لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 03/13/25 في كل الموقع
-
السلام عليكم ورحمة الله وبركاته فيه استفسار مالقيت له جواب واضح ومقلقني صراحة، الان قاعدة البيانات mysql أو غيرها، أنا فرضا صلحت برنامج متجر ألكتروني وأبغى قاعدة البيانات تكون عندي على الجهاز يعني البيانات(كم اسماء المنتجات عددها اسعارها وكل عملية داخل التطبيق) تتخزن على الهاردسك حق اللاب توب حقي، كيف الطريقة وهل بالامكان كذا. الله يعطيكم العافية على جهودكم4 نقاط
-
السلام عليكم هو مش الarray دي كده عبار عن Static Array في الباثيون ؟ دي array = [1,2,3,4,5]4 نقاط
-
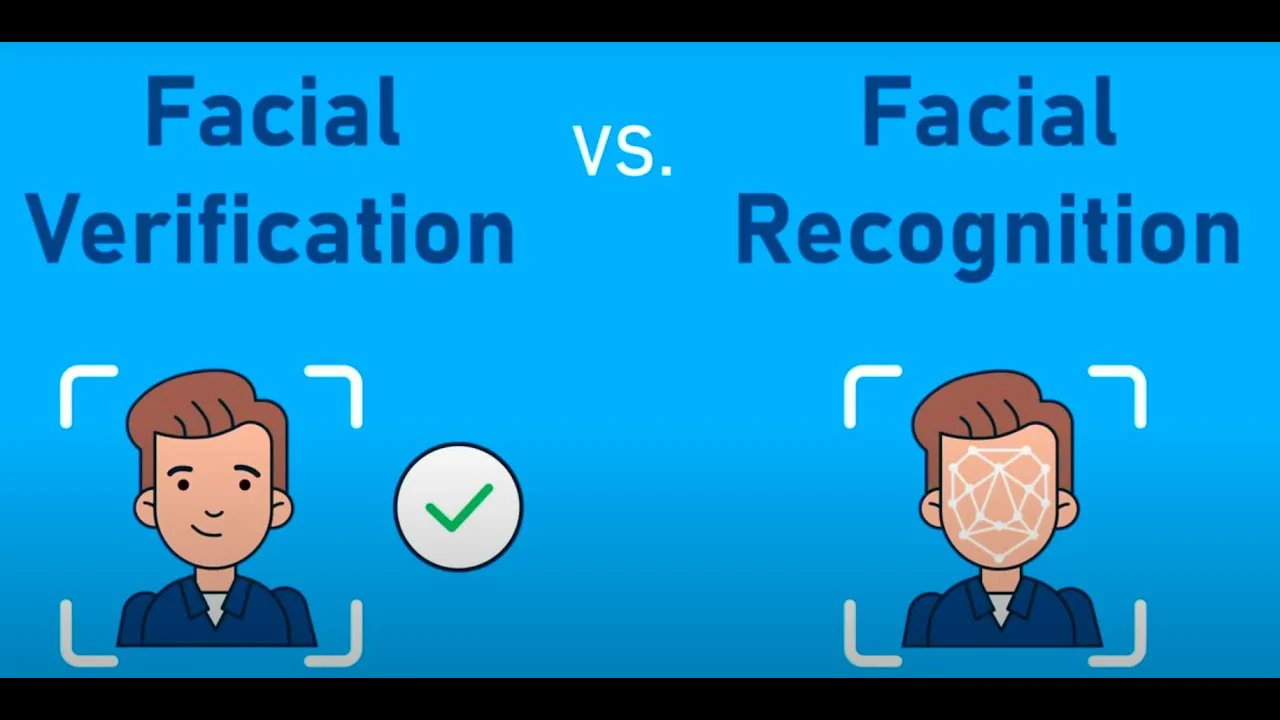
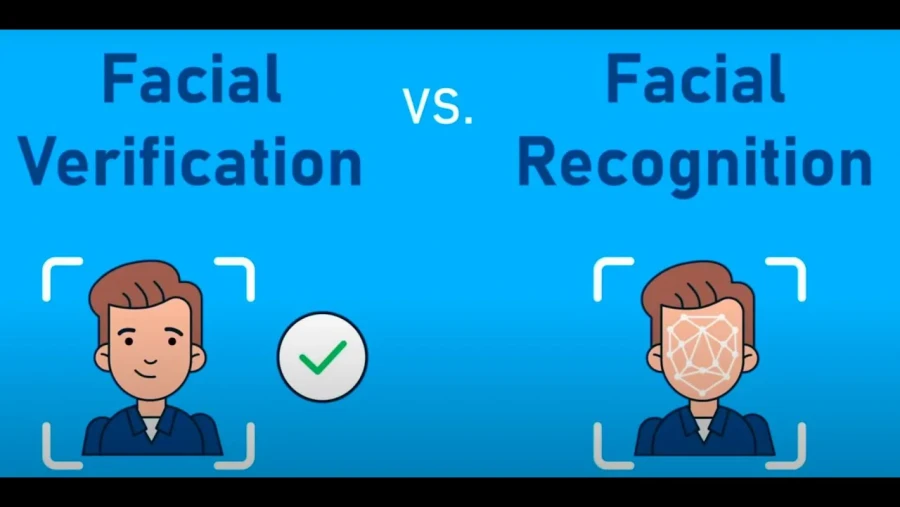
السلام عليكم هو اي الفرق مابين Face Recognition - Face Verification ؟4 نقاط
-
أحتاج إلى مساعدة ممن لديه خبرة عندما ؤحاول تشغيل اللابتوب الخاص بي يعرض لي ھذھ الشاشة لا أدري ما السبب فى ذاك أرجو مساعدتكم وشكرا
 3 نقاط
3 نقاط -
السلام عليكم. أرجو المساعدة في حل المشكلة. Fatal error: Uncaught mysqli_sql_exception: Access denied for user 'if0_38415802'@'192.168.0.20' (using password: NO) in /home/vol17_1/infinityfree.com/if0_38415802/htdocs/includes/config.php:7 Stack trace: #0 /home/vol17_1/infinityfree.com/if0_38415802/htdocs/includes/config.php(7): mysqli_connect('sql108.infinity...', 'if0_38415802', Object(SensitiveParameterValue), 'm07071978') #1 /home/vol17_1/infinityfree.com/if0_38415802/htdocs/includes/header.php(2): include('/home/vol17_1/i...') #2 /home/vol17_1/infinityfree.com/if0_38415802/htdocs/includes/includedFiles.php(24): include('/home/vol17_1/i...') #3 /home/vol17_1/infinityfree.com/if0_38415802/htdocs/index.php(2): include('/home/vol17_1/i...') #4 {main} thrown in /home/vol17_1/infinityfree.com/if0_38415802/htdocs/includes/config.php on line 72 نقاط
-
السلام عليكم هي اي مكتبه Biopython ؟2 نقاط
-
السلام عليكم، تعلمت بعض أساسيات django rest framework وطورت API بسيط لإدارة مخزن وإستعنت بالذكاء الإصطناعي أثناء عملية التطوير ولحل المشكلات، الشروع عبارة عن API يسمح للمستخدم بإضافة منتجات وتصنيفات كما انه يراقب حركة البيع والشراء ودخول وخروج المنتجات كما يمكن البحث عن المنتجات وإضافة شروط وتصفية البحث وترتيبه. هل يستطيع أحد مراجعة المشروع كي يرا ان كان مبني بشكل جيد وان كان بحاجة الى تحسين؟ وهل استخدام الذكاء الإصطناعي أثناء التعلم قد يؤثر علي سلباً؟ مع العلم اني أفهم جيداً كامل البرنامج النهائي وقمت بعدة مشاريع بسيطة من قبل وحدي. وأخيرا هل يجب إضافة الى settings هذا الكود لكي أحول API الى JSON ام ليس هناك داعي واستطيع استدام الAPI كما هو REST_FRAMEWORK = { 'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend'], 'DEFAULT_RENDERER_CLASSES': [ 'rest_framework.renderers.JSONRenderer', ], } يمكنك استخدام حساب admin مع كلمة سر admin ان لزم الامر api-inventory-ms.zip2 نقاط
-
طيب انا شغل عي قاعد بيانات RNA بس التسلسل عبار عن نص يعني كده AUCCG فا لو سبت العمود زي كده هل اقدر بستخدم المكتبه دي ان اتعمل معه والا الافضل ان احول البيانات دي الاول الي ارقم زي كده 1-2-3-4 ؟1 نقطة
-
هناك مشكلة في نظام الإقلاع لديك في الويندوز، هناك طريقة لمحاولة إصلاح ذلك تتضمن أوامر من خلال منفذ الأوامر CMD ويجب وجود فلاشة عليها نفس إصدار نظام الويندوز لديك لكي يتم إصلاح الملفات المعطوبة من خلالها وقد تنجح أو تفشل. لذا الأفضل والأسهل لك هو إعادة تثبيت نظام ويندوز من جديد وحذف القديم، يوجد شروحات على اليوتيوب لفعل ذلك.1 نقطة
-
Django REST Framework يدعم بشكل افتراضي تقديم البيانات بصيغة JSON بفضل JSONRenderer، بالإضافة إلى صيغ أخرى مثل صيغة HTML عبر واجهة المتصفح Browsable API، لذا لا حاجة لإضافة ما ذكرته حيث الإعداد الافتراضي لـ DEFAULT_RENDERER_CLASSES في DRF يشمل: 'rest_framework.renderers.JSONRenderer', 'rest_framework.renderers.BrowsableAPIRenderer', ما قمت به جيد بشكل عام، مجهود تُشكر عليه، وتستطيع استخدام أي أداة تساعدك في التعلم أو الإنتاجية، بشرط أن يكون الاستيعاب والمنطق لديك أنت وليس في الأداة، بمعنى أنت الذي تقود السيارة لا السيارة التي تقودك. كتحسين، حاليًا تعديل أو حذف InventoryTransaction لا يُحدِّث المخزون تلقائيًا، عليك منع التعديلات على المعاملات بعد إنشائها Read-Only وإضافة إشارات Signals أو Override لـ delete() لتحديث المخزون عند الحذف. ومن حيث نقطة الأمان والمصادقة فلا يوجد Authentication للوصول إلى الـ API تحتاج إلى إضافة الإعدادات التالية: REST_FRAMEWORK = { 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination', 'PAGE_SIZE': 10, 'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend'], 'DEFAULT_AUTHENTICATION_CLASSES': [ 'rest_framework.authentication.SessionAuthentication', 'rest_framework.authentication.TokenAuthentication', ], 'DEFAULT_PERMISSION_CLASSES': [ 'rest_framework.permissions.IsAuthenticated', ], } وفي لوحة الإدارة النماذج غير مسجَّلة في Admin، عليك تسجيل النماذج