Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 يمكنك القيام بذلك من خلال الوسيط cbar_kws كما يلي: import pandas as pd import seaborn as sns df = pd.DataFrame({'A':(10,20,30,40), 'B':(10,20,30,40), 'C':(90,110,130,200)}) sns.heatmap(df.pivot_table(index='B', columns='A', values='C'), cbar_kws={'label': 'Hello Hasoub'}) الخرج:
يمكنك القيام بذلك من خلال الوسيط cbar_kws كما يلي: import pandas as pd import seaborn as sns df = pd.DataFrame({'A':(10,20,30,40), 'B':(10,20,30,40), 'C':(90,110,130,200)}) sns.heatmap(df.pivot_table(index='B', columns='A', values='C'), cbar_kws={'label': 'Hello Hasoub'}) الخرج: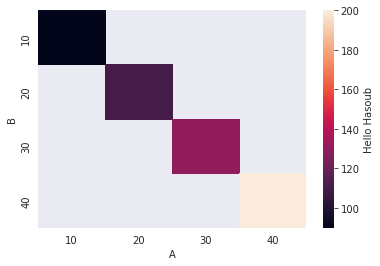
- 2 اجابة
-
- 1
-

-
يجب عليك أن تقوم بإنشاء شكل figure جديد من أجل حل المشكلة، ويمكنك القيام بذلك بإحدى الطرق التالية: 1. إنشاء شكل جديد قبل كل مخطط من خلال استدعاء الدالة plt.figure: import seaborn as sns data = sns.load_dataset('iris') plt.figure() plot1 = sns.barplot(x='sepal_length', y='species', data=data).get_figure() plot1.savefig('plot1.pdf') plt.figure() plot2 = sns.barplot(x='sepal_width', y='species', data=data).get_figure() plot2.savefig('plot2.pdf') 2. عن طريق إلغاء استدعاء الدالة get_figure ثم استدعاء plt.savefig كما يلي: import seaborn as sns import matplotlib.pyplot as plt data = sns.load_dataset('iris') plot1 = sns.barplot(x='sepal_length', y='species', data=data) plt.savefig('plot1.pdf') plt.clf() plot2 = sns.barplot(x='sepal_width', y='species', data=data) plt.savefig('plot2.pdf')
-
لفتح ملف يمكنك استخدام الدالة fopen التي لها الشكل التالي: FILE *fopen(const char *filename, const char *mode) تُرجع هذه الدالة مؤشراً على الملف. حيث أن: filename: هي اسم الملف المطلوب. mode يمثل الحالة التي تريد فتح الملف فيها، ويمكننا أن نختار: 1. "r" للقراءة فقط. 2. "w" للكتابة فقط (تؤدي إلى إنشاء الملف إذا لم يكن موجوداً). 3. "a" لإلحاق الملف ببيانات جديدة في نهايته (أي تبدأ الكتابة من نهاية الملف الموجود). 4. "+r" للقراءة والكتابة في الملف. 5. "+w" للقراءة والكتابة (تؤدي إلى إنشاء الملف إذا لم يكن موجوداً). 6. "+a" للقراءة ,والتحديث (تؤدي إلى إنشاء الملف إذا لم يكن موجوداً). ستبدأ القراءة من البداية، لكن الكتابة يمكن إلحاقها فقط. بعد ذلك يمكنك معالجة الملف بالشكل الذي تحتاجه و باستخدام الدوال المناسبة. وهنا غالباً مانحتاج لدوال مثل دالة القراءة ()fread، ودالة الكتابة ()fwrite، ودالة التنقل ()fseek التي تمكننا من التنقل داخل الملف أثناء القراءة أو الكتابة فيه، والدالة ()ftill التي تدلنا على مكان وجودنا داخل الملف. مثال: // وذلك لأن الملف غير موجود طبعاً file.txt نتيجة الكود التالي هي إنشاء ملف باسم // We are in 2021 سنضع في الملف الجملة #include <stdio.h> #include <stdlib.h> int main () { // مؤشر من نوع ملف FILE * fp; // فتح الملف fp = fopen ("file.txt", "w+"); // محتوى الملف fprintf(fp, "%s %s %s %d", "We", "are", "in", 2021); // إغلاق الملف fclose(fp); return(0); } للكتابة ضمن الملف يمكن أن تستخدم الدالة fwrite: size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream) يستخدم هذا التابع للكتابة بداخل الملف. ويُرجع عدد صحيح يمثل عدد الكلمات التي كُتبت ضمن الملف. ptr: مؤشر لمصفوفة العناصر المراد كتابتها. size: الحجم بالبايت لكل عنصر تتم كتابته. nmemb: عدد العناصر، كل عنصر بحجم البايت. stream: مؤشر إلى كائن FILE. مثال: #include<stdio.h> #include<stdib.h> #include<string.h> int main () { FILE *f=fopen("textfile.txt","w"); // فتح الملف char *s = "blabla"; // تعريف النص المطلوب كتابته fwrite(s, sizeof(char), strlen(s), f); fclose(f); return 0; } الوسيط الثاني الذي مررناه إلى الدالة هو sizeof(char) لأن بياناتنا هي عبارة عن مصفوفة محارف وبالتال كل عنصر هو عبارة عن محرف char حجمه 1 بايت وبالتالي سيكون ال size=1 وبما أن أحجام أنواع البيانات قد تختلف من معمارية جهاز إلى آخر فسنضع sizeof(char). أما الوسيط الثالث هو عدد العناصر التي ستتم كتابتها ضمن الملف وهذا يكافئ عدد عناصر مصفوفة المحارف لذا استخدمنا strlen. للقراءة من الملف نستخدم الدالة fread: size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream) لاحظ أن وسطاء هذه الدالة لاتختلف عن وسطاء دالة الكتابة مع ملاحظة أن الوسيط ptr هنا سنستخدمه لتخزين النص الذي سنقوم بقراءته. الآن بعد أن قمنا بالكتابة ضمن الملف في الخطوة السابقة، سنقوم بكتابة كود آخر لقراءة محتويات الملف، لذا سنقوم أولاً بفتح الملف لكن مع تحديد وضع القراءة هذه المرة "r": FILE *f = fopen("textfile.txt", "r"); ثم سنقوم باستخدام الدالة fread لقراءة المحتويات. لكن الأمر ليس بهذه البساطة فهنا سنحتاج لتحديد