لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 12/12/21 في كل الموقع
-
السلام عليكم ورحمة الله وبركاته اخواني انا حابب ابدا في مجال برمجة وتصميم قوالب ووردبريس و عاوز حد في اليوتيوب بيشرح عن تصميم القوالب بعد اذنكم وكمان عاوز اعرف كيف ابرمج قوالب بلوجر و جزاكم الله خيرا2 نقاط
-
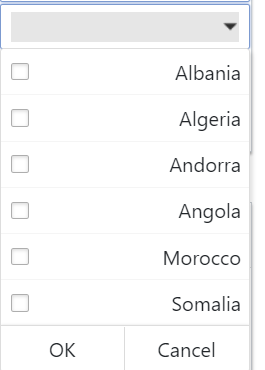
احاول ارسال قيم الى StoredProcedure من خلال : listbox يحتوي اسماء الدول احصل عليهم من قاعدة البيانات المشكله لو قمت باختيار واحد حتى اقوم بارساله الكود يعمل بشكل سليم 100%100 ولكن لو قمت بوضع اختيارين او 3 اختيارات على سبيل المثال احصل على الخطاء التالي: Parameter '@stIdCity' was supplied multiple times. وموقع الخطاء يشير الى : Line 298: da.Fill(ds); الكود كامل كالتالي: protected void lstBoxTestCity_SelectedIndexChanged(object sender, EventArgs e) { string str = ConfigurationManager.ConnectionStrings["ConnectionString"].ConnectionString; using (SqlConnection con = new SqlConnection(str)) { using (SqlCommand cmd = new SqlCommand("Tprocedure", con)) { cmd.CommandType = CommandType.StoredProcedure; foreach (ListItem item in lstBoxTestCity.Items) { if (item.Selected) { cmd.Parameters.AddWithValue("@stIdCity", item.Value); } } SqlDataAdapter da = new SqlDataAdapter(cmd); DataSet ds = new DataSet(); da.Fill(ds); gvProducts.DataSource = ds; gvProducts.DataBind(); } } } والقائمة كالتالي التي يختار منها المستخدم: كيف يمكن تجنب هذا المشكله وحل هذا الامر ياليت لو كان احد مر بنفس التجربه يفيدنا لو تكرمتو
 1 نقطة
1 نقطة -
كمبتدئ، هل يجب أن ألتحق بدورة علوم الحاسب أولا؟ علما أني أريد التسجيل بدورة تطوير واجهات المستخدم، أتسائل هل يتم ي دورة تطوير واجهات المستخدم تعليم الأساسيات مثل الخوارزميات؟1 نقطة
-
هل هناك دالة في nltk لقياس التشابه بين كلمتين؟1 نقطة
-
عندما اقوم باستخدام دالة userschema.pre('save',function(){console.log(this)} يتم طباعة الوثيقة بينما عندما اقوم باستخدام نفس الدالة للupdateOne يتم طباعة كائن غريب1 نقطة
-
أحاول الوصول إلى جسم طلب من نوع POST بغض النظر عن قيمة Content-Type الموجودة في رأس الطلب، لكن أحيانًا عندما أستعمل request.data كما في الكود التالي، لكن أحصل على البيانات بعد عمل parse لها: @app.route('/', methods=['POST']) def index(): data = request.data # يكون فارغ في بعض الأحيان # ... أريد الحصول على جسم الطلب Request Body في شكله الخام raw data بدون تعديل هذه القيمة. كيف يمكنني القيام بهذا الأمر؟1 نقطة
-
1 نقطة
-
هذه الدالة تقبل معامل واحد مع قيمته، ولكي تستطع حل المشكلة، عليك تمرير غرض برمجي var p = cmd.CreateParameter(); p.Name = "wael"; p.age = 24; cmd.Parameters.Add(p); لحل المشكلة بشكل أفضل، نمرر مصفوفة بأسماء المدن. var parameters = new string[100]; // أقصى عدد ممكن var index = 0; foreach (ListItem item in lstBoxTestCity.Items) { if (item.Selected) { parameters[index] = string.Format("@stIdCity{0}", index); cmd.Parameters.AddWithValue(parameters[i], item.Value); index++; } } الآن في الاستعلام لديك، إن كنت تعمل شرط، استخدم المعامل IN في عبارة SQL توثيق موسوعة حسوب: معاملات المجال في SQL لأنه تم تمرير أكثر من دولة1 نقطة
-
