Mustafa Suleiman
-
المساهمات
20435 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 الدورة موجهة لتعلم أساسيات الواجهة الأمامية من خلال تعلم اللغات الأساسية التي يعتمد عليها أي مكتبة أو إطار للواجهة الأمامية وهو HTML, CSS, JS. وتعلم تلك اللغات في البداية واجب وضروري، وبدونها ستعاني في فهم ما يدور في الكود الخاص بك عند تعلم تلك المكتبات والإطارات، وأيضًا ستواجه صعوبة في حل المشكلات التي تواجهك وأيضًا تخصيص مشروعك بالشكل الذي ترغب به. ولتعلم React.js الأمر يحتاج إلى فرد مساحة في دورة مختلفة تمامًا، والدورة لن تكون للمبتدئين في الواجهة الأمامية، فأنت بحاجة إلى تعلم اللغات الأساسية كما ذكرت لتفهم ما يحدث وما فائدة ما تتعلمه وتكتبته. ولذلك ستجد أنه تم تخصيص دورة تطوير التطبيقات باستخدام لغة JavaScript من أجل تعلم مكتبة React وإطارات جافاسكريبت الأخرى مثل React Native لتطوير تطبيقات الهاتف وأيضًا Ionic ثم ستتعلم Electron.js لتطوير برامج سطح المكتب. وأيضًا يوجد شرح لإطار Next.js وهو هام جدًا بعد تعلم React من أجل التصيير من جهة الخادم Server-side Rendering. وجميع المسارات الأولى من الدورات الأخرى متاحة لك، وتستطيع الإطلاع عليها فمثلاً في دورة تطوير التطبيقات باستخدام لغة JavaScript المسار الأول هو أساسيات لغة JavaScript وأنصحك بالإطلاع عليه لتعلم المزيد عن جافاسكريبت بجانب ما درسته في دورة تطوير واجهة المستخدم.
الدورة موجهة لتعلم أساسيات الواجهة الأمامية من خلال تعلم اللغات الأساسية التي يعتمد عليها أي مكتبة أو إطار للواجهة الأمامية وهو HTML, CSS, JS. وتعلم تلك اللغات في البداية واجب وضروري، وبدونها ستعاني في فهم ما يدور في الكود الخاص بك عند تعلم تلك المكتبات والإطارات، وأيضًا ستواجه صعوبة في حل المشكلات التي تواجهك وأيضًا تخصيص مشروعك بالشكل الذي ترغب به. ولتعلم React.js الأمر يحتاج إلى فرد مساحة في دورة مختلفة تمامًا، والدورة لن تكون للمبتدئين في الواجهة الأمامية، فأنت بحاجة إلى تعلم اللغات الأساسية كما ذكرت لتفهم ما يحدث وما فائدة ما تتعلمه وتكتبته. ولذلك ستجد أنه تم تخصيص دورة تطوير التطبيقات باستخدام لغة JavaScript من أجل تعلم مكتبة React وإطارات جافاسكريبت الأخرى مثل React Native لتطوير تطبيقات الهاتف وأيضًا Ionic ثم ستتعلم Electron.js لتطوير برامج سطح المكتب. وأيضًا يوجد شرح لإطار Next.js وهو هام جدًا بعد تعلم React من أجل التصيير من جهة الخادم Server-side Rendering. وجميع المسارات الأولى من الدورات الأخرى متاحة لك، وتستطيع الإطلاع عليها فمثلاً في دورة تطوير التطبيقات باستخدام لغة JavaScript المسار الأول هو أساسيات لغة JavaScript وأنصحك بالإطلاع عليه لتعلم المزيد عن جافاسكريبت بجانب ما درسته في دورة تطوير واجهة المستخدم. -
بعد مسار تعلم الآلة الأصح أن تبدأ بمسار التعلم العميق ثم قم بدراسة مسار تطبيقات عملية باستخدام المحوّلات Transformers لتتعلم كيفية استخدام نماذج مدربة مسبقًا مثل VIT وتعديلها لتناسب بياناتك، لكن قم بدراسة قسم المقدمة وقسم إضافة الذكاء الاصطناعي لمركز خدمات فقط. ثم تنتقل بعده إلى التخصص في الرؤية الحاسوبية، لأنه يعتمد بنسبة كبيرة على تقنيات التعلم العميق، ولو حاولت دراسة CV دون فهم عميق للشبكات العصبية، فستجد نفسك تدرس تقنيات قديمة مثل معالجة الصور التقليدية والتي رغم أهميتها، لا تكفي لبناء أنظمة ذكاء اصطناعي حديثة. كذلك يجب تخصيص الدورة بناءًا على هدفك، ركز على استيعاب CNNs، وتجاوز أي شيء يتعلق بالنصوص NLP أو التنبؤ الزمني المعقد، ثم ابدأ في تطبيقات الـ Computer Vision.
- 1 جواب
-
- 1
-

-
هل قمت بالإشتراك بالدورة؟ في حال اشتركت بالفعل، ستجد الدورات المُشترك بها عند الضغط على تبويب دوراتي: وبالنسبة لمحتوى الدورة، فيجب مشاهدته بالترتيب الموجود بالدورة، لأنّ المسارات التي بالأسفل تعتمد على المسارات التي بالأعلى الخاصة بالأساسيات. وبالنسبة لملفات الكود، ففي كل مسار ستجد رابط للملفات أو مستودع المشروع على GITHUB في بداية المسار، وهو درس المقدمة أو المدخل، وتلك هي الملفات التي سنحتاجها في المسار، والكود هو الكود النهائي للإطلاع عليه. أما ملفات PDF كتلخيص للدورة، فهي غير متوفرة في الوقت الحالي، أرجو الإعتماد على موسوعة حسوب كمرجع، وتستطيع الاستفسار أسفل الدروس في التعليقات عما تحتاجه وسيتم توضيحه لك. عامًة كل شخص له أسلوب يُناسبه في الدراسة، لكن المهم هو تجنب المشاهدة السلبية وتخصيص وقت أكبر للتطبيق العملي، فالبرمجة عبارة عن تفكير منطقي لحل مشكلة ثم تنفيذ ذلك من خلال كتابة الكود. والبعض يُفضل كتابة مُلخصات لكل شيء، لكن لا أنصحك بذلك، اكتفي فقط بكتابة ملاحظات ومُلخصات ورسومات للأمور النظرية أو معلومة معينة تريد الإحتفاظ بها للعودة إليها للمراجعة. بينما البرمجة نفسها اكتفي بالتطبيق العملي فهو الأهم وبدونه فلا معنى للمُلخصات النظرية مهما كتبت، ببساطة لن تستطيع قيادة سيارة بمشاهدة فيديو صحيح؟
- 2 اجابة
-
- 1
-
-
يتم إختبارك في المسارات التي قمت بإنهائها فقط بحد أدنى 4 مسارات، لكن الأفضل إنهاء كامل الدورة لتحقيق استفادة، فذلك الخيار متاح لمن يريد دراسة جزء معين من الدورة أو التخصص في جزئية معينة مثلاً. آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.
