لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 02/06/25 في كل الموقع
-
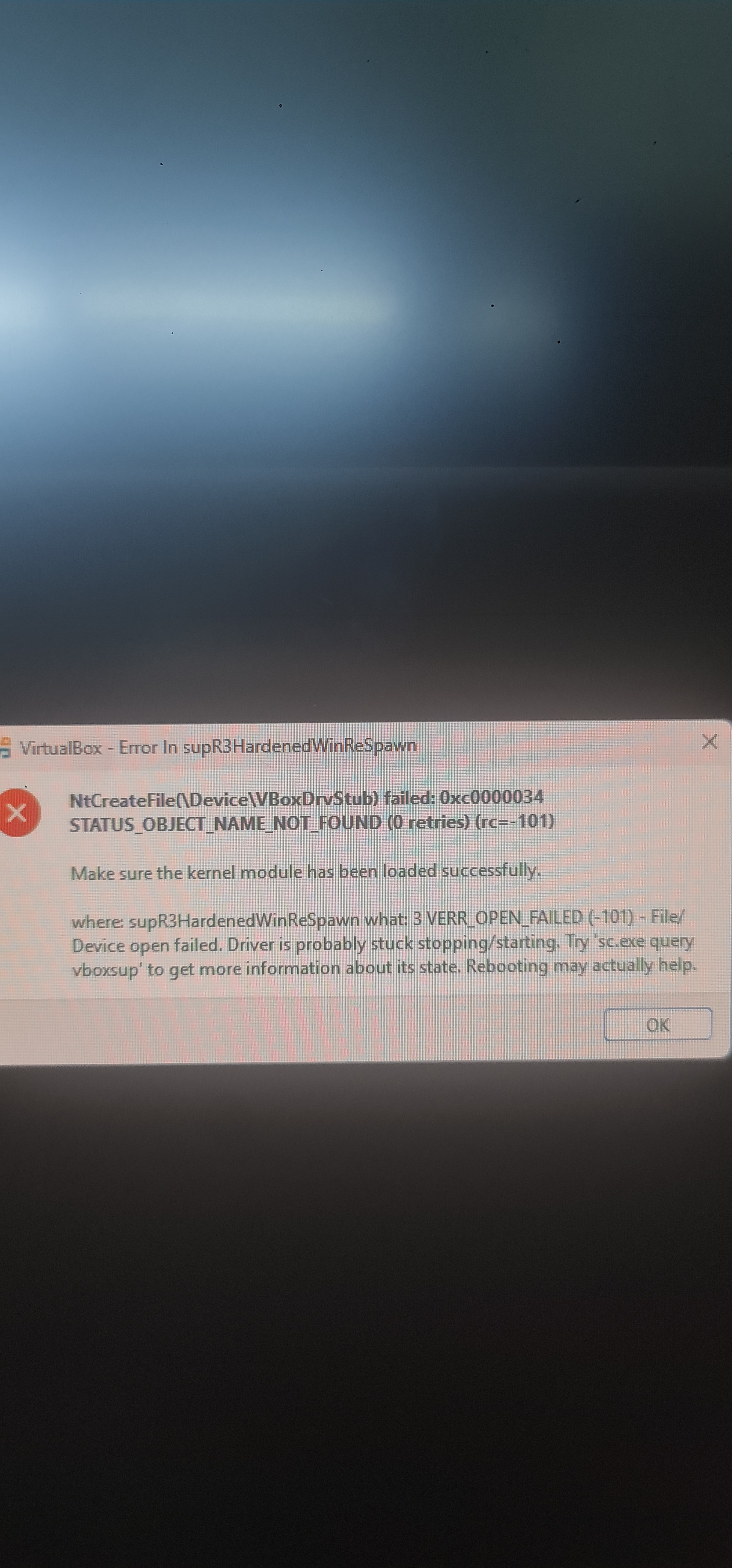
دلوقتي في اول كود في محتوى تعليم البايثون المفروض علشان يشتغل يكون في قائمة run انا ما عندي دي القائمة اشتغل على نظام macOS واحدث اصدار للبايثون2 نقاط
-
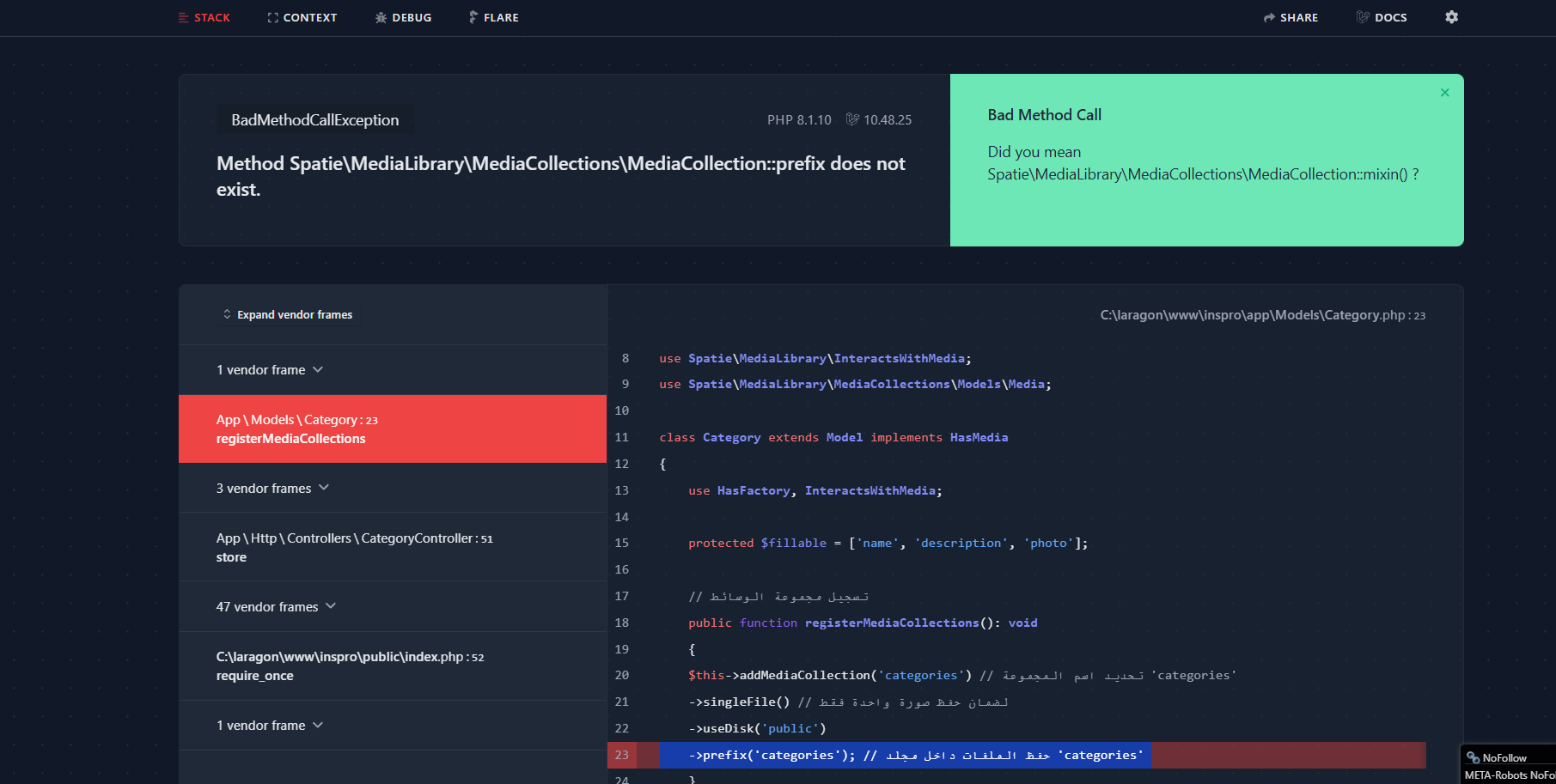
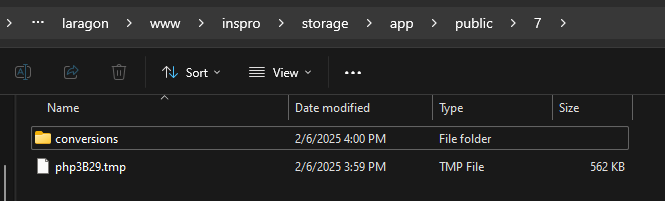
اقوم باستخدام هذه المكتبة لحفظ الصور ولجعلها تتحول تلقائيا لنسختين webp , avif ولكن هناك مشكلة ان الصور يتم حفظها مباشرة في المجلد Public يتم انشاء ملف باسم الid ويتم الحفظ بداخله النسخة الاساسية ومجلد به النسختين المحولتين كالصورة الموضحة ادناه على الرغم من انه يجب حفظهن داخل المسار التالي : C:\laragon\www\inspro\storage\app\public\categories ولكنه فارغ لا يتم حفظ شيء بداخله هذا الكود الذي استخدمه في الموديل <?php namespace App\Models; use Illuminate\Database\Eloquent\Factories\HasFactory; use Illuminate\Database\Eloquent\Model; use Spatie\MediaLibrary\HasMedia; use Spatie\MediaLibrary\InteractsWithMedia; use Spatie\MediaLibrary\MediaCollections\Models\Media; class Category extends Model implements HasMedia { use HasFactory, InteractsWithMedia; protected $fillable = ['name', 'description', 'photo']; // تسجيل مجموعة الوسائط public function registerMediaCollections(): void { $this->addMediaCollection('categories') // تحديد اسم المجموعة 'categories' ->singleFile(); // لضمان حفظ صورة واحدة فقط } // تسجيل التحويلات public function registerMediaConversions(Media $media = null): void { $this->addMediaConversion('webp') ->format('webp') ->quality(90) ->performOnCollections('categories'); $this->addMediaConversion('avif') ->format('avif') ->quality(90) ->performOnCollections('categories'); } // علاقة مع النموذج الفرعي SubCategory public function subCategories() { return $this->hasMany(SubCategory::class); } } وهذا التابع store داخل الكونترولر public function store(Request $request) { $validatedData = $request->validate([ 'name' => 'required|string|max:255', 'description' => 'nullable|string', 'photo' => 'nullable|image|mimes:jpg,png,jpeg|max:2048', ]); // إنشاء الفئة في قاعدة البيانات $category = Category::create([ 'name' => $validatedData['name'], 'description' => $validatedData['description'] ?? null, ]); // التحقق مما إذا كان هناك