Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 في حالة النماذج من الشكل One-to-one يكون لدينا دخل واحد و خرج واحد ولايكون هناك معالجة للتسلسلات لذا يمكنك استخدام طبقة fully-connected أي Dense layer: # One-to-one mymodel.add(Dense(number_of_cells, input_shape=your_input_shape)) أما في حالة many to many فهنا يكون لدينا حالتين إما أن يكون عدد المخرجات = عدد المدخلات وهذا من السهل القيام به كما في المثال في الأسفل: # Many-to-many model = Sequential() model.add(LSTM(1, input_shape=(timesteps, dim), return_sequences=True)) أو أن يكون عدد المخرجات لايساوي عدد المدخلات وهذا صعب جداً القيام به من خلال كيراس، مثلاً: model = Sequential() model.add(LSTM(1, input_shape=(timesteps, data_dim), return_sequences=True)) model.add(Lambda(lambda x: x[:, -N:, :])) #هو عدد الخطوات الأخيرة التي تريد تغطيتها N حيث أن أما Many-to-one فهو عندما يكون لدينا عدة مدخلات وخرج واحد لها مثال: # Many-to-one model = Sequential() model.add(LSTM(1, input_shape=(timesteps,dim))) أما one-to-many فيكون لدينا دخل واحد فقط وعدة مخرجات له، وهي حالة غير مدعومة جيداً في كيراس: # One-to-many mymodel.add(RepeatVector(number_of_times, input_shape=your_input_shape)) mymodel.add(LSTM(number_of_headen_state, return_sequences=True))
في حالة النماذج من الشكل One-to-one يكون لدينا دخل واحد و خرج واحد ولايكون هناك معالجة للتسلسلات لذا يمكنك استخدام طبقة fully-connected أي Dense layer: # One-to-one mymodel.add(Dense(number_of_cells, input_shape=your_input_shape)) أما في حالة many to many فهنا يكون لدينا حالتين إما أن يكون عدد المخرجات = عدد المدخلات وهذا من السهل القيام به كما في المثال في الأسفل: # Many-to-many model = Sequential() model.add(LSTM(1, input_shape=(timesteps, dim), return_sequences=True)) أو أن يكون عدد المخرجات لايساوي عدد المدخلات وهذا صعب جداً القيام به من خلال كيراس، مثلاً: model = Sequential() model.add(LSTM(1, input_shape=(timesteps, data_dim), return_sequences=True)) model.add(Lambda(lambda x: x[:, -N:, :])) #هو عدد الخطوات الأخيرة التي تريد تغطيتها N حيث أن أما Many-to-one فهو عندما يكون لدينا عدة مدخلات وخرج واحد لها مثال: # Many-to-one model = Sequential() model.add(LSTM(1, input_shape=(timesteps,dim))) أما one-to-many فيكون لدينا دخل واحد فقط وعدة مخرجات له، وهي حالة غير مدعومة جيداً في كيراس: # One-to-many mymodel.add(RepeatVector(number_of_times, input_shape=your_input_shape)) mymodel.add(LSTM(number_of_headen_state, return_sequences=True)) -
يمكنك حساب كل المعاملاتا الاحصائية بالطريقة التالية: import numpy as np keys = np.array([ ['A', 'B'], ['A', 'B'], ['A', 'B'], ['A', 'B'], ['C', 'D'], ['C', 'D'], ['C', 'D'], ['E', 'F'], ['E', 'F'], ['G', 'H'] ]) df = pd.DataFrame( np.hstack([keys,np.random.randn(10,4).round(2)]), columns = ['col1', 'col2', 'col3', 'col4', 'col5', 'col6'] ) df[['col3', 'col4', 'col5', 'col6']] = df[['col3', 'col4', 'col5', 'col6']].astype(float) # الآن لحساب ماتريده df[['col1', 'col2', 'col3', 'col4']].groupby(['col1', 'col2']).agg(['mean',"median", 'count',"std","min","max"]) """ col3 col4 mean median count std min max mean median count std min max col1 col2 A B 0.567500 0.685 