لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 11/24/24 في كل الموقع
-
السلام عليكم هي اي الداله دي ttest_ind في مكتبه scipy ؟4 نقاط
-
ما هو الحد الادنى لمواصفات جهاز الحاسوب الذي ساستخدمه4 نقاط
-
هل هناك شرح للمزيد من المكتبات مثل turtle و pygame على اكادمية حاسوب2 نقاط
-
2 نقاط
-
السلام عليكم يظهر لي هذا الخطا عند تسجيل الدخول ولا يتم ارسال البيانات لا اعلم مالسبب my-react-app2.zip
.thumb.png.6eaa9915167fb45ae89845cd89d8c899.png) 1 نقطة
1 نقطة -
1 نقطة
-
السلام عليكم بمعني انا هتدخل النموذج 7ميزات او الFeatures و هيتدرب علي ال7 بس انا ممكن اخلي ان يخلي بالو من 3 ميزات يعني اخلي يتوصي بال3 مع برد التدريب عي باقي الميزات ؟1 نقطة
-
من الطرق السهلة لفعل ذلك هي Permutation Feature Importance أو أهمية ميزة الإزاحة، وستجدها بالعديد من مكتبات التعلم الآلي، مثل scikit-learn، حيث توفر وظائف مدمجة لحسابها. وتلك الطريقة توفر تصنيفًا واضحًا لأهمية الميزة، الأمر الذي يسهل فهم النتائج وتفسيرها، وتستطيع تطبيق أهمية ميزة الإزاحة على أي نموذج تعلم آلي، بما في ذلك النماذج الخطية وغير الخطية، دون الحاجة إلى تعديلات كبيرة على النموذج أو معاملاته الفائقة. أيضًا مقاومة للارتباطات بين الميزات، وهو أمر شائع في العديد من مجموعات البيانات، وبإمكانك حساب أهمية ميزة الإزاحة بسرعة نسبية، خاصة عند مقارنتها بطرق أخرى مثل إزالة الميزة التكرارية (RFE). للتوضيح: from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.inspection import permutation_importance X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train) importances = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=42) # الحصول على درجات أهمية الميزة importance_scores = importances.importances_mean # فرز الميزات حسب الأهمية sorted_features = np.argsort(importance_scores)[::-1] # تحديد أفضل 3 ميزات top_3_features = sorted_features[:3] print("Best 3:", X.columns[top_3_features])1 نقطة
-
نعم يمكنك استخدام مكتبات التعلم الآلي مثل Scikit-learn لتنفيذ هذه الأمور، فهذه المكتبة تحتوي على العديد من الدوال التي تساعدك في هذا الأمر.1 نقطة
