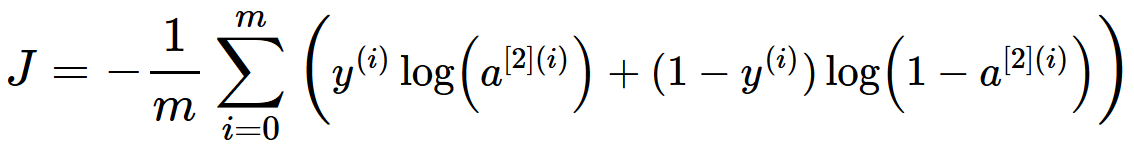لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 09/17/21 في كل الموقع
-
أكتب صنف وسيط Middleware وأريد تنفيذه مرة واحدة فقط عند بدء التشغيل. بحيث يقوم هذا لكود بضبط بعض الإعدادات وتهيئة ققاعدة البيانات بشكل معين بدلًا من القيام بهذه المهمة يدويًا عند تشغيل مشروع جانغو Django. كيف أقوم بهذا الأمر في جانغو Django؟ أنا أستخدم الإصدار 1.7 من جانغو Django2 نقاط
-
كيف يمكنني تحويل ملفات التدريب الخاصة بنموذجي إلى ملف graph.pb واحد لأتمكن من نقلها إلى تطبيق Android الخاص بي؟ علماً أن الملفات التي نتجت من تدريب النموذج الخاص بي هي: model.ckpt-23125.meta checkpoint model.ckpt-23125.data-00000-of-00001 model.ckpt-23125.index2 نقاط
-
قمت ببناء نموذج لمهمة تصنيف ثنائي وأريد حساب F1 score لنموذجي، فيكف يمكننا القيام بذلك من خلال تنسرفلو؟2 نقاط
-
ما فائدة الsemantic tags في html5 حيث أنها ﻻ تعطي أي استايل للعنصر2 نقاط
-
لدي مشكل في استدعاء قيمة من قاعدة البيانات المشكل بتحديد في foreach مع انها لاترجع نوع الخطا try { $conn = new PDO("mysql:host=$serName;dbname=$dabName", $usrName, $usrPass); $stnt = $conn-> prepare("SELECT emailw FROM data"); $stnt-> execute(); $stnt-> setFetchMode(PDO::FETCH_ASSOC); foreach ($stnt as $val) { if ($val["emailw"] != $this - > mail) { return $val["emailw"]; $conn-> setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); // send data to database .. $stmt = $conn-> prepare("INSERT INTO data (namew, emailw, passwordw, datew) VALUES (:name, :mail, :pass, :date)"); $stmt->bindParam(':name', $namep); $stmt->bindParam(':mail', $mailp); $stmt-> bindParam(':pass', $passp); $stmt-> bindParam(':date', $datep); $namep = $this-> name; $mailp = $this-> mail; $passp = $this-> pass; $datep = $this-> date; $stmt - > execute(); return "Successfully connected .."; break; } else { return 'this email has created ..'; } } $conn = null; } catch (PDOException $e) { return 'false connect ..' . $e->getMessage(); }2 نقاط
-
هلا تأكدت من أن مزود الاستضافة الخاص بك يسمح لك بإرسال رسائل البريد الإلكتروني ولا يحد من إرسال رسائل البريد الإلكتروني ؟ و ذلك لأن العديد من مضيفات الويب المشتركة ، وخاصة موفري الاستضافة المجانية ، إما لا تسمح بإرسال رسائل البريد الإلكتروني من خوادمها أو تحد من العدد الذي يمكن إرساله خلال أي فترة زمنية معينة . و قد تحتاج إلى التواصل مع فريق دعمهم للتحقق مما إذا كانت هناك أي قيود مفروضة على إرسال رسائل البريد الإلكتروني أو لا . في مثل هاته الحالات يلحظ سلوك مشابه لدالة mail , إذا تقوم بإعادة قيمة صحيحة و تعتبر أن إرسال الرسالة تام , في حين أنه لا يتم إستقبال أي رسالة في صندوق البريد . شيء اخر قد تحتاج التأكد منه و هو أن القيمة الممررة في : From قيمة صحيحة أي أن عنوان البريد الإلكتروني التالي : info@yhyasyrian.cf موجود بالفعل . ان كان كل شيء صحيحا , قد تحتاج تمكين سجل الأخطاء الخاصة بالوظيفة أو الدالة mail , و لنتأكد أن نقوم بوضع هذا قبل الشيفرة لديك : ini_set("mail.log", "/tmp/mail.log"); ini_set("mail.add_x_header", TRUE); و قد تحتاج في حالات أخرى إستعمال خدمات أو موفرات SMTP أخرى لإرسال و إدارة البريد الإلكتروني , و ذلك لأنها توفر مميزات إضافية و خيارات إرسال أخرى . يقترح أحد التالي : PHPMailer (شائع إستعماله) swiftmailer pearMailer يمكنك التعرف على كيفية إرسال رسالة بإستعمال PHPMailler و إرسال بريد إلكتروني باستخدام php. كما يمكنك القراءة أكثر عن طريقة إرسال بريد إلكتروني في PHP بإستخدام الوظيفة mail .2 نقاط
-

الإصدار 1.0.0
78827 تنزيل
هذا الكتاب ليس وصفةً سريعةً للثّراء! وهو لا يَعِدُكَ بجنيِ آلافِ الدولاراتِ منْ خلالِ بقائكَ نائمًا في البيت. لا يُقدّم الكتاب وَصفاتٍ سحريّةً للحُصولِ على 500$ خلالَ ساعتين من خلال مواقعَ خطيرة. ولا يعرض نماذجَ لأناسٍ حصلوا على مليون دولار في عامهم الأوّل بعد قراءة الكتابْ! هذا الكتاب، كتابٌ واقعيٌّ. يلامسُ الحقيقةَ الصعبة بأنّهُ مِن الصّعبِ الحُصولُ على وظيفة في الكثير من الدُّولِ العربيّة. ويخبرك بأن هناكَ أملًا وبديلًا. بل بديلًا قويًّا قَد يكون أفضل من الوظيفة بمراحل. ويبرهن على ذلك بعرض قصص نجاحٍ لأشخاصٍ مثلك، عاشوا ظروفك نفسها، ومن بلدك، ويعانون من جميع المصاعب التي تعاني منه، وبدأوا بمؤهِّلاتٍ قريبةٍ جدًا من مؤهلاتك، وامتلكوا بعضَ المهاراتِ التي تَمتلكها، ولربما كنتَ تُحسِنُها أكثر مِنْ بَعضِهم. ولكنَّ الفرقَ الوحيد (ليس طبعا أنّهم قرأوا الكتاب)، الفرقُ الوَحيدُ أنّهُم وَجَدوا طَريقَهُم للعملِ عَبْر الأنترنت وتحقيقِ مصدرِ دخلٍ كافٍ ومستمرٍّ لأنفسهم، بعضهم – بل الكثير منهم – يحقِّقُ ضِعف الرّاتِبِ الّذي تَحلُمُ بِه شَهريا. يَستعرضُ الكِتابُ قِصصَ النَّجاح بغرضِ إلهامكَ ومَنحِكَ الدَّافِع لتنجح كما نَجحُوا. ويؤكد أنّهم نجحوا ليس لأنّهم تعلّموا المُعادلة السِّحرية للنَّجاح، وليس لأنّهم وجدوا الوصفة السّرية لعصيرِ النّجاح فأعدّوه وشربوه، وليس لأنّ هناك (واسطةً) أخدتْ بأيديهم وعبرت بهم إلى طريقِ النّجاح. إنّما نجَحوا لأنّهم عَمِلوا وتَعبوا وصَابروا وواصَلوا حتّى وَصَلوا. يعرض عليك الكتابُ فرصةَ أنْ تنجح كَما نجحوا، بَل ويَضَعك في ظروفٍ أَفضَل مِن ظُروفهم. وذلك بشرحِ الخُطواتِ اللّازمِ اتّخاذها لبدءِ عملكَ عبر الأنترنت. فالكثير مِنهم لم تُتَح لَه فرصة الحصول على تلك المعلومات، وإنما جرّبوا فأخطأوا فتعلّموا فجرّبوا ثانيةً فنجحوا. وهنا – في هذا الكتاب – نختصر عليك الطّريق، فنعرضُ لكَ تجارِبَهم وأخْطاءَهُم وأَفْضلَ ما حقَّقُوه. يبدأ الكتاب بتعريفِ العمل الحرّ، ومجالاتِه، ومُميّزاتهِ وعُيوبِه. ثمّ يُرشِدُكَ إِلى الكيفيّةِ التي تَبدأُ بِها عملكَ الحُرّ بخطواتٍ بسيطةٍ وسهلةِ التّطبيق. ويُتابِع معك هذِه الخُطوات خُطوة بخطوة. فيقدّم لكَ النَّصائِحَ حولَ إِنشاءِ ملفِّكَ الشّخصيّ، ويُحدثك عَن الطّريقة التي تُقدّمُ بها عروضَ العمل، ويُعلّمكَ كيفيّة تحديدِ السِّعرِ المُناسِب للمشروع، وكيفيّة تَقدير الزّمن اللّازِم لتنفيذه. ويُواسيكَ في حال عدمِ حُصولِكُ عُلى مَشاريع. يَعرضُ الكتابُ عَددًا مِنَ المَهاراتِ اللّازِمة للعَملِ الحُرّ عبرَ الأنترنت، فيستعرضُ مهاراتِ التّواصلِ معَ الزّبائن، ومهاراتِ التّفاوُضِ والإِقْناعْ، ومهاراتِ إدارةِ وتنظيمِ الوقتْ. الكتابُ لا يَدّعي أنّهُ المرجعُ الشاملُ لكلِّ ما لهُ علاقةٌ بالعملِ الحُرّ، إنَّما يرجو مُؤلّفُ الكتابِ أنْ تَكونَ كلماتُهُ قُد لامستْ مَواطنَ الإرادةِ فِي قَلبك. وفُصولَه قدْ شَقّتْ لكَ طريقًا واضحًا للعملِ الحرِّ عبر الأنترنت. وأن يَكونَ ركيزةَ البدايةِ والخُطوة الأولَى في عملكَ عبْر الأنْترنَت. أُمنِيَتُنا في هَذا الكِتاب، أَنْ تَكونَ قِصّةَ نجاحٍ ملهمةً يُحتَفَى بِها، وتُذكَرُ في إصْداراتٍ لاحقةٍ مِنَ الكِتاب. ضَعْ ذَلكَ نُصبَ عَيْنيكْ خِلالَ قِراءتِكَ للكِتابْ.1 نقطة -
السلام عليكم أثناء تصفحي لكود مصدر موقع إلكتروني وجدت تضمينا لملف باسم init.js كالتالي : <!-- Init JavaScript --> <script src="js/js-init.js"></script> أريد أن أعرف ما معنى الإختصار init ؟ كنت قد سمعت أن الملف كان يستخدم كـ command line سابقا , و قد أصبح في الخمس السنين الأخيرة غير ضرورى إذ يعتمدون أكثر على الملف بإسم package.json , ما مدى صحة هاته المقولة ؟ و ما وظيفة هذا الملف عادة , و هل يتم قراءته أثناء أو قبل أو بعد تحميل الصفحة ؟ و هل محتوياته عبارة عن جيكويري فقط في المثال الاتي ؟ كما أني قد لحظت أن الملف يحتوى على ٦ مكتبات : -------------------------- 1.Ready function 2.Load function 3.Full height function 4.droopy function 5.Chat App function 6.Resize function هل يمكن شرح وظيفة كل على حدة ؟ يمكنكم إيجاد رابط الملف : هنا . كمما أن هذا هو رابط الموقع : هنا . بإنتظار إجابة كاملة, وشكرا مسبقا .1 نقطة
-
في الماضي كان هناك طريقة للحصول على عنوان URL الخاص بأي كائن object في لوحة التحكم وذلك من خلال اسم ملف العرض view مع دالة reverse كالتالي: reverse('django.contrib.admin.views.main.change_stage', args=['My App', model_name, id_]) لكن يبدو أن هذه الطريقة لم تعد تعمل في الإصدار الحالي من جانغو Django، وأنا أحاول التحديث إلى أحدث إصدار من جانغو Django، وهذه إحدى العقبات التي واجهتها ،لا أجد طريقة للحصول على عنوان URL الخاص بلوحة التحكم تعمل بعد الآن. كيف يمكنني الحصول على عنوان URL الخاص بلوحة التحكم لكائن معين في جانغو Django؟1 نقطة
-
عندما اقوم بمحاولة نسخ ولصق عنصر في لينكس يأتيني هذا الخطأ couldn't paste file1 نقطة
-
تحيه طيبه للجميع لدي استفسار لو تكرمتو اقوم بستعمال TextFormField لتعبئة الارقام ولكن واجهتني مشكله مع نظام ios حيث ان المستخدم قادر على ادخال الارقام باللغة العربية وانا فقط ارغب ان يستقبل الحقل الارقام الانجليزية . في نظام ال ios يمكن للمستخدم تغيير الكيبورد من اسفل الكيبورد من انجليزي الى عربي والعكس ايضا. هل يوجد حل لجعل المستخدم فقط يقوم بادخال الارقام الانجليزية في الحقل؟ مع العلم انني قمت بتجربة : keyboardType: TextInputType.number, inputFormatters: <TextInputFormatter>[ FilteringTextInputFormatter.digitsOnly ], ولكن الكل يمنح المستخدم امكانية تغير الارقام من الانجليزية الى العربية هل يوجد حل مختلف لمنع المستخدم من ادخال الارقام العربية ؟1 نقطة
-
نعم يمكن تحديد المجالات التي تريدها، اكتب مثلا اسم اللغة ثم unicode أي arabic unicode في البحث سيظهر لك جدول مجالات اللغة في نظام الترميز وأنت تضمن ما تريده: "[a-zA-Z0-9\u0600-\u065F]" استخدم نفس الفكرة، بداية المجال ثم - ثم نهاية المجال، لمعرفة المحارف بالضبط بدل المحرف x في العمود الأيسر مع الترقيم في أعلى الجدول.. 0 أول حرف في السطر، ثم F الأخير ويمكن وضع أي منهم 012345ِ789ABCDEF ...
