBScript التي لا تشترط استخدامها حتى مع وجود الوسطاء. لننظر الآن في بعض الأمثلة في لغاتنا الثلاث، ولنرى الدوال عمليًا: الدالة Mid في VBScript تعيد الدالة Mid(aString, start, length) مجموعة المحارف من aString بدءًا من start وبعدد محارف length، حيث ستعرض الشيفرة التالية "Good EVENING" مثلًا. <script type="text/vbscript"> Dim time time = "MORNING EVENING AFTERNOON" MsgBox "Good" & Mid(time, 8, 8) </script> نلاحظ أن VBScript لا تتطلب أقواسًا لجمع وسطاء الدالة بل تكتفي بالمسافات كما كنا نفعل مع MsgBox، لكن عند جمعنا دالتين -كما فعلنا هنا- فيجب أن تستخدم الدالة الداخلية أقواسًا، والنصيحة العامة هي استخدام الأقواس عندما نشك هل يجب استخدامها أم لا. الدالة Date في VBScript تعيد الشيفرة التالية التاريخ الحالي للنظام: <script type="text/vbscript"> MsgBox Date </script> بما أن المثال بسيط فلا يوجد ما يمكن شرحه هنا، لكن تجدر الإشارة إلى وجود مجموعة كاملة من دوال التاريخ الأخرى التي تستخرج اليوم والأسبوع والساعة. الدالة startString.replace في جافاسكربت تعيد دالة startString.replace(searchString, newString) سلسلةً نصيةً جديدةً مع وضع newString بدلًا من searchString في startString. <script type="text/javascript"> var r,s = "A long and winding road"; document.write("Original = " + s + "<BR>"); r = s.replace("long", "short"); document.write("Result = " + r); </script> لاحظ أن الدوال في جافاسكربت ما هي إلا مثال لنوع خاص يسمى بالتابع method، وهو دالة ترتبط بكائن، كما شرحنا في مقال البيانات وأنواعها المذكور أعلاه، وكما سنشرح لاحقًا. وما نريد قوله، هو أن الدالة ترتبط بالسلسلة النصية s بواسطة عامل النقطة .، وهذا يعني أن s هي السلسلة التي سننفذ عليها الاستبدال، وهذا أمر عرضناه من قبل باستخدام التابع write() الخاص بالكائن document الذي استخدمناه لعرض الخرج من برامج جافاسكربت باستخدام document.write()، لكننا لم نشرح السبب وراء صيغة الاسم المزدوجة حتى الآن. الدالة Math.pow في جافاسكربت نستخدم الدالة pow(x,y) في وحدة Math -التي ذكرناها في مقال الخامس: البيانات وأنواعها- لرفع x إلى الأس y: <script type="text/javascript"> document.write( Math.pow(2,3) ); </script> الدالة pow في بايثون تستخدم بايثون دالة pow(x,y) لرفع x إلى الأس y: >>> x = 2 # سنستخدم 2 كرقم قاعدة >>> for y in range(0,11): ... print( pow(x,y) ) # y ارفع 2 إلى الأس # أي من 0-10 نولد هنا قيم y من 0 إلى 10، ونستدعي الدالة المضمنة pow() لتمرير وسيطين هما x وy، ونستبدل القيم الحالية لكل منهما في استدعاء pow() في كل مرة، ثم نطبع النتيجة. الدالة dir في بايثون إحدى الدوال المفيدة المضمنة في بايثون هي دالة dir، والتي تعرض جميع الأسماء المصدَّرة داخل وحدة ما إذا مررنا اسم الوحدة إليها، بما في ذلك جميع المتغيرات والدوال التي يمكن استخدامها، وعلى الرغم من أننا لم نشرح إلا بضع وحدات في بايثون، إلا أنها تأتي بوحدات كثيرة. تعيد الدالة dir قائمةً من الأسماء الصالحة في الوحدة، والتي تكون دوالًا في الغالب. لنجرب هذه الدالة على بعض الدوال المضمنة: >>> print( dir(__builtins__) ) لاحظ أن builtins هي إحدى الكلمات السحرية في بايثون، وعلى ذلك يجب إحاطتها بزوج من شرطتين سفليتين على كل جانب. وإذا أردنا استخدام dir() على أي وحدة، فسنحتاج إلى استيرادها أولًا باستخدام import، وإلا فستخبرنا بايثون أنها لا تتعرف عليها. >>> import sys >>> dir(sys) لقد استوردنا وحدة sys في المثال أعلاه، وهي الوحدة التي ذكرناها أول مرة في مقال التسلسلات البسيطة، ونستطيع أن نرى كلًا من exit وargv وstdin وstdout في الخرج الأخير لدالة dir، بين الأشياء الأخرى الموجودة في وحدة sys. لننظر الآن في وحدات بايثون بقليل من التفصيل قبل أن ننتقل إلى ما بعدها. استخدام الوحدات في بايثون تتميز لغة بايثون بقابليتها الكبيرة للتوسع، حيث نستطيع إضافة وحدات جديدة باستيرادها بواسطة import، وفيما يلي بعض الوحدات التي تأتي افتراضيًا مع بايثون. الوحدة sys رأينا sys سابقًا عند الخروج من بايثون، وهي تحتوي على مجموعة من الدوال المفيدة كدالة dir التي سبق شرحها، ويجب أن نستورد وحدة sys أولًا لنصل إلى تلك الدوال: import sys # نجعل الدوال متاحة print( sys.path ) # نرى أين تبحث بايثون عن الدوال sys.exit() # 'sys' أسبقها بـ وإذا علمنا أننا سنستخدم الدوال بكثرة وأنها لن تحمل نفس أسماء الدوال التي استوردناها أو أنشأناها؛ فعندئذ نستطيع فعل ما يلي: from sys import * # sys استورد جميع الأسماء في print( path ) # يمكن استخدامها دون تحديد السابقة 'sys' exit() يتمثل خطر هذا النهج في إمكانية وجود دوال بنفس الاسم في وحدتين مختلفتين، وبالتالي لن نستطيع الوصول إلا إلى الدوال التي استوردناها ثانيًا، لأننا بهذه الطريقة سنلغي الدالة التي استوردناها أولًا، فإذا أردنا أن نستخدم بعض العناصر فقط، فيفضل أن ننفذ ذلك كما يلي: from sys import path, exit # استورد الدوال التي تحتاجها فقط exit() # استخدم دون تحديد السابقة 'sys' لاحظ أن الأسماء التي نحددها لا تحتوي على أقواسًا تليها، ففي تلك الحالة سنحاول تنفيذ الدوال بدلًا من استيرادها، ولا يُعطى هنا إلا اسم الدالة فقط. نريد الآن أن نشرح طريقةً مختصرةً توفر علينا القليل من الكتابة، وهي أننا نستطيع إعادة تسمية الوحدة عند استيرادها إذا كان لها اسم طويل جدًا، مثلًا: import SimpleXMLRPCServer as s s.SimpleXMLRPCRequestHandler() لاحظ كيف أخبرنا بايثون أن تعُد s اختصارًا لـ SimpleXMLRPCServer، ولن نحتاج بعد ذلك إلا إلى كتابة s كي نستخدم دوال الوحدة، مما قلل من الكتابة. وحدات بايثون الأخرى يمكن استيراد أي وحدة من وحدات بايثون واستخدامها بالطريقة السابقة، وهذا يشمل الوحدات التي ننشئها بأنفسنا، لنلق الآن نظرةً على بعض الوحدات القياسية في بايثون، وما توفره من وظائف: وحدة sys: تسمح بالتفاعل مع نظام بايثون: exit(): للخروج. argv: للوصول إلى وسطاء سطر الأوامر. path: للوصول إلى مسار البحث الخاص بوحدة النظام. ps1: لتغيير محث بايثون >>>. وحدة os: تسمح بالتفاعل مع نظام التشغيل: name: تعطينا اسم نظام التشغيل الحالي، وهي مفيدة في البرامج المحمولة التي لا تحتاج إلى تثبيت. system(): تنفذ أمرًا من أوامر نظام التشغيل. mkdir(): تنشئ مجلدًا. getcwd(): تعطينا مجلد العمل الحالي. وحدة re: تسمح هذه الوحدة بتعديل السلاسل النصية باستخدام التعابير النمطية regular expressions لنظام يونكس: search(): تبحث عن النمط في أي موضع في السلسلة النصية. match(): تبحث في البداية فقط. findall(): تبحث عن جميع مرات الورود في سلسلة نصية. split(): تقسيم السلسلة النصية إلى حقول مفصولة بالنمط. ()sub وsubn(): استبدال السلاسل النصية. وحدة math: تسمح بالوصول إلى العديد من الدوال الرياضية. ()sin وcos(): دوال حساب المثلثات. log(), log10(): اللوغاريتمات الطبيعية والعشرية. ()ceil وfloor(): دالتا الجزء الصحيح floor والمتمم الصحيح الأعلى ceiling. pi وe: الثوابت الطبيعية. وحدة time: دوال التاريخ والوقت. time(): تحصل على الوقت الحالي بالثواني. gmtime(): تحول الوقت بالثواني إلى التوقيت العالمي UTC (أو GMT). localtime(): التحويل إلى التوقيت المحلي. mktime(): معكوس التوقيت المحلي. strftime(): تنسيق السلسلة النصية للوقت، مثل YYYYMMDD أو DDMMYYYY. sleep(): إيقاف البرنامج مؤقتًا لمدة n ثانية. وحدة random: تولد أرقامًا عشوائية، وهي مفيدة في برمجة الألعاب. randint(): تولد عددًا صحيحًا عشوائيًا بين نقطتين تضمَّنان في التوليد. sample(): تولد قائمةً فرعيةً عشوائيًا من قائمة أكبر. seed(): إعادة ضبط مفتاح توليد الأعداد. هذه الوحدات على كثرتها ليست إلا شيئًا يسيرًا من الوحدات التي توفرها بايثون، والتي تزيد على مئة واحدة وأكثر يمكن تحميلها. تذكر أننا نستطيع استخدام dir() وhelp() للحصول على معلومات عن كيفية استخدام الدوال المختلفة، وأن المكتبة القياسية موثقة جيدًا في فهرس وحدات بايثون، ومن المصادر الجيدة للوحدات الإضافية فهرس حزم بايثون، الذي ضم عند كتابتنا لهذا المقال أكثر من مئة ألف حزمة، وكذلك مشروع SciPy الذي يستضيف مئات وحدات المعالجة العلمية والعددية، ولا غنى عنه لمن يعمل على مشاريع تحليل علمية، وأفضل وسيلة للوصول إلى تلك الحزم هو تثبيت إحدى إصدارات بايثون التي تحتوي على SciPy كإضافة قياسية فيها، مثل موقع anaconda.org، كما يحتوي sourceforge ومواقع التطوير مفتوح المصدر الأخرى على عدة مشاريع لبايثون فيها وحدات نافعة، ويمكنك الاستعانة بمحرك البحث نظرًا لتعدد المصادر، وتستطيع تصفحها وغيرها إذا أضفت كلمة python في بحثك، ولا تنس قراءة توثيق بايثون للمزيد من المعلومات عن البرمجة للإنترنت والرسوميات وبناء قواعد البيانات وغيرها. والمهم هنا إدراك أن أغلب لغات البرمجة تحوي هذه الدوال، والوظائف الأساسية إما مضمّنة فيها أو تكون جزءًا من مكتبتها القياسية، فابحث أولًا في توثيقك قبل كتابة دالة ما، فربما تكون موجودةً ولا تحتاج إلى كتابتها. تعريف الدوال الخاصة بنا يمكن إنشاء دوال خاصة بنا من خلال تعريفها، أي بكتابة تعليمة تخبر المفسر أننا نعرِّف كتلةً من الشيفرة، ويجب عليه تنفيذها عندما نطلبها في أي مكان في البرنامج. VBScript سننشئ الآن دالةً تطبع مثال جدول الضرب الخاص بنا لأي قيمة نعطيها إليها كوسيط، ;ستبدو هذه الدالة في VBScript كما يلي: <script type="text/vbscript"> Sub Times(N) Dim I For I = 1 To 12 MsgBox I & " x " & N & " = " & I * N Next End Sub </script> sنبدأ هنا في هذا المثال بالكلمة المفتاحية Sub -وهي اختصار برنامج فرعي Subroutine-، التي تلي محدد VBScript لكتل الشيفرات مباشرةً في السطر الثاني، ثم نعطيها قائمةً من المعامِلات بين قوسين. أما الشيفرة التي داخل الكتلة المعرَّفة فهي شيفرة VBScript عادية مع استثناء أنها تعامل المعامِلات على أنها متغيرات محلية، لذا تسمى الدالة في المثال أعلاه Times، وتأخذ معامِلًا واحدًا هو N، كما تعرِّف المتغير المحلي I، ثم تنفذ حلقةً تكراريةً تعرض جدول الضرب الخاص بالعدد N باستخدام المتغيرين N و I، نستدعي هذه الدالة الجديدة كما يلي: <script type="text/vbscript"> MsgBox "Here is the 7 times table..." Times 7 </script> لاحظ أننا عرّفنا معاملًا اسمه N ومررنا إليه الوسيط 7، وقد أخذ المعامل أو المتغير المحلي N داخل الدالة القيمة 7 عندما استدعيناه، ويمكن تعريف أي عدد نريده من المعامِلات في تعريف الدالة، وعلى البرامج المستدعية أن توفر قيمةً لكل معامِل. تسمح بعض لغات البرمجة بتعريف قيم افتراضية للمعامل في حالة عدم توفير قيمة، لتستخدم الدالة تلك القيمة الافتراضية. كذلك فقد غلفنا المعامل N بقوسين أثناء تعريف الدالة، لكن هذا غير ضروري في VBScript عند استدعاء الدالة، كما قلنا من قبل. لا تعيد هذه الدالة أي قيمة، وهو ما نسميه بالإجراء في البرمجة، وما هو إلا دالة لا تعيد قيمةً، وتفرّق لغة VBScript بين الدوال والإجراءات باستخدام أسماء مختلفة لتعريفاتهما، فمثلًا: تعيد الدالة التالية في VBScript جدول الضرب الخاص بنا في سلسلة نصية طويلة واحدة: <script type="text/vbscript"> Function TimesTable (N) Dim I, S S = N & " times table" & vbNewLine For I = 1 to 12 S = S & I & " x " & N & " = " & I*N & vbNewLine Next TimesTable = S End Function Dim Multiplier Multiplier = InputBox("Which table would you like?") MsgBox TimesTable (Multiplier) </script> تكاد صيغة هذه الشيفرة أن تطابق صيغة Sub، مع استثناء أننا استخدمنا الكلمة Function بدلًا من Sub السابقة، ويجب أن نسند النتيجة إلى اسم الدالة داخل التعريف، لهذا ستعيد الدالة أي قيمة يحتويها اسمها عند خروجها: ... TimesTable = S End Function فإذا لم نسند قيمةً لاسم الدالة بشكل صريح، فستعيد الدالة القيمة الافتراضية، والتي تكون في الغالب صفرًا أو سلسلةً نصيةً فارغةً. لاحظ أننا وضعنا أقواسًا حول الوسيط في سطر MsgBox، لأن MsgBox لن يعرف -لولا هذه الأقواس- هل يجب أن يُطبع Multiplier أم يُمرّره إلى الوسيط الأول والذي هو TimesTable، فلما وضعناه داخل الأقواس فهم المفسر أن القيمة هي وسيط للدالة TimesTable بدلًا من MsgBox. بايثون ستكون دالة جدول الضرب في بايثون كما يلي: def times(n): for i in range(1,13): print( "%d x %d = %d" % (i, n, i*n) ) وتُستدعى كما يلي: print( "Here is the 9 times table..." ) times(9) لاحظ أن الإجراءات في بايثون لا تميَّز عن الدوال، ويُستخدم def لتعريفهما، والفرق الوحيد هو أن الدالة التي تعيد قيمةً تستخدم تعليمة return، كما يلي: def timesTable(n): s = "" for i in range(1,13): s = s + "%d x %d = %d\n" % (i,n,n*i) return s الأمر بسيط، إذ تعيد الدالة النتيجة باستخدام تعليمة return، أما إذا لم يكن لدينا تعليمة return صريحة فستعيد بايثون تلقائيًا قيمةً افتراضيةً تسمى None، والتي نتجاهلها في العادة. نستطيع الآن طباعة نتيجة الدالة كما يلي: print( timesTable(7) ) يفضل عدم وضع تعليمات print داخل الدوال، وإنما جعل الدالة تعيد النتيجة باستخدام return، ثم طباعتها من خارج الدالة، ورغم أننا لم نتبع هذا الأسلوب في أمثلتنا، إلا أن هذا يجعل الدوال قابلةً لإعادة الاستخدام في نطاق أوسع من الحالات. يبقى أمر مهم للغاية يجب أن نذكره حول تعليمة return، وهو أنها لا تعيد قيمةً من الدالة فحسب، بل تعيد التحكم إلى الشيفرة التي استدعت الدالة، وتكمن أهمية ذلك في أن الإعادة لا يجب أن تكون آخر سطر في الدالة، فقد تكون هناك تعليمات أكثر، وقد لا تنفَّذ أبدًا، كما يمكن أن يحتوي متن الدالة الواحدة على عدة تعليمات return. تُنهي التعليمة التي نصل إليها أولًا الدالة وتعيد القيمة إلى الشيفرة المستدعية، سنعرض مثالًا عن دالة لها عدة تعليمات return، وهي تعيد أول عدد زوجي تجده في القائمة المزودة بها أو None إذا لم تجد أي عدد زوجي: def firstEven(aList): for num in aList: if num % 2 == 0: # تحقق من كونه زوجيًا return num # اخرج من الدالة فورًا return None # لا نصل إليها إلا إذا لم نجد عددًا زوجيًا ملاحظة بشأن المعاملات قد يصعب على المبتدئين فهم دور المعامِلات في تعريف الدالة، فهل يجب تعريف الدالة كما يلي: def f(x): # داخل الدالة x يمكن استخدام... أم تعريفها بالشكل: x = 42 def f(): # داخل الدالة x يمكن استخدام... يعرِّف المثال الأول هنا المعامِل x ويستخدمه داخل الدالة، بينما يستخدم المثال الثاني متغيرًا معرَّفًا من خارج الدالة مباشرةً، وبما أن المثال الثاني صالح ويعمل دون مشاكل، فلم نتكبد عناء تعريف المعامل؟، والجواب هو أن المعامِلات تتصرف مثل متغيرات محلية، أي مثل المتغيرات التي لا تُستخدم إلا داخل الدالة، وقلنا إن مستخدم الدالة يستطيع أن يمرر وسطاءً إلى هذه المعامِلات، وعلى ذلك تتصرف قائمة المعامِلات مثل بوابة للبيانات التي تتحرك بين البرنامج الرئيسي والدالة. تستطيع الدالة أن ترى بعض البيانات خارجها، لكن إذا أردنا للدالة أن تكون قابلةً لإعادة الاستخدام في أكثر من برنامج، فيجب أن نقلل اعتمادها على البيانات الخارجية، بل يجب أن تُمرَّر البيانات المطلوبة لأداء وظيفة الدالة بكفاءة إليها من خلال معامِلاتها، فإذا عُرِّفت الدالة داخل ملف وحدة، فيجب أن تكون لها صلاحية قراءة البيانات المعرَّفة داخل نفس الوحدة، لكن هذه الخاصية ستقلل من مرونة الدالة التي نعرِّفها. نريد أن نقلل عدد المعامِلات المطلوبة لتشغيل الدالة إلى حد يمكن السيطرة عليه وإدارته، وهذا يراعى في حالة البيانات الكثيرة التي تحتاج إلى معامِلات أكثر، وذلك من خلال استخدام تجميعات البيانات مثل القوائم وصفوف tuples والقواميس وغيرها، كما نستطيع تقليل عدد قيم المعامِلات الفعلية التي يجب أن نوفرها، باستخدام ما يسمى بالوسيط الافتراضي. الوسيط الافتراضي يشير هذا المصطلح إلى طريقة لتعريف معامِلات الدالة التي تأخذ قيمًا افتراضيةً إذا لم تمرَّر كوسطاء صراحةً، وأحد استخدامات هذا الوسيط المنطقية في دالة تعيد يوم الأسبوع، فإذا استدعيناها بدون قيمة فيكون قصدنا اليوم الحالي، وإلا فإننا نوفر رقم اليوم كوسيط، كما يلي: import time # None قيمة اليوم هي def dayOfWeek(DayNum = None): # طابق ترتيب اليوم مع قيم إعادة بايثون days = ['Saturday','Sunday', 'Monday','Tuesday', 'Wednesday', 'Thursday', 'Friday'] # تحقق من القيمة الافتراضية if DayNum == None: theTime = time.localtime(time.time()) DayNum = theTime[6] # استخرج قيمة اليوم return days[DayNum] لا نحتاج إلى استخدام وحدة الوقت إلا إذا كانت قيمة المعامِل الافتراضي مطلوبةً، وبناءً عليه نستطيع تأجيل عملية الاستيراد إلى أن نحتاج إليها، وسيحسن هذا من الأداء تحسينًا طفيفًا إذا لم نضطر إلى استخدام خاصية القيمة الافتراضية للدالة، لكن هذا التحسن يُعَد طفيفًا كما ذكرنا، ويلغي اصطلاح الاستيراد الذي ذكرناه أعلاه، لذا لا يستحق هذا التشوش. نستطيع الآن أن نستدعي ذلك كما يلي: print( "Today is: %s" % dayOfWeek() ) Saturday. print( "The third day is %s" % dayOfWeek(2) ) تذكر أننا نبدأ العد من الصفر في عالم الحواسيب، وأننا افترضنا أن اليوم الأول في الأسبوع هو السبت. عد الكلمات أحد الأمثلة الأخرى على دالة تعيد قيمةً، هو الدالة التي تَعُد الكلمات في سلسلة نصية، ويمكن استخدامها لحساب الكلمات في ملف ما بجمع كلمات كل سطر، وتكون شيفرة هذه الدالة كما يلي: def numwords(s): s = s.strip() # أزل المحارف الزائدة list = s.split() # قائمة كل عنصر فيها يمثل كلمة return len(list) # عدد كلمات القائمة هو عدد كلمات s لقد عرَّفنا الدالة في المثال أعلاه مستفيدين من بعض توابع السلاسل النصية المضمَّنة التي ذكرناها في مقال البيانات وأنواعها، ويمكن استخدام الدالة الآن كما يلي: for line in file: total = total + numwords(line) # راكم مجموع كل سطر print( "File had %d words" % total ) إذا حاولنا كتابة ذلك فلن تنجح الشيفرة، لأن مثل هذه الشيفرة تُعرف باسم الشيفرة الوهمية pseudocode، وهي تقنية تصميم شائعة للشيفرات لتوضيح الفكرة العامة لها، وليست مثالًا لشيفرة حقيقية صحيحة التركيب، وتُعرف أحيانًا باسم لغة وصف البرامج Program Description Language. يتضح لنا سبب أفضلية إعادة قيمة من دالة وطباعة النتيجة خارج الدالة بدلًا من داخلها، فإذا طبعت الدالة الطول بدلًا من إعادته فلم نكن لنستخدمها في عدّ إجمالي الكلمات في الملف، بل كنا سنحصل على قائمة طويلة فيها طول كل سطر، لكننا بإعادة القيمة نستطيع الاختيار بين استخدام القيمة كما هي، أو تخزينها في متغير بهدف المعالجة اللاحقة كما فعلنا هنا من أجل أخذ العدد الإجمالي، وهذه نقطة في غاية الأهمية من ناحية التصميم لفصل عرض البيانات من خلال الطباعة عن معالجها داخل الدالة. هناك ميزة أخرى وهي أننا إذا طبعنا الخرج فلن يكون مفيدًا إلا في بيئة سطر أوامر، أما بإعادة القيمة فنستطيع عرضها في صفحة ويب أو واجهة رسومية، فلفصل عرض البيانات عن معالجتها فائدة كبيرة، لذا اجتهد في إعادة القيم من الدوال بدلًا من طباعتها ما استطعت، وليس ثمة استثناء لهذه القاعدة إلا عند إنشاء دالة مخصصة لطباعة بعض البيانات، ففي تلك الحالة يجب توضيح هذا باستخدام كلمة print أو عرض اسم الدالة. دوال جافاسكربت يمكن إنشاء دوال داخل جافاسكربت باستخدام أمر function، كما يلي: <script type="text/javascript"> var i, values; function times(m) { var results = new Array(); for (i = 1; i <= 12; i++) { results[i] = i * m; } return results; } // استخدم الدالة values = times(8); for (i=1;i<=12;i++){ document.write(values[i] + "<br />"); } </script> لن نستطيع الاستفادة كثيرًا من هذه الدالة بتلك الحالة، لكن هذا المثال يوضح كيف يشبه الهيكل الأساسي لإنشاء الدالة هنا تعريفات الدوال في بايثون وVBSCript، وسننظر في دوال أكثر تعقيدًا في جافاسكربت لاحقًا، لأنها تستخدم الدوال لتعريف الكائنات والدوال أيضًا، وهو الأمر الذي يبدو مربكًا للقارئ أو لمستخدم اللغة. تنبيه تنبع قوة الدوال من سماحها بتوسيع نطاق الوظائف والمهام التي تستطيع اللغة تنفيذها، كما أنها تتيح لنا إمكانية تغيير اللغة من خلال تعريف معنىً جديد لدالة موجودة مسبقًا -لا يُسمح بهذا في بعض اللغات-، ولكن هذا أمر غير محمود العاقبة، إلا إذا تحكمنا فيه بحذر شديد، لأن تغيير السلوك القياسي للغة يجعل قراءة الشيفرة وفهمها يُعَد صعبًا للغاية على غيرك، بل عليك أنت نفسك فيما بعد، وبما أن القارئ يتوقع من الدالة أن تنفذ سلوكًا معينًا لكنك غيرت هذا السلوك إلى شيء آخر، لذا يفضل عدم تغيير السلوك الافتراضي للدوال المضمّنة في اللغة. يمكن التغلب على هذا التقييد للإبقاء على السلوك المضمّن للغة مع الاستمرار في استخدام أسماء ذات معنىً لدوالنا، من خلال وضع الدوال داخل كائن أو وحدة توفر سياقها المحلي. إنشاء الوحدات الخاصة رأينا كيف ننشئ دوالًا خاصةً بنا وكيف نستدعيها من أجزاء أخرى من البرنامج، وهذا أمر جيد لأنه يوفر علينا كثيرًا من الكتابة المتكررة، ويجعل برامجنا سهلة الفهم، لأننا ننسى بعض التفاصيل بعد إنشاء دالة تخفيها، وهو مبدأ متبع في البرمجة عند الحاجة إلى إخفاء بعض التفاصيل، ويسمى إخفاء المعلومات، حيث تغلَّف المعلومات والتفاصيل في دالة ننشئها لها، لكن كيف نستخدم هذه الدوال في البرامج الأخرى؟ الإجابة على هذا هي إنشاء وحدة module لهذا الغرض. وحدات بايثون الوحدة في بايثون ما هي إلا ملف نصي بسيط فيه تعليمات برمجية مكتوبة بلغة بايثون، وتكون تلك التعليمات عادةً تعريفات دوال، فمثلًا عند كتابة: import sys فإننا نخبر مفسر بايثون أن يقرأ هذه الوحدة وينفذ الشيفرة الموجودة فيها، ويتيح لنا الأسماء التي تولدها في ملفنا، ويبدو هذا كأننا ننشئ نسخةً من محتويات sys.py في برنامجنا، على أن بعض الوحدات مثل sys في البرمجة العملية ليس لها ملف sys.py أصلًا، لكننا سنتجاهل هذا الآن، وتوجد لغات برمجة مثل C و++C، التي ينسخ فيها المترجم أو المصرِّف ملفات الوحدة إلى البرنامج الحالي حسب الطلب. ننشئ الوحدة بإنشاء ملف بايثون يحتوي الدوال التي نريد إعادة استخدامها في برامج أخرى، ثم نستورد الوحدة كما نستورد الوحدات القياسية، ولتنفيذ هذا عمليًا، انسخ الدالة التالية إلى ملف، واحفظه باسم timestab.py. يمكنك فعل هذا باستخدام IDLE أو Notepad، أو أي محرر آخر يحفظ الملفات النصية العادية، لكن لا تستخدم برامج معالجة نصوص مثل مايكروسوفت وورد، لأن تلك البرامج تدخل شيفرات تنسيق كثيرةً لن تفهمها بايثون. def print_table(multiplier): print( "--- Printing the %d times table ---" % multiplier ) for n in range(1,13): print( "%d x %d = %d" % (n, multiplier, n*multiplier) ) ثم اكتب في محث بايثون: >>> import timestab >>> timestab.print_table(12) وهكذا تكون قد أنشأت وحدةً واستوردتها واستخدمت الدالة المعرَّفة فيها. لاحظ أنك إن لم تبدأ بايثون من نفس المجلد الذي خزنت فيه ملف timestab.py، فلن تستطيع بايثون أن تجد الملف وستعطيك خطأً، وعندها يمكن إنشاء متغير بيئة اسمه PYTHONPATH يحمل قائمةً من المجلدات الصالحة للبحث فيها عن وحدات، إضافةً إلى الوحدات القياسية التي تأتي مع بايثون، ويفضل تعريف مجلد داخل PYTHONPATH وتخزين جميع ملفات الوحدات القابلة لإعادة الاستخدام داخله، ولا تنسى اختبار الوحدات جيدًا قبل نقلها إليه. يجب التأكد من عدم استخدام اسم تحمله وحدة قياسية في بايثون، لئلا تجعل بايثون تستورد ملفك أنت بدلًا من القياسي، مما سينتج عنه سلوك غريب جدًا كما ذكرنا من قبل في شأن التلاعب في لغة البرمجة. ولا تستخدم اسم إحدى الوحدات التي تحاول استيرادها إلى نفس الملف، فهذا سيؤدي أيضًا إلى حدوث مشاكل. الوحدات في جافاسكربت وVBScript يُعَد إنشاء الوحدات في VBScript أكثر تعقيدًا من بايثون، فلم يكن مفهوم الوحدات موجودًا في هذه اللغة ولا في اللغات التي بنفس عمرها، بل كانت تعتمد على إنشاء الكائنات لإعادة استخدام الشيفرة بين المشاريع، وسننظر الآن في كيفية النسخ من المشاريع السابقة واللصق في مشروعنا الحالي باستخدام المحرر النصي. أما جافاسكربت فتوفر آليةً لإنشاء وحدات من ملفات الشيفرة القابلة لإعادة الاستخدام، لكنها آلية معقدة وتستخدم صيغةً غامضةً تخرج عن نطاق عملنا في هذه المرحلة، غير أن لدينا حلًا أسهل، وهو استخدام وحدات كتبها أشخاص آخرون، باستخدام الصيغة التالية: <script type=text/JavaScript src="mymodule.js"></script> نستطيع الوصول إلى جميع تعريفات الدوال الموجودة في ملف mymodule.js بمجرد إدراج السطر السابق داخل قسم <head> في صفحة الويب الخاصة بنا، وتوجد وحدات عديدة من الطرف الثالث متاحة لمبرمجي الويب ويمكن استيرادها بهذه الطريقة، ولعل أشهرها هي وحدة JQuery؛ أما في المواضع التي تُستخدم فيها جافاسكربت خارج المتصفحات -انظر قسم Windows Script Host اللاحق- فهناك آليات أخرى متاحة، ويُرجع في ذلك إلى التوثيق. تقنية Windows Script Host نظرنا حتى الآن إلى جافاسكربت وVBScript على أنهما لغات للبرمجة داخل الويب، ولكن توجد طريقة أخرى لاستخدامهما داخل بيئة ويندوز، وهو تقنية مضيف سكربت ويندوز Windows Script Host أو WSH اختصارًا، وهي تقنية أتاحتها مايكروسوفت لتمكين المستخدمين من برمجة حواسيبهم بنفس الطريقة التي استخدم بها مستخدمو نظام DOS قديمًا ملفات باتش Batch Files، فهي توفر آليات لقراءة الملفات والسجل والوصول إلى الحواسيب والطابعات التي في الشبكة وغيرها. في الإصدار الثاني من WSH إمكانية تضمين ملف WSH آخر، ومن ثم توفير وحدات قابلة لإعادة الاستخدام، وذلك بإنشاء ملف وحدة أولًا اسمه SomeModule.vbs يحتوي على ما يلي: Function SubtractTwo(N) SubtractTwo = N - 2 End function ننشئ الآن ملف سكربت WSH اسمه testModule.wsf مثلًا، كما يلي: <?xml version="1.0" encoding="UTF-8"?> <job> <script type="text/vbscript" src="SomeModule.vbs" /> <script type="text/vbscript"> Dim value, result WScript.Echo "Type a number" value = WScript.StdIn.ReadLine result = SubtractTwo(CInt(value)) WScript.Echo "The result was " & CStr(result) </script> </job> يمكن تشغيل هذا في ويندوز ببدء جلسة DOS وكتابة ما يلي: C:\> cscript testModule.wsf تسمى الطريقة التي تمت هيكلة ملف (wsf.) بها باسم XML، ويتواجد البرنامج داخل زوج من وسوم <job></job> بدلًا من وسم <html></html> الذي رأيناه في لغة HTML من قبل. يشير أول وسم سكربت في الداخل إلى ملف وحدة اسمه SomeModule.vbs، أما وسم السكربت الثاني فيحتوي على برنامجنا الذي يصل إلى SubtractTwo داخل ملف SomeModule.vbs؛ بينما ملف .vbs فيحتوي على شيفرة VBScript عادية ليس فيها وسوم XML أو HTML. لاحظ أن علينا تهريب محرف & من أجل ضم السلاسل النصية لتعليمة WScript.Echo، لأن التعليمة جزء من ملف XML، وهذا المحرف مستخدم في لغة XML كرمز محدِّد. نستخدم WScript.Stdin لقراءة مدخلات المستخدم، وهو تطبيق لما تحدثنا عنه في مقال قراءة البيانات من المستخدم. تصلح هذه التقنية مع جافاسكربت أيضًا، أو لنكون أدق، مع نسخة مايكروسوفت من جافاسكربت التي تسمى JScript، وذلك بتغيير سمة type=، بل يمكن دمج اللغات في WSH بأن نستورد وحدةً مكتوبةً بجافاسكربت ونستخدمها في شيفرة VBScript أو العكس. فيما يلي سكربت WSH مكافئ لما سبق، حيث تُستخدم جافاسكربت للوصول إلى وحدة من VBScript: <?xml version="1.0" encoding="UTF-8"?> <job> <script type="text/vbscript" src="SomeModule.vbs" /> <script type="text/javascript"> var value, result; WScript.Echo("Type a number"); value = WScript.StdIn.ReadLine(); result = SubtractTwo(parseInt(value)); WScript.Echo("The result was " + result); </script> </job> نستطيع رؤية مدى تقارب هاتين النسختين، فإذا استثنينا بعض الأقواس الزائدة فسيمكننا القول أنهما متشابهتان للغاية؛ أما أغلب الأمور الفنية فتجري من خلال كائنات WScript. لن نستخدم WSH كثيرًا، لكن قد ننظر فيها بين الحين والآخر إذا رأينا أنها توفر لنا مزايا لا يمكن شرحها باستخدام بيئة المتصفح الأكثر تقييدًا، فعلى سبيل المثال، سنستخدم WSH في المقال التالي لبيان كيف يمكن تعديل الملفات باستخدام جافاسكربت وVBScript، وتوجد بعض الكتب التي تتحدث عن WSH إذا كنت مهتمًا بتعلم المزيد عنها، ويحتوي موقع مايكروسوفت على قسم خاص بها مع أمثلة لبرامج وأدوات تطوير وغير ذلك. خاتمة نأمل أن تخرج من هذا المقال وقد تعلمت: الدوال التي هي شكل من أشكال الوحدات. تعيد الدوال قيمًا، أما الإجراءات فلا تعيد شيئًا. تتكون الوحدات في بايثون في العادة من تعريفات للدوال داخل ملف. يمكن إنشاء دوال جديدة في بايثون باستخدام الكلمة المفتاحية def. استخدام Sub أوFunction في VBScript، وfunction في جافاسكربت. ترجمة -بتصرف- للفصل الحادي عشر: Programming with Modules من كتاب Learning To Program لصاحبه Alan Gauld. اقرأ أيضًا المقال التالي: التعامل مع الملفات في البرمجة المقال السابق: مقدمة في البرمجة الشرطية تعلم البرمجة المدخل الشامل لتعلم علوم الحاسوب1 نقطة
