Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 يمكنك أيضاً استخدام Integer.valueOf التي تستخدم للتحويل من String إلى Integer مثال: // تعريف سلسة نصية تمثل عدد صحيح String strTest = "100"; تحويلها إلى عدد صحيح: int iTest = Integer.valueOf(strTest); طباعة السلسة النصية والعدد الصحيح: System.out.println("Actual String:"+ strTest); System.out.println("Converted to Int:" + iTest); هناك حل آخر أيضاً من خلال استخدام الدالة toInt من الكلاس NumberUtils : int num = NumberUtils.toInt("1234"); أيضاً يمكنك استخدام الدالة ()java.lang.Integer.decode لتحويل سلسلة نصية (السلسلة المراد فك تشفيرها) إلى عدد صحيح (تقبل الدالة أيضاً الأعداد العشرية ، والسداسية ، والثمانية). الشكل العام للدالة: public static Integer decode(String str) حيث أن str هو السلسلة النصية المراد فك تشفيرها. تُرجع الدالة كائن يمثل عدد صحيح يحمل قيمة int التي تمثلها سلسلة str الممررة. مثال: import java.lang.*; public class Javadoc1 { public static void main(String[] args) { Integer int1 = new Integer(10); String nstr = "44"; System.out.println("Actual Integral Number = "+ int1.decode(nstr)); } } // الخرج: // Actual Integral Number = 44
يمكنك أيضاً استخدام Integer.valueOf التي تستخدم للتحويل من String إلى Integer مثال: // تعريف سلسة نصية تمثل عدد صحيح String strTest = "100"; تحويلها إلى عدد صحيح: int iTest = Integer.valueOf(strTest); طباعة السلسة النصية والعدد الصحيح: System.out.println("Actual String:"+ strTest); System.out.println("Converted to Int:" + iTest); هناك حل آخر أيضاً من خلال استخدام الدالة toInt من الكلاس NumberUtils : int num = NumberUtils.toInt("1234"); أيضاً يمكنك استخدام الدالة ()java.lang.Integer.decode لتحويل سلسلة نصية (السلسلة المراد فك تشفيرها) إلى عدد صحيح (تقبل الدالة أيضاً الأعداد العشرية ، والسداسية ، والثمانية). الشكل العام للدالة: public static Integer decode(String str) حيث أن str هو السلسلة النصية المراد فك تشفيرها. تُرجع الدالة كائن يمثل عدد صحيح يحمل قيمة int التي تمثلها سلسلة str الممررة. مثال: import java.lang.*; public class Javadoc1 { public static void main(String[] args) { Integer int1 = new Integer(10); String nstr = "44"; System.out.println("Actual Integral Number = "+ int1.decode(nstr)); } } // الخرج: // Actual Integral Number = 44 -
كما قال لك Wael Aljamal، لكن سأعطيك خطوات الحل: لادخال 100 علامة: تحتاج لمصفوفة لتخزينهم. ومن ثم يقوم يايجاد مجموع العلامات والوسط الحسابي للعلامات: تحتاج لدالة تستلم مصفوفة وتقوم بإرجاع مجموع عناصرها + المتوسط.
-
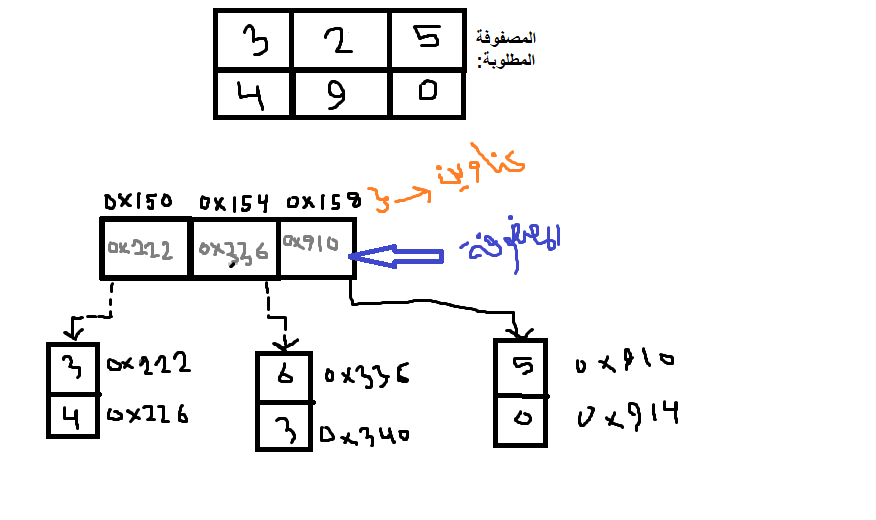
أنت تريد مصفوفة ديناميكية بلغة C++ لتخزين هذه المعلومات. إن عملية إنشاء مصفوفة ديناميكية في هذه اللغة منخفض المستوى قليلاً، سأعطيك الخطوات لذلك وسأعطيك بعدها رأس الخيط لحل مسألتك وأنت أكمل. لتخصيص الذاكرة ديناميكياً نستخدام الدالة malloc أو calloc (وهاتين الدالتين أصلهما لغة السي) أو المؤثر new (وهذا ماسنستخدمه الآن لحجز الذاكرة -الخيار المستحسن-). الآن لإنشاء مصفوفة ديناميكية ثنائية البعد نقوم أولاً بالإعلان عن متغير مؤشر ل مؤشر أي بمعنى: data type **pointer-variable; سنجعل صنف البيانات هو int وسيكون اسم المتغير arr إذاً سنكتب: int** arr; الآن نقوم بحجز ذاكرة لصف أو سطر (row) سيحتفظ بمرجع للعمود column أي: arr = new int*[row]; ثم نقوم بتخصيص مساحة للأعمدة باستخدام المؤثر new في كل خلية صف والتي ستحتوي على القيم الفعلية لعناصر المصفوفة أي بمعنى: arr[i] = new int[col]; الكلام السابق يوضحه المخطط التالي: والكود التالي هو تحقيق لما سبق: #include <iostream> using namespace std; int main() { // نقوم بتعريف المؤشر للمؤشر int** array; // نقوم بتعريف متغيرين يمثلان عدد الأسطر والأعمدة المطلوبين int row, col, i, j; // نطلب إدخالهما من المستخدم cin >> row; cin >> col; // حجز ديناميكي للصف array = new int*[row]; // حجز ديناميكي للعمود for(i=0; i<row; i++){ array[i] = new int[col]; } //إدخال عناصر المصفوفة for(i=0; i<row; i++){ for(j=0; j<col; j++){ cin >> array[i][j]; } } // تحرير الذاكرة بعد الانتهاء من استخدام المصوفة delete [] array; } لطباعة عناصر المصفوفة يمكنك استخدام الدالة التالية: void display(int** a, int r, int c){ for(int i=0; i<r; i++){ for(int j=0; j<c; j++){ cout << a[i][j] << ' '; } cout << endl; } } ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ الآن بالنسبة لمسألتك فيمكنك إتمامها من خلال تعريف مصفوفة ديناميكية كما في المثال السابق لكن يجب أن تكون عناصرها struct أو class يحتوي ال Product information.
