لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/04/25 في كل الموقع
-
هل يتطلب أن تكون لدي خلفية مسبقة عن البرمجة لأستطيع الاشتراك في دورة الذكاء الاصطناعي؟ حيث أنني خريج تسويق ولا املك خبرة في البرمجة3 نقاط
-
السلام عليكم هل يمكنني تدريب النموذج باستخدام IterativeImputer على وحدة معالجة الرسوميات (GPU) بدلاً من وحدة المعالجة المركزية (CPU) في دفتر كاجل (Kaggle Notebook)؟3 نقاط
-
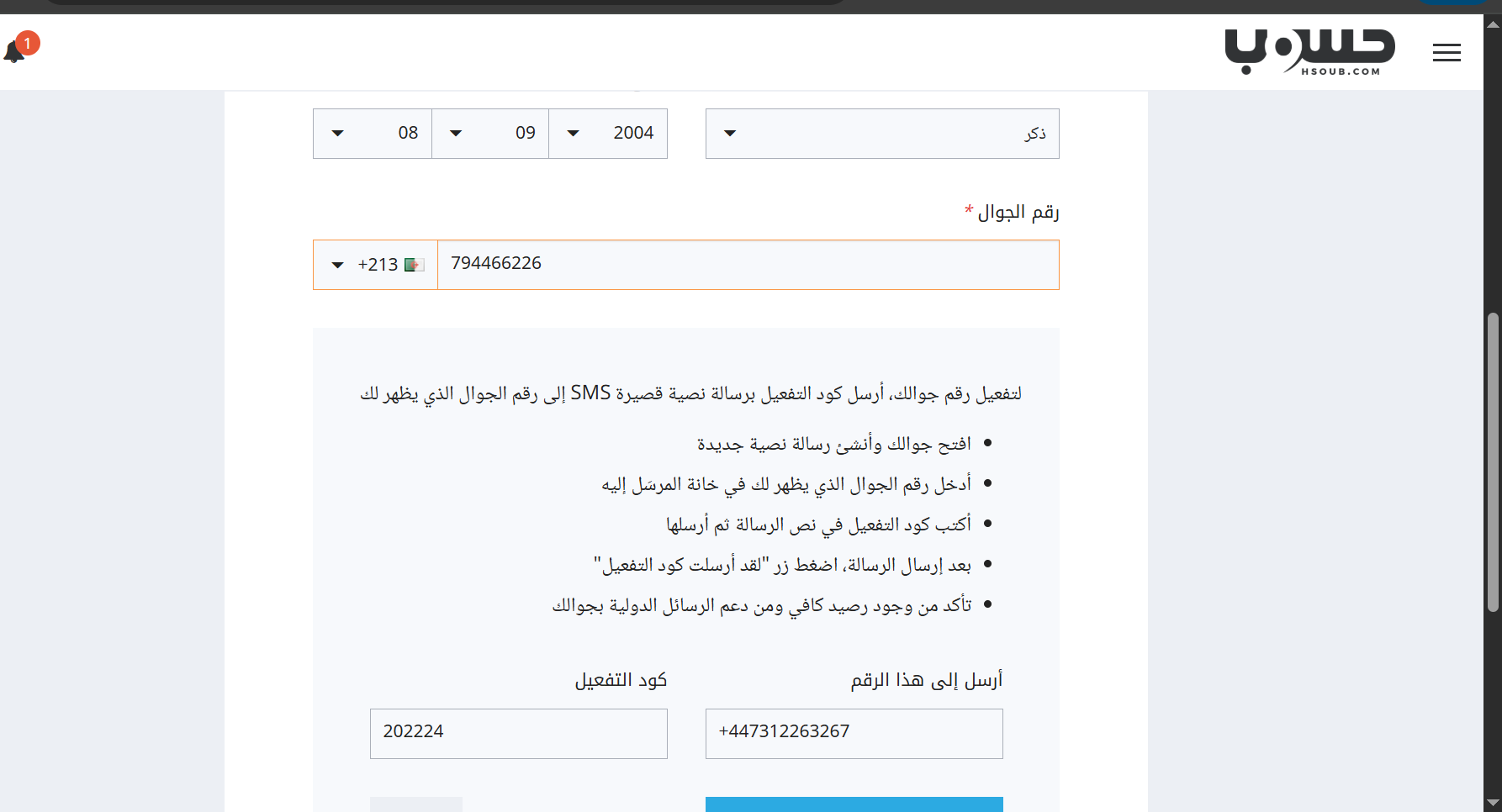
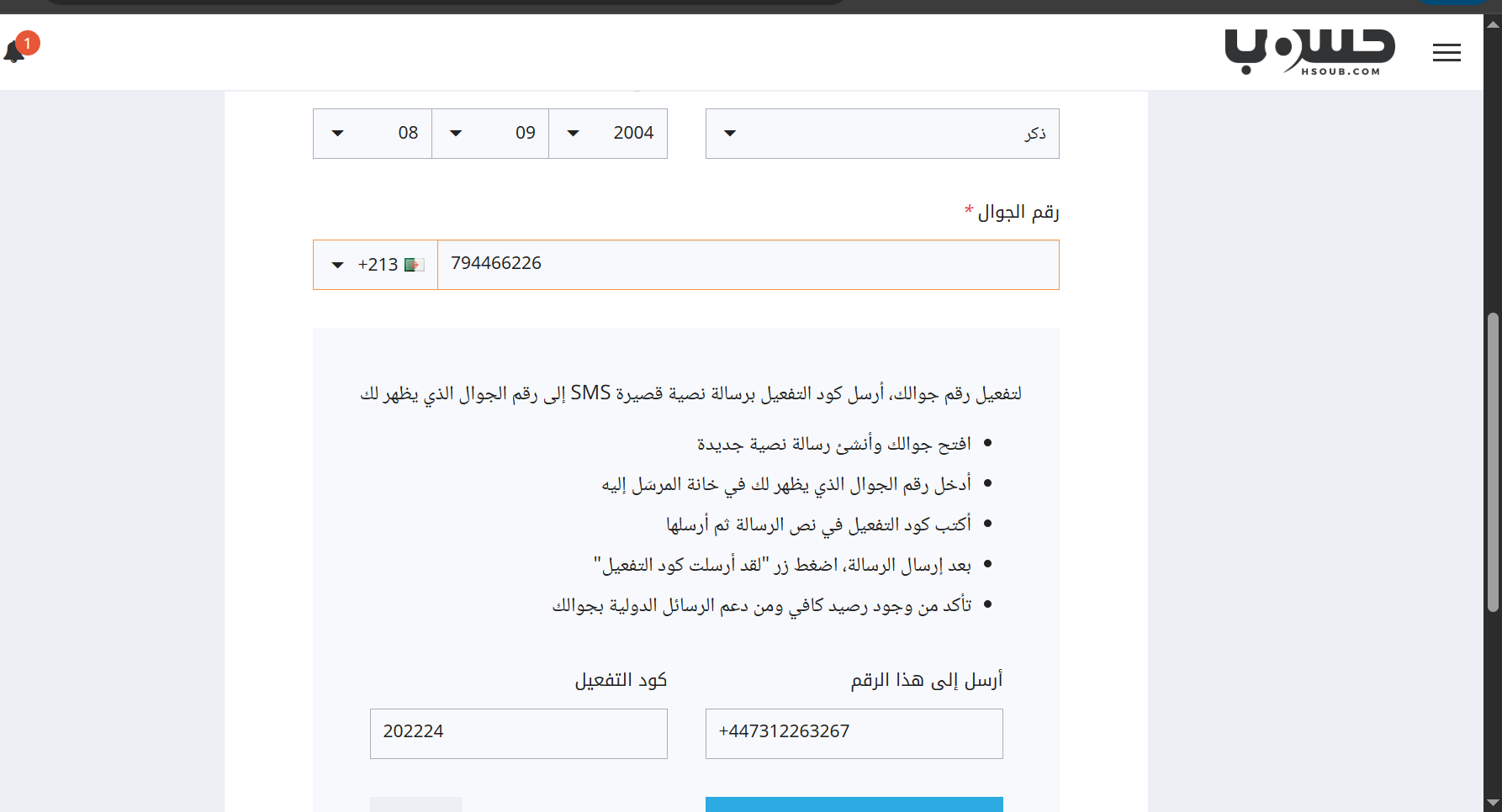
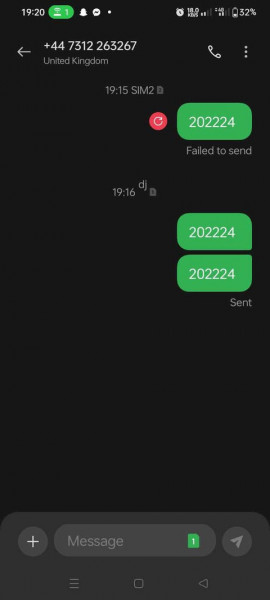
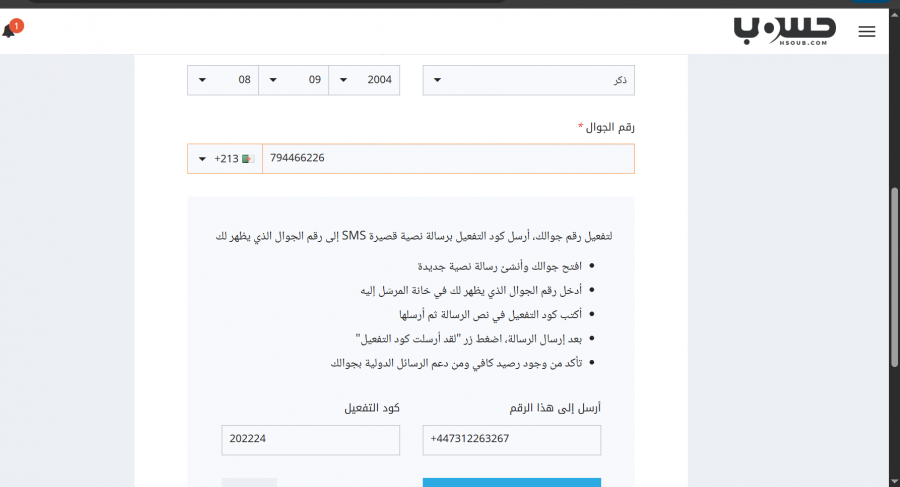
السلام عليكم، أتمنى أن تكونوا بخير. لقد قمت بإرسال كود التفعيل 202224 عبر رسالة نصية قصيرة SMS إلى الرقم +447312263267. أؤكد أن الرسالة قد تم إرسالها، وأرفقت لقطة شاشة (screenshot) كدليل على ذلك. ولكن للأسف، لم يتم تفعيل حسابي حتى الآن. أرجو منكم مساعدتي في تفعيل الحساب. شكرًا لكم على تعاونكم. مع خالص التحية،


 1 نقطة
1 نقطة -
لدي ملف python واحد كيف احوله الى apk1 نقطة
-
لا تقلق بخصوص ذلك، يتم مراجعة حسابك ثم يتم تفعيله طالما قمت بتقديم البيانات المطلوبة، سحتاج إلى الإنتظار ما بين 24 إلى 48 ساعة.1 نقطة
-
السلام عليكم زاي احفظ البيانات بعد ما تعالجها (بـ IterativeImputer مثلاً)، علشان لما تقفل الدفتر على Kaggle وتفتحه تاني، ما تعيدش تنفيذ كود المعالجة من أول وجديد. وده الكود def handle_missing_values(data): numeric_features = data.select_dtypes(include=['number']).columns.tolist() text_features = data.select_dtypes(include=['object']).columns.tolist() preprocessor = ColumnTransformer( transformers=[ ('num',IterativeImputer(),numeric_features), ('text', 'passthrough', text_features), ] ) df_transformed = preprocessor.fit_tranform(data) features_names = numeric_features + text_features data = pd.DataFrame(df_transformed, columns=features_names) return data1 نقطة
-
1 نقطة
-
في حالة IterativeImputer فهي تعتمد بشكل أساسي على مكتبات لا تستفيد من تسريع GPU مثل NumPy وscikit-learn نفسها، والتي تعمل غالبا على وحدة المعالجة المركزية CPU، لذا حتى عند تفعيل بيئة GPU، فإن IterativeImputer سيظل يعمل على الـ CPU لأن مكتبة scikit-learn لا تدعم تسريع GPU بشكل مباشر، يمكنك التفكير في استخدام مكتبات بديلة مثل cuML من RAPIDS، والتي تقدم خوارزميات مشابهة ومدعومة على GPU، لكن قد تحتاج إلى تعديل الكود ليتوافق مع هذه المكتبات.1 نقطة
-
وعليكم السلام ورحمة الله تعالى وبركاته، IterativeImputer من مكتبة scikit-learn لا تدعم التدريب على GPU بشكل مباشر لأن scikit-learn مصممة للعمل على CPU فقط. حتى لو كان لديك GPU متاح في Kaggle Notebook، فإن IterativeImputer سيستخدم CPU للمعالجة. لذا إذا كنت تريد الاستفادة من GPU لمعالجة البيانات المفقودة، يمكنك استخدام بدائل مثل cuML وهي النسخة المحسنة ل GPU من scikit-learn أو يمكنك بدلا من ذلك تنفيذ خوارزمية مشابهة باستخدام PyTorch أو TensorFlow التي تدعم GPU، لكن هذا سيتطلب كتابة كود مخصص لذلك.1 نقطة
-