إن العنصر الرابع من عناصر البرمجة هو الوحدات، ومع أنك تستطيع كتابة بعض البرامج الرائعة بما تعلمته من بداية هذه الدروس إلى الآن دون تعلم الوحدات، إلا أن تتبع ما يحدث في البرامج -مع زيادة حجمها- يصبح صعبًا جدًا، وسنحتاج إلى طريقة لاستخلاص بعض التفاصيل لنستطيع التفكير في المشكلات التي تواجهنا ونريد حلها، بدلًا من صرف الجهد والوقت في التفاصيل الدقيقة المتعلقة بكيفية عمل الحاسوب. توفر بايثون وجافاسكربت وVBScript ذلك إلى حد ما بما فيها من إمكانيات مضمّنة تلقائيًا، فهي تجنبنا التعامل مع عتاد الحواسيب والنظر في كيفية قراءة كل مفتاح على لوحة المفاتيح على حدة، وغير ذلك من الأمور التي تستنزف موارد المبرمجين. وتعتمد فكرة البرمجة باستخدام الوحدات على السماح للمبرمج بتوسيع الإمكانيات الموجودة في لغة البرمجة، عبر تجميع أجزاء من البرنامج في وحدات يمكن توصيلها ببرامجنا، وقد كانت الصورة الأولى للوحدات هي البرامج الفرعية subroutines التي تمثل كتلةً من الشيفرة نستطيع القفز إليها، بدلًا من استخدام GOTO التي ذكرناها في المقال السابق، لكنها تقفز عند تمام الكتلة عائدةً إلى المكان الذي استدعيت منه، ويُعرف هذا الأسلوب من الوحدات بالإجراء procedure أو الدالة function، بل إن مفهوم الوحدة module نفسه يتغير في بعض اللغات مثل بايثون، ليأخذ معنىً أكثر دقة. استخدام الدوال لننظر أولًا في كيفية استخدام الدوال functions الكثيرة التي تأتي في أي لغة برمجة، حيث تسمى مجموعة الدوال القياسية المضمّنة في اللغة باسم المكتبة القياسية، وقد رأينا استخدام بعض الدوال، وذكرناه في قسم العوامل في مقال البيانات وأنواعها؛ أما الآن فسننظر في الأمور المشتركة بينها، وكيف يمكن أن نستخدمها في برامجنا. للدالة الهيكل الأساسي التالي: aValue = someFunction ( anArgument, another, etc... ) يأخذ المتغير aValue القيمة التي نحصل عليها باستدعاء الدالة someFunction، والتي تقبل عدة وسطاء arguments بين القوسين -وقد لا يوجد أي وسيط-، وتعاملها على أنها متغيرات داخلية، وتستطيع الدوال أن تستدعي دوالًا أخرى داخلها. تفرض بعض اللغات وضع القوسين للدالة عند استدعائها حتى لو لم يكن لها وسطاء، وقد ذكرنا أنه يفضل تعويد النفس على استخدام الأقواس حتى في لغات مثل VBScript التي لا تشترط استخدامها حتى مع وجود الوسطاء. لننظر الآن في بعض الأمثلة في لغاتنا الثلاث، ولنرى الدوال عمليًا: الدالة Mid في VBScript تعيد الدالة Mid(aString, start, length) مجموعة المحارف من aString بدءًا من start وبعدد محارف length، حيث ستعرض الشيفرة التالية "Good EVENING" مثلًا. <script type="text/vbscript"> Dim time time = "MORNING EVENING AFTERNOON" MsgBox "Good" & Mid(time, 8, 8) </script> نلاحظ أن VBScript لا تتطلب أقواسًا لجمع وسطاء الدالة بل تكتفي بالمسافات كما كنا نفعل مع MsgBox، لكن عند جمعنا دالتين -كما فعلنا هنا- فيجب أن تستخدم الدالة الداخلية أقواسًا، والنصيحة العامة هي استخدام الأقواس عندما نشك هل يجب استخدامها أم لا. الدالة Date في VBScript تعيد الشيفرة التالية التاريخ الحالي للنظام: <script type="text/vbscript"> MsgBox Date </script> بما أن المثال بسيط فلا يوجد ما يمكن شرحه هنا، لكن تجدر الإشارة إلى وجود مجموعة كاملة من دوال التاريخ الأخرى التي تستخرج اليوم والأسبوع والساعة. الدالة startString.replace في جافاسكربت تعيد دالة startString.replace(searchString, newString) سلسلةً نصيةً جديدةً مع وضع newString بدلًا من searchString في startString. <script type="text/javascript"> var r,s = "A long and winding road"; document.write("Original = " + s + "<BR>"); r = s.replace("long", "short"); document.write("Result = " + r); </script> لاحظ أن الدوال في جافاسكربت ما هي إلا مثال لنوع خاص يسمى بالتابع method، وهو دالة ترتبط بكائن، كما شرحنا في مقال البيانات وأنواعها المذكور أعلاه، وكما سنشرح لاحقًا. وما نريد قوله، هو أن الدالة ترتبط بالسلسلة النصية s بواسطة عامل النقطة .، وهذا يعني أن s هي السلسلة التي سننفذ عليها الاستبدال، وهذا أمر عرضناه من قبل باستخدام التابع write() الخاص بالكائن document الذي استخدمناه لعرض الخرج من برامج جافاسكربت باستخدام document.write()، لكننا لم نشرح السبب وراء صيغة الاسم المزدوجة حتى الآن. الدالة Math.pow في جافاسكربت نستخدم الدالة pow(x,y) في وحدة Math -التي ذكرناها في مقال الخامس: البيانات وأنواعها- لرفع x إلى الأس y: <script type="text/javascript"> document.write( Math.pow(2,3) ); </script> الدالة pow في بايثون تستخدم بايثون دالة pow(x,y) لرفع x إلى الأس y: >>> x = 2 # سنستخدم 2 كرقم قاعدة >>> for y in range(0,11): ... print( pow(x,y) ) # y ارفع 2 إلى الأس # أي من 0-10 نولد هنا قيم y من 0 إلى 10، ونستدعي الدالة المضمنة pow() لتمرير وسيطين هما x وy، ونستبدل القيم الحالية لكل منهما في استدعاء pow() في كل مرة، ثم نطبع النتيجة. الدالة dir في بايثون إحدى الدوال المفيدة المضمنة في بايثون هي دالة dir، والتي تعرض جميع الأسماء المصدَّرة داخل وحدة ما إذا مررنا اسم الوحدة إليها، بما في ذلك جميع المتغيرات والدوال التي يمكن استخدامها، وعلى الرغم من أننا لم نشرح إلا بضع وحدات في بايثون، إلا أنها تأتي بوحدات كثيرة. تعيد الدالة dir قائمةً من الأسماء الصالحة في الوحدة، والتي تكون دوالًا في الغالب. لنجرب هذه الدالة على بعض الدوال المضمنة: >>> print( dir(__builtins__) ) لاحظ أن builtins هي إحدى الكلمات السحرية في بايثون، وعلى ذلك يجب إحاطتها بزوج من شرطتين سفليتين على كل جانب. وإذا أردنا استخدام dir() على أي وحدة، فسنحتاج إلى استيرادها أولًا باستخدام import، وإلا فستخبرنا بايثون أنها لا تتعرف عليها. >>> import sys >>> dir(sys) لقد استوردنا وحدة sys في المثال أعلاه، وهي الوحدة التي ذكرناها أول مرة في مقال التسلسلات البسيطة، ونستطيع أن نرى كلًا من exit وargv وstdin وstdout في الخرج الأخير لدالة dir، بين الأشياء الأخرى الموجودة في وحدة sys. لننظر الآن في وحدات بايثون بقليل من التفصيل قبل أن ننتقل إلى ما بعدها. استخدام الوحدات في بايثون تتميز لغة بايثون بقابليتها الكبيرة للتوسع، حيث نستطيع إضافة وحدات جديدة باستيرادها بواسطة import، وفيما يلي بعض الوحدات التي تأتي افتراضيًا مع بايثون. الوحدة sys رأينا sys سابقًا عند الخروج من بايثون، وهي تحتوي على مجموعة من الدوال المفيدة كدالة dir التي سبق شرحها، ويجب أن نستورد وحدة sys أولًا لنصل إلى تلك الدوال: import sys # نجعل الدوال متاحة print( sys.path ) # نرى أين تبحث بايثون عن الدوال sys.exit() # 'sys' أسبقها بـ وإذا علمنا أننا سنستخدم الدوال بكثرة وأنها لن تحمل نفس أسماء الدوال التي استوردناها أو أنشأناها؛ فعندئذ نستطيع فعل ما يلي: from sys import * # sys استورد جميع الأسماء في print( path ) # يمكن استخدامها دون تحديد السابقة 'sys' exit() يتمثل خطر هذا النهج في إمكانية وجود دوال بنفس الاسم في وحدتين مختلفتين، وبالتالي لن نستطيع الوصول إلا إلى الدوال التي استوردناها ثانيًا، لأننا بهذه الطريقة سنلغي الدالة التي استوردناها أولًا، فإذا أردنا أن نستخدم بعض العناصر فقط، فيفضل أن ننفذ ذلك كما يلي: from sys import path, exit # استورد الدوال التي تحتاجها فقط exit() # استخدم دون تحديد السابقة 'sys' لاحظ أن الأسماء التي نحددها لا تحتوي على أقواسًا تليها، ففي تلك الحالة سنحاول تنفيذ الدوال بدلًا من استيرادها، ولا يُعطى هنا إلا اسم الدالة فقط. نريد الآن أن نشرح طريقةً مختصرةً توفر علينا القليل من الكتابة، وهي أننا نستطيع إعادة تسمية الوحدة عند استيرادها إذا كان لها اسم طويل جدًا، مثلًا: import SimpleXMLRPCServer as s s.SimpleXMLRPCRequestHandler() لاحظ كيف أخبرنا بايثون أن تعُد s اختصارًا لـ SimpleXMLRPCServer، ولن نحتاج بعد ذلك إلا إلى كتابة s كي نستخدم دوال الوحدة، مما قلل من الكتابة. وحدات بايثون الأخرى يمكن استيراد أي وحدة من وحدات بايثون واستخدامها بالطريقة السابقة، وهذا يشمل الوحدات التي ننشئها بأنفسنا، لنلق الآن نظرةً على بعض الوحدات القياسية في بايثون، وما توفره من وظائف: وحدة sys: تسمح بالتفاعل مع نظام بايثون: exit(): للخروج. argv: للوصول إلى وسطاء سطر الأوامر. path: للوصول إلى مسار البحث الخاص بوحدة النظام. ps1: لتغيير محث بايثون >>>. وحدة os: تسمح بالتفاعل مع نظام التشغيل: name: تعطينا اسم نظام التشغيل الحالي، وهي مفيدة في البرامج المحمولة التي لا تحتاج إلى تثبيت. system(): تنفذ أمرًا من أوامر نظام التشغيل. mkdir(): تنشئ مجلدًا. getcwd(): تعطينا مجلد العمل الحالي. وحدة re: تسمح هذه الوحدة بتعديل السلاسل النصية باستخدام التعابير النمطية regular expressions لنظام يونكس: search(): تبحث عن النمط في أي موضع في السلسلة النصية. match(): تبحث في البداية فقط. findall(): تبحث عن جميع مرات الورود في سلسلة نصية. split(): تقسيم السلسلة النصية إلى حقول مفصولة بالنمط. ()sub وsubn(): استبدال السلاسل النصية. وحدة math: تسمح بالوصول إلى العديد من الدوال الرياضية. ()sin وcos(): دوال حساب المثلثات. log(), log10(): اللوغاريتمات الطبيعية والعشرية. ()ceil وfloor(): دالتا الجزء الصحيح floor والمتمم الصحيح الأعلى ceiling. pi وe: الثوابت الطبيعية. وحدة time: دوال التاريخ والوقت. time(): تحصل على الوقت الحالي بالثواني. gmtime(): تحول الوقت بالثواني إلى التوقيت العالمي UTC (أو GMT). localtime(): التحويل إلى التوقيت المحلي. mktime(): معكوس التوقيت المحلي. strftime(): تنسيق السلسلة النصية للوقت، مثل YYYYMMDD أو DDMMYYYY. sleep(): إيقاف البرنامج مؤقتًا لمدة n ثانية. وحدة random: تولد أرقامًا عشوائية، وهي مفيدة في برمجة الألعاب. randint(): تولد عددًا صحيحًا عشوائيًا بين نقطتين تضمَّنان في التوليد. sample(): تولد قائمةً فرعيةً عشوائيًا من قائمة أكبر. seed(): إعادة ضبط مفتاح توليد الأعداد. هذه الوحدات على كثرتها ليست إلا شيئًا يسيرًا من الوحدات التي توفرها بايثون، والتي تزيد على مئة واحدة وأكثر يمكن تحميلها. تذكر أننا نستطيع استخدام dir() وhelp() للحصول على معلومات عن كيفية استخدام الدوال المختلفة، وأن المكتبة القياسية موثقة جيدًا في فهرس وحدات بايثون، ومن المصادر الجيدة للوحدات الإضافية فهرس حزم بايثون، الذي ضم عند كتابتنا لهذا المقال أكثر من مئة ألف حزمة، وكذلك مشروع SciPy الذي يستضيف مئات وحدات المعالجة العلمية والعددية، ولا غنى عنه لمن يعمل على مشاريع تحليل علمية، وأفضل وسيلة للوصول إلى تلك الحزم هو تثبيت إحدى إصدارات بايثون التي تحتوي على SciPy كإضافة قياسية فيها، مثل موقع anaconda.org، كما يحتوي sourceforge ومواقع التطوير مفتوح المصدر الأخرى على عدة مشاريع لبايثون فيها وحدات نافعة، ويمكنك الاستعانة بمحرك البحث نظرًا لتعدد المصادر، وتستطيع تصفحها وغيرها إذا أضفت كلمة python في بحثك، ولا تنس قراءة توثيق بايثون للمزيد من المعلومات عن البرمجة للإنترنت والرسوميات وبناء قواعد البيانات وغيرها. والمهم هنا إدراك أن أغلب لغات البرمجة تحوي هذه الدوال، والوظائف الأساسية إما مضمّنة فيها أو تكون جزءًا من مكتبتها القياسية، فابحث أولًا في توثيقك قبل كتابة دالة ما، فربما تكون موجودةً ولا تحتاج إلى كتابتها. تعريف الدوال الخاصة بنا يمكن إنشاء دوال خاصة بنا من خلال تعريفها، أي بكتابة تعليمة تخبر المفسر أننا نعرِّف كتلةً من الشيفرة، ويجب عليه تنفيذها عندما نطلبها في أي مكان في البرنامج. VBScript سننشئ الآن دالةً تطبع مثال جدول الضرب الخاص بنا لأي قيمة نعطيها إليها كوسيط، ;ستبدو هذه الدالة في VBScript كما يلي: <script type="text/vbscript"> Sub Times(N) Dim I For I = 1 To 12 MsgBox I & " x " & N & " = " & I * N Next End Sub </script> sنبدأ هنا في هذا المثال بالكلمة المفتاحية Sub -وهي اختصار برنامج فرعي Subroutine-، التي تلي محدد VBScript لكتل الشيفرات مباشرةً في السطر الثاني، ثم نعطيها قائمةً من المعامِلات بين قوسين. أما الشيفرة التي داخل الكتلة المعرَّفة فهي شيفرة VBScript عادية مع استثناء أنها تعامل المعامِلات على أنها متغيرات محلية، لذا تسمى الدالة في المثال أعلاه Times، وتأخذ معامِلًا واحدًا هو N، كما تعرِّف المتغير المحلي I، ثم تنفذ حلقةً تكراريةً تعرض جدول الضرب الخاص بالعدد N باستخدام المتغيرين N و I، نستدعي هذه الدالة الجديدة كما يلي: <script type="text/vbscript"> MsgBox "Here is the 7 times table..." Times 7 </script> لاحظ أننا عرّفنا معاملًا اسمه N ومررنا إليه الوسيط 7، وقد أخذ المعامل أو المتغير المحلي N داخل الدالة القيمة 7 عندما استدعيناه، ويمكن تعريف أي عدد نريده من المعامِلات في تعريف الدالة، وعلى البرامج المستدعية أن توفر قيمةً لكل معامِل. تسمح بعض لغات البرمجة بتعريف قيم افتراضية للمعامل في حالة عدم توفير قيمة، لتستخدم الدالة تلك القيمة الافتراضية. كذلك فقد غلفنا المعامل N بقوسين أثناء تعريف الدالة، لكن هذا غير ضروري في VBScript عند استدعاء الدالة، كما قلنا من قبل. لا تعيد هذه الدالة أي قيمة، وهو ما نسميه بالإجراء في البرمجة، وما هو إلا دالة لا تعيد قيمةً، وتفرّق لغة VBScript بين الدوال والإجراءات باستخدام أسماء مختلفة لتعريفاتهما، فمثلًا: تعيد الدالة التالية في VBScript جدول الضرب الخاص بنا في سلسلة نصية طويلة واحدة: <script type="text/vbscript"> Function TimesTable (N) Dim I, S S = N & " times table" & vbNewLine For I = 1 to 12 S = S & I & " x " & N & " = " & I*N & vbNewLine Next TimesTable = S End Function Dim Multiplier Multiplier = InputBox("Which table would you like?") MsgBox TimesTable (Multiplier) </script> تكاد صيغة هذه الشيفرة أن تطابق صيغة Sub، مع استثناء أننا استخدمنا الكلمة Function بدلًا من Sub السابقة، ويجب أن نسند النتيجة إلى اسم الدالة داخل التعريف، لهذا ستعيد الدالة أي قيمة يحتويها اسمها عند خروجها: ... TimesTable = S End Function فإذا لم نسند قيمةً لاسم الدالة بشكل صريح، فستعيد الدالة القيمة الافتراضية، والتي تكون في الغالب صفرًا أو سلسلةً نصيةً فارغةً. لاحظ أننا وضعنا أقواسًا حول الوسيط في سطر MsgBox، لأن MsgBox لن يعرف -لولا هذه الأقواس- هل يجب أن يُطبع Multiplier أم يُمرّره إلى الوسيط الأول والذي هو TimesTable، فلما وضعناه داخل الأقواس فهم المفسر أن القيمة هي وسيط للدالة TimesTable بدلًا من MsgBox. بايثون ستكون دالة جدول الضرب في بايثون كما يلي: def times(n): for i in range(1,13): print( "%d x %d = %d" % (i, n, i*n) ) وتُستدعى كما يلي: print( "Here is the 9 times table..." ) times(9) لاحظ أن الإجراءات في بايثون لا تميَّز عن الدوال، ويُستخدم def لتعريفهما، والفرق الوحيد هو أن الدالة التي تعيد قيمةً تستخدم تعليمة return، كما يلي: def timesTable(n): s = "" for i in range(1,13): s = s + "%d x %d = %d\n" % (i,n,n*i) return s الأمر بسيط، إذ تعيد الدالة النتيجة باستخدام تعليمة return، أما إذا لم يكن لدينا تعليمة return صريحة فستعيد بايثون تلقائيًا قيمةً افتراضيةً تسمى None، والتي نتجاهلها في العادة. نستطيع الآن طباعة نتيجة الدالة كما يلي: print( timesTable(7) ) يفضل عدم وضع تعليمات print داخل الدوال، وإنما جعل الدالة تعيد النتيجة باستخدام return، ثم طباعتها من خارج الدالة، ورغم أننا لم نتبع هذا الأسلوب في أمثلتنا، إلا أن هذا يجعل الدوال قابلةً لإعادة الاستخدام في نطاق أوسع من الحالات. يبقى أمر مهم للغاية يجب أن نذكره حول تعليمة return، وهو أنها لا تعيد قيمةً من الدالة فحسب، بل تعيد التحكم إلى الشيفرة التي استدعت الدالة، وتكمن أهمية ذلك في أن الإعادة لا يجب أن تكون آخر سطر في الدالة، فقد تكون هناك تعليمات أكثر، وقد لا تنفَّذ أبدًا، كما يمكن أن يحتوي متن الدالة الواحدة على عدة تعليمات return. تُنهي التعليمة التي نصل إليها أولًا الدالة وتعيد القيمة إلى الشيفرة المستدعية، سنعرض مثالًا عن دالة لها عدة تعليمات return، وهي تعيد أول عدد زوجي تجده في القائمة المزودة بها أو None إذا لم تجد أي عدد زوجي: def firstEven(aList): for num in aList: if num % 2 == 0: # تحقق من كونه زوجيًا return num # اخرج من الدالة فورًا return None # لا نصل إليها إلا إذا لم نجد عددًا زوجيًا ملاحظة بشأن المعاملات قد يصعب على المبتدئين فهم دور المعامِلات في تعريف الدالة، فهل يجب تعريف الدالة كما يلي: def f(x): # داخل الدالة x يمكن استخدام... أم تعريفها بالشكل: x = 42 def f(): # داخل الدالة x يمكن استخدام... يعرِّف المثال الأول هنا المعامِل x ويستخدمه داخل الدالة، بينما يستخدم المثال الثاني متغيرًا معرَّفًا من خارج الدالة مباشرةً، وبما أن المثال الثاني صالح ويعمل دون مشاكل، فلم نتكبد عناء تعريف المعامل؟، والجواب هو أن المعامِلات تتصرف مثل متغيرات محلية، أي مثل المتغيرات التي لا تُستخدم إلا داخل الدالة، وقلنا إن مستخدم الدالة يستطيع أن يمرر وسطاءً إلى هذه المعامِلات، وعلى ذلك تتصرف قائمة المعامِلات مثل بوابة للبيانات التي تتحرك بين البرنامج الرئيسي والدالة. تستطيع الدالة أن ترى بعض البيانات خارجها، لكن إذا أردنا للدالة أن تكون قابلةً لإعادة الاستخدام في أكثر من برنامج، فيجب أن نقلل اعتمادها على البيانات الخارجية، بل يجب أن تُمرَّر البيانات المطلوبة لأداء وظيفة الدالة بكفاءة إليها من خلال معامِلاتها، فإذا عُرِّفت الدالة داخل ملف وحدة، فيجب أن تكون لها صلاحية قراءة البيانات المعرَّفة داخل نفس الوحدة، لكن هذه الخاصية ستقلل من مرونة الدالة التي نعرِّفها. نريد أن نقلل عدد المعامِلات المطلوبة لتشغيل الدالة إلى حد يمكن السيطرة عليه وإدارته، وهذا يراعى في حالة البيانات الكثيرة التي تحتاج إلى معامِلات أكثر، وذلك من خلال استخدام تجميعات البيانات مثل القوائم وصفوف tuples والقواميس وغيرها، كما نستطيع تقليل عدد قيم المعامِلات الفعلية التي يجب أن نوفرها، باستخدام ما يسمى بالوسيط الافتراضي. الوسيط الافتراضي يشير هذا المصطلح إلى طريقة لتعريف معامِلات الدالة التي تأخذ قيمًا افتراضيةً إذا لم تمرَّر كوسطاء صراحةً، وأحد استخدامات هذا الوسيط المنطقية في دالة تعيد يوم الأسبوع، فإذا استدعيناها بدون قيمة فيكون قصدنا اليوم الحالي، وإلا فإننا نوفر رقم اليوم كوسيط، كما يلي: import time # None قيمة اليوم هي def dayOfWeek(DayNum = None): # طابق ترتيب اليوم مع قيم إعادة بايثون days = ['Saturday','Sunday', 'Monday','Tuesday', 'Wednesday', 'Thursday', 'Friday'] # تحقق من القيمة الافتراضية if DayNum == None: theTime = time.localtime(time.time()) DayNum = theTime[6] # استخرج قيمة اليوم return days[DayNum] لا نحتاج إلى استخدام وحدة الوقت إلا إذا كانت قيمة المعامِل الافتراضي مطلوبةً، وبناءً عليه نستطيع تأجيل عملية الاستيراد إلى أن نحتاج إليها، وسيحسن هذا من الأداء تحسينًا طفيفًا إذا لم نضطر إلى استخدام خاصية القيمة الافتراضية للدالة، لكن هذا التحسن يُعَد طفيفًا كما ذكرنا، ويلغي اصطلاح الاستيراد الذي ذكرناه أعلاه، لذا لا يستحق هذا التشوش. نستطيع الآن أن نستدعي ذلك كما يلي: print( "Today is: %s" % dayOfWeek() ) Saturday. print( "The third day is %s" % dayOfWeek(2) ) تذكر أننا نبدأ العد من الصفر في عالم الحواسيب، وأننا افترضنا أن اليوم الأول في الأسبوع هو السبت. عد الكلمات أحد الأمثلة الأخرى على دالة تعيد قيمةً، هو الدالة التي تَعُد الكلمات في سلسلة نصية، ويمكن استخدامها لحساب الكلمات في ملف ما بجمع كلمات كل سطر، وتكون شيفرة هذه الدالة كما يلي: def numwords(s): s = s.strip() # أزل المحارف الزائدة list = s.split() # قائمة كل عنصر فيها يمثل كلمة return len(list) # عدد كلمات القائمة هو عدد كلمات s لقد عرَّفنا الدالة في المثال أعلاه مستفيدين من بعض توابع السلاسل النصية المضمَّنة التي ذكرناها في مقال البيانات وأنواعها، ويمكن استخدام الدالة الآن كما يلي: for line in file: total = total + numwords(line) # راكم مجموع كل سطر print( "File had %d words" % total ) إذا حاولنا كتابة ذلك فلن تنجح الشيفرة، لأن مثل هذه الشيفرة تُعرف باسم الشيفرة الوهمية pseudocode، وهي تقنية تصميم شائعة للشيفرات لتوضيح الفكرة العامة لها، وليست مثالًا لشيفرة حقيقية صحيحة التركيب، وتُعرف أحيانًا باسم لغة وصف البرامج Program Description Language. يتضح لنا سبب أفضلية إعادة قيمة من دالة وطباعة النتيجة خارج الدالة بدلًا من داخلها، فإذا طبعت الدالة الطول بدلًا من إعادته فلم نكن لنستخدمها في عدّ إجمالي الكلمات في الملف، بل كنا سنحصل على قائمة طويلة فيها طول كل سطر، لكننا بإعادة القيمة نستطيع الاختيار بين استخدام القيمة كما هي، أو تخزينها في متغير بهدف المعالجة اللاحقة كما فعلنا هنا من أجل أخذ العدد الإجمالي، وهذه نقطة في غاية الأهمية من ناحية التصميم لفصل عرض البيانات من خلال الطباعة عن معالجها داخل الدالة. هناك ميزة أخرى وهي أننا إذا طبعنا الخرج فلن يكون مفيدًا إلا في بيئة سطر أوامر، أما بإعادة القيمة فنستطيع عرضها في صفحة ويب أو واجهة رسومية، فلفصل عرض البيانات عن معالجتها فائدة كبيرة، لذا اجتهد في إعادة القيم من الدوال بدلًا من طباعتها ما استطعت، وليس ثمة استثناء لهذه القاعدة إلا عند إنشاء دالة مخصصة لطباعة بعض البيانات، ففي تلك الحالة يجب توضيح هذا باستخدام كلمة print أو عرض اسم الدالة. دوال جافاسكربت يمكن إنشاء دوال داخل جافاسكربت باستخدام أمر function، كما يلي: <script type="text/javascript"> var i, values; function times(m) { var results = new Array(); for (i = 1; i <= 12; i++) { results[i] = i * m; } return results; } // استخدم الدالة values = times(8); for (i=1;i<=12;i++){ document.write(values[i] + "<br />"); } </script> لن نستطيع الاستفادة كثيرًا من هذه الدالة بتلك الحالة، لكن هذا المثال يوضح كيف يشبه الهيكل الأساسي لإنشاء الدالة هنا تعريفات الدوال في بايثون وVBSCript، وسننظر في دوال أكثر تعقيدًا في جافاسكربت لاحقًا، لأنها تستخدم الدوال لتعريف الكائنات والدوال أيضًا، وهو الأمر الذي يبدو مربكًا للقارئ أو لمستخدم اللغة. تنبيه تنبع قوة الدوال من سماحها بتوسيع نطاق الوظائف والمهام التي تستطيع اللغة تنفيذها، كما أنها تتيح لنا إمكانية تغيير اللغة من خلال تعريف معنىً جديد لدالة موجودة مسبقًا -لا يُسمح بهذا في بعض اللغات-، ولكن هذا أمر غير محمود العاقبة، إلا إذا تحكمنا فيه بحذر شديد، لأن تغيير السلوك القياسي للغة يجعل قراءة الشيفرة وفهمها يُعَد صعبًا للغاية على غيرك، بل عليك أنت نفسك فيما بعد، وبما أن القارئ يتوقع من الدالة أن تنفذ سلوكًا معينًا لكنك غيرت هذا السلوك إلى شيء آخر، لذا يفضل عدم تغيير السلوك الافتراضي للدوال المضمّنة في اللغة. يمكن التغلب على هذا التقييد للإبقاء على السلوك المضمّن للغة مع الاستمرار في استخدام أسماء ذات معنىً لدوالنا، من خلال وضع الدوال داخل كائن أو وحدة توفر سياقها المحلي. إنشاء الوحدات الخاصة رأينا كيف ننشئ دوالًا خاصةً بنا وكيف نستدعيها من أجزاء أخرى من البرنامج، وهذا أمر جيد لأنه يوفر علينا كثيرًا من الكتابة المتكررة، ويجعل برامجنا سهلة الفهم، لأننا ننسى بعض التفاصيل بعد إنشاء دالة تخفيها، وهو مبدأ متبع في البرمجة عند الحاجة إلى إخفاء بعض التفاصيل، ويسمى إخفاء المعلومات، حيث تغلَّف المعلومات والتفاصيل في دالة ننشئها لها، لكن كيف نستخدم هذه الدوال في البرامج الأخرى؟ الإجابة على هذا هي إنشاء وحدة module لهذا الغرض. وحدات بايثون الوحدة في بايثون ما هي إلا ملف نصي بسيط فيه تعليمات برمجية مكتوبة بلغة بايثون، وتكون تلك التعليمات عادةً تعريفات دوال، فمثلًا عند كتابة: import sys فإننا نخبر مفسر بايثون أن يقرأ هذه الوحدة وينفذ الشيفرة الموجودة فيها، ويتيح لنا الأسماء التي تولدها في ملفنا، ويبدو هذا كأننا ننشئ نسخةً من محتويات sys.py في برنامجنا، على أن بعض الوحدات مثل sys في البرمجة العملية ليس لها ملف sys.py أصلًا، لكننا سنتجاهل هذا الآن، وتوجد لغات برمجة مثل C و++C، التي ينسخ فيها المترجم أو المصرِّف ملفات الوحدة إلى البرنامج الحالي حسب الطلب. ننشئ الوحدة بإنشاء ملف بايثون يحتوي الدوال التي نريد إعادة استخدامها في برامج أخرى، ثم نستورد الوحدة كما نستورد الوحدات القياسية، ولتنفيذ هذا عمليًا، انسخ الدالة التالية إلى ملف، واحفظه باسم timestab.py. يمكنك فعل هذا باستخدام IDLE أو Notepad، أو أي محرر آخر يحفظ الملفات النصية العادية، لكن لا تستخدم برامج معالجة نصوص مثل مايكروسوفت وورد، لأن تلك البرامج تدخل شيفرات تنسيق كثيرةً لن تفهمها بايثون. def print_table(multiplier): print( "--- Printing the %d times table ---" % multiplier ) for n in range(1,13): print( "%d x %d = %d" % (n, multiplier, n*multiplier) ) ثم اكتب في محث بايثون: >>> import timestab >>> timestab.print_table(12) وهكذا تكون قد أنشأت وحدةً واستوردتها واستخدمت الدالة المعرَّفة فيها. لاحظ أنك إن لم تبدأ بايثون من نفس المجلد الذي خزنت فيه ملف timestab.py، فلن تستطيع بايثون أن تجد الملف وستعطيك خطأً، وعندها يمكن إنشاء متغير بيئة اسمه PYTHONPATH يحمل قائمةً من المجلدات الصالحة للبحث فيها عن وحدات، إضافةً إلى الوحدات القياسية التي تأتي مع بايثون، ويفضل تعريف مجلد داخل PYTHONPATH وتخزين جميع ملفات الوحدات القابلة لإعادة الاستخدام داخله، ولا تنسى اختبار الوحدات جيدًا قبل نقلها إليه. يجب التأكد من عدم استخدام اسم تحمله وحدة قياسية في بايثون، لئلا تجعل بايثون تستورد ملفك أنت بدلًا من القياسي، مما سينتج عنه سلوك غريب جدًا كما ذكرنا من قبل في شأن التلاعب في لغة البرمجة. ولا تستخدم اسم إحدى الوحدات التي تحاول استيرادها إلى نفس الملف، فهذا سيؤدي أيضًا إلى حدوث مشاكل. الوحدات في جافاسكربت وVBScript يُعَد إنشاء الوحدات في VBScript أكثر تعقيدًا من بايثون، فلم يكن مفهوم الوحدات موجودًا في هذه اللغة ولا في اللغات التي بنفس عمرها، بل كانت تعتمد على إنشاء الكائنات لإعادة استخدام الشيفرة بين المشاريع، وسننظر الآن في كيفية النسخ من المشاريع السابقة واللصق في مشروعنا الحالي باستخدام المحرر النصي. أما جافاسكربت فتوفر آليةً لإنشاء وحدات من ملفات الشيفرة القابلة لإعادة الاستخدام، لكنها آلية معقدة وتستخدم صيغةً غامضةً تخرج عن نطاق عملنا في هذه المرحلة، غير أن لدينا حلًا أسهل، وهو استخدام وحدات كتبها أشخاص آخرون، باستخدام الصيغة التالية: <script type=text/JavaScript src="mymodule.js"></script> نستطيع الوصول إلى جميع تعريفات الدوال الموجودة في ملف mymodule.js بمجرد إدراج السطر السابق داخل قسم <head> في صفحة الويب الخاصة بنا، وتوجد وحدات عديدة من الطرف الثالث متاحة لمبرمجي الويب ويمكن استيرادها بهذه الطريقة، ولعل أشهرها هي وحدة JQuery؛ أما في المواضع التي تُستخدم فيها جافاسكربت خارج المتصفحات -انظر قسم Windows Script Host اللاحق- فهناك آليات أخرى متاحة، ويُرجع في ذلك إلى التوثيق. تقنية Windows Script Host نظرنا حتى الآن إلى جافاسكربت وVBScript على أنهما لغات للبرمجة داخل الويب، ولكن توجد طريقة أخرى لاستخدامهما داخل بيئة ويندوز، وهو تقنية مضيف سكربت ويندوز Windows Script Host أو WSH اختصارًا، وهي تقنية أتاحتها مايكروسوفت لتمكين المستخدمين من برمجة حواسيبهم بنفس الطريقة التي استخدم بها مستخدمو نظام DOS قديمًا ملفات باتش Batch Files، فهي توفر آليات لقراءة الملفات والسجل والوصول إلى الحواسيب والطابعات التي في الشبكة وغيرها. في الإصدار الثاني من WSH إمكانية تضمين ملف WSH آخر، ومن ثم توفير وحدات قابلة لإعادة الاستخدام، وذلك بإنشاء ملف وحدة أولًا اسمه SomeModule.vbs يحتوي على ما يلي: Function SubtractTwo(N) SubtractTwo = N - 2 End function ننشئ الآن ملف سكربت WSH اسمه testModule.wsf مثلًا، كما يلي: <?xml version="1.0" encoding="UTF-8"?> <job> <script type="text/vbscript" src="SomeModule.vbs" /> <script type="text/vbscript"> Dim value, result WScript.Echo "Type a number" value = WScript.StdIn.ReadLine result = SubtractTwo(CInt(value)) WScript.Echo "The result was " & CStr(result) </script> </job> يمكن تشغيل هذا في ويندوز ببدء جلسة DOS وكتابة ما يلي: C:\> cscript testModule.wsf تسمى الطريقة التي تمت هيكلة ملف (wsf.) بها باسم XML، ويتواجد البرنامج داخل زوج من وسوم <job></job> بدلًا من وسم <html></html> الذي رأيناه في لغة HTML من قبل. يشير أول وسم سكربت في الداخل إلى ملف وحدة اسمه SomeModule.vbs، أما وسم السكربت الثاني فيحتوي على برنامجنا الذي يصل إلى SubtractTwo داخل ملف SomeModule.vbs؛ بينما ملف .vbs فيحتوي على شيفرة VBScript عادية ليس فيها وسوم XML أو HTML. لاحظ أن علينا تهريب محرف & من أجل ضم السلاسل النصية لتعليمة WScript.Echo، لأن التعليمة جزء من ملف XML، وهذا المحرف مستخدم في لغة XML كرمز محدِّد. نستخدم WScript.Stdin لقراءة مدخلات المستخدم، وهو تطبيق لما تحدثنا عنه في مقال قراءة البيانات من المستخدم. تصلح هذه التقنية مع جافاسكربت أيضًا، أو لنكون أدق، مع نسخة مايكروسوفت من جافاسكربت التي تسمى JScript، وذلك بتغيير سمة type=، بل يمكن دمج اللغات في WSH بأن نستورد وحدةً مكتوبةً بجافاسكربت ونستخدمها في شيفرة VBScript أو العكس. فيما يلي سكربت WSH مكافئ لما سبق، حيث تُستخدم جافاسكربت للوصول إلى وحدة من VBScript: <?xml version="1.0" encoding="UTF-8"?> <job> <script type="text/vbscript" src="SomeModule.vbs" /> <script type="text/javascript"> var value, result; WScript.Echo("Type a number"); value = WScript.StdIn.ReadLine(); result = SubtractTwo(parseInt(value)); WScript.Echo("The result was " + result); </script> </job> نستطيع رؤية مدى تقارب هاتين النسختين، فإذا استثنينا بعض الأقواس الزائدة فسيمكننا القول أنهما متشابهتان للغاية؛ أما أغلب الأمور الفنية فتجري من خلال كائنات WScript. لن نستخدم WSH كثيرًا، لكن قد ننظر فيها بين الحين والآخر إذا رأينا أنها توفر لنا مزايا لا يمكن شرحها باستخدام بيئة المتصفح الأكثر تقييدًا، فعلى سبيل المثال، سنستخدم WSH في المقال التالي لبيان كيف يمكن تعديل الملفات باستخدام جافاسكربت وVBScript، وتوجد بعض الكتب التي تتحدث عن WSH إذا كنت مهتمًا بتعلم المزيد عنها، ويحتوي موقع مايكروسوفت على قسم خاص بها مع أمثلة لبرامج وأدوات تطوير وغير ذلك. خاتمة نأمل أن تخرج من هذا المقال وقد تعلمت: الدوال التي هي شكل من أشكال الوحدات. تعيد الدوال قيمًا، أما الإجراءات فلا تعيد شيئًا. تتكون الوحدات في بايثون في العادة من تعريفات للدوال داخل ملف. يمكن إنشاء دوال جديدة في بايثون باستخدام الكلمة المفتاحية def. استخدام Sub أوFunction في VBScript، وfunction في جافاسكربت. ترجمة -بتصرف- للفصل الحادي عشر: Programming with Modules من كتاب Learning To Program لصاحبه Alan Gauld. اقرأ أيضًا المقال التالي: التعامل مع الملفات في البرمجة المقال السابق: مقدمة في البرمجة الشرطية تعلم البرمجة المدخل الشامل لتعلم علوم الحاسوب1 نقطة -
 تُعدّ البرمجة كائنية التوجه (object-oriented programming - OOP) بمثابة محاولة لتَمْكِين البرامج من نمذجة طريقة تفكيرنا بالعالم الخارجي وتَعامُلنا معه. بالأنماط الأقدم من البرمجة، كان المبرمج مُضطرًّا لتَحْديد المُهِمّة الحاسوبية التي ينبغي له تّنْفيذها لكي يَحلّ المشكلة الفعليّة التي تُواجهه. ووفقًا لهذا التصور، فإن البرمجة تَتكوَّن من محاولة إيجاد متتالية التَعْليمَات المسئولة عن إنجاز تلك المُهِمّة. في المقابل، تُحاوِل البرمجة كائنية التوجه (object-oriented programming) العُثور على عدة كائنات (objects) تُمثِل كيانات (entities) حقيقية أو مُجرّدة مرتبطة بموضوع المشكلة (problem domain). تَملُك تلك الكيانات سلوكيات معينة (behavior)، كما تَتَضمَّن مجموعة من البيانات، وتستطيع أن تَتَفاعَل مع بعضها البعض. ووفقًا لهذا التصور، فإن البرمجة تَتكوَّن من عملية تصميم مجموعة الكائنات (objects) التي يُمكِنها محاكاة المشكلة المطلوب حَلّها. يجعل ذلك تصميم البرامج أكثر طبيعية، وأسهل في الكتابة والفهم عمومًا. يُمكِننا القول أن البرمجة كائنية التوجه (OOP) هي مجرد تَغيير بوجهات النظر؛ فبحَسَب مفاهيم البرمجة القياسية، قد نُفكِر بالكائن (object) على أساس أنه مُجرّد مجموعة من المُتْغيِّرات والبرامج الفرعية (subroutines) المسئولة عن معالجة تلك المُتْغيِّرات ضُمِّنت معًا بطريقة ما. بل حتى يُمكِننا اِستخدَام الأساليب كائنية التوجه (object-oriented) بأي لغة برمجية، ولكن بالطبع هنالك فرق كبير بين لغة تَسمَح بالبرمجة كائنية التوجه، وآخرى تُدعِّمها بشكل نَشِط. تُدعِّم اللغات البرمجية كائنية التوجه، مثل الجافا، عدة مِيزَات تَجعلها مختلفة عن أي لغة قياسية آخرى، ولكي نَستغِل تلك السمات والميزات بأكبر قدر مُمكن، ينبغي أن نُعيد توجيه تفكيرنا على نحو سليم. ملحوظة: عادةً ما يُستخدَم مصطلح "التوابع (methods)" للإشارة إلى البرامج الفرعية (subroutines) ضِمْن سياق البرمجة كائنية التوجه (object-oriented)، ولهذا سيَستخدِم هذا الفصل مصطلح "التوابع (method)" بدلًا من مصطلح "البرامج الفرعية (subroutine)". الكائنات (objects) والأصناف (classes) والنسخ (instances) لقد تحدثنا عن الأصناف (classes) خلال الفصول السابقة، واَتضح لنا أن الصَنْف يُمكِنه أن يَحتوِي على مُتْغيِّرات وتوابع (methods) يُشار إليها باسم البرامج الفرعية. سنَنتقل الآن إلى الحديث عما يُعرَف باسم الكائنات (objects)، والتي هي وثيقة الصلة بالأصناف. بدايةً، تَعَرَّضنا للكائنات (objects) مرة وحيدة من قَبْل خلال القسم ٣.٩، ولم نَلحظ خلالها فارقًا جوهريًا؛ فلقد اِستبعدنا فقط كلمة static من تعريف إحدى البرامج الفرعية (subroutine definition). في الواقع، يَتَكوَّن أي كائن من مجموعة من المُتْغيِّرات والتوابع، فكيف يختلف إذًا عن الأصناف (classes)؟ للإجابة على مثل هذا السؤال، ستحتاج إلى طريقة تفكير مختلفة نسبيًا وذلك حتى تُدرِك أهمية الكائنات وتَتَمكَّن من اِستخدَامها بطريقة فعالة. ذَكَرَنا أن الأصناف تُستخدَم لوصف الكائنات (objects)، أو بتعبير أدق، أن الأجزاء غَيْر الساكنة (non-static) من الأصناف تُستخدَم لوصف الكائنات. قد لا يَكُون المقصود من ذلك واضحًا بما فيه الكفاية، لذا دَعْنَا نُصيغه بطريقة آخرى والتي هي أكثر شيوعًا نوعًا ما. نستطيع أن نقول أن الكائنات تنتمي إلى أصناف (classes)، ولكن ليس بنفس الطريقة التي ينتمي بها مُتْغيِّر عضو معين (member variable) لصنف. فلربما من الأدق أن نقول أن الأصناف تُستخدَم لإنشاء كائنات، فالصَنْف (class) هو أَشْبه ما يَكُون بمصنع أو مُخطط أوَّليّ (blueprint) لإنشاء الكائنات بحيث تُحدِّد الأجزاء غَيْر الساكنة (non-static) منه مجموعة المُتْغيِّرات والتوابع التي يُفْترَض أن تَتَضمَّنها كائنات ذلك الصنف. لذا فإن أحد الاختلافات الجوهرية بين الأصناف والكائنات هو حقيقة أن الكائنات تُنشَئ وتُهدَم أثناء تَشْغِيل البرنامج، بل يُمكِن اِستخدَام صَنْف معين لإنشاء أكثر من كائن (object) بحيث يَكُون لها جميعًا نفس البنية. لنَفْترِض أن لدينا الصَنْف التالي، والذي يَحتوِي على عدة مُتْغيِّرات أعضاء ساكنة (static member variables). يُمكِننا أن نَستخدِمه لتَخْزِين معلومات عن مُستخدِم البرنامج مثلًا: class UserData { static String name; static int age; } عندما يُحمِّل الحاسوب ذلك الصَنْف، فإنه سيُكرِّس جزءًا من الذاكرة له بحيث يَتَضمَّن ذلك الجزء مساحة لقيم المُتْغيِّرين name و age، أيّ سيَكُون هناك نسخة وحيدة فقط من كلا المُتْغيِّرين UserData.name و UserData.age ضِمْن البرنامج عمومًا. تُبيِّن الصورة التالية تَصوُّرًا للصَنْف داخل الذاكرة: تُعدّ المُتْغيِّرات الأعضاء الساكنة (static) جزءًا من تمثيل الصنف داخل الذاكرة، ولهذا تُستخدَم الأسماء الكاملة المُتضمِّنة لاسم الصَنْف ذاته مثل UserData.name و UserData.age للإشارة إليها. في المثال السابق، قررنا اِستخدَام الصنف UserData لتمثيل مُستخدِم البرنامج، ولمّا كان لدينا مساحة بالذاكرة لتَخْزِين البيانات المُتعلِّقة بمُستخدِم واحد فقط، فبطبيعة الحال سيَكُون البرنامج قادرًا على حَمْل بيانات مُستخدِم وحيد. لاحِظ أن الصنف UserData والمُتْغيِّرات الساكنة (static) المُعرَّفة بداخله تَظلّ موجودة طوال فترة تَشْغِيل البرنامج، وهذا هو المقصود بكَوْنها ساكنة بالأساس. لنَفْحَص الآن صَنْفًا مُشابهًا، ولكنه يَتَضمَّن بعضًا من المُتْغيِّرات غَيْر الساكنة (non-static): class PlayerData { static int playerCount; String name; int age; } أُضيف إلى الصنف PlayerData مُتْغيِّر ساكن هو playerCount أيّ أن اسمه الكامل هو PlayerData.playerCount، كما أنه مُخزَّن كجزء من تمثيل الصَنْف بالذاكرة، وتَتَوَّفر منه نُسخة واحدة فقط تَظلّ موجودة طوال فترة تَّنْفيذ البرنامج. بالإضافة إلى ذلك، يَتَضمَّن تعريف الصَنْف (class definition) مُتْغيِّرين غَيْر ساكنين (non-static)، ولأن المُتْغيِّرات غَيْر الساكنة لا تُعدّ جزءًا من الصنف ذاته، فإنه لا يُمكِن الإشارة إلى هذين المُتْغيِّرين بالأسماء PlayerData.name أو PlayerData.age. نستطيع الآن اِستخدَام الصَنْف PlayerData لإنشاء كائنات بأيّ قدر نُريده، بحيث يَمتلك كل كائن منها مُتْغيِّراته الخاصة به والتي تَحمِل الأسماء name و age، أيّ يَحصُل كل كائن على نسخته الخاصة من أجزاء الصَنْف غَيْر الساكنة (non-static)، وهذا هو ما يَعنِيه القول بأن أجزاء الصَنْف غَيْر الساكنة تُعدّ بمثابة مُخططًا أوَّليًّا أو قالبًا (template) للكائنات. تُبيِّن الصورة التالية تصورًا لذاكرة الحاسوب بَعْد إِنشاء عدة كائنات: كما ترى بالأعلى، يُعدّ المُتْغيِّر الساكن playerCount جزءًا من الصنف وتَتَوفَّر منه نُسخة وحيدة، بينما تَتَوفَّر نُسخة خاصة من المُتْغيِّرين غَيْر الساكنين name و age بكل كائن (object) مُنشَئ من ذلك الصنف. يُعدّ أيّ كائن (object) نُسخة (instance) من صَنْفه، ويَكُون على دراية بالصَنْف المُستخدَم لإِنشائه. تُبيِّن الصورة أن الصَنْف PlayerData يَحتوِي على ما يُعرَف باسم "البَانِي أو بَانِي الكائن (constructor)". البَانِي ببساطة هو برنامج فرعي (subroutine) يُستخدَم لإِنشاء الكائنات سنتحدث عنه لاحقًا. ولأننا نستطيع إِنشاء كائنات (objects) جديدة من الصَنْف PlayerData لتَمْثيل لاعبين جُدد بقَدْر ما نَشَاء، فقد يُصبِح لدينا الآن مجموعة من اللاعبين. على سبيل المثال، قد يَستخدِم برنامج معين الصَنْف PlayerData لتَخْزين بيانات مجموعة لاعبين ضِمْن لعبة بحيث يَملُك كُلًا منهم name و age خاص به، وعندما يَنضَم لاعب جديد إلى اللعبة، يَستطيع البرنامج أن يُنشِئ كائنًا جديدًا من الصَنْف PlayerData لتمثيل ذلك اللاعب، أما إذا غادر أحد اللاعبين، يَستطيع البرنامج هَدْم الكائن المُمثِل لذلك اللاعب، أي سيَستخدِم ذلك البرنامج شبكة من الكائنات لنَمذجة أحداث اللعبة بصورة ديناميكية (dynamic)، وهو ما لا يُمكِنك القيام به باِستخدَام المُتْغيِّرات الساكنة (static). يُعدّ أيّ كائن (object) نُسخة (instance) من الصَنْف المُستخدَم لإِنشائه، ونقول أحيانًا بأنه يَنتمي إلى ذلك الصَنْف. يُطلَق اسم مُتْغيِّرات النُسخ (instance variables) على المُتْغيِّرات التي يَتَضمَّنها الكائن بينما يُطلَق اسم توابع النُسخ (instance methods) على التوابع (methods) -أو البرامج الفرعية- ضِمْن الكائن. فمثلًا، إذا اِستخدَمنا الصَنْف PlayerData المُعرَّف بالأعلى لإِنشاء كائن، فإن ذلك الكائن يُعدّ نُسخة (instance) من الصنف PlayerData كما يُعدّ كُلًا من name و age مُتْغيِّرات نُسخ (instance variable) ضِمْن الكائن. لا يَتَضمَّن المثال بالأعلى أيّ توابع (methods)، ولكنها تَعَمَل عمومًا بصورة مشابهة للمُتْغيِّرات أيّ تُعدّ التوابع الساكنة (static) جزءًا من الصَنْف ذاته بينما تُعدّ التوابع غَيْر الساكنة (non-static) أو توابع النُسخ (instance methods) جزءًا من الكائنات (objects) المُنشئة من ذلك الصَنْف. لكن، لا تَأخُذ ذلك بمعناه الحرفي؛ فلا يَحتوِي كل كائن على نُسخته الخاصة من شيفرة توابع النُسخ (instance method) المُعرَّفة ضِمْن الصَنْف بشكل فعليّ وإنما يُعدّ ذلك صحيحًا على نحو منطقي فقط، وعمومًا سنستمر بالإشارة إلى احتواء كائن معين على توابع نُسخ (instance method) صَنْفه. ينبغي عمومًا أن تُميز بين الشيفرة المصدرية (source code) للصَنْف والصَنْف ذاته بالذاكرة. تُحدِّد الشيفرة المصدرية كُلًا من هيئة الصَنْف وهيئة الكائنات المُنشئة منه: تُحدِّد التعريفات الساكنة (static definitions) بالشيفرة العناصر التي ستُصبِح جُزءًا من الصَنْف ذاته بذاكرة الحاسوب بينما تُحدِّد التعريفات غَيْر الساكنة (non-static definitions) بالشيفرة العناصر التي ستُصبِح جُزءًا من كل كائن يُنشَئ من ذلك الصنف. بالمناسبة، يُطلَق اسم مُتْغيِّرات الأصناف (class variables) وتوابع الأصناف (class methods) على المُتْغيِّرات الأعضاء (member variables) الساكنة والبرامج الفرعية الأعضاء (member subroutines) الساكنة المُعرَّفة ضِمْن الصنف على الترتيب؛ وذلك لكَوْنها تنتمي للصَنْف ذاته وليس لنُسخ (instances) ذلك الصَنْف. يَتَّضِح لنا الآن الكيفية التي تَختلِف بها الأجزاء الساكنة من صنف معين عن الأجزاء غَيْر الساكنة، حيث يَخدِم كُلًا منهما غرضًا مُختلفًا تمامًا. وفي العموم، ستَجِدْ أن كثيرًا من الأصناف إِما أنها تَحتوِي على أعضاء ساكنة (static) فقط أو على أعضاء غَيْر ساكنة (non-static) فقط، ومع ذلك سنَرى أمثلة قليلة لأصناف تَحتوِي على مَزيج منهما. أساسيات الكائنات اِقْتصَر حديثنا إلى الآن على الكائنات (objects) في العموم دون ذِكْر أيّ تفاصيل عن طريقة اِستخدَامها بصورة فعليّة ضِمْن برنامج، لذا سنَفْحَص مثالًا مُحدَّدًا لنوضح ذلك. لنَفْترِض أن لدينا الصَنْف Student المُعرَّف بالأسفل، والذي يُمكِننا اِستخدَامه لتَخْزِين بعض بيانات الطلبة المُلتحِقة بدورة تدريبية: public class Student { public String name; // اسم الطالب public double test1, test2, test3; // الدرجة بثلاثة اختبارات public double getAverage() { // احسب متوسط درجة الاختبارات return (test1 + test2 + test3) / 3; } } // نهاية الصنف Student لم يُستخدَم المُبدِّل static أثناء التَّصْريح عن أيّ من أعضاء الصَنْف Student، لذا فالصَنْف موجود فقط بغَرْض إِنشاء الكائنات (objects). يُحدِّد تعريف الصَنْف Student -بالأعلى- أن كائناته أو نُسخه (instance) ستَحتوِي على مُتْغيِّرات النُسخ (instance variables) name و test1 و test2 و test3 كما ستَحتوِي على تابع نسخة (instance method) هو getAverage(). سيَحتوِي كل كائن -يُمثِل طالبًا- في العموم على اسم طالب معين ودرجاته، وعندما يُستدعَى التابع getAverage() لكائن معين، ستُحسَب قيمة المتوسط باِستخدَام درجات الاختبار ضِمْن ذلك الكائن تَحْديدًا أيّ سيَحصُل كل كائن على قيمة متوسط مختلفة، وهذا هو في الواقع ما يَعنِيه انتماء توابع النُسخ (instance method) للكائنات المُفردة لا الأصناف نفسها. الأصناف بلغة الجافا هي أنواع تمامًا كالأنواع المَبنية مُسْبَقًا (built-in) مثل int و boolean، لذا تستطيع اِستخدَام اسم صَنْف معين لتَحْدِيد نوع مُتْغيِّر ضِمْن تَعْليمَة تَّصْريح (declaration statement) أو لتَخْصِيص نوع مُعامِل صُّوريّ (formal parameter) أو لتَحْدِيد نوع القيمة المُعادة (return type) من دالة (function). يُمكِن مثلًا تعريف مُتْغيِّر اسمه std من النوع Student باِستخدَام التَعْليمَة التالية: Student std; انتبه للنقطة الهامة التالية، لا يُؤدي تَّصْرِيحك (declare) عن مُتْغيِّر نوعه عبارة عن صنف إلى إِنشاء الكائن ذاته! تَرتبط هذه النقطة بالحقيقتين التاليتين: لا يُمكِن لأيّ مُتْغيِّر أن يَحمِل كائنًا. يستطيع المُتْغيِّر أن يَحمِل مَرجِعًا (reference) يُشير إلى كائن. يُفضَّل أن تُفكِر بالكائنات (objects) كما لو أنها تَعيش مُستقلة بذاكرة الحاسوب، تحديدًا بقسم الكَوْمة (heap) من الذاكرة. لا تَحمِل المُتْغيِّرات كائنية النوع (object type) قيم الكائنات نفسها وإنما تَحمِل المعلومات الضرورية للعُثور على تلك الكائنات بالذاكرة، تَحْديدًا تَحمِل عناوين مَواضِعها (location address) بالذاكرة، ويُقال عندها أن المُتْغيِّر يَحمِل مَرجِعًا (reference) أو مُؤشرًا (pointer) إلى الكائن. عندما تَستخدِم مُتْغيِّر كائني النوع (object type)، يَستخدِم الحاسوب المَرجِع (reference) المُخْزَّن بالمُتْغيِّر للعُثور على قيمة الكائن الفعليّة. يُنشِئ العَامِل (operator) new كائنًا جديدًا (object) حيث يَستدعِى برنامجًا فرعيًا -ذكرناه سابقًا- يقع ضِمْن الصَنْف يُطلَق عليه اسم البَانِي (constructor)، ثم يُعيد مَرجِعًا (reference) يُشير إلى الكائن المُنشَىء. لنَفْترِض مثلًا أن لدينا مُتْغيِّر std من النوع Student المُصرَّح عنه بالأعلى، يُمكِننا الآن كتابة تَعْليمَة الإِسْناد التالية (assignment statement): std = new Student(); تُنشِئ تَعْليمَة الإِسْناد -بالأعلى- كائنًًا (object) جديدًا بقسم الكَوْمة (heap) من الذاكرة، والذي يُعدّ نُسخة (instance) من الصَنْف Student، ثم تُخزِّن التَعْليمَة مَرجِعًا (reference) إلى ذلك الكائن بالمُتْغيِّر std أيّ أن قيمة المُتْغيِّر عبارة عن مَرجِع (reference) أو مُؤشر (pointer) إلى الكائن الواقع بمكان ما. لا يَصِح في العموم أن تقول "قيمة المُتْغيِّر std هي الكائن ذاته" على الرغم من صعوبة تَجنُّب ذلك أحيانًا، ولكن لا تَقل أبدًا أن "الكائن مُخزَّن بالمُتْغيِّر std" فهو أمر غَيْر صحيح على الإطلاق. يُفْترَض عمومًا أن تقول "يُشير المُتْغيِّر std إلى الكائن"، وهو ما سنُحاول الالتزام به قَدْر الإِمكان. لاحِظ أنه إذا ذَكَرَنا مثلًا أن "std هو كائن"، فالمقصود هو "std هو مُتْغيِّر يُشيِر إلى كائن". لنَفْترِض أن المُتْغيِّر std يُشير إلى كائن (object) عبارة عن نُسخة (instance) من الصَنْف Student أيّ يَحتوِي ذلك الكائن بطبيعة الحال على مُتْغيِّرات النُسخ name و test1 و test2 و test3. يُمكِننا الإشارة إلى تلك المُتْغيِّرات باِستخدَام std.name و std.test1 و std.test2 و std.test3 على الترتيب. يَتَّبِع ذلك نفس نَمْط التسمية المُعتاد بأنه عندما يَكُون B جزءًا من A، فإن اسم B الكامل هو A.B. اُنظر المثال التالي: System.out.println("Hello, " + std.name + ". Your test grades are:"); System.out.println(std.test1); System.out.println(std.test2); System.out.println(std.test3); ستَطبَع الشيفرة بالأعلى الاسم وقيم الدرجات بالكائن المُشار إليه باِستخدَام المُتْغيِّر std. بنفس الأسلوب، يَحتوِي ذلك الكائن على تابع نسخة هو getAverage()، والذي يُمكِننا استدعائه باِستخدَام std.getAverage(). يُمكِنك كتابة الشيفرة التالية لطباعة مُتوسط درجات الطالب: System.out.println( "Your average is " + std.getAverage() ); تستطيع عمومًا اِستخدَام std.name أينما أَمَكَن اِستخدَام مُتْغيِّر من النوع String. فمثلًا، قد تَستخدِمه ضِمْن تعبير (expression) أو قد تُسنِد قيمة إليه أو قد تَستخدِمه حتى لاستدعاء أحد البرامج الفرعية (subroutines) المُعرَّفة بالصَنْف String. فمثلًا، يُمثِل التعبير std.name.length() عدد المحارف باسم الطالب. قد لا تُشير مُتْغيِّرات الكائنات (object variables) أيّ تلك التي نوعها هو عبارة عن صَنْف -مثل المُتْغيِّر std- إلى أيّ كائن نهائيًا، وفي تلك الحالة، يُقال أنها تَحمِل مُؤشرًا فارغًا (null pointer) أو مَرجِعًا فارغًا (null reference). يُكْتَب المُؤشر الفارغ (null pointer) باِستخدَام كلمة null، ولهذا تستطيع اِستخدَام الشيفرة التالية لتَخْزِين مَرجِع فارغ بالمُتْغيِّر std: std = null; في المثال بالأعلى، لا يَحتوِي المُتْغيِّر على مُؤشر لأيّ شيء آخر وإنما تُعدّ null هي قيمته الفعليّة، لذا لا يَصِح أن تقول: "يُشير المُتْغيِّر إلى القيمة الفارغة (null)"، فالمُتْغيِّر نفسه هو قيمة فارغة. تستطيع اختبار ما إذا كانت قيمة المُتْغيِّر std فارغة باِستخدَام التالي: if (std == null) . . . عندما تَكُون قيمة مُتْغيِّر كائن (object variable) فارغة أيّ تَحتوِي على null، يَعنِي ذلك أن المُتْغيِّر لا يُشير إلى أيّ كائن، وبالتالي لا يَكُون هناك أيّ مُتْغيِّرات نُسخ (instance variables) أو توابع نُسخ (instance methods) يُمكِن الإشارة إليها، ويَكُون من الخطأ محاولة القيام بذلك عبر ذاك المُتْغيِّر. فمثلًا، إذا كانت قيمة المُتْغيِّر std هي null، وحَاوَل برنامج معين الإشارة إلى std.test1، سيُؤدِي ذلك إلى محاولة اِستخدَام مؤشر فارغ (null pointer) بطريقة خاطئة، ولهذا سيُبلَّغ عن اِعتراض مُؤشِر فارغ (null pointer exception) من النوع NullPointerException أثناء تّنْفيذ البرنامج. لنَفْحَص مُتتالية التَعْليمَات التالية: Student std, std1, // صرح عن أربعة متغيرات من النوع Student std2, std3; // أنشئ كائن جديد من الصنف Student وخزن مرجعه بالمتغير std std = new Student(); // أنشئ كائن آخر من الصنف Student وخزن مرجعه بالمتغير std1 std1 = new Student(); // انسخ مرجع std1 إلى المتغير std2 std2 = std1; // خزن مؤشرا فارغا بالمتغير std3 std3 = null; // اضبط قيم متغيرات الأعضاء std.name = "John Smith"; std1.name = "Mary Jones"; بعدما يُنفِّذ الحاسوب التَعْليمَات بالأعلى، ستُصبِح ذاكرة الحاسوب كالتالي: يَتَبين لنا التالي بَعْد فَحْص الصورة بالأعلى: أولًا، يَحتوِي أيّ مُتْغيِّر على مَرجِع (reference) إلى كائن ظَهَرَت قيمته ضِمْن الصورة بهيئة سهم يُشير إلى الكائن (object). ثانيًا، يُمكِننا أن نَرَى أن السَلاسِل النصية من النوع String هي كائنات. ثالثًا، لا يُشير المُتْغيِّر std3 إلى أيّ مكان؛ لأنه فارغ ويَحتوِي على القيمة null. وأخيرًا، تُشير الأسهم من std1 و std2 إلى نفس ذات الكائن وهو ما يُبرِز النقطة المهمة التالية: عندما نُسنِد مُتْغيِّر كائن (object variable) إلى آخر، يُنسَخ المَرجِع (reference) فقط لا الكائن (object) المُشار إليه بواسطة ذلك المَرجِع. لنَأخُذ مثلًا التَعْليمَة std2 = std1; كمثال، لمّا كانت تَعْليمَة الإِسْناد (assignment statement) في العموم تَنسَخ فقط القيمة المُخْزَّنة بمُعاملها الأيمن std1 إلى مُعاملها الأيسر std2، ولأن القيمة في تلك الحالة هي مُجرَّد مُؤشِر (pointer) إلى كائن وليست الكائن (object) ذاته، فإن تلك التَعْليمَة لم تُنشِئ كائنًا جديدًا، وإنما ضَبَطَت std2 بحيث يُشير إلى نفس الكائن الذي يُشير إليه std1. يَترتَب على ذلك عدة نتائج قد تَكُون مفاجئة بالنسبة لك. مثلًا، تُعدّ كُلًا من std1.name و std2.name أسماءً مختلفة لنفس مُتْغيِّر النُسخة (instance variable) المُعرَّف ضِمْن الكائن الذي يُشير إليه كِلا المُتْغيِّرين std1 و std2، ولهذا عندما تُسنِد السِلسِلة النصية "Mary Jones" مثلًا إلى std1.name، ستُصبِح قيمة std2.name هي أيضًا "Mary Jones". إذا التبس عليك الأمر، حَاوِل فقط أن تَستحضر الحقيقة التالية: "المُتْغيِّر ليس هو الكائن (object)، فالأول يَحمِل فقط مُؤشرًا (pointer) إلى الثاني." يُستخدَم العَامِلان == و != لاختبار تَساوِي كائنين أو عدم تَساوِيهما على الترتيب، ولكن لاحِظ أن المَعنَى الدلالي (semantics) وراء تلك الاختبارات مُختلف عما أنت مُعتاد عليه. فمثلًا، يَفْحَص الاختبار if (std1 == std2) ما إذا كانت القيم المُخْزَّنة بكُلًا من std1 و std2 مُتساوية، ولأن تلك القيم هي مُجرَّد مَراجِع (references) تُشير إلى كائنات وليست الكائنات ذاتها، فإن ذلك الاختبار يَفْحَص ما إذا كان std1 و std2 يُشيران إلى نفس ذات الكائن أيّ ما إذا كانا يُشيران إلى نفس المَوضِع بالذاكرة. لا يُعدّ ذلك مشكلة إذا كان هذا هو ما تُريد اختباره، لكن أحيانًا يَكُون المقصود هو مَعرِفة ما إذا كانت مُتْغيِّرات النُسخ (instance variables) تَحمِل نفس القيم بغَضْ النظر عن انتمائها لنفس ذات الكائن. في تلك الحالات، ستحتاج إلى إجراء الاختبار التالي: std1.test1 == std2.test1 && std1.test2 == std2.test2 && std1.test3 == std2.test3 && std1.name.equals(std2.name) ذَكَرَنا مُسْبَقًا أن السَلاسِل النصية من النوع String هي بالأساس كائنات، كما أَظَهَرنا السِلسِلتين النصيتين "Mary Jones" و "John Smith" بهيئة كائنات بالصورة التوضيحية بالأعلى ولكن بدون البنية الداخلية للنوع String. تُعدّ تلك السِلاسِل كائنات مميزة، وتُعامَل وفقًا لقواعد صيغة خاصة. كأيّ مُتْغيِّر كائن (object variable)، تَحمِل المُتْغيِّرات من النوع String مَرجِعًا (reference) إلى سِلسِلة نصية وليس السِلسِلة النصية ذاتها. بُناءً على ذلك، لا يَصِح عادةً اِستخدَام العَامِل == لاختبار تَساوِي السَلاسِل النصية. فمثلًا، إذا كان لدينا مُتْغيِّر من النوع String اسمه هو greeting ويُشير إلى السِلسِلة النصية "Hello"، فهل يَكُون الاختبار greeting == "Hello" مُتحقِّقًا؟ في الواقع، يُشير كُلًا من المُتْغيِّر greeting والسِلسِلة النصية المُجرَّدة "Hello" إلى سِلسِلة نصية تَحتوِي على المحارف H-e-l-l-o. ومع ذلك، فإنهما قد يَكُونان كائنين مختلفين صَدَفَ فقط احتوائهما على نفس المحارف، ولأن ذلك التعبير يَختبِر ما إذا كان greeting و "Hello" يَحتوِيان على نفس المحارف، وكذلك ما إذا كانا واقْعين بنفس مَوضِع الذاكرة، فإن الاختبار greeting == "Hello" لا يُعدّ مُتحقِّقًا. في المقابل، تَقْتصِر الدالة greeting.equals("Hello") على اختبار ما إذا كان greeting و "Hello" يَحتوِيان على نفس المحارف وهو عادةً ما تَرغَب باختباره. أخيرًا، يُمكِن للمُتْغيِّرات من النوع String أن تَكُون فارغة أيّ تحتوي على القيمة null، وفي تلك الحالة، سيَكُون اِستخدَام العَامِل == مُناسبًا لاختبار ما إذا كان المُتْغيِّر فارغًا كالتالي greeting == null. ذَكَرَنا أكثر من مرة أن مُتْغيِّرات الكائنات لا تَحمِل الكائنات (objects) ذاتها، وإنما تَحمِل مَراجِع (references) تُشير إلى تلك الكائنات، وهو ما يَترتَب عليه بعض من النتائج الآخرى التي ينبغي أن تَكُون على دراية بها والتي ستَجِدها منطقية إذا استحضرت بذهنك الحقيقة التالية: "لا تُخْزَّن الكائنات (object) بالمُتْغيِّرات، وإنما بأماكن آخرى تُشير إليها المُتْغيِّرات". النتائج كالتالي: أولًا، لنَفْترِض أن لدينا مُتْغيِّر كائن (object variable) صُرِّح عنه باِستخدَام المُبدِّل final أي لا يُمكِن تَغْيير القيمة المُخْزَّنة بذلك المُتْغيِّر نهائيًا بَعْد تهيئته مبدئيًا (initialize)، ولأن تلك القيمة هي مَرجِع (reference) يُشير إلى كائن، فإن المُتْغيِّر سيَستمر بالإشارة إلى نفس الكائن طالما كان موجودًا. مع ذلك، يُمكِن تَعْديل البيانات المُخْزَّنة بالكائن لأن المُتْغيِّر هو ما صُرِّح عنه باِستخدَام المُبدِّل final وليس الكائن نفسه، لذا يُمكِن كتابة الآتي: final Student stu = new Student(); stu.name = "John Doe"; ثانيًا، لنَفْترِض أن obj هو مُتْغيِّر يُشير إلى كائن، ماذا سيَحدُث عند تمرير obj كمُعامِل فعليّ (actual parameter) إلى برنامج فرعي (subroutine)؟ ببساطة، ستُسنَد قيمة obj إلى مُعامِل صُّوريّ (formal parameter)، ثم سيُنفَّذ البرنامج الفرعي، ولأن البرنامج الفرعي ليس لديه سوى نُسخة من قيمة المُتْغيِّر obj، فإنه لن يَستطيع تَغْيير القيمة المُخْزَّنة بالمُتْغيِّر الأصلي. ومع ذلك، لمّا كانت تلك القيمة هي مَرجِع (reference) إلى كائن، سيَتَمكَّن البرنامج الفرعي من تَعْديل البيانات المُخْزَّنة بالكائن. أي أنه وبانتهاء البرنامج الفرعي، فحتمًا ما يزال المُتْغيِّر obj يُشير إلى نفس الكائن، ولكن البيانات المُخزَّنة بالكائن ربما تَكُون قد تَغيَّرت. لنَفْترِض أن لدينا مُتْغيِّر x من النوع int، اُنظر الشيفرة التالية: void dontChange(int z) { z = 42; } x = 17; dontChange(x); System.out.println(x); // output the value 17. لاحظ أن البرنامج الفرعي لم يَتَمكَّن من تَغْيير قيمة x، وهو ما يُكافئ التالي: z = x; z = 42; والآن، لنَفْترِض أن لدينا مُتْغيِّر stu من النوع Student، اُنظر الشيفرة التالية: void change(Student s) { s.name = "Fred"; } stu.name = "Jane"; change(stu); System.out.println(stu.name); // output the value "Fred". في حين لم تَتَغيَّر قيمة stu، تَغيَّرت قيمة stu.name، وهو ما يُكافئ كتابة: s = stu; s.name = "Fred"; الضوابط (setters) والجوالب (getters) ينبغي أن تُراعِي مسألة التَحكُّم بالوصول (access control) عند كتابة أصناف (classes) جديدة، فتَّصْريحك عن كَوْن العضو (member) عامًا (public) يَجعله قابلًا للوصول من أي مكان بما في ذلك الأصناف الآخرى، في حين أن تَّصْريحك عن كَوْنه خاصًا (private) يجعل اِستخدَامه مَقْصورًا على الصَنْف المُعرَّف بداخله فقط. يُفضَّل عمومًا التَّصْريح عن غالبية المُتْغيِّرات الأعضاء (member variables) -إن لم يَكُن كلها- على أساس كَوْنها خاصة (private)؛ حتى يَكُون بإمكانك التَحكُّم بما يُمكِن القيام به بتلك المُتْغيِّرات تَحكُّمًا كاملًا. بَعْد ذلك، إذا أردت أن تَسمَح لأصناف آخرى بالوُصول لقيمة أحد تلك المُتْغيِّرات المُصرَّح عنها بكَوْنها خاصة، فيُمكِنك ببساطة كتابة تابع وُصول عام (public accessor method) يُعيد قيمة ذلك المُتْغيِّر. على سبيل المثال، إذا كان لديك صَنْف يَحتوِي على مُتْغيِّر عضو (member variable) خاص اسمه title من النوع String، تستطيع كتابة التابع (method) التالي: public String getTitle() { return title; } يُعيد التابع -بالأعلى- قيمة المُتْغيِّر العضو title. اُصطلح على تسمية توابع الوصول (accessor methods) للمُتْغيِّرات وفقًا لنمط معين بحيث يَتكوَّن الاسم من كلمة "get" مَتبوعة باسم المُتْغيِّر بعد تَكْبير حُروفه الأولى (capitalizing)، ولهذا يَتكوَّن اسم تابع وصول (accessor method) المُتْغيِّر title -بالأعلى- من الكلمتين "get" و "Title" أيّ يُصبح الاسم getTitle(). ولهذا يُطلَق عادةً على توابع الوصول اسم توابع الجَلْب (getter methods)، لأنها تُوفِّر "تَّصْريح قراءة (read access)" للمُتْغيِّرات. انتبه أنه في حالة المُتْغيِّرات من النوع boolean، تُستخدَم عادةً كلمة "is" بدلًا من "get" أيّ أنه إذا كان لدينا مُتْغيِّر عضو من النوع boolean اسمه done، فإن اسم جَالِبه (getter) قد يَكُون isDone(). قد تحتاج أيضًا إلى تَوْفِير "تصريح كتابة (write access)" لمُتْغيِّر خاص (private)؛ حتى تَتَمكَّن الأصناف الآخرى من تَخْصيص قيم جديدة لذلك المُتْغيِّر. تُستخدَم توابع الضَبْط (setter method) -أو تسمى أحيانًا بتوابع التَعْدِيل (mutator method)- لهذا الغرض، وبالمثل من توابع الجَلْب (getter methods)، ينبغي أن يَتكوَّن اسم تابع ضَبْط (setter method) مُتْغيِّر معين من كلمة "set" مَتبوعة باسم ذلك المُتْغيِّر بعد تَكْبير حُروفه الأولى. بالإضافة إلى ذلك، لابُدّ أن يَستقبِل تابع الضَبْط مُعامِلًا (parameter) من نفس نوع المُتْغيِّر. يُمكِن كتابة تابع ضْبْط (setter method) المُتْغيِّر title كالتالي: public void setTitle( String newTitle ) { title = newTitle; } ستحتاج غالبًا إلى كتابة كُلًا من تابعي الجَلْب (getter method) والضَبْط (setter method) لمُتْغيِّر عضو خاص معين؛ حتى تَتَمكَّن الأصناف الآخرى من رؤية قيمة ذلك المُتْغيِّر والتَعْدِيل عليها كذلك. قد تتساءل، لما لا نُصرِّح عن المُتْغيِّر على أساس كَوْنه عامًا (public) من البداية؟ قد يَكُون ذلك منطقيًا إذا كانت الجوالب (getters) والضوابط (setters) مُقْتصرة على قراءة قيم المُتْغيِّرات وكتابتها، ولكنها في الحقيقة قادرة على القيام بأيّ شيء آخر. فمثلًا، يستطيع تابع جَلْب (getter method) مُتْغيِّر معين أن يَحتفظ بعَدَدَ مرات قرائته كالتالي: public String getTitle() { titleAccessCount++; // Increment member variable titleAccessCount. return title; } كما يستطيع تابع ضَبْط (setter method) مُتْغيِّر آخر أن يَفْحص القيمة المطلوب إِسْنادها إليه لتَحْديد ما إذا كانت صالحة أم لا كالتالي: public void setTitle( String newTitle ) { if ( newTitle == null ) // لا تسمح بسَلاسِل نصية فارغة title = "(Untitled)"; // استخدم قيمة افتراضية else title = newTitle; } يُفضَّل عمومًا كتابة تابعي ضَبْط (setter method) وجَلْب (getter method) المُتْغيِّر حتى لو وَجَدَت أن دورهما مُقْتصِر على قراءة قيمة المُتْغيِّر وكتابتها، فأنت لا تدري، ربما تُغيِّر رأيك مُستقبلًا بينما تُعيد تصميم ذلك الصنف أو تُحسنه. ولأن تابعي الضبط والجلب جزء من الواجهة العامة (public interface) للصنف بعكس المُتْغيِّرات الأعضاء (member variable) الخاصة، فستستطيع ببساطة أن تُعدِّل تَّنْفيذ (implementations) تلك التوابع -هذا إذا كنت قد اِستخدَمتها منذ البداية- بدون تَغْيير الواجهة العامة للصَنْف وبدون أن تُؤثِر على أيّ أصناف أُخرى كانت قد اِستخدَمت ذلك الصَنْف. أما إذا لَمْ تَكُن قد اِستخدَمتها وتُريد ذلك الآن، فستَضطرّ آسفًا إلى التَواصُل مع كل شخص صَدَف وأن اِستخدَم الصَنْف؛ لتُبلِّغه بأن عليه فقط أن يَتَعقَّب كل مَوضِع بشيفرته يَستخدِم فيه ذلك المُتْغيِّر ويُعدِّله بحيث يَستخدِم تابعي الضَبْط (setter method) والجَلْب (getter method) للمُتْغيِّر العضو بدلًا من اسمه. كملاحظة أخيرة: تَشترِط بعض الخصائص المُتقدمة بلغة الجافا تَسمية توابع الضَبْط (setter methods) والجَلْب (getter methods) وفقًا للنَمْط المذكور بالأعلى، لهذا ينبغي في العموم أن تَتَّبِعه بصرامة. انتبه أيضًا للتالي: في حين أننا قد نَاقشنا تابعي الضَبْط والجَلْب ضِمْن سياق المُتْغيِّرات الأعضاء، فإنه في الواقع يُمكِن تَعْرِيف كُلًا منهما حتى في حالة عدم وجود مُتْغيِّر. يُعرِّف تابعي الضَبْط والجَلْب بالأساس خاصية (property) ضِمْن الصَنْف، والتي قد يُناظرها مُتْغيِّر أو لا. بتعبير آخر، إذا كان لديك صَنْف يَحتوِي على تابع نسخة (instance method) مُعرَّف باِستخدَام المُبدِّلات public void، وبَصمته (signature) هي setValue(double)، فإن ذلك الصَنْف حتمًا يَمتلك "خاصية (property)" اسمها value من النوع double، وذلك بغض النظر عن وجود مُتْغيِّر عضو (member variable) يَحمِل الاسم value ضِمْن ذلك الصَنْف من عدمه. المصفوفات والكائنات ذَكَرنا بالقسم الفرعي ٣.٨.١ أن المصفوفات (arrays) هي بالأساس كائنات أو ربما كائنات مميزة -تمامًا كالسَلاسِل النصية من النوع String-، وتُكْتَب وفقًا لقواعد صيغة (syntax) خاصة. فمثلًا تَتَوفَّر نسخة خاصة من العَامِل new لإنشاء المصفوفات. كأيّ مُتْغيِّر كائن (object variable)، لا يَحمِل أيّ مُتْغيِّر مصفوفة (array variable) قيمة مصفوفة فعليّة وإنما يَحمِل مرجعًا (reference) يُشير إلى كائن مصفوفة (array object) والذي يَكُون مُْخْزَّنًا بجزء المَكْدَس (heap) من الذاكرة. يُمكِن أيضًا لمُتْغيِّر مصفوفة أن يَحمِل القيمة null في حالة عدم وجود مصفوفة فعليّة. لاحظ أن كل نوع مصفوفة (array type) كالنوع int[] أو النوع String[] يُقابله صَنْف (class). فلنَفْترِض أن list هو مُتْغيِّر من النوع int[]. إذا كان ذلك المُتْغيِّر يَحمِل القيمة null، فسيَكُون من الخطأ أن تحاول قراءة list.length أو قراءة أيّ من عناصر المصفوفة (array element) list، وسيَتَسبَّب بحُدوث اعتراض (exception) من النوع NullPointerException. بفَرْض أن newlist هو مُتْغيِّر آخر من نفس النوع int[]، اُنظر التَعْليمَة التالية: newlist = list; يَقْتصِر دور تَعْليمَة الإِسْناد (assignment statement) بالأعلى على نَسْخ قيمة المَرجِع (reference) المُخْزَّنة بالمُتْغيِّر list فقط إلى newlist. إذا كان المُتْغيِّر list يَحمِل القيمة null، فسيَحمِل المُتْغيِّر newlist القيمة null أيضًا أما إذا كان المُتْغيِّر list يُشير إلى مصفوفة، فلن تَنسَخ تَعْليمَة الإِسْناد تلك المصفوفة وإنما ستَضبُط المُتْغيِّر newlist فقط بحيث يُشير إلى نفس المصفوفة التي يُشير إليها المُتْغيِّر list. اُنظر الشيفرة التالية كمثال: list = new int[3]; list[1] = 17; // تشير newlist إلى نفس المصفوفة التي يشير إليها list newlist = list; newlist[1] = 42; System.out.println( list[1] ); لأن list[1] و newlist[1] هي مجرد أسماء مختلفة لنفس عنصر المصفوفة، فسيَكُون خَرْج الشيفرة بالأعلى هو 42 وليس 17. قد تَجِدْ كل تلك التفاصيل مُربكة بالبداية، ولكن بمُجرَّد أن تَستحضِر بذهنك أن "أي مصفوفة هي عبارة عن كائن (object) وأن أيّ مُتْغيِّر مصفوفة (array variables) هو فقط يَحمِل مؤشرًا (pointers) إلى مصفوفة"، سيُصبِح كل شيء بديهيًا. تَنطبِق تلك الحقيقة أيضًا على تمرير مصفوفة كمُعامِل (parameter) إلى برنامج فرعي (subroutine) حيث سيَستقبِل البرنامج في تلك الحالة نُسخة فقط من المُؤشر (pointer) وليس المصفوفة ذاتها، وبذلك سيَملُك مَرجِعًا (reference) إلى المصفوفة الأصلية، وعليه فإن أيّ تَعْدِيلات قد يُجرِيها على عناصر المصفوفة (array elements)، سيَمتدّ أثرها إلى المصفوفة الأصلية وستستمر إلى ما بَعْد انتهاء البرنامج الفرعي. بالإضافة إلى كَوْن المصفوفات كائنات (objects) بالأساس، فإنها قد تُستخدَم لحَمل كائنات أيضًا، ويَكُون نوع المصفوفة الأساسي (base type) في تلك الحالة عبارة عن صَنْف. في الواقع، لقد تَعرَّضنا لذلك بالفعل عندما تَعامَلنا مع المصفوفات من النوع String[]، ولكن لا يَقْتصِر الأمر على النوع String بل تستطيع اِستخدَام أيّ صَنْف آخر. فمثلًا، يُمكِننا إنشاء مصفوفة من النوع Student[]، والتي نوعها الأساسي هو الصنف Student المُعرَّف مُسْبَقًا بهذا القسم، وفي تلك الحالة، يَكُون كل عنصر بالمصفوفة عبارة عن مُتْغيِّر من النوع Student. يُمكِننا مثلًا كتابة الشيفرة التالية لتَخْزين بيانات 30 طالب داخل مصفوفة: Student[] classlist; // Declare a variable of type Student[]. classlist = new Student[30]; // The variable now points to an array. تَتَكوَّن المصفوفة -بالأعلى- من 30 عنصر هي classlist[0] و classlist[1] وحتى classlist[29]. عند إنشاء تلك المصفوفة، تُهيَئ عناصرها إلى قيمة مبدئية افتراضية تُساوِي القيمة الفارغة null في حالة الكائنات، لذلك يُصبِح لدينا 30 عنصر مصفوفة، كُلًا منها أينعم من النوع Student لكنه يَحتوِي على القيمة الفارغة (null) وليس على كائن فعليّ من النوع Student. ينبغي أن نُنشِئ تلك الكائنات بأنفسنا كالتالي: Student[] classlist; classlist = new Student[30]; for ( int i = 0; i < 30; i++ ) { classlist[i] = new Student(); } وعليه، يُشير كل عنصر مصفوفة classlist إلى كائن من النوع Student أيّ يُمكِن اِستخدَام classlist بأيّ طريقة يُمكِن بها اِستخدَام مُتْغيِّر من النوع Student. فمثلًا، يُمكِن اِستخدَام classlist[3].name للإشارة إلى اسم الطالب المُخْزَّن برقم المَوضِع الثالث. كمثال آخر، يُمكِن استدعاء classlist.getAverage() لحساب متوسط درجات الطالب المُخْزَّن برقم المَوضِع i. ترجمة -بتصرّف- للقسم Section 1: Objects, Instance Methods, and Instance Variables من فصل Chapter 5: Programming in the Large II: Objects and Classes من كتاب Introduction to Programming Using Java.1 نقطة
تُعدّ البرمجة كائنية التوجه (object-oriented programming - OOP) بمثابة محاولة لتَمْكِين البرامج من نمذجة طريقة تفكيرنا بالعالم الخارجي وتَعامُلنا معه. بالأنماط الأقدم من البرمجة، كان المبرمج مُضطرًّا لتَحْديد المُهِمّة الحاسوبية التي ينبغي له تّنْفيذها لكي يَحلّ المشكلة الفعليّة التي تُواجهه. ووفقًا لهذا التصور، فإن البرمجة تَتكوَّن من محاولة إيجاد متتالية التَعْليمَات المسئولة عن إنجاز تلك المُهِمّة. في المقابل، تُحاوِل البرمجة كائنية التوجه (object-oriented programming) العُثور على عدة كائنات (objects) تُمثِل كيانات (entities) حقيقية أو مُجرّدة مرتبطة بموضوع المشكلة (problem domain). تَملُك تلك الكيانات سلوكيات معينة (behavior)، كما تَتَضمَّن مجموعة من البيانات، وتستطيع أن تَتَفاعَل مع بعضها البعض. ووفقًا لهذا التصور، فإن البرمجة تَتكوَّن من عملية تصميم مجموعة الكائنات (objects) التي يُمكِنها محاكاة المشكلة المطلوب حَلّها. يجعل ذلك تصميم البرامج أكثر طبيعية، وأسهل في الكتابة والفهم عمومًا. يُمكِننا القول أن البرمجة كائنية التوجه (OOP) هي مجرد تَغيير بوجهات النظر؛ فبحَسَب مفاهيم البرمجة القياسية، قد نُفكِر بالكائن (object) على أساس أنه مُجرّد مجموعة من المُتْغيِّرات والبرامج الفرعية (subroutines) المسئولة عن معالجة تلك المُتْغيِّرات ضُمِّنت معًا بطريقة ما. بل حتى يُمكِننا اِستخدَام الأساليب كائنية التوجه (object-oriented) بأي لغة برمجية، ولكن بالطبع هنالك فرق كبير بين لغة تَسمَح بالبرمجة كائنية التوجه، وآخرى تُدعِّمها بشكل نَشِط. تُدعِّم اللغات البرمجية كائنية التوجه، مثل الجافا، عدة مِيزَات تَجعلها مختلفة عن أي لغة قياسية آخرى، ولكي نَستغِل تلك السمات والميزات بأكبر قدر مُمكن، ينبغي أن نُعيد توجيه تفكيرنا على نحو سليم. ملحوظة: عادةً ما يُستخدَم مصطلح "التوابع (methods)" للإشارة إلى البرامج الفرعية (subroutines) ضِمْن سياق البرمجة كائنية التوجه (object-oriented)، ولهذا سيَستخدِم هذا الفصل مصطلح "التوابع (method)" بدلًا من مصطلح "البرامج الفرعية (subroutine)". الكائنات (objects) والأصناف (classes) والنسخ (instances) لقد تحدثنا عن الأصناف (classes) خلال الفصول السابقة، واَتضح لنا أن الصَنْف يُمكِنه أن يَحتوِي على مُتْغيِّرات وتوابع (methods) يُشار إليها باسم البرامج الفرعية. سنَنتقل الآن إلى الحديث عما يُعرَف باسم الكائنات (objects)، والتي هي وثيقة الصلة بالأصناف. بدايةً، تَعَرَّضنا للكائنات (objects) مرة وحيدة من قَبْل خلال القسم ٣.٩، ولم نَلحظ خلالها فارقًا جوهريًا؛ فلقد اِستبعدنا فقط كلمة static من تعريف إحدى البرامج الفرعية (subroutine definition). في الواقع، يَتَكوَّن أي كائن من مجموعة من المُتْغيِّرات والتوابع، فكيف يختلف إذًا عن الأصناف (classes)؟ للإجابة على مثل هذا السؤال، ستحتاج إلى طريقة تفكير مختلفة نسبيًا وذلك حتى تُدرِك أهمية الكائنات وتَتَمكَّن من اِستخدَامها بطريقة فعالة. ذَكَرَنا أن الأصناف تُستخدَم لوصف الكائنات (objects)، أو بتعبير أدق، أن الأجزاء غَيْر الساكنة (non-static) من الأصناف تُستخدَم لوصف الكائنات. قد لا يَكُون المقصود من ذلك واضحًا بما فيه الكفاية، لذا دَعْنَا نُصيغه بطريقة آخرى والتي هي أكثر شيوعًا نوعًا ما. نستطيع أن نقول أن الكائنات تنتمي إلى أصناف (classes)، ولكن ليس بنفس الطريقة التي ينتمي بها مُتْغيِّر عضو معين (member variable) لصنف. فلربما من الأدق أن نقول أن الأصناف تُستخدَم لإنشاء كائنات، فالصَنْف (class) هو أَشْبه ما يَكُون بمصنع أو مُخطط أوَّليّ (blueprint) لإنشاء الكائنات بحيث تُحدِّد الأجزاء غَيْر الساكنة (non-static) منه مجموعة المُتْغيِّرات والتوابع التي يُفْترَض أن تَتَضمَّنها كائنات ذلك الصنف. لذا فإن أحد الاختلافات الجوهرية بين الأصناف والكائنات هو حقيقة أن الكائنات تُنشَئ وتُهدَم أثناء تَشْغِيل البرنامج، بل يُمكِن اِستخدَام صَنْف معين لإنشاء أكثر من كائن (object) بحيث يَكُون لها جميعًا نفس البنية. لنَفْترِض أن لدينا الصَنْف التالي، والذي يَحتوِي على عدة مُتْغيِّرات أعضاء ساكنة (static member variables). يُمكِننا أن نَستخدِمه لتَخْزِين معلومات عن مُستخدِم البرنامج مثلًا: class UserData { static String name; static int age; } عندما يُحمِّل الحاسوب ذلك الصَنْف، فإنه سيُكرِّس جزءًا من الذاكرة له بحيث يَتَضمَّن ذلك الجزء مساحة لقيم المُتْغيِّرين name و age، أيّ سيَكُون هناك نسخة وحيدة فقط من كلا المُتْغيِّرين UserData.name و UserData.age ضِمْن البرنامج عمومًا. تُبيِّن الصورة التالية تَصوُّرًا للصَنْف داخل الذاكرة: تُعدّ المُتْغيِّرات الأعضاء الساكنة (static) جزءًا من تمثيل الصنف داخل الذاكرة، ولهذا تُستخدَم الأسماء الكاملة المُتضمِّنة لاسم الصَنْف ذاته مثل UserData.name و UserData.age للإشارة إليها. في المثال السابق، قررنا اِستخدَام الصنف UserData لتمثيل مُستخدِم البرنامج، ولمّا كان لدينا مساحة بالذاكرة لتَخْزِين البيانات المُتعلِّقة بمُستخدِم واحد فقط، فبطبيعة الحال سيَكُون البرنامج قادرًا على حَمْل بيانات مُستخدِم وحيد. لاحِظ أن الصنف UserData والمُتْغيِّرات الساكنة (static) المُعرَّفة بداخله تَظلّ موجودة طوال فترة تَشْغِيل البرنامج، وهذا هو المقصود بكَوْنها ساكنة بالأساس. لنَفْحَص الآن صَنْفًا مُشابهًا، ولكنه يَتَضمَّن بعضًا من المُتْغيِّرات غَيْر الساكنة (non-static): class PlayerData { static int playerCount; String name; int age; } أُضيف إلى الصنف PlayerData مُتْغيِّر ساكن هو playerCount أيّ أن اسمه الكامل هو PlayerData.playerCount، كما أنه مُخزَّن كجزء من تمثيل الصَنْف بالذاكرة، وتَتَوَّفر منه نُسخة واحدة فقط تَظلّ موجودة طوال فترة تَّنْفيذ البرنامج. بالإضافة إلى ذلك، يَتَضمَّن تعريف الصَنْف (class definition) مُتْغيِّرين غَيْر ساكنين (non-static)، ولأن المُتْغيِّرات غَيْر الساكنة لا تُعدّ جزءًا من الصنف ذاته، فإنه لا يُمكِن الإشارة إلى هذين المُتْغيِّرين بالأسماء PlayerData.name أو PlayerData.age. نستطيع الآن اِستخدَام الصَنْف PlayerData لإنشاء كائنات بأيّ قدر نُريده، بحيث يَمتلك كل كائن منها مُتْغيِّراته الخاصة به والتي تَحمِل الأسماء name و age، أيّ يَحصُل كل كائن على نسخته الخاصة من أجزاء الصَنْف غَيْر الساكنة (non-static)، وهذا هو ما يَعنِيه القول بأن أجزاء الصَنْف غَيْر الساكنة تُعدّ بمثابة مُخططًا أوَّليًّا أو قالبًا (template) للكائنات. تُبيِّن الصورة التالية تصورًا لذاكرة الحاسوب بَعْد إِنشاء عدة كائنات: كما ترى بالأعلى، يُعدّ المُتْغيِّر الساكن playerCount جزءًا من الصنف وتَتَوفَّر منه نُسخة وحيدة، بينما تَتَوفَّر نُسخة خاصة من المُتْغيِّرين غَيْر الساكنين name و age بكل كائن (object) مُنشَئ من ذلك الصنف. يُعدّ أيّ كائن (object) نُسخة (instance) من صَنْفه، ويَكُون على دراية بالصَنْف المُستخدَم لإِنشائه. تُبيِّن الصورة أن الصَنْف PlayerData يَحتوِي على ما يُعرَف باسم "البَانِي أو بَانِي الكائن (constructor)". البَانِي ببساطة هو برنامج فرعي (subroutine) يُستخدَم لإِنشاء الكائنات سنتحدث عنه لاحقًا. ولأننا نستطيع إِنشاء كائنات (objects) جديدة من الصَنْف PlayerData لتَمْثيل لاعبين جُدد بقَدْر ما نَشَاء، فقد يُصبِح لدينا الآن مجموعة من اللاعبين. على سبيل المثال، قد يَستخدِم برنامج معين الصَنْف PlayerData لتَخْزين بيانات مجموعة لاعبين ضِمْن لعبة بحيث يَملُك كُلًا منهم name و age خاص به، وعندما يَنضَم لاعب جديد إلى اللعبة، يَستطيع البرنامج أن يُنشِئ كائنًا جديدًا من الصَنْف PlayerData لتمثيل ذلك اللاعب، أما إذا غادر أحد اللاعبين، يَستطيع البرنامج هَدْم الكائن المُمثِل لذلك اللاعب، أي سيَستخدِم ذلك البرنامج شبكة من الكائنات لنَمذجة أحداث اللعبة بصورة ديناميكية (dynamic)، وهو ما لا يُمكِنك القيام به باِستخدَام المُتْغيِّرات الساكنة (static). يُعدّ أيّ كائن (object) نُسخة (instance) من الصَنْف المُستخدَم لإِنشائه، ونقول أحيانًا بأنه يَنتمي إلى ذلك الصَنْف. يُطلَق اسم مُتْغيِّرات النُسخ (instance variables) على المُتْغيِّرات التي يَتَضمَّنها الكائن بينما يُطلَق اسم توابع النُسخ (instance methods) على التوابع (methods) -أو البرامج الفرعية- ضِمْن الكائن. فمثلًا، إذا اِستخدَمنا الصَنْف PlayerData المُعرَّف بالأعلى لإِنشاء كائن، فإن ذلك الكائن يُعدّ نُسخة (instance) من الصنف PlayerData كما يُعدّ كُلًا من name و age مُتْغيِّرات نُسخ (instance variable) ضِمْن الكائن. لا يَتَضمَّن المثال بالأعلى أيّ توابع (methods)، ولكنها تَعَمَل عمومًا بصورة مشابهة للمُتْغيِّرات أيّ تُعدّ التوابع الساكنة (static) جزءًا من الصَنْف ذاته بينما تُعدّ التوابع غَيْر الساكنة (non-static) أو توابع النُسخ (instance methods) جزءًا من الكائنات (objects) المُنشئة من ذلك الصَنْف. لكن، لا تَأخُذ ذلك بمعناه الحرفي؛ فلا يَحتوِي كل كائن على نُسخته الخاصة من شيفرة توابع النُسخ (instance method) المُعرَّفة ضِمْن الصَنْف بشكل فعليّ وإنما يُعدّ ذلك صحيحًا على نحو منطقي فقط، وعمومًا سنستمر بالإشارة إلى احتواء كائن معين على توابع نُسخ (instance method) صَنْفه. ينبغي عمومًا أن تُميز بين الشيفرة المصدرية (source code) للصَنْف والصَنْف ذاته بالذاكرة. تُحدِّد الشيفرة المصدرية كُلًا من هيئة الصَنْف وهيئة الكائنات المُنشئة منه: تُحدِّد التعريفات الساكنة (static definitions) بالشيفرة العناصر التي ستُصبِح جُزءًا من الصَنْف ذاته بذاكرة الحاسوب بينما تُحدِّد التعريفات غَيْر الساكنة (non-static definitions) بالشيفرة العناصر التي ستُصبِح جُزءًا من كل كائن يُنشَئ من ذلك الصنف. بالمناسبة، يُطلَق اسم مُتْغيِّرات الأصناف (class variables) وتوابع الأصناف (class methods) على المُتْغيِّرات الأعضاء (member variables) الساكنة والبرامج الفرعية الأعضاء (member subroutines) الساكنة المُعرَّفة ضِمْن الصنف على الترتيب؛ وذلك لكَوْنها تنتمي للصَنْف ذاته وليس لنُسخ (instances) ذلك الصَنْف. يَتَّضِح لنا الآن الكيفية التي تَختلِف بها الأجزاء الساكنة من صنف معين عن الأجزاء غَيْر الساكنة، حيث يَخدِم كُلًا منهما غرضًا مُختلفًا تمامًا. وفي العموم، ستَجِدْ أن كثيرًا من الأصناف إِما أنها تَحتوِي على أعضاء ساكنة (static) فقط أو على أعضاء غَيْر ساكنة (non-static) فقط، ومع ذلك سنَرى أمثلة قليلة لأصناف تَحتوِي على مَزيج منهما. أساسيات الكائنات اِقْتصَر حديثنا إلى الآن على الكائنات (objects) في العموم دون ذِكْر أيّ تفاصيل عن طريقة اِستخدَامها بصورة فعليّة ضِمْن برنامج، لذا سنَفْحَص مثالًا مُحدَّدًا لنوضح ذلك. لنَفْترِض أن لدينا الصَنْف Student المُعرَّف بالأسفل، والذي يُمكِننا اِستخدَامه لتَخْزِين بعض بيانات الطلبة المُلتحِقة بدورة تدريبية: public class Student { public String name; // اسم الطالب public double test1, test2, test3; // الدرجة بثلاثة اختبارات public double getAverage() { // احسب متوسط درجة الاختبارات return (test1 + test2 + test3) / 3; } } // نهاية الصنف Student لم يُستخدَم المُبدِّل static أثناء التَّصْريح عن أيّ من أعضاء الصَنْف Student، لذا فالصَنْف موجود فقط بغَرْض إِنشاء الكائنات (objects). يُحدِّد تعريف الصَنْف Student -بالأعلى- أن كائناته أو نُسخه (instance) ستَحتوِي على مُتْغيِّرات النُسخ (instance variables) name و test1 و test2 و test3 كما ستَحتوِي على تابع نسخة (instance method) هو getAverage(). سيَحتوِي كل كائن -يُمثِل طالبًا- في العموم على اسم طالب معين ودرجاته، وعندما يُستدعَى التابع getAverage() لكائن معين، ستُحسَب قيمة المتوسط باِستخدَام درجات الاختبار ضِمْن ذلك الكائن تَحْديدًا أيّ سيَحصُل كل كائن على قيمة متوسط مختلفة، وهذا هو في الواقع ما يَعنِيه انتماء توابع النُسخ (instance method) للكائنات المُفردة لا الأصناف نفسها. الأصناف بلغة الجافا هي أنواع تمامًا كالأنواع المَبنية مُسْبَقًا (built-in) مثل int و boolean، لذا تستطيع اِستخدَام اسم صَنْف معين لتَحْدِيد نوع مُتْغيِّر ضِمْن تَعْليمَة تَّصْريح (declaration statement) أو لتَخْصِيص نوع مُعامِل صُّوريّ (formal parameter) أو لتَحْدِيد نوع القيمة المُعادة (return type) من دالة (function). يُمكِن مثلًا تعريف مُتْغيِّر اسمه std من النوع Student باِستخدَام التَعْليمَة التالية: Student std; انتبه للنقطة الهامة التالية، لا يُؤدي تَّصْرِيحك (declare) عن مُتْغيِّر نوعه عبارة عن صنف إلى إِنشاء الكائن ذاته! تَرتبط هذه النقطة بالحقيقتين التاليتين: لا يُمكِن لأيّ مُتْغيِّر أن يَحمِل كائنًا. يستطيع المُتْغيِّر أن يَحمِل مَرجِعًا (reference) يُشير إلى كائن. يُفضَّل أن تُفكِر بالكائنات (objects) كما لو أنها تَعيش مُستقلة بذاكرة الحاسوب، تحديدًا بقسم الكَوْمة (heap) من الذاكرة. لا تَحمِل المُتْغيِّرات كائنية النوع (object type) قيم الكائنات نفسها وإنما تَحمِل المعلومات الضرورية للعُثور على تلك الكائنات بالذاكرة، تَحْديدًا تَحمِل عناوين مَواضِعها (location address) بالذاكرة، ويُقال عندها أن المُتْغيِّر يَحمِل مَرجِعًا (reference) أو مُؤشرًا (pointer) إلى الكائن. عندما تَستخدِم مُتْغيِّر كائني النوع (object type)، يَستخدِم الحاسوب المَرجِع (reference) المُخْزَّن بالمُتْغيِّر للعُثور على قيمة الكائن الفعليّة. يُنشِئ العَامِل (operator) new كائنًا جديدًا (object) حيث يَستدعِى برنامجًا فرعيًا -ذكرناه سابقًا- يقع ضِمْن الصَنْف يُطلَق عليه اسم البَانِي (constructor)، ثم يُعيد مَرجِعًا (reference) يُشير إلى الكائن المُنشَىء. لنَفْترِض مثلًا أن لدينا مُتْغيِّر std من النوع Student المُصرَّح عنه بالأعلى، يُمكِننا الآن كتابة تَعْليمَة الإِسْناد التالية (assignment statement): std = new Student(); تُنشِئ تَعْليمَة الإِسْناد -بالأعلى- كائنًًا (object) جديدًا بقسم الكَوْمة (heap) من الذاكرة، والذي يُعدّ نُسخة (instance) من الصَنْف Student، ثم تُخزِّن التَعْليمَة مَرجِعًا (reference) إلى ذلك الكائن بالمُتْغيِّر std أيّ أن قيمة المُتْغيِّر عبارة عن مَرجِع (reference) أو مُؤشر (pointer) إلى الكائن الواقع بمكان ما. لا يَصِح في العموم أن تقول "قيمة المُتْغيِّر std هي الكائن ذاته" على الرغم من صعوبة تَجنُّب ذلك أحيانًا، ولكن لا تَقل أبدًا أن "الكائن مُخزَّن بالمُتْغيِّر std" فهو أمر غَيْر صحيح على الإطلاق. يُفْترَض عمومًا أن تقول "يُشير المُتْغيِّر std إلى الكائن"، وهو ما سنُحاول الالتزام به قَدْر الإِمكان. لاحِظ أنه إذا ذَكَرَنا مثلًا أن "std هو كائن"، فالمقصود هو "std هو مُتْغيِّر يُشيِر إلى كائن". لنَفْترِض أن المُتْغيِّر std يُشير إلى كائن (object) عبارة عن نُسخة (instance) من الصَنْف Student أيّ يَحتوِي ذلك الكائن بطبيعة الحال على مُتْغيِّرات النُسخ name و test1 و test2 و test3. يُمكِننا الإشارة إلى تلك المُتْغيِّرات باِستخدَام std.name و std.test1 و std.test2 و std.test3 على الترتيب. يَتَّبِع ذلك نفس نَمْط التسمية المُعتاد بأنه عندما يَكُون B جزءًا من A، فإن اسم B الكامل هو A.B. اُنظر المثال التالي: System.out.println("Hello, " + std.name + ". Your test grades are:"); System.out.println(std.test1); System.out.println(std.test2); System.out.println(std.test3); ستَطبَع الشيفرة بالأعلى الاسم وقيم الدرجات بالكائن المُشار إليه باِستخدَام المُتْغيِّر std. بنفس الأسلوب، يَحتوِي ذلك الكائن على تابع نسخة هو getAverage()، والذي يُمكِننا استدعائه باِستخدَام std.getAverage(). يُمكِنك كتابة الشيفرة التالية لطباعة مُتوسط درجات الطالب: System.out.println( "Your average is " + std.getAverage() ); تستطيع عمومًا اِستخدَام std.name أينما أَمَكَن اِستخدَام مُتْغيِّر من النوع String. فمثلًا، قد تَستخدِمه ضِمْن تعبير (expression) أو قد تُسنِد قيمة إليه أو قد تَستخدِمه حتى لاستدعاء أحد البرامج الفرعية (subroutines) المُعرَّفة بالصَنْف String. فمثلًا، يُمثِل التعبير std.name.length() عدد المحارف باسم الطالب. قد لا تُشير مُتْغيِّرات الكائنات (object variables) أيّ تلك التي نوعها هو عبارة عن صَنْف -مثل المُتْغيِّر std- إلى أيّ كائن نهائيًا، وفي تلك الحالة، يُقال أنها تَحمِل مُؤشرًا فارغًا (null pointer) أو مَرجِعًا فارغًا (null reference). يُكْتَب المُؤشر الفارغ (null pointer) باِستخدَام كلمة null، ولهذا تستطيع اِستخدَام الشيفرة التالية لتَخْزِين مَرجِع فارغ بالمُتْغيِّر std: std = null; في المثال بالأعلى، لا يَحتوِي المُتْغيِّر على مُؤشر لأيّ شيء آخر وإنما تُعدّ null هي قيمته الفعليّة، لذا لا يَصِح أن تقول: "يُشير المُتْغيِّر إلى القيمة الفارغة (null)"، فالمُتْغيِّر نفسه هو قيمة فارغة. تستطيع اختبار ما إذا كانت قيمة المُتْغيِّر std فارغة باِستخدَام التالي: if (std == null) . . . عندما تَكُون قيمة مُتْغيِّر كائن (object variable) فارغة أيّ تَحتوِي على null، يَعنِي ذلك أن المُتْغيِّر لا يُشير إلى أيّ كائن، وبالتالي لا يَكُون هناك أيّ مُتْغيِّرات نُسخ (instance variables) أو توابع نُسخ (instance methods) يُمكِن الإشارة إليها، ويَكُون من الخطأ محاولة القيام بذلك عبر ذاك المُتْغيِّر. فمثلًا، إذا كانت قيمة المُتْغيِّر std هي null، وحَاوَل برنامج معين الإشارة إلى std.test1، سيُؤدِي ذلك إلى محاولة اِستخدَام مؤشر فارغ (null pointer) بطريقة خاطئة، ولهذا سيُبلَّغ عن اِعتراض مُؤشِر فارغ (null pointer exception) من النوع NullPointerException أثناء تّنْفيذ البرنامج. لنَفْحَص مُتتالية التَعْليمَات التالية: Student std, std1, // صرح عن أربعة متغيرات من النوع Student std2, std3; // أنشئ كائن جديد من الصنف Student وخزن مرجعه بالمتغير std std = new Student(); // أنشئ كائن آخر من الصنف Student وخزن مرجعه بالمتغير std1 std1 = new Student(); // انسخ مرجع std1 إلى المتغير std2 std2 = std1; // خزن مؤشرا فارغا بالمتغير std3 std3 = null; // اضبط قيم متغيرات الأعضاء std.name = "John Smith"; std1.name = "Mary Jones"; بعدما يُنفِّذ الحاسوب التَعْليمَات بالأعلى، ستُصبِح ذاكرة الحاسوب كالتالي: يَتَبين لنا التالي بَعْد فَحْص الصورة بالأعلى: أولًا، يَحتوِي أيّ مُتْغيِّر على مَرجِع (reference) إلى كائن ظَهَرَت قيمته ضِمْن الصورة بهيئة سهم يُشير إلى الكائن (object). ثانيًا، يُمكِننا أن نَرَى أن السَلاسِل النصية من النوع String هي كائنات. ثالثًا، لا يُشير المُتْغيِّر std3 إلى أيّ مكان؛ لأنه فارغ ويَحتوِي على القيمة null. وأخيرًا، تُشير الأسهم من std1 و std2 إلى نفس ذات الكائن وهو ما يُبرِز النقطة المهمة التالية: عندما نُسنِد مُتْغيِّر كائن (object variable) إلى آخر، يُنسَخ المَرجِع (reference) فقط لا الكائن (object) المُشار إليه بواسطة ذلك المَرجِع. لنَأخُذ مثلًا التَعْليمَة std2 = std1; كمثال، لمّا كانت تَعْليمَة الإِسْناد (assignment statement) في العموم تَنسَخ فقط القيمة المُخْزَّنة بمُعاملها الأيمن std1 إلى مُعاملها الأيسر std2، ولأن القيمة في تلك الحالة هي مُجرَّد مُؤشِر (pointer) إلى كائن وليست الكائن (object) ذاته، فإن تلك التَعْليمَة لم تُنشِئ كائنًا جديدًا، وإنما ضَبَطَت std2 بحيث يُشير إلى نفس الكائن الذي يُشير إليه std1. يَترتَب على ذلك عدة نتائج قد تَكُون مفاجئة بالنسبة لك. مثلًا، تُعدّ كُلًا من std1.name و std2.name أسماءً مختلفة لنفس مُتْغيِّر النُسخة (instance variable) المُعرَّف ضِمْن الكائن الذي يُشير إليه كِلا المُتْغيِّرين std1 و std2، ولهذا عندما تُسنِد السِلسِلة النصية "Mary Jones" مثلًا إلى std1.name، ستُصبِح قيمة std2.name هي أيضًا "Mary Jones". إذا التبس عليك الأمر، حَاوِل فقط أن تَستحضر الحقيقة التالية: "المُتْغيِّر ليس هو الكائن (object)، فالأول يَحمِل فقط مُؤشرًا (pointer) إلى الثاني." يُستخدَم العَامِلان == و != لاختبار تَساوِي كائنين أو عدم تَساوِيهما على الترتيب، ولكن لاحِظ أن المَعنَى الدلالي (semantics) وراء تلك الاختبارات مُختلف عما أنت مُعتاد عليه. فمثلًا، يَفْحَص الاختبار if (std1 == std2) ما إذا كانت القيم المُخْزَّنة بكُلًا من std1 و std2 مُتساوية، ولأن تلك القيم هي مُجرَّد مَراجِع (references) تُشير إلى كائنات وليست الكائنات ذاتها، فإن ذلك الاختبار يَفْحَص ما إذا كان std1 و std2 يُشيران إلى نفس ذات الكائن أيّ ما إذا كانا يُشيران إلى نفس المَوضِع بالذاكرة. لا يُعدّ ذلك مشكلة إذا كان هذا هو ما تُريد اختباره، لكن أحيانًا يَكُون المقصود هو مَعرِفة ما إذا كانت مُتْغيِّرات النُسخ (instance variables) تَحمِل نفس القيم بغَضْ النظر عن انتمائها لنفس ذات الكائن. في تلك الحالات، ستحتاج إلى إجراء الاختبار التالي: std1.test1 == std2.test1 && std1.test2 == std2.test2 && std1.test3 == std2.test3 && std1.name.equals(std2.name) ذَكَرَنا مُسْبَقًا أن السَلاسِل النصية من النوع String هي بالأساس كائنات، كما أَظَهَرنا السِلسِلتين النصيتين "Mary Jones" و "John Smith" بهيئة كائنات بالصورة التوضيحية بالأعلى ولكن بدون البنية الداخلية للنوع String. تُعدّ تلك السِلاسِل كائنات مميزة، وتُعامَل وفقًا لقواعد صيغة خاصة. كأيّ مُتْغيِّر كائن (object variable)، تَحمِل المُتْغيِّرات من النوع String مَرجِعًا (reference) إلى سِلسِلة نصية وليس السِلسِلة النصية ذاتها. بُناءً على ذلك، لا يَصِح عادةً اِستخدَام العَامِل == لاختبار تَساوِي السَلاسِل النصية. فمثلًا، إذا كان لدينا مُتْغيِّر من النوع String اسمه هو greeting ويُشير إلى السِلسِلة النصية "Hello"، فهل يَكُون الاختبار greeting == "Hello" مُتحقِّقًا؟ في الواقع، يُشير كُلًا من المُتْغيِّر greeting والسِلسِلة النصية المُجرَّدة "Hello" إلى سِلسِلة نصية تَحتوِي على المحارف H-e-l-l-o. ومع ذلك، فإنهما قد يَكُونان كائنين مختلفين صَدَفَ فقط احتوائهما على نفس المحارف، ولأن ذلك التعبير يَختبِر ما إذا كان greeting و "Hello" يَحتوِيان على نفس المحارف، وكذلك ما إذا كانا واقْعين بنفس مَوضِع الذاكرة، فإن الاختبار greeting == "Hello" لا يُعدّ مُتحقِّقًا. في المقابل، تَقْتصِر الدالة greeting.equals("Hello") على اختبار ما إذا كان greeting و "Hello" يَحتوِيان على نفس المحارف وهو عادةً ما تَرغَب باختباره. أخيرًا، يُمكِن للمُتْغيِّرات من النوع String أن تَكُون فارغة أيّ تحتوي على القيمة null، وفي تلك الحالة، سيَكُون اِستخدَام العَامِل == مُناسبًا لاختبار ما إذا كان المُتْغيِّر فارغًا كالتالي greeting == null. ذَكَرَنا أكثر من مرة أن مُتْغيِّرات الكائنات لا تَحمِل الكائنات (objects) ذاتها، وإنما تَحمِل مَراجِع (references) تُشير إلى تلك الكائنات، وهو ما يَترتَب عليه بعض من النتائج الآخرى التي ينبغي أن تَكُون على دراية بها والتي ستَجِدها منطقية إذا استحضرت بذهنك الحقيقة التالية: "لا تُخْزَّن الكائنات (object) بالمُتْغيِّرات، وإنما بأماكن آخرى تُشير إليها المُتْغيِّرات". النتائج كالتالي: أولًا، لنَفْترِض أن لدينا مُتْغيِّر كائن (object variable) صُرِّح عنه باِستخدَام المُبدِّل final أي لا يُمكِن تَغْيير القيمة المُخْزَّنة بذلك المُتْغيِّر نهائيًا بَعْد تهيئته مبدئيًا (initialize)، ولأن تلك القيمة هي مَرجِع (reference) يُشير إلى كائن، فإن المُتْغيِّر سيَستمر بالإشارة إلى نفس الكائن طالما كان موجودًا. مع ذلك، يُمكِن تَعْديل البيانات المُخْزَّنة بالكائن لأن المُتْغيِّر هو ما صُرِّح عنه باِستخدَام المُبدِّل final وليس الكائن نفسه، لذا يُمكِن كتابة الآتي: final Student stu = new Student(); stu.name = "John Doe"; ثانيًا، لنَفْترِض أن obj هو مُتْغيِّر يُشير إلى كائن، ماذا سيَحدُث عند تمرير obj كمُعامِل فعليّ (actual parameter) إلى برنامج فرعي (subroutine)؟ ببساطة، ستُسنَد قيمة obj إلى مُعامِل صُّوريّ (formal parameter)، ثم سيُنفَّذ البرنامج الفرعي، ولأن البرنامج الفرعي ليس لديه سوى نُسخة من قيمة المُتْغيِّر obj، فإنه لن يَستطيع تَغْيير القيمة المُخْزَّنة بالمُتْغيِّر الأصلي. ومع ذلك، لمّا كانت تلك القيمة هي مَرجِع (reference) إلى كائن، سيَتَمكَّن البرنامج الفرعي من تَعْديل البيانات المُخْزَّنة بالكائن. أي أنه وبانتهاء البرنامج الفرعي، فحتمًا ما يزال المُتْغيِّر obj يُشير إلى نفس الكائن، ولكن البيانات المُخزَّنة بالكائن ربما تَكُون قد تَغيَّرت. لنَفْترِض أن لدينا مُتْغيِّر x من النوع int، اُنظر الشيفرة التالية: void dontChange(int z) { z = 42; } x = 17; dontChange(x); System.out.println(x); // output the value 17. لاحظ أن البرنامج الفرعي لم يَتَمكَّن من تَغْيير قيمة x، وهو ما يُكافئ التالي: z = x; z = 42; والآن، لنَفْترِض أن لدينا مُتْغيِّر stu من النوع Student، اُنظر الشيفرة التالية: void change(Student s) { s.name = "Fred"; } stu.name = "Jane"; change(stu); System.out.println(stu.name); // output the value "Fred". في حين لم تَتَغيَّر قيمة stu، تَغيَّرت قيمة stu.name، وهو ما يُكافئ كتابة: s = stu; s.name = "Fred"; الضوابط (setters) والجوالب (getters) ينبغي أن تُراعِي مسألة التَحكُّم بالوصول (access control) عند كتابة أصناف (classes) جديدة، فتَّصْريحك عن كَوْن العضو (member) عامًا (public) يَجعله قابلًا للوصول من أي مكان بما في ذلك الأصناف الآخرى، في حين أن تَّصْريحك عن كَوْنه خاصًا (private) يجعل اِستخدَامه مَقْصورًا على الصَنْف المُعرَّف بداخله فقط. يُفضَّل عمومًا التَّصْريح عن غالبية المُتْغيِّرات الأعضاء (member variables) -إن لم يَكُن كلها- على أساس كَوْنها خاصة (private)؛ حتى يَكُون بإمكانك التَحكُّم بما يُمكِن القيام به بتلك المُتْغيِّرات تَحكُّمًا كاملًا. بَعْد ذلك، إذا أردت أن تَسمَح لأصناف آخرى بالوُصول لقيمة أحد تلك المُتْغيِّرات المُصرَّح عنها بكَوْنها خاصة، فيُمكِنك ببساطة كتابة تابع وُصول عام (public accessor method) يُعيد قيمة ذلك المُتْغيِّر. على سبيل المثال، إذا كان لديك صَنْف يَحتوِي على مُتْغيِّر عضو (member variable) خاص اسمه title من النوع String، تستطيع كتابة التابع (method) التالي: public String getTitle() { return title; } يُعيد التابع -بالأعلى- قيمة المُتْغيِّر العضو title. اُصطلح على تسمية توابع الوصول (accessor methods) للمُتْغيِّرات وفقًا لنمط معين بحيث يَتكوَّن الاسم من كلمة "get" مَتبوعة باسم المُتْغيِّر بعد تَكْبير حُروفه الأولى (capitalizing)، ولهذا يَتكوَّن اسم تابع وصول (accessor method) المُتْغيِّر title -بالأعلى- من الكلمتين "get" و "Title" أيّ يُصبح الاسم getTitle(). ولهذا يُطلَق عادةً على توابع الوصول اسم توابع الجَلْب (getter methods)، لأنها تُوفِّر "تَّصْريح قراءة (read access)" للمُتْغيِّرات. انتبه أنه في حالة المُتْغيِّرات من النوع boolean، تُستخدَم عادةً كلمة "is" بدلًا من "get" أيّ أنه إذا كان لدينا مُتْغيِّر عضو من النوع boolean اسمه done، فإن اسم جَالِبه (getter) قد يَكُون isDone(). قد تحتاج أيضًا إلى تَوْفِير "تصريح كتابة (write access)" لمُتْغيِّر خاص (private)؛ حتى تَتَمكَّن الأصناف الآخرى من تَخْصيص قيم جديدة لذلك المُتْغيِّر. تُستخدَم توابع الضَبْط (setter method) -أو تسمى أحيانًا بتوابع التَعْدِيل (mutator method)- لهذا الغرض، وبالمثل من توابع الجَلْب (getter methods)، ينبغي أن يَتكوَّن اسم تابع ضَبْط (setter method) مُتْغيِّر معين من كلمة "set" مَتبوعة باسم ذلك المُتْغيِّر بعد تَكْبير حُروفه الأولى. بالإضافة إلى ذلك، لابُدّ أن يَستقبِل تابع الضَبْط مُعامِلًا (parameter) من نفس نوع المُتْغيِّر. يُمكِن كتابة تابع ضْبْط (setter method) المُتْغيِّر title كالتالي: public void setTitle( String newTitle ) { title = newTitle; } ستحتاج غالبًا إلى كتابة كُلًا من تابعي الجَلْب (getter method) والضَبْط (setter method) لمُتْغيِّر عضو خاص معين؛ حتى تَتَمكَّن الأصناف الآخرى من رؤية قيمة ذلك المُتْغيِّر والتَعْدِيل عليها كذلك. قد تتساءل، لما لا نُصرِّح عن المُتْغيِّر على أساس كَوْنه عامًا (public) من البداية؟ قد يَكُون ذلك منطقيًا إذا كانت الجوالب (getters) والضوابط (setters) مُقْتصرة على قراءة قيم المُتْغيِّرات وكتابتها، ولكنها في الحقيقة قادرة على القيام بأيّ شيء آخر. فمثلًا، يستطيع تابع جَلْب (getter method) مُتْغيِّر معين أن يَحتفظ بعَدَدَ مرات قرائته كالتالي: public String getTitle() { titleAccessCount++; // Increment member variable titleAccessCount. return title; } كما يستطيع تابع ضَبْط (setter method) مُتْغيِّر آخر أن يَفْحص القيمة المطلوب إِسْنادها إليه لتَحْديد ما إذا كانت صالحة أم لا كالتالي: public void setTitle( String newTitle ) { if ( newTitle == null ) // لا تسمح بسَلاسِل نصية فارغة title = "(Untitled)"; // استخدم قيمة افتراضية else title = newTitle; } يُفضَّل عمومًا كتابة تابعي ضَبْط (setter method) وجَلْب (getter method) المُتْغيِّر حتى لو وَجَدَت أن دورهما مُقْتصِر على قراءة قيمة المُتْغيِّر وكتابتها، فأنت لا تدري، ربما تُغيِّر رأيك مُستقبلًا بينما تُعيد تصميم ذلك الصنف أو تُحسنه. ولأن تابعي الضبط والجلب جزء من الواجهة العامة (public interface) للصنف بعكس المُتْغيِّرات الأعضاء (member variable) الخاصة، فستستطيع ببساطة أن تُعدِّل تَّنْفيذ (implementations) تلك التوابع -هذا إذا كنت قد اِستخدَمتها منذ البداية- بدون تَغْيير الواجهة العامة للصَنْف وبدون أن تُؤثِر على أيّ أصناف أُخرى كانت قد اِستخدَمت ذلك الصَنْف. أما إذا لَمْ تَكُن قد اِستخدَمتها وتُريد ذلك الآن، فستَضطرّ آسفًا إلى التَواصُل مع كل شخص صَدَف وأن اِستخدَم الصَنْف؛ لتُبلِّغه بأن عليه فقط أن يَتَعقَّب كل مَوضِع بشيفرته يَستخدِم فيه ذلك المُتْغيِّر ويُعدِّله بحيث يَستخدِم تابعي الضَبْط (setter method) والجَلْب (getter method) للمُتْغيِّر العضو بدلًا من اسمه. كملاحظة أخيرة: تَشترِط بعض الخصائص المُتقدمة بلغة الجافا تَسمية توابع الضَبْط (setter methods) والجَلْب (getter methods) وفقًا للنَمْط المذكور بالأعلى، لهذا ينبغي في العموم أن تَتَّبِعه بصرامة. انتبه أيضًا للتالي: في حين أننا قد نَاقشنا تابعي الضَبْط والجَلْب ضِمْن سياق المُتْغيِّرات الأعضاء، فإنه في الواقع يُمكِن تَعْرِيف كُلًا منهما حتى في حالة عدم وجود مُتْغيِّر. يُعرِّف تابعي الضَبْط والجَلْب بالأساس خاصية (property) ضِمْن الصَنْف، والتي قد يُناظرها مُتْغيِّر أو لا. بتعبير آخر، إذا كان لديك صَنْف يَحتوِي على تابع نسخة (instance method) مُعرَّف باِستخدَام المُبدِّلات public void، وبَصمته (signature) هي setValue(double)، فإن ذلك الصَنْف حتمًا يَمتلك "خاصية (property)" اسمها value من النوع double، وذلك بغض النظر عن وجود مُتْغيِّر عضو (member variable) يَحمِل الاسم value ضِمْن ذلك الصَنْف من عدمه. المصفوفات والكائنات ذَكَرنا بالقسم الفرعي ٣.٨.١ أن المصفوفات (arrays) هي بالأساس كائنات أو ربما كائنات مميزة -تمامًا كالسَلاسِل النصية من النوع String-، وتُكْتَب وفقًا لقواعد صيغة (syntax) خاصة. فمثلًا تَتَوفَّر نسخة خاصة من العَامِل new لإنشاء المصفوفات. كأيّ مُتْغيِّر كائن (object variable)، لا يَحمِل أيّ مُتْغيِّر مصفوفة (array variable) قيمة مصفوفة فعليّة وإنما يَحمِل مرجعًا (reference) يُشير إلى كائن مصفوفة (array object) والذي يَكُون مُْخْزَّنًا بجزء المَكْدَس (heap) من الذاكرة. يُمكِن أيضًا لمُتْغيِّر مصفوفة أن يَحمِل القيمة null في حالة عدم وجود مصفوفة فعليّة. لاحظ أن كل نوع مصفوفة (array type) كالنوع int[] أو النوع String[] يُقابله صَنْف (class). فلنَفْترِض أن list هو مُتْغيِّر من النوع int[]. إذا كان ذلك المُتْغيِّر يَحمِل القيمة null، فسيَكُون من الخطأ أن تحاول قراءة list.length أو قراءة أيّ من عناصر المصفوفة (array element) list، وسيَتَسبَّب بحُدوث اعتراض (exception) من النوع NullPointerException. بفَرْض أن newlist هو مُتْغيِّر آخر من نفس النوع int[]، اُنظر التَعْليمَة التالية: newlist = list; يَقْتصِر دور تَعْليمَة الإِسْناد (assignment statement) بالأعلى على نَسْخ قيمة المَرجِع (reference) المُخْزَّنة بالمُتْغيِّر list فقط إلى newlist. إذا كان المُتْغيِّر list يَحمِل القيمة null، فسيَحمِل المُتْغيِّر newlist القيمة null أيضًا أما إذا كان المُتْغيِّر list يُشير إلى مصفوفة، فلن تَنسَخ تَعْليمَة الإِسْناد تلك المصفوفة وإنما ستَضبُط المُتْغيِّر newlist فقط بحيث يُشير إلى نفس المصفوفة التي يُشير إليها المُتْغيِّر list. اُنظر الشيفرة التالية كمثال: list = new int[3]; list[1] = 17; // تشير newlist إلى نفس المصفوفة التي يشير إليها list newlist = list; newlist[1] = 42; System.out.println( list[1] ); لأن list[1] و newlist[1] هي مجرد أسماء مختلفة لنفس عنصر المصفوفة، فسيَكُون خَرْج الشيفرة بالأعلى هو 42 وليس 17. قد تَجِدْ كل تلك التفاصيل مُربكة بالبداية، ولكن بمُجرَّد أن تَستحضِر بذهنك أن "أي مصفوفة هي عبارة عن كائن (object) وأن أيّ مُتْغيِّر مصفوفة (array variables) هو فقط يَحمِل مؤشرًا (pointers) إلى مصفوفة"، سيُصبِح كل شيء بديهيًا. تَنطبِق تلك الحقيقة أيضًا على تمرير مصفوفة كمُعامِل (parameter) إلى برنامج فرعي (subroutine) حيث سيَستقبِل البرنامج في تلك الحالة نُسخة فقط من المُؤشر (pointer) وليس المصفوفة ذاتها، وبذلك سيَملُك مَرجِعًا (reference) إلى المصفوفة الأصلية، وعليه فإن أيّ تَعْدِيلات قد يُجرِيها على عناصر المصفوفة (array elements)، سيَمتدّ أثرها إلى المصفوفة الأصلية وستستمر إلى ما بَعْد انتهاء البرنامج الفرعي. بالإضافة إلى كَوْن المصفوفات كائنات (objects) بالأساس، فإنها قد تُستخدَم لحَمل كائنات أيضًا، ويَكُون نوع المصفوفة الأساسي (base type) في تلك الحالة عبارة عن صَنْف. في الواقع، لقد تَعرَّضنا لذلك بالفعل عندما تَعامَلنا مع المصفوفات من النوع String[]، ولكن لا يَقْتصِر الأمر على النوع String بل تستطيع اِستخدَام أيّ صَنْف آخر. فمثلًا، يُمكِننا إنشاء مصفوفة من النوع Student[]، والتي نوعها الأساسي هو الصنف Student المُعرَّف مُسْبَقًا بهذا القسم، وفي تلك الحالة، يَكُون كل عنصر بالمصفوفة عبارة عن مُتْغيِّر من النوع Student. يُمكِننا مثلًا كتابة الشيفرة التالية لتَخْزين بيانات 30 طالب داخل مصفوفة: Student[] classlist; // Declare a variable of type Student[]. classlist = new Student[30]; // The variable now points to an array. تَتَكوَّن المصفوفة -بالأعلى- من 30 عنصر هي classlist[0] و classlist[1] وحتى classlist[29]. عند إنشاء تلك المصفوفة، تُهيَئ عناصرها إلى قيمة مبدئية افتراضية تُساوِي القيمة الفارغة null في حالة الكائنات، لذلك يُصبِح لدينا 30 عنصر مصفوفة، كُلًا منها أينعم من النوع Student لكنه يَحتوِي على القيمة الفارغة (null) وليس على كائن فعليّ من النوع Student. ينبغي أن نُنشِئ تلك الكائنات بأنفسنا كالتالي: Student[] classlist; classlist = new Student[30]; for ( int i = 0; i < 30; i++ ) { classlist[i] = new Student(); } وعليه، يُشير كل عنصر مصفوفة classlist إلى كائن من النوع Student أيّ يُمكِن اِستخدَام classlist بأيّ طريقة يُمكِن بها اِستخدَام مُتْغيِّر من النوع Student. فمثلًا، يُمكِن اِستخدَام classlist[3].name للإشارة إلى اسم الطالب المُخْزَّن برقم المَوضِع الثالث. كمثال آخر، يُمكِن استدعاء classlist.getAverage() لحساب متوسط درجات الطالب المُخْزَّن برقم المَوضِع i. ترجمة -بتصرّف- للقسم Section 1: Objects, Instance Methods, and Instance Variables من فصل Chapter 5: Programming in the Large II: Objects and Classes من كتاب Introduction to Programming Using Java.1 نقطة -
لدي figure يحوي أكثر من subplots: import matplotlib.pyplot as plt import numpy as np x = np.array([0, 1, 2, 3]) y = np.array([3, 8, 1, 10]) # plot1 plt.subplot(1, 2, 1) plt.plot(x,y) x = np.array([0, 1, 2, 3]) y = np.array([10, 20, 30, 40]) # plot2 plt.subplot(1, 2, 2) plt.plot(x,y) plt.show() كيف يمكنني إضافة عنوان إلى كل من هذه ال subplots؟ جربت fig.suptitle لكنه يضيف عنوان إلى كامل الغراف لكنني أريد إضافة اسم لكل plot..1 نقطة
-
سويت كل الي مطلوب بس ما يشتغل عندي البرنامج شفت فيديو على اليوتيوب الفيديو قبل سنتين، يمكن عشان الطريقه الي انا سويته قديمه وفي طريقه غير عن الي انا استخدمه
 1 نقطة
1 نقطة -
ماهي فهرسة البيانات في قواعد البيانات وبمذا تفيد، وكيف يمكنني عمل فهرس لأحد الحقول في جدول، وكيف أزيد سرعة الاستعلامات1 نقطة
-
كيف يمكن تحويل الصورة إلى الصيغة الرمادية أو كيف يمكننا التحويل من نظام لوني إلى آخر: BGR ↔ Gray BGR↔HSV1 نقطة
-
أريد معرفة الفرق في استخدام كل من join و subquery ومتى نستخدم كل منهم1 نقطة
-
نستخدم JOIN عندما نريد الربط بين جدولين اعتماداً على قيمة أحد الحقول والتي غالبا تكون مفتاح رئيسي في أحد الجدولين ومفتاح ثانوي في الجدول الآخر (مع العلم يمكن الربط بين الجدول ونفسه) نستخدمها عندما يكون لدينا معلومات لكائن ما في الجدول موجودة في جدولين أو أكثر، حيث نضطر لعمل ربط بين جدولين مثلا. جدول الموظفين يحوي معلومات الموظف مع رقم القسم فقط، وجدول الأقسام يحوي على رقم القسم و اسم القسم وموقعه، لذلك هنا علينا الربط بين الجدولين لنعرف اسم القسم وموقعه لكل موظف. ويتم الربط بناءاً على رقم القسم. SELECT * FROM Employees INNER JOIN Departement ON Employees.deptID = Departement.ID; أما Subquery نستخدمها لعمل استعلام جزئي يعيد لنا بعض النتائج، والتي نعتمد عليها في الاستعلام الأساسي حيث يكون من الصعب عمل فلترة من خلال استعلام واحد (أو مثلا نحتاج لعمل فلترة في جدول آخر ثم فلترة أخرى في جدولنا). مثلا نجلب معلومات المنتجات (من جدول المنتجات) التي تم بيعها أكثر من 10 مرات (عدد مرات البيع من جدول الفواتير/الطلبيات) SELECT p.Name FROM Products p WHERE ProductID = ANY (SELECT ProductID FROM Orders WHERE Quantity > 10); أحيانا يمكن عمل نفس الاستعلام عن طريق JOIN أو Subquery ويفضل استخدام JOIN لأنه أسرع في معظم الوقت لأن عملية الربط بين الجداول تكون مفهرسة وتعتمد على المفتاح الرئيسي و الثانوي .. أي عملية تطابق السجلات تكون سريعة مع ملاحظة أن الاستعلام الفرعي يتم تنفيذه أولا ولمرة واحدة (أو أكثر حسب نوع الاستعلام فإن كان هنالك عنصر يتم اختباره من الاستعلام الأب سيتكرر استدعاء الاستعلام الفرعي). والدمج ينتج جدول يحوي جميع الحقول في كلا الجدولين المدموجين حسب حقل الربط.1 نقطة
-
لدي جدول في قاعدة البيانات فيه حقول تحوي قيم مكررة، كيف أتمكن من حذفهم1 نقطة
-
