
البحث في الموقع
المحتوى عن 'تعلم لغة سي'.
-
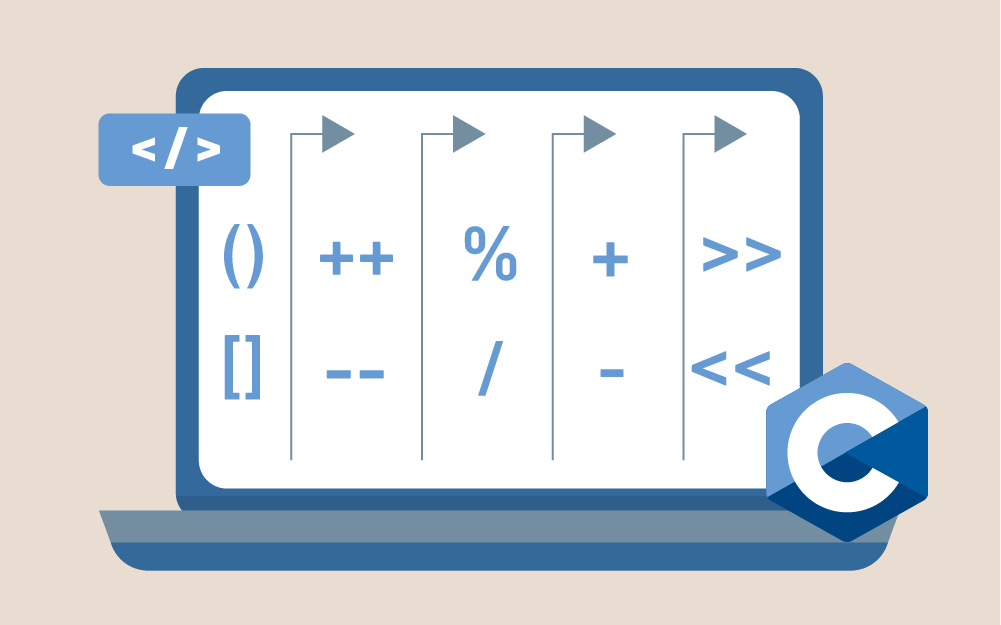 يعرض هذا المقال مفهوم العوامل في لغة C وكيفية استخدامها في العمليات والتعليمات. عوامل المضاعفة تتضمن عوامل المضاعفة multiplicative operators عامل الضرب "*" والقسمة "/" وباقي القسمة "%"، ويعمل عاملا الضرب والقسمة بالطريقة التي تتوقع أن تعملان بها، لكلٍّ من الأنواع الحقيقية والصحيحة، إذ تنتج قيمة مقتطعة دون فواصل عشرية عند تقسيم الأعداد الصحيحة ويكون الاقتطاع باتجاه الصفر. يعمل عامل باقي القسمة وفق تعريفه فقط مع الأنواع الصحيحة، لأن القسمة الناتجة عن الأعداد الحقيقية لن تعطينا باقيًا. إذا كانت القسمة غير صحيحة، وكان أيٌ من المُعاملان غير سالب، فنتيجة العامل "/" هي موجبة ومقرّبة باتجاه الصفر، ونستخدم العامل "%" للحصول على الباقي من هذه العملية، على سبيل المثال: 9/2 == 4 9%2 == 1 إذا كان أحد المُعاملات سالب، فنتيجة العامل "/" قد تكون أقرب عدد صحيح لنتيجة القسمة على أي من الاتجاهين (باتجاه الأكبر أو الأصغر)، وقد تكون إشارة نتيجة العامل "%" موجبةً أو سالبة، وتعتمد النتيجتين السابقتين حسب تعريف التنفيذ. التعبير الآتي مساوٍ الصفر في جميع الحالات عدا حالة b مساوية للصفر. (a/b)*b + a%b - a تُطبّق التحويلات الحسابية الاعتيادية على كلا المُعاملين. عوامل الجمع تتضمن عوامل الجمع additive operators عامل الجمع "+" والطرح "-"، وتتبع طريقة عمل هذه الدوال قواعدها المعتادة التي تعرفها. للعامل الثنائي والأحادي نفس الرمز، ولكن لكل واحد منهما معنًى مختلف؛ فعلى سبيل المثال، يَستخدم التعبيران a+b وa-b عاملًا ثنائيًّا (العامل - للجمع و + للطرح). إذا أردنا استخدام العوامل الأحادية بذات الرموز، فسنكتب b+ أو b-، ولعامل الطرح الأحادي وظيفةٌ واضحة ألا وهي أخذ القيمة السالبة لقيمة المُعامل، ولكن ما وظيفة عامل الجمع الأحادي؟ في الحقيقة لا يؤدي أي دور؛ ويُعد عامل الجمع الأحادي إضافةً جديدة إلى اللغة، إذ يعادل وجوده وجود عامل الطرح الأحادي ولكنه لا يؤدي أي دور لتغيير قيمة التعبير. القلة من مستخدمي لغة سي القديمة لاحظ عدم وجوده. تُطبّق التحويلات الحسابية الاعتيادية على كلٍّ من مُعاملات العوامل الثنائية (للجمع والطرح)، وتُطبّق الترقية العددية الصحيحة على مُعاملات العوامل الأحادية فقط. عوامل العمليات الثنائية واحدة من مزايا لغة سي هي الطريقة التي تسمح بها لمبرمجي النظم بالتعامل مع الشيفرة البرمجية وكأنها شيفرة تجميعية Assembly code، وهو نوع شيفرة برمجية كان شائعًا قبل مجيء لغة سي، وكان هذا النوع من الشيفرات صعب التشغيل على عدة منصات (غير محمول non-portable). كما وضحت لنا لغة سي أن هذا الأمر لا يتطلب سحرًا لجعل الشيفرة محمولة، لكن ما هو هذا الشيء؟ هو ما يُعرف أحيانًا باسم "العبث بالبِتات bit-twiddling" وهي عملية التلاعب ببتات متغيرات الأعداد الصحيحة على نحوٍ منفرد. لا يمكن استخدام عوامل العمليات الثنائية bitwise operators على مُعاملات من نوع أعداد حقيقية إذ لا تُعد البتات الخاصة بها منفردة individual أو يمكن الوصول إليها. هناك ستة عوامل للعمليات الثنائية موضحة في الجدول 7.2، الذي يوضح أيضًا نوع التحويلات الحسابية المُطبّقة. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } العامل التأثير التحويل & العملية الثنائية AND التحويلات الحسابية الاعتيادية \ العملية الثنائية OR التحويلات الحسابية الاعتيادية ^ العملية الثنائية XOR التحويلات الحسابية الاعتيادية >> إزاحة إلى اليسار الترقية العددية الصحيحة << إزاحة إلى اليمين الترقية العددية الصحيحة ~ المتمم الأحادي الترقية العددية الصحيحة [جدول 7.2. عوامل العمليات الثنائية] العامل الوحيد الأحادي هو الأخير (المتمم الأحادي)، إذ يعكس حالة كل بِت في قيمة المُعامل وله نفس تأثير عامل الطرح الأحادي في حاسوب يعمل بنظام المتمم الأحادي، لكن معظم الحواسيب الآن تعمل بنظام المتمم الثنائي، لذلك وجوده مهم. سيسهّل استخدام النظام الست عشري عن استخدام النظام العشري فهم طريقة هذه العوامل، لذا حان الوقت الآن لأن نعرفك على الثوابت الست عشرية. أي رقم يُكتب في بدايته "0x" يفسّر على أنه رقم ست عشري، على سبيل المثال القيمة "15" و"0xf"، أو "0XF" متكافئتان، جرّب تشغيل المثال التالي على حاسوبك، أو الأفضل من ذلك تنبّأ بوظيفة البرنامج قبل تشغيله. #include <stdio.h> #include <stdlib.h> main(){ int x,y; x = 0; y = ~0; while(x != y){ printf("%x & %x = %x\n", x, 0xff, x&0xff); printf("%x | %x = %x\n", x, 0x10f, x|0x10f); printf("%x ^ %x = %x\n", x, 0xf00f, x^0xf00f); printf("%x >> 2 = %x\n", x, x >> 2); printf("%x << 2 = %x\n", x, x << 2); x = (x << 1) | 1; } exit(EXIT_SUCCESS); } [مثال 2.9] لنتكلم أوّلًا عن طريقة عمل الحلقة التكرارية في مثالنا، إذ أن المتغير الذي يتحكم بالحلقة هو x ومُهيّأ بالقيمة صفر، وفي كل دورة تُوازن قيمته مع قيمة y الذي ضُبِط بنمطٍ مستقل بنفس طول الكلمة ومكون من الواحدات، وذلك بأخذ المتمم الأحادي للصفر، وفي أسفل الحلقة يُزاح المتغير x إلى اليسار مرةً واحدةً وتُجرى العملية الثنائية OR عليه، مما ينتج سلسلةً تبدأ على النحو التالي: "0، 1، 11، 111، …" بالنظام الثنائي. تُجرى العمليات الثنائية على x باستخدام كل من عوامل AND وOR وXOR (أي OR الحصرية أو دارة عدم التماثل) إضافةً إلى مُعاملات أخرى جديرة بالاهتمام، ومن ثم تُطبع النتيجة. نجد أيضًا عوامل الإزاحة إلى اليمين واليسار، التي تعطينا نتيجةً بنوع وقيمة المُعامل الموجود على الجهة اليسرى مزاحةً إلى الجهة المحددة عددًا من المراتب حسب المُعامل الموجود على جهتها اليمنى، ويجب أن يكون المُعاملان أعدادًا صحيحة. تختفي البِتات المُزاحة إلى أي من طرفي المُعامل الأيسر، وينتج عن إزاحة مقدار من البتات أكبر من البتات الموجودة في الكلمة نتيجةً معتمدةً على التنفيذ. تضمن الإزاحة إلى اليسار إزاحة الأصفار إلى البتات منخفضة الترتيب، بينما تكون الإزاحة إلى اليمين أكثر تعقيدًا، إذ إن الأمر متروك لتنفيذك للاختيار بين إجراء إزاحة منطقية أو حسابية إلى اليمين عند إزاحة المُعاملات ذات الإشارة. هذا يعني أن الإزاحة المنطقية تُزيح الأصفار باتجاه البت ذو الأكثر أهمية، بينما تنسخ الإزاحة الحسابية محتوى البت الأكثر أهمية الحالي إلى البت نفسه، ويصبح الخيار أوضح إذا أُزيح مُعامل عديم الإشارة إلى اليمين، ولا يوجد أي خيار هنا، إذ يجب أن تكون الإزاحة منطقية. ولهذا السبب يجب أن تتوقع أن تكون القيمة المُزاحة عند استخدام الإزاحة إلى اليمين مصرحٌ عنها مثل قيمةٍ عديمة الإشارة، أو أن يُحوّل نوعها cast إلى عديمة الإشارة لإجراء عملية الإزاحة كما يصف المثال التالي ذلك: int i,j; i = (unsigned)j >> 4; لا ينبغي على المُعامل الثاني (على الطرف الأيمن) لعامل الإزاحة أن يكون ثابتًا، إذ من الممكن استخدام أي دالة ذات نوع عدد صحيح؛ ومن المهم هنا الإشارة إلى أن قوانين مزج أنواع المُعاملات لا تنطبق على عوامل الإزاحة، إذ أن نوع نتيجة الإزاحة هي النوع المُزاح ذاته (بعد الترقية العددية الصحيحة) ولا تعتمد على أي شيءٍ آخر. لنتكلم عن شيء مختلف قليلًا، وهي إحدى الحيل المفيدة التي يستخدمها مبرمجو لغة سي لكتابة برامجهم على نحوٍ أفضل. إذا أردت تشكيل قيمةٍ تحتوي على واحدات "1" في جميع خاناتها عدا البِت الأقل أهمية، بهدف تخزين نمطٍ آخر فيها، فمن غير المطلوب معرفة طول الكلمة في النظام الذي تستخدمه. على سبيل المثال، تستطيع استخدام الطريقة التالية لضبط البتات الأقل ترتيبًا لمتغيرٍ من نوع int إلى 0x0f0 وجميع البتات الأخرى إلى 1: int some_variable; some_variable = ~0xf0f; أُجري المتمم الأحادي على المتمم الأحادي لنمط البتات منخفضة الترتيب المرغوب، وهذا يُعطي بدوره القيمة المطلوبة والمستقلة تمامًا عن طول الكلمة، وهو شيء متكرر الحدوث في شيفرة لغة سي. لا يوجد هناك مزيدٌ من الأشياء لقولها عن عوامل التلاعب بالبتات، وتجربتنا في تعليم لغة سي تدلنا على أنها سهلة الفهم والتعلم من معظم الناس، لذا دعنا ننتقل للموضوع التالي. عوامل الإسناد العنوان ليس خطأً مطبعيًا بل قصدنا "عوامل" بالجمع، إذ أن لدى لغة سي عدة عوامل إسناد على الرغم من رؤيتنا للعامل "=`"فقط حتى الآن. المثير للاهتمام بخصوص هذه العوامل هو أنها تعمل مثل العوامل الثنائية الأخرى، إذ تأخذ مُعاملين وتعطينا نتيجة، وتستخدم النتيجة لتكون جزءًا من التعبير. مثلًا في هذا التعبير: x = 4; تُسند القيمة 4 إلى المتغير x، والنتيجة عن إسناد القيمة إلى المتغير x هو استخدامها على النحو التالي: a = (x = 4); إذ ستخزِّن a القيمة 4 المُسندة إليها بعد أن تُسنَد إلى x. تجاهلت جميع عمليات الإسناد السابقة التي نظرنا إليها لحد اللحظة (عدا مثال واحد) ببساطة القيمة الناتجة عن عملية الإسناد بالرغم من وجودها. بفضل هذه القيمة، يمكننا كتابة تعابير مشابهة لهذه: a = b = c = d; إذ تُسند قيمة المتغير d إلى المتغير c وتُسند هذه النتيجة إلى b وهكذا دواليك، ونلاحظ هنا معالجة تعابير الإسناد من الجهة اليمنى إلى الجهة اليسرى، ولكن ماعدا ذلك فهي تعابير اعتيادية (القوانين التي تصف اتجاه المعالجة من اليمين أو من اليسار موجودةٌ في الجدول 9.2.). هناك وصف موجود في القسم الذي يتكلم عن "التحويلات"، يصف ما الذي سيحدث في حالة التحويل من أنواع طويلة إلى أنواع قصيرة، وهذا ما يحدث عندما يكون المُعامل الذي يقع على يسار عامل الإسناد البسيط أقصر من المُعامل الذي يقع على يمينه. عوامل الإسناد المتبقية هي عوامل إسناد مركّبة، وتعد اختصاراتٌ مفيدة يمكن اختصارها عندما يكون المُعامل ذاته على يمين ويسار عامل الإسناد، على سبيل المثال، يمكن اختصار التعبير التالي: x = x + 1; إلى التعبير: x += 1; وذلك باستخدام إحدى عوامل الإسناد المركّبة، وتكون النتيجة للتعبير الأول هي ذاتها للتعبير الثاني المختصر في أي حالة. يصبح هذا الأمر مفيدًا عندما يكون الجانب الأيسر من العامل تعبيرًا معقّدًا، وليس متغيرًا وحيدًا، وذلك في حالة استخدام المصفوفات والمؤشرات. يميل معظم مبرمجي لغة سي لاستخدام التعبير في المثال الثاني لأنه يبدو "أكثر منطقية"، وهذا ما يختلف عنده الكثير من المبتدئين عند تعلُّم هذه اللغة. يوضح الجدول 8.2 عوامل الإسناد المركبة، وستلاحظ استخدامنا المكثّف لها من الآن فصاعدًا. =* =/ =% =+ =- =& =\ =^ =<< =>> [جدول 8.2. عوامل الإسناد المركبة] تُطبَّق التحويلات الحسابية في كل حالة وكأنها تُطبق على كامل التعبير، أي كأن التعبير a+=b مثلًا مكتوبٌ على النحو a=a+b. عوامل الزيادة والنقصان قدّمت لغة سي عاملين أحاديين مميزين لإضافة واحد أو طرحه من تعبيرٍ ما نظرًا لشيوع هذه العملية البسيطة؛ إذ يضيف عامل الزيادة "++" واحدًا، ويطرح عامل النقصان "--" واحدًا، وتُستخدم هذه العوامل على النحو التالي: x++; ++x; x--; --x; إذ من الممكن أن يقع العامل قبل أو بعد المُعامل، ولا يختلف عمل العامل في الحالات الموضحة سابقًا حتى لو اختلف موقعه، ولكن الحالة تصبح أكثر تعقيدًا في بعض الأحيان ويصبح الفرق وفهمه مهمّان للاستخدام الصحيح. إليك الفرق موضحًا في المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int a,b; a = b = 5; printf("%d\n", ++a+5); printf("%d\n", a); printf("%d\n", b++ +5); printf("%d\n", b); exit(EXIT_SUCCESS); } مثال 10.2 خرج المثال السابق هو: 11 6 10 6 يعود السبب في الفرق في النتائج إلى تغيير مواضع العوامل؛ فإذا ظهر عامل الزيادة أو النقصان قبل المتغير، فستتغيّر القيمة بمقدار واحد و تُستخدم القيمة الجديدة ضمن التعبير؛ أما إذا ظهر العامل بعد المتغير فستُستخدم القيمة القديمة في التعبير، ثم تُغيّر قيمة المتغير. لا يستخدم مبرمجو سي عادةً التعليمة التالية لطرح أو جمع واحد: x += 1; بل يستخدمون التعليمة التالية: x++; /* or */ ++x; ينبغي تجنُّب استخدام المتغير ذاته أكثر من مرة في ذات التعبير إذا كان هذا النوع من العوامل مرتبطًا به، إذ لا يوجد هناك أي قاعدة واضحة تدلك على الجزء المحدد من التعبير الذي ستتغير فيه قيمة المتغير. قد يختار المصرّف "حفظ" جميع التغييرات وتطبيقها دفعةً واحدة، فعلى سبيل المثال لا يضمن التعبير التالي إسناد قيمة x الأصلية مرّتين إلى y: y = x++ + --x; وقد يُقيّم كما لو كان قد جرى توسعته إلى التعبير التالي: y = x + (x-1); لأن المصرّف يلاحظ عدم وجود تأثير أبدًا على قيمة x. تُجرى العمليات الحسابية في هذه الحالة تمامًا كما في حالة تعبير جمع، مثلًا x=x+1، وتُطبّق التحويلات الحسابية الاعتيادية. الأسبقية والتجميع علينا النظر إلى الطريقة التي تعمل بها هذه العوامل بعد التكلم عنها. قد تعتقد أن عملية الجمع ليست بتلك الأهمية، فنتيجة التعبير a + b + c مساويةٌ للتعبير: (a + b) + c أو التعبير: a + (b + c) أليس كذلك؟ في الحقيقة لا، فهناك فرقٌ بين التعابير السابقة؛ فإذا تسبَّب التعبير a+b بحالة طفحان، وكانت قيمة المتغير c قريبة من قيمة b-، فسيعطي التعبير الثاني الإجابة الصحيحة، بينما سيتسبب الأول بسلوك غير محدد. يمكننا ملاحظة هذه المشكلة بوضوح أكبر باستخدام قسمة الأعداد الصحيحة، إذ يعطي التعبير التالي: a/b/c نتائج مختلفةً تمامًا عند تجميعه بالطريقة: a/(b/c) أو بالطريقة: (a/b)/c يمكنك تجربة استخدام القيم a=10 و b=2 و c=3 للتأكُّد، إذ سيكون التعبير الأول: (2/3)/10، ونتيجة 2/3 في قسمة الأعداد الصحيحة هي 0، لذلك سنحصل على 10/0، مما سيسبب طفحانًا overflow؛ بينما سيعطينا التعبير الثاني القيمة (10/2)، وهي 5، وبتقسيمها على 3 تعطينا 1. يُعرَف تجميع العوامل على هذا النحو بمصطلح الارتباط associativity، والمكون الثاني لتحديد طريقة عمل العوامل هو الأسبقية precedence، إذ لبعض العوامل أسبقيةٌ عن عوامل أخرى، وتُحسب قيم العوامل هذه في التعابير الفرعية أولًا قبل الانتقال إلى العوامل الأقل أهمية. تُستخدم قوانين الأسبقية في معظم لغات البرمجة عالية المستوى. "نعلم" أن التعبير: a + b * c + d يُجمّع على النحو التالي: a + (b * c) + d إذ أن عملية الضرب ذات أسبقية أعلى موازنةً بعملية الجمع. تحظى لغة سي بوجود 15 مستوى أسبقية بفضل مجموعة العوامل الكبيرة التي تحتويها، يحاول القلة من الناس تذكرها جميعًا. يوضح الجدول 9.2 جميع المستويات، ويصف كلًّا من الأسبقية والارتباط. لم نتكلم عن جميع العوامل المذكورة في الجدول بعد. كن حذدرًا من استخدام نفس الرمز لبعض العوامل الأحادية والثنائية، والموضحة في الجدول أيضًا. العامل الاتجاه ملاحظات () [] <- . من اليسار إلى اليمين 1 ! ~ ++ -- - + (cast) * & sizeof من اليمين إلى اليسار جميع العوامل أحادية * / % من اليسار إلى اليمين عوامل ثنائية + - من اليسار إلى اليمين عوامل ثنائية << >> من اليسار إلى اليمين عوامل ثنائية < =< > => من اليسار إلى اليمين عوامل ثنائية == =! من اليسار إلى اليمين عوامل ثنائية & من اليسار إلى اليمين عامل ثنائي ^ من اليسار إلى اليمين عامل ثنائي \ من اليسار إلى اليمين عامل ثنائي && من اليسار إلى اليمين عامل ثنائي \\ من اليسار إلى اليمين عامل ثنائي :? من اليمين إلى اليسار 2 = =+ وجميع عوامل الإسناد المركّبة من اليمين إلى اليسار عوامل ثنائية , من اليسار إلى اليمين عامل ثنائي [جدول 9.2. أسبقية العوامل وترابطها] حيث أن: الأقواس بهدف تجميع التعابير، وليس استدعاء الدوال. هذا العامل غير مألوف، راجع القسم 1.4.3. السؤال هنا هو، كيف أستطيع الاستفادة من هذه المعلومات؟ من المهم طبعًا أن تكون قادرًا على كتابة تعابير تعطي قيمًا صحيحة بمعرفة ترتيب تنفيذ العمليات، إضافةً إلى فهم وقراءة تعابير مكتوبة من مبرمجين آخرين. تبدأ خطوات كتابة تعبير أو قراءة تعبير مكتوب بالعثور على العامل الأحادي والمُعاملات المرتبطة معه، وهذه ليست بالمهمة الصعبة ولكنها تحتاج إلى بعض التمرين، بالأخص عندما تعرف أنه يمكن استخدام العوامل عددًا من المرات الاعتباطية بجانب مُعاملاتها، مثل التعبير التالي باستخدام العامل * الأحادي: a*****b يعني التعبير السابق أن المتغير a مضروبٌ بقيمة ما، وهذه القيمة هي تعبير يتضمن b وعددًا من عوامل * الأحادية. تحديد العوامل الأحادية في التعبير ليست بالمهمة الصعبة، إليك بعض القواعد التي يجب أن تلجأ إليها: العاملان "++" و "-" أحاديان في جميع الحالات. العامل الذي يقع على يمين المُعامل مباشرةً هو عامل ثنائي (في حالة لم تتحقق القاعدة 1)، إذا كان العامل الذي يقع على يمين المُعامل ذاك ثنائيًّا. جميع العوامل الواقعة على يسار المُعامل أحادية (في حالة لم تتحقق القاعدة 2). يمكنك دائمًا التفكير بعمل العوامل الأحادية أولًا قبل العوامل الأخرى بسبب أسبقيتها المرتفعة، إذ من الأشياء التي يجب عليك الانتباه عليها هي مواضع العاملين "++" و "--" إذا كانا قبل أو بعد المُعامل، فعلى سبيل المثال يحتوي التعبير التالي: a + -b++ + c على عاملين أحاديين مُطبقّان على b. ترتبط العوامل الأحادية من اليمين إلى اليسار، إذًا على الرغم من قدوم - أولًا، يُكتب التعبير على النحو التالي (باستخدام الأقواس للتوضيح): a + -(b++) + c تصبح الحالة أكثر وضوحًا إذا استُخدم العامل في البداية prefix بدلًا من النهاية postfix مثل عامل زيادة أو نقصان، ويكون الترتيب من اليمين إلى اليسار في هذه الحالة أيضًا، ولكن العوامل ستظهر متتاليةً بجانب بعضها بعضًا. بعد تعلُّمنا لطريقة فهم العوامل الأحادية، أصبح من السهل قراءة التعبير من اليسار إلى اليمين، وعندما تجد عاملًا ثنائيًا أبقِه في بالك، وانظر إلى يمينه؛ فإذا كان العامل الثنائي التالي ذو أسبقية أقل فسيكون العامل الذي تنظر إليه (الذي تبقيه في بالك) هو جزء من تعبير جزئي عليك تقييم قيمته قبل أي خطوة أخرى؛ أما إذا كان العامل الثنائي التالي من نفس الأسبقية فأعِد تنفيذ العملية حتى تصل إلى عامل ذو أسبقية مختلفة؛ وعندما تجد عاملًا ذا أسبقية منخفضة، قيّم قيمة التعبير الجزئي الواقع على يسار العامل وفقًا لقوانين الارتباط؛ أما إذا وجدت عاملًا ذا أسبقية عالية فانسَ جميع ما سبقه، إذ أن المُعامل الواقع على يسار العامل عالي الأسبقية هو جزءٌ من تعبير جزئي آخر يقع على الطرف الأيسر وينتمي إلى العامل الجديد. لا تقلق إذا لم تضّح لديك الصورة بعد، إذ يواجه العديد من مبرمجي لغة سي مشكلات تتعلق بهذه النقطة، ويعتادون فيما بعد على تجميع التعابير "بنظرة عين"، دون الحاجة لتطبيق القوانين مباشرةً. لكن الأمر المهم هنا هو الخطوة التي تلي تجميعك لهذه التعابير، أتذكر "التحويلات الحسابية الاعتيادية"؟ إذ فسَّرت هذه التحويلات كيف يمكنك التنبؤ بنوع التعبير عن طريق النظر إلى المُعاملات الموجودة. والآن إذا مزجت أنواعًا مختلفة في تعبير معقد، ستُحدّد أنواع التعابير الجزئية فقط من خلال أنواع المُعاملات الموجودة في التعبير الجزئي، ألقِ نظرةً على المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int i,j; float f; i = 5; j = 2; f = 3.0; f = f + j / i; printf("value of f is %f\n", f); exit(EXIT_SUCCESS); } [مثال 11.2] قيمة الخرج هي 3.0000 وليس 5.0000 مما يفاجئ البعض الذي اعتقد أن القسمة ستكون قسمة أعداد حقيقية فقط لأن متغير من نوع float كان موجودًا في التعليمة. كان عامل القسمة بالطبع يحتوي على متغيرين من نوع int فقط على الجانبين، لذا أُجريت العملية الحسابية على أنها قسمة أعداد صحيحة وأنتجت صفرًا، واحتوى عامل الجمع على float و int على طرفيه، وبذلك -وحسب قوانين التحويلات الحسابية الاعتيادية- يُحوَّل النوع int إلى float، وهو النوع الصحيح لإجراء عملية الإسناد أيضًا، مما أعفانا من تحويلات أخرى. استعرض القسم السابق عن تحويل الأنواع casts طريقةً لتغيير نوع التعبير من نوعه الطبيعي إلى النوع الذي تريده، ولكن كُن حذرًا، إذ سيستخدم التحويل التالي قسمة صحيحة: (float)(j/i) ثم يحوّل النتيجة إلى float، وللمحافظة على باقي القسمة، يجب عليك كتابة التحويل بالطريقة: (float)j/i مما سيجبر استخدام القسمة الحقيقية. الأقواس كما وضّح المثال السابق، يمكنك تجاوز أسبقية وارتباط لغة سي الاعتيادية عن طريق استخدام الأقواس. لم يكن للأقواس أي معنًى آخر في لغة سي القديمة، ولم تضمن أيضًا ترتيب تقييم القيمة ضمن التعابير، مثل: int a, b, c; a+b+c; (a+b)+c; a+(b+c); إذا كان عليك استخدام متغيرات مؤقتة للحصول على ترتيب التقييم كما أردته، وهو أمر مهم إذا كنت تعرف أن هناك بعض التعابير التي تكون عرضةً للطفحان overflow، ولتجنُّب هذا الأمر عليك أن تعدّل ترتيب تقييم التعبير. ينص معيار سي على أن تقييم التعبير يجب أن يحدث بناءً على الترتيب المحدد وفق الأسبقية وتجميع التعابير، ويمكن للمصرّف أن يعيد تجميع التعابير إن لم يؤثر ذلك على النتيجة النهائية بهدف زيادة الكفاءة. على سبيل المثال، لا يمكن للمصرّف أن يعيد كتابة التعبير التالي: a = 10+a+b+5; إلى: a = 15+a+b; إلا في حالة تأكُّده من أن القيمة النهائية لن تكون مختلفةً عن التعبير الأولي الذي يتضمن قيم a وb، وهذه الحالة محققةٌ إذا كان المتغيران من نوع عدد صحيح عديم الإشارة، أو عدد صحيح ذو إشارة وكانت العملية لا تتسبب في بإطلاق استثناء عند التشغيل run-time exception والناتج عن طفحان. الآثار الجانبية نعيد ونكرر التحذير الوارد بشأن عوامل الزيادة: ليس من الآمن استخدام المتغير ذاته أكثر من مرة في نفس التعبير، وذلك في حالة كان تقييم التعبير يغيّر من قيمة المتغير ويؤثر على القيمة النهائية للتعبير، وذلك بسبب التغيير (أو التغييرات) "المحفوظة" والمُطبّقة فقط عند الوصول لنهاية التعليمة. على سبيل المثال التعبير f = f+1 آمن على الرغم من ظهور المتغير f مرتين في تعبير يغير من قيمتها، والتعبير ++f آمن أيضًا، ولكن ;f = f++ غير آمن. تنبع المشكلة من استخدام عامل الإسناد أو عوامل الزيادة والنقصان أو استدعاء دالة تغيّر من قيمة متغير خارجي External مُستخدم في تعبير ما، وتُعرف هذه المشاكل باسم "الآثار الجانبية Side Effects"، ولا تحدد سي ترتيب حدوث هذه الآثار الجانبية ضمن تعبير ما (سنتوسّع لاحقًا بخصوص هذه المشكلة، ونناقش "نقاط التسلسل Sequence points"). ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: الثوابت وسلاسل الهروب في لغة سي C المقال السابق: التحويلات ما بين الأنواع في تعابير لغة سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C
يعرض هذا المقال مفهوم العوامل في لغة C وكيفية استخدامها في العمليات والتعليمات. عوامل المضاعفة تتضمن عوامل المضاعفة multiplicative operators عامل الضرب "*" والقسمة "/" وباقي القسمة "%"، ويعمل عاملا الضرب والقسمة بالطريقة التي تتوقع أن تعملان بها، لكلٍّ من الأنواع الحقيقية والصحيحة، إذ تنتج قيمة مقتطعة دون فواصل عشرية عند تقسيم الأعداد الصحيحة ويكون الاقتطاع باتجاه الصفر. يعمل عامل باقي القسمة وفق تعريفه فقط مع الأنواع الصحيحة، لأن القسمة الناتجة عن الأعداد الحقيقية لن تعطينا باقيًا. إذا كانت القسمة غير صحيحة، وكان أيٌ من المُعاملان غير سالب، فنتيجة العامل "/" هي موجبة ومقرّبة باتجاه الصفر، ونستخدم العامل "%" للحصول على الباقي من هذه العملية، على سبيل المثال: 9/2 == 4 9%2 == 1 إذا كان أحد المُعاملات سالب، فنتيجة العامل "/" قد تكون أقرب عدد صحيح لنتيجة القسمة على أي من الاتجاهين (باتجاه الأكبر أو الأصغر)، وقد تكون إشارة نتيجة العامل "%" موجبةً أو سالبة، وتعتمد النتيجتين السابقتين حسب تعريف التنفيذ. التعبير الآتي مساوٍ الصفر في جميع الحالات عدا حالة b مساوية للصفر. (a/b)*b + a%b - a تُطبّق التحويلات الحسابية الاعتيادية على كلا المُعاملين. عوامل الجمع تتضمن عوامل الجمع additive operators عامل الجمع "+" والطرح "-"، وتتبع طريقة عمل هذه الدوال قواعدها المعتادة التي تعرفها. للعامل الثنائي والأحادي نفس الرمز، ولكن لكل واحد منهما معنًى مختلف؛ فعلى سبيل المثال، يَستخدم التعبيران a+b وa-b عاملًا ثنائيًّا (العامل - للجمع و + للطرح). إذا أردنا استخدام العوامل الأحادية بذات الرموز، فسنكتب b+ أو b-، ولعامل الطرح الأحادي وظيفةٌ واضحة ألا وهي أخذ القيمة السالبة لقيمة المُعامل، ولكن ما وظيفة عامل الجمع الأحادي؟ في الحقيقة لا يؤدي أي دور؛ ويُعد عامل الجمع الأحادي إضافةً جديدة إلى اللغة، إذ يعادل وجوده وجود عامل الطرح الأحادي ولكنه لا يؤدي أي دور لتغيير قيمة التعبير. القلة من مستخدمي لغة سي القديمة لاحظ عدم وجوده. تُطبّق التحويلات الحسابية الاعتيادية على كلٍّ من مُعاملات العوامل الثنائية (للجمع والطرح)، وتُطبّق الترقية العددية الصحيحة على مُعاملات العوامل الأحادية فقط. عوامل العمليات الثنائية واحدة من مزايا لغة سي هي الطريقة التي تسمح بها لمبرمجي النظم بالتعامل مع الشيفرة البرمجية وكأنها شيفرة تجميعية Assembly code، وهو نوع شيفرة برمجية كان شائعًا قبل مجيء لغة سي، وكان هذا النوع من الشيفرات صعب التشغيل على عدة منصات (غير محمول non-portable). كما وضحت لنا لغة سي أن هذا الأمر لا يتطلب سحرًا لجعل الشيفرة محمولة، لكن ما هو هذا الشيء؟ هو ما يُعرف أحيانًا باسم "العبث بالبِتات bit-twiddling" وهي عملية التلاعب ببتات متغيرات الأعداد الصحيحة على نحوٍ منفرد. لا يمكن استخدام عوامل العمليات الثنائية bitwise operators على مُعاملات من نوع أعداد حقيقية إذ لا تُعد البتات الخاصة بها منفردة individual أو يمكن الوصول إليها. هناك ستة عوامل للعمليات الثنائية موضحة في الجدول 7.2، الذي يوضح أيضًا نوع التحويلات الحسابية المُطبّقة. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } العامل التأثير التحويل & العملية الثنائية AND التحويلات الحسابية الاعتيادية \ العملية الثنائية OR التحويلات الحسابية الاعتيادية ^ العملية الثنائية XOR التحويلات الحسابية الاعتيادية >> إزاحة إلى اليسار الترقية العددية الصحيحة << إزاحة إلى اليمين الترقية العددية الصحيحة ~ المتمم الأحادي الترقية العددية الصحيحة [جدول 7.2. عوامل العمليات الثنائية] العامل الوحيد الأحادي هو الأخير (المتمم الأحادي)، إذ يعكس حالة كل بِت في قيمة المُعامل وله نفس تأثير عامل الطرح الأحادي في حاسوب يعمل بنظام المتمم الأحادي، لكن معظم الحواسيب الآن تعمل بنظام المتمم الثنائي، لذلك وجوده مهم. سيسهّل استخدام النظام الست عشري عن استخدام النظام العشري فهم طريقة هذه العوامل، لذا حان الوقت الآن لأن نعرفك على الثوابت الست عشرية. أي رقم يُكتب في بدايته "0x" يفسّر على أنه رقم ست عشري، على سبيل المثال القيمة "15" و"0xf"، أو "0XF" متكافئتان، جرّب تشغيل المثال التالي على حاسوبك، أو الأفضل من ذلك تنبّأ بوظيفة البرنامج قبل تشغيله. #include <stdio.h> #include <stdlib.h> main(){ int x,y; x = 0; y = ~0; while(x != y){ printf("%x & %x = %x\n", x, 0xff, x&0xff); printf("%x | %x = %x\n", x, 0x10f, x|0x10f); printf("%x ^ %x = %x\n", x, 0xf00f, x^0xf00f); printf("%x >> 2 = %x\n", x, x >> 2); printf("%x << 2 = %x\n", x, x << 2); x = (x << 1) | 1; } exit(EXIT_SUCCESS); } [مثال 2.9] لنتكلم أوّلًا عن طريقة عمل الحلقة التكرارية في مثالنا، إذ أن المتغير الذي يتحكم بالحلقة هو x ومُهيّأ بالقيمة صفر، وفي كل دورة تُوازن قيمته مع قيمة y الذي ضُبِط بنمطٍ مستقل بنفس طول الكلمة ومكون من الواحدات، وذلك بأخذ المتمم الأحادي للصفر، وفي أسفل الحلقة يُزاح المتغير x إلى اليسار مرةً واحدةً وتُجرى العملية الثنائية OR عليه، مما ينتج سلسلةً تبدأ على النحو التالي: "0، 1، 11، 111، …" بالنظام الثنائي. تُجرى العمليات الثنائية على x باستخدام كل من عوامل AND وOR وXOR (أي OR الحصرية أو دارة عدم التماثل) إضافةً إلى مُعاملات أخرى جديرة بالاهتمام، ومن ثم تُطبع النتيجة. نجد أيضًا عوامل الإزاحة إلى اليمين واليسار، التي تعطينا نتيجةً بنوع وقيمة المُعامل الموجود على الجهة اليسرى مزاحةً إلى الجهة المحددة عددًا من المراتب حسب المُعامل الموجود على جهتها اليمنى، ويجب أن يكون المُعاملان أعدادًا صحيحة. تختفي البِتات المُزاحة إلى أي من طرفي المُعامل الأيسر، وينتج عن إزاحة مقدار من البتات أكبر من البتات الموجودة في الكلمة نتيجةً معتمدةً على التنفيذ. تضمن الإزاحة إلى اليسار إزاحة الأصفار إلى البتات منخفضة الترتيب، بينما تكون الإزاحة إلى اليمين أكثر تعقيدًا، إذ إن الأمر متروك لتنفيذك للاختيار بين إجراء إزاحة منطقية أو حسابية إلى اليمين عند إزاحة المُعاملات ذات الإشارة. هذا يعني أن الإزاحة المنطقية تُزيح الأصفار باتجاه البت ذو الأكثر أهمية، بينما تنسخ الإزاحة الحسابية محتوى البت الأكثر أهمية الحالي إلى البت نفسه، ويصبح الخيار أوضح إذا أُزيح مُعامل عديم الإشارة إلى اليمين، ولا يوجد أي خيار هنا، إذ يجب أن تكون الإزاحة منطقية. ولهذا السبب يجب أن تتوقع أن تكون القيمة المُزاحة عند استخدام الإزاحة إلى اليمين مصرحٌ عنها مثل قيمةٍ عديمة الإشارة، أو أن يُحوّل نوعها cast إلى عديمة الإشارة لإجراء عملية الإزاحة كما يصف المثال التالي ذلك: int i,j; i = (unsigned)j >> 4; لا ينبغي على المُعامل الثاني (على الطرف الأيمن) لعامل الإزاحة أن يكون ثابتًا، إذ من الممكن استخدام أي دالة ذات نوع عدد صحيح؛ ومن المهم هنا الإشارة إلى أن قوانين مزج أنواع المُعاملات لا تنطبق على عوامل الإزاحة، إذ أن نوع نتيجة الإزاحة هي النوع المُزاح ذاته (بعد الترقية العددية الصحيحة) ولا تعتمد على أي شيءٍ آخر. لنتكلم عن شيء مختلف قليلًا، وهي إحدى الحيل المفيدة التي يستخدمها مبرمجو لغة سي لكتابة برامجهم على نحوٍ أفضل. إذا أردت تشكيل قيمةٍ تحتوي على واحدات "1" في جميع خاناتها عدا البِت الأقل أهمية، بهدف تخزين نمطٍ آخر فيها، فمن غير المطلوب معرفة طول الكلمة في النظام الذي تستخدمه. على سبيل المثال، تستطيع استخدام الطريقة التالية لضبط البتات الأقل ترتيبًا لمتغيرٍ من نوع int إلى 0x0f0 وجميع البتات الأخرى إلى 1: int some_variable; some_variable = ~0xf0f; أُجري المتمم الأحادي على المتمم الأحادي لنمط البتات منخفضة الترتيب المرغوب، وهذا يُعطي بدوره القيمة المطلوبة والمستقلة تمامًا عن طول الكلمة، وهو شيء متكرر الحدوث في شيفرة لغة سي. لا يوجد هناك مزيدٌ من الأشياء لقولها عن عوامل التلاعب بالبتات، وتجربتنا في تعليم لغة سي تدلنا على أنها سهلة الفهم والتعلم من معظم الناس، لذا دعنا ننتقل للموضوع التالي. عوامل الإسناد العنوان ليس خطأً مطبعيًا بل قصدنا "عوامل" بالجمع، إذ أن لدى لغة سي عدة عوامل إسناد على الرغم من رؤيتنا للعامل "=`"فقط حتى الآن. المثير للاهتمام بخصوص هذه العوامل هو أنها تعمل مثل العوامل الثنائية الأخرى، إذ تأخذ مُعاملين وتعطينا نتيجة، وتستخدم النتيجة لتكون جزءًا من التعبير. مثلًا في هذا التعبير: x = 4; تُسند القيمة 4 إلى المتغير x، والنتيجة عن إسناد القيمة إلى المتغير x هو استخدامها على النحو التالي: a = (x = 4); إذ ستخزِّن a القيمة 4 المُسندة إليها بعد أن تُسنَد إلى x. تجاهلت جميع عمليات الإسناد السابقة التي نظرنا إليها لحد اللحظة (عدا مثال واحد) ببساطة القيمة الناتجة عن عملية الإسناد بالرغم من وجودها. بفضل هذه القيمة، يمكننا كتابة تعابير مشابهة لهذه: a = b = c = d; إذ تُسند قيمة المتغير d إلى المتغير c وتُسند هذه النتيجة إلى b وهكذا دواليك، ونلاحظ هنا معالجة تعابير الإسناد من الجهة اليمنى إلى الجهة اليسرى، ولكن ماعدا ذلك فهي تعابير اعتيادية (القوانين التي تصف اتجاه المعالجة من اليمين أو من اليسار موجودةٌ في الجدول 9.2.). هناك وصف موجود في القسم الذي يتكلم عن "التحويلات"، يصف ما الذي سيحدث في حالة التحويل من أنواع طويلة إلى أنواع قصيرة، وهذا ما يحدث عندما يكون المُعامل الذي يقع على يسار عامل الإسناد البسيط أقصر من المُعامل الذي يقع على يمينه. عوامل الإسناد المتبقية هي عوامل إسناد مركّبة، وتعد اختصاراتٌ مفيدة يمكن اختصارها عندما يكون المُعامل ذاته على يمين ويسار عامل الإسناد، على سبيل المثال، يمكن اختصار التعبير التالي: x = x + 1; إلى التعبير: x += 1; وذلك باستخدام إحدى عوامل الإسناد المركّبة، وتكون النتيجة للتعبير الأول هي ذاتها للتعبير الثاني المختصر في أي حالة. يصبح هذا الأمر مفيدًا عندما يكون الجانب الأيسر من العامل تعبيرًا معقّدًا، وليس متغيرًا وحيدًا، وذلك في حالة استخدام المصفوفات والمؤشرات. يميل معظم مبرمجي لغة سي لاستخدام التعبير في المثال الثاني لأنه يبدو "أكثر منطقية"، وهذا ما يختلف عنده الكثير من المبتدئين عند تعلُّم هذه اللغة. يوضح الجدول 8.2 عوامل الإسناد المركبة، وستلاحظ استخدامنا المكثّف لها من الآن فصاعدًا. =* =/ =% =+ =- =& =\ =^ =<< =>> [جدول 8.2. عوامل الإسناد المركبة] تُطبَّق التحويلات الحسابية في كل حالة وكأنها تُطبق على كامل التعبير، أي كأن التعبير a+=b مثلًا مكتوبٌ على النحو a=a+b. عوامل الزيادة والنقصان قدّمت لغة سي عاملين أحاديين مميزين لإضافة واحد أو طرحه من تعبيرٍ ما نظرًا لشيوع هذه العملية البسيطة؛ إذ يضيف عامل الزيادة "++" واحدًا، ويطرح عامل النقصان "--" واحدًا، وتُستخدم هذه العوامل على النحو التالي: x++; ++x; x--; --x; إذ من الممكن أن يقع العامل قبل أو بعد المُعامل، ولا يختلف عمل العامل في الحالات الموضحة سابقًا حتى لو اختلف موقعه، ولكن الحالة تصبح أكثر تعقيدًا في بعض الأحيان ويصبح الفرق وفهمه مهمّان للاستخدام الصحيح. إليك الفرق موضحًا في المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int a,b; a = b = 5; printf("%d\n", ++a+5); printf("%d\n", a); printf("%d\n", b++ +5); printf("%d\n", b); exit(EXIT_SUCCESS); } مثال 10.2 خرج المثال السابق هو: 11 6 10 6 يعود السبب في الفرق في النتائج إلى تغيير مواضع العوامل؛ فإذا ظهر عامل الزيادة أو النقصان قبل المتغير، فستتغيّر القيمة بمقدار واحد و تُستخدم القيمة الجديدة ضمن التعبير؛ أما إذا ظهر العامل بعد المتغير فستُستخدم القيمة القديمة في التعبير، ثم تُغيّر قيمة المتغير. لا يستخدم مبرمجو سي عادةً التعليمة التالية لطرح أو جمع واحد: x += 1; بل يستخدمون التعليمة التالية: x++; /* or */ ++x; ينبغي تجنُّب استخدام المتغير ذاته أكثر من مرة في ذات التعبير إذا كان هذا النوع من العوامل مرتبطًا به، إذ لا يوجد هناك أي قاعدة واضحة تدلك على الجزء المحدد من التعبير الذي ستتغير فيه قيمة المتغير. قد يختار المصرّف "حفظ" جميع التغييرات وتطبيقها دفعةً واحدة، فعلى سبيل المثال لا يضمن التعبير التالي إسناد قيمة x الأصلية مرّتين إلى y: y = x++ + --x; وقد يُقيّم كما لو كان قد جرى توسعته إلى التعبير التالي: y = x + (x-1); لأن المصرّف يلاحظ عدم وجود تأثير أبدًا على قيمة x. تُجرى العمليات الحسابية في هذه الحالة تمامًا كما في حالة تعبير جمع، مثلًا x=x+1، وتُطبّق التحويلات الحسابية الاعتيادية. الأسبقية والتجميع علينا النظر إلى الطريقة التي تعمل بها هذه العوامل بعد التكلم عنها. قد تعتقد أن عملية الجمع ليست بتلك الأهمية، فنتيجة التعبير a + b + c مساويةٌ للتعبير: (a + b) + c أو التعبير: a + (b + c) أليس كذلك؟ في الحقيقة لا، فهناك فرقٌ بين التعابير السابقة؛ فإذا تسبَّب التعبير a+b بحالة طفحان، وكانت قيمة المتغير c قريبة من قيمة b-، فسيعطي التعبير الثاني الإجابة الصحيحة، بينما سيتسبب الأول بسلوك غير محدد. يمكننا ملاحظة هذه المشكلة بوضوح أكبر باستخدام قسمة الأعداد الصحيحة، إذ يعطي التعبير التالي: a/b/c نتائج مختلفةً تمامًا عند تجميعه بالطريقة: a/(b/c) أو بالطريقة: (a/b)/c يمكنك تجربة استخدام القيم a=10 و b=2 و c=3 للتأكُّد، إذ سيكون التعبير الأول: (2/3)/10، ونتيجة 2/3 في قسمة الأعداد الصحيحة هي 0، لذلك سنحصل على 10/0، مما سيسبب طفحانًا overflow؛ بينما سيعطينا التعبير الثاني القيمة (10/2)، وهي 5، وبتقسيمها على 3 تعطينا 1. يُعرَف تجميع العوامل على هذا النحو بمصطلح الارتباط associativity، والمكون الثاني لتحديد طريقة عمل العوامل هو الأسبقية precedence، إذ لبعض العوامل أسبقيةٌ عن عوامل أخرى، وتُحسب قيم العوامل هذه في التعابير الفرعية أولًا قبل الانتقال إلى العوامل الأقل أهمية. تُستخدم قوانين الأسبقية في معظم لغات البرمجة عالية المستوى. "نعلم" أن التعبير: a + b * c + d يُجمّع على النحو التالي: a + (b * c) + d إذ أن عملية الضرب ذات أسبقية أعلى موازنةً بعملية الجمع. تحظى لغة سي بوجود 15 مستوى أسبقية بفضل مجموعة العوامل الكبيرة التي تحتويها، يحاول القلة من الناس تذكرها جميعًا. يوضح الجدول 9.2 جميع المستويات، ويصف كلًّا من الأسبقية والارتباط. لم نتكلم عن جميع العوامل المذكورة في الجدول بعد. كن حذدرًا من استخدام نفس الرمز لبعض العوامل الأحادية والثنائية، والموضحة في الجدول أيضًا. العامل الاتجاه ملاحظات () [] <- . من اليسار إلى اليمين 1 ! ~ ++ -- - + (cast) * & sizeof من اليمين إلى اليسار جميع العوامل أحادية * / % من اليسار إلى اليمين عوامل ثنائية + - من اليسار إلى اليمين عوامل ثنائية << >> من اليسار إلى اليمين عوامل ثنائية < =< > => من اليسار إلى اليمين عوامل ثنائية == =! من اليسار إلى اليمين عوامل ثنائية & من اليسار إلى اليمين عامل ثنائي ^ من اليسار إلى اليمين عامل ثنائي \ من اليسار إلى اليمين عامل ثنائي && من اليسار إلى اليمين عامل ثنائي \\ من اليسار إلى اليمين عامل ثنائي :? من اليمين إلى اليسار 2 = =+ وجميع عوامل الإسناد المركّبة من اليمين إلى اليسار عوامل ثنائية , من اليسار إلى اليمين عامل ثنائي [جدول 9.2. أسبقية العوامل وترابطها] حيث أن: الأقواس بهدف تجميع التعابير، وليس استدعاء الدوال. هذا العامل غير مألوف، راجع القسم 1.4.3. السؤال هنا هو، كيف أستطيع الاستفادة من هذه المعلومات؟ من المهم طبعًا أن تكون قادرًا على كتابة تعابير تعطي قيمًا صحيحة بمعرفة ترتيب تنفيذ العمليات، إضافةً إلى فهم وقراءة تعابير مكتوبة من مبرمجين آخرين. تبدأ خطوات كتابة تعبير أو قراءة تعبير مكتوب بالعثور على العامل الأحادي والمُعاملات المرتبطة معه، وهذه ليست بالمهمة الصعبة ولكنها تحتاج إلى بعض التمرين، بالأخص عندما تعرف أنه يمكن استخدام العوامل عددًا من المرات الاعتباطية بجانب مُعاملاتها، مثل التعبير التالي باستخدام العامل * الأحادي: a*****b يعني التعبير السابق أن المتغير a مضروبٌ بقيمة ما، وهذه القيمة هي تعبير يتضمن b وعددًا من عوامل * الأحادية. تحديد العوامل الأحادية في التعبير ليست بالمهمة الصعبة، إليك بعض القواعد التي يجب أن تلجأ إليها: العاملان "++" و "-" أحاديان في جميع الحالات. العامل الذي يقع على يمين المُعامل مباشرةً هو عامل ثنائي (في حالة لم تتحقق القاعدة 1)، إذا كان العامل الذي يقع على يمين المُعامل ذاك ثنائيًّا. جميع العوامل الواقعة على يسار المُعامل أحادية (في حالة لم تتحقق القاعدة 2). يمكنك دائمًا التفكير بعمل العوامل الأحادية أولًا قبل العوامل الأخرى بسبب أسبقيتها المرتفعة، إذ من الأشياء التي يجب عليك الانتباه عليها هي مواضع العاملين "++" و "--" إذا كانا قبل أو بعد المُعامل، فعلى سبيل المثال يحتوي التعبير التالي: a + -b++ + c على عاملين أحاديين مُطبقّان على b. ترتبط العوامل الأحادية من اليمين إلى اليسار، إذًا على الرغم من قدوم - أولًا، يُكتب التعبير على النحو التالي (باستخدام الأقواس للتوضيح): a + -(b++) + c تصبح الحالة أكثر وضوحًا إذا استُخدم العامل في البداية prefix بدلًا من النهاية postfix مثل عامل زيادة أو نقصان، ويكون الترتيب من اليمين إلى اليسار في هذه الحالة أيضًا، ولكن العوامل ستظهر متتاليةً بجانب بعضها بعضًا. بعد تعلُّمنا لطريقة فهم العوامل الأحادية، أصبح من السهل قراءة التعبير من اليسار إلى اليمين، وعندما تجد عاملًا ثنائيًا أبقِه في بالك، وانظر إلى يمينه؛ فإذا كان العامل الثنائي التالي ذو أسبقية أقل فسيكون العامل الذي تنظر إليه (الذي تبقيه في بالك) هو جزء من تعبير جزئي عليك تقييم قيمته قبل أي خطوة أخرى؛ أما إذا كان العامل الثنائي التالي من نفس الأسبقية فأعِد تنفيذ العملية حتى تصل إلى عامل ذو أسبقية مختلفة؛ وعندما تجد عاملًا ذا أسبقية منخفضة، قيّم قيمة التعبير الجزئي الواقع على يسار العامل وفقًا لقوانين الارتباط؛ أما إذا وجدت عاملًا ذا أسبقية عالية فانسَ جميع ما سبقه، إذ أن المُعامل الواقع على يسار العامل عالي الأسبقية هو جزءٌ من تعبير جزئي آخر يقع على الطرف الأيسر وينتمي إلى العامل الجديد. لا تقلق إذا لم تضّح لديك الصورة بعد، إذ يواجه العديد من مبرمجي لغة سي مشكلات تتعلق بهذه النقطة، ويعتادون فيما بعد على تجميع التعابير "بنظرة عين"، دون الحاجة لتطبيق القوانين مباشرةً. لكن الأمر المهم هنا هو الخطوة التي تلي تجميعك لهذه التعابير، أتذكر "التحويلات الحسابية الاعتيادية"؟ إذ فسَّرت هذه التحويلات كيف يمكنك التنبؤ بنوع التعبير عن طريق النظر إلى المُعاملات الموجودة. والآن إذا مزجت أنواعًا مختلفة في تعبير معقد، ستُحدّد أنواع التعابير الجزئية فقط من خلال أنواع المُعاملات الموجودة في التعبير الجزئي، ألقِ نظرةً على المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int i,j; float f; i = 5; j = 2; f = 3.0; f = f + j / i; printf("value of f is %f\n", f); exit(EXIT_SUCCESS); } [مثال 11.2] قيمة الخرج هي 3.0000 وليس 5.0000 مما يفاجئ البعض الذي اعتقد أن القسمة ستكون قسمة أعداد حقيقية فقط لأن متغير من نوع float كان موجودًا في التعليمة. كان عامل القسمة بالطبع يحتوي على متغيرين من نوع int فقط على الجانبين، لذا أُجريت العملية الحسابية على أنها قسمة أعداد صحيحة وأنتجت صفرًا، واحتوى عامل الجمع على float و int على طرفيه، وبذلك -وحسب قوانين التحويلات الحسابية الاعتيادية- يُحوَّل النوع int إلى float، وهو النوع الصحيح لإجراء عملية الإسناد أيضًا، مما أعفانا من تحويلات أخرى. استعرض القسم السابق عن تحويل الأنواع casts طريقةً لتغيير نوع التعبير من نوعه الطبيعي إلى النوع الذي تريده، ولكن كُن حذرًا، إذ سيستخدم التحويل التالي قسمة صحيحة: (float)(j/i) ثم يحوّل النتيجة إلى float، وللمحافظة على باقي القسمة، يجب عليك كتابة التحويل بالطريقة: (float)j/i مما سيجبر استخدام القسمة الحقيقية. الأقواس كما وضّح المثال السابق، يمكنك تجاوز أسبقية وارتباط لغة سي الاعتيادية عن طريق استخدام الأقواس. لم يكن للأقواس أي معنًى آخر في لغة سي القديمة، ولم تضمن أيضًا ترتيب تقييم القيمة ضمن التعابير، مثل: int a, b, c; a+b+c; (a+b)+c; a+(b+c); إذا كان عليك استخدام متغيرات مؤقتة للحصول على ترتيب التقييم كما أردته، وهو أمر مهم إذا كنت تعرف أن هناك بعض التعابير التي تكون عرضةً للطفحان overflow، ولتجنُّب هذا الأمر عليك أن تعدّل ترتيب تقييم التعبير. ينص معيار سي على أن تقييم التعبير يجب أن يحدث بناءً على الترتيب المحدد وفق الأسبقية وتجميع التعابير، ويمكن للمصرّف أن يعيد تجميع التعابير إن لم يؤثر ذلك على النتيجة النهائية بهدف زيادة الكفاءة. على سبيل المثال، لا يمكن للمصرّف أن يعيد كتابة التعبير التالي: a = 10+a+b+5; إلى: a = 15+a+b; إلا في حالة تأكُّده من أن القيمة النهائية لن تكون مختلفةً عن التعبير الأولي الذي يتضمن قيم a وb، وهذه الحالة محققةٌ إذا كان المتغيران من نوع عدد صحيح عديم الإشارة، أو عدد صحيح ذو إشارة وكانت العملية لا تتسبب في بإطلاق استثناء عند التشغيل run-time exception والناتج عن طفحان. الآثار الجانبية نعيد ونكرر التحذير الوارد بشأن عوامل الزيادة: ليس من الآمن استخدام المتغير ذاته أكثر من مرة في نفس التعبير، وذلك في حالة كان تقييم التعبير يغيّر من قيمة المتغير ويؤثر على القيمة النهائية للتعبير، وذلك بسبب التغيير (أو التغييرات) "المحفوظة" والمُطبّقة فقط عند الوصول لنهاية التعليمة. على سبيل المثال التعبير f = f+1 آمن على الرغم من ظهور المتغير f مرتين في تعبير يغير من قيمتها، والتعبير ++f آمن أيضًا، ولكن ;f = f++ غير آمن. تنبع المشكلة من استخدام عامل الإسناد أو عوامل الزيادة والنقصان أو استدعاء دالة تغيّر من قيمة متغير خارجي External مُستخدم في تعبير ما، وتُعرف هذه المشاكل باسم "الآثار الجانبية Side Effects"، ولا تحدد سي ترتيب حدوث هذه الآثار الجانبية ضمن تعبير ما (سنتوسّع لاحقًا بخصوص هذه المشكلة، ونناقش "نقاط التسلسل Sequence points"). ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: الثوابت وسلاسل الهروب في لغة سي C المقال السابق: التحويلات ما بين الأنواع في تعابير لغة سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C -
 سنتعرف في هذا المقال عن كيفية إجراء التحويلات ما بين الأنواع في تعابير لغة سي C التعابير والعمليات الحسابية من الممكن أن تكون التعابير في لغة سي معقدةً بعض الشيء نظرًا لاستخدام عدد من الأنواع المختلفة والعوامل operators في التعبير الواحد. سيشرح هذا القسم من الكتاب كيفية عمل التعابير هذه، وقد نتطرق للتفاصيل الصغيرة في بعض الأحيان، لذلك سيتوجب عليك قراءتها عدّة مرات حتى تتحقق من فهمك للفكرة. دعنا نبدأ أولًا ببعض المصطلحات، إذ تُبنى التعابير في لغة سي من مزيجٍ يتكون من العوامل والمُعاملات operands. لنأخذ على سبيل المثال التعبير التالي: x = a+b*(-c) لدينا العوامل = و + و * و -، والمُعاملات التي هي المتغيرات x و a و b و c، كما يمكنك ملاحظة القوسين أيضًا اللذين يمكن استخدامهما في تجميع التعبيرات الجزئية مثل c-. تنقسم معظم مجموعة عوامل لغة سي الواسعة إلى عوامل ثنائية binary operators تأخذ مُعاملين، أو عوامل أحادية unary operators تأخذ مُعاملًا واحدًا؛ ففي مثالنا كان - مُستخدمًا مثل عاملٍ أحادي، ويؤدي دورًا مختلفًا عن عامل الطرح الثنائي الذي يُمثّل بالرمز ذاته. قد تنظر إلى الفرق بأنه لا يستحق الذكر وأن وظيفة العامل ذاتها أو متشابهة في الحالتين، ولكنه على النقيض تمامًا فإنه يستحقّ الذكر، لأن لبعض العوامل -كما ستجد لاحقًا- شكل ثنائي وآخر أحادي وكلّ وظيفة مختلفة كاملًا عن الأخرى، ويُعد عامل الضرب الثنائي * الذي يعمل عمل الموجّه باستخدام المؤشرات في حالته الأحادية مثالًا جيدًا على ذلك. تتميز لغة سي بأن العوامل قد تظهر بصورةٍ متتالية دون الحاجة للأقواس للفصل فيما بينهما في تعبيرٍ ما، إذ يمكننا كتابة المثال السابق على النحو التالي وسيظلّ تعبيرًا صالحًا. x = a+b*-c; بالنظر إلى عدد العوامل في لغة سي والطريقة الغريبة التي تعمل بها عملية الإسناد، تُعد أسبقية precedence العامل وارتباطه associativity مسألةً هامةً جدًا بالنسبة لمبرمجٍ بلغة سي موازنةً باللغات الأخرى، وستُناقش هذه النقطة بالتفصيل بعد التكلم عن أهمية عوامل العمليات الحسابية. لكن علينا قبل ذلك أن ننظر إلى عملية تحويل النوع التي قد تحصل. التحويلات تسمح لغة سي بمزج عدّة أنواع ضمن التعبير الواحد، وتسمح أيضًا بالعوامل التي يؤدي استخدامها إلى تحويلات للأنواع ضمنيًا، يصف هذا القسم الطريقة التي تحدث بها هذه التحويلات. ينبغي على مبرمجي لغة سي القديمة (التي سبقت المعيار) قراءة هذا القسم بانتباه، إذ تغيّرت العديد من القواعد وبالأخص التحويل من float إلى double والتحويل من أنواع الأعداد الصحيحة short، كما أن القواعد الأساسية في حفظ القيم value preserving قد تغيرت جدًأ في لغة سي المعيارية. على الرغم من عدم ارتباط هذه المعلومة مباشرةً في هذا السياق، تجدر الإشارة هنا إلى أن أنواع الأعداد العشرية floating والصحيحة تُعرف باسم الأنواع الحسابية arithmetic types وتدعم لغة سي عدة أنواع أخرى، أبرزها أنواع المؤشر pointer. تنطبق القوانين التي سنناقشها هنا على التعابير التي تحتوي الأنواع الحسابية فقط، إذ أن هناك بعض القواعد الإضافية عند إضافة أنواع مؤشر مع الأنواع الحسابية إلى هذا المزيج وسنناقشها لاحقًا. إليك أنواع التحويلات المتنوعة في التعابير الحسابية: الترقيات العددية الصحيحة integral promotions. التحويلات بين الأنواع العددية الصحيحة. التحويلات بين الأنواع العددية العشرية. التحويلات ما بين الأنواع العددية الصحيحة والعشرية. سبق وأن ناقشنا التحويلات بين الأنواع العددية الصحيحة في مقال الأنواع الحقيقية والصحيحة في لغة سي فقرة الأعداد الصحيحة، وما سنفعله في الوقت الحالي هو تحديد طريقة عمل التحويلات الأخرى، ومن ثم سننظر متى يجب استخدامها، عليك أن تحفظ هذه التحويلات عن ظهر قلب إذا أردت أن تصبح مبرمجًا بارعًا بلغة سي. من الأشياء المختلف عليها التي قدمها المعيار، هي قواعد الحفاظ على القيمة value preserving، إذ تتطلب معرفةً معينةً من الحاسوب الهدف الذي ينفذ البرنامج من أجل معرفة نوع القيمة الناتجة من التعبير. عندما كنا نصادف في السابق نوعًا عديم الإشارة ضمن تعبير ما، كان هذا يعني ضمانًا بأن القيمة الناتجة من نوع unsigned أيضًا، ولكن في الوقت الحالي النتيجة ستكون من نوع unsigned فقط إذا كان التحويل يتطلب ذلك، وهذا يعني أنه في معظم الحالات ستكون النتيجة من نوع signed. السبب في هذا التغيير هو تقليل القيم التي قد تفاجئك عند مزج قيم من نوع ذو إشارة مع آخر عديم الإشارة، ففي معظم الحالات لا تعرف سبب هذا التغيير، وكان الدافع هنا التحويل إلى نتيجة "أكثر استخدامًا وطلبًا". الترقية العددية الصحيحة أقل العمليات الحسابية دقةً في لغة سي هي باستخدام نوع الأعداد الصحيحة int، لذلك تحصل هذه التحويلات ضمنيًّا في كل مرة تُستخدم الكائنات المذكورة في الأسفل ضمن تعبيرٍ ما. التحويل مُعرّف كما يلي: عند تطبيق الترقية العددية الصحيحة إلى نوع short أو char (أو حقل البِت bitfield أو نوع المعدّد enumeration type الذَين لم نتطرق إليهما بعد): ستُحّول القيمة إلى int، إذا كان من الممكن للمتغير تخزين جميع قيم النوع الأصل. عدا ذلك، ستُحوَّل إلى unsigned int. يحفظ هذا التحويل كلًا من القيمة والإشارة الخاصة بالقيمة الأصلية، تذكر أن موضوع معاملة نوع char بإشارة أو دون إشارة يعود إلى التنفيذ. تُطبَّق هذه الترقيات على نحوٍ متكرر بمثابة جزءٍ من التحويلات الحسابية الاعتيادية ومُعاملات عوامل الإزاحة الأحادية، مثل + و - و ~، كما تُطبّق عندما يكون التعبير مُستخدمًا مثل وسيط لدالة ما دون أي معلومات عن النوع ضمن نموذج الدالة الأولي function prototype، كما سنشرح لاحقًا. الأعداد الصحيحة ذات الإشارة وعديمة الإشارة هناك الكثير من التحويلات الناتجة بين عدد من أنواع الأعداد الصحيحة المختلفة ومزج نكهاتها (أنواعها) المختلفة ضمن تعبير ما، وعند حدوث ذلك، ستحدث الترقية العددية الصحيحة. يمكن للنوع الجديد الناتج في جميع الحالات أن يخزن جميع القيم التي يستطيع النوع القديم تخزينها، وبذلك يمكن الحفاظ على القيم دون تغييرها. في حال التحويل من عدد صحيح ذو إشارة إلى عدد صحيح عديم الإشارة وكان طول هذا العدد مساويًا لطول (أو أطول من) النوع الأصلي، فلن تتغير القيمة بعد التحويل إذا كان العدد ذو الإشارة موجبًا؛ أما إذا كانت القيمة سالبة فهذا يعني تحويلها إلى صيغة ذات إشارة للنوع الأطول وجعلها عديمة الإشارة عن طريق إضافة قيمتها إلى القيمة العظمى التي يستطيع النوع عديم الإشارة تخزينها زائد واحد. تُحافظ هذه العملية على نمط البِتّات الأصلي للأرقام الموجبة وتضمن "خانة الإشارة الموسّعة" للأرقام السالبة وذلك في نظام المتمّم الثنائي. لا يوجد هناك أي حالات "طفحان overflow" في جميع حالات تحويل عدد صحيح إلى نوع عديم إشارة قصير، فالنتيجة معرّفةٌ وفق "الباقي غير السالب مقسومًا على القيمة العظمى للرقم عديم الإشارة الذي يمكن تمثيله باستخدام النوع القصير زائد واحد". يعني هذا ببساطة أنه في بيئة تعمل بنظام المتمم الثنائي، تُنسخ البِتات منخفضة الترتيب low-order إلى الهدف ويكون التخلُّص من البتات مرتفعة الترتيب high-order. قد تحصل بعض المشاكل عند تحويل العدد الصحيح إلى نوع ذي إشارة قصير إن لم يكن هناك مساحةٌ كافيةٌ لتخزين القيمة، وفي هذه الحالة تكون النتيجة حسب التنفيذ implementation defined، كما قد يتوقع معظم من اعتاد على سي القديمة أن يُنسخ نمط البِتات منخفضة الترتيب. من الممكن أن يكون البند الأخير مثيرًا للقلق بعض الشيء إذا كنت تتذكر الترقية العددية الصحيحة، لأنك قد تنظر إلى الأمر على النحو التالي: إذا أسندت متغيرًا من نوع char إلى متحولٍ من نوع char، فسيُرقّى المتغير على اليمين إلى نوع من أنوع int. إذًا، هل من الممكن أن يؤدي الإسناد إلى تحويل int إلى char (مثلًا) وتفعيل البند "التعريف حسب التنفيذ"؟ الإجابة هي لا، لأن عملية الإسناد لا تضمّ ترقية الأعداد الصحيحة، لذا لا تقلق. الأعداد العشرية والصحيحة يتخلّص تحويل نوع عدد عشري floating إلى نوع عدد صحيح بسيط من جميع الأجزاء العشرية للقيمة، فإذا كان نوع العدد الصحيح غير قابل لتخزين القيمة المتبقية، فسيصبح لدينا سلوك غير محدد، أي حالة شبيهة بالطفحان overflow. كما ذكرنا سابقًا، لا توجد هناك أي مشكلة إذا حدث التحويل بصورةٍ تصاعدية من float إلى double إلى long double، إذ من الممكن لجميع الأنواع السابقة تخزين جميع القيم التي تتسع في الأنواع الأصغر منها، وبذلك تحصل عملية التحويل دون أي فقدان للمعلومات؛ بينما سينتج في التحويل في الاتجاه المعاكس سلوكٌ غير محدد في حال كانت القيمة خارج مجال القيم التي يمكن للنوع تخزينها، وفي حال كانت القيمة ضمن المجال ولكن لا يمكن تخزينها بدقتها بالضبط النتيجة، ستكون واحدةً من القيمتين المجاورتين الممكن تخزينها، ويجري اختيارها حسب التنفيذ، وهذا يعني أن القيمة ستفقد جزءًا من دقتها. التحويلات الحسابية الاعتيادية هناك العديد من التعابير التي تتضمن استخدام تعابير فرعية subexpressions تحتوي على خليطٍ من الأنواع مع عوامل، مثل "+" و"*" وما شابه. إذا كانت للمُعاملات ضمن التعبير عدّة أنواع، فهذا يعني أن هناك بعض التحويلات الواجب إجراؤها حتى تكون النتيجة النهائية من نوع معين، والتحويلات هي: إذا كان أي من المُعاملَين من نوع long double يُحوَّل المُعامل الآخر إلى long double ويكون هذا هو نوع النتيجة. ماعدا ذلك، إذا كان أيٌ من المُعاملَين من نوع double، يُحوَّل المُعامل الآخر إلى double ويكون هذا هو نوع النتيجة. ماعدا ذلك، إن كان أي من المُعاملَين من نوع float، يُحوًل المُعامل الآخر إلى float ويكون هذا هو نوع النتيجة. ماعدا ذلك، تُطبّق الترقية العددية الصحيحة لكلا المُعاملين حسب التحويلات التالية: إذا كان أيٌ من المُعاملَين من نوع unsigned long int، يُحوَّل المُعامل الآخر إلى unsigned long int ويكون هذا نوع النتيجة. ماعدا ذلك، إذا كان أيٌ من المُعاملَين من نوع long int، يُحوَّل المُعامل الآخر إلى long int ويكون هذا هو نوع النتيجة. ماعدا ذلك، إذا كان أيٌ من المُعاملَين من نوع unsigned int، يُحوَّل المُعامل الآخر إلى unsigned int ويكون هذا نوع النتيجة. ماعدا ذلك، يجب أن يكون كلا المُعاملين من نوع int وعلى هذا نوع النتيجة أيضًا. يتضمن المعيار جملةً غريبة: "يمكن تمثيل قيم المُعاملات من نوع الأعداد العشرية ونتائج تعابيرها بدقة ومجال أكبر من المطلوبة بالنسبة لنوعها، بالتالي لا يحدث تغيير للأنواع". السبب في هذا هو الحفاظ على معاملة لغة سي القديمة للمتغيرات من أنواع الأعداد العشرية، إذ كانت تُرقّى المتغيرات من نوع float في سي القديمة تلقائيًّا إلى double بالطريقة ذاتها التي تُرقّى متغيرات من نوع char إلى int، لذلك يمكن إنجاز التعبير الذي يحوي متغيرات من نوع float فقط كما لو كانت المتغيرات من نوع double، ولكن نوع النتيجة سيكون دائمًا float. التأثير الوحيد لهذه العملية هو على حساب الأداء، وهو غير مهم لمعظم المستخدمين؛ ويُحدَّد ما إذا كانت التحويلات ستُطبّق أم لا، وأي نوع منها سيطبّق، عند الوصول إلى العامل operator. لا تسبّب التحويلات بين الأنواع ومزجها أي مشكلات عمومًا، ولكن هناك بعض النقاط التي يجب الانتباه إليها؛ إذ يُعد المزج بين الأنواع ذات الإشارة وعديمة الإشارة بسيطًا إلى أن يحتوي النوع ذو الإشارة قيمة سالبة، إذ لا يمكن تمثيل قيمته باستخدام متغير عديم الإشارة، وعلينا إيجاد حل لهذه المشكلة. ينص المعيار على أن نتيجة تحويل عدد سالب إلى نوع عديم الإشارة هي أكبر قيمة يمكن تخزينها في النوع عديم الإشارة زائد واحد مضافةً إلى العدد السالب، ولأن الطفحان غير ممكن الحدوث في الأنواع عديمة الإشارة فالنتيجة دائمًا معرّفة على المجال. ولنأخذ int بطول 16 بِت مثالًا، إذ أن مجال النوع عديم الإشارة هو 0 إلى 65535، وبتحويل قيمة سالبة (ولتكن "7-") للنوع هذا يجب إضافة 7- إلى 65536 الذي يعطينا الناتج 65529. يحتفظ المعيار بالطريقة القديمة في لغة سي، إذ يُسند نمط البتات في الرقم ذي الإشارة إلى الرقم عديم الإشارة، والطريقة التي يصفها المعيار هي الطريقة ذاتها التي تنتج عن إسناد نمط بِتّات على حاسوب يعمل بنظام المتمم الثنائي، وعلى أنظمة المتمم الأحادي أن تبذل مزيدًا من المجهود لتصل للنتيجة المرجوّة. لتوضيح الأمر أكثر، سينتج عن رقمٍ صغيرٍ سالب رقمٌ كبيرٌ موجب عند تحويله إلى نوع عديم الإشارة، وإذا لم تُعجبك هذه الطريقة فحاول التفكير بطريقةٍ أفضل من هذه. يُعد إسناد رقم سالب إلى متغير عديم الإشارة خطأً فادحًا، وستكون عواقب هذا الخطأ على عاتقك. من السهل القول "لا تفعل هذا"، ولكن الأمر قد يحدث عن طريق الخطأ وفي هذه الحالة ستكون النتائج مفاجئة جدًا. ألقِ نظرةً على المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int i; unsigned int stop_val; stop_val = 0; i = -10; while(i <= stop_val){ printf("%d\n", i); i = i + 1; } exit(EXIT_SUCCESS); } [مثال 7.2] ربما تتوقع أن يطبع البرنامج لائحة قيم من "10-" إلى "0"، لكن هذا خاطئ، إذ تكمن المشكلة هنا في الموازنة؛ أي يُوازَن المتغير i الذي يخزن القيمة 10- مع متغير عديم الإشارة يخزن القيمة 0، ووفقًا لقواعد الحساب (استذكرها إن أردت) يجب أن نحوّل كلا النوعين إلى unsigned int أوّلًا ومن ثم نجري الموازنة، وتصبح القيمة 10- مساوية 65526 على الأقل (تفقد ملف الترويسة <limits.h>) بعد تحويلها، وتُوازن فيما بعد مع 0 وهي أكبر من القيمة كما هو واضح، وبذلك لا تُنفّذ الحلقة التكرارية إطلاقًا. العبرة هنا هو أنه عليك تجنُّب استخدام الأعداد عديمة الإشارة إلا في حالة استخدامك المقصود لها، وعندما تستخدمها انتبه جيّدًا بخصوص مزجها مع الأعداد ذات الإشارة. المحارف العريضة كما ذكرنا سابقًا، يسمح المعيار بمجموعات المحارف الموسّعة، إذ يمكنك استخدام ترميز الإدخال بالإزاحة shift-in والإخراج بالإزاحة shift-out، التي تسمح بتخزين المحارف متعددة البايتات في سلاسل نصية اعتيادية في لغة سي، والتي في حقيقة الأمر مصفوفات من نوع char كما سنتعرف لاحقًا؛ أو يمكنك استخدام التمثيل الذي يستخدم أكثر من بايت واحد لتخزين كل محرف من المحارف. يمكننا استخدام سلاسل الإزاحة فقط في حالة معالجة المحارف بترتيب محدد، إذ إن الطريقة عديمة الفائدة في حال أردت إنشاء مصفوفة محارف والوصول إليهم بغض النظر عن ترتيبهم. إليك مثالًا استخدمناه سابقًا مضافًا إليه أدلة indexes مصفوفة منطقية وفعلية: 0 1 2 3 4 5 6 7 8 9 (actual array index) a b c <SI> a b g <SO> x y 0 1 2 3 4 5 6 7 (logical index) حتى لو استطعنا الوصول إلى المُدخلة "الصالحة correct" ذات الدليل "5" في المصفوفة، فلن تنتهِ المشكلة، إذ لا يمكن تمييز النتيجة التي حصلنا عليها إن كانت مرمّزة أو هي "g" حرفيًّا. الحل الواضح لهذه المشكلة هو استخدام قيم مميّزة لجميع المحارف في مجموعة المحارف التي نستخدمها، لكن هذا الأمر يتطلب مزيدًا من البتات الموجودة في char اعتيادي، وأن نكون قادرين على تخزين كل قيمة على نحوٍ منفصل دون استخدام تقنية الإزاحة أو أي تقنية تعتمد على موضع القيم، وهذا هو الغرض من استخدام النوع wchar_t؛ إذ يُعدّ هذا النوع مرادفًا لأنواع الأعداد الصحيحة الأخرى (يمكنك الاطلاع على تعريفه في ملف الترويسة "")، وهو نوعٌ معرّفٌ حسب التنفيذ ويُستخدم في تخزين المحارف الموسعة عندما تريد إنشاء مصفوفة منها. يضمن المعيار التفاصيل التالية المتعلقة بقيمة المحارف العريضة: يستطيع المتغير من نوع wchar_t تخزين قيم فريدة لكل محرف من أكبر مجموعة محارف يدعمها التنفيذ. المحرف الفارغ null قيمته الصفر. تماثل قيمة ترميز كل محرف من مجموعة المحارف الأساسية (ألقِ نظرةً على مقال المحارف المُستخدمة في لغة C فقرة الأبجدية الاعتيادية) في النوع wchar_t القيمة المُخزنة في char. هناك دعم أكبر لطريقة ترميز المحارف هذه، مثل السلاسل النصية strings التي تكلمنا عنها سابقًا، إذ تُنفَّذ على أنها مصفوفة من المحارف char، مع أن قيمتها تبدو على النحو التالي: "a string" للحصول على سلاسل نصية من نوع wchar_t، اكتب السلسلة النصية كما هي مسبوقة بالحرف L، على سبيل المثال: L"a string" علينا أن نفهم الفرق بين المثالين السابقين، إذ أن السلاسل النصية هي في حقيقة الأمر مصفوفات وعلى الرغم من غرابة الأمر إلا أنّنا نستطيع استخدام دليل المصفوفة عليها: "a string"[4] L"a string"[4] كلا التعبيرين السابقين صالح، إذ أن التعبير الأول من نوع char وقيمته ممثلةٌ بالحرف r (تذكر أن دليل المصفوفات يبدأ من صفر وليس واحد)، والتعبير الثاني من نوع wchar_t وقيمته ممثلةٌ أيضًا بالحرف r. يصبح الأمر مثيرًا للاهتمام عند استخدامنا للمحارف الموسعة، إذ تظهر لنا بعض المشكلات إذا استخدمنا الترميز <a> و <b> للدلالة على محارف "إضافية" عن مجموعة المحارف الاعتيادية، أي ترميز هذه المحارف باستخدام تقنية إزاحة ما، لاحظ المثالين: "abc<a><b>"[3] L"abc<a><b>"[3] الحالة الثانية سهلة الفهم، فهي مصفوفةٌ من نوع wchar_t والترميز الموافق لها يبدأ بالمحرف <a> أيًّا كان هذا الترميز (لنفترض أنه ترميز إلى الحرف اليوناني الموافق)؛ أما الحالة الأولى فهي غير ممكنة التنبؤ، إذ أن النوع هو char بلا شك لكن قيمته هي وسم الإدخال بالإزاحة غالبًا. كما هو الحال مع السلاسل النصية، هناك ثوابت محارف عريضة، مثل 'a' التي لها نوع char وقيمة الترميز متجاوبة مع قيمة المحرف a، أما المحرف التالي: L'a' فهو ثابت من نوع wchar_t، وعند استخدام المحارف متعددة البايتات في المثال الذي سبقه، فهذا يعني أن قيمته تساوي محارف متعددة في محرف ثابت واحد على سبيل المثال: 'xy' في الحقيقة، يُعد هذا التعبير صحيحًا ولكنه يعني شيئًا طريفًا. وسيُحوَّل المحرف متعدد البايتات في المثال الثاني إلى قيمة wchar_t الموافقة. إذا لم تفهم جميع التفاصيل المتعلقة بالمحارف العريضة، فكل ما هنالك قوله هو أننا حاولنا أفضل ما لدينا لشرحها، عُد مرةً أخرى لاحقًا واقرأها من جديد، لعل التفاصيل تصبح مفهومة عندها. تدعم المحارف العريضة عمليًّا استخدام مجموعات المحارف الموسعة في لغة سي وستفهمها حالما تعتاد عليها. التحويل بين الأنواع في بعض الأحيان، ينتج نوع بيانات من تعبير ما ولكنك لا تريد استخدام هذا النوع، وتريد تحويله قسريًّا إلى نوع مختلف، وهذا هو الغرض من التحويل بين الأنواع casts. عند وضع اسم النوع بين قوسين على النحو التالي: (int) فأنت تنشئ هنا عاملًا أحاديًا unary operator يُسمّى بالتحويل بين الأنواع cast، إذ يغير التحويل بين الأنواع قيمة التعبير الواقع على يمينه إلى النوع المحدد بداخل الأقواس. على سبيل المثال، إذا كنت تجري عملية القسمة بين عددين صحيحين a/b فسيستخدم التعبير الناتج قسمة الأعداد الصحيحة ويتخلص من أي باقي، ويمكنك استخدام متغيرات وسيطة من نوع أعداد عشرية للحفاظ على الجزء العشري من القيمة الناتجة أو استخدام التحويل بين الأنواع. يوضح المثال التالي الطريقتين: #include <stdio.h> #include <stdlib.h> /* * Illustrates casts. * For each of the numbers between 2 and 20, * print the percentage difference between it and the one * before */ main(){ int curr_val; float temp, pcnt_diff; curr_val = 2; while(curr_val <= 20){ /* * % difference is * 1/(curr_val)*100 */ temp = curr_val; pcnt_diff = 100/temp; printf("Percent difference at %d is %f\n", curr_val, pcnt_diff); /* * Or, using a cast: */ pcnt_diff = 100/(float)curr_val; printf("Percent difference at %d is %f\n", curr_val, pcnt_diff); curr_val = curr_val + 1; } exit(EXIT_SUCCESS); } [مثال 8.2] الطريقة الأسهل لتتذكر الاستخدام الصحيح للتحويل بين الأنواع هو كتابته وكأنك تُصرّح عن متحول من نوع تريده، ومن ثم ضع الأقواس حول التصريح بالكامل واحذف اسم المتغير، مما سيعطيك التحويل بين الأنواع. يوضح الجدول 6.2 بعض الأمثلة البسيطة، قد تلاحظ أن بعض الأنواع لم تُقدّم بعد، لكن سيتوضّح التحويل بين الأنواع أكثر عند استخدام الأنواع المعقدة. تجاهل الأمثلة التي لا تفهمها بعد، لأنك ستكون قادرًا على استخدام هذا الجدول مثل مرجعٍ لاحقًا. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } التصريح التحويل بين الأنواع النوع ;int x (int) int ;float f (float) float ;char x[30] (char [30]) مصفوفة من char ;int *ip (* int) مؤشر إلى int ;()int (*f) (() (*) int) مؤشر لدالة تُعيد النوع int [جدول 6.2. التحويل بين الأنواع] ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: العوامل في لغة سي C المقال السابق: الأنواع الحقيقية والصحيحة في لغة سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C
سنتعرف في هذا المقال عن كيفية إجراء التحويلات ما بين الأنواع في تعابير لغة سي C التعابير والعمليات الحسابية من الممكن أن تكون التعابير في لغة سي معقدةً بعض الشيء نظرًا لاستخدام عدد من الأنواع المختلفة والعوامل operators في التعبير الواحد. سيشرح هذا القسم من الكتاب كيفية عمل التعابير هذه، وقد نتطرق للتفاصيل الصغيرة في بعض الأحيان، لذلك سيتوجب عليك قراءتها عدّة مرات حتى تتحقق من فهمك للفكرة. دعنا نبدأ أولًا ببعض المصطلحات، إذ تُبنى التعابير في لغة سي من مزيجٍ يتكون من العوامل والمُعاملات operands. لنأخذ على سبيل المثال التعبير التالي: x = a+b*(-c) لدينا العوامل = و + و * و -، والمُعاملات التي هي المتغيرات x و a و b و c، كما يمكنك ملاحظة القوسين أيضًا اللذين يمكن استخدامهما في تجميع التعبيرات الجزئية مثل c-. تنقسم معظم مجموعة عوامل لغة سي الواسعة إلى عوامل ثنائية binary operators تأخذ مُعاملين، أو عوامل أحادية unary operators تأخذ مُعاملًا واحدًا؛ ففي مثالنا كان - مُستخدمًا مثل عاملٍ أحادي، ويؤدي دورًا مختلفًا عن عامل الطرح الثنائي الذي يُمثّل بالرمز ذاته. قد تنظر إلى الفرق بأنه لا يستحق الذكر وأن وظيفة العامل ذاتها أو متشابهة في الحالتين، ولكنه على النقيض تمامًا فإنه يستحقّ الذكر، لأن لبعض العوامل -كما ستجد لاحقًا- شكل ثنائي وآخر أحادي وكلّ وظيفة مختلفة كاملًا عن الأخرى، ويُعد عامل الضرب الثنائي * الذي يعمل عمل الموجّه باستخدام المؤشرات في حالته الأحادية مثالًا جيدًا على ذلك. تتميز لغة سي بأن العوامل قد تظهر بصورةٍ متتالية دون الحاجة للأقواس للفصل فيما بينهما في تعبيرٍ ما، إذ يمكننا كتابة المثال السابق على النحو التالي وسيظلّ تعبيرًا صالحًا. x = a+b*-c; بالنظر إلى عدد العوامل في لغة سي والطريقة الغريبة التي تعمل بها عملية الإسناد، تُعد أسبقية precedence العامل وارتباطه associativity مسألةً هامةً جدًا بالنسبة لمبرمجٍ بلغة سي موازنةً باللغات الأخرى، وستُناقش هذه النقطة بالتفصيل بعد التكلم عن أهمية عوامل العمليات الحسابية. لكن علينا قبل ذلك أن ننظر إلى عملية تحويل النوع التي قد تحصل. التحويلات تسمح لغة سي بمزج عدّة أنواع ضمن التعبير الواحد، وتسمح أيضًا بالعوامل التي يؤدي استخدامها إلى تحويلات للأنواع ضمنيًا، يصف هذا القسم الطريقة التي تحدث بها هذه التحويلات. ينبغي على مبرمجي لغة سي القديمة (التي سبقت المعيار) قراءة هذا القسم بانتباه، إذ تغيّرت العديد من القواعد وبالأخص التحويل من float إلى double والتحويل من أنواع الأعداد الصحيحة short، كما أن القواعد الأساسية في حفظ القيم value preserving قد تغيرت جدًأ في لغة سي المعيارية. على الرغم من عدم ارتباط هذه المعلومة مباشرةً في هذا السياق، تجدر الإشارة هنا إلى أن أنواع الأعداد العشرية floating والصحيحة تُعرف باسم الأنواع الحسابية arithmetic types وتدعم لغة سي عدة أنواع أخرى، أبرزها أنواع المؤشر pointer. تنطبق القوانين التي سنناقشها هنا على التعابير التي تحتوي الأنواع الحسابية فقط، إذ أن هناك بعض القواعد الإضافية عند إضافة أنواع مؤشر مع الأنواع الحسابية إلى هذا المزيج وسنناقشها لاحقًا. إليك أنواع التحويلات المتنوعة في التعابير الحسابية: الترقيات العددية الصحيحة integral promotions. التحويلات بين الأنواع العددية الصحيحة. التحويلات بين الأنواع العددية العشرية. التحويلات ما بين الأنواع العددية الصحيحة والعشرية. سبق وأن ناقشنا التحويلات بين الأنواع العددية الصحيحة في مقال الأنواع الحقيقية والصحيحة في لغة سي فقرة الأعداد الصحيحة، وما سنفعله في الوقت الحالي هو تحديد طريقة عمل التحويلات الأخرى، ومن ثم سننظر متى يجب استخدامها، عليك أن تحفظ هذه التحويلات عن ظهر قلب إذا أردت أن تصبح مبرمجًا بارعًا بلغة سي. من الأشياء المختلف عليها التي قدمها المعيار، هي قواعد الحفاظ على القيمة value preserving، إذ تتطلب معرفةً معينةً من الحاسوب الهدف الذي ينفذ البرنامج من أجل معرفة نوع القيمة الناتجة من التعبير. عندما كنا نصادف في السابق نوعًا عديم الإشارة ضمن تعبير ما، كان هذا يعني ضمانًا بأن القيمة الناتجة من نوع unsigned أيضًا، ولكن في الوقت الحالي النتيجة ستكون من نوع unsigned فقط إذا كان التحويل يتطلب ذلك، وهذا يعني أنه في معظم الحالات ستكون النتيجة من نوع signed. السبب في هذا التغيير هو تقليل القيم التي قد تفاجئك عند مزج قيم من نوع ذو إشارة مع آخر عديم الإشارة، ففي معظم الحالات لا تعرف سبب هذا التغيير، وكان الدافع هنا التحويل إلى نتيجة "أكثر استخدامًا وطلبًا". الترقية العددية الصحيحة أقل العمليات الحسابية دقةً في لغة سي هي باستخدام نوع الأعداد الصحيحة int، لذلك تحصل هذه التحويلات ضمنيًّا في كل مرة تُستخدم الكائنات المذكورة في الأسفل ضمن تعبيرٍ ما. التحويل مُعرّف كما يلي: عند تطبيق الترقية العددية الصحيحة إلى نوع short أو char (أو حقل البِت bitfield أو نوع المعدّد enumeration type الذَين لم نتطرق إليهما بعد): ستُحّول القيمة إلى int، إذا كان من الممكن للمتغير تخزين جميع قيم النوع الأصل. عدا ذلك، ستُحوَّل إلى unsigned int. يحفظ هذا التحويل كلًا من القيمة والإشارة الخاصة بالقيمة الأصلية، تذكر أن موضوع معاملة نوع char بإشارة أو دون إشارة يعود إلى التنفيذ. تُطبَّق هذه الترقيات على نحوٍ متكرر بمثابة جزءٍ من التحويلات الحسابية الاعتيادية ومُعاملات عوامل الإزاحة الأحادية، مثل + و - و ~، كما تُطبّق عندما يكون التعبير مُستخدمًا مثل وسيط لدالة ما دون أي معلومات عن النوع ضمن نموذج الدالة الأولي function prototype، كما سنشرح لاحقًا. الأعداد الصحيحة ذات الإشارة وعديمة الإشارة هناك الكثير من التحويلات الناتجة بين عدد من أنواع الأعداد الصحيحة المختلفة ومزج نكهاتها (أنواعها) المختلفة ضمن تعبير ما، وعند حدوث ذلك، ستحدث الترقية العددية الصحيحة. يمكن للنوع الجديد الناتج في جميع الحالات أن يخزن جميع القيم التي يستطيع النوع القديم تخزينها، وبذلك يمكن الحفاظ على القيم دون تغييرها. في حال التحويل من عدد صحيح ذو إشارة إلى عدد صحيح عديم الإشارة وكان طول هذا العدد مساويًا لطول (أو أطول من) النوع الأصلي، فلن تتغير القيمة بعد التحويل إذا كان العدد ذو الإشارة موجبًا؛ أما إذا كانت القيمة سالبة فهذا يعني تحويلها إلى صيغة ذات إشارة للنوع الأطول وجعلها عديمة الإشارة عن طريق إضافة قيمتها إلى القيمة العظمى التي يستطيع النوع عديم الإشارة تخزينها زائد واحد. تُحافظ هذه العملية على نمط البِتّات الأصلي للأرقام الموجبة وتضمن "خانة الإشارة الموسّعة" للأرقام السالبة وذلك في نظام المتمّم الثنائي. لا يوجد هناك أي حالات "طفحان overflow" في جميع حالات تحويل عدد صحيح إلى نوع عديم إشارة قصير، فالنتيجة معرّفةٌ وفق "الباقي غير السالب مقسومًا على القيمة العظمى للرقم عديم الإشارة الذي يمكن تمثيله باستخدام النوع القصير زائد واحد". يعني هذا ببساطة أنه في بيئة تعمل بنظام المتمم الثنائي، تُنسخ البِتات منخفضة الترتيب low-order إلى الهدف ويكون التخلُّص من البتات مرتفعة الترتيب high-order. قد تحصل بعض المشاكل عند تحويل العدد الصحيح إلى نوع ذي إشارة قصير إن لم يكن هناك مساحةٌ كافيةٌ لتخزين القيمة، وفي هذه الحالة تكون النتيجة حسب التنفيذ implementation defined، كما قد يتوقع معظم من اعتاد على سي القديمة أن يُنسخ نمط البِتات منخفضة الترتيب. من الممكن أن يكون البند الأخير مثيرًا للقلق بعض الشيء إذا كنت تتذكر الترقية العددية الصحيحة، لأنك قد تنظر إلى الأمر على النحو التالي: إذا أسندت متغيرًا من نوع char إلى متحولٍ من نوع char، فسيُرقّى المتغير على اليمين إلى نوع من أنوع int. إذًا، هل من الممكن أن يؤدي الإسناد إلى تحويل int إلى char (مثلًا) وتفعيل البند "التعريف حسب التنفيذ"؟ الإجابة هي لا، لأن عملية الإسناد لا تضمّ ترقية الأعداد الصحيحة، لذا لا تقلق. الأعداد العشرية والصحيحة يتخلّص تحويل نوع عدد عشري floating إلى نوع عدد صحيح بسيط من جميع الأجزاء العشرية للقيمة، فإذا كان نوع العدد الصحيح غير قابل لتخزين القيمة المتبقية، فسيصبح لدينا سلوك غير محدد، أي حالة شبيهة بالطفحان overflow. كما ذكرنا سابقًا، لا توجد هناك أي مشكلة إذا حدث التحويل بصورةٍ تصاعدية من float إلى double إلى long double، إذ من الممكن لجميع الأنواع السابقة تخزين جميع القيم التي تتسع في الأنواع الأصغر منها، وبذلك تحصل عملية التحويل دون أي فقدان للمعلومات؛ بينما سينتج في التحويل في الاتجاه المعاكس سلوكٌ غير محدد في حال كانت القيمة خارج مجال القيم التي يمكن للنوع تخزينها، وفي حال كانت القيمة ضمن المجال ولكن لا يمكن تخزينها بدقتها بالضبط النتيجة، ستكون واحدةً من القيمتين المجاورتين الممكن تخزينها، ويجري اختيارها حسب التنفيذ، وهذا يعني أن القيمة ستفقد جزءًا من دقتها. التحويلات الحسابية الاعتيادية هناك العديد من التعابير التي تتضمن استخدام تعابير فرعية subexpressions تحتوي على خليطٍ من الأنواع مع عوامل، مثل "+" و"*" وما شابه. إذا كانت للمُعاملات ضمن التعبير عدّة أنواع، فهذا يعني أن هناك بعض التحويلات الواجب إجراؤها حتى تكون النتيجة النهائية من نوع معين، والتحويلات هي: إذا كان أي من المُعاملَين من نوع long double يُحوَّل المُعامل الآخر إلى long double ويكون هذا هو نوع النتيجة. ماعدا ذلك، إذا كان أيٌ من المُعاملَين من نوع double، يُحوَّل المُعامل الآخر إلى double ويكون هذا هو نوع النتيجة. ماعدا ذلك، إن كان أي من المُعاملَين من نوع float، يُحوًل المُعامل الآخر إلى float ويكون هذا هو نوع النتيجة. ماعدا ذلك، تُطبّق الترقية العددية الصحيحة لكلا المُعاملين حسب التحويلات التالية: إذا كان أيٌ من المُعاملَين من نوع unsigned long int، يُحوَّل المُعامل الآخر إلى unsigned long int ويكون هذا نوع النتيجة. ماعدا ذلك، إذا كان أيٌ من المُعاملَين من نوع long int، يُحوَّل المُعامل الآخر إلى long int ويكون هذا هو نوع النتيجة. ماعدا ذلك، إذا كان أيٌ من المُعاملَين من نوع unsigned int، يُحوَّل المُعامل الآخر إلى unsigned int ويكون هذا نوع النتيجة. ماعدا ذلك، يجب أن يكون كلا المُعاملين من نوع int وعلى هذا نوع النتيجة أيضًا. يتضمن المعيار جملةً غريبة: "يمكن تمثيل قيم المُعاملات من نوع الأعداد العشرية ونتائج تعابيرها بدقة ومجال أكبر من المطلوبة بالنسبة لنوعها، بالتالي لا يحدث تغيير للأنواع". السبب في هذا هو الحفاظ على معاملة لغة سي القديمة للمتغيرات من أنواع الأعداد العشرية، إذ كانت تُرقّى المتغيرات من نوع float في سي القديمة تلقائيًّا إلى double بالطريقة ذاتها التي تُرقّى متغيرات من نوع char إلى int، لذلك يمكن إنجاز التعبير الذي يحوي متغيرات من نوع float فقط كما لو كانت المتغيرات من نوع double، ولكن نوع النتيجة سيكون دائمًا float. التأثير الوحيد لهذه العملية هو على حساب الأداء، وهو غير مهم لمعظم المستخدمين؛ ويُحدَّد ما إذا كانت التحويلات ستُطبّق أم لا، وأي نوع منها سيطبّق، عند الوصول إلى العامل operator. لا تسبّب التحويلات بين الأنواع ومزجها أي مشكلات عمومًا، ولكن هناك بعض النقاط التي يجب الانتباه إليها؛ إذ يُعد المزج بين الأنواع ذات الإشارة وعديمة الإشارة بسيطًا إلى أن يحتوي النوع ذو الإشارة قيمة سالبة، إذ لا يمكن تمثيل قيمته باستخدام متغير عديم الإشارة، وعلينا إيجاد حل لهذه المشكلة. ينص المعيار على أن نتيجة تحويل عدد سالب إلى نوع عديم الإشارة هي أكبر قيمة يمكن تخزينها في النوع عديم الإشارة زائد واحد مضافةً إلى العدد السالب، ولأن الطفحان غير ممكن الحدوث في الأنواع عديمة الإشارة فالنتيجة دائمًا معرّفة على المجال. ولنأخذ int بطول 16 بِت مثالًا، إذ أن مجال النوع عديم الإشارة هو 0 إلى 65535، وبتحويل قيمة سالبة (ولتكن "7-") للنوع هذا يجب إضافة 7- إلى 65536 الذي يعطينا الناتج 65529. يحتفظ المعيار بالطريقة القديمة في لغة سي، إذ يُسند نمط البتات في الرقم ذي الإشارة إلى الرقم عديم الإشارة، والطريقة التي يصفها المعيار هي الطريقة ذاتها التي تنتج عن إسناد نمط بِتّات على حاسوب يعمل بنظام المتمم الثنائي، وعلى أنظمة المتمم الأحادي أن تبذل مزيدًا من المجهود لتصل للنتيجة المرجوّة. لتوضيح الأمر أكثر، سينتج عن رقمٍ صغيرٍ سالب رقمٌ كبيرٌ موجب عند تحويله إلى نوع عديم الإشارة، وإذا لم تُعجبك هذه الطريقة فحاول التفكير بطريقةٍ أفضل من هذه. يُعد إسناد رقم سالب إلى متغير عديم الإشارة خطأً فادحًا، وستكون عواقب هذا الخطأ على عاتقك. من السهل القول "لا تفعل هذا"، ولكن الأمر قد يحدث عن طريق الخطأ وفي هذه الحالة ستكون النتائج مفاجئة جدًا. ألقِ نظرةً على المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int i; unsigned int stop_val; stop_val = 0; i = -10; while(i <= stop_val){ printf("%d\n", i); i = i + 1; } exit(EXIT_SUCCESS); } [مثال 7.2] ربما تتوقع أن يطبع البرنامج لائحة قيم من "10-" إلى "0"، لكن هذا خاطئ، إذ تكمن المشكلة هنا في الموازنة؛ أي يُوازَن المتغير i الذي يخزن القيمة 10- مع متغير عديم الإشارة يخزن القيمة 0، ووفقًا لقواعد الحساب (استذكرها إن أردت) يجب أن نحوّل كلا النوعين إلى unsigned int أوّلًا ومن ثم نجري الموازنة، وتصبح القيمة 10- مساوية 65526 على الأقل (تفقد ملف الترويسة <limits.h>) بعد تحويلها، وتُوازن فيما بعد مع 0 وهي أكبر من القيمة كما هو واضح، وبذلك لا تُنفّذ الحلقة التكرارية إطلاقًا. العبرة هنا هو أنه عليك تجنُّب استخدام الأعداد عديمة الإشارة إلا في حالة استخدامك المقصود لها، وعندما تستخدمها انتبه جيّدًا بخصوص مزجها مع الأعداد ذات الإشارة. المحارف العريضة كما ذكرنا سابقًا، يسمح المعيار بمجموعات المحارف الموسّعة، إذ يمكنك استخدام ترميز الإدخال بالإزاحة shift-in والإخراج بالإزاحة shift-out، التي تسمح بتخزين المحارف متعددة البايتات في سلاسل نصية اعتيادية في لغة سي، والتي في حقيقة الأمر مصفوفات من نوع char كما سنتعرف لاحقًا؛ أو يمكنك استخدام التمثيل الذي يستخدم أكثر من بايت واحد لتخزين كل محرف من المحارف. يمكننا استخدام سلاسل الإزاحة فقط في حالة معالجة المحارف بترتيب محدد، إذ إن الطريقة عديمة الفائدة في حال أردت إنشاء مصفوفة محارف والوصول إليهم بغض النظر عن ترتيبهم. إليك مثالًا استخدمناه سابقًا مضافًا إليه أدلة indexes مصفوفة منطقية وفعلية: 0 1 2 3 4 5 6 7 8 9 (actual array index) a b c <SI> a b g <SO> x y 0 1 2 3 4 5 6 7 (logical index) حتى لو استطعنا الوصول إلى المُدخلة "الصالحة correct" ذات الدليل "5" في المصفوفة، فلن تنتهِ المشكلة، إذ لا يمكن تمييز النتيجة التي حصلنا عليها إن كانت مرمّزة أو هي "g" حرفيًّا. الحل الواضح لهذه المشكلة هو استخدام قيم مميّزة لجميع المحارف في مجموعة المحارف التي نستخدمها، لكن هذا الأمر يتطلب مزيدًا من البتات الموجودة في char اعتيادي، وأن نكون قادرين على تخزين كل قيمة على نحوٍ منفصل دون استخدام تقنية الإزاحة أو أي تقنية تعتمد على موضع القيم، وهذا هو الغرض من استخدام النوع wchar_t؛ إذ يُعدّ هذا النوع مرادفًا لأنواع الأعداد الصحيحة الأخرى (يمكنك الاطلاع على تعريفه في ملف الترويسة "")، وهو نوعٌ معرّفٌ حسب التنفيذ ويُستخدم في تخزين المحارف الموسعة عندما تريد إنشاء مصفوفة منها. يضمن المعيار التفاصيل التالية المتعلقة بقيمة المحارف العريضة: يستطيع المتغير من نوع wchar_t تخزين قيم فريدة لكل محرف من أكبر مجموعة محارف يدعمها التنفيذ. المحرف الفارغ null قيمته الصفر. تماثل قيمة ترميز كل محرف من مجموعة المحارف الأساسية (ألقِ نظرةً على مقال المحارف المُستخدمة في لغة C فقرة الأبجدية الاعتيادية) في النوع wchar_t القيمة المُخزنة في char. هناك دعم أكبر لطريقة ترميز المحارف هذه، مثل السلاسل النصية strings التي تكلمنا عنها سابقًا، إذ تُنفَّذ على أنها مصفوفة من المحارف char، مع أن قيمتها تبدو على النحو التالي: "a string" للحصول على سلاسل نصية من نوع wchar_t، اكتب السلسلة النصية كما هي مسبوقة بالحرف L، على سبيل المثال: L"a string" علينا أن نفهم الفرق بين المثالين السابقين، إذ أن السلاسل النصية هي في حقيقة الأمر مصفوفات وعلى الرغم من غرابة الأمر إلا أنّنا نستطيع استخدام دليل المصفوفة عليها: "a string"[4] L"a string"[4] كلا التعبيرين السابقين صالح، إذ أن التعبير الأول من نوع char وقيمته ممثلةٌ بالحرف r (تذكر أن دليل المصفوفات يبدأ من صفر وليس واحد)، والتعبير الثاني من نوع wchar_t وقيمته ممثلةٌ أيضًا بالحرف r. يصبح الأمر مثيرًا للاهتمام عند استخدامنا للمحارف الموسعة، إذ تظهر لنا بعض المشكلات إذا استخدمنا الترميز <a> و <b> للدلالة على محارف "إضافية" عن مجموعة المحارف الاعتيادية، أي ترميز هذه المحارف باستخدام تقنية إزاحة ما، لاحظ المثالين: "abc<a><b>"[3] L"abc<a><b>"[3] الحالة الثانية سهلة الفهم، فهي مصفوفةٌ من نوع wchar_t والترميز الموافق لها يبدأ بالمحرف <a> أيًّا كان هذا الترميز (لنفترض أنه ترميز إلى الحرف اليوناني الموافق)؛ أما الحالة الأولى فهي غير ممكنة التنبؤ، إذ أن النوع هو char بلا شك لكن قيمته هي وسم الإدخال بالإزاحة غالبًا. كما هو الحال مع السلاسل النصية، هناك ثوابت محارف عريضة، مثل 'a' التي لها نوع char وقيمة الترميز متجاوبة مع قيمة المحرف a، أما المحرف التالي: L'a' فهو ثابت من نوع wchar_t، وعند استخدام المحارف متعددة البايتات في المثال الذي سبقه، فهذا يعني أن قيمته تساوي محارف متعددة في محرف ثابت واحد على سبيل المثال: 'xy' في الحقيقة، يُعد هذا التعبير صحيحًا ولكنه يعني شيئًا طريفًا. وسيُحوَّل المحرف متعدد البايتات في المثال الثاني إلى قيمة wchar_t الموافقة. إذا لم تفهم جميع التفاصيل المتعلقة بالمحارف العريضة، فكل ما هنالك قوله هو أننا حاولنا أفضل ما لدينا لشرحها، عُد مرةً أخرى لاحقًا واقرأها من جديد، لعل التفاصيل تصبح مفهومة عندها. تدعم المحارف العريضة عمليًّا استخدام مجموعات المحارف الموسعة في لغة سي وستفهمها حالما تعتاد عليها. التحويل بين الأنواع في بعض الأحيان، ينتج نوع بيانات من تعبير ما ولكنك لا تريد استخدام هذا النوع، وتريد تحويله قسريًّا إلى نوع مختلف، وهذا هو الغرض من التحويل بين الأنواع casts. عند وضع اسم النوع بين قوسين على النحو التالي: (int) فأنت تنشئ هنا عاملًا أحاديًا unary operator يُسمّى بالتحويل بين الأنواع cast، إذ يغير التحويل بين الأنواع قيمة التعبير الواقع على يمينه إلى النوع المحدد بداخل الأقواس. على سبيل المثال، إذا كنت تجري عملية القسمة بين عددين صحيحين a/b فسيستخدم التعبير الناتج قسمة الأعداد الصحيحة ويتخلص من أي باقي، ويمكنك استخدام متغيرات وسيطة من نوع أعداد عشرية للحفاظ على الجزء العشري من القيمة الناتجة أو استخدام التحويل بين الأنواع. يوضح المثال التالي الطريقتين: #include <stdio.h> #include <stdlib.h> /* * Illustrates casts. * For each of the numbers between 2 and 20, * print the percentage difference between it and the one * before */ main(){ int curr_val; float temp, pcnt_diff; curr_val = 2; while(curr_val <= 20){ /* * % difference is * 1/(curr_val)*100 */ temp = curr_val; pcnt_diff = 100/temp; printf("Percent difference at %d is %f\n", curr_val, pcnt_diff); /* * Or, using a cast: */ pcnt_diff = 100/(float)curr_val; printf("Percent difference at %d is %f\n", curr_val, pcnt_diff); curr_val = curr_val + 1; } exit(EXIT_SUCCESS); } [مثال 8.2] الطريقة الأسهل لتتذكر الاستخدام الصحيح للتحويل بين الأنواع هو كتابته وكأنك تُصرّح عن متحول من نوع تريده، ومن ثم ضع الأقواس حول التصريح بالكامل واحذف اسم المتغير، مما سيعطيك التحويل بين الأنواع. يوضح الجدول 6.2 بعض الأمثلة البسيطة، قد تلاحظ أن بعض الأنواع لم تُقدّم بعد، لكن سيتوضّح التحويل بين الأنواع أكثر عند استخدام الأنواع المعقدة. تجاهل الأمثلة التي لا تفهمها بعد، لأنك ستكون قادرًا على استخدام هذا الجدول مثل مرجعٍ لاحقًا. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } التصريح التحويل بين الأنواع النوع ;int x (int) int ;float f (float) float ;char x[30] (char [30]) مصفوفة من char ;int *ip (* int) مؤشر إلى int ;()int (*f) (() (*) int) مؤشر لدالة تُعيد النوع int [جدول 6.2. التحويل بين الأنواع] ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: العوامل في لغة سي C المقال السابق: الأنواع الحقيقية والصحيحة في لغة سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C -
 بعد أن تكلمنا عن المكتبات القياسية المعرفة حسب المعيار، لم يبقَ إلا توضيح هيئة البرامج الكاملة المكتوبة بهذه اللغة، وسنتطرق في هذا المقال إلى بعض الأمثلة التي توضح كيفية جمع هذه العناصر لبناء البرامج. إلا أن هناك بعض النقاط التي يجب مناقشتها في لغة سي قبل عرض هذه الأمثلة. وسطاء الدالة main تقدم وسطاء الدالة main فرصةً مفيدةً لكل من يكتب البرامج ويشغلها في بيئة مُستضافة hosted environment وذلك بإعطاء المعاملات للبرنامج، ويُستخدم ذلك عادةً لتوجيه البرنامج لكيفية تنفيذ مهامه، ومن الشائع أن تكون هذه المعاملات هي أسماء ملفات تُمرّر مثل وسيط. يبدو تصريح الدالة main على النحو التالي: int main(int argc, char *argv[]); يُشير التصريح إلى أن الدالة main تُعيد عددًا صحيحًا، وتُمرّر هذه القيمة عادةً، أو حالة الخروج exit status في البيئات المُستضافة، مثل أنظمة دوس DOS أو يونيكس UNIX إلى مفسّر سطر الأوامر command line interpreter، فعلى سبيل المثال تُستخدم حالة الخروج في نظام يونيكس للدلالة على إتمام البرنامج لمهمته بنجاح (تمثلّه القيمة صفر)، أو حدوث خطأ أثناء التنفيذ (تمثًله قيمة غير صفرية). اتّبع المعيار هذا الاصطلاح أيضًا، إذ تُستخدم exit(0) لإعادة حالة النجاح إلى البيئة المُستضافة وأي قيمة أخرى تدلّ على حدوث خطأ ما، وستُترجم exit القيمة لمعناها إذا كانت البيئة المستضافة تستخدم اصطلاحًا مخالفًا. بما أن الترجمة معرفة حسب التنفيذ، فمن الأفضل استخدام القيمتان المُعرّفتان في ملف الترويسة <stdlib.h>، وهما: EXIT_SUCCESS و EXIT_FAILURE. هناك على الأقل وسيطان للدالة main، وهُما: argc و argv، إذ يدل أولهما على عدد الوسطاء المزودة للبرنامج، بينما يدل الثاني على مصفوفة من المؤشرات تشير إلى سلاسل نصية تمثّل الوسطاء، وهي من النوع "مصفوفة من المؤشرات تشير إلى محرف char"، وتُمرّر هذه الوسطاء إلى البرنامج باستخدام مفسّر سطر الأوامر الخاص بالبيئة المُستضافة، أو لغة التحكم بالوظائف job control language. يُعدّ تصريح الوسيط argv أوّل مصادفة للمبرمجين المبتدئين مع المؤشرات التي تشير إلى مصفوفات من المؤشرات، وقد يكون هذا محيّرًا بعض الشيء في البداية، إلا أن الأمر بسيط الفهم. بما أن argv تُستخدم للإشارة إلى مصفوفة السلاسل النصية، يكون تصريحها على النحو التالي: char *argv[] تذكر أيضًا أن اسم المصفوفة يُحوّل إلى عنوان أول عنصر ضمنها عندما تُمرّر إلى دالة، وهذا يعني أنه يمكننا التصريح عن argv كما يلي: char **argv والتصريحان يؤديان الغرض ذاته في هذه الحالة. سترى تصريح الدالة main مكتوبًا بهذه الطريقة معظم الأحيان، والتصريح التالي مكافئ للتصريح السابق: int main(int argc, char **argv); تُهيًّأ وسطاء الدالة main عند بداية تشغيل البرنامج على نحوٍ موافق للشروط التالية: الوسيط argc أكبر من الصفر. يمثّل argv[argc] مؤشرًا فارغًا null. تمثّل العناصر بدءًا من argv[0] وصولًا إلى argv[argc-1] مؤشرات تشير إلى سلاسل نصية يُحدِّد البرنامج معناها. يحتوي العنصر argv[0] السلسلة النصية التي تحتوي اسم البرنامج أو سلسلة نصية فارغة إذا لم تكن هذه المعلومة متاحة، وتمثل العناصر المتبقية من argv الوسطاء المزودة للبرنامج. يُزوّد محتوى السلاسل النصية إلى البرنامج بحالة الأحرف الصغيرة lower-case في حال توفر الدعم فقط للأحرف الوحيدة single. لتوضيح هذه النقطة، إليك مثالًا عن برنامج يكتب وسطاء الدالة main إلى خرج البرنامج القياسي: #include <stdio.h> #include <stdlib.h> int main(int argc, char **argv) { while(argc--) printf("%s\n", *argv++); exit(EXIT_SUCCESS); } [مثال 1] إذا كان اسم البرنامج show_args وكانت وسطاءه abcde و text و hello عند تشغيله، ستكون حالة الوسطاء وقيمة argv موضّحة في الشكل التالي: [شكل 1 وسطاء البرنامج] تنتقل argv إلى العنصر التالي عند كل زيادة لها، وبالتالي وبعد أول تكرار للحلقة ستُشير argv إلى المؤشر الذي بدوره يشير إلى الوسيط abcde، وهذا الأمر موضح بالشكل التالي: [شكل 2 وسطاء البرنامج بعد زيادة argv] سيعمل البرنامج على النظام الذي جرّبنا فيه البرنامج السابق عن طريق كتابة اسمه، ثم كتابة وسطاءه وفصلهم بمسافات فارغة. إليك ما الذي يحدث (الرمز $ هو رمز الطرفية): $ show_args abcde text hello show_args abcde text hello $ تفسير وسطاء البرنامج الحلقة المُستخدمة لفحص وسطاء البرنامج في المثال السابق شائعة الاستخدام في برامج سي C وستجدها في العديد من البرامج الأخرى، ويُعد استخدام "الخيارات options" للتحكم بسلوك البرنامج طريقةً شائعة أيضًا (تُدعى أيضًا في بعض الأحيان المُبدّلات switches أو الرايات flags)، إذ يدل الوسيط الذي يبدأ بالمحرف - على أنه وسيط يقدّم حرفًا وحيدًا أو أكثر يشير إلى خيار، ويمكن تشغيل الخيارات سويًا أو على نحوٍ منفرد: progname -abxu file1 file2 progname -a -b -x -u file1 file2 يحدّد كلًا من الخيارات جانبًا معينًا من مزايا البرنامج، وقد يُسمح لكل خيار بأخذ وسيط خاص به امتدادًا لهذه الفكرة، فعلى سبيل المثال إذا كان الخيار -x يأخذ وسيطًا خاصًا به، سيبدو ذلك على النحو التالي: progname -x arg file1 وبذلك، فإن arg مرتبطة مع الخيار. تسمح لنا دالة options في الأسفل بأتمتة معالجة أسلوب الاستخدام هذا عن طريق الدعم الإضافي (شائع الاستخدام إلا أنه قد عفا عليه الزمن) لإمكانية تقديم خيار الوسيط مباشرةً بعد حرف الخيار كما يلي: progname -xarg file1 تُعيد برامج الخيارات السابقة في كلٍّ من الحالتين المحرف 'x' وتضبط المؤشر العام global المسمى OptArg ليشير إلى القيمة arg. يجب أن يقدم البرنامج لائحةً من أحرف الخيارات الصالحة بهيئة سلسلة نصية حتى نستطيع استخدام برامج الخيارات، عندما يُلحق حرفٌ ضمن هذه السلسلة النصية بالنقطتين ':'، فهذا يعني أن ما يتبع حرف الخيار هو وسيط. يُستدعى برنامج options مرارًا عند تشغيل البرنامج حتى انتهاء أحرف الخيار. يبدو أن الدوال التي تقرأ السلاسل النصية وتبحث عن تشكيلات مختلفة أو أنماط ضمن السلسلة صعبة القراءة، وإن كان في ذلك عزاءً لكن ليست عملية القراءة بتلك البساطة فعليًا، والشيفرة البرمجية التي تطبّق الخيارات هي واحدةٌ من هذه الدوال، إلا أنها ليست الأصعب ضمن هذا التصنيف. تفحص الدالة options() أحرف الخيار ووسطاء الخيار من قائمة argv، وتُعيد استدعاءات متتابعة للدالة أحرف خيار متتابعة متوافقة مع واحدة من بنود القائمة legal. قد تتطلب أحرف الخيار وسطاء خيار ويُشار إلى ذلك بالنقطتين ':' اللتين تتبعان الحرف في القائمة legal. على سبيل المثال، تشير لائحة legal التي تحتوي على "ab:c" على أن a و b و c جميعها خيارات صالحة وأن b تأخذ وسيط خيار، ويُمرّر وسيط الخيار فيما بعد إلى الدالة التي استُدعيت سابقًا في قيمة المؤشر العام المُسمّى OptArg. يُعطي OptIndex السلسلة النصية التالية في مصفوفة argv[] التي لم تُعالج بعد من قبل الدالة options(). تُعيد الدالة options() القيمة -1 إذا لم يكُن هناك أي أحرف خيار أخرى، أو إذا عُثر على SwitchChar مضاعف، ويُجبر ذلك الدالة options() على إنهاء عملية معالجة الخيارات؛ بينما تُعيد ? إذا كان هناك خيار لا ينتمي إلى مجموعة legal، أو إذا عُثر على خيار ما يحتاج لوسيط دون وجود وسيط يتبعه. #include <stdio.h> #include <string.h> static const char SwitchChar = '-'; static const char Unknown = '?'; int OptIndex = 1; // يجب أن يكون أول خيار هو argv[1] char *OptArg = NULL; // مؤشر عام لوسيط الخيار int options(int argc, char *argv[], const char *legal) { static char *posn = ""; // الموضع في argv[OptIndex] char *legal_index = NULL; int letter = 0; if(!*posn){ // لا يوجد المزيد من args أو SwitchChar أو حرف خيار if((OptIndex >= argc) || (*(posn = argv[OptIndex]) != SwitchChar) || !*++posn) return -1; // إيجاد SwitchChar مضاعف if(*posn == SwitchChar){ OptIndex++; return -1; } } letter = *posn++; if(!(legal_index = strchr(legal, letter))){ if(!*posn) OptIndex++; return Unknown; } if(*++legal_index != ':'){ /*لا يوجد وسيط للخيار */ OptArg = NULL; if(!*posn) OptIndex++; } else { if(*posn) // لا يوجد مسافة فارغة بين opt و opt arg OptArg = posn; else if(argc <= ++OptIndex){ posn = ""; return Unknown; } else OptArg = argv[OptIndex]; posn = ""; OptIndex++; } return letter; } [مثال 2] برنامج لإيجاد الأنماط نقدّم في هذا القسم برنامجًا كاملًا يستخدم أحرف الخيار مثل وسطاء للبرنامج بهدف التحكم بطريقة عمله. يُعالج البرنامج أولًا أي وسيط يمثل خيارًا، ويُحفظ الوسيط الأول -ليس خيار- بكونه "سلسلة بحث نصية search string"، في حين تُستخدم أي وسطاء أخرى متبقية لتحديد أسماء الملفات التي يجب أن تُقرأ دخلًا للبرنامج، وإذا لم يُعثر على أي اسم ملف فسيقرأ البرنامج من دخله القياسي بدلًا من ذلك، وإذا وُجد تطابق لسلسلة البحث النصية ضمن سطر من نص الدخل، يُطبع كامل السطر على الخرج القياسي. تُستخدم الدالة options لمعالجة جميع أحرف الخيار المزودة للبرنامج، ويميّز برنامجنا هنا خمسة خيارات، هي: -c و -i و -l و -n و -v، ولا يُشترط لأي من الخيارات السابقة أن تُتبع بوسيط اختياري. يحدد الخيار -أو الخيارات- سلوك البرنامج عند تشغيله على النحو التالي: الخيار -c: يطبع البرنامج عدد الأسطر الكلية الموافقة لسلسلة البحث النصية التي عُثر عليها في ملف -أو ملفات- الدخل، ولا تُطبع أي أسطر نصية. الخيار -i: تُتجاهل حالة الأحرف لكل من سطر ملف الدخل وسلسلة البحث النصية عند البحث عن تطابق بينها. الخيار -l: يُطبع كل سطر نصي على الخرج مسبوقًا برقم السطر المفحوص في ملف الدخل الحالي. الخيار -n: يُطبع كل سطر نصي على الخرج مسبوقًا باسم الملف الذي يحتوي هذا السطر. الخيار -v: يطبع البرنامج الأسطر فقط دون مطابقة سلسلة البحث النصية المزودة. يُعيد البرنامج بعد الانتهاء من تنفيذه حالةً تدل على واحدة من الحالات التالية: الحالة EXIT_SUCCESS: عُثر على تطابق واحد على الأقل. الحالة EXIT_FAILURE: لم يُعثر على أي تطابق، أو حدث خطأ ما. يعتمد البرنامج جدًا على دوال المكتبة القياسية لإنجاز الجزء الأكبر من العمل، فعلى سبيل المثال تُعالج جميع الملفات باستخدام دوال stdio. لاحظ اعتماد جوهر البرنامج أيضًا على مطابقة السلاسل النصية باستخدام استدعاءات لدالة strstr. إليك الشيفرة البرمجية الكاملة الخاصة بالبرنامج. حتى يعمل البرنامج، عليك طبعًا تصريفه مع الشيفرة البرمجية الخاصة به التي تعالج أحرف الخيارات، والتي استعرضناها سابقًا. /* برنامج بسيط يطبع الأسطر من ملف نصي بحيث يحوي ذلك السطر الكلمة المزودة في سطر الأوامر */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <ctype.h> /* * تصاريح لبرنامج الأنماط * */ #define CFLAG 0x001 // احصِ عدد الأسطر المتطابقة فقط #define IFLAG 0x002 // تجاهل حالة الأحرف #define LFLAG 0x004 // اعرض رقم السطر #define NFLAG 0x008 // اعرض اسماء ملفات الدخل #define VFLAG 0x010 // اعرض السطور التي لاتتطابق extern int OptIndex; // الدليل الحالي للمصفوفة argv[] extern char *OptArg; /* مؤشر وسيط الخيار العام /* * جلب وسطاء سطر الأوامر إلى الدالة main() */ int options(int, char **, const char *); /* تسجيل الخيارات المطلوبة للتحكم بسلوك البرنامج */ unsigned set_flags(int, char **, const char *); /* تفقد كل سطر من الدخل لحالة المطابقة */ int look_in(const char *, const char *, unsigned); /* اطبع سطرًا من ملف الدخل إلى الخرج القياسي بالتنسيق المُحدد بواسطة خيارات سطر الأوامر */ void print_line(unsigned mask, const char *fname, int lnno, const char *text); static const char /* الخيارات الممكنة للنمط */ *OptString = "cilnv", /*الرسالة التي ستُعرض عندما تُدخل الخيارات بصورةٍ غير صحيحة */ *errmssg = "usage: pattern [-cilnv] word [filename]\n"; int main(int argc, char *argv[]) { unsigned flags = 0; int success = 0; char *search_string; if(argc < 2){ fprintf(stderr, errmssg); exit(EXIT_FAILURE); } flags = set_flags(argc, argv, OptString); if(argv[OptIndex]) search_string = argv[OptIndex++]; else { fprintf(stderr, errmssg); exit(EXIT_FAILURE); } if(flags & IFLAG){ /*تجاهل حالة الحرف والتعامل فقط مع الأحرف الصغيرة */ char *p; for(p = search_string ; *p ; p++) if(isupper(*p)) *p = tolower(*p); } if(argv[OptIndex] == NULL){ // لم يُزوّد أي اسم ملف، لذا نستخدم stdin success = look_in(NULL, search_string, flags); } else while(argv[OptIndex] != NULL) success += look_in(argv[OptIndex++], search_string, flags); if(flags & CFLAG) printf("%d\n", success); exit(success ? EXIT_SUCCESS : EXIT_FAILURE); } unsigned set_flags(int argc, char **argv, const char *opts) { unsigned flags = 0; int ch = 0; while((ch = options(argc, argv, opts)) != -1){ switch(ch){ case 'c': flags |= CFLAG; break; case 'i': flags |= IFLAG; break; case 'l': flags |= LFLAG; break; case 'n': flags |= NFLAG; break; case 'v': flags |= VFLAG; break; case '?': fprintf(stderr, errmssg); exit(EXIT_FAILURE); } } return flags; } int look_in(const char *infile, const char *pat, unsigned flgs) { FILE *in; /* يخزن [0]line سطر الدخل كما يُقرأ بينما يحول line[1] السطر إلى حالة أحرف صغيرة إن لزم الأمر */ char line[2][BUFSIZ]; int lineno = 0; int matches = 0; if(infile){ if((in = fopen(infile, "r")) == NULL){ perror("pattern"); return 0; } } else in = stdin; while(fgets(line[0], BUFSIZ, in)){ char *line_to_use = line[0]; lineno++; if(flgs & IFLAG){ /* حالة تجاهل */ char *p; strcpy(line[1], line[0]); for(p = line[1] ; *p ; *p++) if(isupper(*p)) *p = tolower(*p); line_to_use = line[1]; } if(strstr(line_to_use, pat)){ matches++; if(!(flgs & VFLAG)) print_line(flgs, infile, lineno, line[0]); } else if(flgs & VFLAG) print_line(flgs, infile, lineno, line[0]); } fclose(in); return matches; } void print_line(unsigned mask, const char *fname, int lnno, const char *text) { if(mask & CFLAG) return; if(mask & NFLAG) printf("%s:", *fname ? fname : "stdin"); if(mask & LFLAG) printf(" %d :", lnno); printf("%s", text); } [مثال 3] مثال أكثر طموحا أخيرًا نقدّم هنا مجموعةً من البرامج المصمّمة للتلاعب بملف بيانات وحيد والتعامل معه بطريقة مترابطة وسليمة؛ إذ تهدف هذه البرامج لمساعدتنا بتتبع نتائج عدة لاعبين يتنافسون مع بعضهم بعضًا في لعبةٍ ما، مثل الشطرنج، أو الإسكواش على سبيل المثال. يمتلك كل لاعب تصنيفًا من واحد إلى n، إذ تمثل n عدد اللاعبين الكلي وواحد تصنيف أعلى لاعب. يستطيع اللاعبون من تصنيف منخفض تحدي لاعبين آخرين فوق تصنيفهم وينتقل اللاعب إلى تصنيف اللاعب الآخر الأعلى منه إذا انتصر عليه، وفي هذه الحالة يُنقل اللاعب الخاسر وأي لاعبين آخرين بين اللاعب الخاسر والفائز إلى تصنيف واحد أقل، وتبقى التصنيفات مثل ما هي إن لم ينتصر اللاعب الأقل تصنيفًا. لتقديم بعض الضوابط للتوازن في التصنيف، يمكن لأي لاعب أن يتحدى لاعبًا أعلى منه تصنيفًا، إلا أن التحديات مع اللاعبين ذوي التصنيف الذي يزيد عن ثلاثة أو أقل مراتب هي الوحيدة التي ستسمح لهذا اللاعب بالتقدم في التصنيف، وهذا من شأنه أن يُجبر اللاعبين الجدُد المضافين إلى أسفل التصنيف أن يلعبوا أكثر من لعبة واحدة للوصول إلى أعلى التصنيف. هناك ثلاث مهام أساسية يجب تنفيذها للمحافظة على تتبع سليم لنتائج التصنيفات: طباعة التصنيف. إضافة لاعبين جدُد. تسجيل النتائج. سيأخذ تصميم برنامجنا هنا صورة ثلاثة برامج جزئية لتنفيذ كل واحدة من هذه المهام على حدة، ومن الواضح بعد اتخاذنا لهذا القرار أن هناك عددًا من العمليات التي يحتاجها كل برنامج على نحوٍ مشترك بين البرامج الثلاث؛ فعلى سبيل المثال، ستحتاج البرامج الثلاثة إلى قراءة سجلات اللاعب من ملف البيانات وستحتاج اثنان من البرامج على الأقل لكتابة سجلات اللاعب إلى ملف البيانات. قد يكون الخيار الجيد هنا هو تصميم مكتبة من الدوال التي تتلاعب بسجلات اللاعبين وملف البيانات، واستخدام هذه المكتبة مع البرامج الثلاثة للتعامل مع تصنيف اللاعبين، إلا أننا بحاجة تعريف هيكل البيانات الذي سيمثل سجلات اللاعب قبل ذلك. تتألف المعلومات الدنيا اللازمة لإنشاء سجل لكل لاعب من اسمه وتصنيفه، إلا أننا سنحتفظ بعدد التحديات التي فاز بها اللاعب، إضافةً للتحديات التي خسرها وآخر لعبة لعبها لمنح بعض الإمكانيات الإحصائية عند تشكيل لائحة التصنيف، ومن الواضح أن هذه المجموعة من المعلومات يجب تخزينها في هيكل ما. نجد التصريح عن هيكل اللاعب والتصريح عن دوال مكتبة اللاعب في ملف الترويسة player.h، وتُخزّن البيانات في ملف البيانات مثل أسطر نصية، إذ يشير كل سطر إلى معلومات لاعب معين. يتطلب ذلك إجراء تحويلات الدخل والخرج، لكنها تقنيةٌ مفيدةٌ إذا لم تكلّف هذه التحويلات أداءً إضافيًا. /* * * التصاريح والتعاريف للدوال التي تتلاعب بسجلات اللاعب بناءً على ترتيبهم * */ #include <stddef.h> #include <stdio.h> #include <stdlib.h> #include <time.h> #define NAMELEN 12 /* الطول الأعظمي لاسم اللاعب */ #define LENBUF 256 /* الطول الأعظمي لذاكرة الدخل المؤقتة */ #define CHALLENGE_RANGE 3 // عدد اللاعبين الأعلى تصنيفًا الذين من الممكن للاعب أن يتحداهم ليزيد تصنيفه extern char *OptArg; typedef struct { char name[NAMELEN+1]; int rank; int wins; int losses; time_t last_game; } player; #define NULLPLAYER (player *)0 extern const char *LadderFile; extern const char *WrFmt; /* يُستخدم عند كتابة السجلات */ extern const char *RdFmt; /* يُستخدم عند قراءة السجلات */ /* تصاريح البرامج التي تُستخدم للتلاعب بسجلات اللاعب وملف لائحة التصنيف المعرفة في ملف player.c */ int valid_records(FILE *); int read_records(FILE *, int, player *); int write_records(FILE *, player *, int); player *find_by_name(char *, player *, int); player *find_by_rank(int, player *, int); void push_down(player *, int, int, int); int print_records(player *, int); void copy_player(player *, player *); int compare_name(player *, player *); int compare_rank(player *, player *); void sort_players(player *, int); [مثال 4] إليك شيفرة ملف player.c الذي يستخدم بعض الدوال العامة للتلاعب بسجلات اللاعبين وملف البيانات، ويمكن أن تُستخدم هذه الدوال مع برامج أخرى محدد لتشكيل ثلاثة برامج تتعامل مع لائحة النتائج. لاحظ أنه يجب على كل برنامج أن يقرأ كامل البيانات من الملف إلى مصفوفة ديناميكية حتى نستطيع التلاعب بسجلات اللاعبين، ومن المفترض أن تكون جميع السجلات المحتواة داخل المصفوفة مُرتبةً حسب التصنيف قبل كتابتها مجددًا إلى ملف البيانات، وستولّد الدالة push_down بعض النتائج المثيرة للاهتمام إن لم تكن السجلات مرتبة. /* * الدوال الاعتيادية المستخدمة للتلاعب ببيانات ملف لائحة النتائج وسجلات اللاعبين */ #include "player.h" const char *LadderFile = "ladder"; const char *WrFmt = "%s %d %d %d %ld\n"; const char *RdFmt = "%s %d %d %d %ld"; /* تنبيه المستخدم بخصوص ضمّ السلاسل النصية */ const char *HeaderLine = "Player Rank Won Lost Last Game\n" "===============================================\n"; const char *PrtFmt = "%-12s%4d %4d %4d %s\n"; /*إعادة رقم السجلات الموجودة في الملف */ int valid_records(FILE *fp) { int i = 0; long plrs = 0L; long tmp = ftell(fp); char buf[LENBUF]; fseek(fp, 0L, SEEK_SET); for(i = 0; fgets(buf, LENBUF, fp) != NULL ; i++) ; /* استعادة مؤشر الملف إلى حالته الأصلية*/ fseek(fp, tmp, SEEK_SET); return i; } // قراءة القيمة num من سجل اللاعب من الملف fp إلى المصفوفة them int read_records(FILE *fp, int num, player *them) { int i = 0; long tmp = ftell(fp); if(num == 0) return 0; fseek(fp, 0L, SEEK_SET); for(i = 0 ; i < num ; i++){ if(fscanf(fp, RdFmt, (them[i]).name, &((them[i]).rank), &((them[i]).wins), &((them[i]).losses), &((them[i]).last_game)) != 5) break; // خطأ عند fscanf } fseek(fp, tmp, SEEK_SET); return i; } // كتابة num الخاص بسجل اللاعب إلى الملف fp من المصفوفة them int write_records(FILE *fp, player *them, int num) { int i = 0; fseek(fp, 0L, SEEK_SET); for(i = 0 ; i < num ; i++){ if(fprintf(fp, WrFmt, (them[i]).name, (them[i]).rank, (them[i]).wins, (them[i]).losses, (them[i]).last_game) < 0) break; // خطأ عند fprintf } return i; } /* إعادة مؤشر يشير إلى اللاعب في المصفوفة them ذو اسم مطابق للقيمة name */ player *find_by_name(char * name, player *them, int num) { player *pp = them; int i = 0; for(i = 0; i < num; i++, pp++) if(strcmp(name, pp->name) == 0) return pp; return NULLPLAYER; } /* إعادة مؤشر يشير إلى لاعب في مصفوفة them تُطابق رتبته القيمة rank */ player *find_by_rank(int rank, player *them, int num) { player *pp = them; int i = 0; for(i = 0; i < num; i++, pp++) if(rank == pp->rank) return pp; return NULLPLAYER; } /* خفّض رتبة جميع اللاعبين في مصفوفة them إذا كانت رتبتهم بين start و end */ void push_down(player *them, int number, int start, int end) { int i; player *pp; for(i = end; i >= start; i--){ if((pp = find_by_rank(i, them, number)) == NULLPLAYER){ fprintf(stderr, "error: could not find player ranked %d\n", i); free(them); exit(EXIT_FAILURE); } else (pp->rank)++; } } // طباعة سجل اللاعب num بصورةٍ مُنسّقة من المصفوفة them int print_records(player *them, int num) { int i = 0; printf(HeaderLine); for(i = 0 ; i < num ; i++){ if(printf(PrtFmt, (them[i]).name, (them[i]).rank, (them[i]).wins, (them[i]).losses, asctime(localtime(&(them[i]).last_game))) < 0) break; /* error on printf! */ } return i; } /* نسخ القيم من لاعب إلى آخر */ void copy_player(player *to, player *from) { if((to == NULLPLAYER) || (from == NULLPLAYER)) return; *to = *from; return; } /* مقارنة اسم اللاعب الأول مع اسم اللاعب الثاني */ int compare_name(player *first, player *second) { return strcmp(first->name, second->name); } /* مقارنة رتبة اللاعب الأول مع رتبة اللاعب الثاني */ int compare_rank(player *first, player *second) { return (first->rank - second->rank); } // ترتيب num الذي يدل على سجل اللاعب في المصفوفة them void sort_players(player *them, int num) { qsort(them, num, sizeof(player), compare_rank); } [مثال 5] صُرّفت الشيفرة السابقة عند تجربتها إلى كائن ملف object file، الذي كان مربوطًا (مع كائن ملف يحتوي على الشيفرة البرمجية الخاصة بالدالة options) بواحدٍ من البرامج الثلاثة الخاصة بالتعامل مع لائحة النتائج. إليك الشيفرة البرمجية لواحدة من أبسط البرامج هذه، ألا وهو "showlddr"، الذي تحتوي على الملف "showlddr.c". يأخذ هذا البرنامج خيارًا واحدًا وهو -f وقد تلاحظ أن هذا الخيار يأخذ وسيطًا اختياريًا أيضًا، والهدف من هذا الوسيط هو السماح بطباعة ملف بيانات لائحة التصنيف باستخدام اسم مغاير للاسم الافتراضي ladder. يجب أن تُخزّن سجلات اللاعب في ملف البيانات قبل ترتيبها، إلا أن showddlr يرتبها قبل أن يطبعها فقط بهدف التأكُّد. /* برنامج يطبع حالة لائحة النتائج الحالية */ #include "player.h" const char *ValidOpts = "f:"; const char *Usage = "usage: showlddr [-f ladder_file]\n"; char *OtherFile; int main(int argc, char *argv[]) { int number; char ch; player *them; const char *fname; FILE *fp; if(argc == 3){ while((ch = options(argc, argv, ValidOpts)) != -1){ switch(ch){ case 'f': OtherFile = OptArg; break; case '?': fprintf(stderr, Usage); break; } } } else if(argc > 1){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } fname = (OtherFile == 0)? LadderFile : OtherFile; fp = fopen(fname, "r+"); if(fp == NULL){ perror("showlddr"); exit(EXIT_FAILURE); } number = valid_records (fp); them = (player *)malloc((sizeof(player) * number)); if(them == NULL){ fprintf(stderr,"showlddr: out of memory\n"); exit(EXIT_FAILURE); } if(read_records(fp, number, them) != number){ fprintf(stderr, "showlddr: error while reading" " player records\n"); free(them); fclose(fp); exit(EXIT_FAILURE); } fclose(fp); sort_players(them, number); if(print_records(them, number) != number){ fprintf(stderr, "showlddr: error while printing" " player records\n"); free(them); exit(EXIT_FAILURE); } free(them); exit(EXIT_SUCCESS); } [مثال 6] يعمل البرنامج "showlddr" فقط إذا كان هناك ملف بيانات يحتوي على سجلات اللاعب بالتنسيق الصحيح، ويُنشئ البرنامج "newplyr" ملفًا إذا لم يكن هناك أي ملف مُسبقًا ومن ثم يضيف بيانات اللاعب الجديد بالتنسيق الصحيح إلى ذلك الملف. يُدرج اللاعبون الجُدد عادةً أسفل التصنيف إلا أن هناك بعض الحالات الاستثنائية التي يسمح فيها "newplyr" بإدراج اللاعبين وسط التصنيف. يجب أن يظهر اللاعب مرةً واحدةً في التصنيف (إلا إذا تشابهت أسماء اللاعبين المستعارة) ويجب أن يكون لكل تصنيف لاعب واحد فقط، ولذا فإن البرنامج يفحص الإدخالات المتكررة وإذا كان من الواجب إدخال اللاعب الجديد إلى تصنيف مجاور لتصنيف اللاعبين الآخرين، يُزاح اللاعبون بعيدًا عن تصنيف اللاعب الجديد. يتعرّف البرنامج "newplyr" على الخيار -f بصورةٍ مشابهة للبرنامج "showlddr"، ويفسره على أنه طلب إضافة اللاعب الجديد إلى ملف يُسمى باستخدام وسيط الخيار بدلًا من اسم الملف الافتراضي ألا وهو "ladder". يتطلب البرنامج "newplyr" أيضًا خيارين إضافيين ألا وهما n- و r- ويحدد كل وسيط خيار اسم اللاعب الجديد وتصنيفه الأوّلي بالترتيب. /* برنامج يُضيف لاعب جديد إلى لائحة التصنيفات، ويفترض أن تُسنِد رتبةً بقيمة واقعية إلى اللاعب */ #include "player.h" const char *ValidOpts = "n:r:f:"; char *OtherFile; static const char *Usage = "usage: newplyr -r rank -n name [-f file]\n"; /* تصاريح مسبقة للدوال المعرفة في هذا الملف*/ void record(player *extra); int main(int argc, char *argv[]) { char ch; player dummy, *new = &dummy; if(argc < 5){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } while((ch = options(argc, argv, ValidOpts)) != -1){ switch(ch){ case 'f': OtherFile=OptArg; break; case 'n': strncpy(new->name, OptArg, NAMELEN); new->name[NAMELEN] = 0; if(strcmp(new->name, OptArg) != 0) fprintf(stderr, "Warning: name truncated to %s\n", new->name); break; case 'r': if((new->rank = atoi(OptArg)) == 0){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } break; case '?': fprintf(stderr, Usage); break; } } if((new->rank == 0)){ fprintf(stderr, "newplyr: bad value for rank\n"); exit(EXIT_FAILURE); } if(strlen(new->name) == 0){ fprintf(stderr, "newplyr: needs a valid name for new player\n"); exit(EXIT_FAILURE); } new->wins = new->losses = 0; time(& new->last_game); // أسند الوقت الحالي إلى last_game record(new); exit(EXIT_SUCCESS); } void record(player *extra) { int number, new_number, i; player *them; const char *fname =(OtherFile==0)?LadderFile:OtherFile; FILE *fp; fp = fopen(fname, "r+"); if(fp == NULL){ if((fp = fopen(fname, "w")) == NULL){ perror("newplyr"); exit(EXIT_FAILURE); } } number = valid_records (fp); new_number = number + 1; if((extra->rank <= 0) || (extra->rank > new_number)){ fprintf(stderr, "newplyr: rank must be between 1 and %d\n", new_number); exit(EXIT_FAILURE); } them = (player *)malloc((sizeof(player) * new_number)); if(them == NULL){ fprintf(stderr,"newplyr: out of memory\n"); exit(EXIT_FAILURE); } if(read_records(fp, number, them) != number){ fprintf(stderr, "newplyr: error while reading player records\n"); free(them); exit(EXIT_FAILURE); } if(find_by_name(extra->name, them, number) != NULLPLAYER){ fprintf(stderr, "newplyr: %s is already on the ladder\n", extra->name); free(them); exit(EXIT_FAILURE); } copy_player(&them[number], extra); if(extra->rank != new_number) push_down(them, number, extra->rank, number); sort_players(them, new_number); if((fp = freopen(fname, "w+", fp)) == NULL){ perror("newplyr"); free(them); exit(EXIT_FAILURE); } if(write_records(fp, them, new_number) != new_number){ fprintf(stderr, "newplyr: error while writing player records\n"); fclose(fp); free(them); exit(EXIT_FAILURE); } fclose(fp); free(them); } [مثال 7] البرنامج الأخير المطلوب هو البرنامج الذي يسجل نتائج الألعاب، ألا وهو برنامج "result". يقبل "result" خيار -f كما هو الحال في البرنامجين الآخرين، مصحوبًا باسم الملف لتحديد بديل عن اسم ملف اللاعب الافتراضي. يعرض برنامج "result" عملية الإدخال للاعبين الخاسرين والرابحين على نحوٍ تفاعلي على عكس برنامج "newplyr"، ويصرّ على أن الأسماء يجب أن تكون للاعبين موجودين مسبقًا. يجري التحقّق من الأسماء بعد إعطاء اسمين صالحين، وذلك فيما إذا كان الخاسر أعلى تصنيفًا من الفائز، أو أن الفائز ذو تصنيف مقارب مما يسمح له بتغيير تصنيفه؛ وإذا لزُم تغيير للتصنيف، يأخذ المنتصر رتبة الخاسر ويُخفّض الخاسر رتبةً واحدةً (إضافةً إلى أي لاعب من تصنيف متداخل). إليك الشيفرة البرمجية الخاصة ببرنامج result. /* * برنامج يسجل النتائج * */ #include "player.h" /* تصريحات استباقية للدوال المعرفة في هذا الملف */ char *read_name(char *, char *); void move_winner(player *, player *, player *, int); const char *ValidOpts = "f:"; const char *Usage = "usage: result [-f file]\n"; char *OtherFile; int main(int argc, char *argv[]) { player *winner, *loser, *them; int number; FILE *fp; const char *fname; char buf[LENBUF], ch; if(argc == 3){ while((ch = options(argc, argv, ValidOpts)) != -1){ switch(ch){ case 'f': OtherFile = OptArg; break; case '?': fprintf(stderr, Usage); break; } } } else if(argc > 1){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } fname = (OtherFile == 0)? LadderFile : OtherFile; fp = fopen(fname, "r+"); if(fp == NULL){ perror("result"); exit(EXIT_FAILURE); } number = valid_records (fp); them = (player *)malloc((sizeof(player) * number)); if(them == NULL){ fprintf(stderr,"result: out of memory\n"); exit(EXIT_FAILURE); } if(read_records(fp, number, them) != number){ fprintf(stderr, "result: error while reading player records\n"); fclose(fp); free(them); exit(EXIT_FAILURE); } fclose(fp); if((winner = find_by_name(read_name(buf, "winner"), them, number)) == NULLPLAYER){ fprintf(stderr,"result: no such player %s\n",buf); free(them); exit(EXIT_FAILURE); } if((loser = find_by_name(read_name(buf, "loser"), them, number)) == NULLPLAYER){ fprintf(stderr,"result: no such player %s\n",buf); free(them); exit(EXIT_FAILURE); } winner->wins++; loser->losses++; winner->last_game = loser->last_game = time(0); if(loser->rank < winner->rank) if((winner->rank - loser->rank) <= CHALLENGE_RANGE) move_winner(winner, loser, them, number); if((fp = freopen(fname, "w+", fp)) == NULL){ perror("result"); free(them); exit(EXIT_FAILURE); } if(write_records(fp, them, number) != number){ fprintf(stderr,"result: error while writing player records\n"); free(them); exit(EXIT_FAILURE); } fclose(fp); free(them); exit(EXIT_SUCCESS); } void move_winner(player *ww, player *ll, player *them, int number) { int loser_rank = ll->rank; if((ll->rank - ww->rank) > 3) return; push_down(them, number, ll->rank, (ww->rank - 1)); ww->rank = loser_rank; sort_players(them, number); return; } char *read_name(char *buf, char *whom) { for(;;){ char *cp; printf("Enter name of %s : ",whom); if(fgets(buf, LENBUF, stdin) == NULL) continue; /* حذف السطر الجديد */ cp = &buf[strlen(buf)-1]; if(*cp == '\n') *cp = 0; /* محرف واحد على الأقل */ if(cp != buf) return buf; } } [مثال 8] ترجمة -وبتصرف- للفصل Complete Programs in C من كتاب The C Book. اقرأ أيضًا المقال السابق: دوال التعامل مع السلاسل النصية والوقت والتاريخ في لغة سي C .بعض البرامج البسيطة بلغة سي C: المصفوفات والعمليات الحسابية العوامل في لغة سي C
