Khaled Osama3
-
المساهمات
1904 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
1
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Khaled Osama3
-
 وعليكم السلام ورحمة الله، لا، لا تحتاج لطبيب بشكل مباشر فانت تعرف القيمة الشاذة بانها قيمة تختلف بشكل كبير عن باقي القيم الموجودة في البيانات. على سبيل المثال، لو كان لديك بيانات عن درجات حرارة الجسم لعينة من المرضى، وكل القيم تتراوح بين 36 و 38 درجة مئوية، ولكن هناك قيمة واحدة مثل 42 درجة، فهذا قد يكون "قيمة شاذة" لأنها بعيدة جدا عن باقي القيم. لذلك، اكتشاف القيم الشاذة يمكن أن يتم باستخدام الإحصاءات أو أدوات تحليل البيانات، مثل رسم بياني أو استخدام برامج مثل Excel أو Python. لكن إذا كنت تريد معرفة السبب الطبي وراء تلك القيمة أو تفسيرها، قد يكون من الجيد استشارة طبيب للتأكد من أن هذه القيم ليست نتيجة لحالة مرضية خاصة أو خطأ في القياس.
وعليكم السلام ورحمة الله، لا، لا تحتاج لطبيب بشكل مباشر فانت تعرف القيمة الشاذة بانها قيمة تختلف بشكل كبير عن باقي القيم الموجودة في البيانات. على سبيل المثال، لو كان لديك بيانات عن درجات حرارة الجسم لعينة من المرضى، وكل القيم تتراوح بين 36 و 38 درجة مئوية، ولكن هناك قيمة واحدة مثل 42 درجة، فهذا قد يكون "قيمة شاذة" لأنها بعيدة جدا عن باقي القيم. لذلك، اكتشاف القيم الشاذة يمكن أن يتم باستخدام الإحصاءات أو أدوات تحليل البيانات، مثل رسم بياني أو استخدام برامج مثل Excel أو Python. لكن إذا كنت تريد معرفة السبب الطبي وراء تلك القيمة أو تفسيرها، قد يكون من الجيد استشارة طبيب للتأكد من أن هذه القيم ليست نتيجة لحالة مرضية خاصة أو خطأ في القياس.- 4 اجابة
-
- 1
-

-
وعليكم السلام ورحمة الله وبركاته، Exploratory Data Analysis عملية أولية لتحليل البيانات لفهم طبيعتها، واكتشاف الأنماط وتحديد العلاقات بين المتغيرات، والكشف عن القيم الشاذة أو البيانات المفقودة. و هدفها هو توفير فهم عميق للبيانات قبل الانتقال إلى النمذجة أو اتخاذ القرارات بناءً عليها. و هى مفيدة و نحتاج اليها. بسبب: فهم فكرة واضحة عن طبيعة البيانات التي تعمل عليها، مما يساعد في صياغة الفرضيات. الكشف عن الأخطاء، القيم الشاذة، أو البيانات غير المكتملة التي قد تؤثر على التحليل. تحدي أنماط قد تؤثر على نتائج التحليل أو التنبؤ. تساعد في اتخاذ قرارات مستنيرة عند إعداد النماذج الإحصائية أو نماذج تعلم الآلة. و دعنا نفرض مثال: لنفترض أننا نحلل مجموعة بيانات تحتوي على مبيعات متجر. يمكن أن تشمل خطوات EDA ما يلي: التحقق من عدد المنتجات المباعة يوميًا. معرفة المنتج الأكثر مبيعًا. دراسة العلاقة بين العروض الترويجية وزيادة المبيعات. تحليل الفئات العمرية التي تشتري أكثر. بالتوفيق
