
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/15/25 في كل الموقع
-
يوجد مشكلة في media@ اصبحت تنفذ في عرض الشاشات الكبيرة والصغيرة vue-project.zip
 3 نقاط
3 نقاط -
هاخد قد اي وقت عشان اطور نفسي في ال SEO وهل دا هيفيدني في البرمجة ؟3 نقاط
-
fruit = ['orange', 'banana', 'mango', 'lemon '] for x in range(len(fruit)): print (x , fruit[x]) break if fruit[x] == manago: print('stop this loop') ازاي من خلال كود اطبع [orange, banana, lemon] فقط3 نقاط
-
هل يمكنني الانتقال الى تعلم ts من اجل بناء المشاريع من خلال vue ام انتظر الى اكمال المسارات react native , تطبيق دردشة يشبة whatsApp2 نقاط
-
اريد رفع المشروع على netlify2 نقاط
-
هل رياكت افضل من انجولار ام العكس ام لا يمكن القول عن اي منهم الافضل وهل انجولار اصعب من رياكت ام سهل التعلم لانني بصراحة افكر بتعلمه لانه اطار متكاملعلى عكس رياكت2 نقاط
-
اريد شرح لهذا الكود وايضاً ماهي الدالة reduce return this.myArr.reduce((num1,num2) => num1 + num2)2 نقاط
-
اريد شرح لهذا الكود بشكل مبسط methods:{ async getProducts(){ await fetch('https://dummyjson.com/products') .then((response) => response.json()) .then((data) => this.products = data) }1 نقطة
-
اريد شرح لدالات التالية مع مثال في كود عملي filter , match1 نقطة
-
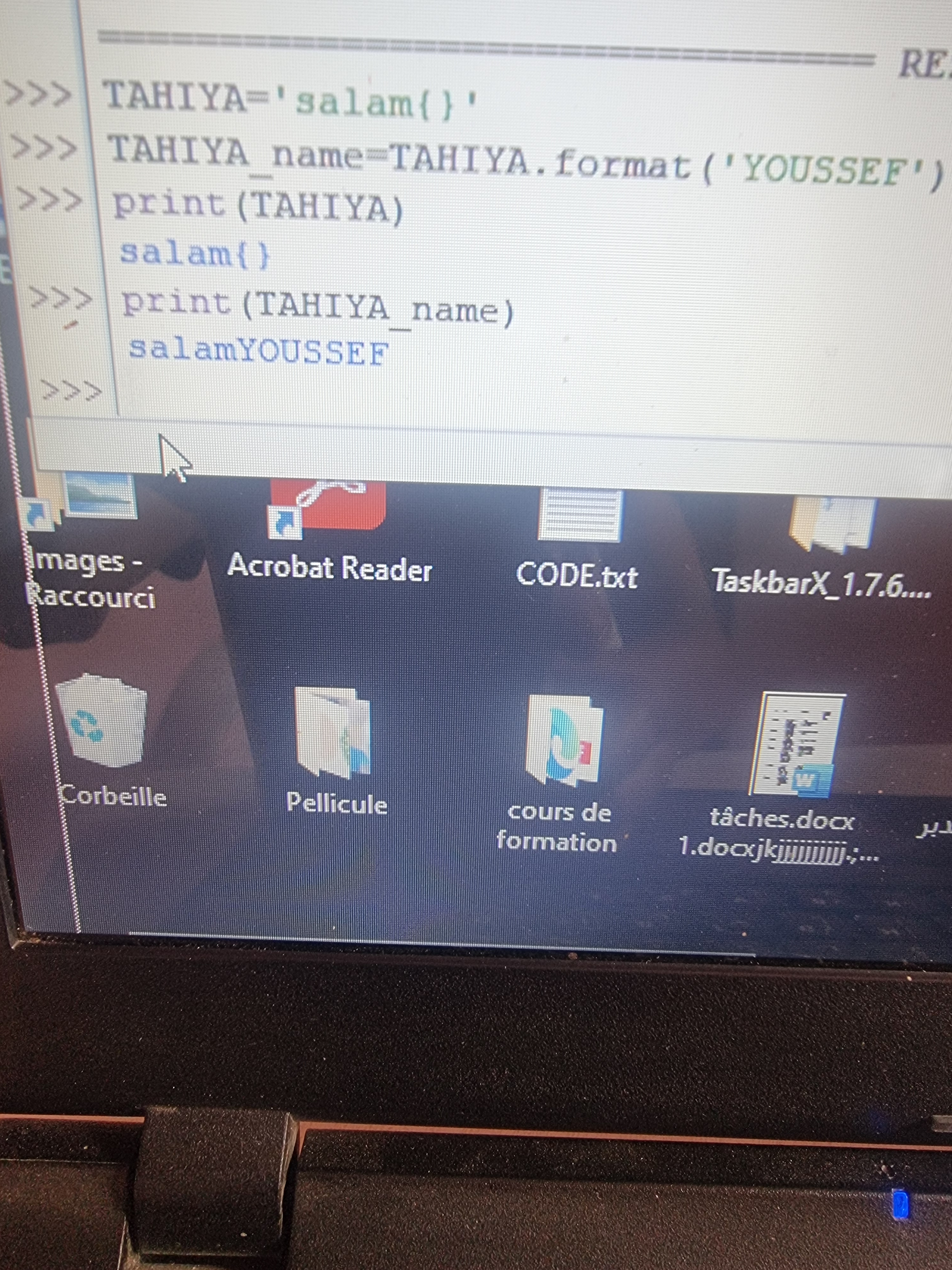
السلام عليكم . 1.الدالة format تقوم باستبدال قيم السلسلة النصية بقيم أخرى ؟لم أفهم كيف تستبدلها فهي فقط تجمع بين قيم مسندة إلى متغيرين عند استدعاء المتغير المسندة إليه القيمة ؟ 2.ولدي سؤال آخر من فضلكم.في: greet _name ما وظيفة العارضة بين المتغيرين؟ 3. وسامحوني لدي سؤال آخر: لماذا يعطيني القيمة المسندة إلى المتغير ين في حين طلبت منه فقط طباعة القيمة المسندة إلى المتغير الثاني ام أن وظيفة الدالةformat تتمثل في ذلك؟
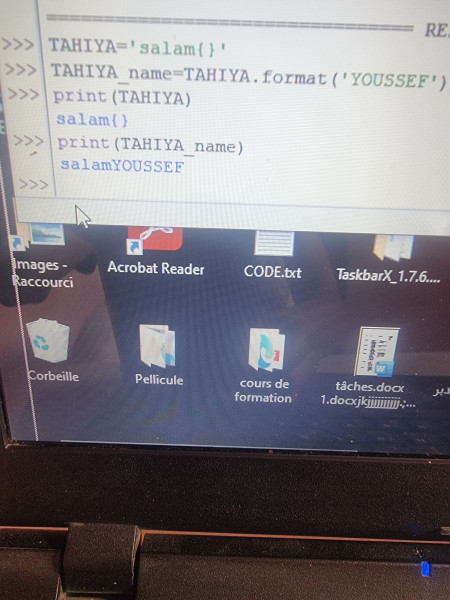 1 نقطة
1 نقطة -
لماذا لاتظهر الصورة بالرغم اني قد ربطت الملف في router وفعلته
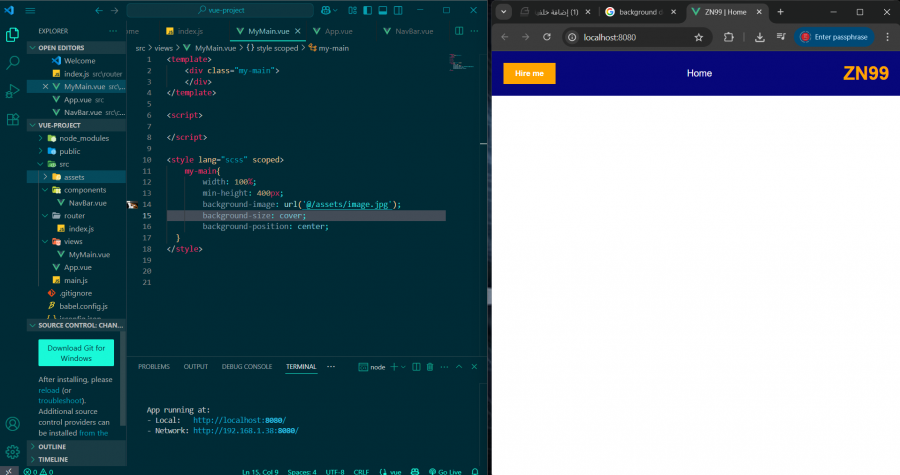 1 نقطة
1 نقطة -
كيف يمكن رفع المشروع vue1 نقطة
-
 شاع استخدام مصطلح البيانات الضخمة Big Data في الآونة الأخيرة، فبعد أن صارت البيانات تُجمع بمعدل غير مسبوق من كل شيء حولنا، سواءً من أجهزة الاستشعار الخاصة بأجهزة إنترنت الأشياء IoT، أو إشارات نظام تحديد المواقع العالمي GPS من الهواتف المحمولة، أو منشورات وسائل التواصل الاجتماعي، أو المعاملات التجارية التي نجريها عبر الإنترنت، وغيرها من المصادر المتنوعة، مما زاد من حجم البيانات كثيرًا؛ دفع هذا الأمر الشركات للاستفادة من هذه البيانات وتحليلها واتخاذ القرارات بناءً عليها، وعليه صارت الكثير من القطاعات اليوم تسعى للاستفادة من هذا الكم الهائل من هذه البيانات لفهم توقعات عملائها وتعزيز عملياتها التجارية وزيادة قدرتها التنافسية في السوق. وفي ظل هذا التوجه والسعي الكبير لجمع البيانات وتحليلها، قد يخطر ببالنا سؤال مهم وهو هل البيانات الضخمة ضرورية بالفعل لعملنا؟ وهل تمتلك الشركات التي تستفيد من البيانات الضخمة قدرةً أكبر على تطوير الحلول المبتكرة مقارنةً بتلك التي نكتفي بالتعامل مع البيانات الصغيرة والمتوسطة الحجم أو التي تعرف باسم البيانات التقليدية؟ سنحاول في هذا المقال الإجابة على هذه التساؤلات، ونعقد مقارنةً بين البيانات الضخمة والبيانات التقليدية وحالات استخدام كل منهما. ما هي البيانات الضخمة Big Data البيانات الضخمة هي بيانات تستخدم لاستخراج وتحليل وإدارة معالجة أحجام هائلة ومعقدة من البيانات التي تنمو بتسارع. ووفقًا لمعدل أُسِّي، فهي تجمع باستمرار من مختلف المصادر وقد يصل حجمها إلى أرقام مهولة وضخمة جدًا. تتسم البيانات الضخمة بتنوع أشكالها، فهي لا تقتصر على البيانات المنظمة المخزنة في قواعد البيانات، بل تشمل أيضًا بيانات غير منظمة مثل النصوص والصور ومقاطع الفيديو. تتدفق هذه البيانات بسرعة كبيرة، لذا يصعب تسجيلها أو تخزينها أو تحليلها باستخدام أنظمة إدارة قواعد البيانات التقليدية، وهذا يستدعي منا استخدام تقنيات متقدمة للتعامل معها. تتميز البيانات الضخمة بخمس سمات رئيسية يشار لها اختصارًا بـ 5Vs، وهي: الحجم Volume: الذي يشير لكمية البيانات الإجمالية، والذي قد يصل إلى عشرات التيرابايت TeraByte السرعة Velocity: وتشير لسرعة توليد البيانات ومعالجتها وتحليلها التنوع Variety: ويشمل بيانات بأشكال مختلفة الدقة Veracity: وتحدد مدى موثوقية البيانات وصحتها وخلوها من الأخطاء القيمة Value: فتراكم البيانات وحده لا يخلق قيمة للبيانات بل يجب أن توفر هذه البيانات فائدة فعلية للعمل وإلا فلا داعي لتكديسها تُستخدم