مرحبا سلطان، يتم في دورة تطوير واجهات المستخدم شرح أساسيات تطوير الويب، إبتداءا من أساسيات HTML مرورا بأساسيات CSS ثم JavaScript ليتم بذلك الإنتقال إلى مجموعة مسارات تطبيقات عملية يتم فيها التعمق في هاته المفاهيم والتعرف عليها بشكل مفصل وعملي أكثر. أما الدورة التي يتم فيها التعرف على الخوارزميات وبنى البيانات وأنماط التصميم وغيرها هي دورة علوم الحاسوب التي ستتدرج فيها إبتداءا من مدخل إلى علوم الحاسب وأساسيات البرمجة والتفكير المنطقي والخوارزميات إلى مبادئ البرمجة مرورا بأنظمة التشغيل وقواعد البيانات. إذ أن كل هذا سيكون كفيلا بأن يجعلك تحسم خيارك بشأن المسار الذي ستأخذه في مستقبلك البرمجي. ولذلك فإنه يقترح -في حالة عدم اكتساب أي خبرة تقنية- البدء بدورة علوم الحاسوب والتأسس جيدا في مفاهيم البرمجة ,التطوير والهندسة ثم سيكون الإنتقال إلى دورة تطوير الويب أكثر سلاسة وسهولة، لأنها حجر الأساس لأي دورة أخرى من الدورات. علما أنه بمجرد تسجيلك في دورة من دورات الأكاديمية سيتم فتح أول مسار من كل دورة من الدورات التي تقدمها الأكاديمية: دورة علوم الحاسب. دورة تطوير واجهات المستخدم. دورة تطوير التطبيقات بإستخدام جافاسكربت. دورة تطوير تطبيقات الويب بإستخدام PHP. دورة تطوير التطبيقات بإستخدام تقنيات الويب. دورة تطوير تطبيقات الويب بإستخدام لغة Ruby.1 نقطة
-
حاولت أن أقوم بعمل نظام تسجيل دخول للمستخدمين في مشروع مبني بإستخدام فلاسك Flask، ولكن عندما حاولت الإتصال بقاعدة البيانات يظهر لي الخطأ التالي: ImportError: No module named MySQLdb قمت بتثبيت MySQL وتأكدت من الكود ولكن ما يزال الخطأ يظهر. أنا أستعمل SQLAlchemy وفلاسك الإصدار 1.1 كيف يمكنني حل هذه المشكلة؟1 نقطة
-
1 نقطة
-
ربي يرزقك جنات النعيم ويزيدك من واسع فضله وعلمه نجح الامر 100%100 سوف اضع الكود للفائدة بعد التعديل: protected void lstBoxTest_SelectedIndexChanged(object sender, EventArgs e) { int temp = gvProducts.Columns.Count; for (int i = 0; i < temp; i++) { gvProducts.Columns[i].Visible = true; } foreach (ListItem item in lstBoxTest.Items) { if (item.Selected) { if (item.Value == "1" ) { gvProducts.Columns[1].Visible = false; } else if (item.Value == "2") { gvProducts.Columns[2].Visible = false; } else if (item.Value == "3") { gvProducts.Columns[3].Visible = false; } } } } } ممكن استعماله في button او عن طريق لسته بشكل مباشر مودتي لك1 نقطة
-
أحاول الوصول لخاصية عدد الأعمدة، يجب وضع خيار autogeneratecolumns="false" => int temp = GridView1.Columns.Count; // will return 6 حسب المثال <asp:GridView ID="GridView1" autogeneratecolumns="false" runat="server"> <columns> <asp:boundfield datafield="CustomerID" headertext="Customer ID"/> <asp:boundfield datafield="CompanyName" headertext="Company Name"/> <asp:boundfield datafield="Address" headertext="Address"/> <asp:boundfield datafield="City" headertext="City"/> <asp:boundfield datafield="PostalCode" headertext="Postal Code"/> <asp:boundfield datafield="Country" headertext="Country"/> </columns> </asp:GridView>1 نقطة
-
لديك مشروع مبني بإستخدام فلاسك Flask ولكن عندما أحاول أن أقوم بعمل API وطلب أحد المسارات بإستخدام Ajax عبر jQuery يظهر لي هذا الخطأ: XMLHttpRequest cannot load http://... No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin ... is therefore not allowed access. أعلم أن سبب هذه المشكلة هو Cross-Origin Resource Sharing (CORS) ولكن لا أعرف كيف أصلح هذه المشكلة في فلاسك Flask، هل يجب أن أقوم بتثبيت مكتبة معينة؟ كيف أصلح هذه المشكلة؟1 نقطة
-