بعد أن تكلمنا عن المكتبات القياسية المعرفة حسب المعيار، لم يبقَ إلا توضيح هيئة البرامج الكاملة المكتوبة بهذه اللغة، وسنتطرق في هذا المقال إلى بعض الأمثلة التي توضح كيفية جمع هذه العناصر لبناء البرامج. إلا أن هناك بعض النقاط التي يجب مناقشتها في لغة سي قبل عرض هذه الأمثلة. وسطاء الدالة main تقدم وسطاء الدالة main فرصةً مفيدةً لكل من يكتب البرامج ويشغلها في بيئة مُستضافة hosted environment وذلك بإعطاء المعاملات للبرنامج، ويُستخدم ذلك عادةً لتوجيه البرنامج لكيفية تنفيذ مهامه، ومن الشائع أن تكون هذه المعاملات هي أسماء ملفات تُمرّر مثل وسيط. يبدو تصريح الدالة main على النحو التالي: int main(int argc, char *argv[]); يُشير التصريح إلى أن الدالة main تُعيد عددًا صحيحًا، وتُمرّر هذه القيمة عادةً، أو حالة الخروج exit status في البيئات المُستضافة، مثل أنظمة دوس DOS أو يونيكس UNIX إلى مفسّر سطر الأوامر command line interpreter، فعلى سبيل المثال تُستخدم حالة الخروج في نظام يونيكس للدلالة على إتمام البرنامج لمهمته بنجاح (تمثلّه القيمة صفر)، أو حدوث خطأ أثناء التنفيذ (تمثًله قيمة غير صفرية). اتّبع المعيار هذا الاصطلاح أيضًا، إذ تُستخدم exit(0) لإعادة حالة النجاح إلى البيئة المُستضافة وأي قيمة أخرى تدلّ على حدوث خطأ ما، وستُترجم exit القيمة لمعناها إذا كانت البيئة المستضافة تستخدم اصطلاحًا مخالفًا. بما أن الترجمة معرفة حسب التنفيذ، فمن الأفضل استخدام القيمتان المُعرّفتان في ملف الترويسة <stdlib.h>، وهما: EXIT_SUCCESS و EXIT_FAILURE. هناك على الأقل وسيطان للدالة main، وهُما: argc و argv، إذ يدل أولهما على عدد الوسطاء المزودة للبرنامج، بينما يدل الثاني على مصفوفة من المؤشرات تشير إلى سلاسل نصية تمثّل الوسطاء، وهي من النوع "مصفوفة من المؤشرات تشير إلى محرف char"، وتُمرّر هذه الوسطاء إلى البرنامج باستخدام مفسّر سطر الأوامر الخاص بالبيئة المُستضافة، أو لغة التحكم بالوظائف job control language. يُعدّ تصريح الوسيط argv أوّل مصادفة للمبرمجين المبتدئين مع المؤشرات التي تشير إلى مصفوفات من المؤشرات، وقد يكون هذا محيّرًا بعض الشيء في البداية، إلا أن الأمر بسيط الفهم. بما أن argv تُستخدم للإشارة إلى مصفوفة السلاسل النصية، يكون تصريحها على النحو التالي: char *argv[] تذكر أيضًا أن اسم المصفوفة يُحوّل إلى عنوان أول عنصر ضمنها عندما تُمرّر إلى دالة، وهذا يعني أنه يمكننا التصريح عن argv كما يلي: char **argv والتصريحان يؤديان الغرض ذاته في هذه الحالة. سترى تصريح الدالة main مكتوبًا بهذه الطريقة معظم الأحيان، والتصريح التالي مكافئ للتصريح السابق: int main(int argc, char **argv); تُهيًّأ وسطاء الدالة main عند بداية تشغيل البرنامج على نحوٍ موافق للشروط التالية: الوسيط argc أكبر من الصفر. يمثّل argv[argc] مؤشرًا فارغًا null. تمثّل العناصر بدءًا من argv[0] وصولًا إلى argv[argc-1] مؤشرات تشير إلى سلاسل نصية يُحدِّد البرنامج معناها. يحتوي العنصر argv[0] السلسلة النصية التي تحتوي اسم البرنامج أو سلسلة نصية فارغة إذا لم تكن هذه المعلومة متاحة، وتمثل العناصر المتبقية من argv الوسطاء المزودة للبرنامج. يُزوّد محتوى السلاسل النصية إلى البرنامج بحالة الأحرف الصغيرة lower-case في حال توفر الدعم فقط للأحرف الوحيدة single. لتوضيح هذه النقطة، إليك مثالًا عن برنامج يكتب وسطاء الدالة main إلى خرج البرنامج القياسي: #include <stdio.h> #include <stdlib.h> int main(int argc, char **argv) { while(argc--) printf("%s\n", *argv++); exit(EXIT_SUCCESS); } [مثال 1] إذا كان اسم البرنامج show_args وكانت وسطاءه abcde و text و hello عند تشغيله، ستكون حالة الوسطاء وقيمة argv موضّحة في الشكل التالي: [شكل 1 وسطاء البرنامج] تنتقل argv إلى العنصر التالي عند كل زيادة لها، وبالتالي وبعد أول تكرار للحلقة ستُشير argv إلى المؤشر الذي بدوره يشير إلى الوسيط abcde، وهذا الأمر موضح بالشكل التالي: [شكل 2 وسطاء البرنامج بعد زيادة argv] سيعمل البرنامج على النظام الذي جرّبنا فيه البرنامج السابق عن طريق كتابة اسمه، ثم كتابة وسطاءه وفصلهم بمسافات فارغة. إليك ما الذي يحدث (الرمز $ هو رمز الطرفية): $ show_args abcde text hello show_args abcde text hello $ تفسير وسطاء البرنامج الحلقة المُستخدمة لفحص وسطاء البرنامج في المثال السابق شائعة الاستخدام في برامج سي C وستجدها في العديد من البرامج الأخرى، ويُعد استخدام "الخيارات options" للتحكم بسلوك البرنامج طريقةً شائعة أيضًا (تُدعى أيضًا في بعض الأحيان المُبدّلات switches أو الرايات flags)، إذ يدل الوسيط الذي يبدأ بالمحرف - على أنه وسيط يقدّم حرفًا وحيدًا أو أكثر يشير إلى خيار، ويمكن تشغيل الخيارات سويًا أو على نحوٍ منفرد: progname -abxu file1 file2 progname -a -b -x -u file1 file2 يحدّد كلًا من الخيارات جانبًا معينًا من مزايا البرنامج، وقد يُسمح لكل خيار بأخذ وسيط خاص به امتدادًا لهذه الفكرة، فعلى سبيل المثال إذا كان الخيار -x يأخذ وسيطًا خاصًا به، سيبدو ذلك على النحو التالي: progname -x arg file1 وبذلك، فإن arg مرتبطة مع الخيار. تسمح لنا دالة options في الأسفل بأتمتة معالجة أسلوب الاستخدام هذا عن طريق الدعم الإضافي (شائع الاستخدام إلا أنه قد عفا عليه الزمن) لإمكانية تقديم خيار الوسيط مباشرةً بعد حرف الخيار كما يلي: progname -xarg file1 تُعيد برامج الخيارات السابقة في كلٍّ من الحالتين المحرف 'x' وتضبط المؤشر العام global المسمى OptArg ليشير إلى القيمة arg. يجب أن يقدم البرنامج لائحةً من أحرف الخيارات الصالحة بهيئة سلسلة نصية حتى نستطيع استخدام برامج الخيارات، عندما يُلحق حرفٌ ضمن هذه السلسلة النصية بالنقطتين ':'، فهذا يعني أن ما يتبع حرف الخيار هو وسيط. يُستدعى برنامج options مرارًا عند تشغيل البرنامج حتى انتهاء أحرف الخيار. يبدو أن الدوال التي تقرأ السلاسل النصية وتبحث عن تشكيلات مختلفة أو أنماط ضمن السلسلة صعبة القراءة، وإن كان في ذلك عزاءً لكن ليست عملية القراءة بتلك البساطة فعليًا، والشيفرة البرمجية التي تطبّق الخيارات هي واحدةٌ من هذه الدوال، إلا أنها ليست الأصعب ضمن هذا التصنيف. تفحص الدالة options() أحرف الخيار ووسطاء الخيار من قائمة argv، وتُعيد استدعاءات متتابعة للدالة أحرف خيار متتابعة متوافقة مع واحدة من بنود القائمة legal. قد تتطلب أحرف الخيار وسطاء خيار ويُشار إلى ذلك بالنقطتين ':' اللتين تتبعان الحرف في القائمة legal. على سبيل المثال، تشير لائحة legal التي تحتوي على "ab:c" على أن a و b و c جميعها خيارات صالحة وأن b تأخذ وسيط خيار، ويُمرّر وسيط الخيار فيما بعد إلى الدالة التي استُدعيت سابقًا في قيمة المؤشر العام المُسمّى OptArg. يُعطي OptIndex السلسلة النصية التالية في مصفوفة argv[] التي لم تُعالج بعد من قبل الدالة options(). تُعيد الدالة options() القيمة -1 إذا لم يكُن هناك أي أحرف خيار أخرى، أو إذا عُثر على SwitchChar مضاعف، ويُجبر ذلك الدالة options() على إنهاء عملية معالجة الخيارات؛ بينما تُعيد ? إذا كان هناك خيار لا ينتمي إلى مجموعة legal، أو إذا عُثر على خيار ما يحتاج لوسيط دون وجود وسيط يتبعه. #include <stdio.h> #include <string.h> static const char SwitchChar = '-'; static const char Unknown = '?'; int OptIndex = 1; // يجب أن يكون أول خيار هو argv[1] char *OptArg = NULL; // مؤشر عام لوسيط الخيار int options(int argc, char *argv[], const char *legal) { static char *posn = ""; // الموضع في argv[OptIndex] char *legal_index = NULL; int letter = 0; if(!*posn){ // لا يوجد المزيد من args أو SwitchChar أو حرف خيار if((OptIndex >= argc) || (*(posn = argv[OptIndex]) != SwitchChar) || !*++posn) return -1; // إيجاد SwitchChar مضاعف if(*posn == SwitchChar){ OptIndex++; return -1; } } letter = *posn++; if(!(legal_index = strchr(legal, letter))){ if(!*posn) OptIndex++; return Unknown; } if(*++legal_index != ':'){ /*لا يوجد وسيط للخيار */ OptArg = NULL; if(!*posn) OptIndex++; } else { if(*posn) // لا يوجد مسافة فارغة بين opt و opt arg OptArg = posn; else if(argc <= ++OptIndex){ posn = ""; return Unknown; } else OptArg = argv[OptIndex]; posn = ""; OptIndex++; } return letter; } [مثال 2] برنامج لإيجاد الأنماط نقدّم في هذا القسم برنامجًا كاملًا يستخدم أحرف الخيار مثل وسطاء للبرنامج بهدف التحكم بطريقة عمله. يُعالج البرنامج أولًا أي وسيط يمثل خيارًا، ويُحفظ الوسيط الأول -ليس خيار- بكونه "سلسلة بحث نصية search string"، في حين تُستخدم أي وسطاء أخرى متبقية لتحديد أسماء الملفات التي يجب أن تُقرأ دخلًا للبرنامج، وإذا لم يُعثر على أي اسم ملف فسيقرأ البرنامج من دخله القياسي بدلًا من ذلك، وإذا وُجد تطابق لسلسلة البحث النصية ضمن سطر من نص الدخل، يُطبع كامل السطر على الخرج القياسي. تُستخدم الدالة options لمعالجة جميع أحرف الخيار المزودة للبرنامج، ويميّز برنامجنا هنا خمسة خيارات، هي: -c و -i و -l و -n و -v، ولا يُشترط لأي من الخيارات السابقة أن تُتبع بوسيط اختياري. يحدد الخيار -أو الخيارات- سلوك البرنامج عند تشغيله على النحو التالي: الخيار -c: يطبع البرنامج عدد الأسطر الكلية الموافقة لسلسلة البحث النصية التي عُثر عليها في ملف -أو ملفات- الدخل، ولا تُطبع أي أسطر نصية. الخيار -i: تُتجاهل حالة الأحرف لكل من سطر ملف الدخل وسلسلة البحث النصية عند البحث عن تطابق بينها. الخيار -l: يُطبع كل سطر نصي على الخرج مسبوقًا برقم السطر المفحوص في ملف الدخل الحالي. الخيار -n: يُطبع كل سطر نصي على الخرج مسبوقًا باسم الملف الذي يحتوي هذا السطر. الخيار -v: يطبع البرنامج الأسطر فقط دون مطابقة سلسلة البحث النصية المزودة. يُعيد البرنامج بعد الانتهاء من تنفيذه حالةً تدل على واحدة من الحالات التالية: الحالة EXIT_SUCCESS: عُثر على تطابق واحد على الأقل. الحالة EXIT_FAILURE: لم يُعثر على أي تطابق، أو حدث خطأ ما. يعتمد البرنامج جدًا على دوال المكتبة القياسية لإنجاز الجزء الأكبر من العمل، فعلى سبيل المثال تُعالج جميع الملفات باستخدام دوال stdio. لاحظ اعتماد جوهر البرنامج أيضًا على مطابقة السلاسل النصية باستخدام استدعاءات لدالة strstr. إليك الشيفرة البرمجية الكاملة الخاصة بالبرنامج. حتى يعمل البرنامج، عليك طبعًا تصريفه مع الشيفرة البرمجية الخاصة به التي تعالج أحرف الخيارات، والتي استعرضناها سابقًا. /* برنامج بسيط يطبع الأسطر من ملف نصي بحيث يحوي ذلك السطر الكلمة المزودة في سطر الأوامر */ #include <stdio.h> #include <stdlib.h> #include <string.h> #include <ctype.h> /* * تصاريح لبرنامج الأنماط * */ #define CFLAG 0x001 // احصِ عدد الأسطر المتطابقة فقط #define IFLAG 0x002 // تجاهل حالة الأحرف #define LFLAG 0x004 // اعرض رقم السطر #define NFLAG 0x008 // اعرض اسماء ملفات الدخل #define VFLAG 0x010 // اعرض السطور التي لاتتطابق extern int OptIndex; // الدليل الحالي للمصفوفة argv[] extern char *OptArg; /* مؤشر وسيط الخيار العام /* * جلب وسطاء سطر الأوامر إلى الدالة main() */ int options(int, char **, const char *); /* تسجيل الخيارات المطلوبة للتحكم بسلوك البرنامج */ unsigned set_flags(int, char **, const char *); /* تفقد كل سطر من الدخل لحالة المطابقة */ int look_in(const char *, const char *, unsigned); /* اطبع سطرًا من ملف الدخل إلى الخرج القياسي بالتنسيق المُحدد بواسطة خيارات سطر الأوامر */ void print_line(unsigned mask, const char *fname, int lnno, const char *text); static const char /* الخيارات الممكنة للنمط */ *OptString = "cilnv", /*الرسالة التي ستُعرض عندما تُدخل الخيارات بصورةٍ غير صحيحة */ *errmssg = "usage: pattern [-cilnv] word [filename]\n"; int main(int argc, char *argv[]) { unsigned flags = 0; int success = 0; char *search_string; if(argc < 2){ fprintf(stderr, errmssg); exit(EXIT_FAILURE); } flags = set_flags(argc, argv, OptString); if(argv[OptIndex]) search_string = argv[OptIndex++]; else { fprintf(stderr, errmssg); exit(EXIT_FAILURE); } if(flags & IFLAG){ /*تجاهل حالة الحرف والتعامل فقط مع الأحرف الصغيرة */ char *p; for(p = search_string ; *p ; p++) if(isupper(*p)) *p = tolower(*p); } if(argv[OptIndex] == NULL){ // لم يُزوّد أي اسم ملف، لذا نستخدم stdin success = look_in(NULL, search_string, flags); } else while(argv[OptIndex] != NULL) success += look_in(argv[OptIndex++], search_string, flags); if(flags & CFLAG) printf("%d\n", success); exit(success ? EXIT_SUCCESS : EXIT_FAILURE); } unsigned set_flags(int argc, char **argv, const char *opts) { unsigned flags = 0; int ch = 0; while((ch = options(argc, argv, opts)) != -1){ switch(ch){ case 'c': flags |= CFLAG; break; case 'i': flags |= IFLAG; break; case 'l': flags |= LFLAG; break; case 'n': flags |= NFLAG; break; case 'v': flags |= VFLAG; break; case '?': fprintf(stderr, errmssg); exit(EXIT_FAILURE); } } return flags; } int look_in(const char *infile, const char *pat, unsigned flgs) { FILE *in; /* يخزن [0]line سطر الدخل كما يُقرأ بينما يحول line[1] السطر إلى حالة أحرف صغيرة إن لزم الأمر */ char line[2][BUFSIZ]; int lineno = 0; int matches = 0; if(infile){ if((in = fopen(infile, "r")) == NULL){ perror("pattern"); return 0; } } else in = stdin; while(fgets(line[0], BUFSIZ, in)){ char *line_to_use = line[0]; lineno++; if(flgs & IFLAG){ /* حالة تجاهل */ char *p; strcpy(line[1], line[0]); for(p = line[1] ; *p ; *p++) if(isupper(*p)) *p = tolower(*p); line_to_use = line[1]; } if(strstr(line_to_use, pat)){ matches++; if(!(flgs & VFLAG)) print_line(flgs, infile, lineno, line[0]); } else if(flgs & VFLAG) print_line(flgs, infile, lineno, line[0]); } fclose(in); return matches; } void print_line(unsigned mask, const char *fname, int lnno, const char *text) { if(mask & CFLAG) return; if(mask & NFLAG) printf("%s:", *fname ? fname : "stdin"); if(mask & LFLAG) printf(" %d :", lnno); printf("%s", text); } [مثال 3] مثال أكثر طموحا أخيرًا نقدّم هنا مجموعةً من البرامج المصمّمة للتلاعب بملف بيانات وحيد والتعامل معه بطريقة مترابطة وسليمة؛ إذ تهدف هذه البرامج لمساعدتنا بتتبع نتائج عدة لاعبين يتنافسون مع بعضهم بعضًا في لعبةٍ ما، مثل الشطرنج، أو الإسكواش على سبيل المثال. يمتلك كل لاعب تصنيفًا من واحد إلى n، إذ تمثل n عدد اللاعبين الكلي وواحد تصنيف أعلى لاعب. يستطيع اللاعبون من تصنيف منخفض تحدي لاعبين آخرين فوق تصنيفهم وينتقل اللاعب إلى تصنيف اللاعب الآخر الأعلى منه إذا انتصر عليه، وفي هذه الحالة يُنقل اللاعب الخاسر وأي لاعبين آخرين بين اللاعب الخاسر والفائز إلى تصنيف واحد أقل، وتبقى التصنيفات مثل ما هي إن لم ينتصر اللاعب الأقل تصنيفًا. لتقديم بعض الضوابط للتوازن في التصنيف، يمكن لأي لاعب أن يتحدى لاعبًا أعلى منه تصنيفًا، إلا أن التحديات مع اللاعبين ذوي التصنيف الذي يزيد عن ثلاثة أو أقل مراتب هي الوحيدة التي ستسمح لهذا اللاعب بالتقدم في التصنيف، وهذا من شأنه أن يُجبر اللاعبين الجدُد المضافين إلى أسفل التصنيف أن يلعبوا أكثر من لعبة واحدة للوصول إلى أعلى التصنيف. هناك ثلاث مهام أساسية يجب تنفيذها للمحافظة على تتبع سليم لنتائج التصنيفات: طباعة التصنيف. إضافة لاعبين جدُد. تسجيل النتائج. سيأخذ تصميم برنامجنا هنا صورة ثلاثة برامج جزئية لتنفيذ كل واحدة من هذه المهام على حدة، ومن الواضح بعد اتخاذنا لهذا القرار أن هناك عددًا من العمليات التي يحتاجها كل برنامج على نحوٍ مشترك بين البرامج الثلاث؛ فعلى سبيل المثال، ستحتاج البرامج الثلاثة إلى قراءة سجلات اللاعب من ملف البيانات وستحتاج اثنان من البرامج على الأقل لكتابة سجلات اللاعب إلى ملف البيانات. قد يكون الخيار الجيد هنا هو تصميم مكتبة من الدوال التي تتلاعب بسجلات اللاعبين وملف البيانات، واستخدام هذه المكتبة مع البرامج الثلاثة للتعامل مع تصنيف اللاعبين، إلا أننا بحاجة تعريف هيكل البيانات الذي سيمثل سجلات اللاعب قبل ذلك. تتألف المعلومات الدنيا اللازمة لإنشاء سجل لكل لاعب من اسمه وتصنيفه، إلا أننا سنحتفظ بعدد التحديات التي فاز بها اللاعب، إضافةً للتحديات التي خسرها وآخر لعبة لعبها لمنح بعض الإمكانيات الإحصائية عند تشكيل لائحة التصنيف، ومن الواضح أن هذه المجموعة من المعلومات يجب تخزينها في هيكل ما. نجد التصريح عن هيكل اللاعب والتصريح عن دوال مكتبة اللاعب في ملف الترويسة player.h، وتُخزّن البيانات في ملف البيانات مثل أسطر نصية، إذ يشير كل سطر إلى معلومات لاعب معين. يتطلب ذلك إجراء تحويلات الدخل والخرج، لكنها تقنيةٌ مفيدةٌ إذا لم تكلّف هذه التحويلات أداءً إضافيًا. /* * * التصاريح والتعاريف للدوال التي تتلاعب بسجلات اللاعب بناءً على ترتيبهم * */ #include <stddef.h> #include <stdio.h> #include <stdlib.h> #include <time.h> #define NAMELEN 12 /* الطول الأعظمي لاسم اللاعب */ #define LENBUF 256 /* الطول الأعظمي لذاكرة الدخل المؤقتة */ #define CHALLENGE_RANGE 3 // عدد اللاعبين الأعلى تصنيفًا الذين من الممكن للاعب أن يتحداهم ليزيد تصنيفه extern char *OptArg; typedef struct { char name[NAMELEN+1]; int rank; int wins; int losses; time_t last_game; } player; #define NULLPLAYER (player *)0 extern const char *LadderFile; extern const char *WrFmt; /* يُستخدم عند كتابة السجلات */ extern const char *RdFmt; /* يُستخدم عند قراءة السجلات */ /* تصاريح البرامج التي تُستخدم للتلاعب بسجلات اللاعب وملف لائحة التصنيف المعرفة في ملف player.c */ int valid_records(FILE *); int read_records(FILE *, int, player *); int write_records(FILE *, player *, int); player *find_by_name(char *, player *, int); player *find_by_rank(int, player *, int); void push_down(player *, int, int, int); int print_records(player *, int); void copy_player(player *, player *); int compare_name(player *, player *); int compare_rank(player *, player *); void sort_players(player *, int); [مثال 4] إليك شيفرة ملف player.c الذي يستخدم بعض الدوال العامة للتلاعب بسجلات اللاعبين وملف البيانات، ويمكن أن تُستخدم هذه الدوال مع برامج أخرى محدد لتشكيل ثلاثة برامج تتعامل مع لائحة النتائج. لاحظ أنه يجب على كل برنامج أن يقرأ كامل البيانات من الملف إلى مصفوفة ديناميكية حتى نستطيع التلاعب بسجلات اللاعبين، ومن المفترض أن تكون جميع السجلات المحتواة داخل المصفوفة مُرتبةً حسب التصنيف قبل كتابتها مجددًا إلى ملف البيانات، وستولّد الدالة push_down بعض النتائج المثيرة للاهتمام إن لم تكن السجلات مرتبة. /* * الدوال الاعتيادية المستخدمة للتلاعب ببيانات ملف لائحة النتائج وسجلات اللاعبين */ #include "player.h" const char *LadderFile = "ladder"; const char *WrFmt = "%s %d %d %d %ld\n"; const char *RdFmt = "%s %d %d %d %ld"; /* تنبيه المستخدم بخصوص ضمّ السلاسل النصية */ const char *HeaderLine = "Player Rank Won Lost Last Game\n" "===============================================\n"; const char *PrtFmt = "%-12s%4d %4d %4d %s\n"; /*إعادة رقم السجلات الموجودة في الملف */ int valid_records(FILE *fp) { int i = 0; long plrs = 0L; long tmp = ftell(fp); char buf[LENBUF]; fseek(fp, 0L, SEEK_SET); for(i = 0; fgets(buf, LENBUF, fp) != NULL ; i++) ; /* استعادة مؤشر الملف إلى حالته الأصلية*/ fseek(fp, tmp, SEEK_SET); return i; } // قراءة القيمة num من سجل اللاعب من الملف fp إلى المصفوفة them int read_records(FILE *fp, int num, player *them) { int i = 0; long tmp = ftell(fp); if(num == 0) return 0; fseek(fp, 0L, SEEK_SET); for(i = 0 ; i < num ; i++){ if(fscanf(fp, RdFmt, (them[i]).name, &((them[i]).rank), &((them[i]).wins), &((them[i]).losses), &((them[i]).last_game)) != 5) break; // خطأ عند fscanf } fseek(fp, tmp, SEEK_SET); return i; } // كتابة num الخاص بسجل اللاعب إلى الملف fp من المصفوفة them int write_records(FILE *fp, player *them, int num) { int i = 0; fseek(fp, 0L, SEEK_SET); for(i = 0 ; i < num ; i++){ if(fprintf(fp, WrFmt, (them[i]).name, (them[i]).rank, (them[i]).wins, (them[i]).losses, (them[i]).last_game) < 0) break; // خطأ عند fprintf } return i; } /* إعادة مؤشر يشير إلى اللاعب في المصفوفة them ذو اسم مطابق للقيمة name */ player *find_by_name(char * name, player *them, int num) { player *pp = them; int i = 0; for(i = 0; i < num; i++, pp++) if(strcmp(name, pp->name) == 0) return pp; return NULLPLAYER; } /* إعادة مؤشر يشير إلى لاعب في مصفوفة them تُطابق رتبته القيمة rank */ player *find_by_rank(int rank, player *them, int num) { player *pp = them; int i = 0; for(i = 0; i < num; i++, pp++) if(rank == pp->rank) return pp; return NULLPLAYER; } /* خفّض رتبة جميع اللاعبين في مصفوفة them إذا كانت رتبتهم بين start و end */ void push_down(player *them, int number, int start, int end) { int i; player *pp; for(i = end; i >= start; i--){ if((pp = find_by_rank(i, them, number)) == NULLPLAYER){ fprintf(stderr, "error: could not find player ranked %d\n", i); free(them); exit(EXIT_FAILURE); } else (pp->rank)++; } } // طباعة سجل اللاعب num بصورةٍ مُنسّقة من المصفوفة them int print_records(player *them, int num) { int i = 0; printf(HeaderLine); for(i = 0 ; i < num ; i++){ if(printf(PrtFmt, (them[i]).name, (them[i]).rank, (them[i]).wins, (them[i]).losses, asctime(localtime(&(them[i]).last_game))) < 0) break; /* error on printf! */ } return i; } /* نسخ القيم من لاعب إلى آخر */ void copy_player(player *to, player *from) { if((to == NULLPLAYER) || (from == NULLPLAYER)) return; *to = *from; return; } /* مقارنة اسم اللاعب الأول مع اسم اللاعب الثاني */ int compare_name(player *first, player *second) { return strcmp(first->name, second->name); } /* مقارنة رتبة اللاعب الأول مع رتبة اللاعب الثاني */ int compare_rank(player *first, player *second) { return (first->rank - second->rank); } // ترتيب num الذي يدل على سجل اللاعب في المصفوفة them void sort_players(player *them, int num) { qsort(them, num, sizeof(player), compare_rank); } [مثال 5] صُرّفت الشيفرة السابقة عند تجربتها إلى كائن ملف object file، الذي كان مربوطًا (مع كائن ملف يحتوي على الشيفرة البرمجية الخاصة بالدالة options) بواحدٍ من البرامج الثلاثة الخاصة بالتعامل مع لائحة النتائج. إليك الشيفرة البرمجية لواحدة من أبسط البرامج هذه، ألا وهو "showlddr"، الذي تحتوي على الملف "showlddr.c". يأخذ هذا البرنامج خيارًا واحدًا وهو -f وقد تلاحظ أن هذا الخيار يأخذ وسيطًا اختياريًا أيضًا، والهدف من هذا الوسيط هو السماح بطباعة ملف بيانات لائحة التصنيف باستخدام اسم مغاير للاسم الافتراضي ladder. يجب أن تُخزّن سجلات اللاعب في ملف البيانات قبل ترتيبها، إلا أن showddlr يرتبها قبل أن يطبعها فقط بهدف التأكُّد. /* برنامج يطبع حالة لائحة النتائج الحالية */ #include "player.h" const char *ValidOpts = "f:"; const char *Usage = "usage: showlddr [-f ladder_file]\n"; char *OtherFile; int main(int argc, char *argv[]) { int number; char ch; player *them; const char *fname; FILE *fp; if(argc == 3){ while((ch = options(argc, argv, ValidOpts)) != -1){ switch(ch){ case 'f': OtherFile = OptArg; break; case '?': fprintf(stderr, Usage); break; } } } else if(argc > 1){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } fname = (OtherFile == 0)? LadderFile : OtherFile; fp = fopen(fname, "r+"); if(fp == NULL){ perror("showlddr"); exit(EXIT_FAILURE); } number = valid_records (fp); them = (player *)malloc((sizeof(player) * number)); if(them == NULL){ fprintf(stderr,"showlddr: out of memory\n"); exit(EXIT_FAILURE); } if(read_records(fp, number, them) != number){ fprintf(stderr, "showlddr: error while reading" " player records\n"); free(them); fclose(fp); exit(EXIT_FAILURE); } fclose(fp); sort_players(them, number); if(print_records(them, number) != number){ fprintf(stderr, "showlddr: error while printing" " player records\n"); free(them); exit(EXIT_FAILURE); } free(them); exit(EXIT_SUCCESS); } [مثال 6] يعمل البرنامج "showlddr" فقط إذا كان هناك ملف بيانات يحتوي على سجلات اللاعب بالتنسيق الصحيح، ويُنشئ البرنامج "newplyr" ملفًا إذا لم يكن هناك أي ملف مُسبقًا ومن ثم يضيف بيانات اللاعب الجديد بالتنسيق الصحيح إلى ذلك الملف. يُدرج اللاعبون الجُدد عادةً أسفل التصنيف إلا أن هناك بعض الحالات الاستثنائية التي يسمح فيها "newplyr" بإدراج اللاعبين وسط التصنيف. يجب أن يظهر اللاعب مرةً واحدةً في التصنيف (إلا إذا تشابهت أسماء اللاعبين المستعارة) ويجب أن يكون لكل تصنيف لاعب واحد فقط، ولذا فإن البرنامج يفحص الإدخالات المتكررة وإذا كان من الواجب إدخال اللاعب الجديد إلى تصنيف مجاور لتصنيف اللاعبين الآخرين، يُزاح اللاعبون بعيدًا عن تصنيف اللاعب الجديد. يتعرّف البرنامج "newplyr" على الخيار -f بصورةٍ مشابهة للبرنامج "showlddr"، ويفسره على أنه طلب إضافة اللاعب الجديد إلى ملف يُسمى باستخدام وسيط الخيار بدلًا من اسم الملف الافتراضي ألا وهو "ladder". يتطلب البرنامج "newplyr" أيضًا خيارين إضافيين ألا وهما n- و r- ويحدد كل وسيط خيار اسم اللاعب الجديد وتصنيفه الأوّلي بالترتيب. /* برنامج يُضيف لاعب جديد إلى لائحة التصنيفات، ويفترض أن تُسنِد رتبةً بقيمة واقعية إلى اللاعب */ #include "player.h" const char *ValidOpts = "n:r:f:"; char *OtherFile; static const char *Usage = "usage: newplyr -r rank -n name [-f file]\n"; /* تصاريح مسبقة للدوال المعرفة في هذا الملف*/ void record(player *extra); int main(int argc, char *argv[]) { char ch; player dummy, *new = &dummy; if(argc < 5){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } while((ch = options(argc, argv, ValidOpts)) != -1){ switch(ch){ case 'f': OtherFile=OptArg; break; case 'n': strncpy(new->name, OptArg, NAMELEN); new->name[NAMELEN] = 0; if(strcmp(new->name, OptArg) != 0) fprintf(stderr, "Warning: name truncated to %s\n", new->name); break; case 'r': if((new->rank = atoi(OptArg)) == 0){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } break; case '?': fprintf(stderr, Usage); break; } } if((new->rank == 0)){ fprintf(stderr, "newplyr: bad value for rank\n"); exit(EXIT_FAILURE); } if(strlen(new->name) == 0){ fprintf(stderr, "newplyr: needs a valid name for new player\n"); exit(EXIT_FAILURE); } new->wins = new->losses = 0; time(& new->last_game); // أسند الوقت الحالي إلى last_game record(new); exit(EXIT_SUCCESS); } void record(player *extra) { int number, new_number, i; player *them; const char *fname =(OtherFile==0)?LadderFile:OtherFile; FILE *fp; fp = fopen(fname, "r+"); if(fp == NULL){ if((fp = fopen(fname, "w")) == NULL){ perror("newplyr"); exit(EXIT_FAILURE); } } number = valid_records (fp); new_number = number + 1; if((extra->rank <= 0) || (extra->rank > new_number)){ fprintf(stderr, "newplyr: rank must be between 1 and %d\n", new_number); exit(EXIT_FAILURE); } them = (player *)malloc((sizeof(player) * new_number)); if(them == NULL){ fprintf(stderr,"newplyr: out of memory\n"); exit(EXIT_FAILURE); } if(read_records(fp, number, them) != number){ fprintf(stderr, "newplyr: error while reading player records\n"); free(them); exit(EXIT_FAILURE); } if(find_by_name(extra->name, them, number) != NULLPLAYER){ fprintf(stderr, "newplyr: %s is already on the ladder\n", extra->name); free(them); exit(EXIT_FAILURE); } copy_player(&them[number], extra); if(extra->rank != new_number) push_down(them, number, extra->rank, number); sort_players(them, new_number); if((fp = freopen(fname, "w+", fp)) == NULL){ perror("newplyr"); free(them); exit(EXIT_FAILURE); } if(write_records(fp, them, new_number) != new_number){ fprintf(stderr, "newplyr: error while writing player records\n"); fclose(fp); free(them); exit(EXIT_FAILURE); } fclose(fp); free(them); } [مثال 7] البرنامج الأخير المطلوب هو البرنامج الذي يسجل نتائج الألعاب، ألا وهو برنامج "result". يقبل "result" خيار -f كما هو الحال في البرنامجين الآخرين، مصحوبًا باسم الملف لتحديد بديل عن اسم ملف اللاعب الافتراضي. يعرض برنامج "result" عملية الإدخال للاعبين الخاسرين والرابحين على نحوٍ تفاعلي على عكس برنامج "newplyr"، ويصرّ على أن الأسماء يجب أن تكون للاعبين موجودين مسبقًا. يجري التحقّق من الأسماء بعد إعطاء اسمين صالحين، وذلك فيما إذا كان الخاسر أعلى تصنيفًا من الفائز، أو أن الفائز ذو تصنيف مقارب مما يسمح له بتغيير تصنيفه؛ وإذا لزُم تغيير للتصنيف، يأخذ المنتصر رتبة الخاسر ويُخفّض الخاسر رتبةً واحدةً (إضافةً إلى أي لاعب من تصنيف متداخل). إليك الشيفرة البرمجية الخاصة ببرنامج result. /* * برنامج يسجل النتائج * */ #include "player.h" /* تصريحات استباقية للدوال المعرفة في هذا الملف */ char *read_name(char *, char *); void move_winner(player *, player *, player *, int); const char *ValidOpts = "f:"; const char *Usage = "usage: result [-f file]\n"; char *OtherFile; int main(int argc, char *argv[]) { player *winner, *loser, *them; int number; FILE *fp; const char *fname; char buf[LENBUF], ch; if(argc == 3){ while((ch = options(argc, argv, ValidOpts)) != -1){ switch(ch){ case 'f': OtherFile = OptArg; break; case '?': fprintf(stderr, Usage); break; } } } else if(argc > 1){ fprintf(stderr, Usage); exit(EXIT_FAILURE); } fname = (OtherFile == 0)? LadderFile : OtherFile; fp = fopen(fname, "r+"); if(fp == NULL){ perror("result"); exit(EXIT_FAILURE); } number = valid_records (fp); them = (player *)malloc((sizeof(player) * number)); if(them == NULL){ fprintf(stderr,"result: out of memory\n"); exit(EXIT_FAILURE); } if(read_records(fp, number, them) != number){ fprintf(stderr, "result: error while reading player records\n"); fclose(fp); free(them); exit(EXIT_FAILURE); } fclose(fp); if((winner = find_by_name(read_name(buf, "winner"), them, number)) == NULLPLAYER){ fprintf(stderr,"result: no such player %s\n",buf); free(them); exit(EXIT_FAILURE); } if((loser = find_by_name(read_name(buf, "loser"), them, number)) == NULLPLAYER){ fprintf(stderr,"result: no such player %s\n",buf); free(them); exit(EXIT_FAILURE); } winner->wins++; loser->losses++; winner->last_game = loser->last_game = time(0); if(loser->rank < winner->rank) if((winner->rank - loser->rank) <= CHALLENGE_RANGE) move_winner(winner, loser, them, number); if((fp = freopen(fname, "w+", fp)) == NULL){ perror("result"); free(them); exit(EXIT_FAILURE); } if(write_records(fp, them, number) != number){ fprintf(stderr,"result: error while writing player records\n"); free(them); exit(EXIT_FAILURE); } fclose(fp); free(them); exit(EXIT_SUCCESS); } void move_winner(player *ww, player *ll, player *them, int number) { int loser_rank = ll->rank; if((ll->rank - ww->rank) > 3) return; push_down(them, number, ll->rank, (ww->rank - 1)); ww->rank = loser_rank; sort_players(them, number); return; } char *read_name(char *buf, char *whom) { for(;;){ char *cp; printf("Enter name of %s : ",whom); if(fgets(buf, LENBUF, stdin) == NULL) continue; /* حذف السطر الجديد */ cp = &buf[strlen(buf)-1]; if(*cp == '\n') *cp = 0; /* محرف واحد على الأقل */ if(cp != buf) return buf; } } [مثال 8] ترجمة -وبتصرف- للفصل Complete Programs in C من كتاب The C Book. اقرأ أيضًا المقال السابق: دوال التعامل مع السلاسل النصية والوقت والتاريخ في لغة سي C .بعض البرامج البسيطة بلغة سي C: المصفوفات والعمليات الحسابية العوامل في لغة سي C -

 نتطرّق في هذا المقال إلى طرق مختلفة في التعامل مع السلاسل النصية والتلاعب بها، وذلك عن طريق دوال مكتبة string.h، ومن ثمّ ننتقل إلى دوال الوقت والتاريخ المحتواة في مكتبة time.h. التعامل مع السلاسل النصية هناك العديد من الدوال التي تسمح لنا بالتعامل مع السلاسل النصية، إذ تكون السلسلة النصية في لغة سي مؤلفةً من مصفوفة من المحارف تنتهي بمحرف فارغ null، وتتوقع الدوال في جميع الحالات تمرير مؤشر يشير إلى المحرف الأول ضمن السلسلة النصية، ويعرّف ملف الترويسة <string.h> هذا النوع من الدوال. النسخ يضم هذا التصنيف الدوال التالية: #include <string.h> void *memcpy(void *s1, const void *s2, size_t n); void *memmove (void *s1, const void *s2, size_t n); char *strcpy(char *s1, const char *s2); char *strncpy(char *s1, const char *s2, size_t n); char *strcat(char *s1, const char *s2); char *strncat(char *s1, const char *s2, size_t n); دالة memcpy: تنسخ هذه الدالة n بايت من المكان الذي يشير إليه المؤشر s2 إلى المكان الذي يشير إليه المؤشر s1، ونحصل على سلوك غير محدد إذا كان الكائنان متداخلان overlapping objects. تعيد الدالة s1. دالة memmove: هذه الدالة مطابقة لعمل دالة memcpy إلا أنها تعمل على الكائنات المتداخلة، إلا أنها قد تكون أبطأ. دالتَي strcpy وstrncpy: تنسخ كلا الدالتين السلسلة النصية التي يشير إليها المؤشر s2 إلى سلسلة نصية يشير المؤشر s1 إليها متضمنًا ذلك المحرف الفارغ في نهاية السلسلة. تنسخ strncpy سلسلةً نصيةً بطول n بايت على الأكثر، وتحشو ما تبقى بمحارف فارغة إذا كانت s2 أقصر من n محرف، ونحصل على سلوك غير معرّف، إذا كانت السلسلتان متقاطعتين، وتُعيد كلا الدالتين s1. الدالتان strcat و strncat: تُضيف كلا الدالتين السلسلة النصية s2 إلى السلسلة s1 بالكتابة فوق overwrite المحرف الفارغ في نهاية السلسلة s1، بينما يُضاف المحرف الفارغ دائمًا إلى نهاية السلسلة. يمكن إضافة n محرف على الأكثر من السلسلة s2 باستخدام الدالة strncat مما يعني أن السلسلة النصية الهدف (أي s1) يجب أن تحتوي على مساحة لطولها الأصلي (دون احتساب المحرف الفارغ) زائد n+1 محرف للتنفيذ الآمن. تعيد الدالتين s1. مقارنة السلسلة النصية والبايت تُستخدم هذه الدوال في مقارنة مصفوفات من البايتات، وهذا يتضمن طبعًا السلاسل النصية في لغة سي إذ أنها سلسلةٌ من المحارف char (أي البايتات) بمحرف فارغ في نهايتها. تعمل جميع هذه الدوال التي سنذكرها على مقارنة بايت تلو الآخر وتتوقف فقط في حالة اختلف بايت مع بايت آخر (في هذه الحالة تُعيد الدالة إشارة الفرق بين البايت والآخر) أو عندما تكون المصفوفتان متساويتين (أي لم يُعثر على أي فرق بينهما وكان طولهما مساوٍ إلى الطول المحدد أو -في حالة المقارنة بين السلاسل النصية- وُجد المحرف الفارغ في النهاية). القيمة المُعادة في جميع الدوال عدا الدالة strxfrm هي أصغر من الصفر، أو تساوي الصفر، أو أكبر من الصفر وذلك في حالة كان الكائن الأول أصغر من الكائن الثاني، أو يساوي الكائن الثاني، أو أكبر من الكائن الثاني على الترتيب. #include <string.h> int memcmp(const void *s1, const void *s2, size_t n); int strcmp(const char *s1, const char *s2); int strncmp(const char *s1, const char *s2, size_t n); size_t strxfrm(char *to, const char *from, int strcoll(const char *s1, const char *s2); دالة memcmp: تُقارن أول n محرف في الكائن الذي يشير إليه المؤشر s1 وs2، إلا أن مقارنة الهياكل بهذه الطريقة ليست مثالية، إذ قد تحتوي الاتحادات unions أو "الثقوب holes" المُسببة بواسطة محاذاة ذاكرة التخزين على بيانات غير صالحة. دالة strcmp: تُقارن سلسلتين نصيتين وهي إحدى أكثر الدوال استخدامًا عند التعامل مع السلاسل النصية. الدالة strncmp: تُطابق عمل الدالة strcmp إلا أنها تقارن n محرف على الأكثر. الدالة strxfrm: تُحوّل السلسلة النصية المُمرّرة إليها (بصورةٍ خاصة ومميزة)، وتُخزّن إلى موضع المؤشر، ويُكتب maxsize محرف على الأكثر إلى موضع المؤشر (متضمنًا المحرف الفارغ في النهاية)، وتضمن طريقة التحويل أننا سنحصل على نتيجة المقارنة ذاتها لسلسلتين نصيتين محوّلتين ضمن إعدادات المستخدم المحلية عند استخدام الدالة strcmp بعد تطبيق الدالة strcoll على السلسلتين النصيتين الأساسيتين. نحصل على طول السلسلة النصية الناتجة مثل قيمة مُعادة في جميع الحالات (باستثناء المحرف الفارغ في نهاية السلسلة)، وتكون محتويات المؤشر to غير معرّفة إذا كانت القيمة مساوية أو أكبر من maxsize، وقد تكون s1 مؤشرًا فارغًا إذا كانت maxsize صفر، ونحصل على سلوك غير معرّف إذا كان الكائنان متقاطعين. دالة strcoll تُقارن هذه الدالة سلسلتين نصيتين بحسب سلسلة الترتيب collating sequence المحدد في إعدادات اللغة المحلية. دوال بحث المحارف والسلاسل النصية يتضمن التصنيف الدوال التالية: #include <string.h> void *memchr(const void *s, int c, size_t n); char *strchr(const char *s, int c); size_t strcspn(const char *s1, const char *s2); char *strpbrk(const char *s1, const char *s2); char *strrchr(const char *s, int c); size_t strspn(const char *s1, const char *s2); char *strstr(const char *s1, const char *s2); char *strtok(const char *s1, const char *s2); دالة memchr: تُعيد مؤشرًا يشير إلى أول ظهور ضمن أول n محرف من s* للمحرف c (من نوع unsigned char)، وتُعيد فراغًا null إن لم يُعثر على أي تطابق. دالة strchr: تُعيد مؤشرًا يشير إلى أول ظهور للمحرف c ضمن s* ويتضمن البحث المحرف الفارغ، وتُعيد فراغًا null إذا لم يُعثر على أي تطابق. دالة strcspn: تُعيد طول الجزء الأولي للسلسلة النصية s1 الذي لا يحتوي أيًّا من محارف السلسلة s2، ولا يؤخذ المحرف الفارغ في نهاية السلسلة s2 بالحسبان. دالة strpbrk: تُعيد مؤشرًا إلى أول محرف ضمن s1 يطابق أي محرف من محارف السلسلة s2 أو تُعيد فراغًا إن لم يُعثر على أي تطابق. دالة strrchr: تُعيد مؤشرًا إلى آخر محرف ضمن s1 يطابق المحرف c آخذة بالحسبان المحرف الفارغ على أنه جزء من السلسلة s1 وتُعيد فراغ إن لم يُعثر على تطابق. دالة strspn: تُعيد طول الجزء الأولي ضمن السلسلة s1 الذي يتألف كاملًا من محارف السلسلة s1. دالة strstr: تُعيد مؤشرًا إلى أول تطابق للسلسلة s2 ضمن السلسلة s1 أو تُعيد فراغ إن لم يُعثر على تطابق. دالة strtok: تقسّم السلسلة النصية s1 إلى "رموز tokens" يُحدّد كل منها بمحرف من محارف السلسلة s2 وتُعيد مؤشرًا يشير إلى الرمز الأول أو فراغًا إن لم يوجد أي رموز. تُعيد استدعاءات لاحقة للدالة باستخدام (char *)0 قيمةً للوسيط s1 الرمز التالي ضمن السلسلة، إلا أن s2 (المُحدِّد) قد يختلف عند كل استدعاء، ويُعاد مؤشر فارغ إذا لم يبق أي رمز. دوال متنوعة أخرى هناك بعض الدوال الأخرى التي لا تنتمي لأي من التصنيفات السابقة: void *memset(void *s, int c, size_t n); char *strerror(int errnum); size_t strlen(const char *s); دالة memset: تضبط n بايت يشير إليها المؤشر s إلى قيمة المحرف c وهو من النوع unsigned char، وتُعيد الدالة المؤشر s. دالة strlen: تُعيد طول السلسلة النصية s دون احتساب المحرف الفارغ في نهاية السلسلة، وهي دالة شائعة الاستخدام. دالة strerror: تُعيد مؤشرًا يشير إلى سلسلة نصية تصف الخطأ رقم errnum، وقد تُعدَّل هذه السلسلة النصية عن طريق استدعاءات لاحقة للدالة sterror، وتعدّ هذه الدالة مفيدةٌ لمعرفة معنى قيم errno. التاريخ والوقت تتعامل هذه الدوال إما مع الوقت المُنقضي elapsed time، أو وقت التقويم calendar time ويحتوي ملف الترويسة <time.h> على تصريح كلا النوعين من الدوال بالاعتماد على التالي: القيمة CLOCKS_PER_SEC: عدد الدقات ticks في الثانية المُعادة من الدالة clock. النوعين clock_t و time_t: أنواع حسابية تُستخدم لتمثيل تنسيقات مختلفة من الوقت. الهيكل struct tm: يُستخدم لتخزين القيمة المُمثّلة لأوقات التقويم، ويحتوي على الأعضاء التالية: int tm_sec // الثواني بعد الدقيقة من 0 إلى 61، وتسمح 61 بثانيتين كبيستين leap-second int tm_min // الدقائق بعد الساعة من 0 إلى 59 int tm_hour // الساعات بعد منتصف الليل من 0 إلى 23 int tm_mday //اليوم في الشهر من 1 إلى 31 int tm_mon // الشهر في السنة من 0 إلى 11 int tm_year // السنة الحالية من 1900 int tm_wday // الأيام منذ يوم الأحد من 0 إلى 6 int tm_yday // الأيام منذ الأول من يناير من 0 إلى 365 int tm_isdst // مؤشر التوقيت الصيفي يكون العنصر tm_isdst موجبًا إذا كان التوقيت الصيفي daylight savings فعّالًا، وصفر إن لم يكن كذلك، وسالبًا إن لم تكن هذه المعلومة متوفرة. إليك دوال التلاعب بالوقت: #include <time.h> clock_t clock(void); double difftime(time_t time1, time_t time2); time_t mktime(struct tm *timeptr); time_t time(time_t *timer); char *asctime(const struct tm *timeptr); char *ctime(const time_t *timer); struct tm *gmtime(const time_t *timer); struct tm *localtime(const time_t *timer); size_t strftime(char *s, size_t maxsize, const char *format, const struct tm *timeptr); تتشارك كل من الدوال asctime و ctime و gmtime و localtime و strftime بهياكل بيانات ساكنة static من نوع struct tm أو من نوع char []، وقد يتسبب استدعاء أحد منها بعملية الكتابة فوق البيانات المخزنة بسبب استدعاء سابق لإحدى الدوال الأخرى، ولذلك يجب على مستخدم الدالة نسخ المعلومات إذا كان هذا سيسبب أية مشاكل. الدالة clock: تُعيد أفضل تقريب للوقت الذي انقضى منذ تشغيل البرنامج مقدرًا بدقات الساعة ticks، وتُعاد القيمة (clock_t)-1 إذا لم يُعثر على أي قيمة. من الضروري العثور على الفرق بين وقت بداية تشغيل البرنامج والوقت الحالي إذا أردنا إيجاد الوقت المُنقضي اللازم لتشغيل البرنامج، وهناك ثابتٌ معرفٌ حسب التنفيذ يعدل على القيمة المُعادة من clock. يجب تقسيم القيمة على CLOCKS_PER_SEC لتحديد الوقت بالثواني. الدالة difftime: تُعيد الفرق بين وقت تقويم ووقت تقويم آخر بالثواني. الدالة mktime: تُعيد وقت تقويم يوافق القيم الموجودة في هيكل يشير إلى المؤشر timeptr، أو تُعيد القيمة (time_t)-1 إذا لم يكن من الممكن تمثيل القيمة. يُتجاهل العضوان tm_wday و tm_yday، ولا تُقيَّد باقي الأعضاء بقيمهم الاعتيادية، إذ يُضبط أعضاء الهيكل إلى قيم مناسبة ضمن النطاق الاعتيادي عند التحويل الناجح، وهذه الدالة مفيدة للعثور على التاريخ والوقت الموافق لقيمة من نوع time_t. الدالة time: تُعيد أفضل تقريب لوقت التقويم الحالي باستخدام ترميز غير محدد unspecified encoding، وتُعيد القيمة (time_t)-1 إذا كان الوقت غير متوفر. الدالة asctime: تُحول الوقت ضمن هيكل يشير إليه المؤشر timptr إلى سلسلة نصية بالتنسيق التالي: Sun Sep 16 01:03:52 1973\n\0 المثال السابق مأخوذٌ من المعيار، إذ يعرِّف المعيار الخوارزمية المستخدمة أيضًا، إلا أنه من المهم ملاحظة أن جميع الحقول ضمن السلسلة النصية ذات عرض ثابت وينطبق استخدامها على المجتمعات التي تتحدث باللغة الإنجليزية فقط. تُخزّن السلسلة النصية في هيكل ساكن static structure ويُمكن إعادة كتابته عن طريق استدعاءات لاحقة لأحد دوال التلاعب بالوقت (المذكورة أعلاه). الدالة ctime: تكافئ عمل asctime(localtime(timer)). اقرأ عن الدالة asctime لمعرفة القيمة المُعادة. الدالة gmtime: تُعيد مؤشرًا إلى struct tm، إذ يُضبط هذا المؤشر إلى وقت التقويم الذي يشير إليه المؤشر timer، ويُمثل الوقت بحسب شروط التوقيت العالمي المُنسّق Coordinated Universal Time -أو اختصارًا UTC-، أو المسمى سابقًا بتوقيت جرينتش Greenwich Mean Time، ونحصل على مؤشر فارغ إذا كان توقيت UTC غير مُتاح. الدالة localtime: تحوّل الوقت الذي يشير إليه المؤشر timer إلى التوقيت المحلي وتُخزن النتيجة في struct tm وتُعيد مؤشرًا يشير إلى ذلك الهيكل. الدالة strftime: تملأ مصفوفة المحارف التي يشير إليها المؤشر s بـمقدار maxsize محرف على الأكثر، وتُستخدم السلسلة النصية format لتنسيق الوقت المُمثّل في الهيكل الذي يشير إليه المؤشر timeptr، تُنسخ المحارف الموجودة في سلسلة التنسيق النصية (متضمنة المحرف الفارغ في نهاية السلسلة) دون أي تغيير إلى المصفوفة إلا إن كان وجِد توجيه تنسيق من التوجيهات التالية، فعندها تُسنخ القيمة المُحددة ضمن الجدول إلى المصفوفة الهدف بما يوافق الإعدادات المحلية. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } %a اسم يوم الأسبوع باختصار %A اسم يوم الأسبوع كاملًا %b اسم الشهر باختصار %B اسم الشهر كاملًا %c تمثيل التاريخ والوقت %d تمثيل يوم الشهر عشريًا من 01 إلى 31 %H الساعة من 00 إلى 23 (تنسيق 24 ساعة) %I الساعة من 01 إلى 12 (تنسيق 12 ساعة) %j يوم السنة من 001 إلى 366 %m الشهر من 01 إلى 12 %M الدقيقة من 00 إلى 59 %p مكافئة PM أو AM المحلي %S الثانية من 00 إلى 61 %U ترتيب الأسبوع ضمن السنة من 00 إلى 53 (الأحد هو اليوم الأول) %w يوم الأسبوع من 0 إلى 6 (الأحد مُمثّل بالرقم 0) %W ترتيب الأسبوع ضمن السنة من 00 إلى 53 (الاثنين هو اليوم الأول) %x تمثيل التاريخ محليًا %X تمثيل الوقت محليًا %y السنة دون سابقة القرن من 00 إلى 99 %Y السنة مع سابقة القرن %Z اسم المنطقة الزمنية، لا نحصل على محارف إن لم يكن هناك أي منطقة زمنية %% محرف % يُعاد عدد المحارف الكلية المنسوخة إلى s* باستثناء محرف الفراغ في نهاية السلسلة، وتُعاد القيمة صفر إذا لم يكن هناك أي مساحة (بحسب قيمة maxsize) للمحرف الفارغ في النهاية. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: تطبيقات عملية في لغة سي C المقال السابق: أدوات مكتبة stdlib في لغة سي C بنية برنامج لغة سي C الدوال في لغة C القيم الحدية والدوال الرياضية في لغة سي C
نتطرّق في هذا المقال إلى طرق مختلفة في التعامل مع السلاسل النصية والتلاعب بها، وذلك عن طريق دوال مكتبة string.h، ومن ثمّ ننتقل إلى دوال الوقت والتاريخ المحتواة في مكتبة time.h. التعامل مع السلاسل النصية هناك العديد من الدوال التي تسمح لنا بالتعامل مع السلاسل النصية، إذ تكون السلسلة النصية في لغة سي مؤلفةً من مصفوفة من المحارف تنتهي بمحرف فارغ null، وتتوقع الدوال في جميع الحالات تمرير مؤشر يشير إلى المحرف الأول ضمن السلسلة النصية، ويعرّف ملف الترويسة <string.h> هذا النوع من الدوال. النسخ يضم هذا التصنيف الدوال التالية: #include <string.h> void *memcpy(void *s1, const void *s2, size_t n); void *memmove (void *s1, const void *s2, size_t n); char *strcpy(char *s1, const char *s2); char *strncpy(char *s1, const char *s2, size_t n); char *strcat(char *s1, const char *s2); char *strncat(char *s1, const char *s2, size_t n); دالة memcpy: تنسخ هذه الدالة n بايت من المكان الذي يشير إليه المؤشر s2 إلى المكان الذي يشير إليه المؤشر s1، ونحصل على سلوك غير محدد إذا كان الكائنان متداخلان overlapping objects. تعيد الدالة s1. دالة memmove: هذه الدالة مطابقة لعمل دالة memcpy إلا أنها تعمل على الكائنات المتداخلة، إلا أنها قد تكون أبطأ. دالتَي strcpy وstrncpy: تنسخ كلا الدالتين السلسلة النصية التي يشير إليها المؤشر s2 إلى سلسلة نصية يشير المؤشر s1 إليها متضمنًا ذلك المحرف الفارغ في نهاية السلسلة. تنسخ strncpy سلسلةً نصيةً بطول n بايت على الأكثر، وتحشو ما تبقى بمحارف فارغة إذا كانت s2 أقصر من n محرف، ونحصل على سلوك غير معرّف، إذا كانت السلسلتان متقاطعتين، وتُعيد كلا الدالتين s1. الدالتان strcat و strncat: تُضيف كلا الدالتين السلسلة النصية s2 إلى السلسلة s1 بالكتابة فوق overwrite المحرف الفارغ في نهاية السلسلة s1، بينما يُضاف المحرف الفارغ دائمًا إلى نهاية السلسلة. يمكن إضافة n محرف على الأكثر من السلسلة s2 باستخدام الدالة strncat مما يعني أن السلسلة النصية الهدف (أي s1) يجب أن تحتوي على مساحة لطولها الأصلي (دون احتساب المحرف الفارغ) زائد n+1 محرف للتنفيذ الآمن. تعيد الدالتين s1. مقارنة السلسلة النصية والبايت تُستخدم هذه الدوال في مقارنة مصفوفات من البايتات، وهذا يتضمن طبعًا السلاسل النصية في لغة سي إذ أنها سلسلةٌ من المحارف char (أي البايتات) بمحرف فارغ في نهايتها. تعمل جميع هذه الدوال التي سنذكرها على مقارنة بايت تلو الآخر وتتوقف فقط في حالة اختلف بايت مع بايت آخر (في هذه الحالة تُعيد الدالة إشارة الفرق بين البايت والآخر) أو عندما تكون المصفوفتان متساويتين (أي لم يُعثر على أي فرق بينهما وكان طولهما مساوٍ إلى الطول المحدد أو -في حالة المقارنة بين السلاسل النصية- وُجد المحرف الفارغ في النهاية). القيمة المُعادة في جميع الدوال عدا الدالة strxfrm هي أصغر من الصفر، أو تساوي الصفر، أو أكبر من الصفر وذلك في حالة كان الكائن الأول أصغر من الكائن الثاني، أو يساوي الكائن الثاني، أو أكبر من الكائن الثاني على الترتيب. #include <string.h> int memcmp(const void *s1, const void *s2, size_t n); int strcmp(const char *s1, const char *s2); int strncmp(const char *s1, const char *s2, size_t n); size_t strxfrm(char *to, const char *from, int strcoll(const char *s1, const char *s2); دالة memcmp: تُقارن أول n محرف في الكائن الذي يشير إليه المؤشر s1 وs2، إلا أن مقارنة الهياكل بهذه الطريقة ليست مثالية، إذ قد تحتوي الاتحادات unions أو "الثقوب holes" المُسببة بواسطة محاذاة ذاكرة التخزين على بيانات غير صالحة. دالة strcmp: تُقارن سلسلتين نصيتين وهي إحدى أكثر الدوال استخدامًا عند التعامل مع السلاسل النصية. الدالة strncmp: تُطابق عمل الدالة strcmp إلا أنها تقارن n محرف على الأكثر. الدالة strxfrm: تُحوّل السلسلة النصية المُمرّرة إليها (بصورةٍ خاصة ومميزة)، وتُخزّن إلى موضع المؤشر، ويُكتب maxsize محرف على الأكثر إلى موضع المؤشر (متضمنًا المحرف الفارغ في النهاية)، وتضمن طريقة التحويل أننا سنحصل على نتيجة المقارنة ذاتها لسلسلتين نصيتين محوّلتين ضمن إعدادات المستخدم المحلية عند استخدام الدالة strcmp بعد تطبيق الدالة strcoll على السلسلتين النصيتين الأساسيتين. نحصل على طول السلسلة النصية الناتجة مثل قيمة مُعادة في جميع الحالات (باستثناء المحرف الفارغ في نهاية السلسلة)، وتكون محتويات المؤشر to غير معرّفة إذا كانت القيمة مساوية أو أكبر من maxsize، وقد تكون s1 مؤشرًا فارغًا إذا كانت maxsize صفر، ونحصل على سلوك غير معرّف إذا كان الكائنان متقاطعين. دالة strcoll تُقارن هذه الدالة سلسلتين نصيتين بحسب سلسلة الترتيب collating sequence المحدد في إعدادات اللغة المحلية. دوال بحث المحارف والسلاسل النصية يتضمن التصنيف الدوال التالية: #include <string.h> void *memchr(const void *s, int c, size_t n); char *strchr(const char *s, int c); size_t strcspn(const char *s1, const char *s2); char *strpbrk(const char *s1, const char *s2); char *strrchr(const char *s, int c); size_t strspn(const char *s1, const char *s2); char *strstr(const char *s1, const char *s2); char *strtok(const char *s1, const char *s2); دالة memchr: تُعيد مؤشرًا يشير إلى أول ظهور ضمن أول n محرف من s* للمحرف c (من نوع unsigned char)، وتُعيد فراغًا null إن لم يُعثر على أي تطابق. دالة strchr: تُعيد مؤشرًا يشير إلى أول ظهور للمحرف c ضمن s* ويتضمن البحث المحرف الفارغ، وتُعيد فراغًا null إذا لم يُعثر على أي تطابق. دالة strcspn: تُعيد طول الجزء الأولي للسلسلة النصية s1 الذي لا يحتوي أيًّا من محارف السلسلة s2، ولا يؤخذ المحرف الفارغ في نهاية السلسلة s2 بالحسبان. دالة strpbrk: تُعيد مؤشرًا إلى أول محرف ضمن s1 يطابق أي محرف من محارف السلسلة s2 أو تُعيد فراغًا إن لم يُعثر على أي تطابق. دالة strrchr: تُعيد مؤشرًا إلى آخر محرف ضمن s1 يطابق المحرف c آخذة بالحسبان المحرف الفارغ على أنه جزء من السلسلة s1 وتُعيد فراغ إن لم يُعثر على تطابق. دالة strspn: تُعيد طول الجزء الأولي ضمن السلسلة s1 الذي يتألف كاملًا من محارف السلسلة s1. دالة strstr: تُعيد مؤشرًا إلى أول تطابق للسلسلة s2 ضمن السلسلة s1 أو تُعيد فراغ إن لم يُعثر على تطابق. دالة strtok: تقسّم السلسلة النصية s1 إلى "رموز tokens" يُحدّد كل منها بمحرف من محارف السلسلة s2 وتُعيد مؤشرًا يشير إلى الرمز الأول أو فراغًا إن لم يوجد أي رموز. تُعيد استدعاءات لاحقة للدالة باستخدام (char *)0 قيمةً للوسيط s1 الرمز التالي ضمن السلسلة، إلا أن s2 (المُحدِّد) قد يختلف عند كل استدعاء، ويُعاد مؤشر فارغ إذا لم يبق أي رمز. دوال متنوعة أخرى هناك بعض الدوال الأخرى التي لا تنتمي لأي من التصنيفات السابقة: void *memset(void *s, int c, size_t n); char *strerror(int errnum); size_t strlen(const char *s); دالة memset: تضبط n بايت يشير إليها المؤشر s إلى قيمة المحرف c وهو من النوع unsigned char، وتُعيد الدالة المؤشر s. دالة strlen: تُعيد طول السلسلة النصية s دون احتساب المحرف الفارغ في نهاية السلسلة، وهي دالة شائعة الاستخدام. دالة strerror: تُعيد مؤشرًا يشير إلى سلسلة نصية تصف الخطأ رقم errnum، وقد تُعدَّل هذه السلسلة النصية عن طريق استدعاءات لاحقة للدالة sterror، وتعدّ هذه الدالة مفيدةٌ لمعرفة معنى قيم errno. التاريخ والوقت تتعامل هذه الدوال إما مع الوقت المُنقضي elapsed time، أو وقت التقويم calendar time ويحتوي ملف الترويسة <time.h> على تصريح كلا النوعين من الدوال بالاعتماد على التالي: القيمة CLOCKS_PER_SEC: عدد الدقات ticks في الثانية المُعادة من الدالة clock. النوعين clock_t و time_t: أنواع حسابية تُستخدم لتمثيل تنسيقات مختلفة من الوقت. الهيكل struct tm: يُستخدم لتخزين القيمة المُمثّلة لأوقات التقويم، ويحتوي على الأعضاء التالية: int tm_sec // الثواني بعد الدقيقة من 0 إلى 61، وتسمح 61 بثانيتين كبيستين leap-second int tm_min // الدقائق بعد الساعة من 0 إلى 59 int tm_hour // الساعات بعد منتصف الليل من 0 إلى 23 int tm_mday //اليوم في الشهر من 1 إلى 31 int tm_mon // الشهر في السنة من 0 إلى 11 int tm_year // السنة الحالية من 1900 int tm_wday // الأيام منذ يوم الأحد من 0 إلى 6 int tm_yday // الأيام منذ الأول من يناير من 0 إلى 365 int tm_isdst // مؤشر التوقيت الصيفي يكون العنصر tm_isdst موجبًا إذا كان التوقيت الصيفي daylight savings فعّالًا، وصفر إن لم يكن كذلك، وسالبًا إن لم تكن هذه المعلومة متوفرة. إليك دوال التلاعب بالوقت: #include <time.h> clock_t clock(void); double difftime(time_t time1, time_t time2); time_t mktime(struct tm *timeptr); time_t time(time_t *timer); char *asctime(const struct tm *timeptr); char *ctime(const time_t *timer); struct tm *gmtime(const time_t *timer); struct tm *localtime(const time_t *timer); size_t strftime(char *s, size_t maxsize, const char *format, const struct tm *timeptr); تتشارك كل من الدوال asctime و ctime و gmtime و localtime و strftime بهياكل بيانات ساكنة static من نوع struct tm أو من نوع char []، وقد يتسبب استدعاء أحد منها بعملية الكتابة فوق البيانات المخزنة بسبب استدعاء سابق لإحدى الدوال الأخرى، ولذلك يجب على مستخدم الدالة نسخ المعلومات إذا كان هذا سيسبب أية مشاكل. الدالة clock: تُعيد أفضل تقريب للوقت الذي انقضى منذ تشغيل البرنامج مقدرًا بدقات الساعة ticks، وتُعاد القيمة (clock_t)-1 إذا لم يُعثر على أي قيمة. من الضروري العثور على الفرق بين وقت بداية تشغيل البرنامج والوقت الحالي إذا أردنا إيجاد الوقت المُنقضي اللازم لتشغيل البرنامج، وهناك ثابتٌ معرفٌ حسب التنفيذ يعدل على القيمة المُعادة من clock. يجب تقسيم القيمة على CLOCKS_PER_SEC لتحديد الوقت بالثواني. الدالة difftime: تُعيد الفرق بين وقت تقويم ووقت تقويم آخر بالثواني. الدالة mktime: تُعيد وقت تقويم يوافق القيم الموجودة في هيكل يشير إلى المؤشر timeptr، أو تُعيد القيمة (time_t)-1 إذا لم يكن من الممكن تمثيل القيمة. يُتجاهل العضوان tm_wday و tm_yday، ولا تُقيَّد باقي الأعضاء بقيمهم الاعتيادية، إذ يُضبط أعضاء الهيكل إلى قيم مناسبة ضمن النطاق الاعتيادي عند التحويل الناجح، وهذه الدالة مفيدة للعثور على التاريخ والوقت الموافق لقيمة من نوع time_t. الدالة time: تُعيد أفضل تقريب لوقت التقويم الحالي باستخدام ترميز غير محدد unspecified encoding، وتُعيد القيمة (time_t)-1 إذا كان الوقت غير متوفر. الدالة asctime: تُحول الوقت ضمن هيكل يشير إليه المؤشر timptr إلى سلسلة نصية بالتنسيق التالي: Sun Sep 16 01:03:52 1973\n\0 المثال السابق مأخوذٌ من المعيار، إذ يعرِّف المعيار الخوارزمية المستخدمة أيضًا، إلا أنه من المهم ملاحظة أن جميع الحقول ضمن السلسلة النصية ذات عرض ثابت وينطبق استخدامها على المجتمعات التي تتحدث باللغة الإنجليزية فقط. تُخزّن السلسلة النصية في هيكل ساكن static structure ويُمكن إعادة كتابته عن طريق استدعاءات لاحقة لأحد دوال التلاعب بالوقت (المذكورة أعلاه). الدالة ctime: تكافئ عمل asctime(localtime(timer)). اقرأ عن الدالة asctime لمعرفة القيمة المُعادة. الدالة gmtime: تُعيد مؤشرًا إلى struct tm، إذ يُضبط هذا المؤشر إلى وقت التقويم الذي يشير إليه المؤشر timer، ويُمثل الوقت بحسب شروط التوقيت العالمي المُنسّق Coordinated Universal Time -أو اختصارًا UTC-، أو المسمى سابقًا بتوقيت جرينتش Greenwich Mean Time، ونحصل على مؤشر فارغ إذا كان توقيت UTC غير مُتاح. الدالة localtime: تحوّل الوقت الذي يشير إليه المؤشر timer إلى التوقيت المحلي وتُخزن النتيجة في struct tm وتُعيد مؤشرًا يشير إلى ذلك الهيكل. الدالة strftime: تملأ مصفوفة المحارف التي يشير إليها المؤشر s بـمقدار maxsize محرف على الأكثر، وتُستخدم السلسلة النصية format لتنسيق الوقت المُمثّل في الهيكل الذي يشير إليه المؤشر timeptr، تُنسخ المحارف الموجودة في سلسلة التنسيق النصية (متضمنة المحرف الفارغ في نهاية السلسلة) دون أي تغيير إلى المصفوفة إلا إن كان وجِد توجيه تنسيق من التوجيهات التالية، فعندها تُسنخ القيمة المُحددة ضمن الجدول إلى المصفوفة الهدف بما يوافق الإعدادات المحلية. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } %a اسم يوم الأسبوع باختصار %A اسم يوم الأسبوع كاملًا %b اسم الشهر باختصار %B اسم الشهر كاملًا %c تمثيل التاريخ والوقت %d تمثيل يوم الشهر عشريًا من 01 إلى 31 %H الساعة من 00 إلى 23 (تنسيق 24 ساعة) %I الساعة من 01 إلى 12 (تنسيق 12 ساعة) %j يوم السنة من 001 إلى 366 %m الشهر من 01 إلى 12 %M الدقيقة من 00 إلى 59 %p مكافئة PM أو AM المحلي %S الثانية من 00 إلى 61 %U ترتيب الأسبوع ضمن السنة من 00 إلى 53 (الأحد هو اليوم الأول) %w يوم الأسبوع من 0 إلى 6 (الأحد مُمثّل بالرقم 0) %W ترتيب الأسبوع ضمن السنة من 00 إلى 53 (الاثنين هو اليوم الأول) %x تمثيل التاريخ محليًا %X تمثيل الوقت محليًا %y السنة دون سابقة القرن من 00 إلى 99 %Y السنة مع سابقة القرن %Z اسم المنطقة الزمنية، لا نحصل على محارف إن لم يكن هناك أي منطقة زمنية %% محرف % يُعاد عدد المحارف الكلية المنسوخة إلى s* باستثناء محرف الفراغ في نهاية السلسلة، وتُعاد القيمة صفر إذا لم يكن هناك أي مساحة (بحسب قيمة maxsize) للمحرف الفارغ في النهاية. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: تطبيقات عملية في لغة سي C المقال السابق: أدوات مكتبة stdlib في لغة سي C بنية برنامج لغة سي C الدوال في لغة C القيم الحدية والدوال الرياضية في لغة سي C -
 نستعرض هنا الأدوات الموجودة في ملف الترويسة <stdlib.h> الذي يصرح عن عدد من الأنواع والماكرو وعدة دوال للاستخدام العام، تتضمن الأنواع والماكرو التالي: النوع size_t: تكلمنا عنه سابقًا. النوع div_t: نوع من الهياكل التي تعيدها الدالة div. النوع ldiv_t: نوع من الهياكل التي تعيدها الدالة ldiv. النوع NULL: تكلمنا عنه سابقًا. القيمة EXIT_FAILURE و EXIT_SUCCESS: يمكن استخدامهما مثل وسيط للدالة exit. القيمة MB_CUR_MAX: العدد الأعظمي للبايتات في محرف متعدد البايتات multibyte character من مجموعة المحارف الإضافية والمحددة حسب إعدادت اللغة المحلية locale. القيمة RAND_MAX: القيمة العظمى المُعادة من استدعاء دالة rand. دوال تحويل السلسلة النصية هناك ثلاث دوال تقبل سلسلة نصية وسيطًا لها وتحوّلها إلى عدد من نوع معين كما هو موضح هنا: #include <stdlib.h> double atof(const char *nptr); long atol(const char *nptr); int atoi(const char *nptr); نحصل على عدد مُحوّل مُعاد لكل من الدوال الثلاث السابقة، ولا تضمن لك أيٌ من الدوال أن تضبط القيمة errno (إلا أن الأمر محقّق في بعض التنفيذات)، وتكون النتائج التي نحصل عليها من تحويلات تتسبب بحدوث طفحان overflow ولا يمكننا تمثيلها غير معرّفة. هناك بعض الدوال أكثر تعقيدًا: #include <stdlib.h> double strtod(const char *nptr, char **endptr); long strtol(const char *nptr, char **endptr, int base); unsigned long strtoul(const char *nptr,char **endptr, int base); تعمل الدوال الثلاث السابقة بطريقة مشابهة، إذ يجري تجاهل أي مسافات فارغة بادئة ومن ثم يُعثر على الثابت المناسب subject sequence متبوعًا بسلسلة محارف غير معترف عليها، ويكون المحرف الفارغ في نهاية السلسلة النصية غير مُعترف عليه دائمًا. تُحدد السلسلة المذكورة حسب التالي: في الدالة strtod: إشارة "+" أو "-" اختيارية في البداية متبوعة بسلسلة أرقام تحتوي على محرف الفاصلة العشرية الاختياري وأس exponent اختياري أيضًا. لا يُعترف على أي لاحقة عائمة (ما بعد الفاصلة العشرية)، وتُعدّ الفاصلة العشرية تابعةً لسلسلة الأرقام إذا وُجدت. في الدالة strtol: إشارة "+" أو "-" اختيارية في البداية متبوعة بسلسلة أرقام، وتُؤخذ هذه الأرقام من الخانات العشرية أو من أحرف صغيرة lower case أو كبيرة upper case ضمن النطاق a إلى z في الأبجدية الإنجليزية ويُعطى لكل من هذه الأحرف القيم ضمن النطاق 10 إلى 35 بالترتيب. يحدِّد الوسيط base القيم المسموحة ويمكن أن تكون قيمة الوسيط صفر أو ضمن النطاق 2 إلى 36. يجري التعرُّف على الخانات التي تبلغ قيمتها أقل من الوسيط base، إذ تسمح القيمة 16 للوسيط base على سبيل المثال للمحارف 0x أو 0X أن تتبع الإشارة الاختيارية، بينما يسمح base بقيمة صفر أن تكون المحارف المدخلة على هيئة أعداد صحيحة ثابتة في سي، ولا يُعترف على أي لاحقة عدد صحيح. في الدالة strtoul: مطابقة للدالة strtol إلا أنها لا تسمح بوجود إشارة. يُخزّن عنوان أول محرف غير مُعترف عليه في الكائن الذي يشير إليه endptr في حال لم يكُن فارغًا، وتكون هذه قيمة nptr إذا كانت السلسلة فارغة أو ذات تنسيق خاطئ. تحوّل الدالة الرقم وتُعيده مع الأخذ بالحسبان كون وجود الإشارة البادئة مسموحًا أو لا، وذلك إذا كان إجراء التحويل ممكنًا، وإلا فإنها تعيد القيمة صفر. عند حدوث الطفحان أو حصول خطأ تُجرى العمليات التالية: في الدالة strtod: تُعيد عند الطفحان القيمة HUGE_VAL± وتعتمد الإشارة على إشارة النتيجة، وتُعيد القيمة صفر عند طفحان الحد الأدنى underflow ويُضبط errno في الحالتين إلى القيمة ERANGE. في الدالة strtol: تُعيد القيمة LONG_MAX أو LONG_MIN عند الطفحان بحسب إشارة النتيحة، ويُضبط errno في كلا الحالتين إلى القيمة ERANGE. في الدالة strtoul: تُعيد القيمة ULONG_MAX عند الطفحان، ويُضبط errno إلى القيمة ERANGE. قد يكون هناك سلاسل أخرى من الممكن التعرُّف عليها في بعض التنفيذات إذا لم تكن الإعدادات المحلية هي إعدادات سي التقليدية. توليد الأرقام العشوائية تقدِّم الدوال التالية طريقةً لتوليد الأرقام العشوائية الزائفة pseudo-random: #include <stdlib.h> int rand(void); void srand(unsigned int seed); تُعيد الدالة rand رقمًا عشوائيًا زائفًا ضمن النطاق من "0" إلى "RAND_MAX"، وهو ثابت قيمته على الأقل "32767". تسمح الدالة srand بتحديد نقطة بداية للنطاق المُختار طبقًا لقيمة الوسيط seed، وهي ذات قيمة "1" افتراضيًا إذا لم تُستدعى srand قبل rand، ونحصل على سلسلة قيم مطابقة من الدالة rand إذا استخدمنا قيمة seed ذاتها. يصف المعيار الخوارزمية المستخدمة في دالتي rand و srand، وتستخدم معظم التنفيذات هذه الخوارزمية عادةً. حجز المساحة تُستخدم هذه الدوال لحجز وتحرير المساحة، إذ يُضمن للمساحة التي حصلنا عليها أن تكون كبيرةً كفاية لتخزين كائن من نوع معين ومُحاذاة ضمن الذاكرة بحيث لا تتسبب بتفعيل استثناءات العنوان addressing exceptions، ولا يجب افتراض أي شيء آخر بخصوص عملها. #include <stdlib.h> void *malloc(size_t size); void *calloc(size_t nmemb, size_t size); void *realloc(void *ptr, size_t size); void *free(void *ptr); تُعيد جميع دوال حجز المساحة مؤشرًا يشير إلى المساحة المحجوزة التي يبلغ حجمها size بايت، وإذا لم يكن هناك أي مساحة فارغة فهي تعيد مؤشرًا فارغًا، إلا أن الفرق بين الدوال هو أن دالة calloc تأخذ وسيطًا يدعى nmemb الذي يحدد عدد العناصر في مصفوفة، وكل عنصر في هذه المصفوفة يبلغ حجمه size بايت، ولذا فهي تحجز مساحةً أكبر من التخزين عادةً من المساحة التي تحجزها malloc، كما أن المساحة المحجوز بواسطة malloc غير مُهيّئة بينما تُهيّأ جميع بتات مساحة التخزين المحجوزة بواسطة calloc إلى الصفر، إلا أن هذا الصفر ليس تمثيلًا مكافئًا للصفر ضمن الفاصلة العائمة floating-point أو مؤشرًا فارغًا null بالضرورة. تُستخدم الدالة realloc لتغيير حجم الشيء المُشار إليه بواسطة المؤشر ptr مما يتطلب بعض النسخ لإنجاز هذا الأمر ومن ثمّ تُحرّر مساحة التخزين القديمة. لا تُغيّر محتويات الكائن المُشار إليه بواسطة ptr بالنسبة للحجمين القديم والجديد، وتتصرف الدالة تصرفًا مماثلًا لتصرف malloc إذا كان المؤشر ptr مؤشرًا فارغًا وذلك للحجم المخصّص. تُستخدم الدالة free لتحرير المساحة المحجوزة مسبقًا من إحدى دوال حجز المساحة، ومن المسموح تمرير مؤشر فارغ إلى الدالة free وسيطًا لها، إلا أن الدالة في هذه الحالة لا تنفّذ أي شيء. إذا حاولت تحرير مساحة لم تُحجز مسبقًا تحصل على سلوك غير محدّد، ويتسبب هذا الأمر في العديد من التنفيذات باستثناء عنوان addressing exception مما يوقف البرنامج، إلا أن هذه ليست بدلالة يمكن الاعتماد عليها. التواصل مع البيئة سنستعرض مجموعةً من الدوال المتنوعة: #include <stdlib.h> void abort(void); int atexit(void (*func)(void)); void exit(int status); char *getenv(const char *name); int system(const char *string); دالة abort: تتسبب بإيقاف غير اعتيادي للبرنامج وذلك باستخدام الإشارة SIGABRT، ويمكن منع الإيقاف غير الاعتيادي فقط إذا حصلنا على الإشارة ولم يُعد معالج الإشارة signal handler أي قيمة، وإلا ستُحذف ملفات الخرج وقد يمكن أيضًا إزالة الملفات المؤقتة بحسب تعريف التنفيذ، وتُعاد حالة "إنهاء برنامج غير ناجح unsuccessful termination" إلى البيئة المُستضافة، كما أن هذه الدالة لا يمكن أن تُعيد أي قيمة. دالة atexit: يصبح وسيط الدالة func دالةً يمكن استدعاؤها دون استخدام أي وسطاء عندما يُغلق البرنامج، ويمكن استخدام ما لا يقل عن 32 دالة مشابهة لهذه الدالة وأن تُستدعى عند إغلاق البرنامج بصورةٍ مُعاكسة لتسجيل كلٍّ منها، ونحصل على القيمة المُعادة صفر للدلالة على النجاح وإلا فقيمة غير صفرية للدلالة على الفشل. دالة exit: تُستدعى هذه الدالة عادةً لإنهاء البرنامج على نحوٍ اعتيادي، وتُستدعى عند تنفيذ الدالة جميع الدوال المُسجّلة باستخدام دالة atexit، لكن انتبه، إذ ستُعد الدالة main بحلول هذه النقطة قد أعادت قيمتها ولا يمكن استخدام أي كائنات ذات مدة تخزين تلقائي automatic storage duration على نحوٍ آمن، من ثمّ تُحذف محتويات جميع مجاري الخرج output streams وتُغلق وتُزال جميع الملفات التلقائية المُنشأة بواسطة tmpfile، وأخيرًا يُعيد البرنامج التحكم إلى البيئة المستضافة بإعادة حالة نجاح أو فشل محدّدة بحسب التنفيذ، وتعتمد الحالة على إذا ما كان وسيط الدالة exit مساوٍ للقيمة EXITSUCCESS (وهذه حالة النجاح) أو EXITFAILURE (حالة الفشل). للتوافق مع لغة سي القديمة، تُستخدم القيمة صفر بدلًا من EXITFAILURE، بينما يكون لباقي القيم تأثيرات معرّفة بحسب التنفيذ. لا يمكن أن تُعاد حالة الخروج. دالة getenv: يجري البحث في لائحة البيئة environment list المعرفة بحسب التنفيذ بهدف العثور على عنصر يوافق السلسلة النصية المُشار إليها بواسطة وسيط الاسم name، إذ تُعيد الدالة مؤشرًا إلى العنصر يشير إلى مصفوفة لا يمكن تعديلها من قبل البرنامج ويمكن تعديلها باستدعاء لاحق للدالة getenv، ونحصل على مؤشر فارغ إذا لم يُعثر على عنصر موافق. يعتمد الهدف من لائحة البيئة وتنفيذها على البيئة المُستضافة. دالة system: تُمرّر سلسلة نصية إلى أمر معالج مُعرف حسب التنفيذ، ويتسبب مؤشر فارغ بإعادة القيمة صفر، وقيمة غير صفرية إذا لم يكن الأمر موجودًا، بينما يتسبب مؤشر غير فارغ بمعالجة الأمر. نتيجة الأمر والقيمة المُعادة معرف حسب التنفيذ. البحث والترتيب هناك دالتان ضمن هذا التصنيف، أولهما دالة للبحث ضمن لائحة مُرتّبة والأخرى لترتيب لائحة غير مرتبة، واستخدام الدالتان عام، إذ يمكن استخدامهما في مصفوفات من أي سعة وعناصرها من أي حجم. يجب أن يلجأ المستخدم إلى دالة مقارنة إذا أراد مقارنة عنصرين عند استخدام الدوال السابقة، إذ تُستدعى هذه الدالة باستخدام المؤشرين الذين يشيران إلى العنصرين مثل وسطاء الدالة، وتُعيد الدالة قيمةً أقل من الصفر إذا كانت قيمة المؤشر الأول أصغر من قيمة المؤشر الثاني، وقيمة أكبر من الصفر إذا كانت قيمة المؤشر الأول أكبر من المؤشر الثاني، والقيمة صفر إذا كانت قيمتا المؤشرين متساويين. #include <stdlib.h> void *bsearch(const void *key, const void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *)); void *qsort(const void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *)); يمثّل الوسيط nmemb في كلٍّ من الدالتين السابقتين عدد العناصر في المصفوفة، ويمثل الوسيط size حجم عنصر المصفوفة الواحد بالبايت و compar هي الدالة التي تُستدعى للمقارنة بين العنصرين، بينما يشير المؤشر base إلى أساس المصفوفة أي بدايتها. ترتّب الدالة qsort المصفوفة ترتيبًا تصاعديًا. تفترض الدالة bsearch أن المصفوفة مرتّبة مسبقًا وتُعيد مؤشرًا إلى أي عنصر يتساوى مع العنصر المُشار إليه بالمؤشر key، وتُعيد الدالة مؤشرًا فارغًا إذا لم تجد أي عناصر متساوية. دوال العمليات الحسابية الصحيحة تقدّم هذه الدوال طريقةً لإيجاد القيمة المطلقة لوسيط يمثل عدد صحيح، إضافةً لحاصل القسمة والباقي من العملية لكلٍّ من النوعين int و long. #include <stdlib.h> int abs(int j); long labs(long j); div_t div(int numerator, int denominator); ldiv_t ldiv(long numerator, long denominator); الدالتان abs و labs: تُعيدان القيمة المطلقة لوسيطهما ويجب اختيار الدالة المناسبة بحسب احتياجاتك. نحصل على سلوك غير معرّف إذا لم تكن القيمة ممكنة التمثيل وقد يحدث ذلك في الأنظمة التي تعمل بنظام المتمم الثنائي two's complement systems، إذ لا يوجد لأكثر رقم سلبيّة أي مكافئ إيجابي. الدالتان div وldiv: تُقسّمان الوسيط numerator على الوسيط denominator وتُعيدان هيكلًا structure للنوع المحدد، وفي أي حالة، سيحتوي الهيكل على عضو يدعى quot يحتوي على حاصل القسمة الصحيحة وعضوًا آخر يدعى rem يحتوي على باقي القسمة، ونوع العضوين هو int في الدالة div و long في الدالة ldiv، ويمكن تمثيل نتيجة العملية على النحو التالي: quot*denominator+rem == numerator الدوال التي تستخدم المحارف متعددة البايت يؤثر تصنيف LC_CTYPE ضمن الإعدادات المحلية الحالية على سلوك هذه الدوال، إذ تُضبط كل دالة إلى حالة ابتدائية باستدعاء يكون وسيطها s الذي يمثل مؤشر المحرف فارغًا null، وذلك في حالة الترميز المُعتمد على الحالة state-dependent endcoding، وتُغيَّر حالة الدالة الداخلية وفق الضرورة عن طريق استدعاءات لاحقة عندما لا يكون s مؤشرًا فارغًا. تُعيد الدالة قيمةً غير صفرية إذا كان الترميز معتمدًا على الحالة، وإلا فتعيد القيمة صفر إذا كان المؤشر s فارغًا. تصبح حالة الإزاحة shift state الخاصة بالدوال غير محددة indeterminate إذا حدث تغيير للتصنيف LC_TYPE. الدوال هي: #include <stdlib.h> int mblen(const char *s, size_t n); int mbtowc(wchar_t *pwc, const char *s, size_t n); int wctomb(char *s, wchar_t wchar); size_t mbstowcs(wchar_t *pwcs, const char *s, size_t n); size_t wcstombs(char *s, const wchar_t *pwcs, size_t n); الدالة mblen: تُعيد عدد البايتات المُحتواة بداخل محرف متعدد البايتات multibyte character المُشار إليه بواسطة المؤشر s أو تُعيد القيمة -1 إذا كان أول n بايت لا يشكّل محرف متعدد البايتات صالحًا، أو تُعيد القيمة صفر إذا كان المؤشر يشير إلى محرف فارغ. الدالة mbtowc: تُحوِّل محرف متعدد البايتات يُشير إليه المؤشر s إلى الرمز الموافق له من النوع wchar_t وتُخزّن النتيجة في الكائن المُشار إليه بالمؤشر pwc، إلا إن كان pwc مؤشرًا فارغًا، وتُعيد الدالة عدد البايتات المُحوّلة بنجاح، أو -1 إذا لم تشكّل أول n بايت محرفًا متعدد البايت صالحًا، ولا يُفحص أكثر من n بايت يُشير إليه المؤشر s، ولن تتعدى القيمة المُعادة قيمة n أو MB_CUR_MAX. دالة wctmob: تُحوِّل رمز القيمة wchar إلى سلسلة من البايتات تمثل محرف متعدد البايتات وتخزن النتيجة في مصفوفة يشير إليها المؤشر s وذلك إن لم يكن s مؤشرًا فارغًا، وتُعيد الدالة عدد البايتات المحتواة داخل محرف متعدد البايتات، أو -1 إذا كانت القيمة المخزنة في wchar لا تمثل محرف متعدد البايات، ومن غير الممكن معالجة عدد بايتات يتجاوز MB_CUR_MAX. دالة mbstowcs: تحوّل سلسلة محارف متعددة البايتات بدءًا من الحالة الأولية للإزاحة initial shift state وذلك ضمن المصفوفة التي يشير إليها المؤشر s إلى سلسلة من الرموز الموافقة ومن ثم تخزّنها في مصفوفة يشير إليها المؤشر pwcs، لا يُخزّن ما يزيد عن n قيمة في pwcs، وتُعيد الدالة 1- إذا صادفت محرفًا متعدد البايت غير صالح، وإلا فإنها تعيد عدد عناصر المصفوفة المُعدّلة باستثناء رمز إنهاء المصفوفة. نحصل على سلوك غير معرّف إذا وجد كائنين متقاطعين. الدالة wcstombs: تُحوِّل سلسلة من الرموز المُشار إليها بالمؤشر pwcs إلى سلسلة من المحارف متعددة البايتات بدءًا من الحالة الأولية للإزاحة وتُخزّن فيما بعد في مصفوفة مُشار إليها بالمؤشر s. تتوقف عملية التحويل عند مصادفة رمز فارغ، أو عند كتابة n بايت إلى s، وتُعيد الدالة -1 إذا كان الرمز المُصادف لا يمثل محرفًا متعدد البايتات صالحًا، وإلا فيُعاد عدد البايتات التي كُتبت باستثناء رمز الإنهاء الفارغ. نحصل على سلوك غير محدد إذا وجد كائنين متقاطعين. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: دوال التعامل مع السلاسل النصية والوقت والتاريخ في لغة سي C المقال السابق: التعامل مع الدخل والخرج I/O وتنسيقه في لغة سي C التعامل مع المكتبات في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C
نستعرض هنا الأدوات الموجودة في ملف الترويسة <stdlib.h> الذي يصرح عن عدد من الأنواع والماكرو وعدة دوال للاستخدام العام، تتضمن الأنواع والماكرو التالي: النوع size_t: تكلمنا عنه سابقًا. النوع div_t: نوع من الهياكل التي تعيدها الدالة div. النوع ldiv_t: نوع من الهياكل التي تعيدها الدالة ldiv. النوع NULL: تكلمنا عنه سابقًا. القيمة EXIT_FAILURE و EXIT_SUCCESS: يمكن استخدامهما مثل وسيط للدالة exit. القيمة MB_CUR_MAX: العدد الأعظمي للبايتات في محرف متعدد البايتات multibyte character من مجموعة المحارف الإضافية والمحددة حسب إعدادت اللغة المحلية locale. القيمة RAND_MAX: القيمة العظمى المُعادة من استدعاء دالة rand. دوال تحويل السلسلة النصية هناك ثلاث دوال تقبل سلسلة نصية وسيطًا لها وتحوّلها إلى عدد من نوع معين كما هو موضح هنا: #include <stdlib.h> double atof(const char *nptr); long atol(const char *nptr); int atoi(const char *nptr); نحصل على عدد مُحوّل مُعاد لكل من الدوال الثلاث السابقة، ولا تضمن لك أيٌ من الدوال أن تضبط القيمة errno (إلا أن الأمر محقّق في بعض التنفيذات)، وتكون النتائج التي نحصل عليها من تحويلات تتسبب بحدوث طفحان overflow ولا يمكننا تمثيلها غير معرّفة. هناك بعض الدوال أكثر تعقيدًا: #include <stdlib.h> double strtod(const char *nptr, char **endptr); long strtol(const char *nptr, char **endptr, int base); unsigned long strtoul(const char *nptr,char **endptr, int base); تعمل الدوال الثلاث السابقة بطريقة مشابهة، إذ يجري تجاهل أي مسافات فارغة بادئة ومن ثم يُعثر على الثابت المناسب subject sequence متبوعًا بسلسلة محارف غير معترف عليها، ويكون المحرف الفارغ في نهاية السلسلة النصية غير مُعترف عليه دائمًا. تُحدد السلسلة المذكورة حسب التالي: في الدالة strtod: إشارة "+" أو "-" اختيارية في البداية متبوعة بسلسلة أرقام تحتوي على محرف الفاصلة العشرية الاختياري وأس exponent اختياري أيضًا. لا يُعترف على أي لاحقة عائمة (ما بعد الفاصلة العشرية)، وتُعدّ الفاصلة العشرية تابعةً لسلسلة الأرقام إذا وُجدت. في الدالة strtol: إشارة "+" أو "-" اختيارية في البداية متبوعة بسلسلة أرقام، وتُؤخذ هذه الأرقام من الخانات العشرية أو من أحرف صغيرة lower case أو كبيرة upper case ضمن النطاق a إلى z في الأبجدية الإنجليزية ويُعطى لكل من هذه الأحرف القيم ضمن النطاق 10 إلى 35 بالترتيب. يحدِّد الوسيط base القيم المسموحة ويمكن أن تكون قيمة الوسيط صفر أو ضمن النطاق 2 إلى 36. يجري التعرُّف على الخانات التي تبلغ قيمتها أقل من الوسيط base، إذ تسمح القيمة 16 للوسيط base على سبيل المثال للمحارف 0x أو 0X أن تتبع الإشارة الاختيارية، بينما يسمح base بقيمة صفر أن تكون المحارف المدخلة على هيئة أعداد صحيحة ثابتة في سي، ولا يُعترف على أي لاحقة عدد صحيح. في الدالة strtoul: مطابقة للدالة strtol إلا أنها لا تسمح بوجود إشارة. يُخزّن عنوان أول محرف غير مُعترف عليه في الكائن الذي يشير إليه endptr في حال لم يكُن فارغًا، وتكون هذه قيمة nptr إذا كانت السلسلة فارغة أو ذات تنسيق خاطئ. تحوّل الدالة الرقم وتُعيده مع الأخذ بالحسبان كون وجود الإشارة البادئة مسموحًا أو لا، وذلك إذا كان إجراء التحويل ممكنًا، وإلا فإنها تعيد القيمة صفر. عند حدوث الطفحان أو حصول خطأ تُجرى العمليات التالية: في الدالة strtod: تُعيد عند الطفحان القيمة HUGE_VAL± وتعتمد الإشارة على إشارة النتيجة، وتُعيد القيمة صفر عند طفحان الحد الأدنى underflow ويُضبط errno في الحالتين إلى القيمة ERANGE. في الدالة strtol: تُعيد القيمة LONG_MAX أو LONG_MIN عند الطفحان بحسب إشارة النتيحة، ويُضبط errno في كلا الحالتين إلى القيمة ERANGE. في الدالة strtoul: تُعيد القيمة ULONG_MAX عند الطفحان، ويُضبط errno إلى القيمة ERANGE. قد يكون هناك سلاسل أخرى من الممكن التعرُّف عليها في بعض التنفيذات إذا لم تكن الإعدادات المحلية هي إعدادات سي التقليدية. توليد الأرقام العشوائية تقدِّم الدوال التالية طريقةً لتوليد الأرقام العشوائية الزائفة pseudo-random: #include <stdlib.h> int rand(void); void srand(unsigned int seed); تُعيد الدالة rand رقمًا عشوائيًا زائفًا ضمن النطاق من "0" إلى "RAND_MAX"، وهو ثابت قيمته على الأقل "32767". تسمح الدالة srand بتحديد نقطة بداية للنطاق المُختار طبقًا لقيمة الوسيط seed، وهي ذات قيمة "1" افتراضيًا إذا لم تُستدعى srand قبل rand، ونحصل على سلسلة قيم مطابقة من الدالة rand إذا استخدمنا قيمة seed ذاتها. يصف المعيار الخوارزمية المستخدمة في دالتي rand و srand، وتستخدم معظم التنفيذات هذه الخوارزمية عادةً. حجز المساحة تُستخدم هذه الدوال لحجز وتحرير المساحة، إذ يُضمن للمساحة التي حصلنا عليها أن تكون كبيرةً كفاية لتخزين كائن من نوع معين ومُحاذاة ضمن الذاكرة بحيث لا تتسبب بتفعيل استثناءات العنوان addressing exceptions، ولا يجب افتراض أي شيء آخر بخصوص عملها. #include <stdlib.h> void *malloc(size_t size); void *calloc(size_t nmemb, size_t size); void *realloc(void *ptr, size_t size); void *free(void *ptr); تُعيد جميع دوال حجز المساحة مؤشرًا يشير إلى المساحة المحجوزة التي يبلغ حجمها size بايت، وإذا لم يكن هناك أي مساحة فارغة فهي تعيد مؤشرًا فارغًا، إلا أن الفرق بين الدوال هو أن دالة calloc تأخذ وسيطًا يدعى nmemb الذي يحدد عدد العناصر في مصفوفة، وكل عنصر في هذه المصفوفة يبلغ حجمه size بايت، ولذا فهي تحجز مساحةً أكبر من التخزين عادةً من المساحة التي تحجزها malloc، كما أن المساحة المحجوز بواسطة malloc غير مُهيّئة بينما تُهيّأ جميع بتات مساحة التخزين المحجوزة بواسطة calloc إلى الصفر، إلا أن هذا الصفر ليس تمثيلًا مكافئًا للصفر ضمن الفاصلة العائمة floating-point أو مؤشرًا فارغًا null بالضرورة. تُستخدم الدالة realloc لتغيير حجم الشيء المُشار إليه بواسطة المؤشر ptr مما يتطلب بعض النسخ لإنجاز هذا الأمر ومن ثمّ تُحرّر مساحة التخزين القديمة. لا تُغيّر محتويات الكائن المُشار إليه بواسطة ptr بالنسبة للحجمين القديم والجديد، وتتصرف الدالة تصرفًا مماثلًا لتصرف malloc إذا كان المؤشر ptr مؤشرًا فارغًا وذلك للحجم المخصّص. تُستخدم الدالة free لتحرير المساحة المحجوزة مسبقًا من إحدى دوال حجز المساحة، ومن المسموح تمرير مؤشر فارغ إلى الدالة free وسيطًا لها، إلا أن الدالة في هذه الحالة لا تنفّذ أي شيء. إذا حاولت تحرير مساحة لم تُحجز مسبقًا تحصل على سلوك غير محدّد، ويتسبب هذا الأمر في العديد من التنفيذات باستثناء عنوان addressing exception مما يوقف البرنامج، إلا أن هذه ليست بدلالة يمكن الاعتماد عليها. التواصل مع البيئة سنستعرض مجموعةً من الدوال المتنوعة: #include <stdlib.h> void abort(void); int atexit(void (*func)(void)); void exit(int status); char *getenv(const char *name); int system(const char *string); دالة abort: تتسبب بإيقاف غير اعتيادي للبرنامج وذلك باستخدام الإشارة SIGABRT، ويمكن منع الإيقاف غير الاعتيادي فقط إذا حصلنا على الإشارة ولم يُعد معالج الإشارة signal handler أي قيمة، وإلا ستُحذف ملفات الخرج وقد يمكن أيضًا إزالة الملفات المؤقتة بحسب تعريف التنفيذ، وتُعاد حالة "إنهاء برنامج غير ناجح unsuccessful termination" إلى البيئة المُستضافة، كما أن هذه الدالة لا يمكن أن تُعيد أي قيمة. دالة atexit: يصبح وسيط الدالة func دالةً يمكن استدعاؤها دون استخدام أي وسطاء عندما يُغلق البرنامج، ويمكن استخدام ما لا يقل عن 32 دالة مشابهة لهذه الدالة وأن تُستدعى عند إغلاق البرنامج بصورةٍ مُعاكسة لتسجيل كلٍّ منها، ونحصل على القيمة المُعادة صفر للدلالة على النجاح وإلا فقيمة غير صفرية للدلالة على الفشل. دالة exit: تُستدعى هذه الدالة عادةً لإنهاء البرنامج على نحوٍ اعتيادي، وتُستدعى عند تنفيذ الدالة جميع الدوال المُسجّلة باستخدام دالة atexit، لكن انتبه، إذ ستُعد الدالة main بحلول هذه النقطة قد أعادت قيمتها ولا يمكن استخدام أي كائنات ذات مدة تخزين تلقائي automatic storage duration على نحوٍ آمن، من ثمّ تُحذف محتويات جميع مجاري الخرج output streams وتُغلق وتُزال جميع الملفات التلقائية المُنشأة بواسطة tmpfile، وأخيرًا يُعيد البرنامج التحكم إلى البيئة المستضافة بإعادة حالة نجاح أو فشل محدّدة بحسب التنفيذ، وتعتمد الحالة على إذا ما كان وسيط الدالة exit مساوٍ للقيمة EXITSUCCESS (وهذه حالة النجاح) أو EXITFAILURE (حالة الفشل). للتوافق مع لغة سي القديمة، تُستخدم القيمة صفر بدلًا من EXITFAILURE، بينما يكون لباقي القيم تأثيرات معرّفة بحسب التنفيذ. لا يمكن أن تُعاد حالة الخروج. دالة getenv: يجري البحث في لائحة البيئة environment list المعرفة بحسب التنفيذ بهدف العثور على عنصر يوافق السلسلة النصية المُشار إليها بواسطة وسيط الاسم name، إذ تُعيد الدالة مؤشرًا إلى العنصر يشير إلى مصفوفة لا يمكن تعديلها من قبل البرنامج ويمكن تعديلها باستدعاء لاحق للدالة getenv، ونحصل على مؤشر فارغ إذا لم يُعثر على عنصر موافق. يعتمد الهدف من لائحة البيئة وتنفيذها على البيئة المُستضافة. دالة system: تُمرّر سلسلة نصية إلى أمر معالج مُعرف حسب التنفيذ، ويتسبب مؤشر فارغ بإعادة القيمة صفر، وقيمة غير صفرية إذا لم يكن الأمر موجودًا، بينما يتسبب مؤشر غير فارغ بمعالجة الأمر. نتيجة الأمر والقيمة المُعادة معرف حسب التنفيذ. البحث والترتيب هناك دالتان ضمن هذا التصنيف، أولهما دالة للبحث ضمن لائحة مُرتّبة والأخرى لترتيب لائحة غير مرتبة، واستخدام الدالتان عام، إذ يمكن استخدامهما في مصفوفات من أي سعة وعناصرها من أي حجم. يجب أن يلجأ المستخدم إلى دالة مقارنة إذا أراد مقارنة عنصرين عند استخدام الدوال السابقة، إذ تُستدعى هذه الدالة باستخدام المؤشرين الذين يشيران إلى العنصرين مثل وسطاء الدالة، وتُعيد الدالة قيمةً أقل من الصفر إذا كانت قيمة المؤشر الأول أصغر من قيمة المؤشر الثاني، وقيمة أكبر من الصفر إذا كانت قيمة المؤشر الأول أكبر من المؤشر الثاني، والقيمة صفر إذا كانت قيمتا المؤشرين متساويين. #include <stdlib.h> void *bsearch(const void *key, const void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *)); void *qsort(const void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *)); يمثّل الوسيط nmemb في كلٍّ من الدالتين السابقتين عدد العناصر في المصفوفة، ويمثل الوسيط size حجم عنصر المصفوفة الواحد بالبايت و compar هي الدالة التي تُستدعى للمقارنة بين العنصرين، بينما يشير المؤشر base إلى أساس المصفوفة أي بدايتها. ترتّب الدالة qsort المصفوفة ترتيبًا تصاعديًا. تفترض الدالة bsearch أن المصفوفة مرتّبة مسبقًا وتُعيد مؤشرًا إلى أي عنصر يتساوى مع العنصر المُشار إليه بالمؤشر key، وتُعيد الدالة مؤشرًا فارغًا إذا لم تجد أي عناصر متساوية. دوال العمليات الحسابية الصحيحة تقدّم هذه الدوال طريقةً لإيجاد القيمة المطلقة لوسيط يمثل عدد صحيح، إضافةً لحاصل القسمة والباقي من العملية لكلٍّ من النوعين int و long. #include <stdlib.h> int abs(int j); long labs(long j); div_t div(int numerator, int denominator); ldiv_t ldiv(long numerator, long denominator); الدالتان abs و labs: تُعيدان القيمة المطلقة لوسيطهما ويجب اختيار الدالة المناسبة بحسب احتياجاتك. نحصل على سلوك غير معرّف إذا لم تكن القيمة ممكنة التمثيل وقد يحدث ذلك في الأنظمة التي تعمل بنظام المتمم الثنائي two's complement systems، إذ لا يوجد لأكثر رقم سلبيّة أي مكافئ إيجابي. الدالتان div وldiv: تُقسّمان الوسيط numerator على الوسيط denominator وتُعيدان هيكلًا structure للنوع المحدد، وفي أي حالة، سيحتوي الهيكل على عضو يدعى quot يحتوي على حاصل القسمة الصحيحة وعضوًا آخر يدعى rem يحتوي على باقي القسمة، ونوع العضوين هو int في الدالة div و long في الدالة ldiv، ويمكن تمثيل نتيجة العملية على النحو التالي: quot*denominator+rem == numerator الدوال التي تستخدم المحارف متعددة البايت يؤثر تصنيف LC_CTYPE ضمن الإعدادات المحلية الحالية على سلوك هذه الدوال، إذ تُضبط كل دالة إلى حالة ابتدائية باستدعاء يكون وسيطها s الذي يمثل مؤشر المحرف فارغًا null، وذلك في حالة الترميز المُعتمد على الحالة state-dependent endcoding، وتُغيَّر حالة الدالة الداخلية وفق الضرورة عن طريق استدعاءات لاحقة عندما لا يكون s مؤشرًا فارغًا. تُعيد الدالة قيمةً غير صفرية إذا كان الترميز معتمدًا على الحالة، وإلا فتعيد القيمة صفر إذا كان المؤشر s فارغًا. تصبح حالة الإزاحة shift state الخاصة بالدوال غير محددة indeterminate إذا حدث تغيير للتصنيف LC_TYPE. الدوال هي: #include <stdlib.h> int mblen(const char *s, size_t n); int mbtowc(wchar_t *pwc, const char *s, size_t n); int wctomb(char *s, wchar_t wchar); size_t mbstowcs(wchar_t *pwcs, const char *s, size_t n); size_t wcstombs(char *s, const wchar_t *pwcs, size_t n); الدالة mblen: تُعيد عدد البايتات المُحتواة بداخل محرف متعدد البايتات multibyte character المُشار إليه بواسطة المؤشر s أو تُعيد القيمة -1 إذا كان أول n بايت لا يشكّل محرف متعدد البايتات صالحًا، أو تُعيد القيمة صفر إذا كان المؤشر يشير إلى محرف فارغ. الدالة mbtowc: تُحوِّل محرف متعدد البايتات يُشير إليه المؤشر s إلى الرمز الموافق له من النوع wchar_t وتُخزّن النتيجة في الكائن المُشار إليه بالمؤشر pwc، إلا إن كان pwc مؤشرًا فارغًا، وتُعيد الدالة عدد البايتات المُحوّلة بنجاح، أو -1 إذا لم تشكّل أول n بايت محرفًا متعدد البايت صالحًا، ولا يُفحص أكثر من n بايت يُشير إليه المؤشر s، ولن تتعدى القيمة المُعادة قيمة n أو MB_CUR_MAX. دالة wctmob: تُحوِّل رمز القيمة wchar إلى سلسلة من البايتات تمثل محرف متعدد البايتات وتخزن النتيجة في مصفوفة يشير إليها المؤشر s وذلك إن لم يكن s مؤشرًا فارغًا، وتُعيد الدالة عدد البايتات المحتواة داخل محرف متعدد البايتات، أو -1 إذا كانت القيمة المخزنة في wchar لا تمثل محرف متعدد البايات، ومن غير الممكن معالجة عدد بايتات يتجاوز MB_CUR_MAX. دالة mbstowcs: تحوّل سلسلة محارف متعددة البايتات بدءًا من الحالة الأولية للإزاحة initial shift state وذلك ضمن المصفوفة التي يشير إليها المؤشر s إلى سلسلة من الرموز الموافقة ومن ثم تخزّنها في مصفوفة يشير إليها المؤشر pwcs، لا يُخزّن ما يزيد عن n قيمة في pwcs، وتُعيد الدالة 1- إذا صادفت محرفًا متعدد البايت غير صالح، وإلا فإنها تعيد عدد عناصر المصفوفة المُعدّلة باستثناء رمز إنهاء المصفوفة. نحصل على سلوك غير معرّف إذا وجد كائنين متقاطعين. الدالة wcstombs: تُحوِّل سلسلة من الرموز المُشار إليها بالمؤشر pwcs إلى سلسلة من المحارف متعددة البايتات بدءًا من الحالة الأولية للإزاحة وتُخزّن فيما بعد في مصفوفة مُشار إليها بالمؤشر s. تتوقف عملية التحويل عند مصادفة رمز فارغ، أو عند كتابة n بايت إلى s، وتُعيد الدالة -1 إذا كان الرمز المُصادف لا يمثل محرفًا متعدد البايتات صالحًا، وإلا فيُعاد عدد البايتات التي كُتبت باستثناء رمز الإنهاء الفارغ. نحصل على سلوك غير محدد إذا وجد كائنين متقاطعين. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: دوال التعامل مع السلاسل النصية والوقت والتاريخ في لغة سي C المقال السابق: التعامل مع الدخل والخرج I/O وتنسيقه في لغة سي C التعامل مع المكتبات في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C -