البيانات الضخمة في العديد من المجالات لتحسين العمليات واتخاذ القرارات الذكية؛ ففي الرعاية الصحية، تساعد في تقديم رعاية مخصصة واكتشاف الأمراض مبكرًا؛ أما في تجارة التجزئة، فتُستخدم لتحليل سلوك العملاء وتقديم توصيات مخصصة وتحسين إدارة المخزون؛ وفي القطاع المالي، تساهم في كشف الاحتيال وتقييم المخاطر الائتمانية؛ أما في قطاع الطاقة، فهي تُستخدم للتنبؤ بالطلب وتحسين كفاءة التوزيع والاستهلاك؛ وفي المدن الذكية، تعزز كفاءة الخدمات عبر تحليل البيانات المتعلقة بالمرور وإدارة الموارد وصيانة البنية التحتية. مصادر البيانات الضخمة قد تكون البيانات الضخمة بأشكال متنوعة ومن مصادر عديدة تشمل: البيانات المنظمة Structured Data على شكل جداول يسهل البحث فيها وتحليلها باستخدام استعلامات محددة تشبه جداول إكسل وقواعد البيانات العلاقية Relational Database، ومن الأمثلة عليها البيانات التي نجمعها من التطبيقات والمواقع الإلكترونية كسجلات المستخدمين أو سجلات المعاملات البنكية. البيانات غير المنظمة Unstructured Data من الصعب هيكلتها ضمن جداول، مثل مقاطع الفيديو والتغريدات ومنشورات وسائل التواصل الاجتماعي، أو بيانات أجهزة إنترنت الأشياء IoT، وهي تحتوي على قيمة تحليلية عالية، لكنها أصعب في التحليل وتحتاج لأساليب متقدمة لتخزين وتحليل البيانات. البيانات شبه المنظمة Semi-Structured Data وهي نوع هجين يحتوي على بعض التنظيم، ولكنه لا يتناسب تمامًا مع قواعد البيانات التقليدية كالبيانات التي تجمعها أجهزة الاستشعار ورسائل البريد الإلكتروني وملفات XML وJSON. أدوات التعامل مع البيانات الضخمة عند اعتماد البيانات الضخمة في بيئة العمل، سنحتاج لاستخدام العديد من الأدوات الاحترافية والمتخصصة للتعامل مع حجمها الهائل وتعقيدها. يمكن تقسيم هذه الأدوات إلى أربع أنواع رئيسية نوضحها فيما يلي: أدوات التخزين يجب أن تتمتع أنظمة تخزين البيانات الضخمة بالقدرة على استيعاب كميات ضخمة من البيانات مع إمكانية التوسع مع مرور الوقت وضمان سرعة نقل البيانات إلى أنظمة المعالجة والتحليل. ومن أبرز التقنيات المستخدمة في هذا المجال منصات تخزين البيانات الموزعة مثل Hadoop HDFS وAmazon S3. أدوات التنقيب في البيانات تهدف إلى استخراج أنماط ورؤى ذات قيمة من كم هائل من البيانات، مما يمكن المؤسسات من التنبؤ بالاتجاهات المستقبلية واتخاذ قرارات أدق. من بين الأدوات المستخدمة في التنقيب في البيانات Apache Spark MLlib وGoogle BigQuery، والتي تعتمد على تقنيات الذكاء الاصطناعي وتعلم الآلة. أدوات تنظيف البيانات قبل تحليل البيانات، يجب تنظيفها والتأكد من خلوها من الأخطاء وتوحيدها قبل معالجتها. تستخدم في هذه المرحلة أدوات مثل Trifacta و OpenRefine لضمان دقة البيانات وتحسين جودتها. أدوات تحليل البيانات بعد تنظيف البيانات، سنحتاج لمعالجتها وتحليلها لاستخلاص رؤى واضحة حول الأنماط والاتجاهات المستقبلية. سنحتاج لأدوات مختلفة لإجراء التحليل مثل Apache Kafka وTableau وPower BI لعرض البيانات بطريقة مرئية تدعم اتخاذ القرارات وتساعدنا على الإجابة على أسئلة معينة حول هذه البيانات وكما نلاحظ، فالعملية ليست بالسهولة التي قد تبدو عليها، إذ يتطلب التعامل مع البيانات الضخمة استخدام عدة أدوات وتقنيات، كما يحتاج لبنية تحتية قوية، ووجود خبرات بشرية متخصصة في هذا المجال، وسنواجه كذلك عدة تحديات أخرى سنناقشها في فقرة لاحقة يجب أخذها بالحسبان قبل أن نقرر جمعها والاعتماد عليها في أعمالنا. حالات استخدام البيانات الضخمة تتيح البيانات الضخمة للشركات والمؤسسات إمكانية جمع ومعالجة أحجام هائلة من البيانات في الوقت الفعلي، لكن البيانات الضخمة التي تجمعها الشركات بحد ذاتها ليس الهدف، فإن لم تكن لدى الشركة أهداف فعلية للاستفادة من هذه البيانات، فلا جدوى من جمعها وتكديسها لديها، وفيما يلي بعض حالات استخدام البيانات الضخمة المفيدة: كشف الاتجاهات والأنماط في سلوك العملاء من أجل توقع احتياجاتهم المستقبلية وتلبيتها تحليل تفضيلات العملاء وسلوكهم الشرائي لتخصيص المنتجات وفقًا لاحتياجاتهم مما يعزز رضاهم ويساهم في زيادة المبيعات المرونة والتكيف مع تغيرات السوق بسرعة والعمل على تحسين المنتجات الحالية أو تطوير منتجات جديدة اتخاذ قرارات استراتيجية في العمل وإيجاد فرص نمو جديدة تحديد نقاط الضعف في العمل واكتشاف الجوانب التي يمكن تحسينها، مثل تقليل التكاليف أو تحسين العمليات التشغيلية تقييم المخاطر والتعرف على التهديدات المحتملة في العمل بوقت مبكر وقبل أن تفع فعلًا، ووضع استراتيجيات فعالة لإدارتها والتخفيف من آثارها التنبؤ في الوقت الفعلي كأن نتوقع متى وأين سيزيد الطلب على منتج معين لتلبية احتياجات السوق وضمان وصوله للعملاء