لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/18/22 في كل الموقع
-
 تُعدّ مسألة تحليل تعليقات وتغريدات الأشخاص على مواقع التواصل الاجتماعي من المسائل المهمة والتي لها الكثير من التطبيقات العملية. مثلًا: تهتم المتاجر الالكترونية كثيرًا بتحليل تعليقات الزبائن على منتجاتهم لاستكشاف توجهات الزبائن ومواطن الضعف والقوة في المتجر. نعرض في هذه المقالة استخدام تقنيات التعلّم العميق deep learning في تحليل المشاعر لنصوص مكتوبة باللغة العربية وباللهجة السعودية بمعنى أن اللغة المستخدمة ليست بالضرورة اللغة العربية الفصحى، بل يُمكن أن تدخل فيها ألفاظ عامية يستخدمها المغردون عادةً. بيانات التدريب تحوي مجموعة البيانات المتوفرة dataset (التي تجدها أيضًا موضحةً بملف بنهاية المقال) حوالي 23500 تغريدة لتعليقات الأشخاص وملاحظاتهم حول مجموعة من الأماكن العامة في المملكة العربية السعودية. جُمّعت هذه التغريدات عن طريق مجموعة من الطلاب الجامعيين وذلك من مجموعة متنوعة من مواقع التواصل الاجتماعي. نُعطي فيما يلي أمثلة عن هذه التغريدات (تعليقات حول حديقة حيوانات مثلًا): "أنصحكم والله بزيارته مكان جميل جدا مرتب ونظيف" "جميلة وكبيرة وتحتاج واحد عنده لياقه يمشي فيها" "حيوانات قليلة جدا ولا يوجد اهتمام مكثف" "كان يعيبها وقت الافتتاح والاغلاق وعدم وجود خريطه" "أول مرة أزور حديقة حيوانات" "أيام العوائل الخميس والجمعة والسبت" يُمكننا، كبشر، تصنيف التغريدات السابقة وبشكل سريع إلى ثلاث فئات: التغريدات الموجبة (الأولى والثانية) أي التغريدات التي تحمل معاني إيجابية تُعّبر عن الرضا والارتياح. التغريدات السالبة (الثالثة والرابعة) أي التغريدات التي تحمل معاني سلبية تُعبّر عن الاستياء. التغريدات المحايدة (الخامسة والسادسة) أي التغريدات التي يُمكن أن تُعطي معلومات ولا تحمل أية مشاعر فيها سواء موجبة أم سالبة. نعرض في هذه المسألة كيفية بناء مُصنّف حاسوبي آلي يُصنّف أي جملة عربية إلى موجبة أو سالبة أو محايدة. تصنيف بيانات التدريب يتطلب استخدام خوارزميات تعلّم الآلة (خوارزميات تصنيف النصوص في حالتنا) توفر بيانات للتدريب أي مجموعة من النصوص مُصنفّة مُسبقًا إلى: موجبة، سالبة، محايدة. يُمكن، في بعض الأحيان، اللجوء إلى الطرق اليدوية: أي الطلب من مجموعة من الأشخاص قراءة النصوص وتصنيفها. وهو حل يصلح في حال كان عدد النصوص صغيرًا نسبيًا. يتميز هذا الحل بالدقة العالية لأن الأشخاص تُدرك، بشكل عام، معاني النصوص من خلال خبرتها اللغوية المُكتسبة وتُصنّف النصوص بشكل صحيح غالبًا. نستخدم، في حالتنا، حلًا إحصائيًا بسيطًا لتصنيف نصوص التدريب إلى موجبة، سالبة، محايدة وذلك باستخدام قاموس للكلمات الموجبة وقاموس آخر للكلمات السالبة. يحوي قاموس الكلمات الموجبة على مجموعة من الكلمات الموجبة الشائعة مع نقاط لكل كلمة (1 موجبة، 2 موجبة جدًا، 3 موجبة كثيرًا). مثلًا: روعة، 3 جيد، 2 معقول، 1 يحوي قاموس الكلمات السالبة على مجموعة من الكلمات السالبة الشائعة مع نقاط لكل كلمة (-1 سالبة، -2 سالبة جدًا، -3 سالبة كثيرًا). مثلًا: مقرف، -3 سيء، -2 زحمه، -1 اختيرت كلمات القواميس الموجبة والسالبة من قبل مجموعة من الطلاب بعد أنا طلبنا منهم استعراض التغريدات المُتاحة وانتقاء الكلمات التي تُعطي التغريدة معنى موجب أو معنى سالب، وإعطاء كل كلمة موجبة نقاط تدل على شدة الإيجابية لها (1,2,3) وكل كلمة سالبة نقاط تدل على شدة السلبية (-3،-2،-1) نعدّ، فيما يلي، نصًا ما أنه موجبًا إذا كان مجموع نقاط الكلمات الموجبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات السالبة الواردة ضمنه. وبالمقابل، نعدّ نصًا ما أنه سالبًا إذا كان مجموع نقاط الكلمات السالبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات الموجبة الواردة ضمنه. يكون نصًا ما محايدًا إذا تساوى مجموع نقاط الكلمات الموجبة فيه مع مجموع نقاط الكلمات السالبة. بالطبع، لا تُعدّ هذه الطريقة صحيحة دومًا إذ يُمكن أن تُخطئ في بعض الحالات إلا أنها على وجه العموم تُستخدم عوضًا عن الطريقة اليدوية. المعالجة الأولية للنصوص تهدف المعالجة الأولية إلى الحصول على الكلمات المهمة فقط من النصوص وذلك عن طريق تنفيذ بعض العمليات اللغوية عليها. تُنفذّ هذه العمليات على كل من التغريدات وكلمات القواميس. لتكن لدينا مثلًا الجملة التالية: "أنا أحب الذهاب إلى الحديقة، كل يوم 9 صباحاً، مع رفاقي هؤلاء!" سنقوم بتنفيذ العمليات التالية: أولًا، حذف إشارات الترقيم المختلفة كالفواصل وإشارات الاستفهام وغيرها، ويكون ناتج الجملة السابقة: ثانيًا، حذف الأرقام الواردة في النص، فيكون ناتج الجملة السابقة: ثالثًا، حذف كلمات التوقف stop words وهي الكلمات التي تتكرر كثيرًا في النصوص ولا تؤثر في معانيها كأحرف الجر (من، إلى، …) والضمائر (أنا، هو، …) وغيرها، فيكون ناتج الجملة السابقة: رابعًا، تجذيع الكلمات stemming أي إرجاع الكلمات المتشابهة إلى كلمة واحدة (جذع أو جذر) مما يُساهم في إنقاص عدد الكلمات الكلية المختلفة في النصوص، ومطابقة الكلمات المتشابهة مع بعضها البعض. مثلًا: يكون للكلمات الأربع: (رائع، رايع، رائعون، رائعين) نفس الجذع المشترك: (رايع). فيكون ناتج الجملة السابقة: ننتبه إلى أن الجذع يختلف عن الجذر اللغوي إذ الجذر هو عملية لغوية لرد الكلمة إلى أصلها وجذرها الأساسي لأغراض مختلفة أشهرها البحث في القاموس، أما الجذع فهو كلمة مشتركة بين مجموعة من الكلمات لا توجد بالضرورة في قاموس اللغة العربية وإنما إيجاد شكل موحد للكلمات. إعداد المشروع يُمكن تنزيل بيانات التدريب والقواميس والشيفرة البرمجية من الملف المرفق هنا. يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ. نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها. نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا. نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا: mkdir sa cd sa نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية: python -m venv sa ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية: source sa/bin/activate أما في Windows، فيكون أمر التنشيط: "sa/Scripts/activate.bat" نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها. نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها: jupyter==1.0.0 keras==2.6.0 Keras-Preprocessing==1.1.2 matplotlib==3.5.1 nltk==3.6.5 numpy==1.19.5 pandas==1.3.5 scikit-learn==1.0.1 seaborn==0.11.2 sklearn==0.0 snowballstemmer==2.2.0 tensorflow==2.6.0 wordcloud==1.8.1 python-bidi==0.4.2 arabic-reshaper==2.1.3 نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي: (sa) $ pip install -r requirements.txt بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا. كتابة شيفرة برنامج تحليل المشاعر في النصوص العربي نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا: (sa) $ jupyter notebook ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم asa مثلًا. يجب أولًا وضع كل من الملفات التالية في مجلد المشروع: ملف التغريدات: tweets.csv. القواميس: lexicon_positive.csv و lexicon_negative.csv. ملف الخط العربي: DroidSansMono.ttf. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن تحميل البيانات نبدأ أولًا بتحميل التغريدات من الملف tweets.csv ضمن إطار من البيانات DataFrame من مكتبة Pandas ومن ثم عرض بعضها: import pandas as pd # قراءة التغريدات وتحميلها ضمن إطار من البيانات tweets_data = pd.read_csv('tweets.csv',encoding = "utf-8") tweets = tweets_data[['tweet']] # إظهار الجزء الأعلى من إطار البيانات tweets.head() يظهر لنا أوائل التغريدات: نُحمّل قاموس الكلمات الموجبة positive.csv وقاموس الكلمات السالبة negative.csv: # قراءة قاموس الكلمات الموجبة positive_data = pd.read_csv('positive.csv' ,encoding = "utf-8") positive = positive_data[['word', 'polarity']] # قراءة قاموس الكلمات السالبة negative_data = pd.read_csv('negative.csv' ,encoding = "utf-8") negative = negative_data[['word', 'polarity']] positive.head() نُظهر مثلًا أوائل الكلمات الموجبة ونقاطها: المعالجة الأولية للنصوص نستخدم فيما يلي بعض الخدمات التي توفرها المكتبة nltk لمعالجة اللغات الطبيعية كتوفير قائمة كلمات التوقف باللغة العربية (حوالي 700 كلمة) واستخراج الوحدات tokens من النصوص. كما نستخدم مجذع الكلمات العربية من مكتبة snowballstemmer. # مكتبة السلاسل النصية import string # مكتبة التعابير النظامية import re # مكتبة معالجة اللغات الطبيعية import nltk nltk.download('punkt') nltk.download('stopwords') # مكتبة كلمات التوقف from nltk.corpus import stopwords # مكتبة استخراج الوحدات from nltk.tokenize import word_tokenize # مكتبة المجذع العربي from snowballstemmer import stemmer ar_stemmer = stemmer("arabic") # دالة حذف المحارف غير اللازمة def remove_chars(text, del_chars): translator = str.maketrans('', '', del_chars) return text.translate(translator) # دالة حذف المحارف المكررة def remove_repeating_char(text): return re.sub(r'(.)\1{2,}', r'\1', text) # دالة تنظيف النصوص def cleaningText(text): # حذف الأرقام text = re.sub(r'[0-9]+', '', text) # حذف المحارف غير اللازمة # علامات الترقيم العربية arabic_punctuations = '''`÷×؛<>_()*&^%][ـ،/:"؟.,'{}~¦+|!”…“–ـ''' # علامات الترقيم الانكليزية english_punctuations = string.punctuation # دمج علامات الترقيم العربية والانكليزية punctuations_list = arabic_punctuations + english_punctuations text = remove_chars(text, punctuations_list) # حذف المحارف المكررة text = remove_repeating_char(text) # استبدال الأسطر الجديدة بفراغات text = text.replace('\n', ' ') # حذف الفراغات الزائدة من اليمين واليسار text = text.strip(' ') return text # دالة تقسيم النص إلى مجموعة من الوحدات def tokenizingText(text): tokens_list = word_tokenize(text) return tokens_list # دالة حذف كلمات التوقف def filteringText(tokens_list): # قائمة كلمات التوقف العربية listStopwords = set(stopwords.words('arabic')) filtered = [] for txt in tokens_list: if txt not in listStopwords: filtered.append(txt) tokens_list = filtered return tokens_list # دالة التجذيع def stemmingText(tokens_list): tokens_list = [ar_stemmer.stemWord(word) for word in tokens_list] return tokens_list # دالة دمج قائمة من الكلمات في جملة def toSentence(words_list): sentence = ' '.join(word for word in words_list) return sentence شرح الدوال التي كتبناها في الشيفرة: cleaningText: تحذف الأرقام وعلامات الترقيم العربية والإنكليزية من النص. remove_repeating_char: تحذف المحارف المكررة والتي قد يستخدمها كاتب التغريدة. tokenizingText: تعمل على تجزئة النص إلى قائمة من الوحدات tokens. filteringText: تحذف كلمات التوقف من قائمة الوحدات. stemmingText: تعمل على تجذيع كلمات قائمة الوحدات المتبقية. يُبين المثال التالي تجذيع بعض الكلمات المتشابهة: # مثال stem = ar_stemmer.stemWord(u"رايع") print (stem) stem = ar_stemmer.stemWord(u"رائع") print (stem) stem = ar_stemmer.stemWord(u"رائعون") print (stem) stem = ar_stemmer.stemWord(u"رائعين") print (stem) يكون ناتج التنفيذ: رايع رايع رايع رايع يُبين المثال التالي نتيجة استدعاء كل دالة من الدوال السابقة: # مثال text= "!أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء " print(text) text=cleaningText(text) print(text) tokens_list=tokenizingText(text) print(tokens_list) tokens_list=filteringText(tokens_list) print(tokens_list) tokens_list=stemmingText(tokens_list) print(tokens_list) يكون ناتج التنفيذ: !أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء أنا أحب الذهاب إلى الحديقة كل يوم صباحاً مع رفاقي هؤلاء ['أنا', 'أحب', 'الذهاب', 'إلى', 'الحديقة', 'كل', 'يوم', 'صباحاً', 'مع', 'رفاقي', 'هؤلاء'] ['أحب', 'الذهاب', 'الحديقة', 'يوم', 'صباحاً', 'رفاقي'] ['احب', 'ذهاب', 'حديق', 'يوم', 'صباح', 'رفاق'] تعرض الشيفرة التالية تنفيذ جميع دوال المعالجة الأولية على نصوص التغريدات ومن ثم حفظ النتائج في ملف جديد tweet_clean.csv. وبنفس الطريقة، نُنفذ دوال المعالجة الأولية على قاموس الكلمات الموجبة وقاموس الكلمات السالبة ونحفظ النتائج في ملفات جديدة لاستخدامها لاحقًا: positive_clean.csv و negative_clean.csv. # المعالجة الأولية للتغريدات tweets['tweet_clean'] = tweets['tweet'].apply(cleaningText) tweets['tweet_preprocessed'] = tweets['tweet_clean'].apply(tokenizingText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(filteringText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(stemmingText) # حذف التغريدات المكررة tweets.drop_duplicates(subset = 'tweet_clean', inplace = True) # التصدير إلى ملف tweets.to_csv(r'tweet_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس الموجب positive['word_clean'] = positive['word'].apply(cleaningText) positive.drop(['word'], axis = 1, inplace = True) positive['word_preprocessed'] = positive['word_clean'].apply(tokenizingText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(filteringText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ positive.drop_duplicates(subset = 'word_clean', inplace = True) nan_value = float("NaN") positive.replace("", nan_value, inplace=True) positive.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف positive.to_csv(r'positive_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس السالب negative['word_clean'] = negative['word'].apply(cleaningText) negative.drop(['word'], axis = 1, inplace = True) negative['word_preprocessed'] = negative['word_clean'].apply(tokenizingText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(filteringText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ negative.drop_duplicates(subset = 'word_clean', inplace = True) negative.replace("", nan_value, inplace=True) negative.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف negative.to_csv(r'negative_clean.csv', encoding="utf-8", index = False, header = True,index_label=None) تعرض الشيفرة التالية بناء قاموسين dict الأول للكلمات الموجبة والثاني للكلمات السالبة وبحيث يكون المفتاح key هو الكلمة والقيمة value هي نقاط الكلمة. يُعدّ استخدام بنية القاموس dict في بايثون مفيدًا جدًا للوصول المباشر إلى نقاط أي كلمة دون القيام بأي عملية بحث. لاحظ أننا نقرأ الكلمات الموجبة والسالبة من الملفات الجديدة ناتج المعالجة الأولية لملفات الكلمات الأصلية. # التصريح عن قاموس للكلمات الموجية dict_positive = dict() # بناء قاموس الكلمات الموجبة myfile = 'positive_clean.csv' positive_data = pd.read_csv(myfile, encoding='utf-8') positive = positive_data[['word_clean', 'polarity']] for i in range(len(positive)): dict_positive[positive_data['word_clean'][i].strip()] = int(positive_data['polarity'][i]) # التصريح عن قاموس للكلمات السالبة dict_negative = dict() # بناء قاموس الكلمات السالبة myfile = 'negative_clean.csv' negative_data = pd.read_csv(myfile, encoding='utf-8') negative = negative_data[['word_clean', 'polarity']] for i in range(len(negative)): dict_negative[negative_data['word_clean'][i].strip()] = int(negative_data['polarity'][i]) تقوم الدالة التالية sentiment_analysis_dict_arabic بحساب مجموع نقاط score قائمة من الكلمات وذلك بجمع نقاط الكلمات الواردة في قاموسي الكلمات الموجبة والسالبة. وفي النهاية تُعدّ قطبية polarity قائمة الكلمات موجبة positive إذا كان مجموع نقاطها أكبر من الصفر، وتُعدّ سالبة negative إذا كان مجموع نقاطها أصغر من الصفر، وإلا فإنها تكون محايدة neutral. # دالة حساب قطبية قائمة من الكلمات def sentiment_analysis_dict_arabic(words_list): score = 0 for word in words_list: if (word in dict_positive): score = score + dict_positive[word] for word in words_list: if (word in dict_negative): score = score + dict_negative[word] polarity='' if (score > 0): polarity = 'positive' elif (score < 0): polarity = 'negative' else: polarity = 'neutral' return score, polarity نستخدم الدالة السابقة في حساب قطبية كل تغريدة وذلك بتنفيذ الدالة على قائمة الكلمات التي حصلنا عليها بعد المعالجة الأولية لنص التغريدة tweet_preprocessed. أي أنه سيكون لكل تغريدة في نهاية المطاف قطبية polarity موجبة أو سالبة أو محايدة وفق مجموع النقاط الحاصلة عليها polarity_score. نحفظ نتائج الحساب في ملف جديد tweets_clean_polarity.csv. # حساب قطبية التغريدات results = tweets['tweet_preprocessed'].apply(sentiment_analysis_dict_arabic) results = list(zip(*results)) tweets['polarity_score'] = results[0] tweets['polarity'] = results[1] # كتابة النتائج في ملف tweets.to_csv(r'tweets_clean_polarity.csv', encoding='utf-8', index = False, header = True,index_label=None) تعرض الشيفرة التالية حساب عدد التغريدات من كل قطبية (موجبة، سالبة، محايدة) ومن ثم استخدام المكتبة matplotlib لرسم مخطط بياني من النوع pie يعرض نسب قطبية التغريدات: # رسم نسب قطبية التغريدات import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize = (6, 6)) # حساب عدد التغريدات من كل قطبية x = [count for count in tweets['polarity'].value_counts()] # تسميات الرسم labels = list(tweets['polarity'].value_counts().index) explode = (0.1, 0, 0) # تنفيذ الرسم ax.pie(x = x, labels = labels, autopct = '%1.1f%%', explode = explode, textprops={'fontsize': 14}) # عنوان الرسم ax.set_title('Tweets Polarities ', fontsize = 16, pad = 20) # الإظهار plt.show() يكون الإظهار: يُمكن الآن إظهار التغريدات الأكثر إيجابيًة باستخدام الشيفرة التالية: # طباعة أكثر التغريدات إيجابية pd.set_option('display.max_colwidth', 3000) positive_tweets = tweets[tweets['polarity'] == 'positive'] positive_tweets = positive_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=False).reset_index(drop = True) positive_tweets.index += 1 positive_tweets[0:10] يكون الإظهار: كما يُمكن إظهار التغريدات الأكثر سلبيًة: # طباعة أكثر التغريدات سلبية pd.set_option('display.max_colwidth', 3000) negative_tweets = tweets[tweets['polarity'] == 'negative'] negative_tweets = negative_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=True)[0:10].reset_index(drop = True) negative_tweets.index += 1 negative_tweets[0:10] يكون الإظهار: يُمكن استخدام مكتبة سحابة الكلمات WordCloud لرسم مجموعة من الكلمات بشكل فني كما تُبين الشيفرة التالية: # سحابة الكلمات from wordcloud import WordCloud # مكتبة للغة العربية import arabic_reshaper from bidi.algorithm import get_display # انتقاء بعض الكلمات المعالجة list_words='' i=0 for tweet in tweets['tweet_preprocessed']: for word in tweet: i=i+1 if i>100: break list_words += ' '+(word) # ضبط اللغة العربية reshaped_text = arabic_reshaper.reshape(list_words) artext = get_display(reshaped_text) # إعدادات سحابة الكلمات wordcloud = WordCloud(font_path='DroidSansMono.ttf', width = 600, height = 400, background_color = 'black', min_font_size = 10).generate(artext) fig, ax = plt.subplots(figsize = (8, 6)) # عنوان السحابة ax.set_title('Word Cloud of Tweets', fontsize = 18) ax.grid(False) ax.imshow((wordcloud)) fig.tight_layout(pad=0) ax.axis('off') plt.show() يكون الإظهار: تُجمّع الدالة التالية words_with_sentiment الكلمات الموجبة والكلمات السالبة المستخرجة من قائمة الكلمات المُمررة للدالة list_words في قائمتين منفصلتين الأولى للكلمات الموجبة والثانية للكلمات السالبة. تستخدم الدالة قاموسي الكلمات الموجبة والسالبة السابقين. # تجميع الكلمات الموجبة والكلمات السالبة def words_with_sentiment(list_words): positive_words=[] negative_words=[] for word in list_words: score_pos = 0 score_neg = 0 if (word in dict_positive): score_pos = dict_positive[word] if (word in dict_negative): score_neg = dict_negative[word] if (score_pos + score_neg > 0): positive_words.append(word) elif (score_pos + score_neg < 0): negative_words.append(word) return positive_words, negative_words نستخدم الدالة السابقة في الشيفرة التالية لاستخراج قائمة الكلمات الموجبة وقائمة الكلمات السالبة من التغريدات، ومن ثم إنشاء سحابتي كلمات لكل منهما لعرض الكلمات الموجبة والكلمات السالبة بشكل فني: # سحابة الكلمات الموجبة والسالبة # فرز الكلمات الموجبة والسالبة sentiment_words = tweets['tweet_preprocessed'].apply(words_with_sentiment) sentiment_words = list(zip(*sentiment_words)) # قائمة الكلمات الموجبة positive_words = sentiment_words[0] # قائمة الكلمات السالبة negative_words = sentiment_words[1] # سحابة الكلمات الموجبة fig, ax = plt.subplots(1, 2,figsize = (12, 10)) list_words_postive='' for row_word in positive_words: for word in row_word: list_words_postive += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_postive) artext = get_display(reshaped_text) wordcloud_positive = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Greens' , min_font_size = 10).generate(artext) ax[0].set_title(' Positive Words', fontsize = 14) ax[0].grid(False) ax[0].imshow((wordcloud_positive)) fig.tight_layout(pad=0) ax[0].axis('off') # سحابة الكلمات السالبة list_words_negative='' for row_word in negative_words: for word in row_word: list_words_negative += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_negative) artext = get_display(reshaped_text) wordcloud_negative = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Reds' , min_font_size = 