لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 11/02/22 في كل الموقع
-
1-هل يمكنني رويه مشروع عل github بدون تنزيله ؟ 2-كيف يمكنني الاستعاد لاختبار حسوب حيث أن الدوره طويله وانسي بعض الأشياء فهل هذا سيؤثر علي أثناء أداء الاختبار؟2 نقاط
-
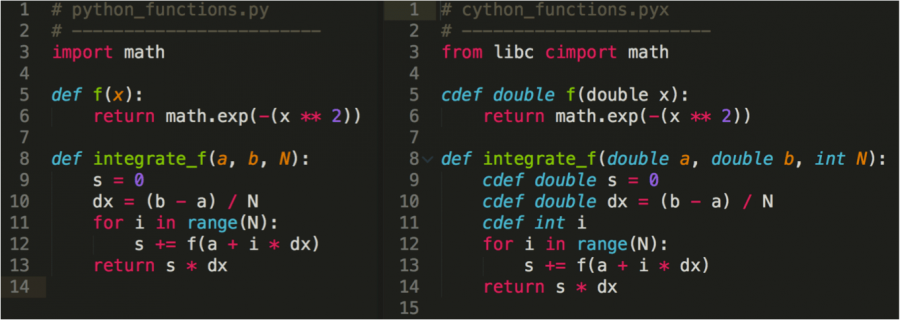
ما الفرق بين Cython و CPython2 نقاط
-
Parse error: syntax error, unexpected token "else" in C:\xampp\htdocs\login\login-php.php on line 34 login-php.php1 نقطة
-
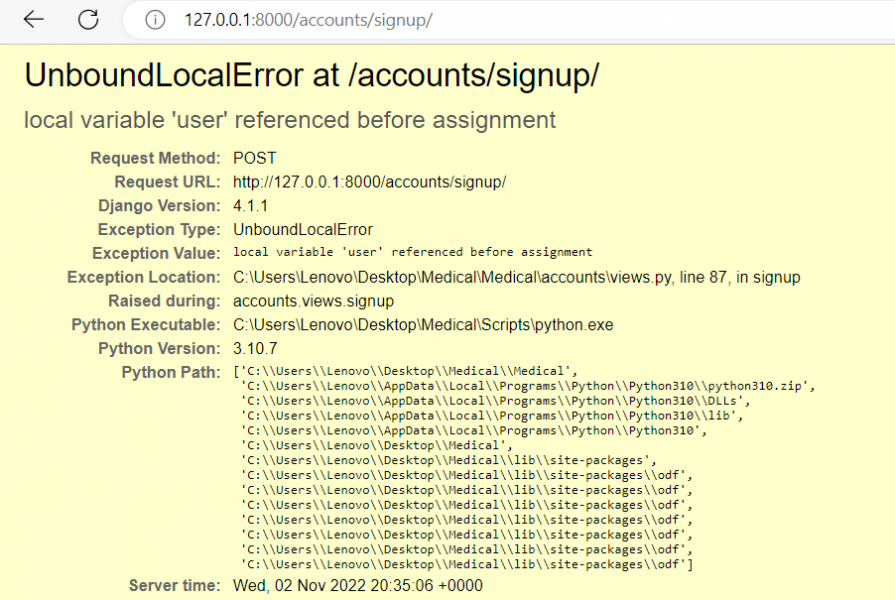
مرحبا لدي خطأ في فورم تسجيل مستخدم جديد يظهر بعد تعبئة البيانات forms,py class UserCreationForms(UserCreationForm): username= forms.CharField(max_length=50) first_name= forms.CharField(max_length=50) last_name= forms.CharField(max_length=50) email= forms.EmailField(max_length=50) password= forms.CharField(widget=forms.PasswordInput(),min_length=8) conf_password=forms.CharField(widget=forms.PasswordInput(),min_length=8) class Meta: model = User fields = ('username','first_name','last_name','email', 'password','conf_password') //views.py def signup(request): if request.method == 'POST': form = UserCreationForms(request.POST) if form.is_valid(): form.save() username = form.cleaned_date.get('username') password = form.cleaned_date.get('password') user = authenticate(username=username , password=password) login(request,user) return redirect('accounts:INDEX') else: form = UserCreationForms() return render(request, 'user/signup.html',{ 'form':form }) <div class="container"> <div class="signup"> <div class="col-md-9" > <form method="POST" enctype="multipart/form-data"> <h4 class="auth-header">أنشاء حساب جديد</h4> {% csrf_token%} <div class="form-group"> {{form.username}} </div> <div class="form-group"> {{form.first_name}} </div> <div class="row"> <div class="col-sm-6"> <div class="form-group"> {{form.last_name}} </div> </div> <div class="col-sm-6"> <div class="form-group"> {{form.email}} </div> </div> <div class="col-sm-6"> <div class="form-group"> {{form.password}} </div> </div> <div class="col-sm-6"> <div class="form-group"> {{form.conf_password}} </div> </div> <div class="buttons-w"><button type="submit" class="btn btn-success">التسجيل</button></div> </form> </div> </div> </div> </div>
 1 نقطة
1 نقطة -
if form.is_valid(): form.save() username = form.cleaned_date.get('username') password = form.cleaned_date.get('password') user = authenticate(username=username , password=password) login(request,user) هنا في السطر الأخير، في حال لم يتنفذ ما بداخل ال if فهذا سيؤدي لخطأ حيث أن ال user غير معرف، أعتقد أنها يجب أن تكون بداخل ال if.1 نقطة
-
سايثون (Cython) هي اللغة الإفتراضية التي يتم من خلالها إنشاء إمتدادات بلغة السي (C) للغة البرمجة بايثون . حيث أنها لغة شبيهة جداً بلغة بايثون نفسها وتساهم بشكل قياسي في تسريع أداء هذه الأخيرة . سي بايثون (CPython) هو التطبيق المصدري للغة بايثون ، والذي تمت كتابته باستخدام لغة السي - وكما هو معروف فإن لغة بايثون تمت كتابتها باستخدام لغة السي . مثال عن كود سايثون و سي بايثون
 1 نقطة
1 نقطة -
عندما اقوم (run main) يظهر الخطئ كما هو في الصورة المرفق
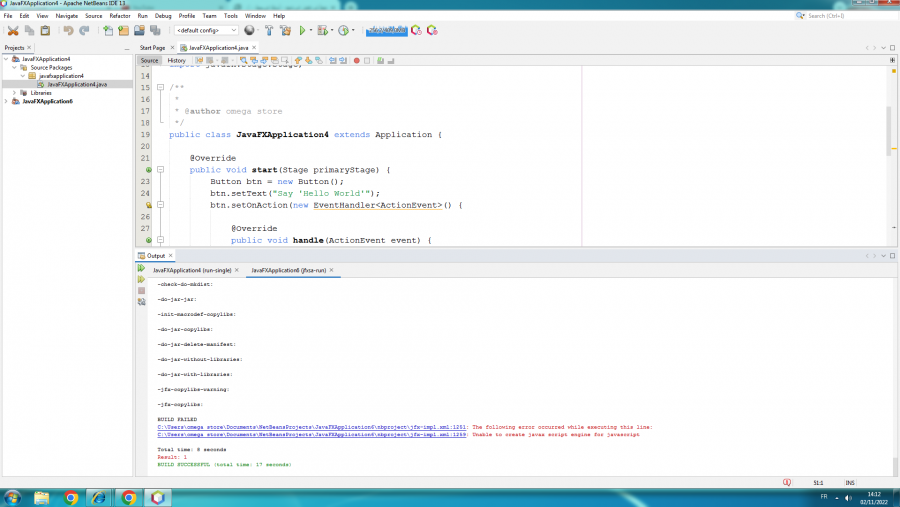 1 نقطة
1 نقطة -
إن SQLCipher لا تحتوي على دعم ل REGEXP، يجب عليك إما عدم استعمالها أو محاولة الوصول إلى المعلومات التي تريدها دون استعمال regex.1 نقطة
-
يمكنك قبل الدخول في تعلم الجافا سكربت التطبيق على عدّة أفكار باستخدام HTML , CSS وليس تطبيق واحد مع زيادة المهارات في كل تصميم ،حتى تتمكن من فهمهم بشكل جيد وتصبح المهارات لديك قوية حتى تدخل سوق العمل بكل سهولة دون وجود عقبات . سوف أقدم لك عدّة أفكار لتطوير مواقع :- موقع ويب أسئلة وأجوبة موقع ويب يمثل متجر إلكتروني موقع ويب عن السياحة والسفر موقع ويب عن الرياضة موقع ويب عن الأخبار موقع ويب عن الموضة والأزياء موقع ويب مختص بالطب و الصحة موقع ويب متخصص في وساطة الخدمات مثل (خمسات ومستقل وغيرها) موقع ويب عن الكورسات ولرؤية المزيد حول الأفكار قم بزيارة المواقع المختصة في الأعمال مثل بيهانس أو يمكنك تصفح معرض أعمال المستقلين ورؤية أعمالهم ، وأخذ أفكار لتطبيقها والتدريب عليها . ويوجد على مدونة خمسات مقال رائع في جلب أفكار لتطوير المواقع ، ويعرض 30 فكرة مميزة ، يمكنك الإطلاع عليه من هنا يمكنك الإطلاع على هذا المقال للإستفادة من أفكار تطوير المواقع1 نقطة
-
أول مشروع أي شخص يقوم به بعد تعلم ال html, css هو القيام ببناء موقع شخصي، يحوي على معلوماتك و خبراتك، أي شيء يشبه ال cv و لكن بشكل أكثر تفاعلي، يمكنك القيام بذلك و حتى نشر الموقع باستعمال ما يوفره github لذلك. يمكنك محاولة تصميم قوالب خاصة بالايميلات، حيث أنه في حال كنت تستعمل الايميل لا بد و أنه جاءك الكثير من الايميلات الترويجية و التي يكون لها عادة شكل جميل و منسق، و هنا يمكنك استعمال ال html, css لذلك، فيمكنك محاولة القيام بذلك، و هناك أحياناً الكثير ممن يطلبون مصمم ايميلات، فهذا يعطيك المهارة اللازمة للعمل في ذلك. في حال لم يكن لديك خبرة في ال animation يمكنك تعلم ذلك و صنع موقع بسيط يحوي على هكذا أمور، أو حتى إضافة هكذا أمور إلى موقعك الشخصي.1 نقطة
-
هناك العديد من الأفكار التي بإمكانك التطبيق عليها بإستعمال لغات الويب الأساسية HTML و CSS و لاحقاً عندما تتعلم جافاسكربت مثل: صفحات شخصية، صفحات البورتفوليو صفحات هبوط لمنتجات صفحات تعريفية لشركات. لوحات تحكم و غيرها العديد ستجد أثناء بحثك و تطبيقك العديد من الأفكار فقط أكتب في البحث: html css free templates سيظهر لك في البحث عدة مواقع توفر قوالب مجانية يُمكنك الدخول على إحداها و إختيار قالب و تحميل ملفاته، إستعراض النتيجة و محاولة تقليد الصفحات. إبدأ بالتصاميم البسيطة ثم تدرج في الأصعب.1 نقطة
-
وجدت فكرة مشابهة لهاته الفكرة عملية جدا وتخدم غرضا لدينا في أحد المشاريع البرمجية مؤخرا أين احتجنا استعمال هاته الصيغة لإرسال البيانات لا لتخزينها. لأن عيب هاته الطريقة أنها تأخذ مساحة تخزين كبيرة جدا من قاعدة البيانات مقارنة بحفظها في خوادم تخزين سحابية او اقراص تخزين عادية بصيغها الأصلية ك raw binary حيث أن فرق صيغة base64 على raw binary هو حوالي ال 33%، وهو فرق كبير جدا. سيعني هذا بطئا في الاستعلام حولها، وسينعكس هذا سلبا بالطبع على آداء الموقع. يمكنك الاستعانة بصيغة base64 لارسال وتبادل البيانات لا أكثر، فإن كان هنالك سبب ما يدفعك الى عدم استعمال data forms فيمكنك تشفير هاته الصور أو الملفات وإرسالها إلى الخادم وترك عملية إلغاء تشفيرها للخادم.1 نقطة
-
يمكنك إستعمال المواقع التي تقوم بإزالة الخلفية بشكل تلقائي عبر الذكاء الإصطناعي، هنا بعض هذه المواقع: remove.bg removal.ai pixlr remove background retoucher.online ويمكنك الوصول لمواقع أكثر من خلال البحث في جوجل على "Remove Background from Images".1 نقطة
-
 تُصبِح البرامج عديمة الفائدة إذا لم تكن قادرةً على التعامل مع العالم الخارجي بشكلٍ أو بآخر، حيث يُشار إلى تعامل البرامج مع العالم الخارجي باسم "الدْخَل والخرج أو I/O". يُعدّ توفير إمكانياتٍ جيدةٍ لعمليات الدْخَل والخرج واحدًا من أصعب التحديات التي تواجه مُصمِّمي اللغات البرمجية، حيث يَستطيِع الحاسوب الاتصال مع أنواعٍ مختلفةٍ كثيرة من أجهزة الدخل والخرج. إذا اضطّرت لغة البرمجة للتعامل مع كل نوعٍ منها على حدة، لكان الأمر غايةً في التعقيد، ولهذا يُعدّ التمثيل المُجرّد لأجهزة الدخل والخرج واحدًا من أعظم الإنجازات بتاريخ البرمجة، ويُطلَق على ذلك التمثيل المُجرّد بلغة جافا اسم مجاري تدفق الدْخَل والخرج I/O streams. تتوفَّر تجريداتٌ أخرى، مثل الملفات والقنوات، ولكننا سنناقش مجاري التدفق فقط، حيث يُمثِّل كل مجرًى مصدرًا يُقرَأ منه الدْخَل أو مقصدًا يُرسَل إليه الخرج. مجاري تدفق البايتات Byte Streams ومجاري تدفق المحارف Character Streams عندما تتعامل مع المُدْخَلات والمخرجات، تذكَّر أن هناك نوعان من البيانات في العموم؛ بياناتٌ مُهيأةٌ للآلة؛ وبياناتٌ مهيأةٌ لنا بمعنى أنها قابلةٌ للقراءة. تُكتَب الأولى بالصيغة الثنائية binary بنفس الطريقة التي تُخزَّن بها البيانات داخل الحاسوب، أي بهيئة سلاسلٍ نصيةٍ مُكوَّنةٍ من "0" و "1"؛ بينما تُكتَب الثانية بهيئة محارف. فعندما تقرأ عددًا، مثل "3.141592654"، فأنت في الواقع تقرأ متتاليةً من المحارف، ولكنك تُفسِّرها عددًا؛ بينما يُمثِّل الحاسوب نفس ذلك العدد بهيئة سلسلةٍ نصيةٍ من البتات أي أنك لن تتمكَّن من تمييزها. تُوفِّر جافا نوعين من مجاري التدفق streams للتعامل مع البيانات المُمثَلة بالصيغتين السابقتين: مجرى بايتات byte streams للبيانات المُهيأة للآلة، ومجرى محارف character streams للبيانات القابلة للقراءة. ستَجِد أصنافًا مُعرَّفةً مُسبقًا تُمثِّل المجاري من كلا النوعين. تنتمي الكائنات المُرسِلة للبيانات إلى مجرى بايت إلى أحد الأصناف الفرعية subclasses المُشتقَّة من الصنف المُجرَّد