في الوقت المناسب فإذا لم تكن أولويات العمل تحتاج لتحليل سلوك العملاء، واتخاذ قرارات استراتيجية بناءً عليها، فلا داعي لتخزين البيانات بكميات ضخمة وتكبد وقت وجهد وتكلفة في تخزينها ومعالجتها. تحديات التعامل مع البيانات الضخمة ينشأ عن الاعتماد على البيانات الضخمة في العمل عدة تحديات وعوائق يجب الانتباه لها ومن أهمها: الخصوصية والأمان يمكن أن تصبح الكمية الضخمة من البيانات في المؤسسات هدفًا سهلًا للتهديدات الأمنية لاحتوائها على معلومات حساسة؛ فمع تزايد حجم البيانات، سيزداد خطر اختراقها وتسريبها، لذا يتوجب على الشركات الحفاظ على أمن بياناتها من خلال المصادقة المناسبة، والتشفير القوي والامتثال لمعايير صارمة لحمايتها. نمو البيانات بسرعة إن نمو البيانات بمعدل سريع يجعل من الصعب استخلاص الرؤى منها؛ فهناك المزيد والمزيد من البيانات التي يتم إنتاجها كل ثانية. ومن بين هذه البيانات، يجب انتقاء البيانات ذات الصلة والمفيدة فعليًا لتحليلها، كما يصعب على المؤسسات تخزين وإدارة كمية كبيرة من البيانات بدون الأدوات والتقنيات المناسبة. سرعة المعالجة بعض التطبيقات مثل أنظمة كشف الاحتيال تتطلب منا تحليل البيانات في الوقت الفعلي، وبالتالي سنحتاج لاستخدام تقنيات مخصصة، مثل Apache Flink و Spark Streaming لضمان الاستجابة الفورية بالوقت المناسب دون أي تأخير مشكلات جودة البيانات لا يمكن أن تكون البيانات الضخمة دقيقةً بنسبة 100٪، كما قد تحتوي على بيانات مكررة أو غير مكتملة؛ إضافةً إلى وجود ضوضاء وأخطاء عديدة فيها، لذا إن لم ننظف هذه البيانات ونجهز جيدًا فستؤدي إلى تحليلات غير دقيقة واستنتاجات خاطئة في العمل صعوبة دمج وتكامل البيانات تستورد فلبيانات من مصادر مختلفة وبصيغ متعددة، وقد لا تكون البيانات من مصدر معين محدثة مقارنةً مع البيانات من مصدر آخر. نقص الكفاءات المتخصصة يتطلب تحليل البيانات الضخمة مهارات تقنية متقدمة، مثل علم البيانات وتحليل البيانات، وعدد المتخصصين في هذا المجال لا يزال محدودًا لا سيما عربيًا. تحديات إدارية وتنظيمية قد تظهر بعض التحديات الإدارية والتنظيمية خلال التعامل مع الكم الهائل للبيانات الضخمة، مثل ضعف الحوكمة وعدم وجود سياسات وآليات واضحة لضبط جمع بيانات الأشخاص، وعدم وجود توضيحات كافية لطريقة استخدامها تضمن التعامل معها بأمان؛ لذا وقبل أن نقرر التعامل مع البيانات الضخمة، يجب أن تطرح على نفسنا السؤال التالي: هل نحن بحاجة فعلًا لكل هذا الكم الكبير من البيانات وكل هذه التحليلات المعقدة لنجاح عملنا، أم أن البيانات التقليدية ـأي البيانات الصغيرة والمتوسطة الحجم- وحدها تكفينا لتسيير أمور العمل بنجاح واستقرار. ما هي البيانات التقليدية؟ تشير البيانات التقليدية إلى البيانات المهيكلة التي يمكن تخزينها على هيئة جداول مكونة من أسطر وأعمدة بهيكلية واضحة ومنظمة، مثل معلومات العملاء وقوائم المخزون والسجلات المالية. وتعتمد معالجة البيانات في هذه الأنظمة على الأساليب الإحصائية التقليدية والأدوات، مثل لغة الاستعلامات الهيكلية SQL للبحث عن المعلومات واسترجاعها؛ فباستخدام هذه الأدوات، يمكن للشركات اتخاذ قرارات مفيدة وتحسين أدائها؛ وعلى الرغم من أن هذه البيانات المنظمة سهلة في التعامل، إلا أنها تكون قد محدودةً في حال احتجنا لتقديم رؤى متطورة ومعقدة تخص بعض الأعمال، مثل الحاجة لنظام مراقبة ذكي يراقب الأسواق المالية ويكشف الاحتيال في المعاملات البنكية فورًا. أدوات التعامل مع البيانات التقليدية البيانات التقليدية أسهل في التعامل من البيانات الضخمة لأنها غالبًا ما تكون صغيرة الحجم ومنظمةً جيدًا ومن أبرز أدوات البيانات التقليدية نذكر: قواعد البيانات العلائقية RDBM مثل MySQL و Oracle و SQL Server، والتي تستخدم لتخزين البيانات في جداول مترابطة، وهي مثالية للبيانات المنظمة والمهيكلة جداول البيانات Spreadsheets مثل إكسل Excel أو جداول جوجل Google Sheets لتحليل البيانات الصغيرة والمتوسطة خاصة عندما تكون البيانات محدودة ومنظمة برامج إدارة البيانات مثل SQLite التي تستخدم لتخزين وإدارة البيانات الصغيرة وتوفر لنا القدرة على إجراء بعض العمليات البسيطة على البيانات حالات استخدام البيانات التقليدية إذا كانت البيانات التي نجمعها في العمل هي بيانات منظمة مثل قواعد البيانات الجاهزة، فإن الحلول التقليدية مثل قواعد البيانات العلائقية غالبا ستكون كافيةً لإدارتها وتحليلها ولا داعي لأن نرهق أنفسنا بتعقيدات البيانات الضخمة. وفيما يلي بعض الحالات التي تعد فيها البيانات التقليدية هي الأنسب للاستخدام: إدارة السجلات المالية ضمن نظام يتعامل مع كمية محدودة من بيانات الفواتير والمدفوعات ويصدر تقارير مالية منظمة إدارة المخزون في متاجر صغيرة أو متوسطة