لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 11/03/24 in أجوبة
-
السلام عليكم, انا الان تقريبا انتهيت من فصل اساسيات لغة البايثون فقط تبقى لي درس تطبيق ادارة المهام وسؤالي هو هل يمكنني بعد الانتهاء ان اذهب مباشرة الى اساسيات اطار العمل جانغو لكي انشئ متجر الكتروني ثم بعد ذلك اعود الى فصل تطبيقات عملية باستخدام بايثون؟3 نقاط
-
السلام عليكم يعني من حيث الذكرا مين بيستهلك اكثر ؟3 نقاط
-
مرحباً، لقد قمت بشراء دورة الذكاء الاصطناعي قبل ساعات قليلة، وأود التأكد من أن محتوى الدورة سيفيدني في تحليل الشكاوى اليومية لعملائنا، والتي تتجاوز المئات يوميًا (حوالي 800-1200 شكوى يوميا يتم انشائها) . أحتاج إلى تطبيقات تساعدني في تصنيف الشكاوى واستخراج الأنماط، والتعرف على القضايا الناشئة والقائمة مع مرور الوقت وكذالك التعرف على مواضيع الشكاوى الحديثة و كمية تكرارها في السابق . على سبيل المثال، أتعامل مع ملف إكسل يحتوي على الشكاوى يتضمن رقم الشكوى، نص الشكوى كما كتبه الموظف أو العميل، تصنيف الشكوى (الأول، الثاني، الثالث) بناءً على تصنيف الموظف، وتاريخ الشكوى. كذلك يحتوي الملف على نص حل الشكوى (مثل إرضاء العميل بخصم، التواصل والاعتذار، وغيرها). نستخدم في الشركة برنامج QLik sense لإظهار البيانات على داشبورد، وأرغب في معرفة كيف يمكن للذكاء الاصطناعي مساعدتي في هذا السياق. بالإضافة إلى ذلك، نظرًا لأهمية سرية البيانات، فإن رفعها على الإنترنت غير ممكن. هل يمكنني التطبيق على خوادم الشركة دون الحاجة إلى رفع البيانات خارجها؟ أيضًا، أرغب في معرفة المواضيع الأساسية التي يجب أن أركز عليها وأتعمق فيها خلال الدورة لضمان استيعابي الجيد للتقنيات المتعلقة بتحليل الشكاوى وتصنيفها واستخراج الأنماط الزمنية منها. ما هي أهم الجوانب التي يجب التركيز عليها وتعلمها بعمق لتحقيق أهدافي من الدورة؟ وشكراً لكم3 نقاط
-
انا احتاج ان اتعلم تحليل البيانات وتعلم الالة لاجل دراستي في الكلية ولكني مازلت في المسار الثاني في بايثون هل ينفع ابدا بهم الان؟2 نقاط
