
البحث في الموقع
المحتوى عن 'سلسلة تعلم sql'.
-

 عند استخدام قاعدة بيانات علاقية Relational Database، سنحتاج إلى استخدام استعلامات فردية باستخدام لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- لاسترجاع البيانات أو معالجتها مثل استعلامات SELECT أو INSERT أو UPDATE أو DELETE من شيفرة التطبيق مباشرةً، إذ تعمل هذه التعليمات مع جداول قاعدة البيانات الأساسية وتعالجها فورًا. لكن إذا استخدمنا التعليمات أو مجموعة التعليمات نفسها ضمن تطبيقات متعددة يمكنها الوصول إلى قاعدة البيانات نفسها، وتكررت هذه التعليمات عدة مرات فيمكننا في هذه الحالة استخدام الإجراءات المخزَّنة Stored Procedures التي يدعمها MySQL كحال العديد من أنظمة إدارة قواعد البيانات العلاقية الأخرى، حيث تساعد هذه الإجراءات المخزنة في تجميع تعليمة SQL واحدة أو أكثر لإعادة استخدامها باسم مشترك من خلال تغليف منطق العمل المشترك ضمن قاعدة البيانات نفسها، ويمكن استدعاء مثل هذه الإجراءات من التطبيق الذي يصل إلى قاعدة البيانات لاسترجاع البيانات أو معالجتها. تساعدنا الإجراءات المخزنة على إنشاء برامج قابلة لإعادة الاستخدام للمهام الشائعة التي سنستخدمها عبر تطبيقات متعددة، كما توفر طريقة للتحقق من صحة البيانات، أو تقديم طبقة إضافية من أمان الوصول إلى البيانات من خلال تقييد مستخدمي قاعدة البيانات من الوصول إلى الجداول الأساسية مباشرةً وإنشاء استعلامات عشوائية. سنتعلّم في هذا المقال ما هي الإجراءات المخزَّنة وكيفية إنشاء إجراءات مخزنة بسيطة تعيد البيانات، وإجراءات تستخدم كلًا من معاملات الدخل والخرج. مستلزمات العمل يجب أن يكون لدينا حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية RDBMS المستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو مع مستخدم بصلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر معرفة أساسية بتنفيذ استعلامات SELECT لاسترجاع البيانات من قاعدة البيانات ملاحظة: تجدر الإشارة لأنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، ولا تُعَد صيغة الإجراءات المخزنة جزءًا من معيار SQL الرسمي. حيث ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن تُعَد الإجراءات المخزنة خاصة بقاعدة البيانات، وبالتالي قد نجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات فارغة يمكن من خلالها إنشاء جداول توضّح استخدام الإجراءات المخزنة، ويمكن مطالعة القسم التالي للحصول على تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية، والتي سنستخدمها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية سنتتصل بخادم MySQL وننشئ قاعدة بيانات تجريبية لاتباع الأمثلة الواردة في هذا المقال، حيث سنستخدم مجموعة سيارات افتراضية، ونخزّن تفاصيل السيارات المملوكة حاليًا مع نوعها وطرازها وسنة بنائها وقيمتها. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات باسم procedures: mysql> CREATE DATABASE procedures; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات procedures من خلال تنفيذ تعليمة USE التالية: $ USE procedures; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، ويمكنك الآن إنشاء جداول تجريبية ضمنها. سيحتوي الجدول cars على بيانات مبسَّطة حول السيارات الموجودة في قاعدة البيانات، حيث سيحتوي على الأعمدة التالية: make: نوع كل سيارة مملوكة، ونمثّل باستخدام نوع البيانات varchar بحد أقصى 100 محرف model: اسم طراز السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 100 محرف year: سنة صنع السيارة باستخدام نوع البيانات int للاحتفاظ بالقيم العددية value: قيمة السيارة باستخدام نوع البيانات decimal بحد أقصى 10 أرقام ورقمين بعد الفاصلة العشرية أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE cars ( mysql> make varchar(100), mysql> model varchar(100), mysql> year int, mysql> value decimal(10, 2) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) سندرج بعض البيانات التجريبية في الجدول cars من خلال تنفيذ عملية INSERT INTO التالية: mysql> INSERT INTO cars mysql> VALUES mysql> ('Porsche', '911 GT3', 2020, 169700), mysql> ('Porsche', 'Cayman GT4', 2018, 118000), mysql> ('Porsche', 'Panamera', 2022, 113200), mysql> ('Porsche', 'Macan', 2019, 27400), mysql> ('Porsche', '718 Boxster', 2017, 48880), mysql> ('Ferrari', '488 GTB', 2015, 254750), mysql> ('Ferrari', 'F8 Tributo', 2019, 375000), mysql> ('Ferrari', 'SF90 Stradale', 2020, 627000), mysql> ('Ferrari', '812 Superfast', 2017, 335300), mysql> ('Ferrari', 'GTC4Lusso', 2016, 268000); تضيف العملية INSERT INTO عشر سيارات رياضية نموذجية للجدول، حيث توجد أربع سيارات من نوع Porsche وخمسة سيارات من نوع Ferrari. يشير الخرج التالي إلى إضافة جميع الصفوف العشرة: الخرج Query OK, 10 rows affected (0.00 sec) Records: 10 Duplicates: 0 Warnings: 0 نحن الآن جاهزون لمتابعة هذا المقال والبدء باستخدام الإجراءات المُخزَّنة في لغة SQL. مقدمة إلى الإجراءات المخزنة Stored Procedures الإجراءات المخزنة في MySQL وفي العديد من أنظمة قواعد البيانات العلاقية الأخرى هي كائنات مُسمَّاة تحتوي على تعليمة واحدة أو أكثر تضعها وتنفّذها قاعدة البيانات عند استدعائها. يمكن للإجراء المخزن حفظ تعليمة مشتركة ضمن برنامج قابل لإعادة الاستخدام مثل استرجاع البيانات من قاعدة البيانات باستخدام المرشّحات Filters المُستخدَمة كثيرًا، حيث يمكنك مثلًا إنشاء إجراء مخزن لاسترجاع عملاء متجر الكتروني قدّموا طلبات خلال عدد معين من الأشهر. يمكن للإجراءات المخزنة أيضًا تمثيل البرامج الشاملة التي تصف منطق الأعمال المعقد للتطبيقات القوية في السيناريوهات الأكثر تعقيدًا. يمكن أن تتضمن مجموعة التعليمات في إجراء مخزَّن تعليمات SQL شائعة مثل استعلامات SELECT أو INSERT التي تعيد البيانات أو تعالجها، ويمكن للإجراءات المخزنة الاستفادة مما يلي: المعاملات المُمرَّرة إلى الإجراء المخزن أو المُعادة منه المتغيرات المُصرَّح عنها لمعالجة البيانات المُسترجَعة من شيفرة الإجراء البرمجية مباشرةً التعليمات الشرطية التي تسمح بتنفيذ أجزاء من شيفرة الإجراء المخزن البرمجية وفق شروط معينة مثل تعليمات IF أو CASE الحلقات مثل WHILE و LOOP و REPEAT لتنفيذ أجزاء من الشيفرة البرمجية عدة مرات تعليمات معالجة الأخطاء مثل إعادة رسائل الخطأ إلى مستخدمي قاعدة البيانات الذين يمكنهم الوصول إلى الإجراء. استدعاءات إجراءات مخزنة أخرى في قاعدة البيانات ملاحظة: تسمح الصيغة الموسَّعة Extensive Syntax التي يدعمها MySQL بكتابة برامج قوية وحل المشكلات المعقدة باستخدام الإجراءات المخزنة مثل التحكم في تدفق البرنامج باستخدام التعليمات الشرطية واستخدام المتغيرات والحلقات ومعالجة الأخطاء المخصصة وغيرها من الاستخدامات ولكن سيغطي هذا المقال فقط الاستخدام الأساسي للإجراءات المخزنة مع تعليمات SQL المُضمَّنة في جسم الإجراء المخزَّن ومعاملات الدخل والخرج، إذ سيكون تنفيذ التعليمات الشرطية واستخدام المتغيرات والحلقات ومعالجة الأخطاء المُخصَّصة خارج نطاق هذا المقال، لذا يمكن مطالعة توثيق MySQL الرسمي لمعرفة المزيد حول الإجراءات المخزنة. إذا استدعينا الإجراء باسمه، فسينفّذه محرّك قاعدة البيانات كما هو مُعرَّف تعليمةً تلو الأخرى. يجب أيضًا أن يكون لدى مستخدم قاعدة البيانات الأذونات المناسبة لتنفيذ الإجراء المُحدَّد، حيث توفر هذه الأذونات المطلوبة طبقة من الأمان، مما يمنع الوصول المباشر إلى قاعدة البيانات مع منح المستخدمين إمكانية الوصول إلى إجراءات فردية مضمونة الأمان لتنفيذها. تُنفَّذ الإجراءات المخزَّنة على خادم قاعدة البيانات مباشرةً مع إجراء جميع العمليات الحسابية محليًا وإعادة النتائج إلى المستخدم المستدعي عند الانتهاء فقط. وإذا أردنا تغيير سلوك الإجراء، فيمكن تحديث الإجراء في قاعدة البيانات، وستلتقط التطبيقات التي تستخدمه الإصدار الجديد تلقائيًا، وسيبدأ جميع المستخدمين باستخدام الشيفرة البرمجية للإجراء الجديد مباشرةً دون الحاجة لتعديل تطبيقاتهم. فيما يلي الهيكل العام لشيفرة SQL المستخدَمة لإنشاء إجراءٍ مخزَّن: mysql> DELIMITER // mysql> CREATE PROCEDURE procedure_name(parameter_1, parameter_2, . . ., parameter_n) mysql> BEGIN mysql> instruction_1; mysql> instruction_2; mysql> . . . mysql> instruction_n; mysql> END // mysql> DELIMITER ; التعليمتان الأولى والأخيرة في مقطع الشيفرة البرمجية السابق هما DELIMITER // و DELIMITER ;، حيث يستخدم MySQL رمز الفاصلة المنقوطة ; لتحديد التعليمات والإشارة إلى بدايتها ونهايتها. إذا نفّذنا تعليمات متعددة في طرفية MySQL مع الفصل بينها بفواصل منقوطة، سيكون التعامل معها كأنها أوامر منفصلة مع تنفيذ كل تعليمة تنفيذًا مستقلًا عن التعليمات الأخرى واحدة تلو الأخرى. يمكن للإجراء المخزَّن أيضًا أن يتضمّن أوامر متعددة ستُنفَّذ تسلسليًا عند استدعائه، مما يشكّل صعوبة عند محاولة إخبار MySQL بإنشاء إجراء جديد، إذ سيرى محرّك قاعدة البيانات علامة الفاصلة المنقوطة في جسم الإجراء المُخزَّن ويعتقد أنه يجب أن يتوقف عن تنفيذ التعليمة، وبالتالي تكون التعليمة المقصودة في هذه الحالة هي الشيفرة البرمجية لإنشاء الإجراء بالكامل، وليس تعليمةً واحدة ضمن الإجراء نفسه، لذا قد يسيء MySQL تفسير ما نقصده. يمكن التغلب على هذا القيد من خلال استخدام الأمر DELIMITER لتغيير هذا المحدِّد مؤقتًا من ; إلى // طوال مدة استدعاء التعليمة CREATE PROCEDURE، ثم ستُمرَّر جميع الفواصل المنقوطة الموجودة في جسم الإجراء المخزَّن إلى الخادم كما هي، ثم يتغير المحدِّد مرة أخرى إلى ; في آخر تعليمة DELIMITER ; بعد الانتهاء من الإجراء بالكامل. يمثّل الاستدعاء CREATE PROCEDURE وبعده اسم الإجراء procedure_name في المثال السابق جوهر الشيفرة البرمجية الخاصة بإنشاء إجراء جديد، ويتبع اسم الإجراء قائمة اختيارية من المعاملات التي سيقبلها الإجراء. الجزء الأخير من الشيفرة البرمجية هو جسم الإجراء المضمَّن ضمن تعليمتي BEGIN و END، ويوجد في الداخل شيفرة الإجراء البرمجية، والتي يمكن أن تحتوي على تعليمة SQL واحدة مثل استعلام SELECT أو شيفرة برمجية أكثر تعقيدًا. ينتهي الأمر END بالرمز //، والذي يُعَد محدِّدًا مؤقتًا عوضًا عن الفاصلة المنقوطة النموذجية. سننشئ في القسم التالي إجراءً مخزنًا بسيطًا بدون معاملات تتضمن استعلامًا واحدًا. إنشاء إجراء مخزن بدون معاملات سننشئ في هذا القسم أول إجراء مخزّن يغلِّف تعليمة SQL واحدة هي التعليمة SELECT لإعادة قائمة السيارات المملوكة المرتبة حسب نوعها وقيمتها بترتيب تنازلي. نبدأ بتنفيذ التعليمة SELECT التي ستستخدمها كما يلي: mysql> SELECT * FROM cars ORDER BY make, value DESC; ستعيد قاعدة البيانات قائمة السيارات من الجدول cars مع ترتيبها حسب نوعها أولًا ثم حسب قيمتها بترتيب تنازلي ضمن نوع السيارة الواحد كما يلي: الخرج +---------+---------------+------+-----------+ | make | model | year | value | +---------+---------------+------+-----------+ | Ferrari | SF90 Stradale | 2020 | 627000.00 | | Ferrari | F8 Tributo | 2019 | 375000.00 | | Ferrari | 812 Superfast | 2017 | 335300.00 | | Ferrari | GTC4Lusso | 2016 | 268000.00 | | Ferrari | 488 GTB | 2015 | 254750.00 | | Porsche | 911 GT3 | 2020 | 169700.00 | | Porsche | Cayman GT4 | 2018 | 118000.00 | | Porsche | Panamera | 2022 | 113200.00 | | Porsche | 718 Boxster | 2017 | 48880.00 | | Porsche | Macan | 2019 | 27400.00 | +---------+---------------+------+-----------+ 10 rows in set (0.00 sec) نلاحظ ظهور سيارة الفيراري الأعلى قيمة في أعلى القائمة، وظهور سيارة البورش الأدنى قيمة في الأسفل. لنفترض استخدام هذا الاستعلام بصورة متكررة في تطبيقات متعددة أو سيستخدمه مستخدمون متعددون ونريد التأكّد من أن الجميع سيستخدمون الطريقة نفسها لترتيب النتائج، لذا يجب إنشاء إجراء مخزن يحفظ تعليمة هذا الاستعلام ضمن إجراء مُسمَّى قابل لإعادة الاستخدام من خلال تنفيذ جزء الشيفرة البرمجية التالي: mysql> DELIMITER // mysql> CREATE PROCEDURE get_all_cars() mysql> BEGIN mysql> SELECT * FROM cars ORDER BY make, value DESC; mysql> END // mysql> DELIMITER ; نلاحظ أن الأمرين الأول DELIMITER // والأخير DELIMITER ; يخبران MySQL بالتوقف عن التعامل مع محرف الفاصلة المنقوطة بوصفه محدِّدًا للتعليمات طوال مدة إنشاء الإجراء كما هو موضّح في القسم السابق. يتبع أمر SQL الذي هو CREATE PROCEDURE اسم الإجراء get_all_cars الذي يمكن تعريفه لوصف ما يفعله الإجراء، ثم يوجد زوج من الأقواس () يمكننا إضافة معاملات ضمنه، ولكن لا يستخدم هذا الإجراء معاملات في مثالنا، لذا ستكون الأقواس فارغة، ثم تُكتَب تعليمة SELECT نفسها المُستخدَمة سابقًا بين الأمرين BEGIN و END اللذين يحددان بداية ونهاية كتلة شيفرة الإجراء البرمجية. ملاحظة: قد يظهر الخطأ ERROR 1044 (42000): Access denied for user 'user'@'localhost' to database 'procedures' عند تنفيذ الأمر CREATE PROCEDURE بناءً على أذونات مستخدم MySQL الخاص بنا. يمكن منح الأذونات اللازمة لإنشاء وتنفيذ الإجراءات المخزنة للمستخدم من خلال تسجيل الدخول إلى MySQL كمستخدم جذر وتنفيذ الأوامر التالية وتغيير اسم مستخدم MySQL والمضيف حسب الحاجة: mysql> GRANT CREATE ROUTINE, ALTER ROUTINE, EXECUTE on *.* TO 'user'@'localhost'; mysql> FLUSH PRIVILEGES; نحدّث أذونات المستخدم، ثم نسجّل الخروج كمستخدم جذر، ونسجّل الدخول مرة أخرى كمستخدم عادي، ثم نعيد تشغيل تعليمة CREATE PROCEDURE. يمكن معرفة المزيد حول تطبيق الأذونات الخاصة بالإجراءات المخزنة لمستخدمي قاعدة البيانات في توثيق MySQL الرسمي الخاص بصلاحيات MySQL والبرامج المُخزَّنة. ستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 0 rows affected (0.02 sec) أصبح الإجراء get_all_cars الآن محفوظًا في قاعدة البيانات، وستُنفَّذ التعليمة المحفوظة كما هي عند استدعائه. يمكن تنفيذ الإجراءات المخزَّنة المحفوظة من خلال استخدام أمر SQL الذي هو CALL متبوعًا باسم الإجراء. نجرّب الآن تشغيل الإجراء الذي أنشأناه كما يلي: mysql> CALL get_all_cars; نحتاج اسم الإجراء get_all_cars فقط لاستخدام هذا الإجراء، إذ لم تَعُد بحاجة إلى كتابة أيّ جزء من تعليمة SELECT التي استخدمناها سابقًا يدويًا، وستعرض قاعدة البيانات النتائج مثل خرج التعليمة SELECT التي نفّذتها سابقًا كما يلي: الخرج +---------+---------------+------+-----------+ | make | model | year | value | +---------+---------------+------+-----------+ | Ferrari | SF90 Stradale | 2020 | 627000.00 | | Ferrari | F8 Tributo | 2019 | 375000.00 | | Ferrari | 812 Superfast | 2017 | 335300.00 | | Ferrari | GTC4Lusso | 2016 | 268000.00 | | Ferrari | 488 GTB | 2015 | 254750.00 | | Porsche | 911 GT3 | 2020 | 169700.00 | | Porsche | Cayman GT4 | 2018 | 118000.00 | | Porsche | Panamera | 2022 | 113200.00 | | Porsche | 718 Boxster | 2017 | 48880.00 | | Porsche | Macan | 2019 | 27400.00 | +---------+---------------+------+-----------+ 10 rows in set (0.00 sec) Query OK, 0 rows affected (0.00 sec) نجحنا في إنشاء إجراء مخزَّن بدون معاملات، حيث يعيد هذا الإجراء جميع السيارات من الجدول cars مرتبةً بطريقة معينة، ويمكن استخدام هذا الإجراء في تطبيقات متعددة. سننشئ في القسم التالي إجراء يقبل المعاملات لتغيير سلوك الإجراء وفقًا لدخل المستخدم. إنشاء إجراء مخزن مع معامل دخل سنضمِّن في هذا القسم معاملات دخل في تعريف الإجراء المخزَّن للسماح للمستخدمين الذين ينفّذون الإجراء بتمرير البيانات إليه، فمثلًا يمكن للمستخدمين توفير مرشّحات للاستعلام. يسترجع الإجراء المخزن get_all_cars الذي أنشأناه مسبقًا جميع السيارات من الجدول cars المصنعة في جميع سنوات التصنيع، ولننشئ الآن إجراء آخر للعثور على السيارات المُصنَّعة في سنة معينة، حيث سنعرِّف معاملًا في تعريف الإجراء من خلال تشغيل الشيفرة البرمجية التالية: mysql> DELIMITER // mysql> CREATE PROCEDURE get_cars_by_year( mysql> IN year_filter int mysql> ) mysql> BEGIN mysql> SELECT * FROM cars WHERE year = year_filter ORDER BY make, value DESC; mysql> END // mysql> DELIMITER ; توجد العديد من التغييرات على شيفرة إنشاء الإجراء مقارنة بالشيفرة المستخدمة في القسم السابق، حيث تغيّر الاسم ليكون get_cars_by_year ليمثل عمل الإجراء، وهو استرجاع السيارات بناءً على سنة إصدارها. كما أصبحت الأقواس الفارغة سابقًا محتوية على تعريف معامل واحد هو IN year_filter int، حيث تخبر الكلمة المفتاحية IN قاعدة البيانات بأن المستخدم المستدعِي سيمرّر المعامل إلى الإجراء. يُعَد year_filter اسمًا عشوائيًا للمعامل، حيث سنستخدمه للإشارة إلى المعامل في شيفرة الإجراء البرمجية، و int هو نوع البيانات، حيث نمثّل سنة التصنيع بقيمة عددية. يظهر المعامل year_filter المُعرَّف بعد اسم الإجراء في تعليمة SELECT ضمن التعليمة WHERE year = year_filter، مما يؤدي إلى ترشيح الجدول cars وفقًا لسنة التصنيع، وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 0 rows affected (0.02 sec) نفّذ الإجراء بدون تمرير أي معاملات إليه كما فعلنا سابقًا: mysql> CALL get_cars_by_year; وستعيد قاعدة بيانات MySQL رسالة الخطأ التالية: رسالة خطأ ERROR 1318 (42000): Incorrect number of arguments for PROCEDURE procedures.get_cars_by_year; expected 1, got 0 يتوقع الإجراء المخزن هذه المرة توفير معامل له، ولكن لم نقدّم له أيّ معامل، لذا يمكننا استدعاء إجراء مخزَّن مع معاملات من خلال توفير قيم المعاملات بين قوسين بنفس الترتيب الذي يتوقعه الإجراء. سننفّذ الإجراء التالي لاسترجاع السيارات المصنعة في عام 2017: mysql> CALL get_cars_by_year(2017); سيُنفَّذ الإجراء المستدعَى الآن تنفيذًا صحيحًا ويعيد قائمة السيارات من عام 2017، وسينتج الخرج التالي: الخرج +---------+---------------+------+-----------+ | make | model | year | value | +---------+---------------+------+-----------+ | Ferrari | 812 Superfast | 2017 | 335300.00 | | Porsche | 718 Boxster | 2017 | 48880.00 | +---------+---------------+------+-----------+ 2 rows in set (0.00 sec) Query OK, 0 rows affected (0.00 sec) تعلّمنا في المثال السابق كيفية تمرير معاملات الدخل إلى الإجراءات المخزنة واستخدامها في الاستعلامات ضمن الإجراء لتوفير خيارات الترشيح، وسنستخدم في القسم التالي معاملات الخرج لإنشاء إجراءات تعيد قيمًا مختلفة متعددة في تنفيذ واحد. إنشاء إجراء مخزن مع معاملات دخل وخرج في الإجراءات المخزَّنة التي أنشأناها في المثالين السابقين استدعينا تعليمة SELECT للحصول على مجموعة نتائج، ولكن قد نحتاج في بعض الحالات إلى إجراء مخزّن يعيد قيمًا مختلفة متعددة مع بعضها البعض بدل إعادة مجموعة نتائج واحدة لاستعلام فردي. لنفترض أننا تريد إنشاء إجراء يوفّر معلومات عن السيارات الصادرة في سنة معينة بما في ذلك كمية السيارات في المجموعة وقيمتها السوقية -الحد الأدنى والحد الأقصى والمتوسط- من خلال استخدام معاملات OUT عند إنشاء إجراء مخزّن جديد. تحتوي معاملات OUT مثل معاملات IN على أسماء وأنواع بيانات مرتبطة بها، ولكن يمكن ملء هذه المعاملات بالبيانات باستخدام الإجراء المخزن بدل تمرير البيانات إلى الإجراء المخزن لإعادة القيم إلى المستخدم المستدعِي. لننشئ الآن الإجراء get_car_stats_by_year التالي الذي سيعيد بيانات موجزة عن السيارات من سنة إنتاج معينة باستخدام معاملات خرج: mysql> DELIMITER // mysql> CREATE PROCEDURE get_car_stats_by_year( mysql> IN year_filter int, mysql> OUT cars_number int, mysql> OUT min_value decimal(10, 2), mysql> OUT avg_value decimal(10, 2), mysql> OUT max_value decimal(10, 2) mysql> ) mysql> BEGIN mysql> SELECT COUNT(*), MIN(value), AVG(value), MAX(value) mysql> INTO cars_number, min_value, avg_value, max_value mysql> FROM cars mysql> WHERE year = year_filter ORDER BY make, value DESC; mysql> END // mysql> DELIMITER ; استخدمنا معامل IN الذي هو year_filter لترشيح السيارات حسب سنة الإصدار، وعرّفنا أربعة معاملات OUT ضمن كتلة الأقواس. نمثّل المعامل cars_number بنوع البيانات int وسنستخدمه لإعادة عدد السيارات في المجموعة، وتمثّل المعاملات min_value و avg_value و max_value القيمة السوقية وتُعرَّف باستخدام نوع البيانات decimal(10, 2) مثل العمود value في الجدول cars، وتُستخدَم هذه المعاملات لإعادة معلومات حول أرخص وأغلى السيارات من المجموعة، بالإضافة إلى متوسط أسعار جميع السيارات المطابقة. تستعلم التعليمة SELECT عن أربع قيم من الجدول cars باستخدام دوال SQL الرياضية وهي: COUNT للحصول على العدد الإجمالي للسيارات، و MIN و AVG و MAX للحصول على القيمة الدنيا والمتوسط والقيمة العليا من العمود value. يمكن مطالعة مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في لغة SQL لمعرفة المزيد حول استخدام الدوال الرياضية في لغة SQL. يمكننا إخبار قاعدة البيانات بأننا نريد تخزين نتائج هذا الاستعلام في معاملات الخرج للإجراء المخزَّن من خلال تقديم كلمة مفتاحية جديدة هي INTO، ونضع بعدها أسماء أربعة معاملات إجراء تقابل البيانات المُسترجَعة، وبالتالي سيحفظ MySQL قيمة COUNT(*) في المعامل cars_number، ونتيجة MIN(value) في المعامل min_value ...إلخ. تؤكد قاعدة البيانات إنشاء الإجراء بنجاح كما يلي: الخرج Query OK, 0 rows affected (0.02 sec) لنشغّل الآن الإجراء الجديد من خلال تنفيذ الأمر التالي: mysql> CALL get_car_stats_by_year(2017, @number, @min, @avg, @max); تبدأ المعاملات الأربعة الجديدة بالإشارة @، وهي أسماء متغيرات محلية في طرفية MySQL يمكنك استخدامها لتخزين البيانات مؤقتًا، وإذا مرّرنا هذه المعاملات إلى الإجراء المخزَّن الذي أنشأناه، فسيدرج الإجراءُ قيمًا في هذه المتغيرات. وستستجيب قاعدة البيانات بالخرج التالي: الخرج Query OK, 1 row affected (0.00 sec) يختلف هذا الخرج عن السلوك السابق، حيث كانت النتائج تُعرَض على الشاشة مباشرةً، لأن نتائج الإجراء المخزَّن محفوظة في معاملات الخرج دون إعادتها كنتيجة للاستعلام، ولكن يمكننا الوصول إلى النتائج من خلال استخدام التعليمة SELECT مباشرةً في صدفة MySQL كما يلي: mysql> SELECT @number, @min, @avg, @max; نحدّد قيمًا من المتغيرات المحلية باستخدام الاستعلام السابق، ولا نستدعي الإجراء مرة أخرى، ويحفظ الإجراء المخزَّن نتائجه في تلك المتغيرات، وستبقى البيانات متاحة حتى قطع الاتصال بالصدفة. ملاحظة: يمكن مطالعة على قسم المتغيرات التي يعرِّفها المستخدم في توثيق MySQL الرسمي لمعرفة المزيد حول استخدام هذه المتغيرات. ستختلف طرق الوصول إلى البيانات المُعادة من الإجراءات المخزنة في لغات البرمجة وأطر العمل المختلفة عند استخدامها في تطوير التطبيقات، لذا يتوجب الاطلاع على توثيق اللغة وإطار العمل لمعرفة الطريقة المناسبة. يعرض الخرج قيم المتغيرات التي استعلمنا عنها كما يلي: الخرج +---------+----------+-----------+-----------+ | @number | @min | @avg | @max | +---------+----------+-----------+-----------+ | 2 | 48880.00 | 192090.00 | 335300.00 | +---------+----------+-----------+-----------+ 1 row in set (0.00 sec) تتوافق القيم مع عدد السيارات المُصنَّعة في عام 2017، والقيمة السوقية الدنيا والمتوسطة والعليا للسيارات في هذه السنة من الإنتاج. تعلّمنا في المثال السابق كيفية استخدام معاملات الخرج لإعادة قيم مختلفة متعددة من الإجراء المخزن لاستخدامها لاحقًا، وسنتعلّم في القسم التالي كيفية إزالة الإجراءات التي أنشأناها. إزالة الإجراءات المخزنة سنزيل في هذا القسم الإجراءات المخزنة الموجودة في قاعدة البيانات، فقد لا تكون هناك حاجة إلى الإجراء الذي أنشأناه في بعض الأحيان، أو قد نرغب في تغيير طريقة عمل الإجراء، حيث لا يسمح MySQL بتغيير تعريف الإجراء بعد إنشائه، فالطريقة الوحيدة لذلك هي إزالة الإجراء أولًا وإعادة إنشائه مرة أخرى مع التغييرات المطلوبة. لنحذف الآن الإجراء الأخير get_car_stats_by_year باستخدام التعليمة DROP PROCEDURE كما يلي: mysql> DROP PROCEDURE get_car_stats_by_year; وستؤكد قاعدة البيانات حذف الإجراء برسالة النجاح التالية: الخرج Query OK, 0 rows affected (0.02 sec) يمكن التحقق من حذف الإجراء من خلال محاولة استدعائه باستخدام الأمر التالي: mysql> CALL get_car_stats_by_year(2017, @number, @min, @avg, @max); سنرى رسالة خطأ تفيد بأن الإجراء غير موجود في قاعدة البيانات كما يلي: رسالة خطأ ERROR 1305 (42000): PROCEDURE procedures.get_car_stats_by_year does not exist تعلمنا في هذا القسم كيفية حذف الإجراءات المخزنة الموجودة في قاعدة البيانات. الخلاصة تعلمنا في هذا المقال ما هي الإجراءات المخزنة وأنواعها المختلفة وكيفية استخدامها في MySQL لحفظ البيانات القابلة لإعادة الاستخدام في إجراءات مسمَّاة وتنفيذها لاحقًا، يمكن استخدام الإجراءات المخزنة لإنشاء برامج قابلة لإعادة الاستخدام، وتوحيد طرق الوصول إلى البيانات عبر تطبيقات متعددة، بالإضافة إلى تنفيذ سلوكيات معقدة تتجاوز الإمكانيات التي توفرها استعلامات SQL الفردية. غطى هذا المقال فقط أساسيات استخدام الإجراءات المخزنة، لذا لمزيد من المعلومات ننصح بالاطلاع على توثيق MySQL للإجراءات المخزنة لمعرفة مزيد من التفاصيل. ترجمة -وبتصرف- للمقال How To Use Stored Procedures in MySQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام المفاتيح الرئيسية Primary Keys في لغة SQL الاستعلامات الفرعية والإجراءات في SQL جلب الاستعلامات عبر SELECT في SQL حذف الجداول وقواعد البيانات في SQL
عند استخدام قاعدة بيانات علاقية Relational Database، سنحتاج إلى استخدام استعلامات فردية باستخدام لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- لاسترجاع البيانات أو معالجتها مثل استعلامات SELECT أو INSERT أو UPDATE أو DELETE من شيفرة التطبيق مباشرةً، إذ تعمل هذه التعليمات مع جداول قاعدة البيانات الأساسية وتعالجها فورًا. لكن إذا استخدمنا التعليمات أو مجموعة التعليمات نفسها ضمن تطبيقات متعددة يمكنها الوصول إلى قاعدة البيانات نفسها، وتكررت هذه التعليمات عدة مرات فيمكننا في هذه الحالة استخدام الإجراءات المخزَّنة Stored Procedures التي يدعمها MySQL كحال العديد من أنظمة إدارة قواعد البيانات العلاقية الأخرى، حيث تساعد هذه الإجراءات المخزنة في تجميع تعليمة SQL واحدة أو أكثر لإعادة استخدامها باسم مشترك من خلال تغليف منطق العمل المشترك ضمن قاعدة البيانات نفسها، ويمكن استدعاء مثل هذه الإجراءات من التطبيق الذي يصل إلى قاعدة البيانات لاسترجاع البيانات أو معالجتها. تساعدنا الإجراءات المخزنة على إنشاء برامج قابلة لإعادة الاستخدام للمهام الشائعة التي سنستخدمها عبر تطبيقات متعددة، كما توفر طريقة للتحقق من صحة البيانات، أو تقديم طبقة إضافية من أمان الوصول إلى البيانات من خلال تقييد مستخدمي قاعدة البيانات من الوصول إلى الجداول الأساسية مباشرةً وإنشاء استعلامات عشوائية. سنتعلّم في هذا المقال ما هي الإجراءات المخزَّنة وكيفية إنشاء إجراءات مخزنة بسيطة تعيد البيانات، وإجراءات تستخدم كلًا من معاملات الدخل والخرج. مستلزمات العمل يجب أن يكون لدينا حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية RDBMS المستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو مع مستخدم بصلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر معرفة أساسية بتنفيذ استعلامات SELECT لاسترجاع البيانات من قاعدة البيانات ملاحظة: تجدر الإشارة لأنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، ولا تُعَد صيغة الإجراءات المخزنة جزءًا من معيار SQL الرسمي. حيث ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن تُعَد الإجراءات المخزنة خاصة بقاعدة البيانات، وبالتالي قد نجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات فارغة يمكن من خلالها إنشاء جداول توضّح استخدام الإجراءات المخزنة، ويمكن مطالعة القسم التالي للحصول على تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية، والتي سنستخدمها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية سنتتصل بخادم MySQL وننشئ قاعدة بيانات تجريبية لاتباع الأمثلة الواردة في هذا المقال، حيث سنستخدم مجموعة سيارات افتراضية، ونخزّن تفاصيل السيارات المملوكة حاليًا مع نوعها وطرازها وسنة بنائها وقيمتها. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات باسم procedures: mysql> CREATE DATABASE procedures; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات procedures من خلال تنفيذ تعليمة USE التالية: $ USE procedures; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، ويمكنك الآن إنشاء جداول تجريبية ضمنها. سيحتوي الجدول cars على بيانات مبسَّطة حول السيارات الموجودة في قاعدة البيانات، حيث سيحتوي على الأعمدة التالية: make: نوع كل سيارة مملوكة، ونمثّل باستخدام نوع البيانات varchar بحد أقصى 100 محرف model: اسم طراز السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 100 محرف year: سنة صنع السيارة باستخدام نوع البيانات int للاحتفاظ بالقيم العددية value: قيمة السيارة باستخدام نوع البيانات decimal بحد أقصى 10 أرقام ورقمين بعد الفاصلة العشرية أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE cars ( mysql> make varchar(100), mysql> model varchar(100), mysql> year int, mysql> value decimal(10, 2) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) سندرج بعض البيانات التجريبية في الجدول cars من خلال تنفيذ عملية INSERT INTO التالية: mysql> INSERT INTO cars mysql> VALUES mysql> ('Porsche', '911 GT3', 2020, 169700), mysql> ('Porsche', 'Cayman GT4', 2018, 118000), mysql> ('Porsche', 'Panamera', 2022, 113200), mysql> ('Porsche', 'Macan', 2019, 27400), mysql> ('Porsche', '718 Boxster', 2017, 48880), mysql> ('Ferrari', '488 GTB', 2015, 254750), mysql> ('Ferrari', 'F8 Tributo', 2019, 375000), mysql> ('Ferrari', 'SF90 Stradale', 2020, 627000), mysql> ('Ferrari', '812 Superfast', 2017, 335300), mysql> ('Ferrari', 'GTC4Lusso', 2016, 268000); تضيف العملية INSERT INTO عشر سيارات رياضية نموذجية للجدول، حيث توجد أربع سيارات من نوع Porsche وخمسة سيارات من نوع Ferrari. يشير الخرج التالي إلى إضافة جميع الصفوف العشرة: الخرج Query OK, 10 rows affected (0.00 sec) Records: 10 Duplicates: 0 Warnings: 0 نحن الآن جاهزون لمتابعة هذا المقال والبدء باستخدام الإجراءات المُخزَّنة في لغة SQL. مقدمة إلى الإجراءات المخزنة Stored Procedures الإجراءات المخزنة في MySQL وفي العديد من أنظمة قواعد البيانات العلاقية الأخرى هي كائنات مُسمَّاة تحتوي على تعليمة واحدة أو أكثر تضعها وتنفّذها قاعدة البيانات عند استدعائها. يمكن للإجراء المخزن حفظ تعليمة مشتركة ضمن برنامج قابل لإعادة الاستخدام مثل استرجاع البيانات من قاعدة البيانات باستخدام المرشّحات Filters المُستخدَمة كثيرًا، حيث يمكنك مثلًا إنشاء إجراء مخزن لاسترجاع عملاء متجر الكتروني قدّموا طلبات خلال عدد معين من الأشهر. يمكن للإجراءات المخزنة أيضًا تمثيل البرامج الشاملة التي تصف منطق الأعمال المعقد للتطبيقات القوية في السيناريوهات الأكثر تعقيدًا. يمكن أن تتضمن مجموعة التعليمات في إجراء مخزَّن تعليمات SQL شائعة مثل استعلامات SELECT أو INSERT التي تعيد البيانات أو تعالجها، ويمكن للإجراءات المخزنة الاستفادة مما يلي: المعاملات المُمرَّرة إلى الإجراء المخزن أو المُعادة منه المتغيرات المُصرَّح عنها لمعالجة البيانات المُسترجَعة من شيفرة الإجراء البرمجية مباشرةً التعليمات الشرطية التي تسمح بتنفيذ أجزاء من شيفرة الإجراء المخزن البرمجية وفق شروط معينة مثل تعليمات IF أو CASE الحلقات مثل WHILE و LOOP و REPEAT لتنفيذ أجزاء من الشيفرة البرمجية عدة مرات تعليمات معالجة الأخطاء مثل إعادة رسائل الخطأ إلى مستخدمي قاعدة البيانات الذين يمكنهم الوصول إلى الإجراء. استدعاءات إجراءات مخزنة أخرى في قاعدة البيانات ملاحظة: تسمح الصيغة الموسَّعة Extensive Syntax التي يدعمها MySQL بكتابة برامج قوية وحل المشكلات المعقدة باستخدام الإجراءات المخزنة مثل التحكم في تدفق البرنامج باستخدام التعليمات الشرطية واستخدام المتغيرات والحلقات ومعالجة الأخطاء المخصصة وغيرها من الاستخدامات ولكن سيغطي هذا المقال فقط الاستخدام الأساسي للإجراءات المخزنة مع تعليمات SQL المُضمَّنة في جسم الإجراء المخزَّن ومعاملات الدخل والخرج، إذ سيكون تنفيذ التعليمات الشرطية واستخدام المتغيرات والحلقات ومعالجة الأخطاء المُخصَّصة خارج نطاق هذا المقال، لذا يمكن مطالعة توثيق MySQL الرسمي لمعرفة المزيد حول الإجراءات المخزنة. إذا استدعينا الإجراء باسمه، فسينفّذه محرّك قاعدة البيانات كما هو مُعرَّف تعليمةً تلو الأخرى. يجب أيضًا أن يكون لدى مستخدم قاعدة البيانات الأذونات المناسبة لتنفيذ الإجراء المُحدَّد، حيث توفر هذه الأذونات المطلوبة طبقة من الأمان، مما يمنع الوصول المباشر إلى قاعدة البيانات مع منح المستخدمين إمكانية الوصول إلى إجراءات فردية مضمونة الأمان لتنفيذها. تُنفَّذ الإجراءات المخزَّنة على خادم قاعدة البيانات مباشرةً مع إجراء جميع العمليات الحسابية محليًا وإعادة النتائج إلى المستخدم المستدعي عند الانتهاء فقط. وإذا أردنا تغيير سلوك الإجراء، فيمكن تحديث الإجراء في قاعدة البيانات، وستلتقط التطبيقات التي تستخدمه الإصدار الجديد تلقائيًا، وسيبدأ جميع المستخدمين باستخدام الشيفرة البرمجية للإجراء الجديد مباشرةً دون الحاجة لتعديل تطبيقاتهم. فيما يلي الهيكل العام لشيفرة SQL المستخدَمة لإنشاء إجراءٍ مخزَّن: mysql> DELIMITER // mysql> CREATE PROCEDURE procedure_name(parameter_1, parameter_2, . . ., parameter_n) mysql> BEGIN mysql> instruction_1; mysql> instruction_2; mysql> . . . mysql> instruction_n; mysql> END // mysql> DELIMITER ; التعليمتان الأولى والأخيرة في مقطع الشيفرة البرمجية السابق هما DELIMITER // و DELIMITER ;، حيث يستخدم MySQL رمز الفاصلة المنقوطة ; لتحديد التعليمات والإشارة إلى بدايتها ونهايتها. إذا نفّذنا تعليمات متعددة في طرفية MySQL مع الفصل بينها بفواصل منقوطة، سيكون التعامل معها كأنها أوامر منفصلة مع تنفيذ كل تعليمة تنفيذًا مستقلًا عن التعليمات الأخرى واحدة تلو الأخرى. يمكن للإجراء المخزَّن أيضًا أن يتضمّن أوامر متعددة ستُنفَّذ تسلسليًا عند استدعائه، مما يشكّل صعوبة عند محاولة إخبار MySQL بإنشاء إجراء جديد، إذ سيرى محرّك قاعدة البيانات علامة الفاصلة المنقوطة في جسم الإجراء المُخزَّن ويعتقد أنه يجب أن يتوقف عن تنفيذ التعليمة، وبالتالي تكون التعليمة المقصودة في هذه الحالة هي الشيفرة البرمجية لإنشاء الإجراء بالكامل، وليس تعليمةً واحدة ضمن الإجراء نفسه، لذا قد يسيء MySQL تفسير ما نقصده. يمكن التغلب على هذا القيد من خلال استخدام الأمر DELIMITER لتغيير هذا المحدِّد مؤقتًا من ; إلى // طوال مدة استدعاء التعليمة CREATE PROCEDURE، ثم ستُمرَّر جميع الفواصل المنقوطة الموجودة في جسم الإجراء المخزَّن إلى الخادم كما هي، ثم يتغير المحدِّد مرة أخرى إلى ; في آخر تعليمة DELIMITER ; بعد الانتهاء من الإجراء بالكامل. يمثّل الاستدعاء CREATE PROCEDURE وبعده اسم الإجراء procedure_name في المثال السابق جوهر الشيفرة البرمجية الخاصة بإنشاء إجراء جديد، ويتبع اسم الإجراء قائمة اختيارية من المعاملات التي سيقبلها الإجراء. الجزء الأخير من الشيفرة البرمجية هو جسم الإجراء المضمَّن ضمن تعليمتي BEGIN و END، ويوجد في الداخل شيفرة الإجراء البرمجية، والتي يمكن أن تحتوي على تعليمة SQL واحدة مثل استعلام SELECT أو شيفرة برمجية أكثر تعقيدًا. ينتهي الأمر END بالرمز //، والذي يُعَد محدِّدًا مؤقتًا عوضًا عن الفاصلة المنقوطة النموذجية. سننشئ في القسم التالي إجراءً مخزنًا بسيطًا بدون معاملات تتضمن استعلامًا واحدًا. إنشاء إجراء مخزن بدون معاملات سننشئ في هذا القسم أول إجراء مخزّن يغلِّف تعليمة SQL واحدة هي التعليمة SELECT لإعادة قائمة السيارات المملوكة المرتبة حسب نوعها وقيمتها بترتيب تنازلي. نبدأ بتنفيذ التعليمة SELECT التي ستستخدمها كما يلي: mysql> SELECT * FROM cars ORDER BY make, value DESC; ستعيد قاعدة البيانات قائمة السيارات من الجدول cars مع ترتيبها حسب نوعها أولًا ثم حسب قيمتها بترتيب تنازلي ضمن نوع السيارة الواحد كما يلي: الخرج +---------+---------------+------+-----------+ | make | model | year | value | +---------+---------------+------+-----------+ | Ferrari | SF90 Stradale | 2020 | 627000.00 | | Ferrari | F8 Tributo | 2019 | 375000.00 | | Ferrari | 812 Superfast | 2017 | 335300.00 | | Ferrari | GTC4Lusso | 2016 | 268000.00 | | Ferrari | 488 GTB | 2015 | 254750.00 | | Porsche | 911 GT3 | 2020 | 169700.00 | | Porsche | Cayman GT4 | 2018 | 118000.00 | | Porsche | Panamera | 2022 | 113200.00 | | Porsche | 718 Boxster | 2017 | 48880.00 | | Porsche | Macan | 2019 | 27400.00 | +---------+---------------+------+-----------+ 10 rows in set (0.00 sec) نلاحظ ظهور سيارة الفيراري الأعلى قيمة في أعلى القائمة، وظهور سيارة البورش الأدنى قيمة في الأسفل. لنفترض استخدام هذا الاستعلام بصورة متكررة في تطبيقات متعددة أو سيستخدمه مستخدمون متعددون ونريد التأكّد من أن الجميع سيستخدمون الطريقة نفسها لترتيب النتائج، لذا يجب إنشاء إجراء مخزن يحفظ تعليمة هذا الاستعلام ضمن إجراء مُسمَّى قابل لإعادة الاستخدام من خلال تنفيذ جزء الشيفرة البرمجية التالي: mysql> DELIMITER // mysql> CREATE PROCEDURE get_all_cars() mysql> BEGIN mysql> SELECT * FROM cars ORDER BY make, value DESC; mysql> END // mysql> DELIMITER ; نلاحظ أن الأمرين الأول DELIMITER // والأخير DELIMITER ; يخبران MySQL بالتوقف عن التعامل مع محرف الفاصلة المنقوطة بوصفه محدِّدًا للتعليمات طوال مدة إنشاء الإجراء كما هو موضّح في القسم السابق. يتبع أمر SQL الذي هو CREATE PROCEDURE اسم الإجراء get_all_cars الذي يمكن تعريفه لوصف ما يفعله الإجراء، ثم يوجد زوج من الأقواس () يمكننا إضافة معاملات ضمنه، ولكن لا يستخدم هذا الإجراء معاملات في مثالنا، لذا ستكون الأقواس فارغة، ثم تُكتَب تعليمة SELECT نفسها المُستخدَمة سابقًا بين الأمرين BEGIN و END اللذين يحددان بداية ونهاية كتلة شيفرة الإجراء البرمجية. ملاحظة: قد يظهر الخطأ ERROR 1044 (42000): Access denied for user 'user'@'localhost' to database 'procedures' عند تنفيذ الأمر CREATE PROCEDURE بناءً على أذونات مستخدم MySQL الخاص بنا. يمكن منح الأذونات اللازمة لإنشاء وتنفيذ الإجراءات المخزنة للمستخدم من خلال تسجيل الدخول إلى MySQL كمستخدم جذر وتنفيذ الأوامر التالية وتغيير اسم مستخدم MySQL والمضيف حسب الحاجة: mysql> GRANT CREATE ROUTINE, ALTER ROUTINE, EXECUTE on *.* TO 'user'@'localhost'; mysql> FLUSH PRIVILEGES; نحدّث أذونات المستخدم، ثم نسجّل الخروج كمستخدم جذر، ونسجّل الدخول مرة أخرى كمستخدم عادي، ثم نعيد تشغيل تعليمة CREATE PROCEDURE. يمكن معرفة المزيد حول تطبيق الأذونات الخاصة بالإجراءات المخزنة لمستخدمي قاعدة البيانات في توثيق MySQL الرسمي الخاص بصلاحيات MySQL والبرامج المُخزَّنة. ستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 0 rows affected (0.02 sec) أصبح الإجراء get_all_cars الآن محفوظًا في قاعدة البيانات، وستُنفَّذ التعليمة المحفوظة كما هي عند استدعائه. يمكن تنفيذ الإجراءات المخزَّنة المحفوظة من خلال استخدام أمر SQL الذي هو CALL متبوعًا باسم الإجراء. نجرّب الآن تشغيل الإجراء الذي أنشأناه كما يلي: mysql> CALL get_all_cars; نحتاج اسم الإجراء get_all_cars فقط لاستخدام هذا الإجراء، إذ لم تَعُد بحاجة إلى كتابة أيّ جزء من تعليمة SELECT التي استخدمناها سابقًا يدويًا، وستعرض قاعدة البيانات النتائج مثل خرج التعليمة SELECT التي نفّذتها سابقًا كما يلي: الخرج +---------+---------------+------+-----------+ | make | model | year | value | +---------+---------------+------+-----------+ | Ferrari | SF90 Stradale | 2020 | 627000.00 | | Ferrari | F8 Tributo | 2019 | 375000.00 | | Ferrari | 812 Superfast | 2017 | 335300.00 | | Ferrari | GTC4Lusso | 2016 | 268000.00 | | Ferrari | 488 GTB | 2015 | 254750.00 | | Porsche | 911 GT3 | 2020 | 169700.00 | | Porsche | Cayman GT4 | 2018 | 118000.00 | | Porsche | Panamera | 2022 | 113200.00 | | Porsche | 718 Boxster | 2017 | 48880.00 | | Porsche | Macan | 2019 | 27400.00 | +---------+---------------+------+-----------+ 10 rows in set (0.00 sec) Query OK, 0 rows affected (0.00 sec) نجحنا في إنشاء إجراء مخزَّن بدون معاملات، حيث يعيد هذا الإجراء جميع السيارات من الجدول cars مرتبةً بطريقة معينة، ويمكن استخدام هذا الإجراء في تطبيقات متعددة. سننشئ في القسم التالي إجراء يقبل المعاملات لتغيير سلوك الإجراء وفقًا لدخل المستخدم. إنشاء إجراء مخزن مع معامل دخل سنضمِّن في هذا القسم معاملات دخل في تعريف الإجراء المخزَّن للسماح للمستخدمين الذين ينفّذون الإجراء بتمرير البيانات إليه، فمثلًا يمكن للمستخدمين توفير مرشّحات للاستعلام. يسترجع الإجراء المخزن get_all_cars الذي أنشأناه مسبقًا جميع السيارات من الجدول cars المصنعة في جميع سنوات التصنيع، ولننشئ الآن إجراء آخر للعثور على السيارات المُصنَّعة في سنة معينة، حيث سنعرِّف معاملًا في تعريف الإجراء من خلال تشغيل الشيفرة البرمجية التالية: mysql> DELIMITER // mysql> CREATE PROCEDURE get_cars_by_year( mysql> IN year_filter int mysql> ) mysql> BEGIN mysql> SELECT * FROM cars WHERE year = year_filter ORDER BY make, value DESC; mysql> END // mysql> DELIMITER ; توجد العديد من التغييرات على شيفرة إنشاء الإجراء مقارنة بالشيفرة المستخدمة في القسم السابق، حيث تغيّر الاسم ليكون get_cars_by_year ليمثل عمل الإجراء، وهو استرجاع السيارات بناءً على سنة إصدارها. كما أصبحت الأقواس الفارغة سابقًا محتوية على تعريف معامل واحد هو IN year_filter int، حيث تخبر الكلمة المفتاحية IN قاعدة البيانات بأن المستخدم المستدعِي سيمرّر المعامل إلى الإجراء. يُعَد year_filter اسمًا عشوائيًا للمعامل، حيث سنستخدمه للإشارة إلى المعامل في شيفرة الإجراء البرمجية، و int هو نوع البيانات، حيث نمثّل سنة التصنيع بقيمة عددية. يظهر المعامل year_filter المُعرَّف بعد اسم الإجراء في تعليمة SELECT ضمن التعليمة WHERE year = year_filter، مما يؤدي إلى ترشيح الجدول cars وفقًا لسنة التصنيع، وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 0 rows affected (0.02 sec) نفّذ الإجراء بدون تمرير أي معاملات إليه كما فعلنا سابقًا: mysql> CALL get_cars_by_year; وستعيد قاعدة بيانات MySQL رسالة الخطأ التالية: رسالة خطأ ERROR 1318 (42000): Incorrect number of arguments for PROCEDURE procedures.get_cars_by_year; expected 1, got 0 يتوقع الإجراء المخزن هذه المرة توفير معامل له، ولكن لم نقدّم له أيّ معامل، لذا يمكننا استدعاء إجراء مخزَّن مع معاملات من خلال توفير قيم المعاملات بين قوسين بنفس الترتيب الذي يتوقعه الإجراء. سننفّذ الإجراء التالي لاسترجاع السيارات المصنعة في عام 2017: mysql> CALL get_cars_by_year(2017); سيُنفَّذ الإجراء المستدعَى الآن تنفيذًا صحيحًا ويعيد قائمة السيارات من عام 2017، وسينتج الخرج التالي: الخرج +---------+---------------+------+-----------+ | make | model | year | value | +---------+---------------+------+-----------+ | Ferrari | 812 Superfast | 2017 | 335300.00 | | Porsche | 718 Boxster | 2017 | 48880.00 | +---------+---------------+------+-----------+ 2 rows in set (0.00 sec) Query OK, 0 rows affected (0.00 sec) تعلّمنا في المثال السابق كيفية تمرير معاملات الدخل إلى الإجراءات المخزنة واستخدامها في الاستعلامات ضمن الإجراء لتوفير خيارات الترشيح، وسنستخدم في القسم التالي معاملات الخرج لإنشاء إجراءات تعيد قيمًا مختلفة متعددة في تنفيذ واحد. إنشاء إجراء مخزن مع معاملات دخل وخرج في الإجراءات المخزَّنة التي أنشأناها في المثالين السابقين استدعينا تعليمة SELECT للحصول على مجموعة نتائج، ولكن قد نحتاج في بعض الحالات إلى إجراء مخزّن يعيد قيمًا مختلفة متعددة مع بعضها البعض بدل إعادة مجموعة نتائج واحدة لاستعلام فردي. لنفترض أننا تريد إنشاء إجراء يوفّر معلومات عن السيارات الصادرة في سنة معينة بما في ذلك كمية السيارات في المجموعة وقيمتها السوقية -الحد الأدنى والحد الأقصى والمتوسط- من خلال استخدام معاملات OUT عند إنشاء إجراء مخزّن جديد. تحتوي معاملات OUT مثل معاملات IN على أسماء وأنواع بيانات مرتبطة بها، ولكن يمكن ملء هذه المعاملات بالبيانات باستخدام الإجراء المخزن بدل تمرير البيانات إلى الإجراء المخزن لإعادة القيم إلى المستخدم المستدعِي. لننشئ الآن الإجراء get_car_stats_by_year التالي الذي سيعيد بيانات موجزة عن السيارات من سنة إنتاج معينة باستخدام معاملات خرج: mysql> DELIMITER // mysql> CREATE PROCEDURE get_car_stats_by_year( mysql> IN year_filter int, mysql> OUT cars_number int, mysql> OUT min_value decimal(10, 2), mysql> OUT avg_value decimal(10, 2), mysql> OUT max_value decimal(10, 2) mysql> ) mysql> BEGIN mysql> SELECT COUNT(*), MIN(value), AVG(value), MAX(value) mysql> INTO cars_number, min_value, avg_value, max_value mysql> FROM cars mysql> WHERE year = year_filter ORDER BY make, value DESC; mysql> END // mysql> DELIMITER ; استخدمنا معامل IN الذي هو year_filter لترشيح السيارات حسب سنة الإصدار، وعرّفنا أربعة معاملات OUT ضمن كتلة الأقواس. نمثّل المعامل cars_number بنوع البيانات int وسنستخدمه لإعادة عدد السيارات في المجموعة، وتمثّل المعاملات min_value و avg_value و max_value القيمة السوقية وتُعرَّف باستخدام نوع البيانات decimal(10, 2) مثل العمود value في الجدول cars، وتُستخدَم هذه المعاملات لإعادة معلومات حول أرخص وأغلى السيارات من المجموعة، بالإضافة إلى متوسط أسعار جميع السيارات المطابقة. تستعلم التعليمة SELECT عن أربع قيم من الجدول cars باستخدام دوال SQL الرياضية وهي: COUNT للحصول على العدد الإجمالي للسيارات، و MIN و AVG و MAX للحصول على القيمة الدنيا والمتوسط والقيمة العليا من العمود value. يمكن مطالعة مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في لغة SQL لمعرفة المزيد حول استخدام الدوال الرياضية في لغة SQL. يمكننا إخبار قاعدة البيانات بأننا نريد تخزين نتائج هذا الاستعلام في معاملات الخرج للإجراء المخزَّن من خلال تقديم كلمة مفتاحية جديدة هي INTO، ونضع بعدها أسماء أربعة معاملات إجراء تقابل البيانات المُسترجَعة، وبالتالي سيحفظ MySQL قيمة COUNT(*) في المعامل cars_number، ونتيجة MIN(value) في المعامل min_value ...إلخ. تؤكد قاعدة البيانات إنشاء الإجراء بنجاح كما يلي: الخرج Query OK, 0 rows affected (0.02 sec) لنشغّل الآن الإجراء الجديد من خلال تنفيذ الأمر التالي: mysql> CALL get_car_stats_by_year(2017, @number, @min, @avg, @max); تبدأ المعاملات الأربعة الجديدة بالإشارة @، وهي أسماء متغيرات محلية في طرفية MySQL يمكنك استخدامها لتخزين البيانات مؤقتًا، وإذا مرّرنا هذه المعاملات إلى الإجراء المخزَّن الذي أنشأناه، فسيدرج الإجراءُ قيمًا في هذه المتغيرات. وستستجيب قاعدة البيانات بالخرج التالي: الخرج Query OK, 1 row affected (0.00 sec) يختلف هذا الخرج عن السلوك السابق، حيث كانت النتائج تُعرَض على الشاشة مباشرةً، لأن نتائج الإجراء المخزَّن محفوظة في معاملات الخرج دون إعادتها كنتيجة للاستعلام، ولكن يمكننا الوصول إلى النتائج من خلال استخدام التعليمة SELECT مباشرةً في صدفة MySQL كما يلي: mysql> SELECT @number, @min, @avg, @max; نحدّد قيمًا من المتغيرات المحلية باستخدام الاستعلام السابق، ولا نستدعي الإجراء مرة أخرى، ويحفظ الإجراء المخزَّن نتائجه في تلك المتغيرات، وستبقى البيانات متاحة حتى قطع الاتصال بالصدفة. ملاحظة: يمكن مطالعة على قسم المتغيرات التي يعرِّفها المستخدم في توثيق MySQL الرسمي لمعرفة المزيد حول استخدام هذه المتغيرات. ستختلف طرق الوصول إلى البيانات المُعادة من الإجراءات المخزنة في لغات البرمجة وأطر العمل المختلفة عند استخدامها في تطوير التطبيقات، لذا يتوجب الاطلاع على توثيق اللغة وإطار العمل لمعرفة الطريقة المناسبة. يعرض الخرج قيم المتغيرات التي استعلمنا عنها كما يلي: الخرج +---------+----------+-----------+-----------+ | @number | @min | @avg | @max | +---------+----------+-----------+-----------+ | 2 | 48880.00 | 192090.00 | 335300.00 | +---------+----------+-----------+-----------+ 1 row in set (0.00 sec) تتوافق القيم مع عدد السيارات المُصنَّعة في عام 2017، والقيمة السوقية الدنيا والمتوسطة والعليا للسيارات في هذه السنة من الإنتاج. تعلّمنا في المثال السابق كيفية استخدام معاملات الخرج لإعادة قيم مختلفة متعددة من الإجراء المخزن لاستخدامها لاحقًا، وسنتعلّم في القسم التالي كيفية إزالة الإجراءات التي أنشأناها. إزالة الإجراءات المخزنة سنزيل في هذا القسم الإجراءات المخزنة الموجودة في قاعدة البيانات، فقد لا تكون هناك حاجة إلى الإجراء الذي أنشأناه في بعض الأحيان، أو قد نرغب في تغيير طريقة عمل الإجراء، حيث لا يسمح MySQL بتغيير تعريف الإجراء بعد إنشائه، فالطريقة الوحيدة لذلك هي إزالة الإجراء أولًا وإعادة إنشائه مرة أخرى مع التغييرات المطلوبة. لنحذف الآن الإجراء الأخير get_car_stats_by_year باستخدام التعليمة DROP PROCEDURE كما يلي: mysql> DROP PROCEDURE get_car_stats_by_year; وستؤكد قاعدة البيانات حذف الإجراء برسالة النجاح التالية: الخرج Query OK, 0 rows affected (0.02 sec) يمكن التحقق من حذف الإجراء من خلال محاولة استدعائه باستخدام الأمر التالي: mysql> CALL get_car_stats_by_year(2017, @number, @min, @avg, @max); سنرى رسالة خطأ تفيد بأن الإجراء غير موجود في قاعدة البيانات كما يلي: رسالة خطأ ERROR 1305 (42000): PROCEDURE procedures.get_car_stats_by_year does not exist تعلمنا في هذا القسم كيفية حذف الإجراءات المخزنة الموجودة في قاعدة البيانات. الخلاصة تعلمنا في هذا المقال ما هي الإجراءات المخزنة وأنواعها المختلفة وكيفية استخدامها في MySQL لحفظ البيانات القابلة لإعادة الاستخدام في إجراءات مسمَّاة وتنفيذها لاحقًا، يمكن استخدام الإجراءات المخزنة لإنشاء برامج قابلة لإعادة الاستخدام، وتوحيد طرق الوصول إلى البيانات عبر تطبيقات متعددة، بالإضافة إلى تنفيذ سلوكيات معقدة تتجاوز الإمكانيات التي توفرها استعلامات SQL الفردية. غطى هذا المقال فقط أساسيات استخدام الإجراءات المخزنة، لذا لمزيد من المعلومات ننصح بالاطلاع على توثيق MySQL للإجراءات المخزنة لمعرفة مزيد من التفاصيل. ترجمة -وبتصرف- للمقال How To Use Stored Procedures in MySQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام المفاتيح الرئيسية Primary Keys في لغة SQL الاستعلامات الفرعية والإجراءات في SQL جلب الاستعلامات عبر SELECT في SQL حذف الجداول وقواعد البيانات في SQL -
 تتميز قواعد البيانات العلاقية Relational Databases بكونها تهيكل البيانات ضمن بنية منظّمة، فهي تستخدم جداول ذات أعمدة ثابتة وتتبع أنواع بيانات مُعرَّفة بدقة وتضمن بأن جميع الصفوف لها الشكل نفسه. ومن المهم أن نكون قادرين في هذه البينة على العثور على الصفوف في الجداول والإشارة إليها دون التباس عند تخزين هذه البيانات ضمن صفوف الجداول. ويمكننا تحقيق ذلك في لغة الاستعلام البنيوية SQL باستخدام المفاتيح الرئيسية Primary Keys، والتي تعمل كمعرّفات مميزة للصفوف في جداول قاعدة البيانات العلاقية. سنتعرّف في هذا المقال على مفهوم المفاتيح الرئيسية، وكيفية استخدام أنواعها المختلفة لتحديد الصفوف الفريدة في جداول قاعدة البيانات، وسننشئ مفاتيح رئيسية من أعمدة فردية وأعمدة متعددة، كما سننشئ مفاتيح تسلسلية مع زيادة تلقائية باستخدام بعض البيانات التجريبية النموذجية. مستلزمات العمل يجب أن يكون لدينا حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو مع مستخدم بصلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر معرفة أساسية بتنفيذ استعلامات SELECT كما هو موضّح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة لأنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر في هذا المقال بنجاح مع معظم هذه الأنظمة، تُعَد المفاتيح الرئيسية جزءًا من معيار SQL، ولكن هناك بعض الميزات خاصة بقاعدة البيانات، لذا قد نجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات فارغة يمكن من خلالها إنشاء جداول توضّح استخدام المفاتيح الرئيسية كما سنشرح بالتفصيل في الفقرات التالية. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وننشئ قاعدة بيانات تجريبية. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بك مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم primary_keys: mysql> CREATE DATABASE primary_keys; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات primary_keys من خلال تنفيذ تعليمة USE التالية: $ USE primary_keys; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، ويمكن الآن إنشاء جداول تجريبية ضمنها، وبذلك أصبحنا جاهزًا لمتابعة هذا المقال والبدء في العمل مع المفاتيح الرئيسية. مقدمة إلى المفاتيح الرئيسية Primary Keys تُخزَّن البيانات في قاعدة البيانات العلاقية في جداول ذات بنية موحَّدة ومحدَّدة من الصفوف الفردية، ويوضّح تعريف الجدول الأعمدة الموجودة فيه وأنواع البيانات التي يمكن حفظها في الأعمدة الفردية، وهذا كافي لتخزين المعلومات في قاعدة البيانات والعثور عليها لاحقًا باستخدام معايير ترشيح مختلفة باستخدام تعليمة WHERE، ولكن لا تضمن هذه البنية إمكانية العثور على أي صف بعينه دون التباس مع صفوف أخرى. لنفترض أن لدينا قاعدة بيانات لجميع السيارات المسجَّلة المسموح لها بالقيادة على الطرق العامة، حيث ستحتوي قاعدة البيانات على معلومات مثل نوع السيارة وطرازها وسنة تصنيعها ولون طلائها، ولكن إذا بحثنا عن سيارة شيفروليه كامارو Chevrolet Camaro حمراء اللون ومصنوعة في عام 2007، فيمكن العثور على أكثر من سيارة، إذ سيبيع المصنعون سيارات متماثلة لعملاء متعددين، لذا تحتوي السيارات المُسجَّلة على أرقام لوحات ترخيص تحدّد كل سيارة فريدة. إذا بحثنا عن سيارة تحمل لوحة الترخيص OFP857، فيمكن التأكد من أن هذا المعيار سيجد سيارة واحدة فقط، لأن أرقام اللوحات تحدد السيارات المسجلة بطريقة فريدة قانونيًا، ويسمى هذا الجزء من البيانات في قاعدة البيانات العلاقية بالمفتاح الرئيسي Primary Key. المفاتيح الرئيسية هي معرّفات فريدة موجودة في عمود واحد أو مجموعة من الأعمدة يمكنها تحديد كل صف في جدول قاعدة البيانات دون التباس. ومن أبرز خصائص المفاتيح الرئيسية نذكر: يجب أن يستخدم المفتاح الرئيسي قيمًا فريدة، وإذا تكوّن المفتاح الرئيسي من أكثر من عمود واحد، فيجب أن تكون مجموعة القيم في هذه الأعمدة فريدة في الجدول بأكمله، إذ لا يمكن أن يظهر المفتاح الرئيسي أكثر من مرة لأنه مخصّص لتحديد كل صف بطريقة فريدة يجب ألا يحتوي المفتاح الرئيسي على قيم NULL يمكن لكل جدول في قاعدة البيانات استخدام مفتاح رئيسي واحد فقط يفرض محرّك قاعدة البيانات هذه القواعد، لذا يمكنك الوثوق بصحة هذه الخاصيات عند تعريف المفتاح الرئيسي لجدول ما، ويجب أن تضع في بالنا محتوى البيانات وما الذي يمكن اختياره منها لتمثيل المفتاح الرئيسي بشكل مناسب. المفاتيح الطبيعية Natural keys هي معرّفات موجودة مسبقًا في مجموعة البيانات، والمفاتيح البديلة Surrogate Keys هي معرّفات اصطناعية، ويمكن مطالعة مقال فهم قيود SQL لمزيد من التفاصيل. تحتوي بعض هياكل البيانات على مفاتيح رئيسية تظهر في مجموعة البيانات طبيعيًا مثل أرقام لوحات الترخيص في قاعدة بيانات السيارات أو أرقام الضمان الاجتماعي في دليل المواطنين، ولا تكون هذه المعرّفات مؤلَّفة من قيمة واحدة بل مؤلفة من زوج أو مجموعة من عدة قيم في بعض الأحيان، فمثلًا لا يمكن تحديد منزل فريد باستخدام اسم الشارع أو رقم الشارع فقط في دليل مدينة محلية للمنازل، إذ يمكن أن يكون هناك عدة منازل في شارع واحد، ويمكن أن يظهر الرقم نفسه في شوارع متعددة، ولكن يمكن افتراض أن كلًا من اسم الشارع ورقمه هو معرّف منزل فريد. تسمّى هذه المعرّفات بالمفاتيح الطبيعية. لكن لا يمكن في بعض الأحيان تمييز البيانات تمييزًا فريدًا باستخدام قيم عمود واحد أو مجموعة فرعية صغيرة من الأعمدة، وبالتالي يجب إنشاء مفاتيح رئيسية اصطناعية باستخدام تسلسل من الأرقام مثلًا أو معرّفات مُولَّدة عشوائيًا مثل معرّفات UUID، وتسمّى هذه المفاتيح بالمفاتيح البديلة. سننشئ في الأقسام التالية مفاتيح طبيعية بناءً على عمود واحد أو أعمدة متعددة، كما سنولّد مفاتيح بديلة للجداول التي لا يكون المفتاح الطبيعي خيارًا فيها. إنشاء مفتاح رئيسي من عمود واحد تحتوي مجموعة البيانات على عمود واحد طبيعيًا في العديد من الحالات، ويمكن استخدام هذا العمود لتحديد الصفوف في الجدول تحديدًا فريدًا، وبالتالي يمكن إنشاء مفتاح طبيعي لوصف هذه البيانات. لنفترض أن لدينا الجدول التالي باتباع المثال السابق لقاعدة بيانات السيارات المُسجَّلة: جدول بسيط +---------------+-----------+------------+-------+------+ | license_plate | brand | model | color | year | +---------------+-----------+------------+-------+------+ | ABC123 | Ford | Mustang | Red | 2018 | | CES214 | Ford | Mustang | Red | 2018 | | DEF456 | Chevrolet | Camaro | Blue | 2016 | | GHI789 | Dodge | Challenger | Black | 2014 | +---------------+-----------+------------+-------+------+ يمثّل الصف الأول والثاني سيارة فورد موستانج Ford Mustang حمراء مصنوعة في عام 2018، ولن تتمكّن من تحديد السيارة بطريقة فريدة باستخدام نوع السيارة وطرازها فقط، لذا تختلف لوحة الترخيص لكل سيارة في كلتا الحالتين، ممّا يوفّر معرّفًا فريدًا جيدًا لكل صف في الجدول. يُعَد رقم لوحة الترخيص جزءًا من البيانات، لذا يؤدي استخدامه بوصفه مفتاحًا رئيسيًا إلى إنشاء مفتاح طبيعي. إذا أنشأنا الجدول دون استخدام مفتاح رئيسي في العمود license_plate، فستخاطر بظهور لوحة مكررة أو فارغة في مجموعة البيانات لاحقًا. لننشئ الآن جدولًا يشبه الجدول السابق مع استخدام العمود license_plate بوصفه مفتاحًا رئيسيًا مع الأعمدة التالية: license_plate: رقم لوحة الترخيص، ونمثله باستخدام نوع البيانات varchar brand: نوع السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا model: طراز السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا color: لون السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 20 محرفًا year: سنة تصنيع السيارة، ونمثّله باستخدام نوع البيانات int لتخزين البيانات العددي. ولننشئ الآن الجدول cars من خلال تنفيذ تعليمة SQL التالية: mysql> CREATE TABLE cars ( mysql> license_plate varchar(8) PRIMARY KEY, mysql> brand varchar(50), mysql> model varchar(50), mysql> color varchar(20), mysql> year int mysql> ); تكون تعليمة PRIMARY KEY بعد تعريف نوع بيانات license_plate، حيث يمكنك استخدام الصيغة المبسَّطة لإنشاء المفتاح وكتابة PRIMARY KEY في تعريف العمود عند التعامل مع المفاتيح الرئيسية المستندة إلى أعمدة مفردة. إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول ببعض الصفوف التجريبية المعروضة في المثال السابق من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO cars VALUES mysql> ('ABC123', 'Ford', 'Mustang', 'Red', 2018), mysql> ('CES214', 'Ford', 'Mustang', 'Red', 2018), mysql> ('DEF456', 'Chevrolet', 'Camaro', 'Blue', 2016), mysql> ('GHI789', 'Dodge', 'Challenger', 'Black', 2014); وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 4 rows affected (0.010 sec) Records: 4 Duplicates: 0 Warnings: 0 يمكن الآن التحقق من أن الجدول الذي أنشأناه يحتوي على البيانات والتنسيق المتوقع باستخدام تعليمة SELECT التالية: mysql> SELECT * FROM cars; وسيظهر الخرج جدولًا مشابهًا للجدول الموجود في بداية هذا القسم: الخرج +---------------+-----------+------------+-------+------+ | license_plate | brand | model | color | year | +---------------+-----------+------------+-------+------+ | ABC123 | Ford | Mustang | Red | 2018 | | CES214 | Ford | Mustang | Red | 2018 | | DEF456 | Chevrolet | Camaro | Blue | 2016 | | GHI789 | Dodge | Challenger | Black | 2014 | +---------------+-----------+------------+-------+------+ يمكن بعد ذلك التحقق من ضمان قواعد المفتاح الرئيسي باستخدام محرّك قاعدة البيانات، لذا نجرّب إدخال سيارة لها رقم لوحة مكرّر من خلال تنفيذ الأمر التالي: mysql> INSERT INTO cars VALUES ('DEF456', 'Jeep', 'Wrangler', 'Yellow', 2019); وسيستجيب MySQL برسالة الخطأ التالية التي تفيد بأن لوحة الترخيص DEF456 تمثّل إدخالًا مكررًا للمفتاح الرئيسي: الخرج ERROR 1062 (23000): Duplicate entry 'DEF456' for key 'cars.PRIMARY' ملاحظة: تُطبَّق المفاتيح الرئيسية باستخدام الفهارس الفريدة Unique Indexes وتشترك في العديد من الخاصيات مع الفهارس التي قد ننشئها يدويًا لأعمدة أخرى في الجدول، وتعمل فهارس المفاتيح الرئيسية أيضًا على تحسين أداء الاستعلام في الجدول للعمود الذي عرّفنا الفهرس له. اطّلع على مقال كيفية استخدام الفهارس في SQL لمزيد من المعلومات. يمكن الآن التأكد من عدم السماح باستخدام لوحات ترخيص مكرّرة، ولنتحقق الآن من إمكانية إدخال سيارة لها لوحة ترخيص فارغة كما يلي: mysql> INSERT INTO cars VALUES (NULL, 'Jeep', 'Wrangler', 'Yellow', 2019); وستستجيب قاعدة البيانات برسالة الخطأ التالية: الخرج ERROR 1048 (23000): Column 'license_plate' cannot be null يمكن التأكّد من أن المفتاح الرئيسي license_plate يحدّد كلّ صف في الجدول تحديدًا فريدًا بفضل القاعدتين السابقتين اللتين تفرضهما قاعدة البيانات، وبالتالي إذا استعلمنا في الجدول عن أي لوحة ترخيص، فسنتوقع إعادة صف واحد في كل مرة. نشرح في القسم التالي كيفية استخدام المفاتيح الرئيسية مع أعمدة متعددة. إنشاء مفتاح رئيسي من أعمدة متعددة إن لم يكن عمود واحد كافيًا لتحديد صف فريد في الجدول، فيمكن إنشاء مفاتيح رئيسية تستخدم أكثر من عمودٍ واحد. لنفترض مثلًا وجود سجلٍ للمنازل بحيث لا يكفي اسم الشارع أو رقمه فقط لتحديد أيّ منزل فردي كما يلي: جدول بسيط +-------------------+---------------+-------------------+------+ | street_name | street_number | house_owner | year | +-------------------+---------------+-------------------+------+ | 5th Avenue | 100 | Bob Johnson | 2018 | | Broadway | 1500 | Jane Smith | 2016 | | Central Park West | 100 | John Doe | 2014 | | Central Park West | 200 | Tom Thompson | 2015 | | Lexington Avenue | 5001 | Samantha Davis | 2010 | | Park Avenue | 7000 | Michael Rodriguez | 2012 | +-------------------+---------------+-------------------+------+ يظهر اسم الشارع Central Park West أكثر من مرة في الجدول، ويظهر رقم الشارع 100 أكثر من مرة أيضًا، ولكن لا تظهَر أي أزواج مكررة من أسماء الشوارع وأرقامها، وبالتالي يمكن استخدام زوج من هاتين القيمتين لتحديد كل صف في الجدول تحديدًا فريدًا في الحالة التي لا يمكن فيها لأي عمود بمفرده أن يكون مفتاحًا رئيسيًا. لننشئ الآن جدولًا يشبه الجدول السابق ويحتوي على الأعمدة التالية: street_name: اسم الشارع الذي يقع فيه المنزل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. street_number: رقم شارع المنزل، ونمثّله باستخدام نوع البيانات varchar، ويمكن لهذا العمود تخزين ما يصل إلى 5 محارف، ولا يستخدم نوع البيانات العددي int لأن بعض أرقام الشوارع قد تحتوي على محارف مثل 200B. house_owner: اسم مالك المنزل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. year: العام الذي بُني فيه المنزل، ونمثّله باستخدام نوع البيانات int لتخزين القيم العددية. سيستخدم المفتاح الرئيسي هذه المرة العمودين street_name و street_number بدلًا من استخدام عمود واحد من خلال تنفيذ تعليمة SQL التالية: mysql> CREATE TABLE houses ( mysql> street_name varchar(50), mysql> street_number varchar(5), mysql> house_owner varchar(50), mysql> year int, mysql> PRIMARY KEY(street_name, street_number) mysql> ); تظهر تعليمة PRIMARY KEY بعد تعريفات الأعمدة على عكس المثال السابق، وتليها أقواس تحتوي على اسمي عمودين هما: street_name و street_number. تنشئ هذه الصيغة المفتاح الرئيسي في الجدول houses الذي يمتد إلى عمودين. إذا ظهر الخرج التالي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول بالصفوف التجريبية المعروضة في المثال السابق من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO houses VALUES mysql> ('Central Park West', '100', 'John Doe', 2014), mysql> ('Broadway', '1500', 'Jane Smith', 2016), mysql> ('5th Avenue', '100', 'Bob Johnson', 2018), mysql> ('Lexington Avenue', '5001', 'Samantha Davis', 2010), mysql> ('Park Avenue', '7000', 'Michael Rodriguez', 2012), mysql> ('Central Park West', '200', 'Tom Thompson', 2015); وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 6 rows affected (0.000 sec) Records: 6 Duplicates: 0 Warnings: 0 يمكن الآن التحقق من أن الجدول الذي أنشأناه يحتوي على البيانات والتنسيق المتوقع باستخدام تعليمة SELECT التالية: mysql> SELECT * FROM houses; وسيُظهِر الخرج جدولًا مشابهًا للجدول الموجود في بداية هذا القسم: الخرج +-------------------+---------------+-------------------+------+ | street_name | street_number | house_owner | year | +-------------------+---------------+-------------------+------+ | 5th Avenue | 100 | Bob Johnson | 2018 | | Broadway | 1500 | Jane Smith | 2016 | | Central Park West | 100 | John Doe | 2014 | | Central Park West | 200 | Tom Thompson | 2015 | | Lexington Avenue | 5001 | Samantha Davis | 2010 | | Park Avenue | 7000 | Michael Rodriguez | 2012 | +-------------------+---------------+-------------------+------+ 6 rows in set (0.000 sec) لنتحقق الآن من سماح قاعدة البيانات بإدراج صفوف تحتوي على أسماء وأرقام شوارع مكرَّرة، مع تقييد ظهور عناوين كاملة مكررة في الجدول. لنبدأ أولًا بإضافة منزل آخر في شارع Park Avenue كما يلي: mysql> INSERT INTO houses VALUES ('Park Avenue', '8000', 'Emily Brown', 2011); سيستجيب MySQL برسالة النجاح التالية لأن العنوان 8000 Park Avenue لم يظهر في الجدول سابقًا: الخرج Query OK, 1 row affected (0.010 sec) وستظهر نتيجة مماثلة عند إضافة منزل في العنوان 8000 Main Street مع تكرار رقم الشارع كما يلي: mysql> INSERT INTO houses VALUES ('Main Street', '8000', 'David Jones', 2009); مما سيؤدي إلى إدراج صف جديد بنجاح بسبب عدم تكرار العنوان الكامل: الخرج Query OK, 1 row affected (0.010 sec) نحاول الآن إضافة منزل آخر في العنوان 100 5th Avenue باستخدام تعليمة INSERT التالية: mysql> INSERT INTO houses VALUES ('5th Avenue', '100', 'Josh Gordon', 2008); وستستجيب قاعدة البيانات برسالة الخطأ التالية لإعلامك بوجود إدخال مكرر للمفتاح الرئيسي لزوج القيم 5th Avenue و 100: الخرج ERROR 1062 (23000): Duplicate entry '5th Avenue-100' for key 'houses.PRIMARY' تطبّق قاعدة البيانات قواعد المفتاح الرئيسي بطريقة صحيحة، مع تعريف المفتاح لزوج من الأعمدة، وبالتالي يمكن التأكّد من عدم تكرار العنوان الكامل المكون من اسم الشارع ورقمه في الجدول. أنشأنا في هذا القسم مفتاحًا طبيعيًا مع زوج من الأعمدة لتحديد كل صف في الجدول house بوصفه صفًا فريدًا، ولكن لا يمكن دائمًا استخلاص المفاتيح الرئيسية من مجموعة البيانات، لذا سنستخدم في القسم التالي المفاتيح الرئيسية الاصطناعية التي لا تأتي من البيانات مباشرةً. إنشاء مفتاح رئيسي تسلسلي Sequential Primary Key أنشأنا مفاتيح رئيسية فريدة باستخدام أعمدة موجودة في مجموعات البيانات التجريبية النموذجية، ولكن البيانات ستتكرّر في بعض الحالات، مما يمنع الأعمدة من أن تكون معرّفات فريدة جيدة، لذا يمكن إنشاء مفاتيح رئيسية تسلسلية باستخدام معرّفات مُولَّدة. تسمَّى المفاتيح الرئيسية التي أنشأناها من المعرّفات الاصطناعية بالمفاتيح البديلة Surrogate Keys عندما تتطلب البيانات المتاحة ابتكار معرّفات جديدة لتحديد الصفوف بطريقة فريدة. لنفترض أن لدينا قائمة بأعضاء نادي الكتاب، وهو تجمع غير رسمي يمكن لأي شخص الانضمام إليه دون بطاقة هوية حكومية، وبالتالي هناك احتمال أن ينضم إلى النادي في وقتٍ ما أشخاص يحملون أسماء متطابقة: جدول بسيط +------------+-----------+ | first_name | last_name | +------------+-----------+ | John | Doe | | Jane | Smith | | Bob | Johnson | | Samantha | Davis | | Michael | Rodriguez | | Tom | Thompson | | Sara | Johnson | | David | Jones | | Jane | Smith | | Bob | Johnson | +------------+-----------+ يتكرر الاسمان Bob Johnson و Jane Smith في الجدول، لذا نحتاج إلى استخدام معرّف إضافي للتأكد من هوية كل منهما، ولا يمكن تحديد الصفوف تحديدًا فريدًا في هذا الجدول بأيّ طريقة، ولكن إذا احتفظنا بقائمة أعضاء نادي الكتاب على الورق، فيمكن الاحتفاظ بمعرّفات مساعدة للتمييز بين الأشخاص الذين يحملون الأسماء نفسها في المجموعة. يمكن إجراء شيء مماثل في قاعدة بيانات علاقية باستخدام عمود إضافي يحتوي على معرّفات مُولَّدة بدون معنى لغرض وحيد هو الفصل بين جميع الصفوف في الجدول بطريقة فريدة، ولنسمي هذا العمود بالاسم member_id، ولكن سيكون من الصعب التوصّل إلى مثل هذا المعرّف كلما أردنا إضافة عضو آخر في نادي الكتاب إلى قاعدة البيانات. يمكن حل هذه المشكلة باستخدام الميزة التي يوفرها MySQL، والتي هي ميزة خاصة بالأعمدة الرقمية المتزايدة تلقائيًا، حيث توفّر قاعدة البيانات قيمة العمود بتسلسل متزايد من الأعداد الصحيحة تلقائيًا. لننشئ الآن جدولًا يشبه الجدول السابق، ولكن سنضيف عمودًا إضافيًا متزايدًا تلقائيًا member_id ليكون محتويًا على العدد المُسنَد لكل عضو في النادي تلقائيًا، وسيمثّل هذا العدد المُسنَد تلقائيًا مفتاحًا رئيسيًا للجدول الذي سيحتوي على الأعمدة التالية: member_id: معرّف رقمي متزايد تلقائيًا، ونمثّله باستخدام نوع البيانات int. first_name: الاسم الأول لأعضاء النادي، والذي نمثله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. last_name: يالاسم الأخير لأعضاء النادي، والذي نمثله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. لننشئ هذا الجدول من خلال تنفيذ تعليمة SQL التالية: mysql> CREATE TABLE club_members ( mysql> member_id int AUTO_INCREMENT PRIMARY KEY, mysql> first_name varchar(50), mysql> last_name varchar(50) mysql> ); تظهَر تعليمة PRIMARY KEY بعد تعريف نوع العمود مثل المفتاح الرئيسي لعمود واحد، ولكن تظهَر سمة Attribute إضافية قبلها هي AUTO_INCREMENT التي تخبر MySQL بتوليد قيم تلقائيًا لهذا العمود باستخدام تسلسلٍ متزايد من الأرقام إن لم تكن متوفّرة صراحةً. ملاحظة: تُعَد الخاصية AUTO_INCREMENT لتعريف عمود خاصةً بقاعدة بيانات MySQL، ولكن توفّر قواعد البيانات الأخرى طرقًا مماثلة لتوليد مفاتيح تسلسلية مع اختلاف صيغتها بين المحرّكات، لذا نشجّعك على الرجوع إلى التوثيق الرسمي لنظام إدارة قواعد البيانات العلاقية الخاص بك لمزيد من التفاصيل. إذا ظهر الخرج التالي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول بالصفوف التجريبية النموذجية المعروضة في المثال السابق من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO club_members (first_name, last_name) VALUES mysql> ('John', 'Doe'), mysql> ('Jane', 'Smith'), mysql> ('Bob', 'Johnson'), mysql> ('Samantha', 'Davis'), mysql> ('Michael', 'Rodriguez'), mysql> ('Tom', 'Thompson'), mysql> ('Sara', 'Johnson'), mysql> ('David', 'Jones'), mysql> ('Jane', 'Smith'), mysql> ('Bob', 'Johnson'); تتضمن تعليمة INSERT الآن قائمة بأسماء الأعمدة first_name و first_name، مما يضمن معرفة قاعدة البيانات بأن العمود member_id غير مُدرَج في مجموعة البيانات، لذا يجب أخذ القيمة الافتراضية له بدلًا من ذلك. وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 10 rows affected (0.002 sec) Records: 10 Duplicates: 0 Warnings: 0 نستخدم تعليمة SELECT التالية للتحقق من البيانات الموجودة في الجدول الذي أنشأناه: mysql> SELECT * FROM club_members; وسيعرض الخرج التالي جدولًا مشابهًا للجدول الموجود في بداية هذا القسم: الخرج +-----------+------------+-----------+ | member_id | first_name | last_name | +-----------+------------+-----------+ | 1 | John | Doe | | 2 | Jane | Smith | | 3 | Bob | Johnson | | 4 | Samantha | Davis | | 5 | Michael | Rodriguez | | 6 | Tom | Thompson | | 7 | Sara | Johnson | | 8 | David | Jones | | 9 | Jane | Smith | | 10 | Bob | Johnson | +-----------+------------+-----------+ 10 rows in set (0.000 sec) ولكن سيظهر العمود member_id في النتيجة، والذي يحتوي على تسلسل من الأرقام من 1 إلى 10، وبالتالي أصبح من الممكن التمييز بين الصفوف Jane Smith و Bob Johnson المكرّرة، إذ سيرتبط كل اسم بمعرّف فريد member_id. لنتحقّق الآن مما إذا كانت قاعدة البيانات ستسمح بإضافة بعضو آخر اسمه Tom Thompson إلى قائمة أعضاء النادي كما يلي: mysql> INSERT INTO club_members (first_name, last_name) VALUES ('Tom', 'Thompson'); وسيستجيب MySQL برسالة النجاح التالية: الخرج Query OK, 1 row affected (0.009 sec) ولنتحقق الآن من المعرّف الرقمي الذي أسندَته قاعدة البيانات للإدخال الجديد من خلال تنفيذ استعلام SELECT التالي: mysql> SELECT * FROM club_members; وسيظهر الخرج التالي الذي سيحتوي على صفٍ جديد: الخرج +-----------+------------+-----------+ | member_id | first_name | last_name | +-----------+------------+-----------+ | 1 | John | Doe | | 2 | Jane | Smith | | 3 | Bob | Johnson | | 4 | Samantha | Davis | | 5 | Michael | Rodriguez | | 6 | Tom | Thompson | | 7 | Sara | Johnson | | 8 | David | Jones | | 9 | Jane | Smith | | 10 | Bob | Johnson | | 11 | Tom | Thompson | +-----------+------------+-----------+ 11 rows in set (0.000 sec) أُسنِد الرقم 11 إلى الصف الجديد تلقائيًا في عمود member_id باستخدام ميزة AUTO_INCREMENT في قاعدة البيانات. إذا لم يكن للبيانات التي نعمل عليها مرشَّحين طبيعيين ليكونوا مفاتيح رئيسية، ولا نريد توفير معرّفات اصطناعية في كل مرة نضيف فيها بيانات جديدة إلى قاعدة البيانات، فيمكن الاعتماد على المعرّفات المولَّدة تسلسليًا لتكون مفاتيح رئيسية. الخلاصة تعلّمنا في هذا المقال ما هي المفاتيح الرئيسية وكيفية إنشاء أنواعها الشائعة في MySQL لتحديد الصفوف الفريدة في جداول قاعدة البيانات، حيث بنينا مفاتيح رئيسية طبيعية، وأنشأنا مفاتيح رئيسية تمتد على أعمدة متعددة، واستخدمنا مفاتيح تسلسلية متزايدة تلقائيًا عند عدم وجود مفاتيح طبيعية. يمكن استخدام المفاتيح الرئيسية لتشكيل بنية قاعدة البيانات، مما يضمن إمكانية التعرّف على صفوف البيانات بطريقة فريدة. وضّح هذا المقال أساسيات استخدام المفاتيح الرئيسية فقط، لذا يمكن مطالعة توثيق MySQL للقيود لمزيد من المعلومات، ويمكن أيضًا الاطلاع على مقال فهم قيود SQL ومقال كيفية استخدام القيود في SQL. ترجمة -وبتصرف- للمقال How To Use Primary Keys in SQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: الفهارس متعددة الأعمدة في SQL كيفية استخدام القوادح Triggers في SQL كيفية إنشاء وإدارة الجداول في SQL مفاتيح الجداول
تتميز قواعد البيانات العلاقية Relational Databases بكونها تهيكل البيانات ضمن بنية منظّمة، فهي تستخدم جداول ذات أعمدة ثابتة وتتبع أنواع بيانات مُعرَّفة بدقة وتضمن بأن جميع الصفوف لها الشكل نفسه. ومن المهم أن نكون قادرين في هذه البينة على العثور على الصفوف في الجداول والإشارة إليها دون التباس عند تخزين هذه البيانات ضمن صفوف الجداول. ويمكننا تحقيق ذلك في لغة الاستعلام البنيوية SQL باستخدام المفاتيح الرئيسية Primary Keys، والتي تعمل كمعرّفات مميزة للصفوف في جداول قاعدة البيانات العلاقية. سنتعرّف في هذا المقال على مفهوم المفاتيح الرئيسية، وكيفية استخدام أنواعها المختلفة لتحديد الصفوف الفريدة في جداول قاعدة البيانات، وسننشئ مفاتيح رئيسية من أعمدة فردية وأعمدة متعددة، كما سننشئ مفاتيح تسلسلية مع زيادة تلقائية باستخدام بعض البيانات التجريبية النموذجية. مستلزمات العمل يجب أن يكون لدينا حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو مع مستخدم بصلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر معرفة أساسية بتنفيذ استعلامات SELECT كما هو موضّح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة لأنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر في هذا المقال بنجاح مع معظم هذه الأنظمة، تُعَد المفاتيح الرئيسية جزءًا من معيار SQL، ولكن هناك بعض الميزات خاصة بقاعدة البيانات، لذا قد نجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات فارغة يمكن من خلالها إنشاء جداول توضّح استخدام المفاتيح الرئيسية كما سنشرح بالتفصيل في الفقرات التالية. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وننشئ قاعدة بيانات تجريبية. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بك مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم primary_keys: mysql> CREATE DATABASE primary_keys; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات primary_keys من خلال تنفيذ تعليمة USE التالية: $ USE primary_keys; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، ويمكن الآن إنشاء جداول تجريبية ضمنها، وبذلك أصبحنا جاهزًا لمتابعة هذا المقال والبدء في العمل مع المفاتيح الرئيسية. مقدمة إلى المفاتيح الرئيسية Primary Keys تُخزَّن البيانات في قاعدة البيانات العلاقية في جداول ذات بنية موحَّدة ومحدَّدة من الصفوف الفردية، ويوضّح تعريف الجدول الأعمدة الموجودة فيه وأنواع البيانات التي يمكن حفظها في الأعمدة الفردية، وهذا كافي لتخزين المعلومات في قاعدة البيانات والعثور عليها لاحقًا باستخدام معايير ترشيح مختلفة باستخدام تعليمة WHERE، ولكن لا تضمن هذه البنية إمكانية العثور على أي صف بعينه دون التباس مع صفوف أخرى. لنفترض أن لدينا قاعدة بيانات لجميع السيارات المسجَّلة المسموح لها بالقيادة على الطرق العامة، حيث ستحتوي قاعدة البيانات على معلومات مثل نوع السيارة وطرازها وسنة تصنيعها ولون طلائها، ولكن إذا بحثنا عن سيارة شيفروليه كامارو Chevrolet Camaro حمراء اللون ومصنوعة في عام 2007، فيمكن العثور على أكثر من سيارة، إذ سيبيع المصنعون سيارات متماثلة لعملاء متعددين، لذا تحتوي السيارات المُسجَّلة على أرقام لوحات ترخيص تحدّد كل سيارة فريدة. إذا بحثنا عن سيارة تحمل لوحة الترخيص OFP857، فيمكن التأكد من أن هذا المعيار سيجد سيارة واحدة فقط، لأن أرقام اللوحات تحدد السيارات المسجلة بطريقة فريدة قانونيًا، ويسمى هذا الجزء من البيانات في قاعدة البيانات العلاقية بالمفتاح الرئيسي Primary Key. المفاتيح الرئيسية هي معرّفات فريدة موجودة في عمود واحد أو مجموعة من الأعمدة يمكنها تحديد كل صف في جدول قاعدة البيانات دون التباس. ومن أبرز خصائص المفاتيح الرئيسية نذكر: يجب أن يستخدم المفتاح الرئيسي قيمًا فريدة، وإذا تكوّن المفتاح الرئيسي من أكثر من عمود واحد، فيجب أن تكون مجموعة القيم في هذه الأعمدة فريدة في الجدول بأكمله، إذ لا يمكن أن يظهر المفتاح الرئيسي أكثر من مرة لأنه مخصّص لتحديد كل صف بطريقة فريدة يجب ألا يحتوي المفتاح الرئيسي على قيم NULL يمكن لكل جدول في قاعدة البيانات استخدام مفتاح رئيسي واحد فقط يفرض محرّك قاعدة البيانات هذه القواعد، لذا يمكنك الوثوق بصحة هذه الخاصيات عند تعريف المفتاح الرئيسي لجدول ما، ويجب أن تضع في بالنا محتوى البيانات وما الذي يمكن اختياره منها لتمثيل المفتاح الرئيسي بشكل مناسب. المفاتيح الطبيعية Natural keys هي معرّفات موجودة مسبقًا في مجموعة البيانات، والمفاتيح البديلة Surrogate Keys هي معرّفات اصطناعية، ويمكن مطالعة مقال فهم قيود SQL لمزيد من التفاصيل. تحتوي بعض هياكل البيانات على مفاتيح رئيسية تظهر في مجموعة البيانات طبيعيًا مثل أرقام لوحات الترخيص في قاعدة بيانات السيارات أو أرقام الضمان الاجتماعي في دليل المواطنين، ولا تكون هذه المعرّفات مؤلَّفة من قيمة واحدة بل مؤلفة من زوج أو مجموعة من عدة قيم في بعض الأحيان، فمثلًا لا يمكن تحديد منزل فريد باستخدام اسم الشارع أو رقم الشارع فقط في دليل مدينة محلية للمنازل، إذ يمكن أن يكون هناك عدة منازل في شارع واحد، ويمكن أن يظهر الرقم نفسه في شوارع متعددة، ولكن يمكن افتراض أن كلًا من اسم الشارع ورقمه هو معرّف منزل فريد. تسمّى هذه المعرّفات بالمفاتيح الطبيعية. لكن لا يمكن في بعض الأحيان تمييز البيانات تمييزًا فريدًا باستخدام قيم عمود واحد أو مجموعة فرعية صغيرة من الأعمدة، وبالتالي يجب إنشاء مفاتيح رئيسية اصطناعية باستخدام تسلسل من الأرقام مثلًا أو معرّفات مُولَّدة عشوائيًا مثل معرّفات UUID، وتسمّى هذه المفاتيح بالمفاتيح البديلة. سننشئ في الأقسام التالية مفاتيح طبيعية بناءً على عمود واحد أو أعمدة متعددة، كما سنولّد مفاتيح بديلة للجداول التي لا يكون المفتاح الطبيعي خيارًا فيها. إنشاء مفتاح رئيسي من عمود واحد تحتوي مجموعة البيانات على عمود واحد طبيعيًا في العديد من الحالات، ويمكن استخدام هذا العمود لتحديد الصفوف في الجدول تحديدًا فريدًا، وبالتالي يمكن إنشاء مفتاح طبيعي لوصف هذه البيانات. لنفترض أن لدينا الجدول التالي باتباع المثال السابق لقاعدة بيانات السيارات المُسجَّلة: جدول بسيط +---------------+-----------+------------+-------+------+ | license_plate | brand | model | color | year | +---------------+-----------+------------+-------+------+ | ABC123 | Ford | Mustang | Red | 2018 | | CES214 | Ford | Mustang | Red | 2018 | | DEF456 | Chevrolet | Camaro | Blue | 2016 | | GHI789 | Dodge | Challenger | Black | 2014 | +---------------+-----------+------------+-------+------+ يمثّل الصف الأول والثاني سيارة فورد موستانج Ford Mustang حمراء مصنوعة في عام 2018، ولن تتمكّن من تحديد السيارة بطريقة فريدة باستخدام نوع السيارة وطرازها فقط، لذا تختلف لوحة الترخيص لكل سيارة في كلتا الحالتين، ممّا يوفّر معرّفًا فريدًا جيدًا لكل صف في الجدول. يُعَد رقم لوحة الترخيص جزءًا من البيانات، لذا يؤدي استخدامه بوصفه مفتاحًا رئيسيًا إلى إنشاء مفتاح طبيعي. إذا أنشأنا الجدول دون استخدام مفتاح رئيسي في العمود license_plate، فستخاطر بظهور لوحة مكررة أو فارغة في مجموعة البيانات لاحقًا. لننشئ الآن جدولًا يشبه الجدول السابق مع استخدام العمود license_plate بوصفه مفتاحًا رئيسيًا مع الأعمدة التالية: license_plate: رقم لوحة الترخيص، ونمثله باستخدام نوع البيانات varchar brand: نوع السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا model: طراز السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا color: لون السيارة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 20 محرفًا year: سنة تصنيع السيارة، ونمثّله باستخدام نوع البيانات int لتخزين البيانات العددي. ولننشئ الآن الجدول cars من خلال تنفيذ تعليمة SQL التالية: mysql> CREATE TABLE cars ( mysql> license_plate varchar(8) PRIMARY KEY, mysql> brand varchar(50), mysql> model varchar(50), mysql> color varchar(20), mysql> year int mysql> ); تكون تعليمة PRIMARY KEY بعد تعريف نوع بيانات license_plate، حيث يمكنك استخدام الصيغة المبسَّطة لإنشاء المفتاح وكتابة PRIMARY KEY في تعريف العمود عند التعامل مع المفاتيح الرئيسية المستندة إلى أعمدة مفردة. إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول ببعض الصفوف التجريبية المعروضة في المثال السابق من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO cars VALUES mysql> ('ABC123', 'Ford', 'Mustang', 'Red', 2018), mysql> ('CES214', 'Ford', 'Mustang', 'Red', 2018), mysql> ('DEF456', 'Chevrolet', 'Camaro', 'Blue', 2016), mysql> ('GHI789', 'Dodge', 'Challenger', 'Black', 2014); وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 4 rows affected (0.010 sec) Records: 4 Duplicates: 0 Warnings: 0 يمكن الآن التحقق من أن الجدول الذي أنشأناه يحتوي على البيانات والتنسيق المتوقع باستخدام تعليمة SELECT التالية: mysql> SELECT * FROM cars; وسيظهر الخرج جدولًا مشابهًا للجدول الموجود في بداية هذا القسم: الخرج +---------------+-----------+------------+-------+------+ | license_plate | brand | model | color | year | +---------------+-----------+------------+-------+------+ | ABC123 | Ford | Mustang | Red | 2018 | | CES214 | Ford | Mustang | Red | 2018 | | DEF456 | Chevrolet | Camaro | Blue | 2016 | | GHI789 | Dodge | Challenger | Black | 2014 | +---------------+-----------+------------+-------+------+ يمكن بعد ذلك التحقق من ضمان قواعد المفتاح الرئيسي باستخدام محرّك قاعدة البيانات، لذا نجرّب إدخال سيارة لها رقم لوحة مكرّر من خلال تنفيذ الأمر التالي: mysql> INSERT INTO cars VALUES ('DEF456', 'Jeep', 'Wrangler', 'Yellow', 2019); وسيستجيب MySQL برسالة الخطأ التالية التي تفيد بأن لوحة الترخيص DEF456 تمثّل إدخالًا مكررًا للمفتاح الرئيسي: الخرج ERROR 1062 (23000): Duplicate entry 'DEF456' for key 'cars.PRIMARY' ملاحظة: تُطبَّق المفاتيح الرئيسية باستخدام الفهارس الفريدة Unique Indexes وتشترك في العديد من الخاصيات مع الفهارس التي قد ننشئها يدويًا لأعمدة أخرى في الجدول، وتعمل فهارس المفاتيح الرئيسية أيضًا على تحسين أداء الاستعلام في الجدول للعمود الذي عرّفنا الفهرس له. اطّلع على مقال كيفية استخدام الفهارس في SQL لمزيد من المعلومات. يمكن الآن التأكد من عدم السماح باستخدام لوحات ترخيص مكرّرة، ولنتحقق الآن من إمكانية إدخال سيارة لها لوحة ترخيص فارغة كما يلي: mysql> INSERT INTO cars VALUES (NULL, 'Jeep', 'Wrangler', 'Yellow', 2019); وستستجيب قاعدة البيانات برسالة الخطأ التالية: الخرج ERROR 1048 (23000): Column 'license_plate' cannot be null يمكن التأكّد من أن المفتاح الرئيسي license_plate يحدّد كلّ صف في الجدول تحديدًا فريدًا بفضل القاعدتين السابقتين اللتين تفرضهما قاعدة البيانات، وبالتالي إذا استعلمنا في الجدول عن أي لوحة ترخيص، فسنتوقع إعادة صف واحد في كل مرة. نشرح في القسم التالي كيفية استخدام المفاتيح الرئيسية مع أعمدة متعددة. إنشاء مفتاح رئيسي من أعمدة متعددة إن لم يكن عمود واحد كافيًا لتحديد صف فريد في الجدول، فيمكن إنشاء مفاتيح رئيسية تستخدم أكثر من عمودٍ واحد. لنفترض مثلًا وجود سجلٍ للمنازل بحيث لا يكفي اسم الشارع أو رقمه فقط لتحديد أيّ منزل فردي كما يلي: جدول بسيط +-------------------+---------------+-------------------+------+ | street_name | street_number | house_owner | year | +-------------------+---------------+-------------------+------+ | 5th Avenue | 100 | Bob Johnson | 2018 | | Broadway | 1500 | Jane Smith | 2016 | | Central Park West | 100 | John Doe | 2014 | | Central Park West | 200 | Tom Thompson | 2015 | | Lexington Avenue | 5001 | Samantha Davis | 2010 | | Park Avenue | 7000 | Michael Rodriguez | 2012 | +-------------------+---------------+-------------------+------+ يظهر اسم الشارع Central Park West أكثر من مرة في الجدول، ويظهر رقم الشارع 100 أكثر من مرة أيضًا، ولكن لا تظهَر أي أزواج مكررة من أسماء الشوارع وأرقامها، وبالتالي يمكن استخدام زوج من هاتين القيمتين لتحديد كل صف في الجدول تحديدًا فريدًا في الحالة التي لا يمكن فيها لأي عمود بمفرده أن يكون مفتاحًا رئيسيًا. لننشئ الآن جدولًا يشبه الجدول السابق ويحتوي على الأعمدة التالية: street_name: اسم الشارع الذي يقع فيه المنزل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. street_number: رقم شارع المنزل، ونمثّله باستخدام نوع البيانات varchar، ويمكن لهذا العمود تخزين ما يصل إلى 5 محارف، ولا يستخدم نوع البيانات العددي int لأن بعض أرقام الشوارع قد تحتوي على محارف مثل 200B. house_owner: اسم مالك المنزل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. year: العام الذي بُني فيه المنزل، ونمثّله باستخدام نوع البيانات int لتخزين القيم العددية. سيستخدم المفتاح الرئيسي هذه المرة العمودين street_name و street_number بدلًا من استخدام عمود واحد من خلال تنفيذ تعليمة SQL التالية: mysql> CREATE TABLE houses ( mysql> street_name varchar(50), mysql> street_number varchar(5), mysql> house_owner varchar(50), mysql> year int, mysql> PRIMARY KEY(street_name, street_number) mysql> ); تظهر تعليمة PRIMARY KEY بعد تعريفات الأعمدة على عكس المثال السابق، وتليها أقواس تحتوي على اسمي عمودين هما: street_name و street_number. تنشئ هذه الصيغة المفتاح الرئيسي في الجدول houses الذي يمتد إلى عمودين. إذا ظهر الخرج التالي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول بالصفوف التجريبية المعروضة في المثال السابق من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO houses VALUES mysql> ('Central Park West', '100', 'John Doe', 2014), mysql> ('Broadway', '1500', 'Jane Smith', 2016), mysql> ('5th Avenue', '100', 'Bob Johnson', 2018), mysql> ('Lexington Avenue', '5001', 'Samantha Davis', 2010), mysql> ('Park Avenue', '7000', 'Michael Rodriguez', 2012), mysql> ('Central Park West', '200', 'Tom Thompson', 2015); وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 6 rows affected (0.000 sec) Records: 6 Duplicates: 0 Warnings: 0 يمكن الآن التحقق من أن الجدول الذي أنشأناه يحتوي على البيانات والتنسيق المتوقع باستخدام تعليمة SELECT التالية: mysql> SELECT * FROM houses; وسيُظهِر الخرج جدولًا مشابهًا للجدول الموجود في بداية هذا القسم: الخرج +-------------------+---------------+-------------------+------+ | street_name | street_number | house_owner | year | +-------------------+---------------+-------------------+------+ | 5th Avenue | 100 | Bob Johnson | 2018 | | Broadway | 1500 | Jane Smith | 2016 | | Central Park West | 100 | John Doe | 2014 | | Central Park West | 200 | Tom Thompson | 2015 | | Lexington Avenue | 5001 | Samantha Davis | 2010 | | Park Avenue | 7000 | Michael Rodriguez | 2012 | +-------------------+---------------+-------------------+------+ 6 rows in set (0.000 sec) لنتحقق الآن من سماح قاعدة البيانات بإدراج صفوف تحتوي على أسماء وأرقام شوارع مكرَّرة، مع تقييد ظهور عناوين كاملة مكررة في الجدول. لنبدأ أولًا بإضافة منزل آخر في شارع Park Avenue كما يلي: mysql> INSERT INTO houses VALUES ('Park Avenue', '8000', 'Emily Brown', 2011); سيستجيب MySQL برسالة النجاح التالية لأن العنوان 8000 Park Avenue لم يظهر في الجدول سابقًا: الخرج Query OK, 1 row affected (0.010 sec) وستظهر نتيجة مماثلة عند إضافة منزل في العنوان 8000 Main Street مع تكرار رقم الشارع كما يلي: mysql> INSERT INTO houses VALUES ('Main Street', '8000', 'David Jones', 2009); مما سيؤدي إلى إدراج صف جديد بنجاح بسبب عدم تكرار العنوان الكامل: الخرج Query OK, 1 row affected (0.010 sec) نحاول الآن إضافة منزل آخر في العنوان 100 5th Avenue باستخدام تعليمة INSERT التالية: mysql> INSERT INTO houses VALUES ('5th Avenue', '100', 'Josh Gordon', 2008); وستستجيب قاعدة البيانات برسالة الخطأ التالية لإعلامك بوجود إدخال مكرر للمفتاح الرئيسي لزوج القيم 5th Avenue و 100: الخرج ERROR 1062 (23000): Duplicate entry '5th Avenue-100' for key 'houses.PRIMARY' تطبّق قاعدة البيانات قواعد المفتاح الرئيسي بطريقة صحيحة، مع تعريف المفتاح لزوج من الأعمدة، وبالتالي يمكن التأكّد من عدم تكرار العنوان الكامل المكون من اسم الشارع ورقمه في الجدول. أنشأنا في هذا القسم مفتاحًا طبيعيًا مع زوج من الأعمدة لتحديد كل صف في الجدول house بوصفه صفًا فريدًا، ولكن لا يمكن دائمًا استخلاص المفاتيح الرئيسية من مجموعة البيانات، لذا سنستخدم في القسم التالي المفاتيح الرئيسية الاصطناعية التي لا تأتي من البيانات مباشرةً. إنشاء مفتاح رئيسي تسلسلي Sequential Primary Key أنشأنا مفاتيح رئيسية فريدة باستخدام أعمدة موجودة في مجموعات البيانات التجريبية النموذجية، ولكن البيانات ستتكرّر في بعض الحالات، مما يمنع الأعمدة من أن تكون معرّفات فريدة جيدة، لذا يمكن إنشاء مفاتيح رئيسية تسلسلية باستخدام معرّفات مُولَّدة. تسمَّى المفاتيح الرئيسية التي أنشأناها من المعرّفات الاصطناعية بالمفاتيح البديلة Surrogate Keys عندما تتطلب البيانات المتاحة ابتكار معرّفات جديدة لتحديد الصفوف بطريقة فريدة. لنفترض أن لدينا قائمة بأعضاء نادي الكتاب، وهو تجمع غير رسمي يمكن لأي شخص الانضمام إليه دون بطاقة هوية حكومية، وبالتالي هناك احتمال أن ينضم إلى النادي في وقتٍ ما أشخاص يحملون أسماء متطابقة: جدول بسيط +------------+-----------+ | first_name | last_name | +------------+-----------+ | John | Doe | | Jane | Smith | | Bob | Johnson | | Samantha | Davis | | Michael | Rodriguez | | Tom | Thompson | | Sara | Johnson | | David | Jones | | Jane | Smith | | Bob | Johnson | +------------+-----------+ يتكرر الاسمان Bob Johnson و Jane Smith في الجدول، لذا نحتاج إلى استخدام معرّف إضافي للتأكد من هوية كل منهما، ولا يمكن تحديد الصفوف تحديدًا فريدًا في هذا الجدول بأيّ طريقة، ولكن إذا احتفظنا بقائمة أعضاء نادي الكتاب على الورق، فيمكن الاحتفاظ بمعرّفات مساعدة للتمييز بين الأشخاص الذين يحملون الأسماء نفسها في المجموعة. يمكن إجراء شيء مماثل في قاعدة بيانات علاقية باستخدام عمود إضافي يحتوي على معرّفات مُولَّدة بدون معنى لغرض وحيد هو الفصل بين جميع الصفوف في الجدول بطريقة فريدة، ولنسمي هذا العمود بالاسم member_id، ولكن سيكون من الصعب التوصّل إلى مثل هذا المعرّف كلما أردنا إضافة عضو آخر في نادي الكتاب إلى قاعدة البيانات. يمكن حل هذه المشكلة باستخدام الميزة التي يوفرها MySQL، والتي هي ميزة خاصة بالأعمدة الرقمية المتزايدة تلقائيًا، حيث توفّر قاعدة البيانات قيمة العمود بتسلسل متزايد من الأعداد الصحيحة تلقائيًا. لننشئ الآن جدولًا يشبه الجدول السابق، ولكن سنضيف عمودًا إضافيًا متزايدًا تلقائيًا member_id ليكون محتويًا على العدد المُسنَد لكل عضو في النادي تلقائيًا، وسيمثّل هذا العدد المُسنَد تلقائيًا مفتاحًا رئيسيًا للجدول الذي سيحتوي على الأعمدة التالية: member_id: معرّف رقمي متزايد تلقائيًا، ونمثّله باستخدام نوع البيانات int. first_name: الاسم الأول لأعضاء النادي، والذي نمثله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. last_name: يالاسم الأخير لأعضاء النادي، والذي نمثله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا. لننشئ هذا الجدول من خلال تنفيذ تعليمة SQL التالية: mysql> CREATE TABLE club_members ( mysql> member_id int AUTO_INCREMENT PRIMARY KEY, mysql> first_name varchar(50), mysql> last_name varchar(50) mysql> ); تظهَر تعليمة PRIMARY KEY بعد تعريف نوع العمود مثل المفتاح الرئيسي لعمود واحد، ولكن تظهَر سمة Attribute إضافية قبلها هي AUTO_INCREMENT التي تخبر MySQL بتوليد قيم تلقائيًا لهذا العمود باستخدام تسلسلٍ متزايد من الأرقام إن لم تكن متوفّرة صراحةً. ملاحظة: تُعَد الخاصية AUTO_INCREMENT لتعريف عمود خاصةً بقاعدة بيانات MySQL، ولكن توفّر قواعد البيانات الأخرى طرقًا مماثلة لتوليد مفاتيح تسلسلية مع اختلاف صيغتها بين المحرّكات، لذا نشجّعك على الرجوع إلى التوثيق الرسمي لنظام إدارة قواعد البيانات العلاقية الخاص بك لمزيد من التفاصيل. إذا ظهر الخرج التالي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول بالصفوف التجريبية النموذجية المعروضة في المثال السابق من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO club_members (first_name, last_name) VALUES mysql> ('John', 'Doe'), mysql> ('Jane', 'Smith'), mysql> ('Bob', 'Johnson'), mysql> ('Samantha', 'Davis'), mysql> ('Michael', 'Rodriguez'), mysql> ('Tom', 'Thompson'), mysql> ('Sara', 'Johnson'), mysql> ('David', 'Jones'), mysql> ('Jane', 'Smith'), mysql> ('Bob', 'Johnson'); تتضمن تعليمة INSERT الآن قائمة بأسماء الأعمدة first_name و first_name، مما يضمن معرفة قاعدة البيانات بأن العمود member_id غير مُدرَج في مجموعة البيانات، لذا يجب أخذ القيمة الافتراضية له بدلًا من ذلك. وستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 10 rows affected (0.002 sec) Records: 10 Duplicates: 0 Warnings: 0 نستخدم تعليمة SELECT التالية للتحقق من البيانات الموجودة في الجدول الذي أنشأناه: mysql> SELECT * FROM club_members; وسيعرض الخرج التالي جدولًا مشابهًا للجدول الموجود في بداية هذا القسم: الخرج +-----------+------------+-----------+ | member_id | first_name | last_name | +-----------+------------+-----------+ | 1 | John | Doe | | 2 | Jane | Smith | | 3 | Bob | Johnson | | 4 | Samantha | Davis | | 5 | Michael | Rodriguez | | 6 | Tom | Thompson | | 7 | Sara | Johnson | | 8 | David | Jones | | 9 | Jane | Smith | | 10 | Bob | Johnson | +-----------+------------+-----------+ 10 rows in set (0.000 sec) ولكن سيظهر العمود member_id في النتيجة، والذي يحتوي على تسلسل من الأرقام من 1 إلى 10، وبالتالي أصبح من الممكن التمييز بين الصفوف Jane Smith و Bob Johnson المكرّرة، إذ سيرتبط كل اسم بمعرّف فريد member_id. لنتحقّق الآن مما إذا كانت قاعدة البيانات ستسمح بإضافة بعضو آخر اسمه Tom Thompson إلى قائمة أعضاء النادي كما يلي: mysql> INSERT INTO club_members (first_name, last_name) VALUES ('Tom', 'Thompson'); وسيستجيب MySQL برسالة النجاح التالية: الخرج Query OK, 1 row affected (0.009 sec) ولنتحقق الآن من المعرّف الرقمي الذي أسندَته قاعدة البيانات للإدخال الجديد من خلال تنفيذ استعلام SELECT التالي: mysql> SELECT * FROM club_members; وسيظهر الخرج التالي الذي سيحتوي على صفٍ جديد: الخرج +-----------+------------+-----------+ | member_id | first_name | last_name | +-----------+------------+-----------+ | 1 | John | Doe | | 2 | Jane | Smith | | 3 | Bob | Johnson | | 4 | Samantha | Davis | | 5 | Michael | Rodriguez | | 6 | Tom | Thompson | | 7 | Sara | Johnson | | 8 | David | Jones | | 9 | Jane | Smith | | 10 | Bob | Johnson | | 11 | Tom | Thompson | +-----------+------------+-----------+ 11 rows in set (0.000 sec) أُسنِد الرقم 11 إلى الصف الجديد تلقائيًا في عمود member_id باستخدام ميزة AUTO_INCREMENT في قاعدة البيانات. إذا لم يكن للبيانات التي نعمل عليها مرشَّحين طبيعيين ليكونوا مفاتيح رئيسية، ولا نريد توفير معرّفات اصطناعية في كل مرة نضيف فيها بيانات جديدة إلى قاعدة البيانات، فيمكن الاعتماد على المعرّفات المولَّدة تسلسليًا لتكون مفاتيح رئيسية. الخلاصة تعلّمنا في هذا المقال ما هي المفاتيح الرئيسية وكيفية إنشاء أنواعها الشائعة في MySQL لتحديد الصفوف الفريدة في جداول قاعدة البيانات، حيث بنينا مفاتيح رئيسية طبيعية، وأنشأنا مفاتيح رئيسية تمتد على أعمدة متعددة، واستخدمنا مفاتيح تسلسلية متزايدة تلقائيًا عند عدم وجود مفاتيح طبيعية. يمكن استخدام المفاتيح الرئيسية لتشكيل بنية قاعدة البيانات، مما يضمن إمكانية التعرّف على صفوف البيانات بطريقة فريدة. وضّح هذا المقال أساسيات استخدام المفاتيح الرئيسية فقط، لذا يمكن مطالعة توثيق MySQL للقيود لمزيد من المعلومات، ويمكن أيضًا الاطلاع على مقال فهم قيود SQL ومقال كيفية استخدام القيود في SQL. ترجمة -وبتصرف- للمقال How To Use Primary Keys in SQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: الفهارس متعددة الأعمدة في SQL كيفية استخدام القوادح Triggers في SQL كيفية إنشاء وإدارة الجداول في SQL مفاتيح الجداول -
 شرحنا في المقال السابق مفهوم الفهارس في قاعدة البيانات، ووضحنا أنواعًا مختلفة من الفهارس على قاعدة البيانات، وكانت جميع هذه الفهارس معرًفة باستخدام اسم عمود واحد single column، حيث يتعلق هذا الفهرس بقيم هذا العمود المختار، ولكن تدعم معظم أنظمة قواعد البيانات الفهارس التي تمتد لأكثر من عمود واحد multiple columns، وهذا ما سنوضّحه في هذا المقال، بالإضافة توضيح كيفية سرد وإزالة الفهارس الموجودة مسبقًا. استخدام الفهارس مع أعمدة متعددة توفر الفهارس متعددة الأعمدة طريقةً لتخزين قيم أعمدة متعددة في فهرس واحد، مما يسمح لمحرّك قاعدة البيانات بتنفيذ الاستعلامات بسرعة وكفاءة أكبر باستخدام مجموعة الأعمدة مع بعضها البعض. فالاستعلامات المستخدَمة بصورة متكررة والتي يجب تحسينها للحصول على أداء أفضل تستخدم شروطًا متعددة في تعليمة الترشيح WHERE في أغلب الأحيان، ومن الأمثلة على هذا النوع من الاستعلامات استعلام يطلب من قاعدة البيانات أن تعثر على شخص معين من خلال اسمه الأول والأخير كما يلي: mysql> SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John'; قد تكون الفكرة الأولى لتحسين هذا الاستعلام باستخدام الفهارس هي إنشاء فهرسين، أحدهما في العمود last_name والآخر في العمود first_name، ولكنه ليس الخيار الأفضل لهذه الحالة، حيث فإذا أنشأنا فهرسين منفصلين بهذه الطريقة، فسيعرف MySQL كيفية العثور على جميع الموظفين الذين يحملون اسم Smith مثلًا، وسيعرف أيضًا كيفية العثور على جميع الموظفين الذين يحملون اسم John، ولكنه لن يعرف كيفية العثور على الموظفين الذين يحملون الاسم John Smith. لنوضّح مشكلة وجود فهرسين فرديين من خلال تخيل وجود دليلي هاتف منفصلين، أحدهما مرتب حسب الاسم الأخير والآخر حسب الاسم الأول، ويشبه هذان الدليلان الفهارس التي أنشأناها في المقال السابق في العمودين last_name و first_name على التوالي. يمكنك التعامل مع مشكلة العثور على الاسم John Smith كمستخدمٍ لدليل الهاتف باستخدام ثلاث طرق ممكنة هي: الطريقة الأولى هي استخدم دليل الهاتف المرتب حسب الاسم الأخير للعثور على جميع الأشخاص الذين يحملون الاسم Smith، وتجاهل دليل الهاتف الثاني، ثم يمكن المرور يدويًا على جميع الأشخاص الذين يحملون اسم Smith واحدًا تلو الآخر حتى نجد الاسم John Smith. الطريقة الثانية هي تطبيق الطريقة المعاكسة من خلال استخدام دليل الهاتف المرتب حسب الاسم الأول للعثور على جميع الأشخاص الذين يحملون اسم John، وتجاهل دليل الهاتف الثاني، ثم المرور يدويًا على جميع الأشخاص الذين يحملون اسم John واحدًا تلو الآخر حتى نجد الاسم John Smith. الطريقة الأخيرة هي محاولة استخدام دليلي الهاتف معًا من خلال البحث عن جميع الأشخاص الذين يحملون اسم John وعن جميع الأشخاص الذين يحملون اسم Smith بطريقة منفصلة، وكتابة النتائج المؤقتة، ثم نحاول يدويًا إيجاد تقاطع هاتين المجموعتين الفرعيتين من البيانات بحثًا عن الأشخاص الموجودين في القائمتين الفرديتين. لا تُعَد أي طريقة من الطرق السابقة مثالية، ويوفر MySQL أيضًا خيارات مماثلة عند التعامل مع العديد من الفهارس المنفصلة والاستعلامات التي تطلب أكثر من شرط ترشيح واحد. توجد طريقة أخرى أيضًا تتمثّل باستخدام الفهارس التي تأخذ عدة أعمدة بدلًا من عمود واحد، حيث يمكنك تخيل ذلك كدليل هاتف موضوع ضمن دليل هاتف آخر، إذ سنبحث أولًا عن الاسم الأخير Smith، مما يوجّهنا إلى الدليل الثاني لجميع الأشخاص الذين يحملون اسم Smith بحيث تكون الأسماء مرتبة أبجديًا حسب الاسم الأول، ويمكننا استخدام هذا الدليل للعثور على الاسم John بسرعة. إنشاء فهرس متعدد الأعمدة يمكن إنشاء فهرس متعدد الأعمدة في MySQL للأسماء الأخيرة والأسماء الأولى في الجدول employees من خلال تنفيذ التعليمة التالية: mysql> CREATE INDEX names ON employees(last_name, first_name); تختلف التعليمة CREATE INDEX في هذه الحالة بعض الشيء، حيث ستحتوي على عمودين هما: last_name ثم first_name بين قوسين بعد اسم الجدول employees، مما يؤدي إلى إنشاء فهرس متعدد الأعمدة مع هذين العمودين، ويُعَد ترتيب الأعمدة في تعريف الفهرس مهمًا. تعرض قاعدة البيانات الرسالة التالية التي تؤكّد إنشاء الفهرس بنجاح: الخرج Query OK, 0 rows affected (0.024 sec) Records: 0 Duplicates: 0 Warnings: 0 نستخدم الآن استعلام SELECT للعثور على الصفوف التي يتطابق فيها الاسم الأول مع John والاسم الأخير مع Smith كما يلي: mysql> SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John'; وتكون النتيجة صفًا واحدًا يحتوي على موظف اسمه John Smith: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) نستخدم الآن استعلام مع أمر EXPLAIN التالي للتحقق من استخدام الفهرس: mysql> EXPLAIN SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John'; وستكون طريقة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+------+---------------+-------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+-------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | ref | names | names | 406 | const,const | 1 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+-------+---------+-------------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) في هذه الحالة استخدمت قاعدة البيانات الفهرس names، ومسحت صفًا واحدًا، لذا لم تمر على الجدول أكثر مما تحتاج إليه. يحتوي العمود Extra على العبارة Using index condition التي تعني أن MySQL يمكنه إكمال الترشيح باستخدام الفهرس فقط، حيث يوفّر الترشيح -وفقًا للأسماء الأولى والأخيرة باستخدام الفهرس متعدد الأعمدة الذي يمتد بين هذين العمودين لقاعدة البيانات- طريقةً مباشرة وسريعة للعثور على النتائج المطلوبة. لنشاهد الآن ما سيحدث إذا حاولنا العثور على جميع الموظفين الذين يحملون اسم Smith دون الترشيح وفقًا للاسم الأول مع تعريف الفهرس في العمودين، ولنشغّل الاستعلام المعدَّل التالي: mysql> SELECT * FROM employees WHERE last_name = 'Smith'; وستظهر النتائج التالية: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 20 | Abigail | Smith | FGH890 | 155000 | | 17 | Daniel | Smith | WXY901 | 140000 | | 1 | John | Smith | ABC123 | 60000 | | 5 | Michael | Smith | MNO345 | 80000 | +-------------+------------+-----------+---------------+--------+ 4 rows in set (0.000 sec) نلاحظ وجود أربع موظفين يحملون الاسم الأخير Smith. ننتقل الآن إلى طريقة تنفيذ الاستعلام باستخدام التعليمة التالية: mysql> EXPLAIN SELECT * FROM employees WHERE last_name = 'Smith'; وستكون طريقة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | ref | names | names | 203 | const | 4 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.01 sec) نلاحظ إعادة 4 صفوف هذه المرة، حيث يوجد أكثر من موظف يحمل هذا الاسم الأخير، ولكن يوضّح جدول طريقة التنفيذ أن قاعدة البيانات استخدمت الفهرس متعدد الأعمدة names لإجراء هذا الاستعلام، ومسحت 4 صفوف فقط، وهو العدد الدقيق المُعاد. مرّرنا في الاستعلامات السابقة العمود المُستخدَم لترشيح النتائج last_name أولًا في تعليمة CREATE INDEX، وسنرشّح الآن الجدول employees وفق العمود first_name، وهو العمود الثاني في قائمة الأعمدة لهذا الفهرس متعدد الأعمدة، لذا ننفّذ الآن الاستعلام التالي: mysql> SELECT * FROM employees WHERE first_name = 'John'; وسيظهر الخرج التالي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) لننتقل الآن لعرض طريقة تنفيذ الاستعلام كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE first_name = 'John'; وسيظهر الخرج التالي: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) تحتوي النتائج المُعادة على موظف واحد دون استخدام أي فهرس هذه المرة، ومسحَت قاعدة البيانات الجدول بالكامل كما يوضح التعليق Using where في العمود Extra، بالإضافة إلى 20 صفًا ممسوحًا. لم تستخدم قاعدة البيانات الفهرس في هذه الحالة بسبب ترتيب الأعمدة المُمرَّرة إلى التعليمة CREATE INDEX عند إنشاء الفهرس لأول مرة: last_name, first_name، إذ لا يمكن لقاعدة البيانات استخدام الفهرس إلا إذا استخدم الاستعلام العمود الأول أو العمودين الأول والثاني، ولا يمكنها دعم الاستعلامات مع الفهرس عند عدم استخدام العمود الأول من تعريف الفهرس. إذا أنشأنا فهرسًا لأعمدة متعددة، فيمكن لقاعدة البيانات استخدام هذا الفهرس لتسريع الاستعلامات التي تتضمن جميع الأعمدة المفهرسَة أو ذات البادئة المتزايدة اليسارية لجميع الأعمدة المفهرسَة، فمثلًا يمكن استخدام فهرس متعدد الأعمدة يتضمن الأعمدة a و b و c لتسريع الاستعلامات التي تتضمن جميع الأعمدة الثلاثة، والاستعلامات التي تتضمن العمودين الأولين فقط، أو حتى الاستعلامات التي تتضمن العمود الأول فقط، ولكن لن يساعد الفهرس في الاستعلامات التي تتضمن العمود الأخير فقط c أو العمودين الأخيرين b و c. يمكن استخدام فهرس واحد متعدد الأعمدة لتسريع الاستعلامات المختلفة للجدول نفسه من خلال اختيار الأعمدة المُضمَّنة في الفهرس بعناية وترتيبها، فمثلًا إذا افترضنا أن نبحث عن الموظفين باستخدام الاسم الأول والأخير أو الاسم الأخير فقط، فسيضمن الترتيب المُقدَّم للأعمدة في الفهرس names أن الفهرس سيسرّع جميع الاستعلامات ذات الصلة. استخدمنا في هذا القسم فهرسًا متعدد الأعمدة وتعلّمنا ترتيب الأعمدة عند تحديد مثل هذا الفهرس، وسنتعلّم في الفقرات التالية كيفية إدارة الفهارس الموجودة مسبقًا. سرد وإزالة الفهارس الموجودة مسبقًا أنشأنا في الأقسام السابقة فهارس جديدة، بما أن الفهارس لها أسماء وتُعرَّف لجداول معينة، فيمكننا أيضًا سردها ومعالجتها عند الحاجة، حيث يمكن سرد جميع الفهارس التي أنشأناها سابقًا للجدول employees من خلال تنفيذ التعليمة التالية: mysql> SHOW INDEXES FROM employees; وسيكون الخرج مشابهًا لما يلي: الخرج +-----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | employees | 0 | device_serial | 1 | device_serial | A | 20 | NULL | NULL | YES | BTREE | | | YES | NULL | | employees | 1 | salary | 1 | salary | A | 20 | NULL | NULL | YES | BTREE | | | YES | NULL | | employees | 1 | names | 1 | last_name | A | 16 | NULL | NULL | YES | BTREE | | | YES | NULL | | employees | 1 | names | 2 | first_name | A | 20 | NULL | NULL | YES | BTREE | | | YES | NULL | +-----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 4 rows in set (0.01 sec) قد يختلف الخرج بعض الشيء اعتمادًا على إصدار MySQL الخاص بنا، ولكنه سيتضمن جميع الفهارس مع أسمائها والأعمدة المستخدمة لتعريف الفهرس والمعلومات التي تجعله فريدًا وتفاصيل أخرى لتعريف الفهرس. يمكن حذف الفهارس الموجودة مسبقًا من خلال استخدام تعليمة SQL التالية: DROP INDEX فإن لم نعد نرغب في فرض جعل العمود device_serial فريدًا، فلن تكون هناك حاجة إلى الفهرس device_serial بعد الآن، وسننفّذ الأمر التالي لحذفه: mysql> DROP INDEX device_serial ON employees; device_serial هو اسم الفهرس و employees هو الجدول الذي عرّفنا الفهرس له، وستؤكد قاعدة البيانات حذف الفهرس كما يلي: الخرج Query OK, 0 rows affected (0.018 sec) Records: 0 Duplicates: 0 Warnings: 0 قد تتغير أنماط الاستعلامات النموذجية بمرور الوقت، وقد تظهر أنواع استعلامات جديدة في بعض الأحيان، لذا قد نحتاج إلى إعادة تقييم الفهارس التي نستخدمها أو إنشاء فهارس جديدة أو حذف الفهارس غير المستخدمة لتجنب تناقص أداء قاعدة البيانات من خلال تحديثها باستمرار. يمكننا إدارة الفهارس في قاعدة بيانات موجودة مسبقًا باستخدام أوامر CREATE INDEX و DROP INDEX من خلال اتباع أفضل الممارسات لإنشاء الفهارس عندما تصبح ضرورية ومفيدة. الخلاصة تعلّمنا في هذا المقال كيف يمكن تعريف فهارس متعددة الأعمدة وكيف يمكن للفهارس أن تؤثر على الاستعلامات عند استخدام أكثر من عمود واحد في شرط الترشيح وكيفية سرد وإزالة الفهارس الموجودة مسبقًا، وقد ركزنا على أمثلة بسيطة توضح أساسيات استخدام الفهارس فقط، ولكن يمكننا دعم الاستعلامات الأكثر تعقيدًا من خلال الفهارس عند فهم كيفية اختيار MySQL للفهارس المُستخدَمة ومتى يستخدمها، لذا يمكن الرجوع لتوثيق MySQL للفهارس لمزيد من المعلومات. ترجمة -وبتصرف- للجزء الثاني من مقال How To Use Indexes in MySQL لصاحبيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: مقدمة إلى الفهارس Indexes في SQL الفهارس Indexes في SQL إنشاء فهرس CREATE INDEX حذف الفهرس DROP INDEX تعديل الفهرس ALTER INDEX
شرحنا في المقال السابق مفهوم الفهارس في قاعدة البيانات، ووضحنا أنواعًا مختلفة من الفهارس على قاعدة البيانات، وكانت جميع هذه الفهارس معرًفة باستخدام اسم عمود واحد single column، حيث يتعلق هذا الفهرس بقيم هذا العمود المختار، ولكن تدعم معظم أنظمة قواعد البيانات الفهارس التي تمتد لأكثر من عمود واحد multiple columns، وهذا ما سنوضّحه في هذا المقال، بالإضافة توضيح كيفية سرد وإزالة الفهارس الموجودة مسبقًا. استخدام الفهارس مع أعمدة متعددة توفر الفهارس متعددة الأعمدة طريقةً لتخزين قيم أعمدة متعددة في فهرس واحد، مما يسمح لمحرّك قاعدة البيانات بتنفيذ الاستعلامات بسرعة وكفاءة أكبر باستخدام مجموعة الأعمدة مع بعضها البعض. فالاستعلامات المستخدَمة بصورة متكررة والتي يجب تحسينها للحصول على أداء أفضل تستخدم شروطًا متعددة في تعليمة الترشيح WHERE في أغلب الأحيان، ومن الأمثلة على هذا النوع من الاستعلامات استعلام يطلب من قاعدة البيانات أن تعثر على شخص معين من خلال اسمه الأول والأخير كما يلي: mysql> SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John'; قد تكون الفكرة الأولى لتحسين هذا الاستعلام باستخدام الفهارس هي إنشاء فهرسين، أحدهما في العمود last_name والآخر في العمود first_name، ولكنه ليس الخيار الأفضل لهذه الحالة، حيث فإذا أنشأنا فهرسين منفصلين بهذه الطريقة، فسيعرف MySQL كيفية العثور على جميع الموظفين الذين يحملون اسم Smith مثلًا، وسيعرف أيضًا كيفية العثور على جميع الموظفين الذين يحملون اسم John، ولكنه لن يعرف كيفية العثور على الموظفين الذين يحملون الاسم John Smith. لنوضّح مشكلة وجود فهرسين فرديين من خلال تخيل وجود دليلي هاتف منفصلين، أحدهما مرتب حسب الاسم الأخير والآخر حسب الاسم الأول، ويشبه هذان الدليلان الفهارس التي أنشأناها في المقال السابق في العمودين last_name و first_name على التوالي. يمكنك التعامل مع مشكلة العثور على الاسم John Smith كمستخدمٍ لدليل الهاتف باستخدام ثلاث طرق ممكنة هي: الطريقة الأولى هي استخدم دليل الهاتف المرتب حسب الاسم الأخير للعثور على جميع الأشخاص الذين يحملون الاسم Smith، وتجاهل دليل الهاتف الثاني، ثم يمكن المرور يدويًا على جميع الأشخاص الذين يحملون اسم Smith واحدًا تلو الآخر حتى نجد الاسم John Smith. الطريقة الثانية هي تطبيق الطريقة المعاكسة من خلال استخدام دليل الهاتف المرتب حسب الاسم الأول للعثور على جميع الأشخاص الذين يحملون اسم John، وتجاهل دليل الهاتف الثاني، ثم المرور يدويًا على جميع الأشخاص الذين يحملون اسم John واحدًا تلو الآخر حتى نجد الاسم John Smith. الطريقة الأخيرة هي محاولة استخدام دليلي الهاتف معًا من خلال البحث عن جميع الأشخاص الذين يحملون اسم John وعن جميع الأشخاص الذين يحملون اسم Smith بطريقة منفصلة، وكتابة النتائج المؤقتة، ثم نحاول يدويًا إيجاد تقاطع هاتين المجموعتين الفرعيتين من البيانات بحثًا عن الأشخاص الموجودين في القائمتين الفرديتين. لا تُعَد أي طريقة من الطرق السابقة مثالية، ويوفر MySQL أيضًا خيارات مماثلة عند التعامل مع العديد من الفهارس المنفصلة والاستعلامات التي تطلب أكثر من شرط ترشيح واحد. توجد طريقة أخرى أيضًا تتمثّل باستخدام الفهارس التي تأخذ عدة أعمدة بدلًا من عمود واحد، حيث يمكنك تخيل ذلك كدليل هاتف موضوع ضمن دليل هاتف آخر، إذ سنبحث أولًا عن الاسم الأخير Smith، مما يوجّهنا إلى الدليل الثاني لجميع الأشخاص الذين يحملون اسم Smith بحيث تكون الأسماء مرتبة أبجديًا حسب الاسم الأول، ويمكننا استخدام هذا الدليل للعثور على الاسم John بسرعة. إنشاء فهرس متعدد الأعمدة يمكن إنشاء فهرس متعدد الأعمدة في MySQL للأسماء الأخيرة والأسماء الأولى في الجدول employees من خلال تنفيذ التعليمة التالية: mysql> CREATE INDEX names ON employees(last_name, first_name); تختلف التعليمة CREATE INDEX في هذه الحالة بعض الشيء، حيث ستحتوي على عمودين هما: last_name ثم first_name بين قوسين بعد اسم الجدول employees، مما يؤدي إلى إنشاء فهرس متعدد الأعمدة مع هذين العمودين، ويُعَد ترتيب الأعمدة في تعريف الفهرس مهمًا. تعرض قاعدة البيانات الرسالة التالية التي تؤكّد إنشاء الفهرس بنجاح: الخرج Query OK, 0 rows affected (0.024 sec) Records: 0 Duplicates: 0 Warnings: 0 نستخدم الآن استعلام SELECT للعثور على الصفوف التي يتطابق فيها الاسم الأول مع John والاسم الأخير مع Smith كما يلي: mysql> SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John'; وتكون النتيجة صفًا واحدًا يحتوي على موظف اسمه John Smith: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) نستخدم الآن استعلام مع أمر EXPLAIN التالي للتحقق من استخدام الفهرس: mysql> EXPLAIN SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John'; وستكون طريقة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+------+---------------+-------+---------+-------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+-------+---------+-------------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | ref | names | names | 406 | const,const | 1 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+-------+---------+-------------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) في هذه الحالة استخدمت قاعدة البيانات الفهرس names، ومسحت صفًا واحدًا، لذا لم تمر على الجدول أكثر مما تحتاج إليه. يحتوي العمود Extra على العبارة Using index condition التي تعني أن MySQL يمكنه إكمال الترشيح باستخدام الفهرس فقط، حيث يوفّر الترشيح -وفقًا للأسماء الأولى والأخيرة باستخدام الفهرس متعدد الأعمدة الذي يمتد بين هذين العمودين لقاعدة البيانات- طريقةً مباشرة وسريعة للعثور على النتائج المطلوبة. لنشاهد الآن ما سيحدث إذا حاولنا العثور على جميع الموظفين الذين يحملون اسم Smith دون الترشيح وفقًا للاسم الأول مع تعريف الفهرس في العمودين، ولنشغّل الاستعلام المعدَّل التالي: mysql> SELECT * FROM employees WHERE last_name = 'Smith'; وستظهر النتائج التالية: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 20 | Abigail | Smith | FGH890 | 155000 | | 17 | Daniel | Smith | WXY901 | 140000 | | 1 | John | Smith | ABC123 | 60000 | | 5 | Michael | Smith | MNO345 | 80000 | +-------------+------------+-----------+---------------+--------+ 4 rows in set (0.000 sec) نلاحظ وجود أربع موظفين يحملون الاسم الأخير Smith. ننتقل الآن إلى طريقة تنفيذ الاستعلام باستخدام التعليمة التالية: mysql> EXPLAIN SELECT * FROM employees WHERE last_name = 'Smith'; وستكون طريقة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | ref | names | names | 203 | const | 4 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+-------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.01 sec) نلاحظ إعادة 4 صفوف هذه المرة، حيث يوجد أكثر من موظف يحمل هذا الاسم الأخير، ولكن يوضّح جدول طريقة التنفيذ أن قاعدة البيانات استخدمت الفهرس متعدد الأعمدة names لإجراء هذا الاستعلام، ومسحت 4 صفوف فقط، وهو العدد الدقيق المُعاد. مرّرنا في الاستعلامات السابقة العمود المُستخدَم لترشيح النتائج last_name أولًا في تعليمة CREATE INDEX، وسنرشّح الآن الجدول employees وفق العمود first_name، وهو العمود الثاني في قائمة الأعمدة لهذا الفهرس متعدد الأعمدة، لذا ننفّذ الآن الاستعلام التالي: mysql> SELECT * FROM employees WHERE first_name = 'John'; وسيظهر الخرج التالي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) لننتقل الآن لعرض طريقة تنفيذ الاستعلام كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE first_name = 'John'; وسيظهر الخرج التالي: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) تحتوي النتائج المُعادة على موظف واحد دون استخدام أي فهرس هذه المرة، ومسحَت قاعدة البيانات الجدول بالكامل كما يوضح التعليق Using where في العمود Extra، بالإضافة إلى 20 صفًا ممسوحًا. لم تستخدم قاعدة البيانات الفهرس في هذه الحالة بسبب ترتيب الأعمدة المُمرَّرة إلى التعليمة CREATE INDEX عند إنشاء الفهرس لأول مرة: last_name, first_name، إذ لا يمكن لقاعدة البيانات استخدام الفهرس إلا إذا استخدم الاستعلام العمود الأول أو العمودين الأول والثاني، ولا يمكنها دعم الاستعلامات مع الفهرس عند عدم استخدام العمود الأول من تعريف الفهرس. إذا أنشأنا فهرسًا لأعمدة متعددة، فيمكن لقاعدة البيانات استخدام هذا الفهرس لتسريع الاستعلامات التي تتضمن جميع الأعمدة المفهرسَة أو ذات البادئة المتزايدة اليسارية لجميع الأعمدة المفهرسَة، فمثلًا يمكن استخدام فهرس متعدد الأعمدة يتضمن الأعمدة a و b و c لتسريع الاستعلامات التي تتضمن جميع الأعمدة الثلاثة، والاستعلامات التي تتضمن العمودين الأولين فقط، أو حتى الاستعلامات التي تتضمن العمود الأول فقط، ولكن لن يساعد الفهرس في الاستعلامات التي تتضمن العمود الأخير فقط c أو العمودين الأخيرين b و c. يمكن استخدام فهرس واحد متعدد الأعمدة لتسريع الاستعلامات المختلفة للجدول نفسه من خلال اختيار الأعمدة المُضمَّنة في الفهرس بعناية وترتيبها، فمثلًا إذا افترضنا أن نبحث عن الموظفين باستخدام الاسم الأول والأخير أو الاسم الأخير فقط، فسيضمن الترتيب المُقدَّم للأعمدة في الفهرس names أن الفهرس سيسرّع جميع الاستعلامات ذات الصلة. استخدمنا في هذا القسم فهرسًا متعدد الأعمدة وتعلّمنا ترتيب الأعمدة عند تحديد مثل هذا الفهرس، وسنتعلّم في الفقرات التالية كيفية إدارة الفهارس الموجودة مسبقًا. سرد وإزالة الفهارس الموجودة مسبقًا أنشأنا في الأقسام السابقة فهارس جديدة، بما أن الفهارس لها أسماء وتُعرَّف لجداول معينة، فيمكننا أيضًا سردها ومعالجتها عند الحاجة، حيث يمكن سرد جميع الفهارس التي أنشأناها سابقًا للجدول employees من خلال تنفيذ التعليمة التالية: mysql> SHOW INDEXES FROM employees; وسيكون الخرج مشابهًا لما يلي: الخرج +-----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | employees | 0 | device_serial | 1 | device_serial | A | 20 | NULL | NULL | YES | BTREE | | | YES | NULL | | employees | 1 | salary | 1 | salary | A | 20 | NULL | NULL | YES | BTREE | | | YES | NULL | | employees | 1 | names | 1 | last_name | A | 16 | NULL | NULL | YES | BTREE | | | YES | NULL | | employees | 1 | names | 2 | first_name | A | 20 | NULL | NULL | YES | BTREE | | | YES | NULL | +-----------+------------+---------------+--------------+---------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 4 rows in set (0.01 sec) قد يختلف الخرج بعض الشيء اعتمادًا على إصدار MySQL الخاص بنا، ولكنه سيتضمن جميع الفهارس مع أسمائها والأعمدة المستخدمة لتعريف الفهرس والمعلومات التي تجعله فريدًا وتفاصيل أخرى لتعريف الفهرس. يمكن حذف الفهارس الموجودة مسبقًا من خلال استخدام تعليمة SQL التالية: DROP INDEX فإن لم نعد نرغب في فرض جعل العمود device_serial فريدًا، فلن تكون هناك حاجة إلى الفهرس device_serial بعد الآن، وسننفّذ الأمر التالي لحذفه: mysql> DROP INDEX device_serial ON employees; device_serial هو اسم الفهرس و employees هو الجدول الذي عرّفنا الفهرس له، وستؤكد قاعدة البيانات حذف الفهرس كما يلي: الخرج Query OK, 0 rows affected (0.018 sec) Records: 0 Duplicates: 0 Warnings: 0 قد تتغير أنماط الاستعلامات النموذجية بمرور الوقت، وقد تظهر أنواع استعلامات جديدة في بعض الأحيان، لذا قد نحتاج إلى إعادة تقييم الفهارس التي نستخدمها أو إنشاء فهارس جديدة أو حذف الفهارس غير المستخدمة لتجنب تناقص أداء قاعدة البيانات من خلال تحديثها باستمرار. يمكننا إدارة الفهارس في قاعدة بيانات موجودة مسبقًا باستخدام أوامر CREATE INDEX و DROP INDEX من خلال اتباع أفضل الممارسات لإنشاء الفهارس عندما تصبح ضرورية ومفيدة. الخلاصة تعلّمنا في هذا المقال كيف يمكن تعريف فهارس متعددة الأعمدة وكيف يمكن للفهارس أن تؤثر على الاستعلامات عند استخدام أكثر من عمود واحد في شرط الترشيح وكيفية سرد وإزالة الفهارس الموجودة مسبقًا، وقد ركزنا على أمثلة بسيطة توضح أساسيات استخدام الفهارس فقط، ولكن يمكننا دعم الاستعلامات الأكثر تعقيدًا من خلال الفهارس عند فهم كيفية اختيار MySQL للفهارس المُستخدَمة ومتى يستخدمها، لذا يمكن الرجوع لتوثيق MySQL للفهارس لمزيد من المعلومات. ترجمة -وبتصرف- للجزء الثاني من مقال How To Use Indexes in MySQL لصاحبيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: مقدمة إلى الفهارس Indexes في SQL الفهارس Indexes في SQL إنشاء فهرس CREATE INDEX حذف الفهرس DROP INDEX تعديل الفهرس ALTER INDEX -
