لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 01/14/25 في كل الموقع
-
السلام عليكم هو اي اهميه الاشتقاق والجبر الخطي في الشبكات العصبيه من ناحيه المطورين يعني انا هستخدم ادوات جاهز ؟ يعني فين الاابدع ؟2 نقاط
-
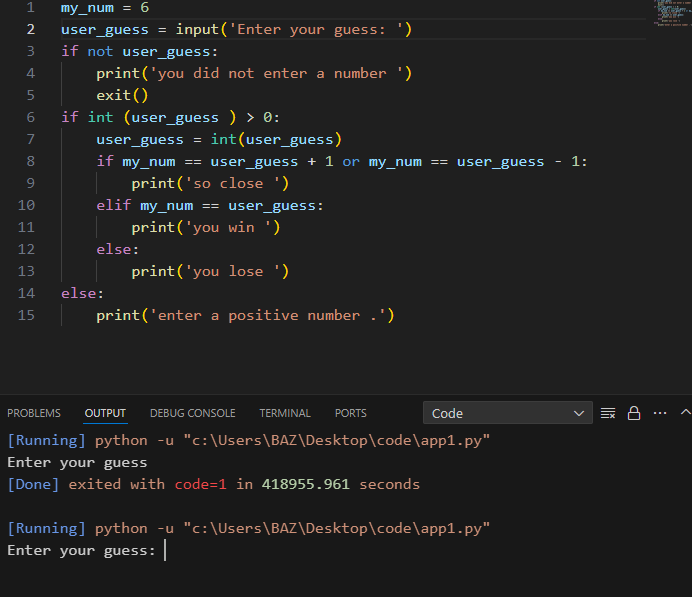
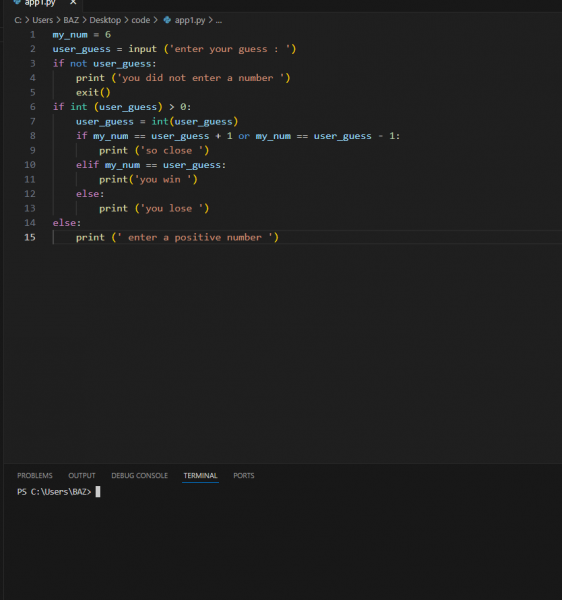
لا استطيع ادخال الرقم لمادا
 2 نقاط
2 نقاط -
sorry , i have the same problem
 2 نقاط
2 نقاط -
لشرح لغات اخري بالتحديد لغة الشي C1 نقطة
-
السلام عليكم. جربت اسوي برنامج بسيط باستخدام multiprocessing و الي قراته انه ينفذ المهام بشكل متوازي و لكن ما فهمت لماذا البرنامج ما يوقف و يعطي النتيجة التي اريدها الا اذا استخدمت time.sleep() و قرات ان هذا ليس جيد في multiprocessing لأنه لا يعطي الفائدة من هذه الميزة. انا جديد في استخدام ثريد و ملتي بروسيسينق غيره و لكن ما فهمت ليش ما تظهر لي النتيجة الا اذا استخدمت أداة time.sleep import multiprocessing import time from multiprocessing import Manager def num(x,y): while y.value==False and x!=10: x.value+=1 print(x.value,"\n") def checkNum(x,y): while x.value<=10 and y.value==False: print(x.value,":") if x.value>=10: print("x equal or greater than 10\n") y.value=True elif x.value<10: print("x desnt equal or greater than 10\n") y.value=False if __name__ == '__main__': manager=Manager() x=manager.Value("d",0) y = manager.Value("b", False) th1=multiprocessing.Process(target=num,args=(x,y)) th2=multiprocessing.Process(target=checkNum,args=(x,y)) th1.start() th2.start() th1.join() th2.join() بدون time.sleep البرنامج يستمر الى ولا يتوقف خصوصا دالة(function) الي اسمها num() import multiprocessing import time from multiprocessing import Manager def num(x,y): while y.value==False and x!=10: x.value+=1 print(x.value,"\n") time.sleep(.01) ##### def checkNum(x,y): while x.value<=10 and y.value==False: print(x.value,":") if x.value>=10: print("x equal or greater than 10\n") y.value=True elif x.value<10: print("x desnt equal or greater than 10\n") y.value=False if __name__ == '__main__': manager=Manager() x=manager.Value("d",0) y = manager.Value("b", False) th1=multiprocessing.Process(target=num,args=(x,y)) th2=multiprocessing.Process(target=checkNum,args=(x,y)) th1.start() th2.start() th1.join() th2.join() هنا مع استخدام time.sleep() لكن في هذه البرنامج يكمل عمله على اكمل وجه و يظهر النتيجة الي اريدها. هل استخدام time.sleep سيء ام ان في الكود الخاص بي يجب استخدامه لأحصل على النتيجة التي اريدها؟1 نقطة