تتضمن بيانات عن المنتجات والمبيعات ومستويات المخزون وتسعى لتحسين استراتيجيات المبيعات باستخدام قواعد بيانات تقليدية الرعاية الصحية ضمن مستشفيات تنظم وتدير معلومات المرضى، مع تتبع تاريخ المرضى ونتائج فحوصاتهم وتتابع خطط علاجهم وترقب التقدم في حالتهم الصحية إدارة الموظفين في الشركات الصغيرة والمتوسط باستخدام أنظمة تقليدية لتخزين المعلومات الشخصية للموظفين وجداول حضورهم وأدائهم إدارة المنصات التعليمية كالمدارس والمعاهد التعليمية التي تحتاج لإدارة بيانات الطلاب وتخزين درجاتهم وتتبع حضورهم ومستوياتهم الدراسية في كل هذه الحالات والحالات المشابهة، سيكون حجم البيانات محدودًا نسبيًا، أو ستكون البيانات منظمةً جيدًا، مما يسهّل معالجتها باستخدام الأنظمة التقليدية دون الحاجة إلى تقنيات معقدة كتلك التي تتطلبها البيانات الضخمة؛ أما في حال زاد تعقيد البيانات سواءً من حيث الحجم أو السرعة أو تنوع المصادر وكانت هناك حاجة لتحليلها بدقة واتخاذ قرارات بناءً عليها بسرعة، فعندها سيكون اللجوء إلى تقنيات البيانات الضخمة أمرًا ضروريًا. مميزات التعامل مع البيانات التقليدية يتسم التعامل مع البيانات التقليدية بما يلي: السهولة يمكن التعامل مع البيانات المعالجة باستخدام الأساليب التقليدية بسهولة باستخدام الأدوات القياسية، مما يجعلها أكثر سهولةً في التعامل ولا تتطلب معرفةً تقنيةً متقدمة. الوصول السريع للبيانات تقدم قواعد البيانات التقليدية وصولًا سريعًا وموثوقًا إلى البيانات من خلال العمل المستقل على خادم أو حاسوب محلي لا على بيئات سحابية أو خارجية، وتتجاوز مشكلات تأخير الشبكة أو انقطاع الخدمة أو اختراقات الأمان. سهولة حماية البيانات تُعَد البيانات الصغيرة والمتوسطة أسهل في تأمينها وحمايتها نظرًا لصغر حجمها وعدم اعتمادها على الهيكلية الموزعة، خاصةً وأنها لا تعتمد في أغلب الأحيان على التخزين الخارجي، مما يجعلها مناسبةً لإدارة المعلومات الحساسة أو السرية. سهولة إدارة البيانات تقدم قواعد البيانات التقليدية للمستخدمين تحكمًا كبيرًا في إدارة البيانات، حيث يمكن للمستخدمين تعريف أنواع البيانات، وتحديد القواعد بينها، وإنشاء العلاقات المخصصة وفقًا لاحتياجاتهم. تتطلب تكاليف وموارد أقل تتطلب الأساليب التقليدية تكاليف أقل وموارد أقل مقارنة بأنظمة معالجة البيانات الضخمة التي تتطلب تكاليف وموارد ضخمة. الخلاصة أصبحت البيانات الضخمة بلا شك جزءًا أساسيًا من العمليات التجارية والخدمات الحكومية، نظرًا للنمو السريع في حجم البيانات الرقمية. ومع تطور تقنيات الذكاء الاصطناعي، أتاح ذلك للمؤسسات القدرة على استخراج رؤى أكثر دقة واتخاذ قرارات أكثر ذكاءً وتحسينات كبيرة في مختلف القطاعات؛ لكن مع ذلك، ينبغي أن نتذكر أن البيانات الضخمة ليست مجرد جمع كميات هائلة من المعلومات، بل هي عملية تتطلب استراتيجيات مدروسة، وأدوات متخصصة، وتخطيطًا دقيقًا لتحقيق أقصى استفادة منها وتحويلها إلى قرارات تدعم النجاح والنمو. مع ذلك، وبالرغم من هذا التطور الكبير في مجال البيانات الضخمة، لازالت البيانات التقليدية الصغيرة والمتوسطة كافية للعديد من الحالات إن لم نقل أغلبها نظرًا لتوفير هذا النوع من البيانات حلولًا مناسبةً سهلة التعامل وبتكاليف أقل. لذا، متى لم يكن ما نعمل عليه يتطلب بيانات ضخمة للحصول على تحليلات وفهم كاف، فلا حاجة لأن نلجأ في أعمالنا لحلول البيانات الضخمة، لاسيما أنها تحتاج لخبرة وتكاليف أكبر وتعقيدات تقنية للتعامل مع البيانات وتحليلها وإدارتها، خاصةً وأننا إذا لم نحسن التعامل مع هذه البيانات ونستخدمها بطريقة صحيحة، فلن نتمكن من فهمها أو اتخاذ قرارات صائبة بناءً عليها. المصادر ?What is Big Data When to Use Big Data — and When Not To 7 Pros and Cons of Big Data Difference Between Traditional Data and Big Data Big Data Analytics Versus Traditional Data Analytics: A Comprehensive Overview اقرأ أيضًا مقدمة إلى مفهوم البيانات الضخمة Big Data المفاهيم الأساسية لتعلم الآلة أساسيات الذكاء الاصطناعي: دليل المبتدئين تعلم الذكاء الاصطناعي1 نقطة
