
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 09/03/21 في كل الموقع
-
السلام عليكم ورحمه الله وبركاته اريد ان اعرف ما هي هندسة البرمجيات و هل من المحتمل أن يكون هناك دورة في المستقبل عنها3 نقاط
-
لدي بيانات على هيئة اثنان dataframes كالتالي: df1 = pandas.DataFrame(data = {'col1' : [1, 2, 3, 4, 5], 'col2' : [6, 7, 8, 9, 10]}) df2 = pandas.DataFrame(data = {'col1' : [1, 2, 3], 'col2' : [6, 7, 8]}) df1 col1 col2 0 1 6 1 2 7 2 3 8 3 4 9 4 5 10 df2 col1 col2 0 1 6 1 2 7 2 3 8 وأريد الحصول على الصفوف التي تحتوى قيماً غير مشتركة بين الاثنتين بحيث يكون كالتالي: col1 col2 3 4 9 4 5 10 كيف يمكنني فعل هذا؟2 نقاط
-
أعرف أن هناك دوال تستخدم لتطبيق شئ ما على كل البيانات في صورة dataframe لكني لا أعرف الفرق بينهم، متى أستخدم map ومتى applymap ولماذا قد استخدم دالة apply هل من الممكن شرحها مع أمثلة؟2 نقاط
-
هل يمكنك إرفاق الكود الخاص بك لأنظر إلى أي جزئية وصلت ؟2 نقاط
-
بمجرد أن أقوم بتغيير DEBUG = False في ملف settings.py، يظهر خطأ 500 (باستخدام wsgi و management.py runserver) في كل الصفحات، بالرغم من أن الموقع يعمل بشكل سليم عندما أقوم بتغيير DEBUG إلى True. ما سبب هذا الخطأ؟ وكيف أقوم بإصلاحه؟2 نقاط
-
لدي ملف .env.local وفي الملف لدي المتغير البيئي API=....... يمكنني استخدام هذا المتغير في getServerSideProps لكن لا يمكنني استخدامه في جسد المكون2 نقاط
-
أريد حل هذا السؤال ولكن عندما أظهر الناتج في المتصفح تظهر القيمة الأخيرة فقط, بالرغم من انها تظهر بشكل صحيح في الكونسول ملف main.js : var i; var x = document.getElementById('num'); function typeWord(){ var y = x.value; for( i=y; i>0; i--){ console.log(i); document.getElementById('demo').innerHTML= "<p>"+i+"</p>"; } } بنية الـ html : <div> <label for="">enter your num</label> <input type="number" id="num"> <button onclick=" typeWord();"> type word</button> <h1>The numbers is <span id="demo"></span></h1> </div> New folder.zip
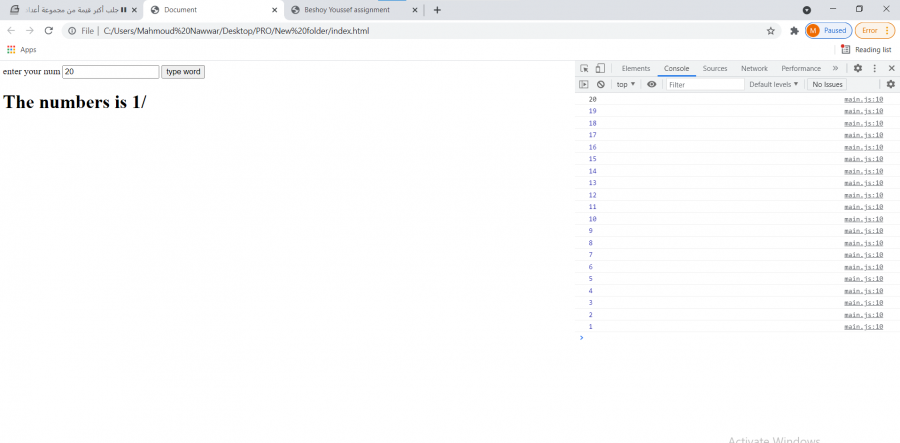
 1 نقطة
1 نقطة -
السلام عليكم اي الفريم ورك أفضل في الوطن العربي وخصوصا مصر react or angular?1 نقطة
-
أحاول حذف عمود معين من dataframe ، حاولت أستخدام هذا الكود: del df.column_name لكنه لا يعمل، كيف يمكنني عمل هذا؟1 نقطة
-
في قاعدة البيانات، أريد إضافة كائن آخر وهو نسخة من الكائن الذي لدي بالفعل. لنفترض أن لدي جدول به صف واحد. أرغب في إدراج نسخة من هذا الكائن في صف آخر باستخدام مفتاح أساسي Primary Key مختلف. كيف أقوم بذلك؟1 نقطة
-
أحاول قراءة العديد من ملفات csv باستخدام pandas لكن يظهر لي هذا الخطأ: File "C:\Importer\src\dfman\importer.py", line 26, in import_chr data = pd.read_csv(filepath, names=fields) File "C:\Python33\lib\site-packages\pandas\io\parsers.py", line 400, in parser_f return _read(filepath_or_buffer, kwds) File "C:\Python33\lib\site-packages\pandas\io\parsers.py", line 205, in _read return parser.read() File "C:\Python33\lib\site-packages\pandas\io\parsers.py", line 608, in read ret = self._engine.read(nrows) File "C:\Python33\lib\site-packages\pandas\io\parsers.py", line 1028, in read data = self._reader.read(nrows) File "parser.pyx", line 706, in pandas.parser.TextReader.read (pandas\parser.c:6745) File "parser.pyx", line 728, in pandas.parser.TextReader._read_low_memory (pandas\parser.c:6964) File "parser.pyx", line 804, in pandas.parser.TextReader._read_rows (pandas\parser.c:7780) File "parser.pyx", line 890, in pandas.parser.TextReader._convert_column_data (pandas\parser.c:8793) File "parser.pyx", line 950, in pandas.parser.TextReader._convert_tokens (pandas\parser.c:9484) File "parser.pyx", line 1026, in pandas.parser.TextReader._convert_with_dtype (pandas\parser.c:10642) File "parser.pyx", line 1046, in pandas.parser.TextReader._string_convert (pandas\parser.c:10853) File "parser.pyx", line 1278, in pandas.parser._string_box_utf8 (pandas\parser.c:15657) UnicodeDecodeError: 'utf-8' codec can't decode byte 0xda in position 6: invalid continuation byte فما سببه وكيف يمكنني حله؟1 نقطة
-