-
وعليكم السلام ورحمة الله وبركاته . المشكلة التي تحدث لك هي مشكلة مشهورة في تعدد المهام (multi threading) وهي التسابق (race condition) وفي تلك الحالة إذا كان هناك أكثر من عملية process تتعامل مع نفس البيانات فهنا تحدث مشكلة في التسابق . حيث كل عملية تقوم بتعديل القيمة قبل الأخرى وبذلك كل عملية يكون لديها بيانات مختلفة لنفس المتغير . هنا في دالة num يوجد حلقة تكرار وبداخل تلك الحلقة تقوم بزيادة قيمة x.value . ولكن في دالة checkNum تقوم بالتحقق من تلك القيمة . هنا يحدث تسابق فتقوم الدالة num بزيادة المتغير بطريقة سريعة جدا . ولكن checkNum لا تستطيع مجاراة ذلك التعديل وبالتالي الدالة checkNum يكون لديها قيم قديمة للمتغير x.value . أى لنفرض أن الدالة num قيمة المتغير x.value وصلت إلى 10000 ولكن بداخل الدالة checkNum قيمة x.value لديها لم تصل إلى ال 10 . وهذا هو سبب المشكلة . ويمكنك قراءة الإجابات التالية والمقالات لمزيد من التفاصيل حول تلك المشكلة : والحل لتلك المشكلة هي القفل Lock . حيث تقوم بقفل هذا المتغير قبل إستخدامه وبهذا إذا أرادت عملية الوصول لهذا المتغير لتعديله أو قراءته لن تستطيع إلا قبل أن يتم إلغاء القفل . وإليك الكود الصحيح بإستخدام ال Lock : import multiprocessing from multiprocessing import Manager def num(x, y, lock): while y.value == False and x.value != 10: with lock: x.value += 1 print(x.value, "\n") def checkNum(x, y, lock): while x.value <= 10 and y.value == False: with lock: print(x.value, ":") if x.value >= 10: print("x equal or greater than 10\n") y.value = True else: print("x doesn't equal or greater than 10\n") if __name__ == '__main__': manager = Manager() x = manager.Value("d", 0) y = manager.Value("b", False) lock = manager.Lock() # قفل لمنع الوصول المتزامن للمتغيرات المشتركة th1 = multiprocessing.Process(target=num, args=(x, y, lock)) th2 = multiprocessing.Process(target=checkNum, args=(x, y, lock)) th1.start() th2.start() th1.join() th2.join()1 نقطة
-
