
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/17/21 في كل الموقع
-
السلام عليكم ورحمة الله هل من احد يساعدني في حل مشكلة عدم قراءة الصور من طرف webpack رغم انه لا يعطيني اية خطا على terminal لم اعرف كيفية حل هادا المشكل بسبب عدم ظهور اية خطا ب terminal جزاكم الله خيرا هادا ملف المشروع الدي اعمل عليه safarni.zip2 نقاط
-
من فضلكم حد يساعدني كيف اخلي الزبون لما يضغط على زر الاضافة للشراء تخرج له صفحة منبثفة اتوماتكيا لملاء معلوماته وارسال طلبه دون توجيهه الى صفحة تانية هاي صفحة المعلومات التي اريدها كلما يختار يشتري بطاقة تخرج له

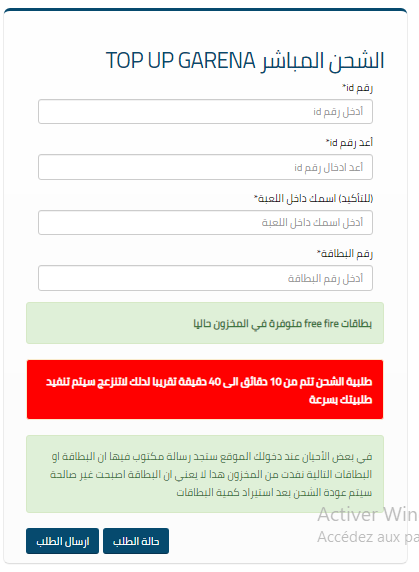 1 نقطة
1 نقطة -
مرحبًا بدأت مؤخرًا رحلتي في تعلم البرمجة وبدأت بلغة الجافا لأنها ستكون اللغة التي سأدرس بها في تخصصي الجامعي، ولكن واجهتني مشكلة وهي انني كلما اردت تطبيق الكود بالجافا وعمل run له يُبلغني بالخطأ التالي، علمًا انني كتبت الكود بطريقة صحيحة تمامًا وهو كود سهل وغير معقد ولكن رغم ذلك يبلغني بفشل عمل الكود بالاشعار التالي Error occurred during initialization of boot layer java.nio.file.InvalidPathException: Illegal char <?> at index 24: C:\Users\anan\OneDrive\?????????\NetBeansProjects\DisplayOutput\build\classes C:\Users\anan\AppData\Local\NetBeans\Cache\12.4\executor-snippets\run.xml:111: The following error occurred while executing this line: C:\Users\anan\AppData\Local\NetBeans\Cache\12.4\executor-snippets\run.xml:68: Java returned: 1 عرض عناصر أقل لذا اردت ان اسألكم ماهي المشكلة بالضبط وكيف اتعامل معها؟1 نقطة
-
السلام عليكم اذا اردت بهذه الدالة بدلا من الحصول على كل حقول الجدول الحصول على حقلين فقط فكيف اكتبها public function index() { $projects = auth()->user()->projects; return view('projects.index', compact('projects')); }1 نقطة
-
السلام عليكم.... أريد موقعاََ أو كتاباََ فيه أمثلة محلولة وأسئلة عن لغة جافا لكي أتمكن من تطبيق ما أتعلمه. جزيلُ الشُكر مُقدماََ 🖤🙏1 نقطة
-
إن معيار قياس كفاءة النموذج الذي تستخدمه لنموذجك هو metrics=['accuracy'] وهو يتوافق مع مهام التصنيف، والمهمة التي لديك هي مهمة توقع لذا يجب عليك استخدام معيار يتناسب مع نوع المهمة مثل MSE أو MAE وبالتالي يجب يصبح الكود كالتالي: from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) =boston_housing.load_data() mean = train_data.mean(axis=0) train_data -= mean std = train_data.std(axis=0) train_data /= std test_data -= mean test_data /= std from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1,activation=None)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) history = model.fit(train_data, train_targets,epochs=7, batch_size=1, verbose=1) ----------------------------------------------------------------------------- Epoch 1/7 404/404 [==============================] - 1s 1ms/step - loss: 309.4995 - mae: 14.3059 Epoch 2/7 404/404 [==============================] - 0s 1ms/step - loss: 29.8972 - mae: 3.6916 Epoch 3/7 404/404 [==============================] - 0s 1ms/step - loss: 19.3192 - mae: 3.0052 Epoch 4/7 404/404 [==============================] - 0s 1ms/step - loss: 11.1953 - mae: 2.4848 Epoch 5/7 404/404 [==============================] - 