لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 09/05/21 في كل الموقع
-
كثيراً ما أسمع عن مصطلح الكود النظيف لكننى لا افهم جيدا ما اللى علي ان افعله حتى يكون كودى نضيف؟3 نقاط
-
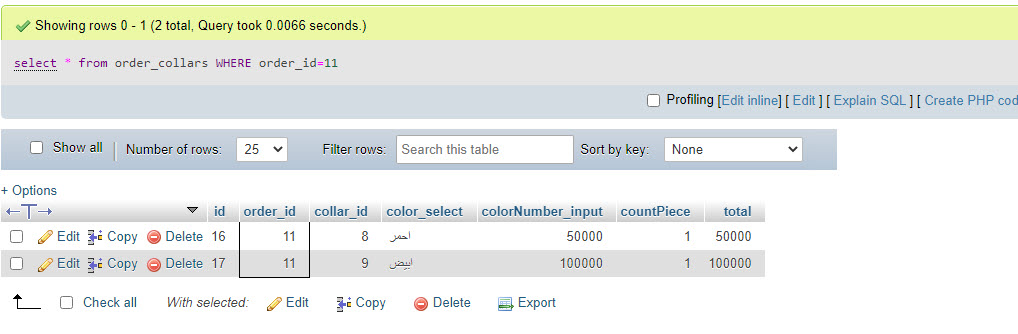
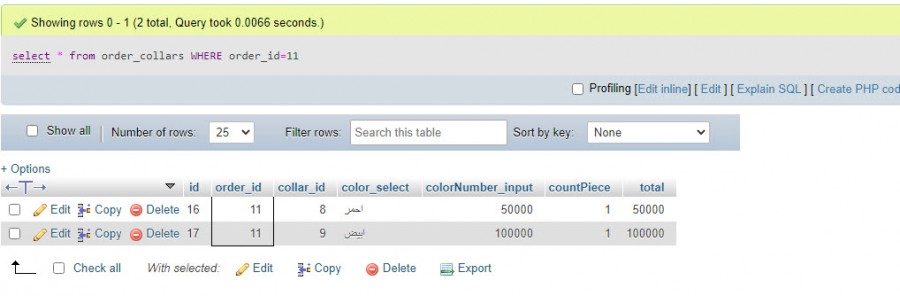
سلام عليكم و رحمة الله عندي جدول اسمه order_collar محتواه كما في الصورة و عندي جدول آخر اسمه orders به حقل اسمه collar ، هذا الحقل مرتبط بجدول order_collar فيأخذ اما قيمة 0 في حال عدم وجود اي بيانات تم ادخالها فيه ، و ياخذ الرقم 1 بمجرد ان يقوم المستخدم بادخال بيانات فيه ( عن جدول order_collar اتحدث ) طيب الان المستخدم قام بادخال بيانات في جدول order_collar و تم تغيير حقل collar في جدول order بنجاح قمت ببرمجة زر حذف جماعي يقوم بحذف كل البيانات في جدول order_collar ثم يذهب لحقل collar و يعطيه القيمه 0 من جديد كالتالي $order = $_POST['order']; //$id = $_POST['id']; $result = $conn->query("DELETE FROM order_collars WHERE order_id='$order'"); $result2 = $conn->query("UPDATE orders SET collar=0 WHERE id='$order'"); if ($result == true) { echo "done"; } else{ echo "Errormessage: %s\n". $conn->error; } و العملية ممتازة المشكلة الان ، كما في الصورة عندي مدخلين مرتبطين بنفس رقم الاوردر و اقوم ببرمجة زر يحذف كل مدخل على حدة و الامر يعمل بنجاح لا مشكلة في هذا ، ما اريده ان اخبر البرنامج به ، ان يقوم بعد الحذف بعمل استعلام لجدول order_collar ، فان كان هناك بيانات ظاهرة لا يقوم بعمل اي تعديل في حقل collar بجدول order اما لو لم يجد اي نتائج للاستعلام ، اذهب لحقل collar و قم يتغييره إلى صفر الكود كالتالي $id = $_POST['id']; $order = $_POST['order']; // Delete Query $result = $conn->query("DELETE FROM order_collars WHERE id='$id'"); // check Query $ask = $conn->query("select * from order_collars WHERE order_id='$id'"); // check if you fount zero result excuse $result2 if (mysqli_num_rows($ask) == 0) { $result2 = $conn->query("UPDATE orders SET collar=0 WHERE id='$order'"); } if ($result == true) { echo "done"; } else{ echo "Errormessage: %s\n". $conn->error; } امر الحذف يتم بشكل ممتاز لكن المشكلة انه بيغير برضه قيمة الحقل collar ل صفر حتى لو استعلام جدول order_collars اداله انه فيه بيانات انا عاوزه ما ينفذش استعلام result2 إلا لما يعمل فحص الاول لجدول order_collars و ما يلاقيش نتائج ، لكن لو لقا نتائج للاستعلام ما ينفذوش شكرا لكم
 2 نقاط
2 نقاط -
لدي dataframe كالتالي: df = pd.DataFrame({'a':list('abccbac')}) وأريد أن أقوم بحساب عدد مرات تكرار الحرف a و c و b بحيث تظهر كالتالي: c 3 a 2 b 2 كيف يمكنني فعل هذا؟2 نقاط
-
لدي بيانات على الشكل التالي: df= col1 col2 0 384444683 593 1 384444684 594 2 384444686 596 وأريد تحويلها الى الشكل التالي بحيث أقوم بتحويل ال index الى عمود باسم index: df= index col1 col2 0 0 384444683 593 1 1 384444684 594 2 2 384444686 596 كيف يمكنني فعل هذا؟2 نقاط
-
أنا أتعلم React / javascript بسرعة كبيرة وارى الجميع يتكلمون عن next و gatsby كنت أتساءل متى سيصل الناس إلى إطار عمل مثل Next.js أو Gatsby.js مقابل تطبيق Create React . أستخدم create react كثيرا لكن هل هناك سبب في المستقبل سيحتم علي استبدال الاطار واستخدام اطار مثل gatsby او nextjs2 نقاط
-
لقد اتبعت بعض الإرشادات لتحميل node.js على نظام التشغيل ubuntu على خادم الويب لدي. ولكن عندما أحاول التأكد من النسخة التي تم تحميلها من خلال الأمر التالي: node --version يظهر لي الخطأ التالي: -bash: /usr/sbin/node: No such file or directory مع العلم أنه يمكنني ملاحظة node ضمن المسار /usr/sbin/ وأيضاً عند طباعة نسخة npm تظهر لي بشكل سليم. وحتى إن قمت بكتابة الأمر التالي: nodejs --version أيضاً يظهر لي رقم النسخة. فما الفرق إذاً بين node و nodejs التي تم تحميلها؟ وكيف يمكنني تحميله لاستخدامه بالشكل الصحيح؟2 نقاط
-
عندما أطلب من نموذج الحصول على كائن معين، فإنه يظهر خطأ DoesNotExist عندما لا يكون هناك كائن مطابق. writers = User.objects.get(role="writer") # DoesNotExist بدلاً من ظهور خطأ DoesNotExist، كيف يمكنني أن أجبره على إعاده None بدلاً من ذلك في حالة عدم وجود الكائن؟2 نقاط
-
ما هي افضل لغة للبداية مع برمجة تطبيقات الموبايل للاندرويد2 نقاط
-
هل يمكنك طباعة عدد السجلات قبل التعديل بهذا الشكل $ask = $conn->query("select * from order_collars WHERE order_id='$id' ORDER BY DESC LIMIT 1"); echo mysqli_num_rows($ask) ; و أخباري بالنتيجة ؟2 نقاط
-
كثيراً ما اسمع عن مصطلح الديزاين باترنز الذى يترجم بالعربية الى انماط التصميم وكنت أتسائل كثيراً عن معنى هذا المصطلح2 نقاط
-
السلام عليكم , كنت اعتقد ان render تعنى عرض الكمبوننت , اى ظهوره على الشاشة لكنى اعتقد ان هده الكلمة عميقة ولها معنى مختلف .. اريد ان اعرف شرح كلمة render المستخدة فى رياكت ورياكت ناتيف2 نقاط