عدد عناصر الملف الذي ستتم قرائته (أقصد ال nmemb)، وذلك لأننا نريد حجز ذاكرة تتسع لما ستتم قرائته، ولمعرفة ذلك سنقوم باستخدام الدالتين ()ftell و ()fseek، حيث سنقوم باستخدام الدالة ()fseek للانتقال من خلالها إلى نهاية الملف: int fseek(FILE *stream, long int offset, int whence) الوسيط الأول هو مؤشر للملف المطلوب. أما الثاني فهو قيمة إزاحة موقع المؤشِّر بالبايت (سنضعها على صفر -سنعرف السبب بعد قليل-). أما الوسيط الأخير فيأخذ إحدى القيم التالية: 0 أو Seek_SET: تغيير موقع المؤشِّر إلى قيمة المعامل offset المعطاة بالبايت. أي تنقلنا تماماً إلى قيمة المعامل الثاني، فلو كان 1 ستنقلنا للمحرف الأول ولو كان 0 -كما في حالتنا- ستنقلنا لبداية الملف، لذا فإن هذه الحالة لاتخدمنا لأن غايتنا الانتقال لنهاية الملف. 1 أو Seek_CUR: تغيير موقع المؤشر إلى قيمة المعامل offset المعطاة بالبايت مضافًا إليها قيمة موقع المؤشِّر الحالي. أي بعبارةٍ أوضح تنقلنا من مكاننا الحالي إلى الأمام بمقدار ال offset التي تم تحديدها، وبالتالي إذا وضعنا مكان ال offset ستنقلنا للمحرف الأول، ولو وضعنا 0 فلن يكون لها أي تأثير. وهذه الحالة أيضاً لاتخدمنا. 2 أو Seek_END: تغيير موقع المؤشِّر إلى قيمة موقع نهاية الملف مضافًا إليها قيمة المعامل offset المعطاة بالبايت. أي تنقلنا لنهاية الملف، وهذا مانحتاج إليه. لذا سنستدعي هذه الدالة في مثالنا بالشكل التالي: fseek(f, 0, SEEK_END); الآن بعد أن انتقلنا إلى نهاية الملف أصبح بإمكاننا معرفة حجم الملف من خلال الدالة tell التي ستخبرنا بالموقع الذي نحن فيه، وهذا يكافئ عدد البايتات من بداية الملف، وبالتالي نكون حصلنا على المطلوب. unsigned int sz = ftell(f); الآن بعد معرفة حجم الملف أصبح بإمكاننا حجز ذاكرة تتسع لما ستتم قرائته، لذلك سنستخدم الدالة malloc، وكذلك سنقوم مرة أخرى باستخدام الدالة fseek للعودة إلى بداية الملف: fseek(f, 0, SEEK_SET); char *data = (char *)malloc(sz); ثم نقوم باستدعاء دالة القراءة بالشكل التالي: fread(data, sizeof(char), sz, f); وأخيراً طباعة النص: printf("File has been printed \n%s", data); free(data); fclose(f); الكود كاملاً: #include <stdlib.h> #include <string.h> #include <stdio.h> int main() { FILE *f = fopen("textfile.txt", "r"); fseek(f, 0, SEEK_END); unsigned int sz = ftell(f); fseek(f, 0, SEEK_SET); char *data = (char *)malloc(sz); fread(data, sizeof(char), sz, f); printf("File has been printed \n%s", data); free(data); fclose(f); return 0; }
-
يمكنك القيام بذلك بالشكل النالي: import seaborn as sns import pandas as pd %pylab inline df = pd.DataFrame({'Alpha' :['one','one','two','two','one','two','one','one','one','two'], 'Beta': [1,2,1,2,1,2,1,2,1,1], 'Gama': [1,2,3,4,6,1,2,3,4,6]}) # بالعدد الذي نريده subplots نقوم بتعريف شكل مع f, axes = plt.subplots(1, 2) # axes[1] والثاني axes[0] هنا قمنا بتعريف اثنين الأول هو # subplot حيث أن المحاور عبارة عن مصفوفة مع كل # نريده subplot الآن نضع كل مخطط ضمن # ax وذلك من خلال الوسيط sns.boxplot( y="Beta", x= "Alpha", data=df, orient='v' , ax=axes[0]) # المخطط الأول sns.boxplot( y="Gama", x= "Alpha", data=df, orient='v' , ax=axes[1]) # المخطط الثاني # وهكذا.. الخرج:
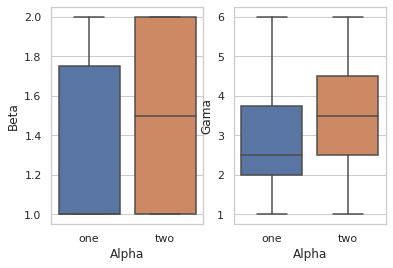
-
يمكنك التحكم بحجم الخط من خلال sns.set والوسيط fontsize كما في المثال التالي: import pandas as pd import matplotlib.pyplot as plt df = pd.DataFrame({"Day 1": [7,1,5,6,3,10,5,8], "Day 2" : [1,2,8,4,3,9,5,2]}) import seaborn as sns sns.set() # نستخدمها قبل الرسم لضبط كل شيء على الحالة الافتراضية p = sns.lineplot(data = df) p.set_xlabel("X-Axis", fontsize = 20) # تحديد حجم تسمية المحور الأفقي p.set_ylabel("Y-Axis", fontsize = 20) # تحديد حجم تسمية المحور العمودي p.set_title("Plot", fontsize = 20) # تحديد حجم العنوان plt.legend(labels=["Legend_Day1","Legend_Day2"], fontsize = 20) # legend تحديد حجم ال الخرج:
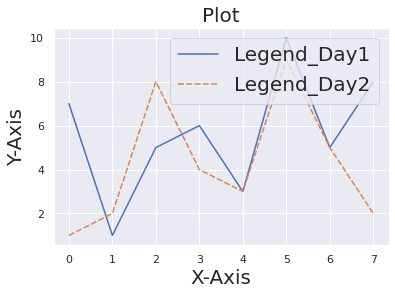
- 2 اجابة
-
- 1
-
-
يمكنك تغيير موقعه من خلال ضبط الوسيط legend في الدالة factorplot على false (لكي لايقوم بعملية إضافة تلقائية له). ثم استخدام الدالة plt.legend لإضافته في الموقع المطلوب: import seaborn as sns import matplotlib.pyplot as plt sns.set(style="whitegrid") titanic = sns.load_dataset("titanic") g = sns.factorplot("class", "survived", "sex", data=titanic, kind="bar", size=6, palette="muted", legend=False) g.despine(left=True) plt.legend(loc='upper left') # في الزاوية العليا اليسارية g.set_ylabels("survival probability") ويمكن تمرير القيم التالية أيضاً: 'upper left', 'upper right', 'lower left', 'lower right' 'upper center', 'lower center', 'center left', 'center right' الخرج:
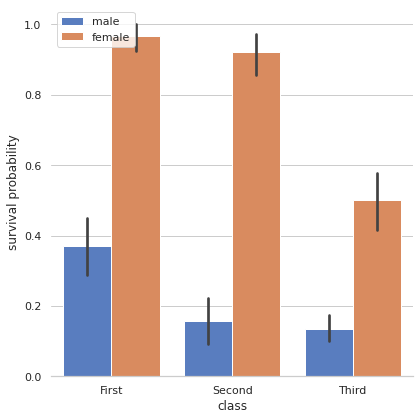
- 2 اجابة
-
- 1
-
-
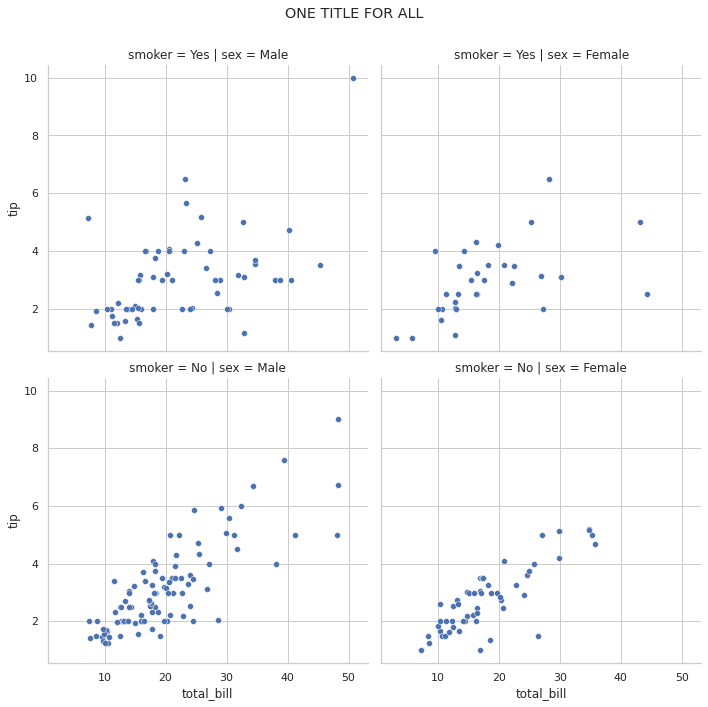
يمكنك وضع عنوان عام من خلال fig.suptitle كما يلي: # plt.xticks(rotation=45) # ax.tick_params(axis='x', rotation=90) import seaborn as sns tips = sns.load_dataset('tips') rp = sns.relplot(data=tips, x='total_bill', y='tip', col='sex', row='smoker', kind='scatter') rp.fig.subplots_adjust(top=0.9) rp.fig.suptitle('ONE TITLE FOR ALL') والخرج: وكحل آخر يمكنك استخدام plt.suptitle كما يلي: import seaborn as sns import matplotlib.pyplot as plt tips = sns.load_dataset('tips') rp = sns.relplot(data=tips, x='total_bill', y='tip', col='sex', row='smoker', kind='scatter') rp.fig.subplots_adjust(top=0.9) plt.suptitle("Title")
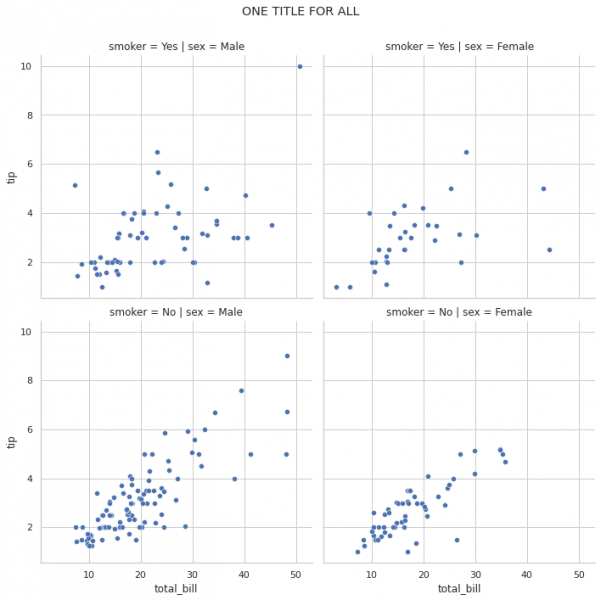
- 3 اجابة
-
- 1
-
-
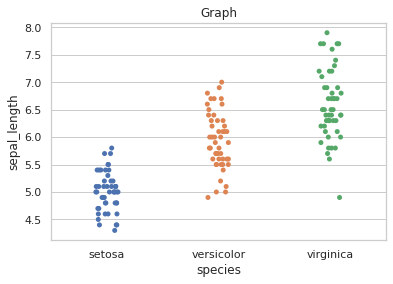
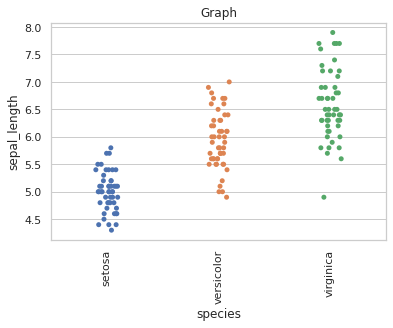
يمكنك القيام بذلك بعدة طرق.. تابع المثال التالي: import seaborn as sns import matplotlib.pyplot as plt sns.set(style="whitegrid") iris = sns.load_dataset('iris') ax = sns.stripplot(x='species', y='sepal_length', data=iris) plt.title('Graph') plt.show() الخرج: الآن لتدوير ال Labels يمكنك استخدام الدالة التالية: ax.tick_params(axis='x', rotation=90) بحيث الوسيط الأول هو اسم المحور المطلوب تطبيق التدوير على ملصقاته، والوسيط الثاني هو درجة التدوير. أو من خلال كائن plt باستخدام الدالة: plt.xticks(rotation=90) # للمحور الأفقي plt.yticks(rotation=90) # للمحور العمودي وبالتالي: import seaborn as sns import matplotlib.pyplot as plt sns.set(style="whitegrid") iris = sns.load_dataset('iris') ax = sns.stripplot(x='species', y='sepal_length', data=iris) ############# ax.tick_params(axis='x', rotation=90) ############# plt.title('Graph') plt.show() الخرج:
-
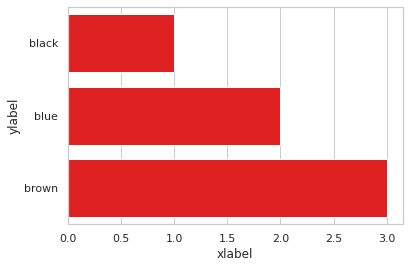
الدالة barplot تُرجع axis-object وليس figure-object لذا لايمكنك استخدام الدالة set_axis_labels مع كائن محور، هنا يجب أن تستخدم الدالة ax.set كما يلي: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df = pd.DataFrame({'color': ['black', 'blue', 'brown'], 'num': [1, 2, 3]}) ax = sns.barplot(x = 'num', y = 'color', data = df, color = 'red') ax.set(xlabel='xlabel', ylabel='ylabel') plt.show() الخرج:
-
يمكنك تحديد حجم الشكل عن طريق استخدام المفتاح 'figure.figsize' وتحديد الأبعاد المطلوبة (في حالة أوراق A4 ستحتاج إلى أبعاد 11.7 و ,8.27) وتمريرها كمعطى إلى الوسيط rc في الدالة set كما يلي: import seaborn seaborn.set(rc={'figure.figsize':(11.7,8.27)}) الآن أي شكل سترسمه سيكون بالأبعاد المحددة. أو من خلال rcParams كالتالي: from matplotlib import rcParams rcParams['figure.figsize'] = 11.7,8.27
-
لتحميل مجموعة بيانات أو نماذج معينة يمكنك استخدم الدالة nltk.download. على سبيل المثال إذا كنت تريد تنزيل النموذج "Punkt" من أجل استخدام ال sentence tokenizer فيمكنك تحميله بالشكل التالي: import nltk nltk.download('punkt') إذا لم تكن متأكداً من البيانات / النموذج الذي تحتاجه، فيمكنك استخدام "popular" لتحميل أهم النماذج والبيانات المتوفرة بالشكل التالي: import nltk nltk.download('popular') """ [nltk_data] Downloading collection 'popular' [nltk_data] | [nltk_data] | Downloading package cmudict to /root/nltk_data... [nltk_data] | Unzipping corpora/cmudict.zip. [nltk_data] | Downloading package gazetteers to /root/nltk_data... [nltk_data] | Unzipping corpora/gazetteers.zip. [nltk_data] | Downloading package genesis to /root/nltk_data... [nltk_data] | Unzipping corpora/genesis.zip. [nltk_data] | Downloading package gutenberg to /root/nltk_data... [nltk_data] | Unzipping corpora/gutenberg.zip. [nltk_data] | Downloading package inaugural to /root/nltk_data... [nltk_data] | Unzipping corpora/inaugural.zip. [nltk_data] | Downloading package movie_reviews to [nltk_data] | /root/nltk_data... [nltk_data] | Unzipping corpora/movie_reviews.zip. [nltk_data] | Downloading package names to /root/nltk_data... [nltk_data] | Unzipping corpora/names.zip. [nltk_data] | Downloading package shakespeare to /root/nltk_data... [nltk_data] | Unzipping corpora/shakespeare.zip. [nltk_data] | Downloading package stopwords to /root/nltk_data... [nltk_data] | Unzipping corpora/stopwords.zip. [nltk_data] | Downloading package treebank to /root/nltk_data... [nltk_data] | Unzipping corpora/treebank.zip. [nltk_data] | Downloading package twitter_samples to [nltk_data] | /root/nltk_data... [nltk_data] | Unzipping corpora/twitter_samples.zip. [nltk_data] | Downloading package omw-1.4 to /root/nltk_data... [nltk_data] | Unzipping corpora/omw-1.4.zip. [nltk_data] | Downloading package omw to /root/nltk_data... [nltk_data] | Unzipping corpora/omw.zip. [nltk_data] | Downloading package wordnet to /root/nltk_data... [nltk_data] | Unzipping corpora/wordnet.zip. [nltk_data] | Downloading package wordnet31 to /root/nltk_data... [nltk_data] | Unzipping corpora/wordnet31.zip. [nltk_data] | Downloading package wordnet_ic to /root/nltk_data... [nltk_data] | Unzipping corpora/wordnet_ic.zip. [nltk_data] | Downloading package words to /root/nltk_data... [nltk_data] | Unzipping corpora/words.zip. [nltk_data] | Downloading package maxent_ne_chunker to [nltk_data] | /root/nltk_data... [nltk_data] | Unzipping chunkers/maxent_ne_chunker.zip. [nltk_data] | Downloading package punkt to /root/nltk_data... [nltk_data] | Unzipping tokenizers/punkt.zip. [nltk_data] | Downloading package snowball_data to [nltk_data] | /root/nltk_data... [nltk_data] | Downloading package averaged_perceptron_tagger to [nltk_data] | /root/nltk_data... [nltk_data] | Unzipping taggers/averaged_perceptron_tagger.zip. [nltk_data] | [nltk_data] Done downloading collection popular True """ وهذا يتضمن الحزم التالية: <collection id="popular" name="Popular packages"> <item ref="cmudict" /> <item ref="gazetteers" /> <item ref="genesis" /> <item ref="gutenberg" /> <item ref="inaugural" /> <item ref="movie_reviews" /> <item ref="names" /> <item ref="shakespeare" /> <item ref="stopwords" /> <item ref="treebank" /> <item ref="twitter_samples" /> <item ref="omw" /> <item ref="wordnet" /> <item ref="wordnet_ic" /> <item ref="words" /> <item ref="maxent_ne_chunker" /> <item ref="punkt" /> <item ref="snowball_data" /> <item ref="averaged_perceptron_tagger" /> </collection> في حال أردت تحميل كل النماذج/ البيانات: import nltk nltk.download('all') في حال واجهك خطأ كهذا: Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/Users/l/alvas/git/nltk/nltk/tokenize/__init__.py", line 128, in word_tokenize sentences = [text] if preserve_line else sent_tokenize(text, language) File "/Users//alvas/git/nltk/nltk/tokenize/__init__.py", line 94, in sent_tokenize tokenizer = load('tokenizers/punkt/{0}.pickle'.format(language)) File "/Users/alvas/git/nltk/nltk/data.py", line 820, in load opened_resource = _open(resource_url) File "/Users/alvas/git/nltk/nltk/data.py", line 938, in _open return find(path_, path + ['']).open() File "/Users/alvas/git/nltk/nltk/data.py", line 659, in find raise LookupError(resource_not_found) LookupError: ********************************************************************** Resource punkt not found. Please use the NLTK Downloader to obtain the resource: >>> import nltk >>> nltk.download('punkt') Searched in: - '/Users/alvas/nltk_data' - '/usr/share/nltk_data' - '/usr/local/share/nltk_data' - '/usr/lib/nltk_data' - '/usr/local/lib/nltk_data' - '' ********************************************************************** فهذا يعني أنك تحاول استخدام نموذج أو بيانات غير موجودة، ويجب عليك تحميلها أولاً، أيضاً يخبرك بالنموذج/ البيانات المطلوب تنزيلها، وفي المثال هنا يطلب منك تثبيت النموذج punkt: import nltk nltk.download('punkt') في حال واجهتك مشاكل أثناء تحميل بيانات ضخمة كهذا الخطأ: import nltk nltk.download('all') """ [nltk_data] | Downloading package panlex_lite to [nltk_data] | /Users/Harshil/nltk_data... [nltk_data] | Unzipping corpora/panlex_lite.zip. Traceback (most recent call last): File "<pyshell#1>", line 1, in <module> nltk.download('all', halt_on_error = False) File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/nltk/downloader.py", line 664, in download for msg in self.incr_download(info_or_id, download_dir, force): File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/nltk/downloader.py", line 543, in incr_download for msg in self.incr_download(info.children, download_dir, force): File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/nltk/downloader.py", line 529, in incr_download for msg in self._download_list(info_or_id, download_dir, force): File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/nltk/downloader.py", line 572, in _download_list