لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 10/20/21 في كل الموقع
-
لدي استعلامين من جدولين بالشكل التالي: -- الجدول الأول Select col_1 col_2 -- الجدول الثاني Select col_1 col_3 -- إن قمت بعمل union col_1 col_2 -- ستكون النتيجة خطأ -- وأنا أريد col_1 col_2 col_3 -- عمود الدمج col_12 نقاط
-
كل حلقات الأنمي والأفلام والمسلسلات والمسرحيات .. إلخ لها حقوق ملكية وفكرية للأستوديوهات التي قامت بصنعها أو لقنوات التلفاز التي تقوم بعرضها، لذلك لن تجد API مجاني يوفر تحميل أو مشاهدة الحلقات بأي شكل من الأشكل وكل التطبيقات والمواقع التي تقوم بتوفير مشاهدة الحلقات أو تحميلها بشكل مجاني تقوم بسرقة هذه الحقوق وهذا الأمر مخالف للقانون بالطبع، لذلك لن تجد أيًا من هذه التطبيقات موجودة على متجر Play على سبيل المثال أو لن تجد إعلانات جوجل أدسنس على أحد هذه المواقع، وذلك لأن جوجل تقوم بمنع وحظر المحتوى المُقرصن pirated content. لكن يمكنك الحصول على API مجاني يعرض لك معلومات عن مسلسلات الأنمي والأفلام مثل Jikan أو MyAnimeList API ولكن لا يوفر أي من هذه المصادر مشاهدة الحلقات أو تحميلها بأي شكل من الأشكال، وذلك لأن هذا الأمر مخالف للقانون كما ذكرت سابقًا. ما يقوم به تطبيق مثل Anime Slayer هو تخزين روابط مشاهدة الحلقات عبر خوادم ok.ru أو 4shared أو غيرها وتكون هذه الروابط عبارة عن embedded URL بالطبع لكي يمكن لهذه الخوادم إضافة إعلانات عليها، وبعد ذلك يقوم التطبيق بمحاولة إستخراج روابط المشاهدة المباشرة من هذه الصفحات وتوفيرها للمستخدم وهذا يعرف بمجال سحب البيانات Web Scraping، بالتأكيد سيكون هناك الكثير من الروابط التي لا تعمل لأن هذه الخوادم تقوم بحذفهال بإستمرار وفقًا لسياستها التي تمنع المحتوى المقرصن أيضًا.2 نقاط
-
.png.9227ffba6d1b4c43cb84450d5abda59c.png) الذكاء الصنعي وخوارزميات تعلم الآلة AI/ML تتفق جميع التقنيات والخوارزميات التي تندرج تحت مسمى الذكاء الصنعي Artificial Intelligence وتعلم الآلة Machine Learning باختلاف أطيافها على البدء بتحليل البيانات الخام والبحث فيها (بطرق خوارزمية ممنهجة) لاستكشاف ما تحتويه من أنماط وعلاقات في داخلها وبين كياناتها. إن معرفة مثل تلك الأنماط والعلاقات ستساعدنا على بناء نماذج قادرة على استقراء الجوهر العام المشترك الذي يجمع ويصنف تلك الكتل من البيانات على الرغم من الاختلافات في التفاصيل الهامشية والتي قد تكون كبيرة ظاهريا ومربكة في عين من لا يتمتع بالخبرة في مجال الدراسة. لقد أثبتت مثل هذه النظم فعاليتها في حوسبة العديد من المهام التي كان يعتقد حتى وقت قريب أنها عصية على عالم البرمجيات، ساعد على ذلك الطفرة التي شهدتها عتاديات الحواسيب في العقد الأخير والتقدم الهائل في إمكانيات الحوسبة المتوازية لوحدات المعالجة الرسومية GPU، وكذلك توافر حلول الحوسبة السحابية لشريحة أكبر من فرق التطوير البرمجية التي كان يصعب عليها في الماضي الحصول على حواسيب فائقة بسهولة. إننا نشهد في الفترة الحالية انتقالا وتحولا جذريا في مفاهيم علم البرمجة مقارنة بما سبق وبما تعلمناه أو استخدمناه خلال القرن الماضي (كالبرمجة الوظيفية ومخططات سير العمل، أو حتى البرمجة الغرضية التوجه بكائناتها وطرائقها)، فالمبرمج هو من كان يضع منطق العمل وخوارزميته ليحدد أسلوب معالجة المدخلات وتوليد المخرجات، وقد امتازت فترة ثمانينيات وتسعينيات القرن الماضي بوفرة القدرة الحاسوبية مقارنة بكمية البيانات المتوافرة للمعالجة أصلا، لكن ما نشهده الآن في القرن الحادي والعشرين قد قلب هذه المعادلة رأسا على عقب، فقد أصبح لدينا فائض كبير من البيانات التي تجمع من كل حدب وصوب على مدار الساعة بدءا من جوالاتنا (التي ما عادت وسيلة للاتصال فقط) وصولا إلى الأقمار الاصطناعية في مداراتها حول الأرض. إن هذا المستوى العالي من الأتمتة في حياتنا ومجتمعاتنا نتج عنه كم هائل من البيانات التي تجاوزت بمراحل القدرة على تحليلها واستخلاص المعلومات منها بالطرق التقليدية، وهو ما أعاد فتح الأبواب مجددا لتقنيات الذكاء الصنعي التي كان لها مجد سابق منتصف القرن الماضي لكنه زال بعد أن عجزت القدرات العتادية في ذلك الحين عن مواكبة شطحات المتنورين من رواد هذا الحقل من العلوم، لكننا اليوم وبتضافر جهود الباحثين في مجالات شتى مثل علم البيانات والإحصاء والحواسيب بلا شك، أصبحنا قادرين على تنفيذ ما كانوا يتحدثون عنه ضمن طيف واسع من التطبيقات ربما بات يتجاوز أقصى طموحاتهم. الشبكات العصبية Neural Networks في جزء من لوحة رافائييل الجصيّة "مدرسة أثينا" تم رسم أفلاطون وأرسطو بشكل يعبّر عن نظريّة كل منهما في المعرفة، فأرسطو يومئ نحو الأرض فيما يشير أفلاطون بإصبعه نحو السماء، حيث كان ينظر أرسطو إلى الطبيعة بحثا عن إجابات في حين أن أفلاطون يبحث عن المثالي. وها نحن ننتقل في عالم البرمجة من فلسفة أفلاطون التي كنا نتّبعها في أدوات بناء تطبيقاتنا من لغات برمجة وما تحويه من متغيرات وتوابع وعبارات شرطية وحلقات وسواها، إلى فلسفة أرسطو حيث نبحث في كيفية عمل أدمغتنا ونحاول محاكاتها في بنيتها وطريقة عملها، وهكذا تماما ولد مجال الشبكات العصبية ضمن علوم الذكاء الصنعي. حيث ابتدأت المحاكاة على مستوى الخلية العصبية (العصبون)، فالعصبونات هي خلايا تتألف من جسم مركزي يتضمن نواة الخلية ويمتد منه استطالة وحيدة تكوّن ليف عصبي طويل يقوم مقام السلك الناقل للإشارة الخارجة من الخلية عند نهايته تفرعات كثيرة تنتهي بعقد مشبكية صغيرة، أما في الطرف الآخر من جسم الخلية العصبية فتبرز تفرّعات تخرج في كافة الاتجاهات والتي عن طريقها ترد إلى جسم الخلية البيانات الداخلة، ولابد للإشارات لكي تمر من عصبون إلى آخر أن تجتاز الفجوة الضيقة ما بين عقدة المشبك والجسم أو التفرّع للعصبون التالي. تتلقى الخلية العصبية عدة تنبيهات من الخلايا المجاورة تؤدي إلى شحنها، فإذا وصلت تلك الشحنة إلى عتبة معينة ينبثق كمون كهربائي عند قاعدة المحور وينتشر دفعة واحدة على طوله. لا تستجيب العصبونات لمختلف التنبيهات بشكل متشابه، فلكل منبه درجة أهمية تزيد أو تنقص، كما أن خرج العصبون لا يمتاز بالتدرج، فإما أن تكون هناك نبضة عصبية تنتشر عبر المحور إلى الخلايا المجاورة أو لن يكون هنالك شيء على الإطلاق. طبعا هذا الوصف لبنية العصبون وطريقة عمله فيه تبسيط شديد لحقيقة الأمر، لكن هذا المستوى من الشرح يفي بالغرض. على الرغم من أننا عندما نحاكي عمل العصبون (بفرض أننا نعلم طريقة عمله تماما) لن نحصل على عصبون حقيقي، لكننا سنحصل على معالجة حقيقية للمعلومات كما لو كان العصبون هو من قام بها، وهذا هو بيت القصيد. إن التمثيل الرياضي للعصبون يفترض أن لدينا n إشارة دخل سنرمز إليها بالمقادير X1, X2, …, Xn يرتبط كل منها بوزن أو تثقيل للتعبير عن دور المشابك العصبية كون العصبونات لا تستجيب بشكل متشابه لمختلف التنبيهات كما اتفقنا سابقا. سنرمز إلى تلك الأوزان بالمقادير W1, W2, …, Wn والتي قد تكون قيما موجبة أو حتى سالبة تكبر أو تصغر بحسب طبيعة ودور إشارة الدخل المرتبطة بها سواء كانت محفّزة أم مثبّطة وإلى أي قدر هي كذلك. وهكذا يمكننا التعبير عن مجمل الدخل الآتي إلى العصبون المفرد بالشكل الرياضي التالي: من جهة أخرى، لتمثيل إشارة خرج العصبون نحتاج إلى دالة رياضية تستطيع توصيف عمل قانون الكل أو لا شيء تبعا لعتبة معيّنة، وهناك عدّة خيارات رياضية شائعة قد يتم تفضيل إحداها على الأخرى بحسب طبيعة البيانات التي نتعامل معها نذكر منها على سبيل المثال لا الحصر: Sigmoid (للقيم الثنائية 0/1 أو نعم/لا أو حتى ذكر/أنثى)، TanH (للفئات أو التصنيفات المتقطعة مثل الأعراق: عربي، أوروبي، أفريقي، آسيوي، هندي، الخ.)، وكذلك ReLU (للقيم المتصلة كالعمر مثلا). يوضح الشكل التالي الصيغة الرياضية والتمثيل البياني الذي يظهر العلاقة فيما بين الدخل والخرج لكل منها: بعد أن قمنا بتوصيف العصبون بشكل رياضي مبسّط، علينا الانتقال للحديث عن بنية الشبكات التي تنتظم بها تلك العصبونات وطرق ارتباطها بعضها ببعض، سنتناول بالشرح شكلا واحدا من أشكال بناء الشبكات العصبية، لكن ذلك لا يعني عدم وجود معماريات أخرى لبناء تلك الشبكات. سنفترض أن العصبونات تنتظم في طبقات ولكل طبقة عدد من العصبونات بحيث أن خرج أي عصبون من هذه الطبقة يتم إيصاله إلى كل عصبونات الطبقة التالية. يمكن تمييز الطبقة الأولى على أنـها طبقة الإدخال والتي تتلقى بياناتها من الوسط الخارجي للشبكة العصبية، كذلك نعرّف طبقة الإخراج على أنـها الطبقة الأخيرة والتي ترسل ناتج معالجة البيانات ثانية إلى الوسط الخارجي، في حين يسمّى كل ما عدى ذلك من طبقات بين هاتين الطبقتين بالطبقات الخفية. كما نلاحظ فإن عدد العصبونات في كل من طبقتي الإدخال والإخراج محدد بحسب طبيعة الوظيفة المناطة بالشبكة العصبية (مثلا عدد العنصورات Pixels الإجمالي في الصورة لكل قناة لونية RGB في الدخل، وعدد الفئات المراد تصنيفها في الخرج)، أمّا عدد الطبقات الخفية وعدد العصبونات في كل منها فلا توجد قواعد ضابطة وواضحة لذلك. مكتبة TensorFlow من Google مكتبة TensorFlow هي منصة متكاملة لتدريب وبناء تطبيقات الذكاء الصنعي وتعلم الآلة بالاعتماد على تقنية الشبكات العصبية طورتها شركة Google باستخدام لغة Python ونشرتها تحت ترخيص البرمجيات الحرة والمفتوحة المصدر، وهي تعد في الوقت الراهن واحدة من أكثر المكتبات شهرة واستخداما في هذا المجال (رغم أنها ليست الوحيدة قطعا)، وذلك نظرا لغزارة وتنوع المصادر والأدوات المتوافرة لها والتي تتيح للباحثين القدرة على بناء واستخدام تطبيقات الذكاء الصنعي في أعمالهم. للمزيد حول TensorFlow يمكنكم الإطلاع على الموقع الرسمي لها على الرابط التالي: https://www.tensorflow.org دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن مكنز TensorFlow Hub للنماذج إحدى أهم التحديات في عالم الذكاء الصنعي بشكل خاص، وعلوم البيانات بشكل عام، هي القدرة على إعادة استخدام ما سبق وما توصل إليه فريق تطوير آخر سابقًا، لذا قدمت Google هذا المكنز لوضع طريقة معيارية في مشاركة نماذج الشبكات العصبية بحيث تتضمن كافة المعلومات المطلوبة لإعادة استخدامها سواء كانت بنية الشبكة العصبية ذاتها (من حيث عدد الطبقات، ونوعها، وعدد العصبونات في كل منها، ونوع الروابط فيما بينها، الخ.)، إضافة إلى قيم الوسطاء والأوزان المختلفة في تلك الشبكة العصبية بعد إتمام عملية تدريبها. يمكن أخذ هذه النماذج وإعادة استخدامها في مهام مختلفة أو حتى إعادة تدريبها بسهولة مستخدمين تقنية تدعى نقل التعلم والتي سنتحدث عنها لاحقا في هذا الدرس. لمزيد من المعلومات حول هذا المكنز يمكنكم زيارة الموقع الرسمي له على الرابط التالي: https://www.tensorflow.org/hub. نموذج MobileNet V2 للرؤية الحاسوبية تم تصميم هذه العائلة من نماذج الشبكات العصبية المخصصة لمهام الرؤية الحاسوبية عامة الأغراض مثل التصنيف وتحديد الأجزاء والعناصر في الصورة وسواها من الوظائف مع مراعاة المصادر المحدودة التي قد تكون متوافرة على الأجهزة المحمولة. إن القدرة على تشغيل تطبيقات التعلم العميق على أجهزة الجوال الشخصية ستحسن من تجربة المستخدم نظرا لأنها ستكون متاحة في أي زمان ومكان بغض النظر عن الحاجة إلى الاتصال بمصادر خارجية على الإنترنت، وهو ما سيترافق مع فوائد إضافية لجهة الأمان والخصوصية والاقتصاد في استهلاك الطاقة. لمزيد من المعلومات يمكنك الإطلاع على الرابط المدرج ضمن قسم المراجع1. تقنية نقل التعلم Transfer Learning إن النماذج الحديثة للتعرف على الصور تحتوي على الملايين من الوسطاء (من أوزان للروابط ما بين الآلاف من العصبونات المرصوفة في العشرات من الطبقات الخفية) والتي يتطلب تدريبها من الصفر كما كبيرا من بيانات التدريب من جهة، والكثير من الطاقة الحاسوبية من جهة أخرى (تقدّر بالمئات من ساعات الحساب على وحدات المعالجة الرسومية GPU أو حتى أكثر بكثير). إن تقنية نقل التعلم تعتمد على حيلة ذكية لاختصار كم المصادر الكبير الذي نحتاجه لتطوير نموذج رؤية حاسوبية جديد تخصص مهاراته في التعرف على نمط مختلف من الصور (مثلا صور الأشعة السينية لتشخيص وجود أورام سرطانية محتملة عوض التعرف على الأنواع المختلفة من الأزهار البرية). تقوم الفكرة على استبدال الطبقة الأخيرة فقط من شبكة عصبية سبق وأن تم تدريبها بشكل جيد على تصنيف الصور ولو لغايات مختلفة، مستفيدين بذلك من كم المهارات التي اكتسبتها بنية الطبقات الخفية في ذلك النموذج، ابتداء من التعرف على أنماط النسج والأشكال وترابط الأجزاء وعلاقات الألوان وغيرها مما هو مشترك بالعموم بين كافة نظم الرؤية الحاسوبية، والتي يمكن إعادة استخدامها ومشاركتها بين النماذج المختلفة. وحدها الطبقة الأخيرة فقط الخاصة بالأصناف تتغير بتغير الغاية والهدف من النموذج الذي يجري تطويره وتخصيصه، لذا هي وحدها التي سيتم تدريبها فعليا عند استخدام تقنية نقل التعلم هذه. لمزيد من المعلومات حول هذه التقنية في التعليم يمكنكم الإطلاع على رابط ورقة البحث العلمي المدرجة ضمن قسم المراجع أدناه2. تجهيز بيئة العمل سنستخدم منصة Docker المخصصة لتطوير ونشر وإدارة التطبيقات باستخدام فكرة الحاويات وذلك لتسهيل بناء بيئة العمل لدينا من أجل تنفيذ التطبيق العملي في هذه الجلسة، حيث أن الحاويات هي عبارة عن حزم تنفيذية خفيفة وقائمة بذاتها لتطبيق ما، تحوي كل المكتبات وملفات الإمداد والاعتماديات والأجزاء الأخرى الضرورية ليعمل التطبيق ضمن بيئة معزولة، هذا عدى عن أنها خفيفة لأنها لا تتطلب حملا إضافيا كالأجهزة الافتراضية كونها تعمل ضمن نواة النظام المضيف مباشرة دون الحاجة إلى نظام ضيف، وبذلك نزيل عن كاهلنا في هذه المرحلة أي تعقيدات تختص بالتنصيب والربط والإعداد لمختلف مكونات بيئة التطوير الخاصة بمكتبة TensorFlow وهي مهمة ليست باليسيرة على المبتدئ، لذا عليك القيام بتثبيت Docker على حاسوبك الشخصي من الموقع الرسمي https://www.docker.com/ قبل الانتقال إلى الخطوة التالية. اطلع على مقال «التعامل مع حاويات Docker» في قسم دوكر في أكاديمية حسوب. تطبيق عملي يقوم بتحديد جنس الشخص من صورة وجهه بداية نقوم بتنصيب TensorFlow على Docker ضمن حاوية تحت تسمية hsoub-ft، قد تتطلب هذه الخطوة بعض الوقت نظرا لكون حجم صورة الحاوية التي سيتم سحبها وتنزيلها عبر الإنترنت يتجاوز 1GB: docker pull tensorflow/tensorflow docker run --name hsoub-tf -it -d tensorflow/tensorflow:latest بعد ذلك نقوم بالدخول إلى سطر الأوامر ضمن الحاوية ونقوم بتنصيب الإصدار 2.0 على الأقل من مكتبة TensorFlow وكذلك الإصدار 0.6 على الأقل من نموذج تصنيف الصور3 الذي سنستخدمه والمستضاف في مكنز TensorFlow Hub، و بعد إتمام هذه الخطوات نخرج باستخدام الأمر exit في سطر الأوامر للعودة إلى الجهاز المضيف: docker exec -it hsoub-tf bash pip install "tensorflow~=2.0" pip install "tensorflow-hub[make_image_classifier]~=0.6" exit الخطوة التالية هي تحضير بيانات التدريب وذلك من خلال الحصول على الصور التي سيتم تدريب الشبكة عليها، في مثالنا هذا استخدمنا مجموعة جزئية تتكون من حوالي 2000 صورة مقسمة إلى فئتين ذكور وإناث وهي مقتطعة من مجموعة بيانات أكبر تدعى UTKFace4 المتاحة للاستخدامات غير التجارية والتي تتضمن بالأساس ما يزيد عن 20 ألف صورة وجه. تم اختيار الصور التي سوف نستخدمها في عملية التدريب بحيث تكون متوازنة من حيث الجنس (أي أن عدد الصور الخاصة بالذكور يساوي تقريبا عددها للإناث) والعرقيات (أي تقارب عدد الأشخاص من ذوي الأصول الأوروبية والأفريقية والهندية الخ.) وذلك لضمان عدم التحيز، إضافة إلى أن الصور تخص أشخاصا تتراوح أعمارهم ما بين 20 إلى 40 سنة. للمتابعة عليك تحميل الملف المضغوط المرفق مع هذا المحتوى، ثم قم بفك ضغطه على حاسوبك وستحصل على مجلد باسم training داخله ثلاث مجلدات هي images و output وكذلك test. ستلاحظ ضمن مجلد images أن هنالك مجلد فرعي لك تصنيف تريد من شبكتك العصبية أن تتعرف عليه (في حالتنا هذه هناك مجلدان فقط بتسمية Male و Female) داخل كل منهما مجموعة الصور التي تنتمي إلى ذلك التصنيف. من جهة أخرى فإن مجلد output هو فارغ حاليا لكنه المكان الذي سيتم فيه حفظ الشبكة العصبية بعد إتمام عملية تدريبها (أي حيث سنخزن النموذج الناتج)، أخيرا ستجد في المجلد الثالث test شيفرة برمجية بسيطة لاختبار النموذج الناتج وبعض الصور التي لم يسبق له أن رآها من قبل (أي أنها لم تكن موجودة أصلا ضمن صور وبيانات التدريب). نحن بحاجة إلى نقل كل هذه المجلدات وما فيها من ملفات إلى داخل الحاوية hsoub-tf وذلك باستخدام الأمر التالي على الجهاز المضيف: docker cp .\training hsoub-tf:/training الآن نستطيع الانتقال مجددا إلى سطر الأوامر ضمن الحاوية باستخدام الأمر التالي: docker exec -it hsoub-tf bash وبعد ذلك يمكننا بدء عملية التدريب باستخدام الأمر التالي: make_image_classifier \ --image_dir training/images dir \ --tfhub_module https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4 \ --image_size 224 \ --saved_model_dir training/output/model \ --labels_output_file training/output/class_labels.txt \ --tflite_output_file training/output/mobile_model.tflite إن وسطاء الأمر التنفيذي السابق تحدد المسار الذي يحتوي على مجلدات الصور التي سيتم استخدامها في عملية التدريب (أي مسار المجلد ضمن الحاوية وليس على الجهاز المضيف)، وكذلك مصدر النموذج الأصلي الذي ستطبق عليه تقنية نقل التعلم باستبدال طبقته الأخيرة، بعد ذلك نحدد الأبعاد المطلوبة للصور ليتم تحجيمها تلقائيا لتلائم هذه الأبعاد (فهذا محدد ومرتبط بطبقة الإدخال في نموذج الشبكة العصبية المستخدمة)، في حالتنا نحن نستخدم نموذج MobileNet V2 والذي يفترض أبعاد الصورة هي 224 عنصورة/بيكسل للطول والعرض، بعد ذلك نحدد المكان الذي سيتم فيه حفظ النموذج المدرّب الناتج، وكذلك أين سيتم حفظ التسميات المرافقة لعصبونات الخرج من شبكتنا العصبية بالترتيب، وأخيرا أين سيتم تصدير هذا النموذج بصيغة tflite المحزومة والموضبة لتطبيقات الجوال. في نهاية عملية التدريب (والتي قد تطول تبعا لعدد الصور من جهة، ولسرعة الحاسوب الذي تتم عليه عملية التدريب من جهة أخرى)، سنجد أننا حصلنا على نموذج شبكة عصبية يستطيع تمييز جنس الشخص من صورته بدقة تتعدى 80% وذلك بمجهود بسيط جدا دون الحاجة إلى عمليات ضبط ومعايرة فائقة التخصص لوسطاء بناء وتدريب الشبكة العصبية، ودون الحاجة كذلك إلى ساعات وساعات من التدريب ولا إلى آلاف وآلاف من الصورة للتدرب عليها! إنها بحق نتيجة مرضية لأوائل مغامراتك مع الشبكات العصبية، لكنها مجرد البداية. ها قد حان الوقت لتجربة النموذج الذي قمنا بتدريبه على صور لم يسبق له أن رآها من قبل، للقيام بذلك سوف نستخدم برنامج معد مسبقا لهذه الغاية5 وهو مكتوب بلغة Python وموجود داخل المجلد training/test صحبة بضعة صور كأمثلة للتجريب (ويمكن أن تستخدم صورك الخاصة في هذه المرحلة)، حيث ستتم عملية الاختبار لكل صورة من خلال الأمر التالي (وفيه نشير إلى مسار الشبكة العصبية التي سيتم تحميلها واستخدامها، والملف النصي الذي يتضمن اسم التصنيف الخاص بكل عصبون خرج ضمن هذه الشبكة بالترتيب، وأخيرا مسار الصورة المراد تصنيفها): python training/test/label_image.py \ --input_mean 0 --input_std 255 \ --model_file training/output/mobile_model.tflite \ --label_file training/output/class_labels.txt \ --image training/test/Ahmed_Zewail.jpg بعد إتمام تدريبنا واختبارنا للشبكة العصبية حان الوقت للخروج من بيئة التدريب هذه باستخدام الأمر exit للعودة إلى سطر الأوامر على الجهاز المضيف، ومن ثم سنرغب طبعا باستخراج النموذج الذي قمنا بتعليمه خلال هذه الجلسة من داخل حاوية Docker وهو ما نستطيع القيام به باستخدام الأمر التالي: docker cp hsoub-tf:/training/output .\training نقاط تستحق التأمل قد يرى البعض في تقنيات الذكاء الصنعي حلا لجميع المشكلات، لكنها في حقيقة الأمر لا تأتي خالية من المخاطر التي قد ترقى إلى حد اعتبارها نقاط ضعف أو عيوب يجب أن تؤخذ بعين الاعتبار، نذكر منها: باعتبار أن النماذج في الشبكات العصبية تبنى انطلاقا من بيانات التدريب، لذا فإنها غير قادرة على حل أي مشاكل كانت موجودة أصلا في تلك البيانات كالأخطاء أو الانحياز أو عدم التكامل والشمول لمختلف الحالات المراد التعامل معها. يصعب في الشبكات العصبية تفسير المنطق الذي استخدمه النموذج لإعطاء إجابته، فالتعامل معه أقرب ما يكون للصندوق الأسود الذي لا نعلم كمستخدمين آلية عمله الدقيقة في الداخل، بل نؤمن بأن ما نحصل عليه من إجابات هو أفضل المتاح، ولهذه الفكرة تداعياتها الفلسفية والاجتماعية التي تصعّب من استخدام هكذا أدوات في الحالات التي تتطلب تقديم تبرير (مثلا عند تطبيق عقوبة أو حرمان من مكافأة). تطوير نماذج الشبكات العصبية يتطلب قدرا كبيرا من بيانات التدريب المشروحة والمجهزة بشكل جيد وملائم، وهو ما قد يعني الكثير من الجهد لتوفير مثل هكذا مصادر للتدريب. عملية تدريب الشبكات العصبية هي عملية متطلّبة من ناحية قدرات المعالجة الحسابية المتوفّرة للعتاد المستخدم، وذلك على عكس عملية استخدامها في التطبيقات عقب إتمام التدريب، لذا قد يجد المطور في الحوسبة السحابية فرصا متاحة بميزانيات في المتناول. إن بناء النماذج باستخدام خوارزميات تعلم الآلة يتطلب مطورين أذكياء وموهوبين، فعلى الرغم من أن تطبيق المثال الذي قمنا بعرضه يبدو سهلا ويسيرا، إلا أن نظرة أكثر تعمقا ستكشف لك الكثير من التفاصيل التي بحاجة إلى معايرة وضبط، منها على سبيل المثال لا الحصر: معمارية الشبكة، وطريقة توصيف تابع تفعيل العصبونات فيها، وعدد طبقاتها الخفية، وعدد العصبونات في كل منها، وطريقة ربطها بعضها ببعض، وكيفية حساب الخطأ ما بين النتيجة المحسوبة والمطلوبة، ومعدل سرعة التعلم، وعدد مرات تكرار عرض الأمثلة على الشبكة العصبية أثناء التدريب، وغيرها الكثير. إن انتقاء التوليفة الأكثر ملائمة لجملة معايير الضبط هذه يؤثر بشكل حاسم على جودة ودقة النموذج الناتج. مراجع أجنبية للاستزادة MobileNetV2: The Next Generation of On-Device Computer Vision Networks DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition Making your own TensorFlow model for image classification UTKFace: Large Scale Face Dataset TensorFlow Lite Python image classification demo اقرأ أيضًا تعلم الذكاء الاصطناعي الذكاء الاصطناعي: دليلك الشامل المقال التالي: إعداد شبكة عصبية صنعية وتدريبها للتعرف على الوجوه الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها1 نقطة
الذكاء الصنعي وخوارزميات تعلم الآلة AI/ML تتفق جميع التقنيات والخوارزميات التي تندرج تحت مسمى الذكاء الصنعي Artificial Intelligence وتعلم الآلة Machine Learning باختلاف أطيافها على البدء بتحليل البيانات الخام والبحث فيها (بطرق خوارزمية ممنهجة) لاستكشاف ما تحتويه من أنماط وعلاقات في داخلها وبين كياناتها. إن معرفة مثل تلك الأنماط والعلاقات ستساعدنا على بناء نماذج قادرة على استقراء الجوهر العام المشترك الذي يجمع ويصنف تلك الكتل من البيانات على الرغم من الاختلافات في التفاصيل الهامشية والتي قد تكون كبيرة ظاهريا ومربكة في عين من لا يتمتع بالخبرة في مجال الدراسة. لقد أثبتت مثل هذه النظم فعاليتها في حوسبة العديد من المهام التي كان يعتقد حتى وقت قريب أنها عصية على عالم البرمجيات، ساعد على ذلك الطفرة التي شهدتها عتاديات الحواسيب في العقد الأخير والتقدم الهائل في إمكانيات الحوسبة المتوازية لوحدات المعالجة الرسومية GPU، وكذلك توافر حلول الحوسبة السحابية لشريحة أكبر من فرق التطوير البرمجية التي كان يصعب عليها في الماضي الحصول على حواسيب فائقة بسهولة. إننا نشهد في الفترة الحالية انتقالا وتحولا جذريا في مفاهيم علم البرمجة مقارنة بما سبق وبما تعلمناه أو استخدمناه خلال القرن الماضي (كالبرمجة الوظيفية ومخططات سير العمل، أو حتى البرمجة الغرضية التوجه بكائناتها وطرائقها)، فالمبرمج هو من كان يضع منطق العمل وخوارزميته ليحدد أسلوب معالجة المدخلات وتوليد المخرجات، وقد امتازت فترة ثمانينيات وتسعينيات القرن الماضي بوفرة القدرة الحاسوبية مقارنة بكمية البيانات المتوافرة للمعالجة أصلا، لكن ما نشهده الآن في القرن الحادي والعشرين قد قلب هذه المعادلة رأسا على عقب، فقد أصبح لدينا فائض كبير من البيانات التي تجمع من كل حدب وصوب على مدار الساعة بدءا من جوالاتنا (التي ما عادت وسيلة للاتصال فقط) وصولا إلى الأقمار الاصطناعية في مداراتها حول الأرض. إن هذا المستوى العالي من الأتمتة في حياتنا ومجتمعاتنا نتج عنه كم هائل من البيانات التي تجاوزت بمراحل القدرة على تحليلها واستخلاص المعلومات منها بالطرق التقليدية، وهو ما أعاد فتح الأبواب مجددا لتقنيات الذكاء الصنعي التي كان لها مجد سابق منتصف القرن الماضي لكنه زال بعد أن عجزت القدرات العتادية في ذلك الحين عن مواكبة شطحات المتنورين من رواد هذا الحقل من العلوم، لكننا اليوم وبتضافر جهود الباحثين في مجالات شتى مثل علم البيانات والإحصاء والحواسيب بلا شك، أصبحنا قادرين على تنفيذ ما كانوا يتحدثون عنه ضمن طيف واسع من التطبيقات ربما بات يتجاوز أقصى طموحاتهم. الشبكات العصبية Neural Networks في جزء من لوحة رافائييل الجصيّة "مدرسة أثينا" تم رسم أفلاطون وأرسطو بشكل يعبّر عن نظريّة كل منهما في المعرفة، فأرسطو يومئ نحو الأرض فيما يشير أفلاطون بإصبعه نحو السماء، حيث كان ينظر أرسطو إلى الطبيعة بحثا عن إجابات في حين أن أفلاطون يبحث عن المثالي. وها نحن ننتقل في عالم البرمجة من فلسفة أفلاطون التي كنا نتّبعها في أدوات بناء تطبيقاتنا من لغات برمجة وما تحويه من متغيرات وتوابع وعبارات شرطية وحلقات وسواها، إلى فلسفة أرسطو حيث نبحث في كيفية عمل أدمغتنا ونحاول محاكاتها في بنيتها وطريقة عملها، وهكذا تماما ولد مجال الشبكات العصبية ضمن علوم الذكاء الصنعي. حيث ابتدأت المحاكاة على مستوى الخلية العصبية (العصبون)، فالعصبونات هي خلايا تتألف من جسم مركزي يتضمن نواة الخلية ويمتد منه استطالة وحيدة تكوّن ليف عصبي طويل يقوم مقام السلك الناقل للإشارة الخارجة من الخلية عند نهايته تفرعات كثيرة تنتهي بعقد مشبكية صغيرة، أما في الطرف الآخر من جسم الخلية العصبية فتبرز تفرّعات تخرج في كافة الاتجاهات والتي عن طريقها ترد إلى جسم الخلية البيانات الداخلة، ولابد للإشارات لكي تمر من عصبون إلى آخر أن تجتاز الفجوة الضيقة ما بين عقدة المشبك والجسم أو التفرّع للعصبون التالي. تتلقى الخلية العصبية عدة تنبيهات من الخلايا المجاورة تؤدي إلى شحنها، فإذا وصلت تلك الشحنة إلى عتبة معينة ينبثق كمون كهربائي عند قاعدة المحور وينتشر دفعة واحدة على طوله. لا تستجيب العصبونات لمختلف التنبيهات بشكل متشابه، فلكل منبه درجة أهمية تزيد أو تنقص، كما أن خرج العصبون لا يمتاز بالتدرج، فإما أن تكون هناك نبضة عصبية تنتشر عبر المحور إلى الخلايا المجاورة أو لن يكون هنالك شيء على الإطلاق. طبعا هذا الوصف لبنية العصبون وطريقة عمله فيه تبسيط شديد لحقيقة الأمر، لكن هذا المستوى من الشرح يفي بالغرض. على الرغم من أننا عندما نحاكي عمل العصبون (بفرض أننا نعلم طريقة عمله تماما) لن نحصل على عصبون حقيقي، لكننا سنحصل على معالجة حقيقية للمعلومات كما لو كان العصبون هو من قام بها، وهذا هو بيت القصيد. إن التمثيل الرياضي للعصبون يفترض أن لدينا n إشارة دخل سنرمز إليها بالمقادير X1, X2, …, Xn يرتبط كل منها بوزن أو تثقيل للتعبير عن دور المشابك العصبية كون العصبونات لا تستجيب بشكل متشابه لمختلف التنبيهات كما اتفقنا سابقا. سنرمز إلى تلك الأوزان بالمقادير W1, W2, …, Wn والتي قد تكون قيما موجبة أو حتى سالبة تكبر أو تصغر بحسب طبيعة ودور إشارة الدخل المرتبطة بها سواء كانت محفّزة أم مثبّطة وإلى أي قدر هي كذلك. وهكذا يمكننا التعبير عن مجمل الدخل الآتي إلى العصبون المفرد بالشكل الرياضي التالي: من جهة أخرى، لتمثيل إشارة خرج العصبون نحتاج إلى دالة رياضية تستطيع توصيف عمل قانون الكل أو لا شيء تبعا لعتبة معيّنة، وهناك عدّة خيارات رياضية شائعة قد يتم تفضيل إحداها على الأخرى بحسب طبيعة البيانات التي نتعامل معها نذكر منها على سبيل المثال لا الحصر: Sigmoid (للقيم الثنائية 0/1 أو نعم/لا أو حتى ذكر/أنثى)، TanH (للفئات أو التصنيفات المتقطعة مثل الأعراق: عربي، أوروبي، أفريقي، آسيوي، هندي، الخ.)