0s 1ms/step - loss: 12.8683 - mae: 2.5286 Epoch 6/7 404/404 [==============================] - 0s 1ms/step - loss: 14.1816 - mae: 2.5489 Epoch 7/7 404/404 [==============================] - 0s 1ms/step - loss: 9.3017 - mae: 2.1364 أهم معايير قياس كفاءة النماذج في كيراس وتنسرفلو: Keras Regression Metrics: Mean Squared Error: mean_squared_error, MSE or mse Mean Absolute Error: mean_absolute_error, MAE, mae Mean Absolute Percentage Error: mean_absolute_percentage_error, MAPE, mape Cosine Proximity: cosine_proximity, cosine Keras Classification Metrics Binary Accuracy: binary_accuracy, acc Categorical Accuracy: categorical_accuracy, acc Sparse Categorical Accuracy: sparse_categorical_accuracy1 نقطة
-
predict_classes متوفر فقط من أجل البنية (أو الصف) Sequential ولكنه غير متوفر من أجل الصف Model لذا فالحل هو استخدام التابع predict والتي سيكون خرجها شعاع من التوقعات الاحتمالية، ثم يمكنك بعدها استخدام التابع argmax من مكتبة نمباي لقصر القيم كالتالي: np.argmax(y_pred,axis=1)1 نقطة
-
هل يوجد من لديه فكرة على عدم ظهور ملفاات ال git في اندرويد استديوا .. تظهر لي مشكل عدم ظهور الملفاااات لا أعلم السبب .. وبوركتم على مجهوداتكم المبدولة . موقع عربي جميل ومفيد ونشيط .جزاكم الله خيرا1 نقطة
-
السلام عليكم اعمل على بناء واجهة موقع يتكون من عدة أقسام بواسطة webpack المشكلة التي أواجهها هي أن أي صفحة html أقوم ببنائها في المجلد الاصلي src فأن webpack عند عملة البناء npm run build يقوم بتضمين جميع ملفات css و javaScript الخاصة بالمشروع في هذه الصفحة حتى لو لم اقوم انا ب استدعائها مثال للتوضيح لدية الملفات التالية style.css index.css index.js main.js فأن webpack يقوم بتضمين هذه الملفات تلقائيا في اي صفحة html انشئها علما ان اي صفحة html انشئها اقوم بربطها ب ملف javascript منفصل خاص بها عن طريق <script defer="defer" type="text/html" src="{requier('index.js')}"></script> واغير الاسم الى اسم الملف الجديد و من خلال هذه الملف استدعي الملفات التي احتاجها فقط لكن عند عرض ملفات html التي قام webpack ببنائها ارى بأنه استدعى جميع الملفات التي في المشروع كاملة1 نقطة
-
يمكنك حساب كفاءة نماذجك خلال التدريب وبعد الانتهاء من التدريب باستخدام المعيار Accuracy، لكن أود لفت انتباهك إلى الأمر التالي، لكي لاتقع في شرك الخطأ الشائع لدى المبتدئين وهو أن هذا المعيار يستخدم فقط لمهام التصنيف ولايستخدم في مهام التوقع أيضاً ملاحظة أخرى لاتعتمد على هذا المعيار إلى في حال كانت البيانات لديك متوازنة ففي حال كانت غير متوازنة ستكون النتائج مضللة تماماً في أغلب الأحيان (نلجأ لمعايير أخرى مثل f1score). إن هذا المعيار يقوم بحساب عدد المرات التي تتطابق فيها القيم المتوقعة مع القيم الحقيقية للبيانات ويعطيك الخرج على شكل قيمة عشرية ضمن المجال 0 إلى 1 بحيث 0 تكافئ 0 حالات تطابق و 1 تكافئ 100% حالات التطابق. لاستخدامها خلال عملية التدريب نقوم بتمريرها إلى الدالة compile كالتالي: model.compile( metrics=["accuracy"]) # أو acc ... ) ولاستخدامها في نهاية التدريب (من أجل حساب الدقة على بيانات الاختبار): acc=model.evaluate(x_test, y_test) print("Test loss:", acc[0]) # الخطأ print("Test accuracy:", acc[1]) # الدقة في المثال التالي سأعرض كيفية