لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/18/25 في كل الموقع
-
السلام عليكم كيف يمكنني حفظ الملفات داخل المسار /kaggle/working/ بشكل دائم حتى بعد إغلاق الجهاز أو إعادة تشغيل النوتبوك؟3 نقاط
-
السلام عليكم هل احتاج الى خبرة في الرياضيات لبدء دورة تطوير الالعاب2 نقاط
-
الدورات تتطلب اشتراك شهري , شراء الدورة على شكل اجزاء (شراء جزء وبعدها يجب ان ادفع لجزء اخر) , الدورات لها مواعيد محددة ???2 نقاط
-
بعد تعلم اساسيات بايثون اريد الانتقال مباشرة الى المسار الخامس تحليل البينات وتنفيذ المشاريع الموجودة بع الانتهاء ارجع الى المسارات الاخرى واتقانها ايضا2 نقاط
-
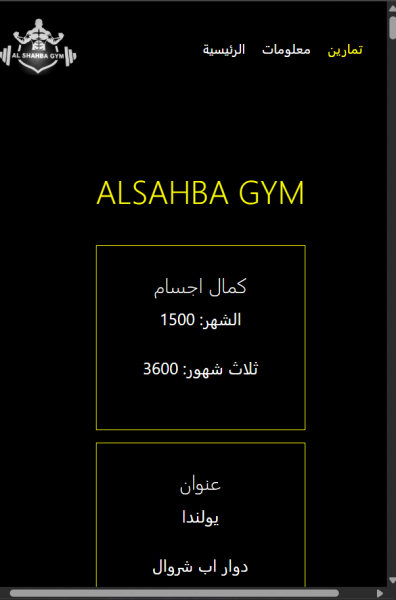
لماذا يظهر سكرول من محور الاكس في ملف GymGym.vue alsahba-gym.zip
 1 نقطة
1 نقطة -