-
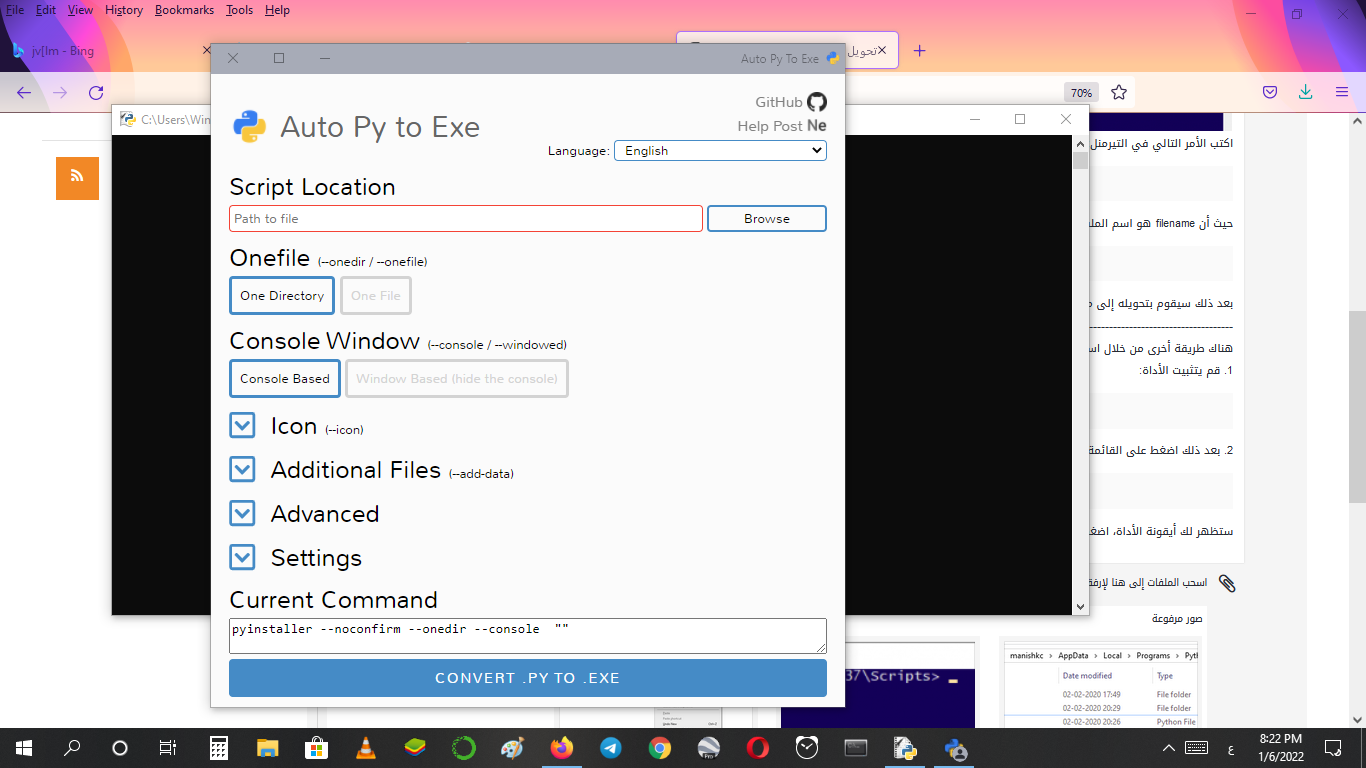
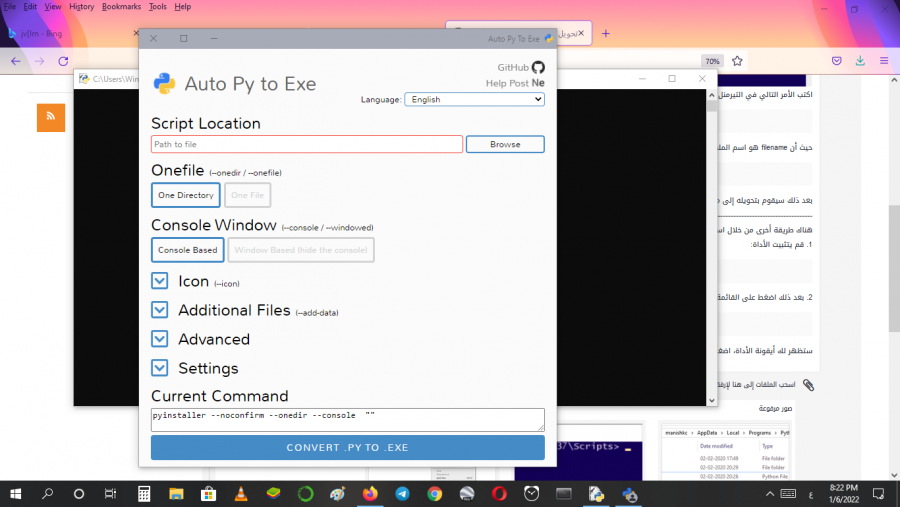
يمكنك القيام بذلك من خلال مكتبة pyinstaller، من خلال الخطوات التالية: 1. تحميل المكتبة: pip install pyinstaller 2. اذهب إلى المجلد الذي يحتوي على ملف بايثون الخاص بك (يكون امتداده py. أو ipynb. في حال قمت بكتابته باستخدام jupyter notebook). 3.اضغط على زر shift وانقر بزر الماوس الأيمن في نفس الموقع. سوف تحصل على المربع أدناه. ثم انقر على "Open PowerShell window here". ستحصل على نافذة كالتالي: اكتب الأمر التالي في التيرمنل: pyinstaller --onefile -w 'filename.py' حيث أن filename هو اسم الملف و py. هو امتداده (في حالتنا اسم الملف هو "1"). لذا سنكتب: pyinstaller --onefile -w '1.py' بعد ذلك سيقوم بتحويله إلى ملف exe ووضعه ضمن مجلد جديد باسم dist ضمن نفس المسار والاسم لكن بامتداد exe. ------------------------------------------------------------------------------------------------------------------------------------------------- هناك طريقة أخرى من خلال استخدام auto-py-to-exe وهي أكثر سهولة: 1. قم يتثبيت الأداة: pip install auto-py-to-exe 2. بعد ذلك اضغط على القائمة ابدأ واكتب في مربع البحث: auto-py-to-exe أو من خلال التيرمنل اكتب ونفذ الأمر التالي: auto-py-to-exe ستظهر لك أيقونة الأداة، اضغط عليها فتظهر بالشكل: كل ماعليك فعله الآن هو الضغط على زر Browse وتحديد ملف بايثون المطلوب. لمزيد من التفاصيل حول هذه الأداة يمكنك زيارة التوثيق هنا.