-
في ضوء قواعد لغة البايثون، اكمل الأوامر التالية بحيث يسمح البرنامج التالي من طباعة الارقام المحصورة بين A و B بمقدار القفزة C ثم طباعة مجموع هذه الارقام S و المتوسط الحسابي a و حاصل ضرب الارقام f و اكبر قيمة من بين هذه الارقام max 1 def new_f(a,b,c): 2 x= 3 s=0; a=0; f=1; max=0 4 for i in range(0,len(x),1): 5 S= 6 a= 7 for i in range(0,len(x),1): 8 f= 9 10 max= return(x,s,a,f,max) الأمر الخاص بالسطر 2 يمكن التعبير عنه الامر الخاص بالسطر 5 يمكن التعبير عنه الامر الخاص بالسطر 6 يمكن التعبير عنه الامر الخاص بالسطر 8 يمكن التعبير عنه الامر الخاص بالسطر 9 يمكن التعبير عنه اذا علمت ان المستخدم قد ادخل 82 2=a فان النتائج المتوقعة تساوي... X=[,, ...], s... a=..., f=...., max=... 32 نقاط
-
كيف تتعامل مع تغييرات تم دفعها (pushed) بالخطأ إلى مستودع بعيد؟1 نقطة
-
اكادمية حسوب هل تعلم git1 نقطة
-
ما هو الموقع الي يعطين مشاريع وهميه تساعدني في بناء سيره ذاتيه كمصمم جرافيكي فتشوب والستريتور1 نقطة
-
1 نقطة
-
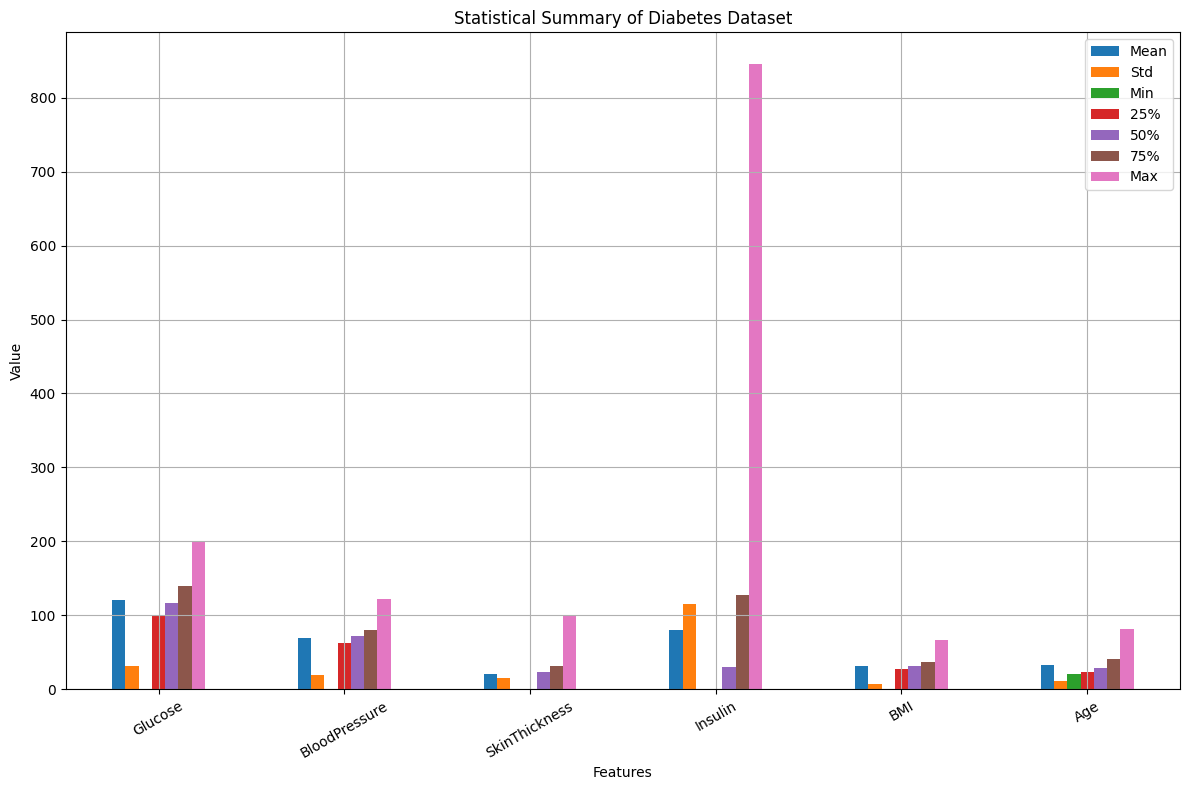
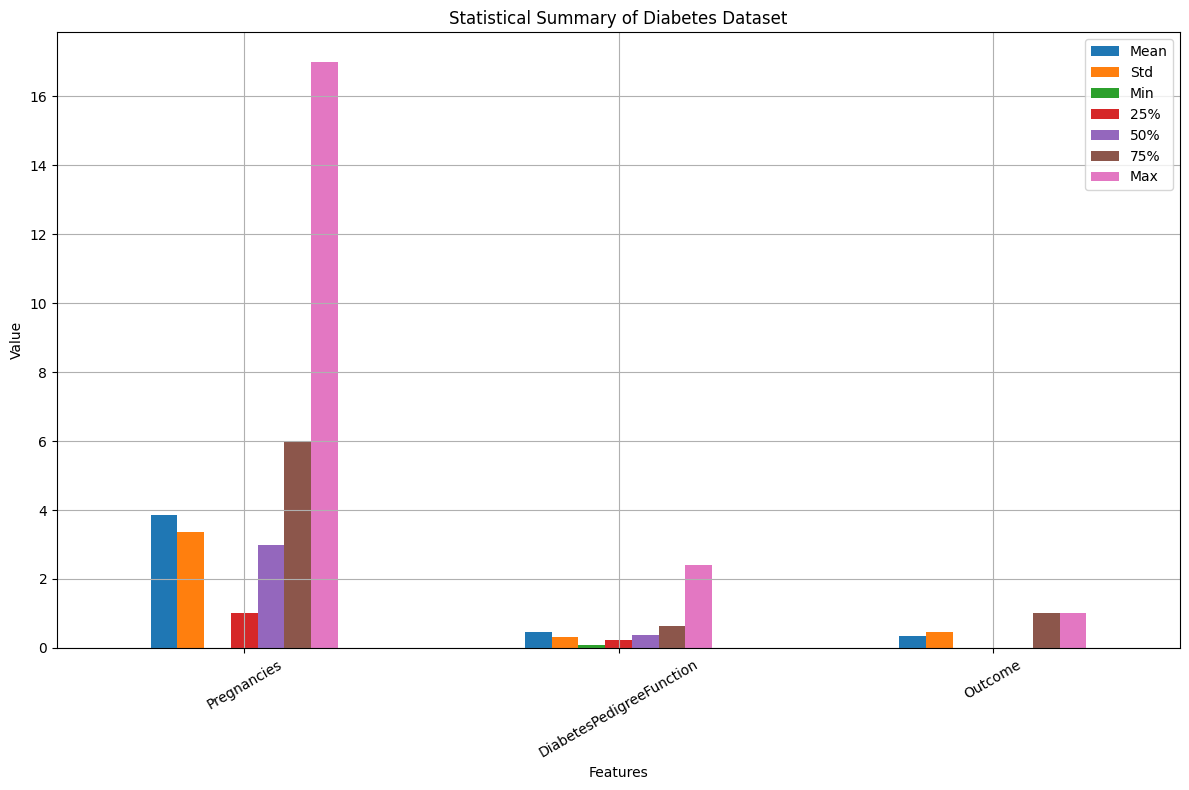
السلام عليكم دي صور بياني من تحليل بيانات مرض السكري في الصور دي الinsuline القميه القصوي اكبر من 800 فا هل ده طبيعي والا قيمه شاذ ه انا عاوز اتحقيق اعمل اي وكمان بردو في الصور التاني القميه القصوي لعمود الpregnancies اكبر من 16 فا هل ده طبيعي ؟
 1 نقطة
1 نقطة -
ذلك طبيعي بالنسبة للإختبار العشوائي لشخص مصاب بالسكر، لكن 800 µU/mL تعني شخص في حالة خطرة جدًا وهو مصاب بالسكر ويحدث في حالات نادرة وشديدة، أو من الممكن بسبب وجود خطأ في القياس أو تسجيل البيانات، أو يمكن أن تكون بسبب حالات طبية معينة مثل مقاومة الأنسولين الحادة أو الأورام المنتجة للأنسولين، مثل ورم خلايا بيتا في البنكرياس (الإنسولينوما). لمعالجة الأمر في البيانات قم بحساب المتوسط وإزالة القيم المنخفضة جدًا والقيم العالية جدًا.1 نقطة
-
