لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 05/24/24 في كل الموقع
-
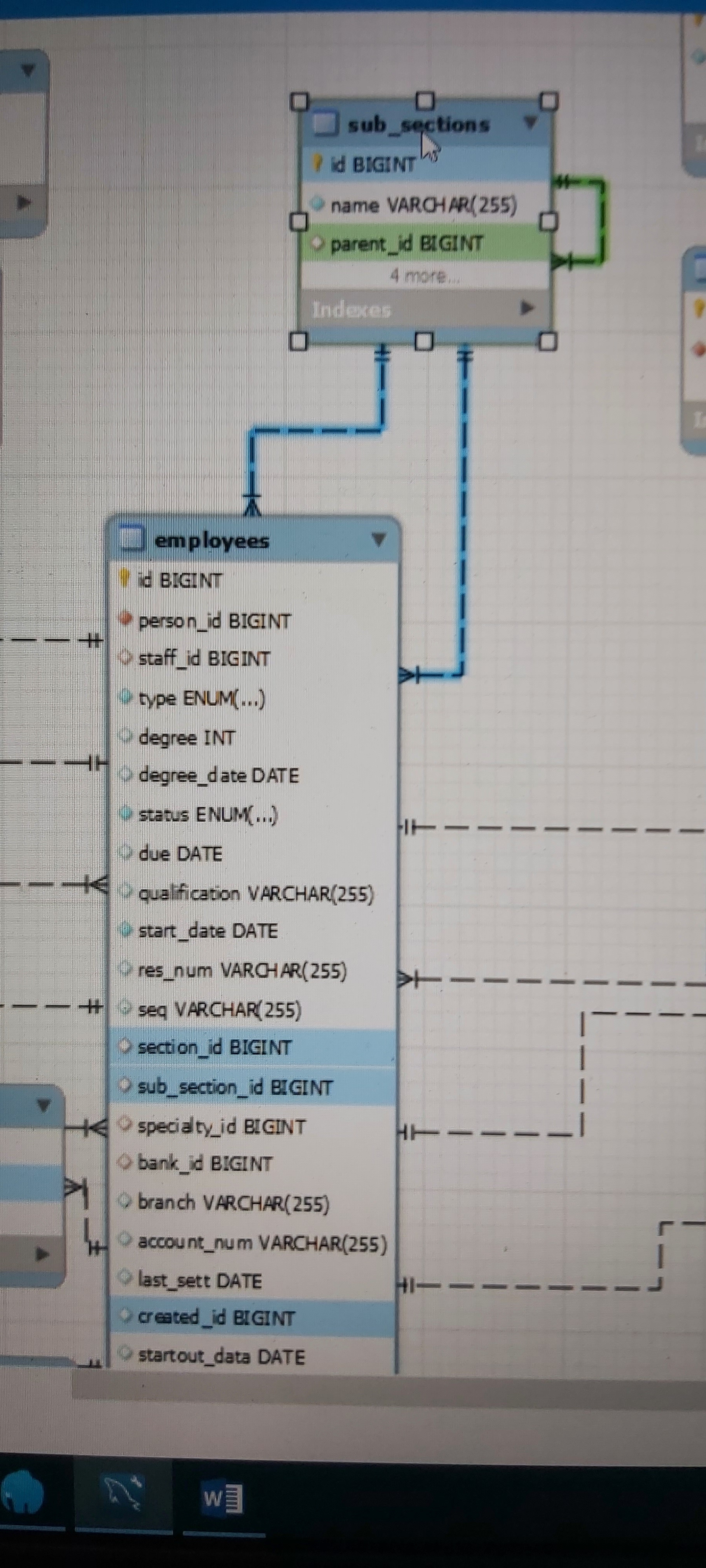
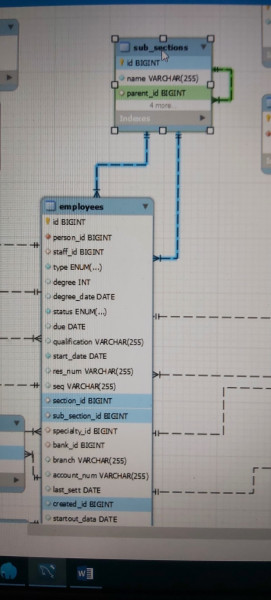
وعليكم السلام ورحمة الله وبركاته، المفترض ان العلاقة بين جدول الإدارات أو الأقسام Sub_sections وجدول الموظفين Employees هي علاقة واحد إلى متعدد one-to-many أي كل سجل في جدول الإدارات يمكنه أن يرتبط بالعديد من السجلات بجدول الموظفين، وهذا منطقي لأن كل إدارة أو قسم يمكن أن يحتوي على موظف (واحد على الأقل) أو أكثر من موظف. ويتضح أيضًا من الصورة أن هناك علاقة ذاتية واحد إلى متعدد بين جدول الإدارات (الأقسام) ونفسه، بحيث كل قسم له قسم رئيسي، فهذه علاقة ذاتية تتم بين الجدول ونفسه في جملة الاستعلام، بحيث كل قسم يمكن أن يحتوي على عدة أقسام فرعية. ولكن ألاحظ وجود خطأ في العلاقة بين جدول الموظفين وجدول الإدارات، حيث يتم الربط بينهما بعلاقتين. ما السبب في هذا؟ المبرمج الذي وضع العلاقتين يقصد أن كل موظف له قسم رئيسي section_id وله قسم فرعي sub_section_id أيضًا لذلك قام بوضع علاقتين بين هذين الجدولين، في الحقيقة لا داعي لهذا لأنه يمكن معرفة القسم الرئيسي للموظف بمجرد أن عرفنا القسم الفرعي له (وذلك لأن القسم الفرعي يستطيع أن يصل إلى القسم الرئيسي الخاص به)، وبذلك يكفي الموظف معرفة القسم الفرعي ومنه يعرف القسم الرئيسي، فيتم الربط أولاً بين جدول الموظفين Employees وجدول الإدارات أو الأقسام Sub_sections ثم يتم الربط ثانيًا مع جدول الإدارات لمعرفة القسم الرئيسي. لذلك وجود علاقتين بين الجدولين بهذا الشكل خطأ كبير وكارثي يجب تجنبه إلا في حالات معينة نادرة (كأن ينتمي الموظف لقسمين في نفس الوقت).2 نقاط
-