استخدامه لقياس الدقة خلال التدريب وبعده على مجموعة بيانات لتصنيف صور الأرقام المكتوبة بخط اليد: import numpy as np from tensorflow import keras from tensorflow.keras import layers num_classes = 10 input_shape = (28, 28, 1) # تحميل البيانات (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data() # تقييس البيانات وجعلها ضمن المجال من 0 إلى 1 x_train = x_train.astype("float32") / 255 x_test = x_test.astype("float32") / 255 # Make sure images have shape (28, 28, 1) x_train = np.expand_dims(x_train, -1) x_test = np.expand_dims(x_test, -1) print("x_train shape:", x_train.shape) print(x_train.shape[0], "train samples") print(x_test.shape[0], "test samples") # الترميز الفئوي للبيانات y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) """ x_train shape: (60000, 28, 28, 1) 60000 train samples 10000 test samples """ # بناء النموذج model = keras.Sequential( [ keras.Input(shape=input_shape), layers.Conv2D(32, kernel_size=(3, 3), activation="relu"), layers.MaxPooling2D(pool_size=(2, 2)), layers.Conv2D(64, kernel_size=(3, 3), activation="relu"), layers.MaxPooling2D(pool_size=(2, 2)), layers.Flatten(), layers.Dropout(0.5), layers.Dense(num_classes, activation="softmax"), ] ) model.summary() """ Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 11, 11, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 1600) 0 _________________________________________________________________ dropout (Dropout) (None, 1600) 0 _________________________________________________________________ dense (Dense) (None, 10) 16010 ================================================================= Total params: 34,826 Trainable params: 34,826 Non-trainable params: 0 _________________________________________________________________ """ # تدريب النموذج batch_size = 128 epochs = 15 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1) """ Epoch 1/15 422/422 [==============================] - 13s 29ms/step - loss: 0.7840 - accuracy: 0.7643 - val_loss: 0.0780 - val_accuracy: 0.9780 Epoch 2/15 422/422 [==============================] - 13s 31ms/step - loss: 0.1199 - accuracy: 0.9639 - val_loss: 0.0559 - val_accuracy: 0.9843 Epoch 3/15 422/422 [==============================] - 14s 33ms/step - loss: 0.0845 - accuracy: 0.9737 - val_loss: 0.0469 - val_accuracy: 0.9877 Epoch 4/15 422/422 [==============================] - 14s 33ms/step - loss: 0.0762 - accuracy: 0.9756 - val_loss: 0.0398 - val_accuracy: 0.9895 Epoch 5/15 422/422 [==============================] - 15s 35ms/step - loss: 0.0621 - accuracy: 0.9812 - val_loss: 0.0378 - val_accuracy: 0.9890 Epoch 6/15 422/422 [==============================] - 17s 40ms/step - loss: 0.0547 - accuracy: 0.9825 - val_loss: 0.0360 - val_accuracy: 0.9910 Epoch 7/15 422/422 [==============================] - 17s 41ms/step - loss: 0.0497 - accuracy: 0.9840 - val_loss: 0.0311 - val_accuracy: 0.9920 Epoch 8/15 422/422 [==============================] - 16s 39ms/step - loss: 0.0443 - accuracy: 0.9862 - val_loss: 0.0346 - val_accuracy: 0.9910 Epoch 9/15 422/422 [==============================] - 17s 39ms/step - loss: 0.0436 - accuracy: 0.9860 - val_loss: 0.0325 - val_accuracy: 0.9915 Epoch 10/15 422/422 [==============================] - 16s 38ms/step - loss: 0.0407 - accuracy: 0.9865 - val_loss: 0.0301 - val_accuracy: 0.9920 Epoch 11/15 422/422 [==============================] - 16s 37ms/step - loss: 0.0406 - accuracy: 0.9874 - val_loss: 0.0303 - val_accuracy: 0.9920 Epoch 12/15 237/422 [===============>..............] - ETA: 7s - loss: 0.0398 - accuracy: 0.9877 """ # تقييم النموذج acc = model.evaluate(x_test, y_test, verbose=0) print("Test loss:", acc[0]) # Test loss: 0.023950600996613503 print("Test accuracy:", acc[1]) # Test accuracy: 0.99220001697540281 نقطة
-
السلام عليكم ورحمة الله وبركاته، استخدم android studio ولغة جافا، كيف اقدر احصل على مسار لفيديو معين موجود في المعرض (gallery)1 نقطة
-
وعليكم السلام @خضر علي2 يمكنك القيام بذلك بعدة طرق من خلال الحصول على البيانات الراجعة من ال Intent هكذا الميثود getPath يتم تمرير المسار من ال intent بعد الإختيار وتقوم Intent intent = new Intent(); intent.setType("video/*"); intent.setAction(Intent.ACTION_GET_CONTENT); startActivityForResult(Intent.createChooser(intent,"Select Your Video"),REQUEST_TAKE_GALLERY_VIDEO); public void onActivityResult(int requestCode, int resultCode, Intent data) { if (resultCode == RESULT_OK) { if (requestCode == REQUEST_TAKE_GALLERY_VIDEO) { Uri selectedImageUri = data.getData(); //Device FILE Manager filemanagerstring = selectedImageUri.getPath(); // Path From GALLERY selectedImagePath = getPath(selectedImageUri); if (selectedImagePath != null) { // new Intent that holdes selected path so we can use it in VideoAvtivity class or whatever your class is Intent intent = new Intent(Mainctivity.this, VideoAvtivity.class); intent.putExtra("path", selectedImagePath); startActivity(intent); } } } } public String getPath(Uri uri) { String[] projection = { MediaStore.Video.Media.DATA }; Cursor cursor = getContentResolver().query(uri, projection, null, null, null); if (cursor != null) { // NULLPOINTER IF CURSOR IS NULL // FILE MANAGER FOR PICKING THE MEDIA int column_index = cursor .getColumnIndexOrThrow(MediaStore.Video.Media.DATA); cursor.moveToFirst(); return cursor.getString(column_index); } else return null; }1 نقطة
-
سوف أشرج لك المشكلة ويمكنك حلها, المشكلة انك قمت بتثبيت حزمة html-loader الاصدار 2.1.2 وهذا الاصدار أصبح يدعم معالجة الملفات ومن ضمن هذه الملفات الصور, وبالتالي هذا الاصدار يتعارض مع عمل حزمة file-loader المسؤولة عن معالجة الملفات ومن ضمن هذه الملفات الصور, وبالتالي تحدث هذه المشكلة, يمكنك حلها بتثبيت الاصدار 1.3.2 من حزمة html-loader1 نقطة
-