- 6 اجابة
-
- 2
-

-
هل قمت بتثبيت المكتبة fuzzy_expert؟ في حال لم تقم بتثبيتها، يجب عليك تثبيتها من خلال فتح التيرمنل وتنفيذ الأمر التالي: pip install fuzzy_expert أو في حال كنت تستخدم google colab: !pip install fuzzy_expert في حال قمت بتثبيتها واستمرت المشكلة، قم بتنفيذ الأمر التالي في التيرمنل فغالباً ستكون المكتبات الأساسية الموجودة لديك قديمة: python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose ولا اعتقد ستحتاج لشيء آخر..
-
IEEE (معهد مهندسي الكهرباء والإلكترونيات Institute of Electrical and Electronics Engineers -آي تربل إي-) هي أكبر مجتمع مهني في العالم وتضم مهندسين ومهنيين من خلفيات مختلفة مع الكثير من المتطوعين الخبراء في جميع أنحاء العالم. هدف المعهد هو تحقيق التقدم التعليميّ والتقنيّ في مجال الهندسة الكهربائية والإلكترونيّة والحاسبات وما في حكمها. تعتبر الجمعية من أشهر واضعي المعايير الصناعية عالميا حيث تشمل مجالات عديدة كالطاقة الكهربائية والأجهزة الطبية والإلكترونيات والاتصالات وتكنلوجيا المعلومات ويقوم فرع متخصص من الجمعية بعملية تحديد وتطوير المعايير الصناعية في المجالات المذكورة، ومن أشهر المعايير المتخذة مجوعة المعايير IEEE 802 LAN/MAN والتي تتضمن المعيار الشهير آي إي إي إي 802.3 إيثرنت والمعيار آي إي إي إي 802.11 المتعلق بالشبكات الاسلكية. ISO وهي اختصاراً ل (المنظمة الدولية للمعايير International Organization for Standardization) هي منظمة تعمل على وضع المعايير، وهي تصرح عن معايير تجارية وصناعية عالمية. إذاً يمكنك أن تلاحظ أن ISO هي أكثر عمومية أما IEEE فهي متخصصة في جوانب محددة. ACM حسب معرفتي فهي لاتركز على وضع معايير كما IEEE و ISO حيث يركز أكثر على الحوسبة والمجالات المتعلقة بال CS مثل تحليلات البيانات والبرمجة وتعدين البيانات والويب والبرمجيات.وهي اختصار ل Association for Computing Machinery وهي أول رابطة علمية وتعليمية للحوسبة في العالم. وتقوم الرابطة بالعديد من النشاطات التعليمية المتعلقة بالحاسوب مع العديد من الجامعات، كما تقوم بتنظيم المؤتمرات والمسابقات وإصدار مجلات ومنشورات متعلقة بالحاسوب. وهي بذلك تقوم بدور مشابه إلى حد ما لما تقوم به منظمة جمعية مهندسي الكهرباء والإلكترونيات IEEE.
- 1 جواب
-
- 2
-
-
الخطأ لايحدث معك عند فتح الصورة، وإنما عند حفظها في السطر 44 من الكود الذي أرفقته. في السطر 44 كتبت السطر التالي: img.save("upload/temp.jpg") وفي السطر 45 تحاول فتح الصورة التي خزنتها في ذلك المسار: name,id,image=.... واعتماداً على الرسالة التي يقدمها لك ال Debugger فإن الخطأ يحدث في السطر 44 لأنه لم يعثر على المجلد المذكور (أيضاً قد يكون المجلد المذكور موجوداً بالفعل لكنك لم تكتب المسار بشكل صحيح -انتبه للإجابة التي قدمها شرف الدين-). لذا يجب أن تصلح الخطأ الذي وقع في عملية الحفظ في السطر 44 وهذا يتم عن طريق كتابة مسار صالح (موجود)، أي عن طريق كتابة المسار المطلق كاملاً. كما ويمكنك استخدام الصيغة التي قدمها شرف الدين في الإجابة السابقة.
-
هذا الرمز تجده في لغة السي++ أيضاً وأصله لغة السي وتحديداً الدالة printf فيها. ويُسمى "placeholder" أو عنصر نائب أو بمعنى آخر هو رمز "symbol" يتم تضمينه ضمن سلسلة نصية أو تعبير رياضي للدلالة على أن هناك تعبيراً نصياً أو قيمة ستحل محله (للدلالة على شيء أو كمية مفقودة). في بايثون نستخدم الرمز d% كعنصر نائب لتحديد قيم عدد صحيح أو أرقام عشرية أو أرقام. يسمح لنا بطباعة الأرقام داخل سلاسل أو قيم أخرى. يتم وضع الرمز d% حيثما نريد وضع العدد (يتم تحويل أرقام الفاصلة العائمة تلقائياً إلى قيم عشرية). مثال: # الإعلان عن متغير يمثل عدد صحيح num = 2021 الآن نريد أن نطبع هذا المتغير ضمن سلسلة نصية، لذا كل ماعلينا فعله هو وضع هذا العنصر ضمن السلسلة لينوب عن المتغير: print("%d is here!!" % num) حيث نقوم بوضع السلسلة النصية المطلوب إظهارها ضمن علامتي اقتباس " " ونقوم بكتابة النص المطلوب إظهاره ضمنها إضافةً إلى العنصر النائب، ثم نكتب بعد علامتي الاقتباس الرمز % متبوعاً باسم المتغير الذي سيحل محل العنصر الذي ينوب عنه (d%). num = 2022 print("%d is here!!" % num) # الخرج: # 2022 is here!! لكن ماذا لو كان لدينا أكثر من متغير نريد وضعه ضمن السلسلة النصية كما في مثالك؟ هنا يجب أن نقوم بوضع عنصر نائب من أجل كل متغير ويجب أن نضع هذه المتغيرات ضمن قوسين، مثلاً: year = 2022 month=1 day = 1 print("%d:%d:%d" % (year,month,day)) # الخرج: # 2022:1:1 اعتقد أن الأمر أصبح واضحاً. حيث استخدمناها في مثالك لطباعة المتغيرات مع بعضها وفصلها ب " : ". الآن لنجرب استخدام هذا الرمز مع الأعداد العشرية و النسبية: # الإعلان عن متغير نسبي frac_num = 8/3 # الآن سنحاول استخدام الطريقة السابقة معه print ("Rational number formatting using %d") print("%d is equal to 8/3 using this operator." % frac_num) # الإعلان عن عدد عشري لنجرب علييها أيضاً dec_num = 10.9785 print ("Decimal number formatting using %d") print("%d is equal to 10.9785 using this operator." % dec_num) الخرج: Rational number formatting using %d 2 is equal to 8/3 using this operator. Decimal number formatting using %d 10 is equal to 10.9785 using this operator. لاحظ من الخرج أنه يقوم بتحويلها إلى أعداد صحيحية.