الأمر يتوقف على البيانات التي لديك، من أين حصلت عليها لتفقد الوحدة التي يتم بها قياس مستوى السكر في الدم؟1 نقطة
-
الفرق الرئيسي بين recursion وloop يكمن في كيفية تنفيذ التكرار فالحلقات تستخدم بنية تحكم لتكرار كتلة من التعليمات البرمجية بشكل مباشر، بينما recursion يحقق التكرار عن طريق استدعاء الدالة نفسها من داخلها. هذا يؤدي إلى اختلافات مهمة في الأداء واستهلاك الذاكرة. الحلقات يمكن اعتبارها مناسبة للمهام التكرارية البسيطة حيث يكون الأداء هو الاعتبار الرئيسي أما recursion فهو مناسب للمشاكل التي يمكن تقسيمها إلى نسخ أصغر من نفسها مثل عمليات البحث في الأشجار مثلا لكن الاعتماد على أيّ منها يعتمد على طبيعة المشكلة والمتطلبات الخاصة بالمشروع ففي كثير من الأحيان يمكن تحويل recursion إلى حلقات والعكس صحيح، ولكن يجب مراعاة تأثير ذلك على الأداء واستهلاك الذاكرة.1 نقطة
-
الكثيرون يجهلون أهمية الدروس الأساسية من اللغة، وللأسف دراسة الدروس نفسها وحدها لا يكفي للتعلم والاحتراف فما بالك بتخطيها لذا أنصحك بدروس المسارات بالترتيب المعلوم به فذلك الترتيب مدروس وبالطبع مع الأخذ بعين الاعتبار المجهود الذاتي في التعلم من خلال التطبيق العملي، يمكنك تصفح عدة نصائح من هنا:1 نقطة
-
وعليكم السلام ورحمة الله، أود أن أشكركم أولاً على الجهد الرائع الذي تبذلونه في الدورة. لقد أتممت بحمد الله قسم Python بالإضافة إلى الأقسام المتعلقة بالنماذج اللغوية الكبيرة (LLMs)، وتحليل البيانات، والتعلم الآلي. لدي رغبة قوية في تطبيق ما تعلمته منكم لبناء Chatbot مخصص لموقع معين، بحيث يكون مدربًا على محتوى الموقع ويقدم أجوبة تفصيلية للسائلين بدون الحاجة إلى استخدام أي نماذج لغوية جاهزة (LLMs) مثل GPT أو غيره. سؤالي هو: هل من الممكن تحقيق هذا الأمر بناءً على المعلومات التي قدمتموها حتى الآن في المحاضرات؟ وإذا كان الجواب نعم، فهل بالإمكان تزويدي بخارطة أو خطوات توجيهية توضّح العناصر والأدوات الأساسية التي سأحتاجها لتطوير هذا الـChatbot؟ بحيث تشمل هذه الخطوات كيفية تجهيز البيانات، وطرق التدريب، وأي أدوات برمجية تنصحون بها لتحقيق هذا الهدف. أشكركم مقدماً على وقتكم ومساعدتكم، وجزاكم الله خيراً.1 نقطة