اعمل على تطبيق قاعدة بيانات Sqlite بالاندرويد ستوديو بلغة الجافا ، حيث يمكن للمستخدم تصدير بياناته في ملف خارجي عن التطبيق ثم اعادة استيراده منه وقت الحاجة ، لانني لاحظت كل ما قام المستخدم بتحديث التطبيق يتم مسح قاعدة البيانات القديمة بجميع بياناتها ، وهذا مشكل مزعج جداً1 نقطة
-
لدي موقع جانغو هل نشر هذا الموقع على الانترنت يطلب مواقع مخصصة لمشاريع جانغو ام يمكن نشره علي اي موقع اخر اريد بعض الاستضافات المجانية او مدفوعة يثمن 1$ الي 3$1 نقطة
-
في الحقيقة هذا السؤال هام جدًا جدًا، وهو من الأسئلة المتقدمة التي ستظهر مع ذوي الخبرة، لأن هذه المشكلة ستظهر عندما يقوم المبرمج بتطوير تطبيق وتوزيعه أو تثبيته عند العميل ثم بعد ذلك يقوم بعمل إضافات على هذا التطبيق، فتظهر هذه المشكلة. دعنا نصف المشكلة: عند تطوير أي تطبيق وإخراج الإصدار الأول منه، تكون إمكانيات هذا التطبيق محدودة إلى حد ما، ولكن مع انتشار التطبيق وأخذ الإفادات من المستخدمين سوف تظهر طلبات وإمكانيات جديدة مطلوب إضافتها إلى التطبيق (وهذا شأن أي تطبيق في العالم). إذًا ما المشكلة؟ المشكلة تكمن عندما يتعامل التطبيق مع ملفات أخرى مثل قواعد البيانات، فسنجد أن الإصدار الأول من التطبيق يتعامل مع قواعد بيانات تحتوي على عدد محدود من الجداول (وليكن 5 جداول)، ولكن مع الإضافات الجديدة سنحتاج إلى إضافة جداول أخرى (وليكن 3 جداول جديدة فيصبح الإجمالي 8 جداول). هنا تكمن المشكلة، لأن المستخدمين الحاليين قد أضافوا بيانات على قواعد البيانات (ذات الخمس جداول) وبالتالي لا يمكن حذف هذه القواعد وتنزيل القاعدة الجديدة (ذات الثمان جداول). فما الحل؟ سأذكر لك الخطوات العامة لأي تطبيق مهما كان نوعه سواء تطبيق أندرويد أو تطبيق ويندوز أو ماك، هذه الخطوات يجب اتباعها أولًا: بالنسبة للتطبيقات التي لا تقوم بحذف قواعد البيانات: هنا سنحتاج فقط تنفيذ بعض الاستعلامات التي تقوم بإنشاء الجداول الجديدة على قاعدة البيانات الموجودة حاليًا، وهكذا تظل الخمس جداول القديمة كما هي ببياناتها، ويضاف إليهم ثلاث جداول أخرى) ويتم تحديث التطبيق فيعمل بدون مشاكل. ثانيًا: بالنسبة للتطبيقات التي تحذف قواعد البيانات مع كل تحديث: إذا استطعنا تعطيل خاصية حذف الملفات مع التحديث عن طريق التحكم في خصائص التطبيق بملف الخصائص مثل gradle.properties كأن نضيف السطر التالي: android.builder.sdkDownload=false أو بأي طريقة تراها مناسبة على حسب التطبيق الذي تقوم به. فإذا فعلت هذا، اتبع التعليمات المذكورة سابقًا (بالنقطة أولاً). أما إذا لم تتمكن من تعطيل هذه الخاصية فيتوجب عليك قبل تحديث التطبيق أن تأخذ نسخة احتياطية من قواعد البيانات، وبعد التحديث، تحذف قواعد البيانات الجديدة التي نزلت حالًا مع التحديث، ثم تقوم باستعادة النسخة الاحتياطية ثم تقوم بإضافة التغييرات الجديدة عليها بعد الاسترجاع (أي إضافة الثلاث جداول الجديدة). بالتأكيد الموضوع متقدم، ويحتاج بحثًا وجهدًا، ولكن هذه الخطوط العامة التي يجب وضعها بالحسبان، والتي اكتسبناها على مدار سنوات خبرتنا بالبرمجيات وكنا نعاني كثيرًا من هذه النقطة، ولم تكن البرمجيات تقدمت بعد (أتحدث عن بدايات الألفينات).1 نقطة
-
السلام عليكم ورحمة الله وبركاته لدي علاقة في جدولين جدول موظفين وجدول الادارات ماذا يعني سهمين زرق رقم الإدارة مفتاح اجنبي لماذا اثنين مفاتيح يتم للربط ممكن توضيح
 1 نقطة
1 نقطة -
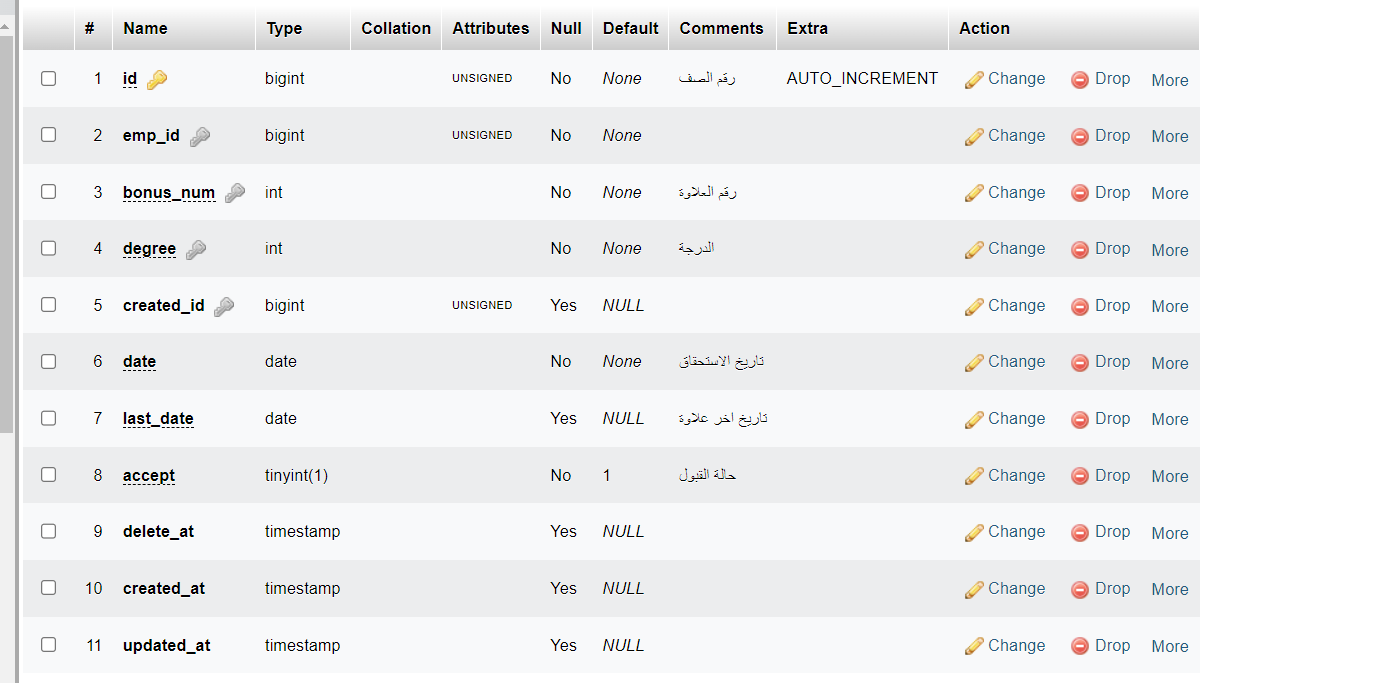
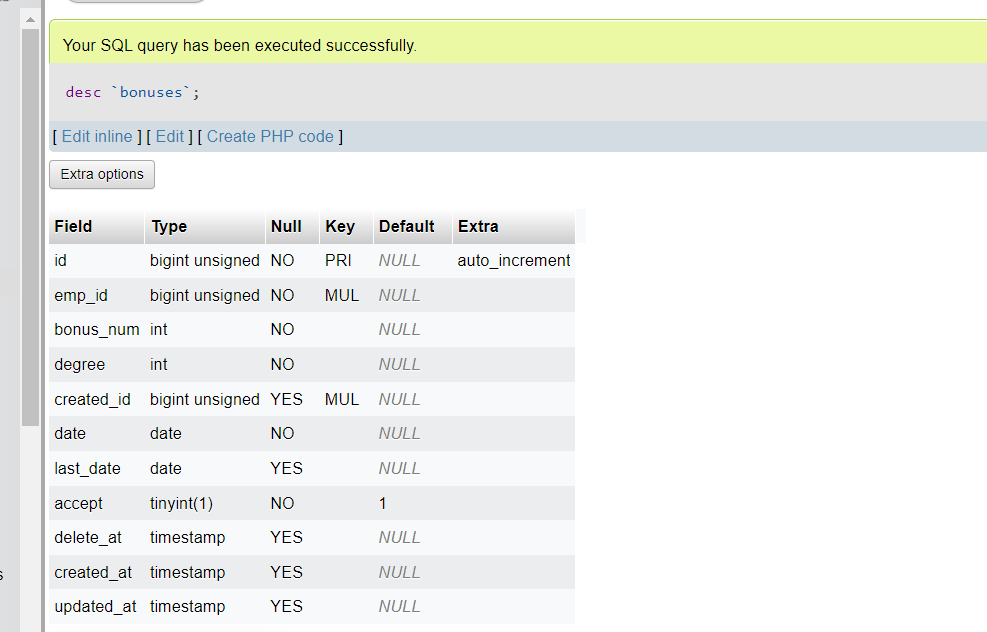