 1 نقطة
1 نقطة -
عندما أحوال ارسال اميل من بي اتش بي ياتي هذا الخطا SMTP Error: Could not authenticate" in PHPMailer على الرغم انى متاكد من صحة اميلي وباسووردي1 نقطة
-
سنحاول تحديد المحارف الممكنة من خلال التعابير المنتظمة حسب مجال المحارف الانكليزية للأرقام.. حيث نمرر RegExp والتي هي اختصار ل regular expression من خلال الدالة allow TextField( inputFormatters: <TextInputFormatter>[ FilteringTextInputFormatter.allow(RegExp("[0-9]")), ], // Only numbers can be entered ), أما مثلا حروف وأرقام انكليزية يمكن التالي: FilteringTextInputFormatter.allow(RegExp("[0-9a-zA-Z]")), وإن أردت السماح بافراغات فقط أضف فراغ "[a-zA-Z ]" ^^^1 نقطة
-
أحاول تصفية المستخدمين حسب حقل مخصص في كل ملف تعريفي خاص بالمستخدم ويسمى الحقل profile. وهو عبارة عن حقل من نوع int، وتكون قيمته بين 0 و 3. إذا قمت بالتصفية باستخدام علامة يساوي ، فسأحصل على قائمة بالمستخدمين بالمستوى المختار كما هو متوقع: users = User.objects.filter(profile__level = 0) لكن عندما أحاول التصفية باستخدام علامة أقل من: users = User.objects.filter(profile__level < 3) يظهر لي الخطأ التالي: global name 'profile__level' is not defined ما الخطأ الذي قمت به هنا وكيف أوم بإصلاحه؟1 نقطة
-
يعني الملف بدونه لا يحمل الصفحة الا بوجوده وهو يعمل عند بدأ تحميل الصفحة لكن اريد ان اعرفةالدالة او الكود الذي يجعل الموقع يقرا ملف init.js في الاول ؟1 نقطة
-
عندي فكرة قد تكون ناجحة نوعا ولكني أحتاج لتمويل لها لا يقل عن ما يقرب 700$ ولكن لا املك هذا المبلغ الآن فهل يمكن أن أبدأ بمشروعي بشكل أولي (مقنن) ثم أوسعها إلى أن أصل لتنفيذ لكامل المشروع؟ أم تنصحوني بالتوجّه لمواقع العمل الحر لأجمع رأس المال علما بأنّي مسجل منذ شهور فيها ولكن دون جدوى؟1 نقطة
-
السيرفر بسيط و يستعمل الlocalhost بإمكانه فقط إرسال رسالة عند الإنضمام إليه ، كنب بدرس عند شخص باليوتيوب وهو قال لتفعيل السيرفر تكتب بالcmd أمر sudo su و لكن المشكلة أن الأمر يعمل فقط على kali linux فكيف أقدر أشغله أو أعمل run على الويندوز ؟1 نقطة
-
أعتقد أن هناك أمر آخر على الأقل تقوم بكتابته بعد هذا الأمر sudo su، لأن هذا الأمر يعني استخدام المستخدم المسئول root لتنفيذ الأوامر، وفي الونيدوز يمكنك أن تقوم بذلك من خلال تشغيل موجهة الأوامر كمسئول administrator، ويمكنك أن تقوم بذلك من خلال البحث عن CMD في قائمة أبدء Start ثم الضغط على البرنامج بزر الفأرة الأيمن وإختيار Run as Administrator، وذلك سوف يعمل معك موجه الأوامر كمسئول. الطريقة السابقة مساوية لكتابة sudo su في نظام لينكس. وبعد أن تقوم ها يمكنك أن تقوم بإكمال الشرح وباقي الأوامر.1 نقطة
-
هو بداية ليس أكثر من ملف جافاسكربت عادي , و في الغالب الملفات بالإختصار الدلالي init هي إختصار للكلمة initialize و التي تعني بدء أو تهيئة بالعربية . و دليله هو احتواءه على ما هو لازم لتهئية مجموعة الوظائف أو الموقع و تفاعليته مثل الذي لديك . لذلك نجده من يضعه في جافاسكربت و يضم به وضائف من مثل : إضافة أحداث و تفاعليات إلى عناصر الـ DOM أو تهيئة و إعداد أي مكتبات أو إضافات لإستعمالها . وهو نفس ما يقوم به صاحب الموقع بنفس الملف , لاحظ قطعة من سلسلة عمليات إضافة الأحداث : /*Sidebar Navigation*/ $(document).on('click', '#toggle_nav_btn,#open_right_sidebar,#setting_panel_btn', function (e) { $(".dropdown.open > .dropdown-toggle").dropdown("toggle"); return false; }); $(document).on('click', '#toggle_nav_btn', function (e) { $wrapper.removeClass('open-right-sidebar open-setting-panel').toggleClass('slide-nav-toggle'); return false; }); $(document).on('click', '#open_right_sidebar', function (e) { $wrapper.toggleClass('open-right-sidebar').removeClass('open-setting-panel'); return false; }); $(document).on('click', '.product-carousel .owl-nav', function (e) { return false; }); $(document).on('click', 'body', function (e) { if ($(e.target).closest('.fixed-sidebar-right,.setting-panel').length > 0) { return; } $('body > .wrapper').removeClass('open-right-sidebar open-setting-panel'); return; }); $(document).on('show.bs.dropdown', '.nav.navbar-right.top-nav .dropdown', function (e) { $wrapper.removeClass('open-right-sidebar open-setting-panel'); return; }); $(document).on('click', '#setting_panel_btn', function (e) { $wrapper.toggleClass('open-setting-panel').removeClass('open-right-sidebar'); return false; }); $(document).on('click', '#toggle_mobile_nav', function (e) { $wrapper.toggleClass('mobile-nav-open').removeClass('open-right-sidebar'); return; }); لاحظ تهيئة العديد من إضافات الجيكويري و البوتستراب للإستعمال : /*Counter Animation*/ var counterAnim = $('.counter-anim'); if (counterAnim.length > 0) { counterAnim.counterUp({ delay: 10, time: 1000 }); } /*Tooltip*/ if ($('[data-toggle="tooltip"]').length > 0) $('[data-toggle="tooltip"]').tooltip(); /*Popover*/ if ($('[data-toggle="popover"]').length > 0) $('[data-toggle="popover"]').popover() أي أنه ليس أكثر من ملف بإسم دلالي لتنظيم عملية سير الموقع و تهيئة اللازم لسيرها بشكلها الصحيح . و بالتالي فإن ما وصفته بالمكتبات : ليس كذلك و إنما أشبه بالوظائف أو العمليات المنفصلة , و تعليقها أعلى الملف ليس أكثر من فهرسة لمحتويات الملف , فمثلا : الوظيفة Ready تشمل مجموع الشيفرات التي يتم إستدعاءها بعد تحميل الوثيقة , و هي نفسها تستدعي الوظيفة droopy . لا أبدا , فالملف يستعمل فقط جيكويري و سياق لتهئية الموقع , المكتبات , الإضافات و الأحداث . لا , فذلك غير منطقي أبدا . و لكل ملف حاجته و دوره و لا علاقة لأحدهما بالثاني , فـ package.json هو مستند JSON ، يعتمد عليه مدير حزم الجافاسكربت npm لإدارة الحزم و القراءة من عليها . أما ملف init.js فهو مجرد ملف كغيره من ملفات الجافاسكربت , يحمل شيفرات جافاسكربت عادية . الشيء الوحيد الذي يجعل اسمه دالا عليه هو أن هاته الشيفرات تستعمل بغرض التهيئة و التحضير .1 نقطة
-
الان فهمت ، انا اقوم بذلك فعلا لكن شلت المتغير عشان احاول اوضح السؤال شكرا جزيلا لك1 نقطة
-
في حالة أنك كتبت البريد الإلكتروني وكلمة السر بشكل صحيح فغالباً يكون الخطأ من إعدادات البريد الإلكتروني , إن كنت تستخدم gmail إذهب إلى إعدادات الحماية قم بتفعيل " السماح بالوصول للتطبيقات الأقل أماناً" والسبب في تلك المشكلة أن جوجل يضيف طبقة من الحماية حتى يتأكد أنه لم يتم إختراق بريدك الإلكتروني من مصدر خارجي أو شئ من هذا القبيل.1 نقطة
-
يا اخي وفيت وكفيت والفكرة وصلت ونفس فكرتك جاءت ببالي لذالك اعطيت للتحقق =! ومع دلك لم تنجح وطريقتك هي الاصح والاكثر منطقية بارك الله فيك اخي ♥♥1 نقطة
-
