


محمد عاطف25
-
المساهمات
9872 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
154
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو محمد عاطف25
-
هل يمكنك توضيح نظام الملفات لديك كيق تستخدم المتحكمات وملفات العرض ؟ هل تستخدم inclued أو require أم ماذا ؟ إذا كنت تستخدم include إذا يجب أن تكون البيانات معرفة قبل سطر include ليتم رؤيتها بداخل الملف الذي إستوردته.
-
هل تعمل على إطار عمل لارافيل ؟ إذا كان كذلك هل يمكنك توضيح الطرق التي إستخدمتها ؟ يمكن تمرير البيانات من خلال الدالة view هكذا : return view('greeting', ['name' => 'James']); حيث أولا معامل للدالة هو إسم ملف ال blade الخاص بال view والمعامل الثاني هو مصفوفة تقوم بتمرير الإسم الذي ستستعمله والبيانات التي سيتم تمريرها لل view.
- 6 اجابة
-
- 1
-

-
ستجد أسفل فيديو الدرس صندوق للتعليقات كما هنا يرجى طرح سؤالك أسفل الدرس وليس هنا حيث هنا قسم الأسئلة العامة ولا نقوم بإجابة الأسئلة الخاصة بمحتوى الدورة أو الدرس، وذلك لمعرفة الدرس الذي توجد به مشكلتك و لمساعدتك بشكل أفضل.
-
ستجد أسفل فيديو الدرس صندوق للتعليقات كما هنا يرجى طرح سؤالك أسفل الدرس وليس هنا حيث هنا قسم الأسئلة العامة ولا نقوم بإجابة الأسئلة الخاصة بمحتوى الدورة أو الدرس، وذلك لمعرفة الدرس الذي توجد به مشكلتك و لمساعدتك بشكل أفضل.
-
هذا مثال على هجوم XSS (Cross-Site Scripting). فالكود عبارة عن payload يستخدمه المخترق لاختبار ما إذا كان موقعك غير محمي ويسمح بحقن JavaScript داخل الصفحة. ويعمل الكود كالتالي : <img src="x:x"> هنا الصورة غير صالحة وبالتالي سيحدث خطأ. onerror=alert('xss') وهذا الجزء عند حدوث الخطأ يتم تنفيذ الكود داخل onerror. وفي هذا المثال سيظهر alert('xss') كدليل على نجاح الاختراق.
-
أولا يجب أن تكون لديك مهارة مناسبة ومطلوبة للعمل الحر على الإنترنت وإذا لم يكن لديك مهارة معينة يجب عليك تعلم واحده من المهارات الكثيرة المطلوبة مثل البرمجة وغيرها . ويوجد الكثير من منصات العمل الحر التي تستطيع التقديم على المشاريع فيها ويتم دفع المال لك لإنشاء المشاريع ومن تلك المنصات هي منصة مستقل ومنصة خمسات وموقع بعيد وهي مواقع عربية ومخصصة أكثر للمبتدئين وتستطيع إنشاء حساب في تلك المنصات والتقدم على الوظائف المطروحة . وإليك المزيد من التفاصيل حول العمل الحر :
-
مرحبا عبدالعزيز . نعتذر لك عن أى مشكلة تواجهك . يمكنك إذا وجدت صعوبة في أى شئ سواء في الدروس أو الدورة عموما أن تسأل ما تريده أسفل الدرس وستجد أن جميع المدربين المتاحين في مساعدتك في أى وقت تريده . بخصوص إسترجاع الأموال فالأمور المالية تتم من خلال مركز المساعدة يمكنك محادثتهم من خلال الرابط التالي . ولا تقلق سيتم الرد عليك ولكن حاليا يوجد ضغط على مركز المساعدة لهذا من الممكن أن يتأخر الرد ولكن بما أن رسالتك قد وصلت إلى الدعم فسيتم الرد عليك بلا شك. شكرا لتفهمك.