لا يمكن لأحد الإجابة على مثل هذه الأسئلة إلا إذا أكملت السؤال ب " من حيث " فرص العمل سهولة التعلم المجتمع االأداء وما إلى ذلك وإليك مقارنة بينهما يعتبر ال react مكتبة على عكس angular إطار عمل والفرق بينهم أن angular يوفر لك المكتبات والأدوات الكاملة التي تحتاجها لتطوير التطبيقات أما react في مكتبة تتيح لك إختيار الحزم أو المكتبات الأخرى لتعمل بها مع react يعتبر تعلم react أسهل نسبياً من angular حيث إذا كنت تعلم javascript جيداً فلن يكون هناك صعوبة في تعلمه بينما مع angular نظراً لأنه إطار عمل فستجد الأمر أكثر تعقيداً نسبياً يعتبر عالمياً ال react أكثر طلباُ ولكن أيضاً angular مطلوب و كما هو الحال في مصر يعتبر تطبيقات ال react أقل حجماً من تطبيقات ال react وأسرع بفرق بسيط عن ال angular حيث يعتمد على ال virtual Dom كما أن مع react يتوفر لك react native وهي تقنية قوية لتطوير تطبيقات الهاتف وهي ميزة قوية لذلك يمكنك الإختيار المكتبة المفضلة لك كما يمكنك قراءة الإجابات على هذه الأسئلة1 نقطة
-
السبب في هذا الأمر هو أنك في كل دورة من دورات الحلقة تقوم بإعادة تعيين محتوى الوسم الذي له ال id demo و لا تقوم بالإضافة للقيمة السابقة، لذلك يظهر لك في المتصفح القيمة الأخيرة(التي تنتهي عندها الحلقة). إذًا ما نحتاج إليه هو إضافة القيمة الجديدة إلى القيم الموجودة داخل الوسم بالطريقة التالية document.getElementById('demo').innerHTML = document.getElementById('demo').innerHTML + "<p>" + i + "</p>"; و الذي يكافئ document.getElementById('demo').innerHTML += "<p>" + i + "</p>"; var i; var x = document.getElementById('num'); function typeWord(){ var y = x.value; for( i=y; i>0; i--){ console.log(i); document.getElementById('demo').innerHTML += "<p>" + i + "</p>"; } }1 نقطة
-
إستخدم insertAdjacentHTML بدلا من insertHtml لأن insertHtml تغير element في كل دورة و تضع مكانه العنصر الجديد و لكن insertAdjacentHTML تضيف العنصر الجديد فقط كالأتي for( i=y; i>0; i--){ console.log(i) document.getElementById('demo').insertAdjacentHTML('beforeend',"<p>"+i+"</p>") } و لاحظ أن المتغير الأول beforeend تضيف element قبل نهاية selector1 نقطة
-
انا هلا عم اعمل مشروع flutter بس ما عرفت شو ال Backend المناسب -مشروعي عبارة عن تطبيق خاص بالطلبة المقبلين عالبكالوريا -التطبيق بيقبل نوعين من المستخدمين: طلاب و اساتذة طبعا كل واحد عندو attributes الخاصة فيه جمل ال fonctions الموجودة التطبيق هي: *المستخدم يقدر ينشر منشورات هالمنشرات عبارة عن "دروس وتمارين" او "مواضيع مع الحلول" كل منشور يحتوي علي id primary key, title, description,#user_id foreign key from table User, #faculty_id foreign key from tbale Faculty, department_id foreign key from table Department المنشور ممكن يحتوي علي صور او فيديوهات او حتى ملفات * التطبيق يسمح للمستخدمين انو يتبادلو الكتب يعني الواحد ينشر معلومات عن الكتاب يلي عندو مع صورة الو ويلي بدو يتبادل معو يكفي انو يضغط عالمنشور ويخل معلومات عن الكتاب يلي معو مع الصورة * رح ضيف quizz للتطبيق وكمان نظام سؤال جواب انا احترت اي backend بستعمل ينفع SQFLite ؟1 نقطة
-
أريد عمل هذا الرنامج في الصورة قمت بكتابة الأكواد ولكنه أحيانا يظهر القيمة الأكر وأحيانا يظهر القيمة الأصغر New folder.zip
 1 نقطة
1 نقطة -
صحيح , يمكنك فعله و لكن كلما زاددت الأعداد التي تريد جلب أكبر قيمة منها يكون الأمر معقد و ما دام هناك دالة تتكفل بهذا الأمر لابد من استخدامها حتى لا نقع بمشاكل, ويمكنك تمرير أكثر من رقمين إلى دالة Math.max .1 نقطة
-
شكرا لك هل من الممكن فعل هذا الأمر بدون دالة Math.max1 نقطة
-
يمكنك استخدام Math.max لتقوم بجلب أكبر عدد من مجموعة الأعداد التي يتم تمريرها إلى دالة Math.max و تكون تركيب الدالة بهذا الشكل Math.max(value, value1, value2); و في حالة الكود الخاص بك يجب إدخال كود جلب قيمة الحقل بداخل دالة typeWord لتصبح الدالة بهذا الشكل function typeWord(){ var x = document.getElementById('num1'); var b = document.getElementById('num2'); var a = Math.max(x.value, b.value); document.getElementById('demo').innerHTML= a } لاحظ أنه قمنا بإنشاء متغير a ليقوم بتخزين أكبر قيمة عن طريق استخدام Math.max و تمرير متغير a إلى العنصر الذي قيمة id الخاصة به هي demo ليتم طباعتها. var a = Math.max(x.value, b.value); document.getElementById('demo').innerHTML= a1 نقطة
-
كيف جلب ip زوار الموقع باستخدام php لقد حاولت باستخدام هذا الكود هل هذا صحيح <?php echo $_SERVER['REMOTE_ADDR']; ?>1 نقطة
-
صحيح , يمكنك الاعتماد على هذه الدالة .1 نقطة
-
هل يمكن بهـذه الدالة جلب ip اي شخص1 نقطة
-
هذا الكود جزء من ألية كاملة لجلب ip زائر الموقع , لذلك يمكنك إنشاء دالة لتقوم بجلب ip الزائر باستخدام مصفوفة $_SERVER فيمكنك إنشاء دالة باسم getClientIP بهذا الشكل function getClientIP( ) { } ثم بداخل الدالة نقوم بإنشاء متغير وليكن باسم ip function getClientIP( ) { $ip = ""; } ثم نقوم باستخدام دالة if لتحقق من ip الزائر بهذا الشكل function getClientIP( ) { $ip = ""; if ( isset( $_SERVER['REMOTE_ADDR'] ) ) { $ip = $_SERVER['REMOTE_ADDR']; } else if ( isset( $_SERVER['HTTP_X_FORWARDED_FOR'] ) ) { $ip = $_SERVER['HTTP_X_FORWARDED_FOR']; } else if ( isset( $_SERVER['HTTP_CLIENT_IP'] ) ) { $ip = $_SERVER['HTTP_CLIENT_IP']; } echo $ip; } لاحظ أن المصفوفة $_SERVER لديها ثلاث قيم لجلب ip الزائر $_SERVER['REMOTE_ADDR']; $_SERVER['HTTP_X_FORWARDED_FOR']; $_SERVER['HTTP_CLIENT_IP']; فقمنا بعمل دالة شرطية للتحقق من هذه القيم الثلاث لنتمكن من جلب ip ثم نقوم بتخزين هذه القيم بداخل متغير ip ثم نستخدم echo لطباعة المتغير ip و يمكنك استخدام هذه الدالة بهذه الطريقة <?php echo getClientIP( ); ?>1 نقطة
