

تحدثنا حتى الآن عمّا يجب على المبدّلات والموجّهات فعله، دون وصف كيفية القيام بذلك. حيث توجد طريقة مباشرة لبناء مبدّلٍ أو موجّه، تتمثل في شرائك لمعالجٍ للأغراض العامة وتجهيزه بواجهات شبكة متعددة. بحيث يمكن لمثل هذا الجهاز الذي يعمل ببرمجياتٍ مناسبة، تلقّي رزمٍ على إحدى واجهاته، وإجراء أيٍّ من وظائف التبديل أو التمرير الموضّحة في هذا الفصل، إلى جانب إرسال رزمٍ عبر واجهاته الأخرى. ويسمى هذا بالمبدّل البرمجي software switch، وهو ليس بعيدًا جدًا عن معمارية العديد من أجهزة الشبكات التجارية المتوسطة إلى المنخفضة. وهذه هي نفس الطريقة التي طُبِّقت فيها موجّهات الإنترنت الأولى، والتي سُمِّيت بـبوابات gateways في ذلك الوقت - في الأيام الأولى للإنترنت -. حيث تستفيد التطبيقات التي تقدم أداءً فائقًا من تسريع العتاد الإضافي - ونشير إليها بالمبدّلات العتادية hardware switches -، رغم اشتمال كلا النَهجَين بوضوح على مزيج من العتاد والبرمجيات.
يقدّم هذا القسم نظرةً عامةً عن كلٍّ من التصميمات التي تتمحور حول البرمجيات software والتصميمات المتمحورة حول العتاد hardware، ولكن تجدر الإشارة إلى أنّ التمييز بين المبدّلات والموجّهات ليس بهذه الأهمية. فقد اتّضح أنّ تطبيق المبدّلات والموجّهات لهما الكثير من القواسم المشتركة لدرجة أنّ مسؤول الشبكة يشتري عادةً صندوق تمرير، بعدها يضبطه ليكون مبدّل L2 أو موجّه L3 أو مزيجًا من الاثنين. سنستخدم الكلمة مبدّل switch لتمثيل كلا المصطلحين (مبدّل وموجّه) في هذا القسم نظرًا لتشابُه تصميماتِهما الداخلية كثيرًا، ولتجنّب الملل من قول "مبدّل أو موجّه" طوال الوقت، كما سنذكر الاختلافات بين الاثنين عند الاقتضاء.
المبدل البرمجي Software Switch
يوضّح الشكل الآتي مبدّلًا برمجيًا أُنشئ باستخدام معالجٍ للأغراض العامة مع أربع واجهات شبكة NIC. حيث يُعَدّ مسار الرزمة التي تصل مثلًا إلى الواجهة NIC 1 وتُمرَر إلى الواجهة NIC 2 مسارًا مباشرًا، إذ تنسخ الواجهة NIC 1 البايتات الخاصة بها مباشرةً من الرزمة التي تستلمها في الذاكرة الرئيسية عبر ناقل الإدخال / الإخراج (وهو PCIe في هذا المثال) باستخدام تقنية تسمى الوصول المباشر للذاكرة direct memory access أو اختصارًا DMA. تفحص وحدة المعالجة المركزية ترويسة الرزمة بمجرد أن تصبح هذه الرزمة في الذاكرة لتحديد الواجهة التي يجب إرسال الرزمة عليها، كما ترشِد الواجهة NIC 2 لإرسال الرزمة مرةً أخرى مباشرةً من الذاكرة الرئيسية باستخدام تقنية DMA. فالمهم هو تخزين الرزمة مؤقتًا في الذاكرة الرئيسية، وهذا هو جزء التخزين من عملية خزّن ومرّر store-and-forward، مع قراءة وحدة المعالجة المركزية لحقول الترويسة الضرورية فقط في مسجّلات المعالجة الداخلية الخاصة بها.
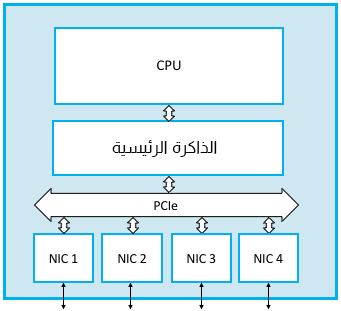
هناك نوعان من الاختناقات bottlenecks المُحتملة مع هذه الطريقة، إذ يحدّ أحد هذين النوعين أو كليهما من سعة تمرير الرزمة الإجمالية للمبدّل البرمجي. والمشكلة الأولى هنا هي تقيّد الأداء بحقيقة وجوب مرور جميع الرزم داخل وخارج الذاكرة الرئيسية. حيث ستختلف المسافة المقطوعة بالأميال بناءً على المبلغ الذي ترغب في دفعه مقابل العتاد، ولكن يمكن لجهاز مقيّد بناقل ذاكرة يبلغ 1333 ميجاهرتز و 64 بت مثلًا، نقل البياناتِ بمعدّل ذروة يزيد قليلًا عن 100 جيجابت في الثانية، وذلك كافٍ لبناء مبدّل مع عدد قليل من منافذ إيثرنت بسرعة 10 جيجابت في الثانية، ولكنه ليس كافيًا لموجّهٍ متطوّر في نواة الإنترنت.