-
نعم يمكنك ذلك عن طريق اختيار الميزات أو Feature Selection، حيث يمكنك إعطاء الأولوية لميزات معينة أثناء التدريب مع عدم تجاهل باقي الميزات، و يمكنك إختيار المميزات إما يدويا أو يمكنك استخدام مقاييس الميزات المهمة التي يتم إنتاجها تلقائيا، مثل Gini Importance أو Permutation Importance، لتوجيه النموذج للتركيز على الميزات المهمة. كما يمكنك تدريب النموذج على مرحلتين، في المرحلة الأولى يتم تدريب النموذج على جميع الميزات لمعرفة التأثير العام، و في المرحلة الثانية قم بإعادة تدريب النموذج مع إعطاء الأولوية للميزات الثلاثة المهمة، إما عن طريق إدخالها بشكل متكرر أو تقليل تأثير الميزات الأخرى.1 نقطة
-
أقصد النتيجة التي حصلنا عليها من خلال اختبارنا الإحصائي ليست نتيجة عشوائية، بل هي نتيجة ذات احتمال ضئيل جدًا للحدوث إن كانت الفرضية الصفرية صحيحة. أي أن هناك احتمالًا ضئيلًا جدًا لأن يكون ذلك الفرق نتيجة للصدفة. للتوضيح: الفرضية الصفرية: لا يوجد فرق بين متوسطي العينتين. الفرضية البديلة: يوجد فرق بين متوسطي العينتين. في حال قيمة p أقل من مستوى الدلالة (عادةً 0.05)، فإننا نرفض الفرضية الصفرية ونستنتج أن هناك فرقًا "ذو دلالة إحصائية" بين متوسطي العينتين.1 نقطة
-
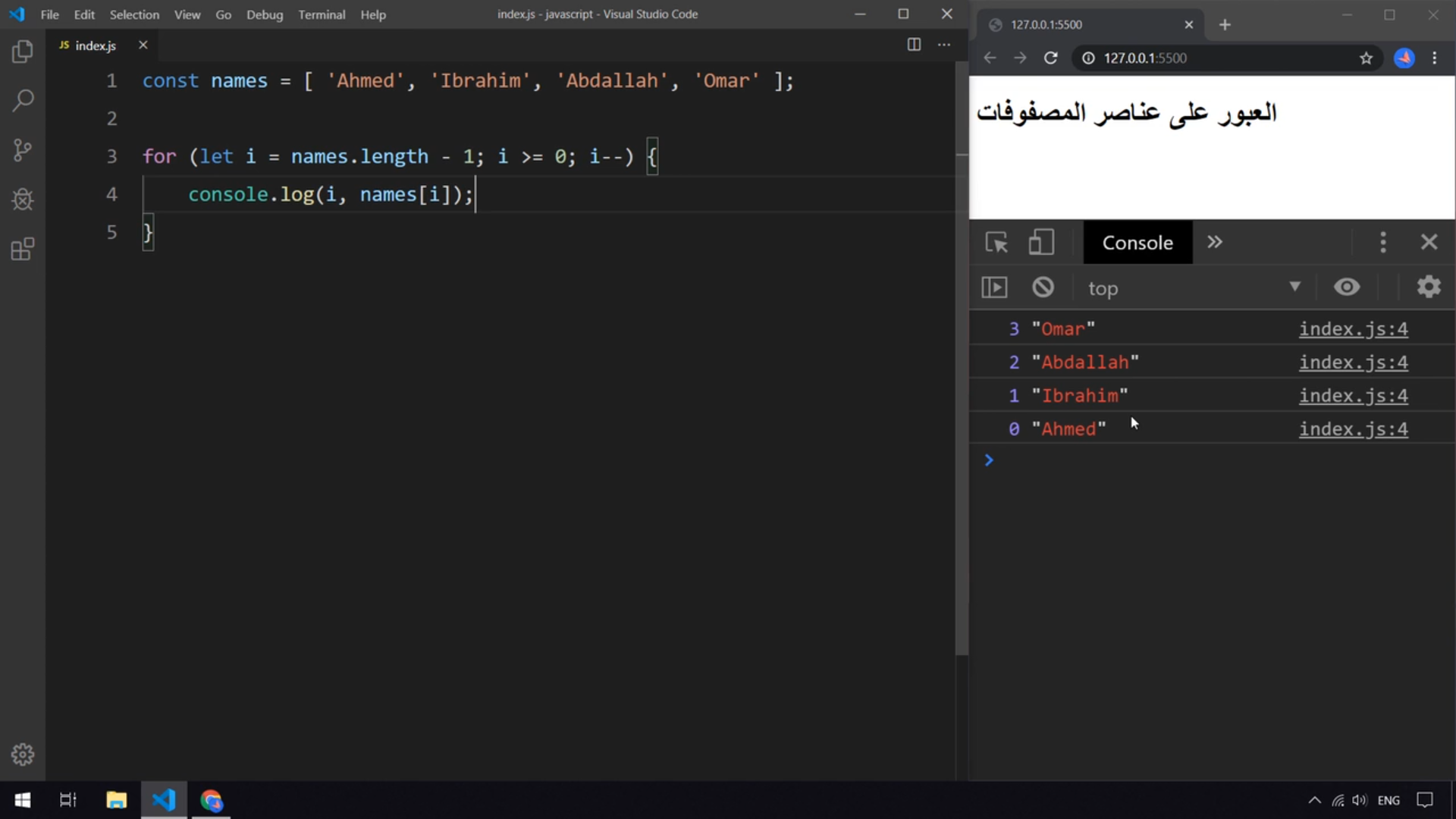
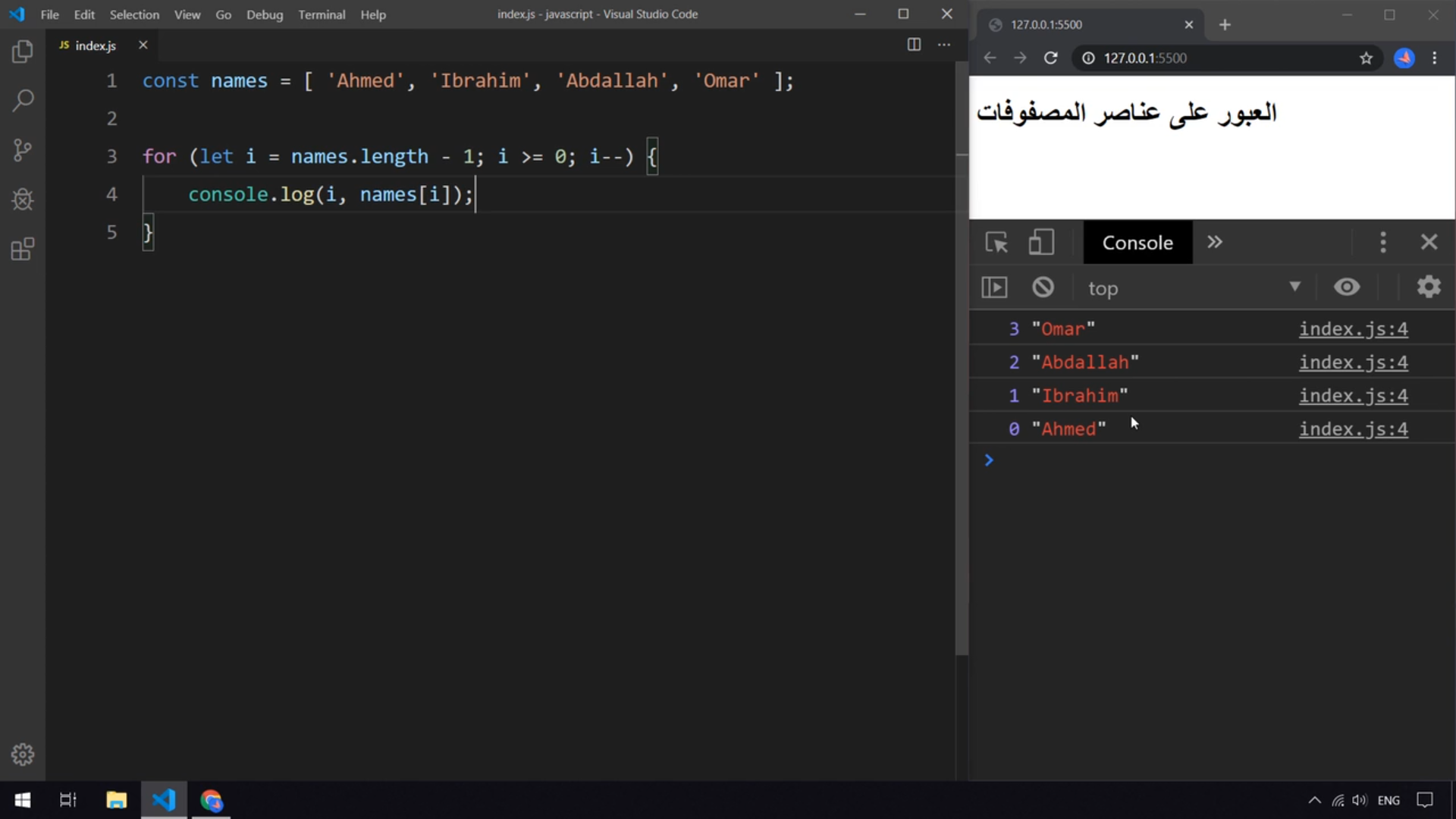
هي عبارة عن دالة تستخدم لعمل ال T-test. T-test هو اختبار إحصائي يُستخدم لتحديد ما إذا كان هناك فرق بين متوسطين لمجموعتين (mean) وكيفية ارتباطهما ببعضهما البعض. يتم استخدام T-test عندما تتبع مجموعات البيانات توزيعًا طبيعيًا وتكون الفروق غير معروفة، مثل درجات الطلاب في درس فيزياء ودرجات مجموعة أخرى من الطلاب في درس رياضيات من غير المحتمل أن يكون لهما نفس المتوسط. مثال: import scipy.stats as stats # الدرجات لدرس الفيزياء data_group1 = np.array([14, 15, 15, 16, 13, 8, 14, 17, 16, 14, 19, 20, 21, 15, 15, 16, 16, 13, 14, 12]) # الدرجات لدرس الفيزياء data_group2 = np.array([15, 17, 14, 17, 14, 8, 12, 19, 19, 14, 17, 22, 24, 16, 13, 16, 13, 18, 15, 13]) # T-test تنفيذ stats.ttest_ind(a=data_group1, b=data_group2, equal_var=True)1 نقطة