في admin.py. from .models import Category, Product, InventoryTransaction admin.site.register(Category) admin.site.register(Product) admin.site.register(InventoryTransaction) وكتحسين للاستعلامات، فحاليًا في low_stock، تُعاد منتجات ذات min_quantity=0 إن وجدت، بالتالي عليك تعديل الاستعلام ليتجاهل min_quantity=0. وفي InventoryTransaction.save()، لو الكمية غير كافية لـ OUT، يتم رفع استثناء ValueError، من الأفضل التعامل مع ذلك في المُسلسل بدلاً من النموذج لإرجاع استجابة مناسبة للمستخدم. ولديك ProductViewSet مع إجراء مخصص @action وهو transactions، والذي يعود بجميع المعاملات InventoryTransaction المرتبطة بمنتج معين، لكن عند تنفيذه، ربما تحدث مشكلة تُعرف بـ N+1 Query Problem أو مشكلة الاستعلامات المتعددة غير الضروري، يعني أن Django يقوم بإجراء استعلامات إضافية على قاعدة البيانات لكل معاملة لجلب بيانات المنتج المرتبط بها، وذلك يؤدي إلى بطء في الأداء إن كان هناك عدد كبير من المعاملات. Django يوفر أداتين لتحسين الاستعلامات وتقليل عدد الطلبات إلى قاعدة البيانات: select_related مع العلاقات من نوع ForeignKey أو OneToOneField يقوم بجلب البيانات المرتبطة في نفس الاستعلام باستخدام JOIN في SQL، بالتالي مناسب للوصول إلى النموذج المرتبط مباشرة مثل transaction.product. prefetch_related مع العلاقات من نوع ManyToManyField أو العلاقات العكسية مثل product.transactions ويقوم بجلب البيانات المرتبطة في استعلام منفصل، ثم يربطها في الذاكرة، مما يقلل من الاستعلامات المتكررة، بالتالي مناسب للتتعامل مع قائمة من الكائنات المرتبطة. @action(detail=True, methods=['get'], url_path='transactions') def transactions(self, request, pk=None): product = self.get_object() transactions = InventoryTransaction.objects.filter(product=product).select_related('product') serializer = InventoryTransactionListSerializer(transactions, many=True) return Response(serializer.data) وعليك معالجة الصور أيضًا حيث image_url كـ URLField لا يدعم رفع ملفات هل تنوي تخزين روابط فقط به؟ في حال تريد رفع صور استخدم ImageField مع تكوين تخزين مناسب مثل django-storages. ولا يوجد توثيق واضح للـ API، تستطيع فعل ذلك بسهولة من إضافة مكتبة drf-yasg أو drf-spectacular إلى INSTALLED_APPS لتوليد واجهة توثيق تلقائية: INSTALLED_APPS += ['drf_spectacular'] REST_FRAMEWORK['DEFAULT_SCHEMA_CLASS'] = 'drf_spectacular.openapi.AutoSchema' ودائمًا في المشاريع يجب تطبيق unit tests أي إختبارات وأسهل طريقة هي من خلال APITestCase من DRF لاختبار الـ API Endpoints.