لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/23/21 في كل الموقع
-
يعتبر هذا التابع تابع لوجيستي "logistic function" وهو تابع غير خطي، الشكل الرياضي له: g=sigmoid(x) = 1 / (1 + exp(-x)). والشكل البياني لهذا التابع هو كالتالي: نلاحظ من الخط البياني للتابع أن قيمه تتراوح بين 0 و 1، حيث: عندما z=-∞ تكون قيمة التابع g=0 وعندما z=0 يكون g=0.5 وعندما z=+∞ يكون g=1. ومن الرسم البياني نلاحظ أنه يمكن استخدامه في تدريب النماذج (أقصد أنه يعطي قيماً مختلفة عن الصفر أي هناك تغيرات في ميل المماس)، وكما نلاحظ من الرسم (المنحني الأزرق) فإن المشتق تكون قيمه فعالة للتدريب عندما تكون قيم z قريبة من الصفر ولكن من أجل قيم كبيرة جداً أو صغيرة جداً فلن تكون فعالة في التدريب لأن المماس يكون شبه مستقيم وبالتالي قيمة المشتقة تكون صغيرة جداً، مما يؤدي الى بطء شديد في عملية التدريب وبالتالي مكلف من الناحية الحسابية. إن الاستخدام الشائع والأهم والأفضل لهذا التابع هو استخدامه كمصنف في آخر طبقة من نموذج عندما تكون المهمة مهمة تصنيف ثنائي حيث أن خرجه يكون قيمة احتمالية بين 0 و 1 وبالتالي خيار ممتاز لمهام التصنيف الثنائي. وفي كيراس وتنسرفلو له الشكل التالي: tf.keras.activations.sigmoid(x) مثال: a = tf.constant([-20, -1.0, 0.0, 1.0, 20], dtype = tf.float32) b = tf.keras.activations.sigmoid(a) b.numpy() # الخرج array([2.0611537e-09, 2.6894143e-01, 5.0000000e-01, 7.3105860e-01, 1.0000000e+00], dtype=float32) لاستخدامه في نماذجك، يمكنك استخدامه في أي طبقة، لكن كما ذكرت يفضل استخدامه فقط في آخر طبقة عندما تكون المهمة مهمة تصنيف ثنائي كما في المثال التالي: from keras.datasets import imdb from keras import preprocessing max_features = 10000 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) # هنا حددنا طول الكلمات ب 20 x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) # بناء نموذجك from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # آخر طبقة model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() # تدريبه history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)2 نقاط
-
واجهة تنسرفلو تم تحديثها من set_random_seed() إلى set_seed(): import tensorflow as tf tf.random.set_seed()1 نقطة
-
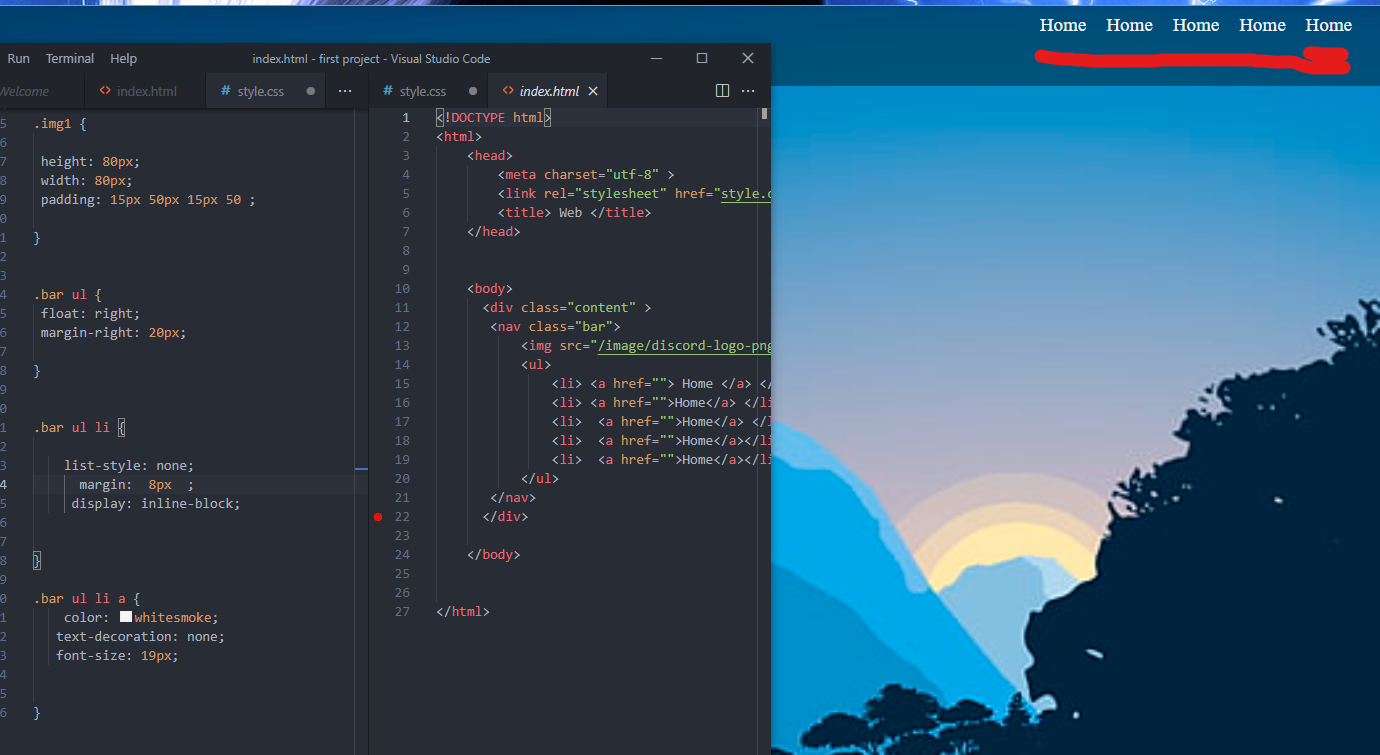
سلام عليكم اريد الخيارات تكون في الوسط مكان الخط الاحمر
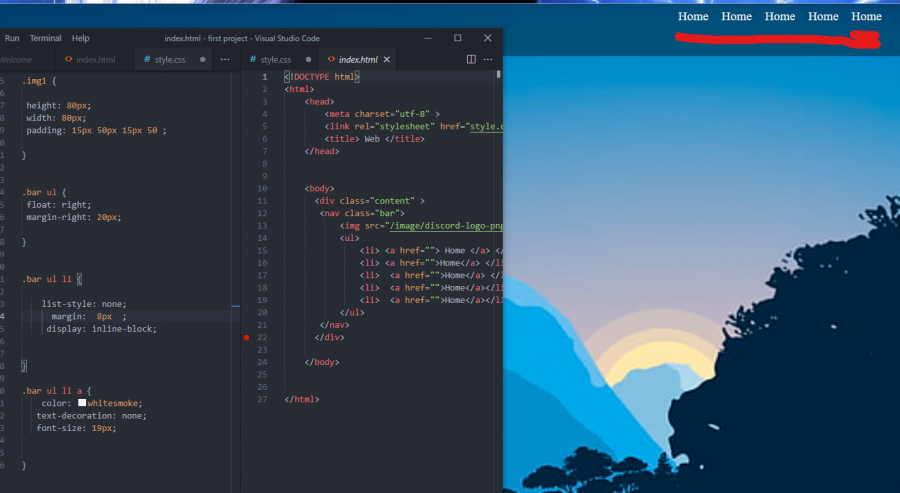 1 نقطة
1 نقطة -
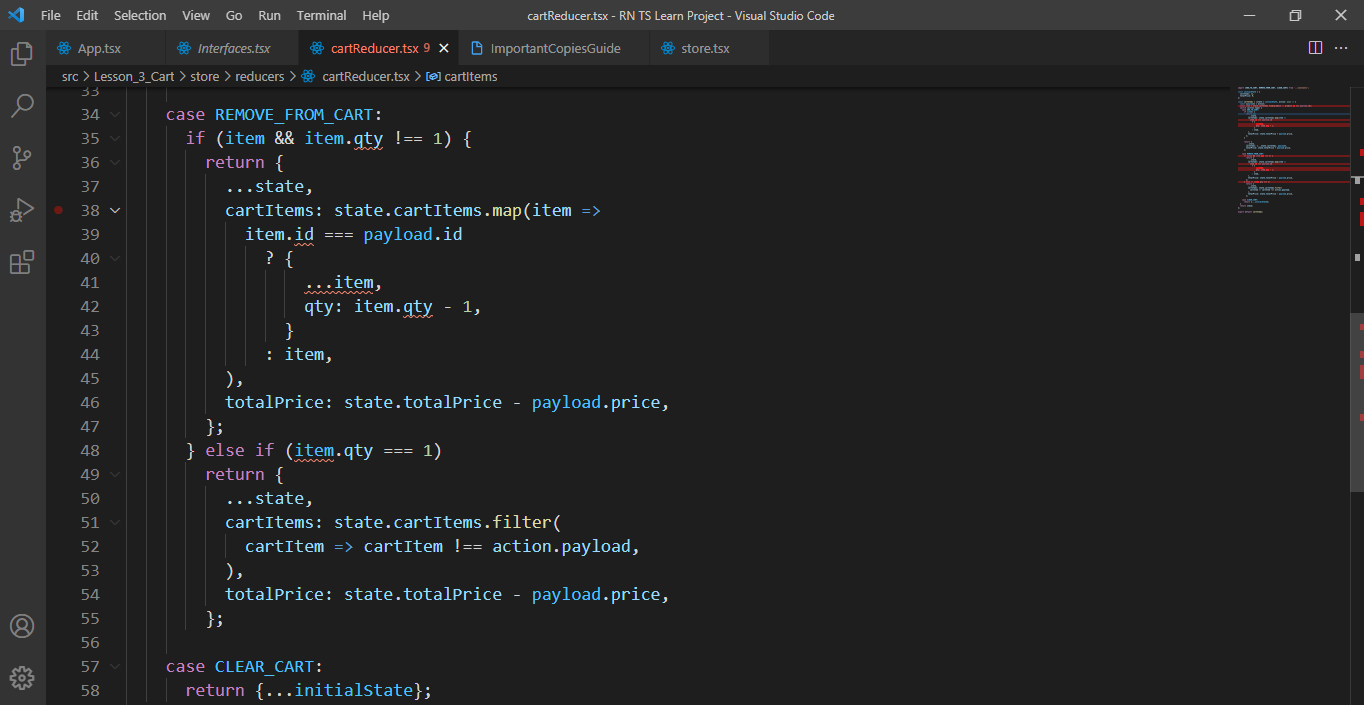
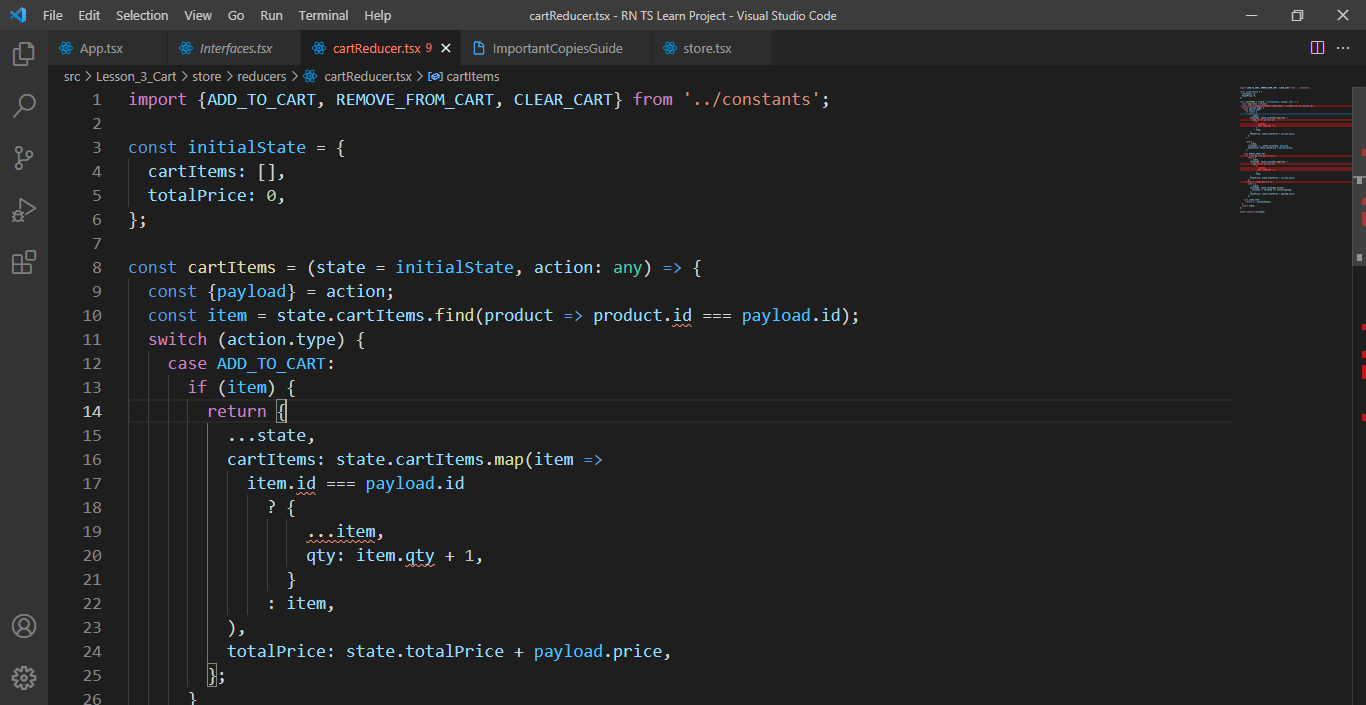
هذا هو الكود بالكامل import {ADD_TO_CART, REMOVE_FROM_CART, CLEAR_CART} from '../constants'; const initialState = { cartItems: [], totalPrice: 0, }; const cartItems = (state = initialState, action: any) => { const {payload} = action; const item = state.cartItems.find(product => product.id === payload.id); switch (action.type) { case ADD_TO_CART: if (item) { return { ...state, cartItems: state.cartItems.map(item => item.id === payload.id ? { ...item, qty: item.qty + 1, } : item, ), totalPrice: state.totalPrice + payload.price, }; } return { ...state, cartItems: [...state.cartItems, payload], totalPrice: state.totalPrice + payload.price, }; case REMOVE_FROM_CART: if (item && item.qty !