Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
Free Pascal (FPC) على وجه الخصوص (لا يزال المبرمجين يعتقدون أنها هي نفسها باسكال السبعينات والثمانينات)، مفيدة لكل شيء تتوقعه، مثل برمجة التطبيقات بأداء جيد (نظرًا لأنه يتم تجميعها compiling)، وبرمجة الألعاب (على سبيل المثال من خلال OpenGL)، وأيضًا لبرمجة الويب حيث يمكنها التحويل إلى Java bytecode. يعمل على جميع المنصات المهمة (MS و Linux و Mac و iOS و Android ..إلخ.). FPC تم تحديثها بشكل كبير وهي لغة حديثة جدًا مقارنة بلغة باسكال التي صدرت في السبعينيات، فهي تحتوي على إضافات خاصة للبرمجة غرضية التوجه OOP (بما في ذلك وضع "Objective Pascal" لاستخدام فئات Objective-C) ، و OOP غير إلزامي تمامًا مثل C ++. كما أن لديها تحميلًا زائدًا للمعاملات operator overloading ، وتحميلًا زائدًا للدوال function overloading، ومصفوفات ديناميكية dynamic arrays، وجامع نفايات، ومساحات أسماء تلقائية automatic namespaces... أيضًا هي لغة معيارية (مثل Java) ، بينما C / C ++ ، رغم كل هذه السنوات فهي لا تزال غير معيارية. كما أنها تساعدك على فهم أساسيات عالم البرمجة لأنها لغة منخفضة المستوى، حيث تساعد المبرمجين على تعلم لغات برمجة أخرى مثل السي والسي++ والبايثون والجافا ..إلخ. وتستخدم في العديد من التطبيقات مثل: Skype و Apply Lisa و TeX.
-
تحتوي وحدة time في بايثون على الدالة time.strftime لعرض الطابع الزمني (أو الختم الزمني timestamp؛ سلسلة من الارقام والاحرف، تدل على التاريخ و/أو الوقت) كسلسلة بتنسيق محدد عن طريق تمرير أكواد التنسيق. تُستخدم الدالة time.gmtime لتحويل القيمة التي تم تمريرها إلى الدالة إلى ثوانٍ. أيضًا تحوّل الدالة time.strftime القيمة التي تم تمريرها من دالة time.gmtime إلى ساعات ودقائق باستخدام رموز التنسيق المحددة. import time sec = 123455 ty_res = time.gmtime(sec) res = time.strftime("%H:%M:%S",ty_res) print(res) الخرج: 10:17:35
-
الإجابة السابقة غير صحيحة، وتعطي خطأ (ربما كانت تعمل في الإصدارات القديمة من بايثون -وأشك في هذا-). الحل هو كالتالي: string = 'string' for i in range(11): string +=str(i) print (string) # string012345678910 حيث نمرر العدد الصحيح إلى الدالة str لكي تحوّله إلى سلسلة نصية قبل إجراء عملية الربط، وإلا سيعطي خطأ.
