
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 10/20/23 في كل الموقع
-
السلام عليكم ورحمه الله وبركاته اود ان اعرف تفاصيل عن الامتحان واليه الامتحان وما هي الشروط الواجب توفرها لخوض الامتحان وشكرا1 نقطة
-
السلام عليكم اي الفرق بين مكتبه face-recognition و مكتبه opencv ؟1 نقطة
-
بعد اتمامك للدورة، سيكون عليك التواصل معنا من خلال مركز مساعدة حسوب من هنا لتحديد موعد امتحان وسيكون على الشكل التالي: اجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع الى أسبوعين. اجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.1 نقطة
-
عندي موقع محتاج ارفع عليه فيديوهات لكورسات لاكن الفيديوهات دي مساحتها كبيره ممكن توصل لي ٣٠٠ جيجا او اكثر اريد خدمه cloud لحفظ هذه الفيديوهات باسعار معقوله انا شوفت cloudinary لاكنها غير عمليه نهائيا في هذه الحاله1 نقطة
-
هناك عدة خيارات , أظن أفضلها Amazon S3 بالنسبة لك , هذه شرح مختصر عن بعض الخيارات الممكن استخدامها : Amazon S3 بتقدمها أمازون وبتوفر مساحة تخزين ضخمة ومرنة. بإمكانك تحميل وتخزين الفيديوهات على Amazon S3 ومن ثم توفير وصول عبر الويب لهذه الفيديوهات. تتميز بتكلفة منخفضة ومرونة في التوسع. Microsoft Azure Blob Storage توفرها مايكروسوفت، تعتبر مماثلة لـ Amazon S3 في المفهوم. يمكنك تخزين الفيديوهات على Blob Storage وتوفير وصول إليها بسهولة. Google Cloud Storage تقدمها جوجل، وتوفر مساحة تخزين موثوقة وآمنة. تتميز بأداء جيد وتكلفة مناسبة.1 نقطة
-
هل يوجد اي طريقه لعمل هندسه عكسيه لملف build واسترجاعه ملفات React.js1 نقطة
-
للأسف لا يمكن عمل هندسة عكسية لملفات build واسترجاع ملفات React.js بشكل كامل. لأن عملية بناء (build) لتطبيق React.js تشمل عدة خطوات لتجميع وتحويل ملفات السورس كود (source files) إلى ملفات قابلة للتشغيل في المتصفح. يشمل ذلك تجميع الملفات، وتحويلها إلى JavaScript مضغوط ومحسّن وتضمين المكتبات والمكونات اللازمة. أقصد بتحويلها إلى javaScript مضغوطة أي إزالة العديد من التفاصيل الأصلية للتطبيق (مثل أسماء المتغيرات والتعليقات والهيكل الأصلي للملفات). وبالتالي، فإن استرجاع ملفات السورس كود الأصلية بشكل كامل من ملفات البناء يكون أمرًا صعبًا جدًا، إن لم يكن مستحيلاً.1 نقطة
-
الفرق ضخم، مكتبة face-recognition خاصة التعرف وتحليل الوجوه في الصور ومقاطع الفيديو، تستطيع الاستفاده منها في تطبيقات كثيرة مثلا لو كان تسجيل الدخول إلى الحساب يتم باستخدام شكل الوجه فاستخدام face-recognition لتمييز وجه عن أخر، ولكن مع ذلك تعتبر face-recognition مبنيه على opencv إي ان الشفرة الداخلية الخاصة face-recognition مثل معالجة الصورة مكتوب باستخدام opencv أما opencv هي المكتبة الأشهر في مجال الرؤية الحاسوبية أو مايعرف ب "computer vision" لا يوجد مطور أو باحث في هذا المجال لم يمر باستخدام opencv لمعالجة الصور والفيديو وبناء تحليل إحصائي للصور، إيجاد الكائنات في الصور وتتبعها وما إلى ذلك لذلك اذا كنت في بداية التعلم أنصحك بالبدء في تعلم opencv والاستفادة من الخصائص التي تقدمها ثم تستطيع بناء تطبيق للتعرف على الوجوه دون الحاجة إلى استخدام مكتبة face-recognition، كذلك تستطيع opencv عندما يمتلك الروبوت camera يستطيع قراءة الصورة في الزمن الحقيقي ومعالجتها.1 نقطة
-
بالفعل يجب عليك أن تتعلم استخدام Jupyter Notebook ليس لأنه لا يمكنك استخدام Visual Studio Code (VSCode) أو Visual Studio ولكن Jupyter Notebook سوف ترى الرسوم الخاصة بالبيانات ونماذج التعلم بشكل جميل، كذلك عندما تريد أن تقوم بتدريب نماذج الذكاء الصنعي، ستحتاج أن تقوم برفع اكوادك إلى google colab و google colab يستخدم خاصية Jupyter Notebook، بعكس لو قمت برفع أكثر من ملف بايثون ثم التحكم بها عبر Jupyter Notebook جديدة كليا لأنه كما ذكرت google colab يستخدم Jupyter Notebook، وبعد تعلمك اساسيات التعلم الالي وعندما تأخذ نماذجك وقت كبير في عملية التدريب سوف تلجأ إلى استخدام google colab بفضل GPU المجانية التي يوفرها والتي سوف تسرع عملية التدريب، لذلك أنصحك بالتعود عليه ثم بعدها استخدم ما تشاء، وهذا رابط google colab لتلقي نظرة عليه والاستفادة منه في حال أردت الاستفادة من عملية التدريب السريعة لنماذجك1 نقطة
-
من الأفضل استخدامه وJupyter Notebook هو بيئة عمل ممتازة لتعلم الآلة لعدد من الأسباب: يسمح Jupyter Notebook بتنفيذ الشفرة وعرض نتائج التحليل بشكل فوري في نفس الوثيقة، مما يجعل من السهل تجربة أفكار جديدة والتوصل إلى رؤى جديدة. يمكن استخدامه لإنشاء وثائق تفاعلية يمكن مشاركتها بسهولة مع الآخرين، وبالتالي يجعل من السهل تعليم الآخرين حول مشاريع تعلم الآلة الخاصة بك. يوفر مجموعة واسعة من المكونات الإضافية والوحدات النمطية التي يمكن استخدامها لتوسيع وظائفه، مما يجعله قابلاً للتخصيص بسهولة لاحتياجاتك المحددة.1 نقطة
-
مكتبة face-recognition ومكتبة OpenCV هما مكتبتان للتعرف على الوجوه، ولكنهما تختلفان في بعض الجوانب الرئيسية، بما في ذلك: مكتبة face-recognition مصممة خصيصًا للتعرف على الوجوه، بينما مكتبة OpenCV هي مكتبة عامة للمعالجة الرؤية الحاسوبية، وتتضمن العديد من الوظائف، بما في ذلك التعرف على الوجوه. مكتبة face-recognition أسهل في الاستخدام من مكتبة OpenCV، حيث توفر واجهة برمجة تطبيقات بسيطة تسهل على المطورين إنشاء تطبيقات للتعرف على الوجوه، أما مكتبة OpenCV أكثر تعقيدًا، ولكنها توفر مزيدًا من التحكم في عملية التعرف على الوجوه. ومن حيث الأداء فمكتبة face-recognition أسرع من مكتبة OpenCV، لأنها تستخدم خوارزميات أكثر كفاءة، بينما مكتبة OpenCV قد تكون أبطأ، لكنها توفر مزيدًا من الدقة أي أنها أبطأ أو أسرع حسب الخوارزمية1 نقطة
-
حيث كلما حاولت الدخول الي حسابي تظهر لي الصورة المرفقة ؟ هل من مساعدة مع العلم ان ترسل لي رسائل علي الايميل بالتفاعل والطلبات علي الصفحة ولكن لااستطيع الدخول اليها باي حال وارسلت ايميلات علي هذا الحال منذ 50 يوم
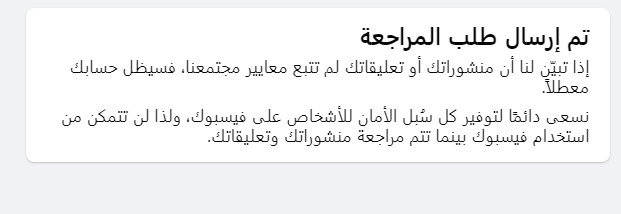 1 نقطة
1 نقطة -
إنشاء شبكة تواصل مثل فيسبوك؟ نعم يمكنك ذلك، هل الخوارزميات الخاصة بتلك الشبكة ستصبح مثل فيسبوك في يوم وليلة؟ بالطبع لا، فأنت بحاجة إلى سنوات من أجل تطوير خورازمية ضخمة مشابهة وبحاجة إلى فريق عمل ضخم. أما عن إنشاء تطبيق مثل واتساب، فيمكنك إنشاء تطبيق مماثل ويمكنك البحث على يوتيوب عن What'sApp Clone. أما عن ChatGPT فذلك مستحيل، حيث أن إنشاء نموذج ذكاء اصطناعي مشابه بحاجة إلى سنوات وفريق عمل خبير وليس شخص واحد فقط بالإضافة إلى أموال طائلة، ولكن يمكنك استخدام نموذج ذكاء اصطناعي مفتوح المصدر LLaMA 2 مثل الخاص بفيسبوك وتدريبه على البيانات الخاصة بك مثلاً أو استخدامه في مشروعك.1 نقطة
-
تستطيع معرفة آخر التحديثات المضافة في أكاديمية حسوب من خلال صفحة آخر التحديثات. وما تم إضافته مؤخرًا في دورة جافاسكريبت هو التالي: أضفنا مسارًا جديدًا لتطوير تطبيق تعلم اللغات باستخدام Next.js وتقنيات الذكاء الاصطناعي المقدمة من OpenAI إلى دورة تطوير التطبيقات باستخدام JavaScript. ستتعلم في 6 ساعات فيديو كيف تتعامل مع OpenAI API ومختلف تقنياتها وأبرزها ChatGPT، وكيف تستفيد من هذه التقنيات في مشاريعك الخاصة بتطويرنا لتطبيق متكامل عبر Next.js و MUI يوضح الاستخدام العملي لها.1 نقطة
-
السلام عليكم الكود بتاع حضرتك يوفر العديد من خيارات الامتدادات لملف الصوت لكن واضح أنه لا يظهر عندك لمشكله ما فلديك بعض الاقتراحات: 1- تحقق أن الامتداد صحيح. 2- تحقق أن لديك التصاريح والأذونات في نظام الWindows لفتح ملف الصوت. 3- أضف Controls كAttribute في عنصر الAudio 4- أختبر في العديد من المتصفحات يمكن أن تكون المشكله من متصفح قديم.1 نقطة
-
حاول تعديل الشيفرة التالية :- <audio> <source src="maman.mp3" type="audio/mpeg"> <source src="maman.ogg" type="audio/ogg"> <source src="maman.wav" type="audio/mpeg"> your browser does not support this type audio </audio> لتصبح <audio controls> <source src="maman.mp3" type="audio/mpeg"> <source src="maman.ogg" type="audio/ogg"> <source src="maman.wav" type="audio/wav"> Your browser does not support this type of audio. </audio> كما أن الشيفرة لديك صحيحة لكن فقط قمنا باضافة controls حتى يظهر على الملف على المتصفح وفقط قمنا بتعديل type في آخر نوع من الملفات. حاول التجربة وأخبرنا بالنتيجة1 نقطة
-
 ربما تقرأ أو تشاهد يوميًا تقارير عن توقع في انخفاض أو ارتفاع مؤشرات أسواق المال أو تغيرات متوقعة في أسعار شراء بعض المنتجات على أساس شهري أو سنوي، أو حتى نجاح أو إخفاق لقاح لأحد الأمراض في مرحلة التجربة السريرية؛ فما مصدر هذه المعلومات؟ لا تُعد هذه الظواهر ظواهر علمية طبيعية أي لا تنتنج عن قوانين ثابتة يمكن تطبيقها في كل زمان ومكان، بل تأتي في معظم الأحيان نتيجة تطبيق طرق استدلالية أو تحليلية أو إحصائية على كم مترابط أو غير مترابط من البيانات المتوفرة عن هذه الظاهرة أو تلك، وتكون نتيجتها مجموعة محددة من المعلومات التي توصِّف هذه الظاهرة بلغة واضحة يمكن البناء عليها لاحقًا لاتخاذ قرار أو توثيق حادثة. يطلق على العلم القائم خلف هذه الطرق الاستدلالية والتحليلية والإحصائية اسم علم البيانات Data science أو العلم القائم على البيانات Data-driven science ويُعدّ حاليًا من أكثر العلوم التي تدفع عجلة التقدم التقني في مجالات تعلم الآلة والبحث عبر الإنترنت والتعرف الآلي على الصوت والصور والنقل والصحة واستكشاف المخاطر وغيرها الكثير. وأصبح هذا المجال أحد أهم المجالات في العالم الرقمي ولا عجب في ذلك فهو العلم الذي يهتم باستخراج القيمة الكامنة في البيانات التي تعد اليوم أهم أصول الشركات حتى أنها أصبحت تسمى النفط الجديد أو الذهب الجديد. وستكتشف في مقال اليوم كل خبايا هذا العلم وتتعرف على فوائده وأهم أدواته وتقنياته وحتى التعرف على سوق العمل فيه ومصادر تعلمه. ما هو علم البيانات Data Science؟ يُعد علم البيانات حقلًا لتطبيق المهارات التحليلية والوسائل العلمية لاستخلاص معلومات ذات قيمة وأهمية انطلاقًا من بيانات خام raw data أو بيانات مهيكلة أو غير مهيكلة وذلك لاتخاذ القرارات أو وضع خطط استراتيجية في مجال عمل معين أو تحليل الأنظمة أو بناء تصورات مسبقة عن سلوكها. تزداد أهمية علم البيانات يومًا بعد يوم، إذ تساعد الإضاءات التي يقدمها علم البيانات على زيادة كفاءة العمل وتحديد فرص عمل جديدة وزيادة فعالية النشاطات التجارية، وتضيف ميزات تنافسية قوية للأعمال التي تعتمد على علم البيانات موازنة بغيرها وفي مختلف المجالات والأصعدة. يتألف علم البيانات من ثلاث تخصصات أو مجالات متقاطعة مع بعضها البعض وهي كالتالي: علم البيانات هندسة البيانات تحليل البيانات قد تتداخل المهام في كل مجال من هذه المجالات، إلا أن المسؤوليات الأساسية لكل منها تختلف في مكان العمل وفيما يلي نوضح أهم الفروقات بين كل تخصص منها. علم البيانات علم البيانات هو المجال الذي يهتم بتطبيق تقنيات التحليلات المتقدمة والمبادئ العلمية لاستخراج معلومات قيمة من البيانات بهدف اتخاذ القرارات التجارية الأفضل والتخطيط الاستراتيجي . يعمل في مجال علم البيانات أشخاص ذوو كفاءة عالية يملكون معرفة أساسية في تخصص تحليل البيانات وهندسة البيانات فهم يتشابهون في عملهم مع مهندسي البيانات إلا أنهم أصحاب اليد العليا في جميع الأنشطة المتعلقة بالبيانات فعندما يتعلق الأمر باتخاذ القرارات المتعلقة بالأعمال يتمتع عالم البيانات بكفاءة أعلى وهو الذي يتخذ القرار النهائي بشأن العمل. يجب أن يمتلك المتخصص في هذا المجال مهارات تحليلية وبرمجية متقدمة تمكنه من حل مشكلات العمل بشكل كامل بالاعتماد على البيانات واستخراج المعلومات القيِّمة والمفيدة منها لتطوير الأعمال مستخدمًا برمجيات متقدمة من خلال الاعتماد على أفضل المنظومات والخوارزميات لحل المسائل المتعلقة بتنظيم البيانات واستخلاص المعلومات منها. يمكن أن نختصر ماهية علم البيانات بالنقاط التالية: طرح الأسئلة الصحيحة عن المسألة المدروسة وتحليل البيانات الخام. نمذجة البيانات باستخدام خوارزميات متنوعة ومتقدمة وعالية الكفاءة. تصوير البيانات لفهمها من منظور أوضح. فهم البيانات المتاحة لاتخاذ قرارات أفضل أو الوصول إلى نتيجة نهائية. باختصار علم البيانات هو العلم المسؤول عن استخراج معلومات مفيدة من بيانات مبعثرة ولا قيمة لها بشكلها الخام بعد تنظيفها وتصحيح أخطائها وإزالة القيم المكررة منها ومعالجة القيم المفقودة منها وهي تشبه عملية استخراج شيء مفيد من النفايات. علم هندسة البيانات Data Engineering هندسة البيانات هي العمود الفقري لعلم البيانات وتتضمن عملية تصميم وبناء أنظمة تسمح للأشخاص بالتنقيب عن البيانات الأولية وجمعها وتنظيفها من مصادر وتنسيقات متعددة وتخزينها واستعادتها ونقلها تمهيدًا لتحليلها واستخراج معلومات مفيدة منها. كما تهتم هندسة البيانات بالبيانات الوصفية التي تُعد بيانات تصف بيانات أخرى. وتأتي أهمية هندسة البيانات من ضرورة تهيئة البيانات التي جرى جمعها حتى تُخزن ويسهل استعادتها عند الطلب فلا معنى لأي تحليل أو تفسير للبيانات ما لم تجري أرشفة النتائج وتخزينها في منظومة معلوماتية يسهل التعامل معها لاتخاذ القرار. تتضمن هندسة البيانات المهام التالية: استخراج البيانات من مصادر مختلفة Data extraction معالجة البيانات Data processing وتحويل البيانات Data transformation والتي تتضمن تنظيف البيانات data cleaning ومعالجة القيم الفارغة وفصل القيم المجمَّعة وإزالة القيم الخطأ أو تحويلها إلى قيم صحيحة موحدة ومتناسقة. تحميل البيانات Data load وتخزين البيانات الناتجة في المصدر النهائي وعادة تكون قاعدة بيانات مخصصة للتحليل Database analysis تنفيذ العمليات الثلاث ETL التي تعني استخراج Extract وتحويل Transfer وتحميل Load والتي تعني مجتمعة عملية تنقل البيانات من قاعدة بيانات واحدة، أو قواعد بيانات متعددة، أو مصادر أخرى إلى مستودع موحد عادة ما يكون مستودع بيانات. فنظرًا لكون تحليل البيانات أمرًا صعبًا لأن البيانات تجمع بواسطة تقنيات مختلفة ويتم تخزينها بهياكل وتنسيقات مختلفة لكن الأدوات المستخدمة لتحليل البيانات تتطلب أن تكون كافة مجموعات البيانات مخزنة بنفس الهيكلية! وهنا يأتي دور هندسة البيانات في توحيد مجموعات البيانات وإنشاء البنية التحتية التي تزود أعضاء فريق البيانات ببيانات عالية الجودة ليعملوا عليها ويفهموها ويعثروا من خلالها على إجابات لأسئلتهم، وهم مسؤولون كذلك عن تصميم وصيانة هذه البنية التحتية. على سبيل المثال يمكن أن تجمع الشركات العديد من البيانات حول عملائها ومن مصادر متنوعة مثل معلومات حول الفواتير من برنامج مخصص لإدارة المبيعات ومعلومات عن الشحن من برنامج إدارة شركات الشحن والخدمات اللوجستية ومعلومات عن دعم العملاء من برنامج دعم العملاء ومراقبة مواقع التواصل الاجتماعي للحصول على المحتوى الذي يهتم به العملاء ويتفاعلون معه ومعلوماتهم الديموغرافية وأوقات نشاطهم …إلخ. توفر هذه البيانات الكثير من المعطيات للعميل لكن الحصول عليها من مصادر مختلفة وبتنسيقات متنوعة يجعل فهمها والحصول على الإجابات التي نريدها منها أمرًا صعبًا للغاية ويستهلك الكثير من الوقت والجهد لذا لا يمكننا أن نُعوِّل على إدراكنا البشري في هذا الأمر. لهذا السبب يقوم مهندسو البيانات بإعداد هذه البيانات وتنسيقها وتنظيمها وتخزينها في مستودعات بيانات