-
نعم في Nltk يمكنك استخدام Part-Of-Speech tagger (pos_tag)، حيث أن ماتطلبه ينتمي إلى فئة NNP. # التي تقوم بتصنيف الكلمات pos_tag استيراد الوحدة from nltk.tag import pos_tag # تحديد الجملة sentence = "Ali Ahmed wishes to travel outside Syria in any way " # tokens نقوم الآن بتقسيم النص إلى وحدات tokens=sentence.split() # تصنيفها النحوي post = pos_tag(tokens) # [('Ali', 'NNP'), ('Ahmed', 'NNP'), ('wishes', 'VBZ'), ('to', 'TO'), ('travel', 'VB'),('outside', 'JJ'), ('Syria', 'NNP'), ('in', 'IN'), ('any', 'DT'), ('way', 'NN')] # NNP استخلالص ال pnouns = [word for word,pos in post if pos == 'NNP'] # ['Ali', 'Ahmed', 'Syria'] لإيجاد ال Possessive Nouns سنأخذ فقط الأسماء التي تنتهي ب " 's " أو " s' " وهنا يمكننا أن نستخدم الدالتين: str.endswith("'s") str.endswith("s'") أي: # التي تقوم بتصنيف الكلمات pos_tag استيراد الوحدة from nltk.tag import pos_tag # تحديد الجملة sentence = "Ali Ahmed wishes to travel outside Syria in any way " # tokens نقوم الآن بتقسيم النص إلى وحدات tokens=sentence.split() # تصنيفها النحوي post = pos_tag(tokens) # [('Ali', 'NNP'), ('Ahmed', 'NNP'), ('wishes', 'VBZ'), ('to', 'TO'), ('travel', 'VB'),('outside', 'JJ'), ('Syria', 'NNP'), ('in', 'IN'), ('any', 'DT'), ('way', 'NN')] # NNP استخلالص ال pnouns = [word for word,pos in post if pos == 'NNP'] # ['Ali', 'Ahmed', 'Syria'] sentence = "Ali took Daniel Jackson's hamburger and Agnes' fries" possessives = [word for word in sentence.split() if word.endswith("'s") or word.endswith("s'")] possessives # ["Jackson's", "Agnes'"]
- 1 جواب
-
- 1
-
-
نعم ف Seaborn متطورة أكثر مما تتخيل، حيث أنها وبشكل افتراضي تقوم برسم ال Confidence Interval وتمكنك من التحكم بمعامل الثقة من خلال الوسيط ci الذي تكون قيمته الافتراضية مساوية ال 95%. على سبيل المثال: import numpy as np import seaborn as sns import matplotlib.pyplot as plt # بفرض البيانات التالية x = np.random.randint(0, 10, 10) y = x+np.random.normal(0, 1, 10) # وسوف نضبط معامل الثقة على 80 regplot سنقوم بتمثيلها من خلال ax = sns.regplot(x, y, ci=80) الخرج: حيث أن الظل الأزرق يمثل ال confidence level (مستوى الثقة) حول نقطة ما حيث أنه كلما زادات سماكة الظل كلما كان ذلك يعني أن الثقة أكبر. مثال آخر على ال linplot: import numpy as np import seaborn as sns import matplotlib.pyplot as plt x = np.random.randint(0, 30, 100) y = x+np.random.normal(0, 1, 100) ax = sns.lineplot(x, y) الخرج: حيث أننا هنا لم نضبط عامل الثقة فاعتبره تلقائياً 95%.
.png.9e2a64d3009de65a888e5132b6613a5e.png)
.png.fcad10b4296267cf555648108aa0a41b.png)
- 1 جواب
-
- 1
-
-
يمكنك استخدام الددالتين Axes.set_xticks للمحور السيني و Axes.set_yticks للمحور العيني لتعين وضبط ال ticks من خلال قائمة محددة بحجم محدد: Axes.set_xticks(self, ticks, minor=False) Axes.set_yticks(self, ticks, minor=False) بحيث أن الوسيط ticks هو قائمة تحتوي مواقع ال tick المراد وضعها لكل من المحورين x-axis/y-axis، والوسيط الثاني لتحديد فيما إذا كنت تريد ضبط ال ticks الثانوية أيضاً حيث أنه في الحالة الافتراضية يكون major أي الرئيسية منها. كما نستخدم الدالة set_xticklabels و set_yticklabels لتعديل تسمياتها حيث نمرر لها قائمة بالتسميات المطلوبة. لذا يمكنك التعديل على الكود الخاص بك ليصبح: import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np sns.set(style="darkgrid") data = pd.DataFrame({'D': np.random.rand(8), 'C': np.random.rand(8)}) ax = sns.lineplot(data=data) # ضبط عدد العلامات للمحور السيني ax.set_xticks(range(8)) # لها labels تحديد ال ax.set_xticklabels(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']) الخرج: أو يمكنك القيام بذلك من خلال الدالة plt.xticks للمحور السيني و plt.yticks للمحور العيني: import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np sns.set(style="darkgrid") data = pd.DataFrame({'D': np.random.rand(8), 'C': np.random.rand(8)}) ax = sns.lineplot(data=data) plt.xticks(range(8), ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']) حيث نمرر لها مُعطيين الأول يمثل عددها والثاني التسميات. ويكون الخرج مطابقاً للخرج أعلاه.
