لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 03/10/25 في كل الموقع
-
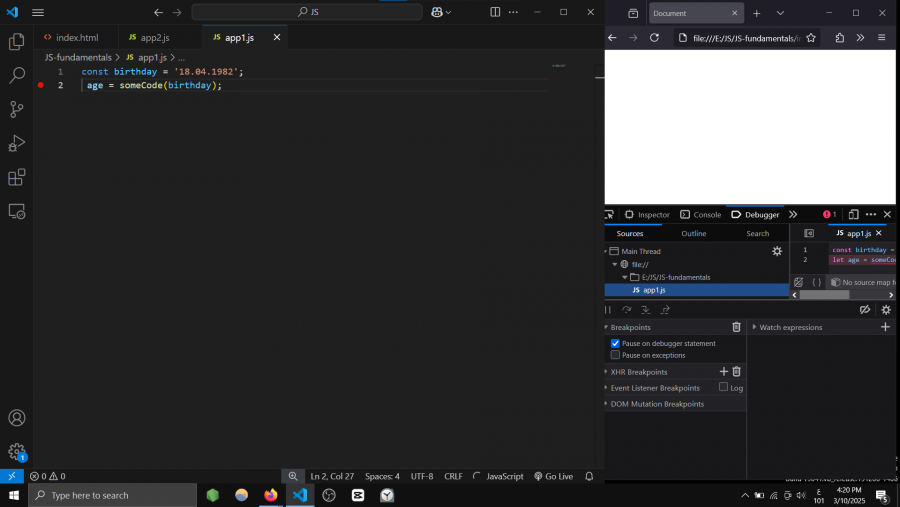
سلام عليكم. ما عمل الداله someCode() في جافاسكربت. جربت كتابه البرنامج التالي أنا مقتبسه من كتاب لجافاسكربت, لكن يظهر لي خطأ. ما هذا الخطأ
 5 نقاط
5 نقاط -
السلام عليكم هو ممكن النموذج يتدريب علي نوعين من الملفات التدريب مش ملف واحد وهل اقدر اعمل كده في الmachine learning , deep learning ؟3 نقاط
-
هل يمكن للطالب تقسيط مبلغ الدورة؟3 نقاط
-
السلام عليكم يوجد في الملف ده 123 عمود و 2515 صف والم يظهر شي في النتجيه ده الكود print(validation_labels.info()) ودي النتجيه <class 'pandas.core.frame.DataFrame'> RangeIndex: 2515 entries, 0 to 2514 Columns: 123 entries, ID to z_40 dtypes: float64(120), int64(1), object(2) memory usage: 2.4+ MB None2 نقاط
-
ايوه بس الازم الاول يتحول الملف ده الي الارقام صح كده يعني ملف النصوص او الصور الو الصوت الازم الاول يتحول اي ارقام1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. نعم، يمكن تدريب النماذج في Machine Learning و Deep Learning على أكثر من نوع من الملفات أو مصادر البيانات. حيث يمكنك تدريب النموذج على بيانات من مصادر مختلفة مثل: نصوص Text من ملفات .txt أو .csv. صور Images من ملفات .jpg أو .png. صوت Audio من ملفات .wav أو .mp3. فيديو Video من ملفات .mp4. إذا كنت تقصد بنوعين أى ملفين أو عدة ملفات ولكنها تحوي نفس شكل البيانات مثل ملفات نصية فقط أو صور فقط أو فيديوهات فقط . فنعم إذا كان كذلك فالأمر بسيط يمكنك دمج البيانات من الملفات المختلفة في ملف واحد باستخدام تقنيات معالجة البيانات مثل الدمج (merge) أو التوحيد (concatenation). وفي حالة البيانات النصية يمكنك دمجها باستخدام أدوات مثل Pandas أما في حالة الصور أو البيانات الصوتية يمكنك استخدام أدوات مختلفة مثل OpenCV قبل دمجها في مجموعة بيانات واحدة. أما إذا كنت تقصد أنواع مختلفة من البيانات مثل إذا كان لديك ملفات نصية وصور فحينها يمكنك بناء نموذج تعلم عميق بعدة طبقات وكل طبقة لها نوع بيانات مدخل خاص .حيث يمر المدخل النصي عبر شبكة عصبية مخصصة لمعالجة النصوص مثل LSTM أو Transformer أما الصور باستخدام شبكة عصبيةCNN.1 نقطة
-
