لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/04/24 in أجوبة
-
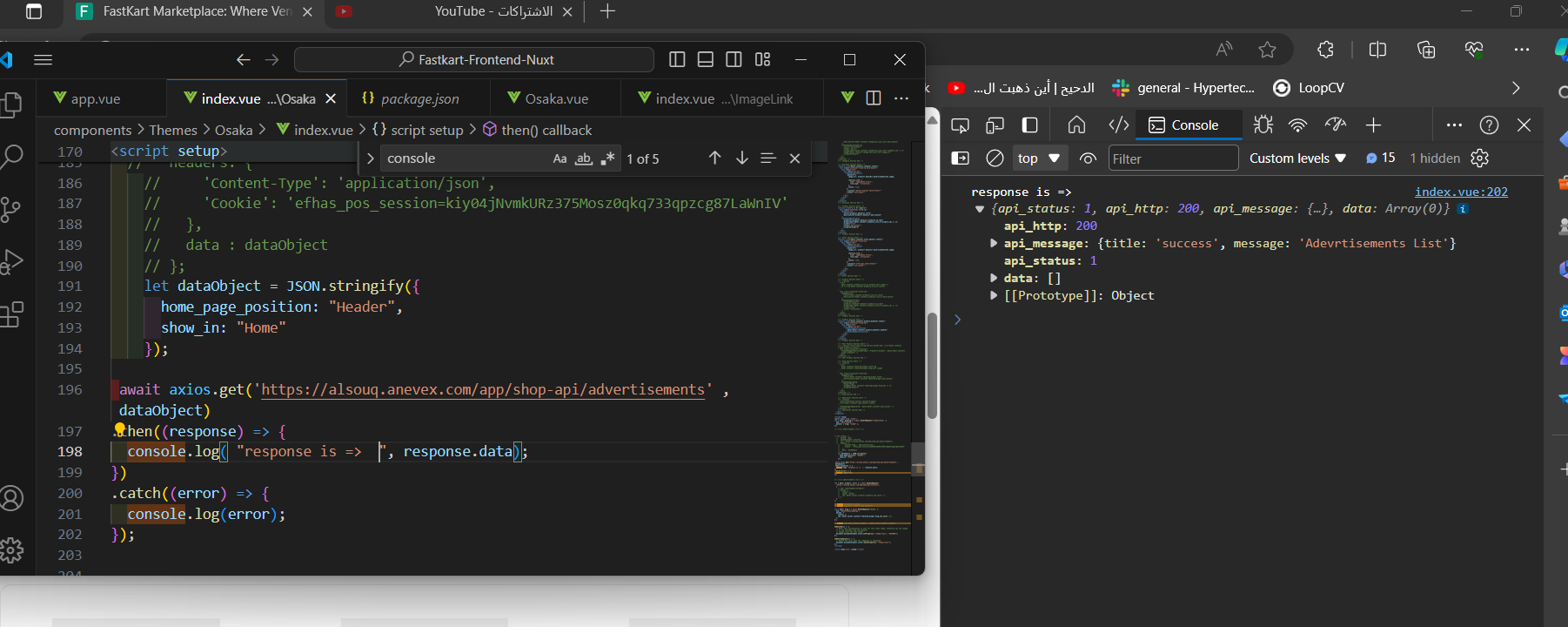
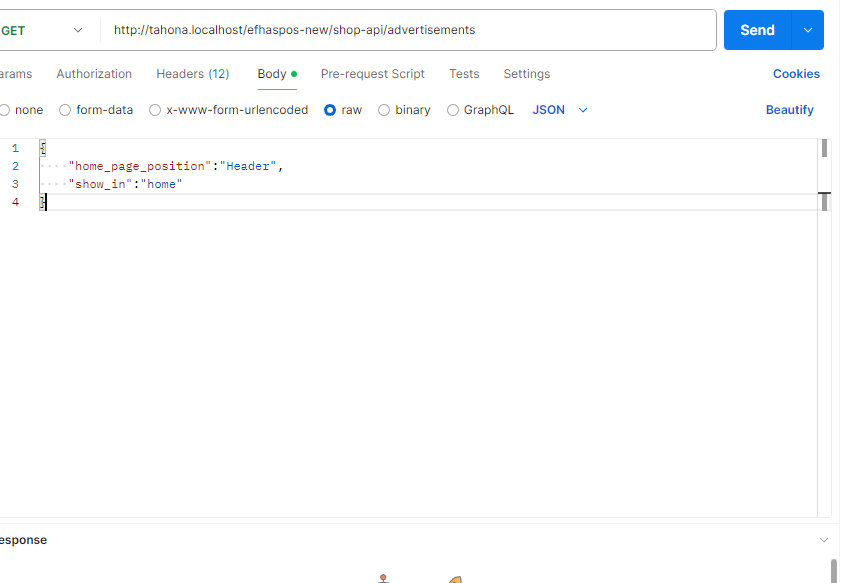
سلام عليكم ازاى اعمل request عن طريق axios للرابط دة https://alsouq.anevex.com/app/shop-api/advertisements لكن مع اضافة المصفوفة اللى ظاهرة فى الصورة تحت عنوان Body => Raw لان بدون اضافة المصفوفة بترجعلى data فاضية
 4 نقاط
4 نقاط -
السلام عليكم في مكتبه sklearn هو الparameters (normalize) مش موجود في الmodel LinearRegression ؟2 نقاط
-
السلام عليكم هل الLinearRegression مش افضل حاجه دلوقتي وهل فيه نموذك افضل من نموذج ؟ يعني مثل الRandomForestClassifier افضل من الLinearRegression والا الا علي حساب البيانات اي2 نقاط
-
اختيار النموذج المناسب يعتمد على العديد من العوامل بما في ذلك طبيعة البيانات، الهدف من النموذج، والأداء المطلوب. بالتالي القول بأن نموذجًا معينًا مثل RandomForestClassifier هو دائمًا أفضل من LinearRegression غير دقيق، لأن كل منهما يخدم أغراضًا مختلفة ويعمل بشكل أفضل في ظروف معينة. لديك LinearRegression نموذج بسيط وسهل الفهم يستخدم للعلاقات الخطية بين المتغيرات المستقلة والمتغير التابع، ومناسب في حال العلاقة بين متغيراتك خطية وتحتاج إلى تفسير بسيط للنموذج. بينما RandomForestClassifier نموذج أكثر تعقيدًا يستخدم للأغراض التصنيفية، ويعمل بشكل جيد عندما تكون البيانات معقدة وتحتوي على العديد من الميزات التي قد تتفاعل مع بعضها بطرق غير خطية، ويتميز بأنه يستخدم مجموعة من الأشجار decision trees ويجمع نتائجها للحصول على تصنيف أكثر دقة. واستخدم التحقق المتبادل لتقييم أداء النموذج على مجموعة من البيانات غير المرئية للنموذج، وقد تحتاج إلى ضبط الباراميترات للنماذج المعقدة لتحسين أدائها.2 نقاط
-
بالضبط، ففي مكتبة scikit-learn، باراميتر normalize لم يعد موجودًا في الإصدار 0.24.0 وما بعده من النموذج LinearRegression. في الإصدارات الأحدث من المكتبة، عليك استخدام StandardScaler أو Normalizer من مكتبة sklearn.preprocessing لتطبيع البيانات قبل تمريرها إلى النموذج. للتوضيح: from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler import numpy as np X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([1, 2, 3, 4]) scaler = StandardScaler() X_scaled = scaler.fit_transform(X) model = LinearRegression() model.fit(X_scaled, y) predictions = model.predict(X_scaled) print(predictions) لاحظ تطبيع البيانات باستخدام StandardScaler قبل استخدامها في تدريب النموذج LinearRegression، وذلك يحقق نفس النتيجة التي كان يحققها استخدام الباراميتر normalize=True في الإصدارات الأقدم.2 نقاط
-
اطفه المستودع القديم والجديد في لينكس منت عندي اخطاى في النطم في لبترمنل هذي التقريارير النطم1 نقطة
-
شكراا جدا لحضرتك تمام1 نقطة
-
في الكود الثاني، قمت بتطبيق التحجيم القياسي (StandardScaler)فقط على بيانات التدريب (x_traing) ولكن لم تقم بتطبيق نفس التحجيم على بيانات الاختبار (x_test). هذا يؤدي إلى عدم توافق في توزيع البيانات بين التدريب والاختبار، مما يسبب زيادة كبيرة في الخطأ. يجب عليك أيضًا تطبيق التحجيم على بيانات الاختبار باستخدام نفس التحجيم الذي استخدمته لبيانات التدريب: import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'], axis=1, inplace=False) outpnt = data['target'] x_traing, x_test, y_traing, y_test = train_test_split(feutures, outpnt, test_size=0.25, random_state=44, shuffle=True) scaler = StandardScaler() x_scaler_traing = scaler.fit_transform(x_traing) x_scaler_test = scaler.transform(x_test) # تطبيق نفس التحجيم على بيانات الاختبار linearregression = LinearRegression(fit_intercept=True, copy_X=True, n_jobs=-1) fit = linearregression.fit(x_scaler_traing, y_traing) y_prodict = fit.predict(x_scaler_test) msevalue = mean_squared_error(y_test, y_prodict, multioutput="uniform_average") print(f"MSEvalue: {msevalue}") وتأكد من أن البيانات في ملف heart_disease.csv لا تحتوي على قيم شاذة أو غير منطقية يمكن أن تؤثر على النتائج بعد التحجيم. بتطبيق التعديلات السابقة، يجب أن تحصل على نتائج أكثر منطقية لقيمة MSE.1 نقطة
-