.png.cc9910ec675c7db3d515335fd09fdc55.png)
- 1 جواب
-
- 1
-
-
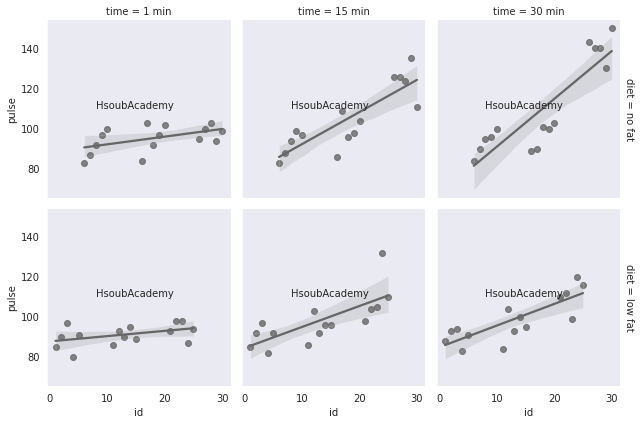
يمكنك القيام بذلك من خلال المرور على كل المحاور axes واستخدام الدالة text: text(x, y, text, fontsize ) حيث أن كل من x و y يمثلان الموقع المراد إضافة النص فيه. بينما text تمثل النص المطلوب كتابته. وأخيراً fontsize للتحكم بحجم النص المكتوب. import seaborn as sb sns.set_style("dark") data = sb.load_dataset("exercise") fg = sb.FacetGrid(data, row="diet", col="time", margin_titles = True) fg.map(sb.regplot, "id", "pulse", color = ".4") # لدينا axes نقوم بالمرور على كل for text in fg.axes.flat: # نضيف النص text.text(8, 110,'HsoubAcademy', fontsize = 10) الخرج: أيضاً يمكنك وضع عنوان لكل محور أو subpllot بالشكل التالي: import seaborn as sb sns.set_style("dark") data = sb.load_dataset("exercise") fg = sb.FacetGrid(data, row="diet", col="time", margin_titles = True) fg.map(sb.regplot, "id", "pulse", color = ".4") names=['Deltaic', 'Plains','Hummock', 'Swale', 'Sand Dunes', 'Mountain'] for text, title in zip(g.axes.flat, names): text.set_title(title) text.text(8, 110,'HsoubAcademy', fontsize = 10)
- 1 جواب
-
- 1
-
-
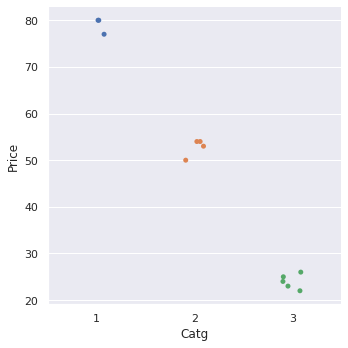
أفضل طريقة هي استخدام catplot وهي مخصصة للتعامل مع البيانات الفئوية، وقد جاءت كتحسين ل FacetGrid، وتقوم الدالة catplot بإرجاع كائن من نوع FacetGrid بحيث يمكن استخدامه بكفاءة لرسم الرسوم البيانية لميزات متعددة ضمن نفس الشكل، ويمكننا من خلالها رسم البيانات في ثمانية أنواع مختلفة من الرسوم البيانية المحددة بواسطة معلمة النوع kind حيث يمكن أن تجعل التمثيل البياني على شكل stripplot أو barplot أو boxplot. المثال التالي يوضح كيفية استخدامها: import pandas as pd import matplotlib.pyplot as plt import seaborn as sns df = pd.DataFrame( {"Catg": [3,1,2,2,3,3,3,3,1,2,2,1], "Price" : [26,80,54,50,24,25,22,23,80,53,54,77]}) sns.catplot(data = df, x = 'Catg', y = 'Price', kind = 'strip') الخرج: حيث قمنا برسم فئة المنتجات على المحور السيني والميزة المطلوبة Max_Price على المحور العيني. أيضاً قمنا بتحديد النوع kind على أنه stripplot لذا يمكنك اختيار أي نوع آخر مثل bar في حالة أردت barplot أو box ل boxplot. ومايلي يجمع كل الأنواع: Categorical scatterplots: stripplot() (with kind="strip"; the default) swarmplot() (with kind="swarm") Categorical distribution plots: boxplot() (with kind="box") violinplot() (with kind="violin") boxenplot() (with kind="boxen") Categorical estimate plots: pointplot() (with kind="point") barplot() (with kind="bar") countplot() (with kind="count")
- 1 جواب
-
- 1
-
-
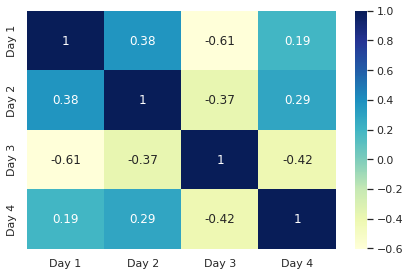
بالتأكيد يمكنك القيام بذلك فالارتباط هو أمر مهم جداً لعلماء البيانات، حيث يخبرنا كيف ترتبط المتغيرات في مجموعة البيانات ببعضها البعض وكيف تتحرك بالنسبة لبعضها البعض. وتتراوح قيمة الارتباط من -1 إلى +1، مع العلم أن 0 تشير إلى أن المتغيرين مستقلين عن بعضهما البعض. والقيم أكبر من 0 (أي الارتباط الموجب) إلى أن المتغيرات تتحرك في نفس الاتجاه أما السلبي إلى عكس ذلك. ويمكنك رسم ال Correlation heatmap باستخدام seaborn بسهولة من خلال الدالة heatmap مع الاستعانة بالتابع corr الذي يُطبق على إطار بيانات ويُرجع correlation matrix أي مصفوفة الارتباط بالشكل التالي: import pandas as pd import matplotlib.pyplot as plt import seaborn as sns data = pd.DataFrame({"Day 1": [7,1,5,6,3,10,5,8], "Day 2" : [1,2,8,4,3,9,5,2], "Day 3" : [4,6,5,8,6,1,2,3], "Day 4" : [5,8,9,5,1,7,8,9]}) # لعرض الارتباطات corr نستخدم الدالة print(data.corr()) """ Day 1 Day 2 Day 3 Day 4 Day 1 1.000000 0.377218 -0.605940 0.194795 Day 2 0.377218 1.000000 -0.373907 0.287647 Day 3 -0.605940 -0.373907 1.000000 -0.416863 Day 4 0.194795 0.287647 -0.416863 1.000000 """ الآن لرسمها: # plotting correlation heatmap dataplot = sb.heatmap(data.corr(), cmap="YlGnBu", annot=True) الخرج:
- 1 جواب
-
- 1
-
-
يمكنك حفظ المخططات البيانية من خلال الدالة savefig: savefig(fname, dpi=None, format=None,bbox_inches=None) حيث أن الوسيط الأول يمثل المسار الذي تود فيه حفظ الملف الناتج، وال dpi أو dots per inch (وهي وحدة قياس تحدد عدد النقاط الفردية التي يمكن وضعها في مربع 1 × 1 بوصة) وزيادتها تؤدي لزيادة حجم الصورة. أما الوسيط الثالث فهو لتحديد الصيغة التي سيتم فيها حفظ الشكل البياني أي 'png', 'pdf', 'svg' ...إلخ. أما الوسيط الأخير ففي حال ضبطه على tight سيتم إزالة المسافة البيضاء الغير مرغوب فيها التي تكون حول الرسم البياني. لذا لحفظ مخططك يمكنك أن تكتب: import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = [7.50, 3.50] plt.rcParams["figure.autolayout"] = True df = pd.DataFrame(np.random.random((5, 5)), columns=["a", "b", "c", "d", "e"]) sn = sns.pairplot(df) sn.savefig("plot.png")
- 1 جواب
-
- 1
-
-