، وكذلك ReLU (للقيم المتصلة كالعمر مثلا). يوضح الشكل التالي الصيغة الرياضية والتمثيل البياني الذي يظهر العلاقة فيما بين الدخل والخرج لكل منها: بعد أن قمنا بتوصيف العصبون بشكل رياضي مبسّط، علينا الانتقال للحديث عن بنية الشبكات التي تنتظم بها تلك العصبونات وطرق ارتباطها بعضها ببعض، سنتناول بالشرح شكلا واحدا من أشكال بناء الشبكات العصبية، لكن ذلك لا يعني عدم وجود معماريات أخرى لبناء تلك الشبكات. سنفترض أن العصبونات تنتظم في طبقات ولكل طبقة عدد من العصبونات بحيث أن خرج أي عصبون من هذه الطبقة يتم إيصاله إلى كل عصبونات الطبقة التالية. يمكن تمييز الطبقة الأولى على أنـها طبقة الإدخال والتي تتلقى بياناتها من الوسط الخارجي للشبكة العصبية، كذلك نعرّف طبقة الإخراج على أنـها الطبقة الأخيرة والتي ترسل ناتج معالجة البيانات ثانية إلى الوسط الخارجي، في حين يسمّى كل ما عدى ذلك من طبقات بين هاتين الطبقتين بالطبقات الخفية. كما نلاحظ فإن عدد العصبونات في كل من طبقتي الإدخال والإخراج محدد بحسب طبيعة الوظيفة المناطة بالشبكة العصبية (مثلا عدد العنصورات Pixels الإجمالي في الصورة لكل قناة لونية RGB في الدخل، وعدد الفئات المراد تصنيفها في الخرج)، أمّا عدد الطبقات الخفية وعدد العصبونات في كل منها فلا توجد قواعد ضابطة وواضحة لذلك. مكتبة TensorFlow من Google مكتبة TensorFlow هي منصة متكاملة لتدريب وبناء تطبيقات الذكاء الصنعي وتعلم الآلة بالاعتماد على تقنية الشبكات العصبية طورتها شركة Google باستخدام لغة Python ونشرتها تحت ترخيص البرمجيات الحرة والمفتوحة المصدر، وهي تعد في الوقت الراهن واحدة من أكثر المكتبات شهرة واستخداما في هذا المجال (رغم أنها ليست الوحيدة قطعا)، وذلك نظرا لغزارة وتنوع المصادر والأدوات المتوافرة لها والتي تتيح للباحثين القدرة على بناء واستخدام تطبيقات الذكاء الصنعي في أعمالهم. للمزيد حول TensorFlow يمكنكم الإطلاع على الموقع الرسمي لها على الرابط التالي: https://www.tensorflow.org دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن مكنز TensorFlow Hub للنماذج إحدى أهم التحديات في عالم الذكاء الصنعي بشكل خاص، وعلوم البيانات بشكل عام، هي القدرة على إعادة استخدام ما سبق وما توصل إليه فريق تطوير آخر سابقًا، لذا قدمت Google هذا المكنز لوضع طريقة معيارية في مشاركة نماذج الشبكات العصبية بحيث تتضمن كافة المعلومات المطلوبة لإعادة استخدامها سواء كانت بنية الشبكة العصبية ذاتها (من حيث عدد الطبقات، ونوعها، وعدد العصبونات في كل منها، ونوع الروابط فيما بينها، الخ.)، إضافة إلى قيم الوسطاء والأوزان المختلفة في تلك الشبكة العصبية بعد إتمام عملية تدريبها. يمكن أخذ هذه النماذج وإعادة استخدامها في مهام مختلفة أو حتى إعادة تدريبها بسهولة مستخدمين تقنية تدعى نقل التعلم والتي سنتحدث عنها لاحقا في هذا الدرس. لمزيد من المعلومات حول هذا المكنز يمكنكم زيارة الموقع الرسمي له على الرابط التالي: https://www.tensorflow.org/hub. نموذج MobileNet V2 للرؤية الحاسوبية تم تصميم هذه العائلة من نماذج الشبكات العصبية المخصصة لمهام الرؤية الحاسوبية عامة الأغراض مثل التصنيف وتحديد الأجزاء والعناصر في الصورة وسواها من الوظائف مع مراعاة المصادر المحدودة التي قد تكون متوافرة على الأجهزة المحمولة. إن القدرة على تشغيل تطبيقات التعلم العميق على أجهزة الجوال الشخصية ستحسن من تجربة المستخدم نظرا لأنها ستكون متاحة في أي زمان ومكان بغض النظر عن الحاجة إلى الاتصال بمصادر خارجية على الإنترنت، وهو ما سيترافق مع فوائد إضافية لجهة الأمان والخصوصية والاقتصاد في استهلاك الطاقة. لمزيد من المعلومات يمكنك الإطلاع على الرابط المدرج ضمن قسم المراجع1. تقنية نقل التعلم Transfer Learning إن النماذج الحديثة للتعرف على الصور تحتوي على الملايين من الوسطاء (من أوزان للروابط ما بين الآلاف من العصبونات المرصوفة في العشرات من الطبقات الخفية) والتي يتطلب تدريبها من الصفر كما كبيرا من بيانات التدريب من جهة، والكثير من الطاقة الحاسوبية من جهة أخرى (تقدّر بالمئات من ساعات الحساب على وحدات المعالجة الرسومية GPU أو حتى أكثر بكثير). إن تقنية نقل التعلم تعتمد على حيلة ذكية لاختصار كم المصادر الكبير الذي نحتاجه لتطوير نموذج رؤية حاسوبية جديد تخصص مهاراته في التعرف على نمط مختلف من الصور (مثلا صور الأشعة السينية لتشخيص وجود أورام سرطانية محتملة عوض التعرف على الأنواع المختلفة من الأزهار البرية). تقوم الفكرة على استبدال الطبقة الأخيرة فقط من شبكة عصبية سبق وأن تم تدريبها بشكل جيد على تصنيف الصور ولو لغايات مختلفة، مستفيدين بذلك من كم المهارات التي اكتسبتها بنية الطبقات الخفية في ذلك النموذج، ابتداء من التعرف على أنماط النسج والأشكال وترابط الأجزاء وعلاقات الألوان وغيرها مما هو مشترك بالعموم بين كافة نظم الرؤية الحاسوبية، والتي يمكن إعادة استخدامها ومشاركتها بين النماذج المختلفة. وحدها الطبقة الأخيرة فقط الخاصة بالأصناف تتغير بتغير الغاية والهدف من النموذج الذي يجري تطويره وتخصيصه، لذا هي وحدها التي سيتم تدريبها فعليا عند استخدام تقنية نقل التعلم هذه. لمزيد من المعلومات حول هذه التقنية في التعليم يمكنكم الإطلاع على رابط ورقة البحث العلمي المدرجة ضمن قسم المراجع أدناه2. تجهيز بيئة العمل سنستخدم منصة Docker المخصصة لتطوير ونشر وإدارة التطبيقات باستخدام فكرة الحاويات وذلك لتسهيل بناء بيئة العمل لدينا من أجل تنفيذ التطبيق العملي في هذه الجلسة، حيث أن الحاويات هي عبارة عن حزم تنفيذية خفيفة وقائمة بذاتها لتطبيق ما، تحوي كل المكتبات وملفات الإمداد والاعتماديات والأجزاء الأخرى الضرورية ليعمل التطبيق ضمن بيئة معزولة، هذا عدى عن أنها خفيفة لأنها لا تتطلب حملا إضافيا كالأجهزة الافتراضية كونها تعمل ضمن نواة النظام المضيف مباشرة دون الحاجة إلى نظام ضيف، وبذلك نزيل عن كاهلنا في هذه المرحلة أي تعقيدات تختص بالتنصيب والربط والإعداد لمختلف مكونات بيئة التطوير الخاصة بمكتبة TensorFlow وهي مهمة ليست باليسيرة على المبتدئ، لذا عليك القيام بتثبيت Docker على حاسوبك الشخصي من الموقع الرسمي https://www.docker.com/ قبل الانتقال إلى الخطوة التالية. اطلع على مقال «التعامل مع حاويات Docker» في قسم دوكر في أكاديمية حسوب. تطبيق عملي يقوم بتحديد جنس الشخص من صورة وجهه بداية نقوم بتنصيب TensorFlow على Docker ضمن حاوية تحت تسمية hsoub-ft، قد تتطلب هذه الخطوة بعض الوقت نظرا لكون حجم صورة الحاوية التي سيتم سحبها وتنزيلها عبر الإنترنت يتجاوز 1GB: docker pull tensorflow/tensorflow docker run --name hsoub-tf -it -d tensorflow/tensorflow:latest بعد ذلك نقوم بالدخول إلى سطر الأوامر ضمن الحاوية ونقوم بتنصيب الإصدار 2.0 على الأقل من مكتبة TensorFlow وكذلك الإصدار 0.6 على الأقل من نموذج تصنيف الصور3 الذي سنستخدمه والمستضاف في مكنز TensorFlow Hub، و بعد إتمام هذه الخطوات نخرج باستخدام الأمر exit في سطر الأوامر للعودة إلى الجهاز المضيف: docker exec -it hsoub-tf bash pip install "tensorflow~=2.0" pip install "tensorflow-hub[make_image_classifier]~=0.6" exit الخطوة التالية هي تحضير بيانات التدريب وذلك من خلال الحصول على الصور التي سيتم تدريب الشبكة عليها، في مثالنا هذا استخدمنا مجموعة جزئية تتكون من حوالي 2000 صورة مقسمة إلى فئتين ذكور وإناث وهي مقتطعة من مجموعة بيانات أكبر تدعى UTKFace4 المتاحة للاستخدامات غير التجارية والتي تتضمن بالأساس ما يزيد عن 20 ألف صورة وجه. تم اختيار الصور التي سوف نستخدمها في عملية التدريب بحيث تكون متوازنة من حيث الجنس (أي أن عدد الصور الخاصة بالذكور يساوي تقريبا عددها للإناث) والعرقيات (أي تقارب عدد الأشخاص من ذوي الأصول الأوروبية والأفريقية والهندية الخ.) وذلك لضمان عدم التحيز، إضافة إلى أن الصور تخص أشخاصا تتراوح أعمارهم ما بين 20 إلى 40 سنة. للمتابعة عليك تحميل الملف المضغوط المرفق مع هذا المحتوى، ثم قم بفك ضغطه على حاسوبك وستحصل على مجلد باسم training داخله ثلاث مجلدات هي images و output وكذلك test. ستلاحظ ضمن مجلد images أن هنالك مجلد فرعي لك تصنيف تريد من شبكتك العصبية أن تتعرف عليه (في حالتنا هذه هناك مجلدان فقط بتسمية Male و Female) داخل كل منهما مجموعة الصور التي تنتمي إلى ذلك التصنيف. من جهة أخرى فإن مجلد output هو فارغ حاليا لكنه المكان الذي سيتم فيه حفظ الشبكة العصبية بعد إتمام عملية تدريبها (أي حيث سنخزن النموذج الناتج)، أخيرا ستجد في المجلد الثالث test شيفرة برمجية بسيطة لاختبار النموذج الناتج وبعض الصور التي لم يسبق له أن رآها من قبل (أي أنها لم تكن موجودة أصلا ضمن صور وبيانات التدريب). نحن بحاجة إلى نقل كل هذه المجلدات وما فيها من ملفات إلى داخل الحاوية hsoub-tf وذلك باستخدام الأمر التالي على الجهاز المضيف: docker cp .\training hsoub-tf:/training الآن نستطيع الانتقال مجددا إلى سطر الأوامر ضمن الحاوية باستخدام الأمر التالي: docker exec -it hsoub-tf bash وبعد ذلك يمكننا بدء عملية التدريب باستخدام الأمر التالي: make_image_classifier \ --image_dir training/images dir \ --tfhub_module https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4 \ --image_size 224 \ --saved_model_dir training/output/model \ --labels_output_file training/output/class_labels.txt \ --tflite_output_file training/output/mobile_model.tflite إن وسطاء الأمر التنفيذي السابق تحدد المسار الذي يحتوي على مجلدات الصور التي سيتم استخدامها في عملية التدريب (أي مسار المجلد ضمن الحاوية وليس على الجهاز المضيف)، وكذلك مصدر النموذج الأصلي الذي ستطبق عليه تقنية نقل التعلم باستبدال طبقته الأخيرة، بعد ذلك نحدد الأبعاد المطلوبة للصور ليتم تحجيمها تلقائيا لتلائم هذه الأبعاد (فهذا محدد ومرتبط بطبقة الإدخال في نموذج الشبكة العصبية المستخدمة)، في حالتنا نحن نستخدم نموذج MobileNet V2 والذي يفترض أبعاد الصورة هي 224 عنصورة/بيكسل للطول والعرض، بعد ذلك نحدد المكان الذي سيتم فيه حفظ النموذج المدرّب الناتج، وكذلك أين سيتم حفظ التسميات المرافقة لعصبونات الخرج من شبكتنا العصبية بالترتيب، وأخيرا أين سيتم تصدير هذا النموذج بصيغة tflite المحزومة والموضبة لتطبيقات الجوال. في نهاية عملية التدريب (والتي قد تطول تبعا لعدد الصور من جهة، ولسرعة الحاسوب الذي تتم عليه عملية التدريب من جهة أخرى)، سنجد أننا حصلنا على نموذج شبكة عصبية يستطيع تمييز جنس الشخص من صورته بدقة تتعدى 80% وذلك بمجهود بسيط جدا دون الحاجة إلى عمليات ضبط ومعايرة فائقة التخصص لوسطاء بناء وتدريب الشبكة العصبية، ودون الحاجة كذلك إلى ساعات وساعات من التدريب ولا إلى آلاف وآلاف من الصورة للتدرب عليها! إنها بحق نتيجة مرضية لأوائل مغامراتك مع الشبكات العصبية، لكنها مجرد البداية. ها قد حان الوقت لتجربة النموذج الذي قمنا بتدريبه على صور لم يسبق له أن رآها من قبل، للقيام بذلك سوف نستخدم برنامج معد مسبقا لهذه الغاية5 وهو مكتوب بلغة Python وموجود داخل المجلد training/test صحبة بضعة صور كأمثلة للتجريب (ويمكن أن تستخدم صورك الخاصة في هذه المرحلة)، حيث ستتم عملية الاختبار لكل صورة من خلال الأمر التالي (وفيه نشير إلى مسار الشبكة العصبية التي سيتم تحميلها واستخدامها، والملف النصي الذي يتضمن اسم التصنيف الخاص بكل عصبون خرج ضمن هذه الشبكة بالترتيب، وأخيرا مسار الصورة المراد تصنيفها): python training/test/label_image.py \ --input_mean 0 --input_std 255 \ --model_file training/output/mobile_model.tflite \ --label_file training/output/class_labels.txt \ --image training/test/Ahmed_Zewail.jpg بعد إتمام تدريبنا واختبارنا للشبكة العصبية حان الوقت للخروج من بيئة التدريب هذه باستخدام الأمر exit للعودة إلى سطر الأوامر على الجهاز المضيف، ومن ثم سنرغب طبعا باستخراج النموذج الذي قمنا بتعليمه خلال هذه الجلسة من داخل حاوية Docker وهو ما نستطيع القيام به باستخدام الأمر التالي: docker cp hsoub-tf:/training/output .\training نقاط تستحق التأمل قد يرى البعض في تقنيات الذكاء الصنعي حلا لجميع المشكلات، لكنها في حقيقة الأمر لا تأتي خالية من المخاطر التي قد ترقى إلى حد اعتبارها نقاط ضعف أو عيوب يجب أن تؤخذ بعين الاعتبار، نذكر منها: باعتبار أن النماذج في الشبكات العصبية تبنى انطلاقا من بيانات التدريب، لذا فإنها غير قادرة على حل أي مشاكل كانت موجودة أصلا في تلك البيانات كالأخطاء أو الانحياز أو عدم التكامل والشمول لمختلف الحالات المراد التعامل معها. يصعب في الشبكات العصبية تفسير المنطق الذي استخدمه النموذج لإعطاء إجابته، فالتعامل معه أقرب ما يكون للصندوق الأسود الذي لا نعلم كمستخدمين آلية عمله الدقيقة في الداخل، بل نؤمن بأن ما نحصل عليه من إجابات هو أفضل المتاح، ولهذه الفكرة تداعياتها الفلسفية والاجتماعية التي تصعّب من استخدام هكذا أدوات في الحالات التي تتطلب تقديم تبرير (مثلا عند تطبيق عقوبة أو حرمان من مكافأة). تطوير نماذج الشبكات العصبية يتطلب قدرا كبيرا من بيانات التدريب المشروحة والمجهزة بشكل جيد وملائم، وهو ما قد يعني الكثير من الجهد لتوفير مثل هكذا مصادر للتدريب. عملية تدريب الشبكات العصبية هي عملية متطلّبة من ناحية قدرات المعالجة الحسابية المتوفّرة للعتاد المستخدم، وذلك على عكس عملية استخدامها في التطبيقات عقب إتمام التدريب، لذا قد يجد المطور في الحوسبة السحابية فرصا متاحة بميزانيات في المتناول. إن بناء النماذج باستخدام خوارزميات تعلم الآلة يتطلب مطورين أذكياء وموهوبين، فعلى الرغم من أن تطبيق المثال الذي قمنا بعرضه يبدو سهلا ويسيرا، إلا أن نظرة أكثر تعمقا ستكشف لك الكثير من التفاصيل التي بحاجة إلى معايرة وضبط، منها على سبيل المثال لا الحصر: معمارية الشبكة، وطريقة توصيف تابع تفعيل العصبونات فيها، وعدد طبقاتها الخفية، وعدد العصبونات في كل منها، وطريقة ربطها بعضها ببعض، وكيفية حساب الخطأ ما بين النتيجة المحسوبة والمطلوبة، ومعدل سرعة التعلم، وعدد مرات تكرار عرض الأمثلة على الشبكة العصبية أثناء التدريب، وغيرها الكثير. إن انتقاء التوليفة الأكثر ملائمة لجملة معايير الضبط هذه يؤثر بشكل حاسم على جودة ودقة النموذج الناتج. مراجع أجنبية للاستزادة MobileNetV2: The Next Generation of On-Device Computer Vision Networks DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition Making your own TensorFlow model for image classification UTKFace: Large Scale Face Dataset TensorFlow Lite Python image classification demo اقرأ أيضًا تعلم الذكاء الاصطناعي الذكاء الاصطناعي: دليلك الشامل المقال التالي: إعداد شبكة عصبية صنعية وتدريبها للتعرف على الوجوه الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها1 نقطة -
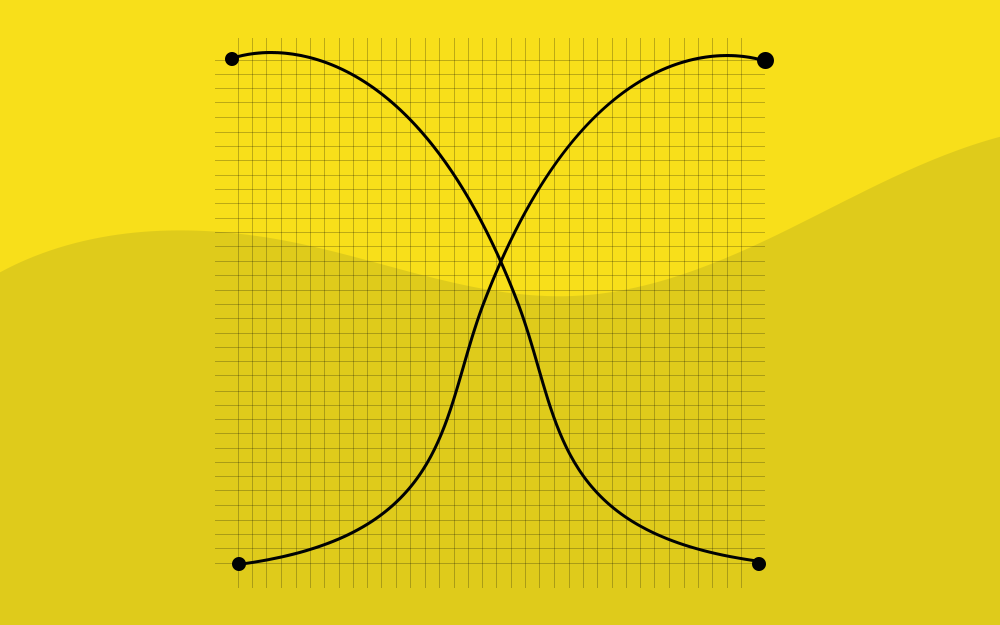 تستخدم منحنيات بيزيه Bezier curves في رسوميات الحاسوب لإنشاء الأشكال والرسوم المتحركة المعتمدة على أوراق التنسيق المتتالية CSS وغيرها. هذه المنحنيات بسيطة وتستحق الدراسة، وبعدها ستكون مرتاحًا عند التعامل مع الرسوميات الشعاعية vector graphics والرسوم المتحركة المتقدمة. نقاط التحكم يحدد منحني بيزيه بواسطة مجموعة من النقاط الحاكمة، وقد يكون عددها 2 أو 3 أو 4 أو أكثر، لاحظ مثلًا منحنيًا من نقطتين: والمنحني التالي محدد بثلاث نقاط: وهذا بأربع نقاط: لو تمعنت في هذه المنحنيات، فيمكنك أن تلاحظ التالي: لا تنتمي النقاط بالضرورة إلى المنحني وهذا أمر طبيعي، وستفهم ذلك عندما سنشرح طريقة بنائه لاحقًا. درجة المنحني curve order تساوي عدد النقاط ناقصًا واحدًا، فالمنحني المؤلف من نقطتين هو خط مستقيم من الدرجة الأولى، والمنحني المؤلف من ثلاث نقاط هو منحن تربيعي، أي قطع مكافئ، وهكذا. ينحصر المنحني ضمن المضلع المحدّب convex hull الذي تشكله النقاط الحاكمة: سنتمكن من أَمثَلة اختبارات التداخل في رسوميات الحاسوب اعتمادًا على الخاصية الأخيرة، فلن تتداخل المنحنيات إن لم تتداخل المضلعات المحدبة، وبالتالي ستعطي دراسة تداخل المضلعات المحدبة جوابًا سريعًا لتداخل المنحنيات، بالإضافة إلى أنّ دراسة تداخل المضلعات أسهل لأنّ أشكالها مثل المثلث والمربع، تُعَد مفهومة موازنةً بالمنحنيات. تكمن الفائدة الرئيسية لاستخدام منحني بيزيه في تغيير شكل المنحني بمجرد تحريك النقاط الحاكمة. لاحظ المنحني الذي تولده الشيفرة التالية، واستخدم الفأرة لتحريك النقاط الحاكمة وراقب تغير المنحني: ستتمكن بعد التمرن قليلًا من رسم المنحني المطلوب بمجرد تحريك النقاط الحاكمة، ويمكنك عمليًا الحصول على أي شكل تريده بوصل عدة منحنيات، إليك بعض الأمثلة: خوارزمية دي كاستلجو De Casteljau يمكننا استخدام صيغة رياضية لرسم منحنيات بيزيه، وهذا ما سنشرحه لاحقًا، لأنّ خوارزمية دي كاستلجو De Casteljau’s algorithm التي نسبت لمخترعها، تتطابق مع التعريف الرياضي، وتساعدنا على تمييز طريقة إنشاء المنحنيات بصريًا. سنرى أولًا مثالًا لمنحن من ثلاث نقاط حاكمة، لاحظ أنه يمكنك تحريك النقاط 1 و 2 و 3 بالفأرة، ثم انقر زر التشغيل الأخضر. خوازمية دي كاستلجو لبناء منحني بيزيه من ثلاث نقاط ارسم النقاط الثلاث، والتي تمثلها النقاط 1 و2 و3 في المثال السابق. صل بين النقاط السابقة باتجاه واحد 3 → 2 → 1، وهي الخطوط البنية في المثال السابق. يأخذ المعامل t قيمه بين "0" و"1"، وقد استخدمنا في مثالنا النموذجي السابق خطوةً مقدارها "0.05"، أي تتحرك حلقة التنفيذ وفق الآتي: 0 ثم 0.05 ثم 0.1 ثم 0.15 وهكذا. لكل قيمة من قيم t: نأخذ على كل خط بني بين نقطتين متتاليتين نقطةً تبعد عن بدايته مسافةً تتناسب مع t، وطالما أن هناك خطان، فسنحصل على نقطتين، وستكون كلتا النقطتين في بداية الخط عندما يكون t=0 مثلًا، كما ستبعد النقطة الأولى عن بداية الخط مسافةً تعادل 25% من طوله عندما تكون t=0.25، وهكذا. نصل بين النقطتين المتشكلتين، والخط الواصل في المثال التالي باللون الأزرق. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } p iframe.code-result__iframe { border: 1px solid #e7e5e3 !important; } t=0.25 t=0.5 خذ على الخط الأزرق السابق نقطةً تبعد عن طرفه مقدارًا يتناسب مع t، ستكون النقطة في نهاية الربع الأخير من الخط من أجل t=0.25، وستكون في منتصف الخط من أجل t=0.5، وهي النقطة الحمراء في الشكل السابق. عندما تتحول t بين 0 و1 ستضيف كل قيمة لهذا المعامل نقطةً من نقاط المنحني، وتمثل هذه المجموعة من النقاط منحني بيزيه. نتبع الأسلوب ذاته بالنسبة لمنحنى مكون من أربع نقاط حاكمة. الخوارزمية المتبعة لأربع نقاط هي: صل بين النقاط الحاكمة 1 إلى 2، و2 إلى 3، و3 إلى 4، وستحصل على ثلاثة خطوط بنية. لكل قيمة للمعامل t بين 0 و1: نأخذ نقاطًا على الخطوط الثلاثة تتناسب مع t كما فعلنا سابقًا، وبوصل هذه النقاط الثلاثة المتشكلة سنحصل على خطين جديدين، باللون الأخضر مثلًا. نأخذ على الخطين الأخضرين نقاطًا متناسبةً مع t، وعندها سنصل بين النقطتين المتشكلتين فنحصل على خط واحد، وليكن باللون الأزرق. نأخذ على الخط الأزرق نقطةً تبعد عن أحد طرفي الخط مسافةً متناسبةً مع t، فنحصل على نقطة حمراء واحدة تمثل أحد نقاط منحني بيزيه. تمثل النقاط الحمراء كلها المنحني الكامل. إن الخوارزمية السابقية تعاودية، أي قادرة على إعادة نفسها، لذلك يمكن تعميمها إلى N نقطة حاكمة: نصل بين النقاط فنحصل على N-1 خطًا. لكل قيمة للمعامل t بين 0 و1 نأخذ على كل خط نقطةً تبعد عن طرف الخط مسافةً متناسبةً مع t، ونصل بين هذه النقاط فنحصل على N-2 خطًا. نكرر الخطوة 2 حتى نحصل على نقطة واحدة تمثل إحدى نقاط منحني بيزيه. تشكل جميع النقاط الناتجة في الخطوة 3 منحني بيزيه. شغّل الرسوميات التالية ولاحظ شكل المنحني: منحن يبدو مثل الخط البياني للدالة y=1/t. نقاط حاكمة بشكل Zig-zag تبدو جيدةً أيضًا: يمكن رسم حلقة: يمكن رسم منحني بيزيه غير أملس أيضًا: تابع الأمثلة الحية السابقة لترى كيف يُبنى المنحني، إذا وجدت شيئًا مبهمًا في وصف الخوارزمية. يمكن استخدام العدد الذي نريده من النقاط الحاكمة لرسم منحني بيزيه من أي درجة، ما دامت الخوارزمية تعاوديةً، لكن يفضل عمليًا استخدام عدد قليل من النقاط -عادةً 2 أو 3 نقاط-، ثم نربط بين عدة منحنيات بسيطة إذا أردنا شكلًا أكثر تعقيدًا. الصيغ الرياضية يمكن توصيف منحني بيزيه باستخدام صيغة رياضية، وكما رأينا فلا حاجة لمعرفة هذه الصيغة. يرسم المستخدمون المنحني بمجرد تحريك النقاط بالفأرة، لكن إذا أردت استخدام الرياضيات فلك هذا. لنفترض أنّ إحداثيي نقطة حاكمة هو Pi. ستكون النقطة الأولى (P1 = (x1, y1، والثانية (P2 = (x2, y2، وهكذا حتى آخر نقطة (Pi = (xi, yi، ويمكن أن نصف منحني بيزيه بمعادلة متغيرها t يأخذ قيمه بين 0 و1. صيغة منحن يمر بنقطتين هي: صيغة منحن يمر من 3 نقاط هي: صيغة منحن يمر من 4 نقاط هي: إنّ المعادلات السابقة هي معادلات شعاعية، أي يمكننا وضع الإحداثيين x وy بدلًا من P، فمن أجل المنحني المار من ثلاث نقاط مثلًا ستصبح الصيغة بدلالة x وy هي: ينبغي تعويض القيم x1, y1, x2, y2, x3, y3 في المعادلات وكتابة الصيغة بدلالة المتغير t، فلو فرضنا أنّ إحداثيات النقاط الحاكمة الثلاثة هي: (0,0) و(0.5, 1) و(1, 0)،فستصبح قيمة إحداثيي النقطة المقابلة من منحني بيزيه: سنحصل على إحداثيي نقطة جديدة (x,y) من نقاط منحني بيزيه كلما تغيرت قيمة t بين 0 و1. خلاصة تُحدَّد منحنيات بيزيه بثلاث نقاط حاكمة، ويمكن رسمها بأسلوبين كما رأينا: باستخدام عملية رسومية: أي خوارزمية دي كاستلجو. باستخدام صيغة رياضية. من الصفات الجيدة لمنحنيات بيزيه: إمكانية رسم منحنيات ملساء عبر تحريك النقاط الحاكمة باستخدام الفأرة. إمكانية رسم أشكال أكثر تعقيدًا بوصل عدة منحنيات بيزيه معًا. استخدامات منحنيات بيزيه: في رسوميات الحاسوب والنمذجة ومحررات الرسوميات الشعاعية، كما توصف بها أنواع خطوط الكتابة. في تطوير تطبيقات الويب، من خلال الرسم ضمن لوحات وفي الملفات بتنسيق SVG، وقد كتبت الأمثلة النموذجية السابقة بتنسيق SVG، وهي عمليًا مستند SVG مفرد أُعطي نقاطًا مختلفةً مثل معاملات، ويمكن فتح هذه النماذج في نوافذ منفصلة والاطلاع على الشيفرة المصدرية: demo.svg. في الرسوميات المتحركة لوصف مسارها وسرعتها. ترجمة -وبتصرف- للفصل Bezier curve من سلسلة The Modern JavaScript Tutorial. اقرأ أيضًا المقال السابق: كائنا localStorage وsessionStorage لتخزين بيانات الويب في جافاسكربت أساسيات منحنى بيزيه Bezier Curve في سكريبوس تأثيرات الانتقال والحركة في CSS1 نقطة
تستخدم منحنيات بيزيه Bezier curves في رسوميات الحاسوب لإنشاء الأشكال والرسوم المتحركة المعتمدة على أوراق التنسيق المتتالية CSS وغيرها. هذه المنحنيات بسيطة وتستحق الدراسة، وبعدها ستكون مرتاحًا عند التعامل مع الرسوميات الشعاعية vector graphics والرسوم المتحركة المتقدمة. نقاط التحكم يحدد منحني بيزيه بواسطة مجموعة من النقاط الحاكمة، وقد يكون عددها 2 أو 3 أو 4 أو أكثر، لاحظ مثلًا منحنيًا من نقطتين: والمنحني التالي محدد بثلاث نقاط: وهذا بأربع نقاط: لو تمعنت في هذه المنحنيات، فيمكنك أن تلاحظ التالي: لا تنتمي النقاط بالضرورة إلى المنحني وهذا أمر طبيعي، وستفهم ذلك عندما سنشرح طريقة بنائه لاحقًا. درجة المنحني curve order تساوي عدد النقاط ناقصًا واحدًا، فالمنحني المؤلف من نقطتين هو خط مستقيم من الدرجة الأولى، والمنحني المؤلف من ثلاث نقاط هو منحن تربيعي، أي قطع مكافئ، وهكذا. ينحصر المنحني ضمن المضلع المحدّب convex hull الذي تشكله النقاط الحاكمة: سنتمكن من أَمثَلة اختبارات التداخل في رسوميات الحاسوب اعتمادًا على الخاصية الأخيرة، فلن تتداخل المنحنيات إن لم تتداخل المضلعات المحدبة، وبالتالي ستعطي دراسة تداخل المضلعات المحدبة جوابًا سريعًا لتداخل المنحنيات، بالإضافة إلى أنّ دراسة تداخل المضلعات أسهل لأنّ أشكالها مثل المثلث والمربع، تُعَد مفهومة موازنةً بالمنحنيات. تكمن الفائدة الرئيسية لاستخدام منحني بيزيه في تغيير شكل المنحني بمجرد تحريك النقاط الحاكمة. لاحظ المنحني الذي تولده الشيفرة التالية، واستخدم الفأرة لتحريك النقاط الحاكمة وراقب تغير المنحني: ستتمكن بعد التمرن قليلًا من رسم المنحني المطلوب بمجرد تحريك النقاط الحاكمة، ويمكنك عمليًا الحصول على أي شكل تريده بوصل عدة منحنيات، إليك بعض الأمثلة: خوارزمية دي كاستلجو De Casteljau يمكننا استخدام صيغة رياضية لرسم منحنيات بيزيه، وهذا ما سنشرحه لاحقًا، لأنّ خوارزمية دي كاستلجو De Casteljau’s algorithm التي نسبت لمخترعها، تتطابق مع التعريف الرياضي، وتساعدنا على تمييز طريقة إنشاء المنحنيات بصريًا. سنرى أولًا مثالًا لمنحن من ثلاث نقاط حاكمة، لاحظ أنه يمكنك تحريك النقاط 1 و 2 و 3 بالفأرة، ثم انقر زر التشغيل الأخضر. خوازمية دي كاستلجو لبناء منحني بيزيه من ثلاث نقاط ارسم النقاط الثلاث، والتي تمثلها النقاط 1 و2 و3 في المثال السابق. صل بين النقاط السابقة باتجاه واحد 3 → 2 → 1، وهي الخطوط البنية في المثال السابق. يأخذ المعامل t قيمه بين "0" و"1"، وقد استخدمنا في مثالنا النموذجي السابق خطوةً مقدارها "0.05"، أي تتحرك حلقة التنفيذ وفق الآتي: 0 ثم 0.05 ثم 0.1 ثم 0.15 وهكذا. لكل قيمة من قيم t: نأخذ على كل خط بني بين نقطتين متتاليتين نقطةً تبعد عن بدايته مسافةً تتناسب مع t، وطالما أن هناك خطان، فسنحصل على نقطتين، وستكون كلتا النقطتين في بداية الخط عندما يكون t=0 مثلًا، كما ستبعد النقطة الأولى عن بداية الخط مسافةً تعادل 25% من طوله عندما تكون t=0.25، وهكذا. نصل بين النقطتين المتشكلتين، والخط الواصل في المثال التالي باللون الأزرق. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } p iframe.code-result__iframe { border: 1px solid #e7e5e3 !important; } t=0.25 t=0.5 خذ على الخط الأزرق السابق نقطةً تبعد عن طرفه مقدارًا يتناسب مع t، ستكون النقطة في نهاية الربع الأخير من الخط من أجل t=0.25، وستكون في منتصف الخط من أجل t=0.5، وهي النقطة الحمراء في الشكل السابق. عندما تتحول t بين 0 و1 ستضيف كل قيمة لهذا المعامل نقطةً من نقاط المنحني، وتمثل هذه المجموعة من النقاط منحني بيزيه. نتبع الأسلوب ذاته بالنسبة لمنحنى مكون من أربع نقاط حاكمة. الخوارزمية المتبعة لأربع نقاط هي: صل بين النقاط الحاكمة 1 إلى 2، و2 إلى 3، و3 إلى 4، وستحصل على ثلاثة خطوط بنية. لكل قيمة للمعامل t بين 0 و1: نأخذ نقاطًا على الخطوط الثلاثة تتناسب مع t كما فعلنا سابقًا، وبوصل هذه النقاط الثلاثة المتشكلة سنحصل على خطين جديدين، باللون الأخضر مثلًا. نأخذ على الخطين الأخضرين نقاطًا متناسبةً مع t، وعندها سنصل بين النقطتين المتشكلتين فنحصل على خط واحد، وليكن باللون الأزرق. نأخذ على الخط الأزرق نقطةً تبعد عن أحد طرفي الخط مسافةً متناسبةً مع t، فنحصل على نقطة حمراء واحدة تمثل أحد نقاط منحني بيزيه. تمثل النقاط الحمراء كلها المنحني الكامل. إن الخوارزمية السابقية تعاودية، أي قادرة على إعادة نفسها، لذلك يمكن تعميمها إلى N نقطة حاكمة: نصل بين النقاط فنحصل على N-1 خطًا. لكل قيمة للمعامل t بين 0 و1 نأخذ على كل خط نقطةً تبعد عن طرف الخط مسافةً متناسبةً مع t، ونصل بين هذه النقاط فنحصل على N-2 خطًا. نكرر الخطوة 2 حتى نحصل على نقطة واحدة تمثل إحدى نقاط منحني بيزيه. تشكل جميع النقاط الناتجة في الخطوة 3 منحني بيزيه. شغّل الرسوميات التالية ولاحظ شكل المنحني: منحن يبدو مثل الخط البياني للدالة y=1/t. نقاط حاكمة بشكل Zig-zag تبدو جيدةً أيضًا: يمكن رسم حلقة: يمكن رسم منحني بيزيه غير أملس أيضًا: تابع الأمثلة الحية السابقة لترى كيف يُبنى المنحني، إذا وجدت شيئًا مبهمًا في وصف الخوارزمية. يمكن استخدام العدد الذي نريده من النقاط الحاكمة لرسم منحني بيزيه من أي درجة، ما دامت الخوارزمية تعاوديةً، لكن يفضل عمليًا استخدام عدد قليل من النقاط -عادةً 2 أو 3 نقاط-، ثم نربط بين عدة منحنيات بسيطة إذا أردنا شكلًا أكثر تعقيدًا. الصيغ الرياضية يمكن توصيف منحني بيزيه باستخدام صيغة رياضية، وكما رأينا فلا حاجة لمعرفة هذه الصيغة. يرسم المستخدمون المنحني بمجرد تحريك النقاط بالفأرة، لكن إذا أردت استخدام الرياضيات فلك هذا. لنفترض أنّ إحداثيي نقطة حاكمة هو Pi. ستكون النقطة الأولى (P1 = (x1, y1، والثانية (P2 = (x2, y2، وهكذا حتى آخر نقطة (Pi = (xi, yi، ويمكن أن نصف منحني بيزيه بمعادلة متغيرها t يأخذ قيمه بين 0 و1. صيغة منحن يمر بنقطتين هي: صيغة منحن يمر من 3 نقاط هي: صيغة منحن يمر من 4 نقاط هي: إنّ المعادلات السابقة هي معادلات شعاعية، أي يمكننا وضع الإحداثيين x وy بدلًا من P، فمن أجل المنحني المار من ثلاث نقاط مثلًا ستصبح الصيغة بدلالة x وy هي: ينبغي تعويض القيم x1, y1, x2, y2, x3, y3 في المعادلات وكتابة الصيغة بدلالة المتغير t، فلو فرضنا أنّ إحداثيات النقاط الحاكمة الثلاثة هي: (0,0) و(0.5, 1) و(1, 0)،فستصبح قيمة إحداثيي النقطة المقابلة من منحني بيزيه: سنحصل على إحداثيي نقطة جديدة (x,y) من نقاط منحني بيزيه كلما تغيرت قيمة t بين 0 و1. خلاصة تُحدَّد منحنيات بيزيه بثلاث نقاط حاكمة، ويمكن رسمها بأسلوبين كما رأينا: باستخدام عملية رسومية: أي خوارزمية دي كاستلجو. باستخدام صيغة رياضية. من الصفات الجيدة لمنحنيات بيزيه: إمكانية رسم منحنيات ملساء عبر تحريك النقاط الحاكمة باستخدام الفأرة. إمكانية رسم أشكال أكثر تعقيدًا بوصل عدة منحنيات بيزيه معًا. استخدامات منحنيات بيزيه: في رسوميات الحاسوب والنمذجة ومحررات الرسوميات الشعاعية، كما توصف بها أنواع خطوط الكتابة. في تطوير تطبيقات الويب، من خلال الرسم ضمن لوحات وفي الملفات بتنسيق SVG، وقد كتبت الأمثلة النموذجية السابقة بتنسيق SVG، وهي عمليًا مستند SVG مفرد أُعطي نقاطًا مختلفةً مثل معاملات، ويمكن فتح هذه النماذج في نوافذ منفصلة والاطلاع على الشيفرة المصدرية: demo.svg. في الرسوميات المتحركة لوصف مسارها وسرعتها. ترجمة -وبتصرف- للفصل Bezier curve من سلسلة The Modern JavaScript Tutorial. اقرأ أيضًا المقال السابق: كائنا localStorage وsessionStorage لتخزين بيانات الويب في جافاسكربت أساسيات منحنى بيزيه Bezier Curve في سكريبوس تأثيرات الانتقال والحركة في CSS1 نقطة -