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. أحسنت عمل رائع أنك تعلمت أساسيات django rest framework وتقوم بالتطبيق عليه . المشروع جيد بالفعل ولكن توجد بعض التحسينات التي يمكنك إضافتها. بما أنك تتعامل في مشروع إدارة مخازن إذا من المتوقع أن البيانات ستكون كبيرة ولهذا يفضل إستخدام الصفحات (Pagination) لتحسين الأداء عند استرجاع البيانات وعدم إرجعاها جميعا كما تفعل من خلال objects.all() . أيضا لاحظ أنك لم تستعمل الصلاحيات حيث يمكن لأى شخص الوصول إلى ال API وإرسال الطلبات وهذا من الممكن أن يؤدي إلى مشاكل في الوصول الغير مرغوب فيه لتطبيقك لهذا يجب إستخدام نظام الصلاحيات. أما بخصوص استخدام الذكاء الاصطناعي فهو من الممكن أن يكون جيدا لك في عملية التعلم. لكن يجب أن تتأكد أنك لا تعتمد بشكل كامل عليه بل تستخدمه كأداة لتحسين مهاراتك وأيضا يجب عليك البحث ولا تأخذ بما يقول كأمر مسلم به حيث أحيانا كثيرة يخطأ ولا يعطيك الإجابة الصحيح أو الجيدة مما يجعلك تتعلم الأمور بطريقة خاطئة. فمثلا: إذا واجهت مشكلة يمكنك استخدام الذكاء الاصطناعي لتوجيهك نحو الحلول الممكنة ولكن تأكد أنك تفهم السبب وراء الحل الذي أعطاه لك والبحث على الإنترنت أو في التوثيقات الرسمية عن هذا الحل هو صحيح أم لا . أما إذا كنت تستخدمه للإجابة على أسئلة أثناء تعلمك فكما وضحت لك يجب التأكد من أن لديك فهم جيد للإجابة وعدم أخذها كأنها أمر مسلم به دون البحث عن تلك المعلومة بشكل متعمق أما بخصوص الكود الذي ذكرته في إعدادات settings.py : DEFAULT_FILTER_BACKENDS: هذا الخيار يتيح لك استخدام django_filters لترشيح البيانات . DEFAULT_RENDERER_CLASSES: هذا الخيار سيحدد كيف يتم عرض البيانات.لذلك إذا كنت ترغب في عرض البيانات بتنسيق JSON فقط فيمكنك إضافة هذا الكود. لكن إذا كنت لا تحتاج إلى تخصيص هذا الإعداد فلا داعي لإضافته . حيث إذا لم تقم بتفعيله وذهبت إلى المتصفح ستجد أنه يوضح لك أمور كثيرة لل api الحالي ويمكنك البحث والفلترة كما لو أنك في موقع واجهة أمامية :
 1 نقطة
1 نقطة -
شكراا جدا جدا لتوضيح عشان ان ما كانتيش عارف افرق مابين الlist الموجود في باثيون وبين الarray في C جزاكم الله كل خير1 نقطة
-
الف شكراا جدا لحضرتك جزاك الله كل خير1 نقطة
-