انا اول ما عملت كده يا أ.مصطفي فا حسابات الMSE فا كان ده النتجيه 87.53644204505163 مع العلم قبل ما اعمل كده فا كانت النتجيه 0.12410403813221675 فا اي السبيب ؟ وده الكود قبل import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'] , axis=1 , inplace=False) outpnt = data['target'] x_traing , x_test , y_traing , y_test = train_test_split(feutures , outpnt , test_size=0.25, random_state=44 , shuffle=True) linearregression = LinearRegression(fit_intercept=True , copy_X=True , n_jobs=-1) fit = linearregression.fit(x_traing , y_traing) y_prodict = fit.predict(x_test) msevalue = mean_squared_error(y_test , y_prodict , multioutput="uniform_average") print(f"MSEvalue: {msevalue}") وده الكود بعد import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'] , axis=1 , inplace=False) outpnt = data['target'] x_traing , x_test , y_traing , y_test = train_test_split(feutures , outpnt , test_size=0.25, random_state=44 , shuffle=True) scaler = StandardScaler() x_scaler_traing = scaler.fit_transform(x_traing) linearregression = LinearRegression(fit_intercept=True , copy_X=True , n_jobs=-1) fit = linearregression.fit(x_scaler_traing , y_traing) y_prodict = fit.predict(x_test) msevalue = mean_squared_error(y_test , y_prodict , multioutput="uniform_average") print(f"MSEvalue: {msevalue}")1 نقطة
-
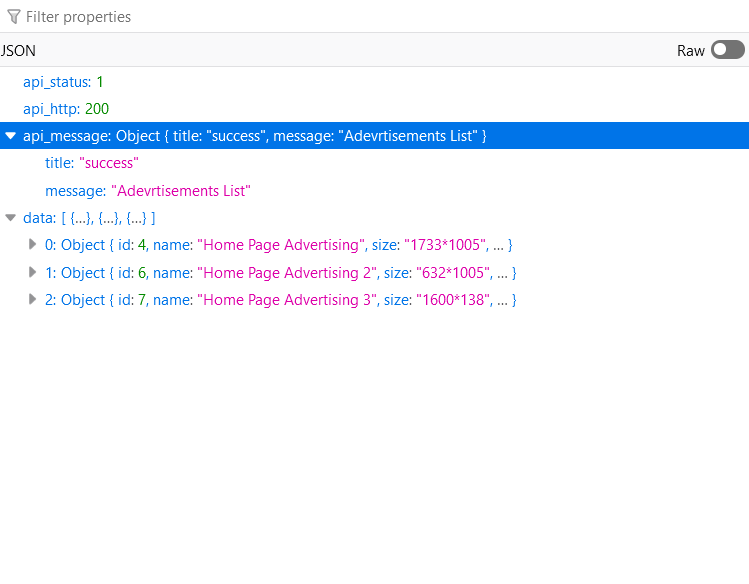
مرحباً محمد , يمكنك نتفيذ هذا الكود سيعمل كما في الصورة المرفقة , أيضاً قمت بتوضيح خطوة خطوة من خلال التعليقات : const url = 'https://alsouq.anevex.com/app/shop-api/advertisements'; const params = { home_page_position: 'Header', show_in: 'home' }; // Send the GET request axios.get(url, { params }) .then(response => { // Handle the response console.log('Data:', response.data); }) .catch(error => { // Handle any errors console.error('Error fetching data:', error); }); ايضاً لاحظ عند ارسال سيكون عنوان url بالشكل التالي لان نوع method الخاصة ب api هي GET : https://alsouq.anevex.com/app/shop-api/advertisements?home_page_position=Header&show_in=home
