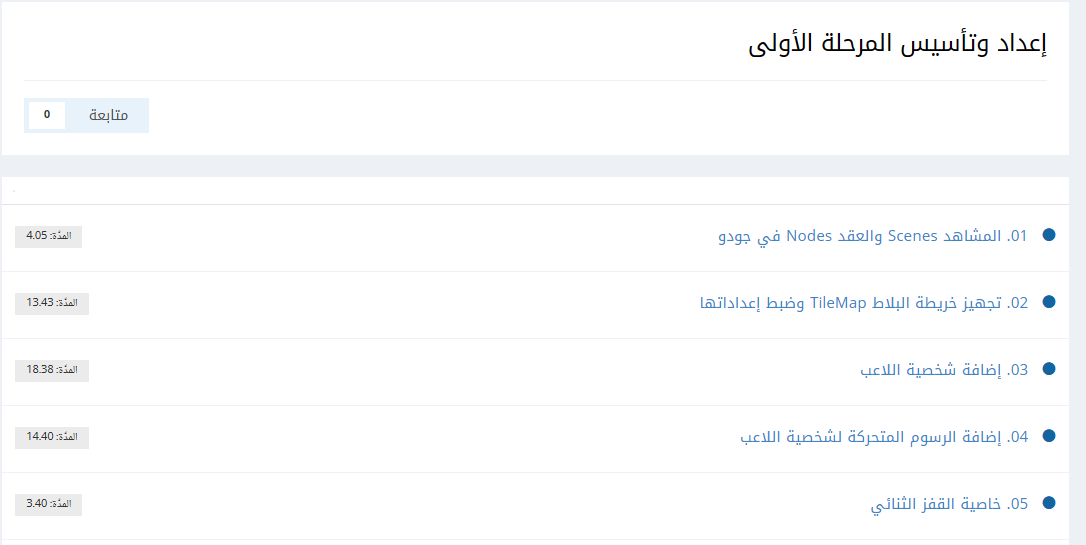
Mustafa Suleiman
-
المساهمات
20334 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
494
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 عليك إنشاء عميل client جديد لـ Passport، وذلك نوع خاص من عملاء Passport نستخدمه لتطبيقات الويب أو الأجهزة المحمولة التي تحتاج إلى الوصول إلى موارد API محمية بواسطة Passport. من خلال الأمر: php artisan passport:client --personal وذلك يحدد العميل الشخصي على أنه شخصي، أي أنه مُصمم للاستخدام من قبل تطبيق واحد فقط. سيخبرك بكتابة اسم التطبيق قم بكتابة أي اسم تريده، ثم قم بتشغيل الخادم، وتجربة تسجيل مستخدم بإيميل مختلف.
عليك إنشاء عميل client جديد لـ Passport، وذلك نوع خاص من عملاء Passport نستخدمه لتطبيقات الويب أو الأجهزة المحمولة التي تحتاج إلى الوصول إلى موارد API محمية بواسطة Passport. من خلال الأمر: php artisan passport:client --personal وذلك يحدد العميل الشخصي على أنه شخصي، أي أنه مُصمم للاستخدام من قبل تطبيق واحد فقط. سيخبرك بكتابة اسم التطبيق قم بكتابة أي اسم تريده، ثم قم بتشغيل الخادم، وتجربة تسجيل مستخدم بإيميل مختلف.- 4 اجابة
-
- 1
-

-
المقصود أنك تستطيع التقدم للإختبار عند إتمام 4 مسارات على الأقل في الدورة، وسيتم سؤالك في تلك المسارات فقط وليس كامل الدورة، فالبعض يريد دراسة مسارات معينة وليس كاملها لذا الخيار متاح لهم، لكن الاستفادة في دراسة الدورة بالكامل في حال كانت تلك المرة الأولى لك بالطبع.