OutputStream؛ بينما تنتمي الكائنات القارئة للبيانات من هذا النوع من المجاري إلى أحد الأصناف الفرعية المُشتقَّة من الصنف المُجرَّد InputStream. إذا أرسلت أعدادًا إلى كائنٍ من الصنف OutputStream، لن تتمكَّن من قراءة البيانات الناتجة بنفسك. في المقابل، ما يزال بإمكان الحاسوب قرائتها مُجدَّدًا عبر كائنٍ من الصنف InputStream. تعمَل عمليتي قراءة البيانات وكتابتها في تلك الحالة بكفاءة لعدم استخدامهما أي ترجمة؛ حيث تُنسَخ فقط البتات المُمثِلة للبيانات بالحاسوب من مجاري التدفق وإليها. في المقابل، يتولَّى الصنفان المجرَّدان Reader وWriter قراءة البيانات القابلة للقراءة وكتابتها على الترتيب، فجميع أصناف مجارى المحرف هي مجرد أصنافٍ فرعيةٍ مُشتقَّةٍ من هذين الصنفين. إذا أرسلت عددًا إلى مجرًى من النوع Writer، فيجب أن يُترجمها الحاسوب إلى متتاليةٍ من المحارف المُمثِلة لذلك العدد والقابلة للقراءة؛ بينما تنطوي عملية قراءة عددٍ من مجرًى من النوع Reader، وتخزينها بمُتغيِّرٍ عددي على عملية ترجمةٍ من متتالية محارف إلى سلسلة بتاتٍ مناسبة. حتى لو كانت البيانات التي تتعامل معها مُكوَّنةً من محارفٍ بالأساس، مثل بعض الكلمات من برنامج معدِّل نصوص، من الممكن أن يتضمَّن الأمر بعضًا من الترجمة أيضًا. يُخزِّن الحاسوب المحارف على انها قيم يونيكود Unicode من 16 بت، وتُخزّن حروف الأبجدية الإنجليزية عمومًا بملفات بشيفرة ASCII، التي تَستخدِم 8 بتات للمحرف الواحد. يتولى الصنفان Reader وWriter أمر تلك الترجمة، كما يمكنهما معالجة الحروف الأبجدية الأخرى، وكذلك المحارف من غير الحروف الأبجدية المكتوبة بلغاتٍ، مثل الصينية. تُستَخدَم مجاري تدفق البايتات للاتصال المباشر بين الحواسيب، كما أنها تكون مفيدةً أحيانًا لتخزين البيانات ضمن ملفات، بالأخص عندما نحتاج إلى تخزين أحجامٍ هائلةٍ من البيانات بطريقةٍ فعالة؛ كما هو الحال مع قواعد البيانات الضخمة. ومع ذلك، تُعدّ البيانات الثنائية هشة نوعًا ما، فهي لا تعبُر بذاتها عن معناها. عندما تتعامل مع سلسلةٍ طويلةٍ من العددين صفر وواحد، ينبغي أن تُعرِّف أولًا نوعية المعلومات المُفترَض لتلك السلسلة أن تُمثِّلها، وكذلك أن تَعرِّف الكيفية التي رُمزَّت بها المعلومات قبل أن تتمكَّن من تفسيرها. ينطبق الأمر نفسه بالطبع على البيانات المحرفية نوعًا ما؛ فالمحارف بالنهاية مثلها مثل أي نوعٍ من البيانات، وينبغي أن تُرمَّز مثل أعدادٍ ثنائية حتى يتمكَّن الحاسوب من تخزينها ومعالجتها، ولكن الترميز الثنائي للبيانات المحرفية على الأقل مُوحدٌ ومفهوم، بل حتى يُمكِننا أن نجعل البيانات بصيغتها المحرفية ذات معنًى للقارئ. يتجه التيار العام إلى استخدام البيانات المحرفية، وتمثيلها بطريقةٍ تجعلها مُفسَّرةً ذاتيًا قدر الإمكان، وسنناقش إحدى تلك الطرائق في مقال مقدمة مختصرة للغة XML. لا يدعم الإصدار الأصلي من جافا مجاري المحارف، حيث يُمكِن لمجاري البايتات أن تحلّ محل مجاري المحارف عند التعامل مع البيانات المُرمزَّة بشيفرة ASCII. يُعدُّ مجريا الدخل القياسي System.in والخرج القياسي System.out مجاري بايتات، وليس مجاري محارف؛ ومع ذلك يُحبَّذ استخدام الصنفين Reader وWriter على الصنفين InputStream وOutputStream عند التعامل مع البيانات المحرفية، وحتى عند التعامل مع مجموعة محارف ASCII القياسية. تقع أصناف مجاري الدخل والخرج القياسية -والتي سنناقشها ضمن هذا المقال - بحزمة java.io بالإضافة إلى عددٍ من الأصناف الأخرى. يجب أن تستورد import أصناف تلك الحزمة إذا أردت اِستخدَامها ضمن البرنامج؛ أي إما أن تستورد الأصناف المطلوبة بصورةٍ فردية؛ أو أن تْكْتُب المُوجِّه import java.io.*; في بداية الملف المصدري. تُستخدَم مجاري الدخل والخرج عند التعامل مع الملفات، وعند الاتصال الشبكي، وكذلك للاتصال بين الخيوط المُتزامنة concurrent threads. تتوفَّر أيضًا أصناف مجاري لقراءة البيانات وكتابتها من وإلى ذاكرة الحاسوب. تَكْمُن فعالية المجاري وأناقتها بكونها تُجرِّد عملية كتابة البيانات؛ حيث تُصبِح عملياتٍ مثل كتابة بياناتٍ إلى ملف أو إرسالها عبر شبكةٍ بنفس سهولة طباعة تلك البيانات على الشاشة. تُوفِّر أصناف الدخل والخرج Reader وWriter وInputStream وOutputStream العمليات الأساسية فقط، حيث يُصرِّح الصنف InputStream مثلًا عن تابع النسخة instance method المُجرَّد التالي: public int read() throws IOException يقرأ هذا التابع بايتًا واحدًا من مجرى دْخَلٍ بهيئة عددٍ يقع بنطاقٍ يتراوح بين "0" و "255"، ويُعيد القيمة "-1" عند وصوله إلى نهاية المجرى. إذا حدث خطأٌ أثناء عملية الدخل، يقع استثناء exception من النوع IOException، ونظرًا لكونه من الاستثناءات المُتحقَّق منها checked exceptions، لا بُدّ من استخدام التابع read() ضمن تعليمة try أو ببرنامجٍ فرعي subroutine يتضمَّن تصريحه عبارة throws IOException. انظر مقال الاستثناءات exceptions وتعليمة try..catch في جافا للمزيد من المعلومات عن الاستثناءات المُتحقَّق منها والمعالجة الاجبارية للاستثناءات. يُعرِّف الصنف InputStream أيضًا توابعًا لقراءة عدة بايتات من البيانات ضمن خطوةٍ واحدة، وتخزينها بمصفوفة بايتات، وهو ما يُعدّ أكثر كفاءة بكثير من قرائتها بصورةٍ إفرادية؛ ولكنه -أي الصنف InputStream- مع ذلك لا يُوفِّر أي توابعٍ لقراءة أنواعٍ أخرى من البيانات، مثل int وdouble من مجرى. لا يُمثِل ذلك مشكلة؛ حيث من النادر أن تستخدِم كائناتٍ من النوع InputStream، وإنما ستعتمد على أصنافٍ فرعية منه. تُعرِّف تلك الأصناف توابع دْخَلٍ إضافية إلى جانب الإمكانيات الأساسية للصنف InputStream، كما يُعرِّف بالمثل الصنف OutputStream تابع الخرج التالي لكتابة بايت واحد إلى مجرى خرج: public void write(int b) throws IOException لاحِظ أن المعامل parameter من النوع int، وليس من النوع byte، ولكنه يُحوَّل type-cast إلى النوع byte قبل كتابته، وهو ما يؤدي إلى إهمال جميع بتات المعامل b باستثناء البتات الثمانية الأقل رتبة. عمليًا، ستَستخدِم دائمًا أصنافًا فرعية مُشتقَّة من الصنف OutputStream، والتي تُعرِّف عمليات خرجٍ إضافية عالية المستوى. يُوفِّر الصنفان Reader وWriter توابعًا منخفضة المستوى مشابهة لعمليتي read وwrite. وكما هو الحال مع أصناف مجاري البايتات، ينتمي كلٌ من معامل التابع write(c) المُعرَّف بالصنف Writer، والقيمة المعادة من التابع read() المُعرَّف بالصنف Reader إلى النوع int، ولكن ما يزال هناك اختلاف؛ حيث تُجرَى بتلك الأصناف المُخصَّصة بالأساس للمحارف عمليتي الدخل والخرج على المحارف، وليس على البايتات. يعيد التابع read() القيمة "-1" عند وصوله إلى نهاية المجرى، أما قبل ذلك، فيجب أن نُحوَّل القيمة المعادة منه إلى النوع char لنَحصُل على المحرف المقروء. عمليًا، ستَستخدِم عادةً أصنافًا فرعيةً مُشتقَّةً من الصنفين Reader وWriter، والتي تُعرِّف عمليات دْخَل وخَرْج إضافية عالية المستوى، كما سنناقش فيما يلي. الصنف PrintWriter تُمكِّنك حزمة جافا للدخل والخرج من إضافة إمكانياتٍ جديدة إلى مجاري التدفق من خلال تغليفها wrapping ضمن كائنات مجاري تدفقٍ أخرى تُوفِّر تلك الإمكانيات. يكون الكائن المُغلِّف مجرًى أيضًا؛ أي يُمكِنك أن تقرأ منه أو تكتب به، ولكن عبر عملياتٍ أكثر فعالية من تلك المتاحة بمجاري التدفق الأصلية. يُعدّ الصنف PrintWriter على سبيل المثال صنفًا فرعيًا من الصنف Writer، ويُوفِّر توابعًا لإخراج جميع أنواع البيانات الأساسية بلغة جافا بصيغة محارف مقروءة. إذا كان لديك كائنٌ منتميٌ إلى الصنف Writer أو أيٍّ من أصنافه الفرعية، وأردت استخدام توابع الصنف PrintWriter لعمليات الخرج الخاصة بذلك الكائن؛ فكل ما عليك فعله هو تغليف كائن الصنف Writer بكائن الصنف PrintWriter، وذلك بتمريره إلى باني الكائن constructor المُعرَّف بالصنف PrintWriter. بفرض أن charSink من النوع Writer، يُمكِنك كتابة ما يَلِي: PrintWriter printableCharSink = new PrintWriter(charSink); يُمكِن للمعامل المُمَّرر إلى الباني أن يكون من النوع OutputStream أو النوع File، وهذا ما سنناقشه في المقال التالي؛ حيث يُنشِئ الباني في العموم كائنًا من النوع PrintWriter، والذي يكون بإمكانه الكتابة إلى مقصد الخرج الخاص بالكائن المُمرَّر إليه. عندما تُرسِل بيانات خرجٍ إلى printableCharSink عبر إحدى توابع الخرج عالية المستوى المُعرَّفة بالصنف PrintWriter، فستُرسَل تلك البيانات إلى نفس المقصد الذي يُرسِل charSink البيانات إليه؛ فكل ما فعلناه هو توفير واجهة أفضل لنفس مقصد الخرج، وهذا يَسمَح لنا باستخدام توابع الصنف PrintWriter لإرسال البيانات إلى ملفٍ أو عبر اتصالٍ شبكي مثلًا. إذا كان out مُتغيّرًا من النوع PrintWriter، فإنه إذًا يُعرِّف التوابع التالية: out.print(x): يُرسِل قيمة المعامل x بهيئة سلسلةٍ نصيةٍ من المحارف إلى مجرى الخرج، ويُمكِن للمعامل x أن يكون تعبيرًا expression من أي نوع، بما في ذلك الأنواع الأساسية primitive types والأنواع الكائنية؛ حيث يُحوِّل التابع أي كائنٍ إلى سلسلةٍ نصيةٍ عبر تابعه toString(). تُمثَّل القيمة الفارغة null بالسلسلة النصية "null". out.println(): يُرسِل مِحرف سطرٍ جديد إلى مجرى الخرج. out.println(x): يُرسِل قيمة x متبوعةً بسطرٍ جديد، وهو ما يُكافِئ استدعاء التابعين out.print(x) وout.println() على التوالي. out.printf(formatString, x1, x2, ...): يُرسِل