4 1.280088 -0.96 1.86 0.205 0.10 4 1.391534 -1.34 1.96 C D -0.086667 -0.040 3 0.641275 -0.75 0.53 0.160 0.58 3 1.187097 -1.18 1.08 E F 0.310000 0.310 2 1.173797 -0.52 1.14 -1.140 -1.14 2 0.098995 -1.21 -1.07 G H 0.640000 0.640 1 NaN 0.64 0.64 0.410 0.41 1 NaN 0.41 0.41 """ كما يمكنك استخدام الدالة describe: df[['col1', 'col2', 'col3', 'col4']].groupby(['col1', 'col2']).describe() كما بمكنك استخدام الدالةvalue_counts لمعرفة عدد عناصر كل مجموعة : df[['col1', 'col2']].value_counts() """ col1 col2 A B 4 C D 3 E F 2 G H 1 dtype: int64 """
- 2 اجابة
-
- 1
-

-
بشكل مشابه تماماً ل SQL، انظر للمثال التالي: # Import pandas package import pandas as pd data1 = { 'name':["Tom", "Sara", "Eva","Jack","Laura"], 'age':[14, 51, 6,88,20] } df1 = pd.DataFrame(data1) data2 = { 'name':["Tom", "Paul", "Eva","Jack","Michelle"], 'gender':["M", "M","F","M","F"] } df2 = pd.DataFrame(data2) # طباعته print("Original DataFrame1:\n", df1) print("Original DataFrame2:\n", df2) """ Original DataFrame1: name age 0 Tom 14 1 Sara 51 2 Eva 6 3 Jack 88 4 Laura 20 Original DataFrame2: name gender 0 Tom M 1 Paul M 2 Eva F 3 Jack M 4 Michelle F """ الآن نريد القيام بعملية دمج. نحن لدينا 4 أنواع من الدمج وهي: Inner Join ويمثل تقاطع الجدولين: # الدمج الداخلي # on تمثل العمود الذي نريد الدمج على أساسه pd.merge(df1,df2, how="inner",on='name') """ name age gender 0 Tom 14 M 1 Eva 6 F 2 Jack 88 M """ لاحظ أنه أعطانا تقاطع الجدولين، أي الأسماء الموجودة في كل من الجدولين + التي ليس لها قيم null. الآن الدمج الخارجي: # الدمج الخارجي pd.merge(df1,df2, how="outer",on='name') """ name age gender 0 Tom 14.0 M 1 Sara 51.0 NaN 2 Eva 6.0 F 3 Jack 88.0 M 4 Laura 20.0 NaN 5 Paul NaN M 6 MichelleNaN F """ لاحظ أنه قام بدمج العناصر المشتركة وغير المشتركة في الجدولين. على أساس العمود name. (ربما تلائم ماتحتاجه أكثر) الآن الدمج اليساري (ماتقوم به هو دمج يساري): # الدمج الخارجي pd.merge(df1,df2, how="left",on='name') """ name age gender 0 Tom 14 M 1 Sara 51 NaN 2 Eva 6 F 3 Jack 88 M 4 Laura 20 NaN """ يقوم هنا بدمج الجدولين على أساس العمود nameالموجود في الجدول اليساري أي df1. الآن الدمج اليميني: frames = [df1, df2] pd.merge(df1,df2, how="right",on='name') """ name age gender 0 Tom 14.0 M 1 Paul NaN M 2 Eva 6.0 F 3 Jack 88.0 M 4 Michelle NaN F """ نفس الفكرة السابقة لكن على أساس العمود name في الجدول اليميني.
-
هناك العديد من الطرق وإليك إياها: ############# JSON format حفظه ك ############# # حفظ النموذج model_json = model.to_json() with open("model.json", "w") as json_file: json_file.write(model_json) # HDF حفظ الأوزان كملف model.save_weights("model.h5") print("Saved model to disk") ############### لتحميله لاحقاً ############# json_file = open('model.json', 'r') loaded_model_json = json_file.read() json_file.close() loaded_model = model_from_json(loaded_model_json) # تحميل الأوزان إلى النموذج loaded_model.load_weights("model.h5") أو: ############ YAML Format ############## # pip install PyYAML model_yaml = model.to_yaml() with open("model.yaml", "w") as yaml_file: yaml_file.write(model_yaml) # weights to HDF5 model.save_weights("model.h5") # تحميله لاحقاً yaml_file = open('model.yaml', 'r') loaded_model_yaml = yaml_file.read() yaml_file.close() loaded_model = model_from_yaml(loaded_model_yaml) # تحميل الأوزان إلى النموذج loaded_model.load_weights("model.h5") أو بشكل مباشر من خلال إطار العمل يمكنك حفظ النموذج مع الأوزان وبالنسبة لي هذه هي الطريقة الأفضل والأكثر راحة: model.save("model.h5") # ولتحميله from tensorflow.keras.models import load_model model = load_model('model.h5')