for msg in self.incr_download(item, download_dir, force): File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/nltk/downloader.py", line 549, in incr_download for msg in self._download_package(info, download_dir, force): File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/nltk/downloader.py", line 638, in _download_package for msg in _unzip_iter(filepath, zipdir, verbose=False): File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/nltk/downloader.py", line 2039, in _unzip_iter outfile.write(contents) OSError: [Errno 22] Invalid argument """ استخدم: $ rm /Users/<your_username>/nltk_data/corpora/panlex_lite.zip $ rm -r /Users/<your_username>/nltk_data/corpora/panlex_lite $ python import nltk dler = nltk.downloader.Downloader() dler._update_index() dler._status_cache['panlex_lite'] = 'installed' dler.download('popular')
-
يمكننا استخدام wordnet لتحقيق كل ماتحتاجه من استخراج علاقات دلالية ... بدايةً ال Entailments كما تعلم هو علاقة دلالية بين فعلين. يستلزم الفعل C الفعل B إذا كان معنى B يتبع منطقياً وتم تضمينه بشكل صارم في معنى C وهذه العلاقة أحادية الاتجاه. على سبيل المثال ، الدخان يستلزم النار، لكن النار لا تستلزم الدخان. و في nltk يمكنك إيجاد ال Entailments لكلمة محددة من خلال الدالة entailments في wordnet كالتالي: from nltk.corpus import wordnet as wn print(wn.synset('eat.v.01').entailments()) # [Synset('chew.v.01'), Synset('swallow.v.01')] الآن بالنسبة لل Meronyms فكما تعلم يعبر عن علاقة "مكونات". بمعنى، علاقة بين مفهومين، حيث يشكل المفهوم Aجزءاً من المفهوم B. ولاستخراجها نستخدم part_meronyms : tree = wn.synset('tree.n.01') print(tree.part_meronyms()) """ [Synset('burl.n.02'), Synset('crown.n.07'), Synset('limb.n.02'), Synset('stump.n.01'), Synset('trunk.n.01')] """ وأخيراً تعبر Holonyms عن علاقة "العضوية في"، أي العلاقة بين مفهومين، حيث يكون المفهوم B عضواً في المفهوم A. print(wn.synset('atom.n.01').part_holonyms()) # [Synset('chemical_element.n.01'), Synset('molecule.n.01')]
-
يمكنك القيام بذلك من خلال wordnet في nltk كما يلي: # wordnet استيراد الوحدة from nltk.corpus import wordnet # تحديد الكلمة المطلوبة word="Plane" My_sysn = wordnet.synsets(word)[0] # synset طباعة اسم ال print("Print just the name:", My_sysn.name()) # للكلمة المحددة hypernyms طباعة ال print("The Hypernym for the word is:",My_sysn.hypernyms(),'\n') # Hyponyms طباعة ال print("The Hyponyms for the word is:",My_sysn.hyponyms()) # الخرج """ Print just the name: airplane.n.01 The Hypernym for the word is: [Synset('heavier-than-air_craft.n.01')] The Hyponyms for the word is: [Synset('airliner.n.01'), Synset('amphibian.n.02'), Synset('biplane.n.01'), Synset('bomber.n.01'), Synset('delta_wing.n.01'), Synset('fighter.n.02'), Synset('hangar_queen.n.01'), Synset('jet.n.01'), Synset('monoplane.n.01'), Synset('multiengine_airplane.n.01'), Synset('propeller_plane.n.01'), Synset('reconnaissance_plane.n.01'), Synset('seaplane.n.01'), Synset('ski-plane.n.01'), Synset('tanker_plane.n.01')] """
-
لاتوجد دالة أو وحدة جاهزة في NLTK للقيام بذلك مباشرةً، لكن يمكنك استخدام NLTK العملية كما في المثال التالي: # استيراد الوحدات from nltk.tokenize import word_tokenize, sent_tokenize import nltk from nltk.corpus import stopwords # قم بتحديد النص المراد تلخيصه text = """ """ # nltk الحصول على كلمات التوقف المعرفة في stopWords = set(stopwords.words("english")) # تقسيم النص إلى وحدات tokens = word_tokenize(text) # إنشاء قاموس للاحتفاظ بنتيجة كل كلمة # score تسمى # نقصد بالنتيجة عدد المرات التي تظهر فيها كل كلمة بعد إزالة كلمات التوقف freq = dict() for w in tokens.lower(): if w in stopWords: continue if w in freq: freq[w] += 1 else: freq[w] = 1 # freqTable الخطوة التالية هي تعيين درجة لكل جملة بناءً على الكلمات التي تحتوي عليها وجدول التردد # score إنشاء قاموس للاحتفاظ بنتيجة كل جملة all_sentences = sent_tokenize(text) sentenceScore = dict() # الآن نقوم بالمرور على كل جملة for sentence in all_sentences: for w, freq in freq.items(): if w in sentence.lower(): if sentence in sentenceScore: sentenceScore[sentence] += freq else: sentenceScore[sentence] = freq """ # الآن الخطوة التالية هي بتعيين درجة معينة لمقارنة الجمل في النص # scores وتتمثل الطريقة الأبسط لمقارنة ال # الجملة score في إيجاد متوسط # مناسبة threshold ويمكن أن يكون المتوسط نفسه """ s = 0 for sent in sentenceScore: s += sentenceScore[sent] avg = s // len(sentenceScore) # نقوم الآن بتطبيق قيمة العتبة وتخزين الجمل بالترتيب في الملخص. smy = '' for sent in all_sentences: if (sent in sentenceScore) and (sentenceScore[sent] > (1.2 * average)): smy += " " + sent print(smy)