شاع استخدام مصطلح البيانات الضخمة Big Data في الآونة الأخيرة، فبعد أن صارت البيانات تُجمع بمعدل غير مسبوق من كل شيء حولنا، سواءً من أجهزة الاستشعار الخاصة بأجهزة إنترنت الأشياء IoT، أو إشارات نظام تحديد المواقع العالمي GPS من الهواتف المحمولة، أو منشورات وسائل التواصل الاجتماعي، أو المعاملات التجارية التي نجريها عبر الإنترنت، وغيرها من المصادر المتنوعة، مما زاد من حجم البيانات كثيرًا؛ دفع هذا الأمر الشركات للاستفادة من هذه البيانات وتحليلها واتخاذ القرارات بناءً عليها، وعليه صارت الكثير من القطاعات اليوم تسعى للاستفادة من هذا الكم الهائل من هذه البيانات لفهم توقعات عملائها وتعزيز عملياتها التجارية وزيادة قدرتها التنافسية في السوق. وفي ظل هذا التوجه والسعي الكبير لجمع البيانات وتحليلها، قد يخطر ببالنا سؤال مهم وهو هل البيانات الضخمة ضرورية بالفعل لعملنا؟ وهل تمتلك الشركات التي تستفيد من البيانات الضخمة قدرةً أكبر على تطوير الحلول المبتكرة مقارنةً بتلك التي نكتفي بالتعامل مع البيانات الصغيرة والمتوسطة الحجم أو التي تعرف باسم البيانات التقليدية؟ سنحاول في هذا المقال الإجابة على هذه التساؤلات، ونعقد مقارنةً بين البيانات الضخمة والبيانات التقليدية وحالات استخدام كل منهما. ما هي البيانات الضخمة Big Data البيانات الضخمة هي بيانات تستخدم لاستخراج وتحليل وإدارة معالجة أحجام هائلة ومعقدة من البيانات التي تنمو بتسارع. ووفقًا لمعدل أُسِّي، فهي تجمع باستمرار من مختلف المصادر وقد يصل حجمها إلى أرقام مهولة وضخمة جدًا. تتسم البيانات الضخمة بتنوع أشكالها، فهي لا تقتصر على البيانات المنظمة المخزنة في قواعد البيانات، بل تشمل أيضًا بيانات غير منظمة مثل النصوص والصور ومقاطع الفيديو. تتدفق هذه البيانات بسرعة كبيرة، لذا يصعب تسجيلها أو تخزينها أو تحليلها باستخدام أنظمة إدارة قواعد البيانات التقليدية، وهذا يستدعي منا استخدام تقنيات متقدمة للتعامل معها. تتميز البيانات الضخمة بخمس سمات رئيسية يشار لها اختصارًا بـ 5Vs، وهي: الحجم Volume: الذي يشير لكمية البيانات الإجمالية، والذي قد يصل إلى عشرات التيرابايت TeraByte السرعة Velocity: وتشير لسرعة توليد البيانات ومعالجتها وتحليلها التنوع Variety: ويشمل بيانات بأشكال مختلفة الدقة Veracity: وتحدد مدى موثوقية البيانات وصحتها وخلوها من الأخطاء القيمة Value: فتراكم البيانات وحده لا يخلق قيمة للبيانات بل يجب أن توفر هذه البيانات فائدة فعلية للعمل وإلا فلا داعي لتكديسها تُستخدم البيانات الضخمة في العديد من المجالات لتحسين العمليات واتخاذ القرارات الذكية؛ ففي الرعاية الصحية، تساعد في تقديم رعاية مخصصة واكتشاف الأمراض مبكرًا؛ أما في تجارة التجزئة، فتُستخدم لتحليل سلوك العملاء وتقديم توصيات مخصصة وتحسين إدارة المخزون؛ وفي القطاع المالي، تساهم في كشف الاحتيال وتقييم المخاطر الائتمانية؛ أما في قطاع الطاقة، فهي تُستخدم للتنبؤ بالطلب وتحسين كفاءة التوزيع والاستهلاك؛ وفي المدن الذكية، تعزز كفاءة الخدمات عبر تحليل البيانات المتعلقة بالمرور وإدارة الموارد وصيانة البنية التحتية. مصادر البيانات الضخمة قد تكون البيانات الضخمة بأشكال متنوعة ومن مصادر عديدة تشمل: البيانات المنظمة Structured Data على شكل جداول يسهل البحث فيها وتحليلها باستخدام استعلامات محددة تشبه جداول إكسل وقواعد البيانات العلاقية Relational Database، ومن الأمثلة عليها البيانات التي نجمعها من التطبيقات والمواقع الإلكترونية كسجلات المستخدمين أو سجلات المعاملات البنكية. البيانات غير المنظمة Unstructured Data من الصعب هيكلتها ضمن جداول، مثل مقاطع الفيديو والتغريدات ومنشورات وسائل التواصل الاجتماعي، أو بيانات أجهزة إنترنت الأشياء IoT، وهي تحتوي على قيمة تحليلية عالية، لكنها أصعب في التحليل وتحتاج لأساليب متقدمة لتخزين وتحليل البيانات. البيانات شبه المنظمة Semi-Structured Data وهي نوع هجين يحتوي على بعض التنظيم، ولكنه لا يتناسب تمامًا مع قواعد البيانات التقليدية كالبيانات التي تجمعها أجهزة الاستشعار ورسائل البريد الإلكتروني وملفات XML وJSON. أدوات التعامل مع البيانات الضخمة عند اعتماد البيانات الضخمة في بيئة العمل، سنحتاج لاستخدام العديد من الأدوات الاحترافية والمتخصصة للتعامل مع حجمها الهائل وتعقيدها. يمكن تقسيم هذه الأدوات إلى أربع أنواع رئيسية نوضحها فيما يلي: أدوات التخزين يجب أن تتمتع أنظمة تخزين البيانات الضخمة بالقدرة على استيعاب كميات ضخمة من البيانات مع إمكانية التوسع مع مرور الوقت وضمان سرعة نقل البيانات إلى أنظمة المعالجة والتحليل. ومن أبرز التقنيات المستخدمة في هذا المجال منصات تخزين البيانات الموزعة مثل Hadoop HDFS وAmazon S3. أدوات التنقيب في البيانات تهدف إلى استخراج أنماط ورؤى ذات قيمة من كم هائل من البيانات، مما يمكن المؤسسات من التنبؤ بالاتجاهات المستقبلية واتخاذ قرارات أدق. من بين الأدوات المستخدمة في التنقيب في البيانات Apache Spark MLlib وGoogle BigQuery، والتي تعتمد على تقنيات الذكاء الاصطناعي وتعلم الآلة. أدوات تنظيف البيانات قبل تحليل البيانات، يجب تنظيفها والتأكد من خلوها من الأخطاء وتوحيدها قبل معالجتها. تستخدم في هذه المرحلة أدوات مثل Trifacta و OpenRefine لضمان دقة البيانات وتحسين جودتها. أدوات تحليل البيانات بعد تنظيف البيانات، سنحتاج