
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/21/21 in أجوبة
-
أواجه مشكلة في عمل allocate مصفوفات ضخمة في numpy على Ubuntu 18 بينما لا أواجه نفس المشكلة على MacOS. أحاول عمل allocate memory لمصفوفة عددية ذات شكل (156816 ، 36 ، 53806) من خلال الكود التالي: >>> import numpy as np >>> np.zeros((156816, 36, 53806), dtype='uint8') أحصل على الخطأ التالي على Ubuntu : numpy.core._exceptions.MemoryError: Unable to allocate array with shape (156816, 36, 53806) and data type uint8 بينما على MacOS أحصل على التالي: >>> import numpy as np >>> np.zeros((156816, 36, 53806), dtype='uint8') array([[[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], [[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], [[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], ..., [[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], [[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]], [[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]]], dtype=uint8) هنا الإصدارات التي لدي على كل نظام تشغيل: Ubuntu os -> ubuntu mate 18 python -> 3.6.8 numpy -> 1.17.0 mac os -> 10.14.6 python -> 3.6.4 numpy -> 1.17.0 حاولت أيضًا أن أقوم بتنفيذ الأكواد على Google Colab ولم أنجح أيضًا، ما السبب في هذا الأمر؟1 نقطة
-
عندي موقع قديم يحتوي على products تابعة ل categories، أريد عندما يضغط المستخدم على product في الموقع الجديد وليس القديم ( باختصار / يعني أريد عمل redirect كيف؟ ) وايضا من باب التوضيح / أريد عندما يدخل المستخدم على الموقع القديم ويعمل له إعادة تحويل يتغير الرابط من ca-123123.html إلى cat=1231231 نقطة
-
لكن إعادة التحويل ستكون إلى موقع آخر، أرجو قراءة السؤال مرة أخرى بلال1 نقطة
-
يمكنك إعادة التحويل باستخدام وسم meta في html <meta http-equiv="refresh" content="30; url='index.html'"> أو باستخدام دالة header في php و هذه الدالة تستخدم لإعادة التوجيه بين الصفحات أو حتى بين المواقع بهذا الشكل header("Location: هنا الرابط أو الصفحة المقصودة"); <?php header("Location: index.php"); ?>1 نقطة
-
هل يمكنن عمل overload للكونستركترات في الجافا؟؟1 نقطة
-
نعم يمكن ذلك في لغة JAVA حيث سيتم عمل عدة دوال بانية constructor وكل منها يستقبل وسطاء parameters مختلفة وسينتج عنهم كائنات تم تهيئتا بطرق مختلفة، مثلا ليكن لدينا صندوق Box له 3 أبعاد عرض-ارتفاع-عمق وسنقوم بعمل 3 دوال بانية مختلفة له: // صنف الصندوق class Box { // خصائصه double width, height, depth; // الباني الذي يسند قيم لجميع الخاصيات Box(double w, double h, double d) { width = w; height = h; depth = d; } // باني بدون وسطاء يسند القيمة 0 لكل الخواص Box() { width = height = depth = 0; } // باني يستقبل وسيط واحد و يسند جميع القيم له Box(double len) { width = height = depth = len; } // حساب الحجم double volume() { return width * height * depth; } } لتجريب الصنف السابق يمكن استخدام الصنف المساعد التالي: public class Test { public static void main(String args[]) { // تعريف عدة صناديق باستخدم دال البناء المختلفة Box mybox1 = new Box(10, 20, 15); Box mybox2 = new Box(); Box mycube = new Box(7); double vol; // متغيرلتخزين الحجم // أول صندوق vol = mybox1.volume(); System.out.println(" Volume of mybox1 is " + vol); // ثاني صندوق vol = mybox2.volume(); System.out.println(" Volume of mybox2 is " + vol); // ثالث صندوق vol = mycube.volume(); System.out.println(" Volume of mycube is " + vol); } } هكذا سيتم بناء 3 أغراض من الصنف الأول لها نفس الخواص ولكن باستعمال overloading للدالة البانية1 نقطة
-