 اتجه تطوير لغات الحاسوب سابقًا في اتجاهٍ من اتجاهين، إذ سلكت كوبول COBOL سلوكًا ركز على استخدام هياكل البيانات بعيدًا عن العمليات الحسابية والخوارزميات، بينما سلكت لغات مثل فورتران FORTRAN وألغول Algol سلوكًا معاكسًا. أراد العلماء وقتها إجراء العمليات الحسابية باستخدام بيانات غير مُهيكلة نسبيًا، إلا أنه سرعان ما لاحظ الجميع أن استخدام المصفوفات لا غنى عنه؛ بينما أراد المستخدمون الاعتياديون طريقةً لإجراء العمليات الحسابية البسيطة فقط، إلا أن طريقة هيكلة البيانات كانت عائقًا أمام تحقيق ذلك. أثر كلا السلوكين في تصميم لغة سي، إذ أنها تحتوي تحكمًا هيكليًا لتدفق البرنامج مناسب للغة من هذا العمر، كما أنها جعلت من مفهوم هياكل البيانات شائعًا. ركزنا على جانب الخوارزميات من اللغة حتى اللحظة، ولم نولي الكثير من الانتباه بخصوص تخزين البيانات، ومع أننا تطرقنا إلى المصفوفات التي تُعدّ هيكل بيانات إلا أنها شائعة الاستخدام وبسيطة ولا تستحق فصلًا مخصصًا لها، واكتفينا إلى الآن بالنظر إلى اللغة انطلاقًا من بينة هيكلية شبيهة بلغة فورتران. كان استخدام كلٍ من البيانات والخوارزميات هو التوجه الأكثر رواجًا في أواخر ثمانينيات وبداية تسعينيات القرن الماضي، وفق ما يُدعى بالبرمجة كائنية التوجه Object-Oriented Programming. لا يوجد أي دعم لهذه الطريقة في لغة سي، إلا أن لغة C++ قدمت دعمًا لها (وهي لغةٌ مبنيةٌ على لغة سي)، ولكن هذا النقاش خارج موضوعنا حاليًا. تأخذ البيانات الانتباه الأكبر لمعظم مشاكل الحوسبة المتقدمة وليس الخوارزميات، فستكون مهمتك بسيطةً ببرمجة البرنامج إن استطعت تصميم هياكل بيانات صحيحة ومناسبة، إلا أنك تحتاج إلى دعمٍ من اللغة في هذه الحالة، فمهمتك ستصبح أقل سهولة ومعرضةً أكثر للأخطاء إن لم يكن هناك أي دعم لأنواع هياكل البيانات المختلفة عن المصفوفات. تقع هذه المهمة على كاهل لغة البرمجة، فليس كافيًا أن تسمح لك اللغة بفعل ما تريد، بل يجب أن تساعدك في فعل ما تريد. تقدم لك لغة سي سعيًا منها بتقديم هياكل بيانات مناسبة كلًا من المصفوفات Arrays والهياكل Structures والاتحادات Unions، وقد برهنت على أنها كافيةٌ لمعظم المستخدمين الاعتياديين وبالتالي لم يُضِف المعيار أي جديد بشأنها. الهياكل Structures تسمح لك المصفوفات بتخزين مجموعة من الكائنات المتماثلة تحت اسم معين، وهذا مفيدٌ لعدد من المهام، ولكنه ليس مرن التعامل، إذ تحتوي معظم كائنات البيانات ذات التطبيقات الواقعية على هيكل معيّن معقد لا يمكن استخدامه مع طريقة تخزين المصفوفة للبيانات. لنوضح ما سبق بالمثال التالي: لنفرض أننا نريد تمثيل سلسلةٍ نصية ذات خصائص معينة، بجانب محتواها. هناك نوع الخط وحجمه، وهما سمتان لا تؤثران في محتوى السلسلة، لكنهما تحددان الطريقة التي تُعرض فيها السلسلة على الشاشة سواءٌ كان النص مكتوبًا بخط غامق أو مائل، والأمر ذاته ينطبق على حجم الخط. كيف نستطيع تمثيل السلسلة النصية بكائن واحد ضمن مصفوفة إذا كان يحتوي على ثلاث سمات مختلفة؟ يمكننا تحقيق ذلك في لغة سي C بسهولة، حاول أولًا تمثيل السمات الثلاث باستخدام الأنواع الأساسية، فعلى فرض أنه يمكننا تخزين كل محرف باستخدام النوع char، يمكننا الإشارة إلى نوع الخط المستخدم باستخدام النوع short (نستخدم "1" للإشارة إلى الخط الاعتيادي و"2" للخط المائل و"3" للخط الغامق، وهكذا)، كما يمكننا تخزين حجم الخط باستخدام النوع short، وتُعد جميع الفرضيات السابقة معقولةً عمليًا، إذ تدعم معظم الأنظمة عددًا قليلًا من الخطوط مهما كانت هذه الأنظمة معقدة، ويتراوح حجم الخط بين 6 ومرتبة المئات القليلة، فأي خط أصغر من 6 هو صعب القراءة، والخط الأكبر من 50 هو خط أكبر من خطوط عناوين الجرائد. إذًا، لدينا الآن محرف وعددين صغيرين وتُعامل هذه البيانات معاملة كائن واحد، إليك كيف نصرّح عن ذلك في لغة سي: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }; يصرح ما سبق عن نوع جديد من الكائنات يمكنك استخدامه ضمن البرنامج، ويعتمد الأمر بصورةٍ رئيسية على ذكر الكلمة المفتاحية struct، المتبوعة بمعرّف identifier اختياري هو الوسم wp_char في هذه الحالة، ويسمح لنا هذا الوسم بتسمية النوع للإشارة إليه فيما بعد. يمكننا أيضًا استخدام الوسم بالطريقة التالية بعد التصريح عنه: struct wp_char x, y; يُعرّف ما سبق متغيرين باسم x و y، بالطريقة ذاتها للتعريف التالي: int x, y; لكن المتغيرات في المثال الأول من نوع struct wp_char عوضًا عن int في المثال الثاني، ويمثّل الوسم اسمًا للنوع الذي صرحنا عنه سابقًا. نذّكر هنا أنه من الممكن استخدام اسم وسم الهيكل مثل أي معرّف اعتيادي بصورةٍ آمنة، ويدل الاسم على معنًى مختلف عندما يُسبق بالكلمة المفتاحية struct فقط، ومن الشائع أن يُعرّف كائن مُهيكل باسم مماثل لوسم الهيكل الخاص به. struct wp_char wp_char; يُعرّف السطر السابق متغيرًا باسم wp_char من النوع struct wp_char، ويمكننا فعل ذلك لأن لوسوم الهياكل "فضاء اسماء name space" خاصة بها ولا تتعارض مع الأسماء الأخرى، وسنتكلم أكثر عن الوسوم عندما نناقش "الأنواع غير المكتملة incomplete types". يمكن التعريف عن المتغيرات على الفور عقب التصريح عن هيكل ما: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }v1; struct wp_char v2; لدينا في هذه الحالة متغيرين، أحدهما باسم v1 والآخر باسم v2، وإذا استخدمنا الطريقة السابقة في التعريف عن v1، يصبح الوسم غير ضروري ويُتخلّى عنه غالبًا إلا في حال احتجنا إلى الوسم لاستخدامه مع عامل sizeof والتحويل بين الأنواع casts. يُعد المتغيران السابقان كائنات مُهيكلة، ويحتوي كل منهما على ثلاثة أعضاء members مستقلين عن بعضهم باسم wp_cval و wp_font و wp_psize، ونستخدم عامل النقطة . للوصول إلى كلّ من الأعضاء السابقة على النحو التالي: v1.wp_cval = 'x'; v1.wp_font = 1; v1.wp_psize = 10; v2 = v1; تُضبط أعضاء المتغير v1 في المثال السابق إلى قيمها المناسبة، ومن ثم تُنسخ قيم v1 إلى v2 باستخدام عملية الإسناد. في الحقيقة، العملية الوحيدة المسموحة في الهياكل بكاملها هي الإسناد؛ إذ يمكن إسناد الهياكل إلى بعضها بعضًا أو تمريرها مثل وسطاء للدوال أو قيمةٍ تُعيدها دالةٌ ما، إلا أن نسخ الهياكل عمليةٌ غير فعالة وتتفاداها معظم البرامج عن طريق التلاعب بالمؤشرات التي تشير إلى الهياكل عوضًا عن ذلك، إذ من الأسرع عمومًا نسخ المؤشرات عوضًا عن الهياكل. تسمح اللغة بمقارنة الهياكل بحثًا عن المساواة فيما بينها، وهي سهوة مفاجئة ولا يوجد سبب مقنع لسماحها بذلك كما سنذكر قريبًا. إليك مثالًا يستخدم مصفوفةً من الهياكل، وهو الهيكل ذاته الذي تكلمنا عنه سابقًا، إذ تُستخدم دالةٌ لقراءة المحارف من دخل البرنامج القياسي وتُعيد هيكلًا مهيّأً بقيمٍ مناسبة مقابله، ومن ثم تُرتّب الهياكل بحسب قيمة كل محرف وتُطبع وذلك عندما يُقرأ محرف سطر جديد، أو عندما تمتلئ المصفوفة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; /* نوع دخل الدالة الذي كان من الممكن التصريح عنه سابقًا، وتعيد الدالة هيكلًا ولا تأخذ أي وسطاء */ struct wp_char infun(void); main(){ int icount, lo_indx, hi_indx; for(icount = 0; icount < ARSIZE; icount++){ ar[icount] = infun(); if(ar[icount].wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة icount * مع تجاهل \n */ break; } } /* نجري الآن عملية الترتيب */ for(lo_indx = 0; lo_indx <= icount-2; lo_indx++) for(hi_indx = lo_indx+1; hi_indx <= icount-1; hi_indx++){ if(ar[lo_indx].wp_cval > ar[hi_indx].wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = ar[lo_indx]; ar[lo_indx] = ar[hi_indx]; ar[hi_indx] = wp_tmp; } } /* طباعة القيم */ for(lo_indx = 0; lo_indx < icount; lo_indx++){ printf("%c %d %d\n", ar[lo_indx].wp_cval, ar[lo_indx].wp_font, ar[lo_indx].wp_psize); } exit(EXIT_SUCCESS); } struct wp_char infun(void){ struct wp_char wp_char; wp_char.wp_cval = getchar(); wp_char.wp_font = 2; wp_char.wp_psize = 10; return(wp_char); } مثال 1 من الطبيعي أن نلجأ إلى التصريح عن مصفوفات من الهياكل حالما نستطيع ونتعلم كيفية التصريح عنها، وأن نستخدم هذه الهياكل عناصرًا لهياكل أخرى وما إلى ذلك، والقيد الوحيد هنا هو أنه لا يمكن للهيكل أن يحتوي مثالًا لنفسه على أنه عضو داخله (يصبح حينها حجمها موضع جدل مثير للفلاسفة، ولكنه غير مفيد لأي مبرمج سي C). المؤشرات والهياكل ذكرنا سابقًا أنه من الشائع استخدام المؤشرات في الهياكل بدلًا من استخدام الهياكل مباشرةً، لنتعلم كيفية تحقيق ذلك إذَا. يُعد التصريح عن المؤشرات سهلًا، ونعتقد أنك أتقنته: struct wp_char *wp_p; يمنحنا التصريح السابق مؤشرًا مباشرةً، ولكن كيف يمكننا الوصول إلى أعضاء الهيكل؟ تتمثل إحدى الطرق باستخدام المؤشر الذي يشير إلى الهيكل، ثم اختيار العضو على النحو التالي: /* نحصل على الهيكل ومن ثم نحدد العضو*/ (*wp_p).wp_cval نستخدم الأقواس لأن أسبقية عامل النقطة . أعلى من *، إلا أن الطريقة السابقة غير سهلة التعامل وقدمت لغة سي نتيجة لذلك عاملًا جديدًا لجعل التعليمة أنيقة ويُعرف باسم العامل "المُشير إلى pointing-to"، إليك مثالًا عن استخدامه: // العضو الذي يشير إليه المؤشر wp_p في الهيكل wp_cval wp_p->wp_cval = 'x'; ومع أن مظهره غير مثالي، إلا أنه مفيد جدًا في حال احتواء هيكل ما على المؤشرات، مثل القوائم المترابطة Linked list، إذ أن استخدام الطريقة السابقة أسهل بكثير إن أردت تتبع مرحلة أو مرحلتين من الروابط ضمن قائمة مترابطة. إذا لم تصادف القوائم المترابطة بعد، فلا تقلق، إذ سنتطرق إليها لاحقًا. إذا كان الكائن على يسار العامل . أو <- نوعًا مؤهّلًا qualified type (باستخدام الكلمة المفتاحية const أو volatile)، فستكون النتيجة أيضًا معرفةً حسب هذه المؤهلات qualifiers. إليك مثالًا عن ذلك باستخدام المؤشرات؛ فعندما يشير المؤشر إلى نوع مؤهل، تكون النتيجة من نوع مؤهل أيضًا. #include <stdio.h> #include <stdlib.h> struct somestruct{ int i; }; main(){ struct somestruct *ssp, s_item; const struct somestruct *cssp; s_item.i = 1; /* مسموح */ ssp = &s_item; ssp->i += 2; /* مسموح */ cssp = &s_item; cssp->i = 0; /*يشير إلى كائن ثابت cssp غير مسموح لأن المؤشر */ exit(EXIT_SUCCESS); } يبدو أن بعض مبرمجي المصرّفات نسوا هذا المتطلب، إذ استخدمنا مصرفًا لتجربة المثال السابق ولم يحذرنا بخصوص الإسناد الأخير الذي خرق القيد. إليك المثال 1 مكتوبًا باستخدام المؤشرات، وبتغيير دالة الدخل infun بحيث تقبل مؤشرًا يشير إلى هيكل بدلًا من إعادة مؤشر، وهذا ما ستراه على الأغلب عندما تنظر إلى بعض البرامج العملية. نتخلى عن نسخ الهياكل في البرامج إن أردنا زيادة فاعلية تنفيذها ونستخدم بدلًا من ذلك مصفوفات تحتوي على مؤشرات؛ إذ تُستخدم هذه المؤشرات للحصول على البيانات المخزنة، إلا أن هذه الطريقة ستزيد من تعقيد الأمور، ولا تستحق العناء في التطبيقات البسيطة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; void infun(struct wp_char *); main(){ struct wp_char wp_tmp, *lo_indx, *hi_indx, *in_p; for(in_p = ar; in_p < &ar[ARSIZE]; in_p++){ infun(in_p); if(in_p->wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة in_p * مع تجاهل \n */ break; } } /* * نبدأ بترتيب القيم * علينا الحرص هنا وتجنب حالة طفحان * لذا نتفقد دائمًا وجود قيمتين لترتيبهما */ if(in_p-ar > 1) for(lo_indx = ar; lo_indx <= in_p-2; lo_indx++){ for(hi_indx = lo_indx+1; hi_indx <= in_p-1; hi_indx++){ if(lo_indx->wp_cval > hi_indx->wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = *lo_indx; *lo_indx = *hi_indx; *hi_indx = wp_tmp; } } } /* طباعة القيم */ for(lo_indx = ar; lo_indx < in_p; lo_indx++){ printf("%c %d %d\n", lo_indx->wp_cval, lo_indx->wp_font, lo_indx->wp_psize); } exit(EXIT_SUCCESS); } void infun( struct wp_char *inp){ inp->wp_cval = getchar(); inp->wp_font = 2; inp->wp_psize = 10; return; } مثال 2 هناك مشكلةٌ أخرى يجب النظر إليها، ألا وهي كيف سيبدو الهيكل عند تخزينه في الذاكرة؟ إلا أننا لن نقلق بهذا الخصوص كثيرًا في الوقت الحالي، ولكن من المفيد أن تستخدم في بعض الأحيان هياكل لغة سي C مكتوبة بواسطة برامج أخرى. تُحجز المساحة للهيكل wp_char كما هو موضح على النحو التالي: شكل 1 مخطط تخزين الهيكل يفترض الشكل بعض الأشياء مسبقًا: يأخذ المتغير من نوع char بايتًا واحدًا من الذاكرة، بينما يأخذ short 2 بايت من الذاكرة، وأن لجميع المتغيرات من نوع short عنوانًا زوجيًا على هذه المعمارية، ونتيجةً لما سبق يبقى عضو واحد بحجم 1 بايت ضمن الهيكل دون تسمية مُدخل من المصرف وذلك لأغراض تتعلق بمعمارية الذاكرة. القيود السابقة شائعة الوجود وتتسبب غالبًا بما يسمى هياكل ذات "ثقوب holes". تضمن لغة سي المعيارية بعض الأمور بخصوص تنسيق الهياكل والاتحادات: تُحجز الذاكرة لكلٍ من أعضاء الهياكل بحسب الترتيب التي ظهرت بها هذه الأعضاء ضمن التصريح عن الهيكل وبترتيبٍ تصاعدي للعناوين. لا يجب أن يكون هناك أي حشو padding في الذاكرة أمام العضو الأول. يماثل عنوان الهيكل عنوان العضو الأول له، وذلك بفرض استخدام تحويل الأنواع casting المناسب، وبالنظر إلى التصريح السابق للهيكل wp_char فإن التالي محقق: (char *)item == &item.wp_cval. ليس لحقول البتات bit fields (سنذكرها لاحقًا) أي عناوين، فهي محزّمةٌ تقنيًا إلى وحدات units وتنطبق عليها القوانين السابقة. القوائم المترابطة وهياكل أخرى يفتح استخدام الهياكل مع المؤشرات الباب لكثيرٍ من الإمكانات. لسنا بصدد تقديم شرح مفصل ومعقد عن هياكل البيانات المترابطة هنا، ولكننا سنشرح مثالين شائعين جدًا من هذه الطبيعة، ألا وهما القوائم المترابطة Linked lists والأشجار Trees، ويجمع بين الهيكلين السابقين استخدام المؤشرات بداخلهما تشير إلى هياكل أخرى، وتكون الهياكل الأخرى عادةً من النوع ذاته. يوضح الشكل 2 طبيعة القائمة المترابطة. شكل 2 قائمة مترابطة باستخدام المؤشرات نحتاج للحصول على ما سبق إلى لتصريح عنه بما يوافق التالي: struct list_ele{ int data; /* تستطيع تسمية العضو بأي اسم*/ struct list_ele *ele_p; }; يبدو للوهلة الأولى أن الهيكل يحتوي نفسه (وهو ممنوع) ولكن يحتوي الهيكل في حقيقة الأمر مؤشرًا يشير إلى نفسه فقط، لكن لمَ يُعد التصريح عن المؤشر بالشكل السابق مسموحًا؟ يعلم المصرف بحلول وصوله إلى تلك النقطة بوجود struct list_ele، ولهذا السبب يكون التصريح مسموح، ومن الممكن أيضًا كتابة تصريح غير مكتمل للهيكل على النحو التالي قبل التصريح الكامل: struct list_ele; يصرح التصريح السابق عن نوع غير مكتمل incomplete type، سيسمح بالتصريح عن المؤشرات قبل التصريح الكامل، يفيد ذلك أيضًا في حال وجود حالة للإشارة إلى هياكل فيما بينها التي يجب أن تحتوي مؤشرًا لكل منها كما هو موضح في المثال. struct s_1; /* نوع غير مكتمل */ struct s_2{ int something; struct s_1 *sp; }; struct s_1{ /* التصريح الكامل */ float something; struct s_2 *sp; }; مثال 3 يوضح المثال السابق حاجتنا للأنواع غير المكتملة، كما يوضح خاصيةً مهمةً لأسماء أعضاء الهيكل إذ يشكّل كل هيكل فضاء أسماء name space خاصٍ به، ويمكن بذلك أن تتماثل أسماء عناصر من هياكل مختلفة دون أي مشاكل. تُستخدم الأنواع غير المكتملة فقط في حال لم نكن بحاجة استخدام حجم الهيكل، وإلا فيجب التصريح كاملًا عن الهيكل قبل استخدام حجمه، ولا يجب أن يكون هذا التصريح بداخل كتلة برمجية داخلية وإلا سيصبح تصريحًا جديدًا لهيكل مختلف. struct x; /* نوع غير مكتمل */ /* استخدام مسموح للوسوم */ struct x *p, func(void); void f1(void){ struct x{int i;}; /* إعادة تصريح */ } /* التصريح الكامل */ struct x{ float f; }s_x; void f2(void){ /* تعليمات صالحة */ p = &s_x; *p = func(); s_x = func(); } struct x func(void){ struct x tmp; tmp.f = 0; return (tmp); } مثال 4 يجدر الانتباه إلى أنك تحصل على هيكل من نوع غير مكتمل فقط عن طريق ذكر اسمه، وبناءً على ما سبق، تعمل الشيفرة التالية دون مشاكل: struct abc{ struct xyz *p;}; /* struct xyz تصريح النوع غير المكتمل */ struct xyz{ struct abc *p;}; /* أصبح النوع غير المكتمل مكتملًا */ هناك خطرٌ كبير في المثال السابق، كما هو موضح هنا: struct xyz{float x;} var1; main(){ struct abc{ struct xyz *p;} var2; /* struct xyz إعادة تصريح للهيكل */ struct xyz{ struct abc *p;} var3; } نتيجةً لما سبق، يمكن للمتغير var2.p أن يخزن عنوان var1، وليس عنوان var3 قطعًا الذي هو من نوع مختلف. يمكن تصحيح ما سبق (بفرض أنك لم تتعمد فعله) على النحو التالي: struct xyz{float x;} var1; main(){ struct xyz; /* نوع جديد غير مكتمل */ struct abc{ struct xyz *p;} var2; struct xyz{ struct abc *p;} var3; } يُستكمل نوع الهيكل أو الاتحاد عند الوصول إلى قوس الإغلاق {، ويجب أن يحتوي عضوًا واحدًا على الأقل أو نحصل على سلوك غير محدد. نستطيع الحصول على أنواع غير مكتملة عن طريق تصريح مصفوفة دون تحديد حجمها، ويصنف النوع على أنه غير مكتمل حتى يقدم تصريحًا آخرًا حجمها: int ar[]; /* نوع غير مكتمل */ int ar[5]; /* نكمل النوع هنا */ سيعمل المثال السابق إن جربته فقط في حال كانت التصريحات خارج أي كتلة برمجية (تصريحات خارجية)، إلا أن السبب في ذلك ليس متعلقًا بموضوعنا. بالعودة إلى مثال القوائم المترابطة، كان لدينا ثلاث عناصر مترابطة في القائمة، التي يمكن بناؤها على النحو التالي: struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ return(0); } مثال 5 يمكننا طباعة محتويات القائمة بطريقتين، إما بالمرور على المصفوفة بحسب دليلها index، أو باستخدام المؤشرات كما سنوضح في المثال التالي: #include <stdio.h> #include <stdlib.h> struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ struct list_ele *lp; ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ /* اتباع المؤشرات */ lp = ar; while(lp){ printf("contents %d\n", lp->data); lp = lp->pointer; } exit(EXIT_SUCCESS); } مثال 6 الطريقة التي تُستخدم فيها المؤشرات في المثال السابق مثيرةٌ للاهتمام، لاحظ كيف أن المؤشر الذي يشير إلى عنصر ما يُستخدم للإشارة إلى العنصر الذي يليه حتى إيجاد المؤشر ذو القيمة 0، مما يتسبب بتوقف حلقة while التكرارية. يمكن ترتيب المؤشرات بأي طريقة وهذا ما يجعل القائمة هيكلًا مرن التعامل. إليك دالةً يمكن تضمينها مثل جزء من برنامجنا السابق بهدف ترتيب القائمة المترابطة بحسب قيمة بياناتها العددية، وذلك عن طريق إعادة ترتيب المؤشرات حتى الوصول إلى عناصر القائمة عند المرور عليها بالترتيب. من المهم أن نشير هنا إلى أن البيانات لا تُنسخ، إذ تعيد الدالة مؤشرًا إلى بداية القائمة لأن بدايتها لا تساوي إلى التعبير ar[0] بالضرورة. struct list_ele * sortfun( struct list_ele *list ) { int exchange; struct list_ele *nextp, *thisp, dummy; /* * الخوارزمية على النحو التالي: * البحث عبر القائمة بصورةٍ متكررة * إذا وجد عنصرين خارج الترتيب * اِربطهما بصورةٍ معاكسة * توقف عند المرور بجميع عناصر القائمة * دون أي تبديل مطلوب * يحدث الخلط عند العمل على العنصر خلف العنصر الأول المثير للاهتمام * وهذا بسبب الآليات البسيطة المتعلقة بربط العناصر وإلغاء ربطها */ dummy.pointer = list; do{ exchange = 0; thisp = &dummy; while( (nextp = thisp->pointer) && nextp->pointer){ if(nextp->data < nextp->pointer->data){ /* exchange */ exchange = 1; thisp->pointer = nextp->pointer; nextp->pointer = thisp->pointer->pointer; thisp->pointer->pointer = nextp; } thisp = thisp->pointer; } }while(exchange); return(dummy.pointer); } مثال 7 ستلاحظ استخدام تعابير مشابهة للتعبير thisp->pointer->pointer عند التعامل مع القوائم، وبالتالي يجب أن تفهم هذه التعابير، وهي بسيطة إذ يدل شكلها على الروابط المتبعة. الأشجار تُعد الأشجار هيكل بيانات شائع أيضًا، وهي في حقيقة الأمر قائمةٌ مترابطةٌ ذات فروع، والنوع الأكثر شيوعًا هو الشجرة الثنائية binary tree، التي تحتوي على عناصر تُدعى العقد "nodes" كما يلي: struct tree_node{ int data; struct tree_node *left_p, *right_p; }; تعمل الأشجار في علوم الحاسوب من الأعلى إلى الأسفل (لأسباب تاريخية لن نناقشها)، إذ توجد عقدة الجذر root أعلى الشجرة وتتفرع فروع هذه الشجرة في الأسفل. تُستبدل بيانات أعضاء الهيكل الخاصة بالعقد بقيمها في الشكل التالي والتي سنستخدمها لاحقًا. شكل 3 شجرة لن تجذب الأشجار انتباهك إذا كان اهتمامك الرئيس هو التعامل مع المحارف والتلاعب بها، ولكنها مهمة جدًا بالنسبة لمصمّمي كل من قواعد البيانات والمصرّفات والأدوات المعقدة الأخرى. تتميز الأشجار بميزة خاصة جدًا ألا وهي أنها مرتبة، فيمكن أن تدعم بكل سهولة خوارزميات البحث الثنائي، ومن الممكن دائمًا إضافة مزيدٍ من العقد الجديدة إلى الشجرة في الأماكن المناسبة، فالشجرة هيكل بيانات مفيدٌ ومرن. بالنظر إلى الشكل السابق، نلاحظ أن الشجرة مبنيّةٌ بحرص حتى تكون مهمة البحث عن قيمة ما في حقول البيانات من العقد مهمةً سهلةً، وإن فرضنا أننا نريد أن نعرف فيما إذا كانت القيمة x موجودةً في الشجرة عبر البحث عنها، نتبع الخوارزمية التالية: نبدأ بعقدة جذر الشجرة: إذا كانت الشجرة فارغة (لا تحتوي على عقد) إعادة القيمة "فشل البحث" إذا كانت القيمة التي نبحث عنها مساويةً إلى قيمة العقدة الحالية إعادة القيمة "نجاح البحث" إذا كانت القيمة في العقدة الحالية أكبر من القيمة التي نبحث عنها ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيسر فيما عدا ذلك، ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيمن إليك الخوارزمية بلغة سي: #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }tree[7]; /* * خوارزمية البحث ضمن الشجرة * تبحث عن القيمةفي الشجرة v * تُعيد مؤشر يشير إلى أول عقدة تحوي النتيجة * أو تُعيد القيمة 0 */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* لا يوجد أي شجرة متبقية ولم يُعثر على القيمة */ return(0); } main(){ /* بناء الشجرة يدويًا */ struct tree_node *tp, *root_p; int i; for(i = 0; i < 7; i++){ int j; j = i+1; tree[i].data = j; if(j == 2 || j == 6){ tree[i].left_p = &tree[i-1]; tree[i].right_p = &tree[i+1]; } } /* الجذر */ root_p = &tree[3]; root_p->left_p = &tree[1]; root_p->right_p = &tree[5]; /* حاول أن تبحث */ tp = t_search(root_p, 9); if(tp) printf("found at position %d\n", tp-tree); else printf("value not found\n"); exit(EXIT_SUCCESS); } مثال 8 يعمل المثال السابق بنجاح دون أخطاء، ومن الجدير بالذكر أنه يمكننا استخدام ذلك في جعل أي قيمة مدخلة إلى الشجرة تُخزن في مكانها الصحيح باستخدام خوارزمية البحث ذاتها، أي بإضافة شيفرة برمجية إضافية تحجز مساحة لقيمة جديدة باستخدام دالة malloc عندما لا تجد الخوارزمية القيمة، وتُضاف العقدة الجديدة في مكان مؤشر الفراغ null pointer الأول. من المعقد تحقيق ما سبق، وذلك بسبب مشكلة التعامل مع مؤشر العقدة الجذر، ونلجأ في هذه الحالة إلى مؤشر يشير إلى مؤشر آخر. اقرأ المثال التالي بانتباه، إذ أنه أحد أكثر الأمثلة تعقيدًا حتى اللحظة، وإذا استطعت فهمه فهذا يعني أنك تستطيع فهم الأغلبية الساحقة من برامج سي. #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }; /* * خوارزمية البحث ضمن شجرة * ابحث عن القيمة v ضمن الشجرة * أعد مؤشرًا إلى أول عقدة تحتوي على القيمة هذه * أعد القيمة 0 إن لم تجد نتيجة */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ printf("looking for %d, looking at %d\n", v, root->data); if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* value not found, no tree left */ return(0); } /* * أدخل عقدة ضمن شجرة * أعد 0 عند نجاح العملية أو * أعد 1 إن كانت القيمة موجودة في الشجرة * أعد 2 إن حصل خطأ في عملية حجز الذاكرة malloc error */ int t_insert(struct tree_node **root, int v){ while(*root){ if((*root)->data == v) return(1); if((*root)->data > v) root = &((*root)->left_p); else root = &((*root)->right_p); } /* value not found, no tree left */ if((*root = (struct tree_node *) malloc(sizeof (struct tree_node))) == 0) return(2); (*root)->data = v; (*root)->left_p = 0; (*root)->right_p = 0; return(0); } main(){ /* construct tree by hand */ struct tree_node *tp, *root_p = 0; int i; /* we ingore the return value of t_insert */ t_insert(&root_p, 4); t_insert(&root_p, 2); t_insert(&root_p, 6); t_insert(&root_p, 1); t_insert(&root_p, 3); t_insert(&root_p, 5); t_insert(&root_p, 7); /* try the search */ for(i = 1; i < 9; i++){ tp = t_search(root_p, i); if(tp) printf("%d found\n", i); else printf("%d not found\n", i); } exit(EXIT_SUCCESS); } مثال 9 تسمح لك الخوارزمية التالية بالمرور على الشجرة وزيارة جميع العُقد بالترتيب باستخدام التعاودية recursion، وهي أحد أكثر الأمثلة أناقةً، انظر إليها وحاول فهمها. void t_walk(struct tree_node *root_p){ if(root_p == 0) return; t_walk(root_p->left_p); printf("%d\n", root_p->data); t_walk(root_p->right_p); } مثال 10 ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C المقال السابق: التعامل مع المؤشرات Pointers في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى
اتجه تطوير لغات الحاسوب سابقًا في اتجاهٍ من اتجاهين، إذ سلكت كوبول COBOL سلوكًا ركز على استخدام هياكل البيانات بعيدًا عن العمليات الحسابية والخوارزميات، بينما سلكت لغات مثل فورتران FORTRAN وألغول Algol سلوكًا معاكسًا. أراد العلماء وقتها إجراء العمليات الحسابية باستخدام بيانات غير مُهيكلة نسبيًا، إلا أنه سرعان ما لاحظ الجميع أن استخدام المصفوفات لا غنى عنه؛ بينما أراد المستخدمون الاعتياديون طريقةً لإجراء العمليات الحسابية البسيطة فقط، إلا أن طريقة هيكلة البيانات كانت عائقًا أمام تحقيق ذلك. أثر كلا السلوكين في تصميم لغة سي، إذ أنها تحتوي تحكمًا هيكليًا لتدفق البرنامج مناسب للغة من هذا العمر، كما أنها جعلت من مفهوم هياكل البيانات شائعًا. ركزنا على جانب الخوارزميات من اللغة حتى اللحظة، ولم نولي الكثير من الانتباه بخصوص تخزين البيانات، ومع أننا تطرقنا إلى المصفوفات التي تُعدّ هيكل بيانات إلا أنها شائعة الاستخدام وبسيطة ولا تستحق فصلًا مخصصًا لها، واكتفينا إلى الآن بالنظر إلى اللغة انطلاقًا من بينة هيكلية شبيهة بلغة فورتران. كان استخدام كلٍ من البيانات والخوارزميات هو التوجه الأكثر رواجًا في أواخر ثمانينيات وبداية تسعينيات القرن الماضي، وفق ما يُدعى بالبرمجة كائنية التوجه Object-Oriented Programming. لا يوجد أي دعم لهذه الطريقة في لغة سي، إلا أن لغة C++ قدمت دعمًا لها (وهي لغةٌ مبنيةٌ على لغة سي)، ولكن هذا النقاش خارج موضوعنا حاليًا. تأخذ البيانات الانتباه الأكبر لمعظم مشاكل الحوسبة المتقدمة وليس الخوارزميات، فستكون مهمتك بسيطةً ببرمجة البرنامج إن استطعت تصميم هياكل بيانات صحيحة ومناسبة، إلا أنك تحتاج إلى دعمٍ من اللغة في هذه الحالة، فمهمتك ستصبح أقل سهولة ومعرضةً أكثر للأخطاء إن لم يكن هناك أي دعم لأنواع هياكل البيانات المختلفة عن المصفوفات. تقع هذه المهمة على كاهل لغة البرمجة، فليس كافيًا أن تسمح لك اللغة بفعل ما تريد، بل يجب أن تساعدك في فعل ما تريد. تقدم لك لغة سي سعيًا منها بتقديم هياكل بيانات مناسبة كلًا من المصفوفات Arrays والهياكل Structures والاتحادات Unions، وقد برهنت على أنها كافيةٌ لمعظم المستخدمين الاعتياديين وبالتالي لم يُضِف المعيار أي جديد بشأنها. الهياكل Structures تسمح لك المصفوفات بتخزين مجموعة من الكائنات المتماثلة تحت اسم معين، وهذا مفيدٌ لعدد من المهام، ولكنه ليس مرن التعامل، إذ تحتوي معظم كائنات البيانات ذات التطبيقات الواقعية على هيكل معيّن معقد لا يمكن استخدامه مع طريقة تخزين المصفوفة للبيانات. لنوضح ما سبق بالمثال التالي: لنفرض أننا نريد تمثيل سلسلةٍ نصية ذات خصائص معينة، بجانب محتواها. هناك نوع الخط وحجمه، وهما سمتان لا تؤثران في محتوى السلسلة، لكنهما تحددان الطريقة التي تُعرض فيها السلسلة على الشاشة سواءٌ كان النص مكتوبًا بخط غامق أو مائل، والأمر ذاته ينطبق على حجم الخط. كيف نستطيع تمثيل السلسلة النصية بكائن واحد ضمن مصفوفة إذا كان يحتوي على ثلاث سمات مختلفة؟ يمكننا تحقيق ذلك في لغة سي C بسهولة، حاول أولًا تمثيل السمات الثلاث باستخدام الأنواع الأساسية، فعلى فرض أنه يمكننا تخزين كل محرف باستخدام النوع char، يمكننا الإشارة إلى نوع الخط المستخدم باستخدام النوع short (نستخدم "1" للإشارة إلى الخط الاعتيادي و"2" للخط المائل و"3" للخط الغامق، وهكذا)، كما يمكننا تخزين حجم الخط باستخدام النوع short، وتُعد جميع الفرضيات السابقة معقولةً عمليًا، إذ تدعم معظم الأنظمة عددًا قليلًا من الخطوط مهما كانت هذه الأنظمة معقدة، ويتراوح حجم الخط بين 6 ومرتبة المئات القليلة، فأي خط أصغر من 6 هو صعب القراءة، والخط الأكبر من 50 هو خط أكبر من خطوط عناوين الجرائد. إذًا، لدينا الآن محرف وعددين صغيرين وتُعامل هذه البيانات معاملة كائن واحد، إليك كيف نصرّح عن ذلك في لغة سي: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }; يصرح ما سبق عن نوع جديد من الكائنات يمكنك استخدامه ضمن البرنامج، ويعتمد الأمر بصورةٍ رئيسية على ذكر الكلمة المفتاحية struct، المتبوعة بمعرّف identifier اختياري هو الوسم wp_char في هذه الحالة، ويسمح لنا هذا الوسم بتسمية النوع للإشارة إليه فيما بعد. يمكننا أيضًا استخدام الوسم بالطريقة التالية بعد التصريح عنه: struct wp_char x, y; يُعرّف ما سبق متغيرين باسم x و y، بالطريقة ذاتها للتعريف التالي: int x, y; لكن المتغيرات في المثال الأول من نوع struct wp_char عوضًا عن int في المثال الثاني، ويمثّل الوسم اسمًا للنوع الذي صرحنا عنه سابقًا. نذّكر هنا أنه من الممكن استخدام اسم وسم الهيكل مثل أي معرّف اعتيادي بصورةٍ آمنة، ويدل الاسم على معنًى مختلف عندما يُسبق بالكلمة المفتاحية struct فقط، ومن الشائع أن يُعرّف كائن مُهيكل باسم مماثل لوسم الهيكل الخاص به. struct wp_char wp_char; يُعرّف السطر السابق متغيرًا باسم wp_char من النوع struct wp_char، ويمكننا فعل ذلك لأن لوسوم الهياكل "فضاء اسماء name space" خاصة بها ولا تتعارض مع الأسماء الأخرى، وسنتكلم أكثر عن الوسوم عندما نناقش "الأنواع غير المكتملة incomplete types". يمكن التعريف عن المتغيرات على الفور عقب التصريح عن هيكل ما: struct wp_char{ char wp_cval; short wp_font; short wp_psize; }v1; struct wp_char v2; لدينا في هذه الحالة متغيرين، أحدهما باسم v1 والآخر باسم v2، وإذا استخدمنا الطريقة السابقة في التعريف عن v1، يصبح الوسم غير ضروري ويُتخلّى عنه غالبًا إلا في حال احتجنا إلى الوسم لاستخدامه مع عامل sizeof والتحويل بين الأنواع casts. يُعد المتغيران السابقان كائنات مُهيكلة، ويحتوي كل منهما على ثلاثة أعضاء members مستقلين عن بعضهم باسم wp_cval و wp_font و wp_psize، ونستخدم عامل النقطة . للوصول إلى كلّ من الأعضاء السابقة على النحو التالي: v1.wp_cval = 'x'; v1.wp_font = 1; v1.wp_psize = 10; v2 = v1; تُضبط أعضاء المتغير v1 في المثال السابق إلى قيمها المناسبة، ومن ثم تُنسخ قيم v1 إلى v2 باستخدام عملية الإسناد. في الحقيقة، العملية الوحيدة المسموحة في الهياكل بكاملها هي الإسناد؛ إذ يمكن إسناد الهياكل إلى بعضها بعضًا أو تمريرها مثل وسطاء للدوال أو قيمةٍ تُعيدها دالةٌ ما، إلا أن نسخ الهياكل عمليةٌ غير فعالة وتتفاداها معظم البرامج عن طريق التلاعب بالمؤشرات التي تشير إلى الهياكل عوضًا عن ذلك، إذ من الأسرع عمومًا نسخ المؤشرات عوضًا عن الهياكل. تسمح اللغة بمقارنة الهياكل بحثًا عن المساواة فيما بينها، وهي سهوة مفاجئة ولا يوجد سبب مقنع لسماحها بذلك كما سنذكر قريبًا. إليك مثالًا يستخدم مصفوفةً من الهياكل، وهو الهيكل ذاته الذي تكلمنا عنه سابقًا، إذ تُستخدم دالةٌ لقراءة المحارف من دخل البرنامج القياسي وتُعيد هيكلًا مهيّأً بقيمٍ مناسبة مقابله، ومن ثم تُرتّب الهياكل بحسب قيمة كل محرف وتُطبع وذلك عندما يُقرأ محرف سطر جديد، أو عندما تمتلئ المصفوفة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; /* نوع دخل الدالة الذي كان من الممكن التصريح عنه سابقًا، وتعيد الدالة هيكلًا ولا تأخذ أي وسطاء */ struct wp_char infun(void); main(){ int icount, lo_indx, hi_indx; for(icount = 0; icount < ARSIZE; icount++){ ar[icount] = infun(); if(ar[icount].wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة icount * مع تجاهل \n */ break; } } /* نجري الآن عملية الترتيب */ for(lo_indx = 0; lo_indx <= icount-2; lo_indx++) for(hi_indx = lo_indx+1; hi_indx <= icount-1; hi_indx++){ if(ar[lo_indx].wp_cval > ar[hi_indx].wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = ar[lo_indx]; ar[lo_indx] = ar[hi_indx]; ar[hi_indx] = wp_tmp; } } /* طباعة القيم */ for(lo_indx = 0; lo_indx < icount; lo_indx++){ printf("%c %d %d\n", ar[lo_indx].wp_cval, ar[lo_indx].wp_font, ar[lo_indx].wp_psize); } exit(EXIT_SUCCESS); } struct wp_char infun(void){ struct wp_char wp_char; wp_char.wp_cval = getchar(); wp_char.wp_font = 2; wp_char.wp_psize = 10; return(wp_char); } مثال 1 من الطبيعي أن نلجأ إلى التصريح عن مصفوفات من الهياكل حالما نستطيع ونتعلم كيفية التصريح عنها، وأن نستخدم هذه الهياكل عناصرًا لهياكل أخرى وما إلى ذلك، والقيد الوحيد هنا هو أنه لا يمكن للهيكل أن يحتوي مثالًا لنفسه على أنه عضو داخله (يصبح حينها حجمها موضع جدل مثير للفلاسفة، ولكنه غير مفيد لأي مبرمج سي C). المؤشرات والهياكل ذكرنا سابقًا أنه من الشائع استخدام المؤشرات في الهياكل بدلًا من استخدام الهياكل مباشرةً، لنتعلم كيفية تحقيق ذلك إذَا. يُعد التصريح عن المؤشرات سهلًا، ونعتقد أنك أتقنته: struct wp_char *wp_p; يمنحنا التصريح السابق مؤشرًا مباشرةً، ولكن كيف يمكننا الوصول إلى أعضاء الهيكل؟ تتمثل إحدى الطرق باستخدام المؤشر الذي يشير إلى الهيكل، ثم اختيار العضو على النحو التالي: /* نحصل على الهيكل ومن ثم نحدد العضو*/ (*wp_p).wp_cval نستخدم الأقواس لأن أسبقية عامل النقطة . أعلى من *، إلا أن الطريقة السابقة غير سهلة التعامل وقدمت لغة سي نتيجة لذلك عاملًا جديدًا لجعل التعليمة أنيقة ويُعرف باسم العامل "المُشير إلى pointing-to"، إليك مثالًا عن استخدامه: // العضو الذي يشير إليه المؤشر wp_p في الهيكل wp_cval wp_p->wp_cval = 'x'; ومع أن مظهره غير مثالي، إلا أنه مفيد جدًا في حال احتواء هيكل ما على المؤشرات، مثل القوائم المترابطة Linked list، إذ أن استخدام الطريقة السابقة أسهل بكثير إن أردت تتبع مرحلة أو مرحلتين من الروابط ضمن قائمة مترابطة. إذا لم تصادف القوائم المترابطة بعد، فلا تقلق، إذ سنتطرق إليها لاحقًا. إذا كان الكائن على يسار العامل . أو <- نوعًا مؤهّلًا qualified type (باستخدام الكلمة المفتاحية const أو volatile)، فستكون النتيجة أيضًا معرفةً حسب هذه المؤهلات qualifiers. إليك مثالًا عن ذلك باستخدام المؤشرات؛ فعندما يشير المؤشر إلى نوع مؤهل، تكون النتيجة من نوع مؤهل أيضًا. #include <stdio.h> #include <stdlib.h> struct somestruct{ int i; }; main(){ struct somestruct *ssp, s_item; const struct somestruct *cssp; s_item.i = 1; /* مسموح */ ssp = &s_item; ssp->i += 2; /* مسموح */ cssp = &s_item; cssp->i = 0; /*يشير إلى كائن ثابت cssp غير مسموح لأن المؤشر */ exit(EXIT_SUCCESS); } يبدو أن بعض مبرمجي المصرّفات نسوا هذا المتطلب، إذ استخدمنا مصرفًا لتجربة المثال السابق ولم يحذرنا بخصوص الإسناد الأخير الذي خرق القيد. إليك المثال 1 مكتوبًا باستخدام المؤشرات، وبتغيير دالة الدخل infun بحيث تقبل مؤشرًا يشير إلى هيكل بدلًا من إعادة مؤشر، وهذا ما ستراه على الأغلب عندما تنظر إلى بعض البرامج العملية. نتخلى عن نسخ الهياكل في البرامج إن أردنا زيادة فاعلية تنفيذها ونستخدم بدلًا من ذلك مصفوفات تحتوي على مؤشرات؛ إذ تُستخدم هذه المؤشرات للحصول على البيانات المخزنة، إلا أن هذه الطريقة ستزيد من تعقيد الأمور، ولا تستحق العناء في التطبيقات البسيطة. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; void infun(struct wp_char *); main(){ struct wp_char wp_tmp, *lo_indx, *hi_indx, *in_p; for(in_p = ar; in_p < &ar[ARSIZE]; in_p++){ infun(in_p); if(in_p->wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة in_p * مع تجاهل \n */ break; } } /* * نبدأ بترتيب القيم * علينا الحرص هنا وتجنب حالة طفحان * لذا نتفقد دائمًا وجود قيمتين لترتيبهما */ if(in_p-ar > 1) for(lo_indx = ar; lo_indx <= in_p-2; lo_indx++){ for(hi_indx = lo_indx+1; hi_indx <= in_p-1; hi_indx++){ if(lo_indx->wp_cval > hi_indx->wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = *lo_indx; *lo_indx = *hi_indx; *hi_indx = wp_tmp; } } } /* طباعة القيم */ for(lo_indx = ar; lo_indx < in_p; lo_indx++){ printf("%c %d %d\n", lo_indx->wp_cval, lo_indx->wp_font, lo_indx->wp_psize); } exit(EXIT_SUCCESS); } void infun( struct wp_char *inp){ inp->wp_cval = getchar(); inp->wp_font = 2; inp->wp_psize = 10; return; } مثال 2 هناك مشكلةٌ أخرى يجب النظر إليها، ألا وهي كيف سيبدو الهيكل عند تخزينه في الذاكرة؟ إلا أننا لن نقلق بهذا الخصوص كثيرًا في الوقت الحالي، ولكن من المفيد أن تستخدم في بعض الأحيان هياكل لغة سي C مكتوبة بواسطة برامج أخرى. تُحجز المساحة للهيكل wp_char كما هو موضح على النحو التالي: شكل 1 مخطط تخزين الهيكل يفترض الشكل بعض الأشياء مسبقًا: يأخذ المتغير من نوع char بايتًا واحدًا من الذاكرة، بينما يأخذ short 2 بايت من الذاكرة، وأن لجميع المتغيرات من نوع short عنوانًا زوجيًا على هذه المعمارية، ونتيجةً لما سبق يبقى عضو واحد بحجم 1 بايت ضمن الهيكل دون تسمية مُدخل من المصرف وذلك لأغراض تتعلق بمعمارية الذاكرة. القيود السابقة شائعة الوجود وتتسبب غالبًا بما يسمى هياكل ذات "ثقوب holes". تضمن لغة سي المعيارية بعض الأمور بخصوص تنسيق الهياكل والاتحادات: تُحجز الذاكرة لكلٍ من أعضاء الهياكل بحسب الترتيب التي ظهرت بها هذه الأعضاء ضمن التصريح عن الهيكل وبترتيبٍ تصاعدي للعناوين. لا يجب أن يكون هناك أي حشو padding في الذاكرة أمام العضو الأول. يماثل عنوان الهيكل عنوان العضو الأول له، وذلك بفرض استخدام تحويل الأنواع casting المناسب، وبالنظر إلى التصريح السابق للهيكل wp_char فإن التالي محقق: (char *)item == &item.wp_cval. ليس لحقول البتات bit fields (سنذكرها لاحقًا) أي عناوين، فهي محزّمةٌ تقنيًا إلى وحدات units وتنطبق عليها القوانين السابقة. القوائم المترابطة وهياكل أخرى يفتح استخدام الهياكل مع المؤشرات الباب لكثيرٍ من الإمكانات. لسنا بصدد تقديم شرح مفصل ومعقد عن هياكل البيانات المترابطة هنا، ولكننا سنشرح مثالين شائعين جدًا من هذه الطبيعة، ألا وهما القوائم المترابطة Linked lists والأشجار Trees، ويجمع بين الهيكلين السابقين استخدام المؤشرات بداخلهما تشير إلى هياكل أخرى، وتكون الهياكل الأخرى عادةً من النوع ذاته. يوضح الشكل 2 طبيعة القائمة المترابطة. شكل 2 قائمة مترابطة باستخدام المؤشرات نحتاج للحصول على ما سبق إلى لتصريح عنه بما يوافق التالي: struct list_ele{ int data; /* تستطيع تسمية العضو بأي اسم*/ struct list_ele *ele_p; }; يبدو للوهلة الأولى أن الهيكل يحتوي نفسه (وهو ممنوع) ولكن يحتوي الهيكل في حقيقة الأمر مؤشرًا يشير إلى نفسه فقط، لكن لمَ يُعد التصريح عن المؤشر بالشكل السابق مسموحًا؟ يعلم المصرف بحلول وصوله إلى تلك النقطة بوجود struct list_ele، ولهذا السبب يكون التصريح مسموح، ومن الممكن أيضًا كتابة تصريح غير مكتمل للهيكل على النحو التالي قبل التصريح الكامل: struct list_ele; يصرح التصريح السابق عن نوع غير مكتمل incomplete type، سيسمح بالتصريح عن المؤشرات قبل التصريح الكامل، يفيد ذلك أيضًا في حال وجود حالة للإشارة إلى هياكل فيما بينها التي يجب أن تحتوي مؤشرًا لكل منها كما هو موضح في المثال. struct s_1; /* نوع غير مكتمل */ struct s_2{ int something; struct s_1 *sp; }; struct s_1{ /* التصريح الكامل */ float something; struct s_2 *sp; }; مثال 3 يوضح المثال السابق حاجتنا للأنواع غير المكتملة، كما يوضح خاصيةً مهمةً لأسماء أعضاء الهيكل إذ يشكّل كل هيكل فضاء أسماء name space خاصٍ به، ويمكن بذلك أن تتماثل أسماء عناصر من هياكل مختلفة دون أي مشاكل. تُستخدم الأنواع غير المكتملة فقط في حال لم نكن بحاجة استخدام حجم الهيكل، وإلا فيجب التصريح كاملًا عن الهيكل قبل استخدام حجمه، ولا يجب أن يكون هذا التصريح بداخل كتلة برمجية داخلية وإلا سيصبح تصريحًا جديدًا لهيكل مختلف. struct x; /* نوع غير مكتمل */ /* استخدام مسموح للوسوم */ struct x *p, func(void); void f1(void){ struct x{int i;}; /* إعادة تصريح */ } /* التصريح الكامل */ struct x{ float f; }s_x; void f2(void){ /* تعليمات صالحة */ p = &s_x; *p = func(); s_x = func(); } struct x func(void){ struct x tmp; tmp.f = 0; return (tmp); } مثال 4 يجدر الانتباه إلى أنك تحصل على هيكل من نوع غير مكتمل فقط عن طريق ذكر اسمه، وبناءً على ما سبق، تعمل الشيفرة التالية دون مشاكل: struct abc{ struct xyz *p;}; /* struct xyz تصريح النوع غير المكتمل */ struct xyz{ struct abc *p;}; /* أصبح النوع غير المكتمل مكتملًا */ هناك خطرٌ كبير في المثال السابق، كما هو موضح هنا: struct xyz{float x;} var1; main(){ struct abc{ struct xyz *p;} var2; /* struct xyz إعادة تصريح للهيكل */ struct xyz{ struct abc *p;} var3; } نتيجةً لما سبق، يمكن للمتغير var2.p أن يخزن عنوان var1، وليس عنوان var3 قطعًا الذي هو من نوع مختلف. يمكن تصحيح ما سبق (بفرض أنك لم تتعمد فعله) على النحو التالي: struct xyz{float x;} var1; main(){ struct xyz; /* نوع جديد غير مكتمل */ struct abc{ struct xyz *p;} var2; struct xyz{ struct abc *p;} var3; } يُستكمل نوع الهيكل أو الاتحاد عند الوصول إلى قوس الإغلاق {، ويجب أن يحتوي عضوًا واحدًا على الأقل أو نحصل على سلوك غير محدد. نستطيع الحصول على أنواع غير مكتملة عن طريق تصريح مصفوفة دون تحديد حجمها، ويصنف النوع على أنه غير مكتمل حتى يقدم تصريحًا آخرًا حجمها: int ar[]; /* نوع غير مكتمل */ int ar[5]; /* نكمل النوع هنا */ سيعمل المثال السابق إن جربته فقط في حال كانت التصريحات خارج أي كتلة برمجية (تصريحات خارجية)، إلا أن السبب في ذلك ليس متعلقًا بموضوعنا. بالعودة إلى مثال القوائم المترابطة، كان لدينا ثلاث عناصر مترابطة في القائمة، التي يمكن بناؤها على النحو التالي: struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ return(0); } مثال 5 يمكننا طباعة محتويات القائمة بطريقتين، إما بالمرور على المصفوفة بحسب دليلها index، أو باستخدام المؤشرات كما سنوضح في المثال التالي: #include <stdio.h> #include <stdlib.h> struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ struct list_ele *lp; ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ /* اتباع المؤشرات */ lp = ar; while(lp){ printf("contents %d\n", lp->data); lp = lp->pointer; } exit(EXIT_SUCCESS); } مثال 6 الطريقة التي تُستخدم فيها المؤشرات في المثال السابق مثيرةٌ للاهتمام، لاحظ كيف أن المؤشر الذي يشير إلى عنصر ما يُستخدم للإشارة إلى العنصر الذي يليه حتى إيجاد المؤشر ذو القيمة 0، مما يتسبب بتوقف حلقة while التكرارية. يمكن ترتيب المؤشرات بأي طريقة وهذا ما يجعل القائمة هيكلًا مرن التعامل. إليك دالةً يمكن تضمينها مثل جزء من برنامجنا السابق بهدف ترتيب القائمة المترابطة بحسب قيمة بياناتها العددية، وذلك عن طريق إعادة ترتيب المؤشرات حتى الوصول إلى عناصر القائمة عند المرور عليها بالترتيب. من المهم أن نشير هنا إلى أن البيانات لا تُنسخ، إذ تعيد الدالة مؤشرًا إلى بداية القائمة لأن بدايتها لا تساوي إلى التعبير ar[0] بالضرورة. struct list_ele * sortfun( struct list_ele *list ) { int exchange; struct list_ele *nextp, *thisp, dummy; /* * الخوارزمية على النحو التالي: * البحث عبر القائمة بصورةٍ متكررة * إذا وجد عنصرين خارج الترتيب * اِربطهما بصورةٍ معاكسة * توقف عند المرور بجميع عناصر القائمة * دون أي تبديل مطلوب * يحدث الخلط عند العمل على العنصر خلف العنصر الأول المثير للاهتمام * وهذا بسبب الآليات البسيطة المتعلقة بربط العناصر وإلغاء ربطها */ dummy.pointer = list; do{ exchange = 0; thisp = &dummy; while( (nextp = thisp->pointer) && nextp->pointer){ if(nextp->data < nextp->pointer->data){ /* exchange */ exchange = 1; thisp->pointer = nextp->pointer; nextp->pointer = thisp->pointer->pointer; thisp->pointer->pointer = nextp; } thisp = thisp->pointer; } }while(exchange); return(dummy.pointer); } مثال 7 ستلاحظ استخدام تعابير مشابهة للتعبير thisp->pointer->pointer عند التعامل مع القوائم، وبالتالي يجب أن تفهم هذه التعابير، وهي بسيطة إذ يدل شكلها على الروابط المتبعة. الأشجار تُعد الأشجار هيكل بيانات شائع أيضًا، وهي في حقيقة الأمر قائمةٌ مترابطةٌ ذات فروع، والنوع الأكثر شيوعًا هو الشجرة الثنائية binary tree، التي تحتوي على عناصر تُدعى العقد "nodes" كما يلي: struct tree_node{ int data; struct tree_node *left_p, *right_p; }; تعمل الأشجار في علوم الحاسوب من الأعلى إلى الأسفل (لأسباب تاريخية لن نناقشها)، إذ توجد عقدة الجذر root أعلى الشجرة وتتفرع فروع هذه الشجرة في الأسفل. تُستبدل بيانات أعضاء الهيكل الخاصة بالعقد بقيمها في الشكل التالي والتي سنستخدمها لاحقًا. شكل 3 شجرة لن تجذب الأشجار انتباهك إذا كان اهتمامك الرئيس هو التعامل مع المحارف والتلاعب بها، ولكنها مهمة جدًا بالنسبة لمصمّمي كل من قواعد البيانات والمصرّفات والأدوات المعقدة الأخرى. تتميز الأشجار بميزة خاصة جدًا ألا وهي أنها مرتبة، فيمكن أن تدعم بكل سهولة خوارزميات البحث الثنائي، ومن الممكن دائمًا إضافة مزيدٍ من العقد الجديدة إلى الشجرة في الأماكن المناسبة، فالشجرة هيكل بيانات مفيدٌ ومرن. بالنظر إلى الشكل السابق، نلاحظ أن الشجرة مبنيّةٌ بحرص حتى تكون مهمة البحث عن قيمة ما في حقول البيانات من العقد مهمةً سهلةً، وإن فرضنا أننا نريد أن نعرف فيما إذا كانت القيمة x موجودةً في الشجرة عبر البحث عنها، نتبع الخوارزمية التالية: نبدأ بعقدة جذر الشجرة: إذا كانت الشجرة فارغة (لا تحتوي على عقد) إعادة القيمة "فشل البحث" إذا كانت القيمة التي نبحث عنها مساويةً إلى قيمة العقدة الحالية إعادة القيمة "نجاح البحث" إذا كانت القيمة في العقدة الحالية أكبر من القيمة التي نبحث عنها ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيسر فيما عدا ذلك، ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيمن إليك الخوارزمية بلغة سي: #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }tree[7]; /* * خوارزمية البحث ضمن الشجرة * تبحث عن القيمةفي الشجرة v * تُعيد مؤشر يشير إلى أول عقدة تحوي النتيجة * أو تُعيد القيمة 0 */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* لا يوجد أي شجرة متبقية ولم يُعثر على القيمة */ return(0); } main(){ /* بناء الشجرة يدويًا */ struct tree_node *tp, *root_p; int i; for(i = 0; i < 7; i++){ int j; j = i+1; tree[i].data = j; if(j == 2 || j == 6){ tree[i].left_p = &tree[i-1]; tree[i].right_p = &tree[i+1]; } } /* الجذر */ root_p = &tree[3]; root_p->left_p = &tree[1]; root_p->right_p = &tree[5]; /* حاول أن تبحث */ tp = t_search(root_p, 9); if(tp) printf("found at position %d\n", tp-tree); else printf("value not found\n"); exit(EXIT_SUCCESS); } مثال 8 يعمل المثال السابق بنجاح دون أخطاء، ومن الجدير بالذكر أنه يمكننا استخدام ذلك في جعل أي قيمة مدخلة إلى الشجرة تُخزن في مكانها الصحيح باستخدام خوارزمية البحث ذاتها، أي بإضافة شيفرة برمجية إضافية تحجز مساحة لقيمة جديدة باستخدام دالة malloc عندما لا تجد الخوارزمية القيمة، وتُضاف العقدة الجديدة في مكان مؤشر الفراغ null pointer الأول. من المعقد تحقيق ما سبق، وذلك بسبب مشكلة التعامل مع مؤشر العقدة الجذر، ونلجأ في هذه الحالة إلى مؤشر يشير إلى مؤشر آخر. اقرأ المثال التالي بانتباه، إذ أنه أحد أكثر الأمثلة تعقيدًا حتى اللحظة، وإذا استطعت فهمه فهذا يعني أنك تستطيع فهم الأغلبية الساحقة من برامج سي. #include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }; /* * خوارزمية البحث ضمن شجرة * ابحث عن القيمة v ضمن الشجرة * أعد مؤشرًا إلى أول عقدة تحتوي على القيمة هذه * أعد القيمة 0 إن لم تجد نتيجة */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ printf("looking for %d, looking at %d\n", v, root->data); if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* value not found, no tree left */ return(0); } /* * أدخل عقدة ضمن شجرة * أعد 0 عند نجاح العملية أو * أعد 1 إن كانت القيمة موجودة في الشجرة * أعد 2 إن حصل خطأ في عملية حجز الذاكرة malloc error */ int t_insert(struct tree_node **root, int v){ while(*root){ if((*root)->data == v) return(1); if((*root)->data > v) root = &((*root)->left_p); else root = &((*root)->right_p); } /* value not found, no tree left */ if((*root = (struct tree_node *) malloc(sizeof (struct tree_node))) == 0) return(2); (*root)->data = v; (*root)->left_p = 0; (*root)->right_p = 0; return(0); } main(){ /* construct tree by hand */ struct tree_node *tp, *root_p = 0; int i; /* we ingore the return value of t_insert */ t_insert(&root_p, 4); t_insert(&root_p, 2); t_insert(&root_p, 6); t_insert(&root_p, 1); t_insert(&root_p, 3); t_insert(&root_p, 5); t_insert(&root_p, 7); /* try the search */ for(i = 1; i < 9; i++){ tp = t_search(root_p, i); if(tp) printf("%d found\n", i); else printf("%d not found\n", i); } exit(EXIT_SUCCESS); } مثال 9 تسمح لك الخوارزمية التالية بالمرور على الشجرة وزيارة جميع العُقد بالترتيب باستخدام التعاودية recursion، وهي أحد أكثر الأمثلة أناقةً، انظر إليها وحاول فهمها. void t_walk(struct tree_node *root_p){ if(root_p == 0) return; t_walk(root_p->left_p); printf("%d\n", root_p->data); t_walk(root_p->right_p); } مثال 10 ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C المقال السابق: التعامل مع المؤشرات Pointers في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى -
 تكلّمنا سابقًا عن الدخل والخرج في لغة سي بالاستعانة بالمكتبات القياسية، وحان الوقت لنتعلم الآن مختلف الدوال الموجودة في هذه المكتبات التي تضمن لنا أساليب مختلفة في القراءة والكتابة. الدخل والخرج المنسق هناك عدد من الدوال المُستخدمة لتنسيق الدخل والخرج، وتحدد كلًا من هذه الدوال التنسيق المتبع للدخل والخرج باستخدام سلسلة التنسيق النصية format string، وتتألف سلسلة التنسيق النصية في حالة الخرج من نص عادي plain text يمثّل الخرج كما هو، إضافةً إلى مواصفات التنسيق format specifications التي تتطلب معالجة خاصة لواحد من الوسطاء المتبقية في الدالة، بينما تتألف سلسلة التنسيق النصية في حالة الخرج من نص عادي يطابق مجرى الدخل وتحدد هنا مواصفات التنسيق معنى الوسطاء المتبقية. يُشار إلى كل واحدة من مواصفات التنسيق باستخدام المحرف "%" متبوعًا ببقية التوصيف. الخرج: دوال printf تتخذ مواصفات التنسيق في دوال الخرج الشكل التالي، ونشير إلى الأجزاء الاختيارية بوضعها بين قوسين: %<flags><field width><precision><length>conversion نشرح معنى كل من الراية flag وعرض الحقل field width والدقة precision والطول length والتحويل conversion أدناه، إلا أنه من الأفضل النظر إلى وصف المعيار إذا أردت وصفًا مطولًا ودقيقًا. الرايات يمكن ألا تأخذ الرايات أي قيمة أو أن تأخذ أحد القيم التالية: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } قيمة الراية الشرح - ملئ سطر التحويل من اليسار ضمن حقوله. + يبدأ التحويل ذو الإشارة بإشارة زائد أو ناقص دائمًا. مسافة فارغة space إذا كان المحرف الأول من تحويل ذو إشارة ليس بإشارة، أضف مسافةً فارغة، ويمكن تجاوز الراية باستخدام "+" إذا وجدت. # يُجبر استخدام تنسيق مختلف للخرج، مثل: الخانة الأولى لأي تحويل ثماني لها القيمة "0"، وإضافة "0x" أمام أي تحويل ست عشري لا تساوي قيمته الصفر، ويُجبِر الفاصلة العشرية في جميع تحويلات الفاصلة العائمة حتى إن لم تكن ضرورية، ولا يُزيل أي صفر لاحق من تحويلات g و G. 0 يُضيف إلى تحويلات d و i و o و u و x و X و e و E و f و F و G أصفارًا إلى يسارها بملئ عرض الحقل، ويمكن تجاوزه باستخدام الراية "-"، وتُتجاهل الراية إذا كان هناك أي دقة محددة لتحويلات d، أو i، أو o، أو u، أو x، أو X، ونحصل على سلوك غير معرف للتعريفات الأخرى. عرض الحقل field width عدد صحيح عشري يحدد عرض حقل الخرج الأدنى ويمكن تجاوزه إن لزم الأمر، يُحوّل الوسيط التالي إلى عدد صحيح ويُستخدم مثل قيمة لعرض الحقل إن استُخدمت علامة النجمة "*"، وتُعامل هذه القيمة إذا كانت سالبة كأنها راية "-" متبوعة بعرض حقل ذي قيمة موجبة. يُملأ الخرج ذو الطول الأقصر من عرض الحقل بالمسافات الفارغة (أو بأصفار إذا كان العدد الصحيح المعبر عن عرض الحقل يبدأ بالصفر)، ويُملأ الخرج من الجهة اليسرى إلا إذا حُدّدَت راية تعديل اليسار left-adjustment. الدقة precision تبدأ قيمة الدقة بالنقطة '.'، وهي تحدد عدد الخانات الدنيا لتحويلات d، أو i، أو o، أو u، أو x، أو X، أو عدد الخانات التي تلي الفاصلة العشرية في تحويلات e، أو E، أو f، أو العدد الأعظمي لخانات تحويلات g وG، أو عدد المحارف المطبوعة من سلسلة نصية في تحويلات s. يتسبب تحديد كمية حشو الحقل padding بتجاهل قيمة field width. يُحوَّل الوسيط التالي في حال استخدامنا لعلامة النجمة "*" إلى عدد صحيح ويُستخدم بمثابة قيمة لعرض الحقل، وتعامل القيمة كأنها مفقودة إذا كانت سالبة، وتكون الدقة صفر إذا وجدت النقطة فقط. الطول length وهي h تسبق محدد specifier لطباعة نوع عدد صحيح integral ويتسبب ذلك في معاملتها وكأنها من النوع "short" (لاحظ أن الأنواع المختلفة القصيرة shorts تُرقّى إلى واحدة من أنواع القيم الصحيحة int عندما تُمرّر مثل وسيط). تعمل l مثل عمل h إلا أنها تُطبّق على وسيط عدد صحيح من نوع "long"، وتُستخدم L للدلالة على أنه يجب طباعة وسيط من نوع "long double"، ويطبَّق ذلك فقط على محددات الفاصلة العائمة. يتسبب استخدام هذا في سلوك غير معرف إذا كانت باستخدام النوع الخاطئ من التحويلات. يوضح الجدول التالي أنواع التحويلات: المحدد التأثير الدقة الافتراضية d عدد عشري ذو إشارة 1 i عدد عشري ذو إشارة 1 u عدد عشري عديم الإشارة 1 o عدد ثماني عديم الإشارة 1 x عدد ست عشري عديم الإشارة من 0 إلى f 1 X عدد ست عشري عديم الإشارة من 0 إلى F 1 تحدد الدقة عدد خانات الأدنى المُستبدل بأصفار إن لزم الأمر، ونحصل على خرج دون أي محارف عند استخدام الدقة صفر لطباعة القيمة صفر f يطبع قيمة من النوع double بعدد خانات الدقة (المقربة) بعد الفاصلة العشرية. استخدم دقة بقيمة صفر للحد من الفاصلة العشرية، وإلا فستظهر خانة واحدة على الأقل بعد الفاصلة العشرية 6 e, E يطبع قيمة من نوع double بالتنسيق الأسي مُقرّبًا بخانة واحدة قبل الفاصلة العشرية، وعدد من الخانات يبلغ الدقة المحددة بعده، وتُلغى الفاصلة العشرية عند استخدام الدقة صفر، وللأس خانتان على الأقل تطبع بالشكل 1.23e15 في تنسيق e أو 1.23E15 في حالة التنسيق E 6 g, G تستخدم أسلوب التنسيق f، أو e (E مع G) بحسب الأس، ولا يُستخدم التنسيق f إذا كان الأس أصغر من "-4" أو أكبر أو يساوي الدقة. تُحدّ الأصفار التي تتبع القيمة وتُطبع الفاصلة العشرية فقط في حال وجود خانات تابعة. غير محدد c يُحوّل الوسيط من نوع عدد صحيح إلى محرف عديم الإشارة ويُطبع المحرف الناتج عن التحويل s تُطبع سلسلة نصية بطول خانات الدقة، ويجب إنهاء السلسلة النصية باستخدام NUL إذا لم تُحدّد الدقة أو كانت أكبر من طول السلسلة النصية لا نهائي p إظهار قيمة مؤشر من نوع (void *) بطريقة تعتمد على النظام n يجب أن يكون الوسيط مؤشرًا يشير إلى عدد صحيح، ويكون عدد محارف الخرج باستخدام هذا الاستدعاء مُسندًا إلى العدد الصحيح % علامة "%" _ [جدول 1 التحويلات] تجد وصف الدوال التي تستخدم هذه التنسيقات في الجدول التالي، وجميع الدوال المُستخدمة مُضمّنة في المكتبة <stdio.h>، إليك تصاريح هذه الدوال: #include <stdio.h> int fprintf(FILE *stream, const char *format, ...); int printf(const char *format, ...); int sprintf(char *s, const char *format, ...); #include <stdarg.h> // بالإضافة إلى stdio.h int vfprintf(FILE *stream, const char *format, va list arg); int vprintf(const char *format, va list arg); int vsprintf(char *s, const char *format, va list arg); الاسم الاستخدام fprintf نحصل على الخرج المنسق العام بواسطتها كما وصفنا سابقًا، ويكتب الخرج إلى الملف المُحدد باستخدام المجرى stream printf دالة مُطابقة لعمل الدالة fprintf إلا أن وسيطها الأول هو stdout sprintf دالة مُطابقة لعمل الدالة fprintf باستثناء أن خرجها لا يُكتب إلى ملف، بل يُكتب إلى مصفوفة محارف يُشار إليها باستخدام المؤشر s vfprintf خرج مُنسَّق مشابه لخرج الدالة fprintf إلا أن لائحة الوسطاء المتغيرة تُستبدل بالوسيط arg الذي يجب أن يُهيَّأ باستخدام va_start، ولا تُستدعى va_end باستخدام هذه الدالة vprintf مطابقة للدالة vfprintf باستثناء أن الوسيط الأول يساوي إلى stdout vsprintf خرج مُنسَّق مشابه لخرج الدالة sprintf إلا أن لائحة الوسطاء المتغيرة تُستبدل بالوسيط arg الذي يجب أن يُهيَّأ باستخدام va_start، ولا تُستدعى va_end باستخدام هذه الدالة [جدول 2 الدوال التي تطبع خرجًا مُنسَّقًا] تُعيد كل الدوال السابقة عدد المحارف المطبوعة أو قيمة سالبة للدلالة على حصول خطأ، ولا يُحسب المحرف الفارغ الزائد بواسطة دالة sprintf و vsprintf. يجب أن تسمح التنفيذات بالحصول على 509 محارف على الأقل عند استخدام أي تحويل. الدخل: دوال scanf هناك عدة دوال مشابهة لمجموعة دوال printf بهدف الحصول على الدخل، والفارق الواضح بين مجموعتي الدوال هذه هو أن مجموعة دوال scanf تأخذ وسيطًا متمثلًا بمؤشر حتى تُسند القيم المقروءة إلى وجهتها المناسبة، ويُعد نسيان تمرير المؤشر خطأ شائع الحدوث ولا يمكن للمصرّف أن يكتشف حدوثه، إذ يمنع استخدام لائحة وسطاء متغيرة من ذلك. تُستخدم سلسلة التنسيق النصية للتحكم بتفسير المجرى للبيانات المُدخلة التي تحتوي غالبًا على قيم تُسند إلى كائنات يُشار إليها باستخدام وسطاء دالة scanf المتبقية، وقد تتألف سلسلة التنسيق النصية من: مساحة فارغة white space: تتسبب بقراءة مجرى الدخل إلى المحرف التالي الذي لا يمثّل محرف مسافة فارغة. محرف اعتيادي ordinary character: ويمثل المحرف أي محرف عدا محارف السلسلة الفارغة أو "%"، ويجب أن يطابق المحرف التالي في مجرى الدخل هذا المحرف المُحدّد. توصيف التحويل conversion specification: وهو محرف "%" متبوع بمحرف "*" اختياري (الذي يكبح التحويل)، ويُتبع بعدد عشري صحيح لا يساوي الصفر يحدد عرض الحقل الأعظمي، ومحرف "h"، أو "l"، أو "L" اختياري للتحكم بطول التحويل، وأخيرًا محدد تحويل إجباري. لاحظ أن استخدام "h"، أو "l"، أو "L" سيؤثر على على نوع المؤشر الواجب استخدامه. حقل الدخل -باستثناء المحددات "c" و "n" و "]"- هو سلسلة من المحارف التي لا تمثل مسافة فارغة وتبدأ من أول محرف في الدخل (بشرط ألا يكون المحرف مسافة فارغة)، وتُنهى السلسلة عند أول محرف متعارض أو عند الوصول إلى عرض الحقل المُحدّد. تُسند النتيجة إلى الشيء الذي يُشير إليه الوسيط إلا إذا كان الإسناد مكبوحًا باستخدام "*" المذكورة سابقًا، ويمكن استخدام محددات التحويل التالية: المحددات d i o u x: تُحوِّل d عدد صحيح ذو إشارة، وتحوّل i عدد صحيح ذو إشارة وتنسيق ملائم لـstrtol، وتحوِّل o عدد صحيح ثماني، وتحوّل u عدد صحيح عديم الإشارة، وتحول x عدد صحيح ست عشري. المحددات e f g: تحوِّل قيمة من نوع float (وليس double). المحدد s: يقرأ سلسلة نصية ويُضيف محرف فارغ في نهايته، وتُنهى السلسلة النصية باستخدام مسافة فارغة عند الدخل (ولا تُقرأ هذه المسافة الفارغة على أنها جزء من الدخل). المحدد ]: يقرأ سلسلة نصية، وتتبع ] لائحة من المحارف تُدعى مجموعة المسح scan set، ويُنهي المحرف [ هذه اللائحة. تُقرأ المحارف إلى (غير متضمنةً) المحرف الأول غير الموجود ضمن مجموعة المسح؛ فإذا كان المحرف الأول في اللائحة هو "^" فهذا يعني أن مجموعة القراءة تحتوي على أي محرف غير موجود في هذه القائمة، وإذا كانت السلسلة الأولية هي "[^]" أو "[]" فهذا يعني أن [ ليس محدّدًا بل جزءًا من السلسلة ويجب إضافة محرف "[" آخر لإنهاء اللائحة. إذا وجدت علامة ناقص "-" في اللائحة، يجب أن يكون موقعها المحرف الأول أو الأخير، وإلا فإن معناها معرف بحسب التنفيذ. المحدد c: يقرأ محرفًا واحدًا متضمنًا محارف المسافات الفارغة، ولقراءة المحرف الأول باستثناء محارف المسافات الفارغة استخدم %1s، ويحدد عرض الحقل مصفوفة المحارف التي يجب قراءتها. المحدد p: يقرأ مؤشرًا من النوع (void *) والمكتوب سابقًا باستخدام المحدد %p ضمن استدعاء سابق لمجموعة دوال printf. المحدد %: المحرف "%" متوقّع في الدخل ولا يُجرى أي إسناد. المحدد n: يُعاد عددًا صحيح يمثل عدد المحارف المقروءة باستخدام هذا الاستدعاء. يوضح الجدول التالي تأثير محددات الحجم size specifiers: المحدد يُحدِّد يُحوِّل l d i o u x عدد صحيح كبير long int h d i o u x عدد صحيح صغير short int l e f عدد عشري مضاعف double L e f عدد عشري مضاعف كبير long double [جدول 3 محددات الحجم] إليك وصف دوال مجموعة scanf مع تصاريحها: #include <stdio.h> int fscanf(FILE *stream, const char *format, ...); int sscanf(const char *s, const char *format, ...); int scanf(const char *format, ...); تأخذ الدالة fscanf دخلها من المجرى المُحدد، وتُطابق الدالة scanf الدالة fscanf مع اختلاف أن الوسيط الأول هو المجرى stdin، بينما تأخذ sscanf دخلها من مصفوفة محارف مُحدّدة. نحصل على القيمة EOF المُعادة في حال حدوث خطأ دخل قبل أي تحويلات، وإلا فنحصل على عدد التحويلات الناجحة الحاصلة وقد يكون هذا العدد صفر إن لم تُجرى أي تحويلات، ونحصل على خطأ دخل إذا قرأنا EOF، أو بوصولنا إلى نهاية سلسلة الدخل النصية، بينما نحصل على خطأ تحويل إذا فشل العثور على نمط مناسب يوافق التحويل المحدّد. عمليات الإدخال والإخراج على المحارف هناك عدد من الدوال التي تسمح لنا بإجراء عمليات الدخل والخرج على المحارف بصورةٍ منفردة، إليك تصاريحها: #include <stdio.h> /* دخل المحرف */ int fgetc(FILE *stream); int getc(FILE *stream); int getchar(void); int ungetc(int c, FILE *stream); /* خرج المحرف */ int fputc(int c, FILE *stream); int putc(int c, FILE *stream); int putchar(int c); /* دخل السلسلة النصية */ char *fgets(char *s, int n, FILE *stream); char *gets(char *s); /* خرج السلسلة النصية */ int fputs(const char *s, FILE *stream); int puts(const char *s); لنستعرض سويًّا كلًّا منها. دخل المحرف تقرأ مجموعة الدوال التي تنفذ هذه المهمة المحرف مثل قيمة من نوع "unsigned char" من مجرى الدخل المحدد أو من stdin، ونحصل على المحرف الذي يليه في كل حالة من مجرى الدخل. يُعامل المحرف مثل قيمة "unsigned char" ويُحوّل إلى "int" وهي القيمة المُعادة من الدالة. نحصل على الثابت EOF عند الوصول إلى نهاية الملف، ويُضبط مؤشر نهاية الملف end-of-file indicator إلى المجرى المحدد، كما نحصل على EOF في حالة الخطأ ويُضبط مؤشر الخطأ إلى المجرى المحدّد. نستطيع الحصول على المحارف بصورةٍ تتابعية باستدعاء الدالة تباعًا. قد نحصل على وسيط المجرى stream أكثر من مرة في حال استخدام هذه الدوال على أنها ماكرو، لذا لا تستخدم الآثار الجانبية هنا. هناك برنامج "ungetc" الداعم أيضًا، الذي يُستخدم لإعادة محرف إلى المجرى مما يجعله المحرف التالي الذي سيُقرأ، إلا أن هذه ليست بعملية خرج ولن تتسبب بتغيير محتوى الملف، ولذا تتسبب عمليات fflush و fseek و rewind على المجرى بين عملية إعادة المحرف وقراءته بتجاهل هذا المحرف، ويمكن إعادة محرف واحد فقط وأي محاولات لإعادة EOF تُتجاهل، ولا يُعدّل على موضع مؤشر الملف في جميع حالات إعادة قراءة مجموعة من المحارف وإعادة قرائتها أو تجاهلها. يتسبب استدعاء ungetc الناجح على مجرى ثنائي بتناقص موضع مؤشر الملف إلا أن ذلك غير محدد عند استخدام مجرى نصي، أو مجرى ثنائي موجود في بداية الملف. خرج المحرف هذه الدوال مطابقة لدوال الدخل الموصوفة سابقًا إلا أنها تجري عمليات الخرج، إذ تعيد المحرف المكتوب أو EOF عند حدوث خطأ ما، ولا يوجد ما يعادل نهاية الملف End Of File في ملف الخرج. خرج السلسلة النصية تكتب هذه الدوال سلاسلًا نصيةً إلى ملف الخرج باستخدام المجرى stream إن ذُكر وإلا فإلى المجرى stdout، ولا يُكتب محرف الإنهاء الفارغ. نحصل على قيمة لا تساوي الصفر عند حدوث خطأ وإلا فالقيمة صفر. تحذير: تضيف puts سطرًا جديدًا إلى سلسلة الخرج النصية بينما لا تفعل fputs ذلك. دخل السلسلة النصية تقرأ الدالة fgets السلسلة النصية إلى مصفوفة يُشار إليها باستخدام المؤشر s من المجرى stream، وتتوقف عن القراءة في حال الوصول إلى EOF أو عند أول سطر جديد (وتقرأ محرف السطر الجديد)، وتضيف محرفًا فارغًا null في النهاية. يُقرأ n-1 محرف على الأكثر (لترك حيز للمحرف الفارغ). تعمل الدالة gets على نحوٍ مشابه لمجرى stdin إلا أنها تتجاهل محرف السطر الجديد. تعيد كلا الدالتين s في حال نجاحهما وإلا فمؤشر فارغ، إذ نحصل على مؤشر فارغ عندما نصادف EOF قبل قراءة أي محرف ولا يطرأ أي تغيير على المصفوفة، بينما تصبح محتويات المصفوفة غير معرفة إذا ما واجهنا خطأ قراءة وسط السلسلة النصية بالإضافة إلى إعادة مؤشر فارغ. الدخل والخرج غير المنسق هذا الجزء بسيط، إذا هناك فقط دالتان تقدمان هذه الخاصية، واحدة منهما للقراءة والأخرى للكتابة ويصرَّح عنهما على النحو التالي: #include <stdio.h> size_t fread(void *ptr, size_t size, size_t nelem, FILE *stream); size_t fwrite(const void *ptr, size_t size, size_t nelem, FILE *stream); تُجرى عملية القراءة أو الكتابة المناسبة للبيانات المُشار إليها بواسطة المؤشر ptr وذلك على nelem عنصر، وبحجم size، ويفشل نقل ذلك المقدار الكامل من العناصر فقط عند الكتابة، إذ قد تعيق نهاية الملف دخل العناصر بأكملها، وتُعيد الدالة عدد العناصر التي نُقلت فعليًّا. نستخدم feof أو ferror للتمييز بين نهاية الملف عند الدخل أو للإشارة على خطأ. تُعيد الدالة القيمة صفر دون أي فعل إذا كانت قيمة size أو nelem تساوي إلى الصفر. قد يساعدنا المثال الآتي في توضيح عمل الدالتين المذكورتين: #include <stdio.h> #include <stdlib.h> struct xx{ int xx_int; float xx_float; }ar[20]; main(){ FILE *fp = fopen("testfile", "w"); if(fwrite((const void *)ar, sizeof(ar[0]), 5, fp) != 5){ fprintf(stderr,"Error writing\n"); exit(EXIT_FAILURE); } rewind(fp); if(fread((void *)&ar[10], sizeof(ar[0]), 5, fp) != 5){ if(ferror(fp)){ fprintf(stderr,"Error reading\n"); exit(EXIT_FAILURE); } if(feof(fp)){ fprintf(stderr,"End of File\n"); exit(EXIT_FAILURE); } } exit(EXIT_SUCCESS); } [مثال 1] ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: أدوات مكتبة stdlib في لغة سي C المقال السابق: مقدمة عن التعامل مع الدخل والخرج I/O في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C
تكلّمنا سابقًا عن الدخل والخرج في لغة سي بالاستعانة بالمكتبات القياسية، وحان الوقت لنتعلم الآن مختلف الدوال الموجودة في هذه المكتبات التي تضمن لنا أساليب مختلفة في القراءة والكتابة. الدخل والخرج المنسق هناك عدد من الدوال المُستخدمة لتنسيق الدخل والخرج، وتحدد كلًا من هذه الدوال التنسيق المتبع للدخل والخرج باستخدام سلسلة التنسيق النصية format string، وتتألف سلسلة التنسيق النصية في حالة الخرج من نص عادي plain text يمثّل الخرج كما هو، إضافةً إلى مواصفات التنسيق format specifications التي تتطلب معالجة خاصة لواحد من الوسطاء المتبقية في الدالة، بينما تتألف سلسلة التنسيق النصية في حالة الخرج من نص عادي يطابق مجرى الدخل وتحدد هنا مواصفات التنسيق معنى الوسطاء المتبقية. يُشار إلى كل واحدة من مواصفات التنسيق باستخدام المحرف "%" متبوعًا ببقية التوصيف. الخرج: دوال printf تتخذ مواصفات التنسيق في دوال الخرج الشكل التالي، ونشير إلى الأجزاء الاختيارية بوضعها بين قوسين: %<flags><field width><precision><length>conversion نشرح معنى كل من الراية flag وعرض الحقل field width والدقة precision والطول length والتحويل conversion أدناه، إلا أنه من الأفضل النظر إلى وصف المعيار إذا أردت وصفًا مطولًا ودقيقًا. الرايات يمكن ألا تأخذ الرايات أي قيمة أو أن تأخذ أحد القيم التالية: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } قيمة الراية الشرح - ملئ سطر التحويل من اليسار ضمن حقوله. + يبدأ التحويل ذو الإشارة بإشارة زائد أو ناقص دائمًا. مسافة فارغة space إذا كان المحرف الأول من تحويل ذو إشارة ليس بإشارة، أضف مسافةً فارغة، ويمكن تجاوز الراية باستخدام "+" إذا وجدت. # يُجبر استخدام تنسيق مختلف للخرج، مثل: الخانة الأولى لأي تحويل ثماني لها القيمة "0"، وإضافة "0x" أمام أي تحويل ست عشري لا تساوي قيمته الصفر، ويُجبِر الفاصلة العشرية في جميع تحويلات الفاصلة العائمة حتى إن لم تكن ضرورية، ولا يُزيل أي صفر لاحق من تحويلات g و G. 0 يُضيف إلى تحويلات d و i و o و u و x و X و e و E و f و F و G أصفارًا إلى يسارها بملئ عرض الحقل، ويمكن تجاوزه باستخدام الراية "-"، وتُتجاهل الراية إذا كان هناك أي دقة محددة لتحويلات d، أو i، أو o، أو u، أو x، أو X، ونحصل على سلوك غير معرف للتعريفات الأخرى. عرض الحقل field width عدد صحيح عشري يحدد عرض حقل الخرج الأدنى ويمكن تجاوزه إن لزم الأمر، يُحوّل الوسيط التالي إلى عدد صحيح ويُستخدم مثل قيمة لعرض الحقل إن استُخدمت علامة النجمة "*"، وتُعامل هذه القيمة إذا كانت سالبة كأنها راية "-" متبوعة بعرض حقل ذي قيمة موجبة. يُملأ الخرج ذو الطول الأقصر من عرض الحقل بالمسافات الفارغة (أو بأصفار إذا كان العدد الصحيح المعبر عن عرض الحقل يبدأ بالصفر)، ويُملأ الخرج من الجهة اليسرى إلا إذا حُدّدَت راية تعديل اليسار left-adjustment. الدقة precision تبدأ قيمة الدقة بالنقطة '.'، وهي تحدد عدد الخانات الدنيا لتحويلات d، أو i، أو o، أو u، أو x، أو X، أو عدد الخانات التي تلي الفاصلة العشرية في تحويلات e، أو E، أو f، أو العدد الأعظمي لخانات تحويلات g وG، أو عدد المحارف المطبوعة من سلسلة نصية في تحويلات s. يتسبب تحديد كمية حشو الحقل padding بتجاهل قيمة field width. يُحوَّل الوسيط التالي في حال استخدامنا لعلامة النجمة "*" إلى عدد صحيح ويُستخدم بمثابة قيمة لعرض الحقل، وتعامل القيمة كأنها مفقودة إذا كانت سالبة، وتكون الدقة صفر إذا وجدت النقطة فقط. الطول length وهي h تسبق محدد specifier لطباعة نوع عدد صحيح integral ويتسبب ذلك في معاملتها وكأنها من النوع "short" (لاحظ أن الأنواع المختلفة القصيرة shorts تُرقّى إلى واحدة من أنواع القيم الصحيحة int عندما تُمرّر مثل وسيط). تعمل l مثل عمل h إلا أنها تُطبّق على وسيط عدد صحيح من نوع "long"، وتُستخدم L للدلالة على أنه يجب طباعة وسيط من نوع "long double"، ويطبَّق ذلك فقط على محددات الفاصلة العائمة. يتسبب استخدام هذا في سلوك غير معرف إذا كانت باستخدام النوع الخاطئ من التحويلات. يوضح الجدول التالي أنواع التحويلات: المحدد التأثير الدقة الافتراضية d عدد عشري ذو إشارة 1 i عدد عشري ذو إشارة 1 u عدد عشري عديم الإشارة 1 o عدد ثماني عديم الإشارة 1 x عدد ست عشري عديم الإشارة من 0 إلى f 1 X عدد ست عشري عديم الإشارة من 0 إلى F 1 تحدد الدقة عدد خانات الأدنى المُستبدل بأصفار إن لزم الأمر، ونحصل على خرج دون أي محارف عند استخدام الدقة صفر لطباعة القيمة صفر f يطبع قيمة من النوع double بعدد خانات الدقة (المقربة) بعد الفاصلة العشرية. استخدم دقة بقيمة صفر للحد من الفاصلة العشرية، وإلا فستظهر خانة واحدة على الأقل بعد الفاصلة العشرية 6 e, E يطبع قيمة من نوع double بالتنسيق الأسي مُقرّبًا بخانة واحدة قبل الفاصلة العشرية، وعدد من الخانات يبلغ الدقة المحددة بعده، وتُلغى الفاصلة العشرية عند استخدام الدقة صفر، وللأس خانتان على الأقل تطبع بالشكل 1.23e15 في تنسيق e أو 1.23E15 في حالة التنسيق E 6 g, G تستخدم أسلوب التنسيق f، أو e (E مع G) بحسب الأس، ولا يُستخدم التنسيق f إذا كان الأس أصغر من "-4" أو أكبر أو يساوي الدقة. تُحدّ الأصفار التي تتبع القيمة وتُطبع الفاصلة العشرية فقط في حال وجود خانات تابعة. غير محدد c يُحوّل الوسيط من نوع عدد صحيح إلى محرف عديم الإشارة ويُطبع المحرف الناتج عن التحويل s تُطبع سلسلة نصية بطول خانات الدقة، ويجب إنهاء السلسلة النصية باستخدام NUL إذا لم تُحدّد الدقة أو كانت أكبر من طول السلسلة النصية لا نهائي p إظهار قيمة مؤشر من نوع (void *) بطريقة تعتمد على النظام n يجب أن يكون الوسيط مؤشرًا يشير إلى عدد صحيح، ويكون عدد محارف الخرج باستخدام هذا الاستدعاء مُسندًا إلى العدد الصحيح % علامة "%" _ [جدول 1 التحويلات] تجد وصف الدوال التي تستخدم هذه التنسيقات في الجدول التالي، وجميع الدوال المُستخدمة مُضمّنة في المكتبة <stdio.h>، إليك تصاريح هذه الدوال: #include <stdio.h> int fprintf(FILE *stream, const char *format, ...); int printf(const char *format, ...); int sprintf(char *s, const char *format, ...); #include <stdarg.h> // بالإضافة إلى stdio.h int vfprintf(FILE *stream, const char *format, va list arg); int vprintf(const char *format, va list arg); int vsprintf(char *s, const char *format, va list arg); الاسم الاستخدام fprintf نحصل على الخرج المنسق العام بواسطتها كما وصفنا سابقًا، ويكتب الخرج إلى الملف المُحدد باستخدام المجرى stream printf دالة مُطابقة لعمل الدالة fprintf إلا أن وسيطها الأول هو stdout sprintf دالة مُطابقة لعمل الدالة fprintf باستثناء أن خرجها لا يُكتب إلى ملف، بل يُكتب إلى مصفوفة محارف يُشار إليها باستخدام المؤشر s vfprintf خرج مُنسَّق مشابه لخرج الدالة fprintf إلا أن لائحة الوسطاء المتغيرة تُستبدل بالوسيط arg الذي يجب أن يُهيَّأ باستخدام va_start، ولا تُستدعى va_end باستخدام هذه الدالة vprintf مطابقة للدالة vfprintf باستثناء أن الوسيط الأول يساوي إلى stdout vsprintf خرج مُنسَّق مشابه لخرج الدالة sprintf إلا أن لائحة الوسطاء المتغيرة تُستبدل بالوسيط arg الذي يجب أن يُهيَّأ باستخدام va_start، ولا تُستدعى va_end باستخدام هذه الدالة [جدول 2 الدوال التي تطبع خرجًا مُنسَّقًا] تُعيد كل الدوال السابقة عدد المحارف المطبوعة أو قيمة سالبة للدلالة على حصول خطأ، ولا يُحسب المحرف الفارغ الزائد بواسطة دالة sprintf و vsprintf. يجب أن تسمح التنفيذات بالحصول على 509 محارف على الأقل عند استخدام أي تحويل. الدخل: دوال scanf هناك عدة دوال مشابهة لمجموعة دوال printf بهدف الحصول على الدخل، والفارق الواضح بين مجموعتي الدوال هذه هو أن مجموعة دوال scanf تأخذ وسيطًا متمثلًا بمؤشر حتى تُسند القيم المقروءة إلى وجهتها المناسبة، ويُعد نسيان تمرير المؤشر خطأ شائع الحدوث ولا يمكن للمصرّف أن يكتشف حدوثه، إذ يمنع استخدام لائحة وسطاء متغيرة من ذلك. تُستخدم سلسلة التنسيق النصية للتحكم بتفسير المجرى للبيانات المُدخلة التي تحتوي غالبًا على قيم تُسند إلى كائنات يُشار إليها باستخدام وسطاء دالة scanf المتبقية، وقد تتألف سلسلة التنسيق النصية من: مساحة فارغة white space: تتسبب بقراءة مجرى الدخل إلى المحرف التالي الذي لا يمثّل محرف مسافة فارغة. محرف اعتيادي ordinary character: ويمثل المحرف أي محرف عدا محارف السلسلة الفارغة أو "%"، ويجب أن يطابق المحرف التالي في مجرى الدخل هذا المحرف المُحدّد. توصيف التحويل conversion specification: وهو محرف "%" متبوع بمحرف "*" اختياري (الذي يكبح التحويل)، ويُتبع بعدد عشري صحيح لا يساوي الصفر يحدد عرض الحقل الأعظمي، ومحرف "h"، أو "l"، أو "L" اختياري للتحكم بطول التحويل، وأخيرًا محدد تحويل إجباري. لاحظ أن استخدام "h"، أو "l"، أو "L" سيؤثر على على نوع المؤشر الواجب استخدامه. حقل الدخل -باستثناء المحددات "c" و "n" و "]"- هو سلسلة من المحارف التي لا تمثل مسافة فارغة وتبدأ من أول محرف في الدخل (بشرط ألا يكون المحرف مسافة فارغة)، وتُنهى السلسلة عند أول محرف متعارض أو عند الوصول إلى عرض الحقل المُحدّد. تُسند النتيجة إلى الشيء الذي يُشير إليه الوسيط إلا إذا كان الإسناد مكبوحًا باستخدام "*" المذكورة سابقًا، ويمكن استخدام محددات التحويل التالية: المحددات d i o u x: تُحوِّل d عدد صحيح ذو إشارة، وتحوّل i عدد صحيح ذو إشارة وتنسيق ملائم لـstrtol، وتحوِّل o عدد صحيح ثماني، وتحوّل u عدد صحيح عديم الإشارة، وتحول x عدد صحيح ست عشري. المحددات e f g: تحوِّل قيمة من نوع float (وليس double). المحدد s: يقرأ سلسلة نصية ويُضيف محرف فارغ في نهايته، وتُنهى السلسلة النصية باستخدام مسافة فارغة عند الدخل (ولا تُقرأ هذه المسافة الفارغة على أنها جزء من الدخل). المحدد ]: يقرأ سلسلة نصية، وتتبع ] لائحة من المحارف تُدعى مجموعة المسح scan set، ويُنهي المحرف [ هذه اللائحة. تُقرأ المحارف إلى (غير متضمنةً) المحرف الأول غير الموجود ضمن مجموعة المسح؛ فإذا كان المحرف الأول في اللائحة هو "^" فهذا يعني أن مجموعة القراءة تحتوي على أي محرف غير موجود في هذه القائمة، وإذا كانت السلسلة الأولية هي "[^]" أو "[]" فهذا يعني أن [ ليس محدّدًا بل جزءًا من السلسلة ويجب إضافة محرف "[" آخر لإنهاء اللائحة. إذا وجدت علامة ناقص "-" في اللائحة، يجب أن يكون موقعها المحرف الأول أو الأخير، وإلا فإن معناها معرف بحسب التنفيذ. المحدد c: يقرأ محرفًا واحدًا متضمنًا محارف المسافات الفارغة، ولقراءة المحرف الأول باستثناء محارف المسافات الفارغة استخدم %1s، ويحدد عرض الحقل مصفوفة المحارف التي يجب قراءتها. المحدد p: يقرأ مؤشرًا من النوع (void *) والمكتوب سابقًا باستخدام المحدد %p ضمن استدعاء سابق لمجموعة دوال printf. المحدد %: المحرف "%" متوقّع في الدخل ولا يُجرى أي إسناد. المحدد n: يُعاد عددًا صحيح يمثل عدد المحارف المقروءة باستخدام هذا الاستدعاء. يوضح الجدول التالي تأثير محددات الحجم size specifiers: المحدد يُحدِّد يُحوِّل l d i o u x عدد صحيح كبير long int h d i o u x عدد صحيح صغير short int l e f عدد عشري مضاعف double L e f عدد عشري مضاعف كبير long double [جدول 3 محددات الحجم] إليك وصف دوال مجموعة scanf مع تصاريحها: #include <stdio.h> int fscanf(FILE *stream, const char *format, ...); int sscanf(const char *s, const char *format, ...); int scanf(const char *format, ...); تأخذ الدالة fscanf دخلها من المجرى المُحدد، وتُطابق الدالة scanf الدالة fscanf مع اختلاف أن الوسيط الأول هو المجرى stdin، بينما تأخذ sscanf دخلها من مصفوفة محارف مُحدّدة. نحصل على القيمة EOF المُعادة في حال حدوث خطأ دخل قبل أي تحويلات، وإلا فنحصل على عدد التحويلات الناجحة الحاصلة وقد يكون هذا العدد صفر إن لم تُجرى أي تحويلات، ونحصل على خطأ دخل إذا قرأنا EOF، أو بوصولنا إلى نهاية سلسلة الدخل النصية، بينما نحصل على خطأ تحويل إذا فشل العثور على نمط مناسب يوافق التحويل المحدّد. عمليات الإدخال والإخراج على المحارف هناك عدد من الدوال التي تسمح لنا بإجراء عمليات الدخل والخرج على المحارف بصورةٍ منفردة، إليك تصاريحها: #include <stdio.h> /* دخل المحرف */ int fgetc(FILE *stream); int getc(FILE *stream); int getchar(void); int ungetc(int c, FILE *stream); /* خرج المحرف */ int fputc(int c, FILE *stream); int putc(int c, FILE *stream); int putchar(int c); /* دخل السلسلة النصية */ char *fgets(char *s, int n, FILE *stream); char *gets(char *s); /* خرج السلسلة النصية */ int fputs(const char *s, FILE *stream); int puts(const char *s); لنستعرض سويًّا كلًّا منها. دخل المحرف تقرأ مجموعة الدوال التي تنفذ هذه المهمة المحرف مثل قيمة من نوع "unsigned char" من مجرى الدخل المحدد أو من stdin، ونحصل على المحرف الذي يليه في كل حالة من مجرى الدخل. يُعامل المحرف مثل قيمة "unsigned char" ويُحوّل إلى "int" وهي القيمة المُعادة من الدالة. نحصل على الثابت EOF عند الوصول إلى نهاية الملف، ويُضبط مؤشر نهاية الملف end-of-file indicator إلى المجرى المحدد، كما نحصل على EOF في حالة الخطأ ويُضبط مؤشر الخطأ إلى المجرى المحدّد. نستطيع الحصول على المحارف بصورةٍ تتابعية باستدعاء الدالة تباعًا. قد نحصل على وسيط المجرى stream أكثر من مرة في حال استخدام هذه الدوال على أنها ماكرو، لذا لا تستخدم الآثار الجانبية هنا. هناك برنامج "ungetc" الداعم أيضًا، الذي يُستخدم لإعادة محرف إلى المجرى مما يجعله المحرف التالي الذي سيُقرأ، إلا أن هذه ليست بعملية خرج ولن تتسبب بتغيير محتوى الملف، ولذا تتسبب عمليات fflush و fseek و rewind على المجرى بين عملية إعادة المحرف وقراءته بتجاهل هذا المحرف، ويمكن إعادة محرف واحد فقط وأي محاولات لإعادة EOF تُتجاهل، ولا يُعدّل على موضع مؤشر الملف في جميع حالات إعادة قراءة مجموعة من المحارف وإعادة قرائتها أو تجاهلها. يتسبب استدعاء ungetc الناجح على مجرى ثنائي بتناقص موضع مؤشر الملف إلا أن ذلك غير محدد عند استخدام مجرى نصي، أو مجرى ثنائي موجود في بداية الملف. خرج المحرف هذه الدوال مطابقة لدوال الدخل الموصوفة سابقًا إلا أنها تجري عمليات الخرج، إذ تعيد المحرف المكتوب أو EOF عند حدوث خطأ ما، ولا يوجد ما يعادل نهاية الملف End Of File في ملف الخرج. خرج السلسلة النصية تكتب هذه الدوال سلاسلًا نصيةً إلى ملف الخرج باستخدام المجرى stream إن ذُكر وإلا فإلى المجرى stdout، ولا يُكتب محرف الإنهاء الفارغ. نحصل على قيمة لا تساوي الصفر عند حدوث خطأ وإلا فالقيمة صفر. تحذير: تضيف puts سطرًا جديدًا إلى سلسلة الخرج النصية بينما لا تفعل fputs ذلك. دخل السلسلة النصية تقرأ الدالة fgets السلسلة النصية إلى مصفوفة يُشار إليها باستخدام المؤشر s من المجرى stream، وتتوقف عن القراءة في حال الوصول إلى EOF أو عند أول سطر جديد (وتقرأ محرف السطر الجديد)، وتضيف محرفًا فارغًا null في النهاية. يُقرأ n-1 محرف على الأكثر (لترك حيز للمحرف الفارغ). تعمل الدالة gets على نحوٍ مشابه لمجرى stdin إلا أنها تتجاهل محرف السطر الجديد. تعيد كلا الدالتين s في حال نجاحهما وإلا فمؤشر فارغ، إذ نحصل على مؤشر فارغ عندما نصادف EOF قبل قراءة أي محرف ولا يطرأ أي تغيير على المصفوفة، بينما تصبح محتويات المصفوفة غير معرفة إذا ما واجهنا خطأ قراءة وسط السلسلة النصية بالإضافة إلى إعادة مؤشر فارغ. الدخل والخرج غير المنسق هذا الجزء بسيط، إذا هناك فقط دالتان تقدمان هذه الخاصية، واحدة منهما للقراءة والأخرى للكتابة ويصرَّح عنهما على النحو التالي: #include <stdio.h> size_t fread(void *ptr, size_t size, size_t nelem, FILE *stream); size_t fwrite(const void *ptr, size_t size, size_t nelem, FILE *stream); تُجرى عملية القراءة أو الكتابة المناسبة للبيانات المُشار إليها بواسطة المؤشر ptr وذلك على nelem عنصر، وبحجم size، ويفشل نقل ذلك المقدار الكامل من العناصر فقط عند الكتابة، إذ قد تعيق نهاية الملف دخل العناصر بأكملها، وتُعيد الدالة عدد العناصر التي نُقلت فعليًّا. نستخدم feof أو ferror للتمييز بين نهاية الملف عند الدخل أو للإشارة على خطأ. تُعيد الدالة القيمة صفر دون أي فعل إذا كانت قيمة size أو nelem تساوي إلى الصفر. قد يساعدنا المثال الآتي في توضيح عمل الدالتين المذكورتين: #include <stdio.h> #include <stdlib.h> struct xx{ int xx_int; float xx_float; }ar[20]; main(){ FILE *fp = fopen("testfile", "w"); if(fwrite((const void *)ar, sizeof(ar[0]), 5, fp) != 5){ fprintf(stderr,"Error writing\n"); exit(EXIT_FAILURE); } rewind(fp); if(fread((void *)&ar[10], sizeof(ar[0]), 5, fp) != 5){ if(ferror(fp)){ fprintf(stderr,"Error reading\n"); exit(EXIT_FAILURE); } if(feof(fp)){ fprintf(stderr,"End of File\n"); exit(EXIT_FAILURE); } } exit(EXIT_SUCCESS); } [مثال 1] ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: أدوات مكتبة stdlib في لغة سي C المقال السابق: مقدمة عن التعامل مع الدخل والخرج I/O في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C -
 يعدّ افتقار لغات البرمجة لدعمها للدخل والخرج إحدى أبرز الأسباب التي منعت التبني واسع النطاق واستخدامها في البرمجة العملية، وهو الموضوع الذي لم يرد أي مصمّم لغة أن يتعامل معه، إلا أن لغة سي تفادت هذه المشكلة، بعدم تضمينها لأي دعم للدخل والخرج، إذ كان سلوك سي هو أن تترك التعامل مع الدخل والخرج لدوال المكتبات، مما عنى أنه بالإمكان لمصمّمي الأنظمة استخدام طرق دخل وخرج مخصصة بدلًا من إجبارهم على تغيير اللغة بذات نفسها. تطوّرت حزمة مكتبات عُرفت باسم "مكتبة الدخل والخرج القياسي Standard I/O Library" -أو اختصارًا stdio- في الوقت ذاته الذي كانت لغة سي تتطوّر، وقد أثبتت هذه المكتبة مرونتها وقابلية نقلها وأصبحت الآن جزءًا من المعيار. اعتمدت حزمة الدخل والخرج القياسي القديمة كثيرًا على نظام يونيكس UNIX للوصول إلى الملفات وبالأخص الافتراض أنه لا يوجد أي فرق بين ملفات ثنائية غير مُهيكلة وملفات أخرى تحتوي على نص مقروء، إلا أن العديد من أنظمة التشغيل تفصل ما بين الاثنين وعُدّلت الحزمة فيما بعد لضمان قابلية نقل برامج لغة سي بين نوعَي نظام الملفات. هناك بعض التغييرات في هذا المجال التي تتسبب بالضرر لكثيرٍ من البرامج المكتوبة مسبقًا على الرغم من الجهود التي تحاول أن تحدّ من هذا الضرر. من المفترض أن تعمل برامج لغة سي القديمة بنجاح دون تعديل في بيئة يونيكس. نموذج الدخل والخرج لا يُميّز نموذج الدخل والخرج بين أنواع الأجهزة المادية التي تدعم الدخل والخرج، إذ يُعامل كل مصدر أو حوض من البيانات بالطريقة ذاتها ويُنظر إليه على أنه مجرًى من البايتات stream of bytes. بما أن الكائن الأصغر الذي يمكن تمثيله في لغة سي هو المحرف، فالوصول إلى الملف مسموحٌ باستخدام حدود أي محرف، وبالتالي يمكن قراءة أو كتابة أي عدد من المحارف انطلاقًا من نقطة متحركة تُعرف باسم مؤشر الموضع position indicator، وتُكتب أو تُقرأ المحارف تباعًا بدءًا من هذه النقطة ويُحرّك مؤشر الموضع خلال ذلك. يُضبط مؤشر الموضع مبدئيًا إلى بداية الملف عند فتحه، لكن من الممكن تحريكه باستخدام طلبات تحديد الموقع، ويُتجاهل مؤشر موضع الملف في حال كان الوصول العشوائي إلى الملف غير ممكن. لفتح الملف في نمط الإضافة append تأثيرات على مجرى موضع المؤشر في الملف معرفة بحسب التنفيذ. الفكرة العامة هي تقديم إمكانية القراءة أو الكتابة بصورةٍ تتابعية، باستثناء حالة فتح المجرى باستخدام نمط الإضافة، أو إذا حُرّك مؤشر موضع الملف مباشرةً. هناك نوعان من أنواع الملفات، هما: الملفات النصية text files والملفات الثنائية binary files التي يمكن التعامل معها داخل البرنامج على أنها مجاري نصية text streams أو مجاري ثنائية binary streams بعد فتحها لعمليات الإدخال والإخراج. لا تسمح حزمة stdio بالعمليات على محتوى الملف مباشرةً، بل بالتعديل على المجرى الذي يحتوي على بيانات الملف. المجاري النصية يحدّد المعيار المجرى النصي text stream، الذي يمثّل ملفًا يحتوي على أسطر نصية ويتألف السطر من صفر محرف أو أكثر ينتهي بمحرف نهاية السطر، ومن الممكن أن يكون تمثيل الأسطر الفعلي في البيئة الخارجية مختلفًا عن تمثيله هنا، كما من الممكن إجراء تحويلات على مجرى البيانات عند دخولها إلى أو خروجها من البرنامج، وأكثر المتطلبات شيوعًا هو ترجمة المحرف الذي ينهي السطر "'\n'" إلى السلسلة "'\r\n'" عند الخرج وإجراء عكس العملية عند الدخل، ومن الممكن تواجد بعض الترجمات الضرورية الأخرى. يُضمن للبيانات التي تُقرأ من المجرى النصي أن تكون مساويةً إلى البيانات المكتوبة سابقًا إلى الملف، وذلك إذا كانت هذه البيانات مؤلفةً من أسطر مكتملة تحتوي على محارف يمكن طباعتها، وكانت محارف التحكم control characters ومحارف مسافة الجدولة الأفقية horizontal-tab ومحارف الأسطر الجديدة newline فقط، ولم يُتبع أي محرف سطر جديد بمحرف مسافة فارغة space مباشرةً، وكان المحرف الأخير في المجرى هو محرف سطر جديد. كما أن هناك ضمان بأن المحرف الأخير المكتوب إلى الملف النصي هو محرف سطر جديد، ومن الممكن قراءة الملف مجددًا بمحتوياته المماثلة التي كُتبت إليه سابقًا. إلحاق المحرف الأخير المكتوب إلى الملف بمحرف سطر جديد معرفٌ بحسب التنفيذ، وذلك لأن الملفات النصية والملفات الثنائية تُعامل نفس المعاملة في بعض التنفيذات. قد تُجرّد بعض التنفيذات المسافة الفارغة البادئة من الأسطر التي تتألف من مسافات فارغة فقط متبوعةً بسطر جديد، أو تُجرّد المسافة الفارغة في نهاية السطر. يجب أن يدعم التنفيذ الملفات النصية التي تحتوي سطورها على 254 محرفًا على الأقل، ويتضمن ذلك محرف السطر الجديد الذي يُنهي السطر. قد نحصل على مجرى ثنائي عند فتح مجرى نصي بنمط التحديث update mode في بعض التنفيذات. قد تتسبب الكتابة على مجرًى نصي باقتطاع الملف عند نقطة الكتابة في بعض التنفيذات، أي ستُهمل جميع البيانات التي تتبع البايت الأخير المكتوب. المجاري الثنائية يمثل المجرى الثنائي سلسلةً من المحارف التي يمكن استخدامها لتسجيل البيانات الداخلية لبرنامج ما، مثل محتويات الهياكل structures، أو المصفوفات وذلك بالشكل الثنائي، إذ تكون البيانات المقروءة من المجاري الثنائية مساويةً للبيانات المكتوبة إلى المجرى ذاته سابقًا ضمن نفس التنفيذ، وقد يُضاف عددٌ من المحارف الفارغة "NULL" في بعض الظروف إلى نهاية المجرى الثنائي، ويكون عدد المحارف معرفًا بحسب التنفيذ. تعتمد بيانات الملفات الثنائية على الآلة التي تعمل عليها لأبعد حد، وهي غير قابلة للنقل عمومًا. المجاري الأخرى قد تتوفر بعض أنواع المجاري الأخرى، إلا أنها معرفة بحسب التنفيذ. ملف الترويسة <stdio.h> هناك عدد من الدوال والماكرو الموجودة لتقديم الدعم لمختلف أنواع المجاري، ويحتوي ملف الترويسة <stdio.h> العديد من التصريحات المهمة لهذه الدوال، إضافةً إلى الماكرو التالية وتصاريح الأنواع: النوع FILE: نوع الكائن المُستخدم لاحتواء معلومات التحكم بالمجرى، ولا يحتاج مستخدمو مكتبة "stdio" لمعرفة محتويات هذه الكائنات، إذ يكفي التعامل مع المؤشرات التي تشير إليهم. لا يُعد نسخ الكائنات هذه ضمن البرنامج آمنًا، إذ أن عناوينهم قد تكون في بعض الأحيان معقدة. النوع fpos_t: نوع الكائن الذي يُستخدم لتسجيل القيم الفريدة من نوعها التي تنتمي إلى مجرى مؤشر موضع الملف. القيم IOFBF_ و IOLBF_ و IONBF_: وهب قيم تُستخدم للتحكم بالتخزين المؤقت buffering للمجرى بالاستعانة بالدالة setvbuf. القيمة BUFSIZ: حجم التخزين المؤقت المُستخدم بواسطة الدالة setbuf، وهو تعبيرٌ رقم صحيح integral ثابت constant تكون قيمته 256 على الأقل. القيمة EOF: تعبير رقم صحيح سالب ثابت يحدد نهاية الملف end-of-file ضمن مجرى، أي عند الوصول إلى نهاية الدخل. القيمة FILENAME_MAX: الطول الأعظمي الذي يمكن لاسم ملف أن يكون إذا كان هناك قيد على ذلك، وإلا فهو الحجم الذي يُنصح به لمصفوفة تحمل اسم ملف. القيمة FOPEN_MAX: العدد الأدنى من الملفات التي يضمن التنفيذ فتحها في وقت آني، وهو ثمانية ملفات. لاحظ أنه من الممكن إغلاق ثلاث مجاري مُعرفة مسبقًا إذا احتاج البرنامج فتح أكثر من خمسة ملفات مباشرةً. القيمة L_tmpnam: الطول الأعظمي المضمون لسلسلة نصية في tmpnam، وهو تعبير رقم صحيح ثابت. القيم SEEK_CUR و SEEK_END و SEEK_SET: تعابير رقم صحيح ثابتة تُستخدم للتحكم بأفعال fseek. القيمة TMP_MAX: العدد الأدنى من أسماء الملفات الفريدة من نوعها المولدة من قبل tmpnam، وهو تعبير رقم صحيح ثابت بقيمة لا تقل عن 25. الكائنات stdin و stdout و stderr: وهي كائنات معرفة مسبقًا من النوع "* FILE" وتشير إلى مجرى الدخل القياسي ومجرى الخرج القياسي ومجرى الخطأ بالترتيب، وتُفتح هذه المجاري تلقائيًا عند بداية تنفيذ البرنامج. العمليات على المجاري بعد أن تعرفنا على أنواع المجاري وطبيعتها والقيم المرتبطة بها، نستعرض الآن العمليات الأساسية عليها ألا وهي فتح المجرى وإغلاقه، إضافةً إلى التخزين المؤقت. فتح المجرى يتصل المجرى بالملف عن طريق دالة fopen، أو freopen، أو tmpfile، إذ تعيد هذه الدوال -إذا كان استدعاؤها ناجحًا- مؤشرًا يشير إلى كائن من نوع FILE. هناك ثلاث أنواع من المجاري المتاحة افتراضيًا دون أي جهد إضافي مطلوب منك، وتتصل هذه المجاري عادةً بالجهاز المادي المُرتبط بالبرنامج المُنفّذ ألا وهو الطرفية Terminal عادةً، ويشار إلى هذه المجاري بالأسماء: stdin: وهو مجرى الدخل القياسي standard input. stdout: وهو مجرى الخرج القياسي standard output. stderr: وهو مجرى الخطأ القياسي standard error. ويكون دخل لوحة المفاتيح في الحالة الطبيعية من المجرى stdin وخرج الطرفية هو stdout، بينما تُوجّه رسائل الأخطاء إلى المجرى stderr. الهدف من فصل رسائل الأخطاء عن رسائل الخرج العادية هو السماح بربط مجرى stdout إلى شيءٍ آخر مغاير لجهاز للطرفية مثل ملف ما والحصول على رسائل الخطأ بنفس الوقت على الشاشة أمامك عوضًا عن توجيه الأخطاء إلى الملف، وتخزّن كامل الملفات مؤقتًا إذا لم توجّه إلى أجهزة تفاعلية. كما ذكرنا سابقًا، قد يكون مؤشر موضع الملف قابلًا للتحريك أو غير قابل للتحريك بحسب الجهاز المُستخدم، إذ يكون مؤشر موضع الملف غير قابل للتحريك ضمن مجرى stdin على سبيل المثال إذا كان متصلًا إلى الطرفية (الحالة الاعتيادية له). جميع الملفات غير المؤقتة تمتلك اسمًا filename وهو سلسلةٌ نصية، والقوانين التي تحدد اسم الملف الصالح معرفةٌ حسب التنفيذ، وينطبق الأمر ذاته على إمكانية فتح الملف لعدة مرات بصورةٍ آنية. قد يتسبب فتح ملف جديد بإنشاء هذا الملف، وتتسبب إعادة إنشاء ملف موجود مسبقًا بإهمال محتوياته السابقة. إغلاق المجرى تُغلق المجاري عند استدعاء fclose أو exit بصورةٍ صريحة، أو عندما يعود البرنامج إلى الدالة main، وتُمسح جميع البيانات المخزنة مؤقتًا عند إغلاق المجرى. تصبح حالة الملفات المفتوحة غير معروفة إذا توقف البرنامج لسببٍ ما دون استخدام الطرق السابقة لإغلاقه. التخزين المؤقت للمجرى هناك ثلاث أنواع للتخزين المؤقت: دون تخزين مؤقت unbuffered: تُستخدم مساحة التخزين بأقل ما يمكن من قبل stdio بهدف إرسال أو تلقي البيانات أسرع ما يمكن. تخزين مؤقت خطي line buffered: تُعالج المحارف سطرًا تلو سطر، ويُستخدم هذا النوع من التخزين المؤقت كثيرًا في البيئات التفاعلية، وتُمسح محتويات الذواكر المؤقتة الداخلية internal buffers فقط عندما تمتلئ أو عندما يُعالج سطر جديد. التخزين المؤقت الكامل fully buffered: تُسمح الذواكر المؤقتة الداخلية فقط عندما تمتلئ. يُمكن مسح محتوى الذاكرة الداخلية المرتبطة بمجرى ما عن طريق استخدام fflush مباشرةً. يُعرَّف الدعم لأنواع التخزين المؤقت المختلفة بحسب التنفيذ، ويمكن التحكم به ضمن الحدود المعرفة باستخدام setbuf و setvbuf. التلاعب بمحتويات الملف مباشرة هناك عدة دوال تسمح لنا بالتعامل مع الملف مباشرةً. #include <stdio.h> int remove(const char *filename); int rename(const char *old, const char *new); char *tmpnam(char *s); FILE *tmpfile(void); الدالة remove: تتسبب بإزالة الملف، وستفشل محاولات فتح هذا الملف لاحقًا إلا في حال إنشاء الملف مجددًا. يكون سلوك الدالة remove عندما يكون الملف مفتوحًا معرفًا بحسب التنفيذ، وتعيد الدالة القيمة صفر للدلالة على النجاح، بينما تدل أي قيمة أخرى على فشل عملها. الدالة rename: تُغيّر اسم الملف المعرف بالكلمة old في مثالنا السابق إلى new، وستفشل محاولات فتح الملف باستخدام اسمه القديم، إلا إذا أنشئ ملفٌ جديد يحمل الاسم القديم ذاته، وكما هو الحال في remove فإن الدالة rename تُعيد القيمة صفر للدلالة على نجاح العملية وأي قيمة مغايرة لذلك تدل على حصول خطأ. السلوك معرف حسب التنفيذ إذا حاولنا تسمية الملف باسم جديد باستخدام rename وكان هناك ملف بالاسم ذاته مسبقًا. لن يُعدّل على الملف إذا فشلت الدالة rename لأي سببٍ كان. الدالة tmpnam: تولّد سلسلة نصية لتُستخدم اسمًا لملف، ويضمن لهذه السلسلة النصية أن تكون فريدةً من نوعها بالنسبة لأي اسم ملف آخر موجود، ويمكن أن تُستدعى بصورةٍ متتالية للحصول على اسم جديد كل مرة. يُستخدم الثابت TMP_MAX لتحديد عدد مرات استدعاء الدالة tmpnam قبل أن يتعذر عليه العثور على اسماء فريدة، وقيمته 25 على الأقل، ونحصل على سلوك غير معرّف من قبل المعيار في حال استدعاء الدالة tmpnam عدد مرات يتجاوز هذا الثابت إلا أن الكثير من التنفيذات تقدم حدًّا لا نهائيًا. تستخدم tmpnam ذاكرة مؤقتة داخلية لبناء الاسم وتُعيد مؤشرًا يشير إليه وذلك إذا ضُبط الوسيط s إلى القيمة NULL، وقد تغيّر الاستدعاءات اللاحقة للدالة الذاكرة المؤقتة الداخلية ذاتها. يمكن استخدام مؤشر يشير إلى مصفوفة مثل وسيط بدلًا من السابق، بحيث تحتوي المصفوفة على L_tmpnam محرف على الأقل، وفي هذه الحالة سُيملأ الاسم إلى الذاكرة المؤقتة المزوّدة (المصفوفة)، ويمكن فيما بعد إنشاء ملف بهذا الاسم واستخدامه ملفًا مؤقتًا. لن يكون اسم الملف مفيدًا ضمن سياقات أخرى غالبًا، بالنظر إلى توليده من قبل الدالة. لا تُزال الملفات المؤقتة من هذا النوع إلا إن استدعيت دالة الحذف، وغالبًا ما تُستخدم هذه الملفات لتمرير البيانات المؤقتة بين برنامجين منفصلين. الدالة tmpfile: تُنشئ ملف ثنائي مؤقت يُمكن التعديل على محتوياته، وتعيد الدالة مؤشرًا يشير إلى مجرى الملف، ويُزال هذا الملف فيما بعد عند إغلاق مجراه، وتُعيد الدالة tmpfile مؤشرًا فارغًا null إذا لم ينجح فتح الملف. فتح الملفات بالاسم يمكن فتح الملفات الموجودة بالاسم عن طريق استدعاء الدالة fopen المصرّح عنها على النحو التالي: #include <stdio.h> FILE *fopen(const char *pathname, const char *mode); يمثل الوسيط pathname اسم الملف الذي تريد فتحه، مثل الاسم الذي تعيده الدالة tmpnam أو أي اسم ملف معين آخر. يمكن فتح الملفات باستخدام عدة أنماط modes، مثل نمط القراءة read لقراءة البيانات، ونمط الكتابة write لكتابة البيانات وهكذا. لاحظ أن الدالة fopen ستُنشئ ملفًا إذا أردت كتابة البيانات على ملف، أو أنها ستتخلص من محتويات الملف إذا وُجد ليصبح طوله صفر (أي أنك ستخسر محتويات الملف السابقة). يوضح الجدول التالي جميع الأنماط الموجودة في المعيار، إلا أن التنفيذ قد يسمح بأنماط أخرى بإضافة محارف إضافية في نهاية كل من الأنماط. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } النمط نوع الملف القراءة الكتابة إنشاء جديد حذف القيمة السابقة "r" نصي نعم لا لا لا "rb" ثنائي نعم لا لا لا "r+" نصي نعم نعم لا لا "r+b" ثنائي نعم نعم لا لا "rb+" ثنائي نعم نعم لا لا "w" نصي لا نعم نعم نعم "wb" ثنائي لا نعم نعم نعم "w+" نصي نعم نعم نعم نعم "w+b" ثنائي نعم نعم نعم نعم "wb+" ثنائي نعم نعم نعم نعم "a" نصي لا نعم نعم لا "ab" ثنائي لا نعم نعم لا "a+" نصي نعم نعم نعم لا "a+b" ثنائي لا نعم نعم لا "ab+" ثنائي لا نعم نعم لا انتبه من بعض التنفيذات التي تضيف إلى النمط الأخير محارف NULL في حالة الملفات الثنائية، إذ قد يتسبب فتح هذه الملفات بالنمط ab أو +ab أو a+b بوضع مؤشر الملف خارج نطاق آخر البيانات المكتوبة. تُكتب جميع البيانات في نهاية الملف إذا فُتح باستخدام نمط الإضافة append، بغض النظر عن محاولة تغيير موضع المؤشر باستخدام الدالة fseek، ويكون موضع مؤشر الملف المبدئي معرف بحسب التنفيذ. تفشل محاولات فتح الملف بنمط القراءة (النمط 'r')، إذا لم يكن الملف موجودًا أو لم يمكن قراءته. يمكن القراءة من والكتابة إلى الملفات المفتوحة بنمط التحديث update (باستخدام '+' مثل المحرف الثاني أو الثالث ضمن النمط) إلا أنه من غير الممكن إلحاق القراءة بالكتابة مباشرةً أو الكتابة بالقراءة دون استدعاء بينهما لدالة واحدة (أو أكثر) من الدوال: fflush أو fseek أو fsetpos أو rewind، والاستثناء الوحيد هنا هو جواز إلحاق الكتابة مباشرةً بعد القراءة إذا قُرأ المحرف EOF (نهاية الملف). من الممكن أيضًا في بعض التنفيذات أن يُتخلى عن b في أنماط فتح الملفات الثنائية واستخدام الأنماط ذاتها الخاصة بالملفات النصية. تُخزّن المجاري المفتوحة باستخدام fopen تخزينًا مؤقتًا بالكامل إذا لم تكن متصلة إلى جهاز تفاعلي، ويضمن ذلك التعامل مع الأسئلة prompts والطلبات responses على النحو الصحيح. تعيد الدالة fopen مؤشرًا فارغًا null إذا فشلت بفتح الملف، وإلا فتعيد مؤشرًا يشير إلى الكائن الذي يتحكم بالمجرى. كائنات المجاري stdin و stdout و stderr غير قابلة للتعديل بالضرورة ومن الممكن عدم وجود إمكانية استخدام القيمة المُعادة من الدالة fopen لإسنادها إلى واحدة من هذه الكائنات، بدلًا من ذلك نستخدم freopen لهذا الغرض. الدالة freopen تُستخدم الدالة freopne لأخذ مؤشر يشير إلى مجرى وربطه مع اسم ملف آخر، وتصرَّح الدالة على النحو التالي: #include <stdio.h> FILE *freopen(const char *pathname, const char *mode, FILE *stream); وسيط mode مشابه لمثيله في دالة fopen. يُغلق المجرى stream أولًا ويحدث تجاهل أي أخطاء متولدة عن ذلك، ونحصل على قيمة NULL في حالة حدوث خطأ عند تنفيذ الدالة، وإلا فإننا نحصل على القيمة الجديدة للمجرى stream. إغلاق الملفات يمكننا إغلاق ملف مفتوح باستخدام الدالة close والمصرح عنها كما يلي: #include <stdio.h> int fclose(FILE *stream); يُتخلّص من أي بيانات موجودة على الذاكرة المؤقتة لم تُكتب على الملف الخاص بالمجرى stream إضافةً إلى أي بيانات أخرى لم تُقرأ، وتُحرّر الذاكرة المؤقتة المرتبطة بالمجرى إذا رُبطت به تلقائيًا، وأخيرًا يُغلق الملف. نحصل على القيمة صفر للدلالة على نجاح العملية، وإلا فالقيمة EOF للدلالة على الخطأ. الدالتان setbuf و setvbuf تُستخدم الدالتان للتعديل على استراتيجية التخزين المؤقتة لمجرى معين مفتوح، ويُصرّح عن الدالتين كما يلي: #include <stdio.h> int setvbuf(FILE *stream, char *buf, int type, size_t size); void setbuf(FILE *stream, char *buf); يجب استخدام الدالتين قبل قراءة الملف أو الكتابة إليه، ويعرف الوسيط type نوع التخزين المؤقت للمجرى stream، ويوضح الجدول التالي أنواع التخزين المؤقت. القيمة التأثير _IONBF لا تخزّن الدخل والخرج مؤقتًا _IOFBF خزِّن الدخل والخرج مؤقتًا _IOLBF تخزين مؤقت خطي: تخلص من محتويات الذاكرة المؤقتة عندما تمتلئ، أو عند كتابة سطر جديد، أو عند طلب القراءة يمكن للوسيط buf أن يكون مؤشرًا فارغًا، وفي هذه الحالة تُنشأ مصفوفة تلقائيًا لتخزين البيانات مؤقتًا، ويمكن بخلاف ذلك للمستخدم توفير ذاكرة مؤقتة لكن يجب التأكد من استمرارية الذاكرة المؤقتة بقدر مساوٍ (أو أكثر) لاستمرارية التدفق stream. يُعد استخدام مساحة التخزين المحجوزة تلقائيًا ضمن تعليمة مركبة compound statement من الأخطاء الشائعة، إذ أن الحصول على المساحة التخزينية على النحو الصحيح في هذه الحالة يجري عن طريق الدالة malloc عوضًا عن ذلك. يُحدد حجم الذاكرة المؤقتة باستخدام الوسيط size. يشابه استدعاء الدالة setbuf استدعاء الدالة setvbuf إذا استخدمنا _IOFBF قيمةً للوسيط type والقيمة BUFSIZ للوسيط size، وتُستخدم القيمة _IONBF للوسيط type إذا كان buf مؤشرًا فارغًا. لا تُعاد أي قيمة بواسطة الدالة setbuf، بينما تُعيد الدالة setvbuf القيمة صفر للدلالة على نجاح الاستدعاء، وإلا فقيمة غير صفرية إذا كانت قيم type، أو size غير صالحة، أو كان الطلب غير ممكن التنفيذ. دالة fflush يُصرّح عن الدالة fflush كما يلي: #include <stdio.h> int fflush(FILE *stream); إذا أشار المجرى stream إلى ملف مفتوح للخرج أو بنمط التحديث، وكان هناك أي بيانات غير مكتوبة فإنها تُكتب خارجًا، وهذا يعني أنه لا يمكن لدالة داخل بيئة مستضافة hosted environment، أو ضمن لغة سي أن تضمن -على سبيل المثال- أن البيانات تصل مباشرةً إلى سطح قرص يدعم الملف. تُهمَل أي عملية ungetc سابقة إذا كان المجرى مرتبطًا بالملف المفتوح بهدف الخرج أو التحديث. يجب أن تكون آخر عملية على المجرى عملية خرج، وإلا فسنحصل على سلوك غير معرّف. يتخلص استدعاء fflush الذي يحتوي على وسيط قيمته صفر من جميع مجاري الدخل والخرج، ويجب هنا الانتباه إلى المجاري التي لم تكن عمليتها الأخيرة عملية خرج، أي تفادي حصول السلوك غير المعرّف الذي ذكرناه سابقًا. تُعيد الدالة القيمة EOF للدلالة على الخطأ، وإلا فالقيمة صفر للدلالة على النجاح. الدوال عشوائية الوصول Random access functions تعمل جميع دوال دخل وخرج الملفات بصورةٍ مشابهة بين بعضها، إذ أن الملفات ستُقرأ أو يُكتب إليها بصورةٍ متتابعة إلا إذا اتخذ المستخدم خطوات مقصودة لتغيير موضع مؤشر الملف. ستتسبب عملية قراءة متبوعة بكتابة متبوعة بقراءة ببدء عملية القراءة الثانية بعد نهاية عملية كتابة البيانات فورًا، وذلك بفرض أن الملف مفتوح باستخدام نمط يسمح بهذا النوع من العمليات، كما يجب أن تتذكر أن المجرى stdio يُصرّ على إدخال المستخدم لعملية تحرير ذاكرة مؤقتة بين كل عنصر من عناصر دورة قراءة- كتابة- قراءة، وللتحكم بذلك، تسمح دالة الوصول العشوائي random access function بالتحكم بموضع الكتابة والقراءة ضمن الملف، إذ يُحرّك موضع مؤشر الملف دون الحاجة لقراءة أو كتابة ويشير إلى البايت الذي سيخضع لعملية القراءة أو الكتابة التالية. هناك ثلاثة أنواع من الدوال التي تسمح بفحص موضع مؤشر الملف أو تغييره، إليك تصاريح كل منهم: #include <stdio.h> /* إعادة موضع مؤشر الملف */ long ftell(FILE *stream); int fgetpos(FILE *stream, fpos_t *pos); /* ضبط موضع مؤشر الملف إلى الصفر */ void rewind(FILE *stream); /* ضبط موضع مؤشر الملف */ int fseek(FILE *stream, long offset, int ptrname); int fsetpos(FILE *stream, const fpos_t *pos); تُعيد الدالة ftell القيمة الحالية لموضع مؤشر الملف (المُقاسة بعدد المحارف)، إذا كان المجرى stream يشير إلى ملف ثنائي، وإلا فإنها تعيد رقمًا مميزًا في حالة الملف النصي، ويمكن استخدام هذه القيمة فقط عند استدعاءات لاحقة لدالة fseek لإعادة ضبط موضع مؤشر الملف الحالة. نحصل على القيمة -1L في حالة الخطأ ويُضبط errno. تضبط الدالة rewind موضع مؤشر الملف الحالي إلى بداية الملف المُشار إليه بالمجرى stream، ويُعاد ضبط مؤشر خطأ الملف باستدعاء الدالة rewind ولا تُعيد الدالة أي قيمة. تسمح الدالة fseek لموضع مؤشر الملف ضمن المجرى أن يُضبط لقيمة عشوائية (للملفات الثنائية)، أو إلى الموضع الذي نحصل عليه من ftell فقط بالنسبة للملفات النصية، وتتبع الدالة القوانين التالية: يُضبط موضع مؤشر الملف في الحالة الاعتيادية بفارق معين من البايتات (المحارف) عن نقطة الملف المُحددة بالقيمة prtname، وقد يكون الفارق offset سالبًا. قد يأخذ ptrname القيمة SEEK_SET التي تضبط موضع مؤشر الملف نسبيًا إلى بداية الملف، أو القيمة SEEK_CUR التي تضبط موضع مؤشر الملف نسبيًا إلى قيمتها الحالية، أو القيمة SEEK_END التي تضبط موضع مؤشر الملف نسبيًا إلى نهاية الملف، إلا أنه من غير المضمون أن تعمل القيمة الأخيرة بنجاح في المجاري الثنائية. يجب أن تكون قيمة offset في الملفات النصية إما صفر أو قيمة مُعادة بواسطة استدعاء سابق للدالة ftell على المجرى ذاته، ويجب أن تكون قيمة ptrnmae مساويةً إلى SEEK_SET. يُفرغ fseek مؤشر نهاية الملف للمجرى المُحدد ويحذف بيانات أي استدعاء لعملية ungetc، ويعمل ذلك لكلٍّ من الدخل والخرج. تُعاد القيمة صفر للدلالة على النجاح وأي قيمة غير صفرية تدل على طلب ممنوع للدالة. لاحظ أنه يمكن لكلٍ من ftell و fseek ترميز قيمة موضع مؤشر الملف إلى قيمة من نوع long، وقد لا يحدث هذا بنجاح في حالة استخدامه على الملفات الطويلة جدًا؛ لذلك، يقدم المعيار كلًا من fgetpos و fsetpos للتغلُّب على هذه المشكلة. تخزِّن الدالة fgetpos موضع مؤشر الملف الحالي ضمن المجرى للكائن المُشار إليه باستخدام المؤشر pos، والقيمة المخزنة هي قيمة مميزة تُستخدم فقط للعودة إلى الموضع المحدد ضمن المجرى ذاته باستخدام الدالة fsetpos. تعمل الدالة fsetpos كما وضحنا سابقًا، كما أنها تُفرغ مؤشر نهاية الملف للمجرى وتُزيل أي تأثير لعمليات ungetc سابقة. نحصل على القيمة صفر في حالة النجاح لكلا الدالتين، بينما نحصل على قيمة غير صفرية في حالة الخطأ ويُضبط errno. التعامل مع الأخطاء تحافظ دوال الدخل والخرج القياسية على مؤشرين لكل مجرى مفتوح للدلالة على نهاية الملف وحالة الخطأ ضمنه، ويمكن الحصول على قيم هذه المؤشرات وضبطها عن طريق الدوال التالية: #include <stdio.h> void clearerr(FILE *stream); int feof(FILE *stream); int ferror(FILE *stream); void perror(const char *s); تُفرّغ الدالة clearerr كلًا من مؤشري الخطأ ونهاية الملف EOF للمجرى stream. تُعيد الدالة feof قيمةً غير صفرية إذا كان لمؤشر نهاية الملف الخاص بالمجرى stream قيمة، وإلا فإنها تعيد القيمة صفر. تُعيد الدالة ferror قيمة غير صفرية إذا كان لمؤشر الخطأ الخاص بالمجرى stream قيمة، وإلا فإنها تعيد القيمة صفر. تطبع الدالة perror سطرًا واحدًا يحتوي على رسالة خطأ على خرج البرنامج القياسي مسبوقًا بالسلسلة النصية المُشار إليها بواسطة المؤشر s مع إضافة مسافة فارغة ونقطتين ":". تُحدد رسالة الخطأ بحسب قيمة errno وتُعطي شرحًا بسيطًا عن سبب الخطأ، على سبيل المثال يتسبب البرنامج التالي برسالة خطأ: #include <stdio.h> #include <stdlib.h> main(){ fclose(stdout); if(fgetc(stdout) >= 0){ fprintf(stderr, "What - no error!\n"); exit(EXIT_FAILURE); } perror("fgetc"); exit(EXIT_SUCCESS); } /* رسالة الخطأ */ fgetc: Bad file number [مثال 2] لم نقُل أن الرسالة التي سنحصل عليها ستكون واضحة. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع الدخل والخرج I/O وتنسيقه في لغة سي C المقال السابق: التعامل مع المكتبات في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C التعامل مع المؤشرات Pointers في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C
