لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 01/02/24 in أجوبة
-
السلام عليكم هذا الكود يعمل بشكل متاز علي vs code ولكن عند نقله لموقع leetcode تظهر مشكله var addTwoNumbers = function(l1, l2) { l11 = Number(l1.join('')); l22 = Number(l2.join('')); ar = l11 + l22; console.log(ar) var myarr = String(ar).split("").reverse().map((ar) => { return Number(ar) }) return myarr };
.thumb.png.0432e487b5d1d619022e6eb2fb3e0366.png) 1 نقطة
1 نقطة -
من المفترض أن يعمل معك الكود التالي بدون مشكلة: var addTwoNumbers = function(l1, l2) { l11 = Number(l1.join('')); l22 = Number(l2.join('')); ar = l11 + l22; console.log(ar) var myarr = String(ar).split("").reverse().map((ar) => { return Number(ar) }) return myarr }; addTwoNumbers([2,4,6], [3,5,6])1 نقطة
-
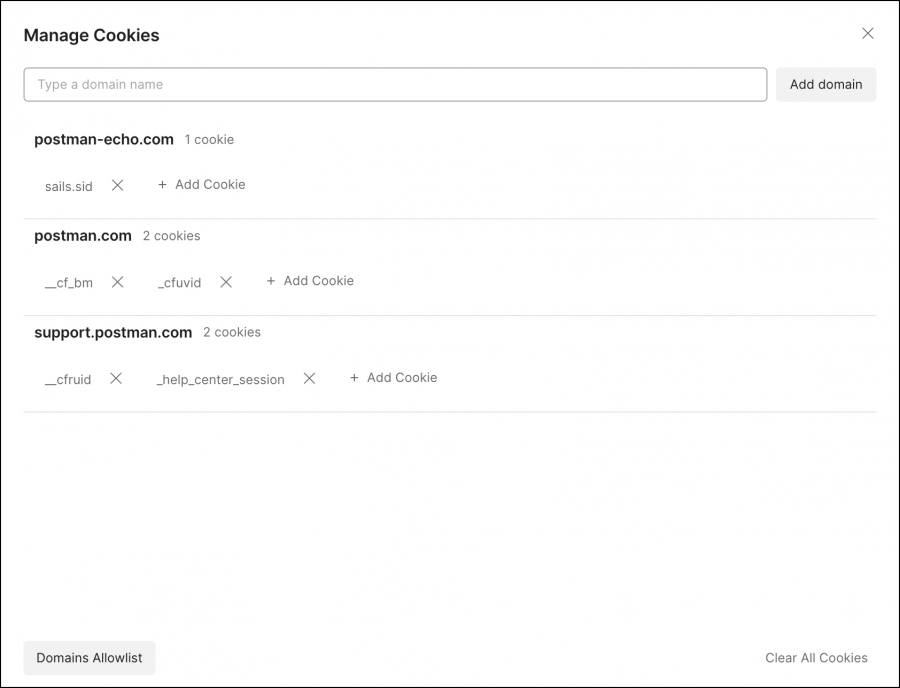
في node js، نستعمل أحيانا cookie session في نظام المصادقة (authorization). كيف يكون هذا الإستعمال عند تطوير النظم الخلفية و تجربته مع postman. شكرا1 نقطة
-
قم بإضافتهم من الخانة الخاصة بالـ cookies اسف الزر send : ثم قم بإضافة الدومين الذي تريد تشغيل ملفات الارتباط عليه وضاف ال cookies التي تريدها للدومين :
 1 نقطة
1 نقطة -
ولكنه يمرر مصفوفات ف السؤال [2,4,6] مثلا هذه مصفوفه فيجب ان تعمل1 نقطة
-
الأمر طبيعي، على ما أظن أنك تحاول تمرير رقمين للدالة كالتالي: addTwoNumbers(3, 5) ولن تعمل ميثود join على الأرقام بل تعمل على المصفوفات فقط، كالتالي: const elements = ['Fire', 'Air', 'Water']; console.log(elements.join()); // Expected output: "Fire,Air,Water" console.log(elements.join('')); // Expected output: "FireAirWater" console.log(elements.join('-')); // Expected output: "Fire-Air-Water"1 نقطة
-
لا داعي لإنشاء متغيرات A و B، بما أننا سنقوم بدمج selected_column_1 و selected_column_2 مباشرة, يفضل إعادة تعيين الفهرس مرة واحدة بعد الدمج لتجنب أي مشاكل. selected_column_1 = df.iloc[8::2, [0,1,2,cl3,cl4,cl5,cl6]] selected_column_2 = df.iloc[9::2, [2,cl3,cl4,cl5,cl6]] self.Table = pd.concat([selected_column_1, selected_column_2], axis=1, ignore_index=True) self.Table.reset_index(drop=True, inplace=True)1 نقطة
-
يبدو انك تضع في الكود فهل يواجهك نفس الخطأ المسبق ام خطأ اخر ؟1 نقطة
-
عفواً أخي هل لك أن توضح لي التعديل على هذا الكود import customtkinter import tkinter as tk from tkinter import filedialog, messagebox, ttk import pandas as pd from pathlib import Path class App(customtkinter.CTk): def __init__(self): super().__init__() self.title("App-v1") self.grid_columnconfigure(0, weight = 1) self.grid_rowconfigure(1, weight = 1) customtkinter.set_appearance_mode("dark") customtkinter.set_default_color_theme("green") Menu(self) def File_dialog(self): self.filename = filedialog.askopenfilename(initialdir="C:\\Users\\Cakow\\PycharmProjects\\Main", title="Open file okay?", filetypes=(("text files", "*.xlsx"),("all files", "*.