- 3 اجابة
-
- 1
-
-
و عليكم السلام Jupyter Notebook شائع جدًا لعدة أسباب: يقدم بيئة تفاعلية تتيح لك كتابة الكود وتنفيذه في خلايا، بحيث تستطيع تجربة وتحليل النتائج خطوة بخطوة بدلاً من تشغيل كود طويل دفعة واحدة. هذا يسهل الفهم والتجريب. يدعم لغات أخرى مثل R وJulia، مما يجعله أداة مرنة للعديد من المستخدمين. و يمكنك إضافة شرح بلغة Markdown بين الخلايا أو حول الكود، مما يسهل عملية توثيق العمل والشرح للأشخاص الآخرين أو حتى لنفسك عند العودة للملف لاحقاً. يسهل عرض النتائج والأشكال البيانية بطريقة بصرية واضحة داخل نفس الملف، مما يجعله مثاليًا للتقارير التفاعلية ولعرض البيانات. اما R Markdown صُمم في الأصل للغة R وهو جزء من RStudio، ولكنه يدعم أيضًا Python ولغات أخرى. يستخدم لإنشاء تقارير نهائية بامتدادات مثل HTML، PDF، وWord مباشرة، وهذا يجعله مناسبًا لكتابة الأبحاث أو تقارير رسمية متكاملة. يميل أكثر للتشغيل الكامل عند الحاجة لإخراج التقرير النهائي . يُفضل في إعداد التقارير الأكاديمية أو المستندات الرسمية المتكاملة.
- 4 اجابة
-
- 1
-
-
وعليكم السلام! لإضافة تحليل لحالات الحمل ضمن هذه الفئات العمرية، يمكنك حساب المتوسط أو مجموع عدد حالات الحمل لكل فئة عمرية. بيانات الحمل موجودة في عمود Pregnancies، يمكنك استخدام الكود التالي لإضافة هذا التحليل إلى الكود الذي كتبته: # إضافة عمود الفئات العمرية bins = [20, 30, 40, 50, 60, 70, 80, np.inf] label = ['20-29', '30-39', '40-49', '50-59', '60-69', '70-97', '80+'] diabetes['Age Group'] = pd.cut(diabetes['Age'], bins=bins, labels=label, right=False) # حساب عدد حالات الحمل لمصابين السكري في كل فئة عمرية pregnancy_counts = diabetes[diabetes['Outcome'] == 1].groupby('Age Group')['Pregnancies'].sum() # عرض النتائج print("عدد حالات الحمل لمصابين السكري في كل فئة عمرية:") print(pregnancy_counts) # رسم مخطط بياني pregnancy_counts.plot(kind='bar', color='lightcoral') plt.title("Total Pregnancies Among Diabetic Patients by Age Group") plt.xlabel("Age Group") plt.ylabel("Number of Pregnancies") plt.xticks(rotation=45) plt.tight_layout() plt.show() و فى ذلك الكود: تم تقسيم البيانات إلى فئات عمرية كما فعلت انت. ثم استخدمنا groupby لجمع عدد حالات الحمل (Pregnancies) في كل فئة عمرية لمن لديهم نتيجة إصابة بالسكري. ثم رسم المخطط البياني لعرض عدد حالات الحمل لكل فئة عمرية. و فى النهاية سيظهر المخطط البياني إجمالي حالات الحمل لمصابي السكري في كل فئة عمرية، مما يسهل التعرف على الفئات العمرية ذات عدد حالات الحمل المرتفع بين المصابين.