10).generate(artext) ax[1].set_title('Negative Words', fontsize = 14) ax[1].grid(False) ax[1].imshow((wordcloud_negative)) fig.tight_layout(pad=0) ax[1].axis('off') plt.show() يكون الإظهار: تحويل النصوص إلى أشعة رقمية لا تقبل بنى تعلم الآلة النصوص كمدخلات لها، بل تحتاج إلى أشعة رقمية كمدخلات، لذا نستخدم الشيفرة التالية لتحويل الشعاع النصي لكل تغريده tweet_preprocessed إلى شعاع رقمي: # تحويل التغريدات إلى أشعة رقمية from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences # تركيب جمل التغريدات من المفردات المعالجة sentences = tweets['tweet_preprocessed'].apply(toSentence) print(sentences.values[25]) max_words = 5000 max_len = 50 # التصريح عن المجزئ # مع تحديد عدد الكلمات التي ستبقى # بالاعتماد على تواترها tokenizer = Tokenizer(num_words=max_words ) # ملائمة المجزئ لنصوص التغريدات tokenizer.fit_on_texts(sentences.values) # تحويل النص إلى قائمة من الأرقام S = tokenizer.texts_to_sequences(sentences.values) print(S[0]) # توحيد أطوال الأشعة X = pad_sequences(S, maxlen=max_len) print(X[0]) X.shape نقاط في الشيفرة السابقة لشرحها: يُحدّد المتغير max_words عدد الكلمات الأعظمي التي سيتم الاحتفاظ بها حيث يُحسب تواتر كل كلمة في كل النصوص ومن ثم تُرتب حسب تواترها (المرتبة الأولى للكلمة ذات التواتر الأكبر). ستُهمل الكلمات ذات المرتبة أكبر من max_words. يُحدّد المتغير max_len طول الشعاع الرقمي النهائي. إذا كان طول الشعاع الرقمي الموافق لنص أقل من max_len تُضاف أصفار للشعاع حتى يُصبح طوله مساويًا إلى max_len. أما إذا كان طوله أكبر يُقتطع جزءًا منه ليُصبح طوله مساويًا إلى max_len. تقوم الدالة fit_on_texts(sentences.values) بملائمة المُجزء tokenizer لنصوص جمل التغريدات أي حساب تواتر الكلمات والاحتفاظ بالكلمات ذات التواتر أكبر أو يساوي max_words. نطبع في الشيفرة السابقة، بهدف التوضيح، ناتج كل مرحلة. اخترنا مثلًا شعاع التغريدة 25 بعد المعالجة: [مكان جميل انصح زيار رسوم دخول] تكون نتيجة تحويل الشعاع السابق النصي إلى شعاع من الأرقام: [246, 1401, 467, 19, 87, 17, 74, 515, 2602, 330, 218, 579, 507, 465, 270, 45, 54, 343, 587, 7, 33, 58, 434, 30, 74, 144, 233, 451, 468] وبعد عملية توحيد الطول يكون الشعاع الرقمي النهائي الناتج: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 246 1401 467 19 87 17 74 515 2602 330 218 579 507 465 270 45 54 343 587 7 33 58 434 30 74 144 233 451 468] تجهيز دخل وخرج الشبكة العصبية تعرض الشيفرة التالية حساب شعاع الخرج أولًا، حيث نقوم بترميز القطبيات الثلاث إلى 0 للسالبة و1 للمحايدة و2 للموجبة. نستخدم الدالة train_test_split لتقسيم البيانات المتاحة إلى 80% منها لعملية التدريب و20% لعملية الاختبار وحساب مقاييس الأداء: # ترميز الخرج polarity_encode = {'negative' : 0, 'neutral' : 1, 'positive' : 2} # توليد شعاع الخرج y = tweets['polarity'].map(polarity_encode).values # مكنبة تقسيم البيانات إلى تدريب واختبار from sklearn.model_selection import train_test_split # تقسيم البيانات إلى تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape) نطبع في الشيفرة السابقة حجوم أشعة الدخل والخرج للتدريب وللاختبار: (16428, 50) (16428,) (4107, 50) (4107,) نموذج الشبكة العصبية المتعلم تُعدّ المكتبة Keras من أهم مكتبات بايثون التي توفر بناء شبكات عصبية لمسائل التعلم الآلي. تعرض الشيفرة التالية التصريح عن دالة بناء نموذج التعلّم create_model مع إعطاء جميع المعاملات المترفعة قيمًا ابتدائية: # تضمين النموذج التسلسلي from keras.models import Sequential # تضمين الطبقات اللازمة from keras.layers import Embedding, Dense, LSTM # دوال التحسين from tensorflow.keras.optimizers import Adam, RMSprop # التصريح عن دالة إنشاء نموذج التعلم # مع إعطاء قيم أولية للمعاملات المترفعة def create_model(embed_dim = 32, hidden_unit = 16, dropout_rate = 0.2, optimizers = RMSprop, learning_rate = 0.001): # التصريح عن نموذج تسلسلي model = Sequential() # طبقة التضمين model.add(Embedding(input_dim = max_words, output_dim = embed_dim, input_length = max_len)) # LSTM model.add(LSTM(units = hidden_unit ,dropout=dropout_rate)) # الطبقة الأخيرة model.add(Dense(units = 3, activation = 'softmax')) # بناء النموذج model.compile(loss = 'sparse_categorical_crossentropy', optimizer = optimizers(learning_rate = learning_rate), metrics = ['accuracy']) # طباعة ملخص النموذج print(model.summary()) return model نستخدم من أجل مسألتنا نموذج شبكة عصبية تسلسلي يتألف من ثلاث طبقات: الطبقة الأولى: طبقة التضمين Embedding نستخدم هذه الطبقة لتوليد ترميز مكثف للكلمات dense word encoding مما يُساهم في تحسين عملية التعلم. نطلب تحويل الشعاع الذي طوله input_length (في حالتنا 50) والذي يحوي قيم ضمن المجال input_dim (من 1 إلى 5000 في مثالنا) إلى شعاع من القيم ضمن المجال output_dim (مثلًا 32 قيمة). الطبقة الثانية LSTM يُحدّد المعامل المترفع units عدد الوحدات المخفية لهذه الطبقة. يُساهم المعامل dropout في معايرة الشبكة خلال التدريب حيث يقوم بإيقاف تشغيل الوحدات المخفية بشكل عشوائي أثناء التدريب، وبهذه الطريقة لا تعتمد الشبكة بنسبة 100٪ على جميع الخلايا العصبية الخاصة بها، وبدلاً من ذلك، تُجبر نفسها على العثور على أنماط أكثر أهمية في البيانات من أجل زيادة المقياس الذي تحاول تحسينه (الدقة مثلًا). الطبقة الثالثة Dense يُحدّد المعامل units حجم الخرج لهذه الطبقة (3 في حالتنا: 0 سالبة، 1 محايدة، 2 موجبة) ويُبين الشكل التالي ملخص النموذج: معايرة المعاملات الفائقة وصولا لنموذج أمثلي يُمكن الوصول لنموذج تعلم أمثلي بمعايرة معاملاته الفائقة وفق معطيات المشروع. لنُبين أولًا الفرق بين المعاملات الفائقة لنموذج والمعاملات الأخرى له: المعاملات الفائقة hyperparameters: هي إعدادات خوارزمية التعلّم قبل التدريب (والتي وضعها مصممو الخوارزمية) . المعاملات parameters: هي المعاملات التي يتعلّمها النموذج أثناء التدريب مثل أوزان الشبكة العصبية. تؤثر عملية معايرة المعاملات الفائقة على أداء النموذج لاسيما لجهة التوزان المطلوب بين مشكلة قلة التخصيص underfitting ومشكلة فرط التخصيص overfitting واللتان تؤديان إلى نموذج غير قادر على تعميم أمثلة التدريب وبالتالي لن يتمكن من التصنيف مع معطيات جديدة (يُمكن العودة للرابط من أكاديمية حسوب للمزيد من التفصيل حول هاتين المشكلتين). تظهر مشكلة قلة التخصيص عندما لا يكون للنموذج درجات حرية كافية ليتعلّم الربط بين الميزات والهدف، وبالتالي يكون له انحياز كبير نحو قيم معينة للهدف. يُمكن تصحيح قلة التخصيص بجعل النموذج أكثر تعقيدًا. أما مشكلة فرط التخصيص فتظهر عندما يقوم النموذج بتخزين بيانات التدريب فيكون له بالتالي تباين كبير والذي يُمكن تصحيحه بالحد من تعقيد النموذج باستخدام التسوية regularization. تكمن المشكلة في معايرة المعاملات الفائقة بأن قيمها المثلى تختلف من مسألة لأخرى! وبالتالي، فإن الطريقة الوحيدة للوصول لهذه القيم المثلى هي تجريب قيم مختلفة مع كل مجموعة بيانات تدريب جديدة. يوفر Scikit-Learn العديد من الطرق لتقويم المعاملات الفائقة وبالتالي سنعتمد في مشروعنا عليها دون أن نُعقّد الأمور أكثر. البحث الشبكي مع التقييم المتقاطع تُدعى الطريقة التي سنستخدمها في إيجاد القيم المثلى بالبحث الشبكي مع التقويم المتقاطع grid search with cross validation: البحث الشبكي grid search: نُعرّف شبكة grid من بعض القيم المُمكنة ومن ثم نولد كل التركيبات المُمكنة بينها. التقييم المتقاطع cross validation: وهو الطريقة المستخدمة لتقييم مجموعة قيم مُحدّدة للمعاملات الفائقة. عوضًا عن تقسيم البيانات إلى بيانات للتدريب وبيانات للتقييم مما يُخفّض من البيانات التي يُمكن لنا استخدامها للتدريب، نستخدم التقييم المتقاطع مع عدد محدّد من الحاويات K-Fold. تُقسم بيانات التدريب إلى عدد K من الحاويات ومن ثم نقوم بتكرار ما يلي K مرة: في كل مرة نقوم بتدريب النموذج مع بيانات K-1 حاوية ومن ثم تقويمه مع بيانات الحاوية K. في النهاية، يكون مقياس الأداء النهائي هو متوسط الخطأ لكل التكرارات. يُمكن تلخيص خطوات البحث الشبكي مع التقييم المتقاطع كما يلي: إعداد شبكة من المعاملات الفائقة. توليد كل تركيبات قيم المعاملات الفائقة. إنشاء نموذج لكل تركيب من القيم. تقييم النموذج باستخدام التقويم المتقاطع. اختيار تركيب قيم المعاملات ذو الأداء الأفضل. بالطبع، لن نقوم ببرمجة هذه الخطوات لأن الكائن GridSearchCV في Scikit-Learn يقوم بكل ذلك (يجب ملاحظة أن تنفيذ الشيفرة قد يستغرق بعض الوقت: حوالي الساعة على حاسوب ذو مواصفات عالية): from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasClassifier # حساب القيم الأمثلية للمعاملات المترفعة model = KerasClassifier(build_fn = create_model, epochs = 25, batch_size=128) # بعض القيم الممكنة للمعاملات المترفعة embed_dim = [32, 64] hidden_unit = [16, 32, 64] dropout_rate = [0.2] optimizers = [Adam, RMSprop] learning_rate = [0.01, 0.001, 0.0001] epochs = [10, 15, 25 ] batch_size = [128, 256] param_grid = dict(embed_dim = embed_dim, hidden_unit = hidden_unit, dropout_rate = dropout_rate, learning_rate = learning_rate, optimizers = optimizers, epochs = epochs, batch_size = batch_size) # تقويم النموذج لاختيار أفضل القيم grid = GridSearchCV(estimator = model, param_grid = param_grid, cv = 3) grid_result = grid.fit(X_train, y_train) results = pd.DataFrame() results['means'] = grid_result.cv_results_['mean_test_score'] results['stds'] = grid_result.cv_results_['std_test_score'] results['params'] = grid_result.cv_results_['params'] print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # حفظ النتائج results.to_csv(r'gridsearchcv_results.csv', index = False, header = True) results.sort_values(by='means', ascending = False).reset_index(drop=True) يُبين خرج الشيفرة السابقة أفضل القيم للمعاملات المترفعة: Best: 0.898588 using {'batch_size': 256, 'dropout_rate': 0.2, 'embed_dim': 32, 'epochs': 10, 'hidden_unit': 64, 'learning_rate': 0.001, 'optimizers': <class 'keras.optimizer_v2.adam.Adam'>} نحفظ نتائج حساب المعاملات الأمثلية في الملف gridsearchcv_results.csv. يُمكن معاينة هذه القيم: # قراءة نتائج معايرة المعاملات المترفعة results = pd.read_csv('gridsearchcv_results.csv') results.sort_values(by='means', ascending = False).reset_index(drop=True) print (results) يكون الخرج: حساب أوزان الصفوف يُمكن أن نلاحظ أن عدد التغريدات ذات القطبية الموجبة (73% من التغريدات) تطغى على عدد التغريدات السلبية (13%) والتغريدات المحايدة (13%) مما قد يؤدي إلى انحراف نتائج التعلم نحو القطبية الموجبة. يُمكن تلافي ذلك عن طريق الموازنة بين هذه الصفوف الثلاثة. نحسب في الشيفرة التالية عدد التغريدات الموجبة والسالبة والمحايدة ونسبها: # حساب أوزان القطبيات posCount=0 negCount=0 neuCount=0 # حساب عدد التغريدات الموجبة والسالبة والمحايدة for index, row in tweets.iterrows(): if row['polarity']=='negative': negCount=negCount+1 elif row['polarity']=='positive': posCount=posCount+1 else: neuCount=neuCount+1 print(negCount, neuCount, posCount) total=posCount+ negCount+ neuCount # حساب النسب weight_for_0 = (1 / negCount) * (total / 3.0) weight_for_1 = (1 / neuCount) * (total / 3.0) weight_for_2 = (1 / posCount) * (total / 3.0) print(weight_for_0, weight_for_1, weight_for_2) class_weight = {0: weight_for_0, 1: weight_for_1, 2:weight_for_2} يكون ناتج طباعة هذه الأوزان ما يلي (لا حظ الوزن الأصغر للتغريدات الموجبة): 2.4954429456799123 2.504573728503476 0.45454545454545453 بناء نموذج التعلم النهائي نستخدم الدالة KerasClassifier من scikit لبناء المُصنف مع الدالة السابقة create_model : # مكتبة التصنيف from keras.wrappers.scikit_learn import KerasClassifier # إنشاء النموذج مع قيم المعاملات المترفعة الأمثلية model = KerasClassifier(build_fn = create_model, # معاملات النموذج dropout_rate = 0.2, embed_dim = 32, hidden_unit = 64, optimizers = Adam, learning_rate = 0.001, # معاملات التدريب epochs=10, batch_size=256, # نسبة بيانات التقييم validation_split = 0.1) # ملائمة النموذج مع بيانات التدريب # مع موازنة الصفوف الثلاثة model_prediction = model.fit(X_train, y_train, class_weight=class_weight) يُمكن الآن رسم منحني الدقة accuracy لكل من بيانات التدريب والتقييم (لاحظ أننا في الشيفرة السابقة احتفاظنا بنسبة 10% من بيانات التدريب للتقييم): # معاينة دقة النموذج # التدريب والتقييم fig, ax = plt.subplots(figsize = (10, 4)) ax.plot(model_prediction.history['accuracy'], label = 'train accuracy') ax.plot(model_prediction.history['val_accuracy'], label = 'val accuracy') ax.set_title('Model Accuracy') ax.set_xlabel('Epoch') ax.set_ylabel('Accuracy') ax.legend(loc = 'upper left') plt.show() يكون للمنحني الشكل التالي: حساب مقاييس الأداء يُمكن الآن حساب مقاييس الأداء المعروفة في مسائل التصنيف (الصحة Accuracy، الدقة Precision، الاستذكار Recall، المقياس F1) للنموذج المتعلم باستخدام الشيفرة التالية: # مقاييس الأداء # مقياس الصحة from sklearn.metrics import accuracy_score # مقياس الدقة from sklearn.metrics import precision_score # مقياس الاستذكار from sklearn.metrics import recall_score # f1 from sklearn.metrics import f1_score # مصفوفة الارتباك from sklearn.metrics import confusion_matrix # تصنيف بيانات الاختبار y_pred = model.predict(X_test) # حساب مقاييس الأداء accuracy = accuracy_score(y_test, y_pred) precision=precision_score(y_test, y_pred , average='weighted') recall= recall_score(y_test, y_pred, zero_division=1, average='weighted') f1= f1_score(y_test, y_pred, zero_division=1, average='weighted') print('Model Accuracy on Test Data:', accuracy*100) print('Model Precision on Test Data:', precision*100) print('Model Recall on Test Data:', recall*100) print('Model F1 on Test Data:', f1*100) confusion_matrix(y_test, y_pred) تكون النتائج (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Model Accuracy on Test Data: 90.1144387630874 Model Precision on Test Data: 90.90281584915091 Model Recall on Test Data: 90.1144387630874 Model F1 on Test Data: 90.32645671662543 array([[ 366, 129, 24], [ 53, 444, 62], [ 20, 118, 2891]], dtype=int64) يُمكن رسم مصفوفة الارتباك confusion matrix بشكل أوضح باستخدام المكتبة seaborn: # رسم مصفوفة الارتباك import seaborn as sns sns.set(style = 'whitegrid') fig, ax = plt.subplots(figsize = (8,6)) sns.heatmap(confusion_matrix(y_true = y_test, y_pred = y_pred), fmt = 'g', annot = True) ax.xaxis.set_label_position('top') ax.xaxis.set_ticks_position('top') ax.set_xlabel('Prediction', fontsize = 14) ax.set_xticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) ax.set_ylabel('Actual', fontsize = 14) ax.set_yticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) plt.show() مما يُظهر: يُمكن حساب بعض مقاييس الأداء الأخرى المُستخدمة في حالة وجود أكثر من صف في المسألة (Micro, Macro, Weighted): # مقاييس الأداء في حالة أكثر من صفين print('\nAccuracy: {:.2f}\n'.format(accuracy_score(y_test, y_pred))) print('Micro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='micro'))) print('Micro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='micro'))) print('Micro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='micro'))) print('Macro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='macro'))) print('Macro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='macro'))) print('Macro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='macro'))) print('Weighted Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='weighted'))) print('Weighted Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='weighted'))) print('Weighted F1-score: {:.2f}'.format(f1_score(y_test, y_pred, average='weighted'))) # تقرير التصنيف from sklearn.metrics import classification_report print('\nClassification Report\n') print(classification_report(y_test, y_pred, target_names=['Class 1', 'Class 2', 'Class 3'])) مما يُعطي (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Accuracy: 0.88 Micro Precision: 0.88 Micro Recall: 0.88 Micro F1-score: 0.88 Macro Precision: 0.79 Macro Recall: 0.83 Macro F1-score: 0.80 Weighted Precision: 0.90 Weighted Recall: 0.88 Weighted F1-score: 0.89 Classification Report precision recall f1-score support Class 1 0.79 0.75 0.77 519 Class 2 0.59 0.82 0.69 559 Class 3 0.98 0.92 0.95 3029 accuracy 0.88 4107 macro avg 0.79 0.83 0.80 4107 weighted avg 0.90 0.88 0.89 4107 يُمكن أيضًا اختيار مجموعة تغريدات عشوائية جديدة وتصنيفها وحفظ النتائج في ملف results.csv: # تصنيف مجموعة اختبار text_clean = tweets['tweet_clean'] text_train, text_test = train_test_split(text_clean, test_size = 0.2, random_state = 0) result_test = pd.DataFrame(data = zip(text_test, y_pred), columns = ['text', 'polarity']) polarity_decode = {0 : 'Negative', 1 : 'Neutral', 2 : 'Positive'} result_test['polarity'] = result_test['polarity'].map(polarity_decode) pd.set_option('max_colwidth', 300) # حفظ النتائج result_test.to_csv("results.csv") result_test تكون النتائج مثلًا: الخلاصة عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لتصنيف النصوص العربية إلى موجبة وسالبة ومحايدة. يُمكن تجربة المثال كاملًا من موقع Google Colab، ولا تنسى الاطلاع على مجموعة البيانات المتوفرة الخاصة بهذا المقال. اقرأ أيضًا دليل المبتدئين لفهم أساسيات التعلم العميق لذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال1 نقطة
تُعدّ مسألة تحليل تعليقات وتغريدات الأشخاص على مواقع التواصل الاجتماعي من المسائل المهمة والتي لها الكثير من التطبيقات العملية. مثلًا: تهتم المتاجر الالكترونية كثيرًا بتحليل تعليقات الزبائن على منتجاتهم لاستكشاف توجهات الزبائن ومواطن الضعف والقوة في المتجر. نعرض في هذه المقالة استخدام تقنيات التعلّم العميق deep learning في تحليل المشاعر لنصوص مكتوبة باللغة العربية وباللهجة السعودية بمعنى أن اللغة المستخدمة ليست بالضرورة اللغة العربية الفصحى، بل يُمكن أن تدخل فيها ألفاظ عامية يستخدمها المغردون عادةً. بيانات التدريب تحوي مجموعة البيانات المتوفرة dataset (التي تجدها أيضًا موضحةً بملف بنهاية المقال) حوالي 23500 تغريدة لتعليقات الأشخاص وملاحظاتهم حول مجموعة من الأماكن العامة في المملكة العربية السعودية. جُمّعت هذه التغريدات عن طريق مجموعة من الطلاب الجامعيين وذلك من مجموعة متنوعة من مواقع التواصل الاجتماعي. نُعطي فيما يلي أمثلة عن هذه التغريدات (تعليقات حول حديقة حيوانات مثلًا): "أنصحكم والله بزيارته مكان جميل جدا مرتب ونظيف" "جميلة وكبيرة وتحتاج واحد عنده لياقه يمشي فيها" "حيوانات قليلة جدا ولا يوجد اهتمام مكثف" "كان يعيبها وقت الافتتاح والاغلاق وعدم وجود خريطه" "أول مرة أزور حديقة حيوانات" "أيام العوائل الخميس والجمعة والسبت" يُمكننا، كبشر، تصنيف التغريدات السابقة وبشكل سريع إلى ثلاث فئات: التغريدات الموجبة (الأولى والثانية) أي التغريدات التي تحمل معاني إيجابية تُعّبر عن الرضا والارتياح. التغريدات السالبة (الثالثة والرابعة) أي التغريدات التي تحمل معاني سلبية تُعبّر عن الاستياء. التغريدات المحايدة (الخامسة والسادسة) أي التغريدات التي يُمكن أن تُعطي معلومات ولا تحمل أية مشاعر فيها سواء موجبة أم سالبة. نعرض في هذه المسألة كيفية بناء مُصنّف حاسوبي آلي يُصنّف أي جملة عربية إلى موجبة أو سالبة أو محايدة. تصنيف بيانات التدريب يتطلب استخدام خوارزميات تعلّم الآلة (خوارزميات تصنيف النصوص في حالتنا) توفر بيانات للتدريب أي مجموعة من النصوص مُصنفّة مُسبقًا إلى: موجبة، سالبة، محايدة. يُمكن، في بعض الأحيان، اللجوء إلى الطرق اليدوية: أي الطلب من مجموعة من الأشخاص قراءة النصوص وتصنيفها. وهو حل يصلح في حال كان عدد النصوص صغيرًا نسبيًا. يتميز هذا الحل بالدقة العالية لأن الأشخاص تُدرك، بشكل عام، معاني النصوص من خلال خبرتها اللغوية المُكتسبة وتُصنّف النصوص بشكل صحيح غالبًا. نستخدم، في حالتنا، حلًا إحصائيًا بسيطًا لتصنيف نصوص التدريب إلى موجبة، سالبة، محايدة وذلك باستخدام قاموس للكلمات الموجبة وقاموس آخر للكلمات السالبة. يحوي قاموس الكلمات الموجبة على مجموعة من الكلمات الموجبة الشائعة مع نقاط لكل كلمة (1 موجبة، 2 موجبة جدًا، 3 موجبة كثيرًا). مثلًا: روعة، 3 جيد، 2 معقول، 1 يحوي قاموس الكلمات السالبة على مجموعة من الكلمات السالبة الشائعة مع نقاط لكل كلمة (-1 سالبة، -2 سالبة جدًا، -3 سالبة كثيرًا). مثلًا: مقرف، -3 سيء، -2 زحمه، -1 اختيرت كلمات القواميس الموجبة والسالبة من قبل مجموعة من الطلاب بعد أنا طلبنا منهم استعراض التغريدات المُتاحة وانتقاء الكلمات التي تُعطي التغريدة معنى موجب أو معنى سالب، وإعطاء كل كلمة موجبة نقاط تدل على شدة الإيجابية لها (1,2,3) وكل كلمة سالبة نقاط تدل على شدة السلبية (-3،-2،-1) نعدّ، فيما يلي، نصًا ما أنه موجبًا إذا كان مجموع نقاط الكلمات الموجبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات السالبة الواردة ضمنه. وبالمقابل، نعدّ نصًا ما أنه سالبًا إذا كان مجموع نقاط الكلمات السالبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات الموجبة الواردة ضمنه. يكون نصًا ما محايدًا إذا تساوى مجموع نقاط الكلمات الموجبة فيه مع مجموع نقاط الكلمات السالبة. بالطبع، لا تُعدّ هذه الطريقة صحيحة دومًا إذ يُمكن أن تُخطئ في بعض الحالات إلا أنها على وجه العموم تُستخدم عوضًا عن الطريقة اليدوية. المعالجة الأولية للنصوص تهدف المعالجة الأولية إلى الحصول على الكلمات المهمة فقط من النصوص وذلك عن طريق تنفيذ بعض العمليات اللغوية عليها. تُنفذّ هذه العمليات على كل من التغريدات وكلمات القواميس. لتكن لدينا مثلًا الجملة التالية: "أنا أحب الذهاب إلى الحديقة، كل يوم 9 صباحاً، مع رفاقي هؤلاء!" سنقوم بتنفيذ العمليات التالية: أولًا، حذف إشارات الترقيم المختلفة كالفواصل وإشارات الاستفهام وغيرها، ويكون ناتج الجملة السابقة: ثانيًا، حذف الأرقام الواردة في النص، فيكون ناتج الجملة السابقة: ثالثًا، حذف كلمات التوقف stop words وهي الكلمات التي تتكرر كثيرًا في النصوص ولا تؤثر في معانيها كأحرف الجر (من، إلى، …) والضمائر (أنا، هو، …) وغيرها، فيكون ناتج الجملة السابقة: رابعًا، تجذيع الكلمات stemming أي إرجاع الكلمات المتشابهة إلى كلمة واحدة (جذع أو جذر) مما يُساهم في إنقاص عدد الكلمات الكلية المختلفة في النصوص، ومطابقة الكلمات المتشابهة مع بعضها البعض. مثلًا: يكون للكلمات الأربع: (رائع، رايع، رائعون، رائعين) نفس الجذع المشترك: (رايع). فيكون ناتج الجملة السابقة: ننتبه إلى أن الجذع يختلف عن الجذر اللغوي إذ الجذر هو عملية لغوية لرد الكلمة إلى أصلها وجذرها الأساسي لأغراض مختلفة أشهرها البحث في القاموس، أما الجذع فهو كلمة مشتركة بين مجموعة من الكلمات لا توجد بالضرورة في قاموس اللغة العربية وإنما إيجاد شكل موحد للكلمات. إعداد المشروع يُمكن تنزيل بيانات التدريب والقواميس والشيفرة البرمجية من الملف المرفق هنا. يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ. نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها. نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا. نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا: mkdir sa cd sa نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية: python -m venv sa ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية: source sa/bin/activate أما في Windows، فيكون أمر التنشيط: "sa/Scripts/activate.bat" نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها. نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها: jupyter==1.0.0 keras==2.6.0 Keras-Preprocessing==1.1.2 matplotlib==3.5.1 nltk==3.6.5 numpy==1.19.5 pandas==1.3.5 scikit-learn==1.0.1 seaborn==0.11.2 sklearn==0.0 snowballstemmer==2.2.0 tensorflow==2.6.0 wordcloud==1.8.1 python-bidi==0.4.2 arabic-reshaper==2.1.3 نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي: (sa) $ pip install -r requirements.txt بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا. كتابة شيفرة برنامج تحليل المشاعر في النصوص العربي نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا: (sa) $ jupyter notebook ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم asa مثلًا. يجب أولًا وضع كل من الملفات التالية في مجلد المشروع: ملف التغريدات: tweets.csv. القواميس: lexicon_positive.csv و lexicon_negative.csv. ملف الخط العربي: DroidSansMono.ttf. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن تحميل البيانات نبدأ أولًا بتحميل التغريدات من الملف tweets.csv ضمن إطار من البيانات DataFrame من مكتبة Pandas ومن ثم عرض بعضها: import pandas as pd # قراءة التغريدات وتحميلها ضمن إطار من البيانات tweets_data = pd.read_csv('tweets.csv',encoding = "utf-8") tweets = tweets_data[['tweet']] # إظهار الجزء الأعلى من إطار البيانات tweets.head() يظهر لنا أوائل التغريدات: نُحمّل قاموس الكلمات الموجبة positive.csv وقاموس الكلمات السالبة negative.csv: # قراءة قاموس الكلمات الموجبة positive_data = pd.read_csv('positive.csv' ,encoding = "utf-8") positive = positive_data[['word', 'polarity']] # قراءة قاموس الكلمات السالبة negative_data = pd.read_csv('negative.csv' ,encoding = "utf-8") negative = negative_data[['word', 'polarity']] positive.head() نُظهر مثلًا أوائل الكلمات الموجبة ونقاطها: المعالجة الأولية للنصوص نستخدم فيما يلي بعض الخدمات التي توفرها المكتبة nltk لمعالجة اللغات الطبيعية كتوفير قائمة كلمات التوقف باللغة العربية (حوالي 700 كلمة) واستخراج الوحدات tokens من النصوص. كما نستخدم مجذع الكلمات العربية من مكتبة snowballstemmer. # مكتبة السلاسل النصية import string # مكتبة التعابير النظامية import re # مكتبة معالجة اللغات الطبيعية import nltk nltk.download('punkt') nltk.download('stopwords') # مكتبة كلمات التوقف from nltk.corpus import stopwords # مكتبة استخراج الوحدات from nltk.tokenize import word_tokenize # مكتبة المجذع العربي from snowballstemmer import stemmer ar_stemmer = stemmer("arabic") # دالة حذف المحارف غير اللازمة def remove_chars(text, del_chars): translator = str.maketrans('', '', del_chars) return text.translate(translator) # دالة حذف المحارف المكررة def remove_repeating_char(text): return re.sub(r'(.)\1{2,}', r'\1', text) # دالة تنظيف النصوص def cleaningText(text): # حذف الأرقام text = re.sub(r'[0-9]+', '', text) # حذف المحارف غير اللازمة # علامات الترقيم العربية arabic_punctuations = '''`÷×؛<>_()*&^%][ـ،/:"؟.,'{}~¦+|!”…“–ـ''' # علامات الترقيم الانكليزية english_punctuations = string.punctuation # دمج علامات الترقيم العربية والانكليزية punctuations_list = arabic_punctuations + english_punctuations text = remove_chars(text, punctuations_list) # حذف المحارف المكررة text = remove_repeating_char(text) # استبدال الأسطر الجديدة بفراغات text = text.replace('\n', ' ') # حذف الفراغات الزائدة من اليمين واليسار text = text.strip(' ') return text # دالة تقسيم النص إلى مجموعة من الوحدات def tokenizingText(text): tokens_list = word_tokenize(text) return tokens_list # دالة حذف كلمات التوقف def filteringText(tokens_list): # قائمة كلمات التوقف العربية listStopwords = set(stopwords.words('arabic')) filtered = [] for txt in tokens_list: if txt not in listStopwords: filtered.append(txt) tokens_list = filtered return tokens_list # دالة التجذيع def stemmingText(tokens_list): tokens_list = [ar_stemmer.stemWord(word) for word in tokens_list] return tokens_list # دالة دمج قائمة من الكلمات في جملة def toSentence(words_list): sentence = ' '.join(word for word in words_list) return sentence شرح الدوال التي كتبناها في الشيفرة: cleaningText: تحذف الأرقام وعلامات الترقيم العربية والإنكليزية من النص. remove_repeating_char: تحذف المحارف المكررة والتي قد يستخدمها كاتب التغريدة. tokenizingText: تعمل على تجزئة النص إلى قائمة من الوحدات tokens. filteringText: تحذف كلمات التوقف من قائمة الوحدات. stemmingText: تعمل على تجذيع كلمات قائمة الوحدات المتبقية. يُبين المثال التالي تجذيع بعض الكلمات المتشابهة: # مثال stem = ar_stemmer.stemWord(u"رايع") print (stem) stem = ar_stemmer.stemWord(u"رائع") print (stem) stem = ar_stemmer.stemWord(u"رائعون") print (stem) stem = ar_stemmer.stemWord(u"رائعين") print (stem) يكون ناتج التنفيذ: رايع رايع رايع رايع يُبين المثال التالي نتيجة استدعاء كل دالة من الدوال السابقة: # مثال text= "!أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء " print(text) text=cleaningText(text) print(text) tokens_list=tokenizingText(text) print(tokens_list) tokens_list=filteringText(tokens_list) print(tokens_list) tokens_list=stemmingText(tokens_list) print(tokens_list) يكون ناتج التنفيذ: !أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء أنا أحب الذهاب إلى الحديقة كل يوم صباحاً مع رفاقي هؤلاء ['أنا', 'أحب', 'الذهاب', 'إلى', 'الحديقة', 'كل', 'يوم', 'صباحاً', 'مع', 'رفاقي', 'هؤلاء'] ['أحب', 'الذهاب', 'الحديقة', 'يوم', 'صباحاً', 'رفاقي'] ['احب', 'ذهاب', 'حديق', 'يوم', 'صباح', 'رفاق'] تعرض الشيفرة التالية تنفيذ جميع دوال المعالجة الأولية على نصوص التغريدات ومن ثم حفظ النتائج في ملف جديد tweet_clean.csv. وبنفس الطريقة، نُنفذ دوال المعالجة الأولية على قاموس الكلمات الموجبة وقاموس الكلمات السالبة ونحفظ النتائج في ملفات جديدة لاستخدامها لاحقًا: positive_clean.csv و negative_clean.csv. # المعالجة الأولية للتغريدات tweets['tweet_clean'] = tweets['tweet'].apply(cleaningText) tweets['tweet_preprocessed'] = tweets['tweet_clean'].apply(tokenizingText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(filteringText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(stemmingText) # حذف التغريدات المكررة tweets.drop_duplicates(subset = 'tweet_clean', inplace = True) # التصدير إلى ملف tweets.to_csv(r'tweet_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس الموجب positive['word_clean'] = positive['word'].apply(cleaningText) positive.drop(['word'], axis = 1, inplace = True) positive['word_preprocessed'] = positive['word_clean'].apply(tokenizingText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(filteringText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ positive.drop_duplicates(subset = 'word_clean', inplace = True) nan_value = float("NaN") positive.replace("", nan_value, inplace=True) positive.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف positive.to_csv(r'positive_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس السالب negative['word_clean'] = negative['word'].apply(cleaningText) negative.drop(['word'], axis = 1, inplace = True) negative['word_preprocessed'] = negative['word_clean'].apply(tokenizingText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(filteringText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ negative.drop_duplicates(subset = 'word_clean', inplace = True) negative.replace("", nan_value, inplace=True) negative.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف negative.to_csv(r'negative_clean.csv', encoding="utf-8", index = False, header = True,index_label=None) تعرض الشيفرة التالية بناء قاموسين dict الأول للكلمات الموجبة والثاني للكلمات السالبة وبحيث يكون المفتاح key هو الكلمة والقيمة value هي نقاط الكلمة. يُعدّ استخدام بنية القاموس dict في بايثون مفيدًا جدًا للوصول المباشر إلى نقاط أي كلمة دون القيام بأي عملية بحث. لاحظ أننا نقرأ الكلمات الموجبة والسالبة من الملفات الجديدة ناتج المعالجة الأولية لملفات الكلمات الأصلية. # التصريح عن قاموس للكلمات الموجية dict_positive = dict() # بناء قاموس الكلمات الموجبة myfile = 'positive_clean.csv' positive_data = pd.read_csv(myfile, encoding='utf-8') positive = positive_data[['word_clean', 'polarity']] for i in range(len(positive)): dict_positive[positive_data['word_clean'][i].strip()] = int(positive_data['polarity'][i]) # التصريح عن قاموس للكلمات السالبة dict_negative = dict() # بناء قاموس الكلمات السالبة myfile = 'negative_clean.csv' negative_data = pd.read_csv(myfile, encoding='utf-8') negative = negative_data[['word_clean', 'polarity']] for i in range(len(negative)): dict_negative[negative_data['word_clean'][i].strip()] = int(negative_data['polarity'][i]) تقوم الدالة التالية sentiment_analysis_dict_arabic بحساب مجموع نقاط score قائمة من الكلمات وذلك بجمع نقاط الكلمات الواردة في قاموسي الكلمات الموجبة والسالبة. وفي النهاية تُعدّ قطبية polarity قائمة الكلمات موجبة positive إذا كان مجموع نقاطها أكبر من الصفر، وتُعدّ سالبة negative إذا كان مجموع نقاطها أصغر من الصفر، وإلا فإنها تكون محايدة neutral. # دالة حساب قطبية قائمة من الكلمات def sentiment_analysis_dict_arabic(words_list): score = 0 for word in words_list: if (word in dict_positive): score = score + dict_positive[word] for word in words_list: if (word in dict_negative): score = score + dict_negative[word] polarity='' if (score > 0): polarity = 'positive' elif (score < 0): polarity = 'negative' else: polarity = 'neutral' return score, polarity نستخدم الدالة السابقة في حساب قطبية كل تغريدة وذلك بتنفيذ الدالة على قائمة الكلمات التي حصلنا عليها بعد المعالجة الأولية لنص التغريدة tweet_preprocessed. أي أنه سيكون لكل تغريدة في نهاية المطاف قطبية polarity موجبة أو سالبة أو محايدة وفق مجموع النقاط الحاصلة عليها polarity_score. نحفظ نتائج الحساب في ملف جديد tweets_clean_polarity.csv. # حساب قطبية التغريدات results = tweets['tweet_preprocessed'].apply(sentiment_analysis_dict_arabic) results = list(zip(*results)) tweets['polarity_score'] = results[0] tweets['polarity'] = results[1] # كتابة النتائج في ملف tweets.to_csv(r'tweets_clean_polarity.csv', encoding='utf-8', index = False, header = True,index_label=None) تعرض الشيفرة التالية حساب عدد التغريدات من كل قطبية (موجبة، سالبة، محايدة) ومن ثم استخدام المكتبة matplotlib لرسم مخطط بياني من النوع pie يعرض نسب قطبية التغريدات: # رسم نسب قطبية التغريدات import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize = (6, 6)) # حساب عدد التغريدات من كل قطبية x = [count for count in tweets['polarity'].value_counts()] # تسميات الرسم labels = list(tweets['polarity'].value_counts().index) explode = (0.1, 0, 0) # تنفيذ الرسم ax.pie(x = x, labels = labels, autopct = '%1.1f%%', explode = explode, textprops={'fontsize': 14}) # عنوان الرسم ax.set_title('Tweets Polarities ', fontsize = 16, pad = 20) # الإظهار plt.show() يكون الإظهار: يُمكن الآن إظهار التغريدات الأكثر إيجابيًة باستخدام الشيفرة التالية: # طباعة أكثر التغريدات إيجابية pd.set_option('display.max_colwidth', 3000) positive_tweets = tweets[tweets['polarity'] == 'positive'] positive_tweets = positive_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=False).reset_index(drop = True) positive_tweets.index += 1 positive_tweets[0:10] يكون الإظهار: كما يُمكن إظهار التغريدات الأكثر سلبيًة: # طباعة أكثر التغريدات سلبية pd.set_option('display.max_colwidth', 3000) negative_tweets = tweets[tweets['polarity'] == 'negative'] negative_tweets = negative_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=True)[0:10].reset_index(drop = True) negative_tweets.index += 1 negative_tweets[0:10] يكون الإظهار: يُمكن استخدام مكتبة سحابة الكلمات WordCloud لرسم مجموعة من الكلمات بشكل فني كما تُبين الشيفرة التالية: # سحابة الكلمات from wordcloud import WordCloud # مكتبة للغة العربية import arabic_reshaper from bidi.algorithm import get_display # انتقاء بعض الكلمات المعالجة list_words='' i=0 for tweet in tweets['tweet_preprocessed']: for word in tweet: i=i+1 if i>100: break list_words += ' '+(word) # ضبط اللغة العربية reshaped_text = arabic_reshaper.reshape(list_words) artext = get_display(reshaped_text) # إعدادات سحابة الكلمات wordcloud = WordCloud(font_path='DroidSansMono.ttf', width = 600, height = 400, background_color = 'black', min_font_size = 10).generate(artext) fig, ax = plt.subplots(figsize = (8, 6)) # عنوان السحابة ax.set_title('Word Cloud of Tweets', fontsize = 18) ax.grid(False) ax.imshow((wordcloud)) fig.tight_layout(pad=0) ax.axis('off') plt.show() يكون الإظهار: تُجمّع الدالة التالية words_with_sentiment الكلمات الموجبة والكلمات السالبة المستخرجة من قائمة الكلمات المُمررة للدالة list_words في قائمتين منفصلتين الأولى للكلمات الموجبة والثانية للكلمات السالبة. تستخدم الدالة قاموسي الكلمات الموجبة والسالبة السابقين. # تجميع الكلمات الموجبة والكلمات السالبة def words_with_sentiment(list_words): positive_words=[] negative_words=[] for word in list_words: score_pos = 0 score_neg = 0 if (word in dict_positive): score_pos = dict_positive[word] if (word in dict_negative): score_neg = dict_negative[word] if (score_pos + score_neg > 0): positive_words.append(word) elif (score_pos + score_neg < 0): negative_words.append(word) return positive_words, negative_words نستخدم الدالة السابقة في الشيفرة التالية لاستخراج قائمة الكلمات الموجبة وقائمة الكلمات السالبة من التغريدات، ومن ثم إنشاء سحابتي كلمات لكل منهما لعرض الكلمات الموجبة والكلمات السالبة بشكل فني: # سحابة الكلمات الموجبة والسالبة # فرز الكلمات الموجبة والسالبة sentiment_words = tweets['tweet_preprocessed'].apply(words_with_sentiment) sentiment_words = list(zip(*sentiment_words)) # قائمة الكلمات الموجبة positive_words = sentiment_words[0] # قائمة الكلمات السالبة negative_words = sentiment_words[1] # سحابة الكلمات الموجبة fig, ax = plt.subplots(1, 2,figsize = (12, 10)) list_words_postive='' for row_word in positive_words: for word in row_word: list_words_postive += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_postive) artext = get_display(reshaped_text) wordcloud_positive = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Greens' , min_font_size = 10).generate(artext) ax[0].set_title(' Positive Words', fontsize = 14) ax[0].grid(False) ax[0].imshow((wordcloud_positive)) fig.tight_layout(pad=0) ax[0].axis('off') # سحابة الكلمات السالبة list_words_negative='' for row_word in negative_words: for word in row_word: list_words_negative += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_negative) artext = get_display(reshaped_text) wordcloud_negative = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Reds' , min_font_size = 10).generate(artext) ax[1].set_title('Negative Words', fontsize = 14) ax[1].grid(False) ax[1].imshow((wordcloud_negative)) fig.tight_layout(pad=0) ax[1].axis('off') plt.show() يكون الإظهار: تحويل النصوص إلى أشعة رقمية لا تقبل بنى تعلم الآلة النصوص كمدخلات لها، بل تحتاج إلى أشعة رقمية كمدخلات، لذا نستخدم الشيفرة التالية لتحويل الشعاع النصي لكل تغريده tweet_preprocessed إلى شعاع رقمي: # تحويل التغريدات إلى أشعة رقمية from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences # تركيب جمل التغريدات من المفردات المعالجة sentences = tweets['tweet_preprocessed'].apply(toSentence) print(sentences.values[25]) max_words = 5000 max_len = 50 # التصريح عن المجزئ # مع تحديد عدد الكلمات التي ستبقى # بالاعتماد على تواترها tokenizer = Tokenizer(num_words=max_words ) # ملائمة المجزئ لنصوص التغريدات tokenizer.fit_on_texts(sentences.values) # تحويل النص إلى قائمة من الأرقام S = tokenizer.texts_to_sequences(sentences.values) print(S[0]) # توحيد أطوال الأشعة X = pad_sequences(S, maxlen=max_len) print(X[0]) X.shape نقاط في الشيفرة السابقة لشرحها: يُحدّد المتغير max_words عدد الكلمات الأعظمي التي سيتم الاحتفاظ بها حيث يُحسب تواتر كل كلمة في كل النصوص ومن ثم تُرتب حسب تواترها (المرتبة الأولى للكلمة ذات التواتر الأكبر). ستُهمل الكلمات ذات المرتبة أكبر من max_words. يُحدّد المتغير max_len طول الشعاع الرقمي النهائي. إذا كان طول الشعاع الرقمي الموافق لنص أقل من max_len تُضاف أصفار للشعاع حتى يُصبح طوله مساويًا إلى max_len. أما إذا كان طوله أكبر يُقتطع جزءًا منه ليُصبح طوله مساويًا إلى max_len. تقوم الدالة fit_on_texts(sentences.values) بملائمة المُجزء tokenizer لنصوص جمل التغريدات أي حساب تواتر الكلمات والاحتفاظ بالكلمات ذات التواتر أكبر أو يساوي max_words. نطبع في الشيفرة السابقة، بهدف التوضيح، ناتج كل مرحلة. اخترنا مثلًا شعاع التغريدة 25 بعد المعالجة: [مكان جميل انصح زيار رسوم دخول] تكون نتيجة تحويل الشعاع السابق النصي إلى شعاع من الأرقام: [246, 1401, 467, 19, 87, 17, 74, 515, 2602, 330, 218, 579, 507, 465, 270, 45, 54, 343, 587, 7, 33, 58, 434, 30, 74, 144, 233, 451, 468] وبعد عملية توحيد الطول يكون الشعاع الرقمي النهائي الناتج: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 246 1401 467 19 87 17 74 515 2602 330 218 579 507 465 270 45 54 343 587 7 33 58 434 30 74 144 233 451 468] تجهيز دخل وخرج الشبكة العصبية تعرض الشيفرة التالية حساب شعاع الخرج أولًا، حيث نقوم بترميز القطبيات الثلاث إلى 0 للسالبة و1 للمحايدة و2 للموجبة. نستخدم الدالة train_test_split لتقسيم البيانات المتاحة إلى 80% منها لعملية التدريب و20% لعملية الاختبار وحساب مقاييس الأداء: # ترميز الخرج polarity_encode = {'negative' : 0, 'neutral' : 1, 'positive' : 2} # توليد شعاع الخرج y = tweets['polarity'].map(polarity_encode).values # مكنبة تقسيم البيانات إلى تدريب واختبار from sklearn.model_selection import train_test_split # تقسيم البيانات إلى تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape) نطبع في الشيفرة السابقة حجوم أشعة الدخل والخرج للتدريب وللاختبار: (16428, 50) (16428,) (4107, 50) (4107,) نموذج الشبكة العصبية المتعلم تُعدّ المكتبة Keras من أهم مكتبات بايثون التي توفر بناء شبكات عصبية لمسائل التعلم الآلي. تعرض الشيفرة التالية التصريح عن دالة بناء نموذج التعلّم create_model مع إعطاء جميع المعاملات المترفعة قيمًا ابتدائية: # تضمين النموذج التسلسلي from keras.models import Sequential # تضمين الطبقات اللازمة from keras.layers import Embedding, Dense, LSTM # دوال التحسين from tensorflow.keras.optimizers