 يمكن استخدام قواعد البيانات العلاقية Relational Databases للعمل مع بيانات من جميع الأحجام بما في ذلك قواعد البيانات الكبيرة التي تحتوي على ملايين الصفوف، وتوفّر لنا لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- طريقة موجزة ومباشرة للعثور على صفوف معينة في جداول قاعدة البيانات وفق معايير محددة، ولكن مع تزايد الحجم سيصبح تحديد موقع صفوف معينة في قواعد البيانات أكثر صعوبة ويشبه البحث عن إبرة في كومة قش! تصعّب قدرة قواعد البيانات على قبول مجموعة واسعة من شروط الاستعلام على محرّك قاعدة البيانات توقّع الاستعلامات الأكثر شيوعًا، إذ يجب أن يكون المحرّك مستعدًا لتحديد موقع الصفوف بكفاءة في جداول قاعدة البيانات بغض النظر عن حجمها، ولكن بطبيعة الحالة سيسوء أداء البحث مع زيادة حجم البيانات وسيصعب العثور على النتائج التي تتطابق مع الاستعلام بسرعة. في هذه الحالة يمكن لمسؤول قواعد البيانات استخدام مفهوم الفهارس Indexes لمساعدة محرّك قاعدة البيانات على تسريع البحث وتحسين أدائه، حيث سنتعلم في هذا المقال مفهوم الفهارس وكيفية إنشائها للاستفادة منها في الاستعلام من قاعدة البيانات. مستلزمات العمل يجب أن يكون لدينا حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذي صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال معرفة أساسية بتنفيذ استعلامات SELECT لاسترجاع البيانات من قاعدة البيانات كما هو موضّح في مقال الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن الفهارس ليست جزءًا من صيغة SQL المعيارية، لذا قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكن من التدرب على استخدام الفهارس، وسنشرح في القسم التالي تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية، والتي سنستخدمها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل بخادم MySQL وسننشئ قاعدة بيانات تجريبية لاتباع الأمثلة الواردة في هذا المقال. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات باسم indexes: mysql> CREATE DATABASE indexes; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات indexes من خلال تنفيذ تعليمة USE التالية: $ USE indexes; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، وسننشئ جدولًا تجريبيًا ضمنها، حيث سنستخدم في هذا المقال قاعدة بيانات افتراضية للموظفين لتخزين تفاصيل الموظفين الحاليين وأجهزة عملهم. سيحتوي الجدول employees على بيانات بسيطة حول الموظفين في قاعدة البيانات، والتي سنمثّلها باستخدام الأعمدة التالية: employee_id: معرّف الموظف، نوع بياناته int، وسيكون هذا العمود المفتاح الرئيسي Primary Key للجدول first_name: الاسم الأول لكل موظف، نوع بياناته varchar بحد أقصى 50 محرفًا last_name: لاسم الأخير لكل موظف، ونمثّله باستخدام نوع بياناته varchar بحد أقصى 50 محرفًا device_serial: الرقم التسلسلي لحاسوب الموظف، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 15 محرفًا salary: راتب كل موظف، ونمثّله باستخدام نوع البيانات int الذي يخزّن البيانات العددية ننشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE employees ( mysql> employee_id int, mysql> first_name varchar(50), mysql> last_name varchar(50), mysql> device_serial varchar(15), mysql> salary int mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول employees ببعض البيانات التجريبية من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO employees VALUES mysql> (1, 'John', 'Smith', 'ABC123', 60000), mysql> (2, 'Jane', 'Doe', 'DEF456', 65000), mysql> (3, 'Bob', 'Johnson', 'GHI789', 70000), mysql> (4, 'Sally', 'Fields', 'JKL012', 75000), mysql> (5, 'Michael', 'Smith', 'MNO345', 80000), mysql> (6, 'Emily', 'Jones', 'PQR678', 85000), mysql> (7, 'David', 'Williams', 'STU901', 90000), mysql> (8, 'Sarah', 'Johnson', 'VWX234', 95000), mysql> (9, 'James', 'Brown', 'YZA567', 100000), mysql> (10, 'Emma', 'Miller', 'BCD890', 105000), mysql> (11, 'William', 'Davis', 'EFG123', 110000), mysql> (12, 'Olivia', 'Garcia', 'HIJ456', 115000), mysql> (13, 'Christopher', 'Rodriguez', 'KLM789', 120000), mysql> (14, 'Isabella', 'Wilson', 'NOP012', 125000), mysql> (15, 'Matthew', 'Martinez', 'QRS345', 130000), mysql> (16, 'Sophia', 'Anderson', 'TUV678', 135000), mysql> (17, 'Daniel', 'Smith', 'WXY901', 140000), mysql> (18, 'Mia', 'Thomas', 'ZAB234', 145000), mysql> (19, 'Joseph', 'Hernandez', 'CDE567', 150000), mysql> (20, 'Abigail', 'Smith', 'FGH890', 155000); ستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 20 rows affected (0.010 sec) Records: 20 Duplicates: 0 Warnings: 0 ملاحظة: مجموعة البيانات هنا ليست كبيرة بما يكفي لتوضيح تأثير الفهارس على الأداء مباشرة، فالهدف منها هنا توضيح لكيفية استخدام الفهارس في MySQL لتقييد عدد الصفوف التي نجتازها لإجراء الاستعلامات والحصول على النتائج المطلوبة. نحن الآن جاهزون لمتابعة هذا المقال والبدء باستخدام الفهارس في MySQL. ما هي الفهارس Indexes يجب أن تمر قاعدة البيانات على جميع الصفوف الموجودة في الجدول واحدًا تلو الآخر عند تنفيذ استعلام على قاعدة بيانات MySQL، فمثلًا قد نرغب في البحث عن الاسم الأخير للموظفين المتطابق مع الاسم Smith أو جميع الموظفين الذين يتقاضون راتبًا أعلى من 100000 دولار، حيث سيُفحَص كل صف في الجدول واحدًا تلو الآخر للتحقق مما إذا كان يتطابق مع الشرط. إذا كان الصف متطابقًا مع الشرط، فسيُضاف إلى قائمة الصفوف المُعادة، وإن لم يكن كذلك، فسيمسح MySQL الصفوف اللاحقة حتى يستعرض الجدول بالكامل. هذه الطريقة للعثور على الصفوف المطابقة فعّالة، ولكنها قد تصبح بطيئة وتستهلك كثيرًا من الموارد عند زيادة حجم الجدول، لذا قد لا تكون مناسبة للجداول الكبيرة أو الاستعلامات التي تتطلب وصولًا متكررًا أو سريعًا إلى البيانات. يمكن حل مشكلات الأداء المتعلقة بالجداول والاستعلامات الكبيرة باستخدام الفهارس، وهي هياكل بيانات فريدة تخزّن مجموعة فرعية مرتبة من البيانات فقط بحيث تكون منفصلة عن صفوف الجدول، وتسمح لمحرّك قاعدة البيانات بالعمل بسرعة وكفاءة أكبر عند البحث عن القيم أو الترتيب وفق حقل معين أو مجموعة من الحقول. لنستخدم الآن الجدول employees، فأحد الاستعلامات النموذجية التي يمكن تنفيذها هو العثور على الموظفين باستخدام اسمهم الأخير. إن لم نستخدم الفهارس، فسيسترجع MySQL كل موظف من الجدول ويتحقق من تطابق الاسم الأخير مع الاستعلام، وإذا استخدمنا فهرسًا ما، فسيحتفظ بقائمة منفصلة من الأسماء الأخيرة، والتي تحتوي فقط على مؤشّرات إلى صفوف الموظفين المحدَّدين في الجدول الرئيسي، ثم سيستخدم هذا الفهرس لاسترجاع النتائج دون مسح الجدول بأكمله. يمكن تشبيه الفهارس بدليل الهاتف، فإذا أردنا تحديد موقع شخص اسمه John Smith في هذا الدليل، ننتقل أولًا إلى الصفحة الصحيحة التي تسرد الأشخاص الذين تبدأ أسماؤهم بالحرف S، ثم نبحث في الصفحات عن الأشخاص الذين تبدأ أسماؤهم بالحرفين Sm، وبذلك يمكن استبعاد العديد من الإدخالات بسرعة، مع العلم أنها لا تتطابق مع الشخص الذي نبحث عنه. تعمل هذه العملية بنجاح لأن البيانات في دليل الهاتف مرتبة أبجديًا، وهو أمر نادر الحدوث مع البيانات المخزَّنة مباشرةً في قاعدة البيانات. يمثّل الفهرس في محرّك قاعدة البيانات غرضًا مشابهًا لدليل الهاتف، حيث يحتفظ بالمراجع المرتبة أبجديًا إلى البيانات، وبالتالي يساعد قاعدة البيانات في العثور على الصفوف المطلوبة بسرعة. لاستخدام الفهارس فوائد متعددة، وأكثرها شيوعًا هو تسريع استعلامات WHERE الشرطية، وفرز البيانات باستخدام تعليمات ORDER BY بسرعة أكبر، وفرض أن تكون القيم فريدة، لكن من ناحية أخرى قد يؤدي استخدام الفهارس إلى تراجع أداء قاعدة البيانات في بعض الظروف، فهي مصممة الفهارس لتسريع استرجاع البيانات وتُنفَّذ باستخدام هياكل بيانات إضافية مخزَّنة مع بيانات الجدول، ويجب تحديث هذه الهياكل عند كل تغيير في قاعدة البيانات، مما قد يؤدي إلى إبطاء أداء استعلامات INSERT و UPDATE و DELETE. لكن إذا كان لدينا مجموعات بيانات كبيرة تتغير كثيرًا، فستتفوق الفوائد الناتجة عن السرعة المُحسَّنة لاستعلامات SELECT أحيانًا على الأداء الأبطأ الملحوظ للاستعلامات التي تكتب البيانات في قاعدة البيانات. يُفضَّل إنشاء الفهارس عند وجود حاجة واضحة إليها فقط مثل الوقت الذي يبدأ فيه أداء التطبيق في الانخفاض. نحتاج لأن نضع في الاعتبار الاستعلامات التي تُنفَّذ بشكل متكرر وتستغرق وقتًا أطول عند اختيار الفهارس التي سننشئها، ونبني الفهارس بناءً على شروط الاستعلام التي ستستفيد منها أكثر من غيرها. ملاحظة: نركز في هذا المقال على شرح فهارس قاعدة البيانات في MySQL وتوضيح تطبيقاتها الشائعة وأنواعها، حيث يدعم محرّك قاعدة البيانات عدة سيناريوهات أكثر تعقيدًا لاستخدام الفهارس لزيادة أداء قاعدة البيانات، لكن هذا خارج نطاق هذا المقال. ويمكن مطالعة توثيق MySQL الرسمي حول الفهارس للحصول على معلومات وافية عن مميزات فهارس قاعدة البيانات. ستنشئ في الأقسام التالية فهارس من أنواع مختلفة لمجموعة من السيناريوهات، وسنتعلم كيفية التحقق من استخدام الفهارس في الاستعلام، وكيفية إزالة الفهارس عند الحاجة. استخدام فهارس العمود الواحد Single-Column فهرس العمود الواحد هو أحد أكثر أنواع الفهارس شيوعًا ووضوحًا، حيث يمكن استخدامه لتحسين أداء الاستعلام، ويساعد هذا النوع من الفهارس قاعدة البيانات على تسريع الاستعلامات التي ترشّح مجموعة البيانات بناءً على قيم عمود واحد. يمكن للفهارس التي أنشأناها على عمود واحد تسريع العديد من الاستعلامات الشرطية التي تستخدم المطابقات التامة باستخدام المعامل = والمقارنات باستخدام > أو <. لا توجد فهارس في قاعدة البيانات التجريبية التي أنشأناها في خطوة سابقة. سنختبر أولًا كيفية تعامل قاعدة البيانات مع استعلامات SELECT للجدول employees عند استخدام التعليمة WHERE لطلب مجموعة فرعية من البيانات من الجدول فقط قبل إنشاء الفهرس. لنفترض أننا نريد العثور على الموظفين الذين راتبهم يساوي 100000 دولار أمريكي تمامًا من خلال تنفيذ الاستعلام التالي: mysql> SELECT * FROM employees WHERE salary = 100000; تطلب التعليمة WHERE مطابقة تامة للموظفين الذين يتطابق راتبهم مع القيمة المطلوبة، وستستجيب قاعدة البيانات كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 9 | James | Brown | YZA567 | 100000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) ملاحظة: استجابت قاعدة البيانات استجابةً آنية تقريبًا للاستعلام كما يظهر الخرج السابق، فلن يؤثر استخدام الفهارس بوضوح على أداء الاستعلام مع وجود عدد قليل من الصفوف في قاعدة البيانات، ولكن سنلاحظ تغييرات كبيرة في زمن تنفيذ الاستعلام في حال تنفيذه على مجموعات البيانات الكبيرة. لا يمكن معرفة كيفية تعامل محرّك قاعدة البيانات مع مسألة العثور على الصفوف المطابقة في الجدول بالاعتماد على خرج الاستعلام فقط، ولكن يوفّر MySQL طريقة لمعرفة الطريقة التي ينفّذ بها المحرّك الاستعلام باستخدام التعليمة EXPLAIN، حيث يمكننا مثلًا الوصول إلى طريقة تنفيذ الاستعلام SELECT من خلال تنفيذ الأمر التالي: mysql> EXPLAIN SELECT * FROM employees WHERE salary = 100000; يخبر الأمر EXPLAIN نظام MySQL بتشغيل استعلام SELECT، ويعرض معلومات حول كيفية إجراء الاستعلام داخليًا إلى جانب إعادة النتائج، وستكون نتيجة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) توضّح الأعمدة في جدول الخرج السابق العديد من جوانب تنفيذ الاستعلام، وقد يحتوي الخرج على أعمدة إضافية بناءً على إصدار MySQL، وفيما يلي أهم هذه المعلومات: يسرد possible_keys الفهارس التي اعتمدها MySQL للاستخدام، حيث لا يوجد فهارس في حالتنا NULL يمثل key الفهرس الذي قرّر MySQL استخدامه عند تنفيذ الاستعلام، حيث لم نستخدم أي فهرس في مثالنا NULL. يحدد rows عدد الصفوف التي يجب على MySQL تحليلها قبل إعادة النتائج، وتبلغ قيمته 20 في مثالنا وهو يمثّل عدد جميع الصفوف الممكنة في الجدول، مما يعني أنه يجب على MySQL مسح جميع الصفوف في الجدول employees للعثور على الصف الوحيد المُعاد يعرض Extra معلومات إضافية تصف خطة الاستعلام، حيث تعني Using where في مثالنا أن قاعدة البيانات رشّحت النتائج مباشرة من الجدول باستخدام التعليمة WHERE تجدر الإشارة لأنه يجب على قاعدة البيانات مسح 20 صفًا لاسترجاع صف واحد في حالة عدم وجود فهرس، وإذا احتوى الجدول على ملايين الصفوف، فيجب على MySQL المرور عليها واحدًا تلو الآخر، مما يؤدي إلى ضعف أداء الاستعلام. ملاحظة: تعرض إصدارات MySQL الأحدث العبارة 1 row in set, 1 warning في الخرج عند استخدام التعليمة EXPLAIN، بينما تعرض إصدارات MySQL الأقدم وقواعد البيانات المتوافقة مع MySQL العبارة 1 row in set، ولا يُعَد التحذير علامة على وجود مشكلة، حيث يستخدم MySQL آلية التحذيرات الخاصة به لتوفير مزيد من المعلومات الموسَّعة حول خطة الاستعلام. يُعَد هذا الاستخدام لهذه المعلومات الإضافية خارج نطاق هذا المقال، حيث يمكنك معرفة المزيد حول هذا السلوك في صفحة تنسيق خرج التعليمة EXPLAIN المُوسَّع في توثيق MySQL. استخدم استعلام SELECT الذي نفّذته سابقًا شرط المساواة WHERE salary = 100000، ولكن لنتحقق مما إذا كانت قاعدة البيانات ستتصرف بطريقة مماثلة مع شرط المقارنة، ونجرب استرجاع الموظفين الذين راتبهم أقل من 70000: mysql> SELECT * FROM employees WHERE salary < 70000; أعادت قاعدة البيانات هذه المرة صفين John Smith و Jane Doe كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | | 2 | Jane | Doe | DEF456 | 65000 | +-------------+------------+-----------+---------------+--------+ 8 rows in set (0.000 sec) ولكن إذا استخدمنا التعليمة EXPLAIN لفهم تنفيذ الاستعلام كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE salary < 70000; فسنلاحظ أن الجدول مطابق تقريبًا للاستعلام السابق: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 33.33 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) مسح MySQL جميع الصفوف 20 في الجدول للعثور على الصفوف التي طلبتها باستخدام تعليمة WHERE في الاستعلام كما هو الحال مع الاستعلام السابق. يُعَد عدد الصفوف المُعادة في الخرج السابق صغيرًا مقارنة بعدد جميع الصفوف في الجدول، ولكن يجب على محرّك قاعدة البيانات إنجاز الكثير من العمل للعثور عليها. يمكن حل هذه المشكلة من خلال إنشاء فهرس للعمود salary، والذي سيخبر MySQL بالحفاظ على هيكل بيانات إضافي ومُحسَّن، وخاصةً لبيانات العمود salary من الجدول employees، لذا ننفّذ الاستعلام التالي: mysql> CREATE INDEX salary ON employees(salary); تتطلب صيغة التعليمة CREATE INDEX ما يلي: اسم الفهرس وهو salary في مثالنا، ويجب أن يكون اسم الفهرس فريدًا في الجدول الواحد ويمكن تكراره بجداول مختلفة في قاعدة البيانات اسم الجدول الذي أنشأنا الفهرس له، وهو employees في مثالنا قائمة الأعمدة التي أنشأنا الفهرس لها، حيث استخدمنا في مثالنا عمودًا واحدًا بالاسم salary لبناء الفهرس قد يظهر الخطأ التالي: ERROR 1142 (42000): INDEX command denied to user 'user'@'host' for table 'employees' عند تنفيذ الأمر CREATE INDEX بناءً على أذونات مستخدم MySQL، حيث يمكن منح أذونات INDEX للمستخدم من خلال تسجيل الدخول إلى MySQL كمستخدم جذر وتنفيذ الأوامر التالية مع تعديل اسم مستخدم MySQL والمضيف حسب الحاجة: mysql> GRANT INDEX on *.* TO 'user'@'localhost'; mysql> FLUSH PRIVILEGES; نسجّل الخروج كمستخدم جذر ونسجّل الدخول مرة أخرى كمستخدم عادي بعد تحديث أذونات المستخدم، ثم نعيد تشغيل التعليمة CREATE INDEX، ستؤكّد الآن قاعدة البيانات إنشاء الفهرس بنجاح كما يلي: الخرج Query OK, 0 rows affected (0.024 sec) Records: 0 Duplicates: 0 Warnings: 0 نجرّب تكرار الاستعلامات السابقة للتحقق مما إذا كان هناك أي تغيير عند استخدام الفهرس، لذا نبدأ باسترجاع الموظف الذي يتقاضى راتبًا قدره 100000 بالضبط كما يلي: mysql> SELECT * FROM employees WHERE salary = 100000; وستبقى النتيجة نفسها مع إعادة الموظف James Brown فقط كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 9 | James | Brown | YZA567 | 100000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) وإذا طلبنا من MySQL شرحَ كيفية تعامله مع الاستعلام، فسيعرض بعض الاختلافات عمّا سبق، لذا ننفّذ تعليمة EXPLAIN كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE salary = 100000; وسيكون الخرج هذه المرة كما يلي: الخرج +----+-------------+-----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | ref | salary | salary | 5 | const | 1 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) يصرّح MySQL أنه قرّر استخدام المفتاح الذي اسمه salary من المفتاح الوحيد الموضح في العمود possible_keys، وهذا المفتاح هو الفهرس الذي أنشأناه. يعرض العمود rows الآن القيمة 1 بدلًا من 20، حيث تجنّبت قاعدة البيانات مسح جميع الصفوف في قاعدة البيانات ويمكنها إعادة الصف المطلوب مباشرة لأنها استخدمت الفهرس. لا يذكر العمود Extra الآن العبارة Using WHERE، لأن التكرار على الجدول الرئيسي والتحقق من أن كل صف يحقق شرط الاستعلام لم يكن ضروريًا لإجراء الاستعلام. وكما ذكرنا سابقًا لن نلاحظ تأثير استخدام الفهرس جدًا مع مجموعة بيانات تجريبية صغيرة، ولكن تطلّب الأمر من قاعدة البيانات عملًا أقل بكثير لاسترجاع النتيجة وسيكون تأثير هذا التغيير كبيرًا على مجموعة بيانات أكبر. نجرّب إعادة تشغيل الاستعلام الثاني واسترجاع الموظفين الذين راتبهم أقل من 70000 للتحقق من استخدام الفهرس، لذا نفّذ الاستعلام التالي: mysql> SELECT * FROM employees WHERE salary < 70000; نلاحظ إعادة بيانات John Smith و Jane Doe أيضًا كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | | 2 | Jane | Doe | DEF456 | 65000 | +-------------+------------+-----------+---------------+--------+ 8 rows in set (0.000 sec) ولكن إذا استخدمنا تعليمة EXPLAIN كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE salary < 70000; فسيكون الجدول مختلفًا عن التنفيذ السابق للاستعلام نفسه كما يلي: الخرج +----+-------------+-----------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | employees | NULL | range | salary | salary | 5 | NULL | 2 | 100.00 | Using index condition | +----+-------------+-----------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) يخبرنا العمود key أن MySQL استخدم الفهرس لإجراء الاستعلام، ويخبرنا العمود rows بتحليل صفين فقط لإعادة النتيجة. يحتوي العمود Extra الآن على العبارة Using index condition، مما يعني أن MySQL أجرى ترشيحًا باستخدام الفهرس في هذه الحالة ثم استخدم الجدول الأساسي فقط لاسترجاع الصفوف المطابقة فعليًا. ملاحظة: قد يقرر MySQL عدم استخدام الفهرس في بعض الأحيان حتى في حالة وجود الفهرس وإمكانية استخدامه، فمثلًا إذا نفذنا الأمر التالي: mysql> EXPLAIN SELECT * FROM employees WHERE salary < 140000; فستكون خطة التنفيذ كما يلي: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | salary | NULL | NULL | NULL | 20 | 80.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) يعني وجود عمود key الفارغ الذي له القيمة NULL أن MySQL قرر عدم استخدام الفهرس، والذي يمكن تأكيده من خلال الصفوف العشرين الممسوحة بالرغم من إدراج الفهرس salary في العمود possible_keys. يحلل مخطِّط استعلام قاعدة البيانات كل استعلام مقابل للفهارس المحتملة لتحديد أسرع مسار للتنفيذ، فإذا كانت تكلفة الوصول إلى الفهرس أكبر من فائدة استخدامه مثل إعادة الاستعلام جزءًا كبيرًا من بيانات الجدول الأصلية، فيمكن لقاعدة البيانات أن تقرر أنه من الأسرع إجراء مسح كامل للجدول فعليًا. توضّح التعليقات في العمود Extra مثل Using index condition أو Using where كيفية تنفيذ محرّك قاعدة البيانات للاستعلام بمزيد من التفصيل، فقد تختار قاعدة البيانات طريقة أخرى لتنفيذ الاستعلام وقد يكون لدينا خرج مع عدم وجود التعليق Using index condition أو أي تعليق آخر اعتمادًا على السياق. لا يعني ذلك عدم استخدام الفهرس استخدامًا صحيحًا، ولكنه يعني أن قاعدة البيانات قرّرت أن الطريقة الأخرى للوصول إلى الصفوف ستكون أفضل في الأداء. أنشأنا واستخدمنا في هذا القسم فهارس مؤلفة من عمود واحد لتحسين أداء استعلامات SELECT التي تعتمد على الترشيح لعمود واحد، وسنتعرّف في القسم التالي على كيفية استخدام الفهارس لضمان أن تكون القيم فريدة في عمود معين. استخدام الفهارس الفريدة لمنع تكرار البيانات أحد الاستخدامات الشائعة للفهارس هو استرجاع البيانات بسرعة من خلال مساعدة محرّك قاعدة البيانات على إجراء عمل أقل لتحقيق النتيجة نفسها كما وضّحنا سابقًا، وهناك استخدام آخر وهو ضمان عدم تكرار البيانات في جزء الجدول الذي عرّفنا الفهرس له، وهذا ما يفعله الفهرس الفريد Unique Index. إن تجنب القيم المكررة ضروري لضمان سلامة البيانات سواءً من وجهة نظر منطقية أو تقنية، فمثلًا لا ينبغي أن يكون هناك شخصان يستخدمان نفس رقم الضمان الاجتماعي، ولا ينبغي لنظام عبر الإنترنت أن يسمح لمستخدمين متعددين أن يسجّلوا باستخدام اسم المستخدم أو عنوان البريد الإلكتروني نفسه. في حالة جدولنا employees لا ينبغي أن يحتوي حقل الرقم التسلسلي على قيمٍ مكررة وإذا كان الأمر كذلك، فهذا قد يتسبب في منح أكثر من موظف الحاسوب نفسه، ففي هذا الجدول يمكن بسهولة إدخال موظفين جدد مع أرقام تسلسلية مكررة. لنحاول إدخال موظف آخر مع رقم تسلسلي لجهاز قيد الاستخدام كما يلي: mysql> INSERT INTO employees VALUES (21, 'Sammy', 'Smith', 'ABC123', 65000); ستدرج قاعدة البيانات هذا الصف وتعلمنا بنجاح العملية كما يلي: الخرج Query OK, 1 row affected (0.009 sec) فإذا استعلمنا عن الموظفين باستخدام الحاسوب ذي الرقم التسلسلي ABCD123 كما يلي: mysql> SELECT * FROM employees WHERE device_serial = 'ABC123'; فسنحصل على شخصين مختلفين كما توضح النتيجة التالية: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | | 21 | Sammy | Smith | ABC123 | 65000 | +-------------+------------+-----------+---------------+--------+ 2 rows in set (0.000 sec) هذا ليس سلوكًا متوقعًا لإبقاء قاعدة بيانات employees صالحة. لذا سنتراجع عن هذا التغيير من خلال حذف الصف الأخير الذي أنشأناه كما يلي: mysql> DELETE FROM employees WHERE employee_id = 21; يمكنك التأكد من ذلك من خلال إعادة تشغيل استعلام SELECT السابق كما يلي: mysql> SELECT * FROM employees WHERE device_serial = 'ABC123'; وبالتالي أصبح الموظف John Smith المستخدم الوحيد للجهاز الذي رقمه التسلسلي ABC123 مرة أخرى: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) لننشئ الآن فهرسًا فريدًا للعمود device_serial لحماية قاعدة البيانات من مثل هذه الأخطاء من خلال تنفيذ التعليمة التالية: mysql> CREATE UNIQUE INDEX device_serial ON employees(device_serial); توجِّه إضافة الكلمة المفتاحية UNIQUE عند إنشاء الفهرس قاعدةَ البيانات للتأكد من عدم تكرار القيم في العمود device_serial، حيث تؤدي الفهارس الفريدة إلى التحقق من جميع الصفوف الجديدة المضافة إلى الجدول مقابل الفهرس لتحديد ما إذا كانت قيمة العمود تتوافق مع القيد أم لا. وستؤكد قاعدة البيانات إنشاء الفهرس كما يلي: الخرج Query OK, 0 rows affected (0.021 sec) Records: 0 Duplicates: 0 Warnings: 0 نتحقق الآن من إمكانية إضافة إدخال مكرر إلى الجدول من خلال تشغيل استعلام INSERT من جديد: mysql> INSERT INTO employees VALUES (21, 'Sammy', 'Smith', 'ABC123', 65000); ستظهر رسالة الخطأ التالية هذه المرة: الخرج ERROR 1062 (23000): Duplicate entry 'ABC123' for key 'device_serial' يمكن التحقق من عدم إضافة الصف الجديد إلى الجدول باستخدام استعلام SELECT مرة أخرى: mysql> SELECT * FROM employees WHERE device_serial = 'ABC123'; وسيُعاد صف واحد فقط هذه المرة: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) تعمل الفهارس الفريدة على الحماية من الإدخالات المكررة، وهي أيضًا فهارس وظيفية بالكامل لتسريع الاستعلامات. ويستخدم محرّك قاعدة البيانات الفهارس الفريدة باستخدام الطريقة نفسها في الخطوة السابقة، حيث يمكننا التحقق من ذلك من خلال تنفيذ التعليمة التالية: mysql> EXPLAIN SELECT * FROM employees WHERE device_serial = 'ABC123'; وستكون نتيجة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+-------+---------------+---------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+---------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | const | device_serial | device_serial | 63 | const | 1 | 100.00 | NULL | +----+-------------+-----------+------------+-------+---------------+---------------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) يظهَر الفهرس device_serial في العمودين possible_keys و key، مما يؤكّد استخدام الفهرس عند تنفيذ الاستعلام. بهذا تعلمنا استخدام الفهارس الفريدة Unique Index للحماية من البيانات المكررة في قاعدة البيانات، وسنستخدم في القسم التالي الفهارس التي تمتد إلى أكثر من عمود واحد. الخلاصة تعلّمنا في هذا المقال ما هي الفهارس واستعرضنا أمثلة متعددة على فهارس العمود الواحد المستخدمة لتسريع استرجاع البيانات من خلال استعلامات SELECT الشرطية، أو للحفاظ على جعل بيانات العمود فريدة، وسنشرح في المقال التالي المزيد حول الفهارس ونوضح كيفية تعريف فهارس متعددة الأعمدة Indexes on Multiple Columns وحالات استخدامها، كما ننصح بالاطلاع على سلسلة تعلم SQL للمزيد حول التعامل مع لغة SQL. ترجمة -وبتصرف- للمقال How To Use Indexes in MySQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا الفهارس Indexes في SQL نظرة سريعة على لغة الاستعلامات الهيكلية SQL فهم قواعد البيانات العلاقية تحسين أداء قواعد بيانات SQL للمطورين
يمكن استخدام قواعد البيانات العلاقية Relational Databases للعمل مع بيانات من جميع الأحجام بما في ذلك قواعد البيانات الكبيرة التي تحتوي على ملايين الصفوف، وتوفّر لنا لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- طريقة موجزة ومباشرة للعثور على صفوف معينة في جداول قاعدة البيانات وفق معايير محددة، ولكن مع تزايد الحجم سيصبح تحديد موقع صفوف معينة في قواعد البيانات أكثر صعوبة ويشبه البحث عن إبرة في كومة قش! تصعّب قدرة قواعد البيانات على قبول مجموعة واسعة من شروط الاستعلام على محرّك قاعدة البيانات توقّع الاستعلامات الأكثر شيوعًا، إذ يجب أن يكون المحرّك مستعدًا لتحديد موقع الصفوف بكفاءة في جداول قاعدة البيانات بغض النظر عن حجمها، ولكن بطبيعة الحالة سيسوء أداء البحث مع زيادة حجم البيانات وسيصعب العثور على النتائج التي تتطابق مع الاستعلام بسرعة. في هذه الحالة يمكن لمسؤول قواعد البيانات استخدام مفهوم الفهارس Indexes لمساعدة محرّك قاعدة البيانات على تسريع البحث وتحسين أدائه، حيث سنتعلم في هذا المقال مفهوم الفهارس وكيفية إنشائها للاستفادة منها في الاستعلام من قاعدة البيانات. مستلزمات العمل يجب أن يكون لدينا حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذي صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال معرفة أساسية بتنفيذ استعلامات SELECT لاسترجاع البيانات من قاعدة البيانات كما هو موضّح في مقال الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن الفهارس ليست جزءًا من صيغة SQL المعيارية، لذا قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكن من التدرب على استخدام الفهارس، وسنشرح في القسم التالي تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية، والتي سنستخدمها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل بخادم MySQL وسننشئ قاعدة بيانات تجريبية لاتباع الأمثلة الواردة في هذا المقال. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات باسم indexes: mysql> CREATE DATABASE indexes; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات indexes من خلال تنفيذ تعليمة USE التالية: $ USE indexes; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، وسننشئ جدولًا تجريبيًا ضمنها، حيث سنستخدم في هذا المقال قاعدة بيانات افتراضية للموظفين لتخزين تفاصيل الموظفين الحاليين وأجهزة عملهم. سيحتوي الجدول employees على بيانات بسيطة حول الموظفين في قاعدة البيانات، والتي سنمثّلها باستخدام الأعمدة التالية: employee_id: معرّف الموظف، نوع بياناته int، وسيكون هذا العمود المفتاح الرئيسي Primary Key للجدول first_name: الاسم الأول لكل موظف، نوع بياناته varchar بحد أقصى 50 محرفًا last_name: لاسم الأخير لكل موظف، ونمثّله باستخدام نوع بياناته varchar بحد أقصى 50 محرفًا device_serial: الرقم التسلسلي لحاسوب الموظف، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 15 محرفًا salary: راتب كل موظف، ونمثّله باستخدام نوع البيانات int الذي يخزّن البيانات العددية ننشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE employees ( mysql> employee_id int, mysql> first_name varchar(50), mysql> last_name varchar(50), mysql> device_serial varchar(15), mysql> salary int mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول employees ببعض البيانات التجريبية من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO employees VALUES mysql> (1, 'John', 'Smith', 'ABC123', 60000), mysql> (2, 'Jane', 'Doe', 'DEF456', 65000), mysql> (3, 'Bob', 'Johnson', 'GHI789', 70000), mysql> (4, 'Sally', 'Fields', 'JKL012', 75000), mysql> (5, 'Michael', 'Smith', 'MNO345', 80000), mysql> (6, 'Emily', 'Jones', 'PQR678', 85000), mysql> (7, 'David', 'Williams', 'STU901', 90000), mysql> (8, 'Sarah', 'Johnson', 'VWX234', 95000), mysql> (9, 'James', 'Brown', 'YZA567', 100000), mysql> (10, 'Emma', 'Miller', 'BCD890', 105000), mysql> (11, 'William', 'Davis', 'EFG123', 110000), mysql> (12, 'Olivia', 'Garcia', 'HIJ456', 115000), mysql> (13, 'Christopher', 'Rodriguez', 'KLM789', 120000), mysql> (14, 'Isabella', 'Wilson', 'NOP012', 125000), mysql> (15, 'Matthew', 'Martinez', 'QRS345', 130000), mysql> (16, 'Sophia', 'Anderson', 'TUV678', 135000), mysql> (17, 'Daniel', 'Smith', 'WXY901', 140000), mysql> (18, 'Mia', 'Thomas', 'ZAB234', 145000), mysql> (19, 'Joseph', 'Hernandez', 'CDE567', 150000), mysql> (20, 'Abigail', 'Smith', 'FGH890', 155000); ستستجيب قاعدة البيانات برسالة النجاح التالية: الخرج Query OK, 20 rows affected (0.010 sec) Records: 20 Duplicates: 0 Warnings: 0 ملاحظة: مجموعة البيانات هنا ليست كبيرة بما يكفي لتوضيح تأثير الفهارس على الأداء مباشرة، فالهدف منها هنا توضيح لكيفية استخدام الفهارس في MySQL لتقييد عدد الصفوف التي نجتازها لإجراء الاستعلامات والحصول على النتائج المطلوبة. نحن الآن جاهزون لمتابعة هذا المقال والبدء باستخدام الفهارس في MySQL. ما هي الفهارس Indexes يجب أن تمر قاعدة البيانات على جميع الصفوف الموجودة في الجدول واحدًا تلو الآخر عند تنفيذ استعلام على قاعدة بيانات MySQL، فمثلًا قد نرغب في البحث عن الاسم الأخير للموظفين المتطابق مع الاسم Smith أو جميع الموظفين الذين يتقاضون راتبًا أعلى من 100000 دولار، حيث سيُفحَص كل صف في الجدول واحدًا تلو الآخر للتحقق مما إذا كان يتطابق مع الشرط. إذا كان الصف متطابقًا مع الشرط، فسيُضاف إلى قائمة الصفوف المُعادة، وإن لم يكن كذلك، فسيمسح MySQL الصفوف اللاحقة حتى يستعرض الجدول بالكامل. هذه الطريقة للعثور على الصفوف المطابقة فعّالة، ولكنها قد تصبح بطيئة وتستهلك كثيرًا من الموارد عند زيادة حجم الجدول، لذا قد لا تكون مناسبة للجداول الكبيرة أو الاستعلامات التي تتطلب وصولًا متكررًا أو سريعًا إلى البيانات. يمكن حل مشكلات الأداء المتعلقة بالجداول والاستعلامات الكبيرة باستخدام الفهارس، وهي هياكل بيانات فريدة تخزّن مجموعة فرعية مرتبة من البيانات فقط بحيث تكون منفصلة عن صفوف الجدول، وتسمح لمحرّك قاعدة البيانات بالعمل بسرعة وكفاءة أكبر عند البحث عن القيم أو الترتيب وفق حقل معين أو مجموعة من الحقول. لنستخدم الآن الجدول employees، فأحد الاستعلامات النموذجية التي يمكن تنفيذها هو العثور على الموظفين باستخدام اسمهم الأخير. إن لم نستخدم الفهارس، فسيسترجع MySQL كل موظف من الجدول ويتحقق من تطابق الاسم الأخير مع الاستعلام، وإذا استخدمنا فهرسًا ما، فسيحتفظ بقائمة منفصلة من الأسماء الأخيرة، والتي تحتوي فقط على مؤشّرات إلى صفوف الموظفين المحدَّدين في الجدول الرئيسي، ثم سيستخدم هذا الفهرس لاسترجاع النتائج دون مسح الجدول بأكمله. يمكن تشبيه الفهارس بدليل الهاتف، فإذا أردنا تحديد موقع شخص اسمه John Smith في هذا الدليل، ننتقل أولًا إلى الصفحة الصحيحة التي تسرد الأشخاص الذين تبدأ أسماؤهم بالحرف S، ثم نبحث في الصفحات عن الأشخاص الذين تبدأ أسماؤهم بالحرفين Sm، وبذلك يمكن استبعاد العديد من الإدخالات بسرعة، مع العلم أنها لا تتطابق مع الشخص الذي نبحث عنه. تعمل هذه العملية بنجاح لأن البيانات في دليل الهاتف مرتبة أبجديًا، وهو أمر نادر الحدوث مع البيانات المخزَّنة مباشرةً في قاعدة البيانات. يمثّل الفهرس في محرّك قاعدة البيانات غرضًا مشابهًا لدليل الهاتف، حيث يحتفظ بالمراجع المرتبة أبجديًا إلى البيانات، وبالتالي يساعد قاعدة البيانات في العثور على الصفوف المطلوبة بسرعة. لاستخدام الفهارس فوائد متعددة، وأكثرها شيوعًا هو تسريع استعلامات WHERE الشرطية، وفرز البيانات باستخدام تعليمات ORDER BY بسرعة أكبر، وفرض أن تكون القيم فريدة، لكن من ناحية أخرى قد يؤدي استخدام الفهارس إلى تراجع أداء قاعدة البيانات في بعض الظروف، فهي مصممة الفهارس لتسريع استرجاع البيانات وتُنفَّذ باستخدام هياكل بيانات إضافية مخزَّنة مع بيانات الجدول، ويجب تحديث هذه الهياكل عند كل تغيير في قاعدة البيانات، مما قد يؤدي إلى إبطاء أداء استعلامات INSERT و UPDATE و DELETE. لكن إذا كان لدينا مجموعات بيانات كبيرة تتغير كثيرًا، فستتفوق الفوائد الناتجة عن السرعة المُحسَّنة لاستعلامات SELECT أحيانًا على الأداء الأبطأ الملحوظ للاستعلامات التي تكتب البيانات في قاعدة البيانات. يُفضَّل إنشاء الفهارس عند وجود حاجة واضحة إليها فقط مثل الوقت الذي يبدأ فيه أداء التطبيق في الانخفاض. نحتاج لأن نضع في الاعتبار الاستعلامات التي تُنفَّذ بشكل متكرر وتستغرق وقتًا أطول عند اختيار الفهارس التي سننشئها، ونبني الفهارس بناءً على شروط الاستعلام التي ستستفيد منها أكثر من غيرها. ملاحظة: نركز في هذا المقال على شرح فهارس قاعدة البيانات في MySQL وتوضيح تطبيقاتها الشائعة وأنواعها، حيث يدعم محرّك قاعدة البيانات عدة سيناريوهات أكثر تعقيدًا لاستخدام الفهارس لزيادة أداء قاعدة البيانات، لكن هذا خارج نطاق هذا المقال. ويمكن مطالعة توثيق MySQL الرسمي حول الفهارس للحصول على معلومات وافية عن مميزات فهارس قاعدة البيانات. ستنشئ في الأقسام التالية فهارس من أنواع مختلفة لمجموعة من السيناريوهات، وسنتعلم كيفية التحقق من استخدام الفهارس في الاستعلام، وكيفية إزالة الفهارس عند الحاجة. استخدام فهارس العمود الواحد Single-Column فهرس العمود الواحد هو أحد أكثر أنواع الفهارس شيوعًا ووضوحًا، حيث يمكن استخدامه لتحسين أداء الاستعلام، ويساعد هذا النوع من الفهارس قاعدة البيانات على تسريع الاستعلامات التي ترشّح مجموعة البيانات بناءً على قيم عمود واحد. يمكن للفهارس التي أنشأناها على عمود واحد تسريع العديد من الاستعلامات الشرطية التي تستخدم المطابقات التامة باستخدام المعامل = والمقارنات باستخدام > أو <. لا توجد فهارس في قاعدة البيانات التجريبية التي أنشأناها في خطوة سابقة. سنختبر أولًا كيفية تعامل قاعدة البيانات مع استعلامات SELECT للجدول employees عند استخدام التعليمة WHERE لطلب مجموعة فرعية من البيانات من الجدول فقط قبل إنشاء الفهرس. لنفترض أننا نريد العثور على الموظفين الذين راتبهم يساوي 100000 دولار أمريكي تمامًا من خلال تنفيذ الاستعلام التالي: mysql> SELECT * FROM employees WHERE salary = 100000; تطلب التعليمة WHERE مطابقة تامة للموظفين الذين يتطابق راتبهم مع القيمة المطلوبة، وستستجيب قاعدة البيانات كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 9 | James | Brown | YZA567 | 100000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) ملاحظة: استجابت قاعدة البيانات استجابةً آنية تقريبًا للاستعلام كما يظهر الخرج السابق، فلن يؤثر استخدام الفهارس بوضوح على أداء الاستعلام مع وجود عدد قليل من الصفوف في قاعدة البيانات، ولكن سنلاحظ تغييرات كبيرة في زمن تنفيذ الاستعلام في حال تنفيذه على مجموعات البيانات الكبيرة. لا يمكن معرفة كيفية تعامل محرّك قاعدة البيانات مع مسألة العثور على الصفوف المطابقة في الجدول بالاعتماد على خرج الاستعلام فقط، ولكن يوفّر MySQL طريقة لمعرفة الطريقة التي ينفّذ بها المحرّك الاستعلام باستخدام التعليمة EXPLAIN، حيث يمكننا مثلًا الوصول إلى طريقة تنفيذ الاستعلام SELECT من خلال تنفيذ الأمر التالي: mysql> EXPLAIN SELECT * FROM employees WHERE salary = 100000; يخبر الأمر EXPLAIN نظام MySQL بتشغيل استعلام SELECT، ويعرض معلومات حول كيفية إجراء الاستعلام داخليًا إلى جانب إعادة النتائج، وستكون نتيجة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) توضّح الأعمدة في جدول الخرج السابق العديد من جوانب تنفيذ الاستعلام، وقد يحتوي الخرج على أعمدة إضافية بناءً على إصدار MySQL، وفيما يلي أهم هذه المعلومات: يسرد possible_keys الفهارس التي اعتمدها MySQL للاستخدام، حيث لا يوجد فهارس في حالتنا NULL يمثل key الفهرس الذي قرّر MySQL استخدامه عند تنفيذ الاستعلام، حيث لم نستخدم أي فهرس في مثالنا NULL. يحدد rows عدد الصفوف التي يجب على MySQL تحليلها قبل إعادة النتائج، وتبلغ قيمته 20 في مثالنا وهو يمثّل عدد جميع الصفوف الممكنة في الجدول، مما يعني أنه يجب على MySQL مسح جميع الصفوف في الجدول employees للعثور على الصف الوحيد المُعاد يعرض Extra معلومات إضافية تصف خطة الاستعلام، حيث تعني Using where في مثالنا أن قاعدة البيانات رشّحت النتائج مباشرة من الجدول باستخدام التعليمة WHERE تجدر الإشارة لأنه يجب على قاعدة البيانات مسح 20 صفًا لاسترجاع صف واحد في حالة عدم وجود فهرس، وإذا احتوى الجدول على ملايين الصفوف، فيجب على MySQL المرور عليها واحدًا تلو الآخر، مما يؤدي إلى ضعف أداء الاستعلام. ملاحظة: تعرض إصدارات MySQL الأحدث العبارة 1 row in set, 1 warning في الخرج عند استخدام التعليمة EXPLAIN، بينما تعرض إصدارات MySQL الأقدم وقواعد البيانات المتوافقة مع MySQL العبارة 1 row in set، ولا يُعَد التحذير علامة على وجود مشكلة، حيث يستخدم MySQL آلية التحذيرات الخاصة به لتوفير مزيد من المعلومات الموسَّعة حول خطة الاستعلام. يُعَد هذا الاستخدام لهذه المعلومات الإضافية خارج نطاق هذا المقال، حيث يمكنك معرفة المزيد حول هذا السلوك في صفحة تنسيق خرج التعليمة EXPLAIN المُوسَّع في توثيق MySQL. استخدم استعلام SELECT الذي نفّذته سابقًا شرط المساواة WHERE salary = 100000، ولكن لنتحقق مما إذا كانت قاعدة البيانات ستتصرف بطريقة مماثلة مع شرط المقارنة، ونجرب استرجاع الموظفين الذين راتبهم أقل من 70000: mysql> SELECT * FROM employees WHERE salary < 70000; أعادت قاعدة البيانات هذه المرة صفين John Smith و Jane Doe كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | | 2 | Jane | Doe | DEF456 | 65000 | +-------------+------------+-----------+---------------+--------+ 8 rows in set (0.000 sec) ولكن إذا استخدمنا التعليمة EXPLAIN لفهم تنفيذ الاستعلام كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE salary < 70000; فسنلاحظ أن الجدول مطابق تقريبًا للاستعلام السابق: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 33.33 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) مسح MySQL جميع الصفوف 20 في الجدول للعثور على الصفوف التي طلبتها باستخدام تعليمة WHERE في الاستعلام كما هو الحال مع الاستعلام السابق. يُعَد عدد الصفوف المُعادة في الخرج السابق صغيرًا مقارنة بعدد جميع الصفوف في الجدول، ولكن يجب على محرّك قاعدة البيانات إنجاز الكثير من العمل للعثور عليها. يمكن حل هذه المشكلة من خلال إنشاء فهرس للعمود salary، والذي سيخبر MySQL بالحفاظ على هيكل بيانات إضافي ومُحسَّن، وخاصةً لبيانات العمود salary من الجدول employees، لذا ننفّذ الاستعلام التالي: mysql> CREATE INDEX salary ON employees(salary); تتطلب صيغة التعليمة CREATE INDEX ما يلي: اسم الفهرس وهو salary في مثالنا، ويجب أن يكون اسم الفهرس فريدًا في الجدول الواحد ويمكن تكراره بجداول مختلفة في قاعدة البيانات اسم الجدول الذي أنشأنا الفهرس له، وهو employees في مثالنا قائمة الأعمدة التي أنشأنا الفهرس لها، حيث استخدمنا في مثالنا عمودًا واحدًا بالاسم salary لبناء الفهرس قد يظهر الخطأ التالي: ERROR 1142 (42000): INDEX command denied to user 'user'@'host' for table 'employees' عند تنفيذ الأمر CREATE INDEX بناءً على أذونات مستخدم MySQL، حيث يمكن منح أذونات INDEX للمستخدم من خلال تسجيل الدخول إلى MySQL كمستخدم جذر وتنفيذ الأوامر التالية مع تعديل اسم مستخدم MySQL والمضيف حسب الحاجة: mysql> GRANT INDEX on *.* TO 'user'@'localhost'; mysql> FLUSH PRIVILEGES; نسجّل الخروج كمستخدم جذر ونسجّل الدخول مرة أخرى كمستخدم عادي بعد تحديث أذونات المستخدم، ثم نعيد تشغيل التعليمة CREATE INDEX، ستؤكّد الآن قاعدة البيانات إنشاء الفهرس بنجاح كما يلي: الخرج Query OK, 0 rows affected (0.024 sec) Records: 0 Duplicates: 0 Warnings: 0 نجرّب تكرار الاستعلامات السابقة للتحقق مما إذا كان هناك أي تغيير عند استخدام الفهرس، لذا نبدأ باسترجاع الموظف الذي يتقاضى راتبًا قدره 100000 بالضبط كما يلي: mysql> SELECT * FROM employees WHERE salary = 100000; وستبقى النتيجة نفسها مع إعادة الموظف James Brown فقط كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 9 | James | Brown | YZA567 | 100000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) وإذا طلبنا من MySQL شرحَ كيفية تعامله مع الاستعلام، فسيعرض بعض الاختلافات عمّا سبق، لذا ننفّذ تعليمة EXPLAIN كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE salary = 100000; وسيكون الخرج هذه المرة كما يلي: الخرج +----+-------------+-----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | ref | salary | salary | 5 | const | 1 | 100.00 | NULL | +----+-------------+-----------+------------+------+---------------+--------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) يصرّح MySQL أنه قرّر استخدام المفتاح الذي اسمه salary من المفتاح الوحيد الموضح في العمود possible_keys، وهذا المفتاح هو الفهرس الذي أنشأناه. يعرض العمود rows الآن القيمة 1 بدلًا من 20، حيث تجنّبت قاعدة البيانات مسح جميع الصفوف في قاعدة البيانات ويمكنها إعادة الصف المطلوب مباشرة لأنها استخدمت الفهرس. لا يذكر العمود Extra الآن العبارة Using WHERE، لأن التكرار على الجدول الرئيسي والتحقق من أن كل صف يحقق شرط الاستعلام لم يكن ضروريًا لإجراء الاستعلام. وكما ذكرنا سابقًا لن نلاحظ تأثير استخدام الفهرس جدًا مع مجموعة بيانات تجريبية صغيرة، ولكن تطلّب الأمر من قاعدة البيانات عملًا أقل بكثير لاسترجاع النتيجة وسيكون تأثير هذا التغيير كبيرًا على مجموعة بيانات أكبر. نجرّب إعادة تشغيل الاستعلام الثاني واسترجاع الموظفين الذين راتبهم أقل من 70000 للتحقق من استخدام الفهرس، لذا نفّذ الاستعلام التالي: mysql> SELECT * FROM employees WHERE salary < 70000; نلاحظ إعادة بيانات John Smith و Jane Doe أيضًا كما يلي: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | | 2 | Jane | Doe | DEF456 | 65000 | +-------------+------------+-----------+---------------+--------+ 8 rows in set (0.000 sec) ولكن إذا استخدمنا تعليمة EXPLAIN كما يلي: mysql> EXPLAIN SELECT * FROM employees WHERE salary < 70000; فسيكون الجدول مختلفًا عن التنفيذ السابق للاستعلام نفسه كما يلي: الخرج +----+-------------+-----------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | employees | NULL | range | salary | salary | 5 | NULL | 2 | 100.00 | Using index condition | +----+-------------+-----------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) يخبرنا العمود key أن MySQL استخدم الفهرس لإجراء الاستعلام، ويخبرنا العمود rows بتحليل صفين فقط لإعادة النتيجة. يحتوي العمود Extra الآن على العبارة Using index condition، مما يعني أن MySQL أجرى ترشيحًا باستخدام الفهرس في هذه الحالة ثم استخدم الجدول الأساسي فقط لاسترجاع الصفوف المطابقة فعليًا. ملاحظة: قد يقرر MySQL عدم استخدام الفهرس في بعض الأحيان حتى في حالة وجود الفهرس وإمكانية استخدامه، فمثلًا إذا نفذنا الأمر التالي: mysql> EXPLAIN SELECT * FROM employees WHERE salary < 140000; فستكون خطة التنفيذ كما يلي: الخرج +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | employees | NULL | ALL | salary | NULL | NULL | NULL | 20 | 80.00 | Using where | +----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) يعني وجود عمود key الفارغ الذي له القيمة NULL أن MySQL قرر عدم استخدام الفهرس، والذي يمكن تأكيده من خلال الصفوف العشرين الممسوحة بالرغم من إدراج الفهرس salary في العمود possible_keys. يحلل مخطِّط استعلام قاعدة البيانات كل استعلام مقابل للفهارس المحتملة لتحديد أسرع مسار للتنفيذ، فإذا كانت تكلفة الوصول إلى الفهرس أكبر من فائدة استخدامه مثل إعادة الاستعلام جزءًا كبيرًا من بيانات الجدول الأصلية، فيمكن لقاعدة البيانات أن تقرر أنه من الأسرع إجراء مسح كامل للجدول فعليًا. توضّح التعليقات في العمود Extra مثل Using index condition أو Using where كيفية تنفيذ محرّك قاعدة البيانات للاستعلام بمزيد من التفصيل، فقد تختار قاعدة البيانات طريقة أخرى لتنفيذ الاستعلام وقد يكون لدينا خرج مع عدم وجود التعليق Using index condition أو أي تعليق آخر اعتمادًا على السياق. لا يعني ذلك عدم استخدام الفهرس استخدامًا صحيحًا، ولكنه يعني أن قاعدة البيانات قرّرت أن الطريقة الأخرى للوصول إلى الصفوف ستكون أفضل في الأداء. أنشأنا واستخدمنا في هذا القسم فهارس مؤلفة من عمود واحد لتحسين أداء استعلامات SELECT التي تعتمد على الترشيح لعمود واحد، وسنتعرّف في القسم التالي على كيفية استخدام الفهارس لضمان أن تكون القيم فريدة في عمود معين. استخدام الفهارس الفريدة لمنع تكرار البيانات أحد الاستخدامات الشائعة للفهارس هو استرجاع البيانات بسرعة من خلال مساعدة محرّك قاعدة البيانات على إجراء عمل أقل لتحقيق النتيجة نفسها كما وضّحنا سابقًا، وهناك استخدام آخر وهو ضمان عدم تكرار البيانات في جزء الجدول الذي عرّفنا الفهرس له، وهذا ما يفعله الفهرس الفريد Unique Index. إن تجنب القيم المكررة ضروري لضمان سلامة البيانات سواءً من وجهة نظر منطقية أو تقنية، فمثلًا لا ينبغي أن يكون هناك شخصان يستخدمان نفس رقم الضمان الاجتماعي، ولا ينبغي لنظام عبر الإنترنت أن يسمح لمستخدمين متعددين أن يسجّلوا باستخدام اسم المستخدم أو عنوان البريد الإلكتروني نفسه. في حالة جدولنا employees لا ينبغي أن يحتوي حقل الرقم التسلسلي على قيمٍ مكررة وإذا كان الأمر كذلك، فهذا قد يتسبب في منح أكثر من موظف الحاسوب نفسه، ففي هذا الجدول يمكن بسهولة إدخال موظفين جدد مع أرقام تسلسلية مكررة. لنحاول إدخال موظف آخر مع رقم تسلسلي لجهاز قيد الاستخدام كما يلي: mysql> INSERT INTO employees VALUES (21, 'Sammy', 'Smith', 'ABC123', 65000); ستدرج قاعدة البيانات هذا الصف وتعلمنا بنجاح العملية كما يلي: الخرج Query OK, 1 row affected (0.009 sec) فإذا استعلمنا عن الموظفين باستخدام الحاسوب ذي الرقم التسلسلي ABCD123 كما يلي: mysql> SELECT * FROM employees WHERE device_serial = 'ABC123'; فسنحصل على شخصين مختلفين كما توضح النتيجة التالية: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | | 21 | Sammy | Smith | ABC123 | 65000 | +-------------+------------+-----------+---------------+--------+ 2 rows in set (0.000 sec) هذا ليس سلوكًا متوقعًا لإبقاء قاعدة بيانات employees صالحة. لذا سنتراجع عن هذا التغيير من خلال حذف الصف الأخير الذي أنشأناه كما يلي: mysql> DELETE FROM employees WHERE employee_id = 21; يمكنك التأكد من ذلك من خلال إعادة تشغيل استعلام SELECT السابق كما يلي: mysql> SELECT * FROM employees WHERE device_serial = 'ABC123'; وبالتالي أصبح الموظف John Smith المستخدم الوحيد للجهاز الذي رقمه التسلسلي ABC123 مرة أخرى: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) لننشئ الآن فهرسًا فريدًا للعمود device_serial لحماية قاعدة البيانات من مثل هذه الأخطاء من خلال تنفيذ التعليمة التالية: mysql> CREATE UNIQUE INDEX device_serial ON employees(device_serial); توجِّه إضافة الكلمة المفتاحية UNIQUE عند إنشاء الفهرس قاعدةَ البيانات للتأكد من عدم تكرار القيم في العمود device_serial، حيث تؤدي الفهارس الفريدة إلى التحقق من جميع الصفوف الجديدة المضافة إلى الجدول مقابل الفهرس لتحديد ما إذا كانت قيمة العمود تتوافق مع القيد أم لا. وستؤكد قاعدة البيانات إنشاء الفهرس كما يلي: الخرج Query OK, 0 rows affected (0.021 sec) Records: 0 Duplicates: 0 Warnings: 0 نتحقق الآن من إمكانية إضافة إدخال مكرر إلى الجدول من خلال تشغيل استعلام INSERT من جديد: mysql> INSERT INTO employees VALUES (21, 'Sammy', 'Smith', 'ABC123', 65000); ستظهر رسالة الخطأ التالية هذه المرة: الخرج ERROR 1062 (23000): Duplicate entry 'ABC123' for key 'device_serial' يمكن التحقق من عدم إضافة الصف الجديد إلى الجدول باستخدام استعلام SELECT مرة أخرى: mysql> SELECT * FROM employees WHERE device_serial = 'ABC123'; وسيُعاد صف واحد فقط هذه المرة: الخرج +-------------+------------+-----------+---------------+--------+ | employee_id | first_name | last_name | device_serial | salary | +-------------+------------+-----------+---------------+--------+ | 1 | John | Smith | ABC123 | 60000 | +-------------+------------+-----------+---------------+--------+ 1 row in set (0.000 sec) تعمل الفهارس الفريدة على الحماية من الإدخالات المكررة، وهي أيضًا فهارس وظيفية بالكامل لتسريع الاستعلامات. ويستخدم محرّك قاعدة البيانات الفهارس الفريدة باستخدام الطريقة نفسها في الخطوة السابقة، حيث يمكننا التحقق من ذلك من خلال تنفيذ التعليمة التالية: mysql> EXPLAIN SELECT * FROM employees WHERE device_serial = 'ABC123'; وستكون نتيجة التنفيذ مشابهة لما يلي: الخرج +----+-------------+-----------+------------+-------+---------------+---------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-----------+------------+-------+---------------+---------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | employees | NULL | const | device_serial | device_serial | 63 | const | 1 | 100.00 | NULL | +----+-------------+-----------+------------+-------+---------------+---------------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec) يظهَر الفهرس device_serial في العمودين possible_keys و key، مما يؤكّد استخدام الفهرس عند تنفيذ الاستعلام. بهذا تعلمنا استخدام الفهارس الفريدة Unique Index للحماية من البيانات المكررة في قاعدة البيانات، وسنستخدم في القسم التالي الفهارس التي تمتد إلى أكثر من عمود واحد. الخلاصة تعلّمنا في هذا المقال ما هي الفهارس واستعرضنا أمثلة متعددة على فهارس العمود الواحد المستخدمة لتسريع استرجاع البيانات من خلال استعلامات SELECT الشرطية، أو للحفاظ على جعل بيانات العمود فريدة، وسنشرح في المقال التالي المزيد حول الفهارس ونوضح كيفية تعريف فهارس متعددة الأعمدة Indexes on Multiple Columns وحالات استخدامها، كما ننصح بالاطلاع على سلسلة تعلم SQL للمزيد حول التعامل مع لغة SQL. ترجمة -وبتصرف- للمقال How To Use Indexes in MySQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا الفهارس Indexes في SQL نظرة سريعة على لغة الاستعلامات الهيكلية SQL فهم قواعد البيانات العلاقية تحسين أداء قواعد بيانات SQL للمطورين -
 عند العمل مع قواعد البيانات العلاقية Relational Databases ولغة الاستعلام البنيوية SQL فإننا نجري معظم العمليات على البيانات الناتجة عن استعلامات منفَّذة صراحةً مثل استعلامات SELECT أو INSERT أو UPDATE. لكن يمكننا توجيه قواعد بيانات SQL لتنفيذ إجراءات مُعرَّفة مسبقًا تلقائيًا في كل مرة يقع فيها حدث معين باستخدام القوادح أو محفّزات التنفيذ Triggers. يمكننا مثلًا استخدام هذه القوادح للاحتفاظ بسجل يتضمن جميع تعليمات الحذف DELETE بحيث نحفظ بعد كل عملية حدث تقع تفاصيل هذه العملية ومن قام بها ومتى، كما يمكن استخدامها لتحديث البيانات التراكمية مثل المجموع أو المتوسط حيث يمكننا تحديث هذه البيانات الإحصائية كلما جرت عملية إضافة أو تحديث على البيانات الموجودة. سنستخدم في هذا المقال قوادح SQL مختلفة لتنفيذ الإجراءات تلقائيًا عندما ندرج الصفوف أو نحدثها أو نحذفها. مستلزمات العمل يجب توفر حاسوب يشغّل نظام إدارة قواعد بيانات علاقية RDBMS مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذي صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، ومقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال معرفة أساسية بتنفيذ استعلامات SELECT و INSERT و UPDATE و DELETE لمعالجة البيانات في قاعدة البيانات كما هو موضح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL وكيفية إدراج البيانات في SQL وتحديث البيانات في لغة الاستعلام البنيوية SQL وحذف البيانات في لغة الاستعلام البنيوية SQL معرفة أساسية باستخدام الاستعلامات المتداخلة كما هو موضَّح في مقال كيفية استخدام الاستعلامات المتداخلة في لغة SQL المعرفة الأساسية باستخدام الدوال الرياضية التجميعية كما هو موضَّح في مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL. فلا يفرض معيار SQL صيغةً للقوادح Triggers أو طريقة صارمة لتحقيقها بالرغم من أنها تُعَد جزءًا من هذا المعيار، لذا يختلف تقديمها من قاعدة البيانات إلى أخرى، وتستخدم الأوامر الموضَّحة في هذا المقال صيغة قاعدة بيانات MySQL وقد لا تعمل على محرّكات قواعد البيانات الأخرى. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام المحفّزات، وفي القسم التالي نوضح تفاصيل الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية لاستخدامها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وننشئ قاعدة بيانات تجريبية لتطبيق الأمثلة الواردة في هذا المقال، حيث سنستخدم قاعدة بيانات تحفظ مجموعة هدايا تذكارية افتراضية، ونخزّن كل تفاصيل الهدايا التذكارية المملوكة حاليًا، وقيمتها الإجمالية المتاحة ونحتاج للتأكد من أن إجراء حذف الهدايا التذكارية سيُحفَظ في سجل دائم يوضح كافة تفاصيل عملية الحذف. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نحتاج للاتصال بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم collectibles: mysql> CREATE DATABASE collectibles; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات collectibles من خلال تنفيذ تعليمة USE التالية: $ USE collectibles; وسيظهر الخرج التالي: Database changed اخترنا قاعدة البيانات، وسننشئ عدة جداول تجريبية ضمنها، حيث سيحتوي الجدول collectibles على بيانات مبسَّطة عن الهدايا التذكارية الموجودة في قاعدة البيانات، ويتضمن الجدول الأعمدة التالية: name: يخزّن اسم كل هدية تذكارية، ويستخدم نوع البيانات varchar بحد أقصى 50 محرفًا value: يخزّن قيمة الهدية التذكارية، ويستخدم نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE collectibles ( mysql> name varchar(50), mysql> value decimal(5, 2) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: Query OK, 0 rows affected (0.00 sec) سنسمّي الجدول الثاني باسم collectibles_stats وسنستخدمه لتتبّع القيمة المتراكمة لجميع الهدايا التذكارية في المجموعة، وسيحتوي هذا الجدول على صف واحد من البيانات مع الأعمدة التالية: count: يحتوي عدد الهدايا التذكارية المملوكة، ونمثّله باستخدام نوع البيانات int value: يخزّن القيمة المتراكمة لجميع الهدايا باستخدام نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE collectibles_stats ( mysql> count int, mysql> value decimal(5, 2) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: Query OK, 0 rows affected (0.00 sec) سنسمي الجدول الثالث والأخير بالاسم collectibles_archive، والذي سيتتبّع جميع الهدايا التذكارية المحذوفة من المجموعة لضمان عدم اختفائها أبدًا، وسيحتوي على بيانات مشابهة للجدول collectibles مع تاريخ الإزالة، وسيستخدم الأعمدة التالية: name: يحتوي اسم كل هدية تذكارية محذوفة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا value: يخزّن قيمة الهدايا التذكارية لحظة الحذف باستخدام نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها removed_on: يخزّن تاريخ ووقت الحذف لكل هدية تذكارية مؤرشفة باستخدام نوع البيانات timestamp باستخدام القيمة الافتراضية NOW() التي تعني التاريخ الحالي لإدراج صف جديد في هذا الجدول أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE collectibles_archive ( mysql> name varchar(50), mysql> value decimal(5, 2), mysql> removed_on timestamp DEFAULT CURRENT_TIMESTAMP mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول collectibles_stats بالبيانات الأولية لمجموعة الهدايا التذكارية من خلال تنفيذ عملية INSERT INTO التالية: mysql> INSERT INTO collectibles_stats SELECT COUNT(name), SUM(value) FROM collectibles; تضيف عملية INSERT INTO السابقة صفًا واحدًا إلى الجدول collectibles_stats مع القيم المحسوبة باستخدام الدوال التجميعية Aggregate Functions لحساب عدد الصفوف في الجدول collectibles ولجمع قيم جميع الهدايا التذكارية باستخدام العمود value والدالة SUM. يشير الخرج التالي إلى إضافة الصف بنجاح: Query OK, 1 row affected (0.002 sec) Records: 1 Duplicates: 0 Warnings: 0 يمكننا التحقق من ذلك من خلال تنفيذ تعليمة SELECT التالية مع الجدول collectibles_stats: mysql> SELECT * FROM collectibles_stats; لا توجد هدايا تذكارية في قاعدة البيانات حتى الآن، لذا يكون العدد الأولي للعناصر هو 0 وتكون القيمة المتراكمة هي NULL كما يلي: +-------+-------+ | count | value | +-------+-------+ | 0 | NULL | +-------+-------+ 1 row in set (0.000 sec) نحن الآن جاهزون لمتابعة هذا المقال والبدء باستخدام القوادح Triggers في MySQL. فهم Triggers القوادح Triggers هي تعليمات مُعرَّفة من أجل جدول معين تنفّذها قاعدة البيانات تلقائيًا في كل مرة يقع فيها حدث محدد في هذا الجدول، ويمكننا استخدامها لضمان تنفيذ بعض الإجراءات بتناسق في كل مرة نُنفَّذ فيها تعليمة معينة مع الجدول بدلًا من أن يحتاج مستخدمو قاعدة البيانات لتنفيذها يدويًا. يُعرَّف كل Trigger مرتبط بجدول باسم يحدده المستخدم، وشرطين لتوجيه محرك قاعدة البيانات وإعلامه بالوقت المناسب لتنفيذ القادح، ويمكن تجميع هذين الشرطين ضمن فئتين منفصلتين هما: حدث قاعدة البيانات: يمكن تنفيذ القوادح عند تشغيل تعليمات INSERT أو UPDATE أو DELETE مع الجدول وقت الحدث: يمكن تنفيذ القوادح أيضًا قبل BEFORE أو بعد AFTER التعليمة المحدَّدة يؤدي الجمع بين مجموعتي الشروط السابقتين لستة احتمالات منفصلة للقوادح التي تُنفَّذ تلقائيًا في كل مرة يتحقق فيها الشرط المشترك. القوادح التي تحدث قبل تنفيذ التعليمة التي تحقق الشرط هي BEFORE INSERT و BEFORE UPDATE و BEFORE DELETE، ويمكن استخدامها لمعالجة البيانات والتحقق من صحتها قبل إدراجها أو تحديثها في الجدول أو لحفظ تفاصيل الصف المحذوف لأغراض التدقيق أو الأرشفة. المحفّزات التي تحدث بعد تنفيذ التعليمة التي تحقق الشرط هي AFTER INSERT و AFTER UPDATE و AFTER DELETE، ويمكن استخدامها لتحديث القيم الملخَّصة في جدول منفصل بناءً على الحالة النهائية لقاعدة البيانات بعد التعليمة. يمكن تنفيذ إجراءات مثل التحقق من صحة بيانات الدخل، ومعالجتها، أو أرشفة الصف المحذوف، إذ تسمح قاعدة البيانات بالوصول إلى قيم البيانات من داخل القوادح، ويمكن استخدام البيانات المدرَجة حديثًا فقط بالنسبة لقوادح INSERT، ويمكن الوصول إلى كلٍّ من البيانات الأصلية والمُحدَّثة بالنسبة لمحفّزات UPDATE، وتكون بيانات الصف الأصلية فقط متاحة للاستخدام بالنسبة لمحفّزات DELETE نظرًا لعدم وجود بيانات جديدة للإشارة إليها. يمكن الوصول للبيانات المُستخدَمة في جسم القادح ضمن السجل OLD بالنسبة للبيانات الموجودة حاليًا في قاعدة البيانات والسجل NEW بالنسبة للبيانات التي سيحفظها الاستعلام، ويمكن الإشارة إلى الأعمدة الفردية باستخدام الصيغة OLD.column_name و OLD.column_name. يوضّح المثال التالي الصيغة العامة لتعليمة SQL المُستخدَمة لإنشاء قادح جديد: mysql> CREATE TRIGGER trigger_name trigger_condition mysql> ON table_name mysql> FOR EACH ROW mysql> trigger_actions; لنشرح التعليمة السابقة بالتفصيل: CREATE TRIGGER: اسم تعليمة SQL المُستخدَمة لإنشاء قادح جديد في قاعدة البيانات trigger_name: هو الاسم الذي يحدّده المستخدم للقادح، ويصف دوره مثل استخدام أسماء الجداول وأسماء الأعمدة لوصف معناها ON table_name: نخبر قاعدة البيانات بأن القادح يجب أن يراقب الأحداث التي تحدث في الجدول table_name trigger_condition: أحد الاختيارات الستة المُحتملة التي تحدد متى يجب تشغيل القادح مثل BEFORE INSERT. FOR EACH ROW: تخبر قاعدة البيانات بأنه يجب تشغيل القادح لكل صف يتأثر بالحدث. تدعم بعض قواعد البيانات أنماطًا إضافية للتنفيذ مختلف عن النمط FOR EACH ROW، ولكن تشغيل التعليمات من جسم القادح لكل صف متأثر بالتعليمة التي تسبّبت في تنفيذ القادح هو الخيار الوحيد في حال MySQL trigger_actions: جسم القادح الذي يحدّد ما يحدث عند تنفيذه، وهو تعليمة SQL واحدة، ويمكن تضمين تعليمات متعددة في جسم القادح لإجراء عمليات معقدة باستخدام الكلمات المفتاحية BEGIN و END لتضمين التعليمات ضمن كتلة، ولكن ذلك خارج نطاق هذا المقال اطّلع على التوثيق الرسمي للمحفّزات لمعرفة المزيد حول الصيغة المُستخدمَة لتعريف القوادح. سننشئ في القسم التالي أمثلة على قوادح تعالج البيانات قبل إجراء عمليتي INSERT و UPDATE. معالجة البيانات باستخدام محفزات BEFORE INSERT و BEFORE UPDATE سنستخدم في هذا القسم قوادح لمعالجة البيانات قبل تنفيذ تعليمات INSERT و UPDATE، حيث سنستخدم المحفّزات في للتأكّد من أن جميع الهدايا التذكارية في قاعدة البيانات تستخدم أسماءً بحروف كبيرة لتحقيق التناسق. في حال لم نستخدم قوادح سيتوجب علينا تذكّر استخدام أسماء الهدايا التذكارية بحروف كبيرة لكل تعليمة INSERT و UPDATE، وإذا نسينا، فستحتفظ قاعدة البيانات بالبيانات كما هي وهذا قد يؤدي إلى حدوث أخطاء محتملة في مجموعة البيانات. لنبدأ بإدخال مثال لعنصر من الهدايا التذكارية بالاسم spaceship model وبقيمة 12.50 دولار، وسنكتب اسم العنصر بحروف صغيرة لتوضيح المشكلة. لننفّذ التعليمة التالية: mysql> INSERT INTO collectibles VALUES ('spaceship model', 12.50); تؤكد الرسالة التالية إضافة العنصر: Query OK, 1 row affected (0.009 sec) يمكننا التحقق من إدراج الصف من خلال تنفيذ استعلام SELECT التالي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | spaceship model | 12.50 | +-----------------+-------+ 1 row in set (0.000 sec) حُفِظ هذا العنصر كما هو مع كتابة اسمه بحروف صغيرة فقط. لنتأكد من كتابة جميع الهدايا التذكارية اللاحقة بحروف كبيرة دائمًا من خلال إنشاء قادح باسم BEFORE INSERT لمعالجة البيانات المُمرَّرة إلى قاعدة البيانات قبل حدوثها. نشغّل الآن التعليمة التالية: mysql> CREATE TRIGGER uppercase_before_insert BEFORE INSERT mysql> ON collectibles mysql> FOR EACH ROW mysql> SET NEW.name = UPPER(NEW.name); ينشئ الأمر السابق قادح باسم uppercase_before_insert، والذي سيُنفَّذ قبل كافة تعليمات INSERT في الجدول collectibles. تُنفَّذ التعليمة الموجودة في القادحSET NEW.name = UPPER(NEW.name) لكل صف مدرج، ويسند أمر SQL الذي هو SET القيمة الموجودة على الجانب الأيمن إلى الجانب الأيسر، حيث يمثل NEW.name قيمة العمود name الذي ستحفظه تعليمة الإدراج. نحوّل حالة الحروف للقيمة التي ستُحفَظ في قاعدة البيانات من خلال تطبيق الدالة UPPER على اسم الهدية وإسناده مرة أخرى لقيمة العمود. ملاحظة: قد تظهر رسالة خطأ مشابهة للخطأ التالي عند تشغيل الأمر CREATE TRIGGER. ERROR 1419 (HY000): You do not have the SUPER privilege, and binary logging is enabled (you might want to use the less safe log_bin_trust_function_creators variable) التسجيل الثنائي Binary Logging هو آلية تُسجل كل التعديلات التي تتم على قاعدة البيانات مثل إضافة أو تعديل أو حذف بيانات في سجل ثنائي، ويحتوي هذا السجل على أحداث Events تصف التعديلات التي حدثت وتحفظها بتنسيق ثنائي يمكن معالجته، وهذا التسجيل يكون مفعَّلًا افتراضيًا في محرّك قاعدة بيانات MySQL وذلك بدءًا من الإصدار MySQL 8، حيث يتعقّب التسجيل الثنائي جميع تعليمات SQL التي تعدّل محتويات قاعدة البيانات في صيغة أحداث محفوظة تَصِف هذه التعديلات، وتُستخدَم هذه السجلات في النسخ المتماثل Replication لقاعدة البيانات للحفاظ على مزامنة النسخ المتماثلة لقاعدة البيانات وأثناء استعادة البيانات في الوقت المناسب. لكن لا يسمح MySQL بإنشاء القوادح Triggers والإجراءات المخزَّنة Stored Procedures في حال تفعيل تسجيل التعديلات أو الأحداث بصيغة ثنائية كإجراء احترازي لضمان سلامة البيانات وتكاملها في بيئات النسخ المتماثل Replication، ولكن فهم كيفية تأثير القوادح والإجراءات المُخزَّنة على النسخ المتماثل خارج نطاق هذا المقال. يمكننا تجاوز القيود التي يفرضها MySQL عند تفعيل التسجيل الثنائي Binary Logging، وذلك لأغراض التعلم أو الاختبار في بيئة محلية على جهازنا الشخصي، ولكن لن يستمر هذا الإعداد الذي عدّلناه بالعمل وسيعود للقيمة الأصلية عند إعادة تشغيل خادم MySQL. يمكن تجاوز الإعداد الافتراضي من خلال تعديل الإعدادات الخاصة بـ MySQL كما يلي: mysql> SET GLOBAL log_bin_trust_function_creators = 1; يتحكم الإعداد log_bin_trust_function_creators بإمكانية الوثوق بالمستخدمين الذين ينشئون القوادح والدوال المخزنة بحيث لا ينشئون قوادح تتسبب في كتابة أحداث غير آمنة في السجل الثنائي. تكون قيمة الإعداد الافتراضية هي 0، مما يسمح للمستخدمين الذين يتمتعون بصلاحيات مميزة فقط بإنشاء قوادح في البيئة التي فعّلنا فيها تسجيل التعديلات أو الأحداث بصيغة ثنائية، وإذا عدّلنا القيمة إلى 1، فسنثق بأيّ مستخدم ينشئ تعليمات CREATE TRIGGER لفهم النتائج. جرى الآن تحديث الإعداد، لنعمل إذًا على تسجيل الخروج كمستخدم جذر، وتسجيل الدخول مرة أخرى كمستخدم عادي، ونعيد تشغيل تعليمة CREATE TRIGGER. ويمكن الاطلاع على توثيق MySQL الرسمي: السجل الثنائي و تسجيل التعديلات أو الأحداث بصيغة ثنائية للبرنامج المخزن، كما يمكن مطالعة مقال كيفية إعداد النسخ المتماثل في MySQL لمعرفة المزيد حول تسجيل التعديلات أو الأحداث بصيغة ثنائية والنسخ المتماثل في MySQL وارتباطه بالقوادح. ملاحظة: قد نتلقى خطأً عند تنفيذ أمر CREATE TRIGGER اعتمادًا على أذونات مستخدم MySQL الخاصة بنا ERROR 1142 (42000): TRIGGER command denied to user 'user'@'host' for table 'collectibles' لحل هذا الخطأ يمكن منح أذونات TRIGGER للمستخدم الخاص بنا من خلال تسجيل الدخول إلى MySQL كمستخدم جذر، وتنفيذ الأوامر التالية مع وضع اسم مستخدم MySQL والمضيف حسب الحاجة: mysql> GRANT TRIGGER on *.* TO 'user'@'localhost'; mysql> FLUSH PRIVILEGES; نحدّث أذونات المستخدم، ثم نسجّل الخروج كمستخدم جذر، ونسجّل الدخول مرة أخرى كمستخدم عادي، ونعيد تشغيل التعليمة CREATE TRIGGER، وسيطبع MySQL الرسالة التالية للتأكد من إنشاء القادح بنجاح: Query OK, 1 row affected (0.009 sec) نحاول الآن إدراج مجموعة هدايا تذكارية جديدة باستخدام وسيط بحروف صغيرة مع استعلام INSERT كما يلي: mysql> INSERT INTO collectibles VALUES ('aircraft model', 10.00); ثم نتحقّق من الصفوف الناتجة في الجدول collectibles كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | spaceship model | 12.50 | | AIRCRAFT MODEL | 10.00 | +-----------------+-------+ 2 rows in set (0.000 sec) يشير الإدخال الجديد هذه المرة إلى أن AIRCRAFT MODEL -مع جميع حروفه الكبيرة- يختلف عن الإدخال الذي حاولنا إدراجه، حيث شُغِّل القادح في الخلفية وحوّل حالة الحروف قبل حفظ الصف في قاعدة البيانات. يحمي القادح جميع الصفوف الجديدة لضمان حفظ الأسماء بحروف كبيرة، ولكن لا يزال من الممكن حفظ البيانات غير المقيَّدة التي تستخدم تعليمات UPDATE، حيث يمكن حماية تعليمات UPDATE باستخدام التأثير نفسه، إذًا لننشئ قادحًا آخر كما يلي: mysql> CREATE TRIGGER uppercase_before_update BEFORE UPDATE mysql> ON collectibles mysql> FOR EACH ROW mysql> SET NEW.name = UPPER(NEW.name); يكمن الفرق بين القادحين في المعايير، فالقادح هنا BEFORE UPDATE، مما يعني تنفيذه في كل مرة تُنفَّذ فيها تعليمة UPDATE مع الجدول، ويؤثر ذلك على الصفوف الموجودة في كل تحديث، بالإضافة إلى الصفوف الجديدة التي يؤثر عليها القادح السابق. سيعطي MySQL تأكيدًا بإنشاء القادح بنجاح كما يلي: Query OK, 0 row affected (0.009 sec) يمكن التحقق من سلوك القادح الجديد من خلال تحديث قيمة سعر spaceship model كما يلي: mysql> UPDATE collectibles SET value = 15.00 WHERE name = 'spaceship model'; ترشّح تعليمة WHERE الصف المراد تحديثه حسب الاسم، وتغيّر تعليمة SET القيمة إلى 15.00، وسيظهر الخرج التالي، مما يؤكد أن التعليمة قد غيّرت صفًا واحدًا: Query OK, 1 row affected (0.002 sec) Rows matched: 1 Changed: 1 Warnings: 0 لنتحقّق الآن من الصفوف الناتجة في الجدول collectibles كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | SPACESHIP MODEL | 15.00 | | AIRCRAFT MODEL | 10.00 | +-----------------+-------+ 2 rows in set (0.000 sec) أصبح الاسم الآن SPACESHIP MODEL بالإضافة إلى تحديث السعر إلى 15.00 باستخدام التعليمة المُنفَّذة. إذا شغّلنا تعليمة UPDATE، فسيُنفَّذ القادح، مما يؤثر على القيم الموجودة في الصف المُحدَّث، مع تحويل عمود الاسم إلى حروف كبيرة قبل الحفظ. أنشأنا في هذا القسم قادحين Triggersيعملان قبل استعلامات INSERT وقبل استعلامات UPDATE لجعل البيانات ملائمةً قبل حفظها في قاعدة البيانات، وسنستخدم في القسم التالي محفّزات BEFORE DELETE لنسخ الصفوف المحذوفة في جدول منفصل للأرشفة. استخدام قوادح BEFORE DELETE قد نرغب في أرشفة البيانات بدلاً من حذفها نهائيًا من قاعدة البيانات، خاصةً إذا كنا بحاجة للاحتفاظ بسجل لهذه البيانات في المستقبل، فإذ أنشأنا في بداية هذا المقال جدول آخر باسم collectibles_archive لتعقّب جميع الهدايا التذكارية المحذوفة من المجموعة وأرشفتها. سنستخدم قادح يُنفَّذ قبل تنفيذ تعليمات الحذف DELETE. نتحقّق أولًا مما إذا كان جدول الأرشيف فارغًا بالكامل من خلال تنفيذ التعليمة التالية: mysql> SELECT * FROM collectibles_archive; وسيظهر الخرج التالي، مما يؤكد أن الجدول collectibles_archive فارغ: Empty set (0.000 sec) إذا نفّذنا استعلام DELETE مع الجدول collectibles، فيمكن حذف أيّ صفٍ من الجدول دون أيّ أثر. يمكن معالجة ذلك من خلال إنشاء قادح يُنفَّذ قبل جميع استعلامات DELETE مع الجدول collectibles، والغرض من هذا القادح هو حفظ نسخة من الكائن المحذوف في جدول الأرشيف قبل حدوث الحذف. لنشغّل الآن الأمر التالي: mysql> CREATE TRIGGER archive_before_delete BEFORE DELETE mysql> ON collectibles mysql> FOR EACH ROW mysql> INSERT INTO collectibles_archive (name, value) VALUES (OLD.name, OLD.value); يُسمَّى هذا القادح باسم archive_before_delete ويحدث قبل أيّ استعلامات DELETE مع الجدول collectibles. ستُنفَّذ تعليمة INSERT لكل صفٍ سيُحذف، بينما تدرج تعليمة INSERT صفًا جديدًا في الجدول collectibles_archive مع قيم البيانات المأخوذة من السجل OLD، وهو السجل المقرّر حذفه، حيث يصبح OLD.name هو العمود name ويصبح OLD.value العمود value. وتؤكد قاعدة البيانات إنشاء هذا القادح كما يلي: Query OK, 0 row affected (0.009 sec) نحاول حذف إحدى الهدايا التذكارية من الجدول collectibles الرئيسي مع استخدام القادح كما يلي: mysql> DELETE FROM collectibles WHERE name = 'SPACESHIP MODEL'; ويؤكّد الخرج التالي نجاح تشغيل الاستعلام السابق: Query OK, 1 row affected (0.004 sec) لنسرد الآن جميع الهدايا التذكارية كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +----------------+-------+ | name | value | +----------------+-------+ | AIRCRAFT MODEL | 10.00 | +----------------+-------+ 1 row in set (0.000 sec) حذفنا SPACESHIP MODEL ولم يَعُد موجودًا في الجدول مع بقاء AIRCRAFT MODEL، ولكن يجب تسجيل هذا الحذف في الجدول collectibles_archive باستخدام القادح الذي أنشأناه مسبقًا، إذًا لنتحقق من ذلك، ولننفّذ استعلامًا آخر كما يلي: mysql> SELECT * FROM collectibles_archive; وسيظهر الخرج التالي: +-----------------+-------+---------------------+ | name | value | removed_on | +-----------------+-------+---------------------+ | SPACESHIP MODEL | 15.00 | 2022-11-20 11:32:01 | +-----------------+-------+---------------------+ 1 row in set (0.000 sec) لاحظ القادح عملية الحذف في هذا الجدول تلقائيًا، مع تعبئة أعمدة name و value بالبيانات من الصف المحذوف، ولم يضبط القادح العمود الثالث removed_on صراحةً، لذلك سيأخذ القيمة الافتراضية المُحدَّدة أثناء إنشاء الجدول، أي تاريخ إنشاء أيّ صف جديد، مما يؤدي دائمًا إلى إضافة تعليق توضيحي لكل إدخال مُضاف بمساعدة القادح مع تاريخ الحذف. يمكننا الآن مع وجود هذا القادح التأكد من أن جميع استعلامات DELETE ستؤدي إلى إدخال سجلٍ في الجدول collectibles_archive مع ترك معلومات حول الهدايا التذكارية المملوكة مسبقًا. سنستخدم في القسم التالي القوادح التي تُنفَّذ بعد تعليمات تحديث الجدول الذي يحتوي على القيم المُجمَّعة بناءً على جميع الهدايا التذكارية. استخدام محفزات AFTER INSERT و AFTER UPDATE و AFTER DELETE استخدمنا في القسمين السابقين القوادح المُنفَّذة قبل التعليمات الرئيسية لتنفيذ العمليات المستندة إلى البيانات الأصلية قبل تحديث قاعدة البيانات، وسنحدّث في هذا القسم جدول البيانات التلخيصية بالعدد والقيمة المتراكمة لجميع الهدايا التذكارية المحدَّثة دائمًا باستخدام القوادح المُنفَّذة بعد التعليمات المطلوبة، وبذلك سنكون متأكدين من أن بيانات الجدول تأخذ في الحسبان الحالة الحالية لقاعدة البيانات. لنبدأ الآن بفحص الجدول collectibles_stats كما يلي: mysql> SELECT * FROM collectibles_stats; لم نضف معلومات إلى هذا الجدول بعد، لذا يكون عدد عناصر الهدايا التذكارية المملوكة هو 0، والقيمة التراكمية هي NULL: +-------+-------+ | count | value | +-------+-------+ | 0 | NULL | +-------+-------+ 1 row in set (0.000 sec) لا توجد قوادح لهذا الجدول، وبالتالي لم تؤثر الاستعلامات الصادرة مسبقًا لإدراج الهدايا التذكارية وتحديثها على هذا الجدول. نريد ضبط القيم في صفٍ واحد من الجدول collectibles_stats لتقديم معلومات مُحدَّثة حول عدد الهدايا التذكارية وقيمتها الإجمالية، حيث نتأكد من تحديث محتويات الجدول بعد كل عملية إدراج INSERT أو تحديث UPDATE أو حذف DELETE من خلال إنشاء ثلاثة قوادح منفصلة وتنفيذها بعد الاستعلام المقابل لها. لننشئ أولًا القادح AFTER INSERT: mysql> CREATE TRIGGER stats_after_insert AFTER INSERT mysql> ON collectibles mysql> FOR EACH ROW mysql> UPDATE collectibles_stats mysql> SET count = ( mysql> SELECT COUNT(name) FROM collectibles mysql> ), value = ( mysql> SELECT SUM(value) FROM collectibles mysql> ); سمّينا القادح بالاسم stats_after_insert وسيُنفَّذ بعد AFTER كل استعلام INSERT في الجدول collectibles مع تشغيل تعليمة UPDATE في جسم القادح. يؤثر استعلام UPDATE على جدول البيانات التلخيصية ويضبط العمودين count و value على القيم التي تعيدها الاستعلامات المتداخلة كما يلي: SELECT COUNT(name) FROM collectibles: يحصل على عدد الهدايا التذكارية SELECT SUM(value) FROM collectibles: يحصل على القيمة الإجمالية لجميع الهدايا التذكارية وتؤكّد قاعدة البيانات إنشاء القادح كما يلي: Query OK, 0 row affected (0.009 sec) نجرّب الآن إعادة إدراج spaceship model المحذوف مسبقًا في الجدول collectibles للتحقق من التحديث الصحيح لجدول البيانات التلخيصية كما يلي: mysql> INSERT INTO collectibles VALUES ('spaceship model', 15.00); وتطبع قاعدة البيانات رسالة النجاح التالية: Query OK, 1 row affected (0.009 sec) يمكن سرد جميع الهدايا التذكارية المملوكة باستخدام الاستعلام التالي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | AIRCRAFT MODEL | 10.00 | | SPACESHIP MODEL | 15.00 | +-----------------+-------+ 2 rows in set (0.000 sec) يوجد نوعان من عناصر الهدايا التذكارية التي تبلغ قيمتها الإجمالية 25.00. لنفحص الآن جدول البيانات التلخيصية بعد العنصر الذي أدرجناه حديثًا من خلال تنفيذ الاستعلام التالي: mysql> SELECT * FROM collectibles_stats; سيسرد الجدول هذه المرة عدد جميع عناصر الهدايا التذكارية المملوكة التي هي 2 وقيمتها التراكمية 25.00، والتي تطابق الخرج السابق: +-------+-------+ | count | value | +-------+-------+ | 2 | 25.00 | +-------+-------+ 1 row in set (0.000 sec) يُنفَّذ القادح stats_after_insert بعد استعلام INSERT ويحدّث الجدول collectibles_stats بالبيانات الحالية count و value للمجموعة، وتُجمَع إحصائيات محتويات المجموعة بأكملها، وليس الإدخال الأخير فقط. تحتوي المجموعة الآن على عنصرين spaceship model و aircraft model، لذا يسرد جدول البيانات التلخيصية عنصرين مع قيمتهما الإجمالية، وبالتالي ستؤدي إضافة أيّ عنصر هدية تذكارية جديد إلى الجدول collectibles إلى تحديث جدول البيانات التلخيصية بالقيم الصحيحة، ولكن لن يؤثر تحديث العناصر الموجودة أو حذف الهدايا التذكارية على جدول البيانات التلخيصية أبدًا، لذا سننشئ قادحين إضافيين لإجراء عمليات متطابقة ولكن تحفّزها أحداث مختلفة كما يلي: mysql> CREATE TRIGGER stats_after_update AFTER UPDATE mysql> ON collectibles mysql> FOR EACH ROW mysql> UPDATE collectibles_stats mysql> SET count = ( mysql> SELECT COUNT(name) FROM collectibles mysql> ), value = ( mysql> SELECT SUM(value) FROM collectibles mysql> ); mysql> mysql> CREATE TRIGGER stats_after_delete AFTER DELETE mysql> ON collectibles mysql> FOR EACH ROW mysql> UPDATE collectibles_stats mysql> SET count = ( mysql> SELECT COUNT(name) FROM collectibles mysql> ), value = ( mysql> SELECT SUM(value) FROM collectibles mysql> ); أنشأنا قادحين جديدين هما: stats_after_update و stats_after_delete، وسيُنفّذان مع الجدول collectible_stats عند تنفيذ تعليمة UPDATE أو DELETE في الجدول collectibles. يؤدي الإنشاء الناجح لهذين القادحين إلى طباعة الخرج التالي: Query OK, 0 row affected (0.009 sec) لنحدّث الآن قيمة السعر لإحدى الهدايا التذكارية كما يلي: mysql> UPDATE collectibles SET value = 25.00 WHERE name = 'AIRCRAFT MODEL'; ترشّح تعليمة WHERE الصف المراد تحديثه حسب الاسم، وتغيّر تعليمة SET القيمة إلى 25.00. يؤكّد الخرج التالي أن التعليمة غيّرت صفًا واحدًا: Query OK, 1 row affected (0.002 sec) Rows matched: 1 Changed: 1 Warnings: 0 لنتحقق مرة أخرى من محتويات جدول البيانات التلخيصية بعد التحديث كما يلي: mysql> SELECT * FROM collectibles_stats; وسيسرد العمود value الآن القيمة 40.00، وهي القيمة الصحيحة بعد التحديث: +-------+-------+ | count | value | +-------+-------+ | 2 | 40.00 | +-------+-------+ 1 row in set (0.000 sec) الخطوة الأخيرة هي التحقق من أن جدول البيانات التلخيصية سيظهِر حذف إحدى الهدايا التذكارية بطريقة صحيحة، فلنحاول حذف العنصر aircraft model كما يلي: mysql> DELETE FROM collectibles WHERE name = 'AIRCRAFT MODEL'; ويؤكد الخرج التالي تشغيل الاستعلام بنجاح: Query OK, 1 row affected (0.004 sec) لنسرد الآن جميع الهدايا التذكارية كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | SPACESHIP MODEL | 15.00 | +-----------------+-------+ 1 row in set (0.000 sec) لاحظ بقاء العنصر SPACESHIP MODEL فقط. لنتحقق الآن من القيم الموجودة في جدول البيانات التلخيصية كما يلي: mysql> SELECT * FROM collectibles_stats; وسيظهر الخرج التالي: +-------+-------+ | count | value | +-------+-------+ | 1 | 15.00 | +-------+-------+ 1 row in set (0.000 sec) يعرض العمود count الآن هدية تذكارية واحدة فقط في الجدول الرئيسي، والقيمة الإجمالية هي 15.00، وهي مطابقة لقيمة العنصر SPACESHIP MODEL. تعمل المحفّزات الثلاثة السابقة مع بعضها البعض بعد استعلامات INSERT و UPDATE و DELETE للحفاظ على مزامنة جدول الملخص مع القائمة الكاملة للهدايا التذكارية. سنتعلم في القسم التالي كيفية معالجة القوادح الموجودة مسبقًا مع قاعدة البيانات. سرد وحذف القوادح Triggers أنشأنا في الأقسام السابقة قوادح جديدة، ولكن يمكنك أيضًا سردها ومعالجتها عند الحاجة لأنها كائنات مسمَّاة ومُعرَّفة في قاعدة البيانات مثل الجداول، حيث يمكنك سرد جميع القوادح من خلال تنفيذ التعليمة SHOW TRIGGERS كما يلي: mysql> SHOW TRIGGERS; وسيتضمن الخرج جميع القوادح مع أسمائها وحدث التحفيز مع الوقت قبل BEFORE أو بعد AFTER تنفيذ التعليمة، بالإضافة إلى التعليمات التي تشكّل جزءًا من جسم القادح والتفاصيل الشاملة الأخرى لتعريفه كما يلي: +-------------------------+--------+--------------+--------(...)+--------+(...) | Trigger | Event | Table | Statement | Timing |(...) +-------------------------+--------+--------------+--------(...)+--------+(...) | uppercase_before_insert | INSERT | collectibles | SET (...)| BEFORE |(...) | stats_after_insert | INSERT | collectibles | UPDATE (...)| AFTER |(...) | uppercase_before_update | UPDATE | collectibles | SET (...)| BEFORE |(...) | stats_after_update | UPDATE | collectibles | UPDATE (...)| AFTER |(...) | archive_before_delete | DELETE | collectibles | INSERT (...)| BEFORE |(...) | stats_after_delete | DELETE | collectibles | UPDATE (...)| AFTER |(...) +-------------------------+--------+--------------+--------(...)+--------+(...) 6 rows in set (0.001 sec) يمكن حذف القوادح الموجودة مسبقًا من خلال استخدام تعليمات SQL التي هي DROP TRIGGER، فمثلًا إن لم نعد نرغب بفرض الحروف الكبيرة على أسماء الهدايا التذكارية، ولم نعد بحاجة إلى القادحين uppercase_before_insert و uppercase_before_update، فيمكننا إزالتهما من خلال تنفيذ الأمرين التالية: mysql> DROP TRIGGER uppercase_before_insert; mysql> DROP TRIGGER uppercase_before_update; ويستجيب MySQL برسالة النجاح التالية: Query OK, 0 rows affected (0.004 sec) لنجرّب الآن إضافة هدية تذكارية جديدة بحروف صغيرة كما يلي: mysql> INSERT INTO collectibles VALUES ('ship model', 10.00); وستؤكد قاعدة البيانات ذلك كما يلي: Query OK, 1 row affected (0.009 sec) يمكننا التحقق من إدراج الصف من خلال تنفيذ استعلام SELECT التالي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | SPACESHIP MODEL | 15.00 | | ship model | 10.00 | +-----------------+-------+ 2 rows in set (0.000 sec) نلاحظ كتابة الهدية التذكارية المضافة حديثًا بحروف صغيرة، إذًا لم يتغيّر الاسم عن الخرج الأصلي، وبالتالي تأكّدنا من أن القادح الذي حوّل حالة الحروف سابقًا لم يَعُد قيد الاستخدام. الخلاصة تعلمنا في هذا المقال ما هي القوادح Triggers في SQL وكيفية استخدامها في MySQL لمعالجة البيانات قبل استعلامات INSERT و UPDATE، وتعلّمنا كيفية استخدام قادح BEFORE DELETE لأرشفة الصف المحذوف في جدول منفصل، بالإضافة إلى استخدام قوادح AFTER بعد التعليمات لإبقاء جدول البيانات التلخيصية مُحدَّثة باستمرار. يمكننا استخدام الدوال لتفريغ بعض عمليات معالجة البيانات والتحقق من صحتها في محرّك قاعدة البيانات، مما يضمن سلامة البيانات أو إخفاء بعض سلوكيات قاعدة البيانات عن المستخدم الذي يستخدم قاعدة البيانات يوميًا، وقد غطّى هذا المقال أساسيات استخدام القوادح لهذا الغرض فقط، ولكن يمكنك أيضًا إنشاء قوادح معقدة تتكوّن من تعليمات متعددة واستخدام المنطق الشرطي لتنفيذ الإجراءات بدقة أكبر. ويمكن مطالعة توثيق MySQL الخاص بالتعامل مع triggers لمزيد من المعلومات. ترجمة -وبتصرف- للمقال How To Use Triggers in MySQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام الدوال Functions في لغة SQL التعامل مع قواعد البيانات مدخل إلى تصميم قواعد البيانات استخدام الدوال Functions في لغة SQL استخدام العروض Views في لغة الاستعلام البنيوية SQL
عند العمل مع قواعد البيانات العلاقية Relational Databases ولغة الاستعلام البنيوية SQL فإننا نجري معظم العمليات على البيانات الناتجة عن استعلامات منفَّذة صراحةً مثل استعلامات SELECT أو INSERT أو UPDATE. لكن يمكننا توجيه قواعد بيانات SQL لتنفيذ إجراءات مُعرَّفة مسبقًا تلقائيًا في كل مرة يقع فيها حدث معين باستخدام القوادح أو محفّزات التنفيذ Triggers. يمكننا مثلًا استخدام هذه القوادح للاحتفاظ بسجل يتضمن جميع تعليمات الحذف DELETE بحيث نحفظ بعد كل عملية حدث تقع تفاصيل هذه العملية ومن قام بها ومتى، كما يمكن استخدامها لتحديث البيانات التراكمية مثل المجموع أو المتوسط حيث يمكننا تحديث هذه البيانات الإحصائية كلما جرت عملية إضافة أو تحديث على البيانات الموجودة. سنستخدم في هذا المقال قوادح SQL مختلفة لتنفيذ الإجراءات تلقائيًا عندما ندرج الصفوف أو نحدثها أو نحذفها. مستلزمات العمل يجب توفر حاسوب يشغّل نظام إدارة قواعد بيانات علاقية RDBMS مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذي صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، ومقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال معرفة أساسية بتنفيذ استعلامات SELECT و INSERT و UPDATE و DELETE لمعالجة البيانات في قاعدة البيانات كما هو موضح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL وكيفية إدراج البيانات في SQL وتحديث البيانات في لغة الاستعلام البنيوية SQL وحذف البيانات في لغة الاستعلام البنيوية SQL معرفة أساسية باستخدام الاستعلامات المتداخلة كما هو موضَّح في مقال كيفية استخدام الاستعلامات المتداخلة في لغة SQL المعرفة الأساسية باستخدام الدوال الرياضية التجميعية كما هو موضَّح في مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL. فلا يفرض معيار SQL صيغةً للقوادح Triggers أو طريقة صارمة لتحقيقها بالرغم من أنها تُعَد جزءًا من هذا المعيار، لذا يختلف تقديمها من قاعدة البيانات إلى أخرى، وتستخدم الأوامر الموضَّحة في هذا المقال صيغة قاعدة بيانات MySQL وقد لا تعمل على محرّكات قواعد البيانات الأخرى. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام المحفّزات، وفي القسم التالي نوضح تفاصيل الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية لاستخدامها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وننشئ قاعدة بيانات تجريبية لتطبيق الأمثلة الواردة في هذا المقال، حيث سنستخدم قاعدة بيانات تحفظ مجموعة هدايا تذكارية افتراضية، ونخزّن كل تفاصيل الهدايا التذكارية المملوكة حاليًا، وقيمتها الإجمالية المتاحة ونحتاج للتأكد من أن إجراء حذف الهدايا التذكارية سيُحفَظ في سجل دائم يوضح كافة تفاصيل عملية الحذف. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نحتاج للاتصال بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم collectibles: mysql> CREATE DATABASE collectibles; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات collectibles من خلال تنفيذ تعليمة USE التالية: $ USE collectibles; وسيظهر الخرج التالي: Database changed اخترنا قاعدة البيانات، وسننشئ عدة جداول تجريبية ضمنها، حيث سيحتوي الجدول collectibles على بيانات مبسَّطة عن الهدايا التذكارية الموجودة في قاعدة البيانات، ويتضمن الجدول الأعمدة التالية: name: يخزّن اسم كل هدية تذكارية، ويستخدم نوع البيانات varchar بحد أقصى 50 محرفًا value: يخزّن قيمة الهدية التذكارية، ويستخدم نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE collectibles ( mysql> name varchar(50), mysql> value decimal(5, 2) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: Query OK, 0 rows affected (0.00 sec) سنسمّي الجدول الثاني باسم collectibles_stats وسنستخدمه لتتبّع القيمة المتراكمة لجميع الهدايا التذكارية في المجموعة، وسيحتوي هذا الجدول على صف واحد من البيانات مع الأعمدة التالية: count: يحتوي عدد الهدايا التذكارية المملوكة، ونمثّله باستخدام نوع البيانات int value: يخزّن القيمة المتراكمة لجميع الهدايا باستخدام نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE collectibles_stats ( mysql> count int, mysql> value decimal(5, 2) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: Query OK, 0 rows affected (0.00 sec) سنسمي الجدول الثالث والأخير بالاسم collectibles_archive، والذي سيتتبّع جميع الهدايا التذكارية المحذوفة من المجموعة لضمان عدم اختفائها أبدًا، وسيحتوي على بيانات مشابهة للجدول collectibles مع تاريخ الإزالة، وسيستخدم الأعمدة التالية: name: يحتوي اسم كل هدية تذكارية محذوفة، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا value: يخزّن قيمة الهدايا التذكارية لحظة الحذف باستخدام نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها removed_on: يخزّن تاريخ ووقت الحذف لكل هدية تذكارية مؤرشفة باستخدام نوع البيانات timestamp باستخدام القيمة الافتراضية NOW() التي تعني التاريخ الحالي لإدراج صف جديد في هذا الجدول أنشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE collectibles_archive ( mysql> name varchar(50), mysql> value decimal(5, 2), mysql> removed_on timestamp DEFAULT CURRENT_TIMESTAMP mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول بنجاح: Query OK, 0 rows affected (0.00 sec) نحمّل بعد ذلك الجدول collectibles_stats بالبيانات الأولية لمجموعة الهدايا التذكارية من خلال تنفيذ عملية INSERT INTO التالية: mysql> INSERT INTO collectibles_stats SELECT COUNT(name), SUM(value) FROM collectibles; تضيف عملية INSERT INTO السابقة صفًا واحدًا إلى الجدول collectibles_stats مع القيم المحسوبة باستخدام الدوال التجميعية Aggregate Functions لحساب عدد الصفوف في الجدول collectibles ولجمع قيم جميع الهدايا التذكارية باستخدام العمود value والدالة SUM. يشير الخرج التالي إلى إضافة الصف بنجاح: Query OK, 1 row affected (0.002 sec) Records: 1 Duplicates: 0 Warnings: 0 يمكننا التحقق من ذلك من خلال تنفيذ تعليمة SELECT التالية مع الجدول collectibles_stats: mysql> SELECT * FROM collectibles_stats; لا توجد هدايا تذكارية في قاعدة البيانات حتى الآن، لذا يكون العدد الأولي للعناصر هو 0 وتكون القيمة المتراكمة هي NULL كما يلي: +-------+-------+ | count | value | +-------+-------+ | 0 | NULL | +-------+-------+ 1 row in set (0.000 sec) نحن الآن جاهزون لمتابعة هذا المقال والبدء باستخدام القوادح Triggers في MySQL. فهم Triggers القوادح Triggers هي تعليمات مُعرَّفة من أجل جدول معين تنفّذها قاعدة البيانات تلقائيًا في كل مرة يقع فيها حدث محدد في هذا الجدول، ويمكننا استخدامها لضمان تنفيذ بعض الإجراءات بتناسق في كل مرة نُنفَّذ فيها تعليمة معينة مع الجدول بدلًا من أن يحتاج مستخدمو قاعدة البيانات لتنفيذها يدويًا. يُعرَّف كل Trigger مرتبط بجدول باسم يحدده المستخدم، وشرطين لتوجيه محرك قاعدة البيانات وإعلامه بالوقت المناسب لتنفيذ القادح، ويمكن تجميع هذين الشرطين ضمن فئتين منفصلتين هما: حدث قاعدة البيانات: يمكن تنفيذ القوادح عند تشغيل تعليمات INSERT أو UPDATE أو DELETE مع الجدول وقت الحدث: يمكن تنفيذ القوادح أيضًا قبل BEFORE أو بعد AFTER التعليمة المحدَّدة يؤدي الجمع بين مجموعتي الشروط السابقتين لستة احتمالات منفصلة للقوادح التي تُنفَّذ تلقائيًا في كل مرة يتحقق فيها الشرط المشترك. القوادح التي تحدث قبل تنفيذ التعليمة التي تحقق الشرط هي BEFORE INSERT و BEFORE UPDATE و BEFORE DELETE، ويمكن استخدامها لمعالجة البيانات والتحقق من صحتها قبل إدراجها أو تحديثها في الجدول أو لحفظ تفاصيل الصف المحذوف لأغراض التدقيق أو الأرشفة. المحفّزات التي تحدث بعد تنفيذ التعليمة التي تحقق الشرط هي AFTER INSERT و AFTER UPDATE و AFTER DELETE، ويمكن استخدامها لتحديث القيم الملخَّصة في جدول منفصل بناءً على الحالة النهائية لقاعدة البيانات بعد التعليمة. يمكن تنفيذ إجراءات مثل التحقق من صحة بيانات الدخل، ومعالجتها، أو أرشفة الصف المحذوف، إذ تسمح قاعدة البيانات بالوصول إلى قيم البيانات من داخل القوادح، ويمكن استخدام البيانات المدرَجة حديثًا فقط بالنسبة لقوادح INSERT، ويمكن الوصول إلى كلٍّ من البيانات الأصلية والمُحدَّثة بالنسبة لمحفّزات UPDATE، وتكون بيانات الصف الأصلية فقط متاحة للاستخدام بالنسبة لمحفّزات DELETE نظرًا لعدم وجود بيانات جديدة للإشارة إليها. يمكن الوصول للبيانات المُستخدَمة في جسم القادح ضمن السجل OLD بالنسبة للبيانات الموجودة حاليًا في قاعدة البيانات والسجل NEW بالنسبة للبيانات التي سيحفظها الاستعلام، ويمكن الإشارة إلى الأعمدة الفردية باستخدام الصيغة OLD.column_name و OLD.column_name. يوضّح المثال التالي الصيغة العامة لتعليمة SQL المُستخدَمة لإنشاء قادح جديد: mysql> CREATE TRIGGER trigger_name trigger_condition mysql> ON table_name mysql> FOR EACH ROW mysql> trigger_actions; لنشرح التعليمة السابقة بالتفصيل: CREATE TRIGGER: اسم تعليمة SQL المُستخدَمة لإنشاء قادح جديد في قاعدة البيانات trigger_name: هو الاسم الذي يحدّده المستخدم للقادح، ويصف دوره مثل استخدام أسماء الجداول وأسماء الأعمدة لوصف معناها ON table_name: نخبر قاعدة البيانات بأن القادح يجب أن يراقب الأحداث التي تحدث في الجدول table_name trigger_condition: أحد الاختيارات الستة المُحتملة التي تحدد متى يجب تشغيل القادح مثل BEFORE INSERT. FOR EACH ROW: تخبر قاعدة البيانات بأنه يجب تشغيل القادح لكل صف يتأثر بالحدث. تدعم بعض قواعد البيانات أنماطًا إضافية للتنفيذ مختلف عن النمط FOR EACH ROW، ولكن تشغيل التعليمات من جسم القادح لكل صف متأثر بالتعليمة التي تسبّبت في تنفيذ القادح هو الخيار الوحيد في حال MySQL trigger_actions: جسم القادح الذي يحدّد ما يحدث عند تنفيذه، وهو تعليمة SQL واحدة، ويمكن تضمين تعليمات متعددة في جسم القادح لإجراء عمليات معقدة باستخدام الكلمات المفتاحية BEGIN و END لتضمين التعليمات ضمن كتلة، ولكن ذلك خارج نطاق هذا المقال اطّلع على التوثيق الرسمي للمحفّزات لمعرفة المزيد حول الصيغة المُستخدمَة لتعريف القوادح. سننشئ في القسم التالي أمثلة على قوادح تعالج البيانات قبل إجراء عمليتي INSERT و UPDATE. معالجة البيانات باستخدام محفزات BEFORE INSERT و BEFORE UPDATE سنستخدم في هذا القسم قوادح لمعالجة البيانات قبل تنفيذ تعليمات INSERT و UPDATE، حيث سنستخدم المحفّزات في للتأكّد من أن جميع الهدايا التذكارية في قاعدة البيانات تستخدم أسماءً بحروف كبيرة لتحقيق التناسق. في حال لم نستخدم قوادح سيتوجب علينا تذكّر استخدام أسماء الهدايا التذكارية بحروف كبيرة لكل تعليمة INSERT و UPDATE، وإذا نسينا، فستحتفظ قاعدة البيانات بالبيانات كما هي وهذا قد يؤدي إلى حدوث أخطاء محتملة في مجموعة البيانات. لنبدأ بإدخال مثال لعنصر من الهدايا التذكارية بالاسم spaceship model وبقيمة 12.50 دولار، وسنكتب اسم العنصر بحروف صغيرة لتوضيح المشكلة. لننفّذ التعليمة التالية: mysql> INSERT INTO collectibles VALUES ('spaceship model', 12.50); تؤكد الرسالة التالية إضافة العنصر: Query OK, 1 row affected (0.009 sec) يمكننا التحقق من إدراج الصف من خلال تنفيذ استعلام SELECT التالي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | spaceship model | 12.50 | +-----------------+-------+ 1 row in set (0.000 sec) حُفِظ هذا العنصر كما هو مع كتابة اسمه بحروف صغيرة فقط. لنتأكد من كتابة جميع الهدايا التذكارية اللاحقة بحروف كبيرة دائمًا من خلال إنشاء قادح باسم BEFORE INSERT لمعالجة البيانات المُمرَّرة إلى قاعدة البيانات قبل حدوثها. نشغّل الآن التعليمة التالية: mysql> CREATE TRIGGER uppercase_before_insert BEFORE INSERT mysql> ON collectibles mysql> FOR EACH ROW mysql> SET NEW.name = UPPER(NEW.name); ينشئ الأمر السابق قادح باسم uppercase_before_insert، والذي سيُنفَّذ قبل كافة تعليمات INSERT في الجدول collectibles. تُنفَّذ التعليمة الموجودة في القادحSET NEW.name = UPPER(NEW.name) لكل صف مدرج، ويسند أمر SQL الذي هو SET القيمة الموجودة على الجانب الأيمن إلى الجانب الأيسر، حيث يمثل NEW.name قيمة العمود name الذي ستحفظه تعليمة الإدراج. نحوّل حالة الحروف للقيمة التي ستُحفَظ في قاعدة البيانات من خلال تطبيق الدالة UPPER على اسم الهدية وإسناده مرة أخرى لقيمة العمود. ملاحظة: قد تظهر رسالة خطأ مشابهة للخطأ التالي عند تشغيل الأمر CREATE TRIGGER. ERROR 1419 (HY000): You do not have the SUPER privilege, and binary logging is enabled (you might want to use the less safe log_bin_trust_function_creators variable) التسجيل الثنائي Binary Logging هو آلية تُسجل كل التعديلات التي تتم على قاعدة البيانات مثل إضافة أو تعديل أو حذف بيانات في سجل ثنائي، ويحتوي هذا السجل على أحداث Events تصف التعديلات التي حدثت وتحفظها بتنسيق ثنائي يمكن معالجته، وهذا التسجيل يكون مفعَّلًا افتراضيًا في محرّك قاعدة بيانات MySQL وذلك بدءًا من الإصدار MySQL 8، حيث يتعقّب التسجيل الثنائي جميع تعليمات SQL التي تعدّل محتويات قاعدة البيانات في صيغة أحداث محفوظة تَصِف هذه التعديلات، وتُستخدَم هذه السجلات في النسخ المتماثل Replication لقاعدة البيانات للحفاظ على مزامنة النسخ المتماثلة لقاعدة البيانات وأثناء استعادة البيانات في الوقت المناسب. لكن لا يسمح MySQL بإنشاء القوادح Triggers والإجراءات المخزَّنة Stored Procedures في حال تفعيل تسجيل التعديلات أو الأحداث بصيغة ثنائية كإجراء احترازي لضمان سلامة البيانات وتكاملها في بيئات النسخ المتماثل Replication، ولكن فهم كيفية تأثير القوادح والإجراءات المُخزَّنة على النسخ المتماثل خارج نطاق هذا المقال. يمكننا تجاوز القيود التي يفرضها MySQL عند تفعيل التسجيل الثنائي Binary Logging، وذلك لأغراض التعلم أو الاختبار في بيئة محلية على جهازنا الشخصي، ولكن لن يستمر هذا الإعداد الذي عدّلناه بالعمل وسيعود للقيمة الأصلية عند إعادة تشغيل خادم MySQL. يمكن تجاوز الإعداد الافتراضي من خلال تعديل الإعدادات الخاصة بـ MySQL كما يلي: mysql> SET GLOBAL log_bin_trust_function_creators = 1; يتحكم الإعداد log_bin_trust_function_creators بإمكانية الوثوق بالمستخدمين الذين ينشئون القوادح والدوال المخزنة بحيث لا ينشئون قوادح تتسبب في كتابة أحداث غير آمنة في السجل الثنائي. تكون قيمة الإعداد الافتراضية هي 0، مما يسمح للمستخدمين الذين يتمتعون بصلاحيات مميزة فقط بإنشاء قوادح في البيئة التي فعّلنا فيها تسجيل التعديلات أو الأحداث بصيغة ثنائية، وإذا عدّلنا القيمة إلى 1، فسنثق بأيّ مستخدم ينشئ تعليمات CREATE TRIGGER لفهم النتائج. جرى الآن تحديث الإعداد، لنعمل إذًا على تسجيل الخروج كمستخدم جذر، وتسجيل الدخول مرة أخرى كمستخدم عادي، ونعيد تشغيل تعليمة CREATE TRIGGER. ويمكن الاطلاع على توثيق MySQL الرسمي: السجل الثنائي و تسجيل التعديلات أو الأحداث بصيغة ثنائية للبرنامج المخزن، كما يمكن مطالعة مقال كيفية إعداد النسخ المتماثل في MySQL لمعرفة المزيد حول تسجيل التعديلات أو الأحداث بصيغة ثنائية والنسخ المتماثل في MySQL وارتباطه بالقوادح. ملاحظة: قد نتلقى خطأً عند تنفيذ أمر CREATE TRIGGER اعتمادًا على أذونات مستخدم MySQL الخاصة بنا ERROR 1142 (42000): TRIGGER command denied to user 'user'@'host' for table 'collectibles' لحل هذا الخطأ يمكن منح أذونات TRIGGER للمستخدم الخاص بنا من خلال تسجيل الدخول إلى MySQL كمستخدم جذر، وتنفيذ الأوامر التالية مع وضع اسم مستخدم MySQL والمضيف حسب الحاجة: mysql> GRANT TRIGGER on *.* TO 'user'@'localhost'; mysql> FLUSH PRIVILEGES; نحدّث أذونات المستخدم، ثم نسجّل الخروج كمستخدم جذر، ونسجّل الدخول مرة أخرى كمستخدم عادي، ونعيد تشغيل التعليمة CREATE TRIGGER، وسيطبع MySQL الرسالة التالية للتأكد من إنشاء القادح بنجاح: Query OK, 1 row affected (0.009 sec) نحاول الآن إدراج مجموعة هدايا تذكارية جديدة باستخدام وسيط بحروف صغيرة مع استعلام INSERT كما يلي: mysql> INSERT INTO collectibles VALUES ('aircraft model', 10.00); ثم نتحقّق من الصفوف الناتجة في الجدول collectibles كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | spaceship model | 12.50 | | AIRCRAFT MODEL | 10.00 | +-----------------+-------+ 2 rows in set (0.000 sec) يشير الإدخال الجديد هذه المرة إلى أن AIRCRAFT MODEL -مع جميع حروفه الكبيرة- يختلف عن الإدخال الذي حاولنا إدراجه، حيث شُغِّل القادح في الخلفية وحوّل حالة الحروف قبل حفظ الصف في قاعدة البيانات. يحمي القادح جميع الصفوف الجديدة لضمان حفظ الأسماء بحروف كبيرة، ولكن لا يزال من الممكن حفظ البيانات غير المقيَّدة التي تستخدم تعليمات UPDATE، حيث يمكن حماية تعليمات UPDATE باستخدام التأثير نفسه، إذًا لننشئ قادحًا آخر كما يلي: mysql> CREATE TRIGGER uppercase_before_update BEFORE UPDATE mysql> ON collectibles mysql> FOR EACH ROW mysql> SET NEW.name = UPPER(NEW.name); يكمن الفرق بين القادحين في المعايير، فالقادح هنا BEFORE UPDATE، مما يعني تنفيذه في كل مرة تُنفَّذ فيها تعليمة UPDATE مع الجدول، ويؤثر ذلك على الصفوف الموجودة في كل تحديث، بالإضافة إلى الصفوف الجديدة التي يؤثر عليها القادح السابق. سيعطي MySQL تأكيدًا بإنشاء القادح بنجاح كما يلي: Query OK, 0 row affected (0.009 sec) يمكن التحقق من سلوك القادح الجديد من خلال تحديث قيمة سعر spaceship model كما يلي: mysql> UPDATE collectibles SET value = 15.00 WHERE name = 'spaceship model'; ترشّح تعليمة WHERE الصف المراد تحديثه حسب الاسم، وتغيّر تعليمة SET القيمة إلى 15.00، وسيظهر الخرج التالي، مما يؤكد أن التعليمة قد غيّرت صفًا واحدًا: Query OK, 1 row affected (0.002 sec) Rows matched: 1 Changed: 1 Warnings: 0 لنتحقّق الآن من الصفوف الناتجة في الجدول collectibles كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | SPACESHIP MODEL | 15.00 | | AIRCRAFT MODEL | 10.00 | +-----------------+-------+ 2 rows in set (0.000 sec) أصبح الاسم الآن SPACESHIP MODEL بالإضافة إلى تحديث السعر إلى 15.00 باستخدام التعليمة المُنفَّذة. إذا شغّلنا تعليمة UPDATE، فسيُنفَّذ القادح، مما يؤثر على القيم الموجودة في الصف المُحدَّث، مع تحويل عمود الاسم إلى حروف كبيرة قبل الحفظ. أنشأنا في هذا القسم قادحين Triggersيعملان قبل استعلامات INSERT وقبل استعلامات UPDATE لجعل البيانات ملائمةً قبل حفظها في قاعدة البيانات، وسنستخدم في القسم التالي محفّزات BEFORE DELETE لنسخ الصفوف المحذوفة في جدول منفصل للأرشفة. استخدام قوادح BEFORE DELETE قد نرغب في أرشفة البيانات بدلاً من حذفها نهائيًا من قاعدة البيانات، خاصةً إذا كنا بحاجة للاحتفاظ بسجل لهذه البيانات في المستقبل، فإذ أنشأنا في بداية هذا المقال جدول آخر باسم collectibles_archive لتعقّب جميع الهدايا التذكارية المحذوفة من المجموعة وأرشفتها. سنستخدم قادح يُنفَّذ قبل تنفيذ تعليمات الحذف DELETE. نتحقّق أولًا مما إذا كان جدول الأرشيف فارغًا بالكامل من خلال تنفيذ التعليمة التالية: mysql> SELECT * FROM collectibles_archive; وسيظهر الخرج التالي، مما يؤكد أن الجدول collectibles_archive فارغ: Empty set (0.000 sec) إذا نفّذنا استعلام DELETE مع الجدول collectibles، فيمكن حذف أيّ صفٍ من الجدول دون أيّ أثر. يمكن معالجة ذلك من خلال إنشاء قادح يُنفَّذ قبل جميع استعلامات DELETE مع الجدول collectibles، والغرض من هذا القادح هو حفظ نسخة من الكائن المحذوف في جدول الأرشيف قبل حدوث الحذف. لنشغّل الآن الأمر التالي: mysql> CREATE TRIGGER archive_before_delete BEFORE DELETE mysql> ON collectibles mysql> FOR EACH ROW mysql> INSERT INTO collectibles_archive (name, value) VALUES (OLD.name, OLD.value); يُسمَّى هذا القادح باسم archive_before_delete ويحدث قبل أيّ استعلامات DELETE مع الجدول collectibles. ستُنفَّذ تعليمة INSERT لكل صفٍ سيُحذف، بينما تدرج تعليمة INSERT صفًا جديدًا في الجدول collectibles_archive مع قيم البيانات المأخوذة من السجل OLD، وهو السجل المقرّر حذفه، حيث يصبح OLD.name هو العمود name ويصبح OLD.value العمود value. وتؤكد قاعدة البيانات إنشاء هذا القادح كما يلي: Query OK, 0 row affected (0.009 sec) نحاول حذف إحدى الهدايا التذكارية من الجدول collectibles الرئيسي مع استخدام القادح كما يلي: mysql> DELETE FROM collectibles WHERE name = 'SPACESHIP MODEL'; ويؤكّد الخرج التالي نجاح تشغيل الاستعلام السابق: Query OK, 1 row affected (0.004 sec) لنسرد الآن جميع الهدايا التذكارية كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +----------------+-------+ | name | value | +----------------+-------+ | AIRCRAFT MODEL | 10.00 | +----------------+-------+ 1 row in set (0.000 sec) حذفنا SPACESHIP MODEL ولم يَعُد موجودًا في الجدول مع بقاء AIRCRAFT MODEL، ولكن يجب تسجيل هذا الحذف في الجدول collectibles_archive باستخدام القادح الذي أنشأناه مسبقًا، إذًا لنتحقق من ذلك، ولننفّذ استعلامًا آخر كما يلي: mysql> SELECT * FROM collectibles_archive; وسيظهر الخرج التالي: +-----------------+-------+---------------------+ | name | value | removed_on | +-----------------+-------+---------------------+ | SPACESHIP MODEL | 15.00 | 2022-11-20 11:32:01 | +-----------------+-------+---------------------+ 1 row in set (0.000 sec) لاحظ القادح عملية الحذف في هذا الجدول تلقائيًا، مع تعبئة أعمدة name و value بالبيانات من الصف المحذوف، ولم يضبط القادح العمود الثالث removed_on صراحةً، لذلك سيأخذ القيمة الافتراضية المُحدَّدة أثناء إنشاء الجدول، أي تاريخ إنشاء أيّ صف جديد، مما يؤدي دائمًا إلى إضافة تعليق توضيحي لكل إدخال مُضاف بمساعدة القادح مع تاريخ الحذف. يمكننا الآن مع وجود هذا القادح التأكد من أن جميع استعلامات DELETE ستؤدي إلى إدخال سجلٍ في الجدول collectibles_archive مع ترك معلومات حول الهدايا التذكارية المملوكة مسبقًا. سنستخدم في القسم التالي القوادح التي تُنفَّذ بعد تعليمات تحديث الجدول الذي يحتوي على القيم المُجمَّعة بناءً على جميع الهدايا التذكارية. استخدام محفزات AFTER INSERT و AFTER UPDATE و AFTER DELETE استخدمنا في القسمين السابقين القوادح المُنفَّذة قبل التعليمات الرئيسية لتنفيذ العمليات المستندة إلى البيانات الأصلية قبل تحديث قاعدة البيانات، وسنحدّث في هذا القسم جدول البيانات التلخيصية بالعدد والقيمة المتراكمة لجميع الهدايا التذكارية المحدَّثة دائمًا باستخدام القوادح المُنفَّذة بعد التعليمات المطلوبة، وبذلك سنكون متأكدين من أن بيانات الجدول تأخذ في الحسبان الحالة الحالية لقاعدة البيانات. لنبدأ الآن بفحص الجدول collectibles_stats كما يلي: mysql> SELECT * FROM collectibles_stats; لم نضف معلومات إلى هذا الجدول بعد، لذا يكون عدد عناصر الهدايا التذكارية المملوكة هو 0، والقيمة التراكمية هي NULL: +-------+-------+ | count | value | +-------+-------+ | 0 | NULL | +-------+-------+ 1 row in set (0.000 sec) لا توجد قوادح لهذا الجدول، وبالتالي لم تؤثر الاستعلامات الصادرة مسبقًا لإدراج الهدايا التذكارية وتحديثها على هذا الجدول. نريد ضبط القيم في صفٍ واحد من الجدول collectibles_stats لتقديم معلومات مُحدَّثة حول عدد الهدايا التذكارية وقيمتها الإجمالية، حيث نتأكد من تحديث محتويات الجدول بعد كل عملية إدراج INSERT أو تحديث UPDATE أو حذف DELETE من خلال إنشاء ثلاثة قوادح منفصلة وتنفيذها بعد الاستعلام المقابل لها. لننشئ أولًا القادح AFTER INSERT: mysql> CREATE TRIGGER stats_after_insert AFTER INSERT mysql> ON collectibles mysql> FOR EACH ROW mysql> UPDATE collectibles_stats mysql> SET count = ( mysql> SELECT COUNT(name) FROM collectibles mysql> ), value = ( mysql> SELECT SUM(value) FROM collectibles mysql> ); سمّينا القادح بالاسم stats_after_insert وسيُنفَّذ بعد AFTER كل استعلام INSERT في الجدول collectibles مع تشغيل تعليمة UPDATE في جسم القادح. يؤثر استعلام UPDATE على جدول البيانات التلخيصية ويضبط العمودين count و value على القيم التي تعيدها الاستعلامات المتداخلة كما يلي: SELECT COUNT(name) FROM collectibles: يحصل على عدد الهدايا التذكارية SELECT SUM(value) FROM collectibles: يحصل على القيمة الإجمالية لجميع الهدايا التذكارية وتؤكّد قاعدة البيانات إنشاء القادح كما يلي: Query OK, 0 row affected (0.009 sec) نجرّب الآن إعادة إدراج spaceship model المحذوف مسبقًا في الجدول collectibles للتحقق من التحديث الصحيح لجدول البيانات التلخيصية كما يلي: mysql> INSERT INTO collectibles VALUES ('spaceship model', 15.00); وتطبع قاعدة البيانات رسالة النجاح التالية: Query OK, 1 row affected (0.009 sec) يمكن سرد جميع الهدايا التذكارية المملوكة باستخدام الاستعلام التالي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | AIRCRAFT MODEL | 10.00 | | SPACESHIP MODEL | 15.00 | +-----------------+-------+ 2 rows in set (0.000 sec) يوجد نوعان من عناصر الهدايا التذكارية التي تبلغ قيمتها الإجمالية 25.00. لنفحص الآن جدول البيانات التلخيصية بعد العنصر الذي أدرجناه حديثًا من خلال تنفيذ الاستعلام التالي: mysql> SELECT * FROM collectibles_stats; سيسرد الجدول هذه المرة عدد جميع عناصر الهدايا التذكارية المملوكة التي هي 2 وقيمتها التراكمية 25.00، والتي تطابق الخرج السابق: +-------+-------+ | count | value | +-------+-------+ | 2 | 25.00 | +-------+-------+ 1 row in set (0.000 sec) يُنفَّذ القادح stats_after_insert بعد استعلام INSERT ويحدّث الجدول collectibles_stats بالبيانات الحالية count و value للمجموعة، وتُجمَع إحصائيات محتويات المجموعة بأكملها، وليس الإدخال الأخير فقط. تحتوي المجموعة الآن على عنصرين spaceship model و aircraft model، لذا يسرد جدول البيانات التلخيصية عنصرين مع قيمتهما الإجمالية، وبالتالي ستؤدي إضافة أيّ عنصر هدية تذكارية جديد إلى الجدول collectibles إلى تحديث جدول البيانات التلخيصية بالقيم الصحيحة، ولكن لن يؤثر تحديث العناصر الموجودة أو حذف الهدايا التذكارية على جدول البيانات التلخيصية أبدًا، لذا سننشئ قادحين إضافيين لإجراء عمليات متطابقة ولكن تحفّزها أحداث مختلفة كما يلي: mysql> CREATE TRIGGER stats_after_update AFTER UPDATE mysql> ON collectibles mysql> FOR EACH ROW mysql> UPDATE collectibles_stats mysql> SET count = ( mysql> SELECT COUNT(name) FROM collectibles mysql> ), value = ( mysql> SELECT SUM(value) FROM collectibles mysql> ); mysql> mysql> CREATE TRIGGER stats_after_delete AFTER DELETE mysql> ON collectibles mysql> FOR EACH ROW mysql> UPDATE collectibles_stats mysql> SET count = ( mysql> SELECT COUNT(name) FROM collectibles mysql> ), value = ( mysql> SELECT SUM(value) FROM collectibles mysql> ); أنشأنا قادحين جديدين هما: stats_after_update و stats_after_delete، وسيُنفّذان مع الجدول collectible_stats عند تنفيذ تعليمة UPDATE أو DELETE في الجدول collectibles. يؤدي الإنشاء الناجح لهذين القادحين إلى طباعة الخرج التالي: Query OK, 0 row affected (0.009 sec) لنحدّث الآن قيمة السعر لإحدى الهدايا التذكارية كما يلي: mysql> UPDATE collectibles SET value = 25.00 WHERE name = 'AIRCRAFT MODEL'; ترشّح تعليمة WHERE الصف المراد تحديثه حسب الاسم، وتغيّر تعليمة SET القيمة إلى 25.00. يؤكّد الخرج التالي أن التعليمة غيّرت صفًا واحدًا: Query OK, 1 row affected (0.002 sec) Rows matched: 1 Changed: 1 Warnings: 0 لنتحقق مرة أخرى من محتويات جدول البيانات التلخيصية بعد التحديث كما يلي: mysql> SELECT * FROM collectibles_stats; وسيسرد العمود value الآن القيمة 40.00، وهي القيمة الصحيحة بعد التحديث: +-------+-------+ | count | value | +-------+-------+ | 2 | 40.00 | +-------+-------+ 1 row in set (0.000 sec) الخطوة الأخيرة هي التحقق من أن جدول البيانات التلخيصية سيظهِر حذف إحدى الهدايا التذكارية بطريقة صحيحة، فلنحاول حذف العنصر aircraft model كما يلي: mysql> DELETE FROM collectibles WHERE name = 'AIRCRAFT MODEL'; ويؤكد الخرج التالي تشغيل الاستعلام بنجاح: Query OK, 1 row affected (0.004 sec) لنسرد الآن جميع الهدايا التذكارية كما يلي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | SPACESHIP MODEL | 15.00 | +-----------------+-------+ 1 row in set (0.000 sec) لاحظ بقاء العنصر SPACESHIP MODEL فقط. لنتحقق الآن من القيم الموجودة في جدول البيانات التلخيصية كما يلي: mysql> SELECT * FROM collectibles_stats; وسيظهر الخرج التالي: +-------+-------+ | count | value | +-------+-------+ | 1 | 15.00 | +-------+-------+ 1 row in set (0.000 sec) يعرض العمود count الآن هدية تذكارية واحدة فقط في الجدول الرئيسي، والقيمة الإجمالية هي 15.00، وهي مطابقة لقيمة العنصر SPACESHIP MODEL. تعمل المحفّزات الثلاثة السابقة مع بعضها البعض بعد استعلامات INSERT و UPDATE و DELETE للحفاظ على مزامنة جدول الملخص مع القائمة الكاملة للهدايا التذكارية. سنتعلم في القسم التالي كيفية معالجة القوادح الموجودة مسبقًا مع قاعدة البيانات. سرد وحذف القوادح Triggers أنشأنا في الأقسام السابقة قوادح جديدة، ولكن يمكنك أيضًا سردها ومعالجتها عند الحاجة لأنها كائنات مسمَّاة ومُعرَّفة في قاعدة البيانات مثل الجداول، حيث يمكنك سرد جميع القوادح من خلال تنفيذ التعليمة SHOW TRIGGERS كما يلي: mysql> SHOW TRIGGERS; وسيتضمن الخرج جميع القوادح مع أسمائها وحدث التحفيز مع الوقت قبل BEFORE أو بعد AFTER تنفيذ التعليمة، بالإضافة إلى التعليمات التي تشكّل جزءًا من جسم القادح والتفاصيل الشاملة الأخرى لتعريفه كما يلي: +-------------------------+--------+--------------+--------(...)+--------+(...) | Trigger | Event | Table | Statement | Timing |(...) +-------------------------+--------+--------------+--------(...)+--------+(...) | uppercase_before_insert | INSERT | collectibles | SET (...)| BEFORE |(...) | stats_after_insert | INSERT | collectibles | UPDATE (...)| AFTER |(...) | uppercase_before_update | UPDATE | collectibles | SET (...)| BEFORE |(...) | stats_after_update | UPDATE | collectibles | UPDATE (...)| AFTER |(...) | archive_before_delete | DELETE | collectibles | INSERT (...)| BEFORE |(...) | stats_after_delete | DELETE | collectibles | UPDATE (...)| AFTER |(...) +-------------------------+--------+--------------+--------(...)+--------+(...) 6 rows in set (0.001 sec) يمكن حذف القوادح الموجودة مسبقًا من خلال استخدام تعليمات SQL التي هي DROP TRIGGER، فمثلًا إن لم نعد نرغب بفرض الحروف الكبيرة على أسماء الهدايا التذكارية، ولم نعد بحاجة إلى القادحين uppercase_before_insert و uppercase_before_update، فيمكننا إزالتهما من خلال تنفيذ الأمرين التالية: mysql> DROP TRIGGER uppercase_before_insert; mysql> DROP TRIGGER uppercase_before_update; ويستجيب MySQL برسالة النجاح التالية: Query OK, 0 rows affected (0.004 sec) لنجرّب الآن إضافة هدية تذكارية جديدة بحروف صغيرة كما يلي: mysql> INSERT INTO collectibles VALUES ('ship model', 10.00); وستؤكد قاعدة البيانات ذلك كما يلي: Query OK, 1 row affected (0.009 sec) يمكننا التحقق من إدراج الصف من خلال تنفيذ استعلام SELECT التالي: mysql> SELECT * FROM collectibles; وسيظهر الخرج التالي: +-----------------+-------+ | name | value | +-----------------+-------+ | SPACESHIP MODEL | 15.00 | | ship model | 10.00 | +-----------------+-------+ 2 rows in set (0.000 sec) نلاحظ كتابة الهدية التذكارية المضافة حديثًا بحروف صغيرة، إذًا لم يتغيّر الاسم عن الخرج الأصلي، وبالتالي تأكّدنا من أن القادح الذي حوّل حالة الحروف سابقًا لم يَعُد قيد الاستخدام. الخلاصة تعلمنا في هذا المقال ما هي القوادح Triggers في SQL وكيفية استخدامها في MySQL لمعالجة البيانات قبل استعلامات INSERT و UPDATE، وتعلّمنا كيفية استخدام قادح BEFORE DELETE لأرشفة الصف المحذوف في جدول منفصل، بالإضافة إلى استخدام قوادح AFTER بعد التعليمات لإبقاء جدول البيانات التلخيصية مُحدَّثة باستمرار. يمكننا استخدام الدوال لتفريغ بعض عمليات معالجة البيانات والتحقق من صحتها في محرّك قاعدة البيانات، مما يضمن سلامة البيانات أو إخفاء بعض سلوكيات قاعدة البيانات عن المستخدم الذي يستخدم قاعدة البيانات يوميًا، وقد غطّى هذا المقال أساسيات استخدام القوادح لهذا الغرض فقط، ولكن يمكنك أيضًا إنشاء قوادح معقدة تتكوّن من تعليمات متعددة واستخدام المنطق الشرطي لتنفيذ الإجراءات بدقة أكبر. ويمكن مطالعة توثيق MySQL الخاص بالتعامل مع triggers لمزيد من المعلومات. ترجمة -وبتصرف- للمقال How To Use Triggers in MySQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام الدوال Functions في لغة SQL التعامل مع قواعد البيانات مدخل إلى تصميم قواعد البيانات استخدام الدوال Functions في لغة SQL استخدام العروض Views في لغة الاستعلام البنيوية SQL -