== 1) { return { ...state, cartItems: state.cartItems.map(item => item.id === payload.id ? { ...item, qty: item.qty - 1, } : item, ), totalPrice: state.totalPrice - payload.price, }; } else if (item.qty === 1) return { ...state, cartItems: state.cartItems.filter( cartItem => cartItem !== action.payload, ), totalPrice: state.totalPrice - payload.price, }; case CLEAR_CART: return {...initialState}; } return state; }; export default cartItems;
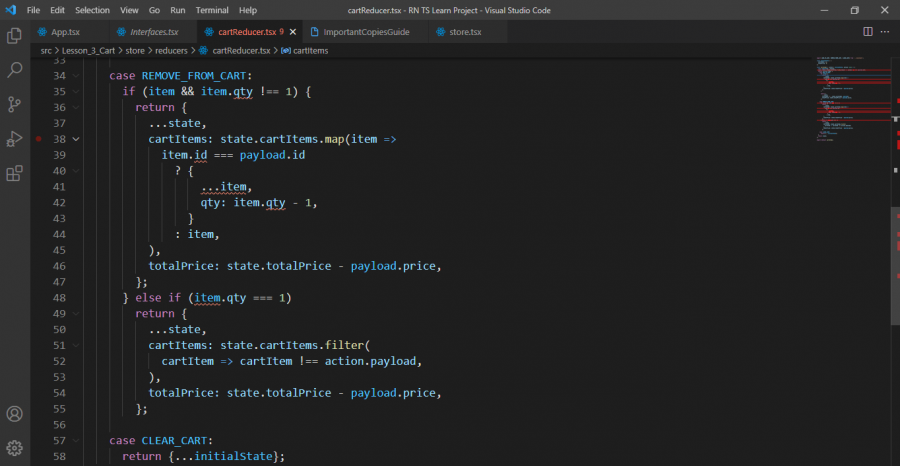
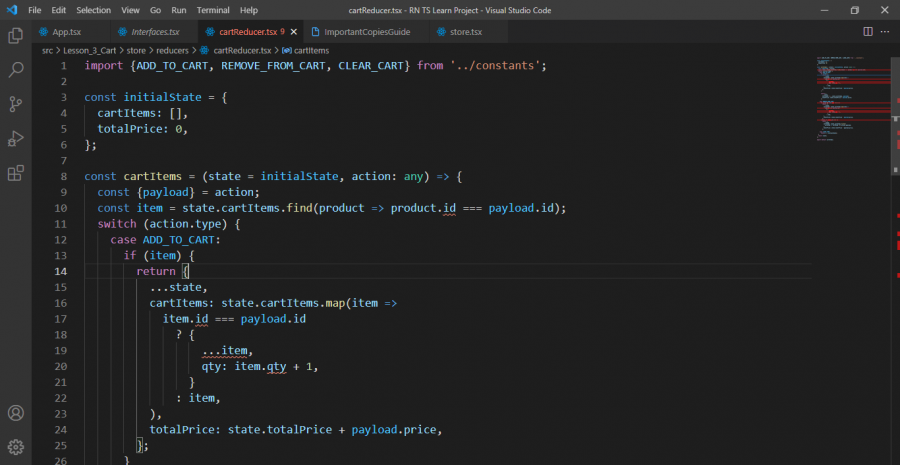 1 نقطة
1 نقطة -
على اي دورة انضم اذا اريد تعلم لغة java ؟1 نقطة
-
هل تقصد لغة جافاسكربت؟ اذا كنت تقصد لغة جافاسكربت يمكنك الانضمام الى دورة تطوير التطبيقات باستخدام لغة JavaScript فهي تحتوي على 26 ساعة فيديو تدريبية ولا تحتاج الى أي خبرة مسبقة حيث سوف يتم البدء في الدورة من الصفر وسوف تحصل على شهادة معتمدة من أكاديمية حسوب بعد اجتيازك للامتحان الخاص بالدورة وأيضا سوف يكون هناك متابعة أثناء الدورة من قبل فريق مختص, تحتوي الدورة على عدة مسارات, تبدأ من أساسيات لغة JavaScript ثم أساسيات مكتبة React.js ثم أساسيات بيئة Node.js تطوير بعض التطبيقات خلال عدة مسارات1 نقطة
-
شكرا لك اخي بعد البحث و القراءة ضبطت معي بهذه الطريقة $(document).ready(function() { $(document).on('change', '.color-select', function() { $(this).closest(".buttons-fields").find('input.number-input').val($(this).val()); }); }); اقوم بوضع class للحاوية الرئيسيه و استدعيه ثم اقوم باستدعاء اي شئ من توابعه1 نقطة
-
لا أستطيع ربط ملف css بملف html my projects.zip1 نقطة
-
ReLU (Rectified Linear Unit) هو تابع تنشيط خطي على القسم الموجب وخطي على القسم السالب، لكن تركيبهما هو مابعطيه الصفة اللاخطية، له الشكل الرياضي البسيط التالي: max(0,x) بحيث من أجل دخل x>0 سيكون خرجه هو x نفسها (أي لاتغيير أي كأننا لم نستخدم تابع تنشيط أي None ) ومن أجل دخل أصغر من الصفر يكون الخرج 0، هذا يعني أنه يسلك سلوك None من أجل الجزء الموجب وكما نعلم فإن أسعار المنازل هي دوماً موجبة وبالتالي استخدام relu سيكون مكافئاً ل None ولكن أفضل لأنه في حالة توقع النموذج قيمة سالبة للنموذج سوف يقصرها على 0 أي إذا توقع -5 سوف يجعلها 0 بسبب تابع ال relu ولهذا السبب كان استخدامه يعطي نتيجة أفضل، لكن هذا لايعني أن استخدامه صحيح وخصوصاً إذا كانت القيم السالبة ضمن مجال التوقع، وأيضاً استخدامه قد يضلل نموذجك قليلاً في الوصول للقيم الصغرى الشاملة لذا أنا أفضل عدم استخدامه. الشكل البياني للتابع: كما نلاحظ فإن قيم المشتق تساوي الصفر أيضاً من أجل القيم السالبة (ليس أمراً جيداً لأنه يسبب بطء لكنه مهمل هنا)، بينما من أجل القيم الموجبة يكون حالة مثالية للتدريب حيث أن قيمة المشتق تكون كبيرة وثابتة (القيمة تساوي 1 كما نلاحظ في الرسم). وهذا يجعل عملية التدريب أسرع (التقارب من القيم الصغرى الشاملة). أحد سلبيات هذا التابع أنه يقوم بتحويل جميع القيم السالبة إلى صفر، اي أنه في حالة القيم السالبة سينظر إليها التابع بشكل واحد وهو الصفر, مما قد يتسبب بخسارة معلومات هامة أثناء تدريب