-
أعتقد أن ما تريده هو وضع السهم في منتصف قسم الـ Hero أي أسفل العنوان الرئيسي، بالتالي عليك وضعه ضمن ذلك الجزء وليس خارجه أي كالتالي: <article> <h1 class="title">We bring the</h1> <br /> <div class="stylespan">BARBERSHOP TO YOU!</div> <i class="fa-solid fa-arrow-down"></i> </article> ثم تعديل التنسيق ليصبح: .fa-solid { display: flex !important; justify-content: center; font-size: 50px; color: #ffffff; } لاحظ display: flex !important; لأن font-awesome تقوم بتطبيق تنسيق inline-block للعنصر ونحن نريد تغيير نوعه ليصبح flex وذلك بكتابة !important لتجاوز التنسيق الحالي. بالطبع من الأفضل كتابة التنسيق التالي للعنصر الأب بدلاً من تنسيق كل عنصر بشكل منفرد: article { display: flex; flex-direction: column; justify-content: center; align-items: center; gap: 10px; } أي قم بحذف تنسيق fa-solid وقم بتطبيق التنسيق السابق.
- 4 اجابة
-
- 1
-

-
بالطبع وذلك الهدف من الدورة بالأساس، لكن يجب تحديد وجهتك من البداية وعدم دراسة كل شيء في نفس الوقت، بمعنى من خلال بايثون تستطيع أن تصبح مطور واجهة خلفية أو أن تصبح محلل بيانات أو مطور ذكاء اصطناعي وتعلم الآلة. إجمالاً المجالات كالتالي: مطور Full-stack لبناء مواقع الويب والمتاجر الإلكترونية أي قادر على تطوير الواجهة الأمامية والخلفية أيضًا من خلال Django و Flask. مطور واجهة خلفية Back-End فقط. مجال تعلم الآلة ولكن هنا أنت بحاجة إلى تعلم المزيد وعدم الإكتفاء بالدورة والأمر بحاجة إلى وقت أكثر من أي مجال آخر. محلل بيانات (Data Analyst )، حيث ستتمكن من استخدام مهارات البرمجة الخاصة بك للتحليل واستخراج البيانات من مصادر متنوعة، ومعالجة البيانات، وإجراء التحليلات الإحصائية والتعلم الآلي باستخدام مكتبات Python مثل pandas و NumPy و scikit-learn. مطور odoo بالتالي عليك البحث عن الوظائف في سوق العمل لديك وتحديد المطلوب بالنسبة لمستوى Junior أو خبرة سنة أو سنتين، وستجد تفصيل هنا:
-
ذلك صحيح فيما يخص الأساسيات، أيضًا في حال لديك خبرة مسبقة بلغتي HTML, CSS فسيقل الوقت الذي تقضيه في استيعاب كل درس، فوق الدرس لا يعني مدة دراسته، بل يشمل المراجعة والتوقف للاستيعاب والبحث والتطبيق بالتالي الوقت مضروب في 4 أو 5. بعد الأساسيات يبدأ الشرح بتعمق بشكل تدرجي ممنهج وباستطالة من خلال المشاريع العملية الكامل خلال الدورة. وفي حال لم يتضح لك شيء أرجو السؤال عنه أسفل الدرس وسيتم إيضاحه لك بالتفصيل.
-
من حيث الاستخدام فكلاهما واحد أي كلاهما دوال، الفرق يكمن في أنّ الميثود هي دالة كلاس أو كائن وليس في النطاق العام. بمعنى Functions دوال مستقلة، تُعرّف خارج أي كلاس أو كائن، وتستطيع استدعاءها مباشرةً من أي مكان في البرنامج لأنه يتم تعريفها في النطاق العام (Global Scope)، وتستقبل قيم إدخال parameters وتعيد قيمة إخراج return value. بينما الـ Methods هي دوال مرتبطة بكلاس أو كائن، وعليك تعريفها داخل الكلاس، وتُستدعى فقط من خلال إنشاء كائن من ذلك الكلاس وتقوم بتنفيذ عمليات معينة عليه. أي هي دالة خاصة تعرف على كائن معين من صنف معين، وتؤدي مهمة محددة على بيانات الكائن، وتؤثر عليه، وتستخدم للوصول إلى بيانات الكائن وتعديلها. لاحظ التالي مثلاً في بايثون، لدينا دالة مستقلة باسم greet وميثود داخل كلاس Person باسم greet. def greet(name): print(f"مرحباً {name}!") class Person: def __init__(self, name): self.name = name def greet(self): print(f"مرحباً {self.name}!") # استدعاء الدالة greet("محمد") person = Person("محمد") # استدعاء الميثود على الكائن person.greet()
- 6 اجابة
-
- 1
-
-
ذلك إختصار لجملة Statistical Analysis System، والتي تعني نظام التحليل الإحصائي، وتم تطوير SAS لأول مرة في أوائل السبعينيات في جامعة ولاية كارولينا الشمالية، وإطلاقه كمنتج تجاري في عام 1976. والغرض منه تحليل البيانات بشكل أساسي، ويتميز بالتالي: القدرة على التعامل مع كميات كبيرة من البيانات مجموعة واسعة من الإجراءات الإحصائية والتحليلية إنشاء تقارير وتحليلات مخصصة الدعم للغات البرمجة الأخرى مثل SQL وPython وR العمل على منصات متعددة، بما في ذلك ويندوز ولينكس وUNIX التكامل مع برامج أخرى مثل Excel و SPSS. وستجد أنه مستخدم في مجالات مختلفة منها البحوث العلمية، الإحصاء والتحليلات، العلوم الصحية، العلوم الاجتماعية، الأعمال والتجارة والحكومة.