طيب ،،، هل الطريقة التي ذكرتها في اول الموضوع ناجحة ؟ بحيث يتم مراقبة هذا المتغير وفي اي تغيير يطرأ عليه يتم عمل إعادة تحميل للصفحة.1 نقطة
-
ما قصدته مثلاً هنا: $(this).parent('div.p').children().find("div.baby").empty(); $(this).parent('div.p').children().find("div.baby").append(showImage); انت تبحث عن العُنصر مرتين و هذا الشيء ليس جيد فالأفضل أن تُخزن العُنصر الذي بحثت عنه في متغير: var $imgElem = $(this).parent('div.p').children().find("div.baby"); $imgElem.empty(); $imgElem.append(showImage);1 نقطة
-
المشكلة الوحيدة لديك هي أن قاعدة البيانات التي تحاول القراءة من عليها فارغة , فمن المنطقي أن لا يتم الإنطلاق في الدور foreach و القراءة من عليه . أي أن أي شيفرة بداخل الدور كالتالي : foreach($stnt as $val) { echo 'يوجد بيانات في قاعدة البيانات'; سيتم تجاهلها في حالة ما كان المعاد من تنفيذ الإستعلام stnt مصفوفة فارغة . في حين أن نفس الشيفرة سيتم تنفيذها في حالة كان المعاد من تنفيذ الإستعلام مصفوفة بعناصر يمكن القراءة من عليها عن طريق الدور . و لذلك تأكد من أن الجدول data الذي تحاول القراءة من عليه يمتلك على الأقل قيمة أو أكثر افتراضيا حتى يكون ما داخل الدور foreach قابلا للوصول . و لكن أفهم أن الفكرة التي تحاول تطبيقها هي : و لكن ما هو عيب هاته الطريقة ؟ => هو أنه لن يتم تسجيل أي عضو في حالة ما لم يتم تسجيل على الأقل عضو أو أكثر يدويا من قبل , فهذه هي الطريقة الوحيدة للوصول إلى ما داخل الدور . و لتجاوز هاته المشكلة سنقوم بتطبيق المنطق التالي : يتم قبول أي عضو تلقائيا ما ان لم تكن بياناته مطابقة لعضو اخر مسجل بالفعل . و ذلك عوضا عن : التحقق من أن كامل الأعضاء لا يطابقون بيانات هذا العضو كشرط لتسجيله , بحيث يقوم هذا بإغفال احتمال فراغ قاعدة البيانات . لنقم بالتالي : تعريف متغير isAlreadyRegistered كمتغير يحمل قيمة false افتراضيا . يتم تغيير قيمة isAlreadyRegistered إلى true في حالة مطابقة بيانات أحد الأعضاء المسجلين لبيانات العضو الذي يحاول التسجيل . يتم في مرحلة أخيرة التحقق من قيمة isAlreadyRegistered و التصرف بناء عليها . فإن كانت isAlreadyRegistered تحمل القيمة false تم تسجيل العضو و إلا فلن يمكن ذلك و ستظهر رسالة الخطأ . ستتبع الشيفرة نحوا مشابها : $isAlreadyRegistered = false; foreach($stnt as $val) { if ($val["emailw"] == $this-> mail) { // لاحظ شرط التطابق $isAlreadyRegistered = true; // إعادة تعيين قيمة المتغير break; } } if (!$isAlreadyRegistered) { // return $val["emailw"]; $conn-> setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); // send data to database .. $stmt = $conn - > prepare("INSERT INTO data (namew, emailw, passwordw, datew) VALUES (:name, :mail, :pass, :date)"); $stmt-> bindParam(':name', $namep); $stmt-> bindParam(':mail', $mailp); $stmt-> bindParam(':pass', $passp); $stmt-> bindParam(':date', $datep); $namep = $this-> name; $mailp = $this-> mail; $passp = $this-> pass; $datep = $this-> date; $stmt-> execute(); return "Successfully connected .."; } else { return 'this email has created ..'; } ثم سيمكنك إنشاء أعضاء في كامل الحالات و وفقا لأي احتمالات . ملاحظة : الشيفرة لديك قد تحتاج بعض التنظيم و التنظيف حتى تصبح مفهومة و سهلة التشخيص و القراءة , و قد كان ذلك ضروريا حتى أستطيع التوغل في شيفرتك و أفهم مرادك منها . يمكنك التحصل على نسخة أكثر تنظيما و تنسيقا لملفك هنا : index.php .1 نقطة
-
أخي الكود الذي أرسلته لا يوجد به صفحات حتى أستطيع إختباره, هل يمكنك أن تحدد لي كيف أقوم بإختبار الكود حتى أستطيع مساعدتك؟1 نقطة
-
برجاء عملexport لقاعدة البيانات بالبيانات التي بداخلها + ما المشكلة التي تحدث تحديداً؟ هل تقوم قاعدة البيانات بإرسال مصفوفة فارغة بدلاً من إرسال البيانات أم ماذا تحديداً؟1 نقطة
-
هل من الممكن أن تقوم بعمل export لقاعدة البيانات حتى أستطيع تجربتها عندي وتحديد الخطأ؟1 نقطة
-
- جميل جداً ، طيب أنا أريد أكون مبرمج ومطور ، لو أخذت الأولى : هل سأتعلم التصميم ؟ أما هناك مواقع تتيح شراء تصميم لتطبيقات جاهزة؟ يعني هناك حلول للتصميم داخل الدورة؟ ، لأن أنا عقدتي التصميم ، أما البرمجة وحل المشكلات أحبها جداً ، - أنا أخذت كورسات بأساسيات البرمجة وفهمتها قليلاً ، هل لازم أخذ دورة علوم الحاسب أم هذا كافي ؟ - طيب ما الأفضل لأكون مبرمج جيد أو حتى شامل كمطور ومبرمج ويفيدني بالتصميم ، هل لدورة الأولى أو الثانيه ؟ والأسهل ؟ لأني إحترت قليلاً بين الأثنين ، والمعذرة منك .1 نقطة
-
values تقوم باعادة QuerySet والتى تقوم باعادة مجموعة من القواميس dictionaries. values_list تقوم باعادة QuerySet والتى تقوم بارجاع tubles المثال التالي يوضح الفرق بين الطريقيتين: >>> list(Article.objects.values_list('id', flat=True)) # flat=True تقوم بتحويل ال tubles الى list [1, 2, 3, 4, 5, 6] >>> list(Article.objects.values('id')) [{'id':1}, {'id':2}, {'id':3}, {'id':4}, {'id':5}, {'id':6}]1 نقطة
-
التابع values يقوم بإعادة QuerySet تحتوي على قواميس dictionaries، وتكون نتيجته كالتالي: <QuerySet [{'comment_id': 1}, {'comment_id': 2}]> بينما التابع values_list يقوم بإعادة كائن QuerySet يحتوي على tuples، وتكون نتيجته كالتالي: <QuerySet [(1,), (2,)]> إذا كنت تستخدم التابع values_list لإعادة حقل واحد فيمكنك أن تضع الخاصية flat بقيمة true لإعادة كائن QuerySet يحتوي على كل المعرفات في شكل قيمة واحدة بدلًا من tuple، كالتالي: <QuerySet [1, 2]>1 نقطة
-
إذا كنت تريد أن تفعل شيئا أكثر تعقيدا مع النص الخاص بك ، يمكنك إنشاء الفلتر الخاص بك والقيام ببعض الأمور قبل إرجاع النص.في ملف Template تستطيع انشاء دالة لفعل ذلك, على فرض اسمها do_something from django import template from django.utils.safestring import mark_safe register = template.Library() @register.filter def do_something(title, content): something = '<h1>%s</h1><p>%s</p>' % (title, content) return mark_safe(something) ثم في ملف القالب الخاص بك تستطيع استدعاء الدالة التي قمت بانشائها والتي اسمها do_something وتمرير النص الذي تريده <body> ... {{ title|do_something:content }} ... </body>1 نقطة
-