للقيام بالأمر عليك باستخدام الوسيط order ضمن barplot والتابع DataFrame.sort_values حيث يقوم هذا التابع بترتيب إطار بيانات على أساس عمود محدد مثلاً: df.sort_values('Growth') """ State Growth 3 Gorgenia 266684 2 Albany 308245 0 NewMexico 860280 1 NewYork 994163 """ إذاً لترتيب أعمدة البيانات سنقوم بالتالي: import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt State = ["NewMexico", "NewYork", "Albany","Gorgenia"] growth = [860280, 994163, 308245, 266684] df = pd.DataFrame({"State": State, "Growth": growth}) sns.barplot(x='State', y="Growth", data=df,palette="hsv_r", order=df.sort_values('Growth').State) الخرج: الآن في حال أردت أن يكون الترتيب تنازلي: import seaborn as sns import pandas as pd import numpy as np import matplotlib.pyplot as plt State = ["NewMexico", "NewYork", "Albany","Gorgenia"] growth = [860280, 994163, 308245, 266684] df = pd.DataFrame({"State": State, "Growth": growth}) sns.barplot(x='State', y="Growth", data=df,palette="hsv_r", order=df.sort_values('Growth',ascending = False).State) الخرج:
.png.b45b365877ba0fd39641ee68a9b838a5.png)
.png.9b42dd66785fd482bd5b6a7ea4bdbf23.png)
- 1 جواب
-
- 1
-
-
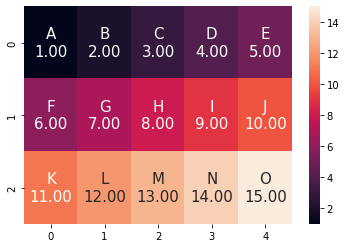
هناك Kwargs (وسيط إضافي) هو annot_kws، ويقبل قاموساً أحد مفاتيحه هو 'size' الذي يتيح لك القدرة على تغيير حجم ال annotations كما يلي: import seaborn as sns import matplotlib.pyplot as plt import numpy as np data = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]) text = np.array([['A', 'B', 'C', 'D', 'E'], ['F', 'G', 'H', 'I', 'J'], ['K', 'L', 'M', 'N', 'O']]) formatted_text = (np.asarray(["{0}\n{1:.2f}".format( text, data) for text, data in zip(text.flatten(), data.flatten())])).reshape(3, 5) fig, ax = plt.subplots() # annot_kws هنا نمرر الوسيطة الإضافية ax = sns.heatmap(data, annot=formatted_text, fmt="", annot_kws={'size': 15}) الخرج:
- 1 جواب
-
- 1
-
-
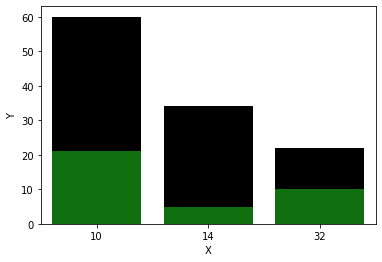
للقيام بذلك نقوم بإنشاء اثنين subplot على نفس المحور Axes كما يلي: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df = pd.DataFrame({ 'A': [10, 32, 14], 'B': [60, 22, 34], 'C': [21, 10, 5] }) # subplots تعريف ax=plt.subplots() # رسم المخططين على نفس المحور ax=sns.barplot(x=df["A"],y=df["B"],color = 'black') ax=sns.barplot(x=df["A"],y=df["C"],color = 'green') # تحديد أسماء للمحاور ax.set(xlabel="X", ylabel="Y") plt.show() الخرج: مثال آخر: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt #creating dataframe df=pd.DataFrame({ 'A':[i for i in range(10,110,10)], 'B':[i for i in range(100,0,-10)], 'C':[i for i in range(10,110,10)] }) axes=plt.subplots() axes=sns.barplot(x=df["A"],y=df["B"],color = 'lime') axes=sns.barplot(x=df["A"],y=df["C"],color = 'green') axes.set(xlabel="x-axis", ylabel="y-axis") plt.show()
- 1 جواب
-
- 1
-
-
كما ذكر وائل هذا البرنامج خاص بالتحويلات. سأشرح لك آخر جزئية طلبتها (لماذا الدوال ولماذا أضفناها). بدايةً بشكل عام عند البرمجة يُفضل دوماً أن نتجه لاستخدام الدوال حتى ولو كان بالإمكان الاستغناء عنها. الآن انسى الكود الذي لديك وتخيل أنه قد طلب منك كتابة البرنامج التالي: برنامج يقوم بتحويل قيمة من الميغابايت إلى إحدى الوحدات التالية: البايت عند إدخال الرقم 1. الكيلو عند إدخال الرقم 2. الغيغا عند إدخال الرقم 3. التيرا عند إدخال الرقم 4. الآن يمكننا كتابة هذا البرنامج بالكامل من دون استخدام التوابع لكن سيكون الأمر مُتخلفاً جداً. لذا سنقوم بتقسيمه إلى دوال، بحيث كل دالة تنجز أمر معين، وهذا التقسيم كالتالي: دالة تقوم بالتحويل من الميغابايت إلى البايت سنسميها showBytesFirstName. دالة تقوم بالتحويل من الميغابايت إلى الكيلوبايت سنسميها showKiloBytesFirstName. دالة تقوم بالتحويل من الميغابايت إلى الغيغا سنسميها showGigaBytesFirstName. دالة تقوم بالتحويل من الميغابايت إلى التيرا سنسميها showTeraBytesFirstName. وأخيراً نقوم ببناء دالة تعرض الرسالة التالية على المستخدم: 1: Convert to bytes 2: Convert to KiloBytes(KB) 3: Convert to GigaBytes(GB) 4: Convert to TeraBytes(TB) 5: Quit the program فإذا اختار 1 تقوم هذه الدالة باستدعاء الدالة showBytesFirstName. وإذا اختار 2 تقوم هذه الدالة باستدعاء الدالة showKiloBytesFirstName... إلخ. وأخيراً تعرض النتيجة .. وأيضاً يجب أن تعرض هذه الدالة الرسالة التالية، والتي تطلب فيها من المستخدم إدخال القيمة المُراد تحويلها (من الميغابايت إلى الوحدة التي تم اختيارها): Enter Data in MegaBytes (MB) وهذا مايُعبر عنه بالكود الذي أرفقته: # دالة للتحويل من الميغابايت إلى البايت def showBytesFirstName(megabytes): # converting into bytes byte=megabytes*1024*1024 # 1MB=1024*1024 bytes print("\n") print(megabytes,"Megabytes is",byte,"Bytes.") # دالة للتحويل من الميغابايت إلى الكيلوبايت def showKiloBytesFirstName(megabytes): # converting into Kilo bytes kbyte=megabytes*1024 #1MB=1024 KiloBytes print("\n") print(megabytes,"Megabytes is",kbyte,"KiloBytes.") # دالة للتحويل من الميغا إلى الغيغا def showGigaBytesFirstName(megabytes): #Converting into GigaBytes gbyte=megabytes/1024 #1024 MB= 1Giga Bytes print("\n") print(megabytes,"Megabytes is",round(gbyte,6),"GigaBytes.") #round function rounds a float upto 6 digit # دالة للتحويل من الميغا إلى التيرا def showTeraBytesFirstName(megabytes): #converting into TeraBytes tbyte=megabytes/(1024*1024) #1024*1024 MB= 1 Tera Bytes print("\n") print(megabytes,"Megabytes is",round(tbyte,6),"TeraBytes.")