-
لا مشكلة وذلك أفضل لك بالطبع، أسهل طريقة لفعل ذلك هي من خلال unsloth حيث يتوفر Notebook جاهز للقيام بذلك على حاسوبك أو من خلال Google colab والأفضل من خلال Google colab. الأمر سيتم كالتالي: تثبيت الحزم المطلوبة لعمل Fine Tuning تجهيز بيانات التدريب Dataset ثم عمل Inference للنموذج، أو ما يُعرف أيضًا بـ الاستدلال أو التنبؤ، هو استخدام النموذج المُدرّب بالفعل لإنتاج مخرجات (تنبؤات) لبيانات جديدة لم يرها من قبل. ثم حفظ النموذج في النهاية على Ollama أو Hugging Face أو على حاسوبك. ستحتاج إلى مشاهدة شرح عملي لذلك، ابحث عن "Fine Tune Llama 3.1 unsloth" على اليوتيوب.1 نقطة
-
و عليكم السلام نعم يمكنك ذلك و لكن : و لكن لا انصحك بهذا فالتطبيقات على لغة البايثون لا غنى عنها فى اى مجال اخر او اطار عمل و سوف تساعدك على اتمام الاساسيات لديك فغير ذلك سياتى بنتيجة عكسية و بعد ذلك و بعد الانتهاء من التطبيقات من الافضل لك أن تنتهى من دورة أساسيات اطار عمل Django قبل البدأ فى انشاء متجر الكترونى باستخدام Django.1 نقطة
-
أعتقد أنّ الانتقال مباشرة من قسم أساسيات لغة بايثون إلى دجانغو سيكون صعبا قليلا إن لم تترسخّ تلك المفاهيم بشكل جيد من خلال التطبيقات العملية، ومسار تطبيق إدارة المهام هو مسار مهم وتم إعداده لهذا الغرض وهو تطبيق أغلب المفاهيم النظرية التي تم التطرق لها، لذا أنصحك بإتمام المسار كاملا ثم الانتقال بعد ذلك إلى إطار العمل دجانغو.1 نقطة
-
لا أنصحك بذلك، الأمر سيأتي بنتيجة عكسية، حيث تحتاج إلى التطبيق على أساسيات بايثون بشكل مطور نسبيًا وذلك من خلال مسار التطبيقات. بينما الإنتقال سريعًا من أجل تعلم إطار أو مكتبة لن يفيدك إلا إن كنت بحاجة إلى ذلك بشكل ضروري مثلاً، أيضًا أنصحك بعد الإنتهاء من مسار التطبيقات أن تبحث على اليوتيوب عن "مشاريع بايثون للمبتدئين" ثم اختر مشروع منهم واعمل على تنفيذه والتعلم من الشرح. بعد ذلك تستطيع الإنتقال لتعلم الإطار أو المكتبة التي تريدها في باقي الدورة، فمرحلة الأساسيات هي الأهم لذا يجب الصبر عليها لكي لا تواجه صعوبة فيما بعد.1 نقطة