 لا يقتصر التعامل في أنظمة إدارة قواعد البيانات العلاقية Relational Database Management System ولغة الاستعلام البنيوية SQL على تخزين البيانات وإدارتها واسترجاعها من قاعدة البيانات. إذ يمكن للغة SQL أيضًا إجراء عمليات حسابية ومعالجة البيانات عن طريق الدوال Functions، حيث يمكننا على سبيل المثال استخدام دوال محددة لاسترجاع أسعار المنتجات مع تقريب أسعارها، أو حساب متوسط عدد عمليات شراء منتج ما، أو تحديد عدد أيام انتهاء صلاحية الضمان على عملية شراء معينة. سنستخدم في هذا المقال دوالًا مختلفة في لغة SQL من أجل إجراء عمليات حسابية رياضية، ومعالجة السلاسل النصية والتواريخ، وحساب إحصائيات باستخدام الدوال التجميعية Aggregate Functions. مستلزمات العمل يجب أن يكون لديك حاسوب يشغّل نظام إدارة قواعد بيانات علاقية RDBMS مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضّح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال من خلال مستخدم مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال معرفة أساسية بتنفيذ استعلامات SELECT لاختيار البيانات من قاعدة البيانات كما هو موضّح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن تحدّد صيغة SQL المعيارية عددًا محدودًا من الدوال، ويختلف دعم الصيغة المعيارية بين محرّكات قواعد البيانات المختلفة، لذا قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام الدوال، ويمكن مطالعة القسم التالي للحصول على تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية التي سنستخدمها في أمثلتنا. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وننشئ قاعدة بيانات تجريبية لنتمكّن من اتباع الأمثلة الواردة في هذا المقال. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشِئ قاعدة بيانات بالاسم bookstore: mysql> CREATE DATABASE bookstore; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات bookstore من خلال تنفيذ تعليمة USE التالية: $ USE bookstore; وسيَظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، وسننشئ عدة جداول تجريبية ضمنها، حيث سنستخدم مكتبة افتراضية تبيع كتبًا لعدة مؤلفين. سيحتوي الجدول inventory على بيانات كتب ممثّلة باستخدام الأعمدة التالية: book_id: المعرّف الخاص بكل كتاب، ونمثّله بنوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي Primary Key للجدول، حيث تصبح كل قيمة معرّفًا فريدًا للصف الخاص بها author: اسم مؤلف الكتاب، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا title: عنوان الكتاب الذي جرى شراؤه، ونمثّله باستخدام نوع بيانات varchar بحد أقصى 200 محرف introduction_date: تاريخ تقديم المكتبة لكل كتاب، ونمثّله باستخدام نوع البيانات date stock: يحتوي هذا العمود على عدد الكتب الموجودة في مخزن المكتبة، ونمثّله باستخدام نوع البيانات int price: سعر الكتاب، ونمثّله باستخدام نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها ننشئ هذا الجدول التجريبي باستخدام الأمر التالي: CREATE TABLE inventory ( mysql> book_id int, mysql> author varchar(50), mysql> title varchar(200), mysql> introduction_date date, mysql> stock int, mysql> price decimal(5, 2), mysql> PRIMARY KEY (book_id) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول الأول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل جدول المشتريات ببعض البيانات التجريبية من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO inventory mysql> VALUES mysql> (1, 'Oscar Wilde', 'The Picture of Dorian Gray', '2022-10-01', 4, 20.83), mysql> (2, 'Jane Austen', 'Pride and Prejudice', '2022-10-04', 12, 42.13), mysql> (3, 'Herbert George Wells', 'The Time Machine', '2022-09-23', 7, 21.99), mysql> (4, 'Mary Shelley', 'Frankenstein', '2022-07-23', 9, 17.43), mysql> (5, 'Mark Twain', 'The Adventures of Huckleberry Finn', '2022-10-01', 14, 23.15); ستضيف عملية INSERT INTO خمسة كتب إلى الجدول inventory، حيث يشير الخرج التالي إلى إضافة جميع الصفوف الخمسة بنجاح: الخرج Query OK, 5 rows affected (0.00 sec) Records: 5 Duplicates: 0 Warnings: 0 نحن الآن جاهزون لمتابعة هذا المقال والبدء في استخدام الدوال في لغة SQL. فهم الدوال في لغة SQL الدوال functions هي عدة تعابير مجمعة ولها اسم محدد، قد تأخذ قيمة واحدة أوعدة قيم تمرر كوسطاء بين قوسين بعد اسم الدالة، وتجري عمليات حسابية أو تحويلات عليها، ثم تعيد قيمة جديدة كنتيجة للدالة، حيث تشبه دوال SQL الدوال الرياضية، فمثلًا تأخذ الدالة log(x) قيمة x وتعيد قيمة لوغاريتم هذه القيمة x. يمكننا استرجاع المعلومات من قاعدة بيانات علاقية دون تحويلها من خلال استخدام استعلام SELECT، حيث نطلب من قاعدة البيانات إعادة قيم للأعمدة الفردية التي نريدها من خلال تحديد أسماء الأعمدة في الاستعلام، فمثلًا إذا أردنا استرجاع جميع عناوين الكتب مع أسعارها وترتيبها من الأكثر إلى الأقل تكلفة، فيمكن تنفيذ التعليمة التالية: mysql> SELECT title, price, introduction_date FROM inventory ORDER BY price DESC; وسيظهر الخرج التالي: الخرج +------------------------------------+-------+-------------------+ | title | price | introduction_date | +------------------------------------+-------+-------------------+ | Pride and Prejudice | 42.13 | 2022-10-04 | | The Adventures of Huckleberry Finn | 23.15 | 2022-10-01 | | The Time Machine | 21.99 | 2022-09-23 | | The Picture of Dorian Gray | 20.83 | 2022-10-01 | | Frankenstein | 17.43 | 2022-07-23 | +------------------------------------+-------+-------------------+ 5 rows in set (0.000 sec) تكون title و price و introduction_date في التعليمة السابقة أسماء الأعمدة، وتعطي قاعدة البيانات في الخرج الناتج قيمًا غير مُعدَّلة مُسترجَعة من تلك الأعمدة لكل كتاب وهي عنوان الكتاب، والسعر ، وتاريخ إدخال الكتاب إلى المكتبة. قد نرغب في استرجاع القيم من قاعدة البيانات بعد إجراء بعض المعالجة، فقد نكون مهتمين بأسعار الكتب مع تقريبها إلى أقرب سعر بالدولار، أو كتابة عناوين الكتب بحروف كبيرة، أو عرض سنة تقديم الكتاب دون تضمين الشهر أو اليوم، لذا يجب أن نستخدم دوال مناسبة لذلك. أشهر الدوال في لغة SQL يمكن تصنيف دوال SQL إلى عدة مجموعات اعتمادًا على نوع البيانات التي نعمل عليها، ونوضح فيما يلي الدوال الأكثر استخدامًا في SQL. الدوال الرياضية هي الدوال التي تعمل على معالجة القيم العددية وتجري العمليات الحسابية عليها، مثل التقريب أو اللوغاريتمات أو الجذور التربيعية أو الرفع لأس دوال معالجة السلاسل النصية هي دوال تعمل على السلاسل والحقول النصية، وتجري تحويلات نصية مثل تحويل أحرف النص إلى حروف كبيرة، أو إزالة الفراغات من بدايات ونهايت السلاسل النصية Trimming، أو استبدال الكلمات في النص بكلمات أخرى. دوال التاريخ والوقت هي دوال تتعامل مع الحقول التي تحتوي على تواريخ، وتُجري هذه الدوال عمليات حسابية وتحويلات مثل إضافة عدد من الأيام إلى التاريخ المُحدَّد، أو أخذ سنة واحدة فقط من التاريخ الكامل. الدوال التجميعية Aggregate Functions هي حالة خاصة من الدوال الرياضية التي تعمل على قيم قادمة من صفوف متعددة مثل حساب متوسط السعر لجميع الصفوف. مثال على استدعاء دالة يوضّح المثال التالي الصيغة العامة لاستخدام دالة وهمية بالاسم EXAMPLE لتغيير نتائج قيم السعر price في قاعدة بيانات المكتبة باستخدام استعلام SELECT التالي: mysql> SELECT EXAMPLE(price) AS new_price FROM inventory; تأخذ الدالة EXAMPLE اسم العمود price كوسيط ، حيث يخبر هذا الجزء من الاستعلام قاعدة البيانات بتنفيذ الدالة EXAMPLE على قيم العمود price وإعادة نتائج هذه العملية، ويخبر جزء الاستعلام AS new_price قاعدة البيانات بإسناد اسم مؤقت new_price للقيم المحسوبة خلال فترة تنفيذ الاستعلام، وبذلك يمكننا تمييز نتائج الدالة في الخرج والإشارة إلى القيم الناتجة باستخدام تعلميتي WHERE و ORDER BY. سنستخدم في القسم التالي الدوال الرياضية لإجراء العمليات الحسابية شائعة الاستخدام. استخدام الدوال الرياضية تعمل الدوال الرياضية على القيم العددية مثل سعر الكتاب أو عدد الكتب الموجودة في المخزن ضمن قاعدة البيانات التجريبية، ويمكن استخدامها لإجراء العمليات الحسابية في قاعدة البيانات لمطابقة النتائج مع متطلباتنا. يُعَد التقريب من التطبيقات الأكثر استخدامًا للدوال الرياضية في لغة SQL، فلنفترض مثلًا أننا نريد استرجاع أسعار جميع الكتب، ولكن نريدها أن تكون مُقرَّبة لأقرب عدد صحيح، لذا نستخدم الدالة ROUND التي تطبّق عملية التقريب، ونجرّب تنفيذ التعليمة التالية: mysql> SELECT title, price, ROUND(price) AS rounded_price FROM inventory; سيظهر الخرج التالي: الخرج +------------------------------------+-------+---------------+ | title | price | rounded_price | +------------------------------------+-------+---------------+ | The Picture of Dorian Gray | 20.83 | 21 | | Pride and Prejudice | 42.13 | 42 | | The Time Machine | 21.99 | 22 | | Frankenstein | 17.43 | 17 | | The Adventures of Huckleberry Finn | 23.15 | 23 | +------------------------------------+-------+---------------+ 5 rows in set (0.000 sec) يختار الاستعلام السابق قيم الأعمدة title و price دون تعديل، بالإضافة إلى العمود rounded_price المؤقت الذي يحتوي على نتائج الدالة ROUND(price). تأخذ هذه الدالة وسيطًا واحدًا هو اسم العمود price في مثالنا، وتعيد القيم من هذا العمود في الجدول مع تقريبها إلى أقرب قيمة عددية صحيحة. يمكن لدالة التقريب أيضًا قبول وسيط إضافي يحدّد عدد المنازل العشرية التي يجب تطبيق التقريب عليها، ويمكن إضافة عمليات حسابية بدلًا من الاكتفاء باسم عمود واحد. لنجرّب مثلًا تشغيل الاستعلام التالي: mysql> SELECT title, price, ROUND(price * stock, 1) AS stock_price FROM inventory; وسيظهر الخرج التالي: الخرج +------------------------------------+-------+-------+-------------+ | title | stock | price | stock_price | +------------------------------------+-------+-------+-------------+ | The Picture of Dorian Gray | 4 | 20.83 | 83.3 | | Pride and Prejudice | 12 | 42.13 | 505.6 | | The Time Machine | 7 | 21.99 | 153.9 | | Frankenstein | 9 | 17.43 | 156.9 | | The Adventures of Huckleberry Finn | 14 | 23.15 | 324.1 | +------------------------------------+-------+-------+-------------+ 5 rows in set (0.000 sec) يؤدي تنفيذ الدالة ROUND(price * stock, 1) أولًا إلى ضرب سعر الكتاب الواحد بعدد الكتب الموجودة في المخزن، ثم تقريب السعر الناتج إلى أول منزلة عشرية، وستُعرَض النتيجة في العمود المؤقت stock_price. تتضمّن الدوال الرياضية الأخرى المُضمَّنة في MySQL الدوال المثلثية والجذور التربيعية والرفع لقوة واللوغاريتمات والدوال الأسية. ويمكن معرفة المزيد حول استخدام الدوال الرياضية في لغة SQL في مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في لغة SQL. استخدام دوال معالجة السلاسل النصية تمكّننا دوال معالجة السلاسل النصية في لغة SQL من تعديل القيم المُخزَّنة في الأعمدة التي تحتوي على نصوص عند معالجة استعلام SQL، ويمكن استخدامها لتحويل حالة الحروف، أو دمج بيانات من أعمدة متعددة، أو إجراء عمليات البحث والاستبدال. سنستخدم مثلًا دوال السلاسل النصية لاسترجاع جميع عناوين الكتب المُحوَّلة إلى حروف صغيرة، وننفّذ التعليمة التالية: mysql> SELECT LOWER(title) AS title_lowercase FROM inventory; وسيظهر الخرج التالي: الخرج +------------------------------------+ | title_lowercase | +------------------------------------+ | the picture of dorian gray | | pride and prejudice | | the time machine | | frankenstein | | the adventures of huckleberry finn | +------------------------------------+ 5 rows in set (0.001 sec) تأخذ دالة SQL التي هي LOWER وسيطًا واحدًا وتحوّل محتوياته إلى حروف صغيرة، وستُعرَض البيانات الناتجة في العمود المؤقت title_lowercase باستخدام تعليمة الاسم البديل للعمود AS title_lowercase. لنسترجع الآن جميع أسماء المؤلفين مع تحويلها إلى حروف كبيرة، لذا نجرّب تشغيل استعلام SQL التالي: mysql> SELECT UPPER(author) AS author_uppercase FROM inventory; وسيظهر الخرج التالي: الخرج +----------------------+ | author_uppercase | +----------------------+ | OSCAR WILDE | | JANE AUSTEN | | HERBERT GEORGE WELLS | | MARY SHELLEY | | MARK TWAIN | +----------------------+ 5 rows in set (0.000 sec) استخدمنا الدالة UPPER بدلًا من الدالة LOWER، حيث تعمل الدالة UPPER بطريقة مشابهة ولكنها تحوّل النص إلى حروف كبيرة، ويمكن استخدام كلتا الدالتين إذا أردنا ضمان تناسق حالة الحروف عند استرجاع البيانات. تأخذ الدالة CONCAT وسطاء متعددة تحتوي على قيم نصية وتضعها مع بعضها بعضًا، لذا سنجرب استرجاع مؤلفي الكتب وعناوين الكتب ودمجها في عمود واحد من خلال تنفيذ التعليمة التالية: mysql> SELECT CONCAT(author, ': ', title) AS full_title FROM inventory; وسيظهر الخرج التالي: الخرج +------------------------------------------------+ | full_title | +------------------------------------------------+ | Oscar Wilde: The Picture of Dorian Gray | | Jane Austen: Pride and Prejudice | | Herbert George Wells: The Time Machine | | Mary Shelley: Frankenstein | | Mark Twain: The Adventures of Huckleberry Finn | +------------------------------------------------+ 5 rows in set (0.001 sec) دمجت الدالة CONCAT السلاسل النصية المتعددة مع بعضها البعض، وقد نفّذناها باستخدام ثلاثة وسطاء: الوسيط الأول author يشير إلى العمود author الذي يحتوي على أسماء المؤلفين، والوسيط الثاني قيمة سلسلة نصية عشوائية للفصل بين المؤلفين وعناوين الكتب بنقطتين، والوسيط الأخير title يشير إلى العمود الذي يحتوي عناوين الكتب. تكون نتيجة هذا الاستعلام هي المؤلفين والعناوين في عمود مؤقت واحد بالاسم full_title. تتضمّن دوال السلاسل النصية الأخرى في MySQL دوال البحث عن السلاسل النصية واستبدالها، واسترجاع السلاسل النصية الفرعية، وإضافة حاشية Padding إلى السلاسل النصية وإزالة الفراغات Trimming من بداية ونهاية السلاسل النصية، وتطبيق التعابير النمطية Regular Expressions وغيرها من الدوال. ويمكنكم مطالعة المزيد حول استخدام دوال SQL لضم قيم متعددة في مقال كيفية معالجة البيانات باستخدام دوال CAST وتعابير الضم في SQL، ويمكنك أيضًا الرجوع إلى دليل دوال ومعاملات السلاسل النصية في توثيق MySQL. استخدام دوال التاريخ والوقت تمكّننا دوال التاريخ والوقت في لغة SQL من معالجة القيم المُخزَّنة في الأعمدة التي تحتوي على التواريخ والعلامات الزمنية عند معالجة استعلام SQL، ويمكن استخدامها لاستخراج أجزاء من معلومات التاريخ، أو إجراء عمليات حسابية على التواريخ، أو تنسيقها بطريقة محددة. لنفترض أننا نحتاج لتقسيم أو فصل تاريخ تقديم الكتاب إلى السنة والشهر واليوم بدلًا من وجود عمود تاريخ واحد في الخرج. لنجرّب تنفيذ التعليمة التالية: mysql> SELECT introduction_date, YEAR(introduction_date) as year, MONTH(introduction_date) as month, DAY(introduction_date) as day FROM inventory; سيظهر الخرج التالي: الخرج +-------------------+------+-------+------+ | introduction_date | year | month | day | +-------------------+------+-------+------+ | 2022-10-01 | 2022 | 10 | 1 | | 2022-10-04 | 2022 | 10 | 4 | | 2022-09-23 | 2022 | 9 | 23 | | 2022-07-23 | 2022 | 7 | 23 | | 2022-10-01 | 2022 | 10 | 1 | +-------------------+------+-------+------+ 5 rows in set (0.000 sec) استخدمنا في تعليمة SQL السابقة ثلاث دوال فردية هي: YEAR و MONTH و DAY، وتأخذ كل دالة اسم العمود بحيث تُخزَّن التواريخ كوسطاء، وتستخرج جزءًا واحدًا فقط من التاريخ الكامل: السنة أو الشهر أو اليوم على التوالي، وبالتالي يمكننا الوصول إلى أجزاء التاريخ الفردية ضمن استعلامات SQL باستخدام هذه الدوال. تسمح الدالة DATEDIFF باسترجاع عدد الأيام بين تاريخين، فلنحاول التحقق من عدد الأيام المنقضية بين تاريخ تقديم كل كتاب والتاريخ الحالي، لذا نشغّل الاستعلام التالي: mysql> SELECT introduction_date, DATEDIFF(introduction_date, CURRENT_DATE()) AS days_since FROM inventory; وسيظهر الخرج التالي: الخرج +-------------------+------------+ | introduction_date | days_since | +-------------------+------------+ | 2022-10-01 | -30 | | 2022-10-04 | -27 | | 2022-09-23 | -38 | | 2022-07-23 | -100 | | 2022-10-01 | -30 | +-------------------+------------+ 5 rows in set (0.000 sec) تأخذ الدالة DATEDIFF وسيطين هما: تاريخ البدء وتاريخ الانتهاء، وتحسب هذه الدالة عدد الأيام التي تفصل بينهما، وقد تكون النتيجة عددًا سالبًا إذا جاء تاريخ الانتهاء أولًا. الوسيط الأول في المثال السابق هو اسم العمود introduction_date الذي يحتوي على التواريخ في الجدول inventory، والوسيط الثاني هو الدالة CURRENT_DATE التي تمثل تاريخ النظام الحالي، ويؤدي تنفيذ هذا الاستعلام إلى استرجاع عدد الأيام بين هذين التاريخين، ويضع النتائج في العمود المؤقت days_since. ملاحظة: لا تُعَد الدالة DATEDIFF جزءًا من مجموعة دوال SQL المعيارية الرسمية، حيث تدعم العديد من قواعد البيانات هذه الدالة، ولكن قد تختلف الصيغة بين محرّكات قواعد البيانات المختلفة، وقد اتبعنا في هذا المثال صيغة MySQL الأصيلة. تتضمن دوال معالجة التاريخ الأخرى المُضمَّنة في MySQL جمع وطرح فترات التواريخ والوقت، أو تنسيق التواريخ بتنسيقات لغات مختلفة، أو استرجاع اسم اليوم والشهر أو إنشاء قيم تواريخ جديدة. ويمكن معرفة المزيد حول التعامل مع التواريخ في لغة SQL في مقال كيفية التعامل مع التواريخ والأوقات في SQL، ويمكن أيضًا الاطلاع على دوال التاريخ والوقت في توثيق MySQL. استخدام الدوال التجميعية Aggregate Functions استخدمنا في الأمثلة السابقة دوال SQL لتطبيق التحويلات أو العمليات الحسابية على قيم الأعمدة الفردية في صفٍ واحد، والذي يمثّل كتابًا في مكتبة، وتوفر لغة SQL طريقة لإجراء العمليات الحسابية على صفوف متعددة لمساعدتنا في العثور على معلومات مُجمَّعة حول مجموعة البيانات بأكملها. تتضمّن الدوال التجميعية الأساسية في لغة SQL الدوال التالية: AVG: لإيجاد متوسط القيم التي نجري العمليات الحسابية عليها COUNT: لإيجاد عدد القيم التي نجري العمليات الحسابية عليها MAX: لإيجاد القيمة الكبرى من مجموعة قيم MIN: لإيجاد القيمة الصغرى من مجموعة قيم SUM: لإيجاد مجموع جميع القيم يمكننا دمج دوال تجميعية متعددة في استعلام SELECT، فلنفترض أننا نريد التحقق من عدد الكتب المدرجَة في المكتبة، والسعر الأكبر لأي كتاب متاح، ومتوسط الأسعار لكافة الكتب، لذا ننفّذ التعليمة التالية: mysql> SELECT COUNT(title) AS count, MAX(price) AS max_price, AVG(price) AS avg_price FROM inventory; تعيد هذه التعليمة الخرج التالي: الخرج +-------+-----------+-----------+ | count | max_price | avg_price | +-------+-----------+-----------+ | 5 | 42.13 | 25.106000 | +-------+-----------+-----------+ 1 row in set (0.001 sec) يستخدم الاستعلام السابق ثلاث دوال تجميعية في الوقت نفسه، حيث تحسب الدالة COUNT عدد الصفوف التي يبحث عنها الاستعلام، ومرّرنا اسم العمود title كوسيط لهذه الدالة، ولكن يمكنك استخدام أي اسم عمود آخر كوسيط لها لأن عدد الصفوف هو نفسه لكل الأعمدة. تحسب الدالة MAX القيمة الكبرى للعمود price، ويكون اسم العمود مهمًا في هذه الحالة، بسبب إجراء الحسابات على قيم هذا العمود. الدالة الأخيرة هي الدالة AVG التي تحسب المتوسط الحسابي لجميع الأسعار من العمود price. يؤدي استخدام الدوال التجميعية بهذه الطريقة إلى إعادة قاعدة البيانات لصف واحد يحتوي على أعمدة مؤقتة تمثّل قيم العمليات الحسابية المُجمَّعة، حيث تستخدم العمليات الحسابية الصفوف المصدر داخليًا ولكن لا يعيدها الاستعلام. يمكن باستخدام لغة SQL أيضًا تقسيم الصفوف في الجدول إلى مجموعات، ثم حساب القيم المُجمَّعة لكل مجموعة على حِدة، فمثلًا يمكننا حساب متوسط أسعار الكتب لمؤلفين مختلفين لمعرفة المؤلف الذي ينشر العناوين ذات السعر الأعلى، حيث يمكنك معرفة المزيد حول تجميع الصفوف لمثل هذه العمليات الحسابية في مقال كيفية استخدام تعليمتي GROUP BY و ORDER BY في لغة SQL، ويمكن مطالعة مزيد من التفاصيل حول استخدام الدوال التجميعية في مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في SQL. الخلاصة تعلّمنا في هذا المقال ما هي دوال SQL وكيفية استخدامها لمعالجة الأعداد والسلاسل النصية والتواريخ من خلال الأمثلة العملية، ويمكن بالطبع استخدام الدوال لمعالجة وتحليل البيانات في محرّك قاعدة البيانات بطرق عديدة أخرى، ولكننا غطينا في هذا المقال الدوال الأساسية فقط. وإذا أردنا التعامل مع البيانات وتحليلها بطرق فعّالة، فيمكننا دمج الدوال مع الاستعلامات الشرطية، ومع تعليمات التجميع في لغة SQL. ترجمة -وبتصرف- للمقال How To Use Functions in SQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام عمليات الدمج Union في لغة SQL أنواع البيانات في SQL التجميع والترتيب في SQL البحث والتنقيب والترشيح في SQL دوال التعامل مع البيانات في SQL
لا يقتصر التعامل في أنظمة إدارة قواعد البيانات العلاقية Relational Database Management System ولغة الاستعلام البنيوية SQL على تخزين البيانات وإدارتها واسترجاعها من قاعدة البيانات. إذ يمكن للغة SQL أيضًا إجراء عمليات حسابية ومعالجة البيانات عن طريق الدوال Functions، حيث يمكننا على سبيل المثال استخدام دوال محددة لاسترجاع أسعار المنتجات مع تقريب أسعارها، أو حساب متوسط عدد عمليات شراء منتج ما، أو تحديد عدد أيام انتهاء صلاحية الضمان على عملية شراء معينة. سنستخدم في هذا المقال دوالًا مختلفة في لغة SQL من أجل إجراء عمليات حسابية رياضية، ومعالجة السلاسل النصية والتواريخ، وحساب إحصائيات باستخدام الدوال التجميعية Aggregate Functions. مستلزمات العمل يجب أن يكون لديك حاسوب يشغّل نظام إدارة قواعد بيانات علاقية RDBMS مستند إلى لغة SQL. وقد اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضّح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال من خلال مستخدم مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال معرفة أساسية بتنفيذ استعلامات SELECT لاختيار البيانات من قاعدة البيانات كما هو موضّح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن تحدّد صيغة SQL المعيارية عددًا محدودًا من الدوال، ويختلف دعم الصيغة المعيارية بين محرّكات قواعد البيانات المختلفة، لذا قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام الدوال، ويمكن مطالعة القسم التالي للحصول على تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية التي سنستخدمها في أمثلتنا. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وننشئ قاعدة بيانات تجريبية لنتمكّن من اتباع الأمثلة الواردة في هذا المقال. إذا كان نظام قاعدة بيانات SQL الخاص بنا يعمل على خادم بعيد، نتصل بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشِئ قاعدة بيانات بالاسم bookstore: mysql> CREATE DATABASE bookstore; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات bookstore من خلال تنفيذ تعليمة USE التالية: $ USE bookstore; وسيَظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، وسننشئ عدة جداول تجريبية ضمنها، حيث سنستخدم مكتبة افتراضية تبيع كتبًا لعدة مؤلفين. سيحتوي الجدول inventory على بيانات كتب ممثّلة باستخدام الأعمدة التالية: book_id: المعرّف الخاص بكل كتاب، ونمثّله بنوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي Primary Key للجدول، حيث تصبح كل قيمة معرّفًا فريدًا للصف الخاص بها author: اسم مؤلف الكتاب، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 50 محرفًا title: عنوان الكتاب الذي جرى شراؤه، ونمثّله باستخدام نوع بيانات varchar بحد أقصى 200 محرف introduction_date: تاريخ تقديم المكتبة لكل كتاب، ونمثّله باستخدام نوع البيانات date stock: يحتوي هذا العمود على عدد الكتب الموجودة في مخزن المكتبة، ونمثّله باستخدام نوع البيانات int price: سعر الكتاب، ونمثّله باستخدام نوع البيانات decimal بحد أقصى 5 قيم قبل الفاصلة العشرية وقيمتين بعدها ننشئ هذا الجدول التجريبي باستخدام الأمر التالي: CREATE TABLE inventory ( mysql> book_id int, mysql> author varchar(50), mysql> title varchar(200), mysql> introduction_date date, mysql> stock int, mysql> price decimal(5, 2), mysql> PRIMARY KEY (book_id) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول الأول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) نحمّل جدول المشتريات ببعض البيانات التجريبية من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO inventory mysql> VALUES mysql> (1, 'Oscar Wilde', 'The Picture of Dorian Gray', '2022-10-01', 4, 20.83), mysql> (2, 'Jane Austen', 'Pride and Prejudice', '2022-10-04', 12, 42.13), mysql> (3, 'Herbert George Wells', 'The Time Machine', '2022-09-23', 7, 21.99), mysql> (4, 'Mary Shelley', 'Frankenstein', '2022-07-23', 9, 17.43), mysql> (5, 'Mark Twain', 'The Adventures of Huckleberry Finn', '2022-10-01', 14, 23.15); ستضيف عملية INSERT INTO خمسة كتب إلى الجدول inventory، حيث يشير الخرج التالي إلى إضافة جميع الصفوف الخمسة بنجاح: الخرج Query OK, 5 rows affected (0.00 sec) Records: 5 Duplicates: 0 Warnings: 0 نحن الآن جاهزون لمتابعة هذا المقال والبدء في استخدام الدوال في لغة SQL. فهم الدوال في لغة SQL الدوال functions هي عدة تعابير مجمعة ولها اسم محدد، قد تأخذ قيمة واحدة أوعدة قيم تمرر كوسطاء بين قوسين بعد اسم الدالة، وتجري عمليات حسابية أو تحويلات عليها، ثم تعيد قيمة جديدة كنتيجة للدالة، حيث تشبه دوال SQL الدوال الرياضية، فمثلًا تأخذ الدالة log(x) قيمة x وتعيد قيمة لوغاريتم هذه القيمة x. يمكننا استرجاع المعلومات من قاعدة بيانات علاقية دون تحويلها من خلال استخدام استعلام SELECT، حيث نطلب من قاعدة البيانات إعادة قيم للأعمدة الفردية التي نريدها من خلال تحديد أسماء الأعمدة في الاستعلام، فمثلًا إذا أردنا استرجاع جميع عناوين الكتب مع أسعارها وترتيبها من الأكثر إلى الأقل تكلفة، فيمكن تنفيذ التعليمة التالية: mysql> SELECT title, price, introduction_date FROM inventory ORDER BY price DESC; وسيظهر الخرج التالي: الخرج +------------------------------------+-------+-------------------+ | title | price | introduction_date | +------------------------------------+-------+-------------------+ | Pride and Prejudice | 42.13 | 2022-10-04 | | The Adventures of Huckleberry Finn | 23.15 | 2022-10-01 | | The Time Machine | 21.99 | 2022-09-23 | | The Picture of Dorian Gray | 20.83 | 2022-10-01 | | Frankenstein | 17.43 | 2022-07-23 | +------------------------------------+-------+-------------------+ 5 rows in set (0.000 sec) تكون title و price و introduction_date في التعليمة السابقة أسماء الأعمدة، وتعطي قاعدة البيانات في الخرج الناتج قيمًا غير مُعدَّلة مُسترجَعة من تلك الأعمدة لكل كتاب وهي عنوان الكتاب، والسعر ، وتاريخ إدخال الكتاب إلى المكتبة. قد نرغب في استرجاع القيم من قاعدة البيانات بعد إجراء بعض المعالجة، فقد نكون مهتمين بأسعار الكتب مع تقريبها إلى أقرب سعر بالدولار، أو كتابة عناوين الكتب بحروف كبيرة، أو عرض سنة تقديم الكتاب دون تضمين الشهر أو اليوم، لذا يجب أن نستخدم دوال مناسبة لذلك. أشهر الدوال في لغة SQL يمكن تصنيف دوال SQL إلى عدة مجموعات اعتمادًا على نوع البيانات التي نعمل عليها، ونوضح فيما يلي الدوال الأكثر استخدامًا في SQL. الدوال الرياضية هي الدوال التي تعمل على معالجة القيم العددية وتجري العمليات الحسابية عليها، مثل التقريب أو اللوغاريتمات أو الجذور التربيعية أو الرفع لأس دوال معالجة السلاسل النصية هي دوال تعمل على السلاسل والحقول النصية، وتجري تحويلات نصية مثل تحويل أحرف النص إلى حروف كبيرة، أو إزالة الفراغات من بدايات ونهايت السلاسل النصية Trimming، أو استبدال الكلمات في النص بكلمات أخرى. دوال التاريخ والوقت هي دوال تتعامل مع الحقول التي تحتوي على تواريخ، وتُجري هذه الدوال عمليات حسابية وتحويلات مثل إضافة عدد من الأيام إلى التاريخ المُحدَّد، أو أخذ سنة واحدة فقط من التاريخ الكامل. الدوال التجميعية Aggregate Functions هي حالة خاصة من الدوال الرياضية التي تعمل على قيم قادمة من صفوف متعددة مثل حساب متوسط السعر لجميع الصفوف. مثال على استدعاء دالة يوضّح المثال التالي الصيغة العامة لاستخدام دالة وهمية بالاسم EXAMPLE لتغيير نتائج قيم السعر price في قاعدة بيانات المكتبة باستخدام استعلام SELECT التالي: mysql> SELECT EXAMPLE(price) AS new_price FROM inventory; تأخذ الدالة EXAMPLE اسم العمود price كوسيط ، حيث يخبر هذا الجزء من الاستعلام قاعدة البيانات بتنفيذ الدالة EXAMPLE على قيم العمود price وإعادة نتائج هذه العملية، ويخبر جزء الاستعلام AS new_price قاعدة البيانات بإسناد اسم مؤقت new_price للقيم المحسوبة خلال فترة تنفيذ الاستعلام، وبذلك يمكننا تمييز نتائج الدالة في الخرج والإشارة إلى القيم الناتجة باستخدام تعلميتي WHERE و ORDER BY. سنستخدم في القسم التالي الدوال الرياضية لإجراء العمليات الحسابية شائعة الاستخدام. استخدام الدوال الرياضية تعمل الدوال الرياضية على القيم العددية مثل سعر الكتاب أو عدد الكتب الموجودة في المخزن ضمن قاعدة البيانات التجريبية، ويمكن استخدامها لإجراء العمليات الحسابية في قاعدة البيانات لمطابقة النتائج مع متطلباتنا. يُعَد التقريب من التطبيقات الأكثر استخدامًا للدوال الرياضية في لغة SQL، فلنفترض مثلًا أننا نريد استرجاع أسعار جميع الكتب، ولكن نريدها أن تكون مُقرَّبة لأقرب عدد صحيح، لذا نستخدم الدالة ROUND التي تطبّق عملية التقريب، ونجرّب تنفيذ التعليمة التالية: mysql> SELECT title, price, ROUND(price) AS rounded_price FROM inventory; سيظهر الخرج التالي: الخرج +------------------------------------+-------+---------------+ | title | price | rounded_price | +------------------------------------+-------+---------------+ | The Picture of Dorian Gray | 20.83 | 21 | | Pride and Prejudice | 42.13 | 42 | | The Time Machine | 21.99 | 22 | | Frankenstein | 17.43 | 17 | | The Adventures of Huckleberry Finn | 23.15 | 23 | +------------------------------------+-------+---------------+ 5 rows in set (0.000 sec) يختار الاستعلام السابق قيم الأعمدة title و price دون تعديل، بالإضافة إلى العمود rounded_price المؤقت الذي يحتوي على نتائج الدالة ROUND(price). تأخذ هذه الدالة وسيطًا واحدًا هو اسم العمود price في مثالنا، وتعيد القيم من هذا العمود في الجدول مع تقريبها إلى أقرب قيمة عددية صحيحة. يمكن لدالة التقريب أيضًا قبول وسيط إضافي يحدّد عدد المنازل العشرية التي يجب تطبيق التقريب عليها، ويمكن إضافة عمليات حسابية بدلًا من الاكتفاء باسم عمود واحد. لنجرّب مثلًا تشغيل الاستعلام التالي: mysql> SELECT title, price, ROUND(price * stock, 1) AS stock_price FROM inventory; وسيظهر الخرج التالي: الخرج +------------------------------------+-------+-------+-------------+ | title | stock | price | stock_price | +------------------------------------+-------+-------+-------------+ | The Picture of Dorian Gray | 4 | 20.83 | 83.3 | | Pride and Prejudice | 12 | 42.13 | 505.6 | | The Time Machine | 7 | 21.99 | 153.9 | | Frankenstein | 9 | 17.43 | 156.9 | | The Adventures of Huckleberry Finn | 14 | 23.15 | 324.1 | +------------------------------------+-------+-------+-------------+ 5 rows in set (0.000 sec) يؤدي تنفيذ الدالة ROUND(price * stock, 1) أولًا إلى ضرب سعر الكتاب الواحد بعدد الكتب الموجودة في المخزن، ثم تقريب السعر الناتج إلى أول منزلة عشرية، وستُعرَض النتيجة في العمود المؤقت stock_price. تتضمّن الدوال الرياضية الأخرى المُضمَّنة في MySQL الدوال المثلثية والجذور التربيعية والرفع لقوة واللوغاريتمات والدوال الأسية. ويمكن معرفة المزيد حول استخدام الدوال الرياضية في لغة SQL في مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في لغة SQL. استخدام دوال معالجة السلاسل النصية تمكّننا دوال معالجة السلاسل النصية في لغة SQL من تعديل القيم المُخزَّنة في الأعمدة التي تحتوي على نصوص عند معالجة استعلام SQL، ويمكن استخدامها لتحويل حالة الحروف، أو دمج بيانات من أعمدة متعددة، أو إجراء عمليات البحث والاستبدال. سنستخدم مثلًا دوال السلاسل النصية لاسترجاع جميع عناوين الكتب المُحوَّلة إلى حروف صغيرة، وننفّذ التعليمة التالية: mysql> SELECT LOWER(title) AS title_lowercase FROM inventory; وسيظهر الخرج التالي: الخرج +------------------------------------+ | title_lowercase | +------------------------------------+ | the picture of dorian gray | | pride and prejudice | | the time machine | | frankenstein | | the adventures of huckleberry finn | +------------------------------------+ 5 rows in set (0.001 sec) تأخذ دالة SQL التي هي LOWER وسيطًا واحدًا وتحوّل محتوياته إلى حروف صغيرة، وستُعرَض البيانات الناتجة في العمود المؤقت title_lowercase باستخدام تعليمة الاسم البديل للعمود AS title_lowercase. لنسترجع الآن جميع أسماء المؤلفين مع تحويلها إلى حروف كبيرة، لذا نجرّب تشغيل استعلام SQL التالي: mysql> SELECT UPPER(author) AS author_uppercase FROM inventory; وسيظهر الخرج التالي: الخرج +----------------------+ | author_uppercase | +----------------------+ | OSCAR WILDE | | JANE AUSTEN | | HERBERT GEORGE WELLS | | MARY SHELLEY | | MARK TWAIN | +----------------------+ 5 rows in set (0.000 sec) استخدمنا الدالة UPPER بدلًا من الدالة LOWER، حيث تعمل الدالة UPPER بطريقة مشابهة ولكنها تحوّل النص إلى حروف كبيرة، ويمكن استخدام كلتا الدالتين إذا أردنا ضمان تناسق حالة الحروف عند استرجاع البيانات. تأخذ الدالة CONCAT وسطاء متعددة تحتوي على قيم نصية وتضعها مع بعضها بعضًا، لذا سنجرب استرجاع مؤلفي الكتب وعناوين الكتب ودمجها في عمود واحد من خلال تنفيذ التعليمة التالية: mysql> SELECT CONCAT(author, ': ', title) AS full_title FROM inventory; وسيظهر الخرج التالي: الخرج +------------------------------------------------+ | full_title | +------------------------------------------------+ | Oscar Wilde: The Picture of Dorian Gray | | Jane Austen: Pride and Prejudice | | Herbert George Wells: The Time Machine | | Mary Shelley: Frankenstein | | Mark Twain: The Adventures of Huckleberry Finn | +------------------------------------------------+ 5 rows in set (0.001 sec) دمجت الدالة CONCAT السلاسل النصية المتعددة مع بعضها البعض، وقد نفّذناها باستخدام ثلاثة وسطاء: الوسيط الأول author يشير إلى العمود author الذي يحتوي على أسماء المؤلفين، والوسيط الثاني قيمة سلسلة نصية عشوائية للفصل بين المؤلفين وعناوين الكتب بنقطتين، والوسيط الأخير title يشير إلى العمود الذي يحتوي عناوين الكتب. تكون نتيجة هذا الاستعلام هي المؤلفين والعناوين في عمود مؤقت واحد بالاسم full_title. تتضمّن دوال السلاسل النصية الأخرى في MySQL دوال البحث عن السلاسل النصية واستبدالها، واسترجاع السلاسل النصية الفرعية، وإضافة حاشية Padding إلى السلاسل النصية وإزالة الفراغات Trimming من بداية ونهاية السلاسل النصية، وتطبيق التعابير النمطية Regular Expressions وغيرها من الدوال. ويمكنكم مطالعة المزيد حول استخدام دوال SQL لضم قيم متعددة في مقال كيفية معالجة البيانات باستخدام دوال CAST وتعابير الضم في SQL، ويمكنك أيضًا الرجوع إلى دليل دوال ومعاملات السلاسل النصية في توثيق MySQL. استخدام دوال التاريخ والوقت تمكّننا دوال التاريخ والوقت في لغة SQL من معالجة القيم المُخزَّنة في الأعمدة التي تحتوي على التواريخ والعلامات الزمنية عند معالجة استعلام SQL، ويمكن استخدامها لاستخراج أجزاء من معلومات التاريخ، أو إجراء عمليات حسابية على التواريخ، أو تنسيقها بطريقة محددة. لنفترض أننا نحتاج لتقسيم أو فصل تاريخ تقديم الكتاب إلى السنة والشهر واليوم بدلًا من وجود عمود تاريخ واحد في الخرج. لنجرّب تنفيذ التعليمة التالية: mysql> SELECT introduction_date, YEAR(introduction_date) as year, MONTH(introduction_date) as month, DAY(introduction_date) as day FROM inventory; سيظهر الخرج التالي: الخرج +-------------------+------+-------+------+ | introduction_date | year | month | day | +-------------------+------+-------+------+ | 2022-10-01 | 2022 | 10 | 1 | | 2022-10-04 | 2022 | 10 | 4 | | 2022-09-23 | 2022 | 9 | 23 | | 2022-07-23 | 2022 | 7 | 23 | | 2022-10-01 | 2022 | 10 | 1 | +-------------------+------+-------+------+ 5 rows in set (0.000 sec) استخدمنا في تعليمة SQL السابقة ثلاث دوال فردية هي: YEAR و MONTH و DAY، وتأخذ كل دالة اسم العمود بحيث تُخزَّن التواريخ كوسطاء، وتستخرج جزءًا واحدًا فقط من التاريخ الكامل: السنة أو الشهر أو اليوم على التوالي، وبالتالي يمكننا الوصول إلى أجزاء التاريخ الفردية ضمن استعلامات SQL باستخدام هذه الدوال. تسمح الدالة DATEDIFF باسترجاع عدد الأيام بين تاريخين، فلنحاول التحقق من عدد الأيام المنقضية بين تاريخ تقديم كل كتاب والتاريخ الحالي، لذا نشغّل الاستعلام التالي: mysql> SELECT introduction_date, DATEDIFF(introduction_date, CURRENT_DATE()) AS days_since FROM inventory; وسيظهر الخرج التالي: الخرج +-------------------+------------+ | introduction_date | days_since | +-------------------+------------+ | 2022-10-01 | -30 | | 2022-10-04 | -27 | | 2022-09-23 | -38 | | 2022-07-23 | -100 | | 2022-10-01 | -30 | +-------------------+------------+ 5 rows in set (0.000 sec) تأخذ الدالة DATEDIFF وسيطين هما: تاريخ البدء وتاريخ الانتهاء، وتحسب هذه الدالة عدد الأيام التي تفصل بينهما، وقد تكون النتيجة عددًا سالبًا إذا جاء تاريخ الانتهاء أولًا. الوسيط الأول في المثال السابق هو اسم العمود introduction_date الذي يحتوي على التواريخ في الجدول inventory، والوسيط الثاني هو الدالة CURRENT_DATE التي تمثل تاريخ النظام الحالي، ويؤدي تنفيذ هذا الاستعلام إلى استرجاع عدد الأيام بين هذين التاريخين، ويضع النتائج في العمود المؤقت days_since. ملاحظة: لا تُعَد الدالة DATEDIFF جزءًا من مجموعة دوال SQL المعيارية الرسمية، حيث تدعم العديد من قواعد البيانات هذه الدالة، ولكن قد تختلف الصيغة بين محرّكات قواعد البيانات المختلفة، وقد اتبعنا في هذا المثال صيغة MySQL الأصيلة. تتضمن دوال معالجة التاريخ الأخرى المُضمَّنة في MySQL جمع وطرح فترات التواريخ والوقت، أو تنسيق التواريخ بتنسيقات لغات مختلفة، أو استرجاع اسم اليوم والشهر أو إنشاء قيم تواريخ جديدة. ويمكن معرفة المزيد حول التعامل مع التواريخ في لغة SQL في مقال كيفية التعامل مع التواريخ والأوقات في SQL، ويمكن أيضًا الاطلاع على دوال التاريخ والوقت في توثيق MySQL. استخدام الدوال التجميعية Aggregate Functions استخدمنا في الأمثلة السابقة دوال SQL لتطبيق التحويلات أو العمليات الحسابية على قيم الأعمدة الفردية في صفٍ واحد، والذي يمثّل كتابًا في مكتبة، وتوفر لغة SQL طريقة لإجراء العمليات الحسابية على صفوف متعددة لمساعدتنا في العثور على معلومات مُجمَّعة حول مجموعة البيانات بأكملها. تتضمّن الدوال التجميعية الأساسية في لغة SQL الدوال التالية: AVG: لإيجاد متوسط القيم التي نجري العمليات الحسابية عليها COUNT: لإيجاد عدد القيم التي نجري العمليات الحسابية عليها MAX: لإيجاد القيمة الكبرى من مجموعة قيم MIN: لإيجاد القيمة الصغرى من مجموعة قيم SUM: لإيجاد مجموع جميع القيم يمكننا دمج دوال تجميعية متعددة في استعلام SELECT، فلنفترض أننا نريد التحقق من عدد الكتب المدرجَة في المكتبة، والسعر الأكبر لأي كتاب متاح، ومتوسط الأسعار لكافة الكتب، لذا ننفّذ التعليمة التالية: mysql> SELECT COUNT(title) AS count, MAX(price) AS max_price, AVG(price) AS avg_price FROM inventory; تعيد هذه التعليمة الخرج التالي: الخرج +-------+-----------+-----------+ | count | max_price | avg_price | +-------+-----------+-----------+ | 5 | 42.13 | 25.106000 | +-------+-----------+-----------+ 1 row in set (0.001 sec) يستخدم الاستعلام السابق ثلاث دوال تجميعية في الوقت نفسه، حيث تحسب الدالة COUNT عدد الصفوف التي يبحث عنها الاستعلام، ومرّرنا اسم العمود title كوسيط لهذه الدالة، ولكن يمكنك استخدام أي اسم عمود آخر كوسيط لها لأن عدد الصفوف هو نفسه لكل الأعمدة. تحسب الدالة MAX القيمة الكبرى للعمود price، ويكون اسم العمود مهمًا في هذه الحالة، بسبب إجراء الحسابات على قيم هذا العمود. الدالة الأخيرة هي الدالة AVG التي تحسب المتوسط الحسابي لجميع الأسعار من العمود price. يؤدي استخدام الدوال التجميعية بهذه الطريقة إلى إعادة قاعدة البيانات لصف واحد يحتوي على أعمدة مؤقتة تمثّل قيم العمليات الحسابية المُجمَّعة، حيث تستخدم العمليات الحسابية الصفوف المصدر داخليًا ولكن لا يعيدها الاستعلام. يمكن باستخدام لغة SQL أيضًا تقسيم الصفوف في الجدول إلى مجموعات، ثم حساب القيم المُجمَّعة لكل مجموعة على حِدة، فمثلًا يمكننا حساب متوسط أسعار الكتب لمؤلفين مختلفين لمعرفة المؤلف الذي ينشر العناوين ذات السعر الأعلى، حيث يمكنك معرفة المزيد حول تجميع الصفوف لمثل هذه العمليات الحسابية في مقال كيفية استخدام تعليمتي GROUP BY و ORDER BY في لغة SQL، ويمكن مطالعة مزيد من التفاصيل حول استخدام الدوال التجميعية في مقال كيفية استخدام التعابير الرياضية والدوال التجميعية في SQL. الخلاصة تعلّمنا في هذا المقال ما هي دوال SQL وكيفية استخدامها لمعالجة الأعداد والسلاسل النصية والتواريخ من خلال الأمثلة العملية، ويمكن بالطبع استخدام الدوال لمعالجة وتحليل البيانات في محرّك قاعدة البيانات بطرق عديدة أخرى، ولكننا غطينا في هذا المقال الدوال الأساسية فقط. وإذا أردنا التعامل مع البيانات وتحليلها بطرق فعّالة، فيمكننا دمج الدوال مع الاستعلامات الشرطية، ومع تعليمات التجميع في لغة SQL. ترجمة -وبتصرف- للمقال How To Use Functions in SQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام عمليات الدمج Union في لغة SQL أنواع البيانات في SQL التجميع والترتيب في SQL البحث والتنقيب والترشيح في SQL دوال التعامل مع البيانات في SQL -
 تنشر العديد من قواعد البيانات المعلومات على جداول مختلفة بحسب معناها وسياقها، وبالتالي قد نحتاج إلى الإشارة إلى أكثر من جدول واحد عند استرجاع معلومات حول البيانات الموجودة في قاعدة البيانات، لذا توفّر لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- طرقًا متعددة لاسترجاع البيانات من جداول مختلفة مثل عمليات المجموعة Set Operations، وخاصةً معامل المجموعة UNION الذي تدعمه معظم أنظمة قواعد البيانات العلاقية Relational Database Systems والذي يأخذ نتائج استعلامين لأعمدة متطابقة ويدمجهما في استعلام واحد. سنشرح في هذا المقال طريقة استخدام المعامل UNION لاسترجاع ودمج البيانات من أكثر من جدول، ونتعلم كيفية دمجه مع عملية الترشيح Filtering لترتيب النتائج. مستلزمات العمل يجب أن يكون لديك حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- المستند إلى لغة SQL. اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم بصلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، ومقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضّح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الفقرة التالية من المقال. معرفة أساسية بتنفيذ استعلامات SELECT لاختيار البيانات من قاعدة البيانات كما هو موضّح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدّمة في هذا المقال بنجاح مع معظم هذه الأنظمة وهي جزء من صيغة لغة SQL المعيارية، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام عمليات UNION. وسنوضح في القسم التالي تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية، والتي سنستخدمها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وسننشئ قاعدة بيانات تجريبية لنتمكّن من اتباع الأمثلة الواردة في هذا المقال. إذا كانت قاعدة بيانات SQL الخاصة بنا تعمل على خادم بعيد، علينا الاتصال بالخادم مُستخدمين بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم bookstore: mysql> CREATE DATABASE bookstore; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات bookstore من خلال تنفيذ تعليمة USE التالية: mysql> USE bookstore; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، وسننشئ عدة جداول تجريبية ضمنها، حيث سنستخدم في هذا المقال مكتبة افتراضية تقدّم خدمة شراء الكتب وتأجيرها، وتُدار كل خدمة من هاتين الخدمتين على حدة، وبالتالي ستُخزَّن البيانات المتعلقة بشراء الكتب وتأجيرها في جداول منفصلة. ملاحظة: بسّطنا مخطط قاعدة البيانات لهذا المثال للتوضيح، إذ تكون هياكل الجداول أكثر تعقيدًا في الحياة الواقعية مع تضمين مفاتيح رئيسية Primary Keys ومفاتيح خارجية Foreign Keys ضمنها. ويمكن مطالعة مقال فهم قواعد البيانات العلاقية لمزيد من المعلومات حول كيفية تنظيم البيانات. يحتوي الجدول الأول book_purchases على بيانات حول الكتب المُشتراة والعملاء الذين أجروا عمليات الشراء، إذ سيحتوي على أربعة أعمدة هي: purchase_id: يحتوي هذا العمود على معرّف عملية الشراء ونمثّله بنوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي للجدول، حيث تصبح كل قيمة معرّفًا فريدًا للصف الخاص بها customer_name: يحتوي هذا العمود على اسم العميل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 30 محرفًا book_title: يحتوي هذا العمود على عنوان الكتاب الذي جرى شراؤه، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 200 محرف date: يستخدم هذا العمود نوع البيانات date، ويحتوي على تاريخ كل عملية شراء ننشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE book_purchases ( mysql> purchase_id int, mysql> customer_name varchar(30), mysql> book_title varchar(40), mysql> date date, mysql> PRIMARY KEY (purchase_id) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول الأول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) يحزّن الجدول الثاني book_leases معلومات حول الكتب المُستعارة، وتكون بنيته مشابهة للجدول السابق، ولكن نميّز عملية تأجير الكتاب بتاريخين مختلفين هما تاريخ التأجير ومدته، وبالتالي سيحتوي هذا الجدول على خمسة أعمدة هي: lease_id: يحتوي هذا العمود على معرّف عملية التأجير، ونمثّله بنوع البيانات int، ويكون هذا العمود هو المفتاح الرئيسي للجدول، حيث تصبح كل قيمة معرّفًا فريدًا للصف الخاص بها customer_name: يحتوي هذا العمود على اسم العميل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 30 محرفًا book_title: يحتوي هذا العمود على عنوان الكتاب المُستعار، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 200 محرف date_from: يستخدم نوع البيانات date، ويحتوي هذا العمود على تاريخ بدء عملية التأجير date_to: يستخدم نوع البيانات date، ويحتوي هذا العمود على تاريخ انتهاء عملية التأجير لننشئ الجدول الثاني باستخدام الأمر التالي: mysql> CREATE TABLE book_leases ( mysql> lease_id int, mysql> customer_name varchar(30), mysql> book_title varchar(40), mysql> date_from date, mysql> date_to date, mysql> PRIMARY KEY (lease_id) ); يؤكّد الخرج التالي إنشاء الجدول الثاني: الخرج Query OK, 0 rows affected (0.00 sec) لنحمّل الآن الجدول book_purchases ببعض البيانات التجريبية من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO book_purchases mysql> VALUES mysql> (1, 'sammy', 'The Picture of Dorian Gray', '2023-10-01'), mysql> (2, 'sammy', 'Pride and Prejudice', '2023-10-04'), mysql> (3, 'sammy', 'The Time Machine', '2023-09-23'), mysql> (4, 'bill', 'Frankenstein', '2023-07-23'), mysql> (5, 'bill', 'The Adventures of Huckleberry Finn', '2023-10-01'), mysql> (6, 'walt', 'The Picture of Dorian Gray', '2023-04-15'), mysql> (7, 'walt', 'Frankenstein', '2023-10-13'), mysql> (8, 'walt', 'Pride and Prejudice', '2023-10-19'); ستضيف عملية INSERT INTO السابقة 8 عمليات شراء مع قيمها المحدَّدة إلى جدول book_purchases، حيث يشير الخرج التالي إلى إضافة جميع الصفوف الثمانية: الخرج Query OK, 8 rows affected (0.00 sec) Records: 8 Duplicates: 0 Warnings: 0 ثم ندخِل بعض البيانات التجريبية في الجدول book_leases كما يلي: mysql> INSERT INTO book_leases mysql> VALUES mysql> (1, 'sammy', 'Frankenstein', '2023-09-14', '2023-11-14'), mysql> (2, 'sammy', 'Pride and Prejudice', '2023-10-01', '2023-12-31'), mysql> (3, 'sammy', 'The Adventures of Huckleberry Finn', '2023-10-01', '2023-12-01'), mysql> (4, 'bill', 'The Picture of Dorian Gray', '2023-09-03', '2023-09-18'), mysql> (5, 'bill', 'Crime and Punishment', '2023-09-27', '2023-12-05'), mysql> (6, 'kim', 'The Picture of Dorian Gray', '2023-10-01', '2023-11-15'), mysql> (7, 'kim', 'Pride and Prejudice', '2023-09-08', '2023-11-17'), mysql> (8, 'kim', 'The Time Machine', '2023-09-04', '2023-10-23'); وسيظهر الخرج التالي الذي يؤكّد إضافة هذه البيانات: الخرج Query OK, 8 rows affected (0.00 sec) Records: 8 Duplicates: 0 Warnings: 0 تتعلق عمليات التأجير والشراء بعملاء وعناوين كتب متماثلة، مما سيكون مفيدًا لتوضيح سلوك المعامل UNION، وبذلك سنكون جاهزين لمتابعة هذا المقال والبدء في استخدام عمليات UNION في لغة SQL. فهم صيغة المعامل UNION يطلب المعامل UNION في لغة SQL من قاعدة البيانات أخذ مجموعتي نتائج منفصلتين ومسترجعتين من استعلامات SELECT فردية ودمجهما في مجموعة نتائج واحدة تحتوي على صفوف مُعادة من كلا الاستعلامين. ملاحظة: يمكن أن تكون استعلامات SELECT المستخدمة مع العملية UNION معقدة وتتطلب استخدام تعليمات JOIN أو دوال تجميعية Aggregations أو استعلامات الفرعية Subqueries. إذ يمكننا استخدام عمليات UNION لدمج نتائج الاستعلامات مهما كانت معقدة، ولكن للسهولة سنستخدم في أمثلتنا التالية استعلامات SELECT بسيطة للتركيز على كيفية تصرف المعامل UNION. يوضّح المثال التالي الصيغة العامة لتعليمة SQL التي تتضمن المعامل UNION: mysql> SELECT column1, column2 FROM table1 mysql> UNION mysql> SELECT column1, column2 FROM table2; تبدأ تعليمة SQL السابقة بتعليمة SELECT التي تعيد عمودين من الجدول table1، ونتبعها بالمعامل UNION وتعليمة SELECT ثانية، ويعيد استعلام SELECT الثاني أيضًا عمودين من الجدول table2. تخبر الكلمة المفتاحية UNION قاعدة البيانات بأخذ الاستعلامات السابقة واللاحقة، وتنفيذها تنفيذًا منفصلًا، ثم ضم مجموعات النتائج الخاصة بها ضمن مجموعة واحدة. يُعَد جزء الشيفرة البرمجية السابق بأكمله -بما في ذلك استعلامات SELECT والكلمة المفتاحية UNION بينهما- تعليمة SQL واحدة، لذلك لا ينتهي استعلام SELECT الأول بفاصلة منقوطة، والتي تظهر بعد اكتمال التعليمة فقط. لنفترض مثلًا أننا نريد إدخال جميع العملاء الذين اشتروا كتابًا أو استأجروه، حيث يحتفظ الجدول book_purchases بسجلات عمليات الشراء، بينما يخزّن الجدول book_leases عمليات تأجير الكتب، لذا لنشغّل الاستعلام التالي: mysql> SELECT customer_name FROM book_purchases mysql> UNION mysql> SELECT customer_name FROM book_leases; وتكون مجموعة نتائج هذا الاستعلام كما يلي: الخرج +---------------+ | customer_name | +---------------+ | sammy | | bill | | walt | | kim | +---------------+ 4 rows in set (0.000 sec) يشير هذا الخرج إلى أن Sammy و Bill و Walt و Kim اشتروا كتبًا أو استأجروها. دعونا نجرّب تنفيذ تعليمتي SELECT تنفيذًا منفصلًا، مرةً لعمليات الشراء ومرةً لعمليات التأجير لفهم كيفية إنشاء مجموعة هذه النتائج. لنشغّل أولًا الاستعلام التالي لإعادة العملاء الذين اشتروا كتبًا فقط: mysql> SELECT customer_name FROM book_purchases; وسيكون الخرج كما يلي: الخرج +---------------+ | customer_name | +---------------+ | sammy | | sammy | | sammy | | bill | | bill | | walt | | walt | | walt | +---------------+ 8 rows in set (0.000 sec) اشترى Sammy و Bill و Walt كتبًا، لكن Kim لم يفعل ذلك. ثم لنشغّل الاستعلام التالي لإعادة العملاء الذين استأجروا كتبًا فقط: mysql> SELECT customer_name FROM book_leases; وسيكون الخرج كما يلي: الخرج +---------------+ | customer_name | +---------------+ | sammy | | sammy | | sammy | | bill | | bill | | kim | | kim | | kim | +---------------+ 8 rows in set (0.000 sec) يشير الجدول book_leases إلى أن Sammy و Bill و Kim يستعيرون كتبًا، ولكن Walt لا يستعير كتبًا أبدًا. إذا جمعنا بين الإجابتين، فيمكننا الحصول على البيانات لكل من عمليات الشراء والتأجير. الفرق المهم بين استخدام عملية UNION وتنفيذ استعلامين تنفيذًا منفصلًا هو أن عملية UNION تزيل القيم المكررة، حيث تُدمَج النتائج دون تكرار أسماء العملاء في النتيجة. يجب أن يعيد كلا الاستعلامين النتائج بالتنسيق نفسه لاستخدام عملية UNION لدمج نتائج استعلامين منفصلين بطريقة صحيحة، إذ ستؤدي التعارضات إلى حدوث أخطاء في محرّك قاعدة البيانات أو إلى ظهور نتائج لا تتطابق مع الهدف من الاستعلام كما سنوضّح في المثالين التاليين. تنفيذ عملية UNION مع عدد غير متطابق من الأعمدة لنجرّب تنفيذ عملية UNION مع تعليمة SELECT تعيد عمودًا واحدًا وتعليمة SELECT أخرى تعيد عمودين: mysql> SELECT purchase_id, customer_name FROM book_purchases mysql> UNION mysql> SELECT customer_name FROM book_leases; سيستجيب خادم قاعدة البيانات بالخطأ التالي: الخرج The used SELECT statements have a different number of columns لا يمكن إجراء عمليات UNION على مجموعات النتائج التي لها أعداد أعمدة مختلفة. تنفيذ عملية UNION مع ترتيب غير متطابق للأعمدة لنجرّب الآن تنفيذ عملية UNION مع تعلميتي SELECT تعيدان القيم نفسها ولكن بترتيب مختلف كما يلي: mysql> SELECT customer_name, book_title FROM book_purchases mysql> UNION mysql> SELECT book_title, customer_name FROM book_leases; لن يعيد خادم قاعدة البيانات خطأ، ولكن لن تكون مجموعة النتائج صحيحة كما يلي: الخرج +------------------------------------+------------------------------------+ | customer_name | book_title | +------------------------------------+------------------------------------+ | sammy | The Picture of Dorian Gray | | sammy | Pride and Prejudice | | sammy | The Time Machine | | bill | Frankenstein | | bill | The Adventures of Huckleberry Finn | | walt | The Picture of Dorian Gray | | walt | Frankenstein | | walt | Pride and Prejudice | | Frankenstein | sammy | | Pride and Prejudice | sammy | | The Adventures of Huckleberry Finn | sammy | | The Picture of Dorian Gray | bill | | Crime and Punishment | bill | | The Picture of Dorian Gray | kim | | Pride and Prejudice | kim | | The Time Machine | kim | +------------------------------------+------------------------------------+ 16 rows in set (0.000 sec) تدمج عملية UNION في هذا المثال العمود الأول من الاستعلام الأول مع العمود الأول من الاستعلام الثاني وتفعل الشيء نفسه بالنسبة للعمود الثاني، وبالتالي ستخلط أسماء العملاء وعناوين الكتب مع بعضها بعضًا. استخدام الشروط وترتيب النتائج باستخدام UNION دمجنا في المثال السابق مجموعات النتائج التي تمثل جميع الصفوف في جدولين متطابقين، ولكن ستحتاج في كثير من الأحيان إلى ترشيح الصفوف وفق شروط محددة قبل دمج النتائج، حيث يمكن لتعليمات SELECT المدموجة باستخدام المعامل UNION استخدام تعليمة WHERE لتطبيق ذلك. لنفترض مثلًا أننا نريد معرفة الكتب التي يقرأها Sammy من خلال شرائها أو استئجارها، لذا نشغّل الاستعلام التالي: mysql> SELECT book_title FROM book_purchases mysql> WHERE customer_name = 'Sammy' mysql> UNION mysql> SELECT book_title FROM book_leases mysql> WHERE customer_name = 'Sammy'; يتضمن كلا الاستعلامين تعليمة WHERE، مما يؤدي إلى ترشيح الصفوف من الجدولين المنفصلين لتضمين عمليات الشراء والتأجير التي أجراها Sammy فقط، وستكون نتائج هذا الاستعلام كما يلي: الخرج +------------------------------------+ | book_title | +------------------------------------+ | The Picture of Dorian Gray | | Pride and Prejudice | | The Time Machine | | Frankenstein | | The Adventures of Huckleberry Finn | +------------------------------------+ 5 rows in set (0.000 sec) تضمن عملية UNION عدم وجود تكرارات في قائمة النتائج. يمكننا استخدام تعليمات WHERE أيضًا لتحديد الصفوف المُعادة في استعلامي SELECT أو أحدهما فقط، ويمكن أن تشير تعليمة WHERE إلى أعمدة وشروط مختلفة في كل من الاستعلامين. إضافةً لذلك، لا تتبع النتائج التي تعيدها عملية UNION ترتيبًا محدَّدًا، ولكن يمكننا تغيير ذلك من خلال استخدام تعليمة ORDER BY، حيث ينفَّذ الترتيب على النتائج النهائية المدموجة وليس على الاستعلامات الفردية. يمكننا فرز عناوين الكتب أبجديًا بعد استرجاع قائمة بجميع الكتب التي اشتراها أو استأجرها Sammy من خلال تنفيذ الاستعلام التالي: mysql> SELECT book_title FROM book_purchases mysql> WHERE customer_name = 'Sammy' mysql> UNION mysql> SELECT book_title FROM book_leases mysql> WHERE customer_name = 'Sammy' mysql> ORDER BY book_title; وسيكون الخرج كما يلي: الخرج +------------------------------------+ | book_title | +------------------------------------+ | Frankenstein | | Pride and Prejudice | | The Adventures of Huckleberry Finn | | The Picture of Dorian Gray | | The Time Machine | +------------------------------------+ 5 rows in set (0.001 sec) نلاحظ أن إعادة النتائج بالترتيب يعتمد على العمود book_title الذي يحتوي على النتائج الناتجة عن دمج استعلامَي SELECT. استخدام العملية UNION ALL للاحتفاظ بالنسخ المكررة يزيل المعامل UNION تلقائيًا الصفوف المكررة من النتائج كما أظهرت الأمثلة السابقة، ولكن قد لا يكون هذا السلوك هو ما نريد تحقيقه باستخدام الاستعلام، فمثلًا لنفترض أننا نريد معرفة الكتب المُشتراة أو المستأجرة في 1 من شهر 11 من عام 2023، حيث يمكننا استرجاع هذه العناوين من خلال اتباع المثال التالي المشابه لما سبق: mysql> SELECT book_title FROM book_purchases mysql> WHERE date = '2022-10-01' mysql> UNION mysql> SELECT book_title FROM book_leases mysql> WHERE date_from = '2022-10-01' mysql> ORDER BY book_title; وسنحصل على النتائج التالية: الخرج +------------------------------------+ | book_title | +------------------------------------+ | Pride and Prejudice | | The Adventures of Huckleberry Finn | | The Picture of Dorian Gray | +------------------------------------+ 3 rows in set (0.001 sec) عناوين الكتب المُعادة هنا صحيحة، ولكن لن تخبرنا النتائج فيما إذا كانت هذه الكتب مشتراة فقط أم مستأجرة فقط أم كليهما، حيث ستظهر عناوين الكتب في الجدولين book_purchases و book_leases في الحالات التي جرى فيها شراء بعض الكتب واستئجارها، ولكن ستُفقَد هذه المعلومات في النتيجة، لأن المعامل UNION يزيل الصفوف المكررة. تمتلك لغة SQL طريقة لتغيير هذا السلوك والاحتفاظ بالصفوف المكررة، حيث يمكننا استخدام المعامل UNION ALL لدمج النتائج من استعلامين دون إزالة الصفوف المكررة، ويعمل المعامل UNION ALL بطريقة مشابهة للمعامل UNION، ولكن إذا وُجِدت تكرارات متعددة للقيم نفسها، فستكون جميعها موجودة في النتيجة. لنشغّل الاستعلام السابق نفسه مع وضع UNION ALL مكان UNION كما يلي: mysql> SELECT book_title FROM book_purchases mysql> WHERE date = '2022-10-01' mysql> UNION ALL mysql> SELECT book_title FROM book_leases mysql> WHERE date_from = '2022-10-01' mysql> ORDER BY book_title; ستكون القائمة الناتجة أطول هذه المرة كما يلي: الخرج +------------------------------------+ | book_title | +------------------------------------+ | Pride and Prejudice | | The Adventures of Huckleberry Finn | | The Adventures of Huckleberry Finn | | The Picture of Dorian Gray | | The Picture of Dorian Gray | +------------------------------------+ 5 rows in set (0.000 sec) يظهَر الكتابان The Adventures of Huckleberry Finn و The Picture of Dorian Gray مرتين في مجموعة النتائج، وهذا يعني أنهما ظهرا في الجدولين book_purchases و book_leases، وبالتالي يمكننا افتراض أنه جرى تأجيرهما وشراؤهما في ذلك اليوم. يمكن الاختيار بين المعاملين UNION و UNION ALL والتبديل بينهما اعتمادًا على ما إذا أردنا إزالة التكرارات أو الاحتفاظ بها. ملاحظة: تنفيذ المعامل UNION ALL أسرع من تنفيذ المعامل UNION، إذ لا تحتاج قاعدة البيانات إلى فحص مجموعة النتائج للعثور على التكرارات. فإذا أردنا دمج نتائج استعلامات SELECT التي نعرف أنها لن تحتوي على أي صفوف مكررة، فيمكن أن يحقق استخدام المعامل UNION ALL أداءً أفضل مع مجموعات البيانات الأكبر حجمًا. الخلاصة تعرّفنا في هذا المقال على كيفية استرجاع البيانات من جداول متعددة باستخدام عمليات UNION و UNION ALL، واستخدمنا أيضًا تعليمات WHERE لترشيح النتائج وتعليمات ORDER BY لترتيبها، وتعلّمنا الأخطاء المحتمَلة والسلوكيات غير المتوقعة إذا أنتجت تعليمات SELECT تنسيقات بيانات مختلفة. يجب أن تعمل الأوامر الواردة في هذا المقال على معظم قواعد البيانات العلاقية، ولكن يجب أن نتذكر أن كل قاعدة بيانات SQL تستخدم تقديمها الفريد للغة، لذا ننصح بالاطلاع على مقال مقارنة بين أنظمة إدارة قواعد البيانات العلاقية: SQLite مع MySQL مع PostgreSQL لمزيد من المعلومات، كما ننصح بالرجوع إلى توثيق RDBMS الرسمي للحصول على شرح مفصّل لكل أمر ومجموعة خياراته الكاملة. ترجمة -وبتصرف- للمقال How To Use Unions in SQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام الاستعلامات المتداخلة Nested Queries في SQL الدمج بين الجداول في SQL أنواع قواعد البيانات وأهم مميزاتها واستخداماتها معالجة الأخطاء والتعديل على قواعد البيانات في SQL التعابير الجدولية الشائعة Common Table Expressions في SQL
تنشر العديد من قواعد البيانات المعلومات على جداول مختلفة بحسب معناها وسياقها، وبالتالي قد نحتاج إلى الإشارة إلى أكثر من جدول واحد عند استرجاع معلومات حول البيانات الموجودة في قاعدة البيانات، لذا توفّر لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- طرقًا متعددة لاسترجاع البيانات من جداول مختلفة مثل عمليات المجموعة Set Operations، وخاصةً معامل المجموعة UNION الذي تدعمه معظم أنظمة قواعد البيانات العلاقية Relational Database Systems والذي يأخذ نتائج استعلامين لأعمدة متطابقة ويدمجهما في استعلام واحد. سنشرح في هذا المقال طريقة استخدام المعامل UNION لاسترجاع ودمج البيانات من أكثر من جدول، ونتعلم كيفية دمجه مع عملية الترشيح Filtering لترتيب النتائج. مستلزمات العمل يجب أن يكون لديك حاسوب يشغّل نظام إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- المستند إلى لغة SQL. اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم بصلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، ومقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضّح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الفقرة التالية من المقال. معرفة أساسية بتنفيذ استعلامات SELECT لاختيار البيانات من قاعدة البيانات كما هو موضّح في مقال كيفية الاستعلام عن السجلات من الجداول في SQL ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدّمة في هذا المقال بنجاح مع معظم هذه الأنظمة وهي جزء من صيغة لغة SQL المعيارية، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام عمليات UNION. وسنوضح في القسم التالي تفاصيل حول الاتصال بخادم MySQL وإنشاء قاعدة بيانات تجريبية، والتي سنستخدمها في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية سنتصل في هذا القسم بخادم MySQL وسننشئ قاعدة بيانات تجريبية لنتمكّن من اتباع الأمثلة الواردة في هذا المقال. إذا كانت قاعدة بيانات SQL الخاصة بنا تعمل على خادم بعيد، علينا الاتصال بالخادم مُستخدمين بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم bookstore: mysql> CREATE DATABASE bookstore; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات bookstore من خلال تنفيذ تعليمة USE التالية: mysql> USE bookstore; وسيظهر الخرج التالي: الخرج Database changed اخترنا قاعدة البيانات، وسننشئ عدة جداول تجريبية ضمنها، حيث سنستخدم في هذا المقال مكتبة افتراضية تقدّم خدمة شراء الكتب وتأجيرها، وتُدار كل خدمة من هاتين الخدمتين على حدة، وبالتالي ستُخزَّن البيانات المتعلقة بشراء الكتب وتأجيرها في جداول منفصلة. ملاحظة: بسّطنا مخطط قاعدة البيانات لهذا المثال للتوضيح، إذ تكون هياكل الجداول أكثر تعقيدًا في الحياة الواقعية مع تضمين مفاتيح رئيسية Primary Keys ومفاتيح خارجية Foreign Keys ضمنها. ويمكن مطالعة مقال فهم قواعد البيانات العلاقية لمزيد من المعلومات حول كيفية تنظيم البيانات. يحتوي الجدول الأول book_purchases على بيانات حول الكتب المُشتراة والعملاء الذين أجروا عمليات الشراء، إذ سيحتوي على أربعة أعمدة هي: purchase_id: يحتوي هذا العمود على معرّف عملية الشراء ونمثّله بنوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي للجدول، حيث تصبح كل قيمة معرّفًا فريدًا للصف الخاص بها customer_name: يحتوي هذا العمود على اسم العميل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 30 محرفًا book_title: يحتوي هذا العمود على عنوان الكتاب الذي جرى شراؤه، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 200 محرف date: يستخدم هذا العمود نوع البيانات date، ويحتوي على تاريخ كل عملية شراء ننشئ هذا الجدول التجريبي باستخدام الأمر التالي: mysql> CREATE TABLE book_purchases ( mysql> purchase_id int, mysql> customer_name varchar(30), mysql> book_title varchar(40), mysql> date date, mysql> PRIMARY KEY (purchase_id) mysql> ); إذا كان الخرج كما يلي، فهذا يعني إنشاء الجدول الأول بنجاح: الخرج Query OK, 0 rows affected (0.00 sec) يحزّن الجدول الثاني book_leases معلومات حول الكتب المُستعارة، وتكون بنيته مشابهة للجدول السابق، ولكن نميّز عملية تأجير الكتاب بتاريخين مختلفين هما تاريخ التأجير ومدته، وبالتالي سيحتوي هذا الجدول على خمسة أعمدة هي: lease_id: يحتوي هذا العمود على معرّف عملية التأجير، ونمثّله بنوع البيانات int، ويكون هذا العمود هو المفتاح الرئيسي للجدول، حيث تصبح كل قيمة معرّفًا فريدًا للصف الخاص بها customer_name: يحتوي هذا العمود على اسم العميل، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 30 محرفًا book_title: يحتوي هذا العمود على عنوان الكتاب المُستعار، ونمثّله باستخدام نوع البيانات varchar بحد أقصى 200 محرف date_from: يستخدم نوع البيانات date، ويحتوي هذا العمود على تاريخ بدء عملية التأجير date_to: يستخدم نوع البيانات date، ويحتوي هذا العمود على تاريخ انتهاء عملية التأجير لننشئ الجدول الثاني باستخدام الأمر التالي: mysql> CREATE TABLE book_leases ( mysql> lease_id int, mysql> customer_name varchar(30), mysql> book_title varchar(40), mysql> date_from date, mysql> date_to date, mysql> PRIMARY KEY (lease_id) ); يؤكّد الخرج التالي إنشاء الجدول الثاني: الخرج Query OK, 0 rows affected (0.00 sec) لنحمّل الآن الجدول book_purchases ببعض البيانات التجريبية من خلال تشغيل عملية INSERT INTO التالية: mysql> INSERT INTO book_purchases mysql> VALUES mysql> (1, 'sammy', 'The Picture of Dorian Gray', '2023-10-01'), mysql> (2, 'sammy', 'Pride and Prejudice', '2023-10-04'), mysql> (3, 'sammy', 'The Time Machine', '2023-09-23'), mysql> (4, 'bill', 'Frankenstein', '2023-07-23'), mysql> (5, 'bill', 'The Adventures of Huckleberry Finn', '2023-10-01'), mysql> (6, 'walt', 'The Picture of Dorian Gray', '2023-04-15'), mysql> (7, 'walt', 'Frankenstein', '2023-10-13'), mysql> (8, 'walt', 'Pride and Prejudice', '2023-10-19'); ستضيف عملية INSERT INTO السابقة 8 عمليات شراء مع قيمها المحدَّدة إلى جدول book_purchases، حيث يشير الخرج التالي إلى إضافة جميع الصفوف الثمانية: الخرج Query OK, 8 rows affected (0.00 sec) Records: 8 Duplicates: 0 Warnings: 0 ثم ندخِل بعض البيانات التجريبية في الجدول book_leases كما يلي: mysql> INSERT INTO book_leases mysql> VALUES mysql> (1, 'sammy', 'Frankenstein', '2023-09-14', '2023-11-14'), mysql> (2, 'sammy', 'Pride and Prejudice', '2023-10-01', '2023-12-31'), mysql> (3, 'sammy', 'The Adventures of Huckleberry Finn', '2023-10-01', '2023-12-01'), mysql> (4, 'bill', 'The Picture of Dorian Gray', '2023-09-03', '2023-09-18'), mysql> (5, 'bill', 'Crime and Punishment', '2023-09-27', '2023-12-05'), mysql> (6, 'kim', 'The Picture of Dorian Gray', '2023-10-01', '2023-11-15'), mysql> (7, 'kim', 'Pride and Prejudice', '2023-09-08', '2023-11-17'), mysql> (8, 'kim', 'The Time Machine', '2023-09-04', '2023-10-23'); وسيظهر الخرج التالي الذي يؤكّد إضافة هذه البيانات: الخرج Query OK, 8 rows affected (0.00 sec) Records: 8 Duplicates: 0 Warnings: 0 تتعلق عمليات التأجير والشراء بعملاء وعناوين كتب متماثلة، مما سيكون مفيدًا لتوضيح سلوك المعامل UNION، وبذلك سنكون جاهزين لمتابعة هذا المقال والبدء في استخدام عمليات UNION في لغة SQL. فهم صيغة المعامل UNION يطلب المعامل UNION في لغة SQL من قاعدة البيانات أخذ مجموعتي نتائج منفصلتين ومسترجعتين من استعلامات SELECT فردية ودمجهما في مجموعة نتائج واحدة تحتوي على صفوف مُعادة من كلا الاستعلامين. ملاحظة: يمكن أن تكون استعلامات SELECT المستخدمة مع العملية UNION معقدة وتتطلب استخدام تعليمات JOIN أو دوال تجميعية Aggregations أو استعلامات الفرعية Subqueries. إذ يمكننا استخدام عمليات UNION لدمج نتائج الاستعلامات مهما كانت معقدة، ولكن للسهولة سنستخدم في أمثلتنا التالية استعلامات SELECT بسيطة للتركيز على كيفية تصرف المعامل UNION. يوضّح المثال التالي الصيغة العامة لتعليمة SQL التي تتضمن المعامل UNION: mysql> SELECT column1, column2 FROM table1 mysql> UNION mysql> SELECT column1, column2 FROM table2; تبدأ تعليمة SQL السابقة بتعليمة SELECT التي تعيد عمودين من الجدول table1، ونتبعها بالمعامل UNION وتعليمة SELECT ثانية، ويعيد استعلام SELECT الثاني أيضًا عمودين من الجدول table2. تخبر الكلمة المفتاحية UNION قاعدة البيانات بأخذ الاستعلامات السابقة واللاحقة، وتنفيذها تنفيذًا منفصلًا، ثم ضم مجموعات النتائج الخاصة بها ضمن مجموعة واحدة. يُعَد جزء الشيفرة البرمجية السابق بأكمله -بما في ذلك استعلامات SELECT والكلمة المفتاحية UNION بينهما- تعليمة SQL واحدة، لذلك لا ينتهي استعلام SELECT الأول بفاصلة منقوطة، والتي تظهر بعد اكتمال التعليمة فقط. لنفترض مثلًا أننا نريد إدخال جميع العملاء الذين اشتروا كتابًا أو استأجروه، حيث يحتفظ الجدول book_purchases بسجلات عمليات الشراء، بينما يخزّن الجدول book_leases عمليات تأجير الكتب، لذا لنشغّل الاستعلام التالي: mysql> SELECT customer_name FROM book_purchases mysql> UNION mysql> SELECT customer_name FROM book_leases; وتكون مجموعة نتائج هذا الاستعلام كما يلي: الخرج +---------------+ | customer_name | +---------------+ | sammy | | bill | | walt | | kim | +---------------+ 4 rows in set (0.000 sec) يشير هذا الخرج إلى أن Sammy و Bill و Walt و Kim اشتروا كتبًا أو استأجروها. دعونا نجرّب تنفيذ تعليمتي SELECT تنفيذًا منفصلًا، مرةً لعمليات الشراء ومرةً لعمليات التأجير لفهم كيفية إنشاء مجموعة هذه النتائج. لنشغّل أولًا الاستعلام التالي لإعادة العملاء الذين اشتروا كتبًا فقط: mysql> SELECT customer_name FROM book_purchases; وسيكون الخرج كما يلي: الخرج +---------------+ | customer_name | +---------------+ | sammy | | sammy | | sammy | | bill | | bill | | walt | | walt | | walt | +---------------+ 8 rows in set (0.000 sec) اشترى Sammy و Bill و Walt كتبًا، لكن Kim لم يفعل ذلك. ثم لنشغّل الاستعلام التالي لإعادة العملاء الذين استأجروا كتبًا فقط: mysql> SELECT customer_name FROM book_leases; وسيكون الخرج كما يلي: الخرج +---------------+ | customer_name | +---------------+ | sammy | | sammy | | sammy | | bill | | bill | | kim | | kim | | kim | +---------------+ 8 rows in set (0.000 sec) يشير الجدول book_leases إلى أن Sammy و Bill و Kim يستعيرون كتبًا، ولكن Walt لا يستعير كتبًا أبدًا. إذا جمعنا بين الإجابتين، فيمكننا الحصول على البيانات لكل من عمليات الشراء والتأجير. الفرق المهم بين استخدام عملية UNION وتنفيذ استعلامين تنفيذًا منفصلًا هو أن عملية UNION تزيل القيم المكررة، حيث تُدمَج النتائج دون تكرار أسماء العملاء في النتيجة. يجب أن يعيد كلا الاستعلامين النتائج بالتنسيق نفسه لاستخدام عملية UNION لدمج نتائج استعلامين منفصلين بطريقة صحيحة، إذ ستؤدي التعارضات إلى حدوث أخطاء في محرّك قاعدة البيانات أو إلى ظهور نتائج لا تتطابق مع الهدف من الاستعلام كما سنوضّح في المثالين التاليين. تنفيذ عملية UNION مع عدد غير متطابق من الأعمدة لنجرّب تنفيذ عملية UNION مع تعليمة SELECT تعيد عمودًا واحدًا وتعليمة SELECT أخرى تعيد عمودين: mysql> SELECT purchase_id, customer_name FROM book_purchases mysql> UNION mysql> SELECT customer_name FROM book_leases; سيستجيب خادم قاعدة البيانات بالخطأ التالي: الخرج The used SELECT statements have a different number of columns لا يمكن إجراء عمليات UNION على مجموعات النتائج التي لها أعداد أعمدة مختلفة. تنفيذ عملية UNION مع ترتيب غير متطابق للأعمدة لنجرّب الآن تنفيذ عملية UNION مع تعلميتي SELECT تعيدان القيم نفسها ولكن بترتيب مختلف كما يلي: mysql> SELECT customer_name, book_title FROM book_purchases mysql> UNION mysql> SELECT book_title, customer_name FROM book_leases; لن يعيد خادم قاعدة البيانات خطأ، ولكن لن تكون مجموعة النتائج صحيحة كما يلي: الخرج +------------------------------------+------------------------------------+ | customer_name | book_title | +------------------------------------+------------------------------------+ | sammy | The Picture of Dorian Gray | | sammy | Pride and Prejudice | | sammy | The Time Machine | | bill | Frankenstein | | bill | The Adventures of Huckleberry Finn | | walt | The Picture of Dorian Gray | | walt | Frankenstein | | walt | Pride and Prejudice | | Frankenstein | sammy | | Pride and Prejudice | sammy | | The Adventures of Huckleberry Finn | sammy | | The Picture of Dorian Gray | bill | | Crime and Punishment | bill | | The Picture of Dorian Gray | kim | | Pride and Prejudice | kim | | The Time Machine | kim | +------------------------------------+------------------------------------+ 16 rows in set (0.000 sec) تدمج عملية UNION في هذا المثال العمود الأول من الاستعلام الأول مع العمود الأول من الاستعلام الثاني وتفعل الشيء نفسه بالنسبة للعمود الثاني، وبالتالي ستخلط أسماء العملاء وعناوين الكتب مع بعضها بعضًا. استخدام الشروط وترتيب النتائج باستخدام UNION دمجنا في المثال السابق مجموعات النتائج التي تمثل جميع الصفوف في جدولين متطابقين، ولكن ستحتاج في كثير من الأحيان إلى ترشيح الصفوف وفق شروط محددة قبل دمج النتائج، حيث يمكن لتعليمات SELECT المدموجة باستخدام المعامل UNION استخدام تعليمة WHERE لتطبيق ذلك. لنفترض مثلًا أننا نريد معرفة الكتب التي يقرأها Sammy من خلال شرائها أو استئجارها، لذا نشغّل الاستعلام التالي: mysql> SELECT book_title FROM book_purchases mysql> WHERE customer_name = 'Sammy' mysql> UNION mysql> SELECT book_title FROM book_leases mysql> WHERE customer_name = 'Sammy'; يتضمن كلا الاستعلامين تعليمة WHERE، مما يؤدي إلى ترشيح الصفوف من الجدولين المنفصلين لتضمين عمليات الشراء والتأجير التي أجراها Sammy فقط، وستكون نتائج هذا الاستعلام كما يلي: الخرج +------------------------------------+ | book_title | +------------------------------------+ | The Picture of Dorian Gray | | Pride and Prejudice | | The Time Machine | | Frankenstein | | The Adventures of Huckleberry Finn | +------------------------------------+ 5 rows in set (0.000 sec) تضمن عملية UNION عدم وجود تكرارات في قائمة النتائج. يمكننا استخدام تعليمات WHERE أيضًا لتحديد الصفوف المُعادة في استعلامي SELECT أو أحدهما فقط، ويمكن أن تشير تعليمة WHERE إلى أعمدة وشروط مختلفة في كل من الاستعلامين. إضافةً لذلك، لا تتبع النتائج التي تعيدها عملية UNION ترتيبًا محدَّدًا، ولكن يمكننا تغيير ذلك من خلال استخدام تعليمة ORDER BY، حيث ينفَّذ الترتيب على النتائج النهائية المدموجة وليس على الاستعلامات الفردية. يمكننا فرز عناوين الكتب أبجديًا بعد استرجاع قائمة بجميع الكتب التي اشتراها أو استأجرها Sammy من خلال تنفيذ الاستعلام التالي: mysql> SELECT book_title FROM book_purchases mysql> WHERE customer_name = 'Sammy' mysql> UNION mysql> SELECT book_title FROM book_leases mysql> WHERE customer_name = 'Sammy' mysql> ORDER BY book_title; وسيكون الخرج كما يلي: الخرج +------------------------------------+ | book_title | +------------------------------------+ | Frankenstein | | Pride and Prejudice | | The Adventures of Huckleberry Finn | | The Picture of Dorian Gray | | The Time Machine | +------------------------------------+ 5 rows in set (0.001 sec) نلاحظ أن إعادة النتائج بالترتيب يعتمد على العمود book_title الذي يحتوي على النتائج الناتجة عن دمج استعلامَي SELECT. استخدام العملية UNION ALL للاحتفاظ بالنسخ المكررة يزيل المعامل UNION تلقائيًا الصفوف المكررة من النتائج كما أظهرت الأمثلة السابقة، ولكن قد لا يكون هذا السلوك هو ما نريد تحقيقه باستخدام الاستعلام، فمثلًا لنفترض أننا نريد معرفة الكتب المُشتراة أو المستأجرة في 1 من شهر 11 من عام 2023، حيث يمكننا استرجاع هذه العناوين من خلال اتباع المثال التالي المشابه لما سبق: mysql> SELECT book_title FROM book_purchases mysql> WHERE date = '2022-10-01' mysql> UNION mysql> SELECT book_title FROM book_leases mysql> WHERE date_from = '2022-10-01' mysql> ORDER BY book_title; وسنحصل على النتائج التالية: الخرج +------------------------------------+ | book_title | +------------------------------------+ | Pride and Prejudice | | The Adventures of Huckleberry Finn | | The Picture of Dorian Gray | +------------------------------------+ 3 rows in set (0.001 sec) عناوين الكتب المُعادة هنا صحيحة، ولكن لن تخبرنا النتائج فيما إذا كانت هذه الكتب مشتراة فقط أم مستأجرة فقط أم كليهما، حيث ستظهر عناوين الكتب في الجدولين book_purchases و book_leases في الحالات التي جرى فيها شراء بعض الكتب واستئجارها، ولكن ستُفقَد هذه المعلومات في النتيجة، لأن المعامل UNION يزيل الصفوف المكررة. تمتلك لغة SQL طريقة لتغيير هذا السلوك والاحتفاظ بالصفوف المكررة، حيث يمكننا استخدام المعامل UNION ALL لدمج النتائج من استعلامين دون إزالة الصفوف المكررة، ويعمل المعامل UNION ALL بطريقة مشابهة للمعامل UNION، ولكن إذا وُجِدت تكرارات متعددة للقيم نفسها، فستكون جميعها موجودة في النتيجة. لنشغّل الاستعلام السابق نفسه مع وضع UNION ALL مكان UNION كما يلي: mysql> SELECT book_title FROM book_purchases mysql> WHERE date = '2022-10-01' mysql> UNION ALL mysql> SELECT book_title FROM book_leases mysql> WHERE date_from = '2022-10-01' mysql> ORDER BY book_title; ستكون القائمة الناتجة أطول هذه المرة كما يلي: الخرج +------------------------------------+ | book_title | +------------------------------------+ | Pride and Prejudice | | The Adventures of Huckleberry Finn | | The Adventures of Huckleberry Finn | | The Picture of Dorian Gray | | The Picture of Dorian Gray | +------------------------------------+ 5 rows in set (0.000 sec) يظهَر الكتابان The Adventures of Huckleberry Finn و The Picture of Dorian Gray مرتين في مجموعة النتائج، وهذا يعني أنهما ظهرا في الجدولين book_purchases و book_leases، وبالتالي يمكننا افتراض أنه جرى تأجيرهما وشراؤهما في ذلك اليوم. يمكن الاختيار بين المعاملين UNION و UNION ALL والتبديل بينهما اعتمادًا على ما إذا أردنا إزالة التكرارات أو الاحتفاظ بها. ملاحظة: تنفيذ المعامل UNION ALL أسرع من تنفيذ المعامل UNION، إذ لا تحتاج قاعدة البيانات إلى فحص مجموعة النتائج للعثور على التكرارات. فإذا أردنا دمج نتائج استعلامات SELECT التي نعرف أنها لن تحتوي على أي صفوف مكررة، فيمكن أن يحقق استخدام المعامل UNION ALL أداءً أفضل مع مجموعات البيانات الأكبر حجمًا. الخلاصة تعرّفنا في هذا المقال على كيفية استرجاع البيانات من جداول متعددة باستخدام عمليات UNION و UNION ALL، واستخدمنا أيضًا تعليمات WHERE لترشيح النتائج وتعليمات ORDER BY لترتيبها، وتعلّمنا الأخطاء المحتمَلة والسلوكيات غير المتوقعة إذا أنتجت تعليمات SELECT تنسيقات بيانات مختلفة. يجب أن تعمل الأوامر الواردة في هذا المقال على معظم قواعد البيانات العلاقية، ولكن يجب أن نتذكر أن كل قاعدة بيانات SQL تستخدم تقديمها الفريد للغة، لذا ننصح بالاطلاع على مقال مقارنة بين أنظمة إدارة قواعد البيانات العلاقية: SQLite مع MySQL مع PostgreSQL لمزيد من المعلومات، كما ننصح بالرجوع إلى توثيق RDBMS الرسمي للحصول على شرح مفصّل لكل أمر ومجموعة خياراته الكاملة. ترجمة -وبتصرف- للمقال How To Use Unions in SQL لصاحبَيه Mateusz Papiernik و Rachel Lee. اقرأ أيضًا المقال السابق: استخدام الاستعلامات المتداخلة Nested Queries في SQL الدمج بين الجداول في SQL أنواع قواعد البيانات وأهم مميزاتها واستخداماتها معالجة الأخطاء والتعديل على قواعد البيانات في SQL التعابير الجدولية الشائعة Common Table Expressions في SQL -
 تفيدنا لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- في إدارة البيانات المخزنة في نظام إدارة قواعد بيانات علاقية Relational Database Management System -أو RDBMS اختصارًا- ومن أبرز الوظائف المفيدة في SQL هي إنشاء استعلام ضمن استعلام آخر، والذي يُعرَف باسم الاستعلام الفرعي Subquery أو الاستعلام المتداخل Nested وهو موضوع مقالنا اليوم. متطلبات العمل يجب توفر حاسوب يشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم لغة SQL. وبالنسبة لهذا المقال فقد اختبرنا التعليمات والأمثلة الواردة فيه باستخدام البيئة التالية: خادم عامل على أحدث إصدار من توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مُفعَّل كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضّح في مقال كيفية تثبيت MySQL على أوبنتو وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة 3 من المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن قد نجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على جدول يحتوي بيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام الاستعلامات المتداخلة، وفي حال لم تكن متوفرة فيمكن مطالعة القسم التالي لمعرفة كيفية إنشاء قاعدة البيانات والجدول المستخدَمَين في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كانت قاعدة بيانات SQL الخاصة بنا تعمل على خادم بعيد، علينا الاتصال بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم zooDB: mysql> CREATE DATABASE zooDB; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات zooDB من خلال تنفيذ تعليمة USE التالية: mysql> USE zooDB; الخرج Database changed اخترنا قاعدة البيانات، وسننشئ جدولًا ضمنها، حيث سننشئ جدولًا يخزّن المعلومات حول الزوار الذين يزورون حديقة الحيوان، وسيحتوي هذا الجدول على الأعمدة السبعة التالية: guest_id: يخزّن قيمًا للزوار الذين يزورون حديقة الحيوان ويستخدم نوع البيانات int، ويمثّل المفتاح الرئيسي Primary Key للجدول، ممّا يعني أن كل قيمة في هذا العمود ستمثّل معرّفًا فريدًا للصف الخاص بها first_name: الاسم الأول لكل زائر ويستخدم نوع البيانات varchar بحد أقصى 30 محرف last_name: الاسم الأخير لكل زائر ويستخدم نوع البيانات varchar بحد أقصى 30 محرف guest_type: يحدد هل الزائر بالغ أو طفل ويستخدم نوع البيانات varchar بحد أقصى 15 محرف membership_type: نوع العضوية لكل زائر ويستخدم نوع بيانات varchar بحد أقصى 30 محرف membership_cost: تكلفة أنواع العضوية المختلفة، ويستخدم نوع البيانات decimal بدقة 5 ومقياس 2، أي أن القيم الموجودة في هذا العمود يمكن أن تحتوي على خمسة أرقام مع وجود رقمين على يمين الفاصلة العشرية total_visits: يسجل إجمالي عدد الزيارات لكل زائر ويستخدم نوع البيانات int سننشئ جدولًا باسم guests يحتوي على الأعمدة السابقة من خلال تشغيل الأمر CREATE TABLE التالي: mysql> CREATE TABLE guests ( mysql> guest_id int, mysql> first_name varchar(30), mysql> last_name varchar(30), mysql> guest_type varchar(15), mysql> membership_type varchar(30), mysql> membership_cost decimal(5,2), mysql> total_visits int, mysql> PRIMARY KEY (guest_id) mysql> ); ثم ندخل بعض البيانات التجريبية في هذا الجدول الفارغ كما يلي: mysql> INSERT INTO guests mysql> (guest_id, first_name, last_name, guest_type, membership_type, membership_cost, total_visits) mysql> VALUES mysql> (1, 'Judy', 'Hopps', 'Adult', 'Resident Premium Pass', 110.0, 168), mysql> (2, 'Nick', 'Wilde', 'Adult', 'Day Pass', 62.0, 1), mysql> (3, 'Duke', 'Weaselton', 'Adult', 'Resident Pass', 85.0, 4), mysql> (4, 'Tommy', 'Yax', 'Child', 'Youth Pass', 67.0, 30), mysql> (5, 'Lizzie', 'Yax', 'Adult', 'Guardian Pass', 209.0, 30), mysql> (6, 'Jenny', 'Bellwether', 'Adult', 'Resident Premium Pass', 110.0, 20), mysql> (7, 'Idris', 'Bogo', 'Child', 'Youth Pass', 67.0, 79), mysql> (8, 'Gideon', 'Grey', 'Child', 'Youth Pass', 67.0, 100), mysql> (9, 'Nangi', 'Reddy', 'Adult', 'Guardian Champion', 400.0, 241), mysql> (10, 'Octavia', 'Otterton', 'Adult', 'Resident Pass', 85.0, 11), mysql> (11, 'Calvin', 'Roo', 'Adult', 'Resident Premium Pass', 110.0, 173), mysql> (12, 'Maurice', 'Big', 'Adult', 'Guardian Champion', 400.0, 2), mysql> (13, 'J.K.', 'Lionheart', 'Child', 'Day Pass', 52.0, 1), mysql> (14, 'Priscilla', 'Bell', 'Child', 'Day Pass', 104.0, 2), mysql> (15, 'Tommy', 'Finnick', 'Adult', 'Day Pass', 62.0, 1); الخرج Query OK, 15 rows affected (0.01 sec) Records: 15 Duplicates: 0 Warnings: 0 نحن الآن جاهزون لبدء استخدام الاستعلامات المتداخلة في لغة SQL. ما هو الاستعلام المتداخل الاستعلام في لغة SQL هو عملية تسترجع البيانات من جدول في قاعدة بيانات وتتضمن تعليمة SELECT دائمًا، أما الاستعلام المتداخل nested query فهو استعلام داخل استعلام آخر، بمعنى آخر الاستعلام المتداخل هو تعليمة SELECT توضع بين قوسين عادة، وتُضمَّن في عملية SELECT أو INSERT أو DELETE رئيسية، ويُعَد الاستعلام المتداخل مفيدًا في الحالات التي نريد فيها تنفيذ أوامر متعددة في تعليمة استعلام واحدة بدلًا من كتابة عدة أوامر لإعادة النتيجة المطلوبة، ويمكننا من خلال الاستعلامات المتداخلة إتمام عمليات معقدة على البيانات بطريقة أسهل. سنستخدم في هذا المقال الاستعلامات المتداخلة مع تعليمات SELECT و INSERT و DELETE، كما سنستخدم الدوال التجميعية Aggregate Functions ضمن استعلام متداخل لمقارنة قيم البيانات بقيم البيانات المفروزة التي حدّدناها باستخدام تعلميتي WHERE و LIKE. استخدام الاستعلامات المتداخلة مع تعليمة SELECT لنوضّح فائدة الاستعلامات المتداخلة عمليًا باستخدام البيانات التجريبية التي أضفناها في خطوة سابقة، ولنفترض مثلًا أننا نريد البحث عن جميع الزوار في الجدول guests الذين زاروا حديقة الحيوان بعدد مرات أكبر من متوسط الزيارات. قد نفترض أن بإمكاننا العثور على هذه المعلومات من خلال الاستعلام التالي: mysql> SELECT first_name, last_name, total_visits mysql> FROM guests mysql> WHERE total_visits > AVG(total_visits); ولكن سيعيد الاستعلام الذي يستخدم الصيغة السابقة خطأ كما يلي: الخرج ERROR 1111 (HY000): Invalid use of group function سبب هذا الخطأ هو أن الدوال التجميعية مثل الدالة AVG() لا تعمل إلا إذا كانت مُنفَّذة ضمن تعليمة SELECT. أحد الخيارات لاسترجاع هذه المعلومات هو تشغيل استعلام للعثور على متوسط عدد زيارات الزوار أولًا، ثم تشغيل استعلام آخر للعثور على النتائج بناءً على تلك القيمة كما هو الحال في المثالين التاليين: mysql> SELECT AVG(total_visits) FROM guests; الخرج +-----------------+ | avg(total_visits) | +-----------------+ | 57.5333 | +-----------------+ 1 row in set (0.00 sec) mysql> SELECT first_name, last_name, total_visits mysql> FROM guests mysql> WHERE total_visits > 57.5333; الخرج +----------+---------+------------+ | first_name | last_name | total_visits | +----------+---------+------------+ | Judy | Hopps | 168 | | Idris | Bogo | 79 | | Gideon | Grey | 100 | | Nangi | Reddy | 241 | | Calvin | Roo | 173 | +----------+---------+------------+ 5 rows in set (0.00 sec) ولكن يمكننا الحصول على مجموعة النتائج نفسها باستخدام استعلام واحد من خلال تداخل الاستعلام الأول (SELECT AVG(total_visits) FROM guests;) مع الاستعلام الثاني. ينبغي أن نضع في الحسبان أن استخدام العدد المناسب من الأقواس مع الاستعلامات المتداخلة أمر ضروري لإكمال العملية التي نريد تنفيذها، لأن الاستعلام المتداخل هو أول عملية تُنفَّذ: mysql> SELECT first_name, last_name, total_visits mysql> FROM guests mysql> WHERE total_visits > mysql> (SELECT AVG(total_visits) FROM guests); الخرج +------------+-----------+--------------+ | first_name | last_name | total_visits | +------------+-----------+--------------+ | Judy | Hopps | 168 | | Idris | Bogo | 79 | | Gideon | Grey | 100 | | Nangi | Reddy | 241 | | Calvin | Roo | 173 | +------------+-----------+--------------+ 5 rows in set (0.00 sec) يوضّح المثال السابق أهمية استخدام استعلام متداخل في تعليمة واحدة كاملة للحصول على النتائج المطلوبة بدلًا من الاضطرار إلى تشغيل استعلامين منفصلين، وفق الخرج الذي حصلنا عليه فقد زار خمسة زوار حديقة الحيوان بعدد مرات أكبر من متوسط الزيارات، ويمكن أن تقدّم هذه المعلومات نظرة مفيدة للتفكير في طرق إبداعية لضمان استمرار الأعضاء الحاليين في زيارة حديقة الحيوان وتجديد عضويتهم كل سنة. استخدام الاستعلامات المتداخلة مع تعليمة INSERT لا يقتصر الأمر على تضمين الاستعلام المتداخل في تعليمات SELECT أخرى فقط، إذ يمكننا أيضًا استخدام الاستعلامات المتداخلة لإدخال البيانات في جدول موجود مسبقًا من خلال تضمين الاستعلام المتداخل في عملية INSERT. لنفترض وجود حديقة حيوانات ما تطلب بعض المعلومات عن زوار حديقة الحيوان خاصة بنا وتود تقديم خصم بنسبة 15% للزوار الذين يشترون العضوية الدائمة في موقعها، لذا سنستخدم تعليمة CREATE TABLE لإنشاء جدول جديد بالاسم upgrade_guests والذي يحتوي على ستة أعمدة، وننتبه جيدًا لأنواع البيانات مثل int و varchar والحد الأقصى من المحارف التي يمكن الاحتفاظ بها، فإن لم تكن متماشية مع أنواع البيانات الأصلية من الجدول guests الذي أنشأناه في قسم إعداد قاعدة بيانات نموذجية، فسنتلقى خطأً عند محاولة إدخال بيانات من الجدول guests باستخدام استعلام متداخل ولن تُنقَل البيانات بطريقة صحيحة. لننشئ هذا الجدول مع المعلومات التالية: mysql> CREATE TABLE upgrade_guests ( mysql> guest_id int, mysql> first_name varchar(30), mysql> last_name varchar(30), mysql> membership_type varchar(30), mysql> membership_cost decimal(5,2), mysql> total_visits int, mysql> PRIMARY KEY (guest_id) mysql> ); احتفظنا بمعظم معلومات نوع البيانات في هذا الجدول كما كانت في الجدول guests من أجل التناسق والدقة، وحذفنا أي أعمدة إضافية لا نريدها في الجدول الجديد. أصبح هذا الجدول الفارغ جاهزًا للبدء، والخطوة التالية هي إدخال قيم البيانات المطلوبة في الجدول. نكتب التعليمة INSERT INTO مع الجدول upgrade_guests الجديد مع وجود اتجاه واضح لمكان إدخال البيانات، ثم نكتب الاستعلام المتداخل باستخدام تعليمة SELECT لاسترجاع قيم البيانات ذات الصلة وتعليمة FROM للتأكد من أن البيانات تأتي من الجدول guests. سيطبّق خصم بقيمة 15% على الأعضاء الدائمين من خلال تضمين عملية الضرب الرياضية * للضرب بالعدد 0.85 ضمن الاستعلام المتداخل (membership_cost * 0.85)، وتفيدنا تعليمة WHERE في فرز القيم الموجودة في العمود membership_type. يمكننا تضييق نطاق النتائج لتشمل فقط نتائج الأعضاء الدائمين باستخدام تعليمة LIKE ووضع رمز النسبة المئوية % قبل وبعد الكلمة "Resident" بين علامتي اقتباس مفردتين لتحديد نوع العضوية التي تتبع النمط أو المفردات نفسها، وسيُكتَب هذا الاستعلام كما يلي: mysql> INSERT INTO upgrade_guests mysql> SELECT guest_id, first_name, last_name, membership_type, mysql> (membership_cost * 0.85), total_visits mysql> FROM guests mysql> WHERE membership_type LIKE '%resident%'; الخرج Query OK, 5 rows affected, 5 warnings (0.01 sec) Records: 5 Duplicates: 0 Warnings: 5 يشير الخرج السابق إلى إضافة خمسة سجلات إلى الجدول upgrade_guests الجديد. يمكن التأكد من نقل البيانات التي طلبتها بنجاح من الجدول guests إلى الجدول upgrade_guests الفارغ الذي أنشأناه من خلال تشغيل الأمر التالي مع الشروط التي حدّدناها مع الاستعلام المتداخل وتعليمة WHERE: mysql> SELECT * FROM upgrade_guests; الخرج +----------+------------+------------+-----------------------+-----------------+--------------+ | guest_id | first_name | last_name | membership_type | membership_cost | total_visits | +----------+------------+------------+-----------------------+-----------------+--------------+ | 1 | Judy | Hopps | Resident Premium Pass | 93.50 | 168 | | 3 | Duke | Weaselton | Resident Pass | 72.25 | 4 | | 6 | Jenny | Bellwether | Resident Premium Pass | 93.50 | 20 | | 10 | Octavia | Otterton | Resident Pass | 72.25 | 11 | | 11 | Calvin | Roo | Resident Premium Pass | 93.50 | 173 | +----------+------------+------------+-----------------------+-----------------+--------------+ 5 rows in set (0.01 sec) نلاحظ الإدراج الصحيح لمعلومات عضوية الزائر الدائم "Resident" ذات الصلة من الجدول guest في الجدول upgrade_guests، مع إعادة حساب التكلفة membership_cost الجديدة مع تطبيق خصم 15%، وبذلك ساعدت هذه العملية في تقسيم الجمهور المناسب واستهدافه، وأصبحت الأسعار المخفَّضة متاحة بسهولة لمشاركتها مع الأعضاء الجدد المحتملين. استخدام الاستعلامات المتداخلة مع تعليمة DELETE لنفترض أننا نريد إزالة الزوار المعتادين والتركيز فقط على الترويج لخصم البطاقة المميزة للأعضاء الذين لا يزورون حديقة الحيوان كثيرًا حاليًا. نبدأ هذه العملية باستخدام تعليمة DELETE FROM بحيث يكون من الواضح المكان الذي ستحذف البيانات منه، وهو الجدول upgrade_guests في حالتنا، ثم نستخدم تعليمة WHERE لفرز أي قيمة من العمود total_visits تزيد عن الكمية المحدَّدة في الاستعلام المتداخل. نستخدم تعليمة SELECT في استعلامنا المتداخل المُضمَّن للعثور على المتوسط الحسابي AVG للعمود total_visits بحيث تحتوي تعليمة WHERE السابقة على قيم البيانات المناسبة للمقارنة معها. وأخيرًا، نستخدم تعليمة FROM لاسترجاع تلك المعلومات من الجدول guests، وسيكون الاستعلام الكامل كما يلي: mysql> DELETE FROM upgrade_guests mysql> WHERE total_visits > mysql> (SELECT AVG(total_visits) FROM guests); الخرج Query OK, 2 rows affected (0.00 sec) لنتأكّد من حذف هذه السجلات بنجاح من الجدول upgrade_guests، ونستخدم تعليمة ORDER BY لتنظيم النتائج وفق العمود total_visits بترتيب رقمي تصاعدي. ملاحظة: لن يؤدي استخدام تعليمة DELETE لحذف السجلات من جدولنا الجديد إلى حذفها من الجدول الأصلي، حيث يمكننا تشغيل التعليمة SELECT * FROM original_table للتأكد من وجود جميع السجلات الأصلية، حتى إن كانت محذوفة من الجدول الجديد. mysql> SELECT * FROM upgrade_guests ORDER BY total_visits; الخرج +----------+------------+------------+-----------------------+-----------------+--------------+ | guest_id | first_name | last_name | membership_type | membership_cost | total_visits | +----------+------------+------------+-----------------------+-----------------+--------------+ | 3 | Duke | Weaselton | Resident Pass | 72.25 | 4 | | 10 | Octavia | Otterton | Resident Pass | 72.25 | 11 | | 6 | Jenny | Bellwether | Resident Premium Pass | 93.50 | 20 | +----------+------------+------------+-----------------------+-----------------+--------------+ 3 rows in set (0.00 sec) يشير هذا الخرج إلى نجاح تعليمة DELETE والاستعلام المتداخل في حذف قيم البيانات المُحدَّدة، لذا سيحتوي هذا الجدول الآن على معلومات الزوار الثلاثة الذين عدد زياراتهم أقل من متوسط عدد الزيارات، وهو ما يُعَد نقطة انطلاق لموظف حديقة الحيوان للتواصل مع هؤلاء الزوار بشأن الترقية إلى التذاكر المميزة بسعر مخفَّض لتشجيعهم على الذهاب أكثر إلى حديقة الحيوان. الخلاصة شرحنا في هذا المقال الاستعلامات المتداخلة ووضحنا فائدتها في الحصول على نتائج دقيقة لم نكن سنتمكن من الحصول عليها إلا من خلال تشغيل استعلامات منفصلة، وعرضنا أمثلة عملية لاستخدام تعليمات SELECT وINSERT و DELETE مع الاستعلامات المتداخلة لتوفير طريقة أخرى لإدخال البيانات أو حذفها في خطوة واحدة. ترجمة -وبتصرف- للمقال How To Use Nested Queries in SQL لصاحبته Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: استخدام تعليمتي GROUP BY و ORDER BY في SQL الاستعلامات الفرعية Subqueries في SQL مفاهيم نموذج البيانات العلائقية RDM الأساسية بعض الدوال المساعدة في SQL
تفيدنا لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- في إدارة البيانات المخزنة في نظام إدارة قواعد بيانات علاقية Relational Database Management System -أو RDBMS اختصارًا- ومن أبرز الوظائف المفيدة في SQL هي إنشاء استعلام ضمن استعلام آخر، والذي يُعرَف باسم الاستعلام الفرعي Subquery أو الاستعلام المتداخل Nested وهو موضوع مقالنا اليوم. متطلبات العمل يجب توفر حاسوب يشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم لغة SQL. وبالنسبة لهذا المقال فقد اختبرنا التعليمات والأمثلة الواردة فيه باستخدام البيئة التالية: خادم عامل على أحدث إصدار من توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مُفعَّل كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضّح في مقال كيفية تثبيت MySQL على أوبنتو وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة 3 من المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن قد نجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على جدول يحتوي بيانات تجريبية نموذجية لنتمكّن من التدرب على استخدام الاستعلامات المتداخلة، وفي حال لم تكن متوفرة فيمكن مطالعة القسم التالي لمعرفة كيفية إنشاء قاعدة البيانات والجدول المستخدَمَين في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كانت قاعدة بيانات SQL الخاصة بنا تعمل على خادم بعيد، علينا الاتصال بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم zooDB: mysql> CREATE DATABASE zooDB; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر الخرج التالي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات zooDB من خلال تنفيذ تعليمة USE التالية: mysql> USE zooDB; الخرج Database changed اخترنا قاعدة البيانات، وسننشئ جدولًا ضمنها، حيث سننشئ جدولًا يخزّن المعلومات حول الزوار الذين يزورون حديقة الحيوان، وسيحتوي هذا الجدول على الأعمدة السبعة التالية: guest_id: يخزّن قيمًا للزوار الذين يزورون حديقة الحيوان ويستخدم نوع البيانات int، ويمثّل المفتاح الرئيسي Primary Key للجدول، ممّا يعني أن كل قيمة في هذا العمود ستمثّل معرّفًا فريدًا للصف الخاص بها first_name: الاسم الأول لكل زائر ويستخدم نوع البيانات varchar بحد أقصى 30 محرف last_name: الاسم الأخير لكل زائر ويستخدم نوع البيانات varchar بحد أقصى 30 محرف guest_type: يحدد هل الزائر بالغ أو طفل ويستخدم نوع البيانات varchar بحد أقصى 15 محرف membership_type: نوع العضوية لكل زائر ويستخدم نوع بيانات varchar بحد أقصى 30 محرف membership_cost: تكلفة أنواع العضوية المختلفة، ويستخدم نوع البيانات decimal بدقة 5 ومقياس 2، أي أن القيم الموجودة في هذا العمود يمكن أن تحتوي على خمسة أرقام مع وجود رقمين على يمين الفاصلة العشرية total_visits: يسجل إجمالي عدد الزيارات لكل زائر ويستخدم نوع البيانات int سننشئ جدولًا باسم guests يحتوي على الأعمدة السابقة من خلال تشغيل الأمر CREATE TABLE التالي: mysql> CREATE TABLE guests ( mysql> guest_id int, mysql> first_name varchar(30), mysql> last_name varchar(30), mysql> guest_type varchar(15), mysql> membership_type varchar(30), mysql> membership_cost decimal(5,2), mysql> total_visits int, mysql> PRIMARY KEY (guest_id) mysql> ); ثم ندخل بعض البيانات التجريبية في هذا الجدول الفارغ كما يلي: mysql> INSERT INTO guests mysql> (guest_id, first_name, last_name, guest_type, membership_type, membership_cost, total_visits) mysql> VALUES mysql> (1, 'Judy', 'Hopps', 'Adult', 'Resident Premium Pass', 110.0, 168), mysql> (2, 'Nick', 'Wilde', 'Adult', 'Day Pass', 62.0, 1), mysql> (3, 'Duke', 'Weaselton', 'Adult', 'Resident Pass', 85.0, 4), mysql> (4, 'Tommy', 'Yax', 'Child', 'Youth Pass', 67.0, 30), mysql> (5, 'Lizzie', 'Yax', 'Adult', 'Guardian Pass', 209.0, 30), mysql> (6, 'Jenny', 'Bellwether', 'Adult', 'Resident Premium Pass', 110.0, 20), mysql> (7, 'Idris', 'Bogo', 'Child', 'Youth Pass', 67.0, 79), mysql> (8, 'Gideon', 'Grey', 'Child', 'Youth Pass', 67.0, 100), mysql> (9, 'Nangi', 'Reddy', 'Adult', 'Guardian Champion', 400.0, 241), mysql> (10, 'Octavia', 'Otterton', 'Adult', 'Resident Pass', 85.0, 11), mysql> (11, 'Calvin', 'Roo', 'Adult', 'Resident Premium Pass', 110.0, 173), mysql> (12, 'Maurice', 'Big', 'Adult', 'Guardian Champion', 400.0, 2), mysql> (13, 'J.K.', 'Lionheart', 'Child', 'Day Pass', 52.0, 1), mysql> (14, 'Priscilla', 'Bell', 'Child', 'Day Pass', 104.0, 2), mysql> (15, 'Tommy', 'Finnick', 'Adult', 'Day Pass', 62.0, 1); الخرج Query OK, 15 rows affected (0.01 sec) Records: 15 Duplicates: 0 Warnings: 0 نحن الآن جاهزون لبدء استخدام الاستعلامات المتداخلة في لغة SQL. ما هو الاستعلام المتداخل الاستعلام في لغة SQL هو عملية تسترجع البيانات من جدول في قاعدة بيانات وتتضمن تعليمة SELECT دائمًا، أما الاستعلام المتداخل nested query فهو استعلام داخل استعلام آخر، بمعنى آخر الاستعلام المتداخل هو تعليمة SELECT توضع بين قوسين عادة، وتُضمَّن في عملية SELECT أو INSERT أو DELETE رئيسية، ويُعَد الاستعلام المتداخل مفيدًا في الحالات التي نريد فيها تنفيذ أوامر متعددة في تعليمة استعلام واحدة بدلًا من كتابة عدة أوامر لإعادة النتيجة المطلوبة، ويمكننا من خلال الاستعلامات المتداخلة إتمام عمليات معقدة على البيانات بطريقة أسهل. سنستخدم في هذا المقال الاستعلامات المتداخلة مع تعليمات SELECT و INSERT و DELETE، كما سنستخدم الدوال التجميعية Aggregate Functions ضمن استعلام متداخل لمقارنة قيم البيانات بقيم البيانات المفروزة التي حدّدناها باستخدام تعلميتي WHERE و LIKE. استخدام الاستعلامات المتداخلة مع تعليمة SELECT لنوضّح فائدة الاستعلامات المتداخلة عمليًا باستخدام البيانات التجريبية التي أضفناها في خطوة سابقة، ولنفترض مثلًا أننا نريد البحث عن جميع الزوار في الجدول guests الذين زاروا حديقة الحيوان بعدد مرات أكبر من متوسط الزيارات. قد نفترض أن بإمكاننا العثور على هذه المعلومات من خلال الاستعلام التالي: mysql> SELECT first_name, last_name, total_visits mysql> FROM guests mysql> WHERE total_visits > AVG(total_visits); ولكن سيعيد الاستعلام الذي يستخدم الصيغة السابقة خطأ كما يلي: الخرج ERROR 1111 (HY000): Invalid use of group function سبب هذا الخطأ هو أن الدوال التجميعية مثل الدالة AVG() لا تعمل إلا إذا كانت مُنفَّذة ضمن تعليمة SELECT. أحد الخيارات لاسترجاع هذه المعلومات هو تشغيل استعلام للعثور على متوسط عدد زيارات الزوار أولًا، ثم تشغيل استعلام آخر للعثور على النتائج بناءً على تلك القيمة كما هو الحال في المثالين التاليين: mysql> SELECT AVG(total_visits) FROM guests; الخرج +-----------------+ | avg(total_visits) | +-----------------+ | 57.5333 | +-----------------+ 1 row in set (0.00 sec) mysql> SELECT first_name, last_name, total_visits mysql> FROM guests mysql> WHERE total_visits > 57.5333; الخرج +----------+---------+------------+ | first_name | last_name | total_visits | +----------+---------+------------+ | Judy | Hopps | 168 | | Idris | Bogo | 79 | | Gideon | Grey | 100 | | Nangi | Reddy | 241 | | Calvin | Roo | 173 | +----------+---------+------------+ 5 rows in set (0.00 sec) ولكن يمكننا الحصول على مجموعة النتائج نفسها باستخدام استعلام واحد من خلال تداخل الاستعلام الأول (SELECT AVG(total_visits) FROM guests;) مع الاستعلام الثاني. ينبغي أن نضع في الحسبان أن استخدام العدد المناسب من الأقواس مع الاستعلامات المتداخلة أمر ضروري لإكمال العملية التي نريد تنفيذها، لأن الاستعلام المتداخل هو أول عملية تُنفَّذ: mysql> SELECT first_name, last_name, total_visits mysql> FROM guests mysql> WHERE total_visits > mysql> (SELECT AVG(total_visits) FROM guests); الخرج +------------+-----------+--------------+ | first_name | last_name | total_visits | +------------+-----------+--------------+ | Judy | Hopps | 168 | | Idris | Bogo | 79 | | Gideon | Grey | 100 | | Nangi | Reddy | 241 | | Calvin | Roo | 173 | +------------+-----------+--------------+ 5 rows in set (0.00 sec) يوضّح المثال السابق أهمية استخدام استعلام متداخل في تعليمة واحدة كاملة للحصول على النتائج المطلوبة بدلًا من الاضطرار إلى تشغيل استعلامين منفصلين، وفق الخرج الذي حصلنا عليه فقد زار خمسة زوار حديقة الحيوان بعدد مرات أكبر من متوسط الزيارات، ويمكن أن تقدّم هذه المعلومات نظرة مفيدة للتفكير في طرق إبداعية لضمان استمرار الأعضاء الحاليين في زيارة حديقة الحيوان وتجديد عضويتهم كل سنة. استخدام الاستعلامات المتداخلة مع تعليمة INSERT لا يقتصر الأمر على تضمين الاستعلام المتداخل في تعليمات SELECT أخرى فقط، إذ يمكننا أيضًا استخدام الاستعلامات المتداخلة لإدخال البيانات في جدول موجود مسبقًا من خلال تضمين الاستعلام المتداخل في عملية INSERT. لنفترض وجود حديقة حيوانات ما تطلب بعض المعلومات عن زوار حديقة الحيوان خاصة بنا وتود تقديم خصم بنسبة 15% للزوار الذين يشترون العضوية الدائمة في موقعها، لذا سنستخدم تعليمة CREATE TABLE لإنشاء جدول جديد بالاسم upgrade_guests والذي يحتوي على ستة أعمدة، وننتبه جيدًا لأنواع البيانات مثل int و varchar والحد الأقصى من المحارف التي يمكن الاحتفاظ بها، فإن لم تكن متماشية مع أنواع البيانات الأصلية من الجدول guests الذي أنشأناه في قسم إعداد قاعدة بيانات نموذجية، فسنتلقى خطأً عند محاولة إدخال بيانات من الجدول guests باستخدام استعلام متداخل ولن تُنقَل البيانات بطريقة صحيحة. لننشئ هذا الجدول مع المعلومات التالية: mysql> CREATE TABLE upgrade_guests ( mysql> guest_id int, mysql> first_name varchar(30), mysql> last_name varchar(30), mysql> membership_type varchar(30), mysql> membership_cost decimal(5,2), mysql> total_visits int, mysql> PRIMARY KEY (guest_id) mysql> ); احتفظنا بمعظم معلومات نوع البيانات في هذا الجدول كما كانت في الجدول guests من أجل التناسق والدقة، وحذفنا أي أعمدة إضافية لا نريدها في الجدول الجديد. أصبح هذا الجدول الفارغ جاهزًا للبدء، والخطوة التالية هي إدخال قيم البيانات المطلوبة في الجدول. نكتب التعليمة INSERT INTO مع الجدول upgrade_guests الجديد مع وجود اتجاه واضح لمكان إدخال البيانات، ثم نكتب الاستعلام المتداخل باستخدام تعليمة SELECT لاسترجاع قيم البيانات ذات الصلة وتعليمة FROM للتأكد من أن البيانات تأتي من الجدول guests. سيطبّق خصم بقيمة 15% على الأعضاء الدائمين من خلال تضمين عملية الضرب الرياضية * للضرب بالعدد 0.85 ضمن الاستعلام المتداخل (membership_cost * 0.85)، وتفيدنا تعليمة WHERE في فرز القيم الموجودة في العمود membership_type. يمكننا تضييق نطاق النتائج لتشمل فقط نتائج الأعضاء الدائمين باستخدام تعليمة LIKE ووضع رمز النسبة المئوية % قبل وبعد الكلمة "Resident" بين علامتي اقتباس مفردتين لتحديد نوع العضوية التي تتبع النمط أو المفردات نفسها، وسيُكتَب هذا الاستعلام كما يلي: mysql> INSERT INTO upgrade_guests mysql> SELECT guest_id, first_name, last_name, membership_type, mysql> (membership_cost * 0.85), total_visits mysql> FROM guests mysql> WHERE membership_type LIKE '%resident%'; الخرج Query OK, 5 rows affected, 5 warnings (0.01 sec) Records: 5 Duplicates: 0 Warnings: 5 يشير الخرج السابق إلى إضافة خمسة سجلات إلى الجدول upgrade_guests الجديد. يمكن التأكد من نقل البيانات التي طلبتها بنجاح من الجدول guests إلى الجدول upgrade_guests الفارغ الذي أنشأناه من خلال تشغيل الأمر التالي مع الشروط التي حدّدناها مع الاستعلام المتداخل وتعليمة WHERE: mysql> SELECT * FROM upgrade_guests; الخرج +----------+------------+------------+-----------------------+-----------------+--------------+ | guest_id | first_name | last_name | membership_type | membership_cost | total_visits | +----------+------------+------------+-----------------------+-----------------+--------------+ | 1 | Judy | Hopps | Resident Premium Pass | 93.50 | 168 | | 3 | Duke | Weaselton | Resident Pass | 72.25 | 4 | | 6 | Jenny | Bellwether | Resident Premium Pass | 93.50 | 20 | | 10 | Octavia | Otterton | Resident Pass | 72.25 | 11 | | 11 | Calvin | Roo | Resident Premium Pass | 93.50 | 173 | +----------+------------+------------+-----------------------+-----------------+--------------+ 5 rows in set (0.01 sec) نلاحظ الإدراج الصحيح لمعلومات عضوية الزائر الدائم "Resident" ذات الصلة من الجدول guest في الجدول upgrade_guests، مع إعادة حساب التكلفة membership_cost الجديدة مع تطبيق خصم 15%، وبذلك ساعدت هذه العملية في تقسيم الجمهور المناسب واستهدافه، وأصبحت الأسعار المخفَّضة متاحة بسهولة لمشاركتها مع الأعضاء الجدد المحتملين. استخدام الاستعلامات المتداخلة مع تعليمة DELETE لنفترض أننا نريد إزالة الزوار المعتادين والتركيز فقط على الترويج لخصم البطاقة المميزة للأعضاء الذين لا يزورون حديقة الحيوان كثيرًا حاليًا. نبدأ هذه العملية باستخدام تعليمة DELETE FROM بحيث يكون من الواضح المكان الذي ستحذف البيانات منه، وهو الجدول upgrade_guests في حالتنا، ثم نستخدم تعليمة WHERE لفرز أي قيمة من العمود total_visits تزيد عن الكمية المحدَّدة في الاستعلام المتداخل. نستخدم تعليمة SELECT في استعلامنا المتداخل المُضمَّن للعثور على المتوسط الحسابي AVG للعمود total_visits بحيث تحتوي تعليمة WHERE السابقة على قيم البيانات المناسبة للمقارنة معها. وأخيرًا، نستخدم تعليمة FROM لاسترجاع تلك المعلومات من الجدول guests، وسيكون الاستعلام الكامل كما يلي: mysql> DELETE FROM upgrade_guests mysql> WHERE total_visits > mysql> (SELECT AVG(total_visits) FROM guests); الخرج Query OK, 2 rows affected (0.00 sec) لنتأكّد من حذف هذه السجلات بنجاح من الجدول upgrade_guests، ونستخدم تعليمة ORDER BY لتنظيم النتائج وفق العمود total_visits بترتيب رقمي تصاعدي. ملاحظة: لن يؤدي استخدام تعليمة DELETE لحذف السجلات من جدولنا الجديد إلى حذفها من الجدول الأصلي، حيث يمكننا تشغيل التعليمة SELECT * FROM original_table للتأكد من وجود جميع السجلات الأصلية، حتى إن كانت محذوفة من الجدول الجديد. mysql> SELECT * FROM upgrade_guests ORDER BY total_visits; الخرج +----------+------------+------------+-----------------------+-----------------+--------------+ | guest_id | first_name | last_name | membership_type | membership_cost | total_visits | +----------+------------+------------+-----------------------+-----------------+--------------+ | 3 | Duke | Weaselton | Resident Pass | 72.25 | 4 | | 10 | Octavia | Otterton | Resident Pass | 72.25 | 11 | | 6 | Jenny | Bellwether | Resident Premium Pass | 93.50 | 20 | +----------+------------+------------+-----------------------+-----------------+--------------+ 3 rows in set (0.00 sec) يشير هذا الخرج إلى نجاح تعليمة DELETE والاستعلام المتداخل في حذف قيم البيانات المُحدَّدة، لذا سيحتوي هذا الجدول الآن على معلومات الزوار الثلاثة الذين عدد زياراتهم أقل من متوسط عدد الزيارات، وهو ما يُعَد نقطة انطلاق لموظف حديقة الحيوان للتواصل مع هؤلاء الزوار بشأن الترقية إلى التذاكر المميزة بسعر مخفَّض لتشجيعهم على الذهاب أكثر إلى حديقة الحيوان. الخلاصة شرحنا في هذا المقال الاستعلامات المتداخلة ووضحنا فائدتها في الحصول على نتائج دقيقة لم نكن سنتمكن من الحصول عليها إلا من خلال تشغيل استعلامات منفصلة، وعرضنا أمثلة عملية لاستخدام تعليمات SELECT وINSERT و DELETE مع الاستعلامات المتداخلة لتوفير طريقة أخرى لإدخال البيانات أو حذفها في خطوة واحدة. ترجمة -وبتصرف- للمقال How To Use Nested Queries in SQL لصاحبته Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: استخدام تعليمتي GROUP BY و ORDER BY في SQL الاستعلامات الفرعية Subqueries في SQL مفاهيم نموذج البيانات العلائقية RDM الأساسية بعض الدوال المساعدة في SQL -
 يمكن لقواعد بيانات لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- تخزين وإدارة بيانات كثيرة لعدد من الجداول، لذا يجب فهم كيفية فرز البيانات مع مجموعات البيانات الكبيرة لتحليل مجموعات النتائج أو تنظيم البيانات للتقارير أو الاتصالات الخارجية. توجد تعليمتان شائعتان في لغة SQL تساعدان في فرز البيانات هما GROUP BY و ORDER BY، حيث تفرز التعليمة GROUP BY البيانات من خلال تجميعها بناء على العمود أو الأعمدة التي نحددها في الاستعلام، وتُستخدَم هذه التعليمة مع دوال التجميع Aggregate Functions، وتسمح التعليمة ORDER BY بتنظيم مجموعات النتائج أبجديًا أو رقميًا وبترتيب تصاعدي أو تنازلي. سنفرز في هذا المقال نتائج استعلام لغة SQL باستخدام تعليمتي GROUP BY و ORDER BY، وسنتدرب على تنفيذ الدوال التجميعية وتعليمة WHERE في استعلاماتنا لفرز النتائج. مستلزمات العمل يجب توفر حاسوب لتشغيل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- التي تستخدم لغة SQL. وفي مقالنا الحالي اختبرنا التعليمات والأمثلة الواردة باستخدام البيئة التالية: خادم عامل على أحدث إصدار من توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مُفعَّل كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضّح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا الخطوات باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال ملاحظة: تجدر الإشارة إلى أن الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدّمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن قد توجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على جدول يتضمن بيانات تجريبية نموذجية لنتمكّن من التدرب على فرز نتائج البيانات، ولكن إن لم يكن لدينا قاعدة بيانات جاهزة، فيمكن مطالعة القسم التالي لمعرفة كيفية إنشاء قاعدة البيانات والجداول المستخدمة في أمثلتنا. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كانت قاعدة بيانات SQL الخاصة بنا تعمل على خادم بعيد، فعلينا الاتصال بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم movieDB: mysql> CREATE DATABASE movieDB; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر خرج كما يلي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات movieDB من خلال تنفيذ تعليمة USE التالية: mysql> USE movieDB; الخرج Database changed بعد أن اخترنا قاعدة البيانات، سننشئ جدولًا ضمنها كي يخزّن معلومات عروض دور السينما المحلية، وسيحتوي هذا الجدول على الأعمدة السبعة التالية: theater_id: يخزّن قيمًا من نوع int لكل من قاعات عرض الأفلام، ويمثّل المفتاح الرئيسي Primary Key للجدول date: يستخدم نوع البيانات DATE لتخزين التاريخ المُحدَّد حسب السنة والشهر واليوم لعرض الفيلم time: يمثّل العرض المُجدوَل للفيلم، ويستخدم نوع البيانات TIME للساعات والدقائق والثواني movie_name: يخزّن اسم الفيلم باستخدام نوع البيانات varchar بحد أقصى 40 محرف movie_genre: يستخدم نوع البيانات varchar بحد أقصى 30 محرفًا للاحتفاظ بمعلومات حول النوع الخاص بكل فيلم guest_total: يستخدم نوع البيانات int لعرض العدد الإجمالي لروّاد السينما الذين حضروا عرض الفيلم ticket_cost: يستخدم نوع البيانات decimal ويمثّل تكلفة تذكرة عرض الفيلم لننشئ جدولًا بالاسم movie_theater يحتوي على الأعمدة السابقة من خلال تشغيل أمر CREATE TABLE التالي: mysql> CREATE TABLE movie_theater ( mysql> theater_id int, mysql> date DATE, mysql> time TIME, mysql> movie_name varchar(40), mysql> movie_genre varchar(30), mysql> guest_total int, mysql> ticket_cost decimal(4,2), mysql> PRIMARY KEY (theater_id) mysql> ); ثم ندخل بعض البيانات التجريبية في هذا الجدول الفارغ كما يلي: mysql> INSERT INTO movie_theater mysql> (theater_id, date, time, movie_name, movie_genre, guest_total, ticket_cost) mysql> VALUES mysql> (1, '2022-05-27', '10:00:00', 'Top Gun Maverick', 'Action', 131, 18.00), mysql> (2, '2022-05-27', '10:00:00', 'Downton Abbey A New Era', 'Drama', 90, 18.00), mysql> (3, '2022-05-27', '10:00:00', 'Men', 'Horror', 100, 18.00), mysql> (4, '2022-05-27', '10:00:00', 'The Bad Guys', 'Animation', 83, 18.00), mysql> (5, '2022-05-28', '09:00:00', 'Top Gun Maverick', 'Action', 112, 8.00), mysql> (6, '2022-05-28', '09:00:00', 'Downton Abbey A New Era', 'Drama', 137, 8.00), mysql> (7, '2022-05-28', '09:00:00', 'Men', 'Horror', 25, 8.00), mysql> (8, '2022-05-28', '09:00:00', 'The Bad Guys', 'Animation', 142, 8.00), mysql> (9, '2022-05-28', '05:00:00', 'Top Gun Maverick', 'Action', 150, 13.00), mysql> (10, '2022-05-28', '05:00:00', 'Downton Abbey A New Era', 'Drama', 118, 13.00), mysql> (11, '2022-05-28', '05:00:00', 'Men', 'Horror', 88, 13.00), mysql> (12, '2022-05-28', '05:00:00', 'The Bad Guys', 'Animation', 130, 13.00); الخرج Query OK, 12 rows affected (0.00 sec) Records: 12 Duplicates: 0 Warnings: 0 أصبحت الجداول جاهزة ومعبأة بالبيانات، ونحن جاهزون الآن لبدء فرز نتائج الاستعلام باستخدام تعليمات لغة SQL. استخدام التعليمة GROUP BY وظيفة التعليمة GROUP BY هي تجميع السجلات ذات القيم المشتركة، وتُستخدَم دائمًا مع دالة تجميعية، حيث تلخّص الدالة التجميعية المعلومات وتعيد نتيجة واحدة، فمثلًا يمكننا الاستعلام عن العدد الإجمالي أو مجموع قيم العمود وستنتج قيمة واحدة. ويمكن باستخدام التعليمة GROUP BY تطبيق الدالة التجميعية للحصول على قيمة نتيجة واحدة لكل مجموعة نريدها. تُعَد التعليمة GROUP BY مفيدة لإعادة النتائج المرغوبة المتعددة مرتبة حسب مجموعة محددة أو عدة مجموعات بدلًا من عمود واحد فقط. ويجب أن تأتي التعليمة GROUP BY دائمًا بعد التعليمة FROM والتعليمة WHERE إذا اخترنا استخدام إحداهما. فيما يلي مثال يوضّح بنية الاستعلام باستخدام التعليمة GROUP BY والدالة التجميعية: mysql> GROUP BY syntax mysql> SELECT column_1, AGGREGATE_FUNCTION(column_2) FROM table GROUP BY mysql> column_1; لنوضّح كيفية استخدام التعليمة GROUP BY من خلال مثال عملي، لنفترض أننا نقود حملة لتسويق عدة إصدارات من الأفلام، ونريد تقييم نجاح جهودنا التسويقية من خلال الطلب من دار السينما المحلية مشاركة البيانات التي جمعتها من روّاد السينما يومي الجمعة والسبت. سنبدأ بمطالعة البيانات من خلال تشغيل التعليمة SELECT مع الرمز * لتحديد جميع الأعمدة في الجدول movie_theater: mysql> SELECT * FROM movie_theater; الخرج +------------+------------+----------+-------------------------+-------------+-------------+-------------+ | theater_id | date | time | movie_name | movie_genre | guest_total | ticket_cost | +------------+------------+----------+-------------------------+-------------+-------------+-------------+ | 1 | 2022-05-27 | 10:00:00 | Top Gun Maverick | Action | 131 | 18.00 | | 2 | 2022-05-27 | 10:00:00 | Downton Abbey A New Era | Drama | 90 | 18.00 | | 3 | 2022-05-27 | 10:00:00 | Men | Horror | 100 | 18.00 | | 4 | 2022-05-27 | 10:00:00 | The Bad Guys | Animation | 83 | 18.00 | | 5 | 2022-05-28 | 09:00:00 | Top Gun Maverick | Action | 112 | 8.00 | | 6 | 2022-05-28 | 09:00:00 | Downton Abbey A New Era | Drama | 137 | 8.00 | | 7 | 2022-05-28 | 09:00:00 | Men | Horror | 25 | 8.00 | | 8 | 2022-05-28 | 09:00:00 | The Bad Guys | Animation | 142 | 8.00 | | 9 | 2022-05-28 | 05:00:00 | Top Gun Maverick | Action | 150 | 13.00 | | 10 | 2022-05-28 | 05:00:00 | Downton Abbey A New Era | Drama | 118 | 13.00 | | 11 | 2022-05-28 | 05:00:00 | Men | Horror | 88 | 13.00 | | 12 | 2022-05-28 | 05:00:00 | The Bad Guys | Animation | 130 | 13.00 | +------------+------------+----------+-------------------------+-------------+-------------+-------------+ 12 rows in set (0.00 sec) هذه البيانات مفيدة، ولكننا نريد إجراء تقييم أعمق وفرز النتائج لبعض الأعمدة المُحدَّدة، فقد نكون مهتمين بمعرفة مدى تقبّل رواد السينما لهذه الأفلام ذات الأنواع المختلفة مثل معرفة متوسط عدد الأشخاص الذين شاهدوا كل نوع من الأفلام. سنستخدم التعليمة SELECT لاسترجاع أنواع الأفلام المختلفة من العمود movie_genre، ثم نطبّق الدالة التجميعية AVG على العمود guest_total، ونستخدم التعليمة AS لإنشاء اسم بديل للعمود بالاسم average، ونضمّن التعليمة GROUP BY لتجميع النتائج وفق العمود movie_genre، إذ سيوفّر تجميعها بهذه الطريقة متوسط النتائج لكل نوع من الأفلام كما يلي: mysql> SELECT movie_genre, AVG(guest_total) AS average mysql> FROM movie_theater mysql> GROUP BY movie_genre; الخرج +-------------+----------+ | movie_genre | average | +-------------+----------+ | Action | 131.0000 | | Drama | 115.0000 | | Horror | 71.0000 | | Animation | 118.3333 | +-------------+----------+ 4 rows in set (0.00 sec) يعطي الخرج السابق المتوسطات الأربعة لكل نوع من الأفلام ضمن المجموعة movie_genre، حيث جذبت أفلام الحركة Action أعلى متوسط لعدد المشاهدين لكل عرض بناء على هذه المعلومات. لنفترض أننا نريد قياس الإيرادات على مدى يومين منفصلين، حيث يعيد الاستعلام التالي القيم من العمود date والقيم التي تعيدها الدالة التجميعية SUM التي تحتوي على معادلة رياضية بين قوسين لضرب عدد إجمالي روّاد السينما في تكلفة التذكرة، والتي نمثّلها على النحو التالي: SUM(guest_total * ticket_cost) يتضمن الاستعلام التالي التعليمةَ AS لتوفير الاسم البديل total_revenue للعمود الذي تعيده الدالة التجميعية، ونكمل الاستعلام باستخدام التعليمة GROUP BY لتجميع نتائج الاستعلام وفق العمود date: mysql> SELECT date, SUM(guest_total * ticket_cost) mysql> AS total_revenue mysql> FROM movie_theater mysql> GROUP BY date; الخرج +------------+---------------+ | date | total_revenue | +------------+---------------+ | 2022-05-27 | 7272.00 | | 2022-05-28 | 9646.00 | +------------+---------------+ 2 rows in set (0.00 sec) استخدمنا هنا التعليمة GROUP BY لتجميع العمود date، لذا يمثّل الخرج نتائج إجمالي الإيرادات في مبيعات التذاكر لكل يوم، والتي هي 7272 دولارًا أمريكيًا ليوم الجمعة 27 من الشهر الخامس، و 9646 دولارًا أمريكيًا ليوم السبت 28 من الشهر الخامس. لنفترض الآن أننا نريد التركيز على فيلم واحد وتحليله وليكن فيلم الرسوم المتحركة The Bad Guys حيث نريد معرفة كيفية تأثير التوقيت والأسعار على اختيار الأسرة لمشاهدة فيلم رسوم متحركة. سنستخدم في هذا الاستعلام الدالة التجميعية MAX لاسترجاع الحد الأقصى لتكلفة التذكرة ticket_cost، مع التأكّد من تضمين التعليمة AS لإنشاء الاسم البديل للعمود وهو price_data، ثم نستخدم التعليمة WHERE لتضييق نطاق النتائج وفق العمود movie_name للحصول على اسم الفيلم فقط، ونستخدم التعليمة AND أيضًا لتحديد أوقات الأفلام الأكثر شيوعًا اعتمادًا على أرقام العمود guest_total التي كانت أكثر من 100 باستخدام معامل المقارنة >، ثم نكمل الاستعلام باستخدام التعليمة GROUP BY ونجمّع النتائج وفق العمود time: mysql> SELECT time, MAX(ticket_cost) AS price_data mysql> FROM movie_theater mysql> WHERE movie_name = "The Bad Guys" mysql> AND guest_total > 100 mysql> GROUP BY time; الخرج +----------+------------+ | time | price_data | +----------+------------+ | 09:00:00 | 8.00 | | 05:00:00 | 13.00 | +----------+------------+ 2 rows in set (0.00 sec) نلاحظ وفقًا لهذا الخرج حضور عدد أكبر من روّاد السينما لها الفيلم في وقت مبكر من العرض الصباحي في الساعة 9:00 صباحًا، حين كان سعره أقل تكلفة وهو 8.00 دولارات أمريكية لكل تذكرة، ولكن تظهر هذه النتائج أيضًا أن روّاد الفيلم دفعوا سعر التذكرة الأعلى وهو 13.00 دولارًا أمريكيًا في الساعة 5:00 مساءً، مما يشير إلى أن العائلات تفضل العروض التي تكون وقت مبكر من المساء وستدفع سعرًا أكبر قليلًا مقابل التذكرة. يمكن لهذه المعلومات أن تفيد مدير دار السينما وتشير له لأن فتح المزيد من الفترات في المساء الباكر يمكن أن يزيد عدد العائلات التي تختار الحضور بناء على الوقت المفضل والسعر. تُستخدَم التعليمة GROUP BY دائمًا مع دالة تجميعية، ولكن قد تكون هناك استثناءات، لذا إذا أردنا تجميع النتائج دون استخدام دالة تجميعية، فيمكن استخدام التعليمة DISTINCT لتحقيق النتيجة نفسها. حيث تزيل التعليمة DISTINCT أيّ تكرارات في مجموعة النتائج من خلال إعادة القيم الفريدة في العمود، ولا يمكن استخدامها إلّا مع التعليمة SELECT، فمثلًا إذا أردنا تجميع جميع الأفلام وفق الاسم، فيمكننا ذلك باستخدام الاستعلام التالي: mysql> SELECT DISTINCT movie_name FROM movie_theater; الخرج +-------------------------+ | movie_name | +-------------------------+ | Top Gun Maverick | | Downton Abbey A New Era | | Men | | The Bad Guys | +-------------------------+ 4 rows in set (0.00 sec) هناك نسخ مكررة لأسماء الأفلام نظرًا لوجود عروض متعددة كما وضحنا عند عرض كافة البيانات الموجودة في الجدول، لذا أزالت التعليمة DISTINCT تلك التكرارات وجمّعت لنا القيم الفريدة بفعالية ضمن عمود واحد هو movie_name، ويُعَد هذا مطابقًا فعليًا للاستعلام التالي الذي يتضمن التعليمة GROUP BY: mysql> SELECT movie_name FROM movie_theater GROUP BY movie_name; بعد أن شرحنا بالتفصيل طريقة استخدام التعليمة GROUP BY مع الدوال التجميعية، لنتعلّم الآن كيفية فرز نتائج الاستعلام باستخدام التعليمة ORDER BY. استخدام التعليمة ORDER BY تتمثل وظيفة التعليمة ORDER BY في فرز النتائج بترتيب تصاعدي أو تنازلي اعتمادًا على العمود أو الأعمدة التي نحدّدها في الاستعلام، حيث ستنظّم هذه التعليمة البيانات بترتيب أبجدي أو رقمي اعتمادًا على نوع البيانات التي يخزّنها العمود الذي نحدّده بعدها. تفرز التعليمة ORDER BY النتائج بترتيب تصاعدي افتراضيًا، ولكن إذا أردنا استخدام الترتيب التنازلي، فيجب تضمين الكلمة المفتاحية DESC في استعلامنا. يمكن أيضًا استخدام التعليمة ORDER BY مع التعليمة GROUP BY، ولكن يجب أن تأتي بعدها لكي تعمل بنجاح، ويجب أن تأتي التعليمة ORDER BY بعد التعليمة FROM والتعليمة WHERE كما هو الحال مع التعليمة GROUP BY. تكون الصيغة العامة لاستخدام التعليمة ORDER BY كما يلي: mysql> SELECT column_1, column_2 FROM table ORDER BY column_1; لنستخدم البيانات التجريبية النموذجية الخاصة بالسينما ونتدرب على فرز النتائج باستخدام التعليمة ORDER BY، ولنبدأ بالاستعلام التالي الذي يسترجع القيم من العمود guest_total وينظّم تلك القيم العددية باستخدام التعليمة ORDER BY: mysql> SELECT guest_total FROM movie_theater mysql> ORDER BY guest_total; الخرج +-------------+ | guest_total | +-------------+ | 25 | | 83 | | 88 | | 90 | | 100 | | 112 | | 118 | | 130 | | 131 | | 137 | | 142 | | 150 | +-------------+ 12 rows in set (0.00 sec) حدّد الاستعلام السابق عمودًا يحتوي على قيم عددية، لذا فقد نظّمت التعليمة ORDER BY النتائج حسب الترتيب الرقمي والتصاعدي بدءًا من القيمة 25 ضمن العمود guest_total. إذا أردنا ترتيب العمود تنازليًا، فيمكننا إضافة الكلمة المفتاحية DESC في نهاية الاستعلام، وإذا أردنا ترتيب البيانات حسب قيم المحارف ضمن العمود movie_name، فيمكن تحديد ذلك في الاستعلام الذي نكتبه. لنطبّق هذا النوع من الاستعلامات باستخدام التعليمة ORDER BY لترتيب العمود movie_name حسب قيم المحارف تنازليًا، ونفرز النتائج أيضًا من خلال تضمين التعليمة WHERE لاسترجاع البيانات الخاصة بالأفلام المعروضة في الساعة 10:00 مساء من العمود time: mysql> SELECT movie_name FROM movie_theater mysql> WHERE time = '10:00:00' mysql> ORDER BY movie_name DESC; الخرج +-------------------------+ | movie_name | +-------------------------+ | Top Gun Maverick | | The Bad Guys | | Men | | Downton Abbey A New Era | +-------------------------+ 4 rows in set (0.01 sec) توضّح هذه المجموعة من النتائج عروض الأفلام الأربعة المختلفة في الساعة 10:00 مساءً بترتيب أبجدي تنازليًا بدءًا من الفيلم Top Gun Maverick إلى الفيلم Downtown Abbey A New Era. لندمج الآن تعليمتي ORDER BY و GROUP BY مع الدالة التجميعية SUM لتوليد نتائج حول إجمالي الإيرادات المُستلَمة لكل فيلم، ولكن لنفترض أن دار السينما أخطأت في حساب إجمالي روّاد السينما ونسيت تضمين الحفلات الخاصة المدفوعة مسبقًا وحجز التذاكر لمجموعة مكونة من 12 شخصًا في كل عرض. سنستخدم في هذا الاستعلام الدالة SUM ونضمّن 12 زائرًا إضافيًا لكل فيلم معروض من خلال تطبيق معامل الجمع + ثم نجمع القيمة 12 مع العمود guest_total، ونتأكّد من وضع ذلك بين قوسين، ثم نضرب المجموع بالعمود ticket_cost، ونكمل المعادلة الرياضية بإغلاق القوسين في النهاية. نضيف التعليمة AS لإنشاء الاسم البديل للعمود الجديد بعنوان total_revenue، ثم نستخدم التعليمة GROUP BY لتجميع نتائج العمود total_revenue لكل فيلم بناءً على البيانات المسترجَعة من العمود movie_name. وأخيرًا، نستخدم التعليمة ORDER BY لتنظيم النتائج ضمن العمود الجديد total_revenue بترتيب تصاعدي: mysql> SELECT movie_name, SUM((guest_total + 12) * ticket_cost) mysql> AS total_revenue mysql> FROM movie_theater mysql> GROUP BY movie_name mysql> ORDER BY total_revenue; الخرج +-------------------------+---------------+ | movie_name | total_revenue | +-------------------------+---------------+ | Men | 3612.00 | | Downton Abbey A New Era | 4718.00 | | The Bad Guys | 4788.00 | | Top Gun Maverick | 5672.00 | +-------------------------+---------------+ 4 rows in set (0.00 sec) تعطينا هذه المجموعة من النتائج إجمالي الإيرادات لكل فيلم مع مبيعات تذاكر الزوار الإضافية التي يبلغ عددها 12 تذكرة، وتنظّم إجمالي مبيعات التذاكر بترتيب تصاعدي من الأقل إلى الأعلى، وبالتالي حصل الفيلم Top Gun Maverick على أكبر عدد من مبيعات التذاكر، بينما حصل فيلم Men على المبيعات الأقل، وكانت أفلام The Bad Guys و Downton Abbey A New Era متقاربة جدًا في إجمالي مبيعات التذاكر. إلى هنا نكون قد وصلنا لنهاية هذا القسم الذي تعرفنا فيه على طرق مختلفة لتطبيق تعليمة ORDER BY وكيفية تحديد الترتيب الذي نفضّله مثل الترتيب التصاعدي والتنازلي لكل من قيم البيانات المحرفية والرقمية، وتعلّمنا أيضًا كيفية تضمين التعليمة WHERE لتضييق نطاق النتائج، وأجرينا استعلامًا باستخدام كلّ من تعليمات GROUP BY و ORDER BY مع دالة تجميعية ومعادلة رياضية. الخلاصة يُعَد فهم كيفية استخدام تعليمتي GROUP BY و ORDER BY أمرًا مهمًا لفرز النتائج والبيانات، حيث يمكننا من خلالهما تنظيم نتائج متعددة ضمن مجموعة واحدة أو تنظيم أحد الأعمدة بترتيب أبجدي وتنازلي أو تطبيق الأمرين معًا في وقت واحد، وتعلّمنا أيضًا طرقًا أخرى لفرز النتائج باستخدام التعليمة WHERE. ولمعرفة المزيد ننصح بمطالعة مقال كيفية استخدام محارف البدل Wildcards في لغة SQL للتدرب على ترشيح النتائج باستخدام التعليمة LIKE، كما ننصح بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب للمزيد حول كيفية التعامل مع لغة SQL. ترجمة -وبتصرف- للمقال How To Use GROUP BY and ORDER BY in SQL لصاحبته Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: استخدام العروض Views في لغة SQL دوال التعامل مع البيانات في SQL التجميع والترتيب في SQL كيفية التعامل مع التواريخ والأوقات في SQL