يفترض هذا الحد الأعلى أنّ نقل البيانات هو المشكلة الوحيدة. وهذا جيدٌ تقريبًا بالنسبة للرزم الطويلة ولكنه ليس كذلك عندما تكون الرزم قصيرة، فهذه هي الحالة الأسوأ التي يجب على مصمّمي المبدّلات التخطيط لها. فمِن المُرَّجح هيمنة تكلفة معالجة كلّ رزمة مع الرزم ذات الحجم الأدنى، والتي تتضمن تحليل ترويستها وتحديد رابط الخرج الذي ستُنقَل عليه، وبالتالي قد ينتج اختناق.
افترض قدرة المعالج مثلًا على إجراء جميع المعالجات اللازمة لتبديل 40 مليون رزمة كلّ ثانية. حيث يُسمى هذا أحيانًا معدّل الرزم في الثانية packet per second أو اختصارًا pps. فإذا كان متوسط الرزم هو 64 بايتًا، فهذا يعني ضمنيًا أن الإنتاجية Throughput تساوي:
Throughput = pps x BitsPerPacket = 40 × 106 × 64 × 8 = 2048 × 107
وهي إنتاجية لسرعة تبلغ حوالي 20 جيجابت في الثانية، ولكنها أقلّ بكثير من النطاق الذي يطلبه المستخدمون من مبدّلاتهم اليوم. ضع في حساباتك تشارك جميع المستخدمين المتصلين بالمبدّل بهذه الـ 20 جيجابت في الثانية، كما يتشارك جميع المستخدمين المتصلين بِالوسيط المشترك بِحيّز النطاق التراسُلي لمقطع إيثرنت واحد (غير قابل للتبديل unswitched. وهكذا، سيكون المبدّل ذي 16 منفذًا مثلًا مع هذه الإنتاجية الكلية، قادرًا فقط على التعامل مع متوسط معدّل بيانات يبلغ حوالي 1 جيجابت في الثانية على كلّ منفذ. حيث لا تمثّل أرقام أداء هذا المثال الحد الأقصى لمعدّل الإنتاجية المطلق الذي قد تحققه البرمجيات عالية المستوى والتي تعمل على خادم متطوّر، ولكنها تشير إلى الحدود التي تواجهها في النهاية عند اتباع هذا النهج.
هناك شيء أخير من المهم فهمُه عند تقييم تطبيقات التبديل. إذ لا تُعَدّ الخوارزميات غير البسيطة non-trivial algorithms التي نوقشت سابقًا في هذا الفصل، -مثل كلٍّ من خوارزمية الشجرة الممتدة التي تستخدمها جسور التعلم learning bridges، وخوارِزمية متّجه المسافة التي يستخدمها بروتوكول RIP، وخوارِزمية حالة الرابط التي يستخدمها بروتوكول OSPF-، جزءًا مباشرًا من قرار تمرير كلّ رزمة. حيث تعمل هذه الخوارزميات دوريًا في الخلفية، ولكن لا يتعيّن على المبدّلات تنفيذ شيفرة OSPF لكلّ رزمة تُمررها مثلًا. ويُعدّ الإجراء الأكثر تكلفةً والذي من المرجح تنفيذه من قِبل وحدة المعالجة المركزية لكلّ رزمة هو البحث في الجدول، مثل: البحث عن رقم VCI في جدول VC، أو عنوان IP في جدول تمرير L3، أو عنوان إيثرنت في جدول تمرير L2.
يُعَدّ التمييز بين هذين النوعين من المعالجة مُهمًا بدرجة كافية لمنحه اسمًا: حيث يتوافق مستوى التحكم control plane مع المعالجة الخلفية المطلوبة "للتحكم" في الشبكة (مثل: تشغيل بروتوكول OSPF، أو RIP، أو بروتوكول BGP الذي سنوضّحه في الفصل التالي)، كما يتوافق مستوى البيانات data plane مع معالجة كلّ رزمة مطلوبة لنقل الرزم من منفذ الإدخال إلى منفذ الإخراج. ويُطلق على هذا التمييز اسم مستوى التحكم ومستوى المستخدم في شبكات الوصول الخلوية، لأسباب تاريخية، ولكن الفكرة هي نفسها، إذ يعرّف المعيار 3GPP مبدأ CUPS (مستوى التحكم / مستوى المستخدم) كمبدأ معماري.