كما تم التطرق في الإجابات السابقة، فإنّ تقنية ال Face Recognition تعني التعرف على الوجه وهو عملية تحديد هوية شخص من خلال صورة أو فيديو عن طريق مقارنة الوجه المدخل بقاعدة بيانات كبيرة تحتوي على وجوه معروفة. تكون العملية عادة مقارنة من واحد إلى متعدد 1:N حيث يسأل النظام: "من هذا الشخص؟" على سبيل المثال قد تستخدم الجهات الأمنية التعرف على الوجه لتحديد مشتبه به في حشد من الأشخاص عبر مقارنة صورته مع قاعدة بيانات لصور المجرمين وهذا أمر مفيد للغاية بحيث يتم على هذا النحو: يكتشف النظام وجود وجه في الصورة (الكشف عن الوجه). يستخرج النظام المميزات الفريدة مثل المسافة بين العينين وشكل الفك وغيرها. ثم يقوم بمقارنة هذه المميزات مع قاعدة بيانات من القوالب المخزنة لإيجاد تطابق. بينما Face Verification هو تقنية التحقق من الوجه من خلال عملية مقارنة من واحد إلى واحد 1:1 أين تستخدم لتأكيد أن الشخص هو بالفعل من يدعي أنه هو بدلا من البحث في عدة صور، يتم مقارنة وجه حي بصورة مسجلة مسبقا نفس الفكرة عند فتح هاتفك باستخدام خاصية Face ID حيث تتم مقارنة وجهك مع الصورة المخزنة للتحقق من هويتك كالتالي: يلتقط النظام صورة للشخص. يستخرج قالبا بيومتريا من الصورة. يقوم بمقارنة هذا القالب مباشرة مع القالب المخزن أثناء عملية التسجيل. إذا كان القالبان متطابقين بدرجة كافية، يتم تأكيد هوية الشخص.1 نقطة
-
في لغة بايثون القائمة المعرفة كالتالي: array = [1, 2, 3, 4, 5] ليست مصفوفة ثابتة بل هي مصفوفة ديناميكية مما يعني أنه بعد إنشاء القائمة يمكنك إضافة أو إزالة أو تعديل عناصرها دون الحاجة لتحديد حجم ثابت مسبقا على سبيل المثال يمكنك إضافة عنصر باستخدام array.append(6) فتصبح القائمة: array = [1, 2, 3, 4, 5, 6] أو إزالة عنصر باستخدام array.pop(). وفي لغات أخرى مثل C أو Java تكون المصفوفات الثابتة ذات حجم محدد عند إنشائها ولا يمكن تغييره دون إنشاء مصفوفة جديدة على سبيل المثال في لغة C يمكنك تعريف مصفوفة كالتالي: int array[5]، حيث لا يمكن تغيير حجمها لاحقا. لا تحتوي بايثون على نوع مدمج للمصفوفة الثابتة، إذ أن القوائم مصممة لتكون أكثر مرونة وإذا كنت بحاجة إلى تسلسل غير قابل للتعديل من العناصر، يمكنك استخدام ال tuple، والذي يتم تعريفه بالشكل التالي: tuple_array = (1, 2, 3, 4, 5) لاحظ استخدمنا الأقواس ( ) بدلا من [ ].1 نقطة
-
تلك ليست مصفوفة ثابتة كما في لغات البرمجة الأخرى، ففي بايثون تسمى قائمة List وهي مصفوفة ديناميكية أي يتغير حجمها. فالمصفوفة الثابتة يكون حجمها ثابتاً ومحدداً منذ تعريفها، ولا يتغير بعد ذلك، أما القائمة في بايثون فهي ديناميكية، أي تستطيع تغيير حجمها بسهولة، وإضافة عناصر جديدة إليها أو حذف عناصر منها، وسيتغير حجمها تلقائياً. ويوجد ما نستطيع اعتباره قريباً من المصفوفة الثابتة، ولكن ليس بنفس الطريقة التي توجد بها في لغات مثل C أو Java، وذلك من خلال استخدام وحدة تسمى array لتكوين مصفوفات من أنواع