يمكن لقواعد بيانات لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- تخزين وإدارة بيانات كثيرة لعدد من الجداول، لذا يجب فهم كيفية فرز البيانات مع مجموعات البيانات الكبيرة لتحليل مجموعات النتائج أو تنظيم البيانات للتقارير أو الاتصالات الخارجية. توجد تعليمتان شائعتان في لغة SQL تساعدان في فرز البيانات هما GROUP BY و ORDER BY، حيث تفرز التعليمة GROUP BY البيانات من خلال تجميعها بناء على العمود أو الأعمدة التي نحددها في الاستعلام، وتُستخدَم هذه التعليمة مع دوال التجميع Aggregate Functions، وتسمح التعليمة ORDER BY بتنظيم مجموعات النتائج أبجديًا أو رقميًا وبترتيب تصاعدي أو تنازلي. سنفرز في هذا المقال نتائج استعلام لغة SQL باستخدام تعليمتي GROUP BY و ORDER BY، وسنتدرب على تنفيذ الدوال التجميعية وتعليمة WHERE في استعلاماتنا لفرز النتائج. مستلزمات العمل يجب توفر حاسوب لتشغيل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- التي تستخدم لغة SQL. وفي مقالنا الحالي اختبرنا التعليمات والأمثلة الواردة باستخدام البيئة التالية: خادم عامل على أحدث إصدار من توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مُفعَّل كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضّح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا الخطوات باستخدام مستخدم MySQL مختلف عن المستخدم الجذر وفق الطريقة الموضحة في الخطوة التالية من المقال ملاحظة: تجدر الإشارة إلى أن الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدّمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن قد توجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. سنحتاج أيضًا إلى قاعدة بيانات تحتوي على جدول يتضمن بيانات تجريبية نموذجية لنتمكّن من التدرب على فرز نتائج البيانات، ولكن إن لم يكن لدينا قاعدة بيانات جاهزة، فيمكن مطالعة القسم التالي لمعرفة كيفية إنشاء قاعدة البيانات والجداول المستخدمة في أمثلتنا. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كانت قاعدة بيانات SQL الخاصة بنا تعمل على خادم بعيد، فعلينا الاتصال بالخادم باستخدام بروتوكول SSH من جهازنا المحلي كما يلي: $ ssh user@your_server_ip ثم نفتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بنا مكان user: $ mysql -u user -p ننشئ قاعدة بيانات بالاسم movieDB: mysql> CREATE DATABASE movieDB; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر خرج كما يلي: الخرج Query OK, 1 row affected (0.01 sec) يمكن اختيار قاعدة البيانات movieDB من خلال تنفيذ تعليمة USE التالية: mysql> USE movieDB; الخرج Database changed بعد أن اخترنا قاعدة البيانات، سننشئ جدولًا ضمنها كي يخزّن معلومات عروض دور السينما المحلية، وسيحتوي هذا الجدول على الأعمدة السبعة التالية: theater_id: يخزّن قيمًا من نوع int لكل من قاعات عرض الأفلام، ويمثّل المفتاح الرئيسي Primary Key للجدول date: يستخدم نوع البيانات DATE لتخزين التاريخ المُحدَّد حسب السنة والشهر واليوم لعرض الفيلم time: يمثّل العرض المُجدوَل للفيلم، ويستخدم نوع البيانات TIME للساعات والدقائق والثواني movie_name: يخزّن اسم الفيلم باستخدام نوع البيانات varchar بحد أقصى 40 محرف movie_genre: يستخدم نوع البيانات varchar بحد أقصى 30 محرفًا للاحتفاظ بمعلومات حول النوع الخاص بكل فيلم guest_total: يستخدم نوع البيانات int لعرض العدد الإجمالي لروّاد السينما الذين حضروا عرض الفيلم ticket_cost: يستخدم نوع البيانات decimal ويمثّل تكلفة تذكرة عرض الفيلم لننشئ جدولًا بالاسم movie_theater يحتوي على الأعمدة السابقة من خلال تشغيل أمر CREATE TABLE التالي: mysql> CREATE TABLE movie_theater ( mysql> theater_id int, mysql> date DATE, mysql> time TIME, mysql> movie_name varchar(40), mysql> movie_genre varchar(30), mysql> guest_total int, mysql> ticket_cost decimal(4,2), mysql> PRIMARY KEY (theater_id) mysql> ); ثم ندخل بعض البيانات التجريبية في هذا الجدول الفارغ كما يلي: mysql> INSERT INTO movie_theater mysql> (theater_id, date, time, movie_name, movie_genre, guest_total, ticket_cost) mysql> VALUES mysql> (1, '2022-05-27', '10:00:00', 'Top Gun Maverick', 'Action', 131, 18.00), mysql> (2, '2022-05-27', '10:00:00', 'Downton Abbey A New Era', 'Drama', 90, 18.00), mysql> (3, '2022-05-27', '10:00:00', 'Men', 'Horror', 100, 18.00), mysql> (4, '2022-05-27', '10:00:00', 'The Bad Guys', 'Animation', 83, 18.00), mysql> (5, '2022-05-28', '09:00:00', 'Top Gun Maverick', 'Action', 112, 8.00), mysql> (6, '2022-05-28', '09:00:00', 'Downton Abbey A New Era', 'Drama', 137, 8.00), mysql> (7, '2022-05-28', '09:00:00', 'Men', 'Horror', 25, 8.00), mysql> (8, '2022-05-28', '09:00:00', 'The Bad Guys', 'Animation', 142, 8.00), mysql> (9, '2022-05-28', '05:00:00', 'Top Gun Maverick', 'Action', 150, 13.00), mysql> (10, '2022-05-28', '05:00:00', 'Downton Abbey A New Era', 'Drama', 118, 13.00), mysql> (11, '2022-05-28', '05:00:00', 'Men', 'Horror', 88, 13.00), mysql> (12, '2022-05-28', '05:00:00', 'The Bad Guys', 'Animation', 130, 13.00); الخرج Query OK, 12 rows affected (0.00 sec) Records: 12 Duplicates: 0 Warnings: 0 أصبحت الجداول جاهزة ومعبأة بالبيانات، ونحن جاهزون الآن لبدء فرز نتائج الاستعلام باستخدام تعليمات لغة SQL. استخدام التعليمة GROUP BY وظيفة التعليمة GROUP BY هي تجميع السجلات ذات القيم المشتركة، وتُستخدَم دائمًا مع دالة تجميعية، حيث تلخّص الدالة التجميعية المعلومات وتعيد نتيجة واحدة، فمثلًا يمكننا الاستعلام عن العدد الإجمالي أو مجموع قيم العمود وستنتج قيمة واحدة. ويمكن باستخدام التعليمة GROUP BY تطبيق الدالة التجميعية للحصول على قيمة نتيجة واحدة لكل مجموعة نريدها. تُعَد التعليمة GROUP BY مفيدة لإعادة النتائج المرغوبة المتعددة مرتبة حسب مجموعة محددة أو عدة مجموعات بدلًا من عمود واحد فقط. ويجب أن تأتي التعليمة GROUP BY دائمًا بعد التعليمة FROM والتعليمة WHERE إذا اخترنا استخدام إحداهما. فيما يلي مثال يوضّح بنية الاستعلام باستخدام التعليمة GROUP BY والدالة التجميعية: mysql> GROUP BY syntax mysql> SELECT column_1, AGGREGATE_FUNCTION(column_2) FROM table GROUP BY mysql> column_1; لنوضّح كيفية استخدام التعليمة GROUP BY من خلال مثال عملي، لنفترض أننا نقود حملة لتسويق عدة إصدارات من الأفلام، ونريد تقييم نجاح جهودنا التسويقية من خلال الطلب من دار السينما المحلية مشاركة البيانات التي جمعتها من روّاد السينما يومي الجمعة والسبت. سنبدأ بمطالعة البيانات من خلال تشغيل التعليمة SELECT مع الرمز * لتحديد جميع الأعمدة في الجدول movie_theater: mysql> SELECT * FROM movie_theater; الخرج +------------+------------+----------+-------------------------+-------------+-------------+-------------+ | theater_id | date | time | movie_name | movie_genre | guest_total | ticket_cost | +------------+------------+----------+-------------------------+-------------+-------------+-------------+ | 1 | 2022-05-27 | 10:00:00 | Top Gun Maverick | Action | 131 | 18.00 | | 2 | 2022-05-27 | 10:00:00 | Downton Abbey A New Era | Drama | 90 | 18.00 | | 3 | 2022-05-27 | 10:00:00 | Men | Horror | 100 | 18.00 | | 4 | 2022-05-27 | 10:00:00 | The Bad Guys | Animation | 83 | 18.00 | | 5 | 2022-05-28 | 09:00:00 | Top Gun Maverick | Action | 112 | 8.00 | | 6 | 2022-05-28 | 09:00:00 | Downton Abbey A New Era | Drama | 137 | 8.00 | | 7 | 2022-05-28 | 09:00:00 | Men | Horror | 25 | 8.00 | | 8 | 2022-05-28 | 09:00:00 | The Bad Guys | Animation | 142 | 8.00 | | 9 | 2022-05-28 | 05:00:00 | Top Gun Maverick | Action | 150 | 13.00 | | 10 | 2022-05-28 | 05:00:00 | Downton Abbey A New Era | Drama | 118 | 13.00 | | 11 | 2022-05-28 | 05:00:00 | Men | Horror | 88 | 13.00 | | 12 | 2022-05-28 | 05:00:00 | The Bad Guys | Animation | 130 | 13.00 | +------------+------------+----------+-------------------------+-------------+-------------+-------------+ 12 rows in set (0.00 sec) هذه البيانات مفيدة، ولكننا نريد إجراء تقييم أعمق وفرز النتائج لبعض الأعمدة المُحدَّدة، فقد نكون مهتمين بمعرفة مدى تقبّل رواد السينما لهذه الأفلام ذات الأنواع المختلفة مثل معرفة متوسط عدد الأشخاص الذين شاهدوا كل نوع من الأفلام. سنستخدم التعليمة SELECT لاسترجاع أنواع الأفلام المختلفة من العمود movie_genre، ثم نطبّق الدالة التجميعية AVG على العمود guest_total، ونستخدم التعليمة AS لإنشاء اسم بديل للعمود بالاسم average، ونضمّن التعليمة GROUP BY لتجميع النتائج وفق العمود movie_genre، إذ سيوفّر تجميعها بهذه الطريقة متوسط النتائج لكل نوع من الأفلام كما يلي: mysql> SELECT movie_genre, AVG(guest_total) AS average mysql> FROM movie_theater mysql> GROUP BY movie_genre; الخرج +-------------+----------+ | movie_genre | average | +-------------+----------+ | Action | 131.0000 | | Drama | 115.0000 | | Horror | 71.0000 | | Animation | 118.3333 | +-------------+----------+ 4 rows in set (0.00 sec) يعطي الخرج السابق المتوسطات الأربعة لكل نوع من الأفلام ضمن المجموعة movie_genre، حيث جذبت أفلام الحركة Action أعلى متوسط لعدد المشاهدين لكل عرض بناء على هذه المعلومات. لنفترض أننا نريد قياس الإيرادات على مدى يومين منفصلين، حيث يعيد الاستعلام التالي القيم من العمود date والقيم التي تعيدها الدالة التجميعية SUM التي تحتوي على معادلة رياضية بين قوسين لضرب عدد إجمالي روّاد السينما في تكلفة التذكرة، والتي نمثّلها على النحو التالي: SUM(guest_total * ticket_cost) يتضمن الاستعلام التالي التعليمةَ AS لتوفير الاسم البديل total_revenue للعمود الذي تعيده الدالة التجميعية، ونكمل الاستعلام باستخدام التعليمة GROUP BY لتجميع نتائج الاستعلام وفق العمود date: mysql> SELECT date, SUM(guest_total * ticket_cost) mysql> AS total_revenue mysql> FROM movie_theater mysql> GROUP BY date; الخرج +------------+---------------+ | date | total_revenue | +------------+---------------+ | 2022-05-27 | 7272.00 | | 2022-05-28 | 9646.00 | +------------+---------------+ 2 rows in set (0.00 sec) استخدمنا هنا التعليمة GROUP BY لتجميع العمود date، لذا يمثّل الخرج نتائج إجمالي الإيرادات في مبيعات التذاكر لكل يوم، والتي هي 7272 دولارًا أمريكيًا ليوم الجمعة 27 من الشهر الخامس، و 9646 دولارًا أمريكيًا ليوم السبت 28 من الشهر الخامس. لنفترض الآن أننا نريد التركيز على فيلم واحد وتحليله وليكن فيلم الرسوم المتحركة The Bad Guys حيث نريد معرفة كيفية تأثير التوقيت والأسعار على اختيار الأسرة لمشاهدة فيلم رسوم متحركة. سنستخدم في هذا الاستعلام الدالة التجميعية MAX لاسترجاع الحد الأقصى لتكلفة التذكرة ticket_cost، مع التأكّد من تضمين التعليمة AS لإنشاء الاسم البديل للعمود وهو price_data، ثم نستخدم التعليمة WHERE لتضييق نطاق النتائج وفق العمود movie_name للحصول على اسم الفيلم فقط، ونستخدم التعليمة AND أيضًا لتحديد أوقات الأفلام الأكثر شيوعًا اعتمادًا على أرقام العمود guest_total التي كانت أكثر من 100 باستخدام معامل المقارنة >، ثم نكمل الاستعلام باستخدام التعليمة GROUP BY ونجمّع النتائج وفق العمود time: mysql> SELECT time, MAX(ticket_cost) AS price_data mysql> FROM movie_theater mysql> WHERE movie_name = "The Bad Guys" mysql> AND guest_total > 100 mysql> GROUP BY time; الخرج +----------+------------+ | time | price_data | +----------+------------+ | 09:00:00 | 8.00 | | 05:00:00 | 13.00 | +----------+------------+ 2 rows in set (0.00 sec) نلاحظ وفقًا لهذا الخرج حضور عدد أكبر من روّاد السينما لها الفيلم في وقت مبكر من العرض الصباحي في الساعة 9:00 صباحًا، حين كان سعره أقل تكلفة وهو 8.00 دولارات أمريكية لكل تذكرة، ولكن تظهر هذه النتائج أيضًا أن روّاد الفيلم دفعوا سعر التذكرة الأعلى وهو 13.00 دولارًا أمريكيًا في الساعة 5:00 مساءً، مما يشير إلى أن العائلات تفضل العروض التي تكون وقت مبكر من المساء وستدفع سعرًا أكبر قليلًا مقابل التذكرة. يمكن لهذه المعلومات أن تفيد مدير دار السينما وتشير له لأن فتح المزيد من الفترات في المساء الباكر يمكن أن يزيد عدد العائلات التي تختار الحضور بناء على الوقت المفضل والسعر. تُستخدَم التعليمة GROUP BY دائمًا مع دالة تجميعية، ولكن قد تكون هناك استثناءات، لذا إذا أردنا تجميع النتائج دون استخدام دالة تجميعية، فيمكن استخدام التعليمة DISTINCT لتحقيق النتيجة نفسها. حيث تزيل التعليمة DISTINCT أيّ تكرارات في مجموعة النتائج من خلال إعادة القيم الفريدة في العمود، ولا يمكن استخدامها إلّا مع التعليمة SELECT، فمثلًا إذا أردنا تجميع جميع الأفلام وفق الاسم، فيمكننا ذلك باستخدام الاستعلام التالي: mysql> SELECT DISTINCT movie_name FROM movie_theater; الخرج +-------------------------+ | movie_name | +-------------------------+ | Top Gun Maverick | | Downton Abbey A New Era | | Men | | The Bad Guys | +-------------------------+ 4 rows in set (0.00 sec) هناك نسخ مكررة لأسماء الأفلام نظرًا لوجود عروض متعددة كما وضحنا عند عرض كافة البيانات الموجودة في الجدول، لذا أزالت التعليمة DISTINCT تلك التكرارات وجمّعت لنا القيم الفريدة بفعالية ضمن عمود واحد هو movie_name، ويُعَد هذا مطابقًا فعليًا للاستعلام التالي الذي يتضمن التعليمة GROUP BY: mysql> SELECT movie_name FROM movie_theater GROUP BY movie_name; بعد أن شرحنا بالتفصيل طريقة استخدام التعليمة GROUP BY مع الدوال التجميعية، لنتعلّم الآن كيفية فرز نتائج الاستعلام باستخدام التعليمة ORDER BY. استخدام التعليمة ORDER BY تتمثل وظيفة التعليمة ORDER BY في فرز النتائج بترتيب تصاعدي أو تنازلي اعتمادًا على العمود أو الأعمدة التي نحدّدها في الاستعلام، حيث ستنظّم هذه التعليمة البيانات بترتيب أبجدي أو رقمي اعتمادًا على نوع البيانات التي يخزّنها العمود الذي نحدّده بعدها. تفرز التعليمة ORDER BY النتائج بترتيب تصاعدي افتراضيًا، ولكن إذا أردنا استخدام الترتيب التنازلي، فيجب تضمين الكلمة المفتاحية DESC في استعلامنا. يمكن أيضًا استخدام التعليمة ORDER BY مع التعليمة GROUP BY، ولكن يجب أن تأتي بعدها لكي تعمل بنجاح، ويجب أن تأتي التعليمة ORDER BY بعد التعليمة FROM والتعليمة WHERE كما هو الحال مع التعليمة GROUP BY. تكون الصيغة العامة لاستخدام التعليمة ORDER BY كما يلي: mysql> SELECT column_1, column_2 FROM table ORDER BY column_1; لنستخدم البيانات التجريبية النموذجية الخاصة بالسينما ونتدرب على فرز النتائج باستخدام التعليمة ORDER BY، ولنبدأ بالاستعلام التالي الذي يسترجع القيم من العمود guest_total وينظّم تلك القيم العددية باستخدام التعليمة ORDER BY: mysql> SELECT guest_total FROM movie_theater mysql> ORDER BY guest_total; الخرج +-------------+ | guest_total | +-------------+ | 25 | | 83 | | 88 | | 90 | | 100 | | 112 | | 118 | | 130 | | 131 | | 137 | | 142 | | 150 | +-------------+ 12 rows in set (0.00 sec) حدّد الاستعلام السابق عمودًا يحتوي على قيم عددية، لذا فقد نظّمت التعليمة ORDER BY النتائج حسب الترتيب الرقمي والتصاعدي بدءًا من القيمة 25 ضمن العمود guest_total. إذا أردنا ترتيب العمود تنازليًا، فيمكننا إضافة الكلمة المفتاحية DESC في نهاية الاستعلام، وإذا أردنا ترتيب البيانات حسب قيم المحارف ضمن العمود movie_name، فيمكن تحديد ذلك في الاستعلام الذي نكتبه. لنطبّق هذا النوع من الاستعلامات باستخدام التعليمة ORDER BY لترتيب العمود movie_name حسب قيم المحارف تنازليًا، ونفرز النتائج أيضًا من خلال تضمين التعليمة WHERE لاسترجاع البيانات الخاصة بالأفلام المعروضة في الساعة 10:00 مساء من العمود time: mysql> SELECT movie_name FROM movie_theater mysql> WHERE time = '10:00:00' mysql> ORDER BY movie_name DESC; الخرج +-------------------------+ | movie_name | +-------------------------+ | Top Gun Maverick | | The Bad Guys | | Men | | Downton Abbey A New Era | +-------------------------+ 4 rows in set (0.01 sec) توضّح هذه المجموعة من النتائج عروض الأفلام الأربعة المختلفة في الساعة 10:00 مساءً بترتيب أبجدي تنازليًا بدءًا من الفيلم Top Gun Maverick إلى الفيلم Downtown Abbey A New Era. لندمج الآن تعليمتي ORDER BY و GROUP BY مع الدالة التجميعية SUM لتوليد نتائج حول إجمالي الإيرادات المُستلَمة لكل فيلم، ولكن لنفترض أن دار السينما أخطأت في حساب إجمالي روّاد السينما ونسيت تضمين الحفلات الخاصة المدفوعة مسبقًا وحجز التذاكر لمجموعة مكونة من 12 شخصًا في كل عرض. سنستخدم في هذا الاستعلام الدالة SUM ونضمّن 12 زائرًا إضافيًا لكل فيلم معروض من خلال تطبيق معامل الجمع + ثم نجمع القيمة 12 مع العمود guest_total، ونتأكّد من وضع ذلك بين قوسين، ثم نضرب المجموع بالعمود ticket_cost، ونكمل المعادلة الرياضية بإغلاق القوسين في النهاية. نضيف التعليمة AS لإنشاء الاسم البديل للعمود الجديد بعنوان total_revenue، ثم نستخدم التعليمة GROUP BY لتجميع نتائج العمود total_revenue لكل فيلم بناءً على البيانات المسترجَعة من العمود movie_name. وأخيرًا، نستخدم التعليمة ORDER BY لتنظيم النتائج ضمن العمود الجديد total_revenue بترتيب تصاعدي: mysql> SELECT movie_name, SUM((guest_total + 12) * ticket_cost) mysql> AS total_revenue mysql> FROM movie_theater mysql> GROUP BY movie_name mysql> ORDER BY total_revenue; الخرج +-------------------------+---------------+ | movie_name | total_revenue | +-------------------------+---------------+ | Men | 3612.00 | | Downton Abbey A New Era | 4718.00 | | The Bad Guys | 4788.00 | | Top Gun Maverick | 5672.00 | +-------------------------+---------------+ 4 rows in set (0.00 sec) تعطينا هذه المجموعة من النتائج إجمالي الإيرادات لكل فيلم مع مبيعات تذاكر الزوار الإضافية التي يبلغ عددها 12 تذكرة، وتنظّم إجمالي مبيعات التذاكر بترتيب تصاعدي من الأقل إلى الأعلى، وبالتالي حصل الفيلم Top Gun Maverick على أكبر عدد من مبيعات التذاكر، بينما حصل فيلم Men على المبيعات الأقل، وكانت أفلام The Bad Guys و Downton Abbey A New Era متقاربة جدًا في إجمالي مبيعات التذاكر. إلى هنا نكون قد وصلنا لنهاية هذا القسم الذي تعرفنا فيه على طرق مختلفة لتطبيق تعليمة ORDER BY وكيفية تحديد الترتيب الذي نفضّله مثل الترتيب التصاعدي والتنازلي لكل من قيم البيانات المحرفية والرقمية، وتعلّمنا أيضًا كيفية تضمين التعليمة WHERE لتضييق نطاق النتائج، وأجرينا استعلامًا باستخدام كلّ من تعليمات GROUP BY و ORDER BY مع دالة تجميعية ومعادلة رياضية. الخلاصة يُعَد فهم كيفية استخدام تعليمتي GROUP BY و ORDER BY أمرًا مهمًا لفرز النتائج والبيانات، حيث يمكننا من خلالهما تنظيم نتائج متعددة ضمن مجموعة واحدة أو تنظيم أحد الأعمدة بترتيب أبجدي وتنازلي أو تطبيق الأمرين معًا في وقت واحد، وتعلّمنا أيضًا طرقًا أخرى لفرز النتائج باستخدام التعليمة WHERE. ولمعرفة المزيد ننصح بمطالعة مقال كيفية استخدام محارف البدل Wildcards في لغة SQL للتدرب على ترشيح النتائج باستخدام التعليمة LIKE، كما ننصح بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب للمزيد حول كيفية التعامل مع لغة SQL. ترجمة -وبتصرف- للمقال How To Use GROUP BY and ORDER BY in SQL لصاحبته Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: استخدام العروض Views في لغة SQL دوال التعامل مع البيانات في SQL التجميع والترتيب في SQL كيفية التعامل مع التواريخ والأوقات في SQL -
 سنتناول في هذا المقال العبارات الشرطية، التي تعد واحدة من العناصر الأساسية في مختلف لغات البرمجة. حيث سنستعرض كيفية استخدام العبارات الشرطية بشكل فعّال في لغة الاستعلام البنيوية SQL ونتعلم كيفية تطبيقها في مختلف سيناريوهات البرمجة. تتضمّن لغات البرمجة عادةً عباراتٍ شرطية، وهي عبارة عن أمر أو عدة أوامر تُنفّذ فعل مُحدّد لدى تحقق شرط معيّن. ولعلّ من أشهر العبارات الشرطية عبارة if, then, else والتي تتبع عادةً المنطق التالي: if condition=true then action A else action B إذ يُترجم منطق هذه العبارة لغويًا على النحو التالي: "إذا كان الشرط محققًا، نفّذ الأمر أو مجموعة الأوامر A. وإلّا في حال كون الشرط غير محققًا، نفّذ الأمر أو مجموعة الأوامر B." تُعدّ تعابير CASE ميزة في لغة الاستعلام البنيوية SQL، فهي تتيح لنا إمكانية تطبيق منطق مماثل للعبارات الشرطية على استعلامات قواعد البيانات، وتعيين شروط لكيفية إرجاع أو عرض القيم في مجموعة النتائج الخاصة بنا. ولمعرفة كيفية استخدام تعبير CASE لتعيين شروط على البيانات باستخدام كل من الكلمات المفتاحية WHEN وTHEN وELSE وEND تابع الفقرات التالية من المقال. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح في المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام إدارة قواعد بيانات MySQL مثبت ومؤمن على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام تعابير CASE في هذا المقال. لذا ننصحك بمتابعة الفقرة التالية بعنوان الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إنشاء قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم caseDB: mysql> CREATE DATABASE caseDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرج كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات caseDB، نفّذ تعليمة USE التالية: mysql> USE caseDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات caseDB، لننشئ جدولًا ضمنها باستخدام الأمر CREATE TABLE. كمثال في مقالنا هذا، سنُنشئ جدولًا يحتفظ ببيانات حول الألبومات الموسيقية العشر الأكثر مبيعًا على مر الزمان. إذ سيحتوي هذا الجدول على الأعمدة الستة التالية: music_id: يُمثّل قيمًا من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. artist_name: مُخصص لتخزين أسماء الفنان أو مجموعة الفنانين المشاركين في الألبوم باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. album_name: يستخدم نمط البيانات varchar، بحد أقصى 30 محرفًا أيضًا لتخزين أسم كل ألبوم. release_date: يتتبع تاريخ إصدار كل ألبوم باستخدام نمط البيانات DATE، الذي يستخدم تنسيق التاريخ YYYY-MM-DD (اليوم بخانتين-الشهر بخانتين-السنة بأربع خانات). genre_type: يعرض تصنيف النوع الموسيقي لكل ألبوم باستخدام نمط البيانات varchar بحد أقصى 25 محرفًا. copies_sold: يستخدم نمط البيانات decimal لتخزين العدد الإجمالي لنسخ الألبوم المباعة بالملايين. إذ سنحدّد لدى تعريف هذا العمود الدقة Precision لتساوي أربعة أرقام، بواقع رقم واحد إلى يمين الفاصلة العشرية. ما يعني أن القيم في هذا العمود يمكن أن تتضمّن أربعة أرقام، واحد منها على يمين الفاصلة العشرية. لننشئ الآن جدولاً باسم top_albums يتضمّن هذه الأعمدة من خلال تنفيذ أمر CREATE TABLE التالي: mysql> CREATE TABLE top_albums ( mysql> music_id int, mysql> artist_name varchar(30), mysql> album_name varchar(30), mysql> release_date DATE, mysql> genre_type varchar(25), mysql> copies_sold decimal(4,1), mysql> PRIMARY KEY (music_id) mysql> ); والآن لنملأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO top_albums mysql> (music_id, artist_name, album_name, release_date, genre_type, copies_sold) mysql> VALUES mysql> (1, 'Michael Jackson', 'Thriller', '1982-11-30', 'Pop', 49.2), mysql> (2, 'Eagles', 'Hotel California', '1976-12-08', 'Soft Rock', 31.5), mysql> (3, 'Pink Floyd', 'The Dark Side of the Moon', '1973-03-01', 'Progressive Rock', 21.7), mysql> (4, 'Shania Twain', 'Come On Over', '1997-11-04', 'Country', 29.6), mysql> (5, 'AC/DC', 'Back in Black', '1980-07-25', 'Hard Rock', 29.5), mysql> (6, 'Whitney Houston', 'The Bodyguard', '1992-11-25', 'R&B', 32.4), mysql> (7, 'Fleetwood Mac', 'Rumours', '1977-02-04', 'Soft Rock', 27.9), mysql> (8, 'Meat Loaf', 'Bat Out of Hell', '1977-10-11', 'Hard Rock', 21.7), mysql> (9, 'Eagles', 'Their Greatest Hits 1971-1975', '1976-02-17', 'Country Rock', 41.2), mysql> (10, 'Bee Gees', 'Saturday Night Fever', '1977-11-15', 'Disco', 21.6); الخرج Query OK, 10 rows affected (0.01 sec) Records: 10 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء تعلّم كيفية استخدام تعابير CASE في SQL. فهم صياغة تعابير CASE تتيح لنا تعابير CASE تحديد شروط لبياناتنا واستخدام منطق مشابه لجمل if-then للبحث ضمنها ومقارنة القيم وتقييم ما إذا كانت تحقق الشروط التي حددناها، بمعنى أنها تجعل هذه الشروط تُقيّم كمحققة "True". وفيما يلي مثال على الصياغة العامة لتعبير CASE: الصيغة العامّة لتعبير CASE . . . CASE WHEN condition_1 THEN outcome_1 WHEN condition_2 THEN outcome_2 WHEN condition_3 THEN outcome_3 ELSE else_outcome END . . . كما سنستخدم الكلمات المفتاحية التالية ضمن تعبير CASE وذلك اعتمادًا على عدد الشروط التي نريد تحديدها لبياناتنا: WHEN: تقيّم هذه الكلمة المفتاحية البيانات في الجدول وتقارنها بالشروط أو المعايير المُحدّدة، وهي مُشابهة بالمبدأ للتعبير if في بنية الجمل الشرطية النموذجية (if-then-else). THEN: تُستخدم لفحص كل شرط لتحديد ما إذا كانت قيمة معينة لا تستوفي المعايير المطلوبة. ELSE: إذا لم تحقق قيمة البيانات أيًا من الشروط المحددة بعد التحقق من جمل WHEN وTHEN، فعندها تُستخدم هذه الكلمة المفتاحية لتحديد الشرط النهائي الذي ستُصنّف القيمة تحته. END: لإنهاء وتنفيذ تعبير CASE بنجاح ولتحديد شروطك، لابدّ من اختتام التعبير بالكلمة المفتاحية END. استخدام تعابير CASE تخيل أنك مُنسّق موسيقي تُعد قائمة أغاني من أجل حفلة لأحد أقاربك من أصحاب الذوق الموسيقي الصعب. لذا قررت أن تبحث عن أفضل عشر ألبومات موسيقية مبيعًا على مر الزمان للاستئناس بها وتوجيه قراراتك الموسيقية. لنراجع بدايةً القائمة التي جمعناها في جدول أفضل الألبومات top_albums بتنفيذ استعلام SELECT واستخدام رمز * لعرض كافّة البيانات من كل عمود: mysql> SELECT * FROM top_albums; الخرج +----------+-----------------+-------------------------------+--------------+------------------+-------------+ | music_id | artist_name | album_name | release_date | genre_type | copies_sold | +----------+-----------------+-------------------------------+--------------+------------------+-------------+ | 1 | Michael Jackson | Thriller | 1982-11-30 | Pop | 49.2 | | 2 | Eagles | Hotel California | 1976-12-08 | Soft Rock | 31.5 | | 3 | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | Progressive Rock | 21.7 | | 4 | Shania Twain | Come On Over | 1997-11-04 | Country | 29.6 | | 5 | AC/DC | Back in Black | 1980-07-25 | Hard Rock | 29.5 | | 6 | Whitney Houston | The Bodyguard | 1992-11-25 | R&B | 32.4 | | 7 | Fleetwood Mac | Rumours | 1977-02-04 | Soft Rock | 27.9 | | 8 | Meat Loaf | Bat Out of Hell | 1977-10-11 | Hard Rock | 21.7 | | 9 | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | Country Rock | 41.2 | | 10 | Bee Gees | Saturday Night Fever | 1977-11-15 | Disco | 21.6 | +----------+-----------------+-------------------------------+--------------+------------------+-------------+ 10 rows in set (0.00 sec) وبما أنّ قريبك ولد في عام 1957، فلا بدّ وأنّه قد استمتع بالكثير من الموسيقى الناجحة في شبابه زمن السبعينيات والثمانينيات. وأنت تعلم أنّه من محبي أنماط موسيقى pop وsoft rock وdisco، لذا سنعطي هذه الأنماط الأولوية في قائمة الأغاني. الأمر الذي يمكننا تنفيذه باستخدام تعبير CASE لتعيين شرط يحدد "أولوية عالية (High Priority)" لهذه الأنماط الموسيقية، من خلال الاستعلام عن قيم البيانات هذه من عمود النمط الموسيقي genre_type. يُنفّذ الاستعلام التالي ذلك، ويُنشئ اسمًا بديلاً للعمود الناتج من تعبير CASE، ليكون priority (الأولوية). كما يتضمّن هذا الاستعلام كل من اسم الفنان artist_name واسم الألبوم album_name وتاريخ الإصدار release_date لتوفير المزيد من المعلومات، ولم ننس استخدام الكلمة المفتاحية END لإكمال تعبير CASE: mysql> SELECT artist_name, album_name, release_date, mysql> CASE WHEN genre_type = 'Pop' THEN 'High Priority' mysql> WHEN genre_type = 'Soft Rock' THEN 'High Priority' mysql> WHEN genre_type = 'Disco' THEN 'High Priority' mysql> END AS priority mysql> FROM top_albums; الخرج +-----------------+-------------------------------+--------------+---------------+ | artist_name | album_name | release_date | priority | +-----------------+-------------------------------+--------------+---------------+ | Michael Jackson | Thriller | 1982-11-30 | High Priority | | Eagles | Hotel California | 1976-12-08 | High Priority | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | NULL | | Shania Twain | Come On Over | 1997-11-04 | NULL | | AC/DC | Back in Black | 1980-07-25 | NULL | | Whitney Houston | The Bodyguard | 1992-11-25 | NULL | | Fleetwood Mac | Rumours | 1977-02-04 | High Priority | | Meat Loaf | Bat Out of Hell | 1977-10-11 | NULL | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | NULL | | Bee Gees | Saturday Night Fever | 1977-11-15 | High Priority | +-----------------+-------------------------------+--------------+---------------+ 10 rows in set (0.00 sec) على الرغم من أنّ هذا الخرج يعكس الشروط المُحددة للأنماط الموسيقية ذات الأولوية العالية High Priority، ولكن ونظرًا لعدم استخدامنا للكلمة المفتاحية ELSE فقد ظهرت قيم بيانات غير معروفة أو مفقودة، والتي تُعرف بالقيم الخالية NULL. ففي حين قد لا يكون استخدام الكلمة المفتاحية ELSE ضروريًا في حال كانت قيم البيانات تلبي جميع الشروط المُحددّة في التعبير CASE، إلّا أنّها مفيدة لأي بيانات متبقية (لا تلبي الشروط المُحددة)، إذ باستخدامها يمكن تصنيفها تحت شرطٍ آخر واحد. للاستعلام التالي، سنكتب نفس تعبير CASE السابق، ولكن سنحدد هذه المرة شرطًا باستخدام الكلمة المفتاحية ELSE. إذ تُصنّف تعليمة ELSE في المثال التالي أي قيم بيانات أنماط موسيقية غير مُصنّفة ضمن الأولوية العالية High Priority على أنّها "Maybe أي قد تؤخذ بالحسبان": mysql> SELECT artist_name, album_name, release_date, mysql> CASE WHEN genre_type = 'Pop' THEN 'High Priority' mysql> WHEN genre_type = 'Soft Rock' THEN 'High Priority' mysql> WHEN genre_type = 'Disco' THEN 'High Priority' mysql> ELSE 'Maybe' mysql> END AS priority mysql> FROM top_albums; [sceondary_label Output] +-----------------+-------------------------------+--------------+---------------+ | artist_name | album_name | release_date | priority | +-----------------+-------------------------------+--------------+---------------+ | Michael Jackson | Thriller | 1982-11-30 | High Priority | | Eagles | Hotel California | 1976-12-08 | High Priority | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | Maybe | | Shania Twain | Come On Over | 1997-11-04 | Maybe | | AC/DC | Back in Black | 1980-07-25 | Maybe | | Whitney Houston | The Bodyguard | 1992-11-25 | Maybe | | Fleetwood Mac | Rumours | 1977-02-04 | High Priority | | Meat Loaf | Bat Out of Hell | 1977-10-11 | Maybe | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | Maybe | | Bee Gees | Saturday Night Fever | 1977-11-15 | High Priority | +-----------------+-------------------------------+--------------+---------------+ 10 rows in set (0.00 sec) وبذلك يُعبّر هذا الخرج على نحوٍ أفضل عن الشروط التي وضعناها لتحديد لألبومات ذات الأولوية الأعلى وتلك بدون أولوية. وعلى الرغم من أنّ ذلك يساعد في إعطاء الأولوية لأفضل أربع ألبومات — وهي Thriller وHotel California وRumours وSaturday Night Fever، ومع ذلك أنت مقتنع بأنّه ينبغي تنويع قائمة الأغاني أكثر، ولكن في هذه الحالة سيتوجب عليك إقناع قريبك بالأمر أيضًا. لذا تقرّر إجراء تجربة بسيطة، طالبًا من قريبك توسيع ذائقته الموسيقية مُستمعًا إلى الألبومات المتبقية. فتقدّم هذه الألبومات له دون أن تعطيه أي تصوّر مُسبق عنها، وتطلب منه تقييمها بأمانة كهادئة Mellow أو ممتعة Fun أو مملة Boring. بعد انتهائه، يُعطيك قائمة مكتوبة بخط اليد تحتوي على تقييماته. وبذلك أصبح لديك المعلومات اللازمة لتحديد الشروط لاستعلامك كما يلي: mysql> SELECT artist_name, album_name, release_date, mysql> CASE WHEN genre_type = 'Hard Rock' THEN 'Boring' mysql> WHEN genre_type = 'Country Rock' THEN 'Mellow' mysql> WHEN genre_type = 'Progressive Rock' THEN 'Fun' mysql> WHEN genre_type = 'Country' THEN 'Fun' mysql> WHEN genre_type = 'R&B' THEN 'Boring' mysql> ELSE 'High Priority' mysql> END AS score mysql> FROM top_albums; الخرج +-----------------+-------------------------------+--------------+---------------+ | artist_name | album_name | release_date | score | +-----------------+-------------------------------+--------------+---------------+ | Michael Jackson | Thriller | 1982-11-30 | High Priority | | Eagles | Hotel California | 1976-12-08 | High Priority | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | Fun | | Shania Twain | Come On Over | 1997-11-04 | Fun | | AC/DC | Back in Black | 1980-07-25 | Boring | | Whitney Houston | The Bodyguard | 1992-11-25 | Boring | | Fleetwood Mac | Rumours | 1977-02-04 | High Priority | | Meat Loaf | Bat Out of Hell | 1977-10-11 | Boring | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | Mellow | | Bee Gees | Saturday Night Fever | 1977-11-15 | High Priority | +-----------------+-------------------------------+--------------+---------------+ 10 rows in set (0.00 sec) بناءً على هذا الخرج، يبدو أنّ قريبك مستعد لتجربة موسيقا جديدة، وقد سرّك على وجه الخصوص تقييمه الجيد لفرقة Pink Floyd. لكنكَ شعرتَ بخيبة أمل لعدم إظهاره الاهتمام الكافي بأغاني AC/DC وMeat Loaf وWhitney Houston الرائعة. ولربما سيكون قريبك أكثر تقبّلاً للتغيير إذا أظهرتَ له أنّ بعض الألبومات تحظى بشعبية أكبر من غيرها على نحوٍ موضوعيّ، لذا تقرّر أن تعرض بعض الأرقام لدعم وجهة نظرك. فهذه الألبومات في الواقع هي الأكثر مبيعًا، إذ حققت مبيعات تُقدّر بملايين النسخ على مرّ العقود. لذا، في استعلامنا القادم، سنُنشئ تعبير CASE جديد يُحدّد تقييمًا استنادًا إلى البيانات الرقمية من عمود عدد النسخ المُباعة copies_sold للألبومات التي تم بيعها حتى الآن. سنستخدم تعبير CASE لتحديد الشروط بحيث نُعيّن الألبومات التي حققت ما لا يقل عن 35 مليون نسخة على أنّها "الأفضل best"، وتلك التي بيع منها 25 مليون نسخة على أنّها "ممتازة great"، وتلك التي بيع منها 20 مليون على أنّها "جيدة good"، وأي شيء أقل من ذلك على أنًه "متوسط mediocre"، كما في المثال التالي: mysql> SELECT artist_name, album_name, release_date, CASE WHEN copies_sold >35.0 THEN 'best' mysql> WHEN copies_sold >25.0 THEN 'great' mysql> WHEN copies_sold >20.0 THEN 'good' mysql> ELSE 'mediocre' END AS score FROM top_albums; الخرج +-----------------+-------------------------------+--------------+-------+ | artist_name | album_name | release_date | score | +-----------------+-------------------------------+--------------+-------+ | Michael Jackson | Thriller | 1982-11-30 | best | | Eagles | Hotel California | 1976-12-08 | great | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | good | | Shania Twain | Come On Over | 1997-11-04 | great | | AC/DC | Back in Black | 1980-07-25 | great | | Whitney Houston | The Bodyguard | 1992-11-25 | great | | Fleetwood Mac | Rumours | 1977-02-04 | great | | Meat Loaf | Bat Out of Hell | 1977-10-11 | good | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | best | | Bee Gees | Saturday Night Fever | 1977-11-15 | good | +-----------------+-------------------------------+--------------+-------+ 10 rows in set (0.00 sec) وفق الخرج السابق لم يُصنّف أي من الألبومات على أنّه "متوسط mediocre"، نظرًا لأنّ كل منها قد حقق مبيعات تزيد عن 20 مليون نسخة. ومع ذلك وبناءً على هذه التقييمات، تبرز بعض الألبومات مقارنةً بالبقية. وبذلك يمكنك الآن أن تقدّم لقريبك دليلًا قويًا يبرّر تشغيل أغاني الفنانين AC/DC أو Whitney Houston، إذ أنّ ألبوماتهم قد حققت مبيعات تزيد عن 25 مليون نسخة، مما يجعلها من أهم الأعمال الموسيقية الموجودة. وبذلك تشكّل لديك فهم لكيفية استخدام تعبير CASE لتحديد شروط تعود لأغراض متنوعة، بحيث تتعامل مع قيم بيانات محرفية ورقمية. كما غدوت على معرفة بكيفية استخدام التعبير CASE لنفس منطق عبارة if-then لمقارنة تلك القيم وإنشاء الردود المناسبة بناءً على الشروط التي ترغب بها. الخلاصة لعلّ فهم كيفية استخدام تعبير CASE قد يساعد على تصفية بياناتك وفقًا للشروط التي تضعها. فسواء كنت تريد تحديد أولويات مختلفة لقيمٍ معينة أو تقييمها بناءً على معايير تعكس الرأي العام أو أرقام مُحدّدة، فإنّها توفّر مرونة تلبي احتياجاتك. وإذا كنت ترغب في معرفة طرق أخرى يمكنك من خلالها معالجة قيم البيانات في مجموعات النتائج الخاصة بك، اطّلع على مقال حول كيفية معالجة البيانات باستخدام دوال CAST وتعابير الضم في SQL. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use CASE Expressions in SQL لصاحبه Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: كيفية معالجة البيانات باستخدام دوال CAST وتعابير الضم في SQL تنفيذ تعليمات شرطية عبر CASE في SQL التجميع والترتيب في SQL دوال التعامل مع البيانات في SQL
سنتناول في هذا المقال العبارات الشرطية، التي تعد واحدة من العناصر الأساسية في مختلف لغات البرمجة. حيث سنستعرض كيفية استخدام العبارات الشرطية بشكل فعّال في لغة الاستعلام البنيوية SQL ونتعلم كيفية تطبيقها في مختلف سيناريوهات البرمجة. تتضمّن لغات البرمجة عادةً عباراتٍ شرطية، وهي عبارة عن أمر أو عدة أوامر تُنفّذ فعل مُحدّد لدى تحقق شرط معيّن. ولعلّ من أشهر العبارات الشرطية عبارة if, then, else والتي تتبع عادةً المنطق التالي: if condition=true then action A else action B إذ يُترجم منطق هذه العبارة لغويًا على النحو التالي: "إذا كان الشرط محققًا، نفّذ الأمر أو مجموعة الأوامر A. وإلّا في حال كون الشرط غير محققًا، نفّذ الأمر أو مجموعة الأوامر B." تُعدّ تعابير CASE ميزة في لغة الاستعلام البنيوية SQL، فهي تتيح لنا إمكانية تطبيق منطق مماثل للعبارات الشرطية على استعلامات قواعد البيانات، وتعيين شروط لكيفية إرجاع أو عرض القيم في مجموعة النتائج الخاصة بنا. ولمعرفة كيفية استخدام تعبير CASE لتعيين شروط على البيانات باستخدام كل من الكلمات المفتاحية WHEN وTHEN وELSE وEND تابع الفقرات التالية من المقال. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح في المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام إدارة قواعد بيانات MySQL مثبت ومؤمن على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام تعابير CASE في هذا المقال. لذا ننصحك بمتابعة الفقرة التالية بعنوان الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إنشاء قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم caseDB: mysql> CREATE DATABASE caseDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرج كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات caseDB، نفّذ تعليمة USE التالية: mysql> USE caseDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات caseDB، لننشئ جدولًا ضمنها باستخدام الأمر CREATE TABLE. كمثال في مقالنا هذا، سنُنشئ جدولًا يحتفظ ببيانات حول الألبومات الموسيقية العشر الأكثر مبيعًا على مر الزمان. إذ سيحتوي هذا الجدول على الأعمدة الستة التالية: music_id: يُمثّل قيمًا من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. artist_name: مُخصص لتخزين أسماء الفنان أو مجموعة الفنانين المشاركين في الألبوم باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. album_name: يستخدم نمط البيانات varchar، بحد أقصى 30 محرفًا أيضًا لتخزين أسم كل ألبوم. release_date: يتتبع تاريخ إصدار كل ألبوم باستخدام نمط البيانات DATE، الذي يستخدم تنسيق التاريخ YYYY-MM-DD (اليوم بخانتين-الشهر بخانتين-السنة بأربع خانات). genre_type: يعرض تصنيف النوع الموسيقي لكل ألبوم باستخدام نمط البيانات varchar بحد أقصى 25 محرفًا. copies_sold: يستخدم نمط البيانات decimal لتخزين العدد الإجمالي لنسخ الألبوم المباعة بالملايين. إذ سنحدّد لدى تعريف هذا العمود الدقة Precision لتساوي أربعة أرقام، بواقع رقم واحد إلى يمين الفاصلة العشرية. ما يعني أن القيم في هذا العمود يمكن أن تتضمّن أربعة أرقام، واحد منها على يمين الفاصلة العشرية. لننشئ الآن جدولاً باسم top_albums يتضمّن هذه الأعمدة من خلال تنفيذ أمر CREATE TABLE التالي: mysql> CREATE TABLE top_albums ( mysql> music_id int, mysql> artist_name varchar(30), mysql> album_name varchar(30), mysql> release_date DATE, mysql> genre_type varchar(25), mysql> copies_sold decimal(4,1), mysql> PRIMARY KEY (music_id) mysql> ); والآن لنملأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO top_albums mysql> (music_id, artist_name, album_name, release_date, genre_type, copies_sold) mysql> VALUES mysql> (1, 'Michael Jackson', 'Thriller', '1982-11-30', 'Pop', 49.2), mysql> (2, 'Eagles', 'Hotel California', '1976-12-08', 'Soft Rock', 31.5), mysql> (3, 'Pink Floyd', 'The Dark Side of the Moon', '1973-03-01', 'Progressive Rock', 21.7), mysql> (4, 'Shania Twain', 'Come On Over', '1997-11-04', 'Country', 29.6), mysql> (5, 'AC/DC', 'Back in Black', '1980-07-25', 'Hard Rock', 29.5), mysql> (6, 'Whitney Houston', 'The Bodyguard', '1992-11-25', 'R&B', 32.4), mysql> (7, 'Fleetwood Mac', 'Rumours', '1977-02-04', 'Soft Rock', 27.9), mysql> (8, 'Meat Loaf', 'Bat Out of Hell', '1977-10-11', 'Hard Rock', 21.7), mysql> (9, 'Eagles', 'Their Greatest Hits 1971-1975', '1976-02-17', 'Country Rock', 41.2), mysql> (10, 'Bee Gees', 'Saturday Night Fever', '1977-11-15', 'Disco', 21.6); الخرج Query OK, 10 rows affected (0.01 sec) Records: 10 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء تعلّم كيفية استخدام تعابير CASE في SQL. فهم صياغة تعابير CASE تتيح لنا تعابير CASE تحديد شروط لبياناتنا واستخدام منطق مشابه لجمل if-then للبحث ضمنها ومقارنة القيم وتقييم ما إذا كانت تحقق الشروط التي حددناها، بمعنى أنها تجعل هذه الشروط تُقيّم كمحققة "True". وفيما يلي مثال على الصياغة العامة لتعبير CASE: الصيغة العامّة لتعبير CASE . . . CASE WHEN condition_1 THEN outcome_1 WHEN condition_2 THEN outcome_2 WHEN condition_3 THEN outcome_3 ELSE else_outcome END . . . كما سنستخدم الكلمات المفتاحية التالية ضمن تعبير CASE وذلك اعتمادًا على عدد الشروط التي نريد تحديدها لبياناتنا: WHEN: تقيّم هذه الكلمة المفتاحية البيانات في الجدول وتقارنها بالشروط أو المعايير المُحدّدة، وهي مُشابهة بالمبدأ للتعبير if في بنية الجمل الشرطية النموذجية (if-then-else). THEN: تُستخدم لفحص كل شرط لتحديد ما إذا كانت قيمة معينة لا تستوفي المعايير المطلوبة. ELSE: إذا لم تحقق قيمة البيانات أيًا من الشروط المحددة بعد التحقق من جمل WHEN وTHEN، فعندها تُستخدم هذه الكلمة المفتاحية لتحديد الشرط النهائي الذي ستُصنّف القيمة تحته. END: لإنهاء وتنفيذ تعبير CASE بنجاح ولتحديد شروطك، لابدّ من اختتام التعبير بالكلمة المفتاحية END. استخدام تعابير CASE تخيل أنك مُنسّق موسيقي تُعد قائمة أغاني من أجل حفلة لأحد أقاربك من أصحاب الذوق الموسيقي الصعب. لذا قررت أن تبحث عن أفضل عشر ألبومات موسيقية مبيعًا على مر الزمان للاستئناس بها وتوجيه قراراتك الموسيقية. لنراجع بدايةً القائمة التي جمعناها في جدول أفضل الألبومات top_albums بتنفيذ استعلام SELECT واستخدام رمز * لعرض كافّة البيانات من كل عمود: mysql> SELECT * FROM top_albums; الخرج +----------+-----------------+-------------------------------+--------------+------------------+-------------+ | music_id | artist_name | album_name | release_date | genre_type | copies_sold | +----------+-----------------+-------------------------------+--------------+------------------+-------------+ | 1 | Michael Jackson | Thriller | 1982-11-30 | Pop | 49.2 | | 2 | Eagles | Hotel California | 1976-12-08 | Soft Rock | 31.5 | | 3 | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | Progressive Rock | 21.7 | | 4 | Shania Twain | Come On Over | 1997-11-04 | Country | 29.6 | | 5 | AC/DC | Back in Black | 1980-07-25 | Hard Rock | 29.5 | | 6 | Whitney Houston | The Bodyguard | 1992-11-25 | R&B | 32.4 | | 7 | Fleetwood Mac | Rumours | 1977-02-04 | Soft Rock | 27.9 | | 8 | Meat Loaf | Bat Out of Hell | 1977-10-11 | Hard Rock | 21.7 | | 9 | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | Country Rock | 41.2 | | 10 | Bee Gees | Saturday Night Fever | 1977-11-15 | Disco | 21.6 | +----------+-----------------+-------------------------------+--------------+------------------+-------------+ 10 rows in set (0.00 sec) وبما أنّ قريبك ولد في عام 1957، فلا بدّ وأنّه قد استمتع بالكثير من الموسيقى الناجحة في شبابه زمن السبعينيات والثمانينيات. وأنت تعلم أنّه من محبي أنماط موسيقى pop وsoft rock وdisco، لذا سنعطي هذه الأنماط الأولوية في قائمة الأغاني. الأمر الذي يمكننا تنفيذه باستخدام تعبير CASE لتعيين شرط يحدد "أولوية عالية (High Priority)" لهذه الأنماط الموسيقية، من خلال الاستعلام عن قيم البيانات هذه من عمود النمط الموسيقي genre_type. يُنفّذ الاستعلام التالي ذلك، ويُنشئ اسمًا بديلاً للعمود الناتج من تعبير CASE، ليكون priority (الأولوية). كما يتضمّن هذا الاستعلام كل من اسم الفنان artist_name واسم الألبوم album_name وتاريخ الإصدار release_date لتوفير المزيد من المعلومات، ولم ننس استخدام الكلمة المفتاحية END لإكمال تعبير CASE: mysql> SELECT artist_name, album_name, release_date, mysql> CASE WHEN genre_type = 'Pop' THEN 'High Priority' mysql> WHEN genre_type = 'Soft Rock' THEN 'High Priority' mysql> WHEN genre_type = 'Disco' THEN 'High Priority' mysql> END AS priority mysql> FROM top_albums; الخرج +-----------------+-------------------------------+--------------+---------------+ | artist_name | album_name | release_date | priority | +-----------------+-------------------------------+--------------+---------------+ | Michael Jackson | Thriller | 1982-11-30 | High Priority | | Eagles | Hotel California | 1976-12-08 | High Priority | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | NULL | | Shania Twain | Come On Over | 1997-11-04 | NULL | | AC/DC | Back in Black | 1980-07-25 | NULL | | Whitney Houston | The Bodyguard | 1992-11-25 | NULL | | Fleetwood Mac | Rumours | 1977-02-04 | High Priority | | Meat Loaf | Bat Out of Hell | 1977-10-11 | NULL | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | NULL | | Bee Gees | Saturday Night Fever | 1977-11-15 | High Priority | +-----------------+-------------------------------+--------------+---------------+ 10 rows in set (0.00 sec) على الرغم من أنّ هذا الخرج يعكس الشروط المُحددة للأنماط الموسيقية ذات الأولوية العالية High Priority، ولكن ونظرًا لعدم استخدامنا للكلمة المفتاحية ELSE فقد ظهرت قيم بيانات غير معروفة أو مفقودة، والتي تُعرف بالقيم الخالية NULL. ففي حين قد لا يكون استخدام الكلمة المفتاحية ELSE ضروريًا في حال كانت قيم البيانات تلبي جميع الشروط المُحددّة في التعبير CASE، إلّا أنّها مفيدة لأي بيانات متبقية (لا تلبي الشروط المُحددة)، إذ باستخدامها يمكن تصنيفها تحت شرطٍ آخر واحد. للاستعلام التالي، سنكتب نفس تعبير CASE السابق، ولكن سنحدد هذه المرة شرطًا باستخدام الكلمة المفتاحية ELSE. إذ تُصنّف تعليمة ELSE في المثال التالي أي قيم بيانات أنماط موسيقية غير مُصنّفة ضمن الأولوية العالية High Priority على أنّها "Maybe أي قد تؤخذ بالحسبان": mysql> SELECT artist_name, album_name, release_date, mysql> CASE WHEN genre_type = 'Pop' THEN 'High Priority' mysql> WHEN genre_type = 'Soft Rock' THEN 'High Priority' mysql> WHEN genre_type = 'Disco' THEN 'High Priority' mysql> ELSE 'Maybe' mysql> END AS priority mysql> FROM top_albums; [sceondary_label Output] +-----------------+-------------------------------+--------------+---------------+ | artist_name | album_name | release_date | priority | +-----------------+-------------------------------+--------------+---------------+ | Michael Jackson | Thriller | 1982-11-30 | High Priority | | Eagles | Hotel California | 1976-12-08 | High Priority | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | Maybe | | Shania Twain | Come On Over | 1997-11-04 | Maybe | | AC/DC | Back in Black | 1980-07-25 | Maybe | | Whitney Houston | The Bodyguard | 1992-11-25 | Maybe | | Fleetwood Mac | Rumours | 1977-02-04 | High Priority | | Meat Loaf | Bat Out of Hell | 1977-10-11 | Maybe | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | Maybe | | Bee Gees | Saturday Night Fever | 1977-11-15 | High Priority | +-----------------+-------------------------------+--------------+---------------+ 10 rows in set (0.00 sec) وبذلك يُعبّر هذا الخرج على نحوٍ أفضل عن الشروط التي وضعناها لتحديد لألبومات ذات الأولوية الأعلى وتلك بدون أولوية. وعلى الرغم من أنّ ذلك يساعد في إعطاء الأولوية لأفضل أربع ألبومات — وهي Thriller وHotel California وRumours وSaturday Night Fever، ومع ذلك أنت مقتنع بأنّه ينبغي تنويع قائمة الأغاني أكثر، ولكن في هذه الحالة سيتوجب عليك إقناع قريبك بالأمر أيضًا. لذا تقرّر إجراء تجربة بسيطة، طالبًا من قريبك توسيع ذائقته الموسيقية مُستمعًا إلى الألبومات المتبقية. فتقدّم هذه الألبومات له دون أن تعطيه أي تصوّر مُسبق عنها، وتطلب منه تقييمها بأمانة كهادئة Mellow أو ممتعة Fun أو مملة Boring. بعد انتهائه، يُعطيك قائمة مكتوبة بخط اليد تحتوي على تقييماته. وبذلك أصبح لديك المعلومات اللازمة لتحديد الشروط لاستعلامك كما يلي: mysql> SELECT artist_name, album_name, release_date, mysql> CASE WHEN genre_type = 'Hard Rock' THEN 'Boring' mysql> WHEN genre_type = 'Country Rock' THEN 'Mellow' mysql> WHEN genre_type = 'Progressive Rock' THEN 'Fun' mysql> WHEN genre_type = 'Country' THEN 'Fun' mysql> WHEN genre_type = 'R&B' THEN 'Boring' mysql> ELSE 'High Priority' mysql> END AS score mysql> FROM top_albums; الخرج +-----------------+-------------------------------+--------------+---------------+ | artist_name | album_name | release_date | score | +-----------------+-------------------------------+--------------+---------------+ | Michael Jackson | Thriller | 1982-11-30 | High Priority | | Eagles | Hotel California | 1976-12-08 | High Priority | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | Fun | | Shania Twain | Come On Over | 1997-11-04 | Fun | | AC/DC | Back in Black | 1980-07-25 | Boring | | Whitney Houston | The Bodyguard | 1992-11-25 | Boring | | Fleetwood Mac | Rumours | 1977-02-04 | High Priority | | Meat Loaf | Bat Out of Hell | 1977-10-11 | Boring | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | Mellow | | Bee Gees | Saturday Night Fever | 1977-11-15 | High Priority | +-----------------+-------------------------------+--------------+---------------+ 10 rows in set (0.00 sec) بناءً على هذا الخرج، يبدو أنّ قريبك مستعد لتجربة موسيقا جديدة، وقد سرّك على وجه الخصوص تقييمه الجيد لفرقة Pink Floyd. لكنكَ شعرتَ بخيبة أمل لعدم إظهاره الاهتمام الكافي بأغاني AC/DC وMeat Loaf وWhitney Houston الرائعة. ولربما سيكون قريبك أكثر تقبّلاً للتغيير إذا أظهرتَ له أنّ بعض الألبومات تحظى بشعبية أكبر من غيرها على نحوٍ موضوعيّ، لذا تقرّر أن تعرض بعض الأرقام لدعم وجهة نظرك. فهذه الألبومات في الواقع هي الأكثر مبيعًا، إذ حققت مبيعات تُقدّر بملايين النسخ على مرّ العقود. لذا، في استعلامنا القادم، سنُنشئ تعبير CASE جديد يُحدّد تقييمًا استنادًا إلى البيانات الرقمية من عمود عدد النسخ المُباعة copies_sold للألبومات التي تم بيعها حتى الآن. سنستخدم تعبير CASE لتحديد الشروط بحيث نُعيّن الألبومات التي حققت ما لا يقل عن 35 مليون نسخة على أنّها "الأفضل best"، وتلك التي بيع منها 25 مليون نسخة على أنّها "ممتازة great"، وتلك التي بيع منها 20 مليون على أنّها "جيدة good"، وأي شيء أقل من ذلك على أنًه "متوسط mediocre"، كما في المثال التالي: mysql> SELECT artist_name, album_name, release_date, CASE WHEN copies_sold >35.0 THEN 'best' mysql> WHEN copies_sold >25.0 THEN 'great' mysql> WHEN copies_sold >20.0 THEN 'good' mysql> ELSE 'mediocre' END AS score FROM top_albums; الخرج +-----------------+-------------------------------+--------------+-------+ | artist_name | album_name | release_date | score | +-----------------+-------------------------------+--------------+-------+ | Michael Jackson | Thriller | 1982-11-30 | best | | Eagles | Hotel California | 1976-12-08 | great | | Pink Floyd | The Dark Side of the Moon | 1973-03-01 | good | | Shania Twain | Come On Over | 1997-11-04 | great | | AC/DC | Back in Black | 1980-07-25 | great | | Whitney Houston | The Bodyguard | 1992-11-25 | great | | Fleetwood Mac | Rumours | 1977-02-04 | great | | Meat Loaf | Bat Out of Hell | 1977-10-11 | good | | Eagles | Their Greatest Hits 1971-1975 | 1976-02-17 | best | | Bee Gees | Saturday Night Fever | 1977-11-15 | good | +-----------------+-------------------------------+--------------+-------+ 10 rows in set (0.00 sec) وفق الخرج السابق لم يُصنّف أي من الألبومات على أنّه "متوسط mediocre"، نظرًا لأنّ كل منها قد حقق مبيعات تزيد عن 20 مليون نسخة. ومع ذلك وبناءً على هذه التقييمات، تبرز بعض الألبومات مقارنةً بالبقية. وبذلك يمكنك الآن أن تقدّم لقريبك دليلًا قويًا يبرّر تشغيل أغاني الفنانين AC/DC أو Whitney Houston، إذ أنّ ألبوماتهم قد حققت مبيعات تزيد عن 25 مليون نسخة، مما يجعلها من أهم الأعمال الموسيقية الموجودة. وبذلك تشكّل لديك فهم لكيفية استخدام تعبير CASE لتحديد شروط تعود لأغراض متنوعة، بحيث تتعامل مع قيم بيانات محرفية ورقمية. كما غدوت على معرفة بكيفية استخدام التعبير CASE لنفس منطق عبارة if-then لمقارنة تلك القيم وإنشاء الردود المناسبة بناءً على الشروط التي ترغب بها. الخلاصة لعلّ فهم كيفية استخدام تعبير CASE قد يساعد على تصفية بياناتك وفقًا للشروط التي تضعها. فسواء كنت تريد تحديد أولويات مختلفة لقيمٍ معينة أو تقييمها بناءً على معايير تعكس الرأي العام أو أرقام مُحدّدة، فإنّها توفّر مرونة تلبي احتياجاتك. وإذا كنت ترغب في معرفة طرق أخرى يمكنك من خلالها معالجة قيم البيانات في مجموعات النتائج الخاصة بك، اطّلع على مقال حول كيفية معالجة البيانات باستخدام دوال CAST وتعابير الضم في SQL. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use CASE Expressions in SQL لصاحبه Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: كيفية معالجة البيانات باستخدام دوال CAST وتعابير الضم في SQL تنفيذ تعليمات شرطية عبر CASE في SQL التجميع والترتيب في SQL دوال التعامل مع البيانات في SQL -

 لدى إنشاء جدول في قاعدة بيانات SQL للمرة الأولى، يجب تحديد بنيته العامّة، وذلك من خلال سرد جميع الأعمدة التي نريد لهذا الجدول أن يحتويها ونمط البيانات التي ستخزنها كل منها. بعدها وعند إضافة بيانات إلى الجدول، يجب أن تتطابق القيم التي نُدخلها مع أنماط البيانات المُحددّة لكل عمود على حدة. إذ يمكن لقاعدة بيانات SQL ضمان عدم إدخال أي قيم على نحو خاطئ من خلال فرض إدخال قيم تتماشى مع البنية المُعرّفة مُسبقًا للجدول. ورغم ذلك، قد تجعل هذه البنية الصارمة الأمور أصعب لدى مقارنة قيمتين بأنماط بيانات مختلفة أو لدى محاولة تجميع قيم من أعمدة متعددة لتظهر كقيمة ناتجة واحدة. نشرح في هذا المقال كيفية معالجة البيانات باستخدام دوال CAST التي تفيد في تحويل نمط بيانات قيمة معينة -أو مجموعة قيم- إلى نمط بيانات آخر، واستخدام تعبير ضم concatenation expression لربط قيم بيانات محرفية ورقمية معًا كسلسلة. كما سنتدرب على تنفيذ دالة CAST وتعبير الضم في نفس الاستعلام للحصول على تعليمة كاملة. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح في المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام دوال CAST وتعابير الضم في هذا المقال. لذا ننصحك بمتابعة الفقرة التالية الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إنشاء قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم castconDB: mysql> CREATE DATABASE castconDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرج كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات castconDB، نفّذ تعليمة USE التالية: mysql> USE castconDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات castconDB، لننشئ جدولًا ضمنها باستخدام الأمر CREATE TABLE. كمثال في مقالنا هذا، سننشئ جدولًا يُسجّل الدرجات خلال فترة فصل الخريف الدراسي لصف الأستاذ فريد لطلاب الصف السادس. سيضم الجدول الأعمدة الخمسة عشر التالية: student_id: يُمثّل قيمًا من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. first_name: مُخصص لأسماء الطلاب الأولى وذلك باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. last_name: مُخصص لتخزين أسماء الطلاب الأخيرة وذلك باستخدام نمط البيانات varchar بحد أقصى أيضًا 20 محرفًا. email_address: لتخزين البريد الإلكتروني لكل طالب باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. participation_grade: يعرض درجة النشاط الصفّي الإجمالية لكل طالب باستخدام نمط البيانات int. attendance_grade: يستخدم نمط بيانات int لعرض درجات حضور كل طالب. midterm_deadline: يستخدم نمط بيانات TIMESTAMP من أجل عرض الموعد النهائي الذي يجب على كل طالب تقديم الامتحان النصفي بحلوله. يجمع هذا النمط بين التاريخ والوقت في سلسلة واحدة ويستخدم الصيغة التالية: (YYYY-MM-DD HH:MM:SS). midterm_submitted: يسجّل اليوم والوقت الدقيق اللذين قدّم فيهما الطلاب الامتحان النصفي باستخدام نمط البيانات TIMESTAMP. midterm_grade: يستخدم نمط بيانات decimal لتخزين درجة كل طالب في الامتحان النصفي. إذ سنحدد لدى تعرف هذا العمود الدقة (Precision) لتساوي أربعة أرقام، بواقع رقم واحد إلى يمين الفاصلة العشرية (Scale). ما يعني أن القيم في هذا العمود يمكن أن تتضمن أربعة أرقام، واحد منها على يمين الفاصلة العشرية. essay_deadline: يعرض الوقت والتاريخ اللذين يجب على الطلاب تقديم مقالاتهم بحلولهما، باستخدام نمط البيانات TIMESTAMP. essay_submitted: يستخدم نمط بيانات TIMESTAMP لتتبع وقت وتاريخ تقديم الطلاب لواجب كتابة المقال. essay_grade: يحتوي على درجات المقال لكل طالب باستخدام نمط البيانات decimal، بدقة أربعة أرقام واحد منها إلى يمين الفاصلة العشرية. finalexam_deadline: يخزن معلومات موعد الامتحان النهائي باستخدام نمط البيانات TIMESTAMP. finalexam_submitted: يستخدم نمط بيانات TIMESTAMP لتسجيل الوقت والتاريخ الفعليين لتقديم الطلاب لامتحانهم النهائي. finalexam_grade: يحتوي على درجة الامتحان النهائي لكل طالب باستخدام نمط البيانات decimal بدقة أربعة أرقام، واحد منها إلى يمين الفاصلة العشرية. لننشئ الآن جدولاً باسم fall_grades يتضمّن هذه الأعمدة من خلال تنفيذ أمر CREATE TABLE التالي: mysql> CREATE TABLE fall_grades ( mysql> student_id int, mysql> first_name varchar(20), mysql> last_name varchar(20), mysql> email_address varchar(30), mysql> participation_grade int, mysql> attendance_grade int, mysql> midterm_deadline TIMESTAMP, mysql> midterm_submitted TIMESTAMP, mysql> midterm_grade decimal(4,1), mysql> essay_deadline TIMESTAMP, mysql> essay_submitted TIMESTAMP, mysql> essay_grade decimal(4,1), mysql> finalexam_deadline TIMESTAMP, mysql> finalexam_submitted TIMESTAMP, mysql> finalexam_grade decimal(4,1), mysql> PRIMARY KEY (student_id) mysql> ); والآن لنملأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO fall_grades mysql> (student_id, first_name, last_name, email_address, participation_grade, attendance_grade, midterm_deadline, midterm_submitted, midterm_grade, essay_deadline, essay_submitted, essay_grade, finalexam_deadline, finalexam_submitted, finalexam_grade) mysql> VALUES mysql> (1, 'Arnold', 'Shortman', 'ashortman@ps118.com', 98, 90, '2022-10-16 12:00:00', '2022-10-16 06:30:00', 85.8, '2022-11-20 12:00:00', '2022-11-20 03:00:00', 90.1, '2022-12-11 12:00:00', '2022-12-11 03:00:00', 82.5), mysql> (2, 'Helga', 'Pataki', 'hpataki@ps118.com', 85, 100, '2022-10-16 12:00:00', '2022-10-16 10:00:00', 88.4, '2022-11-20 12:00:00', '2022-11-21 03:15:00', 72.5, '2022-12-11 12:00:00', '2022-12-11 05:00:00', 90.0), mysql> (3, 'Gerald', 'Johanssen', 'gjohanssen@ps118.com', 100, 95, '2022-10-16 12:00:00', '2022-10-16 02:00:00', 94.2, '2022-11-20 12:00:00', '2022-11-20 02:45:00', 95.8, '2022-12-11 12:00:00', '2022-12-11 11:00:00', 88.1), mysql> (4, 'Phoebe', 'Heyerdahl', 'pheyerdahl@ps118.com', 100, 100, '2022-10-16 12:00:00', '2022-10-16 11:00:00', 98.8, '2022-11-20 12:00:00', '2022-11-20 11:15:00', 90.4, '2022-12-11 12:00:00', '2022-12-11 11:40:00', 100.0), mysql> (5, 'Harold', 'Berman', 'hberman@ps118.com', 100, 75, '2022-10-16 12:00:00', '2022-10-16 08:00:00', 75.7, '2022-11-20 12:00:00', '2022-11-22 09:15:00', 67.5, '2022-12-11 12:00:00', '2022-12-11 09:15:00', 90.9), mysql> (6, 'Eugene', 'Horowitz', 'ehorowitz@ps118.com', 100, 100, '2022-10-16 12:00:00', '2022-10-16 01:00:00', 100.0, '2022-11-20 12:00:00', '2022-11-20 01:22:00', 89.9, '2022-12-11 12:00:00', '2022-12-11 07:55:00', 98.2), mysql> (7, 'Rhonda', 'Lloyd', 'rlloyd@ps118.com', 100, 80, '2022-10-16 12:00:00', '2022-10-16 06:00:00', 90.4, '2022-11-20 12:00:00', '2022-11-20 06:09:00',81.3, '2022-12-11 12:00:00', '2022-12-11 06:45:00', 95.5), mysql> (8, 'Stinky', 'Peterson', 'speterson@ps118.com', 100, 85, '2022-10-16 12:00:00', '2022-10-16 03:00:00', 70.6, '2022-11-20 12:00:00', '2022-11-20 05:55:00', 93.1, '2022-12-11 12:00:00', '2022-12-11 10:11:00', 73.2); الخرج Query OK, 8 rows affected (0.01 sec) Records: 8 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء تعلّم كيفية استخدام الدوال CAST وتعابير الضم في SQL. استخدام دوال CAST تتيح لك الدالة CAST إمكانية تحويل قيمة حرفية أو القيم المُخزنة ضمن عمودٍ ما إلى نمط بياناتٍ محدد. ويُعدّ استخدامها مفيدًا لضمان توافق أنماط بيانات القيم ضمن تعبيرٍ مُعيّن. ولاستخدام الأمر CAST، لابدّ من تحديد العمود أو الأعمدة المُتضمّنة لقيم البيانات الحالية المرغوب بتحويلها، ومن ثم كتابة قيم البيانات المُفضلة و/أو طولها ضمن التعبير. وفيما يلي مثال على الصيغة العامّة: CAST function syntax . . .CAST(قيم البيانات الحالية AS قيم البيانات المرغوبة) . . . وتجدر الملاحظة إلى أنّ دوال CAST تخضع لقواعد معيّنة كي تعمل على نحو صحيح. فعلى سبيل المثال، من المهم التأكد من كون نمط البيانات الذي نرغب في تحويله متوافق مع النمط الذي سنحوّل إليه. فبالعودة إلى البيانات في مثالنا، لن نتمكن باستخدام دالة CAST من تحويل القيم في عمود درجة الامتحان النهائي finalexam_grade من قيم بيانات رقمية (وهو نمط البيانات decimal في حالتنا) مباشرةً إلى قيم سلاسل محرفية، كأن نعبّر عن الدرجات بأحرف. وبالمثل، لا يمكننا تحويل أنماط بيانات مُحدّدة بطول أقصى مثل الأعمدة التي تحمل قيم varchar(30) في مثالنا إلى مقدار أطول مثل varchar(35). كما تجدر الملاحظة إلى أنّ تقديمات SQL المختلفة ستتصرف على نحوٍ مختلف لدى تنفيذ استعلامات باستخدام دوال CAST لتحويل أنماط البيانات. فقد ينتج مثلًا عن تنفيذ استعلام باستخدام دالة CAST في MySQL نتائج مختلفة عن تشغيل نفس الاستعلام في PostgreSQL. الآن ولتحقيق فهم أعمق حول كيفية استخدام دوال CAST، لنتخيل السيناريو التالي بناءً على البيانات في المثال السابق والتي أدخلناها في الخطوة السابقة. إذ يستعد الأستاذ فريد، معلم الصف السادس في مدرسة PS 118، لتقديم درجاته للفصل الدراسي الخريفي. إذ كان يتابع عن كثب تقدم كل طالب، وهو مهتم على وجه الخصوص بدرجاتهم في كل من الامتحان النصفي وواجب كتابة المقال والامتحان النهائي. وبفرض أنّك تعمل مع الأستاذ فريد كمدرّس مساعد، وقد طلب منك تزويده بالمعلومات المُتعلّقة بالمهام الدراسية آنفة الذكر. ستستخرج في هذه الحالة البيانات المطلوبة من خلال إنشاء استعلام عن جدول fall_grades لاسترجاع المعلومات اللازمة، مثل أسماء الطلاب الأولى first_name وأسماءهم الأخيرة last_name، بالإضافة إلى درجاتهم لكل مهمة دراسية، على النحو التالي: mysql> SELECT first_name, last_name, midterm_grade, essay_grade, finalexam_grade FROM fall_grades; الخرج +------------+-----------+---------------+-------------+-----------------+ | first_name | last_name | midterm_grade | essay_grade | finalexam_grade | +------------+-----------+---------------+-------------+-----------------+ | Arnold | Shortman | 85.8 | 90.1 | 82.5 | | Helga | Pataki | 88.4 | 72.5 | 90.0 | | Gerald | Johanssen | 94.2 | 95.8 | 88.1 | | Phoebe | Heyerdahl | 98.8 | 90.4 | 100.0 | | Harold | Berman | 75.7 | 67.5 | 90.9 | | Eugene | Horowitz | 100.0 | 89.9 | 98.2 | | Rhonda | Lloyd | 90.4 | 81.3 | 95.5 | | Stinky | Peterson | 70.6 | 93.1 | 73.2 | +------------+-----------+---------------+-------------+-----------------+ 8 rows in set (0.00 sec) وبعد تقديم هذه النتائج إلى الأستاذ، بيّن لك أنّ النظام الذي يستخدمه يسمح له بإدخال الدرجات كأعداد صحيحة حصرًا، وبالتالي لابدّ من تحويل هذه القيم العشرية إلى أعدادٍ صحيحة. فتقرر استخدام دالة CAST لتحويل عدد القيم المحرفية المحدد (وهو في هذه الحالة أربعة محارف من نمط البيانات decimal) إلى قيمتين محرفيتين. وسنستخدم لهذا الاستعلام نفس صيغة الاستعلام من المثال أعلاه ولكن مع تضمين دالة CAST لتحويل نمط البيانات decimal إلى قيمتين محرفيتين فقط لكل من المهام الدراسية. إذ ستُطبّق الدالة CAST على ثلاث تعابير مختلفة (لكل من midterm_grade و essay_grade و final_exam_grade) وذلك لتحويلها إلى قيم بيانات مكونة من قيمتين محرفيتين فقط: mysql> SELECT first_name, last_name, mysql> CAST(midterm_grade AS char(2)) AS midterm, mysql> CAST(essay_grade AS char(2)) AS essay, mysql> CAST(finalexam_grade AS char(2)) AS finalexam mysql> FROM fall_grades; الخرج +------------+-----------+---------+-------+-----------+ | first_name | last_name | midterm | essay | finalexam | +------------+-----------+---------+-------+-----------+ | Arnold | Shortman | 85 | 90 | 82 | | Helga | Pataki | 88 | 72 | 90 | | Gerald | Johanssen | 94 | 95 | 88 | | Phoebe | Heyerdahl | 98 | 90 | 10 | | Harold | Berman | 75 | 67 | 90 | | Eugene | Horowitz | 10 | 89 | 98 | | Rhonda | Lloyd | 90 | 81 | 95 | | Stinky | Peterson | 70 | 93 | 73 | +------------+-----------+---------+-------+-----------+ 8 rows in set, 24 warnings (0.00 sec) الآن وبعد مراجعة درجات كل طالب، يسأل السيد فريد إذا كان بإمكانك جلب معلومات حول التواريخ والأوقات الدقيقة التي قدم فيها كل طالب مهامه الدراسية، ولجلب هذه البيانات، سننفّذ تعليمة SELECT التالية: mysql> SELECT first_name, last_name, midterm_deadline, essay_deadline, finalexam_deadline FROM fall_grades; الخرج +------------+-----------+---------------------+---------------------+---------------------+ | first_name | last_name | midterm_deadline | essay_deadline | finalexam_deadline | +------------+-----------+---------------------+---------------------+---------------------+ | Arnold | Shortman | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Helga | Pataki | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Gerald | Johanssen | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Phoebe | Heyerdahl | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Harold | Berman | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Eugene | Horowitz | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Rhonda | Lloyd | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Stinky | Peterson | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | +------------+-----------+---------------------+---------------------+---------------------+ 8 rows in set (0.00 sec) يتنهد الأستاذ فريد بعد مراجعة هذا الخرج مُخبرًا إياك بأنّ هذه المعلومات صعبة التحليل للغاية. إذ تم تعيين كل هذه الأعمدة لتخزين قيم من نمط البيانات TIMESTAMP، وهو سبب طولها البالغ. فتقرر استخدام دالة CAST لتحويل الخرج إلى شكل أسهل للقراءة والفهم، وأيضًا لتقسيم الاستعلام إلى قسمين واحد للتواريخ وآخر للأوقات. للاستعلام فقط عن أوقات تقديم الطلاب لواجباتهم، لننفّذ دالة CAST محولين قيم البيانات من تلك الأعمدة المحددة إلى قيم وقت من النمط time: mysql> SELECT first_name, last_name, mysql> CAST(midterm_submitted AS time) AS midterm, mysql> CAST(essay_submitted AS time) AS essay, mysql> CAST(finalexam_submitted AS time) AS finalexam mysql> FROM fall_grades; الخرج +------------+-----------+----------+----------+-----------+ | first_name | last_name | midterm | essay | finalexam | +------------+-----------+----------+----------+-----------+ | Arnold | Shortman | 06:30:00 | 03:00:00 | 03:00:00 | | Helga | Pataki | 10:00:00 | 03:15:00 | 05:00:00 | | Gerald | Johanssen | 02:00:00 | 02:45:00 | 11:00:00 | | Phoebe | Heyerdahl | 11:00:00 | 11:15:00 | 11:40:00 | | Harold | Berman | 08:00:00 | 09:15:00 | 09:15:00 | | Eugene | Horowitz | 01:00:00 | 01:22:00 | 07:55:00 | | Rhonda | Lloyd | 06:00:00 | 06:09:00 | 06:45:00 | | Stinky | Peterson | 03:00:00 | 05:55:00 | 10:11:00 | +------------+-----------+----------+----------+-----------+ 8 rows in set (0.00 sec) يُقدّم هذا الخرج لمحة عامة حول الإطار الزمني الذي أنهى فيه كل طالب واجباته. ومع ملاحظة أنّ موعد تسليم كل من الواجبات يحين عند منتصف ليل يوم الأحد، نجد أنّ العديد من الطلاب كانوا متسقين مع توقيتهم، في حين أنهى آخرون واجباتهم مبكرًا، أو قبل الموعد المحدد عند منتصف الليل بقليل. ولكن تُمثّل هذه المعلومات نصف ما طلبه الأستاذ فريد فقط، لذا دعونا نعمل على الاستعلام التالي الذي سيستخدم دالة CAST لتحويل تلك القيم ذاتها من نمط البيانات TIMESTAMP إلى قيم تواريخ. سننفّذ نفس الاستعلام كما في المرة السابقة، ولكن مستبدلين نمط بيانات التاريخ time بنمط بيانات الوقت time هذه المرة: mysql> SELECT first_name, last_name, mysql> CAST(midterm_submitted AS date) AS midterm, mysql> CAST(essay_submitted AS date) AS essay, mysql> CAST(finalexam_submitted AS date) AS finalexam mysql> FROM fall_grades; الخرج +------------+-----------+------------+------------+------------+ | first_name | last_name | midterm | essay | finalexam | +------------+-----------+------------+------------+------------+ | Arnold | Shortman | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Helga | Pataki | 2022-10-16 | 2022-11-21 | 2022-12-11 | | Gerald | Johanssen | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Phoebe | Heyerdahl | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Harold | Berman | 2022-10-16 | 2022-11-22 | 2022-12-11 | | Eugene | Horowitz | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Rhonda | Lloyd | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Stinky | Peterson | 2022-10-16 | 2022-11-20 | 2022-12-11 | +------------+-----------+------------+------------+------------+ 8 rows in set (0.00 sec) يُمكننا استنادًا إلى هذا الخرج تحديد الطلاب الذين قدموا واجباتهم بعد الموعد النهائي، ما يوضّح سبب تأثر درجاتهم الناتج عن خصم نقاط بسبب التأخر. فعلى سبيل المثال، قدّمت الطالبة هيلجا واجبها بعد يوم واحد من الموعد (2022-11-21)، وقدّم الطالب هارولد واجبه بعد يومين (2022-11-22) من الموعد النهائي للمقال والمُحدد في (2022-11-20). على الرغم من رضا الأستاذ فريد عن هذه النتائج المُنقحة، إلا أنه يحتاج إلى مزيد من المساعدة في صياغة البيانات على نحوٍ أوضح لتقديم تقرير درجاته. ستتدرب في القسم التالي من المقال على كيفية استخدام تعابير الضم القادرة على دمج قيم حرفية متعددة أو القيم من أعمدة مختلفة ضمن قيمة سلسلة نصية واحدة، مما يساعد في جعل المعلومات أوضح للتفسير كعبارة أو جملة كاملة. استخدام تعابير الضم يُمكنك مع استخدام تعبير الضم CONCAT معالجة البيانات بجمع قيم محرفية أو رقمية من أعمدة مختلفة معًا لتظهر كنتيجة واحدة. إذ تعيد قواعد بيانات SQL بوجهٍ عام قيم البيانات ضمن مجموعات نتائج منفصلة في أعمدتها المختلفة. فعلى سبيل المثال، لو استعلمنا عن الاسم الأول first_name والأخير last_name لطلاب PS 118، سيظهر الخرج كما يلي: mysql> SELECT first_name, last_name FROM fall_grades; الخرج +------------+-----------+ | first_name | last_name | +------------+-----------+ | Arnold | Shortman | | Helga | Pataki | | Gerald | Johanssen | | Phoebe | Heyerdahl | | Harold | Berman | | Eugene | Horowitz | | Rhonda | Lloyd | | Stinky | Peterson | +------------+-----------+ 8 rows in set (0.00 sec) لكن هذه المعلومات غير مُقدّمة بالشكل الذي يفضله الأستاذ فريد لتقريره. لذا، لننفّذ استعلامًا آخر باستخدام الضم لدمج الأسماء الأولى والأخيرة للطلاب ضمن سلسلة نصية واحدة. يؤدي الاستعلام التالي هذه المهمة باستخدام الكلمة المفتاحية CONCAT موفرًا للعمود الناتج الاسم بديل full_names، على النحو التالي: mysql> SELECT CONCAT(first_name, last_name) AS full_names FROM fall_grades; الخرج +-----------------+ | full_names | +-----------------+ | ArnoldShortman | | HelgaPataki | | GeraldJohanssen | | PhoebeHeyerdahl | | HaroldBerman | | EugeneHorowitz | | RhondaLloyd | | StinkyPeterson | +-----------------+ 8 rows in set (0.00 sec) تعمل تعابير الضم مع كافة أنماط البيانات إجمالًا، ولكن في حال عدم تحديد تفاصيل من قبيل التباعد بين قيم البيانات، سيظهر الخرج على هيئة سلسلة نصية متصلة دون فواصل كما يتضح من الخرج أعلاه. ولتصحيح ذلك، يمكن إضافة زوج من علامات الاقتباس الفردية مع فراغ بينهما (' ') بين عمودي first_name وlast_name بحيث تظهر القيم على هيئة سلسلة واحدة، ولكن هذه المرة مع فراغ بينهما لجعلها أسهل للقراءة: mysql> SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM fall_grades; الخرج +------------------+ | full_name | +------------------+ | Arnold Shortman | | Helga Pataki | | Gerald Johanssen | | Phoebe Heyerdahl | | Harold Berman | | Eugene Horowitz | | Rhonda Lloyd | | Stinky Peterson | +------------------+ 8 rows in set (0.00 sec) بإدراج فراغ بين علامات الاقتباس الفردية في الاستعلام، يُظهر الخرج الآن أسماء الطلاب بوضوح ككلمتين منفصلتين، بدلًا من كلمة مركبة واحدة. ملاحظة: معظم أنظمة إدارة قواعد البيانات العلاقية الحديثة تستخدم الصياغة الموضحة في هذا القسم لضم القيم. إلّا لأنّ هذه الصياغة (استخدام كلمة CONCAT المفتاحية) ليست الصياغة التقليدية المحددة بمعيار SQL. الطريقة التقليدية لضم القيم في SQL تتمثّل في وضع زوج من الخطوط العمودية بين قيم البيانات التي نريد ضمها. تجدر الملاحظة بأنّ MySQL لا تسمح باستخدام هذه الصياغة على الإطلاق، في حين تسمح بعض أنظمة إدارة قواعد البيانات مثل PostgreSQL باستخدام إحدى الطريقتين. الاستعلام التالي (المُنفذ على قاعدة بيانات PostgreSQL) يُعطي نفس الخرج كالاستعلام السابق، ولكن هذه المرة باستخدام الخطوط العمودية: SELECT first_name || ' ' || last_name AS full_name FROM fall_grades; الخرج full_name ------------------ Arnold Shortman Helga Pataki Gerald Johanssen Phoebe Heyerdahl Harold Berman Eugene Horowitz Rhonda Lloyd Stinky Peterson (8 rows) الآن، لنجرب مثالاً آخر حيث سنسترجع مزيدًا من المعلومات حول كل طالب. إذ نريد في هذه المرة ضم قيم البيانات من أعمدة الاسم الأول first_name والاسم الأخير last_name وعنوان البريد الإلكتروني email_address ودرجة الامتحان النهائي finalexam_grade ووقت وتاريخ تقديم الامتحان النهائي finalexam_submitted ضمن عمود واحد باستخدام CONCAT. ومن المهم هنا عدم نسيان إضافة علامات اقتباس فردية بين كل عمود وآخر نرغب بإضافة فراغ بينهما كما في المثال التالي: mysql> SELECT CONCAT(first_name, ' ', last_name, ' ', mysql> email_address, ' ', finalexam_grade, ' ', finalexam_submitted) mysql> AS student_info FROM fall_grades; الخرج +-----------------------------------------------------------------+ | student_info | +-----------------------------------------------------------------+ | Arnold Shortman ashortman@ps118.com 82.5 2022-12-11 03:00:00 | | Helga Pataki hpataki@ps118.com 90.0 2022-12-11 05:00:00 | | Gerald Johanssen gjohanssen@ps118.com 88.1 2022-12-11 11:00:00 | | Phoebe Heyerdahl pheyerdahl@ps118.com 100.0 2022-12-11 11:40:00 | | Harold Berman hberman@ps118.com 90.9 2022-12-11 09:15:00 | | Eugene Horowitz ehorowitz@ps118.com 98.2 2022-12-11 07:55:00 | | Rhonda Lloyd rlloyd@ps118.com 95.5 2022-12-11 06:45:00 | | Stinky Peterson speterson@ps118.com 73.2 2022-12-11 10:11:00 | +-----------------------------------------------------------------+ 8 rows in set (0.00 sec) الأستاذ فريد راضٍ عن هذه النتائج ولكنه يودّ جعلها أكثر إيجازًا ضمن تقرير درجاته وذلك من خلال تحويل بعض قيم البيانات. سنستخدم في هذا السيناريو دالة CAST لتحويل نمط بيانات عمود finalexam_grade إلى رقم صحيح، ونمط بيانات عمود finalexam_submitted من TIMESTAMP إلى نمط بيانات التاريخ date كما في المثال التالي: mysql> SELECT CONCAT(first_name, ' ', last_name, ' ', email_address, ' ', mysql> CAST(finalexam_grade AS char(2)), ' ', mysql> CAST(finalexam_submitted AS date)) mysql> AS student_info FROM fall_grades; الخرج +-----------------------------------------------------+ | student_info | +-----------------------------------------------------+ | Arnold Shortman ashortman@ps118.com 82 2022-12-11 | | Helga Pataki hpataki@ps118.com 90 2022-12-11 | | Gerald Johanssen gjohanssen@ps118.com 88 2022-12-11 | | Phoebe Heyerdahl pheyerdahl@ps118.com 10 2022-12-11 | | Harold Berman hberman@ps118.com 90 2022-12-11 | | Eugene Horowitz ehorowitz@ps118.com 98 2022-12-11 | | Rhonda Lloyd rlloyd@ps118.com 95 2022-12-11 | | Stinky Peterson speterson@ps118.com 73 2022-12-11 | +-----------------------------------------------------+ 8 rows in set, 8 warnings (0.00 sec) لنحسّن الخرج أكثر، ونكتب استعلامًا يستخدم دالة CAST وتعبير الضم للحصول على جملة كاملة في الخرج. يمكننا القيام بذلك بكتابة عبارة قصيرة بين علامات الاقتباس الفردية. ولا بدّ من الحفاظ على مسافة بين كل عمود وآخر عن طريق إضافة مسافة واحدة قبل وبعد نهاية العبارة أو العبارات المكتوبة: mysql> SELECT CONCAT(first_name, ' ', last_name, ' can be contacted at ', email_address, mysql> ' and received a grade of ', mysql> CAST(finalexam_grade AS char(2)), mysql> ' after submitting the final exam on ', mysql> CAST(finalexam_submitted AS date)) mysql> AS student_info FROM fall_grades; الخرج +------------------------------------------------------------------------------------------------------------------------------------+ | student_info | +------------------------------------------------------------------------------------------------------------------------------------+ | Arnold Shortman can be contacted at ashortman@ps118.com and received a grade of 82 after submitting the final exam on 2022-12-11 | | Helga Pataki can be contacted at hpataki@ps118.com and received a grade of 90 after submitting the final exam on 2022-12-11 | | Gerald Johanssen can be contacted at gjohanssen@ps118.com and received a grade of 88 after submitting the final exam on 2022-12-11 | | Phoebe Heyerdahl can be contacted at pheyerdahl@ps118.com and received a grade of 10 after submitting the final exam on 2022-12-11 | | Harold Berman can be contacted at hberman@ps118.com and received a grade of 90 after submitting the final exam on 2022-12-11 | | Eugene Horowitz can be contacted at ehorowitz@ps118.com and received a grade of 98 after submitting the final exam on 2022-12-11 | | Rhonda Lloyd can be contacted at rlloyd@ps118.com and received a grade of 95 after submitting the final exam on 2022-12-11 | | Stinky Peterson can be contacted at speterson@ps118.com and received a grade of 73 after submitting the final exam on 2022-12-11 | +------------------------------------------------------------------------------------------------------------------------------------+ 8 rows in set, 8 warnings (0.00 sec) يُنتج هذا الخرج جملًا كاملة عن كل طالب في فصل الأستاذ فريد. إذ أحدثت هذه الإضافات الطفيفة بين علامات الاقتباس الفردية فارقًا كبيرًا في جعل المعلومات واضحة من حيث هوية صاحب كل معلومة والبيانات المتعلقة به. وذلك بفضل الأعمدة المحددة التي استخرجنا منها البيانات في استعلامنا. الأستاذ فريد ممتن جدًا لعملك الرائع، وهو راضٍ تمامًا لأنك وفرت عليه الوقت أيضًا بتحويلك البيانات إلى جمل مفهومة يمكنه إضافتها بسهولة إلى تقريره. الخلاصة قدّمنا في هذا المقال شرحًا حول استخدامات متنوعة لمعالجة البيانات باستخدام دالة CAST وتعابير الضم. إذ تدربت على كيفية تحويل قيم عمود من نمط بيانات إلى آخر بفضل الدالة CAST. كما تعلمت كيفية استخدام تعابير الضم لجمع قيم بيانات مختلفة سواء كانت محرفية أو رقمية في سلسلة نصية واحدة. كما نفذت استعلامًا يتضمّن كل من دالة CAST وتعبير الضم معًا، مما أتاح لك إنشاء خرج بجمل كاملة توفر تفسيرًا أشمل للبيانات، الأمر الذي يجعل من الأسهل كتابة الجمل على نحوٍ مستقل عن بعضها، إذ يمكنك تنظيم المعلومات بكفاءة ونسخها ولصقها بالصيغة التي هي عليها مباشرةً. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Manipulate Data with CAST Functions and Concatenation Expressions in SQL لصاحبه Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: كيفية التعامل مع التواريخ والأوقات في SQL مدخل إلى SQL دوال التعامل مع البيانات في SQL دوال التعامل مع النصوص في SQL التعابير الجدولية الشائعة Common Table Expressions في SQL
لدى إنشاء جدول في قاعدة بيانات SQL للمرة الأولى، يجب تحديد بنيته العامّة، وذلك من خلال سرد جميع الأعمدة التي نريد لهذا الجدول أن يحتويها ونمط البيانات التي ستخزنها كل منها. بعدها وعند إضافة بيانات إلى الجدول، يجب أن تتطابق القيم التي نُدخلها مع أنماط البيانات المُحددّة لكل عمود على حدة. إذ يمكن لقاعدة بيانات SQL ضمان عدم إدخال أي قيم على نحو خاطئ من خلال فرض إدخال قيم تتماشى مع البنية المُعرّفة مُسبقًا للجدول. ورغم ذلك، قد تجعل هذه البنية الصارمة الأمور أصعب لدى مقارنة قيمتين بأنماط بيانات مختلفة أو لدى محاولة تجميع قيم من أعمدة متعددة لتظهر كقيمة ناتجة واحدة. نشرح في هذا المقال كيفية معالجة البيانات باستخدام دوال CAST التي تفيد في تحويل نمط بيانات قيمة معينة -أو مجموعة قيم- إلى نمط بيانات آخر، واستخدام تعبير ضم concatenation expression لربط قيم بيانات محرفية ورقمية معًا كسلسلة. كما سنتدرب على تنفيذ دالة CAST وتعبير الضم في نفس الاستعلام للحصول على تعليمة كاملة. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح في المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام دوال CAST وتعابير الضم في هذا المقال. لذا ننصحك بمتابعة الفقرة التالية الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إنشاء قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم castconDB: mysql> CREATE DATABASE castconDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرج كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات castconDB، نفّذ تعليمة USE التالية: mysql> USE castconDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات castconDB، لننشئ جدولًا ضمنها باستخدام الأمر CREATE TABLE. كمثال في مقالنا هذا، سننشئ جدولًا يُسجّل الدرجات خلال فترة فصل الخريف الدراسي لصف الأستاذ فريد لطلاب الصف السادس. سيضم الجدول الأعمدة الخمسة عشر التالية: student_id: يُمثّل قيمًا من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. first_name: مُخصص لأسماء الطلاب الأولى وذلك باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. last_name: مُخصص لتخزين أسماء الطلاب الأخيرة وذلك باستخدام نمط البيانات varchar بحد أقصى أيضًا 20 محرفًا. email_address: لتخزين البريد الإلكتروني لكل طالب باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. participation_grade: يعرض درجة النشاط الصفّي الإجمالية لكل طالب باستخدام نمط البيانات int. attendance_grade: يستخدم نمط بيانات int لعرض درجات حضور كل طالب. midterm_deadline: يستخدم نمط بيانات TIMESTAMP من أجل عرض الموعد النهائي الذي يجب على كل طالب تقديم الامتحان النصفي بحلوله. يجمع هذا النمط بين التاريخ والوقت في سلسلة واحدة ويستخدم الصيغة التالية: (YYYY-MM-DD HH:MM:SS). midterm_submitted: يسجّل اليوم والوقت الدقيق اللذين قدّم فيهما الطلاب الامتحان النصفي باستخدام نمط البيانات TIMESTAMP. midterm_grade: يستخدم نمط بيانات decimal لتخزين درجة كل طالب في الامتحان النصفي. إذ سنحدد لدى تعرف هذا العمود الدقة (Precision) لتساوي أربعة أرقام، بواقع رقم واحد إلى يمين الفاصلة العشرية (Scale). ما يعني أن القيم في هذا العمود يمكن أن تتضمن أربعة أرقام، واحد منها على يمين الفاصلة العشرية. essay_deadline: يعرض الوقت والتاريخ اللذين يجب على الطلاب تقديم مقالاتهم بحلولهما، باستخدام نمط البيانات TIMESTAMP. essay_submitted: يستخدم نمط بيانات TIMESTAMP لتتبع وقت وتاريخ تقديم الطلاب لواجب كتابة المقال. essay_grade: يحتوي على درجات المقال لكل طالب باستخدام نمط البيانات decimal، بدقة أربعة أرقام واحد منها إلى يمين الفاصلة العشرية. finalexam_deadline: يخزن معلومات موعد الامتحان النهائي باستخدام نمط البيانات TIMESTAMP. finalexam_submitted: يستخدم نمط بيانات TIMESTAMP لتسجيل الوقت والتاريخ الفعليين لتقديم الطلاب لامتحانهم النهائي. finalexam_grade: يحتوي على درجة الامتحان النهائي لكل طالب باستخدام نمط البيانات decimal بدقة أربعة أرقام، واحد منها إلى يمين الفاصلة العشرية. لننشئ الآن جدولاً باسم fall_grades يتضمّن هذه الأعمدة من خلال تنفيذ أمر CREATE TABLE التالي: mysql> CREATE TABLE fall_grades ( mysql> student_id int, mysql> first_name varchar(20), mysql> last_name varchar(20), mysql> email_address varchar(30), mysql> participation_grade int, mysql> attendance_grade int, mysql> midterm_deadline TIMESTAMP, mysql> midterm_submitted TIMESTAMP, mysql> midterm_grade decimal(4,1), mysql> essay_deadline TIMESTAMP, mysql> essay_submitted TIMESTAMP, mysql> essay_grade decimal(4,1), mysql> finalexam_deadline TIMESTAMP, mysql> finalexam_submitted TIMESTAMP, mysql> finalexam_grade decimal(4,1), mysql> PRIMARY KEY (student_id) mysql> ); والآن لنملأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO fall_grades mysql> (student_id, first_name, last_name, email_address, participation_grade, attendance_grade, midterm_deadline, midterm_submitted, midterm_grade, essay_deadline, essay_submitted, essay_grade, finalexam_deadline, finalexam_submitted, finalexam_grade) mysql> VALUES mysql> (1, 'Arnold', 'Shortman', 'ashortman@ps118.com', 98, 90, '2022-10-16 12:00:00', '2022-10-16 06:30:00', 85.8, '2022-11-20 12:00:00', '2022-11-20 03:00:00', 90.1, '2022-12-11 12:00:00', '2022-12-11 03:00:00', 82.5), mysql> (2, 'Helga', 'Pataki', 'hpataki@ps118.com', 85, 100, '2022-10-16 12:00:00', '2022-10-16 10:00:00', 88.4, '2022-11-20 12:00:00', '2022-11-21 03:15:00', 72.5, '2022-12-11 12:00:00', '2022-12-11 05:00:00', 90.0), mysql> (3, 'Gerald', 'Johanssen', 'gjohanssen@ps118.com', 100, 95, '2022-10-16 12:00:00', '2022-10-16 02:00:00', 94.2, '2022-11-20 12:00:00', '2022-11-20 02:45:00', 95.8, '2022-12-11 12:00:00', '2022-12-11 11:00:00', 88.1), mysql> (4, 'Phoebe', 'Heyerdahl', 'pheyerdahl@ps118.com', 100, 100, '2022-10-16 12:00:00', '2022-10-16 11:00:00', 98.8, '2022-11-20 12:00:00', '2022-11-20 11:15:00', 90.4, '2022-12-11 12:00:00', '2022-12-11 11:40:00', 100.0), mysql> (5, 'Harold', 'Berman', 'hberman@ps118.com', 100, 75, '2022-10-16 12:00:00', '2022-10-16 08:00:00', 75.7, '2022-11-20 12:00:00', '2022-11-22 09:15:00', 67.5, '2022-12-11 12:00:00', '2022-12-11 09:15:00', 90.9), mysql> (6, 'Eugene', 'Horowitz', 'ehorowitz@ps118.com', 100, 100, '2022-10-16 12:00:00', '2022-10-16 01:00:00', 100.0, '2022-11-20 12:00:00', '2022-11-20 01:22:00', 89.9, '2022-12-11 12:00:00', '2022-12-11 07:55:00', 98.2), mysql> (7, 'Rhonda', 'Lloyd', 'rlloyd@ps118.com', 100, 80, '2022-10-16 12:00:00', '2022-10-16 06:00:00', 90.4, '2022-11-20 12:00:00', '2022-11-20 06:09:00',81.3, '2022-12-11 12:00:00', '2022-12-11 06:45:00', 95.5), mysql> (8, 'Stinky', 'Peterson', 'speterson@ps118.com', 100, 85, '2022-10-16 12:00:00', '2022-10-16 03:00:00', 70.6, '2022-11-20 12:00:00', '2022-11-20 05:55:00', 93.1, '2022-12-11 12:00:00', '2022-12-11 10:11:00', 73.2); الخرج Query OK, 8 rows affected (0.01 sec) Records: 8 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء تعلّم كيفية استخدام الدوال CAST وتعابير الضم في SQL. استخدام دوال CAST تتيح لك الدالة CAST إمكانية تحويل قيمة حرفية أو القيم المُخزنة ضمن عمودٍ ما إلى نمط بياناتٍ محدد. ويُعدّ استخدامها مفيدًا لضمان توافق أنماط بيانات القيم ضمن تعبيرٍ مُعيّن. ولاستخدام الأمر CAST، لابدّ من تحديد العمود أو الأعمدة المُتضمّنة لقيم البيانات الحالية المرغوب بتحويلها، ومن ثم كتابة قيم البيانات المُفضلة و/أو طولها ضمن التعبير. وفيما يلي مثال على الصيغة العامّة: CAST function syntax . . .CAST(قيم البيانات الحالية AS قيم البيانات المرغوبة) . . . وتجدر الملاحظة إلى أنّ دوال CAST تخضع لقواعد معيّنة كي تعمل على نحو صحيح. فعلى سبيل المثال، من المهم التأكد من كون نمط البيانات الذي نرغب في تحويله متوافق مع النمط الذي سنحوّل إليه. فبالعودة إلى البيانات في مثالنا، لن نتمكن باستخدام دالة CAST من تحويل القيم في عمود درجة الامتحان النهائي finalexam_grade من قيم بيانات رقمية (وهو نمط البيانات decimal في حالتنا) مباشرةً إلى قيم سلاسل محرفية، كأن نعبّر عن الدرجات بأحرف. وبالمثل، لا يمكننا تحويل أنماط بيانات مُحدّدة بطول أقصى مثل الأعمدة التي تحمل قيم varchar(30) في مثالنا إلى مقدار أطول مثل varchar(35). كما تجدر الملاحظة إلى أنّ تقديمات SQL المختلفة ستتصرف على نحوٍ مختلف لدى تنفيذ استعلامات باستخدام دوال CAST لتحويل أنماط البيانات. فقد ينتج مثلًا عن تنفيذ استعلام باستخدام دالة CAST في MySQL نتائج مختلفة عن تشغيل نفس الاستعلام في PostgreSQL. الآن ولتحقيق فهم أعمق حول كيفية استخدام دوال CAST، لنتخيل السيناريو التالي بناءً على البيانات في المثال السابق والتي أدخلناها في الخطوة السابقة. إذ يستعد الأستاذ فريد، معلم الصف السادس في مدرسة PS 118، لتقديم درجاته للفصل الدراسي الخريفي. إذ كان يتابع عن كثب تقدم كل طالب، وهو مهتم على وجه الخصوص بدرجاتهم في كل من الامتحان النصفي وواجب كتابة المقال والامتحان النهائي. وبفرض أنّك تعمل مع الأستاذ فريد كمدرّس مساعد، وقد طلب منك تزويده بالمعلومات المُتعلّقة بالمهام الدراسية آنفة الذكر. ستستخرج في هذه الحالة البيانات المطلوبة من خلال إنشاء استعلام عن جدول fall_grades لاسترجاع المعلومات اللازمة، مثل أسماء الطلاب الأولى first_name وأسماءهم الأخيرة last_name، بالإضافة إلى درجاتهم لكل مهمة دراسية، على النحو التالي: mysql> SELECT first_name, last_name, midterm_grade, essay_grade, finalexam_grade FROM fall_grades; الخرج +------------+-----------+---------------+-------------+-----------------+ | first_name | last_name | midterm_grade | essay_grade | finalexam_grade | +------------+-----------+---------------+-------------+-----------------+ | Arnold | Shortman | 85.8 | 90.1 | 82.5 | | Helga | Pataki | 88.4 | 72.5 | 90.0 | | Gerald | Johanssen | 94.2 | 95.8 | 88.1 | | Phoebe | Heyerdahl | 98.8 | 90.4 | 100.0 | | Harold | Berman | 75.7 | 67.5 | 90.9 | | Eugene | Horowitz | 100.0 | 89.9 | 98.2 | | Rhonda | Lloyd | 90.4 | 81.3 | 95.5 | | Stinky | Peterson | 70.6 | 93.1 | 73.2 | +------------+-----------+---------------+-------------+-----------------+ 8 rows in set (0.00 sec) وبعد تقديم هذه النتائج إلى الأستاذ، بيّن لك أنّ النظام الذي يستخدمه يسمح له بإدخال الدرجات كأعداد صحيحة حصرًا، وبالتالي لابدّ من تحويل هذه القيم العشرية إلى أعدادٍ صحيحة. فتقرر استخدام دالة CAST لتحويل عدد القيم المحرفية المحدد (وهو في هذه الحالة أربعة محارف من نمط البيانات decimal) إلى قيمتين محرفيتين. وسنستخدم لهذا الاستعلام نفس صيغة الاستعلام من المثال أعلاه ولكن مع تضمين دالة CAST لتحويل نمط البيانات decimal إلى قيمتين محرفيتين فقط لكل من المهام الدراسية. إذ ستُطبّق الدالة CAST على ثلاث تعابير مختلفة (لكل من midterm_grade و essay_grade و final_exam_grade) وذلك لتحويلها إلى قيم بيانات مكونة من قيمتين محرفيتين فقط: mysql> SELECT first_name, last_name, mysql> CAST(midterm_grade AS char(2)) AS midterm, mysql> CAST(essay_grade AS char(2)) AS essay, mysql> CAST(finalexam_grade AS char(2)) AS finalexam mysql> FROM fall_grades; الخرج +------------+-----------+---------+-------+-----------+ | first_name | last_name | midterm | essay | finalexam | +------------+-----------+---------+-------+-----------+ | Arnold | Shortman | 85 | 90 | 82 | | Helga | Pataki | 88 | 72 | 90 | | Gerald | Johanssen | 94 | 95 | 88 | | Phoebe | Heyerdahl | 98 | 90 | 10 | | Harold | Berman | 75 | 67 | 90 | | Eugene | Horowitz | 10 | 89 | 98 | | Rhonda | Lloyd | 90 | 81 | 95 | | Stinky | Peterson | 70 | 93 | 73 | +------------+-----------+---------+-------+-----------+ 8 rows in set, 24 warnings (0.00 sec) الآن وبعد مراجعة درجات كل طالب، يسأل السيد فريد إذا كان بإمكانك جلب معلومات حول التواريخ والأوقات الدقيقة التي قدم فيها كل طالب مهامه الدراسية، ولجلب هذه البيانات، سننفّذ تعليمة SELECT التالية: mysql> SELECT first_name, last_name, midterm_deadline, essay_deadline, finalexam_deadline FROM fall_grades; الخرج +------------+-----------+---------------------+---------------------+---------------------+ | first_name | last_name | midterm_deadline | essay_deadline | finalexam_deadline | +------------+-----------+---------------------+---------------------+---------------------+ | Arnold | Shortman | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Helga | Pataki | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Gerald | Johanssen | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Phoebe | Heyerdahl | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Harold | Berman | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Eugene | Horowitz | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Rhonda | Lloyd | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | | Stinky | Peterson | 2022-10-16 12:00:00 | 2022-11-20 12:00:00 | 2022-12-11 12:00:00 | +------------+-----------+---------------------+---------------------+---------------------+ 8 rows in set (0.00 sec) يتنهد الأستاذ فريد بعد مراجعة هذا الخرج مُخبرًا إياك بأنّ هذه المعلومات صعبة التحليل للغاية. إذ تم تعيين كل هذه الأعمدة لتخزين قيم من نمط البيانات TIMESTAMP، وهو سبب طولها البالغ. فتقرر استخدام دالة CAST لتحويل الخرج إلى شكل أسهل للقراءة والفهم، وأيضًا لتقسيم الاستعلام إلى قسمين واحد للتواريخ وآخر للأوقات. للاستعلام فقط عن أوقات تقديم الطلاب لواجباتهم، لننفّذ دالة CAST محولين قيم البيانات من تلك الأعمدة المحددة إلى قيم وقت من النمط time: mysql> SELECT first_name, last_name, mysql> CAST(midterm_submitted AS time) AS midterm, mysql> CAST(essay_submitted AS time) AS essay, mysql> CAST(finalexam_submitted AS time) AS finalexam mysql> FROM fall_grades; الخرج +------------+-----------+----------+----------+-----------+ | first_name | last_name | midterm | essay | finalexam | +------------+-----------+----------+----------+-----------+ | Arnold | Shortman | 06:30:00 | 03:00:00 | 03:00:00 | | Helga | Pataki | 10:00:00 | 03:15:00 | 05:00:00 | | Gerald | Johanssen | 02:00:00 | 02:45:00 | 11:00:00 | | Phoebe | Heyerdahl | 11:00:00 | 11:15:00 | 11:40:00 | | Harold | Berman | 08:00:00 | 09:15:00 | 09:15:00 | | Eugene | Horowitz | 01:00:00 | 01:22:00 | 07:55:00 | | Rhonda | Lloyd | 06:00:00 | 06:09:00 | 06:45:00 | | Stinky | Peterson | 03:00:00 | 05:55:00 | 10:11:00 | +------------+-----------+----------+----------+-----------+ 8 rows in set (0.00 sec) يُقدّم هذا الخرج لمحة عامة حول الإطار الزمني الذي أنهى فيه كل طالب واجباته. ومع ملاحظة أنّ موعد تسليم كل من الواجبات يحين عند منتصف ليل يوم الأحد، نجد أنّ العديد من الطلاب كانوا متسقين مع توقيتهم، في حين أنهى آخرون واجباتهم مبكرًا، أو قبل الموعد المحدد عند منتصف الليل بقليل. ولكن تُمثّل هذه المعلومات نصف ما طلبه الأستاذ فريد فقط، لذا دعونا نعمل على الاستعلام التالي الذي سيستخدم دالة CAST لتحويل تلك القيم ذاتها من نمط البيانات TIMESTAMP إلى قيم تواريخ. سننفّذ نفس الاستعلام كما في المرة السابقة، ولكن مستبدلين نمط بيانات التاريخ time بنمط بيانات الوقت time هذه المرة: mysql> SELECT first_name, last_name, mysql> CAST(midterm_submitted AS date) AS midterm, mysql> CAST(essay_submitted AS date) AS essay, mysql> CAST(finalexam_submitted AS date) AS finalexam mysql> FROM fall_grades; الخرج +------------+-----------+------------+------------+------------+ | first_name | last_name | midterm | essay | finalexam | +------------+-----------+------------+------------+------------+ | Arnold | Shortman | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Helga | Pataki | 2022-10-16 | 2022-11-21 | 2022-12-11 | | Gerald | Johanssen | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Phoebe | Heyerdahl | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Harold | Berman | 2022-10-16 | 2022-11-22 | 2022-12-11 | | Eugene | Horowitz | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Rhonda | Lloyd | 2022-10-16 | 2022-11-20 | 2022-12-11 | | Stinky | Peterson | 2022-10-16 | 2022-11-20 | 2022-12-11 | +------------+-----------+------------+------------+------------+ 8 rows in set (0.00 sec) يُمكننا استنادًا إلى هذا الخرج تحديد الطلاب الذين قدموا واجباتهم بعد الموعد النهائي، ما يوضّح سبب تأثر درجاتهم الناتج عن خصم نقاط بسبب التأخر. فعلى سبيل المثال، قدّمت الطالبة هيلجا واجبها بعد يوم واحد من الموعد (2022-11-21)، وقدّم الطالب هارولد واجبه بعد يومين (2022-11-22) من الموعد النهائي للمقال والمُحدد في (2022-11-20). على الرغم من رضا الأستاذ فريد عن هذه النتائج المُنقحة، إلا أنه يحتاج إلى مزيد من المساعدة في صياغة البيانات على نحوٍ أوضح لتقديم تقرير درجاته. ستتدرب في القسم التالي من المقال على كيفية استخدام تعابير الضم القادرة على دمج قيم حرفية متعددة أو القيم من أعمدة مختلفة ضمن قيمة سلسلة نصية واحدة، مما يساعد في جعل المعلومات أوضح للتفسير كعبارة أو جملة كاملة. استخدام تعابير الضم يُمكنك مع استخدام تعبير الضم CONCAT معالجة البيانات بجمع قيم محرفية أو رقمية من أعمدة مختلفة معًا لتظهر كنتيجة واحدة. إذ تعيد قواعد بيانات SQL بوجهٍ عام قيم البيانات ضمن مجموعات نتائج منفصلة في أعمدتها المختلفة. فعلى سبيل المثال، لو استعلمنا عن الاسم الأول first_name والأخير last_name لطلاب PS 118، سيظهر الخرج كما يلي: mysql> SELECT first_name, last_name FROM fall_grades; الخرج +------------+-----------+ | first_name | last_name | +------------+-----------+ | Arnold | Shortman | | Helga | Pataki | | Gerald | Johanssen | | Phoebe | Heyerdahl | | Harold | Berman | | Eugene | Horowitz | | Rhonda | Lloyd | | Stinky | Peterson | +------------+-----------+ 8 rows in set (0.00 sec) لكن هذه المعلومات غير مُقدّمة بالشكل الذي يفضله الأستاذ فريد لتقريره. لذا، لننفّذ استعلامًا آخر باستخدام الضم لدمج الأسماء الأولى والأخيرة للطلاب ضمن سلسلة نصية واحدة. يؤدي الاستعلام التالي هذه المهمة باستخدام الكلمة المفتاحية CONCAT موفرًا للعمود الناتج الاسم بديل full_names، على النحو التالي: mysql> SELECT CONCAT(first_name, last_name) AS full_names FROM fall_grades; الخرج +-----------------+ | full_names | +-----------------+ | ArnoldShortman | | HelgaPataki | | GeraldJohanssen | | PhoebeHeyerdahl | | HaroldBerman | | EugeneHorowitz | | RhondaLloyd | | StinkyPeterson | +-----------------+ 8 rows in set (0.00 sec) تعمل تعابير الضم مع كافة أنماط البيانات إجمالًا، ولكن في حال عدم تحديد تفاصيل من قبيل التباعد بين قيم البيانات، سيظهر الخرج على هيئة سلسلة نصية متصلة دون فواصل كما يتضح من الخرج أعلاه. ولتصحيح ذلك، يمكن إضافة زوج من علامات الاقتباس الفردية مع فراغ بينهما (' ') بين عمودي first_name وlast_name بحيث تظهر القيم على هيئة سلسلة واحدة، ولكن هذه المرة مع فراغ بينهما لجعلها أسهل للقراءة: mysql> SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM fall_grades; الخرج +------------------+ | full_name | +------------------+ | Arnold Shortman | | Helga Pataki | | Gerald Johanssen | | Phoebe Heyerdahl | | Harold Berman | | Eugene Horowitz | | Rhonda Lloyd | | Stinky Peterson | +------------------+ 8 rows in set (0.00 sec) بإدراج فراغ بين علامات الاقتباس الفردية في الاستعلام، يُظهر الخرج الآن أسماء الطلاب بوضوح ككلمتين منفصلتين، بدلًا من كلمة مركبة واحدة. ملاحظة: معظم أنظمة إدارة قواعد البيانات العلاقية الحديثة تستخدم الصياغة الموضحة في هذا القسم لضم القيم. إلّا لأنّ هذه الصياغة (استخدام كلمة CONCAT المفتاحية) ليست الصياغة التقليدية المحددة بمعيار SQL. الطريقة التقليدية لضم القيم في SQL تتمثّل في وضع زوج من الخطوط العمودية بين قيم البيانات التي نريد ضمها. تجدر الملاحظة بأنّ MySQL لا تسمح باستخدام هذه الصياغة على الإطلاق، في حين تسمح بعض أنظمة إدارة قواعد البيانات مثل PostgreSQL باستخدام إحدى الطريقتين. الاستعلام التالي (المُنفذ على قاعدة بيانات PostgreSQL) يُعطي نفس الخرج كالاستعلام السابق، ولكن هذه المرة باستخدام الخطوط العمودية: SELECT first_name || ' ' || last_name AS full_name FROM fall_grades; الخرج full_name ------------------ Arnold Shortman Helga Pataki Gerald Johanssen Phoebe Heyerdahl Harold Berman Eugene Horowitz Rhonda Lloyd Stinky Peterson (8 rows) الآن، لنجرب مثالاً آخر حيث سنسترجع مزيدًا من المعلومات حول كل طالب. إذ نريد في هذه المرة ضم قيم البيانات من أعمدة الاسم الأول first_name والاسم الأخير last_name وعنوان البريد الإلكتروني email_address ودرجة الامتحان النهائي finalexam_grade ووقت وتاريخ تقديم الامتحان النهائي finalexam_submitted ضمن عمود واحد باستخدام CONCAT. ومن المهم هنا عدم نسيان إضافة علامات اقتباس فردية بين كل عمود وآخر نرغب بإضافة فراغ بينهما كما في المثال التالي: mysql> SELECT CONCAT(first_name, ' ', last_name, ' ', mysql> email_address, ' ', finalexam_grade, ' ', finalexam_submitted) mysql> AS student_info FROM fall_grades; الخرج +-----------------------------------------------------------------+ | student_info | +-----------------------------------------------------------------+ | Arnold Shortman ashortman@ps118.com 82.5 2022-12-11 03:00:00 | | Helga Pataki hpataki@ps118.com 90.0 2022-12-11 05:00:00 | | Gerald Johanssen gjohanssen@ps118.com 88.1 2022-12-11 11:00:00 | | Phoebe Heyerdahl pheyerdahl@ps118.com 100.0 2022-12-11 11:40:00 | | Harold Berman hberman@ps118.com 90.9 2022-12-11 09:15:00 | | Eugene Horowitz ehorowitz@ps118.com 98.2 2022-12-11 07:55:00 | | Rhonda Lloyd rlloyd@ps118.com 95.5 2022-12-11 06:45:00 | | Stinky Peterson speterson@ps118.com 73.2 2022-12-11 10:11:00 | +-----------------------------------------------------------------+ 8 rows in set (0.00 sec) الأستاذ فريد راضٍ عن هذه النتائج ولكنه يودّ جعلها أكثر إيجازًا ضمن تقرير درجاته وذلك من خلال تحويل بعض قيم البيانات. سنستخدم في هذا السيناريو دالة CAST لتحويل نمط بيانات عمود finalexam_grade إلى رقم صحيح، ونمط بيانات عمود finalexam_submitted من TIMESTAMP إلى نمط بيانات التاريخ date كما في المثال التالي: mysql> SELECT CONCAT(first_name, ' ', last_name, ' ', email_address, ' ', mysql> CAST(finalexam_grade AS char(2)), ' ', mysql> CAST(finalexam_submitted AS date)) mysql> AS student_info FROM fall_grades; الخرج +-----------------------------------------------------+ | student_info | +-----------------------------------------------------+ | Arnold Shortman ashortman@ps118.com 82 2022-12-11 | | Helga Pataki hpataki@ps118.com 90 2022-12-11 | | Gerald Johanssen gjohanssen@ps118.com 88 2022-12-11 | | Phoebe Heyerdahl pheyerdahl@ps118.com 10 2022-12-11 | | Harold Berman hberman@ps118.com 90 2022-12-11 | | Eugene Horowitz ehorowitz@ps118.com 98 2022-12-11 | | Rhonda Lloyd rlloyd@ps118.com 95 2022-12-11 | | Stinky Peterson speterson@ps118.com 73 2022-12-11 | +-----------------------------------------------------+ 8 rows in set, 8 warnings (0.00 sec) لنحسّن الخرج أكثر، ونكتب استعلامًا يستخدم دالة CAST وتعبير الضم للحصول على جملة كاملة في الخرج. يمكننا القيام بذلك بكتابة عبارة قصيرة بين علامات الاقتباس الفردية. ولا بدّ من الحفاظ على مسافة بين كل عمود وآخر عن طريق إضافة مسافة واحدة قبل وبعد نهاية العبارة أو العبارات المكتوبة: mysql> SELECT CONCAT(first_name, ' ', last_name, ' can be contacted at ', email_address, mysql> ' and received a grade of ', mysql> CAST(finalexam_grade AS char(2)), mysql> ' after submitting the final exam on ', mysql> CAST(finalexam_submitted AS date)) mysql> AS student_info FROM fall_grades; الخرج +------------------------------------------------------------------------------------------------------------------------------------+ | student_info | +------------------------------------------------------------------------------------------------------------------------------------+ | Arnold Shortman can be contacted at ashortman@ps118.com and received a grade of 82 after submitting the final exam on 2022-12-11 | | Helga Pataki can be contacted at hpataki@ps118.com and received a grade of 90 after submitting the final exam on 2022-12-11 | | Gerald Johanssen can be contacted at gjohanssen@ps118.com and received a grade of 88 after submitting the final exam on 2022-12-11 | | Phoebe Heyerdahl can be contacted at pheyerdahl@ps118.com and received a grade of 10 after submitting the final exam on 2022-12-11 | | Harold Berman can be contacted at hberman@ps118.com and received a grade of 90 after submitting the final exam on 2022-12-11 | | Eugene Horowitz can be contacted at ehorowitz@ps118.com and received a grade of 98 after submitting the final exam on 2022-12-11 | | Rhonda Lloyd can be contacted at rlloyd@ps118.com and received a grade of 95 after submitting the final exam on 2022-12-11 | | Stinky Peterson can be contacted at speterson@ps118.com and received a grade of 73 after submitting the final exam on 2022-12-11 | +------------------------------------------------------------------------------------------------------------------------------------+ 8 rows in set, 8 warnings (0.00 sec) يُنتج هذا الخرج جملًا كاملة عن كل طالب في فصل الأستاذ فريد. إذ أحدثت هذه الإضافات الطفيفة بين علامات الاقتباس الفردية فارقًا كبيرًا في جعل المعلومات واضحة من حيث هوية صاحب كل معلومة والبيانات المتعلقة به. وذلك بفضل الأعمدة المحددة التي استخرجنا منها البيانات في استعلامنا. الأستاذ فريد ممتن جدًا لعملك الرائع، وهو راضٍ تمامًا لأنك وفرت عليه الوقت أيضًا بتحويلك البيانات إلى جمل مفهومة يمكنه إضافتها بسهولة إلى تقريره. الخلاصة قدّمنا في هذا المقال شرحًا حول استخدامات متنوعة لمعالجة البيانات باستخدام دالة CAST وتعابير الضم. إذ تدربت على كيفية تحويل قيم عمود من نمط بيانات إلى آخر بفضل الدالة CAST. كما تعلمت كيفية استخدام تعابير الضم لجمع قيم بيانات مختلفة سواء كانت محرفية أو رقمية في سلسلة نصية واحدة. كما نفذت استعلامًا يتضمّن كل من دالة CAST وتعبير الضم معًا، مما أتاح لك إنشاء خرج بجمل كاملة توفر تفسيرًا أشمل للبيانات، الأمر الذي يجعل من الأسهل كتابة الجمل على نحوٍ مستقل عن بعضها، إذ يمكنك تنظيم المعلومات بكفاءة ونسخها ولصقها بالصيغة التي هي عليها مباشرةً. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Manipulate Data with CAST Functions and Concatenation Expressions in SQL لصاحبه Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: كيفية التعامل مع التواريخ والأوقات في SQL مدخل إلى SQL دوال التعامل مع البيانات في SQL دوال التعامل مع النصوص في SQL التعابير الجدولية الشائعة Common Table Expressions في SQL -
 تستخدم لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- مجموعةً متنوعة من هياكل البيانات، وتُعدّ الجداول من أكثرها استخدامًا، ولكن يكون لهذه الجداول قيود أو محدوديات معينة، فمثلًا لا يمكنك تقييد المستخدمين للوصول إلى جزء من الجدول فقط، إذ يجب أن يتمكّن المستخدم من الوصول إلى الجدول بأكمله، وليس إلى بعض الأعمدة ضمنه فقط. لنفترض مثلًا أنك تريد دمج البيانات من عدة جداول في هيكل بيانات جديد، ولكنك لا تريد حذف الجداول الأصلية، حيث يمكنك إنشاء جدول آخر فقط، ولكن سيكون لديك بيانات زائدة مخزَّنة في أماكن متعددة لاحقًا. قد يسبّب ذلك الكثير من الإزعاج، حيث إذا تغيرت بعض بياناتك، فيجب عليك أن تحدّثها في أماكن متعددة، لذا يمكن أن تكون العروض Views مفيدة في مثل هذه الحالات. يُعَد العرض view في لغة SQL جدولًا افتراضيًا، وتكون محتوياته نتيجة لاستعلام محدّد لجدول واحد أو أكثر، حيث تُعرَف هذه الجداول باسم الجداول الأساسية Base Tables. يقدّم هذا المقال نظرة عامة حول عروض SQL وفوائدها، ويوضّح كيفية إنشاء العروض والاستعلام عنها وتعديلها وتدميرها باستخدام صيغة SQL المعيارية. مستلزمات العمل يجب أن يكون لديك حاسوب يشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- التي تستخدم لغة SQL. اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا الخطوات باستخدام مستخدم مُنشَأ وفق الطريقة الموضحة في الخطوة 3 من المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. ستحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لتتمكن من التدرب على إنشاء العروض والتعامل معها، لذا اطّلع على القسم التالي للحصول على تفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة بيانات الاختبار المُستخدَمة في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، فاتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي كما يلي: $ ssh user@your_server_ip ثم افتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بك مكان user: $ mysql -u user -p أنشِئ قاعدة بيانات باسم views_db في موجّه الأوامر: mysql> CREATE DATABASE views_db; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر خرج كما يلي: الخرج Query OK, 1 row affected (0.01 sec) يمكنك اختيار قاعدة البيانات views_db من خلال تنفيذ تعليمة USE التالية: mysql> USE views_db; ويكون الخرج كما يلي: الخرج Database changed اخترنا قاعدة بيانات views_db، وسننشئ جدولين ضمنها. لنفترض مثلًا أنك تدير خدمة رعاية للكلاب، فقررت استخدام قاعدة بيانات SQL لتخزين معلومات حول كل كلب مُسجَّل في الخدمة، بالإضافة إلى معلومات كل متخصص في رعاية الكلاب توظفه خدمتك، حيث نظّمت هذه المعلومات من خلال إنشاء جدولين: أحدهما يمثل الموظفين والآخر يمثل الكلاب التي تعتني بها خدمتك. سيحتوي الجدول الذي يمثل موظفيك على الأعمدة التالية: emp_id: رقم تعريف لكل موظف يقدّم رعايةً للكلاب، ونعبّر عنه باستخدام نوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي Primary Key للجدول، أي أن كل قيمة ستمثّل معرّفًا فريدًا للصف الخاص بها، وسيكون لهذا العمود أيضًا قيد UNIQUE مطبَّق عليه، إذ يجب أن تكون كل قيمة في المفتاح الرئيسي فريدة. emp_name: اسم الموظف، ونعبّر عنه باستخدام نوع البيانات varchar بحد أقصى 20 محرفًا. نفّذ تعليمة CREATE TABLE التالية لإنشاء جدول بالاسم employees ويحتوي على العمودين التاليين: mysql> CREATE TABLE employees ( mysql> emp_id int UNIQUE, mysql> emp_name varchar(20), mysql> PRIMARY KEY (emp_id) mysql> ); سيحتوي الجدول الآخر الذي يمثل الكلاب على الأعمدة الستة التالية: dog_id: رقم تعريف لكل كلب ويُعبَّر عنه بنوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي للجدول dogs مثل العمود emp_id في الجدول employees. dog_name: اسم الكلب ويُعبَّر عنه باستخدام نوع البيانات varchar بحد أقصى 20 محرفًا. walker: يخزّن هذا العمود رقم معرّف الموظف الذي يرعى كل كلب. walk_distance: المسافة التي يجب أن يمشيها كل كلب عند اصطحابه للتمرين، ويُعبَّر عنه باستخدام نوع البيانات decimal، ويمكن أن تحتوي القيم في هذا العمود على ثلاثة أرقام على الأكثر مع وجود رقمين من هذه الأرقام على يمين الفاصلة العشرية. meals_perday: توفر هذه الخدمة لكل كلب عددًا معينًا من الوجبات كل يوم، حيث يحتوي هذا العمود على عدد الوجبات التي يجب أن يحصل عليها كل كلب يوميًا حسب طلب مالكه، ويستخدم نوع البيانات int فهو عدد صحيح. cups_permeal: يمثل هذا العمود عدد أكواب الطعام التي يجب أن يحصل عليها كل كلب في كل وجبة، ويُعبَّر عنه بنوع البيانات decimal مثل العمود walk_distance، ويمكن أن تحتوي القيم في هذا العمود على ما يصل إلى ثلاثة أرقام مع وجود رقمين من هذه الأرقام على يمين الفاصلة العشرية. نتأكد من أن العمود walker يحتوي على القيم التي تمثل أرقام معرّف الموظف الصالحة فقط من خلال تطبيق قيد مفتاح خارجي Foreign Key على العمود walker الذي يشير إلى العمود emp_ID الخاص بالجدول employees. يُعَد قيد المفتاح الخارجي طريقة للتعبير عن العلاقة بين جدولين من خلال اشتراط أن تكون القيم الموجودة في العمود الذي طُبِّق المفتاح الخارجي عليه موجودة في العمود الذي يشير إليه، حيث يشترط قيد FOREIGN KEY في المثال التالي أن تكون أيّ قيمة مضافة إلى العمود walker في الجدول dogs موجودةً في العمود emp_ID الخاص بالجدول employees. لننشئ جدولًا بالاسم dogs يحتوي على هذه الأعمدة باستخدام الأمر التالي: mysql> CREATE TABLE dogs ( mysql> dog_id int UNIQUE, mysql> dog_name varchar(20), mysql> walker int, mysql> walk_distance decimal(3,2), mysql> meals_perday int, mysql> cups_permeal decimal(3,2), mysql> PRIMARY KEY (dog_id), mysql> FOREIGN KEY (walker) mysql> REFERENCES employees(emp_ID) ); يمكنك الآن تحميل الجدولين ببعض البيانات التجريبية النموذجية. نفّذ عملية الإدخال INSERT INTO التالية لإضافة ثلاثة صفوف من البيانات تمثّل ثلاثة من موظفي الخدمة إلى الجدول employees: mysql> INSERT INTO employees mysql> VALUES mysql> (1, 'Peter'), mysql> (2, 'Paul'), mysql> (3, 'Mary'); ثم نفّذ العملية التالية لإدخال سبعة صفوف من البيانات في الجدول dogs: mysql> INSERT INTO dogs mysql> VALUES mysql> (1, 'Dottie', 1, 5, 3, 1), mysql> (2, 'Bronx', 3, 6.5, 3, 1.25), mysql> (3, 'Harlem', 3, 1.25, 2, 0.25), mysql> (4, 'Link', 2, 2.75, 2, 0.75), mysql> (5, 'Otto', 1, 4.5, 3, 2), mysql> (6, 'Juno', 1, 4.5, 3, 2), mysql> (7, 'Zephyr', 3, 3, 2, 1.5); وأصبحتَ الآن جاهزًا لمتابعة بقية هذا المقال والبدء في تعلّم كيفية استخدام العروض في لغة SQL. فهم وإنشاء العروض Views يمكن أن تصبح استعلامات SQL معقدة، ولكن إحدى الفوائد الرئيسية للغة SQL هي أنها تتضمن العديد من الخيارات والتعليمات التي تسمح لك بترشيح بياناتك بمستوى عالٍ من الدقة والتحديد. إذا كانت لديك استعلامات معقدة تريد تشغيلها بصورة متكررة، فقد يصبح الاضطرار إلى كتابتها باستمرار أمرًا مملًا، وإحدى الطرق لحل هذه المشكلات هي استخدام العروض. تُعَد العروض views جداولًا افتراضية كما ذكرنا سابقًا، وهذا يعني أنها تشبه الجداول وظيفيًا، ولكنها تمثّل نوعًا مختلفًا من هياكل البيانات لأن العرض لا يحتوي على أيّ بيانات خاصة به، فهو يسحب البيانات من جدول أساسي واحد أو أكثر، وتكون المعلومات الوحيدة حول العرض التي سيخزنها نظام إدارة قواعد البيانات DBMS هي هيكل العرض. تُسمَّى العروض أحيانًا بالاستعلامات المحفوظة Saved Queries، لأنها تمثّل الاستعلامات المحفوظة باسم مُحدَّد لتسهيل الوصول إليها. ليكن لدينا المثال التالي، تخيل أن أعمال رعاية الكلاب الخاصة بك ناجحة وتريد طباعة جدول يومي لجميع موظفيك، إذ يجب أن يحتوي هذا الجدول على كل كلب ترعاه الخدمة، والموظف المكلف برعايته، والمسافة التي يجب أن يمشيها كل كلب يوميًا، وعدد الوجبات التي يجب إطعامها لكل كلب يوميًا، وكمية الطعام التي ينبغي أن يحصل كل كلب في كل وجبة. استخدم مهاراتك في لغة SQL لإنشاء استعلام مع بياناتٍ تجريبية نموذجية من الخطوة السابقة لاسترجاع جميع هذه المعلومات للجدول، ولاحظ أن هذا الاستعلام يتضمن صيغة JOIN لسحب البيانات من الجدولين employees و dogs: mysql> SELECT emp_name, dog_name, walk_distance, meals_perday, cups_permeal mysql> FROM employees JOIN dogs ON emp_ID = walker; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | cups_permeal | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 1.00 | | Peter | Otto | 4.50 | 3 | 2.00 | | Peter | Juno | 4.50 | 3 | 2.00 | | Paul | Link | 2.75 | 2 | 0.75 | | Mary | Bronx | 6.50 | 3 | 1.25 | | Mary | Harlem | 1.25 | 2 | 0.25 | | Mary | Zephyr | 3.00 | 2 | 1.50 | +----------+----------+---------------+--------------+--------------+ 7 rows in set (0.00 sec) لنفترض أنه يجب تنفيذ هذا الاستعلام بشكل متكرر، إذ قد يصبح أمرًا مملًا إذا اضطررت إلى كتابة الاستعلام مرارًا وتكرارًا، وخاصةً عند إجراء تعليمات استعلام أطول وأكثر تعقيدًا، وإذا أردتَ إجراء تعديلات طفيفة على الاستعلام أو التوسّع فيه، فقد يكون الأمر مملًا عند استكشاف الأخطاء وإصلاحها مع وجود العديد من الاحتمالات للأخطاء الصياغية. يمكن أن يكون العرض مفيدًا في مثل هذه الحالات، لأنه يُعَد جدولًا مشتقًا من نتائج الاستعلام. تستخدم معظم أنظمة RDBMS الصيغة التالية لإنشاء العروض: CREATE VIEW view_name AS SELECT statement; يمكنك بعد تعليمة CREATE VIEW اختيار اسمٍ للعرض الذي ستستخدمه للإشارة إليه لاحقًا، ثم تدخِل الكلمة المفتاحية AS، ثم تضع استعلام SELECT الذي تريد حفظ خرجه. يمكن أن يكون الاستعلام الذي تستخدمه لإنشاء عرضك أيّ تعليمة SELECT صالحة، ويمكن أن تستعلم التعليمة التي تضمّنها عن جدول أساسي واحد أو أكثر طالما أنك تستخدم الصيغة الصحيحة. جرّب إنشاء عرض باستخدام استعلام المثال السابق، حيث تسمّي عملية CREATE VIEW العرض بالاسم walking_schedule: mysql> CREATE VIEW walking_schedule mysql> AS mysql> SELECT emp_name, dog_name, walk_distance, meals_perday, cups_permeal mysql> FROM employees JOIN dogs mysql> ON emp_ID = walker; ستتمكّن بعد ذلك من استخدام هذا العرض والتفاعل معه كما تفعل مع أيّ جدول آخر، فمثلًا يمكنك تنفيذ الاستعلام التالي لإعادة جميع البيانات الموجودة في العرض: mysql> SELECT * FROM walking_schedule; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | cups_permeal | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 1.00 | | Peter | Otto | 4.50 | 3 | 2.00 | | Peter | Juno | 4.50 | 3 | 2.00 | | Paul | Link | 2.75 | 2 | 0.75 | | Mary | Bronx | 6.50 | 3 | 1.25 | | Mary | Harlem | 1.25 | 2 | 0.25 | | Mary | Zephyr | 3.00 | 2 | 1.50 | +----------+----------+---------------+--------------+--------------+ 7 rows in set (0.00 sec) يُعَد هذا العرض مشتقًا من جدولين آخرين، ولكنك لن تتمكّن من الاستعلام عن العرض لأيّ بيانات من هذين الجدولين إن لم تكن موجودة مسبقًا في هذا العرض. يحاول الاستعلام التالي استرجاع العمود walker من العرض walking_schedule، ولكن سيفشل هذا الاستعلام لأن العرض لا يحتوي على أيّ أعمدة بهذا الاسم: mysql> SELECT walker FROM walking_schedule; الخرج ERROR 1054 (42S22): Unknown column 'walker' in 'field list' يعيد هذا الخرج رسالة خطأ لأن العمود walker هو جزء من الجدول dogs، ولكنه غير مُضمَّنٍ في العرض الذي أنشأناه. يمكنك أيضًا تنفيذ الاستعلامات التي تتضمّن دوالًا تجميعية Aggregate Functions تعالج البيانات ضمن العرض، يستخدم المثال التالي الدالة التجميعية MAX مع عبارة GROUP BY للعثور على أطول مسافة يجب على الموظف أن يمشيها في يوم محدّد: mysql> SELECT emp_name, MAX(walk_distance) AS longest_walks mysql> FROM walking_schedule GROUP BY emp_name; الخرج +----------+---------------+ | emp_name | longest_walks | +----------+---------------+ | Peter | 5.00 | | Paul | 2.75 | | Mary | 6.50 | +----------+---------------+ 3 rows in set (0.00 sec) توجد فائدة أخرى للعروض كما ذكرنا سابقًا، وهي أنه يمكنك استخدامها لتقييد وصول مستخدم قاعدة البيانات إلى العرض فقط بدلًا من الوصول إلى الجدول أو قاعدة البيانات بأكملها. لنفترض مثلًا أنك وظّفتَ مدير مكتب لمساعدتك في إدارة الجدول الزمني، وتريد أن يصل إلى معلومات الجدول دون الوصول لأي بيانات أخرى في قاعدة البيانات، حيث يمكنك إنشاء حساب مستخدم جديد له في قاعدة بياناتك كما يلي: mysql> CREATE USER 'office_mgr'@'localhost' IDENTIFIED BY 'password'; يمكنك بعد ذلك منح هذا المستخدم الجديد صلاحية وصول للقراءة إلى العرض walking_schedule فقط باستخدام التعليمة GRANT كما يلي: mysql> GRANT SELECT ON views_db.walking_schedule to 'office_mgr'@'localhost'; وبالتالي سيتمكّن الشخص الذي لديه صلاحية الوصول إلى حساب مستخدم MySQL الذي هو office_mgr من تنفيذ استعلامات SELECT في العرض walking_schedule فقط. تغيير وحذف العروض Views إذا أضفتَ أو غيّرتَ بياناتٍ في أحد الجداول التي نشتق العرض منها، فستُضاف أو تُحدَّث البيانات ذات الصلة في العرض تلقائيًا. نفّذ الأمر INSERT INTO التالي لإضافة صف آخر إلى الجدول dogs: mysql> INSERT INTO dogs VALUES (8, 'Charlie', 2, 3.5, 3, 1); يمكنك بعد ذلك استرجاع جميع البيانات من العرض walking_schedule مرة أخرى كما يلي: mysql> SELECT * FROM walking_schedule; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | cups_permeal | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 1.00 | | Peter | Otto | 4.50 | 3 | 2.00 | | Peter | Juno | 4.50 | 3 | 2.00 | | Paul | Link | 2.75 | 2 | 0.75 | | Paul | Charlie | 3.50 | 3 | 1.00 | | Mary | Bronx | 6.50 | 3 | 1.25 | | Mary | Harlem | 1.25 | 2 | 0.25 | | Mary | Zephyr | 3.00 | 2 | 1.50 | +----------+----------+---------------+--------------+--------------+ 8 rows in set (0.00 sec) لاحظ وجود صف آخر في مجموعة نتائج الاستعلام، والذي يمثّل البيانات التي أضفتها إلى الجدول dogs، ولكن لا يزال العرض يسحب البيانات ذاتها من الجداول الأساسية نفسها، لذلك لم تغيّر هذه العملية العرض. تسمح لك العديد من أنظمة RDBMS بتحديث هيكل العرض بعد إنشائه باستخدام صيغة CREATE OR REPLACE VIEW: mysql> CREATE OR REPLACE VIEW view_name mysql> AS mysql> new SELECT statement إذا كان العرض الذي اسمه view_name موجودًا مسبقًا في هذه الصيغة، فسيحدّث نظام قاعدة البيانات هذا العرض بحيث يمثّل البيانات التي تعيدها التعليمة new SELECT statement. إذا لم يكن العرض بهذا الاسم موجودًا، فسينشئ نظام إدارة قواعد البيانات DBMS عرضًا جديدًا. لنفترض أنك تريد تغيير العرض walking_schedule ليسرد إجمالي كمية الطعام التي تناولها كل كلب على مدار اليوم بدلًا من سرد عدد أكواب الطعام التي يتناولها كل كلب في كل وجبة، ويمكنك تغيير العرض باستخدام الأمر التالي: mysql> CREATE OR REPLACE VIEW walking_schedule mysql> AS mysql> SELECT emp_name, dog_name, walk_distance, meals_perday, (cups_permeal * mysql> meals_perday) AS total_kibble mysql> FROM employees JOIN dogs ON emp_ID = walker; إذا أجربتَ الآن استعلامًا على هذا العرض، فستمثّل مجموعة النتائج بيانات العرض الجديدة كما يلي: mysql> SELECT * FROM walking_schedule; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | total_kibble | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 3.00 | | Peter | Otto | 4.50 | 3 | 6.00 | | Peter | Juno | 4.50 | 3 | 6.00 | | Paul | Link | 2.75 | 2 | 1.50 | | Paul | Charlie | 3.50 | 3 | 3.00 | | Mary | Bronx | 6.50 | 3 | 3.75 | | Mary | Harlem | 1.25 | 2 | 0.50 | | Mary | Zephyr | 3.00 | 2 | 3.00 | +----------+----------+---------------+--------------+--------------+ 8 rows in set (0.00 sec) يمكنك حذف العروض باستخدام صيغة DROP مثل معظم هياكل البيانات الأخرى التي يمكنك إنشاؤها في لغة SQL، وإليك مثالًا: DROP VIEW view_name; يمكنك مثلًا حذف العرض walking_schedule باستخدام الأمر التالي: mysql> DROP VIEW walking_schedule; يؤدي الأمر السابق إلى إزالة العرض walking_schedule من قاعدة بياناتك، ولكنه لن يحذف أيًّا من بيانات قاعدة بياناتك المتعلقة بالعرض إلّا إذا أزلتها من الجداول الأساسية. الخلاصة تعلّمنا في هذا المقال ما هي عروض SQL وكيفية إنشائها والاستعلام عنها وتغييرها وحذفها من قاعدة البيانات، وتعرّفنا على فوائد العروض، وأنشأنا مستخدم MySQL الذي يمكنه فقط قراءة البيانات من العرض التجريبي الذي أنشأناه. يجب أن تعمل الأوامر الواردة في أمثلة هذا المقال على معظم قواعد البيانات العلاقية، ولكن يجب أن تدرك أن كل قاعدة بيانات SQL لها تقديمها الفريد من هذه اللغة، لذا يجب عليك الرجوع إلى التوثيق الرسمي لنظام إدارة قواعد البيانات DBMS الخاص بك للحصول على وصف أشمل لكل أمر ومجموعته الكاملة من الخيارات. ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب للمزيد حول كيفية التعامل مع لغة SQL. ترجمة -وبتصرف- للمقال How To Use Views in SQL لصاحبه Mark Drake. اقرأ أيضًا الاستعلام عن البيانات في SQL جلب الاستعلامات عبر SELECT في SQL المرجع المتقدم إلى لغة SQL لغة معالجة البيانات DML الخاصة بلغة SQL