لماذا في جدول الذي في صورة تاليه به 4 مفاتيح اجنبية لكن عندما اعمل desc مفتاحين فقط هما emp_id و created_id
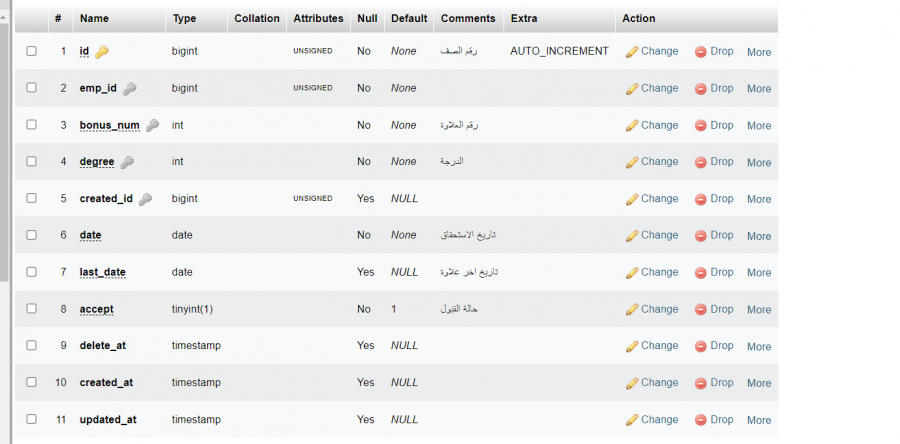
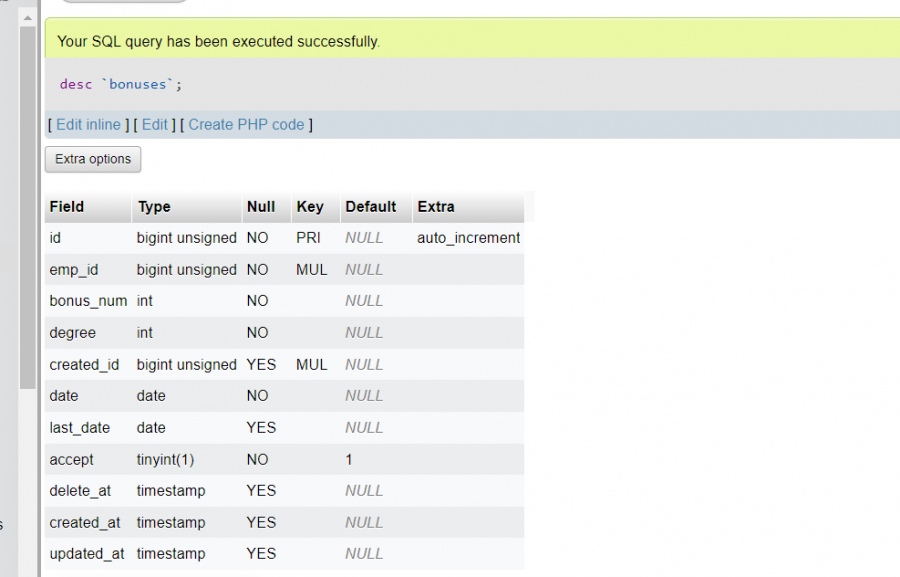 1 نقطة
1 نقطة -
ماذا يعني صورة مفتاح بجانب اسم حقل
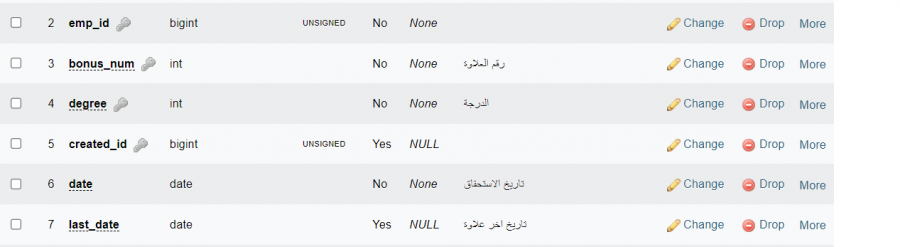 1 نقطة
1 نقطة -
ستحتاج إلى دراسة أساسيات الاحتمالات و الإحصاء و الجبر الخطي، لكن كبداية أنصحك بدراسة أساسيات الاحتمالات و الإحصاء فقط و لاحقاً يمكنك التعمق حسب الحاجة. بخصوص الاحتمالات عليك أن تكون ملمًا لالمتغيرات العشوائية وهي متغيرات تستقبل قيمًا متعددة بناءًا على نوع معين من التجارب أو الأحداث العشوائية. والتوزيعات المتقطعة مثل توزيع بيرنولي، الذي يستخدم لتوصيف تجربة تحتوي على نتيجتين فقط (مثل نجاح أو فشل)، والتوزيعات المستمرة مثل التوزيع الغاوسي Gaussian Distribution، لوصف البيانات التي تتبع نمط الجرس bell curve، والتوزيع الأسي Exponential Distribution لنمذجة الزمن بين الأحداث في عملية بواسونية (Poisson process). إذا كانت لغتك الإنجليزية جيدة، أوصيك بمشاهدة دورة الاحتمالات من معهد ماساتشوستس للتكنولوجيا (MIT) على يوتيوب، حيث ستجد سلسلة من المحاضرات المفيدة جدًا التي تغطي تلك المواضيع بعمق. الإحصاء هو جزء آخر لا غنى عنه في تحليل البيانات، فتعلم كيفية تقييم دقة الإحصاءات المستخرجة من البيانات عبر مفاهيم مثل فترات الثقة confidence intervals واختبارات الفرضيات hypothesis testing. والتعامل مع البيانات الكبيرة التي قد يكون من المستحيل استعراضها بالكامل دفعة واحدة، ستحتاج إلى تقنيات مثل تحليل الانحدار regression analysis، تحليل التباين ANOVA، والتحليل العنقودي cluster analysis التي تساعد في استخراج معلومات هامة ومفيدة من البيانات.1 نقطة
