لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 02/01/25 في كل الموقع
-
دخلت هذه الدورة لحبي الشديد بالبرمجة ولكن ماهي المجالات التي يمكنني العمل بها بعد اجتياز هذه الدورة ان شاء الله؟ طبعاً انا متوقف من فترة بسبب ضغط دراسي كبير خصوصا اني في الصف الثالث الثانوي.3 نقاط
-
السلام عليكم ده الكود data_train = data_train.apply(lambda col: col.astype(int) if original_dtypes[col.name] == 'int64' else col)3 نقاط
-
السلام عليكم هو انا عندي تطبقه الIterativeImputer فا البيانات كلها انحولت لنوع float مع العلم ان كان في int وfloat ازي احل المشكله دي ؟ ده الكود data_train = ordinalencoder_data(data_train) imputer = IterativeImputer(max_iter=5 , random_state=42 , initial_strategy='mean') imputer_data = imputer.fit_transform(data_train) data_train = pd.DataFrame(imputer_data , columns=data_train.columns) print(data_train.info())3 نقاط
-
لقد اشتريت دورة 'برمجة تطبيقات PHP' من أكاديميتكم قبل شهر وقمت بالدفع (300 دولار) وتلقيت تأكيد الدفع، لكن لا أستطيع الدخول للدورة حتى الآن. حاولت التواصل معكم عدة مرات دون رد. هذا غير مقبول! أطالب بحل فوري للمشكلة أو سأضطر لاتخاذ إجراءات قانونية2 نقاط
-
كيفية الدفع للاشتراك في احدي الدورات بدون بطاقة دفع2 نقاط
-
اريد رابط التوثيق المترجم لأكاديمية حاسوب للغة بايثون2 نقاط
-
BAGUERRI AYOUB_20240414_015642_0000.pdf2 نقاط
-
السلام عليكم في دورة الجافاسكريبت اغلب المشاريع واغلب التقنيات المستخدمه تم استخدامها باصدار قديم ولا تتم عملية تحديثها وهذه مشكله كبيرة اننا اذا لم نعتد على الاصدارات الجديدة فلن نصتطيع ان نتعامل مع سوق العمل الجديد و بلاخص اننا سوف نعمل على الاقل بعد مدى ليست قصيرة من انهاء الدوره ففي هه المدة سوف تظهر اصدارات جديده اخرى و تصيح المفاهيم مختلفه تماما عن الذي اخذناها في الدورى و سوف نطر الى اخذ كورسات اضافية لكي نواكب التطور فارجو انكم تحلو المشكلة وشكرا2 نقاط
-
عاوز اتدرب علي الي اتعلمتو في مشاريع علي بايثون مثلا لكن مش عارف ومش لاقي مصدر كويس ومعنديش مشكله لو مصدر بالانجلش1 نقطة
-
السلام عليكم هو انا ازي اقدر اتعلمل مع خاصيه الmin_value و الmax_value في الIterativeImputer ؟ مع العلم ان فيه اعميد كثير جدا 60عمود مختلف جدا1 نقطة
-
أولاً بالنسبة للشرط المذكور فهو من حقك ويمكنك مناقشته مع مركز المساعدة من هذا الرابط https://support.academy.hsoub.com/ وتحتاج للتخصص في مجال تفضله ومتابعة تعلمه حتى تستطيع العمل به بشكل إحترافي وبالتأكيد لست مجبراً بدخول لدورة أخرى هنا بل سيتم مساعدتك في المجال الذي تريده بعد الإنتهاء من الدورة ويرجى الإطلاع على الإجابات التالية للمزيد من الشرح1 نقطة
-
اذاً كيف يمكنني العمل في مجال معين او في شركة معينة او حتى ضمان الاستثمار بعد ستة اشهر المذكور في وصف الدورة 😅 هل انا مجبر بدخول دورة اخرى ؟ اقصد هل انا مجبر على دخول دورة اخرى ليصبح لدي عمل اكتسب من خلاله دخلي؟ ارجوا التوضيح اكثر واعتذر اذا اكثرت الكلام1 نقطة
-