لا اعلم شيي عن البرمجة واريد ان اكون مبرمج full stack او علي الاقل backend الكل نصحني بهذا ويذكر انه اهم وافضل .. بحثت في دورات حسوب وجدت دورة مدخل الي عالم الكمبيوتر كبداية ثم تطوير واجهات المستخدم ولكن لم اري دورات back end ؟1 نقطة
-
كيف يمكنني حذف محور axis محدد من ال plot؟1 نقطة
-
هل هناك طريقة معينة في بايثون أو OpenCV لتدوير الصورة بدرجة معينة؟1 نقطة
-
كيف يمكننا تحويل الصورة من تنسيقOpenCV إلى تنسيق (Pillow )PIL والعكس؟1 نقطة
-
ما الفرق بين الاستعلامين: SELECT * FROM T1 WHERE T1.col IN (SELECT col FROM T2) وهذا: SELECT T1.* FROM T1 JOIN T2 ON T1.col = T2.col1 نقطة
-
![مزيد من المعلومات حول "[فيديو] أساسيات استخدام Sass"](https://academy.hsoub.com/uploads/monthly_2021_10/616ecf352cf00_--Sass.png.eb47f85aae1564b05c7566ecb23506a6.png) يشرح الفيديو لغة Sass التي هي أساسًا امتداد للغة CSS، حيث يوضح الفيديو ميزاتها وفوائد استخدامها، إلى جانب الفرق بينها وبين CSS.1 نقطة
يشرح الفيديو لغة Sass التي هي أساسًا امتداد للغة CSS، حيث يوضح الفيديو ميزاتها وفوائد استخدامها، إلى جانب الفرق بينها وبين CSS.1 نقطة -
يا أهلًا واثق، شكرًا لك، هذه مهتمنا بالطبع! بالنسبة لاستفسارك حول قسم المقالات، فهي تابعة لقسم قواعد البيانات وتتحدث عن كل ما يتعلق بعملية تصميم قواعد البيانات بدءًا من فهم نظام الملفات وحتى تصميم قاعدة بيانات لنظام ما وتنفيذها، وسننظر -نظرًا لاستفسارك هذا- في فصل قسم قواعد البيانات عن قسم الخوادم ليكون قسمًا رئيسيًا. شكرًا جزيلًا لك،1 نقطة
-
احاول استخدام فايربيز مع react import firebase from '@firebase/app'; import '@firebase/storage'; const storage = firebase.storage(); const ref=storage.ref("images"); ولكن يعطيني خطأ TypeError: Cannot read properties of undefined (reading 'storage')1 نقطة
-
إن مشروعي يعتمد على حزمة npm خاصة قمت بعمل لها auth credentials على شكل authentication token وأريد تضمينها في مشروعي وهي مرفوعة على خدمة sinopia1 نقطة
-
تُستخدم الأسماء المستعارة لـ SQL لإعطاء اسم مؤقت لجدول أو عمود في جدول. غالبًا ما تستخدم الأسماء المستعارة لجعل أسماء الأعمدة أكثر قابلية للقراءة. الاسم المستعار موجود فقط لمدة هذا الاستعلام. يتم إنشاء اسم مستعار باستخدام الكلمة الأساسية AS. يوجد أكثر من جدول واحد متضمن في الاستعلام يتم استخدام functions في الاستعلام أسماء الأعمدة كبيرة أو غير مقروءة جيدًا يتم دمج عمودين أو أكثر معًا فنعطي اسم العمود الناتج عن الدمج اسم يعبر عنه يمكن استخدام column_alias في عبارة ORDER BY ، ولكن لا يمكن استخدامها في جملة WHERE أو GROUP BY أو HAVING. لا يسمح SQL القياسي بالإشارة إلى الأسماء المستعارة للأعمدة في جملة WHERE. يتم فرض هذا التقييد لأنه عند تقييم جملة WHERE ، يكون لم يتم تحديد قيمة العمود بعد، بسبب ترتيب تنفيذ أجزاء الاستعلامات. يمكن إعطاء اسم مستعار لنتيجة subquery أي استعلام جزئي يمكن إعطاء اسم مستعار لنتيجة دالة تجميع aggregation function مثل sum - man - avg أمثلة عامة: -- اسم مستعار لعمود Alias Column SELECT column_name_1 AS alias_name_1, column_name_2 AS alias_name_2, FROM table_name_1; -- اسم مستعار لجدول Alias Table SELECT column_name_s, *.. FROM table_name AS alias_name_table; اسم مستعار لعمود مع دوال التجميع: SELECT SQRT(a*b) AS root_square FROM math_table GROUP BY root HAVING root_square > 0; SELECT id, COUNT(*) AS count FROM employees GROUP BY id HAVING count > 0; SELECT id AS 'Customer identity' -- اسم توضيحي FROM Customer; دمج جدول مع نفسه: SELECT o.OrderID, o.OrderDate, c.CustomerName -- استخدام الاسم المستعار في SELECT FROM Customers c, Orders o -- يمكن تجاهل زضع as WHERE c.CustomerName LIKE "wael%" AND c.CustomerID=o.CustomerID; إعادة تسمية ناتج دمج عدة أعمدة: SQL SERVER: SELECT Name, CONCAT(Address,', ',City,', ',Country) AS Address FROM Customers; MySQL: SELECT Name, Address + ', ' + City + ', ' + Country AS Address FROM Customers;1 نقطة
-
تعلمت أساسيات nginx وكيفية تنصيبه، ولكن هل يوجد ميزات أخرى يوفرها هذا الخادم؟1 نقطة
-
كيف نتحكم بعدد الصور؟ قم بتعريف متغير عام، يحوي قيمة ابتدائية 0. يتم تحديثه أولا بعدد الصور التي تأتي من قاعدة البيانات.. imagesCounter = 0 if (response.statusCode == 200) { final items = json.decode(response.body).cast<Map<String, dynamic>>(); List<DataImage> listOfFruits = items.map<DataImage>((json) { return DataImage.fromJson(json); }).toList(); imagesCounter = listOfFruits.length; // هنا return listOfFruits; } ثم نمرر للدالة التي تسمح للمستخدم بجلب الصور من الاستديو عدد الصور التي من الممكن إضافتها، وهي 4 ناقص التي تم تحميلها فعليا maxAssets: 4 - imagesCounter, هكذا يكون لنا متغير عام يضبط عدد الصور.1 نقطة
-
بالإضافة إلى إجابة أستاذ أحمد, يوجد مواقف تحتاج أن تستخدم فيها الأسماء المستعارة (aliases) حتى تتمكن من تنفيذ الجملة الإستعﻻمية المُراد تنفيذها, مثلاً إن كان لدينا الجدول employee وأردنا أن نجلب جميع الموظفين الذين لديهم نفس المدينة, وقتها نحتاج أن نقوم بما يُدعى بالself join حيث أنك تقوم بكتابة جملة join ولكن بدلاً من أن تكون بين جدولين تكون بين الجدول ونفسه, مثال: SELECT a.name AS name1, n.name AS name2, a.City FROM Customers a, Customers n WHERE a.id <>n.id AND a.City = n.City بدون إعطاء أسماء مستعارة لن نتمكن من تفنيذ جملة مثل السابقة1 نقطة
-
يمكن إعداد خادم Nginx كموزع حمل Load Balancer بإستخدام أحد الآليات مثل round-robin أو least-connected أو ip-hash وهنا شرح مبسط عن كل آلية منهم: round-robin: في هذه الطريقة يتم تحديد كل خادم بالتتالي وفقًا للترتيب الذي قمت بتعيينه في ملف الإعدادات، أي يتم إرسال الطلب الأول إلى الخادم الأول ثم الطلب الثاني إلى الخادم الثاني وهكذا. هذا يوازن عدد الطلبات بالتساوي للعمليات القصيرة. وهذه هي الطريقة الإفتراضية التي يعمل بها nginx. least-connected: يتم تعيين الطلب التالي للخادم الذي لديه أقل عدد من الاتصالات النشطة active connection. ip-hash: في هذه الطريقة يتم استخدام دالة التجزئة hash-function لتحديد الخادم الذي يجب أن يقوم بمعالجة الطلب (بناءً على عنوان IP الخاص بالعميل). في الأساس، كل ما عليك فعله هو إعداد nginx مع تعليمات حول نوع الاتصالات التي يجب الاستماع إليها ومكان إعادة توجيهها. وذلك من خلال إنشاء ملف configuration جديد باستخدام أي محرر نصوص. على سبيل المثال: sudo nano /etc/nginx/conf.d/load-balancer.conf الآن في هذا الملف يجب تعريف جزئين رئيسيين، وهما upstream و server، على النحو التالي: http { upstream backend { # نضع هنا عناوين الخوادم التي سيتم إستخدامها server 10.1.0.101; server 10.1.0.102; server 10.1.0.103; } # لاحظ أن اسم upstream و proxy_pass يجب أن يكونا متطابقين. # في هذه الحالة تم إستعمال كلمة backend كاسم لهما server { listen 80; location / { proxy_pass http://backend; } } } الآن يمكن حفظ الملف (عبر الضغط على Ctrl + O) والخروج من محرر النصوص (عبر الضغط على Ctrl + X). نحتاج الآن إلى إستبدال ملف الإعدادات السابق بملف الإعدادات الإفتراضي، وذلك عبر الأوامر التالية: # في Debian و Ubuntu sudo rm /etc/nginx/sites-enabled/default # في نظام CentOS sudo mv /etc/nginx/conf.d/default.conf /etc/nginx/conf.d/default.conf.disabled الآن يجب إعادة تشغيل خادم nginx مرة أخرى وذلك عبر الأمر: sudo systemctl restart nginx طريقة round-robin هي المستخدمة بشكل إفتراضي لذلك لا حاجة لتعديل الملف السابق مرة أخرى، بينما يُمكن تغير الآلية المستعملة في الخادم لموازنة الحمل عبر تعديل قسم upstream في ملف الإعدادات السابق، كالتالي: لإستخدام طريقة least-connected: upstream backend { least_conn; server 10.1.0.101; server 10.1.0.102; server 10.1.0.103; } لإستخدام طريقة ip-hash: upstream backend { ip_hash; server 10.1.0.101; server 10.1.0.102; server 10.1.0.103; }1 نقطة
-
علينا القيام بالخطوات التالية: ربط الجدولين حسب حقل الاسم سوف نستخدم LEFT JOIN للتاكد من ورود أسماء المهندسين تجميع النتائج حسب اسم المهندس نستخدم GROUP BY NAME عمل تجميع ضمن عبارة SELECT باستخدام GROUP_CONCATE التي تدمج السلاسل النصية في سلسة واحدة مع تحديد محرف الفصل بين القيم SELECT x.name, --جلب الاسم GROUP_CONCAT(y.LanguageName SEPARATOR ', ') -- دمج أسماء لغات البرمجة التي تعود لنفس المهندس FROM Engineers e LEFT JOIN ProgramingLanguages pl ON pl.name = e.name -- عمل ربط حسب اسم المهندس GROUP BY e.name -- تجميع حسب اسم المهندس والنتيجة: Ex: wael c++, java, php walid java, javascript wasim c#, asp.NET1 نقطة
-
الأفضل هو عمل جدول منفصل للحالة، يحوي حقلين، هما معرف الحالة والقيمة الاسمية للحالة، أي جدول يعمل ك lookup table ويأخذ الحقل status في جدول الطلبيات القيمة tiny int، يمكن عمل الربط عن طريق المفتاح الثانوي، ولكن الأفضل عدم عمل ربط أثناء الاستعلامات، بل جلب القيم واستبدالها لاحقاً في صفحة الويب أو التطبيق لكي نحسن من الأداء في قاعدة البيانات. tiny int لتوفير مساحة التخيزين، جدول الحالات ك lookup table يمكن استعمال مفهوم العرض view لتركيب استعلام معقد حسب الحالة لديك. status_table status_id | status name 0 pending 1 cooking 2 delevering 3 delevered1 نقطة
-
من أجل توفير المساحة وتحسين الأداء، يجب اختيار الشكل الأمثل للبيانات الذي يكون دقيقا على حجم البيانات التي تريد ادخالها. هنا في status توجد لديك عدة حالات منها استلام - قيد التوصيل - قيد الطهي - في الانتظار وغيرها..، وهنا يعتمد شكل البيانات على طريقة استخدامك لهذة الطرق وهناك طريقتين: اما ان تكون البيانات بداخلها نصا، مثلا "نعم" أو "لا" وهكذا، حينها يجب أن تكون البيانات من نوع Varchar. أما اذا قررت استخدامها ك 0 و 1، بحيث تعني 0 "لا" وتعني 1 "نعم" ، حنها يمكنك اما استخدام int أو tinyint .1 نقطة
-
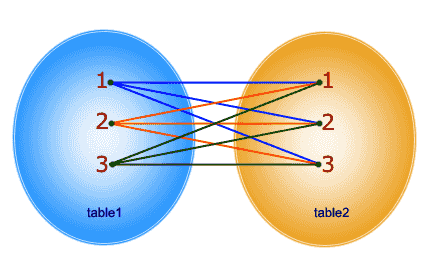
يمكنك استخدام cross join والتي تقوم بعمل مزيج بين كل العناصر في الجدول الأول عناصر الجدول الثاني كما توضح الرسمة التالية: ويتم كتابتها بالشكل التالي: SELECT * FROM table1 CROSS JOIN table2; للتوضيح كمثال، دعنا ننشئ الجدول التالي: Player Department_id Goals Ahmed 1 2 Mohamed 2 2 Eyad 3 5 والجدول الثاني هكذا: Department_id Department_name 1 IT 2 HR 3 Marketing اذا قمنا بكتابة الكود لتالي لعمل cross بين الجدولين: SELECT * FROM MatchScore CROSS JOIN Departments يظهر لنا الجدول التالي: Player Department_id Goals Depatment_id Department_name Ahmed 1 2 1 IT mohamed 2 2 1 IT Eyad 3 5 1 IT Ahmed 1 2 2 HR mohamed 2 2 2 HR Eyad 3 5 2 HR Ahmed 1 2 3 Marketing mohamed 2 2 3 Marketing Eyad 3 5 3 Marketing لاحظ أنه قام بدمج كل عنصر في الجدول الأول بكل عنصر في الجدول الثاني
 1 نقطة
1 نقطة -
مفهوم Redis: Redis هو عبارة عن مخزن مفتوح المصدر يُستعمل لتخزين البيانات على شكل أزواج من مفتاح-قيمة Key-Value في الذاكرة الرئيسية In-Memory، حيث Key-Value storage عبارة عن نظام تخزين يتم فيه تخزين البيانات على شكل أزواج من المفاتيح والقيم ، تخزّن هذه الأزواج في الذاكرة الرئيسية RAM وهذا ما نقصده بـ In-Memory وبهذا يمكننا القول أن تقنية Redis تخزن البيانات في الذاكرة الرئيسية على شكل أزواج من المفاتيح والقيم. يكون المفتاح في هذه التقنية عبارة عن سلسلة نصية String، أما القيمة فيمكن أن تكون سلسلة محارف String أو قائمة List أو مزيج منهما. يُمكن استخدام Redis إمّا كخادوم قاعدة بيانات لوحده أو مرتبطًا مع قاعدة بيانات أخرى مثل MySQL. خطوات تثبيت Redis على أوبنتو: إعداد بيئة ومتطلبات Redis نقوم في البداية بتحديث جميع حزم apt-get: sudo apt-get update بعد ذلك نقوم بتحميل مُترجم (compiler) باستخدام الحزمة build-essential، والّتي من شأنها المساعدة في تنصيب Redis من المصدر: sudo apt-get install build-essential سنقوم بعدها بتحميل الأداة tcl الّتي يَعتمد عليها Redis: sudo apt-get install tcl8.5 تنصيب Redis: بعد أنّ تمّ تنصيب المُتطلّبات الأساسيّة، فمن المُمكن الآن الشروع وتنصيب redis، ويُمكن تحديد الإصدار المطلوب أو تحميل الإصدار الأخير والذي سيحمل دائمًا الاسم redis-stable: wget http://download.redis.io/redis-stable.tar.gz يجب بعد ذلك فك ضغط الملفّ والانتقال إليه: tar xvzf redis-stable.tar.gz cd redis-stable ثم المتابعة بتنفيذ الامر: make make ولتنصيب Redis على كامل النّظام، فيُمكن إما نسخ ملفاته من المصدر: sudo cp src/redis-server /usr/local/bin/ sudo cp src/redis-cli /usr/local/bin/ أو تنفيذ الأمر التّالي: sudo make install بعد انتهاء عمليّة التنصيب، من المُستحسن تشغيل Redis كحارس (daemon) في خلفيّة النّظام، ولعمل ذلك يأتي Redis بملفّ برمجي (سكريبت) لهذه المُهمّة. يجب الانتقال إلى المسار utils للوصول إلى هذا الملفّ: cd utils ومن ثم تشغيل الملفّ الخاص بتوزيعات Ubuntu/Debian: sudo ./install_server.sh سيَعرض السكريبت بعض الأسئلة لإتمام عمليّة التهيئة، ولكن يُمكن الاعتماد على الإعداد الافتراضي والاكتفاء بالضغط على Enter، وبعد انتهاء عملية التهيئة سيكون خادم Redis يعمل في الخلفيّة (background). يُمكن تنفيذ الأمر التّالي للوصول إلى قاعدة البيانات Redis: redis-cli يُمكن اختبار Redis كالتّالي: λ redis-cli 127.0.0.1:6379> ping PONG 127.0.0.1:6379> set name hsoub OK 127.0.0.1:6379> get name "hsoub" 127.0.0.1:6379> بإمكانك المتابعة مع المقال التالي: الذي يشرح كيفية التثبيت بشكل مفصل و الإطلاع على بقية أوامر Redis.1 نقطة
-
Nginx عبارة عن مشروع مفتوح المصدر، له استخدامات مُختلفة قد يكون أهمها هو استخدامه كخادوم ويب. تنصيب NGINX بعد الدخول إلى السيرفر نفذ الأمريين التاليين لتثبيت وتشغيل برنامج Nginx على السيرفر: sudo apt-get update sudo apt-get install -y nginx بعد التثبيت يمكنك زيادة السيرفر من المتصفح عبر وضع عنوان السيرفر (Ip Address) في شريط العنوان في المتصفح، وسوف تظهر لك الصفحة الافتراضية لـNginx. تابع هذا الدرس لمعرفة كيفية التثبيت و ضبط خادم Nginx على توزيعة اوبنتو بالإضافة إلى مثال بسيط لتخديم صفحات html : و أيضا هناك عدة مقالات تم نشرها على الأكاديمية تشرح عن Nginx و كيفية التعامل معه بإمكانك الوصول لها من خلال: مقالات Nginx
 1 نقطة
1 نقطة -
لكي يُمكن تثبيت وإستخدام شهادة SSL على موقع معين، يجب أن يكون الموقع مستضاف على خادم خاص VPS أو dedicated server مع إمكانية التحكم به عبر سطر اللأوامر من خلال SSH أو أي طريقة أخرى، كما يجب أن يكون لديكِ صلاحيات لإستخدام الأمر sudo. بعد التأكد من وجود كل المتطلبات السابقة، يمكن البدء في الخطوات التالية: أولًا يجب تسجيل الدخول إلى الخادم عبر SSH بإستخدام حسساب مستخدم لديه صلاحيات إستخدام الأمر sudo ثانيًا يجب تثبيت Snapd والذي يأتي مثبيت مسبقًا على خوادم Ubuntu 16.04 وما بعد ذلك، لكن إن لم يكن مثبتًا مسبقًا لديكِ، فيمكن تنفيذ هذه الأوامر لتثبيته من جديد: sudo apt update sudo apt install snapd sudo snap install core حذف حزم Certbot: في كثير من الأحيان يحتوي النظام على حزم خاصة بــ Certbot مسبقًا، ويجب حذف هذه الحزم قبل عملية تثبيت Certbot snap الذي سيسمح لنا بتثبيت شهادة SSL، لإلغاء تثبيت Certbot يمكن تنفيذ أحد الأوامر التالية حسب نظام التشغيل الذي لديكِ: sudo apt-get remove certbot sudo dnf remove certbot sudo yum remove certbot الآن سنقوم بتثبيت Certbot Snap من خلال تنفيذ الأمر التالي: sudo snap install --classic certbot وللتأكد من أن عملية التثبيت تمت بنجاح وأنه يمكن تشغيل وإستخدام Certbot، يُمكن تنفيذ الأمر التالي: sudo ln -s /snap/bin/certbot /usr/bin/certbot الآن يمكن الإختيار بين أن يقوم certbot بتعديل إعدادات خادم Apache وتثبيت شهادة SSL تلقائيًا أو تحميل الشهادة فقط، وذلك عبر أحد الأوامر التالية: السماح لـ Certbot بتعديل إعدادات Apache: sudo certbot --apache تحميل الشهادة فقط: sudo certbot certonly --apache ملاحظة: إن كان الخادم يعمل بـ Nginx، فيمكن تبديل apache بـ nginx في الأوامر السابقة، وسيعمل كل شيء على ما يرام. الآن تم تثبيت الشهادة بنجاح، ويمكن تحديث الشهادة كل فترة عبر الأمر التالي: sudo certbot renew --dry-run sudo certbot renew الأمر الأول للتحقق فقط من أن عملية تحديث الشهادة تتم بنجاح، أما الأمر الثاني فهو ما يقوم بتحديث الشهادات بالفعل. يمكن التأكد من أن شهادة SSL تعمل بنجاح من خلال زيارة رابط الموقع عبر بروتوكول HTTPS وليس HTTP مثل https://www.example.com. ملاحظة: عند إستخدام certbot والسماح له بتعديل إعدادات الخادم، يقوم بتوجيه الزيارات التي تتم من خلال HTTP إلى HTTPS تلقائيًا.1 نقطة
-
يستعمل الـ CROSS JOIN عادة لإنشاء ,إنطلاقا من جدولين, توليفة مزدوجة من كل صف من الجدول الأول مع كل صف من الجدول الثاني . أي إن كان الجدول الأول يحوي المعلومات : +++++++++++ |STUDENTS | |---------| |AHMED | |OMAR | |YOUNESS | +++++++++++ و الجدول الثاني المعلومات : +++++++++++ |CARS | |---------| |BMW | |MERCEDES | |HONDA | +++++++++++ فإن إستعمال الـ CROSS JOIN الذي سيقوم بتشكيل : سطر لأحمد بمحاذاة سطر BMW . // // // // MERCEDES . // // // // HONDA . و أيضا : سطر لعمر بمحاذاة سطر BMW . // // // // MERCEDES . // // // // HONDA . و أيضا : سطر ليونس بمحاذاة سطر BMW . // // // // MERCEDES . // // // // HONDA . بمعنى أنه سيتبع منطقا كالتالي : / BMW / |OMAR ---- MERCEDES \ \ HONDA / BMW / |AHMED --- MERCEDES \ \ HONDA / BMW / |YOUNESS --- MERCEDES \ \ HONDA لينتج لنا مجموعة النتائج التالية : ++++++++++++++++++++++ |STUDENTS | CARS | |---------|----------| |AHMED |BMW | |AHMED |MERCEDES | |AHMED |HONDA | | | | |OMAR |BMW | |OMAR |MERCEDES | |OMAR |HONDA | | | | |YOUNESS |BMW | |YOUNESS |MERCEDES | |YOUNESS |HONDA | ++++++++++++++++++++++ يشبه هذا جداء مجموع في الجبر , إذ يتم إستعمال النشر المزدوج كطريقة لتحليل عبارة جبرية تتضمن جداء مجموع , مثال : (a + c )( b + d ) = ab + ad + cb + cd سوى أن النتائج في الـ CROSS JOIN يتم نشرها كصفوف بنتيجة الإستعلام . السياق العام لها هو ما كالتالي : SELECT ColumnName_1, ColumnName_2, ColumnName_N FROM [Table_1] CROSS JOIN [Table_2] أو يكفي : SELECT ColumnName_1, ColumnName_2, ColumnName_N FROM [Table_1],[Table_2] و يتم استخدامه بغرض إنشاء مجموعة من كافة مجموعات العناصر بجدول ما بقاعدة البيانات ، مثل تشكيل مجموعات منازل ذات ألوان و أحجام معينة , هذا مع إمكانية التحكم في عناصر هاته المجموعات لونا أو حجما : select size, color from sizes CROSS JOIN colors ++++++++++++++++++++++ |SIZE | COLOR | |---------|----------| |XS |RED | |XS |BLUE | |XS |GREY | | | | |XM |RED | |XM |BLUE | |XM |GREY | | | | |XL |RED | |XL |GREY | |XL |BLUE | ++++++++++++++++++++++ فلو أردنا مثلا إستثناء المنازل الحمراء , فسنتثني اللون الأحمر فقط ليتم إستثناء كل التوليفات المشكلة من حجم X و لون أحمر .. : و هكذا . أو ربما تريد جدولاً يحتوي على صف لكل دقيقة في اليوم ، وتريد استخدامه للتحقق من تنفيذ إجراء ما كل دقيقة ، لذلك يمكنك تجاوز ثلاثة جداول : select hour, minute from hours CROSS JOIN minutes ++++++++++++++++++++++ |HOUR | MINUTE | |---------|----------| |13:00 |00 | |13:00 |01 | |13:00 |02 | |13:00 |03 | . . . . . . |21:00 |55 | |21:00 |56 | |21:00 |57 | |21:00 |58 | . . . . . . ++++++++++++++++++++++ فهو يخلق مجموعة إحتمالات غير مكررة ,بإعتبار أن الأعمدة تحمل قيما فريدة, إبتداءا من مجموعات محدودة من العناصر . يمكن أن يكون هذا عمليا جدا في عمليات مثل إختبار التطبيق أو بذر قواعد البيانات ببيانات تجريبية .1 نقطة
-
عند الاستعلام من جدول ما عادة نذكر أسماء الأعمدة فقط، ضمنيا تجاهلنا إسباق اسم الجدول الذي ينتمي له العمود ضمنيا أيضا تجاهلنا إسباق اسم قاعدة البيانات الذي ينتمي له الجدول بفرض لدينا جدول المستخدمين users داخل قاعدة البيانات بالاسم company، الثلاث استعلامات التالية متساوية: SELECT * FROM users; # يساوي SELECT users.* FROM users; # يساوي SELECT company.users.* FROM users; تنفيذ الاستعلام من عدة قواعد بيانات بالذكر الصريح لمكان تواجد البيانات يمكن الاستعلام من عدة جداول في قواعد بيانات مختلفة بفرض لدينا الجدول users في قاعدتي بيانات لشركتين بالاسم company1 و company2، نستعلم عن مستخدمي الشركتين معًا كالتالي: SELECT company1.users.*, company2.users.* FROM company1.users, company2.users; لدمج النتائج معا وإظهارها كما لو كنا نستعلم من جدول واحد نقوم بعمل دمج بين الجدولين لمطابقة الأعمدة SELECT * FROM company1.users; JOIN company2.users on company1.users.Id = company2.users.Id1 نقطة
-
بفرض لدينا جدول المستخدمين users التالي: +----+-------+ | Id | Name | +----+-------+ | 1 | أحمد | | 2 | عبدالله | | 3 | يوسف | | 4 | جمال | | 5 | محمد | | 6 | سعيد | +----+-------+ ونريد تصفح النتائج على صفحات كل صفحة فيها ثلاث أسطر، سيكون الجدول السابق عبارة عن صفحتين كل منها تحتوي ثلاث نتائج بالشكل التالي: # الصفحة الأولى +----+-------+ | Id | Name | +----+-------+ | 1 | أحمد | | 2 | عبدالله | | 3 | يوسف | +----+-------+ # الصفحة الثانية +----+-------+ | Id | Name | +----+-------+ | 4 | جمال | | 5 | محمد | | 6 | سعيد | +----+-------+ MYSQL نستخدم الكلمتين: LIMIT لتحديد عدد النتائج في الصفحة الواحدة (3 في حالتنا) OFFSET لتحديد رقم الصفحة يمكن تجاهلها للصفحة الأولى (1 أو 2 في حالتنا) تكون الاستعلامات كالتالي: # الصفحة الأولى SELECT * FROM users LIMIT 3 OFFSET 1; # أو SELECT * FROM users LIMIT 3; # الصفحة الثانية SELECT * FROM users LIMIT 3 OFFSET 2; SQL Server نستخدم الجملتين FETCH NEXT x ROWS ONLY لتحديد عدد النتائج في الصفحة الواحدة حيث x هو عدد النتائج (3 في حالتنا) OFFSET x ROWS لتحديد بداية الصفحة، حيث x يشير إلى ترتيب أول نتيجة نريدها في الصفحة، يمكن حسابها بدليل الصفحة كالتالي (حجم الصفحة × (رقم الصفحة - 1))، يمكن تجاهلها لأول صفحة (0 و 3 في حالتنا) تكون الاستعلامات كالتالي: # الصفحة الأولى SELECT * FROM users OFFSET 0 ROWS FETCH NEXT 3 ROWS ONLY; # أو SELECT * FROM users NEXT 3 ROWS ONLY; # الصفحة الثانية SELECT * FROM users OFFSET 3 ROWS FETCH NEXT 3 ROWS ONLY;1 نقطة
-
أداة Puppet هي أداة لإدارة البرامج تتضمن لغتها التعريفية لوصف إعدادات النظام. توفر Puppet حل يعتمد على لأتمتة العمليات بأقل قدر من المعرفة البرمجية لاستخدامه. يتم إستخدام برنامج الأتمتة Puppet لغة Puppet التعريفية لإدارة مراحل مختلفة من دورة حياة البنية التحتية لتكنولوجيا المعلومات IT، بما في ذلك التصحيح patching، والإعداد configuration، وإدارة نظام التشغيل والتطبيقات عبر مراكز بيانات المؤسسة Data Centers والبنى التحتية السحابية Cloud Structure. يتم إستخدام برنامج Puppet كبرنامج مفتوح المصدر تحت رخصة GPL حتى الإصدار 2.7.0، وتحت رخصة Apache في الإصدارات اللاحقة، كما توجد نسخة مدفوعة للمؤسسات باسم Puppet Enterprise وتحمل ترخيصًا خاصًا. يتبع Puppet عادةً بنية الخادم - العميل Client - Server. يُعرف العميل باسم الوكيل Agent ويُعرف الخادم باسم الرئيس Master. يمكن أيضًا استخدامه كتطبيق مستقل يتم تشغيله من سطر الأوامر للاختبار والإعدادات البسيطة. حيث يتم تثبيت Puppet Server على خادم واحد أو أكثر، ويتم تثبيت Puppet Agent على جميع الأجهزة التي يريد المستخدم إدارتها. يتواصل Puppet Agents مع الخادم Master ويقومون بإحضار تعليمات التكوين configuration. يقوم كل Agent بعد ذلك بتطبيق هذه التعليمات على النظام ويرسل تقرير الحالة status report إلى الخادم Master مرة أخرى. يمكن للأجهزة تشغيل Puppet Agent كبرنامج خفي daemon، يمكن تشغيله بشكل دوري كوظيفة cron أو يمكن تشغيله يدويًا عند الحاجة. هذه التعليمات تكتب بإستخدام لغة Puppet التعريفية Puppet declarative language على الصيغة التالية: type { 'title': attribute => value }1 نقطة
-
يمكنك أن تستخدم سطر الأوامر Command Line لإستخراج وإستدعاء قواعد البيانات خصوصًا إن كانت كبيرة الحجم للغاية، ولكي لا تنتظر تحميل الصفحة في phpMyadmin أو خطأ timeout عندما يتم إستخراج قاعدة البيانات يفضل أن تستخدم سطر الأوامر للقيام بهذه المهمة. أيضًا في كثير من الأحيان لا يكون هنا دعم لـ phpMyadmin على الخادم لذلك لا يتوفر سوى إستخدام سطر الأوامر بشكل إفتراضي. تتوفر MySQL على أداة mysqldump التي تسمح لك بإستخراج وإستيراد قواعد البيانات بشكل سهل وسريع، وذلك من خلال تنفيذ الأمر التالي: mysqldump -u YourUser -p YourDatabaseName > wantedsqlfile.sql سوف يتم طلب إدخال كلمة السر الخاصة بسمتخدم قاعدة البيانات YourUser. ثم لإستيراد قاعدة البيانات على خادم آخر، يمكنك أن تقوم بتنفيذ الأمر التالي: mysql -u YourUser -ptmppassword AnotherDatabaseName < wantedsqlfile.sql قم بتغير اسم المستخدم وكلمة السر واسم قاعدة البيانات وسيبدأ عملية إستيراد قاعدة البيانات.1 نقطة
-
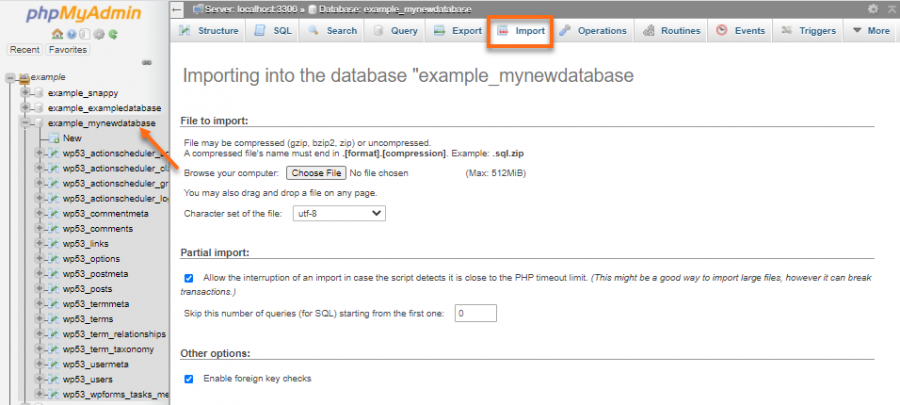
شائع عادة إستعمال مدير قواعد البيانات phpMyadmin لذلك . سواء في المستضيف المحلي أو على الإستضافة المشتركة . لنقم بتلخيص الأمر وفق الخطوات التالية : تصدير قواعد البيانات من المستضيف المحلي بصيغة SQL . يمكنك ذلك عن طريق الدخول إلى phpmyadmin من localhost و التوجه إلى export من قائمة التصفح العلوية التي تظهر بعد الضغط على اسم قواعد البيانات الخاصة بك , ثم اختيار صيغة التصدير و التصدير . (يمكنك تجاهل هاته الخطوة ان كنت تمتلك بالفعل ملف بلاحقة sql خاص بقاعدة البيانات التي لديك ) . الدخول إلى لوحة التحكم الخاصة بإستضافتك . الذهاب إلى phpMyadmin في الجزء الخاص بقواعد البيانات . (المثال من لوحة cPanel) قد تحتاج في بعض لوحات التحكم التي تعطي وصولا محدودا في phpMyadmin إلى إنشاء قاعدة بيانات ومستخدم كامل الصلاحيات . بعد الدخول إلى phpMyadmin تأكد أن تقوم بتحديد قاعدة البيانات المنشأة حديثا , أو أن تقوم بإنشاء واحدة جديدة , ان توفرت صلاحية ذلك , عن طريق الضغط على New أعلى القائمة الجانبية أسفل شعار phpmyAdmin . من قائمة التصفح العلوية نقوم بإختيار تضمين أو Import . قم بالتصفح إلى ملف الـ sql. الذي قمت بتصديره و قم بتحديده و تضمينه بعد الضغط على browse files . ربط موقعك بقواعد البيانات المضافة . يكون هذا عادة بملف إعداد للموقع على شاكلة env. أو init.php_ أو غيرها . قد تحتاج كخطوة إضافية في بعض الأحيان محو الملفات المؤقتة الخاصة بإعداد موقعك , و هذا في حالة إستعماله للملفات المؤقتة بالطبع (مثال : تطبيقات اللارافيل تستعمل ذلك) .