يسهُل الخلط بين هذين النوعين من المعالجة عندما يعمل كلاهما على نفس وحدة المعالجة المركزية، كما هو الحال في المبدّل البرمجي الموضَّح في الشكل السابق. ولكن يمكن تحسين الأداء بصورة كبيرة عن طريق تحسين كيفية تطبيق مستوى البيانات، وبالتالي تحديد واجهةٍ معرّفة جيدًا بين مستوى التحكم ومستويات البيانات.
المبدل العتادي Hardware Switch
كانت المبدّلات والموجّهات عالية الأداء عبارة عن أجهزة متخصصة طوال معظم تاريخ الإنترنت، والتي أُنشئت باستخدام الدارات المتكاملة الخاصة بالتطبيقات Application-Specific Integrated Circuits أو اختصارًا ASICs. بالرغم من إمكانية بناء موجّهات ومبدّلات منخفضة النهاية باستخدام خوادم سلعية تجارية تشغّل برامج C، ولكن كان من الضروري تواجُد دارات ASIC لتحقيق معدّلات الإنتاجية المطلوبة. تكمن مشكلة دارات ASIC في استغراق العتاد لوقت طويل في التصميم والتصنيع، مما يعني أنّ التأخير في إضافة ميزات جديدة إلى مبدّلٍ يُقاس عادةً بالسنوات، وليس بالأيام أو الأسابيع التي اعتادت صناعة البرمجيات اليوم عليها. حيث نرغب في الاستفادة من أداء دارات ASIC ومرونة البرمجيات في الحالة المثالية.
جعلت التطورات الأخيرة في معالجات النطاق المحدد (والمكونات السلعية الأخرى) هذا ممكنًا لحسن الحظ. وبنفس القدر من الأهمية، فإنّ المواصفات المعمارية الكاملة للمبدّلات التي تستفيد من هذه المعالجات الجديدة متاحة الآن عبر الإنترنت، وهي العتاد المكافئ للبرمجيات مفتوحة المصدر. وهذا يعني قدرة أي شخص على إنشاء مبدّل عالي الأداء عن طريق سحب المخطط من الويب (راجع مشروع الحوسبة المفتوحة Open Compute Project أو اختصارًا OCP للحصول على أمثلة) بنفس الطريقة التي يمكن بها بناء حاسوبك. لكنك ما زلت بحاجة إلى برمجيات لتشغّلها على العتاد في كلتا الحالتين، ولكن مثلما يتوفّر نظام لينُكس للتشغيل على حاسوبك المصمَّم في المنزل، فهناك الآن مكدّسات L2 وL3 مفتوحة المصدر متاحة على جيثب GitHub للتشغيل على المبدّل المُنشَأ في المنزل. يمكنك أيضًا ببساطة شراء مبدّلٍ مُبنى مسبقًا من الشركة المصنعة للمبدّلات السلعية ثم تحميل البرنامج الخاص بك عليه. فيما يلي وصفٌ لـ المبدّلات ذات الصندوق الأبيض المفتوحة open white-box switches، والتي يُطلق عليها هذا الاسم لتمييزها عن مبدلات الصندوق الأسود المغلقة open white-box switches التي هيمنت تاريخيًا على الصناعة.
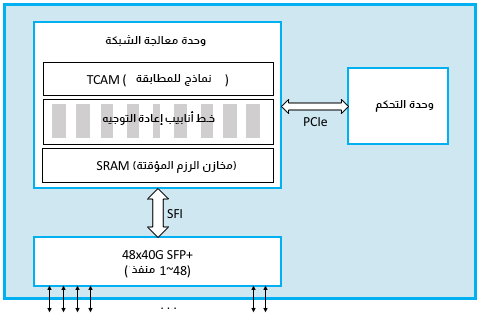
الشكل السابق هو تصويرٌ مبسَّط لمبدّل الصندوق الأبيض. حيث يتمثل الاختلاف الرئيسي عن التطبيق السابق على معالج الأغراض العامة، في إضافة وحدة معالج الشبكة Network Processor Unit أو اختصارًا NPU. وهو معالج خاص بالنطاق، يحوي معمارية ومجموعة تعليمات مُحسَّنة لمعالجة ترويسات الرزم (لتطبيق مستوى البيانات على سبيل المثال). تتشابه وحدات NPU مع وحدات GPU التي تحتوي على بنية محسّنة لمعالجة الرسوميات الحاسوبية، ولكن حُسِّنت وحدة NPU لتحليل ترويسات الرزم واتخاذ قرار التمرير. بحيث بات ممكنًا لها معالجة الرزم (الإدخال، واتخاذ قرار التمرير، والإخراج) بمعدّلات مقاسة بِالتيرابت في الثانية Terabits-per-second أو اختصارًا Tbps، وبسرعة كافية لمواكبة منافذ 32x100-Gbps، أو منافذ 48x40-Gbps الموضحة بالمخطط السابق. ويكمن جمال تصميم هذا المبدّل الجديد في قدرته الآن على برمجة صندوق أبيض معيّن ليصبح مبدّل L2 أوموجّه L3 أو مزيجًا من الاثنين، وذلك فقط عن طريق البرمجة.
