لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 07/04/21 في كل الموقع
-
لدي مجموعة من المستندات وأحاول الحصول على مجموع عناصر مصفوفة بهيئة حقل جديد بشكل مشابه للتالي: { "department": 1, "Count employees" : {$size : "$employees" } } ولكن يظهر لي الخطأ التالي: The argument to $size must be an Array, but was of type: EOO فهل يوجد طريقة لوضع القيمة 0 في حال كان العنصر فارغاً وتجاهل الخطأ السابق؟3 نقاط
-
أحاول تطبيق OOP - Object Oriented Programming ضمن كود المشروع في node.js، ولكن هل يجب أن تتم تجزأة جميع الصفوف ضمن module.export ؟ وحاولت إنشاء الصفوف بالشكل التالي: this.Class = function() { var name = "" this.username = "" var getName = function() {} this.getName = function() {} } لكن واجهت العديد من الأخطاء بهذه المنهجية. فما هي الطريقة الصحيحة لإنشاء الصفوف واتباع OOP ضمن node.js؟ وهل هي مدعومة بشكل تلقائي ضمن node.js ؟2 نقاط
-
السلام عليكم و رحمة الله و بركاته عند تنفيذ الامر php artisan migrate:fresh --seed يشتغل فقط التهجير بينما البذر لا يعمل بل يتجمد فما المشكلة
 2 نقاط
2 نقاط -
<div class="mx-auto"> {{$questions->links()}} </div> لماذا يظهر بهذا الشكل؟
 2 نقاط
2 نقاط -
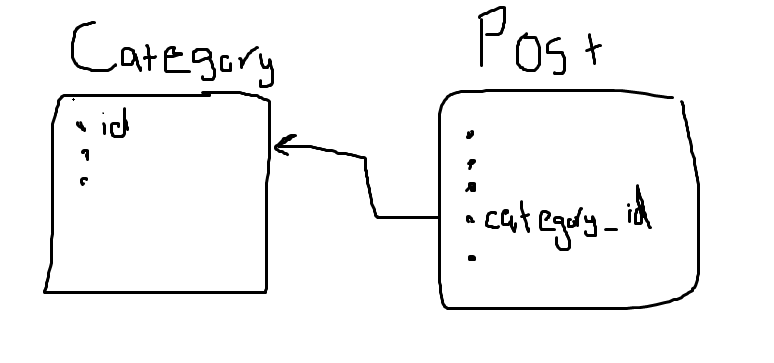
من خلال ال post حصلت على category_id كيف أحصل على اسم هذا ال categary
 2 نقاط
2 نقاط -
هناك عدة طرق لإستدعاء ملف من المجلد الأب ، فيمكنك إضافة المسار الأب الى المسارات التي بايثون سيقوم بالبحث فيها بإستخدام دالة path كالآتي import sys sys.path.append("..") import helpers كما يمكنك إضافة المسار الأب أو أي مسار تريد إستيراد الوحدات modules منه كالآتي # إستدعاء دالة sys import sys # إضافة المسار الى الرقم 1 لأن 0 هو المسار الحالي sys.path.insert(1, '/path/to/application/app/folder') # إستيراد الوحدة من المسار المختلف import file2 نقاط
-
ماهي المواضيع التي يريد ان يعرفها الناس في ايامنا هذه1 نقطة
-
السلام عليكم ورحمة الله لدي سؤال حول كيفية عمل الدالة داخل الـsort method في هذا الكود let numbers =[2, 14, 1, 2, 5]; number.sort((x,y) => y - x);1 نقطة
-
أقوم باستخدام Express في node.js وقمت بإنشاء وسيط قبل تنفيذ تابع معيّن بالشكل التالي: app.get('/admins', Role, function(req,res){ ... }) ولكن هل من الممكن تمرير متغيّرات ضمن هذا الوسيط Role؟ بحيث تكون هذه المتغيرات من الطلب request نفسه؟1 نقطة
-
كيف يمكن تطبيق الكشيدة في مواقع الويب؟ مع أو بدون اللجوء لعمل آلية لوضع (شفت + حرف التاء) في الحروف هل لها CSS معين؟ أو خطوط عربية للويب يمكنها حل هذا اللغز؟ أم لها خوارزمية برمجية؟ مثل بســـــم الله الرحــــمـــــن الرحيـــــــــــم ومثل أبيات الشعر العربية؟ أفيدوني أكرمكم الله1 نقطة
-
لقد اشتركت في دوراتكم وأنا اشتركت لاني اريد أن اعمل واكن عمري فقط 15 سنة هل يمكن لي ان اعمل بعد التعلم وانا علي علم باساسيات البرمجة واكثر من الاساسيات بقليل فهل يمكن أن اعمل وانا في سن ال 151 نقطة
-
بما أنك تتعامل مع شبكة عصبونية التفافية CNN يجب أن تكون الصورة من الشكل: الطول*العرض*عدد القنوات. أي يجب تحويل الأبعاد الخاصة بالداتا كالآتي: x_train = x_train.reshape(60000, 28, 28, 1) x_test = x_test.reshape(10000, 28, 28, 1)1 نقطة
-
لإنشاء أصناف classes في JavaScript فيجب عليك كما في بقية اللغات المشهورة إستخدام الكلمة المحجوزة class كالآتي // إنشاء الصنف class Player{ constructor(name, age){ this.name = name; this.age = age } } // إنشاء نسخة من الصنف let p = new Player('Ali', 14) اما كيفية الإستيراد والتصدير في NodeJS فلديك طريقتين إما عبر CommonJS بإستخدام module.export كالآتي // من ملف Player.js // إنشاء الصنف class Player{ constructor(name, age){ this.name = name; this.age = age } } module.exports = Player; // من ملف آخر const Player = require('./Player') أو بإستخدام الطريقة الجديدة ل ES6 عبر إستخدام export و import كالآتي // ملف Player.js // إنشاء الصنف export default class Player{ constructor(name, age){ this.name = name; this.age = age } } // ملف آخر import Player from './Player.mjs'1 نقطة
-
حاول تعديل كود الجيكويري المسؤول عن إرسال البيانات بهذا الشكل: $(document).ready(function() { //##### Add record when Add Record Button is click ######### $("#content-form").submit(function(e) { e.preventDefault(); //build a post data structure var message = $("#mymessage").val(), name = $("#myname").val(), email = $("#myemail").val(); if (name == '' || email == '' || message == '') { alert("All fields are required"); return false; } jQuery.ajax({ type: "POST", // Post / Get method url: "response.php", //Where form data is sent on submission dataType: "text", // Data type, HTML, json etc. data: { name: name, email: email, message: message }, //Form variables success: function(response) { $("#responds").append(response); $('#content-form').trigger('reset'); }, error: function(xhr, ajaxOptions, thrownError) { alert(thrownError); } }); }); }); حيث أن خصائص الكائن data هي ما ستستقبله في المتغير العام POST_$ و تضيف الحقول الجديدة لإستعلام التخزين: <?php //include db configuration file include_once("config.php"); if(isset($_POST["message"]) && strlen($_POST["message"])>0) { $name = mysqli_real_escape_string($connecDB, $_POST["name"]); $email = mysqli_real_escape_string($connecDB, $_POST["email"]); $message = mysqli_real_escape_string($connecDB, $_POST["message"]); $query = "INSERT INTO add_delete_record(name, email, message) VALUES ('".