-
كيف اطبق طريقة رفع الصور الموجودة في الدالة handleImageChange في الدالة handleCityImageChange create.js1 نقطة
-
إذا كنت تريد رفع أكثر من صورة فيجب وضعهم جميعا فى مكان واحد حتى يتم رفعهم فى الواجهة الخلفية . حيث لاحظت انك تقوم كل مرة بإستدعاء الدالة handleImageChange بإستبدال الصورة الحالية ولهذا سيتم رفع صورة واحده فقط . لذلك أولا يجب عليك تغير طريقة إضافة الصورة هكذا : const handleImageChange = (e) => { const file = image; file.push(e.target.files[0]) setimage(file) } ويجب عليك تغير ال image إلى array فى كل مكان هكذا : const [image, setimage] = useState([]) ويجب عدم وضع الصورة في مصفوفة ال city ولكن فقط قم بوضع الإسم الخاص بالصورة حتى نقوم في الواجهة الخلفية بالتتحقق من الإسم الجديد لها . وبعد ذلك فى الواجهة الخلفية إذا كنت تقوم بإستخدام multer فيجب استخدام array بدلا من single هكذا : upload.single('image') upload.array('image') حيث يجب إستبدال السطر الأول بالسطر الثانى : وبعد ذلك بعد رفع الصور ستجد الصور فى req.files . ويمكنك الآن التكرار على ال files والتحقق من المصفوفة cites والتاكد من الإسم القديم originalname و الإسم فى مصفوفة cities و بعد ذلك إستبدال السم القديم في cities بالاسم الجديد filename و هكذا سيتم حفظها في قاعدة البيانات1 نقطة
-
هناك أسلوب متبع ويعتبر من ضمن الممارسات الجيدة Best practice بحيث نعرف من خلاله المستخدم الذي قام بإضافة هذا السجل، وبالتالي يمكننا مراقبة إدخال البيانات ومعرفة المستبب في الخطأ إن وجد. إضافة إلى هذا العمود يوجد عمودان آخران يفضل إضافتهما وهما updated_id لمعرفة آخر مستخدم قام بالتعديل على هذا السجل creation_date لتسجيل وقت إنشاء هذا السجل ويفيد في معرفة تسلسل إدخال الحركات.1 نقطة
