لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 12/11/24 في كل الموقع
-
السلام عليكم هو اي اهميه عمود زي ده race_group: مجموعة العرق (Categorical) – العرق المعرّف للمريض. القيم: "White", "Black or African-American", "Asian" وغير ذلك. في البيانات طبيه ؟5 نقاط
-
السلام عليكم هو انا ازي اقدر اغير صور الملف الشخصي علي اكاديمه حسوب ؟ انا عاوز اغير الصور CS503 نقاط
-
عندما استدعي beatifulsoup يأتي الكلام معكوس في النتجيه في vscode2 نقاط
-
كنت اريد ان اعرف ما الذي يجب عليا ان اعرف من هذا الدرس2 نقاط
-
انا غيرات الصور بس لسه مظهراتش2 نقاط
-
عندما حملت Python في الفيدهيات المسجله النسخه قديمه في الوقت الحالي الان عندما حملت احدث نسخه يوجد اختلاف في بعض الخانات ايش الحل؟ النسخه المذكوره في الشرح 3.11.4 اما عندي في الوقت الحالي 3.13.11 نقطة
-
تمام جدا جدا انا فكر ان فيه عنصري في الموضوع الف شكراا لحضرتكم جدا1 نقطة
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم الأسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.1 نقطة
-
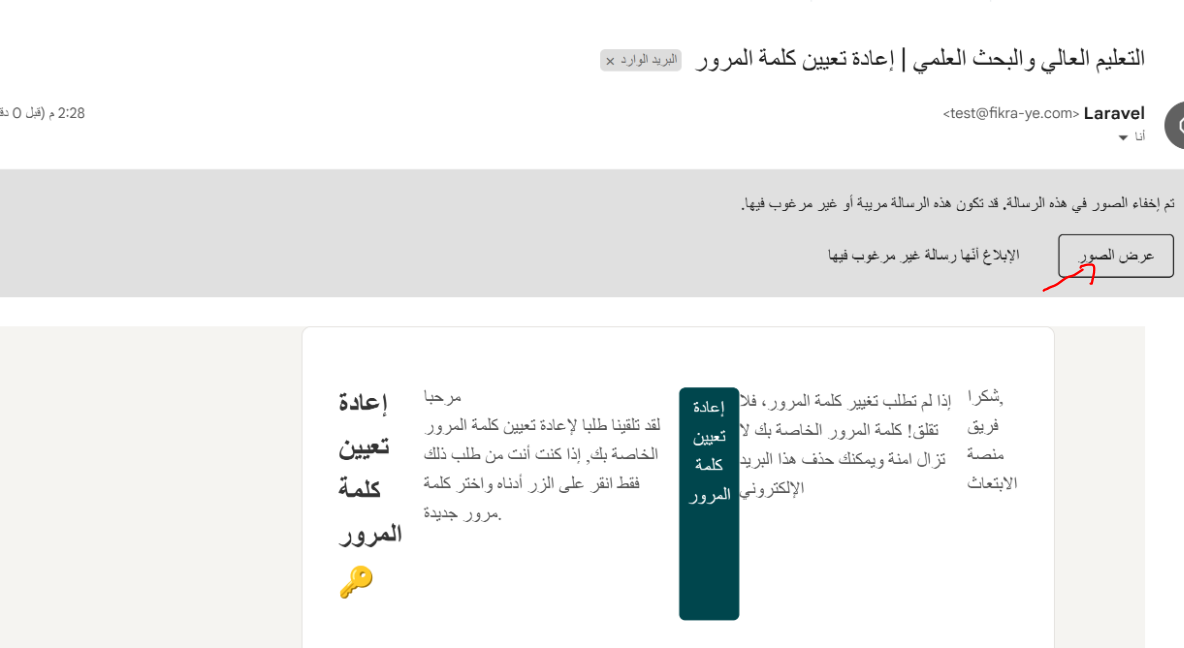
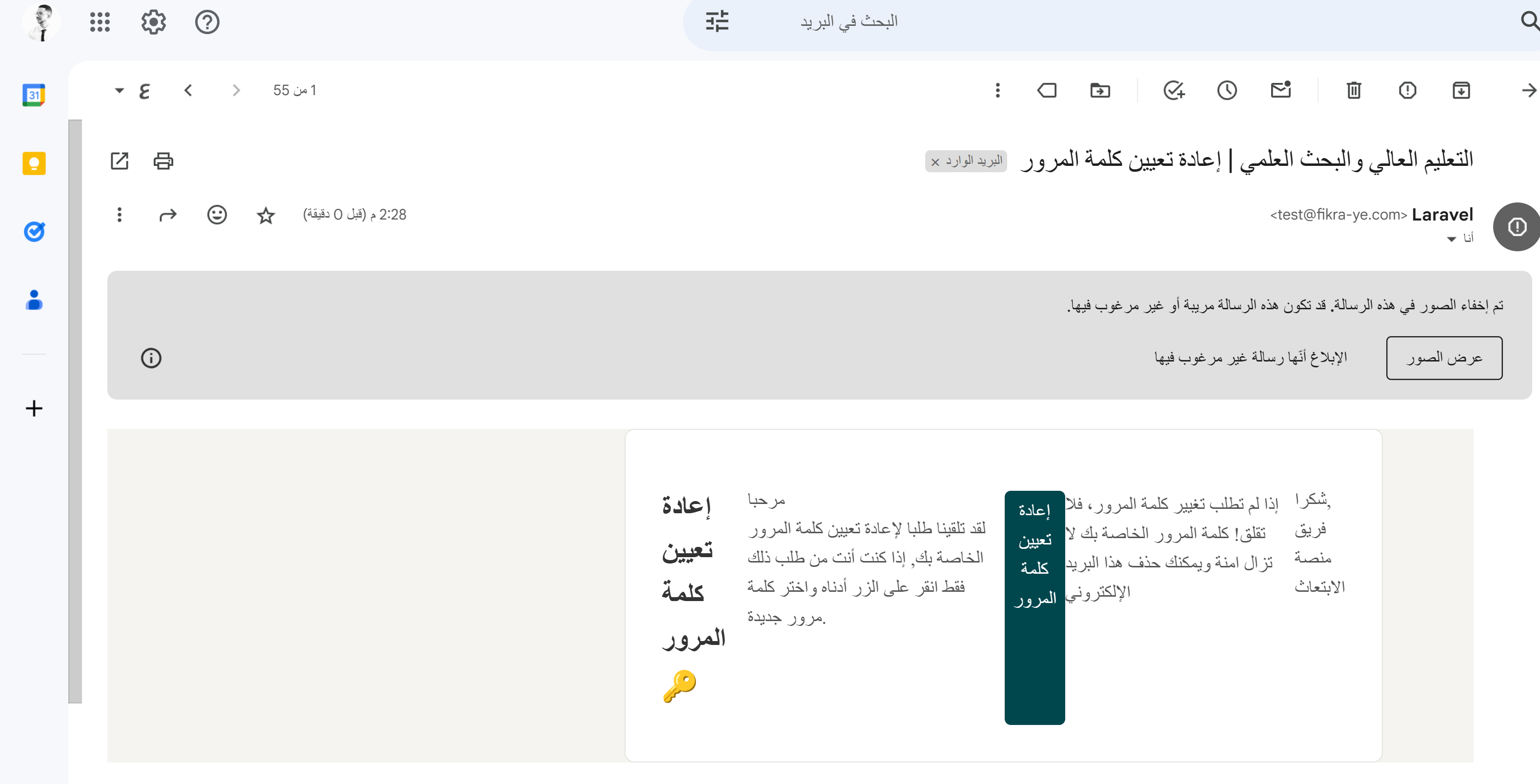
يرجى الضغط على زر عرض الصور حتي تظهر الصور التي في البريد و التنسيقات : حيث يشتبه google بأن هذا البريد هو بريد غير مرغوب فيه (spam) لذها لا يقوم بتحميل أى راوبط فيه.