-
 يمكنك إنجاز ذلك كالتالي: def is_number? string true if Float(string) rescue false end الاستدعاء: my_string = '12.34' is_number?( my_string ) # => true أيضًا يمكنك أن تعرّف هذه الدالة، بحيث تكون قادراً على استدعائها مباشرة من خلال الصنف String كالتالي: class String def is_number? true if Float(self) rescue false end end بالتالي يكون استدعائها بالشكل: my_string.is_number? # => true أو يمكنك تعريفها بالشكل إذا كنت تريد التعامل مع الأعداد الصحيحة فقط: def is_num?(str) !!Integer(str) rescue ArgumentError, TypeError false end
يمكنك إنجاز ذلك كالتالي: def is_number? string true if Float(string) rescue false end الاستدعاء: my_string = '12.34' is_number?( my_string ) # => true أيضًا يمكنك أن تعرّف هذه الدالة، بحيث تكون قادراً على استدعائها مباشرة من خلال الصنف String كالتالي: class String def is_number? true if Float(self) rescue false end end بالتالي يكون استدعائها بالشكل: my_string.is_number? # => true أو يمكنك تعريفها بالشكل إذا كنت تريد التعامل مع الأعداد الصحيحة فقط: def is_num?(str) !!Integer(str) rescue ArgumentError, TypeError false end -
الإجابة السابقة غير صحيحة. بدايةً نحوّل T1 إلى قائمة من القوائم بدلاً من tubel من ال tubels: t = (('13', '17', '18', '21', '32'), ('07', '11', '13', '14', '28'), ('01', '05', '06', '08', '15', '16')) t=list(map(list, t)) """ [['13', '17', '18', '21', '32'], ['07', '11', '13', '14', '28'], ['01', '05', '06', '08', '15', '16']] """ ثم نحوّل كل عنصر إلى عدد صحيح: # idx نخزن فيه فهرس القائمة # li نخزن فيها القائمة for idx,li in enumerate(t): # نمر علر كل عنصر في القائمة ونحول قيمتها إلى الصنف الصحيح t[idx]=[int(x) for x in li] print(t) # [[13, 17, 18, 21, 32], [7, 11, 13, 14, 28], [1, 5, 6, 8, 15, 16]]
-
الطريقة الأفضل والأكثر دقة وتحكماً تكون مع استخدام التعابير المنتظمة من خلال وحدة re. حيث يمكننا تمرير مجموعة من الأحرف دفعة واحدة لإزالتها من خلال الدالة sub. import re # السلسلة النصية قبل إجراء الحذف old_string = 'h?ello, my name is nik! how are you?' new_string = re.sub('[!?]', '', old_string) print(new_string) # hello, my name is nik how are you
-
لا اعتقد أن التفسير السابق دقيق، كل ما في الأمر أنه ستختلف الأولويات. أي أن بايثون سيختبر أولاً [1,0] == True وسيعطي False ثم سيختر إذا كانت 1 محتواة في False، وبالتالي يعطي False. والدليل على ذلك أنه لو وضعنا قوسي الأولوية سيكون الخرج تماماً كما هو متوقع (أي True): (1 in [1,0]) == True # True
-
الطريقة الأبسط لذلك هي: x = '[ "A","B","C" , " D"]' print(list(eval(x))) إذا كنت تريد أيضًا إزالة المسافت الفارغة: x = [x.strip() for x in eval('[ "A","B","C" , " D"]')] أو من خلال الدالة loads من json: import json x = '[ "A","B","C" , " D"]' json.loads(x) # ['A', 'B', 'C', ' D']
-
سأشرح كيفية: إضافة أيام إلى تاريخ محدد. إضافة أيام إلى التاريخ الحالي. من أجل إضافة أيام إلى تاريخ محدد، سيتعين علينا استخدام الوحدة datetime module. في هذه الوحدة هناك العديد من الصفوف المفيدة للتعامل مع التاريخ والوقت. سوف نستخدم الصفوف datetime و timedelta. مثال: from datetime import datetime, timedelta specific_date = datetime(2019, 3, 5) new_date = specific_date + timedelta(21) print (new_date) الخرج: $ python codespeedy.py 2019-03-26 00:00:00 يمكننا أيضًا استخدام timedelta (days= 21) بدلاً من timedelta (21)، كلاهما سيعطيك نفس النتيجة. new_date = specific_date + timedelta(21) يتم استخدام السطر أعلاه لإضافة 21 يوم إلى التاريخ المحدد. في ()datetime، نمرر تاريخًا محددًا كمعطى للدالة، ثم نضيف الأيام باستخدام عامل التشغيل "+". للحصول على التاريخ الحالي يمكننا استخدام الكود: current_date = datetime.today() أو يمكننا أيضًا استخدام ما يلي: current_date = datetime.now() مثال: from datetime import datetime, timedelta # الوقت الحال print(datetime.today()) new_date = datetime.today() + timedelta(12) # طباعة الوقت الحالي بعد الإضافة print (new_date) الخرج: $ python codespeedy.py 2019-04-08 20:59:26.580545 2019-04-20 20:59:26.581544
