لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/20/22 في كل الموقع
-
ماهي وظيفه هذه الداله داخل الكلاسA؟ واين هو الخطا؟ وكيف يمكن استدعائها داخل main؟ انا لم افهم بالضبط عملها وليس كتابتها!!! package F; import java.io.BufferedReader; import java.io.FileReader; public class Arr { public Arr(){ System.out.print("hi"); } public static [] load(String ) throws IOException{ FileReader f=new FileReader("/storage/emulated/0/JavaNIDE/B/app/src/main/java/F/arr.txt"); BufferedReader in=new BufferedReader(f); int n=0; String line=in.readLine(); while (line!=null){ n++; line=in.readLine(); } f.close(); String []v=new String[n]; f=new FileReader("/storage/emulated/0/JavaNIDE/B/app/src/main/java/F/arr.txt"); in=new BufferedReader(f); int i=0; line=in.readLine(); while ((line!=null)&&(i<n)){ v[i]=line; line=in.readLine(); i++; } f.close(); return v; } }2 نقاط
-
لماذا ارتفع سعر الدورات من 160 دولار الى 290 دولار1 نقطة
-
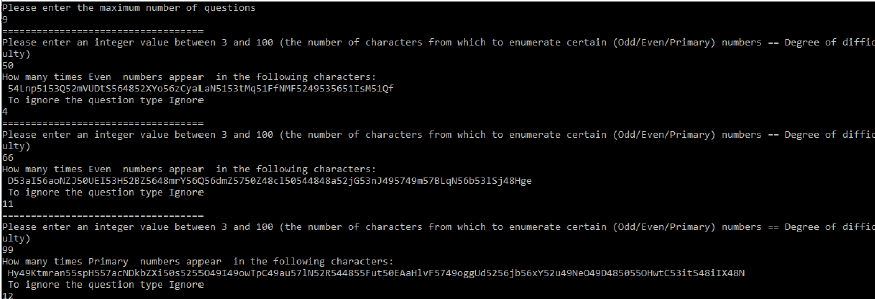
تتألف المسألة من قسمين، يبدأ القسم األول باالستفسار من المستخدم عن عدد األسئلة الواجب طرحها، ومن ثم توليد األسئلة بشكل عشوائي، وتخزين إجابات المستخدم واإلجابات الصحيحة ضمن مصفوفات. يتضمن القسم الثاني اختيار العديد من التوابع التي تقوم بعمليات إحصائية على النتائج المخزنة ضمن المصفوفات. مثل عدد اإلجابات الصحيحة، عدد اإلجابات الخاطئة... فيما يلي خطوات المسألة مع أمثلة فيما يتعلق بالقسم األول من المسألة: 1 -يطلب البرنامج من المستخدم إدخال عدد األسئلة المراد طرحها. 2 - من أجل كل سؤال يطلب البرنامج من المستخدم إدخال قيمة صحيحة بين 3 و 100 تساعد في تحديد عدد الرموز المولدة عشوائيا والواجب تعداد عدد األعداد )الفردية أو الزوجية أو األولية( حسب نص السؤال ضمن هذه السلسلة ً من الرموز. تمثل هذه القيمة مؤشر على درجة صعوبة السؤال. 3 -يجري تركيب كل سؤال من خالل دمج العديد من الرموز المولدة عشوائياً. الرموز تشمل أحرف إنكليزية كبيرة وصغيرة وأرقام من 0 حتى 9 .ومن ثم الطلب من المستخدم تحديد عدد األعداد )الفردية أو الزوجية أو األولية( ضمن بشكل عشوائي. هذه السلسلة. تحديد نوع األعداد المراد عدها )فردي أو زوجي أو أولي( يجري أيضاً 4 -من أجل كل سؤال مطروح، يتم تخزين السلسلة المولدة في مصفوفة ونمط السؤال في مصفوفة ثانية )النمط هو سؤال عن األعداد الفردية أو سؤال عن األعداد الزوجية أو سؤال عن األعداد األولية(، يتم حساب وتخزين النتيجة الصحيحة في مصفوفة مخصصة من أجل تخزين النتائج الصحيحة، ثم يتم طرح السؤال على المستخدم وتخزين الجواب في مصفوفة مخصصة إلجابات المستخدم. - من أجل كل سؤال يجري طرحه على المستخدم يتم تقييم الجواب، وتخزين نتيجة التقييم المقابلة لكل سؤال في مصفوفة خاصة بتقييم النتائج. إذا كانت نتيجة التقييم صحيحة يتم تخزين القيمة 1 وإال القيمة 0. - من أجل أي سؤال يمكن للمستخدم أن يتجاهل السؤال ولكن يجري تسجيله كجواب خاطئ. - كلمة تجاهل السؤال هي Ignore ،وهنا يجب أن تكون المعالجة )insensitive case.) - األعداد األولية هي األعداد الصحيحة أكبر من الواحد وال تقبل القسمة إال على نفسها. الصورة عبارة عن شاشة التنفيذ المطلوبة
 1 نقطة
1 نقطة -
1- هل يوجد اي فيديو يشرح عملية بيع الموقع ؟ عندما حاولت ان ابيع الموقع طلبوا مني ان ادخل عنوان url وهذا يعني انه يجب ان اشترك باستضافة ودومين ، 2-كيف اقوم ببيع الموقع دون ان احتاج لعنوان الurl والدومين1 نقطة
-
السلام عليكم عندما اقوم بعمل git clone لrepo لدي وبعدها اقموم بتنفيذ امرcomposer install يظهر لدي ان
.thumb.png.0a2418248048e689ee1641422fff98c5.png) 1 نقطة
1 نقطة -
السبب في المسار، أعتقد أنك تتواجدين في جذر القرص D اعملي cd لاسم مجلد المشروع، ثم حاولي التثبيت بعدها1 نقطة
-
أحاول أن أقوم بعمل حقل نصي بسيط في نموذج form بالشكل التالي: class UserForm(forms.ModelForm): full_name = forms.TextField(label=_(u'full name')) address = forms.TextField(label=_(u'address'), required=False) لكن المشكلة هنا هي ظهور الخطأ التالي: AttributeError: 'module' object has no attribute 'TextField' ما سبب المشكلة هنا؟ وكيف أقوم بإصلاحها؟1 نقطة
-
لدي نموذج form ويحتوي على زر "add new field" وأريد عند الضغط على هذا الزر أن يتم إضافة حقل جديد إلى النموذج ليتمكن المستخدم من إضافة المزيد من المعلومات. هل يجب أن يتم إعادة تحديث الصفحة ليتم إضافة حقل جديد؟ وكيف أقوم بعمل مثل هذا الزر من الأساس؟1 نقطة
-
توجد الكثير من المواقع التي تقدم خدمة ضغط الصورة مجانًا، أبحث عن "Optimize Images Online"، هنا بعض المواقع التي توفر هذه الخدمة مجانًا: tinypng imagecompressor kraken1 نقطة
-
إذا قمت بعمل ScrollView يعمل التطبيق بشكل ممتاز ويمكن للمستخدم أن يقوم بالتمرير Scroll إلى الأسفل والأعلى بدون مشكلة: return( <ScrollView> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> {/* ... */} </ScrollView> ); لكن تظهر لي مشكلة إن قمت بإضافة المكون ScrollView داخل مكون View: return( <View> <ScrollView> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> <Text>Some Contgent</Text> {/* ... */} </ScrollView> </View> ); حينها لا يمكن للمستخدم أن يقوم بالتمرير إلى الأسفل على الإطلاق، هل يوجد حل لهذه المشكلة في React Native؟1 نقطة
-
أريد أن أقوم بعرض Alert يعرض رسالة "هل تريد الخروج من التطبيق؟" ويحتوي على الأزرار "نعم"، و"لا" ، لكن المشكلة هي أني أريد عند الضغط على زر "نعم" يتم غلق التطبيق والخروج منه. كيف أقوم بإغلاق التطبيق في React Native؟1 نقطة
-
كما أخبرتك الدورة تعتبر حجر الأساس للمجالات البرمجية ، وهي تضعك على أساسيات ومفهوم البرمجة ، وفي حالات التعمق جيداً والدراسة أكثر في أي من المجالات التي ذكرتها أو مجالات أخرى تمت شرحها في الدورة بالتأكيد سوف تحصل على فرص عمل .1 نقطة
-
شكرا لكما أسامة ومحمد على التوضيح. أنا لاحظت ذلك بعدما عرفت شيئاً عن التخصصات في مجال البرمجة بعد حصولي على الدورة. لكن لماذا هو موضح في وصف دورة علوم الحاسوب أن حسوب على استعداد لإعادة ثمن الدورة في حال لم يحصل المشترك على عمل خلال ستة أشهر من اجتياز الامتحان؟ شكراً،1 نقطة
-
شكرا لك اخي ... استطعت ان احل المشكلة بإضافة sheets.Close() في نهاية الكود ليقوم بأغلاق الملف1 نقطة
-
السلام عليكم ما معني هذا الكود لم افهم جزئيه $operation->transactions $operation = DoctorProject::with(['transactions', 'doctor:id,name']) ->where('project_id', $project->id) ->first(); $operation->transactions->each(function (DoctorProjectPayed $transaction) use ($operation) { $transaction->setRelation('doctorProject', $operation); }); وشكرا1 نقطة
-
النموذج DoctorProject يمثل جدولًا في قاعدة البيانات، ويرتبط معه جداول أخرى، إحداها الجدول الممثل بالنموذج DoctorProjectPayed بعلاقة تسمى transactions، للتعرف عليها أكثر ضمن النموذج ستلاحظ وجود دالة بنفس الاسم: class DoctorProject extends Model { //.. function transactions(){ //.. } } بعد جلبك لسجل من نموذج DoctorProject وتعيينه للمتغير operation$ يمكنك الوصول للسجلات المرتبطة معه عبر اسم العلاقة السابقة transactions، والتابع each يمر على كل عنصر من تلك السجلات المرتبطة وينفذ التابع الممرر له، ضمن التابع في مثالك يتم تعيين العلاقة doctorProject ضمن السجل transaction وربطها مع السجل operation، تفاصيل تضمين المشروع وبنية تصميم الجداول ستوضح لك أكثر الفائدة من تلك العملية، يمكنك الاستفادة من قراءة المقالات التالية:1 نقطة
-
في ملف ال admin.py الخاص بال app قم بتعريف class مورث بخصائص ال admin ومن ثم سنقوم بعمل اعادة تعريف للدالة المسؤولة عن زر الحذف اسم الدالة has_delete_permission نكتب داخلها ان ترجع قيمة false من ثم إعطاء هذا ال class لدالة الadmin.site.register مثال توضيحي داخل ملف admin.py: from django.contrib import admin class DisableDeleteButtonAdmin(admin.ModelAdmin): def has_delete_permission(self, request, obj=None): # Disable delete return False admin.site.register(YourModel, DisableDeleteButtonAdmin) وهكذا اضمن لك انه تم الغاء تفعيل زر الحذف وتمت الاجابة على سؤالك مثال بصري للنتيجة .. قبل اضافة الكود : بعد كتابة الكود : ارجو ان تكون قد فهمت الطريقة تحياتي .