 1 نقطة
1 نقطة -
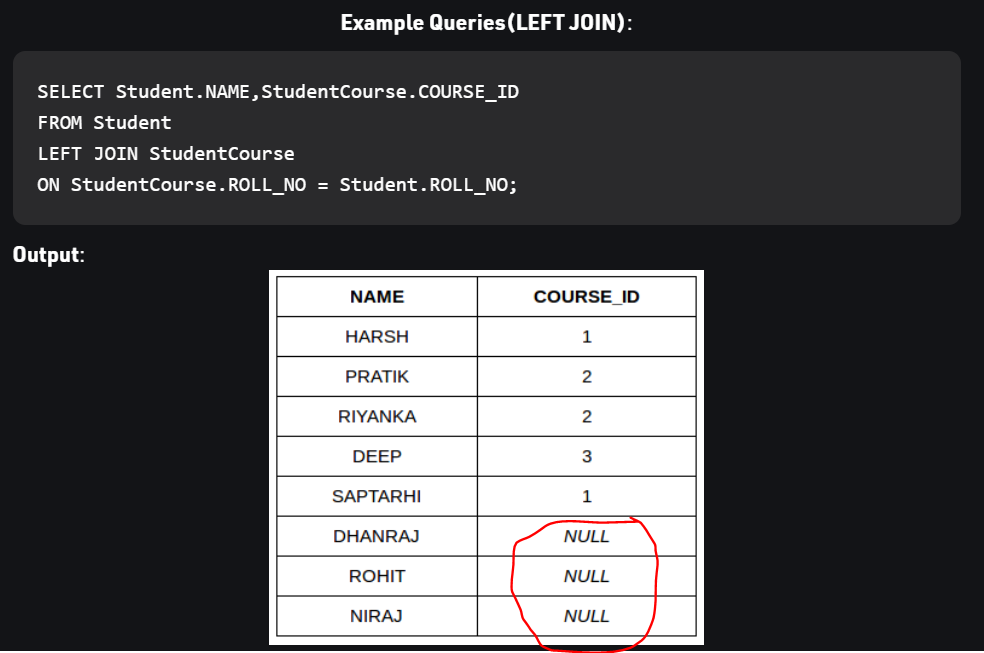
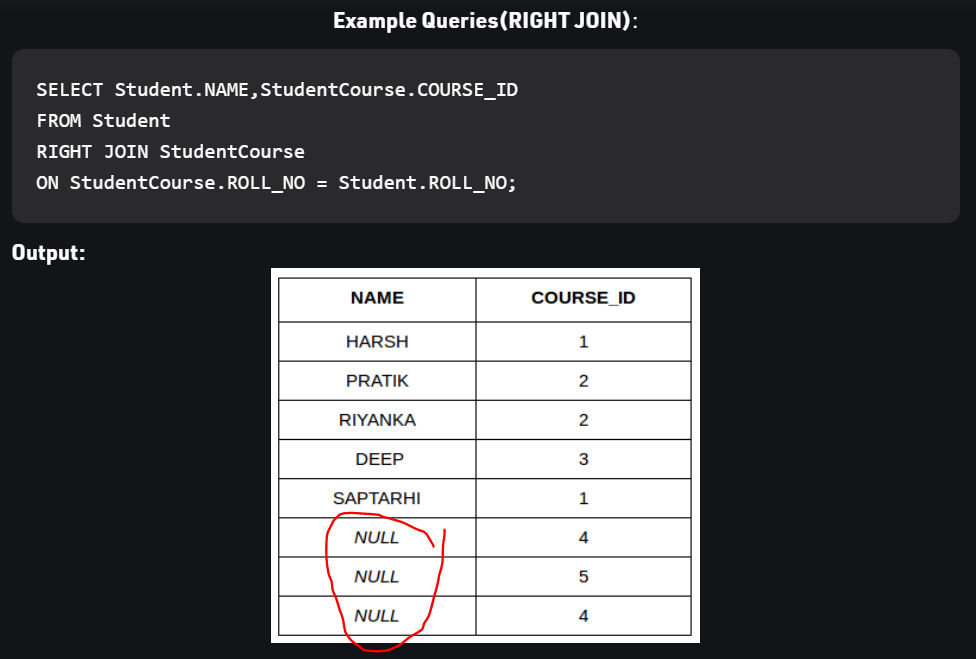
تبديل تررتيب الجداول يؤثر على نتيجة استعلام LEFT - RIGHT _ FULL حيث أن فيهم الربط يعتمد على عرض جميع بيانات أحد الجدولين (حسب جهة العرض) ثم البحث عن عنصر مقابل في الجدول الآخر، لذلك البيانات تختلف. أما في الربط الداخلي INNER JOIN نحصل على نفس النتيجة لكن ترتريب الأعمدة يختلف باختلاف ترتيب الدمج Table col1 col2 A a1 a2 B b1 b2 select * from A, B => a1, a2, b1, b2 select * from B, A => b1, b2, a1, a2 ولتثبيت ترتريب الأعمدة علينا تحديدهم في عبارة SELECT select a1, b1, b2, a2 from B, A => a1, b1, b2, a2 بالنسبة للدمج اليساري: سوف نثبت جدول الزبائن، ولكل زبون نبحث عن الطلبية التي تعود له LEFT JOIN Example SELECT cust_id, cust_name, order_num, order_date FROM customer LEFT JOIN orders ON customer.cust_id = orders.order_id WHERE order_date < '2020-04-30'; بالنسبة للدمج اليميني: سوف نثبت جدول الطلبيات، ولكل طلبية نبحث عن الزبون صاحبها الذي يعود إليها RIGHT JOIN Example SELECT cust_id, cust_name, occupation, order_num, order_date FROM customer RIGHT JOIN orders ON cust_id = order_id ORDER BY order_date; عندما لانجد بيانات من الجدول الثانوي سيعيد NULL وفي حال عمل FULL JOIN سنلحظ ربما وجود قيم فارغة في كلا الحقلين لأنه ليس شرطا تقابل القيم من كلا الجدولين
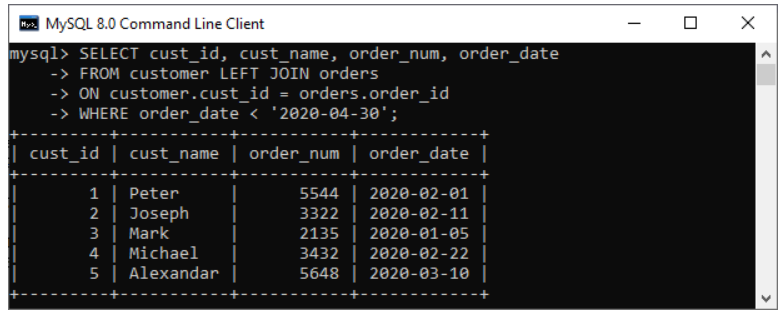

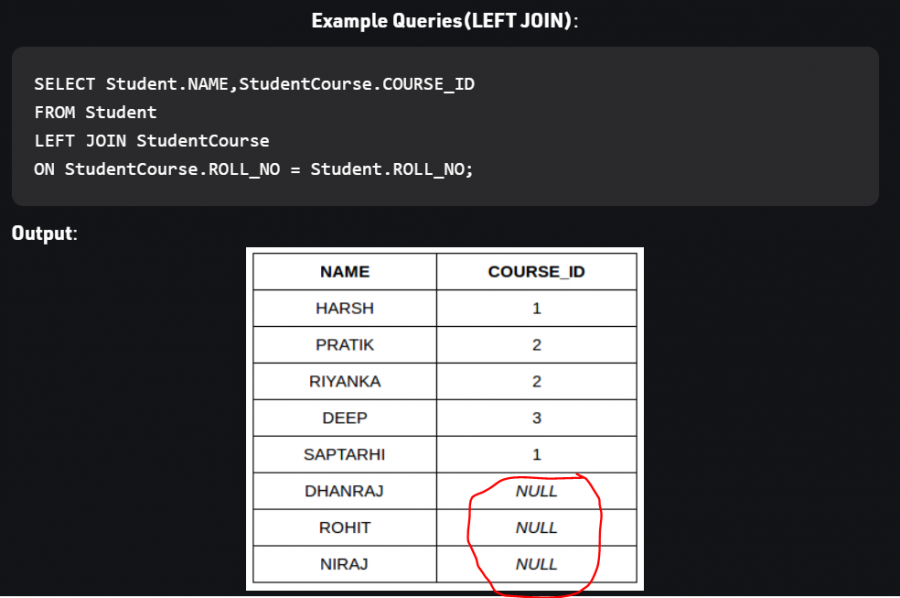
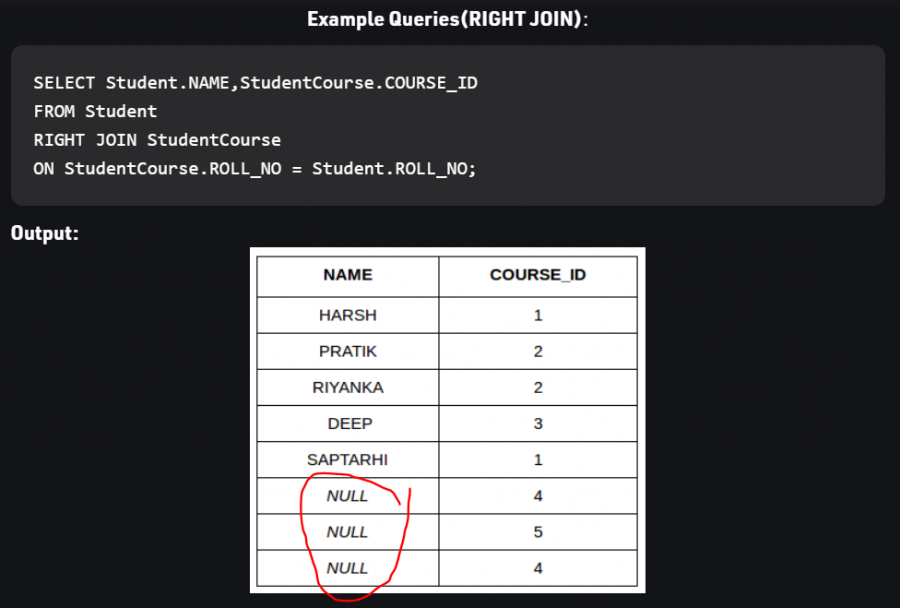 1 نقطة
1 نقطة -
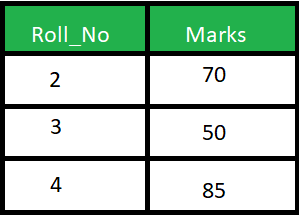
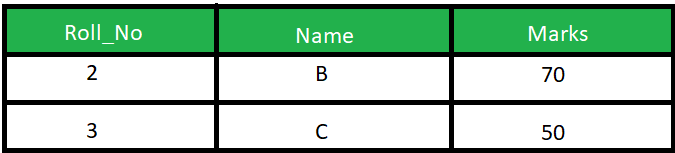
هناك فروق كثيرة بين الطريقتين، لكن بشكل أساسي، فان الفرق يتمثل فيه كيفية عمل كل منهما: Natural Join : تقوم باختيار الأعمدة بناء على التطابق في محتوى عمود مشترك بين الجداول التي يتم الاختيار بينها، بمعني انه يبحث عن عمود مشترك ويقوم باظهار كل الخصائص بدمج الأعمدة المراد دمجها بناء على تطابق هذا العمود المشترك، أنظر المثال التالي: تخيل أن هناك جدول للطلاب كالتالي: وجدول أخر للدرجات كالتالي: لاحظ وجود عمود مشترك Roll_No وبه أشخاص متطابقون في كلا الجدولين (2 و 3)، اذا قمنا بتشغيل هذا الأمر: SELECT * FROM Student NATURAL JOIN Marks; فسيقوم باختيار الأشخاص المشتركون في كلا الجدولين بناء على العمود Roll_No كالتالي: Inner Join : يقوم باختيار العناصر المتشابهة تمام مثلا Natural Join لكن يقوم بارجاع العمود المشترك مرة عن كل جدول، بمعني أخر أنه يقوم بوضع كل جدول بجانب الأخر بعد بحث التطابق بين الجدولين، في المثال السابق ، لو قمنا بتشغيل الأمر: SELECT * FROM student S INNER JOIN Marks M ON S.Roll_No = M.Roll_No; يكون الخرج على الشكل التالي:
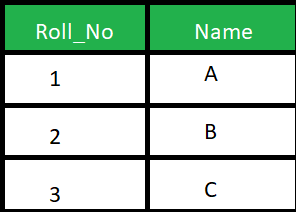
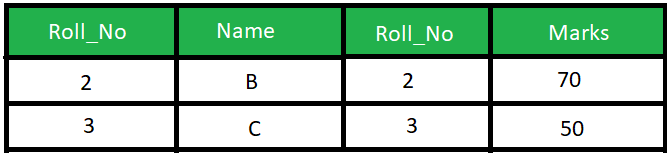 1 نقطة
1 نقطة -
أحد الاختلافات المهمة بين INNER JOIN و NATURAL JOIN هو عدد الأعمدة التي يتم إرجاعها, افترض لدينا الجدولين الآتيين TableA TableB Column1 Column2 Column1 Column3 1 2 1 3 لو حاولنا استخدام INNER JOIN كالتالي SELECT * FROM TableA AS a INNER JOIN TableB AS b USING (Column1); SELECT * FROM TableA AS a INNER JOIN TableB AS b ON a.Column1 = b.Column1; سوف تكون النتيجة كالتالي a.Column1 a.Column2 b.Column1 b.Column3 1 2 1 3 أما لو حاولنا استخدام NATURAL JOIN فسوف تكون النتيحة كالتالي SELECT * FROM TableA NATURAL JOIN TableB Column1 Column2 Column3 1 2 3 يتم تجنب العمدان المكررة1 نقطة
-
الصيغة العامة لاستخدام SELECT هي كالتالي بتحديد الأعمدة التي نريدها في النتيجة SELECT عمود_أول, عمود_ثان FROM جدول إذا أردنا كل الأعمدة يمكننا وضع نجمة "*" لنعبر عن جميع الأعمدة SELECT * FROM جدول إذا كنا نستعلم من عدة جداول معًا يجب وضع إسم أحد الجدولين قبل اسم العمود وبينهما نقطة "." SELECT جدول_أول.عمود, جدول_ثان.عمود FROM جدول_أول, جدول_ثان إذا أردت جلب كل الأعمدة من أحد الجداول نضع نجمة "*" SELECT جدول_أول.* , جدول_ثان.عمود FROM جدول_أول, جدول_ثان ملاحظة: في أول مثالين يمكن وضع اسم الجدول قبل اسم العمود، لكن اختصارا يمكن عدم كتابته في حال كنت تستعلم من جدول واحد1 نقطة
-
اصطلاحات الربط الربط بشكل عام يستخدم للربط بين البيانات (بغض النظر عن مكان وجودها)، أي نوع من أنواع الربط هو اصطلاح وتسمية لمكان وجود البيانات في كلا طرفي الربط الربط الذاتي Self Join عندما تكون البيانات في كلا الطرفين موجودة في نفس الجدول نصطلح أن نوع الربط هذا هو Self Join أي أننا نربط بيانات الجدول ببيانات أخرى من الجدول نفسه، أمثلة: جدول أشخاص، قد يكون هناك علاقة بين الأشخاص (أب - أبن، زوج - زوجة، صديق - صديق) جدول موظفين، قد يكون هناك علاقات بين الموظفين (موظف - مدير، موظف - زملاء)
 1 نقطة
1 نقطة -
 بنية الشبكات العصبية الصنعية تتكون الشبكات العصبية الصنعية من عناصر أولية بسيطة من حيث طريقتها في معالجة البيانات تدعى العصبونات، ويمكن تمثيل أي من تلك العصبونات رياضيا -وفق مفاهيم البرمجة غرضية التوجه- على شكل كائن برمجي Object يتضمن كل نسخة (Instance) منه على مصفوفة من أوزان الدخل يساوي حجمها عدد إشارات الدخل الواردة لهذا العصبون والتي قد تتراوح ما بين العشرات والآلاف تبعا لبنية الشبكة العصبية وهيكليتها. إن معالجة العصبون الواحد للإشارات الواردة بسيطة من الناحية الرياضية، حيث يتم ضرب كل إشارة دخل بقيمة الوزن المقابل لها ومن ثم تجمع كافة النواتج لنحصل على مقدار كلي يمثل درجة استثارة العصبون أو شحنته الإجمالية، ومن ثم يرسل هذا الرقم إلى تابع التفعيل، وهو ببساطة علاقة رياضية تحاكي إلى حد ما سلوك العصبونات الحقيقية فيما يخص قانون الكل أو لاشيء مع بعض التصرف لاعتبارات تتعلق بخوارزميات التعليم المستخدمة (إمكانية حساب المشتق الرياضي كما في حالة تابع Sigmoid) أو لاعتبارات براغماتية عملية (سهولة البرمجة وسرعة التنفيذ كما في حالة التابع ReLU) أو حتى لاعتبارات تتعلق بطبيعة البيانات المعالجة (كشيوع استخدام التابع TanH عند التعامل مع بيانات الفئات والأصناف). في نهاية المطاف تستخدم قيمة الاستثارة الإجمالية للعصبون كدخل لتابع التفعيل x هذا، وبتطبيق العلاقة الرياضية الخاصة بتابع التفعيل المحدد للعصبون نحسب قيمة y المقابلة والتي تمثل الآن خرج هذا العصبون. تتألف الشبكات العصبية من بضع عشرات أو مئات أو حتى الآلاف من تلك الوحدات البنائية الأساسية والتي تنتظم في معمارية على شكل طبقات، حيث يحدد لكل طبقة عدد العصبونات التي تتضمنها، ونوع تابع التفعيل المستخدم لعصبونات تلك الطبقة (أي أن تابع التفعيل قد يختلف من طبقة إلى أخرى لكنه عادة ما يكون ذاته لجميع عصبونات الطبقة الواحدة)، وطريقة ارتباطها بالطبقة التي تسبقها والتي تليها (هل هو ربط كامل كأن تصل إشارة دخل واردة من كل عصبون موجود في الطبقة السابقة، أم هو جزئي يأخذ دخله من عصبونات الطبقة السابقة المجاورة لموضعه الحيزي كما هو حال الشبكات العصبية الصنعية التي تحاكي الباحات البصرية في الدماغ بغية التعرف على الأنماط في الصور). الفرق ما بين تدريب واستخدام الشبكات العصبية الصنعية إن تدريب الشبكات العصبية الصنعية يقصد به إيجاد القيم الأنسب لكافة أوزان الدخل لعصبونات الشبكة بحيث تكون قادرة على إعطاء الإجابات الصحيحة بأقل هامش خطأ في مخرجاتها وذلك للمدخلات المعروضة عليها، في حين يقع على عاتق المطور فن تحديد المعمارية الملائمة من حيث عدد الطبقات ونوع تابع تفعيل كل منها وعدد عصبوناته وطريقة ربطها مع بعضها البعض. قد تكون مهمة تدريب الشبكات العصبية الصنعية تحديا حسابيا هائلا تتطلب كما كبيرا من المعالجات الرياضية والتي قد تستغرق زمنا طويلا حتى لو أجريت على حواسيب فائقة، لكن بمجرد الوصول إلى الحل وإيجاد قيم الأوزان الملائمة التي تعطي نتائج مرضية عند معالجتها للبيانات، تصبح مسألة الاستخدام والتطبيق في منتهى البساطة، فكل ما عليك القيام به هو تمرير وحيد عبر طبقات الشبكة يتم خلاله إجراء بضع عمليات ضرب وجمع ومن ثم تطبيق تابع رياضي ما (تابع التفعيل)، وهكذا تمرر القيم من طبقة إلى أخرى وصولا إلى طبقة الخرج النهائية لتظهر من خلالها الإجابة. كيفية حفظ وتصدير الشبكات العصبية الصنعية بعد إتمام عملية تدريب الشبكة العصبية الصنعية والرضى عن نتائجها، كل ما نحتاج إليه هو حفظ بنيتها من حيث عدد الطبقات، وعدد العصبونات في كل طبقة، وطريقة ارتباط عصبونات الطبقات المختلفة بعضها ببعض، وكذلك تابع التفعيل المستخدم في كل طبقة، إضافة إلى قيم الأوزان لكل عصبون على حدة. هذا كل مافي الأمر! فإن حصلت على هذه الأرقام مجددا فأنت قادر على إعادة بناء واستخدام تلك الشبكة العصبية الصنعية بشكلها النهائي بعد أن اكتملت عملية تدريبها. عادة ما تقوم مكتبة TensorFlow بحفظ نموذج الشبكة العصبية الصنعية بكافة وسطائها وقيمها ضمن مجلد خاص بذلك خلال عملية التدريب والذي يمكن قراءته واستعادة بنية شبكته العصبية باستخدام لغة Python (ستجد ضمنه ملف بامتداد *.pb إضافة إلى مجلدين فرعيين هما variables وassets)، لكن هذه الصيغة من الحفظ ملائمة فقط لبيئة التطوير ولا تصلح للتطبيق العملي. عوضا عن ذلك أتاحت Google مجموعة من الصيغ المعيارية المناسبة للتطبيقات المختلفة من أهمها صيغة *.tfjs الموجهة للمبرمجين بلغة JavaScript ذائعة الصيت وواسعة الانتشار في عالم الويب سواء باستخدامها على طرف المستعرض أو حتى على طرف المخدم من خلال تقنية Node.js، كذلك لدينا صيغة *.tflite والمصممة أصلا لتعمل بموارد محدودة من سرعة معالجة ومساحة ذاكرة وذلك بهدف استخدامها على أجهزة الجوال أو إنترنت الأشياء. لا يقتصر الأمر على ذلك فحسب، لكن حزم الشبكات العصبية الصنعية وإعدادها للاستخدام العملي قد يتضمن بعضا من المقايضة بهدف تصغير حجمها وزيادة سرعة عملها ولو كان ذلك على حساب انخفاض طفيف ومقبول في دقة نتائجها، إحدى تلك الخوارزميات على سبيل المثال تقوم بإزالة الروابط التي تقترب قيم أوزانها من الصفر باعتبارها لا تساهم بشكل كبير في مقدار الاستثارة الكلية للعصبون المرتبطة به، في المقابل نكون قد خفضنا عدد الأوزان التي نحن بحاجة إلى حفظها وكذلك قللنا الزمن الكلي اللازم للحساب كون عدد المدخلات أصبح أقل. مكتبة Face-API كما هو واضح من المقدمة السابقة، فنحن لن نقوم هنا ببناء وتدريب شبكة عصبية صنعية من الصفر، لكننا في المقابل سوف نستعرض كيفية استخدام شبكة عصبية صنعية سبق وأن تم تدريبها وذلك ضمن تطبيقنا الخاص. لهذه الغاية أود تعريفكم بمكتبة face-api.js والتي تم بناؤها لأغراض التعرف على الوجوه وتمييزها ضمن بيئة المتصفح إنطلاقا من مكتبة TensorFlow.js، وهي بذلك تقدم مجموعة من نماذج الشبكات العصبية الصنعية المدربة والجاهزة لطيف متنوع من التطبيقات يمكنك الإطلاع عليها من خلال النقر على الرابط التالي لصفحة التوثيق الخاص بهذه المكتبة: https://justadudewhohacks.github.io/face-api.js/docs/ إن المثال الذي سوف نبنيه فيما يلي سيقوم باستخدام كاميرا حاسوبك أو جوالك من خلال صفحة ويب ستقوم ببرمجتها بنفسك لكي يأخذ صورة المستخدم ويقدّر منها عمره وجنسه. تخيل لو أننا نتحدث عن صفحة تسجيل مستخدم جديد في تطبيقك المستقبلي، سيكون من اللطيف والذكي في آن معا لو استطاع التطبيق تحديد القيم الافتراضية للعمر والجنس بناء على صورة المستخدم بحيث تكون قريبة إلى الواقع بطريقة تحسن من تجربة المستخدم. تم بناء نموذج التعرف على العمر والجنس باستخدام شبكة عصبية صنعية متعددة المهام توظف فيها طبقة استخلاص سمات الوجه لتقدير العمر وكذلك لتصنيف الجنس، يبلغ حجم حزمة النموذج بالإجمال قرابة 420kb، وقد تم تدريبها واختبارها باستخدام قواعد بيانات متعددة لصور الوجوه الموسومة بالعمر والجنس الحقيقيين (منها على سبيل المثال موسوعة Wikipedia وقاعدة IMDB للأفلام والممثلين)، وتبلغ دقتها 95% في تحديد الجنس، وهامش خطئها في تحديد العمر يقارب 4 سنوات ونصف. استخدام الشبكات العصبية في نافذة متصفحك لنقم بداية بإنشاء مجلد جديد وليكن اسمه face-api للمشروع الذي سنعمل عليه اليوم ضمن مخدم الويب المحلي الذي لديك لتجربة تطبيقات الويب التي تعمل عليها (أي ضمن المجلد C:\xampp\htdocs على سبيل المثال في حال كنت تستخدم مخدم XAMPP)، سنضيف داخل ذلك المجلد الرئيسي مجلدين فرعيين باسم js وكذلك models، ومن ثم نقوم بنسخ الملفات التي نحتاجها من مكتبة Face-API الأصلية على الشكل التالي: نُنزِّل الصيغة المصغرة/المضغوطة من المكتبة ذاتها (أي الملف "face-api.min.js") ونسخها إلى داخل المجلد الفرعي js في مشروعنا، يمكن الحصول على ذلك الملف من العنوان التالي: https://github.com/justadudewhohacks/face-api.js/tree/master/dist نُنَزِّل نماذج الشبكات العصبية الصنعية التي سنستخدمها، حيث يوجد ملفين لكل نموذج شبكة عصبية أحدهما ينتهي إسمه بكلمة "shard1" تحفظ فيه قيم أوزان الشبكة، أما الآخر فهو ملف بصيغة json يصف بنية الشبكة حتى يتم قراءة وتحميل قيم الأوزان السابقة بشكل سليم. في مثالنا الحالي سنحتاج إلى استخدام شبكتين عصبيتين هما "age_gender_model" و "tiny_face_detector_model"، أي أننا بحاجة إلى تنزيل أربع ملفات ومن ثم نسخها إلى داخل مجلد models في مشروعنا. يمكنك الحصول على تلك الملفات من العنوان التالي: https://github.com/justadudewhohacks/face-api.js/tree/master/weights بعد ذلك سنُنشِئ ملفين جديدين أحدهما سندعوه index.html سنضعه في المجلد الرئيسي للمشروع، أما الآخر فسندعوه main.js ونضعه ضمن المجلد الفرعي js المخصص لشيفرات لغة JavaScript البرمجية. سنقوم بداية بتنقيح محتوى صفحة HTML والتي سنجعلها بأبسط شكل ممكن بغرض التركيز على العناصر الأساسية التي نهتم بها: <html> <head> <title>Face-API Example</title> </head> <body> </body> </html> ضمن قسم body سنقوم بإضافة عنصر div فيه عنصر video لعرض الفيديو الذي تلتقطه كاميرا حاسوبك ندعوه webcam، ويتم ضبطها لتعمل تلقائيا ضمن النمط الصامت بمجرد تحميل الصفحة: <div class="container"> <video id="webcam" height="360" width="360" autoplay muted></video> </div> ثم نضيف حقل إدخال input مخصص للعمر ندعوه age: Age (years): <input id="age" size="3"><br /> بعد ذلك نضيف مجموعة أزرار اختيار من نوع radio ندعوها gender فيها اختيارين اثنين هما male وfemale: <input id="male" type="radio" name="gender" value="male">Male<br /> <input id="female" type="radio" name="gender" value="female">Female<br /> أخيرا وبعد اكتمال تحميل وعرض كافة عناصر الصفحة، نقوم بتضمين ملفات جافاسكريبت في نهاية محتويات الصفحة حتى نكون متأكدين من وصولها برمجيا لكافة العناصر ضمن تلك الصفحة: <script src="js/face-api.min.js"></script> <script src="js/main.js"></script> ملاحظة هامة: بسبب إعدادات الأمان فإن معظم متصفحات الويب تعرض رسالة للمستخدم تبيّن رغبة الصفحة في الوصول إلى الكاميرا وتطلب الإذن للسماح لها بذلك. هذا كل ما هو مطلوب فعليا ضمن صفحة HTML الخاصة بهذا المثال، أما الآن فعلينا الانتقال إلى لكتابة شيفرات لغة جافاسكريبت التي ستقوم بتحميل نموذج الشبكة العصبية الصنعية، وتمرير صور الكاميرا إليه، ومن ثم قراءة الخرج الناتج عن الشبكة العصبية الصنعية وعرضه ضمن عناصر الإدخال المقابلة في صفحة HTML السابقة. لذلك سنبدأ بكتابة محتوى الملف main.js من الشيفرات البرمجية مع شرح مختصر لكل قسم منها، فالسطر الأول يقوم بتعيين اسم الثابت video للإشارة إلى العنصر المدعوة webcam ضمن صفحة HTML السابقة: const video = document.getElementById("webcam"); بعد ذلك نقوم بتحميل نموذجي الشبكتين العصبيتين الخاصتين بالتعرف على الوجوه ضمن الصورة وتحديد الجنس وتقدير العمر من خلال سمات تلك الوجوه وذلك باستخدام آلية الوعود Promise.all، ومن بعد إتمام ذلك يتم استدعاء التابع startVideo الذي سنقوم بتعريفه لاحقا: Promise.all([ faceapi.nets.tinyFaceDetector.loadFromUri("models"), faceapi.nets.ageGenderNet.loadFromUri("models") ]).then(startVideo); يقوم هذا التابع بقراءة دفق إشارة الفيديو من الكاميرا وعرضها ضمن الكائن video، فإن حدث خطأ يتم كتابة رسالة الخطأ ضمن console.error في المستعرض: function startVideo() { navigator.getUserMedia( { video: {} }, stream => (video.srcObject = stream), err => console.error(err) ); } ومن ثم نضيف حدث يقوم بالإنصات لما يتم عرضه ضمن عنصر video بحيث يستدعي بشكل غير متزامن async (أي دون الحاجة لانتظار الإجابة حتى يتابع عرض الفيديو) وذلك كل ثانية (حيث تم ضبط الفترة الزمنية setInterval لتكون قيمتها 1000 ميلي ثانية). يقوم هذا الاستدعاء الدوري المتكرر بتعيين قيمة الكائن detection بواسطة مكتبة faceapi حيث تحدد جميع الوجوه الموجودة ضمن كائن video بالاستعانة بنموذج TinyFaceDetector مستخدمين الإعدادات الافتراضية، ومن ثم يمرر الناتج (أي الوجوه التي تم التعرف عليها في الصورة)، إلى الشبكة العصبية الأخرى التي تتعرف على العمر والجنس: video.addEventListener("playing", () => { setInterval(async () => { const detections = await faceapi .detectAllFaces(video, new faceapi.TinyFaceDetectorOptions()) .withAgeAndGender(); إن العبارة الشرطية التالية تتأكد إن كان الكائن detections موجودا أصلا (تذكر أن تعيين قيمة هذا الكائن تتم من خلال استدعاء غير متزامن وبالتالي يمكن أن تكون القيمة غير موجودة في البداية ريثما تصل إجابة ذلك الاستدعاء). ليس هذا فحسب، بل يجب أن يتضمن على الأقل وجه واحد على الأقل. فإن تحقق هذين الشرطين يتم قراءة الجنس المتوقع للوجه الأول detections[0].gender وتعيينه لعنصر الإدخال المقابل له، وكذلك قراءة العمر المتوقع لذات الوجه الأول detections[0].age وتقريبه إلى أقرب عدد صحيح باستخدام التابع Math.round ومن ثم إسناده كقيمة لعنصر الإدخال المدعو age ضمن صفحة HTML السابقة: if (detections && Object.keys(detections).length > 0) { document.getElementById(detections[0].gender).checked = true; document.getElementById("age").value = Math.round(detections[0].age); } }, 1000); }); هذا كل شيء! تستطيع الآن تجربة هذا التطبيق البسيط من خلال عرض الصفحة على نافذة المستعرض مستخدمين عنوانها على مخدم الويب المحلي وليكن على سبيل المثال: http://localhost/face-api نقاط تستحق التأمل من منا لا تغريه كم الإسقاطات التي تطرحها تقنية الشبكات العصبية الصنعية على مفهوم البرمجة ككل؟ إنها بذور جيل جديد مختلف جذريا عن كل ما سبق وأن اعتدنا عليه، فرغم أنها تعتمد على وحدات بسيطة في صميمها هي العصبونات، والتي قمنا بوصف آلية عملها بطريقة خوارزمية محددة تماما وواضحة، إلا أننا مع نمو شبكاتنا في الحجم والتعقيد استبدلنا الثقة بالأمل، والتحليل بالتجريب. لنأخذ على سبيل المثال نموذج اللغة العربية، فحتى نستطيع تشكيل أي جملة نستخدم علم النحو والإعراب الذي تعلمناه في مدارسنا، ومن خلال قواعده نحدد بناء الجملة وعناصرها كالفعل والفاعل أو المبتدأ والخبر وسواها من القواعد التي تساعدنا على ضبط أواخر الكلمات. هذه هي تماما الطريقة التي نبرمج بها حواسيبنا حاليا (منذ أيام تشارلز بابيج وحاسوبه الميكانيكي قبل مئتي عام)، فنحن نضع القواعد الصارمة لتدفق البيانات ونترجمها إلى عبارات شرطية وحلقات وسواها من بنى التحكم في عدد منتهي من الخطوات ندعوها بالخوارزمية. لكن لحظة، هل هذه هي الطريقة الصحيحة فعلا التي تجري بها الأمور؟ هل هذا ما نفعله حقيقة عندما يلتبس علينا تشكيل كلمة ما في نص نقرأه أو جملة نتحدثها؟ أغلب الظن ستكون إجابتك هي النفي! فمعظمنا لا يعرب الجملة في رأسه ليضبط أواخر الكلمات، بل نجرب الاحتمالات المختلفة ونرى أيها يملك الوقع الأكثر تجانسا وانسجاما في نفسنا (على سبيل المثال: هل أباك/أبوك/أبيك موجود؟). إنها ببساطة ما ندعوه بالسليقة اللغوية، وهي التي تفسر قدرة الطفل الصغير على التكلم بلغة صحيحة حتى قبل معرفته بوجود علم النحو والإعراب أصلا، فهو يتعلم مما يسمع وينسج على منواله، فكلما كانت الأمثلة كثيرة وصحيحة ازداد اتقانه للغة (ولهذا السبب كان العرب يرسلون أبنائهم إلى البادية لسلامة اللغة من اللحن الأعجمي هناك). إن التعلم من خلال الأمثلة هو ما تقوم به تماما الشبكات العصبية الصنعية التي نقوم بتطويرها، إنها تقوم ببناء خبرتها وسليقتها وفراستها الخاصة، في نهاية المطاف يمتلك كل من المبتدئ والخبير القواعد ذاتها، لكن عين الخبير رأت الكثير من الأمثلة التي صقلت بها خبرتها، حتى وصلت من التعقيد إلى درجة قد يصعب معها التفسير رغم قوة الإحساس ووضوحه في ذهنه. وهكذا ينتقل دور المبرمج رويدا رويدا من وضع القواعد وبنى التحكم لبرمجياته إلى ما بات يدعى اليوم بعلم البيانات وهندسة عملية استخلاص المزايا والخصائص المؤثرة في عملية التعلم من تلك البيانات، حيث أن دقة وجودة النموذج الناتج تعتمد بشكل حاسم على تكامل أمثلة التعليم وشمولها وصحتها، وأصبح امتلاك مثل هكذا مكانز رقمية موصّفة بشكل دقيق ومبنية بطريقة هيكلية سهلة الولوج والاستعلام يعادل قطع ما يتجاوز نصف الطريق إلى الوصول لعالم الذكاء الصنعي التطبيقي وقطف ثماره. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن مراجع للاستزادة مكتبة TensorFlow مكتبة face-api.js Model optimization اقرأ أيضًا المقال السابق: تصنيف الصور والتعرف على الوجه في مجال الذكاء الاصطناعي المفاهيم الأساسية لتعلم الآلة1 نقطة
بنية الشبكات العصبية الصنعية تتكون الشبكات العصبية الصنعية من عناصر أولية بسيطة من حيث طريقتها في معالجة البيانات تدعى العصبونات، ويمكن تمثيل أي من تلك العصبونات رياضيا -وفق مفاهيم البرمجة غرضية التوجه- على شكل كائن برمجي Object يتضمن كل نسخة (Instance) منه على مصفوفة من أوزان الدخل يساوي حجمها عدد إشارات الدخل الواردة لهذا العصبون والتي قد تتراوح ما بين العشرات والآلاف تبعا لبنية الشبكة العصبية وهيكليتها. إن معالجة العصبون الواحد للإشارات الواردة بسيطة من الناحية الرياضية، حيث يتم ضرب كل إشارة دخل بقيمة الوزن المقابل لها ومن ثم تجمع كافة النواتج لنحصل على مقدار كلي يمثل درجة استثارة العصبون أو شحنته الإجمالية، ومن ثم يرسل هذا الرقم إلى تابع التفعيل، وهو ببساطة علاقة رياضية تحاكي إلى حد ما سلوك العصبونات الحقيقية فيما يخص قانون الكل أو لاشيء مع بعض التصرف لاعتبارات تتعلق بخوارزميات التعليم المستخدمة (إمكانية حساب المشتق الرياضي كما في حالة تابع Sigmoid) أو لاعتبارات براغماتية عملية (سهولة البرمجة وسرعة التنفيذ كما في حالة التابع ReLU) أو حتى لاعتبارات تتعلق بطبيعة البيانات المعالجة (كشيوع استخدام التابع TanH عند التعامل مع بيانات الفئات والأصناف). في نهاية المطاف تستخدم قيمة الاستثارة الإجمالية للعصبون كدخل لتابع التفعيل x هذا، وبتطبيق العلاقة الرياضية الخاصة بتابع التفعيل المحدد للعصبون نحسب قيمة y المقابلة والتي تمثل الآن خرج هذا العصبون. تتألف الشبكات العصبية من بضع عشرات أو مئات أو حتى الآلاف من تلك الوحدات البنائية الأساسية والتي تنتظم في معمارية على شكل طبقات، حيث يحدد لكل طبقة عدد العصبونات التي تتضمنها، ونوع تابع التفعيل المستخدم لعصبونات تلك الطبقة (أي أن تابع التفعيل قد يختلف من طبقة إلى أخرى لكنه عادة ما يكون ذاته لجميع عصبونات الطبقة الواحدة)، وطريقة ارتباطها بالطبقة التي تسبقها والتي تليها (هل هو ربط كامل كأن تصل إشارة دخل واردة من كل عصبون موجود في الطبقة السابقة، أم هو جزئي يأخذ دخله من عصبونات الطبقة السابقة المجاورة لموضعه الحيزي كما هو حال الشبكات العصبية الصنعية التي تحاكي الباحات البصرية في الدماغ بغية التعرف على الأنماط في الصور). الفرق ما بين تدريب واستخدام الشبكات العصبية الصنعية إن تدريب الشبكات العصبية الصنعية يقصد به إيجاد القيم الأنسب لكافة أوزان الدخل لعصبونات الشبكة بحيث تكون قادرة على إعطاء الإجابات الصحيحة بأقل هامش خطأ في مخرجاتها وذلك للمدخلات المعروضة عليها، في حين يقع على عاتق المطور فن تحديد المعمارية الملائمة من حيث عدد الطبقات ونوع تابع تفعيل كل منها وعدد عصبوناته وطريقة ربطها مع بعضها البعض. قد تكون مهمة تدريب الشبكات العصبية الصنعية تحديا حسابيا هائلا تتطلب كما كبيرا من المعالجات الرياضية والتي قد تستغرق زمنا طويلا حتى لو أجريت على حواسيب فائقة، لكن بمجرد الوصول إلى الحل وإيجاد قيم الأوزان الملائمة التي تعطي نتائج مرضية عند معالجتها للبيانات، تصبح مسألة الاستخدام والتطبيق في منتهى البساطة، فكل ما عليك القيام به هو تمرير وحيد عبر طبقات الشبكة يتم خلاله إجراء بضع عمليات ضرب وجمع ومن ثم تطبيق تابع رياضي ما (تابع التفعيل)، وهكذا تمرر القيم من طبقة إلى أخرى وصولا إلى طبقة الخرج النهائية لتظهر من خلالها الإجابة. كيفية حفظ وتصدير الشبكات العصبية الصنعية بعد إتمام عملية تدريب الشبكة العصبية الصنعية والرضى عن نتائجها، كل ما نحتاج إليه هو حفظ بنيتها من حيث عدد الطبقات، وعدد العصبونات في كل طبقة، وطريقة ارتباط عصبونات الطبقات المختلفة بعضها ببعض، وكذلك تابع التفعيل المستخدم في كل طبقة، إضافة إلى قيم الأوزان لكل عصبون على حدة. هذا كل مافي الأمر! فإن حصلت على هذه الأرقام مجددا فأنت قادر على إعادة بناء واستخدام تلك الشبكة العصبية الصنعية بشكلها النهائي بعد أن اكتملت عملية تدريبها. عادة ما تقوم مكتبة TensorFlow بحفظ نموذج الشبكة العصبية الصنعية بكافة وسطائها وقيمها ضمن مجلد خاص بذلك خلال عملية التدريب والذي يمكن قراءته واستعادة بنية شبكته العصبية باستخدام لغة Python (ستجد ضمنه ملف بامتداد *.pb إضافة إلى مجلدين فرعيين هما variables وassets)، لكن هذه الصيغة من الحفظ ملائمة فقط لبيئة التطوير ولا تصلح للتطبيق العملي. عوضا عن ذلك أتاحت Google مجموعة من الصيغ المعيارية المناسبة للتطبيقات المختلفة من أهمها صيغة *.tfjs الموجهة للمبرمجين بلغة JavaScript ذائعة الصيت وواسعة الانتشار في عالم الويب سواء باستخدامها على طرف المستعرض أو حتى على طرف المخدم من خلال تقنية Node.js، كذلك لدينا صيغة *.tflite والمصممة أصلا لتعمل بموارد محدودة من سرعة معالجة ومساحة ذاكرة وذلك بهدف استخدامها على أجهزة الجوال أو إنترنت الأشياء. لا يقتصر الأمر على ذلك فحسب، لكن حزم الشبكات العصبية الصنعية وإعدادها للاستخدام العملي قد يتضمن بعضا من المقايضة بهدف تصغير حجمها وزيادة سرعة عملها ولو كان ذلك على حساب انخفاض طفيف ومقبول في دقة نتائجها، إحدى تلك الخوارزميات على سبيل المثال تقوم بإزالة الروابط التي تقترب قيم أوزانها من الصفر باعتبارها لا تساهم بشكل كبير في مقدار الاستثارة الكلية للعصبون المرتبطة به، في المقابل نكون قد خفضنا عدد الأوزان التي نحن بحاجة إلى حفظها وكذلك قللنا الزمن الكلي اللازم للحساب كون عدد المدخلات أصبح أقل. مكتبة Face-API كما هو واضح من