صورة مرفوعة // رفع الصورة إلى Media Library if ($request->hasFile('photo')) { $pathToFile = $request->file('photo')->getPathname(); // الحصول على المسار الفعلي للصورة $category->addMedia($pathToFile)->toMediaCollection('categories'); // إضافة الصورة إلى Media Collection } // إعادة التوجيه مع رسالة نجاح return redirect()->route('categories.index')->with('success', 'Category created successfully!'); }
 2 نقاط
2 نقاط -
السلام عليكم هل يوجد شرح الDeepHIt بستخدم الTesnorFlow علي Github زي الPyTroch ؟2 نقاط
-
السلام عليكم هو لو استخدمات الOne-Hot Encoding في الكود ده بدل OrdinalEnocder عادي لو هيحصل مشكله في قيمه الNULL ؟ ده الكود def ordinalencoder_data(data): # Select the categorical columns (object type) from the dataframe categorical_cols = data.select_dtypes(include=['object']).columns # Create a mask to identify missing values (NaN) in the categorical columns mask = data[categorical_cols].isna() # Fill missing values with the string 'missing' to ensure no NaN values before encoding temp_data = data[categorical_cols].fillna('missing') # Initialize the OrdinalEncoder, which will convert categorical values to numerical labels oe = OrdinalEncoder() # Fit the encoder to the data and transform the categorical columns into numerical labels encoded_data = oe.fit_transform(temp_data) # Convert the encoded data to a DataFrame, keeping the original column names and specifying the dtype as 'Int64' encoded_series = pd.DataFrame(encoded_data, columns=categorical_cols, dtype='Int64') # Restore the missing values (NaN) in the original positions, using pd.NA to indicate missing values encoded_series[mask] = pd.NA # Update the original dataframe with the encoded columns while preserving the missing value positions data[categorical_cols] = encoded_series return data2 نقاط
-
@Mustafa Suleiman ظهر هذا الخطأ عند محاولة ارسال البيانات Method Spatie\MediaLibrary\MediaCollections\MediaCollection::storedIn does not exist. ويتم تحديد ان الخطأ بهذه السطر ->storedIn('categories'); // تحديد المجلد داخل القرص @محمد عاطف17 انه هكذا الضبط داخل الfilesystem لم اقم بتغيير اي شيء هذه الاعدادات الافتراضية 'disks' => [ 'local' => [ 'driver' => 'local', 'root' => storage_path('app'), 'throw' => false, ], 'public' => [ 'driver' => 'local', 'root' => storage_path('app/public'), 'url' => env('APP_URL').'/storage', 'visibility' => 'public', 'throw' => false, ], وقمت باستخدام الكود الذي اعطيتني اياهومازالت ذات المشكلة يحفظهن بالخارج2 نقاط