-
في الواقع هذا النموذج معرّف ضمن gensim لذا ستحتاجها، جمباً إلى جمب مع word_tokenize و sent_tokenize في nltk. المثال التالي سيوضح لك كيفية القيام بذلك: # استيراد الوحدات اللازمة from nltk.tokenize import sent_tokenize, word_tokenize import gensim # Word2Vec استيراد نموذج from gensim.models import Word2Vec # الآن ينبغي عليك تحديد مسار المستند النصي الذي تريد تدريب النموذج عليه text_data = open("d:\\data.txt", "r") file = text_data.read() # استبدال الأسطر الجديدة ب فراغ f = file.replace("\n", " ") # الإعلان عن قائمة فارغة لنضع بها البيانات المستخرجة من الملف النصي data = [] # الآن سنقوم بالمرور على كل جملة في النص for i in sent_tokenize(f): # الإعلان عن قائمة لوضع الكلمات المكونة للجملة ضمنها temp = [] # تقسيم الجملة إلى كلمات for j in word_tokenize(i): # إضافتها temp.append(j.lower()) # نضيف الجملة كعينة إلى البيانات data.append(temp) # وتدريبه CBOW سنقوم الآن بتعريف نموذج model1 = gensim.models.Word2Vec(sentences=data, min_count = 1,vector_size = 100, window = 5) # يمكنك حفظ النموذج لاستخدامه لاحقاً بالشكل التالي # model.save("CBOW.model") # Word2Vec.load("word2vec.model") لتحميله لاحقاً يمكنك استخدام # الآن يمكنك استخدامه لقياس التشابه بين أي كلمتين # wonderland و alice على سبيل المثال print("Cosine similarity between 'alice' " + "and 'wonderland' - CBOW : ", model1.similarity('alice', 'wonderland')) """ Cosine similarity between 'alice' and 'wonderland' - CBOW : 0.90824929840 """ وبشكل مشابه يمكنك استخدام نموذج SkipG: # وتدريبه Skip Gram بنفس الطريقة سنقوم ببناء نموذج model2 = gensim.models.Word2Vec(data, min_count = 1, vector_size = 100, window = 5, sg = 1)
-
يمكنك القيام بذلك من خلال wordnet و الوحدة regex في بايثون، فيما يلي سأقوم ببناء كلاس يمكنك استخدامه لحذف الحروف المكررة من أي نص: # nltk و regex سنستخدم مكتبيتي import re from nltk.corpus import wordnet # سأقوم بتعريف كلاس يمكنك استخدامه لحذف الأحرف المكررة من أي نص class Rep_word_removal(object): def __init__(self): self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)') self.repl = r'\1\2\3' def replace(self, word): if wordnet.synsets(word): return word replace_word = self.repeat_regexp.sub(self.repl, word) if replace_word != word: return self.replace(replace_word) else: return replace_word الاستخدام: # لاستخدامه # أنشئ كائن من هذا الكلاس rep_word = Rep_word_removal() rep_word.replace ("hiiiiii i am soooooooooo happy") # hi i am so hapy
-
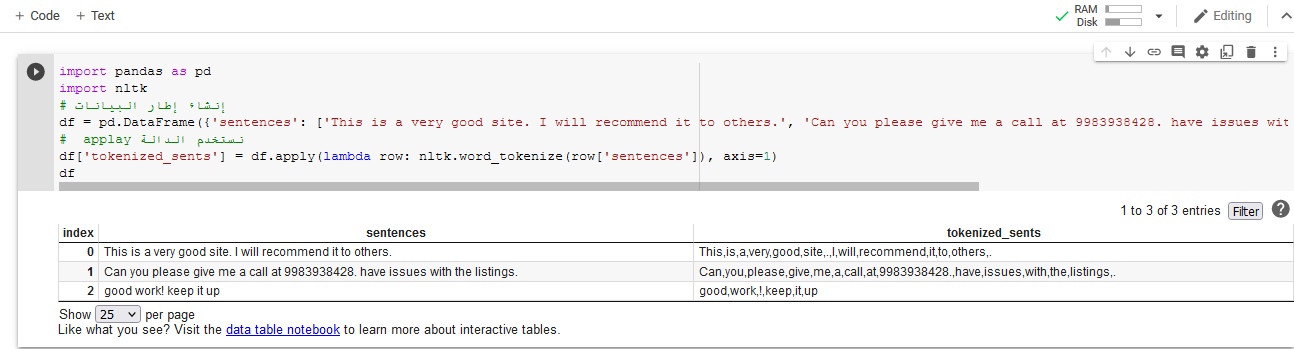
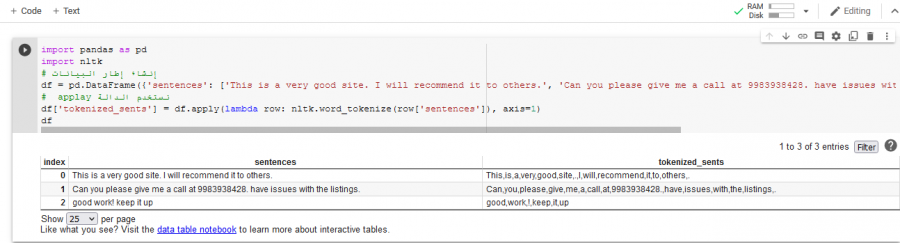
يمكنك القيام بذلك من خلال استخدام التابع apply لتطبيق الدالة word_tokenize على كل صف من البيانات: import pandas as pd import nltk # إنشاء إطار البيانات df = pd.DataFrame({'sentences': ['This is a very good site. I will recommend it to others.', 'Can you please give me a call at 9983938428. have issues with the listings.', 'good work! keep it up']}) # applay نستخدم الدالة df['tokenized_sents'] = df.apply(lambda row: nltk.word_tokenize(row['sentences']), axis=1) df سيكون الخرج كما يلي: بعد ذلك نقوم باستخدام الدالة apply مرة أخرى لإيجاد طول كل نص كما يلي: df['sents_length'] = df.apply(lambda row: len(row['tokenized_sents']), axis=1) فيصبح الخرج:

-
يمكنك القيام بذلك بالشكل التالي، وبتعقيد خطي O(n) كما يلي: import nltk text = '''Natural language processing (NLP) is a field of computer science, artificial intelligence, and computational linguistics concerned with the inter actions between computers and human (natural) languages..''' # تابع لاختبار فيما إذا كانت كلمة ما هي اسم is_noun = lambda pos: pos[:2] in ['NN','NNP','NNS','NNPS'] # تقسيم النص إلى كلمات tokenized = nltk.word_tokenize(text) # استخراج الأسماء # سنستخدم حلقة واحدة فقط nouns = [word for (word, pos) in nltk.pos_tag(tokenized) if is_noun(pos)] print (nouns) كما تجد الملاحظة إلى أن استخدام دوال مثل append و insert يعتبر خيار أبطأ، لذا من الأفضل تجنبها.
-
نعم يمكنك استخدام TreebankWordDetokenizer للقيام بذلك بالشكل التالي: from nltk.tokenize.treebank import TreebankWordDetokenizer TreebankWordDetokenizer().detokenize(['I', "'ll", 'be', 'there', 'within', '5', 'min', '.']) # I'll be there within 5 min.