دورة علوم الحاسوب توفر لك معلومات مكثفة حول مختلف مفاهيم لغات وتقنيات البرمجةو هي أساسية لزيادة معلوماتك حول مجال التقنية بشكل عام. و بانتهائك منها سيكون لديك خبرة جيّدة بدءً من الأساسيات والأفكار والمناهج النظرية مثل هندسة البرمجيات والبرمجة كائنية التوجه إلى التعامل مع أنظمة التشغيل ولغات البرمجة التي تم التطرق لها من خلال الأمثلة العملية في الدروس، وأيضاً سيكون لديك معرفة شاملة حول قواعد البيانات وطرق التعامل مع النوعين العلائقي وغير العلائقي. وفيها أيضاً مسار مخصص للدخول إلى عالم الويب والتعرّف على آلية عمل مطوري الويب في حال أحببت الانتقال إلى مجالات تطوير الويب لاحقاً لهذا إذا أردت التخصص في الواجهة الخلفية أو الأمامية فهذا المسار مهم جدا. ويمكنك قراءة الإجابة التالية لمزيد من التفاصيل حول الدورة : ولذلك فتلك الدورة مهمة للتأسيس عليها وفهم أساسيات الحسوب و التعامل مع الخوادم والأنظمة .1 نقطة
-
وفقك الله في دراستك ومسيرتك في البرمجة. بالنسبة لدورة علوم الحاسوب تقدم لك المفاهيم الأساسية في البرمجة دون التعمق في مجال محدد. هذا التأسيس القوي يُعتبر خطوة أولى مهمة في رحلتك نحو التخصص في مجالات تقنية متعددة.ولذلك يمكنك بعدها التخصص في المجال الذي تميل له بشكل أفضل بدون تعلم هذه الأساسيات . يفضل الإطلاع على الإجابات التالية للتوضيح بشكل أفضل.1 نقطة
-
السلام عليكم عشان عندي تنفيذ الكود ده ما تغير ما نطبق الiterativelmputer print(data_train['psych_disturb'].value_counts()) بتكون دي النتجيه psych_disturb 0 23005 1 3587 ولكن لم ااطبق الiterativelmputer وانقيذ نفس الكود بتكون دي النتجيه warnings.warn( psych_disturb 0 25212 1 3587 -1 1 Name: count, dtype: int641 نقطة
-
تمام جد الف شكراا جدا لحضرتك جزاك الله كل خير الا بجد الالله ينور عليك اي العظمي دي بسم الله ما شاء الله1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. من الممكن أن الدالة IterativeImputer قد تعيد أرقام سالبة وذلك لأن تلك الدالة تقوم بإكمال القيم المفقودة في مجموعة البيانات، مما قد ينتج عنها قيم غير متوقعة مثل الأرقام السالبة وذلك خصوصا إذا كانت البيانات الأصلية ليدك تحتوي على قيم غير مناسبة أو إذا كانت هناك مشكلة في النموذج المستخدم لإكمال القيم المفقودة. وإذا أردت عدم السماح بالقيم السالبة فتلك الدالة من الممكن أن تقبل معامل min_value وهو أقل قيمة من الممكن أن تخرجها الدالة ويمكنك قراءة التوثيق الرسمي : https://scikit-learn.org/stable/modules/generated/sklearn.impute.IterativeImputer.html#:~:text=min_valuefloat or array-like of shape (n_features%2C)%2C default%3D-np.inf أما بالنسبة لـ OrdinalEncoder فهذه الدالة تستخدم لتحويل المتغيرات الفئوية إلى متغيرات عددية ولكنها لا يمكن أن تعطي قيم سالبة لأنها تعمل على تحويل الفئات إلى أرقام صحيحة تبدأ من 0 إلا إذا أردت تحديد الفئات يدويا بنفسك حينها يمكنك وضعها بقيمة سالبة.1 نقطة
-