يعدّ افتقار لغات البرمجة لدعمها للدخل والخرج إحدى أبرز الأسباب التي منعت التبني واسع النطاق واستخدامها في البرمجة العملية، وهو الموضوع الذي لم يرد أي مصمّم لغة أن يتعامل معه، إلا أن لغة سي تفادت هذه المشكلة، بعدم تضمينها لأي دعم للدخل والخرج، إذ كان سلوك سي هو أن تترك التعامل مع الدخل والخرج لدوال المكتبات، مما عنى أنه بالإمكان لمصمّمي الأنظمة استخدام طرق دخل وخرج مخصصة بدلًا من إجبارهم على تغيير اللغة بذات نفسها. تطوّرت حزمة مكتبات عُرفت باسم "مكتبة الدخل والخرج القياسي Standard I/O Library" -أو اختصارًا stdio- في الوقت ذاته الذي كانت لغة سي تتطوّر، وقد أثبتت هذه المكتبة مرونتها وقابلية نقلها وأصبحت الآن جزءًا من المعيار. اعتمدت حزمة الدخل والخرج القياسي القديمة كثيرًا على نظام يونيكس UNIX للوصول إلى الملفات وبالأخص الافتراض أنه لا يوجد أي فرق بين ملفات ثنائية غير مُهيكلة وملفات أخرى تحتوي على نص مقروء، إلا أن العديد من أنظمة التشغيل تفصل ما بين الاثنين وعُدّلت الحزمة فيما بعد لضمان قابلية نقل برامج لغة سي بين نوعَي نظام الملفات. هناك بعض التغييرات في هذا المجال التي تتسبب بالضرر لكثيرٍ من البرامج المكتوبة مسبقًا على الرغم من الجهود التي تحاول أن تحدّ من هذا الضرر. من المفترض أن تعمل برامج لغة سي القديمة بنجاح دون تعديل في بيئة يونيكس. نموذج الدخل والخرج لا يُميّز نموذج الدخل والخرج بين أنواع الأجهزة المادية التي تدعم الدخل والخرج، إذ يُعامل كل مصدر أو حوض من البيانات بالطريقة ذاتها ويُنظر إليه على أنه مجرًى من البايتات stream of bytes. بما أن الكائن الأصغر الذي يمكن تمثيله في لغة سي هو المحرف، فالوصول إلى الملف مسموحٌ باستخدام حدود أي محرف، وبالتالي يمكن قراءة أو كتابة أي عدد من المحارف انطلاقًا من نقطة متحركة تُعرف باسم مؤشر الموضع position indicator، وتُكتب أو تُقرأ المحارف تباعًا بدءًا من هذه النقطة ويُحرّك مؤشر الموضع خلال ذلك. يُضبط مؤشر الموضع مبدئيًا إلى بداية الملف عند فتحه، لكن من الممكن تحريكه باستخدام طلبات تحديد الموقع، ويُتجاهل مؤشر موضع الملف في حال كان الوصول العشوائي إلى الملف غير ممكن. لفتح الملف في نمط الإضافة append تأثيرات على مجرى موضع المؤشر في الملف معرفة بحسب التنفيذ. الفكرة العامة هي تقديم إمكانية القراءة أو الكتابة بصورةٍ تتابعية، باستثناء حالة فتح المجرى باستخدام نمط الإضافة، أو إذا حُرّك مؤشر موضع الملف مباشرةً. هناك نوعان من أنواع الملفات، هما: الملفات النصية text files والملفات الثنائية binary files التي يمكن التعامل معها داخل البرنامج على أنها مجاري نصية text streams أو مجاري ثنائية binary streams بعد فتحها لعمليات الإدخال والإخراج. لا تسمح حزمة stdio بالعمليات على محتوى الملف مباشرةً، بل بالتعديل على المجرى الذي يحتوي على بيانات الملف. المجاري النصية يحدّد المعيار المجرى النصي text stream، الذي يمثّل ملفًا يحتوي على أسطر نصية ويتألف السطر من صفر محرف أو أكثر ينتهي بمحرف نهاية السطر، ومن الممكن أن يكون تمثيل الأسطر الفعلي في البيئة الخارجية مختلفًا عن تمثيله هنا، كما من الممكن إجراء تحويلات على مجرى البيانات عند دخولها إلى أو خروجها من البرنامج، وأكثر المتطلبات شيوعًا هو ترجمة المحرف الذي ينهي السطر "'\n'" إلى السلسلة "'\r\n'" عند الخرج وإجراء عكس العملية عند الدخل، ومن الممكن تواجد بعض الترجمات الضرورية الأخرى. يُضمن للبيانات التي تُقرأ من المجرى النصي أن تكون مساويةً إلى البيانات المكتوبة سابقًا إلى الملف، وذلك إذا كانت هذه البيانات مؤلفةً من أسطر مكتملة تحتوي على محارف يمكن طباعتها، وكانت محارف التحكم control characters ومحارف مسافة الجدولة الأفقية horizontal-tab ومحارف الأسطر الجديدة newline فقط، ولم يُتبع أي محرف سطر جديد بمحرف مسافة فارغة space مباشرةً، وكان المحرف الأخير في المجرى هو محرف سطر جديد. كما أن هناك ضمان بأن المحرف الأخير المكتوب إلى الملف النصي هو محرف سطر جديد، ومن الممكن قراءة الملف مجددًا بمحتوياته المماثلة التي كُتبت إليه سابقًا. إلحاق المحرف الأخير المكتوب إلى الملف بمحرف سطر جديد معرفٌ بحسب التنفيذ، وذلك لأن الملفات النصية والملفات الثنائية تُعامل نفس المعاملة في بعض التنفيذات. قد تُجرّد بعض التنفيذات المسافة الفارغة البادئة من الأسطر التي تتألف من مسافات فارغة فقط متبوعةً بسطر جديد، أو تُجرّد المسافة الفارغة في نهاية السطر. يجب أن يدعم التنفيذ الملفات النصية التي تحتوي سطورها على 254 محرفًا على الأقل، ويتضمن ذلك محرف السطر الجديد الذي يُنهي السطر. قد نحصل على مجرى ثنائي عند فتح مجرى نصي بنمط التحديث update mode في بعض التنفيذات. قد تتسبب الكتابة على مجرًى نصي باقتطاع الملف عند نقطة الكتابة في بعض التنفيذات، أي ستُهمل جميع البيانات التي تتبع البايت الأخير المكتوب. المجاري الثنائية يمثل المجرى الثنائي سلسلةً من المحارف التي يمكن استخدامها لتسجيل البيانات الداخلية لبرنامج ما، مثل محتويات الهياكل structures، أو المصفوفات وذلك بالشكل الثنائي، إذ تكون البيانات المقروءة من المجاري الثنائية مساويةً للبيانات المكتوبة إلى المجرى ذاته سابقًا ضمن نفس التنفيذ، وقد يُضاف عددٌ من المحارف الفارغة "NULL" في بعض الظروف إلى نهاية المجرى الثنائي، ويكون عدد المحارف معرفًا بحسب التنفيذ. تعتمد بيانات الملفات الثنائية على الآلة التي تعمل عليها لأبعد حد، وهي غير قابلة للنقل عمومًا. المجاري الأخرى قد تتوفر بعض أنواع المجاري الأخرى، إلا أنها معرفة بحسب التنفيذ. ملف الترويسة <stdio.h> هناك عدد من الدوال والماكرو الموجودة لتقديم الدعم لمختلف أنواع المجاري، ويحتوي ملف الترويسة <stdio.h> العديد من التصريحات المهمة لهذه الدوال، إضافةً إلى الماكرو التالية وتصاريح الأنواع: النوع FILE: نوع الكائن المُستخدم لاحتواء معلومات التحكم بالمجرى، ولا يحتاج مستخدمو مكتبة "stdio" لمعرفة محتويات هذه الكائنات، إذ يكفي التعامل مع المؤشرات التي تشير إليهم. لا يُعد نسخ الكائنات هذه ضمن البرنامج آمنًا، إذ أن عناوينهم قد تكون في بعض الأحيان معقدة. النوع fpos_t: نوع الكائن الذي يُستخدم لتسجيل القيم الفريدة من نوعها التي تنتمي إلى مجرى مؤشر موضع الملف. القيم IOFBF_ و IOLBF_ و IONBF_: وهب قيم تُستخدم للتحكم بالتخزين المؤقت buffering للمجرى بالاستعانة بالدالة setvbuf. القيمة BUFSIZ: حجم التخزين المؤقت المُستخدم بواسطة الدالة setbuf، وهو تعبيرٌ رقم صحيح integral ثابت constant تكون قيمته 256 على الأقل. القيمة EOF: تعبير رقم صحيح سالب ثابت يحدد نهاية الملف end-of-file ضمن مجرى، أي عند الوصول إلى نهاية الدخل. القيمة FILENAME_MAX: الطول الأعظمي الذي يمكن لاسم ملف أن يكون إذا كان هناك قيد على ذلك، وإلا فهو الحجم الذي يُنصح به لمصفوفة تحمل اسم ملف. القيمة FOPEN_MAX: العدد الأدنى من الملفات التي يضمن التنفيذ فتحها في وقت آني، وهو ثمانية ملفات. لاحظ أنه من الممكن إغلاق ثلاث مجاري مُعرفة مسبقًا إذا احتاج البرنامج فتح أكثر من خمسة ملفات مباشرةً. القيمة L_tmpnam: الطول الأعظمي المضمون لسلسلة نصية في tmpnam، وهو تعبير رقم صحيح ثابت. القيم SEEK_CUR و SEEK_END و SEEK_SET: تعابير رقم صحيح ثابتة تُستخدم للتحكم بأفعال fseek. القيمة TMP_MAX: العدد الأدنى من أسماء الملفات الفريدة من نوعها المولدة من قبل tmpnam، وهو تعبير رقم صحيح ثابت بقيمة لا تقل عن 25. الكائنات stdin و stdout و stderr: وهي كائنات معرفة مسبقًا من النوع "* FILE" وتشير إلى مجرى الدخل القياسي ومجرى الخرج القياسي ومجرى الخطأ بالترتيب، وتُفتح هذه المجاري تلقائيًا عند بداية تنفيذ البرنامج. العمليات على المجاري بعد أن تعرفنا على أنواع المجاري وطبيعتها والقيم المرتبطة بها، نستعرض الآن العمليات الأساسية عليها ألا وهي فتح المجرى وإغلاقه، إضافةً إلى التخزين المؤقت. فتح المجرى يتصل المجرى بالملف عن طريق دالة fopen، أو freopen، أو tmpfile، إذ تعيد هذه الدوال -إذا كان استدعاؤها ناجحًا- مؤشرًا يشير إلى كائن من نوع FILE. هناك ثلاث أنواع من المجاري المتاحة افتراضيًا دون أي جهد إضافي مطلوب منك، وتتصل هذه المجاري عادةً بالجهاز المادي المُرتبط بالبرنامج المُنفّذ ألا وهو الطرفية Terminal عادةً، ويشار إلى هذه المجاري بالأسماء: stdin: وهو مجرى الدخل القياسي standard input. stdout: وهو مجرى الخرج القياسي standard output. stderr: وهو مجرى الخطأ القياسي standard error. ويكون دخل لوحة المفاتيح في الحالة الطبيعية من المجرى stdin وخرج الطرفية هو stdout، بينما تُوجّه رسائل الأخطاء إلى المجرى stderr. الهدف من فصل رسائل الأخطاء عن رسائل الخرج العادية هو السماح بربط مجرى stdout إلى شيءٍ آخر مغاير لجهاز للطرفية مثل ملف ما والحصول على رسائل الخطأ بنفس الوقت على الشاشة أمامك عوضًا عن توجيه الأخطاء إلى الملف، وتخزّن كامل الملفات مؤقتًا إذا لم توجّه إلى أجهزة تفاعلية. كما ذكرنا سابقًا، قد يكون مؤشر موضع الملف قابلًا للتحريك أو غير قابل للتحريك بحسب الجهاز المُستخدم، إذ يكون مؤشر موضع الملف غير قابل للتحريك ضمن مجرى stdin على سبيل المثال إذا كان متصلًا إلى الطرفية (الحالة الاعتيادية له). جميع الملفات غير المؤقتة تمتلك اسمًا filename وهو سلسلةٌ نصية، والقوانين التي تحدد اسم الملف الصالح معرفةٌ حسب التنفيذ، وينطبق الأمر ذاته على إمكانية فتح الملف لعدة مرات بصورةٍ آنية. قد يتسبب فتح ملف جديد بإنشاء هذا الملف، وتتسبب إعادة إنشاء ملف موجود مسبقًا بإهمال محتوياته السابقة. إغلاق المجرى تُغلق المجاري عند استدعاء fclose أو exit بصورةٍ صريحة، أو عندما يعود البرنامج إلى الدالة main، وتُمسح جميع البيانات المخزنة مؤقتًا عند إغلاق المجرى. تصبح حالة الملفات المفتوحة غير معروفة إذا توقف البرنامج لسببٍ ما دون استخدام الطرق السابقة لإغلاقه. التخزين المؤقت للمجرى هناك ثلاث أنواع للتخزين المؤقت: دون تخزين مؤقت unbuffered: تُستخدم مساحة التخزين بأقل ما يمكن من قبل stdio بهدف إرسال أو تلقي البيانات أسرع ما يمكن. تخزين مؤقت خطي line buffered: تُعالج المحارف سطرًا تلو سطر، ويُستخدم هذا النوع من التخزين المؤقت كثيرًا في البيئات التفاعلية، وتُمسح محتويات الذواكر المؤقتة الداخلية internal buffers فقط عندما تمتلئ أو عندما يُعالج سطر جديد. التخزين المؤقت الكامل fully buffered: تُسمح الذواكر المؤقتة الداخلية فقط عندما تمتلئ. يُمكن مسح محتوى الذاكرة الداخلية المرتبطة بمجرى ما عن طريق استخدام fflush مباشرةً. يُعرَّف الدعم لأنواع التخزين المؤقت المختلفة بحسب التنفيذ، ويمكن التحكم به ضمن الحدود المعرفة باستخدام setbuf و setvbuf. التلاعب بمحتويات الملف مباشرة هناك عدة دوال تسمح لنا بالتعامل مع الملف مباشرةً. #include <stdio.h> int remove(const char *filename); int rename(const char *old, const char *new); char *tmpnam(char *s); FILE *tmpfile(void); الدالة remove: تتسبب بإزالة الملف، وستفشل محاولات فتح هذا الملف لاحقًا إلا في حال إنشاء الملف مجددًا. يكون سلوك الدالة remove عندما يكون الملف مفتوحًا معرفًا بحسب التنفيذ، وتعيد الدالة القيمة صفر للدلالة على النجاح، بينما تدل أي قيمة أخرى على فشل عملها. الدالة rename: تُغيّر اسم الملف المعرف بالكلمة old في مثالنا السابق إلى new، وستفشل محاولات فتح الملف باستخدام اسمه القديم، إلا إذا أنشئ ملفٌ جديد يحمل الاسم القديم ذاته، وكما هو الحال في remove فإن الدالة rename تُعيد القيمة صفر للدلالة على نجاح العملية وأي قيمة مغايرة لذلك تدل على حصول خطأ. السلوك معرف حسب التنفيذ إذا حاولنا تسمية الملف باسم جديد باستخدام rename وكان هناك ملف بالاسم ذاته مسبقًا. لن يُعدّل على الملف إذا فشلت الدالة rename لأي سببٍ كان. الدالة tmpnam: تولّد سلسلة نصية لتُستخدم اسمًا لملف، ويضمن لهذه السلسلة النصية أن تكون فريدةً من نوعها بالنسبة لأي اسم ملف آخر موجود، ويمكن أن تُستدعى بصورةٍ متتالية للحصول على اسم جديد كل مرة. يُستخدم الثابت TMP_MAX لتحديد عدد مرات استدعاء الدالة tmpnam قبل أن يتعذر عليه العثور على اسماء فريدة، وقيمته 25 على الأقل، ونحصل على سلوك غير معرّف من قبل المعيار في حال استدعاء الدالة tmpnam عدد مرات يتجاوز هذا الثابت إلا أن الكثير من التنفيذات تقدم حدًّا لا نهائيًا. تستخدم tmpnam ذاكرة مؤقتة داخلية لبناء الاسم وتُعيد مؤشرًا يشير إليه وذلك إذا ضُبط الوسيط s إلى القيمة NULL، وقد تغيّر الاستدعاءات اللاحقة للدالة الذاكرة المؤقتة الداخلية ذاتها. يمكن استخدام مؤشر يشير إلى مصفوفة مثل وسيط بدلًا من السابق، بحيث تحتوي المصفوفة على L_tmpnam محرف على الأقل، وفي هذه الحالة سُيملأ الاسم إلى الذاكرة المؤقتة المزوّدة (المصفوفة)، ويمكن فيما بعد إنشاء ملف بهذا الاسم واستخدامه ملفًا مؤقتًا. لن يكون اسم الملف مفيدًا ضمن سياقات أخرى غالبًا، بالنظر إلى توليده من قبل الدالة. لا تُزال الملفات المؤقتة من هذا النوع إلا إن استدعيت دالة الحذف، وغالبًا ما تُستخدم هذه الملفات لتمرير البيانات المؤقتة بين برنامجين منفصلين. الدالة tmpfile: تُنشئ ملف ثنائي مؤقت يُمكن التعديل على محتوياته، وتعيد الدالة مؤشرًا يشير إلى مجرى الملف، ويُزال هذا الملف فيما بعد عند إغلاق مجراه، وتُعيد الدالة tmpfile مؤشرًا فارغًا null إذا لم ينجح فتح الملف. فتح الملفات بالاسم يمكن فتح الملفات الموجودة بالاسم عن طريق استدعاء الدالة fopen المصرّح عنها على النحو التالي: #include <stdio.h> FILE *fopen(const char *pathname, const char *mode); يمثل الوسيط pathname اسم الملف الذي تريد فتحه، مثل الاسم الذي تعيده الدالة tmpnam أو أي اسم ملف معين آخر. يمكن فتح الملفات باستخدام عدة أنماط modes، مثل نمط القراءة read لقراءة البيانات، ونمط الكتابة write لكتابة البيانات وهكذا. لاحظ أن الدالة fopen ستُنشئ ملفًا إذا أردت كتابة البيانات على ملف، أو أنها ستتخلص من محتويات الملف إذا وُجد ليصبح طوله صفر (أي أنك ستخسر محتويات الملف السابقة). يوضح الجدول التالي جميع الأنماط الموجودة في المعيار، إلا أن التنفيذ قد يسمح بأنماط أخرى بإضافة محارف إضافية في نهاية كل من الأنماط. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } النمط نوع الملف القراءة الكتابة إنشاء جديد حذف القيمة السابقة "r" نصي نعم لا لا لا "rb" ثنائي نعم لا لا لا "r+" نصي نعم نعم لا لا "r+b" ثنائي نعم نعم لا لا "rb+" ثنائي نعم نعم لا لا "w" نصي لا نعم نعم نعم "wb" ثنائي لا نعم نعم نعم "w+" نصي نعم نعم نعم نعم "w+b" ثنائي نعم نعم نعم نعم "wb+" ثنائي نعم نعم نعم نعم "a" نصي لا نعم نعم لا "ab" ثنائي لا نعم نعم لا "a+" نصي نعم نعم نعم لا "a+b" ثنائي لا نعم نعم لا "ab+" ثنائي لا نعم نعم لا انتبه من بعض التنفيذات التي تضيف إلى النمط الأخير محارف NULL في حالة الملفات الثنائية، إذ قد يتسبب فتح هذه الملفات بالنمط ab أو +ab أو a+b بوضع مؤشر الملف خارج نطاق آخر البيانات المكتوبة. تُكتب جميع البيانات في نهاية الملف إذا فُتح باستخدام نمط الإضافة append، بغض النظر عن محاولة تغيير موضع المؤشر باستخدام الدالة fseek، ويكون موضع مؤشر الملف المبدئي معرف بحسب التنفيذ. تفشل محاولات فتح الملف بنمط القراءة (النمط 'r')، إذا لم يكن الملف موجودًا أو لم يمكن قراءته. يمكن القراءة من والكتابة إلى الملفات المفتوحة بنمط التحديث update (باستخدام '+' مثل المحرف الثاني أو الثالث ضمن النمط) إلا أنه من غير الممكن إلحاق القراءة بالكتابة مباشرةً أو الكتابة بالقراءة دون استدعاء بينهما لدالة واحدة (أو أكثر) من الدوال: fflush أو fseek أو fsetpos أو rewind، والاستثناء الوحيد هنا هو جواز إلحاق الكتابة مباشرةً بعد القراءة إذا قُرأ المحرف EOF (نهاية الملف). من الممكن أيضًا في بعض التنفيذات أن يُتخلى عن b في أنماط فتح الملفات الثنائية واستخدام الأنماط ذاتها الخاصة بالملفات النصية. تُخزّن المجاري المفتوحة باستخدام fopen تخزينًا مؤقتًا بالكامل إذا لم تكن متصلة إلى جهاز تفاعلي، ويضمن ذلك التعامل مع الأسئلة prompts والطلبات responses على النحو الصحيح. تعيد الدالة fopen مؤشرًا فارغًا null إذا فشلت بفتح الملف، وإلا فتعيد مؤشرًا يشير إلى الكائن الذي يتحكم بالمجرى. كائنات المجاري stdin و stdout و stderr غير قابلة للتعديل بالضرورة ومن الممكن عدم وجود إمكانية استخدام القيمة المُعادة من الدالة fopen لإسنادها إلى واحدة من هذه الكائنات، بدلًا من ذلك نستخدم freopen لهذا الغرض. الدالة freopen تُستخدم الدالة freopne لأخذ مؤشر يشير إلى مجرى وربطه مع اسم ملف آخر، وتصرَّح الدالة على النحو التالي: #include <stdio.h> FILE *freopen(const char *pathname, const char *mode, FILE *stream); وسيط mode مشابه لمثيله في دالة fopen. يُغلق المجرى stream أولًا ويحدث تجاهل أي أخطاء متولدة عن ذلك، ونحصل على قيمة NULL في حالة حدوث خطأ عند تنفيذ الدالة، وإلا فإننا نحصل على القيمة الجديدة للمجرى stream. إغلاق الملفات يمكننا إغلاق ملف مفتوح باستخدام الدالة close والمصرح عنها كما يلي: #include <stdio.h> int fclose(FILE *stream); يُتخلّص من أي بيانات موجودة على الذاكرة المؤقتة لم تُكتب على الملف الخاص بالمجرى stream إضافةً إلى أي بيانات أخرى لم تُقرأ، وتُحرّر الذاكرة المؤقتة المرتبطة بالمجرى إذا رُبطت به تلقائيًا، وأخيرًا يُغلق الملف. نحصل على القيمة صفر للدلالة على نجاح العملية، وإلا فالقيمة EOF للدلالة على الخطأ. الدالتان setbuf و setvbuf تُستخدم الدالتان للتعديل على استراتيجية التخزين المؤقتة لمجرى معين مفتوح، ويُصرّح عن الدالتين كما يلي: #include <stdio.h> int setvbuf(FILE *stream, char *buf, int type, size_t size); void setbuf(FILE *stream, char *buf); يجب استخدام الدالتين قبل قراءة الملف أو الكتابة إليه، ويعرف الوسيط type نوع التخزين المؤقت للمجرى stream، ويوضح الجدول التالي أنواع التخزين المؤقت. القيمة التأثير _IONBF لا تخزّن الدخل والخرج مؤقتًا _IOFBF خزِّن الدخل والخرج مؤقتًا _IOLBF تخزين مؤقت خطي: تخلص من محتويات الذاكرة المؤقتة عندما تمتلئ، أو عند كتابة سطر جديد، أو عند طلب القراءة يمكن للوسيط buf أن يكون مؤشرًا فارغًا، وفي هذه الحالة تُنشأ مصفوفة تلقائيًا لتخزين البيانات مؤقتًا، ويمكن بخلاف ذلك للمستخدم توفير ذاكرة مؤقتة لكن يجب التأكد من استمرارية الذاكرة المؤقتة بقدر مساوٍ (أو أكثر) لاستمرارية التدفق stream. يُعد استخدام مساحة التخزين المحجوزة تلقائيًا ضمن تعليمة مركبة compound statement من الأخطاء الشائعة، إذ أن الحصول على المساحة التخزينية على النحو الصحيح في هذه الحالة يجري عن طريق الدالة malloc عوضًا عن ذلك. يُحدد حجم الذاكرة المؤقتة باستخدام الوسيط size. يشابه استدعاء الدالة setbuf استدعاء الدالة setvbuf إذا استخدمنا _IOFBF قيمةً للوسيط type والقيمة BUFSIZ للوسيط size، وتُستخدم القيمة _IONBF للوسيط type إذا كان buf مؤشرًا فارغًا. لا تُعاد أي قيمة بواسطة الدالة setbuf، بينما تُعيد الدالة setvbuf القيمة صفر للدلالة على نجاح الاستدعاء، وإلا فقيمة غير صفرية إذا كانت قيم type، أو size غير صالحة، أو كان الطلب غير ممكن التنفيذ. دالة fflush يُصرّح عن الدالة fflush كما يلي: #include <stdio.h> int fflush(FILE *stream); إذا أشار المجرى stream إلى ملف مفتوح للخرج أو بنمط التحديث، وكان هناك أي بيانات غير مكتوبة فإنها تُكتب خارجًا، وهذا يعني أنه لا يمكن لدالة داخل بيئة مستضافة hosted environment، أو ضمن لغة سي أن تضمن -على سبيل المثال- أن البيانات تصل مباشرةً إلى سطح قرص يدعم الملف. تُهمَل أي عملية ungetc سابقة إذا كان المجرى مرتبطًا بالملف المفتوح بهدف الخرج أو التحديث. يجب أن تكون آخر عملية على المجرى عملية خرج، وإلا فسنحصل على سلوك غير معرّف. يتخلص استدعاء fflush الذي يحتوي على وسيط قيمته صفر من جميع مجاري الدخل والخرج، ويجب هنا الانتباه إلى المجاري التي لم تكن عمليتها الأخيرة عملية خرج، أي تفادي حصول السلوك غير المعرّف الذي ذكرناه سابقًا. تُعيد الدالة القيمة EOF للدلالة على الخطأ، وإلا فالقيمة صفر للدلالة على النجاح. الدوال عشوائية الوصول Random access functions تعمل جميع دوال دخل وخرج الملفات بصورةٍ مشابهة بين بعضها، إذ أن الملفات ستُقرأ أو يُكتب إليها بصورةٍ متتابعة إلا إذا اتخذ المستخدم خطوات مقصودة لتغيير موضع مؤشر الملف. ستتسبب عملية قراءة متبوعة بكتابة متبوعة بقراءة ببدء عملية القراءة الثانية بعد نهاية عملية كتابة البيانات فورًا، وذلك بفرض أن الملف مفتوح باستخدام نمط يسمح بهذا النوع من العمليات، كما يجب أن تتذكر أن المجرى stdio يُصرّ على إدخال المستخدم لعملية تحرير ذاكرة مؤقتة بين كل عنصر من عناصر دورة قراءة- كتابة- قراءة، وللتحكم بذلك، تسمح دالة الوصول العشوائي random access function بالتحكم بموضع الكتابة والقراءة ضمن الملف، إذ يُحرّك موضع مؤشر الملف دون الحاجة لقراءة أو كتابة ويشير إلى البايت الذي سيخضع لعملية القراءة أو الكتابة التالية. هناك ثلاثة أنواع من الدوال التي تسمح بفحص موضع مؤشر الملف أو تغييره، إليك تصاريح كل منهم: #include <stdio.h> /* إعادة موضع مؤشر الملف */ long ftell(FILE *stream); int fgetpos(FILE *stream, fpos_t *pos); /* ضبط موضع مؤشر الملف إلى الصفر */ void rewind(FILE *stream); /* ضبط موضع مؤشر الملف */ int fseek(FILE *stream, long offset, int ptrname); int fsetpos(FILE *stream, const fpos_t *pos); تُعيد الدالة ftell القيمة الحالية لموضع مؤشر الملف (المُقاسة بعدد المحارف)، إذا كان المجرى stream يشير إلى ملف ثنائي، وإلا فإنها تعيد رقمًا مميزًا في حالة الملف النصي، ويمكن استخدام هذه القيمة فقط عند استدعاءات لاحقة لدالة fseek لإعادة ضبط موضع مؤشر الملف الحالة. نحصل على القيمة -1L في حالة الخطأ ويُضبط errno. تضبط الدالة rewind موضع مؤشر الملف الحالي إلى بداية الملف المُشار إليه بالمجرى stream، ويُعاد ضبط مؤشر خطأ الملف باستدعاء الدالة rewind ولا تُعيد الدالة أي قيمة. تسمح الدالة fseek لموضع مؤشر الملف ضمن المجرى أن يُضبط لقيمة عشوائية (للملفات الثنائية)، أو إلى الموضع الذي نحصل عليه من ftell فقط بالنسبة للملفات النصية، وتتبع الدالة القوانين التالية: يُضبط موضع مؤشر الملف في الحالة الاعتيادية بفارق معين من البايتات (المحارف) عن نقطة الملف المُحددة بالقيمة prtname، وقد يكون الفارق offset سالبًا. قد يأخذ ptrname القيمة SEEK_SET التي تضبط موضع مؤشر الملف نسبيًا إلى بداية الملف، أو القيمة SEEK_CUR التي تضبط موضع مؤشر الملف نسبيًا إلى قيمتها الحالية، أو القيمة SEEK_END التي تضبط موضع مؤشر الملف نسبيًا إلى نهاية الملف، إلا أنه من غير المضمون أن تعمل القيمة الأخيرة بنجاح في المجاري الثنائية. يجب أن تكون قيمة offset في الملفات النصية إما صفر أو قيمة مُعادة بواسطة استدعاء سابق للدالة ftell على المجرى ذاته، ويجب أن تكون قيمة ptrnmae مساويةً إلى SEEK_SET. يُفرغ fseek مؤشر نهاية الملف للمجرى المُحدد ويحذف بيانات أي استدعاء لعملية ungetc، ويعمل ذلك لكلٍّ من الدخل والخرج. تُعاد القيمة صفر للدلالة على النجاح وأي قيمة غير صفرية تدل على طلب ممنوع للدالة. لاحظ أنه يمكن لكلٍ من ftell و fseek ترميز قيمة موضع مؤشر الملف إلى قيمة من نوع long، وقد لا يحدث هذا بنجاح في حالة استخدامه على الملفات الطويلة جدًا؛ لذلك، يقدم المعيار كلًا من fgetpos و fsetpos للتغلُّب على هذه المشكلة. تخزِّن الدالة fgetpos موضع مؤشر الملف الحالي ضمن المجرى للكائن المُشار إليه باستخدام المؤشر pos، والقيمة المخزنة هي قيمة مميزة تُستخدم فقط للعودة إلى الموضع المحدد ضمن المجرى ذاته باستخدام الدالة fsetpos. تعمل الدالة fsetpos كما وضحنا سابقًا، كما أنها تُفرغ مؤشر نهاية الملف للمجرى وتُزيل أي تأثير لعمليات ungetc سابقة. نحصل على القيمة صفر في حالة النجاح لكلا الدالتين، بينما نحصل على قيمة غير صفرية في حالة الخطأ ويُضبط errno. التعامل مع الأخطاء تحافظ دوال الدخل والخرج القياسية على مؤشرين لكل مجرى مفتوح للدلالة على نهاية الملف وحالة الخطأ ضمنه، ويمكن الحصول على قيم هذه المؤشرات وضبطها عن طريق الدوال التالية: #include <stdio.h> void clearerr(FILE *stream); int feof(FILE *stream); int ferror(FILE *stream); void perror(const char *s); تُفرّغ الدالة clearerr كلًا من مؤشري الخطأ ونهاية الملف EOF للمجرى stream. تُعيد الدالة feof قيمةً غير صفرية إذا كان لمؤشر نهاية الملف الخاص بالمجرى stream قيمة، وإلا فإنها تعيد القيمة صفر. تُعيد الدالة ferror قيمة غير صفرية إذا كان لمؤشر الخطأ الخاص بالمجرى stream قيمة، وإلا فإنها تعيد القيمة صفر. تطبع الدالة perror سطرًا واحدًا يحتوي على رسالة خطأ على خرج البرنامج القياسي مسبوقًا بالسلسلة النصية المُشار إليها بواسطة المؤشر s مع إضافة مسافة فارغة ونقطتين ":". تُحدد رسالة الخطأ بحسب قيمة errno وتُعطي شرحًا بسيطًا عن سبب الخطأ، على سبيل المثال يتسبب البرنامج التالي برسالة خطأ: #include <stdio.h> #include <stdlib.h> main(){ fclose(stdout); if(fgetc(stdout) >= 0){ fprintf(stderr, "What - no error!\n"); exit(EXIT_FAILURE); } perror("fgetc"); exit(EXIT_SUCCESS); } /* رسالة الخطأ */ fgetc: Bad file number [مثال 2] لم نقُل أن الرسالة التي سنحصل عليها ستكون واضحة. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع الدخل والخرج I/O وتنسيقه في لغة سي C المقال السابق: التعامل مع المكتبات في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C التعامل مع المؤشرات Pointers في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C -
 نتحدث في هذا المقال عن مجموعة من الخصائص غير المرتبطة مع بعضها بعضًا مباشرةً ولكنها تصب في موضوع المكتبات والتعامل معها في لغة سي، وهي القفزات اللا محلية والتعامل مع الإشارات والدوال ذات العدد المتغير من الوسطاء، ونستعرض الدوال والأنواع والماكرو الموجودة بداخل ملفات الترويسة الموافقة لكل منها. القفزات اللا محلية تقدم القفزات اللا محلية non-local jumps طريقةً مشابهة لطريقة goto بالانتقال من دالة إلى أخرى. نلجأ إلى استخدام الماكرو setjmp والدالة longjmp لأن الأمر غير ممكن الحدوث باستخدام goto والعناوين labels إذ أن للعناوين نطاق scope داخل الدالة فقط، وتُعرف هذه الطريقة باسم goto اللا محلية أو القفزة اللا محلية. يصرح ملف الترويسة <setjmp.h> شيئًا يدعى jmp_buf، وهو اسم مستخدم في الماكرو والدالة لتخزين المعلومات الضرورية لإجراء القفزة، وتُكتب التصاريح على النحو التالي: #include <setjmp.h> int setjmp(jmp_buf env); void longjmp(jmp_buf env, int val); يُستخدم الماكرو setjmp لتهيئة قيمة jmp_buf ويُعيد القيمة صفر عند استدعائه الأولي، إلا أن الأمر غير الاعتيادي هنا، هو أنه يُعيد مجددًا قيمة غير صفرية لاحقًا عند استدعاء الدالة longjmp، وتكون القيمة غير الصفرية هذه مساويةً للقيمة المُمرّرة للدالة longjmp. لعل الأمر سيتضح لك بوضوح بعد المثال التالي: #include <stdio.h> #include <stdlib.h> #include <setjmp.h> void func(void); jmp_buf place; main(){ int retval; /* يُعيد الاستدعاء الأول القيمة 0، ويعيد استدعاء آخر للدالة longjmp قيمة غير صفرية */ if(setjmp(place) != 0){ printf("Returned using longjmp\n"); exit(EXIT_SUCCESS); } /* لن يُعيد الاستدعاء التالي أي قيمة لأنه يقفز مجددًا إلى الأعلى */ func(); printf("What! func returned!\n"); } void func(void){ /* العودة إلى main، ويبدو أن الاستدعاء الثاني لدالة setjmp يعيد القيمة 4 */ longjmp(place, 4); printf("What! longjmp returned!\n"); } [مثال 1] يمثل وسيط الدالة longjmp المسمى val القيمة المُعادة من الاستدعاء الثاني اللاحق لتعليمة الإعادة return ضمن الدالة setjmp، ويجب أن تكون هذه القيمة قيمة غير صفرية عادةً، وستغيّر القيمة إلى 1 إذا حاولت إعادة القيمة صفر باستخدام longjmp، وبذلك يمكننا معرفة فيما إذا كان استدعاء الدالة setjmp مباشرةً أو عن طريق استدعاء الدالة longjmp. تأثير الدالة setjmp غير محدد إذا لم يكن هناك أي استدعاء لها قبل استدعاء longjmp، وسيتسبب ذلك غالبًا بتوقف البرنامج. لا يُتوقّع من الدالة longjmp أن تُعيد قيمة بعد استدعائها مباشرةً. يكون لجميع الكائنات الممكن الوصول إليها من تعليمة الإعادة return داخل الدالة setjmp القيم السابقة المخزنة عند استدعاء longjmp عدا الكائنات ذات صنف التخزين التلقائي automatic storage class التي لا تحتوي على نوع "volatile"، وتكون قيمها غير محددة إذا تغيرت هذه الكائنات بين استدعاء setjmp واستدعاء longjmp. تُنفّذ الدالة longjmpعلى نحوٍ صحيح بخصوص المقاطعات interrupts والإشارات وأي دوال أخرى مرتبطة، ونحصل على سلوك غير معرف إذا حصل استدعاء longjmp باستخدام دالة نتج استدعائها عن إشارة وصلت بينما تُعالج إشارة أخرى. يُعدّ القفز إلى دالة غير فعالة باستخدام longjmp خطئًا فادحًا (ويُقصد بدالة غير فعالة أنها أعادت قيمة للتو، أو أن استدعاء longjmp آخر تحوّل إلى setjmp ضمن مجموعة من الاستدعاءات المترابطة nested calls). يصرّ المعيار على أن setjmp يجب أن تستخدم فقط مثل تعبير للتحكم في تعليمات if و switch و do و while و for (إضافةً إلى كونها التعليمة الوحيدة الموجودة في تعليمة تعبير)، وامتدادًا لهذه القاعدة، يمكن لاستدعاء setjmp (طالما يشكّل تعبير التحكم بأكمله كما ذكرنا سابقًا) أن يخضع للعامل !، أو أن يُقارن مباشرةً مع تعبير ثابت ذي قيمة عدد صحيح باستخدام إحدى العوامل العلاقيّة أو عوامل المساواة، ولا يجب استخدام أي تعابير معقدة أكثر من ذلك. إليك الأمثلة التالية: setjmp(place); /* تعليمة تعبير */ if(setjmp(place)) ... /* تعبير تحكم كامل */ if(!setjmp(place)) ... /* تعبير تحكم كامل */ if(setjmp(place) < 4) ... /* تعبير تحكم كامل */ if(setjmp(place)<;4 && 1!=2) ... /* ممنوع */ التعامل مع الإشارة تقدّم لنا دالتان إمكانية التعامل مع الأحداث غير المتزامنة؛ وتُعرف الإشارة signal بأنها شرط قد يحدث خلال تنفيذ البرنامج ويمكن تجاهله أو التعامل معه بصورةٍ خاصة أو استخدامه لإنهاء البرنامج كما هي الحالة الاعتيادية. تُرسل إحدى الدوال الإشارة بينما تُستخدم الأخرى لتحديد كيفية معالجة الإشارة، وقد تولّد الكثير من الإشارات من العتاد الصلب أو نظام التشغيل إضافةً إلى دوال إرسال الإشارات raise. الإشارات المُعرّفة في ملف الترويسة <signal.h>، هي: الإشارة SIGABRT: إنهاء غير اعتيادي للبرنامج، مثل الإنهاء الحاصل باستخدام الدالة abort (إبطال). الإشارة SIGFPE: عملية حسابية خاطئة، مثل التقسيم على الصفر أو الطفحان overflow (استثناء الفاصلة والأرقام العشرية Floating point exception). الإشارة SIGILL: العثور على "كائن برنامج غير صالح"، وهذا يعني غالبًا أن هناك تعليمات غير صالحة في البرنامج. (تعليمة غير صالحة Illegal instruction). الإشارة SIGINT: إشارة تفاعلية للفت الانتباه، وتولد هذه الإشارة على الأنظمة التفاعلية عادةً بكتابة مفتاح الهروب break-in في الطرفية terminal (مقاطعة Interrupt). الإشارة SIGSEGV: محاولة غير صالحة للوصول إلى مساحة تخزين، وتُسبب غالبًا بمحاولة تخزين قيمة في كائن مُشار إليه بمؤشر خاطئ. (انتهاك جزء segment violation). الإشارة SIGTERM: طلب إنهاء للبرنامج. (إنهاء Terminate). قد تمتلك بعض التنفيذات implementations بعض الإشارات الإضافية الزائدة عن الإشارات السابقة المعرفة في المعيار، وستبدأ أسماء الإشارات بالأحرف SIG وستمتلك قيمًا مميزة مختلفة عن القيم السابقة. تسمح لك الدالة signal بتحديد الفعل الذي تريد اتخاذه عند تلقي إشارة، وتُصطحب بحالة إشارة من الإشارات المذكورة سابقًا ومؤشر يشير إلى دالة تُنفّذ للتعامل مع الإشارة، وذلك بتغيير المؤشر وإعادة القيمة الأصلية، إذًا، نعرف الدالة كما يلي: #include <signal.h> void (*signal (int sig, void (*func)(int)))(int); يدل ما سبق على أن الدالة signal تُعيد مؤشرًا يشير إلى دالة أخرى وتأخذ الدالة الثانية وسيطًا واحدًا من نوع عدد صحيح وتُعيد void؛ بينما يكون الوسيط الثاني للدالة signal مؤشرًا يشير إلى دالة تعيد void بصورةٍ مشابهة، وتأخذ int وسيطًا لها. يمكن استخدام قيمتين مميزتين لوسيط لدالة func (دالة التعامل مع الإشارة)، ألا وهما SIG_DFL وهي معالج الإشارة الافتراضي الأولي و SIG_IGN الذي يُستخدم لتجاهل الإشارة، ويضبط التنفيذ حالة جميع الإشارات إلى واحدة من هذه القيمتين في بداية البرنامج. تُعاد قيمة func السابقة للإشارة إذ استدعيت signal بنجاح، وإلا فتُعاد SIG_ERR ويُضبط errno إلى قيمة. عند حصول حدث إشارة غير مُتجاهل، يُنفّذ أول signal(sig, SIG_DFL) يطابق الحالة وذلك إذا كانت الدالة func المترافقة تمثّل مؤشرًا يشير إلى دالة، وتتسبب تلك العملية بإعادة تشغيل معالج الإشارة إلى الإجراء الافتراضي ألا وهو إنهاء البرنامج، وإذا كانت الإشارة هي SIGILL فسيكون إعادة التشغيل معرفًا حسب التنفيذ، إذ قد تختار بعض التنفيذات حجب أي حالات أخرى من الإشارة عوضًا عن إعادة التشغيل. بعد ذلك، يُجرى استدعاء لدالة معالجة الإشارة، وسيعاود البرنامج عمله من نقطة حصول الحدث في معظم الحالات وذلك إذا أعادت الدالة قيمة بنجاح، إلا أننا نحصل على سلوك غير معرف إذا كانت قيمة sig مساويةً إلى SIGFPE (استثناء الفاصلة العائمة) أو أي استثناء حسابي معرف بحسب التنفيذ، والحل الأكثر استخدامًا لمعالج SIGFPE هو استدعاء إحدى الدوال: abort، أو exit، أو longjmp. يستعرض الجزء التالي استخدام الإشارة لتحقيق خروج أنيق من البرنامج عند تلقي مقاطعة أو إشارة "الانتباه التفاعلي interactive attention". #include <stdio.h> #include <stdlib.h> #include <signal.h> FILE *temp_file; void leave(int sig); main() { (void) signal(SIGINT,leave); temp_file = fopen("tmp","w"); for(;;) { /* افعل بعض الأشياء هنا */ printf("Ready...\n"); (void)getchar(); } /* لا يمكننا الوصول إلى هذه النقطة */ exit(EXIT_SUCCESS); } /* أغلق الملف tmp عند الحصول على SIGINT، لكن انتبه لأن استدعاء دوال المكتبات من معالج الإشارة غير مضمون العمل في جميع التنفيذات وهذا ليس ببرنامج متجاوب مع جميع التنفيذات بالضرورة */ void leave(int sig) { fprintf(temp_file,"\nInterrupted..\n"); fclose(temp_file); exit(sig); } [مثال 2] من الممكن للبرنامج أن يرسل إشارات إلى نفسه باستخدام دالة raise وهذا معرّف على النحو التالي: include <signal.h> int raise (int sig); تُرسل الإشارة sig في هذه الحالة إلى البرنامج. تُعيد التعليمة raise القيمة صفر في حال النجاح، وقيمة غير صفرية عدا ذلك، تُنفّذ دالة abort على النحو التالي: #include <signal.h> void abort(void) { raise(SIGABRT); } إذا حصلنا على إشارة لأي سبب كان -باستثناء استدعاء abort أو raise- فمن الممكن للدالة أن تستدعي فقط الإشارة أو أن تُسند قيمةً إلى كائن ساكن static متطاير volatile (مؤهل باستخدام volatile) من النوع sig_atomic_t، وهذا النوع مصرّحٌ في ملف الترويسة <signal.h>، وهو النوع الوحيد من الكائنات الممكن تعديله بأمان مثل كيان ذري atomic entity حتى مع وجود المقاطعات اللا متزامنة، وهذا قيدٌ مرهق مفروض من المعيار، الذي على سبيل المثال، يُبطل الدالة leave في مثالنا أعلاه، وعلى الرغم من أن الدالة ستعمل بصورةٍ صحيحة في بعض البيئات إلى أنها لا تتبع القوانين الصارمة الخاصة بالمعيار. أعداد متغيرة من الوسطاء غالبًا ما يكون تنفيذ دالة تأخذ عددًا غير معروفًا أو غير ثابت من الوسطاء محبّذًا عند كتابة الدالة، نذكر دالة printf على سبيل المثال التي سنتكلم عنها لاحقًا. يوضح المثال التالي تصريح دالة مشابهة. int f(int, ... ); int f(int, ... ) { . . . } int g() { f(1,2,3); } [مثال 3] علينا تضمين الدوال المصرح عنها ضمن ملف الترويسة <stdarg.h> لكي نستطيع الوصول إلى الوسطاء الموجودة بداخل الدالة المُستدعاة، ونحصل نتيجةً لذلك على نوع جديد يدعى va_list وثلاثة دوال تتعامل مع كائنات من هذا النوع وتدعى va_start و va_arg و va_end. علينا استدعاء va_start قبل محاولة الوصول إلى لائحة الوسطاء المتغيرة، وهي معرفة على النحو التالي: #include <stdarg.h> void va_start(va_list ap, parmN); يُهيّئ الماكرو va_start الوسيط ap بهدف الاستخدام اللاحق من قبل الدالتين va_arg و va_end، بينما يكون الوسيط الثاني للدالة va_start المسمّى parmN المعرّف identifier الذي يسمّي المعامل الذي يقع أقصى اليمين في لائحة المعاملات المتغيرة (أي المعامل الذي يقع قبل "…,")، ولا يجب التصريح عن المعرف parmN باستخدام صنف التخزين storage class من النوع register أو على أنه دالة أو نوع مصفوفة. يمكن الوصول إلى الوسطاء على نحوٍ تتابعي بعد التهيئة وذلك باستخدام الماكرو va_arg، وهذا غير مألوف لأن النوع المُعاد يحدّد باستخدام وسيط للماكرو. لاحظ أن ذلك مستحيل التنفيذ في دالة فعلية، ويمكن تنفيذه فقط باستخدام الماكرو، وهو معرّف على النحو التالي: #include <stdarg.h> type va_arg(va_list ap, type); سيتسبب كل استدعاء للماكرو السابق بالحصول على الوسيط التالي من لائحة الوسطاء بقيمة من النوع المُحدّد، ويجب للوسيط va_list أن يُهيّأ باستخدام va_start، ونحصل على سلوك غير معرّف إذا لم يكن الوسيط التالي من النوع المُحدّد. احذر من المشاكل التي قد تنتج من التحويلات الحسابية وتفاداها، إذ أن استخدام النوع char أو عدد صغير short وسيطًا ثانيًا للدالة va_arg خطأٌ واضح؛ لأن هذه الأنواع تُرقّى دائمًا إلى signed int أو unsigned int ويُحوّل float إلى double. لاحظ أن ترقية الكائنات المصرّحة عنها من الأنواع char و unsigned char و unsigned short وحقول البت عديمة الإشارة unsigned bitfields إلى النوع unsigned int الذي سيعقّد أكثر استخدام الدالة va_arg هو معرّف بحسب التنفيذ، وقد يكون ذلك هو السبب في الحصول على بعض المشاكل الخفية غير المتوقعة. نحصل على سلوك غير معرف أيضًا إذا استُدعيت الدالة va_arg ولم يكن هناك مزيدًا من الوسطاء. يجب أن يكون الوسيط type -في تعريفنا السابق لدالة va_arg- ممثلًا لاسم نوع يمكن تحويله إلى مؤشر يشير إلى كائن بإضافة المحرف "*" ببساطة (حتى يعمل الماكرو)، وذلك محقق للأنواع البسيطة مثل char (لأن char * يمثّل نوع مؤشر يشير إلى محرف)، لكن لن تعمل مصفوفة المحارف (لا يتحول النوع char [] إلى مؤشر يشير إلى مصفوفة محارف بإضافة "*" إليه). يمكن لحسن الحظ معالجة المصفوفات إذا ما تذكرنا أن اسم المصفوفة الذي يُستخدم وسيطًا فعليًا لاستدعاء الدالة يُحوّل إلى مؤشر، وبذلك فإن النوع الصحيح لوسيط من النوع "مصفوفة من المحارف" هو char *. تُستدعى الدالة va_end بعد معالجة جميع الوسطاء، وهذا سيمنع اللائحة va_list من أن تُستخدم بعد ذلك، ونحصل على سلوك غير معرف إذا لم تُستخدم الدالة va_end. يمكن إعادة قراءة كامل لائحة الوسطاء باستدعاء الدالة va_start مجددًا بعد استدعاء va_end، وتُصرّح الدالة va_end كما يلي: #include <stdarg.h> void va_end(va list ap); يوضح المثال التالي كيفية استخدام كل من va_start و va_arg و va_end ضمن دالة تُعيد أكبر قيم وسطائها التي تكون من نوع عدد صحيح. #include <stdlib.h> #include <stdarg.h> #include <stdio.h> int maxof(int, ...) ; void f(void); main(){ f(); exit(EXIT_SUCCESS); } int maxof(int n_args, ...){ register int i; int max, a; va_list ap; va_start(ap, n_args); max = va_arg(ap, int); for(i = 2; i <= n_args; i++) { if((a = va_arg(ap, int)) > max) max = a; } va_end(ap); return max; } void f(void) { int i = 5; int j[256]; j[42] = 24; printf("%d\n",maxof(3, i, j[42], 0)); } [مثال 4] ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: مقدمة عن التعامل مع الدخل والخرج I/O في لغة سي C المقال السابق: القيم الحدية والدوال الرياضية في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C التعامل مع المؤشرات Pointers في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C
نتحدث في هذا المقال عن مجموعة من الخصائص غير المرتبطة مع بعضها بعضًا مباشرةً ولكنها تصب في موضوع المكتبات والتعامل معها في لغة سي، وهي القفزات اللا محلية والتعامل مع الإشارات والدوال ذات العدد المتغير من الوسطاء، ونستعرض الدوال والأنواع والماكرو الموجودة بداخل ملفات الترويسة الموافقة لكل منها. القفزات اللا محلية تقدم القفزات اللا محلية non-local jumps طريقةً مشابهة لطريقة goto بالانتقال من دالة إلى أخرى. نلجأ إلى استخدام الماكرو setjmp والدالة longjmp لأن الأمر غير ممكن الحدوث باستخدام goto والعناوين labels إذ أن للعناوين نطاق scope داخل الدالة فقط، وتُعرف هذه الطريقة باسم goto اللا محلية أو القفزة اللا محلية. يصرح ملف الترويسة <setjmp.h> شيئًا يدعى jmp_buf، وهو اسم مستخدم في الماكرو والدالة لتخزين المعلومات الضرورية لإجراء القفزة، وتُكتب التصاريح على النحو التالي: #include <setjmp.h> int setjmp(jmp_buf env); void longjmp(jmp_buf env, int val); يُستخدم الماكرو setjmp لتهيئة قيمة jmp_buf ويُعيد القيمة صفر عند استدعائه الأولي، إلا أن الأمر غير الاعتيادي هنا، هو أنه يُعيد مجددًا قيمة غير صفرية لاحقًا عند استدعاء الدالة longjmp، وتكون القيمة غير الصفرية هذه مساويةً للقيمة المُمرّرة للدالة longjmp. لعل الأمر سيتضح لك بوضوح بعد المثال التالي: #include <stdio.h> #include <stdlib.h> #include <setjmp.h> void func(void); jmp_buf place; main(){ int retval; /* يُعيد الاستدعاء الأول القيمة 0، ويعيد استدعاء آخر للدالة longjmp قيمة غير صفرية */ if(setjmp(place) != 0){ printf("Returned using longjmp\n"); exit(EXIT_SUCCESS); } /* لن يُعيد الاستدعاء التالي أي قيمة لأنه يقفز مجددًا إلى الأعلى */ func(); printf("What! func returned!\n"); } void func(void){ /* العودة إلى main، ويبدو أن الاستدعاء الثاني لدالة setjmp يعيد القيمة 4 */ longjmp(place, 4); printf("What! longjmp returned!\n"); } [مثال 1] يمثل وسيط الدالة longjmp المسمى val القيمة المُعادة من الاستدعاء الثاني اللاحق لتعليمة الإعادة return ضمن الدالة setjmp، ويجب أن تكون هذه القيمة قيمة غير صفرية عادةً، وستغيّر القيمة إلى 1 إذا حاولت إعادة القيمة صفر باستخدام longjmp، وبذلك يمكننا معرفة فيما إذا كان استدعاء الدالة setjmp مباشرةً أو عن طريق استدعاء الدالة longjmp. تأثير الدالة setjmp غير محدد إذا لم يكن هناك أي استدعاء لها قبل استدعاء longjmp، وسيتسبب ذلك غالبًا بتوقف البرنامج. لا يُتوقّع من الدالة longjmp أن تُعيد قيمة بعد استدعائها مباشرةً. يكون لجميع الكائنات الممكن الوصول إليها من تعليمة الإعادة return داخل الدالة setjmp القيم السابقة المخزنة عند استدعاء longjmp عدا الكائنات ذات صنف التخزين التلقائي automatic storage class التي لا تحتوي على نوع "volatile"، وتكون قيمها غير محددة إذا تغيرت هذه الكائنات بين استدعاء setjmp واستدعاء longjmp. تُنفّذ الدالة longjmpعلى نحوٍ صحيح بخصوص المقاطعات interrupts والإشارات وأي دوال أخرى مرتبطة، ونحصل على سلوك غير معرف إذا حصل استدعاء longjmp باستخدام دالة نتج استدعائها عن إشارة وصلت بينما تُعالج إشارة أخرى. يُعدّ القفز إلى دالة غير فعالة باستخدام longjmp خطئًا فادحًا (ويُقصد بدالة غير فعالة أنها أعادت قيمة للتو، أو أن استدعاء longjmp آخر تحوّل إلى setjmp ضمن مجموعة من الاستدعاءات المترابطة nested calls). يصرّ المعيار على أن setjmp يجب أن تستخدم فقط مثل تعبير للتحكم في تعليمات if و switch و do و while و for (إضافةً إلى كونها التعليمة الوحيدة الموجودة في تعليمة تعبير)، وامتدادًا لهذه القاعدة، يمكن لاستدعاء setjmp (طالما يشكّل تعبير التحكم بأكمله كما ذكرنا سابقًا) أن يخضع للعامل !، أو أن يُقارن مباشرةً مع تعبير ثابت ذي قيمة عدد صحيح باستخدام إحدى العوامل العلاقيّة أو عوامل المساواة، ولا يجب استخدام أي تعابير معقدة أكثر من ذلك. إليك الأمثلة التالية: setjmp(place); /* تعليمة تعبير */ if(setjmp(place)) ... /* تعبير تحكم كامل */ if(!setjmp(place)) ... /* تعبير تحكم كامل */ if(setjmp(place) < 4) ... /* تعبير تحكم كامل */ if(setjmp(place)<;4 && 1!=2) ... /* ممنوع */ التعامل مع الإشارة تقدّم لنا دالتان إمكانية التعامل مع الأحداث غير المتزامنة؛ وتُعرف الإشارة signal بأنها شرط قد يحدث خلال تنفيذ البرنامج ويمكن تجاهله أو التعامل معه بصورةٍ خاصة أو استخدامه لإنهاء البرنامج كما هي الحالة الاعتيادية. تُرسل إحدى الدوال الإشارة بينما تُستخدم الأخرى لتحديد كيفية معالجة الإشارة، وقد تولّد الكثير من الإشارات من العتاد الصلب أو نظام التشغيل إضافةً إلى دوال إرسال الإشارات raise. الإشارات المُعرّفة في ملف الترويسة <signal.h>، هي: الإشارة SIGABRT: إنهاء غير اعتيادي للبرنامج، مثل الإنهاء الحاصل باستخدام الدالة abort (إبطال). الإشارة SIGFPE: عملية حسابية خاطئة، مثل التقسيم على الصفر أو الطفحان overflow (استثناء الفاصلة والأرقام العشرية Floating point exception). الإشارة SIGILL: العثور على "كائن برنامج غير صالح"، وهذا يعني غالبًا أن هناك تعليمات غير صالحة في البرنامج. (تعليمة غير صالحة Illegal instruction). الإشارة SIGINT: إشارة تفاعلية للفت الانتباه، وتولد هذه الإشارة على الأنظمة التفاعلية عادةً بكتابة مفتاح الهروب break-in في الطرفية terminal (مقاطعة Interrupt). الإشارة SIGSEGV: محاولة غير صالحة للوصول إلى مساحة تخزين، وتُسبب غالبًا بمحاولة تخزين قيمة في كائن مُشار إليه بمؤشر خاطئ. (انتهاك جزء segment violation). الإشارة SIGTERM: طلب إنهاء للبرنامج. (إنهاء Terminate). قد تمتلك بعض التنفيذات implementations بعض الإشارات الإضافية الزائدة عن الإشارات السابقة المعرفة في المعيار، وستبدأ أسماء الإشارات بالأحرف SIG وستمتلك قيمًا مميزة مختلفة عن القيم السابقة. تسمح لك الدالة signal بتحديد الفعل الذي تريد اتخاذه عند تلقي إشارة، وتُصطحب بحالة إشارة من الإشارات المذكورة سابقًا ومؤشر يشير إلى دالة تُنفّذ للتعامل مع الإشارة، وذلك بتغيير المؤشر وإعادة القيمة الأصلية، إذًا، نعرف الدالة كما يلي: #include <signal.h> void (*signal (int sig, void (*func)(int)))(int); يدل ما سبق على أن الدالة signal تُعيد مؤشرًا يشير إلى دالة أخرى وتأخذ الدالة الثانية وسيطًا واحدًا من نوع عدد صحيح وتُعيد void؛ بينما يكون الوسيط الثاني للدالة signal مؤشرًا يشير إلى دالة تعيد void بصورةٍ مشابهة، وتأخذ int وسيطًا لها. يمكن استخدام قيمتين مميزتين لوسيط لدالة func (دالة التعامل مع الإشارة)، ألا وهما SIG_DFL وهي معالج الإشارة الافتراضي الأولي و SIG_IGN الذي يُستخدم لتجاهل الإشارة، ويضبط التنفيذ حالة جميع الإشارات إلى واحدة من هذه القيمتين في بداية البرنامج. تُعاد قيمة func السابقة للإشارة إذ استدعيت signal بنجاح، وإلا فتُعاد SIG_ERR ويُضبط errno إلى قيمة. عند حصول حدث إشارة غير مُتجاهل، يُنفّذ أول signal(sig, SIG_DFL) يطابق الحالة وذلك إذا كانت الدالة func المترافقة تمثّل مؤشرًا يشير إلى دالة، وتتسبب تلك العملية بإعادة تشغيل معالج الإشارة إلى الإجراء الافتراضي ألا وهو إنهاء البرنامج، وإذا كانت الإشارة هي SIGILL فسيكون إعادة التشغيل معرفًا حسب التنفيذ، إذ قد تختار بعض التنفيذات حجب أي حالات أخرى من الإشارة عوضًا عن إعادة التشغيل. بعد ذلك، يُجرى استدعاء لدالة معالجة الإشارة، وسيعاود البرنامج عمله من نقطة حصول الحدث في معظم الحالات وذلك إذا أعادت الدالة قيمة بنجاح، إلا أننا نحصل على سلوك غير معرف إذا كانت قيمة sig مساويةً إلى SIGFPE (استثناء الفاصلة العائمة) أو أي استثناء حسابي معرف بحسب التنفيذ، والحل الأكثر استخدامًا لمعالج SIGFPE هو استدعاء إحدى الدوال: abort، أو exit، أو longjmp. يستعرض الجزء التالي استخدام الإشارة لتحقيق خروج أنيق من البرنامج عند تلقي مقاطعة أو إشارة "الانتباه التفاعلي interactive attention". #include <stdio.h> #include <stdlib.h> #include <signal.h> FILE *temp_file; void leave(int sig); main() { (void) signal(SIGINT,leave); temp_file = fopen("tmp","w"); for(;;) { /* افعل بعض الأشياء هنا */ printf("Ready...\n"); (void)getchar(); } /* لا يمكننا الوصول إلى هذه النقطة */ exit(EXIT_SUCCESS); } /* أغلق الملف tmp عند الحصول على SIGINT، لكن انتبه لأن استدعاء دوال المكتبات من معالج الإشارة غير مضمون العمل في جميع التنفيذات وهذا ليس ببرنامج متجاوب مع جميع التنفيذات بالضرورة */ void leave(int sig) { fprintf(temp_file,"\nInterrupted..\n"); fclose(temp_file); exit(sig); } [مثال 2] من الممكن للبرنامج أن يرسل إشارات إلى نفسه باستخدام دالة raise وهذا معرّف على النحو التالي: include <signal.h> int raise (int sig); تُرسل الإشارة sig في هذه الحالة إلى البرنامج. تُعيد التعليمة raise القيمة صفر في حال النجاح، وقيمة غير صفرية عدا ذلك، تُنفّذ دالة abort على النحو التالي: #include <signal.h> void abort(void) { raise(SIGABRT); } إذا حصلنا على إشارة لأي سبب كان -باستثناء استدعاء abort أو raise- فمن الممكن للدالة أن تستدعي فقط الإشارة أو أن تُسند قيمةً إلى كائن ساكن static متطاير volatile (مؤهل باستخدام volatile) من النوع sig_atomic_t، وهذا النوع مصرّحٌ في ملف الترويسة <signal.h>، وهو النوع الوحيد من الكائنات الممكن تعديله بأمان مثل كيان ذري atomic entity حتى مع وجود المقاطعات اللا متزامنة، وهذا قيدٌ مرهق مفروض من المعيار، الذي على سبيل المثال، يُبطل الدالة leave في مثالنا أعلاه، وعلى الرغم من أن الدالة ستعمل بصورةٍ صحيحة في بعض البيئات إلى أنها لا تتبع القوانين الصارمة الخاصة بالمعيار. أعداد متغيرة من الوسطاء غالبًا ما يكون تنفيذ دالة تأخذ عددًا غير معروفًا أو غير ثابت من الوسطاء محبّذًا عند كتابة الدالة، نذكر دالة printf على سبيل المثال التي سنتكلم عنها لاحقًا. يوضح المثال التالي تصريح دالة مشابهة. int f(int, ... ); int f(int, ... ) { . . . } int g() { f(1,2,3); } [مثال 3] علينا تضمين الدوال المصرح عنها ضمن ملف الترويسة <stdarg.h> لكي نستطيع الوصول إلى الوسطاء الموجودة بداخل الدالة المُستدعاة، ونحصل نتيجةً لذلك على نوع جديد يدعى va_list وثلاثة دوال تتعامل مع كائنات من هذا النوع وتدعى va_start و va_arg و va_end. علينا استدعاء va_start قبل محاولة الوصول إلى لائحة الوسطاء المتغيرة، وهي معرفة على النحو التالي: #include <stdarg.h> void va_start(va_list ap, parmN); يُهيّئ الماكرو va_start الوسيط ap بهدف الاستخدام اللاحق من قبل الدالتين va_arg و va_end، بينما يكون الوسيط الثاني للدالة va_start المسمّى parmN المعرّف identifier الذي يسمّي المعامل الذي يقع أقصى اليمين في لائحة المعاملات المتغيرة (أي المعامل الذي يقع قبل "…,")، ولا يجب التصريح عن المعرف parmN باستخدام صنف التخزين storage class من النوع register أو على أنه دالة أو نوع مصفوفة. يمكن الوصول إلى الوسطاء على نحوٍ تتابعي بعد التهيئة وذلك باستخدام الماكرو va_arg، وهذا غير مألوف لأن النوع المُعاد يحدّد باستخدام وسيط للماكرو. لاحظ أن ذلك مستحيل التنفيذ في دالة فعلية، ويمكن تنفيذه فقط باستخدام الماكرو، وهو معرّف على النحو التالي: #include <stdarg.h> type va_arg(va_list ap, type); سيتسبب كل استدعاء للماكرو السابق بالحصول على الوسيط التالي من لائحة الوسطاء بقيمة من النوع المُحدّد، ويجب للوسيط va_list أن يُهيّأ باستخدام va_start، ونحصل على سلوك غير معرّف إذا لم يكن الوسيط التالي من النوع المُحدّد. احذر من المشاكل التي قد تنتج من التحويلات الحسابية وتفاداها، إذ أن استخدام النوع char أو عدد صغير short وسيطًا ثانيًا للدالة va_arg خطأٌ واضح؛ لأن هذه الأنواع تُرقّى دائمًا إلى signed int أو unsigned int ويُحوّل float إلى double. لاحظ أن ترقية الكائنات المصرّحة عنها من الأنواع char و unsigned char و unsigned short وحقول البت عديمة الإشارة unsigned bitfields إلى النوع unsigned int الذي سيعقّد أكثر استخدام الدالة va_arg هو معرّف بحسب التنفيذ، وقد يكون ذلك هو السبب في الحصول على بعض المشاكل الخفية غير المتوقعة. نحصل على سلوك غير معرف أيضًا إذا استُدعيت الدالة va_arg ولم يكن هناك مزيدًا من الوسطاء. يجب أن يكون الوسيط type -في تعريفنا السابق لدالة va_arg- ممثلًا لاسم نوع يمكن تحويله إلى مؤشر يشير إلى كائن بإضافة المحرف "*" ببساطة (حتى يعمل الماكرو)، وذلك محقق للأنواع البسيطة مثل char (لأن char * يمثّل نوع مؤشر يشير إلى محرف)، لكن لن تعمل مصفوفة المحارف (لا يتحول النوع char [] إلى مؤشر يشير إلى مصفوفة محارف بإضافة "*" إليه). يمكن لحسن الحظ معالجة المصفوفات إذا ما تذكرنا أن اسم المصفوفة الذي يُستخدم وسيطًا فعليًا لاستدعاء الدالة يُحوّل إلى مؤشر، وبذلك فإن النوع الصحيح لوسيط من النوع "مصفوفة من المحارف" هو char *. تُستدعى الدالة va_end بعد معالجة جميع الوسطاء، وهذا سيمنع اللائحة va_list من أن تُستخدم بعد ذلك، ونحصل على سلوك غير معرف إذا لم تُستخدم الدالة va_end. يمكن إعادة قراءة كامل لائحة الوسطاء باستدعاء الدالة va_start مجددًا بعد استدعاء va_end، وتُصرّح الدالة va_end كما يلي: #include <stdarg.h> void va_end(va list ap); يوضح المثال التالي كيفية استخدام كل من va_start و va_arg و va_end ضمن دالة تُعيد أكبر قيم وسطائها التي تكون من نوع عدد صحيح. #include <stdlib.h> #include <stdarg.h> #include <stdio.h> int maxof(int, ...) ; void f(void); main(){ f(); exit(EXIT_SUCCESS); } int maxof(int n_args, ...){ register int i; int max, a; va_list ap; va_start(ap, n_args); max = va_arg(ap, int); for(i = 2; i <= n_args; i++) { if((a = va_arg(ap, int)) > max) max = a; } va_end(ap); return max; } void f(void) { int i = 5; int j[256]; j[42] = 24; printf("%d\n",maxof(3, i, j[42], 0)); } [مثال 4] ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: مقدمة عن التعامل مع الدخل والخرج I/O في لغة سي C المقال السابق: القيم الحدية والدوال الرياضية في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C التعامل مع المؤشرات Pointers في لغة سي C التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C -
 نتطرق في هذا المقال إلى كل من ملفات الترويسة الخاصة بالقيم الحدّية Limits والدوال الرياضية في لغة C، كما نقدّم شرحًا موجزًا عن الأسماء المعرفة بداخل كل من الملفات، ويمكنك الاحتفاظ بهذا القسم كمرجع سريع بخصوص هذا الأمر. القيم الحدية يعرّف ملفا الترويسة <float.h> و <limits.h> عدة قيم حدية معرفة حسب التطبيق. ملف الترويسة <limits.h> يوضح الجدول 1 الأسماء المُصرح عنها في هذا الملف وقيمها المسموحة، إضافةً إلى وصف موجز عن وظيفتها، إذ يوضح وصف SHRT_MIN مثلًا أن قيمة الاسم في بعض التطبيقات يجب أن تكون أقل من أو تساوي القيمة -32767، وهذا يعني أن البرنامج لا يستطيع الاعتماد على متغيرات صغيرة short لتخزين قيم سالبة تتعدى 32767- إذا أردنا قابلية نقل أكبر للبرنامج. قد يدعم التطبيق في بعض الأحيان القيم السالبة الأكبر إلا أن الحد الأدنى الذي يجب أن يدعمه التطبيق هو 32767-. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الاسم القيم المسموحة الوصف CHAR_BIT (≥8) بتات في قيمة من نوع char CHAR_MAX اقرأ الملاحظة القيمة العظمى لنوع char CHAR_MIN اقرأ الملاحظة القيمة الدنيا لنوع char INT_MAX (≥+32767) القيمة العظمى لنوع int INT_MIN (≤−32767) القيمة الدنيا لنوع int LONG_MAX (≥+2147483647) القيمة العظمى لنوع long LONG_MIN (≤−2147483647) القيمة الدنيا لنوع long MB_LEN_MAX (≥1) عدد البتات الأعظمي في محرف متعدد البتات multibyte character SCHAR_MAX (≥+127) القيمة العظمى لنوع signed char SCHAR_MIN (≤−127) القيمة الدنيا لنوع signed char SHRT_MAX (≥+32767) القيمة العظمى لنوع short SHRT_MIN (≤−32767) القيمة الدنيا لنوع short UCHAR_MAX (≥255U) القيمة العظمى لنوع unsigned char UINT_MAX (≥65535U) القيمة الدنيا لنوع unsigned int ULONG_MAX (≥4294967295U) القيمة العظمى لنوع unsigned long USHRT_MAX (≥65535U) القيمة الدنيا لنوع unsigned short [جدول 1 أسماء ملف الترويسة <limits.h>] ملاحظة: إذا كان التطبيق يعامل char على أنه من نوع ذو إشارة فقيمة CHAR_MAX وCHAR_MIN مماثلة لقيمة SCHAR الموافق لها، وإلا فقيمة CHAR_MIN هي صفر وقيمة CHAR_MAX هي مساوية لقيمة UCHAR_MAX. ملف الترويسة <float.h> يتضمن ملف الترويسة <float.h> قيمًا دنيا للأرقام ذات الفاصلة العائمة floating point بصورةٍ مشابهة لما سبق، ويمكن الافتراض عند عدم وجود قيمة دنيا لنوع ما أن هذا النوع لا يمتلك قيمة دنيا أو أن القيمة مرتبطة بقيمة أخرى. الاسم القيم المسموحة الوصف FLT_RADIX (≥2) تمثيل أساس الأس DBL_DIG (≥10) عدد خانات الدقة في نوع double DBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 DBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع double DBL_MAX (≥1E+37) القيمة العظمى لنوع double DBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع double DBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع double DBL_MIN (≤1E−37) القيمة الدنيا للنوع double DBL_MIN_10_EXP (≤37) القيمة الدنيا لأس (أساسه 10) من نوع double DBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع double FLT_DIG (≥6) عدد خانات الدقة في نوع float FLT_EPSILON (≤1E−5) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 FLT_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع float FLT_MAX (≥1E+37) القيمة العظمى للنوع float FLT_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع float FLT_MAX_EXP (—) القيمة العظمة لأس (أساسه FLT_RADIX) من نوع float FLT_MIN (≤1E−37) القيمة الدنيا للنوع float FLT_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع float FLT_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع float FLT_ROUNDS (0) يحدد التقريب للفاصلة العائمة، غير مُحدّد لقيمة 1-، تقريب باتجاه الصفر لقيمة 0، تقريب للقيمة الأقرب لقيمة 1، تقريب إلى اللا نهاية الموجبة لقيمة 2، تقريب إلى اللا نهاية السالبة لقيمة 3. أي قيمة أخرى تكون محددة بحسب التطبيق LDBL_DIG (≥10) عدد خانات الدقة في نوع long double LDBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 LDBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع long double LDBL_MAX (≥1E+37) القيمة العظمى للنوع long double LDBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع long double LDBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع long double LDBL_MIN (≤1E−37) القيمة الدنيا للنوع long double LDBL_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع long double LDBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع long double [جدول 2 أسماء ملف الترويسة <float.h>] الدوال الرياضية إذا كنت تكتب برامجًا رياضيّة تجري عمليات على الفاصلة العائمة وما شابه، فهذا يعني أنك تحتاج الوصول إلى مكتبات الدوال الرياضية دون أدنى شك، ويأخذ هذا النوع من الدوال وسطاءً من النوع double ويعيد نتيجةً من النوع ذاته أيضًا. تُعرَّف الدوال والماكرو المرتبطة بها في ملف الترويسة <math.h>. يُستبدل الماكرو HUGE_VAL المُعرف إلى تعبير ذي قيمة موجبة من نوع عدد عشري مضاعف الدقة "double"، ولا يمكن تمثيله بالضرورة باستخدام النوع float. نحصل على خطأ نطاق domain error في جميع الدوال إذا كانت قيمة الوسيط المُدخل خارج النطاق المُعرّف للدالة، مثل محاولة الحصول على جذر تربيعي لعدد سالب، وإذا حصل هذا الخطأ يُضبط errno إلى الثابت EDOM، وتُعيد الدالة قيمة معرّفة بحسب التطبيق. نحصل على خطأ مجال range error إذا لم يكن من الممكن تمثيل نتيجة الدالة بقيمة عدد عشري مضاعف الدقة، تُعيد الدالة القيمة ±HUGE_VAL إذا كانت قيمة النتيجة كبيرة جدًا (الإشارة موافقة للقيمة) وتُضبط errno إلى ERANGE إذا كانت القيمة صغيرة جدًا وتُعاد القيمة 0.0 وتُعتمد قيمة errno على تعريف التطبيق. تصف اللائحة التالية كلًا من الدوال المتاحة باختصار: الدالة double acos(double x);: تُعيد القيمة الرئيسة Principal value لقوس جيب التمام Arc cosine للوسيط x في النطاق من 0 إلى π راديان، ونحصل على الخطأ EDOM إذا كان x خارج النطاق -1 إلى 1. الدالة double asin(double x);: تُعيد القيمة الرئيسة لقوس الجيب Arc sin للوسيط x في النطاق من -π/2 إلى +π/2 راديان، ونحصل على الخطأ EDOM إذا كان xخارج النطاق -1 إلى 1. الدالة double atan(double x);: تُعيد القيمة الرئيسة لقوس الظل Arc tan للوسيط x في النطاق من -π/2 إلى +π/2 راديان. الدالة double atan2(double y, double x);: تُعيد القيمة الرئيسة لقوس الظل للقيمة y/x في النطاق من -π إلى +π راديان، وتستخدم إشارتي الوسيطين x و y لتحديد الربع الذي تقع فيه قيمة الإجابة، ونحصل على الخطأ EDOM في حال كان x و y مساويين إلى الصفر. الدالة double cos(double x);: تُعيد جيب تمام قيمة الوسيط x (تُقاس x بالراديان). الدالة double sin(double x);: تُعيد جيب قيمة الوسيط x (تُقاس x بالراديان). الدالة double tan(double x);: تُعيد ظل قيمة الوسيط x (تُقاس x بالراديان)، وتكون إشارة HUGE_VAL غير مضمونة الصحّة إذا حدث خطأ مجال. الدالة double cosh(double x);: تُعيد جيب التمام القطعي Hyperbolic للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا جدًا. الدالة double sinh(double x);: تُعيد الجيب القطعي للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا للغاية. الدالة double tanh(double x);: تُعيد الظل القطعي للقيمة x. الدالة double exp(double x);: دالة أسية للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار xكبيرًا جدًا. الدالة double frexp(double value, int *exp);: تجزئة عدد ذو فاصلة عائمة إلى كسر طبيعي وأُس عدد صحيح من الأساس 2، ويخزن هذا العدد الصحيح في الغرض المُشار إليه بواسطة المؤشر exp. الدالة double ldexp(double x, int exp);: ضرب x بمقدار 2 إلى الأُس exp، وقد نحصل على الخطأ ERANGE. الدالة double log(double x);: اللوغاريتم الطبيعي للقيمة x، وقد نحصل على الخطأ EDOM إذا كانت القيمة x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double log10(double x);: اللوغاريتم ذو الأساس 10 للقيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double modf(double value, double *iptr);: تجزئة قيمة الوسيط value إلى جزء عدد صحيح وجزء كسري، ويحمل كل جزء إشارة الوسيط ذاتها، وتُخزن قيمة العدد الصحيح على أنها قيمة من نوع double في الكائن المُشار إليه بواسطة المؤشر iptr وتُعيد الدالة الجزء الكسري. الدالة double pow(double x, double y);: تحسب x إلى الأس y، ونحصل على الخطأ EDOM إذا كانت القيمة x سالبة و y عدد غير صحيح، أو ERANGE إذا لم يكن من الممكن تمثيل النتيجة في حال كانت x تساوي إلى الصفر و y موجبة أو تساوي الصفر. الدالة double sqrt(double x);: تحسب مربع القيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة. الدالة double ceil(double x);: أصغر عدد صحيح لا يكون أصغر من x. الدالة double fabs(double x);: القيمة المطلقة للوسيط x. الدالة double floor(double x);: أكبر عدد صحيح لا يكون أكبر من x. الدالة double fmod(double x, double y);: الباقي العشري من عملية القسمة x/y، ويعتمد الأمر على تعريف التطبيق فيما إذا كانت fmod تُعيد صفرًا أو خطأ نطاق في حال كانت y تساوي إلى الصفر. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: تعلم لغة سي التعامل مع المكتبات في لغة سي C المقال السابق: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C
نتطرق في هذا المقال إلى كل من ملفات الترويسة الخاصة بالقيم الحدّية Limits والدوال الرياضية في لغة C، كما نقدّم شرحًا موجزًا عن الأسماء المعرفة بداخل كل من الملفات، ويمكنك الاحتفاظ بهذا القسم كمرجع سريع بخصوص هذا الأمر. القيم الحدية يعرّف ملفا الترويسة <float.h> و <limits.h> عدة قيم حدية معرفة حسب التطبيق. ملف الترويسة <limits.h> يوضح الجدول 1 الأسماء المُصرح عنها في هذا الملف وقيمها المسموحة، إضافةً إلى وصف موجز عن وظيفتها، إذ يوضح وصف SHRT_MIN مثلًا أن قيمة الاسم في بعض التطبيقات يجب أن تكون أقل من أو تساوي القيمة -32767، وهذا يعني أن البرنامج لا يستطيع الاعتماد على متغيرات صغيرة short لتخزين قيم سالبة تتعدى 32767- إذا أردنا قابلية نقل أكبر للبرنامج. قد يدعم التطبيق في بعض الأحيان القيم السالبة الأكبر إلا أن الحد الأدنى الذي يجب أن يدعمه التطبيق هو 32767-. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الاسم القيم المسموحة الوصف CHAR_BIT (≥8) بتات في قيمة من نوع char CHAR_MAX اقرأ الملاحظة القيمة العظمى لنوع char CHAR_MIN اقرأ الملاحظة القيمة الدنيا لنوع char INT_MAX (≥+32767) القيمة العظمى لنوع int INT_MIN (≤−32767) القيمة الدنيا لنوع int LONG_MAX (≥+2147483647) القيمة العظمى لنوع long LONG_MIN (≤−2147483647) القيمة الدنيا لنوع long MB_LEN_MAX (≥1) عدد البتات الأعظمي في محرف متعدد البتات multibyte character SCHAR_MAX (≥+127) القيمة العظمى لنوع signed char SCHAR_MIN (≤−127) القيمة الدنيا لنوع signed char SHRT_MAX (≥+32767) القيمة العظمى لنوع short SHRT_MIN (≤−32767) القيمة الدنيا لنوع short UCHAR_MAX (≥255U) القيمة العظمى لنوع unsigned char UINT_MAX (≥65535U) القيمة الدنيا لنوع unsigned int ULONG_MAX (≥4294967295U) القيمة العظمى لنوع unsigned long USHRT_MAX (≥65535U) القيمة الدنيا لنوع unsigned short [جدول 1 أسماء ملف الترويسة <limits.h>] ملاحظة: إذا كان التطبيق يعامل char على أنه من نوع ذو إشارة فقيمة CHAR_MAX وCHAR_MIN مماثلة لقيمة SCHAR الموافق لها، وإلا فقيمة CHAR_MIN هي صفر وقيمة CHAR_MAX هي مساوية لقيمة UCHAR_MAX. ملف الترويسة <float.h> يتضمن ملف الترويسة <float.h> قيمًا دنيا للأرقام ذات الفاصلة العائمة floating point بصورةٍ مشابهة لما سبق، ويمكن الافتراض عند عدم وجود قيمة دنيا لنوع ما أن هذا النوع لا يمتلك قيمة دنيا أو أن القيمة مرتبطة بقيمة أخرى. الاسم القيم المسموحة الوصف FLT_RADIX (≥2) تمثيل أساس الأس DBL_DIG (≥10) عدد خانات الدقة في نوع double DBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 DBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع double DBL_MAX (≥1E+37) القيمة العظمى لنوع double DBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع double DBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع double DBL_MIN (≤1E−37) القيمة الدنيا للنوع double DBL_MIN_10_EXP (≤37) القيمة الدنيا لأس (أساسه 10) من نوع double DBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع double FLT_DIG (≥6) عدد خانات الدقة في نوع float FLT_EPSILON (≤1E−5) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 FLT_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع float FLT_MAX (≥1E+37) القيمة العظمى للنوع float FLT_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع float FLT_MAX_EXP (—) القيمة العظمة لأس (أساسه FLT_RADIX) من نوع float FLT_MIN (≤1E−37) القيمة الدنيا للنوع float FLT_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع float FLT_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع float FLT_ROUNDS (0) يحدد التقريب للفاصلة العائمة، غير مُحدّد لقيمة 1-، تقريب باتجاه الصفر لقيمة 0، تقريب للقيمة الأقرب لقيمة 1، تقريب إلى اللا نهاية الموجبة لقيمة 2، تقريب إلى اللا نهاية السالبة لقيمة 3. أي قيمة أخرى تكون محددة بحسب التطبيق LDBL_DIG (≥10) عدد خانات الدقة في نوع long double LDBL_EPSILON (≤1E−9) العدد الموجب الأدنى الذي يحقق 1.0 + x ≠ 1.0 LDBL_MANT_DIG (—) عدد خانات أساس FLT_RADIX في الجزء العشري من النوع long double LDBL_MAX (≥1E+37) القيمة العظمى للنوع long double LDBL_MAX_10_EXP (≥+37) القيمة العظمى لأس (أساسه 10) من نوع long double LDBL_MAX_EXP (—) القيمة العظمى لأس (أساسه FLT_RADIX) من نوع long double LDBL_MIN (≤1E−37) القيمة الدنيا للنوع long double LDBL_MIN_10_EXP (≤−37) القيمة الدنيا لأس (أساسه 10) من نوع long double LDBL_MIN_EXP (—) القيمة الدنيا لأس (أساسه FLT_RADIX) من نوع long double [جدول 2 أسماء ملف الترويسة <float.h>] الدوال الرياضية إذا كنت تكتب برامجًا رياضيّة تجري عمليات على الفاصلة العائمة وما شابه، فهذا يعني أنك تحتاج الوصول إلى مكتبات الدوال الرياضية دون أدنى شك، ويأخذ هذا النوع من الدوال وسطاءً من النوع double ويعيد نتيجةً من النوع ذاته أيضًا. تُعرَّف الدوال والماكرو المرتبطة بها في ملف الترويسة <math.h>. يُستبدل الماكرو HUGE_VAL المُعرف إلى تعبير ذي قيمة موجبة من نوع عدد عشري مضاعف الدقة "double"، ولا يمكن تمثيله بالضرورة باستخدام النوع float. نحصل على خطأ نطاق domain error في جميع الدوال إذا كانت قيمة الوسيط المُدخل خارج النطاق المُعرّف للدالة، مثل محاولة الحصول على جذر تربيعي لعدد سالب، وإذا حصل هذا الخطأ يُضبط errno إلى الثابت EDOM، وتُعيد الدالة قيمة معرّفة بحسب التطبيق. نحصل على خطأ مجال range error إذا لم يكن من الممكن تمثيل نتيجة الدالة بقيمة عدد عشري مضاعف الدقة، تُعيد الدالة القيمة ±HUGE_VAL إذا كانت قيمة النتيجة كبيرة جدًا (الإشارة موافقة للقيمة) وتُضبط errno إلى ERANGE إذا كانت القيمة صغيرة جدًا وتُعاد القيمة 0.0 وتُعتمد قيمة errno على تعريف التطبيق. تصف اللائحة التالية كلًا من الدوال المتاحة باختصار: الدالة double acos(double x);: تُعيد القيمة الرئيسة Principal value لقوس جيب التمام Arc cosine للوسيط x في النطاق من 0 إلى π راديان، ونحصل على الخطأ EDOM إذا كان x خارج النطاق -1 إلى 1. الدالة double asin(double x);: تُعيد القيمة الرئيسة لقوس الجيب Arc sin للوسيط x في النطاق من -π/2 إلى +π/2 راديان، ونحصل على الخطأ EDOM إذا كان xخارج النطاق -1 إلى 1. الدالة double atan(double x);: تُعيد القيمة الرئيسة لقوس الظل Arc tan للوسيط x في النطاق من -π/2 إلى +π/2 راديان. الدالة double atan2(double y, double x);: تُعيد القيمة الرئيسة لقوس الظل للقيمة y/x في النطاق من -π إلى +π راديان، وتستخدم إشارتي الوسيطين x و y لتحديد الربع الذي تقع فيه قيمة الإجابة، ونحصل على الخطأ EDOM في حال كان x و y مساويين إلى الصفر. الدالة double cos(double x);: تُعيد جيب تمام قيمة الوسيط x (تُقاس x بالراديان). الدالة double sin(double x);: تُعيد جيب قيمة الوسيط x (تُقاس x بالراديان). الدالة double tan(double x);: تُعيد ظل قيمة الوسيط x (تُقاس x بالراديان)، وتكون إشارة HUGE_VAL غير مضمونة الصحّة إذا حدث خطأ مجال. الدالة double cosh(double x);: تُعيد جيب التمام القطعي Hyperbolic للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا جدًا. الدالة double sinh(double x);: تُعيد الجيب القطعي للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار x كبيرًا للغاية. الدالة double tanh(double x);: تُعيد الظل القطعي للقيمة x. الدالة double exp(double x);: دالة أسية للقيمة x، ونحصل على الخطأ ERANGE إذا كان مقدار xكبيرًا جدًا. الدالة double frexp(double value, int *exp);: تجزئة عدد ذو فاصلة عائمة إلى كسر طبيعي وأُس عدد صحيح من الأساس 2، ويخزن هذا العدد الصحيح في الغرض المُشار إليه بواسطة المؤشر exp. الدالة double ldexp(double x, int exp);: ضرب x بمقدار 2 إلى الأُس exp، وقد نحصل على الخطأ ERANGE. الدالة double log(double x);: اللوغاريتم الطبيعي للقيمة x، وقد نحصل على الخطأ EDOM إذا كانت القيمة x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double log10(double x);: اللوغاريتم ذو الأساس 10 للقيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة، و ERANGE إذا كانت x تساوي إلى الصفر. الدالة double modf(double value, double *iptr);: تجزئة قيمة الوسيط value إلى جزء عدد صحيح وجزء كسري، ويحمل كل جزء إشارة الوسيط ذاتها، وتُخزن قيمة العدد الصحيح على أنها قيمة من نوع double في الكائن المُشار إليه بواسطة المؤشر iptr وتُعيد الدالة الجزء الكسري. الدالة double pow(double x, double y);: تحسب x إلى الأس y، ونحصل على الخطأ EDOM إذا كانت القيمة x سالبة و y عدد غير صحيح، أو ERANGE إذا لم يكن من الممكن تمثيل النتيجة في حال كانت x تساوي إلى الصفر و y موجبة أو تساوي الصفر. الدالة double sqrt(double x);: تحسب مربع القيمة x، ونحصل على الخطأ EDOM إذا كانت x سالبة. الدالة double ceil(double x);: أصغر عدد صحيح لا يكون أصغر من x. الدالة double fabs(double x);: القيمة المطلقة للوسيط x. الدالة double floor(double x);: أكبر عدد صحيح لا يكون أكبر من x. الدالة double fmod(double x, double y);: الباقي العشري من عملية القسمة x/y، ويعتمد الأمر على تعريف التطبيق فيما إذا كانت fmod تُعيد صفرًا أو خطأ نطاق في حال كانت y تساوي إلى الصفر. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: تعلم لغة سي التعامل مع المكتبات في لغة سي C المقال السابق: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C -
 نستعرض في هذا المقال كيفية التعامل مع المحارف في لغة سي باستخدام دوال المكتبات القياسية، إضافةً إلى التوطين وإعدادات اللغة المحلية locale. التعامل مع المحارف هناك مجموعةٌ متنوعةٌ من الدوال تهدف لفحص وربط mapping المحارف، إذ تسمح لك دوال الفحص test functions -التي سنناقشها أولًا- بفحص فيما إذا كان المحرف من نوع معين، مثل حرف أبجدي، أو حرف صغير أم كبير، أو محرف رقمي، أو محرف تحكّم control character، أو إشارة ترقيم، أو محرف قابل للطباعة أو لا، وهكذا. تُعيد دوال فحص المحرف قيمة عدد صحيح integer تساوي الصفر إذا لم يكن المحرف المُحدّد منتميًا إلى التصنيف المذكور، أو قيمة غير صفرية عدا ذلك، ويأخذ هذا النوع من الدوال وسيطًا ذا قيمة عدد صحيح تُمثّل قيمته من نوع "unsigned char"، أو عدد صحيح ثابت قيمته "EOF" مثل تلك القيمة المُعادة من دوال مشابهة، مثل getchar()، ونحصل على سلوك غير معرّف خارج هذه الحالات. تعتمد هذه الدوال على إعدادات البرنامج المحلية: محرف الطباعة printing character هو عضو من مجموعة المحارف المعرّفة بحسب التطبيق، ويشغل كل محرف طباعة موقع طباعة واحد، ومحرف التحكم control character هو عضو من مجموعة المحارف المعرفة بحسب التطبيق أيضًا إلا أن كل محرف منها ليس بمحرف طباعة. إذا استخدمنا مجموعة محارف معيار ASCII 7-bit، ستكون محارف الطباعة بين الفراغ (0x20) وتيلدا tilde (0x7e)، بينما تكون محارف التحكم بين NUL (0x0) و US (0x1f) والمحرف DEL (0x7f). تجد أدناه ملخصًا يحتوي على جميع دوال فحص المحرف، ويجب تضمين ملف الترويسة <ctype.h> قبل استخدام أيّ منها. دالة isalnum(int c): تُعيد القيمة "True" إذا كان c محرفًا أبجديًا أو رقمًا؛ أي (isalpha(c)||isdigit(c)). دالة isalpha(int c): تُعيد القيمة "True" إذا كان هذا الشرط (isupper(c)||islower(c)) محققًا، كما أنها تُعيد القيمة True لمجموعة المحارف المُعرفة بحسب التطبيق التي لا تعيد القيمة True عند تمريرها على الدالة iscntrl أو isdigit أو ispunct أو isspace وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة iscntrl(int c): تُعيد القيمة True إذا كان المحرف محرف تحكم. دالة isdigit(int c): تُعيدالقيمة True إذا كان المحرف رقمًا عشريًا decimal. دالة isgraph(int c): تُعيد القيمة True إذا كان المحرف هو محرف طباعة عدا محرف المسافة الفارغة. دالة islower(int c): تُعيد القيمة True إذا كان المحرف محرفًا أبجديًا صغيرًا lower case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في C المحلية. دالة isprint(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة (متضمّنًا محرف المسافة الفارغة). دالة ispunct(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة عدا محرف المسافة الفارغة أو المحارف التي تُعيد القيمة True في دالة isalnum. دالة isspace(int c): تُعيد القيمة True إذا كان المحرف محرف مسافة بيضاء (المحرف ' ' أو \f أو \n أو \r أو \t أو \v) دالة isupper(int c): تُعيد القيمة True إذا كان المحرف محرف أبجديًا كبيرًا upper case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة isxdigit(int c): تُعيد القيمة True إذا كان المحرف رقم ستّ عشري صالح. هناك دالتان إضافيتان تربطان المحارف من مجموعةٍ إلى أخرى، إذ تُعيد الدالة tolower محرفًا صغيرًا موافقًا لمحرف كبير مُرِّر لها، على سبيل المثال: tolower('A') == 'a' تُعيد الدالة tolower المحرف ذاته، إذا تلقّت أي محرف مُغاير للمحارف الأبجدية الكبيرة. تربط الدالة toupper المعاكسة للدالة السابقة في عملها المحرف المُمرّر لها إلى مكافئه الكبير. تُجرى عملية الربط في الدالتين السابقتين فقط في حال وجود محرف موافق للمحرف المُمرّر لها، إذ لا تمتلك بعض اللغات محرفًا كبيرًا موافق لمحرف صغير والعكس صحيح. التوطين Localization نستطيع التحكم بالإعدادات المحليّة للبرنامج من هنا، ويصرح ملف الترويسة <locale.h> دوال setlocale و localeconv وعددًا من الماكرو: LC_ALL LC_COLLATE LC_CTYPE LC_MONETARY LC_NUMERIC LC_TIME تُستبدل جميع الماكرو بتعبير ثابت ذي قيمة عدد صحيح وتُستخدم القيمة الناتجة عن التعبير مكان الوسيط category في الدالة setlocale (يمكن تعريف أسماء أخرى أيضًا، ويجب أن يبدأ كل منها بـ LC_X، إذ يمثّل X المحرف الأبجدي الكبير)، ويُستخدم النوع struct lconv لتخزين المعلومات المتعلقة بتنسيق القيم الرقمية، ويُستخدَم CHAR_MAX للأعضاء من النوع char للدلالة على أن القيمة غير متوافرة في الإعدادات المحلية الحالية. يحتوي lconv على عضو واحد على الأقل من الأعضاء التالية: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } العضو الاستخدام تمثيله في إصدارات سي المحلية ملاحظات إضافية char *decimal_point يُستخدم المحرف للفاصلة العشرية في القيم المنسقة غير المالية. "." --- char *thousands_sep يُستخدم المحرف لفصل مجموعات من الخانات الواقعة على يسار الفاصلة العشرية في القيم المنسقة غير المالية. "" --- char *grouping يعرّف عدد الخانات في كل مجموعة في القيم المنسقة غير المالية، وتحدد القيمة CHAR_MAX أنه لا يوجد أي تجميع إضافي مطلوب، بينما تحدد القيمة 0 أنه يجب تكرار العنصر السابق للخانات الرقمية المتبقية، وإذا استُخدمت أي قيمة أخرى فهي تمثل قيمة العدد الصحيح المُمثل لعدد الخانات التي تتألف منها المجموعة الحالية (المحرف اللاحق في السلسلة النصية يُفسَّر قبل التجميع). "" يحدد "\3" أن الخانات يجب أن تجمع كل ثلاثة في مجموعة ويشير محرف الإنهاء الفارغ terminating null في السلسلة النصية إلى تكرار \3. char *int_curr_symbol تُستخدم المحارف الأولى الثلاث لتخزين رمز العملة العالمي الأبجدي لإصدار سي المحلي، بينما يُستخدم المحرف الرابع للفصل بين رمز العملة العالمي والكمية النقدية. "" --- char *currency_symbol يمثل رمز العملة للإصدار المحلي الحالي. "" --- char *mon_decimal_point المحرف المُستخدم مثل فاصلة عشرية عند تنسيق القيم النقدية. "" --- char *mon_thousands_sep يمثل فاصل مجموعات خانات الأرقام ذات القيم المنسقة بتنسيق نقدي. "" --- char *mon_grouping يعرف عدد الخانات في كل مجموعة عند تنسيق قيم نقدية، وتُفسّر عناصره على أنها جزء من التجميع "" --- char *positive_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية غير سالبة. "" --- char *negative_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية سالبة. "" --- char int_frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية منسقة عالميًا. CHAR_MAX --- char frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية غير منسقة عالميًا. CHAR_MAX --- char p_cs_precedes قيمة 1 تدل على وجوب إتباع currency_symbol بالقيمة عند تنسيق قيمة غير سالبة نقدية، بينما تدل القيمة 0 على إسباق currency_symbol بالقيمة. CHAR_MAX --- char p_sep_by_space قيمة 1 تدل على تفريق رمز العملة من القيمة بمسافة فارغة عند تنسيق قيمة غير سالبة نقدية، بينما تدل قيمة 0 على عدم وجود أي مسافة فارغة. CHAR_MAX --- char n_cs_precedes تشابه p_cs_precedes ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sep_by_space تشابه p_sep_by_space ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sign_posn يشابه p_sign_posn ولكن للقيم النقدية السالبة. CHAR_MAX --- char p_sign_posn يمثل موقع positive_sign للقيم النقدية المنسقة غير السالبة. CHAR_MAX يتبع الشروط التالية: تُحيط الأقواس القيمة النقدية وcurrency_symbol. تسبق السلسلة النصية كل من القيمة النقدية و currency_symbol. تتبع السلسلة النصية القيمة النقدية و currency_symbol. تسبق السلسلة النصية القيمة currency_symbol. تتبع السلسلة النصية القيمة currency_symbol دالة setlocale لضبط الإعدادات المحلية يكون تعريف دالة setlocale على النحو التالي: #include <locale.h> char *setlocale(int category, const char *locale); تسمح هذه الدالة بضبط إعدادات البرنامج المحلية، ويمكن ضبط جميع أجزاء الإصدار المحلي باختيار القيم المناسبة لوسيط التصنيف category كما يلي: القيمة LC_ALL: تضبط كامل الإصدار المحلي. القيمة LC_COLLATE: تعديل سلوك strcoll و strxfrm. القيمة LC_CTYPE: تعديل سلوك دوال التعامل مع المحارف character-handling. القيمة LC_MONETARY: تعديل تنسيق القيم النقدية المُعادة من دالة localeconv. القيمة LC_NUMERIC: تعديل محرف الفاصلة العشرية لتنسيق الدخل والخرج وبرامج تحويل السلاسل النصية. القيمة LC_TIME: تعديل سلوك strftime. يمكن ضبط قيم الإعدادات المحلية إلى: "C" تحديد البيئة ذات المتطلبات الدنيا لترجمة سي C "" تحديد البيئة الأصيلة المعرفة حسب التطبيق قيمة معرفة بحسب التنفيذ تحديد البيئة الموافقة لهذه القيمة البيئة الافتراضية عند بداية البرنامج موافقة للبيئة التي نحصل عليها عند تنفيذ التعليمة التالية: setlocale(LC_ALL, "C"); يمكن فحص السلسلة النصية الحالية المترافقة مع تصنيف ما بتمرير مؤشر فارغ null قيمةً للوسيط locale؛ نحصل على السلسلة النصية المترافقة مع التصنيف category المحدد للتوطين الجديد إذا كان من الممكن حصول التصنيف المحدد، وتُستخدم هذه السلسلة النصية في استدعاء لاحق للدالة setlocale مع تصنيفها المترافق لاستعادة الجزء الموافق من إعدادات البرنامج المحلية، وإذا كان التحديد غير ممكن الحصول نحصل على مؤشر فراغ دون تغيير الإعدادات المحلية. دالة localeconv يكون تصريح الدالة على النحو التالي: #include <locale.h> struct lconv *localeconv(void); تُعيد هذه الدالة مؤشرًا يشير إلى هيكل من النوع struct lconv، ويُضبط هذا المؤشر طبقًا للإعدادات المحلية الحالية ويمكن تغييره باستدعاء لاحق للدالة localconv أو setlocale، ويجب ألّا يكون الهيكل قابلًا للتعديل بأي طريقة أخرى. على سبيل المثال، إذا كانت إعدادات القيم النقدية المحلية الحالية مُمثّلةً حسب الإعدادات التالية: IR£1,234.56 تنسيق القيم الموجبة (IR£1,234.56) تنسيق القيم السالبة IRP 1,234.56 التنسيق العالمي يجب أن تحمل الأعضاء التي تمثّل القيم النقدية في lconv القيم التالية: int_curr_symbol "IRP " currency_symbol "IR£" mon_decimal_point "." mon_thousands_sep "," mon_grouping "\3" postive_sign "" negative_sign "" int_frac_digits 2 frac_digits 2 p_cs_precedes 1 p_sep_by_space 0 n_cs_precedes 1` n_sep_by_space 0 p_sign_posn CHAR_MAX n_sign_posn 0 ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: القيم الحدية والدوال الرياضية في لغة سي C المقال السابق: مقدمة إلى مكتبات لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C مدخل إلى المصفوفات في لغة سي C
نستعرض في هذا المقال كيفية التعامل مع المحارف في لغة سي باستخدام دوال المكتبات القياسية، إضافةً إلى التوطين وإعدادات اللغة المحلية locale. التعامل مع المحارف هناك مجموعةٌ متنوعةٌ من الدوال تهدف لفحص وربط mapping المحارف، إذ تسمح لك دوال الفحص test functions -التي سنناقشها أولًا- بفحص فيما إذا كان المحرف من نوع معين، مثل حرف أبجدي، أو حرف صغير أم كبير، أو محرف رقمي، أو محرف تحكّم control character، أو إشارة ترقيم، أو محرف قابل للطباعة أو لا، وهكذا. تُعيد دوال فحص المحرف قيمة عدد صحيح integer تساوي الصفر إذا لم يكن المحرف المُحدّد منتميًا إلى التصنيف المذكور، أو قيمة غير صفرية عدا ذلك، ويأخذ هذا النوع من الدوال وسيطًا ذا قيمة عدد صحيح تُمثّل قيمته من نوع "unsigned char"، أو عدد صحيح ثابت قيمته "EOF" مثل تلك القيمة المُعادة من دوال مشابهة، مثل getchar()، ونحصل على سلوك غير معرّف خارج هذه الحالات. تعتمد هذه الدوال على إعدادات البرنامج المحلية: محرف الطباعة printing character هو عضو من مجموعة المحارف المعرّفة بحسب التطبيق، ويشغل كل محرف طباعة موقع طباعة واحد، ومحرف التحكم control character هو عضو من مجموعة المحارف المعرفة بحسب التطبيق أيضًا إلا أن كل محرف منها ليس بمحرف طباعة. إذا استخدمنا مجموعة محارف معيار ASCII 7-bit، ستكون محارف الطباعة بين الفراغ (0x20) وتيلدا tilde (0x7e)، بينما تكون محارف التحكم بين NUL (0x0) و US (0x1f) والمحرف DEL (0x7f). تجد أدناه ملخصًا يحتوي على جميع دوال فحص المحرف، ويجب تضمين ملف الترويسة <ctype.h> قبل استخدام أيّ منها. دالة isalnum(int c): تُعيد القيمة "True" إذا كان c محرفًا أبجديًا أو رقمًا؛ أي (isalpha(c)||isdigit(c)). دالة isalpha(int c): تُعيد القيمة "True" إذا كان هذا الشرط (isupper(c)||islower(c)) محققًا، كما أنها تُعيد القيمة True لمجموعة المحارف المُعرفة بحسب التطبيق التي لا تعيد القيمة True عند تمريرها على الدالة iscntrl أو isdigit أو ispunct أو isspace وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة iscntrl(int c): تُعيد القيمة True إذا كان المحرف محرف تحكم. دالة isdigit(int c): تُعيدالقيمة True إذا كان المحرف رقمًا عشريًا decimal. دالة isgraph(int c): تُعيد القيمة True إذا كان المحرف هو محرف طباعة عدا محرف المسافة الفارغة. دالة islower(int c): تُعيد القيمة True إذا كان المحرف محرفًا أبجديًا صغيرًا lower case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في C المحلية. دالة isprint(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة (متضمّنًا محرف المسافة الفارغة). دالة ispunct(int c): تُعيد القيمة True إذا كان المحرف محرف طباعة عدا محرف المسافة الفارغة أو المحارف التي تُعيد القيمة True في دالة isalnum. دالة isspace(int c): تُعيد القيمة True إذا كان المحرف محرف مسافة بيضاء (المحرف ' ' أو \f أو \n أو \r أو \t أو \v) دالة isupper(int c): تُعيد القيمة True إذا كان المحرف محرف أبجديًا كبيرًا upper case، كما أنها محققة لمجموعة محارف معرفة حسب التطبيق لا تُعيد القيمة True لأي من الدالة iscntrl أو isdigit أو ispunct أو isspace، وتكون مجموعة المحارف الإضافية هذه فارغة في لغة سي المحلية. دالة isxdigit(int c): تُعيد القيمة True إذا كان المحرف رقم ستّ عشري صالح. هناك دالتان إضافيتان تربطان المحارف من مجموعةٍ إلى أخرى، إذ تُعيد الدالة tolower محرفًا صغيرًا موافقًا لمحرف كبير مُرِّر لها، على سبيل المثال: tolower('A') == 'a' تُعيد الدالة tolower المحرف ذاته، إذا تلقّت أي محرف مُغاير للمحارف الأبجدية الكبيرة. تربط الدالة toupper المعاكسة للدالة السابقة في عملها المحرف المُمرّر لها إلى مكافئه الكبير. تُجرى عملية الربط في الدالتين السابقتين فقط في حال وجود محرف موافق للمحرف المُمرّر لها، إذ لا تمتلك بعض اللغات محرفًا كبيرًا موافق لمحرف صغير والعكس صحيح. التوطين Localization نستطيع التحكم بالإعدادات المحليّة للبرنامج من هنا، ويصرح ملف الترويسة <locale.h> دوال setlocale و localeconv وعددًا من الماكرو: LC_ALL LC_COLLATE LC_CTYPE LC_MONETARY LC_NUMERIC LC_TIME تُستبدل جميع الماكرو بتعبير ثابت ذي قيمة عدد صحيح وتُستخدم القيمة الناتجة عن التعبير مكان الوسيط category في الدالة setlocale (يمكن تعريف أسماء أخرى أيضًا، ويجب أن يبدأ كل منها بـ LC_X، إذ يمثّل X المحرف الأبجدي الكبير)، ويُستخدم النوع struct lconv لتخزين المعلومات المتعلقة بتنسيق القيم الرقمية، ويُستخدَم CHAR_MAX للأعضاء من النوع char للدلالة على أن القيمة غير متوافرة في الإعدادات المحلية الحالية. يحتوي lconv على عضو واحد على الأقل من الأعضاء التالية: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } العضو الاستخدام تمثيله في إصدارات سي المحلية ملاحظات إضافية char *decimal_point يُستخدم المحرف للفاصلة العشرية في القيم المنسقة غير المالية. "." --- char *thousands_sep يُستخدم المحرف لفصل مجموعات من الخانات الواقعة على يسار الفاصلة العشرية في القيم المنسقة غير المالية. "" --- char *grouping يعرّف عدد الخانات في كل مجموعة في القيم المنسقة غير المالية، وتحدد القيمة CHAR_MAX أنه لا يوجد أي تجميع إضافي مطلوب، بينما تحدد القيمة 0 أنه يجب تكرار العنصر السابق للخانات الرقمية المتبقية، وإذا استُخدمت أي قيمة أخرى فهي تمثل قيمة العدد الصحيح المُمثل لعدد الخانات التي تتألف منها المجموعة الحالية (المحرف اللاحق في السلسلة النصية يُفسَّر قبل التجميع). "" يحدد "\3" أن الخانات يجب أن تجمع كل ثلاثة في مجموعة ويشير محرف الإنهاء الفارغ terminating null في السلسلة النصية إلى تكرار \3. char *int_curr_symbol تُستخدم المحارف الأولى الثلاث لتخزين رمز العملة العالمي الأبجدي لإصدار سي المحلي، بينما يُستخدم المحرف الرابع للفصل بين رمز العملة العالمي والكمية النقدية. "" --- char *currency_symbol يمثل رمز العملة للإصدار المحلي الحالي. "" --- char *mon_decimal_point المحرف المُستخدم مثل فاصلة عشرية عند تنسيق القيم النقدية. "" --- char *mon_thousands_sep يمثل فاصل مجموعات خانات الأرقام ذات القيم المنسقة بتنسيق نقدي. "" --- char *mon_grouping يعرف عدد الخانات في كل مجموعة عند تنسيق قيم نقدية، وتُفسّر عناصره على أنها جزء من التجميع "" --- char *positive_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية غير سالبة. "" --- char *negative_sign السلسلة النصية المُستخدمة للدلالة على قيمة نقدية سالبة. "" --- char int_frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية منسقة عالميًا. CHAR_MAX --- char frac_digits عدد الخانات التي تُعرض بعد الفاصلة العشرية في قيمة نقدية غير منسقة عالميًا. CHAR_MAX --- char p_cs_precedes قيمة 1 تدل على وجوب إتباع currency_symbol بالقيمة عند تنسيق قيمة غير سالبة نقدية، بينما تدل القيمة 0 على إسباق currency_symbol بالقيمة. CHAR_MAX --- char p_sep_by_space قيمة 1 تدل على تفريق رمز العملة من القيمة بمسافة فارغة عند تنسيق قيمة غير سالبة نقدية، بينما تدل قيمة 0 على عدم وجود أي مسافة فارغة. CHAR_MAX --- char n_cs_precedes تشابه p_cs_precedes ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sep_by_space تشابه p_sep_by_space ولكن للقيم النقدية السالبة. CHAR_MAX --- char n_sign_posn يشابه p_sign_posn ولكن للقيم النقدية السالبة. CHAR_MAX --- char p_sign_posn يمثل موقع positive_sign للقيم النقدية المنسقة غير السالبة. CHAR_MAX يتبع الشروط التالية: تُحيط الأقواس القيمة النقدية وcurrency_symbol. تسبق السلسلة النصية كل من القيمة النقدية و currency_symbol. تتبع السلسلة النصية القيمة النقدية و currency_symbol. تسبق السلسلة النصية القيمة currency_symbol. تتبع السلسلة النصية القيمة currency_symbol دالة setlocale لضبط الإعدادات المحلية يكون تعريف دالة setlocale على النحو التالي: #include <locale.h> char *setlocale(int category, const char *locale); تسمح هذه الدالة بضبط إعدادات البرنامج المحلية، ويمكن ضبط جميع أجزاء الإصدار المحلي باختيار القيم المناسبة لوسيط التصنيف category كما يلي: القيمة LC_ALL: تضبط كامل الإصدار المحلي. القيمة LC_COLLATE: تعديل سلوك strcoll و strxfrm. القيمة LC_CTYPE: تعديل سلوك دوال التعامل مع المحارف character-handling. القيمة LC_MONETARY: تعديل تنسيق القيم النقدية المُعادة من دالة localeconv. القيمة LC_NUMERIC: تعديل محرف الفاصلة العشرية لتنسيق الدخل والخرج وبرامج تحويل السلاسل النصية. القيمة LC_TIME: تعديل سلوك strftime. يمكن ضبط قيم الإعدادات المحلية إلى: "C" تحديد البيئة ذات المتطلبات الدنيا لترجمة سي C "" تحديد البيئة الأصيلة المعرفة حسب التطبيق قيمة معرفة بحسب التنفيذ تحديد البيئة الموافقة لهذه القيمة البيئة الافتراضية عند بداية البرنامج موافقة للبيئة التي نحصل عليها عند تنفيذ التعليمة التالية: setlocale(LC_ALL, "C"); يمكن فحص السلسلة النصية الحالية المترافقة مع تصنيف ما بتمرير مؤشر فارغ null قيمةً للوسيط locale؛ نحصل على السلسلة النصية المترافقة مع التصنيف category المحدد للتوطين الجديد إذا كان من الممكن حصول التصنيف المحدد، وتُستخدم هذه السلسلة النصية في استدعاء لاحق للدالة setlocale مع تصنيفها المترافق لاستعادة الجزء الموافق من إعدادات البرنامج المحلية، وإذا كان التحديد غير ممكن الحصول نحصل على مؤشر فراغ دون تغيير الإعدادات المحلية. دالة localeconv يكون تصريح الدالة على النحو التالي: #include <locale.h> struct lconv *localeconv(void); تُعيد هذه الدالة مؤشرًا يشير إلى هيكل من النوع struct lconv، ويُضبط هذا المؤشر طبقًا للإعدادات المحلية الحالية ويمكن تغييره باستدعاء لاحق للدالة localconv أو setlocale، ويجب ألّا يكون الهيكل قابلًا للتعديل بأي طريقة أخرى. على سبيل المثال، إذا كانت إعدادات القيم النقدية المحلية الحالية مُمثّلةً حسب الإعدادات التالية: IR£1,234.56 تنسيق القيم الموجبة (IR£1,234.56) تنسيق القيم السالبة IRP 1,234.56 التنسيق العالمي يجب أن تحمل الأعضاء التي تمثّل القيم النقدية في lconv القيم التالية: int_curr_symbol "IRP " currency_symbol "IR£" mon_decimal_point "." mon_thousands_sep "," mon_grouping "\3" postive_sign "" negative_sign "" int_frac_digits 2 frac_digits 2 p_cs_precedes 1 p_sep_by_space 0 n_cs_precedes 1` n_sep_by_space 0 p_sign_posn CHAR_MAX n_sign_posn 0 ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: القيم الحدية والدوال الرياضية في لغة سي C المقال السابق: مقدمة إلى مكتبات لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C مدخل إلى المصفوفات في لغة سي C -