-
:: يُسمى عامل تحليل النطاق. مهمته هي تحديد النطاق الذي يمكن العثور على الوحدة فيه. علي سبيل المثال: module Music module Record # لفرقة البيتلز Abbey Road مثلاً نسخة من end module EightTrack # مثل أغنية سوف أنجو للمغنية غلوريا جاينور end end module Record # لإضافة عنصر إلى قاعدة البيانات end للوصول إلى Record من خارج Music، يمكنك استخدام Music :: Record. للإشارة إلى Record من Music :: EightTrack، يمكنك ببساطة استخدام Record لأنه تم تعريفه في نفس النطاق (نطاق Music ). ومع ذلك، للوصول إلى وحدة Record المسؤولة عن التفاعل مع قاعدة البيانات الخاصة بك من Music :: EightTrack، لا يمكنك فقط استخدام Record لأن روبي يعتقد أنك تريد Music :: Record. وهنا يأتي الوقت الذي ستستخدم فيه عامل تحليل النطاق كبادئة prefix، مع تحديد النطاق الرئيسي Record::
-
الإجابة السابقة ستعطيك حل خاص لمشكلتك. سأعطيك الآن حلًّا عامًّا لطباعة تتبع المكدس Stack trace لاستثناء ما. توفر الوحدة traceback في بايثون كل ماتحتاجه لذلك. الهيكل العام لتتبع المكدس لاستثناء: Traceback for the most recent call. # تتبع آخر استدعاء Location of the program. # موقع البرنامج Line in the program where the error was encountered. # السطر الذي حدث فيه الخطأ Name of the error: relevant information about the exception. # اسم الخطأ: معلومات ذات صلة بالاستثناء. مثال: Traceback (most recent call last): File "C:/Python27/hdg.py", line 5, in value=A[5] IndexError: list index out of range الطريقة الأولى: باستخدام الدالة print_exc: traceback.print_exc(limit=None, file=None, chain=True) إذا كانت limit موجبة مثال: import traceback # نعرّف مصفوفة A = [1, 2, 3, 4] # معالجة الاستثناء try: value = A[5] except: # طباعة تتبع المكدس traceback.print_exc() # لإظهار أن البرنامج يستمر بشكل طبيعي بعد معالجة استثناء try-except رسالة خارج كتلة print("end of program") الخرج: Traceback (most recent call last): File "C:/Python27/hdg.py", line 8, in value=A[5] IndexError: list index out of range end of program الطريقة الثانية: باستخدام print_exception. traceback.print_exception(etype, value, tb, limit=None, file=None, chain=True) مثال: import traceback import sys a = 4 b = 0 # معالجة الاستثناء # سنقسم على صفر try: value = a / b except: # طباعة المسار traceback.print_exception(*sys.exc_info()) print("end of program") الخرج: Traceback (most recent call last): File "C:/Python27/hdg.py", line 10, in value=a/b ZeroDivisionError: integer division or modulo by zero end of program
-
في حال استدعاء التابع fail بدون تمرير أي معامل، فسيُطلق الاستثناء في $! أو يطلق الخطأ RuntimeError إذا كان $! يساوي nil. في حال تمرير سلسلة نصية فقط، فسيُطلَق الخطأ RuntimeError مع إظهار هذه السلسلة النصية كرسالة. خلا ذلك، يجب أن يكون الوسيط الأول اسم الصنف Exception (أو كائنًا يعيد كائنًا من النوع Exception عند إرسال رسالة استثناء). يحدِّد الوسيط الاختياري الثاني الرسالة المرتبطة بالاستثناء، أما الوسيط الثالث فهو مصفوفة تضم معلومات الاستدعاء. تُلتقَط الاستثناءات بواسطة الجملة rescue من الكتل begin...end. البنية العامة له: fail fail(string) fail(exception [, string [, array]]) string: سلسلة نصية تمثل الرسالة المراد إظهارها عند الفشل. exception: اسم الصنف Exception أو كائن يعيد كائنًا من الصنف Exception. array: مصفوفة تضم معلومات الاستدعاء. مثال على استخدام التابع fail: raise "Failed to create socket" raise ArgumentError, "No parameters", caller يمكنك القول أن fail == raise. بمعنى آخر، fail هو مجرد اسم آخر (alias) شائع للدالة raise.