- 5 اجابة
-
- 1
-
-
بالطبع تستطيع تخصيص اسم الدومين وذلك يسمى custom domain عليك شراء دومين أولاً من أحد مقدمي الخدمة مثل Namecheap. ثم التوجه للوحة التحكم لديك وربط الدومين بالمشروع الذي تريده.
- 5 اجابة
-
- 1
-
-
5 أشهر ليست بالفترة القصيرة في البداية بالتالي عليك مراجعة الدورة من البداية وتنفيذ التطبيقات العملية، ولكن لا تكتفي بذلك بل عليك تنفيذ مشروع أو مشروعين بجانب ما جاء بالدورة مع التركيز على HTML, CSS بعد ذلك تنتقل إلى جافاسكريبت وعليك إنشاء مشروع حقيقي وليس نموذج من خلالها ستجد على اليوتيوب مشاريع جافاسكريبت للمبتدئين. في بداية دراستك تحتاج إلى الاستمرار والإلتزام وتثبيت ما تعلمته من خلال التطبيق العملي، لذا تخصيص ساعة أو ساعتين على الأقل يوميًا أو شبه يومي عند إنشغالك أمر ضروري لكي لا تضطر إلى الإعادة من البداية. حاول عدم التسرع ومقامة الرغبة في الإنتقال للغة أو التقنية التالية، فذلك سيضرك فيما بعد ولن ينفعك، عليك إعطاء كل لغة حقها من الدراسة والممارسة العملية، خصص وقت أكبر للأساسيات HTML, CSS, JS وإنشاء مشروع كامل من خلالها.
-
عند تفقد دروس المسار، ستجد علامة دائرة زرقاء بجانب الدروس التي لم تشاهدها بعد داخل كل مسار مثل التالي: أي الدروس التي شاهدتها لن تجد بجانبها تلك العلامة. لكن أرجو عدم الضغط على زر "حدد الموقع كمقروء" فذلك من شأنه جعل كامل الموقع كأنك قرأت المقالات وشاهدت الدروس لذا ارجو عدم الضغط عليه.
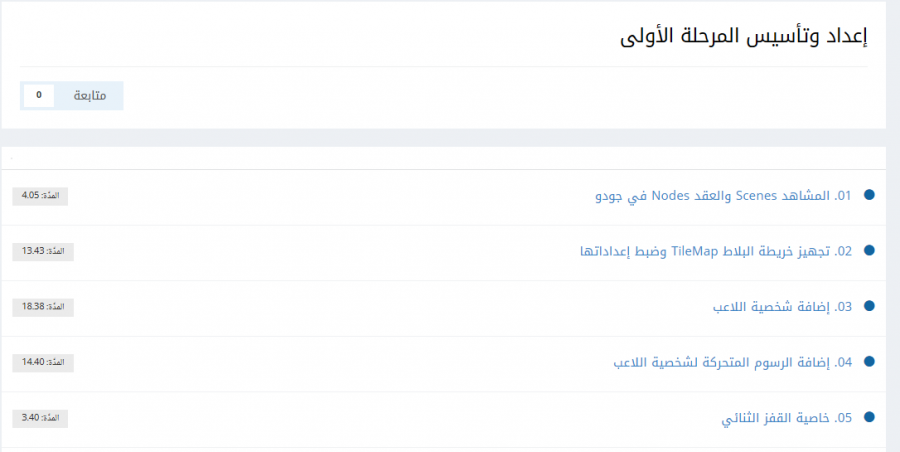
- 2 اجابة
-
- 1
-
-
في الوقت الحالي ذلك غير متوفر، لكن يتم تطوير منصة أكاديمية حسوب باستمرار لذا قد يتم إضافته عما قريب.