أقوم ببعض عمليات المعالجة المسبقة على بياناتي النصي (أعمل على بناء نظام استرجاع)، وأريد تطبيق عملية Lemmatization على النصوص (أي ربط الكلمات ذات المعاني المتشابهة بكلمة واحدة -مفهوم أكثر تعميماً من الاشتقاق البسيط حيث يقوم بتحليل موروفولوجي للنص-). لذا هل هناك طريقة للقيام بذلك في NLTK؟ على سبيل المثال : corpora --> corpus rocks --> rock better --> good1 نقطة
-
أعمل على تطوير شبكة RNN و الآن أنا في مرحلة المعالجة المسبقة للنصوص، وأحتاج إلى اشتقاق الكلمات لكي أقوم بتخفيضها في النصوص. كما تعلمون فإن ال Stemming يقوم بتحويلات مثل تحويل مجموعة الكلمات التالي: “chocolates”, “chocolatey”, “choco” إلى كلمة جذر وحيدة هي: “chocolate” لذا هل هناك طريقة للإيجاد جذر الكلمة ؟ مثلاً في NLTK؟1 نقطة
-
أودّ السؤال عن كيفية إضافة مقال، مثلا هل أقوم بوضع ملخص لمحور معين أم إضافة أرتيكل أشرح فيه نقطة معينة في الدرس كأن أقدم حلّا لمشكل معيّن.1 نقطة
-
المقال يجب ان يضيف للقارئ معارف جديدة، يمكن أن يكون شرحًا عن موضوع ما أو شرح عن مجال ما، أو تدريب على خطوات تنفيذ عمل معين، أو كما ذكرت تقدم مشكلة وحلًا لها، يجب أن تكون صياغة المقال بسيطة وواضحة بعيدة عن الجمل الإنشائية، اقرأ قسم اكتب معنا لمعرفة المزيد، واذا كان لديك مقال جاهز تود نشره حاول التواصل مع مركز الدعم وطلب نشر المقال في الأكاديمية1 نقطة
-
يمكنك التسجيل في دورة تطوير تطبيقات الويب باستخدام لغة PHP هنا في الأكاديمية، ستحصل على محتوى الدورة بشكل دائم ومتجدد وفيها مسار خاص لتطوير قوالب ووردبرس منذ البداية حتى طريقة نشرها مع أمثلة عملية وستحصل في نهاية الدورة إن أتممتها على شهادة من الأكاديمية وستصبح مؤهلا للعمل في هذا المجال1 نقطة
-
ما المدة الزمنية المفترضة لإنهاء دورة علوم الحاسوب؟ وهل ترتيب الموضوعات مهم لا بد من اتباعه؟ والسؤال الاخير : عند الانتهاء من الدورة كيف اقيم نجاحي في فهم الدورة بعيداً عن الاختبار؟1 نقطة
-
عند تمرير المؤشر في الصورة تظهر الشاشة الزرقاء ولكن عند تمرير المؤشر على الفقرة مثلًا تظر أيضًا الشاشة الزرقاء؟ previewcard.zip
 1 نقطة
1 نقطة -
اخواني هل هناك مشكله لو ترجمنا بعض المواقع لفهم المواضيع مثل موقع w3s او MDN عن جوجل ترانس ؟1 نقطة
-
كم هي فترة الاشتراك اقصد هل هي ٣شهور اما نصف عام او هو اشتراك سنوي و انا عمري 16 سنه هل يفضل التعلم حاليا ام لا ؟1 نقطة
-
مع كل تبديل في حالة الاختيار، سيتم إرسال القائمة كاملة مع التعديلات، لذلك في كل مرة، يمكننا تحديد أن جميع الخيارات متاحة، ثم نعود و نزيل ما تم تحديده، سأحاول تطبيق الفكرة: الأولى نعتبرهم جميعاً ظاهرين ثم نخفي ما تم تحديده ضعها قبل for each const int gvProductsCount = gvProducts.Columns.Count; for (int i = 0; i < gvProductsCount; i++) { gvProducts.Columns[i].Visible = true; } ثم تأتي for each لتخفي ما تم اختياره. الفكرة الثانية باستخدام if - else foreach (ListItem item in lstBoxTest.Items) { if (item.Selected) { // item 1 if (item.Value == "1" ) { gvProducts.Columns[1].Visible = false; } else { gvProducts.Columns[1].Visible = true; } // item 2 if (item.Value == "2" ) { gvProducts.Columns[2].Visible = false; } else { gvProducts.Columns[2].Visible = true; } // item 3 if (item.Value == "3" ) { gvProducts.Columns[3].Visible = false; } else { gvProducts.Columns[3].Visible = true; } } }1 نقطة
-