URI هو اختصار لـ: معرف المورد الموحد (Uniform Resource Identifier) وهو عبارة عن عنوان فريد يستخدم لتحديد المحتوى على الشبكة مثل مقطع فيديو، صفحة ويب،.. إلخ. ومن أهم الاختلافات بينه وبين URL (Uniform Resource Locator) باختصار هو أن URL بالإضافة لذلك يقوم بتحديد أين يوجد هذا المحتوى بالتحديد وكيفية الوصول إليه ومواصفات بروتوكول الاتصال. فإذاً وبشكل عام كل URL هو جزء من URI. أما بالنسبة لجافا أو أي لغة برمجة أخرى، قد تحتاج للتعامل مع محتويات موجودة على الشبكة، ويسهّل لك الصف URI الموجود في جافا من خلال java.net.URI تحقيق ذلك. وقد ترى الاختلاف من خلال مثال بسيط في جافا باستخدام URL أو URI كالتالي: كما يتيح لك الصف URI استخدام العديد من الخصائص مثل scheme، اسم المستخدم وكلمة المرور، authority التحقق وأيضاً إضافة استعلامات من خلال هذا الرابط نفسه، بحيث يمكنك جمعها كلها في نفس الرابط أو تقسيمها إلى متغيرات منفصلة عن بعضها، مثال: public void createURI() throws Exception { URI example1 = new URI( "scheme://user:password@authority:80" + "/path?query"); URI example2 = new URI( "scheme", "user:password", "authority", 80, "/path", "query"); assertEquals(example1.getScheme(), example2.getScheme()); assertEquals(example1.getPath(), example2.getPath()); } كما يمكنك استخدام بعض التوابع مثل getScheme و getPath وغيرها من التوابع التي يوفرها الصف URI في جافا. أما استخدام URL ضمن جافا فهو مختلف بعض الشيء، مثال: public void createURL() throws Exception { URL ex = new URL( "http://anywebsitehere.com"); URL ex2 = new URL("http", "somehost", 80, "/path/to/file"); assertEquals(ex.getHost(), ex2.getHost()); assertEquals(ex.getPath(), ex2.getPath()); } وأيضاً يمكنك بأي وقت التحويل من URI إلى URL وبالعكس باستخدام التوابع التالية: URL toURL = uri.toURL(); URI toURI = url.toURI();1 نقطة
-
لدي طريقة أخرى جميلة للقيام بذلك سأشاركها، تعتمد على عكس القاموس أي نجعل القيم مفاتيح والعكس. نعرف تابع يقبل قاموس d وقيمة val ثم يقوم بعكس هذا القاموس (جعل القيم مفاتيح والمفاتيح قيم) ثم يبحث في القاموس الجديد عن القيمة val بالطريقة الاعتيادية ويردها لنا كالتالي: # نعرف تابع يقوم بالمطلوب def get_keys_from_value(d, val): reverse_dict = dict([(value, key) for key, value in d.items()]) # نجعل المفاتيح قيم والقيم مفاتيح return reverse_dict[val] # تعريف القاموس your_dict={'Adam': 18, 'Ebrahim' : 19} # البحث عن طريق التابع الذي عرفناه print(get_keys_from_value(your_dict, 18)) # Adam1 نقطة
-
اعتقد أنك تقصد الفرق بينهما أليس كذلك؟! حسناً... وظائفهما متشابهة لحد ما، لذا فغالباً ماتذكران معاً. لكن جذور التقنيتين مختلفة كثيراً. LVM: هي التقنية الستخدمة من قبل نظام لينوكس وهي اختصار ل Logical Volume Manager "مدير التخزين المنظقي"، تستخدم لعزل الحيز التخزيني المتاح لنظام الملفات (المنطقي) عن الحيز التخزيني الفيزيائي، بحيث تجعل إدارة البيانات أكثر مرونة واستقلالاً عن السعة الحقيقية للأقراص عند تحميل تلك البيانات. RAID: وهي تفنية مستخدمة في التخزين وهي اختصاراً ل "Redundant Array of Independent Disks" أي التخزين الفائض للبيانات على الأقراص بحيث تحمي البيانات من الفقدان الذي قد يحصل بسبب فشل الأقراص أو حدوث عطب ما في أحد الأقراص فهي تستخدم طريقة بأن تخزن الملف على أكثر من قرص (الأقراص تكون رخيصة الثمن ) وله أكثر من مستوى من RAID0 إلى 6 وكل مستوى له خصائصه.1 نقطة
-