يمكنك حذف القيم المكررة في عمود معين في جدول ما بطريقة سهلة من خلال تعديل العمود نفسه وإضافة الخاصية Unique إليه، كالتالي: ALTER IGNORE TABLE table_name ADD UNIQUE INDEX idx_name (column_name); ستقوم التعليمة السابقة بتعديل العمود وتجعله من نوع Unique أي أن القيم فيه يجب ألا تتكرر (وسيظهر خطأ عند محاولة إضافة صف جديد ويحمل قيمة موجودة بالفعل هذا العمود). لاحظ أننا قمنا بإستخدام الكلمة المفتاحية IGNORE والتي تعني تجاهل (حذف) كل الصفوف التي تحتوي على نفس القيمة في هذا العمود. ولإعادة العمود إلى ما كان عليه -أي حذف الخاصية UNIQUE من العمود- يمكنك إن تستخدم تعليمة ALTER مرة أخرى كالتالي: ALTER TABLE table_name DROP INDEX column_name; ربما تواجهة مشكلة بسبب إضافة الخاصية UNIQUE إلى عمود معين في قواعد بيانات MySQL بمحرك InnoDB، ويمكنك أن تتخطى هذه المشكلة من خلال تغير الطريقة المستخدمه في تعديل الجداول نفسها في قاعدة البيانات ثم إرجاعها مرة أخرى، كالتالي: set session old_alter_table=1; ALTER IGNORE TABLE table_name ADD UNIQUE INDEX idx_name (column_name); set session old_alter_table=0;1 نقطة
-
تفيد الفهرسة في تسريع الوصول للبيانات في الجدول عند البحث (خاصة عند كتابة الشروط) وكما نعلم عندما تكون لدينا بيانات مرتبة، تصبح عملية البحث أسرع حيث أن أغلب خوارزميات البحث تعتمد على بيانات مرتبة. مثلاً خوارزمية البحث الثنائي. الفهرس في قاعدة البيانات هو ملف (أو أكثر) يحوي على قيم عمود ما من الجدول ولكن بطريقة مرتبة، وكل قيمة تحوي ارتباط لموقعها الفعلي في الجدول (مثل مؤشر أو رابط) فعندما نريد تطبيق شرط ما على عمود في الجدول، نبحث ضمن الفهرس (لسرعة البحث) ثم يرشدنا الفهرس لمكان البيانات الفعلية (سطر جدول قاعدة البيانات الفعلي) وهنا نسترجع بيانات كامل السجل. مثلا من الجيد استخدام حقل اللإيميل وعمل فهرسة عليه. SELECT * FROM Employee WHERE email = 'wael@hsoub.com' يمكننا إنشاء فهرس أو أكثر للجدول - حسب الحقول التي نختبرها بالشرط بشكل متكرر - لأن حجم الفهارس يصبح كبير ويمكن ألا يكون له فائدة في تسريع الأداء.. لذلك نختاره بدقة # إنشاء فهرس أو أكثر لجدول ما CREATE INDEX [ name ] ON tbl ( col [, ...]); # إنشاء فهرس لتسريع البحث حسب اسم المقالة CREATE INDEX index_title ON posts (title); القيود على إنشاء الفهارس أن تكون قيمة الهود رقمية أو نصية varchar (لا يقبل text) حتى تكون الفهرسة نافعة وسريعة. للفهرس معامل مهم هو fillfactor (معامل الملئ) وهذا يحدد نسبة حشو ملفات الفهرسة، لأننا نعلم أن البيانات تزيد باستمرار ولضمان ترتيبهم ضمن الفهرس في ملفات، علينا إبقاء مساحة فارغة فيهم لضمان وضع البيانات الجديدة في ترتريب سليم بدون الإضطرار لوضعهم في ملفات أخرى وعمل روابط تنقل بين صفحات الفهارس ومثلا نسبة الحجز للملف نضعهم 75%.. حذف فهرس DROP INDEX [ IF EXISTS ] name [ CASCADE | RESTRICT ] تعديل فهرس ALTER INDEX [ IF EXISTS ] name RENAME TO new_name ALTER INDEX distributors SET (fillfactor = 75); قاعدة مهمّة أخرى عند استخدام الفهارس هي أنه ينبغي الانتباه إلى ربط الجداول (عبر التعليمة join مثلا)؛ إذ يجب أن تُنشَأ فهارس للحقول المستخدمة في الربط، كما يجب أن تشترك هذه الحقول في نوع البيانات. تشبه فهرسة الكتب، الهدف منها تسريع البحث.1 نقطة
-
سؤالي هو كيفية إنشاء ملف sitemap وإضافته بشكل ديناميكي إلى مشروع nextjs. لقد أنشأت مدونة باستخدام nextjs و mongodb و express js. هذه هي الواجهة الأمامية لهيكل مشروعي (nextjs) --.next -- components -- node_modules -- pages -- public -- config.js -- next.config.js -- package.json -- package-lock.json1 نقطة
-
أريد شرح عن اختيار نوع مناسب لموقعي ما هو الخيار الأرخص وما هو الأفضل من حيث الأداء، وفي حاول وجود خيار متوسط مناسب. وما أفضل خيار في حال الترقية والتوسع في المستقبل1 نقطة
-
يوجد عدة عوامل في تحديد الاستضافة الأفضل لموقعك، وهذا يعتمد على عدة عوامل مثل عدد الزوار (هذا يتطلب تحديداً قوة معالجة وذاكرة RAM)،ثم الحاجة لتخزين ملفات وصور بحجم تخزين كبير (هذا يتطلب مساحة تخزين كبيرة) أيضاً الأسعار (لا تحجز استضافة غالية أو خدمات لا تحتاجهم)، توافر خدمات النسخ الاحتياطي و البريد الالكتروني. الأرخص والأضعف: الاستضافة المشتركة Shared Hosting يتشارك عدة زبائن نفس المخدم ما يؤدي لتوزيع قوة المخدم عليهم (زبائن كل المواقع) وهذا غير مناسب لعدد زبائن كبير لأنه يسبب توقف المخدم. يفيد في حالة موقع صغير وعدد زبائن قليل. الأقوى والأغلى: الخادم المخصص Dedicated Server هنا عليك شراء الخادم وتثبيت نظام التشغيل ربما توظيف مختص لمتابعته، هنا تستفيد من كل موارد الخادم لكن كل المسؤوليات و الدعم الفني و التطوير و زيادة مساحة التخزين عليك أن تديرها بنفسك. الحل المتوسط هو الخوادم الافتراضية VPS وهو الأكثر مرونة وقوة توفره شركات الخدمات السحابية (يمكن اعتباره خدمة سحابية خاصة) تعطيك كامل التحكم في الإعدادات، وهو مناسب للنمو المعتدل. (قدرة المعالجة محدودة) أما في الخادم السحابي حيث يتم دعم موقعك على عدد كبير من الخوادم (ينفع في حال تعطل أحدهم) وتصبح الخدمة أسرع لأن العميل يتصل على أقرب مخدم له، يمكنك تعديل قوة المعالجة وحجم التخزين من لوحة التحكم وهو الأاسهل من حيث الترقية والتوسع والاتاحية (قوة المعالجة كبيرة بكامل قوة المنظومة)1 نقطة
-
كيفية استخدام العملية bitwise_and في OpenCV؟ وتوضيح فكرة القناع؟1 نقطة
-
بداية إن لم يكن لديك فكرة عن العمليات على مستوى البت، فأنصحك بالمقالة التالية أكاديمية خسوب. هذا التابع له الشكل التالي bitwise_and: bitwise_and(image1, image2, destination_array, mask) الوسيط الأول يمثل الصورة الأولى والوسيط الثاني يمثل الصورة الثانية أما الوسيط الثالث سيمثل المصفوفة التي سيتم وضع الخرج فيها، والوسيط الرابع يمثل القناع. ولهذا التابع فوائد واستخدامات كثيرة جداً على سبيل المثال سأقوم من خلال الكود التالي بتطبيق لوغو (شعار) على صورة. لكن قبل ذلك سنوضح الوسطاء بشكل أكبر: أولاً: الصورتين image1 و image2 كل منهما يتم تمثيله كمصفوفة ثلاثية الأبعاد من الشكل (height,width,channels) والصورتان يجب أن يكون لهما نفس الأبعاد بالضبط. حيث سيتم تنفيذ عملية bitwise_and بين بكسلات الصورة الأولى والثانية (سيتم دمج الصورتين). ثانياً: القناع mask يمكن أن تضعه ويمكن أن لاتضعه حسب المهمة التي تعمل عليها، وهذا القناع يكون من بعدين فقط أي (height,width) فقط (بدون قنوات) وأيضاً يجب أن يكون حجمه مطابق لحجم الصورتين. وتكون قيمه ضمن المجال 0 ل 255. هذا القناع يستخدم لتحديد الأماكن التي سيتم تطبيق عملية bitwise_and عليها والأماكن (البكسلات) التي لن يتم تطبيق عملية bitwise_and عليها بحيث مثلاً من أجل البكسل (x,y) من الصورتين image1 و image2 يتم النظر إلى القيمة الموجودة في ال mask فإذا كانت 0 لايتم تطبيق عملية bitwise_and وإلا فسيتم تطبيق عملية bitwise_and بين البكسلين. الآن سأقوم بكتابة الكود السابق لتفهم بدقة: import cv2 import numpy as np # قراءة الصورتين img1 = cv2.imread(r'C:\Users\Windows.10\Desktop\Safedrive\me.jpg') # الصورة img2 = cv2.imread(r'C:\Users\Windows.10\Desktop\Safedrive\car.webp') # اللوغو # نريد وضع اللوغو في الزاوية العليا اليسارية من الصورة img2=cv2.resize(img2,(180,140)) # سنقوم بتحديد حجم اللوغو بالشكل الذي يناسبنا # نقوم الآن بتحديد أبعاد اللوغو rows,cols,channels = img2.shape # نقوم باقتصاص الزاويا العليا اليسارية من اللوغو بحيث يكون الحجم مطابق لحجم اللوغو roi = img1[0:rows, 0:cols ] #هي المنطقة التي نريد وضع اللوغو فيها roi إذاً # نقوم الآن باستخلاص نسخة من الصورة تكون رمادية img2gray = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY) # img2gray ستمثل النسخة الرمادية من الصورة # النسخة الرمادية: # نقوم الآن بتعتيب الصورة بحيث نحصل على صورة أبيض وأسود # البكسلات التي تكون قيمتها أكبر من 60 ستصبح 255 أي بيضاء # البكسلات الأقل ستصبح 0 أي سوداء _, mask = cv2.threshold(img2gray, 60, 255, cv2.THRESH_BINARY) # mask ستمثل نسخة الأبيض والأسود من الصورة # mask وهذا هو شكل صورة ال : # نقوم بعكس القيم # نعلم أن 255 تكافئ 1111 1111 في النظام الثنائي # ونعلم أن 0 تكافئ 0000 0000 في النظام الثنائي كوننا نمثل البكسل ب8 بت # ستؤدي إلى جعل ال 0 تساوي 255 والعكس bitwise_not وبالتالي تنفيذ عملية # أي الأبيض أسود والأسود أبيض mask_inv = cv2.bitwise_not(mask) # mask_inv سيجعل الخلفية بيضاء أي 255 والشعار 0 أي أسود # mask_inv: #على ال bitwise_and كقناع لتطبيق عملية mask_inv سنقوم باستخدام #وبالتالي المناطق التي تحوي 0 لن تدخل في عملية الدمج roi roi = cv2.bitwise_and(roi,roi,mask = mask_inv) # اي هنا سيتم تعتيم المنطقة التي نريد وضع اللوغو فيها # الآن نكون انتهينا من تحديد المكان الذي سيتم وضع اللوغو ضمنه # roi: # الآن نقوم ياستخلاص المنطقة التي يكون فيها اللوغو فقط من صورة اللوغو وباقي المناطق يتم تعتيمها أي 0 logo = cv2.bitwise_and(img2,img2,mask = mask) # logo: # roi الآن نضع اللوغو ضمن ال # ثم نقوم بتعديل الصورة الأصلية # تذكر أن : black+anycolor=anycolor merge = cv2.add(roi,logo) #roi قمنا بإضافة اللوغو الآن إلى ال img1[0:rows, 0:cols ] = merge cv2.imshow('res',img1) cv2.waitKey(0) cv2.destroyAllWindows()






 1 نقطة
1 نقطة -
انا استخدم ويندوز 8 واريد ان اقوم بفتح ملف x d ولكن البرنامج لا يعمل .. هل توجد طريقة لفتح ملفات x d بدون adobe x d ؟؟1 نقطة
-
حاول استخدام أحد الأدوات المتوفر على الانترنت online مثل PSDETCH. Photopea إن قمت بتصدير ملف التصميم من AdobeXD على شكل SVG فيمكنك فتحه في Figma وهو برنامج تصميم مجاني لكنه لايدعم ملفاتXD1 نقطة
-
يقدم التوثيق الرسمي خطوات للتثبيت على كل أنظمة التشغيل المدعومة مع ملاحظات حسب إصدار كل نسخة لهم و من مونغو. مثلاً في نظام أوبنتو يتم التثبيت من خلال أداة Advanced Packaging Tool (APT) مدير الحزم البرمجية للنظام. الخطوات العريضة: تحميل المفتاح العام من خلال wget -qO - https://www.mongodb.org/static/pgp/server-5.0.asc | sudo apt-key add - ثم تثبيت الحزمة gnupg sudo apt-get install gnupg ثم إعادة الأمر رقم 1 الخاص بامفتاح ثم إنشاء ملف القوائم sources.list.d/mongodb-org-5.0.list # يختلف حسب الإدار للنظام تأكد من التوثيق echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/5.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-5.0.list ثم أمر التثبيت sudo apt-get install -y mongodb-org ثم تشغيل الخدمة mongodb sudo systemctl start mongod توثيق التثبيت: mongodb/manual/installation1 نقطة
-
 تقضي وحدة المعالجة المركزيّة أغلب وقتها في جلب التّعليمات من الذّاكرة وتنفيذها. بيد أنّ وحدة المعالجة المركزيّة والذّاكرة الرّئيسيّة هما اثنان فقط من مكوّنات النّظام الحاسوبي الحقيقي. يتألّف النّظام الكامل من أجهزة أخرى مثل: القرص الصّلب (hard disk) أو وسيط التّخزين ذو الحالة الثابتة (solid state drive أو SSD) لتخزين ملفّات البرامج والبيانات. لاحظ أن الذّاكرة الرّئيسيّة تحتفظ بكميّة صغيرة نسبيًّا من المعلومات وتحتفظ بها طالما هناك تغذية كهربائيّة. يُستخدم القرص الصّلب أو وسيط التّخزين ذو الحالة الثّابتة للتّخزين الدّائم لكميّات ضخمة من المعلومات لكن يجب تحميل البرامج منه إلى الذّاكرة الرّئيسيّة قبل أن يتمّ تنفيذها فعليًّا. يُخزّن القرص الصّلب البيانات على قرص مغناطيسي دوّار، بينما يُمثّل وسيط التّخزين ذو الحالة الثّابتة ssd جهازًا إلكترونيًّا صرفًا بدون أيّ أجزاء متحرّكة. لوحة المفاتيح والفأرة لدخل المستخدم. الشّاشة والطّابعة لعرض خرج الحاسوب. جهاز إخراج صوت للسّماح للحاسوب بتشغيل أصوات. واجهة شبكة للسماح للحاسوب بالتّواصل مع الحواسيب الأخرى المتّصلة به على الشبكة، سواء سلكيًّا أو لاسلكيًّا. الماسحة لتحويل الصور إلى أرقام ثنائيّة مُرمّزة يمكن تخزينها وتعديلها على الحاسوب. قائمة الأجهزة هذه لا نهاية لها وتُبنى الأنظمة الحاسوبية على نحوٍ يجعل توسعتها بإضافة أجهزة جديدةٍ أمرًا سهلًا. يتوجّب على وحدة المعالجة المركزيّة بطريقةٍ ما التّواصل مع جميع هذه الأجهزة والتّحكم بها وتقوم بذلك من خلال تنفيذ تعليمات لغة الآلة فقط – في الواقع، إنّ تنفيذ تعليمات لغة الآلة هو الأمر الوحيد الذي تستطيع وحدة المعالجة المركزيّة فعله. يسير الأمر على النّحو الآتي: لكل جهازٍ في النّظام هناك تعريفٌ (device driver) خاصّ به هو عبارةٌ عن برمجيّة تُنفّذها وحدة المعالجة المركزيّة عندما تتعامل مع هذا الجهاز. عادةً ما تكون هناك خطوتان عند تركيب جهازٍ جديد على النظام: توصيل الجهاز فيزيائيًّا مع الحاسوب وتثبيت برمجية التّعريف الخاصّة بهذا الجهاز. يكون الجهاز عديم الجدوى بدون هذا التّعريف نظرًا لأنّ وحدة المعالجة المركزيّة غير قادرةٍ على التّواصل معه بدونه. يُنظّم النّظام الحاسوبي عادةً بوصل تلك الأجهزة مع ناقلٍ (Bus) أو أكثر. يُمثّل النّاقل مجموعةً من الأسلاك التي تنقل أنواعًا مختلفةً من المعلومات بين الأجهزة المتّصلة بها. تنقلُ تلك الأسلاك البيانات، والعناوين، وإشارات التّحكم. يُوجّه العنوان البيانات إلى جهازٍ معيّن وربّما إلى تسجيلةٍ أو موضع بعينه ضمن ذلك الجهاز. تستخدم الأجهزةُ، على سبيل المثال، إشارات التّحكم لتنبيه بعضها إلى توفّر بيانات جاهزةٍ لها على ناقل البيانات. يمكن تمثيل نظام حاسوبي بسيط كما يلي: تستطيع الأجهزة مثل لوحة المفاتيح، الفأرة، وواجهة الشّبكة أن تُنتج الدّخل الذي ستعالجه وحدة المعالجة المركزيّة. كيف تعرف وحدة المعالجة المركزيّة أنّ البيانات قد وصلت؟ من خلال فكرةٍ بسيطةٍ – وإن كانت غير مُرضِية – وهي أن تقوم وحدة المعالجة المركزيّة بالتّفحص المستمر لوجود بيانات واردة؛ وحالما تجد البيانات، تُعالجها فورًا. ولمّا كانت وحدة المعالجة المركزيّة "تجسّ" أجهزة الدّخل باستمرار لتفقّد ما إذا كان لديها بيانات دخلٍ تريد الإبلاغ عنها، فقد دُعيت هذه العمليّة بالجسّ (polling). لسوء الحظّ، رغم بساطة عمليّة الجسّ إلّا أنّها غير فعالّةٍ أبدًا حيث تُضيع وحدة المعالجة المركزيّة الكثير الكثير من الوقت في انتظار الدّخل فقط. لتجنّب عدم الفعاليّة بهذه العملية، تُستخدَم المُقاطعات (Interrupts) بدلًا من الجسّ. المقاطعة هي إشارةٌ من جهازٍ ما إلى وحدة المعالجة المركزيّة. تستجيب وحدة المعالجة المركزيّة لإشارة المقاطعة بوضع ما تفعله جانبًا للرّد على المقاطعة. تعود وحدة المعالجة المركزيّة لإتمام ما كانت تقوم به قبل حدوث المقاطعة بعد أن تنتهي من معالجتها. على سبيل المثال، عندما تضغط مفتاحًا على لوحة مفاتيح حاسوبك، تُرسل مقاطعة لوحة مفاتيح إلى وحدة المعالجة المركزيّة. تستجيب وحدة المعالجة المركزيّة إلى هذه الإشارة بمقاطعة ما تفعله، وقراءة المفتاح الذي قمت بضغطه، ومعالجته ومن ثمّ العودة إلى المهمّة التي كانت تقوم بأدائها قبل ضغطك للمفتاح. عليك أن تفهم أنّ هذه العمليّة آليّة بالكامل. يُرسل الجهاز إشارة مقاطعة من خلال تمرير تيّار كهربائي في السلك. تُبنى وحدة المعالجة المركزيّة بحيث تحفظ قدرًا كافيًا من المعلومات حول ما تقوم به عندما يُمرّر تيّار كهربائي في ذاك السّلك لتستطيع العودة إلى المرحلة نفسها لاحقًا. تشمل هذه المعلومات محتويات التّسجيلات الدّاخليّة المهمّة مثل عدّاد البرنامج. تقوم عندها وحدة المعالجة المركزيّة بالقفز إلى موقعٍ مُحدّدٍ مسبقًا في الذاكرة وتبدأ بتنفيذ التّعليمات المُخزّنة هناك. تُشكّل هذه التّعليمات مُعالج المُقاطعة (interrupt handler) الذي يقوم بالمعالجة الضّروريّة للاستجابة للمقاطعة. معالج المقاطعة هو جزءٌ من برمجية تعريف الجهاز الذي أرسل إشارة المقاطعة. في نهاية معالج المقاطعة، هناك تعليمة تخبر وحدة المعالجة المركزيّة بالعودة إلى مهمّتها السّابقة قبل المقاطعة، تقوم وحدة المعالجة المركزيّة بذلك من خلال استعادة حالتها السّابقة التي قامت بحفظها. تسمح المقاطعات لوحدة المعالجة المركزيّة بالتعامل مع الأحداث غير المتزامنة. في دورة الجلب والتّنفيذ المُنتظمة، تحدث الأشياء بترتيب مُسبق التّحديد؛ كل ما يجري تنفيذه "مُتزامنٌ" مع كل شيء آخر. تُمكّن المقاطعاتُ وحدةَ المعالجة المركزيّة من التعامل بفعاليّة مع الأحداث التي تحدث على نحوٍ "غير متزامن" أو – بكلمات أخرى – في أوقات يتعذّر التّنبؤ بها. كمثالٍ آخر عن كيفيّة استخدام المقاطعات، تخيّل ماذا يحدث عندما تحتاج وحدة المعالجة المركزيّة النّفاذ إلى بيانات مُخزّنة على القرص الصّلب. لا تستطيع وحدة المعالجة المركزيّة النّفاذ مباشرةً للبيانات إلّا إذا كانت الأخيرة في الذّاكرة الرّئيسيّة. يجب نسخ البيانات من القرص إلى الذّاكرة الرّئيسيّة قبل أن يتسنّى النّفاذ إليها. لسوء الحظ، فالقرص الصّلب بطيء للغاية مقارنةً بسرعة عمل وحدة المعالجة المركزيّة. عندما تحتاج وحدة المعالجة المركزيّة بياناتٍ من القرص، تُرسل إشارةً إلى القرص الصلب تخبره ليُحدّد موضع البيانات ويقوم بتجهيزها. تُرسل هذه الإشارة على نحوٍ متزامن تحت إشراف برنامجٍ عاديٍّ. تقوم وحدة المعالجة المركزيّة بعد ذلك بتنفيذ مهمّة أخرى عوضًا عن انتظار القرص الصّلب لوقتٍ طويل يتعذّر تقديره بدقّة. ما أن ينتهي القرص الصّلب من تجهيز البيانات المطلوبة، يُرسل إشارة مقاطعةٍ لوحدة المعالجة المركزيّة. يستطيع عندئذ معالج المقاطعة قراءةَ البيانات المطلوبة. قد تلاحظ أنّ هذا كلّه منطقيّ فقط عندما يكون لدى وحدة المعالجة المركزيّة عدة مهامٍ تنتظر تأديتها. فلا ضير إن قضت وحدة المعالجة المركزيّة وقتها تجسّ تفحصًّا لوجود دخلٍ أو بانتظار انتهاء عمليات محرك القرص الصلب إن لم يكن لديها شيء أفضل للقيام به. تعتمد جميع الحواسيب الحديثة على تعدّد المهام (multitasking) لأداء عدّة مهامٍ في آن واحد. قد يستخدمُ عدّة مستخدمين نفس الحاسوب. لمّا كانت وحدة المعالجة المركزيّة سريعةً للغاية، يمكنها بسهولةٍ وفعاليّة التّنقل بين المستخدمين مُكرّسة جزءًا من الثّانية لكلٍّ منهم في دوره. يُدعى تطبيق تعدّد المهام هذا بالمشاركة الزّمنيّة (timesharing). لكنّ هذا لا يمنع حاسوبًا حديثًا بمستخدم واحدٍ من استخدام تعدّد المهام. على سبيل المثال، قد يقوم المستخدم بقراءة مستندٍ بينما تعرض السّاعة الوقت على الشّاشة باستمرار أو يتمّ تحميل ملفٍ عبر الشّبكة. تُدعى كلُّ مهمةٍ فريدة من المهام التي تعمل عليها وحدة المعالجة المركزيّة بالخيط (thread أو العمليّة [Process]) – هناك فروق تقنيّة بين الخيوط والعمليّات لكنّها ليست ذات أهمية هنا على نظرًا لأنّ الخيوط فقط هي المُعتمدة في لغة جافا. تستطيع العديد من وحدات المعالجة المركزيّة تنفيذ أكثر من خيط في آن واحد حقًا. تحتوي وحدات المعالجة المركزيّة كهذه عدّة أنوية (core) تُنفّذ كلّ واحدة منها خيطًا مع العلم أنّ هناك حدًّا عدد الخيوط التي يمكن تنفيذها في آن واحد. ولمّا كان المُرجّح وجود خيوط أكثر ممّا يمكن تنفيذه في آن واحد، ينبغي على الحاسوب نقل التّنفيذ من خيط لآخر تمامًا كما يقوم حاسوب المشاركة الزّمنية بنقل التّنفيذ من مستخدمٍ لآخر. في الحالة العامّة، يستمرُّ الخيط الذي يجري تنفيذه بالعمل حتى يحدث أحد الأمور التّالية: قد يتنازل الخيط طوعًا عن سيطرته على النّواة ليمنح الخيوط الأخرى فرصةَ تنفيذ. قد يضطر الخيط لانتظار حصول حدثٍ غير متزامن. على سبيل المثال، قد يطلب الخيط بعض البيانات من القرص الصّلب أو يضطّر لانتظار أن يضغط المستخدم مفتاحًا. يُقال عن الخيط أثناء انتظاره أنّه محجوب (blocked) وتستطيع الخيوط الأخرى، في حال وجودها، أن تدخل التّنفيذ. عند حصول الحدث، تقوم مقاطعةٌ بإيقاظ الخيط لاستئناف تنفيذه. قد يستنفذ الخيط حصّته الزّمنية المخصّصة ويُعلّق مؤقتًا للسّماح بتنفيذ الخيوط الأخرى. تستطيع معظم الحواسيب تعليق خيطٍ قسريًّا بهذه الطريقة، يقال عندئذٍ أنّ هذه الحواسيب تستخدم تعدّد المهام الاستباقي (preemptive multitasking). يحتاج الحاسوب للقيام بتعدّد المهام الاستباقي إلى جهاز مؤقّت زمنيٍ خاص يُولّد مقاطعةً عند فواصل زمنيّة مُنتظمة، 100 مرةٍ في الثّانية مثلًا. عندما تحدث مقاطعة المؤقّت، يتسنّى لوحدة المعالجة المركزيّة الانتقال من خيطٍ إلى آخر بغضّ النّظر عن حالة أو حاجة الخيط الذي يجري تنفيذه. تستخدم جميع الحواسيب الحديثة المكتبيّة منها والمحمولة وحتّى الهواتف الذكيّة والأجهزة اللّوحية تعددَ المهام الاستباقي. لا حاجةَ للمستخدم العاديّ، بل وللمبرمج العاديّ أيضًا، للتّعامل مع المقاطعات ومعالجات المقاطعات. يمكن لهما التّركيز على المهام المختلفة التي يريدان للحاسوب أن يقوم بأدائها بصرف النّظر عن تفاصيل إدارة الحاسوب لعمليّة تنفيذ كل هذه المهام. في الحقيقة، يستطيع معظم المستخدمين – وبعض المبرمجين – تجاهل الخيوط وتعدد المهام كليًّا. على أيّة حال، فقد ازدادت أهميّة الخيوط مع ازدياد قدرة الحواسيب واستثمارها لمفهومي تعدد المهام وتعدد المعالجات. وفي واقع الأمر، أصبحت القدرة على العمل مع الخيوط مهارةً مهنيّةً أساسيّة للمبرمجين. لحسن الحظ، تُقدم جافا دعمًا جيّدًا للخيوط، إذ ضُمّنت الأخيرة في لغة البرمجة جافا على أنّها مفهومٌ برمجيٌّ أساسي. سنتناول البرمجة باستخدام الخيوط في الفصل 12. وعلى نفس المقدار من الأهميّة، في جافا والبرمجة الحديثة على حدٍّ سواء، نجد مفهوم الأحداث غير المتزامنة. وفي حين لا يضطّر المبرمجون للتّعامل مع المقاطعات مباشرةً، يجدون أنفسهم باستمرار وهم يكتبون معالجات أحداث (Event Handler). تُستدعى معالجات الأحداث، كما معالجات المقاطعات، على نحو غير متزامن عند حصول أحداث معينة. تختلف البرمجة المقادة بالأحداث (event-driven programming) هذه كليًّا عن البرمجة التّزامنيّة المباشرة التّقليديّة. سنبدأ أولًا بالبرمجة التقليدية التي لا تزال مستخدمة في برمجة المهام المفردة، ثمّ سنعود إلى الخيوط والأحداث لاحقًا بدءًا من الفصل 6. ولأن الشّيء بالشّيء يُذكر، فالبرمجيّة التي تقوم بجميع عمليّات معالجة المقاطعات وتتولّى التّواصل مع المستخدم وأجهزة العتاديّات، كما تضبط أيّ خيط يُسمح بتنفيذه تُدعى بنظام التّشغيل (Operating System). نظام التّشغيل هو البرمجيّة الجوهريّة الأساسيّة التي لا يستطيع الحاسوب أن يعمل بدونها. أمّا البرامج الأخرى، كمعالجات النّصوص ومتصفّحات الويب، فهي معتمدةٌ كليًّا ومنوطةٌ بنظام التشغيل. نذكر من أنظمة التّشغيل الشّائعة للحواسيب لينوكس (Linux)، ويندوز (Windows)، وماك (Mac OS) ومن أنظمة تشغيل الهواتف الذكية والأجهزة اللّوحية آندرويد (Android) و iOS. ترجمة -وبتصرف- للفصل Asynchronous Events: Polling Loops and Interrupts من الكتاب Introduction to Programming Using Java1 نقطة
تقضي وحدة المعالجة المركزيّة أغلب وقتها في جلب التّعليمات من الذّاكرة وتنفيذها. بيد أنّ وحدة المعالجة المركزيّة والذّاكرة الرّئيسيّة هما اثنان فقط من مكوّنات النّظام الحاسوبي الحقيقي. يتألّف النّظام الكامل من أجهزة أخرى مثل: القرص الصّلب (hard disk) أو وسيط التّخزين ذو الحالة الثابتة (solid state drive أو SSD) لتخزين ملفّات البرامج والبيانات. لاحظ أن الذّاكرة الرّئيسيّة تحتفظ بكميّة صغيرة نسبيًّا من المعلومات وتحتفظ بها طالما هناك تغذية كهربائيّة. يُستخدم القرص الصّلب أو وسيط التّخزين ذو الحالة الثّابتة للتّخزين الدّائم لكميّات ضخمة من المعلومات لكن يجب تحميل البرامج منه إلى الذّاكرة الرّئيسيّة قبل أن يتمّ تنفيذها فعليًّا. يُخزّن القرص الصّلب البيانات على قرص مغناطيسي دوّار، بينما يُمثّل وسيط التّخزين ذو الحالة الثّابتة ssd جهازًا إلكترونيًّا صرفًا بدون أيّ أجزاء متحرّكة. لوحة المفاتيح والفأرة لدخل المستخدم. الشّاشة والطّابعة لعرض خرج الحاسوب. جهاز إخراج صوت للسّماح للحاسوب بتشغيل أصوات. واجهة شبكة للسماح للحاسوب بالتّواصل مع الحواسيب الأخرى المتّصلة به على الشبكة، سواء سلكيًّا أو لاسلكيًّا. الماسحة لتحويل الصور إلى أرقام ثنائيّة مُرمّزة يمكن تخزينها وتعديلها على الحاسوب. قائمة الأجهزة هذه لا نهاية لها وتُبنى الأنظمة الحاسوبية على نحوٍ يجعل توسعتها بإضافة أجهزة جديدةٍ أمرًا سهلًا. يتوجّب على وحدة المعالجة المركزيّة بطريقةٍ ما التّواصل مع جميع هذه الأجهزة والتّحكم بها وتقوم بذلك من خلال تنفيذ تعليمات لغة الآلة فقط – في الواقع، إنّ تنفيذ تعليمات لغة الآلة هو الأمر الوحيد الذي تستطيع وحدة المعالجة المركزيّة فعله. يسير الأمر على النّحو الآتي: لكل جهازٍ في النّظام هناك تعريفٌ (device driver) خاصّ به هو عبارةٌ عن برمجيّة تُنفّذها وحدة المعالجة المركزيّة عندما تتعامل مع هذا الجهاز. عادةً ما تكون هناك خطوتان عند تركيب جهازٍ جديد على النظام: توصيل الجهاز فيزيائيًّا مع الحاسوب وتثبيت برمجية التّعريف الخاصّة بهذا الجهاز. يكون الجهاز عديم الجدوى بدون هذا التّعريف نظرًا لأنّ وحدة المعالجة المركزيّة غير قادرةٍ على التّواصل معه بدونه. يُنظّم النّظام الحاسوبي عادةً بوصل تلك الأجهزة مع ناقلٍ (Bus) أو أكثر. يُمثّل النّاقل مجموعةً من الأسلاك التي تنقل أنواعًا مختلفةً من المعلومات بين الأجهزة المتّصلة بها. تنقلُ تلك الأسلاك البيانات، والعناوين، وإشارات التّحكم. يُوجّه العنوان البيانات إلى جهازٍ معيّن وربّما إلى تسجيلةٍ أو موضع بعينه ضمن ذلك الجهاز. تستخدم الأجهزةُ، على سبيل المثال، إشارات التّحكم لتنبيه بعضها إلى توفّر بيانات جاهزةٍ لها على ناقل البيانات. يمكن تمثيل نظام حاسوبي بسيط كما يلي: تستطيع الأجهزة مثل لوحة المفاتيح، الفأرة، وواجهة الشّبكة أن تُنتج الدّخل الذي ستعالجه وحدة المعالجة المركزيّة. كيف تعرف وحدة المعالجة المركزيّة أنّ البيانات قد وصلت؟ من خلال فكرةٍ بسيطةٍ – وإن كانت غير مُرضِية – وهي أن تقوم وحدة المعالجة المركزيّة بالتّفحص المستمر لوجود بيانات واردة؛ وحالما تجد البيانات، تُعالجها فورًا. ولمّا كانت وحدة المعالجة المركزيّة "تجسّ" أجهزة الدّخل باستمرار لتفقّد ما إذا كان لديها بيانات دخلٍ تريد الإبلاغ عنها، فقد دُعيت هذه العمليّة بالجسّ (polling). لسوء الحظّ، رغم بساطة عمليّة الجسّ إلّا أنّها غير فعالّةٍ أبدًا حيث تُضيع وحدة المعالجة المركزيّة الكثير الكثير من الوقت في انتظار الدّخل فقط. لتجنّب عدم الفعاليّة بهذه العملية، تُستخدَم المُقاطعات (Interrupts) بدلًا من الجسّ. المقاطعة هي إشارةٌ من جهازٍ ما إلى وحدة المعالجة المركزيّة. تستجيب وحدة المعالجة المركزيّة لإشارة المقاطعة بوضع ما تفعله جانبًا للرّد على المقاطعة. تعود وحدة المعالجة المركزيّة لإتمام ما كانت تقوم به قبل حدوث المقاطعة بعد أن تنتهي من معالجتها. على سبيل المثال، عندما تضغط مفتاحًا على لوحة مفاتيح حاسوبك، تُرسل مقاطعة لوحة مفاتيح إلى وحدة المعالجة المركزيّة. تستجيب وحدة المعالجة المركزيّة إلى هذه الإشارة بمقاطعة ما تفعله، وقراءة المفتاح الذي قمت بضغطه، ومعالجته ومن ثمّ العودة إلى المهمّة التي كانت تقوم بأدائها قبل ضغطك للمفتاح. عليك أن تفهم أنّ هذه العمليّة آليّة بالكامل. يُرسل الجهاز إشارة مقاطعة من خلال تمرير تيّار كهربائي في السلك. تُبنى وحدة المعالجة المركزيّة بحيث تحفظ قدرًا كافيًا من المعلومات حول ما تقوم به عندما يُمرّر تيّار كهربائي في ذاك السّلك لتستطيع العودة إلى المرحلة نفسها لاحقًا. تشمل هذه المعلومات محتويات التّسجيلات الدّاخليّة المهمّة مثل عدّاد البرنامج. تقوم عندها وحدة المعالجة المركزيّة بالقفز إلى موقعٍ مُحدّدٍ مسبقًا في الذاكرة وتبدأ بتنفيذ التّعليمات المُخزّنة هناك. تُشكّل هذه التّعليمات مُعالج المُقاطعة (interrupt handler) الذي يقوم بالمعالجة الضّروريّة للاستجابة للمقاطعة. معالج المقاطعة هو جزءٌ من برمجية تعريف الجهاز الذي أرسل إشارة المقاطعة. في نهاية معالج المقاطعة، هناك تعليمة تخبر وحدة المعالجة المركزيّة بالعودة إلى مهمّتها السّابقة قبل المقاطعة، تقوم وحدة المعالجة المركزيّة بذلك من خلال استعادة حالتها السّابقة التي قامت بحفظها. تسمح المقاطعات لوحدة المعالجة المركزيّة بالتعامل مع الأحداث غير المتزامنة. في دورة الجلب والتّنفيذ المُنتظمة، تحدث الأشياء بترتيب مُسبق التّحديد؛ كل ما يجري تنفيذه "مُتزامنٌ" مع كل شيء آخر. تُمكّن المقاطعاتُ وحدةَ المعالجة المركزيّة من التعامل بفعاليّة مع الأحداث التي تحدث على نحوٍ "غير متزامن" أو – بكلمات أخرى – في أوقات يتعذّر التّنبؤ بها. كمثالٍ آخر عن كيفيّة استخدام المقاطعات، تخيّل ماذا يحدث عندما تحتاج وحدة المعالجة المركزيّة النّفاذ إلى بيانات مُخزّنة على القرص الصّلب. لا تستطيع وحدة المعالجة المركزيّة النّفاذ مباشرةً للبيانات إلّا إذا كانت الأخيرة في الذّاكرة الرّئيسيّة. يجب نسخ البيانات من القرص إلى الذّاكرة الرّئيسيّة قبل أن يتسنّى النّفاذ إليها. لسوء الحظ، فالقرص الصّلب بطيء للغاية مقارنةً بسرعة عمل وحدة المعالجة المركزيّة. عندما تحتاج وحدة المعالجة المركزيّة بياناتٍ من القرص، تُرسل إشارةً إلى القرص الصلب تخبره ليُحدّد موضع البيانات ويقوم بتجهيزها. تُرسل هذه الإشارة على نحوٍ متزامن تحت إشراف برنامجٍ عاديٍّ. تقوم وحدة المعالجة المركزيّة بعد ذلك بتنفيذ مهمّة أخرى عوضًا عن انتظار القرص الصّلب لوقتٍ طويل يتعذّر تقديره بدقّة. ما أن ينتهي القرص الصّلب من تجهيز البيانات المطلوبة، يُرسل إشارة مقاطعةٍ لوحدة المعالجة المركزيّة. يستطيع عندئذ معالج المقاطعة قراءةَ البيانات المطلوبة. قد تلاحظ أنّ هذا كلّه منطقيّ فقط عندما يكون لدى وحدة المعالجة المركزيّة عدة مهامٍ تنتظر تأديتها. فلا ضير إن قضت وحدة المعالجة المركزيّة وقتها تجسّ تفحصًّا لوجود دخلٍ أو بانتظار انتهاء عمليات محرك القرص الصلب إن لم يكن لديها شيء أفضل للقيام به. تعتمد جميع الحواسيب الحديثة على تعدّد المهام (multitasking) لأداء عدّة مهامٍ في آن واحد. قد يستخدمُ عدّة مستخدمين نفس الحاسوب. لمّا كانت وحدة المعالجة المركزيّة سريعةً للغاية، يمكنها بسهولةٍ وفعاليّة التّنقل بين المستخدمين مُكرّسة جزءًا من الثّانية لكلٍّ منهم في دوره. يُدعى تطبيق تعدّد المهام هذا بالمشاركة الزّمنيّة (timesharing). لكنّ هذا لا يمنع حاسوبًا حديثًا بمستخدم واحدٍ من استخدام تعدّد المهام. على سبيل المثال، قد يقوم المستخدم بقراءة مستندٍ بينما تعرض السّاعة الوقت على الشّاشة باستمرار أو يتمّ تحميل ملفٍ عبر الشّبكة. تُدعى كلُّ مهمةٍ فريدة من المهام التي تعمل عليها وحدة المعالجة المركزيّة بالخيط (thread أو العمليّة [Process]) – هناك فروق تقنيّة بين الخيوط والعمليّات لكنّها ليست ذات أهمية هنا على نظرًا لأنّ الخيوط فقط هي المُعتمدة في لغة جافا. تستطيع العديد من وحدات المعالجة المركزيّة تنفيذ أكثر من خيط في آن واحد حقًا. تحتوي وحدات المعالجة المركزيّة كهذه عدّة أنوية (core) تُنفّذ كلّ واحدة منها خيطًا مع العلم أنّ هناك حدًّا عدد الخيوط التي يمكن تنفيذها في آن واحد. ولمّا كان المُرجّح وجود خيوط أكثر ممّا يمكن تنفيذه في آن واحد، ينبغي على الحاسوب نقل التّنفيذ من خيط لآخر تمامًا كما يقوم حاسوب المشاركة الزّمنية بنقل التّنفيذ من مستخدمٍ لآخر. في الحالة العامّة، يستمرُّ الخيط الذي يجري تنفيذه بالعمل حتى يحدث أحد الأمور التّالية: قد يتنازل الخيط طوعًا عن سيطرته على النّواة ليمنح الخيوط الأخرى فرصةَ تنفيذ. قد يضطر الخيط لانتظار حصول حدثٍ غير متزامن. على سبيل المثال، قد يطلب الخيط بعض البيانات من القرص الصّلب أو يضطّر لانتظار أن يضغط المستخدم مفتاحًا. يُقال عن الخيط أثناء انتظاره أنّه محجوب (blocked) وتستطيع الخيوط الأخرى، في حال وجودها، أن تدخل التّنفيذ. عند حصول الحدث، تقوم مقاطعةٌ بإيقاظ الخيط لاستئناف تنفيذه. قد يستنفذ الخيط حصّته الزّمنية المخصّصة ويُعلّق مؤقتًا للسّماح بتنفيذ الخيوط الأخرى. تستطيع معظم الحواسيب تعليق خيطٍ قسريًّا بهذه الطريقة، يقال عندئذٍ أنّ هذه الحواسيب تستخدم تعدّد المهام الاستباقي (preemptive multitasking). يحتاج الحاسوب للقيام بتعدّد المهام الاستباقي إلى جهاز مؤقّت زمنيٍ خاص يُولّد مقاطعةً عند فواصل زمنيّة مُنتظمة، 100 مرةٍ في الثّانية مثلًا. عندما تحدث مقاطعة المؤقّت، يتسنّى لوحدة المعالجة المركزيّة الانتقال من خيطٍ إلى آخر بغضّ النّظر عن حالة أو حاجة الخيط الذي يجري تنفيذه. تستخدم جميع الحواسيب الحديثة المكتبيّة منها والمحمولة وحتّى الهواتف الذكيّة والأجهزة اللّوحية تعددَ المهام الاستباقي. لا حاجةَ للمستخدم العاديّ، بل وللمبرمج العاديّ أيضًا، للتّعامل مع المقاطعات ومعالجات المقاطعات. يمكن لهما التّركيز على المهام المختلفة التي يريدان للحاسوب أن يقوم بأدائها بصرف النّظر عن تفاصيل إدارة الحاسوب لعمليّة تنفيذ كل هذه المهام. في الحقيقة، يستطيع معظم المستخدمين – وبعض المبرمجين – تجاهل الخيوط وتعدد المهام كليًّا. على أيّة حال، فقد ازدادت أهميّة الخيوط مع ازدياد قدرة الحواسيب واستثمارها لمفهومي تعدد المهام وتعدد المعالجات. وفي واقع الأمر، أصبحت القدرة على العمل مع الخيوط مهارةً مهنيّةً أساسيّة للمبرمجين. لحسن الحظ، تُقدم جافا دعمًا جيّدًا للخيوط، إذ ضُمّنت الأخيرة في لغة البرمجة جافا على أنّها مفهومٌ برمجيٌّ أساسي. سنتناول البرمجة باستخدام الخيوط في الفصل 12. وعلى نفس المقدار من الأهميّة، في جافا والبرمجة الحديثة على حدٍّ سواء، نجد مفهوم الأحداث غير المتزامنة. وفي حين لا يضطّر المبرمجون للتّعامل مع المقاطعات مباشرةً، يجدون أنفسهم باستمرار وهم يكتبون معالجات أحداث (Event Handler). تُستدعى معالجات الأحداث، كما معالجات المقاطعات، على نحو غير متزامن عند حصول أحداث معينة. تختلف البرمجة المقادة بالأحداث (event-driven programming) هذه كليًّا عن البرمجة التّزامنيّة المباشرة التّقليديّة. سنبدأ أولًا بالبرمجة التقليدية التي لا تزال مستخدمة في برمجة المهام المفردة، ثمّ سنعود إلى الخيوط والأحداث لاحقًا بدءًا من الفصل 6. ولأن الشّيء بالشّيء يُذكر، فالبرمجيّة التي تقوم بجميع عمليّات معالجة المقاطعات وتتولّى التّواصل مع المستخدم وأجهزة العتاديّات، كما تضبط أيّ خيط يُسمح بتنفيذه تُدعى بنظام التّشغيل (Operating System). نظام التّشغيل هو البرمجيّة الجوهريّة الأساسيّة التي لا يستطيع الحاسوب أن يعمل بدونها. أمّا البرامج الأخرى، كمعالجات النّصوص ومتصفّحات الويب، فهي معتمدةٌ كليًّا ومنوطةٌ بنظام التشغيل. نذكر من أنظمة التّشغيل الشّائعة للحواسيب لينوكس (Linux)، ويندوز (Windows)، وماك (Mac OS) ومن أنظمة تشغيل الهواتف الذكية والأجهزة اللّوحية آندرويد (Android) و iOS. ترجمة -وبتصرف- للفصل Asynchronous Events: Polling Loops and Interrupts من الكتاب Introduction to Programming Using Java1 نقطة -