-
اعتقد أن استخدام التعابير المنتظمة في هذه الحالة سيعطيك دقة أكبر قليلاً: URI::DEFAULT_PARSER.regexp[:ABS_URI] سيؤدي ذلك إلى إلغاء عناوين URL التي تحتوي على مسافات، على عكس URI.regexp الذي يسمح بالمسافات. إضافةً إلى ذلك، للتحقق مما إذا كانت السلسلة عبارة عن عنوان URL، استخدم: url =~ /\A#{URI::regexp}\z/ إذا كنت تريد فقط التحقق من عناوين URL على الويب (http أو https) ، فاستخدم هذا: url =~ /\A#{URI::regexp(['http', 'https'])}\z/
-
اعتقد أن Pathname أكثر ملائمة لأسماء الملفات من السلاسل العادية strings. الكود التالي يُعطيك مصفوفة من جميع المجلدات ضمن المجلد المحدد ككائنات Pathname. require "pathname" Pathname.new(directory_name).children.select { |c| c.directory? } سبب آخر لتفضيل Pathname وهو أنه يحذف تلقائيًّا ملفات . و .. وملفات الملكية مثل DS_Store. عمومًا، إذا كنت تريد أن تكون سلاسل: Pathname.new(directory_name).children.select { |c| c.directory? }.collect { |p| p.to_s } إذا كان اسم المجلد مسار مطلق، فإن هذه السلاسل ستكون مطلقة أيضًا.
-
اقترح استخدام الدالة get التي تُستخدم للتحقق مما إذا كان مفتاح معين موجودًا في أزواج المفتاح والقيمة في القاموس. dict.get(key, default=None) مثال: # تعريف قاموس inp_dict = {'Python': "A", 'Java':"B", 'Ruby':"C", 'Kotlin':"D"} # اختبار فيما إذا كان المفتاح موجودًا أم لا if inp_dict.get('Python')!=None: print("The key is present.\n") else: print("The key does not exist in the dictionary.")
-
يمكنك أيضًا استخدام parameterize الذي يقوم بحذف الأحرف الخاصة: parameterize(string, separator: "-", preserve_case: false) public مثال: '@!#$%^&*()111'.parameterize => "111" أو بواسطة الدالة scan، حيث يبحث التابع عن نمط محدَّد ضمن السلسلة النصية التي استدعيت معه ويعيد النتائج المتطابقة في مصفوفة أو يمرِّرها إلى الكتلة المعطاة ويعيد الناتج الذي تعيده. scan(pattern) → array scan(pattern) {|match, ...| block } → str حيث أن pattern هو تعيبر نمطي أو سلسلة نصية يراد البحث عنها ومطابقتها في السلسلة النصية المعطاة. إن لم يحتوي هذا المعامل على مجموعات، فستتألف كل نتيجة فردية من السلسلة النصية المتطابقة (أي &$). أما إن احتوى على مجموعات، فستكون كل نتيجة فردية مصفوفة بحد ذاتها تحوي عنصر واحد لكل مجموعة. مثال، سنستخدم هذه الدالة للحصول على السلسلة بدون الأحرف الخاصة: original = "aøbæcå" stripped = original.scan(/[a-zA-Z]/).to_s puts stripped # الخرج "abc"
-
