


مصطفى القباني
-
المساهمات
89 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو مصطفى القباني
-
سؤال ممتاز، لا يمكن تشغيل كود بايثون داخل المتصفح، ولهذا الغرض بالضبط يتم إرسال البيانات إلى الserver، يقوم الserver بمعالجة المدخلات، وثم إرسال الرد. يمكن للserver أن يقوم بتشغيل أي لغة تختارها، وتقوم بتهيئته كما تريد، ويكون التواصل بين المتصفح والserver من خلال الrequests.
- 6 اجابة
-
- 1
-

-
العفو شكراً جدا على ذوق حضرتك. ليس بالظبط، فهذا يتوقف على المقصود ب"أفضل". للحصول على أفضل نتيجة في التدريب، فبوضع c1 وc2 ب صفر سيعطي أفضل نتيجة خلال التدريب، بسبب الoverfitting. لكن أفضل نتيجة على بيانات الإختبار والcross validation يتم الحصول عليها تجريبياً، بتجربة قيم مختلفة لc1 وc2 في search space أو param space معينة. وتحديد التوزيع الإحصائي الذي يتم سحب منه القيم يكون عن طريق معرفة مجال القيم المنطقية، فمثلا في حالتنا القيم السالبة مستبعدة، لأننا نريد إضافة عقوبة موجبة إلى دالة الخطأ، وأيضاً القيمة يجب أن تكون أقل من واحد في الحالتين، لأننا لن نقوم بإضافة عقوبة على متغيرات المودل بقيمة أكبر من المتغيرات نفسها. (إذا إستخدمنا قيمة اكبر من 1 كمعامل، سيتم إضافة عقوبة حجمها أكبر من مجموع المعاملات أو مجموع مربعات المعاملات). بالتالي بمعرفتنا تلك المعلومات قمنا بحصر الsearch space بين الصفر والواحد، ويتبقى فقط تحديد توزيع إحصائي يعطي قيم في هذا المجال. يمكن مثلاً إستخدام توزيع uniform بين 0 و 1 أو exponential distribution كما في الكود الخاص بك، لكن تأكد من أن الscale المعطى للدالة expon يعطي قيم في المجال المرغوب.
-
وبالنسبة للparam space، في الكود لديك تم إختيار مجال القيم أن تتبع exponential distribution. بالرجوع إلى الdocumentation للدالة RandomizedSearchCV، يمكنك معرفة التالي: أن الparam_distributions أو كما سميته حضرتك في الكود لديك param_space يجب أن يكون توزيع إحصائي، يتم سحب قيم منه لتحديد أي القيم هي الأفضل. في الكود لديك: params_space = { 'c1': scipy.stats.expon(scale=0), 'c2': scipy.stats.expon(scale=500), } قمت بإختيار قيم c1 وc1 من توزيع إحصائي نوعه exponential ، والscale لهذا التوزيع هو 0 و 500 بالترتيب. لمعرفة القيم التي سيتم سحبها يمكن تجربة الآتي: import scipy c1_dist = scipy.stats.expon(scale=0) c2_dist = scipy.stats.expon(scale=500) for i in range(10): print(c1_dist.rvs()) for i in range(10): print(c2_dist.rvs()) تقوم الدالة rvs بسحب أرقام عشوائية من التوزيع الإحصائي. لاحظ أيضاً أن إختيارك للscale = 0 في التوزيع الأول يؤدى إلى إختيار جميع القيم بصفر، بينما إختيارك للscale = 500 للتوزيع الثاني يؤدي إلى سحب قيم كبيرة، وهو غير مرغوب فيه لأن بهذه الطريقة سيكون معامل الregularization كبير جدا ولن يحدث تعلم للمودل.