*"))) self.label_file["text"] = self.filename return None def Load_excel_data(self): file_path = self.label_file["text"] try: excel_filename = r"{}".format(file_path) if excel_filename[-4:] == ".csv": df = pd.read_csv(excel_filename) else: df = pd.ExcelFile(excel_filename) self.optionmenu1.configure(values = df.sheet_names) self.qq = df.sheet_names self.label2["text"] = df.sheet_names except ValueError: tk.messagebox.showerror("Information", "The file you have chosen is invalid") return None except FileNotFoundError: tk.messagebox.showerror("Information", f"إختر ملف أولاً {file_path}") return None def optionmenu_callback(self,choice): self.label2.configure(text=choice) def lod_Frame(self,cl3,cl4,cl5,cl6,xa,xb): df = pd.read_excel(self.filename,sheet_name=self.label2["text"],header=None) selected_column_1 = df.iloc[8::2, [0,1,2,cl3,cl4,cl5,cl6]] selected_column_1.reset_index(drop=True) selected_column_2 = df.iloc[9::2, [2,cl3,cl4,cl5,cl6]] selected_column_2.reset_index(drop=True, inplace=True) A = pd.DataFrame(selected_column_1) B = pd.DataFrame(selected_column_2) self.Table=pd.concat([A,B],axis=1) repeated_values1 = [] repeated_values2 = [] for i in range(len(self.Table)): repeated_values1.append(df.iloc[xa,xb]) repeated_values2.append(df.iloc[3,4]) self.Table['إسم المادة'] = repeated_values1 self.Table['العام الدراسي'] = repeated_values2 self.Table.fillna(0, inplace=True) self.Table['1أكبر_قيمة'] = self.Table.iloc[:, [5,6]].max(axis=1) self.Table['2أكبر_قيمة'] = self.Table.iloc[:, [10,11]].max(axis=1).apply(lambda x: 50 if x > 50 else x) self.Table['3أكبر_قيمة'] = self.Table.apply(lambda row: row.iloc[14] if row.iloc[15] == 0 else row.iloc[15] if 0 < row.iloc[15] <= 50 else None, axis=1) return self.Table def lod_data(self): App() a1= self.lod_Frame(3,4,5,6,6,3) a1 = a1.reset_index(drop=True) a2= self.lod_Frame(7,8,9,10,6,7) a2 = a2.reset_index(drop=True) a3= self.lod_Frame(11,12,13,14,6,11) a3 = a3.reset_index(drop=True) a4= self.lod_Frame(15,16,17,18,6,15) a4 = a4.reset_index(drop=True) a5= self.lod_Frame(19,20,21,22,6,19) a5 = a5.reset_index(drop=True) a6= self.lod_Frame(23,24,25,26,6,23) a6 = a6.reset_index(drop=True) a7= self.lod_Frame(27,28,29,30,6,27) a7 = a7.reset_index(drop=True) a8= self.lod_Frame(31,32,33,34,6,31) a8 = a8.reset_index(drop=True) a9= self.lod_Frame(35,36,37,38,6,35) a9 = a9.reset_index(drop=True) a10= self.lod_Frame(39,40,41,42,6,39) a10 = a10.reset_index(drop=True) a11= self.lod_Frame(43,44,45,46,6,43) a11 = a11.reset_index(drop=True) a12= self.lod_Frame(47,48,49,50,6,47) a12 = a12.reset_index(drop=True) a13= self.lod_Frame(51,52,53,54,6,51) a13 = a13.reset_index(drop=True) a14= self.lod_Frame(55,56,57,58,6,55) a14 = a14.reset_index(drop=True) a15= self.lod_Frame(59,60,61,62,6,59) a15 = a15.reset_index(drop=True) #self.Table = self.Table.reset_index() rtb=pd.concat([a1,a2,a3,a4,a5,a6,a7,a8,a9,a10,a11,a12,a13,a14,a15],axis=0, ignore_index=True) # self.Table.to_excel("ALL2025.xlsx",sheet_name=self.label2["text"]) with pd.ExcelWriter('ALL2030.xlsx',if_sheet_exists="overlay",mode='a') as writer: rtb.to_excel(writer, sheet_name=self.label2["text"],header=None,index=False) class Menu(customtkinter.CTkFrame,App): def __init__(self, master): super().