بالنسبة للصور فلديك مواقع Unsplash, Pexels, Pixabay, Pngtree تقدم صورًا عالية الجودة بدون حقوق ملكية أو بترخيص CC0 الذي يسمح بالاستخدام التجاري والتعديل بدون ذكر المصدر. كذلك Freepik يحتوي على قسم ضخم من الميديا المجانية Vectors, PSDs, Photos, Icons. والمنصات المتخصصة في أصول الألعاب مثل Sprites, Tilesets, Backgrounds, 3D Models هي OpenGameArt.org والذي يحتوي على كم هائل من الرسومات ثنائية وثلاثية الأبعاد، مؤثرات صوتية، وموسيقى. وكذلك Kenney.nl يقدم مجموعات ضخمة من 2D sprites, 3D models, UI elements. بالإضافة إلى https://itch.io/game-assets/free وهو منصة لمطوري الألعاب المستقلين، وكثير منهم يشاركون أصولاً مجانية، وتفقد أيضًا موقع https://craftpix.net/freebies لكن تركيزه على تصميمات البكسل. ولو أردت أيقونات فقط فيتوفر موقع Flaticon وMaterial Icons.1 نقطة
-
وعليكم السلام ورحمة الله، يجب أن نفهم جيدا أن الشيفرة التالية: data_train.isna().sum() تستخدم في مكتبة Pandas لحساب عدد القيم المفقودة (missing values) في كل عمود من أعمدة DataFrame. ولكن من المهم أن نفهم أن هذا الكود لا يتعرف على القيمة -1.0 على أنها مفقودة، بل يتعرف فقط على القيم التي تم تمثيلها فعليا ك: في حالة البيانات من نوع float أو object. أي أنه وبمعنى آخر ف -1.0 هي قيمة عددية صالحة من وجهة نظر Pandas، حتى لو كانت تستخدم أحيانا كترميز يدوي للدلالة على نقص البيانات. أما NaN فهي ليست قيمة عددية، بل تمثل حالة غياب القيمة تماما، كأن تكون الخانة فارغة أو لا تحتوي على أي معلومة. لذا في حال ما إذا