نعم يمكنك ذلك عن طريق تغيير عدد الوسائط التي يقبلها الباني أو عن طريق تغيير نوع بيانات الوسطاء . لاحظ المثال التالي: حيث قمنا بعمل overload للباني Ali. حيث في الاستداعء الأول للباني قمنا باستدعاء الباني ذو الوسيطة الوحيدة (وستتم التهيئة ب 1.1) أما في الاستدعاء الثاني فسيتم تنفيذ الباني ذو الوسيطتين وستتم التهيئة ب 2.5. class Ali { float x; public Ali(float y) { x=y; } public Ali(float y, float m) { System.out.println("Hi"); if(y>m) { x=y; } else { x=m; } } } public class Main { public static void main (String args[]) { Ali t1 = new Ali(1.1); Ali t2 = new Ali(3, 2.5); System.out.println(t1.x); System.out.println(t2.x); } } حيث أننا هنا قمنا بتغيير عدد الوسطاء، ويمكنك أيضاً أن تقوم بتغيير نوع البيانات: class Ali { int x=0; public Ali(int y) { x=y; } float z=0.0; public Ali(float y) { z=y; } } public class Main { public static void main (String args[]) { Ali t1 = new Ali(1.1); // سيؤدي إلى استدعاء الباني الثاني Ali t2 = new Ali(3); // سيؤدي إلى استدعاء الباني الأول } }1 نقطة
-
السلام عليكم , أنا الان اتطلع الى ان اكون محترفا فى redux ولكن احيانا يقف امامى بعض العقبات التى لا استطيع حلها او احتاج الى المساعدة , واحيانا اظن اننى اذا تعلمت data structure ساكون جيدا فى التعامل مع مثل هذا الجزء من الكود , حيث اننى اتعامل مع arrays و objects متداخلان فى بعضها , أنا حقا اريد احتراف التعامل مع arrays و objects بشكل احترافى هل لو قمت بتعلم data structure ساكون جيدا فى التعامل مع اكواد مثل هذه سواء قراءة او كتابة ام اننى احتاج شئيا اخر ؟ import {ADD_TO_CART, REMOVE_FROM_CART, CLEAR_CART} from '../constants'; const initialState = { cartItems: [], totalPrice: 0, }; const cartItems = (state = initialState, action: any) => { const {payload} = action; const item = state.cartItems.find(product => product.id === payload.id); switch (action.type) { case ADD_TO_CART: if (item) { return { ...state, cartItems: state.cartItems.map(item => item.id === payload.id ? { ...item, qty: item.qty + 1, } : item, ), totalPrice: state.totalPrice + payload.price, }; } return { ...state, cartItems: [...state.cartItems, payload], totalPrice: state.totalPrice + payload.price, }; case REMOVE_FROM_CART: if (item && item.qty !== 1) { return { ...state, cartItems: state.cartItems.map(item => item.id === payload.id ? { ...item, qty: item.qty - 1, } : item, ), totalPrice: state.totalPrice - payload.price, }; } else if (item.qty === 1) return { ...state, cartItems: state.cartItems.filter( cartItem => cartItem !== action.payload, ), totalPrice: state.totalPrice - payload.price, }; case CLEAR_CART: return {...initialState}; } return state; }; export default cartItems;1 نقطة
-
أنا اقوم بعمل cart لمتجر واريد انه عندما اضيف منتج موجود فى الكارت .. بدلا من اضافته فى خانة جديدة يقوم التطبيق بزيادة الكمية +1 بدلا من انشاؤه فى خانة جديدة .. هذا هو الرديوسر الخاص بى import {ADD_TO_CART, REMOVE_FROM_CART, CLEAR_CART} from '../constants'; const initialState = { cartItems: [], totalPrice: 0, }; const cartItems = (state = initialState, action: any) => { switch (action.type) { case ADD_TO_CART: return { ...state, cartItems: [...state.cartItems, action.payload], totalPrice: state.totalPrice + action.payload.price, }; case REMOVE_FROM_CART: return { ...state, cartItems: state.cartItems.filter( cartItem => cartItem !== action.payload, ), totalPrice: state.totalPrice - action.payload.price, }; case CLEAR_CART: return {...initialState}; } return state; }; export default cartItems; بفضل الله يعمل بشكل صحيح كلما اضفت منتج الى العربة لكن مشكلتى عندما اريد ان ازيد كمية المنتج بدلا من اضافته مرة اخرى فى خانة جديدة مالذى يجب ان افعله فى هذا الكود حتى احقق هذا الهدف .. ملحوظة حاولت كثيرا وفضلت ان انشر كودى هكذا لانه يعمل بشكل صحيح1 نقطة
-