-
للإنضمام لدورة معينة عليكِ الإشتراك في الدورة التي تريدها وستجد جميع الدورات هنا: دورات تعليمية أما لمتابعة التقدم في الدورة فستجد علامة دائرة زرقاء بجانب الدروس التي لم تشاهدها بعد داخل كل مسار مثل التالي: لكن أرجو عدم الضغط على زر "حدد الموقع كمقروء" فذلك من شأنه جعل كامل الموقع كأنك قرأت المقالات وشاهدت الدروس لذا ارجو عدم الضغط عليه.
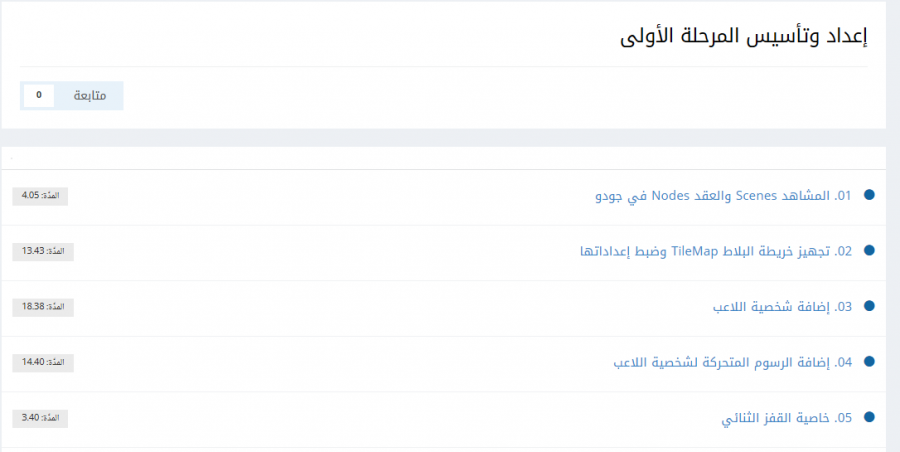
- 4 اجابة
-
- 1
-
-
العمل على منصات العمل الحر يتطلب أن تكون 18 عام كحد أدنى، لذا الأمر غير ممكن، لكن تستطيع العمل خارج تلك المواقع لو أردت ذلك ولكن ليس في شركة بل بشكل حر. في رأي لو قمت بدراسة الدورة ولديك جاهزية للدراسة لمدة 3 سنوات أي تطوير مستواك خلال تلك الفترة فستصبح بمستوى ممتاز جدًا عند إتمام 18 عام، وستتمكن من الحصول على وظيفة جيدة جدًا، حيث أنّ مجال الذكاء الاصطناعي بحاجة إلى وقت طويل لتصل لمستوى متقدم به.
-
ستحتاج إلى تهيئة البيانات أولاً من خلال Word حيث تستطيع إنشاء bibliography بكل سهولة، بعد ذلك نقل البيانات إلى Excel. ١. اختر نظام IEEE من ضمن خيارات أنظمة المراجع المتاحة في قائمة Bibliography Style تحت References كما هو موضح في الصورة (١). ٢. عند إدخال مرجع جديد إذهب إلى آخر الجملة المراد تزويدها بالمرجع ثم أنقر على References > Insert Citation ثم أدخل معلومات المرجع كما هو موضح في الصورة (٢). سيتم إضافة رقم في آخر الجملة. ٣. لإضافة قائمة المراجع، إذهب إلى آخر الملف (أو أينما أردت أن تضع القائمة) ثم انقر على Bibliography كما هو موضح في الصورة (٣).