الف شكرااا جدا جدا لحضرتكم جزاكم الله كل خير1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. مع التدريب الكثير وكتابة الأكواد ستجد أن الأمور تضح لك وستسيطع كتابة أكواد مثل تلك التي ذكرتها. ولكن يجب عليك على الأقل معرفة الأساسيات. حيث هنا إستخدمنا تعبير lambda وهو يعتبر دالة مجهولة حيث هي كما أنك قمت بتعريف دالة تستقبل معاملات ولكنها تعيد قيمة واحدة فقط. يمكنك قراءة الشرح التالي لمزيد من التفاصيل حول تعبير lambda : ولنشرح معا الكود المرفق : data_train.apply : هنا إستخدمنا الدالة apply وتلك الدالة تقوم بأخذ معامل وهذا المعامل هو دالة يتم تنفيذها على كل عمود في الـ DataFrame أى أننا هنا نريد تنفيذ دالة معينة على كل عمود من بيانات ال data_train. وهنا قمنا بتمرير تعبير lambda وكما وضحنا هو دالة مجهولة . lambda col هنا العمود سيتم تمريره للدالة lambda كمعامل . col.astype(int) if original_dtypes[col.name] == 'int64' else col وهنا هو الجزء الذي سيتم إعادته من الدالة . ولاحظ هنا أننا إستخدمنا التعابير الشرطية . حيث سنقوم بتحويل العمود إلى نوع int إذا كان نوع البيانات الأصلي هو int64 أما إذا لم يكن العمود من نوع int64 سيتم إعادته كما هو ولن يتم تحويله.1 نقطة
-
للوصول إلى هذا المستوى ركز على فهم أساسيات لغة البرمجة و تعلم كيفية التعامل مع المكتبات الشائعة مثل Pandas، و أيضا حاول قراءة الكود المكتوب من قبل مطورين متمرسين، سواء من خلال مشاريع مفتوحة المصدر أو أمثلة تعليمية، لتفهم كيفية تنظيم الكود واستخدام الوظائف بشكل فعال، و ايضا بين الحين و الآخر تدرب على كتابة كود نظيف وواضح، مع التركيز على قابلية القراءة والصيانة، مثل استخدام الأسماء الواضحة للمتغيرات والوظائف، وتجنب التكرار، وبالتأكيد كلما مارست أكثر واطلعت على أمثلة متقدمة، ستزداد قدرتك على كتابة كود احترافي وفعال.1 نقطة
-
الف شكرااا لحضرتك جدا جزاك الله كل خير طيب معليش بس هو الكود ده اي الاخطاء data_train = ordinalencoder_data(data_train) original_dtypes = data_train.dtypes.copy() imputer = IterativeImputer(max_iter=5 , random_state=42 , initial_strategy='mean') imputer_data = imputer.fit_transform(data_train) data_train = pd.DataFrame(imputer_data , columns=data_train.columns) data_train[original_dtypes.select_dtypes(include=['int64']).columns] = original_dtypes.select_dtypes(include=['int64']).astype(int) print(data_train.info())1 نقطة
-
المشكلة هنا أن IterativeImputer يحول كل البيانات إلى float، حتى لو كانت بعض الأعمدة int، و هذا السلوك يحدث لأن imputer.fit_transform() يعيد مصفوفة numpy تحتوي على قيم float64، و الحل هو أنه بعد تحويل البيانات باستخدام IterativeImputer، يمكنك إجبار الأعمدة الصحيحة على العودة إلى نوع البيانات الأصلي باستخدام astype(int) للأعمدة التي كانت int بهذا الشكل: for col in data_train.columns: if original_dtypes[col] == 'int64': data_train[col] = data_train[col].astype(int)1 نقطة
-
