لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 02/02/25 في كل الموقع
-
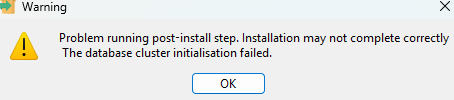
السلام عليكم انا اواجه هذه المشكلة اثناء تنزيل الpostgresql جربت انني اعيد تنزيلها بعد حزفها اكتر من مرى ولاكن بلا فائدة
 3 نقاط
3 نقاط -
انا مشتركة في دورة PHP لم استطع تحميل برنامج xampp عند ضغط تحميل لا يتحمل ، جربت تغير المتصفح ، مالعمل ؟ ارجوا المساعدة2 نقاط
-
السلام عليكم هو لو عندي قيمه من 0.0 الي 2.0 واستخدم الIterativeImputer طلع غير القيمه دي ولكن في نفس الفتره يعني مثل 0.1و 1.8 هل ده يكون طبيعه والا دي بيانات مش دقيق ؟ ودي البيانات قبل iterativelmputer hla_match_c_high 2.0 18565 1.0 5536 0.0 79 Name: count, dtype: int64 ودي بعد استخدم الIterativelmputer hla_match_c_high 2.0 18973 1.0 5566 1.6 1334 1.5 1042 1.7 547 1.8 418 1.4 239 1.3 206 1.2 149 0.0 86 1.9 75 1.1 68 0.9 28 0.8 20 0.7 16 0.4 8 0.1 7 0.5 6 0.2 5 0.3 4 0.6 3 Name: count, dtype: int642 نقاط
-
ممكن نصائح لو حابب اعمل متجر الالكتروني كبير باستخدام اطار العمل Django. يعني ايه الخطوات اللي امشي عليها عشان الموضوع يكون سهل ومنظم بالنسبالي2 نقاط
-
السلام عليكم ارجو توجيهي بـ IDE آخر لان هذا لم يناسبني ابداً وأِشعر بصعوبة في استخدامه اذا هناك امكانيه أبلغني بعد اذنك ي غالي2 نقاط
-
شكرا لك1 نقطة
-
IterativeImputer يعتمد على نماذج إحصائية كالانحدار الخطي أو أشجار القرار لتقدير القيم المفقودة، وتلك النماذج تُنتج توقعات مستمرة (أرقام عشرية)، حتى لو كانت البيانات الأصلية منفصلة أي أعداد صحيحة. بمعنى لو النموذج يتنبأ بقيمة بين 1 و2 (مثل 1.8)، فسيُدخلها كقيمة عشرية بدلًا من تقريبها إلى 2. والسلوك متوقع لأن IterativeImputer مصمم للتعامل مع البيانات العددية المستمرة بشكل افتراضي، لكن لو متغيرك يمثل فئات أو أعدادًا صحيحة (مثل عدد التطابقات الجينية)، فإن القيم العشرية لا معنى لها وذلك يعني مشكلة في النموذج أو طريقة التعامل مع البيانات. بالتالي لو المتغير يجب أن يكون عددًا صحيحًا، فالقيم العشرية غير منطقية وتشوّه تفسير البيانات. ولو المتغير يمثل درجة مستمرة، فتكون القيم مقبولة، لكن يُفضَّل التحقق من سياق البيانات فهي الأساس. أي تفقد هل المتغير يجب أن يكون، فئويًا/منفصلًا، كـ 0 = لا يوجد تطابق، 1 = تطابق جزئي، 2 = تطابق كامل. أو عدديًا مستمرًا مثل نسبة التطابق الدقيقة. في الحالة الأولى استخدم SimpleImputer مع إستراتيجية most_frequent (إدخال المنوال) بدلًا من IterativeImputer. في الثانية استخدم IterativeImputer ثم قَرِّب النتائج إلى أقرب عدد صحيح: from sklearn.impute import IterativeImputer import numpy as np imputer = IterativeImputer() data_imputed = imputer.fit_transform(data) data_imputed = np.round(data_imputed).astype(int)1 نقطة