- 2 اجابة
-
- 1
-
-
الاتصال ناجح لكن الاستعلامات تفشل بسبب timeout، ومتغير البيئة MONGO_URI في ملف .env به مشكلة. تفقد متغير MONGO_URI في ملف .env ويجب أن لا توجد مسافات قبل أو بعد = ولا توجد علامات اقتباس حول القيمة، كذلك اسم المتغير يجب أن يكون MONGO_URI كما في الكود: MONGO_URI=mongodb+srv://username:password@cluster0.mf8buxy.mongodb.net/dbname?retryWrites=true&w=majority
-
لن تجد مشروع حديث يتطلب تقنية JQuey ، فتلك تقنية من زمن قد ولى، ستجدها فقط في المشاريع القديمة Legacy والتي بها استخدام كبير لتلك المكتبة للدرجة التي يُصعب بها تحديث كامل المشروع لاستبدالها بجافاسكريبت، فالإحصائيات تشير إلى أن أكثر من 70% إلى 90% من مواقع الويب حول العالم لا تزال تستخدم jQuery وفقًا لموقع W3Techs. ومؤخرًا صدر الإصدار الرابع من JQuey على الرغم من أنّ المكتبة لا تُستخدم في مشاريع حديثة. والأمر يعود لمنصة ووردبريس التي تشغل 43% من الويب حيث تعتمد بشكل كبير على jQuery، وأي تحديث للمكتبة يعني تحسين أداء وأمان ملايين المواقع دفعة واحدة. والشركات الكبرى لديها أنظمة تعمل منذ سنوات تعتمد على jQuery، وإعادة كتابتها بتقنيات حديثة مكلفة جدًا، لذا هم بحاجة لنسخة أحدث وأسرع دون تغيير الكود بالكامل. تعلمها عند الحاجة فقط.
-
في الواقع العملي لا يتم استخدام المصطلحات العربية بالفعل، اللغة الإنجليزية هي لغة البرمجة، لكن الدارسين بالأكاديمية لغتهم الأولى هي العربية لذا المحتوى موجه لهم في المقام الأول، أي لا تنظر للأمر من جهتك أنت فقط، ويتم في معظم الدروس توضيح المصطلح بالإنجليزية أيضًا، وفي حال لم يتم ذكر ذلك، أرجو الاستعانة بموسوعة حسوب وابحث عن المصطلح وستجده بالعربية والإنجليزية. وفي حال واجهت صعوبة في استيعاب مصطلح ما، تستطيع الاستفسار أسفل الدروس وسيتم توضيحه لك، ويجب معرفة المصطلح بالعريبة والإنجليزية حتى تتمكن من البحث عنه بالرغم من أنّ الإنجليزية أهم بالطبع لكون المصادر أغلبها بالإنجليزية ولن تحتاج العربية إلا في حال شرح أمر ما لشخص آخر أو للفريق وحتى في تلك الحالة يتم استخدام المصطلحات الإنجليزية. وعامًة ستجد مصطلحات متكررة ومستخدمة في أغلب البرمجة ها هي: متغير - Variable: مكان في الذاكرة لتخزين البيانات. نوع البيانات - Data Type: يحدد نوع البيانات التي يمكن تخزينها في المتغير (مثل: نص، عدد صحيح، عدد عشري). عامل - Operator: رمز أو كلمة تستخدم لتنفيذ عملية على البيانات (مثل: + للجمع، - للطرح). تعبير - Expression: مجموعة من المتغيرات والعوامل التي تُرجع قيمة. شرط - Condition: تعبير منطقي يُرجع إما صحيح أو خطأ. جملة - Statement: سطر من التعليمات البرمجية التي تُنفذ مهمة محددة. كتلة - Block: مجموعة من الجمل التي تُنفذ معًا. دالة - Function: مجموعة من التعليمات البرمجية التي تُنفذ مهمة محددة وتُعيد قيمة. معامل - Parameter: قيمة تُمرر إلى دالة عند استدعائها. مصفوفة - Array: مجموعة من البيانات من نفس النوع مخزنة في مكان واحد. حلقة - Loop: تُستخدم لتكرار مجموعة من التعليمات البرمجية عدة مرات. مصفوفة ترابطية - Associative Array / Dictionary: مجموعة من البيانات مخزنة كأزواج من المفتاح والقيمة. كائن - Object: كيان يجمع بين البيانات والوظائف التي تعمل على هذه البيانات. فئة - Class: قالب لإنشاء الكائنات. وراثة - Inheritance: آلية تسمح لفئة ما بوراثة خصائص وصفات فئة أخرى. تعدد الأشكال - Polymorphism: القدرة على استخدام نفس الاسم لوظائف مختلفة في سياقات مختلفة. ملف - File: مجموعة من البيانات المخزنة على وسيط تخزين دائم. استثناء - Exception: حدث غير طبيعي يحدث أثناء تنفيذ البرنامج. معالجة الاستثناءات - Exception Handling: آلية للتعامل مع الاستثناءات ومنع تعطل البرنامج. وبالنسبة للمصطلحات الخاصة ببايثون: وحدة - Module: ملف يحتوي على تعليمات برمجية بايثون يمكن استخدامه في برامج أخرى. حزمة - Package: مجموعة من الوحدات النمطية. قائمة - List: مجموعة مرتبة من العناصر قابلة للتغيير. مجموعة - Tuple: مجموعة مرتبة من العناصر غير قابلة للتغيير. مجموعة - Set: مجموعة غير مرتبة من العناصر الفريدة. قاموس - Dictionary: مجموعة غير مرتبة من أزواج المفتاح والقيمة. تعليمة استيراد - Import Statement: تُستخدم لاستيراد وحدات أو حزم في البرنامج. ديكوريتور - Decorator: دالة تُعدل سلوك دالة أخرى. مولد - Generator: دالة تُعيد سلسلة من القيم. استدعاء ذاتي - Recursion: عندما تستدعي الدالة نفسها داخل تعريفها. تعبير لامبدا - Lambda Expression: دالة مجهولة تُعرّف وتُستخدم في سطر واحد. استيعاب القائمة - List Comprehension: طريقة لإنشاء قائمة جديدة من قائمة موجودة في سطر واحد. استيعاب المجموعة - Set Comprehension: طريقة لإنشاء مجموعة جديدة من مجموعة موجودة في سطر واحد. استيعاب القاموس - Dictionary Comprehension: طريقة لإنشاء قاموس جديد من قاموس موجود في سطر واحد. إدارة الحزم - Package Management: عملية تثبيت وتحديث وإزالة الحزم. بيئة افتراضية - Virtual Environment: بيئة معزولة لتشغيل مشروع بايثون بتبعياته الخاصة.
