Chihab Hedidi
-
المساهمات
3051 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
13
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Chihab Hedidi
-
أسهل طريقة معروفة يمكنك إعتمادها هي إستخدام تقينة WebView في Android و WKWebView في iOS، حيث يمكنك عرض موقع الويب داخل التطبيق، الطريقة يمكن أن تكون سهلة نسبيا إذا كان لديك خبرة في استخدام الأدوات المناسبة، ولكن قد تواجه بعض التحديات في تحويل تجربة المستخدم بشكل مثالي من موقع ويب إلى تطبيق جوال بسبب الاختلافات في تجربة الاستخدام بين الويب وتطبيقات الهواتف. و لكن هذه الطريقة لا تعتبر إحترافية و الأفضل أن يتم برمجة الموقع لوحده و تطبيق الجوال لوحده حيث يكون أكثر تخصيصا كما أن التحكم فيه يكون أفضل و حتى تجربة المستخدم و التصميم يختلف و يكون أفضل، و يمكنك أن تطلع على هذه المقالات لتفهم أكثر : تحويل موقع الكترونى الى تطبيق على الهاتف
- 3 اجابة
-
- 1
-

-
لا تشاهد الفيديو و فقط و إنما طبق مع المدرب ما يقوم به، البرمجة تعتمد بصفة كبيرة على التطبيق المباشر ، و أيضا بعد تطبيق ما تعلمته من الفيديو، حاول إجراء تعديلات صغيرة على الكود لمعرفة كيف تتغير النتائج، هذا سيساعدك على فهم تأثيرات تغييرات الكود، و بين الحين و الآخر خصوصا إذا إنقطعت كثيرا عن المجال حاول إعادة برمجة تطبيقات صغيرة بنفسك أو إعادة مشاهدة بعض الفيديوات مع تسريع الفيديو و فقط لتذكر محتواه.
-
ربط ملف إكسل ليس بالأمر الصعب، بحيث يمكن عرض البيانات وتعديلها من خلال واجهة ويب وتتحديث ملف Excel تلقائيا، وهذا من خلال استخدام مكتبة SheetJS، والتي تتيح لك قراءة وكتابة ملفات Excel باستخدام JavaScript، وهذا مثال بسيط يوضح كيفية استخدام المكتبة لقراءة ملف Excel و التعديل عليه: // تحميل مكتبة SheetJS const XLSX = require('xlsx'); // تحميل ملف Excel const fileInput = document.getElementById('fileInput'); fileInput.addEventListener('change', function(event) { const file = event.target.files[0]; const reader = new FileReader(); reader.onload = function(event) { const data = event.target.result; const workbook = XLSX.read(data, {type: 'binary'}); // قراءة البيانات من ورقة العمل const worksheet = workbook.Sheets[workbook.SheetNames[0]]; const jsonData = XLSX.utils.sheet_to_json(worksheet); // عرض البيانات في صفحة الويب console.log(jsonData); }; reader.readAsBinaryString(file); }); يمكنك دمج هذا الكود مع وظائف إضافية لعرض وتعديل البيانات وحفظها مرة أخرى إلى ملف Excel.
-
 مرحبا حسام، ستجد أسفل الفيديو الخاص بالدورة مكان مخصص بالتعليقاتن هناك، أرجوا وضع سؤالك أسفل فيديو الدورة.
مرحبا حسام، ستجد أسفل الفيديو الخاص بالدورة مكان مخصص بالتعليقاتن هناك، أرجوا وضع سؤالك أسفل فيديو الدورة. -
مرحبا @عزالدين بن تيتي، المشكلة على الأغلب في الملف خصوصا إذا كانت ملفات أخرى الخاصة بإكسال تشتغل بدون مشاكل، فقد يكون الملف نفسه معطوبا مما يتسبب في تعطل الجهاز، أو قد يحتوي الملف على برمجيات خبيثة تسببت في حدوث مشكلات في جهازك، جرب فتح الملف على جهاز آخر لمعرفة ما إذا كان سليما، و أيضا استخدم برنامج مكافحة الفيروسات لفحص جهازك والتأكد من خلوه من البرمجيات الخبيثة، أو كحل أخير قد يكون هناك مشكلة في برنامج إكسال لديك، حاول إعادة تثبيته. بالتوفيق إن شاء الله.