السلام عليكم ورحمه الله وبركاته لقد قمت بشراء دوره تطوير واجهات المستخدم منذ فتره ولان ساقوم بدارستها فا كنت اتساءل هل سيتم تحديث هذه الدوره لكي اقوم بمشاهده الدوره المحدثه او اشاهد المحتوي الحالي واريد معرفه اخر موعد تم تحديث هذه الدوره الحاليه ولو هناك تحديث لها اريد معرفه الموعد1 نقطة
-
width: 100%; display: flex; flex-direction: column; لقد جربت هذا تنسيق ولم ينجح الامر اريد ان يصبح الكرت ياخذ عرض مئة بالمئة في احجام شاشات الهاتف واريدهم بشكل عمودي المشكلة في ملف GymMain.vue alsahba-gym.zip
 1 نقطة
1 نقطة -
الملفات المحفوظة في المسار /kaggle/working/ تحذف تلقائيا بمجرد إغلاق الجلسة أو إعادة تشغيل النوت بوك، لذا إذا أردت الاحتفاظ بها بشكل دائم يمكنك تحميل الملفات يدويا إلى جهازك باستخدام FileLink أو files.download، أو رفعها كـ Dataset جديد في قسم Datasets الخاص بك على Kaggle، مما يسمح لك بالوصول إليها لاحقا في أي نوت بوك.1 نقطة