تعمل رزمة برمجيات مستوى التحكم نفسها المستخدمة في المبدّل البرمجي على وحدة تحكُّم CPU، كما تُحمَّل برامج مستوى البيانات على وحدة NPU لتعكس قرارات التمرير التي تتخذها برمجيات مستوى التحكم إضافةً إلى ذلك. وتعتمد برمجة وحدة NPU على مصنّع الرقائق، إذ يكون خط أنابيب pipeline التمرير ثابتًا في بعض الحالات ويحمِّل معالجُ التحكم فقط جدول التمرير إلى وحدة NPU (نعني بكلمة ثابتًا أنّ وحدة NPU تعرف فقط كيفية معالجة ترويسات معيّنة، مثل الإيثرنت وIP، ولكن في حالاتٍ أخرى يكون خط أنابيب التمرير نفسه قابلًا للبرمجة. لغة P4 هي لغة برمجة جديدة يمكن استخدامها لبرمجة خطوط أنابيب التمرير المستندة إلى وحدة NPU. حيث تحاول لغة P4 إخفاء العديد من الاختلافات في مجموعات تعليمات وحدة NPU الأساسية.
تستفيد وحدة NPU من ثلاث تقنيات داخليًا. أولًا، تخزّن ذاكرةٌ سريعة تعتمد على ذاكرة SRAM الرزمَ مؤقتًا أثناء معالجتها، وتُعَد ذاكرة SRAM وهي الذاكرة العشوائية الثابتة Static Random Access Memory، أسرع من ذاكرة DRAM (الذاكرة العشوائية الديناميكية) التي تستخدمها الذاكرة الرئيسية. ثانيًا، تخزّن الذاكرة المستندة إلى TCAM أنماطَ patterns البت المطلوب مطابقتها مع الرزم المُعالَجة، ويرمز CAM في TCAM إلى Content Addressable Memory أي ذاكرة مُعنونَة بمضمونها، مما يعني أنّ المفتاح الذي تريد البحث عنه في الجدول يمكن استخدامه بفعالية كعنوان في الذاكرة التي تطبّق الجدول. كما يرمز الحرف T إلى Ternary أي ثلاثي وهي طريقة رائعة للقول أنّ المفتاح الذي تريد البحث عنه قد يحتوي على أحرف بديلة wildcards فيه (مثل المفتاح 10*1 الذي يطابق كلًا من 1001 و1011). أخيرًا، تُطبَّق المعالجةُ المتضمنة تمرير كلّ رزمة عن طريق خط أنابيب التمرير. ويُطبَّق خط الأنابيب هذا بواسطة دارات ASIC، ولكن يمكن تعديل سلوك تمرير خط الأنابيب عن طريق تغيير البرنامج الذي يشغّله عندما يكون التصميم جيدًا. إذ يُعبَّر عن هذا البرنامج على مستوى عالٍ مثل مجموعة من أزواج (مطابقة، إجراء) Match, Action، وإذا تطابق حقل كذا وكذا في الترويسة، فنفّذ هذا الإجراء أو ذاك.
تكمن أهمية معالجة الرزم المُطبَّقة بواسطة خط أنابيب متعدد المراحل بدلًا من معالج أحادي المرحلة في تضمُّن تمرير رزمةٍ واحدة النظر في حقول ترويسة متعددة على الأرجح. ويمكن برمجة كلّ مرحلة من خلال النظر في مجموعة مختلفة من الحقول. ويضيف خط الأنابيب متعدد المراحل وقت استجابة بسيطًا من طرف إلى طرف لكلّ رزمة (يُقاس بالنانو ثانية)، ولكنه يعني أيضًا إمكانية معالجة الرزم المتعددة في نفس الوقت. قد تُجري المرحلة 2 بحثًا ثانيًا عن الرزمة A، بينما تجري المرحلة 1 بحثًا أوليًا عن الرزمة B على سبيل المثال، وهكذا. وهذا يعني قدرة كل وحدة NPU على مواكبة سرعات الخط. - كانت سرعة أحدث التقنيات هي 12.8 تيرابت في الثانية حتى وقت كتابة هذا الكتاب -.