 1 نقطة
1 نقطة -
My pleasure, You’re welcome! 😊1 نقطة
-
1 نقطة
-
وعليكم السلام Understanding the mathematical equations associated with models can be helpful for comprehending how each model works and customizing its usage effectively. However, it’s not necessary to memorize all the equations in detail. In fact, you can rely on programming libraries and available tools to execute these equations instead of memorizing them manually. For example, in the case of Linear Regression, the main equation is: [ y = \beta_0 + \beta_1 x ] Where: (y) represents the target value (dependent variable). (x) represents the independent variable. (\beta_0) and (\beta_1) are the regression coefficients. As for the RandomForestClassifier model, it relies on an ensemble of decision trees and doesn’t have a specific mathematical equation in the same way.1 نقطة
-
تمام بس سوال كمان كل نموذج ليا معادلات رياضيه فا هل موطلب مني معرفت المعادالات لكل نموذج استخدمو ؟ ان عرف LinearReagression1 نقطة
-
وعليكم السلام The Linear Regression model and the RandomForestClassifier model differ in their use cases and the contexts where they are most beneficial.: 1Linear Regression: The Linear Regression model is used when we assume a linear relationship between the dependent variable (target) and the independent variables (predictors). It is suitable for continuous numerical data and can be used to predict target values using a straight line. Example: It can be used to predict house prices based on house size. 2Random Forest Classifier: The RandomForestClassifier model is used for classification, not continuous value prediction. It relies on an ensemble of decision trees and combines their predictions for classification. It is suitable for categorical data (such as classifying into specific categories). 3General Considerations: The choice of model depends on the nature of the data and the goal of the analysis. If you want to predict continuous values, Linear Regression is the appropriate choice. If you want to perform classification, RandomForestClassifier is the suitable choice.1 نقطة