-
هل على أن أتعلم كيف تعمل هذه المكتبات ؟ يعني أفهم ماذا في الواقع يمثل هذه المكتبة من الاحصاء والدوال الاخرى حتى افهم آليه عملها أم علي تعلم العمل بها فقط ؟1 نقطة
-
اا في الدرس الاول من تاسيس php ولدي مشكلة الان انا في انشاء اول مشروع لي المشكلة اانه عندما اقوم باعادة تشغيل المشروع لا يعمل على صفحت الويب1 نقطة
-
لماذا اغلب جداول عند انشائه يوجد به عمود created_id1 نقطة
-
عندما قمت بالمرور على اغلب المسارات وجدت انه معظمهم يستخدمون mango db مع بيئة عمل node.js t فهل تنصحني ان اكمل تعلمها و لماذا وجدت mysql مناسبة اكثر لمشروعي مع انك قمت بذكر مميزاتها و التي تعد افضل من mysql1 نقطة
-
عملية التنبؤ بالمبيعات باستخدام تحليل السلاسل الزمنية، يمكننا أن نبدأ بهذه الطريقة، أولا نقوم بجمع بيانات المبيعات التاريخية التي تشمل التواريخ وكميات المبيعات، هذه البيانات يمكن أن تكون يومية، أسبوعية، أو شهرية. بعد جمعها، نبدأ بفهمها من خلال استعراضها ورسمها لرؤية الأنماط العامة مثل الاتجاهات والتغيرات الموسمية وأي تقلبات غير منتظمة. تفكيك السلسلة الزمنية يتضمن ثلاثة مكونات رئيسية وهي الاتجاه (Trend) الذي يمثل التغيرات طويلة الأمد، الموسمية (Seasonality) التي تعكس الأنماط المتكررة على فترات محددة مثل الزيادة في المبيعات خلال فصل الصيف، والتغيرات العشوائية (Noise) التي لا تتبع نمطا محددا. لتحليل وتفكيك السلسلة الزمنية، يمكننا استخدام أدوات برمجية مثل Python، في هذا السياق يمكن أن نستخدم