- 1 جواب
-
- 1
-
-
إليك كل ما قد تحتاجه من معلومات مع المثال التالي: import tensorflow as tf with tf.compat.v1.Session() as sess: hello = tf.constant('hello world') print(sess.run(hello)) ######################################### # للحصول على كل العقد [n for n in tf.compat.v1.get_default_graph().as_graph_def().node] """ [name: "Const" op: "Const" attr { key: "dtype" value { type: DT_STRING } } attr { key: "value" value { tensor { dtype: DT_STRING tensor_shape { } string_val: "hello world" } } }] """ # oprations للحصول على كل العمليات tf.compat.v1.get_default_graph().get_operations() # [<tf.Operation 'Const' type=Const>] # للحصول على كل المتغيرات tf.compat.v1.global_variables() #Tensors للحصول على كل ال [tensor for op in tf.compat.v1.get_default_graph().get_operations() for tensor in op.values()] # [<tf.Tensor 'Const:0' shape=() dtype=string>] # placeholders الحصول على ال [placeholder for op in tf.compat.v1.get_default_graph().get_operations() if op.type=='Placeholder' for placeholder in op.values()]
- 1 جواب
-
- 1
-
-
لا لاداعي لاستخدام ال package هنا.. يمكنك اتباع التالي: أولاً نبدأ من الكلاسات التي قد تتواجد في كلاسات أخرى (موظف عامل مدير). لذا نقوم بتعريف كلاس مجرد نسميه مثلاً human_resource (نضع فيه الصفات المشتركة بين العامل والموظف والمدير) ثم نقوم بوراثة 3 كلاسات من هذا الكلاس أحدهم يمثل مدير والآخر عامل والآخر موظف (ونضيف لكل كلاس منهم الصفات الخاصة به). والآن ننتقل للأقسام: 1. تعريف كلاس مجرد يمثل قسم نضع فيه الصفات المشتركة لكل الأقسام نسميه departments مثلاً . 2.نقوم بتعريف 3 كلاسات كل منها يرث هذا الكلاس بحيث تمثل الأقسام ونضيف الصفات الخاصة بكل قسم. كما يمكنك الاستغناء عن فكرة استخدام صف مجرد (أي الاستغناء عن departments و human_resource ) وتعريف الكلاسلات مباشرةً (لكنها طريقة أقل جودة). والآن حاولي تطبيق ذلك بنفسك حتى لو استغرق الأمر يوم كامل. ملاحظة أخيرة: جافا لاتدعم الوراثة المتعددة.... أيضاً في الرابط التالي سبق وشرحنا مفهوم التجريد يمكنك مراجعته:
-
البيانات لدينا من الشكل: import pandas as pd df = pd.DataFrame({'country': ['US', 'UK', 'Germany', 'China']}) print("Given Dataframe is :\n",df) """ Given Dataframe is : country 0 US blabla 1 US adfv fda 2 Germany adce 3 China """ ونريد فلترة هذه البيانات على أساس الفلتر التالي: countries_to_keep = ['UK', 'China'] أي نريد أن نترك البلدان UK و China، وهذا سيتم كالتالي من خلال الاستعانة بالدالة isin (تكافئ حالة in في SQL) بحيث ستضع True في الأماكن التي تتواجد فيها هذه القيم و False في باقي المناطق: filter=df.country.isin(countries_to_keep) filter """ 0 False 1 True 2 False 3 True Name: country, dtype: bool """ وبالاستعان بمبادئ بايثون نطبق الفلتر: df[filter] """ country 1 UK 3 China """ أما إذا أردت تطبيق المفهوم العكسي أي not in فهذا يقابله فقط استخدام المعامل ~ قبل isin كالتالي: countries_to_keep = ['UK', 'China'] filter=~df.country.isin(countries_to_keep) filter """ 0 True 1 False 2 True 3 False """ df[filter] """ country 0 US 2 Germany """ أو يمكنك استخدام الشكل الدالة query الرائعة مباشرةً: df.query("country in @countries_to_keep") """ country 1 UK 3 China """ df.query("country not in @countries_to_keep") """ country 0 US 2 Germany """
-
كونك لم ترفق لنا شكل بياناتك سأتعامل مع مشكلتك بحالة عامة، وسأقدم المثال التالي، مع أول طريقة وهي استخدام itertuples، ومن خلال الكود التالي ستحصل أيضاً على موقع الأسطر أيضاً import pandas as pd df = pd.DataFrame({'country': ['US blabla', 'US adfv fda', 'Germany adce', 'China']}) print("Given Dataframe is :\n",df) """ Given Dataframe is : country 0 US blabla 1 US adfv fda 2 Germany adce 3 China """ for x in df.itertuples(): if x[1].find('US') != -1: print(x) """ Pandas(Index=0, country='US blabla') Pandas(Index=1, country='US adfv fda') """ حيث أن itertuples يقوم بإنشاء مكرر على الداتا فرام ثم نقوم بالمرور على الأسطر في الداتا من خلاله واستخراج المطلوب بالاعتماد على الدالة find، كما يمكنك استخدام الدالة iterrows أيضاً: for index, row in df.iterrows(): if 'US' in row['country']: print(index, row['country']) """ 0 US blabla 1 US adfv fda """ كما يمكننا استخدام الدالة Search من مكتبة ال regular expressions كالتالي: # regular expressions from re import search for ind in df.index: if search('US', df['country'][ind]): print(ind,df['country'][ind]) """ 0 US blabla 1 US adfv fda """ كما يمكننا تطبيق الطريقة التي قدمها أحمد على الفريم السابق: df[df['country'].str.contains('US', regex=False, case=False, na=False)] """ country 0 US blabla 1 US adfv fda """ أو بالشكل التالي: df[df.country.str.contains('[US]')] """ country 0 US blabla 1 US adfv fda """
- 3 اجابة
-
- 1
-
-
يمكنك استخدام POST كالتالي: request.POST["id"] # فقط نمرر له الوسيط الذي نريده أو من خلال GET: # في حالة كان المفتاح إلزامي request.GET["id"] وهنا سيرد قيمة المفتاح، وإذا لم يجد قيمة له سيرمي استثناء. أما في حالة كان المفتاح اختيارياً: # في حالة كان المفتاح اختياري request.GET.get('id') وفي الحالات التي يكون لديك فيها كائن request فقط يمكنك استخدام: request.parser_context['kwargs']['your_param']
- 2 اجابة
-
- 1
-
-
تابع معي.. أول طريقة هي استخدام الدالة apply: import pandas as pd # هنا فقط تعريف الداتا df = pd.DataFrame({"Fruits": [["Apple", "Oragne"] for i in range(7)]}) print("Given Dataframe is :\n",df) # الآن سنقوم بتطبيق التابع لمدا على كل سطر من البيانات df=df.Fruits.apply(lambda x: pd.Series(" ".join(x).split())) print("\nSplitting Fruits column into two different columns :") # تغيير أسماء الأعمدة بالشمل الذي نريده df.columns=["F1","F@"] print(df) """ Given Dataframe is : Fruits 0 [Apple, Oragne] 1 [Apple, Oragne] 2 [Apple, Oragne] 3 [Apple, Oragne] 4 [Apple, Oragne] 5 [Apple, Oragne] 6 [Apple, Oragne] Splitting Fruits column into two different columns : F1 F@ 0 Apple Oragne 1 Apple Oragne 2 Apple Oragne 3 Apple Oragne 4 Apple Oragne 5 Apple Oragne 6 Apple