بيانات محددة وثابتة. أي نستطيع تغيير حجمها ولكن النوع ثابت كأعداد صحيحة فقط، لاحظ i تعني الأعداد الصحيحة ونستطيع الإضافة: import array fixed_array = array.array('i', [1, 2, 3, 4, 5]) fixed_array.append(6) والأقرب للمفهوم هو الصفوف tuples فهي هياكل بيانات غير قابلة للتغيير immutable ولا تستطيع تغيير محتواها أو حجمها بعد الإنشاء. fixed_array = (1, 2, 3, 4, 5) لكن الصف هيكل بيانات ليس مصممًا خصيصًا للكفاءة الرقمية أو العمليات الحسابية المكثفة مثل array.array أو مكتبة NumPy التي توفر نوع ndarray وهو أقرب إلى المصفوفات في لغات مثل Fortran و MATLAB، حيث الصفوف مصممة أكثر لتمثيل مجموعات ثابتة من البيانات، بغض النظر عن نوعها.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. الفرق بين التعرف على الوجه (Face Recognition) والتحقق من الوجه (Face Verification) هو في مفهوم وكيفية تنفيذ كل منهما. التعرف على الوجه (Face Recognition): هو يهدف إلى تحديد هوية الشخص من بين مجموعة من الأشخاص.حيث يقوم النظام بمقارنة الصورة للوجه الذي تم إدخاله مع قاعدة بيانات تحتوي على صور وجوه معروفة الهوية و الهدف كما وضحت لك هو معرفة من هو الشخص في الصورة.مثل فتح هاتف ذكي باستخدام التعرف على الوجه، حيث يحدد الهاتف هوية المستخدم من بين عدة وجوه مخزنة. أما التحقق من الوجه (Face Verification) : فهو يهدف إلى التأكد من أن الشخص هو بالفعل من يقول أنه هو حيث يقوم النظام بمقارنة صورة الوجه المدخلة مع صورة واحدة محددة (مثل صورة الهوية) لتأكيد المطابقة.1 نقطة
-
وعليكم السلام ورحمة لله وبركاته. هنا فرق كبير بين Face Recognition وFace Verification فيكمن في الغرض والطريقة التي يتم بها استخدام تقنيات التعرف على الوجه. فمثلاً Face Verification هي عملية تُستخدم للتحقق من هوية شخص ما بناءً على صورة وجهه وتعتمد على مقارنة صورة الوجه المُقدمة مع صورة واحدة مُخزنة مسبقًا في قاعدة بيانات. وتقوم بمقارنة صورة واحدة بصورة واحدة أخرى فقط .مثال: عندما تستخدم وجهك لفتح هاتفك، يقارن النظام الصورة التي تلتقطها الكاميرا مع الصورة المُسجلة لك مسبقًا. بينما Face Recognition هي عملية تُستخدم لتحديد هوية شخص ما من خلال صورة وجهه. تعتمد على مقارنة صورة الوجه المُقدمة مع مجموعة من الصور المُخزنة لأشخاص مختلفين في قاعدة بيانات. ولذلك تقوم بمقارنة صورة واحدة بعدد كبير من الصور. وتُستخدم في تطبيقات مثل تحديد هوية المسافرين في المطارات أو العثور على أشخاص في الصور الأمنية.1 نقطة
-