-
نعم هذه النتيجة طبيعية عند استخدام IterativeImputer، فهذا النوع من الـ imputation يعتمد على بناء نموذج إحصائي للتنبؤ بالقيم المفقودة بناء على العلاقات بين المتغيرات الأخرى في البيانات. و بما أن IterativeImputer يحاول التنبؤ بقيم مفقودة كناتج لمعادلات رياضية، فإنه يولد أرقاما مستمرة وليس فقط القيم الأصلية، و أيضا إذا لم تحدد قيود على نطاق القيم أو تجعل المتغير مصنفا، فالنموذج سيتعامل معه كمتغير رقمي عادي، مما يؤدي لإنتاج أرقام عشرية. و إذا كان المتغير يمثل فئات مثل درجات توافق، فمن الأفضل التعامل معه كمتغير تصنيفي وليس رقمي مستمر، وفي هذه الحالة يمكنك استخدام SimpleImputer مع طريقة مثل most_frequent أو KNNImputer للحفاظ على القيم الأصلية.1 نقطة
-
السلام عليكم هو انا ازي اقدر اتعلمل مع خاصيه الmin_value و الmax_value في الIterativeImputer ؟ مع العلم ان فيه اعميد كثير جدا 60عمود مختلف جدا1 نقطة
-
قبل التعويض، حدد الأعمدة التي من نوع int وfloat: import pandas as pd int_cols = df.select_dtypes(include=['int']).columns.tolist() float_cols = df.select_dtypes(include=['float']).columns.tolist() numerical_cols = int_cols + float_cols ثم استخدم IterativeImputer على الأعمدة الرقمية وسيحول جميعها إلى float مؤقتًا: from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer imputer = IterativeImputer(random_state=42) df_imputed = pd.DataFrame( imputer.fit_transform(df[numerical_cols]), columns=numerical_cols ) ثم إعادة تحويل الأعمدة إلى أنواعها الأصلية، بتقريب القيم العشرية إلى أقرب عدد صحيح لو كان ذلك مناسب للبيانات. df_imputed[int_cols] = df_imputed[int_cols].round().astype(int) ولو لديك أعمدة غير رقمية (فئوية)، أعد دمجها، وهنا افترض أن df يحتوي أيضًا على أعمدة فئوية مثل 'category_col'. df_final = pd.concat([ df_imputed, df[['category_col']] ], axis=1)1 نقطة
-
عليك إنشاء قائمتين لكل عمود، فلو لديك 3 أعمدة رقمية: العمود 1 (مثل العمر): min=0, max=100 العمود 2 (مثل الراتب): min=1000, max=10000 العمود 3 (مثل درجة الحرارة): min=-20, max=50 فستكون القوائم: min_values = [0, 1000, -20] max_values = [100, 10000, 50] ثم تحديد القيم ديناميكيًا، ففي حال الأعمدة كثيرة مثل 60 عمودًا، فتستطيع حساب الحدود لكل عمود تلقائيًا باستخدام الرباعيات أو القيم الدنيا/القصوى: import pandas as pd min_values = df[numerical_cols].quantile(0.05).tolist() max_values = df[numerical_cols].quantile(0.95).tolist() لاحظ حساب الحد الأدنى كـ 5% لكل عمود ثم حساب الحد الأقصى كـ 95% لكل عمود. ثم تمرير القوائم