$name."', '".$email."','".$message."')"; if(mysqli_query($connecDB, $query)) { echo '<p>You have entered</p>'; echo '<p>Name:'.$name.'</p>'; echo '<p>email:'.$email.'</p>'; echo '<p>Message : '.$message.'</p>'; } } ?>1 نقطة
-
هو طريقة تحسين مشابهه ل Adam التي تقوم بتسريع GD وتخفف التذبذب وامتداد لها ويكون adamax أفضل من adam أو أكثر فعالية في بعض المشكلات يقوم adam بتحدث الأوزان اعتمادا على متوسط الأوزان الأسية للمشتقات السابقع ومتوسط الأوزان الاسية لمربعات المشتقات السابقة في حين أن adamax يقوم بتوسيع الحد الأقصى للمشتقات السابقة ويقوم إيضا بتكييف معدل تعلم لكل معلمة في عملية التحسين بشكل منفصل لاستخدامها في كبراس نمررها إلى الدالة compile: model.compile( optimizer=Adamax(learning_rate=0.001) ... ) # أو model.compile( optimizer='Adamax' ... ) # لاحظ أنه في الطريقة الثانية سيستخدم معمل الخطوة الافتراضي. # لذا إذا أردت تغييرها استخدم الصيغة الأولى. مثال عن طريقة الاستخدام حيث يأخذ Adamax الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة: #استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import Adamax #تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() #تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 #بناء الشبكه العصبونيه بطبقه واحده وطبقة خرج ب 10 أصناف model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) #0.001مع معامل تعلم Adamax استخدام model.compile(optimizer=Adamax(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) #تدريب الموديل model.fit(X_train,y_train)1 نقطة
-
لدي قائمة تحتوي على أربعة أرقام وأريد أن أقوم بتمرير كل القيم من هذه القائمة إلى دالة تقبل أربعة مدخلات كالتالي: def echo(a, b, c, d): print(a, b, c, d) myLits = [1, 2, 3, 4] أريد تمرير محتوى myList إلى دالة echo، في لغات أخرى مثل JavaScript يمكنني أن أستخدم المعامل "..." كالتالي: echo( ...myList ) كيف أقوم بهذا الأمر في بايثون؟1 نقطة
-
سمعت عن مصطلح memoization من فترة قصيرة ولم أفهم الغرض منه، أعلم أنه يستخدم لتسريع البرامج لكن كيف يتم هذا الأمر؟ ولماذا لا تستعمله كل البرمجيات؟ حاولت البحث عن إجابة لهذه الأسئلة لكن لم أجد مصادر عربية تفيد في هذا الأمر.1 نقطة
-
حسناً أنت محظوظ فهذا النوع من البرمجة كان اختصاصي خلال مشاركاتي في المسابقات البرمجية. عندما تتحدث عن ال memoization فهذا يعني أنك دخلت حقل البرمجة الديناميكية "Dynamic Programming" كبداية سأعرفك بالبرمجة الديناميكية: البرمجة الديناميكية هي أسلوب أو نهج في حل المسائل لتحسين التعقيد الزمني للمسائل التي تحوي "العودية". الفكرة هي ببساطة تخزين نتائج المشكلات الفرعية "Subproblems"، حتى لا نضطر إلى إعادة حسابها عند الحاجة لها لاحقاً. وهذا مايؤدي إلى تقليل التعقيد الزمني للعديد من المسائل من تعقيد أسي إلى تعقيد خطي polynomail. على سبيل المثال، إذا كتبنا حلًا عودياً بسيطًا لأرقام فيبوناتشي، فإننا نحصل على تعقيد زمني أسي، وإذا قمنا بتحسينه عن طريق تخزين حلول المشكلات الفرعية، فإن تعقيد الوقت ينخفض إلى خطي. # تايع لحساب أعداد فيبوناتشي بالطريقة العودية def Fib(n): if n<0: print("error") elif n==0: return 0 elif n==1: return 1 else: return Fib(n-1)+Fib(n-2) print(Fib(5)) # هذا الكود تعقيده أسي وهذا سيئ وغير فعال fib(5) / \ fib(4) fib(3) / \ / \ fib(3) fib(2) fib(2) fib(1) / \ / \ / \ fib(2) fib(1) fib(1) fib(0) fib(1) fib(0) / \ fib(1) fib(0) #تستدعى مرتين fib 3 يمكن مثلاً ملاحظة أنّ الدالة #وإن تسنّى لنا تخزين القيمة الناتجة عن استدعاء هذه الدالة، فستنتفي الحاجة إلى إعادة حساب هذه القيمة وسيكون بالإمكان استخدام القيمة المخزّنة سابقًا عوضًا عن ذلك. أما عند حله باستخدام مفهوم البرمجة الديناميكية: # Dynamic Programming def Fib(n): dp = [0, 1] for i in range(2, n+1): dp.append(dp[i-1] + dp[i-2]) return dp[n] print(Fib(5)) لكن يجب أن تعلم أن ليس كل مسألة عودية أو أي مسألة تحوي استدعاءات متكررة يمكن أن يكون لها حل باستخدام البرمجة الديناميكية، هناك شرطين يجب أن تحققهما أي مسألة قبل أن نحاول حلها باستخدام هذا المفهوم، فإذا تحققا هذا يعني أنه يمكن حلها في ال DP، وإلا فلا تحاول، وهما: مسائل فرعية متداخلة "Overlapping Subproblems": أي هل يمكن تقسيم المسألة إلى مسائل فرعية أصغر، أو إلى مهام أصغر، أو بمعنى آخر هل يمكننا