أردت أن تعتبر -1.0 قيمة مفقودة، فيجب أن تقوم بتحويلها صراحة إلى NaN باستخدام دالة مثل: replace(-1.0, np.nan) لأن مفهوم NaN يعني أن الخلية لا تحتوي على أي قيمة تستخدم في التحليل أو النمذجة، بعكس رقم مثل -1 أو 0 الذي يبقى رقما قابلا للتعامل معه ما لم يتم تحويله يدويا إلى NaN.1 نقطة
-
وعليكم السلام ورحمة الله، كلاهما يؤديان نفس الوظيفة لكن طريقة التنفيذ تختلف قليلا ففي الكود الأول: tof_columns = [col for col in df.columns if col.startswith('tof_')] يتم المرور على كل اسم عمود في df.columns باستخدام list comprehension، ويتم تطبيق دالة startswith('tof_') على كل اسم عمود وهذه الطريقة تعتمد على تنفيذ سلسلة من العمليات داخل مفسر Python نفسه، مما يجعلها أقل كفاءة عند التعامل مع عدد كبير جدا من الأعمدة، لأن كل اسم عمود يتم التحقق منه بطريقة تكرارية يدوية، بينما في الكود الثاني: tof_columns = df.filter(like='tof_').columns يتم استخدام دالة filter() المدمجة في pandas، وهي مكتوبة بلغة C أو Cython داخل مكتبة pandas نفسها وهذه الطريقة أسرع وأكثر كفاءة لأنها تعتمد على عمليات منخفضة المستوى (low-level operations) داخل pandas لمعالجة أسماء الأعمدة دفعة واحدة بدون المرور التكراري على كل عمود باستخدام Python. لذا فمن حيث الكفاءة والسرعة، الكود الثاني غالبا ما يكون أسرع قليلا، خاصة مع عدد كبير من الأعمدة، لأن df.filter() مكتوبة باستخدام Cython أو C داخل مكتبة pandas، مما يجعلها أكثر كفاءة من استخدام startswith(). ومع ذلك يبقى الفرق في الأداء سيكون ضئيلا جدا ولن يكون ملحوظا إلا في حال وجود عدد هائل من الأعمدة.1 نقطة