-
1 نقطة
-
وعليكم السلام! In the scikit-learn library, the normalize parameter is not available in the LinearRegression model. The LinearRegression model is used to fit a linear model with coefficients w = (w1, ..., wp) to minimize the sum of squared residuals between observed targets in the dataset and the predicted targets from the linear approximation If you need to apply normalization to your data before using the LinearRegression model, you can use the normalize function from scikit-learn to normalize the data. This function helps standardize the data and avoids issues related to varying scales.1 نقطة
-
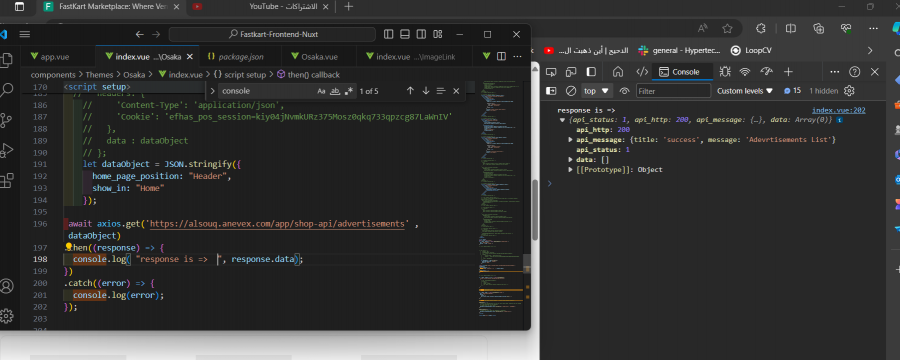
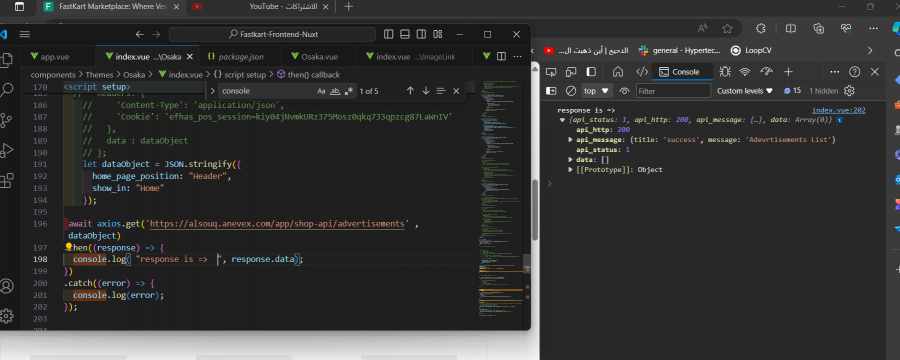
مازالت الداتا ترجعلى فاضية حتى بعد تجربة الكود المتوفر من البرنامج على الرغم من ان ال postman بيرجع داتا موجودة فعلا بعد التجربة مازالت ترجع الداتا فاضية على الرغم من ان ال postman يرجع داتا حقيقية جربت الطريقة لكن ما زالت الداتا ترجع فاضية
 1 نقطة
1 نقطة -
شكرا جزيلا للافادة1 نقطة
-
هذا هو الكود الذي تبحث عنه : axios.get("https://alsouq.anevex.com/app/shop-api/advertisements" , { data:{ home_page_position:"header", show_in:"home" } }) والنتيجة
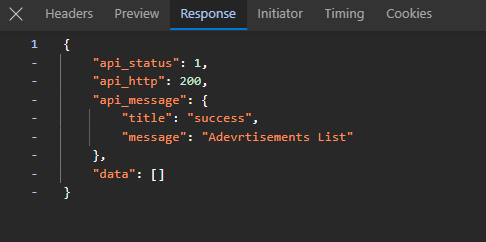 1 نقطة
1 نقطة -
توجد العديد من الطرق لكن بصفة عامة، يمكنك استخدام هذه الشيفرة ولاحظ التعليقات التي وضعتها وهي تشرح بشكل جيد دور كل سطر من البرنامج: // 1. استيراد مكتبة Axios import axios from 'axios'; // 2. تعريف الكائن JavaScript مع نفس بنية الكائن JSON في "Body => Raw" const jsonObject = { "home_page_position": "Headers", "show_in": "home" }; // 3. استخدام طريقة axios.post() لإرسال طلب POST axios.post('https://alsouq.anevex.com/app/shop-api/advertisements', jsonObject) // 4. في حالة نجاح الطلب .then(response => { // طباعة البيانات