-
الإجابة المختصرة نعم يصلح، الإجابة المطولة والتي ستجعلك قادرا على تعديل شكل الفاتورة مستقبلا وتعديل أي محتوى طباعي كما ذكرت لك في الإجابة رقم 1 و 3 في طريقة معاينة كيف سيكون شكل الصفحة عند الطباعة الإجابة المختصرة نعم تحتاج لتنفيذ الأمر print، الإجابة المطولة في الإجابة رقم 2 تم شرح مسؤولية الدالة print ومن يتولى مهمة الطباعة واختيار الطابعة والقياس1 نقطة
-
نعم هذا في حال عملية الاستعلام لا يوجد بها منطق مثل الخطوة رقم 2، عمليات المنطق (التحقق من البيانات) نقوم بها في لغة البرمجة حصرا يمكنك معرفة الخطأ من رسالة الخطأ أو تحديده من المعرف الخاص به (23505 لخاصية ال unique_violation) لتنفيذ عدة عمليات معا اذا كنت تستخدم مكتبة pg مباشرة كالتالي const { Pool } = require("pg"); const pool = new Pool(); pool.connect((err, client, done) => { const shouldAbort = (err) => { if (err) { console.error("Error in transaction", err.stack); // التراجع عن تنفيذ العمليات client.query("ROLLBACK", (err) => { if (err) { console.error("Error rolling back client", err.stack); } // release the client back to the pool done(); }); } return !!err; }; client.query("BEGIN", (err) => { if (shouldAbort(err)) return; // بداية العمليات // INERT..., UPDATE... // نهاية العمليات client.query("COMMIT", (err) => { if (err) console.error("Error committing transaction", err.stack); done(); }); }); }); اذا كنت تستخدم sequelize فالأمر أبسط try { const result = await sequelize.transaction(async (t) => { // نقوم بالعمليات هنا // مع تمرير الخاصية transaction // مثال const user = await User.create({ name: 'Modhy', }, { transaction: t }); //... }); // الوصول إلى هنا يعني اتمام العمليات بنجاح } catch (error) { // أي خطأ يحدث خلال العمليات يتم التراجع عنه آليا والحصول على الخطأ }1 نقطة
-
وعليكم السلام ورحمة الله وبركاته هناك عدة تعريفات لهندسة البرمجيات ولكن وفقاُ لويكيبيديا حيث هندسة البرمجيات تتكون من عدة مراحل كما هي مذكورة في التعريف اما البرمجة فقط فهي جزء من هندسة البرمجيات والفرق كالآتي1 نقطة
-
أحياناً عند التعامل مع proxies يعيدون أحياناً ip متعددة في HTTP_X_FORWARDED_FOR ولذلك للحصول على ال ip الحقيقي سيكون آخر ip في ال list لذلك سينستخدم إجابة سامح مع تعديل بسيط كالتالي def get_client_ip(request): x_forwarded_for = request.META.get('HTTP_X_FORWARDED_FOR') if x_forwarded_for: ip = x_forwarded_for.split(',')[-1].strip() else: ip = request.META.get('REMOTE_ADDR') return ip1 نقطة
-
لدي صفحة index وأردت إعادة التوجيه إلى صفحة orders عندما يدخل إلى صفحة index. ما هي الطريقة الصحيحة للقيام بذلك؟ أنا أستخدم Next JS React. import { useRouter } from 'next/router' const Index = () => { const router = useRouter() return router.replace('/orders') }1 نقطة
-
لاحظت أن هناك طريقة أخرى لإنشاء الجلسة في تنسرفلو وهي tf.InteractiveSession ، فما هو الفرق بينها وبين tf.Session؟1 نقطة
-
السلام عليكم 1-لدي مشكله في عمل كود ال jquery علما" بانني اخذته من مدرب ولكني هناك جزء لم افهمه لماذا وضع slide.lenght ماذا تعني و معني n هل هو عدد الخلفيات ارجو المساعده وكيف اضيف timer بحيث تنتقل كل صوره بعد فتره زمن معينه 2- المشكله الاخري اريد اللوجو بجانب النص مثل الصوره الاصليه قمت بارفاقها لك templete 1.zip
.thumb.png.ed65bbcfeaa0f67f19540d9ad1d77fbd.png)
_LI.thumb.jpg.71378e27cc2a76755d54c064cbf7a36a.jpg) 1 نقطة
1 نقطة -
التأكد من البيانات يحتاج إما جلب البيانات و التأكد منها محليًا، أو التأكد منها مباشرة داخل قاعدة البيانات عبر الاستعلام (خطوة ضرورية) للتأكد من عدم تكرار الأسم يمكن الاعتماد على قاعدة البيانات نفسها لضمان ذلك عبر تعيين الخاصية UNIQUE لحقل الإسم داخل الجدول عند إنشاءه (لا حاجة للإستعلام يمكن اختصاره) الإضافة في A وتحديث البيانات في B هما عمليتا كتابة لا يمكن اختصارهما (خطوة ضرورية) لكن: يمكن لهذه العملية أن تفشل بسبب تكرار الاسم (الخطوة 2) هنا نعلم بأن الإسم مكرر عند فشل هذه العملية يجب الرجوع عن البيانات المضافة في كلا الجدولين نستفيد من مبدأ بداية وتأكيد العمليات Transaction في PostgreSQL حيث يقوم بالرجوع عن أي بيانات تمت اضافتها أو تعديلها خلال هذه العمليات BEGIN; -- بداية العمليات INSERT INTO A ... ; UPDATE B ... ; -- نهاية العمليات COMMIT;1 نقطة