Oragne """ الفكرة الرئيسية في الكود السابق هو السطر: df=df.Fruits.apply(lambda x: pd.Series(" ".join(x).split())) كما نعلم فإن Apply يقوم بالمرور على أسطر البيانات سطر سطر ويطبق عليه تابع معين، ونحن استخدمنا التابع lambda الذي يمكننا من كتابة تابع مباشرةً، حيث يقوم هذا التابع بتحويل كل قائمة من الشكل [Apple, Oragne] إلى string من الشكل "Apple Oragne" ثم نقوم بتطبيق دالة split عليها (تقوم هذه الدالة بتحويل السلسلة النصية إللا قائمة بعد أن تقوم بفصل كلمات السلسلة على أساس محرف معين-افتراضياً يتم الفصل على أساس الفراغات-) ثم يتم تحويل القائمة الناتجة إلى pandas.sreies وهذه هي كل الفكرة. للوضوح أكثر: # هذا مايحدث في كل سطر " ".join(["Apple", "Oragne"]) # "Apple Oragne" "Apple Oragne".split() # ['Apple', 'Oragne'] pd.Series(['Apple', 'Oragne']) """ 0 Apple 1 Oragne dtype: object """ الآن بشكل مشابه قليلاً للطريقة السابقة لكنها تمنحك تحكم أقل في حال كانت المشاكلة أكثر تعقيداً وهي tolist لكنها هنا أسهل: df=pd.DataFrame(df.Fruits.to_list(),columns = ['F1','F2']) print("\nSplitting Fruits column into two different columns :") print(df) """ Splitting Fruits column into two different columns : F1 F2 0 Apple Oragne 1 Apple Oragne 2 Apple Oragne 3 Apple Oragne 4 Apple Oragne 5 Apple Oragne 6 Apple Oragne """ في الحالة العامة أي عندما يكون لدينا نص مركب ونريد وضع كل جزء في عمود كما في المثال التالي، يكفينا استخدام الدالة split مع تحديد المحرف الذي نريد الفصل على أساسه: import pandas as pd df = pd.DataFrame({'Name': ['Ali Ahmad', 'Eyad Ismael']}) print("Given Dataframe is :\n",df) print("\nSplitting 'Name' column into two different columns :\n") df=df.Name.str.split(expand=True) df.columns=["First","Last"] print(df) """ Given Dataframe is : Name 0 Ali Ahmad 1 Eyad Ismael Splitting 'Name' column into two different columns : First Last 0 Ali Ahmad 1 Eyad Ismael """
-
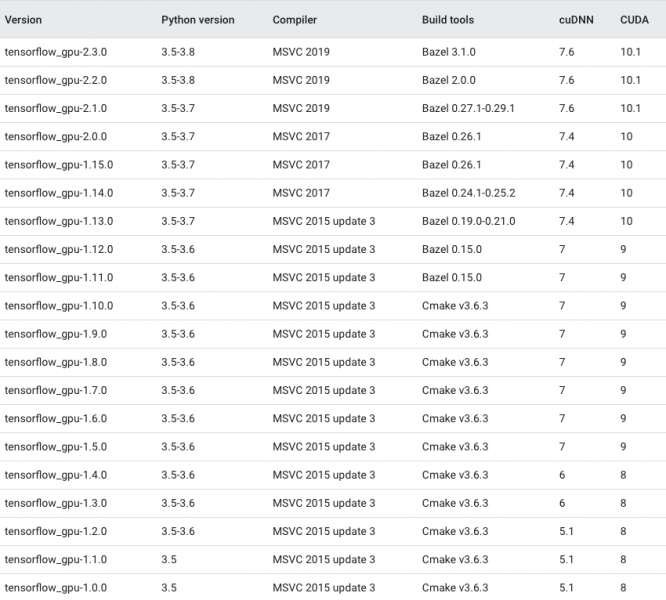
قم بفحص الإصدار الذي لديك من CUDA ومن cuDNN: # cuDNN grep CUDNN_MAJOR -A 2 /usr/local/cuda/include/cudnn.h # CUDA cat /usr/local/cuda/version.txt ثم قم بتنزيل النسخة التي تتطابق معهم من خلال الرابط التالي الذي يحوي جداول كاملة توفر نظرة عامة على المجموعات المدعومة و المختبرة رسمياً من CUDA و TensorFlow على Linux و macOS و Windows: https://www.tensorflow.org/install/source#tested_build_configurations ملاحظة : هذه الجداول يتم تحديثها باستمرار. إليك عينة من هذه الجداول للتركيبات المتوافقة على ال GPU في ويندوز 10:
- 1 جواب
-
- 1
-
-
يجب أن تضيف إلى الأمر الذي تريد تنفيذه سماحية المستخدم "user permission" وهذا مايخبرك به الخطأ أي أضف --user كالتالي: pip3 install --upgrade tensorflow-gpu --user
- 1 جواب
-
- 1
-
-
هنا حل آخر يغطي حالة ال use-case، عند استخدام RunPython. يمكنك الوصول إلى جدول ال ORM من خلال: from django.db.migrations.recorder import MigrationRecorder MigrationRecorder.Migration.objects.all() MigrationRecorder.Migration.objects.latest('id') MigrationRecorder.Migration.objects.latest('id').delete() وبالتالي يمكنك الاستعلام عن الجداول وحذف ماتريده. وبهذه الطريقة يمكنك التعديل بالتفصيل. تحتاج أيضاً في عمليات ترحيل RynPython، إلى الاهتمام بالبيانات التي تمت إضافتها أو تغييرها أو إزالتها.