الواردة في الاستجابة على الكونسول console.log(response.data); }) // 5. في حالة وجود خطأ .catch(error => { // طباعة الخطأ على الكونسول console.error(error); }); ففي البداية نقوم باستيراد مكتبة Axios باستخدام: import axios from 'axios';. بعد ذلك، نعرّف كائنا JavaScript jsonObject بنفس بنية الكائن JSON الموجود في جزء "Body => Raw" من الصورة. ثم نستخدم طريقة axios.post() لإرسال طلب POST إلى الرابط الذي تريد وفي حالتنا https://alsouq.anevex.com/app/shop-api/advertisements. أول Argument للطريقة post() هو الرابط، وأما الثاني هو البيانات التي نريد إرسالها في جسم الطلب، وفي هذه الحالة هو الكائن jsonObject. إذا نجح الطلب، سيتم استدعاء دالة then مع استجابة الخادم ك Argument. داخل هذه الدالة، نقوم بطباعة البيانات الواردة في الاستجابة على الكونسول باستخدام console.log(response.data). إذا حدث خطأ أثناء الطلب، سيتم استدعاء دالة catch مع الخطأ ك Argument. داخل هذه الدالة، نقوم بطباعة الخطأ على الكونسول باستخدام console.error(error). عند استخدام طريقة axios.post() وتمرير الكائن jsonObject ك Argument ثانية، ستقوم Axios تلقائيا بتعيين رؤوس الطلب المناسبة (Content-Type: application/json) وترميز الكائن jsonObject كجسم الطلب.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته . إرسال الطلبات requests بواسطة axios بسيط ولكنه يعتمد على نوع البيانات التي تريد إرساله . فكما في المثال السابق ستقوم بإرسالها بصيغة json والطريقة كالتالي : const json = JSON.stringify({ home_page_position: "Header",show_in:"home" }); const res = await axios.post('https://alsouq.anevex.com/app/shop-api/advertisements', json); وهكذا سيتم إرسال الطلب . أما إذا أردت إرسالها ك form سنقوم بالتالي : let data = new FormData(); data.append("home_page_position", "Header"); data.append("show_in", "home"); const res = await axios.post('https://alsouq.anevex.com/app/shop-api/advertisements', data); وهكذا سيتم إرسالها كأنه تم الإرسال من form1 نقطة
-
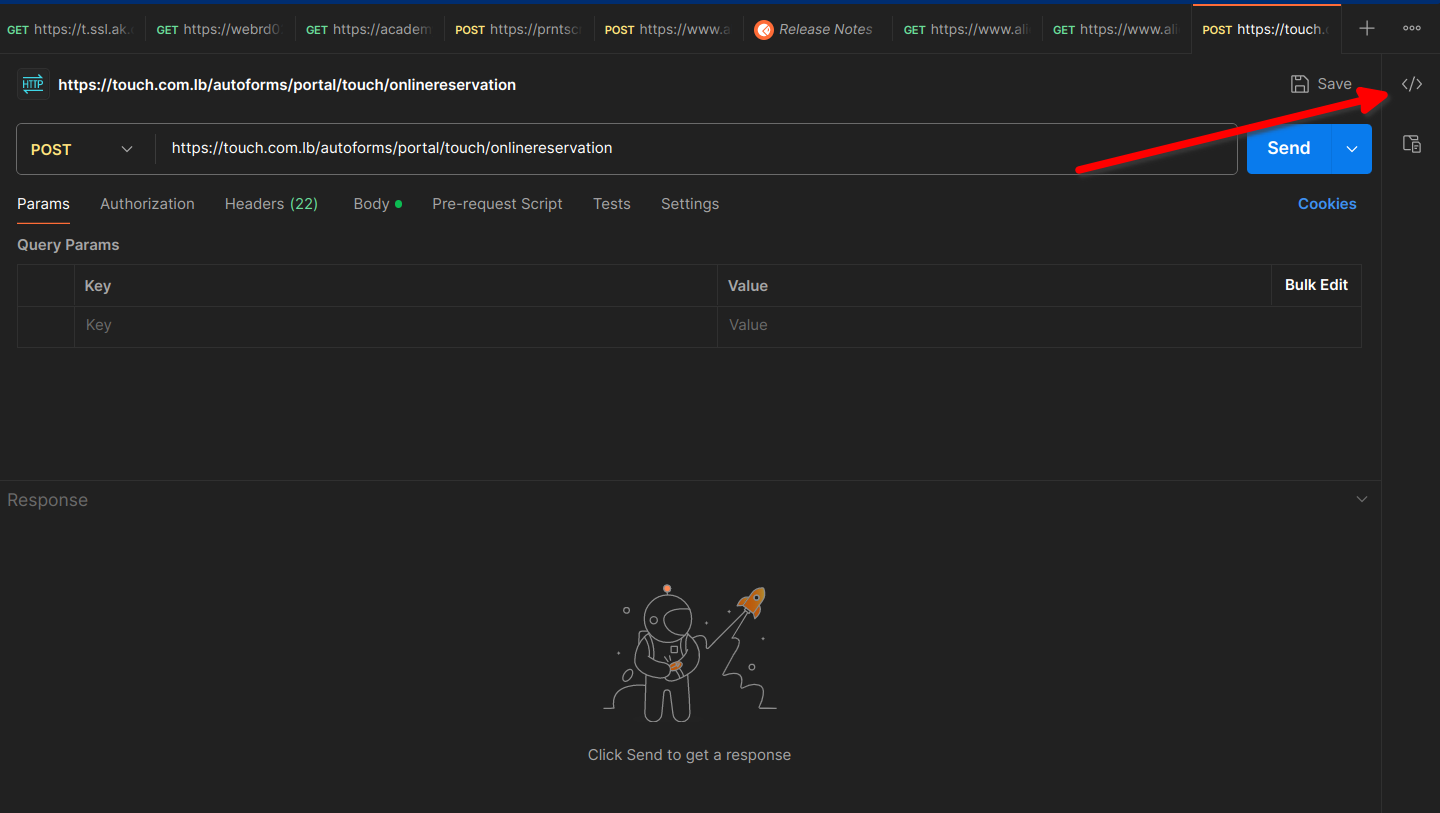
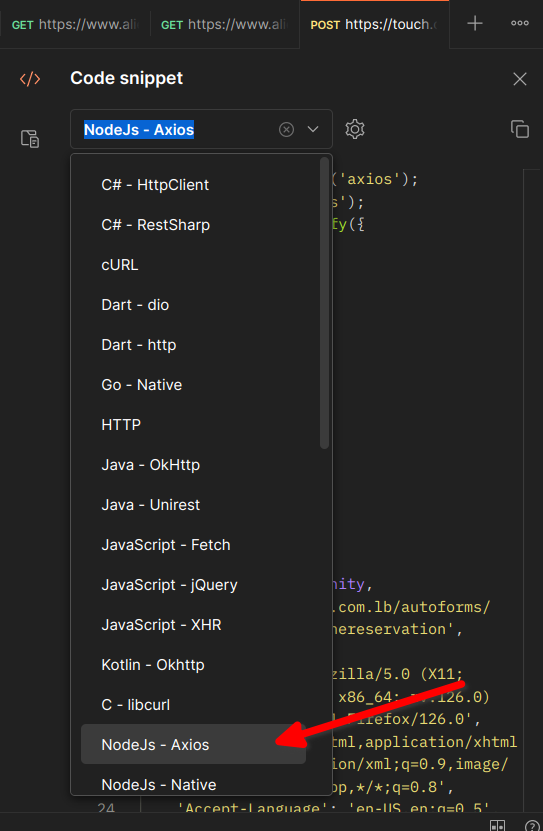