المقدمة السابقة، فنحن لن نقوم هنا ببناء وتدريب شبكة عصبية صنعية من الصفر، لكننا في المقابل سوف نستعرض كيفية استخدام شبكة عصبية صنعية سبق وأن تم تدريبها وذلك ضمن تطبيقنا الخاص. لهذه الغاية أود تعريفكم بمكتبة face-api.js والتي تم بناؤها لأغراض التعرف على الوجوه وتمييزها ضمن بيئة المتصفح إنطلاقا من مكتبة TensorFlow.js، وهي بذلك تقدم مجموعة من نماذج الشبكات العصبية الصنعية المدربة والجاهزة لطيف متنوع من التطبيقات يمكنك الإطلاع عليها من خلال النقر على الرابط التالي لصفحة التوثيق الخاص بهذه المكتبة: https://justadudewhohacks.github.io/face-api.js/docs/ إن المثال الذي سوف نبنيه فيما يلي سيقوم باستخدام كاميرا حاسوبك أو جوالك من خلال صفحة ويب ستقوم ببرمجتها بنفسك لكي يأخذ صورة المستخدم ويقدّر منها عمره وجنسه. تخيل لو أننا نتحدث عن صفحة تسجيل مستخدم جديد في تطبيقك المستقبلي، سيكون من اللطيف والذكي في آن معا لو استطاع التطبيق تحديد القيم الافتراضية للعمر والجنس بناء على صورة المستخدم بحيث تكون قريبة إلى الواقع بطريقة تحسن من تجربة المستخدم. تم بناء نموذج التعرف على العمر والجنس باستخدام شبكة عصبية صنعية متعددة المهام توظف فيها طبقة استخلاص سمات الوجه لتقدير العمر وكذلك لتصنيف الجنس، يبلغ حجم حزمة النموذج بالإجمال قرابة 420kb، وقد تم تدريبها واختبارها باستخدام قواعد بيانات متعددة لصور الوجوه الموسومة بالعمر والجنس الحقيقيين (منها على سبيل المثال موسوعة Wikipedia وقاعدة IMDB للأفلام والممثلين)، وتبلغ دقتها 95% في تحديد الجنس، وهامش خطئها في تحديد العمر يقارب 4 سنوات ونصف. استخدام الشبكات العصبية في نافذة متصفحك لنقم بداية بإنشاء مجلد جديد وليكن اسمه face-api للمشروع الذي سنعمل عليه اليوم ضمن مخدم الويب المحلي الذي لديك لتجربة تطبيقات الويب التي تعمل عليها (أي ضمن المجلد C:\xampp\htdocs على سبيل المثال في حال كنت تستخدم مخدم XAMPP)، سنضيف داخل ذلك المجلد الرئيسي مجلدين فرعيين باسم js وكذلك models، ومن ثم نقوم بنسخ الملفات التي نحتاجها من مكتبة Face-API الأصلية على الشكل التالي: نُنزِّل الصيغة المصغرة/المضغوطة من المكتبة ذاتها (أي الملف "face-api.min.js") ونسخها إلى داخل المجلد الفرعي js في مشروعنا، يمكن الحصول على ذلك الملف من العنوان التالي: https://github.com/justadudewhohacks/face-api.js/tree/master/dist نُنَزِّل نماذج الشبكات العصبية الصنعية التي سنستخدمها، حيث يوجد ملفين لكل نموذج شبكة عصبية أحدهما ينتهي إسمه بكلمة "shard1" تحفظ فيه قيم أوزان الشبكة، أما الآخر فهو ملف بصيغة json يصف بنية الشبكة حتى يتم قراءة وتحميل قيم الأوزان السابقة بشكل سليم. في مثالنا الحالي سنحتاج إلى استخدام شبكتين عصبيتين هما "age_gender_model" و "tiny_face_detector_model"، أي أننا بحاجة إلى تنزيل أربع ملفات ومن ثم نسخها إلى داخل مجلد models في مشروعنا. يمكنك الحصول على تلك الملفات من العنوان التالي: https://github.com/justadudewhohacks/face-api.js/tree/master/weights بعد ذلك سنُنشِئ ملفين جديدين أحدهما سندعوه index.html سنضعه في المجلد الرئيسي للمشروع، أما الآخر فسندعوه main.js ونضعه ضمن المجلد الفرعي js المخصص لشيفرات لغة JavaScript البرمجية. سنقوم بداية بتنقيح محتوى صفحة HTML والتي سنجعلها بأبسط شكل ممكن بغرض التركيز على العناصر الأساسية التي نهتم بها: <html> <head> <title>Face-API Example</title> </head> <body> </body> </html> ضمن قسم body سنقوم بإضافة عنصر div فيه عنصر video لعرض الفيديو الذي تلتقطه كاميرا حاسوبك ندعوه webcam، ويتم ضبطها لتعمل تلقائيا ضمن النمط الصامت بمجرد تحميل الصفحة: <div class="container"> <video id="webcam" height="360" width="360" autoplay muted></video> </div> ثم نضيف حقل إدخال input مخصص للعمر ندعوه age: Age (years): <input id="age" size="3"><br /> بعد ذلك نضيف مجموعة أزرار اختيار من نوع radio ندعوها gender فيها اختيارين اثنين هما male وfemale: <input id="male" type="radio" name="gender" value="male">Male<br /> <input id="female" type="radio" name="gender" value="female">Female<br /> أخيرا وبعد اكتمال تحميل وعرض كافة عناصر الصفحة، نقوم بتضمين ملفات جافاسكريبت في نهاية محتويات الصفحة حتى نكون متأكدين من وصولها برمجيا لكافة العناصر ضمن تلك الصفحة: <script src="js/face-api.min.js"></script> <script src="js/main.js"></script> ملاحظة هامة: بسبب إعدادات الأمان فإن معظم متصفحات الويب تعرض رسالة للمستخدم تبيّن رغبة الصفحة في الوصول إلى الكاميرا وتطلب الإذن للسماح لها بذلك. هذا كل ما هو مطلوب فعليا ضمن صفحة HTML الخاصة بهذا المثال، أما الآن فعلينا الانتقال إلى لكتابة شيفرات لغة جافاسكريبت التي ستقوم بتحميل نموذج الشبكة العصبية الصنعية، وتمرير صور الكاميرا إليه، ومن ثم قراءة الخرج الناتج عن الشبكة العصبية الصنعية وعرضه ضمن عناصر الإدخال المقابلة في صفحة HTML السابقة. لذلك سنبدأ بكتابة محتوى الملف main.js من الشيفرات البرمجية مع شرح مختصر لكل قسم منها، فالسطر الأول يقوم بتعيين اسم الثابت video للإشارة إلى العنصر المدعوة webcam ضمن صفحة HTML السابقة: const video = document.getElementById("webcam"); بعد ذلك نقوم بتحميل نموذجي الشبكتين العصبيتين الخاصتين بالتعرف على الوجوه ضمن الصورة وتحديد الجنس وتقدير العمر من خلال سمات تلك الوجوه وذلك باستخدام آلية الوعود Promise.all، ومن بعد إتمام ذلك يتم استدعاء التابع startVideo الذي سنقوم بتعريفه لاحقا: Promise.all([ faceapi.nets.tinyFaceDetector.loadFromUri("models"), faceapi.nets.ageGenderNet.loadFromUri("models") ]).then(startVideo); يقوم هذا التابع بقراءة دفق إشارة الفيديو من الكاميرا وعرضها ضمن الكائن video، فإن حدث خطأ يتم كتابة رسالة الخطأ ضمن console.error في المستعرض: function startVideo() { navigator.getUserMedia( { video: {} }, stream => (video.srcObject = stream), err => console.error(err) ); } ومن ثم نضيف حدث يقوم بالإنصات لما يتم عرضه ضمن عنصر video بحيث يستدعي بشكل غير متزامن async (أي دون الحاجة لانتظار الإجابة حتى يتابع عرض الفيديو) وذلك كل ثانية (حيث تم ضبط الفترة الزمنية setInterval لتكون قيمتها 1000 ميلي ثانية). يقوم هذا الاستدعاء الدوري المتكرر بتعيين قيمة الكائن detection بواسطة مكتبة faceapi حيث تحدد جميع الوجوه الموجودة ضمن كائن video بالاستعانة بنموذج TinyFaceDetector مستخدمين الإعدادات الافتراضية، ومن ثم يمرر الناتج (أي الوجوه التي تم التعرف عليها في الصورة)، إلى الشبكة العصبية الأخرى التي تتعرف على العمر والجنس: video.addEventListener("playing", () => { setInterval(async () => { const detections = await faceapi .detectAllFaces(video, new faceapi.TinyFaceDetectorOptions()) .withAgeAndGender(); إن العبارة الشرطية التالية تتأكد إن كان الكائن detections موجودا أصلا (تذكر أن تعيين قيمة هذا الكائن تتم من خلال استدعاء غير متزامن وبالتالي يمكن أن تكون القيمة غير موجودة في البداية ريثما تصل إجابة ذلك الاستدعاء). ليس هذا فحسب، بل يجب أن يتضمن على الأقل وجه واحد على الأقل. فإن تحقق هذين الشرطين يتم قراءة الجنس المتوقع للوجه الأول detections[0].gender وتعيينه لعنصر الإدخال المقابل له، وكذلك قراءة العمر المتوقع لذات الوجه الأول detections[0].age وتقريبه إلى أقرب عدد صحيح باستخدام التابع Math.round ومن ثم إسناده كقيمة لعنصر الإدخال المدعو age ضمن صفحة HTML السابقة: if (detections && Object.keys(detections).length > 0) { document.getElementById(detections[0].gender).checked = true; document.getElementById("age").value = Math.round(detections[0].age); } }, 1000); }); هذا كل شيء! تستطيع الآن تجربة هذا التطبيق البسيط من خلال عرض الصفحة على نافذة المستعرض مستخدمين عنوانها على مخدم الويب المحلي وليكن على سبيل المثال: http://localhost/face-api نقاط تستحق التأمل من منا لا تغريه كم الإسقاطات التي تطرحها تقنية الشبكات العصبية الصنعية على مفهوم البرمجة ككل؟ إنها بذور جيل جديد مختلف جذريا عن كل ما سبق وأن اعتدنا عليه، فرغم أنها تعتمد على وحدات بسيطة في صميمها هي العصبونات، والتي قمنا بوصف آلية عملها بطريقة خوارزمية محددة تماما وواضحة، إلا أننا مع نمو شبكاتنا في الحجم والتعقيد استبدلنا الثقة بالأمل، والتحليل بالتجريب. لنأخذ على سبيل المثال نموذج اللغة العربية، فحتى نستطيع تشكيل أي جملة نستخدم علم النحو والإعراب الذي تعلمناه في مدارسنا، ومن خلال قواعده نحدد بناء الجملة وعناصرها كالفعل والفاعل أو المبتدأ والخبر وسواها من القواعد التي تساعدنا على ضبط أواخر الكلمات. هذه هي تماما الطريقة التي نبرمج بها حواسيبنا حاليا (منذ أيام تشارلز بابيج وحاسوبه الميكانيكي قبل مئتي عام)، فنحن نضع القواعد الصارمة لتدفق البيانات ونترجمها إلى عبارات شرطية وحلقات وسواها من بنى التحكم في عدد منتهي من الخطوات ندعوها بالخوارزمية. لكن لحظة، هل هذه هي الطريقة الصحيحة فعلا التي تجري بها الأمور؟ هل هذا ما نفعله حقيقة عندما يلتبس علينا تشكيل كلمة ما في نص نقرأه أو جملة نتحدثها؟ أغلب الظن ستكون إجابتك هي النفي! فمعظمنا لا يعرب الجملة في رأسه ليضبط أواخر الكلمات، بل نجرب الاحتمالات المختلفة ونرى أيها يملك الوقع الأكثر تجانسا وانسجاما في نفسنا (على سبيل المثال: هل أباك/أبوك/أبيك موجود؟). إنها ببساطة ما ندعوه بالسليقة اللغوية، وهي التي تفسر قدرة الطفل الصغير على التكلم بلغة صحيحة حتى قبل معرفته بوجود علم النحو والإعراب أصلا، فهو يتعلم مما يسمع وينسج على منواله، فكلما كانت الأمثلة كثيرة وصحيحة ازداد اتقانه للغة (ولهذا السبب كان العرب يرسلون أبنائهم إلى البادية لسلامة اللغة من اللحن الأعجمي هناك). إن التعلم من خلال الأمثلة هو ما تقوم به تماما الشبكات العصبية الصنعية التي نقوم بتطويرها، إنها تقوم ببناء خبرتها وسليقتها وفراستها الخاصة، في نهاية المطاف يمتلك كل من المبتدئ والخبير القواعد ذاتها، لكن عين الخبير رأت الكثير من الأمثلة التي صقلت بها خبرتها، حتى وصلت من التعقيد إلى درجة قد يصعب معها التفسير رغم قوة الإحساس ووضوحه في ذهنه. وهكذا ينتقل دور المبرمج رويدا رويدا من وضع القواعد وبنى التحكم لبرمجياته إلى ما بات يدعى اليوم بعلم البيانات وهندسة عملية استخلاص المزايا والخصائص المؤثرة في عملية التعلم من تلك البيانات، حيث أن دقة وجودة النموذج الناتج تعتمد بشكل حاسم على تكامل أمثلة التعليم وشمولها وصحتها، وأصبح امتلاك مثل هكذا مكانز رقمية موصّفة بشكل دقيق ومبنية بطريقة هيكلية سهلة الولوج والاستعلام يعادل قطع ما يتجاوز نصف الطريق إلى الوصول لعالم الذكاء الصنعي التطبيقي وقطف ثماره. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن مراجع للاستزادة مكتبة TensorFlow مكتبة face-api.js Model optimization اقرأ أيضًا المقال السابق: تصنيف الصور والتعرف على الوجه في مجال الذكاء الاصطناعي المفاهيم الأساسية لتعلم الآلة1 نقطة -
 سنتناول في هذا القسم نوعًا آخر من الحَلْقات، هو تَعْليمَة الحَلْقة for. ينبغي أن تُدرك أنه يُمكن لأيّ حَلْقة تَكْرارية (loop) عامةً أن تُكتَب بأيّ من التَعْليمَتين for و while، وهو ما يَعني أن لغة الجافا لم تتَحَصَّل على أيّ مِيزَة وظيفية إضافية بتَدْعِيمها لتَعْليمَة for. لا يَعني ذلك أن تَعْليمَة for غَيْر مُهمة، على العكس تمامًا، ففي الواقع، قد يَتجاوز عَدَد حَلْقات for المُستخدَمة ببعض البرامج عَدَد حَلْقات while. (كما أن الكاتب على معرفة بأحد المبرمجين والذي لا يَستخدِم سوى حَلْقات for). الفكرة ببساطة أن تَعْليمَة for تكون أكثر ملائمة لبعض النوعيات من المسائل؛ حيث تُسهِل من كتابة الحَلْقات وقرائتها بالموازنة مع حَلْقة while. حلقة التكرار For عادةً ما تُستخدَم حَلْقة التَكْرار while بالصياغة التالية: <initialization> while ( <continuation-condition> ) { <statements> <update> } مثلًا، اُنظر لهذا المثال من القسم ٣.٢: years = 0; // هيئ المتغير while ( years < 5 ) { // شرط حلقة التكرار // نفذ التعليمات الثلاثة التالية interest = principal * rate; principal += interest; System.out.println(principal); // حدث قيمة المتغير years++; } ولهذا أضيفت تَعْليمَة for للتسهيل من كتابة هذا النوع من الحَلْقات، حيث يُمكِن إِعادة كتابة حَلْقة التَكْرار بالأعلى باستخدام تَعْليمَة for، كالتالي: for ( years = 0; years < 5; years++ ) { interest = principal * rate; principal += interest; System.out.println(principal); } لاحظ كيف دُمجَت كُُلًا من تعليمات التهيئة ، والشَّرْط الاستمراري لحَلْقة التَكْرار ، والتَحْدِيث جميعًا بسَطْر واحد هو السَطْر الأول من حَلْقة التَكْرار for. يُسهِل ذلك من قراءة حَلْقة التَكْرار وفهمها؛ لأن جميع تَعْليمَات التحكُّم بالحَلْقة (loop control) قد ضُمِّنت بمكان واحد بشكل منفصل عن مَتْن الحَلْقة الفعليّ المطلوب تَكْرار تَّنْفيذه. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن تُنفَّذ حَلْقة التَكْرار for بالأعلى بنفس الطريقة التي تُنفَّذ بها الشيفرة الأصلية، أي تُنفَّذ أولًا تعليمة التهيئة مرة وحيدة قبل بدء تَّنْفيذ الحَلْقة، ثم يُفحَص الشَّرْط الاستمراري للحَلْقة قَبْل كل تَكْرار (iteration/execution) لمَتْن الحَلْقة، بما في ذلك التَكْرار الأوَّليّ (first iteration)، بحيث تَتوقَف الحَلْقة عندما يؤول هذا الشَّرْط إلى القيمة false. وأخيرًا، تُنفَّذ تعليمة التَحْدِيث بنهاية كل تَكْرار (iteration/execution) قَبْل العودة لفَحْص الشَّرْط من جديد. تُكتَب تَعْليمَة حَلْقة التَكْرار for بالصياغة التالية: for ( <initialization>; <continuation-condition>; <update> ) <statement> أو كالتالي إذا كانت التعليمة كُتليّة البِنْية (block statement): for ( <initialization>; <continuation-condition>; <update> ) { <statements> } يُمكِن لأيّ تعبير منطقي (boolean-valued expression) أن يُستخدَم محل الشَّرْط الاستمراري . يُمكِن لأيّ تعبير (expression) -طالما كان صالحًا كتَعْليمَة برمجية- أن يُستخدَم محل تعليمة التهيئة ، وفي الواقع غالبًا ما تُستخدَم تَعْليمَة تَّصْريح (declaration) أو إِسْناد (assignment). يُمكِن لأي تَعْليمَة بسيطة (simple statement) أن تُستخدَم محل تعليمة التَحْدِيث ، وعادةً ما تكون تَعْليمَة زيادة/نقصان (increment/decrement) أو إِسْناد (assignment). وأخيرًا، يُمكِن لأي من تلك التعليمات الثلاثة بالأعلى أن تكون فارغة. لاحظ أنه إذا كان الشَّرْط الاستمراري فارغًا، فإنه يُعامَل وكأنه يُعيد القيمة المنطقية true، أي يُعدّ الشَّرْط مُتحقِّقًا، مما يعني تَّنْفيذ مَتْن حَلْقة التَكْرار (loop body) بشكل لا نهائي (infinite loop) إلى أن يتم إيقافها لسبب ما، مثل اِستخدَام تَعْليمَة break. يُفضِّل بعض المبرمجين في الواقع تَّنْفيذ الحَلْقة اللا نهائية (infinite loop) باِستخدَام الصياغة for (;;) بدلًا من while (true). يُوضح المخطط (diagram) التالي مَسار التحكُّم (flow control) أثناء تَّنْفيذ حَلْقة التَكْرار for: عادةً ما تُسْنِد تعليمة التهيئة قيمة ما إلى مُتَغيِّر معين، ثم تُعدِّل تعليمة التَحْدِيث قيمة هذا المُتَغيِّر إِمّا بواسطة تَعْليمَة إِسْناد (assignment) وإِمّا بعملية زيادة/نُقصان (increment/decrement)، وتُفْحَص تلك القيمة من خلال الشَّرْط الاستمراري لحَلْقة التَكْرار (continuation condition)، فتَتوقَف الحَلْقة عندما يؤول الشَّرْط إلى القيمة المنطقية false. يُطلق عادة على المُتَغيِّر المُستخدَم بهذه الطريقة اسم المُتحكِّم بالحَلْقة (loop control variable). في المثال بالأعلى، كان المُتحكِّم بالحَلْقة هو المُتَغيِّر years. تُعدّ حَلْقة العَدّ (counting loop) هي النوع الأكثر شيوعًا من حَلْقات التَكْرار for، والتي يأخذ فيها المُتَغيِّر المُتحكِّم بالحَلْقة (loop control variable) قيم جميع الأعداد الصحيحة (integer) الواقعة بين قيمتين إحداهما صغرى (minimum) والآخرى عظمى (maximum). تُكتَب حَلْقة العَدّ كالتالي: for ( <variable> = <min>; <variable> <= <max>; <variable>++ ) { <statements> } يُمكِن لأيّ تعبير يُعيد عددًا صحيحًا (integer-valued expressions) أن يُستخدَم محل و ، ولكن تُستخدَم عادةً قيم ثابتة (constants). يأخذ المُتَغيِّر -المشار إليه باستخدام بالأعلى والمعروف باسم المُتحكِّم بالحَلْقة (loop control variable)- القيم المتراوحة بين و ، أي القيم <min>+1 و <min>+2 ..وحتى . وغالبًا ما تُستخدَم قيمة هذا المُتَغيِّر داخل المَتْن (body). مثلًا، حَلْقة التَكْرار for بالأعلى هي حَلْقة عَدّ يأخذ فيها المُتَغيِّر المُتحكِّم بالحَلْقة years القيم ١ و ٢ و ٣ و ٤ و ٥. تطبع الشيفرة التالية قيم الأعداد من ١ إلى ١٠ إلى الخَرْج القياسي (standard output): for ( N = 1 ; N <= 10 ; N++ ) System.out.println( N ); مع ذلك، يُفضِّل مبرمجي لغة الجافا بدء العَدّ (counting) من ٠ بدلًا من ١، كما أنهم يميلون إلى اِستخدَام العَامِل > للموازنة بدلًا من <=. تطبع الشيفرة التالية قيم الأعداد العشرة ٠، ١، ٢، …، ٩، كالتالي: for ( N = 0 ; N < 10 ; N++ ) System.out.println( N ); يُعدّ اِستخدَام عَامِل الموازنة > بدلًا من <= أو العكس مصدرًا شائعًا لحُدوث الأخطاء بفارق الواحد (off-by-one errors) بالبرامج. حاول دائمًا أن تأخذ وقتًا للتفكير إذا ما كنت تَرغَب بمعالجة القيمة النهائية أم لا. يُمكنك أيضًا إجراء العَدّ التنازلي، وهو ما قد يكون أسهل قليلًا من العَدّ التصاعدي. فمثلًا، لإجراء عَدّ تنازلي من ١٠ إلى ١. ابدأ فقط بالقيمة ١٠، ثم اِنقص المُتَغيِّر المُتحكِّم بالحَلْقة (loop control variable) بدلًا من زيادته، واستمر طالما كانت قيمة المُتَغيِّر أكبر من أو تُساوِي ١: for ( N = 10 ; N >= 1 ; N-- ) System.out.println( N ); في الواقع، تَسمَح صيغة (syntax) تَعْليمَة for بأن تَشتمِل كُلًا من تعليمتي التهيئة والتَحْدِيث على أكثر من تعبير (expression) مربوطين بفاصلة (comma). يَعنِي ذلك أنه من الممكن الإبقاء على أكثر من عَدَّاد بنفس الوقت، فمثلًا قد يكون لدينا عَدَّاد تصاعدي من ١ إلى ١٠، وآخر تنازلي من ١٠ إلى ١، كالتالي: for ( i=1, j=10; i <= 10; i++, j-- ) { // اطبع قيمة i بخمس خانات System.out.printf("%5d", i); // اطبع قيمة j بخمس خانات System.out.printf("%5d", j); System.out.println(); } كمثال أخير، نريد اِستخدَام حَلْقة التَكْرار for لطباعة الأعداد الزوجية (even numbers) الواقعة بين العددين ٢ و ٢٠، أي بالتحديد طباعة الأعداد ٢، ٤، ٦، ٨، ١٠، ١٢، ١٤، ١٦، ١٨، ٢٠. تتوفَّر أكثر من طريقة للقيام بذلك، نسْتَعْرِض منها أربعة حلول ممكنة (ثلاث منها هي حلول نموذجية تمامًا)؛ وذلك لبيان كيف لمسألة بسيطة مثل تلك المسألة أن تُحلّ بطرائق مختلفة: // (1) // المتغير المتحكم بالحلقة سيأخذ القيم من واحد إلى عشرة // وبالتالي سنطبع القيم 2*1 و 2*2 و ... إلى 2*10 for (N = 1; N <= 10; N++) { System.out.println( 2*N ); } // (2) // المتغير المتحكم بالحلقة سيأخذ القيم المطلوب طباعتها مباشرة // عن طريق إضافة 2 بعبارة التحديث بدلًا من واحد for (N = 2; N <= 20; N = N + 2) { System.out.println( N ); } // (3) // مر على جميع الأرقام من اثنين إلى عشرين // ولكن اطبع فقط الأعداد الزوجية for (N = 2; N <= 20; N++) { if ( N % 2 == 0 ) // is N even? System.out.println( N ); } // (4) // فقط اطبع الأعداد المطلوبة مباشرة // غالبًا سيغضب منك الأستاذ في حالة إطلاعه على مثل هذا الحل for (N = 1; N <= 1; N++) { System.out.println("2 4 6 8 10 12 14 16 18 20"); } من المهم أن نُعيد التأكيد على أنه -باستثناء تَعْليمَة التَّصْريح عن المُتَغيِّرات (variable declaration)- ليس مُمكنًا بأي حال من الأحوال تَّنْفيذ أي تَعْليمَة برمجية، بما في ذلك تَعْليمَة for، بشكل مستقل، وإنما ينبغي أن تُنفَّذ إما داخل البرنامج (routine) الرئيسي main أو داخل إحدى البرامج الفرعية (subroutine)، والمُعرَّفة ضِمْن صَنْف معين (class). لابُدّ أيضًا من التَّصْريح (declaration) عن أي مُتَغيِّر قبل إمكانية اِستخدَامه، بما في ذلك المُتَغيِّر المُتحكِّم بالحَلْقة (loop control variable) المُستخدَم ضِمْن حَلْقة التَكْرار for. صَرَّحنا عن هذا المُتَغيِّر بكونه من النوع العددي الصحيح (int) بالأمثلة التي فحصناها حتى الآن بهذا القسم. مع ذلك، فإنه ليس أمرًا حتميًا، فقد يكون من نوع آخر. فمثلًا، تَستخدِم حَلْقة التَكْرار for -بالمثال التالي- مُتَغيِّرًا من النوع char، وتعتمد على إمكانية تطبيق عَامِل الزيادة ++ على كُلًا من الحروف والأرقام: char ch; // المتغير المتحكم بالحلقة; for ( ch = 'A'; ch <= 'Z'; ch++ ) // اطبع حرف الأبجدية الحالي System.out.print(ch); System.out.println(); مسألة عد القواسم (divisors) سنُلقِي الآن نظرة على مسألة أكثر جدية، والتي يُمكِن حلّها باِستخدَام حَلْقة التَكْرار for. بفَرْض أن لدينا عددين صحيحين موجبين (positive integers) N و D. إذا كان باقي قسمة (remainder) العدد N على العدد D مُساوٍ للصفر، يُقال عندها أن الثاني قَاسِمًا (divisor) للأول أو أن الأول مُضاعَفًا (even multiple) للثاني. بالمثل، يُقال -بتعبير لغة الجافا- أن العدد D قَاسِمًا (divisor) للعدد N إذا تَحقَّق الشَّرْط N % D == 0، حيث % هو عَامِل باقي القسمة. يَسمَح البرنامج التالي للمُستخدِم بإِدْخَال عدد صحيح موجب (positive integer)، ثُمَّ يَحسِب عَدَد القواسم (divisors) المختلفة لذلك العَدَد. لحِساب عَدَد قواسم (divisors) عَدَد معين N، يُمكننا ببساطة فَحْص جميع الأَعْدَاد التي يُحتمَل أن تكون قَاسِمًا للعَدَد N، أيّ جميع الأَعْدَاد الواقعة بدايةً من الواحد ووصولًا للعَدَد N (١، ٢، ٣، … ،N). ثم نَعدّ منها فقط تلكم التي أَمكنها التقسيم الفعليّ للعَدَد N تقسيمًا مُتعادلًا (evenly). على الرغم من أن هذه الطريقة ستُؤدي إلى نتائج صحيحة، فلربما هي ليست الطريقة الأكثر كفاءة لحلّ هذه المسألة. تَسْتَعْرِض الشيفرة التالية الخوارزمية بالشيفرة الوهمية (pseudocode): // اقرأ قيمة عددية موجبة من المستخدم N Get a positive integer, N, from the user // هيئ عداد القواسم Let divisorCount = 0 // لكل عدد من القيمة واحد وحتى القيمة العددية المدخلة testDivisor for each number, testDivisor, in the range from 1 to N: // إذا كان العدد الحالي قاسم للعدد المدخل if testDivisor is a divisor of N: // أزد قيمة العداد بمقدار الواحد Count it by adding 1 to divisorCount // اطبع قيمة العداد Output the count تَسْتَعْرِض الخوارزمية السابقة واحدة من الأنماط البرمجية (programming pattern) الشائعة، والتي تُستخدَم عندما يكون لديك مُتتالية (sequence) من العناصر، وتَرغَب بمعالجة بعضًا من تلك العناصر فقط، وليس كلها. يُمكِن تَعْمِيم هذا النمط للصيغة التالية: // لكل عنصر بالمتتالية for each item in the sequence: // إذا نجح العنصر الحالي بالاختبار if the item passes the test: // عالج العنصر الحالي process it يُمكننا تَحْوِيل حَلْقة التَكْرار for الموجودة ضِمْن خوارزمية عَدّ القواسم بالأعلى (divisor-counting algorithm) إلى لغة الجافا كالتالي: for (testDivisor = 1; testDivisor <= N; testDivisor++) { if ( N % testDivisor == 0 ) divisorCount++; } بإمكان الحواسيب الحديثة تَّنْفيذ حَلْقة التَكْرار (loop) بالأعلى بسرعة، بل لا يَسْتَحِيل حتى تَّنْفيذها على أكبر عَدَد يُمكن أن يَحمله النوع int، والذي يَصِل إلى ٢١٤٧٤٨٣٦٤٧، ربما حتى قد تَستخدِم النوع long للسماح بأعداد أكبر، ولكن بالطبع سيستغرق تَّنْفيذ الخوارزمية وقتًا أطول مع الأعداد الكبيرة جدًا، ولذلك تَقَرَّر إِجراء تعديل على الخوارزمية بهدف طباعة نقطة (dot) -تَعمَل كمؤشر- بَعْد كل مرة ينتهي فيها الحاسوب من اختبار عشرة مليون قَاسِم (divisor) مُحتمَل جديد. سنضطر في النسخة المُعدَّلة من الخوارزمية إلى الإبقاء على عَدَّادين (counters) منفصلين: الأول منهما لعَدّ القواسم (divisors) الفعليّة التي تحصَّلَنا عليها، والآخر لعَدّ جميع الأعداد التي اُختبرت حتى الآن. عندما يَصل العَدَّاد الثاني إلى قيمة عشرة ملايين، سيَطبع البرنامج نقطة .