في حال فهمي لسؤالك بشكل صحيح، فلا مشكلة في تدريب نموذج تعلم آلي أو تعلم عميق باستخدام أنواع مختلفة من البيانات التدريبية بدلاً من الاعتماد على نوع واحد فقط، وذلك النهج يُعرف باسم التدريب متعدد الوسائط Multi-modal Learning، وهو يتيح للنموذج استيعاب ومعالجة أكثر من نوع من البيانات في وقت واحد، مثل الصور والنصوص، أو البيانات الجدولية والنصوص، أو حتى مزيج من الصوت والفيديو والنصوص. بيحث يتم تصميم النموذج للتعامل مع الخصائص الفريدة لكل نوع من البيانات، فالصور مثلاً للصور نستخدم شبكات عصبية تلافيفية CNNs لاستخلاص الميزات. و للنصوص شبكات عصبية متكررة RNNs أو نماذج مثل المحولات Transformers، أما للبيانات الجدولية نستخدم شبكات عصبية تقليدية أو طبقات مخصصة لمعالجة الأرقام والعلاقات. بعد ذلك، دمج مخرجات تلك الشبكات المتخصصة في طبقة مشتركة داخل النموذج، واستخدامها لتعلم تمثيلات مشتركة تجمع بين المعلومات من الأنواع المختلفة للبيانات، الأمر الذي يتيح للنموذج أداء مهام مثل التصنيف، التنبؤ، أو حتى توليد البيانات كإنشاء صور من نصوص.1 نقطة
-
بشكل افتراضي pandas تقوم بتلخيص العرض ولا تقوم بعرض كل الأعمدة إذا كان عددها كبيرا كما لديك هنا 123 عمود.و لحل هذه المشكلة يمكنك تغيير إعدادات العرض في pandas لجعله يعرض جميع الأعمدة. import pandas as pd pd.set_option('display.max_columns', None) print(validation_labels.info()) pd.set_option('display.max_columns', None) هذا السطر يغير إعدادات pandas لجعلها تعرض كل الأعمدة بدلا من تلخيصها.1 نقطة
-
الا انا اقصد ان معرضش زي كده <class 'pandas.core.frame.DataFrame'> RangeIndex: 12 entries, 0 to 11 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 target_id 12 non-null object 1 sequence 12 non-null object 2 temporal_cutoff 12 non-null object 3 description 12 non-null object 4 all_sequences 12 non-null object dtypes: object(5) memory usage: 608.0+ bytes None انا عاوز النتجيه تكون زي كده يعرض ال123 عمود ؟1 نقطة
-
وعليكم السلام ورحمة الله وبركاته . الكود الذي استخدمته صحيح ولا توجد به مشكلة ولاحظ أنه يعرض معلومات عامة عن DataFrame المسمى validation_labels لديك من خلال الدالة info() والنتيجة التي حصلت عليها توضح أن DataFrame يحتوي على 2515 صفًا و123 عمودًا وأنواع البيانات للأعمدة هي float64، int64، وobject. كما أن الذاكرة المستخدمة لتخزين البيانات هي حوالي 2.4 ميجابايت. إذا كنت تتوقع رؤية بيانات فعلية فهذا لن يحدث لأن الدالة info() لا تعرض البيانات الفعلية بل تعرض فقط معلومات وصفية عن DataFrame.1 نقطة