-
توفر حلقة for في القوالب template الكائن forloop الذي يحتوي على الخاصية counter و counter0 والتي تعبر عن رقم التكرار في الحلقة (يمكن إعتباره مثل index)، حيث يبدأ الأول من 1 بينما counter0 يبدأ من 0 في العد لذلك يمكنك الحصول على النتيجة المرجوة من خلال الكود التالي: <ul> {% for day in daysList %} <li># Day {{ forloop.counter }} - From {{ day.from_location }} to {{ day.to_location }}</li> {% endfor %} </ul> كما يوفر هذا الكائن مجموعة أخرى من الخصائص مثل revcounter و revcounter0 و first و last وكذلك parentloop للتعامل مع حلقات for متداخلة.1 نقطة
-
ما تعتقده صحيح، حيث في السطر الأول يجب أن تستدعي التابع save لكي يقوم بحفظ الكائن في قاعدة البيانات، وهذا الأمر يفيد إن كنت تريد التعديل على الكائن قبل حفظه، بينما في السطر الثاني يتم إنشاء الكائن بشكل مباشر في قاعدة البيانات في خطوة واحدة، مما يجعل من الكود أقصر وأكثر قابلية للقراءة. حسب توثيق Django: أي أن التابع save يسمح لك بعمل مجموعة من الخيارات المتقدمة، بينما create يسمح لك بحفظ الكائن في قاعدة البيانات في خطوة واحدة. من المميزات التي يسمح لك التابع save القيام بها هي عمل INSERT OR UPDATE للكائن في قاعدة البيانات وبالتالي في حالة وجود الكائن في قاعدة البيانات بالفعل سوف يتم تحديثه، بينما في حالة إستخدام create سوف يظهر خطأ كالتالي: # django.db.utils.IntegrityError: (1062, "Duplicate entry '13' for key 'PRIMARY'") ويمكنك أن تتحكم في هذه الميزة عبر المدخل force_insert والذي يقبل قيمة منطقية True/False. الأمر الأخير هو أن التابع save يقوم بإرجاع None، بينما create يقوم بإرجاع instance من هذا النموذج.1 نقطة
-
يمكنك أن تقوم بعمل دالة تقوم بإرجاع عنوان IP ، كالتالي: def getClientIP(request): x_forwarded_for = request.META.get('HTTP_X_FORWARDED_FOR') # في حالة وجود العنصر HTTP_X_FORWARDED_FOR سوف يحتوي على عنوان IP في بدايته if x_forwarded_for: ip = x_forwarded_for.split(',')[0] else: ip = request.META.get('REMOTE_ADDR') return ip لاحظ كيف تم إستخدام التابع get حتى تحتدث مشكلة في حالة عدم وجود المفتاح REMOTE_ADDR (سوف يتم إرجاع None في هذه الحالة). كما يجب أن تتأكد من إعدادات reverse proxy بشكل صحيح (إن وجد)، على سبيل المثال: تثبيت mod_rpaf لخادم الويب Apache. ملاحظة: يحتوي العنصر X-Forwarded-For على عنوان IP في بدايته في أغلب الأحيان، ولكن في أحيان أخرى مثل في خوادم Heroku يتم وضع عنوان IP في نهايته، أي أنك يجب أن تستخدم -1 بدلًا من 0، كالتالي: def getClientIP(request): x_forwarded_for = request.META.get('HTTP_X_FORWARDED_FOR') # في حالة وجود العنصر HTTP_X_FORWARDED_FOR سوف يحتوي على عنوان IP في بدايته if x_forwarded_for: ip = x_forwarded_for.split(',')[-1].strip() else: ip = request.META.get('REMOTE_ADDR') return ip الآن يمكنك أن تستعمل الدالة كالتالي: client_ip = getClientIP(request) كما يمكنك أن تستعمل حزمة جاهزة للحصول على عنوان IP مثل حزمة django-ipware، أولًا يجب تثبيتها من خلال أحد الطرق التالية: 1. easy_install django-ipware 2. pip install django-ipware 3. git clone http://github.com/un33k/django-ipware a. cd django-ipware b. run python setup.py install 4. wget https://github.com/un33k/django-ipware/zipball/master a. unzip the downloaded file b. cd into django-ipware-* directory c. run python setup.py install ويتم إستعمال الحزمة كالتالي: # في ملف عرض view أو middleware حيث يكون الكائن `request` متاحًا from ipware import get_client_ip ip, is_routable = get_client_ip(request) if ip is None: # تعذر الحصول على عنوان IP الخاص بالعميل pass else: # في حالة وجود عنوان IP print(ip)1 نقطة
-
المشكلة تحدث بسبب ال GPU وغالباً ما يسببها وجود عمليتين تتنافسان على ال GPU. أي أن هناك عملية ما تستخدم ال GPU الآن. لذا قم بإغلاق الجلسات التفاعلية "interactive sessions" في العمليات الأخرى (إذا كنت تستخدم جوبيتر قم بإعادة تشغيل الكيرنل) أو استخدم الكود التالي لإغلاق الجلسات المحلية الأخرى: if 'session' in locals() and session is not None: print('Close interactive session') session.close() أو يمكنك أن تضبط allow_soft_placement على Trueو gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.3) وبالتالي تحديد نسبة ال GPU التي ستستخدم في الجلسة: gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.3) sess = tf.Session(config=tf.ConfigProto( allow_soft_placement=True, log_device_placement=True))1 نقطة
-