__init__(master) self.grid(row=0, column=0, padx=(10, 10), pady=(10, 10), sticky="ew") self.columnconfigure(0, weight = 1) self.rowconfigure(1, weight = 1) self.configure(border_width=1,border_color="#0087f2") self.create_widgets() def create_widgets(self): self.button1 = customtkinter.CTkButton(self, text = 'File_dialog',command=self.File_dialog) self.button1.grid(row = 0, column = 3, padx=(10, 10), pady=(10, 10), sticky="e") self.label_file = ttk.Label(self, text="") self.label_file.grid(row = 0, column = 0, padx=(10, 10), pady=(10, 10), sticky="e") self.button2 = customtkinter.CTkButton(self, text = 'Load_excel',command=self.Load_excel_data) self.button2.grid(row = 0, column = 2, padx=(10, 10), pady=(10, 10), sticky="e") self.label2 = ttk.Label(self, text="") self.label2.grid(row = 1, column = 0, padx=(10, 10), pady=(10, 10), sticky="e") self.optionmenu1 = customtkinter.CTkOptionMenu(self,values=["إختر ورقة العمل"], font=customtkinter.CTkFont(family="Calibri", size=12, weight="bold")) self.optionmenu1.grid(row=0, column=1, padx=(10, 10), pady=(10, 10), sticky="e") self.optionmenu1.configure(command=self.optionmenu_callback) self.button3 = customtkinter.CTkButton(self, text = 'RUN',command=self.lod_data) self.button3.grid(row = 1, column = 3, padx=(10, 10), pady=(10, 10), sticky="e") app = App() app.mainloop()1 نقطة
-
السلام عليكم أريد حل لهذا الخطأ pandas.errors.InvalidIndexError: Reindexing only valid with uniquely valued Index objects حيث أريد أن أقوم بضم DataFrame على المحور x على سبيل المثال مثل هذا In [1]: df1 = pd.DataFrame( ...: { ...: "A": ["A0", "A1", "A2", "A3"], ...: "B": ["B0", "B1", "B2", "B3"], ...: "C": ["C0", "C1", "C2", "C3"], ...: "D": ["D0", "D1", "D2", "D3"], ...: }, ...: ...: ) ...: In [2]: df2 = pd.DataFrame( ...: { ...: "A": ["A4", "A5", "A6", "A7"], ...: "B": ["B4", "B5", "B6", "B7"], ...: "C": ["C4", "C5", "C6", "C7"], ...: "D": ["D4", "D5", "D6", "D7"], ...: }, ...: ...: ) ...: In [3]: df3 = pd.DataFrame( ...: { ...: "A": ["A8", "A9", "A10", "A11"], ...: "B": ["B8", "B9", "B10", "B11"], ...: "C": ["C8", "C9", "C10", "C11"], ...: "D": ["D8", "D9", "D10", "D11"], ...: }, ...: ...: ) ...: In [4]: frames = [df1, df2, df3] In [5]: result = pd.concat(frames)1 نقطة
-
الخطأ الذي تواجهه يحدث عندما يكون لديك أعمدة متكررة في DataFrame الخاص بك، مما يؤدي إلى فشل عملية إعادة التسمية (Reindexing) لحل هذا الخطأ، يمكنك إضافة ignore_index=True عند استخدام دالة concat و يمكنك تغيير السطر البرمجي الأخير ليصح كالتالي: result = pd.concat(frames, ignore_index=True) بهذه الطريقة، ستقوم pandas بإعادة ترقيم الفهارس بشكل فريد بدلا من محاولة استخدام الفهارس الحالية، مما يمنع حدوث الخطأ الذي تواجهه.1 نقطة
-
يختلف ذلك حسب الدورة التعليمية التي قمت بالإشتراك بها وأعتقد أنك تقصد الدورات الموجود بأكاديمية حسوب ولكن يمكنك التقديم على فرص العمل المتوفره على مواقع التوظيف مثل بعيد و linkedin و العديد من المواقع الأخرى كما أنه يوجد الكثير من مواقع العمل الحر مثل مستقل والتي تكون في البداية صعبة نسبياً ولكن بعد ذلك يمكنك الإعتماد على منصات العمل الحر فقط بشكل جيد وهناك الكثير من الطرق الأخرى لذلك حاول فقط الحصول على الخبرة في المجال الخاص بك وحاول تنفيذ المشاريع التي توضح مدى خبرتك وبما أنك مشترك بإحدي دورات حاسوب فإنه يجب ذكر أن فريق أكاديمية حسوب يقدم الدعم للخريجين للمساعدة في الحصول على فرص عمل. وفي حال عدم تحقيق نجاح في الحصول على وظيفة، يتم استرداد قيمة الدورة بالكامل بدون أي مشكلة. هذا يعكس التزامهم بمساعدة الطلاب في بناء مستقبل مهني ناجح بما يتناسب مع توقعاتهم.1 نقطة