-
السلام عليكم بالنسبة لسؤال حضرتك عن القيمتين c1 وc2 قمت بالرجوع إلى الdocumentation وبه موجود أن: c1: The coefficient for L1 regularization. و c2: The coefficient for L2 regularization. أي أن c1 و c2 هما معاملات الL1 و L2 ـ regularization. والregularization هو أحدى الطرق لمنع الoverfitting عن طريق إضافة عقوبة penalty إلى الloss function، وتكون العقوبة دالة في متغيرات الmodel. بالتحديد الL1 regularization : يقوم بإضافة الterm المظلل إلى دالة الخطأ، وهو مجموع ال القيم المطلقة للparameters المستخدمة في المودل، مضروب في ثابت وهو c1 لديك في الكود. وبالنسبة لL2 regularization: يقوم بإضافة مجموع مربعات الparameters المستخدمة في المودل مضروبة في ثابت وهو c2 المستخدم لديك في الكود. لاحظ أن في الكود الخاص بك القيمة الإفتراضية لc1 هي 0، أي أنه لا يتم إستخدام الl1 regularization والقيمة لc2 هي 1، أي أنه يتم إضافة مجموع المربعات للparameters في المودل إلى دالة الخطأ، هنا يجب أن تسأل ماذا سيؤدي إضافة مجموع الparameters في المودل إلى دالة الخطأ؟ الإجابة أن ذلك سيؤدي إلى أن المودل عند التدريب سيكون من الأفضل له إختيار parameters قيمتها صغيرة، وموزعة بإنتظام، على أن يختار قيم كبيرة، وعدم وجود هذه العقوبة قد يؤدي إلى حدوث overfitting عن طريق إستغلال نمط معين موجود في بيانات التدريب. وسبب أن أداء المودل يكون أفضل عند تقليل قيم معملات الregularization هو أنه بتقليل تلك القيم، يكون للمودل حرية أكبر في إختيار الparameters، ولكنه سيكون في عرضة أكبر لحدوث overfitting. بالتوفيق، يمكنك القراءة أكثر هنا، وقمت بالإعتماد عليها في الشرح.
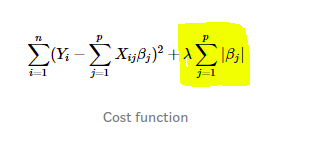
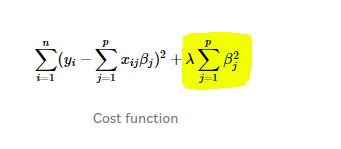
-
يمكنك الكشف على نوع المتغير عن طريق الدالة type. مثلا: x = 1 print(type(x)) y = 'hello' print(type(y)) if type(x) is int: print('the type is int') كما أن بايثون أيضاً تفضل إستخدام ما يسمى بالduck typing، وهو أن تتعامل مع المتغير الذي لديك على أنه نوع معين، وأن تتعامل مع الخطأ إن حدث. مثلاً: x = 1 try: y = x[:1] # أفترضنا أن المتغير إكس عبارة عن مصفوفة أو سترينج except: print("x is not a string or a list, can't be sliced") يمكنك القراءة أكثر عن الduck typing من هنا أو هنا. بالتوفيق
-
تحياتي يمكن عمل ذلك عن طريق الكود الآتي: public class Main { public static void main(String[] args) { String sentence = "To be or not To be : That Is the Question"; float uppercase_count = 0; float lowercase_count = 0; for(int i=0; i<sentence.length(); i++){ char current_letter = sentence.charAt(i); if (current_letter >= 'A' && current_letter <= 'Z') uppercase_count+=1; if (current_letter >= 'a' && current_letter <= 'z') lowercase_count+=1; else continue; } float capital_percentage = uppercase_count / (uppercase_count+lowercase_count) * 100; float lowercase_percentage = lowercase_count / (uppercase_count+lowercase_count) *100; System.out.println("Number of capital letters: "+ uppercase_count); System.out.println("Number of small letters: "+ lowercase_count); System.out.println("Capital letters percentage: "+ capital_percentage + "%"); System.out.println("Small letters percentage: "+ lowercase_percentage + "%"); } } في البدء نقوم بتعريف عداد للأحرف الصغيرة وعداد آخر للأحرف الكبيرة، ثم نقوم بالمرور على الجملة التي لدينا حرف حرف، ونقوم بالكشف على كل حرف إذا كان uppercase أم lowercase. يمكن الكشف عن كون الحرف uppercase أم lowercase بأكثر من طريقة لكن الطريقة التي استخدمناها هنا هي التحقق إذا كان الحرف الذي لدينا يقع بين A و Z ، إذا كانت الإجابة بنعم إذا الحرف كابيتال، وإذا كان بين a و z إذا الحرف small. تم ذلك في السطر التالي: if (current_letter >= 'A' && current_letter <= 'Z') uppercase_count+=1; if (current_letter >= 'a' && current_letter <= 'z') lowercase_count+=1; إما إذا كان الحرف غير ذلك فلا يتم زيادة أياً من العدادين. في النهاية نقوم بحساب النسبة المئوية عن طريق قسمة العداد على مجموع العدادين، والضرب في مائة. يمكنك تجربة الكود من هنا. بالتوفيق.