مناسبة مصممة لمعالجة الاستعلامات بسرعة تضمن الأداء المناسب، وبعدها يقدمون هذه البيانات إلى مستهلكي البيانات النهائية مثل محللي البيانات الذين لن يتمكنوا من الوصول إلى البيانات وتحليلها واستخلاص النتائج والقرارات الصائبة منها بدون البنية التحتية التي ينشؤها لهم مهندسو البيانات. عمومًا، كان هذا تعريفًا مختصرًا بتخصص هندسة البيانات، وقد توسعنا بالحديث عنه في مقال منفصل بعنوان الدليل الشامل إلى هندسة البيانات Data Engineering فارجع إليه للاستزادة. علم تحليل البيانات Data analysis تحليل البيانات هو المجال المسؤول عن معالجة البيانات لاستخراج أو استخلاص معلومات مفيدة من شأنها أن تساعد الشركات والمنظمات في حل مشكلة ما أو الكشف عن فرصة ما لتطوير العمل وعرض هذه المعلومات والنتائج التي تم الحصول عليها بأفضل طريقة لصانعي القرار في العمل حتى يتمكنوا من اتخاذ قرارات من شأنها تطوير العمل نحو الأفضل. على سبيل المثال قد يطلب من محلل البيانات تقسيم العملاء بناءً على سلوك الشراء لديهم لتحديد العملاء الذين يجب أن يتم استهدافهم في الحملات التسويقية وإرسال العروض الأنسب المخصصة لكل منهم بناءً على سلوكه الشرائي أو يطلب منه تحديد التكلفة الأفضل للمنتجات للحفاظ على القوة الشرائية كي لا تنخفض عن مستويات السنوات السابقة. ومن أهم المهام التي يعنى بها تحليل البيانات ما يلي: جمع البيانات الخام من مصادر متعددة وتنظيمها. التأكد من جودة البيانات وتنظيفها وتحويلها عند الضرورة. نمذجة البيانات في تنسيقات محددة. التمثيل الرسومي للبيانات أو تصوير البيانات Data visualization ويقصد به عرض البيانات بطريقة مرئية كي يتمكن المتابع من فهم المحتوى الذي تقدمه ويستوعب الرؤى التي استخلصت من هذه البيانات. إيجاد إجابات وحلول لأي مشكلات أو استفسارات في مجال العمل من خلال تحليل البيانات ذات الصلة. الاستفادة من الإحصائيات الوصفية في تلخيص ووصف خصائص مجموعة البيانات. للقيام بهذه المهام يحتاج المختص في تحليل البيانات لامتلاك مجموعة من المهارات الفنية وأهمها الإلمام الجيد بلغة الاستعلام الهيكلية SQL لاستخراج البيانات التي يحتاجها من قواعد البيانات العلاقية المختلفة وإتقان البرامج المخصصة مثل MS Excel و MS Access و Microsoft Power BI التي تساعد في تحليل هذه البيانات وإنشاء نماذج منها وإجراء العمليات الحسابية والإحصائية المختلفة عليها. كما يحتاج بالطبع لامتلاك معرفة جيدة بالإحصاء والتحليل الرياضي لإضافة المهارات في التنظيم والتخطيط والاهتمام بأدق التفاصيل كي يتمكن من إدارة ومعالجة طلبات العمل بكفاءة، كما تعد مهارات التواصل مفيدة جدًا أيضًا لمحللي البيانات لأنهم بحاجة إلى التعبير عن نتائجهم وتفسيرها بوضوح لأرباب العمل. كان هذا تعريفًا مختصر بمجال تحليل البيانات، وقد توسعنا بالحديث عنه في مقال منفصل بعنوان الدليل الشامل لتحليل البيانات Data Analysis فارجع إليه للاستزادة. الفرق بين علم البيانات والذكاء الاصطناعي يُعرّف الذكاء الاصطناعي Artificial Intelligence واختصارًا AI بأنه وسيلة لتزويد الآلات بسلوك يحاكي السلوك البشري كي تقارب تفكيرهم وتتصرف مثلهم وبالتالي فإن الجانب الأساسي من تقنية الذكاء الاصطناعي مرتبط بتعلم الآلة وتعلم الآلة المعمّق. يلخص الجدول التالي الفرق بين علم البيانات والذكاء الاصطناعي من نواحي عدة كي نستطيع إدراك أوجه الشبه والاختلاف: وجه الموازنة علم البيانات الذكاء الاصطناعي الأساسيات علم البيانات هو دورة عمليات مفصلة تتضمن التحضير الأولي للبيانات وتحليلها ثم تصويرها واتخاذ القرار الذكاء الاصطناعي هو إنجاز نموذج قادر على التوقع بهدف التنبؤ بأحداث مستقبلية. الأهداف التعرف على الأنماط المطلوب إيجادها ضمن البيانات الخام للمشروع قيد الدراسة أتمتة العمليات ووضع بيانات التصرف الذاتي ضمن الوحدة البرمجية المدروسة. نوع البيانات التي يعمل عليها يعمل علم البيانات على أنواع مختلفة من البيانات مثل البيانات الخام والبيانات المهيكلة وغير المهيكلة. يستخدم الذكاء الاصطناعي أنواع معيارية من البيانات على شكل متجهات vectors وأنواع مدمجة أخرى من البيانات التقنيات المستخدمة يستخدم التقنيات الرياضية والإحصائية وخوارزميات تعلم الآلة وأدوات تحليل البيانات وتصويرها. يستخدم بشكل أساسي خوارزميات تعلم الآلة وتعلم الآلة المعمّق. المعرفة المكتسبة تُستخدم المعرفة التي يوفرها علم البيانات في إيجاد الأنماط والسلوكيات في البيانات. تصب المعرفة التي يوفرها الذكاء الاصطناعي في تزويد الوحدات البرمجية بشكل من أشكال التصرف الذاتي. أمثلة عن الأدوات المستخدمة ++R, Python, MATLAB,C Tensor flow, sci-kit-learn, Kaffee متى يُستخدم يُستخدم علم البيانات عندما تقتضي الضرورة استخدام حسابات رياضية سريعة أو تحليل بيانات استطلاعي أو تحليل توقعي predective analysis. لا بد في هذه الحالات من تحديد الأنماط والسلوكيات من خلال البيانات المتاحة ويتطلب ذلك معرفة بالإحصاء الرياضي. يُستخدم الذكاء الاصطناعي عندما تقتضي الضرورة التخلص من عمل ضروري متكرر. لا بد في هذه الحالات من تقييم مخاطر الانتقال إلى الذكاء الاصطناعي وسرعة اتخاذ القرار ودقة في التنفيذ بعيدًا عن المشاعر البشرية والانحياز. أمثلة عن الاستخدام تحسين العمليات واكتشاف سلوكيات العملاء والتحليل المالي وغيرها الكثير. الروبوتات وبرمجيات المحادثة الآلية والألعاب عبر الإنترنت وأنظمة المساعدة الصوتية. هنالك مسارات أخرى بدأت تتبلور تعكس التأثير الكبير لعلم البيانات على الذكاء الاصطناعي مع تزايد الاندفاع نحو ما يُعرف بالذكاء الاصطناعي القابل للتوضيح explainable AI والذي يقدم معلومات تساعد المستخدمين على فهم كيفية عمل نماذج تعلم الآلة ومقدار الثقة التي ينبغي أن يولوها لنتائج عمل هذه الوحدات عند اتخاذ القرارات. بالإضافة إلى دور علم البيانات في صياغة مبادئ تصميم الذكاء الاصطناعي المسؤول responsible AI principles للتأكد من عدالة جميع التقنيات المستخدمة وضمان عدم تحيزها وشفافيتها. مكونات علم البيانات ينبثق علم البيانات من مجموعة من المكوّنات أو العلوم ولا بد من استعراضها حتى تتوضح أبعاد هذا العلم: الإحصاء Statistics الرياضيات Mathematics البرمجة وعلوم الحاسوب Programming and Computer Science أساسيات الرياضيات لتتعلم علم البيانات لا بد من إتقان المفاهيم الأساسية في الرياضيات التي تعد الجزء الأكثر حيوية في مجال علوم البيانات، فهي الفضاء الذي تُدرس ضمنه الكميات والبنى والعلاقات ذات الصلة بالظاهرة المدروسة. إذ يُعد علم الرياضيات اللغة التي توصِّف الظواهر العلمية وتوفر الأدوات الضمنية التي يستخدمها علم البيانات مثل عمليات الاستقراء والتحليل والإحصاء والتفاضل والتكامل وغيرها. الإحصاء الرياضي يُعد الإحصاء الرياضي Statistics من أهم مكوّنات علم البيانات لأنه الوسيلة الأنسب لجمع وتحليل البيانات العددية مهما كانت كميتها كبيرة واستخلاص الأفكار منها. يتعامل هذا العلم مع مجموعات منفصلة من البيانات أو مجموعات مستمرة منها محاولًا تطبيق وسائل رياضية لدراسة ميل هذه البيانات للتقارب أو التباعد والمنحى الذي تأخذه في هذا السلوك ثم تضع أطرًا لتعريف وتصنيف هذه الوسائل. فمن منا لم يسمع في مرحلة ما من تحصيله الدراسي كلمة متوسط حسابي أو انحراف معياري أو منوال مثلًا، فهذه المصطلحات ما هي إلّا مقاييس لابتعاد قيم مجموعة من البيانات عن قيمها الوسطى. البرمجة وعلوم الحاسوب يأتي الحمل الأكبر في علم البيانات على البرمجة وتخصص علوم الحاسوب كي تتمكن من كتابة وتنقيح وتعديل الشيفرات التي تجمع وتحلل وتهيكل البيانات، حيث يجب على من يريد التخصص في علم البيانات تعلم إحدى لغات البرمجة والمكتبات البرمجية التي تدعم الوظائف الإحصائية والرياضية وبرمجيات التحليل وإيجاد علاقات الترابط وغيرها، إضافة لقواعد البيانات المسؤولة بشكل أساسي عن تخزين البيانات وتنظيمها واسترجاعها. كما يعد تعلم الآلة Machine learning أحد التقنيات المتقدمة التي تلعب في الآونة الأخيرة دورًا حيويًا في علم البيانات فمن خلاله يمكننا من الحصول على تنبؤات وقرارات أفضل دون الحاجة للتدخل البشري مما يساعد علماء البيانات في أداء مهامهم والحصول على حلول لمشكلات العمل بطريقة أسرع وأكثر ذكاء مقارنة بالاعتماد على التقنيات الإحصائية التقليدية. وإذا كنت مهتمًا بتعلم أسس علوم الحاسوب والتخصص في مجال علوم البيانات واكتساب خبرة عملية فيه بأسرع الطرق يمكنك مطالعة مقال أساسيات علوم الحاسوب فهو بمثابة دليل شامل يعرفك على اختصاص علوم الحاسب وأهم فوائده وتطبيقاته. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن أهمية علم البيانات لم تكن البيانات المتوفرة حول مختلف المجالات خلال العقد الأول من هذه الألفية وما قبلها -وخاصة بشكلها الرقمي- ذات أحجام كبيرة جدًا، وكان من السهل تخزينها في هياكل مخصصة مثل الجداول الإلكترونية وقواعد البيانات العلاقيّة ومن ثم التعامل معها من خلال أدوات مختلفة بكل سهولة ويسر. فقد جمعت البيانات ما قبل الحقبة الرقمية بأساليب يدوية مرهقة بالاعتماد على الأشخاص والأوراق والجداول ولم تكن بيانات شاملة، بل كانت تقتصر على ما هو ضروري للجهة التي تحتاج هذه البيانات سواء أكانت حكومية أو سواها. مع التحول إلى الرقمنة، أصبحت عملية الحصول على البيانات وتصنيفها أسهل وأيسر وظهرت أنواع جديدة من قواعد البيانات التي تسهل التعامل مع هذه البيانات، لكن كما أشرنا بقيت ضمن حدود السيطرة. لكن الكم الهائل جدًا من البيانات التي تنتج يوميًا عن كل فرد قد وصلت وفق بعض الأبحاث إلى 1.7 ميغا بايت في الثانية عام 2020 وقد تصل إلى أضعاف هذا الرقم في لحظة كتابة هذه الأسطر. فانطلاقًا من البيانات البسيطة التي يسجلها الجوال عن مستخدميه، وبيانات التصفح واستخدام الحاسوب، وبيانات نشاطك على مختلف مواقع التواصل الاجتماعي وعمليات التسجيل والشراء أو أي نشاط على مختلف المواقع قد تُسجل وتؤرشف لغايات خاصة بمشغلي تلك المواقع فتأمل عندها الكميات الكبيرة من البيانات التي ستظهر حتى حركة مؤشر الفأرة على شاشة متصفح مسجلة وتستعملها المواقع عبر أدوات تعقب وتحليل مختلفة مثل تتبع الأقسام التي زرتها والروابط والمنتجات التي أبديت اهتمامُا بها وذلك لتحليل سلوكك وبالتالي تقديم تجربة أفضل لك. ولا ننسى تطور البرامج السحابية التي مكنت المؤسسات من تتبع أحجام ضخمة من بيانات الأعمال في الوقت الفعلي وتوفر مليارات من أجهزة إنترنت الأشياء IoT حول العالم التي تجمع كل لحظة كمًا ضخمًا من البيانات عن كل تحركاتنا، لذا يتوقع أن يكون هناك 175 زيتابايت من البيانات في عالم البيانات العالمي بحلول عام 2025 وللعلم فإن زيتابايت يساوي 1000 بايت للأس 7 وبعبارة أخرى فإن زيتابايت واحد يحتوي على 21 صفرًا ولهذا السبب نحن نعيش بالفعل حقبة انفجار البيانات الضخمة Big Data Explosion ونحتاج لطريقة تمكننا من معالجة هذا الكم الجنوني من البيانات! إن معالجة هذا الكم الهائل من البيانات هي مهمة صعبة جدًا على أي مؤسسة أو جهة، لهذا ظهرت الحاجة الماسة إلى أدوات وتقنيات فعالة لمعالجة وتحليل تلك البيانات وأشخاص مؤهلين قادرين على التعامل معها وبدأ علم البيانات بالتبلور ليكون مزيجًا من عدة علوم تتكامل لإنجاز ما يلي: تجميع البيانات الخام وإعدادها للمعالجة أو التحليل النوعي. تحويل هذه الكميات الكبيرة من البيانات الخام وغير المهيكلة إلى معلومات ذات قيمة. تقديم البيانات وعرضها بصريًا لتوضيح الاستراتيجيات أو القرارات المبنية على نتائج تحليل تلك البيانات. استخلاص الأفكار والرؤى من البيانات المحللة باستخدام تقنيات الذكاء الاصطناعي وخوارزميات تعلم الآلة. وضع استراتيجيات تطوير للأعمال انطلاقًا من نتائج التحليل والدراسة. وضع توقعات صحيحة أو قريبة من الصحة في مختلف المجالات مثل استطلاعات الرأي والانتخابات وحجوزات السفر واستكشاف حالات الغش والدراسات العلمية والاجتماعية وغيرها. لم يكن علم البيانات منذ عقد مضى ولا حتى العاملين في هذا المجال منتشرًا في سوق العمل، لكن الشعبية الكبيرة حاليًا لهذه الفئة من الخبراء تعكس طريقة تفكير الأعمال بالبيانات الضخمة. فلا يمكن بعد الآن تجاهل الكميات الهائلة من البيانات الخام التي أضحت بالنسبة للكثير من الشركات بمثابة منجم ذهب افتراضي طالما أن هناك خبراء متحمسين وطموحين ودقيقي الملاحظة قادرين على التنقيب فيها ورؤية ما لا يراه غيرهم. مجالات علم البيانات يلعب علم البيانات اليوم دورًا فعالًا في جميع جوانب الحياة التجارية والطبية والحكومية …إلخ، ويجد المختصون في المجالات المختلفة كل يوم تطبيقًا جديدًا لعلم البيانات بما يعزز العمل الذي يشرفون عليه ويحقق مكاسب على جميع الأصعدة، لكننا سنقف تاليًا على أبرز المجالات التي شاع استخدام علم البيانات فيها. التعرف على الصور وتمييز الكلام عندما تحمّل صورة على فيسبوك ثم ترى اقتراحات للإشارة إلى أصدقائك في الصورة، فإن ما يجري فعلًا أن موقع فيسبوك قد استخدم خوارزمية تمييز الصور تلقائيًا وقد تعرف على الأشخاص في هذه الصورة. إن هذه الخوارزمية هي جزء من علم البيانات. وكذلك الأمر عندما تقول "Ok Google" ليستجيب هاتفك الذكي ويستعد للأوامر الصوتية، فإن علم البيانات هو السبب في ظهور خوارزمية التعرف على الكلام التي استخدمها التطبيق توًا. محركات البحث عبر الإنترنت هل لاحظت كيف تقترح لك محركات البحث الشهيرة مثل جوجل وياهو وبينج ما هو قريب من نتيجة بحثك؟ هل لاحظت السرعة في عرض النتائج والتحسن المستمر في دقة نتيجة البحث؟ يعود الفضل في ذلك إلى علم البيانات وخوارزمياته التي تجعل تجربة البحث عبر الانترنت أكثر سرعة وفعالية ورضًى للمستخدم. العلوم الطبيعية تُستنبط معظم المعايير العلمية المتعلقة بالظواهر الطبيعية من كم البيانات الهائل الناتج عن مراقبة هذه الظواهر على مدى طويل من الزمن كالمناخ والبيئة والفضاء، إذ ترسل المسابر ملايين البايتات يوميًا إلى مراكز الأبحاث لتحليلها واستقراء النتائج وبالطبع لن يكون من السهل فهم هذه البيانات والربط بينها دون استخدام خوارزميات علم البيانات وطرائقه. عالم الألعاب سواء الألعاب الرياضية الحقيقية كدراسة وتحليل حركات لاعبي كرة القدم وحتى منصات الألعاب الرقمية في تعزيز تجربة اللاعبين. تعتمد الشركات التي ترعى هذه المواضيع على تحليل نتائج البيانات المأخوذة من كم هائل من المباريات ومن تجارب مئات الآلاف الذين يمارسون ألعاب الفيديو عبر الإنترنت. لقد حسَّن استخدام علم البيانات وتقنياته أداء الكثير من شركات الألعاب. النقل إن الهدف الرئيسي لاستخدام علم البيانات في عالم النقل هو الوصول إلى المركبات ذاتية القيادة التي يسعى مصمموها إلى تقليل الخطأ البشري إلى أدنى مستوى وتقليل عدد الحوادث المرورية وضبط معدلات التلوث بعوادم الوقود. إضافة إلى ذلك، يساعد علم البيانات في تحليل حركة المرور واكتشاف الازدحامات والاختناقات المرورية وإرسال إشعارات للسائقين لسلوك طريق آخر مثلًا لوجود ازدحام في الطريق الذي يسير عليه وتحليل الحوادث المرورية واتخاذ القرارات. الرعاية الصحية لعلم البيانات دور بارز في مجال الرعاية الصحية لما يؤمنه من مساهمة في تشخيص الحالات الطبية وتخطيط العلاج والبحث الطبي ويوفر نتائج حاسمة وتوقعات تقترب نسبة الخطأ فيها من الصفر وخاصة في مجالات الكشف عن الأورام وابتكار الأدوية وتحليل الصور الطبية. أنظمة التوصية بالمنتجات تعتمد معظم الشركات مثل غوغل وأمازون ونيتفليكس على علم البيانات الذي يقدم تكنولوجيا مفيدة جدًا في تحسين تجربة مستخدمي هذه الشركات من خلال التوصية بمنتجات هذه الشركات لمستخدميها من معرفة ميولهم وسلوكياتهم أو ما يعرف بالتزكية المخصصة. فعندما تبحث عن شيء ما ثم تجد اقتراحات لأشياء مشابهة لاحقًا فهي نتيجة تطبيق خوارزميات علم البيانات. اكتشاف المخاطر تواجه الشركات المالية مخاطر تتعلق بقضايا التزوير وخسارة رأس المال، لكن بوجود علم البيانات ستقل هذه الأخطار إلى مستويات منخفضة. إذ تستفيد شركات المال من علماء البيانات في دراسة البيانات المالية للاستثمارات المطروحة وإدارة المخاطر المالية واكتشاف المعاملات الاحتيالية وتقييم مخاطر الخسارة أو الإفلاس مما يرفع ثقة العملاء بأداء هذه الشركات، كما يساعد علم البيانات أنظمة تقنية المعلومات في منع الهجمات الإلكترونية ومنع التهديدات الأمنية المختلفة. ومن مجالات هذا العلم الأخرى مساعدة الشركات التجارية على إنشاء حملات تسويقية أقوى وإعلانات مستهدفة أكثر دقة لزيادة المبيعات والأرباح، ومنع حدوث أعطال المعدات في الأماكن الصناعية، ويبرز استخدام علم البيانات المجال الأكاديمية لمراقبة أداء الطلاب وتحسينه للأفضل وغير ذلك الكثير مما لا يتسع المقال لذكره. وقلما تجد اليوم مجالًا لا يساهم علم البيانات الحديث في تحسينه وتطويره نحو الأفضل. دورة حياة مشروع علم البيانات تمر دورة علم البيانات بالمراحل التالية: الاستكشاف إعداد البيانات تخطيط النماذج بناء النماذج التحضير للعمل إيصال النتائج الاستكشاف وهي أولى مراحل هذه الدورة وتبدأ بطرح الأسئلة الصحيحة عن الظاهرة المدروسة. فلا بد قبل أن تبدأ أي مشروع متعلق بعلم البيانات أن تحدد المتطلبات الاساسية لهذا المشروع وأولوياته وميزانيته. لا بد في هذه المرحلة من تحديد كل متطلبات المشروع كعدد العاملين فيه والتقنيات المستخدمة والزمن اللازم لإنجازه والبيانات التي سيجري العمل عليها والغاية منها، وبالتالي سنتمكن من وضع إطار أولي لحل المشكلة التي كانت سببًا في إطلاق المشروع. إعداد البيانات نحتاج في هذه المرحلة إلى إنجاز المهام التالية: تصحيح البيانات وتنظيفها Data cleaning اختزال البيانات وتقليل حجمها Data Reduction تكامل البيانات Data integration نقل البيانات Data transformation بعد إنجاز هذه المراحل الأربعة تصبح البيانات جاهزة لعمليات أخرى. التخطيط لبناء النماذج نحتاج في هذه المرحلة إلى تحديد النماذج المختلفة والتقنيات اللازمة لإيجاد العلاقات والروابط بين متغيرات الدخل. وتجري عادة عملية تحليل بيانات استطلاعي Exploratory data analytics -تختصر إلى EDA- باستخدام الدوال والصيغ الإحصائية ثم أدوات تصوير البيانات لفهم الروابط بين المتغيرات ومن ثم فهم ما ترشدنا إليه تلك البيانات. من أكثر الأدوات شيوعًا في إنجاز هذه المرحلة نجد: SQL Analysis Services R SAS Python بناء النماذج تبدأ في هذه المرحلة عملية بناء النماذج. إذ يجري خلال هذه المرحلة إنشاء مجموعات من البيانات لأغراض التمرين والاختبار لتساعد في تطبيق تقنيات مثل التجميع والتصنيف والربط على البيانات المتوفرة لوضع نماذج عن سلوكها. إليك بعض أدوات بناء النماذج الأكثر شيوعا: SAS Enterprise Miner: عبارة عن إضافة تتكامل مع قواعد بيانات أو جداول (مثل إكسيل) لبناء نماذج تحليلية تعطي توقعات عن البيانات الموجودة وفقًا لمسار التحليل الذي تتبعه. WEKA: وهي مجموعة من خوارزميات لغة الآلة كتبت بلغة جافا للتعامل مع مهام التنقيب عن البيانات. SPSS Modeler: برنامج من شركة IBM لتنفيذ مهام التنقيب عن البيانات وتمثيلها بيانيًا وفهمها واتخاذ القرارات بناء عليها. MATLAB: بيئة عمل رياضية وبرمجية متكاملة لمختلف الأغراض الحسابية والتحليلية وتصوير البيانات وبناء خوارزميات تعلم الآلة وتطبيقها. تحضير المشروع للعمل تُسلم في هذه المرحلة معظم التقارير النهائية عن المشروع إلى جانب الشيفرة والمستندات التقنية. تقدم هذه المرحلة نظرة شاملة عن أداء المشروع على صعيد محدود قبل أن يجري نشر نتائجه كاملةً. إيصال النتائج النهائية يتحقق فريق العمل في هذه المرحلة من أن الهدف الذي وضع للمشروع في مرحلة الاستكشاف قد أنجز أم لا، ثم تُسلم بعد ذلك المعلومات التي تمكن الفريق من حيازتها عن طريق النماذج التي بنيت ومن ثم إيصال النتائج النهائية إلى فريق الأعمال الذي طلب الشروع بالعمل. التخصص في مجال علم البيانات رأينا سابقًا كيف ظهرت الحاجة الملحة لعلم البيانات كتخصص قائم ومستقل بذاته للتنقيب عن المعرفة بين أكوام البيانات الخام ويُعتقد وفقًا لعدة استطلاعات رأي بأنّ هذا التخصص سيكون الأكثر طلبًا في السوق خلال هذا العقد. وبما أن الطلب شديد على هذا المجال فهناك نقص كبير في اليد العاملة فيه عربيًا وعالميًا، لذا أمامك فرصة سانحة لممارسته دون الحاجة لوجود شهادة أكاديمية متخصصة فيه إذ التركيز حاليًا على الخبرة نظرًا لنقص اليد العاملة فيه. أي كل ما تحتاجه هو الخبرة الأساسية في البرمجة والإحصاء الرياضي ورغبة في تعلم هذا المجال وتحصيل كل ما يكسبك الخبرة العملية فيه من دورات ومخيمات تدريبية تؤهلك لدخول سوق العمل والحصول على فرصة مميزة لدى الكثير من الشركات والمنظمات التي ستتهافت على تدريبك وتوظيفك لديها. لهذا السبب لا بد من الاطلاع على التخصصات التي يمكنك العمل بها في حال رغبت في التخصص في مجال علوم البيانات. الوظائف التي يتضمنها علم البيانات حتى تختار التخصص الذي تراه مناسبًا لخبراتك وميولك، سنفرد هذه الفقرة للتفصيل في مجموعة من أهم الوظائف والأدوار الوظيفية المرتبطة بالبيانات والمتطلبات الأساسية لكل وظيفة: عالم بيانات Data scientist محلل بيانات Data analyst مهندس بيانات Data engineer معماري بيانات Data architect مطوّر تصوير بيانات Data Visualization Developer خبير في تعلم الآلة Machine Learning expert لنكتشف المزيد حول كل دور من هذه الأدوار وأهم التقنيات والمهام المنوطة به. محلل البيانات هو شخص خبير ينقّب في أكوام البيانات الخام باحثًا عن نماذج وأنماط علاقات تربط بينها. يعمل بعد ذلك على عرض نتائج ما توصل له بما يساعد على اتخاذ قرار أو حل مشكلة. ما المهارات التي يجب أن يتقنها محلل البيانات؟ معرفة جيدة في الرياضيات. معرفة جيدة في التنقيب ضمن البيانات Data mining. معرفة أساسيات علم الإحصاء Statistic. أن يكون مطلعًا على بعض لغات البرمجة والأدوات البرمجية المستخدمة في علم البيانات مثل: Python MATLAB SQL Hive R JS SAS SPSS وغيرها مهندس بيانات وهو الشخص الذي يعمل مع كميات كبيرة من البيانات ويكون مسؤلًا عن بناء وصيانة بنى مناسبة لهذه البيانات وفقًا لمشروع علم البيانات الذي يعمل عليه. يعمل مهندس البيانات أيضًا على تصميم العمليات التي تتحكم بمجموعات البيانات وتُستخدم في نمذجة هذه المجموعات أو التنقيب فيها أو حيازة معلومات منها أو التحقق من سلامتها. ما المهارات التي يجب أن يتقنها مهندس البيانات؟ معرفة معمقة بتقنيات برمجية مثل: SQL MongoDB Cassandra HBase Apache Spark Hive MapReduce معرفة جيدة بلغات برمجة مثل Python, C/C++, Java, Perl. معماري بيانات وهو الشخص الذي يتصور ويصمم الأسلوب الذي تُنجز وفقه البنية التحتية المسؤولة عن تخزين وإدارة البيانات لأغراض التحليل سواء على صعيد العتاد الصلب أو الصعيد البرمجي. ما المهارات التي يجب أن يتقنها معماري البيانات؟ معرفة معمقة بقواعد تطوير البرمجيات والأنظمة. معرفة معمقة بالمعماريات المستخدمة في إنجاز قواعد البيانات. عالم بيانات عالم البيانات هو شخص خبير يعمل على تجميع وتحليل واستخلاص النتائج من كميات كبيرة من البيانات الخام أو المهيكلة أو غير المهيكلة. يجمع عمل عالم البيانات بين علوم الحواسب وخاصة برمجتها وعلم الإحصاء والرياضيات. يعمل عالم البيانات على تحليل ومعالجة ونمذجة البيانات ثم يفسر النتائج التي حصل عليها كي يُنشئ خطة عمل مناسبة للشركة أو المنظمة أو الجهة التي يعمل لديها. يُسخّر علماء البيانات قدراتهم ومهاراتهم في مختلف المجالات سواء التقنية منها أو الاجتماعية للبحث عن تفاصيل قد لا يراها ولا يفهمها سواهم في كم البيانات الهائل الذي يعملون عليه، إذ يتضمن عملهم عادة إيجاد ترابط منطقي بين بيانات غير مهيكلة أو خام تنتج عن مصادر مختلفة كالأجهزة الذكية وردود الأفعال على مواقع التواصل الاجتماعي ومحتوى رسائل البريد الإلكتروني وغيرها من المصادر التي يصعب ملاءمتها من قواعد البيانات المهيكلة. ما المهارات التي يجب أن يتقنها عالم البيانات؟ فهم معمق لعلم الإحصاء. معرفة جيدة في الرياضيات. مهارة في إحدى لغات البرمجة التالية أو أكثر Python R SAS SQL Hive Pig Apache spark MATLAB قدرة جيدة على تصوير البيانات Visualization. مهارات تواصل جيدة. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن مطور تصوير بيانات وهو شخص يعمل إلى جانب عالم البيانات لتمثيل البيانات بصريًا وتقديم عروض ومخططات تفصّل نتائج تحليل هذه البيانات بطريقة مرئية سهلة الفهم لإيصالها إلى من يستخدمها. ما المهارات التي يجب أن يتقنها مطور تصوير بيانات؟ مهارة في إحدى لغات البرمجة التالية أو أكثر: Python R SAS SQL Hive Pig Apache spark MATLAB قدرة تحليلية ممتازة. قدرة كبيرة على إيجاد الطرق الأمثل في تصوير البيانات. خبير في تعلم الآلة هو الشخص الذي يعمل مع مختلف خوارزميات تعلم الآلة التي تُستخدم في علم البيانات مثل خوارزميات الارتجاع أو الإنحدار Regression والتجميع clustering والتصنيف classification وشجرة القرار decision tree والغابة العشوائية random forest وغيرها. ما المهارات التي يجب أن يتقنها خبير تعلم الآلة؟ خبرة في أحد لغات البرمجة التالية أو أكثر: Python ++C R Java Hadoop فهم جيد للخوارزميات الكثيرة المستخدمة في علم البيانات وتعلم الآلة. مهارة تحليلية في حل المشاكل. معرفة جيدة في علمي الاحتمالات والإحصاء. مصادر تعلم علم البيانات هل أنت متحمس للتخصص في مجال علم البيانات وتعلمه بشكل ذاتي وبأقصر الطرق بعيدًا عن أروقة الجامعات ومناهجها المكثفة -بسنواتها الطويلة التي تمتد لأربع أو خمسة سنوات- لكنك لا تعرف من أين تبدأ؟ سنسلط في القسم الضوء على مصادر تعلم تخصص علم البيانات العربية لدخول سوق العمل، فكما أشرنا حاليًا السوق شره على المتخصصين ويركز على الخبرة والمشاريع العملية المنجزة ولا يتطلب شهادات جامعية حصرية. نفترض أنك أنهيت مراحل جيدة من التعليم الدراسي أو قد أنهيت المرحلة الثانوية أو تخصصت في أحد التخصصات الهندسية وبذلك تكون قد حصَّلت معرفة جيدة بأساسيات الرياضيات والإحصاء وحتى مواضيع متقدمة مثل التفاضل والتكامل (إن كنت قد اخترت التخصص العملي وليس الأدبي) وبذلك تكون قد قطعت شوطًا في تعلم هذا العمل، وعمومًا الأساسيات تكفي للبدء ويمكن لاحقًا التعمق في أي موضوع تحتاج إليه. بعدها يمكنك البدء بتعلم أساسيات علوم الحاسوب ولغات البرمجة المخصصة المستخدمة في علم البيانات وأهمها لغة بايثون و لغة R ولغة SQL فهي من أكثر اللغات المطلوبة والمخصصة للاستخدام مع البيانات. تؤمّن هذه اللغات قدرات وظيفية كبيرة في التواصل مع قواعد البيانات واستخلاص البيانات الخام وتحليلها وتنظيمها واستخلاص الرؤى وفقا للظاهرة المدروسة ومن ثم التقييم وإتخاذ القرار، وكل ذلك من خلال مجموعة واسعة من الخوارزميات التي توفرها هذه اللغات ضمنًا أو من خلال مكتبات متوافقة معها. من أهم المصادر العربية المتكاملة التي ننصحك بها كي تتعلم هذه التقنيات: كتاب ملاحظات للعاملين بلغة SQL 1.0.0 كتاب البرمجة بلغة بايثون الذي يشرح أساسيات لغة بايثون سلسلة تعلم لغة R التي تطلعك على كافة الأساسيات والمواضيع النظرية التي تحتاجها في هذه اللغات. سلسلة مقالات think stats التي توفر لك مجموعة مميزة من المقالات والدروس المتخصصة في تعليم الاحتمالات والإحصائيات لمبرمجي بايثون بأسلوب مبسط وسهل الفهم. وإذا كنت تفضل التعلم بإشراف مختصين يجيبونك على أي سؤال يخطر ببالك ويقرن التعليم النظري بالتطبيق العملي فأنصحك بالاطلاع على دورة أساسيات علوم الحاسب التي توفرها أكاديمية حسوب فهي كفيلة بأن تكسبك كافة الأسس التي تحتاجها لتعلم أسس البرمجة وقواعد البيانات، وكذلك دورة تطوير التطبيقات بلغة بايثون والتي تمكنك من تطوير طيف واسع من التطبيقات في مجالات منوعة من بينها تطبيقات عملية في تحليل البيانات تساعدك في التعرف على أبرز مكتبات بايثون المتخصصة في التعامل مع علم البيانات. إضافة إلى لغات البرمجة التي ذكرناها ستجد الكثير من المنصات والأدوات التي تدعم بشكل مباشر العمل مع البيانات الضخمة وتقدم مختلف الأدوات المساعدة في التحليل والتنظيم واتخاذ القرار والتي يمكنك تعلمها ومن أبرزها SAS و Spark و Hadoop و Azure و AWS. خاتمة ألقينا الضوء في هذا المقال على علم البيانات الذي يُتوقع أن يكون من أكثر الأعمال طلبًا خلال هذا العقد من الألفية نظرًا للحاجة الماسة للعمل ضمن كميات هائلة من البيانات الخام وضرورة الاستفادة منها في تطوير الأعمال على مختلف الأصعدة. كما تحدثنا عن المكونات والتخصصات التي يضمها ومجالات استخدامه وتطبيقه، كما تحدثنا عن دورة الحياة التي يمر بها أي مشروع يعتمد على علم البيانات. ومنعًا لتضارب الأفكار وضياع التسميات، فقد تحدثنا عن الفرق بين علم البيانات وتحليلها وكذلك الفرق بين علم البيانات والذكاء الاصطناعي. وهكذا نكون قد أحطنا بشكل مفصل أساسيات علم البيانات وتخصصاته ومجالاته المختلفة لمن يرغب فعليًا في امتهانه أو احتراف أحد اختصاصاته، ووضحنا المتطلبات الضرورية التي يحتاجها المتعلم حتى يبدأ رحلته في هذا المجال المهم والشيق والمجزي ماديًا والذي ينبئ بمستقبل واعد.1 نقطة