-
كيف يمكنني إزالة أو تحديث معلمات الاستعلام بدون تحديث الصفحة في Next JS (React)؟ المستخدم موجود على URL / about؟ login = success & something = yes انقر فوق الزر وإزالة login = success & something = yes كيف يمكنني تحقيق ذلك؟2 نقاط
-
لنقم بتناول الأمر بشكل عام على هذا النحو : الـ devDependencies : هي مجموع التبعيات و الحزم المطلوبة للتشغيل على بيئة التطوير , أي تلك التي يتم إستعمالها فقط أثناء التطوير أو الإصدار ، على سبيل المثال : الحزم المستعملة في اختبارات الوحدة . مثل حزمة jest في تطبيقات الـ node , react , angular و الـ vueJS , عناصر و حزم webpack . بحيث تشكل مجموع الأدوات التي تساعدك على إدارة كيفية تطوير التطبيق لديك . هاته الحزم يتم تثبيتها عن طريق مدير الحزم npm مثلا بإضافة الخيار save-dev-- : npm install pakcageName --save-dev الـ Dependencies : و هي مجموع التبعيات و الحزم التي يحتاجها مشروعك ليكون قادرًا على العمل في بيئة الإنتاج . على سبيل المثال : الحزم المستعملة في عرض أو تنسيق أو تفاعلية جزء من أجزاء الصفحة , فلو احتجنا إلى حزمة للحصول على اليوم و الشهر . فسنجد أننا نقوم مثلا باستيراد {getDate} من الحزمة "date-fns" في مكون ما , و بالتالي فإنه بدون هذه الحزمة لن يعمل كودنا . هاته الحزم يتم تثبيتها عن طريق مدير الحزم npm مثلا بدون إضافة أي خيار : npm install myPackage الـ PeerDependencies : هي مجموع الحزم التي تحتاجها حزمة ما لكي تشتغل بشكل طبيعي , و نادرا ما يتم التعامل مع هاته التبعيات و الحزم . و يقصد بها أي حزمة B تتطلبه حزمة معينة A ما ولكنها لا تشمله مع نفسه عند تثبيته . على سبيل المثال : حزمة popper.js مع بوتستراب , فهي حزمة يستعملها Bootstrap 4 لإظهار النوافذ المنبثقة و بعض التأثيرات و التفاعليات في بوتستراب , و لكن بوتستراب لا يتضمنها عند التثبيت و قد نغفل في كثير من الحالات عن تثبيتها فتسبب بعض المشاكل من مثل : مثال 2 : . يطلق هنا على popper.js و مثلها من الحزم لفظ peer dependecies لـ bootstrap . يمكن نمذجة طريقة التعامل معها عن طريق مدير الحزم npm كالتالي : ./node_modules/ | | | +- devDependency | | | | +- dependency/node_modules/ | | | +- peerDependency-1/ | | +- dependency | | | | | +- devDependency/node_modules/ | +- peerDependency-2/ كما يوجد أيضا : الـ bundledDependencies و الـ OptionalDependencies . قد لا يختلف الأمر كثيرا مع بيئات و لغات مختلفة , كما قد تختلف طريقة التعامل مع كل منها مع مدراء الحزم من مثل npm , composer , yarn , pip . سواء في أسماءها أو اللواحق أو الخيارات التي إضافتها لتحديد نوع الحزمة أو التبعية , أو ربما في طريقة تنسيق بنية ملفات الحزم و التبعيات أو أيضا في ملف مدير الحزمة (مثل composer.json و package.json) . و لكن يبقى منطقها و تقسيمها سواءا مهما اختلف كل ذلك .2 نقاط
-
مساء الخير ايه هو المسار الكامل لاحتراف wordpress1 نقطة
-

الإصدار 1.0.0
129262 تنزيل
سطع نجم لغة البرمجة بايثون في الآونة الأخيرة حتى بدأت تزاحم أقوى لغات البرمجة في الصدارة وذاك لمزايا هذه اللغة التي لا تنحصر أولها سهولة كتابة وقراءة شيفراتها حتى أصبحت الخيار الأول بين يدي المؤسسات الأكاديمية والتدريبية لتدريسها للطلاب الجدد الراغبين في الدخول إلى مجال علوم الحاسوب والبرمجة. أضف إلى ذلك أن بايثون لغةً متعدَّدة الأغراض والاستخدامات، لذا فهي دومًا الخيار الأول في شتى مجالات علوم الحاسوب الصاعدة مثل الذكاء الصنعي وتعلم الآلة وعلوم البيانات وغيرها، كما أنَّها مطلوبة بشدة في سوق العمل وتعتمدها كبرى الشركات التقنية. دورة تطوير التطبيقات باستخدام لغة Python احترف تطوير التطبيقات مع أكاديمية حسوب والتحق بسوق العمل فور انتهائك من الدورة اشترك الآن بني هذا العمل على كتاب «How to code in Python» لصاحبته ليزا تاغليفيري (Lisa Tagliaferri) وترجمه إلى العربية محمد بغات وعبد اللطيف ايمش، وحرره جميل بيلوني، ويأتي شارحًا المفاهيم البرمجية الأساسية بلغة بايثون، ونأمل في أكاديمية حسوب أن يكون إضافةً نافعةً للمكتبة العربيَّة وأن يفيد القارئ العربي في أن يكون منطلقًا للدخول إلى عالم البرمجة من أوسع أبوابه. رُبط هذا الكتاب مع توثيق لغة بايثون في موسوعة حسوب لتسهيل عملية الاطلاع على أي جزء من اللغة مباشرة وقراءة التفاصيل باللغة العربية. هذا الكتاب مرخص بموجب رخصة المشاع الإبداعي Creative Commons «نسب المُصنَّف - غير تجاري - الترخيص بالمثل 4.0». يمكنك قراءة فصول الكتاب على شكل مقالات من هذه الصفحة، «المرجع الشامل إلى تعلم لغة بايثون»، أو مباشرةً من الآتي: المقال الأول: دليل تعلم بايثون اعتبارات عملية للاختيار ما بين بايثون 2 و بايثون 3 المقال الثاني: تثبيت بايثون 3 وإعداد بيئتها البرمجية المقال الثالث: كيف تكتب أول برنامج لك المقال الرابع: كيفية استخدام سطر أوامر بايثون التفاعلي المقال الخامس: كيفية كتابة