-
المسار /kaggle/working/ يستخدم كمساحة تخزين مؤقتة، وبالتالي يتم حذف كل الملفات الموجودة فيه تلقائيا عند إغلاق النوتبوك أو إعادة تشغيله، وبالتالي لا يمكن الاعتماد عليه لحفظ الملفات بشكل دائم، و إذا كنت ترغب في الاحتفاظ بملفاتك بعد انتهاء الجلسة، يمكنك تحميلها يدويا إلى جهازك من خلال أدوات Kaggle أو استخدام ميزة Create Dataset لحفظ مخرجات مشروعك في شكل مجموعة بيانات خاصة داخل حسابك، مما يسمح لك بإعادة استخدامها لاحقا في مشاريع أخرى.1 نقطة
-
وفق ترتيب دورة الذكاء الاصطناعي، يأتي "التعامل مع البيانات" مباشرة قبل "تحليل البيانات"، وهذا منطقي جدا، لأن تحليل البيانات يعتمد بشكل كبير على المهارات التي يتم اكتسابها في التعامل مع البيانات مثل تنظيف البيانات، التعامل مع القيم المفقودة، وتحويل الصيغ. لذا لا ينصح بتجاوز هذه الخطوة. إذا كنت تتقن المهارات الموجودة في هذا القسم، فيمكنك التقدم بثقة إلى تحليل البيانات بعد ذلك، تأتي مرحلة تعلم الآلة، وهي مبنية مباشرة على مخرجات تحليل البيانات، حيث تتطلب معرفة بكيفية إعداد البيانات للنمذجة. ثم يمكنك الانتقال إلى مسار التعلم العميق، الذي يعد فرعا أكثر تقدما من تعلم الآلة، ويعتمد على الشبكات العصبية، ويحتاج إلى معرفة قوية بأساسيات ML. لذا يمكنك تخطي بعض المسارات لكن من المهم المرور على الأقل بمسار "التعامل مع البيانات" ثم العودة لاحقًا للمسارات المتقدمة أو حتى إعادة دراسة المسارات الأولى لتعزيز الفهم.1 نقطة
-