-
حل المسائل البرمجية problem solving مهم جدا فأهميته تكمن في مهارة حل المشكلات التي ستكتسبها والتفكير المنطقي والذي سيجعل مستواك جيدا في حل المشكلات والتفكير في طرق الحل الجيدة والسريعة وذات الكفاءة العالية . أنصحك بتعلم هياكل البيانات والخوارزميات وهندسة البرمجيات والتي ستجعل لديك أساس قوي للبدء في مجال الذكاء الإصطناعي والعمل فيه . وإذا كنت مشترك في دورة علوم الحاسوب فهي كافية بشكل جيد للبدء في تلك الأساسيات ومن ثم تستطيع البدء في حل المسائل البرمجية.
-
إن ربط LLMs مع قواعد البيانات يتم عبر عدة طرق ويعتمد على ما تريد فعله: فمثلا هل تريد أن يقرأ الـ LLM البيانات من قاعدة البيانات. أو هل تريد أن يولد استعلامات SQL. أو هل تريد RAG (استرجاع معلومات). أو هل تريد ذكاء اصطناعي فوق قاعدة البيانات مثل natural language queries . وبما أن سؤالك عن ال RAG سأوضح لك كيف ذلك . إن ربط LLM مع قاعدة البيانات عبر RAG مناسب لو لديك بيانات غير مهيكلة مثل النصوص أو وصف منتجات أو ملفات PDF أو وثائق. والربط بين نماذج اللغة الكبيرة (LLMs) وقواعد البيانات باستخدام تقنية التوليد المعزز بالاسترجاع (RAG) يتم عبر عمليتين رئيسيتين: أولا تحويل البيانات الخارجية الموجودة في قاعدة البيانات إلى تمثيلات عددية (vectors or embeddings) وتخزن في قاعدة بيانات متجهية ثم عند استلام سؤال أو استعلام من المستخدم يتم تحويله أيضا إلى تمثيلات عددية تستخدم للبحث في قاعدة البيانات لإيجاد المعلومات الأكثر صلة. وبعد إيجاد النتائج ذات الصلة يتم دمج هذه البيانات المسترجعة مع الاستعلام الأصلي وإعطائها لنموذج اللغة الكبير مما يزيد دقة وصحة الإجابات ويقلل من الأخطاء الناتجة عن الهلوسة اللغوية. ولتنفيذ ذلك يجب إتباع الخطوات التالية : أولا نأخذ النصوص من قاعدة البيانات. ثم نقوم بتحويلها إلى embeddings (متجهات). نقوم بحفظ المتجهات في Vector DB مثل: Pinecone Weaviate Chroma MongoDB Atlas Vector Search بعد ذلك المستخدم يقوم بطرح السؤال. نقوم بجعل التطبيق يبحث عن المعلومات الأقرب باستخدام ال embeddings. وأخيرا نرسل النتائج لل LLM كي يشكل الإجابة. وإليك المصادر التالية : https://mongodb-developer.github.io/mongodb-rag/docs/intro https://python.langchain.com/docs/use_cases/question_answering/ https://learn.microsoft.com/en-us/shows/generative-ai-for-beginners/retrieval-augmented-generation-rag-and-vector-databases-generative-ai-for-beginners
-
 وعليكم السلام ورحمة الله وبركاته. دورة علوم الحاسوب هي دورة مخصصة للتأهيل للدخول في عالم البرمجة والحاسوب عموما وهي تعطيك أساس قوي للبناء عليه وفهم ومعرفة كيف يتعامل الحاسوب و أساسيات البرمجة عموما لذلك هي مهمة جدا للمبتدئين حتى لو كنت تريد التخصص في الويب فقط. لذلك الأفضل هو إنهاء الدورة للنهاية إذا لم تكن لديك أى خلفية مسبقة عن الحاسوب عموما . ولكن بما أنك تريد التخصص في الويب فأنصحك بدراسة المسارات التالية : مدخل إلى علوم الحاسوب أساسيات البرمجة قواعد البيانات إلى عالم الويب البرمجة كائنية التوجه وبعد الإنتهاء من المسارات السابقة يمكنك متابعة المسارات التالية فهي مهمة جدا ولكنها متقدمة قليلا يمكنك الرجوع إليها في وقت أخر إذا أردت : الخوارزميات وبنى المعطيات أنماط التصميم أساسيات هندسة البرمجيات إعادة تصميم البرمجيات Refactoring هل تريد أن تصبح مطور full stack أى أن تعمل كمطور واجهة أمامية وخلفية أيضا أم فقط وظيفة واحدة منهما ؟ الأفضل البدء بالمجال الذي تحبه أولا وإتقانه ومن ثم البدء في المجال الأخر . ولكن من وجهة نظري أن الواجهة الخلفية أفضل من ناحية البرمجة فهي ستفيدك في مجال البرمجة بشكل عام والتفكير المنطقي أما الواجهات الأمامية فالتصميم هو الأهم ولذلك إذا بدأت في الواجهات الخلفية ستجد سهولة إلى حد ما في تعلم الواجهات الأمامية . جميع اللغات جيدة ولا توجد لغة أفضل من لغة بل لكل منها ومميزاته وأيضا سوق العمل الذي تريد العمل فيه هو الذي سيحدد اللغة التي تريد العمل عليها فالأفضل لك البحث عن سوق العمل الذي تريده والبحث عن أكثر لغة مطلوبة به وإليك الإجابات التالية لمزيد من التفاصيل :
وعليكم السلام ورحمة الله وبركاته. دورة علوم الحاسوب هي دورة مخصصة للتأهيل للدخول في عالم البرمجة والحاسوب عموما وهي تعطيك أساس قوي للبناء عليه وفهم ومعرفة كيف يتعامل الحاسوب و أساسيات البرمجة عموما لذلك هي مهمة جدا للمبتدئين حتى لو كنت تريد التخصص في الويب فقط. لذلك الأفضل هو إنهاء الدورة للنهاية إذا لم تكن لديك أى خلفية مسبقة عن الحاسوب عموما . ولكن بما أنك تريد التخصص في الويب فأنصحك بدراسة المسارات التالية : مدخل إلى علوم الحاسوب أساسيات البرمجة قواعد البيانات إلى عالم الويب البرمجة كائنية التوجه وبعد الإنتهاء من المسارات السابقة يمكنك متابعة المسارات التالية فهي مهمة جدا ولكنها متقدمة قليلا يمكنك الرجوع إليها في وقت أخر إذا أردت : الخوارزميات وبنى المعطيات أنماط التصميم أساسيات هندسة البرمجيات إعادة تصميم البرمجيات Refactoring هل تريد أن تصبح مطور full stack أى أن تعمل كمطور واجهة أمامية وخلفية أيضا أم فقط وظيفة واحدة منهما ؟ الأفضل البدء بالمجال الذي تحبه أولا وإتقانه ومن ثم البدء في المجال الأخر . ولكن من وجهة نظري أن الواجهة الخلفية أفضل من ناحية البرمجة فهي ستفيدك في مجال البرمجة بشكل عام والتفكير المنطقي أما الواجهات الأمامية فالتصميم هو الأهم ولذلك إذا بدأت في الواجهات الخلفية ستجد سهولة إلى حد ما في تعلم الواجهات الأمامية . جميع اللغات جيدة ولا توجد لغة أفضل من لغة بل لكل منها ومميزاته وأيضا سوق العمل الذي تريد العمل فيه هو الذي سيحدد اللغة التي تريد العمل عليها فالأفضل لك البحث عن سوق العمل الذي تريده والبحث عن أكثر لغة مطلوبة به وإليك الإجابات التالية لمزيد من التفاصيل :- 2 اجابة
-
- 1
-
-
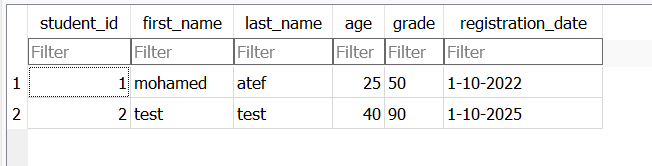
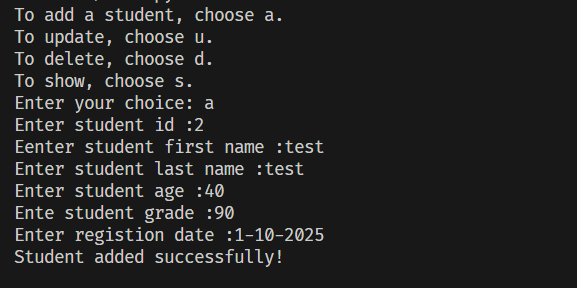
لقد قمت بتجربة الكود وهو يعمل دون أى مشكلة ويتم إضافة الطلاب في قاعدة البيانات وبعد تحديثها تظهر في الجدول : تأكد من أنك تقوم بفتح ملف قاعدة البيانات الصحيح . حيث الملف الصحيح هو الملف school.db بجوار ملف الكود لديك.