التعليقات المقال السادس: فهم أنواع البيانات المقال السابع: مدخل إلى التعامل مع السلاسل النصية المقال الثامن: كيفية تنسيق النصوص المقال التاسع: مقدمة إلى دوال التعامل مع السلاسل النصية المقال العاشر: آلية فهرسة السلاسل النصية وطريقة تقسيمها المقال الحادي عشر: كيفية التحويل بين أنواع البيانات المقال الثاني عشر: كيفية استخدام المتغيرات المقال الثالث عشر: كيفية استخدام آلية تنسيق السلاسل النصية المقال الرابع عشر: كيفية إجراء العمليات الحسابية المقال الخامس عشر: الدوال الرياضية المضمنة المقال السادس عشر: فهم العمليات المنطقية المقال السابع عشر: مدخل إلى القوائم المقال الثامن عشر: كيفية استخدام توابع القوائم المقال التاسع عشر: فهم كيفية استعمال List Comprehensions المقال العشرون: فهم نوع البيانات Tuples المقال الحادي والعشرين: فهم القواميس المقال الثاني والعشرين: كيفية استيراد الوحدات المقال الثالث والعشرين: كيفية كتابة الوحدات المقال الرابع والعشرين: كيفية كتابة التعليمات الشرطية المقال الخامس والعشرين: كيفية إنشاء حلقات تكرار while المقال السادس والعشرين: كيفية إنشاء حلقات تكرار for المقال السابع والعشرين: كيفية استخدام تعابير break وcontinue وpass عند التعامل مع حلقات التكرار المقال الثامن والعشرين: كيفية تعريف الدوال المقال التاسع والعشرين: كيفية استخدام *args و**kwargs المقال الثلاثين: كيفية إنشاء الأصناف وتعريف الكائنات المقال الحادي والثلاثين: فهم متغيرات الأصناف والنسخ المقال الثاني والثلاثين: وراثة الأصناف المقال الثالث والثلاثين: كيفية تطبيق التعددية الشكلية (Polymorphism) على الأصناف المقال الرابع والثلاثين: كيف تستخدم منقح بايثون المقال الخامس والثلاثين: كيفية تنقيح شيفرات بايثون من سطر الأوامر التفاعلي المقال السادس والثلاثين: كيف تستخدم التسجيل Logging المقال السابع والثلاثين: كيفية ترحيل شيفرة بايثون 2 إلى بايثون 31 نقطة -
بأي دورة ابدأ لكي اصبح محترف في البرمجة1 نقطة
-
ما الفرق بين let , var في الجافاسكريبت؟1 نقطة
-
أحاول الحصول على أبعاد ال tensor: x = tf.get_variable("x", [100]) # عندما أقوم بطباعة أبعادها print( tf.shape(x) ) # يعطيني خرجاً # Tensor("Shape:0", shape=(1,), dtype=int32) لكن الخرج المتوقع هو (100) وليس كما أعطاني في الخرج لماذا؟1 نقطة
-
كنت أتصفح توثيق جانغو Django للخاصية is_authenticated ، لكني لم أتمن من فهما، أحتاج إلى التحقق مما إذا كان المستخدم الحالي قد قام بتسجيل الدخول (مصادق عليه) ، ولقد حاولت أن أستخدم الكود التالي: request.user.is_authenticated على الرغم من التأكد من أن المستخدم قد قام بتسجيل الدخول، فإنه يعرض الرمز التالي فقط: > يمكنني تنفيذ طلبات أخرى (من خلال الخاصية is_active) ، مثل: request.user.is_active الذي يعيد استجابة ناجحة. أستخدم جانغو Django اللإصدار 1.91 نقطة
-
أحاول تشغيل الكود التالي: path = 'data.csv' df = pd.read_csv(path) لكن يظهر لي هذا الخطأ pandas.parser.CParserError: Error tokenizing data. C error: Expected 2 fields in line 3, saw 12 كيف يمكنني التغلب على هذا الخطأ؟1 نقطة
-
اشتركت فى أكاديمية حاسوب فى دورات علوم الحاسب الآلي ولم يتم تفعيل الدورة1 نقطة
-
؟؟ قمت بعمل الأكواد التي في الصورة, ألاحظ عندما أقوم بإلغاء width العنصر الأحمر, لا يتغير عرض العنصر الأزرق ؟ فلماذا هذا حدث رغم أنك قلت أن خاصية flex-basis لن تعمل لن تغير عرض العنصر إلا إن تم تحديد حجم باقي العناصر التي بجانبها

 1 نقطة
1 نقطة -
لدي مشروع PHP حالي مع jquery و bootstrap ، ولا يستخدم أي إطار عمل للواجهة الأمامية. أحاول استخدام أداة تجميع وحدات webpack لإنشاء نقطة دخول واحدة لموارد مشروعي ، وإدارة تبعيات js باستخدام مدير حزم العقدة js ، وتشغيل المهام على شكل تصغير js css ، وإعادة حجم الصورة ... إلخ. وتحسين وقت تحميل المتصفح المطلوب لتحميل صفحة واحدة. صادفت برامج webpack التعليمية وحصلت على تثبيتها وتثبيتها على خادم dev الخاص بها ، ولكن المشكلة هي أنني لست قادرًا على فهم كيفية تحويل جميع نصوص js وروابط css الحالية في المشروع (حيث لدي الكثير من مكتبات jquery و CSS المستخدمة لتوفير ميزات متعددة في المشروع) لاستخدام حزمة الويب. هل يجب علي إعادة كتابة جميع ملفات JS و CSS الخاصة بي بطريقة تناسب webpack ؟ بالإضافة إلى ذلك ، لا يمكنني تشغيل تطبيق php الحالي الخاص بي على webpack dev-server ، فهل من المفترض أن يعمل هناك في المقام الأول؟ لقد قمت بإنشاء ملف test index.js واستخدمت تكوين حزمة الويب التالية: var path = require('path'); var webpack = require('webpack'); module.exports = { entry: [ './public/js/index.js', 'webpack/hot/dev-server', 'webpack-dev-server/client?http://localhost:8080' ], plugins: [ new webpack.HotModuleReplacementPlugin() ], output: { path: path.join(__dirname, "public/dist/js"), publicPath : "http://localhost:8080/my_proj/public/dist/js", filename: "bundle.js" } }; <script type="text/javascript" src="public/dist/js/bundle.js"></script> <script type="text/javascript" src="public/js/jquery.min.js"></script> <script type="text/javascript" src="public/js/jquery.migrate.js"></script> <script type="text/javascript" src="public/js/jquery.bxslider.min.js"></script> <script type="text/javascript" src="public/js/jquery.appear.js"></script> <script type="text/javascript" src="public/js/jquery.countTo.js"></script> <script type="text/javascript" src="public/js/bootstrap.js"></script>1 نقطة