تستخدم لغة الاستعلام البنيوية Structured Query Language -أو SQL اختصارًا- مجموعةً متنوعة من هياكل البيانات، وتُعدّ الجداول من أكثرها استخدامًا، ولكن يكون لهذه الجداول قيود أو محدوديات معينة، فمثلًا لا يمكنك تقييد المستخدمين للوصول إلى جزء من الجدول فقط، إذ يجب أن يتمكّن المستخدم من الوصول إلى الجدول بأكمله، وليس إلى بعض الأعمدة ضمنه فقط. لنفترض مثلًا أنك تريد دمج البيانات من عدة جداول في هيكل بيانات جديد، ولكنك لا تريد حذف الجداول الأصلية، حيث يمكنك إنشاء جدول آخر فقط، ولكن سيكون لديك بيانات زائدة مخزَّنة في أماكن متعددة لاحقًا. قد يسبّب ذلك الكثير من الإزعاج، حيث إذا تغيرت بعض بياناتك، فيجب عليك أن تحدّثها في أماكن متعددة، لذا يمكن أن تكون العروض Views مفيدة في مثل هذه الحالات. يُعَد العرض view في لغة SQL جدولًا افتراضيًا، وتكون محتوياته نتيجة لاستعلام محدّد لجدول واحد أو أكثر، حيث تُعرَف هذه الجداول باسم الجداول الأساسية Base Tables. يقدّم هذا المقال نظرة عامة حول عروض SQL وفوائدها، ويوضّح كيفية إنشاء العروض والاستعلام عنها وتعديلها وتدميرها باستخدام صيغة SQL المعيارية. مستلزمات العمل يجب أن يكون لديك حاسوب يشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية Relational Database Management System -أو RDBMS اختصارًا- التي تستخدم لغة SQL. اختبرنا التعليمات والأمثلة الواردة في هذا المقال باستخدام البيئة التالية: خادم عامل على توزيعة أوبنتو Ubuntu مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر وجدار حماية مضبوط باستخدام أداة UFW كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام MySQL مُثبَّت ومؤمَّن على الخادم كما هو موضح في مقال كيفية تثبيت MySQL على أوبنتو، وقد نفذنا الخطوات باستخدام مستخدم مُنشَأ وفق الطريقة الموضحة في الخطوة 3 من المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL، إذ ستعمل الأوامر المُقدمة في هذا المقال بنجاح مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند اختبارها على أنظمة مختلفة عن MySQL. ستحتاج أيضًا إلى قاعدة بيانات تحتوي على بعض الجداول المُحمَّلة ببيانات تجريبية نموذجية لتتمكن من التدرب على إنشاء العروض والتعامل معها، لذا اطّلع على القسم التالي للحصول على تفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة بيانات الاختبار المُستخدَمة في أمثلة هذا المقال. الاتصال بخادم MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، فاتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي كما يلي: $ ssh user@your_server_ip ثم افتح واجهة سطر أوامر خادم MySQL مع وضع اسم حساب مستخدم MySQL الخاص بك مكان user: $ mysql -u user -p أنشِئ قاعدة بيانات باسم views_db في موجّه الأوامر: mysql> CREATE DATABASE views_db; إذا أُنشئِت قاعدة البيانات بنجاح، فسيظهر خرج كما يلي: الخرج Query OK, 1 row affected (0.01 sec) يمكنك اختيار قاعدة البيانات views_db من خلال تنفيذ تعليمة USE التالية: mysql> USE views_db; ويكون الخرج كما يلي: الخرج Database changed اخترنا قاعدة بيانات views_db، وسننشئ جدولين ضمنها. لنفترض مثلًا أنك تدير خدمة رعاية للكلاب، فقررت استخدام قاعدة بيانات SQL لتخزين معلومات حول كل كلب مُسجَّل في الخدمة، بالإضافة إلى معلومات كل متخصص في رعاية الكلاب توظفه خدمتك، حيث نظّمت هذه المعلومات من خلال إنشاء جدولين: أحدهما يمثل الموظفين والآخر يمثل الكلاب التي تعتني بها خدمتك. سيحتوي الجدول الذي يمثل موظفيك على الأعمدة التالية: emp_id: رقم تعريف لكل موظف يقدّم رعايةً للكلاب، ونعبّر عنه باستخدام نوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي Primary Key للجدول، أي أن كل قيمة ستمثّل معرّفًا فريدًا للصف الخاص بها، وسيكون لهذا العمود أيضًا قيد UNIQUE مطبَّق عليه، إذ يجب أن تكون كل قيمة في المفتاح الرئيسي فريدة. emp_name: اسم الموظف، ونعبّر عنه باستخدام نوع البيانات varchar بحد أقصى 20 محرفًا. نفّذ تعليمة CREATE TABLE التالية لإنشاء جدول بالاسم employees ويحتوي على العمودين التاليين: mysql> CREATE TABLE employees ( mysql> emp_id int UNIQUE, mysql> emp_name varchar(20), mysql> PRIMARY KEY (emp_id) mysql> ); سيحتوي الجدول الآخر الذي يمثل الكلاب على الأعمدة الستة التالية: dog_id: رقم تعريف لكل كلب ويُعبَّر عنه بنوع البيانات int، وسيكون هذا العمود هو المفتاح الرئيسي للجدول dogs مثل العمود emp_id في الجدول employees. dog_name: اسم الكلب ويُعبَّر عنه باستخدام نوع البيانات varchar بحد أقصى 20 محرفًا. walker: يخزّن هذا العمود رقم معرّف الموظف الذي يرعى كل كلب. walk_distance: المسافة التي يجب أن يمشيها كل كلب عند اصطحابه للتمرين، ويُعبَّر عنه باستخدام نوع البيانات decimal، ويمكن أن تحتوي القيم في هذا العمود على ثلاثة أرقام على الأكثر مع وجود رقمين من هذه الأرقام على يمين الفاصلة العشرية. meals_perday: توفر هذه الخدمة لكل كلب عددًا معينًا من الوجبات كل يوم، حيث يحتوي هذا العمود على عدد الوجبات التي يجب أن يحصل عليها كل كلب يوميًا حسب طلب مالكه، ويستخدم نوع البيانات int فهو عدد صحيح. cups_permeal: يمثل هذا العمود عدد أكواب الطعام التي يجب أن يحصل عليها كل كلب في كل وجبة، ويُعبَّر عنه بنوع البيانات decimal مثل العمود walk_distance، ويمكن أن تحتوي القيم في هذا العمود على ما يصل إلى ثلاثة أرقام مع وجود رقمين من هذه الأرقام على يمين الفاصلة العشرية. نتأكد من أن العمود walker يحتوي على القيم التي تمثل أرقام معرّف الموظف الصالحة فقط من خلال تطبيق قيد مفتاح خارجي Foreign Key على العمود walker الذي يشير إلى العمود emp_ID الخاص بالجدول employees. يُعَد قيد المفتاح الخارجي طريقة للتعبير عن العلاقة بين جدولين من خلال اشتراط أن تكون القيم الموجودة في العمود الذي طُبِّق المفتاح الخارجي عليه موجودة في العمود الذي يشير إليه، حيث يشترط قيد FOREIGN KEY في المثال التالي أن تكون أيّ قيمة مضافة إلى العمود walker في الجدول dogs موجودةً في العمود emp_ID الخاص بالجدول employees. لننشئ جدولًا بالاسم dogs يحتوي على هذه الأعمدة باستخدام الأمر التالي: mysql> CREATE TABLE dogs ( mysql> dog_id int UNIQUE, mysql> dog_name varchar(20), mysql> walker int, mysql> walk_distance decimal(3,2), mysql> meals_perday int, mysql> cups_permeal decimal(3,2), mysql> PRIMARY KEY (dog_id), mysql> FOREIGN KEY (walker) mysql> REFERENCES employees(emp_ID) ); يمكنك الآن تحميل الجدولين ببعض البيانات التجريبية النموذجية. نفّذ عملية الإدخال INSERT INTO التالية لإضافة ثلاثة صفوف من البيانات تمثّل ثلاثة من موظفي الخدمة إلى الجدول employees: mysql> INSERT INTO employees mysql> VALUES mysql> (1, 'Peter'), mysql> (2, 'Paul'), mysql> (3, 'Mary'); ثم نفّذ العملية التالية لإدخال سبعة صفوف من البيانات في الجدول dogs: mysql> INSERT INTO dogs mysql> VALUES mysql> (1, 'Dottie', 1, 5, 3, 1), mysql> (2, 'Bronx', 3, 6.5, 3, 1.25), mysql> (3, 'Harlem', 3, 1.25, 2, 0.25), mysql> (4, 'Link', 2, 2.75, 2, 0.75), mysql> (5, 'Otto', 1, 4.5, 3, 2), mysql> (6, 'Juno', 1, 4.5, 3, 2), mysql> (7, 'Zephyr', 3, 3, 2, 1.5); وأصبحتَ الآن جاهزًا لمتابعة بقية هذا المقال والبدء في تعلّم كيفية استخدام العروض في لغة SQL. فهم وإنشاء العروض Views يمكن أن تصبح استعلامات SQL معقدة، ولكن إحدى الفوائد الرئيسية للغة SQL هي أنها تتضمن العديد من الخيارات والتعليمات التي تسمح لك بترشيح بياناتك بمستوى عالٍ من الدقة والتحديد. إذا كانت لديك استعلامات معقدة تريد تشغيلها بصورة متكررة، فقد يصبح الاضطرار إلى كتابتها باستمرار أمرًا مملًا، وإحدى الطرق لحل هذه المشكلات هي استخدام العروض. تُعَد العروض views جداولًا افتراضية كما ذكرنا سابقًا، وهذا يعني أنها تشبه الجداول وظيفيًا، ولكنها تمثّل نوعًا مختلفًا من هياكل البيانات لأن العرض لا يحتوي على أيّ بيانات خاصة به، فهو يسحب البيانات من جدول أساسي واحد أو أكثر، وتكون المعلومات الوحيدة حول العرض التي سيخزنها نظام إدارة قواعد البيانات DBMS هي هيكل العرض. تُسمَّى العروض أحيانًا بالاستعلامات المحفوظة Saved Queries، لأنها تمثّل الاستعلامات المحفوظة باسم مُحدَّد لتسهيل الوصول إليها. ليكن لدينا المثال التالي، تخيل أن أعمال رعاية الكلاب الخاصة بك ناجحة وتريد طباعة جدول يومي لجميع موظفيك، إذ يجب أن يحتوي هذا الجدول على كل كلب ترعاه الخدمة، والموظف المكلف برعايته، والمسافة التي يجب أن يمشيها كل كلب يوميًا، وعدد الوجبات التي يجب إطعامها لكل كلب يوميًا، وكمية الطعام التي ينبغي أن يحصل كل كلب في كل وجبة. استخدم مهاراتك في لغة SQL لإنشاء استعلام مع بياناتٍ تجريبية نموذجية من الخطوة السابقة لاسترجاع جميع هذه المعلومات للجدول، ولاحظ أن هذا الاستعلام يتضمن صيغة JOIN لسحب البيانات من الجدولين employees و dogs: mysql> SELECT emp_name, dog_name, walk_distance, meals_perday, cups_permeal mysql> FROM employees JOIN dogs ON emp_ID = walker; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | cups_permeal | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 1.00 | | Peter | Otto | 4.50 | 3 | 2.00 | | Peter | Juno | 4.50 | 3 | 2.00 | | Paul | Link | 2.75 | 2 | 0.75 | | Mary | Bronx | 6.50 | 3 | 1.25 | | Mary | Harlem | 1.25 | 2 | 0.25 | | Mary | Zephyr | 3.00 | 2 | 1.50 | +----------+----------+---------------+--------------+--------------+ 7 rows in set (0.00 sec) لنفترض أنه يجب تنفيذ هذا الاستعلام بشكل متكرر، إذ قد يصبح أمرًا مملًا إذا اضطررت إلى كتابة الاستعلام مرارًا وتكرارًا، وخاصةً عند إجراء تعليمات استعلام أطول وأكثر تعقيدًا، وإذا أردتَ إجراء تعديلات طفيفة على الاستعلام أو التوسّع فيه، فقد يكون الأمر مملًا عند استكشاف الأخطاء وإصلاحها مع وجود العديد من الاحتمالات للأخطاء الصياغية. يمكن أن يكون العرض مفيدًا في مثل هذه الحالات، لأنه يُعَد جدولًا مشتقًا من نتائج الاستعلام. تستخدم معظم أنظمة RDBMS الصيغة التالية لإنشاء العروض: CREATE VIEW view_name AS SELECT statement; يمكنك بعد تعليمة CREATE VIEW اختيار اسمٍ للعرض الذي ستستخدمه للإشارة إليه لاحقًا، ثم تدخِل الكلمة المفتاحية AS، ثم تضع استعلام SELECT الذي تريد حفظ خرجه. يمكن أن يكون الاستعلام الذي تستخدمه لإنشاء عرضك أيّ تعليمة SELECT صالحة، ويمكن أن تستعلم التعليمة التي تضمّنها عن جدول أساسي واحد أو أكثر طالما أنك تستخدم الصيغة الصحيحة. جرّب إنشاء عرض باستخدام استعلام المثال السابق، حيث تسمّي عملية CREATE VIEW العرض بالاسم walking_schedule: mysql> CREATE VIEW walking_schedule mysql> AS mysql> SELECT emp_name, dog_name, walk_distance, meals_perday, cups_permeal mysql> FROM employees JOIN dogs mysql> ON emp_ID = walker; ستتمكّن بعد ذلك من استخدام هذا العرض والتفاعل معه كما تفعل مع أيّ جدول آخر، فمثلًا يمكنك تنفيذ الاستعلام التالي لإعادة جميع البيانات الموجودة في العرض: mysql> SELECT * FROM walking_schedule; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | cups_permeal | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 1.00 | | Peter | Otto | 4.50 | 3 | 2.00 | | Peter | Juno | 4.50 | 3 | 2.00 | | Paul | Link | 2.75 | 2 | 0.75 | | Mary | Bronx | 6.50 | 3 | 1.25 | | Mary | Harlem | 1.25 | 2 | 0.25 | | Mary | Zephyr | 3.00 | 2 | 1.50 | +----------+----------+---------------+--------------+--------------+ 7 rows in set (0.00 sec) يُعَد هذا العرض مشتقًا من جدولين آخرين، ولكنك لن تتمكّن من الاستعلام عن العرض لأيّ بيانات من هذين الجدولين إن لم تكن موجودة مسبقًا في هذا العرض. يحاول الاستعلام التالي استرجاع العمود walker من العرض walking_schedule، ولكن سيفشل هذا الاستعلام لأن العرض لا يحتوي على أيّ أعمدة بهذا الاسم: mysql> SELECT walker FROM walking_schedule; الخرج ERROR 1054 (42S22): Unknown column 'walker' in 'field list' يعيد هذا الخرج رسالة خطأ لأن العمود walker هو جزء من الجدول dogs، ولكنه غير مُضمَّنٍ في العرض الذي أنشأناه. يمكنك أيضًا تنفيذ الاستعلامات التي تتضمّن دوالًا تجميعية Aggregate Functions تعالج البيانات ضمن العرض، يستخدم المثال التالي الدالة التجميعية MAX مع عبارة GROUP BY للعثور على أطول مسافة يجب على الموظف أن يمشيها في يوم محدّد: mysql> SELECT emp_name, MAX(walk_distance) AS longest_walks mysql> FROM walking_schedule GROUP BY emp_name; الخرج +----------+---------------+ | emp_name | longest_walks | +----------+---------------+ | Peter | 5.00 | | Paul | 2.75 | | Mary | 6.50 | +----------+---------------+ 3 rows in set (0.00 sec) توجد فائدة أخرى للعروض كما ذكرنا سابقًا، وهي أنه يمكنك استخدامها لتقييد وصول مستخدم قاعدة البيانات إلى العرض فقط بدلًا من الوصول إلى الجدول أو قاعدة البيانات بأكملها. لنفترض مثلًا أنك وظّفتَ مدير مكتب لمساعدتك في إدارة الجدول الزمني، وتريد أن يصل إلى معلومات الجدول دون الوصول لأي بيانات أخرى في قاعدة البيانات، حيث يمكنك إنشاء حساب مستخدم جديد له في قاعدة بياناتك كما يلي: mysql> CREATE USER 'office_mgr'@'localhost' IDENTIFIED BY 'password'; يمكنك بعد ذلك منح هذا المستخدم الجديد صلاحية وصول للقراءة إلى العرض walking_schedule فقط باستخدام التعليمة GRANT كما يلي: mysql> GRANT SELECT ON views_db.walking_schedule to 'office_mgr'@'localhost'; وبالتالي سيتمكّن الشخص الذي لديه صلاحية الوصول إلى حساب مستخدم MySQL الذي هو office_mgr من تنفيذ استعلامات SELECT في العرض walking_schedule فقط. تغيير وحذف العروض Views إذا أضفتَ أو غيّرتَ بياناتٍ في أحد الجداول التي نشتق العرض منها، فستُضاف أو تُحدَّث البيانات ذات الصلة في العرض تلقائيًا. نفّذ الأمر INSERT INTO التالي لإضافة صف آخر إلى الجدول dogs: mysql> INSERT INTO dogs VALUES (8, 'Charlie', 2, 3.5, 3, 1); يمكنك بعد ذلك استرجاع جميع البيانات من العرض walking_schedule مرة أخرى كما يلي: mysql> SELECT * FROM walking_schedule; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | cups_permeal | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 1.00 | | Peter | Otto | 4.50 | 3 | 2.00 | | Peter | Juno | 4.50 | 3 | 2.00 | | Paul | Link | 2.75 | 2 | 0.75 | | Paul | Charlie | 3.50 | 3 | 1.00 | | Mary | Bronx | 6.50 | 3 | 1.25 | | Mary | Harlem | 1.25 | 2 | 0.25 | | Mary | Zephyr | 3.00 | 2 | 1.50 | +----------+----------+---------------+--------------+--------------+ 8 rows in set (0.00 sec) لاحظ وجود صف آخر في مجموعة نتائج الاستعلام، والذي يمثّل البيانات التي أضفتها إلى الجدول dogs، ولكن لا يزال العرض يسحب البيانات ذاتها من الجداول الأساسية نفسها، لذلك لم تغيّر هذه العملية العرض. تسمح لك العديد من أنظمة RDBMS بتحديث هيكل العرض بعد إنشائه باستخدام صيغة CREATE OR REPLACE VIEW: mysql> CREATE OR REPLACE VIEW view_name mysql> AS mysql> new SELECT statement إذا كان العرض الذي اسمه view_name موجودًا مسبقًا في هذه الصيغة، فسيحدّث نظام قاعدة البيانات هذا العرض بحيث يمثّل البيانات التي تعيدها التعليمة new SELECT statement. إذا لم يكن العرض بهذا الاسم موجودًا، فسينشئ نظام إدارة قواعد البيانات DBMS عرضًا جديدًا. لنفترض أنك تريد تغيير العرض walking_schedule ليسرد إجمالي كمية الطعام التي تناولها كل كلب على مدار اليوم بدلًا من سرد عدد أكواب الطعام التي يتناولها كل كلب في كل وجبة، ويمكنك تغيير العرض باستخدام الأمر التالي: mysql> CREATE OR REPLACE VIEW walking_schedule mysql> AS mysql> SELECT emp_name, dog_name, walk_distance, meals_perday, (cups_permeal * mysql> meals_perday) AS total_kibble mysql> FROM employees JOIN dogs ON emp_ID = walker; إذا أجربتَ الآن استعلامًا على هذا العرض، فستمثّل مجموعة النتائج بيانات العرض الجديدة كما يلي: mysql> SELECT * FROM walking_schedule; الخرج +----------+----------+---------------+--------------+--------------+ | emp_name | dog_name | walk_distance | meals_perday | total_kibble | +----------+----------+---------------+--------------+--------------+ | Peter | Dottie | 5.00 | 3 | 3.00 | | Peter | Otto | 4.50 | 3 | 6.00 | | Peter | Juno | 4.50 | 3 | 6.00 | | Paul | Link | 2.75 | 2 | 1.50 | | Paul | Charlie | 3.50 | 3 | 3.00 | | Mary | Bronx | 6.50 | 3 | 3.75 | | Mary | Harlem | 1.25 | 2 | 0.50 | | Mary | Zephyr | 3.00 | 2 | 3.00 | +----------+----------+---------------+--------------+--------------+ 8 rows in set (0.00 sec) يمكنك حذف العروض باستخدام صيغة DROP مثل معظم هياكل البيانات الأخرى التي يمكنك إنشاؤها في لغة SQL، وإليك مثالًا: DROP VIEW view_name; يمكنك مثلًا حذف العرض walking_schedule باستخدام الأمر التالي: mysql> DROP VIEW walking_schedule; يؤدي الأمر السابق إلى إزالة العرض walking_schedule من قاعدة بياناتك، ولكنه لن يحذف أيًّا من بيانات قاعدة بياناتك المتعلقة بالعرض إلّا إذا أزلتها من الجداول الأساسية. الخلاصة تعلّمنا في هذا المقال ما هي عروض SQL وكيفية إنشائها والاستعلام عنها وتغييرها وحذفها من قاعدة البيانات، وتعرّفنا على فوائد العروض، وأنشأنا مستخدم MySQL الذي يمكنه فقط قراءة البيانات من العرض التجريبي الذي أنشأناه. يجب أن تعمل الأوامر الواردة في أمثلة هذا المقال على معظم قواعد البيانات العلاقية، ولكن يجب أن تدرك أن كل قاعدة بيانات SQL لها تقديمها الفريد من هذه اللغة، لذا يجب عليك الرجوع إلى التوثيق الرسمي لنظام إدارة قواعد البيانات DBMS الخاص بك للحصول على وصف أشمل لكل أمر ومجموعته الكاملة من الخيارات. ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب للمزيد حول كيفية التعامل مع لغة SQL. ترجمة -وبتصرف- للمقال How To Use Views in SQL لصاحبه Mark Drake. اقرأ أيضًا الاستعلام عن البيانات في SQL جلب الاستعلامات عبر SELECT في SQL المرجع المتقدم إلى لغة SQL لغة معالجة البيانات DML الخاصة بلغة SQL -
 قد تضطر في بعض الأحيان إلى التعامل مع قيم تمثل تواريخ أو أوقات محددة لدى العمل مع قواعد البيانات العلاقية ولغة الاستعلام البنيوية SQL. فعلى سبيل المثال، قد ترغب في حساب إجمالي الساعات المُستغرقة في أداء نشاطٍ ما، أو قد تحتاج إلى مُعالجة قيم التواريخ أو الأوقات باستخدام المعاملات الرياضية ودوال التجميع لحساب مجموعها أو متوسطها. ستتعلم في هذا المقال كيفية استخدام التواريخ والأوقات في SQL. إذ ستبدأ بإجراء العمليات الحسابية واستخدام دوال متنوعة مع التواريخ والأوقات باستخدام تعليمة SELECT وحدها. لتتدرب بعد ذلك على تنفيذ استعلامات على بياناتٍ نموذجية تجريبية، وستتعلم كيفية استخدام دالة CAST لجعل النتائج أيسر للقراءة. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على الأمثلة حول كيفية استخدام التاريخ والوقت في هذا المقال. لذا ننصحك بمتابعة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم datetimeDB: mysql> CREATE DATABASE datetimeDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات datetimeDB، نفّذ تعليمة USE التالية: mysql> USE datetimeDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات datetimeDB، لننشئ جدولًا ضمنها. كمثال في مقالنا هذا، سننشئ جدولًا يُسجّل نتائج اثنين من العدائين في مختلف السباقات التي شاركا بها على مدار عام. سيضم الجدول الأعمدة السبعة التالية: race_id: يُمثّل قيمًا من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. runner_name: مُخصص لأسماء هذين العدّائين وهما في مثالنا أحمد ومحمد وذلك باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. race_name: يُخزّن أسماء السباقات باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. start_day: لتسجيل تاريخ السباق باليوم والشهر والسنة باستخدام نمط البيانات DATE. إذ يتبع نمط البيانات هذا الصيغة القياسية التالية: أربعة أرقام للسنة، وحد أقصى من رقمين لكل من الشهر واليوم (YYYY-MM-DD). start_time: يُمثل وقت بداية السباق باستخدام نمط بيانات TIME بالساعات والدقائق والثواني (HH:MM:SS). ويستخدم نمط البيانات هذا الوقت بصيغة 24 ساعة، أي 15:00 على سبيل المثال للتعبير عن الساعة 3:00 مساءً. total_miles: يعرض المسافة الإجمالية لكل سباق باستخدام نمط بيانات decimal، وذلك نظرًا لأن العديد من المسافات الإجمالية للسباقات ليست بأرقامٍ صحيحة. ويُمكّننا نمط البيانات decimal من تمثيل المسافات بدقة تصل إلى ثلاثة أرقام ككل، منها رقم واحد إلى يمين الفاصلة العشرية، أي بدقة تصل إلى عُشر الميل. end_time: يُسجّل وقت انتهاء كل عدّاء من السباق باستخدام نمط بيانات TIMESTAMP، الذي يدمج التاريخ والوقت ضمن تنسيق واحد يجمع بين صيغتي DATE وTIME مُشتملًا على السنة والشهر واليوم متبوعًا بالساعة والدقيقة والثانية، وهو يعتمد في ذلك على الصيغة القياسية (YYYY-MM-DD HH:MM:SS) لتقديم توقيت دقيق للحظة انتهاء السباق. ولإنشاء هذا الجدول، لننفّذ الأمر CREATE TABLE التالي: mysql> CREATE TABLE race_results ( mysql> race_id int, mysql> runner_name varchar(30), mysql> race_name varchar(20), mysql> start_day DATE, mysql> start_time TIME, mysql> total_miles decimal(3, 1), mysql> end_time TIMESTAMP, mysql> PRIMARY KEY (race_id) mysql> ); ثم املأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO race_results mysql> (race_id, runner_name, race_name, start_day, start_time, total_miles, end_time) mysql> VALUES mysql> (1, 'Ahmad', '1600_meters', '2022-09-18', '7:00:00', 1.0, '2022-09-18 7:06:30'), mysql> (2, 'Ahmad', '5K', '2022-10-19', '11:00:00', 3.1, '2022-10-19 11:22:31'), mysql> (3, 'Ahmad', '10K', '2022-11-20', '10:00:00', 6.2, '2022-11-20 10:38:05'), mysql> (4, 'Ahmad', 'half_marathon', '2022-12-21', '6:00:00', 13.1, '2022-12-21 07:39:04'), mysql> (5, 'Ahmad', 'full_marathon', '2023-01-22', '8:00:00', 26.2, '2023-01-22 11:23:10'), mysql> (6, 'Mohammad', '1600_meters', '2022-09-18', '7:00:00', 1.0, '2022-09-18 7:07:15'), mysql> (7, 'Mohammad', '5K', '2022-10-19', '11:00:00', 3.1, '2022-10-19 11:30:50'), mysql> (8, 'Mohammad', '10K', '2022-11-20', '10:00:00', 6.2, '2022-11-20 11:10:17'), mysql> (9, 'Mohammad', 'half_marathon', '2022-12-21', '6:00:00', 13.1, '2022-12-21 08:11:57'), mysql> (10, 'Mohammad', 'full_marathon', '2023-01-22', '8:00:00', 26.2, '2023-01-22 12:02:10'); الخرج Query OK, 10 rows affected (0.00 sec) Records: 10 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء التدرّب على استخدام بعض العمليات الحسابية والدوال مع التواريخ في SQL. استخدام العمليات الحسابية مع التواريخ والأوقات من الممكن معالجة قيم التواريخ والأوقات في SQL باستخدام التعابير الرياضية، ولن تحتاج سوى إلى العامل الرياضي والقيم المطلوب حسابها. كمثال، لو أردنا تحديد تاريخ يأتي بعد عدد محدد من الأيام من تاريخٍ آخر. يأخذ الاستعلام التالي قيمة تاريخ معينة (2022-10-05) ويضيف إليها 17، لإعادة قيمة التاريخ الذي يأتي بعد سبعة عشر يومًا من التاريخ المحدد في الاستعلام. وتجدر الملاحظة إلى أننا حددنا 2022-10-05 هنا كقيمة من نوع DATE لضمان عدم تفسير نظام إدارة قاعدة البيانات لها كنص أو أي نوع بيانات آخر: mysql> SELECT DATE '2022-10-05' + 17 AS new_date; الخرج +----------+ | new_date | +----------+ | 20221022 | +----------+ 1 row in set (0.01 sec) نلاحظ من هذا الخرج أنّ اليوم الذي يأتي بعد سبعة عشر يومًا من تاريخ 2022-10-05 هو 2022-10-22، أو 22 أكتوبر 2022. كمثال آخر، بفرض أننا نريد حساب إجمالي الساعات بين وقتين مختلفين من خلال طرحهما من بعضهما البعض. افترضنا في الاستعلام التالي أنّ 11:00 هو الوقت الأول و3:00 هو الوقت الثاني. ولا بدّ في هذه الحالة من تحديد أن كلاهما من نمط البيانات TIME للحصول على الفرق بالساعات: mysql> SELECT TIME '11:00' - TIME '3:00' AS time_diff; الخرج +-----------+ | time_diff | +-----------+ | 80000 | +-----------+ 1 row in set (0.00 sec) يُظهر هذا الخرج أن الفارق بين الساعة 11:00 والساعة 3:00 هو 80000، أو 8 ساعات. الآن سنطبّق استعلامات على بياناتنا النموذجية بهدف التدرّب على كيفية استخدام العمليات الحسابية على معلومات التاريخ والوقت. بالنسبة للاستعلام الأول، سنحسب الزمن الكلي الذي استغرقه العداءان لإنهاء كل سباق من خلال طرح زمن الانتهاء end_time من زمن البدء start_time، على النحو التالي: mysql> SELECT runner_name, race_name, end_time - start_time mysql> AS total_time mysql> FROM race_results; الخرج +-------------+---------------+----------------+ | runner_name | race_name | total_time | +-------------+---------------+----------------+ | Ahmad | 1600_meters | 20220918000630 | | Ahmad | 5K | 20221019002231 | | Ahmad | 10K | 20221120003805 | | Ahmad | half_marathon | 20221221013904 | | Ahmad | full_marathon | 20230122032310 | | Mohammad | 1600_meters | 20220918000715 | | Mohammad | 5K | 20221019003050 | | Mohammad | 10K | 20221120011017 | | Mohammad | half_marathon | 20221221021157 | | Mohammad | full_marathon | 20230122040210 | +-------------+---------------+----------------+ 10 rows in set (0.00 sec) ستلاحظ أن القيم المُعادة في عمود total_time تظهر على نحوٍ مطوّل وقد تصعب قراءتها. لذا سنشرح في قسمٍ لاحق ضمن هذا المقال كيفية استخدام دالة CAST لتنسيق هذه القيم بطريقة تجعلها أوضح وأسهل للقراءة. بفرض أنّ تركيزنا منصب على أداء العدّائين في السباقات ذات المسافات الأطول، من قبيل سباقات نصف الماراثون والماراثون الكامل، سنستخدم استعلامًا لاسترجاع هذه البيانات على وجه الخصوص. إذ سنطرح زمن الانتهاء end_time من زمن البدء start_time مُستخدمين بنية WHERE للتحديد الدقيق للنتائج، لتشمل فقط السباقات التي تزيد مسافتها في العمود total_miles عن 12 ميل: mysql> SELECT runner_name, race_name, end_time - start_time AS half_full_results mysql> FROM race_results mysql> WHERE total_miles > 12; الخرج +-------------+---------------+-------------------+ | runner_name | race_name | half_full_results | +-------------+---------------+-------------------+ | Ahmad | half_marathon | 20221221013904 | | Ahmad | full_marathon | 20230122032310 | | Mohammad | half_marathon | 20221221021157 | | Mohammad | full_marathon | 20230122040210 | +-------------+---------------+-------------------+ 4 rows in set (0.00 sec) أجرينا في هذا القسم بعض العمليات الحسابية على التواريخ والأوقات باستخدام تعليمة SELECT وذلك لأغراض عملية على البيانات النموذجية التجريبية. فيما يلي، ستتدرب على استخدام استعلامات تشمل دوال متنوعة للتواريخ والأوقات. استخدام دوال التاريخ والوقت وتعابير الفترات الزمنية هناك العديد من الدوال التي يُمكن استخدامها لإيجاد ومعالجة قيم التواريخ والأوقات في SQL. إذ تُستخدم الدوال SQL على نحوٍ أساسي لمعالجة البيانات أو التعامل معها والتحكم بها، وتختلف الدوال المتوفرة باختلاف تقديم SQL المُستخدم. بيد أنّ معظم تقديمات SQL تتيح استرجاع القيم الحالية للتاريخ والوقت من خلال الاستعلام عن قيم دالتيّ current_date وcurrent_time. على سبيل المثال، لمعرفة تاريخ اليوم، فالصياغة بسيطة وتتألف فقط من تعليمة SELECT ودالة current_date كما في المثال التالي: mysql> SELECT current_date; الخرج +--------------+ | current_date | +--------------+ | 2022-02-15 | +--------------+ 1 row in set (0.00 sec) كما يمكننا إيجاد الوقت الحالي باستخدام نفس الصياغة اعتمادًا على الدالة current_time، على النحو التالي: mysql> SELECT current_time; الخرج +--------------+ | current_time | +--------------+ | 17:10:20 | +--------------+ 1 row in set (0.00 sec) أمّا إذا كنت تفضل الاستعلام عن كل من التاريخ والوقت معًا في خرجٍ واحد، فاستخدم الدالة current_timestamp: mysql> SELECT current_timestamp; الخرج +---------------------+ | current_timestamp | +---------------------+ | 2022-02-15 19:09:58 | +---------------------+ 1 row in set (0.00 sec) كما يمكن استخدام دوال التاريخ والوقت كتلك المُستخدمة أعلاه ضمن دوال حسابية على نحوٍ مشابه للقسم السابق من مقالنا. فعلى سبيل المثال، بفرض أنّنا نريد معرفة التاريخ قبل 11 يومًا من تاريخ اليوم الحالي، فيمكننا استخدام نفس الصيغة المُستخدمة سابقًا للاستعلام عن قيمة الدالة current_date مطروحًا منها العدد 11 لإيجاد التاريخ قبل أحد عشر يومًا: mysql> SELECT current_date - 11; الخرج +-------------------+ | current_date - 11 | +-------------------+ | 20220206 | +-------------------+ 1 row in set (0.01 sec) يُشير هذا الخرج لكون التاريخ قبل 11 يومًا من current_date (وقت كتابة هذا النص) هو 2022-02-06، أو 6 فبراير 2022. لنحاول الآن تنفيذ نفس العملية مستبدلين الدالة current_date بالدالة current_time: mysql> SELECT current_time - 11; الخرج +-------------------+ | current_time - 11 | +-------------------+ | 233639 | +-------------------+ 1 row in set (0.00 sec) يُظهر هذا الخرج أنه عند طرح 11 من قيمة current_time، يُطرح فعليًا مقدار 11 ثانية. في حين تُفسّر العملية التي نفذناها سابقًا باستخدام الدالة current_date العدد 11 على أنه أيام وليس ثواني. هذا التباين في تفسير الأرقام لدى التعامل مع دوال التاريخ والوقت قد يكون مربكًا. فبدلاً من اضطرارك لمعالجة قيم التاريخ والوقت باستخدام الحسابات الرياضية بهذا الشكل، توفّر العديد من أنظمة إدارة قواعد البيانات وضوحًا أكبر من خلال استخدام تعابير الفترات الزمنية INTERVAL. تسمح تعابير الفترات الزمنية INTERVAL بإيجاد ما سيكون عليه التاريخ أو الوقت قبل أو بعد فترة محددة من تعبير تاريخ أو وقت معين. وتأخذ هذه التعابير الصيغة التالية: INTERVAL `value` `unit` على سبيل المثال، لإيجاد التاريخ بعد خمسة أيام من الآن، يُمكننا تشغيل الاستعلام التالي: mysql> SELECT current_date + INTERVAL '5' DAY AS "5_days_from_today"; أوجدنا في هذا المثال قيمة current_date، ثم أضفنا إليها تعبير الفترة INTERVAL '5' DAY. ما سيُعيد التاريخ بعد خمسة أيام من الآن: الخرج +-------------------+ | 5_days_from_today | +-------------------+ | 2022-03-06 | +-------------------+ 1 row in set (0.00 sec) وهذا أقل غموضًا بكثير من الاستعلام التالي، الذي ينتج عنه خرج مشابه، وحتى إن لم يكن مطابقًا تمامًا: mysql> SELECT current_date + 5 AS "5_days_from_today"; الخرج +-------------------+ | 5_days_from_today | +-------------------+ | 20220306 | +-------------------+ 1 row in set (0.00 sec) يُلاحظ أنه يُمكن أيضًا طرح فترات زمنية من التواريخ أو الأوقات لإيجاد قيم قبل التاريخ المحدد: mysql> SELECT current_date - INTERVAL '7' MONTH AS "7_months_ago"; الخرج +--------------+ | 7_months_ago | +--------------+ | 2021-08-01 | +--------------+ 1 row in set (0.00 sec) تعتمد الوحدات المتاحة لك لاستخدامها في تعابير INTERVAL على نظام إدارة قواعد البيانات DBMS الذي اخترته، ولكن تتوفّر في معظم الأنظمة خيارات من قبيل HOUR وMINUTE وSECOND: mysql> SELECT current_time + INTERVAL '6' HOUR AS "6_hours_from_now", mysql> current_time - INTERVAL '5' MINUTE AS "5_minutes_ago", mysql> current_time + INTERVAL '20' SECOND AS "20_seconds_from_now"; الخرج +------------------+---------------+---------------------+ | 6_hours_from_now | 5_minutes_ago | 20_seconds_from_now | +------------------+---------------+---------------------+ | 07:51:43 | 01:46:43 | 01:52:03.000000 | +------------------+---------------+---------------------+ 1 row in set (0.00 sec) الآن وبعد أن اطلعت على تعابير الفترات الزمنية وتعرفت على بعض دوال التاريخ والوقت، الفرصة أمامك لتتدرّب مستخدمًا البيانات التجريبية النموذجية التي أدرجتها في الخطوة الأولى. استخدام الدالة CAST ودوال التجميع مع التاريخ والوقت بالعودة إلى المثال الثالث من قسم استخدام العمليات الحسابية مع التاريخ والوقت، حين نفّذنا الاستعلام التالي لطرح زمن الانتهاء end_time من زمن البدء start_time لحساب إجمالي الساعات التي أكملها كل عداء لكل سباق. حصلنا على العمود total_time والذي يتضمّن ناتج طويل جدًا يتبع نمط البيانات TIMESTAMP المُحدد لهذا العمود من الجدول: mysql> SELECT runner_name, race_name, end_time - start_time mysql> AS total_time mysql> FROM race_results; الخرج +-------------+---------------+----------------+ | runner_name | race_name | total_time | +-------------+---------------+----------------+ | Ahmad | 1600_meters | 20220918000630 | | Ahmad | 5K | 20221019002231 | | Ahmad | 10K | 20221120003805 | | Ahmad | half_marathon | 20221221013904 | | Ahmad | full_marathon | 20230122032310 | | Mohammad | 1600_meters | 20220918000715 | | Mohammad | 5K | 20221019003050 | | Mohammad | 10K | 20221120011017 | | Mohammad | half_marathon | 20221221021157 | | Mohammad | full_marathon | 20230122040210 | +-------------+---------------+----------------+ 10 rows in set (0.00 sec) ونظرًا لأنّنا نُجري عملية على عمودين بأنماط بيانات مختلفة (عمود end_time يحمل قيم من نمط TIMESTAMP وعمود start_time يحمل قيم من نمط TIME)، فإنّ قاعدة البيانات لا تعرف أي نمط بيانات يجب أن تستخدم لدى طباعة نتيجة العملية. لذا تحوّل كلا القيمتين إلى أعداد صحيحة لتتمكن من تنفيذ العملية، مما ينتج عنه الأرقام الطويلة في عمود total_time. وكحل لجعل هذه البيانات أوضح للقراءة والتفسير، يمكنك استخدام دالة CAST لتحويل هذه القيم الطويلة من الأعداد الصحيحة إلى نمط بيانات TIME. وللقيام بذلك، ابدأ بالدالة CAST ثم اتبعها مباشرةً بقوس فتح ثم القيم التي تريد تحويلها ثم الكلمة المفتاحية AS متبوعة باسم نمط البيانات الذي تريد التحويل إليه. الاستعلام التالي مطابق للمثال السابق، ولكنه يستخدم دالة CAST لتحويل عمود total_time إلى نمط بيانات TIME: mysql> SELECT runner_name, race_name, CAST(end_time - start_time AS time) mysql> AS total_time mysql> FROM race_results; الخرج +-------------+---------------+------------+ | runner_name | race_name | total_time | +-------------+---------------+------------+ | Ahmad | 1600_meters | 00:06:30 | | Ahmad | 5K | 00:22:31 | | Ahmad | 10K | 00:38:05 | | Ahmad | half_marathon | 01:39:04 | | Ahmad | full_marathon | 03:23:10 | | Mohammad | 1600_meters | 00:07:15 | | Mohammad | 5K | 00:30:50 | | Mohammad | 10K | 01:10:17 | | Mohammad | half_marathon | 02:11:57 | | Mohammad | full_marathon | 04:02:10 | +-------------+---------------+------------+ 10 rows in set (0.00 sec) حوّلت الدالة CAST قيم البيانات في الخرج أعلاه إلى نمط البيانات TIME، ما جعلها أسهل للقراءة والفهم. لنستخدم الآن بعضًا من دوال التجميع مع دالة CAST بهدف إيجاد أقصر وأطول توقيت وإجمالي الوقت لكل عدّاء. لنستعلم بدايةً عن أصغر (أو أقصر) مدة زمنية مستغرقة باستخدام دالة التجميع MIN. ومجددًا لا بدّ من استخدام الدالة CAST هنا لتحويل قيم البيانات من النمط TIMESTAMP إلى النمط TIME مما يجعلها أوضح. وتجدر الملاحظة إلى أنّه عند استخدام دالتين كما في هذا المثال، تتطلب العملية استخدام زوجين من الأقواس الهلالية، إذ يجب أن تكون عملية حساب إجمالي الساعات المُتمثلة في طرح زمن البدء من زمن الانتهاء (end_time - start_time) متداخلةً ضمن إحداها. وأخيرًا، سنضيف بنية GROUP BY لتنظيم هذه القيم بناءً على عمود runner_name بحيث يعرض الخرج نتائج سباقات كلا العدّائين: mysql> SELECT runner_name, MIN(CAST(end_time - start_time AS time)) AS min_time mysql> FROM race_results GROUP BY runner_name; الخرج +-------------+----------+ | runner_name | min_time | +-------------+----------+ | Ahmad | 00:06:30 | | Mohammad | 00:07:15 | +-------------+----------+ 2 rows in set (0.00 sec) يُظهر هذا الخرج أقصر زمن لكل عدّاء، في هذه الحالة الحد الأدنى هو ست دقائق وثلاثون ثانية لأحمد، وسبع دقائق وخمس عشرة ثانية لمحمد. الآن ولإيجاد أطول زمن لكل عدّاء، يمكننا استخدام نفس الصيغة كما في الاستعلام السابق مستبدلين الدالة MIN بالدالة MAX: mysql> SELECT runner_name, MAX(CAST(end_time - start_time AS time)) AS max_time mysql> FROM race_results GROUP BY runner_name; الخرج +-------------+----------+ | runner_name | max_time | +-------------+----------+ | Ahmad | 03:23:10 | | Mohammad | 04:02:10 | +-------------+----------+ 2 rows in set (0.00 sec) يُشير هذا الخرج أن أطول زمن جري لأحمد بلغ كإجمالي ثلاث ساعات وثلاث وعشرين دقيقة وعشر ثوانٍ؛ ولمحمد كان أربع ساعات ودقيقتين وعشر ثوانٍ. أمّا الآن، لنستعلم عن بعض المعلومات العامة (الخلاصة) حول إجمالي الساعات التي قضاها كل عدّاء في الجري. سندمج في هذا الاستعلام دالة التجميع SUM لإيجاد المجموع الإجمالي للساعات بناءً على الفرق بين end_time وstart_time، كما سنستخدم الدالة CAST لتحويل هذه قيم البيانات هذه إلى نمط البيانات TIME. كما لم ننسَ تضمين GROUP BY لتنظيم قيم نتائج كلا العدّاءين: mysql> SELECT runner_name, SUM(CAST(end_time - start_time AS time)) mysql> AS total_hours FROM race_results GROUP BY runner_name; الخرج +-------------+-------------+ | runner_name | total_hours | +-------------+-------------+ | Ahmad | 52880 | | Mohammad | 76149 | +-------------+-------------+ 2 rows in set (0.00 sec) يُبيّن هذا الخرج على نحوٍ مثير للاهتمام كيفية تفسير MySQL للنتائج، والتي في الواقع تحسب الزمن الإجمالي في هيئة أعداد صحيحة. فلو قرأنا هذه النتائج على أنها أزمنة، فإنّ الرقم المُعبّر عن إجمالي زمن أحمد يُفصّل إلى خمس ساعات وثمان وعشرين دقيقة وثمانين ثانية؛ وزمن محمد يُفصّل إلى سبع ساعات وواحد وستين دقيقة وتسع وأربعين ثانية. ومن الواضح أنّ هذا التفصيل للأزمنة لا يبدو منطقيًا وفقًا للقيم الفعلية، مما يشير إلى أنّ MySQL تعاملت مع الأزمنة كأعداد صحيحة. أمّا إذا جربنا الأمر عينه في نظام إدارة قواعد بيانات مختلف، من قبيل PostgreSQL على سبيل المثال، فسيبدو الاستعلام مختلفًا قليلًا: postgres=# SELECT runner_name, SUM(CAST(end_time - start_time AS time)) postgres=# AS total_hours FROM race_results GROUP BY runner_name; الخرج runner_name | total_hours -------------+------------- Mohammad | 10:01:44 Ahmad | 06:09:20 (2 rows) يُفسّر الاستعلام في PostgreSQL القيم كأزمنة في هذه الحالة، وتُحسب على هذا الأساس، إذ يمكن تفصيل نتائج محمد إلى إجمالي عشر ساعات ودقيقة واحدة وأربع وأربعين ثانية؛ وزمن أحمد إلى ست ساعات وتسع دقائق وعشرين ثانية. وما هذا سوى مثال حول كيفية تفسير تنفيذات أنظمة إدارة قواعد البيانات المختلفة للقيم البيانات على نحوٍ مختلف حتى ولو كانت تستخدم نفس الاستعلام ونفس مجموعة البيانات. الخلاصة لعلّ فهم كيفية استخدام التاريخ والوقت في SQL مفيد لدى الاستعلام عن نتائج محددة مثل الدقائق أو الثواني أو الساعات أو الأيام أو الأشهر أو السنوات، أو مزيج من كل هذه الوحدات. ناهيك عن وجود العديد من الدوال المتاحة للتواريخ والأوقات والتي تسهّل العثور على قيم معينة، من قبيل التاريخ أو الوقت الحالي. ورغم استخدامنا في هذا المقال لعمليات حسابية بسيطة مثل الجمع والطرح على التواريخ والأوقات في SQL، ولكن يمكنك استخدام قيم التاريخ والوقت مع أي تعبير رياضي. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Work with Dates and Times in SQL لصاحبه Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: كيفية استخدام التعابير الرياضية والدوال التجميعية في SQL أنواع البيانات في SQL دوال التعامل مع البيانات في SQL نظرة سريعة على لغة الاستعلامات الهيكلية SQL التعامل مع الوقت والتاريخ في PHP معالجة الأخطاء والتعديل على قواعد البيانات في SQL
قد تضطر في بعض الأحيان إلى التعامل مع قيم تمثل تواريخ أو أوقات محددة لدى العمل مع قواعد البيانات العلاقية ولغة الاستعلام البنيوية SQL. فعلى سبيل المثال، قد ترغب في حساب إجمالي الساعات المُستغرقة في أداء نشاطٍ ما، أو قد تحتاج إلى مُعالجة قيم التواريخ أو الأوقات باستخدام المعاملات الرياضية ودوال التجميع لحساب مجموعها أو متوسطها. ستتعلم في هذا المقال كيفية استخدام التواريخ والأوقات في SQL. إذ ستبدأ بإجراء العمليات الحسابية واستخدام دوال متنوعة مع التواريخ والأوقات باستخدام تعليمة SELECT وحدها. لتتدرب بعد ذلك على تنفيذ استعلامات على بياناتٍ نموذجية تجريبية، وستتعلم كيفية استخدام دالة CAST لجعل النتائج أيسر للقراءة. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على الأمثلة حول كيفية استخدام التاريخ والوقت في هذا المقال. لذا ننصحك بمتابعة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم datetimeDB: mysql> CREATE DATABASE datetimeDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات datetimeDB، نفّذ تعليمة USE التالية: mysql> USE datetimeDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات datetimeDB، لننشئ جدولًا ضمنها. كمثال في مقالنا هذا، سننشئ جدولًا يُسجّل نتائج اثنين من العدائين في مختلف السباقات التي شاركا بها على مدار عام. سيضم الجدول الأعمدة السبعة التالية: race_id: يُمثّل قيمًا من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. runner_name: مُخصص لأسماء هذين العدّائين وهما في مثالنا أحمد ومحمد وذلك باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. race_name: يُخزّن أسماء السباقات باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. start_day: لتسجيل تاريخ السباق باليوم والشهر والسنة باستخدام نمط البيانات DATE. إذ يتبع نمط البيانات هذا الصيغة القياسية التالية: أربعة أرقام للسنة، وحد أقصى من رقمين لكل من الشهر واليوم (YYYY-MM-DD). start_time: يُمثل وقت بداية السباق باستخدام نمط بيانات TIME بالساعات والدقائق والثواني (HH:MM:SS). ويستخدم نمط البيانات هذا الوقت بصيغة 24 ساعة، أي 15:00 على سبيل المثال للتعبير عن الساعة 3:00 مساءً. total_miles: يعرض المسافة الإجمالية لكل سباق باستخدام نمط بيانات decimal، وذلك نظرًا لأن العديد من المسافات الإجمالية للسباقات ليست بأرقامٍ صحيحة. ويُمكّننا نمط البيانات decimal من تمثيل المسافات بدقة تصل إلى ثلاثة أرقام ككل، منها رقم واحد إلى يمين الفاصلة العشرية، أي بدقة تصل إلى عُشر الميل. end_time: يُسجّل وقت انتهاء كل عدّاء من السباق باستخدام نمط بيانات TIMESTAMP، الذي يدمج التاريخ والوقت ضمن تنسيق واحد يجمع بين صيغتي DATE وTIME مُشتملًا على السنة والشهر واليوم متبوعًا بالساعة والدقيقة والثانية، وهو يعتمد في ذلك على الصيغة القياسية (YYYY-MM-DD HH:MM:SS) لتقديم توقيت دقيق للحظة انتهاء السباق. ولإنشاء هذا الجدول، لننفّذ الأمر CREATE TABLE التالي: mysql> CREATE TABLE race_results ( mysql> race_id int, mysql> runner_name varchar(30), mysql> race_name varchar(20), mysql> start_day DATE, mysql> start_time TIME, mysql> total_miles decimal(3, 1), mysql> end_time TIMESTAMP, mysql> PRIMARY KEY (race_id) mysql> ); ثم املأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO race_results mysql> (race_id, runner_name, race_name, start_day, start_time, total_miles, end_time) mysql> VALUES mysql> (1, 'Ahmad', '1600_meters', '2022-09-18', '7:00:00', 1.0, '2022-09-18 7:06:30'), mysql> (2, 'Ahmad', '5K', '2022-10-19', '11:00:00', 3.1, '2022-10-19 11:22:31'), mysql> (3, 'Ahmad', '10K', '2022-11-20', '10:00:00', 6.2, '2022-11-20 10:38:05'), mysql> (4, 'Ahmad', 'half_marathon', '2022-12-21', '6:00:00', 13.1, '2022-12-21 07:39:04'), mysql> (5, 'Ahmad', 'full_marathon', '2023-01-22', '8:00:00', 26.2, '2023-01-22 11:23:10'), mysql> (6, 'Mohammad', '1600_meters', '2022-09-18', '7:00:00', 1.0, '2022-09-18 7:07:15'), mysql> (7, 'Mohammad', '5K', '2022-10-19', '11:00:00', 3.1, '2022-10-19 11:30:50'), mysql> (8, 'Mohammad', '10K', '2022-11-20', '10:00:00', 6.2, '2022-11-20 11:10:17'), mysql> (9, 'Mohammad', 'half_marathon', '2022-12-21', '6:00:00', 13.1, '2022-12-21 08:11:57'), mysql> (10, 'Mohammad', 'full_marathon', '2023-01-22', '8:00:00', 26.2, '2023-01-22 12:02:10'); الخرج Query OK, 10 rows affected (0.00 sec) Records: 10 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء التدرّب على استخدام بعض العمليات الحسابية والدوال مع التواريخ في SQL. استخدام العمليات الحسابية مع التواريخ والأوقات من الممكن معالجة قيم التواريخ والأوقات في SQL باستخدام التعابير الرياضية، ولن تحتاج سوى إلى العامل الرياضي والقيم المطلوب حسابها. كمثال، لو أردنا تحديد تاريخ يأتي بعد عدد محدد من الأيام من تاريخٍ آخر. يأخذ الاستعلام التالي قيمة تاريخ معينة (2022-10-05) ويضيف إليها 17، لإعادة قيمة التاريخ الذي يأتي بعد سبعة عشر يومًا من التاريخ المحدد في الاستعلام. وتجدر الملاحظة إلى أننا حددنا 2022-10-05 هنا كقيمة من نوع DATE لضمان عدم تفسير نظام إدارة قاعدة البيانات لها كنص أو أي نوع بيانات آخر: mysql> SELECT DATE '2022-10-05' + 17 AS new_date; الخرج +----------+ | new_date | +----------+ | 20221022 | +----------+ 1 row in set (0.01 sec) نلاحظ من هذا الخرج أنّ اليوم الذي يأتي بعد سبعة عشر يومًا من تاريخ 2022-10-05 هو 2022-10-22، أو 22 أكتوبر 2022. كمثال آخر، بفرض أننا نريد حساب إجمالي الساعات بين وقتين مختلفين من خلال طرحهما من بعضهما البعض. افترضنا في الاستعلام التالي أنّ 11:00 هو الوقت الأول و3:00 هو الوقت الثاني. ولا بدّ في هذه الحالة من تحديد أن كلاهما من نمط البيانات TIME للحصول على الفرق بالساعات: mysql> SELECT TIME '11:00' - TIME '3:00' AS time_diff; الخرج +-----------+ | time_diff | +-----------+ | 80000 | +-----------+ 1 row in set (0.00 sec) يُظهر هذا الخرج أن الفارق بين الساعة 11:00 والساعة 3:00 هو 80000، أو 8 ساعات. الآن سنطبّق استعلامات على بياناتنا النموذجية بهدف التدرّب على كيفية استخدام العمليات الحسابية على معلومات التاريخ والوقت. بالنسبة للاستعلام الأول، سنحسب الزمن الكلي الذي استغرقه العداءان لإنهاء كل سباق من خلال طرح زمن الانتهاء end_time من زمن البدء start_time، على النحو التالي: mysql> SELECT runner_name, race_name, end_time - start_time mysql> AS total_time mysql> FROM race_results; الخرج +-------------+---------------+----------------+ | runner_name | race_name | total_time | +-------------+---------------+----------------+ | Ahmad | 1600_meters | 20220918000630 | | Ahmad | 5K | 20221019002231 | | Ahmad | 10K | 20221120003805 | | Ahmad | half_marathon | 20221221013904 | | Ahmad | full_marathon | 20230122032310 | | Mohammad | 1600_meters | 20220918000715 | | Mohammad | 5K | 20221019003050 | | Mohammad | 10K | 20221120011017 | | Mohammad | half_marathon | 20221221021157 | | Mohammad | full_marathon | 20230122040210 | +-------------+---------------+----------------+ 10 rows in set (0.00 sec) ستلاحظ أن القيم المُعادة في عمود total_time تظهر على نحوٍ مطوّل وقد تصعب قراءتها. لذا سنشرح في قسمٍ لاحق ضمن هذا المقال كيفية استخدام دالة CAST لتنسيق هذه القيم بطريقة تجعلها أوضح وأسهل للقراءة. بفرض أنّ تركيزنا منصب على أداء العدّائين في السباقات ذات المسافات الأطول، من قبيل سباقات نصف الماراثون والماراثون الكامل، سنستخدم استعلامًا لاسترجاع هذه البيانات على وجه الخصوص. إذ سنطرح زمن الانتهاء end_time من زمن البدء start_time مُستخدمين بنية WHERE للتحديد الدقيق للنتائج، لتشمل فقط السباقات التي تزيد مسافتها في العمود total_miles عن 12 ميل: mysql> SELECT runner_name, race_name, end_time - start_time AS half_full_results mysql> FROM race_results mysql> WHERE total_miles > 12; الخرج +-------------+---------------+-------------------+ | runner_name | race_name | half_full_results | +-------------+---------------+-------------------+ | Ahmad | half_marathon | 20221221013904 | | Ahmad | full_marathon | 20230122032310 | | Mohammad | half_marathon | 20221221021157 | | Mohammad | full_marathon | 20230122040210 | +-------------+---------------+-------------------+ 4 rows in set (0.00 sec) أجرينا في هذا القسم بعض العمليات الحسابية على التواريخ والأوقات باستخدام تعليمة SELECT وذلك لأغراض عملية على البيانات النموذجية التجريبية. فيما يلي، ستتدرب على استخدام استعلامات تشمل دوال متنوعة للتواريخ والأوقات. استخدام دوال التاريخ والوقت وتعابير الفترات الزمنية هناك العديد من الدوال التي يُمكن استخدامها لإيجاد ومعالجة قيم التواريخ والأوقات في SQL. إذ تُستخدم الدوال SQL على نحوٍ أساسي لمعالجة البيانات أو التعامل معها والتحكم بها، وتختلف الدوال المتوفرة باختلاف تقديم SQL المُستخدم. بيد أنّ معظم تقديمات SQL تتيح استرجاع القيم الحالية للتاريخ والوقت من خلال الاستعلام عن قيم دالتيّ current_date وcurrent_time. على سبيل المثال، لمعرفة تاريخ اليوم، فالصياغة بسيطة وتتألف فقط من تعليمة SELECT ودالة current_date كما في المثال التالي: mysql> SELECT current_date; الخرج +--------------+ | current_date | +--------------+ | 2022-02-15 | +--------------+ 1 row in set (0.00 sec) كما يمكننا إيجاد الوقت الحالي باستخدام نفس الصياغة اعتمادًا على الدالة current_time، على النحو التالي: mysql> SELECT current_time; الخرج +--------------+ | current_time | +--------------+ | 17:10:20 | +--------------+ 1 row in set (0.00 sec) أمّا إذا كنت تفضل الاستعلام عن كل من التاريخ والوقت معًا في خرجٍ واحد، فاستخدم الدالة current_timestamp: mysql> SELECT current_timestamp; الخرج +---------------------+ | current_timestamp | +---------------------+ | 2022-02-15 19:09:58 | +---------------------+ 1 row in set (0.00 sec) كما يمكن استخدام دوال التاريخ والوقت كتلك المُستخدمة أعلاه ضمن دوال حسابية على نحوٍ مشابه للقسم السابق من مقالنا. فعلى سبيل المثال، بفرض أنّنا نريد معرفة التاريخ قبل 11 يومًا من تاريخ اليوم الحالي، فيمكننا استخدام نفس الصيغة المُستخدمة سابقًا للاستعلام عن قيمة الدالة current_date مطروحًا منها العدد 11 لإيجاد التاريخ قبل أحد عشر يومًا: mysql> SELECT current_date - 11; الخرج +-------------------+ | current_date - 11 | +-------------------+ | 20220206 | +-------------------+ 1 row in set (0.01 sec) يُشير هذا الخرج لكون التاريخ قبل 11 يومًا من current_date (وقت كتابة هذا النص) هو 2022-02-06، أو 6 فبراير 2022. لنحاول الآن تنفيذ نفس العملية مستبدلين الدالة current_date بالدالة current_time: mysql> SELECT current_time - 11; الخرج +-------------------+ | current_time - 11 | +-------------------+ | 233639 | +-------------------+ 1 row in set (0.00 sec) يُظهر هذا الخرج أنه عند طرح 11 من قيمة current_time، يُطرح فعليًا مقدار 11 ثانية. في حين تُفسّر العملية التي نفذناها سابقًا باستخدام الدالة current_date العدد 11 على أنه أيام وليس ثواني. هذا التباين في تفسير الأرقام لدى التعامل مع دوال التاريخ والوقت قد يكون مربكًا. فبدلاً من اضطرارك لمعالجة قيم التاريخ والوقت باستخدام الحسابات الرياضية بهذا الشكل، توفّر العديد من أنظمة إدارة قواعد البيانات وضوحًا أكبر من خلال استخدام تعابير الفترات الزمنية INTERVAL. تسمح تعابير الفترات الزمنية INTERVAL بإيجاد ما سيكون عليه التاريخ أو الوقت قبل أو بعد فترة محددة من تعبير تاريخ أو وقت معين. وتأخذ هذه التعابير الصيغة التالية: INTERVAL `value` `unit` على سبيل المثال، لإيجاد التاريخ بعد خمسة أيام من الآن، يُمكننا تشغيل الاستعلام التالي: mysql> SELECT current_date + INTERVAL '5' DAY AS "5_days_from_today"; أوجدنا في هذا المثال قيمة current_date، ثم أضفنا إليها تعبير الفترة INTERVAL '5' DAY. ما سيُعيد التاريخ بعد خمسة أيام من الآن: الخرج +-------------------+ | 5_days_from_today | +-------------------+ | 2022-03-06 | +-------------------+ 1 row in set (0.00 sec) وهذا أقل غموضًا بكثير من الاستعلام التالي، الذي ينتج عنه خرج مشابه، وحتى إن لم يكن مطابقًا تمامًا: mysql> SELECT current_date + 5 AS "5_days_from_today"; الخرج +-------------------+ | 5_days_from_today | +-------------------+ | 20220306 | +-------------------+ 1 row in set (0.00 sec) يُلاحظ أنه يُمكن أيضًا طرح فترات زمنية من التواريخ أو الأوقات لإيجاد قيم قبل التاريخ المحدد: mysql> SELECT current_date - INTERVAL '7' MONTH AS "7_months_ago"; الخرج +--------------+ | 7_months_ago | +--------------+ | 2021-08-01 | +--------------+ 1 row in set (0.00 sec) تعتمد الوحدات المتاحة لك لاستخدامها في تعابير INTERVAL على نظام إدارة قواعد البيانات DBMS الذي اخترته، ولكن تتوفّر في معظم الأنظمة خيارات من قبيل HOUR وMINUTE وSECOND: mysql> SELECT current_time + INTERVAL '6' HOUR AS "6_hours_from_now", mysql> current_time - INTERVAL '5' MINUTE AS "5_minutes_ago", mysql> current_time + INTERVAL '20' SECOND AS "20_seconds_from_now"; الخرج +------------------+---------------+---------------------+ | 6_hours_from_now | 5_minutes_ago | 20_seconds_from_now | +------------------+---------------+---------------------+ | 07:51:43 | 01:46:43 | 01:52:03.000000 | +------------------+---------------+---------------------+ 1 row in set (0.00 sec) الآن وبعد أن اطلعت على تعابير الفترات الزمنية وتعرفت على بعض دوال التاريخ والوقت، الفرصة أمامك لتتدرّب مستخدمًا البيانات التجريبية النموذجية التي أدرجتها في الخطوة الأولى. استخدام الدالة CAST ودوال التجميع مع التاريخ والوقت بالعودة إلى المثال الثالث من قسم استخدام العمليات الحسابية مع التاريخ والوقت، حين نفّذنا الاستعلام التالي لطرح زمن الانتهاء end_time من زمن البدء start_time لحساب إجمالي الساعات التي أكملها كل عداء لكل سباق. حصلنا على العمود total_time والذي يتضمّن ناتج طويل جدًا يتبع نمط البيانات TIMESTAMP المُحدد لهذا العمود من الجدول: mysql> SELECT runner_name, race_name, end_time - start_time mysql> AS total_time mysql> FROM race_results; الخرج +-------------+---------------+----------------+ | runner_name | race_name | total_time | +-------------+---------------+----------------+ | Ahmad | 1600_meters | 20220918000630 | | Ahmad | 5K | 20221019002231 | | Ahmad | 10K | 20221120003805 | | Ahmad | half_marathon | 20221221013904 | | Ahmad | full_marathon | 20230122032310 | | Mohammad | 1600_meters | 20220918000715 | | Mohammad | 5K | 20221019003050 | | Mohammad | 10K | 20221120011017 | | Mohammad | half_marathon | 20221221021157 | | Mohammad | full_marathon | 20230122040210 | +-------------+---------------+----------------+ 10 rows in set (0.00 sec) ونظرًا لأنّنا نُجري عملية على عمودين بأنماط بيانات مختلفة (عمود end_time يحمل قيم من نمط TIMESTAMP وعمود start_time يحمل قيم من نمط TIME)، فإنّ قاعدة البيانات لا تعرف أي نمط بيانات يجب أن تستخدم لدى طباعة نتيجة العملية. لذا تحوّل كلا القيمتين إلى أعداد صحيحة لتتمكن من تنفيذ العملية، مما ينتج عنه الأرقام الطويلة في عمود total_time. وكحل لجعل هذه البيانات أوضح للقراءة والتفسير، يمكنك استخدام دالة CAST لتحويل هذه القيم الطويلة من الأعداد الصحيحة إلى نمط بيانات TIME. وللقيام بذلك، ابدأ بالدالة CAST ثم اتبعها مباشرةً بقوس فتح ثم القيم التي تريد تحويلها ثم الكلمة المفتاحية AS متبوعة باسم نمط البيانات الذي تريد التحويل إليه. الاستعلام التالي مطابق للمثال السابق، ولكنه يستخدم دالة CAST لتحويل عمود total_time إلى نمط بيانات TIME: mysql> SELECT runner_name, race_name, CAST(end_time - start_time AS time) mysql> AS total_time mysql> FROM race_results; الخرج +-------------+---------------+------------+ | runner_name | race_name | total_time | +-------------+---------------+------------+ | Ahmad | 1600_meters | 00:06:30 | | Ahmad | 5K | 00:22:31 | | Ahmad | 10K | 00:38:05 | | Ahmad | half_marathon | 01:39:04 | | Ahmad | full_marathon | 03:23:10 | | Mohammad | 1600_meters | 00:07:15 | | Mohammad | 5K | 00:30:50 | | Mohammad | 10K | 01:10:17 | | Mohammad | half_marathon | 02:11:57 | | Mohammad | full_marathon | 04:02:10 | +-------------+---------------+------------+ 10 rows in set (0.00 sec) حوّلت الدالة CAST قيم البيانات في الخرج أعلاه إلى نمط البيانات TIME، ما جعلها أسهل للقراءة والفهم. لنستخدم الآن بعضًا من دوال التجميع مع دالة CAST بهدف إيجاد أقصر وأطول توقيت وإجمالي الوقت لكل عدّاء. لنستعلم بدايةً عن أصغر (أو أقصر) مدة زمنية مستغرقة باستخدام دالة التجميع MIN. ومجددًا لا بدّ من استخدام الدالة CAST هنا لتحويل قيم البيانات من النمط TIMESTAMP إلى النمط TIME مما يجعلها أوضح. وتجدر الملاحظة إلى أنّه عند استخدام دالتين كما في هذا المثال، تتطلب العملية استخدام زوجين من الأقواس الهلالية، إذ يجب أن تكون عملية حساب إجمالي الساعات المُتمثلة في طرح زمن البدء من زمن الانتهاء (end_time - start_time) متداخلةً ضمن إحداها. وأخيرًا، سنضيف بنية GROUP BY لتنظيم هذه القيم بناءً على عمود runner_name بحيث يعرض الخرج نتائج سباقات كلا العدّائين: mysql> SELECT runner_name, MIN(CAST(end_time - start_time AS time)) AS min_time mysql> FROM race_results GROUP BY runner_name; الخرج +-------------+----------+ | runner_name | min_time | +-------------+----------+ | Ahmad | 00:06:30 | | Mohammad | 00:07:15 | +-------------+----------+ 2 rows in set (0.00 sec) يُظهر هذا الخرج أقصر زمن لكل عدّاء، في هذه الحالة الحد الأدنى هو ست دقائق وثلاثون ثانية لأحمد، وسبع دقائق وخمس عشرة ثانية لمحمد. الآن ولإيجاد أطول زمن لكل عدّاء، يمكننا استخدام نفس الصيغة كما في الاستعلام السابق مستبدلين الدالة MIN بالدالة MAX: mysql> SELECT runner_name, MAX(CAST(end_time - start_time AS time)) AS max_time mysql> FROM race_results GROUP BY runner_name; الخرج +-------------+----------+ | runner_name | max_time | +-------------+----------+ | Ahmad | 03:23:10 | | Mohammad | 04:02:10 | +-------------+----------+ 2 rows in set (0.00 sec) يُشير هذا الخرج أن أطول زمن جري لأحمد بلغ كإجمالي ثلاث ساعات وثلاث وعشرين دقيقة وعشر ثوانٍ؛ ولمحمد كان أربع ساعات ودقيقتين وعشر ثوانٍ. أمّا الآن، لنستعلم عن بعض المعلومات العامة (الخلاصة) حول إجمالي الساعات التي قضاها كل عدّاء في الجري. سندمج في هذا الاستعلام دالة التجميع SUM لإيجاد المجموع الإجمالي للساعات بناءً على الفرق بين end_time وstart_time، كما سنستخدم الدالة CAST لتحويل هذه قيم البيانات هذه إلى نمط البيانات TIME. كما لم ننسَ تضمين GROUP BY لتنظيم قيم نتائج كلا العدّاءين: mysql> SELECT runner_name, SUM(CAST(end_time - start_time AS time)) mysql> AS total_hours FROM race_results GROUP BY runner_name; الخرج +-------------+-------------+ | runner_name | total_hours | +-------------+-------------+ | Ahmad | 52880 | | Mohammad | 76149 | +-------------+-------------+ 2 rows in set (0.00 sec) يُبيّن هذا الخرج على نحوٍ مثير للاهتمام كيفية تفسير MySQL للنتائج، والتي في الواقع تحسب الزمن الإجمالي في هيئة أعداد صحيحة. فلو قرأنا هذه النتائج على أنها أزمنة، فإنّ الرقم المُعبّر عن إجمالي زمن أحمد يُفصّل إلى خمس ساعات وثمان وعشرين دقيقة وثمانين ثانية؛ وزمن محمد يُفصّل إلى سبع ساعات وواحد وستين دقيقة وتسع وأربعين ثانية. ومن الواضح أنّ هذا التفصيل للأزمنة لا يبدو منطقيًا وفقًا للقيم الفعلية، مما يشير إلى أنّ MySQL تعاملت مع الأزمنة كأعداد صحيحة. أمّا إذا جربنا الأمر عينه في نظام إدارة قواعد بيانات مختلف، من قبيل PostgreSQL على سبيل المثال، فسيبدو الاستعلام مختلفًا قليلًا: postgres=# SELECT runner_name, SUM(CAST(end_time - start_time AS time)) postgres=# AS total_hours FROM race_results GROUP BY runner_name; الخرج runner_name | total_hours -------------+------------- Mohammad | 10:01:44 Ahmad | 06:09:20 (2 rows) يُفسّر الاستعلام في PostgreSQL القيم كأزمنة في هذه الحالة، وتُحسب على هذا الأساس، إذ يمكن تفصيل نتائج محمد إلى إجمالي عشر ساعات ودقيقة واحدة وأربع وأربعين ثانية؛ وزمن أحمد إلى ست ساعات وتسع دقائق وعشرين ثانية. وما هذا سوى مثال حول كيفية تفسير تنفيذات أنظمة إدارة قواعد البيانات المختلفة للقيم البيانات على نحوٍ مختلف حتى ولو كانت تستخدم نفس الاستعلام ونفس مجموعة البيانات. الخلاصة لعلّ فهم كيفية استخدام التاريخ والوقت في SQL مفيد لدى الاستعلام عن نتائج محددة مثل الدقائق أو الثواني أو الساعات أو الأيام أو الأشهر أو السنوات، أو مزيج من كل هذه الوحدات. ناهيك عن وجود العديد من الدوال المتاحة للتواريخ والأوقات والتي تسهّل العثور على قيم معينة، من قبيل التاريخ أو الوقت الحالي. ورغم استخدامنا في هذا المقال لعمليات حسابية بسيطة مثل الجمع والطرح على التواريخ والأوقات في SQL، ولكن يمكنك استخدام قيم التاريخ والوقت مع أي تعبير رياضي. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Work with Dates and Times in SQL لصاحبه Jeanelle Horcasitas. اقرأ أيضًا المقال السابق: كيفية استخدام التعابير الرياضية والدوال التجميعية في SQL أنواع البيانات في SQL دوال التعامل مع البيانات في SQL نظرة سريعة على لغة الاستعلامات الهيكلية SQL التعامل مع الوقت والتاريخ في PHP معالجة الأخطاء والتعديل على قواعد البيانات في SQL -
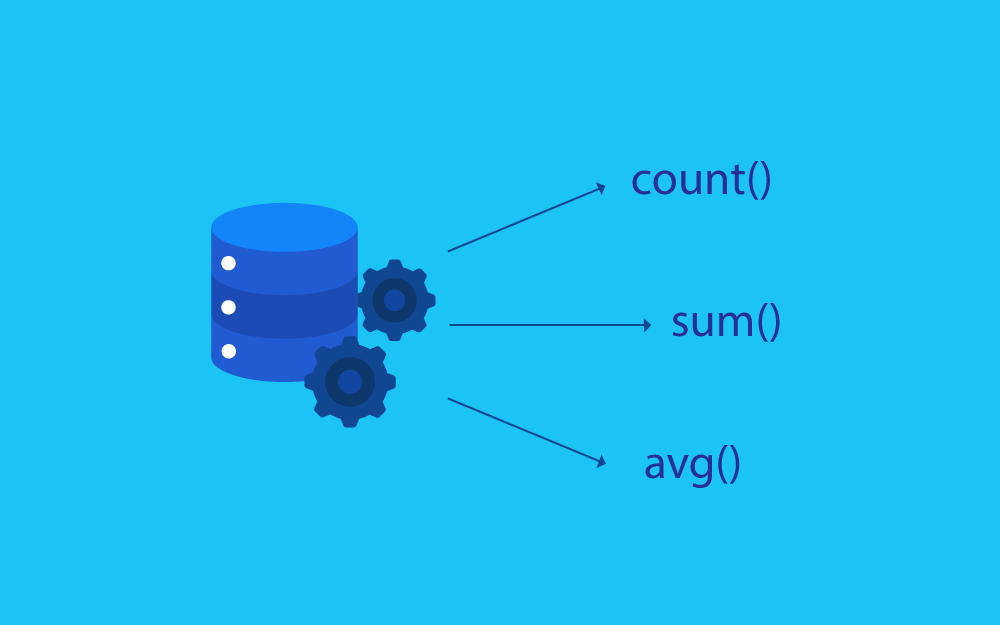 تُستخدم لغة الاستعلام البنيوية SQL لتخزين وإدارة وتنظيم المعلومات في نظام إدارة قواعد البيانات العلاقية RDBMS. كما يمكن لـلغة SQL إجراء الحسابات ومعالجة البيانات باستخدام التعابير Expressions فالتعابير تجمع ما بين معاملات SQL المختلفة مع الدوال والقيم لحساب قيمةٍ ما. وتُستخدم التعابير الرياضية عادةً لجمع وطرح وقسمة وضرب القيم العددية. في حين تُستخدم الدوال التجميعية aggregate functions لتقييم وتجميع القيم ضمن مجموعات بهدف إنشاء ملخص إحصائي حولها، من قبيل المتوسط الحسابي لها أو مجموعها وإظهاره في عمود معين. وبالتالي يمكن أن توفّر التعابير الرياضية والتجميعية رؤًى قيّمة من خلال تحليل البيانات مما يُسهم في اتخاذ قرارات مستقبلية مستنيرة. ستتدرب من خلال هذا المقال على كيفية استخدام التعابير الرياضية. إذ ستتعامل بدايةً مع العمليات الحسابية كما لو كنت تستخدم آلةً حاسبة، لتستخدم بعدها هذه المعاملات مع بيانات نموذجية لتنفيذ استعلامات باستخدام الدوال التجميعية، انتهاءً بسيناريو عملي يتضمّن الاستعلام عن بيانات نموذجية للحصول على معلوماتٍ وتحليلاتٍ أعقد. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على الأمثلة العديدة حول التعابير الرياضية في هذا المقال. لذا ننصحك بمتابعة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم mathDB: mysql> CREATE DATABASE mathDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات mathDB، نفّذ تعليمة USE التالية: mysql> USE mathDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات mathDB، لننشئ جدولًا ضمنها باستخدام الأمر CREATE TABLE. بعد تحديد قاعدة البيانات، سننشئ جدولًا ضمنها باستخدام تعليمة CREATE TABLE. وكمثال في مقالنا هذا، سننشئ جدولاً باسم product_information لتسجيل معلومات المخزون والمبيعات لمحل شاي صغير. سيشتمل هذا الجدول على الأعمدة الثمانية التالية: product_id: يُمثّل قيم من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. product_name: يُوضّح أسماء المنتجات باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. product_type: يُخزّن أنواع المنتجات باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. total_inventory: يُمثّل عدد الوحدات المتبقية في المخزن من كل منتج، باستخدام نمط البيانات int بحد أقصى 200 وحدة. product_cost: يُظهر سعر شراء كل منتج بالتكلفة الأصلية باستخدام نمط البيانات decimal بحد أقصى 3 أرقام إلى يسار الفاصلة العشرية و2 رقم إلى يمينها. product_retail: يُسجّل أسعار كل منتج يُباع بالتجزئة، باستخدام نمط البيانات decimal بحد أقصى 3 أرقام إلى يسار الفاصلة العشرية و2 رقم إلى يمينها. store_units: يعرض عدد وحدات المنتج المحدد المتاحة في المخزون للمبيعات في المتجر الفعلي باستخدام قيم من نمط البيانات int. online_units: يُمثل عدد وحدات المنتج المحدد المتاحة في المخزون للمبيعات عبر الإنترنت، باستخدام قيم من نمط البيانات int. ولإنشاء هذا الجدول النموذجي، نفّذ الأمر التالي: mysql> CREATE TABLE product_information ( mysql> product_id int, mysql> product_name varchar(30), mysql> product_type varchar(30), mysql> total_inventory int(200), mysql> product_cost decimal(3, 2), mysql> product_retail decimal(3, 2), mysql> store_units int(100), mysql> online_units int(100), mysql> PRIMARY KEY (product_id) mysql> ); الخرج Query OK, 0 rows affected, 0 warnings (0.01 sec) ثم املأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO product_information mysql> (product_id, product_name, product_type, total_inventory, product_cost, product_retail, store_units, online_units) mysql> VALUES mysql> (1, 'chamomile', 'tea', 200, 5.12, 7.50, 38, 52), mysql> (2, 'chai', 'tea', 100, 7.40, 9.00, 17, 27), mysql> (3, 'lavender', 'tea', 200, 5.12, 7.50, 50, 112), mysql> (4, 'english_breakfast', 'tea', 150, 5.12, 7.50, 22, 74), mysql> (5, 'jasmine', 'tea', 150, 6.17, 7.50, 33, 92), mysql> (6, 'matcha', 'tea', 100, 6.17, 7.50, 12, 41), mysql> (7, 'oolong', 'tea', 75, 7.40, 9.00, 10, 29), mysql> (8, 'tea sampler', 'tea', 50, 6.00, 8.50, 18, 25), mysql> (9, 'ceramic teapot', 'tea item', 30, 7.00, 9.75, 8, 15), mysql> (10, 'golden teaspoon', 'tea item', 100, 2.00, 5.00, 18, 67); الخرج Query OK, 10 rows affected (0.01 sec) Records: 10 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء استخدام التعابير الرياضية. إجراء العمليات الحسابية باستخدام التعابير الرياضية في SQL تُجرى الاستعلامات في SQL عادةً باستخدام الكلمة المفتاحية SELECT لاسترجاع البيانات المطلوبة من قاعدة البيانات، كما يمكن استخدامها لتنفيذ العديد من العمليات الرياضية. من المهم التذكير بأن SQL تُستخدم على نحوٍ رئيسي في الواقع العملي بهدف تنفيذ الاستعلامات وإجراء الحسابات على القيم الموجودة ضمن قاعدة البيانات الفعلية. ولكننا سنستخدم SELECT في هذا القسم للتعامل مع قيم عددية مباشرة (وليس مع قيم مخزنة في قاعدة البيانات) بهدف التعرف على صيغة التعابير والعمليات الرياضية. ولكن وقبل الشروع، دعونا نلقي نظرة عامّة على المعاملات الرياضية المُستخدمة لإجراء ست عمليات حسابية في SQL. مع الانتباه إلى أنّ هذه القائمة ليست شاملة بالكامل، وأنّ لكل نظام من أنظمة إدارة قواعد البيانات العلاقية مجموعته الخاصة من المعاملات الرياضية: عملية الجمع تستخدم الرمز + عملية الطرح تستخدم الرمز - عملية الضرب تستخدم الرمز * عملية القسمة تستخدم الرمز / عملية باقي القسمة تستخدم الرمز % عملية الرفع إلى قوة تستخدم الدالةPOW(x,y) كما يُمكنك التدرب على إجراء أنماط متنوعة من العمليات الحسابية مُستخدمًا تراكيب قيم من اختيارك. أمّا عنا، فسنُقدم الشرح من خلال الأمثلة التالية، بدءًا بمعادلة للجمع: mysql> SELECT 893 + 579; الخرج +-----------+ | 893 + 579 | +-----------+ | 1472 | +-----------+ 1 row in set (0.00 sec) ومن الجدير بالملاحظة أنه ما من حاجة لتضمين بنية FROM في الاستعلام ضمن مثالنا هذا أو في الأمثلة التالية، وذلك نظرًا لكوننا لا نسترجع أي بيانات من قاعدة البيانات، وإنما نُجري فقط عملياتٍ حسابية على أرقامٍ مباشرة. أمّا الآن، لنجري عملية حسابية باستخدام معامل الطرح. ونلاحظ أنّه من الممكن إجراء العمليات الحسابية على القيم ذات الخانات العشرية كالتالي: mysql> SELECT 437.82 - 66.34; الخرج +----------------+ | 437.82 - 66.34 | +----------------+ | 371.48 | +----------------+ 1 row in set (0.00 sec) كما من الممكن تضمين قيم ومعاملات متعددة ضمن تعبير حسابي واحد في SQL. فمثلًا نستخدم في التعبير الحسابي التالي ثلاث معاملات ضرب لإيجاد حاصل ضرب أربعة أرقام: mysql> SELECT 60 * 1234 * 2 * 117; الخرج +---------------------+ | 60 * 1234 * 2 * 117 | +---------------------+ | 17325360 | +---------------------+ 1 row in set (0.00 sec) لنُجري الآن عملية قسمة تتضمن قيمة عشرية وأخرى من نمط الأعداد الصحيحة، كالتالي: mysql> SELECT 2604.56 / 41; الخرج +--------------+ | 2604.56 / 41 | +--------------+ | 63.525854 | +--------------+ 1 row in set (0.00 sec) كما يعدّ % كمعامل آخر لعملية القسمة والمُسمّى بمعامل باقي القسمة، إذ يحسب قيمة الباقي من قسمة المقسوم على المقسوم عليه: mysql> SELECT 38 % 5; الخرج +--------+ | 38 % 5 | +--------+ | 3 | +--------+ 1 row in set (0.00 sec) كما يعدّ المعامل POW(x,y) من المعاملات المفيدة بدوره، إذ يحسب قيمة القوة لأساس x وأس y، على النحو التالي: mysql> SELECT POW(99,9); الخرج +---------------------+ | POW(99,9) | +---------------------+ | 9.13517247483641e17 | +---------------------+ 1 row in set (0.01 sec) والآن وبعدما تدربت على إجراء العمليات الحسابية مستخدمًا كل عملية على حدة، أصبح بإمكانك تجربة دمج معاملات رياضية مختلفة للتدرب على التعامل مع معادلات رياضية أعقد. فهم ترتيب العمليات في SQL ربما سمعت مسبقًا عن مصطلح PEMDAS، والذي يُمثّل اختصارًا يدل على أولوية ترتيب تنفيذ العمليات الحسابية بدءًا بالأقواس، ثم الرفع إلى قوة، ثم الضرب والقسمة، ثم الجمع والطرح. وهو المصطلح المُستخدم في الولايات المتحدة، وقد تستخدم دول أخرى اختصارات مختلفة لتمثيل قاعدة ترتيب العمليات. ولدى دمج عمليات رياضية مختلفة متداخلة ضمن أقواس، تقرأ SQL العمليات من اليسار إلى اليمين، ومن ثم تقرأ القيم بدءًا من الأقواس الأكثر تداخلًا. لذا، من المهم التأكد بأن القيم داخل الأقواس تعكس بوضوح المعادلة التي نسعى إلى حلها. لنجرّب إجراء العملية الحسابية التالية باستخدام أقواس وبعض المعاملات المختلفة: mysql> SELECT (2 + 4 ) * 8; الخرج +-----------+ | (2+4) * 8 | +-----------+ | 48 | +-----------+ 1 row in set (0.00 sec) تذكّر أنّ مكان وضع الأقواس مهم جدًا، فإذا لم تكن حذرًا قد يتغير الناتج كليًا. على سبيل المثال، سنستخدم فيما يلي نفس القيم الثلاث ونفس المعاملات ولكن بتغيير مكان الأقواس، ما سينتج عنه نتائج مختلفة: mysql> SELECT 2 + (4 * 8); الخرج +-------------+ | 2 + (4 * 8) | +-------------+ | 34 | +-------------+ 1 row in set (0.00 sec) وإذا كنت ممن يفضلون إجراء العمليات الحسابية دون استخدام أقواس، فالأمر ممكن أيضًا، مع ملاحظة أنّ قاعدة ترتيب العمليات تبقى سارية في هذه الحالة؛ وبالتالي وكما في حالة استخدام الأقواس، تأكد من أن المعادلة تعكس بدقة النتيجة المرجوة استنادًا إلى ترتيب العمليات التي ستُقيّم بناءً عليها. في المثال التالي، نلاحظ أنّ عملية القسمة تأخذ الأولوية على معامل الطرح لتنتج قيمة سالبة: mysql> SELECT 100 / 5 - 300; الخرج +---------------+ | 100 / 5 - 300 | +---------------+ | -280.0000 | +---------------+ 1 row in set (0.00 sec) لقد نجحت حتى الآن في استخدام التعابير الرياضية لأداء العمليات الحسابية الأساسية منها والمركبة مستخدمًا مجموعة متنوعة من المعاملات. في الخطوة التالية، ستستخدم البيانات النموذجية لتنفيذ عمليات حسابية باستخدام دوال التجميع مُستخلصًا معلومات جديدة من بياناتك. تحليل البيانات باستخدام دوال التجميع لنفترض بأنك تملك محلًّا صغير لبيع الشاي، وأنّك ترغب في إجراء حسابات تتعلق بالمعلومات المخزنة في قاعدة البيانات لديك. فيمكن لـ SQL استخدام التعابير الرياضية للاستعلام عن البيانات ومعالجتها من خلال استرجاعها من الجداول في قاعدة البيانات بأعمدتها المختلفة، ما يساعد في توليد معلومات جديدة حول البيانات التي تهتم بتحليلها. ستتدرب في هذا القسم على كيفية الاستعلام عن البيانات ومعالجتها باستخدام دوال التجميع وصولًا إلى معلومات ذات طابع تجاري تخص أعمال محل الشاي. تشمل الدوال التجميعية الرئيسية في SQL كل من الدوال SUM و MAX و MIN و AVG و COUNT. تحسب دالة SUM حاصل جمع كافّة القيم في عمودٍ ما. فعلى سبيل المثال، لنستخدم الدالة SUM لحساب حاصل جمع إجمالي الكميات في عمود total_inventory من مجموعة بياناتنا النموذجية: mysql> SELECT SUM(total_inventory) FROM product_information; الخرج +----------------------+ | SUM(total_inventory) | +----------------------+ | 1155 | +----------------------+ 1 row in set (0.00 sec) في حين تحسب الدالة MAX القيمة العظمى في العمود المحدد. لنستخدم الآن هذه الدالة للاستعلام عن القيمة العظمى للتكاليف الأصلية المدفوعة للمنتجات والمُدرجة في عمود product_cost، مع استخدام تعليمة AS لإعادة تسمية ترويسة العمود لتغدو cost_max ما يجعلها أوضح: mysql> SELECT MAX(product_cost) AS cost_max mysql> FROM product_information; الخرج +----------+ | cost_max | +----------+ | 7.40 | +----------+ 1 row in set (0.00 sec) تُعد الدالة MIN النقيض للدالة MAX، إذ تحسب القيمة الدنيا للقيم الموجودة في عمود واحد. لنستخدمها الآن للاستعلام عن القيمة الدنيا المدفوعة للمنتجات بسعر التجزئة في عمود product_retail، على النحو التالي: mysql> SELECT MIN(product_retail) AS retail_min mysql> FROM product_information; الخرج +------------+ | retail_min | +------------+ | 5.00 | +------------+ 1 row in set (0.00 sec) أمّا الدالة AVG فتحسب المتوسط الحسابي لجميع القيم في العمود المحدد. وتجدر الملاحظة إلى إمكانية تشغيل أكثر من دالة تجميعية واحدة في نفس الاستعلام. لنجرّب الآن دمج دالة لإيجاد متوسط سعر المنتجات المباعة بالتجزئة product_retail وأخرى لسعر المنتجات المشتراة بالتكلفة product_cost الأصلية في استعلامٍ واحد: mysql> SELECT AVG(product_retail) AS retail_average, mysql> AVG(product_cost) AS cost_average mysql> FROM product_information; الخرج +----------------+--------------+ | retail_average | cost_average | +----------------+--------------+ | 7.875000 | 5.750000 | +----------------+--------------+ 1 row in set (0.00 sec) في حين تعمل الدالة COUNT على نحوٍ مختلف عن الدوال الأخرى، لأنها تحسب قيمة من الجدول نفسه بعد عد عدد السجلات التي يُعيدها الاستعلام. كمثال، لنستخدم الدالة COUNT بالتزامن مع تعليمة WHERE للاستعلام عن عدد المنتجات التي يزيد سعر بيعها بالتجزئة عن 8 دولارات: mysql> SELECT COUNT(product_retail) mysql> FROM product_information mysql> WHERE product_retail > 8.00; الخرج +-----------------------+ | COUNT(product_retail) | +-----------------------+ | 4 | +-----------------------+ 1 row in set (0.00 sec) الآن لنستعلم عن عدد المنتجات من عمود product_cost المُشتراة من المتجر بسعر يزيد عن 8 دولارات: mysql> SELECT COUNT(product_cost) mysql> FROM product_information mysql> WHERE product_cost > 8.00; الخرج +---------------------+ | COUNT(product_cost) | +---------------------+ | 0 | +---------------------+ 1 row in set (0.00 sec) وبذلك تكون قد استخدمت دوال التجميع بنجاح لتوفير ملخص إحصائي للقيم من قبيل القيمة العظمى والقيمة الدنيا والمتوسط الحسابي والعدد، إذ استرجعت هذه المعلومات من بياناتنا النموذجية لمحاكاة سيناريو واقعي. أمّا في القسم الأخير من هذا المقال، فستطبق كل ما تعلمته حول التعابير الرياضية ودوال التجميع لإجراء استعلامات وتحليلات أكثر تفصيلاً على البيانات النموذجية لمحل الشاي الصغير. تطبيق التعابير الرياضية في سيناريو عملي لأغراض تجارية سنعرض في هذا القسم عدة أمثلة لسيناريوهات مختلفة حول تحليل البيانات لمساعدة مالكي محل الشاي في اتخاذ القرارات المتعلقة بأعمالهم. كسيناريو أول، لنحسب العدد الإجمالي المتاح حاليًا في المخزون من الوحدات بغية فهم كمية المنتجات المتبقية والمتاحة للبيع سواءً في المتجر الفعلي أو عبر الإنترنت. كما سيتضمن هذا الاستعلام تعليمة DESC المُستخدمة لفرز أو ترتيب البيانات من الأكبر إلى الأصغر. فعادةً ما تستخدم قواعد إدارة قواعد البيانات العلاقية الترتيب التصاعدي افتراضيًا، ولكننا في هذا المثال ضمّنا خيار DESC الذي يسمح لنا بعرض البيانات بترتيبٍ تنازلي: mysql> SELECT product_name, mysql> total_inventory - (store_units + online_units) mysql> AS remaining_inventory mysql> FROM product_information mysql> ORDER BY(remaining_inventory) DESC; الخرج +-------------------+---------------------+ | product_name | remaining_inventory | +-------------------+---------------------+ | chamomile | 110 | | chai | 56 | | english_breakfast | 54 | | matcha | 47 | | lavender | 38 | | oolong | 36 | | jasmine | 25 | | golden teaspoon | 15 | | tea sampler | 7 | | ceramic teapot | 7 | +-------------------+---------------------+ 10 rows in set (0.00 sec) هذا الاستعلام مفيد عمليًا لأنه يحسب المخزون المتبقي، الأمر الذي يمكن أن يساعد مالكي محل الشاي في التخطيط لشراء طلبيات جديدة في حال وجود نقص في منتج ما. أمّا للسيناريو التالي، فسنحلل ونقارن مقدار الإيرادات من المبيعات في كل من المتجر الفعلي وعبر الإنترنت: mysql> SELECT product_name, mysql> (online_units * product_retail) AS o, mysql> (store_units * product_retail) AS s mysql> FROM product_information; الخرج +-------------------+--------+--------+ | product_name | o | s | +-------------------+--------+--------+ | chamomile | 390.00 | 285.00 | | chai | 243.00 | 153.00 | | lavender | 840.00 | 375.00 | | english_breakfast | 555.00 | 165.00 | | jasmine | 690.00 | 247.50 | | matcha | 307.50 | 90.00 | | oolong | 261.00 | 90.00 | | tea sampler | 212.50 | 153.00 | | ceramic teapot | 146.25 | 78.00 | | golden teaspoon | 335.00 | 90.00 | +-------------------+--------+--------+ 10 rows in set (0.00 sec) الآن، لنحسب الإيرادات الإجمالية من المبيعات في كل من المتجر الفعلي وعبر الإنترنت باستخدام الدالة SUM مع عدّة معاملات رياضية، على النحو التالي: mysql> SELECT SUM(online_units * product_retail) + mysql> SUM(store_units * product_retail) mysql> AS total_sales mysql> FROM product_information; الخرج +-------------+ | total_sales | +-------------+ | 5706.75 | +-------------+ 1 row in set (0.00 sec) ولعلّ إجراء هذه الاستعلامات مهم لسببين. الأول هو أنه يسمح لمالكي محل الشاي بتقييم أي المنتجات الأكثر مبيعًا وإعطاء الأولوية لتلك المنتجات عند شراء المزيد في المستقبل. والثاني، أنّه يمكّنهم من تحليل مدى نجاح محل الشاي إجمالًا من خلال مبيعات المنتجات في كل من المتجر الفعلي وعبر الإنترنت. سنحسب الآن هامش الربح لكل منتج. وهامش الربح لمنتج ما هو مقدار الإيراد الذي يحققه العمل التجاري من كل وحدة مباعة من هذا المنتج. وبالتالي لفهم مقدار الإيراد الإجمالي الذي حققته، يمكنك ضرب عدد الوحدات المُباعة بهامش الربح. لحساب هامش الربح للمنتجات الفردية في مثالنا، سنطرح سعر التكلفة product_cost من سعر المبيع بالتجزئة product_retail لكل سجل. ثم سنقسّم هذه القيمة على سعر المبيع بالتجزئة للمنتج لحساب نسبة هامش الربح، على النحو التالي: mysql> SELECT product_name, mysql> (product_retail - product_cost) / product_retail mysql> AS profit_margin mysql> FROM product_information; الخرج +-------------------+-------------+ | product_name | profit_margin | +-------------------+-------------+ | chamomile | 0.317333 | | chai | 0.177778 | | lavender | 0.317333 | | english_breakfast | 0.317333 | | jasmine | 0.177333 | | matcha | 0.177333 | | oolong | 0.177778 | | tea sampler | 0.294118 | | ceramic teapot | 0.282051 | | golden teaspoon | 0.600000 | +-------------------+-------------+ 10 rows in set (0.00 sec) نلاحظ استنادًا إلى هذا الخرج أنّ المنتج الذي يتمتع بأعلى هامش ربح هو golden teaspoon بنسبة 60%، والأدنى هو لكل من Chai و Jasmine و Matcha و Oolong بنسبة 18%. بالنسبة لمنتج golden teaspoon، فهامش الربح هذا يعني أنه ومن أجل سعر مبيع بالتجزئة قدره 5.00 دولار مع هامش الربح البالغ 60%، سنحصل على 3.00 دولار كإيرادات. كما يمكننا استخدام دالة التجميع AVG لحساب المتوسط الحسابي لهوامش ربح كافّة منتجات محل الشاي. إذ يلعب هذا المتوسط الحسابي دور المعيار لمالكي محل الشاي لتحديد المنتجات الواقعة تحت هذا الرقم ووضع استراتيجيات لتحسينها: mysql> SELECT AVG((product_retail - product_cost) / product_retail) mysql> AS avg_profit_margin mysql> FROM product_information; الخرج +-------------------+ | avg_profit_margin | +-------------------+ | 0.2838391151 | +-------------------+ 1 row in set (0.00 sec) استنادًا إلى نتيجة الحساب أعلاه نستنتج أنّ المتوسط الحسابي لهوامش الربح للمنتجات في محل بيع الشاي هذا يبلغ 28%. وبفرض أنّ مالكي محل الشاي قد قرروا بناءً على هذه المعلومات الجديدة زيادة هامش الربح إلى 31% في الربع القادم لأي منتج بهامش ربح أقل من 27%. ولإنجاز الأمر، سنطرح هامش الربح المُستهدف من 1 أي (1-0.31) ومن ثم سنقسّم سعر التكلفة الأصلي لكل من المنتجات المُعادة (ذات هامش الربح الأقل من 27%) على هذه القيمة. فتكون النتيجة النهائية هي السعر الجديد الذي ينبغي بيع المنتج بالتجزئة وفقًا له لتحقيق هامش ربح 31%: mysql> SELECT product_name, product_cost / (1 - 0.31) mysql> AS new_retail FROM product_information WHERE (product_retail - product_cost) / product_retail < 0.27; الخرج +--------------+------------+ | product_name | new_retail | +--------------+------------+ | chai | 10.724638 | | jasmine | 8.942029 | | matcha | 8.942029 | | oolong | 10.724638 | +--------------+------------+ 4 rows in set (0.00 sec) تُظهر هذه النتائج أسعار المبيع بالتجزئة الجديدة اللازمة للمنتجات ذات الأداء الضعيف لتحقيق هامش ربح قدره 31%. يزوّد هذا النوع من تحليل البيانات مالكي محل الشاي بالقدرة على اتخاذ قرارات تجارية حاسمة حول كيفية تحسين إيراداتهم للربع القادم وفهم ما يجب التطلع إليه. الخلاصة يُمكن لاستخدام التعابير الرياضية في SQL أن يتراوح من حل المسائل الحسابية ببساطة كما تفعل باستخدام الآلة الحاسبة، إلى تنفيذ تحليلاتٍ معقدة تستند إلى بيانات من العالم الواقعي والتي يمكن أن تلعب دورًا في صياغة قرارات الأعمال. وبمجرد اتقانك لكيفية التعامل مع المعاملات الرياضية الرئيسية وقواعد ترتيب العمليات، ستجد أمامك عالمًا واسعًا من الإمكانيات الحسابية. وحين ترنو إلى تحليلٍ أعمق لبياناتك، يتيح لك دمج هذه المعاملات مع دوال التجميع الغوص في الأسئلة الافتراضية من قبيل "ماذا لو"، مما يوفر لك رؤًى قيمة قد تكون بمثابة الأساس للتخطيط الاستراتيجي لمستقبل أعمالك. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Mathematical Expressions and Aggregate Functions in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام بنى الدمج Joins في لغة الاستعلام البنيوية SQL استخدام الدوال في قواعد بيانات MySQL بعض الدوال المساعدة في SQL لغة معالجة البيانات DML الخاصة بلغة SQL مواضيع متقدمة في SQL
تُستخدم لغة الاستعلام البنيوية SQL لتخزين وإدارة وتنظيم المعلومات في نظام إدارة قواعد البيانات العلاقية RDBMS. كما يمكن لـلغة SQL إجراء الحسابات ومعالجة البيانات باستخدام التعابير Expressions فالتعابير تجمع ما بين معاملات SQL المختلفة مع الدوال والقيم لحساب قيمةٍ ما. وتُستخدم التعابير الرياضية عادةً لجمع وطرح وقسمة وضرب القيم العددية. في حين تُستخدم الدوال التجميعية aggregate functions لتقييم وتجميع القيم ضمن مجموعات بهدف إنشاء ملخص إحصائي حولها، من قبيل المتوسط الحسابي لها أو مجموعها وإظهاره في عمود معين. وبالتالي يمكن أن توفّر التعابير الرياضية والتجميعية رؤًى قيّمة من خلال تحليل البيانات مما يُسهم في اتخاذ قرارات مستقبلية مستنيرة. ستتدرب من خلال هذا المقال على كيفية استخدام التعابير الرياضية. إذ ستتعامل بدايةً مع العمليات الحسابية كما لو كنت تستخدم آلةً حاسبة، لتستخدم بعدها هذه المعاملات مع بيانات نموذجية لتنفيذ استعلامات باستخدام الدوال التجميعية، انتهاءً بسيناريو عملي يتضمّن الاستعلام عن بيانات نموذجية للحصول على معلوماتٍ وتحليلاتٍ أعقد. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول من نوع sudo مختلف عن المستخدم الجذر، وجدار حماية مُفعّل، كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على الأمثلة العديدة حول التعابير الرياضية في هذا المقال. لذا ننصحك بمتابعة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم mathDB: mysql> CREATE DATABASE mathDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات mathDB، نفّذ تعليمة USE التالية: mysql> USE mathDB; الخرج Database changed الآن وبعد اختيار قاعدة البيانات mathDB، لننشئ جدولًا ضمنها باستخدام الأمر CREATE TABLE. بعد تحديد قاعدة البيانات، سننشئ جدولًا ضمنها باستخدام تعليمة CREATE TABLE. وكمثال في مقالنا هذا، سننشئ جدولاً باسم product_information لتسجيل معلومات المخزون والمبيعات لمحل شاي صغير. سيشتمل هذا الجدول على الأعمدة الثمانية التالية: product_id: يُمثّل قيم من نمط بيانات الأعداد الصحيحة int وسيكون المفتاح الأساسي للجدول، ما يعني أن كل قيمة في هذا العمود ستلعب دور المعرّف الفريد لسجلها. product_name: يُوضّح أسماء المنتجات باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. product_type: يُخزّن أنواع المنتجات باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. total_inventory: يُمثّل عدد الوحدات المتبقية في المخزن من كل منتج، باستخدام نمط البيانات int بحد أقصى 200 وحدة. product_cost: يُظهر سعر شراء كل منتج بالتكلفة الأصلية باستخدام نمط البيانات decimal بحد أقصى 3 أرقام إلى يسار الفاصلة العشرية و2 رقم إلى يمينها. product_retail: يُسجّل أسعار كل منتج يُباع بالتجزئة، باستخدام نمط البيانات decimal بحد أقصى 3 أرقام إلى يسار الفاصلة العشرية و2 رقم إلى يمينها. store_units: يعرض عدد وحدات المنتج المحدد المتاحة في المخزون للمبيعات في المتجر الفعلي باستخدام قيم من نمط البيانات int. online_units: يُمثل عدد وحدات المنتج المحدد المتاحة في المخزون للمبيعات عبر الإنترنت، باستخدام قيم من نمط البيانات int. ولإنشاء هذا الجدول النموذجي، نفّذ الأمر التالي: mysql> CREATE TABLE product_information ( mysql> product_id int, mysql> product_name varchar(30), mysql> product_type varchar(30), mysql> total_inventory int(200), mysql> product_cost decimal(3, 2), mysql> product_retail decimal(3, 2), mysql> store_units int(100), mysql> online_units int(100), mysql> PRIMARY KEY (product_id) mysql> ); الخرج Query OK, 0 rows affected, 0 warnings (0.01 sec) ثم املأ هذا الجدول الفارغ ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO product_information mysql> (product_id, product_name, product_type, total_inventory, product_cost, product_retail, store_units, online_units) mysql> VALUES mysql> (1, 'chamomile', 'tea', 200, 5.12, 7.50, 38, 52), mysql> (2, 'chai', 'tea', 100, 7.40, 9.00, 17, 27), mysql> (3, 'lavender', 'tea', 200, 5.12, 7.50, 50, 112), mysql> (4, 'english_breakfast', 'tea', 150, 5.12, 7.50, 22, 74), mysql> (5, 'jasmine', 'tea', 150, 6.17, 7.50, 33, 92), mysql> (6, 'matcha', 'tea', 100, 6.17, 7.50, 12, 41), mysql> (7, 'oolong', 'tea', 75, 7.40, 9.00, 10, 29), mysql> (8, 'tea sampler', 'tea', 50, 6.00, 8.50, 18, 25), mysql> (9, 'ceramic teapot', 'tea item', 30, 7.00, 9.75, 8, 15), mysql> (10, 'golden teaspoon', 'tea item', 100, 2.00, 5.00, 18, 67); الخرج Query OK, 10 rows affected (0.01 sec) Records: 10 Duplicates: 0 Warnings: 0 وبمجرّد إدخالك للبيانات تغدو مستعدًا لبدء استخدام التعابير الرياضية. إجراء العمليات الحسابية باستخدام التعابير الرياضية في SQL تُجرى الاستعلامات في SQL عادةً باستخدام الكلمة المفتاحية SELECT لاسترجاع البيانات المطلوبة من قاعدة البيانات، كما يمكن استخدامها لتنفيذ العديد من العمليات الرياضية. من المهم التذكير بأن SQL تُستخدم على نحوٍ رئيسي في الواقع العملي بهدف تنفيذ الاستعلامات وإجراء الحسابات على القيم الموجودة ضمن قاعدة البيانات الفعلية. ولكننا سنستخدم SELECT في هذا القسم للتعامل مع قيم عددية مباشرة (وليس مع قيم مخزنة في قاعدة البيانات) بهدف التعرف على صيغة التعابير والعمليات الرياضية. ولكن وقبل الشروع، دعونا نلقي نظرة عامّة على المعاملات الرياضية المُستخدمة لإجراء ست عمليات حسابية في SQL. مع الانتباه إلى أنّ هذه القائمة ليست شاملة بالكامل، وأنّ لكل نظام من أنظمة إدارة قواعد البيانات العلاقية مجموعته الخاصة من المعاملات الرياضية: عملية الجمع تستخدم الرمز + عملية الطرح تستخدم الرمز - عملية الضرب تستخدم الرمز * عملية القسمة تستخدم الرمز / عملية باقي القسمة تستخدم الرمز % عملية الرفع إلى قوة تستخدم الدالةPOW(x,y) كما يُمكنك التدرب على إجراء أنماط متنوعة من العمليات الحسابية مُستخدمًا تراكيب قيم من اختيارك. أمّا عنا، فسنُقدم الشرح من خلال الأمثلة التالية، بدءًا بمعادلة للجمع: mysql> SELECT 893 + 579; الخرج +-----------+ | 893 + 579 | +-----------+ | 1472 | +-----------+ 1 row in set (0.00 sec) ومن الجدير بالملاحظة أنه ما من حاجة لتضمين بنية FROM في الاستعلام ضمن مثالنا هذا أو في الأمثلة التالية، وذلك نظرًا لكوننا لا نسترجع أي بيانات من قاعدة البيانات، وإنما نُجري فقط عملياتٍ حسابية على أرقامٍ مباشرة. أمّا الآن، لنجري عملية حسابية باستخدام معامل الطرح. ونلاحظ أنّه من الممكن إجراء العمليات الحسابية على القيم ذات الخانات العشرية كالتالي: mysql> SELECT 437.82 - 66.34; الخرج +----------------+ | 437.82 - 66.34 | +----------------+ | 371.48 | +----------------+ 1 row in set (0.00 sec) كما من الممكن تضمين قيم ومعاملات متعددة ضمن تعبير حسابي واحد في SQL. فمثلًا نستخدم في التعبير الحسابي التالي ثلاث معاملات ضرب لإيجاد حاصل ضرب أربعة أرقام: mysql> SELECT 60 * 1234 * 2 * 117; الخرج +---------------------+ | 60 * 1234 * 2 * 117 | +---------------------+ | 17325360 | +---------------------+ 1 row in set (0.00 sec) لنُجري الآن عملية قسمة تتضمن قيمة عشرية وأخرى من نمط الأعداد الصحيحة، كالتالي: mysql> SELECT 2604.56 / 41; الخرج +--------------+ | 2604.56 / 41 | +--------------+ | 63.525854 | +--------------+ 1 row in set (0.00 sec) كما يعدّ % كمعامل آخر لعملية القسمة والمُسمّى بمعامل باقي القسمة، إذ يحسب قيمة الباقي من قسمة المقسوم على المقسوم عليه: mysql> SELECT 38 % 5; الخرج +--------+ | 38 % 5 | +--------+ | 3 | +--------+ 1 row in set (0.00 sec) كما يعدّ المعامل POW(x,y) من المعاملات المفيدة بدوره، إذ يحسب قيمة القوة لأساس x وأس y، على النحو التالي: mysql> SELECT POW(99,9); الخرج +---------------------+ | POW(99,9) | +---------------------+ | 9.13517247483641e17 | +---------------------+ 1 row in set (0.01 sec) والآن وبعدما تدربت على إجراء العمليات الحسابية مستخدمًا كل عملية على حدة، أصبح بإمكانك تجربة دمج معاملات رياضية مختلفة للتدرب على التعامل مع معادلات رياضية أعقد. فهم ترتيب العمليات في SQL ربما سمعت مسبقًا عن مصطلح PEMDAS، والذي يُمثّل اختصارًا يدل على أولوية ترتيب تنفيذ العمليات الحسابية بدءًا بالأقواس، ثم الرفع إلى قوة، ثم الضرب والقسمة، ثم الجمع والطرح. وهو المصطلح المُستخدم في الولايات المتحدة، وقد تستخدم دول أخرى اختصارات مختلفة لتمثيل قاعدة ترتيب العمليات. ولدى دمج عمليات رياضية مختلفة متداخلة ضمن أقواس، تقرأ SQL العمليات من اليسار إلى اليمين، ومن ثم تقرأ القيم بدءًا من الأقواس الأكثر تداخلًا. لذا، من المهم التأكد بأن القيم داخل الأقواس تعكس بوضوح المعادلة التي نسعى إلى حلها. لنجرّب إجراء العملية الحسابية التالية باستخدام أقواس وبعض المعاملات المختلفة: mysql> SELECT (2 + 4 ) * 8; الخرج +-----------+ | (2+4) * 8 | +-----------+ | 48 | +-----------+ 1 row in set (0.00 sec) تذكّر أنّ مكان وضع الأقواس مهم جدًا، فإذا لم تكن حذرًا قد يتغير الناتج كليًا. على سبيل المثال، سنستخدم فيما يلي نفس القيم الثلاث ونفس المعاملات ولكن بتغيير مكان الأقواس، ما سينتج عنه نتائج مختلفة: mysql> SELECT 2 + (4 * 8); الخرج +-------------+ | 2 + (4 * 8) | +-------------+ | 34 | +-------------+ 1 row in set (0.00 sec) وإذا كنت ممن يفضلون إجراء العمليات الحسابية دون استخدام أقواس، فالأمر ممكن أيضًا، مع ملاحظة أنّ قاعدة ترتيب العمليات تبقى سارية في هذه الحالة؛ وبالتالي وكما في حالة استخدام الأقواس، تأكد من أن المعادلة تعكس بدقة النتيجة المرجوة استنادًا إلى ترتيب العمليات التي ستُقيّم بناءً عليها. في المثال التالي، نلاحظ أنّ عملية القسمة تأخذ الأولوية على معامل الطرح لتنتج قيمة سالبة: mysql> SELECT 100 / 5 - 300; الخرج +---------------+ | 100 / 5 - 300 | +---------------+ | -280.0000 | +---------------+ 1 row in set (0.00 sec) لقد نجحت حتى الآن في استخدام التعابير الرياضية لأداء العمليات الحسابية الأساسية منها والمركبة مستخدمًا مجموعة متنوعة من المعاملات. في الخطوة التالية، ستستخدم البيانات النموذجية لتنفيذ عمليات حسابية باستخدام دوال التجميع مُستخلصًا معلومات جديدة من بياناتك. تحليل البيانات باستخدام دوال التجميع لنفترض بأنك تملك محلًّا صغير لبيع الشاي، وأنّك ترغب في إجراء حسابات تتعلق بالمعلومات المخزنة في قاعدة البيانات لديك. فيمكن لـ SQL استخدام التعابير الرياضية للاستعلام عن البيانات ومعالجتها من خلال استرجاعها من الجداول في قاعدة البيانات بأعمدتها المختلفة، ما يساعد في توليد معلومات جديدة حول البيانات التي تهتم بتحليلها. ستتدرب في هذا القسم على كيفية الاستعلام عن البيانات ومعالجتها باستخدام دوال التجميع وصولًا إلى معلومات ذات طابع تجاري تخص أعمال محل الشاي. تشمل الدوال التجميعية الرئيسية في SQL كل من الدوال SUM و MAX و MIN و AVG و COUNT. تحسب دالة SUM حاصل جمع كافّة القيم في عمودٍ ما. فعلى سبيل المثال، لنستخدم الدالة SUM لحساب حاصل جمع إجمالي الكميات في عمود total_inventory من مجموعة بياناتنا النموذجية: mysql> SELECT SUM(total_inventory) FROM product_information; الخرج +----------------------+ | SUM(total_inventory) | +----------------------+ | 1155 | +----------------------+ 1 row in set (0.00 sec) في حين تحسب الدالة MAX القيمة العظمى في العمود المحدد. لنستخدم الآن هذه الدالة للاستعلام عن القيمة العظمى للتكاليف الأصلية المدفوعة للمنتجات والمُدرجة في عمود product_cost، مع استخدام تعليمة AS لإعادة تسمية ترويسة العمود لتغدو cost_max ما يجعلها أوضح: mysql> SELECT MAX(product_cost) AS cost_max mysql> FROM product_information; الخرج +----------+ | cost_max | +----------+ | 7.40 | +----------+ 1 row in set (0.00 sec) تُعد الدالة MIN النقيض للدالة MAX، إذ تحسب القيمة الدنيا للقيم الموجودة في عمود واحد. لنستخدمها الآن للاستعلام عن القيمة الدنيا المدفوعة للمنتجات بسعر التجزئة في عمود product_retail، على النحو التالي: mysql> SELECT MIN(product_retail) AS retail_min mysql> FROM product_information; الخرج +------------+ | retail_min | +------------+ | 5.00 | +------------+ 1 row in set (0.00 sec) أمّا الدالة AVG فتحسب المتوسط الحسابي لجميع القيم في العمود المحدد. وتجدر الملاحظة إلى إمكانية تشغيل أكثر من دالة تجميعية واحدة في نفس الاستعلام. لنجرّب الآن دمج دالة لإيجاد متوسط سعر المنتجات المباعة بالتجزئة product_retail وأخرى لسعر المنتجات المشتراة بالتكلفة product_cost الأصلية في استعلامٍ واحد: mysql> SELECT AVG(product_retail) AS retail_average, mysql> AVG(product_cost) AS cost_average mysql> FROM product_information; الخرج +----------------+--------------+ | retail_average | cost_average | +----------------+--------------+ | 7.875000 | 5.750000 | +----------------+--------------+ 1 row in set (0.00 sec) في حين تعمل الدالة COUNT على نحوٍ مختلف عن الدوال الأخرى، لأنها تحسب قيمة من الجدول نفسه بعد عد عدد السجلات التي يُعيدها الاستعلام. كمثال، لنستخدم الدالة COUNT بالتزامن مع تعليمة WHERE للاستعلام عن عدد المنتجات التي يزيد سعر بيعها بالتجزئة عن 8 دولارات: mysql> SELECT COUNT(product_retail) mysql> FROM product_information mysql> WHERE product_retail > 8.00; الخرج +-----------------------+ | COUNT(product_retail) | +-----------------------+ | 4 | +-----------------------+ 1 row in set (0.00 sec) الآن لنستعلم عن عدد المنتجات من عمود product_cost المُشتراة من المتجر بسعر يزيد عن 8 دولارات: mysql> SELECT COUNT(product_cost) mysql> FROM product_information mysql> WHERE product_cost > 8.00; الخرج +---------------------+ | COUNT(product_cost) | +---------------------+ | 0 | +---------------------+ 1 row in set (0.00 sec) وبذلك تكون قد استخدمت دوال التجميع بنجاح لتوفير ملخص إحصائي للقيم من قبيل القيمة العظمى والقيمة الدنيا والمتوسط الحسابي والعدد، إذ استرجعت هذه المعلومات من بياناتنا النموذجية لمحاكاة سيناريو واقعي. أمّا في القسم الأخير من هذا المقال، فستطبق كل ما تعلمته حول التعابير الرياضية ودوال التجميع لإجراء استعلامات وتحليلات أكثر تفصيلاً على البيانات النموذجية لمحل الشاي الصغير. تطبيق التعابير الرياضية في سيناريو عملي لأغراض تجارية سنعرض في هذا القسم عدة أمثلة لسيناريوهات مختلفة حول تحليل البيانات لمساعدة مالكي محل الشاي في اتخاذ القرارات المتعلقة بأعمالهم. كسيناريو أول، لنحسب العدد الإجمالي المتاح حاليًا في المخزون من الوحدات بغية فهم كمية المنتجات المتبقية والمتاحة للبيع سواءً في المتجر الفعلي أو عبر الإنترنت. كما سيتضمن هذا الاستعلام تعليمة DESC المُستخدمة لفرز أو ترتيب البيانات من الأكبر إلى الأصغر. فعادةً ما تستخدم قواعد إدارة قواعد البيانات العلاقية الترتيب التصاعدي افتراضيًا، ولكننا في هذا المثال ضمّنا خيار DESC الذي يسمح لنا بعرض البيانات بترتيبٍ تنازلي: mysql> SELECT product_name, mysql> total_inventory - (store_units + online_units) mysql> AS remaining_inventory mysql> FROM product_information mysql> ORDER BY(remaining_inventory) DESC; الخرج +-------------------+---------------------+ | product_name | remaining_inventory | +-------------------+---------------------+ | chamomile | 110 | | chai | 56 | | english_breakfast | 54 | | matcha | 47 | | lavender | 38 | | oolong | 36 | | jasmine | 25 | | golden teaspoon | 15 | | tea sampler | 7 | | ceramic teapot | 7 | +-------------------+---------------------+ 10 rows in set (0.00 sec) هذا الاستعلام مفيد عمليًا لأنه يحسب المخزون المتبقي، الأمر الذي يمكن أن يساعد مالكي محل الشاي في التخطيط لشراء طلبيات جديدة في حال وجود نقص في منتج ما. أمّا للسيناريو التالي، فسنحلل ونقارن مقدار الإيرادات من المبيعات في كل من المتجر الفعلي وعبر الإنترنت: mysql> SELECT product_name, mysql> (online_units * product_retail) AS o, mysql> (store_units * product_retail) AS s mysql> FROM product_information; الخرج +-------------------+--------+--------+ | product_name | o | s | +-------------------+--------+--------+ | chamomile | 390.00 | 285.00 | | chai | 243.00 | 153.00 | | lavender | 840.00 | 375.00 | | english_breakfast | 555.00 | 165.00 | | jasmine | 690.00 | 247.50 | | matcha | 307.50 | 90.00 | | oolong | 261.00 | 90.00 | | tea sampler | 212.50 | 153.00 | | ceramic teapot | 146.25 | 78.00 | | golden teaspoon | 335.00 | 90.00 | +-------------------+--------+--------+ 10 rows in set (0.00 sec) الآن، لنحسب الإيرادات الإجمالية من المبيعات في كل من المتجر الفعلي وعبر الإنترنت باستخدام الدالة SUM مع عدّة معاملات رياضية، على النحو التالي: mysql> SELECT SUM(online_units * product_retail) + mysql> SUM(store_units * product_retail) mysql> AS total_sales mysql> FROM product_information; الخرج +-------------+ | total_sales | +-------------+ | 5706.75 | +-------------+ 1 row in set (0.00 sec) ولعلّ إجراء هذه الاستعلامات مهم لسببين. الأول هو أنه يسمح لمالكي محل الشاي بتقييم أي المنتجات الأكثر مبيعًا وإعطاء الأولوية لتلك المنتجات عند شراء المزيد في المستقبل. والثاني، أنّه يمكّنهم من تحليل مدى نجاح محل الشاي إجمالًا من خلال مبيعات المنتجات في كل من المتجر الفعلي وعبر الإنترنت. سنحسب الآن هامش الربح لكل منتج. وهامش الربح لمنتج ما هو مقدار الإيراد الذي يحققه العمل التجاري من كل وحدة مباعة من هذا المنتج. وبالتالي لفهم مقدار الإيراد الإجمالي الذي حققته، يمكنك ضرب عدد الوحدات المُباعة بهامش الربح. لحساب هامش الربح للمنتجات الفردية في مثالنا، سنطرح سعر التكلفة product_cost من سعر المبيع بالتجزئة product_retail لكل سجل. ثم سنقسّم هذه القيمة على سعر المبيع بالتجزئة للمنتج لحساب نسبة هامش الربح، على النحو التالي: mysql> SELECT product_name, mysql> (product_retail - product_cost) / product_retail mysql> AS profit_margin mysql> FROM product_information; الخرج +-------------------+-------------+ | product_name | profit_margin | +-------------------+-------------+ | chamomile | 0.317333 | | chai | 0.177778 | | lavender | 0.317333 | | english_breakfast | 0.317333 | | jasmine | 0.177333 | | matcha | 0.177333 | | oolong | 0.177778 | | tea sampler | 0.294118 | | ceramic teapot | 0.282051 | | golden teaspoon | 0.600000 | +-------------------+-------------+ 10 rows in set (0.00 sec) نلاحظ استنادًا إلى هذا الخرج أنّ المنتج الذي يتمتع بأعلى هامش ربح هو golden teaspoon بنسبة 60%، والأدنى هو لكل من Chai و Jasmine و Matcha و Oolong بنسبة 18%. بالنسبة لمنتج golden teaspoon، فهامش الربح هذا يعني أنه ومن أجل سعر مبيع بالتجزئة قدره 5.00 دولار مع هامش الربح البالغ 60%، سنحصل على 3.00 دولار كإيرادات. كما يمكننا استخدام دالة التجميع AVG لحساب المتوسط الحسابي لهوامش ربح كافّة منتجات محل الشاي. إذ يلعب هذا المتوسط الحسابي دور المعيار لمالكي محل الشاي لتحديد المنتجات الواقعة تحت هذا الرقم ووضع استراتيجيات لتحسينها: mysql> SELECT AVG((product_retail - product_cost) / product_retail) mysql> AS avg_profit_margin mysql> FROM product_information; الخرج +-------------------+ | avg_profit_margin | +-------------------+ | 0.2838391151 | +-------------------+ 1 row in set (0.00 sec) استنادًا إلى نتيجة الحساب أعلاه نستنتج أنّ المتوسط الحسابي لهوامش الربح للمنتجات في محل بيع الشاي هذا يبلغ 28%. وبفرض أنّ مالكي محل الشاي قد قرروا بناءً على هذه المعلومات الجديدة زيادة هامش الربح إلى 31% في الربع القادم لأي منتج بهامش ربح أقل من 27%. ولإنجاز الأمر، سنطرح هامش الربح المُستهدف من 1 أي (1-0.31) ومن ثم سنقسّم سعر التكلفة الأصلي لكل من المنتجات المُعادة (ذات هامش الربح الأقل من 27%) على هذه القيمة. فتكون النتيجة النهائية هي السعر الجديد الذي ينبغي بيع المنتج بالتجزئة وفقًا له لتحقيق هامش ربح 31%: mysql> SELECT product_name, product_cost / (1 - 0.31) mysql> AS new_retail FROM product_information WHERE (product_retail - product_cost) / product_retail < 0.27; الخرج +--------------+------------+ | product_name | new_retail | +--------------+------------+ | chai | 10.724638 | | jasmine | 8.942029 | | matcha | 8.942029 | | oolong | 10.724638 | +--------------+------------+ 4 rows in set (0.00 sec) تُظهر هذه النتائج أسعار المبيع بالتجزئة الجديدة اللازمة للمنتجات ذات الأداء الضعيف لتحقيق هامش ربح قدره 31%. يزوّد هذا النوع من تحليل البيانات مالكي محل الشاي بالقدرة على اتخاذ قرارات تجارية حاسمة حول كيفية تحسين إيراداتهم للربع القادم وفهم ما يجب التطلع إليه. الخلاصة يُمكن لاستخدام التعابير الرياضية في SQL أن يتراوح من حل المسائل الحسابية ببساطة كما تفعل باستخدام الآلة الحاسبة، إلى تنفيذ تحليلاتٍ معقدة تستند إلى بيانات من العالم الواقعي والتي يمكن أن تلعب دورًا في صياغة قرارات الأعمال. وبمجرد اتقانك لكيفية التعامل مع المعاملات الرياضية الرئيسية وقواعد ترتيب العمليات، ستجد أمامك عالمًا واسعًا من الإمكانيات الحسابية. وحين ترنو إلى تحليلٍ أعمق لبياناتك، يتيح لك دمج هذه المعاملات مع دوال التجميع الغوص في الأسئلة الافتراضية من قبيل "ماذا لو"، مما يوفر لك رؤًى قيمة قد تكون بمثابة الأساس للتخطيط الاستراتيجي لمستقبل أعمالك. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Mathematical Expressions and Aggregate Functions in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام بنى الدمج Joins في لغة الاستعلام البنيوية SQL استخدام الدوال في قواعد بيانات MySQL بعض الدوال المساعدة في SQL لغة معالجة البيانات DML الخاصة بلغة SQL مواضيع متقدمة في SQL -
 غالبًا ما تفصل تصاميم قواعد البيانات المعلومات إلى جداول مختلفة بناءً على العلاقات بين بعض نقاط البيانات. ولكن حتى في مثل هذه الحالات، من المحتمل أن نرغب أحيانًا باسترجاع المعلومات من أكثر من جدول في وقتٍ واحد. إحدى الطرق الشائعة للوصول إلى البيانات من جداول متعددة في عملية واحدة باستخدام لغة الاستعلام البنيوية SQL هي تجميع الجداول باستخدام بنى الدمج JOIN. إذ تُجمّع بنية الدمج JOIN الجداول المنفصلة عن طريق مطابقة السجلات المرتبطة ببعضها البعض من كل جدول مستندةً إلى عمليات الدمج في الجبر العلاقيّ -وهو نظرية تستخدم الهياكل الجبرية لنمذجة البيانات وتحديد الاستعلامات عليها، إذ يُعد إطارًا نظريًا يُستخدم لوصف العمليات على البيانات في قواعد البيانات العلاقية، مثل الدمج والاختيار، ويساعد في تشكيل الأساس الرياضي للغات الاستعلام مثل SQL) -. وعادةً ما تُبنى العلاقة بين الجداول المطلوب دمجها على زوجٍ من الأعمدة - عمود من كل جدول - والتي تتشارك قيمًا مشتركة، كأن نختار مفتاح خارجي لجدول مع مفتاح أساسي لجدول آخر يُشير إليه المفتاح الخارجي آنف الذكر. يوضّح هذا المقال كيفية بناء مجموعة متنوعة من استعلامات SQL التي تتضمن بنية الدمج JOIN. كما يُسلط الضوء على أنماط مختلفة من بنى الدمج وكيفية تجميع البيانات من جداول متعددة وكيفية استخدام الأسماء البديلة alias للأعمدة لجعل كتابة عمليات الدمج JOIN أقل تعقيدًا. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام عمليات الدمج JOIN. لذا ننصحك بمتابعة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسمjoinsDB: mysql> CREATE DATABASE joinsDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرج كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات joinsDB، نفّذ تعليمة USE التالية: mysql> USE joinsDB; الخرج Database changed الآن، بعد اختيار قاعدة البيانات joinsDB لننشئ بعض الجداول ضمنها. لمتابعة الأمثلة المستخدمة في هذا المقال، تخيل أنك تدير مصنعًا وقررت البدء في تتبع المعلومات حول كل من خط الإنتاج، والموظفين في فريق المبيعات، ومبيعات الشركة، وذلك في قاعدة بيانات SQL. فقررت البدء بثلاثة جداول، أولها سيخزن معلومات حول المنتجات، متضمنًا ثلاثة أعمدة: productID: رقم تعريف كل منتج، معبرًا عنه بنمط البيانات int. سيعمل هذا العمود كمفتاح أساسي للجدول، مما يعني أن كل قيمة فيه ستلعب دور مُعرّف فريد للسجل الخاص بها. وبما أن كل قيمة في المفتاح الأساسي يجب أن تكون فريدة، ستطبّق على هذا العمود القيد UNIQUE. productName: اسم كل منتج، معبرًا عنه باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. price: سعر كل منتج، معبرًا عنه باستخدام نمط البيانات decimal. وتُحدد القيم في هذا العمود بحد أقصى قدره أربعة أرقام، بواقع رقمين على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها من -99.99 إلى 99.99. إذًا، أنشئ جدولًا باسم products يحتوي على هذه الأعمدة الثلاثة على النحو التالي: mysql> CREATE TABLE products ( mysql> productID int UNIQUE, mysql> productName varchar(20), mysql> price decimal (4,2), mysql> PRIMARY KEY (productID) mysql>); في حين سيخزّن الجدول الثاني معلومات حول الموظفين في فريق مبيعات الشركة. فارتأيت أن هذا الجدول يحتاج أيضًا إلى ثلاثة أعمدة: empID: مشابه لعمود productID، إذ سيحتوي على مُعرّف فريد لكل موظف في فريق المبيعات مُعبرًا عنه بنمط البيانات int. وبالمثل، سيُطبق على هذا العمود قيد UNIQUE وسيعمل كمفتاح أساسي لجدول الفريق. empName: اسم كل مندوب مبيعات، مُعبرًا عنه باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. productSpecialty: بفرض أنك قررت تخصيص منتج لكل عضو في فريق المبيعات؛ إذ يمكنه بيع أي منتج تصنعه الشركة ولكن تركيزه العام سيكون على المنتج المُخصّص له. وللإشارة إلى هذا الأمر في الجدول، أنشأنا هذا العمود الذي يحتوي على قيمة productID للمنتج المُخصّص لكل موظف. ولضمان أنّ عمود productSpecialty لن يتضمّن سوى قيم تُمثّل مُعرّفات صالحة للمنتجات، يمكنك إنشاء قيد مفتاح خارجي عليه بحيث يُشير إلى عمود productID في جدول المنتجات products. يُعد قيد المفتاح الخارجي طريقة لتحديد علاقة بين جدولين، إذ يفرض أن تكون القيم في العمود المُطبّق عليه موجودة بالفعل في العمود المُشار إليه. يشترط قيد المفتاح الخارجي في تعليمة CREATE TABLE أدناه أن تكون كل قيمة تُضاف إلى عمود productSpecialty من جدول الفريق team موجودة مسبقًا في عمود productID من جدول المنتجات products. أنشئ جدولًا باسم team يحتوي على هذه الأعمدة الثلاثة: mysql> CREATE TABLE team ( mysql> empID int UNIQUE, mysql> empName varchar(20), mysql> productSpecialty int, mysql> PRIMARY KEY (empID), mysql> FOREIGN KEY (productSpecialty) REFERENCES products (productID) ); أمّا الجدول الأخير فسيتضمّن سجلات مبيعات الشركة. وسيكون لهذا الجدول أربعة أعمدة: saleID: مشابه لعمودي productID وempID، إذ سيحتوي هذا العمود على مُعرّف فريد لكل عملية بيع مُعبرًا عنه بنمط البيانات int. سنطبق على هذا العمود أيضًا قيد UNIQUE ليلعب دور المفتاح الأساسي لجدول المبيعات sales. quantity: عدد الوحدات من كل منتج مُباع، مُعبرًا عنه بنمط البيانات int. productID: مُعرّف المنتج المُباع، مُعبرًا عنه بنمط البيانات int. salesperson: مُعرّف الموظف الذي أجرى عملية البيع. وعلى نحوٍ مشابه لعمود productSpecialty من جدول الفريق team، لنُطبّق قيد FOREIGN KEY على كل من عموديّ productID وsalesperson. الأمر الذي سيضمن أنّ هذه الأعمدة لن تتضمّن سوى قيم موجودة بالفعل في عمود productID من جدول المنتجات products وعمود empID من جدول الفريق team على التوالي. لننشئ إذًا جدولًا باسم sales يحتوي على هذه الأعمدة الأربعة: mysql> CREATE TABLE sales ( mysql> saleID int UNIQUE, mysql> quantity int, mysql> productID int, mysql> salesperson int, mysql> PRIMARY KEY (saleID), mysql> FOREIGN KEY (productID) REFERENCES products (productID), mysql> FOREIGN KEY (salesperson) REFERENCES team (empID) mysql> ); ومن ثم املأ جدول المنتجات products ببعض البيانات التجريبية النموذجية عبر تنفيذ عملية INSERT INTO التالية: mysql> INSERT INTO products mysql> VALUES mysql> (1, 'widget', 18.99), mysql> (2, 'gizmo', 14.49), mysql> (3, 'thingamajig', 39.99), mysql> (4, 'doodad', 11.50), mysql> (5, 'whatzit', 29.99); ثم املأ جدول الفريق team ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO team mysql> VALUES mysql> (1, 'Florence', 1), mysql> (2, 'Mary', 4), mysql> (3, 'Diana', 3), mysql> (4, 'Betty', 2); املأ جدول المبيعات sales ببعض البيانات النموذجية أيضًا: mysql> INSERT INTO sales mysql> VALUES mysql> (1, 7, 1, 1), mysql> (2, 10, 5, 4), mysql> (3, 8, 2, 4), mysql> (4, 1, 3, 3), mysql> (5, 5, 1, 3); ونهايةً، تخيّل أن شركتك حققت بعضًا من المبيعات دون مشاركة أحد من فريق المبيعات. لتسجيل هذه المبيعات، أضف ثلاث سجلات إلى جدول المبيعات sales لا تتضمن قيمة لعمود موظف المبيعات salesperson عبر تنفيذ العملية التالية: mysql> INSERT INTO sales (saleID, quantity, productID) mysql> VALUES mysql> (6, 1, 5), mysql> (7, 3, 1), mysql> (8, 4, 5); بهذا، تغدو مستعدًا لمتابعة باقي المقال وبدء تعلم كيفية دمج الجداول معًا في SQL. فهم صيغة عمليات بنى الدمج JOIN يمكن استخدام بنى الدمج JOIN في مجموعة متنوعة من تعليمات SQL، بما في ذلك عمليات التحديث UPDATE والحذف DELETE. ولكن ولأغراض التوضيح، سنستخدم في الأمثلة في هذا المقال استعلامات SELECT لإظهار كيفية عمل بنى الدمج JOIN. يُظهر المثال التالي الصيغة العامة لتعليمة SELECT التي تتضمن بنية الدمج JOIN: mysql> SELECT table1.column1, table2.column2 mysql> FROM table1 JOIN table2 mysql> ON search_condition; تبدأ هذه الصيغة بتعليمة SELECT التي ستعيد عمودين من جدولين منفصلين. لاحظ أنه نظرًا لقدرة بنى JOIN على مقارنة البيانات من عدة جداول، فإن صيغة هذا المثال تُوضّح الجدول المُستهدف لكل عمود بوضع اسم الجدول متبوعًا بنقطة قبل اسم العمود، وهذا ما يُعرف بالإشارة الكاملة والمؤهلة للعمود fully qualified column reference. يمكنك استخدام الإشارة الكاملة والمؤهلة للعمود في أي عملية على نحوٍ اختياريّ، في حين يغدو استخدامها ضرورةً فقط في العمليات التي يكون فيها عمودان يشتركان في نفس الاسم من جداول مختلفة. ومن الجيد عمومًا استخدامها لدى التعامل مع جداول متعددة، إذ يمكن أن تساعد في جعل عمليات الدمج JOIN أسهل للقراءة والفهم. وتأتي بنية FROM بعد بنية SELECT. إذ تُحدد بنية FROM في أي استعلام مجموعة البيانات التي ينبغي البحث فيها لإعادة البيانات المطلوبة. ولعلّ الاختلاف الوحيد هنا هو أن بنية FROM تتضمن جدولين مفصولين بالكلمة المفتاحية JOIN. ومن الطرق المفيدة في فهم الاستعلامات لدى كتابتها هي تذكر أنك تختار (SELECT) الأعمدة التي تريد إعادتها من (FROM) الجدول الذي ترغب في الاستعلام عنه. يلي ذلك بنية ON، والتي تصف كيفية ربط الاستعلام للجدولين معًا عن طريق تحديد شرط بحث. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعابير القادرة على تقييم فيما إذا كان شرط معيّن "محققًا True" أو "غير محقق False" أو "غير محدد Unknown". وبالتالي، من المفيد فهم عملية الدمج JOIN على أنها عملية تجميع كافة السجلات من جدولين، لتعيد بعد ذلك أي سجلات يُقيم شرط البحث في بنية ON من أجلها على أنه "محقق True". ولعلّه من المنطقي في بنية ON أن نُضمّن شرط بحث يختبر ما إذا كان عمودين مرتبطين – من قبيل مفتاح خارجي لجدول ما ومفتاح أساسي لجدول آخر يُشير إليه ذلك المفتاح الخارجي - يتضمنان قيمًا متساوية. وهذا ما يُشار إليه أحيانًا بالدمج عند التساوي equi join. وكمثال على كيفية مطابقة "الدمج عند التساوي" للبيانات من جداول متعددة، لنُنفّذ الاستعلام التالي باستخدام البيانات التجريبية النموذجية المُضافة سابقًا. إذ ستعمل هذه التعليمة على دمج جدولي products وteam باستخدام شرط بحث يختبر تطابق القيم في عمودي productID وproductSpecialty من الجدولين آنفي الذكر، معيدًا أسم كل عضو من فريق المبيعات واسم المنتج المُخصص له وسعر هذا المنتج: mysql> SELECT team.empName, products.productName, products.price mysql> FROM products JOIN team mysql> ON products.productID = team.productSpecialty; وتكون مجموعة نتائج هذا الاستعلام على النحو: الخرج +----------+-------------+-------+ | empName | productName | price | +----------+-------------+-------+ | Florence | widget | 18.99 | | Mary | doodad | 11.50 | | Diana | thingamajig | 39.99 | | Betty | gizmo | 14.49 | +----------+-------------+-------+ 4 rows in set (0.00 sec) ولتوضيح كيفية دمج SQL لهذه الجداول وتشكيل مجموعة النتائج، دعونا نلقي نظرة أقرب على هذه العملية. ومن المهم في هذه المرحلة التنويه إلى كون الخطوات التالية لا نُمثّل بالضبط ما يحدث عند دمج جدولين في نظام إدارة قواعد البيانات، ولكن من المفيد تصوّر عمليات الدمج JOIN وكأنها تتبع خطوات مشابهة لها. أولًا، يعرض الاستعلام كافة سجلات وأعمدة الجدول الأول ضمن بنية FROM، وهو في حالتنا الجدول products: مثال على عملية الدمج +-----------+-------------+-------+ | productID | productName | price | +-----------+-------------+-------+ | 1 | widget | 18.99 | | 2 | gizmo | 14.49 | | 3 | thingamajig | 39.99 | | 4 | doodad | 11.50 | | 5 | whatzit | 29.99 | +-----------+-------------+-------+ بعد ذلك، يخضع كل سجل من جدول products للتحليل ليُطابق مع أي سجل من جدول الفريق team حيث تكون قيمة العمود productSpecialty مطابقة لقيمة productID في السجل المعني: مثال على عملية الدمج +-----------+-------------+-------+-------+----------+------------------+ | productID | productName | price | empID | empName | productSpecialty | +-----------+-------------+-------+-------+----------+------------------+ | 1 | widget | 18.99 | 1 | Florence | 1 | | 2 | gizmo | 14.49 | 4 | Betty | 2 | | 3 | thingamajig | 39.99 | 3 | Diana | 3 | | 4 | doodad | 11.50 | 2 | Mary | 4 | | 5 | whatzit | 29.99 | | | | +-----------+-------------+-------+-------+----------+------------------+ تُستبعد بعد ذلك كافة السجلات التي لا تتطابق فيها قيمة العمود productSpecialty مع قيمة productID، ثم يُعاد تنظيم الأعمدة وفق ترتيب ورودها ضمن بنية SELECT، مع حذف أي أعمدة لم تُحدد في الاستعلام، وأخيرًا يُعاد فرز السجلات المتبقية وتُقدم كمجموعة النتائج النهائية: مثال على عملية الدمج +----------+-------------+-------+ | empName | productName | price | +----------+-------------+-------+ | Florence | widget | 18.99 | | Mary | doodad | 11.50 | | Diana | thingamajig | 39.99 | | Betty | gizmo | 14.49 | +----------+-------------+-------+ 4 rows in set (0.00 sec) ولعلّ استخدام الدمج عند التساوي هو الأسلوب الأكثر شيوعًا لربط الجداول، في حين من الممكن استخدام عوامل SQL أخرى ضمن شروط بحث بنية ON، من قبيل <، >، LIKE، NOT LIKE، أو حتى BETWEEN. ويُنصح بالانتباه إلى أن استخدام شروط بحث أعقد قد يجعل التنبؤ بالبيانات التي ستظهر في مجموعة النتائج أصعب. يُمكنك دمج الجداول في معظم تقديمات SQL باستخدام أي مجموعة من الأعمدة، شرط امتلاكها لما يُشار إليه في المعيار القياسي لـ SQL باسم "نمط بيانات مؤهل للدمج". ما يعني عمومًا أنّه من الممكن دمج عمود يحتوي على بيانات رقمية مع أي عمود آخر يحمل بيانات رقمية، وذلك بغض النظر عن أنماط بياناتهما الدقيقة. وبالمثل، من الممكن عادةً دمج أي عمود يحتوي على قيم محرفية مع آخر يحمل بيانات محرفية. ولكن وكما ذكرنا سابقًا، عادةً ما تكون الأعمدة التي نختارها لدمج جدولين هي تلك التي تُشير بالفعل إلى علاقة بين الجداول، من قبيل مفتاح خارجي مع المفتاح الأساسي لجدول آخر والذي يُشير إليه ذلك المفتاح الخارجي. كما تسمح العديد من تقديمات SQL بدمج الأعمدة التي تحمل نفس الاسم باستخدام الكلمة المفتاحية USING بدلًا من ON. وتبدو صيغة مثل هذه العملية على النحو الآتي: mysql> SELECT table1.column1, table2.column2 mysql> FROM table1 JOIN table2 mysql> USING (related_column); في صيغة هذا المثال، تعادل بنية USING استخدام ON table1.related_column = table2.related_column;. وبما أنّ لكل من جدولي sales وproducts عمود باسم productID، فمن الممكن دمجهما عبر مطابقة هذه الأعمدة باستخدام الكلمة المفتاحية USING. وهذا ما يُمثّل مهمّة الأمر التالي، والذي يُعيد saleID لكل عملية بيع، وكمية الوحدات المباعة، واسم كل منتج تم بيعه وسعره. كما يفرز مجموعة النتائج تصاعديًا استنادًا إلى قيمة saleID: mysql> SELECT sales.saleID, sales.quantity, products.productName, products.price mysql> FROM sales JOIN products mysql> USING (productID) mysql> ORDER BY saleID; الخرج +--------+----------+-------------+-------+ | saleID | quantity | productName | price | +--------+----------+-------------+-------+ | 1 | 7 | widget | 18.99 | | 2 | 10 | whatzit | 29.99 | | 3 | 8 | gizmo | 14.49 | | 4 | 1 | thingamajig | 39.99 | | 5 | 5 | widget | 18.99 | | 6 | 1 | whatzit | 29.99 | | 7 | 3 | widget | 18.99 | | 8 | 4 | whatzit | 29.99 | +--------+----------+-------------+-------+ 8 rows in set (0.00 sec) إذ قد يعيد نظام قاعدة البيانات أحيانًا ترتيب السجلات بطرق لا يسهل التنبؤ بها عند دمج الجداول. ولعلّ الحل يكون بتضمين جملة ORDER BY كما في المثال أعلاه، ما قد يُساعد في جعل مجموعات النتائج أكثر تناسقًا وسهولة في القراءة. دمج أكثر من جدولين نحتاج أحيانًا إلى دمج البيانات من أكثر من جدولين. إذ يُمكننا دمج أي عدد من الجداول معًا عن طريق تضمين بنى دمج JOIN ضمن بنى JOIN أخرى. وتُمثّل الصيغة التالية مثالًا لحالة دمج ثلاثة جداول: mysql> SELECT table1.column1, table2.column2, table3.column3 mysql> FROM table1 JOIN table2 mysql> ON table1.related_column = table2.related_column mysql> JOIN table3 mysql> ON table3.related_column = table1_or_2.related_column; تبدأ صيغة البنية FROM في هذا المثال بدمج الجدول table1 مع table2. لتبدأ عملية دمج JOIN ثانية بعد بنية ON الخاصة بعملية الدمج الأولى، والتي تدمج مجموعة الجداول المدموجة الأولية السابقة مع الجدول table3. ونلاحظ هنا أنه من الممكن دمج الجدول الثالث مع عمود موجود إما في الجدول الأول أو الثاني. ولتوضيح الأمر، لنفرض أننا نرغب بمعرفة قيمة الإيرادات المُحققة من مبيعات الموظفين، لكن اهتمامنا منصب فقط على سجلات المبيعات التي تشمل موظفًا باع المنتج الذي يتخصص فيه تحديدًا دون مبيعاته لأي منتج آخر. وللحصول على هذه المعلومات، يمكننا تنفيذ الاستعلام التالي. والذي يبدأ بدمج جدولي products وsales معًا عن طريق مطابقة عمودي productID في كل منهما. ثم يدمج جدول team مع الجدولين السابقين بمطابقة كل سجل من عملية الدمج الأولية بعمود productSpecialty لكل موظف. بعد ذلك، يعمل الاستعلام على تصفية النتائج باستخدام بنية WHERE بهدف إعادة السجلات التي يكون فيها الموظف، الذي تم تخصيصه للمنتج المُباع، هو نفسه من أتم عملية البيع بالفعل. يتضمن هذا الاستعلام أيضًا بنية ORDER BY التي تفرز النتائج النهائية تصاعديًا استنادًا إلى القيم في عمود saleID. mysql> SELECT sales.saleID, mysql> team.empName, mysql> products.productName, mysql> (sales.quantity * products.price) mysql> FROM products JOIN sales mysql> USING (productID) mysql> JOIN team mysql> ON team.productSpecialty = sales.productID mysql> WHERE team.empID = sales.salesperson mysql> ORDER BY sales.saleID; نلاحظ أنّه من بين الأعمدة المدرجة في بنية SELECT لهذا الاستعلام يوجد تعبير يضرب قيم عمود quantity الموجود في جدول sales بقيم السعر الموجودة في عمود price بجدول products. والذي يُعيد حاصل ضرب هذه القيم في السجلات المتطابقة. الخرج +--------+----------+-------------+-----------------------------------+ | saleID | empName | productName | (sales.quantity * products.price) | +--------+----------+-------------+-----------------------------------+ | 1 | Florence | widget | 132.93 | | 3 | Betty | gizmo | 115.92 | | 4 | Diana | thingamajig | 39.99 | +--------+----------+-------------+-----------------------------------+ 3 rows in set (0.00 sec) استعرضت كافّة الأمثلة حتى الآن نفس نوع بنية الدمج، ألا وهي: الدمج الداخلي INNER JOIN. وللحصول على نظرة عامّة حول كل من الدمج الداخلي والدمج الخارجي OUTER JOIN وأوجه اختلافهما، تابع قراءة القسم التالي. عمليات الدمج الداخلي مقابل الدمج الخارجي يوجد نوعان رئيسيان من بنى الدمج: الدمج الداخلي INNER والدمج الخارجي OUTER. ويكمن الفارق بين هذين النوعين من الدمج بالبيانات التي يعيدها كل منهما. إذ تُعيد عمليات الدمج الداخلي INNER فقط السجلات التي تمتلك تطابقات من كل جدول مدمج، في حين تُعيد عمليات الدمج الخارجي OUTER السجلات مع أو بدون تطابقات. استخدمنا في صيغ الأمثلة والاستعلامات من الأقسام السابقة بنى الدمج الداخلي رغم عدم تضمين الكلمة المفتاحية INNER صراحةً في أي منها. فمعظم تطبيقات SQL تعامل أي بنية دمج على أنها INNER ما لم يُذكر خلاف ذلك صراحةً. تجمع الاستعلامات التي تستخدم الدمج الخارجي OUTER JOIN بين عدة جداول لتعيد السجلات مع أو بدون تطابقات. وهذا الأمر مفيد في الكشف عن السجلات التي تنقصها بعض القيم، أو في الحالات التي تكون فيها التطابقات الجزئية مقبولة. يمكن تقسيم عمليات الدمج الخارجي OUTER JOIN إلى ثلاثة أنواع فرعية، وهي: الدمج الخارجي الأيسر LEFT OUTER، والدمج الخارجي الأيمن RIGHT OUTER، والدمج الخارجي الكامل FULL OUTER. يعيد الدمج الخارجي الأيسر، أو ببساطة الدمج الأيسر LEFT JOIN جميع السجلات التي تمتلك تطابقات من كلا الجدولين المدمجين بالإضافة إلى السجلات دون تطابقات من الجدول الموجود على الجانب الأيسر. إذ يعدّ الجدول "الأيسر" في سياق عمليات الدمج ذلك الجدول الأوّل المُحدّد مباشرةً بعد الكلمة المفتاحية FROM وقبل كلمة JOIN. وبالمثل، يعدّ الجدول "الأيمن" هو الجدول الثاني، أو الجدول الذي يلي كلمة JOIN مباشرةً، ويُعيد الدمج الخارجي الأيمن RIGHT OUTER كافة السجلات ذات التطابقات من الجداول المدمجة بالإضافة إلى كل سجل دون تطابقات من الجدول "الأيمن". في حين يعيد الدمج الخارجي الكامل FULL OUTER JOIN كافة السجلات من كلا الجدولين، بما في ذلك تلك التي لا تمتلك أي مطابقات. لتوضيح كيف تعيد هذه الأنواع المختلفة من بنى الدمج البيانات، لننفذ الاستعلامات التالية على الجداول المُنشأة في الفقرة السابقة "الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية". مع ملاحظة أن هذه الاستعلامات متطابقة باستثناء أن كل واحد منها يستخدم نوعًا مختلفًا من بنى الدمج JOIN. يستخدم هذا المثال الأول الدمج الداخلي INNER JOIN لدمج جدولي sales وteam معًا بمطابقة عمودي salesperson وempID من كل منهما على التوالي. ونؤكّد مجددًا أنّ الاستعلام يعدّ داخليًا حتى وإن لم نُضمّن الكلمة المفتاحية INNER صراحةً ما لم نشير إلى خلاف ذلك ضمن بنية الاستعلام. mysql> SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName mysql> FROM sales JOIN team mysql> ON sales.salesperson = team.empID; نظرًا لأن هذا الاستعلام يستخدم بنية الدمج الداخلي INNER JOIN، فإنه يُعيد فقط السجلات ذات التطابقات من كلا الجدولين: الخرج +--------+----------+-------------+----------+ | saleID | quantity | salesperson | empName | +--------+----------+-------------+----------+ | 1 | 7 | 1 | Florence | | 4 | 1 | 3 | Diana | | 5 | 5 | 3 | Diana | | 2 | 10 | 4 | Betty | | 3 | 8 | 4 | Betty | +--------+----------+-------------+----------+ 5 rows in set (0.00 sec) سنستخدم الآن في هذه النسخة من الاستعلام بنية الدمج الخارجي الأيسر LEFT OUTER JOIN، على النحو: mysql> SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName mysql> FROM sales LEFT OUTER JOIN team mysql> ON sales.salesperson = team.empID; وكما هو الحال مع الاستعلام السابق، يعيد هذا الاستعلام أيضًا كافّة القيم ذات التطابقات من كلا الجدولين. لكنه يعيد أيضًا أي قيم من الجدول "الأيسر" (وهو الجدول sales في هذه الحالة) التي لا تمتلك أي تطابقات مع الجدول "الأيمن" (team). ولكن وبما أنّ هذه السجلات في الجدول الأيسر لا تمتلك تطابقات في الجدول الأيمن، فتُعاد القيمة الفارغة NULL بدلًا من القيم غير المتطابقة من الجدول الأيمن. الخرج +--------+----------+-------------+----------+ | saleID | quantity | salesperson | empName | +--------+----------+-------------+----------+ | 1 | 7 | 1 | Florence | | 2 | 10 | 4 | Betty | | 3 | 8 | 4 | Betty | | 4 | 1 | 3 | Diana | | 5 | 5 | 3 | Diana | | 6 | 1 | NULL | NULL | | 7 | 3 | NULL | NULL | | 8 | 4 | NULL | NULL | +--------+----------+-------------+----------+ 8 rows in set (0.00 sec) أمّا الآن فسنستخدم بنية الدمج الأيمن RIGHT JOIN، على النحو: mysql> SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName mysql> FROM sales RIGHT JOIN team mysql> ON sales.salesperson = team.empID; لاحظ أننا اكتفينا باستخدام التعليمة RIGHT JOIN بدلًا من RIGHT OUTER JOIN في بنية الدمج من هذا الاستعلام. فكما هو الحال من حيث عدم اشتراط استخدام الكلمة المفتاحية INNER لتحديد بنية دمج داخلي INNER JOIN، فإن كلمة OUTER تُطبّق تلقائيًا بدورها بمجرد كتابة LEFT JOIN أو RIGHT JOIN. نتيجة هذا الاستعلام هي العكس تمامًا من الاستعلام السابق، بمعنى أنها تعيد كافّة السجلات ذات التطابقات من كلا الجدولين، والسجلات دون تطابقات من الجدول "الأيمن" فقط: الخرج: +--------+----------+-------------+----------+ | saleID | quantity | salesperson | empName | +--------+----------+-------------+----------+ | 1 | 7 | 1 | Florence | | NULL | NULL | NULL | Mary | | 4 | 1 | 3 | Diana | | 5 | 5 | 3 | Diana | | 2 | 10 | 4 | Betty | | 3 | 8 | 4 | Betty | +--------+----------+-------------+----------+ 6 rows in set (0.00 sec) ملاحظة: انتبه لكون MySQL لا تدعم بنى الدمج الخارجي الكامل FULL OUTER JOIN. ولتوضيح البيانات التي كان من الممكن أن يُعيدها هذا الاستعلام في حال استخدام بنية FULL OUTER JOIN، إليك كيف ستبدو مجموعة النتائج في قاعدة بيانات PostgreSQL: Joinsdb=# SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName Joinsdb=# FROM sales FULL OUTER JOIN team Joinsdb=# ON sales.salesperson = team.empID; الخرج saleid | quantity | salesperson | empname --------+----------+-------------+---------- 1 | 7 | 1 | Florence 2 | 10 | 4 | Betty 3 | 8 | 4 | Betty 4 | 1 | 3 | Diana 5 | 5 | 3 | Diana 6 | 1 | | 7 | 3 | | 8 | 4 | | | | | Mary (9 rows) نلاحظ من النتائج أعلاه أنّ الدمج الكامل FULL JOIN يُعيد كافّة السجلات من كلا الجدولين بما في ذلك تلك التي لا تمتلك تطابقات. تسمية الجداول والأعمدة بأسماء بديلة في بنى الدمج لدى دمج جداول ذات أسماء طويلة أو وصفية للغاية، قد تصبح مهمة كتابة الإشارة الكاملة والمؤهلة للعمود مرهقة. ولتجنب ذلك، يجد المستخدمون أحيانًا أنّه من المفيد تزويد أسماء الجداول أو الأعمدة بأسماء بديلة أقصر. الأمر الذي يمكننا تنفيذه في SQL بإلحاق تعريف الجدول في بنية FROM بكلمة AS المفتاحية، ليأتي بعدها الاسم البديل الذي اخترناه، على النحو التالي: mysql> SELECT t1.column1, t2.column2 mysql> FROM table1 AS t1 JOIN table2 AS t2 mysql> ON t1.related_column = t2.related_column; استخدمنا في صيغة هذا المثال الأسماء البديلة في بنية SELECT رغم أننا لم نُعرف هذه الأسماء إلّا في بنية FROM. وهذا الأمر ممكن لأنّ ترتيب تنفيذ الاستعلامات في SQL يبدأ ببنية FROM أولًا. قد تكون هذه الطريقة مربكة، ولكن من المفيد تذكرها والتفكير في الأسماء البديلة قبل البدء في كتابة الاستعلام. كمثال، لننفذ الاستعلام التالي الذي يدمج جدولي sales وproducts ويزودهما بالأسماء البديلة S وP على التوالي: mysql> SELECT S.saleID, S.quantity, mysql> P.productName, mysql> (P.price * S.quantity) AS revenue mysql> FROM sales AS S JOIN products AS P mysql> USING (productID); نلاحظ أن هذا المثال يُنشئ أيضًا اسمًا بديلًا ثالثًا وهو revenue لحاصل ضرب قيم العمود quantity من الجدول sales بقيمها المقابلة في عمود price من الجدول products. ولن يظهر هذا الاسم سوى ضمن مجموعة النتائج كاسم عمود، لكنه مهم لتوضيح المعنى أو الغرض من نتائج الاستعلام: الخرج +--------+----------+-------------+---------+ | saleID | quantity | productName | revenue | +--------+----------+-------------+---------+ | 1 | 7 | widget | 132.93 | | 2 | 10 | whatzit | 299.90 | | 3 | 8 | gizmo | 115.92 | | 4 | 1 | thingamajig | 39.99 | | 5 | 5 | widget | 94.95 | | 6 | 1 | whatzit | 29.99 | | 7 | 3 | widget | 56.97 | | 8 | 4 | whatzit | 119.96 | +--------+----------+-------------+---------+ 8 rows in set (0.00 sec) وتجدر الملاحظة إلى أنّ استخدام كلمة AS عند تحديد الأسماء البديلة اختياري من الناحية التقنية، إذ من الممكن أيضًا كتابة المثال السابق على النحو: mysql> SELECT S.saleID, S.quantity, P.productName, (P.price * S.quantity) revenue mysql> FROM sales S JOIN products P mysql> USING (productID); ورغم كون كلمة AS ليست ضرورية لتحديد اسم بديل، إلّا أنّ تضمينها يعدّ من الممارسات الجيدة. إذ يُمكن أن يساعد في الحفاظ على وضوح غرض الاستعلام وتحسين مقروئيته. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية استخدام عمليات الدمج JOIN لدمج جداول متفرقة ضمن مجموعة نتائج استعلام واحدة. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Joins in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام محارف البدل في لغة الاستعلام البنيوية SQL الدمج بين الجداول في SQL الاستعلام عن البيانات في SQL مدخل إلى أهم الاستعلامات (queries) في MySQL مواضيع متقدمة في SQL