-
يمكنك استخدام الهاتف المحمول كمصدر إنترنت عن طريق تحويله إلى نقطة اتصال لاسلكية (هوتسبوت)، يمكنك بعد ذلك الاتصال بالهوتسبوت باستخدام جهاز الكمبيوتر أو اللابتوب، بالنسبة للكمبيوتر إذا كان لا يحتوي على أداة wifi يمكنك شراءها حيث تركب في جهة ال usb، أما إذا أردت حل أسهل يمكنك مباشرة ربط الهاتف بالكمبيوتر عن طريق الusb ثم الإختيار من الهاتف usb tethering و ستشتغل معك.
- 2 اجابة
-
- 1
-

-
الحل الخاص بك صحيح و إنما فقط ينقصك أن تستعمل الدالة و إعطائها الجملة aLongAndComplexString كمدخلات و تطبع النتيجة و للقيام بذلك يمكنك التعديل على main، و يمكنك القيام بذلك لوحدك عليك المحاولة أكثر، ما تحتاج القيام به هو تعريف مثلا متغير داخل main هكذا input_string = 'aLongAndComplexString' بعدها استدعيه داخل الدالة ليتم تطبيق التغييرات عليه و إطبع النتيجة، و يمكنك أن تطلع أكثر على كيفية عمل الدوال من هنا:
- 2 اجابة
-
- 1
-
-
لا يوجد ضرورة لاختيار باقة معينة من هوستنجر من أجل جعل الموقع جاهزا للتسويق الرقمي، و أكيد يمكن لأي موقع على هوستنجر أن يكون قابلا لعمليات التسويق الرقمي، و الأمر هنا ليس له علاقة بالإستضافة بل يكون بالتعديل على الكود الخاص بالموقع عن طريق إضافة أكواد التتبع الخاصة بالمواقع المعروفة.
- 1 جواب
-
- 1
-
-
يظهر هذا الخطأ عندما تحاول إدراج قيمة صريحة في عمود هوية في جدول قاعدة البيانات بينما يكون إعداد IDENTITY_INSERT لهذا الجدول مضبوطًا على OFF، و لحل هذه المشكلة، يجب عليك تفعيل IDENTITY_INSERT يمكنك ذلك عن طريق إضافة هذا السطر: -- تفعيل IDENTITY_INSERT SET IDENTITY_INSERT categories ON; -- ثم تنفيذ عملية الإدخال -- إيقاف IDENTITY_INSERT بعد الإدخال SET IDENTITY_INSERT categories OFF; تأكد من إيقاف إعداد IDENTITY_INSERT بعد الانتهاء من الإدراج للحفاظ على سلامة البيانات.
-
الأصل هو أن Visual Studio Code محرر أكواد نصية ولكن يمكن اعتباره أيضا بيئة تطوير متكاملة (IDE) إلى حد ما، لأنه يوفر العديد من الميزات التي تستخدم عادة في بيئات التطوير المتكاملة، كالتكامل مع أدوات التصحيح، دعم مجموعة متنوعة من لغات البرمجة من خلال الملحقات، التكامل مع أنظمة إدارة الإصدارات مثل Git، إمكانية كتابة وتشغيل الأوامر داخل المحرر، و حتى دعم العديد من أدوات التطوير الأخرى مثل Docker و Kubernetes من خلال الملحقات، و هذه المميزات تجدها عادة في بيئات التطوير المتكاملة فقط، كما أنه يمكن تخصيص Visual Studio Code بشكل كبير من خلال استخدام الملحقات، مما يجعله شبيها ببيئة تطوير متكاملة مرنة وقابلة للتخصيص.