تقسيم المسألة إلى مسائل أصغر بحيث تجتمع هذه المسائل لحل المسألة الأكبر. حيث أن البرمجة الديناميكية تشبه نموذج فرّق تسد في أنها تدمج حلول المسائل الفرعية بعضها ببعض. تستخدم البرمجة الديناميكية عمومًا عندما تظهر الحاجة إلى استخدام حلول مجموعة معينة من المسائل الفرعية مرة بعد أخرى. تخزّن حلول المسائل الفرعية في البرمجة الديناميكية في مصفوفة وذلك لتجنّب حسابها مرة أخرى. هذا يعني أنّ البرمجة الديناميكية غير مفيدة عندما لا تكون هناك مسائل فرعية متداخلة؛ إذ لا فائدة من تخزين الحلول إن لم تكن الخوارزمية بحاجة إليها مرة أخرى. قمثلاً تتضمن عملية حساب أعداد فيبوناتشي بطريقة تعاودية العديد من المسائل الفرعية التي يجري حلّها مرة تلو الأخرى مثل fib3 كما رأينا. بنية فرعية مثالية "Optimal Substructure":نقول أنّ مسألة معيّنة تمتلك بنية فرعية مثالية إذا كان بالإمكان الحصول على الحل المثالي للمسألة المعطاة بجمع الحلول المثالية للمسائل المتفرّعة عن المسألة الرئيسية. الآن سأنتقل لك لمفهوم ال Memoization.. نحن قلنا أنه سيتم تخزين الحلول، حسناً كيف سيتم تخزينها؟ هناك طريقتين للقيام بذلك: التحفيظ Memoization (من الأعلى إلى الأسفل): تشبه طريقة التحفيظ في حل مسألة معينة الطريقة التعاودية ولكن مع تعديل بسيط، وهو أنّ هذه الطريقة تبحث في جدول البحث lookup table معين قبل حساب الحلول. تبدأ العملية بتهيئة مصفوفة بحث تحمل القيمة NIL كقيمة أولية. وفي كل مرّة نحتاج فيها إلى إيجاد حلٍّ لمسألة فرعية، نبدأ بالبحث في جدول البحث، فإن كانت القيمة محسوبة مسبقًا موجودة فيه فسنعيد حينئذٍ تلك القيمة، وإلا سنحسب القيمة ونضع النتيجة في جدول البحث ليتسنى لنا إعادة استخدامها في وقت لاحق. مثال لاستخدام هذه الطريقة مع المسألة السابقة: # الدالة المسؤولة عن حساب العدد ذي الترتيب المعطى في متتالية فيبوناتشي def fib(n, lookup): # الحالة الأساس if n == 0 or n == 1 : lookup[n] = n # إن لم تكن القيمة محسوبة مسبقًا فسنحسبها الآن if lookup[n] is None: lookup[n] = fib(n-1 , lookup) + fib(n-2 , lookup) # n تعيد الدالة القيمة المرتبطة بالقيمة المعطاة return lookup[n] # اختبار الدالة السابقة def main(): n = 34 # إنشاء جدول البحث # يستوعب الجدول 100 عنصر lookup = [None]*(101) print "Fibonacci Number is ", fib(n, lookup) if __name__=="__main__": main() 2.الجدولة Tabulation (من الأسفل إلى الأعلى): تبني هذه الطريقة جدولًا من الأسفل إلى الأعلى وتعيد آخر قيمة من الجدول عند الحاجة. فعلى سبيل المثال، تحسب دالة فيبوناتشي الأعداد في المتتالية حسب التسلسل fib(0) ثم fib(1) ثم fib(2) ثم fib(3) وهكذا. وهذا يعني أنّنا نبني جدول الحلول للمسائل الفرعية من الأسفل إلى الأعلى حرفياً. وهي ذات الطريقة التي استخدماتها لتخزين الحلول للمسألة في البداية. مثال آخر للتحفيظ: لنفترض أن لدينا الأعداد {1, 3, 5} والمطلوب هو إيجاد عدد الطرق التي يمكن استخدام هذه الأرقام فيها لحساب رقم معيّن (ليكن N) وذلك بإجراء عملية الجمع مع السماح بتكرار الأعداد وتغيير ترتيبها. لكي نتمكّن من حلّ هذه المسألة ديناميكيًا يجب في البداية اتخاذ قرار بشأن الحالة الخاصة بالمسألة المعطاة، وسنستخدم معاملًا (ليكن n) لاتخاذ القرار بشأن الحالة الراهنة وذلك لإمكانية استخدام هذه المعامل في تشخيص أي مسألة فرعية بطريقة فريدة. وبهذا تكون الحالة في هذه المسألة هي state(n)، والتي تمثّل هنا العدد الكلي للترتيبات التي يمكن استخدامها لتكوين العدد n باستخدام العناصر {1, 3, 5}. ولمّا كان بالإمكان استخدام الأعداد 1 و 3 و 5 فقط لتكوين العدد المعطى، سنفترض أنّنا نعرف نتائج الأعداد n = 1, 2, 3, 4 , 5, 6 مسبقًا، وبمعنى آخر فإنّنا نعرف نتائج كلّ من state (n = 1), state (n = 2), state (n = 3) ……… state (n = 6). // تعيد الدالة عدد الترتيبات لتكوين العدد المعطى int solve(int n) { // الحالة الأساس if (n < 0) return 0; if (n == 0) return 1; return solve(n-1) + solve(n-3) + solve(n-5); } تعمل الشيفرة السابقة بتعقيد زمني أسّي وتحسب الحالة نفسها مرارًا وتكرارًا؛ ولهذا يجب إضافة عملية التحفيظ memoization. إضافة عملية التحفيظ إليها:: // تهيئة القيمة لتكون -1 int dp[MAXN]; // تعيد هذه الدالة عدد الترتيبات لتكوين العدد `n` int solve(int n) { // الحالة الأساس if (n < 0) return 0; if (n == 0) return 1; // التحقق من أنّ الحالة الراهنة محسوبة مسبقًا if (dp[n]!=-1) return dp[n]; // تخزين النتيجة وإعادتها return dp[n] = solve(n-1) + solve(n-3) + solve(n-5); }1 نقطة
-
تقوم دالة sort() بفرز عناصر المصفوفة في مكانها وإرجاع المصفوفة التي تم فرزها. ترتيب الفرز الافتراضي تصاعدي ، مبني على تحويل العناصر إلى سلاسل ، ثم مقارنة تسلسل قيم وحدات رمز UTF-16. حيث أي عنصر في المصفوفة يتم تحويله الى نص ، على سبيل المثال إذا كان العنصر رقم فيتم تحويله الى سلسلة نصية string ومن ثم يتم مقارنة السلاسل النصية وفقاً لقيمها في نظام UTF-16 . هذه هي الحالة الإفتراضية لدالة sort أي إذا لم تقم بتمرير دالة مقارنة إليها ، على سبيل المثال let arr = [4,30,100,1] arr.sort() // [1, 100, 30, 4] /* * تم ترتيب العناصر على أنها سلاسل نصية ووفقاً لقيمها في نظام * UTF-16 */ أما إذا قمت بتمرير دالة مقارنة إليها فيتم ترتيب العناصر بناءً على دالة المقارنة ولايتم الترتيب الافتراضي بتحويل العناصر الى سلاسل نصية string ، كما في الكود الخاص بك let numbers =[2, 14, 1, 2, 5]; /* دالة المقارنة تقوم بمقارنة عنصرين متجاورين حيث المتغير * x * هو المتغير الأول والمتغير * y * هو المتغير التالي المجاور للمتغير * x * ويتم إرجاع المتغير الأكبر */ number.sort((x,y) => y - x);1 نقطة