يتضمن الشكل السابق أخيرًا مكونات سلعية أخرى تجعل كلّ هذا عمليًا. حيث أصبح من الممكن الآن شراء وحدات الإرسال والاستقبال القابلة للتوصيل pluggable transceiver التي تهتم بجميع تفاصيل الوصول إلى الوسائط، سواءً كانت جيجابت إيثرنت Gigabit Ethernet، أو 10 جيجابت إيثرنت 10 Gigabit Ethernet أو SONET، بالإضافة إلى الألياف البصرية. حيث تتوافق جميع أجهزة الإرسال والاستقبال هذه مع عوامل النموذج الموحَّدة، مثل: SFP+، والتي يمكن توصيلها بمكونات أخرى عبر ناقل قياسي مثل SFI. تتمثل الفكرة الرئيسية في دخول صناعة الشبكات الآن إلى نفس العالم السلعي الذي تمتّّعت به صناعة الحوْسبة على مدار العقدين الماضيين.
وحدات معالجة الشبكة Network Processing Units
يُعَدّ استخدامنا لمصطلح NPU غير قياسي بعض الشيء. فقد كان NPU تاريخيًا، هو الاسم الذي يُعطَى لرقائق معالجة الشبكة الأكثر تحديدًا، والمستخدمة لتطبيق جدران الحماية الذكية أو فحص الرزم العميق على سبيل المثال. ولم تكن للأغراض العامة مثل وحدات NPU التي نناقشها هنا، كما لم تكن عالية الأداء. ويبدو من المحتمل أنّ النهج الحالي سيجعل معالجات الشبكة المبنية لهذا الغرض قديمة، ولكنّنا نفضل التسمية NPU لأنها تتوافق مع الاتجاه لبناء معالجات قابلة للبرمجة وخاصة بالنطاق، بما في ذلك وحدات معالجة الرسوميات GPUs للرسوميات ووحدات TPU وحدات معالجة المُوَتِّر Tensor Processing Units، للذكاء الاصطناعي AI.
الشبكات المعرفة بالبرمجيات Software Defined Networks
يتحول الانتباه مع تزايد إضفاء الطابع السلعي على المبدّلات، إلى البرمجيات التي تتحكم بها. وهذا يضعنا مباشرةً في منتصف الاتجاه لبناء شبكات معرّفة بالبرمجيات SDN. وهي فكرة بدأت في الظهور منذ حوالي عشر سنوات، فقد كانت المراحل الأولى من شبكات SDN هي التي دفعت صناعة الشبكات إلى التحرك نحو مبدّلات الصندوق الأبيض.
فكرة SDN الأساسية هي فكرة ناقشناها بالفعل وهي فصل decouple مستوى التحكم في الشبكة (أي حيث تعمل خوارزميات التوجيه، مثل: RIP، وOSPF، وBGP عن مستوى بيانات الشبكة (أي حيث تُتّخَذ قرارات تمرير الرزم)، مع انتقال مستوى التحكم في الشبكة إلى برمجيات تعمل على خوادم سلعية، وتطبيق مستوى بيانات الشبكة بواسطة مبدّلات الصندوق الأبيض. وقد كانت الفكرة الرئيسية وراء شبكات SDN هي أخذ هذا الفصل decoupling خطوةً إلى الأمام، وتحديد واجهة قياسية بين مستوى التحكم ومستوى البيانات. إذ يسمح القيام بذلك لأيّ تطبيقٍ لمستوى التحكم بالتحدُّث مع أيّ تطبيقٍ لمستوى البيانات، وهذا ما يكسر الاعتماد على أيّ حلّ تصنيع مجمَّع. تُسمى الواجهة الأصلية التدفق المفتوح OpenFlow، وقد عُرفت فكرة فصل مستويات التحكم والبيانات باسم التفريق disaggregation، أمّا لغة P4 المذكورة سابقًا فهي محاولة من الجيل الثاني لتعريف هذه الواجهة من خلال تعميم واجهة التدفق المفتوح.
هناك جانب آخر مهم للتفريق، وهو إمكانية استخدام مستوى تحكُّم مركزي منطقيًا للتحكم في مستوى بيانات الشبكة الموّزعة. ونقول "مركزية منطقيًا" لأنه بينما تبقى الحالة التي جمّعَها مستوى التحكم في بنية بيانات عالمية مثل خارطة الشبكة، سيبقى تطبيق بنية البيانات هذا ممكنًا مع توزيعه على خوادم متعددة. حيث يمكنها العمل في سحابة مثلًا. وهذا يُعَدّ أمرًا مهمًا لكلٍّ من قابلية التوسع والتوافرية، فالمفتاح هو ضبط المستويين وتوسّعهما بصورة مستقلة عن بعضهما البعض. وقد انطلقت هذه الفكرة بسرعة في السحابة، حيث يشغّل مزوّدو السحابة اليوم حلولًا قائمة على شبكات SDN داخل مراكز بياناتهم وعبر الشبكات الأساسية التي تربط مراكز بياناتهم ببعضها. ومن بين إحدى نتائج هذا التصميم، نجد عدم وضوح أنّ مستوى التحكم المركزي المنطقي لا يدير فقط شبكةً من المبدّلات الفيزيائية (العتادية) التي تربط الخوادم الفيزيائية، بل يدير أيضًا شبكةً من المبدّلات الافتراضية (البرمجية) التي تربط الخوادم الافتراضية مثل الآلات الافتراضية و الحاويات containers. فإذا كُنتَ تحسب منافذ المبدّل (التي هي مقياسٌ جيد لجميع الأجهزة المتصلة بشبكتك)، فقد يتجاوز عدد المنافذ الافتراضية، عدد المنافذ الفيزيائية في الإنترنت في عام 2012.