فلاسك Flask يقوم بتخزين كل المسارات في app.url_map والذي هو عبارة عن مثيل من الكائن werkzeug.routing.Map ، ويمكنك المرور على كل مسار من خلال إستخدام التابع iter_rules، على النحو التالي: from flask import Flask, request, url_for, Response app = Flask(__name__) @app.route('/users/<user_id>') def index(user_id): pass @app.route('/foo') def foo(): routes = [] for rule in app.url_map.iter_rules(): routes.append(rule.endpoint) print(routes) # ['foo', 'static', 'index'] return "printed routes", 200 app.debug = True app.run(debug=True) بهذا الشكل يمكنك الحصول على كل المسارات. كما يمكنك أن تقوم بالحصول على المسارات من خلال سطر الأوامر عبر إستدعاء ملف المشروع الرئيسي وطباعة قيمة app.url_map: python >>> from app import app >>> app.url_map ['foo', 'static', 'index'] أيضًا تستطيع تنفيذ الأمر flask routes للحصول على قائمة من المسارات وأنواعها: > flask routes Endpoint Methods Rule -------- ------- ----------------------- foo GET /foo index GET /users/<user_id> static GET /static/<path:filename>1 نقطة
-
يوفر الكائن query التابع filter_by والتابع filer ، ويمكن إستخدام أي منهما للقيام بهذه المهمة، على النحو التالي: التابع filter: User.query.filter(User.id == 123).delete() التابع filter_by: User.query.filter_by(id=123).delete() لكن إن كان الجدول users مرتبط بجدول آخر ويتم إعداد إستخدام CASCADE في العلاقة، فعليك أن تستخدم الطريقة الموجودة في سؤال أو الطريقة التالية: user = db.session.query(User).filter(User.user_id==123).first() db.session.delete(user) كما يجب أن تقوم بعمل commit لهذه التغيرات من خلال السطر التالي: db.session.commit() لمزيد من المعلومات عن التابع filter يمكنك أن تلقي نظرة على هذه المقالات هنا:1 نقطة
-
بالتأكيد، يوفر فلاسك Flask طريقة لتعديل الـ headers قبل إرسال الرد response إلى العميل وذلك من خلال إستخدام Response.headers، كالتالي: from flask import Response @app.route('/home') def home(): xml = '<foo>content</foo>' r = Response(response=xml, status=200, mimetype="application/xml") r.headers["Content-Type"] = "text/xml; charset=utf-8" return r كما أن الكائن Response يقبل معامل باسم content_type لتغير نوع البيانات الموجودة في الرد response، ويمكنك إستخدامها كالتالي: r = Response(response=xml, content_type='text/xml; charset=utf-8') أيضًا فلاسك Flask يقبل إرجاع قائمة من الكائنات عند إستخدام return في نهاية المسار، حيث يكون العنصر الأول في هذه القائمة عبارة عن المحتوى المراد إرجاعه إلى العميل، والعنصر الثاني هو رقم حالة الطلب request status code، والعنصر الثالث هو ترويسات الرد response headers، على النحو التالي: from flask import Response @app.route('/home') def home(): xml = '<foo>content</foo>' return xml, 200, {'Content-Type': 'text/xml; charset=utf-8'}1 نقطة
-
نعم في الحقيقة NLTK هي أفضل من قام بذلك. في NLTK يُشار إلى كل علامة نحوية (أو جزء من الكلام) برمز محدد وهذه هي قائمة الرموز: VB verb, base form take VBD verb, past tense took VBG verb, gerund/present participle taking VBN verb, past participle taken VBP verb, sing. present, non-3d take VBZ verb, 3rd person sing. present takes WDT wh-determiner which WP wh-pronoun who, what WP$ possessive wh-pronoun whose WRB wh-abverb where, when CC coordinating conjunction CD cardinal digit DT determiner EX existential there (like: “there is” … think of it like “there exists”) FW foreign word IN preposition/subordinating conjunction JJ adjective ‘big’ JJR adjective, comparative ‘bigger’ JJS adjective, superlative ‘biggest’ LS list marker 1) MD modal could, will NN noun, singular ‘desk’ NNS noun plural ‘desks’ NNP proper noun, singular ‘Harrison’ NNPS proper noun, plural ‘Americans’ PDT predeterminer ‘all the kids’ POS possessive ending parent‘s PRP personal pronoun I, he, she PRP$ possessive pronoun my, his, hers RB adverb very, silently, RBR adverb, comparative better RBS adverb, superlative best RP particle give up TO to go ‘to‘ the store. UH interjection errrrrrrrm الآن لإيجاد ال POS في النص الخاص بك أو أي نص اتبع الكود التالي فقط: # استيراد الوحدات import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize, sent_tokenize # كلمات التوقف stop_words = set(stopwords.words('english')) # تحديد النص txt = "Life is like riding a bicycle. To keep your balance, you must keep moving." # تقسيم النص إلى جمل sent = sent_tokenize(txt) # هنا لدينا جملتين في النص أعلاه # منها POS نقوم الآن بالمرور على كل جملة ونستخرج ال for i in sent: # لإيجاد الكلمات وعلامات الترقيم word_tokenize نستخدم الآن wordsList = nltk.word_tokenize(i) # نقوم بحذف كلمات التوقف منها wordsList = [w for w in wordsList if not w in stop_words] # تصنيف كل كلمة nltk ونمرر لها الكلمات وستتولى pos_tag نقوم الآن باستدعاء الدالة POS = nltk.pos_tag(wordsList) print(POS) والخرج: [('Life', 'NNP'), ('like', 'IN'), ('riding', 'VBG'), ('bicycle', 'NN'), ('.', '.')] [('To', 'TO'), ('keep', 'VB'), ('balance', 'NN'), (',', ','), ('must', 'MD'), ('keep', 'VB'), ('moving', 'NN'), ('.', '.')]1 نقطة
-
من خلال مكتبة nltk يمكنك القيام بهذه العملية من خلال الدالة word_tokenize بالشكل التالي: # word_tokenize استيراد الدالة from nltk.tokenize import word_tokenize # تحديد النص text = """Stopwords are the English words which does not add much meaning to a sentence. They can safely be ignored without sacrificing the meaning of the sentence. For example, the words like the, he, have etc. Such words are already captured this in corpus named corpus. We first download it to our python environment. """ # استخدامها tokens=word_tokenize(text) print(tokens) """ ['Stopwords', 'are', 'the', 'English', 'words', 'which', 'does', 'not', 'add', 'much', 'meaning', 'to', 'a', 'sentence', '.', 'They', 'can', 'safely', 'be', 'ignored', 'without', 'sacrificing', 'the', 'meaning', 'of', 'the', 'sentence', '.', 'For', 'example', ',', 'the', 'words', 'like', 'the', ',', 'he', ',', 'have', 'etc', '.', 'Such', 'words', 'are', 'already', 'captured', 'this', 'in', 'corpus', 'named', 'corpus', '.', 'We', 'first', 'download', 'it', 'to', 'our', 'python', 'environment', '.'] """ كما يمكنك استخادم الكلاس RegexpTokenizer الذي يمكنك من استخدام التعابير المنتظمة لإنجاز عملية ال Tokenization كالتالي: # RegexpTokenizer استيراد الكلاس from nltk.tokenize import RegexpTokenizer # تحديد النص text = """Stopwords are the English words which does not add much meaning to a sentence. They can safely be ignored without sacrificing the meaning of the sentence. For example, the words like the, he, have etc. Such words are already captured this in corpus named corpus. We first download it to our python environment. """ # تعريف كائن من الصنف السابق tk = RegexpTokenizer('\s+', gaps = True) # الوسيط الأول هو التعبير المنتظم الوسيط # tokenizeation المعرفة ضمن هذا الصنف للقيام