import Adam, RMSprop # التصريح عن دالة إنشاء نموذج التعلم # مع إعطاء قيم أولية للمعاملات المترفعة def create_model(embed_dim = 32, hidden_unit = 16, dropout_rate = 0.2, optimizers = RMSprop, learning_rate = 0.001): # التصريح عن نموذج تسلسلي model = Sequential() # طبقة التضمين model.add(Embedding(input_dim = max_words, output_dim = embed_dim, input_length = max_len)) # LSTM model.add(LSTM(units = hidden_unit ,dropout=dropout_rate)) # الطبقة الأخيرة model.add(Dense(units = 3, activation = 'softmax')) # بناء النموذج model.compile(loss = 'sparse_categorical_crossentropy', optimizer = optimizers(learning_rate = learning_rate), metrics = ['accuracy']) # طباعة ملخص النموذج print(model.summary()) return model نستخدم من أجل مسألتنا نموذج شبكة عصبية تسلسلي يتألف من ثلاث طبقات: الطبقة الأولى: طبقة التضمين Embedding نستخدم هذه الطبقة لتوليد ترميز مكثف للكلمات dense word encoding مما يُساهم في تحسين عملية التعلم. نطلب تحويل الشعاع الذي طوله input_length (في حالتنا 50) والذي يحوي قيم ضمن المجال input_dim (من 1 إلى 5000 في مثالنا) إلى شعاع من القيم ضمن المجال output_dim (مثلًا 32 قيمة). الطبقة الثانية LSTM يُحدّد المعامل المترفع units عدد الوحدات المخفية لهذه الطبقة. يُساهم المعامل dropout في معايرة الشبكة خلال التدريب حيث يقوم بإيقاف تشغيل الوحدات المخفية بشكل عشوائي أثناء التدريب، وبهذه الطريقة لا تعتمد الشبكة بنسبة 100٪ على جميع الخلايا العصبية الخاصة بها، وبدلاً من ذلك، تُجبر نفسها على العثور على أنماط أكثر أهمية في البيانات من أجل زيادة المقياس الذي تحاول تحسينه (الدقة مثلًا). الطبقة الثالثة Dense يُحدّد المعامل units حجم الخرج لهذه الطبقة (3 في حالتنا: 0 سالبة، 1 محايدة، 2 موجبة) ويُبين الشكل التالي ملخص النموذج: معايرة المعاملات الفائقة وصولا لنموذج أمثلي يُمكن الوصول لنموذج تعلم أمثلي بمعايرة معاملاته الفائقة وفق معطيات المشروع. لنُبين أولًا الفرق بين المعاملات الفائقة لنموذج والمعاملات الأخرى له: المعاملات الفائقة hyperparameters: هي إعدادات خوارزمية التعلّم قبل التدريب (والتي وضعها مصممو الخوارزمية) . المعاملات parameters: هي المعاملات التي يتعلّمها النموذج أثناء التدريب مثل أوزان الشبكة العصبية. تؤثر عملية معايرة المعاملات الفائقة على أداء النموذج لاسيما لجهة التوزان المطلوب بين مشكلة قلة التخصيص underfitting ومشكلة فرط التخصيص overfitting واللتان تؤديان إلى نموذج غير قادر على تعميم أمثلة التدريب وبالتالي لن يتمكن من التصنيف مع معطيات جديدة (يُمكن العودة للرابط من أكاديمية حسوب للمزيد من التفصيل حول هاتين المشكلتين). تظهر مشكلة قلة التخصيص عندما لا يكون للنموذج درجات حرية كافية ليتعلّم الربط بين الميزات والهدف، وبالتالي يكون له انحياز كبير نحو قيم معينة للهدف. يُمكن تصحيح قلة التخصيص بجعل النموذج أكثر تعقيدًا. أما مشكلة فرط التخصيص فتظهر عندما يقوم النموذج بتخزين بيانات التدريب فيكون له بالتالي تباين كبير والذي يُمكن تصحيحه بالحد من تعقيد النموذج باستخدام التسوية regularization. تكمن المشكلة في معايرة المعاملات الفائقة بأن قيمها المثلى تختلف من مسألة لأخرى! وبالتالي، فإن الطريقة الوحيدة للوصول لهذه القيم المثلى هي تجريب قيم مختلفة مع كل مجموعة بيانات تدريب جديدة. يوفر Scikit-Learn العديد من الطرق لتقويم المعاملات الفائقة وبالتالي سنعتمد في مشروعنا عليها دون أن نُعقّد الأمور أكثر. البحث الشبكي مع التقييم المتقاطع تُدعى الطريقة التي سنستخدمها في إيجاد القيم المثلى بالبحث الشبكي مع التقويم المتقاطع grid search with cross validation: البحث الشبكي grid search: نُعرّف شبكة grid من بعض القيم المُمكنة ومن ثم نولد كل التركيبات المُمكنة بينها. التقييم المتقاطع cross validation: وهو الطريقة المستخدمة لتقييم مجموعة قيم مُحدّدة للمعاملات الفائقة. عوضًا عن تقسيم البيانات إلى بيانات للتدريب وبيانات للتقييم مما يُخفّض من البيانات التي يُمكن لنا استخدامها للتدريب، نستخدم التقييم المتقاطع مع عدد محدّد من الحاويات K-Fold. تُقسم بيانات التدريب إلى عدد K من الحاويات ومن ثم نقوم بتكرار ما يلي K مرة: في كل مرة نقوم بتدريب النموذج مع بيانات K-1 حاوية ومن ثم تقويمه مع بيانات الحاوية K. في النهاية، يكون مقياس الأداء النهائي هو متوسط الخطأ لكل التكرارات. يُمكن تلخيص خطوات البحث الشبكي مع التقييم المتقاطع كما يلي: إعداد شبكة من المعاملات الفائقة. توليد كل تركيبات قيم المعاملات الفائقة. إنشاء نموذج لكل تركيب من القيم. تقييم النموذج باستخدام التقويم المتقاطع. اختيار تركيب قيم المعاملات ذو الأداء الأفضل. بالطبع، لن نقوم ببرمجة هذه الخطوات لأن الكائن GridSearchCV في Scikit-Learn يقوم بكل ذلك (يجب ملاحظة أن تنفيذ الشيفرة قد يستغرق بعض الوقت: حوالي الساعة على حاسوب ذو مواصفات عالية): from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasClassifier # حساب القيم الأمثلية للمعاملات المترفعة model = KerasClassifier(build_fn = create_model, epochs = 25, batch_size=128) # بعض القيم الممكنة للمعاملات المترفعة embed_dim = [32, 64] hidden_unit = [16, 32, 64] dropout_rate = [0.2] optimizers = [Adam, RMSprop] learning_rate = [0.01, 0.001, 0.0001] epochs = [10, 15, 25 ] batch_size = [128, 256] param_grid = dict(embed_dim = embed_dim, hidden_unit = hidden_unit, dropout_rate = dropout_rate, learning_rate = learning_rate, optimizers = optimizers, epochs = epochs, batch_size = batch_size) # تقويم النموذج لاختيار أفضل القيم grid = GridSearchCV(estimator = model, param_grid = param_grid, cv = 3) grid_result = grid.fit(X_train, y_train) results = pd.DataFrame() results['means'] = grid_result.cv_results_['mean_test_score'] results['stds'] = grid_result.cv_results_['std_test_score'] results['params'] = grid_result.cv_results_['params'] print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # حفظ النتائج results.to_csv(r'gridsearchcv_results.csv', index = False, header = True) results.sort_values(by='means', ascending = False).reset_index(drop=True) يُبين خرج الشيفرة السابقة أفضل القيم للمعاملات المترفعة: Best: 0.898588 using {'batch_size': 256, 'dropout_rate': 0.2, 'embed_dim': 32, 'epochs': 10, 'hidden_unit': 64, 'learning_rate': 0.001, 'optimizers': <class 'keras.optimizer_v2.adam.Adam'>} نحفظ نتائج حساب المعاملات الأمثلية في الملف gridsearchcv_results.csv. يُمكن معاينة هذه القيم: # قراءة نتائج معايرة المعاملات المترفعة results = pd.read_csv('gridsearchcv_results.csv') results.sort_values(by='means', ascending = False).reset_index(drop=True) print (results) يكون الخرج: حساب أوزان الصفوف يُمكن أن نلاحظ أن عدد التغريدات ذات القطبية الموجبة (73% من التغريدات) تطغى على عدد التغريدات السلبية (13%) والتغريدات المحايدة (13%) مما قد يؤدي إلى انحراف نتائج التعلم نحو القطبية الموجبة. يُمكن تلافي ذلك عن طريق الموازنة بين هذه الصفوف الثلاثة. نحسب في الشيفرة التالية عدد التغريدات الموجبة والسالبة والمحايدة ونسبها: # حساب أوزان القطبيات posCount=0 negCount=0 neuCount=0 # حساب عدد التغريدات الموجبة والسالبة والمحايدة for index, row in tweets.iterrows(): if row['polarity']=='negative': negCount=negCount+1 elif row['polarity']=='positive': posCount=posCount+1 else: neuCount=neuCount+1 print(negCount, neuCount, posCount) total=posCount+ negCount+ neuCount # حساب النسب weight_for_0 = (1 / negCount) * (total / 3.0) weight_for_1 = (1 / neuCount) * (total / 3.0) weight_for_2 = (1 / posCount) * (total / 3.0) print(weight_for_0, weight_for_1, weight_for_2) class_weight = {0: weight_for_0, 1: weight_for_1, 2:weight_for_2} يكون ناتج طباعة هذه الأوزان ما يلي (لا حظ الوزن الأصغر للتغريدات الموجبة): 2.4954429456799123 2.504573728503476 0.45454545454545453 بناء نموذج التعلم النهائي نستخدم الدالة KerasClassifier من scikit لبناء المُصنف مع الدالة السابقة create_model : # مكتبة التصنيف from keras.wrappers.scikit_learn import KerasClassifier # إنشاء النموذج مع قيم المعاملات المترفعة الأمثلية model = KerasClassifier(build_fn = create_model, # معاملات النموذج dropout_rate = 0.2, embed_dim = 32, hidden_unit = 64, optimizers = Adam, learning_rate = 0.001, # معاملات التدريب epochs=10, batch_size=256, # نسبة بيانات التقييم validation_split = 0.1) # ملائمة النموذج مع بيانات التدريب # مع موازنة الصفوف الثلاثة model_prediction = model.fit(X_train, y_train, class_weight=class_weight) يُمكن الآن رسم منحني الدقة accuracy لكل من بيانات التدريب والتقييم (لاحظ أننا في الشيفرة السابقة احتفاظنا بنسبة 10% من بيانات التدريب للتقييم): # معاينة دقة النموذج # التدريب والتقييم fig, ax = plt.subplots(figsize = (10, 4)) ax.plot(model_prediction.history['accuracy'], label = 'train accuracy') ax.plot(model_prediction.history['val_accuracy'], label = 'val accuracy') ax.set_title('Model Accuracy') ax.set_xlabel('Epoch') ax.set_ylabel('Accuracy') ax.legend(loc = 'upper left') plt.show() يكون للمنحني الشكل التالي: حساب مقاييس الأداء يُمكن الآن حساب مقاييس الأداء المعروفة في مسائل التصنيف (الصحة Accuracy، الدقة Precision، الاستذكار Recall، المقياس F1) للنموذج المتعلم باستخدام الشيفرة التالية: # مقاييس الأداء # مقياس الصحة from sklearn.metrics import accuracy_score # مقياس الدقة from sklearn.metrics import precision_score # مقياس الاستذكار from sklearn.metrics import recall_score # f1 from sklearn.metrics import f1_score # مصفوفة الارتباك from sklearn.metrics import confusion_matrix # تصنيف بيانات الاختبار y_pred = model.predict(X_test) # حساب مقاييس الأداء accuracy = accuracy_score(y_test, y_pred) precision=precision_score(y_test, y_pred , average='weighted') recall= recall_score(y_test, y_pred, zero_division=1, average='weighted') f1= f1_score(y_test, y_pred, zero_division=1, average='weighted') print('Model Accuracy on Test Data:', accuracy*100) print('Model Precision on Test Data:', precision*100) print('Model Recall on Test Data:', recall*100) print('Model F1 on Test Data:', f1*100) confusion_matrix(y_test, y_pred) تكون النتائج (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Model Accuracy on Test Data: 90.1144387630874 Model Precision on Test Data: 90.90281584915091 Model Recall on Test Data: 90.1144387630874 Model F1 on Test Data: 90.32645671662543 array([[ 366, 129, 24], [ 53, 444, 62], [ 20, 118, 2891]], dtype=int64) يُمكن رسم مصفوفة الارتباك confusion matrix بشكل أوضح باستخدام المكتبة seaborn: # رسم مصفوفة الارتباك import seaborn as sns sns.set(style = 'whitegrid') fig, ax = plt.subplots(figsize = (8,6)) sns.heatmap(confusion_matrix(y_true = y_test, y_pred = y_pred), fmt = 'g', annot = True) ax.xaxis.set_label_position('top') ax.xaxis.set_ticks_position('top') ax.set_xlabel('Prediction', fontsize = 14) ax.set_xticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) ax.set_ylabel('Actual', fontsize = 14) ax.set_yticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) plt.show() مما يُظهر: يُمكن حساب بعض مقاييس الأداء الأخرى المُستخدمة في حالة وجود أكثر من صف في المسألة (Micro, Macro, Weighted): # مقاييس الأداء في حالة أكثر من صفين print('\nAccuracy: {:.2f}\n'.format(accuracy_score(y_test, y_pred))) print('Micro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='micro'))) print('Micro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='micro'))) print('Micro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='micro'))) print('Macro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='macro'))) print('Macro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='macro'))) print('Macro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='macro'))) print('Weighted Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='weighted'))) print('Weighted Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='weighted'))) print('Weighted F1-score: {:.2f}'.format(f1_score(y_test, y_pred, average='weighted'))) # تقرير التصنيف from sklearn.metrics import classification_report print('\nClassification Report\n') print(classification_report(y_test, y_pred, target_names=['Class 1', 'Class 2', 'Class 3'])) مما يُعطي (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Accuracy: 0.88 Micro Precision: 0.88 Micro Recall: 0.88 Micro F1-score: 0.88 Macro Precision: 0.79 Macro Recall: 0.83 Macro F1-score: 0.80 Weighted Precision: 0.90 Weighted Recall: 0.88 Weighted F1-score: 0.89 Classification Report precision recall f1-score support Class 1 0.79 0.75 0.77 519 Class 2 0.59 0.82 0.69 559 Class 3 0.98 0.92 0.95 3029 accuracy 0.88 4107 macro avg 0.79 0.83 0.80 4107 weighted avg 0.90 0.88 0.89 4107 يُمكن أيضًا اختيار مجموعة تغريدات عشوائية جديدة وتصنيفها وحفظ النتائج في ملف results.csv: # تصنيف مجموعة اختبار text_clean = tweets['tweet_clean'] text_train, text_test = train_test_split(text_clean, test_size = 0.2, random_state = 0) result_test = pd.DataFrame(data = zip(text_test, y_pred), columns = ['text', 'polarity']) polarity_decode = {0 : 'Negative', 1 : 'Neutral', 2 : 'Positive'} result_test['polarity'] = result_test['polarity'].map(polarity_decode) pd.set_option('max_colwidth', 300) # حفظ النتائج result_test.to_csv("results.csv") result_test تكون النتائج مثلًا: الخلاصة عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لتصنيف النصوص العربية إلى موجبة وسالبة ومحايدة. يُمكن تجربة المثال كاملًا من موقع Google Colab، ولا تنسى الاطلاع على مجموعة البيانات المتوفرة الخاصة بهذا المقال. اقرأ أيضًا دليل المبتدئين لفهم أساسيات التعلم العميق لذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال1 نقطة -
السلام عليكم ورحمة الله وبركاته , احتاج الى طريقة لعمل نموذج استمارة او وصفة طبية تحتوي على بيانات ديناميكية ثم طباعتها . مع العلم اني استعمل مكتبة electrion.js1 نقطة
-
انا تخصصي علوم حاسب، وناخذ لغة Java كـ تأسيس بالجامعة وودي اتعلم لغات خارجيًا بعدها بإذن الله واحترت بـC++ هل ضروري تعلمها ولا عادي لو ما تعلمتها بما ان Java تؤدي نفس مهامها تقريبًا على حسب بحوثاتي، لأن في غيرها نفسي اتعلمها بس احترت هل ضروري تعلمها أو معرفتي بـJava تكفي؟1 نقطة
-
عندي سؤال ,كيف يوتيوب يمكن لكل شخص وضع عنوان و صوره و وصف من اختياره هل هذا الشي يفعله back end ام front end1 نقطة
-
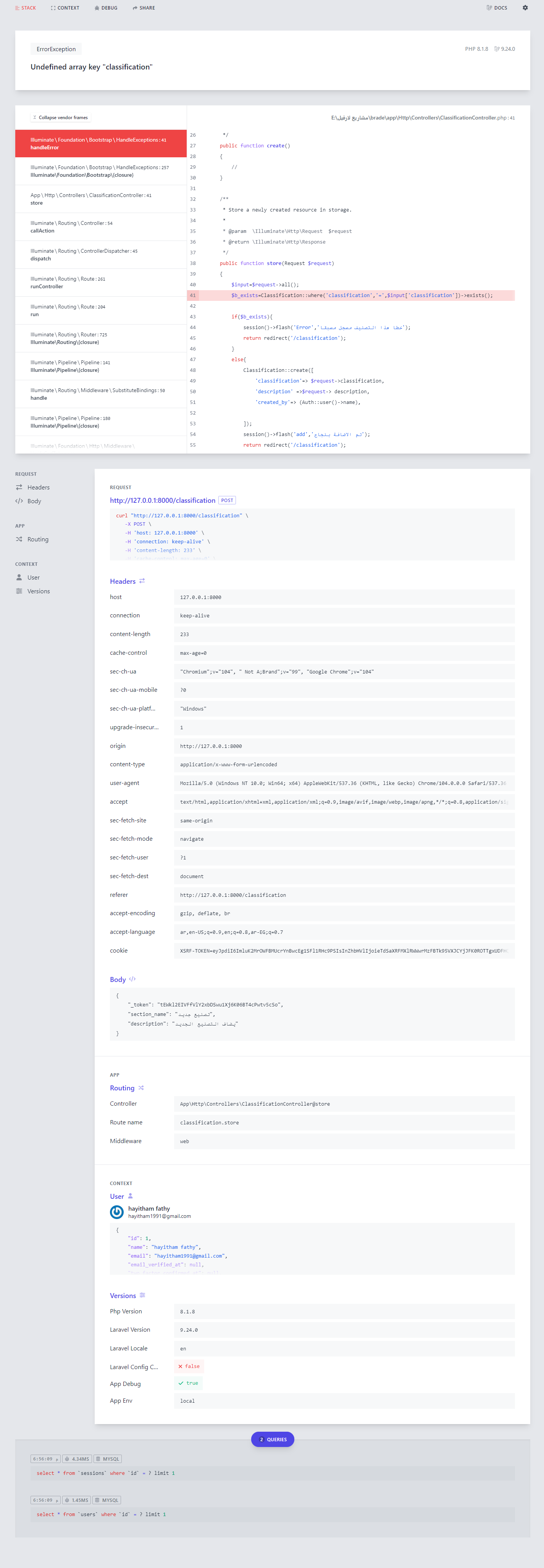
السلام عليكم عندي مشكلة المفروض عاوز ابعت البيانات من الاستور الي داتا بيز بس بيعمل المشكلة مثل التي في الصوره public function store(Request $request) { $input=$request->all(); $b_exists=Classification::where('classification','=',$input['classification'])->exists(); if($b_exists){ session()->flash('Error','خطا هذا التصنيف مسجل مسبقا'); return redirect('/classification'); } else{ Classification::create([ 'classification'=> $request->classification, 'description' =>$request-> description, 'created_by'=> (Auth::user()->name), ]); session()->flash('add','تم الاضافة بنجاح'); return redirect('/classification'); } }
 1 نقطة
1 نقطة -
كنت أود أن أعرف ما هي طريقة الامتحان الذي سأمتحنه بعد الإنتهاء من الدورة؟ وهذا لأن المعلومات الجديدة التي اتلقاها في الدورة كثير وهذا أحيانا يُشعرني بأنني أنسي بعض ما قد درسته جزاكم الله كل خير1 نقطة
-
بل يفعله كل من ال backend وال frontend معاً وذلك لأن ال frontend سيقوم بإنشاء حقول الإدخال الخاصة بإدخال كم من الاسم و الصورة... إلخ ثم سيقوم بإرسالها لل backend الذي سيقوم باستقبال هذه البيانات وتخزينها و ارجاعها لل frontend عندما يطلبها.1 نقطة
-
كلمة السر تخزن بقاعدة البيانات مشفره باستعمال التشفير التالي: 'password' => Hash::make($input['password']), وعند الحصول على كلمة السر من قاعدة البيانات كيف نفك تشفيرها لمقارنتها بكلمة مرور مدخله من طرف المستخدم لإعادة التأكيد.1 نقطة
-
لدي بعض ملفات PHP وقمت بوضعها في المجلد public في المسار التالي: public/php/scripts/ الآن أحاول إستدعاء أحد هذه الملفات من داخل ملف blade بالشكل التالي: @php include_once('/php/scripts/helpers.php'); @endphp ولكن الكود السابق يعرض رسالة الخطأ: include_once(/php/scripts/helpers.php): failed to open stream: No such file or directory ما هي المشكلة؟ هل توجد دوال أخرى جاهزة لإستدعاء ملفات PHP في لارافيل Laravel؟1 نقطة
-
 تُعدّ مسألة تصنيف العملاء أي تجزئتهم إلى مجموعات متشابهة في سلوكها (عمليات الشراء والتسوق) من المسائل الهامة في عالم التسويق وذلك بهدف إعداد حملات تسويقية مختلفة مناسبة لكل مجموعة من المجموعات المُستهدفة. سنعرض في هذه المقالة استخدام خوارزميات العنقدة Clustering لاستكشاف مجموعات العملاء أو الزبائن المختلفة، ويُمكن تنزيل بيانات التدريب والشيفرة البرمجية من الملف المضغوط (والذي تجده أيضًا بنهاية المقال)، لتتمكن من فهم المحتوى أكثر. نستخدم في هذه المقالة التعليمية مجموعة بيانات حول 200 زبون تتألف من عمودين: الدخل السنوي للزبون بآلاف الدولارات Annual Income. تقييم الزبون Spending Score وهو رقم يتراوح بين 1 و 100 ويعكس مدى ولاء الزبون للمتجر والمبالغ التي أنفقها في الشراء منه (100 يعني الزبون الأكثر انفاقًا). يُمكن تنزيل هذه البيانات المتاحة على موقع Kaggle أو من الرابط هنا. ما هي العنقدة Clustering العنقدة هي عملية تجزئة (تقسيم) مجموعة من البيانات إلى عناقيد clusters (مجموعات) وبحيث تكون العناصر الموجودة في عنقود واحد متشابهة فيما بينها وأقل تشابهًا مع عناصر العناقيد الأخرى. تندرج خوارزميات العنقدة ضمن خوارزميات التعلم الآلي المدعوة "ليست تحت الإشراف" unsupervised بمعنى أن البيانات المُقدّمة في البداية لا تحوي أي تسميات labels أو تصنيفات بشكل مُسبق. سنرى مثًلا أن مسألة تحديد عدد العناقيد هو مسألة مهمة يجب الاعتناء بها إذ لا نعرف مُسبقًا ما هو عدد العناقيد الأمثلي. نعرض في هذه المقالة نوعين أساسيين من خوارزميات العنقدة: خوارزميات التجزئة Partitioning: تبدأ هذه الخوارزميات بتجزئة عناصر البيانات إلى k عنقود (مختارة بشكل عشوائي) ومن ثم تُكرر تعديل هذه المجموعات وصولًا إلى حل جيد. من أشهر هذه الخوارزميات الخوارزمية المدعوة k-means (أي k وسطي). الخوارزميات التكتلية Agglomerative: تبني هذه الخوارزمية هرمية من العناقيد حيث تبدأ بوضع كل عنصر من عناصر البيانات في عنقود مستقل ثم تكرر دمج العناقيد المتشابهة وصولًا إلى عنقود واحد في نهاية المطاف. الخوارزمية K-Means تُعدّ الخوارزمية K-Means من أشهر وأبسط خوارزميات العنقدة بالتجزئة: دخل الخوارزمية: عدد العناقيد المطلوب k بيانات التدريب وهي عبارة عن مجموعة من العناصر (أشعة رقمية): {x1, x2, . . . , xN} حيث xi هو شعاع من الأرقام. خرج الخوارزمية: تُسندّ الخوارزمية كل عنصر من عناصر الدخل إلى أحد العناقيد (التي عددها k). المعالجة: تختار الخوارزمية أولًا k شعاع من أشعة الدخل بشكل عشوائي كمراكز العناقيد. تُكرر الخوارزمية ما يلي وصولًا إلى التقارب: إسناد كل شعاع من أشعة الدخل إلى المركز الأقرب حساب المركز الجديد لكل عنقود يعني التقارب عدم انتقال أي شعاع من عنقوده الحالي الموضوع فيه إلى عنقود آخر. يُبين الشكل التالي المراحل الأساسية للخوارزمية: لفهم مراحل الخوارزمية نعرض أولًا خطوات تنفيذها على المثال التعليمي التالي: ليكن لدينا مجموعة العناصر العشرة التالية: D = { (5,3), (10,15), (15,12), (24,10), (30,45), (85,70), (71,80), (60,78), (55,52), (80,91) } وبفرض أننا نريد تقسيمها إلى عنقودين (k=2). لنختار مثلًا العنصر الأول كمركز للعنقود الأول والعنصر الثاني مركزًا للعنقود الثاني أي: c1(x) = 5, c1(y)=3 c2(x) = 10 , c2(y)=15 نحسب الآن بُعد (المسافة الإقليدية euclidean distance) كل عنصر من عناصر البيانات عن كل من المركزين ونُسند العنصر إلى المركز الأقرب. يكون لدينا: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } رقم العنصر المسافة الإقليدية عن المركز الأول المسافة الإقليدية عن المركز الثاني العنقود المُسند إليه 1 (5,3) 0 13 C1 2 (10,15) 13 0 C2 3 (15,12) 13.45 5.83 C2 4 (24,10) 20.24 14.86 C2 5 (30,45) 48.87 36 C2 6 (85,70) 104.35 93 C2 7 (71,80) 101.41 89 C2 8 (60,78) 93 80 C2 9 (55,52) 70 58 C2 10 (80,91) 115.52 103.32 C2 نحسب الآن مركزي العنقودين فنحصل على: c1(x) = 5, c1(y)=3 c2(x) = (10 + 15 + 24 + 30 + 85 + 71 + 60 + 55 + 80) / 9 = 47.77 c2(y) = (15 + 12 + 10 + 45 + 70 + 80 + 78 + 52 + 91) / 9 = 50.33 نُعيد العملية لنحصل على: رقم العنصر المسافة الإقليدية عن المركز الأول المسافة الإقليدية عن المركز الثاني العنقود المُسند إليه 1 (5,3) 0 63.79 C1 2 (10,15) 13 51.71 C1 3 (15,12) 13.45 50.42 C1 4 (24,10) 20.24 46.81 C1 5 (30,45) 48.87 18.55 C2 6 (85,70) 104.35 42.1 C2 7 (71,80) 101.41 37.68 C2 8 (60,78) 93 30.25 C2 9 (55,52) 70 7.42 C2 10 (80,91) 115.52 51.89 C2 نحسب الآن مركزي العنقودين الجديدين فنحصل على: c1(x) = (5, 10, 15, 24) / 4 = 13.5 c1(y) = (3, 15, 12, 10) / 4 = 10.0 c2(x) = (30 + 85 + 71 + 60 + 55 + 80) / 6 = 63.5 c2(y) = (45 + 70 + 80 + 78 + 52 +91) / 6 = 69.33 نُعيد العملية مرة أخرى لنحصل على: رقم العنصر المسافة الإقليدية عن المركز الأول المسافة الإقليدية عن المركز الثاني العنقود المُسند إليه 1 (5,3) 11.01 88.44 C1 2 (10,15) 6.1 76.24 C1 3 (15,12) 2.5 75.09 C1 4 (24,10) 10.5 71.27 C1 5 (30,45) 38.69 41.4 C1 6 (85,70) 93.33 21.51 C2 7 (71,80) 90.58 13.04 C2 8 (60,78) 82.37 9.34 C2 9 (55,52) 59.04 19.3 C2 10 (80,91) 104.8 27.23 C2 نحسب الآن مركزي العنقودين الجديدين فنحصل على: c1(x) = (5, 10, 15, 24, 30) / 5 = 16.8 c1(y) = (3, 15, 12, 10, 45) / 5 = 17.0 c2(x) = (85 + 71 + 60 + 55 + 80) / 5 = 70.2 c2(y) = (70 + 80 + 78 + 52 + 91) / 5 = 74.2 نُعيد العملية فلا يتغير إسناد أي عنصر مما يعني التقارب وثبات المراكز والعناقيد clusters. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن إعداد المشروع يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ. نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة البرمجية بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها. نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا. نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا: mkdir clustering cd clustering نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية: python -m venv clustering ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية: source clustering/bin/activate أما في Windows، فيكون أمر التنشيط: "clustering/Scripts/activate.bat" نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها. نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها: jupyter==1.0.0 numpy==1.21.5 scikit-learn==1.0.1 scipy==1.7.3 pandas==1.3.5 matplotlib==3.5.1 نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي: (clustering) $ pip install -r requirements.txt بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا. كتابة شيفرة تطبيق العنقدة للعملاء نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا: (clustering) $ jupyter notebook ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم clust مثلًا. تنفيذ المثال التعليمي نبدأ أولًا بإنشاء بيانات المثال التعليمي السابق ورسمها باستخدام المكتبة matplotlib: # المكتبة الرقمية import numpy as np # مكتبة الرسم import matplotlib.pyplot as plt # إنشاء البيانات X = np.array([[5,3], [10,15], [15,12], [24,10], [30,45], [85,70], [71,80], [60,78], [55,52], [80,91],]) # الرسم plt.scatter(X[:,0],X[:,1]) plt.show() مما يُظهر: تُبين الشيفرة التالية استخدام الصف KMeans من مكتبة العنقدة sklearn.cluster. نُنشئ أولًا غرض (نموذج model) من هذا الصف مع تحديد عدد العناقيد المطلوبة. تُنفذّ الطريقة fit خوارزمية KMeans على بيانات التدريب لإيجاد العناقيد المطلوبة. تُرقّم الخوارزمية العناقيد بدءًا من الصفر (تسميات labels). يُمكن طبعًا طباعة مراكز العناقيد. # KMeans from sklearn.cluster import KMeans # إنشاء غرض من الصف # تحديد عدد العناقيد المطلوب kmeans = KMeans(n_clusters=2) # الملائمة مع البيانات kmeans.fit(X) # طباعة المراكز print(kmeans.cluster_centers_) # طباعة تسميات العناقيد print(kmeans.labels_) يكون الخرج: [[70.2 74.2] [16.8 17. ]] [1 1 1 1 1 0 0 0 0 0] يُمكن الآن استخدام النموذج المُتعلم السابق للتنبؤ بعنقود أي مثال جديد وذلك باستخدام الطريقة predict كما تُبين الشيفرة التالية: # التنبؤ print(kmeans.predict([[10,10]])) حيث يكون الخرج مثلًا: [1] يُمكن أيضًا رسم نقاط التدريب مع مراكزها بلون مميز كما تُبين الشيفرة التالية: # الرسم مع المراكز plt.scatter(X[:,0],X[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(kmeans.cluster_centers_[:,0] ,kmeans.cluster_centers_[:,1], color='black') يكون الخرج: ننتقل الآن لمعالجة مسألتنا الأساسية وهي عنقدة الزبائن. تعرض الشيفرة التالية تحميل البيانات من الملف shopping-data.csv ووضعها في إطار بيانات من المكتبة pandas. # مكتبة إطار البيانات import pandas as pd # تحميل البيانات customer_data = pd.read_csv('shopping-data.csv') # إظهار ترويسة البيانات customer_data.head() تظهر أوائل البيانات: نحذف في الشيفرة التالية رقم الزبون من إطار البيانات كي لا يدخل في عملية حساب العناقيد. ثم نُنشئ نموذجًا متعلمًا من الصف KMeans مع عدد العناقيد مساويًا لخمسه (نعرض لاحقًا كيفية تحديدنا لهذا الرقم): # حذف رقم الزبون data = customer_data.iloc[:, 1:3].values # إنشاء النموذج المتعلم kmeans = KMeans(n_clusters=5) # الملائمة مع البيانات kmeans.fit(data) # طباعة المراكز print(kmeans.cluster_centers_) # طباعة التسميات print(kmeans.labels_) يكون الإظهار: [[88.2 17.11428571] [55.2962963 49.51851852] [25.72727273 79.36363636] [86.53846154 82.12820513] [26.30434783 20.91304348]] [4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 1 4 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 0 3 1 3 0 3 0 3 1 3 0 3 0 3 0 3 0 3 1 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3] يُمكن الآن أن نرسم النقاط مع المراكز باستخدام الشيفرة التالية: # الرسم plt.scatter(data[:,0],data[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(data[:,0], data[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(kmeans.cluster_centers_[:,0] ,kmeans.cluster_centers_[:,1], color='black') plt.show() مما يُعطي: تفسير نتائج العنقدة تقييمها يُمكن لنا بمعاينة الشكل السابق استنتاج ما يلي (وهو الهدف الأساسي من عملية العنقدة): الزبائن في أعلى اليمين (نقاط البيانات الصفراء) هم الزبائن ذوو الرواتب المرتفعة والإنفاق المرتفع. هؤلاء هم الزبائن الواجب استهدافهم دومًا والمحافظة عليهم. الزبائن في أعلى اليسار (نقاط البيانات الخضراء) هم الزبائن ذوو الرواتب المنخفضة والإنفاق المرتفع. هؤلاء هم الزبائن الواجب العناية بهم واستهدافهم بحملات التخفيضات مثلًا. الزبائن في أسفل اليمين (نقاط البيانات البنفسجية) هم الزبائن ذوو الرواتب المرتفعة والإنفاق المنخفض. هؤلاء هم الزبائن الواجب جذبهم بالطرق التسويقية ما أمكن ذلك. الزبائن في أسفل اليسار (نقاط البيانات الحمراء) هم الزبائن ذوو الرواتب المنخفضة والإنفاق المنخفض. لا داع لإضاعة الكثير من الوقت والجهد معهم. الزبائن في الوسط (نقاط البيانات الزرقاء) هم الزبائن أصحاب الدخل المتوسط والإنفاق المتوسط. يُمكن استهدافهم أيضًا لاسيما أن عددهم كبيرًا كما يُبين الشكل السابق. يُمكن تقييم نتائج العنقدة باستخدام المعامل المدعو Silhouette Coefficient، ويُحسب هذا المعامل من أجل عنصر بيانات x كما يلي: حيث: a هي وسطي المسافات بين x وبين العناصر الموجودة في نفس العنقود الموجود فيه العنصر x. b هي وسطي المسافات بين x وبين العناصر الموجودة في العناقيد القريبة من عنقود x. كما يُبين الشكل التالي: يُمكن ملاحظة ما يلي حول هذا المعامل: أفضل قيمة له هي 1 وأسوأ قيمة له هي -1. تُشير القيمة 0 إلى وجد تراكب overlapping في العناقيد. تدل القيمة السالبة على وجود العنصر x في عنقود خاطئ إذ يوجد عنقود آخر أقرب إلى x. يكون المعامل silhouette_score لمجموعة من البيانات وسطي قيمة المعامل لكل منها أي: يُمكن تضمين حساب هذا المعامل من sklearn.metrics كما تُبين الشيفرة التالية: from sklearn.metrics import silhouette_score cluster_labels = kmeans.fit_predict(data) # حساب المعامل silhouette_avg = silhouette_score(data, cluster_labels) print(silhouette_avg) يكون لطريقة حساب المعامل silhouette_score معاملي دخل الأول هو البيانات والثاني هو تسميات العناقيد الناتجة عن استدعاء الطريقة fit_predict أولًا. يكون الناتج في مثالنا: 0.553931997444648 إيجاد عدد العناقيد الأمثلي يُمكن استخدام المعامل Silhouette Coefficient لإيجاد عدد العناقيد الأمثلي المناسب لبيانات التدريب وذلك بحساب المعامل مع قيم مختلفة لعدد العناقيد ومن ثم اختيار العدد الذي يُعطي قيمة أعظمية للمعامل كما تُبين الشيفرة التالية: # مجموعة القيم الممكنة range_n_clusters = [2, 3, 4, 5, 6, 7] for n_clusters in range_n_clusters: clusterer = KMeans(n_clusters=n_clusters) cluster_labels = clusterer.fit_predict(data) # حساب المعامل silhouette_avg = silhouette_score(data, cluster_labels) print( "For n =", n_clusters, "silhouette_score is :", silhouette_avg, ) مما يُظهر المعامل من أجل كل قيمة محتملة لعدد العناقيد: For n = 2 silhouette_score is : 0.2968969162503008 For n = 3 silhouette_score is : 0.46761358158775435 For n = 4 silhouette_score is : 0.4931963109249047 For n = 5 silhouette_score is : 0.553931997444648 For n = 6 silhouette_score is : 0.5376203956398481 For n = 7 silhouette_score is : 0.5270287298101395 وبالتالي نلاحظ أن القيمة الأمثلية هي خمسة عناقيد. الخوارزميات التكتلية تمتاز الخوارزميات التكتلية بأنها توفر طريقة معاينة بسيطة لإيجاد عدد العناقيد الأمثلي عن طريق رسم شجرة دمج العناقيد مع بعضها البعض dendrogram: دخل الخوارزمية: بيانات التدريب وهي عبارة عن مجموعة من الأشعة الرقمية: {x1, x2, . . . , xN} حيث xi هو شعاع من الأرقام. خرج الخوارزمية: شجرة دمج العناقيد مع بعضها البعض dendrogram. المعالجة: تبدأ الخوارزمية بوضع كل عنصر من عناصر البيانات في عنقود. تُكرر الخوارزمية ما يلي وصولًا إلى عنقود وحيد: دمج أقرب عنقودين مع بعضهما البعض توجد عدة طرق لإيجاد أقرب عنقودين، من أبسطها الطريقة المسماة بالربط البسيط Single Linkage والتي تحسب المسافة بين عنقودين كما يلي: المسافة بين عنقودين هي أصغر مسافة بين عنصرين من هذين العنقودين. نستخدم فيما يلي الخوارزمية التكتلية مع البيانات التعليمية ومن ثم مع بيانات الزبائن. تعرض الشيفرة التالية طريقة بسيطة لتسمية نقاط البيانات التعليمية (العشرة) لتسهيل عملية المشاهدة والمتابعة: # التسميات : 2,1, ..., 10 labels = range(1, 11) plt.subplots_adjust(bottom=0.1) plt.scatter(X[:,0],X[:,1]) # تسمية النقاط for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate( label, xy=(x, y), xytext=(-3, 3), textcoords='offset points', ha='right', va='bottom') plt.show() يكون الخرج: نبدأ أولًا بالشيفرة اللازمة لرسم شجرة الدمج dendrogram من أجل إيجاد عدد العناقيد الأمثل: # المكتبات اللازمة from scipy.cluster.hierarchy import dendrogram, linkage # اختيار الربط البسيط linked = linkage(X, 'single') # التسميات: 2,1, .. ,10 labelList = range(1, 11) # dendrogram dendrogram(linked, orientation='top', labels=labelList, distance_sort='descending', show_leaf_counts=True) plt.show() نُعاين شجرة الدمج الناتجة والتي تُبين أن عدد العناقيد المُمكن هو عنقودين: نستدعي الآن الدالة AgglomerativeClustering مع طلب عدد العناقيد مساويًا إلى 2: from sklearn.cluster import AgglomerativeClustering # العنقدة التكتلية cluster = AgglomerativeClustering(n_clusters=2) # الملائمة مع البيانات cluster.fit_predict(X) والتي تُظهر تسميات عنقود كل عنصر: array([1, 1, 1, 1, 0, 0, 0, 0, 0, 0], dtype=int64) يُمكن أيضًا رسم العناقيد: # الرسم plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow') plt.show() يكون الإظهار: ننتقل الآن إلى مسألة الزبائن باستخدام شيفرة مماثلة: # نوع الربط linked = linkage(data, 'ward') # dendrogram dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True) # الرسم plt.title("Customer Dendograms") plt.show() يُمكن معاينة شجرة الدمج الناتجة: والتي تُبين أن عدد العناقيد المناسب هو 5. نستدعي الدالة AgglomerativeClustering في الشيفرة التالية: cluster = AgglomerativeClustering(n_clusters=5, affinity='euclidean', linkage='ward') cluster.fit_predict(data) # الرسم plt.scatter(data[:,0], data[:,1], c=cluster.labels_, cmap='rainbow') plt.show() ويكون الخرج: وهو، بالطبع، يُشابه ما حصلنا عليه سابقًا مع الخوارزمية KMeans. الخلاصة عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لعنقدة مجموعة من البيانات مع آليات اختيار عدد العناقيد المناسب للمسألة. يُمكن تجربة المثال كاملًا من موقع Google Colab من الرابط، ولا تنس الاطلاع على ملف بيانات التدريب والشيفرة البرمجية. اقرأ أيضًا تعقيد الخوارزميات Algorithms Complexity أمثلة عن أنواع الخوارزميات مدخل إلى تعلم الآلة (Machine learning) في PHP1 نقطة
تُعدّ مسألة تصنيف العملاء أي تجزئتهم إلى مجموعات متشابهة في سلوكها (عمليات الشراء والتسوق) من المسائل الهامة في عالم التسويق وذلك بهدف إعداد حملات تسويقية مختلفة مناسبة لكل مجموعة من المجموعات المُستهدفة. سنعرض في هذه المقالة استخدام خوارزميات العنقدة Clustering لاستكشاف مجموعات العملاء أو الزبائن المختلفة، ويُمكن تنزيل بيانات التدريب والشيفرة البرمجية من الملف المضغوط (والذي تجده أيضًا بنهاية المقال)، لتتمكن من فهم المحتوى أكثر. نستخدم في هذه المقالة التعليمية مجموعة بيانات حول 200 زبون تتألف من عمودين: الدخل السنوي للزبون بآلاف الدولارات Annual Income. تقييم الزبون Spending Score وهو رقم يتراوح بين 1 و 100 ويعكس مدى ولاء الزبون للمتجر والمبالغ التي أنفقها في الشراء منه (100 يعني الزبون الأكثر انفاقًا). يُمكن تنزيل هذه البيانات المتاحة على موقع Kaggle أو من الرابط هنا. ما هي العنقدة Clustering العنقدة هي عملية تجزئة (تقسيم) مجموعة من البيانات إلى عناقيد clusters (مجموعات) وبحيث تكون العناصر الموجودة في عنقود واحد متشابهة فيما بينها وأقل تشابهًا مع عناصر العناقيد الأخرى. تندرج خوارزميات العنقدة ضمن خوارزميات التعلم الآلي المدعوة "ليست تحت الإشراف" unsupervised بمعنى أن البيانات المُقدّمة في البداية لا تحوي أي تسميات labels أو تصنيفات بشكل مُسبق. سنرى مثًلا أن مسألة تحديد عدد العناقيد هو مسألة مهمة يجب الاعتناء بها إذ لا نعرف مُسبقًا ما هو عدد العناقيد الأمثلي. نعرض في هذه المقالة نوعين أساسيين من خوارزميات العنقدة: خوارزميات التجزئة Partitioning: تبدأ هذه الخوارزميات بتجزئة عناصر البيانات إلى k عنقود (مختارة بشكل عشوائي) ومن ثم تُكرر تعديل هذه المجموعات وصولًا إلى حل جيد. من أشهر هذه الخوارزميات الخوارزمية المدعوة k-means (أي k وسطي). الخوارزميات التكتلية Agglomerative: تبني هذه الخوارزمية هرمية من العناقيد حيث تبدأ بوضع كل عنصر من عناصر البيانات في عنقود مستقل ثم تكرر دمج العناقيد المتشابهة وصولًا إلى عنقود واحد في نهاية المطاف. الخوارزمية K-Means تُعدّ الخوارزمية K-Means من أشهر وأبسط خوارزميات العنقدة بالتجزئة: دخل الخوارزمية: عدد العناقيد المطلوب k بيانات التدريب وهي عبارة عن مجموعة من العناصر (أشعة رقمية): {x1, x2, . . . , xN} حيث xi هو شعاع من الأرقام. خرج الخوارزمية: تُسندّ الخوارزمية كل عنصر من عناصر الدخل إلى أحد العناقيد (التي عددها k). المعالجة: تختار الخوارزمية أولًا k شعاع من أشعة الدخل بشكل عشوائي كمراكز العناقيد. تُكرر الخوارزمية ما يلي وصولًا إلى التقارب: إسناد كل شعاع من أشعة الدخل إلى المركز الأقرب حساب المركز الجديد لكل عنقود يعني التقارب عدم انتقال أي شعاع من عنقوده الحالي الموضوع فيه إلى عنقود آخر. يُبين الشكل التالي المراحل الأساسية للخوارزمية: لفهم مراحل الخوارزمية نعرض أولًا خطوات تنفيذها على المثال التعليمي التالي: ليكن لدينا مجموعة العناصر العشرة التالية: D = { (5,3), (10,15), (15,12), (24,10), (30,45), (85,70), (71,80), (60,78), (55,52), (80,91) } وبفرض أننا نريد تقسيمها إلى عنقودين (k=2). لنختار مثلًا العنصر الأول كمركز للعنقود الأول والعنصر الثاني مركزًا للعنقود الثاني أي: c1(x) = 5, c1(y)=3 c2(x) = 10 , c2(y)=15 نحسب الآن بُعد (المسافة الإقليدية euclidean distance) كل عنصر من عناصر البيانات عن كل من المركزين ونُسند العنصر إلى المركز الأقرب. يكون لدينا: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } رقم العنصر المسافة الإقليدية عن المركز الأول المسافة الإقليدية عن المركز الثاني العنقود المُسند إليه 1 (5,3) 0 13 C1 2 (10,15) 13 0 C2 3 (15,12) 13.45 5.83 C2 4 (24,10) 20.24 14.86 C2 5 (30,45) 48.87 36 C2 6 (85,70) 104.35 93 C2 7 (71,80) 101.41 89 C2 8 (60,78) 93 80 C2 9 (55,52) 70 58 C2 10 (80,91) 115.52 103.32 C2 نحسب الآن مركزي العنقودين فنحصل على: c1(x) = 5, c1(y)=3 c2(x) = (10 + 15 + 24 + 30 + 85 + 71 + 60 + 55 + 80) / 9 = 47.77 c2(y) = (15 + 12 + 10 + 45 + 70 + 80 + 78 + 52 + 91) / 9 = 50.33 نُعيد العملية لنحصل على: رقم العنصر المسافة الإقليدية عن المركز الأول المسافة الإقليدية عن المركز الثاني العنقود المُسند إليه 1 (5,3) 0 63.79 C1 2 (10,15) 13 51.71 C1 3 (15,12) 13.45 50.42 C1 4 (24,10) 20.24 46.81 C1 5 (30,45) 48.87 18.55 C2 6 (85,70) 104.35 42.1 C2 7 (71,80) 101.41 37.68 C2 8 (60,78) 93 30.25 C2 9 (55,52) 70 7.42 C2 10 (80,91) 115.52 51.89 C2 نحسب الآن مركزي العنقودين الجديدين فنحصل على: c1(x) = (5, 10, 15, 24) / 4 = 13.5 c1(y) = (3, 15, 12, 10) / 4 = 10.0 c2(x) = (30 + 85 + 71 + 60 + 55 + 80) / 6 = 63.5 c2(y) = (45 + 70 + 80 + 78 + 52 +91) / 6 = 69.33 نُعيد العملية مرة أخرى لنحصل على: رقم العنصر المسافة الإقليدية عن المركز الأول المسافة الإقليدية عن المركز الثاني العنقود المُسند إليه 1 (5,3) 11.01 88.44 C1 2 (10,15) 6.1 76.24 C1 3 (15,12) 2.5 75.09 C1 4 (24,10) 10.5 71.27 C1 5 (30,45) 38.69 41.4 C1 6 (85,70) 93.33 21.51 C2 7 (71,80) 90.58 13.04 C2 8 (60,78) 82.37 9.34 C2 9 (55,52) 59.04 19.3 C2 10 (80,91) 104.8 27.23 C2 نحسب الآن مركزي العنقودين الجديدين فنحصل على: c1(x) = (5, 10, 15, 24, 30) / 5 = 16.8 c1(y) = (3, 15, 12, 10, 45) / 5 = 17.0 c2(x) = (85 + 71 + 60 + 55 + 80) / 5 = 70.2 c2(y) = (70 + 80 + 78 + 52 + 91) / 5 = 74.2 نُعيد العملية فلا يتغير إسناد أي عنصر مما يعني التقارب وثبات المراكز والعناقيد clusters. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن إعداد المشروع يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ. نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة البرمجية بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها. نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا. نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا: mkdir clustering cd clustering نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية: python -m venv clustering ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية: source clustering/bin/activate أما في Windows، فيكون أمر التنشيط: "clustering/Scripts/activate.bat" نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها. نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها: jupyter==1.0.0 numpy==1.21.5 scikit-learn==1.0.1 scipy==1.7.3 pandas==1.3.5 matplotlib==3.5.1 نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي: (clustering) $ pip install -r requirements.txt بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا. كتابة شيفرة تطبيق العنقدة للعملاء نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا: (clustering) $ jupyter notebook ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم clust مثلًا. تنفيذ المثال التعليمي نبدأ أولًا بإنشاء بيانات المثال التعليمي السابق ورسمها باستخدام المكتبة matplotlib: # المكتبة الرقمية import numpy as np # مكتبة الرسم import matplotlib.pyplot as plt # إنشاء البيانات X = np.array([[5,3], [10,15], [15,12], [24,10], [30,45], [85,70], [71,80], [60,78], [55,52], [80,91],]) # الرسم plt.scatter(X[:,0],X[:,1]) plt.show() مما يُظهر: تُبين الشيفرة التالية استخدام الصف KMeans من مكتبة العنقدة sklearn.cluster. نُنشئ أولًا غرض (نموذج model) من هذا الصف مع تحديد عدد العناقيد المطلوبة. تُنفذّ الطريقة fit خوارزمية KMeans على بيانات التدريب لإيجاد العناقيد المطلوبة. تُرقّم الخوارزمية العناقيد بدءًا من الصفر (تسميات labels). يُمكن طبعًا طباعة مراكز العناقيد. # KMeans from sklearn.cluster import KMeans # إنشاء غرض من الصف # تحديد عدد العناقيد المطلوب kmeans = KMeans(n_clusters=2) # الملائمة مع البيانات kmeans.fit(X) # طباعة المراكز print(kmeans.cluster_centers_) # طباعة تسميات العناقيد print(kmeans.labels_) يكون الخرج: [[70.2 74.2] [16.8 17. ]] [1 1 1 1 1 0 0 0 0 0] يُمكن الآن استخدام النموذج المُتعلم السابق للتنبؤ بعنقود أي مثال جديد وذلك باستخدام الطريقة predict كما تُبين الشيفرة التالية: # التنبؤ print(kmeans.predict([[10,10]])) حيث يكون الخرج مثلًا: [1] يُمكن أيضًا رسم نقاط التدريب مع مراكزها بلون مميز كما تُبين الشيفرة التالية: # الرسم مع المراكز plt.scatter(X[:,0],X[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(kmeans.cluster_centers_[:,0] ,kmeans.cluster_centers_[:,1], color='black') يكون الخرج: ننتقل الآن لمعالجة مسألتنا الأساسية وهي عنقدة الزبائن. تعرض الشيفرة التالية تحميل البيانات من الملف shopping-data.csv ووضعها في إطار بيانات من المكتبة pandas. # مكتبة إطار البيانات import pandas as pd # تحميل البيانات customer_data = pd.read_csv('shopping-data.csv') # إظهار ترويسة البيانات customer_data.head() تظهر أوائل البيانات: نحذف في الشيفرة التالية رقم الزبون من إطار البيانات كي لا يدخل في عملية حساب العناقيد. ثم نُنشئ نموذجًا متعلمًا من الصف KMeans مع عدد العناقيد مساويًا لخمسه (نعرض لاحقًا كيفية تحديدنا لهذا الرقم): # حذف رقم الزبون data = customer_data.iloc[:, 1:3].values # إنشاء النموذج المتعلم kmeans = KMeans(n_clusters=5) # الملائمة مع البيانات kmeans.fit(data) # طباعة المراكز print(kmeans.cluster_centers_) # طباعة التسميات print(kmeans.labels_) يكون الإظهار: [[88.2 17.11428571] [55.2962963 49.51851852] [25.72727273 79.36363636] [86.53846154 82.12820513] [26.30434783 20.91304348]] [4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 2 4 1 4 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 0 3 1 3 0 3 0 3 1 3 0 3 0 3 0 3 0 3 1 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3 0 3] يُمكن الآن