- 1 جواب
-
- 3
-
-
يمكنك تجربة بدأ atom بالأمر الآتي: atom --clear-window-state إن لم تحل المشكلة يمكنك تجربة إستخدام محرر آخر مثل vscode.
- 8 اجابة
-
- 1
-
-
جرب مرة أخرى حذفه وإنزاله عن طريق snap وليس apt-get: sudo snap remove --purge atom بعد ذلك: sudo snap install atom
-
تمام الرسالة التي ظهرت تقول أن atom موجود في snap وليس apt، لذلك يجب عمل: sudo snap install atom
-
هل قمت بتجربة حذف atom وإنزاله من جديد؟ قم بعمل هذا الأمر لحذف atom وحذف كل الإعدادات المتعلقة به: sudo apt-get purge atom بعد ذلك قم بإنزاله من جديد: sudo apt-get install atom بالتوفيق.
-
أعتقد أنك بحاجة إلى إحتراف البرمجة إلى درجة كبيرة لتحقيق هذه الغاية، فمعنى الإختراق هو إستغلال نظام ما بطريقة غير متوقعة يكون النظام غير مدرك بوجود تلك الثغرة به، ولإكتشاف مثل هذه الأشياء ومن ثم إستغلالها يجب أن تمتلك درجة عالية جداً من الخبرة ربما تصل إلى سنوات.
-
تحياتي الخطأ في كود حضرتك بسيط وهو أن الattribute اسمه maxlength وليس max . لذلك يجب تعديل الكود ليصبح كالآتي: <input type="text" maxlength="5" required="required" placeholder="enter first name"/> لاحظ أن maxlength تستخدم مع النوع text بينما max تستخدم مع: number, range, date, datetime-local, month, time and week. بالتوفيق
- 1 جواب
-
- 1
-
-
ـ WaveNet هي شبكة عصبية، يتم تدريبها على الأصوات وبعد ذلك يتم إستخدامها لتوليد أصوات مشابهة لما تم التدريب عليه. وتقوم الشبكة بتعلم الأصوات عن طريق تحويل الصوت إلى ما يسمى بmel spectrograms، وهي طريقة لتحويل الصوت من موجات إلى صورة ثنائية الأبعاد. على سبيل المثال في هذا التطبيق لشبكة WaveNet من شركة Nvidia، يتم تدريب الشبكة على أصوات من dataset تسمى arctic data، وبعد إنتهاء التدريب تكون الشبكة قد استوعبت طريقة الكلام، على الرغم من عدم توليدها كلام مفهوم، لكنها تكون قد استوعبت الأصوات ومخارج الحروف والتغيرات في نبرات الصوت. ويمكن إستخدام ما تم تعلمه في الشبكة كخطوة وسيطة في تحويل الكتابة إلى أصوات. يمكنك تدريب الWaveNet على google colab من هنا. بالتوفيق
-
تحياتي في السطر الأول: function AppFormField({name, ...otherProps}){ تم تعريف functional component وهو أحد نوعين من الcomponents في ريأكت، ويستخدم الfunctional component إذا لن يحتوي الcomponent على state. ويتم إنشاء الcomponent بتمرير الخواص name و otherProps مع إستخدام الspread operator. في السطر التالي: const { setFieldTouched, handleChange, errors, touched} = useFormikContext() تم إستدعاء الدالة useFormikContext() (هي في الواقع hook) وتم عمل object destructuring للobject الذي تم إرجاعه من هذا الfunction. لفهم الobject destructuring ، إذا كان لديك الobject الآتي: let x ={ a: 1, b :2, c :'hello', } فيمكن إستقبال ما تم تعريفه داخل الobject هكذا: let {a,b,c} = x وهو ما تم عمله في الكود الخاص بحضرتك. بعد ذلك: return ( <> <AppTextInput onBlur={() => setFieldTouched(name)} onChangeText={handleChange(name)} {...otherProps} /> <ErrorMessage error={errors[name]} visible={touched[name]} /> </> ); export default AppFormField; بعد ذلك تم تعريف دالة الrender، وتقوم بإرجاع : AppTextInput و ErrorMessage وتم إحطاتهم بreact fragment. الcomponent الأول تم إنشائه بالprops onBlur وonChangeText وهما ما إستقبالهم بعمل object destructuring بالأعلى. بعد ذلك تم عمل export للcomponent ليمكن إستدعائه في الملفات الأخرى. بالتوفيق.