بعملية ال tokenize نقوم الآن باستدعاء الدالة tokens=tk.tokenize(text) print(tokens) """ ['Stopwords', 'are', 'the', 'English', 'words', 'which', 'does', 'not', 'add', 'much', 'meaning', 'to', 'a', 'sentence.', 'They', 'can', 'safely', 'be', 'ignored', 'without', 'sacrificing', 'the', 'meaning', 'of', 'the', 'sentence.', 'For', 'example,', 'the', 'words', 'like', 'the,', 'he,', 'have', 'etc.', 'Such', 'words', 'are', 'already', 'captured', 'this', 'in', 'corpus', 'named', 'corpus.', 'We', 'first', 'download', 'it', 'to', 'our', 'python', 'environment.'] """1 نقطة
-
يمكنك القيام بذلك من خلال nltk حيث أنه لديها قاموساً يجمع هذه الكلمات. ويمكنك الوصول لها واستعراضها (وتعديلها إذا أردت عن طريق إضافة أو حذف بعض الكلمات) بالشكل التالي: # stopwords نقوم باستيراد الوحدة from nltk.corpus import stopwords # 'english' ونمرر لها الوسيط words نقوم باستدعاء الدالة stopwords من خلال الوحدة sw=stopwords.words('english') # الآن أصبح لدينا مجموعة كلمات التوقف الأساسية في اللغة الإنجليزية print(sw) """ ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"] """ الآن سنقوم بكتابة مثال لاستخدام هذه القائمة لحذف كلمات التوقف: from nltk.corpus import stopwords from nltk.tokenize import word_tokenize # تحديد النص text = """Stopwords are the English words which does not add much meaning to a sentence. They can safely be ignored without sacrificing the meaning of the sentence. For example, the words like the, he, have etc. Such words are already captured this in corpus named corpus. We first download it to our python environment. """ # إنشاء مجموعة من كلمات التوقف sw = set(stopwords.words('english')) # للنص tokenization القيام بعملية word_tokens = word_tokenize(text) # word_tokens تصفية كلمات التوقف من ال filteredText = [word for word in word_tokens if not word.lower() in sw] print(filteredText)1 نقطة
-
يمكنك استخدام الكلاس WhitespaceTokenizer لحل المشكلة، حيث يمكّنك من تنفيذ عملية ال tokinezation مع معالجة تلقائية للمسافات والأسطر الجديدة (تجاهلها)، ويمكنك استخدامها كما يلي: # WhitespaceTokenizer استيراد الكلاس from nltk.tokenize import WhitespaceTokenizer # إنشاء كائن من هذا الكلاس tk = WhitespaceTokenizer() # تحديد النص text = "The price\t of burger \nin BurgerKing is Rs.36.\n" # لتأدية المطلوب WhitespaceTokenizer المعرفة ضمن الكلاس tokenize استخدام الدالة tokens = tk.tokenize(text) print(tokens) # ['The', 'price', 'of', 'burger', 'in', 'BurgerKing', 'is', 'Rs.36.']1 نقطة
-
يمكنك استخدام الدالة words المعرّفة ضمن الوحدة nltk.corpus.words، حيث تعيد لك هذه الدالة قائمة تحوي جميع الكلمات الإنجليزية تقريباً، وبالتالي يمكنك استخدامها واختبار انتماء كلمة لمجموعة المفردات الإنجليزية من خلال المعامل in كما يلي: from nltk.corpus import words "can" in words.words() # True "try" in words.words() # True "I" in words.words() # True وكحالة خاصة يمكنك استخدام المكتبة PyEnchant المتخصصة بالتدقيق الإملائي بالشكل التالي: # استيراد المكتبة import enchant # وبالتالي يعطيك قاموساً بكل الكلمات الانجليزية en_US القيمة enchant المعرفة ضمن المكتبة Dict نمرر للدالة words = enchant.Dict("en_US") # لاختبار انتماء كلمة لهذا المعجم check ثم نستخدم الدالة words.check("can") # True1 نقطة
-