 الحاسوب نظامٌ مُعقّد مؤلّفٌ من العديد من المُكوّنات المختلفة. إلّا أنَّ هناك مُكوّنًًا فريدًا يقوم بالحوسبةِ الفعليّة، هذا المُكوّن هو وحدة المعالجة المركزيّة (Central Processing Unit) أو (CPU) وهو للحاسوب كالدّماغ للإنسان. في الحواسيب المكتبيّة الحديثة، تكون وحدة المعالجة المركزيّة عبارةً عن "رقاقةٍ" (Chip) لا يتجاوز حجمها إنشًا مُربّعًا (7 سنتيمترات مُربّعةً). مهمّةُ وحدة المعالجة المركزيّة هي تنفيذ البرامج. يتألّف البرنامج (Program) من قائمةٍ من تعليماتٍ واضحة لا لبس فيها يجبُ على الحاسوب اتّباعها آليًّا. صُمّم الحاسوب لتنفيذ التّعليمات المكتوبة بنوعٍ بسيطٍ من اللغات تدعى لغةَ الآلة (Machine Language). يملك كلُّ نوعٍ من الحواسيب لغة آلة خاصة به، ويستطيع الحاسوب تنفيذ البرنامج مباشرةً فقط إذا كان هذا البرنامج مكتوبًا بلغة الآلة المذكورة. يستطيع الحاسوب تنفيذ البرامج المكتوبة باستخدام لغاتٍ أخرى بعد أن تُترجم تلك البرامج إلى لغة الآلة حصرًا. عندما تُنفّذ وحدة المعالجة المركزيّة برنامجاً ما، يُخزّن هذا البرنامج في ذاكرة الحاسوب الرّئيسيّة (تدعى أيضًا ذاكرة الوصول العشوائي [Random Access Memory] أو RAM). بالإضافة إلى البرنامج الذي يجري تنفيذه، تحتفظ الذّاكرة أيضًا بالبيانات التي يقوم هذا البرنامج باستخدمها أو معالجتها. تتألّف الذّاكرة الرّئيسية من مُتتالية من المواقع (Location)؛ هذه المواقع مُرقّمةٌ ويُعبّر الرقم التّسلسليّ للموقع عن عنوانه (Address). يسمح العنوان بانتقاء معلومةٍ بعينها من بين ملايين المعلومات المُخزّنة في الذّاكرة. عندما تحتاج وحدة المعالجة المركزيّة إلى الوصول إلى تعليمة برنامج ما أو جزء من بياناته في موقع معيّن من الذّاكرة، تُرسل عنوان تلك المعلومة على شكلِ إشارةٍ إلى الذّاكرة. تستجيب الذّاكرة بإرسال القيمة المحتواة في ذاك العنوان. تُخزّن وحدة المعالجة المركزيّة المعلومات في الذّاكرة من خلال تحديد المعلومة المُراد تخزينها وعنوان الموقع المُراد تخزينها فيه. أمّا على مستوى لغة الآلة، فإنّ عمل وحدة المعالجة المركزيّة واضحٌ وبسيط إلى حدٍّ كبير على الرّغم من تعقيد تفاصيله. تُنفّذ وحدة المعالجة المركزيّة البرنامجَ المُخزّن على شكل متتاليةٍ من تعليمات لغة الآلة المُخزَّنة في الذّاكرة الرّئيسيّة وذلك بقراءة التّعليمة، أو جلبها (Fetch)، ومن ثُمّ تنفيذها (Execute)، مرارًا وتكرارًا. تُدعى العمليّة المُتمثّلة بجلب التّعليمة وتنفيذها، ثم جلب تعليمة أخرى وتنفيذها وهكذا إلى ما لا نهاية بدورة الجلب والتّنفيذ (fetch-and-execute cycle). هذه العمليّة هي جُلّ ما تقوم به وحدة المعالجة المركزيّة باستثناءٍ وحيد سنتناوله في القسم التّالي. يُصبح هذا الأمر أكثر تعقيدّا في الحواسيب الحديثة حيث تتألّف رقاقة المعالجة هذه الأيام من عدّة "أنوية" (core) تسمح بتنفيذ عدة تعليمات في آنٍ معًا. كما سُرّع الوصول للذّاكرة الرّئيسيّة من خلال الذّاكرة المخبئيّة (cache) التي صُمّمت للاحتفاظ بالبيانات والتّعليمات التي من المُرجّح أن تحتاجها وحدة المعالجة المركزيّة في وقتٍ قريب. على أيّة حال، لا تُغيّر هذه التّعقيدات من الوظيفة الأساسيّة لوحدة المعالجة المركزيّة. تنطوي وحدة المعالجة المركزيّة على وحدة الحساب والمنطق (Arithmetic Logic Unit أو ALU) والتي تُمثّل الجزء الذي يقوم بالعمليّات الرّياضيّة كالجمع والطّرح. كما تحتفظ وحدة المعالجة المركزيّة بعدد صغير من المسجّلات (register) تُمثّل هذه الأخيرة وحدات ذاكرة صغيرة قادرة على تخزين رقم واحد. قد تتوفّر وحدة المعالجة المركزيّة النموذجيّةُ على 16 أو 32 مسجلًا مُتعدّد الأغراض (general purpose)، وهي أحد أنواع الذاكرة، إذ تحتفظ هذه المسجلات بقيم البيانات المُتاحة للمعالجة مباشرةً وتُشير العديد من تعليمات لغة الآلة إلى هذه المسجلات. على سبيل المثال، قد تكون هناك تعليمة تأخذ رقمين من مسجلين مُحدّدين، تجمع هذين الرقمين (باستخدام وحدة الحساب والمنطق)، وتُخزّن النّتيجة في مسجل جديد. وقد تكون هناك تعليمات لنسخ قيم البيانات من الذّاكرة الرّئيسيّة إلى مسجل ما أو من مسجل إلى الذّاكرة الرّئيسيّة. كما تحتوي وحدة المعالجة المركزيّة على مُسجلات ذات أغراض خاصة (special purpose). أهمّ هذه المسجلات هو عدّاد البرنامج (program counter أو PC). تعتمد وحدة المعالجة المركزيّة على عدّاد البرنامج لتعقّب التّعليمة التي تُنفّذها من البرنامج. يُخزّن عدّاد البرنامج عنوان الذّاكرة للتّعليمة التّالية التي يتوجّب على وحدة المعالجة المركزيّة تنفيذها. تفحص وحدةُ المعالجة المركزيّة عدّادَ البرنامج في بداية كل دورة جلب وتنفيذ لمعرفة التّعليمة الواجب جلبها. يُحدَّث عدّادُ البرنامج خلال كل دورة جلب وتنفيذ للإشارة إلى التّعليمة الواجب تنفيذها في الدّورة التّالية والتي - عادةً ولكن ليس دائمًا - ما تكون التّعليمة التي تعقب التّعليمة الحاليّة في البرنامج. تُعدّل بعض لغات الآلة القيم المُخزّنة في عدّاد البرنامج على نحوٍ يسمح للحاسوب أن "يقفز" (jump) من نقطةٍ ما من البرنامج إلى نقطةٍ أخرى؛ هذا الأمر جوهريّ لتطبيق ميّزات برمجية تُعرف بالحلقات والفروع ستُناقَش في الجزء 1.4. يُنفّذ الحاسوب برامج لغة الآلة آليًّا دون الحاجة إلى فهمها أو التّفكير فيها ويعود هذا الأمر ببساطةٍ إلى طريقة التّركيب الفعليّة لهذه البرامج. هذا المفهوم ليس سهلًا. الحاسوبُ آلةٌ مبنيّة من ملايين المُبدّلات الصّغيرة والتي تدعى ترانزستورات (Transistor). تتميّز الترانزستورات بإمكانية توصيلها على نحوٍ يسمح أن يتحكّم خرج أحد هذه التّرانزستورات بترانزستور آخر (تشغيله أو إيقافه). بينما يقوم الحاسوب بالحوسبة، تقوم هذه المُبدّلات بتشغيل وإيقاف تشغيل بعضها بعضًا وفق نمطٍ تُمليه كلٍّ من طريقة وصلها ببعضها بعضًا من جهة والبرنامج الذي ينفذّه الحاسوب من جهة أخرى. تُمثّل تعليمات لغة الآلة على شكل أرقام ثنائيّة. يتألّف الرّقم الثّنائيّ من حالتين لا ثالث لهما: صفر وواحد. يُطلق على كلِّ صفر أو واحد تسمية بت (Bit). إذًا فلغة الآلة ما هي إلّا متتالية من الأصفار والواحدات. تُرمّز كل متتالية محدّدة تعليمة مُحدّدةً بعينها. تُرمّز البيانات التي يُعالجها الحاسوب أيضًا كأرقام ثنائيّة. في الحواسيب الحديثة، يحتفظ كل موقعٍ في الذّاكرة ببايت (Byte) والذي يُمثّل متتاليةً من ثمانية بتّات. عادةً ما تتألّف البيانات أو تعليمة لغة الآلة من عدّة بايتات مُخزّنة في مواضع متعاقبة من الذاكرة. على سبيل المثال، قد يقرأ الحاسوب فعليّا أربعة أو ثمانية بايتات عند قراءته تعليمةً واحدةً من الذّاكرة؛ ويكون عنوان الذّاكرة للتّعليمة هو عنوان أول بايت من تلك البايتات. يستطيع الحاسوب العمل مباشرةً مع الأرقام الثنائيّة لأن المبدّلات قادرةٌ على تمثيل هكذا أرقامٍ بسهولة: تشغيل التّرانزستور لتمثيل الرقم واحد؛ وإيقافه لتمثيل الرقم صفر. تُخزّن تعليمات لغة الآلة في الذّاكرة على شكل أنماطٍ من المبدّلات المُشغّلة أو المتوقّفة. عندما تُحمّل تعليمة لغة الآلة إلى وحدة المعالجة المركزيّة، فإنّ ما يحصل في الحقيقة هو تشغيل أو إيقاف مُبدّلات معينة وفقًا للنّمط الذي يُرمّز تلك التّعليمة. بُنيَت وحدة المعالجة المركزيّة للاستجابة لهذا النّمط بتنفيذ التّعليمة التي يُرمّزها ويُمكّنها من ذلك كونُ جميع المبدّلات في وحدة المعالجة المركزيّة موصولةً معًا. إذًا، عليك فهم ما يلي حول كيفيّة عمل الحاسوب: تحتفظ الذّاكرة الرّئيسيّة ببرامج وبيانات لغة الآلة. تُرمَّز كلٌّ من هاتين الأخيرتين كأرقام ثنائيّة. تجلب وحدة المعالجة المركزيّة تعليمات لغة الآلة من الذّاكرة واحدةً تلو الأخرى وتُنفّذها. تُؤدّي وحدة المعالجة المركزيّة مهامًّا صغيرةً جدًا وفقًا لكل تعليمة، مثل جمع عددين أو نقل البيانات من وإلى الذاكرة. تقوم وحدة المعالجة المركزيّة بكلّ هذا آليًّا بدون التّفكير فيه أو فهم الهدف منه لهذا يتوّجب على البرنامج الذي سيُنفّذ أن يكون مُتقنًا، كاملًا بكل تفاصيله، وخاليًا من أيّ لبس لأن وحدة المعالجة المركزيّة عاجزةٌ إلّا عن تنفيذه تمامًا كما هو مكتوب. إليك رؤيةً تخطيطيّة لهذه المرحلة من فهمنا للحاسوب: ترجمة -وبتصرف- للقسم The Fetch and Execute Cycle: Machine Language من الكتاب Introduction to Programming Using Java1 نقطة
الحاسوب نظامٌ مُعقّد مؤلّفٌ من العديد من المُكوّنات المختلفة. إلّا أنَّ هناك مُكوّنًًا فريدًا يقوم بالحوسبةِ الفعليّة، هذا المُكوّن هو وحدة المعالجة المركزيّة (Central Processing Unit) أو (CPU) وهو للحاسوب كالدّماغ للإنسان. في الحواسيب المكتبيّة الحديثة، تكون وحدة المعالجة المركزيّة عبارةً عن "رقاقةٍ" (Chip) لا يتجاوز حجمها إنشًا مُربّعًا (7 سنتيمترات مُربّعةً). مهمّةُ وحدة المعالجة المركزيّة هي تنفيذ البرامج. يتألّف البرنامج (Program) من قائمةٍ من تعليماتٍ واضحة لا لبس فيها يجبُ على الحاسوب اتّباعها آليًّا. صُمّم الحاسوب لتنفيذ التّعليمات المكتوبة بنوعٍ بسيطٍ من اللغات تدعى لغةَ الآلة (Machine Language). يملك كلُّ نوعٍ من الحواسيب لغة آلة خاصة به، ويستطيع الحاسوب تنفيذ البرنامج مباشرةً فقط إذا كان هذا البرنامج مكتوبًا بلغة الآلة المذكورة. يستطيع الحاسوب تنفيذ البرامج المكتوبة باستخدام لغاتٍ أخرى بعد أن تُترجم تلك البرامج إلى لغة الآلة حصرًا. عندما تُنفّذ وحدة المعالجة المركزيّة برنامجاً ما، يُخزّن هذا البرنامج في ذاكرة الحاسوب الرّئيسيّة (تدعى أيضًا ذاكرة الوصول العشوائي [Random Access Memory] أو RAM). بالإضافة إلى البرنامج الذي يجري تنفيذه، تحتفظ الذّاكرة أيضًا بالبيانات التي يقوم هذا البرنامج باستخدمها أو معالجتها. تتألّف الذّاكرة الرّئيسية من مُتتالية من المواقع (Location)؛ هذه المواقع مُرقّمةٌ ويُعبّر الرقم التّسلسليّ للموقع عن عنوانه (Address). يسمح العنوان بانتقاء معلومةٍ بعينها من بين ملايين المعلومات المُخزّنة في الذّاكرة. عندما تحتاج وحدة المعالجة المركزيّة إلى الوصول إلى تعليمة برنامج ما أو جزء من بياناته في موقع معيّن من الذّاكرة، تُرسل عنوان تلك المعلومة على شكلِ إشارةٍ إلى الذّاكرة. تستجيب الذّاكرة بإرسال القيمة المحتواة في ذاك العنوان. تُخزّن وحدة المعالجة المركزيّة المعلومات في الذّاكرة من خلال تحديد المعلومة المُراد تخزينها وعنوان الموقع المُراد تخزينها فيه. أمّا على مستوى لغة الآلة، فإنّ عمل وحدة المعالجة المركزيّة واضحٌ وبسيط إلى حدٍّ كبير على الرّغم من تعقيد تفاصيله. تُنفّذ وحدة المعالجة المركزيّة البرنامجَ المُخزّن على شكل متتاليةٍ من تعليمات لغة الآلة المُخزَّنة في الذّاكرة الرّئيسيّة وذلك بقراءة التّعليمة، أو جلبها (Fetch)، ومن ثُمّ تنفيذها (Execute)، مرارًا وتكرارًا. تُدعى العمليّة المُتمثّلة بجلب التّعليمة وتنفيذها، ثم جلب تعليمة أخرى وتنفيذها وهكذا إلى ما لا نهاية بدورة الجلب والتّنفيذ (fetch-and-execute cycle). هذه العمليّة هي جُلّ ما تقوم به وحدة المعالجة المركزيّة باستثناءٍ وحيد سنتناوله في القسم التّالي. يُصبح هذا الأمر أكثر تعقيدّا في الحواسيب الحديثة حيث تتألّف رقاقة المعالجة هذه الأيام من عدّة "أنوية" (core) تسمح بتنفيذ عدة تعليمات في آنٍ معًا. كما سُرّع الوصول للذّاكرة الرّئيسيّة من خلال الذّاكرة المخبئيّة (cache) التي صُمّمت للاحتفاظ بالبيانات والتّعليمات التي من المُرجّح أن تحتاجها وحدة المعالجة المركزيّة في وقتٍ قريب. على أيّة حال، لا تُغيّر هذه التّعقيدات من الوظيفة الأساسيّة لوحدة المعالجة المركزيّة. تنطوي وحدة المعالجة المركزيّة على وحدة الحساب والمنطق (Arithmetic Logic Unit أو ALU) والتي تُمثّل الجزء الذي يقوم بالعمليّات الرّياضيّة كالجمع والطّرح. كما تحتفظ وحدة المعالجة المركزيّة بعدد صغير من المسجّلات (register) تُمثّل هذه الأخيرة وحدات ذاكرة صغيرة قادرة على تخزين رقم واحد. قد تتوفّر وحدة المعالجة المركزيّة النموذجيّةُ على 16 أو 32 مسجلًا مُتعدّد الأغراض (general purpose)، وهي أحد أنواع الذاكرة، إذ تحتفظ هذه المسجلات بقيم البيانات المُتاحة للمعالجة مباشرةً وتُشير العديد من تعليمات لغة الآلة إلى هذه المسجلات. على سبيل المثال، قد تكون هناك تعليمة تأخذ رقمين من مسجلين مُحدّدين، تجمع هذين الرقمين (باستخدام وحدة الحساب والمنطق)، وتُخزّن النّتيجة في مسجل جديد. وقد تكون هناك تعليمات لنسخ قيم البيانات من الذّاكرة الرّئيسيّة إلى مسجل ما أو من مسجل إلى الذّاكرة الرّئيسيّة. كما تحتوي وحدة المعالجة المركزيّة على مُسجلات ذات أغراض خاصة (special purpose). أهمّ هذه المسجلات هو عدّاد البرنامج (program counter أو PC). تعتمد وحدة المعالجة المركزيّة على عدّاد البرنامج لتعقّب التّعليمة التي تُنفّذها من البرنامج. يُخزّن عدّاد البرنامج عنوان الذّاكرة للتّعليمة التّالية التي يتوجّب على وحدة المعالجة المركزيّة تنفيذها. تفحص وحدةُ المعالجة المركزيّة عدّادَ البرنامج في بداية كل دورة جلب وتنفيذ لمعرفة التّعليمة الواجب جلبها. يُحدَّث عدّادُ البرنامج خلال كل دورة جلب وتنفيذ للإشارة إلى التّعليمة الواجب تنفيذها في الدّورة التّالية والتي - عادةً ولكن ليس دائمًا - ما تكون التّعليمة التي تعقب التّعليمة الحاليّة في البرنامج. تُعدّل بعض لغات الآلة القيم المُخزّنة في عدّاد البرنامج على نحوٍ يسمح للحاسوب أن "يقفز" (jump) من نقطةٍ ما من البرنامج إلى نقطةٍ أخرى؛ هذا الأمر جوهريّ لتطبيق ميّزات برمجية تُعرف بالحلقات والفروع ستُناقَش في الجزء 1.4. يُنفّذ الحاسوب برامج لغة الآلة آليًّا دون الحاجة إلى فهمها أو التّفكير فيها ويعود هذا الأمر ببساطةٍ إلى طريقة التّركيب الفعليّة لهذه البرامج. هذا المفهوم ليس سهلًا. الحاسوبُ آلةٌ مبنيّة من ملايين المُبدّلات الصّغيرة والتي تدعى ترانزستورات (Transistor). تتميّز الترانزستورات بإمكانية توصيلها على نحوٍ يسمح أن يتحكّم خرج أحد هذه التّرانزستورات بترانزستور آخر (تشغيله أو إيقافه). بينما يقوم الحاسوب بالحوسبة، تقوم هذه المُبدّلات بتشغيل وإيقاف تشغيل بعضها بعضًا وفق نمطٍ تُمليه كلٍّ من طريقة وصلها ببعضها بعضًا من جهة والبرنامج الذي ينفذّه الحاسوب من جهة أخرى. تُمثّل تعليمات لغة الآلة على شكل أرقام ثنائيّة. يتألّف الرّقم الثّنائيّ من حالتين لا ثالث لهما: صفر وواحد. يُطلق على كلِّ صفر أو واحد تسمية بت (Bit). إذًا فلغة الآلة ما هي إلّا متتالية من الأصفار والواحدات. تُرمّز كل متتالية محدّدة تعليمة مُحدّدةً بعينها. تُرمّز البيانات التي يُعالجها الحاسوب أيضًا كأرقام ثنائيّة. في الحواسيب الحديثة، يحتفظ كل موقعٍ في الذّاكرة ببايت (Byte) والذي يُمثّل متتاليةً من ثمانية بتّات. عادةً ما تتألّف البيانات أو تعليمة لغة الآلة من عدّة بايتات مُخزّنة في مواضع متعاقبة من الذاكرة. على سبيل المثال، قد يقرأ الحاسوب فعليّا أربعة أو ثمانية بايتات عند قراءته تعليمةً واحدةً من الذّاكرة؛ ويكون عنوان الذّاكرة للتّعليمة هو عنوان أول بايت من تلك البايتات. يستطيع الحاسوب العمل مباشرةً مع الأرقام الثنائيّة لأن المبدّلات قادرةٌ على تمثيل هكذا أرقامٍ بسهولة: تشغيل التّرانزستور لتمثيل الرقم واحد؛ وإيقافه لتمثيل الرقم صفر. تُخزّن تعليمات لغة الآلة في الذّاكرة على شكل أنماطٍ من المبدّلات المُشغّلة أو المتوقّفة. عندما تُحمّل تعليمة لغة الآلة إلى وحدة المعالجة المركزيّة، فإنّ ما يحصل في الحقيقة هو تشغيل أو إيقاف مُبدّلات معينة وفقًا للنّمط الذي يُرمّز تلك التّعليمة. بُنيَت وحدة المعالجة المركزيّة للاستجابة لهذا النّمط بتنفيذ التّعليمة التي يُرمّزها ويُمكّنها من ذلك كونُ جميع المبدّلات في وحدة المعالجة المركزيّة موصولةً معًا. إذًا، عليك فهم ما يلي حول كيفيّة عمل الحاسوب: تحتفظ الذّاكرة الرّئيسيّة ببرامج وبيانات لغة الآلة. تُرمَّز كلٌّ من هاتين الأخيرتين كأرقام ثنائيّة. تجلب وحدة المعالجة المركزيّة تعليمات لغة الآلة من الذّاكرة واحدةً تلو الأخرى وتُنفّذها. تُؤدّي وحدة المعالجة المركزيّة مهامًّا صغيرةً جدًا وفقًا لكل تعليمة، مثل جمع عددين أو نقل البيانات من وإلى الذاكرة. تقوم وحدة المعالجة المركزيّة بكلّ هذا آليًّا بدون التّفكير فيه أو فهم الهدف منه لهذا يتوّجب على البرنامج الذي سيُنفّذ أن يكون مُتقنًا، كاملًا بكل تفاصيله، وخاليًا من أيّ لبس لأن وحدة المعالجة المركزيّة عاجزةٌ إلّا عن تنفيذه تمامًا كما هو مكتوب. إليك رؤيةً تخطيطيّة لهذه المرحلة من فهمنا للحاسوب: ترجمة -وبتصرف- للقسم The Fetch and Execute Cycle: Machine Language من الكتاب Introduction to Programming Using Java1 نقطة -
هناك الكثير من الاختيارات التي يمكنك استخدامها حيال هذا الأمر والاول هو استخدام atlas cluster وهي استضافة توفرها mongodb لقاعدة البيانات يمكنك البحث عن mongodb atlas في غوغل وفتح حساب في atlas ثم انشاء قاعدة بيانات محمية ب username و password وأيضا يمكنك أن تعمل whitelist لل ip الخاص ب vps خاصتك وستحصل في الأخير على رابط لاستخدام قاعدة البيانات الاختيار الثاني وتوفره digitalocean وهو أيضا cluster ل mongodb يكلف 15 دولار شهريا وهو سهل التثبيت تتبع خطوات جد بسيطة ثم تحصل على الرابط لاستخدام قاعدة البيانات تلك الاختيار الثالث هو أن تثبت mongodb في ال vps نفسه وتستخدمه localy في server انه نفس الشئ كاستخدامه في كمبيوتر محلي لكن هذه الطريقة قد تكون صحيح ليست مكلفة لكن لا انصح بها في تطبيق انتاجي1 نقطة
-
 ركّزنا في المقالات السابقة من هذه السلسلة على صحة البرامج، وإلى جانب ذلك، تُعَد مشكلة الكفاءة efficiency من المشاكل المهمة كذلك، فعندما نحلِّل كفاءة برنامجٍ ما، فعادةً ما تُطرح أسئلةٌ مثل كم من الوقت سيستغرقه البرنامج؟ وهل هناك طريقةٌ أخرى للحصول على نفس الإجابة ولكن بطريقةٍ أسرع؟ وعمومًا دائمًا ما ستكون كفاءة البرنامج أقلّ أهميةً من صحته؛ فإذا لم تهتم بصحة البرنامج، فيمكنك إذًا أن تشغّله بسرعةٍ، ولكن قلّما سيهتم به أحدٌ. كذلك لا توجد أي فائدةٍ من برنامجٍ يستغرق عشرات الآلاف من السنين ليعطيك إجابةً صحيحةً. يشير مصطلح الكفاءة عمومًا إلى الاستخدام الأمثل لأي مورِد resource بما في ذلك الوقت وذاكرة الحاسوب ونطاق التردد الشبكي، وسنركّز في هذا المقال على الوقت، والسؤال الأهم الذي نريد الإجابة عليه هو ما الوقت الذي يستغرقه البرنامج ليُنجز المَهمّة الموكلة إليه؟ في الواقع، ليس هناك أي معنىً من تصنيف البرامج على أنها تعمل بكفاءةٍ أم لا، وإنما يكون من الأنسب أن نوازن بين برنامجين صحيحين ينفّذان نفس المهمة لنعرف أيًا منهما أكثر كفاءةً من الآخر، بمعنى أيهما ينجز مهمّته بصورةٍ أسرع، إلا أن تحديد ذلك ليس بالأمر السهل لأن زمن تشغيل البرنامج غير معرَّف؛ فقد يختلف حسب عدد معالجات الحاسوب وسرعتها، كما قد يعتمد على تصميم آلة جافا الافتراضية Java Virtual Machine (في حالة برامج جافا) المفسِّرة للبرنامج؛ وقد يعتمد كذلك على المصرّف المستخدَم لتصريف البرنامج إلى لغة الآلة، كما يعتمد زمن تشغيل أي برنامجٍ على حجم المشكلة التي ينبغي للبرنامج أن يحلّها، فمثلًا سيستغرق برنامج ترتيب sorting وقتًا أطول لترتيب 10000 عنصر مما سيستغرقه لترتيب 100 عنصر؛ وعندما نوازن بين زمنيْ تشغيل برنامجين، سنجد أن برنامج A يحلّ المشاكل الصغيرة أسرع بكثيرٍ من برنامج B بينما يحلّ البرنامج B المشاكل الكبيرة أسرع من البرنامج A، فلا يوجد برنامجٌ معينٌ هو الأسرع دائمًا في جميع الحالات. عمومًا، هناك حقلٌ ضِمن علوم الحاسوب يُكرّس لتحليل كفاءة البرامج، ويعرف باسم تحليل الخوارزميات Analysis of Algorithms، حيث يركِّز على الخوارزميات نفسها لا البرامج؛ لتجنُّب التعامل مع التنفيذات implementations المختلفة لنفس الخوارزمية باستخدام لغاتٍ برمجيةٍ مختلفةٍ ومصرّفةٍ بأدواتٍ مختلفةٍ وتعمل على حواسيب مختلفةٍ؛ وعمومًا يُعَد مجال تحليل الخوارزميات مجالًا رياضيًا مجرّدًا عن كل تلك التفاصيل الصغيرة، فعلى الرغم من أنه حقلٌ نظريٌ في المقام الأول، إلا أنه يلزَم كلّ مبرمجٍ أن يطّلع على بعضٍ من تقنياته ومفاهيمه الأساسية، ولهذا سيَتناول هذا المقال مقدمةً مختصرةً جدًا عن بعضٍ من تلك الأساسيات والمفاهيم، ولأن هذه السلسلة ليست ذات اتجاه رياضي، فستكون المناقشة عامةً نوعًا ما. يُعَد التحليل المُقارِب asymptotic analysis أحد أهم تقنيات ذلك المجال، ويُقصد بالمُقارِب asymptotic ما يميل إليه على المدى البعيد بازدياد حجم المشكلة، حيث يجيب التحليل المُقارِب لزمن تشغيل run time خوارزميةٍ عن أسئلةٍ مثل، كيف يؤثر حجم المشكلة problem size على زمن التشغيل؟ ويُعَد التحليل مُقارِبًا؛ لأنه يهتم بما سيحدث لزمن التشغيل عند زيادة حجم المشكلة بدون أي قيودٍ، أما ما سيحدث للأحجام الصغيرة من المشاكل فهي أمورٌ لا تعنيه؛ فإذا أظهر التحليل المُقارِب لخوارزمية A أنها أسرع من خوارزمية B، فلا يعني ذلك بالضرورة أن الخوارزمية A ستكون أسرع من B عندما يكون حجم المشكلة صغيرًا مثل 10 أو 1000 أو حتى 1000000، وإنما يعني أنه بزيادة حجم المشكلة، ستصل حتمًا إلى نقطةٍ تكون عندها خوارزمية A أسرع من خوارزمية B. يرتبط مفهوم التحليل المُقارِب بـمصطلح ترميز O الكبير Big-Oh notation، حيث يمكّننا هذا الترميز من قوْل أن زمن تشغيل خوارزميةٍ معينةٍ هو O(n2) أو O(n) أو O(log(n))، وعمومًا يُشار إليه بـ O(f(n))، حيث f(n) عِبارةٌ عن دالة تُسند عددًا حقيقيًا موجبًا لكلّ عددٍ صحيحٍ موجبٍ n، بينما يشير n ضِمن هذا الترميز إلى حجم المشكلة، ولذلك يلزَمك أن تحدّد حجم المشكلة قبل أن تبدأ في تحليلها، وهو ليس أمرًا معقدًا على أية حال؛ فمثلًا، إذا كانت المشكلة هي ترتيب قائمةٍ من العناصر، فإن حجم تلك المشكلة يمكنه أن يكون عدد العناصر ضِمن القائمة، وهذا مثالٌ آخرٌ، عندما يكون مُدخَل الخوارزمية عِبارةٌ عن عددٍ صحيحٍ (لفحْص إذا ما كان ذلك العدد عددًا أوليًا prime أم لا) يكون حجم المشكلة في تلك الحالة هو عدد البتات bits الموجودة ضِمن ذلك العدد المُدخَل لا العدد ذاته؛ وعمومًا يُعَد عدد البتات bits الموجودة في قيمة المُدخَل قياسًا جيدًا لحجم المشكلة. إذا كان زمن تشغيل خوارزميةٍ معينةٍ هو O(f(n))، فذلك يعني أنه بالنسبة للقيم الكبيرة من حجم المشكلة، لن يتعدى الزمن حاصل ضرْب قيمةٍ ثابتةٍ معينةٍ في f(n)، أي أن هناك عدد C وعددٌ صحيحٌ آخرٌ موجبٌ M، وعندما تصبح n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أقلّ من أو يساوي C×f(n)؛ حيث يأخذ الثابت C في حسبانه تفاصيلًا مثل سرعة الحاسوب المستخدَم في تشغيل الخوارزمية، وإذا كان ذلك الحاسوب أبطأ، فقد تستخدم قيمة أكبر للثابت، إلا أن تغييره لن يغيّر من حقيقة أن زمن تشغيل الخوارزمية هو O(f(n)؛ وبفضل ذلك الثابت، لن يكون من الضروري تحديد إذا ما كنا نقيس الزمن بالثواني أو السنوات أو أي وحدة قياسٍ أخرى؛ لأن التحويل من وحدةٍ معينةٍ إلى أخرى يتمثَّل بعملية ضربٍ في قيمة ثابتة، بالإضافة إلى ما سبق، لا تَعتمد O(f(n)) نهائيًا على ما يحدُث في الأحجام الأصغر من المشكلة، وإنما على ما يحدُث على المدى الطويل بينما يزيد حجم المشكلة دون أي قيودٍ. سنفحص مثالًا بسيطًا عِبارةً عن حساب حاصل مجموع العناصر الموجودة ضِمن مصفوفةٍ، وفي هذه الحالة، يكون حجم المشكلة n هو طول تلك المصفوفة، فإذا كان A هو اسم المصفوفة، ستُكتب الخوارزمية بلغة جافا كالتالي: total = 0; for (int i = 0; i < n; i++) total = total + A[i]; تنفِّذ الخوارزمية عملية total = total + A[i] عدد n من المرات، أي أن الزمن الكلي المُستغرق أثناء تلك العملية يساوي a×n، حيث a هو زمن تنفيذ العملية مرةٍ واحدةٍ؛ إلى جانب ذلك، تزيد الخوارزمية قيمة المتغيّر i وتوازنه مع قيمة n في كلّ مرةٍ تنفِّذ فيها مَتْن الحلقة loop، الأمر الذي يؤدي إلى زيادة زمن التشغيل بمقدار يساوي b×n حيث b عِبارةٌ عن ثابتٍ، وبالإضافة إلى ما سبق، يُهيئ كلًا من i وtotal إلى الصفر مبدئيًا مما يزيد من زمن التشغيل بمقدار ثابتٍ معينٍ وليكن c، وبالتالي، يساوي زمن تشغيل الخوارزمية للقيمة (a+b)×n+c، حيث a وb وc عِبارةٌ عن ثوابتٍ تعتمد على عوامل مثل كيفية تصريف compile الشيفرة ونوع الحاسوب المستخدَم، وبالاعتماد على حقيقة أن c دائمًا ما تكون أقلّ من أو تساوي c×n لأي عددٍ صحيحٍ موجبٍ n، يمكننا إذًا أن نقول أن زمن التشغيل أقلّ من أو يساوي (a+b+c)×n، أي أنه أقلّ من أو يساوي حاصل ضرْب ثابتٍ في n، أي يكون زمن تشغيل الخوارزمية هو O(n). إذا استشكل عليك أن تفهم ما سبق، فإنه يعني أنه لأي قيم n كبيرة، فإن الثابت c في المعادلة (a+b)×n+c غير مهمٍ إذا ووزِن مع (a+b)×n، ونصيغ ذلك بأن نقول إن c تعبّر عن عنصرٍ ذات رتبةٍ أقل lower order، وعادةً ما نتجاهل تلك العناصر في سياق التحليل المُقارِب؛ ويمكن لتحليلٍ مُقارِب آخرٍ أكثر حدَّة أن يستنتج ما يلي: "يَستغرق كلّ تكرار iteration ضِمن حلقة for مقدارًا ثابتًا من الوقت، ولأن الخوارزمية تتضمّن عدد n من التكرارات، فإن زمن التشغيل الكلي هو حاصل ضرْب ثابتٍ في n مضافًا إليه عناصر ذات رتبة أقلّ للتهيئة المبدئية، وإذا تجاهلنا تلك العناصر، سنجد أن زمن التشغيل يساوي O(n). يفيد أحيانًا أن نخصِّص حدًا أدنىً lower limit لزمن التشغيل، حيث سيمكّننا ذلك من أن نقول أن زمن تشغيل خوارزميةٍ معينةٍ أكبر من أو يساوي حاصل ضرْب قيمةٍ ثابتةٍ في f(n)، وهو ما يعرّفه ترميزٌ آخرٌ هو Ω(f(n))، ويُقرأ أوميجا لدالة f أو ترميز أوميجا الكبير لدالة f (أوميجا Omega هو حرفٌ أبجديٌ يونانيٌ ويمثِّل الترميز Ω حالته الكبيرة)؛ وإذا شئنا الدقة، عندما نقول أن زمن تشغيل خوارزمية هو Ω(f(n))، فإن المقصود هو وجود عددٍ موجبٍ C وعددٍ صحيحٍ آخرٍ موجبٍ M، وعندما تكون قيمة n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أكبر من أو يساوي حاصل ضرْب C في f(n)، ونستخلّص مما سبق أن O(f(n)) يوفّر معلومةً عن الحد الأقصى للزمن الذي قد تنتظره حتى تنتهي الخوارزمية من العمل، بينما يوفّر Ω(f(n)) معلومةً عن الحد الأدنى للزمن. سنفْحص الآن خوارزميةً أخرى: public static void simpleBubbleSort( int[] A, int n ) { for (int i = 0; i < n; i++) { // Do n passes through the array... for (int j = 0; j < n-1; j++) { if ( A[j] > A[j+1] ) { // A[j] و A[j+1] رتِّب int temp = A[j]; A[j] = A[j+1]; A[j+1] = temp; } } } } يمثِّل المعامِل n في المثال السابق حجم المشكلة، حيث ينفِّذ الحاسوب حلقة for الخارجية عدد n من المرات، وفي كلّ مرة ينفِّذ فيها تلك الحلقة، فإنه ينفِّذ أيضًا حلقة for داخليةً عدد n-1 من المرات، إذًا سينفّذ الحاسوب تعليمة if عدد n×(n-1) من المرات، أي يساوي n2-n، ولأن العناصر ذات الرتبة الأقل غير مهمّةٍ في التحليل المُقارِب، سنكتفي بأن نقول أن تعليمة if تنفَّذ عدد n2 مرةٍ؛ وعلى وجهٍ أكثر تحديدًا، ينفِّذ الحاسوب الاختبار A[j] > A[j+1] عدد n2 من المرات، ويكون زمن تشغيل الخوارزمية هو Ω( n2)، أي يساوي حاصل ضرْب قيمةٍ ثابتةٍ في n2 على الأقل، وإذا فحصنا العمليات الأخرى (تعليمات الإسناد assignment وزيادة i وj بمقدار الواحد..إلخ)، فإننا لن نجد أي عمليةً منها تنفَّذ أكثر من عدد n2 مرة؛ ونستنتج من ذلك أن زمن التشغيل هو O(n2) أيضًا، أي أنه لن يتجاوز حاصل ضرْب قيمةٍ ثابتةٍ في n2، ونظرًا لأن زمن التشغيل يساوي كلًا من Ω( n2) و O( n2)، فإنه أيضًا يساوي Θ( n2). لقد أوضحنا حتى الآن أن زمن التشغيل يعتمد على حجم المشكلة، ولكننا تجاهلنا تفصيلةٍ مهمةٍ أخرى، وهي أنه لا يعتمد فقط على حجم المشكلة، وإنما كثيرًا ما يعتمد على نوعية البيانات المطلوب معالجتها، فمثلًا قد يعتمد زمن تشغيل خوارزمية ترتيب على الترتيب الأولي للعناصر المطلوب ترتيبها، وليس فقط على عددها. لكي نأخذ تلك الاعتمادية في الحسبان، سنُجري تحليلًا لزمن التشغيل على كلًا من الحالة الأسوأ the worst case analysis والحالة الوسطى average case analysis، بالنسبة لتحليل زمن تشغيل الحالة الأسوأ، سنفحص جميع المشاكل المحتملة لحجم يساوي n وسنحدّد أطول زمن تشغيل من بينها جميعًا، بالمِثل بالنسبة للحالة الوسطى، سنفحص جميع المشاكل المحتملة لحجم يساوي n ونحسب قيمة متوسط زمن تشغيلها جميعًا، وعمومًا سيَفترض تحليل زمن التشغيل للحالة الوسطى أن جميع المشاكل بحجم n لها نفس احتمالية الحدوث على الرغم من عدم واقعية ذلك في بعض الأحيان، أو حتى إمكانية حدوثه وذلك في حالة وجود عددٍ لا نهائيٍ من المشاكل المختلفة لحجمٍ معينٍ. عادةً ما يتساوى زمن تشغيل الحالة الأسوأ والوسطى ضِمن مُضاعفٍ ثابتٍ، وذلك يعني أنهما متساويان بقدر اهتمام التحليل المُقارِب، أي أن زمن تشغيل الحالة الوسطى والحالة الأسوأ هو O(f(n)) أو Θ(f(n))، إلا أن هنالك بعض الحالات القليلة التي يختلف فيها التحليل المُقارِب للحالة الأسوأ عن الحالة الوسطى كما سنرى لاحقًا. بالإضافة إلى ما سبق، يمكن مناقشة تحليل زمن تشغيل الحالة المُثلى best case، والذي سيفحص أقصر زمن تشغيلٍ ممكنٍ لجميع المُدخَلات من حجمٍ معينٍ، وعمومًا يُعَد أقلهم فائدةً. حسنًا، ما الذي ينبغي أن تعرفه حقًا عن تحليل الخوارزميات لتستكمل قراءة ما هو متبقّيٍ من هذه السلسلة؟ في الواقع، لن نقدِم على أي تحليلٍ رياضيٍ حقيقيٍ، ولكن ينبغي أن تفهَم بعض المناقشات العامة عن حالاتٍ بسيطةٍ مثل الأمثلة التي رأيناها في هذا المقال، والأهم من ذلك هو أن تفهم ما يعنيه بالضبط قوْل أن وقت تشغيل خوارزميةٍ معينةٍ هو O(f(n)) أو Θ(f(n)) لبعض الدوال الشائعة f(n)، كما أن النقطة المُهمّة هي أن تلك الترميزات لا تُخبرك أي شيءٍ عن القيمة العددية الفعلية لزمن تشغيل الخوارزمية لأي حالةٍ معينةٍ كما أنها لا تخبرك بأي شيءٍ عن زمن تشغيل الخوارزمية للقيم الصغيرة من n، وإنما ستخبرك بمعدل زيادة زمن التشغيل بزيادة حجم المشكلة. سنفترض أننا نوازن بين خوارزميتين لحل نفس المشكلة، وزمن تشغيل إحداها هو Θ( n2) بينما زمن تشغيل الأخرى هو Θ(n3)، فما الذي يعنيه ذلك؟ إذا كنت تريد معرفة أي خوارزميةٍ منهما هي الأسرع لمشكلةٍ حجمها 100 مثلًا، فالأمر غير مؤكدٍ، فوِفقًا للتحليل المُقارِب يمكن أن تكون أي خوارزميةٍ منهما هي الأسرع في هذه الحالة؛ أما بالنسبة للمشاكل الأكبر حجمًا، سيصل حجم المشكلة n إلى نقطةٍ تكون معها خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)؛ وعلاوةً على ذلك، يزداد تميز خوارزمية Θ( n2) عن خوارزمية Θ(n3) بزيادة حجم المشكلة أكثر فأكثر، وعمومًا ستكون هناك قيمٌ لحجم المشكلة n تكون معها خوارزمية Θ( n2) أسرع ألف مرةٍ أو مليون مرةٍ أو حتى بليون مرةٍ وهكذا؛ وذلك لأن دالة a×n3 تنمو أسرع بكثيرٍ من دالة b×n2 لأي ثابتين موجبين a وb، وذلك يعني أنه بالنسبة للمشاكل الكبيرة، ستكون خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)، ونحن لا نعرف بالضبط إلى أي درجةٍ بالضبط ينبغي أن تكون المشكلة كبيرةٌ، وعمليًا، يُحتمل لخوارزمية Θ( n2) أن تكون أسرع حتى للقيم الصغيرة من حجم المشكلة n؛ وعمومًا تُفضّل خوارزمية Θ( n2) عن خوارزمية Θ(n3). لكي تفهم وتطبّق التحليل المُقارِب، لابدّ أن يكون لديك فكرةً عن معدّل نمو بعض الدوال الشائعة، وبالنسبة للدوال الأسية (power) n, n2, n3, n4, …,، كلما كان الأس أكبر، ازداد معدّل نمو الدالة؛ أما بالنسبة للدوال الأسية exponential من النوع 2n و 10n حيث n هو الأس، يكون معدّل نموها أسرع بكثيرٍ من أي دالةٍ أسيةٍ عاديةٍ power، وعمومًا تنمو الدوال الأسية بسرعةٍ جدًا لدرجة تجعل الخوارزميات التي ينمو زمن تشغيلها بذلك المعدّل غير عمليةٍ عمومًا حتى للقيم الصغيرة من n لأن زمن التشغيل طويلٌ جدًا، وإلى جانب ذلك، تُستخدم دالة اللوغاريتم log(n) بكثرةٍ في التحليل المُقارِب، فإذا كان هناك عددٌ كبيرٌ من دوال اللوغاريتم، ولكن تلك التي أساسها يساوي 2 هي الأكثر استخدامًا في علوم الحاسوب، وتُكتب عادة كالتالي log2(n)، حيث تنمو دالة اللوغاريتم ببطئٍ إلى درجةٍ أبطأ من معدّل نمو n، وينبغي أن يساعدك الجدول التالي على فهم الفروق بين معدّلات النمو للدوال المختلفة: يرجع السبب وراء استخدام log(n) بكثرةٍ إلى ارتباطها بالضرب والقسمة على 2، سنفْترض أنك بدأت بعدد n ثم قسَمته على 2 ثم قسَمته على 2 مرةٍ أخرى، وهكذا إلى أن وصَلت إلى عددٍ أقل من أو يساوي 1، سيساوي عدد مرات القسمة (مقربًا لأقرب عدد صحيح) لقيمة log(n). فمثلًا انظر إلى خوارزمية البحث الثنائي binary search في مقال البحث والترتيب في المصفوفات Array في جافا، حيث تبحث تلك الخوارزمية عن عنصرٍ ضِمن مصفوفةٍ مرتّبةٍ، وسنستخدم طول المصفوفة مثل حجمٍ للمشكلة n، إذ يُقسَم عدد عناصر المصفوفة على 2 في كلّ خطوةٍ ضِمن خوارزمية البحث الثنائي، بحيث تتوقّف عندما يصبح عدد عناصرها أقلّ من أو يساوي 1، وذلك يعني أن عدد خطوات الخوارزمية لمصفوفة طولها n يساوي log(n) للحدّ الأقصى؛ ونستنتج من ذلك أن زمن تشغيل الحالة الأسوأ لخوارزمية البحث الثنائي هو Θ(log(n)) كما أنه هو نفسه زمن تشغيل الحالة الوسطى، في المقابل، يساوي زمن تشغيل خوارزمية البحث الخطي الذي تعرّضنا له في مقال السابق ذكره أعلاه حول البحث والترتيب في المصفوفات Array في جافا لقيمة Θ(n)، حيث يمنحك ترميز Θ طريقةً كميّةً quantitative لتعبّر عن حقيقة كون البحث الثنائي أسرع بكثيرٍ من البحث الخطي linear search. تَقسِم كلّ خطوةٍ في خوارزمية البحث الثنائي حجم المسألة على 2، وعمومًا يحدُث كثيرًا أن تُقسَم عمليةٌ معينةٌ ضِمن خوارزمية حجم المشكلة n على 2، وعندما يحدث ذلك ستظهر دالة اللوغاريتم في التحليل المُقارِب لزمن تشغيل الخوارزمية. يُعَد موضوع تحليل الخوارزميات algorithms analysis حقلًا ضخمًا ورائعًا، ناقشنا هنا جزءًا صغيرًا فقط من مفاهيمه الأساسية التي تفيد لفهم واستيعاب الاختلافات بين الخوارزميات المختلفة. ترجمة -بتصرّف- للقسم Section 5: Analysis of Algorithms من فصل Chapter 8: Correctness, Robustness, Efficiency من كتاب Introduction to Programming Using Java. اقرأ أيضًا المقال السابق: التوكيد assertion والتوصيف annotation في لغة جافا مدخل إلى الخوارزميات ترميز Big-O في الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية تعقيد الخوارزميات Algorithms Complexity النسخة الكاملة لكتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة1 نقطة