، ثُمَّ يُعيد ضَبْط قيمة ذلك العَدَّاد إلى صفر؛ ليبدأ العَدّ من جديد. تُصبِح الخوارزمية باِستخدَام الشيفرة الوهمية كالتالي: // اقرأ عدد صحيح موجب من المستخدم Get a positive integer, N, from the user Let divisorCount = 0 // عدد القواسم التي تم العثور عليها Let numberTested = 0 // عدد القواسم المحتملة والتي تم اختبارها // اقرأ رد المستخدم إلى المتغير str // لكل عدد يتراوح من القيمة واحد وحتى قيمة العدد المدخل for each number, testDivisor, in the range from 1 to N: // إذا كان العدد الحالي قاسم للعدد المدخل if testDivisor is a divisor of N: // أزد عدد القواسم التي تم العثور عليها بمقدار الواحد Count it by adding 1 to divisorCount // أزد عدد الأعداد المحتملة التي تم اختبارها بمقدار الواحد Add 1 to numberTested // إذا كان عدد الأعداد المحتملة المختبر يساوي عشرة ملايين if numberTested is 10000000: // اطبع نقطة print out a '.' // أعد ضبط عدد الأعداد المختبرة إلى القيمة صفر Reset numberTested to 0 // اطبع عدد القواسم Output the count وأخيرًا، يُمكننا تَحْوِيل الخوارزمية إلى برنامج كامل بلغة الجافا، كالتالي: import textio.TextIO; public class CountDivisors { public static void main(String[] args) { int N; // القيمة العددية المدخلة من قبل المستخدم int testDivisor; // عدد يتراوح من القيمة واحد وحتى N int divisorCount; // عدد قواسم N التي عثر عليها حتى الآن int numberTested; // عدد القواسم المحتملة التي تم اختبارها // اقرأ قيمة عدد صحيح موجبة من المستخدم while (true) { System.out.print("Enter a positive integer: "); N = TextIO.getlnInt(); if (N > 0) break; System.out.println("That number is not positive. Please try again."); } // عِدّ القواسم واطبع نقطة بعد كل عشرة ملايين اختبار divisorCount = 0; numberTested = 0; for (testDivisor = 1; testDivisor <= N; testDivisor++) { if ( N % testDivisor == 0 ) divisorCount++; numberTested++; if (numberTested == 10000000) { System.out.print('.'); numberTested = 0; } } // اعرض النتائج System.out.println(); System.out.println("The number of divisors of " + N + " is " + divisorCount); } // نهاية البرنامج main } // نهاية الصنف CountDivisors حلقات for المتداخلة كما ذَكَرنا مُسْبَّقًا، فإن بُنَى التحكُّم (control structures) بلغة الجافا هي ببساطة تَعْليمَات مُركَّبة، أي تَتضمَّن مجموعة تَعْليمَات. في الحقيقة، يُمكن أيضًا لبِنْية تحكُّم (control structure) أن تَشتمِل على بِنْية تحكُّم أخرى أو أكثر، سواء كانت من نفس النوع أو من أيّ نوع آخر، ويُطلَق عليها في تلك الحالة اسم بُنَى التحكُّم المُتداخِلة (nested). لقد مررنا بالفعل على عدة أمثلة تَتضمَّن هذا النوع من البُنَى، فمثلًا رأينا تَعْليمَات if ضِمْن حَلْقات تَكْرارية (loops)، كما رأينا حَلْقة while داخلية (inner) مُضمَّنة بداخل حَلْقة while آخرى خارجية. لا يَقتصر الأمر على هذه الأمثلة؛ حيث يُسمَح عامةً بدمج بُنَى التحكُّم بأي طريقة ممكنة، وتستطيع حتى القيام بذلك على عدة مستويات من التَدَاخُل (levels of nesting)، فمثلًا يُمكن لحَلْقة while أن تَحتوِي على تَعْليمَة if، والتي بدورها قد تَحتوِي على تَعْليمَة while آخرى؛ فلغة الجافا Java لا تَضع عامةً أي قيود على عدد مستويات التَدَاخُل المسموح بها، ومع ذلك يَصعُب عمليًا فهم الشيفرة إذا اِحْتَوت على أكثر من عدد قليل من مستويات التَدَاخُل (levels of nesting). تَستخدِم كثير من الخوارزميات حَلْقات for المُتداخِلة (nested)، لذا من المهم أن تفهم طريقة عملها. دعنا نَفحْص عدة أمثلة، مثلًا، مسألة طباعة جدول الضرب (multiplication table) على الصورة التالية: 1 2 3 4 5 6 7 8 9 10 11 12 2 4 6 8 10 12 14 16 18 20 22 24 3 6 9 12 15 18 21 24 27 30 33 36 4 8 12 16 20 24 28 32 36 40 44 48 5 10 15 20 25 30 35 40 45 50 55 60 6 12 18 24 30 36 42 48 54 60 66 72 7 14 21 28 35 42 49 56 63 70 77 84 8 16 24 32 40 48 56 64 72 80 88 96 9 18 27 36 45 54 63 72 81 90 99 108 10 20 30 40 50 60 70 80 90 100 110 120 11 22 33 44 55 66 77 88 99 110 121 132 12 24 36 48 60 72 84 96 108 120 132 144 نُظِّمت البيانات بالجدول إلى ١٢ صف و ١٢ عمود. اُنظر الخوارزمية التالية -بالشيفرة الوهمية (pseudocode)- لطباعة جدول مُشابه: for each rowNumber = 1, 2, 3, ..., 12: // اطبع بسَطر منفصل المضاعفات الاثنى عشر الأولى من قيمة المتغير Print the first twelve multiples of rowNumber on one line // اطبع محرف العودة الى بداية السطر Output a carriage return في الواقع، يُمكن للسطر الأول بمَتْن حَلْقة for بالأعلى "اطبع بسَطر منفصل المضاعفات الاثنى عشر الأولى من قيمة المتغير الحالية" أن يُكتَب على صورة حَلْقة for أخرى منفصلة كالتالي: for N = 1, 2, 3, ..., 12: Print N * rowNumber تحتوي الآن النسخة المُعدَّلة من خوارزمية طباعة جدول الضرب على حَلْقتي for مُتداخِلتين، كالتالي: for each rowNumber = 1, 2, 3, ..., 12: for N = 1, 2, 3, ..., 12: Print N * rowNumber // اطبع محرف العودة الى بداية السطر Output a carriage return يُمكن اِستخدَام مُحدِّدات الصيغة (format specifier) عند طباعة خَرْج ما (output)؛ بهدف تخصيص صيغة هذا الخَرْج، ولهذا سنَستخدِم مُحدِّد الصيغة %4d عند طباعة أيّ عَدَد بالجدول؛ وذلك لجعله يَحْتلَّ أربعة خانات دائمًا دون النظر لعَدَد الخانات المطلوبة فعليًا، مما يُحسِن من شكل الجدول النهائي. بفَرْض أنه قد تم الإعلان عن المُتَغيِّرين rowNumber و N بحيث يَكُونا من النوع العددي int، يمكن عندها كتابة الخوارزمية بلغة الجافا، كالتالي: for ( rowNumber = 1; rowNumber <= 12; rowNumber++ ) { for ( N = 1; N <= 12; N++ ) { // اطبع الرقم بأربع خانات بدون طباعة محرف العودة الى بداية السطر System.out.printf( "%4d", N * rowNumber ); } // اطبع محرف العودة الى بداية السطر System.out.println(); } ربما قد لاحظت أن جميع الأمثلة التي تَعْرَضنا لها -خلال هذا القسم- حتى الآن تَتعامَل فقط مع الأعداد، لذلك سننتقل خلال المثال التالي إلى معالجة النصوص (text processing). لنفْترِض أن لدينا سِلسِلة نصية (string)، ونريد كتابة برنامج لتَحْدِيد الحروف الأبجدية (letters of the alphabet) الموجودة بتلك السِلسِلة. فمثلًا، إذا كان لدينا السِلسِلة النصية "أهلًا بالعالم"، فإن الحروف الموجودة بها هي الألف، والباء، والعين، واللام، والميم، والهاء. سيَستقبِل البرنامج، بالتَحْدِيد، سِلسِلة نصية من المُستخدِم، ثم يَعرِض قائمة بكل تلك الحروف المختلفة الموجودة ضمن تلك السِلسِلة، بالإضافة إلى عَدَدها. كالعادة، سنبدأ أولًا بكتابة الخوارزمية بصيغة الشيفرة الوهمية (pseudocode)، كالتالي: // اطلب من المستخدم إدخال سلسلة نصية Ask the user to input a string // اقرأ رد المستخدم إلى المتغير str Read the response into a variable, str // هيئ عداد لعدّ الحروف المختلفة Let count = 0 (for counting the number of different letters) // لكل حرف أبجدي for each letter of the alphabet: // إذا كان الحرف موجودًا بالسلسلة النصية if the letter occurs in str: // اطبع الحرف Print the letter // أزد قيمة العداد Add 1 to count // اطبع قيمة العداد Output the count سنَستخدِم الدالة TextIO.getln() لقراءة السَطْر الذي أَدْخَله المُستخدِم بالكامل؛ وذلك لحاجتنا إلى معالجته على خطوة واحدة. يُمكننا تَحْوِيل سَطْر الخوارزمية "لكل حرف أبجدي" إلى حَلْقة التَكْرار for كالتالي for (letter='A'; letter<='Z'; letter++). في المقابل، سنحتاج إلى التفكير قليلًا بالطريقة التي سنكتب بها تَعْليمَة if الموجودة ضِمْن تلك الحَلْقة. نُريد تَحْدِيدًا إيجاد طريقة نتحقَّق من خلالها إذا ما كان الحرف الأبجدي الحالي بالتَكْرار (iteration) letter موجودًا بالسِلسِلة النصية str أم لا. أحد الحلول هو المرور على جميع حروف السِلسِلة النصية str حرفًا حرفًا، لفَحْص ما إذا كان أيًا منها مُساو لقيمة الحرف الأبجدي الحالي letter، ولهذا سنَستخدِم الدالة str.charAt(i) لجَلْب الحرف الموجود بموقع معين i بالسِلسِلة النصية str، بحيث تَتراوح قيمة i من الصفر وحتى عدد حروف السِلسِلة النصية، والتي يُمكن حِسَابها باِستخدَام التعبير str.length() - 1. سنواجه مشكلة أخرى، وهي إمكانية وجود الحرف الأبجدي بالسِلسِلة النصية str على صورتين، كحرف كبير (upper case) أو كحرف صغير (lower case). فمثلًا قد يكون الحرف A على الصورة A أو a، ولذلك نحن بحاجة لفَحْص كلتا الحالتين. قد نتجنب، في المقابل، هذه المشكلة بتَحْوِيل جميع حروف السِلسِلة النصية str إلى الحروف الكبيرة (upper case) قبل بدء المعالجة، وعندها نستطيع فَحْص الحروف الكبيرة (upper case) فقط. والآن نُعيد صياغة الخوارزمية كالتالي: // اطلب من المستخدم إدخال سلسلة نصية Ask the user to input a string // اقرأ رد المستخدم إلى المتغير str Read the response into a variable, str // كَبِّر حروف السلسلة النصية Convert str to upper case // هيئ عداد لعدّ الحروف المختلفة Let count = 0 for letter = 'A', 'B', ..., 'Z': for i = 0, 1, ..., str.length()-1: if letter == str.charAt(i): // اطبع الحرف Print letter // أزد قيمة العداد Add 1 to count // اخرج من الحلقة لتجنب إعادة عدّ الحرف أكثر من مرة break Output the count لاحظ اِستخدَامنا لتَعْليمَة break داخل حَلْقة تَكْرار for الداخلية؛ حتى نتجنب طباعة حرف الأبجدية الحالي letter وعَدّه مجددًا إذا كان موجودًا أكثر من مرة بالسِلسِلة النصية. تُوقِف تَعْليمَة break حَلْقة التَكْرار for الداخلية فقط (inner loop)، وليس الخارجية (outer loop)، والتي ينتقل الحاسوب في الواقع إلى تَّنْفيذها بمجرد خروجه من الحَلْقة الداخلية، ولكن مع حرف الأبجدية التالي. حاول استكشاف القيمة النهائية للمُتَغيِّر count في حالة حَذْف تَعْليمَة break. تَسْتَعْرِض الشيفرة التالية البرنامج بالكامل بلغة الجافا: import textio.TextIO; public class ListLetters { public static void main(String[] args) { String str; // السطر المدخل من قبل المستخدم int count; // عدد الحروف المختلفة الموجودة بالسلسلة النصية char letter; System.out.println("Please type in a line of text."); str = TextIO.getln(); str = str.toUpperCase(); count = 0; System.out.println("Your input contains the following letters:"); System.out.println(); System.out.print(" "); for ( letter = 'A'; letter <= 'Z'; letter++ ) { int i; // موضع الحرف بالسِلسِلة النصية for ( i = 0; i < str.length(); i++ ) { if ( letter == str.charAt(i) ) { System.out.print(letter); System.out.print(' '); count++; break; } } } System.out.println(); System.out.println(); System.out.println("There were " + count + " different letters."); } // نهاية البرنامج main } // نهاية الصنف ListLetters في الواقع، تتوفَّر الدالة str.indexOf(letter) المبنية مُسْبَّقًا (built-in function)، والمُستخدَمة لاختبار ما إذا كان الحرف letter موجودًا بالسِلسِلة النصية str أم لا. إذا لم يكن الحرف موجودًا بالسِلسِلة، ستُعيد الدالة القيمة -1، أما إذا كان موجودًا، فإنها ستُعيد قيمة أكبر من أو تُساوي الصفر. ولهذا كان يمكننا ببساطة إجراء عملية فَحْص وجود الحرف بالسِلسِلة باِستخدَام التعبير if (str.indexOf(letter) >= 0)، بدلًا من اِستخدَام حَلْقة تَكْرار مُتداخِلة (nested loop). يتضح لنا من خلال هذا المثال كيف يمكننا اِستخدَام البرامج الفرعية (subroutines)؛ لتبسيط المسائل المعقدة ولكتابة شيفرة مَقْرُوءة. ترجمة -بتصرّف- للقسم Section 4: The for Statement من فصل Chapter 3: Programming in the Small II: Control من كتاب Introduction to Programming Using Java.1 نقطة
سنتناول في هذا القسم نوعًا آخر من الحَلْقات، هو تَعْليمَة الحَلْقة for. ينبغي أن تُدرك أنه يُمكن لأيّ حَلْقة تَكْرارية (loop) عامةً أن تُكتَب بأيّ من التَعْليمَتين for و while، وهو ما يَعني أن لغة الجافا لم تتَحَصَّل على أيّ مِيزَة وظيفية إضافية بتَدْعِيمها لتَعْليمَة for. لا يَعني ذلك أن تَعْليمَة for غَيْر مُهمة، على العكس تمامًا، ففي الواقع، قد يَتجاوز عَدَد حَلْقات for المُستخدَمة ببعض البرامج عَدَد حَلْقات while. (كما أن الكاتب على معرفة بأحد المبرمجين والذي لا يَستخدِم سوى حَلْقات for). الفكرة ببساطة أن تَعْليمَة for تكون أكثر ملائمة لبعض النوعيات من المسائل؛ حيث تُسهِل من كتابة الحَلْقات وقرائتها بالموازنة مع حَلْقة while. حلقة التكرار For عادةً ما تُستخدَم حَلْقة التَكْرار while بالصياغة التالية: <initialization> while ( <continuation-condition> ) { <statements> <update> } مثلًا، اُنظر لهذا المثال من القسم ٣.٢: years = 0; // هيئ المتغير while ( years < 5 ) { // شرط حلقة التكرار // نفذ التعليمات الثلاثة التالية interest = principal * rate; principal += interest; System.out.println(principal); // حدث قيمة المتغير years++; } ولهذا أضيفت تَعْليمَة for للتسهيل من كتابة هذا النوع من الحَلْقات، حيث يُمكِن إِعادة كتابة حَلْقة التَكْرار بالأعلى باستخدام تَعْليمَة for، كالتالي: for ( years = 0; years < 5; years++ ) { interest = principal * rate; principal += interest; System.out.println(principal); } لاحظ كيف دُمجَت كُُلًا من تعليمات التهيئة ، والشَّرْط الاستمراري لحَلْقة التَكْرار ، والتَحْدِيث جميعًا بسَطْر واحد هو السَطْر الأول من حَلْقة التَكْرار for. يُسهِل ذلك من قراءة حَلْقة التَكْرار وفهمها؛ لأن جميع تَعْليمَات التحكُّم بالحَلْقة (loop control) قد ضُمِّنت بمكان واحد بشكل منفصل عن مَتْن الحَلْقة الفعليّ المطلوب تَكْرار تَّنْفيذه. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن تُنفَّذ حَلْقة التَكْرار for بالأعلى بنفس الطريقة التي تُنفَّذ بها الشيفرة الأصلية، أي تُنفَّذ أولًا تعليمة التهيئة مرة وحيدة قبل بدء تَّنْفيذ الحَلْقة، ثم يُفحَص الشَّرْط الاستمراري للحَلْقة قَبْل كل تَكْرار (iteration/execution) لمَتْن الحَلْقة، بما في ذلك التَكْرار الأوَّليّ (first iteration)، بحيث تَتوقَف الحَلْقة عندما يؤول هذا الشَّرْط إلى القيمة false. وأخيرًا، تُنفَّذ تعليمة التَحْدِيث بنهاية كل تَكْرار (iteration/execution) قَبْل العودة لفَحْص الشَّرْط من جديد. تُكتَب تَعْليمَة حَلْقة التَكْرار for بالصياغة التالية: for ( <initialization>; <continuation-condition>; <update> ) <statement> أو كالتالي إذا كانت التعليمة كُتليّة البِنْية (block statement): for ( <initialization>; <continuation-condition>; <update> ) { <statements> } يُمكِن لأيّ تعبير منطقي (boolean-valued expression) أن يُستخدَم محل الشَّرْط الاستمراري . يُمكِن لأيّ تعبير (expression) -طالما كان صالحًا كتَعْليمَة برمجية- أن يُستخدَم محل تعليمة التهيئة ، وفي الواقع غالبًا ما تُستخدَم تَعْليمَة تَّصْريح (declaration) أو إِسْناد (assignment). يُمكِن لأي تَعْليمَة بسيطة (simple statement) أن تُستخدَم محل تعليمة التَحْدِيث ، وعادةً ما تكون تَعْليمَة زيادة/نقصان (increment/decrement) أو إِسْناد (assignment). وأخيرًا، يُمكِن لأي من تلك التعليمات الثلاثة بالأعلى أن تكون فارغة. لاحظ أنه إذا كان الشَّرْط الاستمراري فارغًا، فإنه يُعامَل وكأنه يُعيد القيمة المنطقية true، أي يُعدّ الشَّرْط مُتحقِّقًا، مما يعني تَّنْفيذ مَتْن حَلْقة التَكْرار (loop body) بشكل لا نهائي (infinite loop) إلى أن يتم إيقافها لسبب ما، مثل اِستخدَام تَعْليمَة break. يُفضِّل بعض المبرمجين في الواقع تَّنْفيذ الحَلْقة اللا نهائية (infinite loop) باِستخدَام الصياغة for (;;) بدلًا من while (true). يُوضح المخطط (diagram) التالي مَسار التحكُّم (flow control) أثناء تَّنْفيذ حَلْقة التَكْرار for: عادةً ما تُسْنِد تعليمة التهيئة قيمة ما إلى مُتَغيِّر معين، ثم تُعدِّل تعليمة التَحْدِيث قيمة هذا المُتَغيِّر إِمّا بواسطة تَعْليمَة إِسْناد (assignment) وإِمّا بعملية زيادة/نُقصان (increment/decrement)، وتُفْحَص تلك القيمة من خلال الشَّرْط الاستمراري لحَلْقة التَكْرار (continuation condition)، فتَتوقَف الحَلْقة عندما يؤول الشَّرْط إلى القيمة المنطقية false. يُطلق عادة على المُتَغيِّر المُستخدَم بهذه الطريقة اسم المُتحكِّم بالحَلْقة (loop control variable). في المثال بالأعلى، كان المُتحكِّم بالحَلْقة هو المُتَغيِّر years. تُعدّ حَلْقة العَدّ (counting loop) هي النوع الأكثر شيوعًا من حَلْقات التَكْرار for، والتي يأخذ فيها المُتَغيِّر المُتحكِّم بالحَلْقة (loop control variable) قيم جميع الأعداد الصحيحة (integer) الواقعة بين قيمتين إحداهما صغرى (minimum) والآخرى عظمى (maximum). تُكتَب حَلْقة العَدّ كالتالي: for ( <variable> = <min>; <variable> <= <max>; <variable>++ ) { <statements> } يُمكِن لأيّ تعبير يُعيد عددًا صحيحًا (integer-valued expressions) أن يُستخدَم محل و ، ولكن تُستخدَم عادةً قيم ثابتة (constants). يأخذ المُتَغيِّر -المشار إليه باستخدام بالأعلى والمعروف باسم المُتحكِّم بالحَلْقة (loop control variable)- القيم المتراوحة بين و ، أي القيم <min>+1 و <min>+2 ..وحتى . وغالبًا ما تُستخدَم قيمة هذا المُتَغيِّر داخل المَتْن (body). مثلًا، حَلْقة التَكْرار for بالأعلى هي حَلْقة عَدّ يأخذ فيها المُتَغيِّر المُتحكِّم بالحَلْقة years القيم ١ و ٢ و ٣ و ٤ و ٥. تطبع الشيفرة التالية قيم الأعداد من ١ إلى ١٠ إلى الخَرْج القياسي (standard output): for ( N = 1 ; N <= 10 ; N++ ) System.out.println( N ); مع ذلك، يُفضِّل مبرمجي لغة الجافا بدء العَدّ (counting) من ٠ بدلًا من ١، كما أنهم يميلون إلى اِستخدَام العَامِل > للموازنة بدلًا من <=. تطبع الشيفرة التالية قيم الأعداد العشرة ٠، ١، ٢، …، ٩، كالتالي: for ( N = 0 ; N < 10 ; N++ ) System.out.println( N ); يُعدّ اِستخدَام عَامِل الموازنة > بدلًا من <= أو العكس مصدرًا شائعًا لحُدوث الأخطاء بفارق الواحد (off-by-one errors) بالبرامج. حاول دائمًا أن تأخذ وقتًا للتفكير إذا ما كنت تَرغَب بمعالجة القيمة النهائية أم لا. يُمكنك أيضًا إجراء العَدّ التنازلي، وهو ما قد يكون أسهل قليلًا من العَدّ التصاعدي. فمثلًا، لإجراء عَدّ تنازلي من ١٠ إلى ١. ابدأ فقط بالقيمة ١٠، ثم اِنقص المُتَغيِّر المُتحكِّم بالحَلْقة (loop control variable) بدلًا من زيادته، واستمر طالما كانت قيمة المُتَغيِّر أكبر من أو تُساوِي ١: for ( N = 10 ; N >= 1 ; N-- ) System.out.println( N ); في الواقع، تَسمَح صيغة (syntax) تَعْليمَة for بأن تَشتمِل كُلًا من تعليمتي التهيئة والتَحْدِيث على أكثر من تعبير (expression) مربوطين بفاصلة (comma). يَعنِي ذلك أنه من الممكن الإبقاء على أكثر من عَدَّاد بنفس الوقت، فمثلًا قد يكون لدينا عَدَّاد تصاعدي من ١ إلى ١٠، وآخر تنازلي من ١٠ إلى ١، كالتالي: for ( i=1, j=10; i <= 10; i++, j-- ) { // اطبع قيمة i بخمس خانات System.out.printf("%5d", i); // اطبع قيمة j بخمس خانات System.out.printf("%5d", j); System.out.println(); } كمثال أخير، نريد اِستخدَام حَلْقة التَكْرار for لطباعة الأعداد الزوجية (even numbers) الواقعة بين العددين ٢ و ٢٠، أي بالتحديد طباعة الأعداد ٢، ٤، ٦، ٨، ١٠، ١٢، ١٤، ١٦، ١٨، ٢٠. تتوفَّر أكثر من طريقة للقيام بذلك، نسْتَعْرِض منها أربعة حلول ممكنة (ثلاث منها هي حلول نموذجية تمامًا)؛ وذلك لبيان كيف لمسألة بسيطة مثل تلك المسألة أن تُحلّ بطرائق مختلفة: // (1) // المتغير المتحكم بالحلقة سيأخذ القيم من واحد إلى عشرة // وبالتالي سنطبع القيم 2*1 و 2*2 و ... إلى 2*10 for (N = 1; N <= 10; N++) { System.out.println( 2*N ); } // (2) // المتغير المتحكم بالحلقة سيأخذ القيم المطلوب طباعتها مباشرة // عن طريق إضافة 2 بعبارة التحديث بدلًا من واحد for (N = 2; N <= 20; N = N + 2) { System.out.println( N ); } // (3) // مر على جميع الأرقام من اثنين إلى عشرين // ولكن اطبع فقط الأعداد الزوجية for (N = 2; N <= 20; N++) { if ( N % 2 == 0 ) // is N even? System.out.println( N ); } // (4) // فقط اطبع الأعداد المطلوبة مباشرة // غالبًا سيغضب منك الأستاذ في حالة إطلاعه على مثل هذا الحل for (N = 1; N <= 1; N++) { System.out.println("2 4 6 8 10 12 14 16 18 20"); } من المهم أن نُعيد التأكيد على أنه -باستثناء تَعْليمَة التَّصْريح عن المُتَغيِّرات (variable declaration)- ليس مُمكنًا بأي حال من الأحوال تَّنْفيذ أي تَعْليمَة برمجية، بما في ذلك تَعْليمَة for، بشكل مستقل، وإنما ينبغي أن تُنفَّذ إما داخل البرنامج (routine) الرئيسي main أو داخل إحدى البرامج الفرعية (subroutine)، والمُعرَّفة ضِمْن صَنْف معين (class). لابُدّ أيضًا من التَّصْريح (declaration) عن أي مُتَغيِّر قبل إمكانية اِستخدَامه، بما في ذلك المُتَغيِّر المُتحكِّم بالحَلْقة (loop control variable) المُستخدَم ضِمْن حَلْقة التَكْرار for. صَرَّحنا عن هذا المُتَغيِّر بكونه من النوع العددي الصحيح (int) بالأمثلة التي فحصناها حتى الآن بهذا القسم. مع ذلك، فإنه ليس أمرًا حتميًا، فقد يكون من نوع آخر. فمثلًا، تَستخدِم حَلْقة التَكْرار for -بالمثال التالي- مُتَغيِّرًا من النوع char، وتعتمد على إمكانية تطبيق عَامِل الزيادة ++ على كُلًا من الحروف والأرقام: char ch; // المتغير المتحكم بالحلقة; for ( ch = 'A'; ch <= 'Z'; ch++ ) // اطبع حرف الأبجدية الحالي System.out.print(ch); System.out.println(); مسألة عد القواسم (divisors) سنُلقِي الآن نظرة على مسألة أكثر جدية، والتي يُمكِن حلّها باِستخدَام حَلْقة التَكْرار for. بفَرْض أن لدينا عددين صحيحين موجبين (positive integers) N و D. إذا كان باقي قسمة (remainder) العدد N على العدد D مُساوٍ للصفر، يُقال عندها أن الثاني قَاسِمًا (divisor) للأول أو أن الأول مُضاعَفًا (even multiple) للثاني. بالمثل، يُقال -بتعبير لغة الجافا- أن العدد D قَاسِمًا (divisor) للعدد N إذا تَحقَّق الشَّرْط N % D == 0، حيث % هو عَامِل باقي القسمة. يَسمَح البرنامج التالي للمُستخدِم بإِدْخَال عدد صحيح موجب (positive integer)، ثُمَّ يَحسِب عَدَد القواسم (divisors) المختلفة لذلك العَدَد. لحِساب عَدَد قواسم (divisors) عَدَد معين N، يُمكننا ببساطة فَحْص جميع الأَعْدَاد التي يُحتمَل أن تكون قَاسِمًا للعَدَد N، أيّ جميع الأَعْدَاد الواقعة بدايةً من الواحد ووصولًا للعَدَد N (١، ٢، ٣، … ،N). ثم نَعدّ منها فقط تلكم التي أَمكنها التقسيم الفعليّ للعَدَد N تقسيمًا مُتعادلًا (evenly). على الرغم من أن هذه الطريقة ستُؤدي إلى نتائج صحيحة، فلربما هي ليست الطريقة الأكثر كفاءة لحلّ هذه المسألة. تَسْتَعْرِض الشيفرة التالية الخوارزمية بالشيفرة الوهمية (pseudocode): // اقرأ قيمة عددية موجبة من المستخدم N Get a positive integer, N, from the user // هيئ عداد القواسم Let divisorCount = 0 // لكل عدد من القيمة واحد وحتى القيمة العددية المدخلة testDivisor for each number, testDivisor, in the range from 1 to N: // إذا كان العدد الحالي قاسم للعدد المدخل if testDivisor is a divisor of N: // أزد قيمة العداد بمقدار الواحد Count it by adding 1 to divisorCount // اطبع قيمة العداد Output the count تَسْتَعْرِض الخوارزمية السابقة واحدة من الأنماط البرمجية (programming pattern) الشائعة، والتي تُستخدَم عندما يكون لديك مُتتالية (sequence) من العناصر، وتَرغَب بمعالجة بعضًا من تلك العناصر فقط، وليس كلها. يُمكِن تَعْمِيم هذا النمط للصيغة التالية: // لكل عنصر بالمتتالية for each item in the sequence: // إذا نجح العنصر الحالي بالاختبار if the item passes the test: // عالج العنصر الحالي process it يُمكننا تَحْوِيل حَلْقة التَكْرار for الموجودة ضِمْن خوارزمية عَدّ القواسم بالأعلى (divisor-counting algorithm) إلى لغة الجافا كالتالي: for (testDivisor = 1; testDivisor <= N; testDivisor++) { if ( N % testDivisor == 0 ) divisorCount++; } بإمكان الحواسيب الحديثة تَّنْفيذ حَلْقة التَكْرار (loop) بالأعلى بسرعة، بل لا يَسْتَحِيل حتى تَّنْفيذها على أكبر عَدَد يُمكن أن يَحمله النوع int، والذي يَصِل إلى ٢١٤٧٤٨٣٦٤٧، ربما حتى قد تَستخدِم النوع long للسماح بأعداد أكبر، ولكن بالطبع سيستغرق تَّنْفيذ الخوارزمية وقتًا أطول مع الأعداد الكبيرة جدًا، ولذلك تَقَرَّر إِجراء تعديل على الخوارزمية بهدف طباعة نقطة (dot) -تَعمَل كمؤشر- بَعْد كل مرة ينتهي فيها الحاسوب من اختبار عشرة مليون قَاسِم (divisor) مُحتمَل جديد. سنضطر في النسخة المُعدَّلة من الخوارزمية إلى الإبقاء على عَدَّادين (counters) منفصلين: الأول منهما لعَدّ القواسم (divisors) الفعليّة التي تحصَّلَنا عليها، والآخر لعَدّ جميع الأعداد التي اُختبرت حتى الآن. عندما يَصل العَدَّاد الثاني إلى قيمة عشرة ملايين، سيَطبع البرنامج نقطة .، ثُمَّ يُعيد ضَبْط قيمة ذلك العَدَّاد إلى صفر؛ ليبدأ العَدّ من جديد. تُصبِح الخوارزمية باِستخدَام الشيفرة الوهمية كالتالي: // اقرأ عدد صحيح موجب من المستخدم Get a positive integer, N, from the user Let divisorCount = 0 // عدد القواسم التي تم العثور عليها Let numberTested = 0 // عدد القواسم المحتملة والتي تم اختبارها // اقرأ رد المستخدم إلى المتغير str // لكل عدد يتراوح من القيمة واحد وحتى قيمة العدد المدخل for each number, testDivisor, in the range from 1 to N: // إذا كان العدد الحالي قاسم للعدد المدخل if testDivisor is a divisor of N: // أزد عدد القواسم التي تم العثور عليها بمقدار الواحد Count it by adding 1 to divisorCount // أزد عدد الأعداد المحتملة التي تم اختبارها بمقدار الواحد Add 1 to numberTested // إذا كان عدد الأعداد المحتملة المختبر يساوي عشرة ملايين if numberTested is 10000000: // اطبع نقطة print out a '.' // أعد ضبط عدد الأعداد المختبرة إلى القيمة صفر Reset numberTested to 0 // اطبع عدد القواسم Output the count وأخيرًا، يُمكننا تَحْوِيل الخوارزمية إلى برنامج كامل بلغة الجافا، كالتالي: import textio.TextIO; public class CountDivisors { public static void main(String[] args) { int N; // القيمة العددية المدخلة من قبل المستخدم int testDivisor; // عدد يتراوح من القيمة واحد وحتى N int divisorCount; // عدد قواسم N التي عثر عليها حتى الآن int numberTested; // عدد القواسم المحتملة التي تم اختبارها // اقرأ قيمة عدد صحيح موجبة من المستخدم while (true) { System.out.print("Enter a positive integer: "); N = TextIO.getlnInt(); if (N > 0) break; System.out.println("That number is not positive. Please try again."); } // عِدّ القواسم واطبع نقطة بعد كل عشرة ملايين اختبار divisorCount = 0; numberTested = 0; for (testDivisor = 1; testDivisor <= N; testDivisor++) { if ( N % testDivisor == 0 ) divisorCount++; numberTested++; if (numberTested == 10000000) { System.out.print('.'); numberTested = 0; } } // اعرض النتائج System.out.println(); System.out.println("The number of divisors of " + N + " is " + divisorCount); } // نهاية البرنامج main } // نهاية الصنف CountDivisors حلقات for المتداخلة كما ذَكَرنا مُسْبَّقًا، فإن بُنَى التحكُّم (control structures) بلغة الجافا هي ببساطة تَعْليمَات مُركَّبة، أي تَتضمَّن مجموعة تَعْليمَات. في الحقيقة، يُمكن أيضًا لبِنْية تحكُّم (control structure) أن تَشتمِل على بِنْية تحكُّم أخرى أو أكثر، سواء كانت من نفس النوع أو من أيّ نوع آخر، ويُطلَق عليها في تلك الحالة اسم بُنَى التحكُّم المُتداخِلة (nested). لقد مررنا بالفعل على عدة أمثلة تَتضمَّن هذا النوع من البُنَى، فمثلًا رأينا تَعْليمَات if ضِمْن حَلْقات تَكْرارية (loops)، كما رأينا حَلْقة while داخلية (inner) مُضمَّنة بداخل حَلْقة while آخرى خارجية. لا يَقتصر الأمر على هذه الأمثلة؛ حيث يُسمَح عامةً بدمج بُنَى التحكُّم بأي طريقة ممكنة، وتستطيع حتى القيام بذلك على عدة مستويات من التَدَاخُل (levels of nesting)، فمثلًا يُمكن لحَلْقة while أن تَحتوِي على تَعْليمَة if، والتي بدورها قد تَحتوِي على تَعْليمَة while آخرى؛ فلغة الجافا Java لا تَضع عامةً أي قيود على عدد مستويات التَدَاخُل المسموح بها، ومع ذلك يَصعُب عمليًا فهم الشيفرة إذا اِحْتَوت على أكثر من عدد قليل من مستويات التَدَاخُل (levels of nesting). تَستخدِم كثير من الخوارزميات حَلْقات for المُتداخِلة (nested)، لذا من المهم أن تفهم طريقة عملها. دعنا نَفحْص عدة أمثلة، مثلًا، مسألة طباعة جدول الضرب (multiplication table) على الصورة التالية: 1 2 3 4 5 6 7 8 9 10 11 12 2 4 6 8 10 12 14 16 18 20 22 24 3 6 9 12 15 18 21 24 27 30 33 36 4 8 12 16 20 24 28 32 36 40 44 48 5 10 15 20 25 30 35 40 45 50 55 60 6 12 18 24 30 36 42 48 54 60 66 