 1 نقطة
1 نقطة -
ازاي اقلل الحجم1 نقطة
-
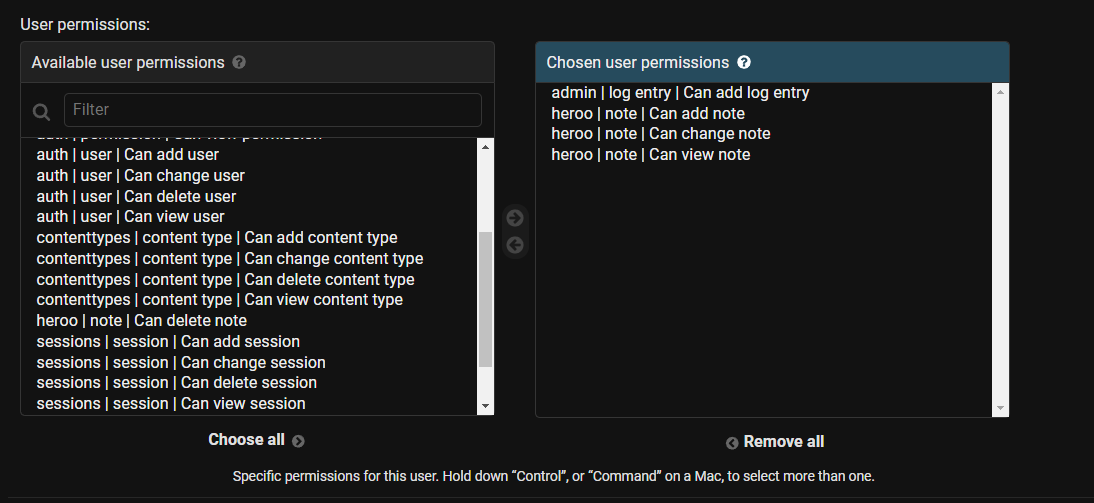
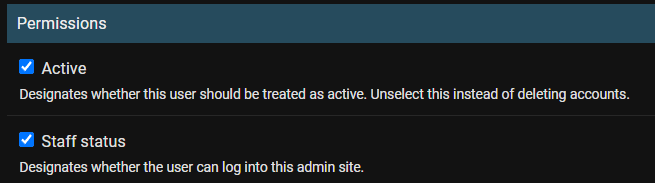
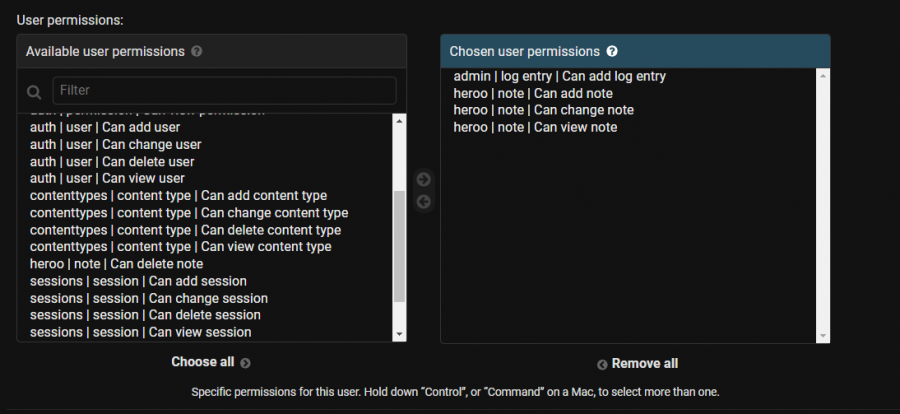
يمكنك فعلها بالتعديل على صلاحيات المستخدمين من نوع Staff status ف من خلال لوحة التحكم Django و الذهاب لقائمة Users و انشاء مستخدم من نوع Staff status هذا الخيار يظهر عند التعديل على المستخدم بعد إنشاء في خانة Permissions عند التعديل على المستخدم كما في الصورة: بعد ذلك ستذهب لخانة User permissions كما هو موضح في الصورة التالية: وتقوم بإضافة الصلاحيات الازمة بدون Delete من قائمة Available user permissions الصلاحيات التي على اليمين بدون الحذف لن يتمكن من حذف أي شئ. من note models ملاحظة يمكنك التحكم بصلاحيات كل models قمت بإنشائه. بعدها قم بحفظ التغيرات. قم بالتسجيل الدخول بالمستخدم الجديد و تأكد من التغيرات. الصورة التالية توضح الفرق قبل و بعد التعديل:
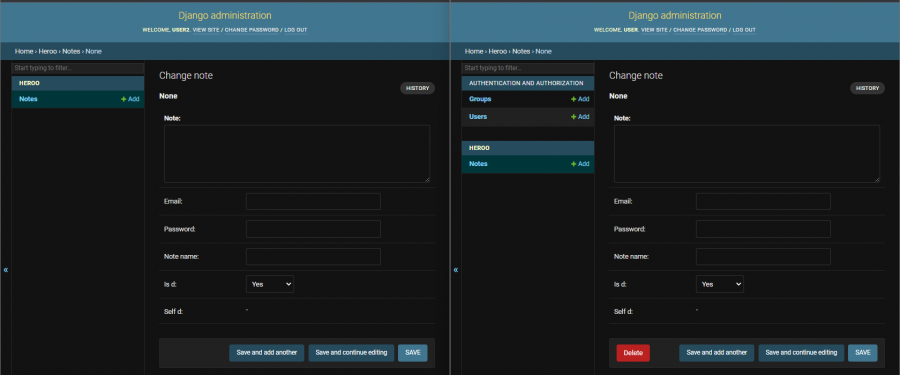 1 نقطة
1 نقطة -
اهلاً، في دالة ال view التي تقوم بتسجيل مستخدم جديد بعد التأكد من إضافة المستخدم بالبيانات المدخلة من ال form تذكر انه بعد عملية تسجيل المستخدم واضافة البيانات أضف هذا الكود: from django.contrib.auth import authenticate auth_user = authenticate(username=request. POST['username'], password=request. POST['password']) بعد عملية تسجيل مستخدم جديد فإن دالة authenticate داخل ال Django تعطي لها اسم المستخدم وكلمة المرور وهي تقوم بفحص اذا كان المستخدم موجود داخل النظام ام لا فترجع لنا object of user تم حفظه في حالتنا داخل المتغير auth_user. ومن ثم نفحص هل المستخدم موجود إذا كان موجود صرح له بتسجيل دخول للنظام باستخدام دالة login ومن ثم انقله لصفحة ال home او اي صفحة تريدها بوضع URL الصفحة مباشرة باستخدام دالة redirect دون جهد منه لقد أصبح مستخدم في النظام ومسجل دخوله لنرى ذلك في الكود لنضيف هذا الكود على الكود السابق: from django.contrib.auth import authenticate from django.contrib.auth import login from django.shortcuts import redirect auth_user = authenticate(username=request. POST['username'], password=request. POST['password']) If auth_user: login(request, auth_user) return redirect('/url/home/') الذي تم توضيحه اعلاه تمت عملية تسجيل الدخول من داخل دالة تسجيل مستخدم جديد دون ان يطر للذهاب لصفحة تسجيل الدخول ولقد تم تحويله مباشرة للصفحة الرئيسية بإستخدام دالة redirect وهذا اجابة لسؤالك اتمنى ان تكون قد وضحت لك الطريقة تحياتي .1 نقطة
-
وعليكم السلام عبدالله ابوشاور تعتبر دورة علوم الحاسوب هي حجر الاساس للمعرفة العامة في العديد من المواضيع التي يجب على مطور التطبيقات بأنواعها ان يكون لديه فكرة عنها, مواضيع مترابطة تساعدك على فهم اي تخصص تريد انت تتعلمه على سبيل المثال لقد وجدت ان تطوير الوجهات الويب قد راق لك و احببت العمل به فتقوم بتطوير مهارتك به وتبدأ تقديم خدماتك على مواقع حاسوب كخمسات أو مستقل فهنا يكون هدف هذه الدورة هي ارشادك لعالم الحاسوب و علومه و بعد هذه دورة سيكون من سهل تعلم اي مهارة أو لغة برمجة جديدة. كالبايثون أو PHP او JAVA أو غيرها يمكنك تطوير نفسك أكثر لتصبح محترف في احد تخصصات علوم الحاسوب يمكنك اكمال مسيرة التعلم الخاصة بك بأخذ الدورات المتقدمة التي تقدمها لك أكادمية حاسوب أو غيرها أختر المجال الذي تجد نفسك فيه أكثر إبداعاً اياً المجال الذي ستختاره طلما احترفته ستعمل و تحقق منه الدخل ان شاء الله فرص العمل كثيرة وهي بإنتظار المبدعين لأخذها.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته بخصوص دورة علوم الحاسوب ، فهي دورة عامة تؤهلك لتعلم تقنيات مختلفة ، بمعنى أنها مدخل لعلوم الحاسوب بشكل عام وجميع تخصصاته ، لكن من أجل الالتحاق في سوق العمل عليك أن تتخصص في مجال معين مثل تطوير واجهات المستخدم Front-End ، أو تطوير الواجهات الخلفية Back-End ، وتطوير تطبيقات الجوال ويوجد في الأكاديمية دورات تشرح هذه المجالات بشكل مفصل وتساعدك على دخول سوق العمل ، لكن تعتبر دورة علوم الحاسوب مؤهل جيد في حال لم يكن لديك معرفة تقنية أو برمجية سابقة لتساعدك على معرفة عالم البرمجة . دورة علوم الحاسوب هي حجر الأساس لعالم البرمجة بشكل خاص والحاسوب بشكل عام ، فهي تساعدك على تقوية المهارات لديك في التعامل مع الحاسوب .1 نقطة
-
مرحبا Mohssen تعتمد إجابة السؤال على طريقة عمل الموقع الخاص بك في حال كنت تستخدم طريقة Templet فالطريقة الأمثل هي استخدام الدوال ()authenticate() and login يمكنك الوصول للمزيد من المعلومات عن الدالتين بالضعط عليهما: حيث ستقوم بإستدعاء كل من هاتين الدالتين من مكتبة auth الخاصة ب Django في ملفات views في هذه الحالة سيتم تحويل المستخدم مباشرة لصفحة الرئيسية. هذا الكود مثال على ذالك في دالة تسجيل حساب جديد في views from django.contrib.auth import authenticate, login def register(request): if request.method == 'POST': form = UserCreationForm(request.POST) if form.is_valid(): new_user = form.save() messages.info(request, "Thanks for registering. You are now logged in.") new_user = authenticate(username=form.cleaned_data['username'], password=form.cleaned_data['password1'], ) login(request, new_user) return HttpResponseRedirect("/dashboard/") طبعاً ['username'] و ['password1']هم البيانات القادمة من الفورم التسجيل. و السطر التالي login(request, new_user) سيقوم بعملية التسجيل و بعدها ستقوم الدالة def register(request): بتحويل المستخدم لصفحة التي تريد المستخدم الذهاب لها فور تسجيله الحساب أول مرة. لكن في حالة كنت تتعامل مع API فالموضوع له منحنى اخر لطريقة التعامل مع هذا الموضوع لكن اتوقع انك تتكلم عن طريقة Templet ان شاء الله كان الشرح وافياً و مفهوماً. في حال كان لديك استفسار اخر سأكون سعيد بسماع ردك. تحياتي.1 نقطة
-
 أصبحت البيانات الضخمة Big Data حديث الناس في الآونة الأخيرة، ولكن ما هي البيانات الضخمة حقيقةً؟ كيف بإمكانها تغيير طريقة فهم الباحثين للعالم سواءً كانوا يعملون في الشركات، أو الهيئات غير الربحية، أو الجهات الحكومية، أو المؤسسات وغيرها من المنظمات؟ ما هي مصادر البيانات، كيف تُعالج، وكيف تُستخدم مخرجات عملية المعالجة؟ ولماذا يُعَد مفهوم المصادر المفتوحة أساسيًا في الإجابة عن التساؤلات السابقة؟ سنتعرّف في هذا المقال على كل ما يتعلّق بمفهوم البيانات الضخمة وأهميته في عالمنا المتغير. ما هي البيانات الضخمة؟ عندما نتحدث عن البيانات الضخمة فلن يحدد حجم قاعدة البيانات كونها ضخمةً أم لا، فلا يوجد قيدٌ صارمٌ ودقيق لحجم البيانات ضمن قاعدة البيانات كي نعدّها "ضخمة"، ولكن ما يحدد ذلك هو مقدار حاجتنا لاستخدام تقنياتٍ وأدواتٍ جديدة لمعالجة هذه البيانات. إذًا، للتعامل مع البيانات الضخمة، لابدّ من استخدام برامج تربط عدّة أجهزة فعلية أو افتراضية لتعمل معًا بتناغم في معالجة جميع البيانات خلال مدةٍ زمنيةٍ مقبولة. يتطلب تشغيل البرمجيات لكي تتخاطب فيما بينها بفعالية عندما تكون موزعةً على عدّة أجهزة تقنياتٍ برمجية خاصّة، بحيث تُوزَّع مهام معالجة البيانات بكفاءة، لتكون كل برمجية مسؤولةً عن قسمٍ محددٍ من البيانات لمعالجتها، وبذلك نستطيع تجميع مخرجات المعالجة من كل الأجهزة معًا بطريقةٍ نحقق من خلالها مفهوم البيانات الكبيرة. عند التفكير في تحديات التعامل مع البيانات الضخمة، لا بدّ من الأخذ في الحسبان أهمية توزيع البيانات في عناقيد clusters وكيفية ربط هذه العناقيد شبكيًا مع بعضها، وذلك نظرًا للمقارنة مع حقيقة أنّ وصول البرامج إلى البيانات المخزنة على جهاز محليًا أسرع بكثير من الوصول إليها شبكيًا. ما هي أنواع مجموعات البيانات التي تعد بيانات ضخمة؟ تتنوع استخدامات البيانات الضخمة بقدر كبر حجمها تقريبًا، وأحد أبرز الأمثلة المألوفة لمعظمنا هو كيفية تحليل شبكات التواصل الاجتماعي لبيانات مستخدميها بهدف الحصول على مزيدٍ من المعلومات عنهم، وبالتالي عرض محتوى وإعلانات ذات صلة باهتماماتهم، أو طريقة تحديد محركات البحث للعلاقة ما بين الاستعلامات والنتائج المعروضة، بحيث تقدّم إجابات أفضل على تساؤلات مستخدميها. استخدامات البيانات الضخمة أعم من ذلك بكثير، وأحد أكبر مصادر البيانات بكميات هائلة هي البيانات المالية، متضمِّنًا أسعار الأسهم والبيانات المصرفية وسجلات دفعات التجار، والمصدر الثاني هو بيانات أجهزة الاستشعار، إذ تأتي معظم هذه البيانات من ما يعرف باسم إنترنت الأشياء Internet of Things -أو اختصارًا IoT-، والتي قد تمثّل بيانات القياسات المأخوذة من قبل الروبوتات العاملة على خط إنتاج آلي في أحد مصانع السيارات، أو بيانات تحديد المواقع في شبكة اتصالات خلوي ما، أو بيانات كميات استهلاك الكهرباء اللحظية في المنازل والشركات، وصولًا إلى معلومات حركة الركاب الواردة من شركات النقل. تتمكن المؤسسات بتحليل هذه البيانات من معرفة صعود أو هبوط البيانات المسجَّلة ومعلومات الأشخاص الذين يمثّلون مصدر هذه البيانات. والآمال معقودة بأن يوفّر تحليل البيانات الضخمة خدمات أكثر تخصّصًا، وكفاءة إنتاجية أعلى في أي مجال صناعي تُجمع منه البيانات. كيفية تحليل البيانات الضخمة تُعد طريقة MapReduce إحدى أهم طرق تحويل البيانات الخام إلى معلوماتٍ مفيدة، وهي منهجية لإجراء العمليات الحسابية على البيانات من خلال عدة حواسيب وعلى التوازي؛ فهي تمثّل نموذجًا لكيفية برمجة العملية، ويُستخدم المصطلح MapReduce غالًا للإشارة إلى التطبيق الفعلي لهذا النموذج. تتألف منهجية MapReduce بصورةٍ رئيسية من جزأين، إذ يتمثَّل الأول في دالة التعيين Map function، والتي تفرز وترشِّح البيانات عبر توزيعها ضمن فئات مما يسهّل عملية تحليلها؛ أمّا الجزء الثاني فهو دالة التقليص Reduce function، التي تختصر البيانات عبر تجميعها معًا. وقد أصبح MapReduce مصطلحًا شاملًا يشير إلى نموذجٍ عام تستخدمه العديد من التقنيات، ويعود الفضل في ذلك إلى حدٍ كبير للبحث الذي أجرته جوجل Google حول هذا النموذج. ما هي الأدوات المستخدمة لتحليل البيانات الضخمة؟ تُعدّ Apache Hadoop الأداة الأكثر تأثيرًا وثباتًا في تحليل البيانات الضخمة؛ فهي إطار عملٍ واسع النطاق مفتوح المصدر يصنِّف ويعالج البيانات؛ كما يمكن لهذه الأداة أن تعمل على عتاد عادي استهلاكي commodity hardware (أو ما يُعرف باسم off-the-shelf hardware، وهي حواسيب أو أيٌ من تجهيزات تقانة المعلومات غير المكلفة وشعبية التوفّر، وتكون عادةً جدوى استبدالها بالكامل في حال حدوث أعطال أكبر من جدوى إصلاحها)، مما يجعلها فعّالة في الاستخدام مع مراكز البيانات الحالية، أو حتى لإجراء تحليل بيانات سحابي. وتُقسم Hadoop إجمالًا إلى أربعة أجزاء رئيسية: HDFS وهو مخزن بيانات يعتمد على نظام الملفات الموزعة، ومصمّمٌ للعمل مع حيز نطاق تراسلي عالٍ جدًا. منصة YARN المسؤولة عن إدارة موارد الأداة Hadoop وجدولة البرامج التي ستعمل على التجهيزات التي تستخدم هذه الأداة. نموذج إنجاز معالجة البيانات الضخمة وهو MapReduce المشروح أعلاه. مجموعة من المكتبات الشائعة الحاوية على نماذج معالجة بيانات أخرى قابلة للاستخدام. كما يوجد أدوات أخرى للتعامل مع البيانات الضخمة، إذ تُعد Apache Spark إحدى هذه الأدوات التي تحظى باهتمام بالغ؛ فهي متميزة بقدرتها على تخزين كمية كبيرة من البيانات في الذاكرة لمعالجتها. وبذلك، وعلى عكس آلية التخزين على الأقراص، تُعد Apache Spark أسرع بكثير لا سيما لبعض أنواع تحليل البيانات، ففي بعض التطبيقات سيحصل المحللون باستخدام هذه الأداة على نتائج أسرع بمئات المرات أو أكثر. ويمكن للأداة Spark استخدام نظام الملفات الموزعة HDFS أو غيره من مخازن البيانات، مثل Apache Cassandra، أو OpenStack Swift؛ كما من الممكن تشغيل Spark على جهاز محلي، مما يسهّل عمليات الاختبار والتطوير. بعض الأدوات الأخرى للتعامل مع البيانات الضخمة يوجد إجمالًا عددٌ غير محدود من الحلول مفتوحة المصدر للتعامل مع البيانات الضخمة، وقد خُصِّصت عدّة حلول منها لتوفير ميزات وأداء أمثل لمجال معين أو حتى لتجهيزات معينة ذات إعدادات خاصّة، وما سنعرضه فيما يلي لا يمثّل سوى جزءٍ من الأدوات التي تتعامل مع البيانات الضخمة. تدعم مؤسسة أباتشي Apache للبرمجيات Apache Software Foundation -أو اختصارًا ASF- عدّة مشاريع للبيانات الضخمة، ونذكر من هذه المشاريع المفيدة ما يلي: Apache Beam وهو نموذجٌ موّحدٌ لتعريف مجاري pipelines كلٍ من الدفعات batches وتدفقات البيانات المتوازية parallel، كما يسمح هذا النموذج للمطورين بكتابة الترميزات البرمجية التي تعمل على عدّة محركات معالجة. Apache Hive وهو مخزن بيانات مبني على Hadoop، ويُعد أحد مشاريع Apache عالية المستوى، إذ يسهّل قراءة وكتابة وإدارة مجموعات البيانات الكبيرة باستخدام SQL. Apache Impala وهو محرّك استعلامات في SQL يعمل مع الأداة Hadoop، وقد ضمِّن إلى حزمة Apache واشتُهر بقدرته على تحسين أداء استعلامات SQL باستخدام واجهة بسيطة مألوفة. Apache Kafka توفّر آلية تسمح للمستخدمين بالاتصال المستمر مع مصادر البيانات للحصول على البيانات باستقبال البيانات وتحديثاتها لحظيًا، وتهدف إلى تحقيق موثوقية عالية لدى استخدام أنظمة التخاطب المختلفة في نقل البيانات. Apache Lucene وهي مكتبة برمجية مختصّة بعمليات البحث وفهرسة البيانات؛ وتوفّر استعلامًا نصيًا لغويًا متقدّمًا لقواعد البيانات أو المستندات النصية full-text indexing؛ كما تستخدم أداة تصفية بيانات بالاعتماد على خوارزميات التعلم الآلي للتوصية بالعناصر الأكثر صلة لمستخدم معين recommendation engines، وتشكّل هذه المكتبة أساسًا للعديد من مشاريع البحث الأخرى مثل محركات البحث Solr وElasticsearch. Apache Pig وهي منصة لتحليل مجموعات البيانات الضخمة التي تعمل على الأداة Hadoop، وقد طورتها شركة ياهو Yahoo لإنجاز مهام MapReduce على مجموعات البيانات الضخمة، وكانت قد ساهمت ياهو في عام 2007 بها ضمن مشروع ASF. Apache Solr وهي منصة بحث متخصّصة للشركات، بُنيت اعتمادًا على مكتبة Lucene. Apache Zeppelin وهو مشروع احتضان (والاحتضان هو مرحلة وليس مكان، إذ تُحتضن المشاريع الجديدة لمدة عام أو عامين بهدف التطوير