يمكنك استخدام الدالة find_element_by_xpath، حيث تُرجع قائمة بجميع العناصر المطابقة للتعبير الذي تمرره لها وهنا نحتاج إلى العنصر span ذو الكلاس rule لذا نكتب: spans = driver.find_elements_by_xpath("//span[@class='rule']") الآن نقوم بالمرور على القائمة spans لاستخراج النص من كل عنصر من خلال استخدام الواصفة text: for span in spans: print(span.text)1 نقطة
-
على أنظمة لينوكس: 1. قم بتحديث فهرس الحزمة عن طريق كتابة الأمر أدناه: sudo apt update 2. تحميل مدير الحزم pip لبايثون 3: sudo apt install python3-pip 3. استخدم الأمر التالي لتثبيت NLTK: sudo pip install -U nltk sudo pip3 install -U nltk على نظام ويندوز: pip install nltk في حال كنت تعمل ضمن بيئة أناكوندا، افتح Anaconda prompt ثم اكتب الأمر التالي: conda install -c anaconda nltk1 نقطة
-
يمكنك استخدام الدالة find_element بالشكل التالي: # سنقوم باستخدام الدالة التي ذكرناها # css_selector سنقوم بإيجاد الجدول من خلال هذه الدالة من خلال ال table = find_element_by_css_selector('table.dAta') # كمعطى للدالة table نقوم بتمرير كلاس الوسم # الآن بعد أن حصلنا على الجدول نقوم باستخدام نفس الدالة لكن هذه المرة لإيجاد جميع الصفوف rows=table.find_elements_by_css_selector('tr') # الآن نقوم بالتكرار عليها for row in rows: # إيجاد كل الخلايا ضمن الصف cells=row.find_elements_by_tag_name('td') # التكرار عليها for td in cells: # text طباعة النص الموجود ضمنها من خلال الواصفة print(td.text)1 نقطة
-
يمكننا العثور على عنصر شقيق تالي من نفس الأب من خلال ال xpath مع استخدام العبارة following-sibling ضمنها بالشكل التالي: driverObj.find_element_by_xpath("//p[@id='A']/following-sibling::p") من المهم ملاحظة أنه من الممكن فقط الانتقال من الأخ الحالي إلى الأخ التالي من خلال ال xpath.1 نقطة
-
يمكنك استخدام اسم المعرف id لتحديد الوسم المطلوب ثم تحديد القيمة value المطلوب تحديدها بالشكل التالي: # xpath من خلال ال driverObj.find_element_by_xpath("//select[@id='X']/option[@value='B']").click() # css_selector أو من خلال driverObj.find_element_by_css_selector("select#X > option[value='B']").click() # لاختيار القيمة المطلوبة select_by_value لكن هنا سنستخدم الدالة css_selector أو من خلال Select(driverObj.find_element_by_css_selector("select#X")).select_by_value(B).click()1 نقطة
-
بداية من الإصدار 2.2 من جانغو Django أصبح بإمكانك تعديل مجموعة من الكائنات دفة واحدة من خلال التابع bulk_update، كالتالي: >>> objs = [ ... Entry.objects.create(name='old name 1'), ... Entry.objects.create(name='old name 2'), ... ] >>> objs[0].name = 'new name 1' >>> objs[1].name = 'new name 2' >>> Entry.objects.bulk_update(objs, ['name']) تقوم هذه الطريقة بتحديث الحقول المحددة بكفاءة في كائنات النموذج المتوفرة، بشكل عام باستخدام استعلام واحد فقط. أما بالنسبة للإصدارات الأقدم (تعمل الطريقة مع كل إصدارات جانغو Django) فيمكنك أن تقوم بعمل التالي: Entry.objects.filter(name='old name').update(name="new name") يعيد الكود السابق عدد الكائنات التي تم تحديثها في قاعدة البيانات كرقم صحيح Integer ملاحظة: إن كان لديك كود في التابع save فلن يتم تنفيذه، حيث أن التابع save لا يتم إستدعائه من البداية.1 نقطة
-
هناك عدة أسباب لحدوث هذا الأمر: هل يحتوي المكون Home على محتوى ليتم عرضه؟ أيضًا يجب التأكد من حفظ كل الملفات. هل تظهر لك أخطاء في ال console في المتصفح؟ الأمر الأخير هو أنه يجب تنفيذ الأمر npm run dev بعد كل تغير في ملفات js و css.1 نقطة