-
لا حاجة لسكراتش في حال لديك سابق دراية بالبرمجة، الفكرة من دراسة سكراتش هي تقديمك للمنطق البرمجي والمفاهيم الخاصة به مثل المتغيرات والجمل الشرطية وحلقات التكرار وكيفية الربط بينهم، وذلك بشكل بسيط دونّ استخدام أي كود. طالما لديك خبرة برمجية أو خلفية تقنية وقادر على تعلم البرمجة من خلال لغة برمجية مباشرًة، فلا مشكلة تستطيع تخطي ذلك المسار، وبقية المسارات مهمة لذا الأفضل دراستها لتحقيق استفادة. ودورة علوم الحاسوب تم إعدادها بشكل خاص لكي يتم تأهيلك لتعلم البرمجة، ففي البداية ستتعلم التفكير المنطقي في البرمجة وطريقة كتابة خوارزمية أو خطوات كتابة البرنامج قبل كتابة الكود أي التفكير أولاً، ثم تطبيق الأمر من خلال سكراتش لكون المنصة بسيطة وتوفر لك التعرف على المفاهيم البرمجية بطريقة ممتعة مثل حلقات التكرار والجمل الشرطية والمتغيرات وغيرها. أي لا نتعلم سكراتش بل المفاهيم البرمجية والمنطق البرمجي وكيفية التفكير قبل البدء في كتابة الكود، فتلك هي المرحلة الأهم وليس كتابة الكود. ثم الإنتقال لاستخدام لغة برمجية فعلية مثل بايثون وجافاسكريبت، ولو انتقلت إليهم مباشرًة، ستجد صعوبة في استيعاب المفاهيم البرمجية في حال لم يكن لديك أي خلفية تقنية أو برمجية سابقة. وهناك أمر هام يجب الإنتباه إليها، لا توجد طرق مختصرة لتعلم البرمجة، تسريع وتيرة عملية التعلم وتخطي الأساسيات يعني مستوى تعلم سطحي لن يصل بك بعيدًا، وفي الوقت الحالي الأساسيات هي الأهم أكثر من أي وقتٍ مضى.
-
منطق الكود الحالي غير مناسب للعمل في بيئة متعددة المستخدمين، فأنت تعتمد على توليد رقم الفاتورة وعرضه في TextBox قبل الحفظ، ولو فتح موظف ما شاشة البيع وحصل على رقم فاتورة 105، وفتح موظف آخر الشاشة في نفس اللحظة وحصل أيضاً على 105، فأول من يحفظ سينجح، والثاني سيحصل على خطأ Primary Key Violation أو سيقوم بتحديث فاتورة زميله حسب التصميم. لذا رقم الفاتورة يجب أن يولد لحظة الحفظ داخل قاعدة البيانات أو داخل الـ Transaction، ولا يؤخذ من الشاشة. كذلك استخدمت SqlDataAdapter لجلب كل الفواتير Select * ثم إضافة سطر واحد وحفظ الجدول بالكامل هو أسلوب يقتل سرعة البرنامج، فتخيل لو يوجد 100 ألف فاتورة، البرنامج سيقوم بتحميلها كلها للذاكرة فقط لإضافة فاتورة واحدة. الصحيح هو استخدام جملة INSERT INTO مباشرة عبر SqlCommand. وفي بيئة متعددة المستخدمين وحتى المستخدم الواحد، استخدام كائن اتصال static أو عام ومشارك، أمرخطير، فقد تتداخل الـ Transactions بين مستخدمين مختلفين إن لم يتم التعامل معها بحذر شديد. الصحيح هو إنشاء اتصال جديد new SqlConnection داخل جملة using لكل عملية حفظ. أيضًا قمت بالخصم من المخزون، لكن لو كانت الكمية المتبقية 5، وقام موظفان ببيع 3 قطع في نفس الثانية، فالكود الحالي سيسمح بذلك ويصبح الرصيد بالسالب (-1). وذكرت أنك تريد الاعتماد على حركة الصنف، لا مشكلة في ذلك، لكن من ناحية الأداء فلو أردت معرفة الرصيد الحالي، فلا يجب أن تقوم بجمع كل الحركات (مبيعات - مشتريات) من أول يوم للنظام في كل مرة تبيع فيها، لأن ذاك سيجعل النظام بطيئ مع الوقت. يجب أن تحتفظ بجدول Inventory به الرصيد الحالي لسرعة الاستعلام، وجدول ItemMovement لتسجيل التاريخ للتقارير والمراجعة، وقمت بذلك بالفعل لكن طريقة التنفيذ تحتاج تعديل، بحيث جدول Inventory يحتوي الرصيد الحالي اللحظي، ويتم التعديل عليه بالزيادة والنقصان لسرعة معرفة كم يوجد الآن؟ عند فتح فاتورة البيع. وجدول ItemDailyMovement هو سجل تاريخي لا يُحذف منه شيء، ولمعرفة رصيد الصنف بتاريخ قديم، أو مراجعة الحسابات، تقوم بجمع الحركات من ذلك الجدول. if (comboBox1.SelectedIndex == -1) { MessageBox.Show("الرجاء إدخال اسم زبون", "تنبيه", MessageBoxButtons.OK, MessageBoxIcon.Warning); return; } if (dataGridView4.Rows.Count == 0) { MessageBox.Show("الرجاء إدخال أصناف في الفاتورة", "تنبيه", MessageBoxButtons.OK, MessageBoxIcon.Warning); return; } decimal totalInvoice = 0; foreach (DataGridViewRow row in dataGridView4.Rows) { if (row.Cells[3].Value != null) totalInvoice += Convert.ToDecimal(row.Cells[3].Value); } textBox2.Text = totalInvoice.ToString("N2"); string totalAr = Class1.NumberToWords(Convert.ToDouble(textBox2.Text), "دينار ", "درهم"); using (SqlConnection con = new SqlConnection(Class1.sqlCon.ConnectionString)) { con.Open(); SqlTransaction trans = con.BeginTransaction(); try { string sqlInsertInvoice = @"INSERT INTO Invoices (invoice_date, customer_name, total_amount, total_ar) VALUES (@date, @cus, @total, @total_ar); SELECT SCOPE_IDENTITY();"; SqlCommand cmdInvoice = new SqlCommand(sqlInsertInvoice, con, trans); cmdInvoice.Parameters.AddWithValue("@date", dateTimePicker1.Value); cmdInvoice.Parameters.AddWithValue("@cus", comboBox1.Text); cmdInvoice.Parameters.AddWithValue("@total", totalInvoice); cmdInvoice.Parameters.AddWithValue("@total_ar", totalAr); object result = cmdInvoice.ExecuteScalar(); string newInvoiceID = result.ToString(); foreach (DataGridViewRow row in dataGridView4.Rows) { if (row.IsNewRow) continue; int itemId = Convert.ToInt32(row.Cells[5].Value); decimal qty = Convert.ToDecimal(row.Cells[1].Value); decimal