- 3 اجابة
-
- 1
-
-
يمكنك القيام بذلك كالتالي: أولاً إنشاء " custom management command " ، على سبيل المثال: python manage.py my_cool_command واستخدم cron على Linux أو at على Windows لتشغيل الأمر الخاص بك في الوقت الذي تحتاجه.ويعمل حل cron بشكل جيد جداً مع التطبيقات الصغيرة والمتوسطة الحجم وحيث لا تريد الكثير من التبعيات الخارجية. وهو حل بسيط لا يتطلب تثبيت مكدس AMQP. أيضاً يمكنك استخدام Celery وهو عبارة عن قائمة انتظار مهام موزعة ، مبنية على AMQP (RabbitMQ). كما أنه يتعامل مع المهام الدورية بطريقة تشبه كرون. ومن السهل جداً إعداد Celery باستخدام django ، وستتخطى المهام الدورية فعلياً المهام الفائتة في حالة حدوث تعطل. يحتوي Celery أيضاً على آليات إعادة المحاولة المضمنة، في حالة فشل المهمة.
- 3 اجابة
-
- 1
-
-
بدءاً من نسخة تنسرفلو Tensorflow2.0 أصبح التنفيذ الافتراضي في تنسرفلو "Eager Execution" وهو مصطلح يشير إلى عملية تقييم العمليات على الفور، دون الانتظار لتشكيل ال Graph. أي يمكنك معرفة قيمة أي متغير أو ناتج أي عملية على الفور أما في النسخ السابقة لهذه النسخة كان التنفيذ الافتراضي للعمليات في تنسرفلو هو "Graph Execution" أي أن العمليات لايتم تقييمها حتى يتم إنشاء الجلسة بواسطة: tf.Session().run() أي لانكون قادرين على معرفة قيم المتغيرات حتى يتم تنفيذ ال Graph من أول عقدة فيه لآخر عقدة من خلال هذا الكود. الآن أنت لديك نسخة 2.4 وتحاول استخدام Session التي لم يعد هناك حاجة لها فهي غير موجودة بعد الآن في تنسرفلو (بدءاً من 2.0). لذا لاداعي لاستخدام session ويمكنك عرض ناتج أي عملية مباشرةً كالتالي: import tensorflow as tf msg = tf.constant('Hello, TensorFlow!') tf.print(msg) # Hello, TensorFlow! أما إذا كنت تريد أن تستخدم Session واعتماد ال Graph Execution فيمكنك تعطيل Eager Execution من خلال السطر التالي: tf.compat.v1.disable_eager_execution() وبالتالي يصبح الكود: import tensorflow as tf tf.compat.v1.disable_eager_execution() hello = tf.constant('Hello, TensorFlow!') sess = tf.compat.v1.Session() print(sess.run(hello)) أو من خلال with: import tensorflow as tf with tf.compat.v1.Session() as sess: hello = tf.constant('hello world') print(sess.run(hello))
- 2 اجابة
-
- 1
-
-
في حال كنت تستخدم tensorflow2.x: print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU'))) في tensorflow1: sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) أو بالشكل التالي حيث يعرض لك قائمة بالأجهزة المتاحة له: from tensorflow.python.client import device_lib print(device_lib.list_local_devices()) """ [name: "/cpu:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 4402277519343584096, name: "/gpu:0" device_type: "GPU" memory_limit: 6772842168 locality { bus_id: 1 } incarnation: 7471795903849088328 physical_device_desc: "device: 0, name: GeForce GTX 1070, pci bus id: 0000:05:00.0" ] """ أو: tf.test.is_gpu_available( cuda_only=False, min_cuda_compute_capability=None) حيث يرد True إذا كانت تنسرفلو تستخدم ال GPU.