-
ميثود info() في pandas لا تعرض البيانات الفعلية داخل DataFrame، بل تعرض معلومات وصفية عنه، بالتالي يظهر عدد الصفوف وعدد الأعمدة، أسماء الأعمدة وأنواع البيانات dtypes واستخدام الذاكرة. وميثود info() نفسها تطبع المعلومات مباشرةً ولا تُرجع قيمة أي تعود بـ None وذلك طبيعي. لعرض البيانات عليك كتابة validation_labels.head() لعرض أول 5 صفوف، أو validation_labels.tail() لعرض آخر 5 صفوف، أو print(validation_labels) لعرض كل البيانات وذلك غير عملي للبيانات الكبيرة، فتجنبه.1 نقطة
-
ما فهمته هو أنك تريد أن يتساوى الشركاء الآخرين في الأموال المسحوبة، الشريك الأول 43.75% سحب 1,000,000 وليكن ريال مثلاً، بما أن الشريك الثاني يملك نفس النسبة 43.75%، فيجب أن يسحب نفس المبلغ 1,000,000 ريال. بالتالي الشريك الثاني يجب أن يسحب 100,000 ريال إضافية. أما الشريك الثالث يجب أن يسحب 211,714.29 ريال إضافية، وذلك بناءًا على حساب نسبته 12.5% بالنسبة إلى نسبة الشركاء الآخرين: 12.5 / 43.75 * 1,000,000 = 285,714.29 ولو طرحنا 74,000 من 285,714.29 سنحصل على 211,714.291 نقطة
-
سلام عليكم لدينا معمل ل 3 شركاء الشريك الاول بنسبة 43.75 والثاني بنسبة 43.75 والثالث بنسبة 12.5 وخلال مدة سنة .الشريك الاول سحب من المعمل اموالا بقيمة 1000.000 والثاني بقيمة 900.000 والثالث بقيمة 74000 السؤال .الشريك الثاني و الثالث كم يجب عليهم ان يسحبو اموال من المعمل1 نقطة
-
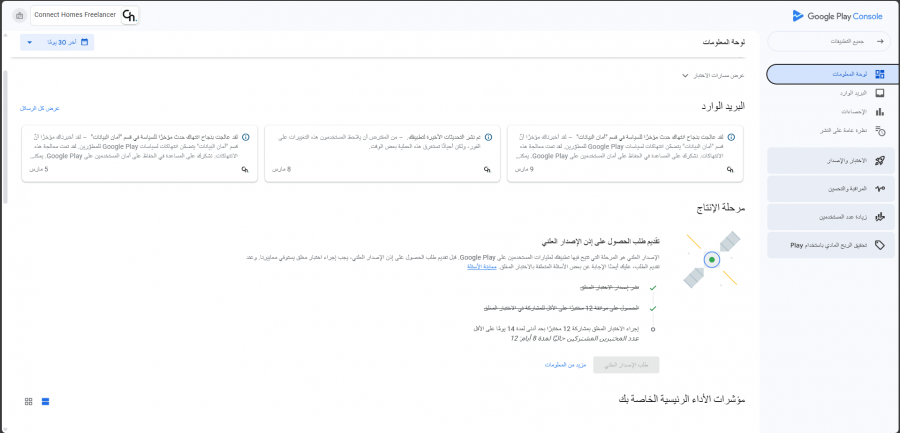
السلام عليكم كنت أعمل على تطبيق هاتف بإستخدام react native with expo ، وحاليا في مرحلة النشر و هذه المرة الأولى التي ارفع فيها تطبيق على جوجل بلاي. لقد اتبعت جميع الخطوات و حللت جميع المشاكل و حاليا في مرحلة الإختبار المغلق ولا أعلم ما هي الخطوة التالية
 1 نقطة
1 نقطة -
ذلك تحديث جديد بالفعل لم يكن موجود من قبل وهو خاص بالحسابات الجديدة بعد تاريخ 13 نوفمبر 2023، حاليًا أنت في مرحلة الاختبار المُغلق وذلك قبل إطلاقه للجمهور العام على متجر Google Play، ويتعين عليك اختيار مجموعة محددة من المختبرين testers وعددهم 20 بأجهزة مختلفة ليجربوا تطبيقك قبل أي شخص آخر لمدة 14 يوم بمعنى التطبيق يظل على الهاتف