لإيقاف التنفيذ الفوري (الحثيث) نستخدم disable_eager_execution من v1 API حيث نضعها في بداية الكود: import tensorflow as tf tf.compat.v1.disable_eager_execution() أو من خلال tensorflow.python.framework.ops كالتالي: import tensorflow as tf from tensorflow.python.framework.ops import disable_eager_execution disable_eager_execution() a = tf.constant(1) b = tf.constant(2) c = a + b print(c)1 نقطة
-
لا .. لا تتضمن Keras أي وسيلة لتصدير غراف TensorFlow كملف بامتداد pd، ولكن يمكنك القيام بذلك بنفسك من خلال TensorFlow. وتحديداُ من خلال freeze_graph.py وهي الطريقة "النموذجية" التي يتم القيام بها، حيث: - يجمد حالة الجلسة في بيان مجتزأ. - يقوم بإنشاء graph جديد حيث يتم استبدال عقد المتغيرات بالثوابت التي تأخذ قيمتها الحالية في الجلسة. - سيتم تجزيئ الغراف الجديد بحيث تتم إزالة ال subgraphs غير الضرورية لحساب المخرجات المطلوبة. def freeze_session(session, keep_var_names=None, output_names=None, clear_devices=True): graph = session.graph with graph.as_default(): freeze_var_names = list(set(v.op.name for v in tf.global_variables()).difference(keep_var_names or [])) output_names = output_names or [] output_names += [v.op.name for v in tf.global_variables()] input_graph_def = graph.as_graph_def() if clear_devices: for node in input_graph_def.node: node.device = "" frozen_graph = tf.graph_util.convert_variables_to_constants( session, input_graph_def, output_names, freeze_var_names) return frozen_graph - الوسيط session: جلسة تنسرفلو التي سيتم تجميدها. - keep_var_names قائمة بأسماء المتغيرات التي لا يجب أن بتم تجميدها،وفي حال تم ضبطه على None سيتم تجميد كل المتغيرات في البيان. - output_names:هي قائمة بأسماء العمليات التي تنتج المخرجات التي تريدها. - clear_devices: لتحسين إمكانية النقل يتم ضبطه على True. وبالتالي يمكنك استخدامه كالتالي: from keras import backend as K # قم ببناء نموذجك frozen_graph = freeze_session(K.get_session(),output_names=[out.op.name for out in model.outputs]) ثم يمكنك كتابة البيان في ملف باستخدام tf.train.write_graph: tf.train.write_graph(frozen_graph, "path", "my_model.pb", as_text=False)1 نقطة
-
أولاً from_tensors تقوم بإنشاء dataset من خلال دمج المدخلات الممررة لها كعنصر واحد (كتلة واحدة) أي مثلاً: data = tf.constant([[4, 5], [1, 7]]) dataset = tf.data.Dataset.from_tensors(data) [x for x in dataset] """ #data لاحظ أن الخرج هو عبارة عن مصفوفة واحدة تمثال ال [<tf.Tensor: shape=(2, 2), dtype=int32, numpy= array([[4, 5], [1, 7]], dtype=int32)>] """ بينما from_tensor_slices تقوم بإنشاء dataset وتعيد عدة عناصر منفصلة بحيث كل عنصر يمثل صف من الإدخال الممرر لها أي: data = tf.constant([[4, 5], [1, 7]]) dataset = tf.data.Dataset.from_tensor_slices(data) [x for x in dataset] """ # لاحظ أن كل سطر من الدخل تم تمثيله بشكل مستقل [<tf.Tensor: shape=(2,), dtype=int32, numpy=array([4, 5], dtype=int32)>, <tf.Tensor: shape=(2,), dtype=int32, numpy=array([1, 7], dtype=int32)>] """ أيضاً هناك اختلاف عندما يكون الدخل هو قائمة، حيث أن from_tensors تقوم بإنشاء tensor ثلاثي الأبعاد أما from_tensor_slices تقوم بدمجهم وتعيد 2D. مثلاً: dataset1 = tf.data.Dataset.from_tensor_slices( [tf.random_uniform([2, 3]), tf.random_uniform([2, 3])]) dataset2 = tf.data.Dataset.from_tensors( [tf.random_uniform([2, 3]), tf.random_uniform([2, 3])]) print(dataset1) # shapes: (2, 3) print(dataset2) # shapes: (2, 2, 3)1 نقطة
-
اعتبارًا من TensorFlow 0.8 ، يمكنك استخدام tf.one_hot للقيام بتحويل ال labels إلى تمثيل ال One-Hot_Encoding. مثال عليها لنفرض أن لديك 4 فئات(قطة 0 ، كلب 1 ، طائر 2 ، إنسان 3) ولدينا عينتان هما (قط و إنسان) أي 0 و 3. import tensorflow.compat.v1 as tf tf.disable_v2_behavior() res = tf.one_hot(indices=[0, 3], depth=4) # نحدد العمق على 4 لأنه لدينا 4 فئات with tf.Session() as sess: print (sess.run(res)) """ [[1. 0. 0. 0.] [0. 0. 0. 1.]] """ بالإضافة إلى ذلك إذا أحببت هناك tf.nn.sparse_softmax_cross_entropy_with_logits، والتي تيح لك حساب الانتروبيا المتقاطعة مباشرة على ال labels (طبعاً Spare Labels) بدلاً من الحاجة إلى تحويلها إلى One-Hot.1 نقطة
-
الخطأ يشير إلى أن نسخة pip التي قمت بتثبيت protobuf من خلالها قديمة وبالتالي قد تتسبب لك في أخطاء بالتثبيت مثل هذا الخطأ (لاحظ أنه لم يعطيك خطأ عند استيراد ops وإنما فقط عند استيراد label_map_util لذا فغالباً المشكلة إما في نظام إدارة الحزم لديك pip أو أنه حدث خطأ ما أثناء تثبيتها). لذا في الحالتين قم بتنفيذ الأوامر التالية: pip uninstall protobuf python3-protobuf pip install --upgrade pip # لتحديث مدير الحزم pip install --upgrade protobuf1 نقطة