إلى IterativeImputer from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer imputer = IterativeImputer( min_value=min_values, max_value=max_values, estimator=RandomForestRegressor(), max_iter=50, random_state=42 ) df_imputed = imputer.fit_transform(df[numerical_cols]) ولو الأعمدة غير مرتبة بنفس ترتيب القوائم min_values و max_values، ستُطبَّق القيم الخاطئة، لذا علينا التأكد من أن ترتيب الأعمدة في df[numerical_cols] مطابق تمامًا لترتيب القيم في min_values و max_values. numerical_cols = df.select_dtypes(include=['number']).columns.tolist() min_values = df[numerical_cols].quantile(0.05).values max_values = df[numerical_cols].quantile(0.95).values وفي حال بعض الأعمدة لا تحتاج إلى حدود (مثل الأعمدة التي يمكن أن تأخذ أي قيمة)، عليك استخدم None أو np.inf: import numpy as np min_values = [0, None, -np.inf] max_values = [100, np.inf, 50] حيث العمود الثاني والثالث بلا حدود دنيا، والعمود الثاني بلا حدود قصوى.1 نقطة
-
ايوه بس ازي اقدر اعمل كده1 نقطة
-
عند استخدام IterativeImputer، يمكنك تحديد القيم الدنيا والعليا التي يمكن أن يأخذها التقدير لكل عمود، و هذا مفيد خصوصا عندما يكون لديك نطاقات محددة للقيم المفقودة وتريد التأكد من أن التقدير لا يخرج عن هذه الحدود، و إذا كنت تريد تعيين حدود مختلفة لكل عمود، فيمكنك تمرير قائمة أو مصفوفة بنفس طول عدد الأعمدة، أما إذا كنت تريد تعيين نفس الحد لكل الأعمدة، فيمكنك تمرير قيمة ثابتة بهذا الشكل: import numpy as np import pandas as pd from sklearn.impute import IterativeImputer min_values = np.full(60, -0.5) # حد أدنى لكل الأعمدة max_values = np.full(60, 2.0) # حد أقصى لكل الأعمدة imputer = IterativeImputer(min_value=min_values, max_value=max_values, random_state=42) df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns) # عرض بعض البيانات بعد التعويض print(df_imputed.head())1 نقطة
-
الأهم هو الأساسيات، فالمكتبات قائمة على اللغة البرمجية وهي بايثون، بالتالي إتقان أساسيات اللغة مثل الهياكل البيانية (القوائم، القواميس، المجموعات)، التحكم بالتدفق (الشروط، الحلقات)، الدوال، والكائنات البرمجية Classes بمعنى OOP. بعد تخطي تلك المرحلة وتنفيذ مشاريع متوسطة المستوى، تستطيع البحث عن أفضل الممارسات عند كتابة كود بايثون Python best practices وكيفية عمل refactoring للكود. ثم ابدء في حل المسائل البرمجية من خلال منصات مثل LeetCode أو HackerRank. بعد ذلك تقوم بالتعمق في تعلم المكتبات مثل pandas وفهم الميثودز التي توفرها المكتبة بشكل عميق لتتمكن من استخدامها كما ينبغي. وبالطبع تنفيذ مشاريع صغيرة باستخدام Pandas لتحليل