قبل الطرح). يتيح Apache Zeppelin إمكانية تحليل البيانات التفاعلية باستخدام لغة الاستعلامات SQL ولغات البرمجة الأخرى. تتضمّن الأدوات المفتوحة المصدر للتعامل مع البيانات الضخمة والتي قد ترغب بالتعرف عليها ما يلي: Elasticsearch وهو محرّك بحث آخر للمؤسسات يعتمد على مكتبة Lucene، ويمثّل جزءًا من محرك البحث المُسمى المكدس المرن Elastic stack والمعروف باسم مكدّس ELK كونه مؤلفًا من ثلاث مكونات، هي: Elasticsearch و Kibana و Logstash (محرك بحث للاستعلام النصي المتقدّم للمستندات النصية، ذو واجهة ويب HTTP يعتمد أيضًا على مكتبة Lucene). يستطيع المحرك Elasticsearch توليد نتائجٍ من البيانات سواءً كانت هذه البيانات مهيكلة أم لا. Cruise Control والتي طوِّرتها شركة لينكد إن LinkedIn لتشغيل مجموعات Apache Kafka على نطاقٍ أوسع. TensorFlow وهي مكتبة برمجية للتعلّم الآلي، تطورت هذه المكتبة سريعًا عندما جعلتها شركة غوغل Google مفتوحة المصدر في أواخر عام 2015، ولطالما أُشيد بها لسهولة استخدامها وتوفُّرها للجميع. وهكذا تستمر البيانات الضخمة بالنمو حجمًا وأهميةً، وبالتالي ستستمر الأدوات المفتوحة المصدر التي تتعامل معها بالنمو بكل تأكيد. ترجمة -وبتصرف- للمقال An introduction to big data من موقع opensource.com. اقرأ أيضًا المفاهيم الأساسية لتعلم الآلة نظرة سريعة على لغة الاستعلامات الهيكلية SQL1 نقطة
أصبحت البيانات الضخمة Big Data حديث الناس في الآونة الأخيرة، ولكن ما هي البيانات الضخمة حقيقةً؟ كيف بإمكانها تغيير طريقة فهم الباحثين للعالم سواءً كانوا يعملون في الشركات، أو الهيئات غير الربحية، أو الجهات الحكومية، أو المؤسسات وغيرها من المنظمات؟ ما هي مصادر البيانات، كيف تُعالج، وكيف تُستخدم مخرجات عملية المعالجة؟ ولماذا يُعَد مفهوم المصادر المفتوحة أساسيًا في الإجابة عن التساؤلات السابقة؟ سنتعرّف في هذا المقال على كل ما يتعلّق بمفهوم البيانات الضخمة وأهميته في عالمنا المتغير. ما هي البيانات الضخمة؟ عندما نتحدث عن البيانات الضخمة فلن يحدد حجم قاعدة البيانات كونها ضخمةً أم لا، فلا يوجد قيدٌ صارمٌ ودقيق لحجم البيانات ضمن قاعدة البيانات كي نعدّها "ضخمة"، ولكن ما يحدد ذلك هو مقدار حاجتنا لاستخدام تقنياتٍ وأدواتٍ جديدة لمعالجة هذه البيانات. إذًا، للتعامل مع البيانات الضخمة، لابدّ من استخدام برامج تربط عدّة أجهزة فعلية أو افتراضية لتعمل معًا بتناغم في معالجة جميع البيانات خلال مدةٍ زمنيةٍ مقبولة. يتطلب تشغيل البرمجيات لكي تتخاطب فيما بينها بفعالية عندما تكون موزعةً على عدّة أجهزة تقنياتٍ برمجية خاصّة، بحيث تُوزَّع مهام معالجة البيانات بكفاءة، لتكون كل برمجية مسؤولةً عن قسمٍ محددٍ من البيانات لمعالجتها، وبذلك نستطيع تجميع مخرجات المعالجة من كل الأجهزة معًا بطريقةٍ نحقق من خلالها مفهوم البيانات الكبيرة. عند التفكير في تحديات التعامل مع البيانات الضخمة، لا بدّ من الأخذ في الحسبان أهمية توزيع البيانات في عناقيد clusters وكيفية ربط هذه العناقيد شبكيًا مع بعضها، وذلك نظرًا للمقارنة مع حقيقة أنّ وصول البرامج إلى البيانات المخزنة على جهاز محليًا أسرع بكثير من الوصول إليها شبكيًا. ما هي أنواع مجموعات البيانات التي تعد بيانات ضخمة؟ تتنوع استخدامات البيانات الضخمة بقدر كبر حجمها تقريبًا، وأحد أبرز الأمثلة المألوفة لمعظمنا هو كيفية تحليل شبكات التواصل الاجتماعي لبيانات مستخدميها بهدف الحصول على مزيدٍ من المعلومات عنهم، وبالتالي عرض محتوى وإعلانات ذات صلة باهتماماتهم، أو طريقة تحديد محركات البحث للعلاقة ما بين الاستعلامات والنتائج المعروضة، بحيث تقدّم إجابات أفضل على تساؤلات مستخدميها. استخدامات البيانات الضخمة أعم من ذلك بكثير، وأحد أكبر مصادر البيانات بكميات هائلة هي البيانات المالية، متضمِّنًا أسعار الأسهم والبيانات المصرفية وسجلات دفعات التجار، والمصدر الثاني هو بيانات أجهزة الاستشعار، إذ تأتي معظم هذه البيانات من ما يعرف باسم إنترنت الأشياء Internet of Things -أو اختصارًا IoT-، والتي قد تمثّل بيانات القياسات المأخوذة من قبل الروبوتات العاملة على خط إنتاج آلي في أحد مصانع السيارات، أو بيانات تحديد المواقع في شبكة اتصالات خلوي ما، أو بيانات كميات استهلاك الكهرباء اللحظية في المنازل والشركات، وصولًا إلى معلومات حركة الركاب الواردة من شركات النقل. تتمكن المؤسسات بتحليل هذه البيانات من معرفة صعود أو هبوط البيانات المسجَّلة ومعلومات الأشخاص الذين يمثّلون مصدر هذه البيانات. والآمال معقودة بأن يوفّر تحليل البيانات الضخمة خدمات أكثر تخصّصًا، وكفاءة إنتاجية أعلى في أي مجال صناعي تُجمع منه البيانات. كيفية تحليل البيانات الضخمة تُعد طريقة MapReduce إحدى أهم طرق تحويل البيانات الخام إلى معلوماتٍ مفيدة، وهي منهجية لإجراء العمليات الحسابية على البيانات من خلال عدة حواسيب وعلى التوازي؛ فهي تمثّل نموذجًا لكيفية برمجة العملية، ويُستخدم المصطلح MapReduce غالًا للإشارة إلى التطبيق الفعلي لهذا النموذج. تتألف منهجية MapReduce بصورةٍ رئيسية من جزأين، إذ يتمثَّل الأول في دالة التعيين Map function، والتي تفرز وترشِّح البيانات عبر توزيعها ضمن فئات مما يسهّل عملية تحليلها؛ أمّا الجزء الثاني فهو دالة التقليص Reduce function، التي تختصر البيانات عبر تجميعها معًا. وقد أصبح MapReduce مصطلحًا شاملًا يشير إلى نموذجٍ عام تستخدمه العديد من التقنيات، ويعود الفضل في ذلك إلى حدٍ كبير للبحث الذي أجرته جوجل Google حول هذا النموذج. ما هي الأدوات المستخدمة لتحليل البيانات الضخمة؟ تُعدّ Apache Hadoop الأداة الأكثر تأثيرًا وثباتًا في تحليل البيانات الضخمة؛ فهي إطار عملٍ واسع النطاق مفتوح المصدر يصنِّف ويعالج البيانات؛ كما يمكن لهذه الأداة أن تعمل على عتاد عادي استهلاكي commodity hardware (أو ما يُعرف باسم off-the-shelf hardware، وهي حواسيب أو أيٌ من تجهيزات تقانة المعلومات غير المكلفة وشعبية التوفّر، وتكون عادةً جدوى استبدالها بالكامل في حال حدوث أعطال أكبر من جدوى إصلاحها)، مما يجعلها فعّالة في الاستخدام مع مراكز البيانات الحالية، أو حتى لإجراء تحليل بيانات سحابي. وتُقسم Hadoop إجمالًا إلى أربعة أجزاء رئيسية: HDFS وهو مخزن بيانات يعتمد على نظام الملفات الموزعة، ومصمّمٌ للعمل مع حيز نطاق تراسلي عالٍ جدًا. منصة YARN المسؤولة عن إدارة موارد الأداة Hadoop وجدولة البرامج التي ستعمل على التجهيزات التي تستخدم هذه الأداة. نموذج إنجاز معالجة البيانات الضخمة وهو MapReduce المشروح أعلاه. مجموعة من المكتبات الشائعة الحاوية على نماذج معالجة بيانات أخرى قابلة للاستخدام. كما يوجد أدوات أخرى للتعامل مع البيانات الضخمة، إذ تُعد Apache Spark إحدى هذه الأدوات التي تحظى باهتمام بالغ؛ فهي متميزة بقدرتها على تخزين كمية كبيرة من البيانات في الذاكرة لمعالجتها. وبذلك، وعلى عكس آلية التخزين على الأقراص، تُعد Apache Spark أسرع بكثير لا سيما لبعض أنواع تحليل البيانات، ففي بعض التطبيقات سيحصل المحللون باستخدام هذه الأداة على نتائج أسرع بمئات المرات أو أكثر. ويمكن للأداة Spark استخدام نظام الملفات الموزعة HDFS