غالبًا ما تفصل تصاميم قواعد البيانات المعلومات إلى جداول مختلفة بناءً على العلاقات بين بعض نقاط البيانات. ولكن حتى في مثل هذه الحالات، من المحتمل أن نرغب أحيانًا باسترجاع المعلومات من أكثر من جدول في وقتٍ واحد. إحدى الطرق الشائعة للوصول إلى البيانات من جداول متعددة في عملية واحدة باستخدام لغة الاستعلام البنيوية SQL هي تجميع الجداول باستخدام بنى الدمج JOIN. إذ تُجمّع بنية الدمج JOIN الجداول المنفصلة عن طريق مطابقة السجلات المرتبطة ببعضها البعض من كل جدول مستندةً إلى عمليات الدمج في الجبر العلاقيّ -وهو نظرية تستخدم الهياكل الجبرية لنمذجة البيانات وتحديد الاستعلامات عليها، إذ يُعد إطارًا نظريًا يُستخدم لوصف العمليات على البيانات في قواعد البيانات العلاقية، مثل الدمج والاختيار، ويساعد في تشكيل الأساس الرياضي للغات الاستعلام مثل SQL) -. وعادةً ما تُبنى العلاقة بين الجداول المطلوب دمجها على زوجٍ من الأعمدة - عمود من كل جدول - والتي تتشارك قيمًا مشتركة، كأن نختار مفتاح خارجي لجدول مع مفتاح أساسي لجدول آخر يُشير إليه المفتاح الخارجي آنف الذكر. يوضّح هذا المقال كيفية بناء مجموعة متنوعة من استعلامات SQL التي تتضمن بنية الدمج JOIN. كما يُسلط الضوء على أنماط مختلفة من بنى الدمج وكيفية تجميع البيانات من جداول متعددة وكيفية استخدام الأسماء البديلة alias للأعمدة لجعل كتابة عمليات الدمج JOIN أقل تعقيدًا. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام عمليات الدمج JOIN. لذا ننصحك بمتابعة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسمjoinsDB: mysql> CREATE DATABASE joinsDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرج كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات joinsDB، نفّذ تعليمة USE التالية: mysql> USE joinsDB; الخرج Database changed الآن، بعد اختيار قاعدة البيانات joinsDB لننشئ بعض الجداول ضمنها. لمتابعة الأمثلة المستخدمة في هذا المقال، تخيل أنك تدير مصنعًا وقررت البدء في تتبع المعلومات حول كل من خط الإنتاج، والموظفين في فريق المبيعات، ومبيعات الشركة، وذلك في قاعدة بيانات SQL. فقررت البدء بثلاثة جداول، أولها سيخزن معلومات حول المنتجات، متضمنًا ثلاثة أعمدة: productID: رقم تعريف كل منتج، معبرًا عنه بنمط البيانات int. سيعمل هذا العمود كمفتاح أساسي للجدول، مما يعني أن كل قيمة فيه ستلعب دور مُعرّف فريد للسجل الخاص بها. وبما أن كل قيمة في المفتاح الأساسي يجب أن تكون فريدة، ستطبّق على هذا العمود القيد UNIQUE. productName: اسم كل منتج، معبرًا عنه باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. price: سعر كل منتج، معبرًا عنه باستخدام نمط البيانات decimal. وتُحدد القيم في هذا العمود بحد أقصى قدره أربعة أرقام، بواقع رقمين على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها من -99.99 إلى 99.99. إذًا، أنشئ جدولًا باسم products يحتوي على هذه الأعمدة الثلاثة على النحو التالي: mysql> CREATE TABLE products ( mysql> productID int UNIQUE, mysql> productName varchar(20), mysql> price decimal (4,2), mysql> PRIMARY KEY (productID) mysql>); في حين سيخزّن الجدول الثاني معلومات حول الموظفين في فريق مبيعات الشركة. فارتأيت أن هذا الجدول يحتاج أيضًا إلى ثلاثة أعمدة: empID: مشابه لعمود productID، إذ سيحتوي على مُعرّف فريد لكل موظف في فريق المبيعات مُعبرًا عنه بنمط البيانات int. وبالمثل، سيُطبق على هذا العمود قيد UNIQUE وسيعمل كمفتاح أساسي لجدول الفريق. empName: اسم كل مندوب مبيعات، مُعبرًا عنه باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. productSpecialty: بفرض أنك قررت تخصيص منتج لكل عضو في فريق المبيعات؛ إذ يمكنه بيع أي منتج تصنعه الشركة ولكن تركيزه العام سيكون على المنتج المُخصّص له. وللإشارة إلى هذا الأمر في الجدول، أنشأنا هذا العمود الذي يحتوي على قيمة productID للمنتج المُخصّص لكل موظف. ولضمان أنّ عمود productSpecialty لن يتضمّن سوى قيم تُمثّل مُعرّفات صالحة للمنتجات، يمكنك إنشاء قيد مفتاح خارجي عليه بحيث يُشير إلى عمود productID في جدول المنتجات products. يُعد قيد المفتاح الخارجي طريقة لتحديد علاقة بين جدولين، إذ يفرض أن تكون القيم في العمود المُطبّق عليه موجودة بالفعل في العمود المُشار إليه. يشترط قيد المفتاح الخارجي في تعليمة CREATE TABLE أدناه أن تكون كل قيمة تُضاف إلى عمود productSpecialty من جدول الفريق team موجودة مسبقًا في عمود productID من جدول المنتجات products. أنشئ جدولًا باسم team يحتوي على هذه الأعمدة الثلاثة: mysql> CREATE TABLE team ( mysql> empID int UNIQUE, mysql> empName varchar(20), mysql> productSpecialty int, mysql> PRIMARY KEY (empID), mysql> FOREIGN KEY (productSpecialty) REFERENCES products (productID) ); أمّا الجدول الأخير فسيتضمّن سجلات مبيعات الشركة. وسيكون لهذا الجدول أربعة أعمدة: saleID: مشابه لعمودي productID وempID، إذ سيحتوي هذا العمود على مُعرّف فريد لكل عملية بيع مُعبرًا عنه بنمط البيانات int. سنطبق على هذا العمود أيضًا قيد UNIQUE ليلعب دور المفتاح الأساسي لجدول المبيعات sales. quantity: عدد الوحدات من كل منتج مُباع، مُعبرًا عنه بنمط البيانات int. productID: مُعرّف المنتج المُباع، مُعبرًا عنه بنمط البيانات int. salesperson: مُعرّف الموظف الذي أجرى عملية البيع. وعلى نحوٍ مشابه لعمود productSpecialty من جدول الفريق team، لنُطبّق قيد FOREIGN KEY على كل من عموديّ productID وsalesperson. الأمر الذي سيضمن أنّ هذه الأعمدة لن تتضمّن سوى قيم موجودة بالفعل في عمود productID من جدول المنتجات products وعمود empID من جدول الفريق team على التوالي. لننشئ إذًا جدولًا باسم sales يحتوي على هذه الأعمدة الأربعة: mysql> CREATE TABLE sales ( mysql> saleID int UNIQUE, mysql> quantity int, mysql> productID int, mysql> salesperson int, mysql> PRIMARY KEY (saleID), mysql> FOREIGN KEY (productID) REFERENCES products (productID), mysql> FOREIGN KEY (salesperson) REFERENCES team (empID) mysql> ); ومن ثم املأ جدول المنتجات products ببعض البيانات التجريبية النموذجية عبر تنفيذ عملية INSERT INTO التالية: mysql> INSERT INTO products mysql> VALUES mysql> (1, 'widget', 18.99), mysql> (2, 'gizmo', 14.49), mysql> (3, 'thingamajig', 39.99), mysql> (4, 'doodad', 11.50), mysql> (5, 'whatzit', 29.99); ثم املأ جدول الفريق team ببعض البيانات التجريبية النموذجية: mysql> INSERT INTO team mysql> VALUES mysql> (1, 'Florence', 1), mysql> (2, 'Mary', 4), mysql> (3, 'Diana', 3), mysql> (4, 'Betty', 2); املأ جدول المبيعات sales ببعض البيانات النموذجية أيضًا: mysql> INSERT INTO sales mysql> VALUES mysql> (1, 7, 1, 1), mysql> (2, 10, 5, 4), mysql> (3, 8, 2, 4), mysql> (4, 1, 3, 3), mysql> (5, 5, 1, 3); ونهايةً، تخيّل أن شركتك حققت بعضًا من المبيعات دون مشاركة أحد من فريق المبيعات. لتسجيل هذه المبيعات، أضف ثلاث سجلات إلى جدول المبيعات sales لا تتضمن قيمة لعمود موظف المبيعات salesperson عبر تنفيذ العملية التالية: mysql> INSERT INTO sales (saleID, quantity, productID) mysql> VALUES mysql> (6, 1, 5), mysql> (7, 3, 1), mysql> (8, 4, 5); بهذا، تغدو مستعدًا لمتابعة باقي المقال وبدء تعلم كيفية دمج الجداول معًا في SQL. فهم صيغة عمليات بنى الدمج JOIN يمكن استخدام بنى الدمج JOIN في مجموعة متنوعة من تعليمات SQL، بما في ذلك عمليات التحديث UPDATE والحذف DELETE. ولكن ولأغراض التوضيح، سنستخدم في الأمثلة في هذا المقال استعلامات SELECT لإظهار كيفية عمل بنى الدمج JOIN. يُظهر المثال التالي الصيغة العامة لتعليمة SELECT التي تتضمن بنية الدمج JOIN: mysql> SELECT table1.column1, table2.column2 mysql> FROM table1 JOIN table2 mysql> ON search_condition; تبدأ هذه الصيغة بتعليمة SELECT التي ستعيد عمودين من جدولين منفصلين. لاحظ أنه نظرًا لقدرة بنى JOIN على مقارنة البيانات من عدة جداول، فإن صيغة هذا المثال تُوضّح الجدول المُستهدف لكل عمود بوضع اسم الجدول متبوعًا بنقطة قبل اسم العمود، وهذا ما يُعرف بالإشارة الكاملة والمؤهلة للعمود fully qualified column reference. يمكنك استخدام الإشارة الكاملة والمؤهلة للعمود في أي عملية على نحوٍ اختياريّ، في حين يغدو استخدامها ضرورةً فقط في العمليات التي يكون فيها عمودان يشتركان في نفس الاسم من جداول مختلفة. ومن الجيد عمومًا استخدامها لدى التعامل مع جداول متعددة، إذ يمكن أن تساعد في جعل عمليات الدمج JOIN أسهل للقراءة والفهم. وتأتي بنية FROM بعد بنية SELECT. إذ تُحدد بنية FROM في أي استعلام مجموعة البيانات التي ينبغي البحث فيها لإعادة البيانات المطلوبة. ولعلّ الاختلاف الوحيد هنا هو أن بنية FROM تتضمن جدولين مفصولين بالكلمة المفتاحية JOIN. ومن الطرق المفيدة في فهم الاستعلامات لدى كتابتها هي تذكر أنك تختار (SELECT) الأعمدة التي تريد إعادتها من (FROM) الجدول الذي ترغب في الاستعلام عنه. يلي ذلك بنية ON، والتي تصف كيفية ربط الاستعلام للجدولين معًا عن طريق تحديد شرط بحث. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعابير القادرة على تقييم فيما إذا كان شرط معيّن "محققًا True" أو "غير محقق False" أو "غير محدد Unknown". وبالتالي، من المفيد فهم عملية الدمج JOIN على أنها عملية تجميع كافة السجلات من جدولين، لتعيد بعد ذلك أي سجلات يُقيم شرط البحث في بنية ON من أجلها على أنه "محقق True". ولعلّه من المنطقي في بنية ON أن نُضمّن شرط بحث يختبر ما إذا كان عمودين مرتبطين – من قبيل مفتاح خارجي لجدول ما ومفتاح أساسي لجدول آخر يُشير إليه ذلك المفتاح الخارجي - يتضمنان قيمًا متساوية. وهذا ما يُشار إليه أحيانًا بالدمج عند التساوي equi join. وكمثال على كيفية مطابقة "الدمج عند التساوي" للبيانات من جداول متعددة، لنُنفّذ الاستعلام التالي باستخدام البيانات التجريبية النموذجية المُضافة سابقًا. إذ ستعمل هذه التعليمة على دمج جدولي products وteam باستخدام شرط بحث يختبر تطابق القيم في عمودي productID وproductSpecialty من الجدولين آنفي الذكر، معيدًا أسم كل عضو من فريق المبيعات واسم المنتج المُخصص له وسعر هذا المنتج: mysql> SELECT team.empName, products.productName, products.price mysql> FROM products JOIN team mysql> ON products.productID = team.productSpecialty; وتكون مجموعة نتائج هذا الاستعلام على النحو: الخرج +----------+-------------+-------+ | empName | productName | price | +----------+-------------+-------+ | Florence | widget | 18.99 | | Mary | doodad | 11.50 | | Diana | thingamajig | 39.99 | | Betty | gizmo | 14.49 | +----------+-------------+-------+ 4 rows in set (0.00 sec) ولتوضيح كيفية دمج SQL لهذه الجداول وتشكيل مجموعة النتائج، دعونا نلقي نظرة أقرب على هذه العملية. ومن المهم في هذه المرحلة التنويه إلى كون الخطوات التالية لا نُمثّل بالضبط ما يحدث عند دمج جدولين في نظام إدارة قواعد البيانات، ولكن من المفيد تصوّر عمليات الدمج JOIN وكأنها تتبع خطوات مشابهة لها. أولًا، يعرض الاستعلام كافة سجلات وأعمدة الجدول الأول ضمن بنية FROM، وهو في حالتنا الجدول products: مثال على عملية الدمج +-----------+-------------+-------+ | productID | productName | price | +-----------+-------------+-------+ | 1 | widget | 18.99 | | 2 | gizmo | 14.49 | | 3 | thingamajig | 39.99 | | 4 | doodad | 11.50 | | 5 | whatzit | 29.99 | +-----------+-------------+-------+ بعد ذلك، يخضع كل سجل من جدول products للتحليل ليُطابق مع أي سجل من جدول الفريق team حيث تكون قيمة العمود productSpecialty مطابقة لقيمة productID في السجل المعني: مثال على عملية الدمج +-----------+-------------+-------+-------+----------+------------------+ | productID | productName | price | empID | empName | productSpecialty | +-----------+-------------+-------+-------+----------+------------------+ | 1 | widget | 18.99 | 1 | Florence | 1 | | 2 | gizmo | 14.49 | 4 | Betty | 2 | | 3 | thingamajig | 39.99 | 3 | Diana | 3 | | 4 | doodad | 11.50 | 2 | Mary | 4 | | 5 | whatzit | 29.99 | | | | +-----------+-------------+-------+-------+----------+------------------+ تُستبعد بعد ذلك كافة السجلات التي لا تتطابق فيها قيمة العمود productSpecialty مع قيمة productID، ثم يُعاد تنظيم الأعمدة وفق ترتيب ورودها ضمن بنية SELECT، مع حذف أي أعمدة لم تُحدد في الاستعلام، وأخيرًا يُعاد فرز السجلات المتبقية وتُقدم كمجموعة النتائج النهائية: مثال على عملية الدمج +----------+-------------+-------+ | empName | productName | price | +----------+-------------+-------+ | Florence | widget | 18.99 | | Mary | doodad | 11.50 | | Diana | thingamajig | 39.99 | | Betty | gizmo | 14.49 | +----------+-------------+-------+ 4 rows in set (0.00 sec) ولعلّ استخدام الدمج عند التساوي هو الأسلوب الأكثر شيوعًا لربط الجداول، في حين من الممكن استخدام عوامل SQL أخرى ضمن شروط بحث بنية ON، من قبيل <، >، LIKE، NOT LIKE، أو حتى BETWEEN. ويُنصح بالانتباه إلى أن استخدام شروط بحث أعقد قد يجعل التنبؤ بالبيانات التي ستظهر في مجموعة النتائج أصعب. يُمكنك دمج الجداول في معظم تقديمات SQL باستخدام أي مجموعة من الأعمدة، شرط امتلاكها لما يُشار إليه في المعيار القياسي لـ SQL باسم "نمط بيانات مؤهل للدمج". ما يعني عمومًا أنّه من الممكن دمج عمود يحتوي على بيانات رقمية مع أي عمود آخر يحمل بيانات رقمية، وذلك بغض النظر عن أنماط بياناتهما الدقيقة. وبالمثل، من الممكن عادةً دمج أي عمود يحتوي على قيم محرفية مع آخر يحمل بيانات محرفية. ولكن وكما ذكرنا سابقًا، عادةً ما تكون الأعمدة التي نختارها لدمج جدولين هي تلك التي تُشير بالفعل إلى علاقة بين الجداول، من قبيل مفتاح خارجي مع المفتاح الأساسي لجدول آخر والذي يُشير إليه ذلك المفتاح الخارجي. كما تسمح العديد من تقديمات SQL بدمج الأعمدة التي تحمل نفس الاسم باستخدام الكلمة المفتاحية USING بدلًا من ON. وتبدو صيغة مثل هذه العملية على النحو الآتي: mysql> SELECT table1.column1, table2.column2 mysql> FROM table1 JOIN table2 mysql> USING (related_column); في صيغة هذا المثال، تعادل بنية USING استخدام ON table1.related_column = table2.related_column;. وبما أنّ لكل من جدولي sales وproducts عمود باسم productID، فمن الممكن دمجهما عبر مطابقة هذه الأعمدة باستخدام الكلمة المفتاحية USING. وهذا ما يُمثّل مهمّة الأمر التالي، والذي يُعيد saleID لكل عملية بيع، وكمية الوحدات المباعة، واسم كل منتج تم بيعه وسعره. كما يفرز مجموعة النتائج تصاعديًا استنادًا إلى قيمة saleID: mysql> SELECT sales.saleID, sales.quantity, products.productName, products.price mysql> FROM sales JOIN products mysql> USING (productID) mysql> ORDER BY saleID; الخرج +--------+----------+-------------+-------+ | saleID | quantity | productName | price | +--------+----------+-------------+-------+ | 1 | 7 | widget | 18.99 | | 2 | 10 | whatzit | 29.99 | | 3 | 8 | gizmo | 14.49 | | 4 | 1 | thingamajig | 39.99 | | 5 | 5 | widget | 18.99 | | 6 | 1 | whatzit | 29.99 | | 7 | 3 | widget | 18.99 | | 8 | 4 | whatzit | 29.99 | +--------+----------+-------------+-------+ 8 rows in set (0.00 sec) إذ قد يعيد نظام قاعدة البيانات أحيانًا ترتيب السجلات بطرق لا يسهل التنبؤ بها عند دمج الجداول. ولعلّ الحل يكون بتضمين جملة ORDER BY كما في المثال أعلاه، ما قد يُساعد في جعل مجموعات النتائج أكثر تناسقًا وسهولة في القراءة. دمج أكثر من جدولين نحتاج أحيانًا إلى دمج البيانات من أكثر من جدولين. إذ يُمكننا دمج أي عدد من الجداول معًا عن طريق تضمين بنى دمج JOIN ضمن بنى JOIN أخرى. وتُمثّل الصيغة التالية مثالًا لحالة دمج ثلاثة جداول: mysql> SELECT table1.column1, table2.column2, table3.column3 mysql> FROM table1 JOIN table2 mysql> ON table1.related_column = table2.related_column mysql> JOIN table3 mysql> ON table3.related_column = table1_or_2.related_column; تبدأ صيغة البنية FROM في هذا المثال بدمج الجدول table1 مع table2. لتبدأ عملية دمج JOIN ثانية بعد بنية ON الخاصة بعملية الدمج الأولى، والتي تدمج مجموعة الجداول المدموجة الأولية السابقة مع الجدول table3. ونلاحظ هنا أنه من الممكن دمج الجدول الثالث مع عمود موجود إما في الجدول الأول أو الثاني. ولتوضيح الأمر، لنفرض أننا نرغب بمعرفة قيمة الإيرادات المُحققة من مبيعات الموظفين، لكن اهتمامنا منصب فقط على سجلات المبيعات التي تشمل موظفًا باع المنتج الذي يتخصص فيه تحديدًا دون مبيعاته لأي منتج آخر. وللحصول على هذه المعلومات، يمكننا تنفيذ الاستعلام التالي. والذي يبدأ بدمج جدولي products وsales معًا عن طريق مطابقة عمودي productID في كل منهما. ثم يدمج جدول team مع الجدولين السابقين بمطابقة كل سجل من عملية الدمج الأولية بعمود productSpecialty لكل موظف. بعد ذلك، يعمل الاستعلام على تصفية النتائج باستخدام بنية WHERE بهدف إعادة السجلات التي يكون فيها الموظف، الذي تم تخصيصه للمنتج المُباع، هو نفسه من أتم عملية البيع بالفعل. يتضمن هذا الاستعلام أيضًا بنية ORDER BY التي تفرز النتائج النهائية تصاعديًا استنادًا إلى القيم في عمود saleID. mysql> SELECT sales.saleID, mysql> team.empName, mysql> products.productName, mysql> (sales.quantity * products.price) mysql> FROM products JOIN sales mysql> USING (productID) mysql> JOIN team mysql> ON team.productSpecialty = sales.productID mysql> WHERE team.empID = sales.salesperson mysql> ORDER BY sales.saleID; نلاحظ أنّه من بين الأعمدة المدرجة في بنية SELECT لهذا الاستعلام يوجد تعبير يضرب قيم عمود quantity الموجود في جدول sales بقيم السعر الموجودة في عمود price بجدول products. والذي يُعيد حاصل ضرب هذه القيم في السجلات المتطابقة. الخرج +--------+----------+-------------+-----------------------------------+ | saleID | empName | productName | (sales.quantity * products.price) | +--------+----------+-------------+-----------------------------------+ | 1 | Florence | widget | 132.93 | | 3 | Betty | gizmo | 115.92 | | 4 | Diana | thingamajig | 39.99 | +--------+----------+-------------+-----------------------------------+ 3 rows in set (0.00 sec) استعرضت كافّة الأمثلة حتى الآن نفس نوع بنية الدمج، ألا وهي: الدمج الداخلي INNER JOIN. وللحصول على نظرة عامّة حول كل من الدمج الداخلي والدمج الخارجي OUTER JOIN وأوجه اختلافهما، تابع قراءة القسم التالي. عمليات الدمج الداخلي مقابل الدمج الخارجي يوجد نوعان رئيسيان من بنى الدمج: الدمج الداخلي INNER والدمج الخارجي OUTER. ويكمن الفارق بين هذين النوعين من الدمج بالبيانات التي يعيدها كل منهما. إذ تُعيد عمليات الدمج الداخلي INNER فقط السجلات التي تمتلك تطابقات من كل جدول مدمج، في حين تُعيد عمليات الدمج الخارجي OUTER السجلات مع أو بدون تطابقات. استخدمنا في صيغ الأمثلة والاستعلامات من الأقسام السابقة بنى الدمج الداخلي رغم عدم تضمين الكلمة المفتاحية INNER صراحةً في أي منها. فمعظم تطبيقات SQL تعامل أي بنية دمج على أنها INNER ما لم يُذكر خلاف ذلك صراحةً. تجمع الاستعلامات التي تستخدم الدمج الخارجي OUTER JOIN بين عدة جداول لتعيد السجلات مع أو بدون تطابقات. وهذا الأمر مفيد في الكشف عن السجلات التي تنقصها بعض القيم، أو في الحالات التي تكون فيها التطابقات الجزئية مقبولة. يمكن تقسيم عمليات الدمج الخارجي OUTER JOIN إلى ثلاثة أنواع فرعية، وهي: الدمج الخارجي الأيسر LEFT OUTER، والدمج الخارجي الأيمن RIGHT OUTER، والدمج الخارجي الكامل FULL OUTER. يعيد الدمج الخارجي الأيسر، أو ببساطة الدمج الأيسر LEFT JOIN جميع السجلات التي تمتلك تطابقات من كلا الجدولين المدمجين بالإضافة إلى السجلات دون تطابقات من الجدول الموجود على الجانب الأيسر. إذ يعدّ الجدول "الأيسر" في سياق عمليات الدمج ذلك الجدول الأوّل المُحدّد مباشرةً بعد الكلمة المفتاحية FROM وقبل كلمة JOIN. وبالمثل، يعدّ الجدول "الأيمن" هو الجدول الثاني، أو الجدول الذي يلي كلمة JOIN مباشرةً، ويُعيد الدمج الخارجي الأيمن RIGHT OUTER كافة السجلات ذات التطابقات من الجداول المدمجة بالإضافة إلى كل سجل دون تطابقات من الجدول "الأيمن". في حين يعيد الدمج الخارجي الكامل FULL OUTER JOIN كافة السجلات من كلا الجدولين، بما في ذلك تلك التي لا تمتلك أي مطابقات. لتوضيح كيف تعيد هذه الأنواع المختلفة من بنى الدمج البيانات، لننفذ الاستعلامات التالية على الجداول المُنشأة في الفقرة السابقة "الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية". مع ملاحظة أن هذه الاستعلامات متطابقة باستثناء أن كل واحد منها يستخدم نوعًا مختلفًا من بنى الدمج JOIN. يستخدم هذا المثال الأول الدمج الداخلي INNER JOIN لدمج جدولي sales وteam معًا بمطابقة عمودي salesperson وempID من كل منهما على التوالي. ونؤكّد مجددًا أنّ الاستعلام يعدّ داخليًا حتى وإن لم نُضمّن الكلمة المفتاحية INNER صراحةً ما لم نشير إلى خلاف ذلك ضمن بنية الاستعلام. mysql> SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName mysql> FROM sales JOIN team mysql> ON sales.salesperson = team.empID; نظرًا لأن هذا الاستعلام يستخدم بنية الدمج الداخلي INNER JOIN، فإنه يُعيد فقط السجلات ذات التطابقات من كلا الجدولين: الخرج +--------+----------+-------------+----------+ | saleID | quantity | salesperson | empName | +--------+----------+-------------+----------+ | 1 | 7 | 1 | Florence | | 4 | 1 | 3 | Diana | | 5 | 5 | 3 | Diana | | 2 | 10 | 4 | Betty | | 3 | 8 | 4 | Betty | +--------+----------+-------------+----------+ 5 rows in set (0.00 sec) سنستخدم الآن في هذه النسخة من الاستعلام بنية الدمج الخارجي الأيسر LEFT OUTER JOIN، على النحو: mysql> SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName mysql> FROM sales LEFT OUTER JOIN team mysql> ON sales.salesperson = team.empID; وكما هو الحال مع الاستعلام السابق، يعيد هذا الاستعلام أيضًا كافّة القيم ذات التطابقات من كلا الجدولين. لكنه يعيد أيضًا أي قيم من الجدول "الأيسر" (وهو الجدول sales في هذه الحالة) التي لا تمتلك أي تطابقات مع الجدول "الأيمن" (team). ولكن وبما أنّ هذه السجلات في الجدول الأيسر لا تمتلك تطابقات في الجدول الأيمن، فتُعاد القيمة الفارغة NULL بدلًا من القيم غير المتطابقة من الجدول الأيمن. الخرج +--------+----------+-------------+----------+ | saleID | quantity | salesperson | empName | +--------+----------+-------------+----------+ | 1 | 7 | 1 | Florence | | 2 | 10 | 4 | Betty | | 3 | 8 | 4 | Betty | | 4 | 1 | 3 | Diana | | 5 | 5 | 3 | Diana | | 6 | 1 | NULL | NULL | | 7 | 3 | NULL | NULL | | 8 | 4 | NULL | NULL | +--------+----------+-------------+----------+ 8 rows in set (0.00 sec) أمّا الآن فسنستخدم بنية الدمج الأيمن RIGHT JOIN، على النحو: mysql> SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName mysql> FROM sales RIGHT JOIN team mysql> ON sales.salesperson = team.empID; لاحظ أننا اكتفينا باستخدام التعليمة RIGHT JOIN بدلًا من RIGHT OUTER JOIN في بنية الدمج من هذا الاستعلام. فكما هو الحال من حيث عدم اشتراط استخدام الكلمة المفتاحية INNER لتحديد بنية دمج داخلي INNER JOIN، فإن كلمة OUTER تُطبّق تلقائيًا بدورها بمجرد كتابة LEFT JOIN أو RIGHT JOIN. نتيجة هذا الاستعلام هي العكس تمامًا من الاستعلام السابق، بمعنى أنها تعيد كافّة السجلات ذات التطابقات من كلا الجدولين، والسجلات دون تطابقات من الجدول "الأيمن" فقط: الخرج: +--------+----------+-------------+----------+ | saleID | quantity | salesperson | empName | +--------+----------+-------------+----------+ | 1 | 7 | 1 | Florence | | NULL | NULL | NULL | Mary | | 4 | 1 | 3 | Diana | | 5 | 5 | 3 | Diana | | 2 | 10 | 4 | Betty | | 3 | 8 | 4 | Betty | +--------+----------+-------------+----------+ 6 rows in set (0.00 sec) ملاحظة: انتبه لكون MySQL لا تدعم بنى الدمج الخارجي الكامل FULL OUTER JOIN. ولتوضيح البيانات التي كان من الممكن أن يُعيدها هذا الاستعلام في حال استخدام بنية FULL OUTER JOIN، إليك كيف ستبدو مجموعة النتائج في قاعدة بيانات PostgreSQL: Joinsdb=# SELECT sales.saleID, sales.quantity, sales.salesperson, team.empName Joinsdb=# FROM sales FULL OUTER JOIN team Joinsdb=# ON sales.salesperson = team.empID; الخرج saleid | quantity | salesperson | empname --------+----------+-------------+---------- 1 | 7 | 1 | Florence 2 | 10 | 4 | Betty 3 | 8 | 4 | Betty 4 | 1 | 3 | Diana 5 | 5 | 3 | Diana 6 | 1 | | 7 | 3 | | 8 | 4 | | | | | Mary (9 rows) نلاحظ من النتائج أعلاه أنّ الدمج الكامل FULL JOIN يُعيد كافّة السجلات من كلا الجدولين بما في ذلك تلك التي لا تمتلك تطابقات. تسمية الجداول والأعمدة بأسماء بديلة في بنى الدمج لدى دمج جداول ذات أسماء طويلة أو وصفية للغاية، قد تصبح مهمة كتابة الإشارة الكاملة والمؤهلة للعمود مرهقة. ولتجنب ذلك، يجد المستخدمون أحيانًا أنّه من المفيد تزويد أسماء الجداول أو الأعمدة بأسماء بديلة أقصر. الأمر الذي يمكننا تنفيذه في SQL بإلحاق تعريف الجدول في بنية FROM بكلمة AS المفتاحية، ليأتي بعدها الاسم البديل الذي اخترناه، على النحو التالي: mysql> SELECT t1.column1, t2.column2 mysql> FROM table1 AS t1 JOIN table2 AS t2 mysql> ON t1.related_column = t2.related_column; استخدمنا في صيغة هذا المثال الأسماء البديلة في بنية SELECT رغم أننا لم نُعرف هذه الأسماء إلّا في بنية FROM. وهذا الأمر ممكن لأنّ ترتيب تنفيذ الاستعلامات في SQL يبدأ ببنية FROM أولًا. قد تكون هذه الطريقة مربكة، ولكن من المفيد تذكرها والتفكير في الأسماء البديلة قبل البدء في كتابة الاستعلام. كمثال، لننفذ الاستعلام التالي الذي يدمج جدولي sales وproducts ويزودهما بالأسماء البديلة S وP على التوالي: mysql> SELECT S.saleID, S.quantity, mysql> P.productName, mysql> (P.price * S.quantity) AS revenue mysql> FROM sales AS S JOIN products AS P mysql> USING (productID); نلاحظ أن هذا المثال يُنشئ أيضًا اسمًا بديلًا ثالثًا وهو revenue لحاصل ضرب قيم العمود quantity من الجدول sales بقيمها المقابلة في عمود price من الجدول products. ولن يظهر هذا الاسم سوى ضمن مجموعة النتائج كاسم عمود، لكنه مهم لتوضيح المعنى أو الغرض من نتائج الاستعلام: الخرج +--------+----------+-------------+---------+ | saleID | quantity | productName | revenue | +--------+----------+-------------+---------+ | 1 | 7 | widget | 132.93 | | 2 | 10 | whatzit | 299.90 | | 3 | 8 | gizmo | 115.92 | | 4 | 1 | thingamajig | 39.99 | | 5 | 5 | widget | 94.95 | | 6 | 1 | whatzit | 29.99 | | 7 | 3 | widget | 56.97 | | 8 | 4 | whatzit | 119.96 | +--------+----------+-------------+---------+ 8 rows in set (0.00 sec) وتجدر الملاحظة إلى أنّ استخدام كلمة AS عند تحديد الأسماء البديلة اختياري من الناحية التقنية، إذ من الممكن أيضًا كتابة المثال السابق على النحو: mysql> SELECT S.saleID, S.quantity, P.productName, (P.price * S.quantity) revenue mysql> FROM sales S JOIN products P mysql> USING (productID); ورغم كون كلمة AS ليست ضرورية لتحديد اسم بديل، إلّا أنّ تضمينها يعدّ من الممارسات الجيدة. إذ يُمكن أن يساعد في الحفاظ على وضوح غرض الاستعلام وتحسين مقروئيته. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية استخدام عمليات الدمج JOIN لدمج جداول متفرقة ضمن مجموعة نتائج استعلام واحدة. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Joins in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام محارف البدل في لغة الاستعلام البنيوية SQL الدمج بين الجداول في SQL الاستعلام عن البيانات في SQL مدخل إلى أهم الاستعلامات (queries) في MySQL مواضيع متقدمة في SQL -
 تسمح لغة الاستعلام البنيوية SQL باستخدام مجموعة متنوعة من محارف البدل (Wildcards) كما هو الحال في العديد من لغات البرمجة. وتُعرّف محارف البدل بأنها محارف مواضع مؤقتة خاصة قادرة على تمثيل محرف آخر أو قيمة أخرى واحدة أو أكثر، وهي ميزة مفيدة في SQL، إذ تمكننا من البحث في قاعدة البيانات عن البيانات دون الحاجة لمعرفة القيم الدقيقة المخزنة فيها. سيتناول هذا المقال كيفية الاستعلام عن البيانات باستخدام محارف البدل المحددة في SQL. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على الإصدار 20.04 من توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدّمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة الدقيقة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام محارف البدل. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إنشاء قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، اتصل بهذا الخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسمwildcardsDB: mysql> CREATE DATABASE wildcardsDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات wildcardsDB، نفّذ تعليمة USE التالية: mysql> USE wildcardsDB; الخرج Database changed الآن، وبعد اختيار قاعدة البيانات، يمكننا إنشاء جدول ضمنها باستخدام الأمر التالي. وبفرض أننا نرغب في إنشاء جدول باسم user_profiles لتخزين معلومات ملفات المستخدمين لتطبيق ما، سيحتوي هذا الجدول على الأعمدة الخمسة التالية: user_id: مُعرّف كل مستخدم مُعبّرًا عنه بنمط بيانات الأعداد الصحيحة int. سيكون هذا العمود هو المفتاح الأساسي للجدول، إذ ستلعب كل قيمة فيه دور مُعرّف فريد لسجلها الموافق. name: اسم كل مستخدم، معبرًا عنه باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. email: سيحتوي هذا العمود على عناوين البريد الإلكتروني للمستخدمين، معبرًا عنها أيضًا باستخدام نمط البيانات varchar ولكن بحد أقصى 40 محرفًا. birthdate: سيحتوي هذا العمود على تاريخ ميلاد كل مستخدم باستخدام نمط البيانات date. quote: الاقتباس المفضل لكل مستخدم. وبهدف توفير عدد كافٍ من المحارف للاقتباسات، سنستخدم في هذا العمود أيضًا نمط البيانات varchar، ولكن بحد أقصى 300 محرف. سنشغّل الآن الأمر التالي لإنشاء هذا الجدول التجريبي النموذجي: mysql> CREATE TABLE user_profiles ( mysql> user_id int, mysql> name varchar(30), mysql> email varchar(40), mysql> birthdate date, mysql> quote varchar(300), mysql> PRIMARY KEY (user_id) mysql> ); الخرج Database changed والآن سنملأ جدولنا الفارغ ببعضٍ من البيانات النموذجية التجريبية، على النحو: INSERT INTO user_profiles VALUES mysql> (1, 'Kim', 'bd_eyes@example.com', '1945-07-20', '"Never let the fear of striking out keep you from playing the game." -Babe Ruth'), mysql> (2, 'Ann', 'cantstandrain@example.com', '1947-04-27', '"The future belongs to those who believe in the beauty of their dreams." -Eleanor Roosevelt'), mysql> (3, 'Phoebe', 'poetry_man@example.com', '1950-07-17', '"100% of the people who give 110% do not understand math." -Demitri Martin'), mysql> (4, 'Jim', 'u_f_o@example.com', '1940-08-13', '"Whoever is happy will make others happy too." -Anne Frank'), mysql> (5, 'Timi', 'big_voice@example.com', '1940-08-04', '"It is better to fail in originality than to succeed in imitation." -Herman Melville'), mysql> (6, 'Taeko', 'sunshower@example.com', '1953-11-28', '"You miss 100% of the shots you don\'t take." -Wayne Gretzky'), mysql> (7, 'Irma', 'soulqueen_NOLA@example.com', '1941-02-18', '"You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose." -Dr. Seuss'), mysql> (8, 'Iris', 'our_town@example.com', '1961-01-05', '"You will face many defeats in life, but never let yourself be defeated." -Maya Angelou'); الخرج Query OK, 8 rows affected (0.00 sec) Records: 8 Duplicates: 0 Warnings: 0 وبذلك، تغدو جاهزًا لمتابعة باقي المقال وبدء التعلم حول كيفية استخدام محارف البدل للاستعلام عن البيانات في SQL. الاستعلام عن البيانات باستخدام محارف البدل في SQL كما ذكرنا في المقدمة، محارف البدل عبارة عن محارف مواضع مؤقتة خاصة، تتميز بقدرتها على تمثيل محرف مختلف أو قيمة مختلفة واحدة أو أكثر. ولا يوجد سوى نمطين فقط من محارف البدل المُعرّفة في SQL، وهما: الشرطة السفلية _ حيث تمثل عند استخدامها كمحرف بدل محرفًا واحدًا. فيتطابق مثلًا النمط s_mmy مع الأسماء sammy أو sbmmy أو sxmmy. محرف إشارة النسبة المئوية % الذي يمثل صفرًا أو أكثر من المحارف. إذ يتطابق مثلًا النمط s%mmy مع كل من الأسماء التالية sammy أو saaaaaammy أو smmy. ملاحظة: تُستخدم محارف البدل هذه حصريًا ضمن بنية WHERE من الاستعلام، مقترنةً بأحد عاملي LIKE أو NOT LIKE. لتوضيح كيفية استخدامها مع البيانات النموذجية المذكورة في قسم مستلزمات العمل، لنفترض أننا نعلم بوجود مستخدم في جدول user_profiles يحمل اسمًا مكونًا من ثلاثة أحرف ينتهي بالمقطع "im"، لكننا غير متأكدين من هويته. بما أن الغموض يكمن فقط في المحرف الأول من الاسم، يمكننا تشغيل الاستعلام التالي الذي يستخدم محرف البدل _ للكشف عن هوية هذا المستخدم، على النحو: mysql> SELECT * FROM user_profiles WHERE name LIKE '_im'; الخرج +---------+------+---------------------+------------+---------------------------------------------------------------------------------+ | user_id | name | email | birthdate | quote | +---------+------+---------------------+------------+---------------------------------------------------------------------------------+ | 1 | Kim | bd_eyes@example.com | 1945-07-20 | "Never let the fear of striking out keep you from playing the game." -Babe Ruth | | 4 | Jim | u_f_o@example.com | 1940-08-13 | "Whoever is happy will make others happy too." -Anne Frank | +---------+------+---------------------+------------+---------------------------------------------------------------------------------+ 2 rows in set (0.00 sec) ملاحظة: ألحقنا الكلمة المفتاحية SELECT بعلامة النجمة (*) مباشرةً في هذا المثال، وهي الطريقة المختصرة في SQL للإشارة إلى "جميع الأعمدة". تُستخدم علامات النجمة *كمحارف بدل في بعض التطبيقات ولغات البرمجة، وحتى بعض تقديمات SQL، إذ تُمثّل صفرًا أو أكثر من المحارف، كما هو الحال تمامًا مع علامة النسبة المئوية المستخدمة في هذا المثال. ولكن النجمة في المثال أعلاه ليست بمحرف بدل، إذ أنّها تُمثّل أمرًا محددًا - ألا وهو: كل الأعمدة في جدول user_profiles - ولا تعبّر عن محرف أو أكثر غير معروف. وبالعودة إلى موضوعنا، تجدر الإشارة إلى أنّه لعامل NOT LIKE تأثير معاكس لعامل LIKE. فبدلاً من إرجاع كل سجل يطابق نمط محرف البدل، سيعيد كل سجل لا يطابق ذلك النمط. ولتوضيح الأمر، لنعد تنفيذ الاستعلام السابق مجددًا مستبدلين العامل LIKE بالعامل NOT LIKE، على النحو: mysql> SELECT * FROM user_profiles WHERE name NOT LIKE '_im'; في هذه المرة، تُستثنى من مجموعة النتائج كل السجلات التي لا تتطابق قيمتها في عمود الاسم name مع النمط _im. الخرج +---------+--------+----------------------------+------------+--------------------------------------------------------------------------------------------------------------------------+ | user_id | name | email | birthdate | quote | +---------+--------+----------------------------+------------+--------------------------------------------------------------------------------------------------------------------------+ | 2 | Ann | cantstandrain@example.com | 1947-04-27 | "The future belongs to those who believe in the beauty of their dreams." -Eleanor Roosevelt | | 3 | Phoebe | poetry_man@example.com | 1950-07-17 | "100% of the people who give 110% do not understand math." -Demitri Martin | | 5 | Timi | big_voice@example.com | 1940-08-04 | "It is better to fail in originality than to succeed in imitation." -Herman Melville | | 6 | Taeko | sunshower@example.com | 1953-11-28 | "You miss 100% of the shots you don't take." -Wayne Gretzky | | 7 | Irma | soulqueen_NOLA@example.com | 1941-02-18 | "You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose." -Dr. Seuss | | 8 | Iris | our_town@example.com | 1961-01-05 | "You will face many defeats in life, but never let yourself be defeated." -Maya Angelou | +---------+--------+----------------------------+------------+--------------------------------------------------------------------------------------------------------------------------+ 6 rows in set (0.00 sec) كمثال آخر، بفرض أننا نعلم بأنّ أسماء عدة مستخدمين مُدرجين في قاعدة البيانات لدينا تبدأ بحرف "I"، ولكننا لا نستطيع تذكرهم جميعًا. فمن الممكن في هذه الحالة استخدام محرف البدل % لعرض قائمة بجميع هؤلاء المستخدمين، كما هو موضح بالاستعلام التالي: mysql> SELECT user_id, name, email FROM user_profiles WHERE name LIKE 'I%'; الخرج +---------+------+----------------------------+ | user_id | name | email | +---------+------+----------------------------+ | 7 | Irma | soulqueen_NOLA@example.com | | 8 | Iris | our_town@example.com | +---------+------+----------------------------+ 2 rows in set (0.00 sec) وتجدر الإشارة إلى أنّ عاملي LIKE وNOT LIKE في MySQL لا يتميزان بالحساسية تجاه حالة الأحرف افتراضيًا. ما يعني أنّ الاستعلام السابق سيعيد نفس النتائج حتى لو لم نكتب حرف "I" ضمن نمط محرف البدل في حالته الكبيرة: mysql> SELECT user_id, name, email FROM user_profiles WHERE name LIKE 'i%'; الخرج +---------+------+----------------------------+ | user_id | name | email | +---------+------+----------------------------+ | 7 | Irma | soulqueen_NOLA@example.com | | 8 | Iris | our_town@example.com | +---------+------+----------------------------+ 2 rows in set (0.00 sec) ولا بدّ من الانتباه إلى أنّ محارف البدل تختلف عن التعابير النمطية regular expressions. فعادةً ما يُشير محرف البدل إلى محرف مُستخدم في مطابقة الأنماط العامّة glob-style pattern matching، وهو أسلوب لمطابقة الأنماط يُستخدم في أنظمة الأوامر وملفات التشغيل لتحديد مجموعات من أسماء الملفات بأنماط معينة. في حين تعتمد التعابير النمطية على لغة نمطية regular language لمطابقة أنماط السلاسل النصية، إذ تُعرّف اللغة النمطية بأنها نوع من اللغات الشكلية التي يمكن وصفها أو التعبير عنها باستخدام التعابير النمطية. تمتاز هذه اللغات ببنية بسيطة نسبيًا يمكن تحليلها باستخدام آلات حالة محدودة Finite State Machines، وهي نماذج رياضية بسيطة تصف كيف يمكن التحول من حالة إلى أخرى استجابةً لبعض المدخلات. تجاهل محارف البدل قد نرغب في بعض الأحيان بالبحث عن مدخلات تحتوي على أحد محارف البدل الخاصة بلغة SQL. وهنا يمكننا استخدام محرف هروب، والذي سيوجّه SQL لتجاهل وظيفة الإبدال لكل من محرفي البدل % أو _ واعتبارهما كنص عادي. على سبيل المثال، بفرض أنّنا نعلم بوجود مستخدمين في قاعدة البيانات لديهم اقتباس مفضل يتضمن علامة النسبة المئوية، ولكننا غير متأكدين من هويتهم على وجه التحديد. لذا سنحاول تنفيذ الاستعلام التالي: mysql> SELECT user_id, name, quote FROM user_profiles WHERE quote LIKE '%'; إلّا أنّ هذا الاستعلام لن يكون مفيدًا إلى ذلك الحد، إذ ستلعب علامة النسبة المئوية دور البديل لأي سلسلة من المحارف وبأي طول، وستعيد بالتالي كافّة سجلات الجدول: الخرج +---------+--------+--------------------------------------------------------------------------------------------------------------------------+ | user_id | name | quote | +---------+--------+--------------------------------------------------------------------------------------------------------------------------+ | 1 | Kim | "Never let the fear of striking out keep you from playing the game." -Babe Ruth | | 2 | Ann | "The future belongs to those who believe in the beauty of their dreams." -Eleanor Roosevelt | | 3 | Phoebe | "100% of the people who give 110% do not understand math." -Demitri Martin | | 4 | Jim | "Whoever is happy will make others happy too." -Anne Frank | | 5 | Timi | "It is better to fail in originality than to succeed in imitation." -Herman Melville | | 6 | Taeko | "You miss 100% of the shots you don't take." -Wayne Gretzky | | 7 | Irma | "You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose." -Dr. Seuss | | 8 | Iris | "You will face many defeats in life, but never let yourself be defeated." -Maya Angelou | +---------+--------+--------------------------------------------------------------------------------------------------------------------------+ 8 rows in set (0.00 sec) لتجاهل علامة النسبة المئوية، يمكننا وضع خط مائل خلفي (\) قبلها، وهو محرف الهروب الافتراضي في MySQL، على النحو: mysql> SELECT * FROM user_profiles WHERE quote LIKE '\%'; إلا أنّ هذا الاستعلام لن يكون مفيدًا بدوره، نظرًا لكونه يحدد أنّ محتويات عمود الاقتباس quote يجب أن تتكون من علامة نسبة مئوية فقط. وبالتالي، ستكون مجموعة النتائج فارغة: الخرج Empty set (0.00 sec) لتصحيح الأمر، لا بدّ من تضمين محارف بدل علامة النسبة المئوية في بداية ونهاية نمط البحث الذي يتبع عامل LIKE، على النحو التالي: mysql> SELECT user_id, name, quote FROM user_profiles WHERE quote LIKE '%\%%'; الخرج +---------+--------+----------------------------------------------------------------------------+ | user_id | name | quote | +---------+--------+----------------------------------------------------------------------------+ | 3 | Phoebe | "100% of the people who give 110% do not understand math." -Demitri Martin | | 6 | Taeko | "You miss 100% of the shots you don't take." -Wayne Gretzky | +---------+--------+----------------------------------------------------------------------------+ 2 rows in set (0.00 sec) يعمل الخط المائل العكسي في هذا الاستعلام على تجاهل علامة النسبة المئوية الثانية فقط، في حين تبقى كل من الأولى والثالثة كمحارف بدل. وبالتالي، سيعيد هذا الاستعلام كل سجل يحتوي عمود الاقتباس quote فيه على علامة نسبة مئوية واحدة على الأقل. وتجدر الملاحظة إلى أنّه من الممكن تحديد محارف هروب مخصصة باستخدام بنية ESCAPE، كما في المثال التالي: mysql> SELECT user_id, name, email FROM user_profiles WHERE email LIKE '%@_%' ESCAPE '@'; الخرج +---------+--------+----------------------------+ | user_id | name | email | +---------+--------+----------------------------+ | 1 | Kim | bd_eyes@example.com | | 3 | Phoebe | poetry_man@example.com | | 4 | Jim | u_f_o@example.com | | 5 | Timi | big_voice@example.com | | 7 | Irma | soulqueen_NOLA@example.com | +---------+--------+----------------------------+ 5 rows in set (0.00 sec) يُعرّف هذا الاستعلام علامة @ كمحرف هروب، ويعيد كل سجل يحتوي عمود البريد الإلكتروني email فيه على شرطة سفلية واحدة على الأقل. أمّا إذا أزلنا بنية ESCAPE، فإنّ الاستعلام سيعيد كافة سجلات الجدول، نظرًا لأن كل منها يتضمّن علامة @ واحدة على الأقل. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية استخدام محارف البدل وتجاهلها في قواعد بيانات SQL التي تتعامل مع محارف البدل. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Wildcards in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام عوامل المقارنة والعامل IS NULL في لغة الاستعلام البنيوية SQL كيفية استخدام عوامل BETWEEN و IN في لغة الاستعلام البنيوية SQL كيفية إنشاء وإدارة الجداول في SQL الاستعلام عن البيانات في SQL البحث والتنقيب والترشيح في SQL
تسمح لغة الاستعلام البنيوية SQL باستخدام مجموعة متنوعة من محارف البدل (Wildcards) كما هو الحال في العديد من لغات البرمجة. وتُعرّف محارف البدل بأنها محارف مواضع مؤقتة خاصة قادرة على تمثيل محرف آخر أو قيمة أخرى واحدة أو أكثر، وهي ميزة مفيدة في SQL، إذ تمكننا من البحث في قاعدة البيانات عن البيانات دون الحاجة لمعرفة القيم الدقيقة المخزنة فيها. سيتناول هذا المقال كيفية الاستعلام عن البيانات باستخدام محارف البدل المحددة في SQL. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على الإصدار 20.04 من توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في دليل الإعداد الأولي للخادم مع الإصدار 20.04 من أوبنتو، كما يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدّمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة الدقيقة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام محارف البدل. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إنشاء قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، اتصل بهذا الخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسمwildcardsDB: mysql> CREATE DATABASE wildcardsDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات wildcardsDB، نفّذ تعليمة USE التالية: mysql> USE wildcardsDB; الخرج Database changed الآن، وبعد اختيار قاعدة البيانات، يمكننا إنشاء جدول ضمنها باستخدام الأمر التالي. وبفرض أننا نرغب في إنشاء جدول باسم user_profiles لتخزين معلومات ملفات المستخدمين لتطبيق ما، سيحتوي هذا الجدول على الأعمدة الخمسة التالية: user_id: مُعرّف كل مستخدم مُعبّرًا عنه بنمط بيانات الأعداد الصحيحة int. سيكون هذا العمود هو المفتاح الأساسي للجدول، إذ ستلعب كل قيمة فيه دور مُعرّف فريد لسجلها الموافق. name: اسم كل مستخدم، معبرًا عنه باستخدام نمط البيانات varchar بحد أقصى 30 محرفًا. email: سيحتوي هذا العمود على عناوين البريد الإلكتروني للمستخدمين، معبرًا عنها أيضًا باستخدام نمط البيانات varchar ولكن بحد أقصى 40 محرفًا. birthdate: سيحتوي هذا العمود على تاريخ ميلاد كل مستخدم باستخدام نمط البيانات date. quote: الاقتباس المفضل لكل مستخدم. وبهدف توفير عدد كافٍ من المحارف للاقتباسات، سنستخدم في هذا العمود أيضًا نمط البيانات varchar، ولكن بحد أقصى 300 محرف. سنشغّل الآن الأمر التالي لإنشاء هذا الجدول التجريبي النموذجي: mysql> CREATE TABLE user_profiles ( mysql> user_id int, mysql> name varchar(30), mysql> email varchar(40), mysql> birthdate date, mysql> quote varchar(300), mysql> PRIMARY KEY (user_id) mysql> ); الخرج Database changed والآن سنملأ جدولنا الفارغ ببعضٍ من البيانات النموذجية التجريبية، على النحو: INSERT INTO user_profiles VALUES mysql> (1, 'Kim', 'bd_eyes@example.com', '1945-07-20', '"Never let the fear of striking out keep you from playing the game." -Babe Ruth'), mysql> (2, 'Ann', 'cantstandrain@example.com', '1947-04-27', '"The future belongs to those who believe in the beauty of their dreams." -Eleanor Roosevelt'), mysql> (3, 'Phoebe', 'poetry_man@example.com', '1950-07-17', '"100% of the people who give 110% do not understand math." -Demitri Martin'), mysql> (4, 'Jim', 'u_f_o@example.com', '1940-08-13', '"Whoever is happy will make others happy too." -Anne Frank'), mysql> (5, 'Timi', 'big_voice@example.com', '1940-08-04', '"It is better to fail in originality than to succeed in imitation." -Herman Melville'), mysql> (6, 'Taeko', 'sunshower@example.com', '1953-11-28', '"You miss 100% of the shots you don\'t take." -Wayne Gretzky'), mysql> (7, 'Irma', 'soulqueen_NOLA@example.com', '1941-02-18', '"You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose." -Dr. Seuss'), mysql> (8, 'Iris', 'our_town@example.com', '1961-01-05', '"You will face many defeats in life, but never let yourself be defeated." -Maya Angelou'); الخرج Query OK, 8 rows affected (0.00 sec) Records: 8 Duplicates: 0 Warnings: 0 وبذلك، تغدو جاهزًا لمتابعة باقي المقال وبدء التعلم حول كيفية استخدام محارف البدل للاستعلام عن البيانات في SQL. الاستعلام عن البيانات باستخدام محارف البدل في SQL كما ذكرنا في المقدمة، محارف البدل عبارة عن محارف مواضع مؤقتة خاصة، تتميز بقدرتها على تمثيل محرف مختلف أو قيمة مختلفة واحدة أو أكثر. ولا يوجد سوى نمطين فقط من محارف البدل المُعرّفة في SQL، وهما: الشرطة السفلية _ حيث تمثل عند استخدامها كمحرف بدل محرفًا واحدًا. فيتطابق مثلًا النمط s_mmy مع الأسماء sammy أو sbmmy أو sxmmy. محرف إشارة النسبة المئوية % الذي يمثل صفرًا أو أكثر من المحارف. إذ يتطابق مثلًا النمط s%mmy مع كل من الأسماء التالية sammy أو saaaaaammy أو smmy. ملاحظة: تُستخدم محارف البدل هذه حصريًا ضمن بنية WHERE من الاستعلام، مقترنةً بأحد عاملي LIKE أو NOT LIKE. لتوضيح كيفية استخدامها مع البيانات النموذجية المذكورة في قسم مستلزمات العمل، لنفترض أننا نعلم بوجود مستخدم في جدول user_profiles يحمل اسمًا مكونًا من ثلاثة أحرف ينتهي بالمقطع "im"، لكننا غير متأكدين من هويته. بما أن الغموض يكمن فقط في المحرف الأول من الاسم، يمكننا تشغيل الاستعلام التالي الذي يستخدم محرف البدل _ للكشف عن هوية هذا المستخدم، على النحو: mysql> SELECT * FROM user_profiles WHERE name LIKE '_im'; الخرج +---------+------+---------------------+------------+---------------------------------------------------------------------------------+ | user_id | name | email | birthdate | quote | +---------+------+---------------------+------------+---------------------------------------------------------------------------------+ | 1 | Kim | bd_eyes@example.com | 1945-07-20 | "Never let the fear of striking out keep you from playing the game." -Babe Ruth | | 4 | Jim | u_f_o@example.com | 1940-08-13 | "Whoever is happy will make others happy too." -Anne Frank | +---------+------+---------------------+------------+---------------------------------------------------------------------------------+ 2 rows in set (0.00 sec) ملاحظة: ألحقنا الكلمة المفتاحية SELECT بعلامة النجمة (*) مباشرةً في هذا المثال، وهي الطريقة المختصرة في SQL للإشارة إلى "جميع الأعمدة". تُستخدم علامات النجمة *كمحارف بدل في بعض التطبيقات ولغات البرمجة، وحتى بعض تقديمات SQL، إذ تُمثّل صفرًا أو أكثر من المحارف، كما هو الحال تمامًا مع علامة النسبة المئوية المستخدمة في هذا المثال. ولكن النجمة في المثال أعلاه ليست بمحرف بدل، إذ أنّها تُمثّل أمرًا محددًا - ألا وهو: كل الأعمدة في جدول user_profiles - ولا تعبّر عن محرف أو أكثر غير معروف. وبالعودة إلى موضوعنا، تجدر الإشارة إلى أنّه لعامل NOT LIKE تأثير معاكس لعامل LIKE. فبدلاً من إرجاع كل سجل يطابق نمط محرف البدل، سيعيد كل سجل لا يطابق ذلك النمط. ولتوضيح الأمر، لنعد تنفيذ الاستعلام السابق مجددًا مستبدلين العامل LIKE بالعامل NOT LIKE، على النحو: mysql> SELECT * FROM user_profiles WHERE name NOT LIKE '_im'; في هذه المرة، تُستثنى من مجموعة النتائج كل السجلات التي لا تتطابق قيمتها في عمود الاسم name مع النمط _im. الخرج +---------+--------+----------------------------+------------+--------------------------------------------------------------------------------------------------------------------------+ | user_id | name | email | birthdate | quote | +---------+--------+----------------------------+------------+--------------------------------------------------------------------------------------------------------------------------+ | 2 | Ann | cantstandrain@example.com | 1947-04-27 | "The future belongs to those who believe in the beauty of their dreams." -Eleanor Roosevelt | | 3 | Phoebe | poetry_man@example.com | 1950-07-17 | "100% of the people who give 110% do not understand math." -Demitri Martin | | 5 | Timi | big_voice@example.com | 1940-08-04 | "It is better to fail in originality than to succeed in imitation." -Herman Melville | | 6 | Taeko | sunshower@example.com | 1953-11-28 | "You miss 100% of the shots you don't take." -Wayne Gretzky | | 7 | Irma | soulqueen_NOLA@example.com | 1941-02-18 | "You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose." -Dr. Seuss | | 8 | Iris | our_town@example.com | 1961-01-05 | "You will face many defeats in life, but never let yourself be defeated." -Maya Angelou | +---------+--------+----------------------------+------------+--------------------------------------------------------------------------------------------------------------------------+ 6 rows in set (0.00 sec) كمثال آخر، بفرض أننا نعلم بأنّ أسماء عدة مستخدمين مُدرجين في قاعدة البيانات لدينا تبدأ بحرف "I"، ولكننا لا نستطيع تذكرهم جميعًا. فمن الممكن في هذه الحالة استخدام محرف البدل % لعرض قائمة بجميع هؤلاء المستخدمين، كما هو موضح بالاستعلام التالي: mysql> SELECT user_id, name, email FROM user_profiles WHERE name LIKE 'I%'; الخرج +---------+------+----------------------------+ | user_id | name | email | +---------+------+----------------------------+ | 7 | Irma | soulqueen_NOLA@example.com | | 8 | Iris | our_town@example.com | +---------+------+----------------------------+ 2 rows in set (0.00 sec) وتجدر الإشارة إلى أنّ عاملي LIKE وNOT LIKE في MySQL لا يتميزان بالحساسية تجاه حالة الأحرف افتراضيًا. ما يعني أنّ الاستعلام السابق سيعيد نفس النتائج حتى لو لم نكتب حرف "I" ضمن نمط محرف البدل في حالته الكبيرة: mysql> SELECT user_id, name, email FROM user_profiles WHERE name LIKE 'i%'; الخرج +---------+------+----------------------------+ | user_id | name | email | +---------+------+----------------------------+ | 7 | Irma | soulqueen_NOLA@example.com | | 8 | Iris | our_town@example.com | +---------+------+----------------------------+ 2 rows in set (0.00 sec) ولا بدّ من الانتباه إلى أنّ محارف البدل تختلف عن التعابير النمطية regular expressions. فعادةً ما يُشير محرف البدل إلى محرف مُستخدم في مطابقة الأنماط العامّة glob-style pattern matching، وهو أسلوب لمطابقة الأنماط يُستخدم في أنظمة الأوامر وملفات التشغيل لتحديد مجموعات من أسماء الملفات بأنماط معينة. في حين تعتمد التعابير النمطية على لغة نمطية regular language لمطابقة أنماط السلاسل النصية، إذ تُعرّف اللغة النمطية بأنها نوع من اللغات الشكلية التي يمكن وصفها أو التعبير عنها باستخدام التعابير النمطية. تمتاز هذه اللغات ببنية بسيطة نسبيًا يمكن تحليلها باستخدام آلات حالة محدودة Finite State Machines، وهي نماذج رياضية بسيطة تصف كيف يمكن التحول من حالة إلى أخرى استجابةً لبعض المدخلات. تجاهل محارف البدل قد نرغب في بعض الأحيان بالبحث عن مدخلات تحتوي على أحد محارف البدل الخاصة بلغة SQL. وهنا يمكننا استخدام محرف هروب، والذي سيوجّه SQL لتجاهل وظيفة الإبدال لكل من محرفي البدل % أو _ واعتبارهما كنص عادي. على سبيل المثال، بفرض أنّنا نعلم بوجود مستخدمين في قاعدة البيانات لديهم اقتباس مفضل يتضمن علامة النسبة المئوية، ولكننا غير متأكدين من هويتهم على وجه التحديد. لذا سنحاول تنفيذ الاستعلام التالي: mysql> SELECT user_id, name, quote FROM user_profiles WHERE quote LIKE '%'; إلّا أنّ هذا الاستعلام لن يكون مفيدًا إلى ذلك الحد، إذ ستلعب علامة النسبة المئوية دور البديل لأي سلسلة من المحارف وبأي طول، وستعيد بالتالي كافّة سجلات الجدول: الخرج +---------+--------+--------------------------------------------------------------------------------------------------------------------------+ | user_id | name | quote | +---------+--------+--------------------------------------------------------------------------------------------------------------------------+ | 1 | Kim | "Never let the fear of striking out keep you from playing the game." -Babe Ruth | | 2 | Ann | "The future belongs to those who believe in the beauty of their dreams." -Eleanor Roosevelt | | 3 | Phoebe | "100% of the people who give 110% do not understand math." -Demitri Martin | | 4 | Jim | "Whoever is happy will make others happy too." -Anne Frank | | 5 | Timi | "It is better to fail in originality than to succeed in imitation." -Herman Melville | | 6 | Taeko | "You miss 100% of the shots you don't take." -Wayne Gretzky | | 7 | Irma | "You have brains in your head. You have feet in your shoes. You can steer yourself any direction you choose." -Dr. Seuss | | 8 | Iris | "You will face many defeats in life, but never let yourself be defeated." -Maya Angelou | +---------+--------+--------------------------------------------------------------------------------------------------------------------------+ 8 rows in set (0.00 sec) لتجاهل علامة النسبة المئوية، يمكننا وضع خط مائل خلفي (\) قبلها، وهو محرف الهروب الافتراضي في MySQL، على النحو: mysql> SELECT * FROM user_profiles WHERE quote LIKE '\%'; إلا أنّ هذا الاستعلام لن يكون مفيدًا بدوره، نظرًا لكونه يحدد أنّ محتويات عمود الاقتباس quote يجب أن تتكون من علامة نسبة مئوية فقط. وبالتالي، ستكون مجموعة النتائج فارغة: الخرج Empty set (0.00 sec) لتصحيح الأمر، لا بدّ من تضمين محارف بدل علامة النسبة المئوية في بداية ونهاية نمط البحث الذي يتبع عامل LIKE، على النحو التالي: mysql> SELECT user_id, name, quote FROM user_profiles WHERE quote LIKE '%\%%'; الخرج +---------+--------+----------------------------------------------------------------------------+ | user_id | name | quote | +---------+--------+----------------------------------------------------------------------------+ | 3 | Phoebe | "100% of the people who give 110% do not understand math." -Demitri Martin | | 6 | Taeko | "You miss 100% of the shots you don't take." -Wayne Gretzky | +---------+--------+----------------------------------------------------------------------------+ 2 rows in set (0.00 sec) يعمل الخط المائل العكسي في هذا الاستعلام على تجاهل علامة النسبة المئوية الثانية فقط، في حين تبقى كل من الأولى والثالثة كمحارف بدل. وبالتالي، سيعيد هذا الاستعلام كل سجل يحتوي عمود الاقتباس quote فيه على علامة نسبة مئوية واحدة على الأقل. وتجدر الملاحظة إلى أنّه من الممكن تحديد محارف هروب مخصصة باستخدام بنية ESCAPE، كما في المثال التالي: mysql> SELECT user_id, name, email FROM user_profiles WHERE email LIKE '%@_%' ESCAPE '@'; الخرج +---------+--------+----------------------------+ | user_id | name | email | +---------+--------+----------------------------+ | 1 | Kim | bd_eyes@example.com | | 3 | Phoebe | poetry_man@example.com | | 4 | Jim | u_f_o@example.com | | 5 | Timi | big_voice@example.com | | 7 | Irma | soulqueen_NOLA@example.com | +---------+--------+----------------------------+ 5 rows in set (0.00 sec) يُعرّف هذا الاستعلام علامة @ كمحرف هروب، ويعيد كل سجل يحتوي عمود البريد الإلكتروني email فيه على شرطة سفلية واحدة على الأقل. أمّا إذا أزلنا بنية ESCAPE، فإنّ الاستعلام سيعيد كافة سجلات الجدول، نظرًا لأن كل منها يتضمّن علامة @ واحدة على الأقل. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية استخدام محارف البدل وتجاهلها في قواعد بيانات SQL التي تتعامل مع محارف البدل. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Wildcards in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام عوامل المقارنة والعامل IS NULL في لغة الاستعلام البنيوية SQL كيفية استخدام عوامل BETWEEN و IN في لغة الاستعلام البنيوية SQL كيفية إنشاء وإدارة الجداول في SQL الاستعلام عن البيانات في SQL البحث والتنقيب والترشيح في SQL -
.png.67261dedc71ec6a6272e56151500bd9f.png) نشرح في هذا المقال المزيد عن طريقة كتابة شروط بنى WHERE التي تتحكم في السجلات التي ستتأثر بعملية معينة. إذ تُحدّد هذه البنى معايير يجب أن تنطبق على كل سجل ليتأثر بالعملية، والتي تُعرف بشروط البحث. إذ تتألّف شروط البحث من تابع شرطي واحد أو أكثر، وهي تعابير خاصة تُقييم لتكون "صحيحة True" أو "خاطئة False" أو "غير معروفة Unknown"، ولا تؤثر العمليات إلا على السجلات التي يُقيّم فيها كل تابع شرطي على أنّه "صحيح True" ضمن بنية WHERE. تمكّن SQL المستخدمين من صياغة شروط بحث تضم أنماط متعددة من التوابع الشرطية، كل منها يستخدم عاملًا خاصًا لتقييم السجلات وسنركز في مقال اليوم على نمطين من التوابع الشرطية والعوامل المستخدمة فيها: عوامل المقارنة وعامل IS NULL. على الرغم من أن هذا المقال يعتمد تحديدًا على تعليمات SELECT في أمثلته، إلّا أنّ المفاهيم الموضحة هنا قابلة للتطبيق على عدد من العمليات في SQL. إذ تعد بنى WHERE وشروط البحث المرتبطة بها عناصر أساسية في عمليات التحديث UPDATE والحذف DELETE على وجه الخصوص. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ستحتاج أيضًا إلى قاعدة بيانات بجداول مُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة استعلامات تتضمّن بنى WHERE. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية المُستخدمة في الأمثلة خلال هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الخرج عند تنفيذها على أنظمة مختلفة عن MySQL. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم comparison_null_db: mysql> CREATE DATABASE comparison_null_db; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات comparison_null_db، نفّذ تعليمة USE التالية: mysql> USE comparison_null_db; الخرج Database changed بعد اختيار قاعدة البيانات comparison_null_db، أنشئ جدولًا ضمنها. لمتابعة الأمثلة المستخدمة في هذا المقال، تخيل أنك قررت مع مجموعة من أصدقائك أن تصبحوا أنشط بدنيًا وأن تبدأوا في ممارسة الجري. ولتحقيق ذلك، حدّد كل من أصدقائك هدفًا شخصيًا لعدد الأميال التي يرغب في قطعها خلال الشهر المقبل. فقررت تتبع أهداف عدد الأميال التي عيّنها أصدقائك، بالإضافة إلى عدد الأميال التي قطعوها فعليًا ضمن جدول SQL يحتوي على الأعمدة الثلاثة التالية: name: أسماء كل من أصدقائك، معبرًا عنها باستخدام نمط البيانات varchar بحد أقصى 15 محرفًا. goal: هدف كل صديق لعدد الأميال التي أمل في قطعها خلال الشهر الماضي، معبرًا عنه كعدد صحيح باستخدام نمط بيانات int. result: عدد الأميال التي قطعها كل صديق في نهاية الشهر، معبرًا عنه أيضًا كعدد صحيح باستخدام نمط بيانات int. نفّذ التعليمة CREATE TABLE التالية لإنشاء جدول باسم running_goals يحتوي على هذه الأعمدة الثلاثة: mysql> CREATE TABLE running_goals ( mysql> name varchar(15), mysql> goal int, mysql> result int mysql> ); الخرج: Query OK, 0 rows affected (0.012 sec) الآن سنملأ جدول running_goals ببعض البيانات التجريبية. نفذ العملية INSERT INTO التالية لإضافة سبع سجلات من البيانات تمثل سبعة من أصدقائك وأهدافهم للجري ونتائجهم: mysql> INSERT INTO running_goals mysql> VALUES mysql> ('Michelle', 55, 48), mysql> ('Jerry', 25, NULL), mysql> ('Milton', 45, 52), mysql> ('Bridget', 40, NULL), mysql> ('Wanda', 30, 38), mysql> ('Stewart', 35, NULL), mysql> ('Leslie', 40, 44); الخرج: Query OK, 7 rows affected (0.004 sec) Records: 7 Duplicates: 0 Warnings: 0 لاحظ أن قيمة العمود result لثلاثة من هذه السجلات هي قيم فارغة NULL. إذ سنفرض كمثال أنّ هؤلاء الأصدقاء لم يُبلغوا بعد عن عدد الأميال التي قطعوها خلال الشهر الماضي لذلك أدخلنا قيم نتائجهم على أنها NULL. وبذلك غدوتَ جاهزًا للمتابعة بباقي أقسام المقال وبدء تعلم كيفية استخدام عوامل المقارنة والعامل IS NULL في SQL. فهم التوابع الشرطية الخاصة ببنية WHERE يمكنك إدراج بنية WHERE بعد بنية FROM في أي عملية SQL تقرأ البيانات من جدول موجود أصلًا وذلك لتحديد البيانات التي ستتأثر بهذه العملية، إذ تُعرّف بنى WHERE شرط بحث، وأي سجل لا يحقق هذا الشرط سيُستثنى من العملية، على عكس السجلات التي تحققه. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown". يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. يمكن أن يكون تعبير القيمة عبارة عن قيمة مُصنفة النوع من قبيل سلسلة نصية أو قيمة عددية، أو تعبير رياضي. ولكن غالبًا ما يكون على الأقل أحد تعبيرات القيمة في شرط بحث بنية WHERE هو اسم عمود من الجدول المُشار إليه ضمن بنية FROM للعملية. ولدى تشغيل استعلامات SQL المُتضمّنة لبنية WHERE، سيطبق نظام إدارة قاعدة البيانات DBMS شرط البحث على كل سجل في الجدول المنطقي المحدد في بنية FROM. ليُعيد فقط السجلات التي يُقيّم من أجلها كل تابع شرطي في شرط البحث على أنه "محقق TRUE". يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، وعلى الرغم من أنّها لا تتوفر كاملةً في كافّة أنظمة إدارة قواعد البيانات العلاقية RDBMS. إليك خمسة من أكثر أنواع التوابع الشرطية شيوعًا في شروط البحث والعوامل المستخدمة في كل منها: المقارنة: تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي كالتالي: =: يختبر ما إذا كانت القيمتان متساويتين. <>: يختبر ما إذا كانت القيمتان غير متساويتين. <: يختبر ما إذا كانت القيمة الأولى أقل من الثانية. >: يختبر ما إذا كانت القيمة الأولى أكبر من الثانية. <=: يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية. >=: يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي الثانية. القيم الفارغة: تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة. النطاق: تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة ما يقع بين تعبيري قيمة آخرين. العضوية: يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تُمثّل عضوًا في مجموعة معينة. تطابق الأنماط: تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محارف بدل. وكما ذكرنا في المقدمة، يركز هذا المقال على توضيح كيفية استخدام عوامل المقارنة والعامل IS NULL في SQL لتصفية البيانات. فإذا كنت ترغب في معرفة كيفية استخدام العوامل BETWEEN وIN في SQL مع التوابع الشرطية النطاقية وتلك الخاصة بالعضوية، ننصحك بقراءة مقالنا السابق حول كيفية استخدام عوامل BETWEEN وIN في لغة الاستعلام البنيوية SQL، أمّا إذا كنت ترغب في معرفة كيفية استخدام عامل LIKE لتصفية البيانات بناءً على نمط نصي يحتوي على محارف بدل، فننصحك بقراءة المقال كيفية استخدام محارف البدل في SQL. وللاطلاع على المزيد حول بنى WHERE عمومًا، ننصحك بقراءة مقالنا حول كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL. التوابع الشرطية للمقارنة في بنية WHERE تستخدم التوابع الشرطية للمقارنة في بنية WHERE واحدًا من ستة عوامل مقارنة وذلك لمقارنة تعبير قيمة مع آخر، والتي تتبع عادةً الصيغة العامة التالية: mysql> SELECT column_list mysql> FROM table_name mysql> WHERE column_name OPERATOR value_expression; ويأتي بعد كلمة WHERE المفتاحية تعبير قيمة، والذي يكون في معظم عمليات SQL عبارة عن اسم عمود. إنّ توفير اسم عمود كتعبير قيمة في شرط البحث يخبر نظام إدارة قواعد البيانات العلاقية (RDBMS) باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. وبما أن نظام قاعدة البيانات يطبق شروط البحث على كل سجل تباعًا، سيعمل عامل المقارنة بالتالي على تضمين أو تصفية السجل بناءً على ما إذا كان شرط البحث "صحيحًا True” لقيمته في العمود المحدد. للتوضيح، لننفّذ الاستعلام التالي. والذي سيُعيد قيم من عمودي name وgoal في جدول running_goals لأي سجلات تكون فيها قيمة goal تساوي 40 وذلك وفق التابع الشرطي للمقارنة المُستخدم ضمن بنية WHERE: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal = 40; وقد كان في مثالنا هدف اثنين فقط من الأصدقاء قطع مسافة 40 ميلًا بالتحديد خلال الشهر الماضي، لذا سيعيد الاستعلام هذين السجلين فقط: الخرج: +---------+------+ | name | goal | +---------+------+ | Bridget | 40 | | Leslie | 40 | +---------+------+ 2 rows in set (0.00 sec) لتوضيح كيفية عمل عوامل المقارنة الأخرى، لنُنفّذ الاستعلامات التالية المُشابهة للمثال السابق باستثناء كون كل واحد منها يستخدم عامل مقارنة مختلف. يختبر العامل <> ما إذا كانت قيمتان غير متساويتين، لذا سيُعيد هذا الاستعلام كل سجل تكون فيه قيمة goal غير مساوية للقيمة 40: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal <> 40; الخرج: +----------+------+ | name | goal | +----------+------+ | Michelle | 55 | | Jerry | 25 | | Milton | 45 | | Wanda | 30 | | Stewart | 35 | +----------+------+ 5 rows in set (0.00 sec) يختبر العامل < ما إذا كان تعبير القيمة الأول أقل من تعبير القيمة الثاني: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal < 40; الخرج: +---------+------+ | name | goal | +---------+------+ | Jerry | 25 | | Wanda | 30 | | Stewart | 35 | +---------+------+ 3 rows in set (0.00 sec) يختبر العامل > ما إذا كان تعبير القيمة الأول أكبر من تعبير القيمة الثاني: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal > 40; الخرج: +----------+------+ | name | goal | +----------+------+ | Michelle | 55 | | Milton | 45 | +----------+------+ 2 rows in set (0.00 sec) يختبر العامل <= ما إذا كانت القيمة الأولى أقل من أو تساوي القيمة الثانية: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal <= 40; الخرج: +---------+------+ | name | goal | +---------+------+ | Jerry | 25 | | Bridget | 40 | | Wanda | 30 | | Stewart | 35 | | Leslie | 40 | +---------+------+ 5 rows in set (0.00 sec) يختبر العامل >= ما إذا كانت القيمة الأولى أكبر من أو تساوي القيمة الثانية: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal >= 40; الخرج: +----------+------+ | name | goal | +----------+------+ | Michelle | 55 | | Milton | 45 | | Bridget | 40 | | Leslie | 40 | +----------+------+ 4 rows in set (0.00 sec) تتعامل عوامل المساواة (=) وعدم المساواة (<>) مع القيم من نمط السلاسل النصية كما هو متوقّع. فمثلًا، يُعيد الاستعلام التالي كل سجل تكون فيه قيمة عمود الاسم name تساوي السلسلة النصية 'Leslie': mysql> SELECT name mysql> FROM running_goals mysql> WHERE name = 'Leslie'; ونظرًا لوجود سجل واحد فقط في الجدول حيث قيمة العمود name تساوي "Leslie"، يقتصر الاستعلام على إعادة هذا السجل فقط. الخرج: +--------+ | name | +--------+ | Leslie | +--------+ 1 row in set (0.00 sec) عند مقارنة القيم من نمط السلاسل النصية، تقيّم كل من عوامل المقارنة <، >، <=، و >= كيفية ترتيب السلاسل أبجديًا. بمعنى آخر، إذا كتبنا تابعًا شرطيًا يختبر ما إذا كانت سلسلة نصية "أقل" من أخرى، فنحن نختبر ما إذا كانت السلسلة الأولى تأتي قبل الثانية أبجديًا. وبالمثل، إذا كان التابع الشرطي يختبر ما إذا كانت سلسلة نصية "أكبر" من أخرى، فنحن نختبر ما إذا كانت السلسلة الأولى تأتي بعد الثانية أبجديًا. لتوضيح الفكرة، لنُنفّذ الاستعلام التالي الذي سيُعيد قيم كل من العمودين name وgoal لكل سجل تكون قيمة name "أقل" من الحرف 'M'. بمعنى آخر، سيُقيّم شرط البحث على أنّه "صحيح True" لكل سجل تأتي قيمته في العمود name أبجديًا قبل الحرف 'M': mysql> SELECT name mysql> FROM running_goals mysql> WHERE name < 'M'; الخرج: +---------+ | name | +---------+ | Jerry | | Bridget | | Leslie | +---------+ 3 rows in set (0.00 sec) نلاحظ أن مجموعة النتائج هذه لا تتضمن الاسمين Michelle أو Milton. السبب في ذلك هو أن الحرف "M" يأتي أبجديًا قبل أي سلسلة نصية تبدأ بالحرف "M" وتحتوي على أكثر من حرف، لذا يُستثنى هذين الاسمين من مجموعة النتائج. التوابع الشرطية للقيمة الفارغة في SQL، NULL عبارة كلمة محجوزة تُستخدم لتمثيل القيم المفقودة أو غير المعروفة. فالقيمة الفارغة Null هي حالة، وليست قيمة فعلية؛ إذ أنّها لا تُمثّل الصفر أو السلسلة النصية الفارغة. يمكنك استخدام عامل IS NULL لاختبار ما إذا كان تعبير قيمة معين فارغًا: mysql> . . . mysql> WHERE column_name IS NULL mysql> . . . سيتتبع نظام قاعدة البيانات في هذا النوع من التوابع الشرطية قيمة كل سجل من العمود المحدد، مُقيّمًا إياها ما إذا كانت فارغة أم لا. فإذا كانت القيمة في العمود فارغة بالفعل، سيُقيّم شرط البحث على أنّه "صحيح True" لذلك السجل وبالتالي سيُضمّن في مجموعة النتائج. للتوضيح، لنُنفّذ الاستعلام التالي الذي يعيد عموديّ name وresult: mysql> SELECT name, result mysql> FROM running_goals mysql> WHERE result IS NULL; يختبر شرط البحث في بنية WHERE لهذا الاستعلام ما إذا كانت قيمة العمود result لكل سجل فارغة. فإذا كان الأمر كذلك، يُقيّم التابع الشرطي على أنّه "صحيح True" ويتم تضمين السجل في مجموعة النتائج: الخرج +---------+--------+ | name | result | +---------+--------+ | Jerry | NULL | | Bridget | NULL | | Stewart | NULL | +---------+--------+ 3 rows in set (0.00 sec) سُجلّت تلك القيم على أنها فارغة NULL لأن ثلاثة من أصدقائك لم يُبلغوا بعد عن عدد الأميال التي قطعوها خلال الشهر الماضي. ونتيجةً لذلك، يُقيّم شرط البحث في الاستعلام بأنه "صحيح True" لهذه السجلات الثلاثة، ولذا فهي السجلات الوحيدة المُضمنة في مجموعة النتائج. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية استخدام عوامل المقارنة والعامل IS NULL في بنى WHERE لتحديد السجلات التي ستتأثر بعملية معينة في SQL. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Comparison and IS NULL Operators in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام عوامل BETWEEN و IN في لغة الاستعلام البنيوية SQL لماذا يجب عليك تعلم SQL فهم قواعد البيانات العلاقية مواضيع متفرقة في SQL
نشرح في هذا المقال المزيد عن طريقة كتابة شروط بنى WHERE التي تتحكم في السجلات التي ستتأثر بعملية معينة. إذ تُحدّد هذه البنى معايير يجب أن تنطبق على كل سجل ليتأثر بالعملية، والتي تُعرف بشروط البحث. إذ تتألّف شروط البحث من تابع شرطي واحد أو أكثر، وهي تعابير خاصة تُقييم لتكون "صحيحة True" أو "خاطئة False" أو "غير معروفة Unknown"، ولا تؤثر العمليات إلا على السجلات التي يُقيّم فيها كل تابع شرطي على أنّه "صحيح True" ضمن بنية WHERE. تمكّن SQL المستخدمين من صياغة شروط بحث تضم أنماط متعددة من التوابع الشرطية، كل منها يستخدم عاملًا خاصًا لتقييم السجلات وسنركز في مقال اليوم على نمطين من التوابع الشرطية والعوامل المستخدمة فيها: عوامل المقارنة وعامل IS NULL. على الرغم من أن هذا المقال يعتمد تحديدًا على تعليمات SELECT في أمثلته، إلّا أنّ المفاهيم الموضحة هنا قابلة للتطبيق على عدد من العمليات في SQL. إذ تعد بنى WHERE وشروط البحث المرتبطة بها عناصر أساسية في عمليات التحديث UPDATE والحذف DELETE على وجه الخصوص. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ستحتاج أيضًا إلى قاعدة بيانات بجداول مُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة استعلامات تتضمّن بنى WHERE. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية المُستخدمة في الأمثلة خلال هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الخرج عند تنفيذها على أنظمة مختلفة عن MySQL. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم comparison_null_db: mysql> CREATE DATABASE comparison_null_db; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات comparison_null_db، نفّذ تعليمة USE التالية: mysql> USE comparison_null_db; الخرج Database changed بعد اختيار قاعدة البيانات comparison_null_db، أنشئ جدولًا ضمنها. لمتابعة الأمثلة المستخدمة في هذا المقال، تخيل أنك قررت مع مجموعة من أصدقائك أن تصبحوا أنشط بدنيًا وأن تبدأوا في ممارسة الجري. ولتحقيق ذلك، حدّد كل من أصدقائك هدفًا شخصيًا لعدد الأميال التي يرغب في قطعها خلال الشهر المقبل. فقررت تتبع أهداف عدد الأميال التي عيّنها أصدقائك، بالإضافة إلى عدد الأميال التي قطعوها فعليًا ضمن جدول SQL يحتوي على الأعمدة الثلاثة التالية: name: أسماء كل من أصدقائك، معبرًا عنها باستخدام نمط البيانات varchar بحد أقصى 15 محرفًا. goal: هدف كل صديق لعدد الأميال التي أمل في قطعها خلال الشهر الماضي، معبرًا عنه كعدد صحيح باستخدام نمط بيانات int. result: عدد الأميال التي قطعها كل صديق في نهاية الشهر، معبرًا عنه أيضًا كعدد صحيح باستخدام نمط بيانات int. نفّذ التعليمة CREATE TABLE التالية لإنشاء جدول باسم running_goals يحتوي على هذه الأعمدة الثلاثة: mysql> CREATE TABLE running_goals ( mysql> name varchar(15), mysql> goal int, mysql> result int mysql> ); الخرج: Query OK, 0 rows affected (0.012 sec) الآن سنملأ جدول running_goals ببعض البيانات التجريبية. نفذ العملية INSERT INTO التالية لإضافة سبع سجلات من البيانات تمثل سبعة من أصدقائك وأهدافهم للجري ونتائجهم: mysql> INSERT INTO running_goals mysql> VALUES mysql> ('Michelle', 55, 48), mysql> ('Jerry', 25, NULL), mysql> ('Milton', 45, 52), mysql> ('Bridget', 40, NULL), mysql> ('Wanda', 30, 38), mysql> ('Stewart', 35, NULL), mysql> ('Leslie', 40, 44); الخرج: Query OK, 7 rows affected (0.004 sec) Records: 7 Duplicates: 0 Warnings: 0 لاحظ أن قيمة العمود result لثلاثة من هذه السجلات هي قيم فارغة NULL. إذ سنفرض كمثال أنّ هؤلاء الأصدقاء لم يُبلغوا بعد عن عدد الأميال التي قطعوها خلال الشهر الماضي لذلك أدخلنا قيم نتائجهم على أنها NULL. وبذلك غدوتَ جاهزًا للمتابعة بباقي أقسام المقال وبدء تعلم كيفية استخدام عوامل المقارنة والعامل IS NULL في SQL. فهم التوابع الشرطية الخاصة ببنية WHERE يمكنك إدراج بنية WHERE بعد بنية FROM في أي عملية SQL تقرأ البيانات من جدول موجود أصلًا وذلك لتحديد البيانات التي ستتأثر بهذه العملية، إذ تُعرّف بنى WHERE شرط بحث، وأي سجل لا يحقق هذا الشرط سيُستثنى من العملية، على عكس السجلات التي تحققه. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown". يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. يمكن أن يكون تعبير القيمة عبارة عن قيمة مُصنفة النوع من قبيل سلسلة نصية أو قيمة عددية، أو تعبير رياضي. ولكن غالبًا ما يكون على الأقل أحد تعبيرات القيمة في شرط بحث بنية WHERE هو اسم عمود من الجدول المُشار إليه ضمن بنية FROM للعملية. ولدى تشغيل استعلامات SQL المُتضمّنة لبنية WHERE، سيطبق نظام إدارة قاعدة البيانات DBMS شرط البحث على كل سجل في الجدول المنطقي المحدد في بنية FROM. ليُعيد فقط السجلات التي يُقيّم من أجلها كل تابع شرطي في شرط البحث على أنه "محقق TRUE". يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، وعلى الرغم من أنّها لا تتوفر كاملةً في كافّة أنظمة إدارة قواعد البيانات العلاقية RDBMS. إليك خمسة من أكثر أنواع التوابع الشرطية شيوعًا في شروط البحث والعوامل المستخدمة في كل منها: المقارنة: تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي كالتالي: =: يختبر ما إذا كانت القيمتان متساويتين. <>: يختبر ما إذا كانت القيمتان غير متساويتين. <: يختبر ما إذا كانت القيمة الأولى أقل من الثانية. >: يختبر ما إذا كانت القيمة الأولى أكبر من الثانية. <=: يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية. >=: يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي الثانية. القيم الفارغة: تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة. النطاق: تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة ما يقع بين تعبيري قيمة آخرين. العضوية: يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تُمثّل عضوًا في مجموعة معينة. تطابق الأنماط: تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محارف بدل. وكما ذكرنا في المقدمة، يركز هذا المقال على توضيح كيفية استخدام عوامل المقارنة والعامل IS NULL في SQL لتصفية البيانات. فإذا كنت ترغب في معرفة كيفية استخدام العوامل BETWEEN وIN في SQL مع التوابع الشرطية النطاقية وتلك الخاصة بالعضوية، ننصحك بقراءة مقالنا السابق حول كيفية استخدام عوامل BETWEEN وIN في لغة الاستعلام البنيوية SQL، أمّا إذا كنت ترغب في معرفة كيفية استخدام عامل LIKE لتصفية البيانات بناءً على نمط نصي يحتوي على محارف بدل، فننصحك بقراءة المقال كيفية استخدام محارف البدل في SQL. وللاطلاع على المزيد حول بنى WHERE عمومًا، ننصحك بقراءة مقالنا حول كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL. التوابع الشرطية للمقارنة في بنية WHERE تستخدم التوابع الشرطية للمقارنة في بنية WHERE واحدًا من ستة عوامل مقارنة وذلك لمقارنة تعبير قيمة مع آخر، والتي تتبع عادةً الصيغة العامة التالية: mysql> SELECT column_list mysql> FROM table_name mysql> WHERE column_name OPERATOR value_expression; ويأتي بعد كلمة WHERE المفتاحية تعبير قيمة، والذي يكون في معظم عمليات SQL عبارة عن اسم عمود. إنّ توفير اسم عمود كتعبير قيمة في شرط البحث يخبر نظام إدارة قواعد البيانات العلاقية (RDBMS) باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. وبما أن نظام قاعدة البيانات يطبق شروط البحث على كل سجل تباعًا، سيعمل عامل المقارنة بالتالي على تضمين أو تصفية السجل بناءً على ما إذا كان شرط البحث "صحيحًا True” لقيمته في العمود المحدد. للتوضيح، لننفّذ الاستعلام التالي. والذي سيُعيد قيم من عمودي name وgoal في جدول running_goals لأي سجلات تكون فيها قيمة goal تساوي 40 وذلك وفق التابع الشرطي للمقارنة المُستخدم ضمن بنية WHERE: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal = 40; وقد كان في مثالنا هدف اثنين فقط من الأصدقاء قطع مسافة 40 ميلًا بالتحديد خلال الشهر الماضي، لذا سيعيد الاستعلام هذين السجلين فقط: الخرج: +---------+------+ | name | goal | +---------+------+ | Bridget | 40 | | Leslie | 40 | +---------+------+ 2 rows in set (0.00 sec) لتوضيح كيفية عمل عوامل المقارنة الأخرى، لنُنفّذ الاستعلامات التالية المُشابهة للمثال السابق باستثناء كون كل واحد منها يستخدم عامل مقارنة مختلف. يختبر العامل <> ما إذا كانت قيمتان غير متساويتين، لذا سيُعيد هذا الاستعلام كل سجل تكون فيه قيمة goal غير مساوية للقيمة 40: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal <> 40; الخرج: +----------+------+ | name | goal | +----------+------+ | Michelle | 55 | | Jerry | 25 | | Milton | 45 | | Wanda | 30 | | Stewart | 35 | +----------+------+ 5 rows in set (0.00 sec) يختبر العامل < ما إذا كان تعبير القيمة الأول أقل من تعبير القيمة الثاني: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal < 40; الخرج: +---------+------+ | name | goal | +---------+------+ | Jerry | 25 | | Wanda | 30 | | Stewart | 35 | +---------+------+ 3 rows in set (0.00 sec) يختبر العامل > ما إذا كان تعبير القيمة الأول أكبر من تعبير القيمة الثاني: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal > 40; الخرج: +----------+------+ | name | goal | +----------+------+ | Michelle | 55 | | Milton | 45 | +----------+------+ 2 rows in set (0.00 sec) يختبر العامل <= ما إذا كانت القيمة الأولى أقل من أو تساوي القيمة الثانية: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal <= 40; الخرج: +---------+------+ | name | goal | +---------+------+ | Jerry | 25 | | Bridget | 40 | | Wanda | 30 | | Stewart | 35 | | Leslie | 40 | +---------+------+ 5 rows in set (0.00 sec) يختبر العامل >= ما إذا كانت القيمة الأولى أكبر من أو تساوي القيمة الثانية: mysql> SELECT name, goal mysql> FROM running_goals mysql> WHERE goal >= 40; الخرج: +----------+------+ | name | goal | +----------+------+ | Michelle | 55 | | Milton | 45 | | Bridget | 40 | | Leslie | 40 | +----------+------+ 4 rows in set (0.00 sec) تتعامل عوامل المساواة (=) وعدم المساواة (<>) مع القيم من نمط السلاسل النصية كما هو متوقّع. فمثلًا، يُعيد الاستعلام التالي كل سجل تكون فيه قيمة عمود الاسم name تساوي السلسلة النصية 'Leslie': mysql> SELECT name mysql> FROM running_goals mysql> WHERE name = 'Leslie'; ونظرًا لوجود سجل واحد فقط في الجدول حيث قيمة العمود name تساوي "Leslie"، يقتصر الاستعلام على إعادة هذا السجل فقط. الخرج: +--------+ | name | +--------+ | Leslie | +--------+ 1 row in set (0.00 sec) عند مقارنة القيم من نمط السلاسل النصية، تقيّم كل من عوامل المقارنة <، >، <=، و >= كيفية ترتيب السلاسل أبجديًا. بمعنى آخر، إذا كتبنا تابعًا شرطيًا يختبر ما إذا كانت سلسلة نصية "أقل" من أخرى، فنحن نختبر ما إذا كانت السلسلة الأولى تأتي قبل الثانية أبجديًا. وبالمثل، إذا كان التابع الشرطي يختبر ما إذا كانت سلسلة نصية "أكبر" من أخرى، فنحن نختبر ما إذا كانت السلسلة الأولى تأتي بعد الثانية أبجديًا. لتوضيح الفكرة، لنُنفّذ الاستعلام التالي الذي سيُعيد قيم كل من العمودين name وgoal لكل سجل تكون قيمة name "أقل" من الحرف 'M'. بمعنى آخر، سيُقيّم شرط البحث على أنّه "صحيح True" لكل سجل تأتي قيمته في العمود name أبجديًا قبل الحرف 'M': mysql> SELECT name mysql> FROM running_goals mysql> WHERE name < 'M'; الخرج: +---------+ | name | +---------+ | Jerry | | Bridget | | Leslie | +---------+ 3 rows in set (0.00 sec) نلاحظ أن مجموعة النتائج هذه لا تتضمن الاسمين Michelle أو Milton. السبب في ذلك هو أن الحرف "M" يأتي أبجديًا قبل أي سلسلة نصية تبدأ بالحرف "M" وتحتوي على أكثر من حرف، لذا يُستثنى هذين الاسمين من مجموعة النتائج. التوابع الشرطية للقيمة الفارغة في SQL، NULL عبارة كلمة محجوزة تُستخدم لتمثيل القيم المفقودة أو غير المعروفة. فالقيمة الفارغة Null هي حالة، وليست قيمة فعلية؛ إذ أنّها لا تُمثّل الصفر أو السلسلة النصية الفارغة. يمكنك استخدام عامل IS NULL لاختبار ما إذا كان تعبير قيمة معين فارغًا: mysql> . . . mysql> WHERE column_name IS NULL mysql> . . . سيتتبع نظام قاعدة البيانات في هذا النوع من التوابع الشرطية قيمة كل سجل من العمود المحدد، مُقيّمًا إياها ما إذا كانت فارغة أم لا. فإذا كانت القيمة في العمود فارغة بالفعل، سيُقيّم شرط البحث على أنّه "صحيح True" لذلك السجل وبالتالي سيُضمّن في مجموعة النتائج. للتوضيح، لنُنفّذ الاستعلام التالي الذي يعيد عموديّ name وresult: mysql> SELECT name, result mysql> FROM running_goals mysql> WHERE result IS NULL; يختبر شرط البحث في بنية WHERE لهذا الاستعلام ما إذا كانت قيمة العمود result لكل سجل فارغة. فإذا كان الأمر كذلك، يُقيّم التابع الشرطي على أنّه "صحيح True" ويتم تضمين السجل في مجموعة النتائج: الخرج +---------+--------+ | name | result | +---------+--------+ | Jerry | NULL | | Bridget | NULL | | Stewart | NULL | +---------+--------+ 3 rows in set (0.00 sec) سُجلّت تلك القيم على أنها فارغة NULL لأن ثلاثة من أصدقائك لم يُبلغوا بعد عن عدد الأميال التي قطعوها خلال الشهر الماضي. ونتيجةً لذلك، يُقيّم شرط البحث في الاستعلام بأنه "صحيح True" لهذه السجلات الثلاثة، ولذا فهي السجلات الوحيدة المُضمنة في مجموعة النتائج. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية استخدام عوامل المقارنة والعامل IS NULL في بنى WHERE لتحديد السجلات التي ستتأثر بعملية معينة في SQL. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Comparison and IS NULL Operators in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام عوامل BETWEEN و IN في لغة الاستعلام البنيوية SQL لماذا يجب عليك تعلم SQL فهم قواعد البيانات العلاقية مواضيع متفرقة في SQL -
 سنتعرف في مقال اليوم على طريقة استخدام بنى WHERE في بعض تعليمات لغة الاستعلام البنيوية SQL لتحديد سجلات معينة ستتأثر بكل عملية نجريها، وذلك بتعريف معايير محددة تُعرف باسم شروط البحث، إذ يجب أن يستوفيها كل سجل ليتأثر بالعملية. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown"، إذ تؤثر العمليات فقط على تلك السجلات التي يُقيّم من أجلها كل تابع شرطي في بنية WHERE على أنّه "صحيح True". تتيح لغة SQL للمستخدمين استرجاع مجموعات نتائج دقيقة من قاعدة البيانات، وذلك بتوفيرها مجموعة متنوعة من أنماط التوابع الشرطية، إذ يستخدم كل منها عاملًا محددًا لتقييم السجلات. وسنوضّح في هذا المقال نمطين من التوابع الشرطية وهي: التوابع الشرطية للنطاق والتي تستخدم عامل BETWEEN. والتوابع الشرطية لعضوية المجموعة التي تستخدم عامل IN. رغم أننا سنستخدم في أمثلتنا بهذا المقال تعليمات SELECT على وجه التحديد، إلّا أنّه من الممكن استخدام المفاهيم الموضحة فيه في العديد من عمليات SQL. إذ تعد بنى WHERE في الواقع مكونات أساسية في عمليات التحديث UPDATE والحذف DELETE. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ستحتاج أيضًا إلى قاعدة بيانات بجداول مُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة استعلامات تتضمّن بنى WHERE. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية المُستخدمة في الأمثلة خلال هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الخرج عند تنفيذها على أنظمة مختلفة عن MySQL. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم between_in_db: mysql> CREATE DATABASE between_in_db; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات between_in_db، نفّذ تعليمة USE التالية: mysql> USE between_in_db; الخرج Database changed بعد اختيار قاعدة البيانات between_in_db، أنشئ جدولًا ضمنها. لمتابعة الأمثلة المستخدمة في هذا المقال، لنفرض أننا نرغب بإدارة فريق مبيعات لشركة ما، وبفرض أن هذه الشركة تبيع ثلاث منتجات فقط: أجهزة صغيرة، وأدوات متنوعة، وأجهزة مبتكرة. وقررنا تتبع عدد الوحدات من كل منتج يبيعه كل عضو في الفريق ضمن قاعدة بيانات SQL. وارتأينا أنّ هذه القاعدة ستحتوي على جدول واحد بأربعة أعمدة: name: أسماء أعضاء فريق المبيعات، معبرًا عنها باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. widgets: العدد الإجمالي للأجهزة الصغيرة التي باعها كل بائع، معبرًا عنها بنمط بيانات الأعداد الصحيحة int. doodads: عدد الأدوات المتنوعة التي باعها كل بائع، معبرًا عنها أيضًا بنمط بيانات الأعداد الصحيحة int. gizmos: عدد الأجهزة المبتكرة التي باعها كل بائع، معبرًا عنها أيضًا بنمط بيانات الأعداد الصحيحة int. لننفّذ تعليمة CREATE TABLE التالية لإنشاء جدول باسم sales يحتوي على هذه الأعمدة الأربعة: mysql> CREATE TABLE sales ( mysql> name varchar(20), mysql> widgets int, mysql> doodads int, mysql> gizmos int mysql> ); الخرج Query OK, 0 rows affected (0.01 sec) الآن سنملأ جدول sales بعض البيانات التجريبية. نفّذ العملية INSERT INTO التالية لإضافة سبع سجلات من البيانات تمثل أعضاء فريق المبيعات وعدد ما باعوه من كل منتج: mysql> INSERT INTO sales mysql> VALUES mysql> ('Tyler', 12, 22, 18), mysql> ('Blair', 19, 8, 13), mysql> ('Lynn', 7, 29, 3), mysql> ('Boris', 16, 16, 15), mysql> ('Lisa', 17, 2, 31), mysql> ('Maya', 5, 9, 7), mysql> ('Henry', 14, 2, 0); وبذلك غدوتَ جاهزًا للمتابعة بباقي أقسام المقال وبدء تعلم كيفية استخدام عوامل BETWEEN وIN لتصفية البيانات. فهم التوابع الشرطية الخاصة ببنية WHERE يمكنك إدراج بنية WHERE بعد بنية FROM في أي عملية SQL تقرأ البيانات من جدول موجود أصلًا وذلك لتحديد البيانات التي ستتأثر بهذه العملية، إذ تُعرّف بنى WHERE شرط بحث، وأي سجل لا يحقق هذا الشرط سيُستثنى من العملية، على عكس السجلات التي تحققه. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown". يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. ويمكن أن يكون تعبير القيمة عبارة عن قيمة مُصنفة النوع من قبيل سلسلة نصية أو قيمة عددية، أو تعبير رياضي. ولكن غالبًا ما يكون على الأقل أحد تعبيرات القيمة في شرط بحث بنية WHERE هو اسم عمود. ومن الجدير بالملاحظة أنّه في معظم الأحيان نستخدم على الأقل اسم عمود من الجدول المُشار إليه ضمن بنية FROM من العملية كأحد تعابير القيمة في التابع الشرطي ضمن بنية WHERE ولدى تشغيل استعلامات SQL المُتضمّنة لبنية WHERE، سيطبق نظام إدارة قاعدة البيانات (DBMS) شرط البحث على كل سجل في الجدول المنطقي المحدد في بنية FROM ليُعيد فقط السجلات التي يُقيّم من أجلها كل تابع شرطي في شرط البحث على أنه "محقق TRUE". يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، وعلى الرغم من أنّها لا تتوفر كاملةً في كافّة أنظمة إدارة قواعد البيانات العلاقية RDBMS. إليك خمسة من أكثر أنواع التوابع المستخدمة في شروط البحث والعوامل المستخدمة في كل منها: المقارنة: تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي: =: يختبر ما إذا كانت القيمتان متساويتين. <>: يختبر ما إذا كانت القيمتان غير متساويتين. <: يختبر ما إذا كانت القيمة الأولى أقل من الثانية. >: يختبر ما إذا كانت القيمة الأولى أكبر من الثانية. <=: يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية. >=: يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي الثانية. القيم الفارغة: تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة. النطاق: تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة ما يقع بين تعبيري قيمة آخرين. العضوية: يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تُمثّل عضوًا في مجموعة معينة. تطابق الأنماط: تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محارف بدل. وكما ذكرنا في المقدمة، يركز هذا المقال على توضيح كيفية استخدام عوامل BETWEEN وIN في SQL لتصفية البيانات. فإذا كنت ترغب في معرفة كيفية استخدام عوامل المقارنة أو عامل IS NULL، ننصحك بقراءة مقالنا حول كيفية استخدام عوامل المقارنة وIS NULL في لغة الاستعلام البنيوية SQL. أمّا إذا كنت ترغب في معرفة كيفية استخدام عامل LIKE لتصفية البيانات بناءً على نمط نصي يحتوي على محارف بدل، فننصحك بقراءة المقال كيفية استخدام محارف البدل في SQL. وللاطلاع على المزيد حول بنى WHERE عمومًا، ننصحك بقراءة مقالنا حول كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL. التوابع الشرطية النطاقية تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة محصور بين تعبيري قيمة آخرين. وتتبع بنية WHERE المُتضمنة لتابع شرطي نطاقي في شرط البحث الخاص بها الصيغة العامة التالية: mysql> SELECT column_list mysql> FROM table_name mysql> WHERE column_name BETWEEN value_expression1 AND value_expression2; ويأتي بعد كلمة WHERE المفتاحية تعبير قيمة، والذي يكون في معظم عمليات SQL عبارة عن اسم عمود. وبما أن نظام قاعدة البيانات يطبق شروط البحث على كل سجل تباعًا، فإن توفير اسم عمود كتعبير قيمة في شرط البحث يخبر نظام إدارة قواعد البيانات العلاقية RDBMS باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. ويأتي بعد اسم العمود عامل BETWEEN وتعبيري قيمة آخرين مفصولين بعامل AND. وسيُقيّم شرط البحث على أنه "صحيح True" لأي سجلات تكون قيمتها في العمود المحدد أكبر من أو تساوي القيمة الأولى من القيمتين المفصولتين بعامل AND وأقل من أو تساوي القيمة الثانية. لتوضيح كيفية عمل التوابع الشرطية النطاقية، لننفّذ الاستعلام التالي. والذي سيُعيد قيم عمودي name وwidgets لأي سجلات تكون فيها قيمة widgets محصورة بين 14 و19ضمنًا: mysql> SELECT name, widgets mysql> FROM sales mysql> WHERE widgets BETWEEN 14 AND 19; الخرج +-------+---------+ | name | widgets | +-------+---------+ | Blair | 19 | | Boris | 16 | | Lisa | 17 | | Henry | 14 | +-------+---------+ 4 rows in set (0.00 sec) تذكر أن النطاق الذي تحدده بعد عامل BETWEEN يمكن أن يتكون من أي زوج من تعابير القيمة، بما في ذلك أسماء الأعمدة. يعيد الاستعلام التالي جميع الأعمدة من جدول sales. وفيه، وبدلًا من تحديد كل عمود على حدة، ألحقنا الكلمة المفتاحية SELECT بعلامة النجمة (*) مباشرةً، وهي الطريقة المختصرة في SQL للإشارة إلى "جميع الأعمدة". وتحدّ بنية WHERE في هذا الاستعلام من إرجاعه للسجلات التي تكون فيها قيمة gizmos أكبر من قيمة doodads لكنها أقل من قيمة widgets: mysql> SELECT * mysql> FROM sales mysql> WHERE gizmos BETWEEN doodads AND widgets; لا يمتلك سوى عضو واحد من فريق المبيعات قيمة في عمود gizmos محصورة بين القيمتين widgets وdoodads. لذا فإنّ السجل الخاص به فقط هو الذي يظهر في مجموعة النتائج. الخرج +-------+---------+---------+--------+ | name | widgets | doodads | gizmos | +-------+---------+---------+--------+ | Blair | 19 | 8 | 13 | +-------+---------+---------+--------+ 1 row in set (0.00 sec) ويجب أن تكون على دراية بترتيب تعابير القيمة المُحدّدة للنطاق: فالقيمة الأولى بعد عامل BETWEEN تُمثّل دائمًا الحد الأدنى للنطاق، أمّا القيمة الثانية فتُمثّل الحد الأعلى. الاستعلام التالي مطابق للسابق، باستثناء أنه يعكس ترتيب الأعمدة التي تُحدد طرفيّ النطاق: mysql> SELECT * mysql> FROM sales mysql> WHERE gizmos BETWEEN widgets AND doodads; يعيد الاستعلام هذه المرة سجلين حيث تكون في كل منهما قيمة gizmos أكبر من أو تساوي قيمة widgets للسجل ولكنها أقل من أو تساوي قيمة doodads. وكما تدل النتائج، يمكن أن يؤدي تغيير الترتيب بهذه الطريقة إلى استرجاع مجموعة نتائج مختلفة تمامًا. الخرج +-------+---------+---------+--------+ | name | widgets | doodads | gizmos | +-------+---------+---------+--------+ | Tyler | 12 | 22 | 18 | | Maya | 5 | 9 | 7 | +-------+---------+---------+--------+ 2 rows in set (0.00 sec) وعلى نحوٍ مشابه لحالة استخدام عوامل المقارنة <، >، <=، و >= لتقييم عمود مُتضمّن لقيم من نمط السلاسل النصية، سيُحدد العامل BETWEEN ما إذا كانت هذه القيم تقع أبجديًا بين قيمتين من نمط السلاسل النصية. لتوضيح الفكرة، لنُنفّذ الاستعلام التالي الذي يعيد قيم العمود name الموافقة لأي سجل من الجدول sales حيث تكون قيمة name محصورة أبجديَا بين الحرفين A و M. استخدمنا في هذا المثال سلسلتين نصيتين مجردتين كتعبيريّ قيمة يمثلان طرفي النطاق. ومن الجدير بالملاحظة أنّه يجب حصر هذه القيم المحرفية بين علامات اقتباس مفردة أو مزدوجة، وإلا سيبحث نظام إدارة قواعد البيانات عن أعمدة باسم A و M، مما قد يؤدي إلى فشل الاستعلام. mysql> SELECT name mysql> FROM sales mysql> WHERE name BETWEEN 'A' AND 'M'; الخرج +-------+ | name | +-------+ | Blair | | Lynn | | Boris | | Lisa | | Henry | +-------+ 5 rows in set (0.00 sec) نلاحظ أن مجموعة النتائج هذه لا تتضمن الاسم Maya رغم كون النطاق المحدد في شرط البحث يمتد من A إلى M. السبب في ذلك هو أن الحرف M يأتي أبجديًا قبل أي سلسلة نصية تبدأ بالحرف M وتحتوي على أكثر من حرف، لذا يُستثنى الاسم Maya من مجموعة النتائج هذه، بالإضافة إلى أي بائعين آخرين لا تقع أسماؤهم ضمن النطاق المحدد. التوابع الشرطية للعضوية تتيح التوابع الشرطية للعضوية إمكانية تصفية نتائج الاستعلام بناءً على ما إذا كانت قيمة ما تُمثّل عضوًا من مجموعة محددة من البيانات. وعادةً ما تتبع الصيغة التالية في بنى WHERE: mysql>. . . mysql> WHERE column_name IN (set_of_data) mysql>. . . يأتي بعد الكلمة المفتاحية WHERE تعبير القيمة، وعادةً ما يكون هذا التعبير عبارة عن اسم عمود. يلي ذلك عامل IN، الذي يُتبع بدوره بمجموعة من البيانات. يمكن تحديد هذه المجموعة بوضوح عن طريق إدراج أي عدد من تعابير القيمة الصالحة مفصولةً بعلامات فاصلة، سواء كانت قيمًا مجردة أو أسماء أعمدة أو تعابير رياضية تتضمن أيًا من العناصر آنفة الذكر. لتوضيح الأمر، لنُنفذ الاستعلام التالي. والذي سيعيد قيم عموديّ name وgizmos لكل سجل تُمثّل فيه قيمة gizmos عضوًا من المجموعة المعرّفة بعد عامل IN: mysql> SELECT name, doodads mysql> FROM sales mysql> WHERE doodads IN (1, 2, 11, 12, 21, 22); نلاحظ أن قيم العمود doodads لثلاثة أعضاء فقط من فريق المبيعات تساوي أي من القيم الموجودة ضمن هذه المجموعة، ولذلك فإن السجلات الخاصة بهم فقط هي المُسترجعة. الخرج +-------+---------+ | name | doodads | +-------+---------+ | Tyler | 22 | | Lisa | 2 | | Henry | 2 | +-------+---------+ 3 rows in set (0.00 sec) وبدلًا من كتابة كل عنصر في مجموعة بنفسك، يُمكنك تكوين مجموعة من خلال إلحاق عامل IN بالاستعلام الفرعي. يُعرف الاستعلام الفرعي أيضًا بالاستعلام المُدمج أو الداخلي، وهو تعليمة SELECT مُدرجة ضمن إحدى بنى تعليمة SELECT أخرى. يُمكن للاستعلام الفرعي أن يستخرج المعلومات من أي جدول ضمن نفس قاعدة البيانات المحددة في بنية FROM للعملية الرئيسة 'الخارجية'. ملاحظة: عند كتابة استعلام فرعي لتحديد مجموعة ضمن التابع الشرطي للعضوية، تأكد من استخدام استعلام فرعي ذو قيمة مفردة، أي استعلام يُعيد عمودًا واحدًا فقط. تميل أنظمة إدارة قواعد البيانات إلى عدم السماح باستعلامات فرعية تُعيد عدة أعمدة ضمن التابع الشرطي للعضوية، نظرًا لعدم وضوح العمود الذي يجب تقييمه لتحديد العناصر المنتمية للمجموعة. كمثال على استخدام الاستعلام الفرعي لتحديد مجموعة في تابع شرطي للعضوية، نفذ التعليمة التالية لإنشاء جدول يُسمى example_set_table يحتوي على عمود واحد فقط. سنسمى هذا العمود prime_numbers وسيحتوي على قيم من نمط البيانات int، على النحو: mysql> CREATE TABLE example_set_table ( mysql> prime_numbers int mysql> ); لنملأ الآن هذا الجدول ببضعة سجلات من البيانات التجريبية النموذجية. وفقًا لاسم العمود الوحيد في الجدول، ستُضيف التعليمة INSERT التالية عشرة سجلات إلى الجدول، ويحتوي كل منها على أحد الأعداد الأولية العشرة الأولى: mysql>INSERT INTO example_set_table mysql>VALUES mysql> (2), mysql> (3), mysql> (5), mysql> (7), mysql> (11), mysql> (13), mysql> (17), mysql> (19), mysql> (23), mysql> (29); لنُشغّل الآن الاستعلام التالي الذي يُعيد قيمًا من أعمدة name و widgets في جدول sales، إذ تختبر بنية WHERE ما إذا كانت كل قيمة في عمود widgets تنتمي للمجموعة التي حصلنا عليها من الاستعلام الفرعي SELECT prime_numbers FROM example_set_table: mysql> SELECT name, widgets mysql> FROM sales mysql> WHERE widgets IN (SELECT prime_numbers FROM example_set_table); الخرج +-------+---------+ | name | widgets | +-------+---------+ | Blair | 19 | | Lynn | 7 | | Lisa | 17 | | Maya | 5 | +-------+---------+ 4 rows in set (0.00 sec) بما أنّ أربعة فقط من أعضاء فريق المبيعات باعوا عددًا من الأجهزة الصغيرة يُطابق أحد الأعداد الأولية الموجودة في جدول example_set_table، سيُعيد هذا الاستعلام تلك السجلات الأربعة فقط. الخلاصة باطلاعك على هذا المقال، ستكون قد اكتسبت المعرفة حول كيفية استخدام العامل BETWEEN في SQL لتحديد ما إذا كانت قيم في عمود ما تندرج ضمن نطاق محدد، كما تعلمت كيفية استخدام عامل IN لتحديد ما إذا كانت قيم في عمود ما تنتمي إلى مجموعة معينة. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use the BETWEEN and IN Operators in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL الاستعلام عن البيانات في SQL الاستعلامات الفرعية والإجراءات في SQL التوثيق العربي للغة SQL
سنتعرف في مقال اليوم على طريقة استخدام بنى WHERE في بعض تعليمات لغة الاستعلام البنيوية SQL لتحديد سجلات معينة ستتأثر بكل عملية نجريها، وذلك بتعريف معايير محددة تُعرف باسم شروط البحث، إذ يجب أن يستوفيها كل سجل ليتأثر بالعملية. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown"، إذ تؤثر العمليات فقط على تلك السجلات التي يُقيّم من أجلها كل تابع شرطي في بنية WHERE على أنّه "صحيح True". تتيح لغة SQL للمستخدمين استرجاع مجموعات نتائج دقيقة من قاعدة البيانات، وذلك بتوفيرها مجموعة متنوعة من أنماط التوابع الشرطية، إذ يستخدم كل منها عاملًا محددًا لتقييم السجلات. وسنوضّح في هذا المقال نمطين من التوابع الشرطية وهي: التوابع الشرطية للنطاق والتي تستخدم عامل BETWEEN. والتوابع الشرطية لعضوية المجموعة التي تستخدم عامل IN. رغم أننا سنستخدم في أمثلتنا بهذا المقال تعليمات SELECT على وجه التحديد، إلّا أنّه من الممكن استخدام المفاهيم الموضحة فيه في العديد من عمليات SQL. إذ تعد بنى WHERE في الواقع مكونات أساسية في عمليات التحديث UPDATE والحذف DELETE. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ستحتاج أيضًا إلى قاعدة بيانات بجداول مُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة استعلامات تتضمّن بنى WHERE. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية المُستخدمة في الأمثلة خلال هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الخرج عند تنفيذها على أنظمة مختلفة عن MySQL. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم between_in_db: mysql> CREATE DATABASE between_in_db; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات between_in_db، نفّذ تعليمة USE التالية: mysql> USE between_in_db; الخرج Database changed بعد اختيار قاعدة البيانات between_in_db، أنشئ جدولًا ضمنها. لمتابعة الأمثلة المستخدمة في هذا المقال، لنفرض أننا نرغب بإدارة فريق مبيعات لشركة ما، وبفرض أن هذه الشركة تبيع ثلاث منتجات فقط: أجهزة صغيرة، وأدوات متنوعة، وأجهزة مبتكرة. وقررنا تتبع عدد الوحدات من كل منتج يبيعه كل عضو في الفريق ضمن قاعدة بيانات SQL. وارتأينا أنّ هذه القاعدة ستحتوي على جدول واحد بأربعة أعمدة: name: أسماء أعضاء فريق المبيعات، معبرًا عنها باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. widgets: العدد الإجمالي للأجهزة الصغيرة التي باعها كل بائع، معبرًا عنها بنمط بيانات الأعداد الصحيحة int. doodads: عدد الأدوات المتنوعة التي باعها كل بائع، معبرًا عنها أيضًا بنمط بيانات الأعداد الصحيحة int. gizmos: عدد الأجهزة المبتكرة التي باعها كل بائع، معبرًا عنها أيضًا بنمط بيانات الأعداد الصحيحة int. لننفّذ تعليمة CREATE TABLE التالية لإنشاء جدول باسم sales يحتوي على هذه الأعمدة الأربعة: mysql> CREATE TABLE sales ( mysql> name varchar(20), mysql> widgets int, mysql> doodads int, mysql> gizmos int mysql> ); الخرج Query OK, 0 rows affected (0.01 sec) الآن سنملأ جدول sales بعض البيانات التجريبية. نفّذ العملية INSERT INTO التالية لإضافة سبع سجلات من البيانات تمثل أعضاء فريق المبيعات وعدد ما باعوه من كل منتج: mysql> INSERT INTO sales mysql> VALUES mysql> ('Tyler', 12, 22, 18), mysql> ('Blair', 19, 8, 13), mysql> ('Lynn', 7, 29, 3), mysql> ('Boris', 16, 16, 15), mysql> ('Lisa', 17, 2, 31), mysql> ('Maya', 5, 9, 7), mysql> ('Henry', 14, 2, 0); وبذلك غدوتَ جاهزًا للمتابعة بباقي أقسام المقال وبدء تعلم كيفية استخدام عوامل BETWEEN وIN لتصفية البيانات. فهم التوابع الشرطية الخاصة ببنية WHERE يمكنك إدراج بنية WHERE بعد بنية FROM في أي عملية SQL تقرأ البيانات من جدول موجود أصلًا وذلك لتحديد البيانات التي ستتأثر بهذه العملية، إذ تُعرّف بنى WHERE شرط بحث، وأي سجل لا يحقق هذا الشرط سيُستثنى من العملية، على عكس السجلات التي تحققه. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown". يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. ويمكن أن يكون تعبير القيمة عبارة عن قيمة مُصنفة النوع من قبيل سلسلة نصية أو قيمة عددية، أو تعبير رياضي. ولكن غالبًا ما يكون على الأقل أحد تعبيرات القيمة في شرط بحث بنية WHERE هو اسم عمود. ومن الجدير بالملاحظة أنّه في معظم الأحيان نستخدم على الأقل اسم عمود من الجدول المُشار إليه ضمن بنية FROM من العملية كأحد تعابير القيمة في التابع الشرطي ضمن بنية WHERE ولدى تشغيل استعلامات SQL المُتضمّنة لبنية WHERE، سيطبق نظام إدارة قاعدة البيانات (DBMS) شرط البحث على كل سجل في الجدول المنطقي المحدد في بنية FROM ليُعيد فقط السجلات التي يُقيّم من أجلها كل تابع شرطي في شرط البحث على أنه "محقق TRUE". يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، وعلى الرغم من أنّها لا تتوفر كاملةً في كافّة أنظمة إدارة قواعد البيانات العلاقية RDBMS. إليك خمسة من أكثر أنواع التوابع المستخدمة في شروط البحث والعوامل المستخدمة في كل منها: المقارنة: تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي: =: يختبر ما إذا كانت القيمتان متساويتين. <>: يختبر ما إذا كانت القيمتان غير متساويتين. <: يختبر ما إذا كانت القيمة الأولى أقل من الثانية. >: يختبر ما إذا كانت القيمة الأولى أكبر من الثانية. <=: يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية. >=: يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي الثانية. القيم الفارغة: تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة. النطاق: تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة ما يقع بين تعبيري قيمة آخرين. العضوية: يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تُمثّل عضوًا في مجموعة معينة. تطابق الأنماط: تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محارف بدل. وكما ذكرنا في المقدمة، يركز هذا المقال على توضيح كيفية استخدام عوامل BETWEEN وIN في SQL لتصفية البيانات. فإذا كنت ترغب في معرفة كيفية استخدام عوامل المقارنة أو عامل IS NULL، ننصحك بقراءة مقالنا حول كيفية استخدام عوامل المقارنة وIS NULL في لغة الاستعلام البنيوية SQL. أمّا إذا كنت ترغب في معرفة كيفية استخدام عامل LIKE لتصفية البيانات بناءً على نمط نصي يحتوي على محارف بدل، فننصحك بقراءة المقال كيفية استخدام محارف البدل في SQL. وللاطلاع على المزيد حول بنى WHERE عمومًا، ننصحك بقراءة مقالنا حول كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL. التوابع الشرطية النطاقية تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة محصور بين تعبيري قيمة آخرين. وتتبع بنية WHERE المُتضمنة لتابع شرطي نطاقي في شرط البحث الخاص بها الصيغة العامة التالية: mysql> SELECT column_list mysql> FROM table_name mysql> WHERE column_name BETWEEN value_expression1 AND value_expression2; ويأتي بعد كلمة WHERE المفتاحية تعبير قيمة، والذي يكون في معظم عمليات SQL عبارة عن اسم عمود. وبما أن نظام قاعدة البيانات يطبق شروط البحث على كل سجل تباعًا، فإن توفير اسم عمود كتعبير قيمة في شرط البحث يخبر نظام إدارة قواعد البيانات العلاقية RDBMS باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. ويأتي بعد اسم العمود عامل BETWEEN وتعبيري قيمة آخرين مفصولين بعامل AND. وسيُقيّم شرط البحث على أنه "صحيح True" لأي سجلات تكون قيمتها في العمود المحدد أكبر من أو تساوي القيمة الأولى من القيمتين المفصولتين بعامل AND وأقل من أو تساوي القيمة الثانية. لتوضيح كيفية عمل التوابع الشرطية النطاقية، لننفّذ الاستعلام التالي. والذي سيُعيد قيم عمودي name وwidgets لأي سجلات تكون فيها قيمة widgets محصورة بين 14 و19ضمنًا: mysql> SELECT name, widgets mysql> FROM sales mysql> WHERE widgets BETWEEN 14 AND 19; الخرج +-------+---------+ | name | widgets | +-------+---------+ | Blair | 19 | | Boris | 16 | | Lisa | 17 | | Henry | 14 | +-------+---------+ 4 rows in set (0.00 sec) تذكر أن النطاق الذي تحدده بعد عامل BETWEEN يمكن أن يتكون من أي زوج من تعابير القيمة، بما في ذلك أسماء الأعمدة. يعيد الاستعلام التالي جميع الأعمدة من جدول sales. وفيه، وبدلًا من تحديد كل عمود على حدة، ألحقنا الكلمة المفتاحية SELECT بعلامة النجمة (*) مباشرةً، وهي الطريقة المختصرة في SQL للإشارة إلى "جميع الأعمدة". وتحدّ بنية WHERE في هذا الاستعلام من إرجاعه للسجلات التي تكون فيها قيمة gizmos أكبر من قيمة doodads لكنها أقل من قيمة widgets: mysql> SELECT * mysql> FROM sales mysql> WHERE gizmos BETWEEN doodads AND widgets; لا يمتلك سوى عضو واحد من فريق المبيعات قيمة في عمود gizmos محصورة بين القيمتين widgets وdoodads. لذا فإنّ السجل الخاص به فقط هو الذي يظهر في مجموعة النتائج. الخرج +-------+---------+---------+--------+ | name | widgets | doodads | gizmos | +-------+---------+---------+--------+ | Blair | 19 | 8 | 13 | +-------+---------+---------+--------+ 1 row in set (0.00 sec) ويجب أن تكون على دراية بترتيب تعابير القيمة المُحدّدة للنطاق: فالقيمة الأولى بعد عامل BETWEEN تُمثّل دائمًا الحد الأدنى للنطاق، أمّا القيمة الثانية فتُمثّل الحد الأعلى. الاستعلام التالي مطابق للسابق، باستثناء أنه يعكس ترتيب الأعمدة التي تُحدد طرفيّ النطاق: mysql> SELECT * mysql> FROM sales mysql> WHERE gizmos BETWEEN widgets AND doodads; يعيد الاستعلام هذه المرة سجلين حيث تكون في كل منهما قيمة gizmos أكبر من أو تساوي قيمة widgets للسجل ولكنها أقل من أو تساوي قيمة doodads. وكما تدل النتائج، يمكن أن يؤدي تغيير الترتيب بهذه الطريقة إلى استرجاع مجموعة نتائج مختلفة تمامًا. الخرج +-------+---------+---------+--------+ | name | widgets | doodads | gizmos | +-------+---------+---------+--------+ | Tyler | 12 | 22 | 18 | | Maya | 5 | 9 | 7 | +-------+---------+---------+--------+ 2 rows in set (0.00 sec) وعلى نحوٍ مشابه لحالة استخدام عوامل المقارنة <، >، <=، و >= لتقييم عمود مُتضمّن لقيم من نمط السلاسل النصية، سيُحدد العامل BETWEEN ما إذا كانت هذه القيم تقع أبجديًا بين قيمتين من نمط السلاسل النصية. لتوضيح الفكرة، لنُنفّذ الاستعلام التالي الذي يعيد قيم العمود name الموافقة لأي سجل من الجدول sales حيث تكون قيمة name محصورة أبجديَا بين الحرفين A و M. استخدمنا في هذا المثال سلسلتين نصيتين مجردتين كتعبيريّ قيمة يمثلان طرفي النطاق. ومن الجدير بالملاحظة أنّه يجب حصر هذه القيم المحرفية بين علامات اقتباس مفردة أو مزدوجة، وإلا سيبحث نظام إدارة قواعد البيانات عن أعمدة باسم A و M، مما قد يؤدي إلى فشل الاستعلام. mysql> SELECT name mysql> FROM sales mysql> WHERE name BETWEEN 'A' AND 'M'; الخرج +-------+ | name | +-------+ | Blair | | Lynn | | Boris | | Lisa | | Henry | +-------+ 5 rows in set (0.00 sec) نلاحظ أن مجموعة النتائج هذه لا تتضمن الاسم Maya رغم كون النطاق المحدد في شرط البحث يمتد من A إلى M. السبب في ذلك هو أن الحرف M يأتي أبجديًا قبل أي سلسلة نصية تبدأ بالحرف M وتحتوي على أكثر من حرف، لذا يُستثنى الاسم Maya من مجموعة النتائج هذه، بالإضافة إلى أي بائعين آخرين لا تقع أسماؤهم ضمن النطاق المحدد. التوابع الشرطية للعضوية تتيح التوابع الشرطية للعضوية إمكانية تصفية نتائج الاستعلام بناءً على ما إذا كانت قيمة ما تُمثّل عضوًا من مجموعة محددة من البيانات. وعادةً ما تتبع الصيغة التالية في بنى WHERE: mysql>. . . mysql> WHERE column_name IN (set_of_data) mysql>. . . يأتي بعد الكلمة المفتاحية WHERE تعبير القيمة، وعادةً ما يكون هذا التعبير عبارة عن اسم عمود. يلي ذلك عامل IN، الذي يُتبع بدوره بمجموعة من البيانات. يمكن تحديد هذه المجموعة بوضوح عن طريق إدراج أي عدد من تعابير القيمة الصالحة مفصولةً بعلامات فاصلة، سواء كانت قيمًا مجردة أو أسماء أعمدة أو تعابير رياضية تتضمن أيًا من العناصر آنفة الذكر. لتوضيح الأمر، لنُنفذ الاستعلام التالي. والذي سيعيد قيم عموديّ name وgizmos لكل سجل تُمثّل فيه قيمة gizmos عضوًا من المجموعة المعرّفة بعد عامل IN: mysql> SELECT name, doodads mysql> FROM sales mysql> WHERE doodads IN (1, 2, 11, 12, 21, 22); نلاحظ أن قيم العمود doodads لثلاثة أعضاء فقط من فريق المبيعات تساوي أي من القيم الموجودة ضمن هذه المجموعة، ولذلك فإن السجلات الخاصة بهم فقط هي المُسترجعة. الخرج +-------+---------+ | name | doodads | +-------+---------+ | Tyler | 22 | | Lisa | 2 | | Henry | 2 | +-------+---------+ 3 rows in set (0.00 sec) وبدلًا من كتابة كل عنصر في مجموعة بنفسك، يُمكنك تكوين مجموعة من خلال إلحاق عامل IN بالاستعلام الفرعي. يُعرف الاستعلام الفرعي أيضًا بالاستعلام المُدمج أو الداخلي، وهو تعليمة SELECT مُدرجة ضمن إحدى بنى تعليمة SELECT أخرى. يُمكن للاستعلام الفرعي أن يستخرج المعلومات من أي جدول ضمن نفس قاعدة البيانات المحددة في بنية FROM للعملية الرئيسة 'الخارجية'. ملاحظة: عند كتابة استعلام فرعي لتحديد مجموعة ضمن التابع الشرطي للعضوية، تأكد من استخدام استعلام فرعي ذو قيمة مفردة، أي استعلام يُعيد عمودًا واحدًا فقط. تميل أنظمة إدارة قواعد البيانات إلى عدم السماح باستعلامات فرعية تُعيد عدة أعمدة ضمن التابع الشرطي للعضوية، نظرًا لعدم وضوح العمود الذي يجب تقييمه لتحديد العناصر المنتمية للمجموعة. كمثال على استخدام الاستعلام الفرعي لتحديد مجموعة في تابع شرطي للعضوية، نفذ التعليمة التالية لإنشاء جدول يُسمى example_set_table يحتوي على عمود واحد فقط. سنسمى هذا العمود prime_numbers وسيحتوي على قيم من نمط البيانات int، على النحو: mysql> CREATE TABLE example_set_table ( mysql> prime_numbers int mysql> ); لنملأ الآن هذا الجدول ببضعة سجلات من البيانات التجريبية النموذجية. وفقًا لاسم العمود الوحيد في الجدول، ستُضيف التعليمة INSERT التالية عشرة سجلات إلى الجدول، ويحتوي كل منها على أحد الأعداد الأولية العشرة الأولى: mysql>INSERT INTO example_set_table mysql>VALUES mysql> (2), mysql> (3), mysql> (5), mysql> (7), mysql> (11), mysql> (13), mysql> (17), mysql> (19), mysql> (23), mysql> (29); لنُشغّل الآن الاستعلام التالي الذي يُعيد قيمًا من أعمدة name و widgets في جدول sales، إذ تختبر بنية WHERE ما إذا كانت كل قيمة في عمود widgets تنتمي للمجموعة التي حصلنا عليها من الاستعلام الفرعي SELECT prime_numbers FROM example_set_table: mysql> SELECT name, widgets mysql> FROM sales mysql> WHERE widgets IN (SELECT prime_numbers FROM example_set_table); الخرج +-------+---------+ | name | widgets | +-------+---------+ | Blair | 19 | | Lynn | 7 | | Lisa | 17 | | Maya | 5 | +-------+---------+ 4 rows in set (0.00 sec) بما أنّ أربعة فقط من أعضاء فريق المبيعات باعوا عددًا من الأجهزة الصغيرة يُطابق أحد الأعداد الأولية الموجودة في جدول example_set_table، سيُعيد هذا الاستعلام تلك السجلات الأربعة فقط. الخلاصة باطلاعك على هذا المقال، ستكون قد اكتسبت المعرفة حول كيفية استخدام العامل BETWEEN في SQL لتحديد ما إذا كانت قيم في عمود ما تندرج ضمن نطاق محدد، كما تعلمت كيفية استخدام عامل IN لتحديد ما إذا كانت قيم في عمود ما تنتمي إلى مجموعة معينة. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use the BETWEEN and IN Operators in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL الاستعلام عن البيانات في SQL الاستعلامات الفرعية والإجراءات في SQL التوثيق العربي للغة SQL -