-
ستحتاج إلى إنهاء المسار الأول وهو الأساسيات ثم المسار الثاني وهو تطبيقات عملية على الأساسيات، بعد ذلك تستطيع تعلم المسار الذي تريده لا مشكلة، الأهم هو الإهتمام بأساسيات بايثون جيدًا وتنفيذ مشروعين على الأقل.1 نقطة
-
بالضبط التكرار فعلا له حالات معينة يكون فيها أكثر فعالية أو سهولة في التعبير عن الحل، وخاصة في مسائل الخوارزميات والرياضيات المقطعية، ولكن ليس كل شيء يمكن حله بكفاءة باستخدام التكرار، خاصة في المسائل التي تتطلب عمق استدعاء كبير، لذا يفضل التفكير في التوازن بين الأداء وسهولة الفهم عند اختيار التكرار أو الحلقات. أما مشكلة Stack Overflow يمكن أن تحدث في جميع اللغات، سواء كانت لغات عالية المستوى مثل بايثون أو لغات منخفضة المستوى مثل C وC++، لأنها تتعلق بالذاكرة المتاحة في الـ Stack، وهي جزء من ذاكرة النظام المخصص لاستدعاءات الدوال، سواء في بايثون أو في C/C++ أو أي لغة تدعم التكرار العميق.1 نقطة
-
بدون استخدام أي LLMS ذلك سيكلفك الكثير من الوقت والمجهود، أيضًا ذلك سيحجم من قدارات الـ chatbot فبدون NLP سيصبح ذكاءه محدود لأنك ستعتمد على Decision Trees أو Keyword Matching. ستحتاج إلى تنفيذ ما يسمى transfer learning بنقل المعرفة إلى نموذج مدرب مسبقًا، وعمل fine-tune للطبقة الأخيرة أو يمكنك تدريبه على البيانات لكن بوتيرة أعلى high learning rate. والمسار الأخير في الدورة سيتم به شرح ذلك "تطبيقات عملية على نقل التعلم Transfer Learning"، لذا أرجو الإنتظار لحين الإنتهاء من الدورة لتنفيذ ما تريده. وللعلم يوجد أداة تمكنك من تنفيذ ما تريد وستحصل على API لاستخدامه بموقعك لكنها مدفوعة ولديك 14 يوم تجريبي: https://chatwith.tools/1 نقطة
-