-
تحياتي بالنسبة للكود الذي قمت بكتابته: package TestingHarmsh; public class One { public static void main(String[] args) { for (int i = 0; i < 1; i++) { System.out.println("* "); for (int a = 0; a < 1; a++) System.out.println("* * "); for (int b = 0; b < 1; b++) System.out.println("* * * "); for (int c = 0; c < 1; c++) System.out.println("* * * * "); for (int d = 0; d < 1; d++) System.out.println("* * * * * "); } } } الloops هنا أنت بغنى عنها لأنك تقوم بعمل العداد من صفر، ويتوقف إذا أصبح مساوي أو أكبر من الواحد، لذلك كل الأوامر بداخل الloop تنفذ مرة واحدة، ويمكنك الإستغناء عن الloop وكتابته كالآتي: package TestingHarmsh; public class One { public static void main(String[] args) { System.out.println("* "); System.out.println("* * "); System.out.println("* * * "); System.out.println("* * * * "); System.out.println("* * * * * "); } } لاحظ أن بتلك الطريقة أنت لم تستغل البرمجة في شيئ، ولكنك قمت بكتابة الناتج بطريقة يدوية. بالنسبة للجزء الذي ذكرته: do { System.out.print("Enter the number of lines: "); n = input.nextInt(); } while( n<=0 ); for (int i=1; i<=n; i++) { for (int j=1; j<=i; j++) { System.out.print("*"); } System.out.println(); } تم فيه إستخدام do while loop، وهي أحدى الطرق الغير تقليدية في عمل اللوب، وهي تقوم بتنفيذ الأوامر بداخل اللوب على الأقل لمرة واحدة، بغض النظر عن تحقق الشرط أم لا. فعلى سبيل المثال لاحظ أن الشرط while( n<=0 ); غير متحقق لأن الرقم المدخل رقم صحيح أكبر من الصفر وهو عدد السطور، ولكن تم تنفيذ جسد اللوب بغض النظر عن تحقق الشرط أم لا لأن الdo while loop تقوم بتنفيذ الأمر للمرة الأولى بغض النظر عن تحقق الشرط أم لا، ويتم التحقق من الشرط في المرات التالية. لاحظ أن ما يمكن عمله بالdo while loop يمكن عمله بأي loop أخرى، وتلك الطريقة الغير تقليدية غير مرغوب فيها والأفضل إستبدالها بloop عادية أخرى. بالنسبة لجسد اللوب نفسه: for (int i=1; i<=n; i++) { for (int j=1; j<=i; j++) { System.out.print("*"); } System.out.println(); } فيتم عمل عدد n من الأسطر،والمسؤؤل عن ذلك اللوب الخارجية ذات العداد i ، وبداخل كل سطر يتم طباعة عدد i من النجوم، لذلك في السطر الأول (i = 1 ) يتم طباعة عدد 1 من النجوم، وفي السطر الثاني يتم طباعة اثنان من النجوم وهكذا. وهذه هي الطريقة البرمجية لعمل المطلوب بدلا من كتابته يدوياً. شكراً لك وبالتوفيق.
-
أعتقد أنه لا يمكن عمل كود لإيقاف تشغيل جهاز أندرويد، لأنه قد يساء إستخدامه.