لمدة 14 يوم، وهم فقط من يمكنهم الوصول إلى تطبيقك وتنزيله من متجر Play خلال فترة الاختبار المغلق. قم بالرجوع للوحة الرئيسية بالضغط على جميع التطبيقات أعلى اليمين ثم اختر التطبيق الخاص بك، ثم انزل للأسفل وستجد قسم باسم الإختبار الداخلي، اضغط به على اختيار المختبرين ثم اختر مجموعات google. الآن توجه للتالي: https://groups.google.com/ ثم قم بالضغط على إنشاء مجموعة، واكتب أي اسم للمجموعة، ثم تحديد خصوصية المجموعة إلى أي مستخدم على الويب ويمكن للجميع طلب الإنضمام، وستحتاج على الأقل لإضافة عضو واحد للإنشاء، قم بإضافة نفسك بها من خلال كتابة أي بريد آخر تمتلكه، ثم عليك تفعيل خيار إضافة أعضاء مباشرةً. ثم اضغط على إنشاء المجموعة، وبعدها ستقوم بمشاركة المجموعة على جروب مثلاً لينضم إليها أشخاص ويختبروا التطبيق، أو إضافة أشخاص إليها عبر البريد. ثم أضف رابط المجموعة في google play console ليتم إضافة الأشخاص الموجودين داخلها، حاول العثور على مجموعة خاصة بالإختبار على فيسبوك أو تيليجرام، أو قم بتجربة تطبيق Testers Community - 12 Testers على جوجل بلاي. الأمر يطول شرحه، لذا ابحث على اليوتيوب عن "Google Play Console إجراء الإختبار المُغلق" وستجد شرح مُفصل عمليًا.1 نقطة
-
كيف اعرف اخر مقطع تابعته عشان اكمل منه1 نقطة
-
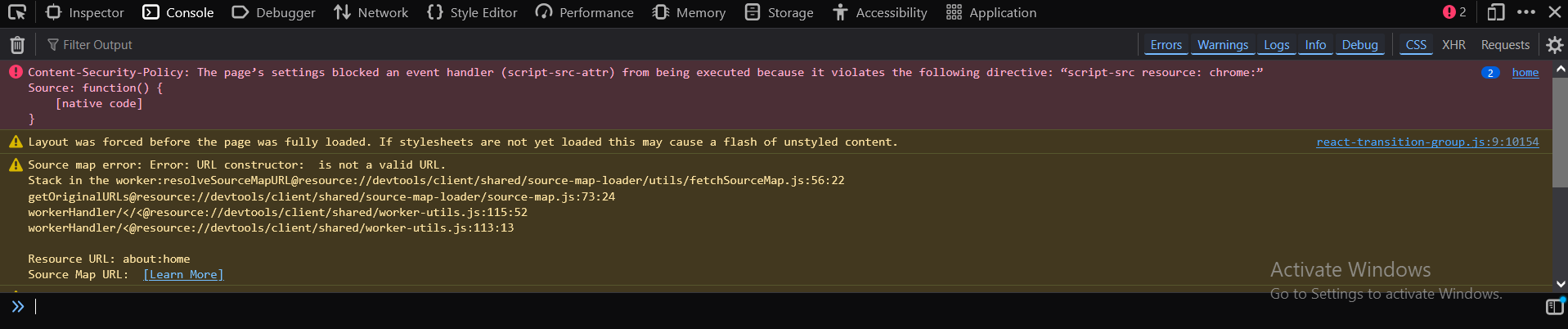
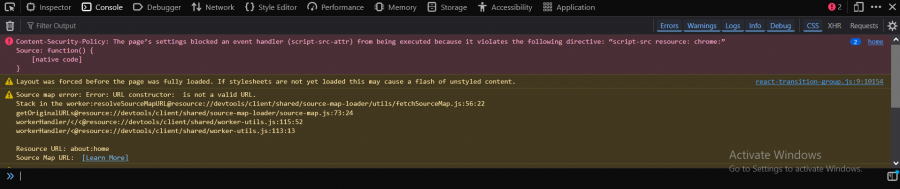
سلام عليكم. أنا أستخدم محرك FireFox. في كتاب الجافا سكربت الصفحه 55 طلب مني أن أفتح المتصفح ثم الضغط علي F12 لفتح الconsole. عندما فتحت المتصفح عندي وجدت رساله الخطأ هذه. كما أن هذه الرسائل تختلف من موقع لاخر. و ما الفرق بين صفحه البحث و محرك البحث. و لما يعمل متصفح بمحرك بحث اخر مثلا يعمل firefox عندي بمحرك بحث microsoftedge. و ذكر الكتاب أن شفره جافاسكربت يمكن أن تعمل خارج المتصفح -علي محرك جافاسكربت- مثل العمل علي الخادم, ما هو الخادم؟ و ما هي الECMAscript و الECMA-262. و ما هي الTranspilation التي تحول لجافاسكربت. و ما هي اللغات التوصيفيه (markup languages). و السلام عليكم.
 1 نقطة
1 نقطة -