السلام عليكم انا هنا في الكود ده عاوز 1- امسح القيمه الNaN ماعد اعمده معين # Select columns that are important for further analysis, focusing on those that may contain missing values data_columns_nulls = data_train[['cyto_score','cyto_score_detail','hla_high_res_6','hla_high_res_8','hla_high_res_10','hla_match_b_high','tce_imm_match','mrd_hct','tce_match','tce_div_match']] # Drop rows with NaN values in columns that are not part of the selected ones # Commented line below would remove any rows with NaN values, but we're handling missing data per column #data_train.dropna(inplace=True) for columns in data_train.columns: if columns not in data_columns_nulls.columns: # Drop rows where the selected column has NaN values data_train = data_train.dropna(subset=[columns]) # Calculate and print the total number of missing values per column (if needed) missing_values = data_train.isna().sum() print(missing_values) ودي نتجيه الmissing_values ID 0 dri_score 0 psych_disturb 0 cyto_score 2491 diabetes 0 hla_match_c_high 0 hla_high_res_8 60 tbi_status 0 arrhythmia 0 hla_low_res_6 0 graft_type 0 vent_hist 0 renal_issue 0 pulm_severe 0 prim_disease_hct 0 hla_high_res_6 60 cmv_status 0 hla_high_res_10 60 hla_match_dqb1_high 0 tce_imm_match 2468 hla_nmdp_6 0 hla_match_c_low 0 rituximab 0 hla_match_drb1_low 0 hla_match_dqb1_low 0 prod_type 0 cyto_score_detail 4105 conditioning_intensity 0 ethnicity 0 year_hct 0 obesity 0 mrd_hct 5884 in_vivo_tcd 0 tce_match 6306 hla_match_a_high 0 hepatic_severe 0 donor_age 0 prior_tumor 0 hla_match_b_low 0 peptic_ulcer 0 age_at_hct 0 hla_match_a_low 0 gvhd_proph 0 rheum_issue 0 sex_match 0 hla_match_b_high 60 race_group 0 comorbidity_score 0 karnofsky_score 0 hepatic_mild 0 tce_div_match 2536 donor_related 0 melphalan_dose 0 hla_low_res_8 0 cardiac 0 hla_match_drb1_high 0 pulm_moderate 0 hla_low_res_10 0 efs 0 efs_time 0 dtype: int64 لحد دلوقتي تمام بعد كده 2- املئ القيمه الNaN في الاعمدا المعين التي لم امسحها # Fill missing values in the columns selected for analysis for columns in data_columns_nulls.columns: # For categorical columns (object type), fill NaN with the most frequent value (mode) if data_train[columns].dtype == 'object': data_train[columns].fillna(data_train[columns].mode()[0]) else: # For numerical columns, fill NaN with the mean of the column data_train[columns].fillna(data_train[columns].mean()) print("-" * 