بالطبع تستهلك الـ Recursion كمية أكبر من الذاكرة مقارنة بالـ Loop، لأن كل استدعاء متكرر للدالة يُنشئ إطارًا جديدًا على المكدس stack. وذلك يؤدي ذلك إلى مشكلة Stack Overflow في حال كان عدد الاستدعاءات كبيرًا جدًا. والمكدس هو منطقة من الذاكرة تُستخدم لتخزين البيانات بطريقة LIFO (Last In First Out)، وتُدار تلك المنطقة من الذاكرة بواسطة وحدة المعالجة المركزية CPU بشكل تلقائي. والـ Recursion أبطأ من الـ Loop في بعض الحالات، خاصةً مع عدد الاستدعاءات الكبيرًا لأن تكلفة إنشاء إطارات المكدس وإدارتها تكون عالية. بالتالي الـ Recursion نستخدمه في حل المشكلات التي يمكن تقسيمها إلى مشكلات أصغر من نفس النوع مثل الـ Tree Traversal والـ Merge Sort. بينما الـ Loop حل المشكلات التي تتطلب تكرار مجموعة من التعليمات لعدد محدد من المرات أو حتى يتم استيفاء شرط معين مثل التكرار على قائمة والتحقق من شرط معين.1 نقطة
-
بالنسبة للتكرار أو Recursion هو عملية استدعاء الدالة لنفسها، و كل مرة يتم استدعاء الدالة من داخل نفسها، يتم تخصيص مساحة إضافية في الـ Stack لتخزين معلومات حول هذه الاستدعاءات، مثل المعاملات الحالية ونقطة العودة، وهذا الأمر يستهلك ذاكرة أكثر عادة، لأنه يحتاج إلى تخصيص ذاكرة جديدة في الـ Stack لكل استدعاء للدالة، وبالتالي يجعل التكرار غير ملائم في بعض الحالات التي تتطلب عمق استدعاء كبير، وقد يؤدي إلى Stack Overflow إذا تجاوز عدد الاستدعاءات الحد الأقصى المسموح به. أما الحلقات تستهلك ذاكرة أقل لأنها لا تحتاج إلى إضافة سياقات استدعاء جديدة كما يحدث في التكرار، و يمكن أن تعمل بشكل مستمر دون خوف من تجاوز ذاكرة الـ Stack، لذا من حيث استهلاك الذاكرة، الحلقات أفضل بكثير من التكرار، ولكن لكل منهما استخداماته وميزاته الخاصة حسب طبيعة المشكلة.1 نقطة
-
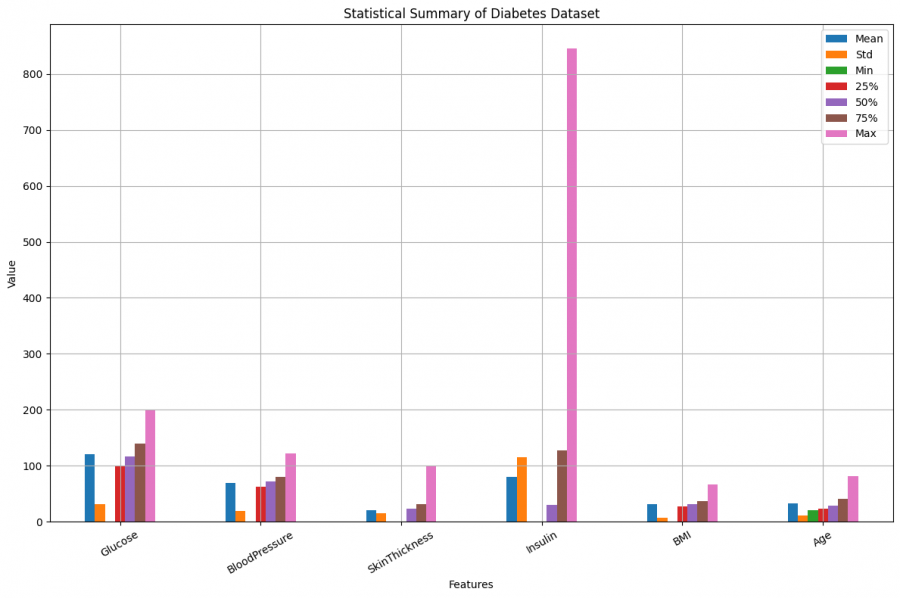
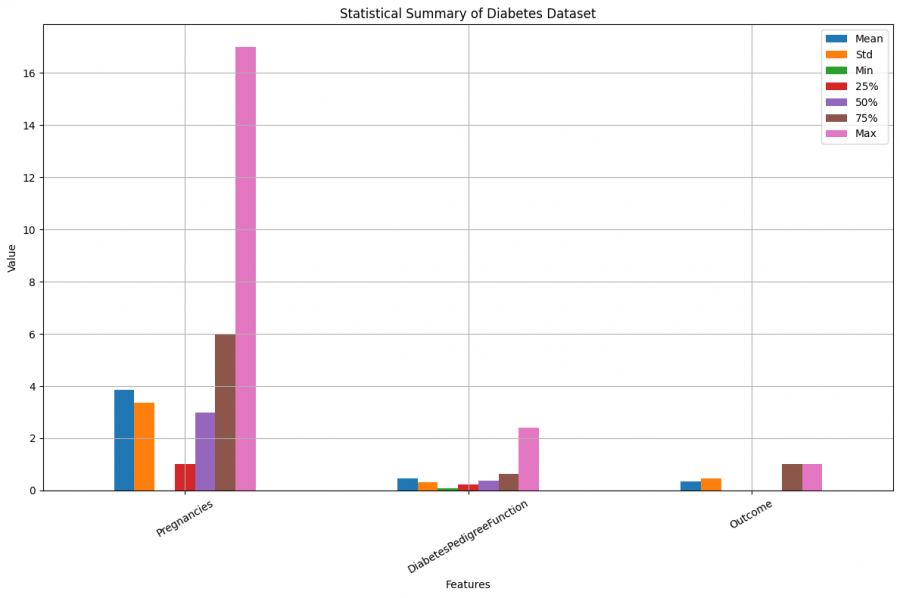