-
السلام عليكم هو عشان استخدم ال PyTorch لبناء نموذج الازم يكون نوع البيانات float ؟2 نقاط
-
السلام عليكم عندي استفسار ايه الفرق بين طبيقات الويب و المواقع الالكترونيه او ايه الفرق بين مشروع شغال عليه ب دجانجو و مشروع اشتغل عليه ب جافا سكريبت و html css والمكتبات الخاصه بهم1 نقطة
-
السلام عليكم هو انا ازي اقدر استخدم الEmbeddings بستخدم torch ؟1 نقطة
-
طيب ازي اقدر احديد دول بشكل دقيق ؟ انا عندي بيانات فئوي فا عاوز استخدم التقنيه دي عشان النموذج يتدريب بشكل صحيح ؟ فا انا هتسخدم الكلام ده في الميزات هل الازم كمان اعملو في الY ؟1 نقطة
-
@محمد عاطف17
 1 نقطة
1 نقطة -
للتوضيح ببساطة، الـ Embeddings طريقة لتمثيل الكائنات مثل الكلمات، أو العناصر، إلخ، كمتجهات ذات أبعاد منخفضة في فضاء رياضي، الفكرة أننا نريد تمثيل الكائنات بطريقة تصبح بها الكائنات المتشابهة قريبة من بعضها في ذلك الفضاء، والكائنات المختلفة تكون بعيدة. PyTorch توفر طبقة جاهزة torch.nn.Embedding لتنفيذ الـ Embeddings بسهولة. import torch.nn as nn import torch بعد ذلك، إنشاء طبقة الـ Embedding باستخدام الدالة البانية nn.Embedding()، والتي تتطلب مُدخلين رئيسيين: num_embeddings: عدد الـ Embeddings المراد إنشاؤها يمثل حجم المعجم لديك بمعنى عدد الكلمات الفريدة أو عدد العناصر الفريدة. embedding_dim: أبعاد كل Embedding، أي طول المتجه الذي سيمثل كل كائن. للتبسيط لو لديك معجم يحتوي على 10000 كلمة وترغب في تمثيل كل كلمة بمتجه ذي 100 بُعد، نكتب: embedding_layer = nn.Embedding(num_embeddings=10000, embedding_dim=100) ولاستخدامها يجب تمرير مؤشرات indices الكائنات التي تريد الحصول على الـ Embedding الخاصة بها، وتلك المؤشرات عبارة عن موتر Tensor من الأعداد الصحيحة. indices = torch.tensor([5, 100, 500]) embeddings = embedding_layer(indices) print(embeddings.shape) print(embeddings) من الأفضل استخدام Pre-trained Embeddings وهي مدربة مسبقًا مثل Word2Vec أو GloVe أو FastText، فهي تعلمت على كميات هائلة من النصوص، وتعتبر نقطة بداية جيدة للتدريب، خاصة لو كمية البيانات المتوفرة لديك محدودة.1 نقطة
-