إذا كنت لا تريد تجاوز HTML، لعرضها بشكل كامل فيمكنك أن تستخدم عامل التصفية safe: {{ myhtml |safe }} كما يمكنك أن تستخدم autoscape لكي يتم إيقاف عملية auto-scaping المسئولة عن تخطي أكواد HTML، يقبل هذا العنصر معامل واحد بيقمة on أو off، على النحو التالي: {% autoescape off %} {{ myhtml }} {% endautoescape %} كما يمكنك إعادة تشغيل عملية تخطي أكواد HTML في جزء معين من خلال المرشح escape، كالتالي: {% autoescape off %} {{ title|escape }} {% endautoescape %} كما يمكنك ان تستخدم التابع format_html والذي يقوم بقبول كود HTML كمعامل أول ثم المتغيرات التي يتم إستخدامها في هذا الكود، كالتالي: from django.utils.html import format_html from django.utils.safestring import mark_safe some_html = "<h1>this is title</h1>" some_text = "this is a strong text" some_other_text = "another text here" format_html("{} <b>{}</b> {}", mark_safe(some_html), some_text, some_other_text, ) أيضًا يوفر جانغو Django طريقة أخرى لعمل render لكود HTML لديك من خلال الصنف Context و Template، على النحو التالي: from django.template import Context, Template t = Template('This is your <span>{{ message }}</span>.') c = Context({'message': 'first message'}) html = t.render(c) # This is your <span>first message</span>.1 نقطة
-
في البداية قمت بتغيير مكان الملف من /shop/shop_name/base.html الى /shop_name/shop/base.html ثم قمت بتجربة الكود التالي: {% extends shop_name|add:"/shop/base.html"%} طريقة أخرى : في الاصدارات الأقدم من django يمكنك استخدام التالي: {{ "Mary had a little"|stringformat:"s lamb." }} ويمكنك كذلك تجربة هذا الكود للاصدارات الأجدد: {{ "Mary had a little"|add:" lamb." }} والنتيجة تكون كالتالي: "Mary had a little lamb."1 نقطة
-
يمكنك استخدام الطريقة get بحيث حيث انها الطريقة الاساسية لجلب قيمة، ويمكنك استخدامها كالتالي: is_published = request.POST.get('is_published', False) وبشكل عام يمكنك استخدامها هكذا: my_var = dict.get(<key>, <default>) يمكنك كذلك تجربة الطريقة التالية: is_published = 'is_published' in request.POST وهذه ايضا تؤدي نفس النتيجة: is_published = 'is_published' in request.POST and request.POST['is_published']1 نقطة
-
يحدث هذا الخطأ لأن المتصفح لا يقوم بإرسال حقل checkbox إن لم تكن محددًا، وبالتالي لا يوجد مفتاح باسم is_published في القاموس request.POST، لذلك يمكنك أن تستخدم التابع get الموجود في أي قاموس dictionary والذي يسمح لك يتمرير قيمة إفتراضية في حالة عدم وجود المفتاح في القاموس، كالتالي: is_published = request.POST.get('is_published', False) أو يمكنك عمل ذلك من خلال جملة if .. else، على النحو التالي: if 'is_published' in request.POST: is_published = request.POST['is_published'] else: is_published = False ويمكن إختصار الكود السابق في سطر واحد، كالتالي: is_published = 'is_published' in request.POST and request.POST['is_published'] كما يمكنك أن تستخدم جملة try ... except: from django.utils.datastructures import MultiValueDictKeyError try: is_published = request.POST['is_published'] except MultiValueDictKeyError: # في حالة لم يوجد المفتاح is_published is_published = False1 نقطة
-
يمكنك أن تستخدم جملة with على النحو التالي: {% with "posts/"|add:myVar|add:"/base.html" as template %} {% include template %} {% endwith %} لكن الطريقة الأفضل هي أن تقوم بعمل وسم مخصص لهذا الأمر كالتالي: أولًا قم بعمل ملف يف المسار: <yourAppName>\templatetags\<yourAppName>_extras.py ثانيًا في هذا الملف قم بعمل وسم مخصص على النحو التالي: from django import template register = template.Library() @register.filter def addStr(str1, str2): return str(str1) + str(str2) والآن أصبح بإمكانك أن تستخدم هذا الوسم على كالتالي: {% load <YourAppName>_extras %} {% with "posts/"|addstr:myVar|addstr:"/base.html" as template %} {% include template %} {% endwith %}1 نقطة
-
من خلال np.isnan يمكنك معرفة ذلك، كل شيئ موضح في الكود التالي: import numpy as np a=np.array([[ 1. , 2.],[ 3. ,np.nan]]) a """ array([[ 1., 2.], [ 3., nan]]) """ # isnan #nan في مكان تواجد قيمة true هذا التابع يرد مصفوفة بوليانية بحيث تضع np.isnan(a) """ array([[False, False], [False, True]]) """ #وبالتالي nan أصغر قيمة هي دوماً np.min(a) #nan ترد np.isnan(np.min(a)) # True #لجمع عناصر مصفوفة تحوي قيم غير معرفة سيعطي نتيجة غير معرفة sum استخدام np.sum(a) # nan # وبالتالي np.isnan(np.sum(a)) # True ومن ناحية الأداء فاستخدام sum أفضل: a = np.random.rand(100000) %timeit np.isnan(np.min(a)) """ 10000 loops, best of 3: 153 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.9 us per loop """ # سأضع قيمة نان لإحدى الخلايا a[2000] = np.nan %timeit np.isnan(np.min(a)) """ 1000 loops, best of 3: 239 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.8 us per loop """ a[0] = np.nan %timeit np.isnan(np.min(a)) """ 1000 loops, best of 3: 326 us per loop """ %timeit np.isnan(np.sum(a)) """ 10000 loops, best of 3: 95.9 us per loop """ نلاحظ أن min يكون أبطأ في وجود NaN أما في غيابها أسرع. أيضا يصبح أبطأ مع اقتراب NaN من بداية المصفوفة. من ناحية أخرى ، sum تبدو ثابتة بغض النظر عما إذا كانت هناك NaNs أو لا.1 نقطة
-
تسطيع حل المشكلة بطريقتن فقط ضع قبل keras مكتبة tensorflow. مكتبة كيراس هي مثل واجهة أمامية ل tensorflow يصبح الكود كالتالي: from tensorflow.keras.utils import to_categorical y_train=to_categorical(y_train) الطريقه الثانيه هي أن to_categorical موجودة في الوحدة الوظيفة np_utils ضمن utils وبتالي يصبح الكود: from keras.utils.np_utils import to_categorical y_train=to_categorical(y_train)1 نقطة
-
معظم مسائل الـ deep learning تعمل بشكل أفضل عندما تعتمد على داتاست كبيرة الحجم مثلاً من رتبة 10 مليون أو أعلى (big data) وستصبح عملية التدريب في الشبكات العصبونية بطيئة نظراً لضخامة الداتاست وفي هذه الحالات نحتاج لوجود خوارزميات تحسين سريعة والتي تساعد في زيادة الفعالية. خوارزمية Batch Gradient Descent هي النوع المعروف والشكل الأصلي لخوارزمية Gradient Descent حيث تمر على كل الداتاست ثم تتقدم خطوة واحدة (تحدث قيم الأوزان) ثم تمر على كامل الداتاست مرة أخرى ثم تتقدم خطوة ثانية وهكذا حتى يتم التقارب Converge. لكن المشكلة فيها أنه عندما تكون الداتاست كبيرة مثلاً من رتبة 5 مليون (طبعاً هذا الرقم ضخم وفي الحقيقة حتى عندما تكون الداتا من رتبة مئات الآلاف يظهر عيبها) ستصبح الخوارزمية بطيئة في التقدم أو التدرج لأنه في كل تكرار تمر على كامل الداتاست، لذلك في Mini Batch Gradient Descent يتم تقسيم الداتاست إلى مجموعات داتاست أصغر وهذه المجموعات تسمى mini-batches والوسيط batch_size يدل على حجم هذه المجموعة في كيراس وتنسرفلو. إن هذا التقسيم يجعل عملية التقارب أسرع بكثير من الطريقة العادية فهو لاينتظر المرور على كامل الداتاسيت حتى يتقدم خطوة (تحديث الأوزان) وإنما على جزء منها. أما فيما يتعلق بالخوارزمية الأخيرة Stochastic Gradient Descent فهي الأسرع، حيث يتم تحديث الأوزان بعد المرور على عينة واحدة فقط أي من أجل كل عينة في الداتاسيت سيتم تحديث الأوزان، لكن عيبها هو أنها في غالب الأحيان لن تستطيع التقارب من القيم الدنيا للتكلفة. لذا فالخيار الأفضل هو تجنب النوع الأول والثالث واستخدام ال Mini-Batch (فهي توازن بين الاثنين -السرعة والدقة-). Batch Gradient Descent: بطيئة ودقيقة. Stochastic Gradient Descent: سريعة جداً وغير دقيقة. Mini Batch Gradient Descent: توازن بين السرعة والدقة. وفي كيراس نستخدم الوسيط batch_size لتحديد عدد الباتشات (عدد التقسيمات للداتا)، فمثلاً 64 باتش تعني أنه سيتم تقسيم البيانات إلى 64 قسم وكل قسم يحوي عدد عينات يساوي (عدد العينات في الداتا مقسوم على 64). عدم تعيين قيمة لل batch_size يعني أنك ستستخدم Batch Gradient Descent واختيارك ل 1 يعني أنك ستستخدم Stochastic . لنأخذ مثال ونلاحظ الفرق: دربنا الموديل على الداتا المعرفه في keras والتي تدعى mnist وسوف نقوم بتدريب نفس الموديل ولكن مع اختلاف أن الأول ينفذ Batch Gradient Descent والثاني Mini Batch Gradient Descent: from keras.models import Sequential from keras import layers from keras.datasets import mnist (X_train,y_train),(X_test,y_test)=mnist.load_data() X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 model = Sequential() model.add(layers.Dense(512, activation='relu', input_shape=(28*28,))) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(X_train,y_train,epochs=1) #الخرج ''' 1875/1875 [==============================] - 8s 4ms/step - loss: 0.3400 - accuracy: 0.9004 الكود الثاني نفس السابق مع إضافة batch_size ''' #Mini-Batch model = Sequential() model.add(layers.Dense(512, activation='relu', input_shape=(28*28,))) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.fit(X_train,y_train, batch_size=60,epochs=1) #الخرج ''' 1000/1000 [==============================] - 5s 5ms/step - loss: 0.3865 - accuracy: 0.8889 الفرق واضح من الخرج في كل كود الأول الذي يحوي gradient descent كان أبطئ واستغرف 8s في حين الثاني الذي يحوي mini-batch gradient descent صحيح أن الدقه ليست كالأول ولكن السرعه كانت أفضل استغرق 5s وطبعا هنا كانت الداتاست صغيره مقارنتا بالداتاست المعياريه '''1 نقطة
-
هي دالة تكلفة (loss) في كيراس وتنسرفلو ويتم استخدامها مع مسائل التصنيف الثنائي أي عندما يكون الخرج 1 أو 0. الصيغة الرياضية: تعتمد هذه الدالة على المفهوم الشهير في نظرية المعلومات والمعروف ب Cross Entropy أو الإنتروبيا المتقطعة، وهي مقياس لمدى تشابه توزعين احتماليين مختلفين لنفس الحدث وفي ال ML نستخدم هذا التعريف وقانونه لكي نقوم بحساب ال Loss (التكلفة Cost). حيث يكون الخرج الخاص بالشبكة العصبية هو توزيع احتمالي لعدة فئات classes. تابع التنشيط Sigmoid هو تابع التنشيط الوحيد المتوافق مع دالة التكلفة Binary CE. له الشكل التالي في كيراس: #في كيراس BinaryCrossentropy الكلاس tf.keras.losses.BinaryCrossentropy( from_logits=False, name="binary_crossentropy", ) # True عندما يكون مجال القيم المتوقعة غير محدود # False عندما يكون مجال القيم المتوقعة بين الصفر والواحد مثال: import tensorflow as tf # إنشاء قيم حقيقية وفيم متوقعة y_true = [1, 1, 0] y_pred1 = [0.7, 0.61, 0.04] # قيم متوقعة بين 0 و 1 y_pred2 = [-11.2, 1.51, 3.94] # قيم متوقعة بين الناقص لانهاية والزائد لانهاية # إنشاء كائن من هذا الكلاس c1 = tf.keras.losses.BinaryCrossentropy(from_logits=False) c2 = tf.keras.losses.BinaryCrossentropy(from_logits=True) # استخدامه وطباعة الناتج print(c1(y_true, y_pred1).numpy()) # 0.29726425 print(c2(y_true, y_pred2).numpy()) # 5.1196237 ولاستخدمها مع الدالة Compile: # كالتالي compile لاستخدامه مع النموذج نقوم بتمريره إلى model.compile( loss=tf.keras.losses.BinaryCrossentropy(), ... ) # أو يمكن تمريرها بسهولة بالشكل التالي model.compile( loss='binary_crossentropy', ... ) في المثال التالي سأبين لك استخدامها، سوف أقوم ببناء Baseline لمسألة تصنيف مشاعر ثنائية مع مجموعة بيانات imdb: # مثال بسيط # تحميل وتجهيز البيانات from keras.datasets import imdb from keras import preprocessing max_features = 100 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) # بناء النموذج from keras.models import Sequential from keras.layers import Flatten, Dense,Embedding model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # تجميع النموذج model.compile(optimizer='rmsprop', loss=tf.keras.losses.BinaryCrossentropy(from_logits=False), metrics=['acc']) # لاحظ كيف قمنا بتمرير دالة التكلفة # عرض ملخص للنموذج model.summary() # تدريب النموذج history = model.fit(x_train, y_train, epochs=2, batch_size=32, validation_split=0.2) #---------------------------------------------------------- ''' Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, 20, 8) 80000 _________________________________________________________________ flatten_1 (Flatten) (None, 160) 0 _________________________________________________________________ dense_1 (Dense) (None, 1) 161 ================================================================= Total params: 80,161 Trainable params: 80,161 Non-trainable params: 0 _________________________________________________________________ Epoch 1/2 625/625 [==============================] - 2s 2ms/step - loss: 0.6919 - acc: 0.5179 - val_loss: 0.6806 - val_acc: 0.5912 Epoch 2/2 625/625 [==============================] - 1s 2ms/step - loss: 0.6671 - acc: 0.6126 - val_loss: 0.6530 - val_acc: 0.6128 '''
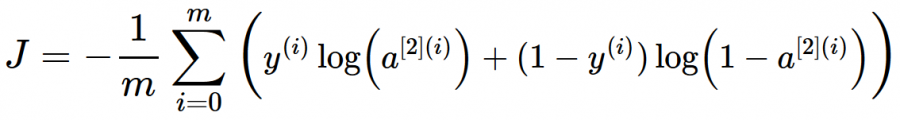 1 نقطة
1 نقطة -