- 2 اجابة
-
- 1
-
-
يمكنك معرفة ماحدث لل object عند وصوله لل template كالتالي: @register.filter def pdb(element): import pdb; pdb.set_trace() return element الآن ، داخل القالب يمكنك القيام ب {{template_var | pdb}} والدخول إلى جلسة pdb حيث يمكنك فحص عنصرك. كما يمكنك استخدام PyCharm فهو يجعلك قادراً بصرياً على المرور عبر الكود الخاص بك ومعرفة ما يحدث (يشير لك لأماكن وجود أخطاء في الكود أثناء كتابته). أيضاً هناك epdb وهو إضافة أو توسيع ل Python Debugge : import epdb; epdb.serve() بمجرد تنفيذ هذا الكود، أفتح "Python interpreter" وأتصل ب serving instance. يمكنك تحليل جميع القيم والخطوات من خلال الكود باستخدام أوامر pdb مثل n ، s ، إلخ. import epdb; epdb.connect() (Epdb) request <WSGIRequest path:/foo, GET:<QueryDict: {}>, POST:<QuestDict: {}>, ... > (Epdb) request.session.session_key 'i31kq7lljj3up5v7hbw9cff0rga2vlq5' (Epdb) list 85 raise some_error.CustomError() 86 87 # Example login view 88 def login(request, username, password): 89 import epdb; epdb.serve() 90 -> return my_login_method(username, password) 91 92 # Example view to show session key 93 def get_session_key(request): 94 return request.session.session_key 95
- 2 اجابة
-
- 1
-
-
إليك كل الطرق، من خلال التيرمينال Terminal Commands أو من خلال واجهة أوامر جانغو Django Shell :Commands ################## Django Shell Commands ############# import pkg_resources pkg_resources.get_distribution('django').version # أو import django django.get_version() أو django.VERSION # أو from django.utils import version version.get_version() أو version.get_complete_version() ############### Terminal Commands ###################3 ./manage.py --version أو python manage.py --version # أو django-admin --version أو django-admin.py version # أو python -m django --version # أو pip freeze | grep Django أو pip3 show django pip show django # أو python -c "import django; print(django.get_version())" # أو python manage.py runserver --version
- 3 اجابة
-
- 1
-
-
يمكنك القيام بذلك بعدة طرق، أولها استخدام الوسيط device_count عند إنشاء الجلسة كالتالي: sess = tf.Session( config=tf.ConfigProto( device_count = {'GPU': 0}) # عنه GPU إخفاء ال ) أو من خلال ضبط قيمة متغير البيئة "environment variable" على 1- أو " ": import os os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ['CUDA_VISIBLE_DEVICES'] = '-1' أو: import tensorflow as tf tf.config.set_visible_devices([], 'GPU') حيث أن كل هذه الطرق تعتمد على إخفاء ال GPU عن المترجم وبالتالي يذهب إلى ال CPU. أو من خلال tf.device مع جملة with حيث نضع كل الكود الذي نريد تنفيذه على ال cpu ضمن البلوك نفسه (أقصد الكتلة نفسها) أي: with tf.device('/CPU:0'): # ضع الكود هنا ضمن الكتلة
- 1 جواب
-
- 1
-
-
يمكنك أيضاً استخدام الدالة df.agg: dataframe = pd.DataFrame({'col_1' : ['a','b','c','d'], 'col_2' : ['name_a','name_b','name_c','name_d'], 'col_3' : ['age_a','age_b','age_c','age_d']}) dataframe['features'] = dataframe.agg( lambda s: r' <{}> '.join(s).format(*range(s.size)), axis=1) """ col_1 col_2 col_3 features 0 a name_a age_a a <0> name_a <1> age_a 1 b name_b age_b b <0> name_b <1> age_b 2 c name_c age_c c <0> name_c <1> age_c 3 d name_d age_d d <0> name_d <1> age_d """ أو بشكل يدوي معقد قليلاً: dataframe = pd.DataFrame({'col_1' : ['a','b','c','d'], 'col_2' : ['name_a','name_b','name_c','name_d'], 'col_3' : ['age_a','age_b','age_c','age_d']}) dataframe['features'] = [" ".join(F"{entry}<{num}>" if ent[-1] != entry else entry for num, entry in enumerate(ent) ) for ent in dataframe.to_numpy()]
- 3 اجابة
-
- 1
-
-
يمكنك إلغاؤها كلها من خلال os.environ: import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' بحيث: نقوم بإسناد القيمة 3 لمنع طباعة المعلومات INFO والتنبيهات WARNING و رسائل الأخطاء ERROR messages أما 2 لمنع ال INFO و ال WARNING messages بينما 1 لمنع المعلومات INFO messages بينما 0 ستؤدي لتسجيل كل الرسائل.