-
لا يتحوي create-react-app على كل المميزات التي قد تحتاجها في المشروع، فعلى سبيل المثال لا يتحتوي على طريقة إفتراضية لتغير المسارات routes ويجب عليك تثبيت حزم أخرى مثل react-router لكي تقوم بذلك، كما أنه لا يمكنك من توليد صفحات ثابتة static pages بسهولة، ولا يحتوي على ميزة SSR (Server Side Rendering) أو SSG (Static Site Generation) بشكل إفتراضي، مما قد يؤثر على السيو SEO الخاص بالموقع، وغيرها من الممزايات التي تجد نفسك في حاجة إليها في كل مشروع تقريبًا تقوم بعمليه. ولحل مثل هذه المشاكل، ظهرت إطارات عمل مختلفة مبنية على React نفسه، مثل Next.js و Gatsby، ولكل منهما مميزات مختلفة، فعلى سبيل المثال يحتوي إطار العمل Next.js على العديد من المميزات منها: دعم TypeScript: لن تحتاج إلى الكثير من الخطوات لتستطيع أن تستخدم TypeScript في المشروع pre-rendering SSR + SSG : يدعم Next.js ما يسمى Hybrid أي أنه يقوم بتحويل الصفحات الثابتة إلى SSG تلقائيًا والصفحات الأخرى تكون من نوع SSR file-system routing: لن تحتاج إلى تثبيت حزم خارجية لكي تقوم بعمل Route System، فقط قم بتنظيم الملفات بالطريقة التي تريد وستجد أن كل المسارات تعمل بنفس طريقة ترتيب الملفات والمجلدات داخل بعضها البعض. zero config: لا يوجد أي إعدادات تحتاج إن أن تقوم بعملها لكي يعمل المشروع بكفاءة، فقط أكتب الكود وشاهد النتيجة في المتصفح مباشرة. Image Optimization: يمكن لإطار العمل Next.js ضغط وإعادة تحجيم الصور لتقليل حجم النطاق الترددي Bandwidth إلى أقصى حد من خلال عمل مكون Image مخصص. code splitting: يقوم Next.js بتقسيم الكود إلى ملفات صغيرة تسمى chunks ويتم تحميل الكود المطلوب فقط إلى المتصفح، وبالتالي يتم تحميل الصفحات بشكل أسرع وعرض النتيجة في وقت أقل. لذلك أنتقل الكثير من مطوري React.js إلى إستخدام Next.js وGatsby بسبب المميزات التي يقدمها.1 نقطة
-
لا أفهم سبب عدم قراءة webpack-config.js في مشروعي. إذا ارتكبت خطأً في بناء الجملة في webpack-config.js ، فلن يظهر الخطأ حتى. package.json: { "name": "ff", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "dev": "webpack-dev-server --mode development --hot --progress --open", "build": "webpack --mode production" }, "author": "", "license": "MIT", "devDependencies": { "path": "^0.12.7", "webpack": "^4.23.1", "webpack-cli": "^3.1.2", "webpack-dev-server": "^3.1.10" }, "dependencies": { "jquery": "^3.3.1" } } webpack-config.js: const path = require('path'); const conf = { entry: './src/index.js', output: { path: path.resolve(__dirname, './dist'), filename: 'main.js', publicPath: 'dist/' }, devServer: { overlay:true } }; module.exports = conf;1 نقطة
-
من المحتمل أنك استخدمت اسم ملف خاطئ حيث أن webpack يبحث عن ملف "webpack.config.js" ، ولكن أنتي قمتي بتسمية الملف لديك "webpack-config.js" , كما تلاحظي شرطة بدلا من نقطة. حاولي إعادة تسمية الملف أو ساعدي webpack في العثور على الملف عن طريق تعيين مسار التكوين الخاص بك بشكل صريح باستخدام الخيار --config1 نقطة
-
شكرا فهمت بعض الأمور, لكن مازال لدي إشكال في سبب عدم اخذ الايقونة عرض 60px التي قمت بإعطائها لها, و أيضا سبب أخذها المفاجئ لهذه القيمة بعض تحديد flex: 1 للعنصر ذو الكلاس text, فأرجو توضيح هذا الأمر لي1 نقطة
-
ماهي الكورسات المتوفرة في اكاديمية حاسوب لتعلم برمجة تطبيقات الجوال علما اني انه ليس لدي علم في البرمجة1 نقطة
-
أحاول تطبيق شرط if على البيان التالي لكنه لاينجح، وفي الواقع توقعت أنه لن ينجح لذا هل هناك طريقة لإضافة شرط if؟ هذا هو الكود الخاص بي: data = tensorflow.placeholder(shape=[None, ins_size**2*3]) wights = tensorflow.Variable(tensorflow.zeros([ins_size**2*3,label_option])) bias = tensorflow.Variable(tensorflow.zeros([label_option])) if tensorflow.placeholder(shape=[1, 1]) > 0: pred = tensorflow.nn.softmax(tensorflow.matmul(data, wights) + bias) else: pred = tensorflow.nn.softmax(tensorflow.matmul(data, wights) - bias)1 نقطة
-
كلا ما زالت قائمة ، و هذا غريب if (mysqli_num_rows($ask) == 0) { $result2 = $conn->query("UPDATE orders SET collar=0 WHERE id='$order'"); } الان انا بقوله لما ناتج mysqli_num_rows($ask) يطلع معاك صفر نفذ الاستعلام result2 طيب الان ناتج mysqli_num_rows($ask) بيديك رقم 4 بتنفذ الاستعلاااام لييييه ؟؟؟ ده اللي مجنني1 نقطة