-
يمكنك تعيين متغيرات environment في ال notebook باستخدام os.environ. حيث يجب أن تقوم بما يلي قبل تهيئة TensorFlow وذلك لقصر TensorFlow على GPU الأول (جعله يستخدم أول Gpu فقط): import os os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"]="0" #وتريد تفعيل عدد محدد منها Gpu في حالة كان لديك 4 وحدات import os os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"]="0,2,3" #هنا Gpu نضع مانريده من ال وبالتالي سيتم قصر تنسرفلو على أول gpu فقط، حيث سيتم إخفاء الثاني عنه، وللتأكد يمكنك استخدام الكود التالي: import notebook_util notebook_util.pick_gpu_lowest_memory() import tensorflow as tf # أو from tensorflow.python.client import device_lib print device_lib.list_local_devices() حيث سيعرضان لك قائمة الأجهزة المرئية (غير المخفية).1 نقطة
-
تستطيع استخدام lambda لفعل ذلك كالتالي combine_lambda = lambda x: '{}{}'.format(x.Year, x.quarter) ثم تستطيع استخدم الناتج في إنشاء العمود الجديد كالتالي df['period'] = df.apply(combine_lambda, axis = 1)1 نقطة
-
أفترض أن عمود DOB الخاص بك بالفعل من النوع datetime64 حيث أن بالفعل قمت بتحويله ولكن تحتاج لتعديل ال format فقط من خلال style.format كالمثال التالي df DOB 0 2019-07-03 1 2019-08-03 2 2019-09-03 3 2019-10-03 لاحظ ال format قبل التعديل df.style.format({"DOB": lambda t: t.strftime("%m/%d/%Y")}) ستصبح mm/dd/yyyy df.style.format({"DOB": lambda t: t.strftime("%d-%m-%Y")}) ستصبح dd-mm-yyyy1 نقطة
-
يمكنك معرفة الدقة Accuracy و ال loss للنموذج من خلال الدالة evaluate، حيث لها الشكل التالي: Model.evaluate( x=None, y=None, batch_size=None, verbose=1, sample_weight=None, steps=None, callbacks=None, return_dict=False ) # أو بالشكل المختصر Model.evaluate( x=None, y=None ) حيث أن x يشير إلى بيانات الدخل (بيانات الاختبار)، ويجب أن يكون مصفوفة نمباي (أو نوع آخر يشابهها)، أو قائمة من المصفوفات "list of arrays" (في حالة كان نموذجك متعدد الدخل multiple inputs). أو يمكن أن تكون مصفوفة تنسر "TensorFlow tensor" أو قائمة من التنسر "list of tensors" (في حالة كان نموذجك متعدد الدخل multiple inputs). أو قاموس يربط اسم بمصفوفة أو تنسر في حال كان لمصفوفات الدخل أسماء. أو tf.data مجموعة بيانات مكونة من خلال تنسرفلو، بحيث تكون من الشكل (inputs, targets) أو (inputs, targets, sample_weights).أو مولد generator أو تسلسل keras.utils.Sequence بحيث يعيد (inputs, targets) أو (inputs, targets, sample_weights). أما ثاني وسيطة y هي بيانات الهدف أو ال Target أو ال label، وبشكل مشابه لبيانات الدخل x يجب أن تكون Numpy array(s) أو TensorFlow tensor(s)، ويجب أن تكوم متسقة مع x، أي بمعنى إذا كانت x تحوي 400 عينة فهذا يعني أنه يجب أن يكون لدينا 400 target، و لايجب أن يكون x نمباي و y تنسر أو العكس. وفي حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence فلا تقم بتمرير قيم ال y لأنهم يحصلون علبها بشكل تلقائي من خلال x. الوسيط الثالث هو ال batch_size وهو يمثل حجم دفعة البيانات، وهو عدد صحيح يشير إلى عدد العيانات التي سيتم تطبيق خوارزمية الانتشار الأمامي عليها لحساب القيم المتوقعة. في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence فلاتقم بتحديد هذا الوسيط لأنهم في الأساس يقومون بتوليد باتشات. وأيضاً في حالة لم تقوم بتعيين قيمة للباتش "None" فسأخذ القيمة الافتراضية 32. الوسيط الرابع هو ال verbose لعرض تفاصيل عملية التوقع في حال ضبطه على 0 لن تظهر لك التفاصيل "أي الوضع الصامت"، أما في حالة ضبطه على 1 فهذا يعني أنك تريد أن تظهر لك التفاصيل. الوسيط الخامس sample_weight هو مصفوفة أوزان (اختياري) لعينات التدريب وتستخدم أيضاً لتوزين دالة التكلفة.ويمكنك إما تمرير مصفوفة Numpy مسطحة (1D) بنفس طول عينات الإدخال (ربط 1: 1 بين الأوزان والعينات). أو في حالة البيانات الزمنية ، يمكنك تمرير مصفوفة ثنائية الأبعاد ذات شكل (عينات ، طول التسلسل) ، لتطبيق وزن مختلف لكل خطوة زمنية لكل عينة. وهذه الخاصية غير مدعومة في حالة كانت بيانات الإدخال x من النوع dataset, generator, أو keras.utils.Sequence.. الوسيط steps هو عدد صحيح أو None إجمالي عدد الخطوات (مجموعات العينات) قبل الإعلان عن انتهاء حقبة واحدة وبدء المرحلة التالية. عند التدريب باستخدام موترات الإدخال مثل TensorFlow data tensors ، فإن القيمة الافتراضيةNone تساوي عدد العينات في مجموعة البيانات الخاصة بك مقسوماً على حجم الباتش، أو 1 إذا تعذر تحديد ذلك. إذا كانت x عبارة عن tf.data ، وكانت "steps=" None ، فسيتم تشغيل الحقبة حتى يتم استنفاد مجموعة بيانات الإدخال. وهذه الوسيطة غير مدعومة عندما