مكتبة statsmodels لتفكيك السلسلة الزمنية من خلال قراءة بيانات المبيعات من ملف CSV، ثم استخدام seasonal_decompose لتفكيك السلسلة الزمنية وعرض النتائج باستخدام الرسوم البيانية. وبعد تحليل السلسلة الزمنية، نختار نموذجا مناسبا للتنبؤ. مثلا نموذج ARIMA أو (الانحدار الذاتي والمتوسط المتحرك) هو أحد النماذج الشائعة. ففي هذا النموذج، نقوم بإعداد النموذج باستخدام بيانات المبيعات، ثم التنبؤ بالمبيعات للأشهر القادمة وعرض التنبؤات. أهم مرحلة وهي تقييم النموذج بمقارنة التنبؤات مع البيانات الفعلية باستخدام مقاييس مثل MAE (متوسط الخطأ المطلق) أو RMSE (جذر متوسط مربعات الخطأ) لتحسين دقة النموذج. أما بالنسبة لتحليل المبيعات، يمكن أن يكون التحليل على مستوى المنتجات الفردية إذا كنا نهتم بأداء منتج معين، أو على مستوى التحصيلات الكلية إذا كنا مهتمين بالأداء العام للشركة من خلال اختيار مستوى التحليل الذي يعتمد على الهدف من التنبؤ.1 نقطة
-
مرحباً احمد, هناك عدة خطوات للتنبؤ بالمبيعات باستخدام تحليل السلاسل الزمنية , بدايةً من جمع البيانات وتفكيك السلاسل الزمنية وتحليلها ومن ثم تنبؤ بالمبيعات وأخيراً تحليل المبيعات . سوف أقوم بشرح كل خطوة على حدا : جمع البيانات : نحتاج في هذه الخطوة إلى جمع البيانات بطريقة ما ( مثلاً من خلال المبيعات التاريخية , او اليومية , او الشهرية ... الخ ) . تفكيك السلاسل الزمنية : السلاسل الزمنية تتكون عادة من ثلاثة مكونات رئيسية: الاتجاه (Trend) : التغيرات طويلة الأجل في السلسلة الزمنية. الموسمية (Seasonality): الأنماط المتكررة التي تحدث بانتظام خلال فترة زمنية معينة (مثل الفصول). الانتظام الدوري (Cyclic/Regularity): التقلبات التي تحدث على