price = Convert.ToDecimal(row.Cells[2].Value); decimal rowTotal = Convert.ToDecimal(row.Cells[3].Value); string itemName = row.Cells[0].Value.ToString(); string storeNum = row.Cells[4].Value.ToString(); string sqlDetails = @"INSERT INTO InvoiceDetails (invoice_number, item_name, item_id, inv_date, quantity, unit_price, total_price, store_number) VALUES (@invNo, @name, @id, @date, @qty, @price, @tot, @store)"; SqlCommand cmdDetails = new SqlCommand(sqlDetails, con, trans); cmdDetails.Parameters.AddWithValue("@invNo", newInvoiceID); cmdDetails.Parameters.AddWithValue("@name", itemName); cmdDetails.Parameters.AddWithValue("@id", itemId); cmdDetails.Parameters.AddWithValue("@date", dateTimePicker1.Value); cmdDetails.Parameters.AddWithValue("@qty", qty); cmdDetails.Parameters.AddWithValue("@price", price); cmdDetails.Parameters.AddWithValue("@tot", rowTotal); cmdDetails.Parameters.AddWithValue("@store", storeNum); cmdDetails.ExecuteNonQuery(); string sqlUpdateStock = @"UPDATE inventory SET quantity = quantity - @qty WHERE item_id = @id AND quantity >= @qty"; SqlCommand cmdStock = new SqlCommand(sqlUpdateStock, con, trans); cmdStock.Parameters.AddWithValue("@qty", qty); cmdStock.Parameters.AddWithValue("@id", itemId); int rowsAffected = cmdStock.ExecuteNonQuery(); if (rowsAffected == 0) { throw new Exception("الكمية غير متوفرة حالياً للصنف: " + itemName); } string dayName = dateTimePicker1.Value.ToString("dddd", new CultureInfo("ar-LY")); string sqlMove = @"INSERT INTO ItemDailyMovement (item_id, movement_date, day_name, quantity_sold, invoice_number, item_name, name_cus, type, invotry_num) VALUES (@id, @date, @day, @qty, @inv, @iname, @cus, 'مبيعات', @store)"; SqlCommand cmdMove = new SqlCommand(sqlMove, con, trans); cmdMove.Parameters.AddWithValue("@id", itemId); cmdMove.Parameters.AddWithValue("@date", dateTimePicker1.Value); cmdMove.Parameters.AddWithValue("@day", dayName); cmdMove.Parameters.AddWithValue("@qty", qty); cmdMove.Parameters.AddWithValue("@inv", newInvoiceID); cmdMove.Parameters.AddWithValue("@iname", itemName); cmdMove.Parameters.AddWithValue("@cus", comboBox1.Text); cmdMove.Parameters.AddWithValue("@store", storeNum); cmdMove.ExecuteNonQuery(); } Class1.OPER_CUSTOMERS(newInvoiceID, DateTime.Today, "مبيعات", totalInvoice, 0, comboBox1.Text, trans, label10.Text); trans.Commit(); MessageBox.Show("تم حفظ الفاتورة رقم " + newInvoiceID + " بنجاح", "تأكيد", MessageBoxButtons.OK, MessageBoxIcon.Information); fill_dgv3(); fill_dgv2_inv(); dataGridView4.Rows.Clear(); comboBox1.SelectedIndex = -1; textBox2.Clear(); label9.Text = ""; } catch (Exception ex) { trans.Rollback(); MessageBox.Show("فشل العملية: " + ex.Message, "خطأ", MessageBoxButtons.OK, MessageBoxIcon.Error); } }
- 3 اجابة
-
- 1
-
-
لعزل المشكلة، يجب التحقق من الخطوات التالية أولاً، في البداية تثبيت إصدار مستقر من Node.js https://nodejs.org/dist/v24.13.0/node-v24.13.0-win-x64.zip وبالطبع يجب حذف الإصدار الذي لديك بالكامل من خلال control panel ثم إعادة التشغيل وتثبيت الإصدار السابق. ثم تفقد Windows Defender Firewall فربما يمنع Node.js من الإتصال، بالخطوات التالية: افتح Windows Security اذهب إلى Firewall & network protection اضغط على Allow an app through firewall اضغط Change settings ابحث عن Node.js وتأكد أنه مفعل Private و Public وإن لم تجده، اضغط Allow another app وأضف مسار تثبيت Node على حاسوبك: C:\Program Files\nodejs\node.exe وفي ملف الاتصال بـ MongoDB أضف الخيارات التالية لاستخدام ipv4 const mongoose = require('mongoose'); mongoose.connect(process.env.MONGO_URI, { useNewUrlParser: true, useUnifiedTopology: true, serverSelectionTimeoutMS: 30000, socketTimeoutMS: 45000, family: 4 }) .then(() => console.log('MongoDB Connected')) .catch(err => console.log('Error:', err)); والتجربة. إن استمرت المشكلة، قم بتنفيذ التالي في CMD nslookup _mongodb._tcp.cluster0.mf8buxy.mongodb.net 8.8.8.8
-
عدد الساعات ليس مقياس على الإطلاق لمدى جودة أي دورة أو محتوى، فالمدرب الخبير يستطيع شرح مفهوم في وقت أقل وبشكل أبسط مع عدم الإخلال بالمعلومات، لذا الأمر يعتمد على الكيف وليس الكم. لن يتم دراسة الواجهة الخلفية في تلك الدورة، بل تعريف بسيط عن Node.js وأداة إدارة الحزم الخاصة بها وهي NPM من أجل إدارة المكتبات التي نحتاج إلى تثبيتها للعمل على المشروع مثل Webpack. فأي تشغيل لكود جافاسكريبت خارج المتصفح يحتاج إلى تثبيت Node.js "للتبسيط لكن في الخلفية يتم العمل من خلال محرك جوجل كروم" فالإعدادات التي تكتبها في ملف webpack.config.js هو عبارة عن كود Node.js كل ما تحتاج معرفته عن Node.js في تلك الحالة هو طريقة الاستيراد والتصدير والفرق بين CommonJS و ESM وبخصوص ترتيب دراسة الدورات، فيجب دراسة دورة تطوير واجهات المستخدم أولاً، ثم دورة جافاسكريبت.