 سنتعرف في مقال اليوم على دور البنية WHERE في تعليمات لغة الاستعلام البنيوية SQL لتحديد السجلات التي ستتأثر بكل عملية استعلام، وذلك بتعريف معايير أو شروط محددة تُعرف باسم شروط البحث والتي يجب أن يستوفيها كل سجل ليتأثر بالعملية المطلوب تنفيذها، حيث سنوفر شرحًا للصيغة العامة المستخدمة في بنية WHERE. ونوضح كيفية دمج عدة شروط بحث في بنية واحدة لتصفية البيانات بدقة أكبر، كما سنوضح كيفية استخدام العامل NOT لاستثناء السجلات التي تلبي شرط بحث معين بدلًا من تضمينها. وبالرغم من أننا سنستخدم في أمثلتنا بهذا المقال تعليمات SELECT على وجه التحديد، إلّا أنّه من الممكن استخدام المفاهيم الموضحة فيه في العديد من عمليات SQL، إذ يمكن استخدام بنية WHERE كذلك في عمليات تحديث البيانات UPDATE أو حذفها DELETE. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية التي تستخدم لغة SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة الثالثة من هذا المقال. ستحتاج أيضًا إلى قاعدة بيانات بجداول مُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة استعلامات تتضمّن بنى WHERE. لذا ننصحك بقراءة الفقرة التالية التي تشرح طريقة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول تنفيذ الأمثلة المُستخدمة خلال هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL، فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات الطفيفة في الصيغة أو الخرج عند تنفيذها على أنظمة مختلفة عن MySQL. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم where_db كما يلي: mysql> CREATE DATABASE where_db; بمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات where_db، نفّذ تعليمة USE التالية: mysql> USE where_db; الخرج Database changed بعد اختيار قاعدة البيانات where_db، أنشئ جدولًا ضمنها. ولمتابعة الأمثلة المستخدمة في هذا المقال، سنفترض أننا نرغب بإدارة دوري للغولف في ملعب غولف محلي. وقررنا تتبع المعلومات حول أداء كل لاعب في الدوري خلال الجولات التي سيشارك بها، لذا قررنا تخزين المعلومات في قاعدة بيانات تتضمن جدولًا باسم golfers. وارتأينا أنّ هذا الجدول يحتاج إلى ستة أعمدة وهي: name: أسماء لاعبي الغولف، مُعبر عنها باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. rounds_played: إجمالي عدد الجولات التي لعبها كل لاعب غولف كاملةً، مُعبر عنها بنمط بيانات الأعداد الصحيحة int. best: أفضل أو أدنى نتيجة لكل لاعب جولف لجولة فردية، مُعبرًا عنها أيضًا بنمط الأعداد الصحيحة int. worst: أسوأ أو أعلى نتيجة لكل لاعب جولف لجولة فردية، مُعبرًا عنها كذلك بنمط الأعداد الصحيحة int. average: متوسط تقريبي لنتائج كل لاعب غولف عبر الجولات التي لعبوها، سيحتوي هذا العمود على قيم من نوع decimal، محددة بحد أقصى 4 أرقام، واحد منها على يمين الفاصلة العشرية. wins: عدد الجولات التي حقق فيها كل لاعب غولف أقل نتيجة بين جميع المشاركين في المجموعة، مُعبر عنها باستخدام نمط int. ملاحظة: قد تستغرب لماذا تكون النتيجة الأفضل best لكل لاعب أدنى من نتيجته الأسوأ worst، وهذا يعود لطبيعة قواعد لعبة الغولف التي تقتضي أن يكون الفائز هو من ينجز اللعبة بأقل عدد من الضربات. بالتالي، وبخلاف الرياضات الأخرى، تُعد النتيجة الأدنى هي الأفضل للاعب الغولف. لإنشاء جدول باسم golfers يحتوي على هذه الأعمدة الستة، نفّذ التعليمة CREATE TABLE التالية: mysql> CREATE TABLE golfers ( mysql> name varchar(20), mysql> rounds_played int, mysql> best int, mysql> worst int, mysql> average decimal (4,1), mysql> wins int mysql> ); الآن سنملأ جدول golfers ببعض البيانات التجريبية. نفّذ العملية INSERT INTO التالية لإضافة سبع سجلات من البيانات تمثل سبعة من لاعبي الدوري للغولف: mysql> INSERT INTO golfers mysql> VALUES mysql> ('George', 22, 68, 103, 84.6, 3), mysql> ('Pat', 25, 65, 74, 68.7, 9), mysql> ('Grady', 11, 78, 118, 97.6, 0), mysql> ('Diane', 23, 70, 92, 78.8, 1), mysql> ('Calvin', NULL, 63, 76, 68.5, 7), mysql> ('Rose', NULL, 69, 84, 76.7, 4), mysql> ('Raymond', 18, 67, 92, 81.3, 1); نلاحظ أن قيم rounds_played لبعض سجلات اللاعبين فارغة NULL. فلنفترض جدلًا أنّ هؤلاء اللاعبين لم يُبلغوا بعد عن عدد الجولات التي شاركوا فيها، ولهذا السبب سُجلت هذه القيم على أنّها فارغة NULL. وبذلك غدوتَ جاهزًا للمتابعة بباقي أقسام المقال وبدء تعلم كيفية استخدام بنى WHERE في SQL. تصفية البيانات باستخدام بنى WHERE تُعرّف التعليمة البرمجية في SQL بأنّها أي عملية تُرسَل إلى نظام قاعدة البيانات لتنفيذ مهمّة محددة، من قبيل إنشاء جدول أو إدخال أو حذف بيانات أو تغيير هيكلية عمود أو جدول. وتتألف تعليمات SQL من بنى مختلفة تتكون بدورها من كلمات مفتاحية معينة مع المعلومات التي تتطلبها هذه الكلمات. وكما ذكرنا في المقدمة، تتيح بنى WHERE إمكانية تصفية بعض السجلات كي لا تتأثر بعملية SQL محددة. وتأتي بنية WHERE في الاستعلامات، بعد بنية FROM، كما في المثال التالي: mysql> SELECT columns_to_query mysql> FROM table_to_query mysql> WHERE search_condition; يأتي شرط البحث بعد كلمة WHERE المفتاحية. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown"، ومن الجدير بالملاحظة أنّه في الحالات التي يحتوي فيها شرط البحث على تابع شرطي واحد فقط، يكون المصطلحان "شرط البحث" و"التابع الشرطي" مترادفين. قد تأخذ التوابع الشرطية في شرط البحث الخاص ببنية WHERE أشكالًا عديدة، لكنها عادةً ما تتبع الصيغة التالية: WHERE column_name OPERATOR value_expression يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. يمكن أن يكون تعبير القيمة عبارة عن قيمة مُصنفة النوع من قبيل سلسلة نصية أو قيمة عددية، أو تعبير رياضي. ولكن غالبًا ما يكون على الأقل أحد تعبيرات القيمة في شرط بحث بنية WHERE هو اسم عمود. فلدى تشغيل استعلامات SQL التي تحتوي على بنية WHERE، سيطبّق نظام إدارة قاعدة البيانات شرط البحث تتابعيًا على كل سجل في الجدول المحدد في بنية FROM. ولن يعيد سوى السجلات التي يُقيّم فيها كل شرط بحث على أنه صحيح True. لتوضيح هذه الفكرة، شغّل الاستعلام التالي. والذي سيعيد كل قيمة من العمود name في الجدول golfers: mysql> SELECT name mysql> FROM golfers mysql> WHERE (2 + 2) = 4; يتضمن هذا الاستعلام بنية WHERE، لكن بدلًا من تحديد اسم عمود فإنها تستخدم (2 + 2) كتعبير قيمة أول وتختبر ما إذا كان مساويًا لتعبير القيمة الثاني 4. ونظرًا لأنّ التعبير (2 + 2) يساوي دائمًا 4، فإن شرط البحث هذا يُقيّم على أنه صحيح لكل سجل في الجدول. ونتيجةً لذلك، تُرجع قبم كافّة السجلات في مجموعة النتائج، على النحو التالي: الخرج +---------+ | name | +---------+ | George | | Pat | | Grady | | Diane | | Calvin | | Rose | | Raymond | +---------+ 7 rows in set (0.01 sec) لعلّ بنية WHERE هذه ليست مفيدة بدرجة كبيرة، إذ إنها تُقيم دائمًا على أنها "صحيحة True" وبالتالي تُرجع دائمًا كافة سجلات الجدول. وكما ذكرنا سابقًا، عادةً ما نستخدم اسم عمود واحد على الأقل كأحد تعبيري القيمة في شرط البحث ضمن بنية WHERE. فلدى تشغيل الاستعلامات، سيطبق نظام قاعدة البيانات شرط البحث على كل سجل على حدة تباعًا. ومن خلال توفير اسم عمود كتعبير قيمة في شرط بحث، فإنك تُخبر نظام إدارة قاعدة البيانات باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. تُطبّق بنية WHERE في الاستعلام التالي شرط بحث أكثر تحديدًا على كل سجل. إذ ستُرجع قيم كل من عمودي name وwins من أي سجل تساوي فيه قيمة wins الرقم 1: mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins = 1; يُرجع هذا الاستعلام سجليّن للاعبي جولف، نظرًا لوجود لاعبين قد فازا بجولة واحدة فقط، فيكون الخرج على هذا النحو: الخرج +---------+------+ | name | wins | +---------+------+ | Diane | 1 | | Raymond | 1 | +---------+------+ 2 rows in set (0.01 sec) من الجدير بالملاحظة أنّنا استخدمنا في الأمثلة السابقة علامة المساواة = لاختبار ما إذا كان تعبيرا القيمة متكافئين، إلا أنّ العامل المُستخدم يعتمد على نوع التابع الشرطي الذي ترغب باستخدامه لتصفية مجموعات النتائج الخاصة بك. يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، على الرغم من أنّها لا تتوفر كاملةً في كافّة تقديمات SQL. إليك خمسة من أكثر أنماط التوابع الشرطية استخدامًا، بالإضافة إلى شرح موجز لكل منها والعوامل المستخدمة فيها: المقارنة تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة باستخدام عامل مقارنة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي: العامل =: يختبر ما إذا كانت القيمتان متساويتين mysql> SELECT name mysql> FROM golfers mysql> WHERE name = 'George'; الخرج +--------+ | name | +--------+ | George | +--------+ 1 row in set (0.00 sec) العامل <>: يختبر ما إذا كانت القيمتان غير متساويتين mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins <> 1; الخرج +--------+------+ | name | wins | +--------+------+ | George | 3 | | Pat | 9 | | Grady | 0 | | Calvin | 7 | | Rose | 4 | +--------+------+ 5 rows in set (0.00 sec) العامل <: يختبر ما إذا كانت القيمة الأولى أقل من الثانية تمامًا mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins < 1; الخرج +-------+------+ | name | wins | +-------+------+ | Grady | 0 | +-------+------+ 1 row in set (0.00 sec) العامل >: يختبر ما إذا كانت القيمة الأولى أكبر من الثانية تمامًا mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins > 1; الخرج +--------+------+ | name | wins | +--------+------+ | George | 3 | | Pat | 9 | | Calvin | 7 | | Rose | 4 | +--------+------+ 4 rows in set (0.00 sec) العامل <=: يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins <= 1; الخرج +---------+------+ | name | wins | +---------+------+ | Grady | 0 | | Diane | 1 | | Raymond | 1 | +---------+------+ 3 rows in set (0.00 sec) العامل >=: يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي القيمة الثانية mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins >= 1; الخرج +---------+------+ | name | wins | +---------+------+ | George | 3 | | Pat | 9 | | Diane | 1 | | Calvin | 7 | | Rose | 4 | | Raymond | 1 | +---------+------+ 6 rows in set (0.00 sec) القيم الفارغة تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة، فإذا كان الأمر كذلك فعلًا، سيقيّم التابع الشرطي على أنه "صحيح"، وبالتالي سيُضمّن السجل في مجموعة النتائج: mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE rounds_played IS NULL; الخرج +--------+---------------+ | name | rounds_played | +--------+---------------+ | Calvin | NULL | | Rose | NULL | +--------+---------------+ 2 rows in set (0.00 sec) النطاق تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كانت قيم العمود محصورة بين تعبيري قيمة آخرين. mysql> SELECT name, best mysql> FROM golfers mysql> WHERE best BETWEEN 67 AND 73; الخرج +---------+------+ | name | best | +---------+------+ | George | 68 | | Diane | 70 | | Rose | 69 | | Raymond | 67 | +---------+------+ 4 rows in set (0.00 sec) الانتماء أو العضوية يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تنتمي لمجموعة معينة. mysql> SELECT name, best mysql> FROM golfers mysql> WHERE best IN (65, 67, 69, 71); الخرج +---------+------+ | name | best | +---------+------+ | Pat | 65 | | Rose | 69 | | Raymond | 67 | +---------+------+ 3 rows in set (0.00 sec) تطابق الأنماط تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محرف بدل واحد أو أكثر. وتُعرّف SQL محرفي بدل هما % و _: محرف _: شرطة سفلية تُمثّل محرفًا واحدًا مجهولًا mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE rounds_played LIKE '2_'; الخرج +--------+---------------+ | name | rounds_played | +--------+---------------+ | George | 22 | | Pat | 25 | | Diane | 23 | +--------+---------------+ 3 rows in set (0.00 sec) محرف %: علامة النسبة المئوية تُمثّل صفر أو أكثر من المحارف المجهولة mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE name LIKE 'G%'; الخرج +--------+---------------+ | name | rounds_played | +--------+---------------+ | George | 22 | | Grady | 11 | +--------+---------------+ 2 rows in set (0.00 sec) لن نفصّل بشرح كل نمط من التوابع الشرطية فهو خارج مجال هذا المقال، ولمعرفة المزيد حول هذه الأنماط، ننصحك بالاطلاع على المقالات التالية: كيفية استخدام عوامل المقارنة وIS NULL في لغة الاستعلام البنيوية SQL كيفية استخدام عوامل BETWEEN وIN في لغة الاستعلام البنيوية SQL كيفية استخدام محارف البدل في SQL دمج التوابع الشرطية المتعددة باستخدام عوامل AND وOR قد نضطر في الكثير من الأحيان إلى تصفية النتائج على نحوٍ أدق مما توفره بنية WHERE ذات تابع شرطي وحيد. ومن ناحيةٍ أخرى، قد تكون السجلات التي تحقق واحدًا من شروط بحث متعددة مقبولة ضمن مجموعة النتائج في بعض الأحيان. وفي هذه الحالات، يمكنك كتابة بنى WHERE تتضمن توابع شرطية متعددة باستخدام عوامل AND أو OR على التوالي. للبدء باستخدام هذه العوامل، لنشغّل الاستعلام التالي الذي يعيد قيم من أعمدة name وbest وworst وaverage في جدول golfers. إذ تتضمن بنية WHERE الخاصة بهذا الاستعلام تابعين شرطيين مفصولين بعامل AND: mysql> SELECT name, best, worst, average mysql> FROM golfers mysql> WHERE best < 70 AND worst < 96; يختبر التابع الشرطي الأول ما إذا كانت أفضل قيمة (قيمة العمود best) لكل سجل تقل عن 70، في حين يختبر التابع الشرطي الثاني ما إذا كانت أسوأ قيمة (قيمة العمود worst) لكل سجل تقل عن 96. الآن وفي حال تقييم أي من الشرطين على أنه "خاطئ False" لسجل ما، فإنّ هذا السجل لن يُعاد ضمن مجموعة النتائج: الخرج +---------+------+-------+---------+ | name | best | worst | average | +---------+------+-------+---------+ | Pat | 65 | 74 | 68.7 | | Calvin | 63 | 76 | 68.5 | | Rose | 69 | 84 | 76.7 | | Raymond | 67 | 92 | 81.3 | +---------+------+-------+---------+ 4 rows in set (0.00 sec) الآن، لنشغّل الاستعلام التالي، وهو كما تلاحظ مطابق للمثال السابق، باستثناء فصل التابعين الشرطيين بعامل OR بدلًا من AND: mysql> SELECT name, best, worst, average mysql> FROM golfers mysql> WHERE best < 70 OR worst < 96; نلاحظ أنّ مجموعة النتائج في هذا المثال تتضمّن سجلين أكثر من المثال السابق، وذلك نظرًا لأنّه مع استخدام عامل OR يكفي تقييم تابع شرطي واحد على أنّه "صحيح True" للسجل لكي يُعاد ضمن مجموعة النتائج: الخرج +---------+------+-------+---------+ | name | best | worst | average | +---------+------+-------+---------+ | George | 68 | 103 | 84.6 | | Pat | 65 | 74 | 68.7 | | Diane | 70 | 92 | 78.8 | | Calvin | 63 | 76 | 68.5 | | Rose | 69 | 84 | 76.7 | | Raymond | 67 | 92 | 81.3 | +---------+------+-------+---------+ 6 rows in set (0.00 sec) يمكنك إدراج العديد من التوابع الشرطية في بنية WHERE واحدة بشرط دمجها باستخدام الصياغة المناسبة. ولكن قد يصعب تنبؤ بالبيانات التي ستُصفى مع زيادة تعقيد شروط البحث. من الجدير بالذكر أن أنظمة قواعد البيانات تميل لإعطاء الأولوية لعوامل AND. هذا يعني أن التوابع الشرطية التي تفصل بينها عوامل AND تعدّ كشرط بحث موحد مستقل يُختبر قبل أي توابع شرطية أخرى في بنية WHERE. لتوضيح ذلك، شغّل الاستعلام التالي الذي يسترجع قيمًا من أعمدة name وaverage وworst وrounds_played لكل سجل يستوفي شروط البحث المحددة في بنية WHERE: mysql> SELECT name, average, worst, rounds_played mysql> FROM golfers mysql> WHERE average < 85 OR worst < 95 AND rounds_played BETWEEN 19 AND 23; يبدأ هذا الاستعلام باختبار ما إذا كان كلا التابعين الشرطيين (worst < 95 و rounds_played BETWEEN 19 AND 23) المفصولين بعامل AND يقيمان على أنهما محققان بالنسبة للسجل قيد الاختبار الحالي. فإذا كان الأمر كذلك، سيظهر هذا السجل ضمن مجموعة النتائج. أمّا إذا قُيّم أحدهما أو كلاهما على أنه غير محقق "false"، فسينتقل الاستعلام لفحص ما إذا كانت قيمة average للصف الحالي أقل من 85. وفي حال كانت كذلك، سيظهر الصف ضمن مجموعة النتائج. الخرج +---------+---------+-------+---------------+ | name | average | worst | rounds_played | +---------+---------+-------+---------------+ | George | 84.6 | 103 | 22 | | Pat | 68.7 | 74 | 25 | | Diane | 78.8 | 92 | 23 | | Calvin | 68.5 | 76 | NULL | | Rose | 76.7 | 84 | NULL | | Raymond | 81.3 | 92 | 18 | +---------+---------+-------+---------------+ 6 rows in set (0.00 sec) يمكنك منح الأولوية لمجموعة من تابعين شرطيين فأكثر بوضعهم داخل أقواس. المثال التالي يطابق المثال السابق، لكنه يضع التابعين الشرطيين average < 85 وworst < 95، المفصولين بعامل OR، ضمن أقواس. mysql> SELECT name, average, worst, rounds_played mysql> FROM golfers mysql> WHERE (average < 85 OR worst < 95) AND rounds_played BETWEEN 19 AND 23; نظرًا لأن التابعين الشرطيين في البداية مُحاطين بأقواس، فيعاملهما عامل AND الذي يليهما كشرط بحث مستقل، والذي يجب أن يُقيّم على أنه محقق “True”. فإذا قُيّم كلا التابعين الشرطيين (average < 85 وworst < 95) على أنهما غير محققين “false”، فسيُعتبر شرط البحث بأكمله غير محقق “False” وبالتالي سيستبعد الاستعلام هذا السجل من مجموعة النتائج على الفور قبل أن ينتقل لتقييم السجل التالي. أمّا إذا قُيّم أي من التابعين الشرطيين بين القوسين على أنه محقق “True”، فيبدأ الاستعلام حينها في اختبار ما إذا كانت قيمة rounds_played للاعب الجولف تقع ضمن النطاق 19 و 23. وفي حال تحقق ذلك، يُضم السجل إلى مجموعة النتائج المُعادة. الخرج +--------+---------+-------+---------------+ | name | average | worst | rounds_played | +--------+---------+-------+---------------+ | George | 84.6 | 103 | 22 | | Diane | 78.8 | 92 | 23 | +--------+---------+-------+---------------+ 2 rows in set (0.00 sec) كما تُظهر هذه النتائج، بإعطاء الأولوية لمجموعات التوابع الشرطية وضمها ضمن أقواس، يمكن أن تُنتج الاستعلامات المتشابهة ظاهريًا مجموعات نتائج متباينة بدرجة كبيرة. مع أنه لا يُشترط دومًا اللجوء إلى هذا الأسلوب، إلا أنه يُوصى باستخدام الأقواس عند دمج أكثر من تابعين شرطيين ضمن شرط بحث واحد ليُعزز من مقروئية الاستعلامات ويسهّل فهمها. استثناء النتائج باستخدام عامل NOT ركّزت جميع الأمثلة في هذا المقال حتى الآن على كيفية كتابة استعلامات باستخدام بنية WHERE، والتي تُضمّن فقط السجلات التي تُحقّق شروط البحث المُحددة في مجموعة النتائج. ولكن يُمكنك كتابة استعلامات تستثني سجلات مُحددة عبر إدراج عامل NOT ضمن بنية WHERE. وعادةً ما تتبع بنى التوابع الشرطية للنطاق والعضوية وتطابق الأنماط التي تشمل عامل NOT الصياغة العامة التالية: mysql> . . . mysql> WHERE column_name NOT OPERATOR value_expression mysql> . . . للتوضيح، شغّل الاستعلام التالي الذي سيعيد قيمًا من عمود name في جدول golfers، ولكن وجود عامل NOT في بنية WHERE سيُلزم نظام إدارة قاعدة البيانات باستثناء أي سجلات تُطابق نمط محرف البدل: mysql> SELECT name mysql> FROM golfers mysql> WHERE name NOT LIKE 'R%'; الخرج +--------+ | name | +--------+ | George | | Pat | | Grady | | Diane | | Calvin | +--------+ 5 rows in set (0.00 sec) تتغير الأمور قليلًا عند إضافة عامل NOT إلى توابع IS NULL الشرطية. في هذه الحالات، يُدرج العامل NOT بين IS وNULL كما في المثال التالي. يُعيد هذا الاستعلام قيم name وrounds_played لجميع لاعبي الغولف الذين لا تكون قيمة rounds_played الخاصة بهم فارغة، على النحو: mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE rounds_played IS NOT NULL; الخرج +---------+---------------+ | name | rounds_played | +---------+---------------+ | George | 22 | | Pat | 25 | | Grady | 11 | | Diane | 23 | | Raymond | 18 | +---------+---------------+ 5 rows in set (0.00 sec) كما يُمكنك وضع عامل NOT مباشرةً بعد الكلمة المفتاحية WHERE. الأمر الذي يعدّ مفيدًا لا سيما في حال رغبتك باستثناء سجلات بناءً على ما إذا كانت تحقق عدة شروط بحث، كما في الاستعلام التالي الذي يعيد قيم كل من أعمدة name و average و best و wins للاعبي الغولف. mysql> SELECT name, average, best, wins mysql> FROM golfers mysql> WHERE NOT (average < 80 AND best < 70) OR wins = 9; الخرج +---------+---------+------+------+ | name | average | best | wins | +---------+---------+------+------+ | George | 84.6 | 68 | 3 | | Pat | 68.7 | 65 | 9 | | Grady | 97.6 | 78 | 0 | | Diane | 78.8 | 70 | 1 | | Raymond | 81.3 | 67 | 1 | +---------+---------+------+------+ 5 rows in set (0.00 sec) بالنظر إلى السجل الثاني من مجموعة النتائج أعلاه، نلاحظ أنّ متوسط نتيجة اللاعبة Pat في العمود average أقل من 80 وأفضل نتيجة لها في العمود best أقل من 70. ومع ذلك سجلها مُضمّن في مجموعة النتائج، وذلك نظرًا لأن عامل NOT يُلغي فقط شروط البحث المُحاطة بالأقواس. تذكر أنه عند إحاطة توابع شرطية متعددة مفصولة بعوامل AND أو OR بأقواس، تُعطى الأولوية لهذه التوابع في SQL وتُعامل كشرط بحث مستقل. بالتالي، يستثني عامل NOT السجلات بناءً على أول تابعي شرط فقط (average<80 و best<70). في حين تُضمّن السجلات بناءً على التابع الشرطي الثالث (wins=9). يمكنك إعادة كتابة الاستعلام لاستبعاد السجلات بناءً على التابع الشرطي الثالث أيضًا بالإضافة إلى التابعين الأول والثاني وذلك بإحاطة التوابع الثلاثة ضمن أقواس، كما في المثال التالي: mysql> SELECT name, average, best, wins mysql> FROM golfers mysql> WHERE NOT ((average < 80 AND best < 70) OR wins = 9); الخرج +---------+---------+------+------+ | name | average | best | wins | +---------+---------+------+------+ | George | 84.6 | 68 | 3 | | Grady | 97.6 | 78 | 0 | | Diane | 78.8 | 70 | 1 | | Raymond | 81.3 | 67 | 1 | +---------+---------+------+------+ 4 rows in set (0.00 sec) قد يعدّ نظام قاعدة البيانات لديك صيغة الاستعلام غير صالحة في حال تضمين العامل NOT قبل عامل مقارنة وذلك تبعًا لتقديم SQL المُستخدم. كمثال، لنجرب تشغيل الاستعلام التالي: mysql> SELECT name mysql> FROM golfers mysql> WHERE name NOT = 'Grady'; سيؤدي استخدام هذا الأمر في MySQL أو أي من الأنظمة المستندة إليها إلى حدوث خطأ. الخرج ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '= 'Grady'' at line 1 السبب وراء هذا الخطأ هو أنّ عامل NOT لا يُستخدم عادةً مع عوامل المقارنة (= و<> و< و<= و> و>=)، وذلك نظرًا لإمكانية تحقيق الأثر المعاكس لعامل مقارنة معيّن باستبداله بآخر يعيد السجلات التي كان الأول سيستثنيها. على سبيل المثال، يمكنك استبدال عامل المساواة (=) بعامل عدم المساواة (<>). الخلاصة باطلاعك على هذا المقال،تكون قد اكتسبت المعرفة حول كيفية كتابة بنى WHERE بطريقة تجعل الاستعلام يُعيد فقط السجلات التي تستوفي شرطًا معينًا. كما تعلمت كيفية دمج عدّة توابع شرطية وشروط بحث في استعلام واحد، ناهيك عن كيفية استخدام العامل NOT لاستثناء معلومات من مجموعات النتائج. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use WHERE Clauses in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية الاستعلام عن السجلات من الجداول في SQL ما هي محركات قواعد البيانات؟ أنواع قواعد البيانات وأهم مميزاتها واستخداماتها التعامل مع قواعد البيانات
سنتعرف في مقال اليوم على دور البنية WHERE في تعليمات لغة الاستعلام البنيوية SQL لتحديد السجلات التي ستتأثر بكل عملية استعلام، وذلك بتعريف معايير أو شروط محددة تُعرف باسم شروط البحث والتي يجب أن يستوفيها كل سجل ليتأثر بالعملية المطلوب تنفيذها، حيث سنوفر شرحًا للصيغة العامة المستخدمة في بنية WHERE. ونوضح كيفية دمج عدة شروط بحث في بنية واحدة لتصفية البيانات بدقة أكبر، كما سنوضح كيفية استخدام العامل NOT لاستثناء السجلات التي تلبي شرط بحث معين بدلًا من تضمينها. وبالرغم من أننا سنستخدم في أمثلتنا بهذا المقال تعليمات SELECT على وجه التحديد، إلّا أنّه من الممكن استخدام المفاهيم الموضحة فيه في العديد من عمليات SQL، إذ يمكن استخدام بنية WHERE كذلك في عمليات تحديث البيانات UPDATE أو حذفها DELETE. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية التي تستخدم لغة SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة الثالثة من هذا المقال. ستحتاج أيضًا إلى قاعدة بيانات بجداول مُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة استعلامات تتضمّن بنى WHERE. لذا ننصحك بقراءة الفقرة التالية التي تشرح طريقة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول تنفيذ الأمثلة المُستخدمة خلال هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL، فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات الطفيفة في الصيغة أو الخرج عند تنفيذها على أنظمة مختلفة عن MySQL. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم where_db كما يلي: mysql> CREATE DATABASE where_db; بمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات where_db، نفّذ تعليمة USE التالية: mysql> USE where_db; الخرج Database changed بعد اختيار قاعدة البيانات where_db، أنشئ جدولًا ضمنها. ولمتابعة الأمثلة المستخدمة في هذا المقال، سنفترض أننا نرغب بإدارة دوري للغولف في ملعب غولف محلي. وقررنا تتبع المعلومات حول أداء كل لاعب في الدوري خلال الجولات التي سيشارك بها، لذا قررنا تخزين المعلومات في قاعدة بيانات تتضمن جدولًا باسم golfers. وارتأينا أنّ هذا الجدول يحتاج إلى ستة أعمدة وهي: name: أسماء لاعبي الغولف، مُعبر عنها باستخدام نمط البيانات varchar بحد أقصى 20 محرفًا. rounds_played: إجمالي عدد الجولات التي لعبها كل لاعب غولف كاملةً، مُعبر عنها بنمط بيانات الأعداد الصحيحة int. best: أفضل أو أدنى نتيجة لكل لاعب جولف لجولة فردية، مُعبرًا عنها أيضًا بنمط الأعداد الصحيحة int. worst: أسوأ أو أعلى نتيجة لكل لاعب جولف لجولة فردية، مُعبرًا عنها كذلك بنمط الأعداد الصحيحة int. average: متوسط تقريبي لنتائج كل لاعب غولف عبر الجولات التي لعبوها، سيحتوي هذا العمود على قيم من نوع decimal، محددة بحد أقصى 4 أرقام، واحد منها على يمين الفاصلة العشرية. wins: عدد الجولات التي حقق فيها كل لاعب غولف أقل نتيجة بين جميع المشاركين في المجموعة، مُعبر عنها باستخدام نمط int. ملاحظة: قد تستغرب لماذا تكون النتيجة الأفضل best لكل لاعب أدنى من نتيجته الأسوأ worst، وهذا يعود لطبيعة قواعد لعبة الغولف التي تقتضي أن يكون الفائز هو من ينجز اللعبة بأقل عدد من الضربات. بالتالي، وبخلاف الرياضات الأخرى، تُعد النتيجة الأدنى هي الأفضل للاعب الغولف. لإنشاء جدول باسم golfers يحتوي على هذه الأعمدة الستة، نفّذ التعليمة CREATE TABLE التالية: mysql> CREATE TABLE golfers ( mysql> name varchar(20), mysql> rounds_played int, mysql> best int, mysql> worst int, mysql> average decimal (4,1), mysql> wins int mysql> ); الآن سنملأ جدول golfers ببعض البيانات التجريبية. نفّذ العملية INSERT INTO التالية لإضافة سبع سجلات من البيانات تمثل سبعة من لاعبي الدوري للغولف: mysql> INSERT INTO golfers mysql> VALUES mysql> ('George', 22, 68, 103, 84.6, 3), mysql> ('Pat', 25, 65, 74, 68.7, 9), mysql> ('Grady', 11, 78, 118, 97.6, 0), mysql> ('Diane', 23, 70, 92, 78.8, 1), mysql> ('Calvin', NULL, 63, 76, 68.5, 7), mysql> ('Rose', NULL, 69, 84, 76.7, 4), mysql> ('Raymond', 18, 67, 92, 81.3, 1); نلاحظ أن قيم rounds_played لبعض سجلات اللاعبين فارغة NULL. فلنفترض جدلًا أنّ هؤلاء اللاعبين لم يُبلغوا بعد عن عدد الجولات التي شاركوا فيها، ولهذا السبب سُجلت هذه القيم على أنّها فارغة NULL. وبذلك غدوتَ جاهزًا للمتابعة بباقي أقسام المقال وبدء تعلم كيفية استخدام بنى WHERE في SQL. تصفية البيانات باستخدام بنى WHERE تُعرّف التعليمة البرمجية في SQL بأنّها أي عملية تُرسَل إلى نظام قاعدة البيانات لتنفيذ مهمّة محددة، من قبيل إنشاء جدول أو إدخال أو حذف بيانات أو تغيير هيكلية عمود أو جدول. وتتألف تعليمات SQL من بنى مختلفة تتكون بدورها من كلمات مفتاحية معينة مع المعلومات التي تتطلبها هذه الكلمات. وكما ذكرنا في المقدمة، تتيح بنى WHERE إمكانية تصفية بعض السجلات كي لا تتأثر بعملية SQL محددة. وتأتي بنية WHERE في الاستعلامات، بعد بنية FROM، كما في المثال التالي: mysql> SELECT columns_to_query mysql> FROM table_to_query mysql> WHERE search_condition; يأتي شرط البحث بعد كلمة WHERE المفتاحية. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر لتعيد نتيجة تكون إمّا "صحيحة True" أو "خاطئة False" أو "غير محددة Unknown"، ومن الجدير بالملاحظة أنّه في الحالات التي يحتوي فيها شرط البحث على تابع شرطي واحد فقط، يكون المصطلحان "شرط البحث" و"التابع الشرطي" مترادفين. قد تأخذ التوابع الشرطية في شرط البحث الخاص ببنية WHERE أشكالًا عديدة، لكنها عادةً ما تتبع الصيغة التالية: WHERE column_name OPERATOR value_expression يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. يمكن أن يكون تعبير القيمة عبارة عن قيمة مُصنفة النوع من قبيل سلسلة نصية أو قيمة عددية، أو تعبير رياضي. ولكن غالبًا ما يكون على الأقل أحد تعبيرات القيمة في شرط بحث بنية WHERE هو اسم عمود. فلدى تشغيل استعلامات SQL التي تحتوي على بنية WHERE، سيطبّق نظام إدارة قاعدة البيانات شرط البحث تتابعيًا على كل سجل في الجدول المحدد في بنية FROM. ولن يعيد سوى السجلات التي يُقيّم فيها كل شرط بحث على أنه صحيح True. لتوضيح هذه الفكرة، شغّل الاستعلام التالي. والذي سيعيد كل قيمة من العمود name في الجدول golfers: mysql> SELECT name mysql> FROM golfers mysql> WHERE (2 + 2) = 4; يتضمن هذا الاستعلام بنية WHERE، لكن بدلًا من تحديد اسم عمود فإنها تستخدم (2 + 2) كتعبير قيمة أول وتختبر ما إذا كان مساويًا لتعبير القيمة الثاني 4. ونظرًا لأنّ التعبير (2 + 2) يساوي دائمًا 4، فإن شرط البحث هذا يُقيّم على أنه صحيح لكل سجل في الجدول. ونتيجةً لذلك، تُرجع قبم كافّة السجلات في مجموعة النتائج، على النحو التالي: الخرج +---------+ | name | +---------+ | George | | Pat | | Grady | | Diane | | Calvin | | Rose | | Raymond | +---------+ 7 rows in set (0.01 sec) لعلّ بنية WHERE هذه ليست مفيدة بدرجة كبيرة، إذ إنها تُقيم دائمًا على أنها "صحيحة True" وبالتالي تُرجع دائمًا كافة سجلات الجدول. وكما ذكرنا سابقًا، عادةً ما نستخدم اسم عمود واحد على الأقل كأحد تعبيري القيمة في شرط البحث ضمن بنية WHERE. فلدى تشغيل الاستعلامات، سيطبق نظام قاعدة البيانات شرط البحث على كل سجل على حدة تباعًا. ومن خلال توفير اسم عمود كتعبير قيمة في شرط بحث، فإنك تُخبر نظام إدارة قاعدة البيانات باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. تُطبّق بنية WHERE في الاستعلام التالي شرط بحث أكثر تحديدًا على كل سجل. إذ ستُرجع قيم كل من عمودي name وwins من أي سجل تساوي فيه قيمة wins الرقم 1: mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins = 1; يُرجع هذا الاستعلام سجليّن للاعبي جولف، نظرًا لوجود لاعبين قد فازا بجولة واحدة فقط، فيكون الخرج على هذا النحو: الخرج +---------+------+ | name | wins | +---------+------+ | Diane | 1 | | Raymond | 1 | +---------+------+ 2 rows in set (0.01 sec) من الجدير بالملاحظة أنّنا استخدمنا في الأمثلة السابقة علامة المساواة = لاختبار ما إذا كان تعبيرا القيمة متكافئين، إلا أنّ العامل المُستخدم يعتمد على نوع التابع الشرطي الذي ترغب باستخدامه لتصفية مجموعات النتائج الخاصة بك. يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، على الرغم من أنّها لا تتوفر كاملةً في كافّة تقديمات SQL. إليك خمسة من أكثر أنماط التوابع الشرطية استخدامًا، بالإضافة إلى شرح موجز لكل منها والعوامل المستخدمة فيها: المقارنة تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة باستخدام عامل مقارنة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي: العامل =: يختبر ما إذا كانت القيمتان متساويتين mysql> SELECT name mysql> FROM golfers mysql> WHERE name = 'George'; الخرج +--------+ | name | +--------+ | George | +--------+ 1 row in set (0.00 sec) العامل <>: يختبر ما إذا كانت القيمتان غير متساويتين mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins <> 1; الخرج +--------+------+ | name | wins | +--------+------+ | George | 3 | | Pat | 9 | | Grady | 0 | | Calvin | 7 | | Rose | 4 | +--------+------+ 5 rows in set (0.00 sec) العامل <: يختبر ما إذا كانت القيمة الأولى أقل من الثانية تمامًا mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins < 1; الخرج +-------+------+ | name | wins | +-------+------+ | Grady | 0 | +-------+------+ 1 row in set (0.00 sec) العامل >: يختبر ما إذا كانت القيمة الأولى أكبر من الثانية تمامًا mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins > 1; الخرج +--------+------+ | name | wins | +--------+------+ | George | 3 | | Pat | 9 | | Calvin | 7 | | Rose | 4 | +--------+------+ 4 rows in set (0.00 sec) العامل <=: يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins <= 1; الخرج +---------+------+ | name | wins | +---------+------+ | Grady | 0 | | Diane | 1 | | Raymond | 1 | +---------+------+ 3 rows in set (0.00 sec) العامل >=: يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي القيمة الثانية mysql> SELECT name, wins mysql> FROM golfers mysql> WHERE wins >= 1; الخرج +---------+------+ | name | wins | +---------+------+ | George | 3 | | Pat | 9 | | Diane | 1 | | Calvin | 7 | | Rose | 4 | | Raymond | 1 | +---------+------+ 6 rows in set (0.00 sec) القيم الفارغة تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة، فإذا كان الأمر كذلك فعلًا، سيقيّم التابع الشرطي على أنه "صحيح"، وبالتالي سيُضمّن السجل في مجموعة النتائج: mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE rounds_played IS NULL; الخرج +--------+---------------+ | name | rounds_played | +--------+---------------+ | Calvin | NULL | | Rose | NULL | +--------+---------------+ 2 rows in set (0.00 sec) النطاق تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كانت قيم العمود محصورة بين تعبيري قيمة آخرين. mysql> SELECT name, best mysql> FROM golfers mysql> WHERE best BETWEEN 67 AND 73; الخرج +---------+------+ | name | best | +---------+------+ | George | 68 | | Diane | 70 | | Rose | 69 | | Raymond | 67 | +---------+------+ 4 rows in set (0.00 sec) الانتماء أو العضوية يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تنتمي لمجموعة معينة. mysql> SELECT name, best mysql> FROM golfers mysql> WHERE best IN (65, 67, 69, 71); الخرج +---------+------+ | name | best | +---------+------+ | Pat | 65 | | Rose | 69 | | Raymond | 67 | +---------+------+ 3 rows in set (0.00 sec) تطابق الأنماط تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محرف بدل واحد أو أكثر. وتُعرّف SQL محرفي بدل هما % و _: محرف _: شرطة سفلية تُمثّل محرفًا واحدًا مجهولًا mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE rounds_played LIKE '2_'; الخرج +--------+---------------+ | name | rounds_played | +--------+---------------+ | George | 22 | | Pat | 25 | | Diane | 23 | +--------+---------------+ 3 rows in set (0.00 sec) محرف %: علامة النسبة المئوية تُمثّل صفر أو أكثر من المحارف المجهولة mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE name LIKE 'G%'; الخرج +--------+---------------+ | name | rounds_played | +--------+---------------+ | George | 22 | | Grady | 11 | +--------+---------------+ 2 rows in set (0.00 sec) لن نفصّل بشرح كل نمط من التوابع الشرطية فهو خارج مجال هذا المقال، ولمعرفة المزيد حول هذه الأنماط، ننصحك بالاطلاع على المقالات التالية: كيفية استخدام عوامل المقارنة وIS NULL في لغة الاستعلام البنيوية SQL كيفية استخدام عوامل BETWEEN وIN في لغة الاستعلام البنيوية SQL كيفية استخدام محارف البدل في SQL دمج التوابع الشرطية المتعددة باستخدام عوامل AND وOR قد نضطر في الكثير من الأحيان إلى تصفية النتائج على نحوٍ أدق مما توفره بنية WHERE ذات تابع شرطي وحيد. ومن ناحيةٍ أخرى، قد تكون السجلات التي تحقق واحدًا من شروط بحث متعددة مقبولة ضمن مجموعة النتائج في بعض الأحيان. وفي هذه الحالات، يمكنك كتابة بنى WHERE تتضمن توابع شرطية متعددة باستخدام عوامل AND أو OR على التوالي. للبدء باستخدام هذه العوامل، لنشغّل الاستعلام التالي الذي يعيد قيم من أعمدة name وbest وworst وaverage في جدول golfers. إذ تتضمن بنية WHERE الخاصة بهذا الاستعلام تابعين شرطيين مفصولين بعامل AND: mysql> SELECT name, best, worst, average mysql> FROM golfers mysql> WHERE best < 70 AND worst < 96; يختبر التابع الشرطي الأول ما إذا كانت أفضل قيمة (قيمة العمود best) لكل سجل تقل عن 70، في حين يختبر التابع الشرطي الثاني ما إذا كانت أسوأ قيمة (قيمة العمود worst) لكل سجل تقل عن 96. الآن وفي حال تقييم أي من الشرطين على أنه "خاطئ False" لسجل ما، فإنّ هذا السجل لن يُعاد ضمن مجموعة النتائج: الخرج +---------+------+-------+---------+ | name | best | worst | average | +---------+------+-------+---------+ | Pat | 65 | 74 | 68.7 | | Calvin | 63 | 76 | 68.5 | | Rose | 69 | 84 | 76.7 | | Raymond | 67 | 92 | 81.3 | +---------+------+-------+---------+ 4 rows in set (0.00 sec) الآن، لنشغّل الاستعلام التالي، وهو كما تلاحظ مطابق للمثال السابق، باستثناء فصل التابعين الشرطيين بعامل OR بدلًا من AND: mysql> SELECT name, best, worst, average mysql> FROM golfers mysql> WHERE best < 70 OR worst < 96; نلاحظ أنّ مجموعة النتائج في هذا المثال تتضمّن سجلين أكثر من المثال السابق، وذلك نظرًا لأنّه مع استخدام عامل OR يكفي تقييم تابع شرطي واحد على أنّه "صحيح True" للسجل لكي يُعاد ضمن مجموعة النتائج: الخرج +---------+------+-------+---------+ | name | best | worst | average | +---------+------+-------+---------+ | George | 68 | 103 | 84.6 | | Pat | 65 | 74 | 68.7 | | Diane | 70 | 92 | 78.8 | | Calvin | 63 | 76 | 68.5 | | Rose | 69 | 84 | 76.7 | | Raymond | 67 | 92 | 81.3 | +---------+------+-------+---------+ 6 rows in set (0.00 sec) يمكنك إدراج العديد من التوابع الشرطية في بنية WHERE واحدة بشرط دمجها باستخدام الصياغة المناسبة. ولكن قد يصعب تنبؤ بالبيانات التي ستُصفى مع زيادة تعقيد شروط البحث. من الجدير بالذكر أن أنظمة قواعد البيانات تميل لإعطاء الأولوية لعوامل AND. هذا يعني أن التوابع الشرطية التي تفصل بينها عوامل AND تعدّ كشرط بحث موحد مستقل يُختبر قبل أي توابع شرطية أخرى في بنية WHERE. لتوضيح ذلك، شغّل الاستعلام التالي الذي يسترجع قيمًا من أعمدة name وaverage وworst وrounds_played لكل سجل يستوفي شروط البحث المحددة في بنية WHERE: mysql> SELECT name, average, worst, rounds_played mysql> FROM golfers mysql> WHERE average < 85 OR worst < 95 AND rounds_played BETWEEN 19 AND 23; يبدأ هذا الاستعلام باختبار ما إذا كان كلا التابعين الشرطيين (worst < 95 و rounds_played BETWEEN 19 AND 23) المفصولين بعامل AND يقيمان على أنهما محققان بالنسبة للسجل قيد الاختبار الحالي. فإذا كان الأمر كذلك، سيظهر هذا السجل ضمن مجموعة النتائج. أمّا إذا قُيّم أحدهما أو كلاهما على أنه غير محقق "false"، فسينتقل الاستعلام لفحص ما إذا كانت قيمة average للصف الحالي أقل من 85. وفي حال كانت كذلك، سيظهر الصف ضمن مجموعة النتائج. الخرج +---------+---------+-------+---------------+ | name | average | worst | rounds_played | +---------+---------+-------+---------------+ | George | 84.6 | 103 | 22 | | Pat | 68.7 | 74 | 25 | | Diane | 78.8 | 92 | 23 | | Calvin | 68.5 | 76 | NULL | | Rose | 76.7 | 84 | NULL | | Raymond | 81.3 | 92 | 18 | +---------+---------+-------+---------------+ 6 rows in set (0.00 sec) يمكنك منح الأولوية لمجموعة من تابعين شرطيين فأكثر بوضعهم داخل أقواس. المثال التالي يطابق المثال السابق، لكنه يضع التابعين الشرطيين average < 85 وworst < 95، المفصولين بعامل OR، ضمن أقواس. mysql> SELECT name, average, worst, rounds_played mysql> FROM golfers mysql> WHERE (average < 85 OR worst < 95) AND rounds_played BETWEEN 19 AND 23; نظرًا لأن التابعين الشرطيين في البداية مُحاطين بأقواس، فيعاملهما عامل AND الذي يليهما كشرط بحث مستقل، والذي يجب أن يُقيّم على أنه محقق “True”. فإذا قُيّم كلا التابعين الشرطيين (average < 85 وworst < 95) على أنهما غير محققين “false”، فسيُعتبر شرط البحث بأكمله غير محقق “False” وبالتالي سيستبعد الاستعلام هذا السجل من مجموعة النتائج على الفور قبل أن ينتقل لتقييم السجل التالي. أمّا إذا قُيّم أي من التابعين الشرطيين بين القوسين على أنه محقق “True”، فيبدأ الاستعلام حينها في اختبار ما إذا كانت قيمة rounds_played للاعب الجولف تقع ضمن النطاق 19 و 23. وفي حال تحقق ذلك، يُضم السجل إلى مجموعة النتائج المُعادة. الخرج +--------+---------+-------+---------------+ | name | average | worst | rounds_played | +--------+---------+-------+---------------+ | George | 84.6 | 103 | 22 | | Diane | 78.8 | 92 | 23 | +--------+---------+-------+---------------+ 2 rows in set (0.00 sec) كما تُظهر هذه النتائج، بإعطاء الأولوية لمجموعات التوابع الشرطية وضمها ضمن أقواس، يمكن أن تُنتج الاستعلامات المتشابهة ظاهريًا مجموعات نتائج متباينة بدرجة كبيرة. مع أنه لا يُشترط دومًا اللجوء إلى هذا الأسلوب، إلا أنه يُوصى باستخدام الأقواس عند دمج أكثر من تابعين شرطيين ضمن شرط بحث واحد ليُعزز من مقروئية الاستعلامات ويسهّل فهمها. استثناء النتائج باستخدام عامل NOT ركّزت جميع الأمثلة في هذا المقال حتى الآن على كيفية كتابة استعلامات باستخدام بنية WHERE، والتي تُضمّن فقط السجلات التي تُحقّق شروط البحث المُحددة في مجموعة النتائج. ولكن يُمكنك كتابة استعلامات تستثني سجلات مُحددة عبر إدراج عامل NOT ضمن بنية WHERE. وعادةً ما تتبع بنى التوابع الشرطية للنطاق والعضوية وتطابق الأنماط التي تشمل عامل NOT الصياغة العامة التالية: mysql> . . . mysql> WHERE column_name NOT OPERATOR value_expression mysql> . . . للتوضيح، شغّل الاستعلام التالي الذي سيعيد قيمًا من عمود name في جدول golfers، ولكن وجود عامل NOT في بنية WHERE سيُلزم نظام إدارة قاعدة البيانات باستثناء أي سجلات تُطابق نمط محرف البدل: mysql> SELECT name mysql> FROM golfers mysql> WHERE name NOT LIKE 'R%'; الخرج +--------+ | name | +--------+ | George | | Pat | | Grady | | Diane | | Calvin | +--------+ 5 rows in set (0.00 sec) تتغير الأمور قليلًا عند إضافة عامل NOT إلى توابع IS NULL الشرطية. في هذه الحالات، يُدرج العامل NOT بين IS وNULL كما في المثال التالي. يُعيد هذا الاستعلام قيم name وrounds_played لجميع لاعبي الغولف الذين لا تكون قيمة rounds_played الخاصة بهم فارغة، على النحو: mysql> SELECT name, rounds_played mysql> FROM golfers mysql> WHERE rounds_played IS NOT NULL; الخرج +---------+---------------+ | name | rounds_played | +---------+---------------+ | George | 22 | | Pat | 25 | | Grady | 11 | | Diane | 23 | | Raymond | 18 | +---------+---------------+ 5 rows in set (0.00 sec) كما يُمكنك وضع عامل NOT مباشرةً بعد الكلمة المفتاحية WHERE. الأمر الذي يعدّ مفيدًا لا سيما في حال رغبتك باستثناء سجلات بناءً على ما إذا كانت تحقق عدة شروط بحث، كما في الاستعلام التالي الذي يعيد قيم كل من أعمدة name و average و best و wins للاعبي الغولف. mysql> SELECT name, average, best, wins mysql> FROM golfers mysql> WHERE NOT (average < 80 AND best < 70) OR wins = 9; الخرج +---------+---------+------+------+ | name | average | best | wins | +---------+---------+------+------+ | George | 84.6 | 68 | 3 | | Pat | 68.7 | 65 | 9 | | Grady | 97.6 | 78 | 0 | | Diane | 78.8 | 70 | 1 | | Raymond | 81.3 | 67 | 1 | +---------+---------+------+------+ 5 rows in set (0.00 sec) بالنظر إلى السجل الثاني من مجموعة النتائج أعلاه، نلاحظ أنّ متوسط نتيجة اللاعبة Pat في العمود average أقل من 80 وأفضل نتيجة لها في العمود best أقل من 70. ومع ذلك سجلها مُضمّن في مجموعة النتائج، وذلك نظرًا لأن عامل NOT يُلغي فقط شروط البحث المُحاطة بالأقواس. تذكر أنه عند إحاطة توابع شرطية متعددة مفصولة بعوامل AND أو OR بأقواس، تُعطى الأولوية لهذه التوابع في SQL وتُعامل كشرط بحث مستقل. بالتالي، يستثني عامل NOT السجلات بناءً على أول تابعي شرط فقط (average<80 و best<70). في حين تُضمّن السجلات بناءً على التابع الشرطي الثالث (wins=9). يمكنك إعادة كتابة الاستعلام لاستبعاد السجلات بناءً على التابع الشرطي الثالث أيضًا بالإضافة إلى التابعين الأول والثاني وذلك بإحاطة التوابع الثلاثة ضمن أقواس، كما في المثال التالي: mysql> SELECT name, average, best, wins mysql> FROM golfers mysql> WHERE NOT ((average < 80 AND best < 70) OR wins = 9); الخرج +---------+---------+------+------+ | name | average | best | wins | +---------+---------+------+------+ | George | 84.6 | 68 | 3 | | Grady | 97.6 | 78 | 0 | | Diane | 78.8 | 70 | 1 | | Raymond | 81.3 | 67 | 1 | +---------+---------+------+------+ 4 rows in set (0.00 sec) قد يعدّ نظام قاعدة البيانات لديك صيغة الاستعلام غير صالحة في حال تضمين العامل NOT قبل عامل مقارنة وذلك تبعًا لتقديم SQL المُستخدم. كمثال، لنجرب تشغيل الاستعلام التالي: mysql> SELECT name mysql> FROM golfers mysql> WHERE name NOT = 'Grady'; سيؤدي استخدام هذا الأمر في MySQL أو أي من الأنظمة المستندة إليها إلى حدوث خطأ. الخرج ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '= 'Grady'' at line 1 السبب وراء هذا الخطأ هو أنّ عامل NOT لا يُستخدم عادةً مع عوامل المقارنة (= و<> و< و<= و> و>=)، وذلك نظرًا لإمكانية تحقيق الأثر المعاكس لعامل مقارنة معيّن باستبداله بآخر يعيد السجلات التي كان الأول سيستثنيها. على سبيل المثال، يمكنك استبدال عامل المساواة (=) بعامل عدم المساواة (<>). الخلاصة باطلاعك على هذا المقال،تكون قد اكتسبت المعرفة حول كيفية كتابة بنى WHERE بطريقة تجعل الاستعلام يُعيد فقط السجلات التي تستوفي شرطًا معينًا. كما تعلمت كيفية دمج عدّة توابع شرطية وشروط بحث في استعلام واحد، ناهيك عن كيفية استخدام العامل NOT لاستثناء معلومات من مجموعات النتائج. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use WHERE Clauses in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية الاستعلام عن السجلات من الجداول في SQL ما هي محركات قواعد البيانات؟ أنواع قواعد البيانات وأهم مميزاتها واستخداماتها التعامل مع قواعد البيانات -
 ينطوي التعامل مع قواعد البيانات بشكلٍ أساسيّ على استخراج المعلومات حول البيانات المُخزّنة ضمنها. ويُطلق مصطلح الاستعلام query على أي عملية لاسترجاع المعلومات من جدول في أنظمة إدارة قواعد البيانات العلاقية. سنبحث في هذا المقال في بنية الاستعلامات بلغة الاستعلام البنيوية SQL وبعض الوظائف والعوامل الأكثر استخدامًا فيها. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، وللقيام بذلك يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة الاستعلامات. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم queries_DB: mysql> CREATE DATABASE queries_DB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات queries_DB، نفّذ تعليمة USE التالية: mysql> USE queries_DB; الخرج Database changed بعد تحديد قاعدة البيانات queries_db، سننشئ عدة جداول داخلها. للمتابعة مع الأمثلة المستخدمة في هذا المقال، تخيل أنك تدير مبادرة لتنظيف المنتزهات العامة في مدينة ما. إذ تضم المبادرة عددًا من المتطوعين الملتزمين بتنظيف منتزه المدينة الأقرب لمنازل كل منهم من خلال جمع القمامة بانتظام. ولدى الانضمام إلى المبادرة، يضع كل متطوع هدفًا لعدد أكياس القمامة التي يود جمعها كل أسبوع. وبفرض أننا قررنا تخزين المعلومات حول أهداف المتطوعين في قاعدة بيانات SQL باستخدام جدول يحتوي على خمسة أعمدة، على النحو: vol_id: مُعرّف كل متطوع، مُعبرًا عنه بنمط بيانات الأعداد الصحيحة int. سيكون هذا العمود هو المفتاح الأساسي للجدول، مما يعني أن كل قيمة منه ستلعب دور المعرّف الفريد لسجلها المقابل. ونظرًا لأن كل قيمة في المفتاح الأساسي يجب أن تكون فريدة، فسيتم تطبيق قيد UNIQUE على هذا العمود أيضًا. name: اسم كل متطوع، مُعبرًا عنه بنمط البيانات varchar بحد أقصى 20 محرفًا. park: اسم المنتزه التي سيجمع فيها كل متطوع القمامة، مُعبرًا عنه بنمط البيانات varchar بحد أقصى 20 محرفًا. لاحظ أنه يمكن لعدة متطوعين تنظيف نفس المنتزه. weekly_goal: هدف كل متطوع لعدد أكياس القمامة التي يرغب في جمعها في الأسبوع، مُعبرًا عنه بنمط البيانات int. max_bags: الرقم القياسي الشخصي لكل متطوع لأكبر عدد من أكياس القمامة التي جمعها في أسبوع واحد، مُعبرًا عنه بنمط البيانات عدد صحيح int. أنشئ جدولًا باسم volunteers يحتوي على هذه الأعمدة الخمسة بتنفيذ تعليمة CREATE TABLE على النحو: mysql> CREATE TABLE volunteers ( mysql> vol_id int UNIQUE, mysql> name varchar(20), mysql> park varchar(30), mysql> weekly_goal int, mysql> max_bags int, mysql> PRIMARY KEY (vol_id) mysql> ); بعد إنشاء جدول volunteers، املأه ببعض البيانات النموذجية. نفّذ تعليمة INSERT INTO التالية لإضافة سبع سجلات تمثل سبعة من متطوعي البرنامج: mysql> INSERT INTO volunteers mysql> VALUES mysql> (1, 'Gladys', 'Prospect Park', 3, 5), mysql> (2, 'Catherine', 'Central Park', 2, 2), mysql> (3, 'Georgeanna', 'Central Park', 2, 1), mysql> (4, 'Wanda', 'Van Cortland Park', 1, 1), mysql> (5, 'Ann', 'Prospect Park', 2, 7), mysql> (6, 'Juanita', 'Riverside Park', 1, 4), mysql> (7, 'Georgia', 'Prospect Park', 1, 3); وبذلك غدوتَ جاهزًا لمتابعة باقي المقال والبدء في تعلم كيفية إنشاء الاستعلامات في لغة الاستعلام البنيوية SQL. مكونات الاستعلام الأساسية: بنيتي SELECT و FROM تُعرّف التعليمة البرمجية في SQL بأنّها أي عملية تُرسَل إلى نظام قاعدة البيانات لتنفيذ مهمّة محددة، من قبيل إنشاء جدول أو إدخال أو حذف بيانات أو تغيير هيكلية عمود أو جدول. وما الاستعلام سوى تعليمة برمجية في SQL تسترجع معلومات حول البيانات المحفوظة في قاعدة البيانات. لن يُغير الاستعلام أي بيانات موجودة في جدول من تلقاء نفسه، إذ سيقتصر الأمر فقط على استرجاع المعلومات حول البيانات التي يطلبها مُنشئ الاستعلام بشكلٍ صريح. ويُشار إلى المعلومات التي يُعيدها استعلام معين بمجموعة نتائجه. والتي عادةً ما تتكون من عمود واحد أو أكثر من جدول محدد، وكل عمود يُعاد في مجموعة النتائج يمكن أن يحتوي على سجل واحد أو أكثر من المعلومات. فيما يلي الصيغة العامة لاستعلام SQL: mysql> SELECT columns_to_return mysql> FROM table_to_query; تتألف تعليمات SQL من بنى مختلفة، والتي تتكون بدورها من كلمات مفتاحية معينة مع المعلومات التي تتطلبها هذه الكلمات. وفي هذا السياق تتطلب الاستعلامات في SQL منك تضمين بنيتين على الأقل، وهما: SELECT و FROM. ملاحظة: كُتبت كل بنية في هذه صيغة هذا المثال في سطرها الخاص. ولكن يمكن كتابة أي تعليمة برمجية في SQL على سطرٍ واحد على النحو التالي: mysql> SELECT columns_to_return FROM table_to_query; يتبع هذا المقال القاعدة الشائعة في أسلوب SQL بتقسيم التعليمات البرمجية على سطور متعددة بحيث يحتوي كل سطر على بنية واحدة فقط. والهدف من ذلك تحسين قابلية القراءة والفهم لكل مثال، لكن ينبغي الإشارة إلى أنه بإمكانك كتابة استعلام على سطر واحد أو توزيعه على عدة سطور، طالما أنه لا يحتوي على أخطاء في الصياغة. تبدأ كل استعلامات SQL عادةً ببنية SELECT، ولذلك يُشار إليها عمومًا بتعليمات SELECT. وتأتي بعد كلمة SELECT المفتاحية قائمة بأسماء الأعمدة التي ترغب في استرجاعها في مجموعة النتائج، والتي يتم اختيارها من الجدول المُحدد في بنية FROM. يبدأ تنفيذ العملية في استعلامات SQL من بنية FROM. الأمر الذي قد يبدو محيرًا نظرًا لأن بنية SELECT تُكتب قبل FROM، ولكن من الضروري أن يحدد نظام إدارة قواعد البيانات أولًا مجموعة البيانات الكاملة التي سيتم الاستعلام عنها قبل البدء في استرجاع المعلومات منها. يُفيد التفكير في الاستعلامات على أنها عملية اختيار SELECT لأعمدة محددة من FROM جدول مُعين. ومن المهم التذكير بأن كل تعليمة SQL يجب أن تختتم بفاصلة منقوطة (;). كمثال، نفذ الاستعلام التالي الذي يسترجع عمود name من جدول volunteers: mysql> SELECT name mysql> FROM volunteers; إليك مجموعة نتائج هذا الاستعلام: الخرج +------------+ | name | +------------+ | Gladys | | Catherine | | Georgeanna | | Wanda | | Ann | | Juanita | | Georgia | +------------+ 7 rows in set (0.00 sec) على الرغم من أن هذه العملية استعرضت جدول volunteers بأكمله، إلا أنها استرجعت فقط العمود المُحدد، ألا وهو name. يمكنك استرجاع المعلومات من عدة أعمدة عن طريق فصل اسماء الأعمدة بعلامات فاصلة، كما في الاستعلام التالي. إذ سيعيد هذا الاستعلام أعمدة vol_id, name, و park من جدول volunteers: mysql> SELECT park, name, vol_id mysql> FROM volunteers; الخرج +-------------------+------------+--------+ | park | name | vol_id | +-------------------+------------+--------+ | Prospect Park | Gladys | 1 | | Central Park | Catherine | 2 | | Central Park | Georgeanna | 3 | | Van Cortland Park | Wanda | 4 | | Prospect Park | Ann | 5 | | Riverside Park | Juanita | 6 | | Prospect Park | Georgia | 7 | +-------------------+------------+--------+ 7 rows in set (0.00 sec) لاحظ أنّ هذه النتيجة تُعيد العمود park أولًا، يليه عمود name ثم vol_id. تُعيد قواعد البيانات SQL الأعمدة عمومًا بالترتيب الذي تم سرده في بنية SELECT. قد تحتاج في بعض الأحيان إلى استرجاع كل الأعمدة من جدول ما. فبدلًا من كتابة أسماء كافّة الأعمدة في استعلامك، يمكنك ببساطة إدخال علامة النجمة (*). وهي الطريقة المختصرة في SQL، للدلالة على "كل الأعمدة". الاستعلام التالي سيُعيد كل الأعمدة من جدول volunteers: mysql> SELECT * mysql> FROM volunteers; الخرج +--------+------------+-------------------+-------------+----------+ | vol_id | name | park | weekly_goal | max_bags | +--------+------------+-------------------+-------------+----------+ | 1 | Gladys | Prospect Park | 3 | 5 | | 2 | Catherine | Central Park | 2 | 2 | | 3 | Georgeanna | Central Park | 2 | 1 | | 4 | Wanda | Van Cortland Park | 1 | 1 | | 5 | Ann | Prospect Park | 2 | 7 | | 6 | Juanita | Riverside Park | 1 | 4 | | 7 | Georgia | Prospect Park | 1 | 3 | +--------+------------+-------------------+-------------+----------+ 7 rows in set (0.00 sec) لاحظ كيف تُعرَض الأعمدة في هذه النتيجة بنفس الترتيب المُحدّد في تعليمة CREATE TABLE من فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية السابقة. وهي الطريقة التي ستُرتب بها معظم أنظمة قواعد البيانات العلاقية الأعمدة في مجموعة النتائج عند تنفيذ استعلام يستخدم علامة النجمة (*) بدلًا من أسماء الأعمدة الفردية. ومن الجدير بالملاحظة أنّه من الممكن استرجاع المعلومات من عدة جداول في نفس الاستعلام باستخدام الكلمة المفتاحية JOIN. ونشجعك في هذا الصدد على قراءة مقال استخدام عمليات الدمج في SQL. استبعاد القيم المكررة باستخدام DISTINCT تُعيد أنظمة إدارة قواعد البيانات العلاقية افتراضيًا جميع القيم من أعمدة الجدول المُستعلم عنه، بما في ذلك القيم المكررة. كمثال، نفّذ الاستعلام التالي. إذ سيُرجع القيم من عمود park في جدول volunteers: mysql> SELECT park mysql> FROM volunteers; الخرج +-------------------+ | park | +-------------------+ | Prospect Park | | Central Park | | Central Park | | Van Cortland Park | | Prospect Park | | Riverside Park | | Prospect Park | +-------------------+ 7 rows in set (0.00 sec) لاحظ أن مجموعة النتائج تتضمّن قيمتين مكررتين هما Prospect Park وCentral Park. وهو أمر منطقي، إذ يمكن لعدد من المتطوعين التعاون في تنظيف نفس المتنزه. ومع ذلك، قد ترغب في بعض الأحيان بمعرفة القيم الفريدة المخزنة في عمود ما ويمكنك تحقيق ذلك وإزالة القيم المكررة من نتائج استعلامك باستخدام الكلمة المفتاحية DISTINCT بعد SELECT. سيُرجع الاستعلام التالي كافة القيم الفريدة من عمود park، مُستبعدًا أية قيم مكررة. وهو مُتشابه للاستعلام السابق ولكن مع إضافة كلمة DISTINCT، كما يلي: mysql> SELECT DISTINCT park mysql> FROM volunteers; الخرج +-------------------+ | park | +-------------------+ | Prospect Park | | Central Park | | Van Cortland Park | | Riverside Park | +-------------------+ 4 rows in set (0.00 sec) تحتوي مجموعة نتائج هذا الاستعلام على ثلاث سجلات أقل من الاستعلام السابق، بسبب إزالة إحدى قيم Central Park واثنتين من قيم Prospect Park. تجدر الإشارة إلى أن SQL تُعامل كل سجل في مجموعة النتائج كسجل فردي، وتُزيل DISTINCT القيم المكررة فقط في حال تشاركت عدة سجلات بنفس القيم في كل الأعمدة. لتوضيح ذلك، لنُصدر الاستعلام التالي المُتضمّن للكلمة المفتاحية DISTINCT والذي يُرجع كلا العمودين name وpark: mysql> SELECT DISTINCT name, park mysql> FROM volunteers; الخرج +------------+-------------------+ | name | park | +------------+-------------------+ | Gladys | Prospect Park | | Catherine | Central Park | | Georgeanna | Central Park | | Wanda | Van Cortland Park | | Ann | Prospect Park | | Juanita | Riverside Park | | Georgia | Prospect Park | +------------+-------------------+ 7 rows in set (0.00 sec) تشتمل مجموعة النتائج هذه على قيم مكررة في عمود park، بواقع ثلاث تكرارات لقيم Prospect Park وتكرارين لقيم Central Park، وذلك على الرغم من إدراج الكلمة المفتاحية DISTINCT في الاستعلام. فعلى الرغم من احتواء الأعمدة الفردية في مجموعة النتائج على قيم مكررة، لكن يجب أن تكون السجلات متطابقة بالكامل لتُستبعد من قبل DISTINCT. وفي حالتنا، ونظرًا لأن القيم في عمود name فريدة لكل سجل، فإن DISTINCT لن تزيل أي من السجلات لدى تحديد هذا العمود ضمن بنية SELECT. تصفية البيانات باستخدام بنى WHERE قد ترغب في بعض الحالات باسترجاع معلومات أكثر تحديدًا من جداول قاعدة البيانات. إذ يمكنك تصفية سجلات معينة بإدراج بنية WHERE في استعلامك بعد بنية FROM، كما في المثال التالي: mysql> SELECT columns_to_return mysql> FROM table_to_query mysql> WHERE search_condition; يأتي شرط البحث بعد كلمة WHERE في الصيغة المذكورة بالمثال، والذي يُحدّد على وجه الخصوص أي السجلات مُراد تصفيتها من مجموعة النتائج. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر. إذ يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. ويمكن أن يكون تعبير القيمة عبارة عن قيمة محددة النوع (سلسلة نصية أو قيمة عددية)، أو تعبير رياضي، أو اسم عمود. يمكن أن تأخذ التوابع الشرطية في شرط البحث الخاص ببنية WHERE أشكالاً مختلفة، ولكنها عادةً ما تتبع الصيغة التالية: WHERE value expression OPERATOR value_expression فقد وضعنا بعد الكلمة المفتاحية WHERE في هذه الصيغة تعبير قيمة، يليه أحد معاملات SQL الخاصة والمُستخدمة لتقييم قيم الأعمدة بالنسبة لتعبير القيمة (أو تعابير القيم) الآتي بعد العامل. وهناك العديد من هذه العوامل المتاحة في SQL، وسنقدّم في هذا القسم لمحة موجزة عن بعضها، ولكن لغرض التوضيح سنركّز فقط على أحد أكثر العوامل استخدامًا، ألا وهو: علامة المساواة (=). يختبر هذا العامل ما إذا كان تعبيرين يحتويان على قيم متطابقة. دائمًا ما تُعطي التوابع الشرطية الناتج "صحيح True" أو "خاطئ False" أو "غير محدد Unknown". فلدى تشغيل استعلامات SQL التي تحتوي على بنية WHERE، سيطبّق نظام إدارة قاعدة البيانات شرط البحث تتابعيًا على كل سجل في الجدول المحدد في بنية FROM. ولن يعيد سوى السجلات التي يُقيّم فيها كل شرط بحث على أنه "صحيح". لتوضيح هذه الفكرة، نفّذ تعليمة SELECT التالية. يُرجع هذا الاستعلام قيمًا من عمود name في جدول volunteers. لكن بدلًا من تقييم قيم أحد أعمدة الجدول، تختبر بنية WHERE في هذا الاستعلام ما إذا كان التعبير (2 + 2) و 4 متساويين. mysql> SELECT name mysql> FROM volunteers mysql> WHERE (2+2) = 4; ونظرًا لأنّ التعبير (2+2) يساوي 4 دائمًا، فإن شرط البحث هذا يُقيّم بأنه صحيح لكل سجل في الجدول. ونتيجةً لذلك، تُرجع قيمة الاسم لكل سجل في مجموعة النتائج، على النحو: الخرج +------------+ | name | +------------+ | Gladys | | Catherine | | Georgeanna | | Wanda | | Ann | | Juanita | | Georgia | +------------+ 7 rows in set (0.00 sec) ولكن ونظرًا لأن شرط البحث هذا يعيد دائمًا نتيجة "صحيحة"، فهو ليس مفيدًا بدرجة كبيرة. وبالتالي من الممكن في هذه الحالة عدم تضمين بنية WHERE أصلًا، لأن تعليمة SELECT name FROM volunteers; ستعطي نفس مجموعة النتائج كما في حالة استخدام WHERE مع شرط بحث مُحقق دومًا. عادةً ما نستخدم اسم عمود كأحد تعبيري القيمة في شرط البحث ضمن بنية WHERE وذلك بدلاً من مقارنة قيمتين مُحددتي النوع كما في الأسلوب أعلاه. وبذلك نُعلم نظام إدارة قاعدة البيانات باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. تُطبّق بنية WHERE في الاستعلام التالي شرط بحث أكثر تحديدًا على كل سجل. إذ ستُرجع قيم كل من عمودي name و max_bags من أي سجل تساوي فيه قيمة max_bags الرقم 4: mysql> SELECT name, max_bags mysql> FROM volunteers mysql> WHERE max_bags = 4; يُرجع هذا الاستعلام سجل متطوع واحد فقط، نظرًا لأنّ قيمة max_bags لهذا المتطوع وحده تساوي 4 تمامًا، فيكون الخرج على النحو: الخرج +---------+----------+ | name | max_bags | +---------+----------+ | Juanita | 4 | +---------+----------+ 1 row in set (0.00 sec) يمكنك أيضًا تقييم قيم السلاسل النصية المحرفية في التوابع الشرطية الخاصة بشروط البحث. فمثلًا يُرجع الاستعلام التالي قيم عمودي vol_id و name لكل سجل تكون قيمة العمود name فيه مساوية لـ 'Wanda': mysql> SELECT vol_id, name mysql> FROM volunteers mysql> WHERE name = 'Wanda'; ونظرًا لوجود متطوعة واحدة فقط تُدعى Wanda، فإن الاستعلام يُرجع معلومات سجلها فقط: الخرج +--------+-------+ | vol_id | name | +--------+-------+ | 4 | Wanda | +--------+-------+ 1 row in set (0.00 sec) من الجدير بالملاحظة أنّنا استخدمنا نفس العامل لشرط البحث في جميع أمثلة هذا القسم وهو علامة المساواة وذلك لتوضيح الفكرة. ولكن يوجد العديد من أنواع المعاملات Operators الأخرى التي تتيح لنا إمكانية كتابة مجموعة متنوعة من التوابع الشرطية، مما يوفر مستوى عالٍ من التحكم في المعلومات التي تُرجعها الاستعلامات. يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، وعلى الرغم من أنّها لا تتوفر كاملةً في كافّة أنظمة إدارة قواعد البيانات العلاقية RDBMS. إليك خمسة من أكثر أنواع توابع الشرط شيوعًا في شروط البحث والعوامل المستخدمة في كل منها: المقارنة: تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي: = يختبر ما إذا كانت القيمتان متساويتين. <> يختبر ما إذا كانت القيمتان غير متساويتين. < يختبر ما إذا كانت القيمة الأولى أقل من الثانية. > يختبر ما إذا كانت القيمة الأولى أكبر من الثانية. <= يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية. >= يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي الثانية. القيم الفارغة: تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة. النطاق: تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة ما يقع بين تعبيري قيمة آخرين. العضوية: يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تُمثّل عضوًا في مجموعة معينة. تطابق الأنماط: تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محارف بدل. لمعرفة المزيد حول هذه الأنواع من التوابع الشرطية، ننصحك بالاطلاع على المقالات التالية: كيفية استخدام عوامل المقارنة و IS NULL في لغة الاستعلام البنيوية SQL كيفية استخدام عوامل BETWEEN و IN في لغة الاستعلام البنيوية SQL كيفية استخدام محارف البدل في SQL وللاطلاع على المزيد حول بنى WHERE عمومًا، ننصحك بقراءة مقالنا حول كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL. فرز نتائج الاستعلام باستخدام بنية ORDER BY قد تُعيد الاستعلامات في بعض الأحيان المعلومات بطرق غير واضحة أو غير متوافقة تمامًا مع احتياجاتك. لذا يمكنك فرز أو ترتيب نتائج الاستعلام بتضمين بنية ORDER BY في نهاية تعليمة الاستعلام. فيما يلي الصيغة العامّة لاستعلام يتضمن بنية ORDER BY: mysql> SELECT columns_to_return mysql> FROM table_to_query mysql> ORDER BY column_name; لتوضيح الأمر، بفرض أننا نرغب في معرفة أي من المتطوعين يحقق أعلى قيمة في عمود max_bags. لنُنفّذ الاستعلام التالي الذي يُعيد قيم عمودي name وmax_bags من جدول volunteers: $ SELECT name, max_bags $ FROM volunteers; ولكن يفرز هذا الاستعلام مجموعة النتائج حسب الترتيب الذي أُضيف فيه كل سجل. الخرج +------------+----------+ | name | max_bags | +------------+----------+ | Gladys | 5 | | Catherine | 2 | | Georgeanna | 1 | | Wanda | 1 | | Ann | 7 | | Juanita | 4 | | Georgia | 3 | +------------+----------+ 7 rows in set (0.00 sec) ولعلّ فرز مجموعة بيانات صغيرة نسبيًا كهذه ليس بتلك الأهمية، إذ يمكننا ببساطة مراجعة قيم max_bags في مجموعة النتائج لإيجاد القيمة الأعلى لكن هذا الأمر قد يصبح متعبًا عند العمل مع كميات أكبر من البيانات. يمكننا تنفيذ الاستعلام ذاته ولكن مع إضافة بنية ORDER BY التي تفرز مجموعة النتائج تبعًا لقيم max_bags للسجلات: $ SELECT name, max_bags $ FROM volunteers $ ORDER BY max_bags; الخرج +------------+----------+ | name | max_bags | +------------+----------+ | Georgeanna | 1 | | Wanda | 1 | | Catherine | 2 | | Georgia | 3 | | Juanita | 4 | | Gladys | 5 | | Ann | 7 | +------------+----------+ 7 rows in set (0.00 sec) كما يُظهر هذا الخرج، فالسلوك الافتراضي لاستعلامات SQL التي تتضمن بنية ORDER BY هو فرز قيم العمود المحدد تصاعديًا (من الأصغر إلى الأكبر). ويمكننا تغيير هذا السلوك وفرزها بترتيب تنازلي عن طريق إضافة الكلمة المفتاحية DESC إلى بنية ORDER BY. $ SELECT name, max_bags $ FROM volunteers $ ORDER BY max_bags DESC; الخرج +------------+----------+ | name | max_bags | +------------+----------+ | Ann | 7 | | Gladys | 5 | | Juanita | 4 | | Georgia | 3 | | Catherine | 2 | | Georgeanna | 1 | | Wanda | 1 | +------------+----------+ 7 rows in set (0.00 sec) الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية كتابة استعلامات أساسية، وكيفية تصفية وفرز مجموعات نتائج الاستعلام، ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL، لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To SELECT Rows FROM Tables in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية حذف البيانات في لغة الاستعلام البنيوية SQL أنواع قواعد البيانات وأهم مميزاتها واستخداماتها تعرف على مكونات قاعدة البيانات ما هي محركات قواعد البيانات؟ فهم قواعد البيانات العلاقية
ينطوي التعامل مع قواعد البيانات بشكلٍ أساسيّ على استخراج المعلومات حول البيانات المُخزّنة ضمنها. ويُطلق مصطلح الاستعلام query على أي عملية لاسترجاع المعلومات من جدول في أنظمة إدارة قواعد البيانات العلاقية. سنبحث في هذا المقال في بنية الاستعلامات بلغة الاستعلام البنيوية SQL وبعض الوظائف والعوامل الأكثر استخدامًا فيها. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، وللقيام بذلك يمكنك الاطلاع على المقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية RDBMS لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على كتابة الاستعلامات. لذا ننصحك بقراءة القسم القادم الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن ومن نافذة سطر الأوامر، أنشئ قاعدة بيانات باسم queries_DB: mysql> CREATE DATABASE queries_DB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات queries_DB، نفّذ تعليمة USE التالية: mysql> USE queries_DB; الخرج Database changed بعد تحديد قاعدة البيانات queries_db، سننشئ عدة جداول داخلها. للمتابعة مع الأمثلة المستخدمة في هذا المقال، تخيل أنك تدير مبادرة لتنظيف المنتزهات العامة في مدينة ما. إذ تضم المبادرة عددًا من المتطوعين الملتزمين بتنظيف منتزه المدينة الأقرب لمنازل كل منهم من خلال جمع القمامة بانتظام. ولدى الانضمام إلى المبادرة، يضع كل متطوع هدفًا لعدد أكياس القمامة التي يود جمعها كل أسبوع. وبفرض أننا قررنا تخزين المعلومات حول أهداف المتطوعين في قاعدة بيانات SQL باستخدام جدول يحتوي على خمسة أعمدة، على النحو: vol_id: مُعرّف كل متطوع، مُعبرًا عنه بنمط بيانات الأعداد الصحيحة int. سيكون هذا العمود هو المفتاح الأساسي للجدول، مما يعني أن كل قيمة منه ستلعب دور المعرّف الفريد لسجلها المقابل. ونظرًا لأن كل قيمة في المفتاح الأساسي يجب أن تكون فريدة، فسيتم تطبيق قيد UNIQUE على هذا العمود أيضًا. name: اسم كل متطوع، مُعبرًا عنه بنمط البيانات varchar بحد أقصى 20 محرفًا. park: اسم المنتزه التي سيجمع فيها كل متطوع القمامة، مُعبرًا عنه بنمط البيانات varchar بحد أقصى 20 محرفًا. لاحظ أنه يمكن لعدة متطوعين تنظيف نفس المنتزه. weekly_goal: هدف كل متطوع لعدد أكياس القمامة التي يرغب في جمعها في الأسبوع، مُعبرًا عنه بنمط البيانات int. max_bags: الرقم القياسي الشخصي لكل متطوع لأكبر عدد من أكياس القمامة التي جمعها في أسبوع واحد، مُعبرًا عنه بنمط البيانات عدد صحيح int. أنشئ جدولًا باسم volunteers يحتوي على هذه الأعمدة الخمسة بتنفيذ تعليمة CREATE TABLE على النحو: mysql> CREATE TABLE volunteers ( mysql> vol_id int UNIQUE, mysql> name varchar(20), mysql> park varchar(30), mysql> weekly_goal int, mysql> max_bags int, mysql> PRIMARY KEY (vol_id) mysql> ); بعد إنشاء جدول volunteers، املأه ببعض البيانات النموذجية. نفّذ تعليمة INSERT INTO التالية لإضافة سبع سجلات تمثل سبعة من متطوعي البرنامج: mysql> INSERT INTO volunteers mysql> VALUES mysql> (1, 'Gladys', 'Prospect Park', 3, 5), mysql> (2, 'Catherine', 'Central Park', 2, 2), mysql> (3, 'Georgeanna', 'Central Park', 2, 1), mysql> (4, 'Wanda', 'Van Cortland Park', 1, 1), mysql> (5, 'Ann', 'Prospect Park', 2, 7), mysql> (6, 'Juanita', 'Riverside Park', 1, 4), mysql> (7, 'Georgia', 'Prospect Park', 1, 3); وبذلك غدوتَ جاهزًا لمتابعة باقي المقال والبدء في تعلم كيفية إنشاء الاستعلامات في لغة الاستعلام البنيوية SQL. مكونات الاستعلام الأساسية: بنيتي SELECT و FROM تُعرّف التعليمة البرمجية في SQL بأنّها أي عملية تُرسَل إلى نظام قاعدة البيانات لتنفيذ مهمّة محددة، من قبيل إنشاء جدول أو إدخال أو حذف بيانات أو تغيير هيكلية عمود أو جدول. وما الاستعلام سوى تعليمة برمجية في SQL تسترجع معلومات حول البيانات المحفوظة في قاعدة البيانات. لن يُغير الاستعلام أي بيانات موجودة في جدول من تلقاء نفسه، إذ سيقتصر الأمر فقط على استرجاع المعلومات حول البيانات التي يطلبها مُنشئ الاستعلام بشكلٍ صريح. ويُشار إلى المعلومات التي يُعيدها استعلام معين بمجموعة نتائجه. والتي عادةً ما تتكون من عمود واحد أو أكثر من جدول محدد، وكل عمود يُعاد في مجموعة النتائج يمكن أن يحتوي على سجل واحد أو أكثر من المعلومات. فيما يلي الصيغة العامة لاستعلام SQL: mysql> SELECT columns_to_return mysql> FROM table_to_query; تتألف تعليمات SQL من بنى مختلفة، والتي تتكون بدورها من كلمات مفتاحية معينة مع المعلومات التي تتطلبها هذه الكلمات. وفي هذا السياق تتطلب الاستعلامات في SQL منك تضمين بنيتين على الأقل، وهما: SELECT و FROM. ملاحظة: كُتبت كل بنية في هذه صيغة هذا المثال في سطرها الخاص. ولكن يمكن كتابة أي تعليمة برمجية في SQL على سطرٍ واحد على النحو التالي: mysql> SELECT columns_to_return FROM table_to_query; يتبع هذا المقال القاعدة الشائعة في أسلوب SQL بتقسيم التعليمات البرمجية على سطور متعددة بحيث يحتوي كل سطر على بنية واحدة فقط. والهدف من ذلك تحسين قابلية القراءة والفهم لكل مثال، لكن ينبغي الإشارة إلى أنه بإمكانك كتابة استعلام على سطر واحد أو توزيعه على عدة سطور، طالما أنه لا يحتوي على أخطاء في الصياغة. تبدأ كل استعلامات SQL عادةً ببنية SELECT، ولذلك يُشار إليها عمومًا بتعليمات SELECT. وتأتي بعد كلمة SELECT المفتاحية قائمة بأسماء الأعمدة التي ترغب في استرجاعها في مجموعة النتائج، والتي يتم اختيارها من الجدول المُحدد في بنية FROM. يبدأ تنفيذ العملية في استعلامات SQL من بنية FROM. الأمر الذي قد يبدو محيرًا نظرًا لأن بنية SELECT تُكتب قبل FROM، ولكن من الضروري أن يحدد نظام إدارة قواعد البيانات أولًا مجموعة البيانات الكاملة التي سيتم الاستعلام عنها قبل البدء في استرجاع المعلومات منها. يُفيد التفكير في الاستعلامات على أنها عملية اختيار SELECT لأعمدة محددة من FROM جدول مُعين. ومن المهم التذكير بأن كل تعليمة SQL يجب أن تختتم بفاصلة منقوطة (;). كمثال، نفذ الاستعلام التالي الذي يسترجع عمود name من جدول volunteers: mysql> SELECT name mysql> FROM volunteers; إليك مجموعة نتائج هذا الاستعلام: الخرج +------------+ | name | +------------+ | Gladys | | Catherine | | Georgeanna | | Wanda | | Ann | | Juanita | | Georgia | +------------+ 7 rows in set (0.00 sec) على الرغم من أن هذه العملية استعرضت جدول volunteers بأكمله، إلا أنها استرجعت فقط العمود المُحدد، ألا وهو name. يمكنك استرجاع المعلومات من عدة أعمدة عن طريق فصل اسماء الأعمدة بعلامات فاصلة، كما في الاستعلام التالي. إذ سيعيد هذا الاستعلام أعمدة vol_id, name, و park من جدول volunteers: mysql> SELECT park, name, vol_id mysql> FROM volunteers; الخرج +-------------------+------------+--------+ | park | name | vol_id | +-------------------+------------+--------+ | Prospect Park | Gladys | 1 | | Central Park | Catherine | 2 | | Central Park | Georgeanna | 3 | | Van Cortland Park | Wanda | 4 | | Prospect Park | Ann | 5 | | Riverside Park | Juanita | 6 | | Prospect Park | Georgia | 7 | +-------------------+------------+--------+ 7 rows in set (0.00 sec) لاحظ أنّ هذه النتيجة تُعيد العمود park أولًا، يليه عمود name ثم vol_id. تُعيد قواعد البيانات SQL الأعمدة عمومًا بالترتيب الذي تم سرده في بنية SELECT. قد تحتاج في بعض الأحيان إلى استرجاع كل الأعمدة من جدول ما. فبدلًا من كتابة أسماء كافّة الأعمدة في استعلامك، يمكنك ببساطة إدخال علامة النجمة (*). وهي الطريقة المختصرة في SQL، للدلالة على "كل الأعمدة". الاستعلام التالي سيُعيد كل الأعمدة من جدول volunteers: mysql> SELECT * mysql> FROM volunteers; الخرج +--------+------------+-------------------+-------------+----------+ | vol_id | name | park | weekly_goal | max_bags | +--------+------------+-------------------+-------------+----------+ | 1 | Gladys | Prospect Park | 3 | 5 | | 2 | Catherine | Central Park | 2 | 2 | | 3 | Georgeanna | Central Park | 2 | 1 | | 4 | Wanda | Van Cortland Park | 1 | 1 | | 5 | Ann | Prospect Park | 2 | 7 | | 6 | Juanita | Riverside Park | 1 | 4 | | 7 | Georgia | Prospect Park | 1 | 3 | +--------+------------+-------------------+-------------+----------+ 7 rows in set (0.00 sec) لاحظ كيف تُعرَض الأعمدة في هذه النتيجة بنفس الترتيب المُحدّد في تعليمة CREATE TABLE من فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية السابقة. وهي الطريقة التي ستُرتب بها معظم أنظمة قواعد البيانات العلاقية الأعمدة في مجموعة النتائج عند تنفيذ استعلام يستخدم علامة النجمة (*) بدلًا من أسماء الأعمدة الفردية. ومن الجدير بالملاحظة أنّه من الممكن استرجاع المعلومات من عدة جداول في نفس الاستعلام باستخدام الكلمة المفتاحية JOIN. ونشجعك في هذا الصدد على قراءة مقال استخدام عمليات الدمج في SQL. استبعاد القيم المكررة باستخدام DISTINCT تُعيد أنظمة إدارة قواعد البيانات العلاقية افتراضيًا جميع القيم من أعمدة الجدول المُستعلم عنه، بما في ذلك القيم المكررة. كمثال، نفّذ الاستعلام التالي. إذ سيُرجع القيم من عمود park في جدول volunteers: mysql> SELECT park mysql> FROM volunteers; الخرج +-------------------+ | park | +-------------------+ | Prospect Park | | Central Park | | Central Park | | Van Cortland Park | | Prospect Park | | Riverside Park | | Prospect Park | +-------------------+ 7 rows in set (0.00 sec) لاحظ أن مجموعة النتائج تتضمّن قيمتين مكررتين هما Prospect Park وCentral Park. وهو أمر منطقي، إذ يمكن لعدد من المتطوعين التعاون في تنظيف نفس المتنزه. ومع ذلك، قد ترغب في بعض الأحيان بمعرفة القيم الفريدة المخزنة في عمود ما ويمكنك تحقيق ذلك وإزالة القيم المكررة من نتائج استعلامك باستخدام الكلمة المفتاحية DISTINCT بعد SELECT. سيُرجع الاستعلام التالي كافة القيم الفريدة من عمود park، مُستبعدًا أية قيم مكررة. وهو مُتشابه للاستعلام السابق ولكن مع إضافة كلمة DISTINCT، كما يلي: mysql> SELECT DISTINCT park mysql> FROM volunteers; الخرج +-------------------+ | park | +-------------------+ | Prospect Park | | Central Park | | Van Cortland Park | | Riverside Park | +-------------------+ 4 rows in set (0.00 sec) تحتوي مجموعة نتائج هذا الاستعلام على ثلاث سجلات أقل من الاستعلام السابق، بسبب إزالة إحدى قيم Central Park واثنتين من قيم Prospect Park. تجدر الإشارة إلى أن SQL تُعامل كل سجل في مجموعة النتائج كسجل فردي، وتُزيل DISTINCT القيم المكررة فقط في حال تشاركت عدة سجلات بنفس القيم في كل الأعمدة. لتوضيح ذلك، لنُصدر الاستعلام التالي المُتضمّن للكلمة المفتاحية DISTINCT والذي يُرجع كلا العمودين name وpark: mysql> SELECT DISTINCT name, park mysql> FROM volunteers; الخرج +------------+-------------------+ | name | park | +------------+-------------------+ | Gladys | Prospect Park | | Catherine | Central Park | | Georgeanna | Central Park | | Wanda | Van Cortland Park | | Ann | Prospect Park | | Juanita | Riverside Park | | Georgia | Prospect Park | +------------+-------------------+ 7 rows in set (0.00 sec) تشتمل مجموعة النتائج هذه على قيم مكررة في عمود park، بواقع ثلاث تكرارات لقيم Prospect Park وتكرارين لقيم Central Park، وذلك على الرغم من إدراج الكلمة المفتاحية DISTINCT في الاستعلام. فعلى الرغم من احتواء الأعمدة الفردية في مجموعة النتائج على قيم مكررة، لكن يجب أن تكون السجلات متطابقة بالكامل لتُستبعد من قبل DISTINCT. وفي حالتنا، ونظرًا لأن القيم في عمود name فريدة لكل سجل، فإن DISTINCT لن تزيل أي من السجلات لدى تحديد هذا العمود ضمن بنية SELECT. تصفية البيانات باستخدام بنى WHERE قد ترغب في بعض الحالات باسترجاع معلومات أكثر تحديدًا من جداول قاعدة البيانات. إذ يمكنك تصفية سجلات معينة بإدراج بنية WHERE في استعلامك بعد بنية FROM، كما في المثال التالي: mysql> SELECT columns_to_return mysql> FROM table_to_query mysql> WHERE search_condition; يأتي شرط البحث بعد كلمة WHERE في الصيغة المذكورة بالمثال، والذي يُحدّد على وجه الخصوص أي السجلات مُراد تصفيتها من مجموعة النتائج. وما شرط البحث سوى مجموعة من التوابع الشرطية أو التعبيرات القادرة على تقييم تعبير قيمة واحد أو أكثر. إذ يُعرّف تعبير القيمة في لغة SQL - والذي يُشار إليه أحيانًا باسم التعبير ذو القيمة المفردة - بأنّه أي تعبير يُعيد قيمة واحدة. ويمكن أن يكون تعبير القيمة عبارة عن قيمة محددة النوع (سلسلة نصية أو قيمة عددية)، أو تعبير رياضي، أو اسم عمود. يمكن أن تأخذ التوابع الشرطية في شرط البحث الخاص ببنية WHERE أشكالاً مختلفة، ولكنها عادةً ما تتبع الصيغة التالية: WHERE value expression OPERATOR value_expression فقد وضعنا بعد الكلمة المفتاحية WHERE في هذه الصيغة تعبير قيمة، يليه أحد معاملات SQL الخاصة والمُستخدمة لتقييم قيم الأعمدة بالنسبة لتعبير القيمة (أو تعابير القيم) الآتي بعد العامل. وهناك العديد من هذه العوامل المتاحة في SQL، وسنقدّم في هذا القسم لمحة موجزة عن بعضها، ولكن لغرض التوضيح سنركّز فقط على أحد أكثر العوامل استخدامًا، ألا وهو: علامة المساواة (=). يختبر هذا العامل ما إذا كان تعبيرين يحتويان على قيم متطابقة. دائمًا ما تُعطي التوابع الشرطية الناتج "صحيح True" أو "خاطئ False" أو "غير محدد Unknown". فلدى تشغيل استعلامات SQL التي تحتوي على بنية WHERE، سيطبّق نظام إدارة قاعدة البيانات شرط البحث تتابعيًا على كل سجل في الجدول المحدد في بنية FROM. ولن يعيد سوى السجلات التي يُقيّم فيها كل شرط بحث على أنه "صحيح". لتوضيح هذه الفكرة، نفّذ تعليمة SELECT التالية. يُرجع هذا الاستعلام قيمًا من عمود name في جدول volunteers. لكن بدلًا من تقييم قيم أحد أعمدة الجدول، تختبر بنية WHERE في هذا الاستعلام ما إذا كان التعبير (2 + 2) و 4 متساويين. mysql> SELECT name mysql> FROM volunteers mysql> WHERE (2+2) = 4; ونظرًا لأنّ التعبير (2+2) يساوي 4 دائمًا، فإن شرط البحث هذا يُقيّم بأنه صحيح لكل سجل في الجدول. ونتيجةً لذلك، تُرجع قيمة الاسم لكل سجل في مجموعة النتائج، على النحو: الخرج +------------+ | name | +------------+ | Gladys | | Catherine | | Georgeanna | | Wanda | | Ann | | Juanita | | Georgia | +------------+ 7 rows in set (0.00 sec) ولكن ونظرًا لأن شرط البحث هذا يعيد دائمًا نتيجة "صحيحة"، فهو ليس مفيدًا بدرجة كبيرة. وبالتالي من الممكن في هذه الحالة عدم تضمين بنية WHERE أصلًا، لأن تعليمة SELECT name FROM volunteers; ستعطي نفس مجموعة النتائج كما في حالة استخدام WHERE مع شرط بحث مُحقق دومًا. عادةً ما نستخدم اسم عمود كأحد تعبيري القيمة في شرط البحث ضمن بنية WHERE وذلك بدلاً من مقارنة قيمتين مُحددتي النوع كما في الأسلوب أعلاه. وبذلك نُعلم نظام إدارة قاعدة البيانات باستخدام قيمة كل سجل من العمود المحدد كجزء من تعبير القيمة للتكرار الخاص بكل سجل في شرط البحث. تُطبّق بنية WHERE في الاستعلام التالي شرط بحث أكثر تحديدًا على كل سجل. إذ ستُرجع قيم كل من عمودي name و max_bags من أي سجل تساوي فيه قيمة max_bags الرقم 4: mysql> SELECT name, max_bags mysql> FROM volunteers mysql> WHERE max_bags = 4; يُرجع هذا الاستعلام سجل متطوع واحد فقط، نظرًا لأنّ قيمة max_bags لهذا المتطوع وحده تساوي 4 تمامًا، فيكون الخرج على النحو: الخرج +---------+----------+ | name | max_bags | +---------+----------+ | Juanita | 4 | +---------+----------+ 1 row in set (0.00 sec) يمكنك أيضًا تقييم قيم السلاسل النصية المحرفية في التوابع الشرطية الخاصة بشروط البحث. فمثلًا يُرجع الاستعلام التالي قيم عمودي vol_id و name لكل سجل تكون قيمة العمود name فيه مساوية لـ 'Wanda': mysql> SELECT vol_id, name mysql> FROM volunteers mysql> WHERE name = 'Wanda'; ونظرًا لوجود متطوعة واحدة فقط تُدعى Wanda، فإن الاستعلام يُرجع معلومات سجلها فقط: الخرج +--------+-------+ | vol_id | name | +--------+-------+ | 4 | Wanda | +--------+-------+ 1 row in set (0.00 sec) من الجدير بالملاحظة أنّنا استخدمنا نفس العامل لشرط البحث في جميع أمثلة هذا القسم وهو علامة المساواة وذلك لتوضيح الفكرة. ولكن يوجد العديد من أنواع المعاملات Operators الأخرى التي تتيح لنا إمكانية كتابة مجموعة متنوعة من التوابع الشرطية، مما يوفر مستوى عالٍ من التحكم في المعلومات التي تُرجعها الاستعلامات. يُحدّد معيار SQL ثمانية عشر نمطًا مختلفًا من التوابع الشرطية، وعلى الرغم من أنّها لا تتوفر كاملةً في كافّة أنظمة إدارة قواعد البيانات العلاقية RDBMS. إليك خمسة من أكثر أنواع توابع الشرط شيوعًا في شروط البحث والعوامل المستخدمة في كل منها: المقارنة: تقارن التوابع الشرطية المقارنِة بين تعبيري قيمة، وفي معظم الاستعلامات يكون أحد هذين التعبيرين هو اسم عمود. وعوامل المقارنة الستة هي: = يختبر ما إذا كانت القيمتان متساويتين. <> يختبر ما إذا كانت القيمتان غير متساويتين. < يختبر ما إذا كانت القيمة الأولى أقل من الثانية. > يختبر ما إذا كانت القيمة الأولى أكبر من الثانية. <= يختبر ما إذا كانت القيمة الأولى أقل من أو تساوي الثانية. >= يختبر ما إذا كانت القيمة الأولى أكبر من أو تساوي الثانية. القيم الفارغة: تختبر التوابع الشرطية التي تستخدم عامل IS NULL ما إذا كانت القيم في عمود معين فارغة. النطاق: تستخدم التوابع الشرطية النطاقية عامل BETWEEN لاختبار ما إذا كان تعبير قيمة ما يقع بين تعبيري قيمة آخرين. العضوية: يستخدم هذا النوع من التوابع الشرطية عامل IN لاختبار ما إذا كانت قيمة ما تُمثّل عضوًا في مجموعة معينة. تطابق الأنماط: تستخدم توابع مطابقة الأنماط الشرطية عامل LIKE لاختبار ما إذا كانت قيمة ما تطابق نمطًا نصيًا يحتوي على محارف بدل. لمعرفة المزيد حول هذه الأنواع من التوابع الشرطية، ننصحك بالاطلاع على المقالات التالية: كيفية استخدام عوامل المقارنة و IS NULL في لغة الاستعلام البنيوية SQL كيفية استخدام عوامل BETWEEN و IN في لغة الاستعلام البنيوية SQL كيفية استخدام محارف البدل في SQL وللاطلاع على المزيد حول بنى WHERE عمومًا، ننصحك بقراءة مقالنا حول كيفية استخدام بنى WHERE في لغة الاستعلام البنيوية SQL. فرز نتائج الاستعلام باستخدام بنية ORDER BY قد تُعيد الاستعلامات في بعض الأحيان المعلومات بطرق غير واضحة أو غير متوافقة تمامًا مع احتياجاتك. لذا يمكنك فرز أو ترتيب نتائج الاستعلام بتضمين بنية ORDER BY في نهاية تعليمة الاستعلام. فيما يلي الصيغة العامّة لاستعلام يتضمن بنية ORDER BY: mysql> SELECT columns_to_return mysql> FROM table_to_query mysql> ORDER BY column_name; لتوضيح الأمر، بفرض أننا نرغب في معرفة أي من المتطوعين يحقق أعلى قيمة في عمود max_bags. لنُنفّذ الاستعلام التالي الذي يُعيد قيم عمودي name وmax_bags من جدول volunteers: $ SELECT name, max_bags $ FROM volunteers; ولكن يفرز هذا الاستعلام مجموعة النتائج حسب الترتيب الذي أُضيف فيه كل سجل. الخرج +------------+----------+ | name | max_bags | +------------+----------+ | Gladys | 5 | | Catherine | 2 | | Georgeanna | 1 | | Wanda | 1 | | Ann | 7 | | Juanita | 4 | | Georgia | 3 | +------------+----------+ 7 rows in set (0.00 sec) ولعلّ فرز مجموعة بيانات صغيرة نسبيًا كهذه ليس بتلك الأهمية، إذ يمكننا ببساطة مراجعة قيم max_bags في مجموعة النتائج لإيجاد القيمة الأعلى لكن هذا الأمر قد يصبح متعبًا عند العمل مع كميات أكبر من البيانات. يمكننا تنفيذ الاستعلام ذاته ولكن مع إضافة بنية ORDER BY التي تفرز مجموعة النتائج تبعًا لقيم max_bags للسجلات: $ SELECT name, max_bags $ FROM volunteers $ ORDER BY max_bags; الخرج +------------+----------+ | name | max_bags | +------------+----------+ | Georgeanna | 1 | | Wanda | 1 | | Catherine | 2 | | Georgia | 3 | | Juanita | 4 | | Gladys | 5 | | Ann | 7 | +------------+----------+ 7 rows in set (0.00 sec) كما يُظهر هذا الخرج، فالسلوك الافتراضي لاستعلامات SQL التي تتضمن بنية ORDER BY هو فرز قيم العمود المحدد تصاعديًا (من الأصغر إلى الأكبر). ويمكننا تغيير هذا السلوك وفرزها بترتيب تنازلي عن طريق إضافة الكلمة المفتاحية DESC إلى بنية ORDER BY. $ SELECT name, max_bags $ FROM volunteers $ ORDER BY max_bags DESC; الخرج +------------+----------+ | name | max_bags | +------------+----------+ | Ann | 7 | | Gladys | 5 | | Juanita | 4 | | Georgia | 3 | | Catherine | 2 | | Georgeanna | 1 | | Wanda | 1 | +------------+----------+ 7 rows in set (0.00 sec) الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية كتابة استعلامات أساسية، وكيفية تصفية وفرز مجموعات نتائج الاستعلام، ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL، لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكل أمر فيها ومجموعة خياراته الكاملة. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To SELECT Rows FROM Tables in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية حذف البيانات في لغة الاستعلام البنيوية SQL أنواع قواعد البيانات وأهم مميزاتها واستخداماتها تعرف على مكونات قاعدة البيانات ما هي محركات قواعد البيانات؟ فهم قواعد البيانات العلاقية -
 سنتعرف في مقال اليوم على تعليمة DELETE في لغة الاستعلام البنيوية SQL واحدة من أقوى العمليات المتاحة للمستخدمين. وهي كما يوحي اسمها، تحذف سجلًا أو أكثر من جدول قاعدة البيانات على نحوٍ لا يمكن التراجع عنه. ومن المهم لمستخدمي SQL فهم كيف تعمل تعليمة DELETE باعتبارها جانبًا أساسيًا من إدارة البيانات. سيغطي المقال كيفية استخدام صيغة DELETE في SQL لحذف البيانات من جدول واحد أو أكثر. كما سيشرح كيف تتعامل SQL مع عمليات الحذف التي قد تتعارض مع قيود المفتاح الخارجي Foreign key. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، ويمكنك إعداد الخادم بالاستعانة بمقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على حذف البيانات. لذا ننصحك بقراءة الفقرة التالية الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسمdeleteDB: mysql> CREATE DATABASE deleteDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات deleteDB، نفّذ تعليمة USE التالية: mysql> USE deleteDB; الخرج Database changed بعد اختيار قاعدة البيانات deleteDB، أنشئ جدولين داخلها. كمثال، تخيل أنك وبعض أصدقائك تملكون ناديًا حيث يمكن للأعضاء مشاركة المعدات الموسيقية مع بعضهم البعض. فقررت إنشاء بعض الجداول لتساعدك في تتبع أعضاء النادي ومعداتهم. سيتضمّن الجدول الأول الأعمدة الأربعة التالية: memberID: مُعرّف كل عضو في النادي، مُعبّر عنه بنمط بيانات الأعداد الصحيحة int. سيكون هذا العمود هو المفتاح الأساسي للجدول. name: اسم كل عضو، مُعبّر عنه بنمط بيانات المحارف varchar مع حد أقصى يصل إلى 30 محرفًا. homeBorough: هذا العمود سيخزن المنطقة التي يعيش فيها كل عضو، مُعبر عنه بنمط البيانات varchar ولكن بحد أقصى يصل إلى 15 محرفًا فقط. email: عنوان البريد الإلكتروني الذي يمكن من خلاله الاتصال بكل عضو، مُعبر عنه بنمط البيانات varchar مع حد أقصى يصل إلى 30 محرفًا. لننشئ إذًا جدولًا باسم clubMembers يحتوي على هذه الأعمدة الأربعة. mysql> CREATE TABLE clubMembers ( mysql> memberID int PRIMARY KEY, mysql> name varchar(30), mysql> homeBorough varchar(15), mysql> email varchar(30) mysql> ); أمّا الجدول الثاني فسيتضمّن الأعمدة التالية: equipmentID: معرّف فريد لكل قطعة من المعدات. إذ ستكون القيم في هذا العمود من نمط بيانات الأعداد الصحيحة int. وسيكون هذا العمود هو المفتاح الأساسي للجدول على نحوٍ مشابه لعمود memberID في جدول clubMembers، equipmentType: نوع الآلة أو الأداة التي يُمثّلها كل سجل (على سبيل المثال الغيتار guitar ومازج الأصوات mixer ومضخّم الصوتamplifier وما إلى ذلك). سنعبّر عن هذه القيم باستخدام نمط البيانات varchar مع حد أقصى يصل إلى 30 محرفًا. brand: العلامة التجارية التي أنتجت كل قطعة من المعدات، معبّر عنها أيضًا بنمط البيانات varchar مع حد أقصى يصل إلى 30 محرفًا. ownerID: هذا العمود سيحتوي على معرّف العضو المالك للقطعة نت المعدات، مُعبر عنه برقم صحيح. ولضمان أنّ عمود ownerID لن يتضمّن سوى قيم تُمثّل مُعرّفات أعضاء صالحة، يمكنك إنشاء قيد مفتاح خارجي عليه بحيث يُشير إلى عمود memberID في جدول clubMembers. يُعد قيد المفتاح الخارجي طريقة لتحديد علاقة بين جدولين، إذ يفرض أن تكون القيم في العمود المُطبّق عليه موجودة بالفعل في العمود المُشار إليه. في المثال التالي، يشترط قيد المفتاح الخارجي أن تكون كل قيمة تُضاف إلى عمود ownerID موجودة مسبقًا في عمود memberID. أنشئ جدولًا بهذه الأعمدة وهذا القيد باسم clubEquipment: mysql> CREATE TABLE clubEquipment ( mysql> equipmentID int PRIMARY KEY, mysql> equipmentType varchar(30), mysql> brand varchar(15), mysql> ownerID int, mysql> CONSTRAINT fk_ownerID mysql> FOREIGN KEY (ownerID) REFERENCES clubMembers(memberID) mysql> ); ومن الجدير بالملاحظة أنّ هذا المثال يوفّر اسمًا لقيد المفتاح الخارجي، ألا وهو: fk_ownerID. إذ تُنشئ MySQL تلقائيًا اسمًا لأي قيد تضيفه، إلّا أنّ تحديد اسم من قبلنا في هذه الحالة سيكون مفيدًا عندما نحتاج للإشارة إلى هذا القيد لاحقًا. بعد ذلك، نفّذ تعليمة INSERT INTO التالية لملء جدول clubMembers بستة سجلات من البيانات النموذجية: mysql> INSERT INTO clubMembers mysql> VALUES mysql> (1, 'Rosetta', 'Manhattan', 'hightower@example.com'), mysql> (2, 'Linda', 'Staten Island', 'lyndell@example.com'), mysql> (3, 'Labi', 'Brooklyn', 'siffre@example.com'), mysql> (4, 'Bettye', 'Queens', 'lavette@example.com'), mysql> (5, 'Phoebe', 'Bronx', 'snow@example.com'), mysql> (6, 'Mariya', 'Brooklyn', 'takeuchi@example.com'); ثم نفّذ تعليمة INSERT INTO أخرى لملء جدول clubEquipment بعشرين سجلًا من البيانات النموذجية: mysql> INSERT INTO clubEquipment mysql> VALUES mysql> (1, 'electric guitar', 'Gilled', 6), mysql> (2, 'trumpet', 'Yemehe', 5), mysql> (3, 'drum kit', 'Purl', 3), mysql> (4, 'mixer', 'Bearinger', 3), mysql> (5, 'microphone', 'Sure', 1), mysql> (6, 'bass guitar', 'Fandar', 4), mysql> (7, 'acoustic guitar', 'Marten', 6), mysql> (8, 'synthesizer', 'Korgi', 4), mysql> (9, 'guitar amplifier', 'Vax', 4), mysql> (10, 'keytar', 'Poland', 3), mysql> (11, 'acoustic/electric bass', 'Pepiphone', 2), mysql> (12, 'trombone', 'Cann', 2), mysql> (13, 'mandolin', 'Rouge', 1), mysql> (14, 'electric guitar', 'Vax', 6), mysql> (15, 'accordion', 'Nonher', 5), mysql> (16, 'electric organ', 'Spammond', 1), mysql> (17, 'bass guitar', 'Peabey', 1), mysql> (18, 'guitar amplifier', 'Fandar', 3), mysql> (19, 'cello', 'Yemehe', 2), mysql> (20, 'PA system', 'Mockville', 5); وبذلك، غدوتَ جاهزًا لمتابعة باقي المقال وبدء التعلم حول كيفية حذف البيانات باستخدام لغة الاستعلام البنيوية SQL. حذف البيانات من جدول واحد إنّ الصيغة العامة لحذف البيانات في SQL على النحو: mysql> DELETE FROM table_name mysql> WHERE conditions_apply; تحذير: الجزء المهم من هذه الصيغة هو البنية WHERE فمن خلالها يمكنك تحديد السجلات التي يجب حذفها بدقة. وبدونها، سيُنفَّذ أمر مثل DELETE FROM table_name; على نحوٍ صحيح، ولكنه سيحذف كل سجلات البيانات من الجدول! وبالعودة إلى موضوعنا، تذكّر أنّ أي عملية حذف ناجحة لا يمكن التراجع عنها. فإذا نفذّت عملية حذف دون معرفة دقيقة بالبيانات التي ستُحذف، فقد تحذف سجلات عن طريق الخطأ. ومن الطرق التي تفيدك في التأكد من عدم حذف بيانات عن طريق الخطأ هي إجراء استعلام عن البيانات المحددة للحذف باستخدام SELECT لرؤية البيانات التي ستعيدها بنية WHERE ضمن عملية الحذف DELETE من البداية قبل تنفيذ عملية الحذف. ولتوضيح الأمر، لنفترض أنّك تريد إزالة أي سجلات مُتعلقة بمعدات الموسيقى المصنعة من قبل العلامة التجارية Korgi. ولكنك قررت البدء بكتابة استعلام لرؤية كافة سجلات الآلات المُتضمنة لعلامة korgi تحديدًا في عمود brand. لمعرفة الآلات الموسيقية في جدولك المُصنّعة من قبل Korgi، يمكنك تنفيذ الاستعلام المبيّن أدناه. ومن الجدير بالملاحظة أنّه وعلى العكس من الاستعلام باستخدام SELECT أو عملية INSERT INTO، فلا تسمح عمليات الحذف بتحديد أعمدة فردية، لأنها مُخصصّة لحذف سجلات البيانات بالكامل. ولمحاكاة هذا السلوك، أتبعنا الكلمة المفتاحية SELECT بعلامة النجمة (*) في الاستعلام التالي والتي تعدّ اختصارًا في SQL يمثل "كل الأعمدة": mysql> SELECT * FROM clubEquipment mysql> WHERE brand = 'Korgi'; الخرج +-------------+---------------+-------+---------+ | equipmentID | equipmentType | brand | ownerID | +-------------+---------------+-------+---------+ | 8 | synthesizer | Korgi | 4 | +-------------+---------------+-------+---------+ 1 row in set (0.00 sec) ولحذف هذا السجل، عليك تنفيذ عملية حذف DELETE تحتوي على بنيتي FROM وWHERE مطابقتين لاستعلام SELECT السابق، على النحو: mysql> DELETE FROM clubEquipment mysql> WHERE brand = 'Korgi'; الخرج Query OK, 1 row affected (0.01 sec) يُظهر هذا الخرج أن عملية الحذف DELETE قد نُفِّذت على سجل واحد فقط. ولكن بإمكانك حذف عدة سجلات باستخدام بنية WHERE تُعيد أكثر من سجل واحد. أمّا استعلام SELECT التالي فيعيد كافّة السجلات في جدول clubEquipment التي يتضمن عمود equipmentType فيها كلمة electric: mysql> SELECT * FROM clubEquipment mysql> WHERE equipmentType LIKE '%electric%'; الخرج +-------------+------------------------+-----------+---------+ | equipmentID | equipmentType | brand | ownerID | +-------------+------------------------+-----------+---------+ | 1 | electric guitar | Gilled | 6 | | 11 | acoustic/electric bass | Pepiphone | 2 | | 14 | electric guitar | Vax | 6 | | 16 | electric organ | Spammond | 1 | +-------------+------------------------+-----------+---------+ 4 rows in set (0.00 sec) ولحذف هذه السجلات الأربعة، لنعد كتابة الاستعلام السابق مستبدلين SELECT * بتعليمة DELETE: mysql> DELETE FROM clubEquipment mysql> WHERE equipmentType LIKE '%electric%'; الخرج Query OK, 4 rows affected (0.00 sec) كما من الممكن استخدام الاستعلامات الفرعية Subqueries لإعادة وحذف مجموعات نتائج أكثر تفصيلاً. ويُعرّف الاستعلام الفرعي بأنّه عملية استعلام كاملة - تعليمة SQL تبدأ بـ SELECT وتتضمن بنية FROM- مُضمنة ضمن عملية أخرى، تأتي عقب بنية FROM الخاصة بالعملية المحيطة (الاستعلام الرئيسي). على سبيل المثال، لنفترض أنك ترغب في حذف أي معدات مُدرجة في جدول clubEquipment تخص أي عضو يبدأ اسمه بالحرف "L". يمكنك أولاً الاستعلام عن هذه البيانات باستخدام تعليمة SELECT كالتالي: mysql> SELECT * mysql> FROM clubEquipment mysql> WHERE ownerID IN mysql> (SELECT memberID FROM clubMembers mysql> WHERE name LIKE 'L%'); تُعيد هذه العملية كل سجل من جدول clubEquipment تظهر قيمة عمود ownerID الخاصة به ضمن القيم المُعادة من الاستعلام الفرعي الذي يبدأ في السطر الرابع. إذ يُعيد هذا الاستعلام الفرعي مُعرّف العضو memberID لأي سجل تبدأ قيمة العمود name الموافقة له بالحرف "L": الخرج +-------------+------------------+-----------+---------+ | equipmentID | equipmentType | brand | ownerID | +-------------+------------------+-----------+---------+ | 12 | trombone | Cann | 2 | | 19 | cello | Yemehe | 2 | | 3 | drum kit | Purl | 3 | | 4 | mixer | Bearinger | 3 | | 10 | keytar | Poland | 3 | | 18 | guitar amplifier | Fandar | 3 | +-------------+------------------+-----------+---------+ 6 rows in set (0.00 sec) يمكنك بعد ذلك حذف هذه البيانات باستخدام تعليمة DELETE التالية: mysql> DELETE FROM clubEquipment mysql> WHERE ownerID IN mysql> (SELECT memberID FROM clubMembers mysql> WHERE name LIKE 'L%'); الخرج Query OK, 6 rows affected (0.01 sec) حذف البيانات من عدة جداول يمكنك حذف البيانات من أكثر من جدول في عملية واحدة عن طريق تضمين بنية JOIN. تُستخدم بنى JOIN لدمج السجلات من جدولين أو أكثر في نتيجة استعلام واحد. يتم ذلك عن طريق إيجاد عمود مشترك بين الجداول وفرز النتائج على نحوٍ مناسب في الخرج. تبدو صيغة عملية الحذف التي تتضمن بنية JOIN على النحو التالي: mysql> DELETE table_1, table_2 mysql> FROM table_1 JOIN table_2 mysql> ON table_2.related_column = table_1.related_column mysql> WHERE conditions_apply; لاحظ أنه نظرًا لقدرة صيغ الدمج JOIN على مقارنة البيانات من عدة جداول، فإن صيغة هذا المثال تُوضّح الجدول المُستهدف لكل عمود بوضع اسم الجدول متبوعًا بنقطة قبل اسم العمود، وهذا ما يُعرف بالإشارة الكاملة والمؤهلة للعمود. ويُمكنك تحديد الجدول المصدر لكل عمود بهذه الطريقة في أي عملية، على الرغم من عدم ضرورتها عند الاختيار من جدول واحد فقط كما فعلنا في الأمثلة السابقة. لتوضيح مفهوم حذف البيانات باستخدام بنية JOIN، لنفترض أن ناديك قرر تحديد العلامات التجارية للمعدات الموسيقية التي يمكن للأعضاء مشاركتها. نفّذ الأمر التالي لإنشاء جدول باسم prohibitedBrands حيث ستسرد العلامات التجارية التي لم تعد مقبولة في النادي. يحتوي هذا الجدول على عمودين فقط، كلاهما يستخدم نمط بيانات varchar، لتخزين اسم كل علامة تجارية والبلد الذي تعمل فيه: mysql> CREATE TABLE prohibitedBrands ( mysql> brandName varchar(30), mysql> homeCountry varchar(30) mysql> ); ثم املأ هذا الجدول الجديد ببعض البيانات النموذجية التجريبية: mysql> INSERT INTO prohibitedBrands mysql> VALUES mysql> ('Fandar', 'USA'), mysql> ('Givson', 'USA'), mysql> ('Muug', 'USA'), mysql> ('Peabey', 'USA'), mysql> ('Yemehe', 'Japan'); بعد ذلك، يقرر النادي حذف أي سجلات للمعدات من جدول clubEquipment التي تظهر علاماتها التجارية في جدول prohibitedBrands ومقرها في الولايات المتحدة. يمكنك الاستعلام عن هذه البيانات بتنفيذ عملية استعلام مثل التالية باستخدام SELECT. إذ تدمج هذه العملية جدولي clubEquipment وprohibitedBrands معًا، وتُرجع فقط السجلات التي تشترك فيها أعمدة brand وbrandName في نفس القيمة. وتعمل بنية WHERE على إتمام تحديد نتائج الاستعلام بإقصاء أي علامة تجارية لا تتضمن القيمة "USA" في عمود homeCountry: mysql> SELECT * mysql> FROM clubEquipment JOIN prohibitedBrands mysql> ON clubEquipment.brand = prohibitedBrands.brandName mysql> WHERE homeCountry = 'USA'; الخرج +-------------+---------------+--------+---------+-----------+-------------+ | equipmentID | equipmentType | brand | ownerID | brandName | homeCountry | +-------------+---------------+--------+---------+-----------+-------------+ | 6 | bass guitar | Fandar | 4 | Fandar | USA | | 17 | bass guitar | Peabey | 1 | Peabey | USA | +-------------+---------------+--------+---------+-----------+-------------+ 2 rows in set (0.00 sec) هذه هي كل المعلومات التي نبحث عنها؛ وهي كل علامة تجارية مقرها الولايات المتحدة والموجودة في جدول prohibitedBrands والتي تظهر أيضًا في جدول clubEquipment. لحذف هذه العلامات التجارية من جدول prohibitedBrands والمعدات المرتبطة بها من جدول clubEquipment، أعد كتابة استعلام SELECT السابق ولكن استبدل تعليمة SELECT * بتعليمة DELETE متبوعةً بأسماء كلا الجدولين: mysql> DELETE clubEquipment, prohibitedBrands mysql> FROM clubEquipment JOIN prohibitedBrands mysql> ON clubEquipment.brand = prohibitedBrands.brandName mysql> WHERE homeCountry = 'USA'; الخرج Query OK, 4 rows affected (0.01 sec) يشير هذا الخرج إلى أن العملية حذفت أربع سجلات من قاعدة البيانات: سجلين من جدول clubEquipment وسجلين من جدول prohibitedBrands. إذا كنت تريد حذف السجلات من جدول clubEquipment فقط والاحتفاظ بجميع السجلات في جدول prohibitedBrands، فعليك إدراج clubEquipment فقط بعد كلمة DELETE، والعكس صحيح. تغيير سلوك تعليمة DELETE للمفاتيح الخارجية ستفشل أي تعليمة DELETE قد تسبب تعارضًا مع قيد FOREIGN KEY افتراضيًا. بالعودة إلى فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية في مستلزمات العمل وبتذكّر أنّ العمود ownerID في جدول المعدات clubEquipment هو مفتاح خارجي يشير إلى عمود memberID في جدول الأعضاء clubMembers. فهذا يعني أنّ أي قيمة مُدخلة في عمود ownerID يجب أن تكون موجودة بالفعل في جدول memberID. إذا حاولت إزالة سجل من جدول clubMembers تُستخدم قيمة memberID المُخصصة له في مكان ما ضمن عمود ownerID من جدول clubEquipment، سيؤدي ذلك إلى ظهور خطأ. mysql> DELETE FROM clubMembers mysql> WHERE memberID = 6; الخرج ERROR 1217 (23000): Cannot delete or update a parent row: a foreign key constraint fails يمكنك تجنب هذا الخطأ بإزالة أي سجلات في الجدول الابن (clubEquipment في هذا المثال) حيث توجد قيمة المفتاح الخارجي في الجدول الأب (clubMembers). كبديل، يمكنك تغيير هذا السلوك بتعديل قيد المفتاح الخارجي القائم بآخر يعالج عمليات الحذف على نحوٍ مختلف. ملاحظة: لا تسمح كافة أنظمة إدارة قواعد البيانات العلاقية أو محركاتها بإضافة أو إزالة قيود من جدول قائم كما هو موضح في الفقرات اللاحقة. فإذا كنت تستخدم نظام RDBMS غير MySQL، يجب عليك مراجعة الوثائق الرسمية الخاصة به لفهم القيود المتعلقة بإدارة القيود. وبالعودة إلى موضوعنا، بذلك ستكون قادرًا على تحديث قيمة clientID لأي سجل في الجدول الأب clubMembers، وستنتقل هذه التغييرات بشكل تلقائي إلى أي سجلات في الجدول الابن clubEquipment المرتبطة به. لاستبدال القيد الحالي، يجب أولًا إزالته باستخدام تعليمة ALTER TABLE. تذكر أننا في تعليمة CREATE TABLE لجدول clubEquipment، قمنا بتحديد fk_ownerID كاسم لقيد المفتاح الخارجي للجدول. mysql> ALTER TABLE clubEquipment mysql> DROP FOREIGN KEY fk_ownerID; الخرج Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 بعد ذلك، أنشئ قيد مفتاح خارجي جديد مُعدّ ليتعامل مع عمليات الحذف DELETE بطريقة تتناسب مع حالة الاستخدام المعطاة. بصرف النظر عن الإعداد الافتراضي الذي يمنع تعليمات DELETE التي تخالف المفتاح الخارجي، هناك خياران آخران متاحان في معظم أنظمة إدارة قواعد البيانات العلاقية: ON DELETE SET NULL: يسمح لك هذا الخيار بحذف السجلات من الجدول الأب، وسيعيد تعيين أي قيم مرتبطة بها في الجدول الابن على أنها قيم فارغة NULL. ON DELETE CASCADE: عند حذف سجل في الجدول الأب، سيدفع هذا الخيار SQL لحذف أي سجلات في الجدول الابن مرتبطة بذلك السجل من الجدول الأب. في سياق هذا المثال، لا يُعد استخدام خيار ON DELETE SET NULL منطقيًا. فإذا غادر أحد الأعضاء النادي وحُذِف سجله من جدول clubMembers، فلن تكون معداته متاحة للأعضاء المتبقين بعد الآن وبالتالي يجب إزالتها من جدول clubEquipment. وفي هذا الصدد يُعدّ خيار ON DELETE CASCADE هو الأنسب لهذا السياق. لإضافة قيد FOREIGN KEY يعمل وفق آلية ON DELETE CASCADE، نفّذ أمر ALTER TABLE التالي لتعديل الجدول. ستنشئ هذه التعليمة قيدًا جديدًا باسم newfk_ownerID يعكس تعريف القيد السابق ولكن مع إضافة خيار ON DELETE CASCADE. mysql> ALTER TABLE clubEquipment mysql> ADD CONSTRAINT newfk_ownerID mysql> FOREIGN KEY (ownerID) mysql> REFERENCES clubMembers(memberID) mysql> ON DELETE CASCADE; الخرج Query OK, 7 rows affected (0.07 sec) Records: 7 Duplicates: 0 Warnings: 0 تشير هذه النتائج إلى أن العملية قد أثرت على جميع السجلات السبعة المتبقية في جدول clubEquipment. ملاحظة: بدلًا من تغيير تعريف جدول مُعرّف مسبقًا لتعديل كيفية تفاعل قيد المفتاح الخارجي مع عمليات DELETE، يُمكنك من البداية تحديد هذا السلوك عند إنشاء الجدول بواسطة تعليمة إنشاء الجدول CREATE TABLE ، وبذلك تُعيّن السلوك المطلوب مُسبقًا، على النحو التالي: mysql> CREATE TABLE clubEquipment ( mysql> equipmentID int PRIMARY KEY, mysql> equipmentType varchar(30), mysql> brand varchar(15), mysql> ownerID int, mysql> CONSTRAINT fk_ownerID mysql> FOREIGN KEY (ownerID) REFERENCES clubMembers(memberID) mysql> ON DELETE CASCADE mysql> ); عقب ذلك، ستكون قادرًا على حذف أي سجل من جدول clubMembers، وستُحذف جميع السجلات المرتبطة به في جدول clubEquipment تلقائيًا: mysql> DELETE FROM clubMembers mysql> WHERE memberID = 6; الخرج Query OK, 1 row affected (0.00 sec) رغم أن هذا الخرج يشير إلى تأثر سجل واحد فقط، إلا أنّ العملية قد حذفت أيضًا كافة سجلات المعدات في جدول clubEquipment ذات القيمة 6 في عمود ownerID. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية حذف البيانات الموجودة في جدول واحد أو أكثر باستخدام تعليمة DELETE في SQL. كما تعرفت على كيفية تعامل SQL مع عمليات الحذف التي تتعارض مع قيود المفتاح الخارجي وطرق تغيير هذا السلوك الافتراضي. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكيفية التعامل مع عمليات الحذف والخيارات المتاحة لها. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Delete Data in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية تحديث البيانات في لغة الاستعلام البنيوية SQL ما هي تقنية SQL تنظيم شيفرات SQL وتأمينها تصميم الجداول ومعلومات المخطط وترتيب تنفيذ الاستعلامات في SQL
سنتعرف في مقال اليوم على تعليمة DELETE في لغة الاستعلام البنيوية SQL واحدة من أقوى العمليات المتاحة للمستخدمين. وهي كما يوحي اسمها، تحذف سجلًا أو أكثر من جدول قاعدة البيانات على نحوٍ لا يمكن التراجع عنه. ومن المهم لمستخدمي SQL فهم كيف تعمل تعليمة DELETE باعتبارها جانبًا أساسيًا من إدارة البيانات. سيغطي المقال كيفية استخدام صيغة DELETE في SQL لحذف البيانات من جدول واحد أو أكثر. كما سيشرح كيف تتعامل SQL مع عمليات الحذف التي قد تتعارض مع قيود المفتاح الخارجي Foreign key. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، ويمكنك إعداد الخادم بالاستعانة بمقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على حذف البيانات. لذا ننصحك بقراءة الفقرة التالية الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسمdeleteDB: mysql> CREATE DATABASE deleteDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات deleteDB، نفّذ تعليمة USE التالية: mysql> USE deleteDB; الخرج Database changed بعد اختيار قاعدة البيانات deleteDB، أنشئ جدولين داخلها. كمثال، تخيل أنك وبعض أصدقائك تملكون ناديًا حيث يمكن للأعضاء مشاركة المعدات الموسيقية مع بعضهم البعض. فقررت إنشاء بعض الجداول لتساعدك في تتبع أعضاء النادي ومعداتهم. سيتضمّن الجدول الأول الأعمدة الأربعة التالية: memberID: مُعرّف كل عضو في النادي، مُعبّر عنه بنمط بيانات الأعداد الصحيحة int. سيكون هذا العمود هو المفتاح الأساسي للجدول. name: اسم كل عضو، مُعبّر عنه بنمط بيانات المحارف varchar مع حد أقصى يصل إلى 30 محرفًا. homeBorough: هذا العمود سيخزن المنطقة التي يعيش فيها كل عضو، مُعبر عنه بنمط البيانات varchar ولكن بحد أقصى يصل إلى 15 محرفًا فقط. email: عنوان البريد الإلكتروني الذي يمكن من خلاله الاتصال بكل عضو، مُعبر عنه بنمط البيانات varchar مع حد أقصى يصل إلى 30 محرفًا. لننشئ إذًا جدولًا باسم clubMembers يحتوي على هذه الأعمدة الأربعة. mysql> CREATE TABLE clubMembers ( mysql> memberID int PRIMARY KEY, mysql> name varchar(30), mysql> homeBorough varchar(15), mysql> email varchar(30) mysql> ); أمّا الجدول الثاني فسيتضمّن الأعمدة التالية: equipmentID: معرّف فريد لكل قطعة من المعدات. إذ ستكون القيم في هذا العمود من نمط بيانات الأعداد الصحيحة int. وسيكون هذا العمود هو المفتاح الأساسي للجدول على نحوٍ مشابه لعمود memberID في جدول clubMembers، equipmentType: نوع الآلة أو الأداة التي يُمثّلها كل سجل (على سبيل المثال الغيتار guitar ومازج الأصوات mixer ومضخّم الصوتamplifier وما إلى ذلك). سنعبّر عن هذه القيم باستخدام نمط البيانات varchar مع حد أقصى يصل إلى 30 محرفًا. brand: العلامة التجارية التي أنتجت كل قطعة من المعدات، معبّر عنها أيضًا بنمط البيانات varchar مع حد أقصى يصل إلى 30 محرفًا. ownerID: هذا العمود سيحتوي على معرّف العضو المالك للقطعة نت المعدات، مُعبر عنه برقم صحيح. ولضمان أنّ عمود ownerID لن يتضمّن سوى قيم تُمثّل مُعرّفات أعضاء صالحة، يمكنك إنشاء قيد مفتاح خارجي عليه بحيث يُشير إلى عمود memberID في جدول clubMembers. يُعد قيد المفتاح الخارجي طريقة لتحديد علاقة بين جدولين، إذ يفرض أن تكون القيم في العمود المُطبّق عليه موجودة بالفعل في العمود المُشار إليه. في المثال التالي، يشترط قيد المفتاح الخارجي أن تكون كل قيمة تُضاف إلى عمود ownerID موجودة مسبقًا في عمود memberID. أنشئ جدولًا بهذه الأعمدة وهذا القيد باسم clubEquipment: mysql> CREATE TABLE clubEquipment ( mysql> equipmentID int PRIMARY KEY, mysql> equipmentType varchar(30), mysql> brand varchar(15), mysql> ownerID int, mysql> CONSTRAINT fk_ownerID mysql> FOREIGN KEY (ownerID) REFERENCES clubMembers(memberID) mysql> ); ومن الجدير بالملاحظة أنّ هذا المثال يوفّر اسمًا لقيد المفتاح الخارجي، ألا وهو: fk_ownerID. إذ تُنشئ MySQL تلقائيًا اسمًا لأي قيد تضيفه، إلّا أنّ تحديد اسم من قبلنا في هذه الحالة سيكون مفيدًا عندما نحتاج للإشارة إلى هذا القيد لاحقًا. بعد ذلك، نفّذ تعليمة INSERT INTO التالية لملء جدول clubMembers بستة سجلات من البيانات النموذجية: mysql> INSERT INTO clubMembers mysql> VALUES mysql> (1, 'Rosetta', 'Manhattan', 'hightower@example.com'), mysql> (2, 'Linda', 'Staten Island', 'lyndell@example.com'), mysql> (3, 'Labi', 'Brooklyn', 'siffre@example.com'), mysql> (4, 'Bettye', 'Queens', 'lavette@example.com'), mysql> (5, 'Phoebe', 'Bronx', 'snow@example.com'), mysql> (6, 'Mariya', 'Brooklyn', 'takeuchi@example.com'); ثم نفّذ تعليمة INSERT INTO أخرى لملء جدول clubEquipment بعشرين سجلًا من البيانات النموذجية: mysql> INSERT INTO clubEquipment mysql> VALUES mysql> (1, 'electric guitar', 'Gilled', 6), mysql> (2, 'trumpet', 'Yemehe', 5), mysql> (3, 'drum kit', 'Purl', 3), mysql> (4, 'mixer', 'Bearinger', 3), mysql> (5, 'microphone', 'Sure', 1), mysql> (6, 'bass guitar', 'Fandar', 4), mysql> (7, 'acoustic guitar', 'Marten', 6), mysql> (8, 'synthesizer', 'Korgi', 4), mysql> (9, 'guitar amplifier', 'Vax', 4), mysql> (10, 'keytar', 'Poland', 3), mysql> (11, 'acoustic/electric bass', 'Pepiphone', 2), mysql> (12, 'trombone', 'Cann', 2), mysql> (13, 'mandolin', 'Rouge', 1), mysql> (14, 'electric guitar', 'Vax', 6), mysql> (15, 'accordion', 'Nonher', 5), mysql> (16, 'electric organ', 'Spammond', 1), mysql> (17, 'bass guitar', 'Peabey', 1), mysql> (18, 'guitar amplifier', 'Fandar', 3), mysql> (19, 'cello', 'Yemehe', 2), mysql> (20, 'PA system', 'Mockville', 5); وبذلك، غدوتَ جاهزًا لمتابعة باقي المقال وبدء التعلم حول كيفية حذف البيانات باستخدام لغة الاستعلام البنيوية SQL. حذف البيانات من جدول واحد إنّ الصيغة العامة لحذف البيانات في SQL على النحو: mysql> DELETE FROM table_name mysql> WHERE conditions_apply; تحذير: الجزء المهم من هذه الصيغة هو البنية WHERE فمن خلالها يمكنك تحديد السجلات التي يجب حذفها بدقة. وبدونها، سيُنفَّذ أمر مثل DELETE FROM table_name; على نحوٍ صحيح، ولكنه سيحذف كل سجلات البيانات من الجدول! وبالعودة إلى موضوعنا، تذكّر أنّ أي عملية حذف ناجحة لا يمكن التراجع عنها. فإذا نفذّت عملية حذف دون معرفة دقيقة بالبيانات التي ستُحذف، فقد تحذف سجلات عن طريق الخطأ. ومن الطرق التي تفيدك في التأكد من عدم حذف بيانات عن طريق الخطأ هي إجراء استعلام عن البيانات المحددة للحذف باستخدام SELECT لرؤية البيانات التي ستعيدها بنية WHERE ضمن عملية الحذف DELETE من البداية قبل تنفيذ عملية الحذف. ولتوضيح الأمر، لنفترض أنّك تريد إزالة أي سجلات مُتعلقة بمعدات الموسيقى المصنعة من قبل العلامة التجارية Korgi. ولكنك قررت البدء بكتابة استعلام لرؤية كافة سجلات الآلات المُتضمنة لعلامة korgi تحديدًا في عمود brand. لمعرفة الآلات الموسيقية في جدولك المُصنّعة من قبل Korgi، يمكنك تنفيذ الاستعلام المبيّن أدناه. ومن الجدير بالملاحظة أنّه وعلى العكس من الاستعلام باستخدام SELECT أو عملية INSERT INTO، فلا تسمح عمليات الحذف بتحديد أعمدة فردية، لأنها مُخصصّة لحذف سجلات البيانات بالكامل. ولمحاكاة هذا السلوك، أتبعنا الكلمة المفتاحية SELECT بعلامة النجمة (*) في الاستعلام التالي والتي تعدّ اختصارًا في SQL يمثل "كل الأعمدة": mysql> SELECT * FROM clubEquipment mysql> WHERE brand = 'Korgi'; الخرج +-------------+---------------+-------+---------+ | equipmentID | equipmentType | brand | ownerID | +-------------+---------------+-------+---------+ | 8 | synthesizer | Korgi | 4 | +-------------+---------------+-------+---------+ 1 row in set (0.00 sec) ولحذف هذا السجل، عليك تنفيذ عملية حذف DELETE تحتوي على بنيتي FROM وWHERE مطابقتين لاستعلام SELECT السابق، على النحو: mysql> DELETE FROM clubEquipment mysql> WHERE brand = 'Korgi'; الخرج Query OK, 1 row affected (0.01 sec) يُظهر هذا الخرج أن عملية الحذف DELETE قد نُفِّذت على سجل واحد فقط. ولكن بإمكانك حذف عدة سجلات باستخدام بنية WHERE تُعيد أكثر من سجل واحد. أمّا استعلام SELECT التالي فيعيد كافّة السجلات في جدول clubEquipment التي يتضمن عمود equipmentType فيها كلمة electric: mysql> SELECT * FROM clubEquipment mysql> WHERE equipmentType LIKE '%electric%'; الخرج +-------------+------------------------+-----------+---------+ | equipmentID | equipmentType | brand | ownerID | +-------------+------------------------+-----------+---------+ | 1 | electric guitar | Gilled | 6 | | 11 | acoustic/electric bass | Pepiphone | 2 | | 14 | electric guitar | Vax | 6 | | 16 | electric organ | Spammond | 1 | +-------------+------------------------+-----------+---------+ 4 rows in set (0.00 sec) ولحذف هذه السجلات الأربعة، لنعد كتابة الاستعلام السابق مستبدلين SELECT * بتعليمة DELETE: mysql> DELETE FROM clubEquipment mysql> WHERE equipmentType LIKE '%electric%'; الخرج Query OK, 4 rows affected (0.00 sec) كما من الممكن استخدام الاستعلامات الفرعية Subqueries لإعادة وحذف مجموعات نتائج أكثر تفصيلاً. ويُعرّف الاستعلام الفرعي بأنّه عملية استعلام كاملة - تعليمة SQL تبدأ بـ SELECT وتتضمن بنية FROM- مُضمنة ضمن عملية أخرى، تأتي عقب بنية FROM الخاصة بالعملية المحيطة (الاستعلام الرئيسي). على سبيل المثال، لنفترض أنك ترغب في حذف أي معدات مُدرجة في جدول clubEquipment تخص أي عضو يبدأ اسمه بالحرف "L". يمكنك أولاً الاستعلام عن هذه البيانات باستخدام تعليمة SELECT كالتالي: mysql> SELECT * mysql> FROM clubEquipment mysql> WHERE ownerID IN mysql> (SELECT memberID FROM clubMembers mysql> WHERE name LIKE 'L%'); تُعيد هذه العملية كل سجل من جدول clubEquipment تظهر قيمة عمود ownerID الخاصة به ضمن القيم المُعادة من الاستعلام الفرعي الذي يبدأ في السطر الرابع. إذ يُعيد هذا الاستعلام الفرعي مُعرّف العضو memberID لأي سجل تبدأ قيمة العمود name الموافقة له بالحرف "L": الخرج +-------------+------------------+-----------+---------+ | equipmentID | equipmentType | brand | ownerID | +-------------+------------------+-----------+---------+ | 12 | trombone | Cann | 2 | | 19 | cello | Yemehe | 2 | | 3 | drum kit | Purl | 3 | | 4 | mixer | Bearinger | 3 | | 10 | keytar | Poland | 3 | | 18 | guitar amplifier | Fandar | 3 | +-------------+------------------+-----------+---------+ 6 rows in set (0.00 sec) يمكنك بعد ذلك حذف هذه البيانات باستخدام تعليمة DELETE التالية: mysql> DELETE FROM clubEquipment mysql> WHERE ownerID IN mysql> (SELECT memberID FROM clubMembers mysql> WHERE name LIKE 'L%'); الخرج Query OK, 6 rows affected (0.01 sec) حذف البيانات من عدة جداول يمكنك حذف البيانات من أكثر من جدول في عملية واحدة عن طريق تضمين بنية JOIN. تُستخدم بنى JOIN لدمج السجلات من جدولين أو أكثر في نتيجة استعلام واحد. يتم ذلك عن طريق إيجاد عمود مشترك بين الجداول وفرز النتائج على نحوٍ مناسب في الخرج. تبدو صيغة عملية الحذف التي تتضمن بنية JOIN على النحو التالي: mysql> DELETE table_1, table_2 mysql> FROM table_1 JOIN table_2 mysql> ON table_2.related_column = table_1.related_column mysql> WHERE conditions_apply; لاحظ أنه نظرًا لقدرة صيغ الدمج JOIN على مقارنة البيانات من عدة جداول، فإن صيغة هذا المثال تُوضّح الجدول المُستهدف لكل عمود بوضع اسم الجدول متبوعًا بنقطة قبل اسم العمود، وهذا ما يُعرف بالإشارة الكاملة والمؤهلة للعمود. ويُمكنك تحديد الجدول المصدر لكل عمود بهذه الطريقة في أي عملية، على الرغم من عدم ضرورتها عند الاختيار من جدول واحد فقط كما فعلنا في الأمثلة السابقة. لتوضيح مفهوم حذف البيانات باستخدام بنية JOIN، لنفترض أن ناديك قرر تحديد العلامات التجارية للمعدات الموسيقية التي يمكن للأعضاء مشاركتها. نفّذ الأمر التالي لإنشاء جدول باسم prohibitedBrands حيث ستسرد العلامات التجارية التي لم تعد مقبولة في النادي. يحتوي هذا الجدول على عمودين فقط، كلاهما يستخدم نمط بيانات varchar، لتخزين اسم كل علامة تجارية والبلد الذي تعمل فيه: mysql> CREATE TABLE prohibitedBrands ( mysql> brandName varchar(30), mysql> homeCountry varchar(30) mysql> ); ثم املأ هذا الجدول الجديد ببعض البيانات النموذجية التجريبية: mysql> INSERT INTO prohibitedBrands mysql> VALUES mysql> ('Fandar', 'USA'), mysql> ('Givson', 'USA'), mysql> ('Muug', 'USA'), mysql> ('Peabey', 'USA'), mysql> ('Yemehe', 'Japan'); بعد ذلك، يقرر النادي حذف أي سجلات للمعدات من جدول clubEquipment التي تظهر علاماتها التجارية في جدول prohibitedBrands ومقرها في الولايات المتحدة. يمكنك الاستعلام عن هذه البيانات بتنفيذ عملية استعلام مثل التالية باستخدام SELECT. إذ تدمج هذه العملية جدولي clubEquipment وprohibitedBrands معًا، وتُرجع فقط السجلات التي تشترك فيها أعمدة brand وbrandName في نفس القيمة. وتعمل بنية WHERE على إتمام تحديد نتائج الاستعلام بإقصاء أي علامة تجارية لا تتضمن القيمة "USA" في عمود homeCountry: mysql> SELECT * mysql> FROM clubEquipment JOIN prohibitedBrands mysql> ON clubEquipment.brand = prohibitedBrands.brandName mysql> WHERE homeCountry = 'USA'; الخرج +-------------+---------------+--------+---------+-----------+-------------+ | equipmentID | equipmentType | brand | ownerID | brandName | homeCountry | +-------------+---------------+--------+---------+-----------+-------------+ | 6 | bass guitar | Fandar | 4 | Fandar | USA | | 17 | bass guitar | Peabey | 1 | Peabey | USA | +-------------+---------------+--------+---------+-----------+-------------+ 2 rows in set (0.00 sec) هذه هي كل المعلومات التي نبحث عنها؛ وهي كل علامة تجارية مقرها الولايات المتحدة والموجودة في جدول prohibitedBrands والتي تظهر أيضًا في جدول clubEquipment. لحذف هذه العلامات التجارية من جدول prohibitedBrands والمعدات المرتبطة بها من جدول clubEquipment، أعد كتابة استعلام SELECT السابق ولكن استبدل تعليمة SELECT * بتعليمة DELETE متبوعةً بأسماء كلا الجدولين: mysql> DELETE clubEquipment, prohibitedBrands mysql> FROM clubEquipment JOIN prohibitedBrands mysql> ON clubEquipment.brand = prohibitedBrands.brandName mysql> WHERE homeCountry = 'USA'; الخرج Query OK, 4 rows affected (0.01 sec) يشير هذا الخرج إلى أن العملية حذفت أربع سجلات من قاعدة البيانات: سجلين من جدول clubEquipment وسجلين من جدول prohibitedBrands. إذا كنت تريد حذف السجلات من جدول clubEquipment فقط والاحتفاظ بجميع السجلات في جدول prohibitedBrands، فعليك إدراج clubEquipment فقط بعد كلمة DELETE، والعكس صحيح. تغيير سلوك تعليمة DELETE للمفاتيح الخارجية ستفشل أي تعليمة DELETE قد تسبب تعارضًا مع قيد FOREIGN KEY افتراضيًا. بالعودة إلى فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية في مستلزمات العمل وبتذكّر أنّ العمود ownerID في جدول المعدات clubEquipment هو مفتاح خارجي يشير إلى عمود memberID في جدول الأعضاء clubMembers. فهذا يعني أنّ أي قيمة مُدخلة في عمود ownerID يجب أن تكون موجودة بالفعل في جدول memberID. إذا حاولت إزالة سجل من جدول clubMembers تُستخدم قيمة memberID المُخصصة له في مكان ما ضمن عمود ownerID من جدول clubEquipment، سيؤدي ذلك إلى ظهور خطأ. mysql> DELETE FROM clubMembers mysql> WHERE memberID = 6; الخرج ERROR 1217 (23000): Cannot delete or update a parent row: a foreign key constraint fails يمكنك تجنب هذا الخطأ بإزالة أي سجلات في الجدول الابن (clubEquipment في هذا المثال) حيث توجد قيمة المفتاح الخارجي في الجدول الأب (clubMembers). كبديل، يمكنك تغيير هذا السلوك بتعديل قيد المفتاح الخارجي القائم بآخر يعالج عمليات الحذف على نحوٍ مختلف. ملاحظة: لا تسمح كافة أنظمة إدارة قواعد البيانات العلاقية أو محركاتها بإضافة أو إزالة قيود من جدول قائم كما هو موضح في الفقرات اللاحقة. فإذا كنت تستخدم نظام RDBMS غير MySQL، يجب عليك مراجعة الوثائق الرسمية الخاصة به لفهم القيود المتعلقة بإدارة القيود. وبالعودة إلى موضوعنا، بذلك ستكون قادرًا على تحديث قيمة clientID لأي سجل في الجدول الأب clubMembers، وستنتقل هذه التغييرات بشكل تلقائي إلى أي سجلات في الجدول الابن clubEquipment المرتبطة به. لاستبدال القيد الحالي، يجب أولًا إزالته باستخدام تعليمة ALTER TABLE. تذكر أننا في تعليمة CREATE TABLE لجدول clubEquipment، قمنا بتحديد fk_ownerID كاسم لقيد المفتاح الخارجي للجدول. mysql> ALTER TABLE clubEquipment mysql> DROP FOREIGN KEY fk_ownerID; الخرج Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 بعد ذلك، أنشئ قيد مفتاح خارجي جديد مُعدّ ليتعامل مع عمليات الحذف DELETE بطريقة تتناسب مع حالة الاستخدام المعطاة. بصرف النظر عن الإعداد الافتراضي الذي يمنع تعليمات DELETE التي تخالف المفتاح الخارجي، هناك خياران آخران متاحان في معظم أنظمة إدارة قواعد البيانات العلاقية: ON DELETE SET NULL: يسمح لك هذا الخيار بحذف السجلات من الجدول الأب، وسيعيد تعيين أي قيم مرتبطة بها في الجدول الابن على أنها قيم فارغة NULL. ON DELETE CASCADE: عند حذف سجل في الجدول الأب، سيدفع هذا الخيار SQL لحذف أي سجلات في الجدول الابن مرتبطة بذلك السجل من الجدول الأب. في سياق هذا المثال، لا يُعد استخدام خيار ON DELETE SET NULL منطقيًا. فإذا غادر أحد الأعضاء النادي وحُذِف سجله من جدول clubMembers، فلن تكون معداته متاحة للأعضاء المتبقين بعد الآن وبالتالي يجب إزالتها من جدول clubEquipment. وفي هذا الصدد يُعدّ خيار ON DELETE CASCADE هو الأنسب لهذا السياق. لإضافة قيد FOREIGN KEY يعمل وفق آلية ON DELETE CASCADE، نفّذ أمر ALTER TABLE التالي لتعديل الجدول. ستنشئ هذه التعليمة قيدًا جديدًا باسم newfk_ownerID يعكس تعريف القيد السابق ولكن مع إضافة خيار ON DELETE CASCADE. mysql> ALTER TABLE clubEquipment mysql> ADD CONSTRAINT newfk_ownerID mysql> FOREIGN KEY (ownerID) mysql> REFERENCES clubMembers(memberID) mysql> ON DELETE CASCADE; الخرج Query OK, 7 rows affected (0.07 sec) Records: 7 Duplicates: 0 Warnings: 0 تشير هذه النتائج إلى أن العملية قد أثرت على جميع السجلات السبعة المتبقية في جدول clubEquipment. ملاحظة: بدلًا من تغيير تعريف جدول مُعرّف مسبقًا لتعديل كيفية تفاعل قيد المفتاح الخارجي مع عمليات DELETE، يُمكنك من البداية تحديد هذا السلوك عند إنشاء الجدول بواسطة تعليمة إنشاء الجدول CREATE TABLE ، وبذلك تُعيّن السلوك المطلوب مُسبقًا، على النحو التالي: mysql> CREATE TABLE clubEquipment ( mysql> equipmentID int PRIMARY KEY, mysql> equipmentType varchar(30), mysql> brand varchar(15), mysql> ownerID int, mysql> CONSTRAINT fk_ownerID mysql> FOREIGN KEY (ownerID) REFERENCES clubMembers(memberID) mysql> ON DELETE CASCADE mysql> ); عقب ذلك، ستكون قادرًا على حذف أي سجل من جدول clubMembers، وستُحذف جميع السجلات المرتبطة به في جدول clubEquipment تلقائيًا: mysql> DELETE FROM clubMembers mysql> WHERE memberID = 6; الخرج Query OK, 1 row affected (0.00 sec) رغم أن هذا الخرج يشير إلى تأثر سجل واحد فقط، إلا أنّ العملية قد حذفت أيضًا كافة سجلات المعدات في جدول clubEquipment ذات القيمة 6 في عمود ownerID. الخلاصة باطلاعك على هذا المقال، اكتسبت المعرفة حول كيفية حذف البيانات الموجودة في جدول واحد أو أكثر باستخدام تعليمة DELETE في SQL. كما تعرفت على كيفية تعامل SQL مع عمليات الحذف التي تتعارض مع قيود المفتاح الخارجي وطرق تغيير هذا السلوك الافتراضي. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكيفية التعامل مع عمليات الحذف والخيارات المتاحة لها. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Delete Data in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية تحديث البيانات في لغة الاستعلام البنيوية SQL ما هي تقنية SQL تنظيم شيفرات SQL وتأمينها تصميم الجداول ومعلومات المخطط وترتيب تنفيذ الاستعلامات في SQL -