-
وعليكم السلام الدالة ttest_ind في مكتبة scipy تُستخدم لإجراء اختبار T مستقل (Independent T-Test). هذا الاختبار يُستخدم لمقارنة متوسطات مجموعتين مستقلتين لمعرفة ما إذا كان الفرق بينهما ذو دلالة إحصائية أم لا. والدالة تكون مثل: scipy.stats.ttest_ind(a, b, axis=0, equal_var=True, nan_policy='propagate', alternative='two-sided') لنرى المعاملات الرئيسيةللدالة: a, b: المصفوفتان اللتان تحتويان على البيانات من المجموعتين اللتين تريد مقارنتهما. axis:المحور الذي يتم عليه إجراء الحساب (بشكل افتراضي 0). equal_var: إذا كانت True (و هى ايضا القيمة الافتراضية)، يفترض الاختبار أن التباين (variance) بين المجموعتين متساوٍ. اما إذا كانت False، يتم استخدام صيغة ويلش (Welch's t-test) التي لا تفترض تساوي التباين. nan_policy:يحدد كيفية التعامل مع القيم المفقودة (NaN). الخيارات: propagate: يعيد NaN إذا كانت هناك قيم مفقودة. omit: يتجاهل القيم المفقودة. raise: يُثير خطأ إذا كانت هناك قيم مفقودة. alternative:لتحديد نوع الاختبار: two-sided (الافتراضي): اختبار ثنائي الاتجاه. less: اختبار أحادي الاتجاه (a < b). greater: اختبار أحادي الاتجاه (a > b). المخرجات: statistic: قيمة اختبار T. pvalue: القيمة الاحتمالية (P-value) التي تُستخدم لتحديد دلالة الفرق. و اليك مثال عملي للدالة: from scipy.stats import ttest_ind # بيانات لمجموعتين group1 = [10, 12, 15, 18, 20] group2 = [11, 14, 14, 16, 21] # إجراء الاختبار stat, pvalue = ttest_ind(group1, group2) print(f"T-statistic: {stat}") print(f"P-value: {pvalue}") و يكون الناتج: T-statistic: -0.0807 P-value: 0.9377 و يتك استخدامه: عندما تكون لديك مجموعتان مستقلتان (مثال: نتائج اختبارات طلاب فصلين مختلفين). للتحقق مما إذا كان الفرق في المتوسطات إحصائيًا وليس بسبب الصدفة. بالتوفيق1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. هي الدالة تستخدم لإجراء إختبار T للعينات المستقلة (T-test) حيث يتم إستخدامها للمقارنة بين متوسطات (means ) تلك العينات المستقلة وذلك لإستخراج أى فروق إحصائية بين المتوسطات (means). ويمكنك قراءة التوثيق الرسمي لها لكيفية الإستخدام والمعاملات التي تستقبلها : https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html1 نقطة