-
في البداية يجب أن يكون تركيزك الأساسي على فهم المفاهيم الأساسية، وكتابة شفرة صحيحة تعمل بشكل سليم، ولا تقلق كثيرًا بشأن أداء الشفرة . فمحاولة تحسين الأداء في البداية قد تزيد من تعقيد العملية التعليمية وتشتت انتباهك عن أساسيات البرمجة كما أن الأولوية القصوى لأي مبرمج مبتدئ هي كتابة شفرة صحيحة تنتج النتائج المرجوة ولذلك لا تضع عبئًا إضافيًا على نفسك بتحسينات غير ضرورية في البداية. فحالياً يمكنك تعلم بعض أساسيات الكود النظيف (التسمية، التعليقات، التنسيق) والتي تكون مفيدة من البداية وبعد اكتساب بعض الخبرة يمكنك التعمق في مبادئ الكود النظيف وافهم كيف تؤثر هياكل البيانات والخوارزميات على الأداء.1 نقطة
-
في البداية ليس المطلوب منك سوى تنفيذ المنطق بشكل صحيح، بغض النظر عن جودة الكود أو إتباع الممارسات الصحيحة، أي أهم هدف هو أن تتعلم ترجمة وصف المشكلة إلى خطوات منطقية واضحة ثم إلى كود يعمل بشكل سليم. واسمح لنفسك أن تكتب كود أطول أو أبطأ ما دمت تتعلم، فالتجربة والخطأ أفضل طريقة لترسيخ ما تعلمته، واحرص في كل مسألة على أن تسأل نفسك هل غطيت كل الحالات المطلوبة؟ قبل أن تقلق بشأن السرعة. بعد الوصول لمستوى متوسط ابدء في تعلم كيف يتم كتابة كود جيد وما هي أفضل الممارسات وكيف يتم تحسين الأداء، ولا تنتظر حتى تتقن كل شيء، فمن الجيد بعد كل حل أن تحسب تعقيد الزمن O() والذاكرة ولو تقديريًا، ويكفي أن تبدأ بالتمييز بين خوارزمية خطية O(n) وخوارزمية تربيعية O(n²) والخوارزميات التي تعتمد على log n.1 نقطة