لا يوجد إصدار رسمي لـ DeepHit في TensorFlow من قِبل المصدر الرسمي، لكن يوجد محاولات من المطورين لإعادة تنفيذ النموذج باستخدام TensorFlow. ستجد تطبيق لذلك هنا: https://github.com/Actis92/DeepHitTF2 https://github.com/carlr67/deephitplus ومن الأفضل استخدام مكتبات مساعدة مثل tensorflow-survival أو tf-keras لتبسيط تنفيذ نماذج Survival Analysis. https://github.com/tensorflow/addons/tree/master/tensorflow_addons/losses1 نقطة
-
يتم حفظهن في المجلد public مباشرة مثلا ضفت صنف جديد وكان رقمه 6 يتم حفظ الصورة الاساسية في المسار التالي C:\laragon\www\inspro\storage\app\public\6 والصور المعدلة في المسار التالي C:\laragon\www\inspro\storage\app\public\6\conversions بينما من المفروض ان يتم حفظهن في المسار التالي C:\laragon\www\inspro\storage\app\public\categories1 نقطة
-
سيؤدي إلى مشاكل كبيرة مع القيم الفارغة NULL/NaN في حال لم يتم التعامل معها بحذر، لديك استخدمت OrdinalEncoder الذي يحوِّل كل عمود فئوي إلى عمود واحد عددي مع الحفاظ على هيكل الأعمدة، وذلك يسمح باستخدام نفس الـ mask لاستعادة القيم الفارغة بعد التشفير. لكن من خلال One-Hot Encoding كـ OneHotEncoder من sklearn، يتم إنشاء أعمدة جديدة لكل فئة، الأمر الذي يغير هيكل البيانات بالكامل، ويجعل تطبيق الـ mask الأصلي الذي يعتمد على عدد الأعمدة القديمة مستحيلًا. بعد التشفير بـ One-Hot، ستنشئ أعمدة جديدة لكل فئة كعمود لون به ٣ فئات سيصبح ٣ أعمدة. والـ mask الأصلي يعتمد على عدد الأعمدة القديمة، ولن يتطابق مع عدد الأعمدة الجديدة، ويؤدي إلى أخطاء. وحتى لو تم تعبئة القيم الفارغة بـ missing قبل التشفير، فإن One-Hot سينشئ عمودًا جديدًا لتلك القيمة، وعند محاولة استعادة القيم الفارغة باستخدام encoded_series[mask] = pd.NA، ستكون العملية غير منطقية لأن الأعمدة الجديدة لا تتوافق مع الـ mask. بالتالي عليك التعامل مع القيم الفارغة كفئة مستقلة، بمعنى املأ القيم الفارغة بـ missing قبل التشفير كما تفعل حاليًا. ثم استخدم OneHotEncoder مع تحديد المعلمة handle_unknown='ignore' وستعتبر missing فئة عادية، ولن تحتاج إلى استعادة القيم الفارغة بعد التشفير. from sklearn.preprocessing import OneHotEncoder def onehotencoder_data(data): categorical_cols = data.select_dtypes(include=['object']).columns temp_data = data[categorical_cols].fillna('missing') ohe = OneHotEncoder(handle_unknown='ignore', sparse_output=False) encoded_data = ohe.fit_transform(temp_data) new_columns = ohe.get_feature_names_out(categorical_cols) encoded_df = pd.DataFrame(encoded_data, columns=new_columns, dtype='Int64') data = data.drop(columns=categorical_cols) data = pd.concat([data, encoded_df], axis=1) return data ثم احذف الصفوف التي تحتوي على قيم فارغة قبل التشفير، وذلك ربما يؤدي إلى فقدان بيانات مهمة، فتعامل بحذر، بمعنى القيم الفارغة يجب أن تُعالَج بشكل منفصل حسب البيانات، أقصد هل تعكس missing معلومة مهمة؟ ففي بعض البيانات هي مهمة وتمثل معلومة.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إذا قمت باستبدال OrdinalEncoder بـ One-Hot Encoding في الكود المرفق فستواجه مشكلة مع القيم المفقودة حيث الكود الحالي سقوم بتحديد الأعمدة الفئوية (categorical) في البيانات. ومن ثم يقوم بملئ القيم المفقودة في تلك الأعمدة بالقيمة 'missing' لكي لا تحدث مشكلة أثناء إستخدام OrdinalEncoder . بعد ذلك يقوم بإستعادة القيم المفقودة الأصلية مرة أخرى بعد إتمام ال OrdinalEncoder. أما عند إستخدام One-Hot Encoding فإنه يقوم بتحول كل فئة إلى عمود منفصل يحتوي على 1 أو 0 بحسب وجود الفئة. وإليك الفرق بين One-Hot Encoding و OrdinalEncoder : OrdinalEncoder: يقوم بتحويل القيم الفئوية إلى أرقام صحيحة فمثلا لو لدينا ["cat", "dog", "bird"] # سيتم تحويلها إلى [0,1,2] وهنا يمكنك بسهوله إمكانية إستبدال القيم المفقودة وإسترجاعها One-Hot Encoding: يحول القيم الفئوية إلى أعمدة منفصلة لكل فئة. فمثلا إذا كانت لدنيا فئة animal مثل المثال السابق : ["cat", "dog", "bird"] فسيتم تحويلها إلى ثلاثة أعمدة animal_cat و animal_dog و animal_bird حيث ستكون قيمة العمود ب1 إذا كانت الفئة موجودة و ب 0 إذا لم تكن موجودة. ولذلك فإنه إذا كانت هناك قيم مفقودة (NaN) في البيانات الأصلية فإن One-Hot Encoding سيحولها إلى عمود جديد مما قد يؤدي إلى زيادة كببيرة في عدد الأعمدة. ولذلك يوجد لديك بعض الحلول وهو إما إهمال البيانات المفقودة وعدم تضمينها أو يمكنك إضافة عمود خاص بالقيم المفقودة حيث يحتوي على 1 إذا كانت القيمة مفقودة و0 إذا لم تكن كذللك.1 نقطة
-
ستحتاج إلى معالجة البيانات الفئوية الاسمة مثل النوع الأول من السكر، من خلالOne-Hot Encoding. أو التمثيلات المضمنة Embeddings أفضل للبيانات الفئوية الاسمية أو الترتيبية في حال عدد الفئات كبيرًا، أو يوجد علاقات معقدة بين الفئات، أو في نماذج تسلسلية.1 نقطة
-