-
صحيح ,لأنه تم فقط إضافة بيانات اختبارية فقط لجدول users. يمكنك إضافة بيانات اختبارية لباقي الجداول كيفما تريد.1 نقطة
-
نعم يوجد و لكن لا يوجد تعليقات او اعجابات اي انها فارغة اي 0 comments و 0 likes1 نقطة
-
هل من الممكن تتفقد جدول users بأنه يوجد به حسابات للمستخدمين ؟1 نقطة
-
من خلال منصات العمل الحر مثل مستقل فبالتأكيد يمكنك العمل بدون مشاكل ولا يشكل العمر عائق في العمل حيث في منصات العمل الحر تنفيذ لعمل على أكمل وجه هو الأولوية أما بالنسبة للشركات فمن الصعب أن تجد وظيفة في هذا العمر ولكن ربما توجد بعض الشركات التي تقبل العمل في هذا العمر وأنا أجد أن محاولة العمل في هذا العمر خطوة جيدة لتكتسب الخبرة مبكراً وما يجب عليك عمله هو التعلم بشكل جيد وكثرة التطبيق1 نقطة
-
تم الأمر و لكن لا يبدو أن لديك ملفات أختبارية تم إنشائها أو تم وضعها في ملف DatabaseSeeder..php .1 نقطة
-
رجاءًا حاول إعادة تشغيل السيرفر من جديد, أو حاول الدخول إلى ملف laravel.log في مجلد storage و قراءة أي أخطاء قد تسبب هذا الأمر , ايضا حاول تنفيذ الأمر التالي php artisan migrate --force ثم محاولة تنفيذ الأمر التالي php artisan migrate:fresh --seed ليتم إضافة البيانات الأختبارية بعد تهجير الجداول إلى قاعدة البيانات. أرجوا إخباري بالنتيجة.1 نقطة
-
هل يعطي أي نتيجة ام فقط يبقى هكذا؟ عادة يحدث ذلك بسبب العدد الكبير للبيانات التي يتم اضافاتها فيظهر وكأنه مجمد, اما أن تنتظر أو تحاول تقليل عدد البيانات التي تحاول ادخالها, جرب بعدد قليل بداية لترى هل يوجد مشاكل في اضافة البيانات أم لا ثم بعد ذلك يمكنك اضافة الكثير منها1 نقطة
-
حاول معرفة أي إصدار bootstrap تستخدمه ومن ثم قم بوضع pagination::bootstrap-4 مع تغيير إصدار البوتستراب {{$questions->links('pagination::bootstrap-4')}} إذا لم يكن مجلد vendor داخل مجلد views فيمكنك استخدام الأمر التالي لتقوم بنشره داخل مجلد views php artisan vendor:publish --tag=laravel-pagination ومن ثم يمكنك تخصيص ملف ترقيم الصفحات بوضع أي استايل تريده عن طريق وضع الملف الجديد {{$questions->links('myfile')}}1 نقطة
-
ربما لأنك تعمل على الاصدار الاخير من لارافيل والذي يعمل مع مكتبة tailwind وليس بوتستراب, يمكنك باستخدام أدوات المطور التي يمكنك الوصول اليها من خلال الضغط بالزر الأيمن للماوس في أي مكان من الصفحة واختيار فحص العنصر أو inspect elements أن تقوم بتفحص التنسيقات واضافة التنسيقات المناسبة ليظهر الشكل بشكل جيد, أو يمكنك استخدام تضمين بوتسراب في المشروع, ثم في ملف AppServiceProvider الذي تجده في المسار التالي app/Providers/AppServiceProvider , وضع السطر التالي في التابع boot Paginator::useBootstrap(); ثم حاول مرة أخرى1 نقطة
-
السلام عليكم عندي مشكلة بسيطة في HTML لدي 2 divs أحتاج أضعهم بنفس الطول زي الصورة بالأسفل إن شاء الله انها واضحة وهذا الكود اللي مستخدمه <div class="y-10"> <div class="block md:flex items-center justify-center"> <div class="flex-1 mt-5 md:mt-0 mx-5 bg-white rounded-lg shadow-lg hover:shadow-xl transition duration-150" style="margin-bottom: auto;"> <div class="w-full h-auto text-center py-3 bg-gradient-to-br from-green-800 to-green-600"> <h6 class="font-semibold text-xl text-white" style="font-family: DroidKufi-Regular; font-size: 18px;"> Lorem </h6> </div> <div> <p class="text-gray-600 p-3" style="text-align: center; font-family: DroidKufi-Regular; font-size: 17px;"> Lorem ipsum dolor sit amet, consectetur </p> </div> </div> <div class="flex-1 mt-5 md:mt-0 mx-5 bg-white rounded-lg shadow-lg hover:shadow-xl transition duration-150" style="margin-bottom: auto;"> <div class="w-full h-auto text-center py-3 bg-gradient-to-br from-green-800 to-green-600"> <h6 class="font-semibold text-xl text-white" style="font-family: DroidKufi-Regular; font-size: 18px;"> Lorem </h6> </div> <div> <p class="text-gray-600 p-3" style="text-align: center; line-height: 2; font-family: DroidKufi-Regular; font-size: 16px;"> Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitatio </p> </div> </div> </div> </div>
 1 نقطة
1 نقطة -