الف شكرااا جدا جدا لحضرتك جزاك الله كل خير1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. هذا بسبب أن IterativeImputer يقوم بإستخادم طرق إحصائية لتقدير القيم المفقودة وأيضا الخوارزمية التي يعمل بها تقوم بإجراء عمليات حسابية مما قد تتضمن قيم غير صحيحة (قيم العشرية). و لحل تلك المشكلة يمكننا أولا الإحتفاظ بقائمة الأعمدة ال int و ال float قبل تطبيق الIterativeImputer ومن ثم بعد ذلك نقوم بتحويلها مرة أخرى إلى int. int_columns = data_train.select_dtypes(include=['int64']).columns float_columns = data_train.select_dtypes(include=['float64']).columns imputer = IterativeImputer(max_iter=5, random_state=42, initial_strategy='mean') imputer_data = imputer.fit_transform(data_train[float_columns]) data_train[float_columns] = imputer_data data_train[int_columns] = data_train[int_columns].astype('int') print(data_train.info())1 نقطة
-
السلام عليكم هو اي الفرق مابين الLabelEncoder وبين الOrdinalEncoder ؟1 نقطة
-
بشكل مبسط الفرق بينهما يكمن في أن Label Encoding يقوم بإعطاء رقم فريد لكل فئة من فئات المتغير النصي. ولكن المشكلة هي أنه قد يُدخل ترتيبًا وهميًا بين الفئات، حتى لو لم يكن هناك أي ترتيب منطقي بينها. على سبيل المثال، إذا كان لدينا ألوان "أحمر"، "أخضر"، "أزرق"، قد يتم ترميزها كـ 0، 1، 2 على التوالي. هنا، قد يفهم النموذج أن "الأزرق" أكبر من "الأخضر"، وهو أمر غير منطقي. لذلك يُفضل استخدامه عندما لا يكون هناك ترتيب منطقي بين الفئات، مثل أسماء المدن أو أنواع المنتجات. بينما Ordinal Encoding يُستخدم عندما يكون هناك ترتيب منطقي بين الفئات على سبيل المثال، إذا كان لدينا مستويات تعليمية "مدرسة ثانوية"، "بكالوريوس"، "ماجستير"، "دكتوراه"، يمكن ترميزها كـ 0، 1، 2، 3 على التوالي. هنا، يحافظ الترميز على الترتيب المنطقي بين المستويات التعليمية. لذلك يُفضل استخدامه عندما يكون هناك ترتيب منطقي بين الفئات، مثل المستويات التعليمية، أو تقييمات العملاء (ضعيف، متوسط، جيد جدًا).1 نقطة
-
مرحبا هل عمل اعلان لمدونتي او موقعي علئ جوجل يساعد في شعبية الموقع او يساعد على تحسين ضهور الموقع1 نقطة
-
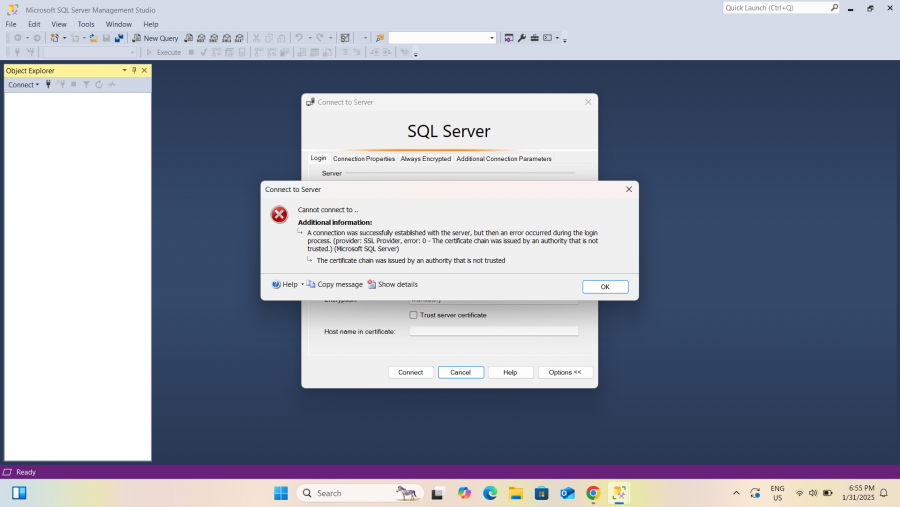
كما بالصورة التالية يوجد خيار Trust Server Certificate أضغط عليه وقم بتفعيله ثم بعد ذلك حاول مرة أخرى الإتصال
 1 نقطة
1 نقطة -
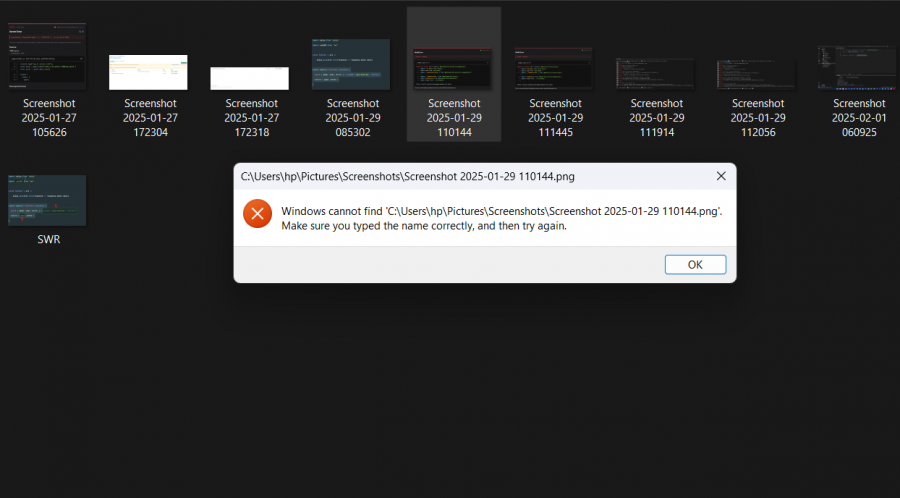
السلام عليكم ورحمه الله وبركاته عندي مشكله يا احبه في كل مره احاول فيها فتح اي صوره من الجهاز يظهر لي هذا الخطأ
 1 نقطة
1 نقطة -
من خلال التوثيق الرسمي للمكتبة أو إطار العمل ستجد قسم migration في التوثيقات يشرح لك الفروقات بين الإصدارات . لذلك تأكد من أنه سيتم تحديث الدورة بما يتناسب مع الإصدارت االحديثة ولكن كما أخبرتك أنه من الأفضل أحياناً دراسة الإصدارت االأقدم نسبياً من مكتبة ما او إطار عمل1 نقطة
-
التوثيق الرسمي يكفي . يمكنك كتابة إسم المكتبة أو إطار العمل في جوجل وبعدها كلمة docs وسيظهر لك الموقع الرسمي للتوثيق. فمثلا إذا أردت توثيق nextjs الرسمي يمكنك كتابة : nextjs docs وأول نتيجة ستظهر لك ستكون التوثيق الرسمي .1 نقطة
-
