لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 01/30/25 في كل الموقع
-
هو اي نموذج الDeepHit ؟3 نقاط
-
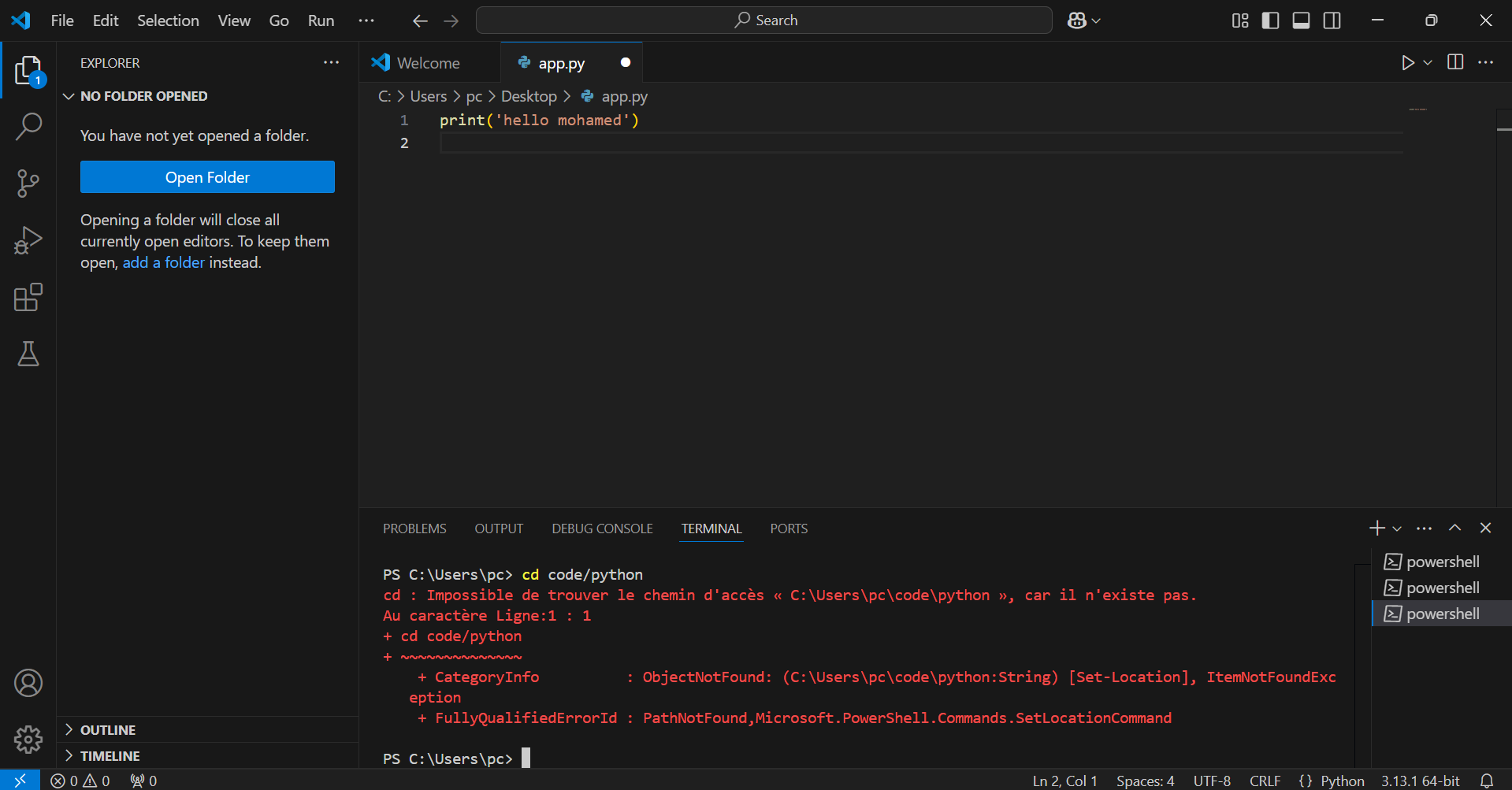
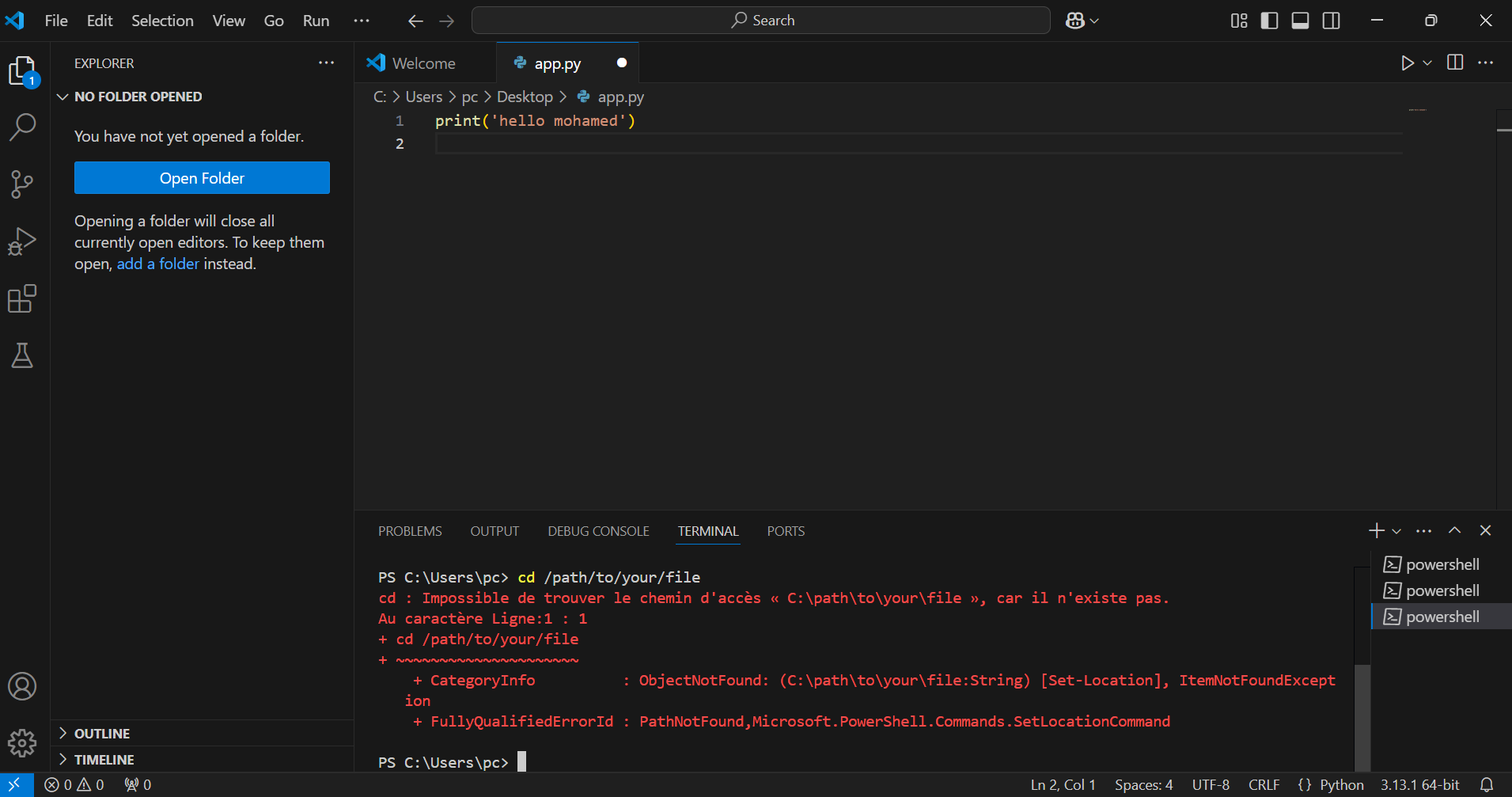
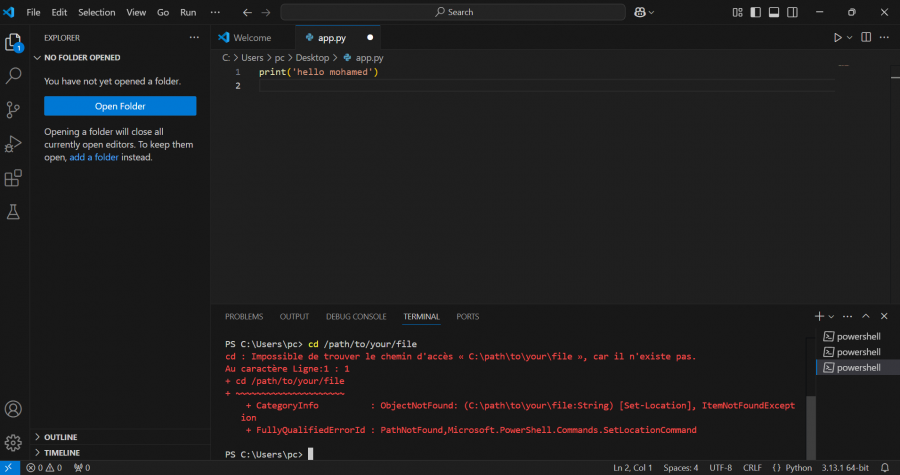
اواجه مشكلة عندما اقوم بكتابة الكود cd /path/to/your/file لا يعمل معي كما في الصورة للعلم انني قمت بحفظ الملف على الحاسوب مادا علي فعله ؟؟؟؟
 2 نقاط
2 نقاط -
في هذا الفيديو هل يمكنني انا استخدم بديل عن GPT مثل DEEPSEEK2 نقاط
-
السلام عليكم ورحمة الله وبركاته ... انا ادرس دورة تطوير التطبيقات باللغة بايثون تحديدا اساسيات بايثون المشكلة التي اواجهها هي ان نتائج المعلم تختلف عن نتائجي مع اني اكتب وانفذ كل ماهو ظاهر ومكتوب دون زيادة او نقصان واضافة لذالك انا استخدم المحرر نفسه ومع ذالك فنتائج تختلف في اغلب الدروس واكثر خطأ يواجهني هو the_number=int(input("Enter the number:")) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ValueError: invalid literal for int() with base 10:2 نقاط
-
السلام عليكم دي المشكله Cannot submit Your Notebook cannot use internet access in this competition. Please disable internet in the Notebook editor and save a new version.1 نقطة
-
كيف يمكنني ان احل هده المشكلة و اجد الملف من فضلك1 نقطة