- 3 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله وبركاته التحليل الإحصائي (Statistical analysis)هو عملية جمع، تنظيم، تفسير، وعرض البيانات بشكل يسمح بفهم الأنماط والعلاقات بين المتغيرات. و يهدف إلى استخراج معلومات ذات معنى من البيانات وتقديمها بشكل يسهل تفسيره واستخدامه لاتخاذ قرارات مستنيرة. و لل Statistical analysis عدة خطوات مثل: تجميع البيانات من مصادر مختلفة. ترتيب البيانات بشكل مناسب وتنسيقها. استخدام الأساليب الإحصائية مثل المتوسطات والانحراف المعياري والارتباط. استخلاص نتائج نهائية من التحليلات. تقديم النتائج بشكل مرئي من خلال الجداول، الرسوم البيانية، والتقارير. و لغة بايثون تُعد من اللغات المثالية لإجراء التحليل الإحصائي بفضل مكتباتها المتخصصة مثل: Pandas: لمعالجة البيانات وتنظيفها. NumPy: لإجراء العمليات الحسابية والمصفوفات. SciPy: لتوفير أدوات الإحصاء وتحليل البيانات. Matplotlib و Seaborn: لإنشاء الرسوم البيانية والمرئيات التي تُسهِّل فهم البيانات. بالتوفيق
-
ارجو ارفاق ملف الصورة بشكل صحيح لانه لا يعمل
-
نعم يمكن ذلك ولكن مقارنة مع بايثون: R يُستخدم بشكل أكبر في الأوساط الأكاديمية وفي التحليل الإحصائي المكثف، وله مكتبات قوية في تعلم الآلة، لكنه يعتبر أقل شيوعًا من بايثون في بعض النواحي مثل التعلم العميق (Deep learning). بايثون لديه مجتمع أكبر في مجال تعلم الآلة والتعلم العميق، (اى عدد المبرمجون اللذين يستخدمون بايثون فى تعلم الاله اكثر مما يسهل البحث و معرفة حلول المشاكل بنسبة اكبر)
-
وعليكم السلام هو بيئة تطوير متكاملة (IDE) خاصة بلغة البرمجة R، التي تُستخدم بشكل رئيسي في تحليل البيانات والإحصاء وتعلم الآلة. يوفر RStudio واجهة سهلة الاستخدام لكتابة وتشغيل الأكواد بلغة R، ويحتوي على أدوات متنوعة لتسهيل العمل مع البيانات. وهو: يجمع كل ما تحتاجه في مكان واحد — محرر للنصوص البرمجية، وحدة التحكم (Console)، عارض للبيانات، وأدوات لإدارة الملفات والمشاريع. يحتوي على أدوات مدمجة تسهّل التعامل مع الرسومات البيانية وإنشاء الرسوم التوضيحية باستخدام مكتبات. يوفر أدوات لإدارة الحزم والمكتبات، مما يجعل من السهل تحميل وتثبيت المكتبات المستخدمة في التحليل. يتيح إمكانية عرض وتحليل البيانات مباشرة، سواء كانت البيانات مخزنة في ملفات Excel أو قواعد بيانات أو مصادر أخرى. يمكنك ربط RStudio مع Git وGitHub لإدارة المشاريع البرمجية. يمكنك من كتابة تقارير باستخدام R Markdown، حيث يمكن دمج النصوص والأكواد ونتائج التحليل في تقرير واحد. و يستخدم فى: تحليل البيانات واستكشافها باستخدام لغة R. إجراء التحليلات الإحصائية المتقدمة. تطوير نماذج تعلم الآلة وتحليل البيانات التنبؤية.
- 7 اجابة
-
- 1
-
-
من فضلك قم بارفاق الخطأ الذى يظهر لك
-
هناك عدة خطوات يمكنك اتخاذها للتراجع عن تلك التغييرات: يمكنك التراجع عن آخر عملية دفع (للتراجع عن آخر commit تم دفعه فقط) git reset --hard HEAD~1 git push --force git reset --hard HEAD~1 يعيد الفرع المحلي إلى الحالة قبل آخر commit. git push --force يقوم بتحديث المستودع البعيد لإزالة الـ commit الأخير الذي تم دفعه. ملحوظة: لا تستخدم هذا الأمر إذا كان هناك زملاء يعتمدون على هذا الـ commit، لأنه سيؤدي إلى تعارضات conflicts. او التراجع عن عدة Commits (إذا كانت هناك عدة تغييرات خاطئة بقدار n) git reset --hard HEAD~n git push --force او يمكنك استخدام Revert لإنشاء Commit عكسي للتغييرات (طريقة آمنة) git revert <commit_hash> git push و يمكنك العثور على commit hash لل commit عن طريق : git log لكن يجب مراعاة أن هذه الخطوات قد تؤثر على زملائك إذا كانوا يعملون على نفس الفرع، خاصة في فروع مثل main أو master.