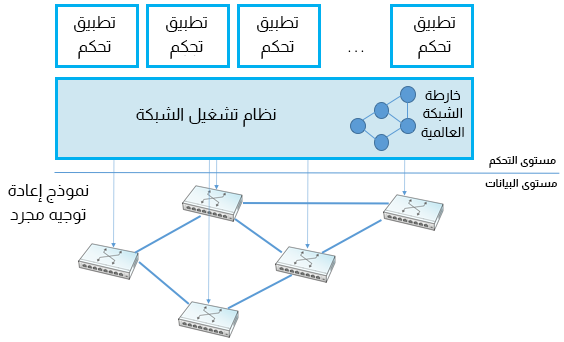
يُعَد نظام تشغيل الشبكة Network Operating System أو اختصارًا NOS أحد العوامل الرئيسية الأخرى لنجاح شبكة SDN، كما هو موضح في الشكل السابق. إذ يُسهّل نظام NOS تنفيذ وظائف التحكم في الشبكة، والمعروفة باسم تطبيقات التحكم Control Apps، مثل نظام تشغيل الخادم، مثل: Linux، وiOS، وAndroid، وWindows الذي يوفّر مجموعةً من التجريدات عالية المستوى التي تسهل تنفيذ التطبيقات (يمكنك قراءة الملفّات وكتابتها بدلًا من الوصول المباشر إلى محركات الأقراص على سبيل المثال). يجرّد نظام NOS الجيد تفاصيل مبدّلات الشبكة ويوفّر لمطوّر التطبيق تجريدًا لـخريطة الشبكة Network Map. كما يكتشف نظام NOS التغييرات في الشبكة الأساسية، مثل: المبدّلات، والمنافذ، والروابط التي تتجه لأعلى ولأسفل)، وينفّذ تطبيق التحكم السلوك الذي يريده ببساطة في هذا الرسم البياني المجرد. وهذا يعني أنّ نظام NOS يتحمّل عبء تجميع حالة الشبكة (الجزء الصعب من الخوارزميات الموّزعة مثل خوارزميات حالة الرابط وخوارزميات متّجه المسافة)، والتطبيق مجاني لتنفيذ خوارزمية أقصر مسار ببساطة وتحميل قواعد التمرير في المبدّلات الأساسية. ويُعَدّ الهدف الأساسي من خلال التركيز على هذا المنطق هو التوصُّل إلى حلٍ مُحسَّن عالميًا. حيث تؤكّد الأدلة المنشورة من مزوّدي السحابة الذين تبنّوا هذا النهج على هذه الميّزة.
اقتباسمن المهم فهم أنّ شبكة SDN هي استراتيجية تطبيق implementation strategy. فهي لا تحل المشكلات الأساسية بطريقة سحرية مثل اختفاء الحاجة إلى حساب جدول التمرير. ولكن بدلًا من إثقال كاهل المبدّلات بضرورة تبادل الرسائل مع بعضها البعض مثل جزءٍ من خوارزمية توجيه موزعة، يُكلَّف متحكّم شبكات SDN المركزية منطقيًا، بجمع معلومات حالة الرابط والمنفذ من المبدّلات الفردية، وإنشاء رؤيةٍ عامة لرسم الشبكة البياني وإتاحة هذا الرسم البياني لِتطبيقات التحكم. تتوفر جميع المعلومات التي يحتاجها تطبيق التحكم حسب منظوره لحساب جدول التمرير محليًّا، مع الأخذ في الحسبان أنّ وحدةَ التحكم SDN هي مركزية منطقيًا، ولكن تُنسَخ فعليًا على خوادم متعددة. ولا يزال السؤال المتنازع عليه بشدة موجودًا وهو ما إذا كان الأسلوب المركزي أو الموزّع هو الأفضل بالنسبة للأداء القابل للتوسّع والتوافرية العالية.