الخطأ ظهر نتيجة لتمرير قائمة من القيم (200 في هذه الحالة) إلى دالة التدريب و التي يجب أن تستقبل مدخل واحد يحتوي على 200 صف، لذلك يجب أن تحول قوائم المدخلات إلى مصفوفات، يمكنك ذلك عن طريق إستخدام الدالة numpy.array أو عن طريق numpy.asarray(): import numpy data = numpy.array(data) label = numpy.array(label) أو بالطريقة الثانية: import numpy data = numpy.asarray(data) label = numpy.asarray(label) الفرق بين الطريقتين هو أن الأولى تنشئ نسخة من القائمة و تحولها إلى مصفوفة بينما في الطريقة الثانية تتحول القائمة الأصل إلى مصفوفة. لاحظ أنه يمكنك تنفيذ التحويل أيضاً داخل دالة التدريب كالتالي: import numpy model.fit(numpy.asarray(data),numpy.asarray(label),epochs = 70)1 نقطة
-
ازاي اقدر أخلي كلمة نينجا تأخذ خانتين أفقيتين في ال table بهذا الشكل
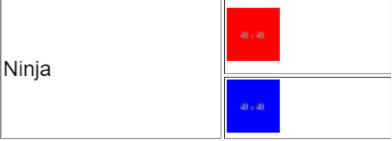 1 نقطة
1 نقطة -
هذه الطبقة كما يشير اسمها هي طبقة تسطيح (أو تسوية أو إعادة تشكيل) المدخلات. نستخدمها عادة مع النماذج عندما نستخدم طبقات RNN و CNN. ولفهمها جيداً سأشرحها مع المثالين التاليين، الأول مع مهمة تحليل مشاعر imdb أي مع مهمة NLP وسنستخدم طبقات RNN وسنتحتاج إلى الطبقة flatten: from keras.datasets import imdb from keras import preprocessing max_features = 10000 maxlen = 20 (x_train, y_train), (x_test, y_test) = imdb.load_data( num_words=max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen) x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen) # بناء النموذج from keras.models import Sequential from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) # هنا سنتحتاج لإضافة طبقة تسطيح model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) model.summary() history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2) حسناً هنا قمنا بتسطيح الخرج الناتج من طبقة التضمين Embedding أي قمنا بتسطيح (تحويل) ال 3D tensor التي أنتجتها طبقة التضمين إلى 2Dtensor بالشكل التالي (samples,maxlen * 8)( أي عدد العينات أو الباتشز لايتأثر كما أشرنا في التعريف وإنما يتم إعادة تشكيل الفيتشرز). لقد قمنا هضه العملية لأن الطبقة التي تلي طبقة التضمين هي طبقة من نوع Dense وهي طبقة تستقبل 2D tensor ولاتستقبل 3D وبالتالي وجب علينا تسطيح مخرجات طبقة التضمين. مثال آخر: def lstm_model_flatten(): embedding_dim = 128 model = Sequential() model.add(layers.Embedding(vocab_size, embedding_dim, input_length=maxlen)) model.add(layers.LSTM(128, return_sequences = True, dropout=0.2)) # Flatten layer هنا أيضاً سنحتاج model.add(layers.Flatten()) model.add(layers.Dense(1,activation='sigmoid')) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) model.summary() return model هنا استخدمنا طبقة التسطيح لأن مخرجات طبقة lstm هي 3D كما نعلم وذلك لأننا ضبطنا return_sequences على true، والطبقة التالية هي dense وبالتالي لابد من تسطيح المخرجات بنفس الطريقة. الآن حالة آخرى مع الطبقات التلاففية حيث أنني بنيت نموذج لتصنيف الأرقام المكتوبة بخط اليد: from keras import layers from keras import models from keras.datasets import mnist from keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) # بناء النموذج model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) # هنا سنتحتاجها model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) # تدريب النموذج model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=5, batch_size=64) حسناً، إن خرج كل طبقة Conv2D و MaxPooling2D هو 3D Tensor من الشكل (height, width, channels). إن آخر خطوة من بناء الشبكة التلاففية هو إضافة طبقة أو مجموعة طبقات dense وبالتالي تتم تغذية هذه الطبقة بآخر tensor أنتجتها طبقاتنا التلاففية (هنا (64, 3, 3)) وكما ذكرنا فإن dense لاتستقبل 3D وبالتالي يجب تسطيحها، ,وبالتالي هنا سيكون ناتج تسطيح الخرج هو شعاع 1D أبعاده 64*3*3 وهذا ماسوف تتغذى به طبقات ال dense.1 نقطة
-