 سيساهم قرار لجنة لغة سي المعيارية بتعريف إجراءات Routines عدد من المكتبات بما يعود بالنفع الكبير لجميع مستخدمي لغة سي دون أي شك، إذ لم يكن هناك أي معيار مُتّفق عليه يعرف إجراءات المكتبات ويقدم دعمًا للغة، وانعكس ذلك سلبًا على قابلية نقل البرامج Portability كثيرًا. ليس من المطلوب أن تتواجد إجراءات المكتبة داخل البرنامج، إذ تتواجد فقط في البيئات المُستضافة Hosted environment وتنطبق هذه الحالة غالبًا على مبرمجي التطبيقات، بينما لن تكون المكتبات موجودةً في حالة مبرمجي النظم المُدمجة ومبرمجي البيئات المُستضافة؛ إذ يستخدم هذا النوع من المبرمجين لغة سي لوحدها ضمن بيئة مستقلة Freestanding environment، وبالتالي لن يكون هذا المقال مهمًّا لهم. لن تكون المواضيع التي ستتبع هذه المقدمة مكتوبةً بهدف قراءتها بالتسلسل، ويمكنك قراءتها أجزاء منفصلة، إذ نهدف هنا إلى توفير محتوى يُستخدم كمرجع بسيط للمعلومات وليس درس تعليمي شامل، وإلا فسيتطلب الأمر كتابًا مخصصًا لنستطيع تغطية جميع المكتبات. ملفات الترويسات والأنواع القياسية تُستخدم عدّة أنواع types وماكرو macro على نحوٍ واسع في دوال المكتبات، وتُعرّف في ملف #include الموافق للدالة. كما سيصرِّح ملف الترويسة Header عن الأنواع والنماذج الأولية المناسبة لدوالّ المكتبة، وعلينا أن نذكر عدّة نقاط مهمة بهذا الخصوص: تُحجز جميع المعرّفات الخارجية External identifiers وأسماء الماكرو المُصرّح عنها في أي ملف ترويسة لمكتبة، بحيث لا يُمكن استخدامها أو إعادة تعريفها لأي استعمال آخر. قد تحمل الأسماء في بعض الأحيان أثرًا "سحريًّا" عندما تكون معروفةً للمصرف ويتسبب ذلك باستخدام بعض الأساليب الخاصة لتطبيقها. جميع المعرفات التي تبدأ بمحرف الشرطة السفلية underscore _ محجوزة. يمكن تضمين ملفات الترويسة بأي ترتيب كان ولأكثر من مرة، إلا أن تضمينها يجب أن يحدث خارج أي تصريح داخلي أو تعريف وقبل أي استخدام للدوال والماكرو المعرّفة بداخلها. نحصل على سلوك غير معرّف إن مرّرنا قيمة غير صالحة لدالة، مثل مؤشر فارغ، أو قيمة خارج نطاق القيم التي تقبلها الدالة. لا يُحدّد المعيار النوع ذاته من القيود الموضحة أعلاه بخصوص المعرّفات، وقد يتبادر إلى ذهنك المغامرة والاستفادة من هذه الثغرات، إلا أننا ننصحك بالالتزام بالطرق الآمنة. ملفات الترويسة المعيارية هي: <assert.h> <locale.h> <stddef.h> <ctype.h> <math.h> <stdio.h> <errno.h> <setjmp.h> <stdlib.h> <float.h> <signal.h> <string.h> <limits.h> <stdarg.h> <time.h> معلومة عامّة أخيرة: تُنفّذ العديد من إجراءات المكتبات على أنها ماكرو في عملها، شرط ألا يتسبب ذلك في أي مشاكل ناتجة عن الآثار الجانبية لهذا الاستخدام (كما وضّح الفصل السابع). يضمن المعيار وجود دالة اعتيادية إذا كان هناك دالة تُستخدم عادةً مثل ماكرو موافقة لها، بحيث تُنجز الدالتان العمل ذاته، وحتى تستخدم الدالة الاعتيادية عليك أن تُلغي تعريف الماكرو باستخدام التوجيه #undef، أو أن تكتب اسم الماكرو داخل قوسين، مما يضمن أنه لن يُعامل معاملة الماكرو: some function("Might be a macro\n"); //قد يمثل هذا ماكرو (some function)("Can't be a macro\n"); //من غير الممكن أن يكون هذا ماكرو مجموعات المحارف والاختلافات اللغوية قدّمت لجنة المعيار بعض المزايا الموجهة لاستخدام سي في البيئات التي لا تستخدم مجموعة محارف معيار US ASCII، والاختلافات اللغوية الأخرى التي تستخدم الفاصلة أو النقطة للدلالة على الفاصلة العشرية. قُدّمت التسهيلات (ألقِ نظرةً على القسم) بفكرة برنامج يتحكم بسلوك دوال المكتبات ليوافق الاختلافات اللغوية. تُعد مهمة تقديم دعم متكامل لمختلف اللغات والتقاليد مهمّة صعبة، وغالبًا ما يُساء فهمها، والتسهيلات المُزوّدة بمكتبات لغة سي هي الخطوة الأولى في هذا المشوار الطويل للوصول إلى الحل الكامل. الحل الوحيد المُعرّف من المعيار هو ما يدعى بلغة C المحلية locale، ويقدّم هذا دعمًا فعالًا على نحوٍ مشابه لعمل لغة سي القديمة، بينما تقدم الإعدادات المحلية الأخرى سلوكًا مختلفًا بحسب تعريف التطبيق. ملف ترويسة <stddef.h> هناك عددٌ صغير من الأنواع والماكرو الموجودة في <stddef.h> والمُستخدمة كثيرًا في ملفات الترويسة الأخرى، الذين سنتكلم عنها لاحقًا. تعطينا عملية طرح مؤشر من آخر نتيجةً من نوع مختلف بحسب التطبيق، وللسماح بالاستخدام الآمن في حال الاختلاف، يعرّف ملف الترويسة <stddef.h> النوع ptrdiff_t، كما يمكنك استخدام النوع size_t لتخزين نتيجة العامل sizeof بصورةٍ مشابهة. لأسباب لا تزال مخفية عنّا للوقت الحالي، هناك "مؤشر ثابت فارغ معرّف بحسب التنفيذ" معرّف في <stddef.h> باسم NULL، قد يبدو ذلك غير ضروريًا بالنظر إلى أن لغة سي تعرّف ثابت الرقم الصحيح 0 إلى القيمة التي يمكن إسنادها إلى مؤشر فارغ ومقارنتها معه، إلا أن الممارسة التالية شائعة جدًا وسط مبرمجي لغة سي المتمرسين: #include <stdio.h> #include <stddef.h> FILE *fp; if((fp = fopen("somefile", "r")) != NULL){ /* وهلمّ جرًّا */ هناك ماكرو باسم offsetof مهمته إيجاد مقدار الإزاحة offset بالبايت لعضو هيكل ما؛ إذ أن مقدار الإزاحة هو المسافة بين العضو وبداية الهيكل، إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> #include <stddef.h> main(){ size_t distance; struct x{ int a, b, c; }s_tr; distance = offsetof(s_tr, c); printf("Offset of x.c is %lu bytes\n", (unsigned long)distance); exit(EXIT_SUCCESS); } [مثال 1] يجب أن يكون التعبير s_tr.c قادرًا على التقييم مثل عنوانٍ لثابت (انظر مقال هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C)، فإذا كان العضو الذي تبحث عن مقدار إزاحته هو حقل بتات bitfield فستحصل على سلوك غير معرّف في هذه الحالة. لاحظ طريقة تحويل الأنواع في size_t التي نحوّل فيها لأطول نوع ممكن عديم الإشارة للتأكد من أن وسيط printf هو من النوع المناسب (%ul هو رمز التنسيق الخاص بطباعة النوع unsigned long) مع المحافظة على دقة القيمة، وهذا بسبب أن نوع size_t مجهول للمبرمج. العنصر الأخير المُصرّح عنه في <stddef.h> هو wchar_t وهو قيمة عدد صحيح كبيرة يُمكن تخزين محرف عريض wide character فيها ينتمي إلى أي مجموعة محارف موسّعة extended character set. ملف الترويسة يعرّف ملف الترويسة ما يُدعى errno الذي يُستبدل بتعبير ثابت ذو قيمة صحيحة لا تساوي الصفر، ويُضمن أن يكون هذا التعبير مقبولًا في موجّهات #if، ويعرّف أيضًا الماكرو EDOM والماكرو ERANGE اللذان يُستخدمان في الدوال الرياضية للدلالة على نوع الخطأ الحاصل وسنشرحهما بتوسعٍ أكبر لاحقًا. يُستخدم errno للدلالة على خطأ مُكتشف من دوال المكتبات، وهو ليس متغير خارجي بالضرورة -كما كان سابقًا- بل هو قيمةٌ متغيرةٌ من نوع int، إذ تُسند القيمة صفر إليه عند بداية تشغيل البرنامج، ولا يُعاد ضبط قيمته من تلك النقطة فصاعدًا إلا إذا جرى ذلك مباشرةً؛ أي بكلمات أخرى، لا تحاول إجراءات المكتبات إعادة ضبطه إطلاقًا، وإذا حدث أي خطأ في إجراء المكتبة فإن قيمة errno تتغير إلى قيمة معينة تشير إلى نوع الخطأ الحاصل ويُعيد الإجراء هذه القيمة (غالبًا -1) للدلالة على الخطأ، إليك تطبيقًا عمليًا عن ذلك: #include <stdio.h> #include <stddef.h> #include <errno.h> errno = 0; if(some_library_function(arguments) < 0){ // خطأ في معالجة الشيفرة المصدرية // قد يستخدم قيمة errno مباشرةً تطبيق errno غير معروف بالنسبة للمبرمج، فلا تحاول فعل أي شيء على هذه القيمة عدا إعادة ضبطها أو فحصها، فعلى سبيل المثال، من غير المضمون أن يكون لهذه القيمة عنوانًا على الذاكرة. يجب أن تتفقّد قيمة errno فقط في حال كانت دالة المكتبة المُستخدمة توثّق تأثيرها على errno، إذ يمكن لدوال المكتبات الأخرى أن تضبطها إلى قيمة عشوائية بعد استدعائها إلا إذا كان وصف الدالة يحدد ما الذي تفعله الدالة بالقيمة بصورةٍ صريحة. تشخيص الأخطاء من المفيد عندما تبحث عن الأخطاء في برنامجك أن تكون قادرًا على فحص قيمة تعبير ما والتأكد من أن قيمته هي ما تتوقّعها فعلًا، وهذا ما تقدمه لك دالة assert. يجب عليك أن تُضمّن ملف الترويسة <assert.h> أولًا حتى تتمكن من استخدام الدالة assert، وهذه الدالة معرفةٌ على النحو التالي: #include <assert.h> void assert(int expression) إذا كانت قيمة التعبير صفر (أي "خطأ false")، فستطبع الدالة assert رسالةً تدل على التعبير الفاشل، وتتضمن الرسالة اسم ملف الشيفرة المصدرية والسطر الذي يحتوي على التوكيد assertion والتعبير، ومن ثم تُستدعى دالة abort التي تقطع عمل البرنامج. assert(1 == 2); /* قد يتسبب ما سبق بالتالي */ Assertion failed: 1 == 2, file silly.c, line 15 في حقيقة الأمر الكلمة Assert معرّفة مثل ماكرو، وليس مثل دالة حقيقية. لتعطيل التوكيدات في برنامج يستوفي شروط عمله دون مشاكل، نعرّف الاسم NDEBUG قبل تضمين <assert.h>، وسيعطّل هذا جميع التوكيدات الموجودة في كامل البرنامج. عليك أن تعرف الآثار الجانبية التي يتسبب بها هذا للتعبير، فلن يُقيّم التعبير تعطيل التوكيدات باستخدام NDEBUG، وبذلك سيسلك المثال التالي سلوكًا غير مُتوقع عند إلغاء التوكيدات باستخدام #define NDEBUG. #define NDEBUG #include <assert.h> void func(void) { int c; assert((c = getchar()) != EOF); putchar(c); } [مثال 2] لاحظ أن الدالة assert لا تُعيد أي قيمة. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C المقال السابق: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة سي C بنية برنامج لغة سي C المحارف المستخدمة في لغة سي C مدخل إلى المصفوفات في لغة سي C
سيساهم قرار لجنة لغة سي المعيارية بتعريف إجراءات Routines عدد من المكتبات بما يعود بالنفع الكبير لجميع مستخدمي لغة سي دون أي شك، إذ لم يكن هناك أي معيار مُتّفق عليه يعرف إجراءات المكتبات ويقدم دعمًا للغة، وانعكس ذلك سلبًا على قابلية نقل البرامج Portability كثيرًا. ليس من المطلوب أن تتواجد إجراءات المكتبة داخل البرنامج، إذ تتواجد فقط في البيئات المُستضافة Hosted environment وتنطبق هذه الحالة غالبًا على مبرمجي التطبيقات، بينما لن تكون المكتبات موجودةً في حالة مبرمجي النظم المُدمجة ومبرمجي البيئات المُستضافة؛ إذ يستخدم هذا النوع من المبرمجين لغة سي لوحدها ضمن بيئة مستقلة Freestanding environment، وبالتالي لن يكون هذا المقال مهمًّا لهم. لن تكون المواضيع التي ستتبع هذه المقدمة مكتوبةً بهدف قراءتها بالتسلسل، ويمكنك قراءتها أجزاء منفصلة، إذ نهدف هنا إلى توفير محتوى يُستخدم كمرجع بسيط للمعلومات وليس درس تعليمي شامل، وإلا فسيتطلب الأمر كتابًا مخصصًا لنستطيع تغطية جميع المكتبات. ملفات الترويسات والأنواع القياسية تُستخدم عدّة أنواع types وماكرو macro على نحوٍ واسع في دوال المكتبات، وتُعرّف في ملف #include الموافق للدالة. كما سيصرِّح ملف الترويسة Header عن الأنواع والنماذج الأولية المناسبة لدوالّ المكتبة، وعلينا أن نذكر عدّة نقاط مهمة بهذا الخصوص: تُحجز جميع المعرّفات الخارجية External identifiers وأسماء الماكرو المُصرّح عنها في أي ملف ترويسة لمكتبة، بحيث لا يُمكن استخدامها أو إعادة تعريفها لأي استعمال آخر. قد تحمل الأسماء في بعض الأحيان أثرًا "سحريًّا" عندما تكون معروفةً للمصرف ويتسبب ذلك باستخدام بعض الأساليب الخاصة لتطبيقها. جميع المعرفات التي تبدأ بمحرف الشرطة السفلية underscore _ محجوزة. يمكن تضمين ملفات الترويسة بأي ترتيب كان ولأكثر من مرة، إلا أن تضمينها يجب أن يحدث خارج أي تصريح داخلي أو تعريف وقبل أي استخدام للدوال والماكرو المعرّفة بداخلها. نحصل على سلوك غير معرّف إن مرّرنا قيمة غير صالحة لدالة، مثل مؤشر فارغ، أو قيمة خارج نطاق القيم التي تقبلها الدالة. لا يُحدّد المعيار النوع ذاته من القيود الموضحة أعلاه بخصوص المعرّفات، وقد يتبادر إلى ذهنك المغامرة والاستفادة من هذه الثغرات، إلا أننا ننصحك بالالتزام بالطرق الآمنة. ملفات الترويسة المعيارية هي: <assert.h> <locale.h> <stddef.h> <ctype.h> <math.h> <stdio.h> <errno.h> <setjmp.h> <stdlib.h> <float.h> <signal.h> <string.h> <limits.h> <stdarg.h> <time.h> معلومة عامّة أخيرة: تُنفّذ العديد من إجراءات المكتبات على أنها ماكرو في عملها، شرط ألا يتسبب ذلك في أي مشاكل ناتجة عن الآثار الجانبية لهذا الاستخدام (كما وضّح الفصل السابع). يضمن المعيار وجود دالة اعتيادية إذا كان هناك دالة تُستخدم عادةً مثل ماكرو موافقة لها، بحيث تُنجز الدالتان العمل ذاته، وحتى تستخدم الدالة الاعتيادية عليك أن تُلغي تعريف الماكرو باستخدام التوجيه #undef، أو أن تكتب اسم الماكرو داخل قوسين، مما يضمن أنه لن يُعامل معاملة الماكرو: some function("Might be a macro\n"); //قد يمثل هذا ماكرو (some function)("Can't be a macro\n"); //من غير الممكن أن يكون هذا ماكرو مجموعات المحارف والاختلافات اللغوية قدّمت لجنة المعيار بعض المزايا الموجهة لاستخدام سي في البيئات التي لا تستخدم مجموعة محارف معيار US ASCII، والاختلافات اللغوية الأخرى التي تستخدم الفاصلة أو النقطة للدلالة على الفاصلة العشرية. قُدّمت التسهيلات (ألقِ نظرةً على القسم) بفكرة برنامج يتحكم بسلوك دوال المكتبات ليوافق الاختلافات اللغوية. تُعد مهمة تقديم دعم متكامل لمختلف اللغات والتقاليد مهمّة صعبة، وغالبًا ما يُساء فهمها، والتسهيلات المُزوّدة بمكتبات لغة سي هي الخطوة الأولى في هذا المشوار الطويل للوصول إلى الحل الكامل. الحل الوحيد المُعرّف من المعيار هو ما يدعى بلغة C المحلية locale، ويقدّم هذا دعمًا فعالًا على نحوٍ مشابه لعمل لغة سي القديمة، بينما تقدم الإعدادات المحلية الأخرى سلوكًا مختلفًا بحسب تعريف التطبيق. ملف ترويسة <stddef.h> هناك عددٌ صغير من الأنواع والماكرو الموجودة في <stddef.h> والمُستخدمة كثيرًا في ملفات الترويسة الأخرى، الذين سنتكلم عنها لاحقًا. تعطينا عملية طرح مؤشر من آخر نتيجةً من نوع مختلف بحسب التطبيق، وللسماح بالاستخدام الآمن في حال الاختلاف، يعرّف ملف الترويسة <stddef.h> النوع ptrdiff_t، كما يمكنك استخدام النوع size_t لتخزين نتيجة العامل sizeof بصورةٍ مشابهة. لأسباب لا تزال مخفية عنّا للوقت الحالي، هناك "مؤشر ثابت فارغ معرّف بحسب التنفيذ" معرّف في <stddef.h> باسم NULL، قد يبدو ذلك غير ضروريًا بالنظر إلى أن لغة سي تعرّف ثابت الرقم الصحيح 0 إلى القيمة التي يمكن إسنادها إلى مؤشر فارغ ومقارنتها معه، إلا أن الممارسة التالية شائعة جدًا وسط مبرمجي لغة سي المتمرسين: #include <stdio.h> #include <stddef.h> FILE *fp; if((fp = fopen("somefile", "r")) != NULL){ /* وهلمّ جرًّا */ هناك ماكرو باسم offsetof مهمته إيجاد مقدار الإزاحة offset بالبايت لعضو هيكل ما؛ إذ أن مقدار الإزاحة هو المسافة بين العضو وبداية الهيكل، إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> #include <stddef.h> main(){ size_t distance; struct x{ int a, b, c; }s_tr; distance = offsetof(s_tr, c); printf("Offset of x.c is %lu bytes\n", (unsigned long)distance); exit(EXIT_SUCCESS); } [مثال 1] يجب أن يكون التعبير s_tr.c قادرًا على التقييم مثل عنوانٍ لثابت (انظر مقال هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C)، فإذا كان العضو الذي تبحث عن مقدار إزاحته هو حقل بتات bitfield فستحصل على سلوك غير معرّف في هذه الحالة. لاحظ طريقة تحويل الأنواع في size_t التي نحوّل فيها لأطول نوع ممكن عديم الإشارة للتأكد من أن وسيط printf هو من النوع المناسب (%ul هو رمز التنسيق الخاص بطباعة النوع unsigned long) مع المحافظة على دقة القيمة، وهذا بسبب أن نوع size_t مجهول للمبرمج. العنصر الأخير المُصرّح عنه في <stddef.h> هو wchar_t وهو قيمة عدد صحيح كبيرة يُمكن تخزين محرف عريض wide character فيها ينتمي إلى أي مجموعة محارف موسّعة extended character set. ملف الترويسة يعرّف ملف الترويسة ما يُدعى errno الذي يُستبدل بتعبير ثابت ذو قيمة صحيحة لا تساوي الصفر، ويُضمن أن يكون هذا التعبير مقبولًا في موجّهات #if، ويعرّف أيضًا الماكرو EDOM والماكرو ERANGE اللذان يُستخدمان في الدوال الرياضية للدلالة على نوع الخطأ الحاصل وسنشرحهما بتوسعٍ أكبر لاحقًا. يُستخدم errno للدلالة على خطأ مُكتشف من دوال المكتبات، وهو ليس متغير خارجي بالضرورة -كما كان سابقًا- بل هو قيمةٌ متغيرةٌ من نوع int، إذ تُسند القيمة صفر إليه عند بداية تشغيل البرنامج، ولا يُعاد ضبط قيمته من تلك النقطة فصاعدًا إلا إذا جرى ذلك مباشرةً؛ أي بكلمات أخرى، لا تحاول إجراءات المكتبات إعادة ضبطه إطلاقًا، وإذا حدث أي خطأ في إجراء المكتبة فإن قيمة errno تتغير إلى قيمة معينة تشير إلى نوع الخطأ الحاصل ويُعيد الإجراء هذه القيمة (غالبًا -1) للدلالة على الخطأ، إليك تطبيقًا عمليًا عن ذلك: #include <stdio.h> #include <stddef.h> #include <errno.h> errno = 0; if(some_library_function(arguments) < 0){ // خطأ في معالجة الشيفرة المصدرية // قد يستخدم قيمة errno مباشرةً تطبيق errno غير معروف بالنسبة للمبرمج، فلا تحاول فعل أي شيء على هذه القيمة عدا إعادة ضبطها أو فحصها، فعلى سبيل المثال، من غير المضمون أن يكون لهذه القيمة عنوانًا على الذاكرة. يجب أن تتفقّد قيمة errno فقط في حال كانت دالة المكتبة المُستخدمة توثّق تأثيرها على errno، إذ يمكن لدوال المكتبات الأخرى أن تضبطها إلى قيمة عشوائية بعد استدعائها إلا إذا كان وصف الدالة يحدد ما الذي تفعله الدالة بالقيمة بصورةٍ صريحة. تشخيص الأخطاء من المفيد عندما تبحث عن الأخطاء في برنامجك أن تكون قادرًا على فحص قيمة تعبير ما والتأكد من أن قيمته هي ما تتوقّعها فعلًا، وهذا ما تقدمه لك دالة assert. يجب عليك أن تُضمّن ملف الترويسة <assert.h> أولًا حتى تتمكن من استخدام الدالة assert، وهذه الدالة معرفةٌ على النحو التالي: #include <assert.h> void assert(int expression) إذا كانت قيمة التعبير صفر (أي "خطأ false")، فستطبع الدالة assert رسالةً تدل على التعبير الفاشل، وتتضمن الرسالة اسم ملف الشيفرة المصدرية والسطر الذي يحتوي على التوكيد assertion والتعبير، ومن ثم تُستدعى دالة abort التي تقطع عمل البرنامج. assert(1 == 2); /* قد يتسبب ما سبق بالتالي */ Assertion failed: 1 == 2, file silly.c, line 15 في حقيقة الأمر الكلمة Assert معرّفة مثل ماكرو، وليس مثل دالة حقيقية. لتعطيل التوكيدات في برنامج يستوفي شروط عمله دون مشاكل، نعرّف الاسم NDEBUG قبل تضمين <assert.h>، وسيعطّل هذا جميع التوكيدات الموجودة في كامل البرنامج. عليك أن تعرف الآثار الجانبية التي يتسبب بها هذا للتعبير، فلن يُقيّم التعبير تعطيل التوكيدات باستخدام NDEBUG، وبذلك سيسلك المثال التالي سلوكًا غير مُتوقع عند إلغاء التوكيدات باستخدام #define NDEBUG. #define NDEBUG #include <assert.h> void func(void) { int c; assert((c = getchar()) != EOF); putchar(c); } [مثال 2] لاحظ أن الدالة assert لا تُعيد أي قيمة. ترجمة -وبتصرف- لقسم من الفصل Libraries من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف وضبط إعدادات التوطين localization في لغة سي C المقال السابق: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة سي C بنية برنامج لغة سي C المحارف المستخدمة في لغة سي C مدخل إلى المصفوفات في لغة سي C -
 استعرضنا في المقالات السابقة مبادئ اللغة وغطّينا معظم الجوانب المعرّفة من المعيار تقريبًا، إلا أن هناك بعض التفاصيل المتفرقة التي لا تنطوي تحت أي عنوان محدد، وتأتي هذه المقالة لجمع هذه التفاصيل المتفرقة العويصة من لغة C. استعدّ لما هو قادم ولا تتردد بتدوين الملاحظات التي تعتقد أنها ستهمّك، واقرأها من وقت إلى وقت آخر، فالأمر الذي تجده للمرة الأولى غير مثير للاهتمام وصعب الفهم سيصبح ضروريًّا ومفيدًا لك بعد أن تكتسب الخبرة الكافية لتوظيفه. معرف النوع typedef يسود الاعتقاد بأن معرّف النوع هو صنف تخزين، إلا أن هذا الاعتقاد خاطئ، إذ يسمح لك هذا المعرّف باختيار مرادفات لأنواع أخرى، والتي من الممكن أن يُصرّح عنها بطريقة مختلفة، ويصبح الاسم الجديد المرادف مكافئًا للنوع الذي تريده، كما سيوضح المثال التالي: typedef int aaa, bbb, ccc; typedef int ar[15], arr[9][6]; typedef char c, *cp, carr[100]; /* صرّح عن بعض الكائنات */ /* جميع الأعداد الصحيحة */ aaa int1; bbb int2; ccc int3; ar yyy; /* مصفوفة من 15 عدد صحيح */ arr xxx; /* مصفوفة من 9×6 عدد صحيح */ c ch; /* محرف */ cp pnt; /* مؤشر يشير لمحرف */ carr chry; /* مصفوفة من 100 محرف */ تنص القاعدة العامة في استخدام معرف النوع على كتابة التصريح وكأنك تصرح عن متغيرات من الأنواع التي تريدها، فعندما يتضمن التصريح الاسم مع نوعه المحدد، فإن إسباق ذلك بمعرّف النوع يعني أنك تصرح عن اسم جديد لنوع ما بدلًا من التصريح عن متغيرات، ويمكن بعدها استخدام أسماء النوع الجديد مثل سابقة prefix لتصريح متغير من النوع الجديد. لا يُعد استخدام الكلمة المفتاحية typedef شائعًا في معظم البرامج، ويُستخدم غالبًا في ملفات الترويسة ومن النادر أن تجده في الممارسة اليومية الاعتيادية. تُعرَّف الأنواع الجديدة للمتغيرات الأساسية في البرامج التي تتطلب قابلية نقل كبيرة غالبًا، وتُستخدم تعليمات typedef المناسبة لكتابة البرنامج بصورة مُخصصة للآلة الهدف، إلا أن استخدامها الزائد قد يتسبب ببعض اللبس لمبرمجي اللغة إذا كانوا يستخدمون بيئة مغايرة، يوضح المثال التالي ما نقصده: // ملف 'mytype.h' typedef short SMALLINT /* النطاق *******30000 */ typedef int BIGINT // النطاق ******* 2E9 /* البرنامج*/ #include "mytype.h" SMALLINT i; BIGINT loop_count; لا يتسع نطاق العدد الصحيح في BIGINT في بعض الآلات، ونتيجةً لذلك يجب إعادة تعريف النوع ليصبح long. لإعادة استخدام الاسم المُصرّح مثل تعريف نوع typedef، يجب أن يحتوي تصريحه محدد نوع واحد على الأقل، وهذا من شأنه أن يبعد أي لبس: typedef int new_thing; func(new_thing x){ float new_thing; new_thing = x; } نحذّر هنا أن الكلمة المفتاحية typedef يمكن استخدامها فقط للتصريح عن نوع القيمة المُعادة من دالة وليس نوع الدالة الكامل، ونقصد بنوع الدالة الكامل معلومات حول معاملات الدالة ونوع القيمة المُعادة أيضًا. /* صرّح عن func باستخدام typedef لتكون من النوع الذي يأخذ وسيطين من نوع عدد صحيح ويعيد قيمة عدد صحيح */ typedef int func(int, int); /* خطأ */ func func_name{ /*....*/ } // مثال صالح، يعيد مؤشر إلى النوع func func *func_name(){ /*....*/ } /* مثال صالح إذا كانت الدوال تعيد دوالًا، لكن هذا غير ممكن في لغة سي */ func func_name(){ /*....*/ } لا يمكن استخدام معرّف مثل معامل صوري في دالة إذا كان ذلك المعرّف مرتبطًا بمعرف نوع typedef معين ضمن النطاق، إذ سيسبب التصريح من الشكل التالي بمشكلة: typedef int i1_t, i2_t, i3_t, i4_t; int f(i1_t, i2_t, i3_t, i4_t) //هنا النقطة X يصل المصرف إلى النقطة "X" عند قراءة تصريح الدالة، ولا يعرف فيما إذا كان يقرأ تصريحًا عن دالة، وهذه الحالة مشابهة إلى: int f(int, int, int, int) /* نموذج أولي */ أو int f(a, b, c, d) /* ليس نموذجًا أوليًا */ يمكن حل المشكلة السابقة (في أسوأ الحالات) بالنظر إلى ما يتبع النقطة "X"؛ فإذا كانت فاصلة منقوطة فهذا تصريح؛ أما إذا كان } فهذا تعريف. تعني القاعدة التي تمنع أسماء تعريف النوع من أن تكون لمعامل صوري أن المصرف يمكنه دائمًا أن يخبر فيما إذا كان يعالج تصريحًا أو تعريفًا بالنظر إلى المعرف الأول الذي يتبع اسم الدالة. استخدام معرف النوع مفيد عندما تريد التصريح عن أشياء ذات صياغة معقدة، مثل "مصفوفة مؤلفة من عشرة مؤشرات تشير إلى مصفوفة تتألف من خمسة أعداد صحيحة"، وهي صيغة معقدة للكتابة حتى لأمهر المبرمجين. يمكنك كتابتها لمرة واحدة فقط باستخدام معرف النوع أو تجزئتها إلى قطع مقبولة التعقيد: typedef int (*a10ptoa5i[10])[5]; /* أو */ typedef int a5i[5]; typedef a5i *atenptoa5i[10]; جرّبها بنفسك. المؤهلان const و volatile تُعد المؤهلات qualifiers من الأشياء الجديدة التي أتت مع لغة سي C المعيارية، على الرغم من أن فكرة const كانت من لغة ++C أصلًا. دعنا أولًا نوضح لك شيئًا، وهو أن مفهومي const و volatile مستقلان كليًا عن بعضهما بعضًا، إذ يسود الاعتقاد الخاطئ أن const تؤدي عكس غرض volatile، إلا أن المفهومين غير مرتبطين ويجب أن تبقي ذلك ببالك. بما أن تصاريح const هي الأبسط فسنبدأ بها، إلا أننا سنستعرض الحالات التي تُستخدم فيها كلا النوعين من المؤهلات. إليك لائحةً بالكلمات المفتاحية المرتبطة بهذا الشأن: char long float volatile short signed double void int unsigned const يمثل كل من const و volatile في اللائحة السابقة أنواع مؤهلات، والكلمات المفتاحية المتبقية هي محددات نوع type specifiers، ويُسمح باستخدام عدة محددات أنواع بالشكل التالي: char, signed char, unsigned char int, signed int, unsigned int short int, signed short int, unsigned short int long int, signed long int, unsigned long int float double long double هناك بعض النقاط التي يجب أن ننوه إليها، وهي أن جميع التصاريح التي تحتوي على int ستكون ذات إشارة signed افتراضيًا، وبذلك فالكلمة المفتاحية signed هي تكرار لا لزوم له في هذا السياق، ويمكن التخلص من int إذا وُجد أي محدد نوع أو مؤهل لأن int هو النوع الافتراضي. يمكن تطبيق الكلمتين المفتاحيتين const و volatile لأي تصريح، متضمّنًا تصريح الهياكل والاتحادات وأنواع المعدّدات أو أسماء typedef، ونقول عن تصريح يحتوي هذه الكلمتين المفتاحيتين بأنه مؤهّل، وهذا السبب في تسمية const و volatile بالمؤهّلات عوضًا عن تسميتهما بمحددات النوع، إليك بعض الأمثلة: volatile i; volatile int j; const long q; const volatile unsigned long int rt_clk; struct{ const long int li; signed char sc; }volatile vs; لا تشعر بالضيق من الأمثلة السابقة، فبعضها معقّد وسنشرح معناها لاحقًا، لكن تذكر أنه من الممكن زيادة التعقيد باستخدام محددات صنف التخزين أيضًا، ويوضح المثال التالي استخدامًا واقعيًا ضمن بعض أنوية نظام تشغيل في الوقت الحقيقي: extern const volatile unsigned long int rt_clk; المؤهل const لنلقي نظرةً على كيفية استخدام المؤهل const، والأمر بسيطٌ جدًا، إذ تعني const أن الشيء ليس قابلًا للتعديل، فإذا صُرّح عن كائن بيانات باستخدام الكلمة المفتاحية const مثل جزءٍ من توصيف نوعه فهذا يعني أنه من غير الممكن إسناد أي قيمة إليه خلال تشغيل البرنامج، ويحتوي التصريح عن الكائن غالبًا على قيمة أولية (وإلا فمتى سيحصل على قيمة إن لم يكن الإسناد إليه مسموحًا؟) إلا أنها ليست الحالة دائمًا؛ فعلى سبيل المثال، إذا أردت الوصول إلى منفذ port للعتاد الصلب ضمن عنوان ذاكرة محدد واحتجت للقراءة منه فقط، فسيُصرّح عنه أنه مؤهل const لكنه لن يُهيأ. يُعدّ أخذُ عنوان كائن بيانات ذي نوع ليس const ووضعه في مؤشر يشير إلى إصدار مؤهل باستخدام const للنوع نفسه طريقةً آمنةً ومسموحة، إذ سيمكنك ذلك من استخدام المؤشر للنظر إلى الكائن دون إمكانية التعديل عليه، بينما يُعدّ وضع عنوان نوع ثابت إلى مؤشر يشير إلى النوع غير المؤهل طريقةً خطرةً وبالتالي فهي محظورة، إلا أنه يمكنك تجاوز ذلك باستخدام تحويل الأنواع cast. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ int i; const int ci = 123; /* تصريح عن مؤشر يشير إلى ثابت */ const int *cpi; /* مؤشر اعتيادي يشير إلى كائن غير ثابت */ int *ncpi; cpi = &ci; ncpi = &i; /* التعليمة التالية صالحة */ cpi = ncpi; /* يتطلب الأمر في هذه الحالة تحويل للأنواع لأنه خطأ كبير، انظر لما يلي لمعرفة السماحيات */ ncpi = (int *)cpi; /* عدّل على ثابت من خلال المؤشر للحصول على سلوك غير محدد */ *ncpi = 0; exit(EXIT_SUCCESS); } [مثال 1] كما يوضح المثال السابق، فمن الممكن أخذ عنوان كائن ثابت وإنشاء مؤشر يشير إلى كائن غير ثابت ومن ثم استخدام المؤشر، وسيولد ذلك خطأً في برنامجك ويؤدي إلى سلوك غير محدد. الهدف الرئيسي من استخدام الكائنات الثابتة هو وضعها في حالة قراءة فقط، والسماح للمصرف بإجراء بعض التفقد الإضافي لها ضمن البرنامج، وسيكون المصرف قادرًا على التحقق من أن كائنات const لم تُعدّل قسريًا من قبل المستخدم إلا إذا كنت قادرًا على تجاوز ذلك باستخدام المؤشرات. إليك ميزةً إضافية. ما الذي يعنيه التالي؟ char c; char *const cp = &c; الأمر بسيط جدًا، إذ أن cp مؤشر يشير إلى char وهي الحالة الاعتيادية إن لم تتواجد الكلمة المفتاحية const، وتعني الكلمة المفتاحية const أن cp لا يمكن التعديل عليه، إلا أنه من الممكن تعديل الشيء المُشار إليه بواسطة المؤشر، فالمؤشر هو الثابت وليس الشيء الذي يشير إليه. المثال المُعاكس لما سبق هو: const char *cp; الذي يعني أن cp هو مؤشر اعتيادي يمكن التعديل عليه، إلا أن الشيء الذي يشير إليه يجب عدم تعديله، إذًا من الممكن اختيار كون المؤشر أو الشيء الذي يشير إليه قابلًا للتعديل أو لا باستخدام التصريح المناسب بحسب التطبيق الذي تحتاجه. المؤهل volatile ننتقل إلى volatile بعد تحدثنا عن const. يعود السبب في استخدامنا لهذا النوع من المؤهلات إلى معالجة المشاكل الناتجة عند وقت التشغيل أو الأنظمة المُدمجة المُبرمجة باستخدام لغة سي. تخيّل كتابة شيفرة برمجية تتحكم بجهاز عتاد صلب بوضع قيم مناسبة في مسجّلات الجهاز في عناوين معروفة، ودعنا نتخيل أيضًا أن للجهاز مسجّلين، كل مسجل بطول 16 بت، بعنوان ذاكرة تصاعدي، والمسجل الأول هو مسجل التحكم والحالة control and status register -أو اختصارًا csr-، والمسجل الثاني هو منفذ البيانات، ونستطيع الوصول إلى جهاز مماثل بالطريقة التالية: // مثال بلغة C المعيارية دون استخدام const أو volatile /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs *dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 2] تُعد الطريقة المتبعة في استخدام تصريح الهيكل لوصف تخطيط مسجل الجهاز واسمه ممارسةً شائعة، لاحظ أنه لا يوجد أي كائنات معرفة من هذا النوع، إذ يحدّد التصريح ببساطة الهيكل دون استخدام أي مساحة. نستخدم تحويل أنواع ثابت للوصول إلى مسجلات الجهاز وكأنها تشير إلى هيكل، إلا أنها تشير في هذه الحالة إلى عنوان الذاكرة بدلًا من ذلك. إلا أن هناك مشكلةً كبيرةً في مصرّفات لغة سي السابقة، وهي متعلقة بحلقة while التكرارية التي تختبر المسجل الأول (مسجل الحالة) وتنتظر البت ERROR أو READY ليظهر، وسيلاحظ أي مصرّف جيد أن الحلقة تفحص عنوان ذاكرة مماثل بصورةٍ متكررة، وسيحاول المصرف أن يشير إلى الذاكرة مرةً واحدةً وأن ينسخ القيمة إلى المسجل لتسريع العملية؛ وهذا ما لا نريده، إذ أن هذه الحالة من الحالات التي يجب علينا التحقق من المكان الذي يشير إليه المؤشر كل دورة ضمن الحلقة. نتيجةً للمشكلة السابقة، لم تكن معظم مصرفات لغة سي قادرةً سابقًا على تحسين أداء البرنامج، وللتخلص من هذه المشكلة (ومشاكل أخرى مشابهة مرتبطة بمتى يمكن الكتابة على شيء يشير إليه المؤشر) قُدِّمت الكلمة المفتاحية volatile، التي تخبر المصرف أن الكائن عرضةٌ للتغير المفاجئ بسبب أسباب لا يمكن التنبؤ بها من خلال النظر إلى البرنامج ذات نفسه، وتُجبر كل مرجع refernece للكائن بأن يصبح مرجعًا فعليًّا (وليس عن طريق مؤشر). إليك البرنامج السابق (مثال 2) مكتوبًا باستخدام volatile و const. /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short volatile csr; unsigned short const volatile data; }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs * const dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 3] تطابق القوانين الخاصة بمزج volatile والأنواع الاعتيادية تلك الخاصة بالمؤهل const، إذ من الممكن إسناد مؤشر يشير إلى كائن مؤهّل بالمؤهّل volatile إلى عنوان كائن اعتيادي بأمان دون أي مشاكل، إلا أنه من الخطر (ويجب استخدام تحويل الأنواع في هذه الحالة) أخذ عنوان الكائن المؤهل بالمؤهل volatile ووضعه في مؤشر يشير إلى كائن اعتيادي، واستخدام مؤشر من هذا النوع سيتسبب بسلوك غير معرّف. إذا صُرّح عن مصفوفة أو هيكل باستخدام إحدى المؤهلين const أو volatile، فمن الممكن لجميع الأعضاء أن تمتلك هذا المؤهل أيضًا، وهذا الأمر المنطقي إذا فكرت به للحظة، فكيف لعضو من هيكل مؤهل بالمؤهل const أن يكون قابلًا للتعديل؟ هذا يعني أن أي محاولة لإعادة كتابة المثال السابق ممكنة، فعوضًا عن تصريح مسجلات الجهاز بكونها volatile في الهيكل، من الممكن للمؤشر أي يُصرّح بأن يشير إلى هيكل volatile عوضًا عن ذلك، على النحو التالي: struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; volatile struct devregs *const dvp=DEVADDR+devno; بما أن dvp يشير إلى كائن volatile، فمن غير المسموح تحسين المراجع عن طريق المؤشرات، وعلى الرغم من أن ما سبق يعمل، إلا أنه ممارسةٌ سيئة، إذ ينتمي تصريح volatile إلى الهيكل، ومسجلات الجهاز هي volatile وهذا المكان الذي يجب أن يبقى فيه التصريح، لتسهيل قراءة الشيفرة البرمجية. إذًا، مؤهل النوع volatile مهم جدًا لأي كائن سيتعرض لتغييرات، سواءٌ كانت التغييرات بواسطة العتاد الصلب أو برامج خدمات المقاطعة الغير المتزامنة asynchronous interrupt service routines. وما إن اعتقدت أنّك فهمت كلّ ما سبق بصورة مثالية، حتى يأتي التصريح التالي الذي سيغير من رأيك: volatile struct devregs{ /* محتوى */ }v_decl; الذي يصرح عن النوع struct devregs إضافةً إلى كائن مؤهل باستخدام volatile من ذلك النوع باسم v_decl. ويتبعه التصريح التالي: struct devregs nv_decl; الذي يصرح عن nv_decl وهو ليس مؤهّلًا باستخدام volatile؛ فالتأهيل ليس جزءًا من النوع struct devregs وإنما ينطبق فقط على تصريح v_decl. لننظر للأمر من زاوية أخرى لعلّ الأمر يتضح لك بعض الشيء (التصريحان متماثلان في نتيجتهما): struct devregs{ /* محتوى */ }volatile v_decl; إذا أردت الطريقة المختصرة لإرفاق مؤهل إلى نوع آخر، فيمكنك استخدام typedef لتحقيق الآتي: struct x{ int a; }; typedef const struct x csx; csx const_sx; struct x non_const_sx = {1}; const_sx = non_const_sx; /* التعديل على ثابت بتسبب بخطأ */ العمليات غير القابلة للتجزئة سيفهم الذي يتعاملون مع تقنيات مقاطعات العتاد الصلب والجوانب الأخرى للوقت الحقيقي في البرمجة أهمية أنواع volatile، وهناك ضرورةٌ في هذا المجال للتأكد من أن الوصول إلى كائنات البيانات متواصل، إلا أن مناقشة هذا الأمر سيأخذنا في رحلة بعيدة عن موضوعنا هنا، لكن دعنا نتكلم عن بعض المشكلات بخصوص هذا الأمر على الأقل. لا تخطئ الاعتقاد وتفترض أن جميع العمليات المكتوبة في لغة سي متواصلة، فعلى سبيل المثال قد يكون التصريح التالي عدّادًا يُحدّث عن طريق مقاطعة برنامج ساعة: extern const volatile unsigned long realtimeclock; من المهم هنا أن يتضمن التصريح على المؤهل volatile بسبب التغييرات اللامتزامنة التي تحصل له، ويحتوي على المؤهل const لأنه من غير الممكن التعديل على قيمته سوى عن طريق برنامج المقاطعة، وإن سُمح للبرنامج الوصول إليه بالطريقة التالية سنحصل على مشكلة: unsigned long int time_of_day; time_of_day = real_time_clock; ماذا لو استغرقت عملية نسخ long إلى long آخر عدّة تعليمات آلة لنسخ الكلمتين real_time_clock و time_of_day؟ من الممكن حدوث مقاطعة خلال عملية الإسناد وستكون أسوأ حالة لهذه المقاطعة هي عندما تكون الكلمة الأقل ترتيبًا لـreal_time_clock تساوي 0xffff والكلمة مرتفعة الترتيب تساوي 0x0000، وبهذا ستكون قيمة الكلمة منخفضة الترتيب مساوية إلى 0xffff. تعمل المقاطعة عملها وتزيد الكلمة منخفضة الترتيب لـreal_time_clock إلى 0x0 والكلمة مرتفعة الترتيب إلى 0x1 ومن ثم تعيد القيمة، ويُستكمل ما تبقى من الإسناد فيما بعد وينتهي الأمر باحتواء time_of_day على القيمة 0x0001ffff و real_time_clock على القيمة الصائبة 0x00010000. تعدّ المشكلات المسابقة لما سبق منطقةً خطرة، ويعلم جميع من يعمل في البيئات غير المتزامنة هذا الأمر جيّدًا، ولا تأخذ لغة سي المعيارية أي إجراءات احترازية لتفادي هذا النوع من المشكلات، ويجب تطبيق الطريقة الاعتيادية. يُصرّح ملف الترويسة signal.h عن نوع باسم sig_atomic_t ومن المضمون إمكانية تعديل هذا النوع بأمان عند التعامل مع الأحداث غير المتزامنة، وهذا يعني أنه من الممكن تعديله عن طريق إسناد قيمة إليه أو زيادة قيمته أو إنقاصها أو أي شيء آخر يعطي قيمة جديدة بحسب القيمة السابقة، وهو ليس آمنًا. نقاط التسلسل ترتبط نقاط التسلسل sequence points بمشكلات برمجة الوقت الحقيقي، إلا أنها مختلفة عن المشكلات التي ناقشناها، وتعدّ بمثابة محاولة للمعيار في تعريف الحالات التي تسمح -أو لا تسمح- بها طرق معينة من التحسين، على سبيل المثال، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> int i_var; void func(void); main(){ while(i_var != 10000){ func(); i_var++; } exit(EXIT_SUCCESS); } void func(void){ printf("in func, i_var is %d\n", i_var); } [مثال 4] قد يحاول المصرّف تحسين الأداء في الحلقة التكرارية بحيث يخزّن i_var في مسجّل الآلة لزيادة السرعة، إلا أن الدالة تحتاج وصولًا إلى القيمة الصحيحة من i_var حتى يمكنها طباعة القيمة الصحيحة، وهذا يعني أن المسجّل يجب أن يعيد تخزين قيمة i_var عند كل استدعاءٍ للدالة على الأقل، ويصف المعيار الشروط التي تحدد متى وأين يحصل ذلك. تُستكمل التأثيرات الجانبية لكل تعبير في نقطة التسلسل التي سبقتها، وهذا السبب في عدم قدرتنا على الاعتماد على تعابير مشابهة لهذه: a[i] = i++; وذلك بسبب عدم وجود أي نقطة تسلسلية مُحدّدة ضمن الإسناد أو عوامل الزيادة والنقصان، ولا يمكننا معرفة متى سيؤثر عامل الزيادة على i تحديدًا. يعرّف المعيار نقاط التسلسل على النحو التالي: نقطة استدعاء دالة، بعد تقييم وسطائها. نهاية المعامل الأول للعامل &&. نهاية المعامل الأول للعامل ||. نهاية المعامل الأول للعامل الشرطي :?. نهاية كل من معاملات عامل الفاصلة ,. نهاية تقييم تعبير كامل، على النحو التالي: تقييم القيمة الأولية لكائن auto. تعبير اعتيادي، أي متبوع بفاصلة منقوطة. تعابير التحكم في تعليمات do أو while أو if أو switch أو for. التعبيران الآخران في تعليمة حلقة for. التعبير في تعليمة return. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: مقدمة إلى مكتبات لغة سي C المقال السابق: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C
استعرضنا في المقالات السابقة مبادئ اللغة وغطّينا معظم الجوانب المعرّفة من المعيار تقريبًا، إلا أن هناك بعض التفاصيل المتفرقة التي لا تنطوي تحت أي عنوان محدد، وتأتي هذه المقالة لجمع هذه التفاصيل المتفرقة العويصة من لغة C. استعدّ لما هو قادم ولا تتردد بتدوين الملاحظات التي تعتقد أنها ستهمّك، واقرأها من وقت إلى وقت آخر، فالأمر الذي تجده للمرة الأولى غير مثير للاهتمام وصعب الفهم سيصبح ضروريًّا ومفيدًا لك بعد أن تكتسب الخبرة الكافية لتوظيفه. معرف النوع typedef يسود الاعتقاد بأن معرّف النوع هو صنف تخزين، إلا أن هذا الاعتقاد خاطئ، إذ يسمح لك هذا المعرّف باختيار مرادفات لأنواع أخرى، والتي من الممكن أن يُصرّح عنها بطريقة مختلفة، ويصبح الاسم الجديد المرادف مكافئًا للنوع الذي تريده، كما سيوضح المثال التالي: typedef int aaa, bbb, ccc; typedef int ar[15], arr[9][6]; typedef char c, *cp, carr[100]; /* صرّح عن بعض الكائنات */ /* جميع الأعداد الصحيحة */ aaa int1; bbb int2; ccc int3; ar yyy; /* مصفوفة من 15 عدد صحيح */ arr xxx; /* مصفوفة من 9×6 عدد صحيح */ c ch; /* محرف */ cp pnt; /* مؤشر يشير لمحرف */ carr chry; /* مصفوفة من 100 محرف */ تنص القاعدة العامة في استخدام معرف النوع على كتابة التصريح وكأنك تصرح عن متغيرات من الأنواع التي تريدها، فعندما يتضمن التصريح الاسم مع نوعه المحدد، فإن إسباق ذلك بمعرّف النوع يعني أنك تصرح عن اسم جديد لنوع ما بدلًا من التصريح عن متغيرات، ويمكن بعدها استخدام أسماء النوع الجديد مثل سابقة prefix لتصريح متغير من النوع الجديد. لا يُعد استخدام الكلمة المفتاحية typedef شائعًا في معظم البرامج، ويُستخدم غالبًا في ملفات الترويسة ومن النادر أن تجده في الممارسة اليومية الاعتيادية. تُعرَّف الأنواع الجديدة للمتغيرات الأساسية في البرامج التي تتطلب قابلية نقل كبيرة غالبًا، وتُستخدم تعليمات typedef المناسبة لكتابة البرنامج بصورة مُخصصة للآلة الهدف، إلا أن استخدامها الزائد قد يتسبب ببعض اللبس لمبرمجي اللغة إذا كانوا يستخدمون بيئة مغايرة، يوضح المثال التالي ما نقصده: // ملف 'mytype.h' typedef short SMALLINT /* النطاق *******30000 */ typedef int BIGINT // النطاق ******* 2E9 /* البرنامج*/ #include "mytype.h" SMALLINT i; BIGINT loop_count; لا يتسع نطاق العدد الصحيح في BIGINT في بعض الآلات، ونتيجةً لذلك يجب إعادة تعريف النوع ليصبح long. لإعادة استخدام الاسم المُصرّح مثل تعريف نوع typedef، يجب أن يحتوي تصريحه محدد نوع واحد على الأقل، وهذا من شأنه أن يبعد أي لبس: typedef int new_thing; func(new_thing x){ float new_thing; new_thing = x; } نحذّر هنا أن الكلمة المفتاحية typedef يمكن استخدامها فقط للتصريح عن نوع القيمة المُعادة من دالة وليس نوع الدالة الكامل، ونقصد بنوع الدالة الكامل معلومات حول معاملات الدالة ونوع القيمة المُعادة أيضًا. /* صرّح عن func باستخدام typedef لتكون من النوع الذي يأخذ وسيطين من نوع عدد صحيح ويعيد قيمة عدد صحيح */ typedef int func(int, int); /* خطأ */ func func_name{ /*....*/ } // مثال صالح، يعيد مؤشر إلى النوع func func *func_name(){ /*....*/ } /* مثال صالح إذا كانت الدوال تعيد دوالًا، لكن هذا غير ممكن في لغة سي */ func func_name(){ /*....*/ } لا يمكن استخدام معرّف مثل معامل صوري في دالة إذا كان ذلك المعرّف مرتبطًا بمعرف نوع typedef معين ضمن النطاق، إذ سيسبب التصريح من الشكل التالي بمشكلة: typedef int i1_t, i2_t, i3_t, i4_t; int f(i1_t, i2_t, i3_t, i4_t) //هنا النقطة X يصل المصرف إلى النقطة "X" عند قراءة تصريح الدالة، ولا يعرف فيما إذا كان يقرأ تصريحًا عن دالة، وهذه الحالة مشابهة إلى: int f(int, int, int, int) /* نموذج أولي */ أو int f(a, b, c, d) /* ليس نموذجًا أوليًا */ يمكن حل المشكلة السابقة (في أسوأ الحالات) بالنظر إلى ما يتبع النقطة "X"؛ فإذا كانت فاصلة منقوطة فهذا تصريح؛ أما إذا كان } فهذا تعريف. تعني القاعدة التي تمنع أسماء تعريف النوع من أن تكون لمعامل صوري أن المصرف يمكنه دائمًا أن يخبر فيما إذا كان يعالج تصريحًا أو تعريفًا بالنظر إلى المعرف الأول الذي يتبع اسم الدالة. استخدام معرف النوع مفيد عندما تريد التصريح عن أشياء ذات صياغة معقدة، مثل "مصفوفة مؤلفة من عشرة مؤشرات تشير إلى مصفوفة تتألف من خمسة أعداد صحيحة"، وهي صيغة معقدة للكتابة حتى لأمهر المبرمجين. يمكنك كتابتها لمرة واحدة فقط باستخدام معرف النوع أو تجزئتها إلى قطع مقبولة التعقيد: typedef int (*a10ptoa5i[10])[5]; /* أو */ typedef int a5i[5]; typedef a5i *atenptoa5i[10]; جرّبها بنفسك. المؤهلان const و volatile تُعد المؤهلات qualifiers من الأشياء الجديدة التي أتت مع لغة سي C المعيارية، على الرغم من أن فكرة const كانت من لغة ++C أصلًا. دعنا أولًا نوضح لك شيئًا، وهو أن مفهومي const و volatile مستقلان كليًا عن بعضهما بعضًا، إذ يسود الاعتقاد الخاطئ أن const تؤدي عكس غرض volatile، إلا أن المفهومين غير مرتبطين ويجب أن تبقي ذلك ببالك. بما أن تصاريح const هي الأبسط فسنبدأ بها، إلا أننا سنستعرض الحالات التي تُستخدم فيها كلا النوعين من المؤهلات. إليك لائحةً بالكلمات المفتاحية المرتبطة بهذا الشأن: char long float volatile short signed double void int unsigned const يمثل كل من const و volatile في اللائحة السابقة أنواع مؤهلات، والكلمات المفتاحية المتبقية هي محددات نوع type specifiers، ويُسمح باستخدام عدة محددات أنواع بالشكل التالي: char, signed char, unsigned char int, signed int, unsigned int short int, signed short int, unsigned short int long int, signed long int, unsigned long int float double long double هناك بعض النقاط التي يجب أن ننوه إليها، وهي أن جميع التصاريح التي تحتوي على int ستكون ذات إشارة signed افتراضيًا، وبذلك فالكلمة المفتاحية signed هي تكرار لا لزوم له في هذا السياق، ويمكن التخلص من int إذا وُجد أي محدد نوع أو مؤهل لأن int هو النوع الافتراضي. يمكن تطبيق الكلمتين المفتاحيتين const و volatile لأي تصريح، متضمّنًا تصريح الهياكل والاتحادات وأنواع المعدّدات أو أسماء typedef، ونقول عن تصريح يحتوي هذه الكلمتين المفتاحيتين بأنه مؤهّل، وهذا السبب في تسمية const و volatile بالمؤهّلات عوضًا عن تسميتهما بمحددات النوع، إليك بعض الأمثلة: volatile i; volatile int j; const long q; const volatile unsigned long int rt_clk; struct{ const long int li; signed char sc; }volatile vs; لا تشعر بالضيق من الأمثلة السابقة، فبعضها معقّد وسنشرح معناها لاحقًا، لكن تذكر أنه من الممكن زيادة التعقيد باستخدام محددات صنف التخزين أيضًا، ويوضح المثال التالي استخدامًا واقعيًا ضمن بعض أنوية نظام تشغيل في الوقت الحقيقي: extern const volatile unsigned long int rt_clk; المؤهل const لنلقي نظرةً على كيفية استخدام المؤهل const، والأمر بسيطٌ جدًا، إذ تعني const أن الشيء ليس قابلًا للتعديل، فإذا صُرّح عن كائن بيانات باستخدام الكلمة المفتاحية const مثل جزءٍ من توصيف نوعه فهذا يعني أنه من غير الممكن إسناد أي قيمة إليه خلال تشغيل البرنامج، ويحتوي التصريح عن الكائن غالبًا على قيمة أولية (وإلا فمتى سيحصل على قيمة إن لم يكن الإسناد إليه مسموحًا؟) إلا أنها ليست الحالة دائمًا؛ فعلى سبيل المثال، إذا أردت الوصول إلى منفذ port للعتاد الصلب ضمن عنوان ذاكرة محدد واحتجت للقراءة منه فقط، فسيُصرّح عنه أنه مؤهل const لكنه لن يُهيأ. يُعدّ أخذُ عنوان كائن بيانات ذي نوع ليس const ووضعه في مؤشر يشير إلى إصدار مؤهل باستخدام const للنوع نفسه طريقةً آمنةً ومسموحة، إذ سيمكنك ذلك من استخدام المؤشر للنظر إلى الكائن دون إمكانية التعديل عليه، بينما يُعدّ وضع عنوان نوع ثابت إلى مؤشر يشير إلى النوع غير المؤهل طريقةً خطرةً وبالتالي فهي محظورة، إلا أنه يمكنك تجاوز ذلك باستخدام تحويل الأنواع cast. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ int i; const int ci = 123; /* تصريح عن مؤشر يشير إلى ثابت */ const int *cpi; /* مؤشر اعتيادي يشير إلى كائن غير ثابت */ int *ncpi; cpi = &ci; ncpi = &i; /* التعليمة التالية صالحة */ cpi = ncpi; /* يتطلب الأمر في هذه الحالة تحويل للأنواع لأنه خطأ كبير، انظر لما يلي لمعرفة السماحيات */ ncpi = (int *)cpi; /* عدّل على ثابت من خلال المؤشر للحصول على سلوك غير محدد */ *ncpi = 0; exit(EXIT_SUCCESS); } [مثال 1] كما يوضح المثال السابق، فمن الممكن أخذ عنوان كائن ثابت وإنشاء مؤشر يشير إلى كائن غير ثابت ومن ثم استخدام المؤشر، وسيولد ذلك خطأً في برنامجك ويؤدي إلى سلوك غير محدد. الهدف الرئيسي من استخدام الكائنات الثابتة هو وضعها في حالة قراءة فقط، والسماح للمصرف بإجراء بعض التفقد الإضافي لها ضمن البرنامج، وسيكون المصرف قادرًا على التحقق من أن كائنات const لم تُعدّل قسريًا من قبل المستخدم إلا إذا كنت قادرًا على تجاوز ذلك باستخدام المؤشرات. إليك ميزةً إضافية. ما الذي يعنيه التالي؟ char c; char *const cp = &c; الأمر بسيط جدًا، إذ أن cp مؤشر يشير إلى char وهي الحالة الاعتيادية إن لم تتواجد الكلمة المفتاحية const، وتعني الكلمة المفتاحية const أن cp لا يمكن التعديل عليه، إلا أنه من الممكن تعديل الشيء المُشار إليه بواسطة المؤشر، فالمؤشر هو الثابت وليس الشيء الذي يشير إليه. المثال المُعاكس لما سبق هو: const char *cp; الذي يعني أن cp هو مؤشر اعتيادي يمكن التعديل عليه، إلا أن الشيء الذي يشير إليه يجب عدم تعديله، إذًا من الممكن اختيار كون المؤشر أو الشيء الذي يشير إليه قابلًا للتعديل أو لا باستخدام التصريح المناسب بحسب التطبيق الذي تحتاجه. المؤهل volatile ننتقل إلى volatile بعد تحدثنا عن const. يعود السبب في استخدامنا لهذا النوع من المؤهلات إلى معالجة المشاكل الناتجة عند وقت التشغيل أو الأنظمة المُدمجة المُبرمجة باستخدام لغة سي. تخيّل كتابة شيفرة برمجية تتحكم بجهاز عتاد صلب بوضع قيم مناسبة في مسجّلات الجهاز في عناوين معروفة، ودعنا نتخيل أيضًا أن للجهاز مسجّلين، كل مسجل بطول 16 بت، بعنوان ذاكرة تصاعدي، والمسجل الأول هو مسجل التحكم والحالة control and status register -أو اختصارًا csr-، والمسجل الثاني هو منفذ البيانات، ونستطيع الوصول إلى جهاز مماثل بالطريقة التالية: // مثال بلغة C المعيارية دون استخدام const أو volatile /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs *dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 2] تُعد الطريقة المتبعة في استخدام تصريح الهيكل لوصف تخطيط مسجل الجهاز واسمه ممارسةً شائعة، لاحظ أنه لا يوجد أي كائنات معرفة من هذا النوع، إذ يحدّد التصريح ببساطة الهيكل دون استخدام أي مساحة. نستخدم تحويل أنواع ثابت للوصول إلى مسجلات الجهاز وكأنها تشير إلى هيكل، إلا أنها تشير في هذه الحالة إلى عنوان الذاكرة بدلًا من ذلك. إلا أن هناك مشكلةً كبيرةً في مصرّفات لغة سي السابقة، وهي متعلقة بحلقة while التكرارية التي تختبر المسجل الأول (مسجل الحالة) وتنتظر البت ERROR أو READY ليظهر، وسيلاحظ أي مصرّف جيد أن الحلقة تفحص عنوان ذاكرة مماثل بصورةٍ متكررة، وسيحاول المصرف أن يشير إلى الذاكرة مرةً واحدةً وأن ينسخ القيمة إلى المسجل لتسريع العملية؛ وهذا ما لا نريده، إذ أن هذه الحالة من الحالات التي يجب علينا التحقق من المكان الذي يشير إليه المؤشر كل دورة ضمن الحلقة. نتيجةً للمشكلة السابقة، لم تكن معظم مصرفات لغة سي قادرةً سابقًا على تحسين أداء البرنامج، وللتخلص من هذه المشكلة (ومشاكل أخرى مشابهة مرتبطة بمتى يمكن الكتابة على شيء يشير إليه المؤشر) قُدِّمت الكلمة المفتاحية volatile، التي تخبر المصرف أن الكائن عرضةٌ للتغير المفاجئ بسبب أسباب لا يمكن التنبؤ بها من خلال النظر إلى البرنامج ذات نفسه، وتُجبر كل مرجع refernece للكائن بأن يصبح مرجعًا فعليًّا (وليس عن طريق مؤشر). إليك البرنامج السابق (مثال 2) مكتوبًا باستخدام volatile و const. /* صرّح عن مسجلات الجهاز، واستخدام العدد الصحيح أو العدد الصحيح القصير معرّف بحسب التطبيق */ struct devregs{ unsigned short volatile csr; unsigned short const volatile data; }; // أنماط البتات في csr #define ERROR 0x1 #define READY 0x2 #define RESET 0x4 /* العنوان المطلق للجهاز */ #define DEVADDR ((struct devregs *)0xffff0004) /* عدد الأجهزة في النظام */ #define NDEVS 4 /* انتظر الدالة حتى تقرأ بت من الجهاز n، ثم تحقق من نطاق رقم الجهاز انتظر حتى READY أو ERROR، واقرأ البايت إن لم يحدث أي خطأ وأعد قيمته وإلا فأعد ضبط الخطأ وأعد القيمة 0xffff */ unsigned int read_dev(unsigned devno){ struct devregs * const dvp = DEVADDR + devno; if(devno >= NDEVS) return(0xffff); while((dvp->csr & (READY | ERROR)) == 0) ; /* فراغ. انتظر حتى الانتهاء من الحلقة */ if(dvp->csr & ERROR){ dvp->csr = RESET; return(0xffff); } return((dvp->data) & 0xff); } [مثال 3] تطابق القوانين الخاصة بمزج volatile والأنواع الاعتيادية تلك الخاصة بالمؤهل const، إذ من الممكن إسناد مؤشر يشير إلى كائن مؤهّل بالمؤهّل volatile إلى عنوان كائن اعتيادي بأمان دون أي مشاكل، إلا أنه من الخطر (ويجب استخدام تحويل الأنواع في هذه الحالة) أخذ عنوان الكائن المؤهل بالمؤهل volatile ووضعه في مؤشر يشير إلى كائن اعتيادي، واستخدام مؤشر من هذا النوع سيتسبب بسلوك غير معرّف. إذا صُرّح عن مصفوفة أو هيكل باستخدام إحدى المؤهلين const أو volatile، فمن الممكن لجميع الأعضاء أن تمتلك هذا المؤهل أيضًا، وهذا الأمر المنطقي إذا فكرت به للحظة، فكيف لعضو من هيكل مؤهل بالمؤهل const أن يكون قابلًا للتعديل؟ هذا يعني أن أي محاولة لإعادة كتابة المثال السابق ممكنة، فعوضًا عن تصريح مسجلات الجهاز بكونها volatile في الهيكل، من الممكن للمؤشر أي يُصرّح بأن يشير إلى هيكل volatile عوضًا عن ذلك، على النحو التالي: struct devregs{ unsigned short csr; /* مسجل التحكم والحالة */ unsigned short data; /* منفذ البيانات */ }; volatile struct devregs *const dvp=DEVADDR+devno; بما أن dvp يشير إلى كائن volatile، فمن غير المسموح تحسين المراجع عن طريق المؤشرات، وعلى الرغم من أن ما سبق يعمل، إلا أنه ممارسةٌ سيئة، إذ ينتمي تصريح volatile إلى الهيكل، ومسجلات الجهاز هي volatile وهذا المكان الذي يجب أن يبقى فيه التصريح، لتسهيل قراءة الشيفرة البرمجية. إذًا، مؤهل النوع volatile مهم جدًا لأي كائن سيتعرض لتغييرات، سواءٌ كانت التغييرات بواسطة العتاد الصلب أو برامج خدمات المقاطعة الغير المتزامنة asynchronous interrupt service routines. وما إن اعتقدت أنّك فهمت كلّ ما سبق بصورة مثالية، حتى يأتي التصريح التالي الذي سيغير من رأيك: volatile struct devregs{ /* محتوى */ }v_decl; الذي يصرح عن النوع struct devregs إضافةً إلى كائن مؤهل باستخدام volatile من ذلك النوع باسم v_decl. ويتبعه التصريح التالي: struct devregs nv_decl; الذي يصرح عن nv_decl وهو ليس مؤهّلًا باستخدام volatile؛ فالتأهيل ليس جزءًا من النوع struct devregs وإنما ينطبق فقط على تصريح v_decl. لننظر للأمر من زاوية أخرى لعلّ الأمر يتضح لك بعض الشيء (التصريحان متماثلان في نتيجتهما): struct devregs{ /* محتوى */ }volatile v_decl; إذا أردت الطريقة المختصرة لإرفاق مؤهل إلى نوع آخر، فيمكنك استخدام typedef لتحقيق الآتي: struct x{ int a; }; typedef const struct x csx; csx const_sx; struct x non_const_sx = {1}; const_sx = non_const_sx; /* التعديل على ثابت بتسبب بخطأ */ العمليات غير القابلة للتجزئة سيفهم الذي يتعاملون مع تقنيات مقاطعات العتاد الصلب والجوانب الأخرى للوقت الحقيقي في البرمجة أهمية أنواع volatile، وهناك ضرورةٌ في هذا المجال للتأكد من أن الوصول إلى كائنات البيانات متواصل، إلا أن مناقشة هذا الأمر سيأخذنا في رحلة بعيدة عن موضوعنا هنا، لكن دعنا نتكلم عن بعض المشكلات بخصوص هذا الأمر على الأقل. لا تخطئ الاعتقاد وتفترض أن جميع العمليات المكتوبة في لغة سي متواصلة، فعلى سبيل المثال قد يكون التصريح التالي عدّادًا يُحدّث عن طريق مقاطعة برنامج ساعة: extern const volatile unsigned long realtimeclock; من المهم هنا أن يتضمن التصريح على المؤهل volatile بسبب التغييرات اللامتزامنة التي تحصل له، ويحتوي على المؤهل const لأنه من غير الممكن التعديل على قيمته سوى عن طريق برنامج المقاطعة، وإن سُمح للبرنامج الوصول إليه بالطريقة التالية سنحصل على مشكلة: unsigned long int time_of_day; time_of_day = real_time_clock; ماذا لو استغرقت عملية نسخ long إلى long آخر عدّة تعليمات آلة لنسخ الكلمتين real_time_clock و time_of_day؟ من الممكن حدوث مقاطعة خلال عملية الإسناد وستكون أسوأ حالة لهذه المقاطعة هي عندما تكون الكلمة الأقل ترتيبًا لـreal_time_clock تساوي 0xffff والكلمة مرتفعة الترتيب تساوي 0x0000، وبهذا ستكون قيمة الكلمة منخفضة الترتيب مساوية إلى 0xffff. تعمل المقاطعة عملها وتزيد الكلمة منخفضة الترتيب لـreal_time_clock إلى 0x0 والكلمة مرتفعة الترتيب إلى 0x1 ومن ثم تعيد القيمة، ويُستكمل ما تبقى من الإسناد فيما بعد وينتهي الأمر باحتواء time_of_day على القيمة 0x0001ffff و real_time_clock على القيمة الصائبة 0x00010000. تعدّ المشكلات المسابقة لما سبق منطقةً خطرة، ويعلم جميع من يعمل في البيئات غير المتزامنة هذا الأمر جيّدًا، ولا تأخذ لغة سي المعيارية أي إجراءات احترازية لتفادي هذا النوع من المشكلات، ويجب تطبيق الطريقة الاعتيادية. يُصرّح ملف الترويسة signal.h عن نوع باسم sig_atomic_t ومن المضمون إمكانية تعديل هذا النوع بأمان عند التعامل مع الأحداث غير المتزامنة، وهذا يعني أنه من الممكن تعديله عن طريق إسناد قيمة إليه أو زيادة قيمته أو إنقاصها أو أي شيء آخر يعطي قيمة جديدة بحسب القيمة السابقة، وهو ليس آمنًا. نقاط التسلسل ترتبط نقاط التسلسل sequence points بمشكلات برمجة الوقت الحقيقي، إلا أنها مختلفة عن المشكلات التي ناقشناها، وتعدّ بمثابة محاولة للمعيار في تعريف الحالات التي تسمح -أو لا تسمح- بها طرق معينة من التحسين، على سبيل المثال، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> int i_var; void func(void); main(){ while(i_var != 10000){ func(); i_var++; } exit(EXIT_SUCCESS); } void func(void){ printf("in func, i_var is %d\n", i_var); } [مثال 4] قد يحاول المصرّف تحسين الأداء في الحلقة التكرارية بحيث يخزّن i_var في مسجّل الآلة لزيادة السرعة، إلا أن الدالة تحتاج وصولًا إلى القيمة الصحيحة من i_var حتى يمكنها طباعة القيمة الصحيحة، وهذا يعني أن المسجّل يجب أن يعيد تخزين قيمة i_var عند كل استدعاءٍ للدالة على الأقل، ويصف المعيار الشروط التي تحدد متى وأين يحصل ذلك. تُستكمل التأثيرات الجانبية لكل تعبير في نقطة التسلسل التي سبقتها، وهذا السبب في عدم قدرتنا على الاعتماد على تعابير مشابهة لهذه: a[i] = i++; وذلك بسبب عدم وجود أي نقطة تسلسلية مُحدّدة ضمن الإسناد أو عوامل الزيادة والنقصان، ولا يمكننا معرفة متى سيؤثر عامل الزيادة على i تحديدًا. يعرّف المعيار نقاط التسلسل على النحو التالي: نقطة استدعاء دالة، بعد تقييم وسطائها. نهاية المعامل الأول للعامل &&. نهاية المعامل الأول للعامل ||. نهاية المعامل الأول للعامل الشرطي :?. نهاية كل من معاملات عامل الفاصلة ,. نهاية تقييم تعبير كامل، على النحو التالي: تقييم القيمة الأولية لكائن auto. تعبير اعتيادي، أي متبوع بفاصلة منقوطة. تعابير التحكم في تعليمات do أو while أو if أو switch أو for. التعبيران الآخران في تعليمة حلقة for. التعبير في تعليمة return. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: مقدمة إلى مكتبات لغة سي C المقال السابق: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C -
 قدمنا سابقًا مفهوم النطاق scope والربط linkage، ووضحنا كيف يمكن استخدامهما سويًّا للتحكم بقابلية الوصول لأجزاء معينة ضمن البرنامج، وعمدنا إلى إعطاء وصف غامض لما يحدّد التعريف Definition لأن شرح ذلك سيتسبب بتشويشك في تلك المرحلة ولن يكون مثمرًا لرحلة تعلمك، إلا أنه علينا تحديد هذا الأمر في مرحلة من المراحل وهذا ما سنفعله في هذ الجزئية من السلسلة، كما سنتكلم عن صنف التخزين Storage class لجعل الأمر أكثر إثارة للاهتمام. لعلك ستجد مزج هذه المفاهيم واستخدامها سويًّا معقدًا ومربكًا، وهذا مبرّر، إلا أننا سنحاول إزالة الغموض بالتكلم عن بعض القوانين المفيدة لاحقًا، لكنك بحاجة لقراءة بعض التفاصيل قبل ذلك على الأقل مرةً واحدةً لتفهم هذه القوانين. حتى تفهم القوانين جيدًا، عليك أن تفهم ثلاثة مفاهيم مختلفة -ولكن مرتبطة- وهي كما يدعوها المعيار: المدة الزمنية duration. النطاق scope. الربط linkage. ويشرح المعيار هذه المصطلحات، كما أننا ناقشنا النطاق والربط في المقالة سابقة الذكر لكننا سنعيد ذكرهما بصورةٍ مقتضبة. محددات صنف التخزين تندرج خمس كلمات مفتاحية تحت تصنيف محدّدات صنف التخزين storage class specifiers، أحدها هو typedef، وبالرغم من أنه أشبه باختصار عن شبهه بخاصيّة، إلا أننا سنناقش هذه الكلمة المفتاحية بالتفصيل لاحقًا. يتبقى لدينا الكلمات المفتاحية auto و extern و register و static. تساعدك محددات صنف التخزين على تحديد نوع التخزين المستخدم لكائنات البيانات، وهناك صنف تخزين واحد مسموح به عند التصريح، وهذا الأمر منطقي لأن هناك طريقةً واحدةً لتخزين الأشياء. يُطبق المحدّد الافتراضي على عملية التصريح إذا أُهمل محدد صف التخزين، ويعتمد اختيار المحدد الافتراضي على نوع التصريح إذا كان خارج دالة (تصريح خارجي) أو داخل الدالة (تصريح داخلي)، إذ أن محدد التخزين الافتراضي للتصريح الخارجي هو extern بينما auto هو محدد التخزين الافتراضي للتصريح الداخلي، والاستثناء الوحيد لهذه القاعدة هو تصريح الدوال، إذ إن قيمة المحدد الافتراضي لها هو extern دائمًا. يمكن أن يؤثر مكان التصريح ومحددات صنف التخزين المستخدمة (أو الافتراضية في حال عدم وجودها) على ربط الاسم، بالإضافة إلى تصريحات الاسم ذاته التي تلي التصريح الأولي، ولحسن الحظ فإن ذلك لا يؤثر على النطاق أو المدة الزمنية. سنستعرض المفاهيم الأسهل أوّلًا. المدة الزمنية تصف المدة الزمنية لكائن ما طبيعة تخزينه، وذلك إذا كان حجز المساحة يصبح مرةً واحدةً عند تشغيل البرنامج أو أنه من طبيعة عابرة بمعنى أن مساحته تُحجز وتحرّر عند الضرورة. هناك نوعان فقط من المدة الزمنية، هما: المدة الساكنة static duration والمدة التلقائية automatic duration؛ إذ تعني المدة الساكنة أن مساحة التخزين المحجوزة للكائن دائمة؛ بينما تعني المدة التلقائية أن مساحة التخزين المحجوزة للكائن تُحرّر وتُحجز عند الضرورة، ومن السهل معرفة أي من المدتين ستحصل عليهما، لأنك ستحصل على المدة التلقائية فقط في حالة: إذا كان التصريح داخل دالة، ولم يكن التصريح يحتوي على أي من الكلمتين المفتاحيتين static أو extern. وليس التصريح تصريحًا لدالة. ستجد أن معاملات الدالة الصورية تطابق هذه القوانين الثلاث دائمًا، وبذلك فهي ذات مدة تلقائية. مع أن تواجد الكلمة المفتاحية static ضمن التصريح يعني أن الكائن ذو مدة ساكنة دون أي شك، إلا أنها ليست الطريقة الوحيدة لإنجاز ذلك، ويسبب هذا بعض اللبس لدى الكثير، وعلينا تقبُّل هذا الأمر. تُمنح كائنات البيانات المصرحة داخل الدوال محدد صنف التخزين الافتراضي auto، إلا إذا استُخدم محدد آخر لصنف التخزين. لن تحتاج الوصول إلى هذه الكائنات من خارج الدالة في معظم الحالات، لذا ستريد أن تكون عديمة الربط no linkage، وفي هذه الحالة نستخدم الحالة الافتراضية auto أو محدّد صنف التخزين register storage، إذ سيعطينا هذا كائنًا عديم الربط وذا مدة تلقائية. لا يمكن تطبيق الكلمة المفتاحية auto أو register ضمن تصريح يقع خارج دالةٍ ما. يُعد صنف التخزين register مثيرًا للاهتمام، فعلى الرغم من قلة استخدامه هذه الأيام إلا أنه يقترح على المصرف تخزين الكائن في مسجل register واحد أو أكثر في الذاكرة والذي ينعكس بالإيجاب على سرعة التنفيذ. لا ينفذ المصرف الأوامر بناءً على هذا الأمر إلا أن متغيرات register لا تمتلك أي عنوان ( يُمنع استخدام العامل & معها) لتسهيل الأمر وذلك لأن بعض الحواسيب لا تدعم المسجلات ذات العناوين. قد يتسبب التصريح عن عدة كائنات register بتأثير عكسي فيبطئ البرنامج بدلًا من تسريعه، وذلك لأن المصرف سوف يضطر إلى حجز مزيدٍ من المسجلات عند الدخول إلى (تنفيذ) الدالة وهي عملية بطيئة، أو لن يكون هناك العدد الكافي من المسجلات المتبقية لتُستخدم في العمليات الحسابية الوسيطة. يعود الاختيار في استخدام المسجلات إلى الآلة المُستخدمة، ويجب استخدام هذه الطريقة فقط عندما توضح الحسابات أن هذا النوع ضروري لتسريع تنفيذ دالة ما بعينها، وعندها يتوجب عليك فحص البرنامج وتجربته. يجب ألّا تصرح عن متغيرات المسجلات أبدًا خلال عملية تطوير البرنامج برأينا، بل تأكد من أن البرنامج يعمل ومن ثم أجرِ بعض القياسات، وعندها قرّر استخدام هذا النوع من المتغيرات حسب النتائج فيما إذا كان يتسبب استخدامها بتحسن ملحوظ في الأداء، ولكن عليك تكرار العملية ذاتها إذا اتبعت هذه الطريقة في كل نوع من المعالجات المسبقة التي تنقل برنامجك إليها، إذ يحتوي كل نوع من المعالجات المسبقة على خصائص مختلفة. ملاحظة أخيرة بخصوص متغيرات register: يُعد محدد صنف التخزين هذا المحدد الوحيد الممكن استخدامه ضمن نموذج دالة أولي function prototype أو تعريف دالة، ويجري تجاهل محدد صنف التخزين في حالة نموذج الدالة الأولي، بينما يشير تعريف الدالة على أن المعامل الفعلي مخزّن في مسجّل إذا كان الأمر ممكنًا. إليك مثالًا يوضح كيفية يمكن توظيف ذلك: #include <stdio.h> #include <stdlib.h> void func(register int arg1, double arg2); main(){ func(5, 2); exit(EXIT_SUCCESS); } /* توضح الدالة أنه يمكن التصريح عن المعاملات الصورية باستخدام صنف تخزين مسجّل */ void func(register int arg1, double arg2){ /* هذا الاستخدام لأهداف توضيحية، فلا أحد يكتب ذلك في هذا السياق لا يمكن أخذ عنوان arg1 حتى لو أردت ذلك */ double *fp = &arg2; while(arg1){ printf("res = %f\n", arg1 * (*fp)); arg1--; } } [مثال 1] تعتمد إذًا المدة الزمنية لكائن على محدد صنف التخزين المستخدَم -بغض النظر عن كون الكائن كائن بيانات أو دالة-، كما تعتمد على مكان التصريح (في كتلة داخلية أو على كامل نطاق الملف؟). يعتمد الربط أيضًا على محدد صنف التخزين، إضافةً إلى نوع الكائن ونطاق التصريح عنه. يوضح الجدول 1 والجدول 2 التاليين مدة التخزين الناتجة والربط لكل من الحالات الممكنة عند استخدام محددات صنف التخزين الممكنة، وموضع التصريح. يُعد ربط الكائنات باستخدام المدة الساكنة أكثر تعقيدًا، لذا ننصحك باستخدام هذه الجداول لتوجيهك في الحالات البسيطة وانتظر قليلًا حتى نصل إلى الجزء الذي نتكلم فيه عن التعريفات. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية static أحدهما داخلي ساكنة extern أحدهما خارجي غالبًا ساكنة لا يوجد دالة خارجي غالبًا ساكنة لا يوجد كائن بيانات خارجي ساكنة أهملنا في الجدول السابق المحددين register و auto لأنه من غير المسموح استخدامهما على نطاق التصريحات الخارجية (على نطاق الملف). محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية register كائن بيانات فقط لا يوجد تلقائية auto كائن بيانات فقط لا يوجد تلقائية static كائن بيانات فقط لا يوجد ساكنة extern كلاهما خارجي غالبًا ساكنة لا يوجد none كائن بيانات لا يوجد تلقائية لا يوجد none دالة خارجي غالبًا ساكنة تحتفظ المتغيرات الساكنة static الداخلية بقيمها بين استدعاءات الدوال التي تحتويها، وهذا شيءٌ مفيدٌ جدًا في بعض الحالات. النطاق علينا الآن إلقاء نظرة على نطاق أسماء الكائنات مجددًا، والذي يعرف أين ومتى يكون لاسمٍ ما معنًى محدد. هناك أنواعٌ مختلفة للنطاق هي: نطاق دالة. نطاق ملف. نطاق كتلة. نطاق نموذج دالة أولي. النطاق الأسهل هو نطاق الدالة، إذ ينطبق ذلك على عناوين labels الأسماء المرئية ضمن دالة ما صُرّح عنها بداخلها، ولا يمكن لعنوانين داخل نفس الدالة أن يمتلكان الاسم ذاته، لكن يمكن للعنوان استخدام الاسم ذاته إذا كان ضمن أي دالةٍ أخرى بحكم أن النطاق هو نطاق دالة. ليست العناوين كائنات فهي لا تمتلك أي مساحة تخزينية ولا يعني مفهوم الربط والمدة الزمنية أي معنًى في عالمها. يمتلك أي اسم مُصرّح عنه خارج الدالة نطاق ملف، وهذا يعني أن الاسم قابلٌ للاستخدام ضمن أي نقطة من البرنامج من لحظة التصريح عنه إلى نهاية ملف الشيفرة المصدرية الذي يحتوي ذلك التصريح، ومن الممكن طبعًا لهذه الأسماء أن تصبح مخفية مؤقتًا باستخدام تصريحات ضمن تعليمات مركبة، لأنه كما نعلم، ينبغي على تعريفات الدالة أن تكون خارج الدوال الأخرى حتى يكون اسم الدالة في التعريف ذو نطاق ملف. يمتلك الاسم المُصرّح عنه بداخل تعليمة مركبة أو معامل دالة صوري نطاق كتلة ومن الممكن استخدامه ضمن الكتلة حتى الوصول للقوس { الذي يغلِق التعليمة المركبة، ويُخفي أي تصريح لاسم ضمن تعليمة مركبة أي تصريح خارجي آخر للاسم ذاته حتى نهاية التعليمة المركبة. يعدّ نطاق النموذج الأولي للدالة مثالًا مميزًا وبسيطًا من النطاقات، إذ يمتد تصريح الاسم حتى نهاية النموذج الأولي للدالة فقط، وهذا يعني أن ما يلي خاطئ (باستخدام نفس الاسم مرتين): void func(int i, int i); وهذا هو الاستعمال الصحيح: void func(int i, int j); وتختفي الأسماء المُصرّح عنها بداخل الأقواس خارجها. نطاق الاسم مستقل تمامًا عن أي محدد صنف تخزين مُستخدم في التصريح. الربط سنذكّر بمصطلح الربط Linkage بصورةٍ مقتضبة هنا أيضًا، إذ يُستخدم الربط لتحديد ما الذي يجعل الاسم المُعلن عنه في نطاقات مختلفة يشير إلى الشيء ذاته، إذ يمتلك الكائن اسمًا واحدًا فقط، ولكننا في بعض الحالات نحتاج للإشارة إلى هذا الكائن على مستوى نطاقات مختلفة، ويُعدّ استدعاء الدالة printf من أماكن متعددة ضمن البرنامج أبسط الأمثلة، حتى لو كانت هذه الأماكن المذكورة لا تنتمي إلى ملف الشيفرة المصدرية ذاته. يحذّر المعيار أنه يجب على التصاريح التي تشير إلى الشيء ذاته أن تكون من نوع متوافق، وإلا فسنحصل على برنامج ذي سلوك غير محدد، وسنتكلم عن الأنواع المتوافقة بالتفصيل لاحقًا، وسنكتفي حاليًا بقول أن التصاريح يجب أن تكون متطابقةً باستثناء استخدام محددات صنف محدد التخزين، وتحقيق هذا من مسؤوليات المبرمج، إلا أن هناك بعض الأدوات لتساعدك في تحقيق هذا غالبًا. هناك ثلاثة أنواع مختلفة من الربط: الربط الخارجي. الربط الداخلي. عديم الربط. إذا كان اسم الكائن ذو ربط خارجي فهذا يعني أن جميع النسخ instances الموجودة في البرنامج -الذي قد يكون مؤلفًا من عدد من ملفات الشيفرة المصدرية والمكتبات- تعود إلى الكائن ذاته، ويعني الربط الداخلي لكائن ما أن نُسخ هذا الكائن الموجودة في ملف الشيفرة المصدرية نفسه فقط تُشير إلى الشيء ذاته، بينما يعني الكائن عديم الربط أن كل كائن ذي اسم مماثل له هو كائنٌ منفصلٌ عنه. الربط والتعاريف يجب لكل كائن بيانات أو دالة مُستخدمة في برنامج (عدا معاملات عامل sizeof) أن تمتلك تعريفًا واحدًا فقط، ومع أننا لم نتطرق إلى هذا بعد، إلا أن هذا الأمر مهمٌ جدًا؛ ويعود السبب بعدم تطرقنا لهذا الأمر إلى استخدام جميع أمثلتنا كائنات بيانات ذات مدة تلقائية فقط وكون تصاريحها تعاريفًا، أو دوالًا كنا قد عرّفناها من خلال كتابة متنها. تعني القاعدة السابقة أنه يجب للكائنات ذات الربط الخارجي أن تحتوي على تعريفٍ واحد فقط ضمن كامل البرنامج، ويجب للكائنات ذات الربط الداخلي (المقيدة داخل ملف شيفرة مصدرية واحد) أن يُعرّف عنها لمرة واحدة فقط ضمن الملف المُصرّح فيه عنها، كما أن للكائنات عديمة الربط تعريفٌ واحد فقط، إذ أن التصريح عنها هو تعريفٌ أيضًا. لجمع النقاط الآنف ذكرها، نسأل الأسئلة التالية: كيف أستطيع الحصول على نوع الربط الذي أريده؟ ما الشيء الذي يحدد التعريف؟ علينا أن ننظر إلى الربط أولًا ومن ثم التعريف. إذّا، كيف نحصل على التعريف المناسب لاسمٍ ما؟ القوانين معقدة بعض الشيء. ينتج التصريح خارج دالة (نطاق ملف) تحتوي على محدد صنف تخزين ساكن ربطًا داخليًا لهذا الاسم، ويحدد المعيار وجوب وجود تصاريح الدالة التي تحتوي على الكلمة المفتاحية static على مستوى الملف وخارج أي كتلة برمجية. إذا احتوى التصريح على محدد صنف التخزين extern، أو إذا كان تصريح الدالة لا يحتوي على محدد صنف التخزين، أو كلا الحالتين، فهذا يعني: إذا وجِد تصريح للمعرف ذاته بنطاق ملف، فهذا يعني أن الربط الناتج مماثلٌ لهذا التصريح السابق المرئي. وإلا، فالنتيجة هي ربط خارجي. إذا لم يكن التصريح ذو نطاق الملف تصريحًا لدالة أو لم يحتوي على محدد صنف تخزين واضح، فالنتيجة هي ربط خارجي. أي شكل آخر من التصاريح سيكون عديم الربط. إذا وجِد معرف ذو ربط داخلي وخارجي في ذات الوقت ضمن ملف شيفرة مصدرية ما، فالنتيجة غير محددة. استُخدمت القوانين السابقة لكتابة جدول الربط السابق (جدول 2) دون تطبيق كامل للقاعدة 2، وهذا السبب في استخدامنا الكلمة "خارجي غالبًا"، وتسمح لك القاعدة 2 بتحديد الربط بدقة في هذه الحالات. ما الذي يجعل التصريح تعريفًا؟ التصاريح التي تعطينا كائنات عديمة الربط هي تعاريف أيضًا. التصاريح التي تتضمن قيمةً أولية هي تعاريف دائمًا، وهذا يتضمن تهيئة دالة ما بكتابة متن الدالة، ويمكن للتصاريح ذات نطاق الكتلة أن تحتوي على قيم أولية فقط في حال كانت عديمة الربط. وإلا، فالتصريح عن الاسم على نطاق ملف بدون محدد صنف التخزين أو مع محدد صنف التخزين static هو تعريف مبدئي tentative definition، وإذا احتوى ملف شيفرة مصدرية على تعريف مبدئي واحد أو أكثر لكائن ما وكان الملف لا يحتوي على أي تعاريف فعلية، يصبح للكائن تعريفٌ افتراضيٌ وهو مشابه لحالة إسناد القيمة الأولية "0" إليه (تُهيّأ عناصر المصفوفات والهياكل جميعها إلى قيمة "0")، ولا يوجد للدوال تعريفٌ مبدئي. طبقًا لما سبق، لا تتسبب التصريحات التي تحتوي على محدد صنف تخزين خارجي extern بتعريف، إلا إذا ضمّنت قيمةً أوليةً للتصريح. الاستخدام العملي لكل من الربط والتعاريف تبدو القوانين التي تحدد كل من الربط والتعريف المرتبطة بالتصاريح معقدةً بعض الشيء، إلا أن استخدام هذه القوانين عمليًّا ليس بالأمر الصعب، دعونا نناقش بعض الحالات الاعتيادية. أنواع إمكانية أو قابلية الوصول الثلاث التي ستريدها لكائنات البيانات أو الدوال هي: على كامل نطاق البرنامج. مقيّد بنطاق ملف شيفرة مصدرية واحد. مقيّد بنطاق دالة واحدة، أو تعليمة مركبة واحدة. ستحتاج إلى ربط خارجي وربط داخلي وربط عديم لكل من الحالات الثلاث السابقة بالترتيب، ومن الممارسات المُحبذة بالنسبة للحالة الأولى والثانية هي التصريح عن الأسماء ضمن ملف الشيفرة المصدرية الموافق لها قبل أن تعرّف أي دالة، ويوضح الشكل 1 هيكل ملف الشيفرة المصدرية بهذا الخصوص. [شكل 1 هيكل ملف الشيفرة المصدرية] يمكن أن تُسبق تصاريح الربط الخارجية بالكلمة المفتاحية extern وتصاريح الربط الداخلية بالكلمة المفتاحية static. إليك مثالًا عن ذلك: /* مثال عن هيكل ملف الشيفرة المصدرية */ #include <stdio.h> /* يمكن الوصول للأشياء ذات الربط الخارجي عبر البرنامج ما يلي هو تصاريح وليس تعاريف، لذا نفترض أن التعاريف في مكان ما آخر */ extern int important_variable; extern int library_func(double, int); /* تعاريف ذات ربط خارجي */ extern int ext_int_def = 0; /* تعريف صريح */ int tent_ext_int_def; /* تعريف مبدئي */ /* * يمكن الوصول للأشياء ذات الربط الداخلي فقط من داخل الملف * يعني استخدام المحدد الساكن أن التعريفات هي تعريفات مبدئية */ static int less_important_variable; static struct{ int member_1; int member_2; }local_struct; /* ذات ربط داخلي لكنها ليست بتعريف مبدئي لأنها دالة */ static void lf(void); /* * التعريف مع الربط الداخلي */ static float int_link_f_def = 5.3; /* وأحيرًا إليك تعاريف الدوال ضمن هذا الملف */ /* للدالة التالية ربط خارجي ويمكن استدعاؤها من أي مكان ضمن البرنامج */ void f1(int a){} /* يمكن استخدام الدالتين التاليتين باسمهما ضمن هذا الملف */ static int local_function(int a1, int a2){ return(a1 * a2); } static void lf(void){ /* متغير ساكن عديم الربط، لذا يمكن استخدامه فقط ضمن هذه الدالة، وهو تعريف بحكم أنه عديم الربط */ static int count; /* متغير تلقائي عديم الربط ولكنه ذو مُهيّأ بقيمة أولية */ int i = 1; printf("lf called for time no %d\n", ++count); } /* ضُمّنت التعاريف الفعلية لجميع التعاريف المبدئية المتبقية في نهاية الملف */ [مثال 2] نقترح عليك قراءة الفقرات السابقة مجددًا لملاحظة القوانين التي طُبّقت في المثال 2. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة C المقال السابق: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C
قدمنا سابقًا مفهوم النطاق scope والربط linkage، ووضحنا كيف يمكن استخدامهما سويًّا للتحكم بقابلية الوصول لأجزاء معينة ضمن البرنامج، وعمدنا إلى إعطاء وصف غامض لما يحدّد التعريف Definition لأن شرح ذلك سيتسبب بتشويشك في تلك المرحلة ولن يكون مثمرًا لرحلة تعلمك، إلا أنه علينا تحديد هذا الأمر في مرحلة من المراحل وهذا ما سنفعله في هذ الجزئية من السلسلة، كما سنتكلم عن صنف التخزين Storage class لجعل الأمر أكثر إثارة للاهتمام. لعلك ستجد مزج هذه المفاهيم واستخدامها سويًّا معقدًا ومربكًا، وهذا مبرّر، إلا أننا سنحاول إزالة الغموض بالتكلم عن بعض القوانين المفيدة لاحقًا، لكنك بحاجة لقراءة بعض التفاصيل قبل ذلك على الأقل مرةً واحدةً لتفهم هذه القوانين. حتى تفهم القوانين جيدًا، عليك أن تفهم ثلاثة مفاهيم مختلفة -ولكن مرتبطة- وهي كما يدعوها المعيار: المدة الزمنية duration. النطاق scope. الربط linkage. ويشرح المعيار هذه المصطلحات، كما أننا ناقشنا النطاق والربط في المقالة سابقة الذكر لكننا سنعيد ذكرهما بصورةٍ مقتضبة. محددات صنف التخزين تندرج خمس كلمات مفتاحية تحت تصنيف محدّدات صنف التخزين storage class specifiers، أحدها هو typedef، وبالرغم من أنه أشبه باختصار عن شبهه بخاصيّة، إلا أننا سنناقش هذه الكلمة المفتاحية بالتفصيل لاحقًا. يتبقى لدينا الكلمات المفتاحية auto و extern و register و static. تساعدك محددات صنف التخزين على تحديد نوع التخزين المستخدم لكائنات البيانات، وهناك صنف تخزين واحد مسموح به عند التصريح، وهذا الأمر منطقي لأن هناك طريقةً واحدةً لتخزين الأشياء. يُطبق المحدّد الافتراضي على عملية التصريح إذا أُهمل محدد صف التخزين، ويعتمد اختيار المحدد الافتراضي على نوع التصريح إذا كان خارج دالة (تصريح خارجي) أو داخل الدالة (تصريح داخلي)، إذ أن محدد التخزين الافتراضي للتصريح الخارجي هو extern بينما auto هو محدد التخزين الافتراضي للتصريح الداخلي، والاستثناء الوحيد لهذه القاعدة هو تصريح الدوال، إذ إن قيمة المحدد الافتراضي لها هو extern دائمًا. يمكن أن يؤثر مكان التصريح ومحددات صنف التخزين المستخدمة (أو الافتراضية في حال عدم وجودها) على ربط الاسم، بالإضافة إلى تصريحات الاسم ذاته التي تلي التصريح الأولي، ولحسن الحظ فإن ذلك لا يؤثر على النطاق أو المدة الزمنية. سنستعرض المفاهيم الأسهل أوّلًا. المدة الزمنية تصف المدة الزمنية لكائن ما طبيعة تخزينه، وذلك إذا كان حجز المساحة يصبح مرةً واحدةً عند تشغيل البرنامج أو أنه من طبيعة عابرة بمعنى أن مساحته تُحجز وتحرّر عند الضرورة. هناك نوعان فقط من المدة الزمنية، هما: المدة الساكنة static duration والمدة التلقائية automatic duration؛ إذ تعني المدة الساكنة أن مساحة التخزين المحجوزة للكائن دائمة؛ بينما تعني المدة التلقائية أن مساحة التخزين المحجوزة للكائن تُحرّر وتُحجز عند الضرورة، ومن السهل معرفة أي من المدتين ستحصل عليهما، لأنك ستحصل على المدة التلقائية فقط في حالة: إذا كان التصريح داخل دالة، ولم يكن التصريح يحتوي على أي من الكلمتين المفتاحيتين static أو extern. وليس التصريح تصريحًا لدالة. ستجد أن معاملات الدالة الصورية تطابق هذه القوانين الثلاث دائمًا، وبذلك فهي ذات مدة تلقائية. مع أن تواجد الكلمة المفتاحية static ضمن التصريح يعني أن الكائن ذو مدة ساكنة دون أي شك، إلا أنها ليست الطريقة الوحيدة لإنجاز ذلك، ويسبب هذا بعض اللبس لدى الكثير، وعلينا تقبُّل هذا الأمر. تُمنح كائنات البيانات المصرحة داخل الدوال محدد صنف التخزين الافتراضي auto، إلا إذا استُخدم محدد آخر لصنف التخزين. لن تحتاج الوصول إلى هذه الكائنات من خارج الدالة في معظم الحالات، لذا ستريد أن تكون عديمة الربط no linkage، وفي هذه الحالة نستخدم الحالة الافتراضية auto أو محدّد صنف التخزين register storage، إذ سيعطينا هذا كائنًا عديم الربط وذا مدة تلقائية. لا يمكن تطبيق الكلمة المفتاحية auto أو register ضمن تصريح يقع خارج دالةٍ ما. يُعد صنف التخزين register مثيرًا للاهتمام، فعلى الرغم من قلة استخدامه هذه الأيام إلا أنه يقترح على المصرف تخزين الكائن في مسجل register واحد أو أكثر في الذاكرة والذي ينعكس بالإيجاب على سرعة التنفيذ. لا ينفذ المصرف الأوامر بناءً على هذا الأمر إلا أن متغيرات register لا تمتلك أي عنوان ( يُمنع استخدام العامل & معها) لتسهيل الأمر وذلك لأن بعض الحواسيب لا تدعم المسجلات ذات العناوين. قد يتسبب التصريح عن عدة كائنات register بتأثير عكسي فيبطئ البرنامج بدلًا من تسريعه، وذلك لأن المصرف سوف يضطر إلى حجز مزيدٍ من المسجلات عند الدخول إلى (تنفيذ) الدالة وهي عملية بطيئة، أو لن يكون هناك العدد الكافي من المسجلات المتبقية لتُستخدم في العمليات الحسابية الوسيطة. يعود الاختيار في استخدام المسجلات إلى الآلة المُستخدمة، ويجب استخدام هذه الطريقة فقط عندما توضح الحسابات أن هذا النوع ضروري لتسريع تنفيذ دالة ما بعينها، وعندها يتوجب عليك فحص البرنامج وتجربته. يجب ألّا تصرح عن متغيرات المسجلات أبدًا خلال عملية تطوير البرنامج برأينا، بل تأكد من أن البرنامج يعمل ومن ثم أجرِ بعض القياسات، وعندها قرّر استخدام هذا النوع من المتغيرات حسب النتائج فيما إذا كان يتسبب استخدامها بتحسن ملحوظ في الأداء، ولكن عليك تكرار العملية ذاتها إذا اتبعت هذه الطريقة في كل نوع من المعالجات المسبقة التي تنقل برنامجك إليها، إذ يحتوي كل نوع من المعالجات المسبقة على خصائص مختلفة. ملاحظة أخيرة بخصوص متغيرات register: يُعد محدد صنف التخزين هذا المحدد الوحيد الممكن استخدامه ضمن نموذج دالة أولي function prototype أو تعريف دالة، ويجري تجاهل محدد صنف التخزين في حالة نموذج الدالة الأولي، بينما يشير تعريف الدالة على أن المعامل الفعلي مخزّن في مسجّل إذا كان الأمر ممكنًا. إليك مثالًا يوضح كيفية يمكن توظيف ذلك: #include <stdio.h> #include <stdlib.h> void func(register int arg1, double arg2); main(){ func(5, 2); exit(EXIT_SUCCESS); } /* توضح الدالة أنه يمكن التصريح عن المعاملات الصورية باستخدام صنف تخزين مسجّل */ void func(register int arg1, double arg2){ /* هذا الاستخدام لأهداف توضيحية، فلا أحد يكتب ذلك في هذا السياق لا يمكن أخذ عنوان arg1 حتى لو أردت ذلك */ double *fp = &arg2; while(arg1){ printf("res = %f\n", arg1 * (*fp)); arg1--; } } [مثال 1] تعتمد إذًا المدة الزمنية لكائن على محدد صنف التخزين المستخدَم -بغض النظر عن كون الكائن كائن بيانات أو دالة-، كما تعتمد على مكان التصريح (في كتلة داخلية أو على كامل نطاق الملف؟). يعتمد الربط أيضًا على محدد صنف التخزين، إضافةً إلى نوع الكائن ونطاق التصريح عنه. يوضح الجدول 1 والجدول 2 التاليين مدة التخزين الناتجة والربط لكل من الحالات الممكنة عند استخدام محددات صنف التخزين الممكنة، وموضع التصريح. يُعد ربط الكائنات باستخدام المدة الساكنة أكثر تعقيدًا، لذا ننصحك باستخدام هذه الجداول لتوجيهك في الحالات البسيطة وانتظر قليلًا حتى نصل إلى الجزء الذي نتكلم فيه عن التعريفات. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية static أحدهما داخلي ساكنة extern أحدهما خارجي غالبًا ساكنة لا يوجد دالة خارجي غالبًا ساكنة لا يوجد كائن بيانات خارجي ساكنة أهملنا في الجدول السابق المحددين register و auto لأنه من غير المسموح استخدامهما على نطاق التصريحات الخارجية (على نطاق الملف). محدد صنف التخزين دالة أو كائن بيانات الربط المدة الزمنية register كائن بيانات فقط لا يوجد تلقائية auto كائن بيانات فقط لا يوجد تلقائية static كائن بيانات فقط لا يوجد ساكنة extern كلاهما خارجي غالبًا ساكنة لا يوجد none كائن بيانات لا يوجد تلقائية لا يوجد none دالة خارجي غالبًا ساكنة تحتفظ المتغيرات الساكنة static الداخلية بقيمها بين استدعاءات الدوال التي تحتويها، وهذا شيءٌ مفيدٌ جدًا في بعض الحالات. النطاق علينا الآن إلقاء نظرة على نطاق أسماء الكائنات مجددًا، والذي يعرف أين ومتى يكون لاسمٍ ما معنًى محدد. هناك أنواعٌ مختلفة للنطاق هي: نطاق دالة. نطاق ملف. نطاق كتلة. نطاق نموذج دالة أولي. النطاق الأسهل هو نطاق الدالة، إذ ينطبق ذلك على عناوين labels الأسماء المرئية ضمن دالة ما صُرّح عنها بداخلها، ولا يمكن لعنوانين داخل نفس الدالة أن يمتلكان الاسم ذاته، لكن يمكن للعنوان استخدام الاسم ذاته إذا كان ضمن أي دالةٍ أخرى بحكم أن النطاق هو نطاق دالة. ليست العناوين كائنات فهي لا تمتلك أي مساحة تخزينية ولا يعني مفهوم الربط والمدة الزمنية أي معنًى في عالمها. يمتلك أي اسم مُصرّح عنه خارج الدالة نطاق ملف، وهذا يعني أن الاسم قابلٌ للاستخدام ضمن أي نقطة من البرنامج من لحظة التصريح عنه إلى نهاية ملف الشيفرة المصدرية الذي يحتوي ذلك التصريح، ومن الممكن طبعًا لهذه الأسماء أن تصبح مخفية مؤقتًا باستخدام تصريحات ضمن تعليمات مركبة، لأنه كما نعلم، ينبغي على تعريفات الدالة أن تكون خارج الدوال الأخرى حتى يكون اسم الدالة في التعريف ذو نطاق ملف. يمتلك الاسم المُصرّح عنه بداخل تعليمة مركبة أو معامل دالة صوري نطاق كتلة ومن الممكن استخدامه ضمن الكتلة حتى الوصول للقوس { الذي يغلِق التعليمة المركبة، ويُخفي أي تصريح لاسم ضمن تعليمة مركبة أي تصريح خارجي آخر للاسم ذاته حتى نهاية التعليمة المركبة. يعدّ نطاق النموذج الأولي للدالة مثالًا مميزًا وبسيطًا من النطاقات، إذ يمتد تصريح الاسم حتى نهاية النموذج الأولي للدالة فقط، وهذا يعني أن ما يلي خاطئ (باستخدام نفس الاسم مرتين): void func(int i, int i); وهذا هو الاستعمال الصحيح: void func(int i, int j); وتختفي الأسماء المُصرّح عنها بداخل الأقواس خارجها. نطاق الاسم مستقل تمامًا عن أي محدد صنف تخزين مُستخدم في التصريح. الربط سنذكّر بمصطلح الربط Linkage بصورةٍ مقتضبة هنا أيضًا، إذ يُستخدم الربط لتحديد ما الذي يجعل الاسم المُعلن عنه في نطاقات مختلفة يشير إلى الشيء ذاته، إذ يمتلك الكائن اسمًا واحدًا فقط، ولكننا في بعض الحالات نحتاج للإشارة إلى هذا الكائن على مستوى نطاقات مختلفة، ويُعدّ استدعاء الدالة printf من أماكن متعددة ضمن البرنامج أبسط الأمثلة، حتى لو كانت هذه الأماكن المذكورة لا تنتمي إلى ملف الشيفرة المصدرية ذاته. يحذّر المعيار أنه يجب على التصاريح التي تشير إلى الشيء ذاته أن تكون من نوع متوافق، وإلا فسنحصل على برنامج ذي سلوك غير محدد، وسنتكلم عن الأنواع المتوافقة بالتفصيل لاحقًا، وسنكتفي حاليًا بقول أن التصاريح يجب أن تكون متطابقةً باستثناء استخدام محددات صنف محدد التخزين، وتحقيق هذا من مسؤوليات المبرمج، إلا أن هناك بعض الأدوات لتساعدك في تحقيق هذا غالبًا. هناك ثلاثة أنواع مختلفة من الربط: الربط الخارجي. الربط الداخلي. عديم الربط. إذا كان اسم الكائن ذو ربط خارجي فهذا يعني أن جميع النسخ instances الموجودة في البرنامج -الذي قد يكون مؤلفًا من عدد من ملفات الشيفرة المصدرية والمكتبات- تعود إلى الكائن ذاته، ويعني الربط الداخلي لكائن ما أن نُسخ هذا الكائن الموجودة في ملف الشيفرة المصدرية نفسه فقط تُشير إلى الشيء ذاته، بينما يعني الكائن عديم الربط أن كل كائن ذي اسم مماثل له هو كائنٌ منفصلٌ عنه. الربط والتعاريف يجب لكل كائن بيانات أو دالة مُستخدمة في برنامج (عدا معاملات عامل sizeof) أن تمتلك تعريفًا واحدًا فقط، ومع أننا لم نتطرق إلى هذا بعد، إلا أن هذا الأمر مهمٌ جدًا؛ ويعود السبب بعدم تطرقنا لهذا الأمر إلى استخدام جميع أمثلتنا كائنات بيانات ذات مدة تلقائية فقط وكون تصاريحها تعاريفًا، أو دوالًا كنا قد عرّفناها من خلال كتابة متنها. تعني القاعدة السابقة أنه يجب للكائنات ذات الربط الخارجي أن تحتوي على تعريفٍ واحد فقط ضمن كامل البرنامج، ويجب للكائنات ذات الربط الداخلي (المقيدة داخل ملف شيفرة مصدرية واحد) أن يُعرّف عنها لمرة واحدة فقط ضمن الملف المُصرّح فيه عنها، كما أن للكائنات عديمة الربط تعريفٌ واحد فقط، إذ أن التصريح عنها هو تعريفٌ أيضًا. لجمع النقاط الآنف ذكرها، نسأل الأسئلة التالية: كيف أستطيع الحصول على نوع الربط الذي أريده؟ ما الشيء الذي يحدد التعريف؟ علينا أن ننظر إلى الربط أولًا ومن ثم التعريف. إذّا، كيف نحصل على التعريف المناسب لاسمٍ ما؟ القوانين معقدة بعض الشيء. ينتج التصريح خارج دالة (نطاق ملف) تحتوي على محدد صنف تخزين ساكن ربطًا داخليًا لهذا الاسم، ويحدد المعيار وجوب وجود تصاريح الدالة التي تحتوي على الكلمة المفتاحية static على مستوى الملف وخارج أي كتلة برمجية. إذا احتوى التصريح على محدد صنف التخزين extern، أو إذا كان تصريح الدالة لا يحتوي على محدد صنف التخزين، أو كلا الحالتين، فهذا يعني: إذا وجِد تصريح للمعرف ذاته بنطاق ملف، فهذا يعني أن الربط الناتج مماثلٌ لهذا التصريح السابق المرئي. وإلا، فالنتيجة هي ربط خارجي. إذا لم يكن التصريح ذو نطاق الملف تصريحًا لدالة أو لم يحتوي على محدد صنف تخزين واضح، فالنتيجة هي ربط خارجي. أي شكل آخر من التصاريح سيكون عديم الربط. إذا وجِد معرف ذو ربط داخلي وخارجي في ذات الوقت ضمن ملف شيفرة مصدرية ما، فالنتيجة غير محددة. استُخدمت القوانين السابقة لكتابة جدول الربط السابق (جدول 2) دون تطبيق كامل للقاعدة 2، وهذا السبب في استخدامنا الكلمة "خارجي غالبًا"، وتسمح لك القاعدة 2 بتحديد الربط بدقة في هذه الحالات. ما الذي يجعل التصريح تعريفًا؟ التصاريح التي تعطينا كائنات عديمة الربط هي تعاريف أيضًا. التصاريح التي تتضمن قيمةً أولية هي تعاريف دائمًا، وهذا يتضمن تهيئة دالة ما بكتابة متن الدالة، ويمكن للتصاريح ذات نطاق الكتلة أن تحتوي على قيم أولية فقط في حال كانت عديمة الربط. وإلا، فالتصريح عن الاسم على نطاق ملف بدون محدد صنف التخزين أو مع محدد صنف التخزين static هو تعريف مبدئي tentative definition، وإذا احتوى ملف شيفرة مصدرية على تعريف مبدئي واحد أو أكثر لكائن ما وكان الملف لا يحتوي على أي تعاريف فعلية، يصبح للكائن تعريفٌ افتراضيٌ وهو مشابه لحالة إسناد القيمة الأولية "0" إليه (تُهيّأ عناصر المصفوفات والهياكل جميعها إلى قيمة "0")، ولا يوجد للدوال تعريفٌ مبدئي. طبقًا لما سبق، لا تتسبب التصريحات التي تحتوي على محدد صنف تخزين خارجي extern بتعريف، إلا إذا ضمّنت قيمةً أوليةً للتصريح. الاستخدام العملي لكل من الربط والتعاريف تبدو القوانين التي تحدد كل من الربط والتعريف المرتبطة بالتصاريح معقدةً بعض الشيء، إلا أن استخدام هذه القوانين عمليًّا ليس بالأمر الصعب، دعونا نناقش بعض الحالات الاعتيادية. أنواع إمكانية أو قابلية الوصول الثلاث التي ستريدها لكائنات البيانات أو الدوال هي: على كامل نطاق البرنامج. مقيّد بنطاق ملف شيفرة مصدرية واحد. مقيّد بنطاق دالة واحدة، أو تعليمة مركبة واحدة. ستحتاج إلى ربط خارجي وربط داخلي وربط عديم لكل من الحالات الثلاث السابقة بالترتيب، ومن الممارسات المُحبذة بالنسبة للحالة الأولى والثانية هي التصريح عن الأسماء ضمن ملف الشيفرة المصدرية الموافق لها قبل أن تعرّف أي دالة، ويوضح الشكل 1 هيكل ملف الشيفرة المصدرية بهذا الخصوص. [شكل 1 هيكل ملف الشيفرة المصدرية] يمكن أن تُسبق تصاريح الربط الخارجية بالكلمة المفتاحية extern وتصاريح الربط الداخلية بالكلمة المفتاحية static. إليك مثالًا عن ذلك: /* مثال عن هيكل ملف الشيفرة المصدرية */ #include <stdio.h> /* يمكن الوصول للأشياء ذات الربط الخارجي عبر البرنامج ما يلي هو تصاريح وليس تعاريف، لذا نفترض أن التعاريف في مكان ما آخر */ extern int important_variable; extern int library_func(double, int); /* تعاريف ذات ربط خارجي */ extern int ext_int_def = 0; /* تعريف صريح */ int tent_ext_int_def; /* تعريف مبدئي */ /* * يمكن الوصول للأشياء ذات الربط الداخلي فقط من داخل الملف * يعني استخدام المحدد الساكن أن التعريفات هي تعريفات مبدئية */ static int less_important_variable; static struct{ int member_1; int member_2; }local_struct; /* ذات ربط داخلي لكنها ليست بتعريف مبدئي لأنها دالة */ static void lf(void); /* * التعريف مع الربط الداخلي */ static float int_link_f_def = 5.3; /* وأحيرًا إليك تعاريف الدوال ضمن هذا الملف */ /* للدالة التالية ربط خارجي ويمكن استدعاؤها من أي مكان ضمن البرنامج */ void f1(int a){} /* يمكن استخدام الدالتين التاليتين باسمهما ضمن هذا الملف */ static int local_function(int a1, int a2){ return(a1 * a2); } static void lf(void){ /* متغير ساكن عديم الربط، لذا يمكن استخدامه فقط ضمن هذه الدالة، وهو تعريف بحكم أنه عديم الربط */ static int count; /* متغير تلقائي عديم الربط ولكنه ذو مُهيّأ بقيمة أولية */ int i = 1; printf("lf called for time no %d\n", ++count); } /* ضُمّنت التعاريف الفعلية لجميع التعاريف المبدئية المتبقية في نهاية الملف */ [مثال 2] نقترح عليك قراءة الفقرات السابقة مجددًا لملاحظة القوانين التي طُبّقت في المثال 2. ترجمة -وبتصرف- لقسم من الفصل Specialized Areas of C من كتاب The C Book. اقرأ أيضًا المقال التالي: معرفات النوع typedef والمؤهلات qualifiers ونقاط التسلسل sequence points في لغة C المقال السابق: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C تهيئة المتغيرات وأنواع البيانات في لغة سي C -
