
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 05/09/24 في كل الموقع
-
السلام عليكم يرجى مساعدتنا في الحصول على اسم البرنامج المستخدم في إنشاء الكتب الإلكترونية لديكم.2 نقاط
-
.png.ff8a1b9d91cd1df7f1c9275066e50b89.png) نستعرض سويًا في الفيديو كيف يمكنك تحديد أسعار المشاريع البرمجية الذي ستعمل على برمجتها، وما هي مدة التنفيذ المناسبة لها، ونناقش أساليب تسعير المشاريع البرمجية سواءً عبر التسعير لكامل المشروع أو وفق مدة العمل بالساعات؛ وكيف ستتمكن من تحديد مدة العمل المناسبة لكل مشروع. نتحدث أيضًا عن العوامل التي قد تؤثر على تطوير المشروع البرمجي، وكيف يمكنها أن تؤثر على الكلفة الإجمالية، وتأخذ بالحسبان مدى تعقيد المشروع وفقًا لمتطلبات العميل، وما هي التحديات التي قد تواجهها أثناء عملية البرمجة وكيف ستتغلب عليها وكم ستأخذ من وقتك. إذا كنت مهتمًا بتعلم البرمجة ومتابعة مستجداتها فلا تنس الاشتراك قسم مقالات البرمجة، وإن كنت تريد احترافها، فاختر المجال الذي ترغب فيه من الدورات المقدمة من أكاديمية حسوب واشترك فيها.1 نقطة
نستعرض سويًا في الفيديو كيف يمكنك تحديد أسعار المشاريع البرمجية الذي ستعمل على برمجتها، وما هي مدة التنفيذ المناسبة لها، ونناقش أساليب تسعير المشاريع البرمجية سواءً عبر التسعير لكامل المشروع أو وفق مدة العمل بالساعات؛ وكيف ستتمكن من تحديد مدة العمل المناسبة لكل مشروع. نتحدث أيضًا عن العوامل التي قد تؤثر على تطوير المشروع البرمجي، وكيف يمكنها أن تؤثر على الكلفة الإجمالية، وتأخذ بالحسبان مدى تعقيد المشروع وفقًا لمتطلبات العميل، وما هي التحديات التي قد تواجهها أثناء عملية البرمجة وكيف ستتغلب عليها وكم ستأخذ من وقتك. إذا كنت مهتمًا بتعلم البرمجة ومتابعة مستجداتها فلا تنس الاشتراك قسم مقالات البرمجة، وإن كنت تريد احترافها، فاختر المجال الذي ترغب فيه من الدورات المقدمة من أكاديمية حسوب واشترك فيها.1 نقطة -
word=["good","bada"] array=[ ] (nada=random.choice(word كيف ممكن اختصر هذه الثلاثة الأسطر إلى سطر واحد يعطي نفس النتيجه،،👇 For i in nada: array.append("_") (array)print1 نقطة
-
مع تطور العالم اصبحت هناك العديد من التطبيقات والبرامج التي تصمم لك موقعك الالكتروني ببساطه من غير الحاجه لكود html واحد منك . فما الفرق بينهم وبين التصميم باللغه الرئيسيه انا لا انتقد فقط اريد ان اعلم لان هناك من سالني هذا السؤال؟1 نقطة
-
هل يحب أن يكون ملف main.py داخل مجلد venv و كيف أجعل البيئة تنشئ الملف بشكل تلقائي كما هو موجود عندك.. و شكرا
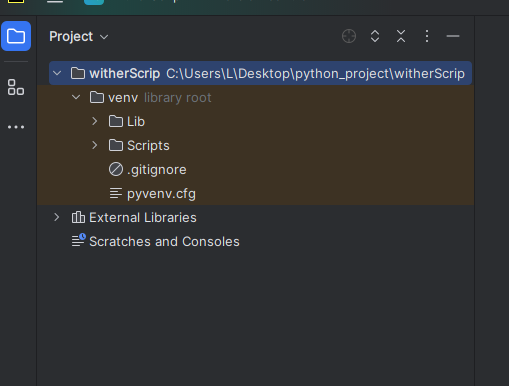 1 نقطة
1 نقطة -
ستجد توضيح شامل هنا والمكتبات المتاحة أيضًا، لكن لا حاجة لذلك فالأمر متوفر من خلال لارافل، لكن المكتبات تجعل الأمر أسهل وكود أقل بالنسبة لك.1 نقطة
-
تلك العملية تسمى RAG، والتي تعني تحويل النصول إلى أجزاء Chunks ثم تحويل ذلك إلى صيغ رقمية Vectors حيث تخزن في قاعدة البيانات مع الجزء النصي ثم يتم عمل بحث دلالي semantic search. والفكرة هو استخراج أجزاء من النصوص المتشابهة عند كتابة شيء ما، أي يتم مقارنة ما تم كتابته مع النص الموجود في الملف كما لو أنك بحثت في جوجل، ثم بعد ذلك ترسل للـ Model الخاص بـ LLM ليفهمها ويضمنها في الـ Context، أي أنّ الفهم لم يتم عن طريق الـ LLM لكامل النصوص الموجودة في قاعدة البيانات إنما فقط لما اختاره البحث الدلالي. وهناك إمكانية لحل تلك المشكلة نسبيًا وتحسين الـ RAG من خلال استخدام مكتبة إو إطار عمل مثل DSPY.1 نقطة
-
وعليكم السلام ورحمة الله وبركاته . يمكنك انشاء ملفات pdf عن طريق تحويل ملفات word او excel او حتى power point ويمكنك انشاء تلك الملفات عن طريق برنامج microsoft office او عن طريق google مثل Google Docs وكتابة ما تريد بداخل تلك الملفات ومن ثم تحويلها الى pdf .1 نقطة
-