- 3 اجابة
-
- 1
-
-
بالنسبة لنظام تشغيل windows: 1- إذهب إلى الStart Menu 2- قم بكتابة cmd ف البحيث الخاص بStart Menu. 3- قم بالضغط على Enter.سيتم فتح نافذة الcmd وبداخلها: لعمل shutdown يتم كتابة: shutdown /s لعمل restart يتم كتابة: shutdown /r لعمل logoff يتم كتابة: shutdown /l بعد كتابة الأمر وضغط enter يتم تنفيذ إمر الإيقاف أو إعادة التشغيل.ويمكن من خلال بايثون على سبيل المثال أو لغات البرمجة الأخرى التواصل مع الcmd وإرسال الأمر لها، على سبيل المثال في بايثون: import subprocess subprocess.Popen("shutdown /r", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) يقوم هذا الكود بإرسال الأمر المطلوب إلى cmd من خلال بايثون. بالتوفيق
- 3 اجابة
-
- 1
-
-
بالفعل السبب هو أن الelement المطلوب موجود بداخل iframe، والذي بدوره موجود بداخل iframe آخر، والذي بدوره بداخل iframe آخر. لذلك يجب عمل switching ثلاث مرات. يمكن عمل التالي كالآتي: #اختصار الاسم الطويل للفانكشن q = driver.find_elements_by_css_selector #إيجاد أول فريم وعمل سويتش إليه frames = q('iframe')[1] a = driver.switch_to_frame(q('iframe')[1]) inside_frame = q('*') #إيجاالفريم بداخل الفريم وعمل سويتش إليه inception_frame = inside_frame[-2] driver.switch_to_frame(inception_frame) #إيجاالفريم بداخل الفريم بداخل الفريم وعمل سويتش إليه double_inception_frame = q("*")[-2] driver.switch_to_frame(double_inception_frame) بعد ذلك لإضافة التاريخ إلى الinput: from selenium.webdriver.common.keys import Keys #الآن يمكننا الوصول للعنصر لأننا بداخل الفريم الحاوي له inp = q('#stop-datetime')[0] our_time = '11/23/2021 11:14 AM' inp.send_keys('11') inp.send_keys('23') inp.send_keys('2021') inp.send_keys(Keys.TAB) inp.send_keys('11') inp.send_keys('14') inp.send_keys('AM') بعد ذلك إن أردت العودة إلى الصفحة خارج جميع الframes: driver.switch_to_default_content() بالتوفيق.
- 3 اجابة
-
- 1
-
-
نعم بالتأكيد. لتعلم الdata structures لابد من بناءها بإستخدام إحدى لغات البرمجة. بالتالي يمكنك تعلم لغة C# بغرض بناء إحدى الdata structures. على سبيل المثال بعد تعلم أساسيات C#، يمكنك محاولة إستخدام ما تعلمته لعمل Stack أو Linked List أو Queue، وهي عادة أول ما يتم تعلمه في هياكل البيانات data structures. بالتوفيق
-
ممتاز جدا هذه هي النتيجة الصحيحة.
-
هل قمت بتخزين الملف بعد التعديل؟ جرب عدم الضرب في 100 في الخطوة قبل الأخيرة؟
-
تمام هذا بسبب وجود عدد ثلاثة ### قبل العلامة العشرية، قم بتغييرها إلى اثنان بحيث تصبح: ##.##
-
يمكنك التحكم بعدد الأرقام التي يتم يتم إظهارها بعد العلامة العشرية عن طريق تغيير عدد ال## كالآتي: Console.WriteLine( (dead_ratio*100).ToString("###.##") + '%'); Console.WriteLine( (healed_ratio*100).ToString("###.##") + '%'); يمكنك تجربة الكود من هنا.
-
يجب أن تقوم أولا بضرب هذه النسب في 100، بحيث تصبح 4.4 و3.7، ثم تحويلهم إلى string بعد ذلك إضافة علامة %. Console.WriteLine( (dead_ratio*100).ToString() + '%'); Console.WriteLine( (healed_ratio*100).ToString() + '%'); يمكنك تجربته من هنا.
-
يمكنك قسمة عدد الوفيات على عدد المرضى لحساب نسبة المتوفين، وبالمثل لحساب نسبة المتعافين. float ill =25353106 ; float dead = 940510; float healed = 1116112; float dead_ratio = dead/ill; float healed_ratio = healed/ill; Console.WriteLine(dead_ratio); Console.WriteLine(healed_ratio); سيقوم الكود بطباعة القيم: 0.037 0.044 والأولى هي نسبة المتوفين أي 3.7 بالمائة، والثانية 4.4 بالمائة. https://onlinegdb.com/ry2elGH7w يمكنك تجربة الكود من هنا.
- 23 اجابة
-
- 1
-