أو غيره من مخازن البيانات، مثل Apache Cassandra، أو OpenStack Swift؛ كما من الممكن تشغيل Spark على جهاز محلي، مما يسهّل عمليات الاختبار والتطوير. بعض الأدوات الأخرى للتعامل مع البيانات الضخمة يوجد إجمالًا عددٌ غير محدود من الحلول مفتوحة المصدر للتعامل مع البيانات الضخمة، وقد خُصِّصت عدّة حلول منها لتوفير ميزات وأداء أمثل لمجال معين أو حتى لتجهيزات معينة ذات إعدادات خاصّة، وما سنعرضه فيما يلي لا يمثّل سوى جزءٍ من الأدوات التي تتعامل مع البيانات الضخمة. تدعم مؤسسة أباتشي Apache للبرمجيات Apache Software Foundation -أو اختصارًا ASF- عدّة مشاريع للبيانات الضخمة، ونذكر من هذه المشاريع المفيدة ما يلي: Apache Beam وهو نموذجٌ موّحدٌ لتعريف مجاري pipelines كلٍ من الدفعات batches وتدفقات البيانات المتوازية parallel، كما يسمح هذا النموذج للمطورين بكتابة الترميزات البرمجية التي تعمل على عدّة محركات معالجة. Apache Hive وهو مخزن بيانات مبني على Hadoop، ويُعد أحد مشاريع Apache عالية المستوى، إذ يسهّل قراءة وكتابة وإدارة مجموعات البيانات الكبيرة باستخدام SQL. Apache Impala وهو محرّك استعلامات في SQL يعمل مع الأداة Hadoop، وقد ضمِّن إلى حزمة Apache واشتُهر بقدرته على تحسين أداء استعلامات SQL باستخدام واجهة بسيطة مألوفة. Apache Kafka توفّر آلية تسمح للمستخدمين بالاتصال المستمر مع مصادر البيانات للحصول على البيانات باستقبال البيانات وتحديثاتها لحظيًا، وتهدف إلى تحقيق موثوقية عالية لدى استخدام أنظمة التخاطب المختلفة في نقل البيانات. Apache Lucene وهي مكتبة برمجية مختصّة بعمليات البحث وفهرسة البيانات؛ وتوفّر استعلامًا نصيًا لغويًا متقدّمًا لقواعد البيانات أو المستندات النصية full-text indexing؛ كما تستخدم أداة تصفية بيانات بالاعتماد على خوارزميات التعلم الآلي للتوصية بالعناصر الأكثر صلة لمستخدم معين recommendation engines، وتشكّل هذه المكتبة أساسًا للعديد من مشاريع البحث الأخرى مثل محركات البحث Solr وElasticsearch. Apache Pig وهي منصة لتحليل مجموعات البيانات الضخمة التي تعمل على الأداة Hadoop، وقد طورتها شركة ياهو Yahoo لإنجاز مهام MapReduce على مجموعات البيانات الضخمة، وكانت قد ساهمت ياهو في عام 2007 بها ضمن مشروع ASF. Apache Solr وهي منصة بحث متخصّصة للشركات، بُنيت اعتمادًا على مكتبة Lucene. Apache Zeppelin وهو مشروع احتضان (والاحتضان هو مرحلة وليس مكان، إذ تُحتضن المشاريع الجديدة لمدة عام أو عامين بهدف التطوير قبل الطرح). يتيح Apache Zeppelin إمكانية تحليل البيانات التفاعلية باستخدام لغة الاستعلامات SQL ولغات البرمجة الأخرى. تتضمّن الأدوات المفتوحة المصدر للتعامل مع البيانات الضخمة والتي قد ترغب بالتعرف عليها ما يلي: Elasticsearch وهو محرّك بحث آخر للمؤسسات يعتمد على مكتبة Lucene، ويمثّل جزءًا من محرك البحث المُسمى المكدس المرن Elastic stack والمعروف باسم مكدّس ELK كونه مؤلفًا من ثلاث مكونات، هي: Elasticsearch و Kibana و Logstash (محرك بحث للاستعلام النصي المتقدّم للمستندات النصية، ذو واجهة ويب HTTP يعتمد أيضًا على مكتبة Lucene). يستطيع المحرك Elasticsearch توليد نتائجٍ من البيانات سواءً كانت هذه البيانات مهيكلة أم لا. Cruise Control والتي طوِّرتها شركة لينكد إن LinkedIn لتشغيل مجموعات Apache Kafka على نطاقٍ أوسع. TensorFlow وهي مكتبة برمجية للتعلّم الآلي، تطورت هذه المكتبة سريعًا عندما جعلتها شركة غوغل Google مفتوحة المصدر في أواخر عام 2015، ولطالما أُشيد بها لسهولة استخدامها وتوفُّرها للجميع. وهكذا تستمر البيانات الضخمة بالنمو حجمًا وأهميةً، وبالتالي ستستمر الأدوات المفتوحة المصدر التي تتعامل معها بالنمو بكل تأكيد. ترجمة -وبتصرف- للمقال An introduction to big data من موقع opensource.com. اقرأ أيضًا المفاهيم الأساسية لتعلم الآلة نظرة سريعة على لغة الاستعلامات الهيكلية SQL1 نقطة -
 راسبيري باي Raspberry Pi هو الاسم التجاري لسلسلة الحواسيب وحيدة اللوحة المُنتجة من قبل مؤسسة Raspberry Pi؛ وهي مؤسسة خيرية بريطانية غير ربحية تهدف إلى نشر ثقافة الحوسبة بين الناس وجعلها متاحةً بسهولة. أُطلقت لوحة راسبيري باي عام 2012، وأُصدرت عدة نسخٍ مكررةٍ ومطورةٍ منها منذ ذلك الحين؛ إذ كانت اللوحة الأساسية ذات وحدة معالجة مركزية CPU وحيدة النواة بسرعة 700 ميغا هرتز وذاكرة وصول عشوائي RAM بسعة 256 ميغا بايت فقط؛ أمّا الإصدار الأحدث منها فكان مع وحدة معالجة مركزية رباعية النواة بمعدّل نبضات ساعة يتجاوز 1.5 غيغا هرتز وذاكرة وصول عشوائي RAM بسعة 4 غيغا بايت، أمّا سعرها فلم يتجاوز 100$ يومًا، وهي عادةً بحدود 35$، حتى أن الإصدار "Pi Zero" كان بسعر 5$ فقط. استخدم الناس حول العالم لوحة راسبيري باي في المجالات التالية: تعلّم البرمجة. بناء مشاريع العتاد Hardware. استخدام الأتمتة في المنازل. تطبيق مجموعات Kubernetes وهو نظامٌ مفتوح المصدر لأتمتة وإدارة التطبيقات المتوضعة في الحاويات عبر عدة أجهزة والبيئات الافتراضية والمادية والسحابية والمحلية. الحوسبة الحدية Edge Computing، التي تجعل الحوسبة وتخزين البيانات أقرب إلى مصادر البيانات. التطبيقات الصناعية. إذًا، تُعَد لوحة راسبيري باي حاسوبًا قليل التكلفة يعمل بنظام تشغيل لينوكس Linux، ويوفّر مجموعةً من منافذ الإدخال والإخراج متعدّدة الأغراض GPIO، التي تسمح بالتحكم بالعناصر الإلكترونية لحالات الحوسبة الفيزيائية والعمل في مجال إنترنت الأشياء Internet of Things- أو اختصارًا IOT. إصدارات اللوحة راسبيري باي أُصدرت العديد من الأجيال للّوحة راسبيري باي ابتداءً من "Pi 1" إلى "Pi 4"، وحتّى Pi 400، كما أُصدر عمومًا نموذجين من معظم الأجيال، هما النموذج A والنموذج B؛ إذ يُعد النموذج A الأرخص وبسعة ذاكرة RAM أقل وعدد أقل من الأرجل (منافذ الـ USB ومنافذ الشبكة Ethernet). يُعَد الجيل "Pi Zero" نموذجًا مبسطًا من الجيل "Pi 1" الأصلي، ويتميز بكونه أصغر حجمًا وأقل سعرًا، ونبيِّن فيما يلي قائمةً بأجيال اللوحة: Pi 1 Model B (2012) Pi 1 Model A (2013) Pi 1 Model B+ (2014) Pi 1 Model A+ (2014) Pi 2 Model B (2015) Pi Zero (2015) Pi 3 Model B (2016) Pi Zero W (2017) Pi 3 Model B+ (2018) Pi 3 Model A+ (2019) Pi 4 Model A (2019) Pi 4 Model B (2020) Pi 400 (2021) مؤسسة راسبيري باي تسعى مؤسسة راسبيري باي لإتاحة الإمكانات الكبيرة للحوسبة والصناعة الرقمية للجميع حول العالم من خلال توفير حواسيب عالية الأداء ورخيصة الثمن ليتمكن الناس من استخدامها للتعلّم، أو حل المشاكل، أو حتى بهدف التسلية. كما أنها تسعى لتأمين طرق التواصل والتعليم اللازمة لمساعدة الناس على تعلّم الحوسبة والصناعة الرقمية، إذ أنها تطوّر مصادرًا مجانيةً لتعلّم الحوسبة وكيفية إنجاز المهام باستخدام الحواسيب، كما أنّها تدرّب أشخاصًا لتوجيه الآخرين نحو التعلُّم. ويُعد كلًا من المشروعين Code Club و CoderDojo جزءًا من مؤسسة راسبيري باي رغم كونهما منصاتٍ مستقلةً غير مرتبطة بلوحات راسبيري باي حصرًا. وتروّج مؤسسة راسبيري باي لهذه المشاريع وتسعى لتوسيع انتشارها بهدف ضمان إمكانية