ربما تقرأ أو تشاهد يوميًا تقارير عن توقع في انخفاض أو ارتفاع مؤشرات أسواق المال أو تغيرات متوقعة في أسعار شراء بعض المنتجات على أساس شهري أو سنوي، أو حتى نجاح أو إخفاق لقاح لأحد الأمراض في مرحلة التجربة السريرية؛ فما مصدر هذه المعلومات؟ لا تُعد هذه الظواهر ظواهر علمية طبيعية أي لا تنتنج عن قوانين ثابتة يمكن تطبيقها في كل زمان ومكان، بل تأتي في معظم الأحيان نتيجة تطبيق طرق استدلالية أو تحليلية أو إحصائية على كم مترابط أو غير مترابط من البيانات المتوفرة عن هذه الظاهرة أو تلك، وتكون نتيجتها مجموعة محددة من المعلومات التي توصِّف هذه الظاهرة بلغة واضحة يمكن البناء عليها لاحقًا لاتخاذ قرار أو توثيق حادثة. يطلق على العلم القائم خلف هذه الطرق الاستدلالية والتحليلية والإحصائية اسم علم البيانات Data science أو العلم القائم على البيانات Data-driven science ويُعدّ حاليًا من أكثر العلوم التي تدفع عجلة التقدم التقني في مجالات تعلم الآلة والبحث عبر الإنترنت والتعرف الآلي على الصوت والصور والنقل والصحة واستكشاف المخاطر وغيرها الكثير. وأصبح هذا المجال أحد أهم المجالات في العالم الرقمي ولا عجب في ذلك فهو العلم الذي يهتم باستخراج القيمة الكامنة في البيانات التي تعد اليوم أهم أصول الشركات حتى أنها أصبحت تسمى النفط الجديد أو الذهب الجديد. وستكتشف في مقال اليوم كل خبايا هذا العلم وتتعرف على فوائده وأهم أدواته وتقنياته وحتى التعرف على سوق العمل فيه ومصادر تعلمه. ما هو علم البيانات Data Science؟ يُعد علم البيانات حقلًا لتطبيق المهارات التحليلية والوسائل العلمية لاستخلاص معلومات ذات قيمة وأهمية انطلاقًا من بيانات خام raw data أو بيانات مهيكلة أو غير مهيكلة وذلك لاتخاذ القرارات أو وضع خطط استراتيجية في مجال عمل معين أو تحليل الأنظمة أو بناء تصورات مسبقة عن سلوكها. تزداد أهمية علم البيانات يومًا بعد يوم، إذ تساعد الإضاءات التي يقدمها علم البيانات على زيادة كفاءة العمل وتحديد فرص عمل جديدة وزيادة فعالية النشاطات التجارية، وتضيف ميزات تنافسية قوية للأعمال التي تعتمد على علم البيانات موازنة بغيرها وفي مختلف المجالات والأصعدة. يتألف علم البيانات من ثلاث تخصصات أو مجالات متقاطعة مع بعضها البعض وهي كالتالي: علم البيانات هندسة البيانات تحليل البيانات قد تتداخل المهام في كل مجال من هذه المجالات، إلا أن المسؤوليات الأساسية لكل منها تختلف في مكان العمل وفيما يلي نوضح أهم الفروقات بين كل تخصص منها. علم البيانات علم البيانات هو المجال الذي يهتم بتطبيق تقنيات التحليلات المتقدمة والمبادئ العلمية لاستخراج معلومات قيمة من البيانات بهدف اتخاذ القرارات التجارية الأفضل والتخطيط الاستراتيجي . يعمل في مجال علم البيانات أشخاص ذوو كفاءة عالية يملكون معرفة أساسية في تخصص تحليل البيانات وهندسة البيانات فهم يتشابهون في عملهم مع مهندسي البيانات إلا أنهم أصحاب اليد العليا في جميع الأنشطة المتعلقة بالبيانات فعندما يتعلق الأمر باتخاذ القرارات المتعلقة بالأعمال يتمتع عالم البيانات بكفاءة أعلى وهو الذي يتخذ القرار النهائي بشأن العمل. يجب أن يمتلك المتخصص في هذا المجال مهارات تحليلية وبرمجية متقدمة تمكنه من حل مشكلات العمل بشكل كامل بالاعتماد على البيانات واستخراج المعلومات القيِّمة والمفيدة منها لتطوير الأعمال مستخدمًا برمجيات متقدمة من خلال الاعتماد على أفضل المنظومات والخوارزميات لحل المسائل المتعلقة بتنظيم البيانات واستخلاص المعلومات منها. يمكن أن نختصر ماهية علم البيانات بالنقاط التالية: طرح الأسئلة الصحيحة عن المسألة المدروسة وتحليل البيانات الخام. نمذجة البيانات باستخدام خوارزميات متنوعة ومتقدمة وعالية الكفاءة. تصوير البيانات لفهمها من منظور أوضح. فهم البيانات المتاحة لاتخاذ قرارات أفضل أو الوصول إلى نتيجة نهائية. باختصار علم البيانات هو العلم المسؤول عن استخراج معلومات مفيدة من بيانات مبعثرة ولا قيمة لها بشكلها الخام بعد تنظيفها وتصحيح أخطائها وإزالة القيم المكررة منها ومعالجة القيم المفقودة منها وهي تشبه عملية استخراج شيء مفيد من النفايات. علم هندسة البيانات Data Engineering هندسة البيانات هي العمود الفقري لعلم البيانات وتتضمن عملية تصميم وبناء أنظمة تسمح للأشخاص بالتنقيب عن البيانات الأولية وجمعها وتنظيفها من مصادر وتنسيقات متعددة وتخزينها واستعادتها ونقلها تمهيدًا لتحليلها واستخراج معلومات مفيدة منها. كما تهتم هندسة البيانات بالبيانات الوصفية التي تُعد بيانات تصف بيانات أخرى. وتأتي أهمية هندسة البيانات من ضرورة تهيئة البيانات التي جرى جمعها حتى تُخزن ويسهل استعادتها عند الطلب فلا معنى لأي تحليل أو تفسير للبيانات ما لم تجري أرشفة النتائج وتخزينها في منظومة معلوماتية يسهل التعامل معها لاتخاذ القرار. تتضمن هندسة البيانات المهام التالية: استخراج البيانات من مصادر مختلفة Data extraction معالجة البيانات Data processing وتحويل البيانات Data transformation والتي تتضمن تنظيف البيانات data cleaning ومعالجة القيم الفارغة وفصل القيم المجمَّعة وإزالة القيم الخطأ أو تحويلها إلى قيم صحيحة موحدة ومتناسقة. تحميل البيانات Data load وتخزين البيانات الناتجة في المصدر النهائي وعادة تكون قاعدة بيانات مخصصة للتحليل Database analysis تنفيذ العمليات الثلاث ETL التي تعني استخراج Extract وتحويل Transfer وتحميل Load والتي تعني مجتمعة عملية تنقل البيانات من قاعدة بيانات واحدة، أو قواعد بيانات متعددة، أو مصادر أخرى إلى مستودع موحد عادة ما يكون مستودع بيانات. فنظرًا لكون تحليل البيانات أمرًا صعبًا لأن البيانات تجمع بواسطة تقنيات مختلفة ويتم تخزينها بهياكل وتنسيقات مختلفة لكن الأدوات المستخدمة لتحليل البيانات تتطلب أن تكون كافة مجموعات البيانات مخزنة بنفس الهيكلية! وهنا يأتي دور هندسة البيانات في توحيد مجموعات البيانات وإنشاء البنية التحتية التي تزود أعضاء فريق البيانات ببيانات عالية الجودة ليعملوا عليها ويفهموها ويعثروا من خلالها على إجابات لأسئلتهم، وهم مسؤولون كذلك عن تصميم وصيانة هذه البنية التحتية. على سبيل المثال يمكن أن تجمع الشركات العديد من البيانات حول عملائها ومن مصادر متنوعة مثل معلومات حول الفواتير من برنامج مخصص لإدارة المبيعات ومعلومات عن الشحن من برنامج إدارة شركات الشحن والخدمات اللوجستية ومعلومات عن دعم العملاء من برنامج دعم العملاء ومراقبة مواقع التواصل الاجتماعي للحصول على المحتوى الذي يهتم به العملاء ويتفاعلون معه ومعلوماتهم الديموغرافية وأوقات نشاطهم …إلخ. توفر هذه البيانات الكثير من المعطيات للعميل لكن الحصول عليها من مصادر مختلفة وبتنسيقات متنوعة يجعل فهمها والحصول على الإجابات التي نريدها منها أمرًا صعبًا للغاية ويستهلك الكثير من الوقت والجهد لذا لا يمكننا أن نُعوِّل على إدراكنا البشري في هذا الأمر. لهذا السبب يقوم مهندسو البيانات بإعداد هذه البيانات وتنسيقها وتنظيمها وتخزينها في مستودعات بيانات مناسبة مصممة لمعالجة الاستعلامات بسرعة تضمن الأداء المناسب، وبعدها يقدمون هذه البيانات إلى مستهلكي البيانات النهائية مثل محللي البيانات الذين لن يتمكنوا من الوصول إلى البيانات وتحليلها واستخلاص النتائج والقرارات الصائبة منها بدون البنية التحتية التي ينشؤها لهم مهندسو البيانات. عمومًا، كان هذا تعريفًا مختصرًا بتخصص هندسة البيانات، وقد توسعنا بالحديث عنه في مقال منفصل بعنوان الدليل الشامل إلى هندسة البيانات Data Engineering فارجع إليه للاستزادة. علم تحليل البيانات Data analysis تحليل البيانات هو المجال المسؤول عن معالجة البيانات لاستخراج أو استخلاص معلومات مفيدة من شأنها أن تساعد الشركات والمنظمات في حل مشكلة ما أو الكشف عن فرصة ما لتطوير العمل وعرض هذه المعلومات والنتائج التي تم الحصول عليها بأفضل طريقة لصانعي القرار في العمل حتى يتمكنوا من اتخاذ قرارات من شأنها تطوير العمل نحو الأفضل. على سبيل المثال قد يطلب من محلل البيانات تقسيم العملاء بناءً على سلوك الشراء لديهم لتحديد العملاء الذين يجب أن يتم استهدافهم في الحملات التسويقية وإرسال العروض الأنسب المخصصة لكل منهم بناءً على سلوكه الشرائي أو يطلب منه تحديد التكلفة الأفضل للمنتجات للحفاظ على القوة الشرائية كي لا تنخفض عن مستويات السنوات السابقة. ومن أهم المهام التي يعنى بها تحليل البيانات ما يلي: جمع البيانات الخام من مصادر متعددة وتنظيمها. التأكد من جودة البيانات وتنظيفها وتحويلها عند الضرورة. نمذجة البيانات في تنسيقات محددة. التمثيل الرسومي للبيانات أو تصوير البيانات Data visualization ويقصد به عرض البيانات بطريقة مرئية كي يتمكن المتابع من فهم المحتوى الذي تقدمه ويستوعب الرؤى التي استخلصت من هذه البيانات. إيجاد إجابات وحلول لأي مشكلات أو استفسارات في مجال العمل من خلال تحليل البيانات ذات الصلة. الاستفادة من الإحصائيات الوصفية في تلخيص ووصف خصائص مجموعة البيانات. للقيام بهذه المهام يحتاج المختص في تحليل البيانات لامتلاك مجموعة من المهارات الفنية وأهمها الإلمام الجيد بلغة الاستعلام الهيكلية SQL لاستخراج البيانات التي يحتاجها من قواعد البيانات العلاقية المختلفة وإتقان البرامج المخصصة مثل MS Excel و MS Access و Microsoft Power BI التي تساعد في تحليل هذه البيانات وإنشاء نماذج منها وإجراء العمليات الحسابية والإحصائية المختلفة عليها. كما يحتاج بالطبع لامتلاك معرفة جيدة بالإحصاء والتحليل الرياضي لإضافة المهارات في التنظيم والتخطيط والاهتمام بأدق التفاصيل كي يتمكن من إدارة ومعالجة طلبات العمل بكفاءة، كما تعد مهارات التواصل مفيدة جدًا أيضًا لمحللي البيانات لأنهم بحاجة إلى التعبير عن نتائجهم وتفسيرها بوضوح لأرباب العمل. كان هذا تعريفًا مختصر بمجال تحليل البيانات، وقد توسعنا بالحديث عنه في مقال منفصل بعنوان الدليل الشامل لتحليل البيانات Data Analysis فارجع إليه للاستزادة. الفرق بين علم البيانات والذكاء الاصطناعي يُعرّف الذكاء الاصطناعي Artificial Intelligence واختصارًا AI بأنه وسيلة لتزويد الآلات بسلوك يحاكي السلوك البشري كي تقارب تفكيرهم وتتصرف مثلهم وبالتالي فإن الجانب الأساسي من تقنية الذكاء الاصطناعي مرتبط بتعلم الآلة وتعلم الآلة المعمّق. يلخص الجدول التالي الفرق بين علم البيانات والذكاء الاصطناعي من نواحي عدة كي نستطيع إدراك أوجه الشبه والاختلاف: وجه الموازنة علم البيانات الذكاء الاصطناعي الأساسيات علم البيانات هو دورة عمليات مفصلة تتضمن التحضير الأولي للبيانات وتحليلها ثم تصويرها واتخاذ القرار الذكاء الاصطناعي هو إنجاز نموذج قادر على التوقع بهدف التنبؤ بأحداث مستقبلية. الأهداف التعرف على الأنماط المطلوب إيجادها ضمن البيانات الخام للمشروع قيد الدراسة أتمتة العمليات ووضع بيانات التصرف الذاتي ضمن الوحدة البرمجية المدروسة. نوع البيانات التي يعمل عليها يعمل علم البيانات على أنواع مختلفة من البيانات مثل البيانات الخام والبيانات المهيكلة وغير المهيكلة. يستخدم الذكاء الاصطناعي أنواع معيارية من البيانات على شكل متجهات vectors وأنواع مدمجة أخرى من البيانات التقنيات المستخدمة يستخدم التقنيات الرياضية والإحصائية وخوارزميات تعلم الآلة وأدوات تحليل البيانات وتصويرها. يستخدم بشكل أساسي خوارزميات تعلم الآلة وتعلم الآلة المعمّق. المعرفة المكتسبة تُستخدم المعرفة التي يوفرها علم البيانات في إيجاد الأنماط والسلوكيات في البيانات. تصب المعرفة التي يوفرها الذكاء الاصطناعي في تزويد الوحدات البرمجية بشكل من أشكال التصرف الذاتي. أمثلة عن الأدوات المستخدمة ++R, Python, MATLAB,C Tensor flow, sci-kit-learn, Kaffee متى يُستخدم يُستخدم علم البيانات عندما تقتضي الضرورة استخدام حسابات رياضية سريعة أو تحليل بيانات استطلاعي أو تحليل توقعي predective analysis. لا بد في هذه الحالات من تحديد الأنماط والسلوكيات من خلال البيانات المتاحة ويتطلب ذلك معرفة بالإحصاء الرياضي. يُستخدم الذكاء الاصطناعي عندما تقتضي الضرورة التخلص من عمل ضروري متكرر. لا بد في هذه الحالات من تقييم مخاطر الانتقال إلى الذكاء الاصطناعي وسرعة اتخاذ القرار ودقة في التنفيذ بعيدًا عن المشاعر البشرية والانحياز. أمثلة عن الاستخدام تحسين العمليات واكتشاف سلوكيات العملاء والتحليل المالي وغيرها الكثير. الروبوتات وبرمجيات المحادثة الآلية والألعاب عبر الإنترنت وأنظمة المساعدة الصوتية. هنالك مسارات أخرى بدأت تتبلور تعكس التأثير الكبير لعلم البيانات على الذكاء الاصطناعي مع تزايد الاندفاع نحو ما يُعرف بالذكاء الاصطناعي القابل للتوضيح explainable AI والذي يقدم معلومات تساعد المستخدمين على فهم كيفية عمل نماذج تعلم الآلة ومقدار الثقة التي ينبغي أن يولوها لنتائج عمل هذه الوحدات عند اتخاذ القرارات. بالإضافة إلى دور علم البيانات في صياغة مبادئ تصميم الذكاء الاصطناعي المسؤول responsible AI principles للتأكد من عدالة جميع التقنيات المستخدمة وضمان عدم تحيزها وشفافيتها. مكونات علم البيانات ينبثق علم البيانات من مجموعة من المكوّنات أو العلوم ولا بد من استعراضها حتى تتوضح أبعاد هذا العلم: الإحصاء Statistics الرياضيات Mathematics البرمجة وعلوم الحاسوب Programming and Computer Science أساسيات الرياضيات لتتعلم علم البيانات لا بد من إتقان المفاهيم الأساسية في الرياضيات التي تعد الجزء الأكثر حيوية في مجال علوم البيانات، فهي الفضاء الذي تُدرس ضمنه الكميات والبنى والعلاقات ذات الصلة بالظاهرة المدروسة. إذ يُعد علم الرياضيات اللغة التي توصِّف الظواهر العلمية وتوفر الأدوات الضمنية التي يستخدمها علم البيانات مثل عمليات الاستقراء والتحليل والإحصاء والتفاضل والتكامل وغيرها. الإحصاء الرياضي يُعد الإحصاء الرياضي Statistics من أهم مكوّنات علم البيانات لأنه الوسيلة الأنسب لجمع وتحليل البيانات العددية مهما كانت كميتها كبيرة واستخلاص الأفكار منها. يتعامل هذا العلم مع مجموعات منفصلة من البيانات أو مجموعات مستمرة منها محاولًا تطبيق وسائل رياضية لدراسة ميل هذه البيانات للتقارب أو التباعد والمنحى الذي تأخذه في هذا السلوك ثم تضع أطرًا لتعريف وتصنيف هذه الوسائل. فمن منا لم يسمع في مرحلة ما من تحصيله الدراسي كلمة متوسط حسابي أو انحراف معياري أو منوال مثلًا، فهذه المصطلحات ما هي إلّا مقاييس لابتعاد قيم مجموعة من البيانات عن قيمها الوسطى. البرمجة وعلوم الحاسوب يأتي الحمل الأكبر في علم البيانات على البرمجة وتخصص علوم الحاسوب كي تتمكن من كتابة وتنقيح وتعديل الشيفرات التي تجمع وتحلل وتهيكل البيانات، حيث يجب على من يريد التخصص في علم البيانات تعلم إحدى لغات البرمجة والمكتبات البرمجية التي تدعم الوظائف الإحصائية والرياضية وبرمجيات التحليل وإيجاد علاقات الترابط وغيرها، إضافة لقواعد البيانات المسؤولة بشكل أساسي عن تخزين البيانات وتنظيمها واسترجاعها. كما يعد تعلم الآلة Machine learning أحد التقنيات المتقدمة التي تلعب في الآونة الأخيرة دورًا حيويًا في علم البيانات فمن خلاله يمكننا من الحصول على تنبؤات وقرارات أفضل دون الحاجة للتدخل البشري مما يساعد علماء البيانات في أداء مهامهم والحصول على حلول لمشكلات العمل بطريقة أسرع وأكثر ذكاء مقارنة بالاعتماد على التقنيات الإحصائية التقليدية. وإذا كنت مهتمًا بتعلم أسس علوم الحاسوب والتخصص في مجال علوم البيانات واكتساب خبرة عملية فيه بأسرع الطرق يمكنك مطالعة مقال أساسيات علوم الحاسوب فهو بمثابة دليل شامل يعرفك على اختصاص علوم الحاسب وأهم فوائده وتطبيقاته. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن أهمية علم البيانات لم تكن البيانات المتوفرة حول مختلف المجالات خلال العقد الأول من هذه الألفية وما قبلها -وخاصة بشكلها الرقمي- ذات أحجام كبيرة جدًا، وكان من السهل تخزينها في هياكل مخصصة مثل الجداول الإلكترونية وقواعد البيانات العلاقيّة ومن ثم التعامل معها من خلال أدوات مختلفة بكل سهولة ويسر. فقد جمعت البيانات ما قبل الحقبة الرقمية بأساليب يدوية مرهقة بالاعتماد على الأشخاص والأوراق والجداول ولم تكن بيانات شاملة، بل كانت تقتصر على ما هو ضروري للجهة التي تحتاج هذه البيانات سواء أكانت حكومية أو سواها. مع التحول إلى الرقمنة، أصبحت عملية الحصول على البيانات وتصنيفها أسهل وأيسر وظهرت أنواع جديدة من قواعد البيانات التي تسهل التعامل مع هذه البيانات، لكن كما أشرنا بقيت ضمن حدود السيطرة. لكن الكم الهائل جدًا من البيانات التي تنتج يوميًا عن كل فرد قد وصلت وفق بعض الأبحاث إلى 1.7 ميغا بايت في الثانية عام 2020 وقد تصل إلى أضعاف هذا الرقم في لحظة كتابة هذه الأسطر. فانطلاقًا من البيانات البسيطة التي يسجلها الجوال عن مستخدميه، وبيانات التصفح واستخدام الحاسوب، وبيانات نشاطك على مختلف مواقع التواصل الاجتماعي وعمليات التسجيل والشراء أو أي نشاط على مختلف المواقع قد تُسجل وتؤرشف لغايات خاصة بمشغلي تلك المواقع فتأمل عندها الكميات الكبيرة من البيانات التي ستظهر حتى حركة مؤشر الفأرة على شاشة متصفح مسجلة وتستعملها المواقع عبر أدوات تعقب وتحليل مختلفة مثل تتبع الأقسام التي زرتها والروابط والمنتجات التي أبديت اهتمامُا بها وذلك لتحليل سلوكك وبالتالي تقديم تجربة أفضل لك. ولا ننسى تطور البرامج السحابية التي مكنت المؤسسات من تتبع أحجام ضخمة من بيانات الأعمال في الوقت الفعلي وتوفر مليارات من أجهزة إنترنت الأشياء IoT حول العالم التي تجمع كل لحظة كمًا ضخمًا من البيانات عن كل تحركاتنا، لذا يتوقع أن يكون هناك 175 زيتابايت من البيانات في عالم البيانات العالمي بحلول عام 2025 وللعلم فإن زيتابايت يساوي 1000 بايت للأس 7 وبعبارة أخرى فإن زيتابايت واحد يحتوي على 21 صفرًا ولهذا السبب نحن نعيش بالفعل حقبة انفجار البيانات الضخمة Big Data Explosion ونحتاج لطريقة تمكننا من معالجة هذا الكم الجنوني من البيانات! إن معالجة هذا الكم الهائل من البيانات هي مهمة صعبة جدًا على أي مؤسسة أو جهة، لهذا ظهرت الحاجة الماسة إلى أدوات وتقنيات فعالة لمعالجة وتحليل تلك البيانات وأشخاص مؤهلين قادرين على التعامل معها وبدأ علم البيانات بالتبلور ليكون مزيجًا من عدة علوم تتكامل لإنجاز ما يلي: تجميع البيانات الخام وإعدادها للمعالجة أو التحليل النوعي. تحويل هذه الكميات الكبيرة من البيانات الخام وغير المهيكلة إلى معلومات ذات قيمة. تقديم البيانات وعرضها بصريًا لتوضيح الاستراتيجيات أو القرارات المبنية على نتائج تحليل تلك البيانات. استخلاص الأفكار والرؤى من البيانات المحللة باستخدام تقنيات الذكاء الاصطناعي وخوارزميات تعلم الآلة. وضع استراتيجيات تطوير للأعمال انطلاقًا من نتائج التحليل والدراسة. وضع توقعات صحيحة أو قريبة من الصحة في مختلف المجالات مثل استطلاعات الرأي والانتخابات وحجوزات السفر واستكشاف حالات الغش والدراسات العلمية والاجتماعية وغيرها. لم يكن علم البيانات منذ عقد مضى ولا حتى العاملين في هذا المجال منتشرًا في سوق العمل، لكن الشعبية الكبيرة حاليًا لهذه الفئة من الخبراء تعكس طريقة تفكير الأعمال بالبيانات الضخمة. فلا يمكن بعد الآن تجاهل الكميات الهائلة من البيانات الخام التي أضحت بالنسبة للكثير من الشركات بمثابة منجم ذهب افتراضي طالما أن هناك خبراء متحمسين وطموحين ودقيقي الملاحظة قادرين على التنقيب فيها ورؤية ما لا يراه غيرهم. مجالات علم البيانات يلعب علم البيانات اليوم دورًا فعالًا في جميع جوانب الحياة التجارية والطبية والحكومية …إلخ، ويجد المختصون في المجالات المختلفة كل يوم تطبيقًا جديدًا لعلم البيانات بما يعزز العمل الذي يشرفون عليه ويحقق مكاسب على جميع الأصعدة، لكننا سنقف تاليًا على أبرز المجالات التي شاع استخدام علم البيانات فيها. التعرف على الصور وتمييز الكلام عندما تحمّل صورة على فيسبوك ثم ترى اقتراحات للإشارة إلى أصدقائك في الصورة، فإن ما يجري فعلًا أن موقع فيسبوك قد استخدم خوارزمية تمييز الصور تلقائيًا وقد تعرف على الأشخاص في هذه الصورة. إن هذه الخوارزمية هي جزء من علم البيانات. وكذلك الأمر عندما تقول "Ok Google" ليستجيب هاتفك الذكي ويستعد للأوامر الصوتية، فإن علم البيانات هو السبب في ظهور خوارزمية التعرف على الكلام التي استخدمها التطبيق توًا. محركات البحث عبر الإنترنت هل لاحظت كيف تقترح لك محركات البحث الشهيرة مثل جوجل وياهو وبينج ما هو قريب من نتيجة بحثك؟ هل لاحظت السرعة في عرض النتائج والتحسن المستمر في دقة نتيجة البحث؟ يعود الفضل في ذلك إلى علم البيانات وخوارزمياته التي تجعل تجربة البحث عبر الانترنت أكثر سرعة وفعالية ورضًى للمستخدم. العلوم الطبيعية تُستنبط معظم المعايير العلمية المتعلقة بالظواهر الطبيعية من كم البيانات الهائل الناتج عن مراقبة هذه الظواهر على مدى طويل من الزمن كالمناخ والبيئة والفضاء، إذ ترسل المسابر ملايين البايتات يوميًا إلى مراكز الأبحاث لتحليلها واستقراء النتائج وبالطبع لن يكون من السهل فهم هذه البيانات والربط بينها دون استخدام خوارزميات علم البيانات وطرائقه. عالم الألعاب سواء الألعاب الرياضية الحقيقية كدراسة وتحليل حركات لاعبي كرة القدم وحتى منصات الألعاب الرقمية في تعزيز تجربة اللاعبين. تعتمد الشركات التي ترعى هذه المواضيع على تحليل نتائج البيانات المأخوذة من كم هائل من المباريات ومن تجارب مئات الآلاف الذين يمارسون ألعاب الفيديو عبر الإنترنت. لقد حسَّن استخدام علم البيانات وتقنياته أداء الكثير من شركات الألعاب. النقل إن الهدف الرئيسي لاستخدام علم البيانات في عالم النقل هو الوصول إلى المركبات ذاتية القيادة التي يسعى مصمموها إلى تقليل الخطأ البشري إلى أدنى مستوى وتقليل عدد الحوادث المرورية وضبط معدلات التلوث بعوادم الوقود. إضافة إلى ذلك، يساعد علم البيانات في تحليل حركة المرور واكتشاف الازدحامات والاختناقات المرورية وإرسال إشعارات للسائقين لسلوك طريق آخر مثلًا لوجود ازدحام في الطريق الذي يسير عليه وتحليل الحوادث المرورية واتخاذ القرارات. الرعاية الصحية لعلم البيانات دور بارز في مجال الرعاية الصحية لما يؤمنه من مساهمة في تشخيص الحالات الطبية وتخطيط العلاج والبحث الطبي ويوفر نتائج حاسمة وتوقعات تقترب نسبة الخطأ فيها من الصفر وخاصة في مجالات الكشف عن الأورام وابتكار الأدوية وتحليل الصور الطبية. أنظمة التوصية بالمنتجات تعتمد معظم الشركات مثل غوغل وأمازون ونيتفليكس على علم البيانات الذي يقدم تكنولوجيا مفيدة جدًا في تحسين تجربة مستخدمي هذه الشركات من خلال التوصية بمنتجات هذه الشركات لمستخدميها من معرفة ميولهم وسلوكياتهم أو ما يعرف بالتزكية المخصصة. فعندما تبحث عن شيء ما ثم تجد اقتراحات لأشياء مشابهة لاحقًا فهي نتيجة تطبيق خوارزميات علم البيانات. اكتشاف المخاطر تواجه الشركات المالية مخاطر تتعلق بقضايا التزوير وخسارة رأس المال، لكن بوجود علم البيانات ستقل هذه الأخطار إلى مستويات منخفضة. إذ تستفيد شركات المال من علماء البيانات في دراسة البيانات المالية للاستثمارات المطروحة وإدارة المخاطر المالية واكتشاف المعاملات الاحتيالية وتقييم مخاطر الخسارة أو الإفلاس مما يرفع ثقة العملاء بأداء هذه الشركات، كما يساعد علم البيانات أنظمة تقنية المعلومات في منع الهجمات الإلكترونية ومنع التهديدات الأمنية المختلفة. ومن مجالات هذا العلم الأخرى مساعدة الشركات التجارية على إنشاء حملات تسويقية أقوى وإعلانات مستهدفة أكثر دقة لزيادة المبيعات والأرباح، ومنع حدوث أعطال المعدات في الأماكن الصناعية، ويبرز استخدام علم البيانات المجال الأكاديمية لمراقبة أداء الطلاب وتحسينه للأفضل وغير ذلك الكثير مما لا يتسع المقال لذكره. وقلما تجد اليوم مجالًا لا يساهم علم البيانات الحديث في تحسينه وتطويره نحو الأفضل. دورة حياة مشروع علم البيانات تمر دورة علم البيانات بالمراحل التالية: الاستكشاف إعداد البيانات تخطيط النماذج بناء النماذج التحضير للعمل إيصال النتائج الاستكشاف وهي أولى مراحل هذه الدورة وتبدأ بطرح الأسئلة الصحيحة عن الظاهرة المدروسة. فلا بد قبل أن تبدأ أي مشروع متعلق بعلم البيانات أن تحدد المتطلبات الاساسية لهذا المشروع وأولوياته وميزانيته. لا بد في هذه المرحلة من تحديد كل متطلبات المشروع كعدد العاملين فيه والتقنيات المستخدمة والزمن اللازم لإنجازه والبيانات التي سيجري العمل عليها والغاية منها، وبالتالي سنتمكن من وضع إطار أولي لحل المشكلة التي كانت سببًا في إطلاق المشروع. إعداد البيانات نحتاج في هذه المرحلة إلى إنجاز المهام التالية: تصحيح البيانات وتنظيفها Data cleaning اختزال البيانات وتقليل حجمها Data Reduction تكامل البيانات Data integration نقل البيانات Data transformation بعد إنجاز هذه المراحل الأربعة تصبح البيانات جاهزة لعمليات أخرى. التخطيط لبناء النماذج نحتاج في هذه المرحلة إلى تحديد النماذج المختلفة والتقنيات اللازمة لإيجاد العلاقات والروابط بين متغيرات الدخل. وتجري عادة عملية تحليل بيانات استطلاعي Exploratory data analytics -تختصر إلى EDA- باستخدام الدوال والصيغ الإحصائية ثم أدوات تصوير البيانات لفهم الروابط بين المتغيرات ومن ثم فهم ما ترشدنا إليه تلك البيانات. من أكثر الأدوات شيوعًا في إنجاز هذه المرحلة نجد: SQL Analysis Services R SAS Python بناء النماذج تبدأ في هذه المرحلة عملية بناء النماذج. إذ يجري خلال هذه المرحلة إنشاء مجموعات من البيانات لأغراض التمرين والاختبار لتساعد في تطبيق تقنيات مثل التجميع والتصنيف والربط على البيانات المتوفرة لوضع نماذج عن سلوكها. إليك بعض أدوات بناء النماذج الأكثر شيوعا: SAS Enterprise Miner: عبارة عن إضافة تتكامل مع قواعد بيانات أو جداول (مثل إكسيل) لبناء نماذج تحليلية تعطي توقعات عن البيانات الموجودة وفقًا لمسار التحليل الذي تتبعه. WEKA: وهي مجموعة من خوارزميات لغة الآلة كتبت بلغة جافا للتعامل مع مهام التنقيب عن البيانات. SPSS Modeler: برنامج من شركة IBM لتنفيذ مهام التنقيب عن البيانات وتمثيلها بيانيًا وفهمها واتخاذ القرارات بناء عليها. MATLAB: بيئة عمل رياضية وبرمجية متكاملة لمختلف الأغراض الحسابية والتحليلية وتصوير البيانات وبناء خوارزميات تعلم الآلة وتطبيقها. تحضير المشروع للعمل تُسلم في هذه المرحلة معظم التقارير النهائية عن المشروع إلى جانب الشيفرة والمستندات التقنية. تقدم هذه المرحلة نظرة شاملة عن أداء المشروع على صعيد محدود قبل أن يجري نشر نتائجه كاملةً. إيصال النتائج النهائية يتحقق فريق العمل في هذه المرحلة من أن الهدف الذي وضع للمشروع في مرحلة الاستكشاف قد أنجز أم لا، ثم تُسلم بعد ذلك المعلومات التي تمكن الفريق من حيازتها عن طريق النماذج التي بنيت ومن ثم إيصال النتائج النهائية إلى فريق الأعمال الذي طلب الشروع بالعمل. التخصص في مجال علم البيانات رأينا سابقًا كيف ظهرت الحاجة الملحة لعلم البيانات كتخصص قائم ومستقل بذاته للتنقيب عن المعرفة بين أكوام البيانات الخام ويُعتقد وفقًا لعدة استطلاعات رأي بأنّ هذا التخصص سيكون الأكثر طلبًا في السوق خلال هذا العقد. وبما أن الطلب شديد على هذا المجال فهناك نقص كبير في اليد العاملة فيه عربيًا وعالميًا، لذا أمامك فرصة سانحة لممارسته دون الحاجة لوجود شهادة أكاديمية متخصصة فيه إذ التركيز حاليًا على الخبرة نظرًا لنقص اليد العاملة فيه. أي كل ما تحتاجه هو الخبرة الأساسية في البرمجة والإحصاء الرياضي ورغبة في تعلم هذا المجال وتحصيل كل ما يكسبك الخبرة العملية فيه من دورات ومخيمات تدريبية تؤهلك لدخول سوق العمل والحصول على فرصة مميزة لدى الكثير من الشركات والمنظمات التي ستتهافت على تدريبك وتوظيفك لديها. لهذا السبب لا بد من الاطلاع على التخصصات التي يمكنك العمل بها في حال رغبت في التخصص في مجال علوم البيانات. الوظائف التي يتضمنها علم البيانات حتى تختار التخصص الذي تراه مناسبًا لخبراتك وميولك، سنفرد هذه الفقرة للتفصيل في مجموعة من أهم الوظائف والأدوار الوظيفية المرتبطة بالبيانات والمتطلبات الأساسية لكل وظيفة: عالم بيانات Data scientist محلل بيانات Data analyst مهندس بيانات Data engineer معماري بيانات Data architect مطوّر تصوير بيانات Data Visualization Developer خبير في تعلم الآلة Machine Learning expert لنكتشف المزيد حول كل دور من هذه الأدوار وأهم التقنيات والمهام المنوطة به. محلل البيانات هو شخص خبير ينقّب في أكوام البيانات الخام باحثًا عن نماذج وأنماط علاقات تربط بينها. يعمل بعد ذلك على عرض نتائج ما توصل له بما يساعد على اتخاذ قرار أو حل مشكلة. ما المهارات التي يجب أن يتقنها محلل البيانات؟ معرفة جيدة في الرياضيات. معرفة جيدة في التنقيب ضمن البيانات Data mining. معرفة أساسيات علم الإحصاء Statistic. أن يكون مطلعًا على بعض لغات البرمجة والأدوات البرمجية المستخدمة في علم البيانات مثل: Python MATLAB SQL Hive R JS SAS SPSS وغيرها مهندس بيانات وهو الشخص الذي يعمل مع كميات كبيرة من البيانات ويكون مسؤلًا عن بناء وصيانة بنى مناسبة لهذه البيانات وفقًا لمشروع علم البيانات الذي يعمل عليه. يعمل مهندس البيانات أيضًا على تصميم العمليات التي تتحكم بمجموعات البيانات وتُستخدم في نمذجة هذه المجموعات أو التنقيب فيها أو حيازة معلومات منها أو التحقق من سلامتها. ما المهارات التي يجب أن يتقنها مهندس البيانات؟ معرفة معمقة بتقنيات برمجية مثل: SQL MongoDB Cassandra HBase Apache Spark Hive MapReduce معرفة جيدة بلغات برمجة مثل Python, C/C++, Java, Perl. معماري بيانات وهو الشخص الذي يتصور ويصمم الأسلوب الذي تُنجز وفقه البنية التحتية المسؤولة عن تخزين وإدارة البيانات لأغراض التحليل سواء على صعيد العتاد الصلب أو الصعيد البرمجي. ما المهارات التي يجب أن يتقنها معماري البيانات؟ معرفة معمقة بقواعد تطوير البرمجيات والأنظمة. معرفة معمقة بالمعماريات المستخدمة في إنجاز قواعد البيانات. عالم بيانات عالم البيانات هو شخص خبير يعمل على تجميع وتحليل واستخلاص النتائج من كميات كبيرة من البيانات الخام أو المهيكلة أو غير المهيكلة. يجمع عمل عالم البيانات بين علوم الحواسب وخاصة برمجتها وعلم الإحصاء والرياضيات. يعمل عالم البيانات على تحليل ومعالجة ونمذجة البيانات ثم يفسر النتائج التي حصل عليها كي يُنشئ خطة عمل مناسبة للشركة أو المنظمة أو الجهة التي يعمل لديها. يُسخّر علماء البيانات قدراتهم ومهاراتهم في مختلف المجالات سواء التقنية منها أو الاجتماعية للبحث عن تفاصيل قد لا يراها ولا يفهمها سواهم في كم البيانات الهائل الذي يعملون عليه، إذ يتضمن عملهم عادة إيجاد ترابط منطقي بين بيانات غير مهيكلة أو خام تنتج عن مصادر مختلفة كالأجهزة الذكية وردود الأفعال على مواقع التواصل الاجتماعي ومحتوى رسائل البريد الإلكتروني وغيرها من المصادر التي يصعب ملاءمتها من قواعد البيانات المهيكلة. ما المهارات التي يجب أن يتقنها عالم البيانات؟ فهم معمق لعلم الإحصاء. معرفة جيدة في الرياضيات. مهارة في إحدى لغات البرمجة التالية أو أكثر Python R SAS SQL Hive Pig Apache spark MATLAB قدرة جيدة على تصوير البيانات Visualization. مهارات تواصل جيدة. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن مطور تصوير بيانات وهو شخص يعمل إلى جانب عالم البيانات لتمثيل البيانات بصريًا وتقديم عروض ومخططات تفصّل نتائج تحليل هذه البيانات بطريقة مرئية سهلة الفهم لإيصالها إلى من يستخدمها. ما المهارات التي يجب أن يتقنها مطور تصوير بيانات؟ مهارة في إحدى لغات البرمجة التالية أو أكثر: Python R SAS SQL Hive Pig Apache spark MATLAB قدرة تحليلية ممتازة. قدرة كبيرة على إيجاد الطرق الأمثل في تصوير البيانات. خبير في تعلم الآلة هو الشخص الذي يعمل مع مختلف خوارزميات تعلم الآلة التي تُستخدم في علم البيانات مثل خوارزميات الارتجاع أو الإنحدار Regression والتجميع clustering والتصنيف classification وشجرة القرار decision tree والغابة العشوائية random forest وغيرها. ما المهارات التي يجب أن يتقنها خبير تعلم الآلة؟ خبرة في أحد لغات البرمجة التالية أو أكثر: Python ++C R Java Hadoop فهم جيد للخوارزميات الكثيرة المستخدمة في علم البيانات وتعلم الآلة. مهارة تحليلية في حل المشاكل. معرفة جيدة في علمي الاحتمالات والإحصاء. مصادر تعلم علم البيانات هل أنت متحمس للتخصص في مجال علم البيانات وتعلمه بشكل ذاتي وبأقصر الطرق بعيدًا عن أروقة الجامعات ومناهجها المكثفة -بسنواتها الطويلة التي تمتد لأربع أو خمسة سنوات- لكنك لا تعرف من أين تبدأ؟ سنسلط في القسم الضوء على مصادر تعلم تخصص علم البيانات العربية لدخول سوق العمل، فكما أشرنا حاليًا السوق شره على المتخصصين ويركز على الخبرة والمشاريع العملية المنجزة ولا يتطلب شهادات جامعية حصرية. نفترض أنك أنهيت مراحل جيدة من التعليم الدراسي أو قد أنهيت المرحلة الثانوية أو تخصصت في أحد التخصصات الهندسية وبذلك تكون قد حصَّلت معرفة جيدة بأساسيات الرياضيات والإحصاء وحتى مواضيع متقدمة مثل التفاضل والتكامل (إن كنت قد اخترت التخصص العملي وليس الأدبي) وبذلك تكون قد قطعت شوطًا في تعلم هذا العمل، وعمومًا الأساسيات تكفي للبدء ويمكن لاحقًا التعمق في أي موضوع تحتاج إليه. بعدها يمكنك البدء بتعلم أساسيات علوم الحاسوب ولغات البرمجة المخصصة المستخدمة في علم البيانات وأهمها لغة بايثون و لغة R ولغة SQL فهي من أكثر اللغات المطلوبة والمخصصة للاستخدام مع البيانات. تؤمّن هذه اللغات قدرات وظيفية كبيرة في التواصل مع قواعد البيانات واستخلاص البيانات الخام وتحليلها وتنظيمها واستخلاص الرؤى وفقا للظاهرة المدروسة ومن ثم التقييم وإتخاذ القرار، وكل ذلك من خلال مجموعة واسعة من الخوارزميات التي توفرها هذه اللغات ضمنًا أو من خلال مكتبات متوافقة معها. من أهم المصادر العربية المتكاملة التي ننصحك بها كي تتعلم هذه التقنيات: كتاب ملاحظات للعاملين بلغة SQL 1.0.0 كتاب البرمجة بلغة بايثون الذي يشرح أساسيات لغة بايثون سلسلة تعلم لغة R التي تطلعك على كافة الأساسيات والمواضيع النظرية التي تحتاجها في هذه اللغات. سلسلة مقالات think stats التي توفر لك مجموعة مميزة من المقالات والدروس المتخصصة في تعليم الاحتمالات والإحصائيات لمبرمجي بايثون بأسلوب مبسط وسهل الفهم. وإذا كنت تفضل التعلم بإشراف مختصين يجيبونك على أي سؤال يخطر ببالك ويقرن التعليم النظري بالتطبيق العملي فأنصحك بالاطلاع على دورة أساسيات علوم الحاسب التي توفرها أكاديمية حسوب فهي كفيلة بأن تكسبك كافة الأسس التي تحتاجها لتعلم أسس البرمجة وقواعد البيانات، وكذلك دورة تطوير التطبيقات بلغة بايثون والتي تمكنك من تطوير طيف واسع من التطبيقات في مجالات منوعة من بينها تطبيقات عملية في تحليل البيانات تساعدك في التعرف على أبرز مكتبات بايثون المتخصصة في التعامل مع علم البيانات. إضافة إلى لغات البرمجة التي ذكرناها ستجد الكثير من المنصات والأدوات التي تدعم بشكل مباشر العمل مع البيانات الضخمة وتقدم مختلف الأدوات المساعدة في التحليل والتنظيم واتخاذ القرار والتي يمكنك تعلمها ومن أبرزها SAS و Spark و Hadoop و Azure و AWS. خاتمة ألقينا الضوء في هذا المقال على علم البيانات الذي يُتوقع أن يكون من أكثر الأعمال طلبًا خلال هذا العقد من الألفية نظرًا للحاجة الماسة للعمل ضمن كميات هائلة من البيانات الخام وضرورة الاستفادة منها في تطوير الأعمال على مختلف الأصعدة. كما تحدثنا عن المكونات والتخصصات التي يضمها ومجالات استخدامه وتطبيقه، كما تحدثنا عن دورة الحياة التي يمر بها أي مشروع يعتمد على علم البيانات. ومنعًا لتضارب الأفكار وضياع التسميات، فقد تحدثنا عن الفرق بين علم البيانات وتحليلها وكذلك الفرق بين علم البيانات والذكاء الاصطناعي. وهكذا نكون قد أحطنا بشكل مفصل أساسيات علم البيانات وتخصصاته ومجالاته المختلفة لمن يرغب فعليًا في امتهانه أو احتراف أحد اختصاصاته، ووضحنا المتطلبات الضرورية التي يحتاجها المتعلم حتى يبدأ رحلته في هذا المجال المهم والشيق والمجزي ماديًا والذي ينبئ بمستقبل واعد.1 نقطة -
 هياكل البيانات data structures -أو تدعى بنى المعطيات أحيانًا- مصطلح يتكرر كثيرًا في علوم الحاسوب خصوصًا والبرمجة عمومًا ويعد من المصطلحات المعقدة البسيطة أو السهلة الممتنعة كما أن الكثير يخلط بينه وبين أنواع البيانات أو لا يكاد يميز بينهما، ولابد على أي داخل لمجال علوم الحاسوب ومن يريد تعلم البرمجة أن يفهم هذا المصطلح جيدًا لأنه الأساس الذي سيستند عليه في بناء بقية المفاهيم الأخرى اللاحقة. بناء على ذلك، جاء هذا المقال ليكون تعريفًا بهياكل البيانات وأنواعها بأسلوب بسيط سهل مدعوم بالصور التوضيحية كل هيكل بيانات بالإضافة إلى ذكر ميزات وعيوب بعض الأنواع، كما يتناول هذا المقال التعريف بأهمية هياكل البيانات وأهم تطبيقاتها والفرق بينها وبين أنواع البيانات، لذا لنبدأ! ما هي هياكل البيانات؟ تُعَدّ هياكل البيانات data structures من أهم المفاهيم التأسيسية في مجال علوم الحاسوب، فهي ببساطة مجموعة من الوسائل والطرق المستعملة في ترتيب البيانات في ذاكرة الحاسوب بهدف التعامل معها بكفاءة وفعالية وتسهيل إجراء العمليات عليها، وتوجد هناك أنواع أساسية ومتطورة من هياكل البيانات وجميعها مصمَّمة لتنظيم البيانات لاستخدامها في هدف محدَّد. أهمية هياكل البيانات data structures أحب بداية ضرب مثال يوضح هياكل البيانات وأهميتها وهو أننا نستعمل هذا المفهوم في حياتنا اليومية بصورة أو بأخرى، لنفترض أن البيانات تمثل ملابسنا، فهل نرمي الملابس في خزانة واحدة كلها؟ لا بالطبع لأن إخراج بنطال معين آنذاك سيستغرق وقتًا من البحث للعثور عليه وإخراج بل نضع الألبسة بطريقة معينة في عدة خزانات وسحابات وبطرق مختلفة بحيث نصل إلى بنطال أو قميص محدد بمجرد طلبه فورًا آنيًا دون تأخير. الأمر نفسه مع ترتيب البهارات وأوعية المطبخ والكتب وكل شيء حولنا تقريبًا. هذا بالضبط ما يحصل عند كتابة كلمة في محرك البحث لتظهر لك اقتراحات عد قد تطابق تمامًا ما تنوي كتابته في غضون أجزاء من الثانية، فهل تساءلت كيف تمكن محرك البحث من البحث في كم البيانات الضخم الموجودة في الإنترنت ووصل إلى النتيجة؟ لا يمكن ذلك بآلية الرمي العشوائي في مكان واحد التي ذكرناها في ترتيب الملابس تلك بل بتنظيم البيانات ضمن هياكل بيانات تشبه الأوعية والخزانات تسهل الوصول إليها بأسرع ما يمكن. نظرًا لتطور التطبيقات وازدياد تعقيدها وازدياد كمية البيانات الضخم يومًا بعد يوم والذي تتطلب عملية معالجتها معالجات هائلة السرعة، فكان لا بد من تنظيم البيانات وإدارتها بكفاءة في هياكل البيانات تمثل أوعية تخزين وتنظيم لها، إذ يمكن أن يساعد استخدام هياكل البيانات المناسبة في توفير قدر كبير من الوقت أثناء إجراء عمليات عليها مثل تخزين البيانات أو استرجاعها أو معالجتها، وبالتالي وصول أسرع إلى الذاكرة وتوفير في استهلاك العتاد من عمليات معالجة وطاقة للحاسوب. من الجدير بالذكر أيضًا أنّ هياكل البيانات ضرورية لتصميم خوارزميات فعالة والتي سنراها في تطبيقات هياكل البيانات ضمن هذا المقال. الفرق بين أنواع البيانات وهياكل البيانات يبدو لك أنّ أنواع البيانات Data Types وهياكل البيانات Data Structures وجهان لعملة واحدة لأنّ كلاهما يتعامل مع طبيعة البيانات وتنظيمها، ولكن في الحقيقة الأول يشرح نوع وطبيعة البيانات في حين يمثِّل الآخر التجميعات التي تُخزَّن تلك البيانات فيها، وفيما يلي الفروق الأساسية بين نوع البيانات وهيكل البيانات. يمثِّل نوع البيانات ماهية البيانات التي سيجري التعامل معها مثل أن تكون البيانات أعداد أو سلاسل نصية أو رموز …إلخ. في حين يُعَدّ هيكل البيانات تجميعةً collection تحوي تلك البيانات وهناك عدة أنواع من الهياكل تناسب مختلف أنواع البيانات. يحدد نوع البيانات ما يترتب عليه من عمليات تطبق على تلك البيانات مثل العمليات الرياضية على الأعداد وعمليات المعالجة على النصوص وهكذا أما هياكل البيانات فتحدد كيفية تخزين البيانات والوصول إليها والبحث فيها وغيرها من العمليات كما تدرس كيفية تحسين الأداء في تلك العمليات. يأخذ نوع البيانات شكل التنفيذ المجرد abstract implementation الذي يُعرَّف من خلال لغات البرمجة نفسها، في حين يُنفَّذ هيكل البيانات تنفيذًا حقيقيًا concrete implementation بحيث يُنشأ ليكون متوافقًا مع التصميم الذي يحتاجه المبرمج بالحجم الذي يريده وبنوع البيانات التي سيحتويها ضمن تطبيقه. يسمى نوع البيانات بأنه عديم القيمة dataless لأنه لا يخزِّن قيمة البيانات وإنما يمثِّل فقط نوع البيانات التي يمكن تخزينها، في حين يستطيع هيكل البيانات الاحتفاظ بأنواع مختلفة من البيانات مع قيمتها في كائن واحد. تحدد أنواع البيانات مع المتغيرات مثلًا في لغات البرمجة عند تعريفها، في حين تحتاج إلى كتابة بعض الخوارزميات لإسناد قيم البيانات إلى المتغيرات عند استخدام هيكل بيانات مثل عمليتَي الإضافة Push والجلب Pop للبيانات. لا يُكترث للزمن عند استخدام نوع البيانات، في حين يؤخذ بالحسبان عند استخدام هيكل البيانات (يطلق عليه تعقيد زمني BigO). تطبيقات هياكل البيانات يكاد لا يخلو أي تطبيق أو برنامج أو خوارزمية برمجية من وجود هيكل بيانات أو بنية معطيات تساعده في تحقيق الهدف المرجو منه، ومن هذه التطبيقات ما يلي: تنظيم البيانات في ذاكرة الحاسوب. تمثيل المعلومات في قواعد البيانات. خوارزميات معالجة البيانات مثل معالجة النصوص. خوارزميات تحليل البيانات مثل data minar. خوارزميات البحث في البيانات مثل محرك البحث. خورزميات توليد البيانات مثل مولِّد الأعداد العشوائية. خوارزميات ضغط البيانات وتفك ضغطها مثل المعتمدَة في برنامج zip. خوارزميات تشفير البيانات وتفك تشفيرها مثل المعتمدَة في نظام الأمان. البرامج التي تدير الملفات والمجلدات مثل مدير الملفات. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن أنواع هياكل البيانات في لغات البرمجة تنقسم هياكل البيانات إلى هياكل بيانات أولية Primitive وهياكل بيانات غير أولية Non Primitive أو هياكل بيانات معقدة وكل منها يضم عدة أقسام سنشرحها تباعًا. هياكل البيانات الأولية Primitive هي هياكل البيانات الأساسية والبسيطة والتي تُستخدَم لتخزين قيمة من جزء واحد فقط ذات نوع محدَّد، ويندرج تحت هذا النوع ما يلي: integer: من أجل الأعداد الصحيحة مثل العدد 15. character: من أجل محرف واحد فقط. float: من أجل الأعداد العشرية. real: من أجل الأعداد الحقيقية. boolean: من أجل القيم البوليانية والذي يأخذ إحدى القيمتين؛ إما محققة true أو غير محققة false. ملاحظة: قد تتساءل عن هياكل تخزين النصوص، وهي في الحقيقة تدخل ضمن الهياكل الغير أولية أن النصوص مجموعة من الحروف والرموز التي تدعى محارف characters لذا تخزن عادة ضمن مصفوفة وأحيانًا تضيف لغات البرمجة نوعًا خاصًا لها يدعى string سلسلة نصية أو لا يضيف وتكون بالشكل char[] وما تراه [] يدل على هيكل مصفوفة. يوجد شيء خاص يدعى مؤشر pointer والمشهور في بعض اللغات البرمجية مثل سي C وسي بلس بلس ++C، إذ يُعَدّ مكانًا في الذاكرة ويخزِّن عنوان المتغير الذي يشير إليه والشي الخاص فيه أنه يملك نوع بيانات والذي يجب أن يطابق نوع البيانات الذي يشير إليها. ملاحظة: ممكن تسمية هياكل البيانات التي تخزن الأعداد العشرية باسم double (عدد عشري مضاعف الدقة) أو float (عدد عشري) عوضًا عن real بصورة عامة ويكمن الاختلاف حسب اللغة البرمجية في عدد الخانات العشرية الممكن تخزينها، أي عدد الخانات بعد الفاصلة العشرية، بالإضافة إلى الحجم في الذاكرة وأخيرًا طريقة التعريف declaration، ففي لغة سي شارب #C يكون تعريف المتغير من نمط float كما يلي: float x = 1.5f; أما تعريفه عندما يكون من نمط double، فيكون كما يلي: double x = 1.5; ملاحظة: يطلق أحيانًا على هياكل البيانات الأولية أنواع البيانات Data Type. هياكل البيانات غير الأولية هي هياكل البيانات التي تُستخدَم من أجل التخزين المعقّد والتي يمكنها أن تحمل أكثر من قيمة في بنيتها، وتنقسم إلى هياكل بيانات خطية Linear وهياكل بيانات غير خطية Non Linear. هياكل البيانات الخطية تكون هياكل البيانات خطيّةً إذا كانت عناصرها تشكل تسلسلًا فيما بينها بحيث يرتبط كل عنصر فيها بعنصر سابق وعنصر لاحق ضمن مستوى واحد وفي مسار واحد، ومن هذه الهياكل ما يلي: المصفوفة Array القائمة المترابطة Linked List المكدس Stack الرتل Queue المصفوفة تُعَدّ المصفوفة الخطية array أو المصفوفة ذات البعد الواحد أبسط أنواع الهياكل الخطية، ويمكن تشبيهها بقائمة من عدد محدود من العناصر التي تمتلك النوع ذاته، ويكون بعدها -أو طولها- هو عدد العناصر التي تملكها، كما تُخزّن في الذاكرة بحجم ثابت وبمواقع متجاورة. كل عنصر من عناصر هذه المصفوفة الخطية يملك فهرسًا للوصول إليه، وعادةً ما يبدأ الفهرس بالعدد 0 أي يكون فهرس العنصر الأخير هو n-1 في مصفوفة بعدها n، وفي بعض لغات البرمجة يكون فهرس البداية هو العدد 1 مثل لغة باسكال، وفيما يلي صورة توضِّح هذه البنية: ملاحظات: يُنظَر إلى السلسلة النصية string على أنها مصفوفة أحادية من المحارف، أي كلمة Hello هي سلسلة نصية وهي مصفوفة طولها 5 مكوّنة من خمسة عناصر بحيث يمثِّل كل عنصر محرفًا من المحارف كما أشرنا سابقًا. المصفوفة ثنائية البعد هي أيضًا مجموعة من المتغيرات المفهرسة التي تحتوي على النوع نفسه من البيانات ولكن تخزين البيانات فيها يكون على صورة جدول له أعمدة وأسطر، بحيث يمكن الوصول إلى العنصر في هذه المصفوفة من خلال فهرسين أحدهما يحدِّد السطر والآخر يحدِّد العمود. من الجدير بالذكر أنّ بُعد المصفوفة ثابت في بعض لغات البرمجة وبالتالي يجب معرفة عدد العناصر قبل تعريفها فإذا أردت تغيير البُعد وإضافة عناصر جديدة، فستحتاج إلى مصفوفة جديدة ببُعد جديد لتنقل إليها العناصر السابقة وبعدها تضيف العناصر الجديدة إليها، كما أنّ إضافة عنصر ما في مكان ما مملوء مسبقًا أي في وسط المصفوفة مثلًا سيستهلك الكثير من العمليات، إذ ستحتاج إلى إزاحة العناصر اللاحقة ليصبح له مكانًا فارغًا، ويُعَدّ ذلك من عيوب استخدام المصفوفات. هنالك لغات أخرى لا تشترط تحديد عدد عناصر المصفوفة ولكنها تستهلك آنذاك عمليات كثيرة وتكون مكلفة لعمليات المعالجة أما تلك التي تحدد عدد العناصر مسبقًا فذلك عائد إلى توفير عمليات المعالجة. ملاحظة: قد تجد كلمة static ساكن وكلمة dynamic متحرك لتصنيف الأنواع الغير خطية ولكن شرحهما متقدم جدًا يحتاج إلى مقال بأكمله وستحتاج إليه عند التعمق كثيرًا وليس في البداية. القائمة المترابطة تُعَدّ القائمة المترابطة linked list مجموعةً من العقد التي تخزَّن في الذاكرة بمواقع غير متجاورة، وكل عقدة من عقد القائمة مرتبطة بالعقدة المجاورة لها بمؤشر عدا العقدة الأخيرة التي يكون المؤشر فيها عبارة عن Null. تسمح هذه البنية بإدراج عناصر جديدة أو حذف عناصر موجودة سابقًا بسهولة وهذا ما يميزها عن المصفوفات؛ أما سرعة الوصول، فتُعَدّ المصفوفات أسرع لأنه يكفي ذكر الفهرس الرابع على عكس القائمة المترابطة التي يجب البدء فيها من الرأس ثم المرور على العناصر بالتتالي إلى حين الوصول إلى العنصر الرابع. من الجدير بالذكر أنّ القائمة المترابطة تحتاج إلى مساحة إضافية في الذاكرة من أجل المؤشر الذي يرتبط بالعنصر، وهذا عيب آخر من عيوب القوائم المترابطة. يوجد نوع متطور من القوائم المترابطة وهو القوائم المترابطة المزدوجة Doubly Linked List، إذ ترتبط كل عقدة بمؤشرَين أحدهما يربطها بالعقدة السابقة ويسمى عادةً prev والآخر يربطها بالعقدة التالية ويسمى عادةً next، وبالتالي تحتاج هذه القائمة إلى مساحة إضافية في الذاكرة لامتلاكها على مؤشر إضافي، وبالمثل يكون المؤشر prev في عقدة الرأس Null ومؤشر next في العقدة الأخيرة هو Null. يوجد نوع أخير من القوائم المترابطة وهو القوائم المترابطة الدائرية Circular Linked Lists والتي تُعَدّ تطويرًا عن المفردة بحيث يشير مؤشر next الخاص بعقدة النهاية إلى عقدة الرأس. كما توجد القوائم الدائرية المزدوجة بحيث يشير مؤشر prev الخاص بعقدة الرأس إلى عقدة النهاية ويشير مؤشر next الخاص بعقدة النهاية إلى عقدة الرأس، وبالتالي لا تحتوي القوائم المترابطة الدائرية على مؤشرات Null. المكدس يُعَدّ المكدِّس stack هيكل بيانات خطية يتبع ترتيبًا محددًا في تنفيذ عمليات الحذف والإضافة، والترتيب يكون LIFO أي الذي يدخل آخرًا يخرج أولًا Last In First Out، والذي يميز المكدس هنا هو دخول العناصر وخروجها من قمة المكدِّس أي من جهة واحدة. تدخل -أو تُضاف- العناصر إلى المكدِّس عن طريق عملية وحيدة وخاصة وهي دفع Push وبالمثل فإنها تخرج منه -أو تُحذَف- عن طريق عملية وحيدة وخاصة أيضًا وتدعى إخراج Pop، وتوجد أيضًا عمليتان خاصتان بالمكدِّس وهما Top -أو Peek- التي تعيد القيمة الموجودة في قمة المكدِّس دون حذفها، والعملية الأخرى هي عملية IsEmpty التي تُعيد القيمة true إذا كان المكدِّس فارغًا. عند إضافة عنصر إلى مكدِّس ممتلئ لا يستوعب المزيد من العناصر فستحصل حالة طفحان المكدِّس overflow؛ أما عند إجراء عملية الحذف من مكدِّس فارغ، فسنواجه حالة