-
دورة بايثون هي الأنسب لك، تستطيع التواصل مع مركز المساعدة وإخبارهم بأنك تريد استبدال دورة جافاسكريبت بدورة بايثون وسيتم مساعدتك، ثم الإنتظار لبعض الوقت لحين الرد. فلغة بايثون هي اللغة الأساسية في مجال الذكاء الاصطناعي، وفي تلك الدورة سندرس ما يلي: رحلة شاملة في Python تبدأ من أبسط المفاهيم وتوصلك إلى إنشاء تطبيق عملي متكامل. التطبيقات العملية على بايثون، وتعلم التعامل مع مختلف الخدمات ستتمكن من إنشاء تطبيقات عملية متنوعة والتعامل مع خدمات متعددة، مثل قواعد البيانات، البريد الإلكتروني، ملفات Excel، واستخراج البيانات من الويب Web Scraping. ستتعرف على مفاهيم إطار العمل Django الأساسية والتطبيقية، وتطور مشروعًا عمليًا لإدارة المهام مع ربط التطبيق بالوظائف العملية المختلفة. ستتعلم أساسيات إطار العمل فلاسك Flask ثم ستتعرف على مفهوم الواجهات البرمجية APIs، وتطور واجهة برمجية. سنستخدم بوابة الدفع سترايب Stripe و PayPal في تطبيقاتنا، وسنتعلم مختلف طرق استعمالها. أساسيات تحليل البيانات وستتعلم مبادئ التعامل مع البيانات، ثم تتعمق في التحليل الإحصائي Statistical analysis والتصوير البياني Data visualization، ثم تطبق ما تعلمته عمليًا على أمثلة حقيقية. ستستكشف مبادئ تعلم الآلة Machine Learning وأنواعها الأساسية مثل الانحدار Regression، التصنيف Classification، والتجميع Clustering.
-
حاليًا أعتقد أنك تمتلك خبرة 6 أشهر في MERN Stack، بالتالي تجاوزت مرحلة الأساسيات CRUD, Authentication, Simple State، وتطبيق الـ Social Media يعتبر معيار للمستوى المتوسط Mid level، لأنه يجمع بين العلاقات Relational Data والـ Real-time البسيط. ولكنك ما زلت في مستوى Junior لذا تحتاج لمشاريع تجعلك تتقن الأدوات وتفهم الـ Best Practices قبل القفز لمنطق الـ Business المعقد، ولا أعتقد أنك جاهز للإنتقال لمستوى Mid-Level فهو بحاجة إلى خبرة 3 سنوات أو سنتين حسب الفروقات والخبرة الفردية. فالانتقال لـ Mid-Level يحتاج وقت وممارسة وتعرض لمشاكل حقيقية على مشاريع حقيقية أو قريبة من الواقع العملي، و 6 أشهر لا تزال فترة تأسيس، أي الهدف الآن ليس أن تقفز لمستوى Mid-Level، بل أن تكون جونيور قوي، فالشركات عندما توظف Junior، لا تتوقع منه بناء نظام معقد، بل أن يكتب كود نظيف، ويفهم كيف يربط الواجهة بالخلفية بشكل صحيح، ويستطيع حل المشاكل اليومية. حاول بناء متجر إلكتروني متخصص ليس مثل أمازون، بل متجر لبيع شيء واحد مثلاً متجر أحذية رياضية أو كتب، لعرض منتجات، إضافتها للسلة، وإتمام طلب وهمي، وعرض 10 منتجات في الصفحة، وتصفيتها حسب السعر أو الماركة، وقم بعمل Form Validation، مع التفكير في ماذا يظهر المستخدم والبيانات يتم تحميلها؟ أي Spinner، وماذا يظهر لو انقطع النت؟ Error Message، فالمبتدئ يترك الشاشة بيضاء، والمحترف يضع Skeleton Loader. ويجب بناء Admin Panel لوحة تحكم بسيطة للـ Admin لإضافة المنتجات ورفع الصور أي تعامل مع Multer وCloudinary.
-
يوجد الكثير من المكتبات المتخصصة في الـ Animations، لذا لتجنب تشتيتك، ما تحتاجه في الواقع العملي هو تعلم أساسيات CSS ثم تعلم المفاهيم المتقدمة الخاصة بالـ Animations في CSS. ثم انتقل لتعلم تلك المكتبات وليس العكس، لكن قبل تثبيت أي مكتبة، يجب أن تسأل نفسك ما هو مدى تعقيد التأثيرات التي أريدها؟ في حال كانت بسيطة إذن لا حاجة لمكتبات خارجية، لديك Tailwind و Bootstrap يوفران كلاسات Transitions. بمعنى للأزرار يوجد Hover effects، وللقوائم المنسدلة البسيطة، فلا داعي لتثبيت مكتبة كاملة لو تريد فقط أن يتغير لون الزر بنعومة استخدم كلاسات مثل transition-all duration-300 ease-in-out. بينما للتأثيرات المتقدمة أكثر لتصميم الواجهة الأمامية لمشاريع React أو Next.js، فالمكتبة المُعتمدة حاليًا هي Framer Motion، لكونها تعتمد على الـ Components وتتعامل بسلاسة مع الـ State ودورة حياة المكونات. كذلك تستطيع استخدام كلاسات Tailwind داخلها بسهولة عبر className، وتدعم التحريك البسيط والتحريك المعقد والإيماءات وحتى الـ Scroll Animations. أما لو المشروع يتطلب تحريكات معقدة جدًا، أو يعتمد بشكل مكثف على حركة العناصر عند التمرير لدرجة أنّ Framer Motion لا تستطيع التعامل معها بدقة، فاستخدم مكتبة GSAP. وللعلم أيضًا لو تريد صور متحركة جاهزة مثل فكتور يتحرك؟ استخدم Lottie حيث تعرض ملفات JSON المصدرة من After Effects.