 لدى التعامل مع قاعدة بيانات، قد تضطر أحيانًا لتعديل بيانات كانت مدرجة من قبل في جدول أو أكثر. كأن تُضطر مثلًا لتصحيح خطأ إملائي في إدخال معين أو إضافة معلومات جديدة إلى سجل غير مكتمل. وتوفّر لغة الاستعلام البنيوية المعروفة بـ SQL الكلمة المفتاحية UPDATE، التي تُمكّن المستخدمين من تعديل البيانات الموجودة في جدول ما. يشرح هذا المقال كيفية استعمال الصيغة UPDATE في SQL لتعديل البيانات في جدول واحد أو عدة جداول مرتبطة ببعضها. كما يتناول الطريقة التي تتعامل بها SQL مع عمليات UPDATE التي قد تتعارض مع قيود المفتاح الخارجي. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، ويمكنك إعداد الخادم بالاستعانة بمقالنا كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، ومُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات مع بعض الجداول المُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على تحديث بيانات SQL. وإذا لم تكن متوفرة لديك، يمكنك مراجعة مقال الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية المُستخدمة في أمثلة هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم updateDB: mysql> CREATE DATABASE updateDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات updateDB، نفّذ تعليمة USE التالية: mysql> USE updateDB; الخرج Database changed وبعد اختيارك لقاعدة البيانات updateDB، أنشئ بعض الجداول ضمنها. ولتوضيح الأمثلة في هذا المقال، تخيّل أنّك تدير وكالة مواهب، وقد قررت تتبّع عملائك وأدائهم عبر قاعدة بيانات SQL، وبأنّك تعتزم البدء بجدولين: الجدول الأوّل لتخزين معلومات عن عملائك. وقد حددت أنّ هذا الجدول يحتاج إلى أربعة أعمدة: clientID: مُعرّف كل عميل، مُعبرًا عنه بنمط بيانات الأعداد الصحيحة int، كما سيُمثّل هذا العمود المفتاح الرئيسي للجدول، بحيث تمثل كل قيمة منه دور المُعرف الفريد للسجل المُرتبط بها. name: اسم كل عميل، مُعبرًا عنه بنمط بيانات varchar بحد أقصى 20 محرفًا. routine: وصف مُختصر لنوع الأداء الرئيسي لكل عميل، مُعبرًا عنه بنمط بيانات varchar بحد أقصى 30 محرفًا. performanceFee: عمود لتسجيل رسوم الأداء القياسية لكل عميل، يستخدم نمط البيانات decimal وتُحدد القيم في هذا العمود بحد أقصى قدره خمسة أرقام، بواقع رقمين على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها من -999.99 إلى 999.99. أنشئ جدولًا باسم clients يشمل هذه الأعمدة الأربعة: mysql> CREATE TABLE clients mysql> (clientID int PRIMARY KEY, mysql> name varchar(20), mysql> routine varchar(30), mysql> standardFee decimal (5,2) mysql> ); أمّا الجدول الثاني فسيكون مخصصًا لتخزين بيانات حول أداء عملائك في مكان عرض محدد محليًا. وبفرض أنك ارتأيت بأنّ هذا الجدول يتطلّب خمسة أعمدة: showID: بمثابة عمود clientID، إذ سيحتفظ هذا العمود بمُعرّف فريد لكل عرض، مُعبرًا عنه بنمط بيانات الأعداد الصحيحة int. كما سيمُثّل هذا العمود المفتاح الرئيسي لجدول العروض shows. showDate: تاريخ كل عرض. يُعبر عن قيم هذا العمود باستخدام نمط بيانات التواريخ date الذي يستخدم الصيغة YYYY-MM-DD (خانتين لليوم وخانتين للشهر وأربع خانات للسنة). clientID: مُعرّف العميل الذي يؤدي في العرض، مُعبرًا عنه كعدد صحيح. attendance: عدد الحضور في كل عرض، مُعبرًا عنه كعدد صحيح. ticketPrice:سعر تذكرة الدخول لكل عرض. يستخدم هذا العمود نمط البيانات decimal وتُحدد القيم في هذا العمود بحد أقصى قدره خمسة أرقام، بواقع رقمين على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها من- 999.99 إلى 999.99. ولضمان أنّ عمود clientID لن يتضمّن سوى قيم تُمثّل مُعرّفات عملاء صالحة، قررتَ تطبيق قيد مفتاح خارجي عليه بحيث يُشير إلى عمود clientID في جدول clients. يُعد قيد المفتاح الخارجي طريقة لتحديد علاقة بين جدولين، إذ يفرض أن تكون القيم في العمود المُطبّق عليه موجودة بالفعل في العمود المُشار إليه. في المثال القادم، يشترط قيد FOREIGN KEY أن تكون كل قيمة تُضاف إلى عمود clientID في جدول shows مُسجلة مسبقًا في عمود clientID بجدول clients. أنشئ جدولًا باسم clients يتضمن هذه الأعمدة الخمسة: mysql> CREATE TABLE shows mysql> (showID int PRIMARY KEY, mysql> showDate date, mysql> clientID int, mysql> attendance int, mysql> ticketPrice decimal (4,2), mysql> CONSTRAINT client_fk mysql> FOREIGN KEY (clientID) mysql> REFERENCES clients(clientID) mysql> ); ومن الجدير بالملاحظة أنّ هذا المثال يوفّر اسمًا لقيد المفتاح الخارجي، ألا وهو: client_fk. إذ تُنشئ MySQL تلقائيًا اسمًا لأي قيد تضيفه، إلّا أنّ تحديد اسم من قبلنا في هذه الحالة سيكون مفيدًا عندما نحتاج للإشارة إلى هذا القيد لاحقًا. بعد ذلك، نفّذ تعليمة INSERT INTO التالية لملء جدول العملاء clients بخمسة سجلات من البيانات النموذجية: mysql> INSERT INTO clients mysql> VALUES mysql> (1, 'Fares', 'song and dance', 180), mysql> (2, 'Camal', 'standup', 99.99), mysql> (3, 'Karam', 'standup', 45), mysql> (4, 'Wael', 'song and dance', 200), mysql> (5, 'Ahmad', 'trained squirrel', 79.99); ثم نفّذ تعليمة INSERT INTO أخرى لملء جدول shows بعشرة سجلات من البيانات النموذجية: mysql> INSERT INTO shows mysql> VALUES mysql> (1, '2019-12-25', 4, 124, 15), mysql> (2, '2020-01-11', 5, 84, 29.50), mysql> (3, '2020-01-17', 3, 170, 12.99), mysql> (4, '2020-01-31', 5, 234, 14.99), mysql> (5, '2020-02-08', 1, 86, 25), mysql> (6, '2020-02-14', 3, 102, 39.5), mysql> (7, '2020-02-15', 2, 101, 26.50), mysql> (8, '2020-02-27', 2, 186, 19.99), mysql> (9, '2020-03-06', 4, 202, 30), mysql> (10, '2020-03-07', 5, 250, 8.99); وبذلك، غدوتَ جاهزًا لمتابعة باقي المقال وبدء تعلم كيفية تحديث البيانات باستخدام لغة الاستعلام البنيوية SQL. تحديث البيانات في جدول واحد تبدو الصيغة العامّة لتعليمة UPDATE على النحو: mysql> UPDATE table_name mysql> SET column_name = value_expression mysql> WHERE conditions_apply; تُتبع الكلمة المفتاحية UPDATE باسم الجدول الذي يحتوي على البيانات المُراد تحديثها. ثم تأتي بنية SET، والتي تُحدّد بيانات العمود المُراد تحديثها وكيفية التحديث. تُعدّ بنية SET وكأنها تعيين لقيم العمود المُحدد لتُصبح مطابقة لأي تعبير قيمة تُقدّمه. يُعرّف تعبير القيمة — الذي يُعرف أحيانًا بالتعبير ذو القيمة المفردة — بأنّه أي تعبير يُعيد قيمة واحدة لكل سجل يُراد تحديثه. يمكن أن تكون القيمة المُعادة عبارة عن سلسلة نصية مجردة، أو عملية رياضية تُجرى على قيم رقمية موجودة في العمود. ولا بُدّ من تضمين عملية إسناد لقيمة واحدة على الأقل في كل تعليمة UPDATE، كما يُمكنك تضمين أكثر من تعليمة واحدة بغية تحديث البيانات في عدة أعمدة. تُتبع بنية SET ببنية WHERE. فإضافة بنية WHERE إلى تعليمة UPDATE كما في صيغة المثال هذه يُمكنّك من تصفية أي سجلات لا ترغب في تحديثها. إنّ بنية WHERE اختيارية تمامًا في تعليمات UPDATE، ولكن إذا لم تُضمنها، ستُحدّث العملية كل سجل في الجدول. لتوضيح كيفية تعامل SQL مع عمليات التحديث UPDATE، ابدأ بالاطلاع على كافة البيانات في جدول العملاء clients. يشتمل الاستعلام التالي على علامة النجمة (*)، وهي اختصار في SQL يُمثّل كل عمود في الجدول، لذا سيُعيد هذا الاستعلام جميع البيانات من كل عمود في جدول clients. $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 180.00 | | 2 | Camal | standup | 99.99 | | 3 | Karam | standup | 45.00 | | 4 | Wael | song and dance | 200.00 | | 5 | Ahmad | trained squirrel | 79.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) لنفترض على سبيل المثال أنّك لاحظت وجود خطأ في تهجئة الاسم Kamal، إذ يجب أن يبدأ بحرف K ولكنه في الجدول يبدأ بحرف C، ولذا قررت تغيير هذه القيمة عبر تنفيذ تعليمة UPDATE التالية. هذه العملية تُحدّث القيم في عمود الاسم name عن طريق تغيير قيمة عمود الاسم name في أي سجل يحتوي على الاسم Camal لتصبح Kamal: mysql> UPDATE clients mysql> SET name = 'Kamal' mysql> WHERE name = 'Camal'; الخرج Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 يُظهر هذا الخرج أن سجلًا واحدًا فقط قد حُدّث. يمكنك التأكد من ذلك بتشغيل استعلام SELECT السابق مجددًا، على النحو: $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 180.00 | | 2 | Kamal | standup | 99.99 | | 3 | Karam | standup | 45.00 | | 4 | Wael | song and dance | 200.00 | | 5 | Ahmad | trained squirrel | 79.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) تُظهر هذه النتائج أن القيمة المُدخلة سابقًا على أنّها Camal قد عُدلت الآن إلى Kamal. لقد حُدثّت قيمة واحدة فقط في عمود الاسم name في هذا المثال. ولكن، يمكنك تحديث عدة قيم باستخدام بنية WHERE أشمل. لإيضاح هذه الفكرة، بفرض أنّك تفاوضت على أجور أداء موحدة لجميع عملائك الذين يؤدون فقرات محددة. ستُحدّث التعليمة التالية القيم في عمود standardFee وتعينها لتكون 140. يرجى ملاحظة أن بنية WHERE في هذا المثال تتضمن المعامل LIKE، لذا فهي تُحدّث قيمة performanceFee لكل عميل تُطابق قيمة routine له النمط المحدد بالمحرف البديل 's%'. بمعنى آخر، سيُحدّث أجر الأداء لأي مؤدي يبدأ نوع عرضه بالحرف "s": mysql> UPDATE clients mysql> SET standardFee = 140 mysql> WHERE routine LIKE 's%'; الخرج Query OK, 4 rows affected (0.00 sec) Rows matched: 4 Changed: 4 Warnings: 0 والآن إذا استعلمت مجددًا عن محتويات جدول العملاء clients، فستؤكد مجموعة النتائج أن أربعة من عملائك غدا لديهم الآن رسوم أداء متطابقة: $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 140.00 | | 2 | Kamal | standup | 140.00 | | 3 | Karam | standup | 140.00 | | 4 | Wael | song and dance | 140.00 | | 5 | Ahmad | trained squirrel | 79.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) في حالة وجود أعمدة بالجدول تحمل قيمًا رقمية، فيُمكن تحديثها بتنفيذ عملية حسابية ضمن بنية SET. لتوضيح الأمر، بفرض أنّك توصلّت لاتفاق على زيادة رسوم الأداء لكل عميل بنسبة أربعين بالمئة، ولتطبيق هذا التغيير على جدول العملاء clients، يمكن تنفيذ عملية UPDATE كالآتي: mysql> UPDATE clients mysql> SET standardFee = standardFee * 1.4; الخرج Query OK, 5 rows affected, 1 warning (0.00 sec) Rows matched: 5 Changed: 5 Warnings: 1 ملاحظة: لاحظ أن الخرج يشير إلى أنّ التحديث قد نتج عنه تحذير. ففي كثير من الأحيان، تُصدر MySQL تحذيرًا عندما تُجبر على إجراء تغيير على بياناتك يتعارض والخصائص أو المحددات القياسية لعمود أو جدول معين. وتوفّر MySQL الاختصار SHOW WARNINGS الذي قد يساعد في شرح أي تحذيرات تتلقاها: mysql> SHOW WARNINGS; الخرج +-------+------+--------------------------------------------------+ | Level | Code | Message | +-------+------+--------------------------------------------------+ | Note | 1265 | Data truncated for column 'standardFee' at row 5 | +-------+------+--------------------------------------------------+ 1 row in set (0.00 sec) يُخبرنا هذا الخرج بأن نظام قاعدة البيانات أصدر التحذير لأنه اضطر إلى اقتطاع إحدى قيم العمود standardFee الجديدة حتى تتوافق مع تنسيق الرقم العشري - خمسة أرقام مع وجود رقمين على يمين الفاصلة العشرية - المُعرّف مسبقًا. لنستعلم عن جدول العملاء clients مجددًا للتأكد من أن رسوم الأداء لكل من العملاء قد ارتفعت بنسبة أربعين بالمئة بالفعل. $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 196.00 | | 2 | Kamal | standup | 196.00 | | 3 | Karam | standup | 196.00 | | 4 | Wael | song and dance | 196.00 | | 5 | Ahmad | trained squirrel | 111.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) كما ذكرنا سابقًا، يمكنك أيضًا تحديث البيانات في عدة أعمدة دفعة واحدة باستخدام تعليمة UPDATE واحدة. للقيام بذلك، يجب تحديد كل عمود ترغب في تحديثه، متبوعًا بالتعبير الخاص بالقيمة المراد تعيينها، ثم تفصل بين كل زوج من اسم عمود وتعبير قيمة بعلامة فاصلة. على سبيل المثال، بفرض أنّك اكتشفت بأنّ القاعة التي يقدم فيها عملاؤك عروضهم قد أخطأت في الإبلاغ عن عدد الحضور لجميع عروض Karam و Wand. وبالصدفة، تبين أيضًا أنك قمت بإدخال أسعار تذاكر خاطئة لكل من عروضهما. قبل الشروع في تحديث البيانات في جدول العروض shows، نفّذ الاستعلام التالي لاسترجاع كافة البيانات الحالية المُخزنة به حاليًا: $ SELECT * FROM shows; الخرج +--------+------------+----------+------------+-------------+ | showID | showDate | clientID | attendance | ticketPrice | +--------+------------+----------+------------+-------------+ | 1 | 2019-12-25 | 4 | 124 | 15.00 | | 2 | 2020-01-11 | 5 | 84 | 29.50 | | 3 | 2020-01-17 | 3 | 170 | 12.99 | | 4 | 2020-01-31 | 5 | 234 | 14.99 | | 5 | 2020-02-08 | 1 | 86 | 25.00 | | 6 | 2020-02-14 | 3 | 102 | 39.50 | | 7 | 2020-02-15 | 2 | 101 | 26.50 | | 8 | 2020-02-27 | 2 | 186 | 19.99 | | 9 | 2020-03-06 | 4 | 202 | 30.00 | | 10 | 2020-03-07 | 5 | 250 | 8.99 | +--------+------------+----------+------------+-------------+ 10 rows in set (0.01 sec) ولتصحيح أعداد الحضور والأسعار لتعبّر عن تلك الفعلية، سنحدّث الجدول لإضافة عشرين حاضرًا إلى كل عرض لهما وزيادة قيم سعر التذكرة ticketPrice لكل عرض بنسبة خمسين في المئة. يمكنك القيام بذلك من خلال عملية على النحو: mysql> UPDATE shows mysql> SET attendance = attendance + 20, mysql> ticketPrice = ticketPrice * 1.5 mysql> WHERE clientID IN mysql> (SELECT clientID mysql> FROM clients mysql> WHERE name = 'Karam' OR name = 'Wael'); الخرج Query OK, 4 rows affected, 1 warning (0.00 sec) Rows matched: 4 Changed: 4 Warnings: 1 لاحظ أن هذا المثال يستخدم استعلامًا فرعيًا في بنية WHERE لإرجاع قيم clientID لكل من Karam و Wael من جدول العملاء clients. وغالبًا ما يكون من الصعب تذكر القيم المجردة من قبيل أرقام التعريف، إلّا أنّ هذه الطريقة التي تستخدم فيها استعلامًا فرعيًا للعثور على قيمة يمكن أن تكون مفيدة في حال معرفتك لبعض السمات فقط حول السجلات المعنية. بعد تحديث جدول العروض shows، لنستعلم عنه مجددًا للتأكد من أن التغييرات قد تمّت كما هو متوقع: $ SELECT * FROM shows; الخرج +--------+------------+----------+------------+-------------+ | showID | showDate | clientID | attendance | ticketPrice | +--------+------------+----------+------------+-------------+ | 1 | 2019-12-25 | 4 | 144 | 22.50 | | 2 | 2020-01-11 | 5 | 84 | 29.50 | | 3 | 2020-01-17 | 3 | 190 | 19.49 | | 4 | 2020-01-31 | 5 | 234 | 14.99 | | 5 | 2020-02-08 | 1 | 86 | 25.00 | | 6 | 2020-02-14 | 3 | 122 | 59.25 | | 7 | 2020-02-15 | 2 | 101 | 26.50 | | 8 | 2020-02-27 | 2 | 186 | 19.99 | | 9 | 2020-03-06 | 4 | 222 | 45.00 | | 10 | 2020-03-07 | 5 | 250 | 8.99 | +--------+------------+----------+------------+-------------+ 10 rows in set (0.00 sec) يشير هذا الخرج إلى أن تعليمة UPDATE قد اكتملت بنجاح. استخدام بنية JOIN لتحديث البيانات في جداول متعددة ركّز هذا المقال حتى الآن على عرض طرق تحديث البيانات في جدول واحد فقط في كل مرة. ولكن، تُتيح بعض الإصدارات من SQL إمكانية تحديث أعمدة متعددة في جداول متعددة من خلال دمج الجداول مؤقتًا باستخدام بنية JOIN. فيما يلي الصيغة العامة التي بإمكانك استخدامها لتحديث عدة جداول دفعة واحدة مستخدمًا بنية JOIN: mysql> UPDATE table_1 JOIN table_2 mysql> ON table_1.related_column = table_2.related_column mysql> SET table_1.column_name = value_expression, mysql> table_2.column_name = value_expression mysql> WHERE conditions_apply; تبدأ صيغة هذا المثال بالكلمة المفتاحية UPDATE متبوعة بأسماء جدولين، يفصل بينهما صيغة JOIN. يلي ذلك صيغة ON، التي توضّح كيف ينبغي للاستعلام أن يدمج الجدولين معًا. في معظم تقديمات SQL، يمكنك دمج الجداول عن طريق إيجاد تطابقات ما بين أي مجموعة من الأعمدة تحتوي على ما يُعرف في معيار SQL باسم "أنواع البيانات المؤهلة للدمج" (JOIN eligible). بمعنى آخر، يُمكن بشكل عام دمج أي عمود يحتوي على بيانات عددية مع أي عمود آخر يحتوي على بيانات عددية، بغض النظر عن أنماط البيانات المحددة لكل منهما. وبالمثل، يمكن دمج أي أعمدة تحتوي على قيم محرفية مع أي عمود آخر يحتوي على بيانات محرفية. لاحظ أنه نظرًا لقدرة بنى JOIN على مقارنة البيانات من عدة جداول، فإن صيغة هذا المثال تُوضّح الجدول المُستهدف لكل عمود بوضع اسم الجدول متبوعًا بنقطة قبل اسم العمود، وهذا ما يُعرف بالإشارة الكاملة والمؤهلة للعمود. يُمكنك تحديد الجدول المصدر لكل عمود بهذه الطريقة في أي عملية، وهي غالبًا ما تُستخدم لزيادة الوضوح عند العمل مع أكثر من جدول. لتوضيح كيفية تنفيذ ذلك باستخدام جداول clients وshows المُنشأة مسبقًا، نفذ تعليمة UPDATE التالية. ما سيدمج جدولي clients وshows بناءً على أعمدة clientID المتطابقة في كلا الجدولين، ومن ثم تحديث قيم routine وticketPrice لسجل Fares في جدول clients وكل عروضها المدرجة في جدول shows. mysql> UPDATE clients JOIN shows mysql> USING (clientID) mysql> SET clients.routine = 'mime', mysql> shows.ticketPrice = 30 mysql> WHERE name = 'Fares'; الخرج Query OK, 2 rows affected (0.01 sec) Rows matched: 2 Changed: 2 Warnings: 0 لاحظ أنّ هذا المثال يدمج الجداول باستخدام الكلمة المفتاحية USING بدلاً من ON المُستخدمة في صيغة المثال السابق. وهذا ممكن لأنّ كل من الجدولين لديهما عمود clientID يتشاركان فيه نفس نوع البيانات. لمزيد من التفاصيل حول عمليات الدمج باستخدام JOIN، ننصحك بقراءة المقال التالي كيفية استخدام عمليات الدمج في SQL. تغيير سلوك تعليمة UPDATE للمفاتيح الخارجية ستفشل أي تعليمة UPDATE قد تسبب تعارضًا مع قيد FOREIGN KEY افتراضيًا. بالعودة إلى فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية في مستلزمات العمل وبتذكّر أنّ العمود clientID في جدول العروض shows هو مفتاح خارجي يشير إلى عمود clientID في جدول العملاء clients. فهذا يعني أنّ أي قيمة مُدخلة في عمود clientID الخاص بجدول العروض يجب أن تكون موجودة بالفعل في جدول العملاء. فإذا حاولت تحديث قيمة clientID لسجل ما في جدول العملاء والتي تظهر أيضًا في عمود clientID لجدول العروض، فسيؤدي ذلك إلى حدوث خطأ: mysql> UPDATE clients mysql> SET clientID = 9 mysql> WHERE name = 'Ahmad'; الخرج ERROR 1217 (23000): Cannot delete or update a parent row: a foreign key constraint fails يمكنك تجنب هذا الخطأ بتغيير قيد المفتاح الخارجي الحالي بآخر يتعامل مع عمليات التحديث على نحوٍ مختلف. ملاحظة: لا تسمح كافة أنظمة إدارة قواعد البيانات العلاقية أو محركات قواعد البيانات بإضافة أو إزالة قيد من جدول موجود بالفعل كما هو موضح في الفقرات التالية. فإذا كنت تستخدم نظام RDBMS غير MySQL، يجب عليك الرجوع إلى الوثائق الرسمية الخاصة به لفهم القيود الموجودة بخصوص إدارة القيود. بالعودة إلى موضوعنا، ولاستبدال القيد الحالي، عليك بدايةً إزالته باستخدام تعليمة ALTER TABLE. تذكّر أننا في تعليمة CREATE TABLE الخاصة بجدول العروض shows، حددنا client_fk كاسم لقيد المفتاح الخارجي FOREIGN KEY للجدول: mysql> ALTER TABLE shows mysql> DROP FOREIGN KEY client_fk; الخرج Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 بعد ذلك، أنشئ قيد مفتاح خارجي جديد مُعدّ ليتعامل مع عمليات التحديث UPDATE بطريقة تتناسب مع الحالة الاستخدامية المعطاة. بصرف النظر عن الإعداد الافتراضي الذي يمنع تعليمات UPDATE التي تخالف المفتاح الخارجي، هناك خياران آخران متاحان في معظم أنظمة إدارة قواعد البيانات العلاقية: ON UPDATE SET NULL: يسمح لك هذا الخيار بتحديث السجلات من الجدول الأب، وسيعيد تعيين أي قيم مرتبطة بها في الجدول الابن على أنها قيم فارغة NULL. ON UPDATE CASCADE: عند تحديث سجل في الجدول الأب، سيدفع هذا الخيار SQL لتحديث أي سجلات في الجدول الابن مرتبطة بذلك السجل من الجدول الأب لتتماشى مع القيمة الجديدة المُحدّثة. في سياق هذا المثال، لا يُعد استخدام خيار ON UPDATE SET NULL منطقيًا، فلو غيّرت مُعرّف لأحد العملاء دون حذفه من جدول clients، ينبغي أن يبقى مرتبطًا بعروضه في الجدول shows. ويجب أن يظهر المُعرّف الجديد ضمن سجلات عروضه، وبالتالي يكون استخدام الخيار ON UPDATE CASCADE هو الأنسب لهذا السياق. لإضافة قيد FOREIGN KEY يعمل وفق آلية ON UPDATE CASCADE، نفّذ أمر ALTER TABLE التالي. ستنشئ هذه التعليمة قيد جديد باسم new_client_fk يعكس تعريف القيد السابق ولكن مع إضافة خيار ON UPDATE CASCADE. mysql> ALTER TABLE shows mysql> ADD CONSTRAINT new_client_fk mysql> FOREIGN KEY (clientID) mysql> REFERENCES clients (clientID) mysql> ON UPDATE CASCADE; الخرج Query OK, 10 rows affected (0.02 sec) Records: 10 Duplicates: 0 Warnings: 0 تشير هذه النتائج إلى أن العملية قد أثرت على جميع السجلات العشرة وقامت بتعديلها في جدول العروض shows. ملاحظة: بدلًا من تغيير تعريف جدول مُعرّف مسبقًا لتعديل كيفية تفاعل قيد المفتاح الخارجي مع عمليات UPDATE، يُمكنك من البداية تحديد هذا السلوك عند إنشاء الجدول بواسطة تعليمة CREATE TABLE، وبذلك تُعيّن السلوك المطلوب مُسبقًا. mysql> CREATE TABLE shows mysql> (showID int PRIMARY KEY, mysql> showDate date, mysql> clientID int, mysql> attendance int, mysql> ticketPrice decimal (4,2), mysql> CONSTRAINT client_fk mysql> FOREIGN KEY (clientID) mysql> REFERENCES clients(clientID) mysql> ON UPDATE CASCADE mysql> ); عقب ذلك، ستكون قادرًا على تحديث قيمة clientID لأي سجل في جدول clients، وستنتقل هذه التغييرات بشكل تلقائي إلى جميع السجلات المرتبطة بها في جدول shows. mysql> UPDATE clients mysql> SET clientID = 9 mysql> WHERE name = 'Ahmad'; الخرج Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 رغم أن هذا الخرج يشير إلى تأثر سجل واحد فقط، إلا أنّ العملية قد حدّثت في الواقع قيمة clientID لكل سجلات جدول العروض المرتبطة بـ Ahmad في جدول shows. وللتحقق من ذلك، نفّذ الاستعلام التالي لاسترجاع كافة البيانات من الجدول shows: $ SELECT * FROM shows; الخرج +--------+------------+----------+------------+-------------+ | showID | showDate | clientID | attendance | ticketPrice | +--------+------------+----------+------------+-------------+ | 1 | 2019-12-25 | 4 | 144 | 22.50 | | 2 | 2020-01-11 | 9 | 84 | 29.50 | | 3 | 2020-01-17 | 3 | 190 | 19.49 | | 4 | 2020-01-31 | 9 | 234 | 14.99 | | 5 | 2020-02-08 | 1 | 86 | 30.00 | | 6 | 2020-02-14 | 3 | 122 | 59.25 | | 7 | 2020-02-15 | 2 | 101 | 26.50 | | 8 | 2020-02-27 | 2 | 186 | 19.99 | | 9 | 2020-03-06 | 4 | 222 | 45.00 | | 10 | 2020-03-07 | 9 | 250 | 8.99 | +--------+------------+----------+------------+-------------+ 10 rows in set (0.00 sec) كما هو متوقع، تسبب التحديث الذي أُجري على عمود clientID في جدول clients في تحديث السجلات المرتبطة في جدول shows. الخلاصة بوصولك إلى نهاية هذا المقال، ستكون قد اكتسبت المعرفة حول كيفية تعديل السجلات الموجودة في جدول واحد أو أكثر باستخدام تعليمة UPDATE في SQL. كما تعرفت على كيفية تعامل SQL مع عمليات التحديث التي تتعارض مع قيود المفتاح الخارجي وطرق تغيير هذا السلوك الافتراضي. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكيفية التعامل مع عمليات التحديث والخيارات المتاحة لها. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Update Data in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية إدراج البيانات في SQL المرجع المتقدم إلى لغة SQL تصميم الجداول ومعلومات المخطط وترتيب تنفيذ الاستعلامات في SQL حذف الجداول وقواعد البيانات في SQL أهمية قواعد البيانات
لدى التعامل مع قاعدة بيانات، قد تضطر أحيانًا لتعديل بيانات كانت مدرجة من قبل في جدول أو أكثر. كأن تُضطر مثلًا لتصحيح خطأ إملائي في إدخال معين أو إضافة معلومات جديدة إلى سجل غير مكتمل. وتوفّر لغة الاستعلام البنيوية المعروفة بـ SQL الكلمة المفتاحية UPDATE، التي تُمكّن المستخدمين من تعديل البيانات الموجودة في جدول ما. يشرح هذا المقال كيفية استعمال الصيغة UPDATE في SQL لتعديل البيانات في جدول واحد أو عدة جداول مرتبطة ببعضها. كما يتناول الطريقة التي تتعامل بها SQL مع عمليات UPDATE التي قد تتعارض مع قيود المفتاح الخارجي. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، ويمكنك إعداد الخادم بالاستعانة بمقالنا كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، ومُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات مع بعض الجداول المُحمّلة ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على تحديث بيانات SQL. وإذا لم تكن متوفرة لديك، يمكنك مراجعة مقال الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية الاتصال بخادم MySQL وإنشاء قاعدة البيانات التجريبية المُستخدمة في أمثلة هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم updateDB: mysql> CREATE DATABASE updateDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات updateDB، نفّذ تعليمة USE التالية: mysql> USE updateDB; الخرج Database changed وبعد اختيارك لقاعدة البيانات updateDB، أنشئ بعض الجداول ضمنها. ولتوضيح الأمثلة في هذا المقال، تخيّل أنّك تدير وكالة مواهب، وقد قررت تتبّع عملائك وأدائهم عبر قاعدة بيانات SQL، وبأنّك تعتزم البدء بجدولين: الجدول الأوّل لتخزين معلومات عن عملائك. وقد حددت أنّ هذا الجدول يحتاج إلى أربعة أعمدة: clientID: مُعرّف كل عميل، مُعبرًا عنه بنمط بيانات الأعداد الصحيحة int، كما سيُمثّل هذا العمود المفتاح الرئيسي للجدول، بحيث تمثل كل قيمة منه دور المُعرف الفريد للسجل المُرتبط بها. name: اسم كل عميل، مُعبرًا عنه بنمط بيانات varchar بحد أقصى 20 محرفًا. routine: وصف مُختصر لنوع الأداء الرئيسي لكل عميل، مُعبرًا عنه بنمط بيانات varchar بحد أقصى 30 محرفًا. performanceFee: عمود لتسجيل رسوم الأداء القياسية لكل عميل، يستخدم نمط البيانات decimal وتُحدد القيم في هذا العمود بحد أقصى قدره خمسة أرقام، بواقع رقمين على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها من -999.99 إلى 999.99. أنشئ جدولًا باسم clients يشمل هذه الأعمدة الأربعة: mysql> CREATE TABLE clients mysql> (clientID int PRIMARY KEY, mysql> name varchar(20), mysql> routine varchar(30), mysql> standardFee decimal (5,2) mysql> ); أمّا الجدول الثاني فسيكون مخصصًا لتخزين بيانات حول أداء عملائك في مكان عرض محدد محليًا. وبفرض أنك ارتأيت بأنّ هذا الجدول يتطلّب خمسة أعمدة: showID: بمثابة عمود clientID، إذ سيحتفظ هذا العمود بمُعرّف فريد لكل عرض، مُعبرًا عنه بنمط بيانات الأعداد الصحيحة int. كما سيمُثّل هذا العمود المفتاح الرئيسي لجدول العروض shows. showDate: تاريخ كل عرض. يُعبر عن قيم هذا العمود باستخدام نمط بيانات التواريخ date الذي يستخدم الصيغة YYYY-MM-DD (خانتين لليوم وخانتين للشهر وأربع خانات للسنة). clientID: مُعرّف العميل الذي يؤدي في العرض، مُعبرًا عنه كعدد صحيح. attendance: عدد الحضور في كل عرض، مُعبرًا عنه كعدد صحيح. ticketPrice:سعر تذكرة الدخول لكل عرض. يستخدم هذا العمود نمط البيانات decimal وتُحدد القيم في هذا العمود بحد أقصى قدره خمسة أرقام، بواقع رقمين على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها من- 999.99 إلى 999.99. ولضمان أنّ عمود clientID لن يتضمّن سوى قيم تُمثّل مُعرّفات عملاء صالحة، قررتَ تطبيق قيد مفتاح خارجي عليه بحيث يُشير إلى عمود clientID في جدول clients. يُعد قيد المفتاح الخارجي طريقة لتحديد علاقة بين جدولين، إذ يفرض أن تكون القيم في العمود المُطبّق عليه موجودة بالفعل في العمود المُشار إليه. في المثال القادم، يشترط قيد FOREIGN KEY أن تكون كل قيمة تُضاف إلى عمود clientID في جدول shows مُسجلة مسبقًا في عمود clientID بجدول clients. أنشئ جدولًا باسم clients يتضمن هذه الأعمدة الخمسة: mysql> CREATE TABLE shows mysql> (showID int PRIMARY KEY, mysql> showDate date, mysql> clientID int, mysql> attendance int, mysql> ticketPrice decimal (4,2), mysql> CONSTRAINT client_fk mysql> FOREIGN KEY (clientID) mysql> REFERENCES clients(clientID) mysql> ); ومن الجدير بالملاحظة أنّ هذا المثال يوفّر اسمًا لقيد المفتاح الخارجي، ألا وهو: client_fk. إذ تُنشئ MySQL تلقائيًا اسمًا لأي قيد تضيفه، إلّا أنّ تحديد اسم من قبلنا في هذه الحالة سيكون مفيدًا عندما نحتاج للإشارة إلى هذا القيد لاحقًا. بعد ذلك، نفّذ تعليمة INSERT INTO التالية لملء جدول العملاء clients بخمسة سجلات من البيانات النموذجية: mysql> INSERT INTO clients mysql> VALUES mysql> (1, 'Fares', 'song and dance', 180), mysql> (2, 'Camal', 'standup', 99.99), mysql> (3, 'Karam', 'standup', 45), mysql> (4, 'Wael', 'song and dance', 200), mysql> (5, 'Ahmad', 'trained squirrel', 79.99); ثم نفّذ تعليمة INSERT INTO أخرى لملء جدول shows بعشرة سجلات من البيانات النموذجية: mysql> INSERT INTO shows mysql> VALUES mysql> (1, '2019-12-25', 4, 124, 15), mysql> (2, '2020-01-11', 5, 84, 29.50), mysql> (3, '2020-01-17', 3, 170, 12.99), mysql> (4, '2020-01-31', 5, 234, 14.99), mysql> (5, '2020-02-08', 1, 86, 25), mysql> (6, '2020-02-14', 3, 102, 39.5), mysql> (7, '2020-02-15', 2, 101, 26.50), mysql> (8, '2020-02-27', 2, 186, 19.99), mysql> (9, '2020-03-06', 4, 202, 30), mysql> (10, '2020-03-07', 5, 250, 8.99); وبذلك، غدوتَ جاهزًا لمتابعة باقي المقال وبدء تعلم كيفية تحديث البيانات باستخدام لغة الاستعلام البنيوية SQL. تحديث البيانات في جدول واحد تبدو الصيغة العامّة لتعليمة UPDATE على النحو: mysql> UPDATE table_name mysql> SET column_name = value_expression mysql> WHERE conditions_apply; تُتبع الكلمة المفتاحية UPDATE باسم الجدول الذي يحتوي على البيانات المُراد تحديثها. ثم تأتي بنية SET، والتي تُحدّد بيانات العمود المُراد تحديثها وكيفية التحديث. تُعدّ بنية SET وكأنها تعيين لقيم العمود المُحدد لتُصبح مطابقة لأي تعبير قيمة تُقدّمه. يُعرّف تعبير القيمة — الذي يُعرف أحيانًا بالتعبير ذو القيمة المفردة — بأنّه أي تعبير يُعيد قيمة واحدة لكل سجل يُراد تحديثه. يمكن أن تكون القيمة المُعادة عبارة عن سلسلة نصية مجردة، أو عملية رياضية تُجرى على قيم رقمية موجودة في العمود. ولا بُدّ من تضمين عملية إسناد لقيمة واحدة على الأقل في كل تعليمة UPDATE، كما يُمكنك تضمين أكثر من تعليمة واحدة بغية تحديث البيانات في عدة أعمدة. تُتبع بنية SET ببنية WHERE. فإضافة بنية WHERE إلى تعليمة UPDATE كما في صيغة المثال هذه يُمكنّك من تصفية أي سجلات لا ترغب في تحديثها. إنّ بنية WHERE اختيارية تمامًا في تعليمات UPDATE، ولكن إذا لم تُضمنها، ستُحدّث العملية كل سجل في الجدول. لتوضيح كيفية تعامل SQL مع عمليات التحديث UPDATE، ابدأ بالاطلاع على كافة البيانات في جدول العملاء clients. يشتمل الاستعلام التالي على علامة النجمة (*)، وهي اختصار في SQL يُمثّل كل عمود في الجدول، لذا سيُعيد هذا الاستعلام جميع البيانات من كل عمود في جدول clients. $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 180.00 | | 2 | Camal | standup | 99.99 | | 3 | Karam | standup | 45.00 | | 4 | Wael | song and dance | 200.00 | | 5 | Ahmad | trained squirrel | 79.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) لنفترض على سبيل المثال أنّك لاحظت وجود خطأ في تهجئة الاسم Kamal، إذ يجب أن يبدأ بحرف K ولكنه في الجدول يبدأ بحرف C، ولذا قررت تغيير هذه القيمة عبر تنفيذ تعليمة UPDATE التالية. هذه العملية تُحدّث القيم في عمود الاسم name عن طريق تغيير قيمة عمود الاسم name في أي سجل يحتوي على الاسم Camal لتصبح Kamal: mysql> UPDATE clients mysql> SET name = 'Kamal' mysql> WHERE name = 'Camal'; الخرج Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 يُظهر هذا الخرج أن سجلًا واحدًا فقط قد حُدّث. يمكنك التأكد من ذلك بتشغيل استعلام SELECT السابق مجددًا، على النحو: $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 180.00 | | 2 | Kamal | standup | 99.99 | | 3 | Karam | standup | 45.00 | | 4 | Wael | song and dance | 200.00 | | 5 | Ahmad | trained squirrel | 79.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) تُظهر هذه النتائج أن القيمة المُدخلة سابقًا على أنّها Camal قد عُدلت الآن إلى Kamal. لقد حُدثّت قيمة واحدة فقط في عمود الاسم name في هذا المثال. ولكن، يمكنك تحديث عدة قيم باستخدام بنية WHERE أشمل. لإيضاح هذه الفكرة، بفرض أنّك تفاوضت على أجور أداء موحدة لجميع عملائك الذين يؤدون فقرات محددة. ستُحدّث التعليمة التالية القيم في عمود standardFee وتعينها لتكون 140. يرجى ملاحظة أن بنية WHERE في هذا المثال تتضمن المعامل LIKE، لذا فهي تُحدّث قيمة performanceFee لكل عميل تُطابق قيمة routine له النمط المحدد بالمحرف البديل 's%'. بمعنى آخر، سيُحدّث أجر الأداء لأي مؤدي يبدأ نوع عرضه بالحرف "s": mysql> UPDATE clients mysql> SET standardFee = 140 mysql> WHERE routine LIKE 's%'; الخرج Query OK, 4 rows affected (0.00 sec) Rows matched: 4 Changed: 4 Warnings: 0 والآن إذا استعلمت مجددًا عن محتويات جدول العملاء clients، فستؤكد مجموعة النتائج أن أربعة من عملائك غدا لديهم الآن رسوم أداء متطابقة: $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 140.00 | | 2 | Kamal | standup | 140.00 | | 3 | Karam | standup | 140.00 | | 4 | Wael | song and dance | 140.00 | | 5 | Ahmad | trained squirrel | 79.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) في حالة وجود أعمدة بالجدول تحمل قيمًا رقمية، فيُمكن تحديثها بتنفيذ عملية حسابية ضمن بنية SET. لتوضيح الأمر، بفرض أنّك توصلّت لاتفاق على زيادة رسوم الأداء لكل عميل بنسبة أربعين بالمئة، ولتطبيق هذا التغيير على جدول العملاء clients، يمكن تنفيذ عملية UPDATE كالآتي: mysql> UPDATE clients mysql> SET standardFee = standardFee * 1.4; الخرج Query OK, 5 rows affected, 1 warning (0.00 sec) Rows matched: 5 Changed: 5 Warnings: 1 ملاحظة: لاحظ أن الخرج يشير إلى أنّ التحديث قد نتج عنه تحذير. ففي كثير من الأحيان، تُصدر MySQL تحذيرًا عندما تُجبر على إجراء تغيير على بياناتك يتعارض والخصائص أو المحددات القياسية لعمود أو جدول معين. وتوفّر MySQL الاختصار SHOW WARNINGS الذي قد يساعد في شرح أي تحذيرات تتلقاها: mysql> SHOW WARNINGS; الخرج +-------+------+--------------------------------------------------+ | Level | Code | Message | +-------+------+--------------------------------------------------+ | Note | 1265 | Data truncated for column 'standardFee' at row 5 | +-------+------+--------------------------------------------------+ 1 row in set (0.00 sec) يُخبرنا هذا الخرج بأن نظام قاعدة البيانات أصدر التحذير لأنه اضطر إلى اقتطاع إحدى قيم العمود standardFee الجديدة حتى تتوافق مع تنسيق الرقم العشري - خمسة أرقام مع وجود رقمين على يمين الفاصلة العشرية - المُعرّف مسبقًا. لنستعلم عن جدول العملاء clients مجددًا للتأكد من أن رسوم الأداء لكل من العملاء قد ارتفعت بنسبة أربعين بالمئة بالفعل. $ SELECT * FROM clients; الخرج +----------+------------+------------------+-------------+ | clientID | name | routine | standardFee | +----------+------------+------------------+-------------+ | 1 | Fares | song and dance | 196.00 | | 2 | Kamal | standup | 196.00 | | 3 | Karam | standup | 196.00 | | 4 | Wael | song and dance | 196.00 | | 5 | Ahmad | trained squirrel | 111.99 | +----------+------------+------------------+-------------+ 5 rows in set (0.00 sec) كما ذكرنا سابقًا، يمكنك أيضًا تحديث البيانات في عدة أعمدة دفعة واحدة باستخدام تعليمة UPDATE واحدة. للقيام بذلك، يجب تحديد كل عمود ترغب في تحديثه، متبوعًا بالتعبير الخاص بالقيمة المراد تعيينها، ثم تفصل بين كل زوج من اسم عمود وتعبير قيمة بعلامة فاصلة. على سبيل المثال، بفرض أنّك اكتشفت بأنّ القاعة التي يقدم فيها عملاؤك عروضهم قد أخطأت في الإبلاغ عن عدد الحضور لجميع عروض Karam و Wand. وبالصدفة، تبين أيضًا أنك قمت بإدخال أسعار تذاكر خاطئة لكل من عروضهما. قبل الشروع في تحديث البيانات في جدول العروض shows، نفّذ الاستعلام التالي لاسترجاع كافة البيانات الحالية المُخزنة به حاليًا: $ SELECT * FROM shows; الخرج +--------+------------+----------+------------+-------------+ | showID | showDate | clientID | attendance | ticketPrice | +--------+------------+----------+------------+-------------+ | 1 | 2019-12-25 | 4 | 124 | 15.00 | | 2 | 2020-01-11 | 5 | 84 | 29.50 | | 3 | 2020-01-17 | 3 | 170 | 12.99 | | 4 | 2020-01-31 | 5 | 234 | 14.99 | | 5 | 2020-02-08 | 1 | 86 | 25.00 | | 6 | 2020-02-14 | 3 | 102 | 39.50 | | 7 | 2020-02-15 | 2 | 101 | 26.50 | | 8 | 2020-02-27 | 2 | 186 | 19.99 | | 9 | 2020-03-06 | 4 | 202 | 30.00 | | 10 | 2020-03-07 | 5 | 250 | 8.99 | +--------+------------+----------+------------+-------------+ 10 rows in set (0.01 sec) ولتصحيح أعداد الحضور والأسعار لتعبّر عن تلك الفعلية، سنحدّث الجدول لإضافة عشرين حاضرًا إلى كل عرض لهما وزيادة قيم سعر التذكرة ticketPrice لكل عرض بنسبة خمسين في المئة. يمكنك القيام بذلك من خلال عملية على النحو: mysql> UPDATE shows mysql> SET attendance = attendance + 20, mysql> ticketPrice = ticketPrice * 1.5 mysql> WHERE clientID IN mysql> (SELECT clientID mysql> FROM clients mysql> WHERE name = 'Karam' OR name = 'Wael'); الخرج Query OK, 4 rows affected, 1 warning (0.00 sec) Rows matched: 4 Changed: 4 Warnings: 1 لاحظ أن هذا المثال يستخدم استعلامًا فرعيًا في بنية WHERE لإرجاع قيم clientID لكل من Karam و Wael من جدول العملاء clients. وغالبًا ما يكون من الصعب تذكر القيم المجردة من قبيل أرقام التعريف، إلّا أنّ هذه الطريقة التي تستخدم فيها استعلامًا فرعيًا للعثور على قيمة يمكن أن تكون مفيدة في حال معرفتك لبعض السمات فقط حول السجلات المعنية. بعد تحديث جدول العروض shows، لنستعلم عنه مجددًا للتأكد من أن التغييرات قد تمّت كما هو متوقع: $ SELECT * FROM shows; الخرج +--------+------------+----------+------------+-------------+ | showID | showDate | clientID | attendance | ticketPrice | +--------+------------+----------+------------+-------------+ | 1 | 2019-12-25 | 4 | 144 | 22.50 | | 2 | 2020-01-11 | 5 | 84 | 29.50 | | 3 | 2020-01-17 | 3 | 190 | 19.49 | | 4 | 2020-01-31 | 5 | 234 | 14.99 | | 5 | 2020-02-08 | 1 | 86 | 25.00 | | 6 | 2020-02-14 | 3 | 122 | 59.25 | | 7 | 2020-02-15 | 2 | 101 | 26.50 | | 8 | 2020-02-27 | 2 | 186 | 19.99 | | 9 | 2020-03-06 | 4 | 222 | 45.00 | | 10 | 2020-03-07 | 5 | 250 | 8.99 | +--------+------------+----------+------------+-------------+ 10 rows in set (0.00 sec) يشير هذا الخرج إلى أن تعليمة UPDATE قد اكتملت بنجاح. استخدام بنية JOIN لتحديث البيانات في جداول متعددة ركّز هذا المقال حتى الآن على عرض طرق تحديث البيانات في جدول واحد فقط في كل مرة. ولكن، تُتيح بعض الإصدارات من SQL إمكانية تحديث أعمدة متعددة في جداول متعددة من خلال دمج الجداول مؤقتًا باستخدام بنية JOIN. فيما يلي الصيغة العامة التي بإمكانك استخدامها لتحديث عدة جداول دفعة واحدة مستخدمًا بنية JOIN: mysql> UPDATE table_1 JOIN table_2 mysql> ON table_1.related_column = table_2.related_column mysql> SET table_1.column_name = value_expression, mysql> table_2.column_name = value_expression mysql> WHERE conditions_apply; تبدأ صيغة هذا المثال بالكلمة المفتاحية UPDATE متبوعة بأسماء جدولين، يفصل بينهما صيغة JOIN. يلي ذلك صيغة ON، التي توضّح كيف ينبغي للاستعلام أن يدمج الجدولين معًا. في معظم تقديمات SQL، يمكنك دمج الجداول عن طريق إيجاد تطابقات ما بين أي مجموعة من الأعمدة تحتوي على ما يُعرف في معيار SQL باسم "أنواع البيانات المؤهلة للدمج" (JOIN eligible). بمعنى آخر، يُمكن بشكل عام دمج أي عمود يحتوي على بيانات عددية مع أي عمود آخر يحتوي على بيانات عددية، بغض النظر عن أنماط البيانات المحددة لكل منهما. وبالمثل، يمكن دمج أي أعمدة تحتوي على قيم محرفية مع أي عمود آخر يحتوي على بيانات محرفية. لاحظ أنه نظرًا لقدرة بنى JOIN على مقارنة البيانات من عدة جداول، فإن صيغة هذا المثال تُوضّح الجدول المُستهدف لكل عمود بوضع اسم الجدول متبوعًا بنقطة قبل اسم العمود، وهذا ما يُعرف بالإشارة الكاملة والمؤهلة للعمود. يُمكنك تحديد الجدول المصدر لكل عمود بهذه الطريقة في أي عملية، وهي غالبًا ما تُستخدم لزيادة الوضوح عند العمل مع أكثر من جدول. لتوضيح كيفية تنفيذ ذلك باستخدام جداول clients وshows المُنشأة مسبقًا، نفذ تعليمة UPDATE التالية. ما سيدمج جدولي clients وshows بناءً على أعمدة clientID المتطابقة في كلا الجدولين، ومن ثم تحديث قيم routine وticketPrice لسجل Fares في جدول clients وكل عروضها المدرجة في جدول shows. mysql> UPDATE clients JOIN shows mysql> USING (clientID) mysql> SET clients.routine = 'mime', mysql> shows.ticketPrice = 30 mysql> WHERE name = 'Fares'; الخرج Query OK, 2 rows affected (0.01 sec) Rows matched: 2 Changed: 2 Warnings: 0 لاحظ أنّ هذا المثال يدمج الجداول باستخدام الكلمة المفتاحية USING بدلاً من ON المُستخدمة في صيغة المثال السابق. وهذا ممكن لأنّ كل من الجدولين لديهما عمود clientID يتشاركان فيه نفس نوع البيانات. لمزيد من التفاصيل حول عمليات الدمج باستخدام JOIN، ننصحك بقراءة المقال التالي كيفية استخدام عمليات الدمج في SQL. تغيير سلوك تعليمة UPDATE للمفاتيح الخارجية ستفشل أي تعليمة UPDATE قد تسبب تعارضًا مع قيد FOREIGN KEY افتراضيًا. بالعودة إلى فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية في مستلزمات العمل وبتذكّر أنّ العمود clientID في جدول العروض shows هو مفتاح خارجي يشير إلى عمود clientID في جدول العملاء clients. فهذا يعني أنّ أي قيمة مُدخلة في عمود clientID الخاص بجدول العروض يجب أن تكون موجودة بالفعل في جدول العملاء. فإذا حاولت تحديث قيمة clientID لسجل ما في جدول العملاء والتي تظهر أيضًا في عمود clientID لجدول العروض، فسيؤدي ذلك إلى حدوث خطأ: mysql> UPDATE clients mysql> SET clientID = 9 mysql> WHERE name = 'Ahmad'; الخرج ERROR 1217 (23000): Cannot delete or update a parent row: a foreign key constraint fails يمكنك تجنب هذا الخطأ بتغيير قيد المفتاح الخارجي الحالي بآخر يتعامل مع عمليات التحديث على نحوٍ مختلف. ملاحظة: لا تسمح كافة أنظمة إدارة قواعد البيانات العلاقية أو محركات قواعد البيانات بإضافة أو إزالة قيد من جدول موجود بالفعل كما هو موضح في الفقرات التالية. فإذا كنت تستخدم نظام RDBMS غير MySQL، يجب عليك الرجوع إلى الوثائق الرسمية الخاصة به لفهم القيود الموجودة بخصوص إدارة القيود. بالعودة إلى موضوعنا، ولاستبدال القيد الحالي، عليك بدايةً إزالته باستخدام تعليمة ALTER TABLE. تذكّر أننا في تعليمة CREATE TABLE الخاصة بجدول العروض shows، حددنا client_fk كاسم لقيد المفتاح الخارجي FOREIGN KEY للجدول: mysql> ALTER TABLE shows mysql> DROP FOREIGN KEY client_fk; الخرج Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 بعد ذلك، أنشئ قيد مفتاح خارجي جديد مُعدّ ليتعامل مع عمليات التحديث UPDATE بطريقة تتناسب مع الحالة الاستخدامية المعطاة. بصرف النظر عن الإعداد الافتراضي الذي يمنع تعليمات UPDATE التي تخالف المفتاح الخارجي، هناك خياران آخران متاحان في معظم أنظمة إدارة قواعد البيانات العلاقية: ON UPDATE SET NULL: يسمح لك هذا الخيار بتحديث السجلات من الجدول الأب، وسيعيد تعيين أي قيم مرتبطة بها في الجدول الابن على أنها قيم فارغة NULL. ON UPDATE CASCADE: عند تحديث سجل في الجدول الأب، سيدفع هذا الخيار SQL لتحديث أي سجلات في الجدول الابن مرتبطة بذلك السجل من الجدول الأب لتتماشى مع القيمة الجديدة المُحدّثة. في سياق هذا المثال، لا يُعد استخدام خيار ON UPDATE SET NULL منطقيًا، فلو غيّرت مُعرّف لأحد العملاء دون حذفه من جدول clients، ينبغي أن يبقى مرتبطًا بعروضه في الجدول shows. ويجب أن يظهر المُعرّف الجديد ضمن سجلات عروضه، وبالتالي يكون استخدام الخيار ON UPDATE CASCADE هو الأنسب لهذا السياق. لإضافة قيد FOREIGN KEY يعمل وفق آلية ON UPDATE CASCADE، نفّذ أمر ALTER TABLE التالي. ستنشئ هذه التعليمة قيد جديد باسم new_client_fk يعكس تعريف القيد السابق ولكن مع إضافة خيار ON UPDATE CASCADE. mysql> ALTER TABLE shows mysql> ADD CONSTRAINT new_client_fk mysql> FOREIGN KEY (clientID) mysql> REFERENCES clients (clientID) mysql> ON UPDATE CASCADE; الخرج Query OK, 10 rows affected (0.02 sec) Records: 10 Duplicates: 0 Warnings: 0 تشير هذه النتائج إلى أن العملية قد أثرت على جميع السجلات العشرة وقامت بتعديلها في جدول العروض shows. ملاحظة: بدلًا من تغيير تعريف جدول مُعرّف مسبقًا لتعديل كيفية تفاعل قيد المفتاح الخارجي مع عمليات UPDATE، يُمكنك من البداية تحديد هذا السلوك عند إنشاء الجدول بواسطة تعليمة CREATE TABLE، وبذلك تُعيّن السلوك المطلوب مُسبقًا. mysql> CREATE TABLE shows mysql> (showID int PRIMARY KEY, mysql> showDate date, mysql> clientID int, mysql> attendance int, mysql> ticketPrice decimal (4,2), mysql> CONSTRAINT client_fk mysql> FOREIGN KEY (clientID) mysql> REFERENCES clients(clientID) mysql> ON UPDATE CASCADE mysql> ); عقب ذلك، ستكون قادرًا على تحديث قيمة clientID لأي سجل في جدول clients، وستنتقل هذه التغييرات بشكل تلقائي إلى جميع السجلات المرتبطة بها في جدول shows. mysql> UPDATE clients mysql> SET clientID = 9 mysql> WHERE name = 'Ahmad'; الخرج Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 رغم أن هذا الخرج يشير إلى تأثر سجل واحد فقط، إلا أنّ العملية قد حدّثت في الواقع قيمة clientID لكل سجلات جدول العروض المرتبطة بـ Ahmad في جدول shows. وللتحقق من ذلك، نفّذ الاستعلام التالي لاسترجاع كافة البيانات من الجدول shows: $ SELECT * FROM shows; الخرج +--------+------------+----------+------------+-------------+ | showID | showDate | clientID | attendance | ticketPrice | +--------+------------+----------+------------+-------------+ | 1 | 2019-12-25 | 4 | 144 | 22.50 | | 2 | 2020-01-11 | 9 | 84 | 29.50 | | 3 | 2020-01-17 | 3 | 190 | 19.49 | | 4 | 2020-01-31 | 9 | 234 | 14.99 | | 5 | 2020-02-08 | 1 | 86 | 30.00 | | 6 | 2020-02-14 | 3 | 122 | 59.25 | | 7 | 2020-02-15 | 2 | 101 | 26.50 | | 8 | 2020-02-27 | 2 | 186 | 19.99 | | 9 | 2020-03-06 | 4 | 222 | 45.00 | | 10 | 2020-03-07 | 9 | 250 | 8.99 | +--------+------------+----------+------------+-------------+ 10 rows in set (0.00 sec) كما هو متوقع، تسبب التحديث الذي أُجري على عمود clientID في جدول clients في تحديث السجلات المرتبطة في جدول shows. الخلاصة بوصولك إلى نهاية هذا المقال، ستكون قد اكتسبت المعرفة حول كيفية تعديل السجلات الموجودة في جدول واحد أو أكثر باستخدام تعليمة UPDATE في SQL. كما تعرفت على كيفية تعامل SQL مع عمليات التحديث التي تتعارض مع قيود المفتاح الخارجي وطرق تغيير هذا السلوك الافتراضي. ومن المفترض أن تعمل الأوامر المشروحة في هذا المقال مع أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن تذكر أن لكل قاعدة بيانات SQL تقديمها الخاص للغة، لذا ينبغي مراجعة التوثيق الرسمي لنظام إدارة قواعد البيانات الخاص بك للحصول على وصف أكثر تفصيلاً لكيفية التعامل مع عمليات التحديث والخيارات المتاحة لها. وللمزيد حول SQL، نشجعك على متابعة المقالات المنشورة تحت وسم سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Update Data in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية إدراج البيانات في SQL المرجع المتقدم إلى لغة SQL تصميم الجداول ومعلومات المخطط وترتيب تنفيذ الاستعلامات في SQL حذف الجداول وقواعد البيانات في SQL أهمية قواعد البيانات -
 تُقدّم لغة الاستعلامات البنيوية SQL، مرونةً هائلةً من حيث الطرق الممكنة لإدراج البيانات في الجداول. فعلى سبيل المثال، يمكنك تحديد سجلات بيانات فردية باستخدام الكلمة المفتاحية VALUES، أو نسخ مجموعات كاملة من البيانات من الجداول الحالية باستخدام الاستعلامات SELECT. كما يمكن تعريف الأعمدة بأساليب تسمح للغة SQL بإدراج البيانات فيها تلقائيًا. في هذا المقال، سنستعرض كيفية استخدام الصيغة INSERT INTO في SQL لإضافة البيانات إلى الجداول وفق كل من هذه الأساليب. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقيَّة RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام إدارة قواعد البيانات MySQL مثبت على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في سياق المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقيَّة تستخدم تقديمات فريدة خاصة بها للغة SQL. فعلى الرغم من أن الأوامر المُوضحة في هذا المقال ستعمل على نحوٍ سليم في معظم هذه الأنظمة، ولكن قد تختلف الصياغة الدقيقة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات يمكنك استخدامها للتدرّب على إدراج البيانات. إذا لم تكن لديك قاعدة بيانات للتجربة، اطلع على فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية** التالي للحصول على تفاصيل حول كيفية إنشائها. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ mysql -u user -p ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم insertDB: mysql> CREATE DATABASE insertDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات insertDB، نفّذ تعليمة USE التالية: mysql> USE insertDB; الخرج Database changed بعد اختيار قاعدة البيانات insertDB، أنشئ جدولًا داخلها. فعلى سبيل المثال، بفرض لديك مصنع وترغب في إنشاء جدول لتخزين بعض المعلومات عن موظفيك. سيحتوي هذا الجدول على الأعمدة الخمسة التالية: name: اسم كل موظف، ويُعبّر عنه باستخدام نمط البيانات varchar مع حد أقصى للطول قدره 30 محرفًا. position: يخزن هذا العمود الموقع الوظيفي لكل موظف، ويُعبّر عنه أيضًا باستخدام نمط البيانات varchar مع حد أقصى للطول قدره 30 محرفًا. department: يمثل القسم الذي يعمل فيه كل موظف، ويُعبّر عنه باستخدام نمط البيانات varchar ولكن بحد أقصى للطول قدره 20 محرفًا فقط. hourlyWage: عمود لتسجيل أجر كل موظف بالساعة، ويستخدم نمط البيانات decimal، إذ تقتصر أي قيم في هذا العمود على حد أقصى قدره أربعة أرقام، مع وجود رقمين من هذه الأرقام على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها في هذا العمود من -99.99 إلى 99.99. startDate: تاريخ تعيين كل موظف، ويُعبّر عنه باستخدام نمط البيانات date. ويجب أن تتوافق القيم من هذا النوع مع التنسيق YYYY-MM-DD. أنشئ جدولًا باسم factoryEmployees يحتوي على هذه الأعمدة الخمسة، على النحو: mysql> CREATE TABLE factoryEmployees ( mysql> name varchar(30), mysql> position varchar(30), mysql> department varchar(20), mysql> hourlyWage decimal(4,2), mysql> startDate date mysql> ); وبهذا، أصبحت جاهزًا لمتابعة الخطوات في المقال وبدء التعلم حول كيفية إدراج البيانات باستخدام SQL. إدراج البيانات يدويًا تبدو الصيغة العامة لإدراج البيانات في SQL كالتالي: mysql> INSERT INTO table_name mysql> (column1, column2, . . . columnN) mysql> VALUES mysql> (value1, value2, . . . valueN); للتوضيح، نفّذ الأمر INSERT INTO التالي لتحميل جدول factoryEmployees مع سجل واحد من البيانات: mysql> INSERT INTO factoryEmployees mysql> (name, position, department, hourlyWage, startDate) mysql> VALUES mysql> ('Agnes', 'thingamajig foreman', 'management', 26.50, '2017-05-01'); الخرج Query OK, 1 row affected (0.00 sec) يبدأ هذا الأمر بالكلمات المفتاحية INSERT INTO، يليها اسم الجدول الذي ترغب في إدراج البيانات فيه. وبعد اسم الجدول، تأتي قائمة بأسماء الأعمدة التي ستضيف البيانات إليها والتي تكون محصورة ضمن أقواس هلالية. وبعد قائمة الأعمدة، تأتي الكلمة المفتاحية VALUES، ومن ثم مجموعة من القيم محاطة بأقواس هلالية ومفصولة برموز فاصلة. الترتيب الذي تُدرج فيه الأعمدة ليس بالأمر المُلزم، ولكن من الأساسي ضمان تطابق ترتيب القيم مع ترتيب الأعمدة المُدرجة. إذ ستُدرج SQL القيمة الأولى في العمود الأول المُحدد، والقيمة الثانية في العمود الثاني، وهكذا. وللتوضيح لاحظ أن الأمر INSERT في المثال التالي سيضيف سجلًا جديدًا من البيانات، ولكن بترتيب مختلف للأعمدة: mysql> INSERT INTO factoryEmployees mysql> (department, hourlyWage, startDate, name, position) mysql> VALUES mysql> ('production', 15.59, '2018-04-28', 'Jim', 'widget tightener'); الخرج Query OK, 1 row affected (0.00 sec) إذا لم تتطابق القيم على نحوٍ صحيح مع ترتيب الأعمدة، قد تُدرج SQL البيانات في الأعمدة الخاطئة. ناهيك عن إمكانية حدوث خطأ في حال تعارضت أي من القيم مع نوع البيانات المحدد للعمود، كما في المثال التالي: mysql> INSERT INTO factoryEmployees mysql> (name, hourlyWage, position, startDate, department) mysql> VALUES mysql> ('Louise', 'doodad tester', 16.50, '2017-05-01', 'quality assurance'); الخرج ERROR 1366 (HY000): Incorrect decimal value: 'doodad tester' for column 'hourlyWage' at row 1 وعلى الرغم من ضرورة توفير قيمة لكل عمود تحدده، ولكن بالمقابل ليس من الضروري تحديد كل عمود في الجدول عند إضافة سجل جديد من البيانات. ففي حال عدم وجود قيود على الأعمدة التي تتجاهلها (كالقيد NOT NULL)، ستضع MySQL القيمة الفارغة NULL في الأعمدة غير المُحددة. mysql> INSERT INTO factoryEmployees mysql> (name, position, hourlyWage) mysql> VALUES mysql> ('Harry', 'whatzit engineer', 26.50); الخرج Query OK, 1 row affected (0.01 sec) فإذا كنت تخطط لإدخال سجل يتضمّن قيمًا لكل عمود في الجدول، فليس من الضروري تضمين أسماء الأعمدة على الإطلاق. ومع ذلك، عليك التأكد من أن القيم المُدخلة تتوافق مع الترتيب الذي عُرّفت الأعمدة وفقًا له لدى تعريف الجدول. في هذا المثال، تتوافق القيم المدرجة مع الترتيب الذي عُرّفت الأعمدة وفقًا له في تعليمة CREATE TABLE الخاصة بالجدول factoryEmployee: mysql> INSERT INTO factoryEmployees mysql> VALUES mysql> ('Marie', 'doodad welder', 'production', 27.88, '2018-03-29'); الخرج Query OK, 1 row affected (0.00 sec) كما يمكنك إضافة سجلات متعددة في وقت واحد عبر فصل كل سجل بعلامة فاصلة، كما في المثال التالي: mysql> INSERT INTO factoryEmployees mysql> VALUES mysql> ('Giles', 'gizmo inspector', 'quality assurance', 26.50, '2019-08-06'), mysql> ('Daphne', 'gizmo presser', 'production', 32.45, '2017-11-12'), mysql> ('Joan', 'whatzit analyst', 'quality assurance', 29.00, '2017-04-29'); الخرج Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 نسخ البيانات باستخدام تعليمات SELECT يمكنك نسخ سجلات البيانات المتعددة من جدول ما وإدراجها في جدول آخر باستخدام استعلام SELECT بدلًا من تحديد البيانات سجلًا تلو الآخر. تبدو صيغة هذه العملية كالتالي: mysql> INSERT INTO table_A (col_A1, col_A2, col_A3) mysql> SELECT col_B1, col_B2, col_B3 mysql> FROM table_B; فبدلًا من إلحاق قائمة الأعمدة بالكلمة المفتاحية VALUES، ألحقنا الصيغة ضمن هذا المثال بتعليمة SELECT. إذ تشمل تعليمة SELECT في هذه الصيغة بنية FROM فقط، ولكن يمكن لأي استعلام صالح أن يعمل هنا على نحوٍ صحيح. لتوضيح ذلك، نفّذ العملية CREATE TABLE التالية لإنشاء جدول جديد باسم showroomEmployees. لاحظ أن أعمدة هذا الجدول لها نفس الأسماء وأنماط البيانات كما في ثلاثة أعمدة من الجدول factoryEmployees المُستخدم في القسم السابق: mysql> CREATE TABLE showroomEmployees ( mysql> name varchar(30), mysql> hourlyWage decimal(4,2), mysql> startDate date mysql> ); الخرج Query OK, 0 rows affected (0.02 sec) الآن يمكنك ملء هذا الجدول الجديد ببعض البيانات من الجدول factoryEmployees المُنشأ سابقًا عن طريق إضافة استعلام SELECT ضمن تعليمة INSERT INTO. إذا أعاد استعلام SELECT نفس عدد الأعمدة وبنفس الترتيب كما في أعمدة الجدول الهدف، وكان لها أيضًا نفس أنماط البيانات، فيمكنك حينها تجاهل قائمة الأعمدة في تعليمة INSERT INTO، على النحو: mysql> INSERT INTO showroomEmployees mysql> SELECT mysql> factoryEmployees.name, mysql> factoryEmployees.hourlyWage, mysql> factoryEmployees.startDate mysql> FROM factoryEmployees mysql> WHERE name = 'Agnes'; الخرج Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0 ملاحظة: كل من الأعمدة المدرجة في الاستعلام SELECT الخاص بالعملية أعلاه مسبوقة باسم الجدول factoryEmployees متبوعًا برمز النقطة. وعندما نُحدد اسم جدول بهذه الطريقة عند الإشارة إلى عمود، فيُطلق عليها مصطلح الإشارة الكاملة للعمود fully qualified column reference. الأمر غير الضروري في هذه الحالة الخاصة في المثال أعلاه. ففي الواقع، ستعطي التعليمة INSERT INTO في الأمثلة التالية نفس النتيجة كالتعليمة السابقة: mysql> INSERT INTO showroomEmployees mysql> SELECT mysql> name, mysql> hourlyWage, mysql> startDate mysql> FROM factoryEmployees mysql> WHERE name = 'Agnes'; وقد استخدمنا في الأمثلة ضمن هذا القسم طريقة الإشارة الكاملة للعمود من باب التوضيح، ولكن من المستحسن استخدامها دائمًا. فهي لا تساعد في جعل لغة الاستعلام SQL أكثر وضوحًا فحسب، ولكنها تغدو كضرورة في العمليات التي تتضمن الإشارة إلى أكثر من جدول، كالاستعلامات التي تحتوي على بنية الدمج JOIN. تشمل تعليمة الاستعلام SELECT في هذه العملية البنية WHERE، وبوجودها سيُعيد الاستعلام من الجدول factoryEmployees السجلات التي تحتوي على القيمة Agnes في العمود name فقط. وبما أن هناك سجلًا واحدًا فقط في الجدول المصدر موافق لهذه القيمة، فينسخ هذا السجل فقط إلى الجدول showroomEmployees. لتأكيد ذلك، نفّذ الاستعلام التالي لاسترجاع جميع السجلات في جدول showroomEmployees: mysql> SELECT * FROM showroomEmployees; الخرج +-------+------------+------------+ | name | hourlyWage | startDate | +-------+------------+------------+ | Agnes | 26.50 | 2017-05-01 | +-------+------------+------------+ 1 row in set (0.00 sec) يمكنك إدراج عدة سجلات من البيانات باستخدام أي استعلام يُعيد أكثر من سجل من الجدول المصدر. فعلى سبيل المثال، سيُعيد الاستعلام في التعليمة التالية جميع سجلات قاعدة البيانات factoryEmployees التي لا تبدأ قيمها ضمن العمود name بالحرف J: mysql> INSERT INTO showroomEmployees mysql> SELECT mysql> factoryEmployees.name, mysql> factoryEmployees.hourlyWage, mysql> factoryEmployees.startDate mysql> FROM factoryEmployees mysql> WHERE name NOT LIKE 'J%'; الخرج Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0 نفّذ هذا الاستعلام مجددًا لاسترجاع جميع السجلات في الجدول showroomEmployees: mysql> SELECT * FROM showroomEmployees; +--------+------------+------------+ | name | hourlyWage | startDate | +--------+------------+------------+ | Agnes | 26.50 | 2017-05-01 | | Agnes | 26.50 | 2017-05-01 | | Harry | 26.50 | NULL | | Marie | 27.88 | 2018-03-29 | | Giles | 26.50 | 2019-08-06 | | Daphne | 32.45 | 2017-11-12 | +--------+------------+------------+ 6 rows in set (0.00 sec) نلاحظ وجود سجلين متطابقين يحملان القيمة Agnes في العمود name. فعند تنفيذ تعليمة INSERT INTO التي تستخدم الاستعلام SELECT, تُعامل SQL نتيجة الاستعلام هذا كمجموعة جديدة من البيانات. فبدون فرض قيود محددة على الجدول أو الاعتماد على استعلامات أدق وأكثر تحديدًا، لن يكون هناك ما يمنع وجود تكرار في السجلات عند إضافة البيانات بهذه الطريقة. إدراج البيانات تلقائيًا يمكن تطبيق بعض السمات على الأعمدة لدى إنشاء جدول، والتي تجعل نظام إدارة قواعد البيانات العلاقيّ يملؤها بالبيانات تلقائيًا. للتوضيح، نفّذ التعليمة التالية لتعريف جدول باسم interns. إذ ستُنشئ هذه العملية جدولًا باسم interns يحتوي على ثلاثة أعمدة. العمود الأول في هذا المثال، وهو internID، يحتوي على بيانات من النمط int. ولكن لاحظ أنه يشمل أيضًا سمة AUTO_INCREMENT. هذه السمة ستجعل SQL تُنشئ قيمة رقمية فريدة تلقائيًا لكل سجل جديد، تبدأ افتراضيًا بالرقم 1 وتزداد تلقائيًا بخطوة مقدارها واحد مع كل سجل تالي. وبالمثل، يشمل تعريف العمود الثاني الذي يُدعى department الكلمة المفتاحية DEFAULT. ما سيجعل نظام إدارة قواعد البيانات العلاقيّ يدرج القيمة الافتراضية – وهي الكلمة 'production' في مثالنا - تلقائيًا وذلك في حال حذف العمود department من قائمة الأعمدة ضمن تعليمة INSERT INTO، على النحو التالي: mysql> CREATE TABLE interns ( mysql> internID int AUTO_INCREMENT PRIMARY KEY, mysql> department varchar(20) DEFAULT 'production', mysql> name varchar(30) mysql> ); ملاحظة: تعدّ السمة AUTO_INCREMENT ميزة خاصة بنظام إدارة قواعد البيانات MySQL، ولكن العديد من أنظمة إدارة قواعد البيانات العلاقيّة لديها طريقتها الخاصة لتحقيق التزايد في الأرقام الصحيحة. وللحصول على فهم أفضل حول كيفية تعامل نظام إدارة قواعد البيانات العلاقي مع مسألة الزيادة التلقائية، يُفضل الرجوع إلى التوثيق الرسمي الخاص بهذا النظام. وإليك التوثيق الرسمي بخصوص هذا الموضوع لبعض قواعد البيانات المفتوحة المصدر الشهيرة: توثيق سمة AUTO_INCREMENT لـ MySQL توثيق نمط البيانات serial لـ PostgreSQL توثيق الكلمة المفتاحية Autoincrement لـ SQLite. ولتوضيح هذه الميزات، لنحمّل الجدول interns ببعض البيانات، وذلك بتنفيذ تعليمة INSERT INTO التالية. إذ تُحدّد هذه العملية القيم للعمود name فقط: mysql> INSERT INTO interns (name) VALUES ('Pierre'), ('Sheila'), ('Francois'); الخرج Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 ومن ثمّ شغّل هذا الاستعلام ليعيد كافّة السجلات من الجدول: mysql> SELECT * FROM interns; الخرج +----------+------------+----------+ | internID | department | name | +----------+------------+----------+ | 1 | production | Pierre | | 2 | production | Sheila | | 3 | production | Francois | +----------+------------+----------+ 3 rows in set (0.00 sec) يُظهر هذا الخرج أنّه وبسبب تعريفات الأعمدة فإنّ التعليمة INSERT INTO السابقة أضافت قيمًا إلى العمودين internID وdepartment، على الرغم من عدم تحديدهما. لإضافة قيمة مختلفة عن تلك الافتراضية لعمود department، يجب تحديد ذلك العمود ضمن تعليمة INSERT INTO، كالتالي: mysql> INSERT INTO interns (name, department) mysql> VALUES mysql> ('Jacques', 'management'), mysql> ('Max', 'quality assurance'), mysql> ('Edith', 'management'), mysql> ('Daniel', DEFAULT); الخرج Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 لاحظ أن السجل الأخير من القيم المُقدمة في هذا المثال يشتمل على الكلمة المفتاحية DEFAULT بدلًا من قيمة نصية. سيؤدي ذلك إلى جعل قاعدة البيانات تدرج القيمة الافتراضية ('production'). mysql> SELECT * FROM interns; الخرج +----------+-------------------+----------+ | internID | department | name | +----------+-------------------+----------+ | 1 | production | Pierre | | 2 | production | Sheila | | 3 | production | Francois | | 4 | management | Jacques | | 5 | quality assurance | Max | | 6 | management | Edith | | 7 | production | Daniel | +----------+-------------------+----------+ 7 rows in set (0.00 sec) الخلاصة تعرفت في هذا المقال على العديد من طرق إدراج البيانات في الجداول، بما في ذلك تحديد سجلات البيانات على نحوٍ فرديّ باستخدام الكلمة المفتاحية VALUES، ونسخ مجموعات كاملة من البيانات باستخدام استعلامات SELECT، وتعريف الأعمدة التي ستُدرج فيها SQL البيانات تلقائيًا. ومن الجدير بالذكر أن الأوامر التي شرحناها هنا يجب أن تعمل على أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن عليك مراعاة أن كل قاعدة بيانات SQL تستخدم تقديمًا فريدًا للّغة، لذلك يُفضّل الرجوع إلى التوثيقات الرسمية لنظام إدارة قواعد البيانات الخاص بك للحصول على توصيف أدق لكيفية التعامل مع تعليمة INSERT INTO والخيارات المتاحة لها. للمزيد حول كيفية التعامل مع SQL، ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Constraints in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام القيود في SQL جلب الاستعلامات عبر SELECT في SQL التعامل مع البيانات (الإدخال، الحذف والتعديل) في SQL مدخل إلى SQL تحديث الجداول في SQL
تُقدّم لغة الاستعلامات البنيوية SQL، مرونةً هائلةً من حيث الطرق الممكنة لإدراج البيانات في الجداول. فعلى سبيل المثال، يمكنك تحديد سجلات بيانات فردية باستخدام الكلمة المفتاحية VALUES، أو نسخ مجموعات كاملة من البيانات من الجداول الحالية باستخدام الاستعلامات SELECT. كما يمكن تعريف الأعمدة بأساليب تسمح للغة SQL بإدراج البيانات فيها تلقائيًا. في هذا المقال، سنستعرض كيفية استخدام الصيغة INSERT INTO في SQL لإضافة البيانات إلى الجداول وفق كل من هذه الأساليب. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقيَّة RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام إدارة قواعد البيانات MySQL مثبت على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في سياق المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقيَّة تستخدم تقديمات فريدة خاصة بها للغة SQL. فعلى الرغم من أن الأوامر المُوضحة في هذا المقال ستعمل على نحوٍ سليم في معظم هذه الأنظمة، ولكن قد تختلف الصياغة الدقيقة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات يمكنك استخدامها للتدرّب على إدراج البيانات. إذا لم تكن لديك قاعدة بيانات للتجربة، اطلع على فقرة الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية** التالي للحصول على تفاصيل حول كيفية إنشائها. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ mysql -u user -p ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم insertDB: mysql> CREATE DATABASE insertDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات insertDB، نفّذ تعليمة USE التالية: mysql> USE insertDB; الخرج Database changed بعد اختيار قاعدة البيانات insertDB، أنشئ جدولًا داخلها. فعلى سبيل المثال، بفرض لديك مصنع وترغب في إنشاء جدول لتخزين بعض المعلومات عن موظفيك. سيحتوي هذا الجدول على الأعمدة الخمسة التالية: name: اسم كل موظف، ويُعبّر عنه باستخدام نمط البيانات varchar مع حد أقصى للطول قدره 30 محرفًا. position: يخزن هذا العمود الموقع الوظيفي لكل موظف، ويُعبّر عنه أيضًا باستخدام نمط البيانات varchar مع حد أقصى للطول قدره 30 محرفًا. department: يمثل القسم الذي يعمل فيه كل موظف، ويُعبّر عنه باستخدام نمط البيانات varchar ولكن بحد أقصى للطول قدره 20 محرفًا فقط. hourlyWage: عمود لتسجيل أجر كل موظف بالساعة، ويستخدم نمط البيانات decimal، إذ تقتصر أي قيم في هذا العمود على حد أقصى قدره أربعة أرقام، مع وجود رقمين من هذه الأرقام على يمين الفاصلة العشرية. وبالتالي، تتراوح القيم المسموح بها في هذا العمود من -99.99 إلى 99.99. startDate: تاريخ تعيين كل موظف، ويُعبّر عنه باستخدام نمط البيانات date. ويجب أن تتوافق القيم من هذا النوع مع التنسيق YYYY-MM-DD. أنشئ جدولًا باسم factoryEmployees يحتوي على هذه الأعمدة الخمسة، على النحو: mysql> CREATE TABLE factoryEmployees ( mysql> name varchar(30), mysql> position varchar(30), mysql> department varchar(20), mysql> hourlyWage decimal(4,2), mysql> startDate date mysql> ); وبهذا، أصبحت جاهزًا لمتابعة الخطوات في المقال وبدء التعلم حول كيفية إدراج البيانات باستخدام SQL. إدراج البيانات يدويًا تبدو الصيغة العامة لإدراج البيانات في SQL كالتالي: mysql> INSERT INTO table_name mysql> (column1, column2, . . . columnN) mysql> VALUES mysql> (value1, value2, . . . valueN); للتوضيح، نفّذ الأمر INSERT INTO التالي لتحميل جدول factoryEmployees مع سجل واحد من البيانات: mysql> INSERT INTO factoryEmployees mysql> (name, position, department, hourlyWage, startDate) mysql> VALUES mysql> ('Agnes', 'thingamajig foreman', 'management', 26.50, '2017-05-01'); الخرج Query OK, 1 row affected (0.00 sec) يبدأ هذا الأمر بالكلمات المفتاحية INSERT INTO، يليها اسم الجدول الذي ترغب في إدراج البيانات فيه. وبعد اسم الجدول، تأتي قائمة بأسماء الأعمدة التي ستضيف البيانات إليها والتي تكون محصورة ضمن أقواس هلالية. وبعد قائمة الأعمدة، تأتي الكلمة المفتاحية VALUES، ومن ثم مجموعة من القيم محاطة بأقواس هلالية ومفصولة برموز فاصلة. الترتيب الذي تُدرج فيه الأعمدة ليس بالأمر المُلزم، ولكن من الأساسي ضمان تطابق ترتيب القيم مع ترتيب الأعمدة المُدرجة. إذ ستُدرج SQL القيمة الأولى في العمود الأول المُحدد، والقيمة الثانية في العمود الثاني، وهكذا. وللتوضيح لاحظ أن الأمر INSERT في المثال التالي سيضيف سجلًا جديدًا من البيانات، ولكن بترتيب مختلف للأعمدة: mysql> INSERT INTO factoryEmployees mysql> (department, hourlyWage, startDate, name, position) mysql> VALUES mysql> ('production', 15.59, '2018-04-28', 'Jim', 'widget tightener'); الخرج Query OK, 1 row affected (0.00 sec) إذا لم تتطابق القيم على نحوٍ صحيح مع ترتيب الأعمدة، قد تُدرج SQL البيانات في الأعمدة الخاطئة. ناهيك عن إمكانية حدوث خطأ في حال تعارضت أي من القيم مع نوع البيانات المحدد للعمود، كما في المثال التالي: mysql> INSERT INTO factoryEmployees mysql> (name, hourlyWage, position, startDate, department) mysql> VALUES mysql> ('Louise', 'doodad tester', 16.50, '2017-05-01', 'quality assurance'); الخرج ERROR 1366 (HY000): Incorrect decimal value: 'doodad tester' for column 'hourlyWage' at row 1 وعلى الرغم من ضرورة توفير قيمة لكل عمود تحدده، ولكن بالمقابل ليس من الضروري تحديد كل عمود في الجدول عند إضافة سجل جديد من البيانات. ففي حال عدم وجود قيود على الأعمدة التي تتجاهلها (كالقيد NOT NULL)، ستضع MySQL القيمة الفارغة NULL في الأعمدة غير المُحددة. mysql> INSERT INTO factoryEmployees mysql> (name, position, hourlyWage) mysql> VALUES mysql> ('Harry', 'whatzit engineer', 26.50); الخرج Query OK, 1 row affected (0.01 sec) فإذا كنت تخطط لإدخال سجل يتضمّن قيمًا لكل عمود في الجدول، فليس من الضروري تضمين أسماء الأعمدة على الإطلاق. ومع ذلك، عليك التأكد من أن القيم المُدخلة تتوافق مع الترتيب الذي عُرّفت الأعمدة وفقًا له لدى تعريف الجدول. في هذا المثال، تتوافق القيم المدرجة مع الترتيب الذي عُرّفت الأعمدة وفقًا له في تعليمة CREATE TABLE الخاصة بالجدول factoryEmployee: mysql> INSERT INTO factoryEmployees mysql> VALUES mysql> ('Marie', 'doodad welder', 'production', 27.88, '2018-03-29'); الخرج Query OK, 1 row affected (0.00 sec) كما يمكنك إضافة سجلات متعددة في وقت واحد عبر فصل كل سجل بعلامة فاصلة، كما في المثال التالي: mysql> INSERT INTO factoryEmployees mysql> VALUES mysql> ('Giles', 'gizmo inspector', 'quality assurance', 26.50, '2019-08-06'), mysql> ('Daphne', 'gizmo presser', 'production', 32.45, '2017-11-12'), mysql> ('Joan', 'whatzit analyst', 'quality assurance', 29.00, '2017-04-29'); الخرج Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 نسخ البيانات باستخدام تعليمات SELECT يمكنك نسخ سجلات البيانات المتعددة من جدول ما وإدراجها في جدول آخر باستخدام استعلام SELECT بدلًا من تحديد البيانات سجلًا تلو الآخر. تبدو صيغة هذه العملية كالتالي: mysql> INSERT INTO table_A (col_A1, col_A2, col_A3) mysql> SELECT col_B1, col_B2, col_B3 mysql> FROM table_B; فبدلًا من إلحاق قائمة الأعمدة بالكلمة المفتاحية VALUES، ألحقنا الصيغة ضمن هذا المثال بتعليمة SELECT. إذ تشمل تعليمة SELECT في هذه الصيغة بنية FROM فقط، ولكن يمكن لأي استعلام صالح أن يعمل هنا على نحوٍ صحيح. لتوضيح ذلك، نفّذ العملية CREATE TABLE التالية لإنشاء جدول جديد باسم showroomEmployees. لاحظ أن أعمدة هذا الجدول لها نفس الأسماء وأنماط البيانات كما في ثلاثة أعمدة من الجدول factoryEmployees المُستخدم في القسم السابق: mysql> CREATE TABLE showroomEmployees ( mysql> name varchar(30), mysql> hourlyWage decimal(4,2), mysql> startDate date mysql> ); الخرج Query OK, 0 rows affected (0.02 sec) الآن يمكنك ملء هذا الجدول الجديد ببعض البيانات من الجدول factoryEmployees المُنشأ سابقًا عن طريق إضافة استعلام SELECT ضمن تعليمة INSERT INTO. إذا أعاد استعلام SELECT نفس عدد الأعمدة وبنفس الترتيب كما في أعمدة الجدول الهدف، وكان لها أيضًا نفس أنماط البيانات، فيمكنك حينها تجاهل قائمة الأعمدة في تعليمة INSERT INTO، على النحو: mysql> INSERT INTO showroomEmployees mysql> SELECT mysql> factoryEmployees.name, mysql> factoryEmployees.hourlyWage, mysql> factoryEmployees.startDate mysql> FROM factoryEmployees mysql> WHERE name = 'Agnes'; الخرج Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0 ملاحظة: كل من الأعمدة المدرجة في الاستعلام SELECT الخاص بالعملية أعلاه مسبوقة باسم الجدول factoryEmployees متبوعًا برمز النقطة. وعندما نُحدد اسم جدول بهذه الطريقة عند الإشارة إلى عمود، فيُطلق عليها مصطلح الإشارة الكاملة للعمود fully qualified column reference. الأمر غير الضروري في هذه الحالة الخاصة في المثال أعلاه. ففي الواقع، ستعطي التعليمة INSERT INTO في الأمثلة التالية نفس النتيجة كالتعليمة السابقة: mysql> INSERT INTO showroomEmployees mysql> SELECT mysql> name, mysql> hourlyWage, mysql> startDate mysql> FROM factoryEmployees mysql> WHERE name = 'Agnes'; وقد استخدمنا في الأمثلة ضمن هذا القسم طريقة الإشارة الكاملة للعمود من باب التوضيح، ولكن من المستحسن استخدامها دائمًا. فهي لا تساعد في جعل لغة الاستعلام SQL أكثر وضوحًا فحسب، ولكنها تغدو كضرورة في العمليات التي تتضمن الإشارة إلى أكثر من جدول، كالاستعلامات التي تحتوي على بنية الدمج JOIN. تشمل تعليمة الاستعلام SELECT في هذه العملية البنية WHERE، وبوجودها سيُعيد الاستعلام من الجدول factoryEmployees السجلات التي تحتوي على القيمة Agnes في العمود name فقط. وبما أن هناك سجلًا واحدًا فقط في الجدول المصدر موافق لهذه القيمة، فينسخ هذا السجل فقط إلى الجدول showroomEmployees. لتأكيد ذلك، نفّذ الاستعلام التالي لاسترجاع جميع السجلات في جدول showroomEmployees: mysql> SELECT * FROM showroomEmployees; الخرج +-------+------------+------------+ | name | hourlyWage | startDate | +-------+------------+------------+ | Agnes | 26.50 | 2017-05-01 | +-------+------------+------------+ 1 row in set (0.00 sec) يمكنك إدراج عدة سجلات من البيانات باستخدام أي استعلام يُعيد أكثر من سجل من الجدول المصدر. فعلى سبيل المثال، سيُعيد الاستعلام في التعليمة التالية جميع سجلات قاعدة البيانات factoryEmployees التي لا تبدأ قيمها ضمن العمود name بالحرف J: mysql> INSERT INTO showroomEmployees mysql> SELECT mysql> factoryEmployees.name, mysql> factoryEmployees.hourlyWage, mysql> factoryEmployees.startDate mysql> FROM factoryEmployees mysql> WHERE name NOT LIKE 'J%'; الخرج Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0 نفّذ هذا الاستعلام مجددًا لاسترجاع جميع السجلات في الجدول showroomEmployees: mysql> SELECT * FROM showroomEmployees; +--------+------------+------------+ | name | hourlyWage | startDate | +--------+------------+------------+ | Agnes | 26.50 | 2017-05-01 | | Agnes | 26.50 | 2017-05-01 | | Harry | 26.50 | NULL | | Marie | 27.88 | 2018-03-29 | | Giles | 26.50 | 2019-08-06 | | Daphne | 32.45 | 2017-11-12 | +--------+------------+------------+ 6 rows in set (0.00 sec) نلاحظ وجود سجلين متطابقين يحملان القيمة Agnes في العمود name. فعند تنفيذ تعليمة INSERT INTO التي تستخدم الاستعلام SELECT, تُعامل SQL نتيجة الاستعلام هذا كمجموعة جديدة من البيانات. فبدون فرض قيود محددة على الجدول أو الاعتماد على استعلامات أدق وأكثر تحديدًا، لن يكون هناك ما يمنع وجود تكرار في السجلات عند إضافة البيانات بهذه الطريقة. إدراج البيانات تلقائيًا يمكن تطبيق بعض السمات على الأعمدة لدى إنشاء جدول، والتي تجعل نظام إدارة قواعد البيانات العلاقيّ يملؤها بالبيانات تلقائيًا. للتوضيح، نفّذ التعليمة التالية لتعريف جدول باسم interns. إذ ستُنشئ هذه العملية جدولًا باسم interns يحتوي على ثلاثة أعمدة. العمود الأول في هذا المثال، وهو internID، يحتوي على بيانات من النمط int. ولكن لاحظ أنه يشمل أيضًا سمة AUTO_INCREMENT. هذه السمة ستجعل SQL تُنشئ قيمة رقمية فريدة تلقائيًا لكل سجل جديد، تبدأ افتراضيًا بالرقم 1 وتزداد تلقائيًا بخطوة مقدارها واحد مع كل سجل تالي. وبالمثل، يشمل تعريف العمود الثاني الذي يُدعى department الكلمة المفتاحية DEFAULT. ما سيجعل نظام إدارة قواعد البيانات العلاقيّ يدرج القيمة الافتراضية – وهي الكلمة 'production' في مثالنا - تلقائيًا وذلك في حال حذف العمود department من قائمة الأعمدة ضمن تعليمة INSERT INTO، على النحو التالي: mysql> CREATE TABLE interns ( mysql> internID int AUTO_INCREMENT PRIMARY KEY, mysql> department varchar(20) DEFAULT 'production', mysql> name varchar(30) mysql> ); ملاحظة: تعدّ السمة AUTO_INCREMENT ميزة خاصة بنظام إدارة قواعد البيانات MySQL، ولكن العديد من أنظمة إدارة قواعد البيانات العلاقيّة لديها طريقتها الخاصة لتحقيق التزايد في الأرقام الصحيحة. وللحصول على فهم أفضل حول كيفية تعامل نظام إدارة قواعد البيانات العلاقي مع مسألة الزيادة التلقائية، يُفضل الرجوع إلى التوثيق الرسمي الخاص بهذا النظام. وإليك التوثيق الرسمي بخصوص هذا الموضوع لبعض قواعد البيانات المفتوحة المصدر الشهيرة: توثيق سمة AUTO_INCREMENT لـ MySQL توثيق نمط البيانات serial لـ PostgreSQL توثيق الكلمة المفتاحية Autoincrement لـ SQLite. ولتوضيح هذه الميزات، لنحمّل الجدول interns ببعض البيانات، وذلك بتنفيذ تعليمة INSERT INTO التالية. إذ تُحدّد هذه العملية القيم للعمود name فقط: mysql> INSERT INTO interns (name) VALUES ('Pierre'), ('Sheila'), ('Francois'); الخرج Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 ومن ثمّ شغّل هذا الاستعلام ليعيد كافّة السجلات من الجدول: mysql> SELECT * FROM interns; الخرج +----------+------------+----------+ | internID | department | name | +----------+------------+----------+ | 1 | production | Pierre | | 2 | production | Sheila | | 3 | production | Francois | +----------+------------+----------+ 3 rows in set (0.00 sec) يُظهر هذا الخرج أنّه وبسبب تعريفات الأعمدة فإنّ التعليمة INSERT INTO السابقة أضافت قيمًا إلى العمودين internID وdepartment، على الرغم من عدم تحديدهما. لإضافة قيمة مختلفة عن تلك الافتراضية لعمود department، يجب تحديد ذلك العمود ضمن تعليمة INSERT INTO، كالتالي: mysql> INSERT INTO interns (name, department) mysql> VALUES mysql> ('Jacques', 'management'), mysql> ('Max', 'quality assurance'), mysql> ('Edith', 'management'), mysql> ('Daniel', DEFAULT); الخرج Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 لاحظ أن السجل الأخير من القيم المُقدمة في هذا المثال يشتمل على الكلمة المفتاحية DEFAULT بدلًا من قيمة نصية. سيؤدي ذلك إلى جعل قاعدة البيانات تدرج القيمة الافتراضية ('production'). mysql> SELECT * FROM interns; الخرج +----------+-------------------+----------+ | internID | department | name | +----------+-------------------+----------+ | 1 | production | Pierre | | 2 | production | Sheila | | 3 | production | Francois | | 4 | management | Jacques | | 5 | quality assurance | Max | | 6 | management | Edith | | 7 | production | Daniel | +----------+-------------------+----------+ 7 rows in set (0.00 sec) الخلاصة تعرفت في هذا المقال على العديد من طرق إدراج البيانات في الجداول، بما في ذلك تحديد سجلات البيانات على نحوٍ فرديّ باستخدام الكلمة المفتاحية VALUES، ونسخ مجموعات كاملة من البيانات باستخدام استعلامات SELECT، وتعريف الأعمدة التي ستُدرج فيها SQL البيانات تلقائيًا. ومن الجدير بالذكر أن الأوامر التي شرحناها هنا يجب أن تعمل على أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن عليك مراعاة أن كل قاعدة بيانات SQL تستخدم تقديمًا فريدًا للّغة، لذلك يُفضّل الرجوع إلى التوثيقات الرسمية لنظام إدارة قواعد البيانات الخاص بك للحصول على توصيف أدق لكيفية التعامل مع تعليمة INSERT INTO والخيارات المتاحة لها. للمزيد حول كيفية التعامل مع SQL، ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Constraints in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية استخدام القيود في SQL جلب الاستعلامات عبر SELECT في SQL التعامل مع البيانات (الإدخال، الحذف والتعديل) في SQL مدخل إلى SQL تحديث الجداول في SQL -
 عند تصميم قاعدة بيانات باستخدام SQL، قد تُضطر أحيانًا إلى فرض قيود على نمط البيانات التي يمكن إضافتها إلى أعمدة معينة ضمن جدول. إذ توفّر لك SQL هذه الإمكانية من خلال ما يُعرف بالقيود constraints. فبمجرد تطبيق قيد على عمود أو جدول، ستفشل أي محاولة لإضافة بيانات لا تتوافق مع هذا القيد. ولعلّ لكل نظام من أنظمة قواعد البيانات التي تستخدم SQL طريقته الخاصة في التعامل مع القيود. يهدف هذا المقال إلى تقديم نظرة عامة حول الصيغة المُتبعة في العديد من أنظمة إدارة قواعد البيانات للتعامل مع القيود، مع التركيز على MySQL كمثال رئيسي في هذا الإطار. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العِلاقيَّة RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقيَّة تستخدم تقديمات فريدة خاصة بها للغة SQL. فعلى الرغم من أن الأوامر المُوضحة في هذا المقال ستعمل على نحوٍ سليم في معظم هذه الأنظمة، ولكن قد تختلف الصياغة الدقيقة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، فمن المفيد أيضًا أن يكون لديك فهم عام حول قيود SQL وكيفية عملها. وللحصول على نظرة عامة حول هذا المفهوم، يمكنك الرجوع إلى مقال فهم قيود SQL. كما ستحتاج إلى قاعدة بيانات يمكنك استخدامها للتدرّب على إنشاء الجداول مع القيود. إذا لم تكن لديك قاعدة بيانات للتجربة، اطلع على القسم إعداد قاعدة بيانات تجريبية نموذجية والاتصال بها التالي للحصول على تفاصيل حول كيفية إنشائها. إعداد قاعدة بيانات تجريبية نموذجية والاتصال بها إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم constraintsDB: mysql> CREATE DATABASE constraintsDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات constraintsDB، نفّذ تعليمة USE التالية: mysql> USE constraintsDB; الخرج Database changed وبذلك تغدو جاهزًا للخوض في الخطوات التالية من مقالنا هذا لتنطلق في تعلّم كيفية إنشاء وإدارة الجداول في SQL. إنشاء الجداول مع القيود عادةً ما تُعرّف القيود أثناء إنشاء الجدول. فمثلًا تُنشئ الصيغة التالية لتعليمة CREATE TABLE جدولًا باسم employeeInfo (معلومات الموظفين) يحتوي على ثلاثة أعمدة: empId (لتخزين مُعرّف الموظف) وempName (لتخزين اسم الموظف) و empPhoneNum (لتخزين رقم هاتف الموظف). كما تُطبّق هذه التعليمة أيضًا القيد UNIQUE على العمود empId. ما سيمنع وجود أي قيم متطابقة فيه: mysql> CREATE TABLE employeeInfo ( mysql> empId int UNIQUE, mysql> empName varchar(30), mysql> empPhoneNum int mysql> ); تُعرّف هذه التعليمة القيد UNIQUE مباشرةً بعد العمود empId، ما يعني أن القيد ينطبق فقط على هذا العمود. فإذا حاولت إضافة أي بيانات إلى هذا الجدول، سيراقب نظام إدارة قواعد البيانات المحتوى الحالي للعمود empId للتأكد من أنّ القيم الجديدة التي تضيفها إليه فريدة بالفعل. وهذا ما يُسمّى بالقيد على مستوى العمود. كما من الممكن تطبيق القيد خارج تعريفات العمود. ففي المثال التالي، نُنشئ جدولًا باسم racersInfo (معلومات المتسابقين) يحتوي على ثلاثة أعمدة: racerId (لتخزين مُعرّف المتسابق) وracerName (لتخزين اسم المتسابق) وfinish (لتخزين ترتيب إنهاء المتسابق للسباق). وأسفل تعريفات الأعمدة، نُطبّق القيد CHECK على العمود finish لضمان أن ترتيب كل متسابق أكبر من أو يساوي 1 (إذ لا يمكن أن يكون ترتيب أي متسابق أقل من المركز الأول): mysql> CREATE TABLE racersInfo ( mysql> racerId int, mysql> finish int, mysql> racerName varchar(30), mysql> CHECK (finish > 0) mysql> ); ونظرًا لتطبيق القيد خارج تعريف أي من الأعمدة الفردية، فيتعين عليك تحديد اسم الأعمدة التي ترغب بتطبيق القيد عليها بين قوسين هلاليين. دائمًا في حال تحديد قيد خارج تعريفات الأعمدة الفردية، نُسمّي هذا القيد بقيد على مستوى الجدول. فالقيود على مستوى العمود تنطبق فقط على الأعمدة الفردية، في حين قد تُطبّق قيود الجدول على عدة أعمدة. تسمية القيود عندما تحدد قيدًا، يولد نظام إدارة قواعد البيانات العِلاقيَّة اسمًا له تلقائيًا. يُستخدم هذا الاسم للإشارة إلى القيد في رسائل الخطأ وفي الأوامر المستخدمة لإدارة القيود. قد يكون من المريح لمدراء قواعد البيانات في بعض الأحيان توفير اسماء خاصة للقيود. فعادةً لا تكون أسماء القيود المُنشأة تلقائيًا وصفية، لذلك قد يساعد توفير الاسم بنفسك في تذكر الغرض من القيد. لتسمية قيد، ضع الكلمة المفتاحية CONSTRAINT متبوعة بالاسم الذي تختاره وذلك قبل نوع القيد. فمثلًا تعيد التعليمات التالية إنشاء جدول racersInfo مع تسميته newRacersInfo وإضافة الاسم noNegativeFinish للقيد CHECK: mysql> CREATE TABLE newRacersInfo ( mysql> racerId int, mysql> finish int, mysql> racerName varchar(30), mysql> CONSTRAINT noNegativeFinish mysql> CHECK (finish >= 1) mysql> ); ملاحظة: إذا لم تُحدّد اسمًا للقيد، أو حددته ونسيته لاحقًا، فمن المحتمل أن تعثر عليه بالرجوع إلى تخطيطات معلومات قاعدة البيانات information schemas لنظام إدارة قواعد البيانات الخاص بك. إذ توفّر العديد من أنظمة قواعد البيانات الحديثة وعملاؤها اختصارًا لعرض تعليمات CREATE الداخلية والتي تشير إلى اسم القيد. وفيما يلي روابط التوثيقات الرسمية لهذه الاختصارات لكل من MySQL وPostgreSQL: MySQL: تتضمّن MySQL التعليمة SHOW CREATE TABLE، والتي تعيد كامل تعليمة CREATE TABLE التي أنشأت الجدول المطوب، على النحو: mysql> SHOW CREATE TABLE table_name; PostgreSQL: يتضمن عميل PostgreSQL المُسمّى psql على العديد من الخيارات التي يمكنك استخدامها للكشف عن معلومات حول جدول معين. فالخيار d\ مثلًا يعيد بياناتٍ وصفية حول الجدول المطلوب: Postgres=# \d table_name إدارة القيود يمكنك إضافة القيود إلى الجداول الموجودة أصلًا في MySQL أو حذفها باستخدام أوامر ALTER TABLE. على سبيل المثال، الأمر التالي يضيف قيد UNIQUE إلى العمود empName في الجدول employeeInfo المُنشأ مسبقًا: mysql> ALTER TABLE employeeInfo ADD UNIQUE (empName); عند إضافة قيد إلى جدول موجود، يمكنك أيضًا استخدام الكلمة المفتاحية CONSTRAINT لتوفير اسم لتعريف القيد. فالأمر في المثال التالي يضيف قيد UNIQUE باسم uID إلى العمود racerId من الجدول racersInfo المُنشأ مسبقًا: mysql> ALTER TABLE racersInfo ADD CONSTRAINT uID UNIQUE (racerId); وستفشل التعليمة ALTER TABLE إذا أدخلت أي سجلات قد تنتهك شرط القيد الجديد قبل إضافته وفق هذه الطريقة. لحذف قيد، استخدم الصيغة DROP CONSTRAINT، متبوعة باسم القيد الذي ترغب في حذفه. فمثلًا الأمر التالي سيحذف القيد uID المُنشأ في الأمر السابق: mysql> ALTER TABLE racersInfo DROP CONSTRAINT uID; الخلاصة تعلمت في هذا المقال كيفية إضافة وحذف القيود للأعمدة والجداول باستخدام SQL. ومن الجدير بالذكر أن الأوامر التي شرحناها هنا يجب أن تعمل على أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن عليك مراعاة أن كل قاعدة بيانات SQL تستخدم تقديمًا فريدًا للّغة، لذلك يُفضّل الرجوع إلى التوثيقات الرسمية لنظام إدارة قواعد البيانات الخاص بك للحصول على توصيف أدق لكل أمر والخيارات المتاحة. للمزيد حول كيفية التعامل مع SQL، ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Constraints in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية إنشاء وإدارة الجداول في SQL نظرة سريعة على لغة الاستعلامات الهيكلية SQL مدخل إلى أهم الاستعلامات (queries) في MySQL مدخل إلى برنامج إدارة قواعد البيانات MySQL
عند تصميم قاعدة بيانات باستخدام SQL، قد تُضطر أحيانًا إلى فرض قيود على نمط البيانات التي يمكن إضافتها إلى أعمدة معينة ضمن جدول. إذ توفّر لك SQL هذه الإمكانية من خلال ما يُعرف بالقيود constraints. فبمجرد تطبيق قيد على عمود أو جدول، ستفشل أي محاولة لإضافة بيانات لا تتوافق مع هذا القيد. ولعلّ لكل نظام من أنظمة قواعد البيانات التي تستخدم SQL طريقته الخاصة في التعامل مع القيود. يهدف هذا المقال إلى تقديم نظرة عامة حول الصيغة المُتبعة في العديد من أنظمة إدارة قواعد البيانات للتعامل مع القيود، مع التركيز على MySQL كمثال رئيسي في هذا الإطار. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز حاسوب يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العِلاقيَّة RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. MySQL مثبتة ومؤمنة على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقيَّة تستخدم تقديمات فريدة خاصة بها للغة SQL. فعلى الرغم من أن الأوامر المُوضحة في هذا المقال ستعمل على نحوٍ سليم في معظم هذه الأنظمة، ولكن قد تختلف الصياغة الدقيقة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، فمن المفيد أيضًا أن يكون لديك فهم عام حول قيود SQL وكيفية عملها. وللحصول على نظرة عامة حول هذا المفهوم، يمكنك الرجوع إلى مقال فهم قيود SQL. كما ستحتاج إلى قاعدة بيانات يمكنك استخدامها للتدرّب على إنشاء الجداول مع القيود. إذا لم تكن لديك قاعدة بيانات للتجربة، اطلع على القسم إعداد قاعدة بيانات تجريبية نموذجية والاتصال بها التالي للحصول على تفاصيل حول كيفية إنشائها. إعداد قاعدة بيانات تجريبية نموذجية والاتصال بها إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم عن بُعد، اتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو: $ ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p أنشئ قاعدة بيانات باسم constraintsDB: mysql> CREATE DATABASE constraintsDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات constraintsDB، نفّذ تعليمة USE التالية: mysql> USE constraintsDB; الخرج Database changed وبذلك تغدو جاهزًا للخوض في الخطوات التالية من مقالنا هذا لتنطلق في تعلّم كيفية إنشاء وإدارة الجداول في SQL. إنشاء الجداول مع القيود عادةً ما تُعرّف القيود أثناء إنشاء الجدول. فمثلًا تُنشئ الصيغة التالية لتعليمة CREATE TABLE جدولًا باسم employeeInfo (معلومات الموظفين) يحتوي على ثلاثة أعمدة: empId (لتخزين مُعرّف الموظف) وempName (لتخزين اسم الموظف) و empPhoneNum (لتخزين رقم هاتف الموظف). كما تُطبّق هذه التعليمة أيضًا القيد UNIQUE على العمود empId. ما سيمنع وجود أي قيم متطابقة فيه: mysql> CREATE TABLE employeeInfo ( mysql> empId int UNIQUE, mysql> empName varchar(30), mysql> empPhoneNum int mysql> ); تُعرّف هذه التعليمة القيد UNIQUE مباشرةً بعد العمود empId، ما يعني أن القيد ينطبق فقط على هذا العمود. فإذا حاولت إضافة أي بيانات إلى هذا الجدول، سيراقب نظام إدارة قواعد البيانات المحتوى الحالي للعمود empId للتأكد من أنّ القيم الجديدة التي تضيفها إليه فريدة بالفعل. وهذا ما يُسمّى بالقيد على مستوى العمود. كما من الممكن تطبيق القيد خارج تعريفات العمود. ففي المثال التالي، نُنشئ جدولًا باسم racersInfo (معلومات المتسابقين) يحتوي على ثلاثة أعمدة: racerId (لتخزين مُعرّف المتسابق) وracerName (لتخزين اسم المتسابق) وfinish (لتخزين ترتيب إنهاء المتسابق للسباق). وأسفل تعريفات الأعمدة، نُطبّق القيد CHECK على العمود finish لضمان أن ترتيب كل متسابق أكبر من أو يساوي 1 (إذ لا يمكن أن يكون ترتيب أي متسابق أقل من المركز الأول): mysql> CREATE TABLE racersInfo ( mysql> racerId int, mysql> finish int, mysql> racerName varchar(30), mysql> CHECK (finish > 0) mysql> ); ونظرًا لتطبيق القيد خارج تعريف أي من الأعمدة الفردية، فيتعين عليك تحديد اسم الأعمدة التي ترغب بتطبيق القيد عليها بين قوسين هلاليين. دائمًا في حال تحديد قيد خارج تعريفات الأعمدة الفردية، نُسمّي هذا القيد بقيد على مستوى الجدول. فالقيود على مستوى العمود تنطبق فقط على الأعمدة الفردية، في حين قد تُطبّق قيود الجدول على عدة أعمدة. تسمية القيود عندما تحدد قيدًا، يولد نظام إدارة قواعد البيانات العِلاقيَّة اسمًا له تلقائيًا. يُستخدم هذا الاسم للإشارة إلى القيد في رسائل الخطأ وفي الأوامر المستخدمة لإدارة القيود. قد يكون من المريح لمدراء قواعد البيانات في بعض الأحيان توفير اسماء خاصة للقيود. فعادةً لا تكون أسماء القيود المُنشأة تلقائيًا وصفية، لذلك قد يساعد توفير الاسم بنفسك في تذكر الغرض من القيد. لتسمية قيد، ضع الكلمة المفتاحية CONSTRAINT متبوعة بالاسم الذي تختاره وذلك قبل نوع القيد. فمثلًا تعيد التعليمات التالية إنشاء جدول racersInfo مع تسميته newRacersInfo وإضافة الاسم noNegativeFinish للقيد CHECK: mysql> CREATE TABLE newRacersInfo ( mysql> racerId int, mysql> finish int, mysql> racerName varchar(30), mysql> CONSTRAINT noNegativeFinish mysql> CHECK (finish >= 1) mysql> ); ملاحظة: إذا لم تُحدّد اسمًا للقيد، أو حددته ونسيته لاحقًا، فمن المحتمل أن تعثر عليه بالرجوع إلى تخطيطات معلومات قاعدة البيانات information schemas لنظام إدارة قواعد البيانات الخاص بك. إذ توفّر العديد من أنظمة قواعد البيانات الحديثة وعملاؤها اختصارًا لعرض تعليمات CREATE الداخلية والتي تشير إلى اسم القيد. وفيما يلي روابط التوثيقات الرسمية لهذه الاختصارات لكل من MySQL وPostgreSQL: MySQL: تتضمّن MySQL التعليمة SHOW CREATE TABLE، والتي تعيد كامل تعليمة CREATE TABLE التي أنشأت الجدول المطوب، على النحو: mysql> SHOW CREATE TABLE table_name; PostgreSQL: يتضمن عميل PostgreSQL المُسمّى psql على العديد من الخيارات التي يمكنك استخدامها للكشف عن معلومات حول جدول معين. فالخيار d\ مثلًا يعيد بياناتٍ وصفية حول الجدول المطلوب: Postgres=# \d table_name إدارة القيود يمكنك إضافة القيود إلى الجداول الموجودة أصلًا في MySQL أو حذفها باستخدام أوامر ALTER TABLE. على سبيل المثال، الأمر التالي يضيف قيد UNIQUE إلى العمود empName في الجدول employeeInfo المُنشأ مسبقًا: mysql> ALTER TABLE employeeInfo ADD UNIQUE (empName); عند إضافة قيد إلى جدول موجود، يمكنك أيضًا استخدام الكلمة المفتاحية CONSTRAINT لتوفير اسم لتعريف القيد. فالأمر في المثال التالي يضيف قيد UNIQUE باسم uID إلى العمود racerId من الجدول racersInfo المُنشأ مسبقًا: mysql> ALTER TABLE racersInfo ADD CONSTRAINT uID UNIQUE (racerId); وستفشل التعليمة ALTER TABLE إذا أدخلت أي سجلات قد تنتهك شرط القيد الجديد قبل إضافته وفق هذه الطريقة. لحذف قيد، استخدم الصيغة DROP CONSTRAINT، متبوعة باسم القيد الذي ترغب في حذفه. فمثلًا الأمر التالي سيحذف القيد uID المُنشأ في الأمر السابق: mysql> ALTER TABLE racersInfo DROP CONSTRAINT uID; الخلاصة تعلمت في هذا المقال كيفية إضافة وحذف القيود للأعمدة والجداول باستخدام SQL. ومن الجدير بالذكر أن الأوامر التي شرحناها هنا يجب أن تعمل على أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن عليك مراعاة أن كل قاعدة بيانات SQL تستخدم تقديمًا فريدًا للّغة، لذلك يُفضّل الرجوع إلى التوثيقات الرسمية لنظام إدارة قواعد البيانات الخاص بك للحصول على توصيف أدق لكل أمر والخيارات المتاحة. للمزيد حول كيفية التعامل مع SQL، ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Use Constraints in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: كيفية إنشاء وإدارة الجداول في SQL نظرة سريعة على لغة الاستعلامات الهيكلية SQL مدخل إلى أهم الاستعلامات (queries) في MySQL مدخل إلى برنامج إدارة قواعد البيانات MySQL -
 الجداول هي الهياكل التنظيمية الأساسية في قواعد بيانات SQL. وهي تتكون من عدد من الأعمدة التي تعكس السمات الفردية لكل صف أو سجل في الجدول. ولعلّ من المهم لكل من يعمل مع قواعد البيانات العلاقية أن يفهم كيفية إنشاء وتغيير وحذف الجداول حسب الحاجة كونها جزءًا أساسيًا من آلية تنظيم البيانات. سنتناول في هذا المقال كيفية إنشاء الجداول في SQL، بالإضافة إلى كيفية تعديل وحذف الجداول الموجودة أصلًا في قاعدة البيانات. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام إدارة قواعد البيانات MySQL مثبت على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات الطفيفة في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام محارف البدل. وإذا لم تكن متوفرة لديك، يمكنك مراجعة الفقرة التالية الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، فاتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن أنشئ قاعدة بيانات باسم tablesDB: mysql> CREATE DATABASE tablesDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات tablesDB، نفّذ تعليمة USE التالية: mysql> USE tablesDB; الخرج Database changed وبذلك تغدو جاهزًا لتجربة الخطوات التالية من مقالنا هذا لتنطلق في تعلّم كيفية إنشاء وإدارة الجداول في SQL. إنشاء الجداول لإنشاء جدول في SQL، استخدم الأمر CREATE TABLE متبوعًا بالاسم الذي ترغب بتسمية الجدول به: mysql> CREATE TABLE table_name; وكما هو الحال مع كل تعليمات SQL، انتبه إلى وجوب انتهاء تعليمات CREATE TABLE برمز الفاصلة المنقوطة ;. تُنشئ الصيغة في المثال السابق جدولًا فارغًا بدون أي أعمدة. أمّا لإنشاء جدول يتضمّن أعمدة محددة، فيجب أن نُتبع اسم الجدول بقائمة تتضمن أسماء الأعمدة وأنماط البيانات الموافقة لكل منها والقيود المتعلقة بها، محصورةً بين أقواس هلالية ومفصولة برمز الفاصلة، على النحو التالي: mysql> CREATE TABLE table_name ( mysql> column1_name column1_data_type, mysql> column2_name column2_data_type, mysql> . . . mysql> columnN_name columnN_data_type mysql> ); كمثال، لنفترض أنك ترغب بإنشاء جدول لتسجيل بعض المعلومات حول المنتزهات التي تفضلها في مدينة نيويورك. فبعد اتخاذ قرار بشأن السمات التي تود تسجيلها حول كل منتزه، ستحدّد أسماء الأعمدة لكل من تلك السمات وكذلك نمط البيانات المناسب لكل منها: parkName: اسم كل منتزه. ونظرًا لوجود تباين واسع في أطوال أسماء المنتزهات، سيكون استخدام نمط البيانات varchar بطول أعظمي يبلغ 30 محرفًا مناسبًا. yearBuilt: السنة التي بُني فيها المنتزه. على الرغم من أنّ MySQL تتضمّن نمط بيانات يُسمّى year (لتخزين السنوات الميلادية)، إلّا أنّه يسمح فقط بقيم تتراوح بين 1901 و 2155. ولأن هناك عدة منتزهات في مدينة نيويورك بُنيت قبل عام 1901، لذلك من الأفضل استخدام نمط بيانات الأعداد الصحيحة int كبديل. firstVisit: تاريخ أول زيارة لك لكل منتزه. تتضمّن MySQL نمط بيانات date لتخزين التواريخ، ومن المناسب استخدامه لهذا العمود، إذ يُخزّن البيانات بالتنسيق YYYY-MM-DD (اليوم بخانتين-الشهر بخانتين-السنة بأربع خانات). lastVisit: تاريخ زيارتك الأخيرة لكل منتزه. ويمكنك هنا استخدام نمط البيانات date مجددًا. ولإنشاء جدول باسم faveParks يحتوي على أعمدة بهذه الأسماء وأنماط البيانات، نفّذ الأمر التالي: mysql> CREATE TABLE faveParks ( mysql> parkName varchar(30), mysql> yearBuilt int, mysql> firstVisit date, mysql> lastVisit date mysql> ); الخرج Query OK, 0 rows affected (0.01 sec) ومن الجدير بالملاحظة أن الأمر أعلاه يُنشئ هيكلية الجدول فقط، إذ أنّك لم تُضف أي بيانات إلى الجدول بعد. كما يمكنك إنشاء جداول جديدة استنادًا إلى جداول موجودة أصلًا باستخدام الصيغة CREATE TABLE AS على النحو التالي: mysql> CREATE TABLE new_table_name AS ( mysql> SELECT column1, column2, . . . columnN mysql> FROM old_table_name mysql> ); فبدلًا من إلحاق اسم الجدول الجديد (new_table_name) بقائمة من أسماء الأعمدة وأنماط البيانات الموافقة، نُتبعه بتعليمه AS ومن ثم تعليمة SELECT بين قوسين هلاليين والتي تُرجع الأعمدة والبيانات التي نرغب في نسخها من الجدول الأصلي (old_table_name) إلى الجدول الجديد. ومن الجدير بالملاحظة أنّه إذا كانت أعمدة الجدول الأصلي تتضمّن أي بيانات، فسيتم نسخ تلك البيانات إلى الجدول الجديد أيضًا. وللتوضيح، تشمل صيغة المثال أعلاه استعلام باستخدام SELECT والذي يحتوي فقط على بنية FROM المطلوبة. ولكن أي تعليمة صحيحة من تعليمات SELECT ستعمل على نحوٍ سليم في هذا المكان. ولمزيد من التوضيح، يُنشئ الأمر التالي جدولًا باسم parkInfo من خلال استخدام عمودين من الجدول faveParks المُنشأ سابقًا: mysql> CREATE TABLE parkInfo AS ( mysql> SELECT parkName, yearBuilt mysql> FROM faveParks mysql> ); الخرج Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 فإذا كان الجدول faveParks يحتوي على أي بيانات، فستنسخ البيانات الموجودة في أعمدة parkName وyearBuilt إلى جدول parkInfo أيضًا. ولكن في حالتنا، كلا الجدولين سيكون فارغًا. أمّا إذا حاولت إنشاء جدول مُستخدمًا اسم جدول موجود مُسبقًا من خلال التعليمات التالية: mysql> CREATE TABLE parkInfo ( mysql> name varchar(30), mysql> squareFootage int, mysql> designer varchar(30) mysql> ); الخرج ERROR 1050 (42S01): Table 'parkInfo' already exists فسيؤدي ذلك إلى وقوع خطأ يشير إلى أنّ الاسم parkinfo موجود أصلًا. ولتجنب هذا الخطأ، يمكنك إضافة الخيار IF NOT EXISTS ضمن أمر CREATE TABLE الخاص بك. إذ سيُخبر هذا الخيار قاعدة البيانات بالتحقق من وجود جدول موجود مسبقًا بنفس الاسم المحدد، ففي حال كان موجودًا، سيظهر تحذير بدلًا من رسالة الخطأ. mysql> CREATE TABLE IF NOT EXISTS parkInfo ( mysql> name varchar(30), mysql> squareFootage int, mysql> designer varchar(30) mysql> ); الخرج Query OK, 0 rows affected, 1 warning (0.00 sec) سيفشل هذا الأمر في إنشاء جدول جديد، إذ أنّ الجدول بالاسم parkInfo ما زال موجودًا أصلًا. ولكن نلاحظ أن الخرج يشير إلى كون تعليمة CREATE TABLE أدت إلى ظهور تحذير. ولعرض رسالة التحذير، نفّذ الأمر التشخيصي SHOW WARNINGS كالتالي: mysql> SHOW WARNINGS; الخرج | Level | Code | Message | +-------+------+---------------------------------+ | Note | 1050 | Table 'parkInfo' already exists | +-------+------+---------------------------------+ 1 row in set (0.00 sec) وكما يشير هذا الخرج، فقد سُجّل نفس الخطأ الذي تلقيته سابقًا على أنه تحذير، ذلك لأنك قد ضمّنت الخيار IF NOT EXISTS. وهذا الأمر قد يكون مفيدًا في بعض الحالات، كما هو الحال عند تنفيذ المعاملات Transactions التي تمثل سلسلة من عمليات SQL تُجرى على قاعدة بيانات وتعامل كما لو كانت عملية واحدة، بحيث إما أن تُنفَّذ جميعها أو لا تنفذ بأكملها، في حين يشير التحذير إلى فشل التعليمة الذي تسببت به فقط. تعديل الجداول قد تضطر في بعض الحالات إلى تغيير تعريف جدول معين وهذا الأمر مختلف عن تحديث البيانات ضمن الجدول فهو يعني تغيير هيكلية الجدول نفسه. وللقيام بذلك، يمكنك استخدام الصيغة ALTER TABLE على النحو التالي: mysql> ALTER TABLE table_name ALTER_OPTION sub_options . . . ; وبعد تضمين تعليمة ALTER TABLE، حدّد اسم الجدول الذي تود تعديله. ومن ثم مرّر الخيارات المتاحة بناءً على نظام إدارة قواعد البيانات الخاص بك لإجراء التعديل المطلوب. على سبيل المثال، قد ترغب في تغيير اسم الجدول أو إضافة عمود جديد أو حذف عمود قديم أو تغيير تعريف أحد الأعمدة. لنطبق بعض الأمثلة على جدول المنتزهات المُفضّلة faveParks الذي أنشأناه سابقًا في قسم إنشاء الجداول لمزيد من التدريب على كتابة تعليمات التعامل مع الجداول. لتغيير اسم الجدول faveParks، يمكنك استخدام صيغة RENAME TO. يغير المثال التالي اسم جدول faveParks إلى faveNYCParks: تحذير: كن حذرًا عند تغيير اسم جدول. فالقيام بذلك قد يسبب مشكلات في حال كان هناك تطبيق يستخدم الجدول أو إذا كانت هناك جداول أخرى في قاعدة البيانات تشير إليه. mysql> ALTER TABLE faveParks RENAME TO faveNYCParks; الخرج Query OK, 0 rows affected (0.01 sec) لإضافة عمود جديد للجدول، استخدم الخيار ADD COLUMN. يضيف المثال التالي عمود بالاسم borough، والذي يُخزّن بيانات من النمط varchar، ولكن بطول أقصى يبلغ 20 محرفًا إلى الجدول faveNYCParks: mysql> ALTER TABLE faveNYCParks ADD COLUMN borough varchar(20); الخرج Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 لحذف عمود من جدول مع أي بيانات يحتوي عليها، يمكنك استخدام الصيغة DROP TABLE. يحذف الأمر في المثال التالي العمود borough: mysql> ALTER TABLE faveNYCParks DROP COLUMN borough; تسمح العديد من تقديمات SQL بتغيير تعريف العمود باستخدام الصيغة ALTER TABLE. ويستخدم المثال التالي بنية MODIFY COLUMN في MySQL، إذ يقوم بتغيير العمود yearBuilt لاستخدام بيانات من النمط smallint بدلًا من النمط int الأصلي: mysql> ALTER TABLE faveNYCParks MODIFY COLUMN yearBuilt smallint; ومما يجب أخذه في الحسبان أنّ كل نظام إدارة قواعد بيانات يتضمّن خيارات مختلفة بخصوص ما يمكنك تغييره باستخدام تعليمة ALTER TABLE. ولتحقيق فهمٍ كامل حول ما يمكنك تنفيذه باستخدام ALTER TABLE, راجع التوثيق الرسمي لنظام إدارة قواعد البيانات الذي تستخدمه لمعرفة الخيارات المتاحة للتعليمة. إليك التوثيق الرسمي حول هذا الموضوع لبعضٍ من أشهر قواعد البيانات مفتوحة المصدر: توثيق ALTER TABLE في MySQL توثيق ALTER TABLE في PostgreSQL توثيق ALTER TABLE في SQLite حذف الجداول لحذف جدول وجميع البيانات الموجودة فيه، استخدم الصيغة DROP TABLE: تحذير: كن حذرًا عند تنفيذ الأمر DROP TABLE، إذ سيقوم بحذف الجدول وجميع بياناته نهائيًا. mysql> DROP TABLE table_name; كما يمكنك حذف عدة جداول باستخدام تعليمة DROP واحدة وذلك بفصل أسماء الجداول برمز فاصلة ومحرف مسافة، كما في المثال التالي: mysql> DROP TABLE table1, table2, table3; للتوضيح، سيحذف الأمر التالي كل من جدولي faveNYCParks و parkInfo المُنشأين سابقًا في هذا المقال: mysql> DROP TABLE IF EXISTS faveNYCParks, parkInfo; لاحظ أن هذا المثال يتضمن الخيار IF EXISTS، والذي يؤدي الوظيفة المعاكسة لخيار IF NOT EXISTS المتاح لأمر إنشاء الجداول CREATE TABLE. إذ سيجعل خيار IF EXISTS تعليمة DROP TABLE تعيد تحذيرًا بدلًا من رسالة خطأ في حال لم يكن أحد الجداول المُحدّدة موجودًا. الخلاصة تعلمت في هذا المقال كيفية إنشاء وتغيير وحذف الجداول في قواعد البيانات المبنية على SQL. ومن الجدير بالذكر أن الأوامر التي شرحناها هنا يجب أن تعمل على أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن عليك مراعاة أن كل قاعدة بيانات SQL تستخدم تقديمًا فريدًا للّغة، لذلك يُفضّل الرجوع إلى التوثيقات الرسمية لنظام إدارة قواعد البيانات الخاص بك للحصول على توصيف أدق لكل أمر والخيارات المتاحة. للمزيد حول كيفية التعامل مع SQL، ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Create and Manage Tables in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: فهم قيود SQL المرجع المتقدم إلى لغة SQL تصميم الجداول ومعلومات المخطط وترتيب تنفيذ الاستعلامات في SQL حذف الجداول وقواعد البيانات في SQL أهمية قواعد البيانات
الجداول هي الهياكل التنظيمية الأساسية في قواعد بيانات SQL. وهي تتكون من عدد من الأعمدة التي تعكس السمات الفردية لكل صف أو سجل في الجدول. ولعلّ من المهم لكل من يعمل مع قواعد البيانات العلاقية أن يفهم كيفية إنشاء وتغيير وحذف الجداول حسب الحاجة كونها جزءًا أساسيًا من آلية تنظيم البيانات. سنتناول في هذا المقال كيفية إنشاء الجداول في SQL، بالإضافة إلى كيفية تعديل وحذف الجداول الموجودة أصلًا في قاعدة البيانات. مستلزمات العمل لمتابعة الخطوات في هذا المقال، ستحتاج إلى جهاز كمبيوتر يُشغّل أحد أنواع أنظمة إدارة قواعد البيانات العلاقية RDBMS التي تستخدم SQL. وقد اختبرنا الأوامر البرمجية والأمثلة في هذا المقال مستخدمين البيئة التالية: خادم عامل على توزيعة أوبنتو، مع مستخدم ذو صلاحيات مسؤول مختلف عن المستخدم الجذر، وجدار حماية مكوّن باستخدام UFW، كما هو موضح في مقال كيفية تثبيت توزيعة أوبنتو من لينكس بأبسط طريقة. نظام إدارة قواعد البيانات MySQL مثبت على الخادم، كما هو موضح في المقال كيفية تثبيت MySQL على أوبونتو. وقد نفذنا خطوات هذا المقال باستخدام مستخدم MySQL مختلف عن المستخدم الجذر، مُنشأ وفق الطريقة الموضحة في الخطوة 3 من هذا المقال. ملاحظة: تجدر الإشارة إلى أنّ الكثير من أنظمة إدارة قواعد البيانات العلاقية لها تقديماتها الفريدة من لغة SQL. فبالرغم من كون الأوامر المُقدمة في هذا المقال ستعمل مع معظم هذه الأنظمة، ولكن قد تجد بعض الاختلافات الطفيفة في الصيغة أو الناتج عند تنفيذها على أنظمة مختلفة عن MySQL. وبالعودة إلى مستلزمات العمل، ستحتاج أيضًا إلى قاعدة بيانات وجدول مُحمّل ببعض البيانات التجريبية النموذجية لتتمكن من التدرب على استخدام محارف البدل. وإذا لم تكن متوفرة لديك، يمكنك مراجعة الفقرة التالية الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية للمزيد من التفاصيل حول كيفية إعداد قاعدة بيانات وجدول لاستخدامهما في الأمثلة خلال هذا المقال. الاتصال بـ MySQL وإعداد قاعدة بيانات تجريبية نموذجية إذا كان نظام قاعدة بيانات SQL الخاص بك يعمل على خادم بعيد، فاتصل بالخادم مُستخدمًا بروتوكول SSH من جهازك المحلي على النحو التالي: $ ssh user@your_server_ip ثم افتح واجهة سطر الأوامر في خادم MySQL، مُستبدلًا user باسم حساب مستخدم MySQL الخاص بك: $ mysql -u user -p الآن أنشئ قاعدة بيانات باسم tablesDB: mysql> CREATE DATABASE tablesDB; وبمجرّد إنشاء قاعدة البيانات بنجاح ستحصل على خرجٍ كالتالي: الخرج Query OK, 1 row affected (0.01 sec) ولاختيار قاعدة البيانات tablesDB، نفّذ تعليمة USE التالية: mysql> USE tablesDB; الخرج Database changed وبذلك تغدو جاهزًا لتجربة الخطوات التالية من مقالنا هذا لتنطلق في تعلّم كيفية إنشاء وإدارة الجداول في SQL. إنشاء الجداول لإنشاء جدول في SQL، استخدم الأمر CREATE TABLE متبوعًا بالاسم الذي ترغب بتسمية الجدول به: mysql> CREATE TABLE table_name; وكما هو الحال مع كل تعليمات SQL، انتبه إلى وجوب انتهاء تعليمات CREATE TABLE برمز الفاصلة المنقوطة ;. تُنشئ الصيغة في المثال السابق جدولًا فارغًا بدون أي أعمدة. أمّا لإنشاء جدول يتضمّن أعمدة محددة، فيجب أن نُتبع اسم الجدول بقائمة تتضمن أسماء الأعمدة وأنماط البيانات الموافقة لكل منها والقيود المتعلقة بها، محصورةً بين أقواس هلالية ومفصولة برمز الفاصلة، على النحو التالي: mysql> CREATE TABLE table_name ( mysql> column1_name column1_data_type, mysql> column2_name column2_data_type, mysql> . . . mysql> columnN_name columnN_data_type mysql> ); كمثال، لنفترض أنك ترغب بإنشاء جدول لتسجيل بعض المعلومات حول المنتزهات التي تفضلها في مدينة نيويورك. فبعد اتخاذ قرار بشأن السمات التي تود تسجيلها حول كل منتزه، ستحدّد أسماء الأعمدة لكل من تلك السمات وكذلك نمط البيانات المناسب لكل منها: parkName: اسم كل منتزه. ونظرًا لوجود تباين واسع في أطوال أسماء المنتزهات، سيكون استخدام نمط البيانات varchar بطول أعظمي يبلغ 30 محرفًا مناسبًا. yearBuilt: السنة التي بُني فيها المنتزه. على الرغم من أنّ MySQL تتضمّن نمط بيانات يُسمّى year (لتخزين السنوات الميلادية)، إلّا أنّه يسمح فقط بقيم تتراوح بين 1901 و 2155. ولأن هناك عدة منتزهات في مدينة نيويورك بُنيت قبل عام 1901، لذلك من الأفضل استخدام نمط بيانات الأعداد الصحيحة int كبديل. firstVisit: تاريخ أول زيارة لك لكل منتزه. تتضمّن MySQL نمط بيانات date لتخزين التواريخ، ومن المناسب استخدامه لهذا العمود، إذ يُخزّن البيانات بالتنسيق YYYY-MM-DD (اليوم بخانتين-الشهر بخانتين-السنة بأربع خانات). lastVisit: تاريخ زيارتك الأخيرة لكل منتزه. ويمكنك هنا استخدام نمط البيانات date مجددًا. ولإنشاء جدول باسم faveParks يحتوي على أعمدة بهذه الأسماء وأنماط البيانات، نفّذ الأمر التالي: mysql> CREATE TABLE faveParks ( mysql> parkName varchar(30), mysql> yearBuilt int, mysql> firstVisit date, mysql> lastVisit date mysql> ); الخرج Query OK, 0 rows affected (0.01 sec) ومن الجدير بالملاحظة أن الأمر أعلاه يُنشئ هيكلية الجدول فقط، إذ أنّك لم تُضف أي بيانات إلى الجدول بعد. كما يمكنك إنشاء جداول جديدة استنادًا إلى جداول موجودة أصلًا باستخدام الصيغة CREATE TABLE AS على النحو التالي: mysql> CREATE TABLE new_table_name AS ( mysql> SELECT column1, column2, . . . columnN mysql> FROM old_table_name mysql> ); فبدلًا من إلحاق اسم الجدول الجديد (new_table_name) بقائمة من أسماء الأعمدة وأنماط البيانات الموافقة، نُتبعه بتعليمه AS ومن ثم تعليمة SELECT بين قوسين هلاليين والتي تُرجع الأعمدة والبيانات التي نرغب في نسخها من الجدول الأصلي (old_table_name) إلى الجدول الجديد. ومن الجدير بالملاحظة أنّه إذا كانت أعمدة الجدول الأصلي تتضمّن أي بيانات، فسيتم نسخ تلك البيانات إلى الجدول الجديد أيضًا. وللتوضيح، تشمل صيغة المثال أعلاه استعلام باستخدام SELECT والذي يحتوي فقط على بنية FROM المطلوبة. ولكن أي تعليمة صحيحة من تعليمات SELECT ستعمل على نحوٍ سليم في هذا المكان. ولمزيد من التوضيح، يُنشئ الأمر التالي جدولًا باسم parkInfo من خلال استخدام عمودين من الجدول faveParks المُنشأ سابقًا: mysql> CREATE TABLE parkInfo AS ( mysql> SELECT parkName, yearBuilt mysql> FROM faveParks mysql> ); الخرج Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 فإذا كان الجدول faveParks يحتوي على أي بيانات، فستنسخ البيانات الموجودة في أعمدة parkName وyearBuilt إلى جدول parkInfo أيضًا. ولكن في حالتنا، كلا الجدولين سيكون فارغًا. أمّا إذا حاولت إنشاء جدول مُستخدمًا اسم جدول موجود مُسبقًا من خلال التعليمات التالية: mysql> CREATE TABLE parkInfo ( mysql> name varchar(30), mysql> squareFootage int, mysql> designer varchar(30) mysql> ); الخرج ERROR 1050 (42S01): Table 'parkInfo' already exists فسيؤدي ذلك إلى وقوع خطأ يشير إلى أنّ الاسم parkinfo موجود أصلًا. ولتجنب هذا الخطأ، يمكنك إضافة الخيار IF NOT EXISTS ضمن أمر CREATE TABLE الخاص بك. إذ سيُخبر هذا الخيار قاعدة البيانات بالتحقق من وجود جدول موجود مسبقًا بنفس الاسم المحدد، ففي حال كان موجودًا، سيظهر تحذير بدلًا من رسالة الخطأ. mysql> CREATE TABLE IF NOT EXISTS parkInfo ( mysql> name varchar(30), mysql> squareFootage int, mysql> designer varchar(30) mysql> ); الخرج Query OK, 0 rows affected, 1 warning (0.00 sec) سيفشل هذا الأمر في إنشاء جدول جديد، إذ أنّ الجدول بالاسم parkInfo ما زال موجودًا أصلًا. ولكن نلاحظ أن الخرج يشير إلى كون تعليمة CREATE TABLE أدت إلى ظهور تحذير. ولعرض رسالة التحذير، نفّذ الأمر التشخيصي SHOW WARNINGS كالتالي: mysql> SHOW WARNINGS; الخرج | Level | Code | Message | +-------+------+---------------------------------+ | Note | 1050 | Table 'parkInfo' already exists | +-------+------+---------------------------------+ 1 row in set (0.00 sec) وكما يشير هذا الخرج، فقد سُجّل نفس الخطأ الذي تلقيته سابقًا على أنه تحذير، ذلك لأنك قد ضمّنت الخيار IF NOT EXISTS. وهذا الأمر قد يكون مفيدًا في بعض الحالات، كما هو الحال عند تنفيذ المعاملات Transactions التي تمثل سلسلة من عمليات SQL تُجرى على قاعدة بيانات وتعامل كما لو كانت عملية واحدة، بحيث إما أن تُنفَّذ جميعها أو لا تنفذ بأكملها، في حين يشير التحذير إلى فشل التعليمة الذي تسببت به فقط. تعديل الجداول قد تضطر في بعض الحالات إلى تغيير تعريف جدول معين وهذا الأمر مختلف عن تحديث البيانات ضمن الجدول فهو يعني تغيير هيكلية الجدول نفسه. وللقيام بذلك، يمكنك استخدام الصيغة ALTER TABLE على النحو التالي: mysql> ALTER TABLE table_name ALTER_OPTION sub_options . . . ; وبعد تضمين تعليمة ALTER TABLE، حدّد اسم الجدول الذي تود تعديله. ومن ثم مرّر الخيارات المتاحة بناءً على نظام إدارة قواعد البيانات الخاص بك لإجراء التعديل المطلوب. على سبيل المثال، قد ترغب في تغيير اسم الجدول أو إضافة عمود جديد أو حذف عمود قديم أو تغيير تعريف أحد الأعمدة. لنطبق بعض الأمثلة على جدول المنتزهات المُفضّلة faveParks الذي أنشأناه سابقًا في قسم إنشاء الجداول لمزيد من التدريب على كتابة تعليمات التعامل مع الجداول. لتغيير اسم الجدول faveParks، يمكنك استخدام صيغة RENAME TO. يغير المثال التالي اسم جدول faveParks إلى faveNYCParks: تحذير: كن حذرًا عند تغيير اسم جدول. فالقيام بذلك قد يسبب مشكلات في حال كان هناك تطبيق يستخدم الجدول أو إذا كانت هناك جداول أخرى في قاعدة البيانات تشير إليه. mysql> ALTER TABLE faveParks RENAME TO faveNYCParks; الخرج Query OK, 0 rows affected (0.01 sec) لإضافة عمود جديد للجدول، استخدم الخيار ADD COLUMN. يضيف المثال التالي عمود بالاسم borough، والذي يُخزّن بيانات من النمط varchar، ولكن بطول أقصى يبلغ 20 محرفًا إلى الجدول faveNYCParks: mysql> ALTER TABLE faveNYCParks ADD COLUMN borough varchar(20); الخرج Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 لحذف عمود من جدول مع أي بيانات يحتوي عليها، يمكنك استخدام الصيغة DROP TABLE. يحذف الأمر في المثال التالي العمود borough: mysql> ALTER TABLE faveNYCParks DROP COLUMN borough; تسمح العديد من تقديمات SQL بتغيير تعريف العمود باستخدام الصيغة ALTER TABLE. ويستخدم المثال التالي بنية MODIFY COLUMN في MySQL، إذ يقوم بتغيير العمود yearBuilt لاستخدام بيانات من النمط smallint بدلًا من النمط int الأصلي: mysql> ALTER TABLE faveNYCParks MODIFY COLUMN yearBuilt smallint; ومما يجب أخذه في الحسبان أنّ كل نظام إدارة قواعد بيانات يتضمّن خيارات مختلفة بخصوص ما يمكنك تغييره باستخدام تعليمة ALTER TABLE. ولتحقيق فهمٍ كامل حول ما يمكنك تنفيذه باستخدام ALTER TABLE, راجع التوثيق الرسمي لنظام إدارة قواعد البيانات الذي تستخدمه لمعرفة الخيارات المتاحة للتعليمة. إليك التوثيق الرسمي حول هذا الموضوع لبعضٍ من أشهر قواعد البيانات مفتوحة المصدر: توثيق ALTER TABLE في MySQL توثيق ALTER TABLE في PostgreSQL توثيق ALTER TABLE في SQLite حذف الجداول لحذف جدول وجميع البيانات الموجودة فيه، استخدم الصيغة DROP TABLE: تحذير: كن حذرًا عند تنفيذ الأمر DROP TABLE، إذ سيقوم بحذف الجدول وجميع بياناته نهائيًا. mysql> DROP TABLE table_name; كما يمكنك حذف عدة جداول باستخدام تعليمة DROP واحدة وذلك بفصل أسماء الجداول برمز فاصلة ومحرف مسافة، كما في المثال التالي: mysql> DROP TABLE table1, table2, table3; للتوضيح، سيحذف الأمر التالي كل من جدولي faveNYCParks و parkInfo المُنشأين سابقًا في هذا المقال: mysql> DROP TABLE IF EXISTS faveNYCParks, parkInfo; لاحظ أن هذا المثال يتضمن الخيار IF EXISTS، والذي يؤدي الوظيفة المعاكسة لخيار IF NOT EXISTS المتاح لأمر إنشاء الجداول CREATE TABLE. إذ سيجعل خيار IF EXISTS تعليمة DROP TABLE تعيد تحذيرًا بدلًا من رسالة خطأ في حال لم يكن أحد الجداول المُحدّدة موجودًا. الخلاصة تعلمت في هذا المقال كيفية إنشاء وتغيير وحذف الجداول في قواعد البيانات المبنية على SQL. ومن الجدير بالذكر أن الأوامر التي شرحناها هنا يجب أن تعمل على أي نظام لإدارة قواعد البيانات يستخدم SQL. لكن عليك مراعاة أن كل قاعدة بيانات SQL تستخدم تقديمًا فريدًا للّغة، لذلك يُفضّل الرجوع إلى التوثيقات الرسمية لنظام إدارة قواعد البيانات الخاص بك للحصول على توصيف أدق لكل أمر والخيارات المتاحة. للمزيد حول كيفية التعامل مع SQL، ننصحك بالاطلاع على سلسلة تعلم SQL في أكاديمية حسوب. ترجمة -وبتصرف- للمقال How To Create and Manage Tables in SQL لصاحبه Mark Drake. اقرأ أيضًا المقال السابق: فهم قيود SQL المرجع المتقدم إلى لغة SQL تصميم الجداول ومعلومات المخطط وترتيب تنفيذ الاستعلامات في SQL حذف الجداول وقواعد البيانات في SQL أهمية قواعد البيانات