20) # Calculate and print the total number of missing values per column (if needed) missing_values = data_train.isna().sum() print(missing_values) نتجه الmissing_values زي الاول بطبظ طيب ازي مش المفروض يكون كلها اصفر ID 0 dri_score 0 psych_disturb 0 cyto_score 2491 diabetes 0 hla_match_c_high 0 hla_high_res_8 60 tbi_status 0 arrhythmia 0 hla_low_res_6 0 graft_type 0 vent_hist 0 renal_issue 0 pulm_severe 0 prim_disease_hct 0 hla_high_res_6 60 cmv_status 0 hla_high_res_10 60 hla_match_dqb1_high 0 tce_imm_match 2468 hla_nmdp_6 0 hla_match_c_low 0 rituximab 0 hla_match_drb1_low 0 hla_match_dqb1_low 0 prod_type 0 cyto_score_detail 4105 conditioning_intensity 0 ethnicity 0 year_hct 0 obesity 0 mrd_hct 5884 in_vivo_tcd 0 tce_match 6306 hla_match_a_high 0 hepatic_severe 0 donor_age 0 prior_tumor 0 hla_match_b_low 0 peptic_ulcer 0 age_at_hct 0 hla_match_a_low 0 gvhd_proph 0 rheum_issue 0 sex_match 0 hla_match_b_high 60 race_group 0 comorbidity_score 0 karnofsky_score 0 hepatic_mild 0 tce_div_match 2536 donor_related 0 melphalan_dose 0 hla_low_res_8 0 cardiac 0 hla_match_drb1_high 0 pulm_moderate 0 hla_low_res_10 0 efs 0 efs_time 01 نقطة
-
عند استخدام fillna، تحتاج إلى إعادة تعيين القيم إلى الأعمدة لأن fillna لا تعدل البيانات في مكانها بشكل افتراضي إلا إذا استخدمت inplace=True، إليك الكود المعدل الذي يجب أن يعمل كما هو متوقع: # تحديد الأعمدة التي تحتوي على القيم المفقودة والتي ترغب في التعامل معها data_columns_nulls = ['cyto_score', 'cyto_score_detail', 'hla_high_res_6', 'hla_high_res_8', 'hla_high_res_10', 'hla_match_b_high', 'tce_imm_match', 'mrd_hct', 'tce_match', 'tce_div_match'] # مسح القيم المفقودة (NaN) في الأعمدة غير المحددة for column in data_train.columns: if column not in data_columns_nulls: data_train = data_train.dropna(subset=[column]) # تعبئة القيم المفقودة (NaN) في الأعمدة المحددة for column in data_columns_nulls: if column in data_train.columns: # إذا كان العمود نصي (object)، املأ بـ mode if data_train[column].dtype == 'object': data_train[column].fillna(data_train[column].mode()[0], inplace=True) else: # إذا كان العمود رقمي، املأ بـ mean data_train[column].fillna(data_train[column].mean(), inplace=True) # التحقق من القيم المفقودة مرة أخرى print("-" * 20) missing_values = data_train.isna().sum() print(missing_values) هنا أضفنا inplace=True مع fillna لضمان تعديل القيم داخل الإطار مباشرة.1 نقطة