و عليكم السلام الخطأ ناتج عن استخدام الأقواس الخطأ في بعض السطور. حيث يتم استخدام loc لتحديد الإحصائيات، تم استخدام الأقواس العادية () بدلاً من الأقواس المربعة []. في pandas، عندما نستخدم loc، يجب أن نستخدم الأقواس المربعة للوصول إلى الأعمدة أو الصفوف المحددة. # الحصول على الوصف الإحصائي لبيانات محددة statistical0 = diabetes.drop(['Outcome','DiabetesPedigreeFunction','Pregnancies'], axis=1).describe() statistical1 = diabetes.drop(['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'Age'], axis=1).value_counts().describe() plt.figure(figsize=(10, 8)) # تصحيح الأقواس في loc statistical0.loc[['mean', 'std', 'min', "25%", "50%", "75%", 'max']].transpose().plot(kind='bar', figsize=(12, 8)) statistical1.loc[['mean', 'std', 'min', '25%', '50%', '75%', 'max']].transpose().plot(kind='bar', figsize=(12, 8)) plt.title("Statistical Summary of Diabetes Dataset") plt.xlabel("Features") plt.ylabel("Value") plt.xticks(rotation=30) plt.legend(["Mean", "Std", "Min", "25%", "50%", "75%", "Max"]) plt.grid(True) plt.tight_layout() plt.show() و يجب ايضا التاكد من قيمة السطر التانى من الكود و يمكنك معرفة قيمتها باستخدام: print(statistical1)1 نقطة
-
نعم هناك فرق بين المكتبة و الوحدة (module) بالرغم أنه يتم إستخدام المصطلحين للتعبير عن بعضهم البعض. المكتبة هي مجموعة من الوحدات (modules) والملفات التي تحتوي على وظائف ودوال عديدة.أما الوحدة (module) هو عبارة عن ملف واحد وليس العديد من الملفات .1 نقطة
-
بالطبع، المكتبة عبارة عن مجموعة من الوحدات Modules بينما الوحدة Module هي ملف واحد به كود لإعادة استخدامه في مكان آخر.1 نقطة
-
يمكن ذلك من خلال اتباع عدة خطوات، أولا يجب إنشاء دالة رئيسية هي التي ستتولى إدارة البرنامج وفي داخل هذه الدالة يمكنك استخدام دالة input() لطلب عدد المواد الدراسية من الطالب، مع التأكد من أن المدخل هو عدد صحيح أكبر من صفر باستخدام حلقة while للتحقق من صحة المدخلات الخطوة التالية هي إنشاء قاموس لتخزين معلومات كل مادة، حيث سيكون لكل مادة مفتاح فريد يمثل رقم المادة وقيمة تتضمن درجة المادة وعدد ساعاتها وهنا سيخطر ببالك استخدام حلقة for لطلب الدرجات وعدد الساعات لكل مادة، مع التحقق من صحة إدخالات الساعات باستخدام try-except للتأكد من أنها أرقام صحيحة أم لا وبعد إدخال جميع البيانات، يمكنك طباعة المعلومات المدخلة. يمكنك إيجاد ما ترغب فيه وأكثر من خلال دروس موسوعة حسوب في بايثون: لغة بايثون Python.1 نقطة