هناك العديد من الحلول لموازنة البيانات غير النصية: هل يمكنك جمع المزيد من البيانات لفئة الأقلية؟ الكثير منا يتجاهل هذا الأمر، رغم أنه قد يكون الحل الأفضل والأسهل لمشكلتنا خصوصاً وأنه يوجد العديد من المصادر على الانترنت. هناك بعض الخوارزميات القوية والتي تتعامل بشكل تلقائي مع البيانات غير المتوازنة مثل أشجار القرار، نظرًا لأنهم يعملون من خلال الخروج بشروط / قواعد في كل مرحلة من مراحل الانقسام ، لذا فينتهي الأمر بأخذ كلا الفئتين في الاعتبار، وأيضاً يمكنك استخدام ال XGBoost. DataAugmentation: هذا المفهوم ليس بالضرورة أن يطبق فقط في مهام الرؤية الحاسوبية وإنما يمكننا أن نطبقه مع البيانات النصية أيضاً لكن بطريقة مختلفة. في الصور هناك توابع جاهزة تقوم لك بهذا الأمر (DataAugmentation)، لكن في البيانات النصية لا أعتقد، لذا يجب أن تقوم بذلك بنفسك واعتماداً على مهاراتك، فمثلاً تتجلى إحدى الطرق بقيامك بتغيير الكلمات و الأفعال والصفات إلى مرادفات لها، ويمكنك أن تستخدم wordnet من مكتبة NLTK لمساعدتك بهذا الأمر (wordnet هي قاموس ضخم من الكلمات ومرادفاتها ومضاداتها و فروعها و معانيها الدلالية ...إلخ). أو مثلاً خلط الجمل وإعادة ترتيبها. ويمكنك أن تبدعي في هذا المحور ففي إحدى مسابقات Kaggle قام أحد المتسابقين بتغيير لغة النص إلى لغة عشوائية ثم إعادة ترجمتها إلى الإنجليزية (عن طريق مترجمات مثل مترجم غوغل)، وحصل على نتائج مبهرة!. حذف نقاط البيانات (العينات) المكررة أو المتشابهة جداً (فمثلاً قد تجدين عينتان تحملان نفس الكلمات والمعنى). إذا كانت مهمتك هي مهمة تصنيف متعدد فقد يكون من الممكن في كثير من الأحيان دمج فئات الأقلية مع بعضها البعض (فمثلاً لديك 3 فئات لتصنيف المنتجات الفئة الأولى ممتاز والفئة الثانية سيئ والثالثة سيئ جداً، والفئة الثانية والثالثة هما فئات أقلية، فهنا يمكن أن نقوم بضم الفئة الثالثة للثانية). Undersampling : حذف عينات بشكل عشوائي من قئة الأغلبية، حتى تتوازن البيانات ( لا أراها فكرة جيدة ). Oversampling : تعتمد على تكرار عينات من فئات الأقلية بشكل عشوائي (أيضاً لا أراها فكرة جيدة لأنها تؤدي إلى Overfitting وسيفشل نموذجك في التعميم generalization ). Penalized Models: يمكنك أن تضيف لنموذجك شيئاً إضافياً وهو مفهوم ال Penalized ويقتضي في أن تقوم بإضافة تكلفة إضافية (عقوبة) عندما يخطئ في التصنيف مع فئات الأقلية، وهذا سيجعل نموذج مجبراً على عدم تجاهل فئات الأقلية وإعطاء أهمية أكبر لها. Anomaly Detection Models: أو نماذج اكتشاف الشذوذ. إذا كانت مهمتك هي مهمة تصنيف ثنائي فيمكنك أن تستخدم هذه النماذج بدلاً من نماذج التصنيف، حيث تعمل هذه النماذج على تشكيل إطار يحيط بفئة الأغلبية وأي عينة لاتنتمي لها تعتبر شذوذاً (تستخدم هذه النماذج في مهام كشف الاحتيال). هذه كانت أشهر وأهم الطرق المستخدمة للتعامل مع هذه المشكلة لكن أحب أن أنوه إلى أن الطريقة التي أشرت لها "SMOTE" ليست فكرة جيدة مع البيانات غير النصية لأن الكلمات يتم تمثيلها في متجهات أبعادها عالية جداً. في النهاية لايوجد طريقة هي الأفضل كما هو الحال مع معظم المواضيع في علوم البيانات وخوارزميات التعلم الآلي، فاعتماداً على بياناتك والفئات ونوع البيانات وماتريد أن تصل إليه تختلف هذه الطرق بين الأفضل و الجيدة والسيئة.1 نقطة
-
المشكلة هنا هي أنك تحاول تثبيت Keras مع إصدار من Numpy لا يحتوي على الوظائف التي تتطلبها Keras، لحل المشكلة يجب ترقية numpy وتنسرفلو: pip install -U numpy pip install -U tensorflow1 نقطة
-
يمكنك استخدامها عبر الموديول: keras.utils.np_utils يقوم التابع to_categorical بتحويل البيانات العددية إلى بيانات فئوية ممثلة بأصفار و واحدات ، حيث يقوم بترميز كل قيمة عددية مميزة (ال class) في شعاع طوله بعدد الفئات Classes المختلفة الموجودة في بياناتنا. وبشكل أكثر وضوح: بعد أن يتم إعطاء كل class في مجموعة البيانات رقمً تعريف فريد Classid يتراوح بين 1 و | Classes | . حيث Classes هي مجموعة الفئات (الأصناف) الموجودة لدينا . ثم يتم تمثيل كل فئة عبر متجه بأبعاد مقدارها | Classes | مملوء كلها بـ صفر باستثناء الفهرس ، حيث index = Classid. حيث نضع في هذا الفهرس ببساطة 1. ونستخدمه عادة عندما يكون لدينا مهمة تصنيف متعدد (عندما يكون لدينا عدة فئات). في المثال التالي لدي شعاع y فيه 3 كلاسات مختلفة وبالتالي كل كلاس سوف يتم تمثيله بشعاع له 3 أبعاد. # استيراد التابع from keras.utils.np_utils import to_categorical # خرج مزيف y=[0,1,0,2,1,0,1,2,0,1,2] # استخدام المحول الفئوي y=to_categorical(y) #طباعة النتائج print(y) ''' array([[1., 0., 0.], [0., 1., 0.], [1., 0., 0.], [0., 0., 1.], [0., 1., 0.], [1., 0., 0.], [0., 1., 0.], [0., 0., 1.], [1., 0., 0.], [0., 1., 0.], [0., 0., 1.]], dtype=float32) ''' سأقوم بتطبيق هذا التابع لترميز مجموعة بيانات routers، حيث أن هذه البيانات لديها 46 فئة (صنف) مختلف: # تحميل الداتا from keras.datasets import reuters (train_data, train_labels), (test_data, test_labels) = reuters.load_data( num_words=100) # ترميز الفئات المختلفة للبيانات from keras.utils.np_utils import to_categorical # One-Hot-Enoding one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) # قمنا بعرض فئة أول عينة من بيانات التدريب print('one_hot_train_labels[0]:\n',one_hot_train_labels[0]) ''' one_hot_train_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' # قمنا بعرض فئة أول عينة من بيانات الاختبار print('one_hot_test_labels[0]:\n',one_hot_test_labels[0]) ''' one_hot_test_labels[0]: [0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] ''' ملاحظة: هذا الترميز هو نفسه ال One-Hot-Encoding1 نقطة
-
نعم منذ Py2.6: قم بتثبيتها أولاً: pip install ordered-set from ordered_set import OrderedSet l = OrderedSet('abraca') print(l) # OrderedSet(['a', 'b', 'r', 'c'])1 نقطة
-
أولاً as: يتم استخدامها لإنشاء اسم مستعار # بدون اسم مستعار import numpy a = numpy.array([2, 3, 4]) # array([2, 3, 4]) b=numpy.zeros((3, 4)) # مع استخدام اسم مستعار import numpy as np a = np.array([2, 3, 4]) # array([2, 3, 4]) b=np.zeros((3, 4)) # لاحظ ان استخدام اسم مستعار يكون أكثر أريحية خصوصاً عندما تتعدد الفروع مثل المثال التالي # بدون اسم مستعار import tensorflow.keras.utils tensorflow.keras.utils.plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True) # مع اسم مستعار import tensorflow.keras.utils as pl pl.plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True) ثانياً: with. تم تقديم عبارة with لأول مرة منذ خمس سنوات، في Python 2.5. تُستخدم with عند العمل مع موارد غير مُدارة "unmanaged resources" مثل file streams Open network connections. Unmanaged memory ومع الأقفال Locks و ال sockets وال subprocesses. يسمح لك بالتأكد من "تنظيف" المورد عند انتهاء تشغيل الكود الذي يستخدمه، حتى إذا تم طرح استثناءات. ففي حال استخدمتها مع الملفات فتتمثل ميزة استخدام عبارة with في ضمان إغلاق الملف بشكل آمن بغض النظر عن كيفية الخروج من الكتل البرمجية المتداخلة الموجودة لديك. بحيث إذا حدث استثناء قبل نهاية الكتلة البرمجية، فسيتم إغلاق الملف بشكل مسبق بواسطة معالج استثناء خارجي. وإذا كانت الكتلة المتداخلة تحتوي على تعليمة return ، أو تعليمة continue أو break، فإن تعليمة with ستغلق الملف تلقائياً في تلك الحالات أيضاً. حيث تضمن عبارة with نفسها بالحصول على الموارد وتحريرها بالشكل المناسب. يكون استخدامها مفيداً عندما يكون لديك عمليتان مترابطتان ترغب في تنفيذهما كزوج، مع وجود كتلة من التعليمات البرمجية بينهما. المثال الكلاسيكي هو فتح ملف ومعالجة الملف ثم إغلاقه وهذا ماسنراه في المثال التالي: # وبدون معالجة للاستثناءات التي قد تحدث with بدون استخدام f = open('path', 'w') f.write('hsoub') f.close() # مع