- 1 جواب
-
- 1
-
-
كلاهما يستخدم لتخزين حالة المتغيرات ضمن ال graph في تنسرفلو (نستخدمهما لتعريف متغيرات ضمن جلسة تنسرفلو) لكن الفرق بينهما هو أن tf.Variable يحتاج إلى تهيئته بقيم أولية بشكل فوري أي بلحظة تعريفه مثلاً: w = tf.Variable([[1.], [2.]]) هنا عرفنا متغير ضمن ال graph نسميها عقدة ضمن الغراف (البيان) واسمينها w، لاحظ أننا قمنا بإعطائه قيم مباشرةً. أما بالنسبة ل tf.placeholder فنعَرف أيضاً من خلاله متغيرات لكن هنا لانحتاج لتهيئة المتغيرات بقيم أولية كما في tf.Variable وهذا مهم جداً جداً. لماذا؟ عند بناء نماذج التعلم (الشبكات العصبية مثلاً) فنحن لدينا نوعين من المتغيرات: بيانات الدخل X التي نجلبها من الDataset + الأوزان التدريبية أي w و b. وكما نعلم فإن الأوزان نحتاج لتهيئتها بقيم ابتدائية (عادةً قيم عشوائية) وهذه المتغيرات نسميها trainable variables أي متغيرات قابلة للتدريب (للتحديث) ونستخدم معها tf.Variable . أما بيانات الدخل X و Y فلايتم تهيئتها بقيم ابتدائية حيث أننا نضطر لتعريفها داخل النموذج (بدون تعيين قيم لها) وننتظر أن يتم إعطاءها قيم عندما يتم تغذية الشبكة بال Dataset. ولهذا السبب نحتاج لتعريفهم ك placeholder. مثال: ##################### Variable ################## weights = tf.Variable(tf.truncated_normal([IMAGE_PIXELS, hidden1_units], stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))), name='weights') biases = tf.Variable(tf.zeros([hidden1_units]), name='biases') ##################### placeholder ############### images_placeholder = tf.placeholder(tf.float32, shape=(batch_size, IMAGE_PIXELS)) labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size)) #################### تغذية الشبكة بالبيانات #### for step in xrange(FLAGS.max_steps): feed_dict = { images_placeholder: images_feed, labels_placeholder: labels_feed, } _, loss_value = sess.run([train_op, loss], feed_dict=feed_dict)
- 1 جواب
-
- 1
-
-
يأتي مصطلح "slug" من المقالات والصحف وهو الاسم الغير رسمي الذي يُطلق على قصة أو مقالة أثناء عملية الإنتاج. أما في جانغو يتم استخدام حقل slug لتخزين وإنشاء عناوين URL صالحة لصفحات الويب التي تم إنشاؤها ديناميكياً. بشكل عام باستخدام البيانات التي تم الحصول عليها بالفعل. على سبيل المثال ، يستخدم slug عنوان المقالة لإنشاء عنوان URL. <title> damn cat </title> <content> Wonderful movie </content> <slug> Wonderful-movie </slug> يمكنك إنشاء slug من خلال SlugField: slug = models.SlugField(max_length=90) وينصح بإنشاء الرابط الثابت عن طريق تابع، بالنظر إلى العنوان أو جزء آخر من البيانات، بدلاً من تعيينه يدوياً. مثال: # الآن لنفرض لدينا النموذج التالي class art(models.Model): title = models.CharField(max_length=59) content = models.TextField(max_length=1900) slug = models.SlugField(max_length=50) #وباسم ذو معنى URL يمكنك الإشارة إلى هذا الكائن بعنوان # :بالشكل URL بحيث يكون عنوان Article.id على سبيل المثال استخدام www.slu.com/art/23 # أو www.slu.com/art/damn cat #20% لذا يجب استبدالها ب URL وبما أن المسافات غير مسموحة في عناوين www.example.com/art/damn%20cat #slugأما باستخدام # - يمكننا استبال الفراغات ب www.example.com/article/damn-cat كما يمكنك استخدام التابع slugify لاستخدام ال slug كعنوان: from django.template.defaultfilters import slugify class art(models.Model): title = models.CharField(max_length=90) def slug(self): return slugify(self.title) كما يمكنك استخدام الوسيط unique=True إذا أردت جعله فريداً: slug = models.SlugField(max_length=90, unique=True)
- 6 اجابة
-
- 1
-
-
يمكنك استخدام الدالة astype للقيام بأي شيئ تريده: import pandas as pd s = pd.Series(["8", 6, "7.5", 3, "0.9"]) # خليط من الأرقام والحروف s """ 0 8 1 6 2 7.5 3 3 4 0.9 dtype: object """ s = s.astype('float32') print(s.dtypes) # float32 ############################ أمثلة أخرى ############################### d = {'col1': [1, 2], 'col2': [3, 4]} df = pd.DataFrame(data=d) """ df.dtypes col1 int64 col2 int64 dtype: object """ df.astype('float64').dtypes """ col1 float64 col2 float64 dtype: object """ ############################################### d = {'col1': [1, 2], 'col2': [3, 4]} df = pd.DataFrame(data=d) """ df.dtypes col1 int64 col2 int64 dtype: object """ df.astype('float64').dtypes """ col1 float64 col2 float64 dtype: object """
- 3 اجابة
-
- 1
-