-
قم بتنفيذ: jupyter contrib nbextension install --user ثم: pip install jupyter_nbextensions_configurator ثم: jupyter nbextensions_configurator enable --user1 نقطة
-
ذلك نموذج تعلم عميق مُصمم خصيصًا لتحليل البقاء Survival Analysis مع مراعاة المخاطر المتعددة المُتنافسة Competing Risks، والفائدة منه التنبؤ بوقت حدوث حدث ما (مثل الوفاة، الفشل، الانتكاسة) في وجود أحداث متعددة قد تمنع حدوث الحدث الرئيسي. بمعنى يتميز بمعالجة المخاطر المُتنافسة أي التعامل مع سيناريوهات توجد فيها أحداث متعددة تؤثر على بعضها البعض كوفاة مريض بسبب سببين مختلفين، أو تحليل مغادرة العملاء مع أسباب متنافسة مثل الانتقال إلى منافس أو إلغاء الخدمة. وعدم افتراض توزيع معين، أي لا يفترض النموذج شكلًا محددًا لوظيفة الخطر، على عكس نماذج مثل Cox Proportional Hazards التي تفترض تناسبًا خطيًا للمخاطر. ويستخدم شبكات عصبية عميقة لاكتشاف العلاقات المعقدة والغير خطية بين الميزات ووقت الحدث. والتنبؤ بتوزيع الوقت بدلًا من تقدير خطر لحظي، يُخرج النموذج توزيعًا احتماليًا لوقت الحدث لكل خطر على حدة. ويعمل بالآلية التالية، يُدرب النموذج على بيانات تحتوي على: ميزات المريض/العينة Features. وقت المراقبة Time-to-event. نوع الحدث Event Type أو الإخفاق Censoring. الهندسة المعمارية: طبقات