فقط استدعي ()tensor.numpy على ال Tensor object # tensorflow_version 2.x # مثال1 import tensorflow as tf t = tf.constant([[1, 2], [4, 8]]) a = t.numpy() print(a) print(type(a)) """ [[1 2] [4 8]] <class 'numpy.ndarray'> """ # مثال 2 import tensorflow as tf a = tf.constant([[1, 2], [3, 4]]) b = tf.add(a, 1) a.numpy() # array([[1, 2], # [3, 4]], dtype=int32) b.numpy() # array([[2, 3], # [4, 5]], dtype=int32) tf.multiply(a, b).numpy() # array([[ 2, 6], # [12, 20]], dtype=int32) إذا كانت النسخة هي TensorFlow version 1.x استخدم: tensor.eval(session=tf.compat.v1.Session()) مثال: # tensorflow_version 1.x import tensorflow as tf t = tf.constant([[1, 2], [4, 8]]) a = t.eval(session=tf.compat.v1.Session()) print(a) print(type(a)) أيضاً يجب أن تعلم أنه بمجرد استخدامك لأي عملية من عمليات نمباي على ال tensor سوف تتحول تلقائياً إلى numpy array، في الكود التالي مثلاً ، نقوم أولاً بإنشاء Tensor وتخزينه في متغير t عن طريق إنشاء ثابت Tensor ثم استخدام تابع الضرب في TensorFlow والناتج هو نوع بيانات Tensor أيضاً . بعد ذلك ، نقوم بإجراء عملية np.add () على Tensor التي تم الحصول عليها من خلال العملية السابقة. وبالتالي ، تكون النتيجة عبارة عن NumPy ndarray حيث تم إجراء التحويل تلقائيًا بواسطة NumPy. import numpy as np import tensorflow as tf #tensor إنشاء كائن t = tf.constant([[1, 2], [4, 8]]) t = tf.multiply(t, 2) print(t) # تطبيق عملية من نمباي a = np.add(t, 1) print(a) # هذا كل شيء1 نقطة
-
كما في التعليق السابق فإنه القيمة NaN تعامل كقيمة رقمية فلذلك يمكنك إجراء العملية الحسابية في وجودها بينما لا يمكنك في حالة وجود القيمة none لذلك يمكنك استخدام none في حالة تريد تعريف قيمة فارغة والكشف عنها بدالة ما لإجراء وظيفة معينة بينما نستخدم NaN عندما نريد إجراء العمليات الحسابية في وجودها ويمكننا تفادي هذه القيمة باستخدام دالة من numpy تسمى nan_to_num أو sumnan مثلاً عند إرجاع مجموع مصفوفة يوجد بها قيمة NaN كالتالي import numpy as np in_arr = np.array([[2, 2, 2], [2, 2, np.nan]]) out_sum = np.nansum(in_arr) print ("مجموع المصفوفة: ", out_sum) #الناتج #مجموع المصفوفة1 نقطة
-
يمكنك استخدام الدالة التالية لحساب ال moving average، و لكنها ستكون أبطأ بعض الشئ من الحلول الخاصة ب numpy mylist = [1, 2, 3, 4, 5, 6, 7] N = 3 cumsum, moving_aves = [0], [] for i, x in enumerate(mylist, 1): cumsum.append(cumsum[i-1] + x) if i>=N: moving_ave = (cumsum[i] - cumsum[i-N])/N #can do stuff with moving_ave here moving_aves.append(moving_ave) و يمكنك استخدام الطريقة التالية أيضًا (تستخدم Convolution): def running_mean(x, N): cumsum = numpy.cumsum(numpy.insert(x, 0, 0)) return (cumsum[N:] - cumsum[:-N]) / float(N) و لكن هذه الطريقة يظهر بها خطأ متعلق بال precision الخاصة بال floating point أو يمكنك استخدام scipy.ndimage.filters.uniform_filter1d فهي طريقة أسرع 50 مرة من np.convolve و لا يظهر معها خطأ متعلق بال precision الخاصة بال floating point : import numpy as np from scipy.ndimage.filters import uniform_filter1d N = 1000 x = np.random.random(100000) y = uniform_filter1d(x, size=N)1 نقطة
-
السبب الرئيسي لاستخدام NaN بدلاً من None هو أنه يمكن تخزينه باستخدام نوع float64 لـ numpy ، بدلاً من نوع object الأقل كفاءة. حيث أن عملية تخزينه على شكل object سوف يجعله غير قابل للتعامل مع عمليات نمباي . بينما NaN يمكن استخدامها كقيمة عددية في العمليات الحسابية وأيضاً في العمليات التي يمكن تطبيقها باستخدام مكتبة نمباي.1 نقطة
-
يمكنك حساب المتوسط المتحرك فيnumpy باستخدام np.convolve. حيث يمكننا الاستفادة من الطريقة التي يتم بها حساب الالتواء المنفصل أو ما يعرف ب discrete convolution واستخدامه لإرجاع rolling mean. يمكن القيام بذلك عن طريق استخدام np.ones بطول معين,بداية سوف نقوم بانشاء الدالة المسؤولة عن حساب moving average def moving_average(x, w): return np.convolve(x, np.ones(w), 'valid') / w والآن نستطيع استخدام هذه الدالة لحساب moving average كالتالي x = np.array([5,3,8,10,2,1,5,1,0,2]) بالنسبة ل moving average مع طول يساوي 2 فسوف يكون شكل الكود كالتالي moving_average(x, 2) وسوف يكون الناتج كالتالي array([4. , 5.5, 9. , 6. , 1.5, 3. , 3. , 0.5, 1. ]) لنفترض أن الطول كان يساوي 4 فسوف يكون الناتج كالتالي moving_average(x, 4) # array([6.5 , 5.75, 5.25, 4.5 , 2.25, 1.75, 2. ])1 نقطة