-
و عليكم السلام نعم يمكنك ذلك و لكن : و لكن لا انصحك بهذا فالتطبيقات على لغة البايثون لا غنى عنها فى اى مجال اخر او اطار عمل و سوف تساعدك على اتمام الاساسيات لديك فغير ذلك سياتى بنتيجة عكسية و بعد ذلك و بعد الانتهاء من التطبيقات من الافضل لك أن تنتهى من دورة أساسيات اطار عمل Django قبل البدأ فى انشاء متجر الكترونى باستخدام Django.
- 4 اجابة
-
- 1
-
-
و عليكم السلام الخطأ ناتج عن استخدام الأقواس الخطأ في بعض السطور. حيث يتم استخدام loc لتحديد الإحصائيات، تم استخدام الأقواس العادية () بدلاً من الأقواس المربعة []. في pandas، عندما نستخدم loc، يجب أن نستخدم الأقواس المربعة للوصول إلى الأعمدة أو الصفوف المحددة. # الحصول على الوصف الإحصائي لبيانات محددة statistical0 = diabetes.drop(['Outcome','DiabetesPedigreeFunction','Pregnancies'], axis=1).describe() statistical1 = diabetes.drop(['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'Age'], axis=1).value_counts().describe() plt.figure(figsize=(10, 8)) # تصحيح الأقواس في loc statistical0.loc[['mean', 'std', 'min', "25%", "50%", "75%", 'max']].transpose().plot(kind='bar', figsize=(12, 8)) statistical1.loc[['mean', 'std', 'min', '25%', '50%', '75%', 'max']].transpose().plot(kind='bar', figsize=(12, 8)) plt.title("Statistical Summary of Diabetes Dataset") plt.xlabel("Features") plt.ylabel("Value") plt.xticks(rotation=30) plt.legend(["Mean", "Std", "Min", "25%", "50%", "75%", "Max"]) plt.grid(True) plt.tight_layout() plt.show() و يجب ايضا التاكد من قيمة السطر التانى من الكود و يمكنك معرفة قيمتها باستخدام: print(statistical1)
- 2 اجابة
-
- 1
-
-
و عليكم السلام: بالتأكيد فالخوارزميات مهمة في جميع مجالات التقنية فالخوارزميات تساعد في معالجة وتحليل البيانات بكفاءة أكبر. على سبيل المثال، خوارزميات الترتيب والتصفية هي أساسية لتحضير البيانات وتنقيحها قبل تحليلها. و لكن لا حاجة للتعمق فيها. فقد لا تكون جميع جوانب الخوارزميات وهياكل البيانات ضرورية لكل محلل بيانات، إلا أن معرفة أساسياتها يمكن أن تضيف الكثير لقيمة المحلل في الفريق وتمكنه من التعامل مع البيانات بشكل أكثر فعالية. فيجب عليك تعلم الاساسيات. ثم انتقل الى:
- 4 اجابة
-
- 1
-
-
وعليكم السلام _ (underscore) في بايثون تستخدم لأغراض تنظيمية ووضوح الكود، وخاصة في تسمية المتغيرات. الطريقة المعتمدة في بايثون لتسمية المتغيرات هي باستخدام النمط المسمى snake_case، بحيث تكون الكلمات مفصولة بعلامة سفلية (underscore). مثل: first_name = 'ali' first_name = 'ali' هذه الطريقة تجعل الكود أكثر وضوحًا ويسهل قراءته، وخصوصًا عند استخدام أسماء متغيرات طويلة تتكون من عدة كلمات.