يمكن ذلك بطريقتين : الطريقه الأولى بعد تهيئة القاموس نقوم باستخدام التابع setdefault حيث يأخذ وسيطين الأول المفتاح والثاني نوع القيم ممكن أن تكون list وset وغيرها وبعد ذلك نستخدم append الخاص ب list لأضافة القيمة #طريقة أولى: dic={} # تعريف قاموس فارغ yourlist=[[88,66],[80,3]] # تعريف قائمة for j in range(len(yourlist)): dic.setdefault(j, list()).append(yourlist[j]) print(dic) # {0: [[88, 66]], 1: [[80, 3]]} الطريقة الثانية بدون التابع setdefault نقوم فقط بعملية إسناد تقليدية #طريقة ثانية: dic={} # تعريف قاموس فارغ yourlist=[[88,66],[80,3]] # تعريف قائمة for j in range(len(yourlist)): dic[j]=yourlist[j]1 نقطة
-
ال multithreading ليست دوماً الحل الأفضل لتسريع البرنامج: هناك عبء overhead مرتبط بإدارة ال Threads، لذلك لايكون من الجيد استخدامها للمهام البسيطة (الغاية الأساسية هي السرعة في التنفيذ، لكن في هكذا حالات قد تكون النتائج سيئة أي قد يزداد زمن التنفيذ وهذا ما لانريده فنحن بالأساس نتجه لتحقيق الThreading لكي يقل زمن التنفيذ وليس العكس) ال multithreading يزيد من تعقيد البرنامج ، مما يجعل تصحيح الأخطاء أكثر صعوبة. ال multiprocessing: هناك عبء مرتبط بها عندما يتعلق الأمر بعمليات الإخراج والإدخال. لاتتم مشاركة الذاكرة بين ال subprocess حيث يكون لكل subprocess نسخة كاملة خاصة به من الذاكرة وهذا يشكل عبء Overhead بالنسبة للبرامج الأخرى. إن الموديول multiprocessing يستخدم ال Processes أي أن التعليمة الثانية التي أشرت لها في كتابتك تقوم بإنشاء Processe أما الموديول multithreading يستخدم ال Threads أي أن التعليمة الأولى التي أشرت لها تقوم بإنشاء Thread، والفرق الأساسي بينهم أن الأولى تستخدم ذاكرة منفصلة لكل subprocess (كما أشرت في الأعلى) بينما ال Threads تتشارك الذاكرة وبالتالي في ال multiprocessing لاخوف من حدوث حالات تلف البيانات أو التوقف التام deadlock بينما في ال multithreading فهذا وارد الحدوث. متى نستخدم كل منها: إذا كان البرنامج يحوي العديد من مهام الإدخال والإخراج أو استخدام الشبكة فيفضل استخدام ال threading لأنها سيترتب عليها overhead أقل من ال multiprocessing. أو إذا كان لديك GUI في برنامجك. إذا كان برنامجك يحوي على العديد من العمليات الحسابية "CPU bound" فيفضل التعامل مع ال multiprocessing.1 نقطة
-
كيف يتصرف إذا أراد حل مشكلة. أعتقد أن هذا أهم أمر. ثم كم ساعة يقضيها على جهازه المحمول في اليوم (أنا أقضي 12 ساعة مثلا). آخر أمر تسألونه عنه هو خبراته. وطبعا يجب أن يكون لديه معرفة في مجال العمل المطلوب منه وليس ضروري أبدا أن يكون ملم به.1 نقطة
-
هي دوال تتألف من سطر واحد تستخدم الكلمة المفتاحية lambda على عكس التوابع الأخرى في بايثون التي تستخدم def ككلمة مفتاحية وهي تقوم بإرجاع قيمة عند استدعاءها لها الشكل التالي: lambda [arg1 [,arg2,.....argn]]:expression الكلمة المفتاحية lambda أسماء متحولات الدخل ويوجد فاصلة بين كل متحول وأخر [arg1 [,arg2,.....argn]] ب expression تتم العمليات على المتحولات مثال بسيط لجمع عددين باستخدام Anonymous Function: T=lambda x,y:x+y على عكس التوابع الأخرى التي تستدعى بالاسم فإن Anonymous Function يتم إسنادها لمتغير ومن ثم يكون المتغير هو الاسم لهذا التابع أي يكون الاستدعاء كالتالي: T(2,3) #output:51 نقطة
-
يمكن استخدام الوظيفة shuffle من المكتبة random كالأتي: from random import shuffle x = [1,2,3,4,5,6,7,8,9] # تعريف القائمة shuffle(x) # خلط القائمة print(x) #output :[3, 5, 7, 9, 1, 4, 8, 2, 6]1 نقطة