خرجًا مُنسَّقًا للمعاملات المُمرَّرة x1 وx2 و .. وهكذا إلى مجرى الخرج. يمثِّل المعامل الأول سلسلةً نصيةً تُخصِّص صيغة الخرج المطلوبة. إلى جانب ذلك، يَستقبِل التابع أي عددٍ من المعاملات الإضافية التي يُمكِنها أن تنتمي لأي نوع، بشرط أن تتوافق مع صيغة الخرج المُخصَّصة بالمعامل الأول. ألقِ نظرةً على قسم الخرج البسيط والخرج المنسق من مقال المدخلات والمخرجات النصية في جافا للمزيد من المعلومات عن الخرج المُنسَّق فيما يتعلَّق بمجرى الخرج القياسي System.out، ويُوفِّر التابع out.printf نفس الوظيفة. out.flush(): يتأكَّد من كتابة المحارف المُرسلة عبر أيٍّ من التوابع السابقة إلى مقصدها بصورةٍ فعليّة. يكون استدعاء هذا التابع ضروريًا في بعض الحالات بالأخص عند إرسال الخرج إلى ملفٍ أو عبر شبكة، وذلك لضمان ظهور الخرج بالمقصد المُحدَّد. لا تُبلِّغ أيٌ من التوابع السابقة عن استثناءٍ من النوع IOException نهائيًا. بدلًا من ذلك، يتضمَّن الصنف PrintWriter التابع التالي: public boolean checkError() يعيد هذا التابع القيمة true في حالة حدوث خطأٍ أثناء عملية الكتابة بمجرى؛ حيث يلتقط الصنف PrintWriter أي استثناءات من النوع IOException، ثم يَضبُط قيمة رايةٍ flag داخليةٍ معينةٍ للإشارة إلى وجود خطأ. يُمكِنك إذًا استخدام التابع checkError() لفحص قيمة تلك الراية، وذلك من خلال استخدام توابع الصنف PrintWriter دون الحاجة لالتقاط أي استثناءات؛ ومع ذلك، إذا كنت تريد كتابة برنامج متين تمامًا، فيجب أن تستدعي التابع checkError() عند استخدام أيٍّ من توابع الصنف PrintWriter لتَتأكَّد من عدم وقوع أي أخطاءٍ مُحتمَلة. مجاري تدفق البيانات Data Streams عندما نَستخدِم الصنف PrintWriter لإرسال بياناتٍ إلى مجرًى معيّن، فسيُحوِّل البيانات إلى متتاليةٍ مقروءةٍ من المحارف المُمثِّلة لتلك البيانات. ماذا لو أردنا إرسال البيانات بصيغةٍ ثنائيةٍ مهيأةٍ للآلة؟ في الواقع، تتضمَّن حزمة java.io الصنف DataOutputStream المُمثِّل لمجرى بايتات، والذي يُمكِننا استخدامه لإرسال البيانات إلى المجاري بهيئةٍ ثنائية. تُعدّ العلاقة بين الصنفين DataOutputStream وOutputStream مشابهةً لتلك الموجودة بين الصنفين PrintWriter وWriter؛ فبينما يَملُك الصنف OutputStream توابع الخرج المُخصَّصة للبايتات فقط؛ يملك الصنف DataOutputStream التابع writeDouble(double x) لقيم الخرج من النوع double، والتابع writeInt(int x) لقيم الخرج من النوع int، وهكذا. علاوةً على ذلك، من الممكن أيضًا تغليف أي كائنٍ من النوع OutputStream ضمن كائنٍ من النوع DataOutputStream؛ لنتمكَّن من استخدام توابع الخرج عالية المستوى المُعرَّفة به. إذا كان byteSink من النوع OutputStream مثلًا، يُمكِن كتابة ما يَلي لتغليفِه ضمن كائنٍ من النوع DataOutputStream: DataOutputStream dataSink = new DataOutputStream(byteSink); تُوفِّر حزمة java.io الصنف DataInputStream بالنسبة للمُدْخلات المُهيأة للآلة، مثل تلك التي يُنشئها DataOutputStream عند اِستخدَامه للكتابة. يُمكِنك تغليف كائنٍ من النوع InputStream ضمن كائنٍ من النوع DataInputStream؛ لتُمكِّنه من قراءة أي نوعٍ من البيانات من مجرى بايتات. أسماء توابع الصنف DataInputStream المسؤولة عن قراءة البيانات الثنائية هي: readDouble() وreadInt() وهكذا. يكْتُب الصنف DataOutputStream البيانات بصيغةٍ يُمكِن للصنف DataInputStream أن يقرأها بالضرورة، حتى لو أنشأ حاسوبٌ من نوعٍ معين المجرى، وكان المطلوب أن يقرأه حاسوبٌ من نوعٍ آخر. تُوفِّر البيانات الثنائية توافقًا compatibility عبر المنصات، ويُعدُّ هذا أحد الجوانب الأساسية لاستقلالية منصة جافا. قد ترغب في بعض الحالات بقراءة محارفٍ من مجرًى من النوع InputStream، أو كتابة محارفٍ إلى مجرًى من النوع OutputStream، ولا يُمثِل ذلك مشكلةً لأن المحارف مثلها مثل جميع البيانات؛ فهي تُمثَّل بهيئة أعدادٍ ثنائيةٍ، على الرغم أنه من الأفضل في تلك الحالة استخدام الصنفين Reader وWriter، بدلًا من InputStream وOutputStream. مع ذلك، تستطيع فعل ذلك بتغليف مجرى البايتات ضمن مجرى محارف. إذا كان byteSource متغيرًا من النوع InputStream وكان byteSink مُتغيرًا من النوع OutputStream، تُنشِئ التعليمات التالية مجاري محارف بإمكانها قراءة المحارف وكتابتها من وإلى مجاري بايتات. Reader charSource = new InputStreamReader( byteSource ); Writer charSink = new OutputStreamWriter( byteSink ); يُمكِننا تحديدًا تغليف مجرى الدخل القياسي System.in، المُنتمي إلى الصنف InputStream لأسبابٍ تاريخية، ضمن كائنٍ من النوع Reader، لتسهيل قراءة المحارف من الدخل القياسي كما يلي: Reader charIn = new InputStreamReader( System.in ); لنأخذ مثالًا آخر؛ حيث تُعدّ مجاري الدخل والخرج المُرتبطِة باتصالٍ شبكي مجاري بايتات لا مجاري محارف، ويُمكننا مع ذلك تغليف مجاري البايتات بمجاري محارف للتسهيل من إرسال البيانات المحرفية واستقبالها عبر الشبكة. سنناقش عمليات الدخل والخرج عبر الشبكة لاحقًا. تتوفَّر طرائقٌ مختلفة لترميز المحارف بهيئة بياناتٍ ثنائية، حيث يُطلَق مُصطلح "طقم محارف charset" على أي ترميز محارف، ويَملُك اسمًا قياسيًا، مثل "UTF-16" و "UTF-8" و "ISO-8859-1"؛ حيث يُرمِّز "UTF-16" المحارف بهيئة قيم يونيكود Unicode مُكوَّنةٍ من "16 بت"، وهو الترميز المُستخدَم داخليًا بجافا؛ بينما يُعدّ "UTF-8" أسلوبًا لترميز محارف اليونيكود بتخصيص "8 بت" لمحارف ASCII الشائعة في مقابل عدد بتاتٍ أكثر للمحارف الأخرى؛ أما ترميز "ISO-8859-1" المعروف أيضًا باسم "Latin-1"، فهو مكوَّنٌ من "8 بت"، ويتضمَّن محارف ASCII إلى جانب محارفٍ أخرى مُستخدَمةٍ ضمن عدة لغاتٍ أوروبية. يَعتمِد الصنفان Reader وWriter على طقم المحارف الافتراضي ضمن الحاسوب المُشّغلان عليه، إلا إذا خصَّصت طقم محارفٍ معين بتمريره عبر الباني على النحو التالي: Writer charSink = new OutputStreamWriter( byteSink, "ISO-8859-1" ); يؤدي اختلاف ترميزات أطقم المحارف وكثرتها إلى تعقيد عملية معالجة النصوص، وهو ما يُعدّ أمرًا سيئًا للمتحدثين بالإنجليزية، ولكنه ضروري لغيرهم ممن يَستخدِمون أطقم محارفٍ مختلفة. لا حاجة للقلق عمومًا بشأن أيٍّ من ذلك، إنما عليك فقط أن تتذكَّر أن هناك أطقم محارفٍ مختلفة إذا واجهت بياناتٍ نصيةٍ مُرمزَّة بطريقةٍ غير اعتيادية. قراءة النصوص تُجرَى كثيرٌ من عمليات الدخل والخرج على محارفٍ مقروءة، ومع ذلك، لا توفِّر جافا صنفًا قياسيًا يُمكِنه قراءة المحارف بإمكانياتٍ متكافئة مع ما يُوفِّره الصنف PrintWriter لإخراج المحارف. قد يَكون الصنف Scanner -الذي تعرَّضنا له في مقال المدخلات والمخرجات النصية في جافا، والذي سنناقشه تفصيليًا فيما يلي مكافئًا نوعًا ما، ولكنه ليس صنفًا فرعيًا من أي صنف مجرى؛ ما يعني أنه لا يتناسب مع إطار عمل مجاري التدفق. هناك مع ذلك حالةٌ بسيطةٌ بإمكان الصنف القياسي BufferedReader معالجتها بسهولة. يتضمَّن هذا الصنف التابع التالي: public String readLine() throws IOException يقرأ هذا التابع سطرًا نصيًا واحدًا من المُدْخلات، ويقرأ خلال ذلك مؤشر نهاية السطر أيضًا، ولكن لا يكون هذا المؤشر جزءًا من السلسلة النصية التي يعيدها التابع؛ بينما يُعيد التابع القيمة null عند وصوله إلى نهاية المجرى. تَستخدِم الأنواع المختلفة من مجاري الدْخَل محارفًا مختلفةً للإشارة إلى نهاية السطر، ولكن يُمكِن للتابع readLine التعامُل مع أغلب الحالات الشائعة. تَستخدِم حواسيب Unix، بما في ذلك Linux و Mac OS X عادةً محرف سطرٍ جديد '\n' للإشارة إلى نهاية السطر؛ بينما يستخدم Macintosh محرف العودة إلى بداية السطر '\r'؛ أما Windows فيَستخدِم المحرفين "\r\n". تستطيع الحواسيب العصرية عمومًا التعامل مع كل تلك الاحتمالات. يُعرِّف الصنف BufferedReader إضافةً إلى ذلك تابع النسخة lines()، والذي يعيد قيمةً من النوع Stream<String> يُمكِن استخدامها مع واجهة برمجة تطبيقات stream API -انظر مقال مقدمة إلى واجهة برمجة التطبيقات Stream API في جافا-. بفرض أن reader متغيرٌ من النوع BufferedReader، ستكون الطريقة الأمثل لمعالجة جميع الأسطر التي قرأها بتطبيق العامل forEach() على مجرى الأسطر على النحو التالي: reader.lines().forEachOrdered(action) حيث تمثِّل action مُستهلِك سلاسلٍ نصية، والذي يُكتَب عادةً بصيغة تعبيرات لامدا lambda expression. تشيع معالجة الأسطر واحدًا تلو الآخر، لذلك يُمكِننا تغليف wrap أي كائنٍ من النوع Reader ضمن كائنٍ من النوع BufferedReader لتسهيل قراءة الأسطر النصية بالكامل. بفرض أن reader من النوع Reader، يُمكِننا تغليفه باستخدام كائنٍ من النوع BufferedReader على النحو التالي: BufferedReader in = new BufferedReader( reader ); كما يُمكِننا مثلًا استخدامه مع الصنف InputStreamReader المذكور بالأعلى لقراءة أسطرٍ نصيةٍ من كائنٍ من النوع InputStream، أو قد نُطبقه على System.in على النحو التالي: BufferedReader in; // BufferedReader for reading from standard input. in = new BufferedReader( new InputStreamReader( System.in ) ); try { String line = in.readLine(); while ( line != null ) { processOneLineOfInput( line ); line = in.readLine(); } } catch (IOException e) { } تقرأ الشيفرة السابقة أسطرًا من الدخل