لمعالجتها وتحليلها لاستخلاص رؤى واضحة حول الأنماط والاتجاهات المستقبلية. سنحتاج لأدوات مختلفة لإجراء التحليل مثل Apache Kafka وTableau وPower BI لعرض البيانات بطريقة مرئية تدعم اتخاذ القرارات وتساعدنا على الإجابة على أسئلة معينة حول هذه البيانات وكما نلاحظ، فالعملية ليست بالسهولة التي قد تبدو عليها، إذ يتطلب التعامل مع البيانات الضخمة استخدام عدة أدوات وتقنيات، كما يحتاج لبنية تحتية قوية، ووجود خبرات بشرية متخصصة في هذا المجال، وسنواجه كذلك عدة تحديات أخرى سنناقشها في فقرة لاحقة يجب أخذها بالحسبان قبل أن نقرر جمعها والاعتماد عليها في أعمالنا. حالات استخدام البيانات الضخمة تتيح البيانات الضخمة للشركات والمؤسسات إمكانية جمع ومعالجة أحجام هائلة من البيانات في الوقت الفعلي، لكن البيانات الضخمة التي تجمعها الشركات بحد ذاتها ليس الهدف، فإن لم تكن لدى الشركة أهداف فعلية للاستفادة من هذه البيانات، فلا جدوى من جمعها وتكديسها لديها، وفيما يلي بعض حالات استخدام البيانات الضخمة المفيدة: كشف الاتجاهات والأنماط في سلوك العملاء من أجل توقع احتياجاتهم المستقبلية وتلبيتها تحليل تفضيلات العملاء وسلوكهم الشرائي لتخصيص المنتجات وفقًا لاحتياجاتهم مما يعزز رضاهم ويساهم في زيادة المبيعات المرونة والتكيف مع تغيرات السوق بسرعة والعمل على تحسين المنتجات الحالية أو تطوير منتجات جديدة اتخاذ قرارات استراتيجية في العمل وإيجاد فرص نمو جديدة تحديد نقاط الضعف في العمل واكتشاف الجوانب التي يمكن تحسينها، مثل تقليل التكاليف أو تحسين العمليات التشغيلية تقييم المخاطر والتعرف على التهديدات المحتملة في العمل بوقت مبكر وقبل أن تفع فعلًا، ووضع استراتيجيات فعالة لإدارتها والتخفيف من آثارها التنبؤ في الوقت الفعلي كأن نتوقع متى وأين سيزيد الطلب على منتج معين لتلبية احتياجات السوق وضمان وصوله للعملاء في الوقت المناسب فإذا لم تكن أولويات العمل تحتاج لتحليل سلوك العملاء، واتخاذ قرارات استراتيجية بناءً عليها، فلا داعي لتخزين البيانات بكميات ضخمة وتكبد وقت وجهد وتكلفة في تخزينها ومعالجتها. تحديات التعامل مع البيانات الضخمة ينشأ عن الاعتماد على البيانات الضخمة في العمل عدة تحديات وعوائق يجب الانتباه لها ومن أهمها: الخصوصية والأمان يمكن أن تصبح الكمية الضخمة من البيانات في المؤسسات هدفًا سهلًا للتهديدات الأمنية لاحتوائها على معلومات حساسة؛ فمع تزايد حجم البيانات، سيزداد خطر اختراقها وتسريبها، لذا يتوجب على الشركات الحفاظ على أمن بياناتها من خلال المصادقة المناسبة، والتشفير القوي والامتثال لمعايير صارمة لحمايتها. نمو البيانات بسرعة إن نمو البيانات بمعدل سريع يجعل من الصعب استخلاص الرؤى منها؛ فهناك المزيد والمزيد من البيانات التي يتم إنتاجها كل ثانية. ومن بين هذه البيانات، يجب انتقاء البيانات ذات الصلة والمفيدة فعليًا لتحليلها، كما يصعب على المؤسسات تخزين وإدارة كمية كبيرة من البيانات بدون الأدوات والتقنيات المناسبة. سرعة المعالجة بعض التطبيقات مثل أنظمة كشف الاحتيال تتطلب منا تحليل البيانات في الوقت الفعلي، وبالتالي سنحتاج لاستخدام تقنيات مخصصة، مثل Apache Flink و Spark Streaming لضمان الاستجابة الفورية بالوقت المناسب دون أي تأخير مشكلات جودة البيانات لا يمكن أن تكون البيانات الضخمة دقيقةً بنسبة 100٪، كما قد تحتوي على بيانات مكررة أو غير مكتملة؛ إضافةً إلى وجود ضوضاء وأخطاء عديدة فيها، لذا إن لم ننظف هذه البيانات ونجهز جيدًا فستؤدي إلى تحليلات غير دقيقة واستنتاجات خاطئة في العمل صعوبة دمج وتكامل البيانات تستورد فلبيانات من مصادر مختلفة وبصيغ متعددة، وقد لا تكون البيانات من مصدر معين محدثة مقارنةً مع البيانات من مصدر آخر. نقص الكفاءات المتخصصة يتطلب تحليل البيانات الضخمة مهارات تقنية متقدمة، مثل علم البيانات وتحليل البيانات، وعدد المتخصصين في هذا المجال لا يزال محدودًا لا سيما عربيًا. تحديات إدارية وتنظيمية قد تظهر بعض التحديات الإدارية والتنظيمية خلال التعامل مع الكم الهائل للبيانات الضخمة، مثل ضعف الحوكمة وعدم وجود سياسات وآليات واضحة لضبط جمع بيانات الأشخاص، وعدم وجود توضيحات كافية لطريقة استخدامها تضمن التعامل معها بأمان؛ لذا وقبل أن نقرر التعامل مع البيانات الضخمة، يجب أن تطرح على نفسنا السؤال التالي: هل نحن بحاجة فعلًا لكل هذا الكم الكبير من البيانات وكل هذه التحليلات المعقدة لنجاح عملنا، أم أن البيانات التقليدية ـأي البيانات الصغيرة والمتوسطة الحجم- وحدها تكفينا لتسيير أمور العمل بنجاح واستقرار. ما هي البيانات التقليدية؟ تشير البيانات التقليدية إلى البيانات المهيكلة التي يمكن تخزينها على هيئة جداول مكونة من أسطر وأعمدة بهيكلية واضحة ومنظمة، مثل معلومات العملاء وقوائم المخزون والسجلات المالية. وتعتمد معالجة البيانات في هذه الأنظمة على الأساليب الإحصائية التقليدية والأدوات، مثل لغة الاستعلامات الهيكلية SQL للبحث عن المعلومات واسترجاعها؛ فباستخدام هذه الأدوات، يمكن للشركات اتخاذ قرارات مفيدة وتحسين أدائها؛ وعلى الرغم من أن هذه البيانات المنظمة سهلة في التعامل، إلا أنها تكون قد محدودةً في حال احتجنا لتقديم رؤى متطورة ومعقدة تخص بعض الأعمال، مثل الحاجة لنظام مراقبة ذكي يراقب الأسواق المالية ويكشف الاحتيال في المعاملات البنكية فورًا. أدوات التعامل مع البيانات التقليدية البيانات التقليدية أسهل في التعامل من البيانات الضخمة لأنها غالبًا ما تكون صغيرة الحجم ومنظمةً جيدًا ومن أبرز أدوات البيانات التقليدية نذكر: قواعد البيانات العلائقية RDBM مثل MySQL و Oracle و SQL Server، والتي تستخدم لتخزين البيانات في جداول مترابطة، وهي مثالية للبيانات المنظمة والمهيكلة جداول البيانات Spreadsheets مثل إكسل Excel أو جداول جوجل Google Sheets لتحليل البيانات الصغيرة والمتوسطة خاصة عندما تكون البيانات محدودة ومنظمة برامج إدارة البيانات مثل SQLite التي تستخدم لتخزين وإدارة البيانات الصغيرة وتوفر لنا القدرة على إجراء بعض العمليات البسيطة على البيانات حالات استخدام البيانات التقليدية إذا كانت البيانات التي نجمعها في العمل هي بيانات منظمة مثل قواعد البيانات الجاهزة، فإن الحلول التقليدية مثل قواعد البيانات العلائقية غالبا ستكون كافيةً لإدارتها وتحليلها ولا داعي لأن نرهق أنفسنا بتعقيدات البيانات الضخمة. وفيما يلي بعض الحالات التي تعد فيها البيانات التقليدية هي الأنسب للاستخدام: إدارة السجلات المالية ضمن نظام يتعامل مع كمية محدودة من بيانات الفواتير والمدفوعات ويصدر تقارير مالية منظمة إدارة المخزون في متاجر صغيرة أو متوسطة تتضمن بيانات عن المنتجات والمبيعات ومستويات المخزون وتسعى لتحسين استراتيجيات المبيعات باستخدام قواعد بيانات تقليدية الرعاية الصحية ضمن مستشفيات تنظم وتدير معلومات المرضى، مع تتبع تاريخ المرضى ونتائج فحوصاتهم وتتابع خطط علاجهم وترقب التقدم في حالتهم الصحية إدارة الموظفين في الشركات الصغيرة والمتوسط باستخدام أنظمة تقليدية لتخزين المعلومات الشخصية للموظفين وجداول حضورهم وأدائهم إدارة المنصات التعليمية كالمدارس والمعاهد التعليمية التي تحتاج لإدارة بيانات الطلاب وتخزين درجاتهم وتتبع حضورهم ومستوياتهم الدراسية في كل هذه الحالات والحالات المشابهة، سيكون حجم البيانات محدودًا نسبيًا، أو ستكون البيانات منظمةً جيدًا، مما يسهّل معالجتها باستخدام الأنظمة التقليدية دون الحاجة إلى تقنيات معقدة كتلك التي تتطلبها البيانات الضخمة؛ أما في حال زاد تعقيد البيانات سواءً من حيث الحجم أو السرعة أو تنوع المصادر وكانت هناك حاجة لتحليلها بدقة واتخاذ قرارات بناءً عليها بسرعة، فعندها سيكون اللجوء إلى تقنيات البيانات الضخمة أمرًا ضروريًا. مميزات التعامل مع البيانات التقليدية يتسم التعامل مع البيانات التقليدية بما يلي: السهولة يمكن التعامل مع البيانات المعالجة باستخدام الأساليب التقليدية بسهولة باستخدام الأدوات القياسية، مما يجعلها أكثر سهولةً في التعامل ولا تتطلب معرفةً تقنيةً متقدمة. الوصول السريع للبيانات تقدم قواعد البيانات التقليدية وصولًا سريعًا وموثوقًا إلى البيانات من خلال العمل المستقل على خادم أو حاسوب محلي لا على بيئات سحابية أو خارجية، وتتجاوز مشكلات تأخير الشبكة أو انقطاع الخدمة أو اختراقات الأمان. سهولة حماية البيانات تُعَد البيانات الصغيرة والمتوسطة أسهل في تأمينها وحمايتها نظرًا لصغر حجمها وعدم اعتمادها على الهيكلية الموزعة، خاصةً وأنها لا تعتمد في أغلب الأحيان على التخزين الخارجي، مما يجعلها مناسبةً لإدارة المعلومات الحساسة أو السرية. سهولة إدارة البيانات تقدم قواعد البيانات التقليدية للمستخدمين تحكمًا كبيرًا في إدارة البيانات، حيث يمكن للمستخدمين تعريف أنواع البيانات، وتحديد القواعد بينها، وإنشاء العلاقات المخصصة وفقًا لاحتياجاتهم. تتطلب تكاليف وموارد أقل تتطلب الأساليب التقليدية تكاليف أقل وموارد أقل مقارنة بأنظمة معالجة البيانات الضخمة التي تتطلب تكاليف وموارد ضخمة. الخلاصة أصبحت البيانات الضخمة بلا شك جزءًا أساسيًا من العمليات التجارية والخدمات الحكومية، نظرًا للنمو السريع في حجم البيانات الرقمية. ومع تطور تقنيات الذكاء الاصطناعي، أتاح ذلك للمؤسسات القدرة على استخراج رؤى أكثر دقة واتخاذ قرارات أكثر ذكاءً وتحسينات كبيرة في مختلف القطاعات؛ لكن مع ذلك، ينبغي أن نتذكر أن البيانات الضخمة ليست مجرد جمع كميات هائلة من المعلومات، بل هي عملية تتطلب استراتيجيات