- 2 اجابة
-
- 1
-
-
لا يوجد فرق، الجميع مبرمجين سواء developer أو Programmer أو Coder أو Software Engineer كلها مسميات تشير لنفس الأمر في إعلانات الوظائف. عامًة لو أردنا التخصيص والمقصود بتلك المسميات فعليًا فالمطور developer قادر على تصميم معمارية المشروع أي تصميم كل جانب من جوانب التطبيق أو النظام وكيفية عملها معًا. وإدارة عملية تطوير المشروع بجانب التعاون مع أعضاء فريق المشروع، والمشاركة في جميع مراحل دورة حياة تطوير البرامج، بما في ذلك التحديثات والتحسينات. في حين المبرمج Programmer يعمل على كتابة الكود وفقًا للمواصفات وتنفيذ مهام البرمجة المتعلقة بعملية التطوير. والتعاون بشكل أساسي مع المبرمجين الآخرين وأعضاء فريق التطوير بجانب المشاركة بشكل أساسي في البرمجة والاختبار وإصلاح الأخطاء. كما ترى يكتب كل من مطوري البرامج والمبرمجين الكود ويصححون الأخطاء ويختبرونه، ولكن المطورين أكثر مشاركة في جميع مراحل دورة حياة تطوير المشروع، ويركزون على ما يجب أن تفعله البرامج، وكيف يجب أن تبدو، وكيف يتفاعل المستخدمون معها. وبمجرد أن يتصوروا تصميم نظام البرامج أو التطبيق، يقررون المواصفات الفنية، ويشرفون على البرمجة، ويقيمون الوظائف، كما يديرون الصيانة أو التحديثات وإضافة ميزات ووظائف وإصدارات جديدة. وخلال عملية تطوير المشروع ، يجتمع المطورون بانتظام مع الـ Software Engineers وخبراء تجربة المستخدم والعملاء لفهم متطلبات الوظائف، والحصول على تقدير للجدول الزمني والميزانية، وطلب التوضيح أو التواصل بشأن التحديات وتقديم تقارير التقدم.
- 4 اجابة
-
- 1
-
-
سأوضح لك الخطوات وحاول القيام بالأمر بنفسك للاستفادة، يجب عليك أولاً استيراد مكتبة collections من بايثون، والتي توفر وظائف لإنشاء طوابير queue والتعامل معها، مثل إضافة عناصر، إزالة عناصر، فحص العناصر، وغيرها. ثم استخدم دالة deque من المكتبة لإنشاء طابور queue فارغ، بعد ذلك استخدم ميثود append لإضافة العناصر إلى نهاية الطابور. وتستطيع تحديد حجم الطابور باستخدام دالة len. ثم استخدم دالة popleft لإزالة العنصر الأول من الطابور. في النهاية قم بطباعة العناصر في الطابور باستخدام دالة print. ويجب أن يكون حجم الطابور 5، لذلك بعد إضافة 5 عناصر، سيتم إزالة العنصر الأول باستخدام popleft للحفاظ على حجم الطابور. وتستطيع استخدام دالة appendleft لإضافة عنصر إلى بداية الطابور، ودالة rotate لتدوير العناصر في الطابور. ستجد تفصيل هنا: كائنات deque في بايثون
-
أنت تستخدم واجهة خلفية غير متناسبة مع الواجهة الأمامية حيث يظهر خطأ SQLSTATE[HY000]: General error: 1364 Field 'google_id' doesn't have a default value (SQL: insert into users (name, email, password, updated_at, created_at) وبالعودة للمتحكم الخاصة بتسجيل حساب جديد في الواجهة الخلفية نجد: $user = User::create([ 'name' => $request->name, 'email' => $request->email, 'password' => Hash::make($request->password) ]); وبالعودة لقاعدة البيانات في جدول users نجد: Schema::create('users', function (Blueprint $table) { $table->id(); $table->string('name'); $table->string('email')->unique(); $table->timestamp('email_verified_at')->nullable(); $table->string('password')->nullable(); $table->string('google_id'); $table->string('google_token'); $table->rememberToken(); $table->timestamps(); }); بالتالي الحقلين: $table->string('google_id'); $table->string('google_token'); ليس لهم أي قيمة يتم تقديمها، وحتى لم يتم وضع لهم قيمة إفتراضية في حال لم تقدم قيمة من الواجهة الأمامية، لذا عليك القيام بأي حل تراه مناسب.