تكون مدخلاتك هي مصفوفات. الوسيط callbacks هو قائمة من keras.callbacks.Callback وهي قائمة الاسترجاعات المطلوب تقديمها أثناء التقييم. الوسيط الأخير في حالة ضبطه على True ٍيتم تخزين النتائج (التكلفة loss والدقة acc ) في قاموس وإلا سيتم التخزين ضمن قائمة. مثال: from keras.datasets import imdb from keras.preprocessing import sequence max_features = 10000 maxlen = 100 batch_size = 32 print('Loading data...') (input_train, y_train), (input_test, y_test) = imdb.load_data( num_words=max_features) print(len(input_train), 'train sequences') print(len(input_test), 'test sequences') print('Pad sequences (samples x time)') input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) print('input_train shape:', input_train.shape) print('input_test shape:', input_test.shape) from keras.layers import Dense,Embedding,SimpleRNN model = Sequential() model.add(Embedding(max_features, 32)) model.add(SimpleRNN(32)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=4, batch_size=128, validation_split=0.2) ################################ results = model.evaluate(input_test, y_test,verbose=1) # 782/782 [==============================] - 7s 8ms/step - loss: 0.4739 - acc: 0.8250 results # [0.4739033281803131, 0.824999988079071]1 نقطة
-
بما أنك تتعامل مع pandas إذن فإنه يمكنك تغيير عدد الأعمدة و الأسطر المعروضة كالتالي: import pandas as pd pd.options.display.max_columns = xxx pd.options.display.max_rows = xxx يمكنك تغيير xxx بالعدد المناسب. و إن كنت تتعامل مع Jupyter Notebook يمكنك أن تقوم بتحديد عرض السطر بإستخدام: import numpy as np np.set_printoptions(linewidth=160)1 نقطة
-
يمكنك القيام بذلك من خلال ModelCheckpoint وهو عبارة عن callback. حيث يقوم بحفظ النموذج الأفضل ضمن ملف h5 ونقوم بتعريفه بالشكل التالي: mc = ModelCheckpoint('best_model.h5') لكن هذا لايكفي حيث يجب علينا أن نقوم بتحديد المقياس الذي ستتم مراقبته لكي يتم حفظ أفضل نموذج على أساسه (غالباً validation accuracy) ويتم ذلك من خلال الوسيط monitor: mc = ModelCheckpoint('best_model.h5', monitor='val_loss') # أو val_acc أي أنه سيتم اعتماد المقياس val_loss لحفظ أفضل نموذج تمت ملاحظته خلال عملية التدريب. أيضاً يجب أن نحدد له ال mode أي الهدف الذي نسعى له وهو إما أقل قيمة للمقياس أو أعلى قيمة له (طبعاً في حالة ال loss سيكون الهدف minimaiz وفي حالة ال accuracy ستكون maximaiz): mc = ModelCheckpoint('best_model.h5', monitor='val_loss', mode='min') أي سيتم حفظ النموذج عند ال epoch الذي يملك أقل قيمة لل validation loss، وفي حالة لم نحدد له ال mod سيأخذ قيمة auto وسيعتبر دوماً min في حالة كانت ال monitor هي loss و max في حالة Accuracy. وأخيراً نحن نريد فقط أفضل نموذج لذا سنستخدم الوسيط save_best_only ونضبطه على True: mc = ModelCheckpoint('best_model.h5', monitor='val_loss', mode='min', save_best_only=True) في حالة عدم ضبطه على true سيتم حفظ النموذج الأفضل مقارنة بال Epoch السابق. والذي قد لايكون الأفضل خلال كامل عملية التدريب. وأخيراً لتطبيقه خلال عملية التدريب يجب أن نقوم بتمريره إلى الدالة fit كالتالي: model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4, verbose=0, callbacks=[mc]) وإذا أردنا معرفة ال Epoch الذي تم حفظ النموذج عنده نضيف الوسيط verbose ونضبطه على 1، وبالتالي يصبح نموذجك كالتالي: from sklearn.datasets import make_moons from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.callbacks import EarlyStopping from tensorflow.keras.callbacks import ModelCheckpoint from matplotlib import pyplot from keras.models import load_model X, y = make_moons(n_samples=100, noise=0.2, random_state=1) n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # define model model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) #callback إضافة ال mc = ModelCheckpoint('best_model.h5', monitor='val_accuracy', mode='max', verbose=1, save_best_only=True) # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4, verbose=0, callbacks=[mc]) ويمكنك استخدامه جنباً إلى جمب مع ال Earlystoping كالتالي: from sklearn.datasets import make_moons from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.callbacks import EarlyStopping from tensorflow.keras.callbacks import ModelCheckpoint from matplotlib import pyplot from keras.models import load_model # generate 2d classification dataset X, y = make_moons(n_samples=100, noise=0.2, random_state=1) # split into train and test n_train = 30 trainX, testX = X[:n_train, :], X[n_train:, :] trainy, testy = y[:n_train], y[n_train:] # define model model = Sequential() model.add(Dense(500, input_dim=2, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) es = EarlyStopping(monitor='val_loss', mode='min', verbose=1) mc = ModelCheckpoint('best_model.h5', monitor='val_accuracy', mode='max', verbose=1, save_best_only=True) # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4, verbose=0, callbacks=[mc,es])1 نقطة