يمكنك أيضًا استخدام الدالة المُضمنة في بايثون list. مثال1: تحويل مصفوفة أحادية البعد إلى قائمة: import numpy as np # مصفوفة أحادية arr = np.array([1,2,3,4]) # طياعتها print("Numpy array: ", arr) # طباعة نوعها print("Type: ",type(arr)) # تحويلها لقائمة ls = list(arr) print("\nList: ", ls) print("Type: ",type(ls)) الخرج: Numpy array: [1 2 3 4] Type: <class 'numpy.ndarray'> List: [1, 2, 3, 4] Type: <class 'list'> مثال2: تحويل مصفوفة ثنائية إلى قائمة: import numpy as np # تعريف مصفوفة arr = np.array([[1,2,3],[4,5,6]]) # طباعتها print("Numpy array: ", arr) # طباعة نوعها print("Type: ",type(arr)) # تحويلها لقائمة ls = list(arr) print("\nList: ", ls) print("Type: ",type(ls)) الخرج: Numpy array: [[1 2 3] [4 5 6]] Type: <class 'numpy.ndarray'> List: [array([1, 2, 3]), array([4, 5, 6])] Type: <class 'list'> كما يمكنك استخدام الدالة tolist، كما في الإجابة السابقة، لكن هناك فرق بين الدالتين يتجلى في حالة المصفوفات متعددة الأبعاد، فلو استخدمنا الدالة tolist مع المصفوفة الثنائية السابقة، سيكون الخرج كالتالي: Numpy array: [[1 2 3] [4 5 6]] Type: <class 'numpy.ndarray'> List: [[1, 2, 3], [4, 5, 6]] Type: <class 'list'> لاحظ أن هناك اختلاف في شكل الخرج بين الدالتين، لكن هناك اختلاف آخر، فباستخدام الدالة tolist، يتم تحويل عناصر البيانات إلى أقرب أنواع بايثون المضمنة المتوافقة معها، بينما يتم الاحتفاظ بأنواع عناصر البيانات عند استخدام list. انظر إلى المثال التالي: import numpy as np arr = np.array([1,2,3,4]) ls1 = arr.tolist() ls2 = list(arr) print("ls1: ", ls1) print("Type of items: ",[type(i) for i in ls1]) print("\nls2: ", ls2) print("Type of items: ",[type(i) for i in ls2]) الخرج: ls1: [1, 2, 3, 4] Type of items: [<class 'int'>, <class 'int'>, <class 'int'>, <class 'int'>] ls2: [1, 2, 3, 4] Type of items: [<class 'numpy.int32'>, <class 'numpy.int32'>, <class 'numpy.int32'>, <class 'numpy.int32'>] لاحظ أنه في القائمة التي تم إرجاعها بواسطة دالة tolist، تم تحويل كل عنصر إلى أقرب نوع بيانات متوافق معه، بينما في القائمة التي تم إرجاعها بواسطة list، يحتفظ كل عنصر بنوعه. وهذا فرق مهم جدًا في بعض الحالات.
-
تشابه جاكارد "Jaccard Similarity"؛ هو مقياس تشابه يُستخدم لتحديد مدى تشابه نقطتي بيانات مع بعضهما البعض. وفي تعريف آخر؛ هو مقياس يقيس التشابه بين مجموعتين من البيانات، وتتراوح قيمته من 0 إلى 1. وكلما زاد الرقم، زاد تشابه مجموعتي البيانات. ويعبر عنه بالشكل: Jaccard Similarity = (number of observations in both sets) / (number in either set) # أي هو مجموعة