-
مظبوط ، قمت بطباعتها و ادتني رقم 1 و لما شلت ال limit ادتني 4 اللي هما عدد القيم1 نقطة
-
حاول طباعة قيمة mysqli_num_rows($ask) و معرفة ماذا ترجع لك , لأنه يبدو أنه ترجع رقم 0 فلذلك ينفذ الشرط , يجب أن يكون لا يساوي صفر الشرط , بسبب أنه يوجد سجل.1 نقطة
-
نعم يوجد سجلات لها نفس قيمة ال order_id و المستخدم من خلال الواجهة الخاصة بالبرنامج يحذف كل سجل على حدة نفذت التعديل اخي لكن نفس المشكلة يقوم بتعديل حقل collar و كانه مش شايف الشرط $id = $_POST['id']; $order = $_POST['order']; // Delete Query $result = $conn->query("DELETE FROM order_collars WHERE id='$id'"); // check Query $ask = $conn->query("select * from order_collars WHERE order_id='$id' ORDER BY order_id DESC LIMIT 1"); // check if you fount zero result excuse $result2 if (mysqli_num_rows($ask) == 0) { $result2 = $conn->query("UPDATE orders SET collar=0 WHERE id='$order'"); } if ($result == true) { echo "done"; } else{ echo "Errormessage: %s\n". $conn->error; }1 نقطة
-
إذا كان يوجد سجلات لها نفس قيمة order_id فيمكنك حذف السجل ثم يمكنك استخدام استعلام ORDER BY DESC LIMIT 1 ليتم فحص آخر سجل هل يساوي id قيمة order_id و بالتالي الاستعلام التالي يكون $ask = $conn->query("select * from order_collars WHERE order_id='$id' ORDER BY order_id DESC LIMIT 1"); و بناء عليه يتم تعديل حقل collar أو لا , هل يمكنك تجربة ذلك وأخباري بالنتيجة.1 نقطة
-
نعم بالتأكيد يمكنك ترقيته طالما أن المعالج ب 64 بت. فقط عليك أن تقوم بتحديث النظام إلى نسخة تتعامل مع ال 64 بت. أما إذا كان 32 بت فبالطبع لايمكنك. لكن جهازك يدعم ال 64 بت إذاً يمكنك أن تقوم بتنزيل نظام يعمل على 64 بت عند أي مركز صيانة للأجهزة.1 نقطة
-
لو سمحت انا شايف ان انا قادر ادخل على كل الدورات اللى على الموقع مع انى اشتريت اول كورس بس فا هل ده يعنى ان بيقت الكورسات مش كملة هى مجرد اسسيات بس ولا المبلغ اللى انا دفعته 160$ كان لكل حاجة مش دورة واحدة بس؟1 نقطة
-
أخي العزيز سؤرفق لك صورة كيف وجدت الترميز وهل أحوله إلى utf8mb4_general_ci
 1 نقطة
1 نقطة -
يمكنك ذلك عن طريق str.contains والتي يمكن إستخدامها ل substring search و ايضاً regex based search (والذي يرمز لل regular expression) و هو طريقة البحث by default وقد تأخذ عملية البحث وقت أطول به إذا لم يتم إلغائه في دالة البحث، لاحظ فرق زمن التنفيذ: import pandas as pd df = pd.DataFrame({'col':['cat','hat','bat','dog','ant']}) df1 = pd.concat([df] * 1000, ignore_index=True) %timeit df1[df1['col'].str.contains('og|at')] %timeit df1[df1['col'].str.contains('og|at', regex=False)] أو يمكننا إستخدام دالة find في مكتبة numpy : import numpy as np import pandas as pd df = pd.DataFrame({'col':['cat','hat','bat','dog','ant']}) df[np.char.find(df['col'].values.astype(str), 'at') & np.char.find(df['col'].values.astype(str), 'og') > -1] أو عن طريق دالة query للdf: df.query('col.str.contains("og|at")', engine='python') كما يمكن ذلك عن طريق الدالة vectorize في numpy: import numpy as np import pandas as pd df = pd.DataFrame({'col':['cat','hat','bat','dog','ant']}) f = np.vectorize(lambda words, w: w in words) df[f(df['col'], 'og') | f(df['col'], 'at')]1 نقطة
-
أريد طريقة لعرض مخطط الغراف، كيف يمكنني القيام بذلك؟1 نقطة
-
لفرق بين هاتين الفئتين هو: فئة container هي ذات العرض الثابت. هذا لا يعني أنه لا يستجيب. إنه متجاوب. ومع ذلك ، تم إصلاحه بناءً على حجم الشاشة. تشمل أحجام الشاشة: Xs للأجهزة الصغيرة جداً (تستخدم لأقل من 768 مثل الهواتف الذكية والجوال وما إلى ذلك). Sm للشاشات الصغيرة (من 768 بكسل وما فوق على سبيل المثال الأجهزة اللوحية). Md للشاشة المتوسطة (> = 992 بكسل. أجهزة الكمبيوتر المكتبية / أجهزة الكمبيوتر المحمولة). Lg للشاشات الكبيرة (> = 1200. بكسل مثل أجهزة الكمبيوتر المكتبية الكبيرة). إذا كنت تستخدم فئة ال container والتحقق من صفحة الويب في المتصفح ، فسيتم ضبطها وفقاً للشاشة وحجم المتصفح. على سبيل المثال، إذا كان عرض متصفحك الحالي يزيد عن 1200، فسيتم ضبطه على 1170 بكسل. إذا قمت بتغيير حجم المتصفح إلى حجم صغير ، فسيظل كما هو حتى يصل إلى 992 بكسل. وفي هذه المرحلة سيتم ضبط فئة ال container على 970 بكسل. (من الناحية التقنية يمكننا القول إنه "عرض ثابت" لأن قيم البكسل محددة). من ناحية أخرى ، ستأخذ فئة ال container-fluid العرض (width) الكامل لإطار العرض (حجم نافذة المتصفح). وإذا كنت تستخدم container-fluid وقمت بتغيير حجم نافذة المتصفح، فقد تلاحظ أن المحتوى الموجود بداخله سيتم ضبطه مع كل بكسل لأخذ العرض المتاح بالكامل (أي دوماً سيكون 100% من حجمه). وبالتالي يكون العرض width مرتبط بعرض منفذ العرض (عرض نافذة المتصفح)، وبالتالي تكون الشاشة ديناميكية. وبالتالي نستنتج أنها مفيدة أكثر في حالة أردت تغيير شكل صفحتك مع كل اختلاف بسيط في حجم منفذ العرض الخاص بها. بينما نستخدم الcontainer عندما تريد تغيير شكل صفحتك إلى 5 أنواع فقط من الأحجام ، والتي تُعرف أيضاً باسم "نقاط التوقف".1 نقطة