هذا هو الكود الخاص بك بعد تعديله (اضافة parentDivClass و yourDivClass وcss المقترح)، اذا كان هناك اكواد css تتعارض مع هذا الكود برجاء مشاركتها لكي نستطيع معرفة المشكلة <div class="y-10"> <div class="block md:flex parentDivClass items-center justify-center"> <div class="flex-1 yourDivClass mt-5 md:mt-0 mx-5 bg-white rounded-lg shadow-lg hover:shadow-xl transition duration-150" style="margin-bottom: auto;"> <div class="w-full h-auto text-center py-3 bg-gradient-to-br from-green-800 to-green-600"> <h6 class="font-semibold text-xl text-white" style="font-family: DroidKufi-Regular; font-size: 18px;"> Lorem </h6> </div> <div> <p class="text-gray-600 p-3" style="text-align: center; font-family: DroidKufi-Regular; font-size: 17px;"> Lorem ipsum dolor sit amet, consectetur </p> </div> </div> <div class="flex-1 yourDivClass mt-5 md:mt-0 mx-5 bg-white rounded-lg shadow-lg hover:shadow-xl transition duration-150" style="margin-bottom: auto;"> <div class="w-full h-auto text-center py-3 bg-gradient-to-br from-green-800 to-green-600"> <h6 class="font-semibold text-xl text-white" style="font-family: DroidKufi-Regular; font-size: 18px;"> Lorem </h6> </div> <div> <p class="text-gray-600 p-3" style="text-align: center; line-height: 2; font-family: DroidKufi-Regular; font-size: 16px;"> Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitatio </p> </div> </div> </div> </div> <style> .parentDivClass{ display: table-row; } .yourDivClass{ display: table-cell; background: #eee; width: 50%; padding: 10px; } </style>1 نقطة
-
يمكنك إنشاء استعلام يمكنك من خلاله جلب بيانات التصنيف بهذه الطريقة $sql = mysqli_query($connection, "SELECT * FROM category WHERE id = $category_id"); هذا استعلام عادي في PHP أو من خلال laravel يمكنك إنشاء علاقة بين جدول posts , categorys بحيث كل تصنيف لديه عدة منشورات و تكون العلاقة في ملفي Model الخاص بالجدولين و لنفرض أن جدول posts لديه ملف Post.php و جدول categories لديه ملف Category.php فالعلاقة ستكون باسم hasMany أي كل تصنيف يملك أكثر من منشور و في ملف Category.php يمكنك إضافة العلاقة التالية public function posts(){ return $this->hasMany(Post::class); } وملف Post.php يحتوي على التالي public function category(){ return $this->belongsTo(Category::class); } وخلال الاستعلام يمكنك جلب هذه العلاقة بهذه الطريقة $posts = Post::with('category')->get(); أي قمنا من خلال with جلب العلاقة category و يمكنك جلب أكثر من علاقة بهذا الشكل $posts = Post::with('category', 'اسم العلاقة الثانية')->get(); و من ثم يمكنك إنشاء حلقة تكرار بحيث تقوم بجلب المنشورات ومن خلال العلاقة category يمكنك الوصول إلى بيانات جدول categories بهذا الشكل @foreach($posts->category() as $category) <h3>{{ $category->name ?? '' }}</h3> @endforeach1 نقطة
-
بداية يجب أن نحصل على الcategary وعلى جميع بياناته كالتالي $categary=Category::find($post->categary_id); بعد ذلك يمكنك الوصول لجيمع بيانات هذا categary فمثلا لو أردت الحصول على اسمه يمكنك ذلك من خلال الكود التالي $categary->name1 نقطة
-
شكرا لك اخ محمد لكن هل من الممكن ان تشرح لي الطريقة بالتفصيل كيف يعمل هذا الكود ؟1 نقطة
-
يمكنك عمل ارتفاع ثابت للحاويتان عن طريق الكود التالي .parentDivClass{ display: table-row; } .yourDivClass{ display: table-cell; } parentDivClass هو الخاص بالحاوية التي بداخلها الحاويتان المراد توحيد ارتفاعها و yourDivClass هو الخاص بالحاويتان1 نقطة
-
ليس على أي شخص متابعة جميع هذه الدورات فإن كل منها في مجال مختلف وتعتمد على تقنيات مختلفة، ولأنه ولكي يتميز المبرمج يجب أن يتخصص في مجال معين ويقوم بعمل مشاريع جيدة ضمنه. أعتقد أن من المفيد البدء بدورة علوم الحاسب، والتعرف على المجال من أوسع أبوابة من الخوارزميات للبرمجة و قواعد البيانات وغيرها من الأساسيات الفيدة، ثم بعدها يمكنك التفكير بالتخصص بتسجيل دورة أخرى والآن بعد أن أصبح لك أساس قوي. مثلا: دورة واجهات المستخدم تكفي ليصبح الشخص ماهرا في تصميم المواقع وجعلها جميلة و متناسقة مع تطبيقات الجوال. دورة برمجة الواجهات الخلفية PHP / Laravel تكفي لفهم شامل للارافيل و عمل مشاريع بها و التعرف على التفاصيل. دورة جافاسكربت تمكن من عمل تصميم للمواقع React و الواجهات الخلفية Node و تطبيقات الهواتف React Native بسبب وجود إطارات عمل تعمل كلها بنفس اللغة (جافاسكربت) و تسمح بتشغيل المشاريع على أكثر من منصة وهذه الدورة عي الأكثر تكاملاً..1 نقطة
-
يمكنك تحديد ارتفاع الحاوية div بكتابة تننسيق للخاصية height: أو أضفها لوسم style لديك.. /* css */ .yourClass{ height: 80px } ويمكن وضع حد أقل للطول مثل min-height هذا يسمح للحاوية بأن تكون أطول منه(حد أدنى)، و max-height وهو طول أعظمي لا يمكن أكبر منه(حد أعلى).1 نقطة
-
طيب حضرتك اه نوع اللاب توب الافضل عشان اشتغل من البيت مهما كان تكلفته المهم يكون في كل مميزات العمل؟1 نقطة
-