معالجة للاستثناءات التي قد تحدث with بدون استخدام f = open('path', 'w') try: f.write('hsoub') finally: f.close() #with استخدام with open('path', 'w') as file: f.write('hsoub') في أول مثال قد يؤدي حدوث استثناء أثناء استدعاء write إلى عدم إغلاق الملف بشكل سليم مما يؤدي إلى حدوث العديد من الأخطاء في الكود. الطريقة الثانية في المثال أعلاه تهتم بجميع الاستثناءات ولكن استخدام تعليمة with يجعل الكود مضغوطاً وقابل للقراءة بشكل أكبر. وبالتالي ، تساعد العبارة في تجنب الأخطاء والتسريبات من خلال ضمان تحرير المورد بشكل صحيح عند تنفيذ التعليمات البرمجية التي تستخدم المورد بالكامل. ولاحظ أنك لن تحتاج لتعليمة close كما في أول حالتين. يمكنك أيضاً استخدام تعليمة with مع كائنات معرفة من قبلك حيث يمكن استخدامها في الكائنات التي يحددها المستخدم وهذا مفيد بالنسبة لك لأن دعم عبارة with في العناصر الخاصة بك سيضمن عدم ترك أي مورد مفتوحًا أبدًا. لاستخدامها مع الكائنات المعرفة من قبل المستخدم، تحتاج فقط إلى إضافة التوابع __enter __ () و __exit __ () في الكائن، مثال: class wr(object): def __init__(self, file_name): self.file_name = file_name def __enter__(self): self.file = open(self.file_name, 'w') return self.file def __exit__(self): self.file.close() #مع الكائن with استخدام التعليمة with wr('file.txt') as f: f.write('hasoub') إن الكلمة المفتاحية with تشكل باني ل wr، وبمجرد وصول التنفيذ لتعليمة with يتم إنشاء كائن من wr، ثم يقوم بايثون باستدعاء التابع enter الذي يقوم بتهيئة المورد الذي تريد أن تستخدمه في ال object الخاص بك، ويجب أن تقوم طريقة __enter __ () دائمًا بإرجاع واصف للمورد "descriptor"(مقبض للوصول للملف) الذي تم الحصول عليه. يتم استخدام f للإشارة لل descriptor الذي تم الحصول عليه من التابع enter، ويتم وضع الكود البرمجي الذي يستخدم المورد بداخل كتلة with وبمجرد تنفيذ الكود الموجود داخل الكتلة with ، يتم استدعاء طريقة __exit __ () ليتم تحرير جميع الموارد.1 نقطة
-
مرحبًا عبد الواحد هذه فقط مسألة تعود على البرامج، في الماضي لم يكن هناك برامج مثل Adobe إكس دي أو Figma وبالتالي لم يكن هناك بديل غير الفوتوشوب لكي يعطي المصمم الفدرة على التحكم في كل تفاصيل الموقع أو التطبيق، فأصبح ضروري أن يتقن المصمم التعامل مع الفوتوشوب حينها. بعد ذلك حاول بعض المصممين أن يقللوا من حجم الموقع من خلال جعل أغلب الصور والأيقونات بإمتداد SVG لذلك حاولوا إستخدام Adobe Illustrator لتصميم المواقع والتطبيقات ثم في 2010 ظهر برنامج Sketch ليكون أفضل برنامج مختص في تصميم واجهة المستخدم حينها، لكن العيب الأكبر له هو أنه متاح على أجهزة أبل فقط، وبالرغم من إمكانيات البرنامج التي تساعد المصمم على الحصول على أفضل نتيجة إلا أن عدد مستخدمينه لم يكن بالكثير وهذا بسبب أن كثير من المصممين كانوا يعملون على ويندوز بالفعل. بعد ذلك في 2015 أعلنت شركة Adobe عن برنامجها الخاص بتصميم الواجهات Adobe إكس دي ليصبح من أشهر البرامج والذي يعد الأشهر حتى الآن، أضاف البرنامج مميزات وإضافات عظيمة مثل تحويل التصميم إلى كود مباشرة أو تجربة الـ Animation وغيرها من المميزات. ظهر بعده بسنة موقع Figma والذي يحتوي على مميزات كثير مثل عمل رابط للتصميم ذاتي التحديث أي يمكن لأي شخص لديه الرابط أن يشاهد ما يقوم به المصمم من تعديلات في الوقت الحقيقي، ومن مميزاته أن Figma يعمل على المتصفح وبالتالي يدعم كل أنواع الأجهزة تقريبًا بغض النظر عن نوع نظام التشغيل Windows, Mac, Linux, Android, iOS في النهاية البرنامج المستخدم في تصميم الموقع أو التطبيق متوقف على طلب العميل وخبرة المصمم.1 نقطة
-
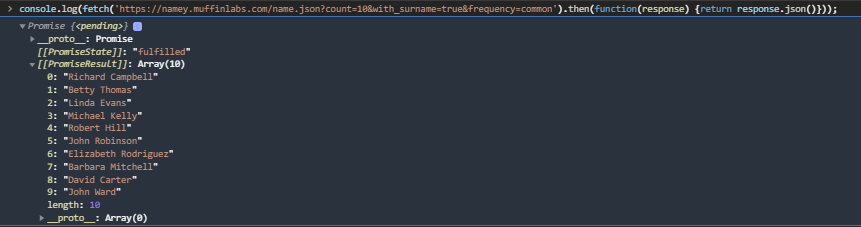
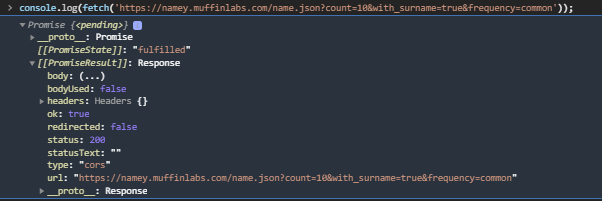
دالة Fetch عبارة عن Web API تسمح لك بإرسال طلبات HTTP Requests وتقوم بجلب لك نتيجة هذا الطلب، فعلى سبيل المثال: تريد أن تجلب 10 أسماء أشخاص عشوائية من API معين، لذلك تستخدم هذا الرابط (قم بزيارته في المتصفح لترى النتيجة)، ما تراه في المتصفح هو ما سوف تجلبه لك دالة Fetch ويسمى إجابة الطلب Response. فإن قمت بكتابة السطر التالي في الـ console: console.log(fetch('https://namey.muffinlabs.com/name.json?count=10&with_surname=true&frequency=common')); ستحصل على هذه النتيجة (الصورة الأولى fetch_then_result.png) هذه النتيجة من نوع Promise وسنرجع لهذا النوع لاحقًا، أما الآن تحتاج لطريقة للحصول على الأسماء من داخل هذه النتيجة، وهنا يأتي دور دالة then، هذه الدالة تسمح لك بالدخول إلى النتيجة من نوع Promise وتستخدمها كما تريد، فإذا قمت بكتابة السطر التالي في الـ console: console.log(fetch('https://namey.muffinlabs.com/name.json?count=10&with_surname=true&frequency=common').then(function(response) {return response.json()})); ستحصل على هذه النتيجة (الصورة الثانية fetch_result.png) وستجد 10 أسماء عشوائية موجودة في PromiseResult دالة then تأخذ متغير عبارة عن دالة في حد ذاته، بعد ذلك يتم تمرير إجابة الطلب من نوع Promise إلى هذه الدالة الأخيرة لتقوم بتحويله إلى كود JSON بدلًا من نص عادي String حتى يسهل التعامل معه في باقي الكود، بمجرد أن يتم تحويل الإجابة response إلى كود JSON ترجعه الدالة then الأولى بإستخدام جملة return ويخزن في PromiseResult لاحظ أنه يمكنك أن تسمي اسم المتغير الممرر إلى الدالة داخل then بأي اسم، مثلًا: .then(function(something) {return something.json()})); // أو هكذا .then(function(data) {return data.json()})); لاحظ أيضُا أنه يمكنك أن تستدعي دالة then أكثر من مرة على التوالي: fetch('https://namey.muffinlabs.com/name.json?count=10&with_surname=true&frequency=common').then(function(response) {return response.json()}).then(function (something){console.log(something)}); وفي كل مرة تأخذ دالة then ما أعادته دالة then التي قبلها، (أنظر الصور الثالثة fetch_then_then_result.png) قد تتسأل لمذا كل هذا التعقيد، لماذا لا يتم تخزين نتيجة الطلب في متغير مباشرة هكذا: var x = fetch('https://namey.muffinlabs.com/name.json?count=10&with_surname=true&frequency=common') لتستخدمها بكل سهولة بعد ذلك للإجابة على ذلك عليك أن ما سيحدث للموقع في حالة تأخر الخادم server في إرسال النتيجة response، بكل بساطة سيتوقف كل شيء حتى يتم تخزين إجابة الطلب في المتغير x ، بالطبع لا نريد حدوث ذلك، لذلك وجب إستخدام عملية غير متزامنة (asynchronous operation) أي يتم تنفيذ دالة fetch وفي نفس الوقت يظل الموقع يعمل كما كان بالضبط. يمكنك الإطلاع على توثيق موسوعة حسوب JavaScript - Promise لشرح أكثر تعمقًا ملاحظة: في دالة then الثانية في سؤالك، تم دالة سهمية Arrow Function وهي نفس الدالة العادية لكن بطريقة كتابة مختلفة فقط. أنظر الدوال السهمية في JavaScript
 1 نقطة
1 نقطة