-
أولاً يجب تفهم أنك ستحتاج إلى 4 أو 5 أضعاف وقت الدورة من أجل دراستها بشكل سليم، وذلك ما بين مشاهدة ثم استيعاب ثم حفظ ثم تطبيق ثم مراجعة وتكرار وبحث. عليك بالتالي: مشاهدة 4 دروس قصيرة ثم التوقف والتطبيق على ما جاء بها من خلال إعادة ما قام به المدرب. أو درس واحد طويل وتقسيمه إلى أجزاء والتوقف ثم التطبيق بمفردك. ولا مشكلة في التطبيق مع المدرب، لكن بعد الإنتهاء عليك إعادة ما قمت به بمفردك لكي تختبر استيعابك وتركيزك يُصبح أكبر. (خصص نسخة للتطبيق مع الشرح مثلاً ونسخة أخرى للتطبيق عليها بمفردك). والمهم هو ألا تقوم بخطوة دون معرفة لماذا قمت بها، فالبرمجة ليست نسخ أكواد بل وظيفتك هي حل مشاكل برمجية لذا استيعابك للأدوات واللغة نقطة فارقة للمبرمج المتميز. وهناك مثال جيد هو "يمكنك مشاهدة فيلم لكن لن تصبح مخرج أفلام" لذا عليك بالممارسة العملية وأن تكون طالب فاعل وليس مشاهد سلبي فقط، يجب التدرب على نماذج صغيرة في البداية ثم التدرج في الصعوبة وإنشاء مشاريع كاملة، وعدم الإكتفاء بمشاريع الدورة ونماذجها فقط. وفي الدورة لا تكتفي ببناء المشروع مرة واحدة فقط، حاول إعادة بنائه بمفردك، ولا مشكلة أبدًا إذا نسيت بعض الأشياء لا تنزعج من ذلك إطلاقًا. فمرة واحدة لا تكفي أبدًا، حيث أنك في المرة الأولى تستوعب بنسبة 70% وأنت بحاجة إلى الـ 30% الأخرى والتي تحصل عليها من خلال إعادة بناء المشروع بمفردك بدون مشاهدة شرح المدرب. وبالطبع ليس عليك تذكر كل شيء قمت بدراسته ولكن يجب استيعاب كل شيء تقريبًا بنسبة 80% وبعض الأمور ستتضح لك من الواقع العملي بعد فترة وتنفيذ المشاريع. فلا أحد يتذكر كل شيء ويتم البحث عن ما نريده ويتم تذكر الأمر لأنك تعرف ما تريد البحث عنه، لكن الحفظ والاستيعاب مهمان في البداية.1 نقطة