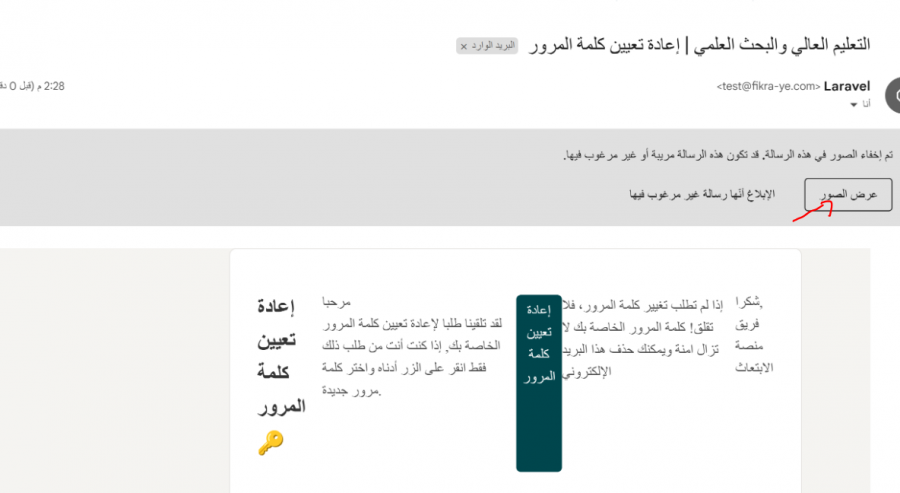 1 نقطة
1 نقطة -
ماهو الحد الاقصي للسحب في المره الاولي وهل يوجد حد ام لا1 نقطة
-
اقصد حد تحويل من موقع مستقل الي باي بال في المره الواحده1 نقطة
-
يمكنك القيام بهذا الأمر عن طريق صفحة حسابات حسوب حيث سيتم تغيير الصورة الخاصة بك في كل المنصات الخاصة بحسوب من خلال هذا الرابط: https://accounts.hsoub.com/1 نقطة
-
إذا كانت لديك مجموعة بيانات تحتوي على العديد من الأعمدة سيعتمد اختيارك بين التعلم العميق والخوارزميات التقليدية على حجم البيانات وتعقيدها فإذا كانت البيانات كبيرة جدا ومعقدة وتحتوي على أنماط غير خطية أو معقدة، فإن التعلم العميق هو الأنسب لأنه قادر على اكتشاف هذه الأنماط بشكل أفضل ولكن إذا كانت البيانات صغيرة أو تحتوي على علاقات بسيطة بين الأعمدة، فإن الخوارزميات التقليدية مثل الأشجار العشوائية أو الانحدار اللوجستي قد تكون أكثر فعالية لأنها أسرع وأسهل في التنفيذ ولا تحتاج إلى موارد ضخمة ولكن 60 عمودا ليست بالضرورة كمية كبيرة من البيانات، بل هي عدد معقول من الأعمدة في مجموعة بيانات وعندما نقول "البيانات الكبيرة" عادة ما نعني عددا كبيرا جدا من السجلات (مثل ملايين أو مئات الآلاف من السجلات)، وليس فقط عدد الأعمدة لذا إذا كان لديك 60 عمودا فقط، ولكن عدد السجلات ليس ضخما جدا، فإن الخوارزميات التقليدية مثل الأشجار العشوائية أو الانحدار اللوجستي قد تكون كافية وفعالة والتعلم العميق يصبح أكثر فائدة عندما تتعامل مع بيانات معقدة جدا أو حجم بيانات ضخم يحتاج إلى قدرات معالجة عالية، ولكن في حالتك، الخوارزميات التقليدية قد تكون الأنسب من حيث السرعة والفعالية.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إن التعلم العميق يحتاج إلى غالبا إلى حجم بيانات كبير جدا لكي يعطي نتائج فعالة وإذا كان لديك بيانات كافية مثل الآلاف أقل شئ فإن التعلم العميق يكون الأفضل في تلك الحالة. أما إذا كانت البيانات محدودة كالتي لديك فالأفضل هو الخوارزميات التقليدية حيث ستكون أكثر فاعلية. و لذلك التفضيل بينهما أولا يكون على حسب عدد البيانات التي لديك وبعد ذلك في حجم تلك البيانات فلو كانت البيانات معقدة مثل الصور والنصوص أو البيانات التي تحتوي على إرتباطات معقدة فالأفضل هنا التعلم العميق ولكن سيحكمك الإمكانيات التي لديك لأنه يستهلك معالجات (GPUs) كثيرة وأيضا وقت كبير في التدريب.1 نقطة