-
كما أشار أحمد يمكنك استخدام Apply لكن أنصح دوماً بالاعتماد على طرق أخرى لأن هذه الطرق بطيئة، لذا يمكن أن نقوم بالأمر من خلال الدالة vectorize التي ستعطيك فرق كبير للغاية بالسرعة كالتالي: import pandas as pd # تعرف داتا فريم لنختبر عليه df = pd.DataFrame({'ID':['1', '2', '3'], 'col1': [0, 1, 2], 'col2':[3, 4, 5]}) df """ ID col1 col2 0 1 0 3 1 2 1 4 2 3 2 5 """ # نعرف تابع لنختبر عليه def f(x,y): return x+y import numpy as np # نقوم بتطبيق التابع على عمودي البيانات df.loc[:,'result'] = np.vectorize(f) (df['col1'], df['col2']) df """ ID col1 col2 result 0 1 0 3 3 1 2 1 4 5 2 3 2 5 7 """ كذلك كان بإمكانك استخدام الدالة apply: df['col_3'] = df.apply(lambda x: f(x.col1, x.col2), axis=1) df """ ID col1 col2 col_3 0 1 0 3 3 1 2 1 4 5 2 3 2 5 7 """ وكتحسين لسرعة التنفيذ باستخدام apply يمكنك استخدام الأداة swifter: import swifter df['col_3'] = df.swifter.apply(lambda x: f(x.col1, x.col2), axis=1) للمقارنة: # توليد داتافريم بحجم كبير df1 = df.sample(100000, replace=True).reset_index(drop=True) # تطبيق نفس العملية واستخلاص زمن التنفيذ %timeit df1.apply(lambda x: f(x.col1, x.col2), axis=1) # 1 loop, best of 5: 1.84 s per loop %timeit df1.swifter.apply(lambda x: f(x.col1, x.col2), axis=1) # 100 loops, best of 5: 2.24 ms per loop %timeit np.vectorize(f) (df['col1'], df['col2']) # 10000 loops, best of 5: 62.7 µs per loop لاحظ أن apply استغرقت ثانيتين تقريباً وع التحسين swifter استغرقت 2 ونصف ميلي ثانية، لكن باستخدام vectorize استغرقت 62 ميكرو ثانية وهو فرق هائل. وهنا نتحدث عن عمليات بسيطة جداً هناك عمليات قد يتطلب تنفيذها وقت يتجاوز النصف ساعة والساعة حتى تنتهي لو استخدمنا Apply. لذا إذا كنت تفكر بالتعامل مع بيانات ضخمة ابتعد عنها.1 نقطة
-
إليك كل ماقد تحتاجه: import pandas as pd df = pd.DataFrame(data = {'col1' : [1, 2], 'col2' : [6, 7]}) df """ col1 col2 0 1 6 1 2 7 """ #drop النهج الذي نتبعه لحذف الأعمدة هو استخدام # إليك كامل التفاصيل # لحذف عمود محدد من خلال اسم العمود df.drop(['col1'], axis = 1) # طبعاً التغيرات لاتطبق على الداتافريم الأصلي وإنما على نسخة منه """ col2 0 6 1 7 """ # inplace إذا أردنا أن تكون التعديلات مباشرة على الداتافريم نقوم بتفعيل الوسيط #df.drop(['col1'], axis = 1,inplace=True) # axis : تشير إلى المحور الذي سيتم تطبيق عملية الحذف على أساسه وهنا حددنا المحور الأفقي أي الأعمدة # الآن لوأردنا حذف سطر محدد نقوم بتمرير الفهرس له df.drop([0], axis = 0) # أيضاً نغير المحور """ col1 col2 1 2 7 """ # ماذا لو أردنا حذف عدة أعمدة من خلال الاسم df.drop(['col1', 'col2'], axis = 1) # إذا أردنا حذف عدة أعمدة أو أسطر من خلال فهرسها df.drop(df.columns[[0,1]], axis = 1) # في حال كانت الأعمدة المراد حذفها كثيرة وضمن مجالات مستمرة أو متتالية #iloc سيكون من المتعب تحديدها واحداً تلو الآخر لذا نستخدم df.drop(df.iloc[:, 0:1], axis = 1) # : نضبه على كل الأسطر أي iloc بحيث الوسيط الأول لل # أما الوسيط الثاني لها نحدد له المجال المراد حذفه #ix أو يمكننا استخدام الدالة # بحيث نحذف كل الأعمدة الموجودة ضمن العمودين المحددين df.drop(df.ix[:, 'col1':'col2'].columns, axis = 1) # حذف كل الأعمدة بين العمودين المحددين # loc وبشكل مشابه أيضاً تستطيع ن تستخدم df.drop(df.loc[:, 'col1':'col2'].columns, axis = 1)1 نقطة
-
حلول أخرى: import pandas as pd df1 = pd.DataFrame(data = {'col1' : [1, 2, 3, 4, 5, 3], 'col2' : [10, 11, 12, 13, 14, 10]}) """ col1 col2 0 1 10 1 2 11 2 3 12 3 4 13 4 5 14 5 3 10 """ df2 = pd.DataFrame(data = {'col1' : [1, 2, 3], 'col2' : [10, 11, 12]}) df2 """ col1 col2 0 1 10 1 2 11 2 3 12 """ # الطريقة 1 # نحدد الأسطر الغير مشتركة uncommon_indices = np.setdiff1d(df1.index.values, df2.index.values) # array([3, 4, 5]) # نقوم باستخلاصها df1.loc[uncommon_indices,:] """ col1 col2 3 4 13 4 5 14 5 3 10 """ # الطريقة 2 df1[~df1.index.isin(df1.merge(df2, how='inner', on=['col1', 'col2']).index)] """ col1 col2 3 4 13 4 5 14 5 3 10 """ # الشرح خطوة بخطوة # تطبيق الدمج الداخلي للحصول على العناصر المشتركة بين إطاري البيانات res1=df1.merge(df2, how='inner', on=['col1', 'col2']) res1 """ col1 col2 0 1 10 1 2 11 2 3 12 """ #في الأماكن التي لاتتواجد فيها False في أماكن تواجد هذه الفهارس و True بحيث تضع isin استخدام الدالة #في الأسطر غير المشتركة True ثم استخدام عملية النفي ليتم وضع res2=~df1.index.isin(res1.index) res2 # array([False, False, False, True, True, True]) # الآن نستخلصها df1[res2] """ col1 col2 3 4 13 4 5 14 5 3 10 """ # الطريقة 3 df = pd.merge(df1, df2, how='outer', suffixes=('','_y'), indicator=True) df[df['_merge']=='left_only'][df1.columns] """ col1 col2 3 4 13 4 5 14 5 3 10 """1 نقطة