يمكنك أن تستعمل خدمة خرائط جوجل للحصول على الموقع الحالي للمستخدم (خطوط الطول ودوائر العرض)، وإن كنت تريد أن تستخدم خدمات تحديد المواقع في موقع إلكتروني أو تطبيق يستعمل HTML5 فأنصحك بالإطلاع على هذه المقالة من الأكاديمية: تحديد الموقع الجغرافي (GeoLocation) في HTML5 كما أن إطار العمل React Native و كوردوفا يدعمان خدمات الموقع الجغرافي GeoLocation، ويمكنك الإطلاع على توثيق كل من هما باللغة العربية من مووسوعة حسوب من هنا: Geolocation في React Native إضافة تحديد الموقع الجغرافي في كوردوفا بالنسبة لدورات حسوب فيمكنك الإطلاع على الأسعار من خلال صفحة الدورات التعليمية من هنا1 نقطة
-
عند التعامل مع المسائل التي تندرج تحت ال NLP هناك خطوة مهمة يجب القيام بها قبل إرسال ال Data إلى الطبقات للتدرب عليها وهي وضع القيم في مصفوفة ذات أبعاد ثابتة. أثناء تجهيز البيانات النصية (النصوص، حيث كل عينة تكون عبارة عن نص) وترميزها رقمياً (إسناد عدد صحيح يمثل كل كلمة ثم تمثيل النص كسلسلة من الأعداد الصحيحة) ستكون بعض النصوص أطول من الأخرى وهذا شيء مؤكد وبديهي (أي أول عينة قد يكون طولها 500 والأخرى 1000 وو). لذا لإدخالها إلى شبكة عصبية يجب علينا أولاً توحيد طول كل عينة (طول كل نص أو طول كل سلسلة رقمية كوننا قمنا بترميزها رقمياً)، وهذا التوحيد يكون عبر اختيارنا للحجم الذي نراه مناسياً لكل سلسلة وليكن x، ثم نمر على كل العينات ونقطع كل سلسلة طولها أكبر من (بالتالي نجعلها 500 فقط)، أما إذا كانت أقل من x فنقوم (بحشوها) بأصفار، وهذا مايتم من خلال التابع pad_sequences كما سترى في المثال، وهذا مايجب عليك القيام به قبل إدخالالبيانات إلى شبكتك، فهذا هو سبب الخطأ الذي ظهر ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type list). فهو غير قادر على تحويل list لإى tensor بأبعاد مختلفة، يجب أن تقوم بتوحيد الأبعاد لكل العينات. التصحيح: from keras.datasets import imdb from keras.layers import Embedding, SimpleRNN from keras.models import Sequential (input_train, y_train), (input_test, y_test) = imdb.load_data( num_words=max_features) print(len(input_train), 'train sequences') print(len(input_test), 'test sequences') ################ نضيف################### from keras.preprocessing import sequence maxlen = 500 print('Pad sequences (samples x time)') input_train = sequence.pad_sequences(input_train, maxlen=maxlen) input_test = sequence.pad_sequences(input_test, maxlen=maxlen) ############# انتهى#################### print('input_train shape:', input_train.shape) print('input_test shape:', input_test.shape) from keras.layers import Dense model = Sequential() model.add(Embedding(10000, 32)) model.add(SimpleRNN(32)) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) history = model.fit(input_train, y_train, epochs=2, batch_size=32, validation_split=0.2) ------------------------------------------------- 25000 train sequences 25000 test sequences Pad sequences (samples x time) input_train shape: (25000, 500) input_test shape: (25000, 500) Epoch 1/2 625/625 [==============================] - 79s 111ms/step - loss: 0.6659 - acc: 0.5671 - val_loss: 0.4343 - val_acc: 0.8116 Epoch 2/2 625/625 [==============================] - 67s 108ms/step - loss: 0.3630 - acc: 0.8477 - val_loss: 0.3880 - val_acc: 0.82621 نقطة
-
يُمكنك إرسال البيانات بالشكل التالي: $.ajax({ ... data : { foo : 'bar', bar : 'foo' }, ... }); في حالتك تقوم بجلب القيم من حقول الإدخال و تُخزنها في متغيرات ثم تمررها لكائن data: var contentText = 'content_txt='+ $("#contentText").val(), name = $("#myname").val(), email = $("#myemail").val(); $.ajax({ //... data : { name: name, email: email, content: contentText}, //... }); و في ملف المعالجة يُمكنك الحصول على البيانات من خلال المتغير العام POST_$ يُمكن إستخدام الطريقة التالية ايضاً: $("#content-form").submit(function (e) { e.preventDefault(); $.ajax({ //... data: $('#content-form').serialize(), //... }); });1 نقطة
-
يمكنك ذلك باستخدام الكلاس make_regression من مكتبة Sklearn : sklearn.datasets.make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, shuffle=True, random_state=None) الوسيط الأول يحدد عدد العينات التي تريدها. افتراضياً 100 الوسيط الثاني يحدد عدد الميزات features التي تريدها. افتراضياً 20 الوسيط الثالث يحدد عدد الميزات لبناء النموذج الخطي المستخدم لتوليد الخرج افتراضيا 10 الوسيط الرابع عدد أهداف التوقع أي أبعاد الخرج y الوسيط الخامس قيمة bias في نموذج التوقع الوسيط السادس لخلط البيانات بعد إنشائها. الوسيط الثامن هو وسيط التحكم بنظام العشوائية في التقسيم. مثال: from sklearn.datasets import make_regression X, y = make_regression(n_samples=1000, n_features=4, n_informative=10, n_targets=1, bias=0.0, shuffle=False, random_state=0) print(X.shape) #(1000, 4) print(y.shape,end='\n\n') # (1000,) print(X) # الخرج (1000, 4) (1000,) [[ 1.76405235 0.40015721 0.97873798 2.2408932 ] [ 1.86755799 -0.97727788 0.95008842 -0.15135721] [-0.10321885 0.4105985 0.14404357 1.45427351] ... [ 0.10672049 -0.9118813 -1.46836696 0.5764787 ] [ 0.06530561 -0.7735128 0.39494819 -0.50388989] [ 1.77955908 -0.03057244 1.57708821 -0.8128021 ]]1 نقطة