ولاكن في اغلب الاحيان الدورات تكون فعلا مختلفى اختلاف جوهري عن الاصدارات الجديده هل هنالك مكان او توثيق يمكنني ان اتابع منه الاصدارات الجديده ؟1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إسمح لي أن أصحح لك بعض الأمور . أولا لا يوجد ما يسمي تغير المفاهيم أو إختلافها في الإصدارات الجديدة سواء من المكتبات أو أطر العمل. إن المفاهيم واحدة ولا يتم الإختلاف فيها . بل الإختلاف يكون في خصائص المكتبات وأطر العمل حيث يتم إضافة خصائص جديدة أو حذف خصائص قديمة لم تعد مهمة . أو تعديل خصائص كانت موجودة وطريقة إستخدامها إختلفت قليلا . لهذا إذا كنت قد فهمت الأساسيات والمفاهيم الرئيسية فسيكفي فقط الإطلاع على الوثائق الرسمية لتعرف كيف تتعامل مع التحديثات. ثانيا لا يوجد مبرمج جيد حينما يتم إصدار تحديث جديد لمكتبة أو إطار عمل أن يذهب ليشترك في دورة ليعرف كيف يتعامل معها . بل ينبغي عليه معرفة كيفية تعلمها أو قراءة التغيرات التي حدثت من خلال الوثائق الرسمية أو غيرها . ولكن الإشتراك في دورة جديدة لتبدا من البداية فهذا ليس بالأمر الجيد. ثالثا عند نزول إصدار حديث لا يتم إهماله أو عدم العمل به . بل توجد مشاريع كثيرة تعمل على إصدارات قديمة جدا منذ أكثر من 5 سنوات . وستجد وظائف في شركات كبيرة أو حتي مواقع عمل حر تعمل على مشاريع بإصدارات قديمة . لهذا فإن ما تعلمته تستطيع العمل به . أما بخصوص الدورات هنا فهي أولا يتم تحديثها بإستمرار ولكن مع التطور السريع للإصدارات والمكتبات من الصعب دائما مواكبة تلك التطورات ولكن دائما ما يتم تحديث الدروس إذا كانت الإصدارات الأحدثت قد إختلفت تماما عن مثيلتها السابقة في الدورة . ويمكنك متابعة التحديثات التي تمت وستجد أنه بالفعل قد تم تحديث عدة مسارات بأحدث الإصدار في شهر 12 السابق : https://academy.hsoub.com/release-notes/ وأيضا لن تحتاج إلى شراء أى دورة أخرى فهنا من مميزات الأكاديمية أنه سيكون لك وصول مدى الحياة للدورة وأى تحديث عليها تستطيع مشاهدة دون دفع أى رسوم إضافة أو الإشتراك من جديد. وأخيرا ينبغي عليك التركيز على فهم الأساسيات و التطبيق مع المدرب بالإصدارات الموجودة في الدروس وبعد الإنتهاء من المسار يمكنك المحاولة مع نفسك في كيفية تحديث أو إنشاء المشروع من البداية بالإصدارات الأحدث وحينها ستحقق أقصي إستفادة وتزداد خبرتك في التعامل مع المكتبات ومع الإصدارات بعد تحديثها.1 نقطة
-
الف شكراا جدا لحضرتك جزاك الله كل خير1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. LabelEncoder: نقوم بإستخدامه لتحويل القيم الفئوية (Categorical) إلى قيم رقمية. فلو لدينا فئات غير مرتبة مثل "أحمر" و "أخضر" و "أزرق" ونحتاج إلى تحويلها إلى قيم عددية لنستيطع تحليلها يساعدنا الLabelEncoder في ذلك. مثال : from sklearn.preprocessing import LabelEncoder labels = ["أحمر"، "أخضر"، "أزرق","أحمر] le = LabelEncoder() encoded_labels = le.fit_transform(labels) print(encoded_labels) # Output: [0, 1, 2, 0] وإليك التوثيق الرسمي : https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html OrdinalEncoder: أيضا نستخدمه لتحويل الفئات النصية إلى أرقام، ولكن الفئات هنا تكون مرتبة أى لها ترتيب معين عكس الLabelEncoder. حيث يجب هنا تحديد الترتيب يدويا . مثال from sklearn.preprocessing import OrdinalEncoder encoder = OrdinalEncoder() encoder.fit([['heigh',3], ['medium',2], ['low',1]]) encoder.transform([['medium'],['heigh'],['low']) وإليك التوثيق الرسمي له : https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OrdinalEncoder.html1 نقطة