أنت تقصد دورة الذكاء الاصطناعي، لا مشكلة في ذلك، لكن ستحتاج إلى دراسة مسار التعامل مع البيانات الذي يسبق مسار تحليل البيانات، حيث سيتم به شرح كيفية الحصول على البيانات من مصادر مختلفة مثل قواعد البيانات وملفات CSV و Excel وكيفية التعامل معها. بعد ذلك تستطيع دراسة الدورة بنفس ترتيب المسارات التي بها.1 نقطة
-
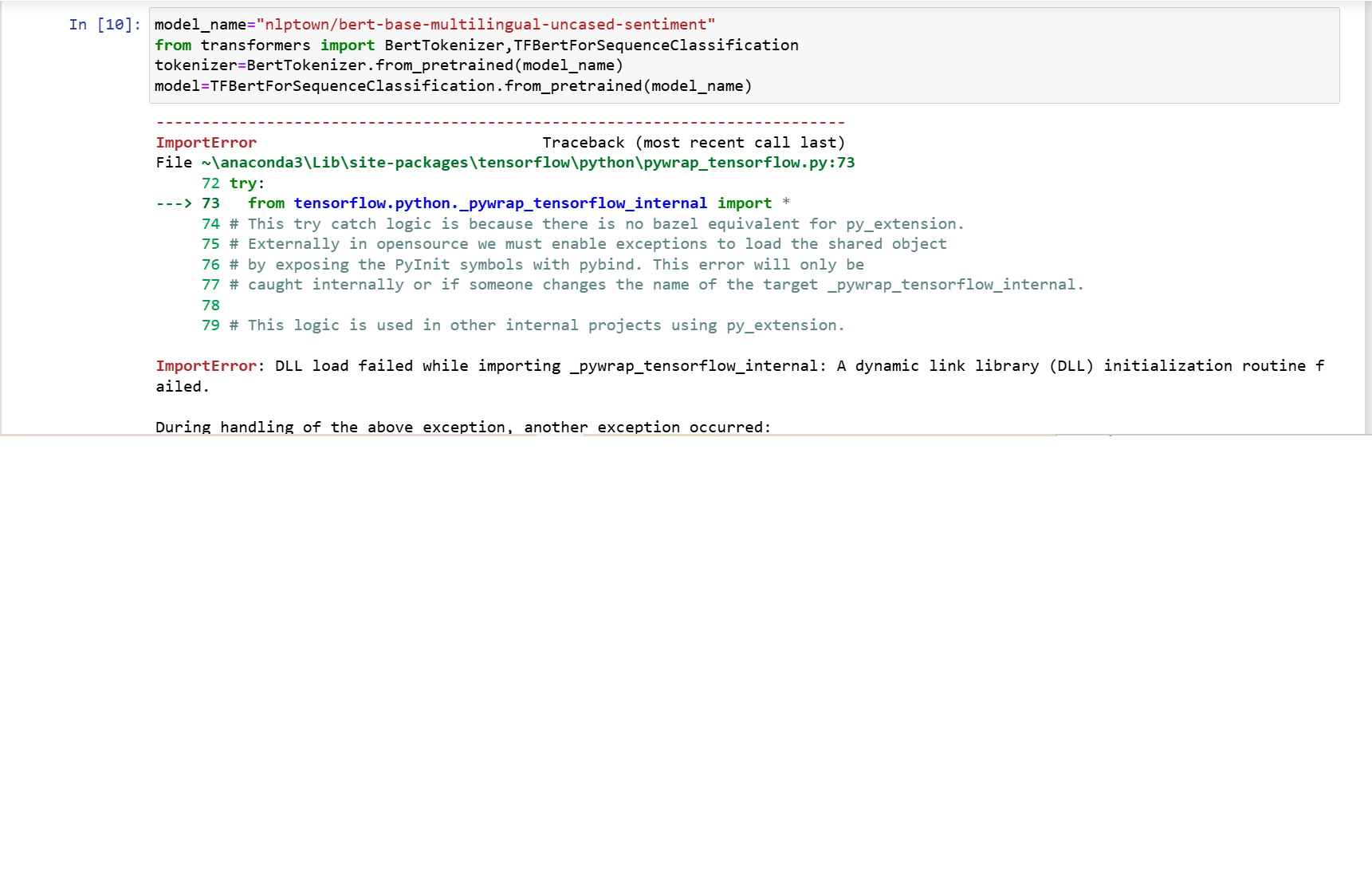
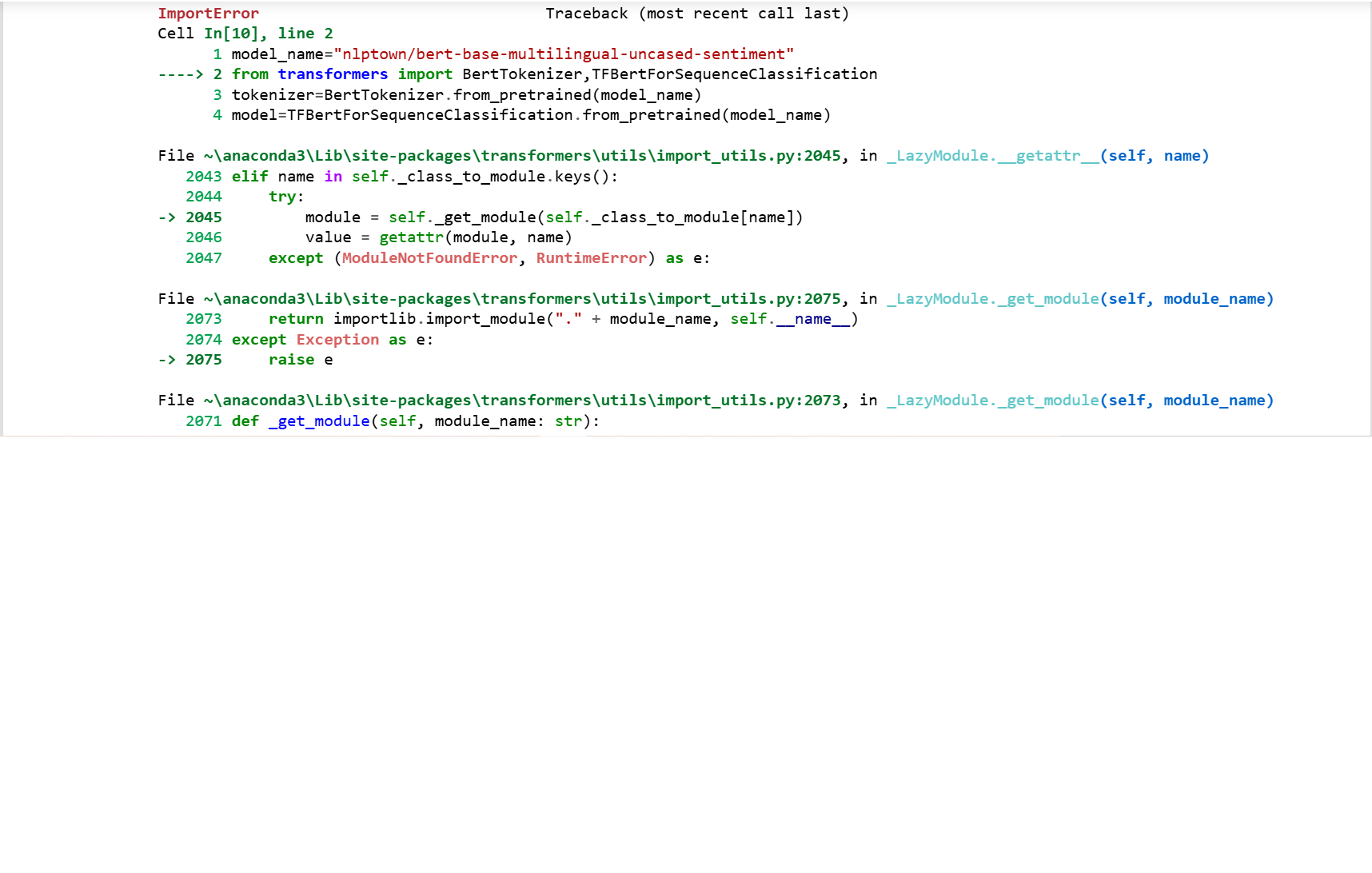
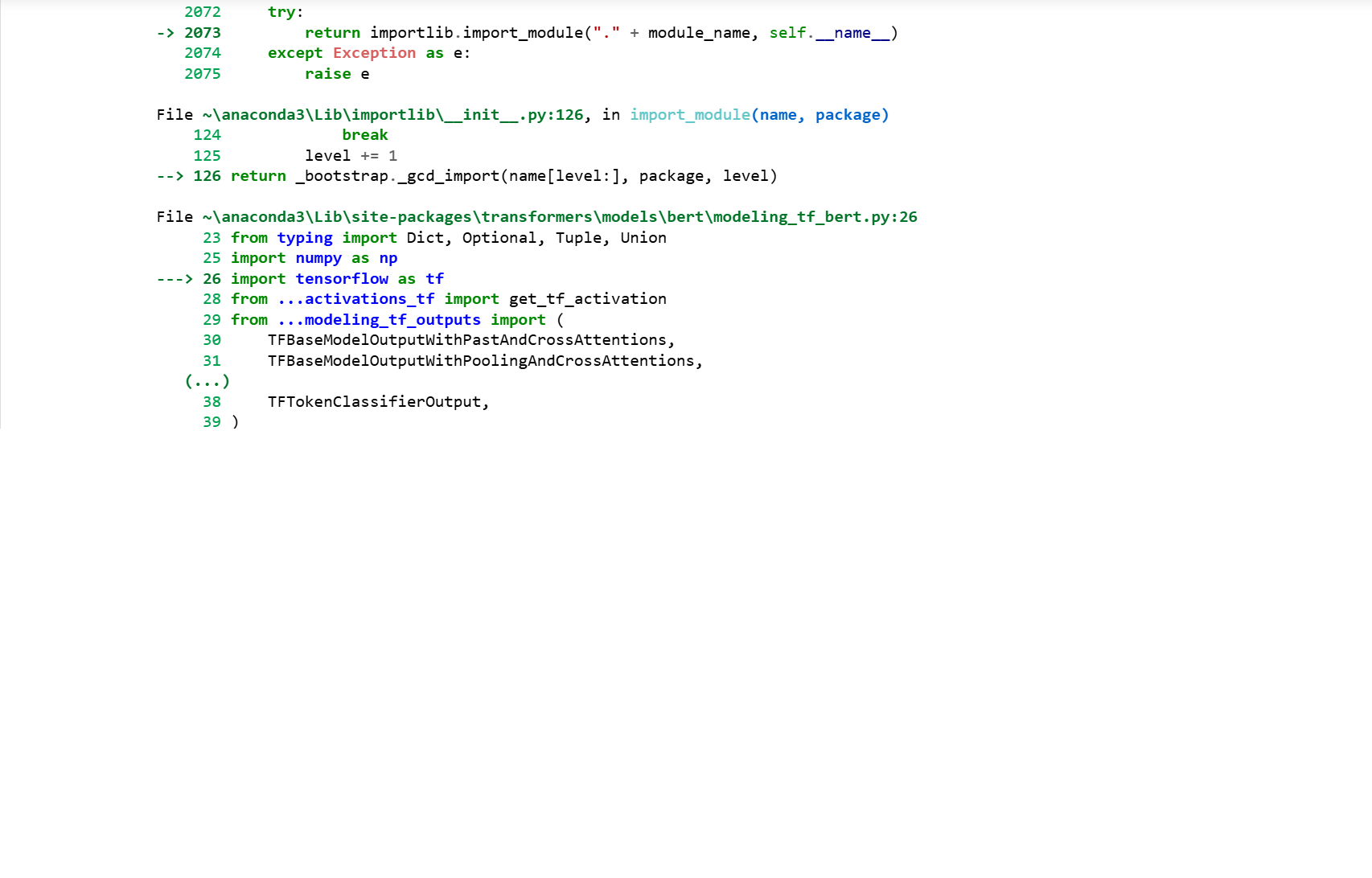
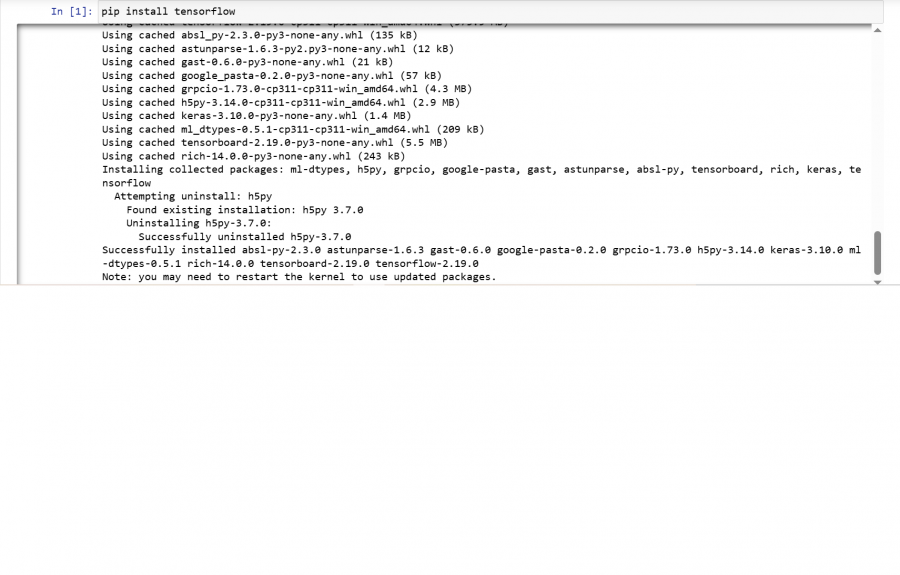
بعد تثبيت وترقية مكتبة tensorflow و transformers بنجاح وعند تنفيذ الأمر التالي model_name="nlptown/bert-base-multilingual-uncased-sentiment" from transformers import BertTokenizer,TFBertForSequenceClassification tokenizer=BertTokenizer.from_pretrained(model_name) model=TFBertForSequenceClassification.from_pretrained(model_name) يصدر خطأ ImportError