الإدخال: تستقبل الميزات (مثل العمر، التشخيص الطبي). طبقات مخفية: تتعلم تمثيلات غير خطية للبيانات. طبقات الإخراج: تُنتج احتمالية حدوث كل حدث في فترات زمنية محددة. دالة الخسارة Loss Function تجمع بين: خسارة الاحتمالية السلبية Negative Log-Likelihood لضمان دقة التنبؤات. عقوبة الاختلاف Difference Penalty لتجنب القفزات المفاجئة في التوزيع الزمني.1 نقطة
-
الف شكرااا جدا جدا لحضرتكم جزاكم الله كل خير انا بستفيد كثير او منكم فالف شكراااا جدا1 نقطة
-
يعني ممكن ان يتنباء بقيه عمود efs وكمان العمود دهefs_time في نفس الوقت1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. أولاً تحليل البقاء (Survival Analysis) هو مجموعة من الأساليب الإحصائية المستخدمة لدراسة الوقت حتى حدوث حدث معين، مثل: الوقت حتى وفاة المريض. الوقت حتى فشل الآلة. الوقت حتى عودة المرض. لذا نموذج DeepHit هو نموذج لتحليل البقاء باستخدام التعلم العميق. ويعتبر تطور مهم في هذا المجال حيث يستخدم DeepHit شبكة عصبية عميقة للتعلم مباشرة من البيانات، بدلاً من الاعتماد على افتراضات إحصائية كما في النماذج التقليدية. هذا يجعله أكثر مرونة وقدرة على التكيف مع العلاقات المعقدة في البيانات.