-
يمكنك القيام بذلك من خلال الوحدة contractions و من خلال الكلاس word_tokenize في nltk بالشكل التالي: # استيراد الوحدات import contractions from nltk.tokenize import word_tokenize # النص text = '''I'll be there within 5 min. Shouldn't you be there too? I'd love to see u there my dear. It's awesome to meet new friends. We've been waiting for this day for so long.''' # قائمة لوضع الخرج ضمنها text_without_contractions = [] # تقسيم النص إلى وحدات words=word_tokenize(text) for word in words: # لإصلاح كل كلمة fix استخدام الدالة text_without_contractions.append(contractions.fix(word)) # نضيفها إلى الخرج new_text = ' '.join(expanded_words) # طباعةالنص بعد الإصلاح print(new_text) """ I will be there within 5 min. should not you be there too? I would love to see you there my dear. it is awesome to meet new friends. we have been waiting for this day for so long. """
-
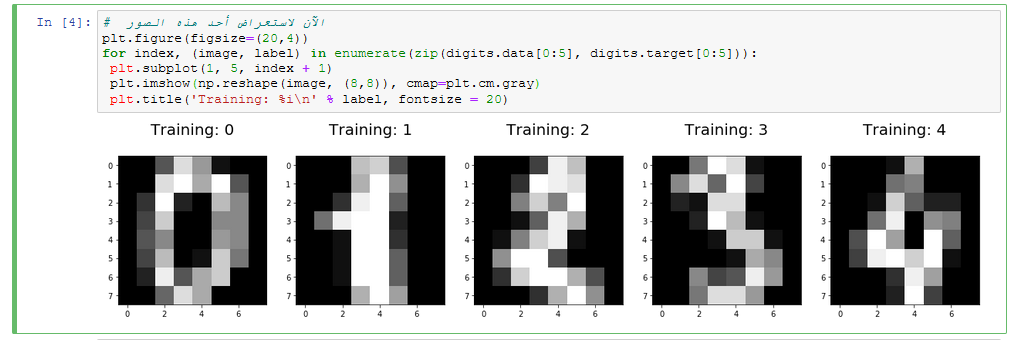
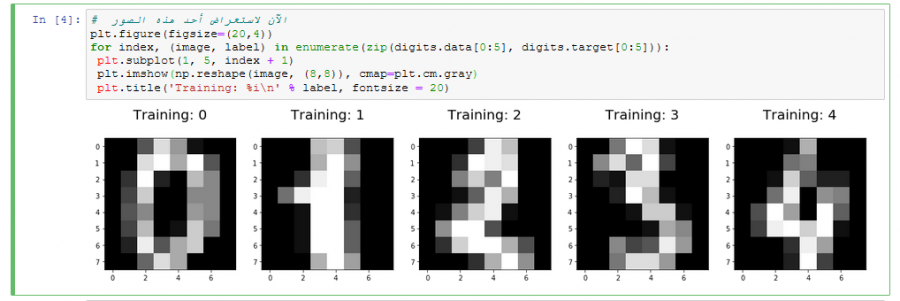
@Safa Marouf، Naive Bayes هو مُصنّف احتمالي خطي. الفئة أو الصنف التي تتعلم الخوارزمية التنبؤ بها هي نتيجة إنشاء التوزيع الاحتمالي لجميع الأصناف التي يتم عرضها عليه، ثم تحديد الصنف الذي سيتم تعيينه لكل عينة من البيانات. وتنظر المصنفات الاحتمالية إلى توزيع الاحتمال الشرطي، أي احتمال تعيين صنف معين بمجموعة معينة من الميزات features. هذه الخوارزمية غير مفضلة للاستخدام مع الصور الاحتمالية والاحتمال الشرطي يدرك ذلك جيداً. لكن عموماً يمكنك استخدامها لكن ستعطي نتائج ضعيفة، كما سنرى.. الآن نعود لسؤالك "هل يمكنني استخدام نفس الخطوات مع الصور" نعم تقريباً ماعدا مرحلة تحضير البيانات، فهي تختلف من طبيعة بيانات إلى أخرى، و سأعطيكي الآن مثال لتطبيق هذه الخوارزمية مع مجموعة بيانات الأرقام المكتوبة بخط اليد handwritten dataset، حيث تحتوي هذه البيانات على 1797 صورة رمادية، كل صورة هي رقم من 0 إلى 9 مكتوبة بخط اليد وكل منها بأبعاد 8*8. بدايةً سأقوم باستخدام خوارزمية Logistic Regression وأعرض لك النتائج، ثم سأستخدم خوارزمية بايز لأريكي الفرق الكبير بالدقة. أولاً سنقوم باستيراد المكتبات اللازمة و سنقوم بتحميل البيانات: # استيراد المكتبات التي سنحتاجها في هذ المثال from sklearn.datasets import load_digits import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegressio # تحميل الداتاسيت digits = load_digits() # تمثلها بكسلات الصورة features يوجد لدينا 1797 صورة أبعادها 8*8 أي لدينا 64 print("Image Data Shape" , digits.data.shape)# Print to show there are 1797 labels (integers from 0–9) # Image Data Shape (1797, 64) # وبما أنه لدينا 1797 صورة فمن الطبيعي وجود 1797 تصنيف، حيث أن كل صورة تمثل رقم صحيح من 0 ل 9 print("Label Data Shape", digits.target.shape) # Label Data Shape (1797,) ملاحظات: -يجب أن تكون البيانات (الصور) موضوعة في مصفوفة ثنائية الأبعاد، بحيث يمثل البعد الأول عدد العينات (الصور) والثاني يمثل البكسلات. -الصور في مثالنا رمادية بأبعاد w*h*chaneels = 1*8*8 بينما في حالة الصور الملونة تكون w*h*3 (مثلاً 3*8*8) وفي هذه الحالة يجب وضع الصور أيضاً في مصفوفة ثنائية بعدها الأول هو عدد العينات والثاني هو البكسلات وهنا يكون (لو افترضنا 3*8*8 سيكون عدد البكسلات هو 8*8*3=192 أي يجب أن نجعل أبعاد المصفوفة (1797,192)). سنقوم الآن بعرض بعض منها: plt.figure(figsize=(20,4)) for index, (image, label) in enumerate(zip(digits.data[0:5], digits.target[0:5])): plt.subplot(1, 5, index + 1) plt.imshow(np.reshape(image, (8,8)), cmap=plt.cm.gray) plt.title('Training: %i\n' % label, fontsize = 20) الآن نقوم بتقسيم هذه البيانات إلى بيانات للتدريب وأخرى للاختبار: x_train, x_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.25, random_state=0) نقوم بإنشاء كائن يمثل المصنف المطلوب: logisticRegr = LogisticRegression() نقوم بتدريب المصنف على بيانات التدريب من خلال الدالة fit: logisticRegr.fit(x_train, y_train) الآن بعد تدريب النموذج يمكننا استخدامه لتوقع أي صورة من بيانات الاختبار، هنا سنقوم بتمرير أول صورة من بيانات الاختبار والتي تمثل العدد 2، لنرى إذا كان سيتنبأ بشكل صحيح: logisticRegr.predict(x_test[0].reshape(1,-1)) # أي أنها تمثل العدد 2 # array([2]) الآن للحصول على دقة المصنف أو المودل الذي بنيناه: score = logisticRegr.score(x_test, y_test) print(score) # 0.9511111111111111 كما تلاحظين الدقة هي 95 بالمئة، وهي دقة جيدة جداً لهذه المسألة. الآن سنقوم بتجربة NB: from sklearn.naive_bayes import GaussianNB NB = GaussianNB() # تدريب المصنّف NB.fit(x_train, y_train) scoreNB = NB.score(x_test, y_test) print(scoreNB) # 0.8333333333333334 كما تلاحظين فإن الدقة ضعيفة بالنسبة لهذه المسألة 83%. الآن سأترك لك عدة ملاحظات: 1. مع الصور يفضل دوماً استخدام الشبكات العصبية وتحديداً CNN. على سبيل المثال لو استخدمنا ال CNN هنا لكنت حصلت على دقة تصل إلى 99%. 2. خورازمية Logistic Reg أعطت نتائج أفضل بكثير من NB رغم أن كلا الخوارزميتين خطيتين لكن Logistic Reg لاتعتمد على الاحتمالات و على وجود أحداث (ميزات هنا) سابقة. 3.خورازمية Logistic Reg ليست أيضاً خورازمية مثالية للصور، لكنها تكون جيدة في بعض الحالات ولكن ليس بشكل عام فهي خوارزمية خطية أي أنها محدودة القدرة على ملائمة الأنواع المعقدة من الميزات إضافةً إلى أن تعقيدها الزمن كبير جداً في حال الصور الأكبر حجماً (صور بأبعاد تبدأ من 150*150 مثلاً) والداتاسيت الأكبر حجماً (تحتوي عدد أكبر من الصور ربما 25000 ألف صورة أو أكثر)، ستكون بطيئة للغاية وفي بعض الحالات قد تحتاج لأيام للانتهاء التدريب وفي حالات أخرى قد تصل لأشهر!. باختصار صور = CNN وانسى أي شيئ آخر.