- 5 اجابة
-
- 1
-
-
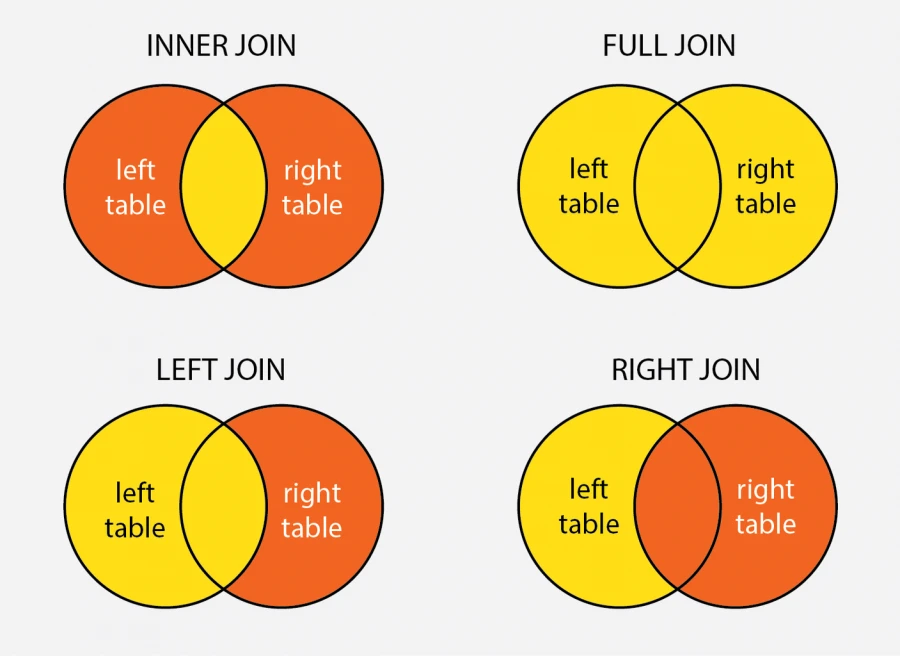
و عليكم السلام ال JOIN: هي عملية تستخدم لربط الجداول مع بعضها البعض بناءً على علاقة مشتركة. و غالبًا ما تُستخدم عندما يكون لديك بيانات موزعة في جداول متعددة وترغب في جلبها معًا في استعلام واحد لتقديم نتائج مفيدة. و هناك عدة انواع له: INNER JOIN: يتم إرجاع السجلات التي لها قيم مطابقة في كلا الجدولين فقط. إذا لم يكن هناك تطابق، فلن يتم عرض السجل في النتيجة. LEFT JOIN (LEFT OUTER JOIN): يتم إرجاع جميع السجلات من الجدول الأيسر (Left Table)، مع السجلات المطابقة من الجدول الأيمن (Right Table). إذا لم يكن هناك تطابق، فستحتوي الأعمدة من الجدول الأيمن على قيمة NULL. RIGHT JOIN (RIGHT OUTER JOIN): يعمل بشكل مشابه لـ LEFT JOIN، لكن يتم إرجاع جميع السجلات من الجدول الأيمن، مع السجلات المطابقة من الجدول الأيسر. إذا لم يكن هناك تطابق، ستكون القيم من الجدول الأيسر هي NULL. FULL JOIN (FULL OUTER JOIN): يجمع نتائج كل من LEFT JOIN و RIGHT JOIN، حيث يتم إرجاع جميع السجلات من كلا الجدولين. إذا لم يكن هناك تطابق، فسيتم ملء القيم غير الموجودة بـ NULL.