لا يٌشترط ذلك، لكن مُستحسن، خاصةً عند التعامل مع النماذج التي تتطلب حسابات رياضية دقيقة كالشبكات العصبونية. ففي معظم عمليات الشبكات العصبونية كالضرب المصفوفي، الاشتقاق التلقائي، مُصمَّمة للعمل مع أعداد float32 أو float16، حيث float16 يُقلل استخدام الذاكرة ويُسرّع الحسابات على GPUs الحديثة كتقنية Tensor Cores في بطاقات NVIDIA، لكنه يُؤثر على الدقّة. والنماذج تتعلم من خلال تحديث الأوزان باستخدام التدرجات gradients، والتي تكون من نوع float. PyTorch يدعم أنواعًا عديدة مثل int، long، double، إلخ، لكن لو أدخلت بيانات من نوع int إلى نموذج يتوقع float، ستحصل على خطأ: RuntimeError: expected scalar type Float but found Long بالتالي عند تحميل البيانات، حوّلها مباشرةً باستخدام .float(): import torch data = torch.tensor([1, 2, 3], dtype=torch.float32) وفي حال البيانات من نوع int في مصفوفة NumPy: import numpy as np numpy_array = np.array([1, 2, 3], dtype=np.float32) tensor = torch.from_numpy(numpy_array)1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. ليس تماما حيث لا يجب أن تكون جميع البيانات من نوع float عند استخدام PyTorch لبناء النماذج. ولكن بالغعل بعض النماذج تتوقع أن تكون بيانات الإدخال من نوع float وذلك لأنه بسبب العمليات الحسابية التي تجريها الطبقات المختلفة في النموذج تعمل بشكل أفضل مع الأعداد الحقيقية مما تعطيك دقة أفضل في الأداء. ولكن يمكنك إستخدم int في الأعمدة التي لا تتطلب حسابات رياضية مثل التسميات (labels) في مهام التصنيف.1 نقطة
-
السلام عليكم ورحمة الله وبركاته تواصلت مع الدعم الخاص بدورة من أجل استرجاع أموال الدورة لكن لم يتم الرد عليه1 نقطة
-
انا الان انهيت اول اربع مسارات من كورس انشاء التطبيقات بالبايثون هل استطيع عمل امتحان1 نقطة
-
هل توجهت للرابط التالي؟ http://localhost:8000/admin/auth/user/send-email/1 نقطة
-
لا توجد أى مشكلة هذا أمر طبيعي . فعند محاولة إغلاق الجهاز يقوم نظام التشغيل windows بإنهاء وإغلاق جميع البرامج التي تعمل حتي يقوم بإغلاق الجهاز . وإذا وجد برنامج يعمل في الخلفية يظهر لكي هذا التحذير وذلك حتي لا تفقدين أى عمل قبل حفظه . ولذلك إذا كان البرنامج مهما يرجى إلغاء إيقاف التشغيل والتأكد من حفظ العمل لديكي . أما إذا كان البرنامج ليس مهما يمكنكي الضغط على إيقاف التشغيل حتي يقوم الويندوز بإجبار البرامج للإغلاق .1 نقطة
-
لا مشكلة في ذلك، عند إغلاق نظام الويندوز يقوم بعمليات ممنهجة لحفظ البيانات قبل الإغلاق ويحذرك من وجود برنامج يعمل، في حال غير مهم بالنسبة لكِ تختارين shutdown أو المتابعة في عملية الإغلاق. في حال وجود برامج هامة قيد التشغيل، تأكدي من حفظ ما كنتي تعملين عليه ثم الإغلاق، حيث تستطيعي التراجع من خلال إختيار إلغاء الأمر، ولكن ذلك لا يحدث دائمًا فأحيانًأ يتم غلق النظام.1 نقطة