-
وعليكم السلام ورحمة الله وبركاته. حتى تقوم بضبط الحقول بدقة متناهية أمام الفراغات فإن أفضل وأسرع طريقة هي استخدام حيلة الماسح الضوئي (The Scanner Trick). فبدلا من القياس بالمسطرة والتخمين سنقوم بوضع صورة الورقة داخل التقرير كخلفية مؤقتة. قم بعمل مسح ضوئي (Scan) للورقة الفارغة بدقة عالية ويفضل أن تكون نفس أبعاد الورقة الحقيقية. بعد ذلك في Crystal Reports اذهب إلى القسم الذي تريد وضع البيانات فيه : قم بالضغط بالزر الأيمن ثم -> Insert ثم Picture. اختر صورة الورقة الممسوحة ضوئيا. الآن قم بجعل الصورة تغطي مساحة التصميم بالكامل بحيث تكون أركان الصورة متطابقة مع أركان التقرير وتأكد أن Page Setup للتقرير يطابق مقاس الورقة الحقيقية. بعد ذلك قم بتفعيل خاصية Underlay: قم بالضغط بالزر الأيمن على القسم الموجودة به الصورة مثلاً Section 1 (Page Header). ثم اختر Section Expert. ثم قم بالتعليم على خيار "Underlay Following Sections" وهذا يجعل الصورة تظهر كخلفية وما بعدها يطبع فوقها. الآن اسحب حقول قاعدة البيانات وضعها بالضبط فوق الفراغات الموجودة في الصورة. ولكن تأكد قبل الطباعة النهائية أنه يجب عليك إما حذف الصورة أو عمل Suppress (إخفاء) لها من Format Object حتى لا تطبع صورة الورقة مرة أخرى فوق الورقة الأصلية فنحن نريد فقط البيانات . بعد ذلك يجب ضبط هوامش الصفحة (Page Margins) : فمشكلة الإزاحة غالبا تأتي من الهوامش الافتراضية للطابعة أو التقرير لهذا قم بالذهاب إلى File ثم Page Setup وقم بتصفير الهوامش أى اجعلها "0.00" أو اجعلها مطابقة تماما للهوامش الخاصة بالورقة المطبوعة وتأكد من تفعيل خيار "No Printer" وأحياناً يسمى (Dissociate Formatting Page Size and Printer Paper Size) أثناء التصميم لمنع التقرير من تغيير الأبعاد بناء على الطابعة الافتراضية لجهازك الحالي. والآن يمكنك طباعة التقرير على ورقة بيضاء للتجربة ولو وجدت مشكلة أو مسافات خاطئة يمكنك تعديلها مرة أخرى.
-
حاليا لا تحتاج إلى أى معلومات أخرى فقد أصبح لديك الأساسيات التي تؤهلك لبناء مشاريع بسيطة ومتوسطة بإستخدام Django . أنصحك بالبحث عن أفكار بسيطة يمكنك تطبيقها بنفسك في مشاريع عملية بإستخدام Django وذلك حتى تتأكد من فهمك التام له ومعرفة هل يوجد قصور لديك في هذا الإطار أم لا . أما بخصوص Flask فهو إطار عمل خفيف ومرن يعطيك تحكم أكبر في اختيار المكونات التي تحتاجها في مشروعك ولكنه يتطلب منك إضافة العديد من الميزات يدويا بنفسك مثل المصادقة أو إدارة النماذج. وإذا كنت تبحث عن فهم أعمق لكيفية عمل الإطارات المختلفة وكيفية بناء تطبيق من الصفر فإن Flask سيكون مفيد جدا لك. ولكن إن كنت تركز على تطوير تطبيقات ويب سريعة ومعقدة فإن Django يظل خيارا أفضل وأسرع وأكثر كفاءة. أما إذا كنت تريد التقدم في المستوى فيمكنك دراسة التالي لتتقدم في مسارك الحالي : تطوير واجهات أمامية (Frontend) باستخدام HTML و CSS وJavaScript لأن هذه المهارات ضرورية لأي مطور ويب محترف وتستطيع مشاهدة أول مسار من دورة "تطوير واجهات المستخدم" فهو مجاني بشكل كامل لك. يمكنك تعلم كيفية بناء واجهات برمجة التطبيقات (APIs) باستخدام Django REST Framework أو Flask-RESTful وذلك لأنها تستخدم بكثرة في تطبيقات الويب الحديثة. أيضا دراسة قواعد البيانات المتقدمة وتحسين الأداء مثل استخدام PostgreSQL أو أى قاعدة بيانات أخرى حسب المشروع الذي تعمل عليه.