وصول كل طفلٍ حول العالم إلى تعلّم الحوسبة. إضافةً لذلك، يُقام الحدث Raspberry Jams لدعوة الناس من كل الفئات العمرية ليتعرفوا معًا على راسبيري باي ويتبادلون الأفكار والمشاريع. راسبيري باي والمصادر المفتوحة تعمل راسبيري باي مع الأنظمة مفتوحة المصدر؛ فهي قادرةٌ على تشغيل نظام لينوكس Linux ودعم عدّة توزيعات منه؛ كما أن نظام تشغيلها الأساسي "Pi OS" مفتوح المصدر أيضًا ويدير مجموعةً من البرامج مفتوحة المصدر. وتعد مؤسسة راسبيري باي من المساهمين في نواة لينوكس وغيرها من المشاريع مفتوحة المصدر، بالإضافة إلى إصدارها عدة برمجيات مفتوحة المصدر خاصّةً بها، ومخططات راسبيري باي دوريًا بمثابة توثيق documentation. ولكن في الواقع، لا تُعد لوحات راسبيري باي عتادً مفتوحًا (العتاد المفتوح هو العتاد المُرخص به، بحيث يمكن لأي شخص دراسته والتعديل عليه وإعادة توزيعه). تعتمد مؤسسة راسبيري باي على الأرباح من مبيعات وحدات راسبيري باي لإنجاز أعمالها الخيرية في قطاع التعليم. ما يمكنك إنجازه مع لوحة راسبيري باي يشتري بعض الناس لوحة راسبيري باي ليتعلموا كتابة الشيفرات البرمجية؛ أما الأشخاص الذين يعرفون أصلًا كتابتها فيستخدمون اللوحة لتعلّم برمجة الدارات الإلكترونية والمشاريع الفيزيائية. تفتح لوحة راسبيري باي أمامك الآفاق لإنشاء مشاريعك الخاصة، والتي من شأنها أتمتة منزلك؛ وهو أمرٌ شائعٌ في مجتمعات المصادر المفتوحة، لأنه يمنحك كافّة إمكانات السيطرة على مشروعك بدلاً من استخدام نظام مغلقٍ خاصٍ بغيرك. تبيّن القائمة التالية بعض المشاريع الممكن تنفيذها باستخدام راسبيري باي: حظر الإعلانات على شبكتك باستخدام "pi-hole". إنشاء قاعدة بيانات "PostgreSQL" في راسبيري باي. إنشاء مجيب آلي لتويتر Twitter الخاص بك باستخدام لغة بايثون Python وراسبيري باي. بناء مشاريع باستخدام الكاميرا الخاصّة بلوحة راسبيري باي وأي تجهيزات وعتاد يمكن وصلها بها. إنشاء عارض صور رقمي. القائمة السابقة هي على سبيل المثال لا الحصر إذ المشاريع التي يمكن تنفيذها براسبيري باي لا تحصى، ونترك بين يديك هذا الحاسوب الرائع لتجرب وتتعلم وتبدع. ترجمة -وبتصرف- للمقال What is Raspberry Pi? من موقع opensource.com. اقرأ أيضًا جولة في راسبيان: نظام تشغيل راسبيري باي تجميع راسبيري باي والتحضير لاستعماله إعداد Raspberry Pi للعمل بدء استخدام راسبيري باي تخصيص واجهة سطح مكتب راسبيري باي1 نقطة
راسبيري باي Raspberry Pi هو الاسم التجاري لسلسلة الحواسيب وحيدة اللوحة المُنتجة من قبل مؤسسة Raspberry Pi؛ وهي مؤسسة خيرية بريطانية غير ربحية تهدف إلى نشر ثقافة الحوسبة بين الناس وجعلها متاحةً بسهولة. أُطلقت لوحة راسبيري باي عام 2012، وأُصدرت عدة نسخٍ مكررةٍ ومطورةٍ منها منذ ذلك الحين؛ إذ كانت اللوحة الأساسية ذات وحدة معالجة مركزية CPU وحيدة النواة بسرعة 700 ميغا هرتز وذاكرة وصول عشوائي RAM بسعة 256 ميغا بايت فقط؛ أمّا الإصدار الأحدث منها فكان مع وحدة معالجة مركزية رباعية النواة بمعدّل نبضات ساعة يتجاوز 1.5 غيغا هرتز وذاكرة وصول عشوائي RAM بسعة 4 غيغا بايت، أمّا سعرها فلم يتجاوز 100$ يومًا، وهي عادةً بحدود 35$، حتى أن الإصدار "Pi Zero" كان بسعر 5$ فقط. استخدم الناس حول العالم لوحة راسبيري باي في المجالات التالية: تعلّم البرمجة. بناء مشاريع العتاد Hardware. استخدام الأتمتة في المنازل. تطبيق مجموعات Kubernetes وهو نظامٌ مفتوح المصدر لأتمتة وإدارة التطبيقات المتوضعة في الحاويات عبر عدة أجهزة والبيئات الافتراضية والمادية والسحابية والمحلية. الحوسبة الحدية Edge Computing، التي تجعل الحوسبة وتخزين البيانات أقرب إلى مصادر البيانات. التطبيقات الصناعية. إذًا، تُعَد لوحة راسبيري باي حاسوبًا قليل التكلفة يعمل بنظام تشغيل لينوكس Linux، ويوفّر مجموعةً من منافذ الإدخال والإخراج متعدّدة الأغراض GPIO، التي تسمح بالتحكم بالعناصر الإلكترونية لحالات الحوسبة الفيزيائية والعمل في مجال إنترنت الأشياء Internet of Things- أو اختصارًا IOT. إصدارات اللوحة راسبيري باي أُصدرت العديد من الأجيال للّوحة راسبيري باي ابتداءً من "Pi 1" إلى "Pi 4"، وحتّى Pi 400، كما أُصدر عمومًا نموذجين من معظم الأجيال، هما النموذج A والنموذج B؛ إذ يُعد النموذج A الأرخص وبسعة ذاكرة RAM أقل وعدد أقل من الأرجل (منافذ الـ USB ومنافذ الشبكة Ethernet). يُعَد الجيل "Pi Zero" نموذجًا مبسطًا من الجيل "Pi 1" الأصلي، ويتميز بكونه أصغر حجمًا وأقل سعرًا، ونبيِّن فيما يلي قائمةً بأجيال اللوحة: Pi 1 Model B (2012) Pi 1 Model A (2013) Pi 1 Model B+ (2014) Pi 1 Model A+ (2014) Pi 2 Model B (2015) Pi Zero (2015) Pi 3 Model B (2016) Pi Zero W (2017) Pi 3 Model B+ (2018) Pi 3 Model A+ (2019) Pi 4 Model A (2019) Pi 4 Model B (2020) Pi 400 (2021) مؤسسة راسبيري باي تسعى مؤسسة راسبيري باي لإتاحة الإمكانات الكبيرة للحوسبة والصناعة الرقمية للجميع حول العالم من خلال توفير حواسيب عالية الأداء ورخيصة الثمن ليتمكن الناس من استخدامها للتعلّم، أو حل المشاكل، أو حتى بهدف التسلية. كما أنها تسعى لتأمين طرق التواصل والتعليم اللازمة لمساعدة الناس على تعلّم الحوسبة والصناعة الرقمية، إذ أنها تطوّر مصادرًا مجانيةً لتعلّم الحوسبة وكيفية إنجاز المهام باستخدام الحواسيب، كما أنّها تدرّب أشخاصًا لتوجيه الآخرين نحو التعلُّم. ويُعد كلًا من المشروعين Code Club و CoderDojo جزءًا من مؤسسة راسبيري باي رغم كونهما منصاتٍ مستقلةً غير مرتبطة بلوحات راسبيري باي حصرًا. وتروّج مؤسسة راسبيري باي لهذه المشاريع وتسعى لتوسيع انتشارها بهدف ضمان إمكانية وصول كل طفلٍ حول العالم إلى تعلّم الحوسبة. إضافةً لذلك، يُقام الحدث Raspberry Jams لدعوة الناس من كل الفئات العمرية ليتعرفوا معًا على راسبيري باي ويتبادلون الأفكار والمشاريع. راسبيري باي والمصادر المفتوحة تعمل راسبيري باي مع الأنظمة مفتوحة المصدر؛ فهي قادرةٌ على تشغيل نظام لينوكس Linux ودعم عدّة توزيعات منه؛ كما أن نظام تشغيلها الأساسي "Pi OS" مفتوح المصدر أيضًا ويدير مجموعةً من البرامج مفتوحة المصدر. وتعد مؤسسة راسبيري باي من المساهمين في نواة لينوكس وغيرها من المشاريع مفتوحة المصدر، بالإضافة إلى إصدارها عدة برمجيات مفتوحة المصدر خاصّةً بها، ومخططات راسبيري باي دوريًا بمثابة توثيق documentation. ولكن في الواقع، لا تُعد لوحات راسبيري باي عتادً مفتوحًا (العتاد المفتوح هو العتاد المُرخص به، بحيث يمكن لأي شخص دراسته والتعديل عليه وإعادة توزيعه). تعتمد مؤسسة راسبيري باي على الأرباح من مبيعات وحدات راسبيري باي لإنجاز أعمالها الخيرية في قطاع التعليم. ما يمكنك إنجازه مع لوحة راسبيري باي يشتري بعض الناس لوحة راسبيري باي ليتعلموا كتابة الشيفرات البرمجية؛ أما الأشخاص الذين يعرفون أصلًا كتابتها فيستخدمون اللوحة لتعلّم برمجة الدارات الإلكترونية والمشاريع الفيزيائية. تفتح لوحة راسبيري باي أمامك الآفاق لإنشاء مشاريعك الخاصة، والتي من شأنها أتمتة منزلك؛ وهو أمرٌ شائعٌ في مجتمعات المصادر المفتوحة، لأنه يمنحك كافّة إمكانات السيطرة على مشروعك بدلاً من استخدام نظام مغلقٍ خاصٍ بغيرك. تبيّن القائمة التالية بعض المشاريع الممكن تنفيذها باستخدام راسبيري باي: حظر الإعلانات على شبكتك باستخدام "pi-hole". إنشاء قاعدة بيانات "PostgreSQL" في راسبيري باي. إنشاء مجيب آلي لتويتر Twitter الخاص بك باستخدام لغة بايثون Python وراسبيري باي. بناء مشاريع باستخدام الكاميرا الخاصّة بلوحة راسبيري باي وأي تجهيزات وعتاد يمكن وصلها بها. إنشاء عارض صور رقمي. القائمة السابقة هي على سبيل المثال لا الحصر إذ المشاريع التي يمكن تنفيذها براسبيري باي لا تحصى، ونترك بين يديك هذا الحاسوب الرائع لتجرب وتتعلم وتبدع. ترجمة -وبتصرف- للمقال What is Raspberry Pi? من موقع opensource.com. اقرأ أيضًا جولة في راسبيان: نظام تشغيل راسبيري باي تجميع راسبيري باي والتحضير لاستعماله إعداد Raspberry Pi للعمل بدء استخدام راسبيري باي تخصيص واجهة سطح مكتب راسبيري باي1 نقطة -