 يتناول المقال مرحلة المعالجة المسبقة للشيفرة المصدرية بما فيها مراحل استبدال الماكرو ومختلف موجهات المعالج المسبق الأخرى. أثر المعيار ستشعر أن المعالج المُسبق Preprocessor لا ينتمي إلى لغة سي عمومًا، إذ لا يسمح لك وجوده بالتعامل بصورةٍ متكاملة مع اللغة كما أنك لا تستطيع الاستغناء عنه في ذات الوقت، وفي الحقيقة، كان استخدام المعالج المُسبق في أيام سي الأولى اختياريًا واعتاد الناس على كتابة برامج لغة سي C بدونه، ويمكننا أن ننظر إلى كونه جزءًا من لغة سي حاليًا صدفةً إلى حدٍ ما، إذ كان يعالج بعضًا من أوجه القصور في اللغة، مثل تعريف الثوابت وتضمين التعريفات القياسية، وأصبح نتيجةً لذلك جزءًا ضمن حزمة لغة سي ككُل. لم يكن هناك في تلك الفترة معيارٌ رسميٌ متفقٌ عليه يوحّد ما يفعله المعالج المسبق، وكانت إصدارات مختلفة منه مُطبّقة بصورةٍ مختلف على عدة أنظمة، وأصبحت عملية نقل البرنامج وتصديره إلى أنظمة أخرى مشكلةً كبيرة إذا استخدم ما يزيد عن الخصائص الأساسية للمعالج. كانت وظيفة المعيار الأساسية هنا هي تعريف سلوك المعالج المُسبق بما يتوافق مع الممارسات الشائعة، وقد سبق حصول ذلك مع لغة سي القديمة، إلا أن المعيار اتخذ إجراءات إضافية وسط الخلاف وحدد مجموعةً من الخصائص الإضافية التي قُدمت مع إصدارات المعالج المُسبق الأكثر شعبية، وعلى الرغم من فائدة هذه الخصائص إلا أن الخلاف كان بخصوص الاتفاق على طريقة تطبيقها. لم يكترث المعيار لمشكلة القابلية مع البرامج القديمة بالنظر إلى أن هذه البرامج تستخدم طرقًا غير قابلة للنقل في المقام الأول، وسيحسِّن تواجد هذه الخصائص المتقدمة ضمن المعيار سهولة نقل برامج لغة سي مستقبلًا بصورةٍ ملحوظة. يعدّ استخدام المعالج المسبق سهلًا إذا استُخدم لمهمته الأساسية البسيطة في جعل البرامج سهلة القراءة والصيانة، ولكن يُفضّل ترك خصائصه المتقدمة لاستخدام الخبراء. بحكم تجربتنا، يُعد استخدام #define ومجموعة تعليمات التصريف الشرطي conditional compilation (أوامر #if) مناسبًا للمبتدئين، وإذا ما زلت مبتدئً في لغة سي، فاقرأ هذه المقالة مرةً واحدة لمعرفة إمكانيات المعالج المُسبق واستخدم التمارين للتأكد من فهمك، وإلا فنحن ننصح بخبرة لا تقل عن ستة أشهر في لغة سي حتى تستطيع فهم إمكانيات المعالج المسبق كاملةً، لذا لن نركز على منحك مقدمة سهلة هنا بل سنركز على التفاصيل الدقيقة فورًا. كيف يعمل المعالج المسبق؟ بالرغم من أن المعالج المسبق الموضح في الشكل التالي سينتهي به المطاف غالبًا بكونه جزءًا هامًا من مصرف لغة سي المعيارية، إلا أنه يمكننا التفكير به على أنه برنامجٌ منفصلٌ يحول شيفرة سي المصدرية التي تحتوي على موجهات المعالج المسبق إلى شيفرة مصدرية لا تحتوي على هذه الموجهات. شكل 1: المعالج المسبق في لغة سي من المهم هنا أن نتذكر أن المعالج المسبق لا يعمل متبعًا القوانين الخاصة بشيفرة لغة سي ذاتها، وإنما يعمل على أساس كل سطرٍ بسطره، وهذا يعني أن نهاية السطر حدثٌ مميز وليس كما تنظر لغة سي إلى نهاية السطر بكونه مشابهًا لمحرف مسافة أو مسافة جدولة. لا يعي المعالج المسبق قوانين لغة سي الخاصة بالنطاق Scope، إذ تأخذ موجهات المعالج المسبق (مثل #define) تأثيرها فور رؤيتها ويبقى تأثيرها موجودًا حتى الوصول إلى نهاية الملف الذي يحتوي هذه الموجهات، ولا ينطبق هنا هيكل البرنامج المتعلق بالكتل البرمجية. من المحبّذ إذًا استخدام موجهات المعالج المسبق بأقل ما أمكن، فكلما قلّ عدد الأجزاء التي لا تتبع قوانين النطاق "الاعتيادية" كلّما قلت إمكانية ارتكاب الأخطاء، وهذا ما نقصده عندما نقول أن تكامل المعالج المسبق ولغة سي C محدودٌ فيما بينهما. يصف المعيار بعض القوانين المعقدة بخصوص كتابة موجهات المعالج المسبق، وبالأخص بالنسبة للمفاتيح Tokens، ويجب عليك معرفة القوانين كلها إذا أردت فهم موجهات المعالج المسبق، فالنص الذي يُعالج لا يعدّ سلسلةً من المحارف بل هو مُجزّأٌ إلى مفاتيح ومن ثم معلومات معالجة مُجزأة. من الأفضل اللجوء إلى المعيار إذا أردت تعريفًا كاملًا بالعملية، إلا أننا سنتطرق إلى شرح بسيط؛ إذ سنشرح كل جزء موجود في القائمة التالية لاحقًا. اسم ملف الترويسة > يمكن استخدام أي محرف هنا (باستثناء) <. مفتاح المعالج المسبق اسم ملف الترويسة كما ذُكر سابقًا لكن فقط في حالة ذكره ضمن #include أو معرّف identifier مثل معرف لغة C أو كلمة مفتاحية أو ثابت وهو أي عدد صحيح أو طبيعي ثابت أو سلسلة نصية وهو سلسلة نصية سي اعتيادية أو عامل وهو من أحد عوامل لغة سي أو واحد من علامات الترقيم [ ] ( ) { } * , : = ; ... # أو أي محرف غير فارغ (محرف فارغ مثل محرف المسافة) غير مذكور في اللائحة أعلاه نقصد أي محرف (باستثناء) أي باستثناء المحرفين < أو محرف السطر الجديد. الموجهات Directives تبدأ موجّهات المعالج المسبق بالمحرف "#" دائمًا، وتُتبع بمحرف مسافة فارغة اختياريًا إلا أن هذا الاستخدام غير شائع، ويوضح الجدول التالي الموجهات المعرّفة في المعيار. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الموجّه المعنى # include تضمين ملف مصدري # define تعريف ماكرو # undef التراجع عن تعريف ماكرو # if تصريف شرطي # ifdef تصريف شرطي # ifndef تصريف شرطي # elif تصريف شرطي # else تصريف شرطي # endif تصريف شرطي # line التحكم بتقارير الأخطاء # error عرض رسالة خطأ قسرية # pragma تُستخدم للتحكم المعتمد على التنفيذ # موجّه فارغ؛ دون تأثير جدول 1 موجّهات المعالج المُسبق سنشرح كل من معنى واستخدام الموجّهات بالتفصيل في الفقرات التالية. لاحظ أن المحرف # والكلمة المفتاحية التي تليه عنصرين مستقلين منفصلين، ويمكن إضافة مسافةٍ بيضاء بينهما. الموجه الفارغ هذا الموجّه بسيط، إذ ليس لإشارة # بمفردها على السطر أي تأثير. موجه تعريف الماكرو define هناك طريقتان لتعريف الماكرو، أولهما تبدو مثل تابع والأخرى على النقيض، إليك مثالًا باستخدام الطريقتين: #define FMAC(a,b) a here, then b #define NONFMAC some text here يعرّف التصريحان السابقان ماكرو ونصًا بديلًا له، إذ سيستخدم ليُستبدل بالماكرو المذكور ضمن كامل البرنامج، ويمكن استخدامهما بعد التصريح عنهما على النحو التالي مع ملاحظة أثر استبدال الماكرو الموضح في التعليقات: NONFMAC /* النص هنا */ FMAC(first text, some more) /* النص الأول، ومزيدٌ من النص */ يُستبدل اسم الماكرو في الحالة التي لا يبدو فيها مثل دالة بالنص البديل ببساطة، وكذلك الأمر بالنسبة لماكرو من نوع دالة، وفي حال كان النص البديل يحتوي على معرّف يطابق اسم معامل من معاملات الماكرو، يُستخدم النص الموجود وسيطًا بدلًا من المعرِّف في النص البديل. يُحدَّد نطاق الأسماء المذكورة في وسطاء الماكرو بالكتلة التي تحتوي الموجه #define. تُهمل أي مسافات فارغة بعد أو قبل النص البديل ضمن تعريف الماكرو، وذلك لكلا الطريقتين على حد سواء. يتبادر إلى البعض السؤال الفضولي التالي: كيف يمكنني تعريف ماكرو بسيط بحيث يكون النص البديل الخاص به ينتهي بالقوس المفتوح ")"؟ الإجابة بسيطة، إذا احتوى تعريف الماكرو على مسافة أمام القوس ")"، فلن يحتسب الماكرو من نوع ماكرو دالة، بل نص بديل لماكرو بسيط فحسب، إلا أنه لا يوجد قيد مماثل عندما تستخدم الماكرو الشبيه بالدالة. يسمح المعيار للماكرو بغض النظر عن نوع أن يُعاد تعريفه في أي لحظة باستخدام موجّه # define آخر، وذلك بفرض عدم تغيير نوع الماكرو وأن تكون المفاتيح التي تشكل التعريف الأساسي وإعادة التعريف متماثلة بالعدد والترتيب والكتابة بما فيها استخدام المسافة الفارغة، وتُعد المسافات الفارغة في هذا السياق متساوية، وطبقًا لذلك فالتالي صحيح: # define XXX abc/*تعليق*/def hij # define XXX abc def hij وذلك لأن التعليق شكلٌ من أشكال المسافات الفارغة، وسلسلة المفاتيح للحالتين السابقتين هي: # w-s define w-s XXX w-s abc w-s def w-s hij w-s إذ تعني w-s مفتاح مسافة بيضاء. استبدال الماكرو أين سيتسبب اسم الماكرو باستبدال النص بالنص البديل؟ يحدث الاستبدال عمليًا في أي مكان يحدث التعرف فيه على المعرّف identifier مثل مفتاح منفصل ضمن البرنامج، عدا المعرف المتبوع بالمحرف "#" الخاص بموجّه المعالج المُسبق. يمكنك كتابة التالي: #define define XXX #define YYY ZZZ ومن المتوقع أن يتسبب استبدال سطر #define الثاني بالسطر #xxx بخطأ. يُستبدل المعرف المرتبط بماكرو بسيط عندما يُرى بمفتاح الماكرو البديل، ومن ثم يُعاد مسحه rescanned (سنتكلم عن ذلك لاحقًا) للعثور على أي استبدالات أخرى. يمكن استخدام ماكرو الدالة مثل أي دالة أخرى اعتيادية، وذلك بوضع مساحات فارغة حول اسم الماكرو ولائحة الوسطاء وغيره، كما قد يحتوي على محرف سطر جديد: #define FMAC(a, b) printf("%s %s\n", a, b) FMAC ("hello", "sailor" ); /* ينتج ما سبق بالتالي */ printf("%s %s\n", "hello", "sailor") يمكن أن تأخذ وسطاء الماكرو من نوع دالة أي تسلسل عشوائي للمفتاح، وتُستخدم الفاصلة "," لفصل الوسطاء عن بعضهم بعضًا، ولكن يمكن إخفاؤها بوضعها داخل أقواس "( )". توازن الأزواج المتطابقة من الأقواس داخل الوسيط بعضها بعضًا، وبالتالي ينهي القوس "(" استدعاء الماكرو إذا كان القوس ")" هو الذي بدأ باستدعائه. #define CALL(a, b) a b CALL(printf, ("%d %d %s\n",1, 24, "urgh")); /* results in */ printf ("%d %d %s\n",1, 24, "urgh"); لاحظ كيف حافظنا على الأقواس حول الوسيط الثاني للدالة CALL عند الاستبدال، ولم تُزال من النص. إذا أردت استخدام ماكرو مثل printt، لن يساعدك المعيار بهذا الخصوص عندما تختار عدد متغير من الوسطاء، فذلك غير مدعوم. نحصل على سلوك غير معرف إذا لم يحتوي أحد الوسطاء على مفتاح معالج مسبق، والأمر مماثل إذا احتوت سلسلة مفاتيح المعالج المسبق التي تشكل الوسيط على موجّه معالج مسبق مغاير: #define CALL(a, b) a b /* كل حالة تنتج عن سلوك غير محدد */ CALL(,hello) CALL(xyz, #define abc def) إلا أننا نعتقد برأينا أن الاستخدام الثاني الخاطئ للدالة CALL يجب أن ينتج بسلوك معرف، إذ أن أي أحد قادر على كتابة ذلك سيستفيد من انتباه المصرّف. تتبع معالجة ماكرو الدالة الخطوات التالية: جميع وسطائها معرفة. إن كان أي من المفاتيح ضمن الوسيط مرشح لاستبدال بواسطة ماكرو، فسيُستبدل حتى الوصول للنقطة التي لا يمكن فيها إجراء المزيد من الاستبدالات، باستثناء الحالات المذكورة في البند الثالث التالي. لا يوجد هناك أي خطر بخصوص امتلاك الماكرو لعدد مختلف من الوسطاء بعد إضافة فاصلة إلى قائمة الوسطاء الأساسية، إذ يُحدد الوسطاء في الخطوة السابقة فقط. تُستبدل المعرفات التي تسمّي وسيط الماكرو في نص الاستبدال بسلسلة مفتاح مثل وسيطٍ فعلي، ويُهمل الاستبدال إذا كان المعرف مسبوقًا بإشارة "#" أو اثنتين "##" أو متبوعًا بالإشارتين "##". التنصيص هناك طريقةٌ خاصة لمعالجة الأماكن التي يسبق فيها وسيط الماكرو الإشارة "#" في نص الماكرو البديل، إذ تًهمل أي مسافة فارغة تسبق أو تلي قائمة الوسطاء الفعلية للمفتاح، ومن ثم تُحوّل قائمة المفتاح والإشارة # إلى سلسلة نصية واحدة، وتُعامل المسافات بين المفاتيح كأنها محارف مسافة في سلسلة نصية؛ ولمنع حدوث أي نتائج مفاجئة، يُسبق أي محرف " أو \ في السلسلة النصية الجديدة بالمحرف \. إليك المثال التالي الذي يوضح الخاصية المذكورة: #define MESSAGE(x) printf("Message: %s\n", #x) MESSAGE (Text with "quotes"); /* * النتيجة هي * printf("Message: %s\n", "Text with \"quotes\""); */ لصق المفتاح Token pasting قد نجد العامل ## في أي مكان ضمن النص البديل للماكرو باستثناء نهايته أو بدايته، وتُستخدم سلسلة مفتاح وسيط الماكرو لاستبدال النص البديل إذا ورد في اسم الوسيط لماكرو دالة مسبوقًا أو متبوعًا بأحد هذه العوامل، وتُدمج المفاتيح المحيطة بالعامل ## سويًا سواءٌ كانت ضمن ماكرو دالة أو ماكرو بسيط، ونحصل على سلوك غير معرف إذا شكّل ذلك مفتاح غير صالح، ويُجرى إعادة مسح بعدها. إليك عملية تحصل على عدة مراحل يُستخدم فيها إعادة المسح لتوضيح لصق المفتاح: #define REPLACE some replacement text #define JOIN(a, b) a ## b JOIN(REP, LACE) becomes, after token pasting, REPLACE becomes, after rescanning some replacement text إعادة المسح يُمسح النص البديل مضافًا إلى مفاتيح الملف المصدري مجددًا حالما تحصل العملية الموضحة في الفقرة السابقة، وذلك للبحث عن أسماء ماكرو أخرى لاستبدالها، مع استثناء أن اسم الماكرو داخل النص البديل لا يُستبدل. من الممكن أن نضيف ماكرو متداخلة Nested macros وبالتالي يمكن لعدد من الماكرو أن تُعالج لاستبدالها في أي نقطة دفعةً واحدة، ولا يوجد في هذه الحالة أي اسم مرشح لاستبداله ضمن المستوى الداخلي لهذا التداخل، وهذا يسمح لنا بإعادة تعريف الدوال الموجودة سابقًا مثل ماكرو: #define exit(x) exit((x)+1) تصبح أسماء الماكرو التي لم تُستبدل مفاتيحٌ محمية من الاستبدال مستقبلًا، حتى لو وردت أي عمليات تالية لتبديلها، وهذا يدرأ الخطر عن حدوث التعادوية recursion اللانهائية في المعالج المسبق، وتنطبق هذه الحماية فقط في حالة نتج اسم الماكرو عن النص البديل، وليس النص المصدري ضمن البرنامج، إليك ما الذي نقصده: #define m(x) m((x)+1) /* هذا */ m(abc); /* ينتج عن هذا بعد الاستبدال */ m((abc)+1); /* * على الرغم من أن النتيجة السابقة تبدو مثل ماكرو * إلا أن القواعد تنص على لزوم عدم استبداله */ m(m(abc)); /* * تبدأ m( الخارجية باستدعاء الماكرو, * لكن تُستبدل الداخلية أولًا * لتصبح بالشكل m((abc)+1) * وتُستخدم مثل وسيط، مما يعطينا */ m(m((abc+1)); /* * ويصبح بعد الاستبدال على النحو التالي */ m((m((abc+1))+1); إذا لم يؤلمك دماغك بقراءة ما سبق، فاذهب واقرأ ما الذي يقوله المعيار عن هذا ونضمن لك أنه سيؤلمك. ملاحظات هناك مشكلة غير واضحة تحدث عند استخدام وسطاء ماكرو الدالة. /* تحذير: هناك مشكلة في هذا البرنامج */ #define SQR(x) ( x * x ) /* * عند ورود المعاملات الصورية في النص البديل، تُستبدل بالمعاملات الفعلية للماكرو */ printf("sqr of %d is %d\n", 2, SQR(2)); المعامل الصوري formal parameter للماكرو SQR هو x، والمعامل الفعلي actual argument هو 2، وبالتالي سينتج النص البديل عن: printf("sqr of %d is %d\n", 2, ( 2 * 2 )); لاحظ استخدام الأقواس، فالمثال التالي قد يتسبب بمشكلة: /* مثال سيء */ #define DOUBLE(y) y+y printf("twice %d is %d\n", 2, DOUBLE(2)); printf("six times %d is %d\n", 2, 3*DOUBLE(2)); تكمن المشكلة في أن التعبير الأخير في استدعاء الدالة printf الثاني يُستبدل بالتالي: 3*2+2 وهذا ينتج عن 8 وليس 12. تنص القاعدة على أنه يجب عليك الحرص بخصوص الأقواس فهي ضرورية في حالة استخدام الماكرو لبناء تعابير. إليك مثالًا آخر: SQR(3+4) /* تصبح بالشكل التالي بعد الاستبدال */ ( 3+4 * 3+4 ) /* للأسف، ما زالت خاطئة! */ لذا، يجب عليك النظر بحرص إلى الوسطاء الصورية عندما ترِد ضمن نصل بديل. إليك الأمثلة الصحيحة عن الدالتين SQR و DOUBLE: #define SQR(x) ((x)*(x)) #define DOUBLE(x) ((x)+(x)) في جعبة الماكرو حيلةٌ صغيرة بعد لمفاجئتك، كما سيوضح لك المثال التالي: #include <stdio.h> #include <stdlib.h> #define DOUBLE(x) ((x)+(x)) main(){ int a[20], *ip; ip = a; a[0] = 1; a[1] = 2; printf("%d\n", DOUBLE(*ip++)); exit(EXIT_SUCCESS); } مثال 1 لمَ يتسبب المثال السابق بمشاكل؟ لأن نص ماكرو البديل يشير إلى *ip++ مرتين، مما يتسبب بزيادة ip مرتين، لا يجب للماكرو أن يُستخدم مع التعابير التي لها آثار جانبية، إلا إذا تحققت بحرص من أمانها. بغض النظر عن هذه التحذيرات التي تخص الماكرو، إلا أنها تقدم خصائص مفيدة، وستُستخدم هذه الخصائص كثيرًا من الآن فصاعدًا. موجه التراجع عن تعريف ماكرو undef يُمكن أن يُهمل (يُنتسى) أي معرّف يعود لموجه #define بكتابة: #undef NAME إذ لا يولد #undef خطأً إن لم يكن الاسم NAME معرفًا مسبقًا. سنستفيد من هذا الموجه كثيرًا عمّا قريب، وسنتكلم لاحقًا عن بعض دوال المكتبات التي هي في الحقيقة ماكرو وليس دالة، وستصبح قادرًا على الوصول إلى الدالة الفعلية عن طريق التراجع عن تعريفها. موجه تضمين ملف مصدري include يمكن كتابة هذا الموجه بشكلين: #include <filename> #include "filename" ينجم عن استخدام أحد الطريقتين قراءة ملف جديد عند نقطة ذكر الموجّه، وكأننا استبدالنا سطر الموجه بمحتويات الملف المذكور، وإذا احتوى هذا الملف على بعض التعليمات الخاطئة ستظهر لك الأخطاء مع إشارتها إلى الملف التي نجمت عنه مصحوبةً برقم السطر، وهذه مهمة مطوّر المصرف، وينص المعيار على أنه يجب للمصرف دعم ثمانية طبقات من موجّهات # include المتداخلة على الأقل. يمكن الاختلاف بين استخدام <> و " " حول اسم الملف بالمكان الذي سيُبحث فيه عن الملف؛ إذ يتسبب استخدام الأقواس في البحث في عددٍ من الأماكن المعرّفة بحسب التطبيق؛ بينما يتسبب استخدام علامتي التنصيص بحثًا في المكان المرتبط بمكان ملف الشيفرة المصدرية، وستُعلمك ملاحظات تطبيقك بما هو المقصود بكلمة "المكان" والتفاصيل المرتبطة بها، إذا لم تعود عملية البحث عن الملف باستخدام علامتي التنصيص بأي نتيجة، تُعاود عملية البحث من جديد وكأنك استخدمت القوسين. تُستخدم الأقواس عمومًا عندما تريد تحديد ملفات ترويسة لمكتبة قياسية Standard library، بينما تُستخدم علامتي التنصيص لملفات الترويسة الخاصة بك، التي تكون مخصصة غالبًا لبرنامج واحد. لا يحدد المعيار كيفية تسمية ملف بصورةٍ صالحة، إلا أنه يحدد وجوب وجود طريقة فريدة معرفة بحسب التطبيق لترجمة اسم الملفات من الشكل xxx.x (يمثّل كل x حرفًا)، إلى أسماء ملفات الشيفرة المصدرية، ويمكن تجاهل الفرق بين الأحرف الكبيرة والصغيرة من قِبل التطبيق، ويمكن أن يختار التطبيق أيضًا ستة محارف ذات أهمية فقط بعد محرف النقطة .. يمكنك أيضًا الكتابة بالشكل التالي: # define NAME <stdio.h> # include NAME للحصول على نتيجة مماثلة لهذا: # include <stdio.h> إلا أن هذه الطريقة تعقيدٌ لا داعي له، وهي معرضةٌ لبعض الأخطاء طبقًا للقواعد المعرفة بحسب التطبيق إذ تحدد هذه القواعد كيف سيُعالج النص بين القوسين < >. من الأبسط أن يكون النص البديل للماكرو NAME سلسلةً نصية، على سبيل المثال: #define NAME "stdio.h" #include NAME لا يوجد في حالتنا السابقة أي فرصة للأخطاء الناتجة عن التصرف المعرف بحسب التطبيق، إلا أن مسارات البحث مختلفة كما وضحنا سابقًا. سلسلة المفتاح في حالتنا الأولى التي تستبدِل NAME هي على النحو التالي (بحسب القوانين التي ناقشناها سابقًا): < stdio . h > أما في الحالة الثانية فهي من الشكل: "stdio.h" الحالة الثانية سهلة الفهم، لأنه يوجد لدينا فقط سلسلة نصية وهي مفتاح تقليدي لموجّه # include، بينما الحالة الثانية معرفةٌ بحسب التطبيق، وبالتالي يعتمد تشكيل سلسلة المفاتيح لاسم ترويسة صالح على التطبيق. أخيرًا، المحرف الأخير من الملف المُضمّن داخل موجه include يجب أن يكون سطرًا جديدًا، وإلا سنحصل على خطأ. الأسماء مسبقة التعريف الأسماء التالية هي أسماء مسبقة التعريف predefined names داخل المعالج المُسبق: الاسم __LINE__: ثابت عدد صحيح بالنظام العشري، ويشير إلى السطر الحالي ضمن ملف الشيفرة المصدرية. الاسم __FILE__: اسم ملف الشيفرة المصدرية الحالي، وهو سلسلة نصية. الاسم __DATE__: التاريخ الحالي، وهو سلسلة نصية من الشكل: Apr 21 1990 إذ يظهر اسم الشهر كما هو معرّف في الدالة المكتبية asctime وأول خانة من التاريخ مسافة فارغة إذان كان التاريخ أقل من 10. الاسم __TIME__: وقت ترجمة الملف، وهو سلسلة نصية موافقة للشكل السابق باستخدام الدالة asctime، أي من الشكل "hh:mm:ss". الاسم __STDC__: عدد صحيح ثابت بقيمة 1، ويُستخدم لاختبار اتباع المصرّف لضوابط المعيار، إذ يمتلك هذا العدد قيمًا مختلفة لإصدارات مختلفة من المعيار. الطريقة الشائعة في استخدام هذه الأسماء المعرفة مسبقًا هي على النحو التالي: #define TEST(x) if(!(x))\ printf("test failed, line %d file %s\n",\ __LINE__, __FILE__) /**/ TEST(a != 23); /**/ مثال 2 إذا كانت نتيجة TEST في المثال السابق خطأ، فستُطبع الرسالة متضمنةً اسم الملف ورقم السطر في الرسالة. إلا أن استخدام تعليمة if في هذه الحالات قد يتسبب ببعض من اللبس، كما يوضح المثال التالي: if(expression) TEST(expr2); else statement_n; إذ سترتبط تعليمة else بتعليمة if المخفية التي ستُستبدل باستخدام الماكرو TEST، وعلى الرغم من أن حدوث هذا الشيء عند الممارسة مستبعد إلا أنه سيكون خطأً لعينًا صعب الحل والتشخيص إذا حدث لك، ولتفادي ذلك، يُحبّذ استخدام الأقواس وجعل محتوى كل تعليمة تحكم بتدفق البرنامج مثل تعليمة مركّبة بغض النظر عن طولها. لا يمكننا استعمال أي من الأسماء __LINE__ أو __FILE__ أو __DATE__ أو __TIME__ أو __STDC__ أو أي من الأسماء المعرفة الأخرى ضمن موجه #define أو #undef. ينص المعيار على أن أي اسم محجوز يجب أن يبدأ بشرطةٍ سفلية underscore وحرفٍ كبير، أو شرطتان، وبالتالي يمكنك استخدام أي اسم لاستخدامك الخاص، لكن انتبه من استخدام الأسماء المحجوزة في ملفات الترويسة التي ضمّنتها في برنامجك. موجه التحكم بتقارير الأخطاء line يُستخدم هذا الموجه في ضبط القيمة التي يحملها كل من __LINE__ و __FILE__، لكن ما المُستفاد من ذلك؟ توّلد العديد من الأدوات في الوقت الحالي شيفرةً بلغة سي C خرجًا لها، ويسمح هذا الموجه لهذه الأدوات بالتحكم برقم السطر الحالي إلا أن استخدامه محدودٌ لمبرمج لغة سي الاعتيادية. يأتي الموجه بالشكل التالي: # line number optional-string-literal newline يضبط الرقم number قيمة __LINE__ وتضبط السلسلة النصية الاختيارية إن وُجدت قيمة __FILE__. في الحقيقة، ستُوسّع سلسلة المفاتيح التي تتبع الموجه #line باستخدام ماكرو، ومن المفترض أن تشكّل موجهًا صالحًا بعد التوسعة. التصريف الشرطي يتحكم بالتصريف الشرطي عدد من الموجهات، إذ تسمح هذه الموجهات بتصريف أجزاء معينة من البرنامج اختياريًا أو تجاهلها حسب الشروط، وهذه الشروط هي: #if و #ifdef و #ifndef و #elif و #else و #endif إضافةً إلى عامل المُعالج المسبق الأحادي. يمكننا استخدام الموجهات على النحو التالي: #ifdef NAME /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif #ifndef NAME /* صرّف هذا القسم إذا كان الاسم غير معرّفًا */ #else /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif يُستخدم كل من #ifdef و #endif لاختبار تعريف اسم الماكرو، ويمكن استخدام #else طبعًا مع #ifdef (و #if أو #elif أيضًا)، لا يوجد التباس حول استخدام #else، لأن استخدام #endif يحدّد نطاق الموجّه مما يبعد أي مجال للشبهات. ينص المعيار على وجوب دعم ثمان طبقات من الموجهات الشرطية المتداخلة، إلا أنه من المستبعد وجود أي حدّ عمليًّا. تُستخدم هذه الموجهات لتحديد فقرات صغيرة من برامج سي التي تعتمد على الآلة التي تعمل عليها (عندما لا يكون بالإمكان جعل كامل البرنامج ذا أداء مستقل غير مرتبط بطبيعة الآلة التي يعمل عليها)، أو لتحديد خوارزميات مختلفة تعتمد على بعض المقايضات لتنفيذها. تأخذ بنية #if و #elif تعبيرًا ثابتًا وحيدًا ذا قيمةٍ صحيحة، وقيم المعالج المسبق هذه مماثلةٌ للقيم الاعتيادية باستثناء أنها يجب أن تخلو من عوامل تحويل الأنواع casts. تخضع سلسلة المفتاح التي تشكّل التعبير الثابت لعملية استبدال بالماكرو، عدا الأسماء المسبوقة بموجه التعريف فلا تُستبدل. بالاعتماد على ما سبق ذكره، فالتعبير defined NAME أو defined ( NAME ) يُقيّمان إلى القيمة 1 إذا كان NAME معرّفًا، وإلى القيمة 0 إن لم يكن معرّفًا، وتُستبدل جميع المعرفات ضمن التعبير -بما فيها كلمات لغة سي المفتاحية- بالقيمة 0، ومن ثم يُقيّم التعبير. يُقصد بالاستبدال (بما فيه استبدال الكلمات المفتاحية) أن sizeof لا يمكن استخدامه في هذه التعابير للحصول على القيمة التي تحصل عليها في الحالة الاعتيادية. تُستخدم القيمة الصفر -كما هو الحال في تعليمات سي الشرطية- للدلالة على القيمة "خطأ false"، وتدل أي قيمة أخرى على القيمة "صواب true". يجب استخدام المعالج المسبق العمليات الحسابية وفق النطاقات المحددة في ملف الترويسة <limits.h>، وأن تُعامل التعابير ذات قيمة العدد الصحيح مثل عدد صحيح طويل والعدد الصحيح عديم الإشارة مثل عدد صحيح طويل عديم الإشارة، بينما لا يتوجب على المحارف أن تكون مساوية إلى القيمة ذاتها عند وقت التنفيذ، لذا من الأفضل في البرامج القابلة للنقل أن نتجنب استخدامها في تعابير المعالج المُسبق. تعني القوانين السابقة عمومًا أنه بإمكاننا أن نحصل على نتائج حسابية من المعالج المسبق التي قد تكون مختلفة عن النتائج التي نحصل عليها عند وقت التنفيذ، وذلك بفرض إجراء الترجمة والتنفيذ على آلات مختلفة. إليك مثالًا: #include <limits.h> #if ULONG_MAX+1 != 0 printf("Preprocessor: ULONG_MAX+1 != 0\n"); #endif if(ULONG_MAX+1 != 0) printf("Runtime: ULONG_MAX+1 != 0\n"); مثال 3 من الممكن أن يُجري المعالج المسبق بعض العمليات الحسابية بنطاق أكبر من النطاق المُستخدم في البيئة المُستهدفة، ويمكن في هذه الحالة ألّا يطفح تعبير المعالج المسبق ULONG MAX+1 ليعطي النتيجة 0، بينما يجب أن يحدث لك في بيئة التنفيذ. يوضح المثال التالي استخدام الثوابت المذكور آنفًا، وتعليمة "وإلّا else" الشرطية #elif. #define NAME 100 #if ((NAME > 50) && (defined __STDC__)) /* افعل شيئًا */ #elif NAME > 25 /* افعل شيئًا آخر */ #elif NAME > 10 /* افعل شيئًا آخر */ #else /* الاحتمال الأخير */ #endif يتوجب التنويه هنا على أن موجهات التصريف الشرطية لا تتبع لقوانين النطاق الخاصة بلغة سي، ولهذا فيجب استخدامها بحرص، إلا إذا أردت أن يصبح برنامجك صعب القراءة، إذ من الصعب أن تقرأ برنامج سي C مع وجود هذه الأشياء كل بضعة أسطر، وسيتملكك الغضب تجاه كاتب البرنامج إذا صادفت شيفرة مشابهة لهذه دون أي موجه #if واضح بالقرب منها: #else } #endif لذلك يجب أن تعامل هذه الموجهات معاملة الصلصة الحارّة، استخدامها ضروري في بعض الأحيان، إلا أن الاستخدام الزائد لها سيعقّد الأمور. موجه التحكم المعتمد على التنفيذ pragma كان هذا الموجه بمثابة محاولة للجنة المعيار بإضافة طريقة للولوج للباب الخلفي، إذ يسمح هذا الموجه بتنفيذ بعض الأشياء المعرفة بحسب التطبيق. إذا لم يعرف التطبيق ما الذي سيفعله بهذا الموجه (أي لم يتعرف على وظيفته) فيستجاهله ببساطة، إليك مثالًا عن استخدامه: #pragma byte_align يُستخدم الموجه السابق لإعلام التطبيق بضرورة محاذاة جميع أعضاء الهياكل بالنسبة لعنوان البايت الخاص بهم، إذ يمكن لبعض معماريات المعالجات أن تتعامل مع أعضاء الهياكل بطول الكلمة بمحاذاة عنوان البايت، ولكن مع خسارة السرعة في الوصول إليها. يمكن أن يُفسّر هذا الأمر بحسب تفسير التطبيق له طبعًا، وإن لم يكن للتطبيق أي تفسير خاص به، فلن يأخذ الموجه أي تأثير، ولن يُعد خطأً، ومن المثير للاهتمام رؤية بعض الاستخدامات الخاصة لهذا النوع من الموجهات. موجه عرض رسالة خطأ قسرية error يُتبع هذا الموجه بمفتاح أو أكثر في نهاية السطر الخاص به، وتُشكّل رسالة تشخيصية من قبل المصرف تحتوي على هذه المفاتيح، ولا توجد مزيدٌ من التفاصيل عن ذلك في المعيار. يُمكن استخدام هذا الموجه لإيقاف عملية التصريف على آلة ذات عتاد صلب غير مناسب لتنفيذ البرنامج: #include <limits.h> #if CHAR_MIN > -128 #error character range smaller than required #endif سيتسبب ذلك ببعض الأخطاء المتوقعة عند مرحلة التصريف إذا نُفّذ الموجه وعُرضت الرسالة. الخاتمة على الرغم من الخصائص القوية والمرنة التي يوفرها المعالج المسبق، إلا أنها شديدة التعقيد، وهناك عددٌ قليل من الجوانب المتعلقة به ضرورية الفهم، مثل القدرة على تعريف الماكرو ودوال الماكرو، والمستخدمة بكثرة في أي برنامج سي تقريبًا عدا البرامج البسيطة، كما أن تضمين ملفات الترويسة مهمّ أيضًا طبعًا. للتصريف الشرطي استخدامان مهمان، أولهما هو القدرة على تصريف البرنامج بوجود أو بعدم وجود تعليمات الاكتشاف عن الأخطاء Debugging ضمن البرنامج، وثانيهما هو القدرة على تحديد تعليمات معينة يعتمد تنفيذها على طبيعة التطبيق أو الآلة التي يعمل عليها البرنامج. باستثناء ما ذكرنا سابقًا، من الممكن نسيان المزايا الأخرى التي ذُكرت في المقال، إذ لن يتسبب التخلي عنها بفقدان كثيرٍ من الخصائص، ولعلّ الحل الأمثل هو تواجد فرد واحد متخصّص في المعالج المسبق ضمن الفريق البرمجي لتطوير الماكرو التي تفيد مشروعًا ما بعينه باستخدام بعض المزايا الغريبة، مثل التنصيص ولصق المفاتيح. سيستفيد معظم مستخدمي لغة سي C أكثر إذا وجّهوا جهدهم بدلًا من ذلك نحو تعلم بعض الأجزاء الأخرى من لغة سي، أو تقنيات التحكم بجودة البرمجيات إذا أتقنوا اللغة. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C المقال السابق: تهيئة المتغيرات وأنواع البيانات في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C
يتناول المقال مرحلة المعالجة المسبقة للشيفرة المصدرية بما فيها مراحل استبدال الماكرو ومختلف موجهات المعالج المسبق الأخرى. أثر المعيار ستشعر أن المعالج المُسبق Preprocessor لا ينتمي إلى لغة سي عمومًا، إذ لا يسمح لك وجوده بالتعامل بصورةٍ متكاملة مع اللغة كما أنك لا تستطيع الاستغناء عنه في ذات الوقت، وفي الحقيقة، كان استخدام المعالج المُسبق في أيام سي الأولى اختياريًا واعتاد الناس على كتابة برامج لغة سي C بدونه، ويمكننا أن ننظر إلى كونه جزءًا من لغة سي حاليًا صدفةً إلى حدٍ ما، إذ كان يعالج بعضًا من أوجه القصور في اللغة، مثل تعريف الثوابت وتضمين التعريفات القياسية، وأصبح نتيجةً لذلك جزءًا ضمن حزمة لغة سي ككُل. لم يكن هناك في تلك الفترة معيارٌ رسميٌ متفقٌ عليه يوحّد ما يفعله المعالج المسبق، وكانت إصدارات مختلفة منه مُطبّقة بصورةٍ مختلف على عدة أنظمة، وأصبحت عملية نقل البرنامج وتصديره إلى أنظمة أخرى مشكلةً كبيرة إذا استخدم ما يزيد عن الخصائص الأساسية للمعالج. كانت وظيفة المعيار الأساسية هنا هي تعريف سلوك المعالج المُسبق بما يتوافق مع الممارسات الشائعة، وقد سبق حصول ذلك مع لغة سي القديمة، إلا أن المعيار اتخذ إجراءات إضافية وسط الخلاف وحدد مجموعةً من الخصائص الإضافية التي قُدمت مع إصدارات المعالج المُسبق الأكثر شعبية، وعلى الرغم من فائدة هذه الخصائص إلا أن الخلاف كان بخصوص الاتفاق على طريقة تطبيقها. لم يكترث المعيار لمشكلة القابلية مع البرامج القديمة بالنظر إلى أن هذه البرامج تستخدم طرقًا غير قابلة للنقل في المقام الأول، وسيحسِّن تواجد هذه الخصائص المتقدمة ضمن المعيار سهولة نقل برامج لغة سي مستقبلًا بصورةٍ ملحوظة. يعدّ استخدام المعالج المسبق سهلًا إذا استُخدم لمهمته الأساسية البسيطة في جعل البرامج سهلة القراءة والصيانة، ولكن يُفضّل ترك خصائصه المتقدمة لاستخدام الخبراء. بحكم تجربتنا، يُعد استخدام #define ومجموعة تعليمات التصريف الشرطي conditional compilation (أوامر #if) مناسبًا للمبتدئين، وإذا ما زلت مبتدئً في لغة سي، فاقرأ هذه المقالة مرةً واحدة لمعرفة إمكانيات المعالج المُسبق واستخدم التمارين للتأكد من فهمك، وإلا فنحن ننصح بخبرة لا تقل عن ستة أشهر في لغة سي حتى تستطيع فهم إمكانيات المعالج المسبق كاملةً، لذا لن نركز على منحك مقدمة سهلة هنا بل سنركز على التفاصيل الدقيقة فورًا. كيف يعمل المعالج المسبق؟ بالرغم من أن المعالج المسبق الموضح في الشكل التالي سينتهي به المطاف غالبًا بكونه جزءًا هامًا من مصرف لغة سي المعيارية، إلا أنه يمكننا التفكير به على أنه برنامجٌ منفصلٌ يحول شيفرة سي المصدرية التي تحتوي على موجهات المعالج المسبق إلى شيفرة مصدرية لا تحتوي على هذه الموجهات. شكل 1: المعالج المسبق في لغة سي من المهم هنا أن نتذكر أن المعالج المسبق لا يعمل متبعًا القوانين الخاصة بشيفرة لغة سي ذاتها، وإنما يعمل على أساس كل سطرٍ بسطره، وهذا يعني أن نهاية السطر حدثٌ مميز وليس كما تنظر لغة سي إلى نهاية السطر بكونه مشابهًا لمحرف مسافة أو مسافة جدولة. لا يعي المعالج المسبق قوانين لغة سي الخاصة بالنطاق Scope، إذ تأخذ موجهات المعالج المسبق (مثل #define) تأثيرها فور رؤيتها ويبقى تأثيرها موجودًا حتى الوصول إلى نهاية الملف الذي يحتوي هذه الموجهات، ولا ينطبق هنا هيكل البرنامج المتعلق بالكتل البرمجية. من المحبّذ إذًا استخدام موجهات المعالج المسبق بأقل ما أمكن، فكلما قلّ عدد الأجزاء التي لا تتبع قوانين النطاق "الاعتيادية" كلّما قلت إمكانية ارتكاب الأخطاء، وهذا ما نقصده عندما نقول أن تكامل المعالج المسبق ولغة سي C محدودٌ فيما بينهما. يصف المعيار بعض القوانين المعقدة بخصوص كتابة موجهات المعالج المسبق، وبالأخص بالنسبة للمفاتيح Tokens، ويجب عليك معرفة القوانين كلها إذا أردت فهم موجهات المعالج المسبق، فالنص الذي يُعالج لا يعدّ سلسلةً من المحارف بل هو مُجزّأٌ إلى مفاتيح ومن ثم معلومات معالجة مُجزأة. من الأفضل اللجوء إلى المعيار إذا أردت تعريفًا كاملًا بالعملية، إلا أننا سنتطرق إلى شرح بسيط؛ إذ سنشرح كل جزء موجود في القائمة التالية لاحقًا. اسم ملف الترويسة > يمكن استخدام أي محرف هنا (باستثناء) <. مفتاح المعالج المسبق اسم ملف الترويسة كما ذُكر سابقًا لكن فقط في حالة ذكره ضمن #include أو معرّف identifier مثل معرف لغة C أو كلمة مفتاحية أو ثابت وهو أي عدد صحيح أو طبيعي ثابت أو سلسلة نصية وهو سلسلة نصية سي اعتيادية أو عامل وهو من أحد عوامل لغة سي أو واحد من علامات الترقيم [ ] ( ) { } * , : = ; ... # أو أي محرف غير فارغ (محرف فارغ مثل محرف المسافة) غير مذكور في اللائحة أعلاه نقصد أي محرف (باستثناء) أي باستثناء المحرفين < أو محرف السطر الجديد. الموجهات Directives تبدأ موجّهات المعالج المسبق بالمحرف "#" دائمًا، وتُتبع بمحرف مسافة فارغة اختياريًا إلا أن هذا الاستخدام غير شائع، ويوضح الجدول التالي الموجهات المعرّفة في المعيار. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } الموجّه المعنى # include تضمين ملف مصدري # define تعريف ماكرو # undef التراجع عن تعريف ماكرو # if تصريف شرطي # ifdef تصريف شرطي # ifndef تصريف شرطي # elif تصريف شرطي # else تصريف شرطي # endif تصريف شرطي # line التحكم بتقارير الأخطاء # error عرض رسالة خطأ قسرية # pragma تُستخدم للتحكم المعتمد على التنفيذ # موجّه فارغ؛ دون تأثير جدول 1 موجّهات المعالج المُسبق سنشرح كل من معنى واستخدام الموجّهات بالتفصيل في الفقرات التالية. لاحظ أن المحرف # والكلمة المفتاحية التي تليه عنصرين مستقلين منفصلين، ويمكن إضافة مسافةٍ بيضاء بينهما. الموجه الفارغ هذا الموجّه بسيط، إذ ليس لإشارة # بمفردها على السطر أي تأثير. موجه تعريف الماكرو define هناك طريقتان لتعريف الماكرو، أولهما تبدو مثل تابع والأخرى على النقيض، إليك مثالًا باستخدام الطريقتين: #define FMAC(a,b) a here, then b #define NONFMAC some text here يعرّف التصريحان السابقان ماكرو ونصًا بديلًا له، إذ سيستخدم ليُستبدل بالماكرو المذكور ضمن كامل البرنامج، ويمكن استخدامهما بعد التصريح عنهما على النحو التالي مع ملاحظة أثر استبدال الماكرو الموضح في التعليقات: NONFMAC /* النص هنا */ FMAC(first text, some more) /* النص الأول، ومزيدٌ من النص */ يُستبدل اسم الماكرو في الحالة التي لا يبدو فيها مثل دالة بالنص البديل ببساطة، وكذلك الأمر بالنسبة لماكرو من نوع دالة، وفي حال كان النص البديل يحتوي على معرّف يطابق اسم معامل من معاملات الماكرو، يُستخدم النص الموجود وسيطًا بدلًا من المعرِّف في النص البديل. يُحدَّد نطاق الأسماء المذكورة في وسطاء الماكرو بالكتلة التي تحتوي الموجه #define. تُهمل أي مسافات فارغة بعد أو قبل النص البديل ضمن تعريف الماكرو، وذلك لكلا الطريقتين على حد سواء. يتبادر إلى البعض السؤال الفضولي التالي: كيف يمكنني تعريف ماكرو بسيط بحيث يكون النص البديل الخاص به ينتهي بالقوس المفتوح ")"؟ الإجابة بسيطة، إذا احتوى تعريف الماكرو على مسافة أمام القوس ")"، فلن يحتسب الماكرو من نوع ماكرو دالة، بل نص بديل لماكرو بسيط فحسب، إلا أنه لا يوجد قيد مماثل عندما تستخدم الماكرو الشبيه بالدالة. يسمح المعيار للماكرو بغض النظر عن نوع أن يُعاد تعريفه في أي لحظة باستخدام موجّه # define آخر، وذلك بفرض عدم تغيير نوع الماكرو وأن تكون المفاتيح التي تشكل التعريف الأساسي وإعادة التعريف متماثلة بالعدد والترتيب والكتابة بما فيها استخدام المسافة الفارغة، وتُعد المسافات الفارغة في هذا السياق متساوية، وطبقًا لذلك فالتالي صحيح: # define XXX abc/*تعليق*/def hij # define XXX abc def hij وذلك لأن التعليق شكلٌ من أشكال المسافات الفارغة، وسلسلة المفاتيح للحالتين السابقتين هي: # w-s define w-s XXX w-s abc w-s def w-s hij w-s إذ تعني w-s مفتاح مسافة بيضاء. استبدال الماكرو أين سيتسبب اسم الماكرو باستبدال النص بالنص البديل؟ يحدث الاستبدال عمليًا في أي مكان يحدث التعرف فيه على المعرّف identifier مثل مفتاح منفصل ضمن البرنامج، عدا المعرف المتبوع بالمحرف "#" الخاص بموجّه المعالج المُسبق. يمكنك كتابة التالي: #define define XXX #define YYY ZZZ ومن المتوقع أن يتسبب استبدال سطر #define الثاني بالسطر #xxx بخطأ. يُستبدل المعرف المرتبط بماكرو بسيط عندما يُرى بمفتاح الماكرو البديل، ومن ثم يُعاد مسحه rescanned (سنتكلم عن ذلك لاحقًا) للعثور على أي استبدالات أخرى. يمكن استخدام ماكرو الدالة مثل أي دالة أخرى اعتيادية، وذلك بوضع مساحات فارغة حول اسم الماكرو ولائحة الوسطاء وغيره، كما قد يحتوي على محرف سطر جديد: #define FMAC(a, b) printf("%s %s\n", a, b) FMAC ("hello", "sailor" ); /* ينتج ما سبق بالتالي */ printf("%s %s\n", "hello", "sailor") يمكن أن تأخذ وسطاء الماكرو من نوع دالة أي تسلسل عشوائي للمفتاح، وتُستخدم الفاصلة "," لفصل الوسطاء عن بعضهم بعضًا، ولكن يمكن إخفاؤها بوضعها داخل أقواس "( )". توازن الأزواج المتطابقة من الأقواس داخل الوسيط بعضها بعضًا، وبالتالي ينهي القوس "(" استدعاء الماكرو إذا كان القوس ")" هو الذي بدأ باستدعائه. #define CALL(a, b) a b CALL(printf, ("%d %d %s\n",1, 24, "urgh")); /* results in */ printf ("%d %d %s\n",1, 24, "urgh"); لاحظ كيف حافظنا على الأقواس حول الوسيط الثاني للدالة CALL عند الاستبدال، ولم تُزال من النص. إذا أردت استخدام ماكرو مثل printt، لن يساعدك المعيار بهذا الخصوص عندما تختار عدد متغير من الوسطاء، فذلك غير مدعوم. نحصل على سلوك غير معرف إذا لم يحتوي أحد الوسطاء على مفتاح معالج مسبق، والأمر مماثل إذا احتوت سلسلة مفاتيح المعالج المسبق التي تشكل الوسيط على موجّه معالج مسبق مغاير: #define CALL(a, b) a b /* كل حالة تنتج عن سلوك غير محدد */ CALL(,hello) CALL(xyz, #define abc def) إلا أننا نعتقد برأينا أن الاستخدام الثاني الخاطئ للدالة CALL يجب أن ينتج بسلوك معرف، إذ أن أي أحد قادر على كتابة ذلك سيستفيد من انتباه المصرّف. تتبع معالجة ماكرو الدالة الخطوات التالية: جميع وسطائها معرفة. إن كان أي من المفاتيح ضمن الوسيط مرشح لاستبدال بواسطة ماكرو، فسيُستبدل حتى الوصول للنقطة التي لا يمكن فيها إجراء المزيد من الاستبدالات، باستثناء الحالات المذكورة في البند الثالث التالي. لا يوجد هناك أي خطر بخصوص امتلاك الماكرو لعدد مختلف من الوسطاء بعد إضافة فاصلة إلى قائمة الوسطاء الأساسية، إذ يُحدد الوسطاء في الخطوة السابقة فقط. تُستبدل المعرفات التي تسمّي وسيط الماكرو في نص الاستبدال بسلسلة مفتاح مثل وسيطٍ فعلي، ويُهمل الاستبدال إذا كان المعرف مسبوقًا بإشارة "#" أو اثنتين "##" أو متبوعًا بالإشارتين "##". التنصيص هناك طريقةٌ خاصة لمعالجة الأماكن التي يسبق فيها وسيط الماكرو الإشارة "#" في نص الماكرو البديل، إذ تًهمل أي مسافة فارغة تسبق أو تلي قائمة الوسطاء الفعلية للمفتاح، ومن ثم تُحوّل قائمة المفتاح والإشارة # إلى سلسلة نصية واحدة، وتُعامل المسافات بين المفاتيح كأنها محارف مسافة في سلسلة نصية؛ ولمنع حدوث أي نتائج مفاجئة، يُسبق أي محرف " أو \ في السلسلة النصية الجديدة بالمحرف \. إليك المثال التالي الذي يوضح الخاصية المذكورة: #define MESSAGE(x) printf("Message: %s\n", #x) MESSAGE (Text with "quotes"); /* * النتيجة هي * printf("Message: %s\n", "Text with \"quotes\""); */ لصق المفتاح Token pasting قد نجد العامل ## في أي مكان ضمن النص البديل للماكرو باستثناء نهايته أو بدايته، وتُستخدم سلسلة مفتاح وسيط الماكرو لاستبدال النص البديل إذا ورد في اسم الوسيط لماكرو دالة مسبوقًا أو متبوعًا بأحد هذه العوامل، وتُدمج المفاتيح المحيطة بالعامل ## سويًا سواءٌ كانت ضمن ماكرو دالة أو ماكرو بسيط، ونحصل على سلوك غير معرف إذا شكّل ذلك مفتاح غير صالح، ويُجرى إعادة مسح بعدها. إليك عملية تحصل على عدة مراحل يُستخدم فيها إعادة المسح لتوضيح لصق المفتاح: #define REPLACE some replacement text #define JOIN(a, b) a ## b JOIN(REP, LACE) becomes, after token pasting, REPLACE becomes, after rescanning some replacement text إعادة المسح يُمسح النص البديل مضافًا إلى مفاتيح الملف المصدري مجددًا حالما تحصل العملية الموضحة في الفقرة السابقة، وذلك للبحث عن أسماء ماكرو أخرى لاستبدالها، مع استثناء أن اسم الماكرو داخل النص البديل لا يُستبدل. من الممكن أن نضيف ماكرو متداخلة Nested macros وبالتالي يمكن لعدد من الماكرو أن تُعالج لاستبدالها في أي نقطة دفعةً واحدة، ولا يوجد في هذه الحالة أي اسم مرشح لاستبداله ضمن المستوى الداخلي لهذا التداخل، وهذا يسمح لنا بإعادة تعريف الدوال الموجودة سابقًا مثل ماكرو: #define exit(x) exit((x)+1) تصبح أسماء الماكرو التي لم تُستبدل مفاتيحٌ محمية من الاستبدال مستقبلًا، حتى لو وردت أي عمليات تالية لتبديلها، وهذا يدرأ الخطر عن حدوث التعادوية recursion اللانهائية في المعالج المسبق، وتنطبق هذه الحماية فقط في حالة نتج اسم الماكرو عن النص البديل، وليس النص المصدري ضمن البرنامج، إليك ما الذي نقصده: #define m(x) m((x)+1) /* هذا */ m(abc); /* ينتج عن هذا بعد الاستبدال */ m((abc)+1); /* * على الرغم من أن النتيجة السابقة تبدو مثل ماكرو * إلا أن القواعد تنص على لزوم عدم استبداله */ m(m(abc)); /* * تبدأ m( الخارجية باستدعاء الماكرو, * لكن تُستبدل الداخلية أولًا * لتصبح بالشكل m((abc)+1) * وتُستخدم مثل وسيط، مما يعطينا */ m(m((abc+1)); /* * ويصبح بعد الاستبدال على النحو التالي */ m((m((abc+1))+1); إذا لم يؤلمك دماغك بقراءة ما سبق، فاذهب واقرأ ما الذي يقوله المعيار عن هذا ونضمن لك أنه سيؤلمك. ملاحظات هناك مشكلة غير واضحة تحدث عند استخدام وسطاء ماكرو الدالة. /* تحذير: هناك مشكلة في هذا البرنامج */ #define SQR(x) ( x * x ) /* * عند ورود المعاملات الصورية في النص البديل، تُستبدل بالمعاملات الفعلية للماكرو */ printf("sqr of %d is %d\n", 2, SQR(2)); المعامل الصوري formal parameter للماكرو SQR هو x، والمعامل الفعلي actual argument هو 2، وبالتالي سينتج النص البديل عن: printf("sqr of %d is %d\n", 2, ( 2 * 2 )); لاحظ استخدام الأقواس، فالمثال التالي قد يتسبب بمشكلة: /* مثال سيء */ #define DOUBLE(y) y+y printf("twice %d is %d\n", 2, DOUBLE(2)); printf("six times %d is %d\n", 2, 3*DOUBLE(2)); تكمن المشكلة في أن التعبير الأخير في استدعاء الدالة printf الثاني يُستبدل بالتالي: 3*2+2 وهذا ينتج عن 8 وليس 12. تنص القاعدة على أنه يجب عليك الحرص بخصوص الأقواس فهي ضرورية في حالة استخدام الماكرو لبناء تعابير. إليك مثالًا آخر: SQR(3+4) /* تصبح بالشكل التالي بعد الاستبدال */ ( 3+4 * 3+4 ) /* للأسف، ما زالت خاطئة! */ لذا، يجب عليك النظر بحرص إلى الوسطاء الصورية عندما ترِد ضمن نصل بديل. إليك الأمثلة الصحيحة عن الدالتين SQR و DOUBLE: #define SQR(x) ((x)*(x)) #define DOUBLE(x) ((x)+(x)) في جعبة الماكرو حيلةٌ صغيرة بعد لمفاجئتك، كما سيوضح لك المثال التالي: #include <stdio.h> #include <stdlib.h> #define DOUBLE(x) ((x)+(x)) main(){ int a[20], *ip; ip = a; a[0] = 1; a[1] = 2; printf("%d\n", DOUBLE(*ip++)); exit(EXIT_SUCCESS); } مثال 1 لمَ يتسبب المثال السابق بمشاكل؟ لأن نص ماكرو البديل يشير إلى *ip++ مرتين، مما يتسبب بزيادة ip مرتين، لا يجب للماكرو أن يُستخدم مع التعابير التي لها آثار جانبية، إلا إذا تحققت بحرص من أمانها. بغض النظر عن هذه التحذيرات التي تخص الماكرو، إلا أنها تقدم خصائص مفيدة، وستُستخدم هذه الخصائص كثيرًا من الآن فصاعدًا. موجه التراجع عن تعريف ماكرو undef يُمكن أن يُهمل (يُنتسى) أي معرّف يعود لموجه #define بكتابة: #undef NAME إذ لا يولد #undef خطأً إن لم يكن الاسم NAME معرفًا مسبقًا. سنستفيد من هذا الموجه كثيرًا عمّا قريب، وسنتكلم لاحقًا عن بعض دوال المكتبات التي هي في الحقيقة ماكرو وليس دالة، وستصبح قادرًا على الوصول إلى الدالة الفعلية عن طريق التراجع عن تعريفها. موجه تضمين ملف مصدري include يمكن كتابة هذا الموجه بشكلين: #include <filename> #include "filename" ينجم عن استخدام أحد الطريقتين قراءة ملف جديد عند نقطة ذكر الموجّه، وكأننا استبدالنا سطر الموجه بمحتويات الملف المذكور، وإذا احتوى هذا الملف على بعض التعليمات الخاطئة ستظهر لك الأخطاء مع إشارتها إلى الملف التي نجمت عنه مصحوبةً برقم السطر، وهذه مهمة مطوّر المصرف، وينص المعيار على أنه يجب للمصرف دعم ثمانية طبقات من موجّهات # include المتداخلة على الأقل. يمكن الاختلاف بين استخدام <> و " " حول اسم الملف بالمكان الذي سيُبحث فيه عن الملف؛ إذ يتسبب استخدام الأقواس في البحث في عددٍ من الأماكن المعرّفة بحسب التطبيق؛ بينما يتسبب استخدام علامتي التنصيص بحثًا في المكان المرتبط بمكان ملف الشيفرة المصدرية، وستُعلمك ملاحظات تطبيقك بما هو المقصود بكلمة "المكان" والتفاصيل المرتبطة بها، إذا لم تعود عملية البحث عن الملف باستخدام علامتي التنصيص بأي نتيجة، تُعاود عملية البحث من جديد وكأنك استخدمت القوسين. تُستخدم الأقواس عمومًا عندما تريد تحديد ملفات ترويسة لمكتبة قياسية Standard library، بينما تُستخدم علامتي التنصيص لملفات الترويسة الخاصة بك، التي تكون مخصصة غالبًا لبرنامج واحد. لا يحدد المعيار كيفية تسمية ملف بصورةٍ صالحة، إلا أنه يحدد وجوب وجود طريقة فريدة معرفة بحسب التطبيق لترجمة اسم الملفات من الشكل xxx.x (يمثّل كل x حرفًا)، إلى أسماء ملفات الشيفرة المصدرية، ويمكن تجاهل الفرق بين الأحرف الكبيرة والصغيرة من قِبل التطبيق، ويمكن أن يختار التطبيق أيضًا ستة محارف ذات أهمية فقط بعد محرف النقطة .. يمكنك أيضًا الكتابة بالشكل التالي: # define NAME <stdio.h> # include NAME للحصول على نتيجة مماثلة لهذا: # include <stdio.h> إلا أن هذه الطريقة تعقيدٌ لا داعي له، وهي معرضةٌ لبعض الأخطاء طبقًا للقواعد المعرفة بحسب التطبيق إذ تحدد هذه القواعد كيف سيُعالج النص بين القوسين < >. من الأبسط أن يكون النص البديل للماكرو NAME سلسلةً نصية، على سبيل المثال: #define NAME "stdio.h" #include NAME لا يوجد في حالتنا السابقة أي فرصة للأخطاء الناتجة عن التصرف المعرف بحسب التطبيق، إلا أن مسارات البحث مختلفة كما وضحنا سابقًا. سلسلة المفتاح في حالتنا الأولى التي تستبدِل NAME هي على النحو التالي (بحسب القوانين التي ناقشناها سابقًا): < stdio . h > أما في الحالة الثانية فهي من الشكل: "stdio.h" الحالة الثانية سهلة الفهم، لأنه يوجد لدينا فقط سلسلة نصية وهي مفتاح تقليدي لموجّه # include، بينما الحالة الثانية معرفةٌ بحسب التطبيق، وبالتالي يعتمد تشكيل سلسلة المفاتيح لاسم ترويسة صالح على التطبيق. أخيرًا، المحرف الأخير من الملف المُضمّن داخل موجه include يجب أن يكون سطرًا جديدًا، وإلا سنحصل على خطأ. الأسماء مسبقة التعريف الأسماء التالية هي أسماء مسبقة التعريف predefined names داخل المعالج المُسبق: الاسم __LINE__: ثابت عدد صحيح بالنظام العشري، ويشير إلى السطر الحالي ضمن ملف الشيفرة المصدرية. الاسم __FILE__: اسم ملف الشيفرة المصدرية الحالي، وهو سلسلة نصية. الاسم __DATE__: التاريخ الحالي، وهو سلسلة نصية من الشكل: Apr 21 1990 إذ يظهر اسم الشهر كما هو معرّف في الدالة المكتبية asctime وأول خانة من التاريخ مسافة فارغة إذان كان التاريخ أقل من 10. الاسم __TIME__: وقت ترجمة الملف، وهو سلسلة نصية موافقة للشكل السابق باستخدام الدالة asctime، أي من الشكل "hh:mm:ss". الاسم __STDC__: عدد صحيح ثابت بقيمة 1، ويُستخدم لاختبار اتباع المصرّف لضوابط المعيار، إذ يمتلك هذا العدد قيمًا مختلفة لإصدارات مختلفة من المعيار. الطريقة الشائعة في استخدام هذه الأسماء المعرفة مسبقًا هي على النحو التالي: #define TEST(x) if(!(x))\ printf("test failed, line %d file %s\n",\ __LINE__, __FILE__) /**/ TEST(a != 23); /**/ مثال 2 إذا كانت نتيجة TEST في المثال السابق خطأ، فستُطبع الرسالة متضمنةً اسم الملف ورقم السطر في الرسالة. إلا أن استخدام تعليمة if في هذه الحالات قد يتسبب ببعض من اللبس، كما يوضح المثال التالي: if(expression) TEST(expr2); else statement_n; إذ سترتبط تعليمة else بتعليمة if المخفية التي ستُستبدل باستخدام الماكرو TEST، وعلى الرغم من أن حدوث هذا الشيء عند الممارسة مستبعد إلا أنه سيكون خطأً لعينًا صعب الحل والتشخيص إذا حدث لك، ولتفادي ذلك، يُحبّذ استخدام الأقواس وجعل محتوى كل تعليمة تحكم بتدفق البرنامج مثل تعليمة مركّبة بغض النظر عن طولها. لا يمكننا استعمال أي من الأسماء __LINE__ أو __FILE__ أو __DATE__ أو __TIME__ أو __STDC__ أو أي من الأسماء المعرفة الأخرى ضمن موجه #define أو #undef. ينص المعيار على أن أي اسم محجوز يجب أن يبدأ بشرطةٍ سفلية underscore وحرفٍ كبير، أو شرطتان، وبالتالي يمكنك استخدام أي اسم لاستخدامك الخاص، لكن انتبه من استخدام الأسماء المحجوزة في ملفات الترويسة التي ضمّنتها في برنامجك. موجه التحكم بتقارير الأخطاء line يُستخدم هذا الموجه في ضبط القيمة التي يحملها كل من __LINE__ و __FILE__، لكن ما المُستفاد من ذلك؟ توّلد العديد من الأدوات في الوقت الحالي شيفرةً بلغة سي C خرجًا لها، ويسمح هذا الموجه لهذه الأدوات بالتحكم برقم السطر الحالي إلا أن استخدامه محدودٌ لمبرمج لغة سي الاعتيادية. يأتي الموجه بالشكل التالي: # line number optional-string-literal newline يضبط الرقم number قيمة __LINE__ وتضبط السلسلة النصية الاختيارية إن وُجدت قيمة __FILE__. في الحقيقة، ستُوسّع سلسلة المفاتيح التي تتبع الموجه #line باستخدام ماكرو، ومن المفترض أن تشكّل موجهًا صالحًا بعد التوسعة. التصريف الشرطي يتحكم بالتصريف الشرطي عدد من الموجهات، إذ تسمح هذه الموجهات بتصريف أجزاء معينة من البرنامج اختياريًا أو تجاهلها حسب الشروط، وهذه الشروط هي: #if و #ifdef و #ifndef و #elif و #else و #endif إضافةً إلى عامل المُعالج المسبق الأحادي. يمكننا استخدام الموجهات على النحو التالي: #ifdef NAME /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif #ifndef NAME /* صرّف هذا القسم إذا كان الاسم غير معرّفًا */ #else /* صرّف هذا القسم إذا كان الاسم معرّفًا */ #endif يُستخدم كل من #ifdef و #endif لاختبار تعريف اسم الماكرو، ويمكن استخدام #else طبعًا مع #ifdef (و #if أو #elif أيضًا)، لا يوجد التباس حول استخدام #else، لأن استخدام #endif يحدّد نطاق الموجّه مما يبعد أي مجال للشبهات. ينص المعيار على وجوب دعم ثمان طبقات من الموجهات الشرطية المتداخلة، إلا أنه من المستبعد وجود أي حدّ عمليًّا. تُستخدم هذه الموجهات لتحديد فقرات صغيرة من برامج سي التي تعتمد على الآلة التي تعمل عليها (عندما لا يكون بالإمكان جعل كامل البرنامج ذا أداء مستقل غير مرتبط بطبيعة الآلة التي يعمل عليها)، أو لتحديد خوارزميات مختلفة تعتمد على بعض المقايضات لتنفيذها. تأخذ بنية #if و #elif تعبيرًا ثابتًا وحيدًا ذا قيمةٍ صحيحة، وقيم المعالج المسبق هذه مماثلةٌ للقيم الاعتيادية باستثناء أنها يجب أن تخلو من عوامل تحويل الأنواع casts. تخضع سلسلة المفتاح التي تشكّل التعبير الثابت لعملية استبدال بالماكرو، عدا الأسماء المسبوقة بموجه التعريف فلا تُستبدل. بالاعتماد على ما سبق ذكره، فالتعبير defined NAME أو defined ( NAME ) يُقيّمان إلى القيمة 1 إذا كان NAME معرّفًا، وإلى القيمة 0 إن لم يكن معرّفًا، وتُستبدل جميع المعرفات ضمن التعبير -بما فيها كلمات لغة سي المفتاحية- بالقيمة 0، ومن ثم يُقيّم التعبير. يُقصد بالاستبدال (بما فيه استبدال الكلمات المفتاحية) أن sizeof لا يمكن استخدامه في هذه التعابير للحصول على القيمة التي تحصل عليها في الحالة الاعتيادية. تُستخدم القيمة الصفر -كما هو الحال في تعليمات سي الشرطية- للدلالة على القيمة "خطأ false"، وتدل أي قيمة أخرى على القيمة "صواب true". يجب استخدام المعالج المسبق العمليات الحسابية وفق النطاقات المحددة في ملف الترويسة <limits.h>، وأن تُعامل التعابير ذات قيمة العدد الصحيح مثل عدد صحيح طويل والعدد الصحيح عديم الإشارة مثل عدد صحيح طويل عديم الإشارة، بينما لا يتوجب على المحارف أن تكون مساوية إلى القيمة ذاتها عند وقت التنفيذ، لذا من الأفضل في البرامج القابلة للنقل أن نتجنب استخدامها في تعابير المعالج المُسبق. تعني القوانين السابقة عمومًا أنه بإمكاننا أن نحصل على نتائج حسابية من المعالج المسبق التي قد تكون مختلفة عن النتائج التي نحصل عليها عند وقت التنفيذ، وذلك بفرض إجراء الترجمة والتنفيذ على آلات مختلفة. إليك مثالًا: #include <limits.h> #if ULONG_MAX+1 != 0 printf("Preprocessor: ULONG_MAX+1 != 0\n"); #endif if(ULONG_MAX+1 != 0) printf("Runtime: ULONG_MAX+1 != 0\n"); مثال 3 من الممكن أن يُجري المعالج المسبق بعض العمليات الحسابية بنطاق أكبر من النطاق المُستخدم في البيئة المُستهدفة، ويمكن في هذه الحالة ألّا يطفح تعبير المعالج المسبق ULONG MAX+1 ليعطي النتيجة 0، بينما يجب أن يحدث لك في بيئة التنفيذ. يوضح المثال التالي استخدام الثوابت المذكور آنفًا، وتعليمة "وإلّا else" الشرطية #elif. #define NAME 100 #if ((NAME > 50) && (defined __STDC__)) /* افعل شيئًا */ #elif NAME > 25 /* افعل شيئًا آخر */ #elif NAME > 10 /* افعل شيئًا آخر */ #else /* الاحتمال الأخير */ #endif يتوجب التنويه هنا على أن موجهات التصريف الشرطية لا تتبع لقوانين النطاق الخاصة بلغة سي، ولهذا فيجب استخدامها بحرص، إلا إذا أردت أن يصبح برنامجك صعب القراءة، إذ من الصعب أن تقرأ برنامج سي C مع وجود هذه الأشياء كل بضعة أسطر، وسيتملكك الغضب تجاه كاتب البرنامج إذا صادفت شيفرة مشابهة لهذه دون أي موجه #if واضح بالقرب منها: #else } #endif لذلك يجب أن تعامل هذه الموجهات معاملة الصلصة الحارّة، استخدامها ضروري في بعض الأحيان، إلا أن الاستخدام الزائد لها سيعقّد الأمور. موجه التحكم المعتمد على التنفيذ pragma كان هذا الموجه بمثابة محاولة للجنة المعيار بإضافة طريقة للولوج للباب الخلفي، إذ يسمح هذا الموجه بتنفيذ بعض الأشياء المعرفة بحسب التطبيق. إذا لم يعرف التطبيق ما الذي سيفعله بهذا الموجه (أي لم يتعرف على وظيفته) فيستجاهله ببساطة، إليك مثالًا عن استخدامه: #pragma byte_align يُستخدم الموجه السابق لإعلام التطبيق بضرورة محاذاة جميع أعضاء الهياكل بالنسبة لعنوان البايت الخاص بهم، إذ يمكن لبعض معماريات المعالجات أن تتعامل مع أعضاء الهياكل بطول الكلمة بمحاذاة عنوان البايت، ولكن مع خسارة السرعة في الوصول إليها. يمكن أن يُفسّر هذا الأمر بحسب تفسير التطبيق له طبعًا، وإن لم يكن للتطبيق أي تفسير خاص به، فلن يأخذ الموجه أي تأثير، ولن يُعد خطأً، ومن المثير للاهتمام رؤية بعض الاستخدامات الخاصة لهذا النوع من الموجهات. موجه عرض رسالة خطأ قسرية error يُتبع هذا الموجه بمفتاح أو أكثر في نهاية السطر الخاص به، وتُشكّل رسالة تشخيصية من قبل المصرف تحتوي على هذه المفاتيح، ولا توجد مزيدٌ من التفاصيل عن ذلك في المعيار. يُمكن استخدام هذا الموجه لإيقاف عملية التصريف على آلة ذات عتاد صلب غير مناسب لتنفيذ البرنامج: #include <limits.h> #if CHAR_MIN > -128 #error character range smaller than required #endif سيتسبب ذلك ببعض الأخطاء المتوقعة عند مرحلة التصريف إذا نُفّذ الموجه وعُرضت الرسالة. الخاتمة على الرغم من الخصائص القوية والمرنة التي يوفرها المعالج المسبق، إلا أنها شديدة التعقيد، وهناك عددٌ قليل من الجوانب المتعلقة به ضرورية الفهم، مثل القدرة على تعريف الماكرو ودوال الماكرو، والمستخدمة بكثرة في أي برنامج سي تقريبًا عدا البرامج البسيطة، كما أن تضمين ملفات الترويسة مهمّ أيضًا طبعًا. للتصريف الشرطي استخدامان مهمان، أولهما هو القدرة على تصريف البرنامج بوجود أو بعدم وجود تعليمات الاكتشاف عن الأخطاء Debugging ضمن البرنامج، وثانيهما هو القدرة على تحديد تعليمات معينة يعتمد تنفيذها على طبيعة التطبيق أو الآلة التي يعمل عليها البرنامج. باستثناء ما ذكرنا سابقًا، من الممكن نسيان المزايا الأخرى التي ذُكرت في المقال، إذ لن يتسبب التخلي عنها بفقدان كثيرٍ من الخصائص، ولعلّ الحل الأمثل هو تواجد فرد واحد متخصّص في المعالج المسبق ضمن الفريق البرمجي لتطوير الماكرو التي تفيد مشروعًا ما بعينه باستخدام بعض المزايا الغريبة، مثل التنصيص ولصق المفاتيح. سيستفيد معظم مستخدمي لغة سي C أكثر إذا وجّهوا جهدهم بدلًا من ذلك نحو تعلم بعض الأجزاء الأخرى من لغة سي، أو تقنيات التحكم بجودة البرمجيات إذا أتقنوا اللغة. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: التصاريح declarations والتعاريف definitions وإمكانية الوصول accessibility في لغة سي C المقال السابق: تهيئة المتغيرات وأنواع البيانات في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C -
 حان الوقت للتكلم عن التهيئة Initialization في لغة سي بعد أن تكلمنا عن جميع أنواع البيانات المدعومة في اللغة، إذ تسمح لغة سي للمتغيرات الاعتيادية والهياكل والاتحادات والمصفوفات بأن تحمل قيمةً أوليةً عند التعريف عنها، وكان للغة سي القديمة بعض القوانين الغريبة بهذا الخصوص التي تعكس تقاعس مبرمجي مصرّفات سي عن إنجاز بعض العمل الإضافي، وأتت لغة C المعيارية لحل هذه المشكلات وأصبح من الممكن الآن تهيئة الأشياء عندما تريد وكيفما تريد. أنواع التهيئة في لغة سي هناك نوعان من التهيئة؛ تهيئة عند وقت التصريف compile time وتهيئة عند وقت التشغيل run time، ويعتمد النوع الذي ستحصل عليه على مدة التخزين storage duration للشيء الذي يُهيّأ. يُصرح عن الكائنات ذات المدة الساكنة static duration إما خارج الدوال، أو داخلها باستخدام الكلمة المفتاحية extern أو static على أنها جزءٌ من التصريح، ويُهيّأ هذا النوع عند وقت التصريف فقط. لجميع الكائنات الأخرى مدةٌ تلقائية automatic duration، يمكن تهيئتها فقط عند وقت التشغيل، إذ أن التصنيفين حصريان فيما بينهما. على الرغم من ارتباط مدة التخزين بالربط (انظر مقال الربط) إلا أنهما مختلفان ويجب عدم الخلط فيما بينهما. يمكن استخدام التهيئة عند وقت التصريف فقط في حال استخدام التعابير الثابتة constant expressions، بينما يمكن استخدام التهيئة عند وقت التشغيل لأي تعبير كان، وقد أُلغي قيد لغة سي القديمة الذي ينص على إمكانية تهيئة المتغيرات البسيطة وحدها عند وقت التشغيل، وليس المصفوفات، أو الهياكل، أو الاتحادات. التعابير الثابتة هناك بعض الاستخدامات الضرورية للتعابير الثابتة، ويُعد تعريف التعبير الثابت بسيط الفهم، إذ يُقيّم التعبير الثابت constant expression عند وقت التصريف وليس عند وقت التشغيل، ويمكن استخدام هذا النوع من التعابير في أي مكان يسمح باستخدام قيمة ثابتة. يُشترط على التعبير الثابت ألا يحتوي على أي عامل إسناد أو زيادة أو نقصان أو استدعاء لدالة ما أو عامل الفاصلة، إلا إذا كان التعبير جزءًا من معامل sizeof، وقد يبدو هذا الشرط غريبًا بعض الشيء، إلا أنه بسبب أن العامل sizeof يُقيّم نوع التعبير وليس قيمته. يؤكد المعيار على وجوب تقييم الأعداد الحقيقية عند وقت التصريف بدقة ونطاق مماثلين لحالة تقييمهم في وقت التشغيل. يوجد هناك طريقةٌ محدودة أكثر تدعى تعابير الأعداد الصحيحة الثابتة integral constant expressions، ولهذه التعابير نوع عدد صحيح وتحتوي على معاملات operands من نوع عدد صحيح ثابت أو معدّدات ثابتة enumeration constants، أو محارف ثابتة، بالإضافة إلى تعابير sizeof والأعداد الحقيقية الثابتة التي تكون معاملات لتحويل الأنواع casts، ويسمح لعوامل تحويل الأنواع بتحويل الأنواع الحسابية إلى أنواع صحيحة فقط. لا تُطبّق أي قيود على محتويات تعابير sizeof طبقًا لما سبق قوله (يُقيّم نوع التعبير وليس قيمته). يُشابه التعبير الحسابي الثابت arithmetic constant expression التعبير الصحيح الثابت، ولكنه يسمح باستخدام الأعداد الصحيحة الثابتة، ويحدّ من استخدام تحويل الأنواع بالتحويل من نوع حسابي إلى آخر. العنوان الثابت address constant هو مؤشر يشير إلى كائن ذي مدة تخزين ساكنة أو إلى مؤشر يشير إلى دالةٍ ما، ويمكنك الحصول على هذه العناوين باستخدام العامل "&" أو باستخدام التحويلات الاعتيادية للمصفوفات وأسماء الدوال إلى مؤشرات عندما تُستخدم ضمن تعبير، ويمكن استخدام كلٍ من العوامل "[]" و "." و "<-" و "&" و "*" ضمن التعبير طالما لا يتضمن ذلك الاستخدام محاولة للوصول لقيمة أي كائن. استكمال عن التهيئة يُسمح لأنواع الثوابت المختلفة بالتواجد في العديد من الأماكن، إلا أن تعابير الأعداد الصحيحة الثابتة شديدة الأهمية على وجه الخصوص لأنها من النوع الوحيد الذي قد يُستخدم لتحديد حجم المصفوفة وقيم ما يسبق تعليمة case. تتميز أنواع الثوابت المسموح باستخدامها مثل قيمة أولية لتهيئة التعابير بأنها أقل محدودية، إذ من المسموح لك باستخدام تعابير حسابية ثابتة، أو مؤشر فراغ، أو عنوان ثابت، أو عنوان ثابت لكائن زائد أو ناقص تعبير صحيح ثابت، ويعتمد الأمر طبعًا على نوع الشيء الذي يجري تهيئته سواءٌ كان نوع تعبير ثابت محدد مناسبًا أم لا. إليك مثالًا يحتوي على تهيئة لعدة متغيرات: #include <stdio.h> #include <stdlib.h> #define NMONTHS 12 int month = 0; short month_days[] = {31,28,31,30,31,30,31,31,30,31,30,31}; char *mnames[] ={ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" }; main(){ int day_count = month; for(day_count = month; day_count < NMONTHS; day_count++){ printf("%d days in %s\n", month_days[day_count], mnames[day_count]); } exit(EXIT_SUCCESS); } مثال 1 تهيئة المتغيرات الاعتيادية بسيطة، فعليك فقط إضافة = expression بعد اسم المتغير في التصريح، والتي تدل expression على التعبير الذي ستُسند قيمته إلى المتغير، وسيُهيّأ المتغير بهذه القيمة، ويعتمد استخدام مجمل التعابير أو استخدام التعابير الثابتة حصرًا على مدة التخزين، وهذا ينطبق على جميع الكائنات. تهيئة المصفوفات أحادية البعد بسيطةٌ أيضًا، إذ عليك فقط كتابة قائمة بالقيم التي تريدها وتفصل كل قيمة بفاصلة داخل أقواس معقوصة؛ ويوضّح المثال التالي طريقة تهيئة المصفوفة، ويُحدّد حجم المصفوفة طبقًا للقيم الأولية الموجودة إن لم تحدد حجم المصفوفة على نحوٍ صريح، أما إذا حددت الحجم صراحةً، فيجب أن يكون عدد القيم الأولية التي تزودها يساوي أو أصغر من الحجم، إذ يسبب إضافة قيم أكبر من حجم المصفوفة خطئًا، بينما ستهيّئ القيم الموجودة -وإن كانت قليلة- العناصر الأولى من المصفوفة. يمكنك بناء سلسلة نصية يدويًا بالطريقة: char str[] = {'h', 'e', 'l', 'l', 'o', 0}; يمكن أيضًا استخدام سلسلة نصية ضمن علامتي تنصيص لتهيئة مصفوفة من المحارف: char str[] = "hello"; سيُضمّن المحرف الفارغ في نهاية المصفوفة في حالتنا السابقة تلقائيًا إذا كانت هناك مساحةٌ كافية، أو إذا لم يُحدد حجم المصفوفة، إليك المثال التالي: /* لا يوجد مكان للمحرف الفارغ */ char str[5] = "hello"; /* يوجد مكان للمحرف الفارغ */ char str[6] = "hello"; استخدم البرنامج في مثال 1 السلاسل النصية لأهداف مختلفة، إذ كان استخدامهم بهدف تهيئة مصفوفة من مؤشرات تشير إلى محارف، وهذا استخدام مختلفٌ تمامًا. يمكن استخدام تعبير من نوع مناسب لتهيئة هياكل من نوع مدة تلقائية، وإلا فيجب استخدام قائمة تحتوي على تعابير ثابتة بين قوسين على النحو التالي: #include <stdio.h> #include <stdlib.h> struct s{ int a; char b; char *cp; }ex_s = { 1, 'a', "hello" }; main(){ struct s first = ex_s; struct s second = { 2, 'b', "byebye" }; exit(EXIT_SUCCESS); } مثال 2 يمكن تهيئة العنصر الأول فقط من الاتحاد. يحدث تجاهلٌ للأعضاء عديمة الاسم ضمن الهيكل أو الاتحاد خلال عملية التهيئة، سواءٌ كانت حقول بتات bitfields، أو مسافات فارغة لمحاذاة عنوان التخزين، فمن غير المطلوب أخذهم بالحسبان عندما تختار القيم الأولية لأعضاء الهيكل الحقيقية (ذات الاسم). هناك طريقتان لكتابة القيم الأولية لكائنات تحتوي على كائنات فرعية بداخلها، فيمكن كتابة قيمة أولية لكل عضو بالطريقة: struct s{ int a; struct ss{ int c; char d; }e; }x[] = { 1, 2, 'a', 3, 4, 'b' }; مثال 3 سيُسنِد ما سبق القيمة 1 إلى x[0].a و 2 إلى x[0].e.c و a إلى x[0].e.d و 3 إلى x[1].a وهكذا. استخدام الأقواس الداخلية أكثر أمانًا للتعبير عن القيم التي تقصدها، إذ تسبّب قيمةٌ خاطئةٌ واحدة فوضى عارمة. struct s{ int a; struct ss{ int c; char d; }e; }x[] = { {1, {2, 'a'}}, {3, {4, 'b'}} }; مثال 4 استخدم الأقواس دائمًا، لأن هذه الطريقة آمنة، والأمر مماثل بالنسبة للمصفوفات بكونها هياكل: float y[4][3] = { {1, 3, 5}, /* y[0][0], y[0][1], y[0][2] */ {2, 4, 6}, /* y[1][0], y[1][1], y[1][2] */ {3, 5, 7} /* y[2][0], y[2][1], y[2][2] */ }; مثال 5 تُهيّأ قيم الأسطر الثلاث الأولى كاملةً من y، ويبقى السطر الرابع y[3] غير مُهيّأ. تُسند لجميع الكائنات ذات المدة الساكنة قيمٌ أولية ضمنية تلقائية إذا لم يوجد أي قيمة أولية لها، ويكون أثر القيمة الأولية التلقائية الضمنية مماثلًا لأثر إسناد القيمة 0 الثابتة، وهذا الأمر شائع الاستخدام، وتفترض معظم برامج لغة سي نتيجةً لذلك أن الكائنات الخارجية والكائنات الساكنة الداخلية تبدأ بالقيمة صفر. تُضمن عملية التهيئة للكائنات ذات المدة التلقائية فقط في حالة وجود تعليمتها المركبة "في الأعلى"، إذ قد يتسبب الانتقال إلى أحد الكائنات فورًا بعدم حصول عملية التهيئة وهذا الأمر غير مستحب ويجب تجنبه. يشير المعيار بصراحة إلى أن وجود القيم الأولية في التصريح ضمن تعليمات switch لن يكون مفيدًا، لأن التصريح لا يُصنف بكونه تعليمة، ويمكن عنونة label التعليمة فقط، ونتيجةً لذلك فلا يمكن للقيم الأولية في تعليمات switch أن تُنفّذ لأن كتلة الشيفرة البرمجية التي تحتويها يجب أن تلي ذكر التصاريح. يمكن أن يُستخدم التصريح داخل دالة ما (نطاق مرتبط بكتلة الدالة) للإشارة إلى كائن ذي ربطٍ خارجي External linkage أو ربط داخلي Internal linkage باستخدام عدّة طرق تطرقنا إليها في مقال الربط والنطاق وهناك مزيدٌ من الطرق التي سنتطرق إليها لاحقًا. إذا اتبعت الطرق السابقة (التي من المستبعد أن تتحقق من قبيل الصدفة)، فلا يمكنك تهيئة الكائن على أنه جزء من التصريح، وإليك الطريقة الوحيدة التي تستطيع تحقيق ذلك بها: int x; /* ربط خارجي */ main(){ extern int x = 5; /* استخدام ممنوع */ } لم يكشف مصرّفنا التهيئة الممنوعة في هذا المثال أيضًا. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C المقال السابق: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C
حان الوقت للتكلم عن التهيئة Initialization في لغة سي بعد أن تكلمنا عن جميع أنواع البيانات المدعومة في اللغة، إذ تسمح لغة سي للمتغيرات الاعتيادية والهياكل والاتحادات والمصفوفات بأن تحمل قيمةً أوليةً عند التعريف عنها، وكان للغة سي القديمة بعض القوانين الغريبة بهذا الخصوص التي تعكس تقاعس مبرمجي مصرّفات سي عن إنجاز بعض العمل الإضافي، وأتت لغة C المعيارية لحل هذه المشكلات وأصبح من الممكن الآن تهيئة الأشياء عندما تريد وكيفما تريد. أنواع التهيئة في لغة سي هناك نوعان من التهيئة؛ تهيئة عند وقت التصريف compile time وتهيئة عند وقت التشغيل run time، ويعتمد النوع الذي ستحصل عليه على مدة التخزين storage duration للشيء الذي يُهيّأ. يُصرح عن الكائنات ذات المدة الساكنة static duration إما خارج الدوال، أو داخلها باستخدام الكلمة المفتاحية extern أو static على أنها جزءٌ من التصريح، ويُهيّأ هذا النوع عند وقت التصريف فقط. لجميع الكائنات الأخرى مدةٌ تلقائية automatic duration، يمكن تهيئتها فقط عند وقت التشغيل، إذ أن التصنيفين حصريان فيما بينهما. على الرغم من ارتباط مدة التخزين بالربط (انظر مقال الربط) إلا أنهما مختلفان ويجب عدم الخلط فيما بينهما. يمكن استخدام التهيئة عند وقت التصريف فقط في حال استخدام التعابير الثابتة constant expressions، بينما يمكن استخدام التهيئة عند وقت التشغيل لأي تعبير كان، وقد أُلغي قيد لغة سي القديمة الذي ينص على إمكانية تهيئة المتغيرات البسيطة وحدها عند وقت التشغيل، وليس المصفوفات، أو الهياكل، أو الاتحادات. التعابير الثابتة هناك بعض الاستخدامات الضرورية للتعابير الثابتة، ويُعد تعريف التعبير الثابت بسيط الفهم، إذ يُقيّم التعبير الثابت constant expression عند وقت التصريف وليس عند وقت التشغيل، ويمكن استخدام هذا النوع من التعابير في أي مكان يسمح باستخدام قيمة ثابتة. يُشترط على التعبير الثابت ألا يحتوي على أي عامل إسناد أو زيادة أو نقصان أو استدعاء لدالة ما أو عامل الفاصلة، إلا إذا كان التعبير جزءًا من معامل sizeof، وقد يبدو هذا الشرط غريبًا بعض الشيء، إلا أنه بسبب أن العامل sizeof يُقيّم نوع التعبير وليس قيمته. يؤكد المعيار على وجوب تقييم الأعداد الحقيقية عند وقت التصريف بدقة ونطاق مماثلين لحالة تقييمهم في وقت التشغيل. يوجد هناك طريقةٌ محدودة أكثر تدعى تعابير الأعداد الصحيحة الثابتة integral constant expressions، ولهذه التعابير نوع عدد صحيح وتحتوي على معاملات operands من نوع عدد صحيح ثابت أو معدّدات ثابتة enumeration constants، أو محارف ثابتة، بالإضافة إلى تعابير sizeof والأعداد الحقيقية الثابتة التي تكون معاملات لتحويل الأنواع casts، ويسمح لعوامل تحويل الأنواع بتحويل الأنواع الحسابية إلى أنواع صحيحة فقط. لا تُطبّق أي قيود على محتويات تعابير sizeof طبقًا لما سبق قوله (يُقيّم نوع التعبير وليس قيمته). يُشابه التعبير الحسابي الثابت arithmetic constant expression التعبير الصحيح الثابت، ولكنه يسمح باستخدام الأعداد الصحيحة الثابتة، ويحدّ من استخدام تحويل الأنواع بالتحويل من نوع حسابي إلى آخر. العنوان الثابت address constant هو مؤشر يشير إلى كائن ذي مدة تخزين ساكنة أو إلى مؤشر يشير إلى دالةٍ ما، ويمكنك الحصول على هذه العناوين باستخدام العامل "&" أو باستخدام التحويلات الاعتيادية للمصفوفات وأسماء الدوال إلى مؤشرات عندما تُستخدم ضمن تعبير، ويمكن استخدام كلٍ من العوامل "[]" و "." و "<-" و "&" و "*" ضمن التعبير طالما لا يتضمن ذلك الاستخدام محاولة للوصول لقيمة أي كائن. استكمال عن التهيئة يُسمح لأنواع الثوابت المختلفة بالتواجد في العديد من الأماكن، إلا أن تعابير الأعداد الصحيحة الثابتة شديدة الأهمية على وجه الخصوص لأنها من النوع الوحيد الذي قد يُستخدم لتحديد حجم المصفوفة وقيم ما يسبق تعليمة case. تتميز أنواع الثوابت المسموح باستخدامها مثل قيمة أولية لتهيئة التعابير بأنها أقل محدودية، إذ من المسموح لك باستخدام تعابير حسابية ثابتة، أو مؤشر فراغ، أو عنوان ثابت، أو عنوان ثابت لكائن زائد أو ناقص تعبير صحيح ثابت، ويعتمد الأمر طبعًا على نوع الشيء الذي يجري تهيئته سواءٌ كان نوع تعبير ثابت محدد مناسبًا أم لا. إليك مثالًا يحتوي على تهيئة لعدة متغيرات: #include <stdio.h> #include <stdlib.h> #define NMONTHS 12 int month = 0; short month_days[] = {31,28,31,30,31,30,31,31,30,31,30,31}; char *mnames[] ={ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" }; main(){ int day_count = month; for(day_count = month; day_count < NMONTHS; day_count++){ printf("%d days in %s\n", month_days[day_count], mnames[day_count]); } exit(EXIT_SUCCESS); } مثال 1 تهيئة المتغيرات الاعتيادية بسيطة، فعليك فقط إضافة = expression بعد اسم المتغير في التصريح، والتي تدل expression على التعبير الذي ستُسند قيمته إلى المتغير، وسيُهيّأ المتغير بهذه القيمة، ويعتمد استخدام مجمل التعابير أو استخدام التعابير الثابتة حصرًا على مدة التخزين، وهذا ينطبق على جميع الكائنات. تهيئة المصفوفات أحادية البعد بسيطةٌ أيضًا، إذ عليك فقط كتابة قائمة بالقيم التي تريدها وتفصل كل قيمة بفاصلة داخل أقواس معقوصة؛ ويوضّح المثال التالي طريقة تهيئة المصفوفة، ويُحدّد حجم المصفوفة طبقًا للقيم الأولية الموجودة إن لم تحدد حجم المصفوفة على نحوٍ صريح، أما إذا حددت الحجم صراحةً، فيجب أن يكون عدد القيم الأولية التي تزودها يساوي أو أصغر من الحجم، إذ يسبب إضافة قيم أكبر من حجم المصفوفة خطئًا، بينما ستهيّئ القيم الموجودة -وإن كانت قليلة- العناصر الأولى من المصفوفة. يمكنك بناء سلسلة نصية يدويًا بالطريقة: char str[] = {'h', 'e', 'l', 'l', 'o', 0}; يمكن أيضًا استخدام سلسلة نصية ضمن علامتي تنصيص لتهيئة مصفوفة من المحارف: char str[] = "hello"; سيُضمّن المحرف الفارغ في نهاية المصفوفة في حالتنا السابقة تلقائيًا إذا كانت هناك مساحةٌ كافية، أو إذا لم يُحدد حجم المصفوفة، إليك المثال التالي: /* لا يوجد مكان للمحرف الفارغ */ char str[5] = "hello"; /* يوجد مكان للمحرف الفارغ */ char str[6] = "hello"; استخدم البرنامج في مثال 1 السلاسل النصية لأهداف مختلفة، إذ كان استخدامهم بهدف تهيئة مصفوفة من مؤشرات تشير إلى محارف، وهذا استخدام مختلفٌ تمامًا. يمكن استخدام تعبير من نوع مناسب لتهيئة هياكل من نوع مدة تلقائية، وإلا فيجب استخدام قائمة تحتوي على تعابير ثابتة بين قوسين على النحو التالي: #include <stdio.h> #include <stdlib.h> struct s{ int a; char b; char *cp; }ex_s = { 1, 'a', "hello" }; main(){ struct s first = ex_s; struct s second = { 2, 'b', "byebye" }; exit(EXIT_SUCCESS); } مثال 2 يمكن تهيئة العنصر الأول فقط من الاتحاد. يحدث تجاهلٌ للأعضاء عديمة الاسم ضمن الهيكل أو الاتحاد خلال عملية التهيئة، سواءٌ كانت حقول بتات bitfields، أو مسافات فارغة لمحاذاة عنوان التخزين، فمن غير المطلوب أخذهم بالحسبان عندما تختار القيم الأولية لأعضاء الهيكل الحقيقية (ذات الاسم). هناك طريقتان لكتابة القيم الأولية لكائنات تحتوي على كائنات فرعية بداخلها، فيمكن كتابة قيمة أولية لكل عضو بالطريقة: struct s{ int a; struct ss{ int c; char d; }e; }x[] = { 1, 2, 'a', 3, 4, 'b' }; مثال 3 سيُسنِد ما سبق القيمة 1 إلى x[0].a و 2 إلى x[0].e.c و a إلى x[0].e.d و 3 إلى x[1].a وهكذا. استخدام الأقواس الداخلية أكثر أمانًا للتعبير عن القيم التي تقصدها، إذ تسبّب قيمةٌ خاطئةٌ واحدة فوضى عارمة. struct s{ int a; struct ss{ int c; char d; }e; }x[] = { {1, {2, 'a'}}, {3, {4, 'b'}} }; مثال 4 استخدم الأقواس دائمًا، لأن هذه الطريقة آمنة، والأمر مماثل بالنسبة للمصفوفات بكونها هياكل: float y[4][3] = { {1, 3, 5}, /* y[0][0], y[0][1], y[0][2] */ {2, 4, 6}, /* y[1][0], y[1][1], y[1][2] */ {3, 5, 7} /* y[2][0], y[2][1], y[2][2] */ }; مثال 5 تُهيّأ قيم الأسطر الثلاث الأولى كاملةً من y، ويبقى السطر الرابع y[3] غير مُهيّأ. تُسند لجميع الكائنات ذات المدة الساكنة قيمٌ أولية ضمنية تلقائية إذا لم يوجد أي قيمة أولية لها، ويكون أثر القيمة الأولية التلقائية الضمنية مماثلًا لأثر إسناد القيمة 0 الثابتة، وهذا الأمر شائع الاستخدام، وتفترض معظم برامج لغة سي نتيجةً لذلك أن الكائنات الخارجية والكائنات الساكنة الداخلية تبدأ بالقيمة صفر. تُضمن عملية التهيئة للكائنات ذات المدة التلقائية فقط في حالة وجود تعليمتها المركبة "في الأعلى"، إذ قد يتسبب الانتقال إلى أحد الكائنات فورًا بعدم حصول عملية التهيئة وهذا الأمر غير مستحب ويجب تجنبه. يشير المعيار بصراحة إلى أن وجود القيم الأولية في التصريح ضمن تعليمات switch لن يكون مفيدًا، لأن التصريح لا يُصنف بكونه تعليمة، ويمكن عنونة label التعليمة فقط، ونتيجةً لذلك فلا يمكن للقيم الأولية في تعليمات switch أن تُنفّذ لأن كتلة الشيفرة البرمجية التي تحتويها يجب أن تلي ذكر التصاريح. يمكن أن يُستخدم التصريح داخل دالة ما (نطاق مرتبط بكتلة الدالة) للإشارة إلى كائن ذي ربطٍ خارجي External linkage أو ربط داخلي Internal linkage باستخدام عدّة طرق تطرقنا إليها في مقال الربط والنطاق وهناك مزيدٌ من الطرق التي سنتطرق إليها لاحقًا. إذا اتبعت الطرق السابقة (التي من المستبعد أن تتحقق من قبيل الصدفة)، فلا يمكنك تهيئة الكائن على أنه جزء من التصريح، وإليك الطريقة الوحيدة التي تستطيع تحقيق ذلك بها: int x; /* ربط خارجي */ main(){ extern int x = 5; /* استخدام ممنوع */ } لم يكشف مصرّفنا التهيئة الممنوعة في هذا المثال أيضًا. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: الماكرو Macro والمعالج المسبق Preprocessor في لغة سي C المقال السابق: هياكل البيانات: الاتحادات Unions وحقول البتات Bitfields والمعددات Eums في لغة سي C هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C -
 تطرقنا في المقال السابق إلى الهياكل وبعض الهياكل الشائعة، مثل الأشجار والقوائم المرتبطة، وننتقل الآن إلى الاتحادات وحقول البتات والمعددات ونتكلم عن استعمال وخصائص كل منها. الاتحادات Unions لن تستغرق الاتحادات Unions وقتًا طويلًا لشرحها، فهي تشابه الهياكل بفرق أنك لا تستخدم الكلمة المفتاحية struct بل تستخدم union، وتعمل الاتحادات بالطريقة ذاتها التي تعمل بها الهياكل structures بفرق أن أعضائها مُخزنون على كتلة تخزينية واحدة بعكس أعضاء الهياكل التي تُخزن على كتل تخزينية متفرقة متعاقبة، ولكن ما الذي يفيدنا هذا الأمر؟ تدفعنا الحاجة في بعض الأحيان إلى استخدام الهياكل بهدف تخزين قيم مختلفة بأنواع مختلفة وبأوقاتٍ مختلفة مع المحافظة قدر الإمكان على مساحة التخزين وعدم هدر الموارد؛ في حين يمكننا باستخدام الاتحادات تحديد النوع الذي ندخله إليها والتأكد من استرجاع القيمة بنوعها المناسب فيما بعد. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ union { float u_f; int u_i; }var; var.u_f = 23.5; printf("value is %f\n", var.u_f); var.u_i = 5; printf("value is %d\n", var.u_i); exit(EXIT_SUCCESS); } مثال 1 إذا أضفنا قيمةً من نوع float إلى الاتحاد في مثالنا السابق، ثم استعدناه على أنه قيمةٌ من نوع int، فسنحصل على قيمة غير معروفة، لأن النوعان يُخزنان على نحوٍ مختلف وأضف على ذلك أنهما من أطوالٍ مختلفة؛ فالقيمة من نوع int ستكون غالبًا تمثيل الآلة (الحاسوب) لبتات float منخفضة الترتيب، ولربما ستشكل جزءًا من قيمة float العشرية (ما بعد الفاصلة). ينص المعيار على اعتماد النتيجة في هذه الحالة على تعريف التطبيق (وليست سلوكًا غير معرفًا)، والنتيجة معرفةٌ من المعيار في حالة واحدة، ألا وهي أن يكون لبعض أعضاء الاتحاد هياكل ذات "سلسلة مبدئية مشتركة common initial sequence"، أي أن لأول عضو من كل هيكل نوع متوافق compatible type، أو من الطول ذاته في حالة حقول البتات bitfields، ويوافق اتحادنا الشروط التي ذكرناها، وبالتالي يمكننا استخدام السلسلة المبدئية المشتركة على نحوٍ تبادلي، يا لحظنا الرائع. يعمل مصرّف لغة سي على حجز المساحة اللازمة لأكبر عضو ضمن الاتحاد لا أكثر (بعنوان مناسب إن أمكن)، أي لا يوجد هناك أي تفقد للتأكد من أن استخدام الأعضاء صائب فهذه مهمتك، وستكتشف عاجلًا أم آجلًا إذا فشلت في تحقيق هذه المهمة. تبدأ أعضاء الاتحاد من عنوان التخزين ذاته (من المضمون أنه لا يوجد هناك أي فراغات بين أيٍ من الأعضاء). يُعد تضمين الاتحاد في هيكل من أكثر الطرق شيوعًا لتذكر طريقة عمل الاتحاد، وذلك باستخدام عضو آخر من الهيكل ذاته ليدل على نوع الشيء الموجود في الاتحاد. إليك مثالًا عمّا سيبدو ذلك: #include <stdio.h> #include <stdlib.h> /* شيفرة للأنواع في الاتحاد */ #define FLOAT_TYPE 1 #define CHAR_TYPE 2 #define INT_TYPE 3 struct var_type{ int type_in_union; union{ float un_float; char un_char; int un_int; }vt_un; }var_type; void print_vt(void){ switch(var_type.type_in_union){ default: printf("Unknown type in union\n"); break; case FLOAT_TYPE: printf("%f\n", var_type.vt_un.un_float); break; case CHAR_TYPE: printf("%c\n", var_type.vt_un.un_char); break; case INT_TYPE: printf("%d\n", var_type.vt_un.un_int); break; } } main(){ var_type.type_in_union = FLOAT_TYPE; var_type.vt_un.un_float = 3.5; print_vt(); var_type.type_in_union = CHAR_TYPE; var_type.vt_un.un_char = 'a'; print_vt(); exit(EXIT_SUCCESS); } مثال 2 يوضح المثال السابق أيضًا استخدام عامل النقطة للوصول إلى ما داخل الهياكل أو الاتحادات التي تحتوي على هياكل أو اتحادات أخرى بدورها، تسمح لك بعض مصرفات لغة سي الحالية بإهمال بعض الأجزاء من أسماء الكائنات المُدمجة شرط ألا يتسبب ذلك بجعل الاسم غامض، فعلى سبيل المثال يسمح استخدام الاسم الواضح var_type.un_int للمصرف بمعرفة ما تقصده، إلا أن هذا غير مسموح في المعيار. لا يمكن مقارنة الهياكل بحثًا عن المساواة فيما بينها ويقع اللوم على الاتحادات، إذ أن احتمالية احتواء هيكل ما على اتحاد يجعل من مهمة المقارنة مهمةً صعبة، إذ لا يمكن للمصرّف أن يعرف ما الذي يحويه الاتحاد في الوقت الحالي مما لا يسمح له بإجراء عملية المقارنة. قد يبدو الكلام السابق صعب الفهم وغير دقيق بنسبة 100%، إذ أن معظم الهياكل لا تحتوي على اتحادات، ولكن هناك مشكلة فلسفية بخصوص القصد من كلمة "مساواة" عندما نُسقطها على الهياكل. بغض النظر، تمنح الاتحادات عذرًا مناسبًا للمعيار بتجنبه لأي مشاكل بواسطة عدم دعمه لمقارنة الهياكل. حقول البتات Bitfields دعنا نلقي نظرةً على حقول البتات بما أننا نتكلم عن موضوع هياكل البيانات، إذ يمكن تعريفها فقط بداخل هيكل أو اتحاد، وتسمح لك حقول البتات بتحديد بعض الكائنات الصغيرة بحسب طول بتات محدد، إلا أن فائدتها محدودةٌ ولا تُستخدم إلا في حالات نادرة، ولكننا سنتطرق إلى الموضوع بغض النظر عن ذلك. يوضح لك المثال استخدام حقول البتات: struct { /* كل حقل بسعة 4 بتات */ unsigned field1 :4; /* * حقل بسعة 3 بتات دون اسم * تسمح الحقول عديمة الاسم بالفراغات بين عناوين الذاكرة */ unsigned :3; /* * حقل بسعة بت واحد * تكون قيمته 0 أو 1- في نظام المتمم الثنائي */ signed field2 :1; /* محاذاة الحقل التالي مع وحدة التخزين */ unsigned :0; unsigned field3 :6; }full_of_fields; مثال 3 يمكن التلاعب والوصول إلى كل حقل بصورةٍ منفردة وكأنه عضو اعتيادي من هيكل ما، وتعني الكلمتان المفتاحيتان signed وunsigned ما هو متوقع، إلا أنه يجدر بالذكر أن حقلًا بحجم 1 بت ذا إشارة سيأخذ واحدةً من القيمتين 0 أو -1 وذلك في آلة تعمل بنظام المتمم الثنائي، ويُسمح للتصريحات بأن تحتوي المؤهلين const أو volatile. تُستخدم حقول البتات بشكل رئيس إما للسماح بتحزيم مجموعة من البيانات بأقل مساحة، أو لتحديد الحقول ضمن ملفات بيانات خارجية. لا تقدم لغة سي أي ضمانات بخصوص ترتيب الحقول بكلمات الآلة التي تعمل عليها، لذا إذا كنت تريد استخدام حقول البتات للهدف الثاني، فسيصبح برنامجك غير قابل للتنقل ومعتمدًا على المصرّف الذي يصرف البرنامج أيضًا. ينص المعيار على أن الحقول مُحزّمة بما يدعى "وحدات تخزين"، التي تكون عادةً كلمات آلة. يُحدّد ترتيب التحزيم وفيما إذا كان سيتجاوز حقل البتات حاجز التخزين أم لا بحسب تعريف التطبيق، ونستخدم حقلًا بعرض صفر قبل الحقل الذي تريد تطبيق الحد عنده لإجبار الحقل على البقاء ضمن حدود وحدة التخزين. كن حذرًا عند استخدام حقول البتات، إذ يتطلب الأمر شيفرة وقت تشغيل run-time طويلة للتلاعب بهذه الأشياء، وقد ينتج ذلك بتوفير الكثير من المساحة (أكثر من حاجتك). ليس لحقول البتات أي عناوين، وبالتالي لا يمكنك استخدام المؤشرات أو المصفوفات معها. المعددات enums تقع المُعدّدات enums تحت تصنيف "منجزة جزئيًا"، إذ ليست بأنواع مُعددة بصورٍ كاملة مثل لغة باسكال، ومهمتها الوحيدة هي مساعدتك في التخفيف من عدد تعليمات #define في برنامجك، إليك ما تبدو عليه: enum e_tag{ a, b, c, d=20, e, f, g=20, h }var; يمثل e_tag الوسم بصورةٍ مشابهة لما تكلمنا عنه في الهياكل والاتحادات، ويمثل var تعريفًا للمتغير. الأسماء المُعلنة بداخل المُعدد ثوابت من نوع int، إليك قيمها: a == 0 b == 1 c == 2 d == 20 e == 21 f == 22 g == 20 h == 21 تلاحظ أنه بغياب أي قيمة مُسندة للمتغيرات، تبدأ القيم من الصفر تصاعديًا، ويمكنك إسناد قيمة مخصصة إنذا أردت في البداية، إلا أن القيم التي ستتزايد بعدها ستكون من نوع عدد صحيح ثابت integral constant (كما سنرى لاحقًا)، وتُمثّل هذه القيمة بنوع int ومن الممكن أن تحمل عدة أسماء القيمة ذاتها. تُستخدم المُعدّدات للحصول على إصدار ملائم للنطاق Scope بدلًا من استخدام #define على النحو التالي: #define a 0 #define b 1 /* وهكذا دواليك */ إذ يتبع استخدام المعددات لقوانين نطاق لغة سي C، بينما تشمل تعليمات #define كامل نطاق الملف. قد لا تهمك هذه المعلومة، ولكن المعيار ينص على أن أنواع المعددات من نوع متوافق مع أنواع الأعداد الصحيحة بحسب تعريف التطبيق، لكن ما الذي يعنيه ذلك؟ لاحظ المثال التالي: enum ee{a,b,c}e_var, *ep; تسلك الأسماء a و b و c سلوك الأعداد الصحيحة الثابتة int عندما تستخدمها، و e_var من نوع enum ee و ep مؤشر يشير إلى المعدد ee. تعني متطلبات التوافقية بين الأنواع (بالإضافة لمشكلات أخرى) أن هناك نوع عدد صحيح ذو عنوان يمكن إسناده إلى ep من غير خرق أي من متطلبات التوافقية بين الأنواع للمؤشرات. المؤهلات والأنواع المشتقة تعد المصفوفات والهياكل والاتحادات "مشتقةٌ من derived from" (أي تحتوي) أنواعٍ أخرى، ولا يمكن لأي ممّا سبق أن تُشتق من أنواع غير مكتملة incomplete types، وهذا يعني أنه من غير الممكن للهيكل أو الاتحاد أن يحتوي مثالًا من نفسه، لأن نوعه غير مكتمل حتى ينتهي التصريح عنه، وبما أن المؤشر الذي يشير إلى نوع غير مكتمل ليس بنوع غير مكتمل بذات نفسه فمن الممكن استخدامه باشتقاق المصفوفات والهياكل والاتحادات. لا ينتقل التأهيل إلى النوع المُشتق إن كان أي من الأنواع التي اشتُق منها تحتوي على مؤهلات مثل const أو volatile، وهذا يعني أن الهيكل الذي يحتوي على كائن ذو مؤهل ثابت const لا يجعل من الهيكل بنفسه مؤهلًا بهذا المؤهل، ويمكن لأي عضو غير ثابت أن يُعدّل عليه بداخل الهيكل، وهذا ما هو متوقع، إلا أن المعيار ينص على أن أي نوع مشتق يحتوي على نوع مؤهل باستخدام const (أو أي نوع داخلي تعاودي) لا يمكن التعديل عليه، فالهيكل الذي يحتوي الثابت لا يمكن وضعه على الطرف الأيسر من عامل الإسناد. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: تهيئة المتغيرات وأنواع البيانات في لغة سي C المقال السابق: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C
تطرقنا في المقال السابق إلى الهياكل وبعض الهياكل الشائعة، مثل الأشجار والقوائم المرتبطة، وننتقل الآن إلى الاتحادات وحقول البتات والمعددات ونتكلم عن استعمال وخصائص كل منها. الاتحادات Unions لن تستغرق الاتحادات Unions وقتًا طويلًا لشرحها، فهي تشابه الهياكل بفرق أنك لا تستخدم الكلمة المفتاحية struct بل تستخدم union، وتعمل الاتحادات بالطريقة ذاتها التي تعمل بها الهياكل structures بفرق أن أعضائها مُخزنون على كتلة تخزينية واحدة بعكس أعضاء الهياكل التي تُخزن على كتل تخزينية متفرقة متعاقبة، ولكن ما الذي يفيدنا هذا الأمر؟ تدفعنا الحاجة في بعض الأحيان إلى استخدام الهياكل بهدف تخزين قيم مختلفة بأنواع مختلفة وبأوقاتٍ مختلفة مع المحافظة قدر الإمكان على مساحة التخزين وعدم هدر الموارد؛ في حين يمكننا باستخدام الاتحادات تحديد النوع الذي ندخله إليها والتأكد من استرجاع القيمة بنوعها المناسب فيما بعد. إليك مثالًا عن ذلك: #include <stdio.h> #include <stdlib.h> main(){ union { float u_f; int u_i; }var; var.u_f = 23.5; printf("value is %f\n", var.u_f); var.u_i = 5; printf("value is %d\n", var.u_i); exit(EXIT_SUCCESS); } مثال 1 إذا أضفنا قيمةً من نوع float إلى الاتحاد في مثالنا السابق، ثم استعدناه على أنه قيمةٌ من نوع int، فسنحصل على قيمة غير معروفة، لأن النوعان يُخزنان على نحوٍ مختلف وأضف على ذلك أنهما من أطوالٍ مختلفة؛ فالقيمة من نوع int ستكون غالبًا تمثيل الآلة (الحاسوب) لبتات float منخفضة الترتيب، ولربما ستشكل جزءًا من قيمة float العشرية (ما بعد الفاصلة). ينص المعيار على اعتماد النتيجة في هذه الحالة على تعريف التطبيق (وليست سلوكًا غير معرفًا)، والنتيجة معرفةٌ من المعيار في حالة واحدة، ألا وهي أن يكون لبعض أعضاء الاتحاد هياكل ذات "سلسلة مبدئية مشتركة common initial sequence"، أي أن لأول عضو من كل هيكل نوع متوافق compatible type، أو من الطول ذاته في حالة حقول البتات bitfields، ويوافق اتحادنا الشروط التي ذكرناها، وبالتالي يمكننا استخدام السلسلة المبدئية المشتركة على نحوٍ تبادلي، يا لحظنا الرائع. يعمل مصرّف لغة سي على حجز المساحة اللازمة لأكبر عضو ضمن الاتحاد لا أكثر (بعنوان مناسب إن أمكن)، أي لا يوجد هناك أي تفقد للتأكد من أن استخدام الأعضاء صائب فهذه مهمتك، وستكتشف عاجلًا أم آجلًا إذا فشلت في تحقيق هذه المهمة. تبدأ أعضاء الاتحاد من عنوان التخزين ذاته (من المضمون أنه لا يوجد هناك أي فراغات بين أيٍ من الأعضاء). يُعد تضمين الاتحاد في هيكل من أكثر الطرق شيوعًا لتذكر طريقة عمل الاتحاد، وذلك باستخدام عضو آخر من الهيكل ذاته ليدل على نوع الشيء الموجود في الاتحاد. إليك مثالًا عمّا سيبدو ذلك: #include <stdio.h> #include <stdlib.h> /* شيفرة للأنواع في الاتحاد */ #define FLOAT_TYPE 1 #define CHAR_TYPE 2 #define INT_TYPE 3 struct var_type{ int type_in_union; union{ float un_float; char un_char; int un_int; }vt_un; }var_type; void print_vt(void){ switch(var_type.type_in_union){ default: printf("Unknown type in union\n"); break; case FLOAT_TYPE: printf("%f\n", var_type.vt_un.un_float); break; case CHAR_TYPE: printf("%c\n", var_type.vt_un.un_char); break; case INT_TYPE: printf("%d\n", var_type.vt_un.un_int); break; } } main(){ var_type.type_in_union = FLOAT_TYPE; var_type.vt_un.un_float = 3.5; print_vt(); var_type.type_in_union = CHAR_TYPE; var_type.vt_un.un_char = 'a'; print_vt(); exit(EXIT_SUCCESS); } مثال 2 يوضح المثال السابق أيضًا استخدام عامل النقطة للوصول إلى ما داخل الهياكل أو الاتحادات التي تحتوي على هياكل أو اتحادات أخرى بدورها، تسمح لك بعض مصرفات لغة سي الحالية بإهمال بعض الأجزاء من أسماء الكائنات المُدمجة شرط ألا يتسبب ذلك بجعل الاسم غامض، فعلى سبيل المثال يسمح استخدام الاسم الواضح var_type.un_int للمصرف بمعرفة ما تقصده، إلا أن هذا غير مسموح في المعيار. لا يمكن مقارنة الهياكل بحثًا عن المساواة فيما بينها ويقع اللوم على الاتحادات، إذ أن احتمالية احتواء هيكل ما على اتحاد يجعل من مهمة المقارنة مهمةً صعبة، إذ لا يمكن للمصرّف أن يعرف ما الذي يحويه الاتحاد في الوقت الحالي مما لا يسمح له بإجراء عملية المقارنة. قد يبدو الكلام السابق صعب الفهم وغير دقيق بنسبة 100%، إذ أن معظم الهياكل لا تحتوي على اتحادات، ولكن هناك مشكلة فلسفية بخصوص القصد من كلمة "مساواة" عندما نُسقطها على الهياكل. بغض النظر، تمنح الاتحادات عذرًا مناسبًا للمعيار بتجنبه لأي مشاكل بواسطة عدم دعمه لمقارنة الهياكل. حقول البتات Bitfields دعنا نلقي نظرةً على حقول البتات بما أننا نتكلم عن موضوع هياكل البيانات، إذ يمكن تعريفها فقط بداخل هيكل أو اتحاد، وتسمح لك حقول البتات بتحديد بعض الكائنات الصغيرة بحسب طول بتات محدد، إلا أن فائدتها محدودةٌ ولا تُستخدم إلا في حالات نادرة، ولكننا سنتطرق إلى الموضوع بغض النظر عن ذلك. يوضح لك المثال استخدام حقول البتات: struct { /* كل حقل بسعة 4 بتات */ unsigned field1 :4; /* * حقل بسعة 3 بتات دون اسم * تسمح الحقول عديمة الاسم بالفراغات بين عناوين الذاكرة */ unsigned :3; /* * حقل بسعة بت واحد * تكون قيمته 0 أو 1- في نظام المتمم الثنائي */ signed field2 :1; /* محاذاة الحقل التالي مع وحدة التخزين */ unsigned :0; unsigned field3 :6; }full_of_fields; مثال 3 يمكن التلاعب والوصول إلى كل حقل بصورةٍ منفردة وكأنه عضو اعتيادي من هيكل ما، وتعني الكلمتان المفتاحيتان signed وunsigned ما هو متوقع، إلا أنه يجدر بالذكر أن حقلًا بحجم 1 بت ذا إشارة سيأخذ واحدةً من القيمتين 0 أو -1 وذلك في آلة تعمل بنظام المتمم الثنائي، ويُسمح للتصريحات بأن تحتوي المؤهلين const أو volatile. تُستخدم حقول البتات بشكل رئيس إما للسماح بتحزيم مجموعة من البيانات بأقل مساحة، أو لتحديد الحقول ضمن ملفات بيانات خارجية. لا تقدم لغة سي أي ضمانات بخصوص ترتيب الحقول بكلمات الآلة التي تعمل عليها، لذا إذا كنت تريد استخدام حقول البتات للهدف الثاني، فسيصبح برنامجك غير قابل للتنقل ومعتمدًا على المصرّف الذي يصرف البرنامج أيضًا. ينص المعيار على أن الحقول مُحزّمة بما يدعى "وحدات تخزين"، التي تكون عادةً كلمات آلة. يُحدّد ترتيب التحزيم وفيما إذا كان سيتجاوز حقل البتات حاجز التخزين أم لا بحسب تعريف التطبيق، ونستخدم حقلًا بعرض صفر قبل الحقل الذي تريد تطبيق الحد عنده لإجبار الحقل على البقاء ضمن حدود وحدة التخزين. كن حذرًا عند استخدام حقول البتات، إذ يتطلب الأمر شيفرة وقت تشغيل run-time طويلة للتلاعب بهذه الأشياء، وقد ينتج ذلك بتوفير الكثير من المساحة (أكثر من حاجتك). ليس لحقول البتات أي عناوين، وبالتالي لا يمكنك استخدام المؤشرات أو المصفوفات معها. المعددات enums تقع المُعدّدات enums تحت تصنيف "منجزة جزئيًا"، إذ ليست بأنواع مُعددة بصورٍ كاملة مثل لغة باسكال، ومهمتها الوحيدة هي مساعدتك في التخفيف من عدد تعليمات #define في برنامجك، إليك ما تبدو عليه: enum e_tag{ a, b, c, d=20, e, f, g=20, h }var; يمثل e_tag الوسم بصورةٍ مشابهة لما تكلمنا عنه في الهياكل والاتحادات، ويمثل var تعريفًا للمتغير. الأسماء المُعلنة بداخل المُعدد ثوابت من نوع int، إليك قيمها: a == 0 b == 1 c == 2 d == 20 e == 21 f == 22 g == 20 h == 21 تلاحظ أنه بغياب أي قيمة مُسندة للمتغيرات، تبدأ القيم من الصفر تصاعديًا، ويمكنك إسناد قيمة مخصصة إنذا أردت في البداية، إلا أن القيم التي ستتزايد بعدها ستكون من نوع عدد صحيح ثابت integral constant (كما سنرى لاحقًا)، وتُمثّل هذه القيمة بنوع int ومن الممكن أن تحمل عدة أسماء القيمة ذاتها. تُستخدم المُعدّدات للحصول على إصدار ملائم للنطاق Scope بدلًا من استخدام #define على النحو التالي: #define a 0 #define b 1 /* وهكذا دواليك */ إذ يتبع استخدام المعددات لقوانين نطاق لغة سي C، بينما تشمل تعليمات #define كامل نطاق الملف. قد لا تهمك هذه المعلومة، ولكن المعيار ينص على أن أنواع المعددات من نوع متوافق مع أنواع الأعداد الصحيحة بحسب تعريف التطبيق، لكن ما الذي يعنيه ذلك؟ لاحظ المثال التالي: enum ee{a,b,c}e_var, *ep; تسلك الأسماء a و b و c سلوك الأعداد الصحيحة الثابتة int عندما تستخدمها، و e_var من نوع enum ee و ep مؤشر يشير إلى المعدد ee. تعني متطلبات التوافقية بين الأنواع (بالإضافة لمشكلات أخرى) أن هناك نوع عدد صحيح ذو عنوان يمكن إسناده إلى ep من غير خرق أي من متطلبات التوافقية بين الأنواع للمؤشرات. المؤهلات والأنواع المشتقة تعد المصفوفات والهياكل والاتحادات "مشتقةٌ من derived from" (أي تحتوي) أنواعٍ أخرى، ولا يمكن لأي ممّا سبق أن تُشتق من أنواع غير مكتملة incomplete types، وهذا يعني أنه من غير الممكن للهيكل أو الاتحاد أن يحتوي مثالًا من نفسه، لأن نوعه غير مكتمل حتى ينتهي التصريح عنه، وبما أن المؤشر الذي يشير إلى نوع غير مكتمل ليس بنوع غير مكتمل بذات نفسه فمن الممكن استخدامه باشتقاق المصفوفات والهياكل والاتحادات. لا ينتقل التأهيل إلى النوع المُشتق إن كان أي من الأنواع التي اشتُق منها تحتوي على مؤهلات مثل const أو volatile، وهذا يعني أن الهيكل الذي يحتوي على كائن ذو مؤهل ثابت const لا يجعل من الهيكل بنفسه مؤهلًا بهذا المؤهل، ويمكن لأي عضو غير ثابت أن يُعدّل عليه بداخل الهيكل، وهذا ما هو متوقع، إلا أن المعيار ينص على أن أي نوع مشتق يحتوي على نوع مؤهل باستخدام const (أو أي نوع داخلي تعاودي) لا يمكن التعديل عليه، فالهيكل الذي يحتوي الثابت لا يمكن وضعه على الطرف الأيسر من عامل الإسناد. ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book. اقرأ أيضًا المقال التالي: تهيئة المتغيرات وأنواع البيانات في لغة سي C المقال السابق: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C بنية برنامج لغة سي C العوامل في لغة سي C- 1 تعليق
-
- 1
-

-
 تحدثنا في مقال سابق عن المؤشرات Pointers في لغة سي C وتعرفنا عليها بوصفها موضوعًا مهمًا للغاية في لغة سي، وسنكمل في هذا المقال الحديث عنها وكيفية التعامل معها مثل استخدامها ضمن التعابير التي تحوي عوامل الإسناد والزيادة والنقصان بالإضافة لأمثلة عملية، فإن لم تطلع على الفصل المذكور، فارجع له أولًا لارتباط المقالين مع بعضهما. مؤشرات الدوال من المفيد أن يكون لدينا إمكانية استخدام المؤشرات على الدوال، كما أن التصريح عن هذا النوع من المؤشرات سهلٌ عن طريق كتابته وكأنك تصرّح عن دالة على النحو التالي: int func(int a, float b); ومن ثم إضافة قوسين حول اسم الدالة والرمز * أمامه، مما يدل على أن هذا التصريح يعود لمؤشر. لاحظ أن التخلي عن القوسين يتسبب بالتصريح عن دالة تُعيد مؤشرًا حسب قوانين الأسبقية: /* int دالةٌ تعيد مؤشرًا إلى قيمة صحيحة */ int *func(int a, float b); /* مؤشر إلى دالة تعيد قيمة صحيحة int*/ int (*func)(int a, float b); حالما تحصل على المؤشر تستطيع إسناد العنوان إلى النوع المحدد للدالة باستخدام اسمها، إذ يُحوَّل اسم الدالة إلى عنوان في أي تعبير تحتويه بصورةٍ مشابهة لاسم المصفوفة، ويمكنك استدعاء الدالة في هذه الحالة باستخدام إحدى الطريقتين: (*func)(1,2); /* or */ func(1,2); تفضّل لغة سي المعيارية الطريقة الثانية، إليك مثالًا بسيطًا عنها: #include <stdio.h> #include <stdlib.h> void func(int); main(){ void (*fp)(int); fp = func; (*fp)(1); fp(2); exit(EXIT_SUCCESS); } void func(int arg){ printf("%d\n", arg); } [مثال 1] يمكنك توظيف مصفوفة من المؤشرات التي تشير إلى مصفوفات مختلفة إذا أردت كتابة آلةً محدودة الحالات finite state machine، وسيبدو التصريح عنها مماثلًا لما يلي: void (*fparr[])(int, float) = { /* المهيئات initializers*/ }; /* استدعاء أحد القيم */ fparr[5](1, 3.4); [مثال 17.5] ولكننا لن نتكلم عن هذه الطريقة. المؤشرات في التعابير بعد إدخال الأنواع المؤهّلة qualified types ومفهوم الأنواع غير المُكتملة incomplete types مع استخدام مؤشر الفراغ * void، أصبح هناك بعض القواعد المعقدة عن مزج المؤشرات وما هو مسموحٌ لك فعليًا في العمليات الحسابية معها. قد تستطيع تجاوز هذه القواعد دون أي مشكلات، لأن معظمها "بديهي" ولكننا سنتكلم عنها بغض النظر عن ذلك، ولا شكّ أنك سترغب بقراءة معيار لغة سي لتحرّي الدقة، لأن ما سيأتي هو تفسير بلغة بسيطة لما ورد في المعيار. لعلك لا تعلم بدقة ما الذي يقصده المعيار عندما يذكر مصطلحي الكائنات objects والأنواع غير المُكتملة incomplete types، فقد استخدمنا هذه المصطلحات حتى الآن بتهاون. يُعد الكائن جزءًا من البيانات المخزنة التي يمكن تفسير محتوياتها إلى قيمة، وبناءً على ذلك فالدالة ليست كائنًا؛ بينما يُعرف النوع غير المكتمل بكونه نوعًا معروفًا ذا اسم معروف لكن دون حجم محدّد بعد، ويمكنك الحصول على هذا النوع عن طريق وسيلتين، هما: التصريح عن مصفوفة دون تحديد حجمها: int x[]; ويجب توفير المزيد من المعلومات بخصوص هذه المصفوفة في التعريف لاحقًا، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. التصريح عن هيكل Structure أو اتحاد Union دون التعريف عن محتوياته، ويجب التعريف عن محتوياته لاحقًا في هذه الحالة، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. سنناقش المزيد عن الأنواع غير المكتملة لاحقًا. التحويلات يمكن تحويل المؤشرات التي تشير إلى void إلى مؤشرات تشير إلى أي كائن أو نوع غير مكتمل، وتحصل على قيمةٍ مساوية لقيمة المؤشر الأصل بعد تحويل مؤشر يشير إلى كائن أو نوع غير مكتمل إلى مؤشر من نوع * void: int i; int *ip; void *vp; ip = &i; vp = ip; ip = vp; if(ip != &i) printf("Compiler error\n"); يمكن تحويل مؤشر من نوع غير مؤهّل unqualified إلى مؤشر من نوع مؤهل، ولكن العكس غير ممكن، وستكون قيمة المؤشرين متكافئتين: int i; int *ip; const int *cpi; ip = &i; cpi = ip; /* مسموح*/ if(cpi != ip) printf("Compiler error\n"); ip = cpi; /* ممنوع */ لا يساوي مؤشر ثابت فارغ null pointer constant (سنتكلم عن هذا النوع لاحقًا) أيّ مؤشر يشير لأي كائن أو دالة. العمليات الحسابية يمكن للتعابير Expressions أن تجمع (أو تطرح، وهو ما يكافئ جمع قيم سالبة) أعدادًا صحيحةً إلى قيمة المؤشرات بغض النظر عن نوع الكائن الذي تشير إليه، وتكون النتيجة مماثلةً لنوع المؤشر؛ وفي حالة إضافة القيمة n، فسيشير المؤشر إلى العنصر الذي يلي العنصر السابق ضمن المصفوفة بمقدار n، والاستخدام الأكثر شيوعًا لهذه الميزة هي بإضافة 1 إلى المؤشر لتمريره على المصفوفة من بدايتها إلى نهايتها، إلا أن استخدام قيم مغايرة للقيمة 1 والطرح بدلًا من الجمع ممكن. نحصل على حالة طفحان overflow أو طفحان تجاوز الحد الأدنى underflow إذا كان المؤشر الناتج عن عملية الجمع يشير إلى ما يسبق المصفوفة أو ما يلي العنصر المعدوم الأخير للمصفوفة، وهذا يعني أن النتيجة غير مُعرّفة. يملك العنصر الأخير الزائد في المصفوفة عنوانًا صالحًا، ويؤكد المعيار لنا ذلك، إلا أنه ليس من المفترض أن تحاول الوصول إلى ذلك العنصر، وعنوانه موجودٌ للتأكد من وجوده لتجنُّب الوقوع في حالة طفحان. تعمّدنا استخدام الكلمة "تعبير" عوضًا عن قولنا "إضافة قيمة إلى المؤشر بنفسه"، إلا أنه يمكنك فعل ذلك شرط ألا يكون المؤشر مؤهلًا بالكلمة المفتاحية "const"، ويكافئ طبعًا استخدام عامل الزيادة "++" وعامل النقصان "--" جمع أو طرح واحد. يمكن طرح مؤشرين من أنواع متوافقة compatible types أو غير مؤهلة من بعضهما بعضًا، وتكون النتيجة من النوع "ptrdiff_t"، المعرّف في ملف الترويسة stddef.h، إلا أنه يجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها، أو على الأقل أن يشير واحدًا منها إلى ما بعد أو قبل المصفوفة، وإلا سنحصل على سلوك غير محدد، وتكون نتيجة عملية الطرح هي عدد العناصر التي تفصل المؤشرين ضمن المصفوفة. إليك المثال التالي: int x[100]; int *pi, *cpi = &x[99]; /* x إلى العنصر الأخير من ال cpi يشير*/ pi = x; if((cpi - pi) != 99) printf("Error\n"); pi = cpi; pi++; /* increment past end of x */ if((pi - cpi) != 1) printf("Error\n"); التعابير العلاقية تسمح لنا التعابير العلاقية بالمقارنة بين المؤشرات، لكن يمكنك فقط مقارنة: المؤشرات التي تشير لكائنات ذات أنواع متوافقة مع بعضها الآخر. المؤشرات التي تشير لأنواع غير مكتملة متوافقة مع بعضها الآخر. ولا يهم إذا كانت الأنواع المُشارة إليها مؤهلة أو غير مؤهلة. إذا تساوت قيم مؤشرين، فهذا يعني أن المؤشرين يشيران إلى الشيء ذاته، سواءٌ كان هذا الشيء كائنًا أو عنصرًا غير موجودًا خارج مصفوفة ما (راجع فقرة العمليات الحسابية أعلاه). تقدِّم العوامل العلاقية ">" و "=>" وغيرها النتيجة التي تتوقعها عند استخدامها مع المؤشرات ضمن نفس المصفوفة، وإذا كانت قيمة أحد المؤشرات أقل مقارنةً مع الآخر، فهذا يعني أنه يشير لقيمةٍ أقرب لمقدمة المصفوفة (العنصر ذو الدليل index الأقل). يمكن إسناد مؤشر فارغ ثابت إلى مؤشر آخر، وسيكون متساوي مع مؤشر فارغ ثابت آخر إذا فحصناهما باستخدام عامل المقارنة، بينما لن يتساوى مؤشر فارغ ثابت أو غير ثابت عند مقارنتهما مع أي مؤشر آخر يشير لشيءٍ ما. الإسناد يمكنك استخدام المؤشرات مع عوامل الإسناد، شرط أن يستوفي الاستخدام الشروط التالية: يجب أن يكون الجانب الأيسر من عامل الإسناد مؤشرًا، وأن يكون الجانب الأيمن منه مؤشرًا فارغًا ثابتًا. يجب أن يكون مُعاملٌ من المعاملات مؤشرًا يشير إلى كائن أو نوع غير مُكتمل، والمعامل الآخر مؤشرًا إلى الفراغ "void"، سواءٌ كان مؤهلًا أو لا. يُعدّ المُعاملان مؤشرين لأنواع متوافقة سواءٌ كانت مؤهلةً أم لا. يجب أن يكون للنوع المُشار إليه في الحالتين الأخيرتين على الجانب الأيسر من عامل الإسناد النوع ذاته من المؤهلات على الأقل، والموافق لمؤهل النوع الواقع على الجانب الأيمن من عامل الإسناد، أو أكثر من مؤهل مماثل. يمكنك إذًا إسناد مؤشر يشير إلى قيمة صحيحة "int" إلى مؤشر يشير إلى قيمة من نوع عدد صحيح ثابت "const int" (مؤهلات النوع الأيسر تزيد عن مؤهلات النوع الأيمن) ولكن لا يمكنك إسناد مؤشر يشير إلى "const int" إلى مؤشر يشير إلى "int"، والأمر منطقي جدًا إذا أخذت لحظةً للتفكير به. يمكن استخدام العاملين "=+" و "=-" مع المؤشرات طالما أن الجانب الأيسر من العامل مؤشر يشير إلى كائن، والجانب الأيمن من العامل تعبير ينتج قيمةً صحيحة integral، وتوضح قوانين العمليات الحسابية في الفقرات السابقة ما سيحصل في هذه الحالة. العامل الشرطي وضّحنا سابقًا سلوك العامل الشرطي conditional operator عند استخدامه مع المؤشرات. المصفوفات وعامل & والدوال ذكرنا عدّة مرات أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول، وقلنا أن الاستثناء الوحيد هو عند استخدام اسم المصفوفة مع عامل "sizeof"، وهو عاملٌ مهمٌ إذا أردت استخدام الدالة "malloc"، إلا أن هناك استثناءً آخر، ألا وهو عندما يكون اسم المصفوفة مُعاملًا لعامل "&" (عنوان العامل)، إذ يُحوّل اسم المصفوفة هنا إلى عنوان كامل المصفوفة بدلًا من عنوان عنصرها الأول عادةً، لكن ما الفرق؟ لعلك تعتقد أن العنوانين متماثلان، إلا أن الفرق هو نوعهما، فبالنسبة لمصفوفةٍ تحتوي "n" عنصر بنوع "T"، يكون عنوان عنصرها الأول من نوع "مؤشر إلى T"، بينما يكون عنوان كامل المصفوفة من نوع " مؤشر إلى مصفوفة من n عنصر من نوع T"، وهو مختلف جدًا. إليك مثالًا عن ذلك: int ar[10]; int *ip; int (*ar10i)[10]; /* مؤشر لمصفوفة من 10 عناصر صحيحة */ ip = ar; /* عنوان العنصر الأول */ ip = &ar[0]; /* عنوان العنصر الأول */ ar10i = &ar; /* عنوان كامل المصفوفة */ أين تُستخدم المؤشرات إلى المصفوفات؟ في الحقيقة ليس غالبًا، إلا أننا نعلم أن التصريح عن مصفوفة متعددة الأبعاد هو في الحقيقة تصريح عن مصفوفة مصفوفات. إليك مثالًا يستخدم هذا المفهوم (إلا أن فهم ما يفعل يقع على عاتقك)، وليس من الشائع استخدام هذه الطريقة: int ar2d[5][4]; int (*ar4i)[4]; /* مؤشر إلى مصفوفة من 4 أعداد صحيحة */ for(ar4i= ar2d; ar4i < &(ar2d[5]); ar4i++) (*ar4i)[2] = 0; /* ar2d[n][2] = 0 */ ما قد يثير اهتمامك أكثر من عناوين المصفوفات هو ما الذي قد يحدث عندما نصرِّح عن دالة تأخذ مصفوفةً في أحد وسطائها. بالنظر إلى أن المصفوفة تحوّل إلى عنوان عنصرها الأول فحتى لو حاولت تمرير مصفوفة إلى دالة باستخدام اسم المصفوفة وسيطًا، فسينتهي بك الأمر بتمرير مؤشر إلى عنصر المصفوفة الأول. لكن ماذا لو صرّحت عن الدالة بكونها تأخذ وسيطًا من نوع "مصفوفة من نوع ما" على النحو التالي: void f(int ar[10]); ما الذي يحدث في هذه الحالة؟ قد تفاجئك الإجابة هنا، إذ أن المصرّف ينظر إلى السطر السابق ويقول لنفسه "سيكون هذا مؤشرًا لهذه المصفوفة" ويعيد كتابة الوسيط على أنه من نوع مؤشر، ووفقًا لذلك نجد أن التصريحات الثلاثة التالية متكافئة: void f(int ar[10]); void f(int *ar); void f(int ar[]); /* !حجم المصفوفة هنا لا علاقة له */ قد تضع يدك على رأسك بعد هذه المعلومة، لكن تمهّل! إليك بعض الأسئلة للتهدئة من غضبك وإحباطك: لم كانت المعلومة السابقة منطقية؟ لماذا تعمل التعابير بالصياغة [ar[5 أو أي صياغةٍ أخرى ضمن التصريح عن دالة، ثم داخل الدالة كما هو متوقعٌ منها؟ فكّر في الأسئلة السابقة، وستفهم استخدام المؤشرات مع المصفوفات بصورةٍ ممتازة عندما تتوصل لإجابة ترضيك. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C المقال السابق: عامل sizeof وحجز مساحات التخزين في لغة سي C المؤشرات Pointers في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C
