
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/23/22 في كل الموقع
-
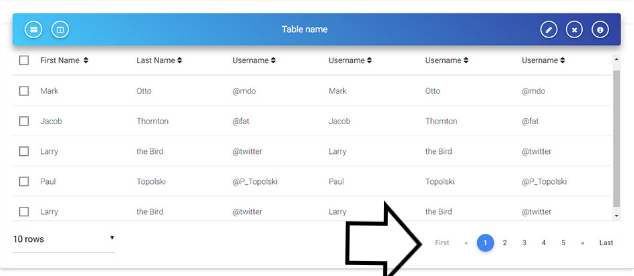
لقد قمت بأنشاء جدول بواسطة bootstrap اريد ان اقوم بأختصار اسطر الجدول بحيث اذا اصبح في الجدول عشرة اسطر يقوم بأنشاء صفحة ثانية للجدول وتوضع بها الاسطر الجديدة لكي لا يزيد طول الجدول .... مثل الصورة التالية
 2 نقاط
2 نقاط -
اتواصل مع فريق الدعم منذ اكثر من يومين وليس هناك اي استجابة2 نقاط
-
باي باب في كورس الواجهات المطورة ؟ هل بعلوم الحاسب ام ماذا؟1 نقطة
-
السلام عليكم ورحمته الله وبركاته اريد التعلم البرمجة وليس لدي اي فكرة في هذا المجال ولا اعرف من اين كورس ابدأ في هذا المجال لان في اكاديمية حسوب يوجد لديهم 7 كورسات الان، وانا اريد التعلم برمجة المواقع والتطبيقات الجوال. فماذا تنصحوني اشترك؟1 نقطة
-
ما هي اللغة التي تستخدمها في البرمجة ؟1 نقطة
-
السلام عليكم.. كم هي تكلفة انشاء موقع تجاري الكتروني خاص بالقهَوة، ايضاً يملك جميع وسائل الدفع بالإضافة الى وحدة تحكم خاصة بصاحب الموقع؟1 نقطة
-
Create student class that contain name, ID and grade as a data member for each student and output how many students with grade A, B and C. Using ++ operator overloading1 نقطة
-
mstor.rar1 نقطة
-
سيتواصل معك مركز المساعدة في أقرب وقت ، ربما هناك الكثير من التذاكر التي يعملون عليها ، لذلك تحتاج إلى أن تصبر بعض الشيء و سيتم الرد عليك.1 نقطة
-
يمكننا بسهولة معرفة إذا كان العدد فردي Odd أو زوجي even من خلال قسمته على 2، فإن كان باقي القسمة 0 فهذا يعني أن الرقم زوجي وإن كان باقي القسمة 1 فهذا يعني أن الرقم فردي، مثال: const x = 15; if (x % 2 === 0) { // معامل باقي القسمة console.log("X is even") } else { console.log("X is odd") } الآن يمكننا عمل حلقة loop للمرور على الأرقام من 0 إلى 100 على سبيل المثال، وطباعة كل رقم فردي: for (let i = 0; i <= 100; i++) { // طباعة الرقم إن كان فردي if (i % 2 !== 0) { console.log(i) } } معلومات عن معامل باقي القسمة.1 نقطة
-
 سنتعرّف من خلال هذا المقال على كيفية التعامل مع الملفات والمجلدات في Node.js من خلال شرح واصفات الملفات وإحصائياتها ومساراتها وقراءتها وكتابتها، كما سنتعرّف على مفهوم المجاري streams وميّزاتها وأنواعها. واصفات الملفات File descriptors يمكن التفاعل مع واصفات الملفات باستخدام نود Node، إذ يجب أن تحصل على واصف ملف قبل تمكنك من التفاعل مع ملف موجود في نظام الملفات الخاص بك، وواصف الملف هو ما يُعاد عند فتح الملف باستخدام التابع open() الذي توفره وحدة fs: const fs = require('fs') fs.open('/Users/flavio/test.txt', 'r', (err, fd) => { //fd هو واصف الملف }) استخدمنا الراية r على أساس معامِل ثانٍ لاستدعاء fs.open()، إذ تعني هذه الراية أننا نفتح الملف للقراءة؛ أما الرايات الأخرى المُستخدَمة فهي: r+ فتح الملف للقراءة والكتابة. w+ فتح الملف للقراءة والكتابة، مع وضع المجرى stream في بداية الملف وإنشاء الملف إذا لم يكن موجودًا مسبقًا. a فتح الملف للكتابة، مع وضع المجرى في نهاية الملف وإنشاء الملف إن لم يكن موجودًا مسبقًا. a+ فتح الملف للقراءة والكتابة، مع وضع المجرى في نهاية الملف وإنشاء الملف إن لم يكن موجودًا مسبقًا. يمكنك فتح الملف باستخدام التابع fs.openSync الذي يعيد كائن واصف الملف بدلًا من توفيره في دالة رد نداء: const fs = require('fs') try { const fd = fs.openSync('/Users/flavio/test.txt', 'r') } catch (err) { console.error(err) } يمكنك تنفيذ جميع العمليات المطلوبة مثل استدعاء التابع fs.open() والعديد من العمليات الأخرى التي تتفاعل مع نظام الملفات بمجرد حصولك على واصف الملف بأيّ طريقة تختارها. إحصائيات الملف يأتي كل ملف مع مجموعة من التفاصيل التي يمكننا فحصها باستخدام نود Node باستخدام التابع stat() الذي توفِّره وحدة fs، حيث يمكنك استدعاؤه مع تمرير مسار ملف إليه، حيث سيستدعي نود بعد حصوله على تفاصيل الملف دالة رد النداء التي تمررها مع معاملين هما رسالة خطأ وإحصائيات الملف: const fs = require('fs') fs.stat('/Users/flavio/test.txt', (err, stats) => { if (err) { console.error(err) return } //يمكننا الوصول إلى إحصائيات الملف في `stats` }) كما يوفِّر نود تابعًا متزامنًا يوقِف الخيط thread إلى أن تصبح إحصائيات الملف جاهزةً: const fs = require('fs') try { const stats = fs.stat('/Users/flavio/test.txt') } catch (err) { console.error(err) } تُضمَّن معلومات الملف في المتغير stats، ويمكننا استخراج أنواع معلومات متعددة باستخدام توابع stats كما يلي: استخدم التابع stats.isFile() والتابع stats.isDirectory() لمعرفة إذا كان الملف عبارة عن مجلد أو ملف. استخدم التابع stats.isSymbolicLink() لمعرفة إذا كان الملف وصلةً رمزيةً symbolic link. استخدم التابع stats.size لمعرفة حجم الملف مقدَّرًا بالبايت. هناك توابع متقدمة أخرى، ولكن الجزء الأكبر مما ستستخدمه هو التوابع السابقة. const fs = require('fs') fs.stat('/Users/flavio/test.txt', (err, stats) => { if (err) { console.error(err) return } stats.isFile() //true stats.isDirectory() //false stats.isSymbolicLink() //false stats.size //1024000 //= 1MB }) مسارات الملفات سنتعرّف على كيفية التفاعل مع مسارات الملفات والتعامل معها في نود Node، فلكل ملف في النظام مسار، وقد يبدو المسار في نظامَي لينكس Linux وmacOS كما يلي: /users/flavio/file.txt بينما الحواسيب التي تعمل بنظام ويندوز Windows مختلفة، إذ يكون للمسار بنية كما يلي: C:\users\flavio\file.txt يجب الانتباه عند استخدام المسارات في تطبيقاتك، إذ يجب مراعاة هذا الاختلاف، كما يمكنك تضمين وحدة المسار في ملفاتك كما ما يلي: const path = require('path') ثم يمكنك البدء في استخدام توابعها، كما يمكنك استخراج معلومات من مسار باستخدام التوابع التالية: dirname: للحصول على مجلد الملف الأب. basename: للحصول على جزء اسم الملف. extname: للحصول على امتداد الملف. إليك المثال التالي: const notes = '/users/flavio/notes.txt' path.dirname(notes) // /users/flavio path.basename(notes) // notes.txt path.extname(notes) // .txt يمكنك الحصول على اسم الملف بدون امتداده عن طريق تحديد وسيط ثانٍ للتابع basename كما يلي: path.basename(notes, path.extname(notes)) //notes كما يمكنك ربط جزأين أو أكثر من المسار مع بعضها البعض باستخدام التابع path.join() كما يلي: const name = 'flavio' path.join('/', 'users', name, 'notes.txt') //'/users/flavio/notes.txt' يمكنك حساب مسار الملف المطلق absolute path من مساره النسبي relative path باستخدام التابع path.resolve() كما يلي: path.resolve('flavio.txt') //'/Users/flavio/flavio.txt' if run from my home folder سيُلحِق في هذه الحالة نود Node ببساطة المسارَ النسبي /flavio.txt بدليل أو مجلد العمل الحالي، فإذا حددت مجلدًا على أساس معامل آخر، فسيستخدِم تابع resolve المعامل الأول أساسًا للمعامل الثاني كما يلي: path.resolve('tmp', 'flavio.txt')//'/Users/flavio/tmp/flavio.txt' إذا شُغِّل من المجلد المحلي إذا بدأ المعامل الأول بشرطة مائلة، فهذا يعني أنه مسار مطلق مثل المثال التالي: path.resolve('/etc', 'flavio.txt')//'/etc/flavio.txt' يُعَدّ path.normalize() تابعًا آخرًا مفيدًا يحسب المسار الفعلي عندما يحتوي على محددات نسبية مثل . أو .. أو شرطة مائلة مزدوجة كما يلي: path.normalize('/users/flavio/..//test.txt') ///users/test.txt لن يتحقق التابعان resolve وnormalize من وجود المسار، وإنما يحسبان المسار فقط بناءً على المعلومات المتاحة. قراءة الملفات أبسط طريقة لقراءة ملف في نود هي استخدام تابع fs.readFile()، حيث نمرِّر له مسار الملف ودالة رد النداء التي ستُستدعَى مع بيانات الملف ومع الخطأ كما يلي: const fs = require('fs') fs.readFile('/Users/flavio/test.txt', (err, data) => { if (err) { console.error(err) return } console.log(data) }) يمكنك بدلًا من ذلك استخدام الإصدار المتزامن من التابع السابق وهو التابع fs.readFileSync(): const fs = require('fs') try { const data = fs.readFileSync('/Users/flavio/test.txt', 'utf8') console.log(data) } catch (err) { console.error(err) } الترميز الافتراضي هو utf8، ولكن يمكنك تحديد ترميز مُخصَّص باستخدام معامل ثانٍ، كما يقرأ كل من التابعَين fs.readFile() وfs.readFileSync() محتوى الملف الكامل في الذاكرة قبل إعادة البيانات، وهذا يعني أن الملفات الكبيرة سيكون لها تأثير كبير على استهلاك الذاكرة وسرعة تنفيذ البرنامج، وبالتالي يكون الخيار الأفضل في هذه الحالة هو قراءة محتوى الملف باستخدام المجاري streams. كتابة الملفات أسهل طريقة للكتابة في الملفات في Node.js هي استخدام واجهة برمجة تطبيقات fs.writeFile()، وإليك المثال التالي: const fs = require('fs') const content = 'Some content!' fs.writeFile('/Users/flavio/test.txt', content, (err) => { if (err) { console.error(err) return } //كُتِب الملف بنجاح }) يمكنك بدلًا من ذلك استخدام الإصدار المتزامن وهو fs.writeFileSync(): const fs = require('fs') const content = 'Some content!' try { const data = fs.writeFileSync('/Users/flavio/test.txt', content) //كُتِب الملف بنجاح } catch (err) { console.error(err) } ستبدّل واجهة برمجة التطبيقات هذه افتراضيًا محتويات الملف إذا كان موجودًا مسبقًا، ولكن يمكنك تعديل الإعداد الافتراضي عن طريق تحديد راية كما يلي: fs.writeFile('/Users/flavio/test.txt', content, { flag: 'a+' }, (err) => {}) الرايات التي يمكنك استخدامها هي: r+ لفتح الملف للقراءة والكتابة. w+ لفتح الملف للقراءة والكتابة مع وضع المجرى في بداية الملف وإنشاء الملف إذا لم يكن موجودًا مسبقًا. a لفتح الملف للكتابة مع وضع المجرى في نهاية الملف وإنشاء الملف إذا لم يكن موجودًا مسبقًا. a+ لفتح الملف للقراءة والكتابة، مع وضع المجرى في نهاية الملف، وإنشاء الملف إن لم يكن موجودًا مسبقًا. يمكنك العثور على المزيد من الرايات على /nodejs. إلحاق محتوى بملف يمكنك إلحاق محتوى بنهاية الملف من خلال استخدام التابع fs.appendFile() ونسخته المتزامنة التابع fs.appendFileSync(): const content = 'Some content!' fs.appendFile('file.log', content, (err) => { if (err) { console.error(err) return } //done! }) استخدام المجاري streams تكتب كل التوابع السابقة المحتوى الكامل في الملف قبل إعادة التحكم إلى برنامجك مرةً أخرى، أي تنفيذ دالة رد النداء في النسخة غير المتزامنة، وبالتالي الخيار الأفضل هو كتابة محتوى الملف باستخدام المجاري streams. لنتعرّف على الغرض الأساسي من المجاري streams وسبب أهميتها وكيفية استخدامها، حيث سنقدِّم مدخلًا بسيطًا إلى المجاري، ولكن هناك جوانب أكثر تعقيدًا لتحليلها. مفهوم المجاري streams تُعَدّ المجاري أحد المفاهيم الأساسية التي تعمل على تشغيل تطبيقات Node.js، وهي طريقة للتعامل مع ملفات القراءة/الكتابة أو اتصالات الشبكة أو أيّ نوع من تبادل المعلومات من طرف إلى طرف بطريقة فعالة، كما ليست المجاري مفهومًا خاصًا بنود Node.js، إذ توفّرت في نظام التشغيل يونيكس Unix منذ عقود، ويمكن للبرامج أن تتفاعل مع بعضها البعض عبر تمرير المجاري من خلال معامِل الشريط العمودي أو الأنبوب pipe operator (|). يُقرأ الملف في الذاكرة من البداية إلى النهاية ثم تعالجه، عندما تطلب من البرنامج قراءة ملف بالطريقة التقليدية على سبيل المثال، لكن يمكنك قراءة الملف قطعةً تلو الأخرى باستخدام المجاري، ومعالجة محتواه دون الاحتفاظ به بالكامل في الذاكرة، إذ توفِّر وحدة نود stream الأساس الذي يُبنَى عليه جميع واجهات برمجة التطبيقات ذات المجرى، كما توفِّر المجاري ميزتَين رئيسيتَين باستخدام طرق معالجة البيانات الأخرى هما: فعالية الذاكرة Memory efficiency: لست بحاجة إلى تحميل كميات كبيرة من البيانات في الذاكرة قبل أن تكون قادرًا على معالجتها. فعالية الوقت Time efficiency: تستغرق وقتًا أقل لبدء معالجة البيانات بمجرد حصولك عليها، بدلًا من انتظار اكتمال حمولة البيانات للبدء. يوضِّح المثال التالي قراءة ملفات من القرص الصلب، حيث يمكنك باستخدام وحدة نود fs قراءة ملف وتقديمه عبر بروتوكول HTTP عند إنشاء اتصال جديد بخادم http: const http = require('http') const fs = require('fs') const server = http.createServer(function (req, res) { fs.readFile(__dirname + '/data.txt', (err, data) => { res.end(data) }) }) server.listen(3000) يقرأ التابع readFile() محتويات الملف الكاملة، ويستدعي دالة رد النداء callback function عند الانتهاء، بينما سيعيد التابع res.end(data) في دالة رد النداء محتويات الملف إلى عميل HTTP، فإذا كان الملف كبيرًا، فستستغرق العملية وقتًا طويلًا، ويمكن تطبيق الأمر نفسه باسخدام المجاري streams كما يلي: const http = require('http') const fs = require('fs') const server = http.createServer((req, res) => { const stream = fs.createReadStream(__dirname + '/data.txt') stream.pipe(res) }) server.listen(3000) يمكننا بث الملف عبر المجاري إلى عميل HTTP بمجرد أن يكون لدينا مجموعة كبيرة من البيانات جاهزة للإرسال بدلًا من انتظار قراءة الملف بالكامل؛ ويستخدم المثال السابق stream.pipe(res)، أي استدعاء تابع pipe() في مجرى الملف، حيث يأخذ هذا التابع المصدر، ويضخّه إلى وجهة معينة، كما يُستدعَى هذا التابع على مجرى المصدر، وبالتالي يُضَخ مجرى الملف إلى استجابة HTTP في هذه الحالة، وتكون القيمة المُعادة من التابع pipe() هي مجرى الوجهة، وهذا أمر ملائم للغاية لربط استدعاءات pipe() متعددة كما يلي: src.pipe(dest1).pipe(dest2) الذي يكافئ ما يلي: src.pipe(dest1) dest1.pipe(dest2) تتوفَّر واجهات برمجة تطبيقات API الخاصة بنود Node التي تعمل باستخدام المجاري Streams، إذ توفِّر العديد من وحدات Node.js الأساسية إمكانات معالجة المجرى الأصيلة، ومن أبرزها: process.stdin التي تعيد مجرًى متصلًا بمجرى stdin. process.stdout التي تعيد مجرًى متصلًا بمجرى stdout. process.stderr التي تعيد مجرًى متصلًا بمجرى stderr. fs.createReadStream() الذي ينشئ مجرًى قابلًا للقراءة إلى ملف. fs.createWriteStream() الذي ينشئ مجرًى قابلًا للكتابة إلى ملف. net.connect() الذي يبدأ اتصالًا قائمًا على مجرى. http.request() الذي يعيد نسخة من الصنف http.ClientRequest، وهو مجرى قابل للكتابة. zlib.createGzip() الذي يضغط البيانات باستخدام خوارزمية الضغط gzip في مجرى. zlib.createGunzip() الذي يفك ضغط مجرى gzip. zlib.createDeflate() الذي يضغط البيانات باستخدام خوارزمية الضغط deflate في مجرى. zlib.createInflate() الذي يفك ضغط مجرى deflate. أنواع المجاري المختلفة هناك أربع أصناف من المجاري هي: Readable: هو مجرى يمكن الضخ pipe منه ولكن لا يمكن الضخ إليه، أي يمكنك تلقي البيانات منه ولكن لا يمكنك إرسال البيانات إليه، فإذا دفعتَ بيانات إلى مجرى قابل للقراءة، فستُخزَّن مؤقتًا حتى يبدأ المستهلك في قراءة البيانات. Writable: هو مجرى يمكن الضخ إليه، ولكن لا يمكن الضخ منه، أي يمكنك إرسال البيانات إليه، ولكن لا يمكنك تلقي البيانات منه. Duplex: هو مجرى يمكن الضخ منه وإليه، أي هو مزيج من مجرى Readable ومجرى Writable. Transform: مجرى التحويل مشابه للمجرى Duplex، ولكن خرجه هو تحويل لدخله. كيفية إنشاء مجرى قابل للقراءة يمكن الحصول على مجرى قابل للقراءة من وحدة stream، كما يمكن تهيئته كما يلي: const Stream = require('stream') const readableStream = new Stream.Readable() ثم يمكننا إرسال البيانات إليه بعد تهيئته: readableStream.push('hi!') readableStream.push('ho!') كيفية إنشاء مجرى قابل للكتابة يمكنك إنشاء مجرى قابل للكتابة من خلال وراثة كائن Writable الأساسي وتطبيق تابعه _write(). أنشئ أولًا كائن Stream كما يلي: const Stream = require('stream') const writableStream = new Stream.Writable() ثم التابع _write كما يلي: writableStream._write = (chunk, encoding, next) => { console.log(chunk.toString()) next() } يمكنك الآن الضخ إلى مجرى قابل للقراءة كما يلي: process.stdin.pipe(writableStream) كيفية الحصول على بيانات من مجرى قابل للقراءة يمكنك قراءة البيانات من مجرًى قابل للقراءة باستخدام مجرى قابل للكتابة كما يلي: const Stream = require('stream') const readableStream = new Stream.Readable() const writableStream = new Stream.Writable() writableStream._write = (chunk, encoding, next) => { console.log(chunk.toString()) next() } readableStream.pipe(writableStream) readableStream.push('hi!') readableStream.push('ho!') كما يمكنك استهلاك مجرى قابل للقراءة مباشرةً باستخدام الحدث readable كما يلي: readableStream.on('readable', () => { console.log(readableStream.read()) }) كيفية إرسال بيانات إلى مجرى قابل للكتابة استخدم تابع المجرى write() كما يلي: writableStream.write('hey!\n') إعلام مجرى قابل للكتابة بانتهاء الكتابة استخدم التابع end() كما يلي: const Stream = require('stream') const readableStream = new Stream.Readable() const writableStream = new Stream.Writable() writableStream._write = (chunk, encoding, next) => { console.log(chunk.toString()) next() } readableStream.pipe(writableStream) readableStream.push('hi!') readableStream.push('ho!') writableStream.end() التعامل مع المجلدات توفِّر وحدة Node.js الأساسية fs توابعًا متعددةً مفيدةً يمكنك استخدامها للتعامل مع المجلدات. التحقق من وجود مجلد يُستخدَم التابع fs.access() للتحقق مما إذا كان المجلد موجودًا، ويمكن لنود الوصول إلى المجلد باستخدام أذوناته. إنشاء مجلد جديد يُستخدَم التابع fs.mkdir() أو التابع fs.mkdirSync() لإنشاء مجلد جديد. const fs = require('fs') const folderName = '/Users/flavio/test' try { if (!fs.existsSync(dir)){ fs.mkdirSync(dir) } } catch (err) { console.error(err) } قراءة محتوى مجلد يُستخدَم التابع fs.readdir() أو التابع fs.readdirSync لقراءة محتويات مجلد، ويقرأ جزء الشيفرة التالية محتوى مجلد من ملفات ومجلدات فرعية، ويعيد مساراتها النسبية: const fs = require('fs') const path = require('path') const folderPath = '/Users/flavio' fs.readdirSync(folderPath) يمكنك الحصول على المسار الكامل من خلال ما يلي: fs.readdirSync(folderPath).map(fileName => { return path.join(folderPath, fileName) } كما يمكنك تصفية النتائج لإعادة الملفات فقط واستبعاد المجلدات كما يلي: const isFile = fileName => { return fs.lstatSync(fileName).isFile() } fs.readdirSync(folderPath).map(fileName => { return path.join(folderPath, fileName)).filter(isFile) } إعادة تسمية مجلد يُستخدَم التابع fs.rename() أو التابع fs.renameSync() لإعادة تسمية مجلد، حيث يكون المعامِل الأول هو المسار الحالي، والمعامِل الثاني هو المسار الجديد: const fs = require('fs') fs.rename('/Users/flavio', '/Users/roger', (err) => { if (err) { console.error(err) return } //done }) كما يمكنك استخدام التابع fs.renameSync() الذي هو النسخة المتزامنة كما يلي: const fs = require('fs') try { fs.renameSync('/Users/flavio', '/Users/roger') } catch (err) { console.error(err) } إزالة مجلد يُستخدَم التابع fs.rmdir() أو التابع fs.rmdirSync() لإزالة مجلد، ويمكن أن تكون إزالة مجلد أكثر تعقيدًا إذا تضمّن محتوىً، لذلك نوصي في هذه الحالة بتثبيت وحدة fs-extra التي تحظى بشعبية ودعم كبيرَين، وهي بديل سريع لوحدة fs، وبالتالي تضيف مزيدًا من الميزات عليها، كما ستحتاج استخدام التابع remove(). ثبّت وحدة fs-extra باستخدام الأمر: npm install fs-extra، واستخدمها كما يلي: const fs = require('fs-extra') const folder = '/Users/flavio' fs.remove(folder, err => { console.error(err) }) كما يمكن استخدامها مع الوعود promises كما يلي: fs.remove(folder).then(() => { //done }).catch(err => { console.error(err) }) أو مع صيغة async/await كما يلي: async function removeFolder(folder) { try { await fs.remove(folder) //done } catch (err) { console.error(err) } } const folder = '/Users/flavio' removeFolder(folder) للمزيد، يمكنك الرجوع إلى توثيق التعامل مع نظام الملفات في Node.js في موسوعة حسوب. ترجمة -وبتصرّف- للفصل File System من كتاب The Node.js handbook لصاحبه Flavio Copes. اقرأ أيضًا المقال التالي: تعرف على وحدات Node.js الأساسية المقال السابق: التعامل مع الطلبيات الشبكية في Node.js التعامل مع الملفات في البرمجة مدخل إلى التعامل مع الملفات في جافا كيفية التعامل مع الملفات النصية في بايثون 3 التعامل مع الملفات النصية في لغة سي شارب #C1 نقطة
سنتعرّف من خلال هذا المقال على كيفية التعامل مع الملفات والمجلدات في Node.js من خلال شرح واصفات الملفات وإحصائياتها ومساراتها وقراءتها وكتابتها، كما سنتعرّف على مفهوم المجاري streams وميّزاتها وأنواعها. واصفات الملفات File descriptors يمكن التفاعل مع واصفات الملفات باستخدام نود Node، إذ يجب أن تحصل على واصف ملف قبل تمكنك من التفاعل مع ملف موجود في نظام الملفات الخاص بك، وواصف الملف هو ما يُعاد عند فتح الملف باستخدام التابع open() الذي توفره وحدة fs: const fs = require('fs') fs.open('/Users/flavio/test.txt', 'r', (err, fd) => { //fd هو واصف الملف }) استخدمنا الراية r على أساس معامِل ثانٍ لاستدعاء fs.open()، إذ تعني هذه الراية أننا نفتح الملف للقراءة؛ أما الرايات الأخرى المُستخدَمة فهي: r+ فتح الملف للقراءة والكتابة. w+ فتح الملف للقراءة والكتابة، مع وضع المجرى stream في بداية الملف وإنشاء الملف إذا لم يكن موجودًا مسبقًا. a فتح الملف للكتابة، مع وضع المجرى في نهاية الملف وإنشاء الملف إن لم يكن موجودًا مسبقًا. a+ فتح الملف للقراءة والكتابة، مع وضع المجرى في نهاية الملف وإنشاء الملف إن لم يكن موجودًا مسبقًا. يمكنك فتح الملف باستخدام التابع fs.openSync الذي يعيد كائن واصف الملف بدلًا من توفيره في دالة رد نداء: const fs = require('fs') try { const fd = fs.openSync('/Users/flavio/test.txt', 'r') } catch (err) { console.error(err) } يمكنك تنفيذ جميع العمليات المطلوبة مثل استدعاء التابع fs.open() والعديد من العمليات الأخرى التي تتفاعل مع نظام الملفات بمجرد حصولك على واصف الملف بأيّ طريقة تختارها. إحصائيات الملف يأتي كل ملف مع مجموعة من التفاصيل التي يمكننا فحصها باستخدام نود Node باستخدام التابع stat() الذي توفِّره وحدة fs، حيث يمكنك استدعاؤه مع تمرير مسار ملف إليه، حيث سيستدعي نود بعد حصوله على تفاصيل الملف دالة رد النداء التي تمررها مع معاملين هما رسالة خطأ وإحصائيات الملف: const fs = require('fs') fs.stat('/Users/flavio/test.txt', (err, stats) => { if (err) { console.error(err) return } //يمكننا الوصول إلى إحصائيات الملف في `stats` }) كما يوفِّر نود تابعًا متزامنًا يوقِف الخيط thread إلى أن تصبح إحصائيات الملف جاهزةً: const fs = require('fs') try { const stats = fs.stat('/Users/flavio/test.txt') } catch (err) { console.error(err) } تُضمَّن معلومات الملف في المتغير stats، ويمكننا استخراج أنواع معلومات متعددة باستخدام توابع stats كما يلي: استخدم التابع stats.isFile() والتابع stats.isDirectory() لمعرفة إذا كان الملف عبارة عن مجلد أو ملف. استخدم التابع stats.isSymbolicLink() لمعرفة إذا كان الملف وصلةً رمزيةً symbolic link. استخدم التابع stats.size لمعرفة حجم الملف مقدَّرًا بالبايت. هناك توابع متقدمة أخرى، ولكن الجزء الأكبر مما ستستخدمه هو التوابع السابقة. const fs = require('fs') fs.stat('/Users/flavio/test.txt', (err, stats) => { if (err) { console.error(err) return } stats.isFile() //true stats.isDirectory() //false stats.isSymbolicLink() //false stats.size //1024000 //= 1MB }) مسارات الملفات سنتعرّف على كيفية التفاعل مع مسارات الملفات والتعامل معها في نود Node، فلكل ملف في النظام مسار، وقد يبدو المسار في نظامَي لينكس Linux وmacOS كما يلي: /users/flavio/file.txt بينما الحواسيب التي تعمل بنظام ويندوز Windows مختلفة، إذ يكون للمسار بنية كما يلي: C:\users\flavio\file.txt يجب الانتباه عند استخدام المسارات في تطبيقاتك، إذ يجب مراعاة هذا الاختلاف، كما يمكنك تضمين وحدة المسار في ملفاتك كما ما يلي: const path = require('path') ثم يمكنك البدء في استخدام توابعها، كما يمكنك استخراج معلومات من مسار باستخدام التوابع التالية: dirname: للحصول على مجلد الملف الأب. basename: للحصول على جزء اسم الملف. extname: للحصول على امتداد الملف. إليك المثال التالي: const notes = '/users/flavio/notes.txt' path.dirname(notes) // /users/flavio path.basename(notes) // notes.txt path.extname(notes) // .txt يمكنك الحصول على اسم الملف بدون امتداده عن طريق تحديد وسيط ثانٍ للتابع basename كما يلي: path.basename(notes, path.extname(notes)) //notes كما يمكنك ربط جزأين أو أكثر من المسار مع بعضها البعض باستخدام التابع path.join() كما يلي: const name = 'flavio' path.join('/', 'users', name, 'notes.txt') //'/users/flavio/notes.txt' يمكنك حساب مسار الملف المطلق absolute path من مساره النسبي relative path باستخدام التابع path.resolve() كما يلي: path.resolve('flavio.txt') //'/Users/flavio/flavio.txt' if run from my home folder سيُلحِق في هذه الحالة نود Node ببساطة المسارَ النسبي /flavio.txt بدليل أو مجلد العمل الحالي، فإذا حددت مجلدًا على أساس معامل آخر، فسيستخدِم تابع resolve المعامل الأول أساسًا للمعامل الثاني كما يلي: path.resolve('tmp', 'flavio.txt')//'/Users/flavio/tmp/flavio.txt' إذا شُغِّل من المجلد المحلي إذا بدأ المعامل الأول بشرطة مائلة، فهذا يعني أنه مسار مطلق مثل المثال التالي: path.resolve('/etc', 'flavio.txt')//'/etc/flavio.txt' يُعَدّ path.normalize() تابعًا آخرًا مفيدًا يحسب المسار الفعلي عندما يحتوي على محددات نسبية مثل . أو .. أو شرطة مائلة مزدوجة كما يلي: path.normalize('/users/flavio/..//test.txt') ///users/test.txt لن يتحقق التابعان resolve وnormalize من وجود المسار، وإنما يحسبان المسار فقط بناءً على المعلومات المتاحة. قراءة الملفات أبسط طريقة لقراءة ملف في نود هي استخدام تابع fs.readFile()، حيث نمرِّر له مسار الملف ودالة رد النداء التي ستُستدعَى مع بيانات الملف ومع الخطأ كما يلي: const fs = require('fs') fs.readFile('/Users/flavio/test.txt', (err, data) => { if (err) { console.error(err) return } console.log(data) }) يمكنك بدلًا من ذلك استخدام الإصدار المتزامن من التابع السابق وهو التابع fs.readFileSync(): const fs = require('fs') try { const data = fs.readFileSync('/Users/flavio/test.txt', 'utf8') console.log(data) } catch (err) { console.error(err) } الترميز الافتراضي هو utf8، ولكن يمكنك تحديد ترميز مُخصَّص باستخدام معامل ثانٍ، كما يقرأ كل من التابعَين fs.readFile() وfs.readFileSync() محتوى الملف الكامل في الذاكرة قبل إعادة البيانات، وهذا يعني أن الملفات الكبيرة سيكون لها تأثير كبير على استهلاك الذاكرة وسرعة تنفيذ البرنامج، وبالتالي يكون الخيار الأفضل في هذه الحالة هو قراءة محتوى الملف باستخدام المجاري streams. كتابة الملفات أسهل طريقة للكتابة في الملفات في Node.js هي استخدام واجهة برمجة تطبيقات fs.writeFile()، وإليك المثال التالي: const fs = require('fs') const content = 'Some content!' fs.writeFile('/Users/flavio/test.txt', content, (err) => { if (err) { console.error(err) return } //كُتِب الملف بنجاح }) يمكنك بدلًا من ذلك استخدام الإصدار المتزامن وهو fs.writeFileSync(): const fs = require('fs') const content = 'Some content!' try { const data = fs.writeFileSync('/Users/flavio/test.txt', content) //كُتِب الملف بنجاح } catch (err) { console.error(err) } ستبدّل واجهة برمجة التطبيقات هذه افتراضيًا محتويات الملف إذا كان موجودًا مسبقًا، ولكن يمكنك تعديل الإعداد الافتراضي عن طريق تحديد راية كما يلي: fs.writeFile('/Users/flavio/test.txt', content, { flag: 'a+' }, (err) => {}) الرايات التي يمكنك استخدامها هي: r+ لفتح الملف للقراءة والكتابة. w+ لفتح الملف للقراءة والكتابة مع وضع المجرى في بداية الملف وإنشاء الملف إذا لم يكن موجودًا مسبقًا. a لفتح الملف للكتابة مع وضع المجرى في نهاية الملف وإنشاء الملف إذا لم يكن موجودًا مسبقًا. a+ لفتح الملف للقراءة والكتابة، مع وضع المجرى في نهاية الملف، وإنشاء الملف إن لم يكن موجودًا مسبقًا. يمكنك العثور على المزيد من الرايات على /nodejs. إلحاق محتوى بملف يمكنك إلحاق محتوى بنهاية الملف من خلال استخدام التابع fs.appendFile() ونسخته المتزامنة التابع fs.appendFileSync(): const content = 'Some content!' fs.appendFile('file.log', content, (err) => { if (err) { console.error(err) return } //done! }) استخدام المجاري streams تكتب كل التوابع السابقة المحتوى الكامل في الملف قبل إعادة التحكم إلى برنامجك مرةً أخرى، أي تنفيذ دالة رد النداء في النسخة غير المتزامنة، وبالتالي الخيار الأفضل هو كتابة محتوى الملف باستخدام المجاري streams. لنتعرّف على الغرض الأساسي من المجاري streams وسبب أهميتها وكيفية استخدامها، حيث سنقدِّم مدخلًا بسيطًا إلى المجاري، ولكن هناك جوانب أكثر تعقيدًا لتحليلها. مفهوم المجاري streams تُعَدّ المجاري أحد المفاهيم الأساسية التي تعمل على تشغيل تطبيقات Node.js، وهي طريقة للتعامل مع ملفات القراءة/الكتابة أو اتصالات الشبكة أو أيّ نوع من تبادل المعلومات من طرف إلى طرف بطريقة فعالة، كما ليست المجاري مفهومًا خاصًا بنود Node.js، إذ توفّرت في نظام التشغيل يونيكس Unix منذ عقود، ويمكن للبرامج أن تتفاعل مع بعضها البعض عبر تمرير المجاري من خلال معامِل الشريط العمودي أو الأنبوب pipe operator (|). يُقرأ الملف في الذاكرة من البداية إلى النهاية ثم تعالجه، عندما تطلب من البرنامج قراءة ملف بالطريقة التقليدية على سبيل المثال، لكن يمكنك قراءة الملف قطعةً تلو الأخرى باستخدام المجاري، ومعالجة محتواه دون الاحتفاظ به بالكامل في الذاكرة، إذ توفِّر وحدة نود stream الأساس الذي يُبنَى عليه جميع واجهات برمجة التطبيقات ذات المجرى، كما توفِّر المجاري ميزتَين رئيسيتَين باستخدام طرق معالجة البيانات الأخرى هما: فعالية الذاكرة Memory efficiency: لست بحاجة إلى تحميل كميات كبيرة من البيانات في الذاكرة قبل أن تكون قادرًا على معالجتها. فعالية الوقت Time efficiency: تستغرق وقتًا أقل لبدء معالجة البيانات بمجرد حصولك عليها، بدلًا من انتظار اكتمال حمولة البيانات للبدء. يوضِّح المثال التالي قراءة ملفات من القرص الصلب، حيث يمكنك باستخدام وحدة نود fs قراءة ملف وتقديمه عبر بروتوكول HTTP عند إنشاء اتصال جديد بخادم http: const http = require('http') const fs = require('fs') const server = http.createServer(function (req, res) { fs.readFile(__dirname + '/data.txt', (err, data) => { res.end(data) }) }) server.listen(3000) يقرأ التابع readFile() محتويات الملف الكاملة، ويستدعي دالة رد النداء callback function عند الانتهاء، بينما سيعيد التابع res.end(data) في دالة رد النداء محتويات الملف إلى عميل HTTP، فإذا كان الملف كبيرًا، فستستغرق العملية وقتًا طويلًا، ويمكن تطبيق الأمر نفسه باسخدام المجاري streams كما يلي: const http = require('http') const fs = require('fs') const server = http.createServer((req, res) => { const stream = fs.createReadStream(__dirname + '/data.txt') stream.pipe(res) }) server.listen(3000) يمكننا بث الملف عبر المجاري إلى عميل HTTP بمجرد أن يكون لدينا مجموعة كبيرة من البيانات جاهزة للإرسال بدلًا من انتظار قراءة الملف بالكامل؛ ويستخدم المثال السابق stream.pipe(res)، أي استدعاء تابع pipe() في مجرى الملف، حيث يأخذ هذا التابع المصدر، ويضخّه إلى وجهة معينة، كما يُستدعَى هذا التابع على مجرى المصدر، وبالتالي يُضَخ مجرى الملف إلى استجابة HTTP في هذه الحالة، وتكون القيمة المُعادة من التابع pipe() هي مجرى الوجهة، وهذا أمر ملائم للغاية لربط استدعاءات pipe() متعددة كما يلي: src.pipe(dest1).pipe(dest2) الذي يكافئ ما يلي: src.pipe(dest1) dest1.pipe(dest2) تتوفَّر واجهات برمجة تطبيقات API الخاصة بنود Node التي تعمل باستخدام المجاري Streams، إذ توفِّر العديد من وحدات Node.js الأساسية إمكانات معالجة المجرى الأصيلة، ومن أبرزها: process.stdin التي تعيد مجرًى متصلًا بمجرى stdin. process.stdout التي تعيد مجرًى متصلًا بمجرى stdout. process.stderr التي تعيد مجرًى متصلًا بمجرى stderr. fs.createReadStream() الذي ينشئ مجرًى قابلًا للقراءة إلى ملف. fs.createWriteStream() الذي ينشئ مجرًى قابلًا للكتابة إلى ملف. net.connect() الذي يبدأ اتصالًا قائمًا على مجرى. http.request() الذي يعيد نسخة من الصنف http.ClientRequest، وهو مجرى قابل للكتابة. zlib.createGzip() الذي يضغط البيانات باستخدام خوارزمية الضغط gzip في مجرى. zlib.createGunzip() الذي يفك ضغط مجرى gzip. zlib.createDeflate() الذي يضغط البيانات باستخدام خوارزمية الضغط deflate في مجرى. zlib.createInflate() الذي يفك ضغط مجرى deflate. أنواع المجاري المختلفة هناك أربع أصناف من المجاري هي: Readable: هو مجرى يمكن الضخ pipe منه ولكن لا يمكن الضخ إليه، أي يمكنك تلقي البيانات منه ولكن لا يمكنك إرسال البيانات إليه، فإذا دفعتَ بيانات إلى مجرى قابل للقراءة، فستُخزَّن مؤقتًا حتى يبدأ المستهلك في قراءة البيانات. Writable: هو مجرى يمكن الضخ إليه، ولكن لا يمكن الضخ منه، أي يمكنك إرسال البيانات إليه، ولكن لا يمكنك تلقي البيانات منه. Duplex: هو مجرى يمكن الضخ منه وإليه، أي هو مزيج من مجرى Readable ومجرى Writable. Transform: مجرى التحويل مشابه للمجرى Duplex، ولكن خرجه هو تحويل لدخله. كيفية إنشاء مجرى قابل للقراءة يمكن الحصول على مجرى قابل للقراءة من وحدة stream، كما يمكن تهيئته كما يلي: const Stream = require('stream') const readableStream = new Stream.Readable() ثم يمكننا إرسال البيانات إليه بعد تهيئته: readableStream.push('hi!') readableStream.push('ho!') كيفية إنشاء مجرى قابل للكتابة يمكنك إنشاء مجرى قابل للكتابة من خلال وراثة كائن Writable الأساسي وتطبيق تابعه _write(). أنشئ أولًا كائن Stream كما يلي: const Stream = require('stream') const writableStream = new Stream.Writable() ثم التابع _write كما يلي: writableStream._write = (chunk, encoding, next) => { console.log(chunk.toString()) next() } يمكنك الآن الضخ إلى مجرى قابل للقراءة كما يلي: process.stdin.pipe(writableStream) كيفية الحصول على بيانات من مجرى قابل للقراءة يمكنك قراءة البيانات من مجرًى قابل للقراءة باستخدام مجرى قابل للكتابة كما يلي: const Stream = require('stream') const readableStream = new Stream.Readable() const writableStream = new Stream.Writable() writableStream._write = (chunk, encoding, next) => { console.log(chunk.toString()) next() } readableStream.pipe(writableStream) readableStream.push('hi!') readableStream.push('ho!') كما يمكنك استهلاك مجرى قابل للقراءة مباشرةً باستخدام الحدث readable كما يلي: readableStream.on('readable', () => { console.log(readableStream.read()) }) كيفية إرسال بيانات إلى مجرى قابل للكتابة استخدم تابع المجرى write() كما يلي: writableStream.write('hey!\n') إعلام مجرى قابل للكتابة بانتهاء الكتابة استخدم التابع end() كما يلي: const Stream = require('stream') const readableStream = new Stream.Readable() const writableStream = new Stream.Writable() writableStream._write = (chunk, encoding, next) => { console.log(chunk.toString()) next() } readableStream.pipe(writableStream) readableStream.push('hi!') readableStream.push('ho!') writableStream.end() التعامل مع المجلدات توفِّر وحدة Node.js الأساسية fs توابعًا متعددةً مفيدةً يمكنك استخدامها للتعامل مع المجلدات. التحقق من وجود مجلد يُستخدَم التابع fs.access() للتحقق مما إذا كان المجلد موجودًا، ويمكن لنود الوصول إلى المجلد باستخدام أذوناته. إنشاء مجلد جديد يُستخدَم التابع fs.mkdir() أو التابع fs.mkdirSync() لإنشاء مجلد جديد. const fs = require('fs') const folderName = '/Users/flavio/test' try { if (!fs.existsSync(dir)){ fs.mkdirSync(dir) } } catch (err) { console.error(err) } قراءة محتوى مجلد يُستخدَم التابع fs.readdir() أو التابع fs.readdirSync لقراءة محتويات مجلد، ويقرأ جزء الشيفرة التالية محتوى مجلد من ملفات ومجلدات فرعية، ويعيد مساراتها النسبية: const fs = require('fs') const path = require('path') const folderPath = '/Users/flavio' fs.readdirSync(folderPath) يمكنك الحصول على المسار الكامل من خلال ما يلي: fs.readdirSync(folderPath).map(fileName => { return path.join(folderPath, fileName) } كما يمكنك تصفية النتائج لإعادة الملفات فقط واستبعاد المجلدات كما يلي: const isFile = fileName => { return fs.lstatSync(fileName).isFile() } fs.readdirSync(folderPath).map(fileName => { return path.join(folderPath, fileName)).filter(isFile) } إعادة تسمية مجلد يُستخدَم التابع fs.rename() أو التابع fs.renameSync() لإعادة تسمية مجلد، حيث يكون المعامِل الأول هو المسار الحالي، والمعامِل الثاني هو المسار الجديد: const fs = require('fs') fs.rename('/Users/flavio', '/Users/roger', (err) => { if (err) { console.error(err) return } //done }) كما يمكنك استخدام التابع fs.renameSync() الذي هو النسخة المتزامنة كما يلي: const fs = require('fs') try { fs.renameSync('/Users/flavio', '/Users/roger') } catch (err) { console.error(err) } إزالة مجلد يُستخدَم التابع fs.rmdir() أو التابع fs.rmdirSync() لإزالة مجلد، ويمكن أن تكون إزالة مجلد أكثر تعقيدًا إذا تضمّن محتوىً، لذلك نوصي في هذه الحالة بتثبيت وحدة fs-extra التي تحظى بشعبية ودعم كبيرَين، وهي بديل سريع لوحدة fs، وبالتالي تضيف مزيدًا من الميزات عليها، كما ستحتاج استخدام التابع remove(). ثبّت وحدة fs-extra باستخدام الأمر: npm install fs-extra، واستخدمها كما يلي: const fs = require('fs-extra') const folder = '/Users/flavio' fs.remove(folder, err => { console.error(err) }) كما يمكن استخدامها مع الوعود promises كما يلي: fs.remove(folder).then(() => { //done }).catch(err => { console.error(err) }) أو مع صيغة async/await كما يلي: async function removeFolder(folder) { try { await fs.remove(folder) //done } catch (err) { console.error(err) } } const folder = '/Users/flavio' removeFolder(folder) للمزيد، يمكنك الرجوع إلى توثيق التعامل مع نظام الملفات في Node.js في موسوعة حسوب. ترجمة -وبتصرّف- للفصل File System من كتاب The Node.js handbook لصاحبه Flavio Copes. اقرأ أيضًا المقال التالي: تعرف على وحدات Node.js الأساسية المقال السابق: التعامل مع الطلبيات الشبكية في Node.js التعامل مع الملفات في البرمجة مدخل إلى التعامل مع الملفات في جافا كيفية التعامل مع الملفات النصية في بايثون 3 التعامل مع الملفات النصية في لغة سي شارب #C1 نقطة -
 منذ زمن سحيق، كانت الذاكرةُ أكثر وظيفة نحتاجها ونعتمد عليها في الحاسوب. ورغم اختلاف التقنيات وأساليب التنفيذ الكامنة وراءها، إلّا أنّ معظم الحواسيب تأتي بالعتاد الضروريّ لمعالجة المعلومات وحفظها بأمان لاستخدامها في المستقبل متى احتجنا لها. لقد صار من المستحيل في عالمنا الحديث تخيل أيّ عمل لا يستفيد من هذه القدرة في الأجهزة، سواء كانت خواديم أو حواسيب شخصية أو كفّيّة. تُعالَج البيانات وتُسجَّل وتُسترجَع مع كل عملية، وفي كل مكان من الألعاب إلى الأدوات المتعلقة بالأعمال، بما فيها المواقع. أنظمة إدارة قواعد البيانات (DataBase Management Systems – DBMS) هي برمجيات عالية المستوى تعمل مع واجهات برمجة تطبيقات (APIs) أدنى منها في المستوى، وتلك الواجهات بدورها تهتم بهذه العمليات. لقد تم تطوير العديد من أنظمة إدارة قواعد البيانات (كقواعد البيانات العلائقيّة relational databases، وnoSQL، وغيرها) لعقود من الزمن للمساعدة على حلّ المشكلات المختلفة، إضافة إلى برامج لها (مثل MySQL ,PostgreSQL ,MongoDB ,Redis، إلخ). سنقوم في هذا المقال بالمرور على أساسيّات قواعد البيانات وأنظمة إدارة قواعد البيانات. وسنتعرف من خلالها على المنطق الذي تعمل به قواعد البيانات المختلفة، وكيفية التفرقة بينها. أنظمة إدارة قواعد البياناتإن مفهوم نظام إدارة قاعدة البيانات مظلّةٌ تندرج تحتها كلّ الأدوات المختلفة أنواعها (كبرامج الحاسوب والمكتبات المضمّنة)، والتي غالبًا تعمل بطرق مختلفة وفريدة جدًّا. تتعامل هذه التطبيقات مع مجموعات من المعلومات، أو تساعد بكثرة في التعامل معها. وحيث أن المعلومات (أو البيانات) يُمكِن إن تأتي بأشكال وأحجام مختلفة، فقد تم تطوير العشرات من أنظمة قواعد البيانات، ومعها أعداد هائلة من تطبيقات قواعد البيانات منذ بداية النصف الثاني من القرن الحادي والعشرين، وذلك من أجل تلبية الاحتياجات الحوسبيّة والبرمجية المختلفة. تُبنى أنظمة إدارة قواعد البيانات على نماذج لقواعد البيانات: وهي بُنى محدّدة للتعامل مع البيانات. وكل تطبيق ونظام إدارة محتوى جديد أنشئ لتطبيق أساليبها يعمل بطريقة مختلفة فيما يتعلق بالتعريفات وعمليات التخزين والاسترجاع للمعلومات المُعطاة. ورغم أنّ هناك عددًا كبيرًا من الحلول التي تُنشئ أنظمة إدارة قواعد بيانات مختلفة، إلّا أنّ كلّ مدة زمنية تضمّنت خيارات محدودة صارت شائعة جدًّا وبقيت قيد الاستخدام لمدة أطول، والغالب أنّ أكثرها هيمنة على هذه الساحة خلال العقدين الأخيرين (وربما أكثر من ذلك) هي أنظمة إدارة قواعد البيانات العلائقيّة (Relational Database Management Systems – RDBMS). أنواع قواعد البياناتيستخدم كلُّ نظام إدارة بياناتٍ نموذجًا لقواعد البيانات لترتيب البيانات التي يديرها منطقيًّا. هذه النماذج (أو الأنواع) هي الخطوة الأولى والمحدّد الأهم لكيفية عمل تطبيق قواعد البيانات وكيفية تعامله مع المعلومات وتصرفه بها. هناك بعض الأنواع المختلفة لنماذج لقواعد البيانات التي تعرض بوضوع ودقّة معنى هيكلة البيانات، والغالب أن أكثر هذه الأنواع شهرةً قواعدُ البيانات العلائقيّة. ورغم أنّ النموذج العلائقيّ وقواعد البيانات العلائقيّة (relational databases) مرنة وقويّة للغاية –عندما يعلم المبرمج كيف يستخدمها–، إلّا أنّ هناك بعض المشكلات التي واجهات عديدين، وبعض المزايا التي لم تقدمها هذه الحلول. لقد بدأت حديثًا مجموعة من التطبيقات والأنظمة المختلفة المدعوّة بقواعد بيانات NoSQL بالاشتهار بسرعة كبيرة، والتي قدمت وعودًا لحل هذه المشكلات وتقديم بعض الوظائف المثيرة للاهتمام بشدّة. بالتخلص من البيانات المهيكلة بطريقة متصلّبة (بإبقاء النمط المعرّف في النموذج العلائقيّ (relational model))، تعمل هذه الأنظمة بتقديم طريقة حرّة أكثر في التعامل مع المعلومات، وبهذا توفّر سهولة ومرونة عاليتين جدًّا؛ رغم أنّها تأتي بمشاكل خاصة بها –والتي تكون بعضها جدّيّة– فيما يتعلق بطبيعة البيانات الهامّة والتي لا غنى عنها. النموذج العلائقيّيقدّم النظام العلائقيّ الذي ظهر في تسعينات القرن الماضي طريقة مناسبة للرياضيات في هيكلة وحفظ واستخدام البيانات. توسّع هذه الطريقة من التصاميم القديمة، كالنموذج المسطّح (flat)، والشبكيّ، وغيرها، وذلك بتقديمها مفهوم "العلاقات". تقدّم العلاقات فوائد تتعلق بتجميع البيانات كمجموعات مقيّدة، تربط فيها جداول البيانات –المحتوية على معلومات بطريقة منظمة (كاسم شخص وعنوانه مثلاً)– كل المدخلات بإعطاء قيم للصفات (كرقم هوية الشخص مثلًا). وبفضل عقود من البحث والتطوير، تعمل أنظمة قواعد البيانات التي تستخدم النموذج العلائقيّ بكفاءة وموثوقيّة عاليتين جدًّا. أضف إلى ذلك الخبرة الطويلة للمبرمجين ومديري قواعد البيانات في التعامل مع هذه الأدوات؛ لقد أدّى هذا إلى أن يصبح استخدام تطبيقات قواعد البيانات العلائقيّة الخيار الأمثل للتطبيقات ذات المهام الحرجة، والتي لا يمكنها احتمال فقدان أيّة بيانات تحت أيّ ظرف، وخاصة كنتيجة لخلل ما أو لطبيعة التطبيق نفسه الذي قد يكون أكثر عرضة للأخطاء. ورغم طبيعتها الصارمة المتعلقة بتشكيل والتعامل مع البيانات، يمكن لقواعد البيانات العلائقيّة أن تكون مرنة للغاية وأن تقدم الكثير، وذلك بتقديم قدر ضئيل من المجهود. التوجّه عديم النموذج (Model-less) أو NoSQLتعتمد طريقة NoSQL في هيكلة البيانات على التخلص من هذه القيود، حيث تحرر أساليب حفظ، واستعلام، واستخدام المعلومات. تسعى قواعد بيانات NoSQL إلى التخلص من العلائقات المعقدة، وتقدم أنواع عديدة من الطرق للحفاظ على البيانات والعمل عليها لحالات استخدام معينة بكفاءة (كتخزين مستندات كاملة النصوص)، وذلك من خلال استخدامها توجّها غير منظم (أو الهيكلة على الطريق / أثناء العمل). أنظمة إدارة قواعد بيانات شائعةهدفنا في هذا المقال هو أن نقدم لك نماذج عن بعض أشهر حلول قواعد البيانات وأكثرها استخدامًا. ورغم صعوبة الوصول إلى نتيجة بخصوص نسبة الاستخدام، يمكننا بوضوح افتراض أنّه بالنسبة لغالب الناس، تقع الاختيارات بين محرّكات قواعد البيانات العلائقيّة، أو محرك NoSQL أحدث. لكن قبل البدء بشرح الفروقات بين التطبيقات المختلفة لكل منهما، دعنا نرى ما يجري خلف الستار. أنظمة إدارة قواعد البيانات العلائقيّةلقد حصلت أنظمة إدارة قواعد البيانات العلائقيّة على اسمها من النموذج الذي تعتمد عليه، وهو النموذج العلائقيّ الذي ناقشناه أعلاه. إنّ هذه الأنظمة –الآن، وستبقى لمدة من الزمن في المستقبل– الخيار المفضّل للحفاظ على البيانات موثوقة وآمنة؛ وهي كذلك كفؤة. تتطلب أنظمة إدارة قواعد البيانات العلائقيّة مخططات معرفة ومحددة جيدًا –ولا يجب أن يختلط الأمر مع تعريف PostgreSQL الخاص بهذه الأنظمة– لقبول هذه البيانات. تشكّل هذه الهيئات التي يحددها المستخدم كيفية حفظ واستخدام البيانات. إنّ هذه المخططات شبيهة جدًّا بالجداول، وفيها أعمدة تمثّل عدد ونوع المعلومات التي تنتمي لكل سجل، والصفوف التي تمثّل المدخلات. من أنظمة إدارة قواعد البيانات الشائعة نذكر: SQLite: نظام إدارة قواعد بيانات علائقيّة مضمّن قويّ جدًّا.MySQL: نظام إدارة قواعد بيانات علائقيّة الأكثر شهرة والشائع استخدامه.PostgreSQL: أكثر نظام إدارة قواعد بيانات علائقيّة كيانيّ (objective-RDBMS) متقدم وهو متوافق مع SQL ومفتوح المصدر.ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد بيانات NoSQL، راجع المقالة التالية عن الموضوع: A Comparison Of NoSQL Database Management Systems. أنظمة قواعد بيانات NoSQL (أو NewSQL)لا تأتي أنظمة قواعد بيانات NoSQL بنموذج كالمستخدم في (أو الذي تحتاجه) الحلول العلائقيّة المهيكلة. هناك العديد من التطبيقات، وكلّ منها تعمل بطريقة مختلفة كليًّا، وتخدم احتياجات محدّدة. هذه الحلول عديمة المخططات (schema-less) إمّا تسمح تشكيلات غير محدودة للمدخلات، أو –على العكس– بسيطة جدًّا ولكنها كفؤة للغاية كمخازن قيم معتمد على المفاتيح (key based value stores) مفيدة. على خلاف قواعد البيانات العلائقيّة التقليديّة، يمكن تجميع مجموعات من البينات معًا باستخدام قواعد بيانات NoSQL، كـ MongoDB مثلًا. تُبقي مخازن المستندات هذه كل قطعة من البيانات مع بعضها كمجموعة واحدة (أي كملف) في قاعدة البيانات. يمكن تمثيل هذه المستندات ككيانات بيانات منفردة، مثلها في ذلك كمثل JSON، ومع ذلك تبقى كراسات، وذلك يعتمد على خصائصها. ليس لقواعد بيانات NoSQL طريقة موحدة للاستعلام عن البيانات (مثل SQL لقواعد البيانات العلائقيّة) ويقدم كلّ من الحلول طريقته الخاصّة للاستعلام. ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد البيانات العلائقيّة، ألق نظرة على هذه المقالة المتعلقة بالموضوع: A Comparison Of Relational Database Management Systems. مقارنة بين أنظمة إدارة قواعد بيانات SQL و NoSQLمن أجل الوصول إلى نتيجة بسيطة ومفهومة، لنحلّل أولًا الاختلافات بين أنظمة إدارة قواعد البيانات: هيكلية ونوع البيانات المحتفظ بها:تتطلب قواعد البيانات العلائقيّة SQL هيكلة ذات خصائص محدّدة للحفاظ على البيانات، على خلاف قواعد بيانات NoSQL التي تسمح بعمليات انسياب حُرّ (free-flow operations). الاستعلام: وبغضّ النظر عن تراخيصها، تستخدم كلّ قواعد البيانات العلائقيّة معيار SQL إلى حدّ ما، ولهذا يمكن الاستعلام فيها بلغة SQL (أي Structured Query Language). أما قواعد بيانات NoSQL فلا تستخدم طريقة محدّدة للعمل على البيانات التي تديرها. التحجيم: يمكن تحجيم كلي الحلين عموديًّا (أي بزيادة موارد النظام). لكن لكون حلول NoSQL تطبيقات أحدث (وأبسط)، فهذا يجعلها تقدّم وسائل أسهل بكثير لتحجيمها أفقيًّا (أي بإنشاء شبكة عنقودية cluster من أجهزة متعدّدة). المتانة Reliability: عندما يتعلق الأمر بالمتانة والثقة الآمنة بالقَيد المنفّذ، تبقى قواعد بيانات SQL الخيار الأفضل. الدعم: لأنظمة إدارة قواعد البيانات العلائقيّة تاريخ طويل استمر لعقود من الزمن. إنها شائعة جدًّا، ومن السهل إيجاد دعم سواء مجانيّ أو مدفوع. إذا حدثت مشكلة، فمن الأسهل حلّها عليها من قواعد بيانات NoSQL التي شاعت حديثًا، وخاصة إذا كان الحلّ موضع السؤال ذا طبيعة معقّدة (مثل MongoDB). احتياجات حفظ واستعلام البيانات المعقدة: إنّ قواعد البيانات العلائقيّة بطبيعتها الخيار الأمثل لاحتياجات حفظ البيانات والاستعلامات المعقّدة. إنها أكثر كفاءة وتتفوق في هذا المجال. ترجمة -وبتصرّف- للمقال Understanding SQL And NoSQL Databases And Different Database Models لصاحبه O.S. Tezer.1 نقطة
منذ زمن سحيق، كانت الذاكرةُ أكثر وظيفة نحتاجها ونعتمد عليها في الحاسوب. ورغم اختلاف التقنيات وأساليب التنفيذ الكامنة وراءها، إلّا أنّ معظم الحواسيب تأتي بالعتاد الضروريّ لمعالجة المعلومات وحفظها بأمان لاستخدامها في المستقبل متى احتجنا لها. لقد صار من المستحيل في عالمنا الحديث تخيل أيّ عمل لا يستفيد من هذه القدرة في الأجهزة، سواء كانت خواديم أو حواسيب شخصية أو كفّيّة. تُعالَج البيانات وتُسجَّل وتُسترجَع مع كل عملية، وفي كل مكان من الألعاب إلى الأدوات المتعلقة بالأعمال، بما فيها المواقع. أنظمة إدارة قواعد البيانات (DataBase Management Systems – DBMS) هي برمجيات عالية المستوى تعمل مع واجهات برمجة تطبيقات (APIs) أدنى منها في المستوى، وتلك الواجهات بدورها تهتم بهذه العمليات. لقد تم تطوير العديد من أنظمة إدارة قواعد البيانات (كقواعد البيانات العلائقيّة relational databases، وnoSQL، وغيرها) لعقود من الزمن للمساعدة على حلّ المشكلات المختلفة، إضافة إلى برامج لها (مثل MySQL ,PostgreSQL ,MongoDB ,Redis، إلخ). سنقوم في هذا المقال بالمرور على أساسيّات قواعد البيانات وأنظمة إدارة قواعد البيانات. وسنتعرف من خلالها على المنطق الذي تعمل به قواعد البيانات المختلفة، وكيفية التفرقة بينها. أنظمة إدارة قواعد البياناتإن مفهوم نظام إدارة قاعدة البيانات مظلّةٌ تندرج تحتها كلّ الأدوات المختلفة أنواعها (كبرامج الحاسوب والمكتبات المضمّنة)، والتي غالبًا تعمل بطرق مختلفة وفريدة جدًّا. تتعامل هذه التطبيقات مع مجموعات من المعلومات، أو تساعد بكثرة في التعامل معها. وحيث أن المعلومات (أو البيانات) يُمكِن إن تأتي بأشكال وأحجام مختلفة، فقد تم تطوير العشرات من أنظمة قواعد البيانات، ومعها أعداد هائلة من تطبيقات قواعد البيانات منذ بداية النصف الثاني من القرن الحادي والعشرين، وذلك من أجل تلبية الاحتياجات الحوسبيّة والبرمجية المختلفة. تُبنى أنظمة إدارة قواعد البيانات على نماذج لقواعد البيانات: وهي بُنى محدّدة للتعامل مع البيانات. وكل تطبيق ونظام إدارة محتوى جديد أنشئ لتطبيق أساليبها يعمل بطريقة مختلفة فيما يتعلق بالتعريفات وعمليات التخزين والاسترجاع للمعلومات المُعطاة. ورغم أنّ هناك عددًا كبيرًا من الحلول التي تُنشئ أنظمة إدارة قواعد بيانات مختلفة، إلّا أنّ كلّ مدة زمنية تضمّنت خيارات محدودة صارت شائعة جدًّا وبقيت قيد الاستخدام لمدة أطول، والغالب أنّ أكثرها هيمنة على هذه الساحة خلال العقدين الأخيرين (وربما أكثر من ذلك) هي أنظمة إدارة قواعد البيانات العلائقيّة (Relational Database Management Systems – RDBMS). أنواع قواعد البياناتيستخدم كلُّ نظام إدارة بياناتٍ نموذجًا لقواعد البيانات لترتيب البيانات التي يديرها منطقيًّا. هذه النماذج (أو الأنواع) هي الخطوة الأولى والمحدّد الأهم لكيفية عمل تطبيق قواعد البيانات وكيفية تعامله مع المعلومات وتصرفه بها. هناك بعض الأنواع المختلفة لنماذج لقواعد البيانات التي تعرض بوضوع ودقّة معنى هيكلة البيانات، والغالب أن أكثر هذه الأنواع شهرةً قواعدُ البيانات العلائقيّة. ورغم أنّ النموذج العلائقيّ وقواعد البيانات العلائقيّة (relational databases) مرنة وقويّة للغاية –عندما يعلم المبرمج كيف يستخدمها–، إلّا أنّ هناك بعض المشكلات التي واجهات عديدين، وبعض المزايا التي لم تقدمها هذه الحلول. لقد بدأت حديثًا مجموعة من التطبيقات والأنظمة المختلفة المدعوّة بقواعد بيانات NoSQL بالاشتهار بسرعة كبيرة، والتي قدمت وعودًا لحل هذه المشكلات وتقديم بعض الوظائف المثيرة للاهتمام بشدّة. بالتخلص من البيانات المهيكلة بطريقة متصلّبة (بإبقاء النمط المعرّف في النموذج العلائقيّ (relational model))، تعمل هذه الأنظمة بتقديم طريقة حرّة أكثر في التعامل مع المعلومات، وبهذا توفّر سهولة ومرونة عاليتين جدًّا؛ رغم أنّها تأتي بمشاكل خاصة بها –والتي تكون بعضها جدّيّة– فيما يتعلق بطبيعة البيانات الهامّة والتي لا غنى عنها. النموذج العلائقيّيقدّم النظام العلائقيّ الذي ظهر في تسعينات القرن الماضي طريقة مناسبة للرياضيات في هيكلة وحفظ واستخدام البيانات. توسّع هذه الطريقة من التصاميم القديمة، كالنموذج المسطّح (flat)، والشبكيّ، وغيرها، وذلك بتقديمها مفهوم "العلاقات". تقدّم العلاقات فوائد تتعلق بتجميع البيانات كمجموعات مقيّدة، تربط فيها جداول البيانات –المحتوية على معلومات بطريقة منظمة (كاسم شخص وعنوانه مثلاً)– كل المدخلات بإعطاء قيم للصفات (كرقم هوية الشخص مثلًا). وبفضل عقود من البحث والتطوير، تعمل أنظمة قواعد البيانات التي تستخدم النموذج العلائقيّ بكفاءة وموثوقيّة عاليتين جدًّا. أضف إلى ذلك الخبرة الطويلة للمبرمجين ومديري قواعد البيانات في التعامل مع هذه الأدوات؛ لقد أدّى هذا إلى أن يصبح استخدام تطبيقات قواعد البيانات العلائقيّة الخيار الأمثل للتطبيقات ذات المهام الحرجة، والتي لا يمكنها احتمال فقدان أيّة بيانات تحت أيّ ظرف، وخاصة كنتيجة لخلل ما أو لطبيعة التطبيق نفسه الذي قد يكون أكثر عرضة للأخطاء. ورغم طبيعتها الصارمة المتعلقة بتشكيل والتعامل مع البيانات، يمكن لقواعد البيانات العلائقيّة أن تكون مرنة للغاية وأن تقدم الكثير، وذلك بتقديم قدر ضئيل من المجهود. التوجّه عديم النموذج (Model-less) أو NoSQLتعتمد طريقة NoSQL في هيكلة البيانات على التخلص من هذه القيود، حيث تحرر أساليب حفظ، واستعلام، واستخدام المعلومات. تسعى قواعد بيانات NoSQL إلى التخلص من العلائقات المعقدة، وتقدم أنواع عديدة من الطرق للحفاظ على البيانات والعمل عليها لحالات استخدام معينة بكفاءة (كتخزين مستندات كاملة النصوص)، وذلك من خلال استخدامها توجّها غير منظم (أو الهيكلة على الطريق / أثناء العمل). أنظمة إدارة قواعد بيانات شائعةهدفنا في هذا المقال هو أن نقدم لك نماذج عن بعض أشهر حلول قواعد البيانات وأكثرها استخدامًا. ورغم صعوبة الوصول إلى نتيجة بخصوص نسبة الاستخدام، يمكننا بوضوح افتراض أنّه بالنسبة لغالب الناس، تقع الاختيارات بين محرّكات قواعد البيانات العلائقيّة، أو محرك NoSQL أحدث. لكن قبل البدء بشرح الفروقات بين التطبيقات المختلفة لكل منهما، دعنا نرى ما يجري خلف الستار. أنظمة إدارة قواعد البيانات العلائقيّةلقد حصلت أنظمة إدارة قواعد البيانات العلائقيّة على اسمها من النموذج الذي تعتمد عليه، وهو النموذج العلائقيّ الذي ناقشناه أعلاه. إنّ هذه الأنظمة –الآن، وستبقى لمدة من الزمن في المستقبل– الخيار المفضّل للحفاظ على البيانات موثوقة وآمنة؛ وهي كذلك كفؤة. تتطلب أنظمة إدارة قواعد البيانات العلائقيّة مخططات معرفة ومحددة جيدًا –ولا يجب أن يختلط الأمر مع تعريف PostgreSQL الخاص بهذه الأنظمة– لقبول هذه البيانات. تشكّل هذه الهيئات التي يحددها المستخدم كيفية حفظ واستخدام البيانات. إنّ هذه المخططات شبيهة جدًّا بالجداول، وفيها أعمدة تمثّل عدد ونوع المعلومات التي تنتمي لكل سجل، والصفوف التي تمثّل المدخلات. من أنظمة إدارة قواعد البيانات الشائعة نذكر: SQLite: نظام إدارة قواعد بيانات علائقيّة مضمّن قويّ جدًّا.MySQL: نظام إدارة قواعد بيانات علائقيّة الأكثر شهرة والشائع استخدامه.PostgreSQL: أكثر نظام إدارة قواعد بيانات علائقيّة كيانيّ (objective-RDBMS) متقدم وهو متوافق مع SQL ومفتوح المصدر.ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد بيانات NoSQL، راجع المقالة التالية عن الموضوع: A Comparison Of NoSQL Database Management Systems. أنظمة قواعد بيانات NoSQL (أو NewSQL)لا تأتي أنظمة قواعد بيانات NoSQL بنموذج كالمستخدم في (أو الذي تحتاجه) الحلول العلائقيّة المهيكلة. هناك العديد من التطبيقات، وكلّ منها تعمل بطريقة مختلفة كليًّا، وتخدم احتياجات محدّدة. هذه الحلول عديمة المخططات (schema-less) إمّا تسمح تشكيلات غير محدودة للمدخلات، أو –على العكس– بسيطة جدًّا ولكنها كفؤة للغاية كمخازن قيم معتمد على المفاتيح (key based value stores) مفيدة. على خلاف قواعد البيانات العلائقيّة التقليديّة، يمكن تجميع مجموعات من البينات معًا باستخدام قواعد بيانات NoSQL، كـ MongoDB مثلًا. تُبقي مخازن المستندات هذه كل قطعة من البيانات مع بعضها كمجموعة واحدة (أي كملف) في قاعدة البيانات. يمكن تمثيل هذه المستندات ككيانات بيانات منفردة، مثلها في ذلك كمثل JSON، ومع ذلك تبقى كراسات، وذلك يعتمد على خصائصها. ليس لقواعد بيانات NoSQL طريقة موحدة للاستعلام عن البيانات (مثل SQL لقواعد البيانات العلائقيّة) ويقدم كلّ من الحلول طريقته الخاصّة للاستعلام. ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد البيانات العلائقيّة، ألق نظرة على هذه المقالة المتعلقة بالموضوع: A Comparison Of Relational Database Management Systems. مقارنة بين أنظمة إدارة قواعد بيانات SQL و NoSQLمن أجل الوصول إلى نتيجة بسيطة ومفهومة، لنحلّل أولًا الاختلافات بين أنظمة إدارة قواعد البيانات: هيكلية ونوع البيانات المحتفظ بها:تتطلب قواعد البيانات العلائقيّة SQL هيكلة ذات خصائص محدّدة للحفاظ على البيانات، على خلاف قواعد بيانات NoSQL التي تسمح بعمليات انسياب حُرّ (free-flow operations). الاستعلام: وبغضّ النظر عن تراخيصها، تستخدم كلّ قواعد البيانات العلائقيّة معيار SQL إلى حدّ ما، ولهذا يمكن الاستعلام فيها بلغة SQL (أي Structured Query Language). أما قواعد بيانات NoSQL فلا تستخدم طريقة محدّدة للعمل على البيانات التي تديرها. التحجيم: يمكن تحجيم كلي الحلين عموديًّا (أي بزيادة موارد النظام). لكن لكون حلول NoSQL تطبيقات أحدث (وأبسط)، فهذا يجعلها تقدّم وسائل أسهل بكثير لتحجيمها أفقيًّا (أي بإنشاء شبكة عنقودية cluster من أجهزة متعدّدة). المتانة Reliability: عندما يتعلق الأمر بالمتانة والثقة الآمنة بالقَيد المنفّذ، تبقى قواعد بيانات SQL الخيار الأفضل. الدعم: لأنظمة إدارة قواعد البيانات العلائقيّة تاريخ طويل استمر لعقود من الزمن. إنها شائعة جدًّا، ومن السهل إيجاد دعم سواء مجانيّ أو مدفوع. إذا حدثت مشكلة، فمن الأسهل حلّها عليها من قواعد بيانات NoSQL التي شاعت حديثًا، وخاصة إذا كان الحلّ موضع السؤال ذا طبيعة معقّدة (مثل MongoDB). احتياجات حفظ واستعلام البيانات المعقدة: إنّ قواعد البيانات العلائقيّة بطبيعتها الخيار الأمثل لاحتياجات حفظ البيانات والاستعلامات المعقّدة. إنها أكثر كفاءة وتتفوق في هذا المجال. ترجمة -وبتصرّف- للمقال Understanding SQL And NoSQL Databases And Different Database Models لصاحبه O.S. Tezer.1 نقطة