 دوكر Docker هو إطار عملٍ برمجي، يهدف إلى بناء وتشغيل وإدارة الحاويات على الخوادم والسحابة؛ وهو جزءٌ من مشروع Moby؛ ويشير عادةً المصطلح "دوكر" إلى الأدوات من أوامرٍ وبرامج خفية، أو إلى الملفات من النوع دوكر Dockerfile. إذا أردت تشغيل تطبيق ويب، جرت العادة بأن تشتري خادمًا وتنزّل عليه نظام تشغيل لينكس، وتبدأ بإعداد حزمة LAMP، ومن ثمّ تشغِّل التطبيق؛ وعند زيادة الطلب على تطبيقك، ستلجأ إلى موازنة الحمل من خلال إعداد خادمٍ ثانٍ لضمان عدم توقّف التطبيق بسبب كثرة الزيارات. أمّا في وقتنا هذا اختلف الأمر؛ فبدلًا من الاعتماد على استخدام خادماتٍ وحيدة، بُنيت شبكة الإنترنت مثلًا اعتمادًا على مصفوفةٍ ضخمة من الخوادم المترابطة ضمن نظامٍ اسمه الشائع هو "السحابة"، وبالتالي وبفضل الابتكارات، مثل نواة نطاق الأسماء و cgroups من لينكس، تحرّر مفهوم الخادم من قيود كونه عتادًا وأصبح عوضًا عن ذلك مفهومًا برمجيًا. يُطلق على الخوادم المبنية برمجيًا اسم الحاويات Containers؛ وهي مزيجٌ هجين من نظام التشغيل لينكس الذي يشغّلها، إضافةً إلى بيئة وقت تشغيل تفاعلية متوضعّة ضمن الخادم تمثّل محتويات الحاوية. التعرف على مفهوم الحاويات يمكن تصنيف تقنية الحاويات إلى ثلاثة جوانب مختلفة: البناء: إذ تُستخدم أداةٌ أو مجموعةٌ من الأدوات لبناء الحاوية، مثل أداة distrobuilder لحاويات LXC؛ وهي إحدى حاويات نظام لينكس وتمثّل بيئةً وهميةً تعمل على مستوى النظام تشغِّل عدة أنظمة لينكس معزولة على جهازٍ واحدٍ ذي نظام لينكس مضيف، وأداة Dockerfile لحاويات دوكر. التشغيل (المحرّك): إذ يُستخدم تطبيقٌ لتشغيل الحاوية، ويمثّل هذا التطبيق بالنسبة لحاويات دوكر واجهة أسطر الأوامر docker command وتطبيق دوكر الخفي dockerd daemon؛ أمّا بالنسبة للحاويات الأُخرى فهو يشير غالبًا إلى التطبيق الخفي وأوامره، مثل podman (وهي أداةٌ مفتوحة المصدر مصمّمةٌ لتسهيل العثور على التطبيقات وتشغيلها وبنائها ومشاركتها ونشرها باستخدام الحاويات المفتوحة، كما توفّر واجهة سطر أوامر مألوفةٍ لأي شخص استخدم محرّك حاويات دوكر). التناسق Orchestration: وهي التقنية المستخدمة لإدارة مجموعةٍ من الحاويات وتتضمّن أنظمة تناسق الحاويات، مثل "Kubernetes" و "OKD". توفّر الحاويات غالبًا كلًا من التطبيق والضبط اللازم لعملها، وبالتالي لن يضطر مدير النظام لقضاء وقتٍ طويل في الحصول على تطبيقٍ لتشغيل الحاوية كون هذا التطبيق موجودٌ ومثبّتٌ أصلًا. ويمثّل كل من Dockerhub و Quay.io مستودعات توفّر صورًا لاستخدامها من قِبل محركات الحاويات. ومن أهم ميزات الحاويات هي ديناميكيتها العالية؛ فهي قادرةٌ على التوقّف عن العمل والاختفاء ومن ثمّ العودة بكل مرونة، وذلك حسب حالة الحمل وبما يضمن توازنه، وتكون عملية إعادة تشغيل الحاوية سريعة ومنخفضة المتطلبات سواءً كان توقّفها ناتجٌ عن عطلٍ ما، أو ببساطة بسبب عدم الحاجة إليها عند انخفاض مستوى الحركة على الخادم، فالحاويات مصمّمةٌ لتظهر وتختفي بكل سلاسة. نظرًا لهذه الميزات وبما أنّ الحاويات سريعة الاختفاء من ناحية، وقادرة على تشغيل العديد منها عند الحاجة من ناحية أُخرى، فمن المتوقّع ألّا يجري مراقبتها وإدارتها من قِبل إنسانٍ في الوقت الفعلي، بل يحدث ذلك تلقائيًا. بدائل حاويات دوكر سهّلت حاويات لينكس إحراز تقدمٍ هائلٍ في الحوسبة عالية التوفّر، إذ يوجد العديد من مجموعات الأدوات القادرة على مساعدتك في تشغيل الخدمات، أو نظام التشغيل كاملًا في الحاويات. تشجّع مبادرة الحاوية المفتوحة OCI -وهي منظمة معايير صناعية- الابتكار بما يضمن تجنُّب مشكلة قفل العميل vendor lock-in، أي اضطرار العميل إلى الاستمرار في استخدام منتجٍ أو خدمة بغض النظر عن جودتها؛ حيث أصبح بإمكانك وبفضل هذه المبادرة اختيار مجموعة أدوات الحاويات سواءٌ كانت دوكر، CRI-O، Podman، LXC، أو غيرها. خدمات الحاويات لقد صُمّمت الحاويات بحيث تتضاعف بسرعة عند الحاجة، سواءٌ كنت تشغّل عدّة خدماتٍ مختلفةٍ معًا، أو نسخًا عديدة من خدماتٍ قليلة؛ فإذا قررت تشغيل خدمات في حاوية، فستحتاج إلى برمجية لاستضافة وإدارة هذه الحاوية، وهو ما يُسمّى بتنسيق الحاوية container orchestration، فبالرغم من كون دوكر وغيره من محركات الحاويات، مثل "Podman" و "CRI-O" أدواتٍ جيدة لتعريف الحاويات وصورها، إلّا أنّ عملها ينحصر في إنشاء وتشغيل الحاوية نفسها وليس تنظيمها وإدارتها. وتوفّر بعض المشاريع، مثل Kubernetes و OKD منظمات للحاويات لكل من دوكر و "Podman" و "CRI-O" وغيرها. قد ترغب عند استخدامك لأي من هذه المشاريع في الحصول على الدعم اللاحق عبر مشروعٍ مثل OpenShift المُعتمد أصلًا على "OKD". ما عليك معرفته حول الإصدار المشترك من دوكر جُمِّعت المكونات مفتوحة المصدر من دوكر ضمن منتجٍ يُدعى الإصدار المشترك من دوكر -أو اختصارًا docker-ce-، الذي يتضمّن محرك دوكر ومجموعةً من أوامر الطرفية لمساعدة مدراء الأنظمة على إدارة جميع الحاويات قيد الاستخدام. يمكنك تثبيت مجموعة الأدوات هذه عبر البحث عن دوكر في مدير الحزم الموزعة distribution's package manager. لماذا نستخدم دوكر ؟ تُعدّ إمكانية اختيار التقنية المستخدمة في إنجاز مهمّةٍ ما واحدةً من أهم ميزات المصادر المفتوحة. ويوفّر محرّك دوكر بيئة تجريب مفيدة للمطورين كونها بيئةً نظيفةً وخفيفة الحمولة لا تحتاج تنظيمًا معقدًا، إذ يُعد استخدام الإصدار المشترك من دوكر docker-ce أحد أفضل الطرق للبدء باستخدام الحاويات لا سيما في حال كونه متوفرًا على نظامك وكنت على درايةٍ بسلسلة أدوات دوكر. يُعد كلٌ من Dockerhub و Quay.io مستودعاتٍ تقدم صورًا لمحرك الحاوية الذي اخترته، ويُفضَّل استخدام "Podman" إذا كان الإصدار المشترك من دوكر غير متاح أو غير مدعوم. لا تزال الجهود تُبذل لتمكين المصادر المفتوحة على نحوٍ أكبر، لذا يجب أن تتماشى مشاريعك المستقبلية باستخدام الحاويات مع المصادر والمعايير المفتوحة؛ فبالرغم من كون الاضافات الاحتكارية مغلقة المصدر قد تبدو جذابة إلا أنّها تفقد مرونتها من حيث إمكانية الاختيار، كون أدواتك محصورةً في منتجٍ واحد. باختصار، ستمنحك الحاويات الحرية، طالما كانت هي حرة أصلًا. ترجمة -وبتصرف- للمقال ?What is Docker من موقع opensource.com. اقرأ أيضًا مقدّمة عن المُكوّنات المُشترَكة في Docker نظرة عامّة على إعداد الحاويّات containerization على Docker التعامل مع حاويات Docker1 نقطة