مجموعات بيانات مختلفة، للتطبيق على المفاهيم وتثبيت المعلومات، ثم زيادة صعوبة المشاريع شيئًا فشيئًا. ثم اطلع على مشاريع مفتوحة المصدر على منصات مثل GitHub، ودراسة كيفية تنظيم الكود وطريقة كتابته وربطه ببعضه البعض، كتابة التوثيق، واستخدام الـ Design patterns. بمعنى قم بتحليل كود من مكتبات شهيرة، ففهم كيفية كتابة مكتبات ووحدات برمجية مستخدمة على نطاق واسع يوفر رؤى قيمة حول أفضل الممارسات.1 نقطة
-
المشكلة في السطر التالي: data_train[original_dtypes.select_dtypes(include=['int64']).columns] = original_dtypes.select_dtypes(include=['int64']).astype(int) فما تريده هو تحويل الأعمدة التي كانت في الأصل من نوع صحيح int64 مرة أخرى إلى أعداد صحيحة بعد الإكمال، ولكن ما يتم في الكود هو تعيين أنواع البيانات الأصلية المحولة إلى أعداد صحيحة بدلاً من تحويل بيانات الأعمدة نفسها. بمعنى original_dtypes.select_dtypes(include=['int64']).columns يجلب أسماء الأعمدة التي كانت في الأصل من نوع int64. original_dtypes.select_dtypes(include=['int64']).astype(int) يعمل على تحويل أنواع البيانات التي تكون كائنات dtype إلى أعداد صحيحة، وذلك غير منطقي لأنك تريد تحويل القيم في الأعمدة إلى أعداد صحيحة وليس أنواع البيانات. عليك تطبيق دالة astype(int) مباشرة على بيانات تلك الأعمدة وليس على معلومات أنواع البيانات. data_train = ordinalencoder_data(data_train) original_dtypes = data_train.dtypes.copy() imputer = IterativeImputer(max_iter=5, random_state=42, initial_strategy='mean') imputer_data = imputer.fit_transform(data_train) data_train = pd.DataFrame(imputer_data, columns=data_train.columns) int_columns = original_dtypes[original_dtypes == 'int64'].index data_train[int_columns] = data_train[int_columns].astype(int) print(data_train.info())1 نقطة
-
وعليك السلام ورحمة الله وبركاته. إذا لم يتم حل المشكلة من خلال الحل السابق يمكنك تنفيذ الأمر التالي sfc /scannow انتظر حتى يكتمل الفحص (قد يستغرق بضع دقائق).ثم أعد تشغيل الجهاز وحاول فتح الصور مرة أخرى. وإذا لم يتم حل المشكلة أيضاً حاول تنفيذ الأمر التالي في ال terminal Dism /Online /Cleanup-Image /CheckHealth ويفضل لو تقوم بمشاركة النتيجة التي تظهر لك بعد تنفيذ هذا الأمر1 نقطة
-
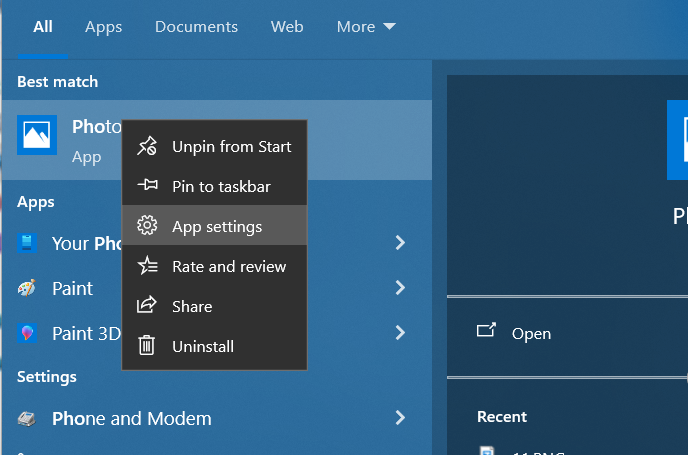
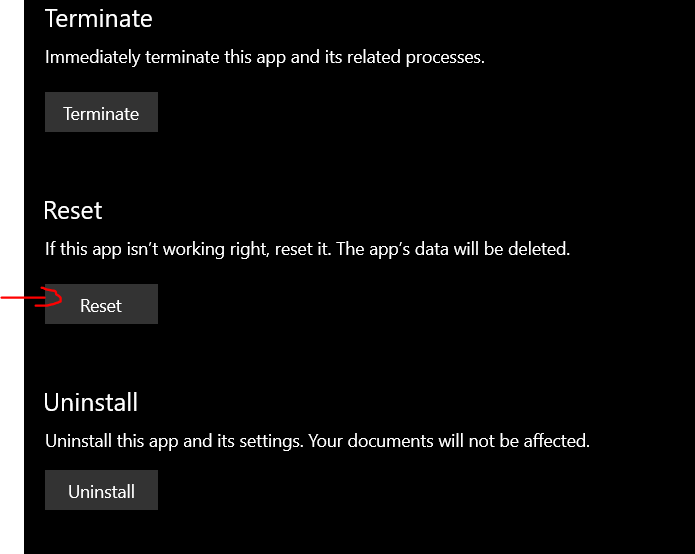
وعليكم السلام ورحمة الله وبركاته. يرجى فتح قائمة ويندوز وكتابة Photos . عندما يظهر برنامج Photos يرجى الضغط بالزر الأيمن عليه وإختيار App settings : بعد ذلك يرجى الذهاب إلى أسفل والبحث عن Reset . يرجى الضغط على Reset : ويمكنك محاولة فتح الصور مرة أخرى الآن
 1 نقطة
1 نقطة