القياسي، وتعالجها حتى الوصول إلى نهاية المجرى. تَعمَل مؤشرات نهاية المجرى حتى مع المُْدْخَلات التفاعلية، حيث يُولِّد النقر على زر Control-D ببعض الحواسيب على الأقل مثلًا مؤشر نهاية مجرى بمجرى الدخل القياسي. تُعدُّ معالجة الاستثناءات إلزامية نظرًا لإمكانية تبليغ التابع readLine عن استثناءاتٍ exception من النوع IOException، ولهذا كان من الضروري إحاطة التابع بتعليمة try..catch. يُمكِننا بدلًا من ذلك كتابة عبارة throws IOException بتصريح التابع المُتضمِّن للشيفرة بالأعلى. يجب أن تُستورد الأصناف الآتية من حزمة java.io: BufferedReader. InputStreamReader. IOException. على الرغم من تسهيل الصنف BufferedReader عملية قراءة الأسطر النصية، فإن هذا ليس الغرض الأساسي من وجوده، حيث تعمَل بعض أجهزة الدخل والخرج بأعلى كفائتها عند قراءة أو كتابة قدرٍ كبيرٍ من البيانات دفعةً واحدةً بدلًا من مجرد قراءة بايتاتٍ أو محارفٍ مفردة. يُوفِّر الصنف BufferedReader تلك الإمكانية، حيث يُمكِنه قراءة دفعةٍ من البيانات، وتخزينها ضمن ذاكرةٍ داخلية، تُعرَف باسم المخزن المؤقت buffer. عندما تقرأ من كائنٍ من الصنف BufferedReader، فإنه في الواقع يستعيد البيانات من المخزن المؤقت إذا كان ذلك ممكنًا، أي إذا لم يَكن المخزن فارغًا؛ حيث يضطّر تلك الحالة فقط من التعامل مع مصدر الدْخل مرةً أخرى لجلب المزيد من البيانات. يتوفَّر أيضًا الصنف المكافئ BufferedWriter، بالإضافة إلى وجود أصناف مجاري تدفق في مخزنٍ مؤقت للعمل مع مجاري البايتات. اِستخدمنا الصنف غير القياسي TextIO سابقًا لقراءة المُدْخَلات من المُستخدِمين والملفات؛ حيث يتميز ذلك الصنف بسهولة قراءة البيانات المنتمية لأي نوعٍ من الأنواع الأساسية primitive types، ولكنه لا يستطيع مع ذلك القراءة من أكثر من مصدر دخلٍ واحد بنفس الوقت، وهو بذلك لا يَتّبِع نفس نمط أصناف جافا القياسية المبنية مُسبقًا للدْخَل والخَرْج. إذا أعجبك أسلوب الصنف TextIO في التعامل مع المُدْخَلات، يُمكِنك إلقاء نظرةٍ على الصنف TextReader.java، الذي يُنفِّذ implement أسلوبًا مشابهًا بطريقةٍ أكثر كائنية object-oriented. لم نَستخدِم الصنف TextReader ضمن هذا الإصدار من الكتاب، ولكننا أشرنا إليه ضمن بعض الإصدارات السابقة. الصنف Scanner لم تُوفِّر جافا بإصداراتها الأولى دعمًا مبنيًا مسبقًا للمُدْخلات البسيطة، حيث اعتمد الدعم الذي وفِّرته على بعض التقنيات المتقدمة نوعًا ما، ووفَّرت بعد ذلك الصنف Scanner المُعرَّف بحزمة java.util لتسهيل قراءة المُدْخَلات من الأنواع البسيطة، وهو ما يُعدّ تَحسُنًا كبيرًا، ولكنه لم يَحِل المشكلة بالكامل. تعرَّضنا للصنف Scanner في المقال مقدمة إلى واجهة برمجة التطبيقات Stream API في جافا، ولكننا لم نَستخدِمه بعدها، ولهذا سنعتمد بغالبية الأمثلة التالية على الصنف Scanner بدلًا من TextIO. يُعرِّف الصنف البرامج المسؤولة عن عمليات الدْخَل على هيئة توابع نسخ instance methods؛ أي ينبغي أن نُنشِئ كائنًا منه إذا أردنا أن نَستخدِمها. يَستقبِل باني الصنف constructor المصدر الذي ينبغي أن تُقرَأ منه المحارف؛ أي أنه يَعمَل مثل مُغلِّف لذلك المصدر. يُمكِن للمصدر أن يكون من الصنف Reader، أوInputStream، أوString، أوFile، أو غيرها من الاحتمالات الأخرى. إذا اِستخدَمنا النوع String مصدرًا للمُدْخَلات، فسيقرأ الصنف Scanner محارف السلسلة النصية ببساطة من بدايتها إلى نهايتها بنفس الكيفية التي كان سيتعامل بها مع متتالية محارفٍ مصدرها مجرى، حيث يُمكِننا مثلًا استخدام كائنٍ من النوع Scanner للقراءة من الدْخَل القياسي بكتابة ما يلي: Scanner standardInputScanner = new Scanner( System.in ); وبفرض أن charSource من النوع Reader، يُمكِننا بالمثل أن نُنشِئ كائنًا من الصنف Scanner للقراءة منه بكتابة ما يَلي: Scanner scanner = new Scanner( charSource ); يُعالِج الصنف Scanner المُدَْخَلات عادةً وحدةً token تلو الأخرى؛ حيث يُقصَد بالوحدة سلسلةً نصيةً من المحارف لا يُمكِن تقسيمها إلى وحداتٍ أصغر، وإلا ستفقد معناها وفقًا للمهمة المعنية بها. يُمكِن للوحدة أن تكون كلمةً مفردةً مثلًا أو سلسلةً نصيةً مُمثِّلةً لقيمةٍ من النوع double. يحتاج الصنف Scanner أيضًا لوجود "فاصلٍ delimiter" بين تلك الوحدات، والذي يُمثَّل عادةً ببضعة فراغات، مثل محارف الفراغ، أو محارف tab، أو مؤشرات نهاية السطر. يُهمِل الصنف Scanner تلك الفراغات، حيث يقتصر الهدف من وجودها على الفصل بين الوحدات. يتضمَّن الصنف توابع نسخٍ لقراءة مختلف أنواع الوحدات. لنفترض أن scanner كائنٌ من النوع Scanner، يكون لدينا التوابع التالية: scanner.next(): يقرأ الوحدة التالية من مصدر المُدْخَلات، ويعيد قيمةً من النوع String. scanner.nextInt() وscanner.nextDouble() وغيرها: يقرأون الوحدة التالية من مصدر المُدْخَلات، ويحاولون تحويلها إلى قيمةٍ من النوع int وdouble وغيرها. تتوفَّر توابعٌ لقراءة جميع الأنواع الأساسية. scanner.nextLine(): يقرأ سطرًا كاملًا من المُدْخَلات حتى يَصِل إلى مؤشر نهاية السطر، ثم يعيد السطر على أنه قيمةٌ من النوع String. في حين يقرأ التابع مؤشر نهاية السطر، فإنه لا يُضمُّنه بالقيمة التي يُعيدها، كما أنه لا يعتمد على مفهوم الوحدات؛ فهو يعيد سطرًا كاملًا بما قد يحتويه من أية فراغات. يُمكِن أن تكون القيمة المُعادة من التابع مجرد سلسلةٍ نصيةٍ فارغة. يُمكِن للتوابع السابقة أن تُبلِّغ عن بعض أنواع الاستثناءات، حيث يمكنها على سبيل المثال التبليغ عن استثناءٍ من النوع NoSuchElementException عند محاولتها القراءة من مصدرٍ تجاوزت نهايته بالفعل. كما تُبلِّغ توابعٌ، مثل scanner.getInt() عن حدوث استثناءٍ من النوع InputMismatchException، إذا لم تكُن الوحدة token التالية من النوع المطلوب. لا تُعدّ معالجة الاستثناءات التي تُبلِّغ عنها تلك التوابع إلزامية. يتمتع الصنف Scanner بإمكانياتٍ جيدة لفحص المُدْخَلات دون قرائتها؛ حيث يُمكِنه مثلًا أن يُحدِّد فيما إذا كان هناك المزيد من الوحدات للقراءة، أو إذا كانت الوحدة التالية من نوعٍ معين. إذا كان scanner كائنًا من النوع Scanner، يُمكِننا استخدام التوابع التالية: scanner.hasNext(): يُعيد القيمة المنطقية true في حالة وجود وحدةٍ واحدةٍ على الأقل بمصدر المُدْخَلات. scanner.hasNextInt() وscanner.hasNextDouble()، وهكذا: يعيدون القيمة المنطقية true إذا كان هناك وحدةً واحدةً على الأقل بمصدر المُدْخَلات، وكانت تلك الوحدة قيمةً من النوع المطلوب. scanner.hasNextLine(): يعيد القيمة المنطقية true في حالة وجود سطرٍ واحدٍ على الأقل بمصدر المُدْخَلات. تَحِد ضرورة اِستخدَام فاصلٍ بين الوحدات من فعالية الصنف Scanner نوعًا ما، لكنه رغم ذلك سهل الاستخدام، ومناسبٌ للعديد من التطبيقات المختلفة. نظرًا لوجود الكثير من الأصناف المسؤولة عن عمليات الدْخَل، مثل BufferedReader وTextIO وScanner، قد تُصيبك الحيرة لإختيار الأنسب للاستخدام. يُفضَّل عمومًا اِستخدام الصنف Scanner إلا إذا كان هناك سببٌ واضحٌ يدفعك لتفضيل أسلوب الصنف TextIO. في المقابل، يُعدّ الصنف BufferedReader بديلًا بسيطًا، إذا كان كل ما تحتاجه هو مجرد قراءة أسطرٍ نصيةٍ كاملةٍ من مصدر المُدْخَلات. لاحِظ أنه من الممكن تغيير الفاصل الذي يَعتمِد عليه الصنف Scanner للفصل بين الوحدات tokens، ولكن يتطلَّب ذلك التعامل مع ما يُعرَف باسم التعبيرات النمطية regular expression، والتي قد تكون معقدةً بعض الشيء، وهي عمومًا ليست ضمن أهداف هذا الكتاب، ولكن سنأخذ مثالًا بسيطًا عنها؛ ولنفترض مثلًا أننا نريد وحداتٍ مؤلفةً من كلماتٍ مُكوَّنةٍ فقط من أحرف الأبجدية الإنجليزية. يُمكِن في تلك الحالة للفاصل أن يَكون أي محرفٍ من غير تلك الأحرف؛ فإذا كان لدينا كائنٌ من الصنف Scanner اسمه scnr، فإننا نستطيع كتابة scnr.useDelimiter("[^a-zA-Z]+") لجعله يَستخدِم هذا النوع من الفواصل، وستكون بذلك الوحدات المعادة من scnr.next() مُكوَّنةً بالكامل من أحرف الأبجدية الإنجليزية. تُعدّ السلسلة النصية [^a-zA-Z]+ تعبيرًا نمطيًا، وهي في الواقع أداةً مهمةً لأي مبرمج، وعليك أن تشرُع بتعلُّمها إذا واتتك الفرصة لذلك. إدخال وإخراج الكائنات المسلسلة Serialized تَسمَح لنا الأصناف الآتية: PrintWriter. Scanner. DataInputStream. DataOutputStream. بمعالجة الدْخَل والخَرْج من جميع أنواع جافا الأساسية، ولكن ماذا لو أردنا أن نقرأ أو نكتب كائنات؟ سنحتاج بالضرورة إلى العثور على طريقةٍ ما لترميز الكائنات، وتحويلها إلى متتاليةٍ من القيم المنتمية لأي من الأنواع الأساسية، والتي يُمكِن بعد ذلك إرسالها على أنها خَرْجٌ بهيئة بايتات أو محارف. يُطلَق على تلك العملية اسم سَلسَلة serialize الكائن. سنضطّر من الناحية الأخرى لقراءة البيانات المُسَلسَلة، ثم اِستخدَامها لإعادة بناء الكائن الأصلي. إذا كان الكائن معقدًا بعض الشيء، فسيضطّرنا ذلك إلى الكثير من العمل الذي هو في أساسه مجرد عمل روتيني. تُوفِّر جافا لحسن الحظ الصنفين ObjectInputStream وObjectOutputStream؛ لتحمُّل عبء غالبية ذلك العمل. لاحِظ أنهما صنفان فرعيان من الصنفين InputStream وOutputStream، ويُمكِنهما العمل مع الكائنات المُسَلسَلة. يُعدّ الصنفان ObjectInputStream وObjectOutputStream أصنافًا مغلِّفة؛ أي يُمكِنها أن تُغلِّف مجارٍ streams من النوعين InputStream وOutputStream على الترتيب، وهو ما يَسمَح بإدْخال وإخراج الكائنات عبر أي مجرى بايتات؛ حيث يتضمَّن الصنف ObjectInputStream التابع readObject()؛ بينما يتضمَّن الصنف ObjectOutputStream التابع writeObject(Object obj)، ويُمكِنهما التبليغ عن استثناءاتٍ من النوع IOException. يتضمَّن الصنف ObjectOutputStream التوابع writeInt() وwriteDouble() وما يُشبهها، لإرسال قيمٍ منتميةٍ لأي من الأنواع الأساسية إلى مجرى الخرج، كما يتضمَّن الصنف ObjectInputStream توابعًا مكافئةً لقراءة قيمٍ منتميةٍ لأي من الأنواع الأساسية. لاحِظ أنه من الممكن إرسال كائناتٍ أثناء إرسال قيم تنتمي لأي من الأنواع الأساسية، حيث تُمثَّل القيم المنتمية للأنواع الأساسية بصيغتها الثنائية binary الداخلية عند تخزينها بملف. تُعدّ مجاري الكائنات بمثابة مجاري بايتات؛ حيث تُمثَّل الكائنات بصيغةٍ ثنائيةٍ مهيأة للآلة. في حين يُعزز ذلك من كفائتها، فإنه يتسبَّب بنفس الهشاشة التي تُعاني منها البيانات الثنائية في العموم. ونظرًا لأن الصيغة الثنائية للكائنات مُهيأةٌ للغة جافا، لا يكون من السهل إتاحة بيانات مجاري الكائنات للبرامج المكتوبة بلغاتٍ برمجيةٍ مختلفة. بناءً على ذلك، يُفضَّل اِستخدَام مجاري الكائنات فقط عند الحاجة إلى تخزينها تخزينًا مؤقتًا، أو إلى نَقْلها عبر اتصالٍ شبكي بين برنامجي جافا؛ أما بالنسبة للتخزين طويل الأمد أو الاتصال مع برامج مكتوبة بلغات آخرى، فهناك طرائقٌ بديلةٌ أفضل لسَلسَلة الكائنات (ألقِ نظرةً على المقال مقدمة مختصرة للغة XML لطريقةٍ معتمدةٍ على المحارف). يَعمَل الصنفان ObjectInputStream وObjectOutputStream مع الكائنات التي تُنفِّذ الواجهة Serializable فقط، كما يجب أن تكون جميع متغيرات النسخ المُضمَّنة بتلك الكائنات قابلةً للسَلسَلة. لا تنطوي عملية جعل كائنٍ معينٍ قابلًا للسَلسَلة على أي عملٍ تقريبًا؛ حيث لا تُصرّح الواجهة Serializable حقيقةً عن أي توابع، وإنما هي موجودةٌ فقط مثل إشارةٍ للمُصرِّف على أن الكائن المُنفِّذ لها قابل للكتابة والقراءة. يَعنِي ذلك أن كل ما علينا فعله هو إضافة الكلمات implements Serializable إلى تعريف الصنف. لاحِظ أن الكثير من أصناف جافا القياسية مُصرَّح عنها بحيث تكون قابلة للسَلسَلة بالفعل. تنبيه عن استخدام الصنف ObjectOutputStream: أُعدَّت مجاري ذلك الصنف لتجنَّبنا إعادة كتابة نفس الكائن أكثر من مرة، ولهذا، إذا واجه المجرى كائنًا معينًا للمرة الثانية، فإنه في الواقع يَستخدِم مرجعًا reference إلى كائن المرة الأولى أثناء الكتابة. يَعنِي ذلك أنه في حالة كان الكائن قد عُدّل بين المرتين الأولى والثانية، فإننا لن نَحصُل على البيانات الجديدة؛ لأن القيمة المُعدَّلة لا تُرسَل بصورةٍ صحيحة إلى المجرى. يَرجِع ذلك إلى أن مجاري الصنف ObjectOutputStream قد أُعدّت بالأساس للعمل مع الكائنات الثابتة immutable التي لا يُمكِن تعديلها بعد إنشائها، مثل السلاسل النصية من النوع String. ومع ذلك، إذا أردت حقًا أن تُرسِل كائنًا مُتغيرًا mutable إلى هذا النوع من المجاري، وكان من المحتمل أن تُرسِل نفس الكائن أكثر من مرة، فيُمكِنك في تلك الحالة أن تضمَن إرسال النسخة الصحيحة من الكائن باستدعاء تابع المجرى reset() قبل إرسال الكائن إليه. ترجمة -بتصرّف- للقسم Section 1: I/O Streams, Readers, and Writers من فصل Chapter 11: Input/Output Streams, Files, and Networking من كتاب Introduction to Programming Using Java. اقرأ أيضًا التعامل مع المدخلات وإظهار المخرجات في لغة جافا كيفية قراءة البرامج لمدخلات المستخدم القوائم lists والأطقم sets في جافا الواجهات Interfaces في جافا1 نقطة
تُصبِح البرامج عديمة الفائدة إذا لم تكن قادرةً على التعامل مع العالم الخارجي بشكلٍ أو بآخر، حيث يُشار إلى تعامل البرامج مع العالم الخارجي باسم "الدْخَل والخرج أو I/O". يُعدّ توفير إمكانياتٍ جيدةٍ لعمليات الدْخَل والخرج واحدًا من أصعب التحديات التي تواجه مُصمِّمي اللغات البرمجية، حيث يَستطيِع الحاسوب الاتصال مع أنواعٍ مختلفةٍ كثيرة من أجهزة الدخل والخرج. إذا اضطّرت لغة البرمجة للتعامل مع كل نوعٍ منها على حدة، لكان الأمر غايةً في التعقيد، ولهذا يُعدّ التمثيل المُجرّد لأجهزة الدخل والخرج واحدًا من أعظم الإنجازات بتاريخ البرمجة، ويُطلَق على ذلك التمثيل المُجرّد بلغة جافا اسم مجاري تدفق الدْخَل والخرج I/O streams. تتوفَّر تجريداتٌ أخرى، مثل الملفات والقنوات، ولكننا سنناقش مجاري التدفق فقط، حيث يُمثِّل كل مجرًى مصدرًا يُقرَأ منه الدْخَل أو مقصدًا يُرسَل إليه الخرج. مجاري تدفق البايتات Byte Streams ومجاري تدفق المحارف Character Streams عندما تتعامل مع المُدْخَلات والمخرجات، تذكَّر أن هناك نوعان من البيانات في العموم؛ بياناتٌ مُهيأةٌ للآلة؛ وبياناتٌ مهيأةٌ لنا بمعنى أنها قابلةٌ للقراءة. تُكتَب الأولى بالصيغة الثنائية binary بنفس الطريقة التي تُخزَّن بها البيانات داخل الحاسوب، أي بهيئة سلاسلٍ نصيةٍ مُكوَّنةٍ من "0" و "1"؛ بينما تُكتَب الثانية بهيئة محارف. فعندما تقرأ عددًا، مثل "3.141592654"، فأنت في الواقع تقرأ متتاليةً من المحارف، ولكنك تُفسِّرها عددًا؛ بينما يُمثِّل الحاسوب نفس ذلك العدد بهيئة سلسلةٍ نصيةٍ من البتات أي أنك لن تتمكَّن من تمييزها. تُوفِّر جافا نوعين من مجاري التدفق streams للتعامل مع البيانات المُمثَلة بالصيغتين السابقتين: مجرى بايتات byte streams للبيانات المُهيأة للآلة، ومجرى محارف character streams للبيانات القابلة للقراءة. ستَجِد أصنافًا مُعرَّفةً مُسبقًا تُمثِّل المجاري من كلا النوعين. تنتمي الكائنات المُرسِلة للبيانات إلى مجرى بايت إلى أحد الأصناف الفرعية subclasses المُشتقَّة من الصنف المُجرَّد OutputStream؛ بينما تنتمي الكائنات القارئة للبيانات من هذا النوع من المجاري إلى أحد الأصناف الفرعية المُشتقَّة من الصنف المُجرَّد InputStream. إذا أرسلت أعدادًا إلى كائنٍ من الصنف OutputStream، لن تتمكَّن من قراءة البيانات الناتجة بنفسك. في المقابل، ما يزال بإمكان الحاسوب قرائتها مُجدَّدًا عبر كائنٍ من الصنف InputStream. تعمَل عمليتي قراءة البيانات وكتابتها في تلك الحالة بكفاءة لعدم استخدامهما أي ترجمة؛ حيث تُنسَخ فقط البتات المُمثِلة للبيانات بالحاسوب من مجاري التدفق وإليها. في المقابل، يتولَّى الصنفان المجرَّدان Reader وWriter قراءة البيانات القابلة للقراءة وكتابتها على الترتيب، فجميع أصناف مجارى المحرف هي مجرد أصنافٍ فرعيةٍ مُشتقَّةٍ من هذين الصنفين. إذا أرسلت عددًا إلى مجرًى من النوع Writer، فيجب أن يُترجمها الحاسوب إلى متتاليةٍ من المحارف المُمثِلة لذلك العدد والقابلة للقراءة؛ بينما تنطوي عملية قراءة عددٍ من مجرًى من النوع Reader، وتخزينها بمُتغيِّرٍ عددي على عملية ترجمةٍ من متتالية محارف إلى سلسلة بتاتٍ مناسبة. حتى لو كانت البيانات التي تتعامل معها مُكوَّنةً من محارفٍ بالأساس، مثل بعض الكلمات من برنامج معدِّل نصوص، من الممكن أن يتضمَّن الأمر بعضًا من الترجمة أيضًا. يُخزِّن الحاسوب المحارف على انها قيم يونيكود Unicode من 16 بت، وتُخزّن حروف الأبجدية الإنجليزية عمومًا بملفات بشيفرة ASCII، التي تَستخدِم 8 بتات للمحرف الواحد. يتولى الصنفان Reader وWriter أمر تلك الترجمة، كما يمكنهما معالجة الحروف الأبجدية الأخرى، وكذلك المحارف من غير الحروف الأبجدية المكتوبة بلغاتٍ، مثل الصينية. تُستَخدَم مجاري تدفق البايتات للاتصال المباشر بين الحواسيب، كما أنها تكون مفيدةً أحيانًا لتخزين البيانات ضمن ملفات، بالأخص عندما نحتاج إلى تخزين أحجامٍ هائلةٍ من البيانات بطريقةٍ فعالة؛ كما هو الحال مع قواعد البيانات الضخمة. ومع ذلك، تُعدّ البيانات الثنائية هشة نوعًا ما، فهي لا تعبُر بذاتها عن معناها. عندما تتعامل مع سلسلةٍ طويلةٍ من العددين صفر وواحد، ينبغي أن تُعرِّف أولًا نوعية المعلومات المُفترَض لتلك السلسلة أن تُمثِّلها، وكذلك أن تَعرِّف الكيفية التي رُمزَّت بها المعلومات قبل أن تتمكَّن من تفسيرها. ينطبق الأمر نفسه بالطبع على البيانات المحرفية نوعًا ما؛ فالمحارف بالنهاية مثلها مثل أي نوعٍ من البيانات، وينبغي أن تُرمَّز مثل أعدادٍ ثنائية حتى يتمكَّن الحاسوب من تخزينها ومعالجتها، ولكن الترميز الثنائي للبيانات المحرفية على الأقل مُوحدٌ ومفهوم، بل حتى يُمكِننا أن نجعل البيانات بصيغتها المحرفية ذات معنًى للقارئ. يتجه التيار العام إلى استخدام البيانات المحرفية، وتمثيلها بطريقةٍ تجعلها مُفسَّرةً ذاتيًا قدر الإمكان، وسنناقش إحدى تلك الطرائق في مقال مقدمة مختصرة للغة XML. لا يدعم الإصدار الأصلي من جافا مجاري المحارف، حيث يُمكِن لمجاري البايتات أن تحلّ محل مجاري المحارف عند التعامل مع البيانات المُرمزَّة بشيفرة ASCII. يُعدُّ مجريا الدخل القياسي System.in والخرج القياسي System.out مجاري بايتات، وليس مجاري محارف؛ ومع ذلك يُحبَّذ استخدام الصنفين Reader وWriter على الصنفين InputStream وOutputStream عند التعامل مع البيانات المحرفية، وحتى عند التعامل مع مجموعة محارف ASCII القياسية. تقع أصناف مجاري الدخل والخرج القياسية -والتي سنناقشها ضمن هذا المقال - بحزمة java.io بالإضافة إلى عددٍ من الأصناف الأخرى. يجب أن تستورد import أصناف تلك الحزمة إذا أردت اِستخدَامها ضمن البرنامج؛ أي إما أن تستورد الأصناف المطلوبة بصورةٍ فردية؛ أو أن تْكْتُب المُوجِّه import java.io.*; في بداية الملف المصدري. تُستخدَم مجاري الدخل والخرج عند التعامل مع الملفات، وعند الاتصال الشبكي، وكذلك للاتصال بين الخيوط المُتزامنة concurrent threads. تتوفَّر أيضًا أصناف مجاري لقراءة البيانات وكتابتها من وإلى ذاكرة الحاسوب. تَكْمُن فعالية المجاري وأناقتها بكونها تُجرِّد عملية كتابة البيانات؛ حيث تُصبِح عملياتٍ مثل كتابة بياناتٍ إلى ملف أو إرسالها عبر شبكةٍ بنفس سهولة طباعة تلك البيانات على الشاشة. تُوفِّر أصناف الدخل والخرج Reader وWriter وInputStream وOutputStream العمليات الأساسية فقط، حيث يُصرِّح الصنف InputStream مثلًا عن تابع النسخة instance method المُجرَّد التالي: public int read() throws IOException يقرأ هذا التابع بايتًا واحدًا من مجرى دْخَلٍ بهيئة عددٍ يقع بنطاقٍ يتراوح بين "0" و "255"، ويُعيد القيمة "-1" عند وصوله إلى نهاية المجرى. إذا حدث خطأٌ أثناء عملية الدخل، يقع استثناء exception من النوع IOException، ونظرًا لكونه من الاستثناءات المُتحقَّق منها checked exceptions، لا بُدّ من استخدام التابع read() ضمن تعليمة try أو ببرنامجٍ فرعي subroutine يتضمَّن تصريحه عبارة throws IOException. انظر مقال الاستثناءات exceptions وتعليمة try..catch في جافا للمزيد من المعلومات عن الاستثناءات المُتحقَّق منها والمعالجة الاجبارية للاستثناءات. يُعرِّف الصنف InputStream أيضًا توابعًا لقراءة عدة بايتات من البيانات ضمن خطوةٍ واحدة، وتخزينها بمصفوفة بايتات، وهو ما يُعدّ أكثر كفاءة بكثير من قرائتها بصورةٍ إفرادية؛ ولكنه -أي الصنف InputStream- مع ذلك لا يُوفِّر أي توابعٍ لقراءة أنواعٍ أخرى من البيانات، مثل int وdouble من مجرى. لا يُمثِل ذلك مشكلة؛ حيث من النادر أن تستخدِم كائناتٍ من النوع InputStream، وإنما ستعتمد على أصنافٍ فرعية منه. تُعرِّف تلك الأصناف توابع دْخَلٍ إضافية إلى جانب الإمكانيات الأساسية للصنف InputStream، كما يُعرِّف بالمثل الصنف OutputStream تابع الخرج التالي لكتابة بايت واحد إلى مجرى خرج: public void write(int b) throws IOException لاحِظ أن المعامل parameter من النوع int، وليس من النوع byte، ولكنه يُحوَّل type-cast إلى النوع byte قبل كتابته، وهو ما يؤدي إلى إهمال جميع بتات المعامل b باستثناء البتات الثمانية الأقل رتبة. عمليًا، ستَستخدِم دائمًا أصنافًا فرعية مُشتقَّة من الصنف OutputStream، والتي تُعرِّف عمليات خرجٍ إضافية عالية المستوى. يُوفِّر الصنفان Reader وWriter توابعًا منخفضة المستوى مشابهة لعمليتي read وwrite. وكما هو الحال مع أصناف مجاري البايتات، ينتمي كلٌ من معامل التابع write(c) المُعرَّف بالصنف Writer، والقيمة المعادة من التابع read() المُعرَّف بالصنف Reader إلى النوع int، ولكن ما يزال هناك اختلاف؛ حيث تُجرَى بتلك الأصناف المُخصَّصة بالأساس للمحارف عمليتي الدخل والخرج على المحارف، وليس على البايتات. يعيد التابع read() القيمة "-1" عند وصوله إلى نهاية المجرى، أما قبل ذلك، فيجب أن نُحوَّل القيمة المعادة منه إلى النوع char لنَحصُل على المحرف المقروء. عمليًا، ستَستخدِم عادةً أصنافًا فرعيةً مُشتقَّةً من الصنفين Reader وWriter، والتي تُعرِّف عمليات دْخَل وخَرْج إضافية عالية المستوى، كما سنناقش فيما يلي. الصنف PrintWriter تُمكِّنك حزمة جافا للدخل والخرج من إضافة إمكانياتٍ جديدة إلى مجاري التدفق من خلال تغليفها wrapping ضمن كائنات مجاري تدفقٍ أخرى تُوفِّر تلك الإمكانيات. يكون الكائن المُغلِّف مجرًى أيضًا؛ أي يُمكِنك أن تقرأ منه أو تكتب به، ولكن عبر عملياتٍ أكثر فعالية من تلك المتاحة بمجاري التدفق الأصلية. يُعدّ الصنف PrintWriter على سبيل المثال صنفًا فرعيًا من الصنف Writer، ويُوفِّر توابعًا لإخراج جميع أنواع البيانات الأساسية بلغة جافا بصيغة محارف مقروءة. إذا كان لديك كائنٌ منتميٌ إلى الصنف Writer أو أيٍّ من أصنافه الفرعية، وأردت استخدام توابع الصنف PrintWriter لعمليات الخرج الخاصة بذلك الكائن؛ فكل ما عليك فعله هو تغليف كائن الصنف Writer بكائن الصنف PrintWriter، وذلك بتمريره إلى باني الكائن constructor المُعرَّف بالصنف PrintWriter. بفرض أن charSink من النوع Writer، يُمكِنك كتابة ما يَلِي: PrintWriter printableCharSink = new PrintWriter(charSink); يُمكِن للمعامل المُمَّرر إلى الباني أن يكون من النوع OutputStream أو النوع File، وهذا ما سنناقشه في المقال التالي؛ حيث يُنشِئ الباني في العموم كائنًا من النوع PrintWriter، والذي يكون بإمكانه الكتابة إلى مقصد الخرج الخاص بالكائن المُمرَّر إليه. عندما تُرسِل بيانات خرجٍ إلى printableCharSink عبر إحدى توابع الخرج عالية المستوى المُعرَّفة بالصنف PrintWriter، فستُرسَل تلك البيانات إلى نفس المقصد الذي يُرسِل charSink البيانات إليه؛ فكل ما فعلناه هو توفير واجهة أفضل لنفس مقصد الخرج، وهذا يَسمَح لنا باستخدام توابع الصنف PrintWriter لإرسال البيانات إلى ملفٍ أو عبر اتصالٍ شبكي مثلًا. إذا كان out مُتغيّرًا من النوع PrintWriter، فإنه إذًا يُعرِّف التوابع التالية: out.print(x): يُرسِل قيمة المعامل x بهيئة سلسلةٍ نصيةٍ من المحارف إلى مجرى الخرج، ويُمكِن للمعامل x أن يكون تعبيرًا expression من أي نوع، بما في ذلك الأنواع الأساسية primitive types والأنواع الكائنية؛ حيث يُحوِّل التابع أي كائنٍ إلى سلسلةٍ نصيةٍ عبر تابعه toString(). تُمثَّل القيمة الفارغة null بالسلسلة النصية "null". out.println(): يُرسِل مِحرف سطرٍ جديد إلى مجرى الخرج. out.println(x): يُرسِل قيمة x متبوعةً بسطرٍ جديد، وهو ما يُكافِئ استدعاء التابعين out.print(x) وout.println() على التوالي. out.printf(formatString, x1, x2, ...): يُرسِل خرجًا مُنسَّقًا للمعاملات المُمرَّرة x1 وx2 و .. وهكذا إلى مجرى الخرج. يمثِّل المعامل الأول سلسلةً نصيةً تُخصِّص صيغة الخرج المطلوبة. إلى جانب ذلك، يَستقبِل التابع أي عددٍ من المعاملات الإضافية التي يُمكِنها أن تنتمي لأي نوع، بشرط أن تتوافق مع صيغة الخرج المُخصَّصة بالمعامل الأول. ألقِ نظرةً على قسم الخرج البسيط والخرج المنسق من مقال المدخلات والمخرجات النصية في جافا للمزيد من المعلومات عن الخرج المُنسَّق فيما يتعلَّق بمجرى الخرج القياسي System.out، ويُوفِّر التابع out.printf نفس الوظيفة. out.flush(): يتأكَّد من كتابة المحارف المُرسلة عبر أيٍّ من التوابع السابقة إلى مقصدها بصورةٍ فعليّة. يكون استدعاء هذا التابع ضروريًا في بعض الحالات بالأخص عند إرسال الخرج إلى ملفٍ أو عبر شبكة، وذلك لضمان ظهور الخرج بالمقصد المُحدَّد. لا تُبلِّغ أيٌ من التوابع السابقة عن استثناءٍ من النوع IOException نهائيًا. بدلًا من ذلك، يتضمَّن الصنف PrintWriter التابع التالي: public boolean checkError() يعيد هذا التابع القيمة true في حالة حدوث خطأٍ أثناء عملية الكتابة بمجرى؛ حيث يلتقط الصنف PrintWriter أي استثناءات من النوع IOException، ثم يَضبُط قيمة رايةٍ flag داخليةٍ معينةٍ للإشارة إلى وجود خطأ. يُمكِنك إذًا استخدام التابع checkError() لفحص قيمة تلك الراية، وذلك من خلال استخدام توابع الصنف PrintWriter دون الحاجة لالتقاط أي استثناءات؛ ومع ذلك، إذا كنت تريد كتابة برنامج متين تمامًا، فيجب أن تستدعي التابع checkError() عند استخدام أيٍّ من توابع الصنف PrintWriter لتَتأكَّد من عدم وقوع أي أخطاءٍ مُحتمَلة. مجاري تدفق البيانات Data Streams عندما نَستخدِم الصنف PrintWriter لإرسال بياناتٍ إلى مجرًى معيّن، فسيُحوِّل البيانات إلى متتاليةٍ مقروءةٍ من المحارف المُمثِّلة لتلك البيانات. ماذا لو أردنا إرسال البيانات بصيغةٍ ثنائيةٍ مهيأةٍ للآلة؟ في الواقع، تتضمَّن حزمة java.io الصنف DataOutputStream المُمثِّل لمجرى بايتات، والذي يُمكِننا استخدامه لإرسال البيانات إلى المجاري بهيئةٍ ثنائية. تُعدّ العلاقة بين الصنفين DataOutputStream وOutputStream مشابهةً لتلك الموجودة بين الصنفين PrintWriter وWriter؛ فبينما يَملُك الصنف OutputStream توابع الخرج المُخصَّصة للبايتات فقط؛ يملك الصنف DataOutputStream التابع writeDouble(double x) لقيم الخرج من النوع double، والتابع writeInt(int x) لقيم الخرج من النوع int، وهكذا. علاوةً على ذلك، من الممكن أيضًا تغليف أي كائنٍ من النوع OutputStream ضمن كائنٍ من النوع DataOutputStream؛ لنتمكَّن من استخدام توابع الخرج عالية المستوى المُعرَّفة به. إذا كان byteSink من النوع OutputStream مثلًا، يُمكِن كتابة ما يَلي لتغليفِه ضمن كائنٍ من النوع DataOutputStream: DataOutputStream dataSink = new DataOutputStream(byteSink); تُوفِّر حزمة java.io الصنف DataInputStream بالنسبة للمُدْخلات المُهيأة للآلة، مثل تلك التي يُنشئها DataOutputStream عند اِستخدَامه للكتابة. يُمكِنك تغليف كائنٍ من النوع InputStream ضمن كائنٍ من النوع DataInputStream؛ لتُمكِّنه من قراءة أي نوعٍ من البيانات من مجرى بايتات. أسماء توابع الصنف DataInputStream المسؤولة عن قراءة البيانات الثنائية هي: readDouble() وreadInt() وهكذا. يكْتُب الصنف DataOutputStream البيانات بصيغةٍ يُمكِن للصنف DataInputStream أن يقرأها بالضرورة، حتى لو أنشأ حاسوبٌ من نوعٍ معين المجرى، وكان المطلوب أن يقرأه حاسوبٌ من نوعٍ آخر. تُوفِّر البيانات الثنائية توافقًا compatibility عبر المنصات، ويُعدُّ هذا أحد الجوانب الأساسية لاستقلالية منصة جافا. قد ترغب في بعض الحالات بقراءة محارفٍ من مجرًى من النوع InputStream، أو كتابة محارفٍ إلى مجرًى من النوع OutputStream، ولا يُمثِل ذلك مشكلةً لأن المحارف مثلها مثل جميع البيانات؛ فهي تُمثَّل بهيئة أعدادٍ ثنائيةٍ، على الرغم أنه من الأفضل في تلك الحالة استخدام الصنفين Reader وWriter، بدلًا من InputStream وOutputStream. مع ذلك، تستطيع فعل ذلك بتغليف مجرى البايتات ضمن مجرى محارف. إذا كان byteSource متغيرًا من النوع InputStream وكان byteSink مُتغيرًا من النوع OutputStream، تُنشِئ التعليمات التالية مجاري محارف بإمكانها قراءة المحارف وكتابتها من وإلى مجاري بايتات. Reader charSource = new InputStreamReader( byteSource ); Writer charSink = new OutputStreamWriter( byteSink ); يُمكِننا تحديدًا تغليف مجرى الدخل القياسي System.in، المُنتمي إلى الصنف InputStream لأسبابٍ تاريخية، ضمن كائنٍ من النوع Reader، لتسهيل قراءة المحارف من الدخل القياسي كما يلي: Reader charIn = new InputStreamReader( System.in ); لنأخذ مثالًا آخر؛ حيث تُعدّ مجاري الدخل والخرج المُرتبطِة باتصالٍ شبكي مجاري بايتات لا مجاري محارف، ويُمكننا مع ذلك تغليف مجاري البايتات بمجاري محارف للتسهيل من إرسال البيانات المحرفية واستقبالها عبر الشبكة. سنناقش عمليات الدخل والخرج عبر الشبكة لاحقًا. تتوفَّر طرائقٌ مختلفة لترميز المحارف بهيئة بياناتٍ ثنائية، حيث يُطلَق مُصطلح "طقم محارف charset" على أي ترميز محارف، ويَملُك اسمًا قياسيًا، مثل "UTF-16" و "UTF-8" و "ISO-8859-1"؛ حيث يُرمِّز "UTF-16" المحارف بهيئة قيم يونيكود Unicode مُكوَّنةٍ من "16 بت"، وهو الترميز المُستخدَم داخليًا بجافا؛ بينما يُعدّ "UTF-8" أسلوبًا لترميز محارف اليونيكود بتخصيص "8 بت" لمحارف ASCII الشائعة في مقابل عدد بتاتٍ أكثر للمحارف الأخرى؛ أما ترميز "ISO-8859-1" المعروف أيضًا باسم "Latin-1"، فهو مكوَّنٌ من "8 بت"، ويتضمَّن محارف ASCII إلى جانب محارفٍ أخرى مُستخدَمةٍ ضمن عدة لغاتٍ أوروبية. يَعتمِد الصنفان Reader وWriter على طقم المحارف الافتراضي ضمن الحاسوب المُشّغلان عليه، إلا إذا خصَّصت طقم محارفٍ معين بتمريره عبر الباني على النحو التالي: Writer charSink = new OutputStreamWriter( byteSink, "ISO-8859-1" ); يؤدي اختلاف ترميزات أطقم المحارف وكثرتها إلى تعقيد عملية معالجة النصوص، وهو ما يُعدّ أمرًا سيئًا للمتحدثين بالإنجليزية، ولكنه ضروري لغيرهم ممن يَستخدِمون أطقم محارفٍ مختلفة. لا حاجة للقلق عمومًا بشأن أيٍّ من ذلك، إنما عليك فقط أن تتذكَّر أن هناك أطقم محارفٍ مختلفة إذا واجهت بياناتٍ نصيةٍ مُرمزَّة بطريقةٍ غير اعتيادية. قراءة النصوص تُجرَى كثيرٌ من عمليات الدخل والخرج على محارفٍ مقروءة، ومع ذلك، لا توفِّر جافا صنفًا قياسيًا يُمكِنه قراءة المحارف بإمكانياتٍ متكافئة مع ما يُوفِّره الصنف PrintWriter لإخراج المحارف. قد يَكون الصنف Scanner -الذي تعرَّضنا له في مقال المدخلات والمخرجات النصية في جافا، والذي سنناقشه تفصيليًا فيما يلي مكافئًا نوعًا ما، ولكنه ليس صنفًا فرعيًا من أي صنف مجرى؛ ما يعني أنه لا يتناسب مع إطار عمل مجاري التدفق. هناك مع ذلك حالةٌ بسيطةٌ بإمكان الصنف القياسي BufferedReader معالجتها بسهولة. يتضمَّن هذا الصنف التابع التالي: public String readLine() throws IOException يقرأ هذا التابع سطرًا نصيًا واحدًا من المُدْخلات، ويقرأ خلال ذلك مؤشر نهاية السطر أيضًا، ولكن لا يكون هذا المؤشر جزءًا من السلسلة النصية التي يعيدها التابع؛ بينما يُعيد التابع القيمة null عند وصوله إلى نهاية المجرى. تَستخدِم الأنواع المختلفة من مجاري الدْخَل محارفًا مختلفةً للإشارة إلى نهاية السطر، ولكن يُمكِن للتابع readLine التعامُل مع أغلب الحالات الشائعة. تَستخدِم حواسيب Unix، بما في ذلك Linux و Mac OS X عادةً محرف سطرٍ جديد '\n' للإشارة إلى نهاية السطر؛ بينما يستخدم Macintosh محرف العودة إلى بداية السطر '\r'؛ أما Windows فيَستخدِم المحرفين "\r\n". تستطيع الحواسيب العصرية عمومًا التعامل مع كل تلك الاحتمالات. يُعرِّف الصنف BufferedReader إضافةً إلى ذلك تابع النسخة lines()، والذي يعيد قيمةً من النوع Stream<String> يُمكِن استخدامها مع واجهة برمجة تطبيقات stream API -انظر مقال مقدمة إلى واجهة برمجة التطبيقات Stream API في جافا-. بفرض أن reader متغيرٌ من النوع BufferedReader، ستكون الطريقة الأمثل لمعالجة جميع الأسطر التي قرأها بتطبيق العامل forEach() على مجرى الأسطر على النحو التالي: reader.lines().forEachOrdered(action) حيث تمثِّل action مُستهلِك سلاسلٍ نصية، والذي يُكتَب عادةً بصيغة تعبيرات لامدا lambda expression. تشيع معالجة الأسطر واحدًا تلو الآخر، لذلك يُمكِننا تغليف wrap أي كائنٍ من النوع Reader ضمن كائنٍ من النوع BufferedReader لتسهيل قراءة الأسطر النصية بالكامل. بفرض أن reader من النوع Reader، يُمكِننا تغليفه باستخدام كائنٍ من النوع BufferedReader على النحو التالي: BufferedReader in = new BufferedReader( reader ); كما يُمكِننا مثلًا استخدامه مع الصنف InputStreamReader المذكور بالأعلى لقراءة أسطرٍ نصيةٍ من كائنٍ من النوع InputStream، أو قد نُطبقه على System.in على النحو التالي: BufferedReader in; // BufferedReader for reading from standard input. in = new BufferedReader( new InputStreamReader( System.in ) ); try { String line = in.readLine(); while ( line != null ) { processOneLineOfInput( line ); line = in.readLine(); } } catch (IOException e) { } تقرأ الشيفرة السابقة أسطرًا من الدخل القياسي، وتعالجها حتى الوصول إلى نهاية المجرى. تَعمَل مؤشرات نهاية المجرى حتى مع المُْدْخَلات التفاعلية، حيث يُولِّد النقر على زر Control-D ببعض الحواسيب على الأقل مثلًا مؤشر نهاية مجرى بمجرى الدخل القياسي. تُعدُّ معالجة الاستثناءات إلزامية نظرًا لإمكانية تبليغ التابع readLine عن استثناءاتٍ exception من النوع IOException، ولهذا كان من الضروري إحاطة التابع بتعليمة try..catch. يُمكِننا بدلًا من ذلك كتابة عبارة throws IOException بتصريح التابع المُتضمِّن للشيفرة بالأعلى. يجب أن تُستورد الأصناف الآتية من حزمة java.io: BufferedReader. InputStreamReader. IOException. على الرغم من تسهيل الصنف BufferedReader عملية قراءة الأسطر النصية، فإن هذا ليس الغرض الأساسي من وجوده، حيث تعمَل بعض أجهزة الدخل والخرج بأعلى كفائتها عند قراءة أو كتابة قدرٍ كبيرٍ من البيانات دفعةً واحدةً بدلًا من مجرد قراءة بايتاتٍ أو محارفٍ مفردة. يُوفِّر الصنف BufferedReader تلك الإمكانية، حيث يُمكِنه قراءة دفعةٍ من البيانات، وتخزينها ضمن ذاكرةٍ داخلية، تُعرَف باسم المخزن المؤقت buffer. عندما تقرأ من كائنٍ من الصنف BufferedReader، فإنه في الواقع يستعيد البيانات من المخزن المؤقت إذا كان ذلك ممكنًا، أي إذا لم يَكن المخزن فارغًا؛ حيث يضطّر تلك الحالة فقط من التعامل مع مصدر الدْخل مرةً أخرى لجلب المزيد من البيانات. يتوفَّر أيضًا الصنف المكافئ BufferedWriter، بالإضافة إلى وجود أصناف مجاري تدفق في مخزنٍ مؤقت للعمل مع مجاري البايتات. اِستخدمنا الصنف غير القياسي TextIO سابقًا لقراءة المُدْخَلات من المُستخدِمين والملفات؛ حيث يتميز ذلك الصنف بسهولة قراءة البيانات المنتمية لأي نوعٍ من الأنواع الأساسية primitive types، ولكنه لا يستطيع مع ذلك القراءة من أكثر من مصدر دخلٍ واحد بنفس الوقت، وهو بذلك لا يَتّبِع نفس نمط أصناف جافا القياسية المبنية مُسبقًا للدْخَل والخَرْج. إذا أعجبك أسلوب الصنف TextIO في التعامل مع المُدْخَلات، يُمكِنك إلقاء نظرةٍ على الصنف TextReader.java، الذي يُنفِّذ implement أسلوبًا مشابهًا بطريقةٍ أكثر كائنية object-oriented. لم نَستخدِم الصنف TextReader ضمن هذا الإصدار من الكتاب، ولكننا أشرنا إليه ضمن بعض الإصدارات السابقة. الصنف Scanner لم تُوفِّر جافا بإصداراتها الأولى دعمًا مبنيًا مسبقًا للمُدْخلات البسيطة، حيث اعتمد الدعم الذي وفِّرته على بعض التقنيات المتقدمة نوعًا ما، ووفَّرت بعد ذلك الصنف Scanner المُعرَّف بحزمة java.util لتسهيل قراءة المُدْخَلات من الأنواع البسيطة، وهو ما يُعدّ تَحسُنًا كبيرًا، ولكنه لم يَحِل المشكلة بالكامل. تعرَّضنا للصنف Scanner في المقال مقدمة إلى واجهة برمجة التطبيقات Stream API في جافا، ولكننا لم نَستخدِمه بعدها، ولهذا سنعتمد بغالبية الأمثلة التالية على الصنف Scanner بدلًا من TextIO. يُعرِّف الصنف البرامج المسؤولة عن عمليات الدْخَل على هيئة توابع نسخ instance methods؛ أي ينبغي أن نُنشِئ كائنًا منه إذا أردنا أن نَستخدِمها. يَستقبِل باني الصنف constructor المصدر الذي ينبغي أن تُقرَأ منه المحارف؛ أي أنه يَعمَل مثل مُغلِّف لذلك المصدر. يُمكِن للمصدر أن يكون من الصنف Reader، أوInputStream، أوString، أوFile، أو غيرها من الاحتمالات الأخرى. إذا اِستخدَمنا النوع String مصدرًا للمُدْخَلات، فسيقرأ الصنف Scanner محارف السلسلة النصية ببساطة من بدايتها إلى نهايتها بنفس الكيفية التي كان سيتعامل بها مع متتالية محارفٍ مصدرها مجرى، حيث يُمكِننا مثلًا استخدام كائنٍ من النوع Scanner للقراءة من الدْخَل القياسي بكتابة ما يلي: Scanner standardInputScanner = new Scanner( System.in ); وبفرض أن charSource من النوع Reader، يُمكِننا بالمثل أن نُنشِئ كائنًا من الصنف Scanner للقراءة منه بكتابة ما يَلي: Scanner scanner = new Scanner( charSource ); يُعالِج الصنف Scanner المُدَْخَلات عادةً وحدةً token تلو الأخرى؛ حيث يُقصَد بالوحدة سلسلةً نصيةً من المحارف لا يُمكِن تقسيمها إلى وحداتٍ أصغر، وإلا ستفقد معناها وفقًا للمهمة المعنية بها. يُمكِن للوحدة أن تكون كلمةً مفردةً مثلًا أو سلسلةً نصيةً مُمثِّلةً لقيمةٍ من النوع double. يحتاج الصنف Scanner أيضًا لوجود "فاصلٍ delimiter" بين تلك الوحدات، والذي يُمثَّل عادةً ببضعة فراغات، مثل محارف الفراغ، أو محارف tab، أو مؤشرات نهاية السطر. يُهمِل الصنف Scanner تلك الفراغات، حيث يقتصر الهدف من وجودها على الفصل بين الوحدات. يتضمَّن الصنف توابع نسخٍ لقراءة مختلف أنواع الوحدات. لنفترض أن scanner كائنٌ من النوع Scanner، يكون لدينا التوابع التالية: scanner.next(): يقرأ الوحدة التالية من مصدر المُدْخَلات، ويعيد قيمةً من النوع String. scanner.nextInt() وscanner.nextDouble() وغيرها: يقرأون الوحدة التالية من مصدر المُدْخَلات، ويحاولون تحويلها إلى قيمةٍ من النوع int وdouble وغيرها. تتوفَّر توابعٌ لقراءة جميع الأنواع الأساسية. scanner.nextLine(): يقرأ سطرًا كاملًا من المُدْخَلات حتى يَصِل إلى مؤشر نهاية السطر، ثم يعيد السطر على أنه قيمةٌ من النوع String. في حين يقرأ التابع مؤشر نهاية السطر، فإنه لا يُضمُّنه بالقيمة التي يُعيدها، كما أنه لا يعتمد على مفهوم الوحدات؛ فهو يعيد سطرًا كاملًا بما قد يحتويه من أية فراغات. يُمكِن أن تكون القيمة المُعادة من التابع مجرد سلسلةٍ نصيةٍ فارغة. يُمكِن للتوابع السابقة أن تُبلِّغ عن بعض أنواع الاستثناءات، حيث يمكنها على سبيل المثال التبليغ عن استثناءٍ من النوع NoSuchElementException عند محاولتها القراءة من مصدرٍ تجاوزت نهايته بالفعل. كما تُبلِّغ توابعٌ، مثل scanner.getInt() عن حدوث استثناءٍ من النوع InputMismatchException، إذا لم تكُن الوحدة token التالية من النوع المطلوب. لا تُعدّ معالجة الاستثناءات التي تُبلِّغ عنها تلك التوابع إلزامية. يتمتع الصنف Scanner بإمكانياتٍ جيدة لفحص المُدْخَلات دون قرائتها؛ حيث يُمكِنه مثلًا أن يُحدِّد فيما إذا كان هناك المزيد من الوحدات للقراءة، أو إذا كانت الوحدة التالية من نوعٍ معين. إذا كان scanner كائنًا من النوع Scanner، يُمكِننا استخدام التوابع التالية: scanner.hasNext(): يُعيد القيمة المنطقية true في حالة وجود وحدةٍ واحدةٍ على الأقل بمصدر المُدْخَلات. scanner.hasNextInt() وscanner.hasNextDouble()، وهكذا: يعيدون القيمة المنطقية true إذا كان هناك وحدةً واحدةً على الأقل بمصدر المُدْخَلات، وكانت تلك الوحدة قيمةً من النوع المطلوب. scanner.hasNextLine(): يعيد القيمة المنطقية true في حالة وجود سطرٍ واحدٍ على الأقل بمصدر المُدْخَلات. تَحِد ضرورة اِستخدَام فاصلٍ بين الوحدات من فعالية الصنف Scanner نوعًا ما، لكنه رغم ذلك سهل الاستخدام، ومناسبٌ للعديد من التطبيقات المختلفة. نظرًا لوجود الكثير من الأصناف المسؤولة عن عمليات الدْخَل، مثل BufferedReader وTextIO وScanner، قد تُصيبك الحيرة لإختيار الأنسب للاستخدام. يُفضَّل عمومًا اِستخدام الصنف Scanner إلا إذا كان هناك سببٌ واضحٌ يدفعك لتفضيل أسلوب الصنف TextIO. في المقابل، يُعدّ الصنف BufferedReader بديلًا بسيطًا، إذا كان كل ما تحتاجه هو مجرد قراءة أسطرٍ نصيةٍ كاملةٍ من مصدر المُدْخَلات. لاحِظ أنه من الممكن تغيير الفاصل الذي يَعتمِد عليه الصنف Scanner للفصل بين الوحدات tokens، ولكن يتطلَّب ذلك التعامل مع ما يُعرَف باسم التعبيرات النمطية regular expression، والتي قد تكون معقدةً بعض الشيء، وهي عمومًا ليست ضمن أهداف هذا الكتاب، ولكن سنأخذ مثالًا بسيطًا عنها؛ ولنفترض مثلًا أننا نريد وحداتٍ مؤلفةً من كلماتٍ مُكوَّنةٍ فقط من أحرف الأبجدية الإنجليزية. يُمكِن في تلك الحالة للفاصل أن يَكون أي محرفٍ من غير تلك الأحرف؛ فإذا كان لدينا كائنٌ من الصنف Scanner اسمه scnr، فإننا نستطيع كتابة scnr.useDelimiter("[^a-zA-Z]+") لجعله يَستخدِم هذا النوع من الفواصل، وستكون بذلك الوحدات المعادة من scnr.next() مُكوَّنةً بالكامل من أحرف الأبجدية الإنجليزية. تُعدّ السلسلة النصية [^a-zA-Z]+ تعبيرًا نمطيًا، وهي في الواقع أداةً مهمةً لأي مبرمج، وعليك أن تشرُع بتعلُّمها إذا واتتك الفرصة لذلك. إدخال وإخراج الكائنات المسلسلة Serialized تَسمَح لنا الأصناف الآتية: PrintWriter. Scanner. DataInputStream. DataOutputStream. بمعالجة الدْخَل والخَرْج من جميع أنواع جافا الأساسية، ولكن ماذا لو أردنا أن نقرأ أو نكتب كائنات؟ سنحتاج بالضرورة إلى العثور على طريقةٍ ما لترميز الكائنات، وتحويلها إلى متتاليةٍ من القيم المنتمية لأي من الأنواع الأساسية، والتي يُمكِن بعد ذلك إرسالها على أنها خَرْجٌ بهيئة بايتات أو محارف. يُطلَق على تلك العملية اسم سَلسَلة serialize الكائن. سنضطّر من الناحية الأخرى لقراءة البيانات المُسَلسَلة، ثم اِستخدَامها لإعادة بناء الكائن الأصلي. إذا كان الكائن معقدًا بعض الشيء، فسيضطّرنا ذلك إلى الكثير من العمل الذي هو في أساسه مجرد عمل روتيني. تُوفِّر جافا لحسن الحظ الصنفين ObjectInputStream وObjectOutputStream؛ لتحمُّل عبء غالبية ذلك العمل. لاحِظ أنهما صنفان فرعيان من الصنفين InputStream وOutputStream، ويُمكِنهما العمل مع الكائنات المُسَلسَلة. يُعدّ الصنفان ObjectInputStream وObjectOutputStream أصنافًا مغلِّفة؛ أي يُمكِنها أن تُغلِّف مجارٍ streams من النوعين InputStream وOutputStream على الترتيب، وهو ما يَسمَح بإدْخال وإخراج الكائنات عبر أي مجرى بايتات؛ حيث يتضمَّن الصنف ObjectInputStream التابع readObject()؛ بينما يتضمَّن الصنف ObjectOutputStream التابع writeObject(Object obj)، ويُمكِنهما التبليغ عن استثناءاتٍ من النوع IOException. يتضمَّن الصنف ObjectOutputStream التوابع writeInt() وwriteDouble() وما يُشبهها، لإرسال قيمٍ منتميةٍ لأي من الأنواع الأساسية إلى مجرى الخرج، كما يتضمَّن الصنف ObjectInputStream توابعًا مكافئةً لقراءة قيمٍ منتميةٍ لأي من الأنواع الأساسية. لاحِظ أنه من الممكن إرسال كائناتٍ أثناء إرسال قيم تنتمي لأي من الأنواع الأساسية، حيث تُمثَّل القيم المنتمية للأنواع الأساسية بصيغتها الثنائية binary الداخلية عند تخزينها بملف. تُعدّ مجاري الكائنات بمثابة مجاري بايتات؛ حيث تُمثَّل الكائنات بصيغةٍ ثنائيةٍ مهيأة للآلة. في حين يُعزز ذلك من كفائتها، فإنه يتسبَّب بنفس الهشاشة التي تُعاني منها البيانات الثنائية في العموم. ونظرًا لأن الصيغة الثنائية للكائنات مُهيأةٌ للغة جافا، لا يكون من السهل إتاحة بيانات مجاري الكائنات للبرامج المكتوبة بلغاتٍ برمجيةٍ مختلفة. بناءً على ذلك، يُفضَّل اِستخدَام مجاري الكائنات فقط عند الحاجة إلى تخزينها تخزينًا مؤقتًا، أو إلى نَقْلها عبر اتصالٍ شبكي بين برنامجي جافا؛ أما بالنسبة للتخزين طويل الأمد أو الاتصال مع برامج مكتوبة بلغات آخرى، فهناك طرائقٌ بديلةٌ أفضل لسَلسَلة الكائنات (ألقِ نظرةً على المقال مقدمة مختصرة للغة XML لطريقةٍ معتمدةٍ على المحارف). يَعمَل الصنفان ObjectInputStream وObjectOutputStream مع الكائنات التي تُنفِّذ الواجهة Serializable فقط، كما يجب أن تكون جميع متغيرات النسخ المُضمَّنة بتلك الكائنات قابلةً للسَلسَلة. لا تنطوي عملية جعل كائنٍ معينٍ قابلًا للسَلسَلة على أي عملٍ تقريبًا؛ حيث لا تُصرّح الواجهة Serializable حقيقةً عن أي توابع، وإنما هي موجودةٌ فقط مثل إشارةٍ للمُصرِّف على أن الكائن المُنفِّذ لها قابل للكتابة والقراءة. يَعنِي ذلك أن كل ما علينا فعله هو إضافة الكلمات implements Serializable إلى تعريف الصنف. لاحِظ أن الكثير من أصناف جافا القياسية مُصرَّح عنها بحيث تكون قابلة للسَلسَلة بالفعل. تنبيه عن استخدام الصنف ObjectOutputStream: أُعدَّت مجاري ذلك الصنف لتجنَّبنا إعادة كتابة نفس الكائن أكثر من مرة، ولهذا، إذا واجه المجرى كائنًا معينًا للمرة الثانية، فإنه في الواقع يَستخدِم مرجعًا reference إلى كائن المرة الأولى أثناء الكتابة. يَعنِي ذلك أنه في حالة كان الكائن قد عُدّل بين المرتين الأولى والثانية، فإننا لن نَحصُل على البيانات الجديدة؛ لأن القيمة المُعدَّلة لا تُرسَل بصورةٍ صحيحة إلى المجرى. يَرجِع ذلك إلى أن مجاري الصنف ObjectOutputStream قد أُعدّت بالأساس للعمل مع الكائنات الثابتة immutable التي لا يُمكِن تعديلها بعد إنشائها، مثل السلاسل النصية من النوع String. ومع ذلك، إذا أردت حقًا أن تُرسِل كائنًا مُتغيرًا mutable إلى هذا النوع من المجاري، وكان من المحتمل أن تُرسِل نفس الكائن أكثر من مرة، فيُمكِنك في تلك الحالة أن تضمَن إرسال النسخة الصحيحة من الكائن باستدعاء تابع المجرى reset() قبل إرسال الكائن إليه. ترجمة -بتصرّف- للقسم Section 1: I/O Streams, Readers, and Writers من فصل Chapter 11: Input/Output Streams, Files, and Networking من كتاب Introduction to Programming Using Java. اقرأ أيضًا التعامل مع المدخلات وإظهار المخرجات في لغة جافا كيفية قراءة البرامج لمدخلات المستخدم القوائم lists والأطقم sets في جافا الواجهات Interfaces في جافا1 نقطة