- 4 اجابة
-
- 1
-
-
وعليكم السلام تحليل الانحدار (Regression Analysis) هو أسلوب إحصائي يُستخدم لفهم العلاقة بين متغيرين أو أكثر. يهدف هذا التحليل إلى تقدير كيفية تأثير متغير مستقل (أو عدة متغيرات مستقلة) على متغير تابع (أو متغير يعتمد). و يساعد تحليل الانحدار في اتخاذ القرارات المبنية على البيانات، ويتيح للباحثين فهم العلاقات المعقدة بين المتغيرات. و له عدة أنواع أساسية: الانحدار الخطي البسيط: يتضمن متغيرًا تابعًا واحدًا ومتغيرًا مستقلًا واحدًا. يُستخدم لنمذجة العلاقة الخطية بين المتغيرين. الانحدار الخطي المتعدد: يتضمن متغير تابع واحد وعدة متغيرات مستقلة. يُستخدم لفهم كيف تؤثر مجموعة من المتغيرات على المتغير التابع. الانحدار اللوجستي: يُستخدم عندما يكون المتغير التابع نوعيًا (مثل النجاح/الفشل)، حيث يهدف إلى تقدير الاحتمالات. و يستخدم فى: مجالات مثل الاقتصاد والعلوم الاجتماعية للتنبؤ بالاتجاهات المستقبلية. فهم كيفية تأثير مجموعة من العوامل على نتيجة معينة. تحسين تصنيف الملاحظات بناءً على الخصائص المدروسة. (في بعض الحالات) و يمكنك الاطلاع على المقال التالى
- 5 اجابة
-
- 1
-
-
و عليكم السلام في الوقت الحالى لا يوجد أكواد خصم متاحة، فآخر عرض كان متاح هو عرض العطلة الصيفية 2024 و قد انتهى. و يمكنك أيضا التوجه إلى مركز المساعدة و سوف تجد تفاصيل أكثر حول هذا الأمر من توافر لكوبانات الخصم من عدمه.
-
و عليكم السلام CareerCon: مؤتمر تنظمه منصة Kaggle، ويهدف إلى مساعدة العلماء والمبرمجين المهتمين بمجال التعلم الآلي وعلوم البيانات في تطوير مهاراتهم والحصول على نصائح حول مساراتهم المهنية. يعرض المؤتمر محادثات (conversation)، ورش عمل (Workshops)، ومسابقات خاصة بعلم البيانات والتعلم الآلي، حيث يتشارك فيه المتخصصون في المجال تجاربهم ويوجهون الحضور حول كيفية تحسين فرصهم الوظيفية وبناء مسارات مهنية ناجحة. في إطار هذا المؤتمر، قد يتم تنظيم مسابقات، تحديات، وجلسات تعليمية تتعلق بالتحليل الإحصائي، البرمجة، والنماذج التنبؤية، مما يتيح للمشاركين التعلم وتوسيع مهاراتهم العملية.
- 2 اجابة
-
- 1
-
-
و عليكم السلام هذه البيانات بمرض السكري ، بها عوامل الخطر المختلفة المرتبطة بمرض السكري. Pregnancies (الحمل): عدد مرات الحمل السابقة للمرأة. Glucose (الجلوكوز): مستوى الجلوكوز في الدم (ملغ/ديسيلتر) عند الاختبار. loodPressure (ضغط الدم): قياس ضغط الدم (مم زئبق). SkinThickness (سمك الجلد): سمك جلد السرة (مم). Insulin (الأنسولين): مستوى الأنسولين (مكاييل وحدة). BMI (مؤشر كتلة الجسم): هو قياس يستخدم لتحديد الوزن المثالي بالنسبة للطول. DiabetesPedigreeFunction (وظيفة شجرة العائلة للسكري): مؤشر يستخدم لقياس وجود تاريخ عائلي للسكري. Age (العمر): عمر الشخص (سنوات). يزداد خطر الإصابة بالسكري مع تقدم العمر. Outcome (النتيجة): هذا العمود يعكس ما إذا كان الشخص مصاباً بالسكري (1) أم لا (0). يعتبر هذا العمود الهدف الرئيسي لتحليل البيانات. و للتوضيح فسوف نأخد مثال على تحليل البيانات: First record: يشير إلى امرأة عمرها 50 سنة، لديها 6 حالات حمل سابقة، مستوى جلوكوز 148، وضغط دم 72، وBMI 33.6. بناءً على هذه المعطيات، النتيجة هي 1، مما يعني أنها مصابة بالسكري. Second record:السجل الثاني يشير إلى امرأة عمرها 31 سنة، لديها حمل واحد، مستوى جلوكوز 85، وضغط دم 66، وBMI 26.6، والنتيجة 0، مما يعني أنها غير مصابة بالسكري.