مدى فترة زمنية أطول من الموسم ولكنها ليست ثابتة. يمكنك تفكيك السلسلة الزمنية باستخدام طرق مختلفة، مثل: نموذج الإضافي أو المضاعف (Additive or Multiplicative Model) : يعتمد الاختيار بينهما على طبيعة السلسلة الزمنية. تحليل المكونات الأساسية (Decomposition): يمكن استخدام مكتبات في بايثون مثل statsmodels و seasonal_decompose. تحليل السلاسل الزمنية : يمكن استخدام مكتبة statsmodels لتفكيك السلاسل الزمنية. مثال: import pandas as pd import statsmodels.api as sm import matplotlib.pyplot as plt # قراءة بيانات السلسلة الزمنية data = pd.read_csv('sales_data.csv', index_col='date', parse_dates=True) data = data.asfreq('M') # تحويل البيانات إلى سلسلة شهرية # تفكيك السلسلة الزمنية decomposition = sm.tsa.seasonal_decompose(data, model='multiplicative') # رسم المكونات decomposition.plot() plt.show() التنبؤ بالمبيعات يمكنك استخدام نماذج مثل: نموذج الانحدار الذاتي والمتوسط المتحرك (ARIMA): نموذج شهير للتنبؤ بالسلاسل الزمنية. نماذج التعلم الآلي: مثل الشبكات العصبية والـ XGBoost. باستخدام ARIMA: from statsmodels.tsa.arima.model import ARIMA # إعداد النموذج model = ARIMA(data, order=(5,1,0)) model_fit = model.fit() # التنبؤ forecast = model_fit.forecast(steps=12) # التنبؤ للأشهر الـ 12 القادمة print(forecast) تحليل المبيعات تحليل المبيعات يمكن أن يكون على مستوى المنتجات الفردية أو على مستوى التحصيلات الكلية. الخيار يعتمد على الهدف من التحليل: منتجات فردية: إذا كنت مهتماً بفهم أداء منتج معين أو مجموعة منتجات. تحصيلات كلية: إذا كنت مهتماً بالأداء الكلي للشركة.1 نقطة