-
يمكنك استخدامه عن طريق الموديول: sklearn.ensemble الصيغة العامة: sklearn.ensemble.ExtraTreesRegressor(n_estimators=100, criterion='mse', max_depth=None, min_samples_split=2, min_samples_leaf=1, max_features='auto', max_leaf_nodes=None, bootstrap=False, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None) n_estimators : عدد أشجار القرار المستخدمة.default=100 criterion: معيار قياس جودة التقسيم وتكون {“mse”, “mae”}, default=”mse” max_depth : عمق الأشجار. min_samples_split:الحد الأدنى لعدد العينات المطلوبة لتقسيم عقدة داخلية. int , default=2. min_samples_leaf: الحد الأدنى لعدد العينات المطلوبة في العقدة التي تمثل الاوراق. default=1. max_features:العدد المناسب من الفيتشرز التي يتم احتسابها {“auto”, “sqrt”, “log2”}. في حال auto: max_features=sqrt(n_features). sqrt: ax_features=sqrt(n_features). log2: max_features=log2(n_features). None: max_features=n_features. إذا وضعت قيمة float: max_features=int(max_features * n_features) قيمة int: سيتم أخذ ال features عند كل تقسيمة ك max_features. bootstrap: لتحديد فيما إذا كان سيتم استخدام عينات ال bootstrap عند بناء الأشجار. في حال ضبطها على true سيتم استخدام كامل البيانات لبناء كل شجرة. افتراضياً تكون False. oob_score: لتحديد فيما إذا كان سيتم استخدام عينات out-of-bag لتقدير قيمة التعميم "generalization score". ويجب أن تكون bootstrap مضبوطة على True لاستخدامها. n_jobs: عدد المهام التي يتم تنفيذها بالتوازي. -1 للتنفيذ بأقصى سرعة ممكنة. random_state: يتحكم بعملية التقسيم افتراضياً يكون None. verbose: لعرض التفاصيل التي تحدث في التدريب. افاراضياً 0 أي لايظهر شيء، أما وضع أي قيمة أكبر من الصفر سيعرض التفاصيل int. ccp_alpha: معامل تعقيد يستخدم لتقليل التكلفة الزمانية والمكانية. non-negative float, default=0.0 التوابع: fit(data): للقيام بعملية التدريب. predict(data): لتوقع القيم. score(data): لتقييم كفاءة النموذج. ()get_depth: يرد عمق الشجرة. ال attributtes: n_outputs_: عدد المرخرجات الناتجة عن عملية ال fitting. estimators_: عرض معلومات عن كل الأشجار التي تم تشكيلها. base_estimator_:عرض معلومات الشجرة الأساسية. n_features_: عدد الفيتشرز. مثال: # بيانات أسعار المنازل في مدينة بوسطن from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.ensemble import ExtraTreesRegressor # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) # DecisionTreeRegressor تطبيق extra = ExtraTreesRegressor(random_state=20) extra.fit(X_train, y_train) #حساب الدقة print('Train Score is : ' , extra.score(X_train, y_train)) # Train Score is : 1.0 print('Test Score is : ' , extra.score(X_test, y_test)) # Test Score is : 0.8465469931793999 #حعرض التوقعات y_pred = extra.predict(X_test) print(y_pred)1 نقطة
-
تفترض خوارزميات التعلم الآلي مثل Linear Regression و Gaussian Naive Bayes أن المتغيرات العددية لها توزيع احتمالي غاوسي. قد لا تحتوي بياناتك على توزيع غاوسي وبدلاً من ذلك قد يكون لها توزيع يشبه Gaussian (على سبيل المثال تقريبًا Gaussian ولكن مع القيم المتطرفة أو الانحراف) أو توزيع مختلف تمامًا (على سبيل المثال الأسي). وعلى هذا النحو قد تكون قادراً على تحقيق أداء أفضل على نطاق واسع من خوارزميات التعلم الآلي عن طريق تحويل متغيرات الإدخال و/ أو الإخراج للحصول على توزيع غاوسي. توفر تحويلات Power transforms مثل تحويل Box-Cox وتحويل Yeo-Johnson طريقة تلقائية لإجراء هذه التحولات على بياناتك ويتم توفيرها في مكتبة التعلم الآلي لـ scikit-Learn Python. لاستخدامه، يجب أن يتم استيراده عبر الموديول: sklearn.preprocessing الصيغة العامة: sklearn.preprocessing.PowerTransformer(method='yeo-johnson', standardize=True, copy=True) method: خوارزمية التحويل التي ذكرناها {‘yeo-johnson’, ‘box-cox’} وافتراضيا ’yeo-johnson’ مع الانتباه إلى أن ال box-cox تعمل فقط مع القيم الموجبة. standardize:لتطبيق تطبيع متوسط التباين الصفري على الناتج المحول في حالة True. copy: لإنشاء نسخة، أي لكي لايتم التعديل على البيانات الأصلية. مثال: # سنشكل بيانات تبع توزيعاً أسياً from sklearn.preprocessing import PowerTransformer from numpy import exp from numpy.random import randn from matplotlib import pyplot # تشكيل بيانات غاوصية data = randn(2000) # تحويلها لبيانات أسية data = exp(data) # رسم الهستوغرام للبيانات الأسية pyplot.hist(data, bins=50) pyplot.show() #على البيانات PowerTransformer الآن سنجري تحويل data = data.reshape((len(data),1)) power = PowerTransformer(method='yeo-johnson', standardize=True) data_trans = power.fit_transform(data) # عرض الهستوغرام للبيانات بعد القيام بالتحويل pyplot.hist(data_trans, bins=25) pyplot.show()