- 2 اجابة
-
- 1
-
-
هي اختصار لـ Unified Modeling Language هي لغة نمذجة تستخدم في هندسة البرمجيات لتصميم وتوثيق هياكل وبرمجيات الأنظمة. تتضمن مجموعة من الرسوم التخطيطية، بما في ذلك الرسوم التخطيطية الطبقية التي تمثل الفئات وعلاقاتها، والرسوم التخطيطية التتابعية التي تظهر التفاعلات بين الكائنات في تسلسل زمني، والرسوم التخطيطية التشاركية التي توضح كيفية تفاعل الكائنات مع بعضها البعض. كما تشمل الرسوم التخطيطية للحالة التي تمثل حالات الكائنات وتغيراتها، والرسوم التخطيطية للنشاط التي توضح تسلسل الأنشطة وكيفية تدفقها، والرسوم التخطيطية للاستخدامات التي تبين التفاعل بين المستخدمين والنظام. تساعد هذه الرسوم التخطيطية في توضيح البنية العامة للأنظمة وتسهيل التواصل بين الفرق المختلفة. و تكمن استخدامات UML في تطوير البرمجيات لفهم وتصميم البنية العامة للأنظمة، كما تساعد على التواصل بين الفرق المختلفة من المطورين والمصممين والمديرين، وتسهل توثيق الأنظمة والبرمجيات. و يمكنك أن تطلع أكثر عليها من خلال هذه المقالات: بالتوفيق إن شاء الله.
- 1 جواب
-
- 1
-
-
يمكنك استخدام JavaScript لإضافة عناصر جديدة أو نصوص إلى عنصر `div فارغ باستخدام DOM Manipulation، حيث يمكنك استخدام innerHTML أو appendChild أو insertBefore، وغيرها لإضافة محتوى. أو يمكنك حتى استخدام خاصية content مع الـ Pseudo Elements و يمكنك أن تطلع أكثر على الموضوع من خلال هذه المقالات:
- 3 اجابة
-
- 1
-
-
تعمل الأكاديمية جاهدة لتوفير دورات في كل المجالات الممكنة و أيضا على تحديث الدورات الحالية، و بالنسبة لدورة في الأمن السيبيراني سيصل إقتراحك إن شاء الله للإدارة، لا أستطيع أن أعطيك توقع لمتى تتوفر الدورة و لكن بالتأكيد ستكون في القريب العاجل.
- 3 اجابة
-
- 1
-
-
مرحبا يوسف، ارجوا وضع تساؤلاتك تحت كل فيديو حتى يتسنى لنا مساعدتك بشكل أفضل. بالتوفيق إن شاء الله.
-
يمكنك دراسة الإثنين مع بعض، بالنسبة لطريقة دراستها الأفضل أن تشاهد فيديوات شرح أفضل لأنهم يتم تبسيطها بشكل كبير و بالتالي يسهل عليك فهمها.
- 4 اجابة
-
- 1
-
-
الفرق بينهما يكمن في الهدف الأساسي لكل منهما والطريقة التي يتم بها تحقيق ذلك، حيث أن أنماط التصميم تعتبر حلول مجربة ومعتمدة لمشاكل معينة في التصميم البرمجي، تمثل النماذج التي تستخدم مجموعة من التقنيات والمبادئ لحل مشكلة معينة بشكل فعال وقابل للتوسع والصيانة، وتهدف إلى توفير طرق قياسية لحل مشاكل معينة مثل إدارة التواصل بين الكائنات، وتقسيم المشاكل الكبيرة إلى أقسام صغيرة، وتنظيم هيكل التطبيق. أما الكود النظيف فيشير إلى كتابة الكود بطريقة تجعله سهل القراءة والفهم والصيانة والتعديل، يشمل ذلك استخدام تسميات مفصلة للمتغيرات والدوال، وتقسيم الكود إلى وحدات صغيرة ومستقلة، والتعليقات المفصلة لشرح الخوارزميات المعقدة. بالنسبة لمبرمجي الذكاء الاصطناعي، فإن فهم Design Patterns يمكن أن يكون مفيدا بشكل كبير، إذ يمكن أن تساعدهم في تنظيم وتصميم النظم بشكل أفضل، وتحسين الأداء والكفاءة، وزيادة قابلية التوسع والصيانة، كما أن فهم الأنماط التقليدية للتصميم يمكن أن يوفر الوقت والجهد من خلال استخدام حلول مجربة ومعتمدة. و يمكنك أن تقرأ أكثر عليها من خلال هذه المقالات:
- 4 اجابة
-
- 1
-
-
مكتبة sys توفر وصولا إلى المتغيرات والوظائف المرتبطة بالنظام، هذه المكتبة مفيدة للتعامل مع المعلومات البيئية للنظام والبرنامج الذي يعمل عليه، و تحتوي على العديد من الوظائف و لكن الأهم و الأكثر إستخداما هي : sys.argv: قائمة تحتوي على الوسائط التي تم تمريرها إلى البرنامج من خلال سطر الأوامر. sys.path: قائمة تحتوي على المسارات التي يتم البحث فيها للوصول إلى المكتبات المستخدمة في البرنامج. sys.platform: يوفر معلومات حول المنصة التي يتم تشغيل البرنامج عليها (مثل win32 لنظام Windows أو linux لنظام Linux). sys.exit(): يتيح إنهاء تنفيذ البرنامج في أي وقت.و هذا كود صغير لكيف يتم إستخدام هذه المكتبة: import sys # استخدام sys.argv لطباعة الوسائط الممررة من سطر الأوامر print("الوسائط الممررة:", sys.argv) # استخدام sys.exit() للخروج من البرنامج بشكل نظيم if len(sys.argv) < 2: print("الرجاء تمرير معلمة واحدة على الأقل.") sys.exit(1) # يعني خروج بحالة خطأ # استخدام sys.platform للتعامل مع الأنظمة المختلفة بطرق مختلفة if sys.platform == "win32": print("أنت تستخدم ويندوز.") elif sys.platform == "linux": print("أنت تستخدم لينكس.")