يمكنك استخدام Power Point لإنشاء مثل تلك الرسومات والعروض، ثم تحويل ذلك إلى PDF.1 نقطة
-
1 نقطة
-
كيف يمكن استخراج الهيكلية للملف PDF وكيف لي ان اخزن الشكل على ماذا اعتمد في هذه الحالة ؟؟1 نقطة
-

الإصدار 1.0.0
7586 تنزيل
تُعدّ هياكل البيانات data structures والخوارزميات algorithms واحدةً من أهم الاختراعات التي وقعت بالخمسين عامًا الأخيرة، وهي من الأدوات الأساسية التي لابُدّ أن يدرسها مهندسي البرمجيات. غالبًا ما تكون الكتب المتناولة لتلك الموضوعات -وفقًا للكاتب- ضخمةً للغاية، كما أنها عادةً ما تُركزّ على الجانب النظري، وتُقدِّم هذه المادة العلمية بدون سياق واضح وبدون أي حافز، فتَعرِض الهياكل البيانية واحدةً تلو الأخرى. هذا الكتاب مترجم عن الكتاب الشهير Think Data Structures لمؤلفه Allen B. Downey والذي يعد مرجعًا عمليًا في شرح موضوعي هياكل البيانات والخوارزميات اللذين يحتاج إلى تعلمهما كل مبرمج ومهندس برمجيات يتطلع إلى احتراف مهنته وصقل عمله ورفع مستواه. يحاول هذا الكتاب تنظيم الموضوعات نوعًا ما من خلال التركيز على برمجة تطبيق -برمجة محرك بحث-، ويَستخدِم هذا التطبيق هياكل البيانات بشكل مكثف، وهو في الواقع موضوع مهم وشيق بحد ذاته. في الحقيقة، سيدفعنا هذا التطبيق إلى دراسة بعض الموضوعات التي ربما لن تتعرَّض لها ببعض الفصول الدراسية التمهيدية الخاصة بمادة هياكل البيانات، حيث سنتعرَّض هنا مثلًا، لحفظ هياكل البيانات persistent data structure مثل ريدس Redis. يُقدِّم الكتاب أيضًا بعض الأساسيات التي تُمارَس عادةً بهندسة البرمجيات، بما في ذلك نظم التحكُّم بالإصدار version control، واختبار الوحدات unit testing. تتضمَّن غالبية فصول الكتاب تمرينًا يَسمَح للقراء بتطبيق ما تعلموه خلال الفصل، حيث يُوفِّر كل تمرين اختبارات أوتوماتيكية لفحص الحل، وبالإضافة إلى ذلك، يُوفِّر الكاتب حلًا لغالبية التمارين ببداية الفصل التالي. هذا الكتاب مُخصَّص لطلبة الجامعات بمجال علوم الحاسوب والمجالات المرتبطة به، ولمهندسي البرمجيات المحترفين، وللمتدربين بمجال هندسة البرمجيات، وكذلك للأشخاص الذين يستعدون لمقابلات العمل التقنية. ينبغي أن تكون على معرفة جيدة بلغة البرمجة جافا قبل أن تبدأ بقراءة هذا الكتاب. وبالتحديد، لابُدّ أن تَعرِف كيف تُعرِّف صنفًا class جديدًا يمتدّ extend أو يرث من صنف آخر موجود، إلى جانب إمكانية تعريف صنف يُنفِّذ واجهة interface. إذا لم تكن لديك تلك المعرفة، فيُمكِنك البدء بسلسلة مدخل إلى جافا فهي مترجمة عن كتاب شهير يشرح لغة البرمجة جافا. يمكنك قراءة الكتاب على شكل فصول منشورة على موقع أكاديمية حسوب مباشرةً إن كنت تحب القراءة على المتصفح مباشرة، وتجد الفصول مجمعة تحت وسم "هياكل البيانات 101" وإليك روابطها تاليًا: طريقة عمل الواجهات في لغة جافا مدخل إلى تحليل الخوارزميات تحليل زمن تشغيل القوائم المنفذة باستخدام مصفوفة تحليل زمن تشغيل القوائم المنفذة باستخدام قائمة مترابطة تحليل زمن تشغيل القوائم المنفذة باستخدام قائمة ازدواجية الترابط تنفيذ أسلوب البحث بالعمق أولا باستخدام طريقتي التعاود والتكرار في جافا تنفيذ أسلوب البحث بالعمق أولا باستخدام الواجهتين Iterables وIterators استخدام خريطة ومجموعة لبناء مفهرس Indexer تحليل زمن تشغيل الخرائط المنفذة باستخدام مصفوفة في جافا تنفيذ الخرائط باستخدام التعمية hashing في جافا تحسين أداء الخرائط المنفذة باستخدام التعمية HashMap في جافا تحليل زمن تشغيل الخرائط المنفذة باستخدام شجرة بحث ثنائية TreeMap في جافا استخدام أشجار البحث الثنائية والأشجار المتزنة balanced trees لتنفيذ الخرائط استخدام قاعدة بيانات Redis لحفظ البيانات فهرسة الصفحات وتحليل زمن تشغيلها باستخدام قاعدة بيانات Redis البحث الثنائي Boolean search ودمج نتائج البحث وترتيبها نظرة سريعة على بعض خوارزميات الترتيب1 نقطة