الشبكة. في كيراس أو تنسرفلو له الشكل التالي: tf.keras.activations.relu(x, alpha=0.0, max_value=None, threshold=0) بحيث أن x هي tensor أو متغير ما. أما alpha فيتحكم في ميل القيم الأقل من العتبة. أما max_value فهي التي تحدد عتبة التشبع (أكبر قيمة سترجعها الدالة). أما الوسيط الأخير فهو العتبة أي إعطاء القيمة الحدية لوظيفة التنشيط التي تحتها القيم التي سيتم تثبيطها أو ضبطها على الصفر. وافتراضياً تكون 0. ولاستخدامه في تدريب نموذجك يمكنك استخدامه مع جميع الطبقات في الشبكة عدا طبقة الخرج. وشخصياً أنصحك باستخدامه في جميع طبقات شبكتك (عدا طبقة الخرج طبعاً) لأنه سيجعل نموذجك يتقارب من القيم الصغرى بشكل أسرع كما ذكرت. إليك المثال التالي الذي سأقوم فيه باستخدام هذا التابع في تدريب نموذجي، أول مثال لمهمة توقع: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) =boston_housing.load_data() mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers model = models.Sequential() # يمكنك تمريره إلى طبقتك بالشكل التالي # أو tf.keras.activations.relu() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) history = model.fit(train_data, train_targets,epochs=7, batch_size=1, verbose=1) ------------------------------------------------- Epoch 1/7 404/404 [==============================] - 1s 967us/step - loss: 338.1444 - mae: 15.1877 Epoch 2/7 404/404 [==============================] - 0s 1ms/step - loss: 21.6941 - mae: 3.1332 Epoch 3/7 404/404 [==============================] - 0s 1ms/step - loss: 17.6999 - mae: 2.8479 Epoch 4/7 404/404 [==============================] - 0s 947us/step - loss: 13.1258 - mae: 2.4018 Epoch 5/7 404/404 [==============================] - 0s 970us/step - loss: 15.7603 - mae: 2.6360 Epoch 6/7 404/404 [==============================] - 0s 1ms/step - loss: 12.1877 - mae: 2.3640 Epoch 7/7 404/404 [==============================] - 0s 965us/step - loss: 9.7259 - mae: 2.2152 و لاستخدامه مع مهام التصنيف، يكون أيضاً بنفس الطريقة.1 نقطة
-
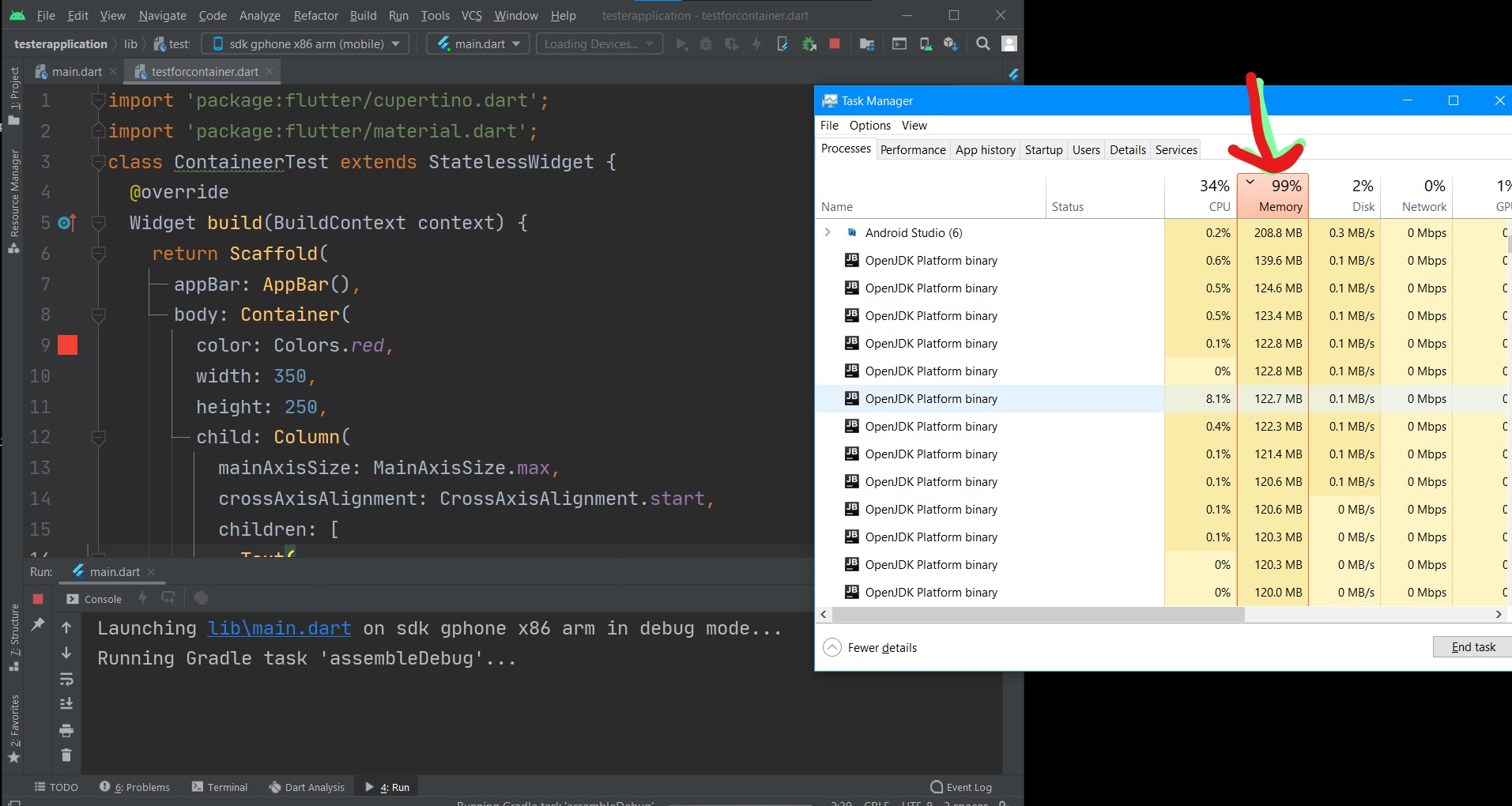
انا امتلك Ram 12 giga ومع ذلك عند عمل run لـــمشروع في Android studio يتم تشغيل Open jdk platform binary ويأخذ من الRam مساحه كبيره ما الحل في ذلك ؟
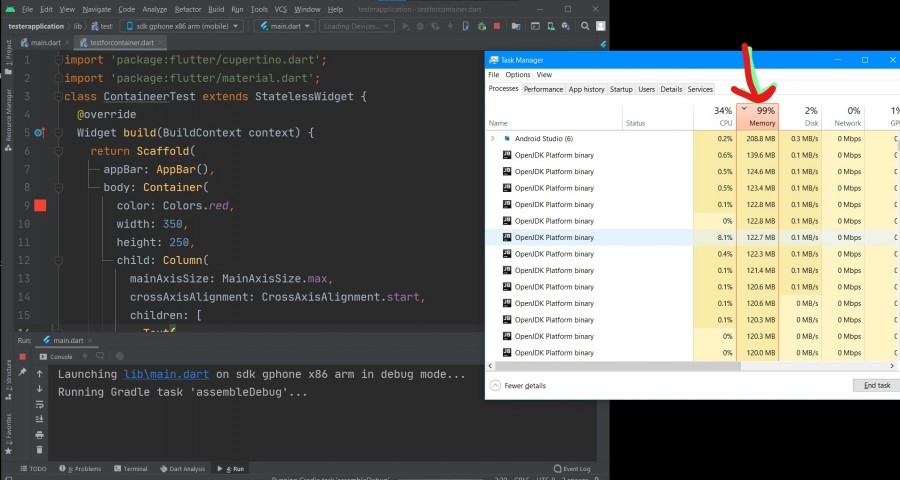 1 نقطة
1 نقطة -
لاحظ أن السطر التالي <link rel="stylesheet" href="style.css"> هو السطر المسؤول عن جلب ملف التنسيقات و كل شيء جيد ما عدا أنه مسار الملف style.css غير صحيح لأنه بداخل مجلد css فيجب وضع المسار الصحيح للملف بهذا الشكل <link rel="stylesheet" href="css/style.css">1 نقطة
-
هذه ليست أخطاء في الكود، إنما بسبب الإضافات extentions في محرر الأكواد vs code. حاول الدخول لمتجر الإضافات ضمن vs code و البحث عن إضافات خاصة ب react وقم بتثبيتهم، وعادةً يوجد في الاسفل جهة اليمين أيقونة تحدد نوع الملف تأكد من توافقه مع لغة البرمجة التي تعمل بها و إطار العمل أيضا. أخبرني إن بقي لديك مشكلة فيها..1 نقطة
-