الأرقام التي ظهرت في كلتا المجموعتين على عدد الأرقام كلها # أو بالعلاقة J(A, B) = |A∩B| / |A∪B| ويمكن تمثيل ذلك في دالة في بايثون: def jaccard(list1, list2): intersection = len(list(set(list1).intersection(list2))) union = (len(list1) + len(list2)) - intersection return float(intersection) / union مثال: import numpy as np # لدينا نقطتي البيانات التاليتين a = [0, 1, 2, 5, 6, 8, 9] b = [0, 2, 3, 4, 5, 7, 9] # حساب نسبة التشابه بين المجموعتين jaccard(a, b) # 0.4
-
إذا أردت معرفة فيما إذا كانت تحوي قيم متكررة، وتريد أن تعرف هذه القيم أيضًا، يمكنك القيام بذلك بالشكل التالي: dups = [1,1,1,2,2,3].group_by{|e| e}.keep_if{|_, e| e.length > 1} # => {1=>[1, 1, 1], 2=>[2, 2]} الآن إذا كنت تريد القيم المكررة فقط: dups.keys # => [1, 2] إذا كنت تريد عدد التكرارات لكل عنصر: dups.map{|k, v| {k => v.length}} # => [{1=>3}, {2=>2}]
-
يمكنك استخدام التعليمة python file.py لتشغيل ملف بايثون من الطرفية Terminal، لكن تشغيله من خلال IDLE python shell يكون مختلفًا. لتشغيل الملف في IDLE python shell ، نستخدم الدالة exec بالشكل التالي: exec(open("path/script_name.py").read()) طبعًا استبدل path و script_name بمسار واسم الملف الخاص بك. لكن في حال كنت قد فتحت ال shell في نفس المكان الذي يوجد فيه الملف، فيمكنك الاكتفاء باسم الملف: exec(open("script_name.py").read())
- 1 جواب
-
- 1
-

-
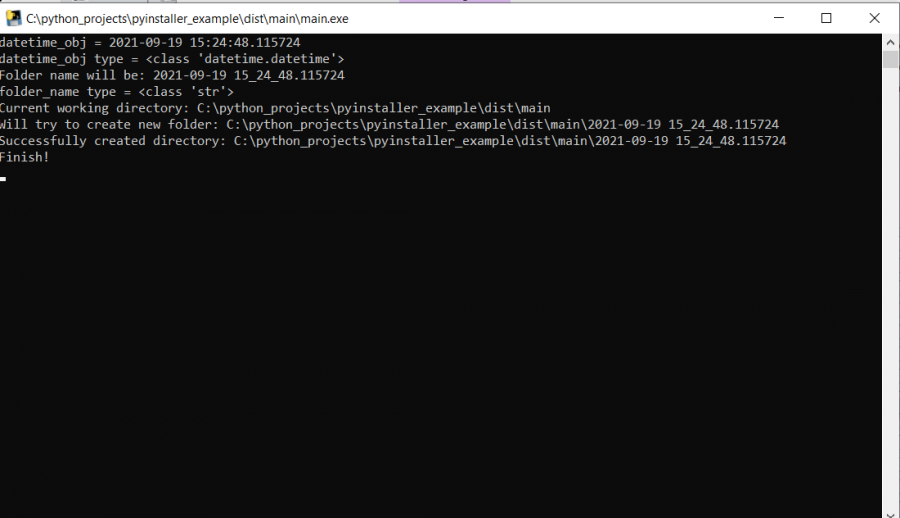
بدايةً قم بتثبيت المكتبة: pip install pyinstaller ثم تأكد من أنه تم تثبيتها: pyinstaller --version الآن بفرض لدينا البرنامج التالي: from datetime import datetime import os import time if __name__ == '__main__': # قراءة الوقت الحالي datetime_obj = datetime.now() print(f"datetime_obj = {datetime_obj}") print(f"datetime_obj type = {type(datetime_obj)}") # حتى نتمكن من استخدامه لتكوين اسم مجلد لإنشاء مجلد جديد str إلى سلسلة datetime_obj نقوم الآن بتحويل folder_name = datetime_obj.strftime("%Y-%m-%d %H:%M:%S.%f") # يحتوي على رمز النقطتين ":" الذي لا يُسمح باستخدامه لتسمية الملفات datetime_obj هناك شيء آخر يجب ملاحظته وهو أن # ‘_’ لذا نستبدله بالرمز folder_name = folder_name.replace(':', '_') print(f"Folder name will be: {folder_name}") print(f"folder_name type = {type(folder_name)}") #للحصول على مجلد العمل الحالي os الآن نستخدم # يساعدنا هذا في تشكيل المجلد النهائي لمجلدنا الجديد cwd = os.getcwd() print(f"Current working directory: {cwd}") folder_directory = cwd + "\\" + folder_name print(f"Will try to create new folder: {folder_directory}") # الذي قمنا بتشكيله folder_directory في هذه المرحلة ، نحن جاهزون لإنشاء مجلد جديد باستخدام try: if not os.path.exists(folder_directory): os.mkdir(folder_directory) print(f"Successfully created directory: {folder_directory}") except Exception as e: print(f"Failed to create directory! {e}") # طباعة رسالة تشير الى الانتهاء print("Finish!") time.sleep(5) الآن سنقوم بتحويل هذا الكود إلى ملف تنفيذي، من خلال ما يلي: # نضع اسم ملف الكود # أو نضع اسم الملف مسبوقاً بالمسار، في حال كان ملف الكود ليس ضمن المجلد الافتراضي pyinstaller main.py في حال تم التنفيذ بنجاح، سترى بعض المجلدات الجديدة التي تم إنشاؤها ضمن مجلد العمل الخاص بك (هنا استخدمنا مجلد العمل الافتراضي). فيما يلي مثال لما يجب أن تراه: الآن للعثور على الملف التنفيذي الخاص بك ، عليك الذهاب إلى المجلد dist (دوماً بكون بهذا الاسم) والدخول إلى المجلد main (بنفس اسم ملف الكود). يجب أن ترى شيئًا كما في الصورة التالية: الآن إذا قمت بتشغيل هذا الملف، فسترى نافذة منبثقة جديدة ستعرض جميع بيانات الطباعة التي أضفناها في الكود. الآن يتم إغلاق هذه النافذة تلقائيًا بعد 5 ثوان، وهذا هو سبب إضافة time.sleep (5) في نهاية الكود، حتى تتمكن من رؤية خرج الملف التنفيذي. الآن إذا قمت بتشغيل هذا الملف لعدة مرات، فسترى مجلدات جديدة تم إنشاؤها في نفس المجلد حيث يوجد الملف التنفيذي الخاص بك:
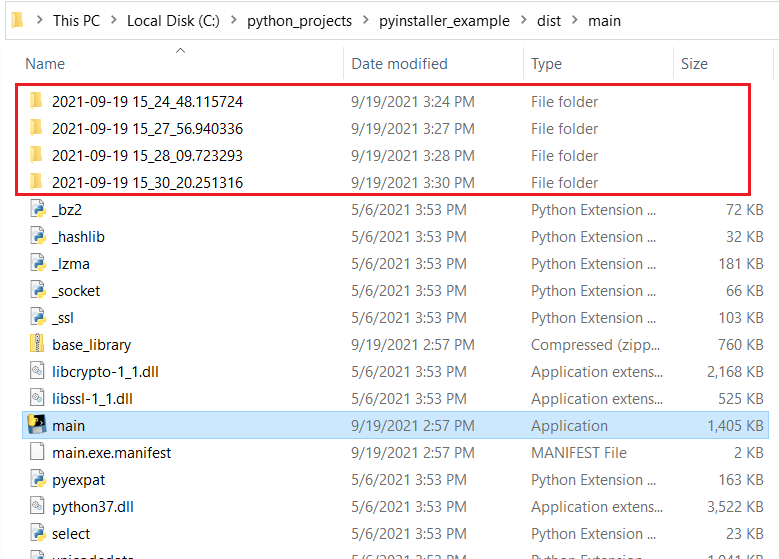
-
بدايةً لا أتفق مع الإجابة، حيث أن RegEx (Regular expression) لن تفيدك في هكذا أمر. بالنسبة لسؤالك الأول "حساب التشابه الدلالي semantic similarity بين نصين": فهناك العديد من الأساليب، كل منها يعتمد على تكنيكات وخوارزميات معينة، وللحصول على نتيجة تشابه أفضل، يستخدم العديد من الباحثين التعلم العميق لتحسين العملية.هنا سأستخدم مكتبة difflib للحساب، وهي طريقة بسيطة جدًا للمبتدئين. import difflib # إنشاء دالة لحساب التشابه بين جملتين def string_similar(s1, s2): return difflib.SequenceMatcher(None, s1, s2).quick_ratio() # بفرض لدينا الجملتين التاليتين s1 = 'i love this book' s2 = 'this book is my favorite' # يمكن حساب التشابه بينهما من خلال استدعاء الدالة السابقة: print (string_similar(s1, s2)) # 0.75 # أي أن نسبة التشابه هي 75 في المئة يمكنك أيضاً استخدام مكتبة genism: import gensim # الخاص بتمثيل الكلمات word2vec تحميل نموذج model = gensim.models.KeyedVectors.load_word2vec_format('yelp-2013-embedding-200d.txt', binary=False) يمكننا