-
الغرض منها إجراء اختبار t للعينات المستقلة وهو اختبار إحصائي لمقارنة متوسطين لعينتين مستقلتين. وذلك عندما تريد معرفة هل هناك فرق ذو دلالة إحصائية بين متوسطين لعينتين مستقلتين. حيث تُجري ttest_ind اختبار t للعينات المستقلة وتُعيد قيمتين: القيمة p: وهي احتمال الحصول على الفرق المُلاحظ بين متوسطي العينتين إن لم يكن هناك فرق حقيقي بينهما. إحصائية t: وهي قياس الفرق بين متوسطي العينتين مُقسّمًا على خطأ المعياري. وتستقبل المعلمات التالية: a: مصفوفة NumPy تحتوي على البيانات للعينة الأولى. b: مصفوفة NumPy تحتوي على البيانات للعينة الثانية. axis: المحور الذي يتم حساب الاختبار عليه (افتراضيًا 0). equal_var: قيمة منطقية تُشير إلى ما إن كان يُفترض أن يكون التباين متساويًا بين العينتين (افتراضيًا True). nan_policy: كيفية التعامل مع القيم المفقودة (افتراضيًا "propagate"). للتوضيح: import scipy.stats as stats import numpy as np data1 = np.array([1, 2, 3, 4, 5]) data2 = np.array([6, 7, 8, 9, 10]) result = stats.ttest_ind(data1, data2) print(" p:", result.pvalue) print(" t:", result.statistic) لاحظ في حال كانت القيمة p أقل من مستوى الدلالة (عادةً 0.05)، فإننا نرفض الفرضية الصفرية ونستنتج أن هناك فرقًا ذو دلالة إحصائية بين متوسطي العينتين. أما لو القيمة p أكبر من مستوى الدلالة، فإننا لا نرفض الفرضية الصفرية ونستنتج أنه لا يوجد فرق ذو دلالة إحصائية بين متوسطي العينتين.1 نقطة
-
مرحبًا، هذه الدالة تقوم بتطبيق اختبار يدعى T-test على مجموعتين من عينات البيانات. يقوم هذا الاختبار بالتحقق من مدى تقارب المتوسط الحسابي لكل من المجموعتين و هو يستعمل في حال كانت هذه العينات تتبع إلى توزع طبيعي. أي فعليًا هي لا تفترض أي شيء حول الانحراف المعياري للتوزع الخاص بالبيانات، و لكنها تحاول قياس تقاربهما من ناحية المتوسط الحسابي فقط. تحياتي.1 نقطة
-
هل mac يعتبر خيار افضل للبرمجة وعلم البيانات1 نقطة
-
تم استعمال دالة trim() وانحلت المشكلة شكرا لك يالغالي1 نقطة