-
هذا لأن دورة تطوير واجهات المستخدم تعتمد على إنشاء المواقع الثابتة وليس الديناميكية أى التي تتغير بإستمرار بتغير محتواها ولهذا يتم إستخدام الأدوات التي تساعد في ذلك مثل Bootstrap و Jquery وغيرها من الأدوات اللازمة لذلك . وقد تم فصل الدورتين عن بعضهم البعض لأن إهتمام كل دورة مختلف عن الدورة الأخرى . فدورة تطوير واجهات المستخدم مصممة أكثر للأشخاص المبتدئين والذين لا يريدون الدخول في مجال أطر عمل الواجهات الأمامية وتعقيدات البرمجة وغيرها من التعمق في لغة JS وهي أيضا للأشخاص الذين يريدون تصميم المواقع الثابتة مثل صفحات الهبوط أو حتى القوالب الثابته التي يتم بيعها كثيمات للمواقع الكبيرة . ولهذا تم فصل الدورتين حيث دورة "تطوير التطبيقات باستخدام JavaScript" هي من أقوى وأكبر الدورات في الأكاديمية حيث تتعلم فيها الواجهات الخلفية مع الواجهات الأمامية وأيضا تصميم تطبيقات الهاتف وسطح المكتب وتعتمد على كثير من أطر العمل وهذا الأمر ليس مناسبا مع كثير من الأشخاص . لذلك إذا أردت أن تعمل على أطر العمل يمكنك التأكد أولا من إنهاء أساسيات HTML و CSS من دورة تطوير واجهات المستخدم وإنشاء التطبيقات العملية في الدورة حتى تتأكد تماما من أنك تستطيع إنشاء أى تصميم تراه بنفسك وبعد ذلك يمكنك الدخول مباشرة في دورة "تطوير التطبيقات باستخدام JavaScript"
-
لا المسار الجديد يتحدث عن إطار عمل Bootstrap بإستفاضة وتقسيمه بشكل سهل من حيث الشرح والتوضيح فقد تم تقسيم المسار إلى عدة أقسام فرعية كل فرع خاص بجزئية مهمة في Bootstrap مما يسهل على الطلاب فهم طريقة وكيفية عمل Bootstrap . ومن الممكن مستقبلا أن يتم تحديث الدورة وإضافة إطار Tailwind ولكن حاليا Bootstrap هو الأفضل من ناحية المواقع الثابتة ومستخدم بكثرة في كثير من القوالب و المواقع . وإليك الرابط الخاص بتحديثات الدورات التي تتم وستجد فيه ما تم تحديثه في دورة تطوير واجهات المستخدم : https://academy.hsoub.com/release-notes/
-
وعليكم السلام ورحمة الله وبركاته. إن الموقع HTMLrev.com يوفر عدد كبير جدا من القوالب المجانية لتطوير واجهات Frontend وجميع القوالب الموجودة على الموقع مجانية للاستخدام الشخصي والتجاري دون الحاجة إلى دفع أي رسوم أو الاشتراك ولا يطلب الموقع منك التسجيل أو إدخال بيانات شخصية للحصول على القوالب فقط قم بتحميل القالب الذي يناسبك من خلال رابط التحميل أو صفحة العرض. ويفضل إستخدام خيارات الفلترة لاختيار التقنية أو نوع القالب مثلاً landing page أو dashboard أو blog وغيرها . و كل قالب يحتوي على رابط معاينة مباشرة (Live Preview) لتجربة القالب قبل التحميل وتأكد دائما من أن القالب يناسب مشروعك من حيث التصميم والتقنيات المستخدمة قبل تنزيله .