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. إن نموذج DeepHit هو نموذج تعلم عميق حيث يستخدم في مجال التنبؤ بتوقيت الأحداث النجاة أو الفشل (Survival Analysis) في الحالات التي تعتمد على بيانات معقدة ومتغيرة بمرور الوقت وهذا بالنسبة للسياق الطبي . ويعتمد هذا النموذج بشكل أساسي على الشبكات العصبية العميقة ويُستخدم عادةً في تحليل البيانات الزمنية و تحليل بيانات النجاة مثل التنبؤ بمعدل النجاة للمرضى .1 نقطة
-
السلام عليكم X = train_f.drop(['efs', 'efs_time'], axis=1).values y_event = train_f['efs'].values y_duration = train_f['efs_time'].values1 نقطة
-
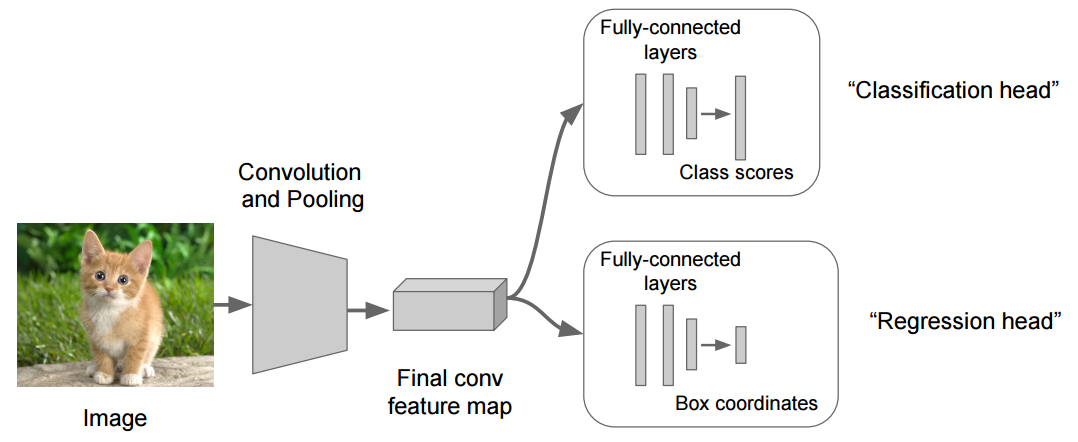
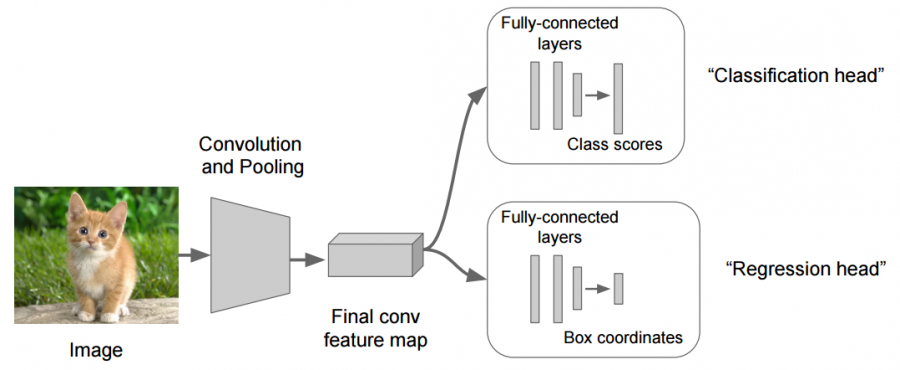
و عليكم السلام، يمكنك استعمال ما تشاء من قيم الخرج، لا وجود لحد نظري يخبرك أنه لا يمكن استعمال أكثر من خرج. أي أن هناك الكثير من الشبكات تقوم بتوقع العديد من الأمور في نفس الوقت، مثلًا ال YOLO تقوم بتوقع موقع الغرض (عن طريق صندوق يحيط به)، الصنف الذي يتبع له هذا الغرض، و مقدار الثقة في التوقع. لذلك عندما تريد توقع أكثر من قيمة ببساطة يجب أن يكون هناك أكثر من label، بحيث تقارن توقع النموذج به. بالطبع قد تحتاج إلى بعض التغييرات في هيكلية الشبكة، حيث يتم قسمها إلى قسم مختص باستخراج الميزات، و عدد من الرؤوس كل منها مبني على قسم الاستخراج و يقوم بتوقع قيمة ما. هذه صورة توضح أحد الأمثلة على استعمال رأسين للشبكة: تحياتي.