#rounding a float upto 6 digit # دالة تجمع الدوال السابقة لبناء برنامج تحويل من الميغا إلى باقي الوحدات def menuFirstName(): # حلقة لانهائية أي سيتم تكرار الكود المُعرّف ضمنها # True طبعاً هي حلقة لانهائية لأن الشرط دوماً محقق حيث أن 1 يكافئ while(1): # loop countinue until 5 is pressed # هنا يطلب إدخال عدد من المستخدم num = int(input(""" 1: Convert to bytes 2: Convert to KiloBytes(KB) 3: Convert to GigaBytes(GB) 4: Convert to TeraBytes(TB) 5: Quit the program Please enter your choice: """)) # في حال أدخل الرقم 5 تتوقف الحلقة اللانهائة وينتهي التنفيذ أي يتوقف البرنامج if(num==5): # if 5 is pressed loop will break program terminated print("Bye!") # تؤدي إلى كسر الحلقةأي جعلها تتوقف عن التكرار وبالتالي يتوقف التنفيذ break هنا تعليمة break # الآن إذا لم يدخل المستخدم الرقم 5 يطلب منه إدخال القيمة المراد تحويلها elif(num<5): #if num is less than 5 we will ask user to enter Mega bytes megabytes=int(input("Enter Data in MegaBytes (MB)")) # الآن إذا كان المستخدم قد أدخل الرقم 1 فهذا يعني أنه يريد تحويل القيمة # إلى البايت if(num==1): # if num==1 calling bytes method # وبالتالي نستدعي الدالة التي تقوم بالتحويل إلى البايت ونمرر لها القيمة showBytesFirstName(megabytes) # وهكذا...... elif(num==2): #if num=2 calling kilobytes showKiloBytesFirstName(megabytes) elif(num==3): #if num=3 calling giga bytes showGigaBytesFirstName(megabytes) elif(num==4):#if num==4 calling tera bytes showTeraBytesFirstName(megabytes) else: #else loop will countinue print("\n") print("Please Enter Valid Choice") # هنا يتم استدعاء الدالة السابقة menuFirstName() طبعاً الكود يستخدم حلقة while بحيث يتم تكرار تنفيذ التعليمات حتى تخرج من البرنامج من خلال إدخال الرقم 5. على سبيل المثال سأقوم بتشغيل البرنامج السابق وتجربته: 1: Convert to bytes 2: Convert to KiloBytes(KB) 3: Convert to GigaBytes(GB) 4: Convert to TeraBytes(TB) 5: Quit the program Please enter your choice: 2 Enter Data in MegaBytes (MB)1 1 Megabytes is 1024 KiloBytes. 1: Convert to bytes 2: Convert to KiloBytes(KB) 3: Convert to GigaBytes(GB) 4: Convert to TeraBytes(TB) 5: Quit the program Please enter your choice: 1 Enter Data in MegaBytes (MB)1 1 Megabytes is 1048576 Bytes. 1: Convert to bytes 2: Convert to KiloBytes(KB) 3: Convert to GigaBytes(GB) 4: Convert to TeraBytes(TB) 5: Quit the program Please enter your choice: 3 Enter Data in MegaBytes (MB)5 5 Megabytes is 0.004883 GigaBytes. 1: Convert to bytes 2: Convert to KiloBytes(KB) 3: Convert to GigaBytes(GB) 4: Convert to TeraBytes(TB) 5: Quit the program Please enter your choice: 5 Bye!
-
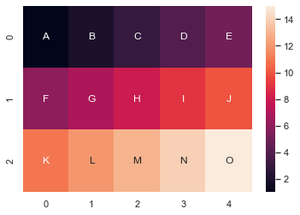
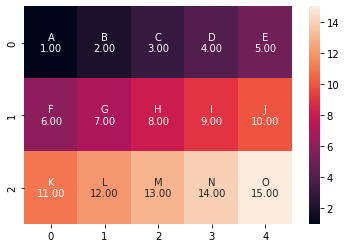
لإضافة نصوص توضيحية نستخدم الوسيط annot ونمرر له قائمة تحتوي العبارات التوضيحية للخلايا بالترتيب كما يلي: import seaborn as sns import matplotlib.pyplot as plt import numpy as np data = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]) text = np.array([['A', 'B', 'C', 'D', 'E'], ['F', 'G', 'H', 'I', 'J'], ['K', 'L', 'M', 'N', 'O']]) fig, ax = plt.subplots() ax = sns.heatmap(data, annot=text, fmt="") الخرج: الآن للدمج بين data و ال text يمكنك استخدام الطريقة التالية: import seaborn as sns import matplotlib.pyplot as plt import numpy as np data = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]]) text = np.array([['A', 'B', 'C', 'D', 'E'], ['F', 'G', 'H', 'I', 'J'], ['K', 'L', 'M', 'N', 'O']]) # نقوم بدمجهم يدوياً formatted_text = (np.asarray(["{0}\n{1:.2f}".format( text, data) for text, data in zip(text.flatten(), data.flatten())])).reshape(3, 5) fig, ax = plt.subplots() ax = sns.heatmap(data, annot=formatted_text, fmt="") الخرج:
- 2 اجابة
-
- 1
-
-
للقيام بالأمر يمكنك أن تستخدام كُلاً من الدالة axvline التي تقوم برسم خط عمودي والدالة axhline التي تقوم برسم خط أفقي.حيث نقوم برسم خطين أفقين وخطين عموديين وبالتالي نشكل إطار. سنرسم الخط الأفقي الأول عند النقطة y=0، والخط الأفقي الثاني عند y=عدد الصفوف في مجموعة البيانات الخاصة بك. سنرسم الخط العمودي عند x=0 و الثاني عند x=عدد الأعمدة في مجموعة البيانات. import seaborn as sns import matplotlib.pyplot as plt example = sns.load_dataset("flights") example = example.pivot("month", "year", "passengers") res = sns.heatmap(example) # الخطين الافقيين res.axhline(y = 0, color='c',linewidth = 10) res.axhline(y = example.shape[1], color = 'c', linewidth = 10) # العموديين res.axvline(x = 0, color = 'c', linewidth = 10) res.axvline(x = example.shape[0], color = 'c', linewidth = 10) plt.show() هنا أضفنا إطار لونه أزرق فاتح (سمائي).