Face Recognition تعني التعرف على الوجه، أما Face Verification وهي التحقق من الوجه، بمعنى في Face Recognition يتم تحديد هوية الشخص من خلال مقارنة صورة وجهه بقاعدة بيانات تحتوي على صور وجوه متعددة، ثم تحليل ملامح الوجه مالمسافة بين العينين، شكل الأنف، خط الفك، ومقارنتها مع جميع الصور المخزنة لإيجاد تطابق، وذلك للإجابة على سؤال من هذا الشخص؟ وستجد ذلك في الأنظمة الأمنية نظام لتحديد هوية شخص معين من بين آلاف أو ملايين الأشخاص ككاميرات المراقبة في المطارات. في حين Face Verification هي للتحقق من الوجه المقدم هل يتطابق مع هوية محددة مسبقًا وذلك لتأكيد الهوية، من خلال مقارنة صورة الوجه بصورة واحدة فقط أو مجموعة محددة مسبقًا، وذلك يحدث عند فتح قفل الهاتف باستخدام الوجه، حيث يتحقق النظام من أنّ الوجه يتطابق مع مالك الجهاز المسجل أم لا؟ أي هل هذا الشخص هو نفسه الشخص المسجل؟
 1 نقطة
1 نقطة -
السلام عليكم مساء الخير. لدي طلب أرجو منكم تلبيتله . لقد اشتركت معكم منذ أيام في دورة علوم الحاسوب ولكن لم تعجبني الدورة. أرغب في استبدالھا بدورة تطوير التطبيقات باستخدام لغة php. إذا كان ذاك ممكنا وشكراً1 نقطة
-
لقد راسلتھم من خلال مركز المساعدة، ومن خلال البريد ، لكنھم لم يتفاعلو معي، لا أدري ما السبب1 نقطة
-
One-hot Encoding مناسب في الحالات البسيطة جدًا كأن يكون القاموس صغيرًا، ونادرًا ما تُستخدم في التطبيقات الحديثة لمعالجة اللغات الطبيعية بسبب قيودها. الاستخدام: تُستخدم Embedding Layer هي المستخدمة حاليًا بشكل واسع في نماذج التعلم العميق، كالشبكات العصبية في معالجة اللغات الطبيعية NLP، لأنها توفر تمثيلًا غنيًا وفعالًا للكلمات، فهي تقنية متقدمة لتمثيل الكلمات في فضاء متعدد الأبعاد، حيث كل كلمة تُمثل بمتجه vector يحتوي على أرقام حقيقية، ويتم تعلم قيم المتجهات تلقائيًا أثناء تدريب النموذج بناءً على السياق الذي تظهر فيه الكلمات. بمعنى أننا نستخدم فضاءً بـ 3 أبعاد فقط للتبسيط، فبعد التدريب، ستُمثل الكلمات كالتالي: "ملك" بـ [0.9, 0.8, 0.2] "ملكة" بـ [-0.9, 0.7, 0.1] "شعب" بـ [0.1, -0.5, -0.9] الكلمات ذات المعاني المشابهة مثل "ملك" و"ملكة" ستكون قريبة من بعضها في الفضاء، بينما الكلمات المختلفة "شعب" ستكون بعيدة. كل بعد في الفضاء يمثل ميزة أو خاصية معينة كالجنس، العمر، المكانة المجتمعية، لكن تلك الأبعاد ليست محددة مسبقًا يدويًا، بل يتم تعلمها تلقائيًا من البيانات، وذلك يسمح بفهم العلاقات بين الكلمات، بمعنى لو البعد الأول يمثل الجنس تقريبًا، فستكون القيمة الموجبة تشير إلى ذكر والسالبة إلى أنثى. وحجم المتجه ثابت 50، 100، أو 300 بعد بغض النظر عن حجم القاموس، لذا هي تقنية أكثر كفاءة من One-hot Encoding عند التعامل مع قواميس كبيرة.