-
وعليكم السلام الخطأ هنا يقول أن إطارات البيانات التي تم توحيدها (a1, a2, a3) لديها مؤشرات مكررة. فيجب تعيين الفهرس مجددًا بشكل فريد لكل إطار بيانات قبل الدمج: a1 = a1.reset_index(drop=True) a2 = a2.reset_index(drop=True) a3 = a3.reset_index(drop=True) self.Table = pd.concat([a1, a2, a3], axis=0) يجب استخدام `ignore_index=True` أثناء عملية الدمج: باستخدام ignore_index=True سيقوم pandas بإعادة تعيين الأرقام بشكل متلاحق دون تكرار، حتى لو كانت مكررة في الأصل. فهذا سيؤدي لدمج البيانات بشكل صحيح دون أخطاء. self.Table = pd.concat([a1, a2, a3], axis=0, ignore_index=True) تأكد من أن المؤشرات فريدة لكل إطار بيانات قبل الدمج لتجنب هذه المشكلة.1 نقطة
-
السلام عليكم وجدت كثيرا من المبرمجين يرشحون node.js ك backend بدلا من اي لغه اخري بقوه ولكن عند الدخول عل وظائف العمل الحر لا اجد غير php لا أجد ruby ولا python ولا node.js1 نقطة
-
جزاك الله خيرا. طريقة حفظ الأعمدة دون طباعتها في الجدول، يمكنك حفظ قيم الأعمدة في متغيرات منفصلة بدلاً من إضافتها للجدول مباشرة. مثال: # حساب العمود الأول col1_values = Table.iloc[:, [5,6]].max(axis=1) # حساب العمود الثاني col2_values = Table.iloc[:, [10,11]].max(axis=1).apply(lambda x: 50 if x > 50 else x) # استخدام القيم في العملية التالية Table['3أكبر_قيمة'] = Table.apply(lambda row: col1_values[i] if col2_values[i]==0 else col2_values[i] if 0 < col2_values[i] <= 50 else None, axis=1) فهذا يحافظ على القيم دون إضافتها للجدول. اما هذا الكود محتاج بعض التعديلات: 1. لا تضف القيم مباشرة للمتغيرات repeated، بل احفظها في متغيرات مستقلة 2. استخدم المؤشر i للوصول لقيم المتغيرات داخل الدوال 3. حساب قيم الأعمدة خارج الدوال وليس داخلها repeated_values1 = [] repeated_values2 = [] col1_values = [] col2_values = [] for i in range(len(Table)): repeated_values1.append(df.iloc[6,3]) repeated_values2.append(df.iloc[3,4]) Table['إسم المادة'] = repeated_values1 Table['العام الدراسي'] = repeated_values2 Table.fillna(0, inplace=True) col1_values = Table.iloc[:, [5,6]].max(axis=1) col2_values = Table.iloc[:, [10,11]].max(axis=1).apply(lambda x: 50 if x > 50 else x) Table['3أكبر_قيمة'] = Table.apply(lambda row: col1_values[i] if col2_values[i]==0 else col2_values[i] if 0 < col2_values[i] <= 50 else None, axis=1)1 نقطة
-
الطريق الأسهل هو أن تصبح لديك نسبة في أسهم الشركة كإمتياز لك من ضمن إمتيازات الوظيفة، وبعض الشركات توفر ذلك، والطريقة الثانية هي شراء الأسهم ولكن الأمر بحاجة إلى مبالغ كبيرة لكي تحصل على نسبة جيدة من الشركة. لكن إذا أردت الاستثمار، فيمكنك الاستثمار في أسهم البورصة في السعودية وأمريكا خاصًة S&P 500 ، لكن تجنب الاستثمار في الأسهم الخاصة بالبنوك بسبب الربا. الأسهم، كيف يمكنني الاستثمار به؟ الاستثمار، ما هي أنواعه؟ وما هو أفضلها في وقتنا الحالي؟1 نقطة
.png.a0ae2516b2442930abe710ef7c94b951.png)