تحدثنا في مقال سابق عن المؤشرات Pointers في لغة سي C وتعرفنا عليها بوصفها موضوعًا مهمًا للغاية في لغة سي، وسنكمل في هذا المقال الحديث عنها وكيفية التعامل معها مثل استخدامها ضمن التعابير التي تحوي عوامل الإسناد والزيادة والنقصان بالإضافة لأمثلة عملية، فإن لم تطلع على الفصل المذكور، فارجع له أولًا لارتباط المقالين مع بعضهما. مؤشرات الدوال من المفيد أن يكون لدينا إمكانية استخدام المؤشرات على الدوال، كما أن التصريح عن هذا النوع من المؤشرات سهلٌ عن طريق كتابته وكأنك تصرّح عن دالة على النحو التالي: int func(int a, float b); ومن ثم إضافة قوسين حول اسم الدالة والرمز * أمامه، مما يدل على أن هذا التصريح يعود لمؤشر. لاحظ أن التخلي عن القوسين يتسبب بالتصريح عن دالة تُعيد مؤشرًا حسب قوانين الأسبقية: /* int دالةٌ تعيد مؤشرًا إلى قيمة صحيحة */ int *func(int a, float b); /* مؤشر إلى دالة تعيد قيمة صحيحة int*/ int (*func)(int a, float b); حالما تحصل على المؤشر تستطيع إسناد العنوان إلى النوع المحدد للدالة باستخدام اسمها، إذ يُحوَّل اسم الدالة إلى عنوان في أي تعبير تحتويه بصورةٍ مشابهة لاسم المصفوفة، ويمكنك استدعاء الدالة في هذه الحالة باستخدام إحدى الطريقتين: (*func)(1,2); /* or */ func(1,2); تفضّل لغة سي المعيارية الطريقة الثانية، إليك مثالًا بسيطًا عنها: #include <stdio.h> #include <stdlib.h> void func(int); main(){ void (*fp)(int); fp = func; (*fp)(1); fp(2); exit(EXIT_SUCCESS); } void func(int arg){ printf("%d\n", arg); } [مثال 1] يمكنك توظيف مصفوفة من المؤشرات التي تشير إلى مصفوفات مختلفة إذا أردت كتابة آلةً محدودة الحالات finite state machine، وسيبدو التصريح عنها مماثلًا لما يلي: void (*fparr[])(int, float) = { /* المهيئات initializers*/ }; /* استدعاء أحد القيم */ fparr[5](1, 3.4); [مثال 17.5] ولكننا لن نتكلم عن هذه الطريقة. المؤشرات في التعابير بعد إدخال الأنواع المؤهّلة qualified types ومفهوم الأنواع غير المُكتملة incomplete types مع استخدام مؤشر الفراغ * void، أصبح هناك بعض القواعد المعقدة عن مزج المؤشرات وما هو مسموحٌ لك فعليًا في العمليات الحسابية معها. قد تستطيع تجاوز هذه القواعد دون أي مشكلات، لأن معظمها "بديهي" ولكننا سنتكلم عنها بغض النظر عن ذلك، ولا شكّ أنك سترغب بقراءة معيار لغة سي لتحرّي الدقة، لأن ما سيأتي هو تفسير بلغة بسيطة لما ورد في المعيار. لعلك لا تعلم بدقة ما الذي يقصده المعيار عندما يذكر مصطلحي الكائنات objects والأنواع غير المُكتملة incomplete types، فقد استخدمنا هذه المصطلحات حتى الآن بتهاون. يُعد الكائن جزءًا من البيانات المخزنة التي يمكن تفسير محتوياتها إلى قيمة، وبناءً على ذلك فالدالة ليست كائنًا؛ بينما يُعرف النوع غير المكتمل بكونه نوعًا معروفًا ذا اسم معروف لكن دون حجم محدّد بعد، ويمكنك الحصول على هذا النوع عن طريق وسيلتين، هما: التصريح عن مصفوفة دون تحديد حجمها: int x[]; ويجب توفير المزيد من المعلومات بخصوص هذه المصفوفة في التعريف لاحقًا، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. التصريح عن هيكل Structure أو اتحاد Union دون التعريف عن محتوياته، ويجب التعريف عن محتوياته لاحقًا في هذه الحالة، ويبقى النوع غير مُكتملًا حتى الوصول لنقطة التعريف. سنناقش المزيد عن الأنواع غير المكتملة لاحقًا. التحويلات يمكن تحويل المؤشرات التي تشير إلى void إلى مؤشرات تشير إلى أي كائن أو نوع غير مكتمل، وتحصل على قيمةٍ مساوية لقيمة المؤشر الأصل بعد تحويل مؤشر يشير إلى كائن أو نوع غير مكتمل إلى مؤشر من نوع * void: int i; int *ip; void *vp; ip = &i; vp = ip; ip = vp; if(ip != &i) printf("Compiler error\n"); يمكن تحويل مؤشر من نوع غير مؤهّل unqualified إلى مؤشر من نوع مؤهل، ولكن العكس غير ممكن، وستكون قيمة المؤشرين متكافئتين: int i; int *ip; const int *cpi; ip = &i; cpi = ip; /* مسموح*/ if(cpi != ip) printf("Compiler error\n"); ip = cpi; /* ممنوع */ لا يساوي مؤشر ثابت فارغ null pointer constant (سنتكلم عن هذا النوع لاحقًا) أيّ مؤشر يشير لأي كائن أو دالة. العمليات الحسابية يمكن للتعابير Expressions أن تجمع (أو تطرح، وهو ما يكافئ جمع قيم سالبة) أعدادًا صحيحةً إلى قيمة المؤشرات بغض النظر عن نوع الكائن الذي تشير إليه، وتكون النتيجة مماثلةً لنوع المؤشر؛ وفي حالة إضافة القيمة n، فسيشير المؤشر إلى العنصر الذي يلي العنصر السابق ضمن المصفوفة بمقدار n، والاستخدام الأكثر شيوعًا لهذه الميزة هي بإضافة 1 إلى المؤشر لتمريره على المصفوفة من بدايتها إلى نهايتها، إلا أن استخدام قيم مغايرة للقيمة 1 والطرح بدلًا من الجمع ممكن. نحصل على حالة طفحان overflow أو طفحان تجاوز الحد الأدنى underflow إذا كان المؤشر الناتج عن عملية الجمع يشير إلى ما يسبق المصفوفة أو ما يلي العنصر المعدوم الأخير للمصفوفة، وهذا يعني أن النتيجة غير مُعرّفة. يملك العنصر الأخير الزائد في المصفوفة عنوانًا صالحًا، ويؤكد المعيار لنا ذلك، إلا أنه ليس من المفترض أن تحاول الوصول إلى ذلك العنصر، وعنوانه موجودٌ للتأكد من وجوده لتجنُّب الوقوع في حالة طفحان. تعمّدنا استخدام الكلمة "تعبير" عوضًا عن قولنا "إضافة قيمة إلى المؤشر بنفسه"، إلا أنه يمكنك فعل ذلك شرط ألا يكون المؤشر مؤهلًا بالكلمة المفتاحية "const"، ويكافئ طبعًا استخدام عامل الزيادة "++" وعامل النقصان "--" جمع أو طرح واحد. يمكن طرح مؤشرين من أنواع متوافقة compatible types أو غير مؤهلة من بعضهما بعضًا، وتكون النتيجة من النوع "ptrdiff_t"، المعرّف في ملف الترويسة stddef.h، إلا أنه يجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها، أو على الأقل أن يشير واحدًا منها إلى ما بعد أو قبل المصفوفة، وإلا سنحصل على سلوك غير محدد، وتكون نتيجة عملية الطرح هي عدد العناصر التي تفصل المؤشرين ضمن المصفوفة. إليك المثال التالي: int x[100]; int *pi, *cpi = &x[99]; /* x إلى العنصر الأخير من ال cpi يشير*/ pi = x; if((cpi - pi) != 99) printf("Error\n"); pi = cpi; pi++; /* increment past end of x */ if((pi - cpi) != 1) printf("Error\n"); التعابير العلاقية تسمح لنا التعابير العلاقية بالمقارنة بين المؤشرات، لكن يمكنك فقط مقارنة: المؤشرات التي تشير لكائنات ذات أنواع متوافقة مع بعضها الآخر. المؤشرات التي تشير لأنواع غير مكتملة متوافقة مع بعضها الآخر. ولا يهم إذا كانت الأنواع المُشارة إليها مؤهلة أو غير مؤهلة. إذا تساوت قيم مؤشرين، فهذا يعني أن المؤشرين يشيران إلى الشيء ذاته، سواءٌ كان هذا الشيء كائنًا أو عنصرًا غير موجودًا خارج مصفوفة ما (راجع فقرة العمليات الحسابية أعلاه). تقدِّم العوامل العلاقية ">" و "=>" وغيرها النتيجة التي تتوقعها عند استخدامها مع المؤشرات ضمن نفس المصفوفة، وإذا كانت قيمة أحد المؤشرات أقل مقارنةً مع الآخر، فهذا يعني أنه يشير لقيمةٍ أقرب لمقدمة المصفوفة (العنصر ذو الدليل index الأقل). يمكن إسناد مؤشر فارغ ثابت إلى مؤشر آخر، وسيكون متساوي مع مؤشر فارغ ثابت آخر إذا فحصناهما باستخدام عامل المقارنة، بينما لن يتساوى مؤشر فارغ ثابت أو غير ثابت عند مقارنتهما مع أي مؤشر آخر يشير لشيءٍ ما. الإسناد يمكنك استخدام المؤشرات مع عوامل الإسناد، شرط أن يستوفي الاستخدام الشروط التالية: يجب أن يكون الجانب الأيسر من عامل الإسناد مؤشرًا، وأن يكون الجانب الأيمن منه مؤشرًا فارغًا ثابتًا. يجب أن يكون مُعاملٌ من المعاملات مؤشرًا يشير إلى كائن أو نوع غير مُكتمل، والمعامل الآخر مؤشرًا إلى الفراغ "void"، سواءٌ كان مؤهلًا أو لا. يُعدّ المُعاملان مؤشرين لأنواع متوافقة سواءٌ كانت مؤهلةً أم لا. يجب أن يكون للنوع المُشار إليه في الحالتين الأخيرتين على الجانب الأيسر من عامل الإسناد النوع ذاته من المؤهلات على الأقل، والموافق لمؤهل النوع الواقع على الجانب الأيمن من عامل الإسناد، أو أكثر من مؤهل مماثل. يمكنك إذًا إسناد مؤشر يشير إلى قيمة صحيحة "int" إلى مؤشر يشير إلى قيمة من نوع عدد صحيح ثابت "const int" (مؤهلات النوع الأيسر تزيد عن مؤهلات النوع الأيمن) ولكن لا يمكنك إسناد مؤشر يشير إلى "const int" إلى مؤشر يشير إلى "int"، والأمر منطقي جدًا إذا أخذت لحظةً للتفكير به. يمكن استخدام العاملين "=+" و "=-" مع المؤشرات طالما أن الجانب الأيسر من العامل مؤشر يشير إلى كائن، والجانب الأيمن من العامل تعبير ينتج قيمةً صحيحة integral، وتوضح قوانين العمليات الحسابية في الفقرات السابقة ما سيحصل في هذه الحالة. العامل الشرطي وضّحنا سابقًا سلوك العامل الشرطي conditional operator عند استخدامه مع المؤشرات. المصفوفات وعامل & والدوال ذكرنا عدّة مرات أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول، وقلنا أن الاستثناء الوحيد هو عند استخدام اسم المصفوفة مع عامل "sizeof"، وهو عاملٌ مهمٌ إذا أردت استخدام الدالة "malloc"، إلا أن هناك استثناءً آخر، ألا وهو عندما يكون اسم المصفوفة مُعاملًا لعامل "&" (عنوان العامل)، إذ يُحوّل اسم المصفوفة هنا إلى عنوان كامل المصفوفة بدلًا من عنوان عنصرها الأول عادةً، لكن ما الفرق؟ لعلك تعتقد أن العنوانين متماثلان، إلا أن الفرق هو نوعهما، فبالنسبة لمصفوفةٍ تحتوي "n" عنصر بنوع "T"، يكون عنوان عنصرها الأول من نوع "مؤشر إلى T"، بينما يكون عنوان كامل المصفوفة من نوع " مؤشر إلى مصفوفة من n عنصر من نوع T"، وهو مختلف جدًا. إليك مثالًا عن ذلك: int ar[10]; int *ip; int (*ar10i)[10]; /* مؤشر لمصفوفة من 10 عناصر صحيحة */ ip = ar; /* عنوان العنصر الأول */ ip = &ar[0]; /* عنوان العنصر الأول */ ar10i = &ar; /* عنوان كامل المصفوفة */ أين تُستخدم المؤشرات إلى المصفوفات؟ في الحقيقة ليس غالبًا، إلا أننا نعلم أن التصريح عن مصفوفة متعددة الأبعاد هو في الحقيقة تصريح عن مصفوفة مصفوفات. إليك مثالًا يستخدم هذا المفهوم (إلا أن فهم ما يفعل يقع على عاتقك)، وليس من الشائع استخدام هذه الطريقة: int ar2d[5][4]; int (*ar4i)[4]; /* مؤشر إلى مصفوفة من 4 أعداد صحيحة */ for(ar4i= ar2d; ar4i < &(ar2d[5]); ar4i++) (*ar4i)[2] = 0; /* ar2d[n][2] = 0 */ ما قد يثير اهتمامك أكثر من عناوين المصفوفات هو ما الذي قد يحدث عندما نصرِّح عن دالة تأخذ مصفوفةً في أحد وسطائها. بالنظر إلى أن المصفوفة تحوّل إلى عنوان عنصرها الأول فحتى لو حاولت تمرير مصفوفة إلى دالة باستخدام اسم المصفوفة وسيطًا، فسينتهي بك الأمر بتمرير مؤشر إلى عنصر المصفوفة الأول. لكن ماذا لو صرّحت عن الدالة بكونها تأخذ وسيطًا من نوع "مصفوفة من نوع ما" على النحو التالي: void f(int ar[10]); ما الذي يحدث في هذه الحالة؟ قد تفاجئك الإجابة هنا، إذ أن المصرّف ينظر إلى السطر السابق ويقول لنفسه "سيكون هذا مؤشرًا لهذه المصفوفة" ويعيد كتابة الوسيط على أنه من نوع مؤشر، ووفقًا لذلك نجد أن التصريحات الثلاثة التالية متكافئة: void f(int ar[10]); void f(int *ar); void f(int ar[]); /* !حجم المصفوفة هنا لا علاقة له */ قد تضع يدك على رأسك بعد هذه المعلومة، لكن تمهّل! إليك بعض الأسئلة للتهدئة من غضبك وإحباطك: لم كانت المعلومة السابقة منطقية؟ لماذا تعمل التعابير بالصياغة [ar[5 أو أي صياغةٍ أخرى ضمن التصريح عن دالة، ثم داخل الدالة كما هو متوقعٌ منها؟ فكّر في الأسئلة السابقة، وستفهم استخدام المؤشرات مع المصفوفات بصورةٍ ممتازة عندما تتوصل لإجابة ترضيك. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: هياكل البيانات: القوائم المترابطة Linked lists والأشجار Trees في لغة سي C المقال السابق: عامل sizeof وحجز مساحات التخزين في لغة سي C المؤشرات Pointers في لغة سي C التعامل مع المحارف والسلاسل النصية في لغة سي C -
-.png.e98612179a26f1fca6d9fb3f5bbeb86b.png) بما أننا ما زلنا في مرحلة التكلم عن لغة سي عمومًا، دعونا نتناول مثالين آخرين، إذ ستجد أن بعض التعليمات الموجودة ضمن هذين المثالين أصبحت معروفةً بالنسبة لك ولن نتطرّق إليها، ولكننا سنتكلّم عن المزايا والتعليمات الجديدة التي لم نشرحها بعد عن اللغة. برنامج لإيجاد الأعداد الأولية /* * * * Dumb program that generates prime numbers. */ #include <stdio.h> #include <stdlib.h> main(){ int this_number, divisor, not_prime; this_number = 3; while(this_number < 10000){ divisor = this_number / 2; not_prime = 0; while(divisor > 1){ if(this_number % divisor == 0){ not_prime = 1; divisor = 0; } else divisor = divisor-1; } if(not_prime == 0) printf("%d is a prime number\n", this_number); this_number = this_number + 1; } exit(EXIT_SUCCESS); } [مثال 2.1] هناك الكثير من الأمور الجديدة المثيرة للاهتمام في هذا البرنامج. أوّلًا، البرنامج يعمل بغباء بعض الشيء، إذ يقسِّم العدد على جميع الأرقام الواقعة في المجال بين نصف قيمته والرقم 2 للتحقّق ما إذا كان أوليًّا أم لا، وإذا كان هناك أي قسمةٍ دون باقٍ فهذا يعني أنه ليس أوليًّا. هذه المرة الأولى التي نستخدم فيها كلًا من العامل % وعامل المساواة المُمثَّل بإشارتَي مساواة ==، إذ يتسبب هذا العامل بكثير من الأخطاء في برنامجك عادةً، نظرًا للخلط بينه وبين عامل الإسناد =، فكن حذرًا. المشكلة في فحص المساواة هذا وأيّ فحص آخر، هي أن استبدال == بالرمز = هو تعليمة صالحة، ففي الحالة الأولى (استخدام ==) تُوازَن القيمتان وتُفحص حالة المساواة، كما في المثال التالي: if(a == b) while (c == d) كما يمكن استخدام عامل الإسناد = في الموضع ذاته، ولكن لإسناد القيمة الواقعة على يسار الإشارة للمتغيّر على يمينها. تصبح المشكلة مهمةً أكثر إذا كنت معتادًا على البرمجة باللغات التي تستخدم عامل المساواة بصورةٍ مماثلة لما تستخدمه لغة سي لعامل الإسناد، إذ لا يوجد أي شيء يمكنك فعله لتغيير ذلك سوى الاعتياد على هذا الأمر من الآن فصاعدًا، ولحسن الحظ تعطيك بعض المصرّفات الحديثة بعض التحذيرات عندما تلاحظ استخدامًا غريبًا لعامل الإسناد في غير موضعه المعتاد، ولكن يصبح الأمر مزعجًا أحيانًا إذا كان هذا فعلًا ما تريد فعله وليس خطأً. نلاحظ في مثالنا السابق أيضًا أول استخدام للتعليمة if، إذ تفحص هذه التعليمة تعبيرًا expression موجودًا داخل القوسين على نحوٍ مشابه لتعليمة while، إذ تتطلب جميع التعليمات الشرطية التي تتحكّم بتدفق البرنامج تعبيرًا محتوًى داخل قوسين بعد الكلمة المفتاحية، وفي هذه الحالة الكلمة المفتاحية هي if. تُكتب التعليمة if على النحو التالي: if(expression) statement if(expression) statement else statement يوضِّح المثال المبين أعلاه أن التعليمة تأتي بنموذجين، إذ يحتوي الأول على الكلمة if والثاني على الكلمة else؛ فإذا كان التعبير صحيحًا وفقًا للنموذج الأول، فستُنفَّذ مجموعة التعليمات الموجودة داخل متن if، أما إذا كان التعبير خاطئًا فلن تُنفّذ؛ بينما تنفّذ التعليمات الموجودة ضمن else وفقًا للنموذج الثاني فقط في حالة كان التعبير خاطئًا (أي تعبير if السابق لها). يتميز استخدام تعليمة if بمشكلة شائعة، ألقِ نظرةً على المثال التالي وأجِب، هل ستُنفَّذ التعليمة statement-2 أم لا؟ if(1 > 0) if(1 < 0) statement-1 else statement-2 الإجابة هي نعم ستُنفَّذ التعليمة. لا تركّز تفكيرك على مسافة الإزاحة فهي مضللةٌ غالبًا، فقد تكون تعليمة else تابعةً لتعليمة if الأولى أو الثانية بحسب وصف كلٍّ منهما، لذا علينا اللجوء لقاعدةٍ ما لجعل الأمور أوضح. القاعدة ببساطة هي أن else تابعةٌ لتعليمة if الأقرب (التي تسبق else)، والتي لا تحتوي على تعليمة else مسبقًا. لنجعل البرنامج يعمل كما نريد وفق تنسيق مسافات الإزاحة، علينا إنشاء تعليمة مركبة باستخدام الأقواس المعقوصة كما يلي: if(1 > 0){ if(1 < 0) statement-1 } else statement-2 تتبَع لغة سي -على الأقل في هذه الحالة- لعمل معظم لغات البرمجة واصطلاحاتهم. في الحقيقة، قد يشعر بعض القراء أن هذه القاعدة "بديهية" إن سبق وتعاملوا مع لغة برمجة مشابهة للغة سي وأنها لا تستحق الذكر. لنأمل أن يفكر الجميع بهذه الطريقة. عامل القسمة يُشار إلى عامل القسمة بالرمز "/"، وعامل باقي القسمة بالرمز "%". تفعل عملية القسمة المتوقّع منها، إلا أن إجراء القسمة على أعداد صحيحة int ستعطي نتيجةً مقربةً باتجاه الحد الأدنى (الصفر)، إذ تعطي العملية 5/2 مثلًا النتيجة 2، وتعطي التعليمة 5/3 النتيجة 1؛ وللحصول على القيمة المقتطعة من الناتج نستخدم عامل باقي القسمة، إذ تعطينا العملية 2%5 النتيجة 1، والعملية 3%5 النتيجة 2. تعتمد إشارة باقي القسمة وناتج القسمة على المقسوم والمقسوم عليه وهي مُعرّفة في المعيار. مثال عن تنفيذ عملية الدخل من المفيد أن نكون قادرين على الحصول على الدخل وكتابة برامج قادرة على طباعة وعرض النتائج ضمن قوائم أو جداول في الخرج، والطريقة الأبسط لتنفيذ هذا هي عن طريق استخدام الدالة getchar، وهي الطريقة الوحيدة التي سنناقشها حاليًّا؛ إذ تقرأ هذه الدالة كلّ محرف على حدى من دخل البرنامج وتعيد قيمةً عدديّة int تمثّله، ويمكن استخدام هذه القيمة الممثلة للمحرف في طباعة المحرف ذاته في خرج البرنامج، ويمكن أيضًا موازنة هذا المحرف (القيمة) مع محارف معيّنة أو محارف قُرأت مسبقًا، إلا أن الاستخدام الأكثر منطقية هو موازنة المحرف المُدخل مع محرف معيّن. لا تُعد موازنة قيمة المحارف ما إذا كانت أصغر أو أكبر خيارًا جيّدًا، إذ لا يوجد أي ضمان بأن قيمة a أصغر من قيمة b، مع أن ذلك الأمر محققٌ في معظم الأنظمة، ولكن الضمان الوحيد هنا الذي يقدمه لك المعيار هو أن القيمة ستكون متتابعة من 0 إلى 9. ألقِ نظرةً على المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int ch; ch = getchar(); while(ch != 'a'){ if(ch != '\n') printf("ch was %c, value %d\n", ch, ch); ch = getchar(); } exit(EXIT_SUCCESS); } [مثال 3.1] هناك ملاحظتان جديرتان بالاهتمام، هما: سنجد في نهاية كل سطر دخل المحرف n\ (محرف ثابت)، وهو المحرف ذاته الذي نستخدمه في دالة printf عندما نريد طباعة سطر جديد. نظام الدخل والخرج الخاص بلغة سي غير مبني على مفهوم الأسطر بل على مفهوم المحارف؛ فإذا كنت تريد التفكير بالأمر من منطلق مفهوم الأسطر، فانظر للمحرف n\ على أنه إعلان لنهاية السطر. استخدام c% لطباعة المحرف بواسطة الدالة printf، إذ يسمح لنا هذا الأمر بطباعة المحرف على أنه محرف على الشاشة، بالموازنة مع استخدام d% الذي سيطبع المحرف ذاته ولكن بتمثيله العددي المُستخدم ضمن البرنامج. إذا جربت تنفيذ هذا البرنامج بنفسك، قد تجد أن بعض الأنظمة لا تمرّر المحرف الواحد تلو الآخر عند كتابته، بل تجبرك على كتابة سطر كاملٍ للدخل أولًا، ثم تبدأ معالجة المحرف الواحد تلو الآخر. قد يبدو الأمر مشوّشًا لبعض المبتدئين عندما يكتبون محرفًا ما ولا يحدث شيء بعد ذلك، وليس للغة سي أي علاقةٍ بذلك، بل يعتمد الأمر على حاسوبك ونظام تشغيله. المصفوفات البسيطة يكون غالبًا استخدام المصفوفات arrays في لغة سي للمبتدئين بمثابة تحدٍ، إذ أن التصريح عن المصفوفات ليس صعبًا، بالأخص المصفوفات أحادية البعد one-dimensional، ولكن سبب الأخطاء هنا هو بدء الدليل index الخاص بها من الرقم 0. للتصريح عن مصفوفة مؤلفة من 5 أعداد من نوع int، نكتب: int something[5]; تستخدم لغة سي الأقواس المعقوفة square brackets للتصريح عن المصفوفات، ولا تدعم أيّ مصفوفة لا تقع أدلتها بين 0 وما فوق. العناصر الصالحة في مثالنا هي [something[0 إلى [something[4، و [something[5 غير موجود في المصفوفة وهو عنصر غير صالح. يقرأ البرنامج التالي المحارف من الدخل، ويرتبها وفقًا لقيمتها العددية، ويطبعها في الخرج مرةً أخرى. ألقِ نظرةً على البرنامج وحاول فهم ما يحصل، إذ لن نتكلم عن الخوارزمية مفصلًا في شرحنا. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 main(){ int ch_arr[ARSIZE],count1; int count2, stop, lastchar; lastchar = 0; stop = 0; /* * Read characters into array. * Stop if end of line, or array full. */ while(stop != 1){ ch_arr[lastchar] = getchar(); if(ch_arr[lastchar] == '\n') stop = 1; else lastchar = lastchar + 1; if(lastchar == ARSIZE) stop = 1; } lastchar = lastchar-1; /* * Now the traditional bubble sort. */ count1 = 0; while(count1 < lastchar){ count2 = count1 + 1; while(count2 <= lastchar){ if(ch_arr[count1] > ch_arr[count2]){ /* swap */ int temp; temp = ch_arr[count1]; ch_arr[count1] = ch_arr[count2]; ch_arr[count2] = temp; } count2 = count2 + 1; } count1 = count1 + 1; } count1 = 0; while(count1 <= lastchar){ printf("%c\n", ch_arr[count1]); count1 = count1 + 1; } exit(EXIT_SUCCESS); } [مثال 4.1] ستلاحظ استخدام الثابت المُعرّف ARSIZE في كل مكان ضمن المثال السابق بدلًا من كتابة حجم المصفوفة الفعلي بصورةٍ صريحة، ويمكننا بفضل ذلك تغيير العدد الأقصى من المحارف الممكن ترتيبها ضمن هذا البرنامج بتغيير سطرٍ واحدٍ منه وإعادة تصريفه. الانتباه إلى امتلاء المصفوفة هي نقطة غير مشدّد عليها ولكنها هامّة لأمان برنامجنا؛ فإذا نظرت بتمعّن للمثال، ستجد أن البرنامج يتوقف عند تمرير العنصر ذو الدليل ARSIZE-1 للمصفوفة، وذلك لأن أي مصفوفة بحجم N عنصر تحتوي العناصر من 0 إلى N-1 فقط أي ما مجموعه N عنصر. على عكس بعض اللغات، لا تُعْلمك لغة سي أنك وصلت إلى نهاية المصفوفة، بل تُنتج ذلك بما يعرف باسم التصرف غير المحدد undefined behaviour في البرنامج، وهذا ما يتسبب ببعض الأخطاء الغامضة في برنامجك. يتجنّب المبرمجون الخبراء هذا الخطأ عن طريق اختبار البرنامج المتكرّر للتأكد من عدم حصول ذلك عند تطبيق الخوارزميّة المستخدمة، أو عن طريق فحص القيمة قبل محاولة الحصول عليها من المصفوفة. وتُعد هذه المشكلة من أبرز مصادر أخطاء وقت التشغيل run-time في لغة سي، لقد حذرتك! خلاصة القول: تبدأ المصفوفات بالدليل 0 دائمًا، ولا يمكنك تجنّب هذا الاصطلاح. تحتوي المصفوفة من الحجم "N" على عناصر من الدليل "0" إلى الدليل "N-1"، والعنصر "N" غير موجود داخل المصفوفة هذه، ومحاولة الوصول إليه هو خطأ فادح. مصطلحات هناك نوعان من الأشياء المختلفة في البرامج المكتوبة بلغة سي، أشياء تُستخدم لتخزين القيَم، وأشياء تدعى بالدوال، وبدلًا عن الإشارة للشيئين بصورةٍ منفصلة بعبارة طويلة، نعتقد أنه من الأفضل أن نرمز إليهما بتسميةٍ واحدةٍ عامّة ألا وهي "الكائنات objects"، وسنستخدم هذه التسمية كثيرًا في الفصول القادمة، إذ يتبع الشيئان نفس القواعد إلى حدٍّ ما؛ ولكن يجدر الذكر هنا إلى أن معنى المصطلح هذا مختلف عمّا يقصده المعيار، إذ يُستخدم مصطلح "كائن" في المعيار على نحوٍ خاص لوصف منطقة من الذاكرة المحجوزة لتمثيل قيمة، والدالة مختلفة عن هذا التعريف تمامًا. يؤدي هذا لاستخدام المعيار المصطلحين على نحوٍ منفصل وغالبًا ما ستجد العبارة "… الدوال والكائنات …"؛ ونظرًا لأن هذا الاختلاف لا يؤدي لكثيرٍ من الخلط ويحسِّن قراءة النص في كثيرٍ من الحالات، فسنستمرّ في استخدام المصطلح العامّ "كائن" للدلالة على الدوال والقيَم، وسنستخدم المصطلح "دالة" و"كائن بيانات Data object" عندما نريد التمييز بين الاثنين وفقًا للحالة. لذا، قد تجد اختلافًا بسيطًا في المعنى إن كنت تقرأ المعيار. ترجمة -وبتصرف- لقسم من الفصل Chapter 1 An Introduction to C من كتاب The C Book. اقرأ أيضًا المقال السابق: بنية برنامج لغة سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C
بما أننا ما زلنا في مرحلة التكلم عن لغة سي عمومًا، دعونا نتناول مثالين آخرين، إذ ستجد أن بعض التعليمات الموجودة ضمن هذين المثالين أصبحت معروفةً بالنسبة لك ولن نتطرّق إليها، ولكننا سنتكلّم عن المزايا والتعليمات الجديدة التي لم نشرحها بعد عن اللغة. برنامج لإيجاد الأعداد الأولية /* * * * Dumb program that generates prime numbers. */ #include <stdio.h> #include <stdlib.h> main(){ int this_number, divisor, not_prime; this_number = 3; while(this_number < 10000){ divisor = this_number / 2; not_prime = 0; while(divisor > 1){ if(this_number % divisor == 0){ not_prime = 1; divisor = 0; } else divisor = divisor-1; } if(not_prime == 0) printf("%d is a prime number\n", this_number); this_number = this_number + 1; } exit(EXIT_SUCCESS); } [مثال 2.1] هناك الكثير من الأمور الجديدة المثيرة للاهتمام في هذا البرنامج. أوّلًا، البرنامج يعمل بغباء بعض الشيء، إذ يقسِّم العدد على جميع الأرقام الواقعة في المجال بين نصف قيمته والرقم 2 للتحقّق ما إذا كان أوليًّا أم لا، وإذا كان هناك أي قسمةٍ دون باقٍ فهذا يعني أنه ليس أوليًّا. هذه المرة الأولى التي نستخدم فيها كلًا من العامل % وعامل المساواة المُمثَّل بإشارتَي مساواة ==، إذ يتسبب هذا العامل بكثير من الأخطاء في برنامجك عادةً، نظرًا للخلط بينه وبين عامل الإسناد =، فكن حذرًا. المشكلة في فحص المساواة هذا وأيّ فحص آخر، هي أن استبدال == بالرمز = هو تعليمة صالحة، ففي الحالة الأولى (استخدام ==) تُوازَن القيمتان وتُفحص حالة المساواة، كما في المثال التالي: if(a == b) while (c == d) كما يمكن استخدام عامل الإسناد = في الموضع ذاته، ولكن لإسناد القيمة الواقعة على يسار الإشارة للمتغيّر على يمينها. تصبح المشكلة مهمةً أكثر إذا كنت معتادًا على البرمجة باللغات التي تستخدم عامل المساواة بصورةٍ مماثلة لما تستخدمه لغة سي لعامل الإسناد، إذ لا يوجد أي شيء يمكنك فعله لتغيير ذلك سوى الاعتياد على هذا الأمر من الآن فصاعدًا، ولحسن الحظ تعطيك بعض المصرّفات الحديثة بعض التحذيرات عندما تلاحظ استخدامًا غريبًا لعامل الإسناد في غير موضعه المعتاد، ولكن يصبح الأمر مزعجًا أحيانًا إذا كان هذا فعلًا ما تريد فعله وليس خطأً. نلاحظ في مثالنا السابق أيضًا أول استخدام للتعليمة if، إذ تفحص هذه التعليمة تعبيرًا expression موجودًا داخل القوسين على نحوٍ مشابه لتعليمة while، إذ تتطلب جميع التعليمات الشرطية التي تتحكّم بتدفق البرنامج تعبيرًا محتوًى داخل قوسين بعد الكلمة المفتاحية، وفي هذه الحالة الكلمة المفتاحية هي if. تُكتب التعليمة if على النحو التالي: if(expression) statement if(expression) statement else statement يوضِّح المثال المبين أعلاه أن التعليمة تأتي بنموذجين، إذ يحتوي الأول على الكلمة if والثاني على الكلمة else؛ فإذا كان التعبير صحيحًا وفقًا للنموذج الأول، فستُنفَّذ مجموعة التعليمات الموجودة داخل متن if، أما إذا كان التعبير خاطئًا فلن تُنفّذ؛ بينما تنفّذ التعليمات الموجودة ضمن else وفقًا للنموذج الثاني فقط في حالة كان التعبير خاطئًا (أي تعبير if السابق لها). يتميز استخدام تعليمة if بمشكلة شائعة، ألقِ نظرةً على المثال التالي وأجِب، هل ستُنفَّذ التعليمة statement-2 أم لا؟ if(1 > 0) if(1 < 0) statement-1 else statement-2 الإجابة هي نعم ستُنفَّذ التعليمة. لا تركّز تفكيرك على مسافة الإزاحة فهي مضللةٌ غالبًا، فقد تكون تعليمة else تابعةً لتعليمة if الأولى أو الثانية بحسب وصف كلٍّ منهما، لذا علينا اللجوء لقاعدةٍ ما لجعل الأمور أوضح. القاعدة ببساطة هي أن else تابعةٌ لتعليمة if الأقرب (التي تسبق else)، والتي لا تحتوي على تعليمة else مسبقًا. لنجعل البرنامج يعمل كما نريد وفق تنسيق مسافات الإزاحة، علينا إنشاء تعليمة مركبة باستخدام الأقواس المعقوصة كما يلي: if(1 > 0){ if(1 < 0) statement-1 } else statement-2 تتبَع لغة سي -على الأقل في هذه الحالة- لعمل معظم لغات البرمجة واصطلاحاتهم. في الحقيقة، قد يشعر بعض القراء أن هذه القاعدة "بديهية" إن سبق وتعاملوا مع لغة برمجة مشابهة للغة سي وأنها لا تستحق الذكر. لنأمل أن يفكر الجميع بهذه الطريقة. عامل القسمة يُشار إلى عامل القسمة بالرمز "/"، وعامل باقي القسمة بالرمز "%". تفعل عملية القسمة المتوقّع منها، إلا أن إجراء القسمة على أعداد صحيحة int ستعطي نتيجةً مقربةً باتجاه الحد الأدنى (الصفر)، إذ تعطي العملية 5/2 مثلًا النتيجة 2، وتعطي التعليمة 5/3 النتيجة 1؛ وللحصول على القيمة المقتطعة من الناتج نستخدم عامل باقي القسمة، إذ تعطينا العملية 2%5 النتيجة 1، والعملية 3%5 النتيجة 2. تعتمد إشارة باقي القسمة وناتج القسمة على المقسوم والمقسوم عليه وهي مُعرّفة في المعيار. مثال عن تنفيذ عملية الدخل من المفيد أن نكون قادرين على الحصول على الدخل وكتابة برامج قادرة على طباعة وعرض النتائج ضمن قوائم أو جداول في الخرج، والطريقة الأبسط لتنفيذ هذا هي عن طريق استخدام الدالة getchar، وهي الطريقة الوحيدة التي سنناقشها حاليًّا؛ إذ تقرأ هذه الدالة كلّ محرف على حدى من دخل البرنامج وتعيد قيمةً عدديّة int تمثّله، ويمكن استخدام هذه القيمة الممثلة للمحرف في طباعة المحرف ذاته في خرج البرنامج، ويمكن أيضًا موازنة هذا المحرف (القيمة) مع محارف معيّنة أو محارف قُرأت مسبقًا، إلا أن الاستخدام الأكثر منطقية هو موازنة المحرف المُدخل مع محرف معيّن. لا تُعد موازنة قيمة المحارف ما إذا كانت أصغر أو أكبر خيارًا جيّدًا، إذ لا يوجد أي ضمان بأن قيمة a أصغر من قيمة b، مع أن ذلك الأمر محققٌ في معظم الأنظمة، ولكن الضمان الوحيد هنا الذي يقدمه لك المعيار هو أن القيمة ستكون متتابعة من 0 إلى 9. ألقِ نظرةً على المثال التالي: #include <stdio.h> #include <stdlib.h> main(){ int ch; ch = getchar(); while(ch != 'a'){ if(ch != '\n') printf("ch was %c, value %d\n", ch, ch); ch = getchar(); } exit(EXIT_SUCCESS); } [مثال 3.1] هناك ملاحظتان جديرتان بالاهتمام، هما: سنجد في نهاية كل سطر دخل المحرف n\ (محرف ثابت)، وهو المحرف ذاته الذي نستخدمه في دالة printf عندما نريد طباعة سطر جديد. نظام الدخل والخرج الخاص بلغة سي غير مبني على مفهوم الأسطر بل على مفهوم المحارف؛ فإذا كنت تريد التفكير بالأمر من منطلق مفهوم الأسطر، فانظر للمحرف n\ على أنه إعلان لنهاية السطر. استخدام c% لطباعة المحرف بواسطة الدالة printf، إذ يسمح لنا هذا الأمر بطباعة المحرف على أنه محرف على الشاشة، بالموازنة مع استخدام d% الذي سيطبع المحرف ذاته ولكن بتمثيله العددي المُستخدم ضمن البرنامج. إذا جربت تنفيذ هذا البرنامج بنفسك، قد تجد أن بعض الأنظمة لا تمرّر المحرف الواحد تلو الآخر عند كتابته، بل تجبرك على كتابة سطر كاملٍ للدخل أولًا، ثم تبدأ معالجة المحرف الواحد تلو الآخر. قد يبدو الأمر مشوّشًا لبعض المبتدئين عندما يكتبون محرفًا ما ولا يحدث شيء بعد ذلك، وليس للغة سي أي علاقةٍ بذلك، بل يعتمد الأمر على حاسوبك ونظام تشغيله. المصفوفات البسيطة يكون غالبًا استخدام المصفوفات arrays في لغة سي للمبتدئين بمثابة تحدٍ، إذ أن التصريح عن المصفوفات ليس صعبًا، بالأخص المصفوفات أحادية البعد one-dimensional، ولكن سبب الأخطاء هنا هو بدء الدليل index الخاص بها من الرقم 0. للتصريح عن مصفوفة مؤلفة من 5 أعداد من نوع int، نكتب: int something[5]; تستخدم لغة سي الأقواس المعقوفة square brackets للتصريح عن المصفوفات، ولا تدعم أيّ مصفوفة لا تقع أدلتها بين 0 وما فوق. العناصر الصالحة في مثالنا هي [something[0 إلى [something[4، و [something[5 غير موجود في المصفوفة وهو عنصر غير صالح. يقرأ البرنامج التالي المحارف من الدخل، ويرتبها وفقًا لقيمتها العددية، ويطبعها في الخرج مرةً أخرى. ألقِ نظرةً على البرنامج وحاول فهم ما يحصل، إذ لن نتكلم عن الخوارزمية مفصلًا في شرحنا. #include <stdio.h> #include <stdlib.h> #define ARSIZE 10 main(){ int ch_arr[ARSIZE],count1; int count2, stop, lastchar; lastchar = 0; stop = 0; /* * Read characters into array. * Stop if end of line, or array full. */ while(stop != 1){ ch_arr[lastchar] = getchar(); if(ch_arr[lastchar] == '\n') stop = 1; else lastchar = lastchar + 1; if(lastchar == ARSIZE) stop = 1; } lastchar = lastchar-1; /* * Now the traditional bubble sort. */ count1 = 0; while(count1 < lastchar){ count2 = count1 + 1; while(count2 <= lastchar){ if(ch_arr[count1] > ch_arr[count2]){ /* swap */ int temp; temp = ch_arr[count1]; ch_arr[count1] = ch_arr[count2]; ch_arr[count2] = temp; } count2 = count2 + 1; } count1 = count1 + 1; } count1 = 0; while(count1 <= lastchar){ printf("%c\n", ch_arr[count1]); count1 = count1 + 1; } exit(EXIT_SUCCESS); } [مثال 4.1] ستلاحظ استخدام الثابت المُعرّف ARSIZE في كل مكان ضمن المثال السابق بدلًا من كتابة حجم المصفوفة الفعلي بصورةٍ صريحة، ويمكننا بفضل ذلك تغيير العدد الأقصى من المحارف الممكن ترتيبها ضمن هذا البرنامج بتغيير سطرٍ واحدٍ منه وإعادة تصريفه. الانتباه إلى امتلاء المصفوفة هي نقطة غير مشدّد عليها ولكنها هامّة لأمان برنامجنا؛ فإذا نظرت بتمعّن للمثال، ستجد أن البرنامج يتوقف عند تمرير العنصر ذو الدليل ARSIZE-1 للمصفوفة، وذلك لأن أي مصفوفة بحجم N عنصر تحتوي العناصر من 0 إلى N-1 فقط أي ما مجموعه N عنصر. على عكس بعض اللغات، لا تُعْلمك لغة سي أنك وصلت إلى نهاية المصفوفة، بل تُنتج ذلك بما يعرف باسم التصرف غير المحدد undefined behaviour في البرنامج، وهذا ما يتسبب ببعض الأخطاء الغامضة في برنامجك. يتجنّب المبرمجون الخبراء هذا الخطأ عن طريق اختبار البرنامج المتكرّر للتأكد من عدم حصول ذلك عند تطبيق الخوارزميّة المستخدمة، أو عن طريق فحص القيمة قبل محاولة الحصول عليها من المصفوفة. وتُعد هذه المشكلة من أبرز مصادر أخطاء وقت التشغيل run-time في لغة سي، لقد حذرتك! خلاصة القول: تبدأ المصفوفات بالدليل 0 دائمًا، ولا يمكنك تجنّب هذا الاصطلاح. تحتوي المصفوفة من الحجم "N" على عناصر من الدليل "0" إلى الدليل "N-1"، والعنصر "N" غير موجود داخل المصفوفة هذه، ومحاولة الوصول إليه هو خطأ فادح. مصطلحات هناك نوعان من الأشياء المختلفة في البرامج المكتوبة بلغة سي، أشياء تُستخدم لتخزين القيَم، وأشياء تدعى بالدوال، وبدلًا عن الإشارة للشيئين بصورةٍ منفصلة بعبارة طويلة، نعتقد أنه من الأفضل أن نرمز إليهما بتسميةٍ واحدةٍ عامّة ألا وهي "الكائنات objects"، وسنستخدم هذه التسمية كثيرًا في الفصول القادمة، إذ يتبع الشيئان نفس القواعد إلى حدٍّ ما؛ ولكن يجدر الذكر هنا إلى أن معنى المصطلح هذا مختلف عمّا يقصده المعيار، إذ يُستخدم مصطلح "كائن" في المعيار على نحوٍ خاص لوصف منطقة من الذاكرة المحجوزة لتمثيل قيمة، والدالة مختلفة عن هذا التعريف تمامًا. يؤدي هذا لاستخدام المعيار المصطلحين على نحوٍ منفصل وغالبًا ما ستجد العبارة "… الدوال والكائنات …"؛ ونظرًا لأن هذا الاختلاف لا يؤدي لكثيرٍ من الخلط ويحسِّن قراءة النص في كثيرٍ من الحالات، فسنستمرّ في استخدام المصطلح العامّ "كائن" للدلالة على الدوال والقيَم، وسنستخدم المصطلح "دالة" و"كائن بيانات Data object" عندما نريد التمييز بين الاثنين وفقًا للحالة. لذا، قد تجد اختلافًا بسيطًا في المعنى إن كنت تقرأ المعيار. ترجمة -وبتصرف- لقسم من الفصل Chapter 1 An Introduction to C من كتاب The C Book. اقرأ أيضًا المقال السابق: بنية برنامج لغة سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C -
 سنتطرق في هذا المقال إلى الأنواع الحقيقية والصحيحة في لغة سي C الأنواع الحقيقية سيكون من الأسهل التعامل مع الأنواع الحقيقية real أوّلًا، لأن هناك تفاصيل وتعقيدات أقل بخصوصها موازنةً بنوع الأعداد الطبيعية Integers. يقدّم المعيار تفاصيلًا جديدةً بخصوص دقة ونطاق الأعداد الحقيقية، ويمكن أن تجدهم في ملف الترويسة "float.h" الذي سنناقشه بالتفصيل لاحقًا. هذه التفاصيل مهمة جدًا ولكنها ذات طبيعة تقنية للغاية، ولن تُفهم بالكامل غالبًا إلا من قبل مختصّي التحليل العددي. أنواع الأعداد الحقيقية هي: float: العدد العشري double: العدد العشري مضاعف الدقة long double: العدد العشري الأدق يسمح لنا كل واحد من هذه الأنواع بتمثيل الأعداد الحقيقية بطريقة معينة باستخدام الحاسوب؛ فإذا كان هناك نوعٌ واحدٌ لتمثيل الأعداد الحقيقية، فهذا يعني أن تمثيل الأعداد سيكون متماثلًا بغض النظر عن الاستخدام؛ أما إذا كان العدد يتجاوز الثلاثة أنوع، فهذا يعني أن لغة سي لن تستطيع تصنيف أي من الأنواع الإضافية. يُستخدم النوع float للتمثيل السريع والبسيط للأرقام الصغيرة وهو مشابهٌ للنوع REAL في لغة فورتران؛ أما double فيستخدم للدقة الإضافية، و long double لدقة أكبر من سابقتها. التركيز الأساسي هنا هو أنّ الزيادة في "دقة" كلٍ من float و double و long double تعطي لكل نوعٍ نطاقًا ودقّة مساويةً للنوع الذي يسبقها على الأقل، فأخذ القيمة من متغير نوع double مثلًا، وتخزينها في متغير من نوع long double، يجب أن يمثِّل القيمة ذاتها. لا توجد هناك أي متطلبات للأنواع الثلاثة من متغيرات الأعداد "الحقيقية" لتختلف في خصائصها، وبالتالي إن لم توفّر الآلة سوى نوع واحدٍ من أنواع متغيرات الأعداد الحقيقية، فيمكن عندئذٍ تمثيل جميع أنواع الأعداد الحقيقية الثلاثة في لغة سي بهذا النوع المتوفِّر. لكن بغض النظر، يجب أن يُنظر إلى هذه الأنواع الثلاثة بأنها مختلفة، وكأنّ هناك فرقٌ بينها حقًأ، وهذا يساعد في نقل البرنامج إلى نظام تختلف فيه هذه الأنواع حقًّا، بحيث لن يظهر لك مجموعةٌ من التحذيرات من المصرّف بخصوص عدم توافق الأنواع التي لم تكُن موجودةً على النظام الأول. تسمح لغة سي بمزج جميع أنواع البيانات العددية في التعابير بعكس كثيرٍ من لغات البرمجة الصارمة بخصوص قواعد كتابتها، وذلك يضم مختلف أنواع الأعداد الصحيحة إضافةً إلى الأعداد الحقيقية وأنواع المؤشرات؛ وعندما يتضمن التعبير مزيجًا من أنواع الأعداد الحقيقية والصحيحة، سيُستدعى تحويلٌ ضمني يعمل بدوره على معرفة نوع المزيج الكلّي الناتج. هذه القواعد مهمةٌ جدًا وتدعى التحويلات الحسابية الاعتيادية usual arithmetic conversions، ومن المفيد أن تتذكرها، إذ سنشرح كامل هذه القواعد لاحقًا، إلا أننا سننظر في الوقت الحالي إلى الحالات التي تتضمن مزيجًا من float و double و long double ونحاول فهمها. الحالة الوحيدة التي نحتاج فيها إجراء التحويلات المذكورة هي عندما يُمزج نوعان من البيانات في تعبير، كما في هو موضح في المثال التالي: int f(void){ float f_var; double d_var; long double l_d_var; f_var = 1; d_var = 1; l_d_var = 1; d_var = d_var + f_var; l_d_var = d_var + f_var; return(l_d_var); } [مثال 1.2] نلاحظ في المثال السابق وجود كثيرٍ من التحويلات القسرية، لنبدأ بأسهلها أوّلًا، ولننظر إلى تعيين القيمة الثابتة 1 لكلٍ من المتغيرات الثلاثة. لا بُد من التنويه (كما سيشير القسم الذي يتكلم عن القيم الثابتة constants لاحقًا) إلى أن القيمة 1 هي من نوع int، أي تمثّل عددًا صحيحًا وليس قيمةً ثابتةً حقيقية، ويحوّل الإسناد قيمة العدد الصحيح إلى نوع العدد الحقيقي المناسب والأسهل للتعامل معه. التحويلات المثيرة للاهتمام تأتي بعدها، وأولها ضمن السطر التالي: d_var = d_var + f_var; ما هو نوع التعبير الذي يتضمن العامل +؟ الإجابة عن هذا السؤال سهلة ما دمت ملمًّا ببعض القواعد؛ إذ يُحوَّل النوع الأقل دقةً ضمنيًا إلى النوع الأكثر دقةً وتُنجز العملية الحسابية باستخدام هذه الدقة، وذلك عندما يجتمع نوعان من الأعداد الحقيقية في التعبير ذاته. يتضمن المثال السابق استخدام كلٍّ من double و float، لذلك تُحوّل قيمة المتغير f_var إلى النوع double وتُضاف فيما بعد إلى قيمة النوع double أي المتغير d_var، وتكون نتيجة هذا التعبير هي من نوع double أيضًا، لذا من الواضح أن عملية الإسناد إلى المتغير d_var صائبة. عملية الجمع الثانية أكثر تعقيدّا، ولكنها ما زالت سهلة الفهم، إذ تُحوّل قيمة المتغير f_var وتُجرى العملية الحسابية باستخدام دقة النوع double، ألا وهي عملية جمع المتغيرين، لكن هناك مشكلة، وهي أن نتيجة عملية الجمع من نوع double، لكن عملية الإسناد من نوع long double، ويكون مجدّدًا الحل البديهي في هذه الحالة هو تحويل القيمة الأقل دقة إلى الأكبر دقّة، وهو ما يُجرى ضمنيًّا قبل عملية الإسناد. الآن بعد أن أخذنا نظرةً سريعةً على الأمثلة السهلة، حان وقت الأمثلة الأكثر صعوبة وهي الحالة التي يتسبب فيها التحويل القسري بتحويل نتيجةٍ بدقةٍ عالية إلى دقةٍ أقل منها، ففي مثل هذه الحالات قد يكون من الضروري خسارة الدقة بطريقة محدّدة من تنفيذ التحويل. ببساطة، يجب أن يحدد التنفيذ طريقة تقريب أو اقتطاعٍ للقيمة، وفي أسوأ الحالات قد يكون نوع الهدف غير قادرٍ على تخزين تلك القيمة الضرورية (على سبيل المثال محاولة جمع أكبر قيمة لعدد إلى نفسه)، وتُعد نتيجة التنفيذ في هذه الحالة غير محددة، والبرنامج يشكو من خطأ ولا يمكنك التنبؤ بتصرفه. لا ضرر من تكرار فكرتنا السابقة، إذ يقصد المعيار بحالة السلوك غير المحدد undefined behaviour معنى اسمه حرفيًا، وحالما يدخل البرنامج منطقة السلوك غير المحدد، يمكن لأي شيء أن يحدث؛ فمن الممكن إيقاف البرنامج من طرف نظام التشغيل مصحوبًا برسالة معيّنة؛ أو قد يحدث شيء غير مُلاحظ ويستمر البرنامج للعمل باستخدام قيم خاطئة مُخزَّنة في المتغير. منع البرنامج من إبداء أي سلوك غير محدّد تعد من مسؤولياتك، فتوخّ الحذر. لتلخيص ما سبق: تُجرى العمليات الحسابية التي تتضمن نوعين باستخدام النوع الأعلى دقّة منهما. قد يتضمن الإسناد خسارة لدقة القيمة في حال كان نوع المتغير الهدف ذو دقة أقل من دقة القيمة التي تُسنَد لهذا المتغير. هناك مزيدٌ من التحويلات التي تُجرى عند مزج الأنواع ضمن تعبير واحد، إذ لم نصِف جميعها بعد. طباعة الأعداد الحقيقية يمكن استخدام دالة الخرج التقليدي printf لتنسيق الأعداد الحقيقية وطباعتها، كما يوجد العديد من الطرق لتنسيق هذه الأعداد، ولكننا سنتطرق إلى طريقة واحدة في الوقت الحالي. يوضح الجدول 4.2 التنسيق الموافق لكل نوعٍ من أنواع الأعداد الحقيقية. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } النوع التنسيق float f% double f% long double Lf% [جدول 4.2. رموز التنسيق للأعداد الحقيقية] ألقِ نظرةً على المثال التالي لتجربة المعلومة السابقة: #include <stdio.h> #include <stdlib.h> #define BOILING 212 /* degrees Fahrenheit */ main(){ float f_var; double d_var; long double l_d_var; int i; i = 0; printf("Fahrenheit to Centigrade\n"); while(i <= BOILING){ l_d_var = 5*(i-32); l_d_var = l_d_var/9; d_var = l_d_var; f_var = l_d_var; printf("%d %f %f %Lf\n", i, f_var, d_var, l_d_var); i = i+1; } exit(EXIT_SUCCESS); } [مثال 2.2] جرّب المثال السابق على حاسوبك الشخصي، ولاحظ النتائج. الأنواع الصحيحة كانت الأنواع الحقيقية أسهل الأنواع، إذ تتصف القوانين الخاصة بالأنواع الصحيحة بتعقيد أكبر، ولكنها ما زالت مفهومة وينبغي تعلُّمها. لحسن الحظ، الأنواع الوحيدة المستخدمة في لغة سي لتخزين البيانات هي الأنواع الحقيقية والصحيحة، إضافةً إلى الهياكل structures والمصفوفات arrays المبنيّة عليهما، إذ لا تحتوي لغة سي على أنواع مميزة للتلاعب بالمحارف، أو التعامل مع القيم البوليانية boolean، وإنما تستخدم الأنواع الصحيحة بدلًا من ذلك، وهذا يعني أنه حالما تفهم الأنواع الصحيحة والحقيقية فأنت تعرف جميع الأنواع. سنبدأ بالنظر إلى الأنواع المختلفة للأعداد الصحيحة وقوانين التحويل فيما بينها. الأعداد الصحيحة البسيطة هناك نوعان من متغيرات الأعداد الصحيحة يطلق عليهما "نكهات flavours"، ويمكن بناء أنواع أخرى انطلاقًا من هذين النوعين كما سنرى لاحقًا، لكن تبقى الأنواع البسيطة int هي الأساس. النوع الأكثر شهرةً هو العدد الصحيح ذو الإشارة signed أو int، أما النوع الأقل شهرة هو العدد الصحيح عديم الإشارة أو unsigned int، ومن المفترض أن تُخزّن القيم في المتغيرات ذات النوع المناسب حسب الآلة التي تشغل البرنامج. عندما تبحث عن نوع بيانات بسيط لتمثيل عدد صحيح، فإن النوع int هو الاختيار البديهي لأي استخدام مُتساهل، مثل عدّاد ضمن حلقة تكرارية قصيرة، إذ لا توجد هناك أي قاعدة تحدّد عدد البتّات التي يخزنها نوع int لقيمةٍ ما، لكنه سيكون دائمًا مساويًا إلى 16 بِت أو أكثر، ويفصِّل ملف الترويسة القياسي "" العدد الفعلي للبتات المُتاحة في تنفيذٍ معين. لم تحتوِ لغة سي القديمة على أية معلومات بخصوص طول متغيّر من نوع int، ولكن الجميع كان يفترض اصطلاحًا أنها على الأقل 16 بِت. في الحقيقة، لا يحدّد ملف الترويسة "" العدد الدقيق للبتات، ولكنه يقدِّم تقديرًا لأعظم عدد وأقل عدد بتات لقيمةٍ في متغيرٍ من نوع int، والقيم التي يحددها هي ما بين 32767 و32767- أي 16 بت فما فوق، سواءٌ كانت عملية المتمم الأحادي أو الثنائي الحسابية مستخدمةُ أم لا، وبالطبع لا يوجد هناك أي قيود من توفير نطاق أكبر في أي الطرفين في حال توفرت الطريقة المناسبة. يتراوح النطاق المحدد وفق المعيار للمتغير من نوع unsigned int من 0 إلى 65535، مما يعني أن القيمة لا يمكن أن تكون سالبة، وسنتكلم بإسهاب عن هذه النقطة لاحقًا. إذا لم تعتَد التفكير بعدد البتات لمتغيّر ما، وبدأت بالقلق عمّا إذا سيؤثر ذلك على قابلية نقل البرنامج كون هذه المشكلة مرتبطةً بوضوح بالآلة (أي الحاسوب الذي يشغّل البرنامج)، فقلقك في محلّه. تأخذ لغة سي قابلية نقل البرنامج على محمل الجدّ كما تدلّك على القيم والمجالات الآمنة، وتشجِّعك أيضًا عوامل العوامل الثنائية bitwise operators على التفكير بعدد البتّات في متغيرٍ ما، لأنها تمنحك الوصول المباشر إلى بتات المتغيرالتي تعالجها بصورةٍ منفردة (كل بت على حدى) أو في مجموعات. ونتيجة لذلك تكوَّن لدى مبرمجي لغة سي المعرفة الكافية بخصوص مشكلات قابلية نقل البرنامج، ممّا يتسبب ببرمجة برامج قابلة للنقل، لكننا لا ننفي هنا إمكانية كتابة برامج غير قابلة للنقل إطلاقًا. متغيرات المحارف المتغير char هو النوع الثاني من أنواع الأعداد الصحيحة البسيطة، فهو نوعٌ آخر من int ولكن بتطبيقٍ مختلف، إذ تُعدّ فكرة تخصيص نوعٍ خاص للتعامل مع المحارف فكرةً جيّدة خاصةً وأن كثيرًا من برامج سي تتعامل بالمحارف، لأن تمثيل القيم باستخدام النوع int يأخذ كثيرًا من المساحة غير الضرورية لتمثيل المحرف. يصف ملف ترويسة الحدود "limits" ثلاثة أشياء عن النوع char ألا وهي: عدد البتات 8 على الأقل. يمكنها تخزين قيمة 127+ على الأقل. القيمة الدنيا للنوع char هي صفر أو أقل، مما يعني أن المجال يتراوح ما بين 0 إلى 127. يحدِّد تنفيذ المتحول char فيما إذا كان سيتصرف تصرُّف المتحولات ذات الإشارة signed أو عديمة الإشارة unsigned. باختصار، تحتل متغيرات المحارف مساحةً أقل من المتغيرات الصحيحة int التقليدية، ويمكن استخدامها لمعالجة المحارف، لكنها تندرج تحت تصنيف الأعداد الصحيحة، ويمكن استخدامها لإجراء العمليات الحسابية كما هو موضح في المثال التالي: include <limits.h> include <stdio.h> include <stdlib.h> main(){ char c; c = CHAR_MIN; while(c != CHAR_MAX){ printf("%d\n", c); c = c+1; } exit(EXIT_SUCCESS); } [مثال 3.2] تشغيل البرنامج في المثال السابق تمرينٌ لك، وربما ستثير النتائج إعجابك. إذا كنت تتسائل عن قيمة CHAR_MIN وCHAR_MAX، فاطّلع على ملف الترويسة limits.h واقرأه. إليك مثالٌ آخر مثيرٌ للإعجاب حقًا، إذ سنستخدم فيه محارف ثابتة constants، والتي يمكن كتابتها بين إشارتين تنصيص أحاديّة على النحو التالي: 'x' لأن القواعد الحسابية تُطبَّق هنا، فسيُحوّل المحرف الثابت السابق ليكون من النوع int، ولكن هذا لا يهم حقًّا لأن قيمة المحرف صغيرة دائمًا ويمكن تخزينها في متغير من نوع char دون فقدان أي دقة (لسوء الحظ هناك بعض الحالات التي لا ينطبق فيها هذا الكلام، تجاهلها في الوقت الحالي). عندما يُطبع محرف باستخدام الرمز c% ضمن دالة printf، يُطبع المحرف كما هو، لكن يمكنك استخدام الرمز d% إذا أردت طباعة قيمة العدد الصحيح الموافقة لهذا المحرف. لماذا استُخدم الرمز d%؟ كما ذكرنا سابقًا، النوع char هو في الحقيقة نوع من أنواع الأعداد الصحيحة. من المهم أيضًا وجود طريقة لقراءة المحارف إلى البرنامج، وتتكفل الدالة getchar بهذه المهمة، إذ تقرأ المحارف من الدخل القياسي standard input للبرنامج وتُعيد قيمةً صحيحةً int موافقة لتخزين هذا المحرف في متغير من نوع char، تخدم هذه القيمة المُمرّرة من نوع int غرضين، هما: تمثيل جميع قيم المحارف الممكنة بواسطتها، إضافةً إلى تمرير قيمة إضافية للدلالة على نهاية الدخل. لا يتسع مجال قيم متغير من نوع char في جميع الحالات لهذه القيمة الإضافية، لذلك يُستخدم النوع int. يقرأ البرنامج التالي الدخل ويعدّ الفواصل والنقاط المُدخلة، وعند وصولة لنهاية الدخل يطبع النتيجة. #include <stdio.h> #include <stdlib.h> main(){ int this_char, comma_count, stop_count; comma_count = stop_count = 0; this_char = getchar(); while(this_char != EOF){ if(this_char == '.') stop_count = stop_count+1; if(this_char == ',') comma_count = comma_count+1; this_char = getchar(); } printf("%d commas, %d stops\n", comma_count, stop_count); exit(EXIT_SUCCESS); } [مثال 4.2] هناك ميزتان نستطيع ملاحظتهما من المثال السابق، الأولى هي الإسناد المتعدّد للعدادين، والثانية هي استخدام الثابت المعرّف EOF؛ وهي قيمة تُمرّر من الدالة getchar في نهاية الدخل وتمثِّل اختصارًا لكلمة نهاية الملف End Of File، وتكون معرفةً ضمن ملف الترويسة ""؛ أما الإسناد المتعدد فهي ميزةٌ شائعةٌ الاستخدام في برامج لغة سي. لنأخذ مثالًا آخر، وليكن برنامجًا لطباعة جميع الأحرف الأبجدية بأحرف صغيرة إذا كان تنفيذك يحتوي على محارف مخزنة بصورةٍ متتالية، أو طباعة نتيجةٍ مثيرةٍ للاهتمام إذا لم يكن كذلك. لا تقدّم لغة سي العديد من الضمانات بترتيب المحارف داخليًّا، لذلك قد يتسبب هذا البرنامج بنتائج مختلفة ويكون غير محمول. #include <stdio.h> #include <stdlib.h> main(){ char c; c = 'a'; while(c <= 'z'){ printf("value %d char %c\n", c, c); c = c+1; } exit(EXIT_SUCCESS); } [مثال 5.2] يذكرنا هذا المثال مرةً أخرى بأن char شكلٌ مختلفٌ من أشكال متغيرات الأعداد الصحيحة ويمكن استخدامه مثل أي عدد صحيح آخر، فهو ليس نوع مميّز بقواعد مختلفة. تصبح المساحة التي يوفرها char موازنةً مع int ملحوظةً ومهمةً عندما يُستخدام الكثير من المتغيرات. تستخدم معظم عمليات معالجة المحارف مصفوفات كبيرة منها وليس محرفًا واحدًا أو اثنين فقط، وفي هذه الحالة يصبح الفرق واضحًا بين الاثنين. لنتخيل سويًّا مصفوفةً مؤلفةً من 1024 متغيرًا من نوع int، تحجز هذه المصفوفة مساحة 4098 بايت (كل بايت 8-بت) من التخزين على معظم الآلات، على افتراض أن طول كل int هو 4 بايت؛ فإذا كانت معمارية الحاسوب تسمح بتخزين هذه المعلومات بطريقة فعّالة، قد تطبّق لغة سي هذا عن طريق متغيرات من نوع char بحيث يأخذ كل متغير بايتًا واحدًا، وبذلك ستأخذ المصفوفة مساحة 1024 بايت، مما سيوفّر مساحة 3072 بايت. لا يهمنا في بعض الحالات إن كان سيوفِّر البرنامج مساحةً أم لا، ولكنه يوفِّرها بغض النظر، ومن الجيد أن تعطينا لغة سي فرصة اختيار نوع المتغير المناسب لاستخدامنا. المزيد من الأنواع المعقدة النوعان السابقان الذين تكلمنا عنهما سابقًا بسيطان، سواءٌ بخصوص تصريحهما أو استخدامهما، ولكن دقتهما في التحكم بالتخزين وسلوكهما غير كافيين في استخدامات نظم البرمجة المعقدة. تقدّم لغة سي أنواعًا إضافية من أنواع الأعداد الصحيحة للتغلُّب على هذه المشكلة وتُقسم إلى تصنيفين، الأنواع ذات الإشارة signed والأنواع عديمة الإشارة unsigned (بالرغم من هذه المصطلحات كلمات محجوز في لغة سي إلا أن معناها يدلّ على غرضها أيضًا)، والفرق بين النوعين واضح؛ إذ يمكن للأنواع ذات الإشارة أن تكون قيمتها سالبة؛ بينما يكون من المستحيل أن تخزِّن الأنواع عديمة الإشارة قيمةً سالبة، وتُستخدم الأنواع عديمة الإشارة في معظم الأحيان لحالتين، هما: إعطاء القيمة دقةً أكبر، أو عندما نضمن أن المتغير لن يخزن أي قيمٍ سالبة في استخدامه، والحالة الثانية هي الحالة الأكثر شيوعًا. تملك الأنواع عديمة الإشارة خاصيةً مميزة ألا وهي أنها ليست عرضةً للطفحان الحسابي overflowing عند إجراء العمليات الحسابية، إذ سيتسبب إضافة 1 إلى متغيرٍ من نوعٍ ذي إشارة يخزّن أكبر قيمة يمكن تخزينها بحدوث طفحان، ويصبح سلوك البرنامج نتيجةً لذلك غير محدّد، ولا يحصل هذا الأمر مع المتغيرات من نوعٍ عديم الإشارة، لأنّها تعمل وفق "باقي قسمة واحد زائد القيمة العظمى التي يمكن للمتغير تخزينها على هذه القيمة"، أي باقي قسمة "max+1)/max)"، والمثال التالي يوضح ما نقصده: #include <stdio.h> #include <stdlib.h> main(){ unsigned int x; x = 0; while(x >= 0){ printf("%u\n", x); x = x+1; } exit(EXIT_SUCCESS); } [مثال 6.2] بفرض أن المتغير x يحتل مساحة 16 بِت، فهذا يعني أن مجال قيمته يترواح بين 0 و 65535، وأن الحلقة التكرارية في المثال ستتكرر لأجل غير مسمّى، إذ أن الشرط التالي محققٌ دائمًا: x >= 0 وذلك بالنسبة لأي متغير عديم الإشارة. يوجد ثلاثة أنواع فرعية لكلٍ من الأعداد الصحيحة ذات الإشارة وعديمة الإشارة، هي: short والنوع الاعتيادي و long، ونستطيع بعد أخذ هذه المعلومة بالحسبان كتابة لائحة بجميع أنواع متغيرات الأعداد الصحيحة في لغة سي باستثناء نوع تخزين المحرف char، على النحو التالي: unsigned short int unsigned int unsigned long int signed short int signed int signed long int ليس مهمًّا استخدام الكلمة المفتاحية signed ويمكن الاستغناء عنها في الأنواع الثلاث الأخيرة، إذ أن نوع int ذو إشارة افتراضيًا، ولكن ينبغي عليك استخدام الكلمة المفتاحية unsigned إذا أردت الحصول على نتيجة مغايرة لذلك. من الممكن أيضًا التخلِّي عن الكلمة المفتاحية int من أي تعليمة تصريح شرط أن تحتوي على كلمة مفتاحية أخرى، مثل long أو short، وسيُفهم المتغير على أنه int ضمنيًّا ولكنه أمرٌ غير محبّذ، على سبيل المثال الكلمة المفتاحية long مساوية للكلمات signed long int. يمنحك النوع long و short تحكّمًا أكبر بمقدار المساحة التي تريد حجزها للمتغير، ولكلّ منهما مجال أدنى محدّد في ملف الترويسة <limits.h>، وهو 16 بِت على الأقل لكل من short و int، و32 بتًا على الأقل للنوع long، سواءً كان ذو إشارة signed أو دون إشارة unsigned. وكما ذكرنا آنفًا من الممكن للتنفيذ أن يحجز مقدارًا يزيد على المقدار الأدنى من البتات إذا أراد ذلك، والقيد الوحيد هنا هو أن حدود المجال يجب أن تكون متساويةً أو محسّنة، وألا تحصل على عددٍ أكبر من البتات في متغيرٍ من نوع أصغر موازنةً بنوعٍ أكبر منه، وهي قاعدة منطقية. أنواع متغيرات المحارف الوحيدة هي signed char و unsigned char، ويتمثّل الفرق بين متغيرات من نوع int و char في أن جميع متغيرات int ذات إشارة إن لم يُذكر عكس ذلك، وهذا لا ينطبق على أنواع المحارف char التي قد تكون ذات إشارة أو عديمة الإشارة اعتمادًا على اختيار المُنفّذ، وعادةً ما يُتخذ القرار بناءً على أسس الكفاءة. يمكنك طبعًا اختيار نوع المتغير قسريًا إذا أردت باستخدام الكلمة المفتاحية الموافقة، ولكن هذه النقطة لا تهمّك إلا في حالة استخدامك لمتغيرات المحارف بنوعها القصير short لتوفير مساحة التخزين. لتلخيص ما سبق: تتضمن أنواع الأعداد الصحيحة short و long و signed و unsigned و النوع الاعتيادي int. النوع الأكثر استخدامًا وشيوعًا هو النوع الاعتيادي int وهو ذو إشارة إلا في حالة تحديد عكس ذلك. يمكن للمتغيرات من نوع char أن تكون ذات إشارة أو عديمة الإشارة حسب تفضيلك، ولكن في حال غياب تخصيصك لها ستُخصّص الحالة الأفضل افتراضيًا. طباعة أنواع الأعداد الصحيحة يمكننا طباعة هذه الأنواع المختلفة أيضًا باستخدام الدالة printf، إذ تعمل متغيرات المحارف بنفس الطريقة التي تعمل بها الأعداد الصحيحة الأخرى، ويمكنك استخدام الترميز القياسي لطباعة محتوياتها (أي العدد الذي يمثل المحرف)، على الرغم من كون القيم الخاصة بها غير مثيرة للاهتمام أو مفيدة في معظم الاستخدامات. نستخدم الرمز c% لطباعة محتويات متغيرات المحارف كما أشرنا سابقًا، كما يمكن طباعة جميع قيم الأعداد الصحيحة بالنظام العشري باستخدام الرمز d% أو ld% لأنواع long، ويوضح الجدول 5.2 المزيد من الرموز المفيدة لطباعة القيم بتنسيقٍ مختلف. لاحظ أنّه في كل حالة تبدأ بالحرف l تُطبع قيمةٌ من نوع long، وهذا التخصيص ليس موجودًا فقط لعرض القيمة الصحيحة بل لتجنُّب السلوك غير المحدد لدالة printf إذا أُدخل الترميز الخاطئ. التنسيق يُستخدم مع c% char (طباعة المحرف) d% القيمة العشرية للأنواع signed int و short و char u% القيمة العشرية للأنواع unsigned int و unsigned short وunsigned char x% القيمة الست عشرية للأنواع int وshort وchar o% القيمة الثمانية للأنواع int وshortوchar ld% القيمة العشرية للنوع signed long lu% lx% lo% كما ذُكر في الأعلى ولكن للنوع long [جدول 5.2. المزيد من رموز التنسيق] سنتكلم على نحوٍ مفصّل حول التنسيق المستخدمة مع الدالة printf لاحقًا. ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: التحويلات ما بين الأنواع في تعابير لغة سي C المقال السابق: البنية النصية لبرامج سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C
سنتطرق في هذا المقال إلى الأنواع الحقيقية والصحيحة في لغة سي C الأنواع الحقيقية سيكون من الأسهل التعامل مع الأنواع الحقيقية real أوّلًا، لأن هناك تفاصيل وتعقيدات أقل بخصوصها موازنةً بنوع الأعداد الطبيعية Integers. يقدّم المعيار تفاصيلًا جديدةً بخصوص دقة ونطاق الأعداد الحقيقية، ويمكن أن تجدهم في ملف الترويسة "float.h" الذي سنناقشه بالتفصيل لاحقًا. هذه التفاصيل مهمة جدًا ولكنها ذات طبيعة تقنية للغاية، ولن تُفهم بالكامل غالبًا إلا من قبل مختصّي التحليل العددي. أنواع الأعداد الحقيقية هي: float: العدد العشري double: العدد العشري مضاعف الدقة long double: العدد العشري الأدق يسمح لنا كل واحد من هذه الأنواع بتمثيل الأعداد الحقيقية بطريقة معينة باستخدام الحاسوب؛ فإذا كان هناك نوعٌ واحدٌ لتمثيل الأعداد الحقيقية، فهذا يعني أن تمثيل الأعداد سيكون متماثلًا بغض النظر عن الاستخدام؛ أما إذا كان العدد يتجاوز الثلاثة أنوع، فهذا يعني أن لغة سي لن تستطيع تصنيف أي من الأنواع الإضافية. يُستخدم النوع float للتمثيل السريع والبسيط للأرقام الصغيرة وهو مشابهٌ للنوع REAL في لغة فورتران؛ أما double فيستخدم للدقة الإضافية، و long double لدقة أكبر من سابقتها. التركيز الأساسي هنا هو أنّ الزيادة في "دقة" كلٍ من float و double و long double تعطي لكل نوعٍ نطاقًا ودقّة مساويةً للنوع الذي يسبقها على الأقل، فأخذ القيمة من متغير نوع double مثلًا، وتخزينها في متغير من نوع long double، يجب أن يمثِّل القيمة ذاتها. لا توجد هناك أي متطلبات للأنواع الثلاثة من متغيرات الأعداد "الحقيقية" لتختلف في خصائصها، وبالتالي إن لم توفّر الآلة سوى نوع واحدٍ من أنواع متغيرات الأعداد الحقيقية، فيمكن عندئذٍ تمثيل جميع أنواع الأعداد الحقيقية الثلاثة في لغة سي بهذا النوع المتوفِّر. لكن بغض النظر، يجب أن يُنظر إلى هذه الأنواع الثلاثة بأنها مختلفة، وكأنّ هناك فرقٌ بينها حقًأ، وهذا يساعد في نقل البرنامج إلى نظام تختلف فيه هذه الأنواع حقًّا، بحيث لن يظهر لك مجموعةٌ من التحذيرات من المصرّف بخصوص عدم توافق الأنواع التي لم تكُن موجودةً على النظام الأول. تسمح لغة سي بمزج جميع أنواع البيانات العددية في التعابير بعكس كثيرٍ من لغات البرمجة الصارمة بخصوص قواعد كتابتها، وذلك يضم مختلف أنواع الأعداد الصحيحة إضافةً إلى الأعداد الحقيقية وأنواع المؤشرات؛ وعندما يتضمن التعبير مزيجًا من أنواع الأعداد الحقيقية والصحيحة، سيُستدعى تحويلٌ ضمني يعمل بدوره على معرفة نوع المزيج الكلّي الناتج. هذه القواعد مهمةٌ جدًا وتدعى التحويلات الحسابية الاعتيادية usual arithmetic conversions، ومن المفيد أن تتذكرها، إذ سنشرح كامل هذه القواعد لاحقًا، إلا أننا سننظر في الوقت الحالي إلى الحالات التي تتضمن مزيجًا من float و double و long double ونحاول فهمها. الحالة الوحيدة التي نحتاج فيها إجراء التحويلات المذكورة هي عندما يُمزج نوعان من البيانات في تعبير، كما في هو موضح في المثال التالي: int f(void){ float f_var; double d_var; long double l_d_var; f_var = 1; d_var = 1; l_d_var = 1; d_var = d_var + f_var; l_d_var = d_var + f_var; return(l_d_var); } [مثال 1.2] نلاحظ في المثال السابق وجود كثيرٍ من التحويلات القسرية، لنبدأ بأسهلها أوّلًا، ولننظر إلى تعيين القيمة الثابتة 1 لكلٍ من المتغيرات الثلاثة. لا بُد من التنويه (كما سيشير القسم الذي يتكلم عن القيم الثابتة constants لاحقًا) إلى أن القيمة 1 هي من نوع int، أي تمثّل عددًا صحيحًا وليس قيمةً ثابتةً حقيقية، ويحوّل الإسناد قيمة العدد الصحيح إلى نوع العدد الحقيقي المناسب والأسهل للتعامل معه. التحويلات المثيرة للاهتمام تأتي بعدها، وأولها ضمن السطر التالي: d_var = d_var + f_var; ما هو نوع التعبير الذي يتضمن العامل +؟ الإجابة عن هذا السؤال سهلة ما دمت ملمًّا ببعض القواعد؛ إذ يُحوَّل النوع الأقل دقةً ضمنيًا إلى النوع الأكثر دقةً وتُنجز العملية الحسابية باستخدام هذه الدقة، وذلك عندما يجتمع نوعان من الأعداد الحقيقية في التعبير ذاته. يتضمن المثال السابق استخدام كلٍّ من double و float، لذلك تُحوّل قيمة المتغير f_var إلى النوع double وتُضاف فيما بعد إلى قيمة النوع double أي المتغير d_var، وتكون نتيجة هذا التعبير هي من نوع double أيضًا، لذا من الواضح أن عملية الإسناد إلى المتغير d_var صائبة. عملية الجمع الثانية أكثر تعقيدّا، ولكنها ما زالت سهلة الفهم، إذ تُحوّل قيمة المتغير f_var وتُجرى العملية الحسابية باستخدام دقة النوع double، ألا وهي عملية جمع المتغيرين، لكن هناك مشكلة، وهي أن نتيجة عملية الجمع من نوع double، لكن عملية الإسناد من نوع long double، ويكون مجدّدًا الحل البديهي في هذه الحالة هو تحويل القيمة الأقل دقة إلى الأكبر دقّة، وهو ما يُجرى ضمنيًّا قبل عملية الإسناد. الآن بعد أن أخذنا نظرةً سريعةً على الأمثلة السهلة، حان وقت الأمثلة الأكثر صعوبة وهي الحالة التي يتسبب فيها التحويل القسري بتحويل نتيجةٍ بدقةٍ عالية إلى دقةٍ أقل منها، ففي مثل هذه الحالات قد يكون من الضروري خسارة الدقة بطريقة محدّدة من تنفيذ التحويل. ببساطة، يجب أن يحدد التنفيذ طريقة تقريب أو اقتطاعٍ للقيمة، وفي أسوأ الحالات قد يكون نوع الهدف غير قادرٍ على تخزين تلك القيمة الضرورية (على سبيل المثال محاولة جمع أكبر قيمة لعدد إلى نفسه)، وتُعد نتيجة التنفيذ في هذه الحالة غير محددة، والبرنامج يشكو من خطأ ولا يمكنك التنبؤ بتصرفه. لا ضرر من تكرار فكرتنا السابقة، إذ يقصد المعيار بحالة السلوك غير المحدد undefined behaviour معنى اسمه حرفيًا، وحالما يدخل البرنامج منطقة السلوك غير المحدد، يمكن لأي شيء أن يحدث؛ فمن الممكن إيقاف البرنامج من طرف نظام التشغيل مصحوبًا برسالة معيّنة؛ أو قد يحدث شيء غير مُلاحظ ويستمر البرنامج للعمل باستخدام قيم خاطئة مُخزَّنة في المتغير. منع البرنامج من إبداء أي سلوك غير محدّد تعد من مسؤولياتك، فتوخّ الحذر. لتلخيص ما سبق: تُجرى العمليات الحسابية التي تتضمن نوعين باستخدام النوع الأعلى دقّة منهما. قد يتضمن الإسناد خسارة لدقة القيمة في حال كان نوع المتغير الهدف ذو دقة أقل من دقة القيمة التي تُسنَد لهذا المتغير. هناك مزيدٌ من التحويلات التي تُجرى عند مزج الأنواع ضمن تعبير واحد، إذ لم نصِف جميعها بعد. طباعة الأعداد الحقيقية يمكن استخدام دالة الخرج التقليدي printf لتنسيق الأعداد الحقيقية وطباعتها، كما يوجد العديد من الطرق لتنسيق هذه الأعداد، ولكننا سنتطرق إلى طريقة واحدة في الوقت الحالي. يوضح الجدول 4.2 التنسيق الموافق لكل نوعٍ من أنواع الأعداد الحقيقية. table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } النوع التنسيق float f% double f% long double Lf% [جدول 4.2. رموز التنسيق للأعداد الحقيقية] ألقِ نظرةً على المثال التالي لتجربة المعلومة السابقة: #include <stdio.h> #include <stdlib.h> #define BOILING 212 /* degrees Fahrenheit */ main(){ float f_var; double d_var; long double l_d_var; int i; i = 0; printf("Fahrenheit to Centigrade\n"); while(i <= BOILING){ l_d_var = 5*(i-32); l_d_var = l_d_var/9; d_var = l_d_var; f_var = l_d_var; printf("%d %f %f %Lf\n", i, f_var, d_var, l_d_var); i = i+1; } exit(EXIT_SUCCESS); } [مثال 2.2] جرّب المثال السابق على حاسوبك الشخصي، ولاحظ النتائج. الأنواع الصحيحة كانت الأنواع الحقيقية أسهل الأنواع، إذ تتصف القوانين الخاصة بالأنواع الصحيحة بتعقيد أكبر، ولكنها ما زالت مفهومة وينبغي تعلُّمها. لحسن الحظ، الأنواع الوحيدة المستخدمة في لغة سي لتخزين البيانات هي الأنواع الحقيقية والصحيحة، إضافةً إلى الهياكل structures والمصفوفات arrays المبنيّة عليهما، إذ لا تحتوي لغة سي على أنواع مميزة للتلاعب بالمحارف، أو التعامل مع القيم البوليانية boolean، وإنما تستخدم الأنواع الصحيحة بدلًا من ذلك، وهذا يعني أنه حالما تفهم الأنواع الصحيحة والحقيقية فأنت تعرف جميع الأنواع. سنبدأ بالنظر إلى الأنواع المختلفة للأعداد الصحيحة وقوانين التحويل فيما بينها. الأعداد الصحيحة البسيطة هناك نوعان من متغيرات الأعداد الصحيحة يطلق عليهما "نكهات flavours"، ويمكن بناء أنواع أخرى انطلاقًا من هذين النوعين كما سنرى لاحقًا، لكن تبقى الأنواع البسيطة int هي الأساس. النوع الأكثر شهرةً هو العدد الصحيح ذو الإشارة signed أو int، أما النوع الأقل شهرة هو العدد الصحيح عديم الإشارة أو unsigned int، ومن المفترض أن تُخزّن القيم في المتغيرات ذات النوع المناسب حسب الآلة التي تشغل البرنامج. عندما تبحث عن نوع بيانات بسيط لتمثيل عدد صحيح، فإن النوع int هو الاختيار البديهي لأي استخدام مُتساهل، مثل عدّاد ضمن حلقة تكرارية قصيرة، إذ لا توجد هناك أي قاعدة تحدّد عدد البتّات التي يخزنها نوع int لقيمةٍ ما، لكنه سيكون دائمًا مساويًا إلى 16 بِت أو أكثر، ويفصِّل ملف الترويسة القياسي "" العدد الفعلي للبتات المُتاحة في تنفيذٍ معين. لم تحتوِ لغة سي القديمة على أية معلومات بخصوص طول متغيّر من نوع int، ولكن الجميع كان يفترض اصطلاحًا أنها على الأقل 16 بِت. في الحقيقة، لا يحدّد ملف الترويسة "" العدد الدقيق للبتات، ولكنه يقدِّم تقديرًا لأعظم عدد وأقل عدد بتات لقيمةٍ في متغيرٍ من نوع int، والقيم التي يحددها هي ما بين 32767 و32767- أي 16 بت فما فوق، سواءٌ كانت عملية المتمم الأحادي أو الثنائي الحسابية مستخدمةُ أم لا، وبالطبع لا يوجد هناك أي قيود من توفير نطاق أكبر في أي الطرفين في حال توفرت الطريقة المناسبة. يتراوح النطاق المحدد وفق المعيار للمتغير من نوع unsigned int من 0 إلى 65535، مما يعني أن القيمة لا يمكن أن تكون سالبة، وسنتكلم بإسهاب عن هذه النقطة لاحقًا. إذا لم تعتَد التفكير بعدد البتات لمتغيّر ما، وبدأت بالقلق عمّا إذا سيؤثر ذلك على قابلية نقل البرنامج كون هذه المشكلة مرتبطةً بوضوح بالآلة (أي الحاسوب الذي يشغّل البرنامج)، فقلقك في محلّه. تأخذ لغة سي قابلية نقل البرنامج على محمل الجدّ كما تدلّك على القيم والمجالات الآمنة، وتشجِّعك أيضًا عوامل العوامل الثنائية bitwise operators على التفكير بعدد البتّات في متغيرٍ ما، لأنها تمنحك الوصول المباشر إلى بتات المتغيرالتي تعالجها بصورةٍ منفردة (كل بت على حدى) أو في مجموعات. ونتيجة لذلك تكوَّن لدى مبرمجي لغة سي المعرفة الكافية بخصوص مشكلات قابلية نقل البرنامج، ممّا يتسبب ببرمجة برامج قابلة للنقل، لكننا لا ننفي هنا إمكانية كتابة برامج غير قابلة للنقل إطلاقًا. متغيرات المحارف المتغير char هو النوع الثاني من أنواع الأعداد الصحيحة البسيطة، فهو نوعٌ آخر من int ولكن بتطبيقٍ مختلف، إذ تُعدّ فكرة تخصيص نوعٍ خاص للتعامل مع المحارف فكرةً جيّدة خاصةً وأن كثيرًا من برامج سي تتعامل بالمحارف، لأن تمثيل القيم باستخدام النوع int يأخذ كثيرًا من المساحة غير الضرورية لتمثيل المحرف. يصف ملف ترويسة الحدود "limits" ثلاثة أشياء عن النوع char ألا وهي: عدد البتات 8 على الأقل. يمكنها تخزين قيمة 127+ على الأقل. القيمة الدنيا للنوع char هي صفر أو أقل، مما يعني أن المجال يتراوح ما بين 0 إلى 127. يحدِّد تنفيذ المتحول char فيما إذا كان سيتصرف تصرُّف المتحولات ذات الإشارة signed أو عديمة الإشارة unsigned. باختصار، تحتل متغيرات المحارف مساحةً أقل من المتغيرات الصحيحة int التقليدية، ويمكن استخدامها لمعالجة المحارف، لكنها تندرج تحت تصنيف الأعداد الصحيحة، ويمكن استخدامها لإجراء العمليات الحسابية كما هو موضح في المثال التالي: include <limits.h> include <stdio.h> include <stdlib.h> main(){ char c; c = CHAR_MIN; while(c != CHAR_MAX){ printf("%d\n", c); c = c+1; } exit(EXIT_SUCCESS); } [مثال 3.2] تشغيل البرنامج في المثال السابق تمرينٌ لك، وربما ستثير النتائج إعجابك. إذا كنت تتسائل عن قيمة CHAR_MIN وCHAR_MAX، فاطّلع على ملف الترويسة limits.h واقرأه. إليك مثالٌ آخر مثيرٌ للإعجاب حقًا، إذ سنستخدم فيه محارف ثابتة constants، والتي يمكن كتابتها بين إشارتين تنصيص أحاديّة على النحو التالي: 'x' لأن القواعد الحسابية تُطبَّق هنا، فسيُحوّل المحرف الثابت السابق ليكون من النوع int، ولكن هذا لا يهم حقًّا لأن قيمة المحرف صغيرة دائمًا ويمكن تخزينها في متغير من نوع char دون فقدان أي دقة (لسوء الحظ هناك بعض الحالات التي لا ينطبق فيها هذا الكلام، تجاهلها في الوقت الحالي). عندما يُطبع محرف باستخدام الرمز c% ضمن دالة printf، يُطبع المحرف كما هو، لكن يمكنك استخدام الرمز d% إذا أردت طباعة قيمة العدد الصحيح الموافقة لهذا المحرف. لماذا استُخدم الرمز d%؟ كما ذكرنا سابقًا، النوع char هو في الحقيقة نوع من أنواع الأعداد الصحيحة. من المهم أيضًا وجود طريقة لقراءة المحارف إلى البرنامج، وتتكفل الدالة getchar بهذه المهمة، إذ تقرأ المحارف من الدخل القياسي standard input للبرنامج وتُعيد قيمةً صحيحةً int موافقة لتخزين هذا المحرف في متغير من نوع char، تخدم هذه القيمة المُمرّرة من نوع int غرضين، هما: تمثيل جميع قيم المحارف الممكنة بواسطتها، إضافةً إلى تمرير قيمة إضافية للدلالة على نهاية الدخل. لا يتسع مجال قيم متغير من نوع char في جميع الحالات لهذه القيمة الإضافية، لذلك يُستخدم النوع int. يقرأ البرنامج التالي الدخل ويعدّ الفواصل والنقاط المُدخلة، وعند وصولة لنهاية الدخل يطبع النتيجة. #include <stdio.h> #include <stdlib.h> main(){ int this_char, comma_count, stop_count; comma_count = stop_count = 0; this_char = getchar(); while(this_char != EOF){ if(this_char == '.') stop_count = stop_count+1; if(this_char == ',') comma_count = comma_count+1; this_char = getchar(); } printf("%d commas, %d stops\n", comma_count, stop_count); exit(EXIT_SUCCESS); } [مثال 4.2] هناك ميزتان نستطيع ملاحظتهما من المثال السابق، الأولى هي الإسناد المتعدّد للعدادين، والثانية هي استخدام الثابت المعرّف EOF؛ وهي قيمة تُمرّر من الدالة getchar في نهاية الدخل وتمثِّل اختصارًا لكلمة نهاية الملف End Of File، وتكون معرفةً ضمن ملف الترويسة ""؛ أما الإسناد المتعدد فهي ميزةٌ شائعةٌ الاستخدام في برامج لغة سي. لنأخذ مثالًا آخر، وليكن برنامجًا لطباعة جميع الأحرف الأبجدية بأحرف صغيرة إذا كان تنفيذك يحتوي على محارف مخزنة بصورةٍ متتالية، أو طباعة نتيجةٍ مثيرةٍ للاهتمام إذا لم يكن كذلك. لا تقدّم لغة سي العديد من الضمانات بترتيب المحارف داخليًّا، لذلك قد يتسبب هذا البرنامج بنتائج مختلفة ويكون غير محمول. #include <stdio.h> #include <stdlib.h> main(){ char c; c = 'a'; while(c <= 'z'){ printf("value %d char %c\n", c, c); c = c+1; } exit(EXIT_SUCCESS); } [مثال 5.2] يذكرنا هذا المثال مرةً أخرى بأن char شكلٌ مختلفٌ من أشكال متغيرات الأعداد الصحيحة ويمكن استخدامه مثل أي عدد صحيح آخر، فهو ليس نوع مميّز بقواعد مختلفة. تصبح المساحة التي يوفرها char موازنةً مع int ملحوظةً ومهمةً عندما يُستخدام الكثير من المتغيرات. تستخدم معظم عمليات معالجة المحارف مصفوفات كبيرة منها وليس محرفًا واحدًا أو اثنين فقط، وفي هذه الحالة يصبح الفرق واضحًا بين الاثنين. لنتخيل سويًّا مصفوفةً مؤلفةً من 1024 متغيرًا من نوع int، تحجز هذه المصفوفة مساحة 4098 بايت (كل بايت 8-بت) من التخزين على معظم الآلات، على افتراض أن طول كل int هو 4 بايت؛ فإذا كانت معمارية الحاسوب تسمح بتخزين هذه المعلومات بطريقة فعّالة، قد تطبّق لغة سي هذا عن طريق متغيرات من نوع char بحيث يأخذ كل متغير بايتًا واحدًا، وبذلك ستأخذ المصفوفة مساحة 1024 بايت، مما سيوفّر مساحة 3072 بايت. لا يهمنا في بعض الحالات إن كان سيوفِّر البرنامج مساحةً أم لا، ولكنه يوفِّرها بغض النظر، ومن الجيد أن تعطينا لغة سي فرصة اختيار نوع المتغير المناسب لاستخدامنا. المزيد من الأنواع المعقدة النوعان السابقان الذين تكلمنا عنهما سابقًا بسيطان، سواءٌ بخصوص تصريحهما أو استخدامهما، ولكن دقتهما في التحكم بالتخزين وسلوكهما غير كافيين في استخدامات نظم البرمجة المعقدة. تقدّم لغة سي أنواعًا إضافية من أنواع الأعداد الصحيحة للتغلُّب على هذه المشكلة وتُقسم إلى تصنيفين، الأنواع ذات الإشارة signed والأنواع عديمة الإشارة unsigned (بالرغم من هذه المصطلحات كلمات محجوز في لغة سي إلا أن معناها يدلّ على غرضها أيضًا)، والفرق بين النوعين واضح؛ إذ يمكن للأنواع ذات الإشارة أن تكون قيمتها سالبة؛ بينما يكون من المستحيل أن تخزِّن الأنواع عديمة الإشارة قيمةً سالبة، وتُستخدم الأنواع عديمة الإشارة في معظم الأحيان لحالتين، هما: إعطاء القيمة دقةً أكبر، أو عندما نضمن أن المتغير لن يخزن أي قيمٍ سالبة في استخدامه، والحالة الثانية هي الحالة الأكثر شيوعًا. تملك الأنواع عديمة الإشارة خاصيةً مميزة ألا وهي أنها ليست عرضةً للطفحان الحسابي overflowing عند إجراء العمليات الحسابية، إذ سيتسبب إضافة 1 إلى متغيرٍ من نوعٍ ذي إشارة يخزّن أكبر قيمة يمكن تخزينها بحدوث طفحان، ويصبح سلوك البرنامج نتيجةً لذلك غير محدّد، ولا يحصل هذا الأمر مع المتغيرات من نوعٍ عديم الإشارة، لأنّها تعمل وفق "باقي قسمة واحد زائد القيمة العظمى التي يمكن للمتغير تخزينها على هذه القيمة"، أي باقي قسمة "max+1)/max)"، والمثال التالي يوضح ما نقصده: #include <stdio.h> #include <stdlib.h> main(){ unsigned int x; x = 0; while(x >= 0){ printf("%u\n", x); x = x+1; } exit(EXIT_SUCCESS); } [مثال 6.2] بفرض أن المتغير x يحتل مساحة 16 بِت، فهذا يعني أن مجال قيمته يترواح بين 0 و 65535، وأن الحلقة التكرارية في المثال ستتكرر لأجل غير مسمّى، إذ أن الشرط التالي محققٌ دائمًا: x >= 0 وذلك بالنسبة لأي متغير عديم الإشارة. يوجد ثلاثة أنواع فرعية لكلٍ من الأعداد الصحيحة ذات الإشارة وعديمة الإشارة، هي: short والنوع الاعتيادي و long، ونستطيع بعد أخذ هذه المعلومة بالحسبان كتابة لائحة بجميع أنواع متغيرات الأعداد الصحيحة في لغة سي باستثناء نوع تخزين المحرف char، على النحو التالي: unsigned short int unsigned int unsigned long int signed short int signed int signed long int ليس مهمًّا استخدام الكلمة المفتاحية signed ويمكن الاستغناء عنها في الأنواع الثلاث الأخيرة، إذ أن نوع int ذو إشارة افتراضيًا، ولكن ينبغي عليك استخدام الكلمة المفتاحية unsigned إذا أردت الحصول على نتيجة مغايرة لذلك. من الممكن أيضًا التخلِّي عن الكلمة المفتاحية int من أي تعليمة تصريح شرط أن تحتوي على كلمة مفتاحية أخرى، مثل long أو short، وسيُفهم المتغير على أنه int ضمنيًّا ولكنه أمرٌ غير محبّذ، على سبيل المثال الكلمة المفتاحية long مساوية للكلمات signed long int. يمنحك النوع long و short تحكّمًا أكبر بمقدار المساحة التي تريد حجزها للمتغير، ولكلّ منهما مجال أدنى محدّد في ملف الترويسة <limits.h>، وهو 16 بِت على الأقل لكل من short و int، و32 بتًا على الأقل للنوع long، سواءً كان ذو إشارة signed أو دون إشارة unsigned. وكما ذكرنا آنفًا من الممكن للتنفيذ أن يحجز مقدارًا يزيد على المقدار الأدنى من البتات إذا أراد ذلك، والقيد الوحيد هنا هو أن حدود المجال يجب أن تكون متساويةً أو محسّنة، وألا تحصل على عددٍ أكبر من البتات في متغيرٍ من نوع أصغر موازنةً بنوعٍ أكبر منه، وهي قاعدة منطقية. أنواع متغيرات المحارف الوحيدة هي signed char و unsigned char، ويتمثّل الفرق بين متغيرات من نوع int و char في أن جميع متغيرات int ذات إشارة إن لم يُذكر عكس ذلك، وهذا لا ينطبق على أنواع المحارف char التي قد تكون ذات إشارة أو عديمة الإشارة اعتمادًا على اختيار المُنفّذ، وعادةً ما يُتخذ القرار بناءً على أسس الكفاءة. يمكنك طبعًا اختيار نوع المتغير قسريًا إذا أردت باستخدام الكلمة المفتاحية الموافقة، ولكن هذه النقطة لا تهمّك إلا في حالة استخدامك لمتغيرات المحارف بنوعها القصير short لتوفير مساحة التخزين. لتلخيص ما سبق: تتضمن أنواع الأعداد الصحيحة short و long و signed و unsigned و النوع الاعتيادي int. النوع الأكثر استخدامًا وشيوعًا هو النوع الاعتيادي int وهو ذو إشارة إلا في حالة تحديد عكس ذلك. يمكن للمتغيرات من نوع char أن تكون ذات إشارة أو عديمة الإشارة حسب تفضيلك، ولكن في حال غياب تخصيصك لها ستُخصّص الحالة الأفضل افتراضيًا. طباعة أنواع الأعداد الصحيحة يمكننا طباعة هذه الأنواع المختلفة أيضًا باستخدام الدالة printf، إذ تعمل متغيرات المحارف بنفس الطريقة التي تعمل بها الأعداد الصحيحة الأخرى، ويمكنك استخدام الترميز القياسي لطباعة محتوياتها (أي العدد الذي يمثل المحرف)، على الرغم من كون القيم الخاصة بها غير مثيرة للاهتمام أو مفيدة في معظم الاستخدامات. نستخدم الرمز c% لطباعة محتويات متغيرات المحارف كما أشرنا سابقًا، كما يمكن طباعة جميع قيم الأعداد الصحيحة بالنظام العشري باستخدام الرمز d% أو ld% لأنواع long، ويوضح الجدول 5.2 المزيد من الرموز المفيدة لطباعة القيم بتنسيقٍ مختلف. لاحظ أنّه في كل حالة تبدأ بالحرف l تُطبع قيمةٌ من نوع long، وهذا التخصيص ليس موجودًا فقط لعرض القيمة الصحيحة بل لتجنُّب السلوك غير المحدد لدالة printf إذا أُدخل الترميز الخاطئ. التنسيق يُستخدم مع c% char (طباعة المحرف) d% القيمة العشرية للأنواع signed int و short و char u% القيمة العشرية للأنواع unsigned int و unsigned short وunsigned char x% القيمة الست عشرية للأنواع int وshort وchar o% القيمة الثمانية للأنواع int وshortوchar ld% القيمة العشرية للنوع signed long lu% lx% lo% كما ذُكر في الأعلى ولكن للنوع long [جدول 5.2. المزيد من رموز التنسيق] سنتكلم على نحوٍ مفصّل حول التنسيق المستخدمة مع الدالة printf لاحقًا. ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: التحويلات ما بين الأنواع في تعابير لغة سي C المقال السابق: البنية النصية لبرامج سي C إدارة الذاكرة (Memory management) في لغة C المتغيرات الشرطية وحلها مشاكل التزامن بين العمليات في لغة C متغيرات تقييد الوصول (Semaphores) في لغة البرمجة سي C -
 سنلقي في الجزئية الثانية من السلسلة، نظرةً على الأجزاء التي لم نلقِ لها بالًا في المقال السابق من هذه السلسلة، الذي كان بمثابة مقدمة سريعة عن لغة سي، التحدي هنا هو التكلم عن أساسيات اللغة بصورةٍ موسّعة وكافية للسماح لك بفهم المزيد عن اللغة دون إغراق المبتدئين بالمعلومات والتفاصيل غير الضرورية في هذه المرحلة. سنغطي في هذه الجزئية من السلسلة بعض المفاهيم والمشاكل الدقيقة التي لا تقرأ عنها في النصوص التقديمية للغة، فيجب عليك أن تقرأه بعقلية منفتحة وبمزاج جيّد. قد يجد دماغك المرهَق التمارين الموجودة بين الفقرات استراحةً مفيدة، إذ ننصحك بشدّة أن تحاول حلّ التمارين هذه بينما تقرأ المقال، إذ أن ذلك من شأنه أن يساعدك في موازنة الكفة بين تعلُّم المفاهيم الجديدة -التي قد تشعر في بعض المراحل بغزارتها- والتمارين. حان الوقت لتقديم بعض الأساسيات في لغة سي. المحارف المستخدمة في لغة سي هذه الفقرة مثيرة للاهتمام، وسندعو المحارف المُستخدمة في لغة سي بأبجدية سي C، وهذه الأبجدية مهمة جدًا، وربما يكون هذا الجزء الوحيد من هذا المقال الذي يمكنك قراءته بصورةٍ سطحية وفهم جميع محتوياته من المرة الأولى. لذلك، اقرأه لتضمن أنك تعرف محتوياته والمعلومات الواردة فيه جيّدًا وتذكر أن تعود إليه في حال أردت مرجعًا بهذا الخصوص. الأبجدية الاعتيادية تعرّف قلةٌ من لغات البرمجة أبجديتها أو تلقي بالًا لهذا الأمر، إذ أن هناك افتراضًا مسبقًا بأن أحرف الأبجدية الإنجليزية وخليطًا من علامات الترقيم والرموز ستكون متاحةً في أي بيئة داعمة للّغة، ولكن هذا الافتراض غير محقّقٍ دائمًا. تعاني لغات البرمجة القديمة من هذه المشكلة بدرجةٍ أقل حدّة، ولكن تخيل إرسال برنامج مكتوب بلغة سي عبر جهاز تلكس Telex أو عن طريق نظام بريد إلكتروني يحتوي على بعض القيود، أتعي أهمية الأمر الآن؟ يوصّف المعيار مجموعتين مختلفتين من المحارف: واحدةٌ تُكتب بها البرامج وأخرى تُنفَّذ بها، وذلك للسماح للأنظمة المختلفة بتصريف البرنامج وتنفيذه بغض النظر عن اختلاف طرق ترميز المحارف لكل نظام. في الحقيقة، الأمر مهمّ فقط في حال استخدامك محارفًا ثابتة constant في المعالج المُسبق preprocessor، إذ من الممكن أن تختلف قيم هذه المحارف عند التنفيذ، وهذا السلوك معرّف عند التنفيذ implementation-defined، فهو موثّق بالتأكيد، ولكن لا تقلق بخصوص هذا الأمر الآن. يملي المعيار وجود أبجدية مؤلفة من 96 رمزًا للغة سي، وهي: المسافات ومسافات الجدولة الأفقية والعمودية ومحرف السطر الجديد وفاصل الصفحة table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 3 4 5 6 7 8 9 ! " # % & ' ( ) * + , - . / : ; < = > ? [ \ ] ^ _ {|} ~ [جدول 1 أبجدية لغة سي] اتّضح أن معظم أبجديات الحاسوب الشائعة تحتوي على جميع الرموز اللازمة للغة سي، عدا بعض الحالات الشاذة النادرة مثل المحارف الموجودة في الأسفل، والتي تُعد مثالًا عن محارف أبجدية لغة سي المفقودة من مجموعة المحارف ذات 7 بت لمعيار منظمة المعايير العالمية International Standards Organization المدعوّ ISO 646، وهي مجموعة جزئية من المحارف المُستخدمة في أبجديات الحاسوب على نطاقٍ واسع. # [ \ ] ^ { | } ~ لتضمين هذه الأنظمة التي لا تحتوي على مجموعة المحارف البالغ عددها 96 والمطلوبة لكتابة برامج بلغة سي، حدّد المعيار طريقةً لاستخدام معيار ISO 646 لتمثيل المحارف المفقودة ألا وهي تقنية ثُلاثيات المحارف trigraphs. ثلاثيات المحارف ثلاثيات المحارف Trigraphs هي سلسلةٌ من ثلاثة محارف ضمن المعيار ISO 646، وتُعامل معاملة محرفٍ واحدٍ ضمن أبجدية لغة سي. تبدأ جميع ثلاثيات المحارف بعلامتَي استفهام "??"، ويساعد هذا في الدلالة على أن هناك شيءٌ "خارجٌ عن المألوف" ضمن البرنامج. يوضّح الجدول 2 أدناه جميع ثلاثيات المحارف المُعرّفة ضمن المعيار. محرف أبجدية سي C ثلاثي المحرف # =?? ] )?? [ (?? } >?? { <?? \ /?? \ !?? ~ -?? ^ '?? [جدول 2 ثلاثيات المحارف] دعنا نفترض مثلًا، أن طرفيتك terminal لا تحتوي على الرمز "#" لكتابة سطر المعالج المُسبق التالي: #define MAX 32767 عندها، نستطيع استخدام طريقة ثلاثيات المحارف على النحو التالي: ??=define MAX 32767 ستعمل ثلاثيات المحارف حتى لو كان المحرف "#" موجودًا، ولكن هذه التقنية موجودةٌ لمساعدتك في الحالات الحرجة ولا يُحبَّذ استخدامها بديلًا عن محارف أبجدية سي دومًا. ترتبط إشارة الاستفهام "?" بالمحرف الواقع على يمينها، لذا في أي سلسلة مؤلفة من عدّة إشارات استفهام، تشكِّل إشارتان فقط ضمن السلسلة ثلاثي محارف، ويعتمد المحرف الذي تمثِّله على المحرف الذي يقع بعد الإشارتين مباشرةً، وهذا من شأنه أن يجنّبك كثيرًا من الالتباس. من الخطأ الاعتقاد أن البرامج المكتوبة بلغة سي، والتي تلقي بالًا كبيرًا لإمكانية تشغيلها على نحوٍ محمول portable وعلى جميع الأنظمة مكتوبةٌ باستخدام ثلاثيات المحارف "إلا في حال ضرورة نقلها إلى نظام يدعم معيار ISO 646 فقط"؛ فإذا كان نظامك يدعم جميع المحارف البالغ عددها 96 محرفًأ، واللازمة لكتابة البرامج بلغة سي، فيجب استخدامها دون الاستعانة بثلاثيات المحارف، إذ وُجدت هذه التقنية لتنفيذها ضمن بيئات محدودة، ومن السهل جدًا كتابة مفسّر يحوِّل برنامجك بين التمثيلين عن طريق فحص كل محرف بمحرفه. ستميّز جميع المصرّفات المتوافقة مع المعيار ثلاثيات المحارف عندما تجدها، إذ أن تبديل ثلاثيات الأحرف هو من أولى العمليات التي يجريها المصرّف على البرنامج. المحارف متعددة البايت أُضيف دعم المحارف متعددة البايت multibyte characters إلى المعيار، ولكن ما هو السبب؟ تتضمن نسبةٌ كبيرة من الحوسبة الاعتيادية اليومية بياناتٍ ممثّلة بنص بشكلٍ أو بآخر، وساد الاعتقاد في مجال الحوسبة أنه من الكافي دعم ما يقارب مئة محرف مطبوع فقط، ومن هنا كان عدد المحارف الممثلة لأبجدية سي 96 محرفًا، وذلك بناءً على متطلبات اللغة الإنجليزية وهذا الأمر ليس مفاجئًا بالنظر إلى أن معظم سوق تطوير البرمجيات والحوسبة التجاري كان في الولايات المتحدة الأمريكية. تُعرف مجموعة المحارف هذه باسم المخزون repertoire وتتناسب مع 7 أو 8 بتات من الذاكرة، وهذا السبب في أهمية استخدام 8-بت واحدةً لتخزين وقياس للبيانات بصورةٍ أساسية في معيار US-ASCII ومعمارية الحواسيب المصغرة minicomputers والحواسيب الدقيقة microcomputers. تتّبع لغة سي أيضًا توجّهًا في تخزين البيانات باستخدام البايت byte، إذ أن أصغر وحدات التخزين الممكن استخدامها مباشرةً في لغة سي هي البايت، والمعرّفة بكونها تتألف من 8 بِت. قد تشكو الأنظمة والمعماريات القديمة التي لم تُصمم مباشرةً لدعم ذلك من بطء بسيط في الأداء عند تشغيل لغة سي، لكن لا ينظر معظم الناس لذلك الأمر بكونه مشكلةً كبيرة. لربما كانت الأبجدية الإنجليزية مقبولةً لتطبيقات معالجة البيانات حول العالم في وقتٍ مضى، إذ استُخدمت الحواسيب في أماكن يتوقّع من مستخدميها الاعتياد على هذا الأمر، لكن هذا لا يصلح في زمننا الحالي؛ إذ أصبح من الضروري في وقتنا المعاصر تزويد الأنظمة بوسائل معالجة البيانات وتخزينها باللغة الأم لمستخدميها. قد نستطيع حشر جميع المحارف المستخدمة في لغات كلٍّ من الولايات المتحدة الأمريكية وأوروبا الغربية ضمن مجموعة محارف لا يتجاوز حجمها 8 بِت لكل محرف، ولكن الأمر مستحيلٌ بالنسبة للغات الآسيوية. هناك طريقتان لتوسعة مجموعة المحارف، الأولى عن طريق إضافة عددٍ معين من البايتات (عادةً اثنين) لكل محرف، وهذه هي الطريقة المصممة لدعم محارف أكبر حجمًا في لغة سي؛ أما الطريقة الأخرى فهي باستخدام مخطط ترميز الإدخال بالإزاحة shift-in والخرج بالإزاحة shift-out؛ وهو ترميزٌ شائع في قنوات الاتصال ذات سعة 8-بت. ألقِ نظرةً على سلسلة المحارف التالية: a b c <SI> a b g <SO> x y إذ يعني المحرف <SI> "بدّل إلى اليونانية" والمحرف <SO> "بدّل مجددًَا إلى الإنجليزية"، ويعرض جهاز العرض المُهيّأ للعمل وفق هذا الترميز النتيجة على النحو التالي: a, b, c, alpha, beta, gamma, x, y. هذه هي الطريقة المُتبعة تقريبًا في معيار shift-JIS الياباني، والاختلاف في ذلك المعيار هو أن المحارف الموجودة ضمن الإدخال بالإزاحة تتألف من مِحرفين يُستخدمان في تمثيل محرفٍ واحدٍ باللغة اليابانية، وهناك العديد من الطرق البديلة التي تستخدم عدة محارف مدخلة بالإزاحة، ولكنها أقل شيوعًا. يسمح المعيار الآن باستخدام مجموعات المحارف الموسّعة extended character sets، إذ تُستخدم المحارف المُعرفة مُسبقًا والبالغ عددها 96 في كتابة برنامج بلغة سي، ولكن مجموعة المحارف المُوسعة مسموحة في كتابة التعليقات والسلاسل النصية والمحارف الثابتة وأسماء ملفات الترويسة (جميع ما ذُكر يمثل بيانات وليسَ جزءًا من كتابة البرنامج). يضع المعيار بعض القواعد البديهية لوصف طريقة استخدام هذه المجموعات، ولن نكررها هنا، لكن أبرزها هو أن البايت ذو القيمة الصفرية يُفسّر محرفًا فارغًا null بغض النظر عن أي حالة إزاحة. هذا المحرف مهم لأن لغة سي ترمز لنهاية السلسلة النصية به وتعتمد عليه العديد من دوال المكتبات. هناك متطلبٌ آخر ألا وهو أن سلاسل المحارف متعددة البايت يجب أن تبدأ وتنتهي ضمن حالة الإزاحة المبدئية. يصف المعيار النوع char بكونه مناسبًا لتخزين قيمة جميع المحارف ضمن "مجموعة محارف التنفيذ execution character set" التي ستكون مُعرفةً في توثيق نظامك؛ وهذا يعني (في المثال السابق) أن نوع char يمكنه تخزين 'a' أو 'b' أو محرف الإزاحة إلى اللغة اليونانية بنفسه <SI>، إذ لا يوجد أي فرق في القيم المخزنة بداخل المتغير من نوع char بسبب تقنية الإدخال والإخراج بالإزاحة؛ وهذا يعني أنه لا يمكننا تمثيل 'a' على أنه محرف "ألفا" في اللغة اليونانية، وحتى نستطيع تحقيق ذلك يلزمنا أكثر من 8 بتات، وهو أكبر من حجم char في معظم الأنظمة، وهنا يأتي دور نوع المتغير wchar_t الذي قدَّمه المعيار، ولكن يجب تضمين ملف الترويسة <stddef.h> قبل استخدامه، لأن wchar_t معرّفٌ على أنه اسم بديل عن نوعٍ موجودٍ في لغة سي. سنناقش هذا الأمر بتوسع أكبر لاحقًا. ختامًا، نستطيع تلخيص ما سبق: تتطلب لغة سي مجموعة محارف عددها 96 محرف على الأقل لاستخدامها في محارف الشيفرة المصدرية للبرنامج. لا تحتوي جميع مجموعات المحارف على 96 محرف، بالتالي تسمح ثلاثيات المحارف للمعيار ISO 646 الأساسي كتابة برامج سي في حال الضرورة. أُضيفت المحارف متعددة البايت حديثًا مع المعيار، وتدعم: المحارف متعددة البايت المُرمّزة بالإزاحة Shift-encoded multibyte characters، التي تسمح بحشر المحارف الإضافية ضمن سلاسل محارف "اعتيادية"، بحيث يمكننا استخدام النوع char معها. المحارف الموسّعة wide characters التي تتسع لمساحة أكبر من المحارف الاعتيادية، ولها نوع بيانات مختلف عن النوع char. ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: البنية النصية لبرامج سي C المقال السابق: بعض البرامج البسيطة بلغة سي C: المصفوفات والعمليات الحسابية بنية برنامج لغة سي C
سنلقي في الجزئية الثانية من السلسلة، نظرةً على الأجزاء التي لم نلقِ لها بالًا في المقال السابق من هذه السلسلة، الذي كان بمثابة مقدمة سريعة عن لغة سي، التحدي هنا هو التكلم عن أساسيات اللغة بصورةٍ موسّعة وكافية للسماح لك بفهم المزيد عن اللغة دون إغراق المبتدئين بالمعلومات والتفاصيل غير الضرورية في هذه المرحلة. سنغطي في هذه الجزئية من السلسلة بعض المفاهيم والمشاكل الدقيقة التي لا تقرأ عنها في النصوص التقديمية للغة، فيجب عليك أن تقرأه بعقلية منفتحة وبمزاج جيّد. قد يجد دماغك المرهَق التمارين الموجودة بين الفقرات استراحةً مفيدة، إذ ننصحك بشدّة أن تحاول حلّ التمارين هذه بينما تقرأ المقال، إذ أن ذلك من شأنه أن يساعدك في موازنة الكفة بين تعلُّم المفاهيم الجديدة -التي قد تشعر في بعض المراحل بغزارتها- والتمارين. حان الوقت لتقديم بعض الأساسيات في لغة سي. المحارف المستخدمة في لغة سي هذه الفقرة مثيرة للاهتمام، وسندعو المحارف المُستخدمة في لغة سي بأبجدية سي C، وهذه الأبجدية مهمة جدًا، وربما يكون هذا الجزء الوحيد من هذا المقال الذي يمكنك قراءته بصورةٍ سطحية وفهم جميع محتوياته من المرة الأولى. لذلك، اقرأه لتضمن أنك تعرف محتوياته والمعلومات الواردة فيه جيّدًا وتذكر أن تعود إليه في حال أردت مرجعًا بهذا الخصوص. الأبجدية الاعتيادية تعرّف قلةٌ من لغات البرمجة أبجديتها أو تلقي بالًا لهذا الأمر، إذ أن هناك افتراضًا مسبقًا بأن أحرف الأبجدية الإنجليزية وخليطًا من علامات الترقيم والرموز ستكون متاحةً في أي بيئة داعمة للّغة، ولكن هذا الافتراض غير محقّقٍ دائمًا. تعاني لغات البرمجة القديمة من هذه المشكلة بدرجةٍ أقل حدّة، ولكن تخيل إرسال برنامج مكتوب بلغة سي عبر جهاز تلكس Telex أو عن طريق نظام بريد إلكتروني يحتوي على بعض القيود، أتعي أهمية الأمر الآن؟ يوصّف المعيار مجموعتين مختلفتين من المحارف: واحدةٌ تُكتب بها البرامج وأخرى تُنفَّذ بها، وذلك للسماح للأنظمة المختلفة بتصريف البرنامج وتنفيذه بغض النظر عن اختلاف طرق ترميز المحارف لكل نظام. في الحقيقة، الأمر مهمّ فقط في حال استخدامك محارفًا ثابتة constant في المعالج المُسبق preprocessor، إذ من الممكن أن تختلف قيم هذه المحارف عند التنفيذ، وهذا السلوك معرّف عند التنفيذ implementation-defined، فهو موثّق بالتأكيد، ولكن لا تقلق بخصوص هذا الأمر الآن. يملي المعيار وجود أبجدية مؤلفة من 96 رمزًا للغة سي، وهي: المسافات ومسافات الجدولة الأفقية والعمودية ومحرف السطر الجديد وفاصل الصفحة table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } a b c d e f g h i j k l m n o p q r s t u v w x y z A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 0 1 2 3 4 5 6 7 8 9 ! " # % & ' ( ) * + , - . / : ; < = > ? [ \ ] ^ _ {|} ~ [جدول 1 أبجدية لغة سي] اتّضح أن معظم أبجديات الحاسوب الشائعة تحتوي على جميع الرموز اللازمة للغة سي، عدا بعض الحالات الشاذة النادرة مثل المحارف الموجودة في الأسفل، والتي تُعد مثالًا عن محارف أبجدية لغة سي المفقودة من مجموعة المحارف ذات 7 بت لمعيار منظمة المعايير العالمية International Standards Organization المدعوّ ISO 646، وهي مجموعة جزئية من المحارف المُستخدمة في أبجديات الحاسوب على نطاقٍ واسع. # [ \ ] ^ { | } ~ لتضمين هذه الأنظمة التي لا تحتوي على مجموعة المحارف البالغ عددها 96 والمطلوبة لكتابة برامج بلغة سي، حدّد المعيار طريقةً لاستخدام معيار ISO 646 لتمثيل المحارف المفقودة ألا وهي تقنية ثُلاثيات المحارف trigraphs. ثلاثيات المحارف ثلاثيات المحارف Trigraphs هي سلسلةٌ من ثلاثة محارف ضمن المعيار ISO 646، وتُعامل معاملة محرفٍ واحدٍ ضمن أبجدية لغة سي. تبدأ جميع ثلاثيات المحارف بعلامتَي استفهام "??"، ويساعد هذا في الدلالة على أن هناك شيءٌ "خارجٌ عن المألوف" ضمن البرنامج. يوضّح الجدول 2 أدناه جميع ثلاثيات المحارف المُعرّفة ضمن المعيار. محرف أبجدية سي C ثلاثي المحرف # =?? ] )?? [ (?? } >?? { <?? \ /?? \ !?? ~ -?? ^ '?? [جدول 2 ثلاثيات المحارف] دعنا نفترض مثلًا، أن طرفيتك terminal لا تحتوي على الرمز "#" لكتابة سطر المعالج المُسبق التالي: #define MAX 32767 عندها، نستطيع استخدام طريقة ثلاثيات المحارف على النحو التالي: ??=define MAX 32767 ستعمل ثلاثيات المحارف حتى لو كان المحرف "#" موجودًا، ولكن هذه التقنية موجودةٌ لمساعدتك في الحالات الحرجة ولا يُحبَّذ استخدامها بديلًا عن محارف أبجدية سي دومًا. ترتبط إشارة الاستفهام "?" بالمحرف الواقع على يمينها، لذا في أي سلسلة مؤلفة من عدّة إشارات استفهام، تشكِّل إشارتان فقط ضمن السلسلة ثلاثي محارف، ويعتمد المحرف الذي تمثِّله على المحرف الذي يقع بعد الإشارتين مباشرةً، وهذا من شأنه أن يجنّبك كثيرًا من الالتباس. من الخطأ الاعتقاد أن البرامج المكتوبة بلغة سي، والتي تلقي بالًا كبيرًا لإمكانية تشغيلها على نحوٍ محمول portable وعلى جميع الأنظمة مكتوبةٌ باستخدام ثلاثيات المحارف "إلا في حال ضرورة نقلها إلى نظام يدعم معيار ISO 646 فقط"؛ فإذا كان نظامك يدعم جميع المحارف البالغ عددها 96 محرفًأ، واللازمة لكتابة البرامج بلغة سي، فيجب استخدامها دون الاستعانة بثلاثيات المحارف، إذ وُجدت هذه التقنية لتنفيذها ضمن بيئات محدودة، ومن السهل جدًا كتابة مفسّر يحوِّل برنامجك بين التمثيلين عن طريق فحص كل محرف بمحرفه. ستميّز جميع المصرّفات المتوافقة مع المعيار ثلاثيات المحارف عندما تجدها، إذ أن تبديل ثلاثيات الأحرف هو من أولى العمليات التي يجريها المصرّف على البرنامج. المحارف متعددة البايت أُضيف دعم المحارف متعددة البايت multibyte characters إلى المعيار، ولكن ما هو السبب؟ تتضمن نسبةٌ كبيرة من الحوسبة الاعتيادية اليومية بياناتٍ ممثّلة بنص بشكلٍ أو بآخر، وساد الاعتقاد في مجال الحوسبة أنه من الكافي دعم ما يقارب مئة محرف مطبوع فقط، ومن هنا كان عدد المحارف الممثلة لأبجدية سي 96 محرفًا، وذلك بناءً على متطلبات اللغة الإنجليزية وهذا الأمر ليس مفاجئًا بالنظر إلى أن معظم سوق تطوير البرمجيات والحوسبة التجاري كان في الولايات المتحدة الأمريكية. تُعرف مجموعة المحارف هذه باسم المخزون repertoire وتتناسب مع 7 أو 8 بتات من الذاكرة، وهذا السبب في أهمية استخدام 8-بت واحدةً لتخزين وقياس للبيانات بصورةٍ أساسية في معيار US-ASCII ومعمارية الحواسيب المصغرة minicomputers والحواسيب الدقيقة microcomputers. تتّبع لغة سي أيضًا توجّهًا في تخزين البيانات باستخدام البايت byte، إذ أن أصغر وحدات التخزين الممكن استخدامها مباشرةً في لغة سي هي البايت، والمعرّفة بكونها تتألف من 8 بِت. قد تشكو الأنظمة والمعماريات القديمة التي لم تُصمم مباشرةً لدعم ذلك من بطء بسيط في الأداء عند تشغيل لغة سي، لكن لا ينظر معظم الناس لذلك الأمر بكونه مشكلةً كبيرة. لربما كانت الأبجدية الإنجليزية مقبولةً لتطبيقات معالجة البيانات حول العالم في وقتٍ مضى، إذ استُخدمت الحواسيب في أماكن يتوقّع من مستخدميها الاعتياد على هذا الأمر، لكن هذا لا يصلح في زمننا الحالي؛ إذ أصبح من الضروري في وقتنا المعاصر تزويد الأنظمة بوسائل معالجة البيانات وتخزينها باللغة الأم لمستخدميها. قد نستطيع حشر جميع المحارف المستخدمة في لغات كلٍّ من الولايات المتحدة الأمريكية وأوروبا الغربية ضمن مجموعة محارف لا يتجاوز حجمها 8 بِت لكل محرف، ولكن الأمر مستحيلٌ بالنسبة للغات الآسيوية. هناك طريقتان لتوسعة مجموعة المحارف، الأولى عن طريق إضافة عددٍ معين من البايتات (عادةً اثنين) لكل محرف، وهذه هي الطريقة المصممة لدعم محارف أكبر حجمًا في لغة سي؛ أما الطريقة الأخرى فهي باستخدام مخطط ترميز الإدخال بالإزاحة shift-in والخرج بالإزاحة shift-out؛ وهو ترميزٌ شائع في قنوات الاتصال ذات سعة 8-بت. ألقِ نظرةً على سلسلة المحارف التالية: a b c <SI> a b g <SO> x y إذ يعني المحرف <SI> "بدّل إلى اليونانية" والمحرف <SO> "بدّل مجددًَا إلى الإنجليزية"، ويعرض جهاز العرض المُهيّأ للعمل وفق هذا الترميز النتيجة على النحو التالي: a, b, c, alpha, beta, gamma, x, y. هذه هي الطريقة المُتبعة تقريبًا في معيار shift-JIS الياباني، والاختلاف في ذلك المعيار هو أن المحارف الموجودة ضمن الإدخال بالإزاحة تتألف من مِحرفين يُستخدمان في تمثيل محرفٍ واحدٍ باللغة اليابانية، وهناك العديد من الطرق البديلة التي تستخدم عدة محارف مدخلة بالإزاحة، ولكنها أقل شيوعًا. يسمح المعيار الآن باستخدام مجموعات المحارف الموسّعة extended character sets، إذ تُستخدم المحارف المُعرفة مُسبقًا والبالغ عددها 96 في كتابة برنامج بلغة سي، ولكن مجموعة المحارف المُوسعة مسموحة في كتابة التعليقات والسلاسل النصية والمحارف الثابتة وأسماء ملفات الترويسة (جميع ما ذُكر يمثل بيانات وليسَ جزءًا من كتابة البرنامج). يضع المعيار بعض القواعد البديهية لوصف طريقة استخدام هذه المجموعات، ولن نكررها هنا، لكن أبرزها هو أن البايت ذو القيمة الصفرية يُفسّر محرفًا فارغًا null بغض النظر عن أي حالة إزاحة. هذا المحرف مهم لأن لغة سي ترمز لنهاية السلسلة النصية به وتعتمد عليه العديد من دوال المكتبات. هناك متطلبٌ آخر ألا وهو أن سلاسل المحارف متعددة البايت يجب أن تبدأ وتنتهي ضمن حالة الإزاحة المبدئية. يصف المعيار النوع char بكونه مناسبًا لتخزين قيمة جميع المحارف ضمن "مجموعة محارف التنفيذ execution character set" التي ستكون مُعرفةً في توثيق نظامك؛ وهذا يعني (في المثال السابق) أن نوع char يمكنه تخزين 'a' أو 'b' أو محرف الإزاحة إلى اللغة اليونانية بنفسه <SI>، إذ لا يوجد أي فرق في القيم المخزنة بداخل المتغير من نوع char بسبب تقنية الإدخال والإخراج بالإزاحة؛ وهذا يعني أنه لا يمكننا تمثيل 'a' على أنه محرف "ألفا" في اللغة اليونانية، وحتى نستطيع تحقيق ذلك يلزمنا أكثر من 8 بتات، وهو أكبر من حجم char في معظم الأنظمة، وهنا يأتي دور نوع المتغير wchar_t الذي قدَّمه المعيار، ولكن يجب تضمين ملف الترويسة <stddef.h> قبل استخدامه، لأن wchar_t معرّفٌ على أنه اسم بديل عن نوعٍ موجودٍ في لغة سي. سنناقش هذا الأمر بتوسع أكبر لاحقًا. ختامًا، نستطيع تلخيص ما سبق: تتطلب لغة سي مجموعة محارف عددها 96 محرف على الأقل لاستخدامها في محارف الشيفرة المصدرية للبرنامج. لا تحتوي جميع مجموعات المحارف على 96 محرف، بالتالي تسمح ثلاثيات المحارف للمعيار ISO 646 الأساسي كتابة برامج سي في حال الضرورة. أُضيفت المحارف متعددة البايت حديثًا مع المعيار، وتدعم: المحارف متعددة البايت المُرمّزة بالإزاحة Shift-encoded multibyte characters، التي تسمح بحشر المحارف الإضافية ضمن سلاسل محارف "اعتيادية"، بحيث يمكننا استخدام النوع char معها. المحارف الموسّعة wide characters التي تتسع لمساحة أكبر من المحارف الاعتيادية، ولها نوع بيانات مختلف عن النوع char. ترجمة -وبتصرف- لقسم من الفصل Variables and Arithmetic من كتاب The C Book. اقرأ أيضًا المقال التالي: البنية النصية لبرامج سي C المقال السابق: بعض البرامج البسيطة بلغة سي C: المصفوفات والعمليات الحسابية بنية برنامج لغة سي C -