-
ماهو الفرق بين القواميس و القائمة و المصفوفة؟1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. الاشتقاق والجبر الخطي هما الأساسان المهمان في فهم الشبكات العصبية وكيفية تدريبها وعملها. وبالرغم من وجود العديد من الأدوات الجاهزة أمثال TensorFlow وPyTorch وغيرها والتي تسهل بناء وتدريب النماذج إلا أن الفهم لهذان المجالان مهم جدا. وحيث أن الأدوات الجاهزة توفر لك أساس لبناء النماذج لكن الفهم الجيد للاشتقاق والجبر الخطي يمكنك من تحسين تلك الأدوات وإستعمالها بكفائة عالية وحتى يمكنك من تعديلها تطويريها . فهناك أمثلة عديدة لذلك مثل برامج تصميم المباني وغيرها . هي بالفعل متاحة لجميع المهندسين ولكن كل شخص من الإبداع ومهارته يستطيع إستخدام تلك الأدوات والبرانج بالطريقة التي تمكنه من الإبداع . وهنا لن يتساوي المهندس الجيد بغيره .1 نقطة
-
الاشتقاق والجبر الخطي لهما أهمية كبيرة في فهم عمل الشبكات العصبية وتطويرها، حتى لو كنت ستستخدم أدوات جاهزة مثل TensorFlow أو PyTorch، هذه الأدوات تقوم بتبسيط العمليات الرياضية المعقدة مثل حساب التدرجات في عملية تحسين الأوزان باستخدام خوارزمية الانحدار العكسي، ولكن فهم الأساسيات مثل المصفوفات، المتجهات، والاشتقاق يتيح لك إدراك كيفية عمل هذه العمليات في الخلفية. و الإبداع يظهر عندما تفهم المبادئ الأساسية وتستطيع تحسين النموذج أو تعديله بطرق مبتكرة، و الفهم العميق يساعدك أيضًا في تحديد الأسباب وراء مشكلات مثل الإفراط في التخصيص أي Overfitting أو عدم استقرار التدريب، وإيجاد حلول فعالة لها بدلا من الاعتماد الكامل على الأدوات الجاهزة دون إدراك، لذا هذه الأدوات تسهل التنفيذ، لكن الإبداع يظهر في كيفية استخدام هذه الأدوات بذكاء واستغلال الرياضيات لفهم وتحسين النماذج بشكل عملي.1 نقطة
-
السلام عليكم ده الكود data_columns_nulls = data_train[['cyto_score','cyto_score_detail','hla_high_res_6','hla_high_res_8','hla_high_res_10']] for columns in data_columns_nulls.columns: mean = data_train[columns].mean() print(f'{columns}: {mean}') ودي الخطاء TypeError: unsupported operand type(s) for +: 'int' and 'str'1 نقطة
-
تمام جدا الف شكرااا لحضرتك1 نقطة
-