-
لنبدأ من البداية تماما فعندما يرسل لك المصمم رابط المشروع ستقوم بفتح الواجهة التي تنقسم لثلاثة أقسام رئيسية: القائمة اليسرى (Layers): تحتوي على الصفحات (Pages) والعناصر الموجودة في التصميم. المنتصف (Canvas): مساحة العمل التي ترى فيها التصميم. القائمة اليمنى (Inspect/Properties): هذا هو الجزء الذي ستعمل عليه حيث هنا ستجد كود CSS و الألوان والخطوط وزر التصدير (Export). ثانيا وضع المطور (Dev Mode) : ففي التحديثات الأخيرة أضافت فيجما زرا خاص للمبرمجين قم باابحث عن أيقونة تشبه المفتاح"</>" في أعلى يمين الشاشة أو زر أخضر مكتوب عليه Dev Mode. وعند تفعيله تتحول الواجهة لتركز فقط على الأكواد والمقاسات وتخفي أدوات التصميم التي لا تحتاجها. نأتي الآن لكيفية إستخراج الأكواد (CSS/Styling) : بمجرد الضغط على أي عنصر في التصميم مثل زر أو نص أو صورة انظر للقائمة اليمنى وستجد قسما للكود (Code Section). يمكنك نسخ خصائص مثل border-radius أو font-size أو color أو shadows مباشرة ولصقها في ملف CSS الخاص بك. ولمعرفة المسافات والأبعاد (Measuring) حيث هذه أهم ميزة لضبط الشكل بدقة قم بتحديد العنصر وقم بتحريك الفأرة فوق أي عنصر آخر بجانبه وهنا ستظهر لك خطوط حمراء وأرقام توضح المسافة (Margin/Padding) بين العنصرين بالبكسل. وإذا أردت تصدير الصور والأيقونات (Exporting Assets) مثلا لو أردت تحميل شعار أو أيقونة لاستخدامها في الكود قم بالضغط على الصورة أو الأيقونة التي تريدها واذهب للقائمة اليمنى وأبحث عن كلمة Export ثم اضغط على علامة + وقم باختير الصيغة مثل:\ SVG: للأيقونات والشعارات لأنه أفضل دقة. PNG/JPG: للصور . وأخيرا قم بالضغط على زر Export وسيبدأ التحميل.
-
نعم صحيح بالفعل لقد تم تحديث بعض المسارات الموجودة في الدورة وذلك لإضافة الإصدارات الجديدة من المكتبات وأطر العمل المستخدمه وأيضا تحسين طريقة الشرح المتبعة . ولذلك الأفضل لك هو إعادة مشاهدة المسار الجديد للحصول على المعلومات الجديدة التي تم توفيرها . إذا أردت ستجد المسار القديم في مسار "أرشيف المسارات الأقدم" في نهاية الدورة وستجد به المسارات القديمة السابقة ومنها المسار الذي كنت تتباعه يمكنك المتباعة من هناك إذا أردت. ولكن كما نصحتك الأفضل مشاهدة المسار الجديد بعد التحديثات.
-
وعليكم السلام ورحمة الله وبركاته. ما تقوم به حاليا ممتاز وهذا الأمر سيفيدك كثيرا في التعلم فنعم الأمر سيأخذ الكثير من الوقت حينما تقوم بالبحث في التوثيق الرسمي أو على جوجل أو على المواقع المشهورة مثل stackoverflow وغيرها وهذا الأمر سيعلمك كيفية البحث عن ما تريده بسهوله وسيعطيك تلك المهارة وهي مفيدة جدا مستقبلا . وأيضا في بداية تعلمك قد يضرك الذكاء الإصطناعي فقد يعطيك معلومات خاطئة أو غير مكتملة مما يجعلك تتعلم أشياء ليست صحيحة ولكن من التوثيق الرسمي سيكون كل شئ صحيح ومتكامل مما سيجعلك تتعلم بالطريقة الصحيح . لذلك إذا كان لديك الوقت الكافي فهذه الطريقة هي الطريقة الممتازة لذلك . أما لو كان وقتك محدودا فإذا واجهتك مشكلة يمكنك السؤال عنها مباشرة أسفل الدرس وسيتم مساعدتك في أسرع وقت . الأفضل من وجهة نظري هو مشاهدة المدرب مثلا في جزء معين ومن ثم إيقاف الدرس والتطبيق وكتابة الأكواد التي قام بكتابها المدرب ويمكنك بعد الإنتهاء من المسار تماما في المشاريع العملية أن تقوم بإنشاء المشروع بنفسك من البداية لتقيم نفسك ومحاولة معرفة هل ستستطيع إنشاء المشروع دون مشكلة أم لا . ولكن لو قمت بمشاهدة الدرس بشكل كامل ومن ثم كتابة ما جاء به فستواجه صعوبة في إستذكار المنطق الخاص الذي قام به المدرب أو لو قام بإستخدام أكواد تحتاج إلى تكرار وتطبيق كثرا لحفظها مما سيجعلك تعيد الدرس مرة أخرى لإستذكارها .