-
ما شاء الله عليك ضبط واشتغل معاي الله يسعدك في الدارين فيه شغلة بسيطة اذا مسحت اللي بداخل الحقل بيظهر كل البيانات اللي في القاعدة انا ابغاه ما يظهر شي الا اذا انكتب واول ما امسح بتختفي النتائج واخيرا اعتذر عن التأخير في الرد لم يصلني اشعارات من الموقع ان فيه رد على موضوعي .1 نقطة
-
وعليكم السلام، في مكتبات بتحسن استجابات النماذج اللغوية عشان تخليها ترد بشكل أكتر طبيعي وتفهم اللي بتطلبه بشكل أحسن. واحدة من المكتبات اللي بتستخدم بشكل كبير هي مكتبة RLHF (Reinforcement Learning from Human Feedback) (تعلم التعزيز من التغذية الراجعة البشرية). ببساطة، المكتبة دي بتساعدك تضبط النموذج بتاعك باستخدام ردود الأفعال اللي بيقدمها المستخدمين، وده بيخلي النموذج يتعلم ويرد بشكل أفضل. كمان فيه مكتبة Transformers من Hugging Face، اللي فيها أدوات ومميزات تساعدك تحسن طريقة تعامل النموذج مع المدخلات اللي بيدخلها المستخدمين. وفي حالة إنك عايز تحسن أداء النماذج الكبيرة زي GPT، تقدر تستخدم حاجة اسمها PPO (تحسين سياسة الاقتراب)، ودي طريقة تدريب للنموذج بتحسّن استجابته على أساس التفاعل مع المستخدم وتخلّيه يرد على الطلبات بشكل أفضل كل مرة. الأدوات دي كلها بتساعدك تخلي النموذج يستوعب أكتر ويستجيب بشكل أذكى مع كل موقف بيواجهه.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته. أولا يجب وضع كود الإستعلام المرفق في ملف php منفصل حتى يتم إرسال طلب البحث له و لنفرض أن إسم الملف هو search.php . الآن يجب وضع كود javascript التالي في نفس الملف الموجود به كود html : function showResult(str) { document.getElementById("livesearch").innerHTML = ""; fetch(`search.php?q=${encodeURIComponent(str)}`) .then(response => response.text()) .then(data => { document.getElementById("livesearch").innerHTML = data; }) .catch(error => { console.error('Error:', error); // التعامل مع الأخطاء إذا حدثت }); } وهكذا قمنا بإنشاء الدالة showResult الذي يتم إستدعاءها عند الحدث keyup . ونقوم فيها أولا بتفريغ محتوى العنصر livesearch وبعد ذلك نرسل طلب البحث إلى الملف search.php