بما أنك تستخدم برنامج Postman، فأسهل طريقة لفعل ذلك هي جعل البرنامج نفسه يولد لك الكود اللازم! أولا، إضغط على أيقونة توليد الكود: بعد ذلك اختر من قائمة لغات البرمجة والمكتبات خيار: Node.js - Axios والآن يمكنك نسخ الكود الظاهر واستخدامه في مشروعك بكل بساطة.
 1 نقطة
1 نقطة -
مجالات العمل كثيرة, و أغلبها مطلوبة في سوق العمل لكن مع وجود بعض التفاوت, ففرص مطوري ال flutter و مطوري الواجهات الأمامية تكون أكبر من فرص مطوري الواجهات الخلفية. و لكن سواء أردت العمل ضمن شركة أو بشكل مستقل فأنت تحتاج إلى الخبرة, فلا يوجد أحد ممكن أن يسلمك عمل من دون أن يتأكد من أنك قادر على إنجازه, لذا عليك أن تقوم بالتدريب اليومي المنظم و المستمر لكي تكسب الخبرة والمهارات التي تؤهلك للدخول في سوق العمل. عليك أن تقوم ببناء مشاريع جذابة وهادفة و تضعها في معرض الأعمال الخاص بك , و عليك أن تقوم ببنائها بطريقة منظمة كما تفعل الشركات لكي تمتلك المهارات التي تؤهلك للعمل مستقبلا, يمكنك الدخول لموقع مستقل و رؤية الأعمال التي يتم طلبها و اختر منها أحد المشاريع و أنجزه , وأنصحك بأن تقوم بتطويير مشاريع مثل ال e-commerce و لوحات التحكم dashboards. الدخول في سوق العمل أمر صعب في البداية لعدم امتلاك خبرة سابقة, لكن إن قمت بالتعلم جيدا و طورت عدة مشاريع في المجال الذي تعلمته فسيصبح الأمر سهلا ان شاء الله.1 نقطة
-
Write a program in python that take 2 image and add them, then present the output1 نقطة
-
الأسئلة الإختبارية لا يتم الإجابة عليها بشكل مباشر، لكن كمساعدة في تنفيذ المطلوب. المطلوب دمج صورتين بواسطة بايثون، لذا ستحتاج استخدام مكتبة OpenCV لمعالجة الصور ومكتبة NumPy للتعامل مع المصفوفات. حيث ستقوم بقراءة الصورة الأولى من خلال دالة معينة في OpenCV، ثم نفس الأمر للصورة الثانية. بعد ذلك التحقق من تطابق أبعاد الصورتين و إظهار رسالة خطأ إذا لم تتطابق أبعاد الصورتين، ثم دمج الصورتين باستخدام دالة معينة في OpenCV أيضًا. بعد ذلك عرض الصورة الناتجة و انتظار ضغط مفتاح لإغلاق النافذة، ويمكن حفظ الصورة الناتجة في ملف باسم output.jpg لكن تلك نقطة إختيارية. وتستطيع استخدام مكتبات أخرى لدمج الصور مثل Pillow.1 نقطة