هذه المشكلة تظهر في حالة تعاملك مع مكتبة keras أعلى من 2.2.0 يمكنك تنزيل مستوى المكتبة بإستخدام: pip install keras==2.2.0 أو في حالة إستخدام keras==2.5.0rc0 كالتالي: pip install keras==2.5.0rc0 أما في حالة كنت تستخدم colab يمكنك تنفيذ التالي: import keras !pip install keras_applications from keras_applications.imagenet_utils import _obtain_input_shape1 نقطة
-
مرحبا ، في هذا الموقع: https://t7dy.org/4BvWwp يقوم الزائر بالتصويت ،لكن لا يمكنه التصويت لأكثر من مرة و أعتقد انه يتم ذلك عن طريق Cookies فلاحظت عند تغيير المتصفح يمكن التصويت مرة أخرى و أيضا عند ايقاف Cookies لا يمكنني التصويت. كيف يمكنني عمل ذلك داخل موقع مبني بإطار العمل لارافيل؟1 نقطة
-
أهلاً بك @اسماعيل صدوقي يمكن عمل ذلك ليس فقط من خلال الكوكيز , بل من خلال أيضاً sessionStorage أو localStorage , لكن على ما طلبت من خلال الكوكيز يمكنك عمل ميوثود في الكونترولر المسؤول وهذه الميثود وظيفتها تخزين قيمة مثلاً 1 في حالة قام بالتصويت أو 0 في حالة لم يصوت بعد ,لكن لا أنصح بذلك مباشرة لأنه ممكن أن ينشأ عن ذلك ثغرة أمنية , لكن الأفضل عند قيام المستخدم بالتصويت تقوم بحفظ القيمة 1 أو 0 في حقل مثلاً voted بعد ذلك نقوم بإسترجاع تلك القيمة من قاعدة البيانات وتخزينها في الكوكي هكذا مثال نقوم بعمل ميثود لتخزين و إسترجاع الكوكي في الكونترولر هكذا public function setVotedCookie(Request $request) { $minutes = 1; $voteResult = Vote::findOrFail($request->id)->setVoted('1'); $voteResult->withCookie(cookie('isvoted', '1', $minutes)); return $voteResult; ثم نقوم بإعادة قيمة الكوكي إلى الواجهة هكذا public function getVotedCookie(Request $request) { $value = $request->cookie('isvoted'); return view('main.votes',$value); } بعد ذلك فقط تتأكد من قيمة الكوكي الذي تم إرجاعها في الواجهة مثلاً if (!$value == 1) { {{echo "Not Voted!"}} }else{ {{echo "Already Voted!,Show Error MSG"}} } ,ملاحظة الطريقة المستخدمة في الموقع إن كان قيمة الكوكي فقط تخزن في الجلسة الحالية فطريقة الموقع لا أنصح بها , لأنه ببساطة يمكن للمستخدم تغيير قيمة الكوكي ويصبح لم يصوت ! بينما هو قام بالتصويت ,إن كان لا يوجد عمليات تحقق إضافية .1 نقطة
-
هذه الطبقة كما يشير اسمها هي طبقة تسطيح (أو تسوية أو إعادة تشكيل) المدخلات. نستخدمها عادة مع النماذج عندما نستخدم طبقات RNN و CNN. ولفهمها جيداً سأشرحها مع المثالين التاليين، الأول مع مهمة تحليل مشاعر imdb أي مع مهمة NLP وسنستخدم طبقات RNN وسنتحتاج إلى الطبقة flatten: from keras.datasets import imdb from keras import preprocessing max_features = 10000 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) # بناء النموذج from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) # هنا سنتحتاج لإضافة طبقة تسطيح model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2) حسناً هنا قمنا بتسطيح الخرج الناتج من طبقة التضمين Embedding أي قمنا بتسطيح (تحويل) ال 3D tensor التي أنتجتها طبقة التضمين إلى 2Dtensor بالشكل التالي (samples,maxlen * 8)( أي عدد العينات أو الباتشز لايتأثر كما أشرنا في التعريف وإنما يتم إعادة تشكيل الفيتشرز). لقد قمنا هضه العملية لأن الطبقة التي تلي طبقة التضمين هي طبقة من نوع Dense وهي طبقة تستقبل 2D tensor ولاتستقبل 3D وبالتالي وجب علينا تسطيح مخرجات طبقة التضمين. مثال آخر: def lstm_model_flatten(): embedding_dim = 128 model = Sequential() model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen)) model.add(layers.LSTM(128, return_sequences = True, dropout=0.2)) # Flatten layer هنا أيضاً سنحتاج model.add(layers.Flatten()) model.add(layers.Dense(1,activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model.summary() return model هنا استخدمنا طبقة التسطيح لأن مخرجات طبقة lstm هي 3D كما نعلم وذلك لأننا ضبطنا return_sequences على true، والطبقة التالية هي dense وبالتالي لابد من تسطيح المخرجات بنفس الطريقة. الآن حالة آخرى مع الطبقات التلاففية حيث أنني بنيت نموذج لتصنيف الأرقام المكتوبة بخط اليد: from keras import layers from keras import models from keras.datasets import mnist from keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) # بناء النموذج model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) # هنا سنتحتاجها model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) # تدريب النموذج model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=5, batch_size=64) حسناً، إن خرج كل طبقة Conv2D و MaxPooling2D هو 3D Tensor من الشكل (height, width, channels). إن آخر خطوة من بناء الشبكة التلاففية هو إضافة طبقة أو مجموعة طبقات dense وبالتالي تتم تغذية هذه الطبقة بآخر tensor أنتجتها طبقاتنا التلاففية (هنا (64, 3, 3)) وكما ذكرنا فإن dense لاتستقبل 3D وبالتالي يجب تسطيحها، ,وبالتالي هنا سيكون ناتج تسطيح الخرج هو شعاع 1D أبعاده 64*3*3 وهذا ماسوف تتغذى به طبقات ال dense.1 نقطة
-
قم بتبديل: from keras.applications.imagenet_utils import _obtain_input_shape إلى: from keras_applications.imagenet_utils import _obtain_input_shape فهي غير موجودة في keras.applications.imagenet_utils، يمكنك أن تجدها في keras_applications.imagenet_utils1 نقطة
-
فقط استدعي ()tensor.numpy على ال Tensor object # tensorflow_version 2.x # مثال1 import tensorflow as tf t = tf.constant([[1, 2], [4, 8]]) a = t.numpy() print(a) print(type(a)) """ [[1 2] [4 8]] <class 'numpy.ndarray'> """ # مثال 2 import tensorflow as tf a = tf.constant([[1, 2], [3, 4]]) b = tf.add(a, 1) a.numpy() # array([[1, 2], # [3, 4]], dtype=int32) b.numpy() # array([[2, 3], # [4, 5]], dtype=int32) tf.multiply(a, b).numpy() # array([[ 2, 6], # [12, 20]], dtype=int32) إذا كانت النسخة هي TensorFlow version 1.x استخدم: tensor.eval(session=tf.compat.v1.Session()) مثال: # tensorflow_version 1.x import tensorflow as tf t = tf.constant([[1, 2], [4, 8]]) a = t.eval(session=tf.compat.v1.Session()) print(a) print(type(a)) أيضاً يجب أن تعلم أنه بمجرد استخدامك لأي عملية من عمليات نمباي على ال tensor سوف تتحول تلقائياً إلى numpy array، في الكود التالي مثلاً ، نقوم أولاً بإنشاء Tensor وتخزينه في متغير t عن طريق إنشاء ثابت Tensor ثم استخدام تابع الضرب في TensorFlow والناتج هو نوع بيانات Tensor أيضاً . بعد ذلك ، نقوم بإجراء عملية np.add () على Tensor التي تم الحصول عليها من خلال العملية السابقة. وبالتالي ، تكون النتيجة عبارة عن NumPy ndarray حيث تم إجراء التحويل تلقائيًا بواسطة NumPy. import numpy as np import tensorflow as tf #tensor إنشاء كائن t = tf.constant([[1, 2], [4, 8]]) t = tf.multiply(t, 2) print(t) # تطبيق عملية من نمباي a = np.add(t, 1) print(a) # هذا كل شيء1 نقطة