-
الغراف Graph يقوم بتمثيل العمليات والمتغيرات التي قمت بتعريفها في الكود وتحديد العلاقات بينها على شكل عقد تشكل مجتمعةً البيان أي ال Graph . وهو لا يحسب أي شيء، ولا يحتفظ بأي قيم، هو فقط يحدد العمليات التي حددتها في التعليمات البرمجية الخاصة بك (الكود الذي كتبته). أما Session تسمح بتنفيذ ال graph أو جزء منه إذ يقوم بتنفيذ كل العقد node الموجودة في البيان وينفذ العمليات فيه ويحمل القيم الفعلية للنتائج والمتغيرات الوسيطية . ويقوم بتخصيص الموارد (على جهاز واحد أو أكثر) لتنفيذ هذه المهام. مثلاً هنا لدينا غراف مع 3 متغيرات و 3 عمليات: graph = tf.Graph() with graph.as_default(): variable = tf.Variable(42, name='foo') # تعريف متغير initialize = tf.global_variables_initializer() # يعين القيمة الأولية 42 لهذا المتغير assign = variable.assign(13) # يعين القيمة الجديدة 13 لهذا المتغير أيضاً تجدر الملاحظة إلى أنك لست مجبراً على كتابة أول سطرين، فتنشرفلو تقوم بإنشاء غراف افتراضي لك (أي لست مضطراً لتعريفه بنفسك). الآن لتنفيذ أي من العمليات الثلاث المحددة، نحتاج إلى إنشاء جلسة لهذا البيان. حيث ستخصص الجلسة أيضاً ذاكرة لتخزين القيمة الحالية للمتغير variable. with tf.Session(graph=graph) as sess: sess.run(initialize) sess.run(assign) print(sess.run(variable)) # Output: 13 أيضاً يجب أن تدرك أن قيمة المتغير صالحة فقط خلال جلسة واحدة. إذا حاولنا الاستعلام عن القيمة بعد ذلك في جلسة ثانية، فسيقوم TensorFlow بإعطاء خطأ لأن المتغير لم تتم تهيئته هناك. with tf.Session(graph=graph) as sess: print(sess.run(variable)) # Error: Attempting to use uninitialized value foo وبالطبع ، يمكننا استخدام البيان في أكثر من جلسة، حيث علينا فقط إعادة تهيئة المتغيرات مرة أخرى. لكن ستكون القيم في الجلسة الجديدة مستقلة تماماً عن الأولى: with tf.Session(graph=graph) as sess: sess.run(initialize) print(sess.run(variable)) # Output: 421 نقطة
-
يمكنك استخدام الدالة iloc أو الدالة .loc من أجل تحديد أماكن العناصر التي تحقق الشرط الذي تريد تغييره كالتالي: edge = df.my_channel > 100 column_name = 'my_channel' df.loc[edge, column_name] = 0 أو في سطر واحد يمكنك كتابتها كالتالي: df.loc[df.my_channel > 100, 'my_channel'] = 01 نقطة
-
إضافة لما ذكره أحمد، يمكنك استخدام set options بالشكل التالي لعرض أقصى مايمكن: pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1) ويمكنك أيضاً استخدام option_context كالتالي: with pd.option_context('display.max_rows', None, 'display.max_columns', None): print (df)1 نقطة
-
إضافة لما قدمه أحمد يمكنك القيام بذلك بالشكل التالي من خلال الدالة json_normalize: import pandas as pd from ast import literal_eval import numpy as np df = {'Station ID': [8809, 8810, 8811, 8812, 8813, 8814], 'Pollutants': ['{"a": "46", "b": "3", "c": "12"}', '{"a": "36", "b": "5", "c": "8"}', '{"b": "2", "c": "7"}', '{"c": "11"}', '{"a": "82", "c": "15"}', np.nan]} df = pd.DataFrame(df) df """ Station ID Pollutants 0 8809 {"a": "46", "b": "3", "c": "12"} 1 8810 {"a": "36", "b": "5", "c": "8"} 2 8811 {"b": "2", "c": "7"} 3 8812 {"c": "11"} 4 8813 {"a": "82", "c": "15"} 5 8814 NaN """ # '{}' نقوم باستبدال القيم المفقودة ب # وذلك إذا كان العمود عبارة عن سلاسل نصية # df.Pollutants = df.Pollutants.fillna('{}') df.Pollutants = df.Pollutants.fillna({i: {} for i in df.index}) # {} أما إذا لم يكن سلاسل نصية نستبدله ب # تحويل عمود القواميس إلى قواميس # تخطي هذا السطر، إذا كان العمود يحتوي على قاموس df.Pollutants = df.Pollutants.apply(literal_eval) # لتقسيم العمود json_normalize الآن نقوم بتطبيق التابع #لدمج الناتج مع بيانات الداتافريم الأساسي join ثم بعدها نقوم بتطبيق df = df.join(pd.json_normalize(df.Pollutants)) #Pollutants الآن نحذف العمود df.drop(columns=['Pollutants'], inplace=True) # نستعرض البيانات df """ Station ID a b c 0 8809 46 3 12 1 8810 36 5 8 2 8811 NaN 2 7 3 8812 NaN NaN 11 4 8813 82 NaN 15 5 8814 NaN NaN NaN """1 نقطة















.png.9d0c8669186f1a52df886e58731434fc.png)
_LI.jpg.4bd42e3918446e82f534c41eee16082b.jpg)