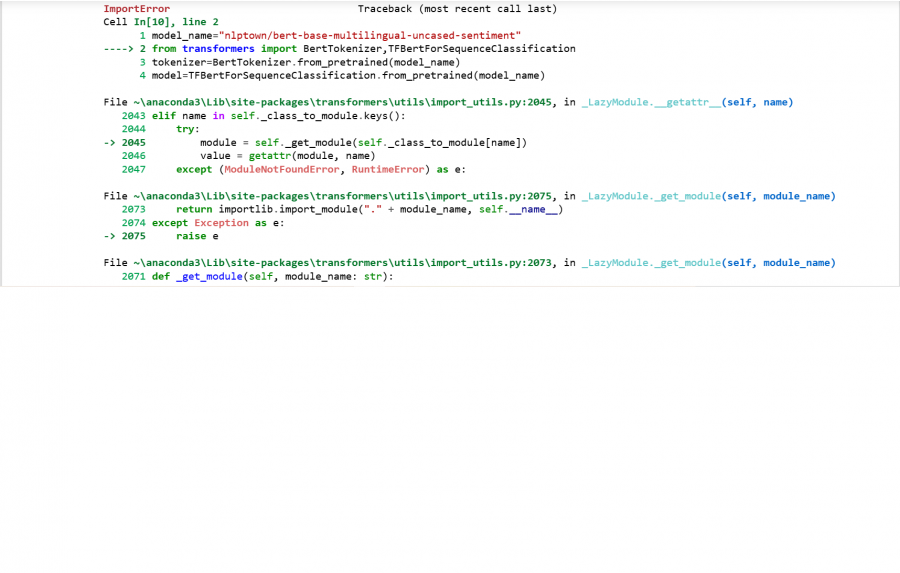
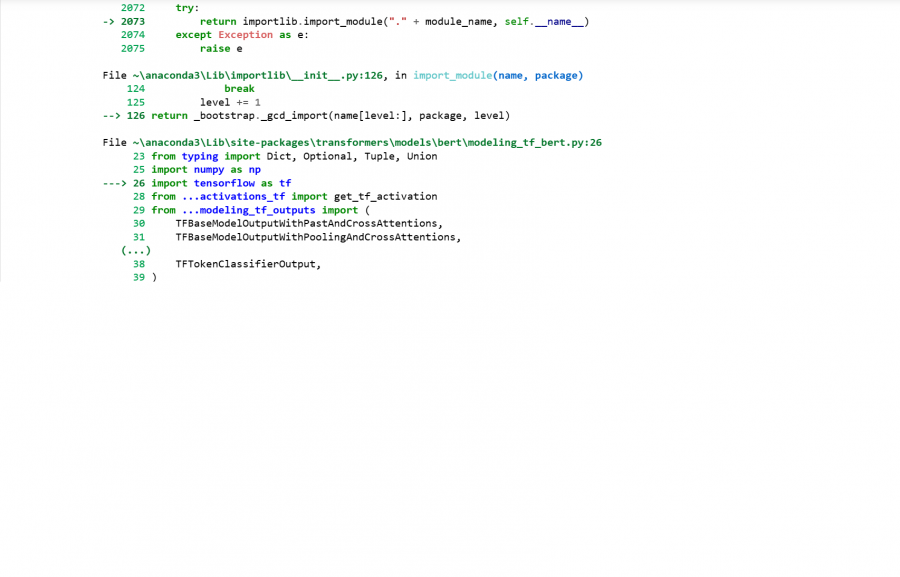
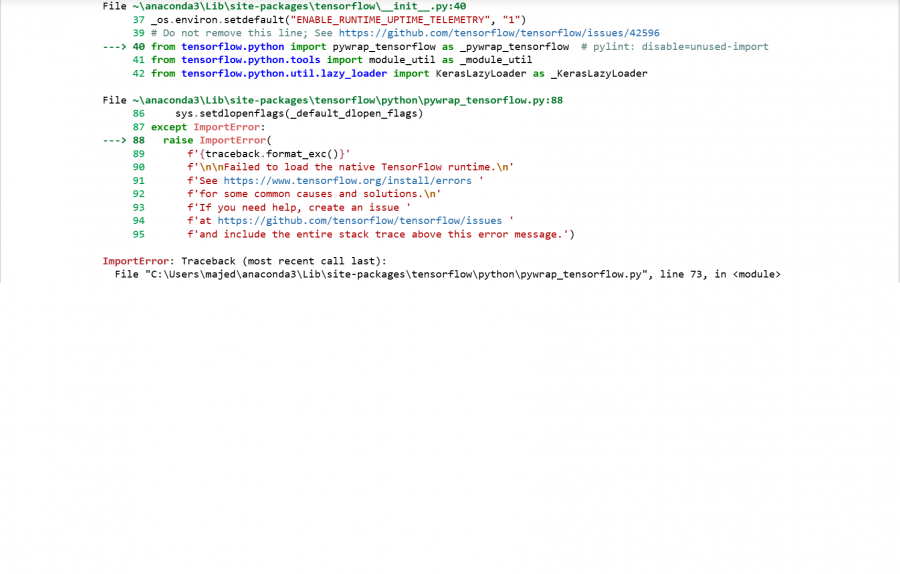
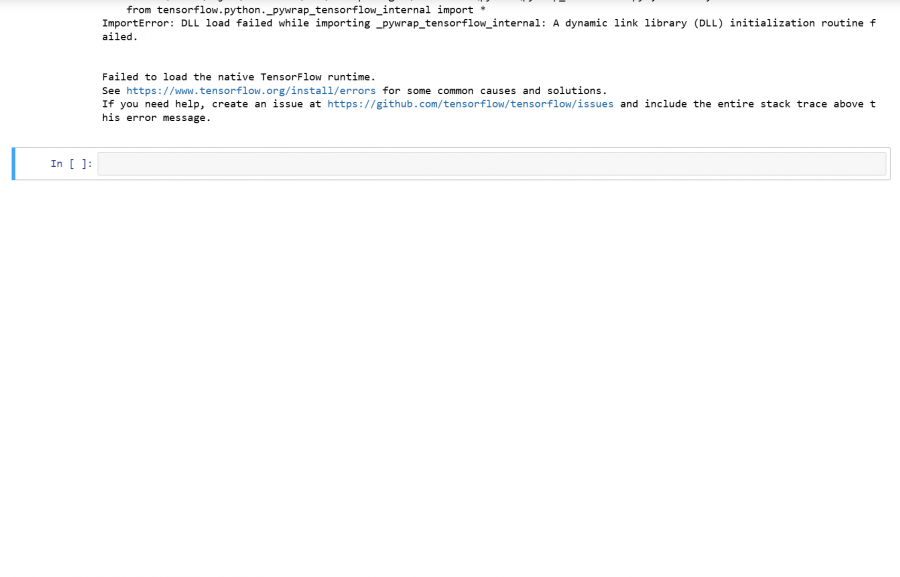 1 نقطة
1 نقطة -
غير صحيح، الحل الأبسط كما وضحت هو تصحيح ترتيب دمج قوائم الأسماء لتتطابق مع ترتيب المحولات في ColumnTransformer. features_names = numeric_features + text_features1 نقطة
-
المشكلة في عدم التطابق في ترتيب الأعمدة بعد تحويلها بواسطة ColumnTransformer مع ترتيب أسماء الأعمدة التي تقوم بإنشائها يدويًا، أسهل حل هو عكس ترتيب دمج قوائم الأسماء لتصبح الأعمدة الرقمية أولاً. features_names = numeric_features + text_features لكن الأفضل بدلاً من إدارة ترتيب الأعمدة يدويًا، الإعتماد على scikit-learn لتوليد أسماء الأعمدة الناتجة تلقائيًا من خلال get_feature_names_out()، بالتالي ستتجنب الأخطاء في حال قمت بتغيير ترتيب المحولات فيما بعد. df_transformed_array = preprocessor.fit_transform(data) new_columns = preprocessor.get_feature_names_out() وللعلم get_feature_names_out() تضيف بادئات مثل num__ و text__ وبإمكانك إزالتها لو أردت كالتالي: data_processed.columns = [col.split('__')[-1] for col in data_processed.columns]1 نقطة
-
استخدامها يهدف إلى ضمان إعادة نفس النتائج في كل مرة يتم فيها تشغيل الكود، مما يجعل النتائج قابلة للتكرار، و ذلك لأن IterativeImputer يعتمد على عمليات عشوائية، مثل اختيار القيم المبدئية أو ترتيب الأعمدة أثناء التكرار، وبالتالي بدون تحديد random_state قد تختلف النتائج في كل تشغيل، أما الرقم 42 هو مجرد قيمة شائعة الاستخدام كمثال، ويمكن استخدام أي رقم ثابت آخر.1 نقطة