كان اعتماد شبكة SDN في المؤسسات وشركات الاتصالات بطيئًا على عكس مزودي السحابة. حيث يتعلق هذا جزئيًا بقدرة الأسواق المختلفة على إدارة شبكاتها، إذ تمتلك كلٌّ من شركات Google، وMicrosoft، وAmazon، المهندسين ومهارات DevOps اللازمة للاستفادة من هذه التقنية، بينما لا يزال البعض الآخر يفضّل الحلول الجاهزة والمتكاملة التي تدعم الإدارة وواجهات سطر الأوامر المألوفة لديهم.
الشبكات الافتراضية على طول الطريق
كانت هناك أفكارٌ حول كيفية جعل شبكات تبديل الرزم افتراضية منذ البداية، بدءًا من الدارات الافتراضية. ولكن ماذا يعني بالضبط جعل الشبكة افتراضية؟
تُعَدّ الذاكرة الافتراضية مثالًا مفيدًا. إذ تخلق الذاكرة الافتراضية تجريدًا لمجموعةٍ كبيرةٍ وخاصةٍ من الذاكرة، على الرغم من إمكانية مشاركة الذاكرة الحقيقية الأساسية بواسطة العديد من التطبيقات وأصغر بكثير من تجمُّع pool للذواكر الافتراضية. ويمكّن هذا التجريد المبرمجين من العمل تحت وهم وجود الكثير من الذاكرة التي لا يوجد أحدٌ آخر يستخدمها، بينما يعتني نظام إدارة الذاكرة في الخفاء بأشياء مثل: ربط الذاكرة الوهمية بالموارد الفيزيائية، وتجنّب التعارض بين المستخدمين .
وبالمثل، تقدِّم افتراضية الخادم تجريدًا لآلة افتراضية VM، تحتوي على جميع ميزات الآلة الفيزيائية. وقد تكون هناك العديد من الآلات الافتراضية المدعومة على خادمٍ فيزيائي واحد، بينما يكون نظام التشغيل والمستخدمون على الآلة الافتراضية غير مدركين لحسن الحظ ارتباط الآلة الافتراضية بالموارد الفيزيائية. أي أنّ النقطة الأساسية هي افتراضية موارد الحوسبة التي تحافظ على التجريدات والواجهات التي كانت موجودة قبل أن تكون افتراضية. ويُعَدّ هذا مهمًّا، فهو يعني عدم حاجة مستخدمي هذه الأفكار التجريدية إلى التغيير، فهم يرون إعادة إنتاجٍ حقيقية للمورد المُحوَّل إلى الوضع الافتراضي. كما تعني الافتراضية أيضًا أنّ المستخدمين المختلفين (يُطلق عليهم أحيانًا المستأجرون) لا يمكنهم التداخل مع بعضهم بعضًا. إذًا ماذا يحدث عندما نحاول جعل الشبكة افتراضية؟
كانت الشبكات الافتراضية الخاصة الموضّحة سابقًا، إحدى النجاحات المُبكرة للشبكات الافتراضية. فقد سمحت لشركات الاتصالات بتقديم وهمٍ لعملاء الشركات بأنّ لديهم شبكةً خاصةً بهم، رغم تشاركهم في الواقع في الروابط والمبدّلات الأساسية مع العديد من المستخدمين الآخرين. ولكن تضيف الشبكات الافتراضية الخاصة الطابع الافتراضي فقط على بعض الموارد، لا سيما جداول العنوَنة والتوجيه. بينما تذهب افتراضية الشبكة إلى أبعد من ذلك اليوم، وتجعل كلّ جانب من جوانب الشبكات افتراضيًا، وهذا يعني وجوب دعم الشبكة الافتراضية لجميع المفاهيم الأساسية للشبكة الفيزيائية، فهي تشبه الآلة الافتراضية، مع دعمها لجميع موارد الخادم، ووحدة المعالجة المركزية، وأجهزة التخزين، وأجهزة الإدخال / الإخراج وغيرها.
تحقيقًا لهذه الغاية، تُعَدّ شبكات VLAN -الموضَّحة سابقًا- الطريقة التي نستخدم بها شبكة L2 افتراضيًا. فقد أثبتت شبكات VLAN فائدتها الكبيرة للمؤسسات التي أرادت عزل مجموعات داخلية مختلفة (الأقسام والمختبرات مثلًا)، مما يمنح كلًا منها مظهرًا وكأنها تمتلك شبكة LAN خاصة بها. كما كان يُنظر إلى شبكات VLAN على أنّها طريقة واعدة لإضفاء الطابع الافتراضي على شبكات L2 في مراكز البيانات السحابية، مما يجعل من الممكن منح كلّ مستأجر شبكة L2 خاصةٍ به لعزل حركة مرور البيانات الخاصة به عن حركة مرور بيانات جميع المستأجرين الآخرين. ولكن كانت هناك مشكلة، حيث أن 4096 شبكةً محليةً افتراضيةً محتملةً غير كافية لحساب جميع المستأجرين الذين قد تستضيفهم السحابة، فهي تحتاج ضمن السحابة، إلى توصيل الآلات الافتراضية بدلًا من الآلات الفيزيائية التي تعمل عليها تلك الآلات الافتراضية.