-
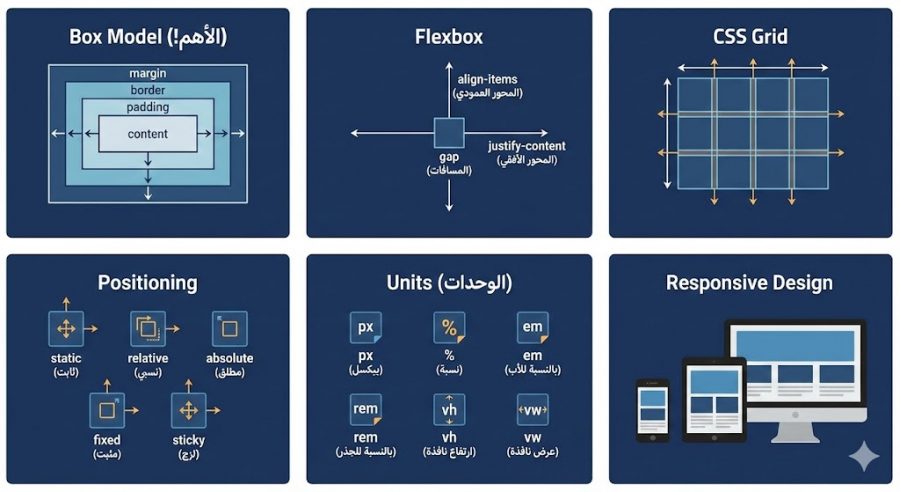
هناك أمور تؤدي إلى ذلك وهي حفظ كل الخصائص بدون استيعاب ما يجب فعله هو استيعاب المفاهيم الأساسية، كذلك نسخ كود بدون فهم بل قم بالتجربة وأخطئ لا مشكلة، كذلك تعلم كل شيء مرة واحدةركز تجنبه تمامًا، ركز أولاً على Flexbox وتعمق به. ولن تتقن CSS بالحفظ، بل عن طريق الاستيعاب والممارسة، وحتى من لديه خبرة سنوات يبحث في جوجل عن خصائص CSS يوميًا لا مشكلة. في البداية تحتاج إلى استيعاب مفهوم Box Model وكيف تؤثر خواص margin وborder وpadding على حجم الـ content داخل العناصر، وماذا يحدث عند تعيين قيمة border-box إلى خاصية box-sizing. ثم دراسة أساسيات Flexbox وتعمق به ولا تنتقل إلى Grid إلا بعدما تشعر بأريحية في التعامل مع Flexbox، قم بتنفيذ التحديات التالية: https://flexboxfroggy.com/ ثم قم بتطبيق ما تعلمته على تصميم بسيط وزد في درجة التعقيد بعد ذلك. ثم انتقل لتعلم أساسيات Positioning من خلال خواص absolute وrelative وخلافه وممارسة الأمر عمليًا لاستيعاب الفرق. ثم تعلم الفرق بين الوحدات px, %, em, rem, vh, vw ومتى نستخدم كل منهم. ثم تعلم Grid وتنفيذ التمارين التالية: https://cssgridgarden.com/ ولا تشغل بالك بالتجاوبية في الوقت الحالي، وقم بتنفيذ نماذج بسيطة ثم تصاميم كاملة وأنصحك بتنفيذ التحديات على موقع Frontend mentor مع تحديد التمارين الخاصة بالمستوى المبتدئ newbie ثم junior ثم تستطيع زيادة الصعوبة فيما بعد إلى intermediate، وإليك التمارين مباشرًة: https://www.frontendmentor.io/challenges?difficulty=1&type=free%2Cfree-plus ثم التمارين التالية: وبعد ذلك تعلم عن كيفية تصميم الموقع بشكل تجاوبي Responsive Design عن طريق @media
-
في البداية ستحتاج إلى تعلم أساسيات الرياضيات، وتستطيع دراسة دورة الذكاء الاصطناعي بدونها، لكن ستواجه صعوبة في استيعاب الخوارزميات والأمور النظرية وما يحدث في الخلفية، وفيما بعد ستعود لنقطة الصفر لدراسة أساسيات الرياضيات لا مفر. أرجو التوجه لليوتيوب ودراسة الأساسيات وتستطيع دراسة الدورة بدونها لا مشكلة، لكن ستواجه صعوبة في استيعاب المفاهيم وما يحدث في الخلفية، لكن الأساسيات فقط، فالتعمق سيستغرق وقت وستفقد الحماس والدافع، والكثير من المفاهيم الرياضية لن تحتاجها فعليًا. لذا في البداية خصص شهر لدراسة الرياضيات، ودراسة التالي: ابدء بالجبر الخطي ودراسة المصفوفات، العمليات الأساسية، الضرب النقطي. ثم التفاضل ودراسة المشتقات، قاعدة السلسلة، التدرج. ثم الإحصاء ودراسة المتوسط، الانحراف المعياري، التوزيعات الأساسية بعد ذلك كلما واجهتك مفاهيم رياضية، توقف وادرسها. ستجد تفصيل هنا: بعد ذلك قم بدراسة المسار الأول من دورة بايثون بالأكاديمية، فهو مجاني لك وكذلك المسارات الأولى من جميع الدورات الغير مشترك بها بالأكاديمية، لذا تستطيع دراسة أساسيات بايثون بشكل تفصيلي أكثر من خلال المسار الأول من دورة بايثون. ثم العودة لدورة الذكاء الاصطناعي دراسة الدورة بالترتيب، وفي حال واجهت صعوبة عند دراسة مسار تطبيقات عملية باستخدام المحوّلات Transformers، فأرجو قراءة التالي:
-
التخصص الذي تريده غير واضح، هل تريد التخصص في مجال الذكاء الاصطناعي أم مجال تطوير الويب؟ فالمسار التعليمي لكلاهما مختلف تمامًا، دورة جافاسكريبت لن تفيدك في حال أردت الخصص في مجال الذكاء الاصطناعي، الدورة المناسبة والمُكملة هي دورة بايثون بأكاديمية حسوب. وللعلم المسار الأول من دورة بايثون مجاني لك وكذلك المسارات الأولى من جميع الدورات الغير مشترك بها بالأكاديمية، لذا تستطيع دراسة أساسيات بايثون بشكل تفصيلي أكثر من خلال المسار الأول من دورة بايثون. الطلب على مشاريع الذكاء الاصطناعي ارتفع بشكل كبير على منصات العمل الحر مثل مستقل بنمو 56%، وفي الشركات في الخليج فرواتب المجال ضمن الأعلى عربيًا، حيث في السعودية والإمارات يبدأ المبتدئ براتب يتراوح بين 15,000 و22,000 ريال/درهم شهريًا، بينما يتقاضى نظيره في مصر ما بين 25,000 و35,000 جنيه شهريًا، مع فرص كبيرة لمضاعفة الدخل عبر العمل عن بعد لشركات أجنبية. وبالنسبة للتخصصات، فقم بمشاهدة التالي:
-
ستحتاج إلى دراسة أساسيات الرياضيات من أجل استيعاب الشرح بشكل أفضل، أرجو التوجه لليوتيوب ودراسة الأساسيات وتستطيع دراسة الدورة بدونها لا مشكلة، لكن ستواجه صعوبة في استيعاب المفاهيم وما يحدث في الخلفية، لكن الأساسيات فقط، فالتعمق سيستغرق وقت وستفقد الحماس والدافع، والكثير من المفاهيم الرياضية لن تحتاجها فعليًا. لذا في البداية خصص شهر لدراسة الرياضيات، ودراسة التالي: ابدء بالجبر الخطي ودراسة المصفوفات، العمليات الأساسية، الضرب النقطي. ثم التفاضل ودراسة المشتقات، قاعدة السلسلة، التدرج. ثم الإحصاء ودراسة المتوسط، الانحراف المعياري، التوزيعات الأساسية بعد ذلك كلما واجهتك مفاهيم رياضية، توقف وادرسها. ستجد تفصيل هنا:
-
كمطور واجهات أمامية فأنت لست مجرد منفذ للتصميم، بل شريك أساسي في صناعة التجربة، بمعنى المطور المحترف هو الذي يفهم لماذا نضع الزر هنا، أو لماذا يجب أن تظهر الصورة بهذا الشكل، وليس التنفيذ بشكل أعمى. وتجربة المستخدم تعني كيف يشعر المستخدم أثناء تصفحه للموقع؟ هل هو تائه؟ هل هو محبط؟ أم أن الأمور تجري بسلاسة؟ وللتسهيل إليك قائمة بأمور عملية عامة تستطيع برمجتها وتطبيقها لتحسين التجربة: زر الصعود للأعلى Scroll to Top كما ذكرت أنت، ذلك مثال ممتاز، ففي الصفحات الطويلة، يوفر على المستخدم عناء التمرير العكسي الطويل. فتات الخبز Breadcrumbs بمعنى روابط التوجيه الرئيسية > المنتجات > إلكترونيات تساعد المستخدم معرفة مكانه والعودة خطوة للخلف بسهولة. القائمة الثابتة Sticky Header، أي عند النزول للأسفل، بقاء القائمة العلوية ظاهرة يسهل التنقل دون الحاجة للصعود لأعلى الصفحة. التحميل الكسول Lazy Loading فلا تقم بتحميل كل الصور في الصفحة دفعة واحدة بل اجعل الصور تظهر فقط عندما يصل المستخدم إليها وذاك يسرع الموقع، والسرعة هي جزء أساسي من UX. تحسين معرض الصور Lightbox عند النقر على صورة منتج، يجب أن تفتح في نافذة منبثقة Modal مع خلفية معتمة وإمكانية التكبير والتنقل بين الصور بأسهم لوحة المفاتيح. Skeleton Screens بدلاً من عرض شاشة بيضاء أو دائرة تدور أثناء تحميل البيانات، اعرض هيكل رمادي يشبه شكل المحتوى القادم مثل فيسبوك ويوتيوب، الأمر الذي يخدع الدماغ بأن الموقع أسرع. وأمور أخرى مثل Real-time Validation، Button Feedback، Auto-focus وTouch Target تستطيع البحث عنهم. وبخصوص الـ UI فهي ليست فقط عبارة عن ألوان جميلة، بل اللغة البصرية التي توجه المستخدم، وأهم مفاهيم UI يجب أن تراعيها في الكود هي: التسلسل الهرمي البصري Visual Hierarchy المساحات البيضاء Whitespace وNegative Space التناسق Consistency وعندما يطلب العميل تحسين UX/UI، فهو لا يريد منك إعادة تصميم اللوجو، بل يريد منك كمطور واجهات أن يكون الموقع متجاوب مع الجوال، أن تكون التفاعلات Animations ناعمة وغير مزعجة، أن يكون الموقع سريع، وأن تكون النصوص مقروءة بوضوح أي تباين الألوان.
- 2 اجابة
-
- 1
-
-
شكرًا على إهتمامك إبراهيم، ونعتذر لك عن أي إزعاج أثناء تواجدك بالأكاديمية، ومكتبة React من الأساسيات الواجب إتقانها بالفعل، فما بعدها قائم عليها من إطار Next.js و React Native وخلافه. وكل فترة يتم تحديث محتوى الدورات، وهناك الكثير من المسارات تم تحديثها بالفعل، وتستطيع المتابعة من هنا: آخِرالتحديثات في الوقت الحالي أرجو الاستفسار أسفل الدروس عند مواجهة صعوبة في الاستيعاب وسيتم شرح الأمر بشكل تفصيلي لك. وعامًة في عالم البرمجة، لا يوجد كورس واحد كافٍ، وستحتاج دائمًا إلى التعمق والبحث، فلو يوجد شرح لجزئية معينة مثل Hooks أو Redux غير واضح، فقم بالبحث عن شرح لنفس العنوان في مكان آخر، ثم عد للأكاديمية للتطبيق.