- 2 تعليقات
-
- 1
-
-
- تعلم الآلة
- بايثون
- (و 1 أكثر)
-
يجب أن يتم تمريرها ك tuble في هذه الحالة أي بالشكل التالي: freqbig[("will", "be")] وفي حال كنت تحتاج لتمريرها كسلاسل فيمنك تعريف دالة مساعدة لذلك تتولى التحويل إلى tuble كالتالي: def myfunc(s): return freqbig[tuple(s.split(" "))]
-
لايوجد دالة في nltk تمكنك من حساب CS بين جملتين، لكن بإمكانك تحقيق ذلك من خلالها. كما نعلم فإن تشابه جيب التمام هو مقياس للتشابه بين متجهين غير صفريين لفضاء الجداء الداخلي الذي يقيس جيب التمام للزاوية بينهما. ويعبر عنه بالمعادلة التالية التي سنقوم بتحقيقها: Similarity = (A.B) / (||A||.||B||) حيث أن كل من A و B هما أشعة. الكود: # استيراد الوحدات اللازمة from nltk.tokenize import word_tokenize # tokens لتقسيم النص إلأى وحدات from nltk.corpus import stopwords # لحذف كلمات التوقف من الجمل # نقوم بتحديد الجملتين s1 ="I love programming in Python" s2 ="I love programming in java" # نقوم الآن باستخراج الوحدات من النصوص s1_tokens = word_tokenize(s1) s2_tokens = word_tokenize(s2) # نقوم بحذف كلمات التوقف من النصوص sw = stopwords.words('english') l1 =[];l2 =[] s1_tokens = {w for w in s1_tokens if not w in sw} s2_tokens = {w for w in s2_tokens if not w in sw} # تشكل مجموعة تحتوي على كلمات رئيسية لكلا السلسلتين vector = s1_tokens.union(s2_tokens) for w in vector: if w in s1_tokens: l1.append(1) # إنشاء شعاع else: l1.append(0) if w in s2_tokens: l2.append(1) else: l2.append(0) c = 0 # الآن يمكننا تطبيق معادلة التشابه for i in range(len(vector)): c+= l1[i]*l2[i] # طباعة الناتج print("similarity: ", c / float((sum(l1)*sum(l2))**0.5)) النتيجة: similarity: 0.75 أي أن نسبة التشابه بين الجملتين تصل إلى 75% وفق هذا المقياس، وهي نتيجة منطقية.
-
word_tokenize تقوم بتقسيم النص إلى كلمات بناءاً على مكوناته بغض النظر عن ماهيتها لذا سيعتبر علامات الترقيم على أنها tokens، لذا يمكنك استخدام الكلاسRegexpTokenizer بدلاً من word_tokenize التي نمرر لبانيه تعبيراً منتظماً يتحكم بما سيتم أخذه وبما سيتم تجاهله، كما في المثال التالي الذي سنقوم فيه باستخدام هذه الوحدة وسنمرر لها تعبيراً منتظماً يختار تسلسل الأحرف الأبجدية الرقمية alphanumeric كرموز ويتجاهل كل شيء آخر. from nltk.tokenize import RegexpTokenizer sentence = 'Web oficial de Lionel Messi, jugador del Futbol Club Barcelona y uno de los mejores jugadores del mundo.' tokenizer = RegexpTokenizer(r'\w+') tokens=tokenizer.tokenize(sentence) print(tokens) """ ['Web', 'oficial', 'de', 'Lionel', 'Messi', 'jugador', 'del', 'Futbol', 'Club', 'Barcelona', 'y', 'uno', 'de', 'los', 'mejores', 'jugadores', 'del', 'mundo'] """ أو يمكنك استخدام word_tokenize وبعد ذلك تصفية علامات الترقيم من الخرج، من خلال المرور على ال tokens ثم تقيتها من خلال الدالة isalnum التي تختبر السلسلة إذا كانت alphanumeric أو لا: import nltk sentence = 'Web oficial de Lionel Messi, jugador del Futbol Club Barcelona y uno de los mejores jugadores del mundo.' words = nltk.word_tokenize(sentence) new_words= [word for word in words if word.isalnum()] print(new_words)
-
أنت مخطئ، ف NLTK تحتوي على الوحدة ngrams (ربما لا يعرفها الكثيرون) التي تمنحك حرية التقسيم إلى 2 , 3 , 4, 5 ,6 , .... , n-grams. مثال: # استيراد الوحدة from nltk import ngrams # تحديد نص text = 'Web oficial de Lionel Messi jugador del Futbol Club Barcelona y uno de los mejores jugadores del mundo.' # grams تحديد عدد ال n = 5 # tokens نقوم بتمرير النص كوحدات # ونمرر أيضاً عدد التقسيمات sixgrams = ngrams(text.split(), n) # نقوم بالمرور عليها وطباعتها بالشكل for grams in sixgrams: print(grams) """ ('Web', 'oficial', 'de', 'Lionel', 'Messi') ('oficial', 'de', 'Lionel', 'Messi', 'jugador') ('de', 'Lionel', 'Messi', 'jugador', 'del') ('Lionel', 'Messi', 'jugador', 'del', 'Futbol') ('Messi', 'jugador', 'del', 'Futbol', 'Club') ('jugador', 'del', 'Futbol', 'Club', 'Barcelona') ('del', 'Futbol', 'Club', 'Barcelona', 'y') ('Futbol', 'Club', 'Barcelona', 'y', 'uno') ('Club', 'Barcelona', 'y', 'uno', 'de') ('Barcelona', 'y', 'uno', 'de', 'los') ('y', 'uno', 'de', 'los', 'mejores') ('uno', 'de', 'los', 'mejores', 'jugadores') ('de', 'los', 'mejores', 'jugadores', 'del') ('los', 'mejores', 'jugadores', 'del', 'mundo.') """