 1 نقطة
1 نقطة -
من الأفضل عدم فعل ذلك، لأنّ LabelEncoder مُصمم خصيصًا لتحويل الفئات النصية مثل أحمر، أزرق إلى أرقام 0, 1, 2. ولو البيانات من نوع float وتُمثِّل قيمًا عددية مثل 1.5, 2.3، فهي ليست فئوية، ولا يجب تحويلها باستخدام LabelEncoder، وستحتاج إلى تسوية البيانات Normalization/Standardization في حال كانت قيمًا عددية أو التعامل معها كفئات لو تمثل تصنيفات مثل 1.0 = منخفض، 2.0 = متوسط. ففي حال القيم float وليست فئات حقيقية، أحيانًا يُفسرها النموذج بشكل خاطئ كقيم عددية، ويؤثر على الأداء، أو تظهر قيم عشرية غير متوقعة أثناء التنبؤ مثل 2.5، بينما الـ LabelEncoder يُحوّلها إلى أعداد صحيحة (0, 1, 2) فقط. بالتالي لو الـ float تمثِّل فئات حوّلها إلى نص أولاً، ثم استخدم LabelEncoder أو OrdinalEncoder: import pandas as pd from sklearn.preprocessing import LabelEncoder df['column'] = df['column'].astype(str) le = LabelEncoder() df['column_encoded'] = le.fit_transform(df['column']) أما القيم العددية فلا تستخدم LabelEncoder، بل استخدم تقنيات معالجة البيانات العددية: from sklearn.preprocessing import StandardScaler scaler = StandardScaler() df['column_scaled'] = scaler.fit_transform(df[['column']]) وفي حال القيم العشرية تمثِّل فئات مُرتبة Ordinal، عليك استخدام OrdinalEncoder مع تحديد الترتيب يدويًّا: from sklearn.preprocessing import OrdinalEncoder categories = [['1.0', '2.0', '3.0']] encoder = OrdinalEncoder(categories=categories) df['column_encoded'] = encoder.fit_transform(df[['column']]) وللعلم إن كانت القيم العشرية ناتجة عن أخطاء في البيانات كـ 1.0 بدلًا من 1، حوّلها إلى أعداد صحيحة int أولاً: df['column'] = df['column'].astype(int)1 نقطة
-
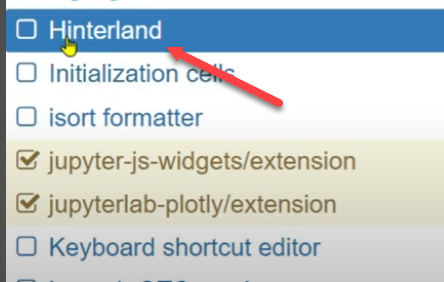
ما تقصده هو ميزة مثل IntelliSense الموجودة في vscode للإكمال التلقائي للكود autocomplete، ستحتاج إلى تثبيت مكتبة jupyter-contrib-nbextensions: pip install jupyter-contrib-nbextensions وسيظهر لك تبويب باسم nbextensions في jupyter اضغط عليه ثم ابحث عن Hinterland وقم بتفعيل تلك الميزة:

 1 نقطة
1 نقطة -
أعتقد أنك تقصد تفعيل الإكمال التلقائي (autocomplete) إذا كان كذلك يرجى وضع الكود التالي في خلية وتنفيذها: %config Completer.use_jedi = False حيث الكود السابق يعطل مكتبة Jedi الافتراضية في Jupyter والتي قد تسبب في بعض الأوقات عدم تفعيل الإكمال التلقائي بشكل صحيح. إذا لم تعمل أيضا يمكننا تثبيت مكتبات إضافية مثل jedi و IPython : pip install jedi ipython حيث من الممكن أن الإصدار الذي يوجد لديك لا يأتي مع jedi .1 نقطة