- 2 اجابة
-
- 1
-
-
نعم هذا الكورس مناسب للمبتدئين في مجال الذكاء الاصطناعي، لأنه يحتوي على المفاهيم الأساسية للذكاء الاصطناعي بشكل عام ويغطي فروعا مختلفة منه، بما في ذلك تعلم الآلة وتعلم الآلة العميق و غيرها، و يهدف الكورس بشكل أساسي إلى تزويد الطلاب بالأسس اللازمة لفهم وتطبيق تقنيات الذكاء الاصطناعي في مختلف المجالات، وبالنسبة للفرع الذي يغطيه الكورس بشكل خاص، فهو أكثر تركيزا على تعلم الآلة (Machine Learning) بمختلف فروعه، ولكنه يتطرق أيضا إلى مواضيع أخرى مثل تحليل البيانات والذكاء الاصطناعي التطبيقي.
- 2 اجابة
-
- 1
-
-
في الدورة العديد من التطبيقات، الأفضل أن تقوم بإنشاء مجلد للدورة، و من ثم أنشئ داخله مجلد لكل مسار و قم بوضع التطبيقات العملية للمسارات داخل كل مجلد خاص بها وضعها بالكامل في مستودع واحد، لأن التطبيقات العملية هناك صغيرة، و يوجد أيضا في الأخير مشروع قم بإنشاء مستودع منفصل له على GitHub. بالتوفيق إن شاء الله.
-
Ubuntu Linux 22.04 LTS هو إصدار طويل الدعم (LTS) من نظام التشغيل Ubuntu Linux، و يعتبر LTS الإصدار الرئيسي لـ Ubuntu الذي يتم دعمه لمدة طويلة (عادة 5 سنوات) مع التركيز على الاستقرار والأمان. بالنسبة للميزات تم التركيز على تجربة مستخدم محسنة مع إضافة مبدل مساحة عمل أفقي ومشغل تطبيق أفقي، و تم تحسين مدير الملفات مع إضافة ميزات جديدة مثل شريط المسار القابل للتمرير والإكمال التلقائي للمسارات، كما يضم النظام تجربة لقطة شاشة جديدة وخيارات لتعطيل الرسوم المتحركة لسهولة الوصول. تم أيضا تحسين مظهر النظام بألوان مميزة ووضع مظلم حقيقي، مع تحسينات في واجهة سطح المكتب كما تم تحديث صفحات التطبيقات في مركز برامج Ubuntu Software، بالنسبة للعيوب المحتملة يمكن أن يكون هناك مشاكل في التوافق مع بعض البرامج والأجهزة القديمة، بالإضافة إلى التكيف الأولي للمستخدمين الجدد في نظام التشغيل Linux. و هذه أحد الصور للتقنيات الجديدة:
-
لديك خطأ بسيط في المتغير gradients حيث أنك في السطر 14 قمت بكتابته بشكل خاطئ بالشكل التالي: gradinets, عدله فقط ليصبح هكذا gradients.