- 2 اجابة
-
- 1
-
-
نعم تحتوي seaborn على العديد من لوحات التلوين: CMRmap, CMRmap_r, Dark2, Dark2_r, GnBu, GnBu_r, Greens, Greens_r, Greys, Greys_r, OrRd, OrRd_r, Oranges, Oranges_r, PRGn, PRGn_r, Paired, Paired_r, Pastel1, Pastel1_r, Pastel2, Pastel2_r, PiYG, PiYG_r, PuBu, PuBuGn, PuBuGn_r, PuBu_r, PuOr, PuOr_r, PuRd, PuRd_r, Purples, Purples_r, RdBu, RdBu_r, RdGy, RdGy_r, RdPu, RdPu_r, RdYlBu, RdYlBu_r, RdYlGn, RdYlGn_r, Reds, Reds_r, Set1, Set1_r, Set2, Set2_r, Set3, Set3_r, Spectral, Spectral_r, Wistia, Wistia_r, YlGn, YlGnBu, YlGnBu_r, YlGn_r, YlOrBr, YlOrBr_r, YlOrRd, YlOrRd_r, afmhot, afmhot_r, autumn, autumn_r, binary, binary_r, bone, bone_r, brg, brg_r, bwr, bwr_r, cividis, cividis_r, cool, cool_r, coolwarm, coolwarm_r, copper, copper_r, cubehelix Accent, Accent_r, Blues, Blues_r, BrBG, BrBG_r, BuGn, BuGn_r, BuPu, BuPu_r, ويمكنك استخدام أيّاً منها من خلال الوسيط palette كما يلي: data_df = df.melt(var_name='Pulses', value_name='Tons Consumed') sns.boxplot(x="Pulses", y="Tons Consumed", data=data_df, palette="Set1") كما يمكنك إنشاء لوحة ألوان خاصة بك لتلوين ال boxplot كما يلي: # تعريف قائمة تحتوي الألوان بالترتيب my_colors = [ "#3498db","#9b59b6","#2ecc71", "#006a4e"] # ونمرر لها قائمة الألوان set_palette نستخدم الدالة sns.set_palette( my_colors ) # boxplot الآن نستدعي ال sns.boxplot( x = "Pulses", y = "Tons Consumed", data = data_df)
- 2 اجابة
-
- 1
-
-
يمكنك استخدام الوسيط cbar_kws للقيام بذلك حيث نمرر له قاموساً يحتوي المفتاح shrink ومن خلال قيمة هذا المفتاح يمكننا التحكم بحجمه، فبشكل افتراضي يكون 1، وبالتالي أي قيمة أقل من 1 تؤدي لتصغيره وأي قيمة أكبر من واحد تؤدي لتكبيره. import numpy as np; np.random.seed(0) import seaborn as sns; sns.set_theme() uniform_data = np.random.rand(10, 12) ax = sns.heatmap(uniform_data, cbar_kws={'shrink': 0.5}) الخرج:
.png.dec5da703f81ed78ba4a1c5d101ade48.png)
- 2 اجابة
-
- 1
-
-
يمكنك تغييرها من خلال استخدام الوسيط rc ضمن الدالة set حيث نمرر له قاموساً مفاتيحه هي axes.facecolor وقيمته تمثل لون ال axes (أي لون المكان الذي يتم فيه رسم الشكل البياني) و figure.facecolor وقيمته تمثل لون ال figure (الحاوية الكلية). import seaborn as sns import matplotlib.pyplot as plt # loading dataset data = sns.load_dataset("iris") # draw lineplot sns.lineplot(x="sepal_length", y="sepal_width", data=data) # هنا سنجعل اللون أحمر للمحور وأزرق للحاوية sns.set(rc={'axes.facecolor':'red', 'figure.facecolor':'blue'}) plt.show() الخرج: حل آخر من خلال الدالة set_style التي تأخذ القيم التالية ticks - white - dark - darkgrid - whitegrid: import seaborn as sns import matplotlib.pyplot as plt # loading dataset data = sns.load_dataset("iris") # draw lineplot sns.lineplot(x="sepal_length", y="sepal_width", data=data) sns.set_style("dark") plt.show() الخرج:
.png.d9a26cd8ddcc300ba5f3a8ba7cace982.png)
- 2 اجابة
-
- 1
-
-
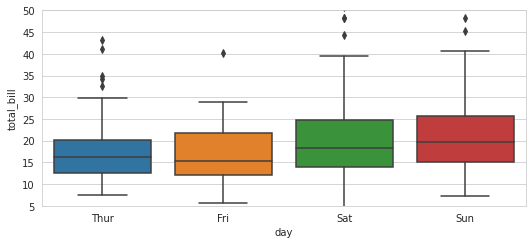
يمكنك القيام بذلك من خلال الدالة plt.ylim للمحور العمودي و plt.xlim للمحور الأفقي، حيث نمرر له القيمة الصغرى والعليا. from matplotlib import pyplot as plt import seaborn as sns plt.rcParams["figure.figsize"] = [7.50, 3.50] plt.rcParams["figure.autolayout"] = True sns.set_style("whitegrid") tips = sns.load_dataset("tips") ax = sns.boxplot(x="day", y="total_bill", data=tips) plt.ylim(5, 50) plt.show() الخرج: أو من خلال ax.set_ylim و ax.set_xlim: from matplotlib import pyplot as plt import seaborn as sns plt.rcParams["figure.figsize"] = [7.50, 3.50] plt.rcParams["figure.autolayout"] = True sns.set_style("whitegrid") tips = sns.load_dataset("tips") ax = sns.boxplot(x="day", y="total_bill", data=tips) ax.set_ylim(5, 50) plt.show() والنتيجة نفسها.. أو من خلال ax.set(ylim=(5, 50)).
- 2 اجابة
-
- 1
-