-
توقف عمل ملفات : main.js stripe.js ولا يتم انشاء order أيضا سأرفق ملف المشروع وشكرا Book_Stopr.zip1 نقطة
-
في pandas، توجد دوال مُخصصة لتسهيل معالجة البيانات بشكل فعال، ومنها select_dtypes وapply(). حيث select_dtypes تسمح لك بفلترة (تصفية) أعمدة الـ DataFrame حسب نوع البيانات dtypes، بالشكل التالي: df.select_dtypes(include=[int, float], exclude=[object]) include اختيار الأعمدة ذات الأنواع المحددة (مثل int، float، datetime) و exclude استبعاد الأعمدة ذات الأنواع المحددة. import pandas as pd data = {'A': [1, 2], 'B': ['x', 'y'], 'C': [3.0, 4.0]} df = pd.DataFrame(data) numeric_df = df.select_dtypes(include='number') أما apply() تطبق دالة مُخصصة على جميع الصفوف أو الأعمدة (حسب المحور axis). df.apply(func, axis=0) df.apply(func, axis=1) كالتالي: df['sum'] = df.apply(lambda row: row.sum(), axis=1) ودوال pandas مثل select_dtypes وapply() تكون أسرع بشكل عام لأنها مبنية على تحسينات مُستوى منخفض مثل C أو NumPy. أما الحلقات التقليدية (for/if) في Python تكون أبطأ، خاصة مع البيانات الكبيرة، لأنها تُنفذ بشكل تسلسلي ولا تستفيد من تحسينات المتجهات vectorization.1 نقطة
-
عليك استخدام نوع البيانات الصالحة للقيم المفقودة في Pandas (Int32)، بمعنى استخدام Int32 بدلاً من float من خلال dtype='Int32' (بـ I كبيرة) لإنشاء عمود صحيح مع دعم القيم المفقودة. واستبدال np.nan بـ pd.NA من pandas لتمثيل القيم المفقودة في الأعمدة من النوع الصحيح. وإزالة التحويل إلى float، فلم يعد هناك حاجة للتحويل إلى float لأن Int32 يدعم القيم المفقودة مباشرةً. data_encoded = data_train.copy() for col in data_encoded.select_dtypes(include=['object']).columns: mask = data_encoded[col].isna() temp_data = data_encoded[col].fillna('missing') le = LabelEncoder() encoded_data = le.fit_transform(temp_data) encoded_series = pd.Series(encoded_data, dtype='Int32') encoded_series[mask] = pd.NA data_encoded[col] = encoded_series ويجب أن يكون تأكد إصدار Pandas لديك هو 0.24 أو أحدث لدعم الأنواع الصحيحة القابلة للفقدان، وفي حال تريد التعامل مع القيم المفقودة كفئة منفصلة (بدلاً من حفظها كـ NaN)، تستطيع حذف الخطوة التي تستخدم mask و pd.NA.1 نقطة
-
الف شكرااا جدا جدا لحضرتك جزاك الله كل خير1 نقطة
-
مرحبا مهندس مصطفى, github.com/khaled21developer/django_store الان المشروع عام , from .admin import CustomUserAdmin ImportError: cannot import name 'CustomUserAdmin' from partially initialized module 'store.admin' (most likely due to a circular import) (C:\Users\khham\Desktop\django_store\store\admin.py) هذا الي يظهر لي واول مرة اواجه الخطا حاولت البحث كثير مهندس1 نقطة