72 7 14 21 28 35 42 49 56 63 70 77 84 8 16 24 32 40 48 56 64 72 80 88 96 9 18 27 36 45 54 63 72 81 90 99 108 10 20 30 40 50 60 70 80 90 100 110 120 11 22 33 44 55 66 77 88 99 110 121 132 12 24 36 48 60 72 84 96 108 120 132 144 نُظِّمت البيانات بالجدول إلى ١٢ صف و ١٢ عمود. اُنظر الخوارزمية التالية -بالشيفرة الوهمية (pseudocode)- لطباعة جدول مُشابه: for each rowNumber = 1, 2, 3, ..., 12: // اطبع بسَطر منفصل المضاعفات الاثنى عشر الأولى من قيمة المتغير Print the first twelve multiples of rowNumber on one line // اطبع محرف العودة الى بداية السطر Output a carriage return في الواقع، يُمكن للسطر الأول بمَتْن حَلْقة for بالأعلى "اطبع بسَطر منفصل المضاعفات الاثنى عشر الأولى من قيمة المتغير الحالية" أن يُكتَب على صورة حَلْقة for أخرى منفصلة كالتالي: for N = 1, 2, 3, ..., 12: Print N * rowNumber تحتوي الآن النسخة المُعدَّلة من خوارزمية طباعة جدول الضرب على حَلْقتي for مُتداخِلتين، كالتالي: for each rowNumber = 1, 2, 3, ..., 12: for N = 1, 2, 3, ..., 12: Print N * rowNumber // اطبع محرف العودة الى بداية السطر Output a carriage return يُمكن اِستخدَام مُحدِّدات الصيغة (format specifier) عند طباعة خَرْج ما (output)؛ بهدف تخصيص صيغة هذا الخَرْج، ولهذا سنَستخدِم مُحدِّد الصيغة %4d عند طباعة أيّ عَدَد بالجدول؛ وذلك لجعله يَحْتلَّ أربعة خانات دائمًا دون النظر لعَدَد الخانات المطلوبة فعليًا، مما يُحسِن من شكل الجدول النهائي. بفَرْض أنه قد تم الإعلان عن المُتَغيِّرين rowNumber و N بحيث يَكُونا من النوع العددي int، يمكن عندها كتابة الخوارزمية بلغة الجافا، كالتالي: for ( rowNumber = 1; rowNumber <= 12; rowNumber++ ) { for ( N = 1; N <= 12; N++ ) { // اطبع الرقم بأربع خانات بدون طباعة محرف العودة الى بداية السطر System.out.printf( "%4d", N * rowNumber ); } // اطبع محرف العودة الى بداية السطر System.out.println(); } ربما قد لاحظت أن جميع الأمثلة التي تَعْرَضنا لها -خلال هذا القسم- حتى الآن تَتعامَل فقط مع الأعداد، لذلك سننتقل خلال المثال التالي إلى معالجة النصوص (text processing). لنفْترِض أن لدينا سِلسِلة نصية (string)، ونريد كتابة برنامج لتَحْدِيد الحروف الأبجدية (letters of the alphabet) الموجودة بتلك السِلسِلة. فمثلًا، إذا كان لدينا السِلسِلة النصية "أهلًا بالعالم"، فإن الحروف الموجودة بها هي الألف، والباء، والعين، واللام، والميم، والهاء. سيَستقبِل البرنامج، بالتَحْدِيد، سِلسِلة نصية من المُستخدِم، ثم يَعرِض قائمة بكل تلك الحروف المختلفة الموجودة ضمن تلك السِلسِلة، بالإضافة إلى عَدَدها. كالعادة، سنبدأ أولًا بكتابة الخوارزمية بصيغة الشيفرة الوهمية (pseudocode)، كالتالي: // اطلب من المستخدم إدخال سلسلة نصية Ask the user to input a string // اقرأ رد المستخدم إلى المتغير str Read the response into a variable, str // هيئ عداد لعدّ الحروف المختلفة Let count = 0 (for counting the number of different letters) // لكل حرف أبجدي for each letter of the alphabet: // إذا كان الحرف موجودًا بالسلسلة النصية if the letter occurs in str: // اطبع الحرف Print the letter // أزد قيمة العداد Add 1 to count // اطبع قيمة العداد Output the count سنَستخدِم الدالة TextIO.getln() لقراءة السَطْر الذي أَدْخَله المُستخدِم بالكامل؛ وذلك لحاجتنا إلى معالجته على خطوة واحدة. يُمكننا تَحْوِيل سَطْر الخوارزمية "لكل حرف أبجدي" إلى حَلْقة التَكْرار for كالتالي for (letter='A'; letter<='Z'; letter++). في المقابل، سنحتاج إلى التفكير قليلًا بالطريقة التي سنكتب بها تَعْليمَة if الموجودة ضِمْن تلك الحَلْقة. نُريد تَحْدِيدًا إيجاد طريقة نتحقَّق من خلالها إذا ما كان الحرف الأبجدي الحالي بالتَكْرار (iteration) letter موجودًا بالسِلسِلة النصية str أم لا. أحد الحلول هو المرور على جميع حروف السِلسِلة النصية str حرفًا حرفًا، لفَحْص ما إذا كان أيًا منها مُساو لقيمة الحرف الأبجدي الحالي letter، ولهذا سنَستخدِم الدالة str.charAt(i) لجَلْب الحرف الموجود بموقع معين i بالسِلسِلة النصية str، بحيث تَتراوح قيمة i من الصفر وحتى عدد حروف السِلسِلة النصية، والتي يُمكن حِسَابها باِستخدَام التعبير str.length() - 1. سنواجه مشكلة أخرى، وهي إمكانية وجود الحرف الأبجدي بالسِلسِلة النصية str على صورتين، كحرف كبير (upper case) أو كحرف صغير (lower case). فمثلًا قد يكون الحرف A على الصورة A أو a، ولذلك نحن بحاجة لفَحْص كلتا الحالتين. قد نتجنب، في المقابل، هذه المشكلة بتَحْوِيل جميع حروف السِلسِلة النصية str إلى الحروف الكبيرة (upper case) قبل بدء المعالجة، وعندها نستطيع فَحْص الحروف الكبيرة (upper case) فقط. والآن نُعيد صياغة الخوارزمية كالتالي: // اطلب من المستخدم إدخال سلسلة نصية Ask the user to input a string // اقرأ رد المستخدم إلى المتغير str Read the response into a variable, str // كَبِّر حروف السلسلة النصية Convert str to upper case // هيئ عداد لعدّ الحروف المختلفة Let count = 0 for letter = 'A', 'B', ..., 'Z': for i = 0, 1, ..., str.length()-1: if letter == str.charAt(i): // اطبع الحرف Print letter // أزد قيمة العداد Add 1 to count // اخرج من الحلقة لتجنب إعادة عدّ الحرف أكثر من مرة break Output the count لاحظ اِستخدَامنا لتَعْليمَة break داخل حَلْقة تَكْرار for الداخلية؛ حتى نتجنب طباعة حرف الأبجدية الحالي letter وعَدّه مجددًا إذا كان موجودًا أكثر من مرة بالسِلسِلة النصية. تُوقِف تَعْليمَة break حَلْقة التَكْرار for الداخلية فقط (inner loop)، وليس الخارجية (outer loop)، والتي ينتقل الحاسوب في الواقع إلى تَّنْفيذها بمجرد خروجه من الحَلْقة الداخلية، ولكن مع حرف الأبجدية التالي. حاول استكشاف القيمة النهائية للمُتَغيِّر count في حالة حَذْف تَعْليمَة break. تَسْتَعْرِض الشيفرة التالية البرنامج بالكامل بلغة الجافا: import textio.TextIO; public class ListLetters { public static void main(String[] args) { String str; // السطر المدخل من قبل المستخدم int count; // عدد الحروف المختلفة الموجودة بالسلسلة النصية char letter; System.out.println("Please type in a line of text."); str = TextIO.getln(); str = str.toUpperCase(); count = 0; System.out.println("Your input contains the following letters:"); System.out.println(); System.out.print(" "); for ( letter = 'A'; letter <= 'Z'; letter++ ) { int i; // موضع الحرف بالسِلسِلة النصية for ( i = 0; i < str.length(); i++ ) { if ( letter == str.charAt(i) ) { System.out.print(letter); System.out.print(' '); count++; break; } } } System.out.println(); System.out.println(); System.out.println("There were " + count + " different letters."); } // نهاية البرنامج main } // نهاية الصنف ListLetters في الواقع، تتوفَّر الدالة str.indexOf(letter) المبنية مُسْبَّقًا (built-in function)، والمُستخدَمة لاختبار ما إذا كان الحرف letter موجودًا بالسِلسِلة النصية str أم لا. إذا لم يكن الحرف موجودًا بالسِلسِلة، ستُعيد الدالة القيمة -1، أما إذا كان موجودًا، فإنها ستُعيد قيمة أكبر من أو تُساوي الصفر. ولهذا كان يمكننا ببساطة إجراء عملية فَحْص وجود الحرف بالسِلسِلة باِستخدَام التعبير if (str.indexOf(letter) >= 0)، بدلًا من اِستخدَام حَلْقة تَكْرار مُتداخِلة (nested loop). يتضح لنا من خلال هذا المثال كيف يمكننا اِستخدَام البرامج الفرعية (subroutines)؛ لتبسيط المسائل المعقدة ولكتابة شيفرة مَقْرُوءة. ترجمة -بتصرّف- للقسم Section 4: The for Statement من فصل Chapter 3: Programming in the Small II: Control من كتاب Introduction to Programming Using Java.1 نقطة -
 تُصنَّف التَعْليمات البرمجية (statements) بأي لغة برمجة -ومنها الجافا Java- إلى تَعْليمات بسيطة (simple) وأخرى مُركَّبة (compound). تُعدّ التَعْليمات البسيطة -مثل تَعْليمَة الإِسْناد (assignment) وتَعْليمَة اِسْتدعاء البرامج الفرعية (subroutine call)- اللَبِنة الأساسية لأيّ برنامج. في المُقابل، تتكون التَعْليمات المُركَّبة -مثل تَعْليمَة حَلْقة التَكْرار while وتَعْليمَة التَفْرِيع الشَّرطيّة if- من عدد من التَعْليمات البسيطة، وتُعرَف باسم بُنَى التحكُّم (control structures)؛ نظرًا لأنها تَتَحكَّم بترتيب تَّنْفيذ التَعْليمات. سنتناول بُنَى التحكُّم (control structures) المُدَعَّمة بلغة الجافا Java بشئٍ من التفصيل خلال الأقسام الخمسة التالية، بحيث نبدأ في هذا القسم بتَعْليمتي الحَلْقة while و do..while. سنتَعرَّض، خلال ذلك، لكثير من الأمثلة البرمجية التي تُوظِّف بُنَى التحكُّم تلك، كما أننا وبينما نقوم بذلك، سنُطبِّق التقنيات المُتَّبَعة بتصميم الخوارزميات (algorithms)، والتي قد تَعرَّضنا لها بالفصل السابق. تَعْليمَة while تُكتَب تَعْليمَة حَلْقة التَكْرار (loop) while -والتي قد تَعرَّضت لها مُسْبقًا بالقسم ٣.١- بالصياغة التالية: while ( <boolean-expression> ) <statement> لا يُشترَط أن تتكوَّن التعليمة -المُشار إليها بالأعلى، والمعروفة باسم مَتْن حَلْقة التَكْرار (loop body)- من تَعْليمَة واحدة فقط، فبالطبع يُمكنها أن تكون كُتليّة البِنْية (block statement)، بحيث تَتضمَّن عدة تَعْليمَات مُحَاطة بزوج من الأقواس. يَتكرَّر تَّنْفيذ مَتْن الحَلْقة (body of the loop) طالما كان التعبير -المُشار إليه بالأعلى- مُتحقِّقًا. تتكون تلك العبارة من تَعبير منطقي (boolean expression)، وتُعرَف باسم الشَّرْط الاستمراري (continuation condition) لحَلْقة التَكْرار أو باسم اختبار حَلْقة التَكْرار. نحتاج الآن لإِيضاح عدة نقاط بشيء من التفصيل. أولًا، ماذا يَحدُث إذا لم يَتحقَّق شَّرْط حَلْقة التَكْرار ولو لمرة واحدة على الأقل، بمعنى أنه لم يَكُن متحقِّقًا قبل التَّنْفيذ الأوَّليّ لمَتْن الحَلْقة؟ في هذه الحالة، لا يُنفَّذ مَتْن الحَلْقة (body) نهائيًا، وهو ما يعني أن مَتْن حَلْقة while يُمكِن أن يُنفَّذ أيّ عدد من المرات بما في ذلك الصفر. ثانيًا، ماذا لو كان شَّرْط حَلْقة التَكْرار مُتحقِّقًا، لكن وبينما يُنفَّذ مَتْن الحَلْقة لم يَعُدْ الشَّرْط كذلك؟ هل يَتوقَف تَّنْفيذ الحَلْقة بمجرد حُدُوث ذلك؟ ببساطة لا؛ حيث يَستمِر الحاسوب بتَّنْفيذ مَتْن الحَلْقة بالكامل حتى يَصِل إلى نهايته، وعِندها فقط يَقفز عائدًا إلى بداية حَلْقة التَكْرار لفَحْص شَّرْطها (continuation condition) مُجددًا، ومِنْ ثَمَّ، يَستطيع في تلك اللحظة فقط إِيقاف الحَلْقة وليس قبل ذلك. لنفْحَص إِحدى المشكلات التي تُحلّ باِستخدَام حَلْقة التَكْرار while: حِساب قيمة متوسط (average) مجموعة من الأعداد الصحيحة الموجبة (positive integers)، والتي يَتم إِدْخالها من قِبَل المُستخدِم. تُحسَب قيمة المتوسط (average) عمومًا بحِساب حاصل مجموع الأعداد ثم قِسمته على عَدَدها. سيَطلب البرنامج من المُستخدِم إِدْخال عدد صحيح (integer) وحيد في المرة، وسيَحتفِظ دومًا بقيمة المجموع الكلي للأعداد الصحيحة المُدْخَلة حتى اللحظة الراهنة، وكذلك عَدَدها، كما سيُبقي هذه القيم مُحْدَثة مع كل عملية إِدْخال. هاك خوارزمية البرنامج (algorithm) مَكتوبة بأسلوب الشيفرة الوهمية (pseudocode): Let sum = 0 Let count = 0 // طالما لا يوجد المزيد من الأعداد الصحيحة للمعالجة while there are more integers to process: // اقرأ عدد صحيح Read an integer // أضف قيمته إلى المتغير sum Add it to the sum // أزد قيمة العداد Count it // اقسم المجموع sum على count لحساب قيمة المتوسط Divide sum by count to get the average // اطبع قيمة المتوسط Print out the average لكن كيف سنتحقَّق فعليًا من شَّرْط الحَلْقة بالأعلى "طالما لا يوجد المزيد من الأعداد الصحيحة للمعالجة"؟ أحد الحلول هو إِبلاغ المُستخدِم بأن يُدخِل القيمة صفر بعد أن يَنتهِي من إِدْخال جميع البيانات الفعليَّة. ستَنجح تلك الطريقة نظرًا لأننا نَفترِض أن البيانات الفعليَّة المُدْخَلة لابُدّ وأن تَكون من الأعداد الصحيحة الموجبة، وهو ما يَعني أن الصفر يُعدّ قيمة غيْر صالحة من الأساس. لاحِظ أن الصفر هنا ليس قيمة بحدّ ذاتِها يَنبغي تَضْمِينها مع الأعداد المطلوب حِساب مُتوسطها، وإِنما هي فقط مطلوبة كعلامة للإشارة إلى نهاية البيانات الفعليَّة. يُطلق أحيانًا على قِيَم البيانات المُستخدَمة بطريقة مُشابهة اسم بَيَان البداية/النهاية (sentinel value). سنُعدِّل الآن اختبار حَلْقة التَكْرار while ليُصبِح "طالما العدد الصحيح المُدخل لا يساوي الصفر". ستُواجهنا مشكلة آخرى، عندما يُنفَّذ اختبار حَلْقة التَكْرار (loop) لأول مرة، أي قَبْل التَّنْفيذ الأوَّليّ لمَتْن الحَلْقة، لن يكون هناك عدد صحيح قد قُرأ بَعْد، بل ليس هناك أيّ بيانات قد قُرِأت أساسًا، مما يَعني أنه لا يوجد "عدد صحيح مُدخل". ولهذا، يُصبِح اختبار الحَلْقة "طالما العدد الصحيح المُدخل لا يساوي الصفر" -ضِمْن هذا السياق- غَيْر ذي مَعنى. لذلك يَنبغي القيام بأمر ما قَبل البدء بتَّنْفيذ حَلْقة التَكْرار while للتأكد من صلاحية الاختبار حتى مع أول تَّنْفيذ له. تُعرَف هذه العملية باسم التهيئة المبدئية (priming the loop) لحَلْقة التَكْرار، وفي هذه الحالة بالتحديد، يُمكننا ببساطة تهيئة الحَلْقة عن طريق قراءة أول عدد صحيح مُدْخَل قَبل بدء تَّنْفيذ حَلْقة التَكْرار. هاك الخوارزمية (algorithm) المُعدَّلة: Let sum = 0 Let count = 0 // اقرأ عدد صحيح Read an integer // طالما العدد الصحيح المُدخل لا يساوي الصفر while the integer is not zero: // أضف قيمته إلى المتغير sum Add the integer to the sum // أزد قيمة العداد Count it // اقرأ عدد صحيح Read an integer // اقسم المجموع sum على count لحساب قيمة المتوسط Divide sum by count to get the average // اطبع قيمة المتوسط Print out the average لاحِظ إعادة ترتيب تَعْليمَات مَتْن حَلْقة التَكْرار (loop body)؛ لأنه لمّا أصْبَحت أول محاولة لقراءة عدد صحيح (integer) تَحدُث قَبْل بداية حَلْقة التَكْرار (loop)، كان لابُدّ لمَتْن الحَلْقة من أن يبدأ أولًا بمُعالجة ذلك العدد. ثُمَّ بنهاية المَتْن، سيُحاول الحاسوب قراءة عدد صحيح جديد، ليَقفِز بَعْدها عائدًا لبداية الحَلْقة ليَختبِر العدد الجديد المَقروء للتو. عندما يَقرأ الحاسوب قيمة بَيَان النهاية (sentinel value)، ستَتوقَف الحَلْقة، ومِنْ ثَمَّ لن تُعالَج تلك القيمة، كما أنها لن تُضاف إلى حاصل المجموع sum، أو هذه هى الطريقة التي ينبغي أن تَعمَل بها الخوارزمية على الأقل؛ لأن قيمة بَيَان النهاية ليست جزءً من البيانات الفعليَّة كما ذَكَرنا مُسْبَّقًا. لا تَعمَل الخوارزمية الأصلية طِبقًا لذلك بطريقة صحيحة -بفَرْض إِمكانية تَّنْفيذها بدون إِجراء التهيئة المبدئية (priming) بطريقة ما-؛ لأنها ستَحسِب حاصل مجموع جميع الأعداد الصحيحة وكذلك عَدَدها (count) بما يتَضمَّن قيمة بَيَان النهاية (sentinel value). لمّا كانت تلك القيمة -المُتفق عليها- تُساوي الصفر، فإن حاصل المجموع سيظِلّ لحسن الحظ صحيحًا، ولكن في المقابل سيكون عَدَدها (count) خطأ بفارق واحد. يُطلَق على الأخطاء المُشابهة اسم الأخطاء بفارق الواحد (off-by-one errors)، وهي واحدة من أكثر الأخطاء شيوعًا. اِتضح أن العَدّ أصعب مما قد يبدو عليه. سنُحوِّل الآن الخورازمية إلى برنامج كامل، نُلاحِظ أولًا أنه لا يُمكِن اِستخدَام التَعْليمَة average = sum/count; لحساب قيمة المتوسط (average)؛ لأنه لمّا كانت قيمة كُلًا من المُتَغيِّرين sum و count من النوع العددي الصحيح int، فإن حاصل قِسمة الأول على الثاني sum/count ستكون أيضًا من النوع العددي الصحيح int، في حين ينبغي للمتوسط أن يكون عددًا حقيقيًا (real number). لقد واجهنا هذه المشكلة مِن قَبْل، ويَتلخَّص حَلّها بضرورة تَحْوِيل واحد من القيمتين إلى النوع double؛ وذلك لإجبار الحاسوب على حِسَاب قيمة حاصل القِسمة (quotient) كعَدَد حقيقي (real number). يُمكِن القيام بذلك عن طريق إجراء عملية التَحْوِيل بين الأنواع (type-casting) على أحد المُتَغيِّرين على الأقل، بحيث يُحوَّل إلى النوع double عن طريق اِستخدَام (double)sum. ولهذا يَحسِب البرنامج قيمة المتوسط باستخدام التعبير average = ((double)sum) / count;. يَتوفَّر حلّ آخر، وهو التَّصْريح (declaration) عن المُتَغيِّر sum بحيث يكون أساسًا من النوع double. حُلَّت مشكلة آخرى بالبرنامج التالي، وهي أنه في حالة إِدْخال المُستخدِم القيمة صفر كأول قيمة مُدْخَل، فلن تتوفَّر أيّ بيانات للمُعالجة، ولهذا يُمكننا اختبار حُدُوث تلك الحالة بفَحْص ما إذا كانت قيمة المُتَغيِّر count ما تزال مُساوية للصفر حتى بَعْد انتهاء حَلْقة التَكْرار while. قد تبدو هذه المشكلة ثانوية، ولكن لابُدّ أن يُغطي أيّ مبرمج مُنتبِه جميع الحالات المُمكنة. انظر شيفرة البرنامج بالكامل: import textio.TextIO; public class ComputeAverage { public static void main(String[] args) { int inputNumber; // إحدى القيم المدخلة من قبل المستخدم int sum; // حاصل مجموع الأعداد الصحيحة الموجبة int count; // عدد الأعداد الصحيحة double average; // قيمة متوسط الأعداد الصحيحة الموجبة // هيئ قيمة كلا من متغير المجموع والعداد sum = 0; count = 0; // اقرأ مدخل من المستخدم لمعالجته System.out.print("Enter your first positive integer: "); inputNumber = TextIO.getlnInt(); while (inputNumber != 0) { // أضف قيمة المتغير للمجموع الحالي sum += inputNumber; // أزد قيمة العداد بمقدار الواحد count++; System.out.print("Enter your next positive integer, or 0 to end: "); inputNumber = TextIO.getlnInt(); } // اعرض النتائج if (count == 0) { System.out.println("You didn't enter any data!"); } else { average = ((double)sum) / count; System.out.println(); System.out.println("You entered " + count + " positive integers."); System.out.printf("Their average is %1.3f.\n", average); } } // نهاية البرنامج main } // نهاية الصنف ComputeAverage تعليمة do..while تَفحْص تَعْليمَة حَلْقة التَكْرار while الشَّرْط الاستمراري لحَلْقة التَكْرار (continuation condition) ببداية الحَلْقة، ولكن أحيانًا ما يكون من الأنسب فَحْصه بنهاية الحَلْقة لا بدايتها، وهذا في الواقع ما تُوفِّره تَعْليمَة do..while. تَتشابه صياغة (syntax) تَعْليمَة الحَلْقة do..while مع تَعْليمَة while تمامًا باستثناء بعض التَغْيِيرات الطفيفة، حيث تُنْقَل كلمة while مصحوبة مع الشَّرْط إلى نهاية الحَلْقة، في حين تُضاف كلمة do في بداية الحَلْقة بدلًا منها. تُكتَب تَعْليمَة حَلْقة التَكْرار do..while بالصياغة التالية: do <statement> while ( <boolean-expression> ); إذا كانت التعليمة كُتلَة (block) بذاتها، تُصاغ التَعْليمَة كالتالي: do { <statements> } while ( <boolean-expression> ); لاحِظ وجود الفاصلة المَنقوطة (semicolon) ; بنهاية التَعْليمَة do..while. تُعدّ هذه الفاصلة جزءً أساسيًا من التَعْليمَة do..while، مثلما تُعدّ الفاصلة بنهاية أي تَعْليمَة أخرى -كالإِسْناد (assignment) أو التَّصْريح (declaration)- جزءً أساسيًا منها. ولهذا سيؤدي حَذْف الفاصلة المنقوطة ;، في هذه الحالة، إلى التَسبُّب بحُدوث خطأ في بناء الجملة (syntax error). ينبغي عمومًا أن تنتهي أيّ تَعْليمَة برمجية -بلغة الجافا Java- إِمّا بفاصلة منقوطة ; أو بقوس مُغلِق {. عندما يُنفَّذ الحاسوب تَعْليمَة حَلْقة التَكْرار do..while، فإنه يبدأ أولًا بتَّنْفيذ مَتْنها (loop body)-التَعْليمَة أو مجموعة التَعْليمَات بداخل الحَلْقة-، ثم يَحسِب قيمة التعبير المنطقي (boolean expression)، فإذا كانت مُساوية للقيمة المنطقية true، فإنه يَقفِز عَائدًا إلى بداية الحَلْقة ويُعيد تَّنْفيذ مَتْنها، لتستمر العملية بَعْدها بنفس الطريقة. أما إذا كانت قيمة التعبير المنطقي مُساوية للقيمة المنطقية false، فإنه يَتوقَف عن تَّنْفيذ الحَلْقة، وينتقل إلى الجزء التالي من الشيفرة. لاحظ أنه لمّا كان شَّرْط الحَلْقة لا يُفحْص إلا بنهاية الحَلْقة، فإن مَتْن حَلْقة التَكْرار do..while دائمًا ما يُنفَّذ مرة واحدة على الأقل. على سبيل المثال، اُنظر الشيفرة الوهمية (pseudocode) التالية لبرنامج لعبة. ستجد أن استخدام تَعْليمَة الحَلْقة do..while أكثر مُلائمة في هذه الحالة؛ لأنها ستَضمَن أن المُستخدِم قد لعِبَ مباراة واحدة على الأقل. علاوة على ذلك، فإن شَّرْط حَلْقة التَكْرار بالأسفل لن يكون له أيّ مَعنى في حالة تَّنْفيذه في بداية الحَلْقة. do { // العب مباراة Play a Game // اسأل المستخدم إذا ما كان يريد اللعب مرة آخرى Ask user if he wants to play another game // اقرأ رد المستخدم Read the user's response // أعد التكرار طالما كان رد المستخدم هو نعم } while ( the user's response is yes ); سنُحوِّل الآن هذه الشيفرة الوهمية إلى لغة الجافا. بدايةً ولكي نتجنب الخَوْض في تفاصيل ليست ذا أهمية، سنفترض أن لدينا صَنْف (class) يَحمِل اسم Checkers. أحد أعضاء (member) هذا الصَنْف هو البرنامج الفرعي الساكن (static subroutine) playGame(). يُغلِّف هذا البرنامج الفرعي التفاصيل الخاصة باللعبة، ويُمثِل استدعائه إجراء مباراة دَّامَا (checkers) واحدة مع المُستخدِم. يُمكننا الآن اِستخدَام تَعْليمَة استدعاء البرنامج الفرعي (subroutine call) الساكن Checkers.playGame(); كبديل عن سَطْر الشيفرة "العب مباراة". سنَستخدِم الصنف TextIO لتَلَقِّي رد المُستخدِم على سؤال من النوع نعم أم لا؛ حيث يُوفِّر هذا النوع الدالة (function) TextIO.getlnBoolean()، والتي تَسمَح للمُستخدِم بإِدْخال إحدى القيمتين "Yes/No" ضِمْن عدة ردود أُخرى صالحة، بحيث يؤول الرد "Yes" إلى القيمة المنطقية true، بينما يؤول الرد "No" إلى القيمة المنطقية false. سنحتاج الآن إلى مُتَغيِّر لتخزين رد المُستخدِم، والذي سيكون بطبيعة الحال من النوع المنطقي (boolean). يُمكن كتابة الخوارزمية كالتالي: // تساوي True في حالة رغب المستخدم باللعب مجددًا boolean wantsToContinue; do { Checkers.playGame(); System.out.print("Do you want to play again? "); wantsToContinue = TextIO.getlnBoolean(); } while (wantsToContinue == true); وفقًا لشَّرْط حَلْقة التَكْرار بالأعلى، فإنه عندما تَتَساوى قيمة المُتَغيِّر المنطقي wantsToContinue مع القيمة المنطقية false، سيكون ذلك إشارة (signal) إلى ضرورة تَوقُف حَلْقة التَكْرار. يُطلَق عادةً على المُتَغيِّرات المنطقية (boolean variables) المُستخدَمة بهذه الطريقة اسم راية (flag) أو مُتَغيِّر راية -هي متغيرات تُضبَط (set) بمكان ما بالشيفرة لتُفحَص قيمتها بمكان آخر-. بالمناسبة، عادةً ما يَسخَر بعض المبرمجين -ربما قد يَصفهم البعض بالمُتَحذلِقين- من شَّرْط حَلْقة التَكْرار while (wantsToContinue == true)؛ وذلك لأنه مُكافئ تمامًا للشَّرْط while (wantsToContinue)؛ فاختبار ما إذا كان التعبير wantsToContinue == true يُعيد القيمة المنطقية true لا يَختلف نهائيًا عن اختبار ما إذا كان المُتَغيِّر wantsToContinue يَحمِل القيمة true ويُعيدها. بالمثل، -وبفَرْض أن لدينا مُتَغيِّر اسمه flag من النوع المنطقي (boolean variable)- يُكافئ التعبير flag == false، والذي يُعدّ أقل فَجاجة من التعبير السابق، تمامًا التعبير !flag، حيث الحرف ! هو عَامِل النفي المنطقي (negation operator). يُفضَّل عمومًا كتابة while (!flag) بدلًا من while (flag == false)، وبالمثل، كتابة if (!flag) بدلًا من if (flag == false). على الرغم من أن اِستخدَام تَعْليمَة حَلْقة التَكْرار do..while أحيانًا ما يكون أكثر ملائمة في بعض المسائل، فعمومًا لا يَجعل وجود نوعين مختلفين من تَعْليمَة الحَلْقة (loops) لغة البرمجة أكثر قوة؛ فبالنهاية، أي مشكلة تُحلّ بإحداهما، ستجد أنه من الممكن حلّها بالآخرى. في الواقع، بفرض أن العبارة تُمثل أي كُتلَة شيفرة، فإن التالي: do { <doSomething> } while ( <boolean-expression> ); يُكافئ تمامًا: <doSomething> while ( <boolean-expression> ) { <doSomething> } بالمثل: while ( <boolean-expression> ) { <doSomething> } يُكافئ: if ( <boolean-expression> ) { do { <doSomething> } while ( <boolean-expression> ); } بدون أي تَغْيِير بمَقصِد البرنامج نهائيًا. تعليمتي break و continue تَسمَح لك صيغتي حَلْقتي التَكْرار while و do..while باختبار الشَّرْط الاستمراري (continuation condition) إِمّا ببداية الحَلْقة أو بنهايتها على الترتيب. ولكن أحيانًا سترغب في إجراء عملية اختبار شَّرْط أثناء تَّنْفيذ الحَلْقة، أيّ داخل مَتْن الحَلْقة نفسها، أو حتى قد ترغب بإجراء أكثر من عملية اختبار بأماكن مختلفة داخل نفس الحَلْقة. تُستخدَم تَعْليمَة break بلغة الجافا لإيقاف تَّنْفيذ أيّ حَلْقة تَكْرار (loop)، والخروج منها، وذلك بمجرد استدعائها بأيّ مكان داخل الحَلْقة. تُكتَب كالتالي: break; عندما يُنفِّذ الحاسوب تَعْليمَة break داخل حَلْقة (loop)، فإنه سيَقفِز مُباشرةً خارج الحَلْقة، ويُنفِّذ الشيفرة التالية بالبرنامج والموجودة أسفل الحَلْقة. انظر المثال التالي: while (true) { // يبدو وكأنها ستنفذ بشكل لا نهائي System.out.print("Enter a positive number: "); N = TextIO.getlnInt(); // إما أن تكون قيمة المدخل سليمة أو اقفز خارج الحلقة if (N > 0) break; System.out.println("Your answer must be > 0."); } // اكمل هنا بعد break في المثال بالأعلى، إذا أَدْخَل المُستخدِم عدد أكبر من الصفر، سيتحقَّق الشَّرْط، وستُنفَّذ تَعْليمَة break، ولهذا سيَقفِز الحاسوب مباشرة خارج الحَلْقة إلى ما بَعْدها. في المقابل، إذا لم يتحقَّق الشَّرْط، ستُطبَع السِلسِلة النصية "Your answer must be > 0"، ثم سيَقفِز الحاسوب عَائدًا إلى بداية الحَلْقة ليَقرأ مُدْخَل جديد. قد يبدو السَطْر الأول من الشيفرة بالأعلى while (true) غَيْر مألوف نوعًا ما، ولكنه في الواقع سليم تمامًا. يُسمَح عمومًا لأيّ تعبير منطقي (boolean-valued expression) بأن يكون شَّرْطًا لحَلْقة التَكْرار، أيّ لابُدّ فقط أن تؤول قيمته النهائية إلى قيمة منطقية؛ ليَفحْصها الحاسوب لمعرفة ما إذا كانت مُساوية للقيمة true أم للقيمة false. تُعدّ القيمة المُجرَّدة (literal) true تعبيرًا منطقيًا، والذي يؤول دائمًا إلى القيمة المنطقية true، ولذلك يُمكِن اِستخدَامها كشَّرْط للحَلْقة. يُستخدَم الشَّرْط while (true) لكتابة حَلْقة لا نهائية (infinite loop) أو حَلْقة يُفْترَض الخروج منها باِستخدَام تَعْليمَة break. يُسمَح باِستخدَام حَلْقات التَكْرار المُتداخِلة (nested loops)، بمَعنى وجود تَعْليمَة حَلْقة تَكْرار داخل أُخرى، ولذلك لابُدّ لنا من فهم طريقة عَمَل تَعْليمَة break ضِمْن هذا السياق. كقاعدة عامة، تُوقِف تَعْليمَة break حَلْقة التَكْرار الأقرب لها فقط، بمَعنى أنها إذا اُستخدِمت بداخل الحَلْقة الداخلية (inner loop)، فإنها ستُوقِف فقط تلك الحَلْقة، لا الحَلْقة الخارجية (outer loop) التي تَشَمَلها. أما إذا أردت إيقاف تَّنْفيذ الحلقة الخارجية، يُمكِنك اِستخدَام ما يُعرَف باسم تَعْليمَة break المُعنوَنة (labeled break). تَسمَح تَعْليمَة break المُعنوَنة بتحديد صريح للحَلْقة المطلوب الخروج منها. اِستخدَام هذه التَعْليمَة المُعنوَنة غَيْر شائع، ولذلك سنمر عليها سريعًا. تَعمَل العناوين (labels) كالتالي: يُمكِنك ببساطة عَنوَنة أيّ حَلْقة تَكْرار بوَضْع مُعرَّف (identifier) مَتبوع بنقطتان رأسيتان : بمقدمة الحَلْقة. فمثلًا، يمكن عَنوَنة حَلْقة تَكْرار while باِستخدَام mainloop: while.... تستطيع الآن اِستخدَام تَعْليمَة break المُعنوَنة بأيّ مكان داخل هذه الحَلْقة عن طريق اِستخدَام الصيغة break mainloop;، وذلك بهدف الخروج من هذه الحَلْقة تحديدًا. على سبيل المثال، تَفحْص الشيفرة بالأسفل ما إذا كانت السِلسِلتين النصيتين s1 و s2 تحتويان على حرف مُشتَرَك. في حالة تَحقُّق الشَّرْط، ستُسْنَد القيمة المنطقية false إلى مُتَغيِّر الراية nothingInCommon، ثُمَّ تُسْتَدعى تَعْليمَة break المُعنوَنة لإيقاف المعالجة عند تلك النقطة: boolean nothingInCommon; // افترض أن السلسلتين لا يشتركان بأي حرف nothingInCommon = true; // متغيرات حلقتي التكرار والتي ستأخذ قيم حروف السلسلتين int i,j; i = 0; bigloop: while (i < s1.length()) { j = 0; while (j < s2.length()) { // إذا كان هناك حرفًا مشتركا if (s1.charAt(i) == s2.charAt(j)) { // اضبط قيمة المتغير إلى القيمة false nothingInCommon = false; // اخرج من الحلقتين break bigloop; } j++; // Go on to the next char in s2. } i++; //Go on to the next char in s1. } تُعدّ تَعْليمَة continue مرتبطة نوعًا ما بتَعْليمَة break، لكنها أقل اِستخدَامًا منها. تتَخَطَّى تَعْليمَة continue الجزء المُتبقي من التَكْرار الحالي (current iteration) فقط، أي أنها لا تتَسبَّب بالقفز خارج الحَلْقة تمامًا إلى ما بَعْدها كتَعْليمَة break؛ وإنما تَقفِز عائدة إلى بداية نفس الحَلْقة لتَّنْفيذ التَكْرار التالي (next iteration) -بالطبع إذا كان الشَّرْط الاستمراري (continuation condition) لحَلْقة التَكْرار ما زال مُتحقِّقًا. عندما تُستخدَم تَعْليمَة continue داخل حَلْقة مُتداخِلة (nested loop)، فإنها، مثل تَعْليمَة break، تُجرِي هذه العملية على حَلْقة التَكْرار الأقرب لها فقط، أيّ الحَلْقة الداخلية (inner nested loop). وبالمثل، تتوفَّر تَعْليمَة continue المُعنوَنة (labeled continue)، وذلك لتخصيص حَلْقة التَكْرار المراد إجراء عملية continue عليها. يمكن اِستخدَام تَعْليمَتي break و continue داخل جميع حَلْقات التَكْرار مثل while، و do..while، و for. سنتحدث عن الأخيرة تفصيليًا بالقسم التالي. يُمكن أيضًا اِستخدَام تَعْليمَة break للخروج من تَعْليمَة switch، وهو ما سنتناوله بالقسم ٣.٦. يُسمَح أيضًا باِستخدَامها داخل تَعْليمَة التَفْرِيع الشَّرْطيّة if إذا كانت تَعْليمَة التَفْرِيع موجودة إِمّا ضِمْن حَلْقة تَكْراريّة أو ضِمْن تَعْليمَة switch، ولكن عندها لا يكون المقصود هو الخروج من تَعْليمَة التَفْرِيع if، وإنما الخروج من التَعْليمَة التي تَشتَملها، أي من تَعْليمَة الحَلْقة أو من تَعْليمَة switch. بالمثل، يُمكِن اِستخدَام تَعْليمَة continue داخل تَعْليمَة if بنفس الطريقة، وتتبِّع نفس القواعد بالأعلى. ترجمة -بتصرّف- للقسم Section 3: The while and do..while Statements من فصل Chapter 3: Programming in the Small II: Control من كتاب Introduction to Programming Using Java.1 نقطة
تُصنَّف التَعْليمات البرمجية (statements) بأي لغة برمجة -ومنها الجافا Java- إلى تَعْليمات بسيطة (simple) وأخرى مُركَّبة (compound). تُعدّ التَعْليمات البسيطة -مثل تَعْليمَة الإِسْناد (assignment) وتَعْليمَة اِسْتدعاء البرامج الفرعية (subroutine call)- اللَبِنة الأساسية لأيّ برنامج. في المُقابل، تتكون التَعْليمات المُركَّبة -مثل تَعْليمَة حَلْقة التَكْرار while وتَعْليمَة التَفْرِيع الشَّرطيّة if- من عدد من التَعْليمات البسيطة، وتُعرَف باسم بُنَى التحكُّم (control structures)؛ نظرًا لأنها تَتَحكَّم بترتيب تَّنْفيذ التَعْليمات. سنتناول بُنَى التحكُّم (control structures) المُدَعَّمة بلغة الجافا Java بشئٍ من التفصيل خلال الأقسام الخمسة التالية، بحيث نبدأ في هذا القسم بتَعْليمتي الحَلْقة while و do..while. سنتَعرَّض، خلال ذلك، لكثير من الأمثلة البرمجية التي تُوظِّف بُنَى التحكُّم تلك، كما أننا وبينما نقوم بذلك، سنُطبِّق التقنيات المُتَّبَعة بتصميم الخوارزميات (algorithms)، والتي قد تَعرَّضنا لها بالفصل السابق. تَعْليمَة while تُكتَب تَعْليمَة حَلْقة التَكْرار (loop) while -والتي قد تَعرَّضت لها مُسْبقًا بالقسم ٣.١- بالصياغة التالية: while ( <boolean-expression> ) <statement> لا يُشترَط أن تتكوَّن التعليمة -المُشار إليها بالأعلى، والمعروفة باسم مَتْن حَلْقة التَكْرار (loop body)- من تَعْليمَة واحدة فقط، فبالطبع يُمكنها أن تكون كُتليّة البِنْية (block statement)، بحيث تَتضمَّن عدة تَعْليمَات مُحَاطة بزوج من الأقواس. يَتكرَّر تَّنْفيذ مَتْن الحَلْقة (body of the loop) طالما كان التعبير -المُشار إليه بالأعلى- مُتحقِّقًا. تتكون تلك العبارة من تَعبير منطقي (boolean expression)، وتُعرَف باسم الشَّرْط الاستمراري (continuation condition) لحَلْقة التَكْرار أو باسم اختبار حَلْقة التَكْرار. نحتاج الآن لإِيضاح عدة نقاط بشيء من التفصيل. أولًا، ماذا يَحدُث إذا لم يَتحقَّق شَّرْط حَلْقة التَكْرار ولو لمرة واحدة على الأقل، بمعنى أنه لم يَكُن متحقِّقًا قبل التَّنْفيذ الأوَّليّ لمَتْن الحَلْقة؟ في هذه الحالة، لا يُنفَّذ مَتْن الحَلْقة (body) نهائيًا، وهو ما يعني أن مَتْن حَلْقة while يُمكِن أن يُنفَّذ أيّ عدد من المرات بما في ذلك الصفر. ثانيًا، ماذا لو كان شَّرْط حَلْقة التَكْرار مُتحقِّقًا، لكن وبينما يُنفَّذ مَتْن الحَلْقة لم يَعُدْ الشَّرْط كذلك؟ هل يَتوقَف تَّنْفيذ الحَلْقة بمجرد حُدُوث ذلك؟ ببساطة لا؛ حيث يَستمِر الحاسوب بتَّنْفيذ مَتْن الحَلْقة بالكامل حتى يَصِل إلى نهايته، وعِندها فقط يَقفز عائدًا إلى بداية حَلْقة التَكْرار لفَحْص شَّرْطها (continuation condition) مُجددًا، ومِنْ ثَمَّ، يَستطيع في تلك اللحظة فقط إِيقاف الحَلْقة وليس قبل ذلك. لنفْحَص إِحدى المشكلات التي تُحلّ باِستخدَام حَلْقة التَكْرار while: حِساب قيمة متوسط (average) مجموعة من الأعداد الصحيحة الموجبة (positive integers)، والتي يَتم إِدْخالها من قِبَل المُستخدِم. تُحسَب قيمة المتوسط (average) عمومًا بحِساب حاصل مجموع الأعداد ثم قِسمته على عَدَدها. سيَطلب البرنامج من المُستخدِم إِدْخال عدد صحيح (integer) وحيد في المرة، وسيَحتفِظ دومًا بقيمة المجموع الكلي للأعداد الصحيحة المُدْخَلة حتى اللحظة الراهنة، وكذلك عَدَدها، كما سيُبقي هذه القيم مُحْدَثة مع كل عملية إِدْخال. هاك خوارزمية البرنامج (algorithm) مَكتوبة بأسلوب الشيفرة الوهمية (pseudocode): Let sum = 0 Let count = 0 // طالما لا يوجد المزيد من الأعداد الصحيحة للمعالجة while there are more integers to process: // اقرأ عدد صحيح Read an integer // أضف قيمته إلى المتغير sum Add it to the sum // أزد قيمة العداد Count it // اقسم المجموع sum على count لحساب قيمة المتوسط Divide sum by count to get the average // اطبع قيمة المتوسط Print out the average لكن كيف سنتحقَّق فعليًا من شَّرْط الحَلْقة بالأعلى "طالما لا يوجد المزيد من الأعداد الصحيحة للمعالجة"؟ أحد الحلول هو إِبلاغ المُستخدِم بأن يُدخِل القيمة صفر بعد أن يَنتهِي من إِدْخال جميع البيانات الفعليَّة. ستَنجح تلك الطريقة نظرًا لأننا نَفترِض أن البيانات الفعليَّة المُدْخَلة لابُدّ وأن تَكون من الأعداد الصحيحة الموجبة، وهو ما يَعني أن الصفر يُعدّ قيمة غيْر صالحة من الأساس. لاحِظ أن الصفر هنا ليس قيمة بحدّ ذاتِها يَنبغي تَضْمِينها مع الأعداد المطلوب حِساب مُتوسطها، وإِنما هي فقط مطلوبة كعلامة للإشارة إلى نهاية البيانات الفعليَّة. يُطلق أحيانًا على قِيَم البيانات المُستخدَمة بطريقة مُشابهة اسم بَيَان البداية/النهاية (sentinel value). سنُعدِّل الآن اختبار حَلْقة التَكْرار while ليُصبِح "طالما العدد الصحيح المُدخل لا يساوي الصفر". ستُواجهنا مشكلة آخرى، عندما يُنفَّذ اختبار حَلْقة التَكْرار (loop) لأول مرة، أي قَبْل التَّنْفيذ الأوَّليّ لمَتْن الحَلْقة، لن يكون هناك عدد صحيح قد قُرأ بَعْد، بل ليس هناك أيّ بيانات قد قُرِأت أساسًا، مما يَعني أنه لا يوجد "عدد صحيح مُدخل". ولهذا، يُصبِح اختبار الحَلْقة "طالما العدد الصحيح المُدخل لا يساوي الصفر" -ضِمْن هذا السياق- غَيْر ذي مَعنى. لذلك يَنبغي القيام بأمر ما قَبل البدء بتَّنْفيذ حَلْقة التَكْرار while للتأكد من صلاحية الاختبار حتى مع أول تَّنْفيذ له. تُعرَف هذه العملية باسم التهيئة المبدئية (priming the loop) لحَلْقة التَكْرار، وفي هذه الحالة بالتحديد، يُمكننا ببساطة تهيئة الحَلْقة عن طريق قراءة أول عدد صحيح مُدْخَل قَبل بدء تَّنْفيذ حَلْقة التَكْرار. هاك الخوارزمية (algorithm) المُعدَّلة: Let sum = 0 Let count = 0 // اقرأ عدد صحيح Read an integer // طالما العدد الصحيح المُدخل لا يساوي الصفر while the integer is not zero: // أضف قيمته إلى المتغير sum Add the integer to the sum // أزد قيمة العداد Count it // اقرأ عدد صحيح Read an integer // اقسم المجموع sum على count لحساب قيمة المتوسط Divide sum by count to get the average // اطبع قيمة المتوسط Print out the average لاحِظ إعادة ترتيب تَعْليمَات مَتْن حَلْقة التَكْرار (loop body)؛ لأنه لمّا أصْبَحت أول محاولة لقراءة عدد صحيح (integer) تَحدُث قَبْل بداية حَلْقة التَكْرار (loop)، كان لابُدّ لمَتْن الحَلْقة من أن يبدأ أولًا بمُعالجة ذلك العدد. ثُمَّ بنهاية المَتْن، سيُحاول الحاسوب قراءة عدد صحيح جديد، ليَقفِز بَعْدها عائدًا لبداية الحَلْقة ليَختبِر العدد الجديد المَقروء للتو. عندما يَقرأ الحاسوب قيمة بَيَان النهاية (sentinel value)، ستَتوقَف الحَلْقة، ومِنْ ثَمَّ لن تُعالَج تلك القيمة، كما أنها لن تُضاف إلى حاصل المجموع sum، أو هذه هى الطريقة التي ينبغي أن تَعمَل بها الخوارزمية على الأقل؛ لأن قيمة بَيَان النهاية ليست جزءً من البيانات الفعليَّة كما ذَكَرنا مُسْبَّقًا. لا تَعمَل الخوارزمية الأصلية طِبقًا لذلك بطريقة صحيحة -بفَرْض إِمكانية تَّنْفيذها بدون إِجراء التهيئة المبدئية (priming) بطريقة ما-؛ لأنها ستَحسِب حاصل مجموع جميع الأعداد الصحيحة وكذلك عَدَدها (count) بما يتَضمَّن قيمة بَيَان النهاية (sentinel value). لمّا كانت تلك القيمة -المُتفق عليها- تُساوي الصفر، فإن حاصل المجموع سيظِلّ لحسن الحظ صحيحًا، ولكن في المقابل سيكون عَدَدها (count) خطأ بفارق واحد. يُطلَق على الأخطاء المُشابهة اسم الأخطاء بفارق الواحد (off-by-one errors)، وهي واحدة من أكثر الأخطاء شيوعًا. اِتضح أن العَدّ أصعب مما قد يبدو عليه. سنُحوِّل الآن الخورازمية إلى برنامج كامل، نُلاحِظ أولًا أنه لا يُمكِن اِستخدَام التَعْليمَة average = sum/count; لحساب قيمة المتوسط (average)؛ لأنه لمّا كانت قيمة كُلًا من المُتَغيِّرين sum و count من النوع العددي الصحيح int، فإن حاصل قِسمة الأول على الثاني sum/count ستكون أيضًا من النوع العددي الصحيح int، في حين ينبغي للمتوسط أن يكون عددًا حقيقيًا (real number). لقد واجهنا هذه المشكلة مِن قَبْل، ويَتلخَّص حَلّها بضرورة تَحْوِيل واحد من القيمتين إلى النوع double؛ وذلك لإجبار الحاسوب على حِسَاب قيمة حاصل القِسمة (quotient) كعَدَد حقيقي (real number). يُمكِن القيام بذلك عن طريق إجراء عملية التَحْوِيل بين الأنواع (type-casting) على أحد المُتَغيِّرين على الأقل، بحيث يُحوَّل إلى النوع double عن طريق اِستخدَام (double)sum. ولهذا يَحسِب البرنامج قيمة المتوسط باستخدام التعبير average = ((double)sum) / count;. يَتوفَّر حلّ آخر، وهو التَّصْريح (declaration) عن المُتَغيِّر sum بحيث يكون أساسًا من النوع double. حُلَّت مشكلة آخرى بالبرنامج التالي، وهي أنه في حالة إِدْخال المُستخدِم القيمة صفر كأول قيمة مُدْخَل، فلن تتوفَّر أيّ بيانات للمُعالجة، ولهذا يُمكننا اختبار حُدُوث تلك الحالة بفَحْص ما إذا كانت قيمة المُتَغيِّر count ما تزال مُساوية للصفر حتى بَعْد انتهاء حَلْقة التَكْرار while. قد تبدو هذه المشكلة ثانوية، ولكن لابُدّ أن يُغطي أيّ مبرمج مُنتبِه جميع الحالات المُمكنة. انظر شيفرة البرنامج بالكامل: import textio.TextIO; public class ComputeAverage { public static void main(String[] args) { int inputNumber; // إحدى القيم المدخلة من قبل المستخدم int sum; // حاصل مجموع الأعداد الصحيحة الموجبة int count; // عدد الأعداد الصحيحة double average; // قيمة متوسط الأعداد الصحيحة الموجبة // هيئ قيمة كلا من متغير المجموع والعداد sum = 0; count = 0; // اقرأ مدخل من المستخدم لمعالجته System.out.print("Enter your first positive integer: "); inputNumber = TextIO.getlnInt(); while (inputNumber != 0) { // أضف قيمة المتغير للمجموع الحالي sum += inputNumber; // أزد قيمة العداد بمقدار الواحد count++; System.out.print("Enter your next positive integer, or 0 to end: "); inputNumber = TextIO.getlnInt(); } // اعرض النتائج if (count == 0) { System.out.println("You didn't enter any data!"); } else { average = ((double)sum) / count; System.out.println(); System.out.println("You entered " + count + " positive integers."); System.out.printf("Their average is %1.3f.\n", average); } } // نهاية البرنامج main } // نهاية الصنف ComputeAverage تعليمة do..while تَفحْص تَعْليمَة حَلْقة التَكْرار while الشَّرْط الاستمراري لحَلْقة التَكْرار (continuation condition) ببداية الحَلْقة، ولكن أحيانًا ما يكون من الأنسب فَحْصه بنهاية الحَلْقة لا بدايتها، وهذا في الواقع ما تُوفِّره تَعْليمَة do..while. تَتشابه صياغة (syntax) تَعْليمَة الحَلْقة do..while مع تَعْليمَة while تمامًا باستثناء بعض التَغْيِيرات الطفيفة، حيث تُنْقَل كلمة while مصحوبة مع الشَّرْط إلى نهاية الحَلْقة، في حين تُضاف كلمة do في بداية الحَلْقة بدلًا منها. تُكتَب تَعْليمَة حَلْقة التَكْرار do..while بالصياغة التالية: do <statement> while ( <boolean-expression> ); إذا كانت التعليمة كُتلَة (block) بذاتها، تُصاغ التَعْليمَة كالتالي: do { <statements> } while ( <boolean-expression> ); لاحِظ وجود الفاصلة المَنقوطة (semicolon) ; بنهاية التَعْليمَة do..while. تُعدّ هذه الفاصلة جزءً أساسيًا من التَعْليمَة do..while، مثلما تُعدّ الفاصلة بنهاية أي تَعْليمَة أخرى -كالإِسْناد (assignment) أو التَّصْريح (declaration)- جزءً أساسيًا منها. ولهذا سيؤدي حَذْف الفاصلة المنقوطة ;، في هذه الحالة، إلى التَسبُّب بحُدوث خطأ في بناء الجملة (syntax error). ينبغي عمومًا أن تنتهي أيّ تَعْليمَة برمجية -بلغة الجافا Java- إِمّا بفاصلة منقوطة ; أو بقوس مُغلِق {. عندما يُنفَّذ الحاسوب تَعْليمَة حَلْقة التَكْرار do..while، فإنه يبدأ أولًا بتَّنْفيذ مَتْنها (loop body)-التَعْليمَة أو مجموعة التَعْليمَات بداخل الحَلْقة-، ثم يَحسِب قيمة التعبير المنطقي (boolean expression)، فإذا كانت مُساوية للقيمة المنطقية true، فإنه يَقفِز عَائدًا إلى بداية الحَلْقة ويُعيد تَّنْفيذ مَتْنها، لتستمر العملية بَعْدها بنفس الطريقة. أما إذا كانت قيمة التعبير المنطقي مُساوية للقيمة المنطقية false، فإنه يَتوقَف عن تَّنْفيذ الحَلْقة، وينتقل إلى الجزء التالي من الشيفرة. لاحظ أنه لمّا كان شَّرْط الحَلْقة لا يُفحْص إلا بنهاية الحَلْقة، فإن مَتْن حَلْقة التَكْرار do..while دائمًا ما يُنفَّذ مرة واحدة على الأقل. على سبيل المثال، اُنظر الشيفرة الوهمية (pseudocode) التالية لبرنامج لعبة. ستجد أن استخدام تَعْليمَة الحَلْقة do..while أكثر مُلائمة في هذه الحالة؛ لأنها ستَضمَن أن المُستخدِم قد لعِبَ مباراة واحدة على الأقل. علاوة على ذلك، فإن شَّرْط حَلْقة التَكْرار بالأسفل لن يكون له أيّ مَعنى في حالة تَّنْفيذه في بداية الحَلْقة. do { // العب مباراة Play a Game // اسأل المستخدم إذا ما كان يريد اللعب مرة آخرى Ask user if he wants to play another game // اقرأ رد المستخدم Read the user's response // أعد التكرار طالما كان رد المستخدم هو نعم } while ( the user's response is yes ); سنُحوِّل الآن هذه الشيفرة الوهمية إلى لغة الجافا. بدايةً ولكي نتجنب الخَوْض في تفاصيل ليست ذا أهمية، سنفترض أن لدينا صَنْف (class) يَحمِل اسم Checkers. أحد أعضاء (member) هذا الصَنْف هو البرنامج الفرعي الساكن (static subroutine) playGame(). يُغلِّف هذا البرنامج الفرعي التفاصيل الخاصة باللعبة، ويُمثِل استدعائه إجراء مباراة دَّامَا (checkers) واحدة مع المُستخدِم. يُمكننا الآن اِستخدَام تَعْليمَة استدعاء البرنامج الفرعي (subroutine call) الساكن Checkers.playGame(); كبديل عن سَطْر الشيفرة "العب مباراة". سنَستخدِم الصنف TextIO لتَلَقِّي رد المُستخدِم على سؤال من النوع نعم أم لا؛ حيث يُوفِّر هذا النوع الدالة (function) TextIO.getlnBoolean()، والتي تَسمَح للمُستخدِم بإِدْخال إحدى القيمتين "Yes/No" ضِمْن عدة ردود أُخرى صالحة، بحيث يؤول الرد "Yes" إلى القيمة المنطقية true، بينما يؤول الرد "No" إلى القيمة المنطقية false. سنحتاج الآن إلى مُتَغيِّر لتخزين رد المُستخدِم، والذي سيكون بطبيعة الحال من النوع المنطقي (boolean). يُمكن كتابة الخوارزمية كالتالي: // تساوي True في حالة رغب المستخدم باللعب مجددًا boolean wantsToContinue; do { Checkers.playGame(); System.out.print("Do you want to play again? "); wantsToContinue = TextIO.getlnBoolean(); } while (wantsToContinue == true); وفقًا لشَّرْط حَلْقة التَكْرار بالأعلى، فإنه عندما تَتَساوى قيمة المُتَغيِّر المنطقي wantsToContinue مع القيمة المنطقية false، سيكون ذلك إشارة (signal) إلى ضرورة تَوقُف حَلْقة التَكْرار. يُطلَق عادةً على المُتَغيِّرات المنطقية (boolean variables) المُستخدَمة بهذه الطريقة اسم راية (flag) أو مُتَغيِّر راية -هي متغيرات تُضبَط (set) بمكان ما بالشيفرة لتُفحَص قيمتها بمكان آخر-. بالمناسبة، عادةً ما يَسخَر بعض المبرمجين -ربما قد يَصفهم البعض بالمُتَحذلِقين- من شَّرْط حَلْقة التَكْرار while (wantsToContinue == true)؛ وذلك لأنه مُكافئ تمامًا للشَّرْط while (wantsToContinue)؛ فاختبار ما إذا كان التعبير wantsToContinue == true يُعيد القيمة المنطقية true لا يَختلف نهائيًا عن اختبار ما إذا كان المُتَغيِّر wantsToContinue يَحمِل القيمة true ويُعيدها. بالمثل، -وبفَرْض أن لدينا مُتَغيِّر اسمه flag من النوع المنطقي (boolean variable)- يُكافئ التعبير flag == false، والذي يُعدّ أقل فَجاجة من التعبير السابق، تمامًا التعبير !flag، حيث الحرف ! هو عَامِل النفي المنطقي (negation operator). يُفضَّل عمومًا كتابة while (!flag) بدلًا من while (flag == false)، وبالمثل، كتابة if (!flag) بدلًا من if (flag == false). على الرغم من أن اِستخدَام تَعْليمَة حَلْقة التَكْرار do..while أحيانًا ما يكون أكثر ملائمة في بعض المسائل، فعمومًا لا يَجعل وجود نوعين مختلفين من تَعْليمَة الحَلْقة (loops) لغة البرمجة أكثر قوة؛ فبالنهاية، أي مشكلة تُحلّ بإحداهما، ستجد أنه من الممكن حلّها بالآخرى. في الواقع، بفرض أن العبارة تُمثل أي كُتلَة شيفرة، فإن التالي: do { <doSomething> } while ( <boolean-expression> ); يُكافئ تمامًا: <doSomething> while ( <boolean-expression> ) { <doSomething> } بالمثل: while ( <boolean-expression> ) { <doSomething> } يُكافئ: if ( <boolean-expression> ) { do { <doSomething> } while ( <boolean-expression> ); } بدون أي تَغْيِير بمَقصِد البرنامج نهائيًا. تعليمتي break و continue تَسمَح لك صيغتي حَلْقتي التَكْرار while و do..while باختبار الشَّرْط الاستمراري (continuation condition) إِمّا ببداية الحَلْقة أو بنهايتها على الترتيب. ولكن أحيانًا سترغب في إجراء عملية اختبار شَّرْط أثناء تَّنْفيذ الحَلْقة، أيّ داخل مَتْن الحَلْقة نفسها، أو حتى قد ترغب بإجراء أكثر من عملية اختبار بأماكن مختلفة داخل نفس الحَلْقة. تُستخدَم تَعْليمَة break بلغة الجافا لإيقاف تَّنْفيذ أيّ حَلْقة تَكْرار (loop)، والخروج منها، وذلك بمجرد استدعائها بأيّ مكان داخل الحَلْقة. تُكتَب كالتالي: break; عندما يُنفِّذ الحاسوب تَعْليمَة break داخل حَلْقة (loop)، فإنه سيَقفِز مُباشرةً خارج الحَلْقة، ويُنفِّذ الشيفرة التالية بالبرنامج والموجودة أسفل الحَلْقة. انظر المثال التالي: while (true) { // يبدو وكأنها ستنفذ بشكل لا نهائي System.out.print("Enter a positive number: "); N = TextIO.getlnInt(); // إما أن تكون قيمة المدخل سليمة أو اقفز خارج الحلقة if (N > 0) break; System.out.println("Your answer must be > 0."); } // اكمل هنا بعد break في المثال بالأعلى، إذا أَدْخَل المُستخدِم عدد أكبر من الصفر، سيتحقَّق الشَّرْط، وستُنفَّذ تَعْليمَة break، ولهذا سيَقفِز الحاسوب مباشرة خارج الحَلْقة إلى ما بَعْدها. في المقابل، إذا لم يتحقَّق الشَّرْط، ستُطبَع السِلسِلة النصية "Your answer must be > 0"، ثم سيَقفِز الحاسوب عَائدًا إلى بداية الحَلْقة ليَقرأ مُدْخَل جديد. قد يبدو السَطْر الأول من الشيفرة بالأعلى while (true) غَيْر مألوف نوعًا ما، ولكنه في الواقع سليم تمامًا. يُسمَح عمومًا لأيّ تعبير منطقي (boolean-valued expression) بأن يكون شَّرْطًا لحَلْقة التَكْرار، أيّ لابُدّ فقط أن تؤول قيمته النهائية إلى قيمة منطقية؛ ليَفحْصها الحاسوب لمعرفة ما إذا كانت مُساوية للقيمة true أم للقيمة false. تُعدّ القيمة المُجرَّدة (literal) true تعبيرًا منطقيًا، والذي يؤول دائمًا إلى القيمة المنطقية true، ولذلك يُمكِن اِستخدَامها كشَّرْط للحَلْقة. يُستخدَم الشَّرْط while (true) لكتابة حَلْقة لا نهائية (infinite loop) أو حَلْقة يُفْترَض الخروج منها باِستخدَام تَعْليمَة break. يُسمَح باِستخدَام حَلْقات التَكْرار المُتداخِلة (nested loops)، بمَعنى وجود تَعْليمَة حَلْقة تَكْرار داخل أُخرى، ولذلك لابُدّ لنا من فهم طريقة عَمَل تَعْليمَة break ضِمْن هذا السياق. كقاعدة عامة، تُوقِف تَعْليمَة break حَلْقة التَكْرار الأقرب لها فقط، بمَعنى أنها إذا اُستخدِمت بداخل الحَلْقة الداخلية (inner loop)، فإنها ستُوقِف فقط تلك الحَلْقة، لا الحَلْقة الخارجية (outer loop) التي تَشَمَلها. أما إذا أردت إيقاف تَّنْفيذ الحلقة الخارجية، يُمكِنك اِستخدَام ما يُعرَف باسم تَعْليمَة break المُعنوَنة (labeled break). تَسمَح تَعْليمَة break المُعنوَنة بتحديد صريح للحَلْقة المطلوب الخروج منها. اِستخدَام هذه التَعْليمَة المُعنوَنة غَيْر شائع، ولذلك سنمر عليها سريعًا. تَعمَل العناوين (labels) كالتالي: يُمكِنك ببساطة عَنوَنة أيّ حَلْقة تَكْرار بوَضْع مُعرَّف (identifier) مَتبوع بنقطتان رأسيتان : بمقدمة الحَلْقة. فمثلًا، يمكن عَنوَنة حَلْقة تَكْرار while باِستخدَام mainloop: while.... تستطيع الآن اِستخدَام تَعْليمَة break المُعنوَنة بأيّ مكان داخل هذه الحَلْقة عن طريق اِستخدَام الصيغة break mainloop;، وذلك بهدف الخروج من هذه الحَلْقة تحديدًا. على سبيل المثال، تَفحْص الشيفرة بالأسفل ما إذا كانت السِلسِلتين النصيتين s1 و s2 تحتويان على حرف مُشتَرَك. في حالة تَحقُّق الشَّرْط، ستُسْنَد القيمة المنطقية false إلى مُتَغيِّر الراية nothingInCommon، ثُمَّ تُسْتَدعى تَعْليمَة break المُعنوَنة لإيقاف المعالجة عند تلك النقطة: boolean nothingInCommon; // افترض أن السلسلتين لا يشتركان بأي حرف nothingInCommon = true; // متغيرات حلقتي التكرار والتي ستأخذ قيم حروف السلسلتين int i,j; i = 0; bigloop: while (i < s1.length()) { j = 0; while (j < s2.length()) { // إذا كان هناك حرفًا مشتركا if (s1.charAt(i) == s2.charAt(j)) { // اضبط قيمة المتغير إلى القيمة false nothingInCommon = false; // اخرج من الحلقتين break bigloop; } j++; // Go on to the next char in s2. } i++; //Go on to the next char in s1. } تُعدّ تَعْليمَة continue مرتبطة نوعًا ما بتَعْليمَة break، لكنها أقل اِستخدَامًا منها. تتَخَطَّى تَعْليمَة continue الجزء المُتبقي من التَكْرار الحالي (current iteration) فقط، أي أنها لا تتَسبَّب بالقفز خارج الحَلْقة تمامًا إلى ما بَعْدها كتَعْليمَة break؛ وإنما تَقفِز عائدة إلى بداية نفس الحَلْقة لتَّنْفيذ التَكْرار التالي (next iteration) -بالطبع إذا كان الشَّرْط الاستمراري (continuation condition) لحَلْقة التَكْرار ما زال مُتحقِّقًا. عندما تُستخدَم تَعْليمَة continue داخل حَلْقة مُتداخِلة (nested loop)، فإنها، مثل تَعْليمَة break، تُجرِي هذه العملية على حَلْقة التَكْرار الأقرب لها فقط، أيّ الحَلْقة الداخلية (inner nested loop). وبالمثل، تتوفَّر تَعْليمَة continue المُعنوَنة (labeled continue)، وذلك لتخصيص حَلْقة التَكْرار المراد إجراء عملية continue عليها. يمكن اِستخدَام تَعْليمَتي break و continue داخل جميع حَلْقات التَكْرار مثل while، و do..while، و for. سنتحدث عن الأخيرة تفصيليًا بالقسم التالي. يُمكن أيضًا اِستخدَام تَعْليمَة break للخروج من تَعْليمَة switch، وهو ما سنتناوله بالقسم ٣.٦. يُسمَح أيضًا باِستخدَامها داخل تَعْليمَة التَفْرِيع الشَّرْطيّة if إذا كانت تَعْليمَة التَفْرِيع موجودة إِمّا ضِمْن حَلْقة تَكْراريّة أو ضِمْن تَعْليمَة switch، ولكن عندها لا يكون المقصود هو الخروج من تَعْليمَة التَفْرِيع if، وإنما الخروج من التَعْليمَة التي تَشتَملها، أي من تَعْليمَة الحَلْقة أو من تَعْليمَة switch. بالمثل، يُمكِن اِستخدَام تَعْليمَة continue داخل تَعْليمَة if بنفس الطريقة، وتتبِّع نفس القواعد بالأعلى. ترجمة -بتصرّف- للقسم Section 3: The while and do..while Statements من فصل Chapter 3: Programming in the Small II: Control من كتاب Introduction to Programming Using Java.1 نقطة