- 3 اجابة
-
- 1
-
-
و عليكم السلام قم بارفاق الخطأ هنا من فضلك لكى نتمكن من مساعدتك
-
لا يوجد وقت فعند شرائك للدوره ستبقي مفتوحه طيله العمر مع كامل التحديثات لها فلن تضطر لشراء نفس الدوره مرتين او تحديث اشتراك وليس لها وقت نهايه
- 3 اجابة
-
- 1
-
-
وعليكم السلام ورحمة الله وبركاته، Sample Size Calculator: أداة تُستخدم لحساب حجم العينة المناسب لإجراء دراسة أو تجربة معينة بناءً على بعض المعايير الإحصائية. و الهدف الرئيسي من استخدام هذه الأداة هو تحديد العدد الأمثل من العناصر التي يجب جمع بياناتهم من أجل الوصول إلى نتائج دقيقة وموثوقة. و من العوامل المؤثرة على Sample Size Calculator: حجم المجتمع (Population Size): العدد الإجمالي للأفراد العناصر هامش الخطأ (Margin of Error): مدى التفاوت المسموح به في نتائج العينة مقارنة بالمجتمع. عادةً يتم التعبير عنه بالنسبة المئوية. كلما كان هامش الخطأ أصغر، زادت دقة النتائج. مستوى الثقة (Confidence Level): يشير إلى مدى الثقة في أن النتائج المستخلصة من العينة تمثل المجتمع بشكل دقيق. أكثر مستويات الثقة شيوعًا هي 90%، 95%، و99%. مستوى الثقة 95% يعني أنك تتوقع أن تكون نتائجك صحيحة في 95% من المرات. التباين المتوقع في المجتمع (Population Variability): يعبّر عن مدى اختلاف القيم داخل المجتمع. إذا كنت تتوقع تباينًا كبيرًا في المجتمع، ستحتاج إلى حجم عينة أكبر. نسبة النجاح (Proportion): في بعض الأحيان، يتم تقدير نسبة معينة لظاهرة معينة (مثل 50% من المجتمع يوافقون على موضوع معين). إذا لم يكن لديك تقدير مسبق، يُستخدم عادةً 50% كأساس لأنه ينتج عنه أكبر حجم عينة مطلوب. و يمكنك العثور على Sample Size Calculators هنا.
- 2 اجابة
-
- 1
-
-
و عليكم السلام ذلك نتيجة لقاعدة تسمى Rule of 30 و هى من التطبيقات الشائعة فى الإحصاء. و ذلك لعدة اسباب منها: تحقيق دقة أكبر: عندما تكون العينة صغيرة، فإن النتائج تكون أكثر تأثرًا بالتحيز أو التقلبات العشوائية. حجم العينة الأكبر (30 فأكثر) يساعد على تقليل التباين وتحسين دقة التقديرات. تقليل الخطأ المعياري: لانه بزيادة حجم العينة، يقل الخطأ المعياري (Standard Error)، مما يعني أن متوسط العينة يكون أقرب إلى متوسط المجتمع الفعلي. و لذلك فإن 30 من الحدود الأمنه و المناسبة و لكن ليست قاعدة إجبارية الاستخدام. ففى بعض الاحيان يمكن استخدام حجم اكبر او اصغر على حسب طبيعة البيانات.