مدروسة، وأدوات متخصصة، وتخطيطًا دقيقًا لتحقيق أقصى استفادة منها وتحويلها إلى قرارات تدعم النجاح والنمو. مع ذلك، وبالرغم من هذا التطور الكبير في مجال البيانات الضخمة، لازالت البيانات التقليدية الصغيرة والمتوسطة كافية للعديد من الحالات إن لم نقل أغلبها نظرًا لتوفير هذا النوع من البيانات حلولًا مناسبةً سهلة التعامل وبتكاليف أقل. لذا، متى لم يكن ما نعمل عليه يتطلب بيانات ضخمة للحصول على تحليلات وفهم كاف، فلا حاجة لأن نلجأ في أعمالنا لحلول البيانات الضخمة، لاسيما أنها تحتاج لخبرة وتكاليف أكبر وتعقيدات تقنية للتعامل مع البيانات وتحليلها وإدارتها، خاصةً وأننا إذا لم نحسن التعامل مع هذه البيانات ونستخدمها بطريقة صحيحة، فلن نتمكن من فهمها أو اتخاذ قرارات صائبة بناءً عليها. المصادر ?What is Big Data When to Use Big Data — and When Not To 7 Pros and Cons of Big Data Difference Between Traditional Data and Big Data Big Data Analytics Versus Traditional Data Analytics: A Comprehensive Overview اقرأ أيضًا مقدمة إلى مفهوم البيانات الضخمة Big Data المفاهيم الأساسية لتعلم الآلة أساسيات الذكاء الاصطناعي: دليل المبتدئين تعلم الذكاء الاصطناعي1 نقطة -
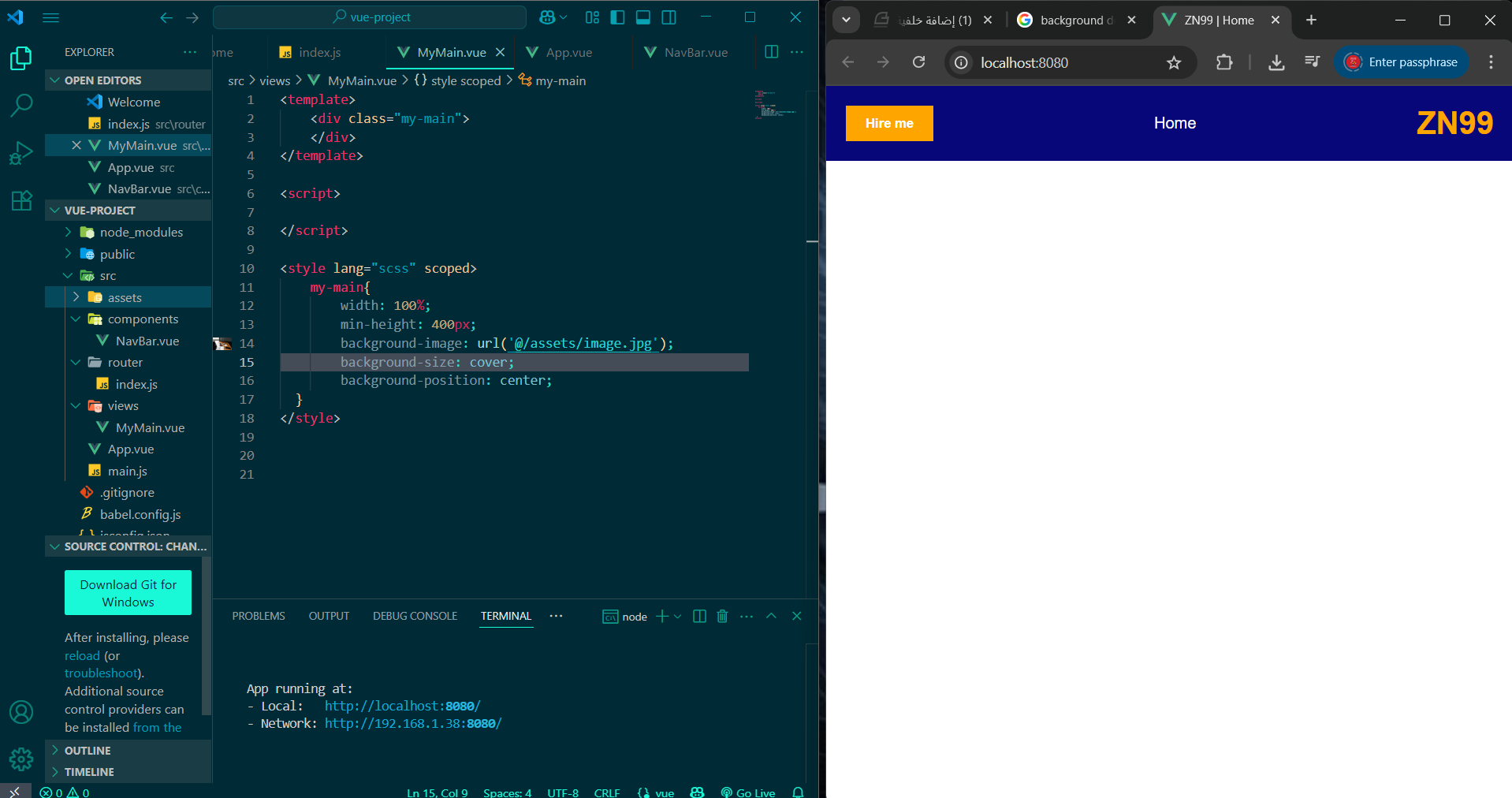
كيف يمكنني ان اضع صورة من خلال bg url في اطار العمل vue من خلال ملف assets1 نقطة
-
ستجد أسفل فيديو الدرس صندوق للتعليقات كما هنا يرجى طرح سؤالك أسفل الدرس وليس هنا حيث هنا قسم الأسئلة العامة ولا نقوم بإجابة الأسئلة الخاصة بمحتوى الدورة أو الدرس، وذلك لمعرفة الدرس الذي توجد به مشكلتك و لمساعدتك بشكل أفضل.1 نقطة
-

الإصدار 1.0.0
70366 تنزيل
لا يخفى على أي متعلم لمجال علوم الحاسوب كثرة الاهتمام بمجال الذكاء الاصطناعي وتعلم الآلة، وكذلك الأمر بالنسبة لمستخدم التقنية العادي الذي بات يرى تطورًا كبيرًا في الآلات والتقنيات التي تحيط به بدءًا من المساعد الصوتي الآلي في جواله وحتى سيارته وبقية الأشياء الذكية المحيطة به. تتوالى الاختراعات والاكتشافات يومًا بعد يوم وتتنافس كبرى الشركات حول من يحرز أكبر تقدم ليخطف الأضواء من غيره. ونظرًا لهذا الاهتمام، ولضعف المحتوى العربي وسطحيته في هذا المجال أيضًا، قررنا توفير مصدر عربي دسم لشرح مجال الذكاء الاصطناعي وتعلم الآلة نظريًا وعمليًا لذا وضعنا فهرس المحتوى آنذاك وبدأنا العمل. هذا الكتاب هو الجزء الأول النظري التأسيسي من أصل جزآن عن الذكاء الاصطناعي وتعلم الآلة، ويبدأ بعرض أهمية الذكاء الاصطناعي وتعلم الآلة عبر الإشارة إلى المشاريع والإنجازات التي قدَّمها هذا المجال إلى البشرية حتى يومنا هذا وكيف أثرت على كل مجالات حياتنا اليومية. ينتقل بعدها إلى لمحة تاريخية عن المجال وكيفية ولادته ومراحل حياته حتى يومنا الحالي. ستجد بعدئذٍ المعلومات الدسمة في الفصل الثالث الذي يشرح المصطلحات المتعلقة بمجال تعلم الآلة ويشرح أساليب تعليم الإنسان للآلة والأسس التي بنيت عليها عمليات تعليم الآلة (منها شرح طرائق تعلم الآلة التقليدية ثم التجميع والتعلم المعزز وحتى الشبكات العصبية والتعلم العميق). يعرض الفصل الأخير تحديات عملية تعليم الآلة وما علاقة البيانات فيها، ثم أخيرًا عرض خارطة طريق لأهم المفاهيم التي يجب أن تتقنها في حال أردت التوسع في المجال وإتقانه. بعد الانتهاء من الجزء الأول في هذا الكتاب وتأسيس المفاهيم والمصطلحات التي يقوم عليها مجال الذكاء الاصطناعي وتعلم الآلة، يمكنك الانتقال إلى الجزء الثاني وهو كتاب عشرة مشاريع عملية عن الذكاء الاصطناعي لبدء تطبيق مشاريع عملية تطبيقية مبنية على بيانات واقعية وتنفيذ أفكار مشاريع من الحياة العملية باستخدام الذكاء الاصطناعي. ساهم بالعمل على هذا الكتاب، محمد لحلح تأليفًا، وجميل بيلوني تحريرًا وإشرافًا، وأخرجه فنيًا فرج الشامي. أرجو أن نكون قد وُفقنَا في هذا العمل لسد ثغرةً كبيرةً في المحتوى العربي -كما خططنا لذلك- الذي يفتقر أشد الافتقار إلى محتوى جيد ورصين في مجال الذكاء الاصطناعي وتعلم الآلة. هذا الكتاب مرخص بموجب رخصة المشاع الإبداعي Creative Commons «نسب المُصنَّف - غير تجاري - الترخيص بالمثل 4.0». يمكنك قراءة فصول الكتاب على شكل مقالات من هذه الصفحة، «الذكاء الاصطناعي: أهم الإنجازات والاختراعات وكيف أثرت في حياتنا اليومية»، أو من مباشرةً من الآتي: الفصل الأول: الذكاء الاصطناعي: أهم الإنجازات والاختراعات وكيف أثرت في حياتنا اليومية الفصل الثاني: الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها الفصل الثالث: المفاهيم الأساسية لتعلم الآلة الفصل الرابع: تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال1 نقطة


.png.6430340f5c11ba7afd485c2251dc2092.png)