طفحان أو تجاوز الحد الأدنى underflow (قعر المكدس). الرتل يُعَدّ الرتل queue أحد هياكل البيانات الخطية شبيه بالمكدس لامتلاكه عمليات خاصة للحذف والإضافة ولكنه يختلف عنه في مكان الحذف والإضافة كما سنرى. يدعى الرتل أو الطابور بـ FIFO أي الذي يدخل أولًا يخرج أولًا First In First Out بحيث يكون الدخول -أو الإضافة- من الجهة الخلفية rear والخروج -أو الحذف- من الجهة الأخرى أي الأمامية front (كما يحصل عند الوقوف ضمن الطوابير تمامًا لشراء شيء ما)، وتحدث الإضافة عن طريق عملية ENQUEUE أما عملية الحذف فتكون عن طريق عملية DEQUEUE. يتميز الرتل أيضًا بامتلاكه عمليات خاصة وهي العملية IsFull التي تُعيد true إذا كان الرتل ممتلئًا، والعملية IsEmpty التي تُعيد true إذا كان الرتل فارغًا، والعملية Front التي تُعيد العنصر الأمامي من الرتل، بالإضافة إلى العملية Rear التي تُعيد العنصر الخلفي من الرتل. هياكل البيانات غير الخطية لا تحتوي هياكل البيانات غير الخطية -أو المتشعبة- على أيّ تسلسل محدد يربط جميع عناصرها، إذ يمكن أن يكون لكل عنصر أكثر من مسار ليرتبط بالعناصر الأخرى، كما أنّ العناصر الموجودة ضمن هذه الهياكل لا يمكن اجتيازها أو المرور عليها في جولة واحدة أو باستخدام حلقة برمجية واحدة. وأهم ما يميّز هذا النوع على الرغم من صعوبة التنفيذ موازنةً بالهياكل الخطية التي يزداد فيها تعقيد الوقت مع ازدياد حجم البيانات أنه يُعد أكثر كفاءة في استخدام الذاكرة وأكثر سرعة في تطبيق العمليات مثل عمليات البحث، ومن هذه الهياكل: الشجرة الرسم البياني الشجرة تُعَدّ الشجرة tree هيكل بيانات متعدد المستويات وتُعرَّف على أنها مجموعة من العقد التي تحتوي فيما بينها على علاقة هرمية بحيث تسمى العقدة العليا بالعقدة الجذر، كما تحتوي كل عقدة على أب وحيد، في حين يمكن أن يكون لها أكثر من ابن أو تابع. تسمى العقد التي تتفرع من عقدة معينة بأبناء children تلك العقدة والتي بدورها تدعى بالعقدة الأب parent، في حين تسمى العقد التي لا تمتلك أبناء بالأوراق leaves. تمتلك الشجرة عدة أنواع وهي: الشجرة الثنائية binary tree شجرة البحث الثنائية binary search tree شجرة AVL شجرة R-B شجرة البادئات الشجرة الثنائية الشجرة الثنائية binary tree هي شجرة بيانات تمتلك كل عقدة فيها -ما عدا الأوراق- على عقدَتي ابن فقط وهما الابن الأيمن والابن الأيسر. شجرة البحث الثنائية شجرة البحث الثنائية binary search tree أو BST اختصارًا هي شجرة ثنائية تحقق خاصيتان أساسيتان وهما أنّ العقد الواقعة في الفرع اليميني تكون أكبر من العقدة الأب والعقد الواقعة في الفرع اليساري تكون أصغر من العقدة الأب، مع ضمان وجود ابنَين لكل عقدة وعدم تكرار العقد. شجرة AVL تُعَدّ اختصارًا لـ Adelson-Velskii Tree إذ يُعَدّ أديسون Adelson وفيلسكي Velskii مخترعَيها للحفاظ على توازن شجرة البحث الثنائي وذلك لمنع تدهورها إلى قائمة مرتبطة عندما تحتوي الشجرة بأكملها على الشجرة الفرعية اليسرى فقط أو على الشجرة اليمنى فقط مما سينعكس سلبًا على أداء الشجرة، إذ يمكن استخدام سلسلة من عمليات التدوير بحيث تُحدَّد في كل عملية عقدة جذر إلى حين الوصول إلى شجرة بعقدة جذر معينة بحيث تكون متوازنة أي ارتفاع الشجرة اليسرى مساويًا لارتفاع الشجرة اليمنى، ويمكن القول هنا أنّ شجرة AVL هي شجرة BST تحقق شرط التوازن، علمًا أنّ ارتفاع الشجرة هو أكبر عمق موجود لها. شجرة R-B تعني الشجرة الحمراء والسوداء Red-Black tree وهي شجرة بحث ثنائية لها خصائص تميزها بحيث تحتوي كل عقدة فيها على بت تخزين يشير إلى لون العقدة والتي يمكن أن تكون حمراء أو سوداء فقط، كما أنّ عقدة الجذر والعقد الأوراق سوداء دائمًا، وإذا كانت العقدة حمراء فيجب أن يكون أبناءها سود، وأخيرًا يجب أن تحتوي جميع المسارات من عقدة إلى أحفادها العدد نفسه من العقد السوداء، فإذا تحقق ما سبق، فستكون الشجرة شجرة بحث ثنائية متوازنة. شجرة البادئات تُعَدّ شجرة البادئات Prefix tree نوعًا من أشجار البحث وتعرف أيضًا بالشجرة الرقمية أو tri كما تُعرَف بشجرة القاموس وتُستخدَم في البحث عن الكلمات بصورة عامة بما أنها مكوَّنة من أحرف الهجاء، وأهم ما يميزها أنّ جذرها لا يحتوي على أيّ محرف. الكومة تُعَدّ الكومة Heap بنية معطيات شجرية تمتلك خاصة الكومة وهي وجود أسلوب ترتيب متَّبع بين العقد الآباء والعقد الأبناء مثل أن يكون كل أب أكبر من جميع أبنائه وتسمى حينها بالكومة العظمى Max-Heap أو أن يكون كل أب أصغر من جميع أبنائه وتسمى حينها بالكومة الصغرى Min-Heap، وتُستخدَم الكومة بكثرة في خوارزميات الترتيب، كما تتميز الكومة بأنّ جميع مستوياتها ممتلئة بالكامل عدا المستوى الأخير، وفيما يلي صورة توضِّح كومة صغرى. الرسم البياني يختلف الرسم البياني graph أو المبيان عن الشجرة في عدم احتوائه على جذر ومن الممكن أن تتصل العقد مع بعضها باتجاه واحد directed graph أو بالاتجاهين معًا Bi-directional أو بدون اتجاه undirected، كما أنّ طبيعة العلاقات بين العقد في هذا النوع ليست ذات طبيعة هرمية، كما تسمى العقد بالرؤوس vertices والروابط التي بينها تسمى بالحواف أو الأضلاع edges ويكون عدد كل من الرؤوس والأضلاع محدودًا. يكون الزوج (1,2) في الرسم البياني الموجَّه والذي يدل على وجود اتجاه من الرأس 1 إلى الرأس 2 مختلفًا عن الزوج (2,1)، كما تُرمَز مجموعة الرؤوس في هذا النوع بالرمز V ومجموعة الأضلاع بالرمز E ويُستخدَم هذا النوع من البنى في تمثيل الشبكات الواقعية مثل شبكة الهاتف المحمول أو شبكات التواصل الاجتماعي مثل الفيسبوك على سبيل المثال. التقطيع Hashing يُعَدّ التقطيع Hashing أو التجزئة تحسينًا لهياكل البيانات السابقة في بعض التطبيقات التي تحتاج إلى ترتيب بياناتها بواسطة أعداد كبيرة وفريدة موجودة ضمن هذه البيانات مثل ترتيب سجلات المرضى ضمن المستشفيات بناءً على أرقام هواتفهم والتي تُعَدّ مفاتيحًا فريدةً unique لهذه السجلات، ويكون ذلك من خلال الاستعانة بدالة تدعى دالة التقطيع hashing function والتي تحوِّل هذا المفتاح الفريد إلى عدد صغير وصحيح بحيث يكون فهرسًا لجدول جديد يدعى جدول التقطيع hashing table. من الممكن أن يكون فهرس جدول التقطيع هو ذاته رقم هاتف المريض بحيث يكون طوله هو أكبر رقم هاتف موجود ضمن السجلات زائد واحد بما أنّ الفهرسة تبدأ من الصفر، وبالتالي نحصل على سرعة وصول عالية لأيّ سجل من خلال رقم الهاتف الخاص به، ولكن سيتسبب ذلك بتواجد فجوات gaps بين العناصر لعدم الحاجة لوجود جميع أرقام الهواتف المحتملة وبالتالي زيادة حجم التخزين في الذاكرة، لذا تُستخدَم دالة التقطيع لحل هذه المشكلة، وعندها يكون جدول التقطيع مصفوفةً يمثِّل كل عنصر فيها مؤشرًا على السجل الذي يحتوي على رقم الهاتف -في مثالنا- والذي تكون نتيجة تطبيق دالة التقطيع عليه هي فهرس هذا العنصر. من الضروري التأكد من أنّ دالة التقطيع لا تعطي النتيجة ذاتها لأكثر من مفتاح، فإذا كانت دالة التقطيع مثلًا هي تأخذ فقط الرقم الأخير من رقم الهاتف، فسيكون لرقمَي الهاتف 45451 و 56561 على سبيل المثال النتيجة نفسها أي العدد 1 وبالتالي سيحدث تصادم في جدول التقطيع الذي فهرسه العدد 1، وأحد حلول هذه المشكلة أن يكون كل عنصر من جدول التقطيع مؤشرًا على قائمة مترابطة تحتوي على السجلات التي نتيجة تطبيق دالة التقطيع على أرقام هواتفها هي ذاتها. ليكن لدينا الأعداد التالية 12 – 17 – 29 – 6 – 30 – 31 – 4 – 8، فإذا كان فهرس جدول التقطيع هو ذاته العدد المعطى، فسنحتاج إلى جدول بحجم 32، ولكن فعليًا نحتاج إلى 8 أماكن للتخزين وبالتالي سنحصل على فجوات وهدر في الذاكرة، لذا سنلجأ إلى دالة التقطيع والتي ستعطي آحاد العدد المُعطى، وبالتالي ستكون نتيجتها 2 – 7 – 9 – 6 – 0 – 1 – 4 – 8 عند تطبيقها على الأعداد السابقة على الترتيب، بحيث يُخزَّن العدد 12 في العنصر الذي فهرسه هو العدد 2 وهكذا، وبالتالي سنحتاج إلى جدول تقطيع بحجم 8 بدلًا من 32 كما يلي: 12 17 29 6 30 31 4 8 2 7 9 6 0 1 4 8 يمكن تقليص حجم هذا الجدول ليصبح 4 بتحسين دالة التقطيع، بحيث يكون الفهرس هو باقي قسمة كل عدد من الأعداد المعطاة على العدد 4، ولكن ستكون نتيجة الأعداد 17 و 19 هي الفهرس 1، أي سيحدث تصادم، ويمكن حل هذه المشكلة بجعل كل عنصر من عناصر جدول التقطيع مؤشرًا على قائمة مترابطة من الأعداد التي باقي قسمتها على العدد 4 هو فهرس هذا العنصر، أي كما في الشكل التالي: يمكن زيادة حجم جدول التقطيع في المستقبل، كما أنّ هذه التقنية هي الأكثر استخدامًا في جوجل google. الخاتمة تعرَّفنا في هذا المقال على هياكل البيانات بكافة أنواعها مع إعطاء أمثلة توضيحية تساعدك على تخيل هذه البنى، بالإضافة إلى التطرق إلى ذكر أهميتها والفرق بينها وبين أنواع البيانات مع ذكر أهم تطبيقاتها. اقرأ أيضًا مقدمة إلى مفهوم البيانات الضخمة Big Data هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C هياكل البيانات: الكائنات والمصفوفات في جافاسكريبت تصميم قواعد البيانات table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; }1 نقطة
هياكل البيانات data structures -أو تدعى بنى المعطيات أحيانًا- مصطلح يتكرر كثيرًا في علوم الحاسوب خصوصًا والبرمجة عمومًا ويعد من المصطلحات المعقدة البسيطة أو السهلة الممتنعة كما أن الكثير يخلط بينه وبين أنواع البيانات أو لا يكاد يميز بينهما، ولابد على أي داخل لمجال علوم الحاسوب ومن يريد تعلم البرمجة أن يفهم هذا المصطلح جيدًا لأنه الأساس الذي سيستند عليه في بناء بقية المفاهيم الأخرى اللاحقة. بناء على ذلك، جاء هذا المقال ليكون تعريفًا بهياكل البيانات وأنواعها بأسلوب بسيط سهل مدعوم بالصور التوضيحية كل هيكل بيانات بالإضافة إلى ذكر ميزات وعيوب بعض الأنواع، كما يتناول هذا المقال التعريف بأهمية هياكل البيانات وأهم تطبيقاتها والفرق بينها وبين أنواع البيانات، لذا لنبدأ! ما هي هياكل البيانات؟ تُعَدّ هياكل البيانات data structures من أهم المفاهيم التأسيسية في مجال علوم الحاسوب، فهي ببساطة مجموعة من الوسائل والطرق المستعملة في ترتيب البيانات في ذاكرة الحاسوب بهدف التعامل معها بكفاءة وفعالية وتسهيل إجراء العمليات عليها، وتوجد هناك أنواع أساسية ومتطورة من هياكل البيانات وجميعها مصمَّمة لتنظيم البيانات لاستخدامها في هدف محدَّد. أهمية هياكل البيانات data structures أحب بداية ضرب مثال يوضح هياكل البيانات وأهميتها وهو أننا نستعمل هذا المفهوم في حياتنا اليومية بصورة أو بأخرى، لنفترض أن البيانات تمثل ملابسنا، فهل نرمي الملابس في خزانة واحدة كلها؟ لا بالطبع لأن إخراج بنطال معين آنذاك سيستغرق وقتًا من البحث للعثور عليه وإخراج بل نضع الألبسة بطريقة معينة في عدة خزانات وسحابات وبطرق مختلفة بحيث نصل إلى بنطال أو قميص محدد بمجرد طلبه فورًا آنيًا دون تأخير. الأمر نفسه مع ترتيب البهارات وأوعية المطبخ والكتب وكل شيء حولنا تقريبًا. هذا بالضبط ما يحصل عند كتابة كلمة في محرك البحث لتظهر لك اقتراحات عد قد تطابق تمامًا ما تنوي كتابته في غضون أجزاء من الثانية، فهل تساءلت كيف تمكن محرك البحث من البحث في كم البيانات الضخم الموجودة في الإنترنت ووصل إلى النتيجة؟ لا يمكن ذلك بآلية الرمي العشوائي في مكان واحد التي ذكرناها في ترتيب الملابس تلك بل بتنظيم البيانات ضمن هياكل بيانات تشبه الأوعية والخزانات تسهل الوصول إليها بأسرع ما يمكن. نظرًا لتطور التطبيقات وازدياد تعقيدها وازدياد كمية البيانات الضخم يومًا بعد يوم والذي تتطلب عملية معالجتها معالجات هائلة السرعة، فكان لا بد من تنظيم البيانات وإدارتها بكفاءة في هياكل البيانات تمثل أوعية تخزين وتنظيم لها، إذ يمكن أن يساعد استخدام هياكل البيانات المناسبة في توفير قدر كبير من الوقت أثناء إجراء عمليات عليها مثل تخزين البيانات أو استرجاعها أو معالجتها، وبالتالي وصول أسرع إلى الذاكرة وتوفير في استهلاك العتاد من عمليات معالجة وطاقة للحاسوب. من الجدير بالذكر أيضًا أنّ هياكل البيانات ضرورية لتصميم خوارزميات فعالة والتي سنراها في تطبيقات هياكل البيانات ضمن هذا المقال. الفرق بين أنواع البيانات وهياكل البيانات يبدو لك أنّ أنواع البيانات Data Types وهياكل البيانات Data Structures وجهان لعملة واحدة لأنّ كلاهما يتعامل مع طبيعة البيانات وتنظيمها، ولكن في الحقيقة الأول يشرح نوع وطبيعة البيانات في حين يمثِّل الآخر التجميعات التي تُخزَّن تلك البيانات فيها، وفيما يلي الفروق الأساسية بين نوع البيانات وهيكل البيانات. يمثِّل نوع البيانات ماهية البيانات التي سيجري التعامل معها مثل أن تكون البيانات أعداد أو سلاسل نصية أو رموز …إلخ. في حين يُعَدّ هيكل البيانات تجميعةً collection تحوي تلك البيانات وهناك عدة أنواع من الهياكل تناسب مختلف أنواع البيانات. يحدد نوع البيانات ما يترتب عليه من عمليات تطبق على تلك البيانات مثل العمليات الرياضية على الأعداد وعمليات المعالجة على النصوص وهكذا أما هياكل البيانات فتحدد كيفية تخزين البيانات والوصول إليها والبحث فيها وغيرها من العمليات كما تدرس كيفية تحسين الأداء في تلك العمليات. يأخذ نوع البيانات شكل التنفيذ المجرد abstract implementation الذي يُعرَّف من خلال لغات البرمجة نفسها، في حين يُنفَّذ هيكل البيانات تنفيذًا حقيقيًا concrete implementation بحيث يُنشأ ليكون متوافقًا مع التصميم الذي يحتاجه المبرمج بالحجم الذي يريده وبنوع البيانات التي سيحتويها ضمن تطبيقه. يسمى نوع البيانات بأنه عديم القيمة dataless لأنه لا يخزِّن قيمة البيانات وإنما يمثِّل فقط نوع البيانات التي يمكن تخزينها، في حين يستطيع هيكل البيانات الاحتفاظ بأنواع مختلفة من البيانات مع قيمتها في كائن واحد. تحدد أنواع البيانات مع المتغيرات مثلًا في لغات البرمجة عند تعريفها، في حين تحتاج إلى كتابة بعض الخوارزميات لإسناد قيم البيانات إلى المتغيرات عند استخدام هيكل بيانات مثل عمليتَي الإضافة Push والجلب Pop للبيانات. لا يُكترث للزمن عند استخدام نوع البيانات، في حين يؤخذ بالحسبان عند استخدام هيكل البيانات (يطلق عليه تعقيد زمني BigO). تطبيقات هياكل البيانات يكاد لا يخلو أي تطبيق أو برنامج أو خوارزمية برمجية من وجود هيكل بيانات أو بنية معطيات تساعده في تحقيق الهدف المرجو منه، ومن هذه التطبيقات ما يلي: تنظيم البيانات في ذاكرة الحاسوب. تمثيل المعلومات في قواعد البيانات. خوارزميات معالجة البيانات مثل معالجة النصوص. خوارزميات تحليل البيانات مثل data minar. خوارزميات البحث في البيانات مثل محرك البحث. خورزميات توليد البيانات مثل مولِّد الأعداد العشوائية. خوارزميات ضغط البيانات وتفك ضغطها مثل المعتمدَة في برنامج zip. خوارزميات تشفير البيانات وتفك تشفيرها مثل المعتمدَة في نظام الأمان. البرامج التي تدير الملفات والمجلدات مثل مدير الملفات. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن أنواع هياكل البيانات في لغات البرمجة تنقسم هياكل البيانات إلى هياكل بيانات أولية Primitive وهياكل بيانات غير أولية Non Primitive أو هياكل بيانات معقدة وكل منها يضم عدة أقسام سنشرحها تباعًا. هياكل البيانات الأولية Primitive هي هياكل البيانات الأساسية والبسيطة والتي تُستخدَم لتخزين قيمة من جزء واحد فقط ذات نوع محدَّد، ويندرج تحت هذا النوع ما يلي: integer: من أجل الأعداد الصحيحة مثل العدد 15. character: من أجل محرف واحد فقط. float: من أجل الأعداد العشرية. real: من أجل الأعداد الحقيقية. boolean: من أجل القيم البوليانية والذي يأخذ إحدى القيمتين؛ إما محققة true أو غير محققة false. ملاحظة: قد تتساءل عن هياكل تخزين النصوص، وهي في الحقيقة تدخل ضمن الهياكل الغير أولية أن النصوص مجموعة من الحروف والرموز التي تدعى محارف characters لذا تخزن عادة ضمن مصفوفة وأحيانًا تضيف لغات البرمجة نوعًا خاصًا لها يدعى string سلسلة نصية أو لا يضيف وتكون بالشكل char[] وما تراه [] يدل على هيكل مصفوفة. يوجد شيء خاص يدعى مؤشر pointer والمشهور في بعض اللغات البرمجية مثل سي C وسي بلس بلس ++C، إذ يُعَدّ مكانًا في الذاكرة ويخزِّن عنوان المتغير الذي يشير إليه والشي الخاص فيه أنه يملك نوع بيانات والذي يجب أن يطابق نوع البيانات الذي يشير إليها. ملاحظة: ممكن تسمية هياكل البيانات التي تخزن الأعداد العشرية باسم double (عدد عشري مضاعف الدقة) أو float (عدد عشري) عوضًا عن real بصورة عامة ويكمن الاختلاف حسب اللغة البرمجية في عدد الخانات العشرية الممكن تخزينها، أي عدد الخانات بعد الفاصلة العشرية، بالإضافة إلى الحجم في الذاكرة وأخيرًا طريقة التعريف declaration، ففي لغة سي شارب #C يكون تعريف المتغير من نمط float كما يلي: float x = 1.5f; أما تعريفه عندما يكون من نمط double، فيكون كما يلي: double x = 1.5; ملاحظة: يطلق أحيانًا على هياكل البيانات الأولية أنواع البيانات Data Type. هياكل البيانات غير الأولية هي هياكل البيانات التي تُستخدَم من أجل التخزين المعقّد والتي يمكنها أن تحمل أكثر من قيمة في بنيتها، وتنقسم إلى هياكل بيانات خطية Linear وهياكل بيانات غير خطية Non Linear. هياكل البيانات الخطية تكون هياكل البيانات خطيّةً إذا كانت عناصرها تشكل تسلسلًا فيما بينها بحيث يرتبط كل عنصر فيها بعنصر سابق وعنصر لاحق ضمن مستوى واحد وفي مسار واحد، ومن هذه الهياكل ما يلي: المصفوفة Array القائمة المترابطة Linked List المكدس Stack الرتل Queue المصفوفة تُعَدّ المصفوفة الخطية array أو المصفوفة ذات البعد الواحد أبسط أنواع الهياكل الخطية، ويمكن تشبيهها بقائمة من عدد محدود من العناصر التي تمتلك النوع ذاته، ويكون بعدها -أو طولها- هو عدد العناصر التي تملكها، كما تُخزّن في الذاكرة بحجم ثابت وبمواقع متجاورة. كل عنصر من عناصر هذه المصفوفة الخطية يملك فهرسًا للوصول إليه، وعادةً ما يبدأ الفهرس بالعدد 0 أي يكون فهرس العنصر الأخير هو n-1 في مصفوفة بعدها n، وفي بعض لغات البرمجة يكون فهرس البداية هو العدد 1 مثل لغة باسكال، وفيما يلي صورة توضِّح هذه البنية: ملاحظات: يُنظَر إلى السلسلة النصية string على أنها مصفوفة أحادية من المحارف، أي كلمة Hello هي سلسلة نصية وهي مصفوفة طولها 5 مكوّنة من خمسة عناصر بحيث يمثِّل كل عنصر محرفًا من المحارف كما أشرنا سابقًا. المصفوفة ثنائية البعد هي أيضًا مجموعة من المتغيرات المفهرسة التي تحتوي على النوع نفسه من البيانات ولكن تخزين البيانات فيها يكون على صورة جدول له أعمدة وأسطر، بحيث يمكن الوصول إلى العنصر في هذه المصفوفة من خلال فهرسين أحدهما يحدِّد السطر والآخر يحدِّد العمود. من الجدير بالذكر أنّ بُعد المصفوفة ثابت في بعض لغات البرمجة وبالتالي يجب معرفة عدد العناصر قبل تعريفها فإذا أردت تغيير البُعد وإضافة عناصر جديدة، فستحتاج إلى مصفوفة جديدة ببُعد جديد لتنقل إليها العناصر السابقة وبعدها تضيف العناصر الجديدة إليها، كما أنّ إضافة عنصر ما في مكان ما مملوء مسبقًا أي في وسط المصفوفة مثلًا سيستهلك الكثير من العمليات، إذ ستحتاج إلى إزاحة العناصر اللاحقة ليصبح له مكانًا فارغًا، ويُعَدّ ذلك من عيوب استخدام المصفوفات. هنالك لغات أخرى لا تشترط تحديد عدد عناصر المصفوفة ولكنها تستهلك آنذاك عمليات كثيرة وتكون مكلفة لعمليات المعالجة أما تلك التي تحدد عدد العناصر مسبقًا فذلك عائد إلى توفير عمليات المعالجة. ملاحظة: قد تجد كلمة static ساكن وكلمة dynamic متحرك لتصنيف الأنواع الغير خطية ولكن شرحهما متقدم جدًا يحتاج إلى مقال بأكمله وستحتاج إليه عند التعمق كثيرًا وليس في البداية. القائمة المترابطة تُعَدّ القائمة المترابطة linked list مجموعةً من العقد التي تخزَّن في الذاكرة بمواقع غير متجاورة، وكل عقدة من عقد القائمة مرتبطة بالعقدة المجاورة لها بمؤشر عدا العقدة الأخيرة التي يكون المؤشر فيها عبارة عن Null. تسمح هذه البنية بإدراج عناصر جديدة أو حذف عناصر موجودة سابقًا بسهولة وهذا ما يميزها عن المصفوفات؛ أما سرعة الوصول، فتُعَدّ المصفوفات أسرع لأنه يكفي ذكر الفهرس الرابع على عكس القائمة المترابطة التي يجب البدء فيها من الرأس ثم المرور على العناصر بالتتالي إلى حين الوصول إلى العنصر الرابع. من الجدير بالذكر أنّ القائمة المترابطة تحتاج إلى مساحة إضافية في الذاكرة من أجل المؤشر الذي يرتبط بالعنصر، وهذا عيب آخر من عيوب القوائم المترابطة. يوجد نوع متطور من القوائم المترابطة وهو القوائم المترابطة المزدوجة Doubly Linked List، إذ ترتبط كل عقدة بمؤشرَين أحدهما يربطها بالعقدة السابقة ويسمى عادةً prev والآخر يربطها بالعقدة التالية ويسمى عادةً next، وبالتالي تحتاج هذه القائمة إلى مساحة إضافية في الذاكرة لامتلاكها على مؤشر إضافي، وبالمثل يكون المؤشر prev في عقدة الرأس Null ومؤشر next في العقدة الأخيرة هو Null. يوجد نوع أخير من القوائم المترابطة وهو القوائم المترابطة الدائرية Circular Linked Lists والتي تُعَدّ تطويرًا عن المفردة بحيث يشير مؤشر next الخاص بعقدة النهاية إلى عقدة الرأس. كما توجد القوائم الدائرية المزدوجة بحيث يشير مؤشر prev الخاص بعقدة الرأس إلى عقدة النهاية ويشير مؤشر next الخاص بعقدة النهاية إلى عقدة الرأس، وبالتالي لا تحتوي القوائم المترابطة الدائرية على مؤشرات Null. المكدس يُعَدّ المكدِّس stack هيكل بيانات خطية يتبع ترتيبًا محددًا في تنفيذ عمليات الحذف والإضافة، والترتيب يكون LIFO أي الذي يدخل آخرًا يخرج أولًا Last In First Out، والذي يميز المكدس هنا هو دخول العناصر وخروجها من قمة المكدِّس أي من جهة واحدة. تدخل -أو تُضاف- العناصر إلى المكدِّس عن طريق عملية وحيدة وخاصة وهي دفع Push وبالمثل فإنها تخرج منه -أو تُحذَف- عن طريق عملية وحيدة وخاصة أيضًا وتدعى إخراج Pop، وتوجد أيضًا عمليتان خاصتان بالمكدِّس وهما Top -أو Peek- التي تعيد القيمة الموجودة في قمة المكدِّس دون حذفها، والعملية الأخرى هي عملية IsEmpty التي تُعيد القيمة true إذا كان المكدِّس فارغًا. عند إضافة عنصر إلى مكدِّس ممتلئ لا يستوعب المزيد من العناصر فستحصل حالة طفحان المكدِّس overflow؛ أما عند إجراء عملية الحذف من مكدِّس فارغ، فسنواجه حالة طفحان أو تجاوز الحد الأدنى underflow (قعر المكدس). الرتل يُعَدّ الرتل queue أحد هياكل البيانات الخطية شبيه بالمكدس لامتلاكه عمليات خاصة للحذف والإضافة ولكنه يختلف عنه في مكان الحذف والإضافة كما سنرى. يدعى الرتل أو الطابور بـ FIFO أي الذي يدخل أولًا يخرج أولًا First In First Out بحيث يكون الدخول -أو الإضافة- من الجهة الخلفية rear والخروج -أو الحذف- من الجهة الأخرى أي الأمامية front (كما يحصل عند الوقوف ضمن الطوابير تمامًا لشراء شيء ما)، وتحدث الإضافة عن طريق عملية ENQUEUE أما عملية الحذف فتكون عن طريق عملية DEQUEUE. يتميز الرتل أيضًا بامتلاكه عمليات خاصة وهي العملية IsFull التي تُعيد true إذا كان الرتل ممتلئًا، والعملية IsEmpty التي تُعيد true إذا كان الرتل فارغًا، والعملية Front التي تُعيد العنصر الأمامي من الرتل، بالإضافة إلى العملية Rear التي تُعيد العنصر الخلفي من الرتل. هياكل البيانات غير الخطية لا تحتوي هياكل البيانات غير الخطية -أو المتشعبة- على أيّ تسلسل محدد يربط جميع عناصرها، إذ يمكن أن يكون لكل عنصر أكثر من مسار ليرتبط بالعناصر الأخرى، كما أنّ العناصر الموجودة ضمن هذه الهياكل لا يمكن اجتيازها أو المرور عليها في جولة واحدة أو باستخدام حلقة برمجية واحدة. وأهم ما يميّز هذا النوع على الرغم من صعوبة التنفيذ موازنةً بالهياكل الخطية التي يزداد فيها تعقيد الوقت مع ازدياد حجم البيانات أنه يُعد أكثر كفاءة في استخدام الذاكرة وأكثر سرعة في تطبيق العمليات مثل عمليات البحث، ومن هذه الهياكل: الشجرة الرسم البياني الشجرة تُعَدّ الشجرة tree هيكل بيانات متعدد المستويات وتُعرَّف على أنها مجموعة من العقد التي تحتوي فيما بينها على علاقة هرمية بحيث تسمى العقدة العليا بالعقدة الجذر، كما تحتوي كل عقدة على أب وحيد، في حين يمكن أن يكون لها أكثر من ابن أو تابع. تسمى العقد التي تتفرع من عقدة معينة بأبناء children تلك العقدة والتي بدورها تدعى بالعقدة الأب parent، في حين تسمى العقد التي لا تمتلك أبناء بالأوراق leaves. تمتلك الشجرة عدة أنواع وهي: الشجرة الثنائية binary tree شجرة البحث الثنائية binary search tree شجرة AVL شجرة R-B شجرة البادئات الشجرة الثنائية الشجرة الثنائية binary tree هي شجرة بيانات تمتلك كل عقدة فيها -ما عدا الأوراق- على عقدَتي ابن فقط وهما الابن الأيمن والابن الأيسر. شجرة البحث الثنائية شجرة البحث الثنائية binary search tree أو BST اختصارًا هي شجرة ثنائية تحقق خاصيتان أساسيتان وهما أنّ العقد الواقعة في الفرع اليميني تكون أكبر من العقدة الأب والعقد الواقعة في الفرع اليساري تكون أصغر من العقدة الأب، مع ضمان وجود ابنَين لكل عقدة وعدم تكرار العقد. شجرة AVL تُعَدّ اختصارًا لـ Adelson-Velskii Tree إذ يُعَدّ أديسون Adelson وفيلسكي Velskii مخترعَيها للحفاظ على توازن شجرة البحث الثنائي وذلك لمنع تدهورها إلى قائمة مرتبطة عندما تحتوي الشجرة بأكملها على الشجرة الفرعية اليسرى فقط أو على الشجرة اليمنى فقط مما سينعكس سلبًا على أداء الشجرة، إذ يمكن استخدام سلسلة من عمليات التدوير بحيث تُحدَّد في كل عملية عقدة جذر إلى حين الوصول إلى شجرة بعقدة جذر معينة بحيث تكون متوازنة أي ارتفاع الشجرة اليسرى مساويًا لارتفاع الشجرة اليمنى، ويمكن القول هنا أنّ شجرة AVL هي شجرة BST تحقق شرط التوازن، علمًا أنّ ارتفاع الشجرة هو أكبر عمق موجود لها. شجرة R-B تعني الشجرة الحمراء والسوداء Red-Black tree وهي شجرة بحث ثنائية لها خصائص تميزها بحيث تحتوي كل عقدة فيها على بت تخزين يشير إلى لون العقدة والتي يمكن أن تكون حمراء أو سوداء فقط، كما أنّ عقدة الجذر والعقد الأوراق سوداء دائمًا، وإذا كانت العقدة حمراء فيجب أن يكون أبناءها سود، وأخيرًا يجب أن تحتوي جميع المسارات من عقدة إلى أحفادها العدد نفسه من العقد السوداء، فإذا تحقق ما سبق، فستكون الشجرة شجرة بحث ثنائية متوازنة. شجرة البادئات تُعَدّ شجرة البادئات Prefix tree نوعًا من أشجار البحث وتعرف أيضًا بالشجرة الرقمية أو tri كما تُعرَف بشجرة القاموس وتُستخدَم في البحث عن الكلمات بصورة عامة بما أنها مكوَّنة من أحرف الهجاء، وأهم ما يميزها أنّ جذرها لا يحتوي على أيّ محرف. الكومة تُعَدّ الكومة Heap بنية معطيات شجرية تمتلك خاصة الكومة وهي وجود أسلوب ترتيب متَّبع بين العقد الآباء والعقد الأبناء مثل أن يكون كل أب أكبر من جميع أبنائه وتسمى حينها بالكومة العظمى Max-Heap أو أن يكون كل أب أصغر من جميع أبنائه وتسمى حينها بالكومة الصغرى Min-Heap، وتُستخدَم الكومة بكثرة في خوارزميات الترتيب، كما تتميز الكومة بأنّ جميع مستوياتها ممتلئة بالكامل عدا المستوى الأخير، وفيما يلي صورة توضِّح كومة صغرى. الرسم البياني يختلف الرسم البياني graph أو المبيان عن الشجرة في عدم احتوائه على جذر ومن الممكن أن تتصل العقد مع بعضها باتجاه واحد directed graph أو بالاتجاهين معًا Bi-directional أو بدون اتجاه undirected، كما أنّ طبيعة العلاقات بين العقد في هذا النوع ليست ذات طبيعة هرمية، كما تسمى العقد بالرؤوس vertices والروابط التي بينها تسمى بالحواف أو الأضلاع edges ويكون عدد كل من الرؤوس والأضلاع محدودًا. يكون الزوج (1,2) في الرسم البياني الموجَّه والذي يدل على وجود اتجاه من الرأس 1 إلى الرأس 2 مختلفًا عن الزوج (2,1)، كما تُرمَز مجموعة الرؤوس في هذا النوع بالرمز V ومجموعة الأضلاع بالرمز E ويُستخدَم هذا النوع من البنى في تمثيل الشبكات الواقعية مثل شبكة الهاتف المحمول أو شبكات التواصل الاجتماعي مثل الفيسبوك على سبيل المثال. التقطيع Hashing يُعَدّ التقطيع Hashing أو التجزئة تحسينًا لهياكل البيانات السابقة في بعض التطبيقات التي تحتاج إلى ترتيب بياناتها بواسطة أعداد كبيرة وفريدة موجودة ضمن هذه البيانات مثل ترتيب سجلات المرضى ضمن المستشفيات بناءً على أرقام هواتفهم والتي تُعَدّ مفاتيحًا فريدةً unique لهذه السجلات، ويكون ذلك من خلال الاستعانة بدالة تدعى دالة التقطيع hashing function والتي تحوِّل هذا المفتاح الفريد إلى عدد صغير وصحيح بحيث يكون فهرسًا لجدول جديد يدعى جدول التقطيع hashing table. من الممكن أن يكون فهرس جدول التقطيع هو ذاته رقم هاتف المريض بحيث يكون طوله هو أكبر رقم هاتف موجود ضمن السجلات زائد واحد بما أنّ الفهرسة تبدأ من الصفر، وبالتالي نحصل على سرعة وصول عالية لأيّ سجل من خلال رقم الهاتف الخاص به، ولكن سيتسبب ذلك بتواجد فجوات gaps بين العناصر لعدم الحاجة لوجود جميع أرقام الهواتف المحتملة وبالتالي زيادة حجم التخزين في الذاكرة، لذا تُستخدَم دالة التقطيع لحل هذه المشكلة، وعندها يكون جدول التقطيع مصفوفةً يمثِّل كل عنصر فيها مؤشرًا على السجل الذي يحتوي على رقم الهاتف -في مثالنا- والذي تكون نتيجة تطبيق دالة التقطيع عليه هي فهرس هذا العنصر. من الضروري التأكد من أنّ دالة التقطيع لا تعطي النتيجة ذاتها لأكثر من مفتاح، فإذا كانت دالة التقطيع مثلًا هي تأخذ فقط الرقم الأخير من رقم الهاتف، فسيكون لرقمَي الهاتف 45451 و 56561 على سبيل المثال النتيجة نفسها أي العدد 1 وبالتالي سيحدث تصادم في جدول التقطيع الذي فهرسه العدد 1، وأحد حلول هذه المشكلة أن يكون كل عنصر من جدول التقطيع مؤشرًا على قائمة مترابطة تحتوي على السجلات التي نتيجة تطبيق دالة التقطيع على أرقام هواتفها هي ذاتها. ليكن لدينا الأعداد التالية 12 – 17 – 29 – 6 – 30 – 31 – 4 – 8، فإذا كان فهرس جدول التقطيع هو ذاته العدد المعطى، فسنحتاج إلى جدول بحجم 32، ولكن فعليًا نحتاج إلى 8 أماكن للتخزين وبالتالي سنحصل على فجوات وهدر في الذاكرة، لذا سنلجأ إلى دالة التقطيع والتي ستعطي آحاد العدد المُعطى، وبالتالي ستكون نتيجتها 2 – 7 – 9 – 6 – 0 – 1 – 4 – 8 عند تطبيقها على الأعداد السابقة على الترتيب، بحيث يُخزَّن العدد 12 في العنصر الذي فهرسه هو العدد 2 وهكذا، وبالتالي سنحتاج إلى جدول تقطيع بحجم 8 بدلًا من 32 كما يلي: 12 17 29 6 30 31 4 8 2 7 9 6 0 1 4 8 يمكن تقليص حجم هذا الجدول ليصبح 4 بتحسين دالة التقطيع، بحيث يكون الفهرس هو باقي قسمة كل عدد من الأعداد المعطاة على العدد 4، ولكن ستكون نتيجة الأعداد 17 و 19 هي الفهرس 1، أي سيحدث تصادم، ويمكن حل هذه المشكلة بجعل كل عنصر من عناصر جدول التقطيع مؤشرًا على قائمة مترابطة من الأعداد التي باقي قسمتها على العدد 4 هو فهرس هذا العنصر، أي كما في الشكل التالي: يمكن زيادة حجم جدول التقطيع في المستقبل، كما أنّ هذه التقنية هي الأكثر استخدامًا في جوجل google. الخاتمة تعرَّفنا في هذا المقال على هياكل البيانات بكافة أنواعها مع إعطاء أمثلة توضيحية تساعدك على تخيل هذه البنى، بالإضافة إلى التطرق إلى ذكر أهميتها والفرق بينها وبين أنواع البيانات مع ذكر أهم تطبيقاتها. اقرأ أيضًا مقدمة إلى مفهوم البيانات الضخمة Big Data هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C هياكل البيانات: الكائنات والمصفوفات في جافاسكريبت تصميم قواعد البيانات table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; }1 نقطة