-
البعض يُفضل كتابة مُلخصات لكل شيء، لكن لا أنصحك بذلك، اكتفي فقط بكتابة ملاحظات ومُلخصات ورسومات للأمور النظرية أو معلومة معينة تريد الإحتفاظ بها للعودة إليها للمراجعة. بينما البرمجة نفسها اكتفي بالتطبيق العملي فهو الأهم وبدونه فلا معنى للمُلخصات النظرية مهما كتبت، ببساطة لن تستطيع قيادة سيارة بمشاهدة فيديو صحيح؟ وليس المطلوب منك أن تعلم كل شيء عن كل شيء، وجميع من في مجال البرمجة لا يحفظ كل شيء عن ظهر قلب، بمعنى مثلاً تعلمت دالة معينة تقوم بوظيفة معينة في اللغة البرمجية أو إطار العمل، فكل ما تحتاجه هو معرفة المعاملات الأساسية التي تجعل الدالة تعمل، ومعاملين أو ثلاثة للتحسين، وباقي المعاملات وُضعت لحالات نادرة أو متقدمة، ولن تحتاجها إلا مرة كل سنة، وحينها ستبحث عنها. لذا في البداية المطلوب فهم الفكرة العامة أي ماذا تفعل الدالة؟ وماذا تحتاج لتعمل؟ كذلك لست مضطر للتوجه لصفحات الإنترنت في كل مرة، فالبيئة التي تعمل بها مثل vscode توفر لك تكملة تلقائية، عند كتابة اسم الدالة ضع مؤشر الماوس داخل القوسين واضغط على زر CTRL + Space في لوحة المفاتيح وستظهر لك نافذة صغيرة فيها كل المعاملات المتاحة.
- 3 اجابة
-
- 1
-

-
بالطبع لا، العملية معقدة تجمع بين التشفير، الرياضيات، ونظام قواعد البيانات، وذلك للوصول إلى ثلاثة أمور وهم عشوائية تامة بحيث لا يمكن لأحد تخمين الرقم التالي، التفرد لعدم تكرار نفس الرقم مرتين والأمان لحماية الأرقام من السرقة قبل طباعتها أو بيعها. فالشركات لا تستخدم الأرقام المتتالية مثل 1000، 1001، 1002 لأن ذلك يسهل عملية التخمين، وتعتمد على خوارزميات لتوليد أرقام عشوائية معقدة جداً CSPRNG - Cryptographically Secure Pseudo-Random Number Generator. ويتم توليد سلسلة طويلة من الأرقام ما بين 14 أو 15 أو 16 رقم وهي عشوائية ولا تتبع نمط معين. وقبل إرسال الأرقام لمصانع الطباعة، يتم تشفيرها وتحويل الأرقام إلى رموز مشفرة لا يمكن قراءتها إلا من قبل الآلة الخاصة التي ستطبع البطاقات أو الأنظمة التي سترسلها رسائل نصية. وذلك يمنع الموظفين في شركات الطباعة من معرفة الأرقام أو سرقتها. حتى بعد طباعة البطاقة، أحيانًا لا تكون فعالة، إلا عند تفعيلها فقط عند بيعها في نقطة البيع أو عند تسليمها للوكيل، ليتم ربطها بالنظام المالي.
-
مجهود جيد، لكن يجب التركيز أولاً على الأساسيات، أي التعمق في HTML, CSS, JS وبناء مشاريع من خلالهم فقط بدون استخدام أي إطار أو تقنية مثل بوتستراب. وبعد ذلك تستطيع استخدام التقنيات في مشاريعك ومنها بوتستراب لتسريع عملية التطوير، ثم تعلم React.js ولكن بعد الوصول لمستوى متوسط في جافاسكريبت أي مستوى جيد من الاستيعاب للغة البرمجية وليس سطحي. ابحث على اليوتيوب عن مشروع جافاسكريبت بسيط مثلاً وحاول تنفيذه ولا مشكلة في رؤية الشرح والتعلم. ثم انتقل لتعلم React.js من خلال الدورة، وستحتاج إلى التعمق أكثر في React من خلال مصادر أخرى، ابحث أيضًا على يوتيوب عن مشروع React.js بسيط وقم بتنفيذه بجانب المشروع الذي ستقوم به بالدورة. الفكرة هي التركيز على الأساسيات قدر الإمكان وتجنب التسرع في التنقل بين التقنيات، فـ React.js هي الأساس للإطار الذي ستدرسه بعد ذلك وهو Next.js
- 7 اجابة
-
- 1
-
-
ندرس تحليل البيانات Data Analysis مُبكرًا لأننا سنحتاج ذلك في المسارات التالية، ولن نحتاج دراسة قواعد البيانات والـ APIs مُبكرًا، لذا الترتيب مناسب لمنهج الدورة. فلا يمكنك بناء أي موديل ذكاء اصطناعي بدون أن تعرف كيف تنظف البيانات وتعالجه، فذلك هو الأساس. ومجال الـ Computer Vision الحديث يعتمد بنسبة 90% على تقنيات الـ Deep Learning، والـ Deep Learning هو فرع متطور من الـ Machine Learning. لذا تستطيع دراسة الدورة بنفس الترتيب لترى النتيجة أي التطبيق العملي أولاً، مثل اكتشاف الأشياء باستخدام YOLO في البداية لتشعر بقوة المجال، ثم العودة للخلف لنشرح الأساسيات أي الرياضيات والخوارزميات في مسار ML و DL. أو الترتيب التالي لو أردت تعلم الأساسيات ثم التطبيق العملي: Machine Learning Deep Learning Computer Vision ولا مشكلة في تدريس الأساسيات النظرية أولاً أي التعلم العميق والشبكات العصبية، ثم الانتقال إلى البنى المتقدمة المبنية عليها كالـ Transformers. لكن الفكرة من إعادة الترتيب هو إتباع منهجية حديثة وهي من الأعلى إلى الأسفل أو التطبيق أولاً، وذلك بدلاً من المنهجية التقليدية من الأسفل إلى الأعلى أو النظرية أولاً. وذلك لتعلم كيفية قيادة السيارة وتحقيق بها نتائج ملموسة تطبيقات المحولات، ثم بعد أن يدرك الطلبة أهميتها وقوتها، سيتعلمون كيف يعمل محركها الداخلي أي التعلم العميق. بمعنى المحولات هي نوع من الشبكات العصبية، لكن استخدامها كأداة لا يتطلب بالضرورة فهم كل تفاصيلها النظرية المعقدة مسبقًا، تمامًا كما أنك تستخدم هاتفك الذكي كل يوم دون الحاجة لمعرفة تصميم أشباه الموصلات في معالجه. لذا الترتيب الجديد غرضه، تعليمك المهارات التطبيقية الأكثر طلبًا أولاً، وإبقائك متحفزة عبر بناء مشاريع حقيقية مبكرًا، وتأهيلك بشكل عملي لفهم النظرية لاحقًا بشكل أسهل وأكثر جدوى.
-
مواصفات الحاسوب منخفضة، لذا ستحتاج إلى تثبيت نظام Kali Linux بشكل منفصل على حاسوبك بجانب الويندوز.