ركّزنا في المقالات السابقة من هذه السلسلة على صحة البرامج، وإلى جانب ذلك، تُعَد مشكلة الكفاءة efficiency من المشاكل المهمة كذلك، فعندما نحلِّل كفاءة برنامجٍ ما، فعادةً ما تُطرح أسئلةٌ مثل كم من الوقت سيستغرقه البرنامج؟ وهل هناك طريقةٌ أخرى للحصول على نفس الإجابة ولكن بطريقةٍ أسرع؟ وعمومًا دائمًا ما ستكون كفاءة البرنامج أقلّ أهميةً من صحته؛ فإذا لم تهتم بصحة البرنامج، فيمكنك إذًا أن تشغّله بسرعةٍ، ولكن قلّما سيهتم به أحدٌ. كذلك لا توجد أي فائدةٍ من برنامجٍ يستغرق عشرات الآلاف من السنين ليعطيك إجابةً صحيحةً. يشير مصطلح الكفاءة عمومًا إلى الاستخدام الأمثل لأي مورِد resource بما في ذلك الوقت وذاكرة الحاسوب ونطاق التردد الشبكي، وسنركّز في هذا المقال على الوقت، والسؤال الأهم الذي نريد الإجابة عليه هو ما الوقت الذي يستغرقه البرنامج ليُنجز المَهمّة الموكلة إليه؟ في الواقع، ليس هناك أي معنىً من تصنيف البرامج على أنها تعمل بكفاءةٍ أم لا، وإنما يكون من الأنسب أن نوازن بين برنامجين صحيحين ينفّذان نفس المهمة لنعرف أيًا منهما أكثر كفاءةً من الآخر، بمعنى أيهما ينجز مهمّته بصورةٍ أسرع، إلا أن تحديد ذلك ليس بالأمر السهل لأن زمن تشغيل البرنامج غير معرَّف؛ فقد يختلف حسب عدد معالجات الحاسوب وسرعتها، كما قد يعتمد على تصميم آلة جافا الافتراضية Java Virtual Machine (في حالة برامج جافا) المفسِّرة للبرنامج؛ وقد يعتمد كذلك على المصرّف المستخدَم لتصريف البرنامج إلى لغة الآلة، كما يعتمد زمن تشغيل أي برنامجٍ على حجم المشكلة التي ينبغي للبرنامج أن يحلّها، فمثلًا سيستغرق برنامج ترتيب sorting وقتًا أطول لترتيب 10000 عنصر مما سيستغرقه لترتيب 100 عنصر؛ وعندما نوازن بين زمنيْ تشغيل برنامجين، سنجد أن برنامج A يحلّ المشاكل الصغيرة أسرع بكثيرٍ من برنامج B بينما يحلّ البرنامج B المشاكل الكبيرة أسرع من البرنامج A، فلا يوجد برنامجٌ معينٌ هو الأسرع دائمًا في جميع الحالات. عمومًا، هناك حقلٌ ضِمن علوم الحاسوب يُكرّس لتحليل كفاءة البرامج، ويعرف باسم تحليل الخوارزميات Analysis of Algorithms، حيث يركِّز على الخوارزميات نفسها لا البرامج؛ لتجنُّب التعامل مع التنفيذات implementations المختلفة لنفس الخوارزمية باستخدام لغاتٍ برمجيةٍ مختلفةٍ ومصرّفةٍ بأدواتٍ مختلفةٍ وتعمل على حواسيب مختلفةٍ؛ وعمومًا يُعَد مجال تحليل الخوارزميات مجالًا رياضيًا مجرّدًا عن كل تلك التفاصيل الصغيرة، فعلى الرغم من أنه حقلٌ نظريٌ في المقام الأول، إلا أنه يلزَم كلّ مبرمجٍ أن يطّلع على بعضٍ من تقنياته ومفاهيمه الأساسية، ولهذا سيَتناول هذا المقال مقدمةً مختصرةً جدًا عن بعضٍ من تلك الأساسيات والمفاهيم، ولأن هذه السلسلة ليست ذات اتجاه رياضي، فستكون المناقشة عامةً نوعًا ما. يُعَد التحليل المُقارِب asymptotic analysis أحد أهم تقنيات ذلك المجال، ويُقصد بالمُقارِب asymptotic ما يميل إليه على المدى البعيد بازدياد حجم المشكلة، حيث يجيب التحليل المُقارِب لزمن تشغيل run time خوارزميةٍ عن أسئلةٍ مثل، كيف يؤثر حجم المشكلة problem size على زمن التشغيل؟ ويُعَد التحليل مُقارِبًا؛ لأنه يهتم بما سيحدث لزمن التشغيل عند زيادة حجم المشكلة بدون أي قيودٍ، أما ما سيحدث للأحجام الصغيرة من المشاكل فهي أمورٌ لا تعنيه؛ فإذا أظهر التحليل المُقارِب لخوارزمية A أنها أسرع من خوارزمية B، فلا يعني ذلك بالضرورة أن الخوارزمية A ستكون أسرع من B عندما يكون حجم المشكلة صغيرًا مثل 10 أو 1000 أو حتى 1000000، وإنما يعني أنه بزيادة حجم المشكلة، ستصل حتمًا إلى نقطةٍ تكون عندها خوارزمية A أسرع من خوارزمية B. يرتبط مفهوم التحليل المُقارِب بـمصطلح ترميز O الكبير Big-Oh notation، حيث يمكّننا هذا الترميز من قوْل أن زمن تشغيل خوارزميةٍ معينةٍ هو O(n2) أو O(n) أو O(log(n))، وعمومًا يُشار إليه بـ O(f(n))، حيث f(n) عِبارةٌ عن دالة تُسند عددًا حقيقيًا موجبًا لكلّ عددٍ صحيحٍ موجبٍ n، بينما يشير n ضِمن هذا الترميز إلى حجم المشكلة، ولذلك يلزَمك أن تحدّد حجم المشكلة قبل أن تبدأ في تحليلها، وهو ليس أمرًا معقدًا على أية حال؛ فمثلًا، إذا كانت المشكلة هي ترتيب قائمةٍ من العناصر، فإن حجم تلك المشكلة يمكنه أن يكون عدد العناصر ضِمن القائمة، وهذا مثالٌ آخرٌ، عندما يكون مُدخَل الخوارزمية عِبارةٌ عن عددٍ صحيحٍ (لفحْص إذا ما كان ذلك العدد عددًا أوليًا prime أم لا) يكون حجم المشكلة في تلك الحالة هو عدد البتات bits الموجودة ضِمن ذلك العدد المُدخَل لا العدد ذاته؛ وعمومًا يُعَد عدد البتات bits الموجودة في قيمة المُدخَل قياسًا جيدًا لحجم المشكلة. إذا كان زمن تشغيل خوارزميةٍ معينةٍ هو O(f(n))، فذلك يعني أنه بالنسبة للقيم الكبيرة من حجم المشكلة، لن يتعدى الزمن حاصل ضرْب قيمةٍ ثابتةٍ معينةٍ في f(n)، أي أن هناك عدد C وعددٌ صحيحٌ آخرٌ موجبٌ M، وعندما تصبح n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أقلّ من أو يساوي C×f(n)؛ حيث يأخذ الثابت C في حسبانه تفاصيلًا مثل سرعة الحاسوب المستخدَم في تشغيل الخوارزمية، وإذا كان ذلك الحاسوب أبطأ، فقد تستخدم قيمة أكبر للثابت، إلا أن تغييره لن يغيّر من حقيقة أن زمن تشغيل الخوارزمية هو O(f(n)؛ وبفضل ذلك الثابت، لن يكون من الضروري تحديد إذا ما كنا نقيس الزمن بالثواني أو السنوات أو أي وحدة قياسٍ أخرى؛ لأن التحويل من وحدةٍ معينةٍ إلى أخرى يتمثَّل بعملية ضربٍ في قيمة ثابتة، بالإضافة إلى ما سبق، لا تَعتمد O(f(n)) نهائيًا على ما يحدُث في الأحجام الأصغر من المشكلة، وإنما على ما يحدُث على المدى الطويل بينما يزيد حجم المشكلة دون أي قيودٍ. سنفحص مثالًا بسيطًا عِبارةً عن حساب حاصل مجموع العناصر الموجودة ضِمن مصفوفةٍ، وفي هذه الحالة، يكون حجم المشكلة n هو طول تلك المصفوفة، فإذا كان A هو اسم المصفوفة، ستُكتب الخوارزمية بلغة جافا كالتالي: total = 0; for (int i = 0; i < n; i++) total = total + A[i]; تنفِّذ الخوارزمية عملية total = total + A[i] عدد n من المرات، أي أن الزمن الكلي المُستغرق أثناء تلك العملية يساوي a×n، حيث a هو زمن تنفيذ العملية مرةٍ واحدةٍ؛ إلى جانب ذلك، تزيد الخوارزمية قيمة المتغيّر i وتوازنه مع قيمة n في كلّ مرةٍ تنفِّذ فيها مَتْن الحلقة loop، الأمر الذي يؤدي إلى زيادة زمن التشغيل بمقدار يساوي b×n حيث b عِبارةٌ عن ثابتٍ، وبالإضافة إلى ما سبق، يُهيئ كلًا من i وtotal إلى الصفر مبدئيًا مما يزيد من زمن التشغيل بمقدار ثابتٍ معينٍ وليكن c، وبالتالي، يساوي زمن تشغيل الخوارزمية للقيمة (a+b)×n+c، حيث a وb وc عِبارةٌ عن ثوابتٍ تعتمد على عوامل مثل كيفية تصريف compile الشيفرة ونوع الحاسوب المستخدَم، وبالاعتماد على حقيقة أن c دائمًا ما تكون أقلّ من أو تساوي c×n لأي عددٍ صحيحٍ موجبٍ n، يمكننا إذًا أن نقول أن زمن التشغيل أقلّ من أو يساوي (a+b+c)×n، أي أنه أقلّ من أو يساوي حاصل ضرْب ثابتٍ في n، أي يكون زمن تشغيل الخوارزمية هو O(n). إذا استشكل عليك أن تفهم ما سبق، فإنه يعني أنه لأي قيم n كبيرة، فإن الثابت c في المعادلة (a+b)×n+c غير مهمٍ إذا ووزِن مع (a+b)×n، ونصيغ ذلك بأن نقول إن c تعبّر عن عنصرٍ ذات رتبةٍ أقل lower order، وعادةً ما نتجاهل تلك العناصر في سياق التحليل المُقارِب؛ ويمكن لتحليلٍ مُقارِب آخرٍ أكثر حدَّة أن يستنتج ما يلي: "يَستغرق كلّ تكرار iteration ضِمن حلقة for مقدارًا ثابتًا من الوقت، ولأن الخوارزمية تتضمّن عدد n من التكرارات، فإن زمن التشغيل الكلي هو حاصل ضرْب ثابتٍ في n مضافًا إليه عناصر ذات رتبة أقلّ للتهيئة المبدئية، وإذا تجاهلنا تلك العناصر، سنجد أن زمن التشغيل يساوي O(n). يفيد أحيانًا أن نخصِّص حدًا أدنىً lower limit لزمن التشغيل، حيث سيمكّننا ذلك من أن نقول أن زمن تشغيل خوارزميةٍ معينةٍ أكبر من أو يساوي حاصل ضرْب قيمةٍ ثابتةٍ في f(n)، وهو ما يعرّفه ترميزٌ آخرٌ هو Ω(f(n))، ويُقرأ أوميجا لدالة f أو ترميز أوميجا الكبير لدالة f (أوميجا Omega هو حرفٌ أبجديٌ يونانيٌ ويمثِّل الترميز Ω حالته الكبيرة)؛ وإذا شئنا الدقة، عندما نقول أن زمن تشغيل خوارزمية هو Ω(f(n))، فإن المقصود هو وجود عددٍ موجبٍ C وعددٍ صحيحٍ آخرٍ موجبٍ M، وعندما تكون قيمة n أكبر من M، فإن زمن تشغيل الخوارزمية يكون أكبر من أو يساوي حاصل ضرْب C في f(n)، ونستخلّص مما سبق أن O(f(n)) يوفّر معلومةً عن الحد الأقصى للزمن الذي قد تنتظره حتى تنتهي الخوارزمية من العمل، بينما يوفّر Ω(f(n)) معلومةً عن الحد الأدنى للزمن. سنفْحص الآن خوارزميةً أخرى: public static void simpleBubbleSort( int[] A, int n ) { for (int i = 0; i < n; i++) { // Do n passes through the array... for (int j = 0; j < n-1; j++) { if ( A[j] > A[j+1] ) { // A[j] و A[j+1] رتِّب int temp = A[j]; A[j] = A[j+1]; A[j+1] = temp; } } } } يمثِّل المعامِل n في المثال السابق حجم المشكلة، حيث ينفِّذ الحاسوب حلقة for الخارجية عدد n من المرات، وفي كلّ مرة ينفِّذ فيها تلك الحلقة، فإنه ينفِّذ أيضًا حلقة for داخليةً عدد n-1 من المرات، إذًا سينفّذ الحاسوب تعليمة if عدد n×(n-1) من المرات، أي يساوي n2-n، ولأن العناصر ذات الرتبة الأقل غير مهمّةٍ في التحليل المُقارِب، سنكتفي بأن نقول أن تعليمة if تنفَّذ عدد n2 مرةٍ؛ وعلى وجهٍ أكثر تحديدًا، ينفِّذ الحاسوب الاختبار A[j] > A[j+1] عدد n2 من المرات، ويكون زمن تشغيل الخوارزمية هو Ω( n2)، أي يساوي حاصل ضرْب قيمةٍ ثابتةٍ في n2 على الأقل، وإذا فحصنا العمليات الأخرى (تعليمات الإسناد assignment وزيادة i وj بمقدار الواحد..إلخ)، فإننا لن نجد أي عمليةً منها تنفَّذ أكثر من عدد n2 مرة؛ ونستنتج من ذلك أن زمن التشغيل هو O(n2) أيضًا، أي أنه لن يتجاوز حاصل ضرْب قيمةٍ ثابتةٍ في n2، ونظرًا لأن زمن التشغيل يساوي كلًا من Ω( n2) و O( n2)، فإنه أيضًا يساوي Θ( n2). لقد أوضحنا حتى الآن أن زمن التشغيل يعتمد على حجم المشكلة، ولكننا تجاهلنا تفصيلةٍ مهمةٍ أخرى، وهي أنه لا يعتمد فقط على حجم المشكلة، وإنما كثيرًا ما يعتمد على نوعية البيانات المطلوب معالجتها، فمثلًا قد يعتمد زمن تشغيل خوارزمية ترتيب على الترتيب الأولي للعناصر المطلوب ترتيبها، وليس فقط على عددها. لكي نأخذ تلك الاعتمادية في الحسبان، سنُجري تحليلًا لزمن التشغيل على كلًا من الحالة الأسوأ the worst case analysis والحالة الوسطى average case analysis، بالنسبة لتحليل زمن تشغيل الحالة الأسوأ، سنفحص جميع المشاكل المحتملة لحجم يساوي n وسنحدّد أطول زمن تشغيل من بينها جميعًا، بالمِثل بالنسبة للحالة الوسطى، سنفحص جميع المشاكل المحتملة لحجم يساوي n ونحسب قيمة متوسط زمن تشغيلها جميعًا، وعمومًا سيَفترض تحليل زمن التشغيل للحالة الوسطى أن جميع المشاكل بحجم n لها نفس احتمالية الحدوث على الرغم من عدم واقعية ذلك في بعض الأحيان، أو حتى إمكانية حدوثه وذلك في حالة وجود عددٍ لا نهائيٍ من المشاكل المختلفة لحجمٍ معينٍ. عادةً ما يتساوى زمن تشغيل الحالة الأسوأ والوسطى ضِمن مُضاعفٍ ثابتٍ، وذلك يعني أنهما متساويان بقدر اهتمام التحليل المُقارِب، أي أن زمن تشغيل الحالة الوسطى والحالة الأسوأ هو O(f(n)) أو Θ(f(n))، إلا أن هنالك بعض الحالات القليلة التي يختلف فيها التحليل المُقارِب للحالة الأسوأ عن الحالة الوسطى كما سنرى لاحقًا. بالإضافة إلى ما سبق، يمكن مناقشة تحليل زمن تشغيل الحالة المُثلى best case، والذي سيفحص أقصر زمن تشغيلٍ ممكنٍ لجميع المُدخَلات من حجمٍ معينٍ، وعمومًا يُعَد أقلهم فائدةً. حسنًا، ما الذي ينبغي أن تعرفه حقًا عن تحليل الخوارزميات لتستكمل قراءة ما هو متبقّيٍ من هذه السلسلة؟ في الواقع، لن نقدِم على أي تحليلٍ رياضيٍ حقيقيٍ، ولكن ينبغي أن تفهَم بعض المناقشات العامة عن حالاتٍ بسيطةٍ مثل الأمثلة التي رأيناها في هذا المقال، والأهم من ذلك هو أن تفهم ما يعنيه بالضبط قوْل أن وقت تشغيل خوارزميةٍ معينةٍ هو O(f(n)) أو Θ(f(n)) لبعض الدوال الشائعة f(n)، كما أن النقطة المُهمّة هي أن تلك الترميزات لا تُخبرك أي شيءٍ عن القيمة العددية الفعلية لزمن تشغيل الخوارزمية لأي حالةٍ معينةٍ كما أنها لا تخبرك بأي شيءٍ عن زمن تشغيل الخوارزمية للقيم الصغيرة من n، وإنما ستخبرك بمعدل زيادة زمن التشغيل بزيادة حجم المشكلة. سنفترض أننا نوازن بين خوارزميتين لحل نفس المشكلة، وزمن تشغيل إحداها هو Θ( n2) بينما زمن تشغيل الأخرى هو Θ(n3)، فما الذي يعنيه ذلك؟ إذا كنت تريد معرفة أي خوارزميةٍ منهما هي الأسرع لمشكلةٍ حجمها 100 مثلًا، فالأمر غير مؤكدٍ، فوِفقًا للتحليل المُقارِب يمكن أن تكون أي خوارزميةٍ منهما هي الأسرع في هذه الحالة؛ أما بالنسبة للمشاكل الأكبر حجمًا، سيصل حجم المشكلة n إلى نقطةٍ تكون معها خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)؛ وعلاوةً على ذلك، يزداد تميز خوارزمية Θ( n2) عن خوارزمية Θ(n3) بزيادة حجم المشكلة أكثر فأكثر، وعمومًا ستكون هناك قيمٌ لحجم المشكلة n تكون معها خوارزمية Θ( n2) أسرع ألف مرةٍ أو مليون مرةٍ أو حتى بليون مرةٍ وهكذا؛ وذلك لأن دالة a×n3 تنمو أسرع بكثيرٍ من دالة b×n2 لأي ثابتين موجبين a وb، وذلك يعني أنه بالنسبة للمشاكل الكبيرة، ستكون خوارزمية Θ( n2) أسرع بكثيرٍ من خوارزمية Θ(n3)، ونحن لا نعرف بالضبط إلى أي درجةٍ بالضبط ينبغي أن تكون المشكلة كبيرةٌ، وعمليًا، يُحتمل لخوارزمية Θ( n2) أن تكون أسرع حتى للقيم الصغيرة من حجم المشكلة n؛ وعمومًا تُفضّل خوارزمية Θ( n2) عن خوارزمية Θ(n3). لكي تفهم وتطبّق التحليل المُقارِب، لابدّ أن يكون لديك فكرةً عن معدّل نمو بعض الدوال الشائعة، وبالنسبة للدوال الأسية (power) n, n2, n3, n4, …,، كلما كان الأس أكبر، ازداد معدّل نمو الدالة؛ أما بالنسبة للدوال الأسية exponential من النوع 2n و 10n حيث n هو الأس، يكون معدّل نموها أسرع بكثيرٍ من أي دالةٍ أسيةٍ عاديةٍ power، وعمومًا تنمو الدوال الأسية بسرعةٍ جدًا لدرجة تجعل الخوارزميات التي ينمو زمن تشغيلها بذلك المعدّل غير عمليةٍ عمومًا حتى للقيم الصغيرة من n لأن زمن التشغيل طويلٌ جدًا، وإلى جانب ذلك، تُستخدم دالة اللوغاريتم log(n) بكثرةٍ في التحليل المُقارِب، فإذا كان هناك عددٌ كبيرٌ من دوال اللوغاريتم، ولكن تلك التي أساسها يساوي 2 هي الأكثر استخدامًا في علوم الحاسوب، وتُكتب عادة كالتالي log2(n)، حيث تنمو دالة اللوغاريتم ببطئٍ إلى درجةٍ أبطأ من معدّل نمو n، وينبغي أن يساعدك الجدول التالي على فهم الفروق بين معدّلات النمو للدوال المختلفة: يرجع السبب وراء استخدام log(n) بكثرةٍ إلى ارتباطها بالضرب والقسمة على 2، سنفْترض أنك بدأت بعدد n ثم قسَمته على 2 ثم قسَمته على 2 مرةٍ أخرى، وهكذا إلى أن وصَلت إلى عددٍ أقل من أو يساوي 1، سيساوي عدد مرات القسمة (مقربًا لأقرب عدد صحيح) لقيمة log(n). فمثلًا انظر إلى خوارزمية البحث الثنائي binary search في مقال البحث والترتيب في المصفوفات Array في جافا، حيث تبحث تلك الخوارزمية عن عنصرٍ ضِمن مصفوفةٍ مرتّبةٍ، وسنستخدم طول المصفوفة مثل حجمٍ للمشكلة n، إذ يُقسَم عدد عناصر المصفوفة على 2 في كلّ خطوةٍ ضِمن خوارزمية البحث الثنائي، بحيث تتوقّف عندما يصبح عدد عناصرها أقلّ من أو يساوي 1، وذلك يعني أن عدد خطوات الخوارزمية لمصفوفة طولها n يساوي log(n) للحدّ الأقصى؛ ونستنتج من ذلك أن زمن تشغيل الحالة الأسوأ لخوارزمية البحث الثنائي هو Θ(log(n)) كما أنه هو نفسه زمن تشغيل الحالة الوسطى، في المقابل، يساوي زمن تشغيل خوارزمية البحث الخطي الذي تعرّضنا له في مقال السابق ذكره أعلاه حول البحث والترتيب في المصفوفات Array في جافا لقيمة Θ(n)، حيث يمنحك ترميز Θ طريقةً كميّةً quantitative لتعبّر عن حقيقة كون البحث الثنائي أسرع بكثيرٍ من البحث الخطي linear search. تَقسِم كلّ خطوةٍ في خوارزمية البحث الثنائي حجم المسألة على 2، وعمومًا يحدُث كثيرًا أن تُقسَم عمليةٌ معينةٌ ضِمن خوارزمية حجم المشكلة n على 2، وعندما يحدث ذلك ستظهر دالة اللوغاريتم في التحليل المُقارِب لزمن تشغيل الخوارزمية. يُعَد موضوع تحليل الخوارزميات algorithms analysis حقلًا ضخمًا ورائعًا، ناقشنا هنا جزءًا صغيرًا فقط من مفاهيمه الأساسية التي تفيد لفهم واستيعاب الاختلافات بين الخوارزميات المختلفة. ترجمة -بتصرّف- للقسم Section 5: Analysis of Algorithms من فصل Chapter 8: Correctness, Robustness, Efficiency من كتاب Introduction to Programming Using Java. اقرأ أيضًا المقال السابق: التوكيد assertion والتوصيف annotation في لغة جافا مدخل إلى الخوارزميات ترميز Big-O في الخوارزميات دليل شامل عن تحليل تعقيد الخوارزمية تعقيد الخوارزميات Algorithms Complexity النسخة الكاملة لكتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة1 نقطة -
أنا أستخدم nextjs على vercel. إجراء اختبار google lighthouse Pagespeed على صفحتي الرئيسية. تقوم بإرجاع "إزالة ملفات جافا سكريبت غير المستخدمة" وتسرد ملفات جافا سكريبت لصفحاتي الثابتة الأخرى مثل privacy-policy.js about.js.... لماذا يتم تحميل صفحات أخرى وأنا لست في تلك الصفحات؟ كيف يمكنني إيقافها بحيث يتم تحميلها على عنوان url الخاص بهم فقط.1 نقطة
-
أنا أقرأ Nextjs جزء البيانات من الوثائق وخطر ببالي سؤال واحد. يمكن لـ Nextjs جلب البيانات باستخدام getStaticProps و getStaticPaths و getInitialProps و getServersideProps ، أليس كذلك؟ لكن البعض يحدث في وقت البناء كما أقتبس: getStaticProps (Static Generation): Fetch data at build-time متى يحدث هذا وقت البناء؟ هل هو عند تشغيل npm تشغيل البناء؟ (لبناء بناء الإنتاج) أو عندما يصل المستخدم إلى تطبيق Nextjs الخاص بنا؟ (عند كل طلب)1 نقطة
-
مرحبا لدي مشروع nextjs أعمل عليه وهو حاليا في استضافة vps في السابق كنت عندما أعمل git pull في vps ثم أبني المشروع يعمل بدون مشاكل الأن قمت بتطوير المشروع و واردت أن أجلب التحديثات الأخيرة في vps ثم البناء لكن يظهر هذا الخطأ بعد أن يأخذ وقت كبير process killed رغم أنني قمت بالبناء محليا دون مشاكل1 نقطة
-
أولاً عليك قراءة البيانات في بايثون ويفضل تحويلها إلى ملف CSV ثم قراءتها ك Dataframe ليسهل التعامل معها (لامشكلة المهم أن تقوم بقراءتها بالشكل المناسب)، ثم بعد ذلك يمكنك استخدام مكتبة sklearn لتنفيذ الطلبات المتبقية حيث توفر لك مكتبة sklearn ماتحتاجه لتقسيم البيانات (الطلب 2 ) وبناء نموذج LinearR وإليك الروابط التالية التي تشرحهما: وبالنسبة للطلب الأخير (تقييم أداء النموذج) فهنا يوجد كل الطرق مع شرحها، ويمكنك استخدام واحدة منها:1 نقطة
-
مرحبًا طارق في حالة operating system not found لن تستطيع الدخول للنظام بدون أسطوانة CD أو ذاكرة فلاش USB، وأن يكون على هذه نسخة من نظام التشغيل (ويندوز 10 على سبيل المثال) وتقوم بإعادة تثبيت النظام من جديد أو محاولة إصلاحه من خلال خيار Repair Windows والذي سيظهر لك قبل بدء عملية التثبيت. إن لم تعمل أسطوانة الويندوز أو الـ USB مباشرة بعد تشغيل الجهاز، يجب عليك الدخول إلى قائمة الإقلاع Boot Menu من خلال الضغط على F2 أو Del أو F12 أو غيرها حسب نوع اللابتوب الخاص بك، ثم تختار الUSB أو CD / DVD Room حسب ما تستخدمه لتثبيت النظام. بعد أن تقوم بإعادة تثبيت النظام (أو إصلاحه)، يمكنك أن تستعمل برامج مثل Recuva أو Recover My Files في محاولة لإستعادة أي صور أو ملفات تم حذفها أثناء عملية الـ Format.1 نقطة
-
مرحبًا عبد الواحد هذه فقط مسألة تعود على البرامج، في الماضي لم يكن هناك برامج مثل Adobe إكس دي أو Figma وبالتالي لم يكن هناك بديل غير الفوتوشوب لكي يعطي المصمم الفدرة على التحكم في كل تفاصيل الموقع أو التطبيق، فأصبح ضروري أن يتقن المصمم التعامل مع الفوتوشوب حينها. بعد ذلك حاول بعض المصممين أن يقللوا من حجم الموقع من خلال جعل أغلب الصور والأيقونات بإمتداد SVG لذلك حاولوا إستخدام Adobe Illustrator لتصميم المواقع والتطبيقات ثم في 2010 ظهر برنامج Sketch ليكون أفضل برنامج مختص في تصميم واجهة المستخدم حينها، لكن العيب الأكبر له هو أنه متاح على أجهزة أبل فقط، وبالرغم من إمكانيات البرنامج التي تساعد المصمم على الحصول على أفضل نتيجة إلا أن عدد مستخدمينه لم يكن بالكثير وهذا بسبب أن كثير من المصممين كانوا يعملون على ويندوز بالفعل. بعد ذلك في 2015 أعلنت شركة Adobe عن برنامجها الخاص بتصميم الواجهات Adobe إكس دي ليصبح من أشهر البرامج والذي يعد الأشهر حتى الآن، أضاف البرنامج مميزات وإضافات عظيمة مثل تحويل التصميم إلى كود مباشرة أو تجربة الـ Animation وغيرها من المميزات. ظهر بعده بسنة موقع Figma والذي يحتوي على مميزات كثير مثل عمل رابط للتصميم ذاتي التحديث أي يمكن لأي شخص لديه الرابط أن يشاهد ما يقوم به المصمم من تعديلات في الوقت الحقيقي، ومن مميزاته أن Figma يعمل على المتصفح وبالتالي يدعم كل أنواع الأجهزة تقريبًا بغض النظر عن نوع نظام التشغيل Windows, Mac, Linux, Android, iOS في النهاية البرنامج المستخدم في تصميم الموقع أو التطبيق متوقف على طلب العميل وخبرة المصمم.1 نقطة
-
 سنتعرف فيما سيأتي على أهم موضوع في هذا المنهاج، بالتحديد على مكتبة React. لنبدأ إذًا بكتابة تطبيق بسيط يمهد الطريق لفهم المبادئ الأساسية لهذه المكتبة. سنستعمل الأداة create-react-app التي ستسهل علينا كثيرا التعامل مع الملفات الأساسية لمشروع React، فمن الممكن تثبيت هذه الأداة على حاسوبك طالما أن نسخة الأداة npm التي ثُبِّتت مع Node على الأقل 5.3، وبالطبع يبقى موضوع استخدام هذه الأداة اختيارًا شخصيًا. لننشئ الآن تطبيقًا باسم (Part1) ولننتقل إلى المجلد الذي يضم هذا التطبيق من خلال تنفيذ الشيفرة التالية: $ npx create-react-app part1 $ cd part1 سيبدأ كل سطر في هذا التطبيق وفي كل تطبيق بالرمز $ ضمن واجهة الطرفية. لن تضطر إلى كتابة هذا الرمز باستمرار لأنه في الواقع سيمثل مَحثَّ سطر الأوامر. سنشغل التطبيق بكتابة الأمر التالي: $ npm start سيعمل التطبيق بشكل افتراضي على الخادم المحلي (LocalHost) لجهازك عند المنفذ (Port) رقم 3000 وعلى العنوان http://localhost:3000 وسيفتح متصفحك الافتراضي آليًا صفحة الويب. افتح طرفية المتصفح مباشرةً وافتح أيضًا محرر نصوص لتتمكن من عرض الشيفرة وصفحة الويب في نفس الوقت على شاشتك. يحتوي المجلد src على شيفرة التطبيق. سنبسِّط شيفرة التطبيق المكتوبة في الملف index.js التي ستظهر كالتالي: import React from 'react' import ReactDOM from 'react-dom' const App = () => ( <div> <p>Hello world</p> </div> ) ReactDOM.render(<App />, document.getElementById('root')) يمكنك حذف الملفات التالية فلن تحتاجها حاليًا في التطبيق: App.js App.css App.test.js logo.svg setupTests.js service Worker.js المكوِّنات Components يعّرف الملف index.js مكوّنَ React يدعى App، سيصيّره السطر الأخير من الشيفرة إلى عنصرdiv الذي ستجده معرفًا في الملف public/index.html ويحمل القيمة "root" في الخاصية id. ReactDOM.render(<App />, document.getElementById('root')) ستجد ملف html السابق فارغًا بشكل افتراضي، حيث يمكنك إضافة ما تشاء من شيفرة html إليه. لكن طالما أننا نستخدم الآن React، فكل المحتوى الذي سيصيَّر ستجده معرّفًا على شكل مكوِّنات React. لنلق نظرة أقرب على الشيفرة التي تعرّف المكوِّن: const App = () => ( <div> <p>Hello world</p> </div> ) إن كان تخمينك صحيحًا، سيُصيَّر المكوِّن إلى عنصرdiv يضم عنصرp يحوي داخله العبارة "Hello Word". في الواقع عُرّف المكوِّن على شكل دالة JavaScript، فتمثل الشيفرة التالية دالة لا تمتلك أية مُعاملات: () => ( <div> <p>Hello world</p> </div> ) ثم تُسند الدالة بعدها إلى متغيّر ثابت القيمة (Constant Variable) يدعى App: const App = ... تُعرّف الدوال في JavaScript بطرق عدة، سنستخدم هنا الدوال السهمية التي وصِّفت في النسخ الأحدث من JavaScript تحت عنوان ECMAScript 6 والذي يدعى أيضًا ES6. ونظرًا لاحتواء الدالة على عبارة وحيدة، فقد استخدمنا طريقة مختصرة في تمثيلها كما تظهرها الشيفرة التالية: const App = () => { return ( <div> <p>Hello world</p> </div> ) } لاحظ أنّ الدالة قد أعادت قيمة العبارة التي احتوتها. قد تحتوي الدالة التي تعرِّف المكوِّن أية شيفرة مكتوبة بلغة JavaScript. عدِّل الشيفرة لتصبح على النحو التالي وراقب ما الذي سيتغير على شاشة الطرفية: const App = () => { console.log('Hello from component') return ( <div> <p>Hello world</p> </div> ) } من الممكن أيضًا تصيير المحتويات الديناميكية إن وجدت داخل المكوِّن، عدِّل الشيفرة لتصبح كالتالي: const App = () => { const now = new Date() const a = 10 const b = 20 return ( <div> <p>Hello world, it is {now.toString()}</p> <p> {a} plus {b} is {a + b} </p> </div> ) } تُنفَّذ شيفرة JavaScript الموجودة داخل الأقواس المعقوصة (curly braces) وتظهر نتيجتها ضمن أسطر HTML التي يولدها المكوِّن. JSX يبدو للوهلة الأولى أن مكوِّنات React تعيد شيفرة HTML، لكن ليس تمامًا. تُصمم مكوِّنات React غالبًا باستخدام JSX. قد تبدو JSX شبيهة بتنسيق HTML، لكنها في الواقع مجرد طريقة لكتابة JavaScript وستعيد المكوِّنات شيفرة JSX وقد ترجمت إلى JavaScript. سيبدو التطبيق الذي نعمل عليه بالشكل التالي بعد ترجمته: import React from 'react' import ReactDOM from 'react-dom' const App = () => { const now = new Date() const a = 10 const b = 20 return React.createElement( 'div', null, React.createElement( 'p', null, 'Hello world, it is ', now.toString() ), React.createElement( 'p', null, a, ' plus ', b, ' is ', a + b ) ) } ReactDOM.render( React.createElement(App, null), document.getElementById('root') ) تُرجم التطبيق باستخدام Babel. تترجم المشاريع التي أُنشئت باستخدام create-react-app أليًا، وسنطّلع أكثر على هذا الموضوع في القسم 7 من هذا المنهاج. من الممكن أيضًا كتابة تطبيقات React مستخدمين شيفرة JavaScript صرفة دون اعتماد JSX، لكن لن يرغب أحد بفعل ذلك. تتشابه من الناحية العملية كل من JSX و HTML، ويكمن الاختلاف البسيط بينهما في سهولة إدراج شيفرة JavaScript ضمن أقواس معقوصة وتنفيذها ضمن JSX. إن فكرة JSX مشابهة لفكرة العديد من اللغات التي تعتمد على القوالب مثل لغة Thymeleaf التي تستخدم مع Java Spring على الخادم. وهي تشابه XML في أن معرِّفي البداية والنهاية لكل عنصر يجب أن يكونا موجودين. فعلى سبيل المثال يمكن كتابة عنصر السطر الجديد <br> في HTML على النحو: <br> لكن عندما نستخدم JSX، لابد من إغلاق العنصر أي وضع معرِّف النهاية كالتالي: <br /> المكوّنات المتعددة سنعدّل شيفرة التطبيق على النحو التالي: const Hello = () => { return ( <div> <p>Hello world</p> </div> ) } const App = () => { return ( <div> <h1>Greetings</h1> <Hello /> </div> ) } ReactDOM.render(<App />, document.getElementById('root')) انتبه: لم ندرج الملفات الرأسية (الملفات المدرجة باستخدام تعليمة import) في الشيفرة المعروضة سابقًا ولن نفعل في المستقبل، لكن عليك إدراجها دائمًا عندما تحاول تشغيل التطبيق. عرّفنا داخل المكوّن App مكوِّنًا جديدًا يدعى Hello استُخدم أكثر من مرة ويعتبر ذلك أمرًا طبيعيًًا: const App = () => { return ( <div> <h1>Greetings</h1> <Hello /> <Hello /> <Hello /> </div> ) } من السهل إنشاء المكوِّنات في React، وبضم المكوِّنات إلى بعضها ستنتج تطبيقات أكثر تعقيدًا لكنها مع ذلك تبقى قابلة للتنفيذ. إنها فلسفة React التي تعتمد في جوهرها على بناء التطبيقات باستخدام مكوِّنات لها أغراض محددة يمكن إعادة استخدامها في أي وقت. تعتبر فكرة المكوّن الجذري (root component) الذي يمثله هنا App (المكوّن الذي يقع أعلى شجرة المكوِّنات)، نقطة قوة أخرى في React. مع ذلك سنجد في القسم 6 أنّ هذا المكوّن لن يكون جذريًّا تمامًا، لكنه سيُغلَّف ضمن مكوِّن تخديمي (utility component) مناسب. الخصائص (Props): تمرير البيانات إلى المكوِّنات من الممكن تمرير البيانات إلى المكوّنات مستخدمين مايسمى الخصائص (Props). سنعدّل المكوِّن Hello كالتالي: const Hello = (props) => { return ( <div> <p>Hello {props.name}</p> </div> ) } تمتلك الدالة التي تعرّف المكوِّن Hello مُعاملًا يدعى props. يستقبل المُعامل (الذي يلعب دور الوسيط هنا) كائنًا يمتلك حقولًا تمثل كل الخصائص التي عُرِّفت في المكوّن. سنستعرض ذلك من خلال الشيفرة التالية: const App = () => { return ( <div> <h1>Greetings</h1> <Hello name="George" /> <Hello name="Daisy" /> </div> ) } لا يوجد عدد محدد من الخصائص لمكوّن ما، ويمكن أن تحمل هذه الخصائص نصوصًا جاهزةً (hard coded) أو قيمًا ناتجة عن تنفيذ عبارات JavaScript. ينبغي وضع قيم الخصائص الناتجة عن تنفيذ تلك العبارات ضمن أقواس معقوصة. سنعدل شيفرة المكوّن Hello ليمتلك خاصيتين كالتالي: const Hello = (props) => { return ( <div> <p> Hello {props.name}, you are {props.age} years old </p> </div> ) } const App = () => { const name = 'Peter' const age = 10 return ( <div> <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <Hello name={name} age={age} /> </div> ) } أرسل المكوِّن App الخاصيتين على شكل قيم عائدة لمتغيّرات، كما أرسلهما أيضًا كنتيجة لتنفيذ عبارتي JavaScript، أحداهما عبارة جمع والأخرى قيمة نصية. بعض الملاحظات هُيّئت React لتولّد رسائل خطأ واضحةً تمامًا، وبالرغم من ذلك عليك التقدم بخطوات صغيرة، وأن تتأكد أنّ كل تغيير قد أجريته حقق الغاية منه، اتبع هذا الأسلوب في البداية على الأقل. ابق طرفية التطوير مفتوحةً دومًا. ولا ننصحك بمتابعة العمل إن أبلغك المتصفح بوجود أخطاء، بل عليك أن تتفهم سبب الخطأ قبل كل شيئ، وتذكر أنه يمكنك التراجع دائمًا إلى حالة العمل السابقة. سينفعك أن تكتب التعليمة ()console.log بين الحين والأخر ضمن أسطر شيفرة تطبيقك، حيث تطبع هذه التعليمة سجلات تنفيذ الشيفرة على الطرفية. وتذكر أنّ أسماء مكوِّنات React تبدأ بأحرف كبيرة (Capitals)، فلو حاولت تعريف مكوِّن بالشكل التالي: const footer = () => { return ( <div> greeting app created by <a href="https://github.com/mluukkai">mluukkai</a> </div> ) } ثم استخدمته كما يلي: const App = () => { return ( <div> <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <footer /> </div> ) } لن تعرض الصفحة حينها المحتوى الذي يقدمه المكوِّن Footer، بل ستنشئ عنصرًا فارغًا يحمل اسم footer. لكن إن حولت الحرف الأول من اسم المكوِّن إلى F، ستنشئ React عنصر div المعرّف ضمن المكوّن Footer وسيصيّره على الصفحة. تذكر أن مكوِّنات React تتطلب عادة وجود عنصر جذري (root element) وحيد، فلو حاولنا تعريف المكوِّن App على سبيل المثال دون وجود العنصر div في البداية كالتالي: const App = () => { return ( <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <Footer /> ) } ستكون النتيجة رسالة الخطأ التالية: يمكن أن نستخدم وسيلة بديلة عن العنصر الجذري تتمثل بإنشاء مصفوفة من المكوِّنات كما يلي: const App = () => { return [ <h1>Greetings</h1>, <Hello name="Maya" age={26 + 10} />, <Footer /> ] } لا يعتبر -على الرغم من ذلك- تعريف العنصر الجذري ضمن المكوِّن الجذري لتطبيق ما أمرًا مفضلًا، بل ستظهر الشيفرة بمظهر سيئٍ قليلًا. ذلك أنّ العنصر الجذري المحدد مسبقًا، سيسبب زيادة في عدد عناصرdiv في شجرة DOM. يمكن تلافي هذا الأمر باستخدام الأجزاء (fragments)، أي بتغليف العناصر ليعيدها المكوِّن على شكل عناصر فارغة كالتالي: const App = () => { const name = 'Peter' const age = 10 return ( <> <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <Hello name={name} age={age} /> <Footer /> </> ) } سيُترجم الآن التطبيق بنجاح، ولن تحتوي شيفرة DOM على عناصر div زائدة. التمارين 1.1 - 1.2 تسلّم التمارين عبر GitHub، وتحدَّد التمارين التي نفذت من خلال تطبيق تسليم الملفات submission application. يمكنك وضع كل تمارين المنهاج التي سلمتها في نفس المكان على المنصة أو في عدة أماكن، لكن عليك أن تستخدم تسميات منطقية للمجلدات إن كنت ستضع تمارين كل الأقسام في نفس المكان. يمكنك اتباع المخطط التالي لتنظيم المجلدات والتمارين المسلمة: part0 part1 courseinfo unicafe anecdotes part2 phonebook countries ألق نظرة على طريقة تنظيم الملفات. فلكل قسم مجلد خاص به يتفرع إلى مجلدات أخرى تضم تمارين مثل "unicafe" الموجود في القسم 1. يفضل تسليم سلسلة التمارين التي تشكل تطبيقًا معًا، ماعدا المجلد node_modules. يتوجب تسليم تمارين كل قسم على حدى، إذ لا يمكنك تسليم أية تمارين جديدة تعود إلى قسم ما إذا كنت قد سلمت غيرها من ذات القسم. انتبه يضم هذا القسم تمارين أخرى غير التمارين التي سنستعرضها الآن، لا تسلم التمارين التي ستنجزها في هذا الفصل بل انتظر حتى تنهي جميع تمارين القسم. 1.1- معلومات عن المنهاج course information، الخطوة 1 سنطور التطبيق الذي ننفذه انطلاقًا من هذا التمرين خلال التمارين القليلة القادمة. يكفي أن تسلم التطبيق في حالته النهائية دون تسليمه تمرينًا تمرينًا، وينطبق هذا الكلام على مجموعات التمارين المشابهة التي ستواجهها لاحقًا. بالطبع يمكنك ترك ملاحظة تشير إلى ذلك ضمن كل تمرين من السلسلة، لكنه أمر اختياري بحت. استخدم create-react-app لإنشاء تطبيق جديد وعدل الملف index.js ليظهر كالتالي: import React from 'react' import ReactDOM from 'react-dom' const App = () => { const course = 'Half Stack application development' const part1 = 'Fundamentals of React' const exercises1 = 10 const part2 = 'Using props to pass data' const exercises2 = 7 const part3 = 'State of a component' const exercises3 = 14 return ( <div> <h1>{course}</h1> <p> {part1} {exercises1} </p> <p> {part2} {exercises2} </p> <p> {part3} {exercises3} </p> <p>Number of exercises {exercises1 + exercises2 + exercises3}</p> </div> ) } ReactDOM.render(<App />, document.getElementById('root')) احذف الملفات الزائدة وهي: App.js وApp.css وApp.test.js وlogo.svg وsetupTests.js وserviceWorker.js. لسوء الحظ فالتطبيق ككل محتوًى في نفس المكوِّن، أعد صياغة التطبيق ليضم ثلاثة مكوِّنات جديدة: Header وContent وTotal. عدل الشيفرة التي تمرر البيانات في التطبيق App عبر الخصائص واجعل المكوِّن Header يتولى أمر البيانات المتعلقة باسم المنهاج، واجعل المكوِّن Content مسؤولًا عن تصيير البيانات المتعلقة بالأقسام وعدد التمارين في كل منها، وأخيرًا اجعل المكوِّن Total مسؤولًا عن تصيير البيانات المتعلقة بالعدد الكلي للتمارين. سيظهر جسم التطبيق الجديد تقريبًا كما يلي: const App = () => { // const-definitions return ( <div> <Header course={course} /> <Content ... /> <Total ... /> </div> ) } تحذير تنشئ الأداة create-react-app مستودع git محلي يحتوي المشروع ، إلا إن كان في المجلد مستودع محلي سابق. من المرجح أنك لا تريد أن يغدو المشروع مستودعًا، لهذا نفذ الأمر التالي rm -rf .git في مسار المشروع. 1.2- معلومات عن المنهاج، الخطوة 2 أعد صياغة المكوِّن Content بحيث لا يصيّر بنفسه أسماء الأقسام أو عدد التمارين التي تضمها، بل يصير ثلاثة مكوِّنات تدعى Part، ثم يُصيّر كل مكوّن منها اسم قسم واحد وعدد التمارين التي يضمها. const Content = ... { return ( <div> <Part .../> <Part .../> <Part .../> </div> ) } يمرر تطبيقنا حاليًا المعلومات بطريقة بدائية لاعتماده على متغيرات مفردة. سيتحسن الأمر قريبًا. اقترح تعديلًا على مضمون الفصل الأصلي. ترجمة -وبتصرف- للفصل Introduction to React من سلسلة Deep Dive Into Modern Web Development1 نقطة