- 3 اجابة
-
- 1
-
-
أعتقد أن هناك بعض الأخطاء في عملية الربط وفي ترتيب الجداول، حاول تنفيذ الاستعلام التالي الذي يحل الأخطاء ويعطيك النتائج المطلوبة: SELECT f.path_file, p.name_project, s.Num_std, s.Name_std, s.Email_STD, t.Name_teah, d.Name_dept FROM file_project f LEFT JOIN projects p ON f.id_p = p.id_Pro RIGHT JOIN student s ON p.Num_STD = s.Num_std RIGHT JOIN teachers t ON s.id_teah = t.id_teah RIGHT JOIN departments d ON t.id_dept = d.id_dept; هذا الاستعلام يستخدم عمليات الانضمام لربط الجداول معا، و يتم الانضمام من جدول file_project إلى جدول projects باستخدام LEFT JOIN ومن ثم الانضمام بين الجدولين student و teachers و departments باستخدام RIGHT JOIN.
-
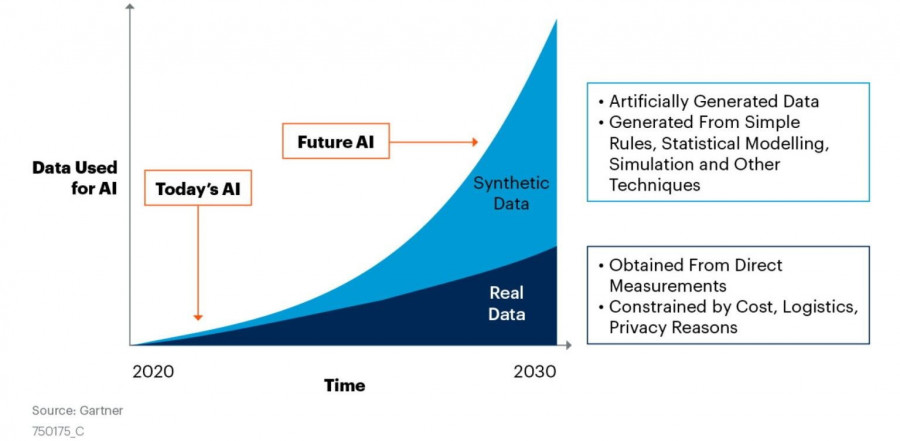
البيانات الاصطناعية هي بيانات يتم إنشاؤها بواسطة الحاسوب وتكون مشابهة للبيانات الحقيقية الموجودة في العالم الحقيقي، و تستخدم بغرض زيادة الخصوصية وسلامة الأنظمة، و في حالة التعلم الآلي، نستخدم البيانات الاصطناعية لتحسين أداء النماذج، كما أنها مفيدة في الحالات التي يكون فيها البيانات قليلة أو غير متوازنة، و مكتبة faker أحد المكتبات الأكثر إستخداما في هذا الأمر. و يوجد حتى بعض الدراسات التي تشير أنه في 2024 ستكون 60٪ من البيانات المستخدمة في تطوير تطبيقات التعلم الآلي والتحليلية مولدة بشكل اصطناعي، ويعود هذا للاستخدام الزائد للبيانات الاصطناعية إلى التكلفة العالية لجمع وتنظيف البيانات الحقيقية، وندرة البيانات في بعض الحالات، والحاجة المتزايدة إلى البيانات لتدريب النماذج واختبارها. و هذه نتائج الدراسة التي تم إجرائها، يعني حاليا يعتبر هذا الأمر من توجهات الذكاء الإصطناعي، صحيح في بعض الخالات يتعين علينا إستخدام بيانات حقيقة، و لكن يمكن دعمها بهذا النوع من البيانات.
- 3 اجابة
-
- 1
-
-
نعم من الطبيعي أن ينسى الشخص بعض الأسماء الدقيقة للوظائف أو الأساليب المتاحة في لغة برمجة معينة، و الأمر ليس متعلق ب shuffle فقط، و إنما بأي دالة لا تستخدمها كثيرة و بالتالي ستنساها بعد مدة من عدم الاستخدام، في هذه الحالة يمكنك استخدام البحث عبر الإنترنت للتحقق من الاسم الصحيح واستخدامه في الشيفرة.
-
لذا حاول إستخدام أحد البرامج التي ذكرت لك من أجل حفظ الملفات في مجلد معين، و من ثم قراءة محتوى الملف في تطبيقك.