- 3 اجابة
-
- 1
-
-
هناك وجهات نظر مختلفة ولكن الأفضل بالنسبة إلى هو الاستيعاب والحفظ فهما مهمان جدا في بداية التعلم فالاستيعاب وحده لا يكفي والتطبيق العملي يقوم بتثبيت ذلك الاستيعاب والحفظ بنسبة أكبر، وبعد ذلك لو نسيت بعض الأمور لا مشكلة وليس جميعها بالطبع، ومع التكرار ستترسخ لديك الأمور التي أنت بحاجة بشكل متكرر في المشاريع. وباقي الأمور تستطيع البحث عنها واسترجاعها لكونك قد استوعبتها من قبل وتستطيع استخدامها بدون مشكلة، والجميع كذلك. النقطة المحورية هي التطبيق العملي بمفردك، فلا يكفي التطبيق وراء الشرح فقط، وذلك أمر يتكاسل عنه الغالبية رغم أن الفائدة تكمن به. ويمكنك قراءة المزيد من التفاصيل التالية :
-
يرجى إرفاق صورة للخطأ الذي يظهر لك كما أخبرتك .لقد قمت بتجربة الكود المرفق بعد التعديل الذي وضحته لك وهو يعمل دون مشكلة.
- 4 اجابة
-
- 1
-
-
في ملف chatbot_client.py سطر يجب تغيره ليكون كالتالي : client = OpenAI(api_key=api_key) أو الأفضل عدم تمريره وتكتفي فقط بوضع OPENAI_API_KEY في متغيرات البيئة . إذا ظهرت مشكلة أخرى يرجى إرفاق صورة للمشكلة.
-
نعم بالطبع يمكنك إستخدام أى لغة برمجة في vs code حيث يمكنك إنشاء الملف وفتحه في vs code وتنزيل الإضافة الخاصة باللغة التي تعمل عليها . ولكن بالفعل vs code يأتي إفتراضيا بإضافات بايثون ولن تحتاج لتنزيل أى شئ.
- 5 اجابة
-
- 1
-

-
لا يتم تحصيل الرسوم سوى بالدولار الأمريكي ولكن يمكنك محادثة خدمة العملاء الخاصة بالبنك التابع له حيث يمكن الدفع بالجنيه المصري من خلال البنك ولكن من خلال بطاقات الإئتمان وأيضا من خلال عمولة يأخذها البنك . أو يمكنكِ إستخدام بطاقات هدايا حيث يمكن جعل شخص يشتري بطاقة هدايا بقيمة الدورة وتدفعين له المبلغ بالجنيه المصري.
-
نعم يوجد دورة مختصة بواجهات المستخدمه ومن خلالها سيتم شرح HTML و CSS و JavaScript و Bootstrap وغيرها من الأدوات واللغات الخاصة بتنفيذ واجهات المستخدم وهذه تفاصيل الدورة : https://academy.hsoub.com/learn/front-end-web-development/ أما إذا أردتي شئ مجاني فيمكنك قراءة المقالات الموجودة هنا في الأكاديمية : https://academy.hsoub.com/programming/html/ أو قراءة الدروس التالية على موقع موسوعة حسوب : https://wiki.hsoub.com/HTML