الحصول على التمثيل (أو التضمين embedding) لكل كلمة في الجملة من ملف word2vec (نموذج تم إطلاقه من قبل الباحث ميكلوف في سنة 2013 وهو نموذج شهير جداً لتمثيل الكلمات). وبعد ذلك نكون حصلنا على جملة من الكلمات المُمثلة ضمن أشعة تعكس معناها الدلالي (جملة من التضمينات). بفرض لدينا الجملتين التاليتين: sen_1 = "i love this book" sen_2 = 'this book is my favorite' الآن كيف نحصل على جملة من التضمينات؟ هناك عدة طرق يمكنك التفكير فيها، سأقترح أن نقوم بعمل average لكل تضمينات الكلمات في الجملة: sen_1_words = [w for w in sen_1.split() if w in model.vocab] sen_2_words = [w for w in sen_2.split() if w in model.vocab] sim = model.n_similarity(sen_1_words, sen_2_words) print(sim) # 0.839574928046 # أي متشابهتين بنسبة 83 بالمئة # وهي نتيجة أفضل من النتييجة التي حصلنا عليها من خلال المكتبة السابقة هناك العديد من الطرق الأخرى التي يتم اقتراحها في الأوراق البحثية للقيام بهذه العملية، وبالتالي إذا أردت أن يكون حساب التشابه دقيقاً، فأنصح بقراءة آخر الأبحاث والاعتماد عليها.
-
لايوجد هناك حاجة لأن تقوم بتثبيت أو تحديث أي شيء. المشكلة واضحة صديقي وهي: "SyntaxError: non-default argument follows default argument" حيث يظهر هذا الخطأ عندما تقوم بتحديد قيمة المُعطى (القيمة التي تمررها لوسيطا الدالة) لوسيط افتراضي قبل الوسيط غير الافتراضي. لحل هذا الخطأ، تأكد من ترتيب جميع الوسائط في الدالة بحيث تأتي الوسيطات الافتراضية بعد الوسيطات غير الافتراضية، وسيتم حل المشكلة بكل تأكيد! لمزيد من التفصيل؛ يٌمرر بايثون المعطيات للمتغيرات بالترتيب الذي تظهر به في استدعاء الدالة، ويجب أن تأتي معطيات الوسيطات الافتراضية قبل الغير افتراضية. هذا لأن الوسيطات غير الافتراضية إلزامية. أما الوسيطات الافتراضية فلها قيمة افتراضية تأخذها في حال لم تمرر قيمة لها أثناء استدعاء الدالة. مثلاً في الكود التالي: def test_function(score=25, class=6, name): pass test_function("John", 22) في هذا الكود، لا تعرف بايثون ما إذا كان "John" قد تم تعيينه لـ "name" أو "Score".
-
المشكل تبدأ في السطر الأول، حيث أنك قمت بفتح الملف في الوضع الثنائي binary mode، وبالتالي البيانات التي تتم قراءتها ستكون ثنائية bytes objects، وبالتالي لايمكنك في السطر الأخير: if 'text' in x أن تستخدم معامل اختبار الاحتواء in لأن الكائن هنا ليس من الصنف str. لذا يجب عليك إما أن تقرأ الملف في وضع القراءة العادي 'r'، أو أن تحوّله إلى bytes object كالتالي: if b'text' in x:
-
نعم بالتأكيد، سيتم إطلاق هذه الدورات في وقتٍ ما، لكن ليس في الوقت الحالي.