-
كما في التعليقات السابقة فإنه المشكلة في ال encoding وفي حالة أنك لم تستطع معرفته يمكنك استخدام الكود التالي لمعرفته with open('filename.csv') as f: print(f) ثم بعد ذلك قم بتحديد ال encoding الذي وجدته data=pd.read_csv('filename.csv', encoding="encoding you found ") كما أن إذا كنت تريد حل واحد لهذه المشكلة قم باستخدام ال Script التالي حيث يجرب الكثير من ال encoding واستخدام الصحيح import pandas as pd encoding_list = ['ascii', 'big5', 'big5hkscs', 'cp037', 'cp273', 'cp424', 'cp437', 'cp500', 'cp720', 'cp737' , 'cp775', 'cp850', 'cp852', 'cp855', 'cp856', 'cp857', 'cp858', 'cp860', 'cp861', 'cp862' , 'cp863', 'cp864', 'cp865', 'cp866', 'cp869', 'cp874', 'cp875', 'cp932', 'cp949', 'cp950' , 'cp1006', 'cp1026', 'cp1125', 'cp1140', 'cp1250', 'cp1251', 'cp1252', 'cp1253', 'cp1254' , 'cp1255', 'cp1256', 'cp1257', 'cp1258', 'euc_jp', 'euc_jis_2004', 'euc_jisx0213', 'euc_kr' , 'gb2312', 'gbk', 'gb18030', 'hz', 'iso2022_jp', 'iso2022_jp_1', 'iso2022_jp_2' , 'iso2022_jp_2004', 'iso2022_jp_3', 'iso2022_jp_ext', 'iso2022_kr', 'latin_1', 'iso8859_2' , 'iso8859_3', 'iso8859_4', 'iso8859_5', 'iso8859_6', 'iso8859_7', 'iso8859_8', 'iso8859_9' , 'iso8859_10', 'iso8859_11', 'iso8859_13', 'iso8859_14', 'iso8859_15', 'iso8859_16', 'johab' , 'koi8_r', 'koi8_t', 'koi8_u', 'kz1048', 'mac_cyrillic', 'mac_greek', 'mac_iceland', 'mac_latin2' , 'mac_roman', 'mac_turkish', 'ptcp154', 'shift_jis', 'shift_jis_2004', 'shift_jisx0213', 'utf_32' , 'utf_32_be', 'utf_32_le', 'utf_16', 'utf_16_be', 'utf_16_le', 'utf_7', 'utf_8', 'utf_8_sig'] for encoding in encoding_list: worked = True try: df = pd.read_csv(path, encoding=encoding, nrows=5) except: worked = False if worked: print(encoding, ':\n', df.head())1 نقطة
-
إضافة لطريقة الحل التي شرحها أحمد يمكنك حذف عمود بواسطة ال index كالتالي df = df.drop(df.columns[[0, 1, 3]], axis=1) # df.columns تعتبر zero-based كما يمكنك استخدام الدالة pop كالتالي df.pop('column-name') لاحظ المثال التالي df = DataFrame.from_items([('A', [1, 2, 3]), ('B', [4, 5, 6]), ('C', [7,8, 9])], orient='index', columns=['one', 'two', 'three']) print df one two three A 1 2 3 B 4 5 6 C 7 8 9 df.drop(df.columns[[0]], axis=1, inplace=True) print df two three A 2 3 B 5 6 C 8 9 three = df.pop('three') print df two A 2 B 5 C 81 نقطة
-
applymap: تعمل فقط على ال Dataframe حيث نستخدمها عادةً ليتم تطبيق دالة على كل عنصر على حدة elementwise. مثال: # Importing pandas library with an alias pd import pandas as pd # سنشكل داتا فريم كالتالي Hsoub_string = 'HsoubHsoub' Hsoub_list = 3 * [pd.Series(list(Hsoub_string))] Hsoub_df = pd.DataFrame(data = Hsoub_list) print("Original dataframe:\n" + \ Hsoub_df.to_string(index = False, header = False), end = '\n\n') """ Original dataframe: H s o u b H s o u b H s o u b H s o u b H s o u b H s o u b """ # لفرز كل صف applymap استخدام الدالة # اعتماداً على الأحرف #applymap فقط نقوم بتمرير الدالة المطلوب تنفيذها كوسيط للدالة #lambda هنا سنستخدم new_Hsoub_df = Hsoub_df.applymap(str.upper) print("Transformed dataframe:\n" + \ new_Hsoub_df.to_string(index = False, header = False), end = '\n\n') """ Transformed dataframe: H S O U B H S O U B H S O U B H S O U B H S O U B H S O U B """ apply: يمكن تطبيقها على كل من ال series و ال Dataframe حيث يمكننا تطبيق الدالة على كل من العناصر المتسلسلة والعناصر الفردية بناءً على نوع الدالة التي تم تقديمها ويمكن تطبيقها على الأسطر أو الأعمدة. المثال التالي يوضح تطبيقها على Dataframe. import pandas as pd # سنشكل داتا فريم كالتالي Hsoub_string = 'HsoubHsoub' Hsoub_list = 3 * [pd.Series(list(Hsoub_string))] Hsoub_df = pd.DataFrame(data = Hsoub_list) print("Original dataframe:\n" + \ Hsoub_df.to_string(index = False, header = False), end = '\n\n') """ Original dataframe: H s o u b H s o u b H s o u b H s o u b H s o u b H s o u b """ # لفرز كل صف apply استخدام الدالة # اعتماداً على الأحرف #apply