-
بما أنّ العمود يحتوي على 66% من القيم الفارغة فبإمكانك ملء القيم الفارغة باستخدام القيم الافتراضية (مثل 0 أو قيمة معقولة أخرى)، أو حساب القيم المفقودة باستخدام المتوسط أو الوسيط وإذا كان من الصعب ملء القيم، يمكنك استخدام تقنيات التنبؤ مثل الانحدار أو التعلم الآلي وفي حالة تأثير القيم الفارغة بشكل كبير على التحليل، قد يكون من الأفضل استبعاد الصفوف التي تحتوي على القيم الفارغة، مع التأكد من تحسين جودة البيانات في المستقبل.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إذا كان العمود مهم جدا فبالطبع ستحدث مشكلة حيث أنه أكثر من نصف البيانات غير موجودة ولهذا إذا كانت البيانات لديك قليلة وليست كثيرة فلن يكوم النموذج ذو دقة جيدة . ويجب عليك محاولة البحث عن مصادر أخرى للبيانات . أو يمكنك محاولة وضع قيمة إفتراضية أو إستخدام المتوسط إذا كانت البيانات عددية ولكن هذا ليس حلا جيدا.1 نقطة
-
لا يخفى عليك أن القيم المفقودة كبيرة و بالتالي سيؤثر هذا الأمر على النتيجة بشكل كبير، مع ذلك إذا كان العمود عددي، يمكن استبدال القيم المفقودة بمتوسط القيم الموجودة، أما إذا كان هناك تباين كبير في القيم أو وجود قيم شاذة، يمكن استخدام الوسيط بدلا من المتوسط. و إذا كان العمود يحتوي على بيانات تصنيفية، يمكن تعبئة القيم المفقودة بالنمط، أي القيمة الأكثر تكرارا بهذا الشكل لكل واحدة: import pandas as pd # استبدال القيم باستخدام المتوسط df['column_name'].fillna(df['column_name'].mean(), inplace=True) # استبدال القيم باستخدام الوسيط df['column_name'].fillna(df['column_name'].median(), inplace=True) # استبدال القيم باستخدام النمط df['column_name'].fillna(df['column_name'].mode()[0], inplace=True) يوجد أيضا حل يمكن تطبيق حيث إذا كانت البيانات مرتبطة بعمود أو أعمدة أخرى، يمكن استخدام خوارزميات تعلم الآلة لتخمين القيم المفقودة، كاستخدام KNNImputer من مكتبة sklearn لتقدير القيم بناء على القيم الأقرب بهذا الشكل تقريبا: from sklearn.impute import KNNImputer import pandas as pd imputer = KNNImputer(n_neighbors=5) # عدد الجيران يمكن تعديله df[['column_name']] = imputer.fit_transform(df[['column_name']])1 نقطة