-
لاحظ أن الخطأ يظهر can't resolve react-router-dom أي أن هذه الحزمة غير موجودة، أعتقد أنك تستخدم بعض الحزم غير المثبتة في المشروع، يمكنك تثبيت كل من حزمة react-router-dom و react-icons من خلال الأمر التالي: npm install react-router-dom react-icons --save1 نقطة
-
ذلك لأن القيمة flex مثلها مثل block و inline و inline-block، تقوم بالتأثير على العناصر بشكل معين، فعلى سبيل المثال، الخاصية display: block تجعل العناصر تترتب أسفل بعضهم البعض، بينما الخاصية inline تجعل العناصر بجانب بعضهم البعض لكن لا يمكنك أن تحدد طول height للعناصر، بينما القيمة inline-block تجعل العناصر بجانب بعضهم البعض ويمكنك أن تحدد طول height ... إلخ. وكذلك القيمة flex تجعل العنصر ينكمش على محتوياته بشكل إفتراضي وتجعل المحتويات (العناصر الأبناء بجانب بعضهم البعض)، وبالطبع يمكن تغير هذا الأمر من خلال بعض خصائص flexbox مثل الخاصية flex أو الخاصية flex-direction. يمكنك معرفة المزيد عن خصائص Flexbox في CSS من خلال هذه المقالات:1 نقطة
-
سبب حدوث ذلك هو أن الصور تكون من نوع inline بشكل إفتراضي وبالتالي يتم حساب طولها من خلال ما يسمى بطول السطر line-height وهذه القيمة تختلف من متصفح لآخر، وبالتالي يمكن حل هذه المشكلة بطريقتين: يمكنك أن تحدد طول السطر line-height بقيمة 0 للعنصر .logo-container، كالتالي: .logo-container { line-height: 0; } كما يمكن حل المشكلة من خلال إضافة الخاصية display للصورة بقيمة block، كالتالي: img { display: block; } وذلك لأن في العناصر من نوع inline، تُستخدم خاصية line-height لحساب ارتفاع المحتوى نفسه. بينما في العناصر من نوع block، تُستخدم الخاصية line-height لتحديد الحد الأدنى لارتفاع المحتوى داخل العنصر. يمكنك أن تلقي نظرة على توثيق الخاصية line-height من خلال موسوعة حسوب لمعرفة المزيد عن هذه الخاصية.1 نقطة
-
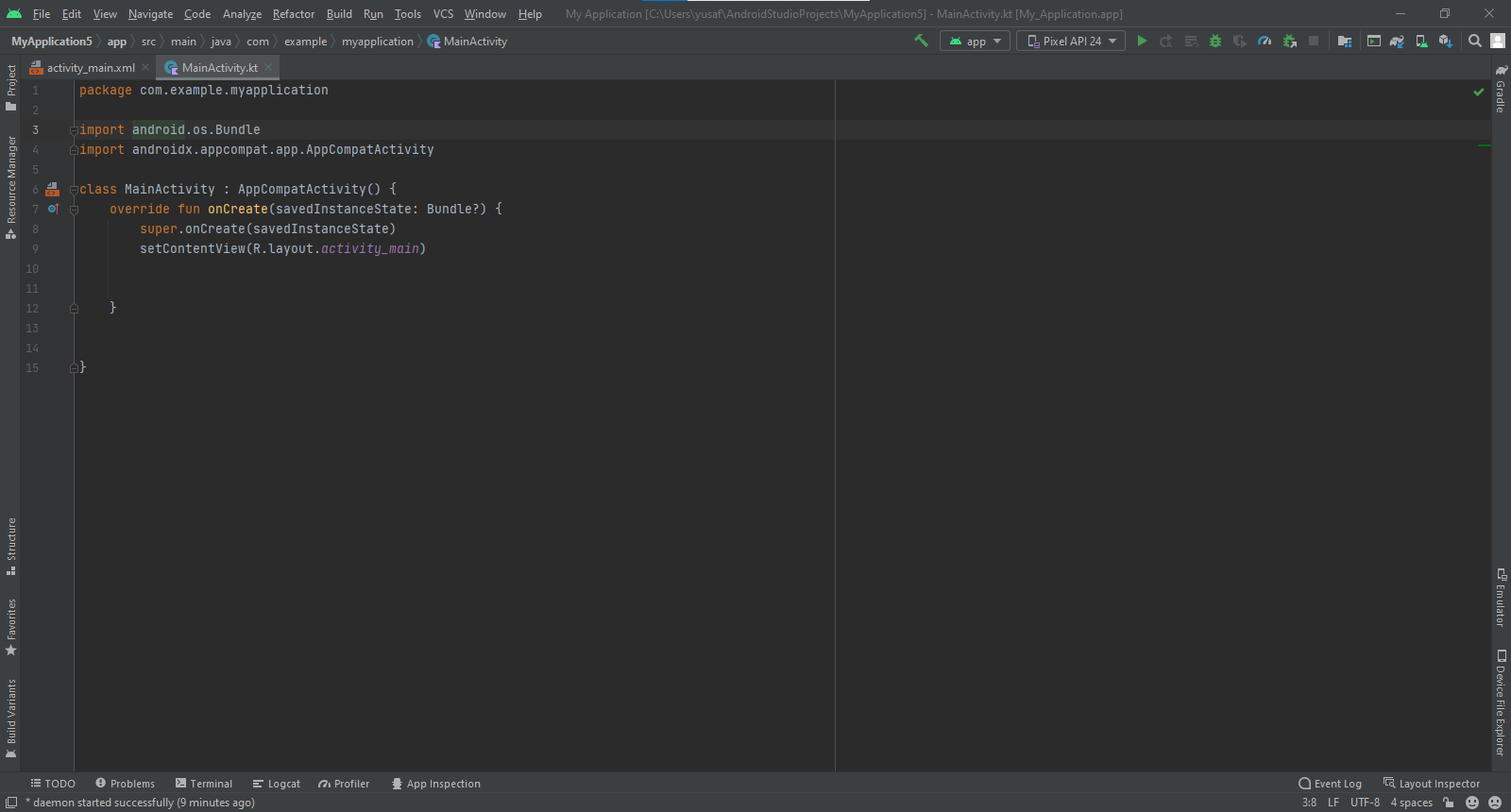
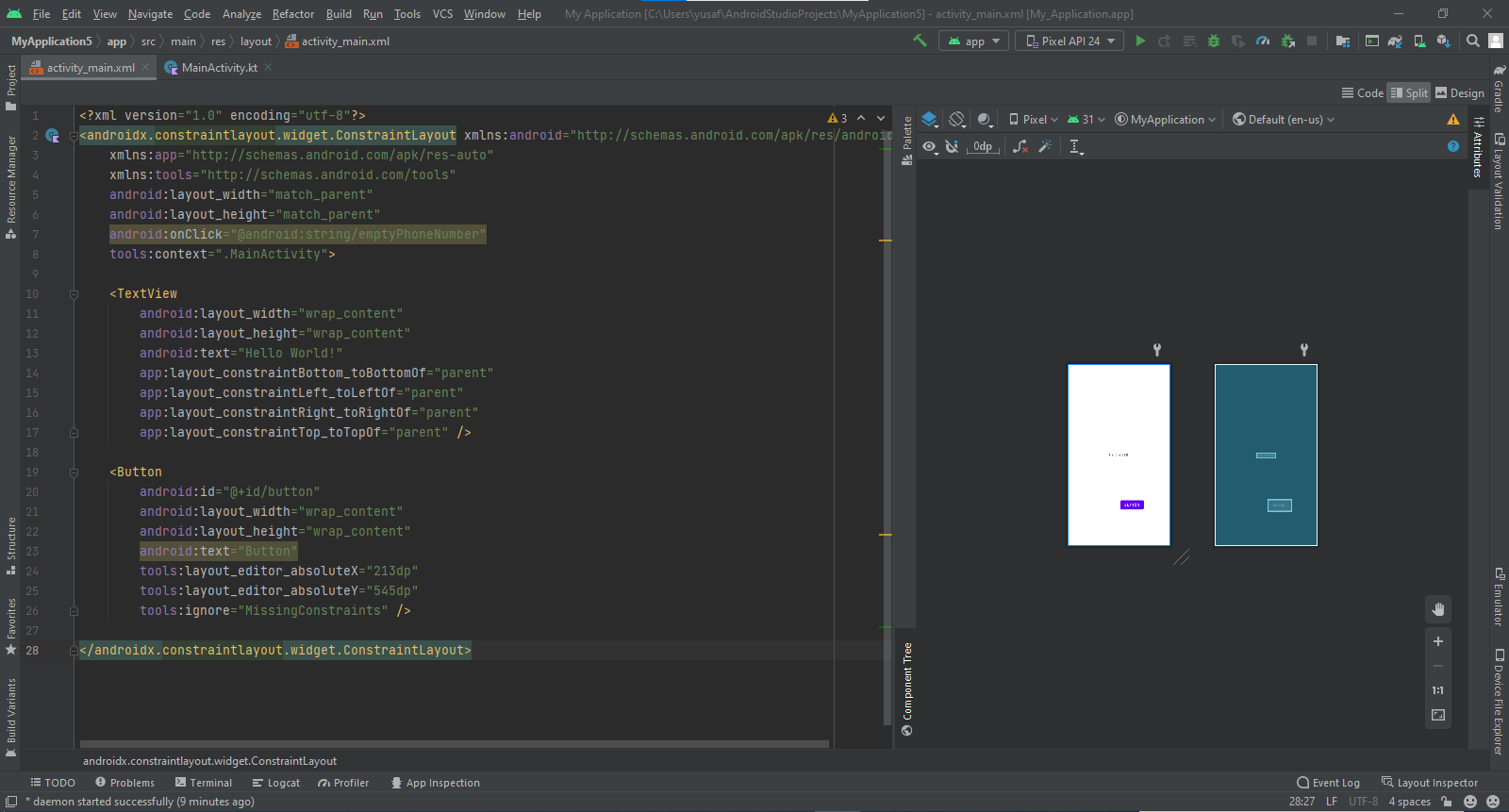
أرجو إرفاق المشروع مع لقطة شاشة للخطأ لديك، من الصعب معرفة السبب. val button = findViewById<Button>(R.id.play) button.setOnClickListener { _ -> //do what you want after click inside here } هذا مثال لاستعمال الزر مع الواجهة التالية (عليك جلب Reference للعنصر) من خلال استخدام محدد وصول الموارد R <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="wrap_content" android:layout_centerInParent="true" tools:context=".FragmentMain"> <LinearLayout android:id="@+id/container_frag" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="vertical" android:layout_marginLeft="50dp" android:layout_marginRight="50dp" > <Button android:id="@+id/play" android:layout_width="match_parent" android:layout_height="wrap_content" android:text="Play" /> <Button android:id="@+id/about" android:layout_width="match_parent" android:layout_height="wrap_content" android:text="About" /> </LinearLayout> وهذا مع استخدام الدالة findViewById أو يمكنك الوصول للعناصر مباشرة لكن عليك تضمين المكتبة التالية: import kotlinx.android.synthetic.main.activity_main.* يصبح الاستدعاء هكذا: override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) welcomeMessage.text = "Hello Kotlin!" } ونضيف في Gradle الخارجية: apply plugin: 'com.android.application' apply plugin: 'kotlin-android' apply plugin: 'kotlin-android-extensions' يمكنك البحث عن الموضوع التالي: Kotlin Android Extensions: Say goodbye to findViewById1 نقطة