-
 «إنّ فكرتي ليست جيدة بما يكفي»؛ هكذا قال صديقي الذي يُفكِّر في تأسيس شركته الخاصة، وينتظر أن تتجسَّد الفكرة تمامًا قبل أن يُقدِم على الخطوة. إليكَ هذا الوضع: إنَّ فكرتك على الأرجح فاشلة، ولا يُهم ذلك؛ لأنَّ مشروعك سيصبح في النهاية شيئًا مُختلفًا تمامًا على الأرجح. هل يبدو ذلك خاطئًا؟ لِنَرَ. سنة 1998 تلقَّت شركةٌ تمويلًا قيمته 4.8 مليون دولار لكي «تنقل المال بين أجهزة Palm Pilot»، سأُطلِق على هذا المُنتَج اسمًا رمزيًّا هو ناقل الأموال. الأمرُ كالتالي، ترغب آليس في منح بوب بعض المال ولكن ليس لديها نقود أو دفتر شيكات، ولا توجد ماكينة صرَّاف آلي في الجوار. يمتلك كلٌ من آليس وبوب أجهزة Palm Pilot وقد نصَّبا عليها برنامج ناقل الأموال مُسبقًا، وبرغم أنَّهما قد نسيا كل وسائلهم العادية لتحويل المال، إلَّا أنَّهما قد تذكَّرا إحضار أجهزة Palm Pilot. سيُتيح ناقل الأموال لآليس إرسال المال إلى بوب. لن يفعل ذلك في الحقيقة، وإنما سيتذكَّر أنّ آليس تريد إرسال مال إلى بوب، وبمجرد أن تعود آليس إلى منزلها وتصل جهاز Palm Pilot الخاص بها بالحاسب الآلي، وبعد أن تتَّصل بالإنترنت، سيتواصل ناقل الأموال مع خادِمٍ ويُحوِّل المال، بشرط أن يكون المال بحوزة آليس بالطبع وأنَّها لم تُغيِّر رأيها سِرًّا في تلك الأثناء. هل كنتَ لتستثمر في هذه الشّركة النّاشئة؟ ليس بفكرةٍ كهذه. ولكنَّك كنت ستكون مخطئًا، فقد كانت تلك هي PayPal. جعل عملهم في التشفير بالإضافة إلى فكرة نظام مصرفي إلكتروني يستهدف المُستهلِك من تلك الطريقة هي الأسهل لإرسال الأموال، عبر البريد الإلكتروني. اشترتها eBay مقابل 1.3 مليار دولار. وهم يعالجون اليوم عمليات دفع قدرها ألفا دولار في الثانية. إنَّني متأكد من أنَّك لن تتعرَّف على هذا التّطبيق: هذه هي اللعبة اللامتناهية Neverending؛ وهي لعبة إلكترونيَّة على المتصفِّح لأكثر من لاعبٍ «دون طريقةٍ للفوز، ولا تعريفٍ للنجاح» (تبدو لي شبيهةً جدًا بشركات ويب 2.0)، وهي لم تخرج إلى النور إطلاقًا. الأمر الذي كان أكثر أهميةً، لمستخدميها الأوائل، هو إمكانيَّة مشاركة الناس لأغراض اللعبة بسحبها إلى نوافذ المحادثات، رأوا أنَّ هذا تحسينًا مُفيدًا لتطبيقات المحادثات بصورةٍ عامة، وهكذا مع إخفاق خطط اللعبة صنع المهندسون تطبيق (Flash) للمحادثات الفورية بالإضافة إلى مشاركة الملفَّات مع تأكيدٍ خاص على مشاركة الصور. كان تطبيق Flash للأسف فوريًا فقط؛ فصورك لا تظل موجودة عندما تغلقه، وكان ذلك قاتلًا لأنَّ الناس كانوا مُهتمِّين، كما اتَّضح، بالجزء المُتعلِّق بالمشاركة أكثر من الجزء الفوري. لذا أعادوا كتابة التطبيق في لحظةٍ ثائرة أخرى على هيئة موقع إلكترونيّ عادي ووُلِد موقع فليكر Flickr، وهو الآن أحد أكبر مواقع مشاركة الصور في العالم بصور يصل عددها إلى 3 مليارات صورة وخمسة آلاف صورة تُرفَع كل دقيقة. لن تكتمل بالطبع مثل تلك الثورة دون إدانةٍ ذاتية؛ لذا لنعد بالذّاكرة إلى بدايات شركتي؛ Smart Bear. كانت فكرتي الأولى مُنتَجًا يُدعى مؤرِّخ الشفرات، ويمكنه الغوص في تاريخ ملفٍ ما ليُريك ما تغيَّر.