فقط نقوم بتمرير الدالة المطلوب تنفيذها كوسيط للدالة #lambda هنا سنستخدم new_Hsoub_df = Hsoub_df.apply(lambda x:x.sort_values(), axis = 1) print("Transformed dataframe:\n" + \ new_Hsoub_df.to_string(index = False, header = False), end = '\n\n') """ Transformed dataframe: H H b b o o s s u u H H b b o o s s u u H H b b o o s s u u """ تطبيقها على series: import pandas as pd # Series إنشاء Hsoub_string = 'HsoubHsoub' Hsoub_series = pd.Series(list(Hsoub_string)) print("Original series\n" + \ Hsoub_series.to_string(index = False, header = False), end = '\n\n') """ Original series H s o u b H s o u b """ # تحويل الأحرف إلى أحرف كبيرة #apply فقط نقوم بتمرير الدالة المطلوب تنفيذها كوسيط للدالة new_Hsoub_series = Hsoub_series.apply(str.upper) print("Transformed series:\n" + \ new_Hsoub_series.to_string(index = False, header = False), end = '\n\n') """ Transformed series: H S O U B H S O U B """ map: تعمل فقط مع ال series حيث يعتمد نوع العملية التي سيتم تطبيقها على الوسيطة التي تم تمريرها كوظيفة أو قاموس أو قائمة. تُستخدم هذه الطريقة بشكل عام لربط القيم من سلسلتين لهما نفس العمود. import pandas as pd # Series إنشاء Hsoub_string = 'HsoubHsoub' Hsoub_series = pd.Series(list(Hsoub_string)) print("Original series\n" + \ Hsoub_series.to_string(index = False, header = False), end = '\n\n') """ Original series H s o u b H s o u b """ # تحويل الأحرف إلى أحرف كبيرة #map فقط نقوم بتمرير الدالة المطلوب تنفيذها كوسيط للدالة new_Hsoub_series = Hsoub_series.map(str.upper) print("Transformed series:\n" + \ new_Hsoub_series.to_string(index = False, header = False), end = '\n\n') """ Transformed series: H S O U B H S O U B """1 نقطة
-
في الواقع هناك طريقيتين سهلتين للحصول على الفرق بين dataframes: الأولى عن طريق جمع الاثنين معا ثم اختيار العناصر التي لا تشتركان فيهم سوياً كالتالي: In [2]: common = df1.merge(df2,on=['col1','col2']) print(common) col1 col2 0 1 6 1 2 7 2 3 8 df1[(~df1.col1.isin(common.col1))&(~df1.col2.isin(common.col2))] Out[2]: col1 col2 3 4 9 4 5 10 الثانية عن طريق اختيار العناصر التي لا تتواجد في ال dataframe الصغيرة باستخدام الدالة isin كالتالي: In [3]: df1[~df1.isin(df2)].dropna() Out[3]: col1 col2 3 4 9 4 5 10 لاحظ استخدام العلامة ~ والتي تعني not او النفي، وهنا تعني "غير متواجد" أي تختار العناصر من df1 غير المتواجدة في df21 نقطة
-
الدالة read_csv تأخذ الوسيطة encoding للتعامل مع الملفات من مختلف التنسيقات. عندما نريد أن نحفظ شيئ ما كملف csv عادةً يستخدم الجميع utf-8 لكن ليس بالضرورة دوماً أن يكون تنسيقه utf-8 فقد يكون الملف تم حفظه بتنسيق آخر اوبالتالي إذا حاولت قراءته بالشكل التالي سيعطيك خطأ: data = pd.read_csv('file_name.csv', encoding='utf-8') # أو data = pd.read_csv('file_name.csv') لذا إذا كنت تعلم تنسيق الملف فقم بتمريره مباشرةً للوسيطة encoding وإذا لم تكن تعرف يجب أن تجرب بنفسك التنسيقات الأخرى: import pandas as pd data = pd.read_csv('file_name.csv', encoding = "ISO-8859-1") # أو data = pd.read_csv('file_name.csv', encoding = "cp1252") # أو data = pd.read_csv('file_name.csv', encoding = "latin1") أحدهما يجب أن يعمل... هناك الكثير من التنسيقات الأخرى لكن نادري الاستخدام.1 نقطة
-
يمكنك استخدام replace: import pandas as pd import numpy as np # للأعمدة df['col'] = df['col'].replace(np.nan, 0) # لكامل الداتافريم df = df.replace(np.nan, 0) # إذا أردت أن يتم التعديل على البيانات الأصلية دون نسخة df.replace(np.nan, 0, inplace=True) أو باستخدام : # قراءة الداتافريم df = pandas.read_csv('somefile.txt') # استبدال القيم المفقودة ب0 df = df.fillna(0) # وبشكل أكثر دقة # يمكنك أن تحدد له عمود محدد df['column_name'].fillna(0) #في حال أردنا التعديل على البيانات الأصلية inplace=True ونضيف1 نقطة
-
يمكنك استخدام الدالة json_normalize() لتسطيح البيانات flatten العائدة من ال api بعد ذلك تحولها الى dataframe بسهوله، الكود التالى يوضح تلك الخطوات: from urllib2 import Request, urlopen import json import pandas as pd path1 = '40,-81.1' request=Request('http://maps.googleapis.com/maps/api/elevation/json?locations='+path1+'&sensor=false') response = urlopen(request) elevations = response.read() data = json.loads(elevations) df = pd.json_normalize(data['results']) يمكنك كذلك تحويلها الى قاموس dictionary ثم تحويلها الى dataframe كالتالي: train = pd.DataFrame.from_dict(data, orient='index') train.reset_index(level=0, inplace=True) اذا قمت بطباعة البيانات في الحالتين ستجدها على الشكل والصيغة dataframe.1 نقطة