-
التزامن ببساطة تقنية برمجية تتيح للبرنامج تنفيذ عدة مهام في نفس الوقت، أي أن البرنامج يمكنه القيام بمهام متعددة في نفس الوقت، بدلاً من انتظار انتهاء المهام السابقة قبل البدء في المهام الجديدة. للتوضيح، ساستخدم مكتبة threading في بايثون لإنشاء خيطين Threads منفصلين، الخيط Thread الأول سيقوم بطباعة الأرقام من 1 إلى 10، والخيط الثاني سيقوم بطباعة الأحرف من A إلى J. وسيصبح البرنامج كالتالي وإليك تعليقات لتوضيح الأمر: import threading import time # دالة للخيط الأول def print_numbers(): for i in range(1, 11): print(i) time.sleep(0.5) # انتظر نصف ثانية قبل الطباعة التالية # دالة للخيط الثاني def print_letters(): for letter in 'ABCDEFGHIJ': print(letter) time.sleep(0.5) # انتظر نصف ثانية قبل الطباعة التالية # إنشاء خيطين thread1 = threading.Thread(target=print_numbers) thread2 = threading.Thread(target=print_letters) # بدء الخيطين thread1.start() thread2.start() # انتظار انتهاء الخيطين thread1.join() thread2.join() عندما تشغل البرنامج، ستلاحظ أن الأرقام والأحرف يتم طباعتها في نفس الوقت، وذلك يعني أن البرنامج يقوم بمهام متعددة في نفس الوقت، وهو ما يسمى بالتزامن. 1 A 2 B 3 C 4 D 5 E 6 F 7 G 8 H 9 I 10 J وللعلم بايثون لديها بعض القيود فيما يتعلق بالتزامن، بسبب ما يعرف بـ "Global Interpreter Lock" (GIL). ويعني أن بايثون لا يمكنه استخدام أكثر من نواة واحدة في المعالج في نفس الوقت، حتى لو كان لديك معالج متعدد النواة.
- 3 اجابة
-
- 1
-
-
طالما لديكِ إلمام بأساسيات البرمجة من خلال لغة قوية جدًا مثل C++ فلا حاجة إطلاقًا لدراسة مسار سكراتش فهو مناسب لتقديم مفاهيم البرمجة بشكل مبسط لمن ليس لديهم أي دراية بمجال البرمجة. على عكسك أنتِ، بالتالي عليكِ دراسة المسارات التالية لمسار سكراتش بالكامل وستجدي استفادة منهم، حيث سيتم التطرق إلى: أساسيات البرمجة من خلال جافاسكريبت (ستتمكني من دراسته بسهولة بما أن لديك خلفية برمجية وستتعلمي لغة جافاسكريبت أيضًا) أنظمة التشغيل ونظام لينكس قواعد البيانات مجال الويب والواجهة الأمامية والخلفية البرمجة كائنية التوجه من خلال بايثون الخوارزميات وبنى المعطيات algorithm and data structure أنماط التصميم design patterns أساسيات هندسة البرمجيات Software Development Life Cycle (SDLC) إعادة تصميم البرمجيات Refactoring وكل ما سبق مطلوب منك معرفته ودراسته لتصبحي مهندسة برمجيات software engineer.
- 5 اجابة
-
- 1
-
-
أرجو توفير صورة لما يحدث لديك في منفذ الأوامر والخطوات التي قمت بها لرفع المشروع أي ما هي الأوامر التي كتبتها. وأيضًا عرض نتيجة الأمر التالي: git remote show origin مع توضيح رابط المستودع الخاص بك على github أيضًا. ستجد هنا تفصيل لطريقة رفع المشاريع:
-
لا يوجد دورة مخصصة بالأكاديمية لتطوير تطبيقات الهاتف المحمول، لكن في في دورة "تطوير التطبيقات من خلال جافاسكريبت" يوجد شرح لإطاري React Native و Ionic وهما لتطوير تطبيقات الهاتف لأندرويد وIos من خلال جافاسكريبت. لذا من خلال تلك الدورة تستطيع تعلم بناء أي مشروع تريده، فيوجد بها أيضًا شرح لبناء تطبيقات سطح المكتب.