ذلك خطأ يظهر من المتصفح نفسه وليس بسبب الكود لديك ربما بسبب إضافة في المتصفح أو ما شابه، حيث script-src resource: chrome هو التوجيه المحدد داخل سياسة CSP ويحدد مصادر النصوص المسموح بها، ويسمح فقط بالنصوص التي تأتي من المصادر التي تبدأ بـ resource: chrome ويعني موارد داخلية للمتصفح نفسه أو ملحقات المتصفح. والرسائل تختلف من موقع لآخر حسب الكود الخاص بالموقع، فالكونسول في المتصفح يعكس حالة الكود والأداء والتكوين للموقع الذي تتصفحه حاليًا، ومن الطبيعي جدًا أن ترى رسائل مختلفة عند زيارة مواقع مختلفة. محرك البحث يسمى Search Engine وهو النظام الأساسي أو التكنولوجيا التي تعمل في الخلفية وتقوم بالعمل الحقيقي للبحث، وفي الأساس بشكل مُختصر هو عبارة عن خوارزميات. ويقوم بما يلي: زحف الويب Web Crawling لتصفح الإنترنت بشكل مستمر وفهرسة صفحات الويب. فهرسة المحتوى لتنظيم المعلومات التي تم جمعها من صفحات الويب بطريقة تسمح بالبحث السريع والفعال. معالجة الاستعلامات لتحليل طلبات البحث التي يدخلها المستخدمون. ترتيب النتائج لتحديد أفضل النتائج ذات الصلة بطلب البحث وترتيبها حسب الأهمية. وأمثلة محركات البحث كثيرة منها Google Search، Bing، DuckDuckGo، Yahoo Search، Baidu. أما صفحة البحث Search Page هي واجهة المستخدم التي تراها في متصفح الويب عندما تستخدم محرك بحث، وتسمح لك بإدخال استعلام البحث وهو المربع الذي تكتب فيه الكلمات التي تريد البحث عنها، وتعرض نتائج البحث من خلال قائمة الروابط والملخصات التي يعرضها محرك البحث استجابة لاستعلامك. أما بخصوص محرك البحث الموجود في المتصفح فتستطيع تعيين أي محرك بحث تريد من خلال إعدادات المتصفح. الخادم هو جهاز كمبيوتر أو نظام برمجي مصمم لتقديم خدمات أو موارد لأجهزة كمبيوتر أخرى تُعرف باسم العملاء Client، وفي الويب، الخادم هو المسؤول عن استضافة مواقع الإنترنت وإرسال صفحات الويب إلى المتصفحات عندما يطلبها المستخدم. والمقصود بأن شفرة جافاسكريبت يمكن أن تعمل خارج المتصفح، مثل العمل على الخادم، هو استخدامها كلغة واجهة خلفية back-end من أجل العمل خارج بيئة المتصفح نوعًا ما من خلال بيئة تشغيل runtime، وذلك يتيح استخدام جافاسكريبت لكتابة تطبيقات تعمل على الخادم، مثل إدارة قواعد البيانات أو معالجة الطلبات. وبيئة التشغيل الأشهر هي Node.js، وهي بيئة تشغيل تمكنك من تشغيل شفرة جافاسكريبت على الخادم وهي مبنية على محرك جافاسكريبت Chrome V8 الخاص بمتصفح جوجل كروم، وبفضلها أصبح بإمكان المبرمجين استخدام جافاسكريبت على كل من الخادم والعميل. ستحتاج إلى تفصيل أكثر، ستجده هنا: و ECMAScript هي مواصفة أو معيار للغة برمجة تم تطويرها بواسطة