-
إذا كان العمود مهما جدا حاول جمع البيانات المفقودة من مصدر آخر أو إعادة حسابها باستخدام مصادر خارجية، فهذا هو الحل المثالي، أو يمكنك استخدام المتوسط إذا كانت البيانات رقمية ومستقرة بهذا الشكل: df['column_name'].fillna(df['column_name'].mean(), inplace=True) إذا كنت تعمل على مشكلة تتعلق بالتنبؤ، يمكنك تجربة استبعاد الصفوف ذات القيم المفقودة ومقارنة الأداء، لكن هذا قد يؤدي إلى فقدان قدر كبير من البيانات أي 33% فقط متاحة.1 نقطة
-
وعليكم السلام السؤال، يعتمد الخيار بين التعلم العميق و الخوارزميات التقليدية على طبيعة البيانات وحجمها. إذا كانت البيانات تحتوي على 60 عمودًا فقط: الخوارزميات التقليدية مثل شجرة القرار، الانحدار اللوجستي، SVM، XGBoost قد تكون أكثر كفاءة في هذه الحالة، خاصة إذا كانت البيانات هي بيانات هيكلية (Structured Data) مع ميزات محددة وأبعاد قليلة. هذه الخوارزميات تعمل بشكل جيد مع حجم بيانات صغير إلى متوسط، وتكون أقل تطلبًا من حيث القدرة الحسابية مقارنة بالتعلم العميق. إذا كانت البيانات تحتوي على أعمدة كثيرة جدًا: التعلم العميق (Deep Learning) يتفوق في الحالات التي تحتوي على بيانات ضخمة جدًا وميزات معقدة، مثل النصوص أو الصور أو الصوت. يمكن أن يكون مفيدًا إذا كان لديك بيانات غير هيكلية أو معقدة للغاية، ولكن قد يحتاج إلى موارد حسابية ضخمة. عندما تختار بينهما: إذا كان لديك بيانات هيكلية وتحتاج إلى تفسير النتائج بسهولة، فالخوارزميات التقليدية تكون أكثر فاعلية. إذا كانت لديك بيانات معقدة أو نطاق واسع من العلاقات بين الأعمدة (مثل الصور أو النصوص)، فقد يكون التعلم العميق خيارًا أفضل. وبالتوفيق1 نقطة
-
الأمر يعود إلى عدد الصفوف بشكل أولى حيث إذا كان العدد صغير أو متوسط أي أقل من 10-20 ألف، فإن خوارزميات تعلم الآلة التقليدية تعد الخيار الأفضل لأنها فعالة وسريعة للبيانات الجدولية، أما إذا كان لديك حجم بيانات ضخم ومعقد جدا، فيمكنك التوجه إلى التعلم العميق، لكنه يتطلب موارد كبيرة وحجم بيانات كبير لتجنب الإفراط في التعميم، و في هذه الحالة يمكنك الإعتماد على google colab حيث يوفر لك Gpu سريع جدا مما يساعدك في العمليات.1 نقطة
-
تنعرض في البريد الاساسي
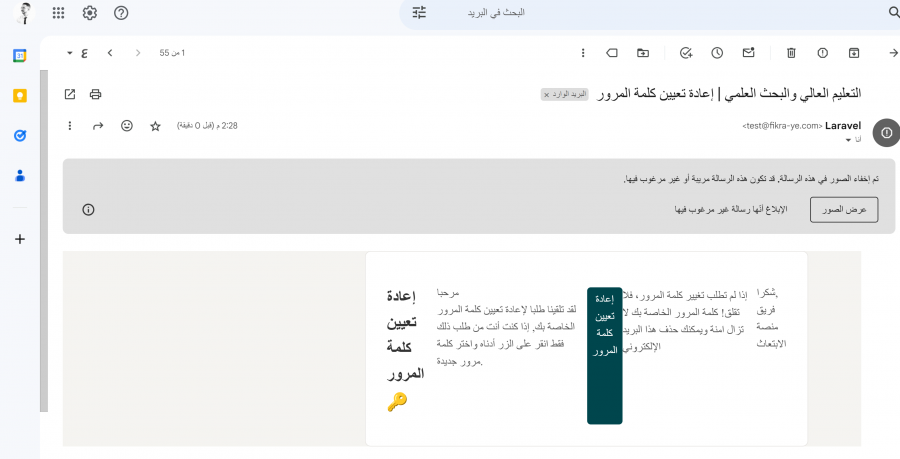
 1 نقطة
1 نقطة