أن نرسم النقاط مع المراكز باستخدام الشيفرة التالية: # الرسم plt.scatter(data[:,0],data[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(data[:,0], data[:,1], c=kmeans.labels_, cmap='rainbow') plt.scatter(kmeans.cluster_centers_[:,0] ,kmeans.cluster_centers_[:,1], color='black') plt.show() مما يُعطي: تفسير نتائج العنقدة تقييمها يُمكن لنا بمعاينة الشكل السابق استنتاج ما يلي (وهو الهدف الأساسي من عملية العنقدة): الزبائن في أعلى اليمين (نقاط البيانات الصفراء) هم الزبائن ذوو الرواتب المرتفعة والإنفاق المرتفع. هؤلاء هم الزبائن الواجب استهدافهم دومًا والمحافظة عليهم. الزبائن في أعلى اليسار (نقاط البيانات الخضراء) هم الزبائن ذوو الرواتب المنخفضة والإنفاق المرتفع. هؤلاء هم الزبائن الواجب العناية بهم واستهدافهم بحملات التخفيضات مثلًا. الزبائن في أسفل اليمين (نقاط البيانات البنفسجية) هم الزبائن ذوو الرواتب المرتفعة والإنفاق المنخفض. هؤلاء هم الزبائن الواجب جذبهم بالطرق التسويقية ما أمكن ذلك. الزبائن في أسفل اليسار (نقاط البيانات الحمراء) هم الزبائن ذوو الرواتب المنخفضة والإنفاق المنخفض. لا داع لإضاعة الكثير من الوقت والجهد معهم. الزبائن في الوسط (نقاط البيانات الزرقاء) هم الزبائن أصحاب الدخل المتوسط والإنفاق المتوسط. يُمكن استهدافهم أيضًا لاسيما أن عددهم كبيرًا كما يُبين الشكل السابق. يُمكن تقييم نتائج العنقدة باستخدام المعامل المدعو Silhouette Coefficient، ويُحسب هذا المعامل من أجل عنصر بيانات x كما يلي: حيث: a هي وسطي المسافات بين x وبين العناصر الموجودة في نفس العنقود الموجود فيه العنصر x. b هي وسطي المسافات بين x وبين العناصر الموجودة في العناقيد القريبة من عنقود x. كما يُبين الشكل التالي: يُمكن ملاحظة ما يلي حول هذا المعامل: أفضل قيمة له هي 1 وأسوأ قيمة له هي -1. تُشير القيمة 0 إلى وجد تراكب overlapping في العناقيد. تدل القيمة السالبة على وجود العنصر x في عنقود خاطئ إذ يوجد عنقود آخر أقرب إلى x. يكون المعامل silhouette_score لمجموعة من البيانات وسطي قيمة المعامل لكل منها أي: يُمكن تضمين حساب هذا المعامل من sklearn.metrics كما تُبين الشيفرة التالية: from sklearn.metrics import silhouette_score cluster_labels = kmeans.fit_predict(data) # حساب المعامل silhouette_avg = silhouette_score(data, cluster_labels) print(silhouette_avg) يكون لطريقة حساب المعامل silhouette_score معاملي دخل الأول هو البيانات والثاني هو تسميات العناقيد الناتجة عن استدعاء الطريقة fit_predict أولًا. يكون الناتج في مثالنا: 0.553931997444648 إيجاد عدد العناقيد الأمثلي يُمكن استخدام المعامل Silhouette Coefficient لإيجاد عدد العناقيد الأمثلي المناسب لبيانات التدريب وذلك بحساب المعامل مع قيم مختلفة لعدد العناقيد ومن ثم اختيار العدد الذي يُعطي قيمة أعظمية للمعامل كما تُبين الشيفرة التالية: # مجموعة القيم الممكنة range_n_clusters = [2, 3, 4, 5, 6, 7] for n_clusters in range_n_clusters: clusterer = KMeans(n_clusters=n_clusters) cluster_labels = clusterer.fit_predict(data) # حساب المعامل silhouette_avg = silhouette_score(data, cluster_labels) print( "For n =", n_clusters, "silhouette_score is :", silhouette_avg, ) مما يُظهر المعامل من أجل كل قيمة محتملة لعدد العناقيد: For n = 2 silhouette_score is : 0.2968969162503008 For n = 3 silhouette_score is : 0.46761358158775435 For n = 4 silhouette_score is : 0.4931963109249047 For n = 5 silhouette_score is : 0.553931997444648 For n = 6 silhouette_score is : 0.5376203956398481 For n = 7 silhouette_score is : 0.5270287298101395 وبالتالي نلاحظ أن القيمة الأمثلية هي خمسة عناقيد. الخوارزميات التكتلية تمتاز الخوارزميات التكتلية بأنها توفر طريقة معاينة بسيطة لإيجاد عدد العناقيد الأمثلي عن طريق رسم شجرة دمج العناقيد مع بعضها البعض dendrogram: دخل الخوارزمية: بيانات التدريب وهي عبارة عن مجموعة من الأشعة الرقمية: {x1, x2, . . . , xN} حيث xi هو شعاع من الأرقام. خرج الخوارزمية: شجرة دمج العناقيد مع بعضها البعض dendrogram. المعالجة: تبدأ الخوارزمية بوضع كل عنصر من عناصر البيانات في عنقود. تُكرر الخوارزمية ما يلي وصولًا إلى عنقود وحيد: دمج أقرب عنقودين مع بعضهما البعض توجد عدة طرق لإيجاد أقرب عنقودين، من أبسطها الطريقة المسماة بالربط البسيط Single Linkage والتي تحسب المسافة بين عنقودين كما يلي: المسافة بين عنقودين هي أصغر مسافة بين عنصرين من هذين العنقودين. نستخدم فيما يلي الخوارزمية التكتلية مع البيانات التعليمية ومن ثم مع بيانات الزبائن. تعرض الشيفرة التالية طريقة بسيطة لتسمية نقاط البيانات التعليمية (العشرة) لتسهيل عملية المشاهدة والمتابعة: # التسميات : 2,1, ..., 10 labels = range(1, 11) plt.subplots_adjust(bottom=0.1) plt.scatter(X[:,0],X[:,1]) # تسمية النقاط for label, x, y in zip(labels, X[:, 0], X[:, 1]): plt.annotate( label, xy=(x, y), xytext=(-3, 3), textcoords='offset points', ha='right', va='bottom') plt.show() يكون الخرج: نبدأ أولًا بالشيفرة اللازمة لرسم شجرة الدمج dendrogram من أجل إيجاد عدد العناقيد الأمثل: # المكتبات اللازمة from scipy.cluster.hierarchy import dendrogram, linkage # اختيار الربط البسيط linked = linkage(X, 'single') # التسميات: 2,1, .. ,10 labelList = range(1, 11) # dendrogram dendrogram(linked, orientation='top', labels=labelList, distance_sort='descending', show_leaf_counts=True) plt.show() نُعاين شجرة الدمج الناتجة والتي تُبين أن عدد العناقيد المُمكن هو عنقودين: نستدعي الآن الدالة AgglomerativeClustering مع طلب عدد العناقيد مساويًا إلى 2: from sklearn.cluster import AgglomerativeClustering # العنقدة التكتلية cluster = AgglomerativeClustering(n_clusters=2) # الملائمة مع البيانات cluster.fit_predict(X) والتي تُظهر تسميات عنقود كل عنصر: array([1, 1, 1, 1, 0, 0, 0, 0, 0, 0], dtype=int64) يُمكن أيضًا رسم العناقيد: # الرسم plt.scatter(X[:,0],X[:,1], c=cluster.labels_, cmap='rainbow') plt.show() يكون الإظهار: ننتقل الآن إلى مسألة الزبائن باستخدام شيفرة مماثلة: # نوع الربط linked = linkage(data, 'ward') # dendrogram dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True) # الرسم plt.title("Customer Dendograms") plt.show() يُمكن معاينة شجرة الدمج الناتجة: والتي تُبين أن عدد العناقيد المناسب هو 5. نستدعي الدالة AgglomerativeClustering في الشيفرة التالية: cluster = AgglomerativeClustering(n_clusters=5, affinity='euclidean', linkage='ward') cluster.fit_predict(data) # الرسم plt.scatter(data[:,0], data[:,1], c=cluster.labels_, cmap='rainbow') plt.show() ويكون الخرج: وهو، بالطبع، يُشابه ما حصلنا عليه سابقًا مع الخوارزمية KMeans. الخلاصة عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لعنقدة مجموعة من البيانات مع آليات اختيار عدد العناقيد المناسب للمسألة. يُمكن تجربة المثال كاملًا من موقع Google Colab من الرابط، ولا تنس الاطلاع على ملف بيانات التدريب والشيفرة البرمجية. اقرأ أيضًا تعقيد الخوارزميات Algorithms Complexity أمثلة عن أنواع الخوارزميات مدخل إلى تعلم الآلة (Machine learning) في PHP1 نقطة -
بشكل عام عليك أن يكون لديك معرفة بأحد تقنيات Backend بالإضافة ل Front end لتستطيع تصميم و برمجة هذا الموقع1 نقطة
-
 التعابير النمطية Regular expressions هي أنماط تزودنا بأسلوب فعّال للبحث عن النصوص التي تطابق نمطًا محددًا واستبدالها في JavaScript، يتيح الكائن RegExp استخدام هذه التعابير، وتُدمج مع التوابع التي تتعامل مع النصوص. مقدمة إلى التعابير النمطية تتألف التعابير النمطية من نمط pattern، ورايات flags اختيارية، ولإنشاء كائن تعبير نمطي يمكن استخدام صيغتين، صيغة طويلة وصيغة قصيرة، أما الصيغة الطويلة فتكتب بالشكل: regexp = new RegExp("pattern", "flags"); وأما الصيغة القصيرة فتكتب باستخدام المحرف "/" بالشكل: regexp = /pattern/; // لا رايات regexp = /pattern/gmi; // g و m و i باستخدام الرايات تخبر الخطوط المائلة JavaScript بأننا ننشئ تعبيرًا نمطيًا، فهي تلعب دورًا مماثلًا لعلامة الاقتباس في النصوص، وفي كلتا الصيغتين سيصبح الكائن regexp نسخةً عن الصنف المدمج RegExp. لا يُسمح بإدخال متغيرات تمثل الأنماط ضمن صيغة الخطوط المائلة /.../ باستخدام القوالب {...}$ الديناميكية مثلًا كما نفعل في النصوص، فهي ثابتة بشكل كامل، وهذا هو الاختلاف الرئيسي بين الصيغتين، إذ نستخدم الخطوط المائلة عندما نريد استخدام تعابير نمطية محددة ومعروفة بالنسبة لنا عند كتابة الشيفرة، وهذه هي الحالة الأكثر شيوعًا، بينما نستخدم الصيغة new RegExp عادةً عندما نحتاج إلى إنشاء تعابير نمطية أثناء التنفيذ انطلاقًا من نص أُنشئ ديناميكيًا. let tag = prompt("What tag do you want to find?", "h2"); let regexp = new RegExp(`<${tag}>`); // "h2" إن كان الجواب /<h2>/ نفس نتيجة الرايات للتعابير النمطية رايات تؤثر على نتيجة البحث، وتستخدم JavaScript ستةً منها، وهي: i: سيكون البحث غير حساس لحالة الأحرف مع هذه الراية، أي لن يكون هناك فرق بين "a" و"A". g: سيعيد البحث جميع النتائج المتطابقة مع هذه الراية، وإلا فسيعيد النتيجة الأولى. m: سيعمل البحث في نمط الأسطر المتعددة، وسنغطي ذلك لاحقًا. s: ستمكّن نمط "dotall" الذي يسمح بأن نعدَّ النقطة . هي محرف نهاية السطر n\، وسنغطيه لاحقًا. u: سيمكّن الدعم الكامل لترميز Unicode، وبالتالي المعالجة الصحيحة لمحتويات الأقواس المعقوصة {..}، وسنغطيه لاحقًا. y: سيمكّن النمط اللاصق "Sticky"، حيث يبحث في المكان المحدد تمامًا من النص، وسنغطيه لاحقًا. البحث باستخدام التابع str.match تتكامل التعابير النمطية مع توابع النصوص، إذ يبحث التابع (str.match(regexp عن كل ما يطابق التعبير regexp في النص str، ويعمل وفق ثلاثة أنماط: النمط الأول، التعبير النمطي مع الراية g، ويعيد مصفوفةً تضم النتائج المطابقة: let str = "We will, we will rock you"; alert( str.match(/we/gi) ); // سيعيد مصفوفة من الحالتين المتطابقتين للبحث وانتبه إلى أنّ البحث سيعيد النتيجتين "we" و"We" لأن راية حالة الأحرف i مفعّلة. النمط الثاني، إذا لم نفعّل الراية g، فسيعيد البحث النتيجة الأولى فقط ضمن مصفوفة، مع وضع التطابق في الدليل 0، بالإضافة إلى تفاصيل أخرى في الخصائص: let str = "We will, we will rock you"; let result = str.match(/we/i); // g دون الراية alert( result[0] ); // We (التطابق الأول) alert( result.length ); // 1 // Details: alert( result.index ); // 0 (موقع التطابق) alert( result.input ); // We will, we will rock you (النص الأصلي) قد تحتوي المصفوفة على عناصر أخرى بالإضافة إلى العنصر ذي الدليل 0؛ إذا كان جزء من التعبير النمطي ضمن قوسين مغلقين وسنغطي ذلك في المقالات القادمة. النمط الثالث، إذا لم توجد أي تطابقات، فسيعيد التابع القيمة null، بوجود الراية g أو عدم وجودها، لذا انتبه أننا لن نحصل في هذه الحالة على مصفوفة فارغة، بل على القيمة null، وسيؤدي نسيان هذه الحقيقة إلى مشاكل عدة: let matches = "JavaScript".match(/HTML/); // = null if (!matches.length) { //length خطأ لا يمكن قراءة الخاصية alert("Error in the line above"); } إذا أردنا أن نحصل دائمًا على مصفوفة، فيمكننا أن ننفذ الأمر بالشكل التالي: let matches = "JavaScript".match(/HTML/) || []; if (!matches.length) { alert("No matches"); // ستعمل الآن } الاستبدال باستخدام التابع str.replace يستبدل التابع (str.replace(regexp, replacement التطابقات الموافقة للكائن regexp في النص str بقيمة replacement، وستستبدل كل التطابقات عند استخدام الراية g، وإلا فسيستبدل أول تطابق فقط، وإليك مثالًا: // g دون الراية alert( "We will, we will".replace(/we/i, "I") ); // I will, we will // مع الراية alert( "We will, we will".replace(/we/ig, "I") ); // I will, I will يمكن استخدام محارف خاصة ضمن الوسيط الثاني replacement للبحث عن أجزاء من معيار التطابق: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الرمز ما يفعله ضمن النص replacment &$ يمثل نص التطابق `$ يمثل النص الواقع قبل نص التطابق. '$ يمثل النص الواقع بعد نص التطابق. n$ يمثل التطابق ذا الرقم n من مجموعة التطابق (الموجود ضمن قوسي تجميع"()" ) . $<name> يمثل التطابق ذا الاسم name من مجموعة التطابق (الموجود ضمن قوسي تجميع"()" ). $$ يمثل المحرف $ مثال باستخدام &$: alert( "I love HTML".replace(/HTML/, "$& and JavaScript") ); // I love HTML and JavaScript الاختبار باستخدام التابع regexp.test يبحث التابع (regexp.test(str عن تطابق واحد على الأقل -إن وُجد- ويعيد القيمة true، وإن لم يجد تطابقًا فسيعيد القيمة false. let str = "I love JavaScript"; let regexp = /LOVE/i; alert( regexp.test(str) ); // true سندرس لاحقًا في هذا القسم تعابير نمطيةً أكثر، وسنتعرف على توابع أخرى لاحقًا. أصناف المحارف لنتأمل مهمةً تتطلب تحويل رقم هاتف، مثل "67-45-123-(903)7+"، إلى رقم صرف، أي 79031234567، لتنفيذ ذلك يمكننا تتبع وحذف أي محرف لا يمثل رقمًا، وستساعدنا أصناف المحارف في ذلك، حيث تمثل إشارات خاصةً تطابق أي رمز ضمن مجموعة معينة، وسنتعرف بدايةً على الصنف "digit"، الذي يُعبَّر عنه بالشكل d\، ويرتبط بأي رقم مفرد، فمثلًا لنجد الرقم الأول في رقم الهاتف: let str = "+7(903)-123-45-67"; let regexp = /\d/; alert( str.match(regexp) ); // 7 سيبحث التابع عن كل الأرقام التي سيجدها في النص بإضافة الراية g، وسيعيدها ضمن مصفوفة: let str = "+7(903)-123-45-67"; let regexp = /\d/g; alert( str.match(regexp) ); // 7,9,0,3,1,2,3,4,5,6,7 // لنشكل عددًا من أرقام المصفوفة: alert( str.match(regexp).join('') ); // 79031234567 سنستعرض الآن بعض الأصناف الأكثر استعمالًا، وهي: d\: من كلمة digit رقم، ويعيد أي رقم بين 0 و9. \s: من كلمة space فراغ، وتضم محارف الفراغ، مثل: مسافة الجدولة t\، والسطر الجديد n\، وغيرها من الرموز النادرة الاستخدام مثل r\ وv\ وf\. w\: من كلمة word كلمة، وتعيد محارف قد تشكل كلمةً، مثل الأحرف اللاتينية أو الأرقام أو الشرطة السفلية _، ولا تنتمي الأحرف غير اللاتينية، مثل العربية، إلى هذا الصنف، إذ تشير الرموز d\s\w\ مثلًا إلى رقم متبوع بمحرف فراغ، ويليه محرف كلمة مثل 1 a. يمكن أن يضم الكائن محارف تعابير نمطية بالإضافة إلى الأصناف، فمثلًا سيبحث التعبير CSS\d عن الكلمة CSS متبوعةً برقم: let str = "Is there CSS4?"; let regexp = /CSS\d/ alert( str.match(regexp) ); // CSS4 كما يمكن استخدام أصناف محارف عدة: alert( "I love HTML5!".match(/\s\w\w\w\w\d/) ); // ' HTML5' الأصناف المعكوسة لكل صنف من أصناف المحارف صنف معكوس inverse class، يرمز له بالحرف نفسه لكن بحالة حرف كبير uppercase، ويعني ذلك الحصول على أي محرف عدا المحرف الذي يعيده الصنف عادةً، أي: D\: لا يعيد رقمًا، وإنما يعيد أي محرف عدا المحارف التي يعيدها d\، مثل الأحرف اللاتينية. S\: لا يعيد محرف فراغ، وإنما يعيد أي محرف عدا المحارف التي يعيدها s\، مثل الأحرف اللاتينية. W\: لا يعيد محرف كلمة، وإنما يعيد أي محرف عدا المحارف التي يعيدها w\، مثل الأحرف غير اللاتينية أو الفراغات. لاحظ كيف سنستخدَم هذه الأصناف في تحويل رقم الهاتف في المثال السابق إلى رقم صرف وبطريقة أقصر، وذلك بإزالة المحارف التي لا تمثل أرقامًا D\: let str = "+7(903)-123-45-67"; alert( str.replace(/\D/g, "") ); // 79031234567 يمثل المحرف نقطة أي محرف يمثل المحرف . صنفًا مميزًا من المحارف، ويطابق أي محرف عدا محرف السطر الجديد، إليك مثالًا: alert( "Z".match(/./) ); // Z كما يمكن إدراجه وسط التعبير regexp: let regexp = /CS.4/; alert( "CSS4".match(regexp) ); // CSS4 alert( "CS-4".match(regexp) ); // CS-4 alert( "CS 4".match(regexp) ); // CS 4 (الفراغ هو محرف أيضًا) لاحظ أن النقطة تطابق أي محرف، لكنها لن تبحث عن محرف غير موجود، فلا بدّ من وجود محرف حتى يعيده هذا الصنف: alert( "CS4".match(/CS.4/) ); // null, لن يعيد الصنف شيئًا لعدم وجود محرف لاحظ أن محرف النقطة يمثل أي محرف بالفعل بوجود الراية "s"، فلا تعيد النقطة عادةً محرف السطر الجديد، إذ يعيد التعبير A.B الحرفين A وB وأي محارف بينهما عدا محرف السطر الجديد n\: alert( "A\nB".match(/A.B/) ); // null (لا تطابقات) لكننا في عدة حالات نريد للنقطة أن تعني أي محارف فعلًا، بما في ذلك السطر الجديد، لذلك سنستخدم الراية s وسنحصل على المطلوب: alert( "A\nB".match(/A.B/s) ); // A\nB (match!) انتبه إلى أن المتصفح IE لا يدعم الراية s، لكن يمكن استخدام التعبير النمطي [\s\S] الذي يعيد أي محرف في أي مكان، وسنغطي ذلك لاحقًا. alert( "A\nB".match(/A[\s\S]B/) ); // A\nB (match!) ويعني التعبير [\s\S] البحث عن (محرف فراغ أو محرف لا يمثل فراغًا)، وهذا يمثل عمليًا أي محارف، ويمكن استخدام أي أزواج من الأصناف وعكسها، مثل [\d\D]، كما يمكن استخدام التعبير [^] الذي يعني البحث عن أي محرف عدا "لا شيء"، ويمكن استخدام الحيلة ذاتها إن أردنا أن يؤدي المحرف "نقطة" . كلا الوظيفتين، أي مطابقة أي محارف عدا السطر الجديد . أو مع السطر الجديد [\s\S]. انتبه أيضًا إلى الفراغات، إذ لا نكترث عادةً لوجود فراغات زائدة، وسنعتبر النص 1-5 مماثلًا للنص 1 - 5، لكن قد يخفق التعبير النمطي regexp إن لم يأخذ هذه الفراغات في الحسبان. لنحاول مثلًا أن نجد أرقامًا مفصولةً بشرطة صغيرة (-): alert( "1 - 5".match(/\d-\d/) ); // null, لا تطابق سنصلح ذلك بإضافة فراغات إلى التعبير النمطي d - \d\: alert( "1 - 5".match(/\d - \d/) ); // 1 - 5, سنجد الآن تطابقًا // \s أو يمكن استخدام الصنف: alert( "1 - 5".match(/\d\s-\s\d/) ); // 1 - 5, سيعمل أيًا فالفراغ هو محرف، ولا يمكننا إضافة أو إزالة الفراغات من تعبير نمطي، ثم نتوقع أن يعمل كما هو مطلوب، فكل المحارف التي ندخلها في التعبير النمطي ستُؤخذ في الحسبان عند البحث، بما فيها الفراغات. تعامل التعابير النمطية مع ترميز يونيكود Unicode تستخدم JavaScript ترميز يونيكود Unicode لتمثيل النصوص، حيث تُرمّز معظم المحارف باستخدام 2 بايت، وهذا ما يسمح بترميز 65536 محرف كحد أقصى، ولا يعتبر العدد السابق كافيًا لترميز كل المحارف الممكنة، لذلك ستجد أن بعض المحارف الخاصة رمِّزت باستخدام 4 بايت، مثل المحرف ? -التمثيل الرياضي للمحرف X- أو ? -الابتسامة- وبعض المحارف الهيروغليفية وغيرها، وإليك قيم Unicode لبعض المحارف الخاصة: المحرف ترميز Unicode عدد البايتات المستخدمة a 0x0061 2 ≈ 0x2248 2 ? 0x1d4b3 4 ? 0x1d4b4 4 ? 0x1f604 4 تشغل محارف -مثل a- بايتين اثنين، ومحارف -مثل ? و?- أربعة بايتات. كان ترميز Unicode في الأيام الأولى لظهور JavaScript أكثر بساطةً، حيث لم توجد محارف من أربعة بايتات، لذلك ستجد أن بعض ميزات اللغة ستتعامل معها بشكل غير صحيح، فتعتقد الخاصية length مثلًا أنها عبارة عن محرفين: alert('?'.length); // 2 alert('?'.length); // 2 والسبب في ذلك أنّ هذه الخاصية ستعامل المحرف ذا البايتات الأربعة على أنه محرفان لكل منهما بايتان فقط، وهذا أمر خاطئ، حيث ينبغي اعتبارها محرفًا واحدًا، وتُدعى "الزوج البديل" surrogate pair، وسنرى ذلك لاحقًا. تعامل التعابير النمطية regular expression المحارف الطويلة ذات البايتات الأربع مثل زوج من البايتات الثنائية، وقد يقود ذلك إلى أخطاء كما هو الحال في النصوص، لكن -وعلى خلاف النصوص- للتعابير النمطية الراية u التي تعالج هذه المشكلة، إذ يعالج التعبير المحارف ذات البايتات الأربع بشكل صحيح عند وجود هذه الراية، وسيصبح البحث متاحًا ضمن خصائص الترميز Unicode كما سنرى تاليًا. خصائص ترميز Unicode باستعمال {…}p\ لمحارف Unicode العديد من الخصائص التي تصف الفئة التي ينتمي إليها المحرف، كما تقدم معلومات متنوعةً عنها، فلو كان للمحرف الخاصية Letter فسيعني ذلك أنه ينتمي إلى أبجدية ما، كما يعني امتلاكه الخاصية Number أنه رقم، وقد يكون رقمًا عربيًا أو صينيًا وهكذا، ويمكن البحث عن محرف يمتلك خاصيةً معينةً باستخدام الصنف {...