منظمة ECMA International، وهي هيئة تضع معايير لتقنيات المعلومات، حيث جافاسكريبت هي إحدى اللغات التي تطبق تلك المواصفة، وECMAScript تحدد القواعد والميزات التي يجب أن تكون موجودة في اللغة، وجافاسكريبت هي تطبيق عملي لتلك القواعد. أما ECMA-262 هو الاسم الرسمي لوثيقة المواصفة التي تصف بالتفصيل كيف يجب أن تعمل ECMAScript، وتُحدث الوثيقة باستمرار، وكل إصدار جديد يضيف ميزات جديدة للغة. بينما مفهوم Transpilation يعني عملية تحويل شفرة برمجية مكتوبة بلغة معينة إلى شفرة بلغة أخرى، أو تحويل إصدار حديث من كود لغة معينة إلى إصدار أقدم ليعمل على البرامج القديمة، بالتالي في جافاسكريبت ما يتم هو تحويل الشفرة من إصدار حديث من ECMAScript مثل ES6 أو أحدث إلى إصدار أقدم مثل ES5، فبعض المتصفحات القديمة لا تدعم الميزات الحديثة لجافاسكريبت، لذا نحتاج إلى تحويل الشفرة لتكون متوافقة مع تلك المتصفحات. واللغات التوصيفية Markup Languages هي لغات لتنسيق النصوص والبيانات بطريقة يمكن لأجهزة الكمبيوتر فهمها وعرضها، وتعتمد على علامات Tags أو عناصر element لتحديد كيفية تنظيم المحتوى أو عرضه، ومنها HTML (HyperText Markup Language) وهي اللغة الأساسية لإنشاء صفحات الويب، وستجد بها عنصار مثل <p> للفقرات و <h1> للعناوين. لديك أيضًا Markdown وهي لغة بسيطة لكتابة النصوص ويمكن تحويلها إلى HTML.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إن الفرق بين Multi-task Learning و Transfer Learning يكمن في كيفية استخدام المعلومات تم إستخلاصها من البيانات في تعلم النماذج و الإثنين موجودان الفعل في مجال Machine Learning، ولكنهما يختلفان في الأهداف والطرق. Multi-task Learning : يهدف إلى تعلم عدة مهام مرتبطة معا في نفس الوقت باستخدام نموذج واحد. تم مشاركة المعرفة المكتسبة بين المهام لتحسين الأداء العام خيث يتعلم النموذج من الممعلومات مشتركة تفيد في جميع المهام. Transfer Learning يهدف إلى استخدام المعرفة المكتسبة من مهمة أو مجال معين لتحسين الأداء في مهمة أو مجال آخر . حيث يتم تدريب النموذج على مهمة أساسية (source task) ومن ثم يتم نقل المعرفة المكتسبة إلى مهمة جديدة (target task) عن طريق إعادة استخدام الأوزان أو التمثيلات. وهو مفيد عندما تكون البيانات في المهمة الجديدة قليلة حيث يمكن الاستفادة من المعرفة المكتسبة مسبقا من البيانات السابقة.1 نقطة