- 4 اجابة
-
- 1
-
-
الخطأ الذي يظهر لديك مرتبط بمكتبة TensorFlow، وقد يكون ناتجًا عن مشاكل في التثبيت أو عدم التوافق بين إصدارات TensorFlow و Keras أو التبعيات المرتبطة. لحل هذا المشكلة، تأكد من أنك تستخدم أحدث إصدارات TensorFlow و Keras. يمكنك تحديث المكتبات باستخدام الأوامر التالية: pip install --upgrade tensorflow keras إذا استمر الخطأ بعد التحديث، قد تحتاج إلى إعادة تثبيت TensorFlow بشكل كامل: pip uninstall tensorflow pip install tensorflow و تأكد أن البيئة التي تعمل فيها لا تحتوي على تعارضات بين المكتبات. يمكنك إنشاء بيئة افتراضية جديدة وتجربة تشغيل الكود فيها: python -m venv myenv myenv\Scripts\activate pip install tensorflow keras pandas scikit-learn كل امر على حدى
- 9 اجابة
-
- 1
-
-
السبب الأساسي أن البيانات لا يتم حفظها في المتغير user بعد إغلاق البرنامج: أن المتغيرات في البرامج (مثل المتغير user في هذه الحالة) يتم تخزينها في الذاكرة المؤقتة (RAM) أثناء تشغيل البرنامج. بمجرد إيقاف البرنامج، يتم تحرير الذاكرة المؤقتة وبالتالي تفقد جميع البيانات التي كانت موجودة في المتغيرات. عندما تقوم بإعادة تشغيل البرنامج، يبدأ من الصفر ويعود المتغير user فارغًا. اذا كنت تريد حفظ بيانات ال user فيمكنك استخدام ملف لحفظ البيانات مثل ال json او csv. او يمكنك استخاد قواعد البيانات. و اضف الى الكود عملية استرجاع البيانات. واليك مثال عن طريق ال json: import json from sys import exit from time import sleep class User: def __init__(self, first_name, last_name, email, password, status="inactive"): self.first_name = first_name self.last_name = last_name self.email = email self.password = password self.status = status def display(self): print(f"First name: {self.first_name}") print(f"Last name: {self.last_name}") print(f"Email: {self.email}") print(f"Password: {self.password}") print(f"Status: {self.status}\n") print("_" * 20) def to_dict(self): return { "first_name": self.first_name, "last_name": self.last_name, "email": self.email, "password": self.password, "status": self.status } @classmethod def from_dict(cls, data): return cls(data["first_name"], data["last_name"], data["email"], data["password"], data["status"]) def username(): first_name = input("First_name: ") last_name = input("last_name: ") email = input("Email: ") password = input("password: ") return User(first_name, last_name, email, password) def save_users(users): with open('users.json', 'w') as file: json_data = [user.to_dict() for user in users] json.dump(json_data, file) def load_users(): try: with open('users.json', 'r') as file: json_data = json.load(file) return [User.from_dict(user_data) for user_data in json_data] except FileNotFoundError: return [] users = load_users() while True: print("Welcome to user management\n") print("Choose an action\n") print("1. Add new user") print("2. Display all users") print("3. Exit\n") choice = input("Enter your choice: ") if choice == '1': new_user = username() users.append(new_user) save_users(users) print("User added successfully!\n") sleep(2) elif choice == '2': if users: for user in users: user.display() sleep(2) else: print("No users found!") sleep(2) elif choice == '3': print("Exiting...") exit(0) else: print("Invalid choice! Please choose 1, 2, or 3.") و لاحظ فى الكود: @classmethod تستخدم لتعريف "طريقة" (method) تابعة للفئة (class method). و على عكس الدوال العادية (التي تستخدم self للوصول إلى خصائص الكائن)، الدالة التي توصف بـ @classmethod تأخذ دائمًا المعامل الأول كـ cls، والذي يمثل الفئة نفسها (class) وليس الكائن.
- 5 اجابة
-
- 1
-