}p\، ولاستخدام هذا الصنف لا بد أن نفعّل الراية u في التعبير النمطي. يبحث التعبير {p{Letter\مثلًا عن حرف في أي لغة، كما يمكن كتابته بالشكل {p{L\، وهو اسم مستعار للخاصية Letter، ولمعظم الخصائص أسماء مستعارة قصيرة. سيجد البحث في المثال التالي ثلاثة أنواع من الأحرف: انكليزي وجورجي وكوري. let str = "A ბ ㄱ"; alert( str.match(/\p{L}/gu) ); // A,ბ,ㄱ alert( str.match(/\p{L}/g) ); // null (no matches, \p doesn't work without the flag "u") إليك الفئات الأساسية للمحارف، وفئاتها الفرعية: الحرف Letter: واسمها المستعار L. Ll: حرف صغير. Lm: حرف معدِّل modifier. Lt: عنوان. Lu: حرف كبير. Lo: غير ذلك. العدد Number: واسمها المستعار N. Nd: رقم بالصيغة العشرية. Nl: رقم حرف. No: غير ذلك. علامات الترقيم Punctuation: واسمها المستعار P. Pc: واصلة. Pd: خط فاصل dash. Pi: علامة اقتباس فاتحة. Pf: علامة اقتباس غالقة. Ps: مفتوح. Pe: مغلق. Po: غير ذلك. العلامة أو الحركة Mark: واسمها المستعار M، مثل العلامات أو الحركات فوق الأحرف وغيرها. Mc: علامة ضم مع فراغ spacing combining، وعلامة الضم هي محرف يعدّل محرفًا آخر بإضافة علامة أو حركة فوقه أو تحته وهكذا. Me: علامة ضم محيطة enclosing. Mn: علامة ضم دون فراغ non-spacing. الرمز Symbol: واسمه المستعار S. Sc: رموز عملة. Sk: رمز مُعدِّل. Sm: رمز رياضي. So: رمز آخر. الفواصل Separator: واسمها المستعار Z. Zl: خط. Zp: مقطع. Zs: فراغ. فئات أخرى: واسمها المستعار C. Cc: تحكم. Cf: تنسيق. Cn: لم يحدد بعد. Co: استخدام خاص. Cs: بديل. فلو أردنا مثلًا أحرفًا كبيرة فسنستخدم {p{Ll\، بينما نستخدم {p{p\ لعلامات الترقيم وهكذا. ستجد أيضًا بعض الفئات المشتقة، مثل: Alphabetic: واسمها المستعار Alpha، وتضم الأحرف L، والأرقام على شكل أحرف Nl، مثل Ⅻ وهو 12 بالرومانية. Hex_Digit: وتضم الأرقام الست عشرية: 0-9 وa-f. يدعم الترميز Unicode خصائص عديدةً، وسيزيد ذكرها من حجم المقالة بشكل كبير، لكن يمكنك الاطلاع على المراجع التالية: قائمة بكل الخصائص وفقًا للمحرف. قائمة بكل المحارف وفقًا للخاصية. قائمة بالاسماء المستعارة القصيرة للخصائص. قاعدة كاملة بمحارف Unicode بتنسيق نصي مع كامل خصائصها. مثال: الأعداد الست عشرية لننظر مثلًا إلى الأعداد الست عشرية المكتوبة بالشكل xFF، حيث F هو رقم ست عشري (0-1 أو A-F)، ويمكن الإشارة إلى الرقم الست عشري بالشكل {p{Hex_Digit\: let regexp = /x\p{Hex_Digit}\p{Hex_Digit}/u; alert("number: xAF".match(regexp)); // xAF مثال: الكتابة التصويرية الصينية في ترميز Unicode خاصية تحدد نظام الكتابة، ويمكن أن تأخذ قيمًا مثل: Cyrillic وGreek وArabic وHan (الصينية) وغيرها من القيم المشابهة، وللبحث عن محرف في نظام كتابة محدد علينا استخدام الخاصية <Script=<value، فللعربية مثلًا نستخدم {p{sc=Arabic\، وللصينية نستخدم {p{sc=Han\ وهكذا. let regexpHan = /\p{sc=Han}/gu; // يعيد التصويرية الصينية let regexpArab = /\p{sc=Arabic}/gu; // يعيد العربية let str = `Hello Привет 你好 جميل 123_456`; alert( str.match(regexpHan) ); // 你,好 alert( str.match(regexpArab) ); // ج,م,ي,ل مثال: رموز العملة للمحارف التي ترمز إلى العملات -مثل $ و€ و¥- خاصية في ترميز Unicode، هي {p{Currency_Symbol\، واسمها المختصر {p{Sc\، لنستخدم هذه الخاصية في الحصول على سعر منتج ضمن تنسيق يحوي رمز عملة يليه رقم: let regexp = /\p{Sc}\d/gu; let str = `Prices: $2, €1, ¥9`; alert( str.match(regexp) ); // $2,€1,¥9 وسنتعرف لاحقًا في مقالات قادمة على آلية البحث عن أعداد تحتوي عدة أرقام. محارف الارتكاز: محرفا بداية النص ^ ونهايته $ يحمل المحرفان ^ و$ معانٍ خاصةً في التعابير النمطية regular expression، وتسمى بالمرتكزات أو المرابط Anchors، حيث تبحث العلامة ^ عن تطابق في بداية النص، بينما تبحث $ عن تطابق في نهايته، لنر مثلًا إن بدأ نص ما بالكلمة "Mary": let str1 = "Mary had a little lamb"; alert( /^Mary/.test(str1) ); // true يعني النمط أن نبحث عن الكلمة "Mary" في بداية السطر حصرًا، وبشكل مشابه يمكن أن نستخدم $ للتحقق من وجود الكلمة "snow" مثلًا في نهاية نص: let str1 = "it's fleece was white as snow"; alert( /snow$/.test(str1) ); // true يمكن استخدام توابع التعامل مع النصوص startsWith/endsWith في هذه الحالات بالتحديد، لكن ينبغي استخدام التعابير النمطية في الحالات الأكثر تعقيدًا. اختبار التطابق الكامل يستخدم المرتكزان السابقان معًا $...^ لاختبار تطابق نص بشكل كامل مع النمط، مثل التحقق من مطابقة ما يدخله المستخدم للتنسيق المطلوب، لنتحقق مثلًا أن نصًا له التنسيق الزمني التالي 12:34، وهو عدد من رقمين، تليه نقطتان ":"، ثم عدد من رقمين، لذا سنستخدم التعبير d\d:\d\d\ في عالم التعابير النمطية: let goodInput = "12:34"; let badInput = "12:345"; let regexp = /^\d\d:\d\d$/; alert( regexp.test(goodInput) ); // true alert( regexp.test(badInput) ); // false يجب أن يبدأ التطابق مباشرة ًعند بداية النص ^، وينتهي بنهايته $، ويجب أن يطابق تنسيق النص تنسيق التعبير النمطي، فإذا وجدَت أي اختلافات أو محارف زائدة فستكون النتيجة "false"، وتسلك المرتكزات سلوكًا مختلفًا بوجود الراية m، وسنطلع على ذلك لاحقًا. انتبه إلى أن ليس للمرتكزات عرض، فالمرتكزات محارف اختبار، وليس لها عرض، فهي لا تطابق محارف محددةً، بل تجبر محرك التعبير النمطي للتحقق من الشرط (بداية ونهاية نص). نمط الأسطر المتعددة: تأثير الراية "m" على المرتكزان ^ و $ يُفعّل نمط الأسطر المتعددة باستخدام الراية m، التي تؤثر على سلوك المرتكزين $ و^ فقط، فلا تطابق المرتكزات في نمط الأسطر المتعددة بداية ونهاية النص فقط، بل بداية ونهاية السطر. البحث عند بداية سطر ^ يحتوي النص في المثال التالي على عدة أسطر، وسيأخذ النمط d/gm\^/ رقمًا من بداية كل سطر: let str = `1st place: Winnie 2nd place: Piglet 3rd place: Eeyore`; alert( str.match(/^\d/gm) ); // 1, 2, 3 سنحصل دون الراية m على الرقم الموجود في أول سطر فقط يطابق النمط: let str = `1st place: Winnie 2nd place: Piglet 3rd place: Eeyore`; alert( str.match(/^\d/g) ); // 1 والسبب أنّ العلامة ^ ستطابق افتراضيًا بداية النص فقط، بينما ستطابق في نمط الأسطر المتعددة بداية أي سطر. انتبه، فتعني بداية السطر رسميًا المحرف الذي يأتي بعد محرف السطر الجديد، وهكذا ستطابق العلامة ^ في نمط الأسطر المتعددة كل المحارف التي يسبقها محرف السطر الجديد n\. البحث عند نهاية سطر $ يسلك المرتكز $ السلوك السابق نفسه، إذ يجد التعبير النمطي $d\ مثلًا آخر رقم في كل سطر: let str = `Winnie: 1 Piglet: 2 Eeyore: 3`; alert( str.match(/\d$/gm) ); // 1,2,3 سيطابق المرتكز $ نهاية النص ككل دون استخدام الراية m، وبالتالي سنحصل فقط على آخر رقم. انتبه، فتعني نهاية السطر رسميًا المحرف الذي يأتي قبل محرف السطر الجديد، وهكذا ستطابق العلامة $ في نمط الأسطر المتعددة كل المحارف التي تسبق محرف السطر الجديد n\ مباشرةً. البحث عن محرف السطر الجديد n\ بدل المرتكز $ يمكن البحث عن سطر جديد باستخدام المحرف n\ بدلًا من البحث عن المرتكزين ^ و$، لكن ما الفرق؟ سنبحث في المثال التالي عن d\n\بدلًا من $d\: let str = `Winnie: 1 Piglet: 2 Eeyore: 3`; alert( str.match(/\d\n/gm) ); // 1\n,2\n ستجد الشيفرة تطابقين بدلًا من ثلاث، وذلك لعدم وجود سطر جديد بعد الرقم 3، على الرغم من وجود مرتكز نهاية النص الذي يطابق $، أما الاختلاف الآخر فهو أنّ n\محرف، وسيظهر ضمن النتيجة، وليس مثل المرتكزين ^ و$ اللذين يحددان شرط البحث في بداية ونهاية النص، وبالتالي سنستخدم n\ إذا أردنا ظهور محرف السطر الجديد في النتيجة، وإلا استخدمنا ^ و$. حدود الكلمة: b\ حدود الكلمة اختبار، مثل ^ و$، حيث يشير وجود العلامة b\ بأنّ الموقع الذي وصل إليه محرك بحث التعابير النمطية هو حد لكلمة، وتوجد ثلاثة مواقع مختلفة يمكن اعتبارها حدودًا لكلمة، وهي: في بداية نص، إذا كان أول محرف نصي فيه هو محرف كلمة w\. بين محرفين في نص، إذا كان أحدهما محرف كلمة w\ والآخر ليس كذلك. في نهاية نص، إذا كان آخر محرف فيه هو محرف الكلمة w\. يمكن أن تجد التعبير bJava\b\ مثلًا في النص !Hello, Java عندما تكون الكلمة Java منفصلةً عن غيرها، لكنك لن تحصل على نفس النتيجة في النص !Hello, JavaScript alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, JavaScript!".match(/\bJava\b/) ); // null في الشكل التالي ستمثل المواقع المشار إليها العلامة b\ في النص !Hello, Java: لذلك فهي تطابق النمط bHello\b\ لأن: بداية النص تتطابق مع العلامة b\. ثم تتطابق مع الكلمة Hello. ثم تتطابق مع العلامة b\ مرةً أخرى، كما لو أنها بين المحرف o والفاصلة. إذًا سنعثر على النمط bHello\b\، لكن ليس النمط bHell\b\، لعدم وجود علامة حد الكلمة b\ بعد المحرف l، كما لن نحصل على النمط Java!\b لأن علامة التعجب ليست محرف كلمة w\، وبالتالي لا وجود لعلامة حد الكلمة b\ بعده. alert( "Hello, Java!".match(/\bHello\b/) ); // Hello alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, Java!".match(/\bHell\b/) ); // null (no match) alert( "Hello, Java!".match(/\bJava!\b/) ); // null (no match) يمكن استخدام b\ مع الأرقام أيضًا، إذ يبحث النمط b\d\d\b\ مثلًا عن عدد من رقمين -عدد بخانتين- منفصل عن غيره، أي يبحث عن عدد بخانتين غير محاط بمحارف الكلمة w\، مثل محارف الفراغات أو علامات الترقيم أو مرتكزات بداية ونهاية نص. alert( "1 23 456 78".match(/\b\d\d\b/g) ); // 23,78 alert( "12,34,56".match(/\b\d\d\b/g) ); // 12,34,56 انتبه، لا تعمل العلامة b\ مع الأبجديات غير اللاتينية، إذ تتحقق العلامة b\ من وجود محرف كلمة w\ في طرف نص وعدم وجوده في الطرف الآخر، وبما أنّ محرف الكلمة w\ سيدل على الأحرف اللاتينية a-z أو الأرقام أو الشرطة السفلية فقط، فلن يعمل مع محارف اللغات الأخرى، مثل العربية أو الصينية. المحارف الخاصة وطريقة تجاوزها يُستخدم المحرف \ كما رأينا للإشارة إلى أصناف المحارف -مثل d\- فهو إذًا محرف خاص، وستجد محارف خاصةً أخرى تحمل معنىً خاصًا في التعابير النمطية، وتستخدم لتنفيذ عمليات بحث أكثر قدرةً، وهذه المحارف هي: [ ]\ ^ $ . | ? * + ( )، ولا حاجة طبعًا لتذكر هذه القائمة، فسنتعامل مع كل محرف منها بشكل منفصل وستحفظها تلقائيًا. التجاوز لنفترض أننا نريد البحث عن محرف النقطة بذاته، وليس أي محرف، في هذه الحالة -وبقية الحالات التي نريد فيها البحث عن محرف خاص بحد ذاته كما لو أنه محرف عادي- سنضع المحرف \ قبله، أي .\ في حالة النقطة، وتُدعى هذه العملية بالتجاوز أو تهريب محرف escaping a character، إليك مثالًا: alert( "Chapter 5.1".match(/\d\.\d/) ); // 5.1 (تطابق!) alert( "Chapter 511".match(/\d\.\d/) ); // null تعتبر الأقواس محارف خاصةً أيضًا، فلا بد من البحث عنها وفق النمط )\، ويبحث المثال التالي عن النص "()g": alert( "function g()".match(/g\(\)/) ); // "g()" إذا أردنا البحث عن المحرف الخاص \ فلا بدّ من مضاعفته \\: alert( "1\\2".match(/\\/) ); // '\' الشرطة المائلة "/" لا تعتبر الشرطة المائلة '/' من المحارف الخاصة، لكنها تستخدم في JavaScript لفتح وإغلاق التعابير النمطية /...pattern.../ فلا بد من تجاوزها أيضًا، إليك الطريقة التي نبحث فيها عن الشرطة المائلة: alert( "/".match(/\//) ); // '/' لا داعي لتجاوز الشرطة المائلة في الحالة التي لا نستخدم فيها النمط /.../، بل ننشئ كائن تعبير نمطي باستخدام new RegExp: alert( "/".match(new RegExp("/")) ); // / يجد الإنشاء باستخدام new RegExp عندما ننشئ تعبيرًا نمطيًا باستخدام new RegExp، فلا حاجة لتجاوز المحرف / لكن يتحتم علينا تجاوز غيره. تأمل الشيفرة التالية: let regexp = new RegExp("\d\.\d"); alert( "Chapter 5.1".match(regexp) ); // null لقد نجح البحث المشابه في أمثلة سابقة عندما استخدمنا /\d\.\d/، لكن لن يعمل البحث باستخدام ("new RegExp("\d\.\d فما السبب؟ السبب أن الشرطة المائلة ستُستهلك من قبل النص، وكما نتذكر فللنصوص العادية محارفها الخاصة -مثل n\- وقد استخدمت الشرطة المعكوسة backslash للتهريب. إليك مثالًا: alert("\d\.\d"); // d.d تستهلك إشارتا التنصيص الشرطة المعكوسة وتفسرها بطريقتها، فمثلًا: تتحول n\ إلى محرف السطر الجديد. تتحول u1234\ إلى محرف Unicode بهذا الرمز. وفي حال لم يوجد معنىً لوجود الشرطة المعكوسة -مثل d\ أو z\- فستُزال هذه الشرطة ببساطة. يحصل new RegExp على نص بلا شرطات معكوسة، لهذا لن يفلح البحث، ولحل المشكلة لا بدّ من مضاعفة الشرطة المعكوسة، لأن إشارتي التنصيص تحولان \\ إلى \. let regStr = "\\d\\.\\d"; alert(regStr); // \d\.\d (عملية صحيحة) let regexp = new RegExp(regStr); alert( "Chapter 5.1".match(regexp) ); // 5.1 خلاصة يتألف التعبير النمطي من نمط pattern، ورايات flags اختيارية هي: g وi وm وu وs وy. لا تختلف عملية البحث دون استخدام الرايات والرموز الخاصة عن أي عملية بحث اعتيادية ضمن نص. يبحث التابع (str.match(regexp عن كل حالات التطابق التي يحددها التعبير regexp بوجود الراية g، وإلا فسيبحث عن أول تطابق فقط. يستبدل التابع (str.replace(regexp, replacement التطابقات التي يحددها التعبير regexp بالنص replacement، حيث يستبدل التطابقات كلها عند وجود الراية g، وإلا فسيستبدل أولها فقط. يعيد التابع (regexp.test(str القيمة true إن وجد تطابقًا على الأقل مع التعبير المستخدم، وإلا فسيعيد false. هنالك أصناف محارف متعددة، هي: d\: للأرقام. D\: لغير الأرقام. s\: لمحارف الفراغات والجدولة والسطر الجديد. S\: لكل المحارف عدا محارف الفراغات والجدولة والسطر الجديد. w\: كل الأرقام والأحرف اللاتينية والشرطة السفلية (_). W\: كل المحارف عدا ما ذكرناه في السطر السابق. .: أي محرف عدا محرف السطر الجديد، وأي محرف تمامًا عند استخدام الراية "s". تؤمن مجموعة المحارف Unicode التي تستخدمها JavaScript العديد من الميزات المتعلقة بالمحارف، مثل تحديد اللغة التي ينتمي إليها محرف معين، وهل يمثل المحرف علامة ترقيم وغيرها، ويتطلب ذلك استخدام الراية u. تدعم الراية u استخدام رموز Unicode في التعابير النمطية، ويعني ذلك أمرين اثنين: ستتعامل الميزات والخصائص مع المحارف المكونة من أربع بايتات بشكل صحيح ومثل محرف واحد، وليس مثل محرفين يتكون كل منهما من بايتين. يمكن استخدام خصائص Unicode في عمليات البحث من خلال {...}\p. يمكن البحث عن كلمات في لغة محددة باستخدام خصائص Unicode، بالإضافة إلى البحث عن محارف خاصة مثل إشارات التنصيص، العملات،…. للبحث عن المحارف الخاصة [ \ ^ $ . | ? * + ( ) بذاتها، لا بدّ من وضع الشرطة المائلة \ قبلها لتجاوز الوظيفة الخاصة للمحرف. ينبغي تجاوز الشرطة المعكوسة \ أيضًا في النمط /.../، لكن ليس ضمن new RegExp. عند تمرير نص إلى new RegExp فلا بدّ من مضاعفة الشرطة المعكوسة، لأن إشارة التنصيص \\ تستهلك إحداهما. ترجمة -وبتصرف- للفصول: Patterns and flags character classes Unicode: flag "u" and class \p{…} Anchors: string start ^ and end $ Multiline mode of anchors ^ $, flag "m" Word boundary: \b Escaping special characters من سلسلة The Modern JavaScript Tutorial. اقرأ أيضًا المقال السابق: مكونات الويب: التعامل مع شجرة DOM الخفية التعابير النمطية (regexp/PCRE) في PHP مقدمة في التعابير النمطية Regular Expressions كيفية التعامل مع النصوص في البرمجة1 نقطة
التعابير النمطية Regular expressions هي أنماط تزودنا بأسلوب فعّال للبحث عن النصوص التي تطابق نمطًا محددًا واستبدالها في JavaScript، يتيح الكائن RegExp استخدام هذه التعابير، وتُدمج مع التوابع التي تتعامل مع النصوص. مقدمة إلى التعابير النمطية تتألف التعابير النمطية من نمط pattern، ورايات flags اختيارية، ولإنشاء كائن تعبير نمطي يمكن استخدام صيغتين، صيغة طويلة وصيغة قصيرة، أما الصيغة الطويلة فتكتب بالشكل: regexp = new RegExp("pattern", "flags"); وأما الصيغة القصيرة فتكتب باستخدام المحرف "/" بالشكل: regexp = /pattern/; // لا رايات regexp = /pattern/gmi; // g و m و i باستخدام الرايات تخبر الخطوط المائلة JavaScript بأننا ننشئ تعبيرًا نمطيًا، فهي تلعب دورًا مماثلًا لعلامة الاقتباس في النصوص، وفي كلتا الصيغتين سيصبح الكائن regexp نسخةً عن الصنف المدمج RegExp. لا يُسمح بإدخال متغيرات تمثل الأنماط ضمن صيغة الخطوط المائلة /.../ باستخدام القوالب {...}$ الديناميكية مثلًا كما نفعل في النصوص، فهي ثابتة بشكل كامل، وهذا هو الاختلاف الرئيسي بين الصيغتين، إذ نستخدم الخطوط المائلة عندما نريد استخدام تعابير نمطية محددة ومعروفة بالنسبة لنا عند كتابة الشيفرة، وهذه هي الحالة الأكثر شيوعًا، بينما نستخدم الصيغة new RegExp عادةً عندما نحتاج إلى إنشاء تعابير نمطية أثناء التنفيذ انطلاقًا من نص أُنشئ ديناميكيًا. let tag = prompt("What tag do you want to find?", "h2"); let regexp = new RegExp(`<${tag}>`); // "h2" إن كان الجواب /<h2>/ نفس نتيجة الرايات للتعابير النمطية رايات تؤثر على نتيجة البحث، وتستخدم JavaScript ستةً منها، وهي: i: سيكون البحث غير حساس لحالة الأحرف مع هذه الراية، أي لن يكون هناك فرق بين "a" و"A". g: سيعيد البحث جميع النتائج المتطابقة مع هذه الراية، وإلا فسيعيد النتيجة الأولى. m: سيعمل البحث في نمط الأسطر المتعددة، وسنغطي ذلك لاحقًا. s: ستمكّن نمط "dotall" الذي يسمح بأن نعدَّ النقطة . هي محرف نهاية السطر n\، وسنغطيه لاحقًا. u: سيمكّن الدعم الكامل لترميز Unicode، وبالتالي المعالجة الصحيحة لمحتويات الأقواس المعقوصة {..}، وسنغطيه لاحقًا. y: سيمكّن النمط اللاصق "Sticky"، حيث يبحث في المكان المحدد تمامًا من النص، وسنغطيه لاحقًا. البحث باستخدام التابع str.match تتكامل التعابير النمطية مع توابع النصوص، إذ يبحث التابع (str.match(regexp عن كل ما يطابق التعبير regexp في النص str، ويعمل وفق ثلاثة أنماط: النمط الأول، التعبير النمطي مع الراية g، ويعيد مصفوفةً تضم النتائج المطابقة: let str = "We will, we will rock you"; alert( str.match(/we/gi) ); // سيعيد مصفوفة من الحالتين المتطابقتين للبحث وانتبه إلى أنّ البحث سيعيد النتيجتين "we" و"We" لأن راية حالة الأحرف i مفعّلة. النمط الثاني، إذا لم نفعّل الراية g، فسيعيد البحث النتيجة الأولى فقط ضمن مصفوفة، مع وضع التطابق في الدليل 0، بالإضافة إلى تفاصيل أخرى في الخصائص: let str = "We will, we will rock you"; let result = str.match(/we/i); // g دون الراية alert( result[0] ); // We (التطابق الأول) alert( result.length ); // 1 // Details: alert( result.index ); // 0 (موقع التطابق) alert( result.input ); // We will, we will rock you (النص الأصلي) قد تحتوي المصفوفة على عناصر أخرى بالإضافة إلى العنصر ذي الدليل 0؛ إذا كان جزء من التعبير النمطي ضمن قوسين مغلقين وسنغطي ذلك في المقالات القادمة. النمط الثالث، إذا لم توجد أي تطابقات، فسيعيد التابع القيمة null، بوجود الراية g أو عدم وجودها، لذا انتبه أننا لن نحصل في هذه الحالة على مصفوفة فارغة، بل على القيمة null، وسيؤدي نسيان هذه الحقيقة إلى مشاكل عدة: let matches = "JavaScript".match(/HTML/); // = null if (!matches.length) { //length خطأ لا يمكن قراءة الخاصية alert("Error in the line above"); } إذا أردنا أن نحصل دائمًا على مصفوفة، فيمكننا أن ننفذ الأمر بالشكل التالي: let matches = "JavaScript".match(/HTML/) || []; if (!matches.length) { alert("No matches"); // ستعمل الآن } الاستبدال باستخدام التابع str.replace يستبدل التابع (str.replace(regexp, replacement التطابقات الموافقة للكائن regexp في النص str بقيمة replacement، وستستبدل كل التطابقات عند استخدام الراية g، وإلا فسيستبدل أول تطابق فقط، وإليك مثالًا: // g دون الراية alert( "We will, we will".replace(/we/i, "I") ); // I will, we will // مع الراية alert( "We will, we will".replace(/we/ig, "I") ); // I will, I will يمكن استخدام محارف خاصة ضمن الوسيط الثاني replacement للبحث عن أجزاء من معيار التطابق: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الرمز ما يفعله ضمن النص replacment &$ يمثل نص التطابق `$ يمثل النص الواقع قبل نص التطابق. '$ يمثل النص الواقع بعد نص التطابق. n$ يمثل التطابق ذا الرقم n من مجموعة التطابق (الموجود ضمن قوسي تجميع"()" ) . $<name> يمثل التطابق ذا الاسم name من مجموعة التطابق (الموجود ضمن قوسي تجميع"()" ). $$ يمثل المحرف $ مثال باستخدام &$: alert( "I love HTML".replace(/HTML/, "$& and JavaScript") ); // I love HTML and JavaScript الاختبار باستخدام التابع regexp.test يبحث التابع (regexp.test(str عن تطابق واحد على الأقل -إن وُجد- ويعيد القيمة true، وإن لم يجد تطابقًا فسيعيد القيمة false. let str = "I love JavaScript"; let regexp = /LOVE/i; alert( regexp.test(str) ); // true سندرس لاحقًا في هذا القسم تعابير نمطيةً أكثر، وسنتعرف على توابع أخرى لاحقًا. أصناف المحارف لنتأمل مهمةً تتطلب تحويل رقم هاتف، مثل "67-45-123-(903)7+"، إلى رقم صرف، أي 79031234567، لتنفيذ ذلك يمكننا تتبع وحذف أي محرف لا يمثل رقمًا، وستساعدنا أصناف المحارف في ذلك، حيث تمثل إشارات خاصةً تطابق أي رمز ضمن مجموعة معينة، وسنتعرف بدايةً على الصنف "digit"، الذي يُعبَّر عنه بالشكل d\، ويرتبط بأي رقم مفرد، فمثلًا لنجد الرقم الأول في رقم الهاتف: let str = "+7(903)-123-45-67"; let regexp = /\d/; alert( str.match(regexp) ); // 7 سيبحث التابع عن كل الأرقام التي سيجدها في النص بإضافة الراية g، وسيعيدها ضمن مصفوفة: let str = "+7(903)-123-45-67"; let regexp = /\d/g; alert( str.match(regexp) ); // 7,9,0,3,1,2,3,4,5,6,7 // لنشكل عددًا من أرقام المصفوفة: alert( str.match(regexp).join('') ); // 79031234567 سنستعرض الآن بعض الأصناف الأكثر استعمالًا، وهي: d\: من كلمة digit رقم، ويعيد أي رقم بين 0 و9. \s: من كلمة space فراغ، وتضم محارف الفراغ، مثل: مسافة الجدولة t\، والسطر الجديد n\، وغيرها من الرموز النادرة الاستخدام مثل r\ وv\ وf\. w\: من كلمة word كلمة، وتعيد محارف قد تشكل كلمةً، مثل الأحرف اللاتينية أو الأرقام أو الشرطة السفلية _، ولا تنتمي الأحرف غير اللاتينية، مثل العربية، إلى هذا الصنف، إذ تشير الرموز d\s\w\ مثلًا إلى رقم متبوع بمحرف فراغ، ويليه محرف كلمة مثل 1 a. يمكن أن يضم الكائن محارف تعابير نمطية بالإضافة إلى الأصناف، فمثلًا سيبحث التعبير CSS\d عن الكلمة CSS متبوعةً برقم: let str = "Is there CSS4?"; let regexp = /CSS\d/ alert( str.match(regexp) ); // CSS4 كما يمكن استخدام أصناف محارف عدة: alert( "I love HTML5!".match(/\s\w\w\w\w\d/) ); // ' HTML5' الأصناف المعكوسة لكل صنف من أصناف المحارف صنف معكوس inverse class، يرمز له بالحرف نفسه لكن بحالة حرف كبير uppercase، ويعني ذلك الحصول على أي محرف عدا المحرف الذي يعيده الصنف عادةً، أي: D\: لا يعيد رقمًا، وإنما يعيد أي محرف عدا المحارف التي يعيدها d\، مثل الأحرف اللاتينية. S\: لا يعيد محرف فراغ، وإنما يعيد أي محرف عدا المحارف التي يعيدها s\، مثل الأحرف اللاتينية. W\: لا يعيد محرف كلمة، وإنما يعيد أي محرف عدا المحارف التي يعيدها w\، مثل الأحرف غير اللاتينية أو الفراغات. لاحظ كيف سنستخدَم هذه الأصناف في تحويل رقم الهاتف في المثال السابق إلى رقم صرف وبطريقة أقصر، وذلك بإزالة المحارف التي لا تمثل أرقامًا D\: let str = "+7(903)-123-45-67"; alert( str.replace(/\D/g, "") ); // 79031234567 يمثل المحرف نقطة أي محرف يمثل المحرف . صنفًا مميزًا من المحارف، ويطابق أي محرف عدا محرف السطر الجديد، إليك مثالًا: alert( "Z".match(/./) ); // Z كما يمكن إدراجه وسط التعبير regexp: let regexp = /CS.4/; alert( "CSS4".match(regexp) ); // CSS4 alert( "CS-4".match(regexp) ); // CS-4 alert( "CS 4".match(regexp) ); // CS 4 (الفراغ هو محرف أيضًا) لاحظ أن النقطة تطابق أي محرف، لكنها لن تبحث عن محرف غير موجود، فلا بدّ من وجود محرف حتى يعيده هذا الصنف: alert( "CS4".match(/CS.4/) ); // null, لن يعيد الصنف شيئًا لعدم وجود محرف لاحظ أن محرف النقطة يمثل أي محرف بالفعل بوجود الراية "s"، فلا تعيد النقطة عادةً محرف السطر الجديد، إذ يعيد التعبير A.B الحرفين A وB وأي محارف بينهما عدا محرف السطر الجديد n\: alert( "A\nB".match(/A.B/) ); // null (لا تطابقات) لكننا في عدة حالات نريد للنقطة أن تعني أي محارف فعلًا، بما في ذلك السطر الجديد، لذلك سنستخدم الراية s وسنحصل على المطلوب: alert( "A\nB".match(/A.B/s) ); // A\nB (match!) انتبه إلى أن المتصفح IE لا يدعم الراية s، لكن يمكن استخدام التعبير النمطي [\s\S] الذي يعيد أي محرف في أي مكان، وسنغطي ذلك لاحقًا. alert( "A\nB".match(/A[\s\S]B/) ); // A\nB (match!) ويعني التعبير [\s\S] البحث عن (محرف فراغ أو محرف لا يمثل فراغًا)، وهذا يمثل عمليًا أي محارف، ويمكن استخدام أي أزواج من الأصناف وعكسها، مثل [\d\D]، كما يمكن استخدام التعبير [^] الذي يعني البحث عن أي محرف عدا "لا شيء"، ويمكن استخدام الحيلة ذاتها إن أردنا أن يؤدي المحرف "نقطة" . كلا الوظيفتين، أي مطابقة أي محارف عدا السطر الجديد . أو مع السطر الجديد [\s\S]. انتبه أيضًا إلى الفراغات، إذ لا نكترث عادةً لوجود فراغات زائدة، وسنعتبر النص 1-5 مماثلًا للنص 1 - 5، لكن قد يخفق التعبير النمطي regexp إن لم يأخذ هذه الفراغات في الحسبان. لنحاول مثلًا أن نجد أرقامًا مفصولةً بشرطة صغيرة (-): alert( "1 - 5".match(/\d-\d/) ); // null, لا تطابق سنصلح ذلك بإضافة فراغات إلى التعبير النمطي d - \d\: alert( "1 - 5".match(/\d - \d/) ); // 1 - 5, سنجد الآن تطابقًا // \s أو يمكن استخدام الصنف: alert( "1 - 5".match(/\d\s-\s\d/) ); // 1 - 5, سيعمل أيًا فالفراغ هو محرف، ولا يمكننا إضافة أو إزالة الفراغات من تعبير نمطي، ثم نتوقع أن يعمل كما هو مطلوب، فكل المحارف التي ندخلها في التعبير النمطي ستُؤخذ في الحسبان عند البحث، بما فيها الفراغات. تعامل التعابير النمطية مع ترميز يونيكود Unicode تستخدم JavaScript ترميز يونيكود Unicode لتمثيل النصوص، حيث تُرمّز معظم المحارف باستخدام 2 بايت، وهذا ما يسمح بترميز 65536 محرف كحد أقصى، ولا يعتبر العدد السابق كافيًا لترميز كل المحارف الممكنة، لذلك ستجد أن بعض المحارف الخاصة رمِّزت باستخدام 4 بايت، مثل المحرف ? -التمثيل الرياضي للمحرف X- أو ? -الابتسامة- وبعض المحارف الهيروغليفية وغيرها، وإليك قيم Unicode لبعض المحارف الخاصة: المحرف ترميز Unicode عدد البايتات المستخدمة a 0x0061 2 ≈ 0x2248 2 ? 