قُدِّم معيارٌ آخر سُمّي الشبكة المحلية الافتراضية الموسَّعة Virtual Extensible LAN أو اختصارًا VXLAN لمعالجة هذه المشكلة. حيث يغلِّف معيار VXLAN إطار إيثرنت افتراضي داخل رزمة UDP على عكس النهج الأصلي، الذي غَلَّف بفعالية إطار إيثرنت افتراضي داخل إطار إيثرنت آخر. هذا يعني أن الشبكة الافتراضية المستندة إلى VXLAN، والتي يشار إليها غالبًا باسم شبكة تراكب Overlay Network، تعمل فوق شبكة قائمة على IP، والتي تعمل بدورها على شبكة إيثرنت أساسية (أو ربما في شبكة VLAN واحدة فقط من شبكة الإيثرنت الأساسية). كما يتيح معيار VXLAN أيضًا لمستأجر واحد في السحابة، امتلاك شبكات VLAN متعدِّدة خاصة به، مما يسمح له بفصل حركة مرور بياناته الداخلية، وهذا يعني أنه من الممكن في النهاية أن يكون لديك شبكة VLAN مغلَّفة ضمن شبكة VXLAN تراكبية overlay ومغلَّفة ضمن شبكة VLAN.
الشيء القوي في الافتراضية هو أنّها إذا تمت بصورة صحيحة، فيجب أن يكون من الممكن دمج موردٍ افتراضي داخل موردٍ افتراضي آخر، إذ يجب أن يتصرّف المورّد الافتراضي تمامًا مثل الموارد الفيزيائية، والقدرة على جعل مورد افتراضي افتراضيًا أيضًا هو أفضل دليل على عملك الجيد في جعل المورد الفيزيائي الأصلي افتراضيًا، فهي شبكات افتراضية على طول الطريق.
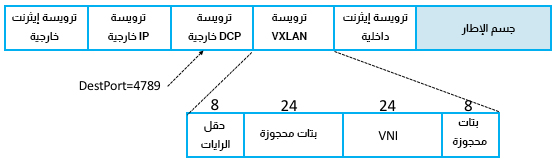
تُعد ترويسة VXLAN الفعلية بسيطةً، كما هو موضح في الشكل السابق. تتضمن الترويسة معرّف شبكةٍ افتراضية ذو 24 بت Virtual Network Id أو اختصارًا VNI، بالإضافة إلى بعض الرايات flag والبِتات المحجوزة. كما يتضمن أيضًا إعدادًا معينًا لحقلي مصدر ووجهة UDP، مع حجز منفذ الوجهة 4789 رسميًا لشبكات VXLAN. ويُعَدّ اكتشاف كيفية التعرف بصورة فريدة على شبكات LAN الافتراضية (وسوم VLAN والشبكات الافتراضية (معرّفات VXLAN VID) الجزء السهل. وذلك لكون التغليف هو حجر الزاوية الأساسي لِلافتراضية، فكلّ ما تحتاج إلى إضافته هو معرّفٌ يخبرك إلى أيٍّ من المستخدمين المحتملين تنتمي هذه الرزمة المغلّفة.
يتواجَه الجزء الصعب مع فكرة تداخُل الشبكات الافتراضية (مغلَّفة) داخل الشبكات الافتراضية، والتي هي نسخة version الشبكات من التعاود recursion. أمّا التحدي الآخر، فهو فهم كيفية أتمتة إنشاء الشبكات الافتراضية وإدارتها ونقلها وحذفها، إذ لا يزال هناك مجال كبير للتحسين على هذا المجال، وسيكون إتقان هذا، هو التحدي في صميم الشبكات في العقد المقبل. وبينما سيحدث بعض هذا العمل بلا شك في إعدادات الملكية، فهناك منصات افتراضية للشبكات مفتوحة المصدر (مثل مشروع تنغستن فابريك Tungsten Fabric التابع لمؤسسة لينكس Linux تقود الطريق.
اقتباسنوصي بما يلي لمعرفة المزيد حول نضوج الشبكات الافتراضية:
- Network Heresy, 2012
- Tungsten Fabric, 2018
ترجمة -وبتصرّف- للقسم Implementation من فصل Internetworking من كتاب Computer Networks: A Systems Approach.
اقرأ أيضًا
- المقال التالي: التشبيك المتقدم Advanced Internetworking في الشبكات الحاسوبية
- المقال السابق: توجيه Routing الرزم ضمن الشبكات الحاسوبية








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.