و نقوم بوضع كلمة البحث في parameter يسمى q و بعد ذلك نستقبل ال data وهي البيانات التي تم إرجاعها من الخادم من ملف search.php و نضعها بداخل العنصر livesearch. الآن في ملف search.php نستقبل الطلب كالتالي : <?php if (isset($_GET['q'])) { $SS_age = $conn->real_escape_string($_GET['q']); $qq = mysql_query("select * from `AA` where `BB` LIKE '%$SS_age%' "); if (mysql_num_rows($qq)) { // عرض النتائج while ($row = mysql_fetch_assoc($qq)) { echo "<div>" . $row['BB'] . "</div>"; // يمكنك تغير هذا السطر بناء على البيانات التي لديك } } else { echo "No results found"; } } وهكذا سيتم إرسال البيانات إذا وجدت في قاعدة البيانات . ويمكنك تغير السطر بداخل حلقة while إلى الكود الذي تريده لبناء القائمة الخاصة بالنتائج1 نقطة
-
انا بالفعل انهيت الوحدة وعلقت علي اخر درس ام تقصد اخر درس في المسار (الخاتمة)1 نقطة
-
الدومين ستحتاج إلى شرائه فهو غير مجاني ولديك منصة مثل Namecheap توفر ذلك، وبعد شرائه تستطيع ربطه على الاستضافة حتى لو مجانية. حيث أنّ الاستضافة المجانية توفر لك دومين فرعي subdomain مثلاً على netlify ستحصل على دومين فرعي مشابه للتالي: portfolio-project.netlify.app1 نقطة
-
توجد العديد من الإستضافات المجانية منها: GitHub Pages : وهو مجاني بالكامل وهو ممتاز للمشاريع الثابتة مثل (HTML/CSS/JS) لذلك يمكنك عمل build لمشروع weback ورفع مجلد build الذي يتم إنشاءه بعد تحزيم الملفات على GitHub Pages. netlify و vercel تلك الإستضافتين جيدتين لرفع المشاريع التي تعتمد بشكل أساسي على Java Script وتدعم العديد من أطر العمل مثل React, Angular, Vue.js, Next.js, و غيرها من اطر العمل لكن هذه اشهرها render تدعم معظم لغات البرمجة وأطر العمل الحديثة المتعلقة بالويب (Python, JavaScript, Go, Ruby, Elixir, Rust)، كما يمكنها أن تدعم أي شيء آخر عن طريق Docker أيضا. يمكنك الإطلاع على الخيارات المدعومة مع كيفية نشر المشاريع من هنا: https://docs.render.com/ وإذا كان مشروعك هو واجهة أمامية ثابتة فأنصحك Netlify أو Vercel و أخيرا GitHub Pages .1 نقطة


.png.b438c21f624375f6b3a8dcf261b0050c.png)