دوكر Docker هو إطار عملٍ برمجي، يهدف إلى بناء وتشغيل وإدارة الحاويات على الخوادم والسحابة؛ وهو جزءٌ من مشروع Moby؛ ويشير عادةً المصطلح "دوكر" إلى الأدوات من أوامرٍ وبرامج خفية، أو إلى الملفات من النوع دوكر Dockerfile. إذا أردت تشغيل تطبيق ويب، جرت العادة بأن تشتري خادمًا وتنزّل عليه نظام تشغيل لينكس، وتبدأ بإعداد حزمة LAMP، ومن ثمّ تشغِّل التطبيق؛ وعند زيادة الطلب على تطبيقك، ستلجأ إلى موازنة الحمل من خلال إعداد خادمٍ ثانٍ لضمان عدم توقّف التطبيق بسبب كثرة الزيارات. أمّا في وقتنا هذا اختلف الأمر؛ فبدلًا من الاعتماد على استخدام خادماتٍ وحيدة، بُنيت شبكة الإنترنت مثلًا اعتمادًا على مصفوفةٍ ضخمة من الخوادم المترابطة ضمن نظامٍ اسمه الشائع هو "السحابة"، وبالتالي وبفضل الابتكارات، مثل نواة نطاق الأسماء و cgroups من لينكس، تحرّر مفهوم الخادم من قيود كونه عتادًا وأصبح عوضًا عن ذلك مفهومًا برمجيًا. يُطلق على الخوادم المبنية برمجيًا اسم الحاويات Containers؛ وهي مزيجٌ هجين من نظام التشغيل لينكس الذي يشغّلها، إضافةً إلى بيئة وقت تشغيل تفاعلية متوضعّة ضمن الخادم تمثّل محتويات الحاوية. التعرف على مفهوم الحاويات يمكن تصنيف تقنية الحاويات إلى ثلاثة جوانب مختلفة: البناء: إذ تُستخدم أداةٌ أو مجموعةٌ من الأدوات لبناء الحاوية، مثل أداة distrobuilder لحاويات LXC؛ وهي إحدى حاويات نظام لينكس وتمثّل بيئةً وهميةً تعمل على مستوى النظام تشغِّل عدة أنظمة لينكس معزولة على جهازٍ واحدٍ ذي نظام لينكس مضيف، وأداة Dockerfile لحاويات دوكر. التشغيل (المحرّك): إذ يُستخدم تطبيقٌ لتشغيل الحاوية، ويمثّل هذا التطبيق بالنسبة لحاويات دوكر واجهة أسطر الأوامر docker command وتطبيق دوكر الخفي dockerd daemon؛ أمّا بالنسبة للحاويات الأُخرى فهو يشير غالبًا إلى التطبيق الخفي وأوامره، مثل podman (وهي أداةٌ مفتوحة المصدر مصمّمةٌ لتسهيل العثور على التطبيقات وتشغيلها وبنائها ومشاركتها ونشرها باستخدام الحاويات المفتوحة، كما توفّر واجهة سطر أوامر مألوفةٍ لأي شخص استخدم محرّك حاويات دوكر). التناسق Orchestration: وهي التقنية المستخدمة لإدارة مجموعةٍ من الحاويات وتتضمّن أنظمة تناسق الحاويات، مثل "Kubernetes" و "OKD". توفّر الحاويات غالبًا كلًا من التطبيق والضبط اللازم لعملها، وبالتالي لن يضطر مدير النظام لقضاء وقتٍ طويل في الحصول على تطبيقٍ لتشغيل الحاوية كون هذا التطبيق موجودٌ ومثبّتٌ أصلًا. ويمثّل كل من Dockerhub و Quay.io مستودعات توفّر صورًا لاستخدامها من قِبل محركات الحاويات. ومن أهم ميزات الحاويات هي ديناميكيتها العالية؛ فهي قادرةٌ على التوقّف عن العمل والاختفاء ومن ثمّ العودة بكل مرونة، وذلك حسب حالة الحمل وبما يضمن توازنه، وتكون عملية إعادة تشغيل الحاوية سريعة ومنخفضة المتطلبات سواءً كان توقّفها ناتجٌ عن عطلٍ ما، أو ببساطة بسبب عدم الحاجة إليها عند انخفاض مستوى الحركة على الخادم، فالحاويات مصمّمةٌ لتظهر وتختفي بكل سلاسة. نظرًا لهذه الميزات وبما أنّ الحاويات سريعة الاختفاء من ناحية، وقادرة على تشغيل العديد منها عند الحاجة من ناحية أُخرى، فمن المتوقّع ألّا يجري مراقبتها وإدارتها من قِبل إنسانٍ في الوقت الفعلي، بل يحدث ذلك تلقائيًا. بدائل حاويات دوكر سهّلت حاويات لينكس إحراز تقدمٍ هائلٍ في الحوسبة عالية التوفّر، إذ يوجد العديد من مجموعات الأدوات القادرة على مساعدتك في تشغيل الخدمات، أو نظام التشغيل كاملًا في الحاويات. تشجّع مبادرة الحاوية المفتوحة OCI -وهي منظمة معايير صناعية- الابتكار بما يضمن تجنُّب مشكلة قفل العميل vendor lock-in، أي اضطرار العميل إلى الاستمرار في استخدام منتجٍ أو خدمة بغض النظر عن جودتها؛ حيث أصبح بإمكانك وبفضل هذه المبادرة اختيار مجموعة أدوات الحاويات سواءٌ كانت دوكر، CRI-O، Podman، LXC، أو غيرها. خدمات الحاويات لقد صُمّمت الحاويات بحيث تتضاعف بسرعة عند الحاجة، سواءٌ كنت تشغّل عدّة خدماتٍ مختلفةٍ معًا، أو نسخًا عديدة من خدماتٍ قليلة؛ فإذا قررت تشغيل خدمات في حاوية، فستحتاج إلى برمجية لاستضافة وإدارة هذه الحاوية، وهو ما يُسمّى بتنسيق الحاوية container orchestration، فبالرغم من كون دوكر وغيره من محركات الحاويات، مثل "Podman" و "CRI-O" أدواتٍ جيدة لتعريف الحاويات وصورها، إلّا أنّ عملها ينحصر في إنشاء وتشغيل الحاوية نفسها وليس تنظيمها وإدارتها. وتوفّر بعض المشاريع، مثل Kubernetes و OKD منظمات للحاويات لكل من دوكر و "Podman" و "CRI-O" وغيرها. قد ترغب عند استخدامك لأي من هذه المشاريع في الحصول على الدعم اللاحق عبر مشروعٍ مثل OpenShift المُعتمد أصلًا على "OKD". ما عليك معرفته حول الإصدار المشترك من دوكر جُمِّعت المكونات مفتوحة المصدر من دوكر ضمن منتجٍ يُدعى الإصدار المشترك من دوكر -أو اختصارًا docker-ce-، الذي يتضمّن محرك دوكر ومجموعةً من أوامر الطرفية لمساعدة مدراء الأنظمة على إدارة جميع الحاويات قيد الاستخدام. يمكنك تثبيت مجموعة الأدوات هذه عبر البحث عن دوكر في مدير الحزم الموزعة distribution's package manager. لماذا نستخدم دوكر ؟ تُعدّ إمكانية اختيار التقنية المستخدمة في إنجاز مهمّةٍ ما واحدةً من أهم ميزات المصادر المفتوحة. ويوفّر محرّك دوكر بيئة تجريب مفيدة للمطورين كونها بيئةً نظيفةً وخفيفة الحمولة لا تحتاج تنظيمًا معقدًا، إذ يُعد استخدام الإصدار المشترك من دوكر docker-ce أحد أفضل الطرق للبدء باستخدام الحاويات لا سيما في حال كونه متوفرًا على نظامك وكنت على درايةٍ بسلسلة أدوات دوكر. يُعد كلٌ من Dockerhub و Quay.io مستودعاتٍ تقدم صورًا لمحرك الحاوية الذي اخترته، ويُفضَّل استخدام "Podman" إذا كان الإصدار المشترك من دوكر غير متاح أو غير مدعوم. لا تزال الجهود تُبذل لتمكين المصادر المفتوحة على نحوٍ أكبر، لذا يجب أن تتماشى مشاريعك المستقبلية باستخدام الحاويات مع المصادر والمعايير المفتوحة؛ فبالرغم من كون الاضافات الاحتكارية مغلقة المصدر قد تبدو جذابة إلا أنّها تفقد مرونتها من حيث إمكانية الاختيار، كون أدواتك محصورةً في منتجٍ واحد. باختصار، ستمنحك الحاويات الحرية، طالما كانت هي حرة أصلًا. ترجمة -وبتصرف- للمقال ?What is Docker من موقع opensource.com. اقرأ أيضًا مقدّمة عن المُكوّنات المُشترَكة في Docker نظرة عامّة على إعداد الحاويّات containerization على Docker التعامل مع حاويات Docker1 نقطة -
الخطأ الذي يظهر لك عند تنفيذ الأمر route:cache يحدث بسبب الكود الموجود في الملف routes\api.php وذلك لأن لارافيل لا يمكنه أن يقوم بعمل cache للمسارات routes إن كان أحد المسارات يحتوي على كود مباشر في داخل function وليس مسار لتابع في متحكم controller، وإذا قمت بإزالة الكود الموجود في الملف routes\api.php، بالشكل التالي: // Route::middleware('auth:api')->get('/user', function (Request $request) { // return $request->user(); // }); ثم قمت بتنفيذ الأمر التالي مرة أخرى: php artisan route:cache فستجد أنه يعمل بدون مشكلة.1 نقطة





.png.8a2c7d1db46f212e8889df70fbbf2715.png)