و عليكم السلام علي، يبدو أن بعض الأعمدة تحمل قيم نصية، يبدو أن هذه نفس البيانات التي قمت بسؤالنا عنها منذ فترة، مثلًا العمود cyto_score يحمل قيمة نصية و ليس عددية، و لا يمكنك تطبيق عملية المتوسط الحسابي عليه. تحياتي.1 نقطة
-
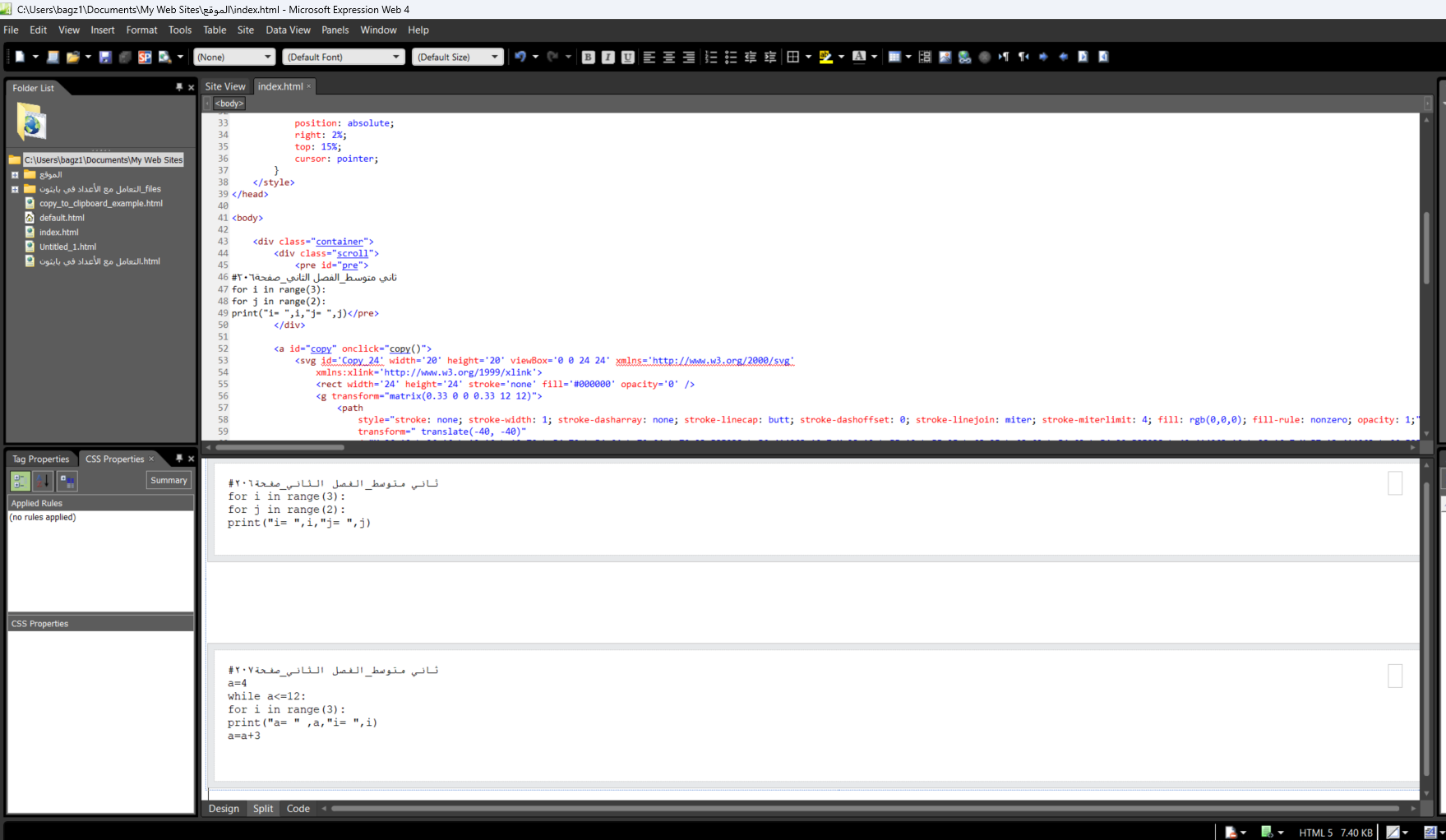
شكرا جزيلاً عند نسخ الكود الذي يحتوي مربع النص و الزر النسخ لمثال اخر عند الضغط على زر النسخ لمثال الثاني ينسخ المثال الاول . ماهو التعديل بالكود لأجل نسخ الكود الثاني او عند الضغط على زر النسخ لمثال صفحة 207 index.html
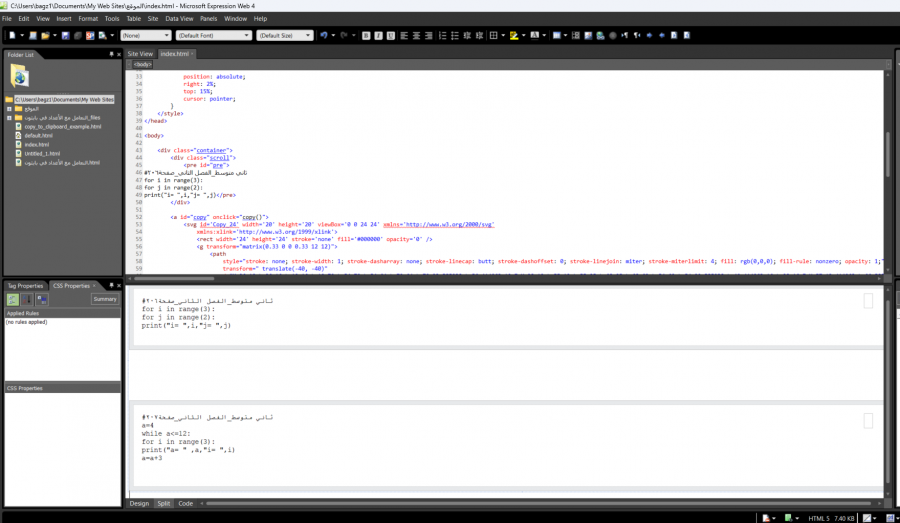 1 نقطة
1 نقطة -
لم توضح المطلوب بالضبط، لكن من الوصف ما تريده هو تحويل البيانات في الملف إلى تطبيق ويب بنفس الوظائف، صحيح؟ لكن هل سيتم القراءة والكتابة من الملف مباشرًة أم من قاعدة البيانات؟ عامًة ستحتاج إلى مكتبتي django-import-export و pandas لاستيراد البيانات من الملف وعرضها وتخزينها في قاعدة البيانات.1 نقطة
-
وعليكم السلام كلمة API عامة وهي تعني: دوال يقوم ببرمجتها المبرمج ليستفيد من البرنامج أو النظام مبرمجون أو مستخدمون آخرون. مثلا أنا قمت بعمل برنامج صغير تعطيه قيمة بالكيلو جرام، يخرجها لك بالباوند مثلا، وأريد أن أجعل مبرمج غيري يستدعي دالة التحويل بدون أن يعرف محتواها، ولكنه سيستفيد منها وسيرى مخرجات. الآن WebServices هي طريقة أو بروتوكول لاخراج هذه الدوال إلى المبرمجين الخارجيين، مع العلم أنه يمكن اخراج الدوال بدون WebServices مثلا في نظام تشغيل ويندوز، ويفر لك الويندوز دوال عامة يمكنك استدعاءها، مثلا دالة إفراغ سلة المحذوفات، يمكنك استدعاءها من كود برنامجك هذه الدالة يتم استدعاءها ليس عن طريق WebServices . الدالة مقصود بها دالة برمجية Function أو إجراء subroutine ، وقد ترسل لها وسيطة Parameter إما تكون متغير نصي أو عبارة عن Class أو واجهة ... إلخ. الويب سيرفس ، طريقة لنقل الدوال والاجراءات بين أجهزة مختلفة، وغالبا يكون عبر استخدام HTTP ، وله عدة صيغ وطرق للنقل أشهرها رسالة SOAP وبروتوكول WSDL وهنالك JSON و XML ... إلخ بمعنى أنت تقوم بعمل API ( دوال ) وتقوم بتصديرها للغيرك ( مبرمج خارجي ) على هيئة مبادئ وبروتوكولات WebServices ، لكي يستخدمها من مكان بعيد. هذا يقودنا للتالي: 1- كل Web services هي APIs والعكس غير صحيح. 2- قد تكون عندك APIs في دوال كثيرة، ولكنك تسمح فقط باخراج بعضها في WebServices ، وبعضها في WebServices أخرى، وبعضها تجعله محلي، وبعضها تربطه مع دوال أخرى خارجية. 3- Web Services تحتاج إلى اتصال انترنت للعمل عليها، ولكن الدوال التقليدية API لا يلزمها غالبا اتصال ، مثلا دوال الويندوز كحذف ملف. مصدر مميز1 نقطة