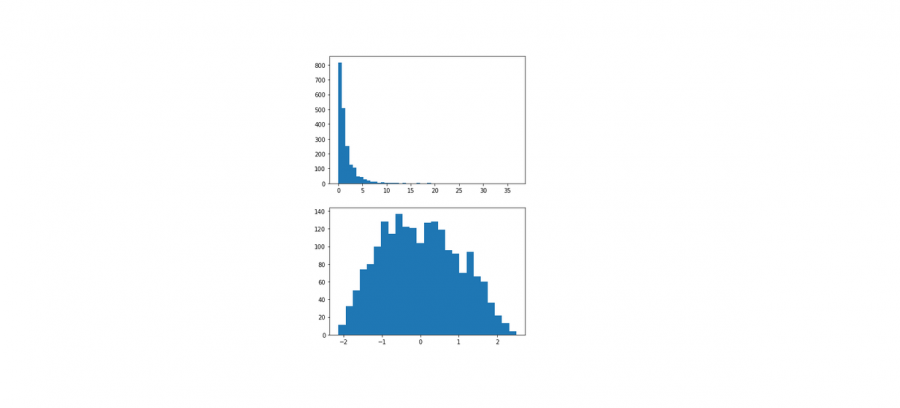 1 نقطة
1 نقطة -
AdaBoost "adaptive boosting" : فكرة هذه الخوارزمية أن وزن العينات المتوقعة بشكل سيئ بواسطة ال base_estimator السابق يزداد (وبالتالي يصبح أكثر أهمية)، بينما سينخفض وزن العينات المتوقعة بشكل جيد وهذه الأوزان تستخدم مرة أخرى لتدريب ال base_estimator التالي. و في كل تكرار، تتم إضافة learner ضعيف جديد، ولا يتم تحديد ال learner النهائي الأفضل حتى يتم الوصول إلى معدل خطأ صغير معين أو الانتهاء من التكرارات. يمكنك استخدامها عبر الموديول: sklearn.ensemble.AdaBoostRegressor الصيغة العامة: sklearn.ensemble.AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None الوسطاء: base_estimator: ال estimator الأساسي الذي تبنى منه باقي المجموعة المعززة (boosted ensemble). افتراضياً None. ويفضل تركه none ليعطي أفضل النتائج في حال لم تكن لديك خبرة، افتراضياً يكون DecisionTreeRegressor. random_state: يتحكم بعملية التقسيم افتراضياً يكون None. n_estimators : عدد الخوارزميات أو ال estimator المستخدمة. default=50. learning_rate: مقدار معامل التعلم (حجم الخطوة)، ويأخذ فيمة من النمط float. loss: تابع التكلفة الذي يجب استخدامه عند تحديث الأوزان بعد كل تكرار معزز. ويمكن اختيار {‘linear’, ‘square’, ‘exponential’} وافتراضياً linear. Attributes: estimator_weights_: أوزان كل estimator تم تطبيقه. estimators_: عرض معلومات عن ال estimator التي تم تشكيلها. base_estimator_:عرض معلومات ال estimator الأساسية. estimator_errors_: خطأ التوقع في كل estimator من المجموعة المعززة. أهم التوابع: fit(data): للقيام بعملية التدريب. predict(data): لتوقع القيم. score(data): لتقييم كفاءة النموذج. مثال: # بيانات أسعار المنازل في مدينة بوسطن from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.ensemble import AdaBoostRegressor # تحميل الداتا BostonData = load_boston() data = BostonData.data labels = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, shuffle =True, random_state=2021) # DecisionTreeRegressor تطبيق Ada = AdaBoostRegressor(random_state=20) Ada.fit(X_train, y_train) #حساب الدقة print('Train Score is : ' , Ada.score(X_train, y_train)) print('Test Score is : ' , Ada.score(X_test, y_test)) #حعرض التوقعات y_pred = Ada.predict(X_test) print(y_pred)1 نقطة
-
هو طريقة تدرج عشوائي SGD تعتمد على تحديث معامل التعلم بناء على تحديثات gradient descent يساهم في حل مشكلة التدهور المستمر لمعدلات التعلم خلال عملية التدريب كذلك يعطي معامل تعلم أولي، وهذا يساعد في أن لا نقوم بوضع معامل تعلم يمكن أن يأثر على الموديل سلباً. وهذا يقلل عدد العمليات للوصول إلى المعاملات العليا. لاستخدامها في كبراس نمررها إلى الدالة compile: model.compile( optimizer=Adadelta(learning_rate=0.001) ... ) # أو model.compile( optimizer='adadelta' ... ) # لاحظ أنه في الطريقة الثانية سيستخدم معمل الخطوة الافتراضي # لذا إذا أردت تغييرها استخدم الصيغة الأولى مثال عن طريقة الاستخدام حيث يأخذ Adadelta الوسيط learning_rate الذي يمثل معامل التعلم أو مقدار الخطوة: #استدعاء المكتبات from keras.models import Sequential from keras import layers from keras.datasets import mnist from keras.optimizers import Adadelta #تحميل الداتا (X_train,y_train),(X_test,y_test)=mnist.load_data() #تقييس الداتا وتغيير حجم الدخل منعنا لحدوث خطأ X_train = X_train.reshape((60000, 28 * 28))/255.0 X_test = X_test.reshape((10000, 28 * 28))/255.0 #بناء الشبكه العصبونيه بطبقه واحده وطبقة خرج ب 10 أصناف model = Sequential() model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu', input_shape=( 28*28,))) model.add(layers.Dense(10, activation='softmax')) #0.001مع معامل تعلم Adadelta استخدام model.compile(optimizer=Adadelta(learning_rate=0.001), loss='sparse_categorical_crossentropy',metrics=['accuracy']) #تدريب الموديل model.fit(X_train,y_train)1 نقطة
-
بما أن الموقع تم إنشاؤه لحماية حقوق كل من البائع والمشتري، من الطبيعي أخذ إجراءات لتجنب أي عملية احتيال أو خداع .. يوجد الكثير من المشترين الذين لا يمكلون أدنى فكرة عمّا يقومون بشرائه، فقط يعلمون أنهم بحاجة إلى هذه الخدمة ويضعون كامل ثقتهم في البائع. تخيل لو أنك مشتري طلبت من أحد البائعين إنشاء موقع الكتروني خاص بك .. ثم قمت بتفقده وأعجبك التصميم والموقع بشكل عام واستلمت المشروع .. لكن بعد عشرة أيام واستخدام الزوار المتكرر له، تتلقى شكوى بعدم عمل قسم كامل في الموقع، من الطبيعي أن تتكلم مع البائع لكي يقوم بإصلاح المشكلة، لكن الطامة الكبرى هي رفض البائع أن يقوم بإصلاح ما قصّر فيه! بالطبع حقوقك محمية تحت سياسة موقع حسوب، ستتواصل مع المنصة وسيقومون بتجميد أرباحه حتى يقوم بإصلاح المشكلة ورضاك عن الإصلاح .. هذا هو الهدف من الإبقاء على الأرباح 14 يوم .. ضمان حقوقك كمشتري عزيزي.1 نقطة
-
السلام عليكم يمكنك عمل محتوى صحي على اليوتيوب وأظن أن هذا المجال من المجالات المطلوبة1 نقطة