كان الاسم دقيقًا، ولكن اتَّضح أنَّه تقريبًا غير مجدٍ. مَرَّت الشركة، كالمراهق، بالعديد من المراحل المُحرِجة 1. 24 من مارس 2003: كريه، «افعل شيئًا واحدًا وافعله على نحوٍ سيء». 2. 22 من ديسمبر 2003: قبيح للغاية، «ثلاثة مُنتَجات: هل تكفي لحزمةٍ؟» 3. 10 من أكتوبر 2004: مُمل، «كل العناصر في الجزء العلوي من الموقع، وأكثرها تكلفةً أولًا». 4. 11 من يناير 2006: اقتربنا، «أنت بحاجة حقًّا إلى مُصمِّم جرافيك، حقًّا». 5. 10 من سبتمبر 2007: ليس سيِّئًا، «أنت تعترف على الأقلّ أنّ مراجعة الشفرات هي كلّ ما يهم». 6. الوقت الحاضر: جيِّد، «مهلًا، إلى أين ذهبت كل تلك المُنتَجات الأخرى؟» كُنَّا نبيع في إحدى المراحل ستَّ أدوات مختلفة؛ كانت الوحيدة التي تهمُّ حقًا هي مُراجِع الشفرات، ربما ستوضِّح لقطة الشاشة هذه الأمر: ليس الغرض من كل هذا توبيخ أي شخصٍ بسبب أفكاره السيئة، بل العكس تمامًا في الحقيقة، فالغرض هو أنَّ فكرتك الأولى لا تهمُّ. أولًا: ذلك قولٌ خاطئ على الأرجح، وثانيًا: إنَّ الطريقة الوحيدة لمعرفة الفكرة الصحيحة هي تجربة الفكرة الخاطئة ورؤية ما سيحدث، لن تجدها من خلال العبث بشرائح عرض PowerPoint والنماذج المُصغَّرة لفوتوشوب. إذًا فاخرج إلى العالم وارتكب بعض الأخطاء، فكما قال Neil Davidson مؤخرًّا: لا تحتاج لنموٍ هائل وسوقٍ بمليار دولار لبدء تمويل شركة برمجيَّات من مدخراتك الخاصة. ففرصة سوق قيمته 50 ألف دولار كافية لتقف على قدميك، وبمجرَّد أن تبدأ ستعرف البقيَّة. (Neil هو عضو مؤسس بشركة Red Gate، التي بدأت كنظام إلكتروني آخر لتعقُّب الأخطاء البرمجيّة، ولم يهتمّ بها أحدٌ، ولكنّها الآن أصبحت مُتعهِّدًا شهيرًا لأدوات قواعد البيانات بلغة SQL ولديها 95 ألف عميل). ترجمة -وبتصرّف- للمقال Your idea sucks, now go do it anyway لصاحبه Jason Cohen.1 نقطة
«إنّ فكرتي ليست جيدة بما يكفي»؛ هكذا قال صديقي الذي يُفكِّر في تأسيس شركته الخاصة، وينتظر أن تتجسَّد الفكرة تمامًا قبل أن يُقدِم على الخطوة. إليكَ هذا الوضع: إنَّ فكرتك على الأرجح فاشلة، ولا يُهم ذلك؛ لأنَّ مشروعك سيصبح في النهاية شيئًا مُختلفًا تمامًا على الأرجح. هل يبدو ذلك خاطئًا؟ لِنَرَ. سنة 1998 تلقَّت شركةٌ تمويلًا قيمته 4.8 مليون دولار لكي «تنقل المال بين أجهزة Palm Pilot»، سأُطلِق على هذا المُنتَج اسمًا رمزيًّا هو ناقل الأموال. الأمرُ كالتالي، ترغب آليس في منح بوب بعض المال ولكن ليس لديها نقود أو دفتر شيكات، ولا توجد ماكينة صرَّاف آلي في الجوار. يمتلك كلٌ من آليس وبوب أجهزة Palm Pilot وقد نصَّبا عليها برنامج ناقل الأموال مُسبقًا، وبرغم أنَّهما قد نسيا كل وسائلهم العادية لتحويل المال، إلَّا أنَّهما قد تذكَّرا إحضار أجهزة Palm Pilot. سيُتيح ناقل الأموال لآليس إرسال المال إلى بوب. لن يفعل ذلك في الحقيقة، وإنما سيتذكَّر أنّ آليس تريد إرسال مال إلى بوب، وبمجرد أن تعود آليس إلى منزلها وتصل جهاز Palm Pilot الخاص بها بالحاسب الآلي، وبعد أن تتَّصل بالإنترنت، سيتواصل ناقل الأموال مع خادِمٍ ويُحوِّل المال، بشرط أن يكون المال بحوزة آليس بالطبع وأنَّها لم تُغيِّر رأيها سِرًّا في تلك الأثناء. هل كنتَ لتستثمر في هذه الشّركة النّاشئة؟ ليس بفكرةٍ كهذه. ولكنَّك كنت ستكون مخطئًا، فقد كانت تلك هي PayPal. جعل عملهم في التشفير بالإضافة إلى فكرة نظام مصرفي إلكتروني يستهدف المُستهلِك من تلك الطريقة هي الأسهل لإرسال الأموال، عبر البريد الإلكتروني. اشترتها eBay مقابل 1.3 مليار دولار. وهم يعالجون اليوم عمليات دفع قدرها ألفا دولار في الثانية. إنَّني متأكد من أنَّك لن تتعرَّف على هذا التّطبيق: هذه هي اللعبة اللامتناهية Neverending؛ وهي لعبة إلكترونيَّة على المتصفِّح لأكثر من لاعبٍ «دون طريقةٍ للفوز، ولا تعريفٍ للنجاح» (تبدو لي شبيهةً جدًا بشركات ويب 2.0)، وهي لم تخرج إلى النور إطلاقًا. الأمر الذي كان أكثر أهميةً، لمستخدميها الأوائل، هو إمكانيَّة مشاركة الناس لأغراض اللعبة بسحبها إلى نوافذ المحادثات، رأوا أنَّ هذا تحسينًا مُفيدًا لتطبيقات المحادثات بصورةٍ عامة، وهكذا مع إخفاق خطط اللعبة صنع المهندسون تطبيق (Flash) للمحادثات الفورية بالإضافة إلى مشاركة الملفَّات مع تأكيدٍ خاص على مشاركة الصور. كان تطبيق Flash للأسف فوريًا فقط؛ فصورك لا تظل موجودة عندما تغلقه، وكان ذلك قاتلًا لأنَّ الناس كانوا مُهتمِّين، كما اتَّضح، بالجزء المُتعلِّق بالمشاركة أكثر من الجزء الفوري. لذا أعادوا كتابة التطبيق في لحظةٍ ثائرة أخرى على هيئة موقع إلكترونيّ عادي ووُلِد موقع فليكر Flickr، وهو الآن أحد أكبر مواقع مشاركة الصور في العالم بصور يصل عددها إلى 3 مليارات صورة وخمسة آلاف صورة تُرفَع كل دقيقة. لن تكتمل بالطبع مثل تلك الثورة دون إدانةٍ ذاتية؛ لذا لنعد بالذّاكرة إلى بدايات شركتي؛ Smart Bear. كانت فكرتي الأولى مُنتَجًا يُدعى مؤرِّخ الشفرات، ويمكنه الغوص في تاريخ ملفٍ ما ليُريك ما تغيَّر.كان الاسم دقيقًا، ولكن اتَّضح أنَّه تقريبًا غير مجدٍ. مَرَّت الشركة، كالمراهق، بالعديد من المراحل المُحرِجة 1. 24 من مارس 2003: كريه، «افعل شيئًا واحدًا وافعله على نحوٍ سيء». 2. 22 من ديسمبر 2003: قبيح للغاية، «ثلاثة مُنتَجات: هل تكفي لحزمةٍ؟» 3. 10 من أكتوبر 2004: مُمل، «كل العناصر في الجزء العلوي من الموقع، وأكثرها تكلفةً أولًا». 4. 11 من يناير 2006: اقتربنا، «أنت بحاجة حقًّا إلى مُصمِّم جرافيك، حقًّا». 5. 10 من سبتمبر 2007: ليس سيِّئًا، «أنت تعترف على الأقلّ أنّ مراجعة الشفرات هي كلّ ما يهم». 6. الوقت الحاضر: جيِّد، «مهلًا، إلى أين ذهبت كل تلك المُنتَجات الأخرى؟» كُنَّا نبيع في إحدى المراحل ستَّ أدوات مختلفة؛ كانت الوحيدة التي تهمُّ حقًا هي مُراجِع الشفرات، ربما ستوضِّح لقطة الشاشة هذه الأمر: ليس الغرض من كل هذا توبيخ أي شخصٍ بسبب أفكاره السيئة، بل العكس تمامًا في الحقيقة، فالغرض هو أنَّ فكرتك الأولى لا تهمُّ. أولًا: ذلك قولٌ خاطئ على الأرجح، وثانيًا: إنَّ الطريقة الوحيدة لمعرفة الفكرة الصحيحة هي تجربة الفكرة الخاطئة ورؤية ما سيحدث، لن تجدها من خلال العبث بشرائح عرض PowerPoint والنماذج المُصغَّرة لفوتوشوب. إذًا فاخرج إلى العالم وارتكب بعض الأخطاء، فكما قال Neil Davidson مؤخرًّا: لا تحتاج لنموٍ هائل وسوقٍ بمليار دولار لبدء تمويل شركة برمجيَّات من مدخراتك الخاصة. ففرصة سوق قيمته 50 ألف دولار كافية لتقف على قدميك، وبمجرَّد أن تبدأ ستعرف البقيَّة. (Neil هو عضو مؤسس بشركة Red Gate، التي بدأت كنظام إلكتروني آخر لتعقُّب الأخطاء البرمجيّة، ولم يهتمّ بها أحدٌ، ولكنّها الآن أصبحت مُتعهِّدًا شهيرًا لأدوات قواعد البيانات بلغة SQL ولديها 95 ألف عميل). ترجمة -وبتصرّف- للمقال Your idea sucks, now go do it anyway لصاحبه Jason Cohen.1 نقطة