
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 10/03/22 في كل الموقع
-
ما هو الفرق الجوهري بين sql , nosql وما استخدامها2 نقاط
-
ما معنى arg ؟1 نقطة
-
هي اختصار لكلمة argument أو معامل أو متغير أو قيمة ويتم تمريرها الى الوظيفة او الدالة او الفنكشن (function) عند استدعاء الدالة, مثال على ذلك باستخدام لغة جافاسكربت <script> function sum(arg1,arg2){ const sum = arg1 + arg2; console.log('The sum of ' + arg1 + ' and ' + arg2 + ' is: ' + sum); } sum(3,5); </script> في المثال السابق نلاحظ أننا عرفنا دالة او فنكنش اسمها sum تقوم باستقبال معاملين او قيمتين وتم التعبير عنهما باسم arg1 و arg2 , يمكنك تسمية المتغيرين بأي اسم وليس شرطا arg, عند استدعاء الدالة نقوم بتمرير القيم اليها كما هو موضح في الاعلى1 نقطة
-
مع أني عربي بس ساعات مش بفهم المصطلحات العربية اللي بيستخدمها الاستاذ كل شوية بروح ادور على معانيها انا آخر مرة سمعت الكلامات دي كان في ناشيونال جيوغرافيك ههههههههه1 نقطة
-
لا توجد واحدة منهما أفضل من الأخرى في كل شيء، كل منهما له محاسنه و مساوئه و يجب علينا معرفتها و من ثم معرفة متطلبات التطبيق الذي نريد بناءه حتى نعرف ما الذي يجب علينا استعماله. ال SQL تستطيع أن تستعلم بشكل مهيكل بينما ال nosql ليست كذلك، و بالتالي في حال كان هناك هيكلية معينة للبيانات فستكون ال sql أفضل. يمكنك بسهولة توسعة ال nosql من ناحية ال attributes فهي ديناميكية أكثر من ال sql، و بالتالي في حال كان لديك تطبيق فيه كيانات ستتغير بشكل كثير فيفضل استعمال ال nosql. هذه هي الميزات الأساسية لكل منهما و التي يجب أن تكون كافية لتحديد ما الذي تريده.1 نقطة
-
السلام عليكم أنا قبل مايقارب الشهر سجلت في دورة علوم الحاسوب ولكن لسبب معين قررت استرجاع طلب استرجاع الرسوم والغاء اشتراكي في الدورة . تواصلت بمركز المساعدة وأخبروني انهم تواصلوا مع الفريق المختص ولكن الى الآن لايوجد أي رد منهم , حاولت الوصول لفريق المساعدة بعدة طرق ولكن ما من مجيب . أتمنى منكم مساعدتي في هذا الأمر . شكراََ مقدماََ ناصر شيبان1 نقطة
-
الجهة الوحيدة المخولة بمساعدتك في أي أمر يتعلق بالدورات والاشتراك هم فريق مركز المساعدة، ابقَ على تواصل معهم، وأحيانًا قد يستغرق الأمر وقتًا ريثما يتم الرد ومساعدتك تأكد أنك تتواصل معهم من نفس الحساب، اشرح مشكلتك بالكامل وانتظر الرد سيساعدونك في النهاية مهما كانت مشكلتك لا تقلق1 نقطة
-
في البداية، كلمة Nanodegree عبارة عن مصطلح تسويقي تطلقه Udacity على دوراتها كوسيلة تسويقية ليس إلا، ولكن في الحقيقة هذا المصطلح ليس له علاقة بالشهادات العلمية على الإطلاق. ودورات Udacity هذه عبارة عن دورات متخصصة في مجالات معينة، فعلى سبيل المثال تجد دورة متخصصة في أساسيات الواجهة الخلفية Backend، ويتم شرح الأساس الذي تعمل به أغلب تقنيات الواجهات الخلفية، ولدى تجربة طويلة في شهادات Nanodegree، حيث أني قُمت بتجربة العديد من دورات Udacity وحصلت على ثلاث شهادات Nanodegree جميعها في مجال الويب (Backend و Frontend)، ومن خلاصة تجربتي وجدت أن: المحتوى مقسم إلى فصول وكل فصل عبارة عن مجموعة من المقالات والفيديوهات القصيرة. يغلب طابع المقالات والشرح النصي على محتوى الدورة، حيث تجد أن إجمالي طول الفيديوهات (في أحد الفصول) حوالي 30 دقيقة تقريبًا بينما عدد المقالات أكبر بكثير ويستغرق قرائتها حوالي ساعة أو أكثير. تحتوي بعض الدروس على بعض التمارين الأساسية للغاية، كلها إختيارية وتقتصر على إعادة تنفيذ ما تم ذكره في الدرس لذلك وجدت أنها بدون فائدة في أغلب الأحيان. تتخرج من الدورة عندما تقوم بإتمام رفع المشاريع المطلوبة، وتحتوي الشهادة على 3-4 مشاريع (بسيطة ومتوسطة) يظل محتوى الدورة متاح لك لمدة عام واحد فقط، وبعد ذلك تختفي الدورة من حسابك ولا تستطيع الوصول إلى المحتوى مرة أخرى. بالطبع هذه المميزات أفضل من مشاهدة قائمة فيديوهات على اليوتيوب بدون التطبيق أو القيام بأي مشاريع أو وجود دعم فني على الإطلاق، ولكن إن كنت جادًا في الحصول على شهادة متخصصة في أحد مجالات البرمجة وتريد العمل بهذه الشهادة فأنصحك بأحد دورات أكاديمية حسوب، حيث أنها تحتوي على كل المميزات الموجودة في شهادات Nanodegree من Udacity وأكثر، فعلى سبيل المثال لا الحصر تتميز هذه الدورات بـ : وصول مدى الحياة إلى الدورات، فإذا إشتركت في أحد الدورات فسوف يكون لديك وصول كامل طوال العمر إلى محتوى الدورة (يشمل ذلك التحديثات التي تتم على الدورة)، وبالتالي سوف تبقى على إطلاع بأحدث التقنيات المستخدمه في المجال. يمكنك أن تحدد الوقت الذي ترغب في التعلم فيه، فبما أن الدورة متاحة لك مدى الحياة فيمكنك أن تتعلم محتوى الدورة في أي وقت تشاء، ولست محددًا بوقت معين لتنهي الدورة، بينما شهاداة Nanodegree لها وقت معين لتقوم بإنهاء الدورة وإذا لم تنتهي منها في الوقت المناسب فسوف يتم إستبعادك منها ولن تتمكن من الحصول على الشهادة. محتوى عملي كامل على شكل فيديوهات، كل محتوى دورات حسوب عبارة عن فيديوهات عالية الجودة، يتم تحديثها كل فترة. دعم فني سريع ومساعدة لحل كل المشاكل التي تواجهك أثناء التعلم، تتميز أكاديمية حسوب بعدد كبير من المدربين الذي يساعدون الطلاب بشكل مباشر خلال وقت قليل جدًا من وقت طرح السؤال، حيث يتم الإجابة على أي سؤال خلال 15 دقيقة فقط من وقت طرح السؤال. شرح كامل باللغة العربية الفصحى، قد تكون اللغة عائق لدى بعض الأشخاص الذي يرغبون في التعلم، فعلى عكس دورات Udacity الإنجليزية، فإن كل محتوى أكاديمية حسوب (الدورات والمقالات والأسئلة .. إلخ) يكون باللغة العربية الفصحى. يتم إصدار جميع الشهادات من أكاديمية حسوب فقط بعد اجتياز الامتحان بنجاح. هذه ليست مجرد "شهادات حضور"، ولا يمكن الحصول عليها من خلال الالتحاق بالدورة فقط، ولكن يجب على الطالب عملياً التقديم أثناء الدورة وإجراء المقابلة وإثبات قدراته. وبوجود أكثر من 5000 مقالة تُعد أكاديمية حسوب أكبر مصدر تقني عربي على الإطلاق، ستجد هنا مئات المقالات التقنية في كل المجالات البرمجية والتصميم والعمل الحر ورياد الأعمال. يتم إضافة مقالات بشكل يومي وفي مختلف المجالات، لذلك ستجد محتوى جديد يومًا بعد آخر. تستطيع أيضًا الإطلاع على موسوعة حسوب أكبر موسوعة تقنية في العالم العربي، والتي تُعد مرجع شامل في العديد من التقنيات البرمجية.1 نقطة
-
هذا الكود خاص بمتتالية فيبوناتسي Fibonacci Sequence وهي بالشكل التالي: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144 ... تبدأ هذه المتتالية بالأرقام 0 ثم 1 ، ويكون كل رقم فيها عبارة عن مجموع الرقمين السابقين له، فجمع هذين الرقمين (0 و 1) يساوي 1 ثم يتم جمع الرقمين الأخيرين 1 و 1 معًا للحصول على 2 ، ثم يتم جمع الرقمين الأخيرين 1 و 2 للحصول على 3 وهكذا ، أي أننا نقوم بجمع كل رقمين للحصول على رقم جديد الكود الخاص بك يقوم بجلب العنصر الذي ترتيبه k، حيث يتم تمرير رقم k وليكن 4 على سبيل المثال، فيتم إعادة الرقم الرابع في المتتالية السابقة، أي 3 (نبدأ العد من صفر) 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144 ... ^ ^ ^ ^ ^ 0 1 2 3 4 يتم إعادة الرقم الرابع أما إذا تم تمرير الرقم 6 على سبيل المثال فسيتم إعادة الرقم 8 (لأنه الرقم السادس في المتتالية). يمكن تتبع طريقة عمل الدالة g في الكود الخاص بك من خلال رسم شجرة تفرعية، بالشكل التالي: في هذه الصورة يتم تمرير الرقم 4 إلى الدالة g والتي بدورها تستدعي الدالة g مرتيبن، مرة بالرقم 3 (4-1) ومرة أخرى بالرقم 2 (4-2). ثم في كل مرة من المرتين يتم إستدعاء الدالة g مرتين إضافيتين، مرة بالرقم 2 (3-1)، ومرة بالرقم 1 (3-2) ... إلخ يمكننا أن نقوم بإستبدال الإستدعائات الأخيرة حيث سيتم إعادة الأرقام 2 و 1 و 0، جمع هذه الأقام معًا سوف يؤدي إلى إعادة الأرقام 3 و 2 في النهاية سوف نحل على الرقم 5 وهو العنصر الرابع في المتتالية: يمكنك الإطلاع على شرح كامل لهذه المتتالية وكيفية التعامل معها بأكثر من لغة برمجة من خلال موسوعة حسوب (أعداد فيبوناتشي).
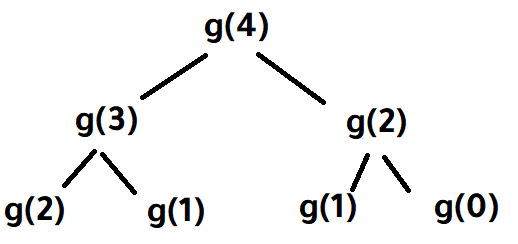
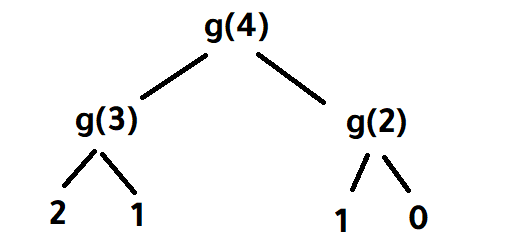
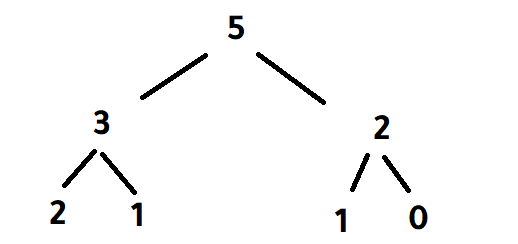 1 نقطة
1 نقطة -
يخبرك الخطأ بأن هناك الصنف CreatePersonalAccessTokensTable موجود مسبقًا، ويوجد أكثر من سبب لهذا الخطأ منهم: يوجد لديك أكثر من ملف تهجير يقومون بنفس الشيء، مثل أن يكون لديك ملفين بأسماء مختلفة: 2022_01_31_020910_create_users_table.php 2019_01_30_020910_create_users_table.php كلا الملفان يحتويان على صنف باسم CreateUsersTable وبالتالي يظهر الخطأ مثل الموجود لديك، لذلك عليك حذف أحد الملفين (إن كانا يقومان بنفس المهمة)، أو إعادة تسمية أحد الأصناف classes في هذه الملفات. بعد ذلك قمت بتنفيذ الأمر التالي حتى يتعرف composer على التغيرات: composer dump-autoload أحيانًا يتسبب التحميل التلقائي للأصناف الداخلية لـ composer في حدوث هذه المشكلة. وعليك فقط تنفيذ الأمر التالي لحل المشكلة: composer install1 نقطة
-
قواعد البيانات هي مجرد وسيلة لتخزين البيانات في شكل منظم، يمكنك لملف نصي بسيط أن يكون عبارة عن قاعدة بيانات، أو ربما تستخدم قاعدة بيانات لها إمكانيات أكثر مثل MySQL أ, Postgres أو غيرها، ولكن في النهاية ستجد أن البنية واحدة وأن البيانات يتم تخزينها بشكل منظم في قاعدة البيانات، ويمكن ببساطة أن تستخدم قاعدة البيانات لعمل موقع كامل، وتستخدم نفس قاعدة البيانات لتطبيق هاتف للموقع بدون مشكلة. ويمكنك أن تستعمل نفس التقنيات في المواقع والتطبيقات كذلك، ولكن بالنسبة لتطبيقات الهواتف هناك نوعين أساسين من قواعد البيانات: قواعد بيانات محلية Local Database: وفيها يتم تخزين قاعدة البيانات بالكامل على جهاز العميل، لحفظ بعض البيانات مثل إعدادات التطبيق أو لكي يعمل التطبيق بدون إنترنت .. إلخ. قواعد بيانات عامة Global Database: وهي عندما تقوم بإنشاء قاعدة بيانات وتضعها على خادم Server ليتمكن كل المستخدمين من الوصول إليها (عبر التطبيق أو الموقع أو حتى برنامج لسطح المكتب) والحصول على البيانات منها. لذلك يمكنك أن تقوم بعمل قاعدة بيانات واحدة لأكثر من إستخدام بدون مشكلة. يمكنك الإطلاع على هذه المقارنة بين أشهر أنواع قواعد البيانات: وهنا شرح لقواعد بيانات SQLite (غالبًا ما تستعمل كقاعدة بيانات محلية): كل قواعد البيانات السابقة عبارة عن قواعد منظمة Structured وتستعمل لغة SQL لتنفيذ التعليمات، ويوجد نوع آخر من قواعد البيانات وهو NoSQL، هنا مقالة تتحدث عن الفرق بينهما:1 نقطة
-
.png.1f46c5bdbd4bf701efd3c5db020ea7ed.png) يتضمَّن أي كائنٍ object صالحٍ للاستعمال عددًا من متغيِّرات النسخ instance variables. عندما يُعطى نوع متغير نسخةٍ معين من قِبل اسم صنف class أو واجهة interface، فسيحمل هذا المتغير مرجًعا reference إلى كائنٍ آخر، ويُطلَق على المرجع اسم مؤشر pointer، ويُقال أن المُتغيِّر يُشير إلى كائنٍ ما. ومع ذلك، قد يحتوي المتغيِّر على القيمة الخاصة null؛ وفي تلك الحالة، لا يُشير المُتغير فعليًا إلى أي شيء. في المقابل، عندما يحتوي كائنٌ على متغير نسخة instance variable يُشير فعليًا إلى كائنٍ آخر، يُقال أن الكائنين مربوطين من خلال المؤشر. إن غالبية بنى البيانية data structures المعقدة مبنيّةٌ على تلك الفكرة؛ أي ربط عدة كائناتٍ ببعضها بعضًا. الترابط التعاودي Recursive Linking عندما يتضمَّن كائنٌ معينٌ مُتغيِّر نسخة instance variable يُشير إلى كائنٍ آخر من نفس نوع الكائن الأصلي، يُقال أن تعريف الصنف تعاودي recursive. يحدث هذا النوع من التعاود في كثير من الحالات، فإذا كان لدينا مثلًا صنفٌ مُصمَّمٌ لتمثيل الموظفين العاملين ضمن شركةٍ معينة، بحيث يُشرف على كل موظف باستنثاء رئيس الشركة موظفٌ آخر ضمن نفس الشركة. في تلك الحالة، ينبغي أن يتضمَّن الصنف Employee مُتغيّر نسخة من النوع Employee لتمثيل المشرف. يمكننا تعريف الصنف على النحو التالي: public class Employee { String name; // اسم الموظف Employee supervisor; // مشرف الموظف . . // متغيرات وتوابع نسخ أخرى . } // نهاية صنف الموظف إذا كان emp متغيرًا من النوع Employee، فإن emp.supervisor هو بالضرورة متغيرٌ آخر من النوع Employee؛ فإذا كان emp يُشير إلى رئيس الشركة، فينبغي أن تكون قيمة emp.supervisor فارغة أي تُساوِي null للدلالة على أن رئيس الشركة ليس لديه أي مشرف. إذا أردنا طباعة اسم المشرف الخاص بموظف معين، يُمكِننا استخدام الشيفرة التالية على سبيل المثال: if ( emp.supervisor == null) { System.out.println( emp.name + " is the boss and has no supervisor!" ); } else { System.out.print( "The supervisor of " + emp.name + " is " ); System.out.println( emp.supervisor.name ); } لنفترض الآن أننا نريد معرفة عدد المشرفين الواقعين بين موظفٍ معين وبين رئيس الشركة. كل ما علينا فعله هو تتبُّع متتاليةٍ من المشرفين، وعَدّ عدد الخطوات المطلوبة حتى نصل إلى رئيس الشركة. ألقِ نظرةً على الشيفرة التالية. if ( emp.supervisor == null ) { System.out.println( emp.name + " is the boss!" ); } else { Employee runner; // For "running" up the chain of command. runner = emp.supervisor; if ( runner.supervisor == null) { System.out.println( emp.name + " reports directly to the boss." ); } else { int count = 0; while ( runner.supervisor != null ) { count++; // Count the supervisor on this level. runner = runner.supervisor; // Move up to the next level. } System.out.println( "There are " + count + " supervisors between " + emp.name + " and the boss." ); } } بينما يُنفِّذ الحاسوب حلقة التكرار while بالأعلى، سيشير runner مبدئيًا إلى الموظف الأصلي أي emp، ثم إلى مشرف الموظف emp، ثم إلى مشرف مشرف الموظف emp، وهكذا. ستزداد قيمة المُتغيّر count بمقدار الواحد بكل مرةٍ يزور خلالها المُتغيّر runner موظفًا جديدًا، وتنتهي حلقة التكرار عندما يُصبِح runner.supervisor فارغًا، وهو ما يُشير إلى وصولنا إلى رئيس الشركة. سيحتوِي المتغير count في تلك النقطة من البرنامج على عدد الخطوات بين emp ورئيس الشركة. يُعدّ المتغير supervisor في هذا المثال مفيدًا وبديهيًا نوعًا ما، حيث تُعدّ بنى البيانات data structures المعتمدة على ربط عدة كائناتٍ ببعضها بعضًا مفيدةً جدًا لدرجة أنها تُمثِل موضوعًا رئيسيًا للدراسة بعلوم الحاسوب computer science. سنناقش عدة أمثلةٍ نموذجيةٍ متعلّقةٍ بهذا النوع من بنى البيانات، وسنتناول بالتحديد القوائم المترابطة linked lists ضمن هذا المقال وما يليه. تتكوَّن أي قائمةٍ مترابطة linked list من سلسلةٍ من الكائنات من نفس النوع، حيث يَربُط مؤشرٌ pointer كائنًا معينًا بالكائن الذي يليه. يشبه ذلك كثيرًا سلسلة المشرفين الواقعة بين الموظف emp ورئيس الشركة بالمثال السابق. من الممكن أيضًا أن نتعرَّض لمواقف ٍأكثر تعقيدًا، وعندها قد يَتضمَّن كائنٌ واحدٌ روابطًا إلى كائناتٍ أخرى عديدة، وهو ما سنناقشه بمقال قادم. القوائم المترابطة Linked Lists ستُبنَى القوائم المترابطة linked lists في غالبية الأمثلة المتبقية ضمن هذا المقال من كائناتٍ objects تنتمي إلى الصنف Node المُعرَّف على النحو التالي: class Node { String item; Node next; } يُستخدم عادةً مصطلح العقدة node للإشارة إلى أحد الكائنات الموجودة ببنيةٍ بيانيةٍ مترابطة linked data structure، حيث يُمكِننا ربط كائناتٍ من النوع Node ببعضها بعضًا كما هو مُوضَّح بالجزء العلوي من الصورة السابقة. تحتوي كل عقدةٍ على سلسلةٍ نصيةٍ من النوع String بالإضافة إلى مؤشرٍ للعقدة التالية ضمن القائمة إن وُجدت. يُمكِننا دائمًا تمييز العقدة الأخيرة بمثل تلك القائمة؛ حيث سيحمل متغير النسخة next ضمن تلك العقدة القيمة الفارغة null، وليس مؤشرًا إلى عقدةٍ أخرى. الهدف من ربط العقد بتلك الطريقة هو تمثيل قائمةٍ من السلاسل النصية strings؛ حيث تكون السلسلة النصية الأولى ضمن تلك القائمة مُخزَّنةً بالعقدة الأولى؛ بينما تكون السلسلة النصية الثانية مُخزَّنةً بالعقدة الثانية، وهكذا. في حين اِستخدَمنا مؤشراتٍ وكائناتٍ من النوع Node لبناء البنية البيانية data structure، ستكون البيانات التي نريد تمثيلها بالأساس هي قائمة السلاسل النصية. ونستطيع كذلك تمثيل قائمةٍ من الأعداد الصحيحة، أو قائمةٍ من الأزرار من النوع Button، أو قائمةٍ من أي نوعٍ آخر من البيانات فقط بتغيير نوع متغير النسخة item المُخزَّن بكل عقدة. على الرغم من تعريف الصنف Nodes بهذا المثال تعريفًا بسيطًا، فما يزال بإمكاننا استخدامه لتوضيح العمليات الشائعة على القوائم المترابطة linked lists، حيث تتضمَّن تلك العمليات ما يلي: حذف عقدةٍ من القائمة، أو إضافة عقدةٍ جديدة إلى القائمة، أو البحث عن سلسلةٍ نصية معينةٍ من النوع String ضمن عناصر القائمةitems. سنناقش مجموعةً من البرامج الفرعية subroutines المسؤولة عن تنفيذ جميع تلك العمليات. لاستخدام قائمةٍ مترابطةٍ ضمن برنامج، فإنه يحتاج إلى تعريف مُتغيّرٍ يشير إلى العقدة الأولى من تلك القائمة. في الواقع، كل ما يحتاجه البرنامج هو مؤشرٌ واحدٌ فقط إلى العقدة الأولى؛ بينما يمكن الوصول لجميع العقد الأخرى ضمن القائمة من خلال البدء من العقدة الأولى ثم التنقُّل من عقدةٍ لأخرى باتباع الروابط عبر القائمة. سنستخدم دائمًا بالأمثلة التالية متغيرًا اسمه head من النوع Node للإشارة إلى العقدة الأولى بالقائمة المترابطة، وعندما تَكون القائمة فارغةً، ستكون قيمة المتغير head هي القيمة الفارغة null. إجراء المعالجات الأساسية على قائمة مترابطة نحتاج عادةً إلى إجراء معالجةٍ معينةٍ على جميع العناصر الموجودة ضمن قائمةٍ مترابطة linked list، حيث لا بُدّ من البدء من رأس head القائمة، ثم التحرُّك من كل عقدةٍ للعقدة التي تليها باتباع المؤشر المُعرَّف ضمن كل عقدة، والتوقُّف أخيرًا عند الوصول إلى نهاية القائمة، وهو ما سندركه عند الوصول إلى القيمة الفارغة null. فإذا كان head متغيرًا من النوع Node، وكان يُشير إلى العقدة الأولى ضِمْن قائمةٍ مترابطة، فستكون الصياغة العامة المُستخدمة لمعالجة جميع عناصر تلك القائمة على النحو التالي: Node runner; // المؤشر المستخدم لاجتياز القائمة runner = head; // سيُشير runner إلى رأس القائمة مبدئيًا while ( runner != null ) { // استمر إلى أن تصل إلى القيمة الفارغة process( runner.item ); // عالج العنصر الموجود بالعقدة الحالية runner = runner.next; // تحرك إلى العقدة التالية } يُعدّ المتغير head الطريقة الوحيدة المُتاحة للوصول إلى عناصر القائمة. ونظرًا لأننا بحاجةٍ إلى تعديل قيمة المُتغيِّر runner، فلا بُدّ من إنشاء نسخةٍ من المتغير head، وإلا سنخسر الطريقة الوحيدة المتاحة للوصول إلى القائمة. بناءً على ذلك، سنستخدم تعليمة الإسناد assignment statement التالية runner = head لإنشاء نسخةٍ من المتغير head، حيث سيُشير المتغير runner إلى كل عقدةٍ ضمن القائمة تباعًا، وسيحمل runner.next مؤشرًا إلى العقدة التالية ضمن القائمة. وبالتالي، ستُحرِك تعليمة الإسناد runner = runner.next المؤشر على طول القائمة من عقدةٍ إلى أخرى، وعندما تُصبِح قيمة runner مساويةً للقيمة الفارغة null، نكون قد وصلنا إلى نهاية القائمة. لاحظ أن شيفرة المعالجة بالأعلى ستعمل بنجاح حتى لو كانت القائمة فارغة؛ لأن قيمة head لقائمةٍ فارغة هي القيمة الفارغة null، وعندها لن يُنفَّذ متن body حلقة التكرار while نهائيًا. يُمكِننا مثلًا طباعة جميع السلاسل النصية strings ضمن قائمةٍ من النوع String بكتابة ما يلي: Node runner = head; while ( runner != null ) { System.out.println( runner.item ); runner = runner.next; } يمكننا إعادة كتابة حلقة التكرار while باستخدام حلقة التكرار for، فعلى الرغم من أن المتغير المُتحكِّم بحلقة التكرار for عادةً ما يكون من النوع العددي، فإن ذلك ليس أمرًا ضروريًا. تعرض الشيفرة التالية حلقة تكرار for مُكافِئة لحلقة while بالأعلى: for ( Node runner = head; runner != null; runner = runner.next ) { System.out.println( runner.item ); } بالمثل، يُمكِننا أن نجتاز traverse قائمة أعدادٍ صحيحة لحساب حاصل مجموع الأعداد ضمن تلك القائمة، ويُمكننا بناء قائمةٍ مترابطة من الأعداد الصحيحة باستخدام الصنف التالي: public class IntNode { int item; // أحد الأعداد الصحيحة ضمن القائمة IntNode next; // مؤشر إلى العقدة التالية } إذا كان head متغيرًا من النوع IntNode، وكان يشير إلى قائمةٍ مترابطة من الأعداد الصحيحة، فإن الشيفرة التالية تحسب حاصل مجموع الأعداد الصحيحة ضمن تلك القائمة. int sum = 0; IntNode runner = head; while ( runner != null ) { sum = sum + runner.item; // أضف العنصر الحالي إلى المجموع runner = runner.next; } System.out.println("The sum of the list of items is " + sum); يُمكِننا أيضًا استخدام التعاود recursion لمعالجة قائمة مترابطة، ولكن من النادر استخدامه لمعالجة قائمة؛ لأنه من السهل دومًا استخدام حلقة loop لاجتيازها. ومع ذلك، قد يُساعد فهم طريقة تطبيق التعاود على القوائم على استيعاب كيفية تطبيق المعالجة التعاودية على بنى البيانات الأكثر تعقيدًا. يُمكِننا النظر لأي قائمةٍ مترابطة غير فارغة على أنها مُكوَّنة من جزئين: رأس القائمة head المُكوَّن من العقدة الأولى بالقائمة. ذيل القائمة tail المُكوَّن من جميع ما هو متبقي من القائمة. يُعدّ ذيل القائمة ذاته بمثابة قائمةٍ مترابطةٍ أخرى، والتي هي أقصر من القائمة الأصلية بفارق عقدةٍ واحدة. يُمثِل ذلك أرضيةً مناسبةً نوعًا ما لتطبيق التعاود، حيث يمكن تقسيم معالجة القائمة إلى معالجة رأس القائمة ومعالجةٍ تعاوديةٍ لذيل القائمة، ويُمثِّل العثور على قائمةٍ فارغة الحالة الأساسية base case. تعرض الشيفرة التالية مثلًا خوارزميةً تعاوديةً recursive algorithm لحساب حاصل مجموع الأعداد الصحيحة ضمن قائمة مترابطة. // إذا كانت القائمة فارغة if the list is empty then // أعد صفر لأنه ليس هناك أي أعداد لجمعها return 0 (since there are no numbers to be added up) otherwise // اضبط listsum إلى العدد الموجود بعقدة الرأس let listsum = the number in the head node // اضبط tailsum إلى حاصل مجموع الأعداد الموجودة بقائمة الذيل تعاوديًا let tailsum be the sum of the numbers in the tail list (recursively) // أضف tailsum إلى listsum add tailsum to listsum return listsum يتبقى الآن الإجابة على السؤال التالي: كيف نحصل على ذيل قائمة مترابطة غير فارغة؟ إذا كان head متغيرًا يُشير إلى عقدة الرأس لقائمةٍ معينة، فسيشير متغير head.next إلى العقدة الثانية ضمن تلك القائمة، والتي تُمثِل في الوقت نفسه العقدة الأولى بذيل القائمة. لذلك، يُمكِننا النظر إلى head.next على أنه مؤشرٌ إلى ذيل القائمة. لاحِظ أنه في حالة كانت القائمة الأصلية مُكوَّنةً من عقدةٍ واحدةٍ فقط، فسيكون ذيل القائمة فارغًا، وعليه ستكون قيمة head.next مُساويةً للقيمة الفارغة null. نظرًا لاستخدام مؤشرٍ فارغٍ null pointer عمومًا لتمثيل القوائم الفارغة، فسيظل head.next مُمثِلًا مناسبًا لذيل القائمة حتى في تلك الحالة الخاصة. يمكننا إذًا تعريف الدالة التعاودية التالية بلغة جافا لحساب حاصل مجموع الأعداد ضمن قائمة. public static int addItemsInList( IntNode head ) { if ( head == null ) { // تُمثِل القائمة الفارغة أحد الحالات الأساسية return 0; } else { // 1 int listsum = head.item; int tailsum = addItemsInList( head.next ); listsum = listsum + tailsum; return listsum; } } تشير [1] إلى الحالة التعاودية وذلك عندما لا تكون القائمة فارغةً، احسب حاصل مجموع قائمة الذيل، ثم أضفه إلى العنصر الموجود بعقدة الرأس. لاحِظ أنه من الممكن كتابة ذلك في خطوةٍ واحدة على النحو التالي return head.item + addItemsInList( head.next );. سنناقش الآن مشكلةً أخرى يَسهُل حلها باستخدام التعاود بينما يَصعُب قليلًا بدونه، حيث تتمثل المشكلة بطباعة جميع السلاسل النصية الموجودة ضمن قائمةٍ مترابطةٍ من السلاسل النصية بترتيبٍ معاكسٍ لترتيب حدوثها ضمن القائمة؛ يعني ذلك أن نطبع العنصر الموجود برأس القائمة head بعد طباعة جميع عناصر ذيل القائمة. يقودنا ذلك إلى البرنامج التعاودي recursive routine التالي: public static void printReversed( Node head ) { if ( head == null ) { // الحالة الأساسية: أن تكون القائمة فارغة // ليس هناك أي شيءٍ لطباعته return; } else { // الحالة التعاودية: القائمة غير فارغة printReversed( head.next ); // اطبع السلاسل النصية بالذيل بترتيب معكوس System.out.println( head.item ); // اطبع السلسلة النصية بعقدة الرأس } } لا بُدّ من الاقتناع بأن هذا البرنامج يعمل، مع التفكير بإمكانية تنفيذه دون استخدام التعاود recursion. سنناقش خلال بقية هذا المقال عددًا من العمليات الأكثر تعقيدًا على قائمةٍ مترابطةٍ من السلاسل النصية، حيث ستكون جميع البرامج الفرعية subroutines التي سنتناولها توابع نُسخ instance methods مُعرَّفةً ضمن الصنف StringList الذي نفذَّه الكاتب. يُمثِل أي كائنٍ من النوع StringList قائمةً مترابطةً من السلاسل النصية، حيث يَملُك الصنف متغير نسخة خاص private اسمه head من النوع Node، ويشير إلى العقدة الأولى ضمن القائمة أو يحتوي على القيمة null إذا كانت القائمة فارغة. تستطيع توابع النسخ instance methods المُعرَّفة بالصنف StringList الوصول إلى head مثل متغير عام global. يُمكِنك العثور على الشيفرة المصدرية للصنف StringList بالملف StringList.java، كما أنه مُستخدمٌ بالبرنامج التوضيحي ListDemo.java، الذي يُمكِّنك من رؤية طريقة استخدامه بوضوح. سنُلقِي نظرةً على إحدى التوابع المُعرَّفة بالصنف StringList للإطلاع على مثالٍ عن المعالجة البسيطة للقوائم واجتيازها، حيث يبحث التابع ذو النوع StringList عن سلسلةٍ نصيةٍ معينة ضمن قائمة؛ إذا كان searchItem مُمثِلًا للسلسلة النصية التي نبحث عنها، فعلينا موازنة searchItem مع كل عنصرٍ ضمن تلك القائمة، بحيث نتوقف عن المعالجة عند العثور على العنصر الذي نبحث عنه. انظر الشيفرة التالية: public boolean find(String searchItem) { Node runner; // مؤشر لاجتياز القائمة // ابدأ بفحص رأس القائمة runner = head; while ( runner != null ) { // 1 if ( runner.item.equals(searchItem) ) return true; runner = runner.next; // تحرك إلى العقدة التالية } // 2 return false; } // end find() حيث تشير كل من [1] و[2] إلى الآتي: [1] افحص السلاسل النصية الموجودة بكل عقدة. إذا كانت السلسلة النصية هي نفسها التي نبحث عنها، أعد القيمة المنطقية true؛ لأننا ببساطة قد وجدناها بالقائمة. [2] عند وصولنا إلى تلك النقطة من البرنامج، نكون قد فحصنا جميع العناصر الموجودة بالقائمة دون العثور على searchItem، ولذلك سنعيد القيمة المنطقية false للإشارة إلى حقيقة عدم وجود العنصر بالقائمة. لاحِظ أنه من الممكن أن تكون القائمة فارغةً أي تكون قيمة head مساويةً للقيمة الفارغة null، لذلك ينبغي معالجة تلك الحالة معالجةً سليمةً؛ فإذا احتوى head المُعرَّف بالشيفرة بالأعلى على القيمة null، فلن يُنفَّذ متن حلقة التكرار while نهائيًا، أي لن يعالج التابع أي عقد nodes، وستكون القيمة المعادة هي القيمة false. هذا هو ما نريد فعله تمامًا عندما تكون القائمة فارغة؛ نظرًا لعدم امكانية حدوث searchItem ضمن قائمةٍ فارغة. الإضافة إلى قائمة مترابطة قد تكون مشكلة إضافة عنصرٍ جديدٍ إلى قائمةٍ مترابطة أكثر صعوبةً نوعًا ما، بالأخص عندما يكون من الضروري إضافة العنصر إلى منتصف القائمة، وتُعد هذه المشكلة أعقد معالجةٍ سنُجرِيها على بنى البيانات المترابطة linked data structures خلال هذا المقال بالكامل. تُحفَظ العناصر الموجودة بعُقد القائمة المترابطة في الصنف StringList مُرتَّبةً تصاعديًا، لذلك عند إضافة عنصرٍ جديدٍ إلى القائمة، لابُدّ من إضافته إلى الموضع الصحيح وفقًا لذلك الترتيب؛ وهذا يعني أننا سنضطَّر في أغلب الحالات إلى إضافة العنصر الجديد إلى مكانٍ ما بمنتصف القائمة أي بين عقدتين موجودتين بالفعل. لكي نتمكَّن من فعل ذلك، سيكون من الضروري تعريف متغيرين من النوع Node للإشارة إلى العقدتين اللتين ينبغي أن تقعا على جانبي العقدة الجديدة، حيث يُمثّل previous وrunner بالصورة التالية المتغيرين المذكورين. إلى جانب ذلك، سنحتاج إلى متغيرٍ آخر newNode للإشارة إلى العقدة الجديدة. لتمكين عملية الإضافة insertion، لا بُدّ من إلغاء الرابط الموجود من previous إلى runner، وإضافة رابطين جديدين من previous إلى newNode، ومن newNode إلى runner. بمجرد ضبط قيمة المتغيرين previous وrunner بحيث يُشيرا إلى العقد الصحيحة، يُمكِننا استخدام الأمر previous.next = newNode; لضبط previous.next لكي يشير إلى العقدة الجديدة، والأمر newNode.next = runner لضبط newNode.next لكي يُشير إلى المكان الصحيح. ولكن قبل أن نستطيع تنفيذ أي من تلك الأوامر، سنحتاج أولًا لضبط كلٍ من runner وprevious كما هو موضحٌ بالصورة السابقة. الفكرة ببساطة هي أن نبدأ من العقدة الأولى بالقائمة، ثم نتحرك على طول القائمة مرورًا بجميع العناصر الأقل من العنصر الجديد، ويجب علينا الانتباه جيدًا أثناء ذلك حتى لا نقع بمشكلة السقوط خارج نهاية القائمة؛ أي أننا لن نستطيع الاستمرار إذا وصل runner إلى نهاية القائمة وأصبحت قيمته تساوي null. لنفترض أن insertItem هو العنصر المطلوب إضافته إلى القائمة، ولنفترض أيضًا أنه ينتمي إلى مكانٍ ما بمنتصف القائمة، ستَتَمكَّن الشيفرة التالية من ضبط قيمة المتغيرين previous وrunner على نحوٍ صحيح. Node runner, previous; previous = head; // ابدأ من مقدمة القائمة runner = head.next; while ( runner != null && runner.item.compareTo(insertItem) < 0 ) { previous = runner; // "previous = previous.next" would also work runner = runner.next; } يستخدم المثال الموضح أعلاه تابع النسخة compareTo() -انظر إلى مقال السلاسل النصية String والأصناف Class والكائنات Object والبرامج الفرعية Subroutine في جافا- المُعرَّف بالصنف String لاختبار ما إذا كان العنصر الموجود بالعقدة node أقل من العنصر المطلوب إضافته. ليس هناك أي مشكلةٍ فيما سبق باستثناء افتراضنا الدائم بانتماء العقدة الجديدة إلى مكانٍ ما بمنتصف القائمة، وهو أمرٌ غير صحيح؛ فقد تكون قيمة العقدة المطلوب إضافتها insertItem أحيانًا أقل من قيمة العنصر الأول ضمن القائمة، وهنا لا بُدّ من إضافة العقدة الجديدة إلى رأس القائمة، وهو ما تفعله الشيفرة التالية. newNode.next = head; // Make newNode.next point to the old head. head = newNode; // Make newNode the new head of the list. من الممكن أيضًا أن تكون القائمة فارغة، وينبغي في هذه الحالة أن تكون newNode هي العقدة الأولى والوحيدة ضمن القائمة. يمكننا إنجاز ذلك ببساطةٍ من خلال تنفيذ تعليمة الإسناد التالية head = newNode، ويعالِج التعريف التالي للتابع insert()، المُعرَّف بالصنف StringList جميع تلك الاحتمالات. public void insert(String insertItem) { Node newNode; // عقدة تحتوي على العنصر الجديد newNode = new Node(); newNode.item = insertItem; // (N.B. newNode.next == null.) if ( head == null ) { // العنصر الجديد هو العنصر الأول والوحيد ضمن القائمة // اضبط head بحيث تشير إليه head = newNode; } else if ( head.item.compareTo(insertItem) >= 0 ) { // العنصر الجديد أقل من أول عنصر ضمن القائمة // لذلك ينبغي أن يُضبَط بحيث يكون رأسًا للقائمة newNode.next = head; head = newNode; } else { // ينتمي العنصر الجديد إلى مكان ما بعد العنصر الأول ضمن القائمة // ابحث عن موضعه المناسب وأضِفه إليه Node runner; // العقدة المستخدمة لاجتيار القائمة Node previous; // تُشير دائمًا إلى العقدة السابقة لـ runner runner = head.next; // ابدأ بفحص الموضع الثاني ضمن القائمة previous = head; while ( runner != null && runner.item.compareTo(insertItem) < 0 ) { // 1 previous = runner; runner = runner.next; } newNode.next = runner; // أضف newNode بعد previous previous.next = newNode; } } // end insert() يعني [1] حرّك previous وrunner على طول القائمة إلى أن يقع runner خارج القائمة، أو إلى أن يصل إلى عنصرٍ أكبر من أو يساوي insertItem. بانتهاء تلك الحلقة، سيشير previous إلى الموضع الذي ينبغي إضافة insertItem إليه. إذا كنت منتبهًا للمناقشة الموضحة أعلاه، فقد تكون لاحظت أن هناك حالةً خاصةً أخرى لم نذكرها، فما الذي سيحدث إذا كان علينا إضافة العقدة الجديدة إلى نهاية القائمة؟ وهذا يحدث إذا كانت جميع عناصر القائمة أقل من العنصر الجديد. في الواقع، يُعالِج البرنامج الفرعي subroutine المُعرَّف بالأعلى تلك الحالة أيضًا ضمن الجزء الأخير من تعليمة if؛ فإذا كان insertItem أكبر من جميع عناصر القائمة، فستنتهي حلقة while بعدما يجتاز runner القائمة بالكامل، وستُصبِح قيمته عندها مساويةً للقيمة الفارغة null. ولكن عند الوصول إلى تلك النقطة، سيكون previous ما يزال يشير إلى العقدة الأخيرة بالقائمة؛ ولهذا سنُنفِّذ التعليمة previous.next = newNode لإضافة newNode إلى نهاية القائمة. ونظرًا لأن runner يُساوِي القيمة الفارغة null، فسيَضبُط الأمر newNode.next = runner قيمة newNode.next إلى القيمة الفارغة null، وهو ما نحتاج إليه تمامًا لنتمكَّن من الإشارة إلى أن القائمة قد انتهت. الحذف من قائمة مترابطة تشبه عملية الحذف عملية الإدخال على الرغم من أنها أبسط نوعًا ما، حيث توجد حالاتٌ خاصة ينبغي أخذها بالحسبان؛ فإذا أردنا حذف العقدة الأولى بقائمة، فينبغي علينا ضبط المُتغيِّر head، وجعله يُشيِر إلى العقدة التي كانت تُعدّ مُسبقًا العقدة الثانية بتلك القائمة. بما أن المتغير head.next يشير بالأساس إلى العقدة الثانية بالقائمة، يُمكِننا إجراء التعديل المطلوب بتنفيذ التعليمة head = head.next، وعلينا أيضًا التأكُّد من أن البرنامج يعمل على نحوٍ سليم حتى وإن كانت قيمة head.next تُساوِي null. عندما لا يكون هناك سوى عقدةٍ واحدةٍ ضمن قائمةٍ معينة، فستصبح القائمة فارغةً. أما إذا كنا نريد حذف عقدةٍ بمنتصف قائمةٍ معينة، فعلينا ضبط قيمة المتغيرين previous وrunner كما فعلنا سابقًا؛ حيث يُشير runner إلى العقدة المطلوب حذفها، بينما يُشيِر previous إلى العقدة التي تسبق العقدة المطلوب حذفها ضمن تلك القائمة. بمجرد انتهائنا من ضبط قيمة المتغيرين، سيحذف الأمر previous.next = runner.next; العقدة المعنية، وسيتولى كانس المهملات garbage collector مسؤولية تحريرها. حاول رسم صورةٍ توضيحيةٍ لعملية الحذف. يُمكِننا الآن تعريف التابع delete() على النحو التالي: public boolean delete(String deleteItem) { if ( head == null ) { // القائمة فارغة، وبالتالي هي بالتأكيد لا تحتوي على deleteString return false; } else if ( head.item.equals(deleteItem) ) { // عثرنا على السلسلة النصية بأول عنصر بالقائمة. احذفه head = head.next; return true; } else { // إذا كانت السلسلة النصية موجودةً بالقائمة، فإنها موجودة بمكانٍ ما بعد // العنصر الأول، وعليه سنبحث عنه بتلك القائمة Node runner; // العقدة المستخدمة لاجتياز القائمة Node previous; // تُشير دائمًا إلى العقدة السابقة للعقدة runner runner = head.next; // ابدأ بفحص الموضع الثاني ضمن القائمة previous = head; while ( runner != null && runner.item.compareTo(deleteItem) < 0 ) { // 1 previous = runner; runner = runner.next; } if ( runner != null && runner.item.equals(deleteItem) ) { // يشير runner إلى العقدة المطلوب حذفها // احذف تلك العقدة بتعديل المؤشر بالعقدة السابقة previous.next = runner.next; return true; } else { // العنصر غير موجود بالقائمة return false; } } } // end delete() وتعني [1] حَرِك previous وrunner على طول القائمة إلى أن يقع runner خارج القائمة أو إلى أن يَصِل إلى عنصرٍ أكبر من أو يساوي deleteItem. بانتهاء تلك الحلقة، سيُشير runner إلى موضع العنصر المطلوب حذفه، إذا كان موجودًا بالقائمة. ترجمة -بتصرّف- للقسم Section 2: Linked Data Structures من فصل Chapter 9: Linked Data Structures and Recursion من كتاب Introduction to Programming Using Java. اقرأ أيضًا الحلقات التكرارية في البرمجة الأصناف المتداخلة Nested Classes في جافا تعرف على أهم الأحداث والتعامل معها في مكتبة جافا إف إكس JavaFX تعرف على المصفوفات (Arrays) في جافا1 نقطة
يتضمَّن أي كائنٍ object صالحٍ للاستعمال عددًا من متغيِّرات النسخ instance variables. عندما يُعطى نوع متغير نسخةٍ معين من قِبل اسم صنف class أو واجهة interface، فسيحمل هذا المتغير مرجًعا reference إلى كائنٍ آخر، ويُطلَق على المرجع اسم مؤشر pointer، ويُقال أن المُتغيِّر يُشير إلى كائنٍ ما. ومع ذلك، قد يحتوي المتغيِّر على القيمة الخاصة null؛ وفي تلك الحالة، لا يُشير المُتغير فعليًا إلى أي شيء. في المقابل، عندما يحتوي كائنٌ على متغير نسخة instance variable يُشير فعليًا إلى كائنٍ آخر، يُقال أن الكائنين مربوطين من خلال المؤشر. إن غالبية بنى البيانية data structures المعقدة مبنيّةٌ على تلك الفكرة؛ أي ربط عدة كائناتٍ ببعضها بعضًا. الترابط التعاودي Recursive Linking عندما يتضمَّن كائنٌ معينٌ مُتغيِّر نسخة instance variable يُشير إلى كائنٍ آخر من نفس نوع الكائن الأصلي، يُقال أن تعريف الصنف تعاودي recursive. يحدث هذا النوع من التعاود في كثير من الحالات، فإذا كان لدينا مثلًا صنفٌ مُصمَّمٌ لتمثيل الموظفين العاملين ضمن شركةٍ معينة، بحيث يُشرف على كل موظف باستنثاء رئيس الشركة موظفٌ آخر ضمن نفس الشركة. في تلك الحالة، ينبغي أن يتضمَّن الصنف Employee مُتغيّر نسخة من النوع Employee لتمثيل المشرف. يمكننا تعريف الصنف على النحو التالي: public class Employee { String name; // اسم الموظف Employee supervisor; // مشرف الموظف . . // متغيرات وتوابع نسخ أخرى . } // نهاية صنف الموظف إذا كان emp متغيرًا من النوع Employee، فإن emp.supervisor هو بالضرورة متغيرٌ آخر من النوع Employee؛ فإذا كان emp يُشير إلى رئيس الشركة، فينبغي أن تكون قيمة emp.supervisor فارغة أي تُساوِي null للدلالة على أن رئيس الشركة ليس لديه أي مشرف. إذا أردنا طباعة اسم المشرف الخاص بموظف معين، يُمكِننا استخدام الشيفرة التالية على سبيل المثال: if ( emp.supervisor == null) { System.out.println( emp.name + " is the boss and has no supervisor!" ); } else { System.out.print( "The supervisor of " + emp.name + " is " ); System.out.println( emp.supervisor.name ); } لنفترض الآن أننا نريد معرفة عدد المشرفين الواقعين بين موظفٍ معين وبين رئيس الشركة. كل ما علينا فعله هو تتبُّع متتاليةٍ من المشرفين، وعَدّ عدد الخطوات المطلوبة حتى نصل إلى رئيس الشركة. ألقِ نظرةً على الشيفرة التالية. if ( emp.supervisor == null ) { System.out.println( emp.name + " is the boss!" ); } else { Employee runner; // For "running" up the chain of command. runner = emp.supervisor; if ( runner.supervisor == null) { System.out.println( emp.name + " reports directly to the boss." ); } else { int count = 0; while ( runner.supervisor != null ) { count++; // Count the supervisor on this level. runner = runner.supervisor; // Move up to the next level. } System.out.println( "There are " + count + " supervisors between " + emp.name + " and the boss." ); } } بينما يُنفِّذ الحاسوب حلقة التكرار while بالأعلى، سيشير runner مبدئيًا إلى الموظف الأصلي أي emp، ثم إلى مشرف الموظف emp، ثم إلى مشرف مشرف الموظف emp، وهكذا. ستزداد قيمة المُتغيّر count بمقدار الواحد بكل مرةٍ يزور خلالها المُتغيّر runner موظفًا جديدًا، وتنتهي حلقة التكرار عندما يُصبِح runner.supervisor فارغًا، وهو ما يُشير إلى وصولنا إلى رئيس الشركة. سيحتوِي المتغير count في تلك النقطة من البرنامج على عدد الخطوات بين emp ورئيس الشركة. يُعدّ المتغير supervisor في هذا المثال مفيدًا وبديهيًا نوعًا ما، حيث تُعدّ بنى البيانات data structures المعتمدة على ربط عدة كائناتٍ ببعضها بعضًا مفيدةً جدًا لدرجة أنها تُمثِل موضوعًا رئيسيًا للدراسة بعلوم الحاسوب computer science. سنناقش عدة أمثلةٍ نموذجيةٍ متعلّقةٍ بهذا النوع من بنى البيانات، وسنتناول بالتحديد القوائم المترابطة linked lists ضمن هذا المقال وما يليه. تتكوَّن أي قائمةٍ مترابطة linked list من سلسلةٍ من الكائنات من نفس النوع، حيث يَربُط مؤشرٌ pointer كائنًا معينًا بالكائن الذي يليه. يشبه ذلك كثيرًا سلسلة المشرفين الواقعة بين الموظف emp ورئيس الشركة بالمثال السابق. من الممكن أيضًا أن نتعرَّض لمواقف ٍأكثر تعقيدًا، وعندها قد يَتضمَّن كائنٌ واحدٌ روابطًا إلى كائناتٍ أخرى عديدة، وهو ما سنناقشه بمقال قادم. القوائم المترابطة Linked Lists ستُبنَى القوائم المترابطة linked lists في غالبية الأمثلة المتبقية ضمن هذا المقال من كائناتٍ objects تنتمي إلى الصنف Node المُعرَّف على النحو التالي: class Node { String item; Node next; } يُستخدم عادةً مصطلح العقدة node للإشارة إلى أحد الكائنات الموجودة ببنيةٍ بيانيةٍ مترابطة linked data structure، حيث يُمكِننا ربط كائناتٍ من النوع Node ببعضها بعضًا كما هو مُوضَّح بالجزء العلوي من الصورة السابقة. تحتوي كل عقدةٍ على سلسلةٍ نصيةٍ من النوع String بالإضافة إلى مؤشرٍ للعقدة التالية ضمن القائمة إن وُجدت. يُمكِننا دائمًا تمييز العقدة الأخيرة بمثل تلك القائمة؛ حيث سيحمل متغير النسخة next ضمن تلك العقدة القيمة الفارغة null، وليس مؤشرًا إلى عقدةٍ أخرى. الهدف من ربط العقد بتلك الطريقة هو تمثيل قائمةٍ من السلاسل النصية strings؛ حيث تكون السلسلة النصية الأولى ضمن تلك القائمة مُخزَّنةً بالعقدة الأولى؛ بينما تكون السلسلة النصية الثانية مُخزَّنةً بالعقدة الثانية، وهكذا. في حين اِستخدَمنا مؤشراتٍ وكائناتٍ من النوع Node لبناء البنية البيانية data structure، ستكون البيانات التي نريد تمثيلها بالأساس هي قائمة السلاسل النصية. ونستطيع كذلك تمثيل قائمةٍ من الأعداد الصحيحة، أو قائمةٍ من الأزرار من النوع Button، أو قائمةٍ من أي نوعٍ آخر من البيانات فقط بتغيير نوع متغير النسخة item المُخزَّن بكل عقدة. على الرغم من تعريف الصنف Nodes بهذا المثال تعريفًا بسيطًا، فما يزال بإمكاننا استخدامه لتوضيح العمليات الشائعة على القوائم المترابطة linked lists، حيث تتضمَّن تلك العمليات ما يلي: حذف عقدةٍ من القائمة، أو إضافة عقدةٍ جديدة إلى القائمة، أو البحث عن سلسلةٍ نصية معينةٍ من النوع String ضمن عناصر القائمةitems. سنناقش مجموعةً من البرامج الفرعية subroutines المسؤولة عن تنفيذ جميع تلك العمليات. لاستخدام قائمةٍ مترابطةٍ ضمن برنامج، فإنه يحتاج إلى تعريف مُتغيّرٍ يشير إلى العقدة الأولى من تلك القائمة. في الواقع، كل ما يحتاجه البرنامج هو مؤشرٌ واحدٌ فقط إلى العقدة الأولى؛ بينما يمكن الوصول لجميع العقد الأخرى ضمن القائمة من خلال البدء من العقدة الأولى ثم التنقُّل من عقدةٍ لأخرى باتباع الروابط عبر القائمة. سنستخدم دائمًا بالأمثلة التالية متغيرًا اسمه head من النوع Node للإشارة إلى العقدة الأولى بالقائمة المترابطة، وعندما تَكون القائمة فارغةً، ستكون قيمة المتغير head هي القيمة الفارغة null. إجراء المعالجات الأساسية على قائمة مترابطة نحتاج عادةً إلى إجراء معالجةٍ معينةٍ على جميع العناصر الموجودة ضمن قائمةٍ مترابطة linked list، حيث لا بُدّ من البدء من رأس head القائمة، ثم التحرُّك من كل عقدةٍ للعقدة التي تليها باتباع المؤشر المُعرَّف ضمن كل عقدة، والتوقُّف أخيرًا عند الوصول إلى نهاية القائمة، وهو ما سندركه عند الوصول إلى القيمة الفارغة null. فإذا كان head متغيرًا من النوع Node، وكان يُشير إلى العقدة الأولى ضِمْن قائمةٍ مترابطة، فستكون الصياغة العامة المُستخدمة لمعالجة جميع عناصر تلك القائمة على النحو التالي: Node runner; // المؤشر المستخدم لاجتياز القائمة runner = head; // سيُشير runner إلى رأس القائمة مبدئيًا while ( runner != null ) { // استمر إلى أن تصل إلى القيمة الفارغة process( runner.item ); // عالج العنصر الموجود بالعقدة الحالية runner = runner.next; // تحرك إلى العقدة التالية } يُعدّ المتغير head الطريقة الوحيدة المُتاحة للوصول إلى عناصر القائمة. ونظرًا لأننا بحاجةٍ إلى تعديل قيمة المُتغيِّر runner، فلا بُدّ من إنشاء نسخةٍ من المتغير head، وإلا سنخسر الطريقة الوحيدة المتاحة للوصول إلى القائمة. بناءً على ذلك، سنستخدم تعليمة الإسناد assignment statement التالية runner = head لإنشاء نسخةٍ من المتغير head، حيث سيُشير المتغير runner إلى كل عقدةٍ ضمن القائمة تباعًا، وسيحمل runner.next مؤشرًا إلى العقدة التالية ضمن القائمة. وبالتالي، ستُحرِك تعليمة الإسناد runner = runner.next المؤشر على طول القائمة من عقدةٍ إلى أخرى، وعندما تُصبِح قيمة runner مساويةً للقيمة الفارغة null، نكون قد وصلنا إلى نهاية القائمة. لاحظ أن شيفرة المعالجة بالأعلى ستعمل بنجاح حتى لو كانت القائمة فارغة؛ لأن قيمة head لقائمةٍ فارغة هي القيمة الفارغة null، وعندها لن يُنفَّذ متن body حلقة التكرار while نهائيًا. يُمكِننا مثلًا طباعة جميع السلاسل النصية strings ضمن قائمةٍ من النوع String بكتابة ما يلي: Node runner = head; while ( runner != null ) { System.out.println( runner.item ); runner = runner.next; } يمكننا إعادة كتابة حلقة التكرار while باستخدام حلقة التكرار for، فعلى الرغم من أن المتغير المُتحكِّم بحلقة التكرار for عادةً ما يكون من النوع العددي، فإن ذلك ليس أمرًا ضروريًا. تعرض الشيفرة التالية حلقة تكرار for مُكافِئة لحلقة while بالأعلى: for ( Node runner = head; runner != null; runner = runner.next ) { System.out.println( runner.item ); } بالمثل، يُمكِننا أن نجتاز traverse قائمة أعدادٍ صحيحة لحساب حاصل مجموع الأعداد ضمن تلك القائمة، ويُمكننا بناء قائمةٍ مترابطة من الأعداد الصحيحة باستخدام الصنف التالي: public class IntNode { int item; // أحد الأعداد الصحيحة ضمن القائمة IntNode next; // مؤشر إلى العقدة التالية } إذا كان head متغيرًا من النوع IntNode، وكان يشير إلى قائمةٍ مترابطة من الأعداد الصحيحة، فإن الشيفرة التالية تحسب حاصل مجموع الأعداد الصحيحة ضمن تلك القائمة. int sum = 0; IntNode runner = head; while ( runner != null ) { sum = sum + runner.item; // أضف العنصر الحالي إلى المجموع runner = runner.next; } System.out.println("The sum of the list of items is " + sum); يُمكِننا أيضًا استخدام التعاود recursion لمعالجة قائمة مترابطة، ولكن من النادر استخدامه لمعالجة قائمة؛ لأنه من السهل دومًا استخدام حلقة loop لاجتيازها. ومع ذلك، قد يُساعد فهم طريقة تطبيق التعاود على القوائم على استيعاب كيفية تطبيق المعالجة التعاودية على بنى البيانات الأكثر تعقيدًا. يُمكِننا النظر لأي قائمةٍ مترابطة غير فارغة على أنها مُكوَّنة من جزئين: رأس القائمة head المُكوَّن من العقدة الأولى بالقائمة. ذيل القائمة tail المُكوَّن من جميع ما هو متبقي من القائمة. يُعدّ ذيل القائمة ذاته بمثابة قائمةٍ مترابطةٍ أخرى، والتي هي أقصر من القائمة الأصلية بفارق عقدةٍ واحدة. يُمثِل ذلك أرضيةً مناسبةً نوعًا ما لتطبيق التعاود، حيث يمكن تقسيم معالجة القائمة إلى معالجة رأس القائمة ومعالجةٍ تعاوديةٍ لذيل القائمة، ويُمثِّل العثور على قائمةٍ فارغة الحالة الأساسية base case. تعرض الشيفرة التالية مثلًا خوارزميةً تعاوديةً recursive algorithm لحساب حاصل مجموع الأعداد الصحيحة ضمن قائمة مترابطة. // إذا كانت القائمة فارغة if the list is empty then // أعد صفر لأنه ليس هناك أي أعداد لجمعها return 0 (since there are no numbers to be added up) otherwise // اضبط listsum إلى العدد الموجود بعقدة الرأس let listsum = the number in the head node // اضبط tailsum إلى حاصل مجموع الأعداد الموجودة بقائمة الذيل تعاوديًا let tailsum be the sum of the numbers in the tail list (recursively) // أضف tailsum إلى listsum add tailsum to listsum return listsum يتبقى الآن الإجابة على السؤال التالي: كيف نحصل على ذيل قائمة مترابطة غير فارغة؟ إذا كان head متغيرًا يُشير إلى عقدة الرأس لقائمةٍ معينة، فسيشير متغير head.next إلى العقدة الثانية ضمن تلك القائمة، والتي تُمثِل في الوقت نفسه العقدة الأولى بذيل القائمة. لذلك، يُمكِننا النظر إلى head.next على أنه مؤشرٌ إلى ذيل القائمة. لاحِظ أنه في حالة كانت القائمة الأصلية مُكوَّنةً من عقدةٍ واحدةٍ فقط، فسيكون ذيل القائمة فارغًا، وعليه ستكون قيمة head.next مُساويةً للقيمة الفارغة null. نظرًا لاستخدام مؤشرٍ فارغٍ null pointer عمومًا لتمثيل القوائم الفارغة، فسيظل head.next مُمثِلًا مناسبًا لذيل القائمة حتى في تلك الحالة الخاصة. يمكننا إذًا تعريف الدالة التعاودية التالية بلغة جافا لحساب حاصل مجموع الأعداد ضمن قائمة. public static int addItemsInList( IntNode head ) { if ( head == null ) { // تُمثِل القائمة الفارغة أحد الحالات الأساسية return 0; } else { // 1 int listsum = head.item; int tailsum = addItemsInList( head.next ); listsum = listsum + tailsum; return listsum; } } تشير [1] إلى الحالة التعاودية وذلك عندما لا تكون القائمة فارغةً، احسب حاصل مجموع قائمة الذيل، ثم أضفه إلى العنصر الموجود بعقدة الرأس. لاحِظ أنه من الممكن كتابة ذلك في خطوةٍ واحدة على النحو التالي return head.item + addItemsInList( head.next );. سنناقش الآن مشكلةً أخرى يَسهُل حلها باستخدام التعاود بينما يَصعُب قليلًا بدونه، حيث تتمثل المشكلة بطباعة جميع السلاسل النصية الموجودة ضمن قائمةٍ مترابطةٍ من السلاسل النصية بترتيبٍ معاكسٍ لترتيب حدوثها ضمن القائمة؛ يعني ذلك أن نطبع العنصر الموجود برأس القائمة head بعد طباعة جميع عناصر ذيل القائمة. يقودنا ذلك إلى البرنامج التعاودي recursive routine التالي: public static void printReversed( Node head ) { if ( head == null ) { // الحالة الأساسية: أن تكون القائمة فارغة // ليس هناك أي شيءٍ لطباعته return; } else { // الحالة التعاودية: القائمة غير فارغة printReversed( head.next ); // اطبع السلاسل النصية بالذيل بترتيب معكوس System.out.println( head.item ); // اطبع السلسلة النصية بعقدة الرأس } } لا بُدّ من الاقتناع بأن هذا البرنامج يعمل، مع التفكير بإمكانية تنفيذه دون استخدام التعاود recursion. سنناقش خلال بقية هذا المقال عددًا من العمليات الأكثر تعقيدًا على قائمةٍ مترابطةٍ من السلاسل النصية، حيث ستكون جميع البرامج الفرعية subroutines التي سنتناولها توابع نُسخ instance methods مُعرَّفةً ضمن الصنف StringList الذي نفذَّه الكاتب. يُمثِل أي كائنٍ من النوع StringList قائمةً مترابطةً من السلاسل النصية، حيث يَملُك الصنف متغير نسخة خاص private اسمه head من النوع Node، ويشير إلى العقدة الأولى ضمن القائمة أو يحتوي على القيمة null إذا كانت القائمة فارغة. تستطيع توابع النسخ instance methods المُعرَّفة بالصنف StringList الوصول إلى head مثل متغير عام global. يُمكِنك العثور على الشيفرة المصدرية للصنف StringList بالملف StringList.java، كما أنه مُستخدمٌ بالبرنامج التوضيحي ListDemo.java، الذي يُمكِّنك من رؤية طريقة استخدامه بوضوح. سنُلقِي نظرةً على إحدى التوابع المُعرَّفة بالصنف StringList للإطلاع على مثالٍ عن المعالجة البسيطة للقوائم واجتيازها، حيث يبحث التابع ذو النوع StringList عن سلسلةٍ نصيةٍ معينة ضمن قائمة؛ إذا كان searchItem مُمثِلًا للسلسلة النصية التي نبحث عنها، فعلينا موازنة searchItem مع كل عنصرٍ ضمن تلك القائمة، بحيث نتوقف عن المعالجة عند العثور على العنصر الذي نبحث عنه. انظر الشيفرة التالية: public boolean find(String searchItem) { Node runner; // مؤشر لاجتياز القائمة // ابدأ بفحص رأس القائمة runner = head; while ( runner != null ) { // 1 if ( runner.item.equals(searchItem) ) return true; runner = runner.next; // تحرك إلى العقدة التالية } // 2 return false; } // end find() حيث تشير كل من [1] و[2] إلى الآتي: [1] افحص السلاسل النصية الموجودة بكل عقدة. إذا كانت السلسلة النصية هي نفسها التي نبحث عنها، أعد القيمة المنطقية true؛ لأننا ببساطة قد وجدناها بالقائمة. [2] عند وصولنا إلى تلك النقطة من البرنامج، نكون قد فحصنا جميع العناصر الموجودة بالقائمة دون العثور على searchItem، ولذلك سنعيد القيمة المنطقية false للإشارة إلى حقيقة عدم وجود العنصر بالقائمة. لاحِظ أنه من الممكن أن تكون القائمة فارغةً أي تكون قيمة head مساويةً للقيمة الفارغة null، لذلك ينبغي معالجة تلك الحالة معالجةً سليمةً؛ فإذا احتوى head المُعرَّف بالشيفرة بالأعلى على القيمة null، فلن يُنفَّذ متن حلقة التكرار while نهائيًا، أي لن يعالج التابع أي عقد nodes، وستكون القيمة المعادة هي القيمة false. هذا هو ما نريد فعله تمامًا عندما تكون القائمة فارغة؛ نظرًا لعدم امكانية حدوث searchItem ضمن قائمةٍ فارغة. الإضافة إلى قائمة مترابطة قد تكون مشكلة إضافة عنصرٍ جديدٍ إلى قائمةٍ مترابطة أكثر صعوبةً نوعًا ما، بالأخص عندما يكون من الضروري إضافة العنصر إلى منتصف القائمة، وتُعد هذه المشكلة أعقد معالجةٍ سنُجرِيها على بنى البيانات المترابطة linked data structures خلال هذا المقال بالكامل. تُحفَظ العناصر الموجودة بعُقد القائمة المترابطة في الصنف StringList مُرتَّبةً تصاعديًا، لذلك عند إضافة عنصرٍ جديدٍ إلى القائمة، لابُدّ من إضافته إلى الموضع الصحيح وفقًا لذلك الترتيب؛ وهذا يعني أننا سنضطَّر في أغلب الحالات إلى إضافة العنصر الجديد إلى مكانٍ ما بمنتصف القائمة أي بين عقدتين موجودتين بالفعل. لكي نتمكَّن من فعل ذلك، سيكون من الضروري تعريف متغيرين من النوع Node للإشارة إلى العقدتين اللتين ينبغي أن تقعا على جانبي العقدة الجديدة، حيث يُمثّل previous وrunner بالصورة التالية المتغيرين المذكورين. إلى جانب ذلك، سنحتاج إلى متغيرٍ آخر newNode للإشارة إلى العقدة الجديدة. لتمكين عملية الإضافة insertion، لا بُدّ من إلغاء الرابط الموجود من previous إلى runner، وإضافة رابطين جديدين من previous إلى newNode، ومن newNode إلى runner. بمجرد ضبط قيمة المتغيرين previous وrunner بحيث يُشيرا إلى العقد الصحيحة، يُمكِننا استخدام الأمر previous.next = newNode; لضبط previous.next لكي يشير إلى العقدة الجديدة، والأمر newNode.next = runner لضبط newNode.next لكي يُشير إلى المكان الصحيح. ولكن قبل أن نستطيع تنفيذ أي من تلك الأوامر، سنحتاج أولًا لضبط كلٍ من runner وprevious كما هو موضحٌ بالصورة السابقة. الفكرة ببساطة هي أن نبدأ من العقدة الأولى بالقائمة، ثم نتحرك على طول القائمة مرورًا بجميع العناصر الأقل من العنصر الجديد، ويجب علينا الانتباه جيدًا أثناء ذلك حتى لا نقع بمشكلة السقوط خارج نهاية القائمة؛ أي أننا لن نستطيع الاستمرار إذا وصل runner إلى نهاية القائمة وأصبحت قيمته تساوي null. لنفترض أن insertItem هو العنصر المطلوب إضافته إلى القائمة، ولنفترض أيضًا أنه ينتمي إلى مكانٍ ما بمنتصف القائمة، ستَتَمكَّن الشيفرة التالية من ضبط قيمة المتغيرين previous وrunner على نحوٍ صحيح. Node runner, previous; previous = head; // ابدأ من مقدمة القائمة runner = head.next; while ( runner != null && runner.item.compareTo(insertItem) < 0 ) { previous = runner; // "previous = previous.next" would also work runner = runner.next; } يستخدم المثال الموضح أعلاه تابع النسخة compareTo() -انظر إلى مقال السلاسل النصية String والأصناف Class والكائنات Object والبرامج الفرعية Subroutine في جافا- المُعرَّف بالصنف String لاختبار ما إذا كان العنصر الموجود بالعقدة node أقل من العنصر المطلوب إضافته. ليس هناك أي مشكلةٍ فيما سبق باستثناء افتراضنا الدائم بانتماء العقدة الجديدة إلى مكانٍ ما بمنتصف القائمة، وهو أمرٌ غير صحيح؛ فقد تكون قيمة العقدة المطلوب إضافتها insertItem أحيانًا أقل من قيمة العنصر الأول ضمن القائمة، وهنا لا بُدّ من إضافة العقدة الجديدة إلى رأس القائمة، وهو ما تفعله الشيفرة التالية. newNode.next = head; // Make newNode.next point to the old head. head = newNode; // Make newNode the new head of the list. من الممكن أيضًا أن تكون القائمة فارغة، وينبغي في هذه الحالة أن تكون newNode هي العقدة الأولى والوحيدة ضمن القائمة. يمكننا إنجاز ذلك ببساطةٍ من خلال تنفيذ تعليمة الإسناد التالية head = newNode، ويعالِج التعريف التالي للتابع insert()، المُعرَّف بالصنف StringList جميع تلك الاحتمالات. public void insert(String insertItem) { Node newNode; // عقدة تحتوي على العنصر الجديد newNode = new Node(); newNode.item = insertItem; // (N.B. newNode.next == null.) if ( head == null ) { // العنصر الجديد هو العنصر الأول والوحيد ضمن القائمة // اضبط head بحيث تشير إليه head = newNode; } else if ( head.item.compareTo(insertItem) >= 0 ) { // العنصر الجديد أقل من أول عنصر ضمن القائمة // لذلك ينبغي أن يُضبَط بحيث يكون رأسًا للقائمة newNode.next = head; head = newNode; } else { // ينتمي العنصر الجديد إلى مكان ما بعد العنصر الأول ضمن القائمة // ابحث عن موضعه المناسب وأضِفه إليه Node runner; // العقدة المستخدمة لاجتيار القائمة Node previous; // تُشير دائمًا إلى العقدة السابقة لـ runner runner = head.next; // ابدأ بفحص الموضع الثاني ضمن القائمة previous = head; while ( runner != null && runner.item.compareTo(insertItem) < 0 ) { // 1 previous = runner; runner = runner.next; } newNode.next = runner; // أضف newNode بعد previous previous.next = newNode; } } // end insert() يعني [1] حرّك previous وrunner على طول القائمة إلى أن يقع runner خارج القائمة، أو إلى أن يصل إلى عنصرٍ أكبر من أو يساوي insertItem. بانتهاء تلك الحلقة، سيشير previous إلى الموضع الذي ينبغي إضافة insertItem إليه. إذا كنت منتبهًا للمناقشة الموضحة أعلاه، فقد تكون لاحظت أن هناك حالةً خاصةً أخرى لم نذكرها، فما الذي سيحدث إذا كان علينا إضافة العقدة الجديدة إلى نهاية القائمة؟ وهذا يحدث إذا كانت جميع عناصر القائمة أقل من العنصر الجديد. في الواقع، يُعالِج البرنامج الفرعي subroutine المُعرَّف بالأعلى تلك الحالة أيضًا ضمن الجزء الأخير من تعليمة if؛ فإذا كان insertItem أكبر من جميع عناصر القائمة، فستنتهي حلقة while بعدما يجتاز runner القائمة بالكامل، وستُصبِح قيمته عندها مساويةً للقيمة الفارغة null. ولكن عند الوصول إلى تلك النقطة، سيكون previous ما يزال يشير إلى العقدة الأخيرة بالقائمة؛ ولهذا سنُنفِّذ التعليمة previous.next = newNode لإضافة newNode إلى نهاية القائمة. ونظرًا لأن runner يُساوِي القيمة الفارغة null، فسيَضبُط الأمر newNode.next = runner قيمة newNode.next إلى القيمة الفارغة null، وهو ما نحتاج إليه تمامًا لنتمكَّن من الإشارة إلى أن القائمة قد انتهت. الحذف من قائمة مترابطة تشبه عملية الحذف عملية الإدخال على الرغم من أنها أبسط نوعًا ما، حيث توجد حالاتٌ خاصة ينبغي أخذها بالحسبان؛ فإذا أردنا حذف العقدة الأولى بقائمة، فينبغي علينا ضبط المُتغيِّر head، وجعله يُشيِر إلى العقدة التي كانت تُعدّ مُسبقًا العقدة الثانية بتلك القائمة. بما أن المتغير head.next يشير بالأساس إلى العقدة الثانية بالقائمة، يُمكِننا إجراء التعديل المطلوب بتنفيذ التعليمة head = head.next، وعلينا أيضًا التأكُّد من أن البرنامج يعمل على نحوٍ سليم حتى وإن كانت قيمة head.next تُساوِي null. عندما لا يكون هناك سوى عقدةٍ واحدةٍ ضمن قائمةٍ معينة، فستصبح القائمة فارغةً. أما إذا كنا نريد حذف عقدةٍ بمنتصف قائمةٍ معينة، فعلينا ضبط قيمة المتغيرين previous وrunner كما فعلنا سابقًا؛ حيث يُشير runner إلى العقدة المطلوب حذفها، بينما يُشيِر previous إلى العقدة التي تسبق العقدة المطلوب حذفها ضمن تلك القائمة. بمجرد انتهائنا من ضبط قيمة المتغيرين، سيحذف الأمر previous.next = runner.next; العقدة المعنية، وسيتولى كانس المهملات garbage collector مسؤولية تحريرها. حاول رسم صورةٍ توضيحيةٍ لعملية الحذف. يُمكِننا الآن تعريف التابع delete() على النحو التالي: public boolean delete(String deleteItem) { if ( head == null ) { // القائمة فارغة، وبالتالي هي بالتأكيد لا تحتوي على deleteString return false; } else if ( head.item.equals(deleteItem) ) { // عثرنا على السلسلة النصية بأول عنصر بالقائمة. احذفه head = head.next; return true; } else { // إذا كانت السلسلة النصية موجودةً بالقائمة، فإنها موجودة بمكانٍ ما بعد // العنصر الأول، وعليه سنبحث عنه بتلك القائمة Node runner; // العقدة المستخدمة لاجتياز القائمة Node previous; // تُشير دائمًا إلى العقدة السابقة للعقدة runner runner = head.next; // ابدأ بفحص الموضع الثاني ضمن القائمة previous = head; while ( runner != null && runner.item.compareTo(deleteItem) < 0 ) { // 1 previous = runner; runner = runner.next; } if ( runner != null && runner.item.equals(deleteItem) ) { // يشير runner إلى العقدة المطلوب حذفها // احذف تلك العقدة بتعديل المؤشر بالعقدة السابقة previous.next = runner.next; return true; } else { // العنصر غير موجود بالقائمة return false; } } } // end delete() وتعني [1] حَرِك previous وrunner على طول القائمة إلى أن يقع runner خارج القائمة أو إلى أن يَصِل إلى عنصرٍ أكبر من أو يساوي deleteItem. بانتهاء تلك الحلقة، سيُشير runner إلى موضع العنصر المطلوب حذفه، إذا كان موجودًا بالقائمة. ترجمة -بتصرّف- للقسم Section 2: Linked Data Structures من فصل Chapter 9: Linked Data Structures and Recursion من كتاب Introduction to Programming Using Java. اقرأ أيضًا الحلقات التكرارية في البرمجة الأصناف المتداخلة Nested Classes في جافا تعرف على أهم الأحداث والتعامل معها في مكتبة جافا إف إكس JavaFX تعرف على المصفوفات (Arrays) في جافا1 نقطة