سنتعرف فيما سيأتي على أهم موضوع في هذا المنهاج، بالتحديد على مكتبة React. لنبدأ إذًا بكتابة تطبيق بسيط يمهد الطريق لفهم المبادئ الأساسية لهذه المكتبة. سنستعمل الأداة create-react-app التي ستسهل علينا كثيرا التعامل مع الملفات الأساسية لمشروع React، فمن الممكن تثبيت هذه الأداة على حاسوبك طالما أن نسخة الأداة npm التي ثُبِّتت مع Node على الأقل 5.3، وبالطبع يبقى موضوع استخدام هذه الأداة اختيارًا شخصيًا. لننشئ الآن تطبيقًا باسم (Part1) ولننتقل إلى المجلد الذي يضم هذا التطبيق من خلال تنفيذ الشيفرة التالية: $ npx create-react-app part1 $ cd part1 سيبدأ كل سطر في هذا التطبيق وفي كل تطبيق بالرمز $ ضمن واجهة الطرفية. لن تضطر إلى كتابة هذا الرمز باستمرار لأنه في الواقع سيمثل مَحثَّ سطر الأوامر. سنشغل التطبيق بكتابة الأمر التالي: $ npm start سيعمل التطبيق بشكل افتراضي على الخادم المحلي (LocalHost) لجهازك عند المنفذ (Port) رقم 3000 وعلى العنوان http://localhost:3000 وسيفتح متصفحك الافتراضي آليًا صفحة الويب. افتح طرفية المتصفح مباشرةً وافتح أيضًا محرر نصوص لتتمكن من عرض الشيفرة وصفحة الويب في نفس الوقت على شاشتك. يحتوي المجلد src على شيفرة التطبيق. سنبسِّط شيفرة التطبيق المكتوبة في الملف index.js التي ستظهر كالتالي: import React from 'react' import ReactDOM from 'react-dom' const App = () => ( <div> <p>Hello world</p> </div> ) ReactDOM.render(<App />, document.getElementById('root')) يمكنك حذف الملفات التالية فلن تحتاجها حاليًا في التطبيق: App.js App.css App.test.js logo.svg setupTests.js service Worker.js المكوِّنات Components يعّرف الملف index.js مكوّنَ React يدعى App، سيصيّره السطر الأخير من الشيفرة إلى عنصرdiv الذي ستجده معرفًا في الملف public/index.html ويحمل القيمة "root" في الخاصية id. ReactDOM.render(<App />, document.getElementById('root')) ستجد ملف html السابق فارغًا بشكل افتراضي، حيث يمكنك إضافة ما تشاء من شيفرة html إليه. لكن طالما أننا نستخدم الآن React، فكل المحتوى الذي سيصيَّر ستجده معرّفًا على شكل مكوِّنات React. لنلق نظرة أقرب على الشيفرة التي تعرّف المكوِّن: const App = () => ( <div> <p>Hello world</p> </div> ) إن كان تخمينك صحيحًا، سيُصيَّر المكوِّن إلى عنصرdiv يضم عنصرp يحوي داخله العبارة "Hello Word". في الواقع عُرّف المكوِّن على شكل دالة JavaScript، فتمثل الشيفرة التالية دالة لا تمتلك أية مُعاملات: () => ( <div> <p>Hello world</p> </div> ) ثم تُسند الدالة بعدها إلى متغيّر ثابت القيمة (Constant Variable) يدعى App: const App = ... تُعرّف الدوال في JavaScript بطرق عدة، سنستخدم هنا الدوال السهمية التي وصِّفت في النسخ الأحدث من JavaScript تحت عنوان ECMAScript 6 والذي يدعى أيضًا ES6. ونظرًا لاحتواء الدالة على عبارة وحيدة، فقد استخدمنا طريقة مختصرة في تمثيلها كما تظهرها الشيفرة التالية: const App = () => { return ( <div> <p>Hello world</p> </div> ) } لاحظ أنّ الدالة قد أعادت قيمة العبارة التي احتوتها. قد تحتوي الدالة التي تعرِّف المكوِّن أية شيفرة مكتوبة بلغة JavaScript. عدِّل الشيفرة لتصبح على النحو التالي وراقب ما الذي سيتغير على شاشة الطرفية: const App = () => { console.log('Hello from component') return ( <div> <p>Hello world</p> </div> ) } من الممكن أيضًا تصيير المحتويات الديناميكية إن وجدت داخل المكوِّن، عدِّل الشيفرة لتصبح كالتالي: const App = () => { const now = new Date() const a = 10 const b = 20 return ( <div> <p>Hello world, it is {now.toString()}</p> <p> {a} plus {b} is {a + b} </p> </div> ) } تُنفَّذ شيفرة JavaScript الموجودة داخل الأقواس المعقوصة (curly braces) وتظهر نتيجتها ضمن أسطر HTML التي يولدها المكوِّن. JSX يبدو للوهلة الأولى أن مكوِّنات React تعيد شيفرة HTML، لكن ليس تمامًا. تُصمم مكوِّنات React غالبًا باستخدام JSX. قد تبدو JSX شبيهة بتنسيق HTML، لكنها في الواقع مجرد طريقة لكتابة JavaScript وستعيد المكوِّنات شيفرة JSX وقد ترجمت إلى JavaScript. سيبدو التطبيق الذي نعمل عليه بالشكل التالي بعد ترجمته: import React from 'react' import ReactDOM from 'react-dom' const App = () => { const now = new Date() const a = 10 const b = 20 return React.createElement( 'div', null, React.createElement( 'p', null, 'Hello world, it is ', now.toString() ), React.createElement( 'p', null, a, ' plus ', b, ' is ', a + b ) ) } ReactDOM.render( React.createElement(App, null), document.getElementById('root') ) تُرجم التطبيق باستخدام Babel. تترجم المشاريع التي أُنشئت باستخدام create-react-app أليًا، وسنطّلع أكثر على هذا الموضوع في القسم 7 من هذا المنهاج. من الممكن أيضًا كتابة تطبيقات React مستخدمين شيفرة JavaScript صرفة دون اعتماد JSX، لكن لن يرغب أحد بفعل ذلك. تتشابه من الناحية العملية كل من JSX و HTML، ويكمن الاختلاف البسيط بينهما في سهولة إدراج شيفرة JavaScript ضمن أقواس معقوصة وتنفيذها ضمن JSX. إن فكرة JSX مشابهة لفكرة العديد من اللغات التي تعتمد على القوالب مثل لغة Thymeleaf التي تستخدم مع Java Spring على الخادم. وهي تشابه XML في أن معرِّفي البداية والنهاية لكل عنصر يجب أن يكونا موجودين. فعلى سبيل المثال يمكن كتابة عنصر السطر الجديد <br> في HTML على النحو: <br> لكن عندما نستخدم JSX، لابد من إغلاق العنصر أي وضع معرِّف النهاية كالتالي: <br /> المكوّنات المتعددة سنعدّل شيفرة التطبيق على النحو التالي: const Hello = () => { return ( <div> <p>Hello world</p> </div> ) } const App = () => { return ( <div> <h1>Greetings</h1> <Hello /> </div> ) } ReactDOM.render(<App />, document.getElementById('root')) انتبه: لم ندرج الملفات الرأسية (الملفات المدرجة باستخدام تعليمة import) في الشيفرة المعروضة سابقًا ولن نفعل في المستقبل، لكن عليك إدراجها دائمًا عندما تحاول تشغيل التطبيق. عرّفنا داخل المكوّن App مكوِّنًا جديدًا يدعى Hello استُخدم أكثر من مرة ويعتبر ذلك أمرًا طبيعيًًا: const App = () => { return ( <div> <h1>Greetings</h1> <Hello /> <Hello /> <Hello /> </div> ) } من السهل إنشاء المكوِّنات في React، وبضم المكوِّنات إلى بعضها ستنتج تطبيقات أكثر تعقيدًا لكنها مع ذلك تبقى قابلة للتنفيذ. إنها فلسفة React التي تعتمد في جوهرها على بناء التطبيقات باستخدام مكوِّنات لها أغراض محددة يمكن إعادة استخدامها في أي وقت. تعتبر فكرة المكوّن الجذري (root component) الذي يمثله هنا App (المكوّن الذي يقع أعلى شجرة المكوِّنات)، نقطة قوة أخرى في React. مع ذلك سنجد في القسم 6 أنّ هذا المكوّن لن يكون جذريًّا تمامًا، لكنه سيُغلَّف ضمن مكوِّن تخديمي (utility component) مناسب. الخصائص (Props): تمرير البيانات إلى المكوِّنات من الممكن تمرير البيانات إلى المكوّنات مستخدمين مايسمى الخصائص (Props). سنعدّل المكوِّن Hello كالتالي: const Hello = (props) => { return ( <div> <p>Hello {props.name}</p> </div> ) } تمتلك الدالة التي تعرّف المكوِّن Hello مُعاملًا يدعى props. يستقبل المُعامل (الذي يلعب دور الوسيط هنا) كائنًا يمتلك حقولًا تمثل كل الخصائص التي عُرِّفت في المكوّن. سنستعرض ذلك من خلال الشيفرة التالية: const App = () => { return ( <div> <h1>Greetings</h1> <Hello name="George" /> <Hello name="Daisy" /> </div> ) } لا يوجد عدد محدد من الخصائص لمكوّن ما، ويمكن أن تحمل هذه الخصائص نصوصًا جاهزةً (hard coded) أو قيمًا ناتجة عن تنفيذ عبارات JavaScript. ينبغي وضع قيم الخصائص الناتجة عن تنفيذ تلك العبارات ضمن أقواس معقوصة. سنعدل شيفرة المكوّن Hello ليمتلك خاصيتين كالتالي: const Hello = (props) => { return ( <div> <p> Hello {props.name}, you are {props.age} years old </p> </div> ) } const App = () => { const name = 'Peter' const age = 10 return ( <div> <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <Hello name={name} age={age} /> </div> ) } أرسل المكوِّن App الخاصيتين على شكل قيم عائدة لمتغيّرات، كما أرسلهما أيضًا كنتيجة لتنفيذ عبارتي JavaScript، أحداهما عبارة جمع والأخرى قيمة نصية. بعض الملاحظات هُيّئت React لتولّد رسائل خطأ واضحةً تمامًا، وبالرغم من ذلك عليك التقدم بخطوات صغيرة، وأن تتأكد أنّ كل تغيير قد أجريته حقق الغاية منه، اتبع هذا الأسلوب في البداية على الأقل. ابق طرفية التطوير مفتوحةً دومًا. ولا ننصحك بمتابعة العمل إن أبلغك المتصفح بوجود أخطاء، بل عليك أن تتفهم سبب الخطأ قبل كل شيئ، وتذكر أنه يمكنك التراجع دائمًا إلى حالة العمل السابقة. سينفعك أن تكتب التعليمة ()console.log بين الحين والأخر ضمن أسطر شيفرة تطبيقك، حيث تطبع هذه التعليمة سجلات تنفيذ الشيفرة على الطرفية. وتذكر أنّ أسماء مكوِّنات React تبدأ بأحرف كبيرة (Capitals)، فلو حاولت تعريف مكوِّن بالشكل التالي: const footer = () => { return ( <div> greeting app created by <a href="https://github.com/mluukkai">mluukkai</a> </div> ) } ثم استخدمته كما يلي: const App = () => { return ( <div> <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <footer /> </div> ) } لن تعرض الصفحة حينها المحتوى الذي يقدمه المكوِّن Footer، بل ستنشئ عنصرًا فارغًا يحمل اسم footer. لكن إن حولت الحرف الأول من اسم المكوِّن إلى F، ستنشئ React عنصر div المعرّف ضمن المكوّن Footer وسيصيّره على الصفحة. تذكر أن مكوِّنات React تتطلب عادة وجود عنصر جذري (root element) وحيد، فلو حاولنا تعريف المكوِّن App على سبيل المثال دون وجود العنصر div في البداية كالتالي: const App = () => { return ( <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <Footer /> ) } ستكون النتيجة رسالة الخطأ التالية: يمكن أن نستخدم وسيلة بديلة عن العنصر الجذري تتمثل بإنشاء مصفوفة من المكوِّنات كما يلي: const App = () => { return [ <h1>Greetings</h1>, <Hello name="Maya" age={26 + 10} />, <Footer /> ] } لا يعتبر -على الرغم من ذلك- تعريف العنصر الجذري ضمن المكوِّن الجذري لتطبيق ما أمرًا مفضلًا، بل ستظهر الشيفرة بمظهر سيئٍ قليلًا. ذلك أنّ العنصر الجذري المحدد مسبقًا، سيسبب زيادة في عدد عناصرdiv في شجرة DOM. يمكن تلافي هذا الأمر باستخدام الأجزاء (fragments)، أي بتغليف العناصر ليعيدها المكوِّن على شكل عناصر فارغة كالتالي: const App = () => { const name = 'Peter' const age = 10 return ( <> <h1>Greetings</h1> <Hello name="Maya" age={26 + 10} /> <Hello name={name} age={age} /> <Footer /> </> ) } سيُترجم الآن التطبيق بنجاح، ولن تحتوي شيفرة DOM على عناصر div زائدة. التمارين 1.1 - 1.2 تسلّم التمارين عبر GitHub، وتحدَّد التمارين التي نفذت من خلال تطبيق تسليم الملفات submission application. يمكنك وضع كل تمارين المنهاج التي سلمتها في نفس المكان على المنصة أو في عدة أماكن، لكن عليك أن تستخدم تسميات منطقية للمجلدات إن كنت ستضع تمارين كل الأقسام في نفس المكان. يمكنك اتباع المخطط التالي لتنظيم المجلدات والتمارين المسلمة: part0 part1 courseinfo unicafe anecdotes part2 phonebook countries ألق نظرة على طريقة تنظيم الملفات. فلكل قسم مجلد خاص به يتفرع إلى مجلدات أخرى تضم تمارين مثل "unicafe" الموجود في القسم 1. يفضل تسليم سلسلة التمارين التي تشكل تطبيقًا معًا، ماعدا المجلد node_modules. يتوجب تسليم تمارين كل قسم على حدى، إذ لا يمكنك تسليم أية تمارين جديدة تعود إلى قسم ما إذا كنت قد سلمت غيرها من ذات القسم. انتبه يضم هذا القسم تمارين أخرى غير التمارين التي سنستعرضها الآن، لا تسلم التمارين التي ستنجزها في هذا الفصل بل انتظر حتى تنهي جميع تمارين القسم. 1.1- معلومات عن المنهاج course information، الخطوة 1 سنطور التطبيق الذي ننفذه انطلاقًا من هذا التمرين خلال التمارين القليلة القادمة. يكفي أن تسلم التطبيق في حالته النهائية دون تسليمه تمرينًا تمرينًا، وينطبق هذا الكلام على مجموعات التمارين المشابهة التي ستواجهها لاحقًا. بالطبع يمكنك ترك ملاحظة تشير إلى ذلك ضمن كل تمرين من السلسلة، لكنه أمر اختياري بحت. استخدم create-react-app لإنشاء تطبيق جديد وعدل الملف index.js ليظهر كالتالي: import React from 'react' import ReactDOM from 'react-dom' const App = () => { const course = 'Half Stack application development' const part1 = 'Fundamentals of React' const exercises1 = 10 const part2 = 'Using props to pass data' const exercises2 = 7 const part3 = 'State of a component' const exercises3 = 14 return ( <div> <h1>{course}</h1> <p> {part1} {exercises1} </p> <p> {part2} {exercises2} </p> <p> {part3} {exercises3} </p> <p>Number of exercises {exercises1 + exercises2 + exercises3}</p> </div> ) } ReactDOM.render(<App />, document.getElementById('root')) احذف الملفات الزائدة وهي: App.js وApp.css وApp.test.js وlogo.svg وsetupTests.js وserviceWorker.js. لسوء الحظ فالتطبيق ككل محتوًى في نفس المكوِّن، أعد صياغة التطبيق ليضم ثلاثة مكوِّنات جديدة: Header وContent وTotal. عدل الشيفرة التي تمرر البيانات في التطبيق App عبر الخصائص واجعل المكوِّن Header يتولى أمر البيانات المتعلقة باسم المنهاج، واجعل المكوِّن Content مسؤولًا عن تصيير البيانات المتعلقة بالأقسام وعدد التمارين في كل منها، وأخيرًا اجعل المكوِّن Total مسؤولًا عن تصيير البيانات المتعلقة بالعدد الكلي للتمارين. سيظهر جسم التطبيق الجديد تقريبًا كما يلي: const App = () => { // const-definitions return ( <div> <Header course={course} /> <Content ... /> <Total ... /> </div> ) } تحذير تنشئ الأداة create-react-app مستودع git محلي يحتوي المشروع ، إلا إن كان في المجلد مستودع محلي سابق. من المرجح أنك لا تريد أن يغدو المشروع مستودعًا، لهذا نفذ الأمر التالي rm -rf .git في مسار المشروع. 1.2- معلومات عن المنهاج، الخطوة 2 أعد صياغة المكوِّن Content بحيث لا يصيّر بنفسه أسماء الأقسام أو عدد التمارين التي تضمها، بل يصير ثلاثة مكوِّنات تدعى Part، ثم يُصيّر كل مكوّن منها اسم قسم واحد وعدد التمارين التي يضمها. const Content = ... { return ( <div> <Part .../> <Part .../> <Part .../> </div> ) } يمرر تطبيقنا حاليًا المعلومات بطريقة بدائية لاعتماده على متغيرات مفردة. سيتحسن الأمر قريبًا. اقترح تعديلًا على مضمون الفصل الأصلي. ترجمة -وبتصرف- للفصل Introduction to React من سلسلة Deep Dive Into Modern Web Development1 نقطة -
مقدمه رائعه متابع للدوره في انتظار الدروس المتقدمه1 نقطة
-
 تتألّف لغة الآلة من تعليماتٍ بسيطةٍ جدًا يُمكن تنفيذها مباشرةً من قبل وحدة المعالجةِ المركزيّة للحاسوب. رغم ذلك، فإنّ جميع البرامج تقريبًا مكتوبةٌ بلغات برمجة عالية المستوى (high-level programming languages) مثل جافا أو بايثون أو C++. لا يُمكن تنفيذ البرنامج المكتوب بلغة برمجةٍ عالية المستوى مباشرةً على أيّ حاسوب. يجب أوّلًا أن يُترجم إلى لغة الآلة. يُمكن إجراء التّرجمة هذه من قبل برنامجٍ يُدعى المُصرّف (Compiler). يأخذ المُصرّف برنامجًا مكتوبًا بلغة برمجةٍ عالية المستوى ويترجمه إلى برنامج قابلٍ للتّنفيذ بلغة الآلة. حالما تنتهي التّرجمة، يُمكن تنفيذ البرنامج المُترجم إلى لغة الآلة في أي وقتٍ ولأيّ عددٍ من المرات على نوعٍ واحد من الحواسيب (نظرًا لأنّ لكلّ نوعٍ من الحواسيب لغة آلةٍ فريدةٌ خاصةٌ به). إذا ما أُريد للبرنامج أن يُنفّذ على نوع حواسيب مختلف، يجب إعادة ترجمته إلى لغة الآلة الموائمة باستخدام مُصرّف مختلف. هنالك بديلٌ لترجمة البرامج المكتوبة بلغاتٍ عالية المستوى. عوضًا عن استخدام المُصرّف الذي يُترجم البرنامج دفعةً واحدة، يمكنك استخدام المُفسّر (Interpreter) الذي يترجمه تعليمةً تلو تعليمةٍ حسب الحاجة. المُفسّر هو برنامج يعمل بنفس آلية عمل وحدة المعالجة المركزيّة، عبر ما يشبه دورة جلب وتنفيذ خاصّة به. لتنفيذ برنامجٍ ما، يقوم المُفسّر بتشغيل حلقةٍ يقوم فيها بقراءة تعليمة واحدةٍ من البرنامج، تحديد ما يلزم لتنفيذ هذه التّعليمة، ومن ثم تنفيذ أوامر لغة الآلة الموافقة. (يُشبه المُصرّف المُترجم البشريّ الذي يترجم كتابًا كاملًا من لغة إلى أخرى مما يُنتج كتابًا جديدًا في اللغة الهدف. أما المُفسّر فيقابل المُفسّر البشري الذي يترجم خطابًا في الأمم المتحدة من لغة إلى أخرى في الوقت ذاته الذي يُلقى فيه الخطاب.) أحد استخدامات المفسّرات هو تنفيذ البرامج المكتوبة بلغات عالية المستوى. تُنفَّذ لغة البرمجة Lisp، على سبيل المثال، باستخدام مفسّر وليس مُصرّف. على أيّة حال، للمفسّرات غرضٌ آخر: تسمح المفسّرات لك باستخدام برنامج بلغة الآلة مُخصّص لنوع حواسيب معين على نوع آخر مختلفٍ كليًّا. على سبيل المثال، كان Commodore 64 أو "C64" أحد الحواسيب المنزليّة الأولى. وعلى الرغم من أنّك لن تجد C64 متوفرًا الآن في الأسواق، إلا أنّك تستطيع العثور على برامج محاكية له تعمل على حواسيب أخرى أو حتى ضمن مُتصفحات الويب. يستطيع محاكٍ كهذا تنفيذ برامج الحاسوب C64 عبر العمل كمفسّر للغة آلة C64. اختار مصممو جافا استخدام مزيج بين التّصريف والتّفسير. تُصرّف البرامج المكتوبة بلغة جافا إلى لغة آلة، لكنها لغة آلة لحاسوبٍ غير موجود في الواقع. يُعرف هذا الحاسوب الافتراضي المزعوم بآلة جافا الافتراضيّة (Java Virtual Machine)، أو JVM. تُدعى لغة الآلة الخاصّة بآلة جافا الافتراضيّة بشيفرة جافا الثُّمانيّة أو جافا بايتكود (Java bytecode). لا يوجد سببٌ يمنع استخدام شيفرة جافا الثُّمانيَّة أو لغة البايتكود كلغة آلة لحاسوبٍ حقيقيٍّ بدلًا من الحاسوب الافتراضي. إلّا أنّ استخدام الآلة الافتراضيّة يفتح الطريق أمام أهم نقاط قوّة وشعبيّة جافا ألا وهي إمكانيّة استخدام هذه الشّيفرة على أي حاسوب. جلّ ما سيحتاجه هذا الحاسوب هو مفسّر لشيفرة جافا الثُّمانيَّة. يُحاكي مفسّر كهذا آلة جافا الافتراضيّة كما يُحاكي محاكي C64 حاسوبَ Commodore 64 الأصلي. يُستخدم مصطلح آلة جافا الافتراضيّة أيضًا للإشارة إلى برنامج مفسّر شيفرة البايتكود الذي سيقوم بعمليّة المحاكاة، لذا نقول أنّ الحاسوب سيحتاج إلى آلة جافا الافتراضيّة لكي يُنفّذ برامج جافا. من الأدقّ – تقنيًّا – القول أنّ المفسّر يعمل على تحقيق أو تنفيذ (implement) آلة جافا الافتراضيّة بدلًا من القول أنّ المفسّر هو آلة جافا الافتراضيّة. نحتاج بالطّبع إلى مفسّر مختلف لشيفرة جافا بايتكود من أجل كل نوعٍ من الحواسيب، لكن ما أن يتوفّر مفسّر شيفرة جافا بايتكود على حاسوبٍ ما حتّى يتسنّى له تنفيذ أيّ برنامج مكتوب بلغة جافا بايتكود، ويمكن تنفيذ هذا البرنامج نفسه على أيّ حاسوبٍ يمتلك مفسّرًا مشابهًا. هذه واحدةٌ من أهم ميّزات جافا: يمكن تنفيذ البرنامج المُصرّف ذاته على عدّة أنواعٍ مختلفةٍ من الحواسيب. قد تتساءل الآن، لم استخدام شيفرة جافا بايتكود من الأصل؟ لم لا نقوم فقط بتوزيع برنامج جافا الأصلي وندعُ كل مستخدمٍ يُصرّفه إلى لغة الحاسوب الذي يريد تشغيل البرنامج عليه؟ هناك عدّة أسبابٍ. بادئ ذي بدء، على المُصرّف أن يفهم جافا، والتي هي لغةٌ معقّدةٌ عالية المستوى. المُصرّف بحدِّ ذاته برنامج معقّد. بالمقابل، مُفسّر شيفرة جافا بايتكود هو برنامج بسيط صغيرٌ نسبيًّا. تجعل هذه الحقيقةُ كتابةَ مفسّر شيفرة بايتكود لأي حاسوب جديد أمرًا أكثر سهولةً؛ وما أن يتمّ ذلك حتى يصبح هذا الحاسوب قادرًا على تنفيذ أي برنامج جافا مُصرّف. بينما تكون كتابة مُصرّف جافا لذلك الحاسوب نفسه أمرًا أصعب بكثير. علاوةً على ذلك، يُفترض أنّ بعض برامج جافا سيتمّ تنزيلها عبر شبكة. يؤدي هذا إلى مخاوف أمنيّة بديهية: أنت لا ترغب بالتأكيد بتنزيل وتنفيذ برنامج قد يتسبب بأذية لحاسوبك أو ملفاتك. يؤدي مُفسّر الشّيفرة بايتكود دور مخزنٍ مؤقّت (buffer) بينك وبين البرنامج الذي قمت بتنزيله. أنت في الحقيقة تُنفّذ برنامج المُفسّر، الأمر الذي يُنفّذ البرنامج المُحمّل على نحوٍ غير مباشر. يُمكن للمُفسّر أن يحميك من الأنشطة الخطرة المُحتملة من طرف هذا البرنامج. انتُقِدت جافا عندما كانت لغةً حديثةً العهد لأنها بطيئة: نظرًا لأن شيفرة جافا بايتكود تُنفّذ من قبل مُفسّر، كان يبدو أنّ برامج شيفرة جافا بايتكود لا يمكن لها أبدًا أن تُنفّذ بسرعة البرامج المُصرّفة إلى لغة آلة أصيلة (يُقصد بها لغة الآلة الحقيقيّة للحاسوب الذي يُنفّذ البرنامج عليه). مع ذلك، حُلّت هذه المشكلة إلى حدٍّ كبير باستخدام المُصرّفات في الوقت المُناسب (Just-in-time compilers) لتنفيذ شيفرة جافا بايتكود. يترجم المُصرّف في الوقت المناسب شيفرة جافا بايتكود إلى لغة آلة أصيلة وذلك أثناء تنفيذ البرنامج. يكون دخل المُصرّف في الوقت المناسب – كما أيّ مُفسّر عادي- عبارةً عن برنامج شيفرة جافا بايتكود ومهمّته هي تنفيذ هذا البرنامج. إلّا أنه أثناء تنفيذ البرنامج، يترجم أيضًا أجزاء منه إلى لغة الآلة. يُمكن عندئذٍ للأجزاء المترجمة من البرنامج أن تُنفّذ على نحو أسرع بكثيرٍ من الزمن اللازم لتفسيرها. نظرًا لأنّ بعض أجزاء البرنامج تُنفّذ عادةً مرّاتٍ كثيرة أثناء تنفيذ البرنامج، يُمكن للمصرف في الوقت المناسب أن يزيد من سرعة زمن التنفيذ الكلّي. يجدرُ بالذكر أنّ لا يوجد رابطٌ بالضرورة بين جافا وشيفرة جافا بايتكود. يمكن بالتأكيد تصريف برنامج مكتوب بلغة جافا إلى لغة الآلة لحاسوب حقيقيّ. ويمكن تصريف البرامج المكتوبة بلغات أخرى إلى شيفرة جافا بايتكود. بيد أنّ اتحاد جافا وشيفرة جافا الثمانيّة مستقلٌّ عن المنصة، آمن، ومتوافق مع الشبكة ويسمح لك في الوقت ذااته بالبرمجة بلغة حديثة عالية المستوى وكائنيّة التّوجّه. في السنوات الأخيرة الماضية، غدا شائعًا إحداثُ لغات برمجة جديدة أو إصدارات من لغات قديمة تُصرّف إلى شيفرة جافا بايتكود. يمكن لبرامج الشيفرة الثمانية المُصرّفة أن تُنفّذ على آلة جافا الافتراضيّة المعياريّة. من اللغات الحديثة التي طُوّرت خصيصًا لبرمجة آلة جافا الافتراضيّة نذكرُ: Scala، و Groovy، و Clojure و Processing. بينما Jython وJRuby هما الإصداران من لغتين قديمتين هما Python و Ruby اللذان يستهدفان آلة جافا الافتراضية. تسمح هذه اللغات بالاستفادة من مزايا آلة جافا الافتراضية وفي الوقت ذاته تجنّب بعض التفاصيل التقنية للغة جافا. في الحقيقة، إنّ استخدام لغات أخرى مع آلة جافا الافتراضيّة أصبح مهمًا للدرجة التي استدعت إضافة عدّة ميزات جديدة إلى آلة جافا الافتراضيّة خصيصًا لإضافة دعم أفضل لبعض هذه اللغات. بدورها، فتحت هذه التحسينات في آلة جافا الافتراضيّة المجال أمام ميزات جديدة في جافا. يجدر أيضًا أن نذكر أنّ الجزء الأصعب بحقٍّ في الاستقلالية عن المنصة هو تأمين "واجهة مستخدم رسوميّة" (Graphical User Interface) تتضمن نوافذ، وأزرارًا وغيرها يمكنها العمل على جميع المنصات التي تدعم جافا. سنتطرق للمزيد حول هذا لاحقًا. ترجمة -وبتصرف- للفصل The Java Virtual Machine من الكتاب Introduction to Programming Using Java1 نقطة
تتألّف لغة الآلة من تعليماتٍ بسيطةٍ جدًا يُمكن تنفيذها مباشرةً من قبل وحدة المعالجةِ المركزيّة للحاسوب. رغم ذلك، فإنّ جميع البرامج تقريبًا مكتوبةٌ بلغات برمجة عالية المستوى (high-level programming languages) مثل جافا أو بايثون أو C++. لا يُمكن تنفيذ البرنامج المكتوب بلغة برمجةٍ عالية المستوى مباشرةً على أيّ حاسوب. يجب أوّلًا أن يُترجم إلى لغة الآلة. يُمكن إجراء التّرجمة هذه من قبل برنامجٍ يُدعى المُصرّف (Compiler). يأخذ المُصرّف برنامجًا مكتوبًا بلغة برمجةٍ عالية المستوى ويترجمه إلى برنامج قابلٍ للتّنفيذ بلغة الآلة. حالما تنتهي التّرجمة، يُمكن تنفيذ البرنامج المُترجم إلى لغة الآلة في أي وقتٍ ولأيّ عددٍ من المرات على نوعٍ واحد من الحواسيب (نظرًا لأنّ لكلّ نوعٍ من الحواسيب لغة آلةٍ فريدةٌ خاصةٌ به). إذا ما أُريد للبرنامج أن يُنفّذ على نوع حواسيب مختلف، يجب إعادة ترجمته إلى لغة الآلة الموائمة باستخدام مُصرّف مختلف. هنالك بديلٌ لترجمة البرامج المكتوبة بلغاتٍ عالية المستوى. عوضًا عن استخدام المُصرّف الذي يُترجم البرنامج دفعةً واحدة، يمكنك استخدام المُفسّر (Interpreter) الذي يترجمه تعليمةً تلو تعليمةٍ حسب الحاجة. المُفسّر هو برنامج يعمل بنفس آلية عمل وحدة المعالجة المركزيّة، عبر ما يشبه دورة جلب وتنفيذ خاصّة به. لتنفيذ برنامجٍ ما، يقوم المُفسّر بتشغيل حلقةٍ يقوم فيها بقراءة تعليمة واحدةٍ من البرنامج، تحديد ما يلزم لتنفيذ هذه التّعليمة، ومن ثم تنفيذ أوامر لغة الآلة الموافقة. (يُشبه المُصرّف المُترجم البشريّ الذي يترجم كتابًا كاملًا من لغة إلى أخرى مما يُنتج كتابًا جديدًا في اللغة الهدف. أما المُفسّر فيقابل المُفسّر البشري الذي يترجم خطابًا في الأمم المتحدة من لغة إلى أخرى في الوقت ذاته الذي يُلقى فيه الخطاب.) أحد استخدامات المفسّرات هو تنفيذ البرامج المكتوبة بلغات عالية المستوى. تُنفَّذ لغة البرمجة Lisp، على سبيل المثال، باستخدام مفسّر وليس مُصرّف. على أيّة حال، للمفسّرات غرضٌ آخر: تسمح المفسّرات لك باستخدام برنامج بلغة الآلة مُخصّص لنوع حواسيب معين على نوع آخر مختلفٍ كليًّا. على سبيل المثال، كان Commodore 64 أو "C64" أحد الحواسيب المنزليّة الأولى. وعلى الرغم من أنّك لن تجد C64 متوفرًا الآن في الأسواق، إلا أنّك تستطيع العثور على برامج محاكية له تعمل على حواسيب أخرى أو حتى ضمن مُتصفحات الويب. يستطيع محاكٍ كهذا تنفيذ برامج الحاسوب C64 عبر العمل كمفسّر للغة آلة C64. اختار مصممو جافا استخدام مزيج بين التّصريف والتّفسير. تُصرّف البرامج المكتوبة بلغة جافا إلى لغة آلة، لكنها لغة آلة لحاسوبٍ غير موجود في الواقع. يُعرف هذا الحاسوب الافتراضي المزعوم بآلة جافا الافتراضيّة (Java Virtual Machine)، أو JVM. تُدعى لغة الآلة الخاصّة بآلة جافا الافتراضيّة بشيفرة جافا الثُّمانيّة أو جافا بايتكود (Java bytecode). لا يوجد سببٌ يمنع استخدام شيفرة جافا الثُّمانيَّة أو لغة البايتكود كلغة آلة لحاسوبٍ حقيقيٍّ بدلًا من الحاسوب الافتراضي. إلّا أنّ استخدام الآلة الافتراضيّة يفتح الطريق أمام أهم نقاط قوّة وشعبيّة جافا ألا وهي إمكانيّة استخدام هذه الشّيفرة على أي حاسوب. جلّ ما سيحتاجه هذا الحاسوب هو مفسّر لشيفرة جافا الثُّمانيَّة. يُحاكي مفسّر كهذا آلة جافا الافتراضيّة كما يُحاكي محاكي C64 حاسوبَ Commodore 64 الأصلي. يُستخدم مصطلح آلة جافا الافتراضيّة أيضًا للإشارة إلى برنامج مفسّر شيفرة البايتكود الذي سيقوم بعمليّة المحاكاة، لذا نقول أنّ الحاسوب سيحتاج إلى آلة جافا الافتراضيّة لكي يُنفّذ برامج جافا. من الأدقّ – تقنيًّا – القول أنّ المفسّر يعمل على تحقيق أو تنفيذ (implement) آلة جافا الافتراضيّة بدلًا من القول أنّ المفسّر هو آلة جافا الافتراضيّة. نحتاج بالطّبع إلى مفسّر مختلف لشيفرة جافا بايتكود من أجل كل نوعٍ من الحواسيب، لكن ما أن يتوفّر مفسّر شيفرة جافا بايتكود على حاسوبٍ ما حتّى يتسنّى له تنفيذ أيّ برنامج مكتوب بلغة جافا بايتكود، ويمكن تنفيذ هذا البرنامج نفسه على أيّ حاسوبٍ يمتلك مفسّرًا مشابهًا. هذه واحدةٌ من أهم ميّزات جافا: يمكن تنفيذ البرنامج المُصرّف ذاته على عدّة أنواعٍ مختلفةٍ من الحواسيب. قد تتساءل الآن، لم استخدام شيفرة جافا بايتكود من الأصل؟ لم لا نقوم فقط بتوزيع برنامج جافا الأصلي وندعُ كل مستخدمٍ يُصرّفه إلى لغة الحاسوب الذي يريد تشغيل البرنامج عليه؟ هناك عدّة أسبابٍ. بادئ ذي بدء، على المُصرّف أن يفهم جافا، والتي هي لغةٌ معقّدةٌ عالية المستوى. المُصرّف بحدِّ ذاته برنامج معقّد. بالمقابل، مُفسّر شيفرة جافا بايتكود هو برنامج بسيط صغيرٌ نسبيًّا. تجعل هذه الحقيقةُ كتابةَ مفسّر شيفرة بايتكود لأي حاسوب جديد أمرًا أكثر سهولةً؛ وما أن يتمّ ذلك حتى يصبح هذا الحاسوب قادرًا على تنفيذ أي برنامج جافا مُصرّف. بينما تكون كتابة مُصرّف جافا لذلك الحاسوب نفسه أمرًا أصعب بكثير. علاوةً على ذلك، يُفترض أنّ بعض برامج جافا سيتمّ تنزيلها عبر شبكة. يؤدي هذا إلى مخاوف أمنيّة بديهية: أنت لا ترغب بالتأكيد بتنزيل وتنفيذ برنامج قد يتسبب بأذية لحاسوبك أو ملفاتك. يؤدي مُفسّر الشّيفرة بايتكود دور مخزنٍ مؤقّت (buffer) بينك وبين البرنامج الذي قمت بتنزيله. أنت في الحقيقة تُنفّذ برنامج المُفسّر، الأمر الذي يُنفّذ البرنامج المُحمّل على نحوٍ غير مباشر. يُمكن للمُفسّر أن يحميك من الأنشطة الخطرة المُحتملة من طرف هذا البرنامج. انتُقِدت جافا عندما كانت لغةً حديثةً العهد لأنها بطيئة: نظرًا لأن شيفرة جافا بايتكود تُنفّذ من قبل مُفسّر، كان يبدو أنّ برامج شيفرة جافا بايتكود لا يمكن لها أبدًا أن تُنفّذ بسرعة البرامج المُصرّفة إلى لغة آلة أصيلة (يُقصد بها لغة الآلة الحقيقيّة للحاسوب الذي يُنفّذ البرنامج عليه). مع ذلك، حُلّت هذه المشكلة إلى حدٍّ كبير باستخدام المُصرّفات في الوقت المُناسب (Just-in-time compilers) لتنفيذ شيفرة جافا بايتكود. يترجم المُصرّف في الوقت المناسب شيفرة جافا بايتكود إلى لغة آلة أصيلة وذلك أثناء تنفيذ البرنامج. يكون دخل المُصرّف في الوقت المناسب – كما أيّ مُفسّر عادي- عبارةً عن برنامج شيفرة جافا بايتكود ومهمّته هي تنفيذ هذا البرنامج. إلّا أنه أثناء تنفيذ البرنامج، يترجم أيضًا أجزاء منه إلى لغة الآلة. يُمكن عندئذٍ للأجزاء المترجمة من البرنامج أن تُنفّذ على نحو أسرع بكثيرٍ من الزمن اللازم لتفسيرها. نظرًا لأنّ بعض أجزاء البرنامج تُنفّذ عادةً مرّاتٍ كثيرة أثناء تنفيذ البرنامج، يُمكن للمصرف في الوقت المناسب أن يزيد من سرعة زمن التنفيذ الكلّي. يجدرُ بالذكر أنّ لا يوجد رابطٌ بالضرورة بين جافا وشيفرة جافا بايتكود. يمكن بالتأكيد تصريف برنامج مكتوب بلغة جافا إلى لغة الآلة لحاسوب حقيقيّ. ويمكن تصريف البرامج المكتوبة بلغات أخرى إلى شيفرة جافا بايتكود. بيد أنّ اتحاد جافا وشيفرة جافا الثمانيّة مستقلٌّ عن المنصة، آمن، ومتوافق مع الشبكة ويسمح لك في الوقت ذااته بالبرمجة بلغة حديثة عالية المستوى وكائنيّة التّوجّه. في السنوات الأخيرة الماضية، غدا شائعًا إحداثُ لغات برمجة جديدة أو إصدارات من لغات قديمة تُصرّف إلى شيفرة جافا بايتكود. يمكن لبرامج الشيفرة الثمانية المُصرّفة أن تُنفّذ على آلة جافا الافتراضيّة المعياريّة. من اللغات الحديثة التي طُوّرت خصيصًا لبرمجة آلة جافا الافتراضيّة نذكرُ: Scala، و Groovy، و Clojure و Processing. بينما Jython وJRuby هما الإصداران من لغتين قديمتين هما Python و Ruby اللذان يستهدفان آلة جافا الافتراضية. تسمح هذه اللغات بالاستفادة من مزايا آلة جافا الافتراضية وفي الوقت ذاته تجنّب بعض التفاصيل التقنية للغة جافا. في الحقيقة، إنّ استخدام لغات أخرى مع آلة جافا الافتراضيّة أصبح مهمًا للدرجة التي استدعت إضافة عدّة ميزات جديدة إلى آلة جافا الافتراضيّة خصيصًا لإضافة دعم أفضل لبعض هذه اللغات. بدورها، فتحت هذه التحسينات في آلة جافا الافتراضيّة المجال أمام ميزات جديدة في جافا. يجدر أيضًا أن نذكر أنّ الجزء الأصعب بحقٍّ في الاستقلالية عن المنصة هو تأمين "واجهة مستخدم رسوميّة" (Graphical User Interface) تتضمن نوافذ، وأزرارًا وغيرها يمكنها العمل على جميع المنصات التي تدعم جافا. سنتطرق للمزيد حول هذا لاحقًا. ترجمة -وبتصرف- للفصل The Java Virtual Machine من الكتاب Introduction to Programming Using Java1 نقطة