 1 نقطة
1 نقطة -
يعتبر الترميز باستخدام One-hot Encoding طريقة بسيطة لتحويل المتغيرات الفئوية إلى تمثيل عددي يمكن للحواسيب التعامل معه بسهولة ففي هذه الطريقة يتم تحويل كل فئة إلى متجه ثنائي حيث يكون عنصر واحد فقط مساويا للرقم 1 مما يدل على وجود تلك الفئة بينما تكون بقية العناصر مساوية للصفر. وبهذا ينشَأ بُعد منفصل لكل فئة فريدة، مما يؤدي إلى الحصول على متجهات عالية الأبعاد ومتفرقة (Sparse Vectors) في حال زيادة عدد الفئات ومن الجدير بالذكر أن هذه الطريقة لا تظهر أي تشابه أو علاقة دلالية بين الفئات، إذ أن جميع المتجهات تكون متعامدة مع بعضها البعض، مما يعني أنه لا يمكن استنتاج أي علاقة بين الفئات اعتمادا على هذه التمثيلات لذلك تعتبر هذه التقنية ملائمة للمجموعات الصغيرة التي تحتوي على عدد محدود من الفئات فهي سهلة التطبيق وسريعة. ويمكنك الاطلاع من هنا على كيفية تطبيق One-Hot Encoding باستخدام مكتبة Sklearn: فبالرغم من أنه ينتج متجهات عالية الأبعاد لكنه لا يظهر أي علاقة بين الفئات في حين أنّ ال Embedding Layer يتعلم تمثيلا كثيفا ومنخفض الأبعاد إلا أنه يمكنه التقاط العلاقات الدلالية بين الفئات، مما يجعله أكثر كفاءة عند التعامل مع مجموعات بيانات كبيرة أو مفردات واسعة.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إن One-hot Encoding هو تمثيل رقمي للمتغيرات الفئوية حيث نقوم بتحويل كل فئة إلى متجه ثنائي (binary vector) بطول يساوي عدد الفئات حيث كل عنصر في المتجه يمثل فئة معينة وتكون القيمة 1 إذا كانت الفئة موجودة و 0 إذا كانت غير موجودة. وهو بسيط وسهل التطبيق و مناسب إذا كانت عدد الفئات صغيرة. ولكنه لا يعكس العلاقات بين الفئات مثل التشابه بين الفئات أى أنه لا يمكنك فهم معنى التحويل وسيتم فصل كل فئة عن الأخرى. أما Embedding Layer فهي طبقة في الشبكات العصبية تقوم بتحويل المتغيرات الفئوية إلى متجهات ذات أبعاد أقل حيث يتم تعلم هذه المتجهات أثناء التدريب مما يمكننا من تمثيل و إعطاء معنى للفئات. وأخيرا نستطيع أن نقومل أن One-hot Encoding هو بسيط ولكن غير جيد للفئات الكبيرة ولا يعكس العلاقات بينها ولهذا إذا كان لديك فئات كبيرة و تريد فهم العلاقات بينها فهذا ليس مناسبا. أما Embedding Layer فهو معقد أكثر من One-hot Encoding ولكنه أكثر كفاءة في الفئات الكبيرة ويعكس العلاقات بينها مما يجعله مناسبا للتطبيقات المعقدة مثل معالجة اللغة الطبيعية (NLP).1 نقطة
-
و عليكم السلام، كلاهما عبارة عن طريقة لتمثيل الكلمات بشكل رقمي. الطريقة الأولى فقط تقوم بتحويل الكلمات إلى أرقام بدون أي معنى، أي أنها تقوم باعتبار أن كل كلمة مستقلة عن غيرها بشكل كامل، لذلك يتم تمثيلها على شكل 1 في الدليل الخاص بالكلمة و 0 في كل مكان آخر. الطريقة الثانية تعتبر أن الكلمات لها معاني، و بالتالي يمكن تمثيلها حسب المعاني التي تحملها، لذلك تقوم بإنشاء فضاء أشعة كل بعد فيه يمثل معنى ما، و بذلك يتم تمثيل الكلمات كأشعة ضمن هذا الفضاء بحيث قيمة هذا الشعاع عند كل بعد هو مدى علاقة هذه الكلمة بذلك البعد. مثلًا لنفترض أن الفضاء يحوي على بعدين أحدهما يمثل الجنس (ذكر و أنثى، مثلًا الذكر بالاتجاه الموجب و الأنثى بالسالب)، بعد آخر يمثل العمر، بعد آخر يمثل المكانة المجتمعية (مثلًا مواطن عادي، أو رئيس) الخ.. بتلك الحالة يمكن تمثيل كلمة "ملك" على أن لها قيمة موجبة في بعد الجنس و قيمة موجبة كبيرة في بعد المكانة الاجتماعية، و قيمة موجبة كبيرة نوعًا ما في بعد العمر (فالملك غالبًا لا يكون عمره صغير). هذا مثال بسيط جدًا، بالطبع هذه الأبعاد يتم تعلمها بشكل تلقائي و لكن يمكن فهم ما تمثله عن طريق رؤية تمثيل العديد من الكلمات بعد القيام بتدريب النموذج. بالطبع عليك استعمال Embedding Layer، فهي الطريقة المعتمدة حاليًا. تحياتي.1 نقطة