-
التعلم العميق هو أحد فروع تعلم الآلة، وتعلم الآلة هو فرع من فروع الذكاء الاصطناعي (AI) يركز على تطوير خوارزميات وطرق يمكنها من التعلم من البيانات وتحسين أدائها دون الحاجة إلى برمجة صريحة، ويستخدم مختلف الأساليب والتقنيات، مثل التعلم الإشرافي والتعلم غير الإشرافي والتعلم المعزز. من جانبه، التعلم العميق هو فرع من فروع تعلم الآلة يركز على تطوير خوارزميات تعتمد على الشبكات العصبية الاصطناعية ANNs ذات الطبقات المتعددة، وهي تحاكي هيكل الدماغ البشري وتسمح للآلة بالتعلم من البيانات وتحليلها بطريقة أكثر تعقيداً، ويستخدم تقنيات مثل الشبكات العصبية التلافيفية CNNs والشبكات العصبية الدلالية RNNs والشبكات العصبية التلافيفية الدلالية LSTMs وغيرها. بالتالي عليك البدء بتعلم أساسيات "تعلم الآلة" قبل البدء في التعلم العميق من خلال دراسة التالي: Regularization. Underfitting and Overfitting and how to identify them Various cost functions A thorough understanding of stochastic gradient descent Hyper parameter tuning Cross validation techniques ثم دراسة: Regression Classification (Both Sample Based and Probabilistic) Decision Trees Neural Networks

- 4 اجابة
-
- 1
-
-
بسبب طريقة حساب الأهمية في كل منهما، ففي الرسم الأول، الذي يظهر الترتيب حسب قيمة الارتباط مع Outcome، تقوم بحساب الارتباط باستخدام معامل الارتباط بين كل ميزة و Outcome، أي أن الميزات التي لها قيمة ارتباط أعلى تكون أكثر ارتباطًا مع Outcome. في الرسم الثاني، يظهر الترتيب حسب الأهمية باستخدام Permutation Importance، وتقوم بحساب الأهمية من خلال تقييم تأثير كل ميزة على دقة النموذج من خلال تغيير قيمة كل ميزة بشكل عشوائي وتقييم التغيير في دقة النموذج، والميزات التي لها تأثير أكبر على دقة النموذج تكون أكثر أهمية. بالتالي الفرق بين الطريقتين هو أن الارتباط لا يعتبر تأثير الميزة على دقة النموذج، بينما الأهمية تعتبر تأثير الميزة على دقة النموذج. ولتعديل الترتيب، استخدم تقنية Feature Engineering لتحسين الأهمية للميزات التي تريدها، وأحد الطرق هي Feature Scaling والتي تقوم بتوسيم الميزات وتصبح جميعها بنفس النطاق، مما يمنع الميزات ذات القيم الأكبر من التأثير بشكل أكبر على النموذج. أي لو ميزة Glucose تتراوح بين 0 و 300، بينما ميزة Insulin تتراوح بين 0 و 10، فإن Glucose ستكون لها تأثير أكبر على النموذج، وتستطيع استخدام StandardScaler أو MinMaxScaler لتوسيم الميزات إلى نطاق موحد. كالتالي: from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train_scaled = scaler.fit_transform(x_train) x_test_scaled = scaler.transform(x_test) modle_diabetes_randomforestregressor = RandomForestRegressor(n_estimators=10000 , max_depth=4 , random_state=33) train = modle_diabetes_randomforestregressor.fit(x_train_scaled , y_train) importances = permutation_importance(modle_diabetes_randomforestregressor , x_test_scaled , y_test , n_repeats=10 , random_state=42) importance_scores = importances.importances_mean
- 2 اجابة
-
- 1
-
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم الأسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
أولاً عليك تنظيم مجلد المشروع الرئيسي بحيث تقوم به بإنشاء مجلد لكل مشروع ثم داخل كل مجلد تضع ملفات المشروع الخاصة به. ثم بإنشاء مستودع git محلي بالمجلد الرئيسي ثم تقوم بإنشاء مستودع على GitHub لنرفع به المجلد الرئيسي ثم تقوم بدفع المجلد إلى المستودع على GitHub. ستجد خطوات رفع المشاريع هنا: لكن لتوفر على نفسك الكثير من العناء الأفضل مشاهدة التالي أولاً لتعلم Git الأمر سيستغرق منك ساعة: وستجد هنا مرجع لأوامر git: