لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 03/26/22 في كل الموقع
-
اقوم بعمل لعبه وهي عبارة عن كروت اريد انها تظهر للممستخدم لمدة ثانيتين وتختفي ، فهمت ان set time out هي من تقوم بهذا العمل فكيف الطريقة لينتظر ثانيتين ثم تختفي، انا مشكلتي مع الوقت لا اعلم كيف اخليه ينتظر ثانتين3 نقاط
-
للتحقق من ملف XML: نتأكد من أن كل وسم تم فتحه يجب إغلاقه بنفس الاسم وأن تداخل العناصر سليم من تم فتحة أخيراً نغلقه أولاً <abc> <cde> </cde> </abc> وفي مثالك: <funcdef> <function>ctime</fnuction> <!-- ^^^^^^^^^ ^^^^^^^^^^^ --> </funcdef> لانضع فراغات في اسم الوسم أو وسم الإغلاق <parameter> time < /parameter>,as returned by ^^^ لا نقوم بتعريف نفس الخاصية أكثر من مرة <para><emphasis role="strong" targetgroup="beginners" role="strong"> ^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^ وبالنسبة ل &doubleclick; هنا نقوم بجلب قيمة Entity References بدون أن تكون معرفة مسبقاً يجب وضع قيمة لها <!DOCTYPE definition [ <!ENTITY red " & # 1 7 4 ;"> مثال <!ENTITY ampdoubleclick "&doubleclick;"> ]> حيث ان "&doubleclick;" هي القيمة التي نريدها <!ENTITY ampdoubleclick "132131"> أي جميع هذه ال Reference يجب أن يتم تعريفها مسبقاً لنستطيع قراءة قيمتها لاحقا <?xml version="1.0"?> <!DOCTYPE definition [ <!ENTITY ampdoubleclick "1231"> <!ENTITY ampbuttonleft "9987"> <!ENTITY ampidhelp782 "979798"> <!ENTITY ampidhelp785 "983759"> ]> <function> <title>ctime</title> <funcsynopsis> <funcdef> <function>ctime</function> </funcdef> <paramdef> <parameter>time</parameter> <parameter role="opt">gmt</parameter> </paramdef> </funcsynopsis> <para>This function converts the value <parameter> time </parameter>,as returned by <function>time()</function> <function>file_mtime()</function>, into a string of the form produced by <function>time_date()</function>. If the optional argument <parameter>gmt</parameter> is specified and non-zero,the time is returned in <parameter>gmt</parameter>. Otherwise, the time is given in the local time zone. </para> <para><emphasis role="strong" targetgroup="beginners"> Related topics</emphasis> </para> <para>&doubleclick; the <mousebutton>LEFT &buttonleft;</mousebutton> mouse button on a topic </para> <itemizedlist> <listitem> <para><ulink url="&idhelp782;"><function>file_mtime()</function>built-in function</ulink> </para> </listitem> <listitem> <para><ulink url="&idhelp785;"><function>time()</function> built-infunction</ulink> </para> </listitem> </itemizedlist> </function>2 نقاط
-
 تُعدّ مسألة تحليل تعليقات وتغريدات الأشخاص على مواقع التواصل الاجتماعي من المسائل المهمة والتي لها الكثير من التطبيقات العملية. مثلًا: تهتم المتاجر الالكترونية كثيرًا بتحليل تعليقات الزبائن على منتجاتهم لاستكشاف توجهات الزبائن ومواطن الضعف والقوة في المتجر. نعرض في هذه المقالة استخدام تقنيات التعلّم العميق deep learning في تحليل المشاعر لنصوص مكتوبة باللغة العربية وباللهجة السعودية بمعنى أن اللغة المستخدمة ليست بالضرورة اللغة العربية الفصحى، بل يُمكن أن تدخل فيها ألفاظ عامية يستخدمها المغردون عادةً. بيانات التدريب تحوي مجموعة البيانات المتوفرة dataset (التي تجدها أيضًا موضحةً بملف بنهاية المقال) حوالي 23500 تغريدة لتعليقات الأشخاص وملاحظاتهم حول مجموعة من الأماكن العامة في المملكة العربية السعودية. جُمّعت هذه التغريدات عن طريق مجموعة من الطلاب الجامعيين وذلك من مجموعة متنوعة من مواقع التواصل الاجتماعي. نُعطي فيما يلي أمثلة عن هذه التغريدات (تعليقات حول حديقة حيوانات مثلًا): "أنصحكم والله بزيارته مكان جميل جدا مرتب ونظيف" "جميلة وكبيرة وتحتاج واحد عنده لياقه يمشي فيها" "حيوانات قليلة جدا ولا يوجد اهتمام مكثف" "كان يعيبها وقت الافتتاح والاغلاق وعدم وجود خريطه" "أول مرة أزور حديقة حيوانات" "أيام العوائل الخميس والجمعة والسبت" يُمكننا، كبشر، تصنيف التغريدات السابقة وبشكل سريع إلى ثلاث فئات: التغريدات الموجبة (الأولى والثانية) أي التغريدات التي تحمل معاني إيجابية تُعّبر عن الرضا والارتياح. التغريدات السالبة (الثالثة والرابعة) أي التغريدات التي تحمل معاني سلبية تُعبّر عن الاستياء. التغريدات المحايدة (الخامسة والسادسة) أي التغريدات التي يُمكن أن تُعطي معلومات ولا تحمل أية مشاعر فيها سواء موجبة أم سالبة. نعرض في هذه المسألة كيفية بناء مُصنّف حاسوبي آلي يُصنّف أي جملة عربية إلى موجبة أو سالبة أو محايدة. تصنيف بيانات التدريب يتطلب استخدام خوارزميات تعلّم الآلة (خوارزميات تصنيف النصوص في حالتنا) توفر بيانات للتدريب أي مجموعة من النصوص مُصنفّة مُسبقًا إلى: موجبة، سالبة، محايدة. يُمكن، في بعض الأحيان، اللجوء إلى الطرق اليدوية: أي الطلب من مجموعة من الأشخاص قراءة النصوص وتصنيفها. وهو حل يصلح في حال كان عدد النصوص صغيرًا نسبيًا. يتميز هذا الحل بالدقة العالية لأن الأشخاص تُدرك، بشكل عام، معاني النصوص من خلال خبرتها اللغوية المُكتسبة وتُصنّف النصوص بشكل صحيح غالبًا. نستخدم، في حالتنا، حلًا إحصائيًا بسيطًا لتصنيف نصوص التدريب إلى موجبة، سالبة، محايدة وذلك باستخدام قاموس للكلمات الموجبة وقاموس آخر للكلمات السالبة. يحوي قاموس الكلمات الموجبة على مجموعة من الكلمات الموجبة الشائعة مع نقاط لكل كلمة (1 موجبة، 2 موجبة جدًا، 3 موجبة كثيرًا). مثلًا: روعة، 3 جيد، 2 معقول، 1 يحوي قاموس الكلمات السالبة على مجموعة من الكلمات السالبة الشائعة مع نقاط لكل كلمة (-1 سالبة، -2 سالبة جدًا، -3 سالبة كثيرًا). مثلًا: مقرف، -3 سيء، -2 زحمه، -1 اختيرت كلمات القواميس الموجبة والسالبة من قبل مجموعة من الطلاب بعد أنا طلبنا منهم استعراض التغريدات المُتاحة وانتقاء الكلمات التي تُعطي التغريدة معنى موجب أو معنى سالب، وإعطاء كل كلمة موجبة نقاط تدل على شدة الإيجابية لها (1,2,3) وكل كلمة سالبة نقاط تدل على شدة السلبية (-3،-2،-1) نعدّ، فيما يلي، نصًا ما أنه موجبًا إذا كان مجموع نقاط الكلمات الموجبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات السالبة الواردة ضمنه. وبالمقابل، نعدّ نصًا ما أنه سالبًا إذا كان مجموع نقاط الكلمات السالبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات الموجبة الواردة ضمنه. يكون نصًا ما محايدًا إذا تساوى مجموع نقاط الكلمات الموجبة فيه مع مجموع نقاط الكلمات السالبة. بالطبع، لا تُعدّ هذه الطريقة صحيحة دومًا إذ يُمكن أن تُخطئ في بعض الحالات إلا أنها على وجه العموم تُستخدم عوضًا عن الطريقة اليدوية. المعالجة الأولية للنصوص تهدف المعالجة الأولية إلى الحصول على الكلمات المهمة فقط من النصوص وذلك عن طريق تنفيذ بعض العمليات اللغوية عليها. تُنفذّ هذه العمليات على كل من التغريدات وكلمات القواميس. لتكن لدينا مثلًا الجملة التالية: "أنا أحب الذهاب إلى الحديقة، كل يوم 9 صباحاً، مع رفاقي هؤلاء!" سنقوم بتنفيذ العمليات التالية: أولًا، حذف إشارات الترقيم المختلفة كالفواصل وإشارات الاستفهام وغيرها، ويكون ناتج الجملة السابقة: ثانيًا، حذف الأرقام الواردة في النص، فيكون ناتج الجملة السابقة: ثالثًا، حذف كلمات التوقف stop words وهي الكلمات التي تتكرر كثيرًا في النصوص ولا تؤثر في معانيها كأحرف الجر (من، إلى، …) والضمائر (أنا، هو، …) وغيرها، فيكون ناتج الجملة السابقة: رابعًا، تجذيع الكلمات stemming أي إرجاع الكلمات المتشابهة إلى كلمة واحدة (جذع أو جذر) مما يُساهم في إنقاص عدد الكلمات الكلية المختلفة في النصوص، ومطابقة الكلمات المتشابهة مع بعضها البعض. مثلًا: يكون للكلمات الأربع: (رائع، رايع، رائعون، رائعين) نفس الجذع المشترك: (رايع). فيكون ناتج الجملة السابقة: ننتبه إلى أن الجذع يختلف عن الجذر اللغوي إذ الجذر هو عملية لغوية لرد الكلمة إلى أصلها وجذرها الأساسي لأغراض مختلفة أشهرها البحث في القاموس، أما الجذع فهو كلمة مشتركة بين مجموعة من الكلمات لا توجد بالضرورة في قاموس اللغة العربية وإنما إيجاد شكل موحد للكلمات. إعداد المشروع يُمكن تنزيل بيانات التدريب والقواميس والشيفرة البرمجية من الملف المرفق هنا. يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ. نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها. نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا. نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا: mkdir sa cd sa نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية: python -m venv sa ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية: source sa/bin/activate أما في Windows، فيكون أمر التنشيط: "sa/Scripts/activate.bat" نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها. نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها: jupyter==1.0.0 keras==2.6.0 Keras-Preprocessing==1.1.2 matplotlib==3.5.1 nltk==3.6.5 numpy==1.19.5 pandas==1.3.5 scikit-learn==1.0.1 seaborn==0.11.2 sklearn==0.0 snowballstemmer==2.2.0 tensorflow==2.6.0 wordcloud==1.8.1 python-bidi==0.4.2 arabic-reshaper==2.1.3 نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي: (sa) $ pip install -r requirements.txt بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا. كتابة شيفرة برنامج تحليل المشاعر في النصوص العربي نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا: (sa) $ jupyter notebook ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم asa مثلًا. يجب أولًا وضع كل من الملفات التالية في مجلد المشروع: ملف التغريدات: tweets.csv. القواميس: lexicon_positive.csv و lexicon_negative.csv. ملف الخط العربي: DroidSansMono.ttf. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن تحميل البيانات نبدأ أولًا بتحميل التغريدات من الملف tweets.csv ضمن إطار من البيانات DataFrame من مكتبة Pandas ومن ثم عرض بعضها: import pandas as pd # قراءة التغريدات وتحميلها ضمن إطار من البيانات tweets_data = pd.read_csv('tweets.csv',encoding = "utf-8") tweets = tweets_data[['tweet']] # إظهار الجزء الأعلى من إطار البيانات tweets.head() يظهر لنا أوائل التغريدات: نُحمّل قاموس الكلمات الموجبة positive.csv وقاموس الكلمات السالبة negative.csv: # قراءة قاموس الكلمات الموجبة positive_data = pd.read_csv('positive.csv' ,encoding = "utf-8") positive = positive_data[['word', 'polarity']] # قراءة قاموس الكلمات السالبة negative_data = pd.read_csv('negative.csv' ,encoding = "utf-8") negative = negative_data[['word', 'polarity']] positive.head() نُظهر مثلًا أوائل الكلمات الموجبة ونقاطها: المعالجة الأولية للنصوص نستخدم فيما يلي بعض الخدمات التي توفرها المكتبة nltk لمعالجة اللغات الطبيعية كتوفير قائمة كلمات التوقف باللغة العربية (حوالي 700 كلمة) واستخراج الوحدات tokens من النصوص. كما نستخدم مجذع الكلمات العربية من مكتبة snowballstemmer. # مكتبة السلاسل النصية import string # مكتبة التعابير النظامية import re # مكتبة معالجة اللغات الطبيعية import nltk nltk.download('punkt') nltk.download('stopwords') # مكتبة كلمات التوقف from nltk.corpus import stopwords # مكتبة استخراج الوحدات from nltk.tokenize import word_tokenize # مكتبة المجذع العربي from snowballstemmer import stemmer ar_stemmer = stemmer("arabic") # دالة حذف المحارف غير اللازمة def remove_chars(text, del_chars): translator = str.maketrans('', '', del_chars) return text.translate(translator) # دالة حذف المحارف المكررة def remove_repeating_char(text): return re.sub(r'(.)\1{2,}', r'\1', text) # دالة تنظيف النصوص def cleaningText(text): # حذف الأرقام text = re.sub(r'[0-9]+', '', text) # حذف المحارف غير اللازمة # علامات الترقيم العربية arabic_punctuations = '''`÷×؛<>_()*&^%][ـ،/:"؟.,'{}~¦+|!”…“–ـ''' # علامات الترقيم الانكليزية english_punctuations = string.punctuation # دمج علامات الترقيم العربية والانكليزية punctuations_list = arabic_punctuations + english_punctuations text = remove_chars(text, punctuations_list) # حذف المحارف المكررة text = remove_repeating_char(text) # استبدال الأسطر الجديدة بفراغات text = text.replace('\n', ' ') # حذف الفراغات الزائدة من اليمين واليسار text = text.strip(' ') return text # دالة تقسيم النص إلى مجموعة من الوحدات def tokenizingText(text): tokens_list = word_tokenize(text) return tokens_list # دالة حذف كلمات التوقف def filteringText(tokens_list): # قائمة كلمات التوقف العربية listStopwords = set(stopwords.words('arabic')) filtered = [] for txt in tokens_list: if txt not in listStopwords: filtered.append(txt) tokens_list = filtered return tokens_list # دالة التجذيع def stemmingText(tokens_list): tokens_list = [ar_stemmer.stemWord(word) for word in tokens_list] return tokens_list # دالة دمج قائمة من الكلمات في جملة def toSentence(words_list): sentence = ' '.join(word for word in words_list) return sentence شرح الدوال التي كتبناها في الشيفرة: cleaningText: تحذف الأرقام وعلامات الترقيم العربية والإنكليزية من النص. remove_repeating_char: تحذف المحارف المكررة والتي قد يستخدمها كاتب التغريدة. tokenizingText: تعمل على تجزئة النص إلى قائمة من الوحدات tokens. filteringText: تحذف كلمات التوقف من قائمة الوحدات. stemmingText: تعمل على تجذيع كلمات قائمة الوحدات المتبقية. يُبين المثال التالي تجذيع بعض الكلمات المتشابهة: # مثال stem = ar_stemmer.stemWord(u"رايع") print (stem) stem = ar_stemmer.stemWord(u"رائع") print (stem) stem = ar_stemmer.stemWord(u"رائعون") print (stem) stem = ar_stemmer.stemWord(u"رائعين") print (stem) يكون ناتج التنفيذ: رايع رايع رايع رايع يُبين المثال التالي نتيجة استدعاء كل دالة من الدوال السابقة: # مثال text= "!أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء " print(text) text=cleaningText(text) print(text) tokens_list=tokenizingText(text) print(tokens_list) tokens_list=filteringText(tokens_list) print(tokens_list) tokens_list=stemmingText(tokens_list) print(tokens_list) يكون ناتج التنفيذ: !أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء أنا أحب الذهاب إلى الحديقة كل يوم صباحاً مع رفاقي هؤلاء ['أنا', 'أحب', 'الذهاب', 'إلى', 'الحديقة', 'كل', 'يوم', 'صباحاً', 'مع', 'رفاقي', 'هؤلاء'] ['أحب', 'الذهاب', 'الحديقة', 'يوم', 'صباحاً', 'رفاقي'] ['احب', 'ذهاب', 'حديق', 'يوم', 'صباح', 'رفاق'] تعرض الشيفرة التالية تنفيذ جميع دوال المعالجة الأولية على نصوص التغريدات ومن ثم حفظ النتائج في ملف جديد tweet_clean.csv. وبنفس الطريقة، نُنفذ دوال المعالجة الأولية على قاموس الكلمات الموجبة وقاموس الكلمات السالبة ونحفظ النتائج في ملفات جديدة لاستخدامها لاحقًا: positive_clean.csv و negative_clean.csv. # المعالجة الأولية للتغريدات tweets['tweet_clean'] = tweets['tweet'].apply(cleaningText) tweets['tweet_preprocessed'] = tweets['tweet_clean'].apply(tokenizingText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(filteringText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(stemmingText) # حذف التغريدات المكررة tweets.drop_duplicates(subset = 'tweet_clean', inplace = True) # التصدير إلى ملف tweets.to_csv(r'tweet_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس الموجب positive['word_clean'] = positive['word'].apply(cleaningText) positive.drop(['word'], axis = 1, inplace = True) positive['word_preprocessed'] = positive['word_clean'].apply(tokenizingText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(filteringText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ positive.drop_duplicates(subset = 'word_clean', inplace = True) nan_value = float("NaN") positive.replace("", nan_value, inplace=True) positive.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف positive.to_csv(r'positive_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس السالب negative['word_clean'] = negative['word'].apply(cleaningText) negative.drop(['word'], axis = 1, inplace = True) negative['word_preprocessed'] = negative['word_clean'].apply(tokenizingText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(filteringText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ negative.drop_duplicates(subset = 'word_clean', inplace = True) negative.replace("", nan_value, inplace=True) negative.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف negative.to_csv(r'negative_clean.csv', encoding="utf-8", index = False, header = True,index_label=None) تعرض الشيفرة التالية بناء قاموسين dict الأول للكلمات الموجبة والثاني للكلمات السالبة وبحيث يكون المفتاح key هو الكلمة والقيمة value هي نقاط الكلمة. يُعدّ استخدام بنية القاموس dict في بايثون مفيدًا جدًا للوصول المباشر إلى نقاط أي كلمة دون القيام بأي عملية بحث. لاحظ أننا نقرأ الكلمات الموجبة والسالبة من الملفات الجديدة ناتج المعالجة الأولية لملفات الكلمات الأصلية. # التصريح عن قاموس للكلمات الموجية dict_positive = dict() # بناء قاموس الكلمات الموجبة myfile = 'positive_clean.csv' positive_data = pd.read_csv(myfile, encoding='utf-8') positive = positive_data[['word_clean', 'polarity']] for i in range(len(positive)): dict_positive[positive_data['word_clean'][i].strip()] = int(positive_data['polarity'][i]) # التصريح عن قاموس للكلمات السالبة dict_negative = dict() # بناء قاموس الكلمات السالبة myfile = 'negative_clean.csv' negative_data = pd.read_csv(myfile, encoding='utf-8') negative = negative_data[['word_clean', 'polarity']] for i in range(len(negative)): dict_negative[negative_data['word_clean'][i].strip()] = int(negative_data['polarity'][i]) تقوم الدالة التالية sentiment_analysis_dict_arabic بحساب مجموع نقاط score قائمة من الكلمات وذلك بجمع نقاط الكلمات الواردة في قاموسي الكلمات الموجبة والسالبة. وفي النهاية تُعدّ قطبية polarity قائمة الكلمات موجبة positive إذا كان مجموع نقاطها أكبر من الصفر، وتُعدّ سالبة negative إذا كان مجموع نقاطها أصغر من الصفر، وإلا فإنها تكون محايدة neutral. # دالة حساب قطبية قائمة من الكلمات def sentiment_analysis_dict_arabic(words_list): score = 0 for word in words_list: if (word in dict_positive): score = score + dict_positive[word] for word in words_list: if (word in dict_negative): score = score + dict_negative[word] polarity='' if (score > 0): polarity = 'positive' elif (score < 0): polarity = 'negative' else: polarity = 'neutral' return score, polarity نستخدم الدالة السابقة في حساب قطبية كل تغريدة وذلك بتنفيذ الدالة على قائمة الكلمات التي حصلنا عليها بعد المعالجة الأولية لنص التغريدة tweet_preprocessed. أي أنه سيكون لكل تغريدة في نهاية المطاف قطبية polarity موجبة أو سالبة أو محايدة وفق مجموع النقاط الحاصلة عليها polarity_score. نحفظ نتائج الحساب في ملف جديد tweets_clean_polarity.csv. # حساب قطبية التغريدات results = tweets['tweet_preprocessed'].apply(sentiment_analysis_dict_arabic) results = list(zip(*results)) tweets['polarity_score'] = results[0] tweets['polarity'] = results[1] # كتابة النتائج في ملف tweets.to_csv(r'tweets_clean_polarity.csv', encoding='utf-8', index = False, header = True,index_label=None) تعرض الشيفرة التالية حساب عدد التغريدات من كل قطبية (موجبة، سالبة، محايدة) ومن ثم استخدام المكتبة matplotlib لرسم مخطط بياني من النوع pie يعرض نسب قطبية التغريدات: # رسم نسب قطبية التغريدات import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize = (6, 6)) # حساب عدد التغريدات من كل قطبية x = [count for count in tweets['polarity'].value_counts()] # تسميات الرسم labels = list(tweets['polarity'].value_counts().index) explode = (0.1, 0, 0) # تنفيذ الرسم ax.pie(x = x, labels = labels, autopct = '%1.1f%%', explode = explode, textprops={'fontsize': 14}) # عنوان الرسم ax.set_title('Tweets Polarities ', fontsize = 16, pad = 20) # الإظهار plt.show() يكون الإظهار: يُمكن الآن إظهار التغريدات الأكثر إيجابيًة باستخدام الشيفرة التالية: # طباعة أكثر التغريدات إيجابية pd.set_option('display.max_colwidth', 3000) positive_tweets = tweets[tweets['polarity'] == 'positive'] positive_tweets = positive_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=False).reset_index(drop = True) positive_tweets.index += 1 positive_tweets[0:10] يكون الإظهار: كما يُمكن إظهار التغريدات الأكثر سلبيًة: # طباعة أكثر التغريدات سلبية pd.set_option('display.max_colwidth', 3000) negative_tweets = tweets[tweets['polarity'] == 'negative'] negative_tweets = negative_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=True)[0:10].reset_index(drop = True) negative_tweets.index += 1 negative_tweets[0:10] يكون الإظهار: يُمكن استخدام مكتبة سحابة الكلمات WordCloud لرسم مجموعة من الكلمات بشكل فني كما تُبين الشيفرة التالية: # سحابة الكلمات from wordcloud import WordCloud # مكتبة للغة العربية import arabic_reshaper from bidi.algorithm import get_display # انتقاء بعض الكلمات المعالجة list_words='' i=0 for tweet in tweets['tweet_preprocessed']: for word in tweet: i=i+1 if i>100: break list_words += ' '+(word) # ضبط اللغة العربية reshaped_text = arabic_reshaper.reshape(list_words) artext = get_display(reshaped_text) # إعدادات سحابة الكلمات wordcloud = WordCloud(font_path='DroidSansMono.ttf', width = 600, height = 400, background_color = 'black', min_font_size = 10).generate(artext) fig, ax = plt.subplots(figsize = (8, 6)) # عنوان السحابة ax.set_title('Word Cloud of Tweets', fontsize = 18) ax.grid(False) ax.imshow((wordcloud)) fig.tight_layout(pad=0) ax.axis('off') plt.show() يكون الإظهار: تُجمّع الدالة التالية words_with_sentiment الكلمات الموجبة والكلمات السالبة المستخرجة من قائمة الكلمات المُمررة للدالة list_words في قائمتين منفصلتين الأولى للكلمات الموجبة والثانية للكلمات السالبة. تستخدم الدالة قاموسي الكلمات الموجبة والسالبة السابقين. # تجميع الكلمات الموجبة والكلمات السالبة def words_with_sentiment(list_words): positive_words=[] negative_words=[] for word in list_words: score_pos = 0 score_neg = 0 if (word in dict_positive): score_pos = dict_positive[word] if (word in dict_negative): score_neg = dict_negative[word] if (score_pos + score_neg > 0): positive_words.append(word) elif (score_pos + score_neg < 0): negative_words.append(word) return positive_words, negative_words نستخدم الدالة السابقة في الشيفرة التالية لاستخراج قائمة الكلمات الموجبة وقائمة الكلمات السالبة من التغريدات، ومن ثم إنشاء سحابتي كلمات لكل منهما لعرض الكلمات الموجبة والكلمات السالبة بشكل فني: # سحابة الكلمات الموجبة والسالبة # فرز الكلمات الموجبة والسالبة sentiment_words = tweets['tweet_preprocessed'].apply(words_with_sentiment) sentiment_words = list(zip(*sentiment_words)) # قائمة الكلمات الموجبة positive_words = sentiment_words[0] # قائمة الكلمات السالبة negative_words = sentiment_words[1] # سحابة الكلمات الموجبة fig, ax = plt.subplots(1, 2,figsize = (12, 10)) list_words_postive='' for row_word in positive_words: for word in row_word: list_words_postive += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_postive) artext = get_display(reshaped_text) wordcloud_positive = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Greens' , min_font_size = 10).generate(artext) ax[0].set_title(' Positive Words', fontsize = 14) ax[0].grid(False) ax[0].imshow((wordcloud_positive)) fig.tight_layout(pad=0) ax[0].axis('off') # سحابة الكلمات السالبة list_words_negative='' for row_word in negative_words: for word in row_word: list_words_negative += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_negative) artext = get_display(reshaped_text) wordcloud_negative = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Reds' , min_font_size = 10).generate(artext) ax[1].set_title('Negative Words', fontsize = 14) ax[1].grid(False) ax[1].imshow((wordcloud_negative)) fig.tight_layout(pad=0) ax[1].axis('off') plt.show() يكون الإظهار: تحويل النصوص إلى أشعة رقمية لا تقبل بنى تعلم الآلة النصوص كمدخلات لها، بل تحتاج إلى أشعة رقمية كمدخلات، لذا نستخدم الشيفرة التالية لتحويل الشعاع النصي لكل تغريده tweet_preprocessed إلى شعاع رقمي: # تحويل التغريدات إلى أشعة رقمية from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences # تركيب جمل التغريدات من المفردات المعالجة sentences = tweets['tweet_preprocessed'].apply(toSentence) print(sentences.values[25]) max_words = 5000 max_len = 50 # التصريح عن المجزئ # مع تحديد عدد الكلمات التي ستبقى # بالاعتماد على تواترها tokenizer = Tokenizer(num_words=max_words ) # ملائمة المجزئ لنصوص التغريدات tokenizer.fit_on_texts(sentences.values) # تحويل النص إلى قائمة من الأرقام S = tokenizer.texts_to_sequences(sentences.values) print(S[0]) # توحيد أطوال الأشعة X = pad_sequences(S, maxlen=max_len) print(X[0]) X.shape نقاط في الشيفرة السابقة لشرحها: يُحدّد المتغير max_words عدد الكلمات الأعظمي التي سيتم الاحتفاظ بها حيث يُحسب تواتر كل كلمة في كل النصوص ومن ثم تُرتب حسب تواترها (المرتبة الأولى للكلمة ذات التواتر الأكبر). ستُهمل الكلمات ذات المرتبة أكبر من max_words. يُحدّد المتغير max_len طول الشعاع الرقمي النهائي. إذا كان طول الشعاع الرقمي الموافق لنص أقل من max_len تُضاف أصفار للشعاع حتى يُصبح طوله مساويًا إلى max_len. أما إذا كان طوله أكبر يُقتطع جزءًا منه ليُصبح طوله مساويًا إلى max_len. تقوم الدالة fit_on_texts(sentences.values) بملائمة المُجزء tokenizer لنصوص جمل التغريدات أي حساب تواتر الكلمات والاحتفاظ بالكلمات ذات التواتر أكبر أو يساوي max_words. نطبع في الشيفرة السابقة، بهدف التوضيح، ناتج كل مرحلة. اخترنا مثلًا شعاع التغريدة 25 بعد المعالجة: [مكان جميل انصح زيار رسوم دخول] تكون نتيجة تحويل الشعاع السابق النصي إلى شعاع من الأرقام: [246, 1401, 467, 19, 87, 17, 74, 515, 2602, 330, 218, 579, 507, 465, 270, 45, 54, 343, 587, 7, 33, 58, 434, 30, 74, 144, 233, 451, 468] وبعد عملية توحيد الطول يكون الشعاع الرقمي النهائي الناتج: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 246 1401 467 19 87 17 74 515 2602 330 218 579 507 465 270 45 54 343 587 7 33 58 434 30 74 144 233 451 468] تجهيز دخل وخرج الشبكة العصبية تعرض الشيفرة التالية حساب شعاع الخرج أولًا، حيث نقوم بترميز القطبيات الثلاث إلى 0 للسالبة و1 للمحايدة و2 للموجبة. نستخدم الدالة train_test_split لتقسيم البيانات المتاحة إلى 80% منها لعملية التدريب و20% لعملية الاختبار وحساب مقاييس الأداء: # ترميز الخرج polarity_encode = {'negative' : 0, 'neutral' : 1, 'positive' : 2} # توليد شعاع الخرج y = tweets['polarity'].map(polarity_encode).values # مكنبة تقسيم البيانات إلى تدريب واختبار from sklearn.model_selection import train_test_split # تقسيم البيانات إلى تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape) نطبع في الشيفرة السابقة حجوم أشعة الدخل والخرج للتدريب وللاختبار: (16428, 50) (16428,) (4107, 50) (4107,) نموذج الشبكة العصبية المتعلم تُعدّ المكتبة Keras من أهم مكتبات بايثون التي توفر بناء شبكات عصبية لمسائل التعلم الآلي. تعرض الشيفرة التالية التصريح عن دالة بناء نموذج التعلّم create_model مع إعطاء جميع المعاملات المترفعة قيمًا ابتدائية: # تضمين النموذج التسلسلي from keras.models import Sequential # تضمين الطبقات اللازمة from keras.layers import Embedding, Dense, LSTM # دوال التحسين from tensorflow.keras.optimizers import Adam, RMSprop # التصريح عن دالة إنشاء نموذج التعلم # مع إعطاء قيم أولية للمعاملات المترفعة def create_model(embed_dim = 32, hidden_unit = 16, dropout_rate = 0.2, optimizers = RMSprop, learning_rate = 0.001): # التصريح عن نموذج تسلسلي model = Sequential() # طبقة التضمين model.add(Embedding(input_dim = max_words, output_dim = embed_dim, input_length = max_len)) # LSTM model.add(LSTM(units = hidden_unit ,dropout=dropout_rate)) # الطبقة الأخيرة model.add(Dense(units = 3, activation = 'softmax')) # بناء النموذج model.compile(loss = 'sparse_categorical_crossentropy', optimizer = optimizers(learning_rate = learning_rate), metrics = ['accuracy']) # طباعة ملخص النموذج print(model.summary()) return model نستخدم من أجل مسألتنا نموذج شبكة عصبية تسلسلي يتألف من ثلاث طبقات: الطبقة الأولى: طبقة التضمين Embedding نستخدم هذه الطبقة لتوليد ترميز مكثف للكلمات dense word encoding مما يُساهم في تحسين عملية التعلم. نطلب تحويل الشعاع الذي طوله input_length (في حالتنا 50) والذي يحوي قيم ضمن المجال input_dim (من 1 إلى 5000 في مثالنا) إلى شعاع من القيم ضمن المجال output_dim (مثلًا 32 قيمة). الطبقة الثانية LSTM يُحدّد المعامل المترفع units عدد الوحدات المخفية لهذه الطبقة. يُساهم المعامل dropout في معايرة الشبكة خلال التدريب حيث يقوم بإيقاف تشغيل الوحدات المخفية بشكل عشوائي أثناء التدريب، وبهذه الطريقة لا تعتمد الشبكة بنسبة 100٪ على جميع الخلايا العصبية الخاصة بها، وبدلاً من ذلك، تُجبر نفسها على العثور على أنماط أكثر أهمية في البيانات من أجل زيادة المقياس الذي تحاول تحسينه (الدقة مثلًا). الطبقة الثالثة Dense يُحدّد المعامل units حجم الخرج لهذه الطبقة (3 في حالتنا: 0 سالبة، 1 محايدة، 2 موجبة) ويُبين الشكل التالي ملخص النموذج: معايرة المعاملات الفائقة وصولا لنموذج أمثلي يُمكن الوصول لنموذج تعلم أمثلي بمعايرة معاملاته الفائقة وفق معطيات المشروع. لنُبين أولًا الفرق بين المعاملات الفائقة لنموذج والمعاملات الأخرى له: المعاملات الفائقة hyperparameters: هي إعدادات خوارزمية التعلّم قبل التدريب (والتي وضعها مصممو الخوارزمية) . المعاملات parameters: هي المعاملات التي يتعلّمها النموذج أثناء التدريب مثل أوزان الشبكة العصبية. تؤثر عملية معايرة المعاملات الفائقة على أداء النموذج لاسيما لجهة التوزان المطلوب بين مشكلة قلة التخصيص underfitting ومشكلة فرط التخصيص overfitting واللتان تؤديان إلى نموذج غير قادر على تعميم أمثلة التدريب وبالتالي لن يتمكن من التصنيف مع معطيات جديدة (يُمكن العودة للرابط من أكاديمية حسوب للمزيد من التفصيل حول هاتين المشكلتين). تظهر مشكلة قلة التخصيص عندما لا يكون للنموذج درجات حرية كافية ليتعلّم الربط بين الميزات والهدف، وبالتالي يكون له انحياز كبير نحو قيم معينة للهدف. يُمكن تصحيح قلة التخصيص بجعل النموذج أكثر تعقيدًا. أما مشكلة فرط التخصيص فتظهر عندما يقوم النموذج بتخزين بيانات التدريب فيكون له بالتالي تباين كبير والذي يُمكن تصحيحه بالحد من تعقيد النموذج باستخدام التسوية regularization. تكمن المشكلة في معايرة المعاملات الفائقة بأن قيمها المثلى تختلف من مسألة لأخرى! وبالتالي، فإن الطريقة الوحيدة للوصول لهذه القيم المثلى هي تجريب قيم مختلفة مع كل مجموعة بيانات تدريب جديدة. يوفر Scikit-Learn العديد من الطرق لتقويم المعاملات الفائقة وبالتالي سنعتمد في مشروعنا عليها دون أن نُعقّد الأمور أكثر. البحث الشبكي مع التقييم المتقاطع تُدعى الطريقة التي سنستخدمها في إيجاد القيم المثلى بالبحث الشبكي مع التقويم المتقاطع grid search with cross validation: البحث الشبكي grid search: نُعرّف شبكة grid من بعض القيم المُمكنة ومن ثم نولد كل التركيبات المُمكنة بينها. التقييم المتقاطع cross validation: وهو الطريقة المستخدمة لتقييم مجموعة قيم مُحدّدة للمعاملات الفائقة. عوضًا عن تقسيم البيانات إلى بيانات للتدريب وبيانات للتقييم مما يُخفّض من البيانات التي يُمكن لنا استخدامها للتدريب، نستخدم التقييم المتقاطع مع عدد محدّد من الحاويات K-Fold. تُقسم بيانات التدريب إلى عدد K من الحاويات ومن ثم نقوم بتكرار ما يلي K مرة: في كل مرة نقوم بتدريب النموذج مع بيانات K-1 حاوية ومن ثم تقويمه مع بيانات الحاوية K. في النهاية، يكون مقياس الأداء النهائي هو متوسط الخطأ لكل التكرارات. يُمكن تلخيص خطوات البحث الشبكي مع التقييم المتقاطع كما يلي: إعداد شبكة من المعاملات الفائقة. توليد كل تركيبات قيم المعاملات الفائقة. إنشاء نموذج لكل تركيب من القيم. تقييم النموذج باستخدام التقويم المتقاطع. اختيار تركيب قيم المعاملات ذو الأداء الأفضل. بالطبع، لن نقوم ببرمجة هذه الخطوات لأن الكائن GridSearchCV في Scikit-Learn يقوم بكل ذلك (يجب ملاحظة أن تنفيذ الشيفرة قد يستغرق بعض الوقت: حوالي الساعة على حاسوب ذو مواصفات عالية): from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasClassifier # حساب القيم الأمثلية للمعاملات المترفعة model = KerasClassifier(build_fn = create_model, epochs = 25, batch_size=128) # بعض القيم الممكنة للمعاملات المترفعة embed_dim = [32, 64] hidden_unit = [16, 32, 64] dropout_rate = [0.2] optimizers = [Adam, RMSprop] learning_rate = [0.01, 0.001, 0.0001] epochs = [10, 15, 25 ] batch_size = [128, 256] param_grid = dict(embed_dim = embed_dim, hidden_unit = hidden_unit, dropout_rate = dropout_rate, learning_rate = learning_rate, optimizers = optimizers, epochs = epochs, batch_size = batch_size) # تقويم النموذج لاختيار أفضل القيم grid = GridSearchCV(estimator = model, param_grid = param_grid, cv = 3) grid_result = grid.fit(X_train, y_train) results = pd.DataFrame() results['means'] = grid_result.cv_results_['mean_test_score'] results['stds'] = grid_result.cv_results_['std_test_score'] results['params'] = grid_result.cv_results_['params'] print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # حفظ النتائج results.to_csv(r'gridsearchcv_results.csv', index = False, header = True) results.sort_values(by='means', ascending = False).reset_index(drop=True) يُبين خرج الشيفرة السابقة أفضل القيم للمعاملات المترفعة: Best: 0.898588 using {'batch_size': 256, 'dropout_rate': 0.2, 'embed_dim': 32, 'epochs': 10, 'hidden_unit': 64, 'learning_rate': 0.001, 'optimizers': <class 'keras.optimizer_v2.adam.Adam'>} نحفظ نتائج حساب المعاملات الأمثلية في الملف gridsearchcv_results.csv. يُمكن معاينة هذه القيم: # قراءة نتائج معايرة المعاملات المترفعة results = pd.read_csv('gridsearchcv_results.csv') results.sort_values(by='means', ascending = False).reset_index(drop=True) print (results) يكون الخرج: حساب أوزان الصفوف يُمكن أن نلاحظ أن عدد التغريدات ذات القطبية الموجبة (73% من التغريدات) تطغى على عدد التغريدات السلبية (13%) والتغريدات المحايدة (13%) مما قد يؤدي إلى انحراف نتائج التعلم نحو القطبية الموجبة. يُمكن تلافي ذلك عن طريق الموازنة بين هذه الصفوف الثلاثة. نحسب في الشيفرة التالية عدد التغريدات الموجبة والسالبة والمحايدة ونسبها: # حساب أوزان القطبيات posCount=0 negCount=0 neuCount=0 # حساب عدد التغريدات الموجبة والسالبة والمحايدة for index, row in tweets.iterrows(): if row['polarity']=='negative': negCount=negCount+1 elif row['polarity']=='positive': posCount=posCount+1 else: neuCount=neuCount+1 print(negCount, neuCount, posCount) total=posCount+ negCount+ neuCount # حساب النسب weight_for_0 = (1 / negCount) * (total / 3.0) weight_for_1 = (1 / neuCount) * (total / 3.0) weight_for_2 = (1 / posCount) * (total / 3.0) print(weight_for_0, weight_for_1, weight_for_2) class_weight = {0: weight_for_0, 1: weight_for_1, 2:weight_for_2} يكون ناتج طباعة هذه الأوزان ما يلي (لا حظ الوزن الأصغر للتغريدات الموجبة): 2.4954429456799123 2.504573728503476 0.45454545454545453 بناء نموذج التعلم النهائي نستخدم الدالة KerasClassifier من scikit لبناء المُصنف مع الدالة السابقة create_model : # مكتبة التصنيف from keras.wrappers.scikit_learn import KerasClassifier # إنشاء النموذج مع قيم المعاملات المترفعة الأمثلية model = KerasClassifier(build_fn = create_model, # معاملات النموذج dropout_rate = 0.2, embed_dim = 32, hidden_unit = 64, optimizers = Adam, learning_rate = 0.001, # معاملات التدريب epochs=10, batch_size=256, # نسبة بيانات التقييم validation_split = 0.1) # ملائمة النموذج مع بيانات التدريب # مع موازنة الصفوف الثلاثة model_prediction = model.fit(X_train, y_train, class_weight=class_weight) يُمكن الآن رسم منحني الدقة accuracy لكل من بيانات التدريب والتقييم (لاحظ أننا في الشيفرة السابقة احتفاظنا بنسبة 10% من بيانات التدريب للتقييم): # معاينة دقة النموذج # التدريب والتقييم fig, ax = plt.subplots(figsize = (10, 4)) ax.plot(model_prediction.history['accuracy'], label = 'train accuracy') ax.plot(model_prediction.history['val_accuracy'], label = 'val accuracy') ax.set_title('Model Accuracy') ax.set_xlabel('Epoch') ax.set_ylabel('Accuracy') ax.legend(loc = 'upper left') plt.show() يكون للمنحني الشكل التالي: حساب مقاييس الأداء يُمكن الآن حساب مقاييس الأداء المعروفة في مسائل التصنيف (الصحة Accuracy، الدقة Precision، الاستذكار Recall، المقياس F1) للنموذج المتعلم باستخدام الشيفرة التالية: # مقاييس الأداء # مقياس الصحة from sklearn.metrics import accuracy_score # مقياس الدقة from sklearn.metrics import precision_score # مقياس الاستذكار from sklearn.metrics import recall_score # f1 from sklearn.metrics import f1_score # مصفوفة الارتباك from sklearn.metrics import confusion_matrix # تصنيف بيانات الاختبار y_pred = model.predict(X_test) # حساب مقاييس الأداء accuracy = accuracy_score(y_test, y_pred) precision=precision_score(y_test, y_pred , average='weighted') recall= recall_score(y_test, y_pred, zero_division=1, average='weighted') f1= f1_score(y_test, y_pred, zero_division=1, average='weighted') print('Model Accuracy on Test Data:', accuracy*100) print('Model Precision on Test Data:', precision*100) print('Model Recall on Test Data:', recall*100) print('Model F1 on Test Data:', f1*100) confusion_matrix(y_test, y_pred) تكون النتائج (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Model Accuracy on Test Data: 90.1144387630874 Model Precision on Test Data: 90.90281584915091 Model Recall on Test Data: 90.1144387630874 Model F1 on Test Data: 90.32645671662543 array([[ 366, 129, 24], [ 53, 444, 62], [ 20, 118, 2891]], dtype=int64) يُمكن رسم مصفوفة الارتباك confusion matrix بشكل أوضح باستخدام المكتبة seaborn: # رسم مصفوفة الارتباك import seaborn as sns sns.set(style = 'whitegrid') fig, ax = plt.subplots(figsize = (8,6)) sns.heatmap(confusion_matrix(y_true = y_test, y_pred = y_pred), fmt = 'g', annot = True) ax.xaxis.set_label_position('top') ax.xaxis.set_ticks_position('top') ax.set_xlabel('Prediction', fontsize = 14) ax.set_xticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) ax.set_ylabel('Actual', fontsize = 14) ax.set_yticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) plt.show() مما يُظهر: يُمكن حساب بعض مقاييس الأداء الأخرى المُستخدمة في حالة وجود أكثر من صف في المسألة (Micro, Macro, Weighted): # مقاييس الأداء في حالة أكثر من صفين print('\nAccuracy: {:.2f}\n'.format(accuracy_score(y_test, y_pred))) print('Micro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='micro'))) print('Micro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='micro'))) print('Micro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='micro'))) print('Macro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='macro'))) print('Macro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='macro'))) print('Macro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='macro'))) print('Weighted Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='weighted'))) print('Weighted Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='weighted'))) print('Weighted F1-score: {:.2f}'.format(f1_score(y_test, y_pred, average='weighted'))) # تقرير التصنيف from sklearn.metrics import classification_report print('\nClassification Report\n') print(classification_report(y_test, y_pred, target_names=['Class 1', 'Class 2', 'Class 3'])) مما يُعطي (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Accuracy: 0.88 Micro Precision: 0.88 Micro Recall: 0.88 Micro F1-score: 0.88 Macro Precision: 0.79 Macro Recall: 0.83 Macro F1-score: 0.80 Weighted Precision: 0.90 Weighted Recall: 0.88 Weighted F1-score: 0.89 Classification Report precision recall f1-score support Class 1 0.79 0.75 0.77 519 Class 2 0.59 0.82 0.69 559 Class 3 0.98 0.92 0.95 3029 accuracy 0.88 4107 macro avg 0.79 0.83 0.80 4107 weighted avg 0.90 0.88 0.89 4107 يُمكن أيضًا اختيار مجموعة تغريدات عشوائية جديدة وتصنيفها وحفظ النتائج في ملف results.csv: # تصنيف مجموعة اختبار text_clean = tweets['tweet_clean'] text_train, text_test = train_test_split(text_clean, test_size = 0.2, random_state = 0) result_test = pd.DataFrame(data = zip(text_test, y_pred), columns = ['text', 'polarity']) polarity_decode = {0 : 'Negative', 1 : 'Neutral', 2 : 'Positive'} result_test['polarity'] = result_test['polarity'].map(polarity_decode) pd.set_option('max_colwidth', 300) # حفظ النتائج result_test.to_csv("results.csv") result_test تكون النتائج مثلًا: الخلاصة عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لتصنيف النصوص العربية إلى موجبة وسالبة ومحايدة. يُمكن تجربة المثال كاملًا من موقع Google Colab، ولا تنسى الاطلاع على مجموعة البيانات المتوفرة الخاصة بهذا المقال. اقرأ أيضًا دليل المبتدئين لفهم أساسيات التعلم العميق لذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال1 نقطة
تُعدّ مسألة تحليل تعليقات وتغريدات الأشخاص على مواقع التواصل الاجتماعي من المسائل المهمة والتي لها الكثير من التطبيقات العملية. مثلًا: تهتم المتاجر الالكترونية كثيرًا بتحليل تعليقات الزبائن على منتجاتهم لاستكشاف توجهات الزبائن ومواطن الضعف والقوة في المتجر. نعرض في هذه المقالة استخدام تقنيات التعلّم العميق deep learning في تحليل المشاعر لنصوص مكتوبة باللغة العربية وباللهجة السعودية بمعنى أن اللغة المستخدمة ليست بالضرورة اللغة العربية الفصحى، بل يُمكن أن تدخل فيها ألفاظ عامية يستخدمها المغردون عادةً. بيانات التدريب تحوي مجموعة البيانات المتوفرة dataset (التي تجدها أيضًا موضحةً بملف بنهاية المقال) حوالي 23500 تغريدة لتعليقات الأشخاص وملاحظاتهم حول مجموعة من الأماكن العامة في المملكة العربية السعودية. جُمّعت هذه التغريدات عن طريق مجموعة من الطلاب الجامعيين وذلك من مجموعة متنوعة من مواقع التواصل الاجتماعي. نُعطي فيما يلي أمثلة عن هذه التغريدات (تعليقات حول حديقة حيوانات مثلًا): "أنصحكم والله بزيارته مكان جميل جدا مرتب ونظيف" "جميلة وكبيرة وتحتاج واحد عنده لياقه يمشي فيها" "حيوانات قليلة جدا ولا يوجد اهتمام مكثف" "كان يعيبها وقت الافتتاح والاغلاق وعدم وجود خريطه" "أول مرة أزور حديقة حيوانات" "أيام العوائل الخميس والجمعة والسبت" يُمكننا، كبشر، تصنيف التغريدات السابقة وبشكل سريع إلى ثلاث فئات: التغريدات الموجبة (الأولى والثانية) أي التغريدات التي تحمل معاني إيجابية تُعّبر عن الرضا والارتياح. التغريدات السالبة (الثالثة والرابعة) أي التغريدات التي تحمل معاني سلبية تُعبّر عن الاستياء. التغريدات المحايدة (الخامسة والسادسة) أي التغريدات التي يُمكن أن تُعطي معلومات ولا تحمل أية مشاعر فيها سواء موجبة أم سالبة. نعرض في هذه المسألة كيفية بناء مُصنّف حاسوبي آلي يُصنّف أي جملة عربية إلى موجبة أو سالبة أو محايدة. تصنيف بيانات التدريب يتطلب استخدام خوارزميات تعلّم الآلة (خوارزميات تصنيف النصوص في حالتنا) توفر بيانات للتدريب أي مجموعة من النصوص مُصنفّة مُسبقًا إلى: موجبة، سالبة، محايدة. يُمكن، في بعض الأحيان، اللجوء إلى الطرق اليدوية: أي الطلب من مجموعة من الأشخاص قراءة النصوص وتصنيفها. وهو حل يصلح في حال كان عدد النصوص صغيرًا نسبيًا. يتميز هذا الحل بالدقة العالية لأن الأشخاص تُدرك، بشكل عام، معاني النصوص من خلال خبرتها اللغوية المُكتسبة وتُصنّف النصوص بشكل صحيح غالبًا. نستخدم، في حالتنا، حلًا إحصائيًا بسيطًا لتصنيف نصوص التدريب إلى موجبة، سالبة، محايدة وذلك باستخدام قاموس للكلمات الموجبة وقاموس آخر للكلمات السالبة. يحوي قاموس الكلمات الموجبة على مجموعة من الكلمات الموجبة الشائعة مع نقاط لكل كلمة (1 موجبة، 2 موجبة جدًا، 3 موجبة كثيرًا). مثلًا: روعة، 3 جيد، 2 معقول، 1 يحوي قاموس الكلمات السالبة على مجموعة من الكلمات السالبة الشائعة مع نقاط لكل كلمة (-1 سالبة، -2 سالبة جدًا، -3 سالبة كثيرًا). مثلًا: مقرف، -3 سيء، -2 زحمه، -1 اختيرت كلمات القواميس الموجبة والسالبة من قبل مجموعة من الطلاب بعد أنا طلبنا منهم استعراض التغريدات المُتاحة وانتقاء الكلمات التي تُعطي التغريدة معنى موجب أو معنى سالب، وإعطاء كل كلمة موجبة نقاط تدل على شدة الإيجابية لها (1,2,3) وكل كلمة سالبة نقاط تدل على شدة السلبية (-3،-2،-1) نعدّ، فيما يلي، نصًا ما أنه موجبًا إذا كان مجموع نقاط الكلمات الموجبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات السالبة الواردة ضمنه. وبالمقابل، نعدّ نصًا ما أنه سالبًا إذا كان مجموع نقاط الكلمات السالبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات الموجبة الواردة ضمنه. يكون نصًا ما محايدًا إذا تساوى مجموع نقاط الكلمات الموجبة فيه مع مجموع نقاط الكلمات السالبة. بالطبع، لا تُعدّ هذه الطريقة صحيحة دومًا إذ يُمكن أن تُخطئ في بعض الحالات إلا أنها على وجه العموم تُستخدم عوضًا عن الطريقة اليدوية. المعالجة الأولية للنصوص تهدف المعالجة الأولية إلى الحصول على الكلمات المهمة فقط من النصوص وذلك عن طريق تنفيذ بعض العمليات اللغوية عليها. تُنفذّ هذه العمليات على كل من التغريدات وكلمات القواميس. لتكن لدينا مثلًا الجملة التالية: "أنا أحب الذهاب إلى الحديقة، كل يوم 9 صباحاً، مع رفاقي هؤلاء!" سنقوم بتنفيذ العمليات التالية: أولًا، حذف إشارات الترقيم المختلفة كالفواصل وإشارات الاستفهام وغيرها، ويكون ناتج الجملة السابقة: ثانيًا، حذف الأرقام الواردة في النص، فيكون ناتج الجملة السابقة: ثالثًا، حذف كلمات التوقف stop words وهي الكلمات التي تتكرر كثيرًا في النصوص ولا تؤثر في معانيها كأحرف الجر (من، إلى، …) والضمائر (أنا، هو، …) وغيرها، فيكون ناتج الجملة السابقة: رابعًا، تجذيع الكلمات stemming أي إرجاع الكلمات المتشابهة إلى كلمة واحدة (جذع أو جذر) مما يُساهم في إنقاص عدد الكلمات الكلية المختلفة في النصوص، ومطابقة الكلمات المتشابهة مع بعضها البعض. مثلًا: يكون للكلمات الأربع: (رائع، رايع، رائعون، رائعين) نفس الجذع المشترك: (رايع). فيكون ناتج الجملة السابقة: ننتبه إلى أن الجذع يختلف عن الجذر اللغوي إذ الجذر هو عملية لغوية لرد الكلمة إلى أصلها وجذرها الأساسي لأغراض مختلفة أشهرها البحث في القاموس، أما الجذع فهو كلمة مشتركة بين مجموعة من الكلمات لا توجد بالضرورة في قاموس اللغة العربية وإنما إيجاد شكل موحد للكلمات. إعداد المشروع يُمكن تنزيل بيانات التدريب والقواميس والشيفرة البرمجية من الملف المرفق هنا. يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ. نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها. نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا. نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا: mkdir sa cd sa نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية: python -m venv sa ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية: source sa/bin/activate أما في Windows، فيكون أمر التنشيط: "sa/Scripts/activate.bat" نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها. نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها: jupyter==1.0.0 keras==2.6.0 Keras-Preprocessing==1.1.2 matplotlib==3.5.1 nltk==3.6.5 numpy==1.19.5 pandas==1.3.5 scikit-learn==1.0.1 seaborn==0.11.2 sklearn==0.0 snowballstemmer==2.2.0 tensorflow==2.6.0 wordcloud==1.8.1 python-bidi==0.4.2 arabic-reshaper==2.1.3 نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي: (sa) $ pip install -r requirements.txt بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا. كتابة شيفرة برنامج تحليل المشاعر في النصوص العربي نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا: (sa) $ jupyter notebook ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم asa مثلًا. يجب أولًا وضع كل من الملفات التالية في مجلد المشروع: ملف التغريدات: tweets.csv. القواميس: lexicon_positive.csv و lexicon_negative.csv. ملف الخط العربي: DroidSansMono.ttf. دورة الذكاء الاصطناعي احترف برمجة الذكاء الاصطناعي AI وتحليل البيانات وتعلم كافة المعلومات التي تحتاجها لبناء نماذج ذكاء اصطناعي متخصصة. اشترك الآن تحميل البيانات نبدأ أولًا بتحميل التغريدات من الملف tweets.csv ضمن إطار من البيانات DataFrame من مكتبة Pandas ومن ثم عرض بعضها: import pandas as pd # قراءة التغريدات وتحميلها ضمن إطار من البيانات tweets_data = pd.read_csv('tweets.csv',encoding = "utf-8") tweets = tweets_data[['tweet']] # إظهار الجزء الأعلى من إطار البيانات tweets.head() يظهر لنا أوائل التغريدات: نُحمّل قاموس الكلمات الموجبة positive.csv وقاموس الكلمات السالبة negative.csv: # قراءة قاموس الكلمات الموجبة positive_data = pd.read_csv('positive.csv' ,encoding = "utf-8") positive = positive_data[['word', 'polarity']] # قراءة قاموس الكلمات السالبة negative_data = pd.read_csv('negative.csv' ,encoding = "utf-8") negative = negative_data[['word', 'polarity']] positive.head() نُظهر مثلًا أوائل الكلمات الموجبة ونقاطها: المعالجة الأولية للنصوص نستخدم فيما يلي بعض الخدمات التي توفرها المكتبة nltk لمعالجة اللغات الطبيعية كتوفير قائمة كلمات التوقف باللغة العربية (حوالي 700 كلمة) واستخراج الوحدات tokens من النصوص. كما نستخدم مجذع الكلمات العربية من مكتبة snowballstemmer. # مكتبة السلاسل النصية import string # مكتبة التعابير النظامية import re # مكتبة معالجة اللغات الطبيعية import nltk nltk.download('punkt') nltk.download('stopwords') # مكتبة كلمات التوقف from nltk.corpus import stopwords # مكتبة استخراج الوحدات from nltk.tokenize import word_tokenize # مكتبة المجذع العربي from snowballstemmer import stemmer ar_stemmer = stemmer("arabic") # دالة حذف المحارف غير اللازمة def remove_chars(text, del_chars): translator = str.maketrans('', '', del_chars) return text.translate(translator) # دالة حذف المحارف المكررة def remove_repeating_char(text): return re.sub(r'(.)\1{2,}', r'\1', text) # دالة تنظيف النصوص def cleaningText(text): # حذف الأرقام text = re.sub(r'[0-9]+', '', text) # حذف المحارف غير اللازمة # علامات الترقيم العربية arabic_punctuations = '''`÷×؛<>_()*&^%][ـ،/:"؟.,'{}~¦+|!”…“–ـ''' # علامات الترقيم الانكليزية english_punctuations = string.punctuation # دمج علامات الترقيم العربية والانكليزية punctuations_list = arabic_punctuations + english_punctuations text = remove_chars(text, punctuations_list) # حذف المحارف المكررة text = remove_repeating_char(text) # استبدال الأسطر الجديدة بفراغات text = text.replace('\n', ' ') # حذف الفراغات الزائدة من اليمين واليسار text = text.strip(' ') return text # دالة تقسيم النص إلى مجموعة من الوحدات def tokenizingText(text): tokens_list = word_tokenize(text) return tokens_list # دالة حذف كلمات التوقف def filteringText(tokens_list): # قائمة كلمات التوقف العربية listStopwords = set(stopwords.words('arabic')) filtered = [] for txt in tokens_list: if txt not in listStopwords: filtered.append(txt) tokens_list = filtered return tokens_list # دالة التجذيع def stemmingText(tokens_list): tokens_list = [ar_stemmer.stemWord(word) for word in tokens_list] return tokens_list # دالة دمج قائمة من الكلمات في جملة def toSentence(words_list): sentence = ' '.join(word for word in words_list) return sentence شرح الدوال التي كتبناها في الشيفرة: cleaningText: تحذف الأرقام وعلامات الترقيم العربية والإنكليزية من النص. remove_repeating_char: تحذف المحارف المكررة والتي قد يستخدمها كاتب التغريدة. tokenizingText: تعمل على تجزئة النص إلى قائمة من الوحدات tokens. filteringText: تحذف كلمات التوقف من قائمة الوحدات. stemmingText: تعمل على تجذيع كلمات قائمة الوحدات المتبقية. يُبين المثال التالي تجذيع بعض الكلمات المتشابهة: # مثال stem = ar_stemmer.stemWord(u"رايع") print (stem) stem = ar_stemmer.stemWord(u"رائع") print (stem) stem = ar_stemmer.stemWord(u"رائعون") print (stem) stem = ar_stemmer.stemWord(u"رائعين") print (stem) يكون ناتج التنفيذ: رايع رايع رايع رايع يُبين المثال التالي نتيجة استدعاء كل دالة من الدوال السابقة: # مثال text= "!أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء " print(text) text=cleaningText(text) print(text) tokens_list=tokenizingText(text) print(tokens_list) tokens_list=filteringText(tokens_list) print(tokens_list) tokens_list=stemmingText(tokens_list) print(tokens_list) يكون ناتج التنفيذ: !أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء أنا أحب الذهاب إلى الحديقة كل يوم صباحاً مع رفاقي هؤلاء ['أنا', 'أحب', 'الذهاب', 'إلى', 'الحديقة', 'كل', 'يوم', 'صباحاً', 'مع', 'رفاقي', 'هؤلاء'] ['أحب', 'الذهاب', 'الحديقة', 'يوم', 'صباحاً', 'رفاقي'] ['احب', 'ذهاب', 'حديق', 'يوم', 'صباح', 'رفاق'] تعرض الشيفرة التالية تنفيذ جميع دوال المعالجة الأولية على نصوص التغريدات ومن ثم حفظ النتائج في ملف جديد tweet_clean.csv. وبنفس الطريقة، نُنفذ دوال المعالجة الأولية على قاموس الكلمات الموجبة وقاموس الكلمات السالبة ونحفظ النتائج في ملفات جديدة لاستخدامها لاحقًا: positive_clean.csv و negative_clean.csv. # المعالجة الأولية للتغريدات tweets['tweet_clean'] = tweets['tweet'].apply(cleaningText) tweets['tweet_preprocessed'] = tweets['tweet_clean'].apply(tokenizingText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(filteringText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(stemmingText) # حذف التغريدات المكررة tweets.drop_duplicates(subset = 'tweet_clean', inplace = True) # التصدير إلى ملف tweets.to_csv(r'tweet_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس الموجب positive['word_clean'] = positive['word'].apply(cleaningText) positive.drop(['word'], axis = 1, inplace = True) positive['word_preprocessed'] = positive['word_clean'].apply(tokenizingText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(filteringText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ positive.drop_duplicates(subset = 'word_clean', inplace = True) nan_value = float("NaN") positive.replace("", nan_value, inplace=True) positive.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف positive.to_csv(r'positive_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس السالب negative['word_clean'] = negative['word'].apply(cleaningText) negative.drop(['word'], axis = 1, inplace = True) negative['word_preprocessed'] = negative['word_clean'].apply(tokenizingText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(filteringText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ negative.drop_duplicates(subset = 'word_clean', inplace = True) negative.replace("", nan_value, inplace=True) negative.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف negative.to_csv(r'negative_clean.csv', encoding="utf-8", index = False, header = True,index_label=None) تعرض الشيفرة التالية بناء قاموسين dict الأول للكلمات الموجبة والثاني للكلمات السالبة وبحيث يكون المفتاح key هو الكلمة والقيمة value هي نقاط الكلمة. يُعدّ استخدام بنية القاموس dict في بايثون مفيدًا جدًا للوصول المباشر إلى نقاط أي كلمة دون القيام بأي عملية بحث. لاحظ أننا نقرأ الكلمات الموجبة والسالبة من الملفات الجديدة ناتج المعالجة الأولية لملفات الكلمات الأصلية. # التصريح عن قاموس للكلمات الموجية dict_positive = dict() # بناء قاموس الكلمات الموجبة myfile = 'positive_clean.csv' positive_data = pd.read_csv(myfile, encoding='utf-8') positive = positive_data[['word_clean', 'polarity']] for i in range(len(positive)): dict_positive[positive_data['word_clean'][i].strip()] = int(positive_data['polarity'][i]) # التصريح عن قاموس للكلمات السالبة dict_negative = dict() # بناء قاموس الكلمات السالبة myfile = 'negative_clean.csv' negative_data = pd.read_csv(myfile, encoding='utf-8') negative = negative_data[['word_clean', 'polarity']] for i in range(len(negative)): dict_negative[negative_data['word_clean'][i].strip()] = int(negative_data['polarity'][i]) تقوم الدالة التالية sentiment_analysis_dict_arabic بحساب مجموع نقاط score قائمة من الكلمات وذلك بجمع نقاط الكلمات الواردة في قاموسي الكلمات الموجبة والسالبة. وفي النهاية تُعدّ قطبية polarity قائمة الكلمات موجبة positive إذا كان مجموع نقاطها أكبر من الصفر، وتُعدّ سالبة negative إذا كان مجموع نقاطها أصغر من الصفر، وإلا فإنها تكون محايدة neutral. # دالة حساب قطبية قائمة من الكلمات def sentiment_analysis_dict_arabic(words_list): score = 0 for word in words_list: if (word in dict_positive): score = score + dict_positive[word] for word in words_list: if (word in dict_negative): score = score + dict_negative[word] polarity='' if (score > 0): polarity = 'positive' elif (score < 0): polarity = 'negative' else: polarity = 'neutral' return score, polarity نستخدم الدالة السابقة في حساب قطبية كل تغريدة وذلك بتنفيذ الدالة على قائمة الكلمات التي حصلنا عليها بعد المعالجة الأولية لنص التغريدة tweet_preprocessed. أي أنه سيكون لكل تغريدة في نهاية المطاف قطبية polarity موجبة أو سالبة أو محايدة وفق مجموع النقاط الحاصلة عليها polarity_score. نحفظ نتائج الحساب في ملف جديد tweets_clean_polarity.csv. # حساب قطبية التغريدات results = tweets['tweet_preprocessed'].apply(sentiment_analysis_dict_arabic) results = list(zip(*results)) tweets['polarity_score'] = results[0] tweets['polarity'] = results[1] # كتابة النتائج في ملف tweets.to_csv(r'tweets_clean_polarity.csv', encoding='utf-8', index = False, header = True,index_label=None) تعرض الشيفرة التالية حساب عدد التغريدات من كل قطبية (موجبة، سالبة، محايدة) ومن ثم استخدام المكتبة matplotlib لرسم مخطط بياني من النوع pie يعرض نسب قطبية التغريدات: # رسم نسب قطبية التغريدات import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize = (6, 6)) # حساب عدد التغريدات من كل قطبية x = [count for count in tweets['polarity'].value_counts()] # تسميات الرسم labels = list(tweets['polarity'].value_counts().index) explode = (0.1, 0, 0) # تنفيذ الرسم ax.pie(x = x, labels = labels, autopct = '%1.1f%%', explode = explode, textprops={'fontsize': 14}) # عنوان الرسم ax.set_title('Tweets Polarities ', fontsize = 16, pad = 20) # الإظهار plt.show() يكون الإظهار: يُمكن الآن إظهار التغريدات الأكثر إيجابيًة باستخدام الشيفرة التالية: # طباعة أكثر التغريدات إيجابية pd.set_option('display.max_colwidth', 3000) positive_tweets = tweets[tweets['polarity'] == 'positive'] positive_tweets = positive_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=False).reset_index(drop = True) positive_tweets.index += 1 positive_tweets[0:10] يكون الإظهار: كما يُمكن إظهار التغريدات الأكثر سلبيًة: # طباعة أكثر التغريدات سلبية pd.set_option('display.max_colwidth', 3000) negative_tweets = tweets[tweets['polarity'] == 'negative'] negative_tweets = negative_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=True)[0:10].reset_index(drop = True) negative_tweets.index += 1 negative_tweets[0:10] يكون الإظهار: يُمكن استخدام مكتبة سحابة الكلمات WordCloud لرسم مجموعة من الكلمات بشكل فني كما تُبين الشيفرة التالية: # سحابة الكلمات from wordcloud import WordCloud # مكتبة للغة العربية import arabic_reshaper from bidi.algorithm import get_display # انتقاء بعض الكلمات المعالجة list_words='' i=0 for tweet in tweets['tweet_preprocessed']: for word in tweet: i=i+1 if i>100: break list_words += ' '+(word) # ضبط اللغة العربية reshaped_text = arabic_reshaper.reshape(list_words) artext = get_display(reshaped_text) # إعدادات سحابة الكلمات wordcloud = WordCloud(font_path='DroidSansMono.ttf', width = 600, height = 400, background_color = 'black', min_font_size = 10).generate(artext) fig, ax = plt.subplots(figsize = (8, 6)) # عنوان السحابة ax.set_title('Word Cloud of Tweets', fontsize = 18) ax.grid(False) ax.imshow((wordcloud)) fig.tight_layout(pad=0) ax.axis('off') plt.show() يكون الإظهار: تُجمّع الدالة التالية words_with_sentiment الكلمات الموجبة والكلمات السالبة المستخرجة من قائمة الكلمات المُمررة للدالة list_words في قائمتين منفصلتين الأولى للكلمات الموجبة والثانية للكلمات السالبة. تستخدم الدالة قاموسي الكلمات الموجبة والسالبة السابقين. # تجميع الكلمات الموجبة والكلمات السالبة def words_with_sentiment(list_words): positive_words=[] negative_words=[] for word in list_words: score_pos = 0 score_neg = 0 if (word in dict_positive): score_pos = dict_positive[word] if (word in dict_negative): score_neg = dict_negative[word] if (score_pos + score_neg > 0): positive_words.append(word) elif (score_pos + score_neg < 0): negative_words.append(word) return positive_words, negative_words نستخدم الدالة السابقة في الشيفرة التالية لاستخراج قائمة الكلمات الموجبة وقائمة الكلمات السالبة من التغريدات، ومن ثم إنشاء سحابتي كلمات لكل منهما لعرض الكلمات الموجبة والكلمات السالبة بشكل فني: # سحابة الكلمات الموجبة والسالبة # فرز الكلمات الموجبة والسالبة sentiment_words = tweets['tweet_preprocessed'].apply(words_with_sentiment) sentiment_words = list(zip(*sentiment_words)) # قائمة الكلمات الموجبة positive_words = sentiment_words[0] # قائمة الكلمات السالبة negative_words = sentiment_words[1] # سحابة الكلمات الموجبة fig, ax = plt.subplots(1, 2,figsize = (12, 10)) list_words_postive='' for row_word in positive_words: for word in row_word: list_words_postive += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_postive) artext = get_display(reshaped_text) wordcloud_positive = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Greens' , min_font_size = 10).generate(artext) ax[0].set_title(' Positive Words', fontsize = 14) ax[0].grid(False) ax[0].imshow((wordcloud_positive)) fig.tight_layout(pad=0) ax[0].axis('off') # سحابة الكلمات السالبة list_words_negative='' for row_word in negative_words: for word in row_word: list_words_negative += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_negative) artext = get_display(reshaped_text) wordcloud_negative = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Reds' , min_font_size = 10).generate(artext) ax[1].set_title('Negative Words', fontsize = 14) ax[1].grid(False) ax[1].imshow((wordcloud_negative)) fig.tight_layout(pad=0) ax[1].axis('off') plt.show() يكون الإظهار: تحويل النصوص إلى أشعة رقمية لا تقبل بنى تعلم الآلة النصوص كمدخلات لها، بل تحتاج إلى أشعة رقمية كمدخلات، لذا نستخدم الشيفرة التالية لتحويل الشعاع النصي لكل تغريده tweet_preprocessed إلى شعاع رقمي: # تحويل التغريدات إلى أشعة رقمية from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences # تركيب جمل التغريدات من المفردات المعالجة sentences = tweets['tweet_preprocessed'].apply(toSentence) print(sentences.values[25]) max_words = 5000 max_len = 50 # التصريح عن المجزئ # مع تحديد عدد الكلمات التي ستبقى # بالاعتماد على تواترها tokenizer = Tokenizer(num_words=max_words ) # ملائمة المجزئ لنصوص التغريدات tokenizer.fit_on_texts(sentences.values) # تحويل النص إلى قائمة من الأرقام S = tokenizer.texts_to_sequences(sentences.values) print(S[0]) # توحيد أطوال الأشعة X = pad_sequences(S, maxlen=max_len) print(X[0]) X.shape نقاط في الشيفرة السابقة لشرحها: يُحدّد المتغير max_words عدد الكلمات الأعظمي التي سيتم الاحتفاظ بها حيث يُحسب تواتر كل كلمة في كل النصوص ومن ثم تُرتب حسب تواترها (المرتبة الأولى للكلمة ذات التواتر الأكبر). ستُهمل الكلمات ذات المرتبة أكبر من max_words. يُحدّد المتغير max_len طول الشعاع الرقمي النهائي. إذا كان طول الشعاع الرقمي الموافق لنص أقل من max_len تُضاف أصفار للشعاع حتى يُصبح طوله مساويًا إلى max_len. أما إذا كان طوله أكبر يُقتطع جزءًا منه ليُصبح طوله مساويًا إلى max_len. تقوم الدالة fit_on_texts(sentences.values) بملائمة المُجزء tokenizer لنصوص جمل التغريدات أي حساب تواتر الكلمات والاحتفاظ بالكلمات ذات التواتر أكبر أو يساوي max_words. نطبع في الشيفرة السابقة، بهدف التوضيح، ناتج كل مرحلة. اخترنا مثلًا شعاع التغريدة 25 بعد المعالجة: [مكان جميل انصح زيار رسوم دخول] تكون نتيجة تحويل الشعاع السابق النصي إلى شعاع من الأرقام: [246, 1401, 467, 19, 87, 17, 74, 515, 2602, 330, 218, 579, 507, 465, 270, 45, 54, 343, 587, 7, 33, 58, 434, 30, 74, 144, 233, 451, 468] وبعد عملية توحيد الطول يكون الشعاع الرقمي النهائي الناتج: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 246 1401 467 19 87 17 74 515 2602 330 218 579 507 465 270 45 54 343 587 7 33 58 434 30 74 144 233 451 468] تجهيز دخل وخرج الشبكة العصبية تعرض الشيفرة التالية حساب شعاع الخرج أولًا، حيث نقوم بترميز القطبيات الثلاث إلى 0 للسالبة و1 للمحايدة و2 للموجبة. نستخدم الدالة train_test_split لتقسيم البيانات المتاحة إلى 80% منها لعملية التدريب و20% لعملية الاختبار وحساب مقاييس الأداء: # ترميز الخرج polarity_encode = {'negative' : 0, 'neutral' : 1, 'positive' : 2} # توليد شعاع الخرج y = tweets['polarity'].map(polarity_encode).values # مكنبة تقسيم البيانات إلى تدريب واختبار from sklearn.model_selection import train_test_split # تقسيم البيانات إلى تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape) نطبع في الشيفرة السابقة حجوم أشعة الدخل والخرج للتدريب وللاختبار: (16428, 50) (16428,) (4107, 50) (4107,) نموذج الشبكة العصبية المتعلم تُعدّ المكتبة Keras من أهم مكتبات بايثون التي توفر بناء شبكات عصبية لمسائل التعلم الآلي. تعرض الشيفرة التالية التصريح عن دالة بناء نموذج التعلّم create_model مع إعطاء جميع المعاملات المترفعة قيمًا ابتدائية: # تضمين النموذج التسلسلي from keras.models import Sequential # تضمين الطبقات اللازمة from keras.layers import Embedding, Dense, LSTM # دوال التحسين from tensorflow.keras.optimizers import Adam, RMSprop # التصريح عن دالة إنشاء نموذج التعلم # مع إعطاء قيم أولية للمعاملات المترفعة def create_model(embed_dim = 32, hidden_unit = 16, dropout_rate = 0.2, optimizers = RMSprop, learning_rate = 0.001): # التصريح عن نموذج تسلسلي model = Sequential() # طبقة التضمين model.add(Embedding(input_dim = max_words, output_dim = embed_dim, input_length = max_len)) # LSTM model.add(LSTM(units = hidden_unit ,dropout=dropout_rate)) # الطبقة الأخيرة model.add(Dense(units = 3, activation = 'softmax')) # بناء النموذج model.compile(loss = 'sparse_categorical_crossentropy', optimizer = optimizers(learning_rate = learning_rate), metrics = ['accuracy']) # طباعة ملخص النموذج print(model.summary()) return model نستخدم من أجل مسألتنا نموذج شبكة عصبية تسلسلي يتألف من ثلاث طبقات: الطبقة الأولى: طبقة التضمين Embedding نستخدم هذه الطبقة لتوليد ترميز مكثف للكلمات dense word encoding مما يُساهم في تحسين عملية التعلم. نطلب تحويل الشعاع الذي طوله input_length (في حالتنا 50) والذي يحوي قيم ضمن المجال input_dim (من 1 إلى 5000 في مثالنا) إلى شعاع من القيم ضمن المجال output_dim (مثلًا 32 قيمة). الطبقة الثانية LSTM يُحدّد المعامل المترفع units عدد الوحدات المخفية لهذه الطبقة. يُساهم المعامل dropout في معايرة الشبكة خلال التدريب حيث يقوم بإيقاف تشغيل الوحدات المخفية بشكل عشوائي أثناء التدريب، وبهذه الطريقة لا تعتمد الشبكة بنسبة 100٪ على جميع الخلايا العصبية الخاصة بها، وبدلاً من ذلك، تُجبر نفسها على العثور على أنماط أكثر أهمية في البيانات من أجل زيادة المقياس الذي تحاول تحسينه (الدقة مثلًا). الطبقة الثالثة Dense يُحدّد المعامل units حجم الخرج لهذه الطبقة (3 في حالتنا: 0 سالبة، 1 محايدة، 2 موجبة) ويُبين الشكل التالي ملخص النموذج: معايرة المعاملات الفائقة وصولا لنموذج أمثلي يُمكن الوصول لنموذج تعلم أمثلي بمعايرة معاملاته الفائقة وفق معطيات المشروع. لنُبين أولًا الفرق بين المعاملات الفائقة لنموذج والمعاملات الأخرى له: المعاملات الفائقة hyperparameters: هي إعدادات خوارزمية التعلّم قبل التدريب (والتي وضعها مصممو الخوارزمية) . المعاملات parameters: هي المعاملات التي يتعلّمها النموذج أثناء التدريب مثل أوزان الشبكة العصبية. تؤثر عملية معايرة المعاملات الفائقة على أداء النموذج لاسيما لجهة التوزان المطلوب بين مشكلة قلة التخصيص underfitting ومشكلة فرط التخصيص overfitting واللتان تؤديان إلى نموذج غير قادر على تعميم أمثلة التدريب وبالتالي لن يتمكن من التصنيف مع معطيات جديدة (يُمكن العودة للرابط من أكاديمية حسوب للمزيد من التفصيل حول هاتين المشكلتين). تظهر مشكلة قلة التخصيص عندما لا يكون للنموذج درجات حرية كافية ليتعلّم الربط بين الميزات والهدف، وبالتالي يكون له انحياز كبير نحو قيم معينة للهدف. يُمكن تصحيح قلة التخصيص بجعل النموذج أكثر تعقيدًا. أما مشكلة فرط التخصيص فتظهر عندما يقوم النموذج بتخزين بيانات التدريب فيكون له بالتالي تباين كبير والذي يُمكن تصحيحه بالحد من تعقيد النموذج باستخدام التسوية regularization. تكمن المشكلة في معايرة المعاملات الفائقة بأن قيمها المثلى تختلف من مسألة لأخرى! وبالتالي، فإن الطريقة الوحيدة للوصول لهذه القيم المثلى هي تجريب قيم مختلفة مع كل مجموعة بيانات تدريب جديدة. يوفر Scikit-Learn العديد من الطرق لتقويم المعاملات الفائقة وبالتالي سنعتمد في مشروعنا عليها دون أن نُعقّد الأمور أكثر. البحث الشبكي مع التقييم المتقاطع تُدعى الطريقة التي سنستخدمها في إيجاد القيم المثلى بالبحث الشبكي مع التقويم المتقاطع grid search with cross validation: البحث الشبكي grid search: نُعرّف شبكة grid من بعض القيم المُمكنة ومن ثم نولد كل التركيبات المُمكنة بينها. التقييم المتقاطع cross validation: وهو الطريقة المستخدمة لتقييم مجموعة قيم مُحدّدة للمعاملات الفائقة. عوضًا عن تقسيم البيانات إلى بيانات للتدريب وبيانات للتقييم مما يُخفّض من البيانات التي يُمكن لنا استخدامها للتدريب، نستخدم التقييم المتقاطع مع عدد محدّد من الحاويات K-Fold. تُقسم بيانات التدريب إلى عدد K من الحاويات ومن ثم نقوم بتكرار ما يلي K مرة: في كل مرة نقوم بتدريب النموذج مع بيانات K-1 حاوية ومن ثم تقويمه مع بيانات الحاوية K. في النهاية، يكون مقياس الأداء النهائي هو متوسط الخطأ لكل التكرارات. يُمكن تلخيص خطوات البحث الشبكي مع التقييم المتقاطع كما يلي: إعداد شبكة من المعاملات الفائقة. توليد كل تركيبات قيم المعاملات الفائقة. إنشاء نموذج لكل تركيب من القيم. تقييم النموذج باستخدام التقويم المتقاطع. اختيار تركيب قيم المعاملات ذو الأداء الأفضل. بالطبع، لن نقوم ببرمجة هذه الخطوات لأن الكائن GridSearchCV في Scikit-Learn يقوم بكل ذلك (يجب ملاحظة أن تنفيذ الشيفرة قد يستغرق بعض الوقت: حوالي الساعة على حاسوب ذو مواصفات عالية): from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasClassifier # حساب القيم الأمثلية للمعاملات المترفعة model = KerasClassifier(build_fn = create_model, epochs = 25, batch_size=128) # بعض القيم الممكنة للمعاملات المترفعة embed_dim = [32, 64] hidden_unit = [16, 32, 64] dropout_rate = [0.2] optimizers = [Adam, RMSprop] learning_rate = [0.01, 0.001, 0.0001] epochs = [10, 15, 25 ] batch_size = [128, 256] param_grid = dict(embed_dim = embed_dim, hidden_unit = hidden_unit, dropout_rate = dropout_rate, learning_rate = learning_rate, optimizers = optimizers, epochs = epochs, batch_size = batch_size) # تقويم النموذج لاختيار أفضل القيم grid = GridSearchCV(estimator = model, param_grid = param_grid, cv = 3) grid_result = grid.fit(X_train, y_train) results = pd.DataFrame() results['means'] = grid_result.cv_results_['mean_test_score'] results['stds'] = grid_result.cv_results_['std_test_score'] results['params'] = grid_result.cv_results_['params'] print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # حفظ النتائج results.to_csv(r'gridsearchcv_results.csv', index = False, header = True) results.sort_values(by='means', ascending = False).reset_index(drop=True) يُبين خرج الشيفرة السابقة أفضل القيم للمعاملات المترفعة: Best: 0.898588 using {'batch_size': 256, 'dropout_rate': 0.2, 'embed_dim': 32, 'epochs': 10, 'hidden_unit': 64, 'learning_rate': 0.001, 'optimizers': <class 'keras.optimizer_v2.adam.Adam'>} نحفظ نتائج حساب المعاملات الأمثلية في الملف gridsearchcv_results.csv. يُمكن معاينة هذه القيم: # قراءة نتائج معايرة المعاملات المترفعة results = pd.read_csv('gridsearchcv_results.csv') results.sort_values(by='means', ascending = False).reset_index(drop=True) print (results) يكون الخرج: حساب أوزان الصفوف يُمكن أن نلاحظ أن عدد التغريدات ذات القطبية الموجبة (73% من التغريدات) تطغى على عدد التغريدات السلبية (13%) والتغريدات المحايدة (13%) مما قد يؤدي إلى انحراف نتائج التعلم نحو القطبية الموجبة. يُمكن تلافي ذلك عن طريق الموازنة بين هذه الصفوف الثلاثة. نحسب في الشيفرة التالية عدد التغريدات الموجبة والسالبة والمحايدة ونسبها: # حساب أوزان القطبيات posCount=0 negCount=0 neuCount=0 # حساب عدد التغريدات الموجبة والسالبة والمحايدة for index, row in tweets.iterrows(): if row['polarity']=='negative': negCount=negCount+1 elif row['polarity']=='positive': posCount=posCount+1 else: neuCount=neuCount+1 print(negCount, neuCount, posCount) total=posCount+ negCount+ neuCount # حساب النسب weight_for_0 = (1 / negCount) * (total / 3.0) weight_for_1 = (1 / neuCount) * (total / 3.0) weight_for_2 = (1 / posCount) * (total / 3.0) print(weight_for_0, weight_for_1, weight_for_2) class_weight = {0: weight_for_0, 1: weight_for_1, 2:weight_for_2} يكون ناتج طباعة هذه الأوزان ما يلي (لا حظ الوزن الأصغر للتغريدات الموجبة): 2.4954429456799123 2.504573728503476 0.45454545454545453 بناء نموذج التعلم النهائي نستخدم الدالة KerasClassifier من scikit لبناء المُصنف مع الدالة السابقة create_model : # مكتبة التصنيف from keras.wrappers.scikit_learn import KerasClassifier # إنشاء النموذج مع قيم المعاملات المترفعة الأمثلية model = KerasClassifier(build_fn = create_model, # معاملات النموذج dropout_rate = 0.2, embed_dim = 32, hidden_unit = 64, optimizers = Adam, learning_rate = 0.001, # معاملات التدريب epochs=10, batch_size=256, # نسبة بيانات التقييم validation_split = 0.1) # ملائمة النموذج مع بيانات التدريب # مع موازنة الصفوف الثلاثة model_prediction = model.fit(X_train, y_train, class_weight=class_weight) يُمكن الآن رسم منحني الدقة accuracy لكل من بيانات التدريب والتقييم (لاحظ أننا في الشيفرة السابقة احتفاظنا بنسبة 10% من بيانات التدريب للتقييم): # معاينة دقة النموذج # التدريب والتقييم fig, ax = plt.subplots(figsize = (10, 4)) ax.plot(model_prediction.history['accuracy'], label = 'train accuracy') ax.plot(model_prediction.history['val_accuracy'], label = 'val accuracy') ax.set_title('Model Accuracy') ax.set_xlabel('Epoch') ax.set_ylabel('Accuracy') ax.legend(loc = 'upper left') plt.show() يكون للمنحني الشكل التالي: حساب مقاييس الأداء يُمكن الآن حساب مقاييس الأداء المعروفة في مسائل التصنيف (الصحة Accuracy، الدقة Precision، الاستذكار Recall، المقياس F1) للنموذج المتعلم باستخدام الشيفرة التالية: # مقاييس الأداء # مقياس الصحة from sklearn.metrics import accuracy_score # مقياس الدقة from sklearn.metrics import precision_score # مقياس الاستذكار from sklearn.metrics import recall_score # f1 from sklearn.metrics import f1_score # مصفوفة الارتباك from sklearn.metrics import confusion_matrix # تصنيف بيانات الاختبار y_pred = model.predict(X_test) # حساب مقاييس الأداء accuracy = accuracy_score(y_test, y_pred) precision=precision_score(y_test, y_pred , average='weighted') recall= recall_score(y_test, y_pred, zero_division=1, average='weighted') f1= f1_score(y_test, y_pred, zero_division=1, average='weighted') print('Model Accuracy on Test Data:', accuracy*100) print('Model Precision on Test Data:', precision*100) print('Model Recall on Test Data:', recall*100) print('Model F1 on Test Data:', f1*100) confusion_matrix(y_test, y_pred) تكون النتائج (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Model Accuracy on Test Data: 90.1144387630874 Model Precision on Test Data: 90.90281584915091 Model Recall on Test Data: 90.1144387630874 Model F1 on Test Data: 90.32645671662543 array([[ 366, 129, 24], [ 53, 444, 62], [ 20, 118, 2891]], dtype=int64) يُمكن رسم مصفوفة الارتباك confusion matrix بشكل أوضح باستخدام المكتبة seaborn: # رسم مصفوفة الارتباك import seaborn as sns sns.set(style = 'whitegrid') fig, ax = plt.subplots(figsize = (8,6)) sns.heatmap(confusion_matrix(y_true = y_test, y_pred = y_pred), fmt = 'g', annot = True) ax.xaxis.set_label_position('top') ax.xaxis.set_ticks_position('top') ax.set_xlabel('Prediction', fontsize = 14) ax.set_xticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) ax.set_ylabel('Actual', fontsize = 14) ax.set_yticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) plt.show() مما يُظهر: يُمكن حساب بعض مقاييس الأداء الأخرى المُستخدمة في حالة وجود أكثر من صف في المسألة (Micro, Macro, Weighted): # مقاييس الأداء في حالة أكثر من صفين print('\nAccuracy: {:.2f}\n'.format(accuracy_score(y_test, y_pred))) print('Micro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='micro'))) print('Micro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='micro'))) print('Micro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='micro'))) print('Macro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='macro'))) print('Macro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='macro'))) print('Macro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='macro'))) print('Weighted Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='weighted'))) print('Weighted Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='weighted'))) print('Weighted F1-score: {:.2f}'.format(f1_score(y_test, y_pred, average='weighted'))) # تقرير التصنيف from sklearn.metrics import classification_report print('\nClassification Report\n') print(classification_report(y_test, y_pred, target_names=['Class 1', 'Class 2', 'Class 3'])) مما يُعطي (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف): Accuracy: 0.88 Micro Precision: 0.88 Micro Recall: 0.88 Micro F1-score: 0.88 Macro Precision: 0.79 Macro Recall: 0.83 Macro F1-score: 0.80 Weighted Precision: 0.90 Weighted Recall: 0.88 Weighted F1-score: 0.89 Classification Report precision recall f1-score support Class 1 0.79 0.75 0.77 519 Class 2 0.59 0.82 0.69 559 Class 3 0.98 0.92 0.95 3029 accuracy 0.88 4107 macro avg 0.79 0.83 0.80 4107 weighted avg 0.90 0.88 0.89 4107 يُمكن أيضًا اختيار مجموعة تغريدات عشوائية جديدة وتصنيفها وحفظ النتائج في ملف results.csv: # تصنيف مجموعة اختبار text_clean = tweets['tweet_clean'] text_train, text_test = train_test_split(text_clean, test_size = 0.2, random_state = 0) result_test = pd.DataFrame(data = zip(text_test, y_pred), columns = ['text', 'polarity']) polarity_decode = {0 : 'Negative', 1 : 'Neutral', 2 : 'Positive'} result_test['polarity'] = result_test['polarity'].map(polarity_decode) pd.set_option('max_colwidth', 300) # حفظ النتائج result_test.to_csv("results.csv") result_test تكون النتائج مثلًا: الخلاصة عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لتصنيف النصوص العربية إلى موجبة وسالبة ومحايدة. يُمكن تجربة المثال كاملًا من موقع Google Colab، ولا تنسى الاطلاع على مجموعة البيانات المتوفرة الخاصة بهذا المقال. اقرأ أيضًا دليل المبتدئين لفهم أساسيات التعلم العميق لذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال1 نقطة -
مثلا عندي تطبيق وداخله ١٠ شاشه من نوع Fragments وقبل ما اطلع من التطبيق اكون فاتح الشاشه رقم ٨ مثلا فبعد ما افتح التطبيق مره ثاني ابيه يفتح لي دايركت علي الصفحه الي كنت فيه قبل ما اسكر التطبيق1 نقطة
-
لدي مجموعة من النطاقات الفرعية subdomains وفي كل نطاق فرعي لدي نفس المسارات تمامًا، وحاليًا أقوم بكتابة الكود بالشكل التالي: Route::group(array('domain' => array('dashboard.example.com')), function() { // ... }); Route::group(array('domain' => array('dev.example.com')), function() { // ... }); في الكود السابق أقوم بكتابة نفس المسارات مرتين مما يجعل الكود مكررًا بدون فائدة. هل توجد طريقة لتجميع النطاقات معًا في لارافيل Laravel بدلًا من تكرار الكود بالشكل التالي؟ Route::group(array('domain' => array('dev.example.com','dashboard.example.com')), function() { // ... });1 نقطة
-
مرحبا, لدي مشكلة في تشغيل instagram hsoub من خلال الشيفرة الجاهزة من مستودع حسوب على github. يظهر لس هذا الخطأ: و قمت باتباع الخطوات التالية لأقوم بتشغيله و عملت جميعها بالشكل الصحيح. فكيف يمكنني حل هذه المشكلة و شكرا لكم.
.thumb.png.0d2805a9ceae9347db7da7120c29630a.png)
.thumb.png.10a5cef5f6c0327187c7130367d8848d.png) 1 نقطة
1 نقطة -
كيفية انشاء فنكشن في php تاخذ مجموعة من الارقام وترجع مصفوفة من المربعات لكل رقم. وهذه محاولتي في الحل function s(...$numbers) { foreach ($numbers as $n) {$m =$n**2;} return $m ; } echo s( 3).','; echo s( 5);1 نقطة
-
أنا متشتت بين إستخدام mysqli أو PDO للإتصال بقاعدة البيانات. وأقوم بإستعمال mysqli في بعض المشاريع، وPDO في بعضها الآخر. ولم أفهم الفرق حتى الآن. هل هناك أي إيجابيات وسلبيات أخرى لاختيار واحد على الآخر كلي أقوم بتوحيد مشاريعي لاستخدام نهج واحد فقط بدلًا من التشتت بين أنواع مختلفة؟1 نقطة
-
بالتأكيد فإنه توجد هنالك فروقات جوهرية بين الاثنين، نذكر من بينها: PDO تدعم أكثر من 12 نظام قواعد بيانات مختلف في حين ان MySQLi يمكنها العمل مع Mysql فقط. PDO تستعمل البرمجة الكائنية التوجه في عملها في حين Mysqli توفر بجانب خيار الـ OOP واجهة اتصال بسيطة (يعرفان ب Mysqli الاجرائية و Mysqli كائنية التوجه). في هاته الناحية تعطى الافضلية ل PDO فعند تبديل نظام قواعد البيانات لن يكفي في mysqli تغيير نوع الاتصال وانما سيشمل ذلك تغيير كامل الشيفرة ومن بينها استعلامات قواعد البيانات. تعتبر PDO أفضل من ناحية تشخصي الاخطاء وتقريرها. في PDO يمكن تسمية المعاملات وعنونتها بشكل عام global بشكل يجعل من السهل التعديل عليها لاحقا اما في mysqli فلا يمكن. لـ PDO أفضلية استخدامها من قبل اغلب المجتمع البرمجي بلغة PHP، يعني هذا ان اخطاءها ومشاكلها اسهل تشخيصا وحلا مقارنة بـ MySQLi. مبدئيا، استعمال PDO سيكون أفضل بكثير، من ناحية التنفيذ والتعديل وخدمة انظمة قواعد البيانات. اما Mysqli فتعتبر افضل من ناحية التخصص، فإن كنت لا تستعمل الا اتصال MySQL دون وجود اي احتمال لتوسيع قواعد البيانات او تغيير نمطها او نظامها فسيكون استعمال MySQLi عمليا.1 نقطة
-
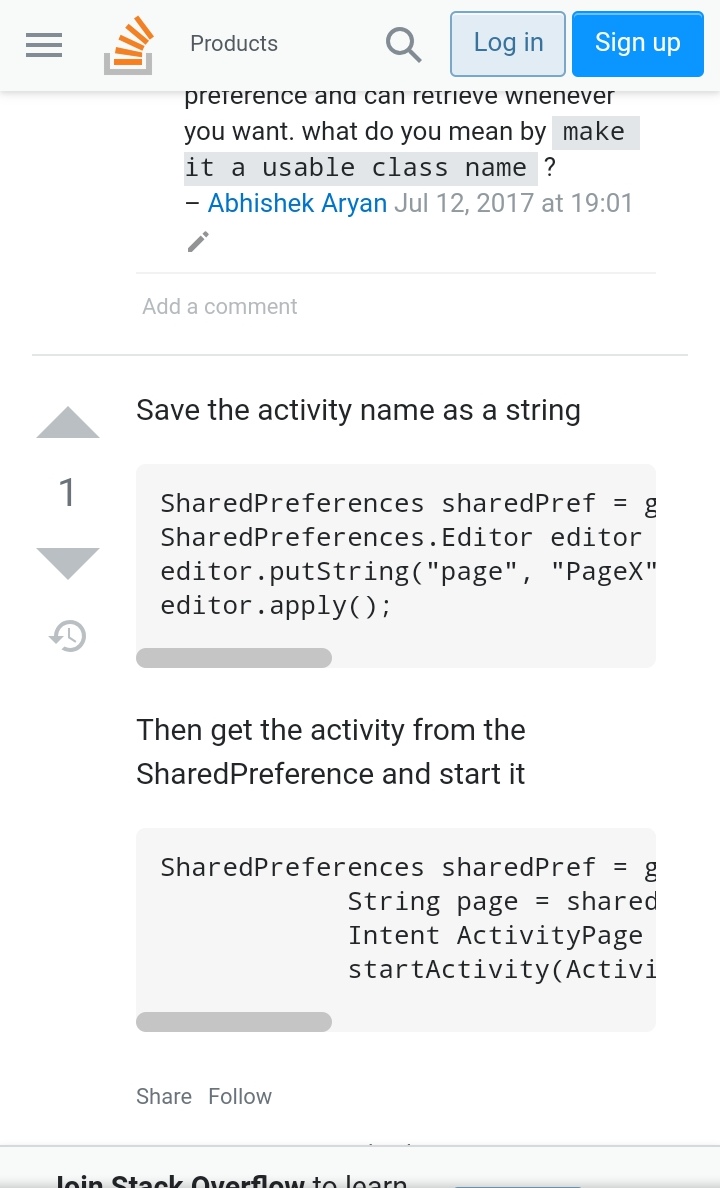
بعد النقر على زر ما، نستدعي دالة تقوم بإظهار البطاقات ثم ضمنها نستدعي setTimeOut مع تمرير 2000 ميلي ثانية (2 ثانية) ليتم تنفيذ الدالة المرتبطة بها بعد هذه المدة. في HTML <button onclick="showCards();"> start game </button> والكود: function showCard() { // منطق إظهار البطاقات // بعد ثانيتين ستختفي window.setTimeout(hideCards, 2000); } function hideCards() { // منطق إخفاء البطاقات }1 نقطة
-
يمكنك استخدام ذلك الكود من أجل الإنتظار ثانيتين فقط setTimeout(() => { console.log('hi'); }, 2000); كما يمكنك استخدام الكود المقابل له في جافا سكربت في حال الحاجة إليه setTimeout(function(){ alert("Sup!"); }, 2000);1 نقطة
-
لدي تطبيق مبني بإستخدام جانغو Django ويحتوي على العديد من النماذج models، أريد الحصول على كل النماذج الموجودة في التطبيق، النماذج موجودة في الملف models.py في مجلد التطبيق، ويحتوي على الكود بالشكل التالي: from django.db import models class First_Model(models.Model): # ... class Second_Model(models.Model): # ... كيف يمكنني الحصول على قائمة بأسماء تلك النماذج في جانغو Django؟1 نقطة
-
يُمكنك الحصول على أسماء كل النماذج في تطبيق ما باستخدام الشيفرة التالية: from django.apps import apps # للحصول على كل النماذج في التطبيق app_models = apps.get_app_config('my_app').get_models() model_names = [] # نقوم بحفظ أسماء النماذج في المتغير # model_names for model in app_models: model_names.append(model.__name__) كما يُمكنك استخدام الدالة all_models من الوحدة apps للحصول على كل النماذج: from django.apps import apps app_models = apps.all_models['my_app'] حيث: my_app هو اسم تطبيق جانغو.1 نقطة
-
ما يتم طباعته هي عناصر المصفوفة المسترجعة من الدالة s , اذا بالفعل لدينا مصفوفة , ولكن لا يمكن طباعة المصفوفة الا بالمرور على جميع عناصرها باستخدام حلقات التكرار , استخدمنا حلقة التكرار foreach وقمنا بطباعة عناصر المصفوفة , اذا كنتي تريدين أن يكون الناتج يأخذ شكل المصفوفة فيمكنك فعل ذلك كالتالي <?php function s(...$numbers) { foreach ($numbers as $n) { $m[] = $n**2; } return $m; } $result='[';// قمنا بإنشاء متغير واسندنا اليه قيمة نصية قيمتها فقط القوس الواضح أمامك foreach(s(3, 5) as $square) { $result.= $square . ','; // نقوم بإلحاق قيمة العناصر بالمتغير الذي انشأناه } $result.=']';// بعد انتهاء حلقة التكرار نقوم بإغلاق القوس echo $result;// نقوم بطباعة قيمة المتغير الذي أنشأناه ?>1 نقطة
-
function s(...$numbers) { foreach ($numbers as $n) { $m[] = $n**2; } return $m; } foreach(s(3, 5) as $square) { echo s($square) . ','; }1 نقطة
-
لماذا عندما اكتب الكود الذي كتبته ينتج لدي error في سطر الطباعة echo1 نقطة
-
التابع المذكور يقوم بالمرور على الأرقام الممررة له ويحسب مربع كل منها ويخزنه ضمن المتغير m$، الخطأ لديك هو عند تخزين تلك القيمة سيتم مسح القيمة السابقة لها وبالتالي لن نحصل سوى على آخر نتيجة فقط، بما أن استخدامك للتابع هو فقط لتمرير عدد مفرد يمكن كتابته لإرجاع نتيجة مفردة وليس مصفوفة كالتالي: function s($number) { return $number**2; } echo s(3).','; echo s(5); // 9, 25 أما في حالة إرجاع مصفوفة حصرًا يجب تغيير طريقة اسنادك للنتيجة لمتغير مصفوفة النتائج وإضافة قوسين مربعين، ويجب تغيير طريقة استعمال المصفوفة باعتبار أنها ترجع مصفوفة وليس عدد مفرد، لتصبح كالتالي: function s(...$numbers) { foreach ($numbers as $n) { $m[] = $n**2; } return $m; } foreach(s(3, 5) as $square) { echo s($square) . ','; }1 نقطة
-
import requests import time #global variables api_key = '15******-ce*0-42*d-9c*6-17******49*0' bot_key = '51******56:A*H-o_hf******Gm******ON******M4*bg' chat_id = '10******03' limit = 59000 #لو قل المبلغ عن هذا الرقم ارسل رسالة على بوت التلغرام time_interval = 60 * 5 #الاتصال بالموقع لمعرفة السعر كل 5 دقائق # دالة لمخاطبة الموقع وجلب السعر def get_price(): url = 'https://sandbox-api.coinmarketcap.com/v1/cryptocurrency/listings/latest' parameters = { 'start':'1', 'limit':'2', 'convert':'USD' } headers = { 'Accepts': 'application/json', 'X-CMC_PRO_API_KEY': api_key, } response = requests.get(url, headers=headers, params=parameters).json() btc_price = response['data'][0]['quote']['USD']['price'] return btc_price # دالة ترسل رسالة لو قل المبلغ عن الرقم المحدد ارسل رسالة على بوت التلغرام def send_update(chat_id, msg): url = f'https://api.telegram.org/bot{bot_key}/sendMessage?chat_id={chat_id}&text={msg}' requests.get(url) # دالة لتشغيل الدوال السابقة def main(): while True: price = get_price() print(price) if price < limit: send_update(chat_id, f"سعر البتكوين:{price}") time.sleep(time_interval) main() code: import requests import time #global variables api_key = '15******-ce*0-42*d-9c*6-17******49*0' bot_key = '51******56:A*H-o_hf******Gm******ON******M4*bg' chat_id = '10******03' limit = 59000 #لو قل المبلغ عن هذا الرقم ارسل رسالة على بوت التلغرام time_interval = 60 * 5 #الاتصال بالموقع لمعرفة السعر كل 5 دقائق # دالة لمخاطبة الموقع وجلب السعر def get_price(): url = 'https://sandbox-api.coinmarketcap.com/v1/cryptocurrency/listings/latest' parameters = { 'start':'1', 'limit':'2', 'convert':'USD' } headers = { 'Accepts': 'application/json', 'X-CMC_PRO_API_KEY': api_key, } response = requests.get(url, headers=headers, params=parameters).json() btc_price = response['data'][0]['quote']['USD']['price'] return btc_price # دالة ترسل رسالة لو قل المبلغ عن الرقم المحدد ارسل رسالة على بوت التلغرام def send_update(chat_id, msg): url = f'https://api.telegram.org/bot{bot_key}/sendMessage?chat_id={chat_id}&text={msg}' requests.get(url) # دالة لتشغيل الدوال السابقة def main(): while True: price = get_price() print(price) if price < limit: send_update(chat_id, f"سعر البتكوين:{price}") time.sleep(time_interval) main()1 نقطة
-
سلام عليكم لو سمحتوا انا عايز انا عايز اشتغل علي نفسي عايز ابدا بتعلمflutter من الصفر وانا معرفش اي حاجه ف انا بتمنا من حد يوجهني ويعرفني البدايه وكله بيقولي فلتر بتتحدث وانا مش عارف ابدا واي المصادر الصح والمتحدثه وهو انا ابدا بس هي دي الفكره وامشي ازاي لأني ف حسابات ومعلومات وزي م فيها زي غيرها ف انا عايز اشتغل علي نفسي1 نقطة
-
اريد المساعدة في التأكد من الاسطر التي باللون الاصفر , وكيفية تصحيحها ؟ <?xml version="1.0"?> <function> <title>ctime</title> <funcsynopsis> <funcdef> <function>ctime</fnuction> </funcdef> <paramdef> <parameter>time</parameter> <parameter role="opt">gmt</parameter> </paramdef> </funcsynopsis> <para>This function converts the value <parameter> time < /parameter>,as returned by <function>time()</function> <function>file_mtime()</function>, into a string of the form produced by <function>time_date()</function>. If the optional argument <parameter>gmt</parameter> is specified and non-zero,the time is returned in <parameter>gmt</parameter>. Otherwise, the time is given in the local time zone. </para> <para><emphasis role="strong" targetgroup="beginners" role="strong"> Related topics</emphasis> </para> <para>&doubleclick; the <mousebutton>LEFT &buttonleft;</mousebutton> mouse button on a topic </para> <itemizedlist> <listitem> <para><ulink url="&idhelp782;"><function>file_mtime()</function>built-in function</ulink> </para> </listitem> <listitem> <para><ulink url="&idhelp785;"><function>time()</function> built-infunction</ulink> </para> </listitem> </itemizedlist> </function> XML.docx1 نقطة
-
الحين اسوي حق كل Fragment داخله shared preferences ولا اسويه مره وحده في Main activity عشان يستديعه لما افتح التطبيق؟ ولا اسوي كل الأكواد داخل Main activity?1 نقطة
-
نفس المثال هذا او اذا عندك مثال او فيديو يشرح لي اكثر
 1 نقطة
1 نقطة -
وضع الشيفرة كاملة في أقل عدد من الملفات أفضل من ناحية الأداء (نسبيًا) للموقع، حيث لن يحتاج الموقع عند الوصول إليه سوى لطلب ملف واحد فقط من المصدر، بينما إذا تطلب الأمر إرسال العديد من الطلبات سيؤثر ذلك على سرعة وأداء الموقع الأولية من ناحية الأداء نعم، يفضل تقليل عدد الملفات التي ستطلب من قبل الموقع ووضع الشيفرة كاملة في ملف واحد على الناحية الأخرى الملفات الطويلة تؤثر على المطور وتعيق عملية التطوير ومن الأسهل وجود العديد من الملفات الصغيرة كل منها وحدة منفصلة صغيرة وواضحة، لكن في بعض الحالات الاستثنائية تكون مضطرًا لوجود ملف ما طويل لا نتكلم عن ذلك هنا، من ناحية سهولة التطوير لا، فيجب تقسيم الشيفرة لقطع صغيرة بسيطة الفهم (قد تكون بعدة ملفات منفصلة أو ملف واحد لكن بوحدات كتوابع منفصلة صغيرة سهلة الفهم). ما الحل إذًا؟ الحل النهائي للمحافظة على الأداء وسهولة التطوير بآن معًا هو استخدام المحزّمات Bundlers، حيث تقوم بكتابة الشيفرة وتركز على الوضوح وسهولة التطوير ما أمكن، ويقوم المحزم خلال مرحلة البناء بدمج الوحدات (الملفات) التي قمت بكتابتها معًا في ملف واحد لرفع سرعة أداء الموقع، هكذا نكون حافظنا على الأداء وسهولة التطوير يمكنك استخدام Webpack لتطبيق ذلك، يمكنك الاستفادة من قراءة المقالات التالية:1 نقطة
-
بارك الله فيك اخي وائل. سانتظر رد الدعم الفني على استفساري لعل وعسى يكون هناك امل ... لانني مهتم بدورة تطوير صفحات الويب.1 نقطة
-
تبين بعد تجريب الشيفرة أن الفراغ بسبب عمل سطر جديد بين الوسوم a tags <nav> <a class="home" href="#">Home</a><a class="news" href="#">News</a><a class="contact" href="#">Contact</a><a class="about" href="#">About</a> </nav> وأحد الحلول بعمل تعليق بشكل غريب كالتالي <ul> <li>Item 1</li><!-- --><li>Item 2</li><!-- --><li>Item 2</li> </ul> المهم عدم وجود فراغ بين بداية و نهاية وسم، أو يمكنك تطبيق float left أو display flex1 نقطة
-
يمكننا لكل عبارة شرطية مرتبطة ب And فصلها ضمن عبارة where مستقلة، أما الشروط التي بينها علاقة Or يمكننا كتابتها مباشرة ضمن نفس الاستعلام في نفس عبارة where أي أن الاستعلام السابق يمكننا تعديله ليصبح DB::table("posts") ->where(DB::raw("(col_1 = 123 or col_2 = 123)")) ->where(DB::raw("(col_3 = 456 or col_4 = 456)")) ->get(); يمكنك الإطلاع على laravel #advanced-wheres1 نقطة
-
يمكنك تحديد مجموعة شروط عن طريق السطر التالي $query->where([ ['column_1', '=', 'value_1'], ['column_2', '<>', 'value_2'], [COLUMN, OPERATOR, VALUE], ... ]) أما إذا أردت الدمج ما بين WHERE , AND يمكنك استخدام الأسطر التالية $matchThese = ['field' => 'value', 'another_field' => 'another_value', ...]; // if you need another group of wheres as an alternative: $orThose = ['yet_another_field' => 'yet_another_value', ...]; ثم $results = User::where($matchThese)->get(); // with another group $results = User::where($matchThese) ->orWhere($orThose) ->get(); لتعادل نفس نتيجة تلك الأسطر SELECT * FROM users WHERE (field = value AND another_field = another_value AND ...) OR (yet_another_field = yet_another_value AND ...)1 نقطة
-
إن سبب الخطأ لوجود شيفرة PHP على سطر جديد new line مما سبب في ظهور المسافة البيضاء. يمكننا كتابة الشيفرة على سطر واحد إن كان بالإمكان مما يزيل الخطأ <textarea cols="60" rows="10" name="user_bio"><?php if($user_bio) echo $user_bio;?> </textarea> وفي حال كان هنالك الكثير من الشيفرات البرمجية يمكننا تطبيق الدالة trim مثلاً في جيكويري على الحقل $('textarea').val($('textarea').val().trim()) هذا يقوم بإعادة إسناد قيمة الحقل نفسه بدون فراغات1 نقطة
-
لا يظهر أي فيديو في الصفحة التي قمت بارفاق رابطها. هلا قمت باضافة تفاصيل أكثر؟1 نقطة
-
لا يوجد أمر مدمج ولكن يمكنك القيام بذلك بسهولة عبر > python manage.py shell $ from django.contrib.auth.models import User $ User.objects.get(username="name", is_superuser=True).delete()1 نقطة
-
اذا كنت تستخدم Django 3.2 فما فوق يمكنك استخدام python manage.py makemigrations --check --dry-run إذا لم تكن هناك تغييرات معلقة في النماذج تتطلب إنشاء تهجير سيكون الناتج المتوقع كالتالي: 'No changes detected' او يمكنك استخدام python manage.py migrate --plan سيكون الناتج المتوقع: 'Planned operations: No planned migration operations.' يمكنك استخدام ايا من الطرق في نص بيثون مع call_command وتطوير طريقة للتحقق من الإخراج المتوقع. إذا كانت هناك أي عمليات تهجير معلقة لمكالمات تهجير، فسيكون الإخراج مختلفًا عن المتوقع.1 نقطة
-
في نسخ جانقو القديمة يتم استخدام الدالة defer لاستبعاد أعمدة من الاستعلام defer('col1', 'col2') كما يتم استخدام الدالة only للحصول على مجموعة محددة من الأعمدة فقط. only('col1', 'col2') الدالة values تفعل شيئًا مختلفًا قليلاً - بواسطتها ستحصل فقط على الأعمدة التي تحددها ، لكنها تُرجع قائمة من القواميس بدلاً من مجموعة من كائنات النموذج. لاستخدامها قم بإلحاقها باستعلامك كالاتي: queryset = User.objects.filter( first_name__startswith='R' ).values('first_name', 'last_name') هذا استعلام للحصول على الاسم الأول والاسم الأخير لجميع المستخدمين الذين يبدأ أسماؤهم بالحرف R.1 نقطة
-
يمكنك جلب مجموعة أعمدة محددة في نموذج Django من خلال السطر التالي qs = Blog.objects.values_list('id', 'name') حيثُ أن Blog يتم استبداله بإسم النموذج الذي تم استدعاؤه من ملف models.py و الجديد في الأمر انك ستستخدم values_list من أجل جلب فقط الأعمدة المخصصة من النموذج و تكون بين الأقواس1 نقطة
-
برجاء ارفاق شيفرة البرنامج ليتم معرفة مكان الخطأ حتى نستطيع معالجة المشكلة شكرا لك,1 نقطة
-
حاول التواصل مع مركز مساعدة و اشرح لهم ما تريده مركز مساعدة حسوب1 نقطة
-
 يُعَد عمل البرنامج صحيحًا إذا أنجز المَهمَّة المُوكَلة إليه بصورةٍ صائبة، بينما يُعَد البرنامج متينًا robust إذا عالَج قِيم المُدخَلات غير الصالحة أو غيرها من المواقف غير المُتوقَّعة على نحوٍ مقبولٍ، فمثلًا إذا صُمِّم برنامج لقراءة مجموعةٍ من الأعداد المدخَلة من قِبل المستخدِم ثم طباعتها بصورةٍ مرتّبة، فسيعمل البرنامج بصورةٍ صحيحةٍ إذا أعاد حاصل المجموع الصحيح لأي أعدادٍ مدخَلةٍ، بينما سيكون متينًا إذا طُبعت رسالة خطأ مع المدخَلات غير العددية أو تم تجاهلها؛ أما البرامج غير المتينة فقد تنهار في هذه الحالة أو تعطي خرجًا غير مقبول. لابدّ لأي برنامجٍ أن يعمل بصورةٍ صحيحة؛ فما الفائدة إذًا من برنامج ترتيب sorting لا ينجز عملية الترتيب بصورة سليمة؟ وليس من الضروري دائمًا أن يكون البرنامج متينًا بالكامل، فذلك يعتمد على المستخدم وطريقة استخدامه؛ فمثلًا لا يُشترط لبرنامج مساعدة صغيرٍ كتبته لنفسك أن يكون متينًا. يعتمد عملُ المبرمِج على توصيف specification ما يُفترَض أن يعمل به البرنامج، ويصح عمل المبرمِج إذا توافق البرنامج مع توصيفه، ولكن هل يعني ذلك أن البرنامج نفسه سيكون صحيحًا؟ وماذا لو كان التوصيف غير صحيح أو غير كامل؟ في الواقع، يُعرَّف البرنامج الصحيح على أنه تنفيذ implementation صحيح لتوصيف صحيح وكاملٍ؛ الأمر الذي ينقلنا إلى السؤال عمَّا إذا ما كان التوصيف يعبِّر عن نية مستخدمي البرنامج ورغباتهم تعبيرًا صحيحًا أم لا؛ إلا أن هذا السؤال يقع خارج مجال علوم الحاسوب. قصص مرعبة لقد حظى معظم مستخدمي الحاسوب بتجربةٍ مع تعطل البرامج أثناء تشغيلها أو حتى انهيارها بالكامل، فعادةً ما تسبب تلك المشاكل الضجر للمستخدمين، كما قد تتسبب أيضًا في نتائج أخطر من ذلك بكثيرٍ مثل خسارة عملٍ مهم أو خسارة نقود؛ فببساطة عندما تُسند مهمات جدية للحاسوب، فسيتوقع أن تكون توابع فشلها بنفس جدية تلك المهمات. منذ عشرين عامًا، فشلت بعثتي فضاء إلى المريخ بتكاليف تصل إلى ملايين الدولارات، ورجح أن سبب الفشل في كلتا الحالتين كان نتيجةً لمشاكل برمجية، ومع ذلك لم تكن المشكلة بسبب برنامج مكتوب بطريقة خاطئة، ففي سبتمبر 1999، احترقت مركبة المريخ المناخية المدارية Mars Climate Orbiter في الغلاف الجوي للمريخ، وذلك نتيجةً لإدخال البيانات بوحدة القياس الإنجليزية مثل القدم والرطل إلى برنامج حاسوب صُمم لاستقبال قياسات بوحدات قياس النظام العالمي مثل السنتيمتر والجرام؛ كما تحطمت بعد أشهر قليلة مركبة الهبوط على قطب المريخ Mars Polar Lander، وذلك لأن البرنامج أغلق محركات الهبوط قبل الهبوط الفعلي للمركبة، إذ صُمِّم البرنامج ليغلق المحركات عندما يستشعر أي ارتطام أثناء هبوط المركبة الفضائية، واتضح بعد ذلك أن معدات الهبوط اهتزت بصورة شديدة حتى فُعِّل نظام الارتطام، وعليه أُغلِقت المحركات بينما كانت المركبة ما تزال مرتفعةً عن الأرض، الأمر الذي أدى لسقوطها على سطح المريخ. فإذا كان البرنامج أكثر متانةً، لَفحَص ارتفاعها عن الأرض قبل أن يغلق المحركات. وهناك حكاياتٌ أخرى بنفس المأساوية تسببت فيها برامج لا تعمل بصورة صحيحة، أو رديئة لا تعمل بكفاءةٍ جيدة؛ وفيما يلي بعضًا من الحوادث القليلة المسرودة في كتاب "أخلاقيات الحاسوب Computer Ethics" للكاتبين Tom Forester وPerry Morrison، والذي يُناقِشان فيه قضايا أخلاقية مختلفة تتعلّق بالحوسبة، وسنذكر منها الآتي: تسببت جرعة إشعاع مفرطة في عاميْ 1985 و1986 في قتل شخص وإصابة آخرين أثناء خضعوهم لعلاج إشعاعيٍ نتيجة لبرمجة آلة الإشعاع الحاسوبية بصورة خاطئة؛ كما تَعرّض حوالي 1000 مصاب بالسرطان لجرعات إشعاع أقلّ من الموصوفة لهم بحوالي 30% بسبب خطأ برمجي آخر في عام 1992، أي بعد 6 سنوات من الحالة السابقة تقريبًا. حذَف حاسوب في بنك نيويورك معاملات جارية بسبب خطأ برمجي، الأمر الذي استغرق قرابة 24 ساعة لإصلاح المشكلة، وحينها دفع البنك فائدة تقدر بـحوالي 5,000,000 دولار على المدفوعات التي اقترضها لتغطية المشكلة، وذلك في عام 1985. اكتُشف خطأ خلال محاكاة برمجة نظام التوجيه بالقصور الذاتي المستخدم في مقاتلة F-16، الأمر الذي كان سيتسبب في قلب الطائرة رأسًا على عقب بعد عبورها لخط الاستواء، كما فُقد مكوك الفضاء Mariner 18 بسبب خطأ برمجي في سطر واحد من برنامج تشغيله، وكذلك تجاوزت كبسولة الفضاء Gemini V موقع هبوطها المقرر بمائة ميل، حيث نسي المبرمج أن يأخذ في حسبانه دوران الأرض. في عام 1990، تعطلت خدمة هاتف AT&T في الولايات المتحدة الأمريكية بعد اكتشاف خطأ برمجي في نسختها المحدثة. بالطبع، هناك مشاكلٌ أخرى أحدث من ذلك، فمثلًا ساهم خطأ برمجي في أحد أكبر انقطاعات التيار الكهربي في التاريخ في شمال شرق أمريكا عام 2003، وفي عام 2006 تأخرت طائرة Airbus A380 بسبب مشاكل عدم توافُق البرمجيات، حيث كلَّفتها خسائر تصل إلى بلايين الدولارات، كما أدى خطأ برمجي في عام 2007 إلى تَوقُّف الآلاف من الطائرات في مطار Los Angeles الدولي، كما تسبَّب خطأ في برنامج تداول آلي في انخفاض مؤشِّر داو جونز الصناعي بحوالي 1000 نقطة، وذلك في مايو 2010. هذه بعض الأمثلة القليلة، فمن المعروف أن المشاكل البرمجية تنتشر بكثرة، وعلينا نحن المبرمجين أن نفهَم سبب ذلك وما الذي يمكن أن نفعله حِيال ذلك؟ المنقذ جافا وفقًا لمطوري لغة جافا، يعود سبب المشكلة إلى طريقة تصميم اللغات البرمجية ذاتها، ولهذا صُممت جافا بطريقة توفِّر حمايةً من تلك النوعية من الأخطاء. قد تتساءل عن كيف يمكن لخاصيةٍ في اللغة أن تمنع حدوث مثل تلك الأخطاء؟ ولهذا دعنا نفحَص بعض الأمثلة. لا تتطلب بعض لغات البرمجة تعريف المتغيرات قبل استخدامها، حيث يُنشَئ المتغير تلقائيًا عندما تستخدمه لأول مرة ضِمن برنامج كُتب بإحدى تلك اللغات، وقد ترى أن ذلك مناسبٌ أكثر من تعريف عن كلِّ متغير على حدة، الأمر الذي قد يكون صحيحًا أحيانًا، إلا أنه قد يؤدِّي إلى نتائج مؤسفة، فقد يَتسبَّب خطأ إملائي في إنشاء متغير جديد مثلًا دون أي نية لذلك؛ وفي الواقع، يقال أن خطأ مماثلًا كان هو المسئول عن فقدان سفينة فضاء؛ فلتُكتَب حلقة عدِّ بلغة FORTRAN مثلًا؛ فسيُستخدَم الأمر DO 20 I = 1,5، ولمَّا كانت المسافات غير مهمة بلغة FORTRAN، فستكافئ التعليمَة السابقة الأمر DO20I=1,5، بينما يمثل الأمر DO20I=1.5 (في حال استبدلنا الفاصلة بنقطةٍ) تعليمة إسناد assignment، فتسند القيمة 1.5 إلى متغير اسمه DO20I، يمكنك ملاحظة كيف تسبب استبدالٌ غير مقصود في تعليمة مماثلة إلى انفجار الصاروخ أثناء الاقلاع؛ ونظرًا لأن لغة FORTRAN لا تتطلب تعريفًا للمتغيرات، فسيقبل المحرر تعليمةً مثل DO20I=1.5، وينشِئ متغيرًا جديدًا اسمه DO20I، بينما إذا كانت FORTRAN تتطلب تعريف المتغيِّرات أولًا، فسيُظهر المحرِّر رسالة خطأ، كون المتغير DO20I لم يُعرَّف بَعد. عمومًا، تتطلب غالبية لغات البرمجة حاليًا تعريف المتغيرات قبل استخدامها، وبالرغم من ذلك ما تزال هناك خاصيات أخرى يكثر استخدامها رغم أنها قد تتسبب في حدوث المشكلات؛ وقد ألغت جافا بعضًا من تلك الخاصيات. وبينما يشكو بعض المبرمجين من أن ذلك يقلل من قوة وكفاءة اللغة، إلا أن هذا النقد قد يكون عادلًا إلى حدٍ ما، إذ تستحق زيادة أمن ومتانة اللغة تلك التكلفة في غالبية الأحوال، فأفضل دفاع ضد بعض الأخطاء هو تصميم اللغة بصورةٍ يستحِيل معها حدوث تلك الأخطاء من الأساس. في حالات أخرى، لا يسهل التخلص من الخطأ بصورةٍ كاملة، وعندها تصمَّم لغة البرمجة بطريقةٍ تمكنها من اكتشاف تلك الأخطاء عندما تحدث بصورة تلقائية، وتمنعها من التسبب في حدوث المشاكل البرمجية؛ حيث تنبه المبرمج إلى وجود خطأ برمجي ينبغي تصحيحه؛ ولنفحَص مجموعةً من الحالات التي اتبعها مصمِّمي جافا. تتكون أي مصفوفةٍ من عدد محدَّد من العناصر، بحيث تُرقم من الصفر إلى قيمة عظمى معينة، وبالطبع من الخطأ استخدام عنصر مصفوفة من خارج ذلك النطاق؛ ولهذا تكتشف جافا أي محاولة لفعل ذلك بصورةٍ تلقائيةٍ، بينما تُلقِي بعض لغات البرمجة الأخرى مثل C وC++ مسؤولية التأكد من استخدام العنصر ضمن النطاق المسموح به للمبرمِج. سَنفترِض أن لدينا مصفوفةً A تتكون من ثلاثة عناصر A[0] وA[1] وA[2]، أي أن عناصر مثل A[3] وA[4] تشير إلى مواضع تقع خارج المصفوفة؛ بلغة جافا، ستُكتشف أي محاولةٍ لتخزين بياناتٍ في العنصر A[3] بصورةٍ تلقائية، ولا ينتهي البرنامج إلا إذا التقط catching الخطأ كما ناقشنا في القسم 3.7؛ أما بلغتي C وC++، فسيخزِّن الحاسوب البيانات في موضع في الذاكرة رغم أنه لا يُعَد جزءًا من المصفوفة، ولأن معرفة الغرض من موضعٍ معينٍ في الذاكرة غير ممكنٍ، فلن نتوقَّع النتائج، إلا أنها قد تكون أكثر خطورةً بكثيرٍ من مجرد انتهاء البرنامج (سنناقش لاحقًا في هذا القسم مثال خطأ تجاوز سعة المُخزِّن المؤقَّت buffer overflow). تُعَد المؤشرات pointers في العموم مصدرًا شائعًا للأخطاء البرمجية، ويحمل أي متغيِّر كائني النوع object type في جافا مؤشرًا يشير إما إلى كائن أو قيمة خاصة null، وبهذا يكتشف النظام أي محاولةٍ تستخدم القيمة الخاصة null على أنها مؤشر إلى كائن فعلي، بينما في المقابل، تلقي بعض لغات البرمجة الأخرى مسئولية تجنب أخطاء المؤشر الفارغ null pointer على المبرمج، وفي الواقع نُفذ implement المؤشر الفارغ بحواسيب ماكنتوش Macintosh على أنه مؤشر إلى موضع الذاكرة 0؛ ولسوء الحظ كانت تلك الحواسيب تُخزِّن بعض بيانات النظام المهمة ضمن تلك المواضع، وكان من الممكن لأي برنامج أن يستخدم مؤشرًا فارغًا ليعدّل القيم المُخزَّنة بالقرب من الموضع 0 في الذاكرة، الأمر الذي قد يؤدي إلى انهيار النظام بالكامل، وهي نتيجة أسوأ بكثير من مجرد انهيار برنامجٍ واحدٍ بكل تأكيد. يَحدُث نوع آخر من أخطاء المؤشر عندما يُضبط مؤشر إلى كائن من غير النوع الصحيح أو إلى جزء من الذاكرة لا يَحمل كائنًا صالحًا من الأساس، وهذا النوع من الأخطاء لا يحدث في جافا لأنها لا تسمح للمبرمجين بالتعامل مع المؤشِّرات تعاملًا مباشرًا، بينما في المقابل، تسمح بعض لغات البرمجة الأخرى بضبط مؤشر معين، بحيث يشير إلى أي موضع في الذاكرة؛ وإذا حدث ذلك بطريقةٍ خاطئة، فإنه قد يؤدي إلى نتائج غير متوقعة. تسريب الذاكرة memory leak هو نوع آخر من الأخطاء غير الممكنة في لغة جافا، فعندما لا يوجد أي مؤشِّرٍ آخر إلى كائن معين، فسيحرر جامع المهملات garbage collector ذلك الكائن وتصبح المساحة التي احتلها قابلةً لإعادة الاستخدام مرةً أخرى؛ بينما في لغات أخرى، تقع مسؤولية تحرير الذاكرة غير المُستخدَمة على عاتق المبرمج، وإذا فشل المبرمج في ذلك، فستتراكم الذاكرة غير المستخدمة، بحيث تترك مساحةً أقل للبرامج والبيانات. يُقال إن أغلب برامج نظام التشغيل ويندوز Windows القديمة تعاني كثيرًا من مشكلات تسريب الذاكرة، الأمر الذي يتسبب في نفاذ ذاكرة الحاسوب بعد أيام قليلة من الاستخدام، ولذلك تصبح إعادة تشغيل الحاسوب عمليةً ضروريةً. علاوةً على ذلك، وُجد أن الكثير من البرامج تعاني من أخطاء تجاوز سعة المخزّن المؤقَّت وكثيرًا ما تُذاع أخبار عن تلك الأخطاء، حيث ترتبط كتيرًا بالمشاكل المتعلقة بأمن الشبكة network security، فعندما يَستقبِل حاسوب ما بياناتٍ من حاسوبٍ آخر عبر الشبكة، فستُخزن تلك البيانات في مخزن مؤقت buffer، إذ تستطيع البرامج أن تخصِّص أجزاءً من الذاكرة للمخزنات المؤقتة لكي تحمل البيانات التي يُتوقَّع أن تستقبلها؛ حيث تَحدث أخطاء تجاوز سعة المخزن المؤقت عندما يَستقبل بيانات حجمها أكبر من سعته، وهنا يَطرح السؤال التالي نفسه: ماذا يحدث في تلك الحالة؟ إذا اكتشف هذا البرنامج أو برنامج الاتصال الشبكي ذلك الخطأ، فستفشل عملية نقل البيانات عبر الشبكة، بينما تَقَع المشكلة الحقيقية عندما لا يكتشف البرنامج حدوث ذلك؛ وفي تلك الحالة سيستمر البرنامج في تخزين البيانات في الذاكرة حتى بعد امتلاء المخزن المؤقت، وبالتالي ستُخزَّن البيانات الإضافية في مكانٍ في الذاكرة لم يَكُن مُخصصا ليكون جزءًا من المخزِّن المؤقت؛ وقد يُستخدم ذلك المكان لبعض الأغراض الأخرى، أو قد يحتوي على بيانات مهمة، أو على أجزاء من البرنامج نفسه، وهنا تكمن المشاكل الأمنية الحقيقية. لنفترض أن خطأ تجاوز سعة المخزِّن المؤقّت قد استبدَل بعض البيانات الإضافية المستقبَلة عبر الشبكة بأجزاء من البرنامج نفسه، فعندما يُنفِّذ البرنامج ذلك الجزء من البرنامج المستبدَل، فإنه سينفِّذ البيانات المستقبَلة من حاسوبٍ آخر، وقد تحتوي تلك البيانات على أي شيء قد يتسبب في انهيار الحاسوب أو التحكم به، وإذا عثر مبرمج ضار malicious على خطأ من ذلك النوع في برنامج يعمل عبر الشبكة؛ فسيستغله ليخدع الحواسيب الأخرى لكي تنفَّذ برامجه. أما بالنسبة للبرامج المكتوبة بالكامل بلغة جافا، فإن أخطاء تجاوز سعة المخزِّن المؤقت غير ممكنة؛ وذلك لأن اللغة لا توفِّر أي طريقة لتخزين البيانات في مواضع الذاكرة غير المخصصة لها، ولكي تفعل ذلك، ستحتاج إلى مؤشِّر يشير إلى موضع غير مخصَّص في الذاكرة، أو يشير إلى موضع مصفوفة يقع خارج نطاقها المسموح به؛ وكما أوضحنا سابقًا، لا تسمح جافا بوقوع أي من الأمرين، ومع ذلك ربما ما تزال هناك بعض الأخطاء في تصنيفات جافا القياسية Java standard classes، لأن بعض التوابع methods ضمن تلك التصنيفات تُكتب بلغة سي بدلًا من جافا. يتضح لنا الآن أن تصميم لغة البرمجة قد يساعد على منع الأخطاء أو اكتشافها عند حدوثها. على الرغم من أنه قد يقيِّد بعضًا مما يفعله المبرمِج أو يتطلّب إجراء اختبارات، مثل فحص ما إذا كان المؤشر فارغًا أم لا، وهو ما يستغرق وقتًا أطول للمعالجة، ويرى بعض المبرمجين أن التضحية بالقوة والكفاءة تكلفة كبيرة لزيادة الحماية، وقد يصح ذلك في بعض التطبيقات، إلا أن هناك الكثير من المواقف الأخرى التي تكون فيها الأولوية للحماية والأمن، إذ صُممت لغة جافا لتلك المواقف. مشاكل متبقية بجافا اختار مصممي جافا ألا تُحدَّد الأخطاء المتعلقة بالحسابات العددية بصورةٍ تلقائية؛ فمثلاً بلغة جافا، تُمثِّل أي قيمةٍ من نوع int عددًا ثنائيًا 32 bits يمكِنه أن يحمل ما يصل إلى أكثر بقليل من أربعة بلايين قيمة مختلفة، إذ تتراوح قيم النوع int من -2147483648 إلى 2147483647، فماذا يحدث إذًا عندما تقع نتيجة حسبةٍ معينةٍ خارج ذلك النطاق؟ فمثلًا، ما هو مجموع 2147483647+1؟ أو ما هو حاصل ضرب 2000000000*2؟ في الحالتين، لا تُمثَّل النتيجة الصحيحة حسابيًا مثل قيمة من النوع int، إذ يشار إلى ذلك عادةً باسم تجاوز المتغير العددي integer overflow، وهو ما ينبغي أن يُعامل مثل نوع من الخطأ، ومع ذلك لا تُحدِّد جافا هذا النوع من الأخطاء بصورةٍ تلقائية، إذ تعيد جافا العدد -2147483648 مثلًا، مثل قيمةٍ لحاصل مجموع 2147483647+1، أي أنها تُحوِّل القيم الأكبر من 2147483647 إلى قيم سالبة. انظر إلى مسألة 3N+1، والتي ناقشناها سابقًا في القسم الفرعي 3.2.2، يحسب البرنامج التالي متتاليةً محددةً من الأعداد الصحيحة بدءًا من عددٍ صحيحٍ موجب N: while ( N != 1 ) { if ( N % 2 == 0 ) // If N is even... N = N / 2; else N = 3 * N + 1; System.out.println(N); } إذا كانت قيمة N كبيرةً جدًا، فستجد هنا مشكلة؛ إذ لن تكون قيمة 3N+1 صحيحةٌ رياضيًا نتيجةً لحدوث ما يعرف بتجاوز المتغيِّر العددي، وستظهر المشكلة تحديدًا عندما تزيد قيمة 3N+1 عن 2147483647 أي عندما تزيد قيمة N عن 2147483646/3. ولكي نُصحِّح ذلك الخطأ، لابد أن نفحص تلك الاحتمالية أولًا كالتالي: while ( N != 1 ) { if ( N % 2 == 0 ) // If N is even... N = N / 2; else { if (N > 2147483646/3) { System.out.println("Sorry, but the value of N has become"); System.out.println("too large for your computer!"); break; } N = 3 * N + 1; } System.out.println(N); } لا يمكننا أن نختبر الآتي if (3*N+1 > 2147483647) بصورةٍ مباشرة، فمن المُلاحظ أن المشكلة هنا ليست في وجود خطأ في خوارزمية حساب قيم متتالية الأعداد 3N+1، وإنما تكمن في عدم إمكانية تنفيذ الخوارزمية باستخدام نوع عددي صحيح 32 Bits، وبينما تتجاهل الكثير من البرامج هذا النوع من المشكلات، فقد ثَبتَت مسؤولية تجاوز المتغير العددي عن عدد لا بأس به من مشكلات فشل الحواسيب، ولذلك لابد لأي برنامجٍ متينٍ وضع تلك الاحتمالية في الحسبان؛ إذ عُدَت المشكلة البرمجية Y2K سيئة السمعة في بداية عام 2000 نوعًا من تلك الأخطاء. تعاني الأعداد من النوع double من مشكلاتٍ أكثر، كما تتواجد أيضًا مشكلة تجاوز المتغير العددي والتي تحدث عندما يتعدَّى ناتج حسبة معينة النطاق المسموح به للنوع double، أي 1.7*10^308. وبخلاف النوع int، لا تتحوَّل الأعداد في تلك الحالة إلى قيمٍ سالبةٍ، وإنما تعيد البرامج عندها قيمًا خاصةً ليس لها أيّ معنى عددي مكافئٍ، حيث تُمثِّل القيم الخاصة الآتية: Double.POSITIVE_INFINITY. Double.NEGATIVE_INFINITY. الأعداد من خارج النطاق المسموح به، بحيث يعيد الناتج 20*1e308 القيمة Double.POSITIVE_INFINITY، كما تمثِّل القيمة الخاصة Double.NaN النتائج غير المعرَّفة أو غير الصالحة، حيث تكون نتيجة قسمة صفر على صفر أو حساب الجذر التربيعي لعددٍ سالبٍ مثلًا مساويةً للقيمة Double.Nan، ويُمكِنك استدعاء الدالة Double.isNaN(x) لتَختبِر إذا ما كان عددٌ معينٌ x يحتوي على القيمة الخاصة Double.Nan أم لا. إلى جانب ما سبق، هناك جانب آخر من التعقيد يكمن في أن غالبية الأعداد الحقيقية تمثَّل بصورةٍ تقريبية فقط؛ وذلك لأنها تحتوي على عدد لا نهائي من الأرقام العشرية، حيث تصِل دقة الأرقام العشرية في النوع double إلى 15 رقم، فالعدد الحقيقي 1/3 هو الرقم المكرر …0.3333333333، فلا يمكن تمثيله بدقة متناهية باستخدام عدد محدود من الأرقام، ولذلك فإن الحسابات المتضمنة لأعداد حقيقية ليست دقيقةً تمامًا. في الواقع، يُعَد علم التحليل العددي numerical analysis أحد علوم الحاسوب المخصَّصة لدراسة الخوارزميات التي تتعامل مع الأعداد الحقيقية، إذًا لا تُحدِّد جافا جميع أنواع الأخطاء الممكنة تلقائيًا، وحتى عندما تكتشف الخطأ بصورةٍ تلقائيةِ فسيبلَّغ عن الخطأ ويُغلق النظام بصورةٍ افتراضية، وهو تصرُّف لا يصدر عن برنامج يتمتع بالمتانة الكافية، فما يزال المبرمج بحاجةٍ إلى تعلم التقنيات اللازمة ليتجنب الأخطاء ويتعامل معها، وهو موضوع الأقسام الثلاثة القادمة. ترجمة -بتصرّف- للقسم Section 1: Introduction to Correctness and Robustness من فصل Chapter 8: Correctness, Robustness, Efficiency من كتاب Introduction to Programming Using Java. اقرأ أيضًا المقال السابق: المصفوفات ثنائية البعد Two-dimensional Arrays في جافا كيفية إنشاء عدة خيوط وفهم التزامن في جافا1 نقطة
يُعَد عمل البرنامج صحيحًا إذا أنجز المَهمَّة المُوكَلة إليه بصورةٍ صائبة، بينما يُعَد البرنامج متينًا robust إذا عالَج قِيم المُدخَلات غير الصالحة أو غيرها من المواقف غير المُتوقَّعة على نحوٍ مقبولٍ، فمثلًا إذا صُمِّم برنامج لقراءة مجموعةٍ من الأعداد المدخَلة من قِبل المستخدِم ثم طباعتها بصورةٍ مرتّبة، فسيعمل البرنامج بصورةٍ صحيحةٍ إذا أعاد حاصل المجموع الصحيح لأي أعدادٍ مدخَلةٍ، بينما سيكون متينًا إذا طُبعت رسالة خطأ مع المدخَلات غير العددية أو تم تجاهلها؛ أما البرامج غير المتينة فقد تنهار في هذه الحالة أو تعطي خرجًا غير مقبول. لابدّ لأي برنامجٍ أن يعمل بصورةٍ صحيحة؛ فما الفائدة إذًا من برنامج ترتيب sorting لا ينجز عملية الترتيب بصورة سليمة؟ وليس من الضروري دائمًا أن يكون البرنامج متينًا بالكامل، فذلك يعتمد على المستخدم وطريقة استخدامه؛ فمثلًا لا يُشترط لبرنامج مساعدة صغيرٍ كتبته لنفسك أن يكون متينًا. يعتمد عملُ المبرمِج على توصيف specification ما يُفترَض أن يعمل به البرنامج، ويصح عمل المبرمِج إذا توافق البرنامج مع توصيفه، ولكن هل يعني ذلك أن البرنامج نفسه سيكون صحيحًا؟ وماذا لو كان التوصيف غير صحيح أو غير كامل؟ في الواقع، يُعرَّف البرنامج الصحيح على أنه تنفيذ implementation صحيح لتوصيف صحيح وكاملٍ؛ الأمر الذي ينقلنا إلى السؤال عمَّا إذا ما كان التوصيف يعبِّر عن نية مستخدمي البرنامج ورغباتهم تعبيرًا صحيحًا أم لا؛ إلا أن هذا السؤال يقع خارج مجال علوم الحاسوب. قصص مرعبة لقد حظى معظم مستخدمي الحاسوب بتجربةٍ مع تعطل البرامج أثناء تشغيلها أو حتى انهيارها بالكامل، فعادةً ما تسبب تلك المشاكل الضجر للمستخدمين، كما قد تتسبب أيضًا في نتائج أخطر من ذلك بكثيرٍ مثل خسارة عملٍ مهم أو خسارة نقود؛ فببساطة عندما تُسند مهمات جدية للحاسوب، فسيتوقع أن تكون توابع فشلها بنفس جدية تلك المهمات. منذ عشرين عامًا، فشلت بعثتي فضاء إلى المريخ بتكاليف تصل إلى ملايين الدولارات، ورجح أن سبب الفشل في كلتا الحالتين كان نتيجةً لمشاكل برمجية، ومع ذلك لم تكن المشكلة بسبب برنامج مكتوب بطريقة خاطئة، ففي سبتمبر 1999، احترقت مركبة المريخ المناخية المدارية Mars Climate Orbiter في الغلاف الجوي للمريخ، وذلك نتيجةً لإدخال البيانات بوحدة القياس الإنجليزية مثل القدم والرطل إلى برنامج حاسوب صُمم لاستقبال قياسات بوحدات قياس النظام العالمي مثل السنتيمتر والجرام؛ كما تحطمت بعد أشهر قليلة مركبة الهبوط على قطب المريخ Mars Polar Lander، وذلك لأن البرنامج أغلق محركات الهبوط قبل الهبوط الفعلي للمركبة، إذ صُمِّم البرنامج ليغلق المحركات عندما يستشعر أي ارتطام أثناء هبوط المركبة الفضائية، واتضح بعد ذلك أن معدات الهبوط اهتزت بصورة شديدة حتى فُعِّل نظام الارتطام، وعليه أُغلِقت المحركات بينما كانت المركبة ما تزال مرتفعةً عن الأرض، الأمر الذي أدى لسقوطها على سطح المريخ. فإذا كان البرنامج أكثر متانةً، لَفحَص ارتفاعها عن الأرض قبل أن يغلق المحركات. وهناك حكاياتٌ أخرى بنفس المأساوية تسببت فيها برامج لا تعمل بصورة صحيحة، أو رديئة لا تعمل بكفاءةٍ جيدة؛ وفيما يلي بعضًا من الحوادث القليلة المسرودة في كتاب "أخلاقيات الحاسوب Computer Ethics" للكاتبين Tom Forester وPerry Morrison، والذي يُناقِشان فيه قضايا أخلاقية مختلفة تتعلّق بالحوسبة، وسنذكر منها الآتي: تسببت جرعة إشعاع مفرطة في عاميْ 1985 و1986 في قتل شخص وإصابة آخرين أثناء خضعوهم لعلاج إشعاعيٍ نتيجة لبرمجة آلة الإشعاع الحاسوبية بصورة خاطئة؛ كما تَعرّض حوالي 1000 مصاب بالسرطان لجرعات إشعاع أقلّ من الموصوفة لهم بحوالي 30% بسبب خطأ برمجي آخر في عام 1992، أي بعد 6 سنوات من الحالة السابقة تقريبًا. حذَف حاسوب في بنك نيويورك معاملات جارية بسبب خطأ برمجي، الأمر الذي استغرق قرابة 24 ساعة لإصلاح المشكلة، وحينها دفع البنك فائدة تقدر بـحوالي 5,000,000 دولار على المدفوعات التي اقترضها لتغطية المشكلة، وذلك في عام 1985. اكتُشف خطأ خلال محاكاة برمجة نظام التوجيه بالقصور الذاتي المستخدم في مقاتلة F-16، الأمر الذي كان سيتسبب في قلب الطائرة رأسًا على عقب بعد عبورها لخط الاستواء، كما فُقد مكوك الفضاء Mariner 18 بسبب خطأ برمجي في سطر واحد من برنامج تشغيله، وكذلك تجاوزت كبسولة الفضاء Gemini V موقع هبوطها المقرر بمائة ميل، حيث نسي المبرمج أن يأخذ في حسبانه دوران الأرض. في عام 1990، تعطلت خدمة هاتف AT&T في الولايات المتحدة الأمريكية بعد اكتشاف خطأ برمجي في نسختها المحدثة. بالطبع، هناك مشاكلٌ أخرى أحدث من ذلك، فمثلًا ساهم خطأ برمجي في أحد أكبر انقطاعات التيار الكهربي في التاريخ في شمال شرق أمريكا عام 2003، وفي عام 2006 تأخرت طائرة Airbus A380 بسبب مشاكل عدم توافُق البرمجيات، حيث كلَّفتها خسائر تصل إلى بلايين الدولارات، كما أدى خطأ برمجي في عام 2007 إلى تَوقُّف الآلاف من الطائرات في مطار Los Angeles الدولي، كما تسبَّب خطأ في برنامج تداول آلي في انخفاض مؤشِّر داو جونز الصناعي بحوالي 1000 نقطة، وذلك في مايو 2010. هذه بعض الأمثلة القليلة، فمن المعروف أن المشاكل البرمجية تنتشر بكثرة، وعلينا نحن المبرمجين أن نفهَم سبب ذلك وما الذي يمكن أن نفعله حِيال ذلك؟ المنقذ جافا وفقًا لمطوري لغة جافا، يعود سبب المشكلة إلى طريقة تصميم اللغات البرمجية ذاتها، ولهذا صُممت جافا بطريقة توفِّر حمايةً من تلك النوعية من الأخطاء. قد تتساءل عن كيف يمكن لخاصيةٍ في اللغة أن تمنع حدوث مثل تلك الأخطاء؟ ولهذا دعنا نفحَص بعض الأمثلة. لا تتطلب بعض لغات البرمجة تعريف المتغيرات قبل استخدامها، حيث يُنشَئ المتغير تلقائيًا عندما تستخدمه لأول مرة ضِمن برنامج كُتب بإحدى تلك اللغات، وقد ترى أن ذلك مناسبٌ أكثر من تعريف عن كلِّ متغير على حدة، الأمر الذي قد يكون صحيحًا أحيانًا، إلا أنه قد يؤدِّي إلى نتائج مؤسفة، فقد يَتسبَّب خطأ إملائي في إنشاء متغير جديد مثلًا دون أي نية لذلك؛ وفي الواقع، يقال أن خطأ مماثلًا كان هو المسئول عن فقدان سفينة فضاء؛ فلتُكتَب حلقة عدِّ بلغة FORTRAN مثلًا؛ فسيُستخدَم الأمر DO 20 I = 1,5، ولمَّا كانت المسافات غير مهمة بلغة FORTRAN، فستكافئ التعليمَة السابقة الأمر DO20I=1,5، بينما يمثل الأمر DO20I=1.5 (في حال استبدلنا الفاصلة بنقطةٍ) تعليمة إسناد assignment، فتسند القيمة 1.5 إلى متغير اسمه DO20I، يمكنك ملاحظة كيف تسبب استبدالٌ غير مقصود في تعليمة مماثلة إلى انفجار الصاروخ أثناء الاقلاع؛ ونظرًا لأن لغة FORTRAN لا تتطلب تعريفًا للمتغيرات، فسيقبل المحرر تعليمةً مثل DO20I=1.5، وينشِئ متغيرًا جديدًا اسمه DO20I، بينما إذا كانت FORTRAN تتطلب تعريف المتغيِّرات أولًا، فسيُظهر المحرِّر رسالة خطأ، كون المتغير DO20I لم يُعرَّف بَعد. عمومًا، تتطلب غالبية لغات البرمجة حاليًا تعريف المتغيرات قبل استخدامها، وبالرغم من ذلك ما تزال هناك خاصيات أخرى يكثر استخدامها رغم أنها قد تتسبب في حدوث المشكلات؛ وقد ألغت جافا بعضًا من تلك الخاصيات. وبينما يشكو بعض المبرمجين من أن ذلك يقلل من قوة وكفاءة اللغة، إلا أن هذا النقد قد يكون عادلًا إلى حدٍ ما، إذ تستحق زيادة أمن ومتانة اللغة تلك التكلفة في غالبية الأحوال، فأفضل دفاع ضد بعض الأخطاء هو تصميم اللغة بصورةٍ يستحِيل معها حدوث تلك الأخطاء من الأساس. في حالات أخرى، لا يسهل التخلص من الخطأ بصورةٍ كاملة، وعندها تصمَّم لغة البرمجة بطريقةٍ تمكنها من اكتشاف تلك الأخطاء عندما تحدث بصورة تلقائية، وتمنعها من التسبب في حدوث المشاكل البرمجية؛ حيث تنبه المبرمج إلى وجود خطأ برمجي ينبغي تصحيحه؛ ولنفحَص مجموعةً من الحالات التي اتبعها مصمِّمي جافا. تتكون أي مصفوفةٍ من عدد محدَّد من العناصر، بحيث تُرقم من الصفر إلى قيمة عظمى معينة، وبالطبع من الخطأ استخدام عنصر مصفوفة من خارج ذلك النطاق؛ ولهذا تكتشف جافا أي محاولة لفعل ذلك بصورةٍ تلقائيةٍ، بينما تُلقِي بعض لغات البرمجة الأخرى مثل C وC++ مسؤولية التأكد من استخدام العنصر ضمن النطاق المسموح به للمبرمِج. سَنفترِض أن لدينا مصفوفةً A تتكون من ثلاثة عناصر A[0] وA[1] وA[2]، أي أن عناصر مثل A[3] وA[4] تشير إلى مواضع تقع خارج المصفوفة؛ بلغة جافا، ستُكتشف أي محاولةٍ لتخزين بياناتٍ في العنصر A[3] بصورةٍ تلقائية، ولا ينتهي البرنامج إلا إذا التقط catching الخطأ كما ناقشنا في القسم 3.7؛ أما بلغتي C وC++، فسيخزِّن الحاسوب البيانات في موضع في الذاكرة رغم أنه لا يُعَد جزءًا من المصفوفة، ولأن معرفة الغرض من موضعٍ معينٍ في الذاكرة غير ممكنٍ، فلن نتوقَّع النتائج، إلا أنها قد تكون أكثر خطورةً بكثيرٍ من مجرد انتهاء البرنامج (سنناقش لاحقًا في هذا القسم مثال خطأ تجاوز سعة المُخزِّن المؤقَّت buffer overflow). تُعَد المؤشرات pointers في العموم مصدرًا شائعًا للأخطاء البرمجية، ويحمل أي متغيِّر كائني النوع object type في جافا مؤشرًا يشير إما إلى كائن أو قيمة خاصة null، وبهذا يكتشف النظام أي محاولةٍ تستخدم القيمة الخاصة null على أنها مؤشر إلى كائن فعلي، بينما في المقابل، تلقي بعض لغات البرمجة الأخرى مسئولية تجنب أخطاء المؤشر الفارغ null pointer على المبرمج، وفي الواقع نُفذ implement المؤشر الفارغ بحواسيب ماكنتوش Macintosh على أنه مؤشر إلى موضع الذاكرة 0؛ ولسوء الحظ كانت تلك الحواسيب تُخزِّن بعض بيانات النظام المهمة ضمن تلك المواضع، وكان من الممكن لأي برنامج أن يستخدم مؤشرًا فارغًا ليعدّل القيم المُخزَّنة بالقرب من الموضع 0 في الذاكرة، الأمر الذي قد يؤدي إلى انهيار النظام بالكامل، وهي نتيجة أسوأ بكثير من مجرد انهيار برنامجٍ واحدٍ بكل تأكيد. يَحدُث نوع آخر من أخطاء المؤشر عندما يُضبط مؤشر إلى كائن من غير النوع الصحيح أو إلى جزء من الذاكرة لا يَحمل كائنًا صالحًا من الأساس، وهذا النوع من الأخطاء لا يحدث في جافا لأنها لا تسمح للمبرمجين بالتعامل مع المؤشِّرات تعاملًا مباشرًا، بينما في المقابل، تسمح بعض لغات البرمجة الأخرى بضبط مؤشر معين، بحيث يشير إلى أي موضع في الذاكرة؛ وإذا حدث ذلك بطريقةٍ خاطئة، فإنه قد يؤدي إلى نتائج غير متوقعة. تسريب الذاكرة memory leak هو نوع آخر من الأخطاء غير الممكنة في لغة جافا، فعندما لا يوجد أي مؤشِّرٍ آخر إلى كائن معين، فسيحرر جامع المهملات garbage collector ذلك الكائن وتصبح المساحة التي احتلها قابلةً لإعادة الاستخدام مرةً أخرى؛ بينما في لغات أخرى، تقع مسؤولية تحرير الذاكرة غير المُستخدَمة على عاتق المبرمج، وإذا فشل المبرمج في ذلك، فستتراكم الذاكرة غير المستخدمة، بحيث تترك مساحةً أقل للبرامج والبيانات. يُقال إن أغلب برامج نظام التشغيل ويندوز Windows القديمة تعاني كثيرًا من مشكلات تسريب الذاكرة، الأمر الذي يتسبب في نفاذ ذاكرة الحاسوب بعد أيام قليلة من الاستخدام، ولذلك تصبح إعادة تشغيل الحاسوب عمليةً ضروريةً. علاوةً على ذلك، وُجد أن الكثير من البرامج تعاني من أخطاء تجاوز سعة المخزّن المؤقَّت وكثيرًا ما تُذاع أخبار عن تلك الأخطاء، حيث ترتبط كتيرًا بالمشاكل المتعلقة بأمن الشبكة network security، فعندما يَستقبِل حاسوب ما بياناتٍ من حاسوبٍ آخر عبر الشبكة، فستُخزن تلك البيانات في مخزن مؤقت buffer، إذ تستطيع البرامج أن تخصِّص أجزاءً من الذاكرة للمخزنات المؤقتة لكي تحمل البيانات التي يُتوقَّع أن تستقبلها؛ حيث تَحدث أخطاء تجاوز سعة المخزن المؤقت عندما يَستقبل بيانات حجمها أكبر من سعته، وهنا يَطرح السؤال التالي نفسه: ماذا يحدث في تلك الحالة؟ إذا اكتشف هذا البرنامج أو برنامج الاتصال الشبكي ذلك الخطأ، فستفشل عملية نقل البيانات عبر الشبكة، بينما تَقَع المشكلة الحقيقية عندما لا يكتشف البرنامج حدوث ذلك؛ وفي تلك الحالة سيستمر البرنامج في تخزين البيانات في الذاكرة حتى بعد امتلاء المخزن المؤقت، وبالتالي ستُخزَّن البيانات الإضافية في مكانٍ في الذاكرة لم يَكُن مُخصصا ليكون جزءًا من المخزِّن المؤقت؛ وقد يُستخدم ذلك المكان لبعض الأغراض الأخرى، أو قد يحتوي على بيانات مهمة، أو على أجزاء من البرنامج نفسه، وهنا تكمن المشاكل الأمنية الحقيقية. لنفترض أن خطأ تجاوز سعة المخزِّن المؤقّت قد استبدَل بعض البيانات الإضافية المستقبَلة عبر الشبكة بأجزاء من البرنامج نفسه، فعندما يُنفِّذ البرنامج ذلك الجزء من البرنامج المستبدَل، فإنه سينفِّذ البيانات المستقبَلة من حاسوبٍ آخر، وقد تحتوي تلك البيانات على أي شيء قد يتسبب في انهيار الحاسوب أو التحكم به، وإذا عثر مبرمج ضار malicious على خطأ من ذلك النوع في برنامج يعمل عبر الشبكة؛ فسيستغله ليخدع الحواسيب الأخرى لكي تنفَّذ برامجه. أما بالنسبة للبرامج المكتوبة بالكامل بلغة جافا، فإن أخطاء تجاوز سعة المخزِّن المؤقت غير ممكنة؛ وذلك لأن اللغة لا توفِّر أي طريقة لتخزين البيانات في مواضع الذاكرة غير المخصصة لها، ولكي تفعل ذلك، ستحتاج إلى مؤشِّر يشير إلى موضع غير مخصَّص في الذاكرة، أو يشير إلى موضع مصفوفة يقع خارج نطاقها المسموح به؛ وكما أوضحنا سابقًا، لا تسمح جافا بوقوع أي من الأمرين، ومع ذلك ربما ما تزال هناك بعض الأخطاء في تصنيفات جافا القياسية Java standard classes، لأن بعض التوابع methods ضمن تلك التصنيفات تُكتب بلغة سي بدلًا من جافا. يتضح لنا الآن أن تصميم لغة البرمجة قد يساعد على منع الأخطاء أو اكتشافها عند حدوثها. على الرغم من أنه قد يقيِّد بعضًا مما يفعله المبرمِج أو يتطلّب إجراء اختبارات، مثل فحص ما إذا كان المؤشر فارغًا أم لا، وهو ما يستغرق وقتًا أطول للمعالجة، ويرى بعض المبرمجين أن التضحية بالقوة والكفاءة تكلفة كبيرة لزيادة الحماية، وقد يصح ذلك في بعض التطبيقات، إلا أن هناك الكثير من المواقف الأخرى التي تكون فيها الأولوية للحماية والأمن، إذ صُممت لغة جافا لتلك المواقف. مشاكل متبقية بجافا اختار مصممي جافا ألا تُحدَّد الأخطاء المتعلقة بالحسابات العددية بصورةٍ تلقائية؛ فمثلاً بلغة جافا، تُمثِّل أي قيمةٍ من نوع int عددًا ثنائيًا 32 bits يمكِنه أن يحمل ما يصل إلى أكثر بقليل من أربعة بلايين قيمة مختلفة، إذ تتراوح قيم النوع int من -2147483648 إلى 2147483647، فماذا يحدث إذًا عندما تقع نتيجة حسبةٍ معينةٍ خارج ذلك النطاق؟ فمثلًا، ما هو مجموع 2147483647+1؟ أو ما هو حاصل ضرب 2000000000*2؟ في الحالتين، لا تُمثَّل النتيجة الصحيحة حسابيًا مثل قيمة من النوع int، إذ يشار إلى ذلك عادةً باسم تجاوز المتغير العددي integer overflow، وهو ما ينبغي أن يُعامل مثل نوع من الخطأ، ومع ذلك لا تُحدِّد جافا هذا النوع من الأخطاء بصورةٍ تلقائية، إذ تعيد جافا العدد -2147483648 مثلًا، مثل قيمةٍ لحاصل مجموع 2147483647+1، أي أنها تُحوِّل القيم الأكبر من 2147483647 إلى قيم سالبة. انظر إلى مسألة 3N+1، والتي ناقشناها سابقًا في القسم الفرعي 3.2.2، يحسب البرنامج التالي متتاليةً محددةً من الأعداد الصحيحة بدءًا من عددٍ صحيحٍ موجب N: while ( N != 1 ) { if ( N % 2 == 0 ) // If N is even... N = N / 2; else N = 3 * N + 1; System.out.println(N); } إذا كانت قيمة N كبيرةً جدًا، فستجد هنا مشكلة؛ إذ لن تكون قيمة 3N+1 صحيحةٌ رياضيًا نتيجةً لحدوث ما يعرف بتجاوز المتغيِّر العددي، وستظهر المشكلة تحديدًا عندما تزيد قيمة 3N+1 عن 2147483647 أي عندما تزيد قيمة N عن 2147483646/3. ولكي نُصحِّح ذلك الخطأ، لابد أن نفحص تلك الاحتمالية أولًا كالتالي: while ( N != 1 ) { if ( N % 2 == 0 ) // If N is even... N = N / 2; else { if (N > 2147483646/3) { System.out.println("Sorry, but the value of N has become"); System.out.println("too large for your computer!"); break; } N = 3 * N + 1; } System.out.println(N); } لا يمكننا أن نختبر الآتي if (3*N+1 > 2147483647) بصورةٍ مباشرة، فمن المُلاحظ أن المشكلة هنا ليست في وجود خطأ في خوارزمية حساب قيم متتالية الأعداد 3N+1، وإنما تكمن في عدم إمكانية تنفيذ الخوارزمية باستخدام نوع عددي صحيح 32 Bits، وبينما تتجاهل الكثير من البرامج هذا النوع من المشكلات، فقد ثَبتَت مسؤولية تجاوز المتغير العددي عن عدد لا بأس به من مشكلات فشل الحواسيب، ولذلك لابد لأي برنامجٍ متينٍ وضع تلك الاحتمالية في الحسبان؛ إذ عُدَت المشكلة البرمجية Y2K سيئة السمعة في بداية عام 2000 نوعًا من تلك الأخطاء. تعاني الأعداد من النوع double من مشكلاتٍ أكثر، كما تتواجد أيضًا مشكلة تجاوز المتغير العددي والتي تحدث عندما يتعدَّى ناتج حسبة معينة النطاق المسموح به للنوع double، أي 1.7*10^308. وبخلاف النوع int، لا تتحوَّل الأعداد في تلك الحالة إلى قيمٍ سالبةٍ، وإنما تعيد البرامج عندها قيمًا خاصةً ليس لها أيّ معنى عددي مكافئٍ، حيث تُمثِّل القيم الخاصة الآتية: Double.POSITIVE_INFINITY. Double.NEGATIVE_INFINITY. الأعداد من خارج النطاق المسموح به، بحيث يعيد الناتج 20*1e308 القيمة Double.POSITIVE_INFINITY، كما تمثِّل القيمة الخاصة Double.NaN النتائج غير المعرَّفة أو غير الصالحة، حيث تكون نتيجة قسمة صفر على صفر أو حساب الجذر التربيعي لعددٍ سالبٍ مثلًا مساويةً للقيمة Double.Nan، ويُمكِنك استدعاء الدالة Double.isNaN(x) لتَختبِر إذا ما كان عددٌ معينٌ x يحتوي على القيمة الخاصة Double.Nan أم لا. إلى جانب ما سبق، هناك جانب آخر من التعقيد يكمن في أن غالبية الأعداد الحقيقية تمثَّل بصورةٍ تقريبية فقط؛ وذلك لأنها تحتوي على عدد لا نهائي من الأرقام العشرية، حيث تصِل دقة الأرقام العشرية في النوع double إلى 15 رقم، فالعدد الحقيقي 1/3 هو الرقم المكرر …0.3333333333، فلا يمكن تمثيله بدقة متناهية باستخدام عدد محدود من الأرقام، ولذلك فإن الحسابات المتضمنة لأعداد حقيقية ليست دقيقةً تمامًا. في الواقع، يُعَد علم التحليل العددي numerical analysis أحد علوم الحاسوب المخصَّصة لدراسة الخوارزميات التي تتعامل مع الأعداد الحقيقية، إذًا لا تُحدِّد جافا جميع أنواع الأخطاء الممكنة تلقائيًا، وحتى عندما تكتشف الخطأ بصورةٍ تلقائيةِ فسيبلَّغ عن الخطأ ويُغلق النظام بصورةٍ افتراضية، وهو تصرُّف لا يصدر عن برنامج يتمتع بالمتانة الكافية، فما يزال المبرمج بحاجةٍ إلى تعلم التقنيات اللازمة ليتجنب الأخطاء ويتعامل معها، وهو موضوع الأقسام الثلاثة القادمة. ترجمة -بتصرّف- للقسم Section 1: Introduction to Correctness and Robustness من فصل Chapter 8: Correctness, Robustness, Efficiency من كتاب Introduction to Programming Using Java. اقرأ أيضًا المقال السابق: المصفوفات ثنائية البعد Two-dimensional Arrays في جافا كيفية إنشاء عدة خيوط وفهم التزامن في جافا1 نقطة -
ال epoch هو عملية مرور على كامل بيانات التدريب التي لديك، فمثلاً إذا كان لديك 5000 عينة تدريبية، مقسمة إلى 100 باتش-حزمة- (مفهوم ال Mini-Batches) وبالتالي سيكون لدينا حجم كل باتش batch-size يساوي 50 عينة. هذا يعني أنه عند المرور على كامل البيانات (ال 5000 عينة) سنكون قد قمنا ب 100 iteration أي 100 عملية forward و backward على البيانات (مرور على البيانات ثم تحديث قيم الأوزان في الشبكة). وهذا هو الفرق، ولهذا السبب نستخدم مفهوم ال epoch بدلاً من ال iteration فهو أعم، ونحتاجه في حالة التعامل مع ال Mini-Batches.1 نقطة




.png.27fbbf0ac45e9622eaa83bd2d2bcfb17.png)
.png.9862820c80e8b9764bc5d3001574bdb2.png)