0x1d4b3 4 ? 0x1d4b4 4 ? 0x1f604 4 تشغل محارف -مثل a- بايتين اثنين، ومحارف -مثل ? و?- أربعة بايتات. كان ترميز Unicode في الأيام الأولى لظهور JavaScript أكثر بساطةً، حيث لم توجد محارف من أربعة بايتات، لذلك ستجد أن بعض ميزات اللغة ستتعامل معها بشكل غير صحيح، فتعتقد الخاصية length مثلًا أنها عبارة عن محرفين: alert('?'.length); // 2 alert('?'.length); // 2 والسبب في ذلك أنّ هذه الخاصية ستعامل المحرف ذا البايتات الأربعة على أنه محرفان لكل منهما بايتان فقط، وهذا أمر خاطئ، حيث ينبغي اعتبارها محرفًا واحدًا، وتُدعى "الزوج البديل" surrogate pair، وسنرى ذلك لاحقًا. تعامل التعابير النمطية regular expression المحارف الطويلة ذات البايتات الأربع مثل زوج من البايتات الثنائية، وقد يقود ذلك إلى أخطاء كما هو الحال في النصوص، لكن -وعلى خلاف النصوص- للتعابير النمطية الراية u التي تعالج هذه المشكلة، إذ يعالج التعبير المحارف ذات البايتات الأربع بشكل صحيح عند وجود هذه الراية، وسيصبح البحث متاحًا ضمن خصائص الترميز Unicode كما سنرى تاليًا. خصائص ترميز Unicode باستعمال {…}p\ لمحارف Unicode العديد من الخصائص التي تصف الفئة التي ينتمي إليها المحرف، كما تقدم معلومات متنوعةً عنها، فلو كان للمحرف الخاصية Letter فسيعني ذلك أنه ينتمي إلى أبجدية ما، كما يعني امتلاكه الخاصية Number أنه رقم، وقد يكون رقمًا عربيًا أو صينيًا وهكذا، ويمكن البحث عن محرف يمتلك خاصيةً معينةً باستخدام الصنف {...}p\، ولاستخدام هذا الصنف لا بد أن نفعّل الراية u في التعبير النمطي. يبحث التعبير {p{Letter\مثلًا عن حرف في أي لغة، كما يمكن كتابته بالشكل {p{L\، وهو اسم مستعار للخاصية Letter، ولمعظم الخصائص أسماء مستعارة قصيرة. سيجد البحث في المثال التالي ثلاثة أنواع من الأحرف: انكليزي وجورجي وكوري. let str = "A ბ ㄱ"; alert( str.match(/\p{L}/gu) ); // A,ბ,ㄱ alert( str.match(/\p{L}/g) ); // null (no matches, \p doesn't work without the flag "u") إليك الفئات الأساسية للمحارف، وفئاتها الفرعية: الحرف Letter: واسمها المستعار L. Ll: حرف صغير. Lm: حرف معدِّل modifier. Lt: عنوان. Lu: حرف كبير. Lo: غير ذلك. العدد Number: واسمها المستعار N. Nd: رقم بالصيغة العشرية. Nl: رقم حرف. No: غير ذلك. علامات الترقيم Punctuation: واسمها المستعار P. Pc: واصلة. Pd: خط فاصل dash. Pi: علامة اقتباس فاتحة. Pf: علامة اقتباس غالقة. Ps: مفتوح. Pe: مغلق. Po: غير ذلك. العلامة أو الحركة Mark: واسمها المستعار M، مثل العلامات أو الحركات فوق الأحرف وغيرها. Mc: علامة ضم مع فراغ spacing combining، وعلامة الضم هي محرف يعدّل محرفًا آخر بإضافة علامة أو حركة فوقه أو تحته وهكذا. Me: علامة ضم محيطة enclosing. Mn: علامة ضم دون فراغ non-spacing. الرمز Symbol: واسمه المستعار S. Sc: رموز عملة. Sk: رمز مُعدِّل. Sm: رمز رياضي. So: رمز آخر. الفواصل Separator: واسمها المستعار Z. Zl: خط. Zp: مقطع. Zs: فراغ. فئات أخرى: واسمها المستعار C. Cc: تحكم. Cf: تنسيق. Cn: لم يحدد بعد. Co: استخدام خاص. Cs: بديل. فلو أردنا مثلًا أحرفًا كبيرة فسنستخدم {p{Ll\، بينما نستخدم {p{p\ لعلامات الترقيم وهكذا. ستجد أيضًا بعض الفئات المشتقة، مثل: Alphabetic: واسمها المستعار Alpha، وتضم الأحرف L، والأرقام على شكل أحرف Nl، مثل Ⅻ وهو 12 بالرومانية. Hex_Digit: وتضم الأرقام الست عشرية: 0-9 وa-f. يدعم الترميز Unicode خصائص عديدةً، وسيزيد ذكرها من حجم المقالة بشكل كبير، لكن يمكنك الاطلاع على المراجع التالية: قائمة بكل الخصائص وفقًا للمحرف. قائمة بكل المحارف وفقًا للخاصية. قائمة بالاسماء المستعارة القصيرة للخصائص. قاعدة كاملة بمحارف Unicode بتنسيق نصي مع كامل خصائصها. مثال: الأعداد الست عشرية لننظر مثلًا إلى الأعداد الست عشرية المكتوبة بالشكل xFF، حيث F هو رقم ست عشري (0-1 أو A-F)، ويمكن الإشارة إلى الرقم الست عشري بالشكل {p{Hex_Digit\: let regexp = /x\p{Hex_Digit}\p{Hex_Digit}/u; alert("number: xAF".match(regexp)); // xAF مثال: الكتابة التصويرية الصينية في ترميز Unicode خاصية تحدد نظام الكتابة، ويمكن أن تأخذ قيمًا مثل: Cyrillic وGreek وArabic وHan (الصينية) وغيرها من القيم المشابهة، وللبحث عن محرف في نظام كتابة محدد علينا استخدام الخاصية <Script=<value، فللعربية مثلًا نستخدم {p{sc=Arabic\، وللصينية نستخدم {p{sc=Han\ وهكذا. let regexpHan = /\p{sc=Han}/gu; // يعيد التصويرية الصينية let regexpArab = /\p{sc=Arabic}/gu; // يعيد العربية let str = `Hello Привет 你好 جميل 123_456`; alert( str.match(regexpHan) ); // 你,好 alert( str.match(regexpArab) ); // ج,م,ي,ل مثال: رموز العملة للمحارف التي ترمز إلى العملات -مثل $ و€ و¥- خاصية في ترميز Unicode، هي {p{Currency_Symbol\، واسمها المختصر {p{Sc\، لنستخدم هذه الخاصية في الحصول على سعر منتج ضمن تنسيق يحوي رمز عملة يليه رقم: let regexp = /\p{Sc}\d/gu; let str = `Prices: $2, €1, ¥9`; alert( str.match(regexp) ); // $2,€1,¥9 وسنتعرف لاحقًا في مقالات قادمة على آلية البحث عن أعداد تحتوي عدة أرقام. محارف الارتكاز: محرفا بداية النص ^ ونهايته $ يحمل المحرفان ^ و$ معانٍ خاصةً في التعابير النمطية regular expression، وتسمى بالمرتكزات أو المرابط Anchors، حيث تبحث العلامة ^ عن تطابق في بداية النص، بينما تبحث $ عن تطابق في نهايته، لنر مثلًا إن بدأ نص ما بالكلمة "Mary": let str1 = "Mary had a little lamb"; alert( /^Mary/.test(str1) ); // true يعني النمط أن نبحث عن الكلمة "Mary" في بداية السطر حصرًا، وبشكل مشابه يمكن أن نستخدم $ للتحقق من وجود الكلمة "snow" مثلًا في نهاية نص: let str1 = "it's fleece was white as snow"; alert( /snow$/.test(str1) ); // true يمكن استخدام توابع التعامل مع النصوص startsWith/endsWith في هذه الحالات بالتحديد، لكن ينبغي استخدام التعابير النمطية في الحالات الأكثر تعقيدًا. اختبار التطابق الكامل يستخدم المرتكزان السابقان معًا $...^ لاختبار تطابق نص بشكل كامل مع النمط، مثل التحقق من مطابقة ما يدخله المستخدم للتنسيق المطلوب، لنتحقق مثلًا أن نصًا له التنسيق الزمني التالي 12:34، وهو عدد من رقمين، تليه نقطتان ":"، ثم عدد من رقمين، لذا سنستخدم التعبير d\d:\d\d\ في عالم التعابير النمطية: let goodInput = "12:34"; let badInput = "12:345"; let regexp = /^\d\d:\d\d$/; alert( regexp.test(goodInput) ); // true alert( regexp.test(badInput) ); // false يجب أن يبدأ التطابق مباشرة ًعند بداية النص ^، وينتهي بنهايته $، ويجب أن يطابق تنسيق النص تنسيق التعبير النمطي، فإذا وجدَت أي اختلافات أو محارف زائدة فستكون النتيجة "false"، وتسلك المرتكزات سلوكًا مختلفًا بوجود الراية m، وسنطلع على ذلك لاحقًا. انتبه إلى أن ليس للمرتكزات عرض، فالمرتكزات محارف اختبار، وليس لها عرض، فهي لا تطابق محارف محددةً، بل تجبر محرك التعبير النمطي للتحقق من الشرط (بداية ونهاية نص). نمط الأسطر المتعددة: تأثير الراية "m" على المرتكزان ^ و $ يُفعّل نمط الأسطر المتعددة باستخدام الراية m، التي تؤثر على سلوك المرتكزين $ و^ فقط، فلا تطابق المرتكزات في نمط الأسطر المتعددة بداية ونهاية النص فقط، بل بداية ونهاية السطر. البحث عند بداية سطر ^ يحتوي النص في المثال التالي على عدة أسطر، وسيأخذ النمط d/gm\^/ رقمًا من بداية كل سطر: let str = `1st place: Winnie 2nd place: Piglet 3rd place: Eeyore`; alert( str.match(/^\d/gm) ); // 1, 2, 3 سنحصل دون الراية m على الرقم الموجود في أول سطر فقط يطابق النمط: let str = `1st place: Winnie 2nd place: Piglet 3rd place: Eeyore`; alert( str.match(/^\d/g) ); // 1 والسبب أنّ العلامة ^ ستطابق افتراضيًا بداية النص فقط، بينما ستطابق في نمط الأسطر المتعددة بداية أي سطر. انتبه، فتعني بداية السطر رسميًا المحرف الذي يأتي بعد محرف السطر الجديد، وهكذا ستطابق العلامة ^ في نمط الأسطر المتعددة كل المحارف التي يسبقها محرف السطر الجديد n\. البحث عند نهاية سطر $ يسلك المرتكز $ السلوك السابق نفسه، إذ يجد التعبير النمطي $d\ مثلًا آخر رقم في كل سطر: let str = `Winnie: 1 Piglet: 2 Eeyore: 3`; alert( str.match(/\d$/gm) ); // 1,2,3 سيطابق المرتكز $ نهاية النص ككل دون استخدام الراية m، وبالتالي سنحصل فقط على آخر رقم. انتبه، فتعني نهاية السطر رسميًا المحرف الذي يأتي قبل محرف السطر الجديد، وهكذا ستطابق العلامة $ في نمط الأسطر المتعددة كل المحارف التي تسبق محرف السطر الجديد n\ مباشرةً. البحث عن محرف السطر الجديد n\ بدل المرتكز $ يمكن البحث عن سطر جديد باستخدام المحرف n\ بدلًا من البحث عن المرتكزين ^ و$، لكن ما الفرق؟ سنبحث في المثال التالي عن d\n\بدلًا من $d\: let str = `Winnie: 1 Piglet: 2 Eeyore: 3`; alert( str.match(/\d\n/gm) ); // 1\n,2\n ستجد الشيفرة تطابقين بدلًا من ثلاث، وذلك لعدم وجود سطر جديد بعد الرقم 3، على الرغم من وجود مرتكز نهاية النص الذي يطابق $، أما الاختلاف الآخر فهو أنّ n\محرف، وسيظهر ضمن النتيجة، وليس مثل المرتكزين ^ و$ اللذين يحددان شرط البحث في بداية ونهاية النص، وبالتالي سنستخدم n\ إذا أردنا ظهور محرف السطر الجديد في النتيجة، وإلا استخدمنا ^ و$. حدود الكلمة: b\ حدود الكلمة اختبار، مثل ^ و$، حيث يشير وجود العلامة b\ بأنّ الموقع الذي وصل إليه محرك بحث التعابير النمطية هو حد لكلمة، وتوجد ثلاثة مواقع مختلفة يمكن اعتبارها حدودًا لكلمة، وهي: في بداية نص، إذا كان أول محرف نصي فيه هو محرف كلمة w\. بين محرفين في نص، إذا كان أحدهما محرف كلمة w\ والآخر ليس كذلك. في نهاية نص، إذا كان آخر محرف فيه هو محرف الكلمة w\. يمكن أن تجد التعبير bJava\b\ مثلًا في النص !Hello, Java عندما تكون الكلمة Java منفصلةً عن غيرها، لكنك لن تحصل على نفس النتيجة في النص !Hello, JavaScript alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, JavaScript!".match(/\bJava\b/) ); // null في الشكل التالي ستمثل المواقع المشار إليها العلامة b\ في النص !Hello, Java: لذلك فهي تطابق النمط bHello\b\ لأن: بداية النص تتطابق مع العلامة b\. ثم تتطابق مع الكلمة Hello. ثم تتطابق مع العلامة b\ مرةً أخرى، كما لو أنها بين المحرف o والفاصلة. إذًا سنعثر على النمط bHello\b\، لكن ليس النمط bHell\b\، لعدم وجود علامة حد الكلمة b\ بعد المحرف l، كما لن نحصل على النمط Java!\b لأن علامة التعجب ليست محرف كلمة w\، وبالتالي لا وجود لعلامة حد الكلمة b\ بعده. alert( "Hello, Java!".match(/\bHello\b/) ); // Hello alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, Java!".match(/\bHell\b/) ); // null (no match) alert( "Hello, Java!".match(/\bJava!\b/) ); // null (no match) يمكن استخدام b\ مع الأرقام أيضًا، إذ يبحث النمط b\d\d\b\ مثلًا عن عدد من رقمين -عدد بخانتين- منفصل عن غيره، أي يبحث عن عدد بخانتين غير محاط بمحارف الكلمة w\، مثل محارف الفراغات أو علامات الترقيم أو مرتكزات بداية ونهاية نص. alert( "1 23 456 78".match(/\b\d\d\b/g) ); // 23,78 alert( "12,34,56".match(/\b\d\d\b/g) ); // 12,34,56 انتبه، لا تعمل العلامة b\ مع الأبجديات غير اللاتينية، إذ تتحقق العلامة b\ من وجود محرف كلمة w\ في طرف نص وعدم وجوده في الطرف الآخر، وبما أنّ محرف الكلمة w\ سيدل على الأحرف اللاتينية a-z أو الأرقام أو الشرطة السفلية فقط، فلن يعمل مع محارف اللغات الأخرى، مثل العربية أو الصينية. المحارف الخاصة وطريقة تجاوزها يُستخدم المحرف \ كما رأينا للإشارة إلى أصناف المحارف -مثل d\- فهو إذًا محرف خاص، وستجد محارف خاصةً أخرى تحمل معنىً خاصًا في التعابير النمطية، وتستخدم لتنفيذ عمليات بحث أكثر قدرةً، وهذه المحارف هي: [ ]\ ^ $ . | ? * + ( )، ولا حاجة طبعًا لتذكر هذه القائمة، فسنتعامل مع كل محرف منها بشكل منفصل وستحفظها تلقائيًا. التجاوز لنفترض أننا نريد البحث عن محرف النقطة بذاته، وليس أي محرف، في هذه الحالة -وبقية الحالات التي نريد فيها البحث عن محرف خاص بحد ذاته كما لو أنه محرف عادي- سنضع المحرف \ قبله، أي .\ في حالة النقطة، وتُدعى هذه العملية بالتجاوز أو تهريب محرف escaping a character، إليك مثالًا: alert( "Chapter 5.1".match(/\d\.\d/) ); // 5.1 (تطابق!) alert( "Chapter 511".match(/\d\.\d/) ); // null تعتبر الأقواس محارف خاصةً أيضًا، فلا بد من البحث عنها وفق النمط )\، ويبحث المثال التالي عن النص "()g": alert( "function g()".match(/g\(\)/) ); // "g()" إذا أردنا البحث عن المحرف الخاص \ فلا بدّ من مضاعفته \\: alert( "1\\2".match(/\\/) ); // '\' الشرطة المائلة "/" لا تعتبر الشرطة المائلة '/' من المحارف الخاصة، لكنها تستخدم في JavaScript لفتح وإغلاق التعابير النمطية /...pattern.../ فلا بد من تجاوزها أيضًا، إليك الطريقة التي نبحث فيها عن الشرطة المائلة: alert( "/".match(/\//) ); // '/' لا داعي لتجاوز الشرطة المائلة في الحالة التي لا نستخدم فيها النمط /.../، بل ننشئ كائن تعبير نمطي باستخدام new RegExp: alert( "/".match(new RegExp("/")) ); // / يجد الإنشاء باستخدام new RegExp عندما ننشئ تعبيرًا نمطيًا باستخدام new RegExp، فلا حاجة لتجاوز المحرف / لكن يتحتم علينا تجاوز غيره. تأمل الشيفرة التالية: let regexp = new RegExp("\d\.\d"); alert( "Chapter 5.1".match(regexp) ); // null لقد نجح البحث المشابه في أمثلة سابقة عندما استخدمنا /\d\.\d/، لكن لن يعمل البحث باستخدام ("new RegExp("\d\.\d فما السبب؟ السبب أن الشرطة المائلة ستُستهلك من قبل النص، وكما نتذكر فللنصوص العادية محارفها الخاصة -مثل n\- وقد استخدمت الشرطة المعكوسة backslash للتهريب. إليك مثالًا: alert("\d\.\d"); // d.d تستهلك إشارتا التنصيص الشرطة المعكوسة وتفسرها بطريقتها، فمثلًا: تتحول n\ إلى محرف السطر الجديد. تتحول u1234\ إلى محرف Unicode بهذا الرمز. وفي حال لم يوجد معنىً لوجود الشرطة المعكوسة -مثل d\ أو z\- فستُزال هذه الشرطة ببساطة. يحصل new RegExp على نص بلا شرطات معكوسة، لهذا لن يفلح البحث، ولحل المشكلة لا بدّ من مضاعفة الشرطة المعكوسة، لأن إشارتي التنصيص تحولان \\ إلى \. let regStr = "\\d\\.\\d"; alert(regStr); // \d\.\d (عملية صحيحة) let regexp = new RegExp(regStr); alert( "Chapter 5.1".match(regexp) ); // 5.1 خلاصة يتألف التعبير النمطي من نمط pattern، ورايات flags اختيارية هي: g وi وm وu وs وy. لا تختلف عملية البحث دون استخدام الرايات والرموز الخاصة عن أي عملية بحث اعتيادية ضمن نص. يبحث التابع (str.match(regexp عن كل حالات التطابق التي يحددها التعبير regexp بوجود الراية g، وإلا فسيبحث عن أول تطابق فقط. يستبدل التابع (str.replace(regexp, replacement التطابقات التي يحددها التعبير regexp بالنص replacement، حيث يستبدل التطابقات كلها عند وجود الراية g، وإلا فسيستبدل أولها فقط. يعيد التابع (regexp.test(str القيمة true إن وجد تطابقًا على الأقل مع التعبير المستخدم، وإلا فسيعيد false. هنالك أصناف محارف متعددة، هي: d\: للأرقام. D\: لغير الأرقام. s\: لمحارف الفراغات والجدولة والسطر الجديد. S\: لكل المحارف عدا محارف الفراغات والجدولة والسطر الجديد. w\: كل الأرقام والأحرف اللاتينية والشرطة السفلية (_). W\: كل المحارف عدا ما ذكرناه في السطر السابق. .: أي محرف عدا محرف السطر الجديد، وأي محرف تمامًا عند استخدام الراية "s". تؤمن مجموعة المحارف Unicode التي تستخدمها JavaScript العديد من الميزات المتعلقة بالمحارف، مثل تحديد اللغة التي ينتمي إليها محرف معين، وهل يمثل المحرف علامة ترقيم وغيرها، ويتطلب ذلك استخدام الراية u. تدعم الراية u استخدام رموز Unicode في التعابير النمطية، ويعني ذلك أمرين اثنين: ستتعامل الميزات والخصائص مع المحارف المكونة من أربع بايتات بشكل صحيح ومثل محرف واحد، وليس مثل محرفين يتكون كل منهما من بايتين. يمكن استخدام خصائص Unicode في عمليات البحث من خلال {...}\p. يمكن البحث عن كلمات في لغة محددة باستخدام خصائص Unicode، بالإضافة إلى البحث عن محارف خاصة مثل إشارات التنصيص، العملات،…. للبحث عن المحارف الخاصة [ \ ^ $ . | ? * + ( ) بذاتها، لا بدّ من وضع الشرطة المائلة \ قبلها لتجاوز الوظيفة الخاصة للمحرف. ينبغي تجاوز الشرطة المعكوسة \ أيضًا في النمط /.../، لكن ليس ضمن new RegExp. عند تمرير نص إلى new RegExp فلا بدّ من مضاعفة الشرطة المعكوسة، لأن إشارة التنصيص \\ تستهلك إحداهما. ترجمة -وبتصرف- للفصول: Patterns and flags character classes Unicode: flag "u" and class \p{…} Anchors: string start ^ and end $ Multiline mode of anchors ^ $, flag "m" Word boundary: \b Escaping special characters من سلسلة The Modern JavaScript Tutorial. اقرأ أيضًا المقال السابق: مكونات الويب: التعامل مع شجرة DOM الخفية التعابير النمطية (regexp/PCRE) في PHP مقدمة في التعابير النمطية Regular Expressions كيفية التعامل مع النصوص في البرمجة1 نقطة -
إن كانت هذه الدالة homepage بداخل class فلا توجد في الكود مشكلة. إن الكود يعمل ولا يظهر مشكلة أو خطأ فهو كود سليم وليس بحاجة إلى تعديل، لكن يفضل أن يكون الكود منظم ومرتب ويحتوي على تعليقات لشرح كل الخطوات. مثال لنفس الكود بداخل class: namespace App\Http\Controllers; use Illuminate\Http\Request; use App\Slide; use App\About; class HomeController extends Controller { public function homepage(){ $slides = Slide::all(); $about = About::whereIn('id', [1,2])->get(); return view ('front.homepage', compact('slides','about')); } }1 نقطة
-
التابع first() يقوم بجلب أول سجل يجده فقط، بينما التابع get() يجلب صنف collection، ويمكن تخيل هذا الصنف على أنه مصفوفة array من السجلات يمكن إستخدامها في حلقات التكرار مثل for loop أو while loop. بالنسبة لجلب عدد محدد من السجلات فيمكن إستخدام التابع limit(num) والذي يقبل عدد يتم تمريره إليه يعبر عن عدد السجلات المراد جلبها. $user = User::limit(2)->get(); بالنسبة لجلب السجلات بطريقة عشوائية in random order فيمكن إستخدام التابع ()inRandomOrder ليجلب كل السجلات في ترتيب عشوائي. $users = User::inRandomOrder()->get();1 نقطة
-
مرحبًا @Hanan Han تختلف أنواع التقارير بإختلاف نوع المشروع وحجمه والمتفق عليه مع العميل. لذلك عليكً أن تسألي العميل عن الأشياء التي يريدها في التقرير. في الغالب يجب أن تضيفي كل التقنيات التي سيتم إستعمالها، فعلى سبيل المثال: في تطوير المواقع تستخدم اللغات HTML, CSS, JavaScript إلخ مع بعض المكتبات وإطارات العمل مثل Bootstrap و Laravel في التصميم يتم إستهدام برامج مثل Adobe Photoshop و Adobe Illustrator إلخ في الموشن جرافيك والمنتاج تستخدم برامج مثل adobe premiere و Adobe after effect كما يجب إضافة كيف ستكون خطوات العمل مرتبة بالوقت، مع إضافة خطوات المراجعة والتأكد من سلامة كل ملفات المشروع، وفي النهاية يتم إضافة الوقت اللازم لإنهاء المشروع مع التكلفة الإجمالية.1 نقطة
-
مرحباً @ريان بهنام دانيال هندسة الحاسوب سأحاول شرح الفكرة العامة وعليك أن تحول الشرح إلى كود لتطبقه بنفسك. يجب أن تكون على دراية ببعض الأمور كـ (linked list أو queue أو غيرها من هياكل البيانات Data Structures)، ولكي تستطيع تنفيذ ال circular queue تحتاج لصنفين two classes صنف Node: يحتوي على قيمة وعنوان لعنصر آخر (Data & Another Node Address) صنف Queue: يحتوي على العمليات التي ستتم على ال circular queue وهي كالتالي: Front: الحصول على أول عنصر في القائمة Rear: الحصول على آخر عنصر في القائمة (enQueue(value: إضافة عنصر لآخر القائمة لاحظ أن أي عنصر جديد يتم إضافته في مكان Rear وستكون الخطواط كالتالي: عمل عنصر node جديد وإضافة قيمة له التحقق من إذا كان Front يساوي null، إن تحقق الشرط (= true) إذا Front = Rear = العنصر الجديد newly node إذا لم يتحقق الشرط (= false)، سيتم وضع العنصر الجديد في مكان Rear وتغيير العنوان الموجود في العنصر Rear القديم بعنوان العنصر Rear الجديد لاحظ أن العنصر Rear يحتوي دائما على عنوان العنصر Front ()deQueue: حذف أول عنصر في القائمة لاحظ أن أول عنصر هو ما يتم حذفه أولاً، أي يتم حذف Front دائماً وستكون الخطواط كالتالي: التحقق من أن القائمة ليست فارغة ( Front != Null) التحقق من أن العنصر Front يساوي العنصر Rear (القائمة تحتوي على عنصر واحد فقط)، حينها يتم تعيين قيمة null للعنصرين Front و Rear على حد سواء في حالة لم يكونا متساويين (الثائمة تحتوي على أكثر من عنصر)، يتم حذف العنصر Front وتعيين العنصر الذي يليه مكانه وتغيير عنوان العنصر في Front الذي لدي العنصر Rear
 1 نقطة
1 نقطة