 تُستخدم لغة سي على نطاق واسع في تطبيقات المعالجة والتعامل بالمحارف characters والسلاسل النصية strings، وهذا الأمر غريب بعض الشيء لأن اللغة لا تحتوي على مزايا موجهة لهذا الغرض بالتحديد،؛ وإذا كنت معتادًا على لغات البرمجة التي تحتوي على مزايا موجهة للتعامل مع المحارف والسلاسل النصية، فستجد التعامل مع لغة سي بهذا الخصوص مضجرًا على أقل تقدير. تحتوي المكتبة القياسية على العديد من الدوال التي تساعدك في التعامل مع السلاسل النصية، إلا أن الأمر يبقى صعبًا بعض الشيء مقارنةً بلغاتٍ أخرى. على سبيل المثال، عليك استدعاء دالة مخصصة للمقارنة ما بين سلسلتين نصيتين بدلًا من استخدام عامل المساواة "="، ولكن هناك جانبٌ مشرقٌ لهذا الأمر، إذ يعني ذلك أن اللغة غير مُثقلة بطرق دعم معالجة السلاسل النصية مما يساعد بالمحافظة على برامج أصغر وأقل تشعّبًا، وحالما تكتب برنامجًا لمعالجة السلاسل النصية بلغة سي بنجاح أخيرًا، ستكون قادرًا على تشغيله بسرعة أكبر مقارنةً باللغات الأخرى. التعامل مع المحارف يجري التعامل مع محارف السلسلة النصية في لغة سي عن طريق التصريح عن مصفوفات، أو حجزهم ديناميكيًا، والتعامل مع المحارف وتحريكها "يدويًّا". إليك مثالًا عن برنامج يقرأ نصًّا سطرًا بسطر من دخل البرنامج القياسي، ويتوقف البرنامج عن القراءة إذا كان السطر مكوّنًا من السلسلة النصية "stop"، ويُطبع طول السطر فيما عدا ذلك. يعتمد البرنامج على تقنية تُستخدم في معظم برامج سي ألا وهي: يقرأ البرنامج المحارف ويحوّلها إلى مصفوفة ويحدّد نهاية المصفوفة بمحرفٍ إضافي له القيمة صفر؛ كما يستخدم هذا المثال دالة strcmp للمقارنة بين سلسلتين نصيتين من خلال تضمين المكتبة string.h. #include <stdio.h> #include <stdlib.h> #include <string.h> #define LINELNG 100 /* الطول الأعظمي لسطر الدخل الواحد */ main(){ char in_line[LINELNG]; char *cp; int c; cp = in_line; while((c = getc(stdin)) != EOF){ if(cp == &in_line[LINELNG-1] || c == '\n'){ /*إدخال ما يدل على نهاية السطر*/ *cp = 0; if(strcmp(in_line, "stop") == 0 ) exit(EXIT_SUCCESS); else printf("line was %d characters long\n", (int)(cp-in_line)); cp = in_line; } else *cp++ = c; } exit(EXIT_SUCCESS); } [مثال 1] يوضح لنا هذا المثال مزيدًا من مزايا وطرق لغة سي المُستخدمة في برامجها، وأهمها هو طريقة تمثيل السلاسل النصية ومعالجتها. إليك تطبيقًا عمليًّا عن الدالة strcmp التي تقارن بين سلسلتين نصيتين وتعيد القيمة صفر إن تساوت قيمتهما، وللدالة هذه في الحقيقة تطبيقات أكثر ولكننا سنتجاهل المعلومات التي قد تزيد من تعقيد شرحنا. لاحظ استخدام الكلمة المفتاحية const في التصريح عن الوسطاء، والذي يوضِّح أن الدالة لن تعدل على محتويات السلسلة النصية بل ستفحص قيم محتوياتها فقط، ونلاحظ استخدام هذه الطريقة في التعريف عن العديد من دوال المكتبة القياسية. /* * برنامج يختبر مساواة سلسلتين نصيتين * يُعيد القيمة "خطأ" إذا تساوت السلسلتين */ int str_eq(const char *s1, const char *s2){ while(*s1 == *s2){ /* * إعادة 0 عند نهاية السلسلة النصية */ if(*s1 == 0) return(0); s1++; s2++; } /* عُثر على فرق بين السلسلتين */ return(1); } [مثال 2] السلاسل النصية يعرف كل مبرمجٍ للغة سي معنى السلسلة النصية، فهي مصفوفةٌ من متغيرات من نوع "char"، ويكون المحرف الأخير لهذه السلسلة النصية متبوعًا بمحرف فراغ null. ربما تصرخ الآن وتقول "ولكنني اعتقدت أن السلسلة النصية هي نصٌ محتوًى داخل إشارتي تنصيص!" أنت محقّ، إذ تُعد السلسلة التالية في لغة سي مصفوفةً من المحارف: "a string" وهذا الشيء الوحيد الذي يمكنك التصريح عنه لحظة استخدامه، أي دون التصريح عن مصفوفة المحارف وتحديد حجمها. احذر: كانت السلاسل النصية في لغة سي القديمة تُخزّن مثل أي سلسلة محارف اعتيادية، وكانت قابلةً للتعديل. إلا أن المعيار ينص على أن محاولة التعديل على سلسلة نصية سيتسبب بسلوك غير محدد على الرغم من كون السلاسل النصية مصفوفةً من نوع "char" وليس "const char". لاستخدام السلسلة النصية داخل علامتي تنصيص أثران: أولهما أن السلسلة النصية تحلّ محل تصريح وبديل عن الاسم، كما أنها تمثِّل تصريحًا خفيًّا لمصفوفة من المحارف، وتُهيّأ قيمة هذه المصفوفة إلى قيم المحارف الموجودة في السلسلة النصية متبوعةً بمحرف قيمته صفر، ولا يوجد لهذه المصفوفة أي اسم، لذا باستثناء الاسم، يكون الوضع مشابهًا للتالي: char secret[9]; secret[0] = 'a'; secret[1] = ' '; secret[2] = 's'; secret[3] = 't'; secret[4] = 'r'; secret[5] = 'i'; secret[6] = 'n'; secret[7] = 'g'; secret[8] = 0; وهي مصفوفةٌ من المحارف متبوعةٌ بقيمة صفر، وتحتوي جميع قيم المحارف بداخلها، لكنها عديمة الاسم إذا صُرِّح عنها باستخدام طريقة السلسلة النصية المحاطة بعلامتي تنصيص، فكيف نستطيع استخدامها؟ يكون وجود السلسلة النصية بمثابة اسمٍ مخفي لها حالما تراها لغة سي محاطةً بعلامتي تنصيص، إذ أن وجود السلسلة النصية بهذا الشكل لا يؤدي إلى تصريح ضمني فقط، بل يؤدي إلى إعطاء اسمٍ لمصفوفة موافقة. نتذكر جميعنا أن اسم المصفوفة مساوٍ لعنوان عنصرها الأول (تفقد مقالة المؤشرات) فما نوع السلسلة التالية؟ "a string" النوع مؤشر طبعًا، إذ أن السلسلة النصية المكتوبة بالشكل السابق تكافئ مؤشرًا إلى أول عناصر المصفوفة الخفية عديمة الاسم، وهي مصفوفةٌ من نوع char، فالمؤشر من نوع "مؤشر إلى char"، ويوضح الشكل 1 هذه الحالة. شكل 1 أثر استخدام السلسلة النصية للبرهان على السابق، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> main(){ int i; char *cp; cp = "a string"; while(*cp != 0){ putchar(*cp); cp++; } putchar('\n'); for(i = 0; i < 8; i++) putchar("a string"[i]); putchar('\n'); exit(EXIT_SUCCESS); } [مثال 3] تضبط الحلقة الأولى مؤشرًا يشير إلى بداية المصفوفة، ويُمرّر المؤشر على المصفوفة إلى أن يصل المؤشر إلى القيمة صفر في النهاية، بينما "تَعرف" الحلقة الثانية طول السلسلة النصية وهي أقل فائدة مقارنةً بسابقتها. لاحظ أن الحلقة الأولى غير معتمدة على طول السلسلة النصية بل على وصولها لنهايتها وهو الشيء الأهم الذي ينبغي عليك تذكره من هذا المثال. يجري التعامل مع السلاسل النصية في لغة سي بطريقة ثابتة دون أي استثناءات وهي الطريقة التي تتوقعها جميع دوال التعامل مع السلاسل النصية، فيسمح الصفر في نهاية السلسلة النصية للدوال بمعرفة نهاية السلسلة النصية. عُد للمثال السابق الخاص بدالة str_eq، إذ تأخذ الدالة مؤشرين يشيران لمحرفين مثل وسطاء (تُقبل السلسلة النصية ذاتها بكونها واحدًا من الوسيطين أو كلاهما) وتُقارن السلسلة النصية بالتحقق من كل محرف واحدًا تلو الآخر، وإذا تساوى المحرفين فتتحقّق من أن المؤشر لم يصل إلى نهاية السلسلة عن طريق الجملة الشرطية التالية: if(*s1 == 0): وإذا وصل المؤشر للنهاية فإنها تُعيد 0 للدلالة على أن السلسلتين متساويتين، يمكن إجراء الاختبار ذاته باستخدام المؤشر s2* دون أي فارق؛ أما في حالة الفرق بين المحرفين تُعاد القيمة 1 للدلالة على فشل المساواة. تُستدعى الدالة strcmp في المثال باستخدام وسيطين مختلفين عن بعضهما، إذ أن الوسيط الأول هو مصفوفة محارف والثاني سلسلة نصية، لكنهما في الحقيقة يمثلان الشيء ذاته؛ فمصفوفة المحارف التي تنتهي بالعنصر صفر (يسند برنامجنا القيمة صفر إلى أول عنصر فارغ في مصفوفة in_line) والسلسلة النصية بين قوسين (التي تُمثّل بدورها أيضًا مصفوفة محارف تنتهي بصفر) من نفس الطبيعة، واستخدامهما مثل وسيطين للدالة strcmp ينتج بتمرير مؤشرَي محارف (وقد شرحنا السبب بذلك بإفاضة سابقًا). المؤشرات وعامل الزيادة ذكرنا سابقًا التعبير التالي، وقلنا أنّنا ستعيد النظر فيه لاحقًا: (*p)++; حان الوقت الآن للكلام عن ذلك؛ إذ تُستخدم المؤشرات بكثرة مع المصفوفات والتمرير بينها، لذلك من الطبيعي استخدام العاملين -- و ++ معها. يوضح المثال التالي إسناد القيمة صفر إلى مصفوفة باستخدام المؤشر وعامل الزيادة: #define ARLEN 10 int ar[ARLEN], *ip; ip = ar; while(ip < &ar[ARLEN]) *(ip++) = 0; [مثال 4] يُضبط المؤشر ip ليبدأ من بداية المصفوفة، وعلى الرغم من إشارة المؤشر إلى داخل المصفوفة إلا أن القيمة التي يشير إليها تساوي الصفر، وعند وصولنا للحركة التكرارية ينجز عامل الزيادة ما هو متوقع ويُنقل المؤشر للعنصر الذي يليه داخل المصفوفة، وبالتالي استخدام العامل ++ عامل إلحاق postfix مفيدٌ في هذه الحالة. معظم الأشياء التي ناقشناها شائعة الوجود، وستجدها في معظم البرامج (استخدام عامل الزيادة والمؤشرات بالشكل الموضح في المثال السابق) ليس مرةً واحدةً أو مرتين بل تقريبًا كل عدّة أسطر ضمن الشيفرة البرمجية، وستعتقد أنك تراها بصورةٍ أكثر إذا كنت تجد استخدامها صعب الفهم. لكن ما هي التشكيلات التي يمكننا الحصول عليها؟ بالنظر إلى أن * تعني التأشير و ++ تعني الزيادة و -- تعني النقصان، كما أنه لدينا خياري وضع العاملين السابقين مثل عامل إلحاق postfix أو عامل إسباق prefix، نحصل على الاحتمالات التالية (بغض النظر عن عامل الزيادة أو النقصان) مع التركيز على موضع الأقواس: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } (p*)++ زيادة سابقة للشيء الذي يشير إليه المؤشر ++(p*) زيادة لاحقة للشيء الذي يشير إليه المؤشر (++p)* زيادة لاحقة على المؤشر *(p++)* زيادة سابقة على المؤشر [جدول 1 معاني المؤشرات] اقرأ الجدول السابق بحرص وتأكد أنك تفهم جميع التركيبات التي ذُكرت. يمكن فهم محتوى الجدول السابق بعد تفكير بسيط، ولكن هل يمكنك توقع ما الذي سيحدث عند إزالة الأقواس بالنظر إلى أن الأسبقية للعوامل الثلاث * و -- و ++ متساوية؟ تتوقع حدوث أخطاء كارثية، أليس كذلك؟ يوضّح الجدول 1 أن هناك حالةٌ واحدةٌ يجب أن تحافظ فيها على الأقواس. مع أقواس دون أقواس إن أمكن (p*)++ p*++ ++(p*) ++(p*) (++p)* ++p* (p++)* p++* [جدول 2 المزيد من معاني المؤشرات] لعلّ الأشكال المثيرة للتشويش في الجدول السابق ستدفعك لاستخدام الأقواس بغض النظر عن أهمية استعمالها في أي حالة سعيًا منك لتحسين قابلية قراءة الشيفرة البرمجية وفهمها، لكن يتخلى معظم مبرمجي لغة سي عن استخدام الأقواس بعد تعلُّم قوانين الأسبقية ونادرًا ما يستخدمون الأقواس في تعابيرهم، لذا عليك الاعتياد على قراءة الأمثلة التالية سواءٌ كانت مع أقواس أو بدونها، فالاعتياد على هذا الأمر سيساعدك بحقّ في تعلمك. المؤشرات عديمة النوع من المهم في بعض الأحيان تحويل نوعٍ من المؤشرات إلى نوع آخر بمساعدة التحويل بين الأنواع مثل التعبير التالي: (type *) expression يُحوَّل التعبير expression في المثال السابق إلى مؤشر من نوع "مؤشر إلى نوع type" بغض النظر عن نوع التعبير السابق، إلا أنه يجب تفادي هذه الطريقة إلا في حال كنت مدركًا تمامًا لما تفعله، فمن غير المحبّذ استخدامها إلا إذا كنت مبرمجًا خبيرًا. لا تفترض أن التحويل بين الأنواع يلغي أي حسابات أخرى بخصوص "الأنواع غير المتوافقة مع بعضها" التي تقع على عاتق المصرّف، إذ من المهم إعادة حساب القيم الجديدة للمؤشر بعد تغيير نوعه على العديد من معماريات الحاسوب. هناك بعض الحالات التي ستحتاج فيها لاستخدام مؤشر "معمّم generic"، وأبرز مثال على ذلك هو تطبيق لدالة المكتبة القياسية malloc التي تُستخدم لحجز المساحة على الذاكرة للكائن الذي لم يصرّح عنه بعد، ويجري تزويد الحجم المراد حجزه عن طريق تزويد مثل وسيطٍ سواءٌ كان الكائن متغيرًا من نوع float أو مصفوفة من نوع int أو أي شيء آخر. تعيد الدالة مؤشرًا إلى عنوان التخزين المحجوز التي تختاره بطريقتها الخاصة (والتي لن نتطرق إليها) من مجموعةٍ من عناوين الذاكرة الفارغة، ومن ثم يُحوَّل المؤشر إلى النوع المناسب. على سبيل المثال، تحتاج القيمة من نوع float إلى 4 بايتات من الذاكرة، وبالتالي نكتب ما يلي لحجز مساحة للقيمة: float *fp; fp = (float *)malloc(4); تعثر الدالة malloc على 4 بايتات من الذاكرة الفارغة، ويُحوَّل عنوان الذاكرة إلى مؤشر من نوع "مؤشر إلى float"، ثم تُسند القيمة إلى المؤشر (fp في حالة مثالنا السابق). لكن ما هو نوع المؤشر الذي ستُسند قيمة malloc إليه؟ نحن بحاجة نوع يمكن أن يحتوي جميع أنواع المؤشرات فنحن لا نعلم نوع المؤشر الذي ستعيده الدالة malloc. الحل هو باستخدام نوع المؤشر * void الذي تكلمنا عنه سابقًا، إليك المثال السابق مع إضافة تصريح للدالة malloc: void *malloc(); float *fp; fp = (float *)malloc(4); لا حاجة لاستخدام تحويل الأنواع على القيمة المُعادة من الدالة malloc حسب قوانين الإسناد للمؤشرات، ولكن استُخدم تحويل الأنواع لممارسة الأمر لا أكثر. لا بد من طريقة لمعرفة قيمة وسيط malloc الدقيقة في نهاية المطاف، ولكن القيمة ستكون مختلفةً على أجهزة بمعماريات مختلفة، لذا لا يمكنك الاكتفاء باستخدام القيمة الثابتة 4 فقط، بل يجب علينا استخدام عامل sizeof. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: عامل sizeof وحجز مساحات التخزين في لغة سي C المقال السابق: المؤشرات Pointers في لغة سي C المحارف المستخدمة في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى البنية النصية لبرامج سي C
تُستخدم لغة سي على نطاق واسع في تطبيقات المعالجة والتعامل بالمحارف characters والسلاسل النصية strings، وهذا الأمر غريب بعض الشيء لأن اللغة لا تحتوي على مزايا موجهة لهذا الغرض بالتحديد،؛ وإذا كنت معتادًا على لغات البرمجة التي تحتوي على مزايا موجهة للتعامل مع المحارف والسلاسل النصية، فستجد التعامل مع لغة سي بهذا الخصوص مضجرًا على أقل تقدير. تحتوي المكتبة القياسية على العديد من الدوال التي تساعدك في التعامل مع السلاسل النصية، إلا أن الأمر يبقى صعبًا بعض الشيء مقارنةً بلغاتٍ أخرى. على سبيل المثال، عليك استدعاء دالة مخصصة للمقارنة ما بين سلسلتين نصيتين بدلًا من استخدام عامل المساواة "="، ولكن هناك جانبٌ مشرقٌ لهذا الأمر، إذ يعني ذلك أن اللغة غير مُثقلة بطرق دعم معالجة السلاسل النصية مما يساعد بالمحافظة على برامج أصغر وأقل تشعّبًا، وحالما تكتب برنامجًا لمعالجة السلاسل النصية بلغة سي بنجاح أخيرًا، ستكون قادرًا على تشغيله بسرعة أكبر مقارنةً باللغات الأخرى. التعامل مع المحارف يجري التعامل مع محارف السلسلة النصية في لغة سي عن طريق التصريح عن مصفوفات، أو حجزهم ديناميكيًا، والتعامل مع المحارف وتحريكها "يدويًّا". إليك مثالًا عن برنامج يقرأ نصًّا سطرًا بسطر من دخل البرنامج القياسي، ويتوقف البرنامج عن القراءة إذا كان السطر مكوّنًا من السلسلة النصية "stop"، ويُطبع طول السطر فيما عدا ذلك. يعتمد البرنامج على تقنية تُستخدم في معظم برامج سي ألا وهي: يقرأ البرنامج المحارف ويحوّلها إلى مصفوفة ويحدّد نهاية المصفوفة بمحرفٍ إضافي له القيمة صفر؛ كما يستخدم هذا المثال دالة strcmp للمقارنة بين سلسلتين نصيتين من خلال تضمين المكتبة string.h. #include <stdio.h> #include <stdlib.h> #include <string.h> #define LINELNG 100 /* الطول الأعظمي لسطر الدخل الواحد */ main(){ char in_line[LINELNG]; char *cp; int c; cp = in_line; while((c = getc(stdin)) != EOF){ if(cp == &in_line[LINELNG-1] || c == '\n'){ /*إدخال ما يدل على نهاية السطر*/ *cp = 0; if(strcmp(in_line, "stop") == 0 ) exit(EXIT_SUCCESS); else printf("line was %d characters long\n", (int)(cp-in_line)); cp = in_line; } else *cp++ = c; } exit(EXIT_SUCCESS); } [مثال 1] يوضح لنا هذا المثال مزيدًا من مزايا وطرق لغة سي المُستخدمة في برامجها، وأهمها هو طريقة تمثيل السلاسل النصية ومعالجتها. إليك تطبيقًا عمليًّا عن الدالة strcmp التي تقارن بين سلسلتين نصيتين وتعيد القيمة صفر إن تساوت قيمتهما، وللدالة هذه في الحقيقة تطبيقات أكثر ولكننا سنتجاهل المعلومات التي قد تزيد من تعقيد شرحنا. لاحظ استخدام الكلمة المفتاحية const في التصريح عن الوسطاء، والذي يوضِّح أن الدالة لن تعدل على محتويات السلسلة النصية بل ستفحص قيم محتوياتها فقط، ونلاحظ استخدام هذه الطريقة في التعريف عن العديد من دوال المكتبة القياسية. /* * برنامج يختبر مساواة سلسلتين نصيتين * يُعيد القيمة "خطأ" إذا تساوت السلسلتين */ int str_eq(const char *s1, const char *s2){ while(*s1 == *s2){ /* * إعادة 0 عند نهاية السلسلة النصية */ if(*s1 == 0) return(0); s1++; s2++; } /* عُثر على فرق بين السلسلتين */ return(1); } [مثال 2] السلاسل النصية يعرف كل مبرمجٍ للغة سي معنى السلسلة النصية، فهي مصفوفةٌ من متغيرات من نوع "char"، ويكون المحرف الأخير لهذه السلسلة النصية متبوعًا بمحرف فراغ null. ربما تصرخ الآن وتقول "ولكنني اعتقدت أن السلسلة النصية هي نصٌ محتوًى داخل إشارتي تنصيص!" أنت محقّ، إذ تُعد السلسلة التالية في لغة سي مصفوفةً من المحارف: "a string" وهذا الشيء الوحيد الذي يمكنك التصريح عنه لحظة استخدامه، أي دون التصريح عن مصفوفة المحارف وتحديد حجمها. احذر: كانت السلاسل النصية في لغة سي القديمة تُخزّن مثل أي سلسلة محارف اعتيادية، وكانت قابلةً للتعديل. إلا أن المعيار ينص على أن محاولة التعديل على سلسلة نصية سيتسبب بسلوك غير محدد على الرغم من كون السلاسل النصية مصفوفةً من نوع "char" وليس "const char". لاستخدام السلسلة النصية داخل علامتي تنصيص أثران: أولهما أن السلسلة النصية تحلّ محل تصريح وبديل عن الاسم، كما أنها تمثِّل تصريحًا خفيًّا لمصفوفة من المحارف، وتُهيّأ قيمة هذه المصفوفة إلى قيم المحارف الموجودة في السلسلة النصية متبوعةً بمحرف قيمته صفر، ولا يوجد لهذه المصفوفة أي اسم، لذا باستثناء الاسم، يكون الوضع مشابهًا للتالي: char secret[9]; secret[0] = 'a'; secret[1] = ' '; secret[2] = 's'; secret[3] = 't'; secret[4] = 'r'; secret[5] = 'i'; secret[6] = 'n'; secret[7] = 'g'; secret[8] = 0; وهي مصفوفةٌ من المحارف متبوعةٌ بقيمة صفر، وتحتوي جميع قيم المحارف بداخلها، لكنها عديمة الاسم إذا صُرِّح عنها باستخدام طريقة السلسلة النصية المحاطة بعلامتي تنصيص، فكيف نستطيع استخدامها؟ يكون وجود السلسلة النصية بمثابة اسمٍ مخفي لها حالما تراها لغة سي محاطةً بعلامتي تنصيص، إذ أن وجود السلسلة النصية بهذا الشكل لا يؤدي إلى تصريح ضمني فقط، بل يؤدي إلى إعطاء اسمٍ لمصفوفة موافقة. نتذكر جميعنا أن اسم المصفوفة مساوٍ لعنوان عنصرها الأول (تفقد مقالة المؤشرات) فما نوع السلسلة التالية؟ "a string" النوع مؤشر طبعًا، إذ أن السلسلة النصية المكتوبة بالشكل السابق تكافئ مؤشرًا إلى أول عناصر المصفوفة الخفية عديمة الاسم، وهي مصفوفةٌ من نوع char، فالمؤشر من نوع "مؤشر إلى char"، ويوضح الشكل 1 هذه الحالة. شكل 1 أثر استخدام السلسلة النصية للبرهان على السابق، ألقِ نظرةً على البرنامج التالي: #include <stdio.h> #include <stdlib.h> main(){ int i; char *cp; cp = "a string"; while(*cp != 0){ putchar(*cp); cp++; } putchar('\n'); for(i = 0; i < 8; i++) putchar("a string"[i]); putchar('\n'); exit(EXIT_SUCCESS); } [مثال 3] تضبط الحلقة الأولى مؤشرًا يشير إلى بداية المصفوفة، ويُمرّر المؤشر على المصفوفة إلى أن يصل المؤشر إلى القيمة صفر في النهاية، بينما "تَعرف" الحلقة الثانية طول السلسلة النصية وهي أقل فائدة مقارنةً بسابقتها. لاحظ أن الحلقة الأولى غير معتمدة على طول السلسلة النصية بل على وصولها لنهايتها وهو الشيء الأهم الذي ينبغي عليك تذكره من هذا المثال. يجري التعامل مع السلاسل النصية في لغة سي بطريقة ثابتة دون أي استثناءات وهي الطريقة التي تتوقعها جميع دوال التعامل مع السلاسل النصية، فيسمح الصفر في نهاية السلسلة النصية للدوال بمعرفة نهاية السلسلة النصية. عُد للمثال السابق الخاص بدالة str_eq، إذ تأخذ الدالة مؤشرين يشيران لمحرفين مثل وسطاء (تُقبل السلسلة النصية ذاتها بكونها واحدًا من الوسيطين أو كلاهما) وتُقارن السلسلة النصية بالتحقق من كل محرف واحدًا تلو الآخر، وإذا تساوى المحرفين فتتحقّق من أن المؤشر لم يصل إلى نهاية السلسلة عن طريق الجملة الشرطية التالية: if(*s1 == 0): وإذا وصل المؤشر للنهاية فإنها تُعيد 0 للدلالة على أن السلسلتين متساويتين، يمكن إجراء الاختبار ذاته باستخدام المؤشر s2* دون أي فارق؛ أما في حالة الفرق بين المحرفين تُعاد القيمة 1 للدلالة على فشل المساواة. تُستدعى الدالة strcmp في المثال باستخدام وسيطين مختلفين عن بعضهما، إذ أن الوسيط الأول هو مصفوفة محارف والثاني سلسلة نصية، لكنهما في الحقيقة يمثلان الشيء ذاته؛ فمصفوفة المحارف التي تنتهي بالعنصر صفر (يسند برنامجنا القيمة صفر إلى أول عنصر فارغ في مصفوفة in_line) والسلسلة النصية بين قوسين (التي تُمثّل بدورها أيضًا مصفوفة محارف تنتهي بصفر) من نفس الطبيعة، واستخدامهما مثل وسيطين للدالة strcmp ينتج بتمرير مؤشرَي محارف (وقد شرحنا السبب بذلك بإفاضة سابقًا). المؤشرات وعامل الزيادة ذكرنا سابقًا التعبير التالي، وقلنا أنّنا ستعيد النظر فيه لاحقًا: (*p)++; حان الوقت الآن للكلام عن ذلك؛ إذ تُستخدم المؤشرات بكثرة مع المصفوفات والتمرير بينها، لذلك من الطبيعي استخدام العاملين -- و ++ معها. يوضح المثال التالي إسناد القيمة صفر إلى مصفوفة باستخدام المؤشر وعامل الزيادة: #define ARLEN 10 int ar[ARLEN], *ip; ip = ar; while(ip < &ar[ARLEN]) *(ip++) = 0; [مثال 4] يُضبط المؤشر ip ليبدأ من بداية المصفوفة، وعلى الرغم من إشارة المؤشر إلى داخل المصفوفة إلا أن القيمة التي يشير إليها تساوي الصفر، وعند وصولنا للحركة التكرارية ينجز عامل الزيادة ما هو متوقع ويُنقل المؤشر للعنصر الذي يليه داخل المصفوفة، وبالتالي استخدام العامل ++ عامل إلحاق postfix مفيدٌ في هذه الحالة. معظم الأشياء التي ناقشناها شائعة الوجود، وستجدها في معظم البرامج (استخدام عامل الزيادة والمؤشرات بالشكل الموضح في المثال السابق) ليس مرةً واحدةً أو مرتين بل تقريبًا كل عدّة أسطر ضمن الشيفرة البرمجية، وستعتقد أنك تراها بصورةٍ أكثر إذا كنت تجد استخدامها صعب الفهم. لكن ما هي التشكيلات التي يمكننا الحصول عليها؟ بالنظر إلى أن * تعني التأشير و ++ تعني الزيادة و -- تعني النقصان، كما أنه لدينا خياري وضع العاملين السابقين مثل عامل إلحاق postfix أو عامل إسباق prefix، نحصل على الاحتمالات التالية (بغض النظر عن عامل الزيادة أو النقصان) مع التركيز على موضع الأقواس: table { width: 100%; } thead { vertical-align: middle; text-align: center; } td, th { border: 1px solid #dddddd; text-align: right; padding: 8px; text-align: inherit; } tr:nth-child(even) { background-color: #dddddd; } (p*)++ زيادة سابقة للشيء الذي يشير إليه المؤشر ++(p*) زيادة لاحقة للشيء الذي يشير إليه المؤشر (++p)* زيادة لاحقة على المؤشر *(p++)* زيادة سابقة على المؤشر [جدول 1 معاني المؤشرات] اقرأ الجدول السابق بحرص وتأكد أنك تفهم جميع التركيبات التي ذُكرت. يمكن فهم محتوى الجدول السابق بعد تفكير بسيط، ولكن هل يمكنك توقع ما الذي سيحدث عند إزالة الأقواس بالنظر إلى أن الأسبقية للعوامل الثلاث * و -- و ++ متساوية؟ تتوقع حدوث أخطاء كارثية، أليس كذلك؟ يوضّح الجدول 1 أن هناك حالةٌ واحدةٌ يجب أن تحافظ فيها على الأقواس. مع أقواس دون أقواس إن أمكن (p*)++ p*++ ++(p*) ++(p*) (++p)* ++p* (p++)* p++* [جدول 2 المزيد من معاني المؤشرات] لعلّ الأشكال المثيرة للتشويش في الجدول السابق ستدفعك لاستخدام الأقواس بغض النظر عن أهمية استعمالها في أي حالة سعيًا منك لتحسين قابلية قراءة الشيفرة البرمجية وفهمها، لكن يتخلى معظم مبرمجي لغة سي عن استخدام الأقواس بعد تعلُّم قوانين الأسبقية ونادرًا ما يستخدمون الأقواس في تعابيرهم، لذا عليك الاعتياد على قراءة الأمثلة التالية سواءٌ كانت مع أقواس أو بدونها، فالاعتياد على هذا الأمر سيساعدك بحقّ في تعلمك. المؤشرات عديمة النوع من المهم في بعض الأحيان تحويل نوعٍ من المؤشرات إلى نوع آخر بمساعدة التحويل بين الأنواع مثل التعبير التالي: (type *) expression يُحوَّل التعبير expression في المثال السابق إلى مؤشر من نوع "مؤشر إلى نوع type" بغض النظر عن نوع التعبير السابق، إلا أنه يجب تفادي هذه الطريقة إلا في حال كنت مدركًا تمامًا لما تفعله، فمن غير المحبّذ استخدامها إلا إذا كنت مبرمجًا خبيرًا. لا تفترض أن التحويل بين الأنواع يلغي أي حسابات أخرى بخصوص "الأنواع غير المتوافقة مع بعضها" التي تقع على عاتق المصرّف، إذ من المهم إعادة حساب القيم الجديدة للمؤشر بعد تغيير نوعه على العديد من معماريات الحاسوب. هناك بعض الحالات التي ستحتاج فيها لاستخدام مؤشر "معمّم generic"، وأبرز مثال على ذلك هو تطبيق لدالة المكتبة القياسية malloc التي تُستخدم لحجز المساحة على الذاكرة للكائن الذي لم يصرّح عنه بعد، ويجري تزويد الحجم المراد حجزه عن طريق تزويد مثل وسيطٍ سواءٌ كان الكائن متغيرًا من نوع float أو مصفوفة من نوع int أو أي شيء آخر. تعيد الدالة مؤشرًا إلى عنوان التخزين المحجوز التي تختاره بطريقتها الخاصة (والتي لن نتطرق إليها) من مجموعةٍ من عناوين الذاكرة الفارغة، ومن ثم يُحوَّل المؤشر إلى النوع المناسب. على سبيل المثال، تحتاج القيمة من نوع float إلى 4 بايتات من الذاكرة، وبالتالي نكتب ما يلي لحجز مساحة للقيمة: float *fp; fp = (float *)malloc(4); تعثر الدالة malloc على 4 بايتات من الذاكرة الفارغة، ويُحوَّل عنوان الذاكرة إلى مؤشر من نوع "مؤشر إلى float"، ثم تُسند القيمة إلى المؤشر (fp في حالة مثالنا السابق). لكن ما هو نوع المؤشر الذي ستُسند قيمة malloc إليه؟ نحن بحاجة نوع يمكن أن يحتوي جميع أنواع المؤشرات فنحن لا نعلم نوع المؤشر الذي ستعيده الدالة malloc. الحل هو باستخدام نوع المؤشر * void الذي تكلمنا عنه سابقًا، إليك المثال السابق مع إضافة تصريح للدالة malloc: void *malloc(); float *fp; fp = (float *)malloc(4); لا حاجة لاستخدام تحويل الأنواع على القيمة المُعادة من الدالة malloc حسب قوانين الإسناد للمؤشرات، ولكن استُخدم تحويل الأنواع لممارسة الأمر لا أكثر. لا بد من طريقة لمعرفة قيمة وسيط malloc الدقيقة في نهاية المطاف، ولكن القيمة ستكون مختلفةً على أجهزة بمعماريات مختلفة، لذا لا يمكنك الاكتفاء باستخدام القيمة الثابتة 4 فقط، بل يجب علينا استخدام عامل sizeof. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: عامل sizeof وحجز مساحات التخزين في لغة سي C المقال السابق: المؤشرات Pointers في لغة سي C المحارف المستخدمة في لغة سي C العوامل المنطقية في لغة سي C وعوامل أخرى البنية النصية لبرامج سي C -
 يُعيد العامل "sizeof" حجم المُعامل operator بالبايتات، وتعتمد نتيجة العامل "sizeof" بكونها عددًا صحيحًا عديم الإشارة "unsigned int" أو عددًا كبيرًا عديم الإشارة "unsigned long" على التطبيق implementation، وهذا هو السبب في تفادينا لأي مشكلات في المثال السابق (المقال السابق) عند التصريح عن دالة malloc على الرغم من عدم تزويد التصريح بأي تفاصيل عن معاملاتها؛ إذ يجب استخدام ملف الترويسة stdlib.h عوضًا عن ذلك عادةً للتصريح عن malloc على النحو الصحيح. إليك المثال ذاته ولكن بتركيز على جعله قابلًا للتنقل portable عبر مختلف الأجهزة: #include <stdlib.h> /* malloc() يتضمن ملف الترويسة تصريحًا عن */ float *fp; fp = (float *)malloc(sizeof(float)); يجب أن يُكتب معامل sizeof داخل قوسين إذا كان فقط اسمًا لنوع بيانات (وهي الحالة في مثالنا السابق)، بينما يمكنك التخلي عن القوسين إذا كنت تستخدم اسم كائن بيانات عوضًا عن ذلك، ولكن هذه الحالة نادرة الحدوث. #include <stdlib.h> int *ip, ar[100]; ip = (int *)malloc(sizeof ar); لدينا في المثال السابق مصفوفة باسم ar مكونةٌ من 100 عنصر من نوع عدد صحيح int، ويشير ip إلى مساحة التخزين الخاصة بهذه المصفوفة (مساحةٌ لمئة قيمة من نوع int) بعد استدعاء malloc (بفرض أن الاستدعاء كان ناجحًا). تعدّ char (محرف وهي اختصارٌ إلى character) وحدة القياس الأساسية للتخزين في لغة سي، وتساوي بايتًا واحدًا، جرّب نتيجة التعليمة الآتية: sizeof(char) وبناءً على ذلك، يمكنك حجز مساحة لعشرة قيم من نوع char على النحو التالي: malloc(10) ولحجز مساحة لمصفوفة بحجم عشرة قيم من نوع int، نكتب: malloc(sizeof(int[10])) تُعيد الدالة malloc مؤشرًا إلى الفراغ null pointer في حال لم تتوفر المساحة الكافية للإشارة إلى خطأ ما. يحتوي ملف الترويسة stdio.h ثابتًا معرّفًا باسم NULL، والذي يُستخدم عادةً للتحقق من القيمة المُعادة من الدالة malloc ودوال أخرى من المكتبة القياسية، وتُعد القيمة 0 أو (void *)0 مساويةً لهذا الثابت ويمكن استخدامها. إليك المثال التالي لتوضيح استخدام الدالة malloc، إذ يقرأ البرنامج في المثال سلاسلًا نصيةً بعدد MAXSTRING من الدخل، ثمّ يرتب السلاسل النصية أبجديًّا باستخدام الدالة strcmp. يُشار إلى نهاية السلسلة النصية بمحرف الهروب escape character التالي n\، وتُرتَّب السلاسل باستخدام مصفوفة من المؤشرات تُشير إلى السلسلة النصية وتبديل مواضع المؤشرات حتى الوصول إلى الترتيب الصحيح، مما يجنُّبنا عناء نسخ السلاسل النصية ويحسّن من سرعة تنفيذ البرنامج ويحد من هدر الموارد إلى حدٍّ ما. استخدمنا في الإصدار الأول من المثال مصفوفةً ثابتة الحجم، ثم استخدمنا في الإصدار الثاني حجز المساحة باستخدام malloc لكل سلسلة نصية عند وقت التشغيل run-time، بينما بقيت مصفوفة المؤشرات -لسوء الحظ- ثابتة الحجم، إلا أنه يمكننا تطبيق حلّ أفضل باستخدام قائمة مترابطة Linked list، أو أي هيكل بيانات مشابه لتخزين المؤشرات دون الحاجة لاستخدام المصفوفات ثابتة الحجم إطلاقًا، ولكننا لم نتكلم عن هياكل البيانات بعد. إليك ما يبدو عليه هيكل برنامجنا: while(number of strings read < MAXSTRING && input still remains){ read next string; } sort array of pointers; print array of pointers; exit; سنستخدم بعض الدوال في برنامجنا أيضًا: char *next_string(char *destination) تقرأ الدالة السابقة سطرًا من المحارف بحيث ينتهي السطر بالمحرف n\ من دخل البرنامج، وتُسند المحارف البالغ عددها MAXLEN-1 إلى المصفوفة المُشار إليها بالمصفوفة الهدف destination، إذ يمثّل MAXLEN قيمةً ثابتةً لطول السلسلة النصية العظمى. إذا كان المحرف الأول المقروء هو EOF (أي نهاية الملف)، أعِد مؤشرًا إلى الفراغ، وفيما عدا ذلك أعِد عنوان بداية السلسلة النصية (الهدف destination)، بحيث تحتوي السلسلة النصية الهدف دائمًا على المحرف n\، الذي يشير إلى نهاية السلسلة. void sort_arr(const char *p_array[]) تمثل المصفوفة p_array[] مصفوفة المؤشرات التي تشير للمحارف، ويمكن أن تكون المصفوفة كبيرة الحجم ولكن يُشار إلى نهايتها بأول عنصر يحتوي على مؤشر فراغ null pointer. ترتّب الدالة sort_arr المؤشرات بحيث تُشير إلى السلاسل النصية المرتبة أبجديًا عند اجتياز مصفوفة المؤشرات بناءً على دليل index المؤشر. void print_arr(const char *p_array[]) تُشابه دالة print_arr الدالة sort_arr ولكنها تطبع السلاسل النصية حسب ترتيبها الأبجدي. تذكّر أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول في أي تعبير يحتوي على اسمها، ومن شأن ذلك أن يساعدك في فهم الأمثلة على نحوٍ أفضل؛ والأمر مماثلٌ بالنسبة لمصفوفة ثنائية البعد، مثل مصفوفة strings في المثال التالي، فنوع التعبير strings[1][2] هو char، ولكن للعنصر strings[1] نوع "مصفوفة من char"، ولذلك يُحوَّل اسم المصفوفة إلى عنوان العنصر الأول ونحصل على &strings[1][0]. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(char *destination); main(){ /* نصرح عن المصفوفة مع إضافة عنصر فارغ في نهايتها */ char *p_array[MAXSTRING+1]; /* مصفوفة تخزين السلاسل النصية */ char strings[MAXSTRING][MAXLEN]; /* عدد السلاسل النصية المقروءة */ int nstrings; nstrings = 0; while(nstrings < MAXSTRING && next_string(strings[nstrings]) != 0){ p_array[nstrings] = strings[nstrings]; nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(char *destination){ char *cp; int c; cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); return(destination); } [مثال 1] إعادة الدالة next_string لمؤشر ليس من قبيل المصادفة، إذ أصبح بإمكاننا الآن الاستغناء عن استخدام مصفوفة السلاسل النصية واستخدام next_string لحجز مساحة التخزين الموافقة لها. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(void); main(){ char *p_array[MAXSTRING+1]; int nstrings; nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 2] وأخيرًا إليك المثال كاملًا مع استخدام مصفوفة p_array للدالة malloc، ولاحظ إعادة كتابة معظم أدلة المصفوفة لتستخدم ترميز المؤشرات. إذا كنت تشعر بالإرهاق من جميع المعلومات التي قرأتها فتجاوز المثال التالي، فهو صعبٌ بعض الشيء. شرح المثال: تعني char **p مؤشرًا يشير إلى المؤشر الذي يشير إلى محرف، ويجد معظم مبرمجو لغة سي هذه الطريقة في استخدام المؤشرات صعبة الفهم. #include <stdio.h> #include <stdlib.hi> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /*الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char **p_array); void sort_arr(const char **p_array); char *next_string(void); main(){ char **p_array; int nstrings; /* عدد السلاسل النصية المقروءة */ p_array = (char **)malloc( sizeof(char *[MAXSTRING+1])); if(p_array == 0){ printf("No memory\n"); exit(EXIT_FAILURE); } nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char **p_array){ while(*p_array) printf("%s\n", *p_array++); } void sort_arr(const char **p_array){ const char **lo_p, **hi_p, *tmp; for(lo_p = p_array; *lo_p != 0 && *(lo_p+1) != 0; lo_p++){ for(hi_p = lo_p+1; *hi_p != 0; hi_p++){ if(strcmp(*hi_p, *lo_p) >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = *hi_p; *hi_p = *lo_p; *lo_p = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 3] سنستعرض مثالًا آخر لتوضيح استخدام دالة malloc وإمكاناتها في التعامل مع السلاسل النصية الطويلة؛ إذ يقرأ المثال السلاسل النصية من الدخل ويبحث عن محرف سطر جديد لتحديد نهاية السلسلة النصية (أي n\)، ثم يطبع السلسلة النصية إلى الخرج، ويتوقف البرنامج عن العمل عندما يصادف محرف نهاية الملف EOF. تُسنَد المحارف إلى مصفوفة، ويُدلّ على نهاية المصفوفة -كما هو معتاد- بالقيمة صفر، مع ملاحظة أن محرف السطر الجديد لا يُخزَّن بالمصفوفة بل يُستخدم فقط لتحديد سطر الدخل الواجب طباعته للخرج. لا يعلم البرنامج طول السلسلة النصية تحديدًا، ولذلك يبدأ بفحص كل عشرة محارف وحجز المساحة الخاصة بهم (الثابت GROW_BY). تُستدعى الدالة malloc في حال كانت السلسلة النصية أطول من عشرة محارف لحجز المساحة للسلسلة النصية وإضافة عشرة محارف أخرى، ثم تُنسخ المحارف الحالية للمساحة الجديدة وتُستخدم من البرنامج وتُحرّر المساحة القديمة. تُستخدم الدالة free لتحرير المساحة القديمة المحجوزة من malloc مسبقًا، إذ يجب عليك تحرير المساحة غير المُستخدمة بعد الآن دوريًا قبل أن تتراكم، واستخدام free يحرّر المساحة ويسمح بإعادة استخدامها لاحقًا. يستخدم البرنامج الدالة fprintf لعرض أي أخطاء، وهي دالةٌ مشابهة للدالة printf التي اعتدنا على رؤيتها، والفرق الوحيد بينهما هو أن الدالة fprintf تأخذ وسيطًا إضافيًّا يدل على وسيط الخرج الذي سيُطبع إليه، وهناك ثابتان لهذا الغرض معرّفان في ملف الترويسة stdio.h؛ إذ أن استخدام الثابت الأول stdout يعني استخدام خرج البرنامج القياسي، بينما يشير استخدام الثابت الثاني stderr إلى مجرى أخطاء البرنامج القياسي standard error stream، وقد يكون وسيطا الخرج متماثلين في بعض الأنظمة إلا أن بعض الأنظمة الأخرى تفصل بين الاثنين. #include <stdio.h> #include <stdlib.h> #include <string.h> #define GROW_BY 10 /* يزداد حجم السلسلة النصية كل مرة بمقدار 10 */ main(){ char *str_p, *next_p, *tmp_p; int ch, need, chars_read; if(GROW_BY < 2){ fprintf(stderr, "Growth constant too small\n"); exit(EXIT_FAILURE); } str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; chars_read = 0; while((ch = getchar()) != EOF){ /* (*) */ if(ch == '\n'){ /* الإشارة إلى نهاية السطر */ *next_p = 0; printf("%s\n", str_p); free(str_p); chars_read = 0; str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; continue; } /* * التحقق من وصولنا إلى نهاية المساحة المحجوزة */ if(chars_read == GROW_BY-1){ *next_p = 0; /* للدلالة على نهاية السلسلة النصية */ /* نستخدم الطرح بين المؤشرات لإيجاد طول السلسلة النصية الحالية*/ need = next_p - str_p +1; tmp_p = (char *)malloc(need+GROW_BY); if(tmp_p == NULL){ fprintf(stderr,"No more store\n"); exit(EXIT_FAILURE); } /* ننسخ السلسلة النصية باستخدام دالة المكتبة */ strcpy(tmp_p, str_p); free(str_p); str_p = tmp_p; /* * next_p إعادة ضبط */ next_p = str_p + need-1; chars_read = 0; } /* * إسناد المحرف إلى نهاية السلسلة النصية */ *next_p++ = ch; chars_read++; } /* * عند وصولنا إلى نهاية الملف * هل توجد محارف غير مطبوعة؟ */ if(str_p - next_p){ *next_p = 0; fprintf(stderr,"Incomplete last line\n"); printf("%s\n", str_p); } exit(EXIT_SUCCESS); } [مثال 4] (*) تُعاد الحلقة في الموضع المذكور عند كل سطر، وهناك مساحةٌ للعنصر صفر في نهاية السلسلة النصية دائمًا، لأننا نتحقق من أصغر من 2 وهو ما تحققنا منه سابقًا GROW_BY ذلك في الشرط التالي إلا في حال كان. قد لا يكون برنامجنا السابق مثالًا واقعيًا عن التعامل مع السلاسل النصية الطويلة، إذ يتطلب حجم التخزين الأعظمي ضعف الحجم المطلوب لأطول سلسلة نصية، ولكنه برنامج يعمل صحيحًا بغض النظر، إلا أنه يكلفنا الكثير بخصوص الموارد بنسخ السلاسل النصية ويمكن حل المشكلتين عن طريق استخدام دالة realloc. نستطيع استخدام القوائم المترابطة لطريقة أكثر تعقيدًا، مع استخدام الهياكل Structures التي سنتكلم عنها لاحقًا، إلا أن هذه الطريقة تأتي أيضًا ببعض المشكلات لأن دوال المكتبة القياسية لن تعمل عند استخدام طريقة مغايرة لتخزين السلاسل النصية. ما الأشياء التي لا يستطيع العامل sizeof فعلها؟ يرتكب المبتدئون غالبًا الخطأ التالي عند استخدام العامل sizeof: #include <stdio.h> #include <stdlib.h> const char arr[] = "hello"; const char *cp = arr; main(){ printf("Size of arr %lu\n", (unsigned long) sizeof(arr)); printf("Size of *cp %lu\n", (unsigned long) sizeof(*cp)); exit(EXIT_SUCCESS); } [مثال 5] لن تكون الأرقام ذاتها عند الطباعة، إذ سيعرف أولًا حجم arr بكونها 6 بصورةٍ صحيحة (خمسة محارف متبوعةٍ بمحرف الفراغ null)، بينما ستطبع التعليمة الثانية -على جميع الأنظمة- القيمة 1، لأن المؤشر cp* من نوع const char ذو الحجم 1 بايت، بينما arr مختلفةٌ فهي مصفوفةٌ من نوع const char. تسبب هذه المشكلة مصدرًا للحيرة، إذ أن هذه الحالة الوحيدة التي لا يجري فيها تحويل المصفوفة إلى مؤشر أولًا، فمن المستحيل استخدام sizeof لإيجاد طول مصفوفة باستخدام مؤشر يشير إليها، ويجب عليك استخدام اسم المصفوفة حصرًا. نوع قيمة sizeof لعلك تتساءل الآن عن نتيجة التالي: sizeof ( sizeof (anything legal) ) فما هو نوع نتيجة عامل sizeof؟ الإجابة على هذا السؤال معرّفة بحسب التطبيق، وقد تكون unsigned long أو unsigned int بحسب تطبيقك، إلا أن هناك شيئان يمكن فعلهما للتأكد من أنك تستخدم القيمة بصورة صحيحة، وهما: يمكنك استخدام تحويل الأنواع cast وتحويل القيمة إلى unsigned long قسريًا (كما فعلنا في المثال السابق). يمكنك استخدام النوع المُعرّف size_t الموجود في ملف الترويسة stddef.h كما يوضح المثال التالي: #include <stddef.h> #include <stdio.h> #include <stdlib.h> main(){ size_t sz; sz = sizeof(sz); printf("size of sizeof is %lu\n", (unsigned long)sz); exit(EXIT_SUCCESS); } [مثال 6] ترجمة -وبتصرف- لقسم Sizeof and storage allocation من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المؤشرات Pointers في لغة سي C المقال السابق: التعامل مع المحارف والسلاسل النصية في لغة سي C الذاكرة الوهمية (Virtual memory) في نظام التشغيل فهم الملفات Files وأنظمة الملفات file systems
يُعيد العامل "sizeof" حجم المُعامل operator بالبايتات، وتعتمد نتيجة العامل "sizeof" بكونها عددًا صحيحًا عديم الإشارة "unsigned int" أو عددًا كبيرًا عديم الإشارة "unsigned long" على التطبيق implementation، وهذا هو السبب في تفادينا لأي مشكلات في المثال السابق (المقال السابق) عند التصريح عن دالة malloc على الرغم من عدم تزويد التصريح بأي تفاصيل عن معاملاتها؛ إذ يجب استخدام ملف الترويسة stdlib.h عوضًا عن ذلك عادةً للتصريح عن malloc على النحو الصحيح. إليك المثال ذاته ولكن بتركيز على جعله قابلًا للتنقل portable عبر مختلف الأجهزة: #include <stdlib.h> /* malloc() يتضمن ملف الترويسة تصريحًا عن */ float *fp; fp = (float *)malloc(sizeof(float)); يجب أن يُكتب معامل sizeof داخل قوسين إذا كان فقط اسمًا لنوع بيانات (وهي الحالة في مثالنا السابق)، بينما يمكنك التخلي عن القوسين إذا كنت تستخدم اسم كائن بيانات عوضًا عن ذلك، ولكن هذه الحالة نادرة الحدوث. #include <stdlib.h> int *ip, ar[100]; ip = (int *)malloc(sizeof ar); لدينا في المثال السابق مصفوفة باسم ar مكونةٌ من 100 عنصر من نوع عدد صحيح int، ويشير ip إلى مساحة التخزين الخاصة بهذه المصفوفة (مساحةٌ لمئة قيمة من نوع int) بعد استدعاء malloc (بفرض أن الاستدعاء كان ناجحًا). تعدّ char (محرف وهي اختصارٌ إلى character) وحدة القياس الأساسية للتخزين في لغة سي، وتساوي بايتًا واحدًا، جرّب نتيجة التعليمة الآتية: sizeof(char) وبناءً على ذلك، يمكنك حجز مساحة لعشرة قيم من نوع char على النحو التالي: malloc(10) ولحجز مساحة لمصفوفة بحجم عشرة قيم من نوع int، نكتب: malloc(sizeof(int[10])) تُعيد الدالة malloc مؤشرًا إلى الفراغ null pointer في حال لم تتوفر المساحة الكافية للإشارة إلى خطأ ما. يحتوي ملف الترويسة stdio.h ثابتًا معرّفًا باسم NULL، والذي يُستخدم عادةً للتحقق من القيمة المُعادة من الدالة malloc ودوال أخرى من المكتبة القياسية، وتُعد القيمة 0 أو (void *)0 مساويةً لهذا الثابت ويمكن استخدامها. إليك المثال التالي لتوضيح استخدام الدالة malloc، إذ يقرأ البرنامج في المثال سلاسلًا نصيةً بعدد MAXSTRING من الدخل، ثمّ يرتب السلاسل النصية أبجديًّا باستخدام الدالة strcmp. يُشار إلى نهاية السلسلة النصية بمحرف الهروب escape character التالي n\، وتُرتَّب السلاسل باستخدام مصفوفة من المؤشرات تُشير إلى السلسلة النصية وتبديل مواضع المؤشرات حتى الوصول إلى الترتيب الصحيح، مما يجنُّبنا عناء نسخ السلاسل النصية ويحسّن من سرعة تنفيذ البرنامج ويحد من هدر الموارد إلى حدٍّ ما. استخدمنا في الإصدار الأول من المثال مصفوفةً ثابتة الحجم، ثم استخدمنا في الإصدار الثاني حجز المساحة باستخدام malloc لكل سلسلة نصية عند وقت التشغيل run-time، بينما بقيت مصفوفة المؤشرات -لسوء الحظ- ثابتة الحجم، إلا أنه يمكننا تطبيق حلّ أفضل باستخدام قائمة مترابطة Linked list، أو أي هيكل بيانات مشابه لتخزين المؤشرات دون الحاجة لاستخدام المصفوفات ثابتة الحجم إطلاقًا، ولكننا لم نتكلم عن هياكل البيانات بعد. إليك ما يبدو عليه هيكل برنامجنا: while(number of strings read < MAXSTRING && input still remains){ read next string; } sort array of pointers; print array of pointers; exit; سنستخدم بعض الدوال في برنامجنا أيضًا: char *next_string(char *destination) تقرأ الدالة السابقة سطرًا من المحارف بحيث ينتهي السطر بالمحرف n\ من دخل البرنامج، وتُسند المحارف البالغ عددها MAXLEN-1 إلى المصفوفة المُشار إليها بالمصفوفة الهدف destination، إذ يمثّل MAXLEN قيمةً ثابتةً لطول السلسلة النصية العظمى. إذا كان المحرف الأول المقروء هو EOF (أي نهاية الملف)، أعِد مؤشرًا إلى الفراغ، وفيما عدا ذلك أعِد عنوان بداية السلسلة النصية (الهدف destination)، بحيث تحتوي السلسلة النصية الهدف دائمًا على المحرف n\، الذي يشير إلى نهاية السلسلة. void sort_arr(const char *p_array[]) تمثل المصفوفة p_array[] مصفوفة المؤشرات التي تشير للمحارف، ويمكن أن تكون المصفوفة كبيرة الحجم ولكن يُشار إلى نهايتها بأول عنصر يحتوي على مؤشر فراغ null pointer. ترتّب الدالة sort_arr المؤشرات بحيث تُشير إلى السلاسل النصية المرتبة أبجديًا عند اجتياز مصفوفة المؤشرات بناءً على دليل index المؤشر. void print_arr(const char *p_array[]) تُشابه دالة print_arr الدالة sort_arr ولكنها تطبع السلاسل النصية حسب ترتيبها الأبجدي. تذكّر أنه يجري تحويل اسم المصفوفة إلى عنوانها وعنصرها الأول في أي تعبير يحتوي على اسمها، ومن شأن ذلك أن يساعدك في فهم الأمثلة على نحوٍ أفضل؛ والأمر مماثلٌ بالنسبة لمصفوفة ثنائية البعد، مثل مصفوفة strings في المثال التالي، فنوع التعبير strings[1][2] هو char، ولكن للعنصر strings[1] نوع "مصفوفة من char"، ولذلك يُحوَّل اسم المصفوفة إلى عنوان العنصر الأول ونحصل على &strings[1][0]. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(char *destination); main(){ /* نصرح عن المصفوفة مع إضافة عنصر فارغ في نهايتها */ char *p_array[MAXSTRING+1]; /* مصفوفة تخزين السلاسل النصية */ char strings[MAXSTRING][MAXLEN]; /* عدد السلاسل النصية المقروءة */ int nstrings; nstrings = 0; while(nstrings < MAXSTRING && next_string(strings[nstrings]) != 0){ p_array[nstrings] = strings[nstrings]; nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(char *destination){ char *cp; int c; cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); return(destination); } [مثال 1] إعادة الدالة next_string لمؤشر ليس من قبيل المصادفة، إذ أصبح بإمكاننا الآن الاستغناء عن استخدام مصفوفة السلاسل النصية واستخدام next_string لحجز مساحة التخزين الموافقة لها. #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /* الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char *p_array[]); void sort_arr(const char *p_array[]); char *next_string(void); main(){ char *p_array[MAXSTRING+1]; int nstrings; nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char *p_array[]){ int index; for(index = 0; p_array[index] != 0; index++) printf("%s\n", p_array[index]); } void sort_arr(const char *p_array[]){ int comp_val, low_index, hi_index; const char *tmp; for(low_index = 0; p_array[low_index] != 0 && p_array[low_index+1] != 0; low_index++){ for(hi_index = low_index+1; p_array[hi_index] != 0; hi_index++){ comp_val=strcmp(p_array[hi_index], p_array[low_index]); if(comp_val >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = p_array[hi_index]; p_array[hi_index] = p_array[low_index]; p_array[low_index] = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 2] وأخيرًا إليك المثال كاملًا مع استخدام مصفوفة p_array للدالة malloc، ولاحظ إعادة كتابة معظم أدلة المصفوفة لتستخدم ترميز المؤشرات. إذا كنت تشعر بالإرهاق من جميع المعلومات التي قرأتها فتجاوز المثال التالي، فهو صعبٌ بعض الشيء. شرح المثال: تعني char **p مؤشرًا يشير إلى المؤشر الذي يشير إلى محرف، ويجد معظم مبرمجو لغة سي هذه الطريقة في استخدام المؤشرات صعبة الفهم. #include <stdio.h> #include <stdlib.hi> #include <string.h> #define MAXSTRING 50 /* العدد الأعظمي للسلاسل النصية */ #define MAXLEN 80 /*الطول الأعظمي لكل سلسلة نصية */ void print_arr(const char **p_array); void sort_arr(const char **p_array); char *next_string(void); main(){ char **p_array; int nstrings; /* عدد السلاسل النصية المقروءة */ p_array = (char **)malloc( sizeof(char *[MAXSTRING+1])); if(p_array == 0){ printf("No memory\n"); exit(EXIT_FAILURE); } nstrings = 0; while(nstrings < MAXSTRING && (p_array[nstrings] = next_string()) != 0){ nstrings++; } /* إعدام قيمة المصفوفة */ p_array[nstrings] = 0; sort_arr(p_array); print_arr(p_array); exit(EXIT_SUCCESS); } void print_arr(const char **p_array){ while(*p_array) printf("%s\n", *p_array++); } void sort_arr(const char **p_array){ const char **lo_p, **hi_p, *tmp; for(lo_p = p_array; *lo_p != 0 && *(lo_p+1) != 0; lo_p++){ for(hi_p = lo_p+1; *hi_p != 0; hi_p++){ if(strcmp(*hi_p, *lo_p) >= 0) continue; /* التبديل بين السلسلتين النصيتين */ tmp = *hi_p; *hi_p = *lo_p; *lo_p = tmp; } } } char *next_string(void){ char *cp, *destination; int c; destination = (char *)malloc(MAXLEN); if(destination != 0){ cp = destination; while((c = getchar()) != '\n' && c != EOF){ if(cp-destination < MAXLEN-1) *cp++ = c; } *cp = 0; if(c == EOF && cp == destination) return(0); } return(destination); } [مثال 3] سنستعرض مثالًا آخر لتوضيح استخدام دالة malloc وإمكاناتها في التعامل مع السلاسل النصية الطويلة؛ إذ يقرأ المثال السلاسل النصية من الدخل ويبحث عن محرف سطر جديد لتحديد نهاية السلسلة النصية (أي n\)، ثم يطبع السلسلة النصية إلى الخرج، ويتوقف البرنامج عن العمل عندما يصادف محرف نهاية الملف EOF. تُسنَد المحارف إلى مصفوفة، ويُدلّ على نهاية المصفوفة -كما هو معتاد- بالقيمة صفر، مع ملاحظة أن محرف السطر الجديد لا يُخزَّن بالمصفوفة بل يُستخدم فقط لتحديد سطر الدخل الواجب طباعته للخرج. لا يعلم البرنامج طول السلسلة النصية تحديدًا، ولذلك يبدأ بفحص كل عشرة محارف وحجز المساحة الخاصة بهم (الثابت GROW_BY). تُستدعى الدالة malloc في حال كانت السلسلة النصية أطول من عشرة محارف لحجز المساحة للسلسلة النصية وإضافة عشرة محارف أخرى، ثم تُنسخ المحارف الحالية للمساحة الجديدة وتُستخدم من البرنامج وتُحرّر المساحة القديمة. تُستخدم الدالة free لتحرير المساحة القديمة المحجوزة من malloc مسبقًا، إذ يجب عليك تحرير المساحة غير المُستخدمة بعد الآن دوريًا قبل أن تتراكم، واستخدام free يحرّر المساحة ويسمح بإعادة استخدامها لاحقًا. يستخدم البرنامج الدالة fprintf لعرض أي أخطاء، وهي دالةٌ مشابهة للدالة printf التي اعتدنا على رؤيتها، والفرق الوحيد بينهما هو أن الدالة fprintf تأخذ وسيطًا إضافيًّا يدل على وسيط الخرج الذي سيُطبع إليه، وهناك ثابتان لهذا الغرض معرّفان في ملف الترويسة stdio.h؛ إذ أن استخدام الثابت الأول stdout يعني استخدام خرج البرنامج القياسي، بينما يشير استخدام الثابت الثاني stderr إلى مجرى أخطاء البرنامج القياسي standard error stream، وقد يكون وسيطا الخرج متماثلين في بعض الأنظمة إلا أن بعض الأنظمة الأخرى تفصل بين الاثنين. #include <stdio.h> #include <stdlib.h> #include <string.h> #define GROW_BY 10 /* يزداد حجم السلسلة النصية كل مرة بمقدار 10 */ main(){ char *str_p, *next_p, *tmp_p; int ch, need, chars_read; if(GROW_BY < 2){ fprintf(stderr, "Growth constant too small\n"); exit(EXIT_FAILURE); } str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; chars_read = 0; while((ch = getchar()) != EOF){ /* (*) */ if(ch == '\n'){ /* الإشارة إلى نهاية السطر */ *next_p = 0; printf("%s\n", str_p); free(str_p); chars_read = 0; str_p = (char *)malloc(GROW_BY); if(str_p == NULL){ fprintf(stderr,"No initial store\n"); exit(EXIT_FAILURE); } next_p = str_p; continue; } /* * التحقق من وصولنا إلى نهاية المساحة المحجوزة */ if(chars_read == GROW_BY-1){ *next_p = 0; /* للدلالة على نهاية السلسلة النصية */ /* نستخدم الطرح بين المؤشرات لإيجاد طول السلسلة النصية الحالية*/ need = next_p - str_p +1; tmp_p = (char *)malloc(need+GROW_BY); if(tmp_p == NULL){ fprintf(stderr,"No more store\n"); exit(EXIT_FAILURE); } /* ننسخ السلسلة النصية باستخدام دالة المكتبة */ strcpy(tmp_p, str_p); free(str_p); str_p = tmp_p; /* * next_p إعادة ضبط */ next_p = str_p + need-1; chars_read = 0; } /* * إسناد المحرف إلى نهاية السلسلة النصية */ *next_p++ = ch; chars_read++; } /* * عند وصولنا إلى نهاية الملف * هل توجد محارف غير مطبوعة؟ */ if(str_p - next_p){ *next_p = 0; fprintf(stderr,"Incomplete last line\n"); printf("%s\n", str_p); } exit(EXIT_SUCCESS); } [مثال 4] (*) تُعاد الحلقة في الموضع المذكور عند كل سطر، وهناك مساحةٌ للعنصر صفر في نهاية السلسلة النصية دائمًا، لأننا نتحقق من أصغر من 2 وهو ما تحققنا منه سابقًا GROW_BY ذلك في الشرط التالي إلا في حال كان. قد لا يكون برنامجنا السابق مثالًا واقعيًا عن التعامل مع السلاسل النصية الطويلة، إذ يتطلب حجم التخزين الأعظمي ضعف الحجم المطلوب لأطول سلسلة نصية، ولكنه برنامج يعمل صحيحًا بغض النظر، إلا أنه يكلفنا الكثير بخصوص الموارد بنسخ السلاسل النصية ويمكن حل المشكلتين عن طريق استخدام دالة realloc. نستطيع استخدام القوائم المترابطة لطريقة أكثر تعقيدًا، مع استخدام الهياكل Structures التي سنتكلم عنها لاحقًا، إلا أن هذه الطريقة تأتي أيضًا ببعض المشكلات لأن دوال المكتبة القياسية لن تعمل عند استخدام طريقة مغايرة لتخزين السلاسل النصية. ما الأشياء التي لا يستطيع العامل sizeof فعلها؟ يرتكب المبتدئون غالبًا الخطأ التالي عند استخدام العامل sizeof: #include <stdio.h> #include <stdlib.h> const char arr[] = "hello"; const char *cp = arr; main(){ printf("Size of arr %lu\n", (unsigned long) sizeof(arr)); printf("Size of *cp %lu\n", (unsigned long) sizeof(*cp)); exit(EXIT_SUCCESS); } [مثال 5] لن تكون الأرقام ذاتها عند الطباعة، إذ سيعرف أولًا حجم arr بكونها 6 بصورةٍ صحيحة (خمسة محارف متبوعةٍ بمحرف الفراغ null)، بينما ستطبع التعليمة الثانية -على جميع الأنظمة- القيمة 1، لأن المؤشر cp* من نوع const char ذو الحجم 1 بايت، بينما arr مختلفةٌ فهي مصفوفةٌ من نوع const char. تسبب هذه المشكلة مصدرًا للحيرة، إذ أن هذه الحالة الوحيدة التي لا يجري فيها تحويل المصفوفة إلى مؤشر أولًا، فمن المستحيل استخدام sizeof لإيجاد طول مصفوفة باستخدام مؤشر يشير إليها، ويجب عليك استخدام اسم المصفوفة حصرًا. نوع قيمة sizeof لعلك تتساءل الآن عن نتيجة التالي: sizeof ( sizeof (anything legal) ) فما هو نوع نتيجة عامل sizeof؟ الإجابة على هذا السؤال معرّفة بحسب التطبيق، وقد تكون unsigned long أو unsigned int بحسب تطبيقك، إلا أن هناك شيئان يمكن فعلهما للتأكد من أنك تستخدم القيمة بصورة صحيحة، وهما: يمكنك استخدام تحويل الأنواع cast وتحويل القيمة إلى unsigned long قسريًا (كما فعلنا في المثال السابق). يمكنك استخدام النوع المُعرّف size_t الموجود في ملف الترويسة stddef.h كما يوضح المثال التالي: #include <stddef.h> #include <stdio.h> #include <stdlib.h> main(){ size_t sz; sz = sizeof(sz); printf("size of sizeof is %lu\n", (unsigned long)sz); exit(EXIT_SUCCESS); } [مثال 6] ترجمة -وبتصرف- لقسم Sizeof and storage allocation من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المؤشرات Pointers في لغة سي C المقال السابق: التعامل مع المحارف والسلاسل النصية في لغة سي C الذاكرة الوهمية (Virtual memory) في نظام التشغيل فهم الملفات Files وأنظمة الملفات file systems -
 يشابه استخدام المؤشرات Pointers في لغة سي عملية تعلُّم قيادة الدراجة الهوائية، فعندما تصل إلى النقطة التي تعتقد أنك لن تتعلمها أبدًا، تبدأ بإتقانها، وبعد أن تتعلمها سيكون من الصعب نسيانها. لا يوجد هناك أي شيء مميّز بخصوص المؤشرات، ونعتقد أن معظم القرّاء يعرفون عنها مسبقًا، وفي الحقيقة، واحدةٌ من ميزات لغة سي هي اعتمادها الكبير على استخدام المؤشرات مقارنةً باللغات الأخرى، إضافةً إلى الأشياء الأخرى الممكن إنجازها بواسطة المؤشرات بسهولة ودون قيود إلى حدٍّ ما. التصريح عن المؤشرات ينبغي التصريح عن المؤشرات قبل استخدامها بصورةٍ مماثلة لأي متغير آخر تعاملنا معه مسبقًا. يتشابه التصريح عن المؤشر مع أي تصريح آخر، ولكن هناك نقطة مهمّة، إذ تدلّ الكلمة المفتاحية عند التصريح عن المؤشر في البداية، مثل int أوchar وغيرها عن نوع المتغير الذي سيشير المؤشر إليه، وليس نوع المؤشر بذات نفسه، ويشير المؤشّر على قيمة واحدة كل مرة من ذلك النوع وليس جميع القيم من النوع ذاته. إليك مثالًا يوضح التصريح عن مصفوفة ومؤشر: int ar[5], *ip; يصبح لدينا بعد التصريح مصفوفة ومؤشر، كما يوضح الشكل 1: شكل 1 مصفوفة ومؤشر يوضح الرمز * الموجود أمام ip أن هذا مؤشر، وليس متغيرًا اعتياديًا، وهو مؤشرٌ من النوع pointer to int، أي يشير إلى قيمة من نوع int فقط، لكن لم تُسند له قيمة أوليّة بعد، ولا يمكننا استخدامه في هذه الحالة قبل أن نجعله يؤشّر على قيمةٍ ما. لاحظ أنه لا يمكنك تعيين قيمةٍ من نوع int فورًا، لأن القيم الصحيحة لها النوع int ونحن نريد هنا قيمةً من نوع "مؤشر إلى نوع صحيح pointer to int". لكن، ما الذي سيشير إليه ip في هذه الحالة إذا كانت التعليمة التالية صحيحة ؟ ip = 6; قد تختلف الإجابة هنا، ولا يوجد إجابةً واحدةً عمّا قد يشير إليه ip، ولكن خلاصة الأمر أن هذا النوع من الإسناد غير صحيح في لغة سي. إليك الطريقة الصحيحة لإسناد قيمة أولية لمؤشر ما: int ar[5], *ip; ip = &ar[3]; يؤشّر المؤشر في هذا المثال إلى عنصرٍ من المصفوفة ar بدليل 3، أي العنصر الرابع من المصفوفة. تحذير هام: يمكنك إسناد القيم إلى المؤشرات كما في أي متغير اعتدت عليه، ولكن تكمن الأهمية في نوع هذه القيمة وما الذي تعنيه. يدل الشكل 2 على قيم المتغيرات الموجودة بعد التصريح، ويدل ?? على كون المتغير غير مُسند لقيمة أولية أي غير مهيَّأ. شكل 2 مصفوفة ومؤشر مهيّأ نلاحظ أن قيمة المتغير ip مساوية لقيمة التعبير &ar[3]، ويشير السهم إلى أن المؤشر ip يشير إلى المتغير [ar[3. لكن ما الذي يعنيه العامل الأحادي &؟ يُشار إلى هذا العامل بكونه عامل "عنوان المتغير"، إذ أن المؤشرات تخزّن عنوان المتغير الذي تؤشّر عليه في معظم الأنظمة. ربّما ستواجه صعوبةً بخصوص هذا الأمر إذا كنت تفهم ما نعني هنا بالعنوان مقارنةً بالأشخاص الذين لا يفهمون هذا الأمر، إذ أن التفكير بالمؤشرات كونها عناوينًا يؤدي إلى كثيرٍ من المشاكل في الفهم. قد تكون عملية التلاعب بعناوين معالج "أ" مستحيلةً على متحكّم آلة غسيل من نوع "ب" يستخدم عناوينًا بسعة 17-بِت عندما تكون في طور الغسيل، ويقلب ترتيب البِتات الزوجية والفردية عندما ينفد من مسحوق الغسيل. من المستبعد لأي أحد أن يستخدم لغة سي بمعمارية مشابهة لمثالنا السابق، ولكن هناك بعض الحالات الأخرى والأقل شدّة التي قد يمكن تشغيل لغة سي على معماريتها. لكننا سنتابع استخدام الكلمة "عنوان المتغير"، لأن استخدام مصطلح أو كلمة مغايرة لذلك سيتسبب بمزيدٍ من المشكلات. يعيد تطبيق العامل & لمعامل ما مؤشّرًا لهذا المعامل: int i; float f; /* مؤشر إلى عدد صحيح '&i' */ /* مؤشر إلى عدد حقيقي '&f'*/ وسيشير المؤشر في كل حالة إلى الكائن الذي يوافق اسمه اسم المستخدم في التعبير. المؤشر مفيدٌ فقط في حال وجود طريقة للوصول إلى الشيء الذي يشير إليه، وتستخدم لغة سي العامل الأحادي * لتحقيق ذلك؛ فإذا كان p من نوع "مؤشر إلى نوعٍ ما pointer to something"، فيشير التعبير *p إلى الشيء الذي يشير إليه ذلك المؤشر. على سبيل المثال، نتبع مايلي للوصول إلى المتغير x باستخدام المؤشر p: #include <stdio.h> #include <stdlib.h> main(){ int x, *p; p = &x; //تهيئة المؤشر *p = 0; // x إسناد القيمة 0 إلى المتغير printf("x is %d\n", x); printf("*p is %d\n", *p); *p += 1; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); (*p)++; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); exit(EXIT_SUCCESS); } [مثال 1] من الجدير بالذكر معرفة أن استخدام التركيب المؤلف من & و * بالشكل &* يلغي تأثير كلٍّ منهما، لأن & تعيد عنوان الكائن أي قيمة مؤشّره، و* تعني "القيمة التي يشير إليها المؤشر". لكن انتبه، فليس لبعض الأشياء مثل الثوابت أي عنوان، وبذلك لا يمكن تطبيق العامل & عليها، والتعبير 1.5& ليسَ مؤشّرًا بل تعبيرًا خاطئًا. من المثير للانتباه أيضًا إلى أن لغة سي من اللغات القليلة التي تسمح بوجود تعبير على الجانب الأيسر من عامل الإسناد. انظر مجدّدًا إلى المثال؛ إذ نصادف التعبير p* مرتين، ومن ثم التعليمة (*p)++; المثيرة للاهتمام، وستثير هذه التساؤلات من معظم المبتدئين حتى لو استطعت فهم أن التعليمة p = 0* تسند القيمة 0 إلى المتغير المُشار إليه بواسطة المؤشر p، وأن التعليمة p += 1* تضيف واحدًا إلى المتغير المُشار إليه بالمؤشر p، فاستخدام العامل ++ مع p* يبدو صعب الفهم قليلًا. تستحق أسبقية التعبير ++(p*) النظر إليها بدقة، وسنناقش مزيدًا من التفاصيل بهذا الخصوص، ولكن دعونا نركّز عمّا يحدث في هذا المثال تحديدًا. تُستخدم الأقواس للتأكد بأن * تُطبَّق على p فقط، ومن ثم تحدث زيادةً بمقدار واحد على الشيء المُشار إليه بالمؤشر p، وبالنظر إلى جدول الأسبقية في مقال العوامل في لغة سي C نلاحظ أن للعاملين ++ و* الأسبقية ذاتها، ولكن العاملين يرتبطان من اليمين إلى اليسار، وبمعنى آخر تصبح العملية بالتخلص من الأقواس مكافئةً للعملية (++p)*، وبغض النظر عن معنى هذه العملية (التي سنتكلم عن معناها لاحقًا)، لا بُدّ من الحفاظ على الأقواس في هذه الحالة والانتباه إلى مواضعها الصحيحة. لذا، وبما أن المؤشر يعطي عنوان الشيء الذي يشير إليه، فاستخدام pointer* (إذ أن pointer هو أيضًا مؤشر) يعيد الشيء بذاته مباشرةً، ولكن ما الذي نستفيد من ذلك؟ أول الأمور التي نستفيد منها هي تجاوز قيد الاستدعاء بالقيمة call-by-value عند استخدام الدوال؛ فعلى سبيل المثال تخيل دالةً تعيد قيمتين ممثلتين بأعداد صحيحة تمثّل الشهر واليوم لهذا الشهر، وأن لهذه الدالة طريقةً (غير محددة) لتحديد هذه القيم، والتحدي هنا هو إعادة قيمتين منفصلتين بنفس الوقت. إليك طريقةً لتجاوز هذه العقبة بالمثال: #include <stdio.h> #include <stdlib.h> void date(int *, int *); /* التصريح عن الدالة */ main(){ int month, day; date (&day, &month); printf("day is %d, month is %d\n", day, month); exit(EXIT_SUCCESS); } void date(int *day_p, int *month_p){ int day_ret, month_ret; /*حساب قيمة day و month في day_ret و month_ret*/ *day_p = day_ret; *month_p = month_ret; } [مثال 2] لاحظ طريقة التصريح عن date المتقدمة، التي توضح أنها دالةٌ تأخذ وسيطين من نوع "مؤشر إلى قيمة من نوع int"، وتعيد void لأن القيم التي تُمرّر بواسطة المؤشرات ليست من نوع قيمة اعتيادية. تمرِّر الدالة main المؤشرات إلى الدالة date على أنها وسطاء باستخدام المتغيرات الداخلية day_ret و month_ret، ومن ثم تأخذ قيمتهما وتسندها إلى الأماكن التي تشير إليها وسطاء الدالة (المؤشرات). يوضح الشكل 3 ما الذي يحدث عند استدعاء الدالة date: شكل 3 عند استدعاء الدالة date تُمرَّر الوسطاء إلى date، ولكن المتغيرين day و month غير مهيّأين بقيمةٍ أولية ضمن الدالة main. يوضح الشكل 4 ما الذي يحدث عندما تصل الدالة date إلى تعليمة return، بفرض أن قيمة day هي "12" وقيمة month هي "5". شكل 4 عندما تصل الدالة date إلى تعليمة return واحدةٌ من المزايا الرائعة التي قدّمتها لغة سي المعيارية هي السماح بالتصريح عن أنواع وسطاء دالة date مسبقًا، إذ كان نسيان أن الدالة تقبل مؤشرات وسطاءً لها وتمرير نوع آخر أمرًا شائع الحدوث. تخيل استدعاء الدالة date دون أي تصريح واضح مُسبقٍ لها على النحو التالي: date(day, month); لن يعرف المصرّف هنا أن الدالة تقبل المؤشرات وسطاءً لها وستُمرر قيمًا من نوع int افتراضيًا لكل من day و month، وبما أن تمرير المؤشرات والأعداد الصحيحة يجري على معظم الحواسيب بالطريقة نفسها، لذا ستُنفَّذ الدالة في هذه الحالة، ثم تعيد القيم في النهاية وتسندها إلى المكان الذي يشير إليه كلًا من day و month، إذا كانا مؤشرين. لن يعطي ذلك أي نتيجة بل وربما يتسبب بضرر مفاجئ للبيانات في مكان آخر بذاكرة الحاسوب، وتعقُّب هذا النوع من الأخطاء صعبٌ جدًا. لحسن الحظ، يمكن أن يعرف المصرّف المعلومات الكافية عن date بالتصريح عن الدالة مسبقًا، وذلك من شأنه أن يحذره بخصوص أي أخطاء مرتكبة. قد يفاجئك سماع أن المؤشرات لا تستخدم كثيرًا لتمكين طريقة الاستدعاء بالإشارة call-by-reference، إذ يُعدّ استخدام الاستدعاء بالقيمة call-by-value وإعادة قيمة واحدة باستخدام return كافٍ في معظم الحالات، والاستخدام الأكثر شيوعًا للمؤشرات هو الانتقال ما بين المصفوفات. المصفوفات والمؤشرات تملك عناصر المصفوفة عناوينًا مثل أي متغير اعتيادي آخر. int ar[20], *ip; ip = &ar[5]; *ip = 0; // يكافئ التعبير ar[5] = 0; في المثال السابق، يُخزَّن عنوان العنصر ar[5] في المؤشر ip، ثم تُسند القيمة صفر إلى موضع المؤشر في السطر الذي يليه. هذا الشيء غير مثير للإعجاب بحد ذاته، بل إن طريقة عمل العمليات الحسابية والمؤشر سويًّا هي التي تستدعي الاهتمام، فعلى الرغم من بساطة هذا الأمر، إلا أنه يُعد واحدًا من أساسات لغة سي المميزة. نحصل على مؤشر إذا أضفنا قيمة عدد صحيح إلى مؤشر ما، ويكون للمؤشر الذي حصلنا عليه نفس نوع المؤشر الأصلي؛ فبإضافة العدد "n" إلى مؤشر ما يشير إلى عنصر في مصفوفة، سنحصل على عنصر يشير إلى العنصر الذي يلي العنصر السابق بمقدار "n" داخل المصفوفة ذاتها، ويمكن تطبيق حالة الطرح بما أن العدد "n" يمكن أن يكون سالبًا. بالرجوع إلى المثال السابق، ينتج عن التعبير التالي: *(ip+1) = 0; تغيير قيمة ar[6] إلى صفر، وهكذا. لا تعدّ هذه الطريقة تحسينًا على طرق الوصول إلى عناصر المصفوفة الاعتيادية، إليك مثالًا عن ذلك بدلًا من السابق: int ar[20], *ip; for(ip = &ar[0]; ip < &ar[20]; ip++) *ip = 0; يوضّح المثال السابق ميزةً كلاسيكيةً للغة سي، إذ يشير المؤشر إلى بداية المصفوفة، وبينما يشير المؤشر إلى المصفوفة يمكن الوصول إلى عناصر المصفوفة واحدًا تلو الآخر بزيادة المؤشر بمقدار واحد كلّ مرة. يدعم معيار سي بعض الممارسات الموجودة وذلك بالسماح لاستخدام عنوان العنصر ar[20] على الرغم من عدم وجود هذا العنصر، ويسمح لك هذا باستخدام المؤشرات لاختبار حدود المصفوفة ضمن الحلقات التكرارية كما هو الحال في المثال السابق، إذ أن ضمان عمله يمتد لعنصر واحد فقط خارج نهاية المصفوفة وليس أكثر من ذلك. لكن ما المميز في هذه الطريقة مقارنةً باستخدام دليل المصفوفة للوصول إلى العنصر بالطريقة الاعتيادية؟ يمكن الوصول إلى عناصر المصفوفات في معظم الحالات بالتعاقب، واستعرضت القليل من الأمثلة البرمجية السابقة خيار الوصول إلى العناصر "عشوائيًا". إذا أردت الوصول إلى عناصر المصفوفة بالتعاقب فسيقدّم استخدام المؤشرات تنفيذًا أسرع، إذ يتطلب الأمر على معظم معماريات الحاسوب عملية ضرب وجمع واحدةً للوصول إلى عنصر ضمن مصفوفة أحادية البعد باستخدام دليله، بينما لا يتطلب الأمر باستخدام المؤشرات إجراء أي عمليات حسابية إطلاقًا، إذ يخزن المؤشر العنوان الدقيق للكائن (عنصر المصفوفة في هذه الحالة). العملية الحسابية الوحيدة المُجراة في المثال السابق هي ضمن حلقة for التكرارية، إذ تحدث عملية إضافة ومقارنة كل دورة داخل الحلقة. إذا أردنا استخدام طريقة الوصول لعناصر المصفوفة باستخدام الأدلة، نكتب: int ar[20], i; for(i = 0; i < 20; i++) ar[i] = 0; تحدث العمليات الحسابية ذاتها في الحلقة التكرارية كما في المثال السابق، لكن بإضافة حسابات العنوان المُجراة كل دورة في الحلقة. لا تعدّ نقطة توفير الوقت والفاعلية مشكلةً كبيرةً في معظم الأحيان، إلا أن الأمر مهمٌ هنا في حالة الحلقات التكرارية، إذ تتكرر الحلقات عددًا كبيرًا من المرات وكل جزء من الثانية يمكن توفيره في كل دورة له تأثير، ولا يستطيع المصرّف مهما كان ذكيًّا التعرُّف على جميع الحالات التي يمكن له استخدام المؤشرات بدلًا من طريقة دليل المصفوفة ضمنيًا. إذا استوعبت جميع ما قرأته حتى الآن فتابع معنا، وإلّا فتجاوز هذا القسم واذهب للمقال التالي، فعلى الرغم من المعلومات المثيرة للاهتمام في الأقسام التالية إلا أنها غير ضرورية وتُعرَف برهبتها لمبرمجي لغة سي المتمرسين حتى. في حقيقة الأمر، لا "تفهم" لغة سي مبدأ الوصول لعناصر المصفوفة باستخدام أدلتها (باستثناء نقطة التصريح عن المصفوفة)، فالتعبير x[n] يُترجم بالنسبة للمصرّف على النحو التالي: (x+n)*، إذ يُحوَّل اسم المصفوفة إلى مؤشر يشير إلى العنصر الأول للمصفوفة وذلك أينما وجد اسم المصفوفة ضمن تعبير ما. يُعد هذا سببٌ من ضمن أسباب أخرى لبدء عناصر المصفوفة بالرقم صفر؛ فإذا كان x اسم المصفوفة، سيكون التعبير &x[0] مساوٍ للمصفوفة x، أي مؤشر إلى العنصر الأول من المصفوفة. نستطيع الوصول إلى x[0] باستخدام المؤشرات باستخدام التعبير *(&x[0])، مما يعني أن *(&x[0] + 5) مساوٍ للتعبير *(x + 5) وهو ذات التعبير [x[5. يفتح ذلك الأمر سيلًا من التساؤلات عن الإمكانيات الناتجة، فإذا كان التعبير x[5] يُترجم إلى *(x + 5) والتعبير x + 5 يعطي النتيجة ذاتها للتعبير: 5 + x فالتعبير 5[x] مساوٍ للتعبير x[5]. إليك برنامجًا يُصرّف وينفذ دون أي أخطاء إن لم تصدق هذا الأمر: #include <stdio.h> #include <stdlib.h> #define ARSZ 20 main(){ int ar[ARSZ], i; for(i = 0; i < ARSZ; i++){ ar[i] = i; i[ar]++; printf("ar[%d] now = %d\n", i, ar[i]); } printf("15[ar] = %d\n", 15[ar]); exit(EXIT_SUCCESS); } [مثال 3] لتلخيص ما سبق: تبدأ العناصر في أي مصفوفة من الدليل ذي الرقم صفر. ليس هناك أي وجود للمصفوفات متعددة الأبعاد، بل هي في حقيقة الأمر مصفوفاتٌ تحتوي على مصفوفات. تُشير المؤشرات إلى أشياء، والمؤشرات التي تشير إلى أشياء من أنواع مختلفة هي بدورها من أنواع مختلفة أيضًا ولا يوجد أي تشابه بين الأنواع المختلفة في لغة سي وأي تحويل ضمني تلقائي بينهما. يمكن استخدام المؤشرات لمحاكاة استخدام الاستدعاء بالإشارة ضمن الدوال، ولكن الأمر يستغرق بعضًا من الجهد لتحقيقه. تُستخدم زيادة أو نقصان قيمة مؤشر ما للتنقل بين عناصر المصفوفة. يضمن المعيار أن محاولة الوصول إلى العنصر ذي الدليل "n" في مصفوفة ذات حجم "n" محاولةٌ صالحة على الرغم من عدم وجود هذا العنصر وذلك لتسهيل أمر التنقل داخل المصفوفة بزيادة قيمة المؤشر، ويكون مجال قيم مصفوفة مصرّح عنها على النحو int ar[N] هو &ar[0] وصولًا إلى &ar[N] ولكن يجب عليك تفادي الوصول إلى قيمة العنصر الأخير الزائف. الأنواع المؤهلة Qualified تابع قراءة الفقرات التالية إن كنت واثقًا من فهمك لأساسيات عملية التصريح عن المؤشرات واستخدامها، وإلا فمن المهم العودة إلى الفقرات السابقة ومحاولة فهمها جيّدًا قبل قراءة الفقرات التالية، إذ أن المعلومات المذكورة في الفقرات التالية أكثر تعقيدًا، ولا داعِ لجعل الأمر أسوأ بعدم تحضيرك وفهمك لما سبق. قدم المعيار شيئان باسم مؤهلات النوع type qualifiers، إذ لم يكونا في لغة سي القديمة مسبقًا، ويمكن تطبيقهما لأي نوع مصرّحٌ عنه للتعديل من تصرفه، ومن هنا أتى اسمهما. سنتجاهل إحداهما (المدعو باسم "volatile") إلا أنه لا يمكننا تجاهل الآخر "const". إذا سبقت الكلمة المفتاحية "const" أي تصريح، فهذا يعني أن الشيء الذي صُرّح عنه هو ثابت، ويجب عليك تجنب محاولة التغيير على قيمة الكائنات الثابتة "const" وإلا فستحصل على سلوك غير محدّد undefined behaviour، وسيحذّرك المصرّف عادةً بمنعك من هذه المحاولة إلا إذا تجاوزت هذا القيد بحيلةٍ ما. هناك فائدتان مرجوتان من تصريح كائن ما بكونه ثابتًا "const": يشير استخدام الكلمة المفتاحية "const" إلى أن القيمة غير قابلة للتغيير، مما يجبر المصرّف على التحقق من أي تغييرات طرأت على هذه القيمة ضمن الشيفرة البرمجية، وهذا الأمر باعث للطمأنينة في حال أردت استخدام قيمٍ ثابتة، مثل المؤشرات التي تُستخدم وسطاءً في بعض الدوال. إذا احتوى التصريح عن الدالة مؤشرات تشير إلى كائنات ثابتة على أنها وسطاء، فهذا يعني أن الدالة لن تشير إلى أي كائن آخر. عندما يعلم المصرّف بأن الأشياء هي كائنات ثابتة، ينعكس ذلك إيجابيًا على قدرته برفع فاعلية الشيفرة البرمجية وسرعتها. الثوابت عديمة الفائدة في حال لم تسند إليها أي قيمة، لن نتطرق بالتفصيل بخصوص تهيئة الثوابت (سنناقش الأمر لاحقًا)، كل ما عليك تذكره الآن هو أنه من الممكن لأي تصريح إسناد القيمة لتعبيرٍ ثابت. إليك بعض الأمثلة عن التصريح عن ثوابت: const int x = 1; /* ثابت x */ const float f = 3.5; /* ثابت f*/ const char y[10]; /* y مصفوفة من 10 عناصر ذات قيم صحيحة ثابتة */ /* لا تفكر بخصوص تهيئة قيمها بعد */ ما يثير الاهتمام هو كون هذا المؤهل ممكن التطبيق على المؤشرات بطريقتين: إما بجعل الشيء الذي يشير إليه المؤشر ثابتًا، بحيث يصبح نوع المؤشر "مؤشر إلى ثابت"، أو بجعل المؤشر بذات نفسه ثابتًا (مؤشرًا ثابتًا)، إليك مثالًا عن ذلك: int i; /* عدد صحيح اعتيادي i */ const int ci = 1; /* عدد صحيح ثابت ci */ int *pi; /* مؤشر إلى عدد صحيح pi */ const int *pci; /* مؤشر إلى عدد صحيح ثابت pci */ /* بالانتقال إلى الأمثلة الأكثر تعقيدًا */ // مؤشر ثابت يشير إلى قيمة عدد صحيح cpi int *const cpi = &i; // مؤشر ثابت يشير إلى قيمة عدد صحيح ثابتة cpci const int *const cpci = &ci; التصريح الأول (للمتغير i) اعتيادي، ولكن تصريح ci يوضح أنه عدد صحيح ثابت وبذلك لا يمكن التعديل على قيمته، وسيكون بلا فائدة إن لم يُهيّأ (إسناد قيمة أولية له). ليس من الصعب فهم الغرض من مؤشر لعدد صحيح، ومؤشر لعدد صحيح ثابت، ولكن يجب الانتباه إلى أنواع المؤشرات المختلفة، إذ لا يجوز الخلط بينهم. يمكنك تغيير قيمة كل من pi و pci بجعلهما يشيران إلى أشياء أخرى، كما يمكنك تغيير قيمة الشيء الذي يشير إليه المؤشر pi بالنظر إلى كونه عدد صحيح غير ثابت، ولكن لا يمكنك إلّا الوصول إلى قيمة الشيء الذي يشير إليه المؤشر pci دون التعديل عليه نظرًا لكونه ثابتًا. يُعد التصريحان الأخيران أكثر التصريحات تعقيدًا ضمن المثال؛ فإذا كانت المؤشرات بذات نفسها ثابتةً، فمن غير المسموح تغيير المكان الذي تشير إليه، وبالتالي يجب تهيأتهما بقيمة أولية مثل ci. يمكن للشيء المُشار إليه بالمؤشر أن يكون ثابتًا أو غير ثابت بغض النظر عن كون المؤشر ثابتًا بدوره أم لا، وهذا يملي بعض القيود على استخدام الكائن المُشار إليه. أخيرًا للتوضيح: ما الذي يملي وجود نوع مؤهّل؟ كان ci في المثال السابق نوعًا مؤهلًا بكل وضوح، ولكن pci لم تنطبق عليه هذه الحالة بما أن المؤشر ليس من نوع مؤهّل بل الشيء الذي يشير إليه. الأشياء الوحيدة الذي كانت ذات أنواع مؤهلة في المثال هي: ci و cpi و cpci. سيتطلب منك الأمر بعض الوقت للاعتياد على هذا النوع من التصريحات، ولكن استخدامها سيكون تلقائيًّا وطبيعيًا بعد فترة فلا تقلق، إلا أن التعقيدات تبدأ بالظهور لاحقًا عندما يتوجب عليك الإجابة على السؤال: "هل من المسموح لي -على سبيل المثال- مقارنة مؤشر اعتيادي مع مؤشر ثابت؟ وإذا كان الجواب نعم، ما الذي تعنيه المقارنة؟". معظم القوانين واضحة بهذا الخصوص، ولكن يجب ذكرها وتوضيحها بغض النظر عن سهولتها. سنتكلم عن أنواع البيانات المؤهلة بتوسعٍ أكبر لاحقًا. عمليات المؤشرات الحسابية سنتكلم بالتفصيل لاحقًا عن عمليات المؤشرات الحسابية، ولكننا سنكتفي الآن بإصدار مختصرٍ يفي بالغرض. يمكنك الطرح أو المقارنة بين مؤشرين من النوع نفسه بالإضافة إلى إضافة قيمة عددية صحيحة إلى المؤشر، ويجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها وإلا حصلنا على سلوك غير محدد. نتيجة طرح مؤشرين هي قيمة العناصر التي تفصل بينهما في المصفوفة، ونوع النتيجة معرفٌ بحسب التطبيق وسيكون إما "short" أو "int" أو "long"، ويوضح المثال القادم مثالًا على حساب الفرق بين مؤشرين واستخدام النتيجة، ولكن قبل أن ننتقل إلى المثال يجب أن تعرف معلومةً مهمة. يُحوَّل اسم المصفوفة في أي تعبير إلى مؤشر يشير إلى العنصر الأول ضمن هذه المصفوفة، والحالة الوحيدة الاستثنائية هي عند استخدام اسم المصفوفة مع الكلمة المفتاحية "sizeof"، أو عند استخدام سلسلة نصية لتهيئة قيمة مصفوفة ما، أو عندما يكون اسم المصفوفة مرتبطًا بعامل "عنوان الكائن" (العامل الأحادي "&")، لكننا لم نتطرق إلى أيّ من الحالات السابقة بعد، وسنناقشها لاحقًا. إليك المثال: #include <stdio.h> #include <stdlib.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %d\n", (int)(fp2-fp1)); fp2++; } exit(EXIT_SUCCESS); } [مثال 4] يشير المؤشر fp2 إلى عناصر المصفوفة، ويُطبع الفرق بين قيمته الحالية وقيمته الأصلية، وللتأكد من عدم تمرير النوع الخاطئ للوسيط للدالة printf تُحوَّل القيمة الناتجة عن فرق المؤشرين قسريًّا إلى int باستخدام تحويل الأنواع (int)، وهذا يجنّبنا من الأخطاء على الحواسيب التي تعيد قيمة long لهذا النوع من العمليات. قد يعود إلينا المثال السابق بإجابات خاطئة إذا كان الفرق بين القيمتين من نوع long وكانت المصفوفة كبيرة الحجم، ونلاحظ في المثال التالي إصدارًا آمنًا من المثال السابق، إذ يُستخدم تحويل الأنواع قسريًا للسماح بوجود قيم long: #include <stdio.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %ld\n", (long)(fp2-fp1)); fp2++; } return(0); } [مثال 5] مؤشرات void و null والمؤشرات الإشكالية لغة سي حريصة بشأن أنواع المؤشرات، ولن تسمح لك عمومًا باستخدام مؤشرات ذات أنوع مختلفة ضمن التعبير ذاته. يختلف مؤشر إلى نوع "char" عن مؤشر إلى نوع "int" ولا يمكنك -على سبيل المثال- إسناد قيمة أحدهما إلى الآخر أو المقارنة فيما بينهما أو طرحهما من بعضهما واستخدام النتيجة مثل وسيط في دالة ما، كما يمكن أيضًا تخزين النوعين في الذاكرة بصورةٍ مختلفة وأن يكونا بأطوال مختلفة. لكن نريد في بعض الحالات تجاوز هذه القيود، فكيف نفعل ذلك؟ يكمن الحل هنا باستخدام أنواع خاصة، وقد قدمنا واحدًا من هذه الأنواع سابقًا ألا وهو "مؤشر إلى void"، وقُدّمت هذه الميزة مع سي المعيارية إذ افتُرض سابقًا أن المؤشر من نوع "مؤشر إلى char" كافٍ لهذه المهمة، وكان الافتراض صحيحًا إلى حدٍّ ما إلا أنه كان حلًّا غير منظّمًا، بينما قدّم الحل الجديد طريقةً أكثر أمانًا وأقل تشويشًا. لا يوجد أي استخدام للمؤشر هذا، لأن "* void" لا يشير إلى أي قيمة، لذا يحسّن هذا الأمر من سهولة قراءة الشيفرة البرمجية. يمكن أن يخزن المؤشر من النوع "* void" أي قيمة من أي مؤشر آخر، ويمكن إسناده إلى مؤشر آخر من أي نوع أيضًا، إلا أنه يجب استخدام هذا النوع من المؤشرات بحذر لأنه قد ينتهي الأمر بك ببعض الأخطاء الوخيمة، وسنناقش استخدامه الآمن مع دالة "malloc" لاحقًا. قد تحتاج أيضًا في بعض الحالات إلى مؤشر مضمون أنه لا يشير إلى أي كائن والذي يُدعى مؤشر من نوع "null" أو مؤشر الفراغ null pointer. من الشائع في لغة سي كتابة بعض الإجراءات routines التي تعيد مؤشرات، بحيث يمكن الدلالة على فشل ذلك الإجراء بعدم قدرته على إعادة مؤشر صالح عن طريق إعادة مؤشر الفراغ. ومن الأمثلة على ذلك إجراء فحصٍ لقيم موجودة في جدول ما بحثًا عن قيمة معينة ويعيد مؤشرًا على الكائن المُطابق إن وُجدت النتيجة أو مؤشر الفراغ إن لم تُوجد أي نتيجةٍ مطابقة. لكن كيف يمكن كتابة مؤشر فراغ؟ هناك طريقتان لفعل ذلك وكلا الطريقتين متماثلتين في النتيجة، إما باستخدام رقم صحيح ثابت بقيمة "0" أو تحويل القيمة إلى نوع "* void" باستخدام التحويل بين الأنواع، وتدعى نتيجة الطريقتين بمؤشر الفراغ الثابت null pointer constant. إذا أسندت مؤشر فراغ إلى أي مؤشر آخر أو قارنت بين مؤشر الفراغ ومؤشر آخر فسيُحوَّل مؤشر الفراغ إلى نوع المؤشر الآخر تلقائيًّا، مما سيحلّ أي مشكلة بخصوص توافقية الأنواع، ولن تُساوي القيمة التي يشير إليها ذلك المؤشر -مؤشر الفراغ- أي قيمة كائن آخر يشير إليها أي مؤشر داخل البرنامج (أي سيشير إلى قيمة فريدة). القيم الوحيدة الممكن إسنادها للمؤشرات باستثناء القيمة "0" هي قيم المؤشرات الأخرى من نفس النوع، إلا أن الأمر الذي يجعل من لغة سي مميزة وبديلًا مفيدًا للغة التجميعية هو سماحها لك بفعل بعض الأشياء التي لا تسمح لك بها معظم لغات البرمجة الأخرى، جرّب التالي: int *ip; ip = (int *)6; *ip = 0xFF; ما نتيجة السابق؟ تُهيأ قيمة المؤشر إلى 6 (لاحظ تحويل نوع 6 من int إلى مؤشر)، وهذه عملية تُجرى على مستوى الآلة غالبًا ويكون تمثيل قيمة المؤشر بالبتات غير مشابه لما قد يكون تمثيل الرقم 6، كما تُسند القيمة الست عشرية FF بعد التهيئة إلى الكائن الذي يشير إليه المؤشر. تُكتب القيمة 0xFF على الرقم الصحيح ذو الموضع 6، إذ يعتمد الموضع 6 على تفسير الآلة له على الذاكرة. قد تحتاج لهذا النوع من الأشياء وقد لا تحتاج إليها إطلاقًا، ولكن لغة سي تعطيك الخيار، ومن الواجب معرفتها إذ أنه من الممكن كتابتها على نحوٍ خاطئ غير مقصود مما سيتسبب بنتائج مفاجئة جدًا. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف والسلاسل النصية في لغة سي C المقال السابق: مدخل إلى المصفوفات في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C البنية النصية لبرامج سي C
يشابه استخدام المؤشرات Pointers في لغة سي عملية تعلُّم قيادة الدراجة الهوائية، فعندما تصل إلى النقطة التي تعتقد أنك لن تتعلمها أبدًا، تبدأ بإتقانها، وبعد أن تتعلمها سيكون من الصعب نسيانها. لا يوجد هناك أي شيء مميّز بخصوص المؤشرات، ونعتقد أن معظم القرّاء يعرفون عنها مسبقًا، وفي الحقيقة، واحدةٌ من ميزات لغة سي هي اعتمادها الكبير على استخدام المؤشرات مقارنةً باللغات الأخرى، إضافةً إلى الأشياء الأخرى الممكن إنجازها بواسطة المؤشرات بسهولة ودون قيود إلى حدٍّ ما. التصريح عن المؤشرات ينبغي التصريح عن المؤشرات قبل استخدامها بصورةٍ مماثلة لأي متغير آخر تعاملنا معه مسبقًا. يتشابه التصريح عن المؤشر مع أي تصريح آخر، ولكن هناك نقطة مهمّة، إذ تدلّ الكلمة المفتاحية عند التصريح عن المؤشر في البداية، مثل int أوchar وغيرها عن نوع المتغير الذي سيشير المؤشر إليه، وليس نوع المؤشر بذات نفسه، ويشير المؤشّر على قيمة واحدة كل مرة من ذلك النوع وليس جميع القيم من النوع ذاته. إليك مثالًا يوضح التصريح عن مصفوفة ومؤشر: int ar[5], *ip; يصبح لدينا بعد التصريح مصفوفة ومؤشر، كما يوضح الشكل 1: شكل 1 مصفوفة ومؤشر يوضح الرمز * الموجود أمام ip أن هذا مؤشر، وليس متغيرًا اعتياديًا، وهو مؤشرٌ من النوع pointer to int، أي يشير إلى قيمة من نوع int فقط، لكن لم تُسند له قيمة أوليّة بعد، ولا يمكننا استخدامه في هذه الحالة قبل أن نجعله يؤشّر على قيمةٍ ما. لاحظ أنه لا يمكنك تعيين قيمةٍ من نوع int فورًا، لأن القيم الصحيحة لها النوع int ونحن نريد هنا قيمةً من نوع "مؤشر إلى نوع صحيح pointer to int". لكن، ما الذي سيشير إليه ip في هذه الحالة إذا كانت التعليمة التالية صحيحة ؟ ip = 6; قد تختلف الإجابة هنا، ولا يوجد إجابةً واحدةً عمّا قد يشير إليه ip، ولكن خلاصة الأمر أن هذا النوع من الإسناد غير صحيح في لغة سي. إليك الطريقة الصحيحة لإسناد قيمة أولية لمؤشر ما: int ar[5], *ip; ip = &ar[3]; يؤشّر المؤشر في هذا المثال إلى عنصرٍ من المصفوفة ar بدليل 3، أي العنصر الرابع من المصفوفة. تحذير هام: يمكنك إسناد القيم إلى المؤشرات كما في أي متغير اعتدت عليه، ولكن تكمن الأهمية في نوع هذه القيمة وما الذي تعنيه. يدل الشكل 2 على قيم المتغيرات الموجودة بعد التصريح، ويدل ?? على كون المتغير غير مُسند لقيمة أولية أي غير مهيَّأ. شكل 2 مصفوفة ومؤشر مهيّأ نلاحظ أن قيمة المتغير ip مساوية لقيمة التعبير &ar[3]، ويشير السهم إلى أن المؤشر ip يشير إلى المتغير [ar[3. لكن ما الذي يعنيه العامل الأحادي &؟ يُشار إلى هذا العامل بكونه عامل "عنوان المتغير"، إذ أن المؤشرات تخزّن عنوان المتغير الذي تؤشّر عليه في معظم الأنظمة. ربّما ستواجه صعوبةً بخصوص هذا الأمر إذا كنت تفهم ما نعني هنا بالعنوان مقارنةً بالأشخاص الذين لا يفهمون هذا الأمر، إذ أن التفكير بالمؤشرات كونها عناوينًا يؤدي إلى كثيرٍ من المشاكل في الفهم. قد تكون عملية التلاعب بعناوين معالج "أ" مستحيلةً على متحكّم آلة غسيل من نوع "ب" يستخدم عناوينًا بسعة 17-بِت عندما تكون في طور الغسيل، ويقلب ترتيب البِتات الزوجية والفردية عندما ينفد من مسحوق الغسيل. من المستبعد لأي أحد أن يستخدم لغة سي بمعمارية مشابهة لمثالنا السابق، ولكن هناك بعض الحالات الأخرى والأقل شدّة التي قد يمكن تشغيل لغة سي على معماريتها. لكننا سنتابع استخدام الكلمة "عنوان المتغير"، لأن استخدام مصطلح أو كلمة مغايرة لذلك سيتسبب بمزيدٍ من المشكلات. يعيد تطبيق العامل & لمعامل ما مؤشّرًا لهذا المعامل: int i; float f; /* مؤشر إلى عدد صحيح '&i' */ /* مؤشر إلى عدد حقيقي '&f'*/ وسيشير المؤشر في كل حالة إلى الكائن الذي يوافق اسمه اسم المستخدم في التعبير. المؤشر مفيدٌ فقط في حال وجود طريقة للوصول إلى الشيء الذي يشير إليه، وتستخدم لغة سي العامل الأحادي * لتحقيق ذلك؛ فإذا كان p من نوع "مؤشر إلى نوعٍ ما pointer to something"، فيشير التعبير *p إلى الشيء الذي يشير إليه ذلك المؤشر. على سبيل المثال، نتبع مايلي للوصول إلى المتغير x باستخدام المؤشر p: #include <stdio.h> #include <stdlib.h> main(){ int x, *p; p = &x; //تهيئة المؤشر *p = 0; // x إسناد القيمة 0 إلى المتغير printf("x is %d\n", x); printf("*p is %d\n", *p); *p += 1; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); (*p)++; /* زيادة القيمة التي يشير إليها المؤشر */ printf("x is %d\n", x); exit(EXIT_SUCCESS); } [مثال 1] من الجدير بالذكر معرفة أن استخدام التركيب المؤلف من & و * بالشكل &* يلغي تأثير كلٍّ منهما، لأن & تعيد عنوان الكائن أي قيمة مؤشّره، و* تعني "القيمة التي يشير إليها المؤشر". لكن انتبه، فليس لبعض الأشياء مثل الثوابت أي عنوان، وبذلك لا يمكن تطبيق العامل & عليها، والتعبير 1.5& ليسَ مؤشّرًا بل تعبيرًا خاطئًا. من المثير للانتباه أيضًا إلى أن لغة سي من اللغات القليلة التي تسمح بوجود تعبير على الجانب الأيسر من عامل الإسناد. انظر مجدّدًا إلى المثال؛ إذ نصادف التعبير p* مرتين، ومن ثم التعليمة (*p)++; المثيرة للاهتمام، وستثير هذه التساؤلات من معظم المبتدئين حتى لو استطعت فهم أن التعليمة p = 0* تسند القيمة 0 إلى المتغير المُشار إليه بواسطة المؤشر p، وأن التعليمة p += 1* تضيف واحدًا إلى المتغير المُشار إليه بالمؤشر p، فاستخدام العامل ++ مع p* يبدو صعب الفهم قليلًا. تستحق أسبقية التعبير ++(p*) النظر إليها بدقة، وسنناقش مزيدًا من التفاصيل بهذا الخصوص، ولكن دعونا نركّز عمّا يحدث في هذا المثال تحديدًا. تُستخدم الأقواس للتأكد بأن * تُطبَّق على p فقط، ومن ثم تحدث زيادةً بمقدار واحد على الشيء المُشار إليه بالمؤشر p، وبالنظر إلى جدول الأسبقية في مقال العوامل في لغة سي C نلاحظ أن للعاملين ++ و* الأسبقية ذاتها، ولكن العاملين يرتبطان من اليمين إلى اليسار، وبمعنى آخر تصبح العملية بالتخلص من الأقواس مكافئةً للعملية (++p)*، وبغض النظر عن معنى هذه العملية (التي سنتكلم عن معناها لاحقًا)، لا بُدّ من الحفاظ على الأقواس في هذه الحالة والانتباه إلى مواضعها الصحيحة. لذا، وبما أن المؤشر يعطي عنوان الشيء الذي يشير إليه، فاستخدام pointer* (إذ أن pointer هو أيضًا مؤشر) يعيد الشيء بذاته مباشرةً، ولكن ما الذي نستفيد من ذلك؟ أول الأمور التي نستفيد منها هي تجاوز قيد الاستدعاء بالقيمة call-by-value عند استخدام الدوال؛ فعلى سبيل المثال تخيل دالةً تعيد قيمتين ممثلتين بأعداد صحيحة تمثّل الشهر واليوم لهذا الشهر، وأن لهذه الدالة طريقةً (غير محددة) لتحديد هذه القيم، والتحدي هنا هو إعادة قيمتين منفصلتين بنفس الوقت. إليك طريقةً لتجاوز هذه العقبة بالمثال: #include <stdio.h> #include <stdlib.h> void date(int *, int *); /* التصريح عن الدالة */ main(){ int month, day; date (&day, &month); printf("day is %d, month is %d\n", day, month); exit(EXIT_SUCCESS); } void date(int *day_p, int *month_p){ int day_ret, month_ret; /*حساب قيمة day و month في day_ret و month_ret*/ *day_p = day_ret; *month_p = month_ret; } [مثال 2] لاحظ طريقة التصريح عن date المتقدمة، التي توضح أنها دالةٌ تأخذ وسيطين من نوع "مؤشر إلى قيمة من نوع int"، وتعيد void لأن القيم التي تُمرّر بواسطة المؤشرات ليست من نوع قيمة اعتيادية. تمرِّر الدالة main المؤشرات إلى الدالة date على أنها وسطاء باستخدام المتغيرات الداخلية day_ret و month_ret، ومن ثم تأخذ قيمتهما وتسندها إلى الأماكن التي تشير إليها وسطاء الدالة (المؤشرات). يوضح الشكل 3 ما الذي يحدث عند استدعاء الدالة date: شكل 3 عند استدعاء الدالة date تُمرَّر الوسطاء إلى date، ولكن المتغيرين day و month غير مهيّأين بقيمةٍ أولية ضمن الدالة main. يوضح الشكل 4 ما الذي يحدث عندما تصل الدالة date إلى تعليمة return، بفرض أن قيمة day هي "12" وقيمة month هي "5". شكل 4 عندما تصل الدالة date إلى تعليمة return واحدةٌ من المزايا الرائعة التي قدّمتها لغة سي المعيارية هي السماح بالتصريح عن أنواع وسطاء دالة date مسبقًا، إذ كان نسيان أن الدالة تقبل مؤشرات وسطاءً لها وتمرير نوع آخر أمرًا شائع الحدوث. تخيل استدعاء الدالة date دون أي تصريح واضح مُسبقٍ لها على النحو التالي: date(day, month); لن يعرف المصرّف هنا أن الدالة تقبل المؤشرات وسطاءً لها وستُمرر قيمًا من نوع int افتراضيًا لكل من day و month، وبما أن تمرير المؤشرات والأعداد الصحيحة يجري على معظم الحواسيب بالطريقة نفسها، لذا ستُنفَّذ الدالة في هذه الحالة، ثم تعيد القيم في النهاية وتسندها إلى المكان الذي يشير إليه كلًا من day و month، إذا كانا مؤشرين. لن يعطي ذلك أي نتيجة بل وربما يتسبب بضرر مفاجئ للبيانات في مكان آخر بذاكرة الحاسوب، وتعقُّب هذا النوع من الأخطاء صعبٌ جدًا. لحسن الحظ، يمكن أن يعرف المصرّف المعلومات الكافية عن date بالتصريح عن الدالة مسبقًا، وذلك من شأنه أن يحذره بخصوص أي أخطاء مرتكبة. قد يفاجئك سماع أن المؤشرات لا تستخدم كثيرًا لتمكين طريقة الاستدعاء بالإشارة call-by-reference، إذ يُعدّ استخدام الاستدعاء بالقيمة call-by-value وإعادة قيمة واحدة باستخدام return كافٍ في معظم الحالات، والاستخدام الأكثر شيوعًا للمؤشرات هو الانتقال ما بين المصفوفات. المصفوفات والمؤشرات تملك عناصر المصفوفة عناوينًا مثل أي متغير اعتيادي آخر. int ar[20], *ip; ip = &ar[5]; *ip = 0; // يكافئ التعبير ar[5] = 0; في المثال السابق، يُخزَّن عنوان العنصر ar[5] في المؤشر ip، ثم تُسند القيمة صفر إلى موضع المؤشر في السطر الذي يليه. هذا الشيء غير مثير للإعجاب بحد ذاته، بل إن طريقة عمل العمليات الحسابية والمؤشر سويًّا هي التي تستدعي الاهتمام، فعلى الرغم من بساطة هذا الأمر، إلا أنه يُعد واحدًا من أساسات لغة سي المميزة. نحصل على مؤشر إذا أضفنا قيمة عدد صحيح إلى مؤشر ما، ويكون للمؤشر الذي حصلنا عليه نفس نوع المؤشر الأصلي؛ فبإضافة العدد "n" إلى مؤشر ما يشير إلى عنصر في مصفوفة، سنحصل على عنصر يشير إلى العنصر الذي يلي العنصر السابق بمقدار "n" داخل المصفوفة ذاتها، ويمكن تطبيق حالة الطرح بما أن العدد "n" يمكن أن يكون سالبًا. بالرجوع إلى المثال السابق، ينتج عن التعبير التالي: *(ip+1) = 0; تغيير قيمة ar[6] إلى صفر، وهكذا. لا تعدّ هذه الطريقة تحسينًا على طرق الوصول إلى عناصر المصفوفة الاعتيادية، إليك مثالًا عن ذلك بدلًا من السابق: int ar[20], *ip; for(ip = &ar[0]; ip < &ar[20]; ip++) *ip = 0; يوضّح المثال السابق ميزةً كلاسيكيةً للغة سي، إذ يشير المؤشر إلى بداية المصفوفة، وبينما يشير المؤشر إلى المصفوفة يمكن الوصول إلى عناصر المصفوفة واحدًا تلو الآخر بزيادة المؤشر بمقدار واحد كلّ مرة. يدعم معيار سي بعض الممارسات الموجودة وذلك بالسماح لاستخدام عنوان العنصر ar[20] على الرغم من عدم وجود هذا العنصر، ويسمح لك هذا باستخدام المؤشرات لاختبار حدود المصفوفة ضمن الحلقات التكرارية كما هو الحال في المثال السابق، إذ أن ضمان عمله يمتد لعنصر واحد فقط خارج نهاية المصفوفة وليس أكثر من ذلك. لكن ما المميز في هذه الطريقة مقارنةً باستخدام دليل المصفوفة للوصول إلى العنصر بالطريقة الاعتيادية؟ يمكن الوصول إلى عناصر المصفوفات في معظم الحالات بالتعاقب، واستعرضت القليل من الأمثلة البرمجية السابقة خيار الوصول إلى العناصر "عشوائيًا". إذا أردت الوصول إلى عناصر المصفوفة بالتعاقب فسيقدّم استخدام المؤشرات تنفيذًا أسرع، إذ يتطلب الأمر على معظم معماريات الحاسوب عملية ضرب وجمع واحدةً للوصول إلى عنصر ضمن مصفوفة أحادية البعد باستخدام دليله، بينما لا يتطلب الأمر باستخدام المؤشرات إجراء أي عمليات حسابية إطلاقًا، إذ يخزن المؤشر العنوان الدقيق للكائن (عنصر المصفوفة في هذه الحالة). العملية الحسابية الوحيدة المُجراة في المثال السابق هي ضمن حلقة for التكرارية، إذ تحدث عملية إضافة ومقارنة كل دورة داخل الحلقة. إذا أردنا استخدام طريقة الوصول لعناصر المصفوفة باستخدام الأدلة، نكتب: int ar[20], i; for(i = 0; i < 20; i++) ar[i] = 0; تحدث العمليات الحسابية ذاتها في الحلقة التكرارية كما في المثال السابق، لكن بإضافة حسابات العنوان المُجراة كل دورة في الحلقة. لا تعدّ نقطة توفير الوقت والفاعلية مشكلةً كبيرةً في معظم الأحيان، إلا أن الأمر مهمٌ هنا في حالة الحلقات التكرارية، إذ تتكرر الحلقات عددًا كبيرًا من المرات وكل جزء من الثانية يمكن توفيره في كل دورة له تأثير، ولا يستطيع المصرّف مهما كان ذكيًّا التعرُّف على جميع الحالات التي يمكن له استخدام المؤشرات بدلًا من طريقة دليل المصفوفة ضمنيًا. إذا استوعبت جميع ما قرأته حتى الآن فتابع معنا، وإلّا فتجاوز هذا القسم واذهب للمقال التالي، فعلى الرغم من المعلومات المثيرة للاهتمام في الأقسام التالية إلا أنها غير ضرورية وتُعرَف برهبتها لمبرمجي لغة سي المتمرسين حتى. في حقيقة الأمر، لا "تفهم" لغة سي مبدأ الوصول لعناصر المصفوفة باستخدام أدلتها (باستثناء نقطة التصريح عن المصفوفة)، فالتعبير x[n] يُترجم بالنسبة للمصرّف على النحو التالي: (x+n)*، إذ يُحوَّل اسم المصفوفة إلى مؤشر يشير إلى العنصر الأول للمصفوفة وذلك أينما وجد اسم المصفوفة ضمن تعبير ما. يُعد هذا سببٌ من ضمن أسباب أخرى لبدء عناصر المصفوفة بالرقم صفر؛ فإذا كان x اسم المصفوفة، سيكون التعبير &x[0] مساوٍ للمصفوفة x، أي مؤشر إلى العنصر الأول من المصفوفة. نستطيع الوصول إلى x[0] باستخدام المؤشرات باستخدام التعبير *(&x[0])، مما يعني أن *(&x[0] + 5) مساوٍ للتعبير *(x + 5) وهو ذات التعبير [x[5. يفتح ذلك الأمر سيلًا من التساؤلات عن الإمكانيات الناتجة، فإذا كان التعبير x[5] يُترجم إلى *(x + 5) والتعبير x + 5 يعطي النتيجة ذاتها للتعبير: 5 + x فالتعبير 5[x] مساوٍ للتعبير x[5]. إليك برنامجًا يُصرّف وينفذ دون أي أخطاء إن لم تصدق هذا الأمر: #include <stdio.h> #include <stdlib.h> #define ARSZ 20 main(){ int ar[ARSZ], i; for(i = 0; i < ARSZ; i++){ ar[i] = i; i[ar]++; printf("ar[%d] now = %d\n", i, ar[i]); } printf("15[ar] = %d\n", 15[ar]); exit(EXIT_SUCCESS); } [مثال 3] لتلخيص ما سبق: تبدأ العناصر في أي مصفوفة من الدليل ذي الرقم صفر. ليس هناك أي وجود للمصفوفات متعددة الأبعاد، بل هي في حقيقة الأمر مصفوفاتٌ تحتوي على مصفوفات. تُشير المؤشرات إلى أشياء، والمؤشرات التي تشير إلى أشياء من أنواع مختلفة هي بدورها من أنواع مختلفة أيضًا ولا يوجد أي تشابه بين الأنواع المختلفة في لغة سي وأي تحويل ضمني تلقائي بينهما. يمكن استخدام المؤشرات لمحاكاة استخدام الاستدعاء بالإشارة ضمن الدوال، ولكن الأمر يستغرق بعضًا من الجهد لتحقيقه. تُستخدم زيادة أو نقصان قيمة مؤشر ما للتنقل بين عناصر المصفوفة. يضمن المعيار أن محاولة الوصول إلى العنصر ذي الدليل "n" في مصفوفة ذات حجم "n" محاولةٌ صالحة على الرغم من عدم وجود هذا العنصر وذلك لتسهيل أمر التنقل داخل المصفوفة بزيادة قيمة المؤشر، ويكون مجال قيم مصفوفة مصرّح عنها على النحو int ar[N] هو &ar[0] وصولًا إلى &ar[N] ولكن يجب عليك تفادي الوصول إلى قيمة العنصر الأخير الزائف. الأنواع المؤهلة Qualified تابع قراءة الفقرات التالية إن كنت واثقًا من فهمك لأساسيات عملية التصريح عن المؤشرات واستخدامها، وإلا فمن المهم العودة إلى الفقرات السابقة ومحاولة فهمها جيّدًا قبل قراءة الفقرات التالية، إذ أن المعلومات المذكورة في الفقرات التالية أكثر تعقيدًا، ولا داعِ لجعل الأمر أسوأ بعدم تحضيرك وفهمك لما سبق. قدم المعيار شيئان باسم مؤهلات النوع type qualifiers، إذ لم يكونا في لغة سي القديمة مسبقًا، ويمكن تطبيقهما لأي نوع مصرّحٌ عنه للتعديل من تصرفه، ومن هنا أتى اسمهما. سنتجاهل إحداهما (المدعو باسم "volatile") إلا أنه لا يمكننا تجاهل الآخر "const". إذا سبقت الكلمة المفتاحية "const" أي تصريح، فهذا يعني أن الشيء الذي صُرّح عنه هو ثابت، ويجب عليك تجنب محاولة التغيير على قيمة الكائنات الثابتة "const" وإلا فستحصل على سلوك غير محدّد undefined behaviour، وسيحذّرك المصرّف عادةً بمنعك من هذه المحاولة إلا إذا تجاوزت هذا القيد بحيلةٍ ما. هناك فائدتان مرجوتان من تصريح كائن ما بكونه ثابتًا "const": يشير استخدام الكلمة المفتاحية "const" إلى أن القيمة غير قابلة للتغيير، مما يجبر المصرّف على التحقق من أي تغييرات طرأت على هذه القيمة ضمن الشيفرة البرمجية، وهذا الأمر باعث للطمأنينة في حال أردت استخدام قيمٍ ثابتة، مثل المؤشرات التي تُستخدم وسطاءً في بعض الدوال. إذا احتوى التصريح عن الدالة مؤشرات تشير إلى كائنات ثابتة على أنها وسطاء، فهذا يعني أن الدالة لن تشير إلى أي كائن آخر. عندما يعلم المصرّف بأن الأشياء هي كائنات ثابتة، ينعكس ذلك إيجابيًا على قدرته برفع فاعلية الشيفرة البرمجية وسرعتها. الثوابت عديمة الفائدة في حال لم تسند إليها أي قيمة، لن نتطرق بالتفصيل بخصوص تهيئة الثوابت (سنناقش الأمر لاحقًا)، كل ما عليك تذكره الآن هو أنه من الممكن لأي تصريح إسناد القيمة لتعبيرٍ ثابت. إليك بعض الأمثلة عن التصريح عن ثوابت: const int x = 1; /* ثابت x */ const float f = 3.5; /* ثابت f*/ const char y[10]; /* y مصفوفة من 10 عناصر ذات قيم صحيحة ثابتة */ /* لا تفكر بخصوص تهيئة قيمها بعد */ ما يثير الاهتمام هو كون هذا المؤهل ممكن التطبيق على المؤشرات بطريقتين: إما بجعل الشيء الذي يشير إليه المؤشر ثابتًا، بحيث يصبح نوع المؤشر "مؤشر إلى ثابت"، أو بجعل المؤشر بذات نفسه ثابتًا (مؤشرًا ثابتًا)، إليك مثالًا عن ذلك: int i; /* عدد صحيح اعتيادي i */ const int ci = 1; /* عدد صحيح ثابت ci */ int *pi; /* مؤشر إلى عدد صحيح pi */ const int *pci; /* مؤشر إلى عدد صحيح ثابت pci */ /* بالانتقال إلى الأمثلة الأكثر تعقيدًا */ // مؤشر ثابت يشير إلى قيمة عدد صحيح cpi int *const cpi = &i; // مؤشر ثابت يشير إلى قيمة عدد صحيح ثابتة cpci const int *const cpci = &ci; التصريح الأول (للمتغير i) اعتيادي، ولكن تصريح ci يوضح أنه عدد صحيح ثابت وبذلك لا يمكن التعديل على قيمته، وسيكون بلا فائدة إن لم يُهيّأ (إسناد قيمة أولية له). ليس من الصعب فهم الغرض من مؤشر لعدد صحيح، ومؤشر لعدد صحيح ثابت، ولكن يجب الانتباه إلى أنواع المؤشرات المختلفة، إذ لا يجوز الخلط بينهم. يمكنك تغيير قيمة كل من pi و pci بجعلهما يشيران إلى أشياء أخرى، كما يمكنك تغيير قيمة الشيء الذي يشير إليه المؤشر pi بالنظر إلى كونه عدد صحيح غير ثابت، ولكن لا يمكنك إلّا الوصول إلى قيمة الشيء الذي يشير إليه المؤشر pci دون التعديل عليه نظرًا لكونه ثابتًا. يُعد التصريحان الأخيران أكثر التصريحات تعقيدًا ضمن المثال؛ فإذا كانت المؤشرات بذات نفسها ثابتةً، فمن غير المسموح تغيير المكان الذي تشير إليه، وبالتالي يجب تهيأتهما بقيمة أولية مثل ci. يمكن للشيء المُشار إليه بالمؤشر أن يكون ثابتًا أو غير ثابت بغض النظر عن كون المؤشر ثابتًا بدوره أم لا، وهذا يملي بعض القيود على استخدام الكائن المُشار إليه. أخيرًا للتوضيح: ما الذي يملي وجود نوع مؤهّل؟ كان ci في المثال السابق نوعًا مؤهلًا بكل وضوح، ولكن pci لم تنطبق عليه هذه الحالة بما أن المؤشر ليس من نوع مؤهّل بل الشيء الذي يشير إليه. الأشياء الوحيدة الذي كانت ذات أنواع مؤهلة في المثال هي: ci و cpi و cpci. سيتطلب منك الأمر بعض الوقت للاعتياد على هذا النوع من التصريحات، ولكن استخدامها سيكون تلقائيًّا وطبيعيًا بعد فترة فلا تقلق، إلا أن التعقيدات تبدأ بالظهور لاحقًا عندما يتوجب عليك الإجابة على السؤال: "هل من المسموح لي -على سبيل المثال- مقارنة مؤشر اعتيادي مع مؤشر ثابت؟ وإذا كان الجواب نعم، ما الذي تعنيه المقارنة؟". معظم القوانين واضحة بهذا الخصوص، ولكن يجب ذكرها وتوضيحها بغض النظر عن سهولتها. سنتكلم عن أنواع البيانات المؤهلة بتوسعٍ أكبر لاحقًا. عمليات المؤشرات الحسابية سنتكلم بالتفصيل لاحقًا عن عمليات المؤشرات الحسابية، ولكننا سنكتفي الآن بإصدار مختصرٍ يفي بالغرض. يمكنك الطرح أو المقارنة بين مؤشرين من النوع نفسه بالإضافة إلى إضافة قيمة عددية صحيحة إلى المؤشر، ويجب أن يشير كلا المؤشرين إلى المصفوفة ذاتها وإلا حصلنا على سلوك غير محدد. نتيجة طرح مؤشرين هي قيمة العناصر التي تفصل بينهما في المصفوفة، ونوع النتيجة معرفٌ بحسب التطبيق وسيكون إما "short" أو "int" أو "long"، ويوضح المثال القادم مثالًا على حساب الفرق بين مؤشرين واستخدام النتيجة، ولكن قبل أن ننتقل إلى المثال يجب أن تعرف معلومةً مهمة. يُحوَّل اسم المصفوفة في أي تعبير إلى مؤشر يشير إلى العنصر الأول ضمن هذه المصفوفة، والحالة الوحيدة الاستثنائية هي عند استخدام اسم المصفوفة مع الكلمة المفتاحية "sizeof"، أو عند استخدام سلسلة نصية لتهيئة قيمة مصفوفة ما، أو عندما يكون اسم المصفوفة مرتبطًا بعامل "عنوان الكائن" (العامل الأحادي "&")، لكننا لم نتطرق إلى أيّ من الحالات السابقة بعد، وسنناقشها لاحقًا. إليك المثال: #include <stdio.h> #include <stdlib.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %d\n", (int)(fp2-fp1)); fp2++; } exit(EXIT_SUCCESS); } [مثال 4] يشير المؤشر fp2 إلى عناصر المصفوفة، ويُطبع الفرق بين قيمته الحالية وقيمته الأصلية، وللتأكد من عدم تمرير النوع الخاطئ للوسيط للدالة printf تُحوَّل القيمة الناتجة عن فرق المؤشرين قسريًّا إلى int باستخدام تحويل الأنواع (int)، وهذا يجنّبنا من الأخطاء على الحواسيب التي تعيد قيمة long لهذا النوع من العمليات. قد يعود إلينا المثال السابق بإجابات خاطئة إذا كان الفرق بين القيمتين من نوع long وكانت المصفوفة كبيرة الحجم، ونلاحظ في المثال التالي إصدارًا آمنًا من المثال السابق، إذ يُستخدم تحويل الأنواع قسريًا للسماح بوجود قيم long: #include <stdio.h> #define ARSZ 10 main(){ float fa[ARSZ], *fp1, *fp2; fp1 = fp2 = fa; /* عنوان العنصر الأول */ while(fp2 != &fa[ARSZ]){ printf("Difference: %ld\n", (long)(fp2-fp1)); fp2++; } return(0); } [مثال 5] مؤشرات void و null والمؤشرات الإشكالية لغة سي حريصة بشأن أنواع المؤشرات، ولن تسمح لك عمومًا باستخدام مؤشرات ذات أنوع مختلفة ضمن التعبير ذاته. يختلف مؤشر إلى نوع "char" عن مؤشر إلى نوع "int" ولا يمكنك -على سبيل المثال- إسناد قيمة أحدهما إلى الآخر أو المقارنة فيما بينهما أو طرحهما من بعضهما واستخدام النتيجة مثل وسيط في دالة ما، كما يمكن أيضًا تخزين النوعين في الذاكرة بصورةٍ مختلفة وأن يكونا بأطوال مختلفة. لكن نريد في بعض الحالات تجاوز هذه القيود، فكيف نفعل ذلك؟ يكمن الحل هنا باستخدام أنواع خاصة، وقد قدمنا واحدًا من هذه الأنواع سابقًا ألا وهو "مؤشر إلى void"، وقُدّمت هذه الميزة مع سي المعيارية إذ افتُرض سابقًا أن المؤشر من نوع "مؤشر إلى char" كافٍ لهذه المهمة، وكان الافتراض صحيحًا إلى حدٍّ ما إلا أنه كان حلًّا غير منظّمًا، بينما قدّم الحل الجديد طريقةً أكثر أمانًا وأقل تشويشًا. لا يوجد أي استخدام للمؤشر هذا، لأن "* void" لا يشير إلى أي قيمة، لذا يحسّن هذا الأمر من سهولة قراءة الشيفرة البرمجية. يمكن أن يخزن المؤشر من النوع "* void" أي قيمة من أي مؤشر آخر، ويمكن إسناده إلى مؤشر آخر من أي نوع أيضًا، إلا أنه يجب استخدام هذا النوع من المؤشرات بحذر لأنه قد ينتهي الأمر بك ببعض الأخطاء الوخيمة، وسنناقش استخدامه الآمن مع دالة "malloc" لاحقًا. قد تحتاج أيضًا في بعض الحالات إلى مؤشر مضمون أنه لا يشير إلى أي كائن والذي يُدعى مؤشر من نوع "null" أو مؤشر الفراغ null pointer. من الشائع في لغة سي كتابة بعض الإجراءات routines التي تعيد مؤشرات، بحيث يمكن الدلالة على فشل ذلك الإجراء بعدم قدرته على إعادة مؤشر صالح عن طريق إعادة مؤشر الفراغ. ومن الأمثلة على ذلك إجراء فحصٍ لقيم موجودة في جدول ما بحثًا عن قيمة معينة ويعيد مؤشرًا على الكائن المُطابق إن وُجدت النتيجة أو مؤشر الفراغ إن لم تُوجد أي نتيجةٍ مطابقة. لكن كيف يمكن كتابة مؤشر فراغ؟ هناك طريقتان لفعل ذلك وكلا الطريقتين متماثلتين في النتيجة، إما باستخدام رقم صحيح ثابت بقيمة "0" أو تحويل القيمة إلى نوع "* void" باستخدام التحويل بين الأنواع، وتدعى نتيجة الطريقتين بمؤشر الفراغ الثابت null pointer constant. إذا أسندت مؤشر فراغ إلى أي مؤشر آخر أو قارنت بين مؤشر الفراغ ومؤشر آخر فسيُحوَّل مؤشر الفراغ إلى نوع المؤشر الآخر تلقائيًّا، مما سيحلّ أي مشكلة بخصوص توافقية الأنواع، ولن تُساوي القيمة التي يشير إليها ذلك المؤشر -مؤشر الفراغ- أي قيمة كائن آخر يشير إليها أي مؤشر داخل البرنامج (أي سيشير إلى قيمة فريدة). القيم الوحيدة الممكن إسنادها للمؤشرات باستثناء القيمة "0" هي قيم المؤشرات الأخرى من نفس النوع، إلا أن الأمر الذي يجعل من لغة سي مميزة وبديلًا مفيدًا للغة التجميعية هو سماحها لك بفعل بعض الأشياء التي لا تسمح لك بها معظم لغات البرمجة الأخرى، جرّب التالي: int *ip; ip = (int *)6; *ip = 0xFF; ما نتيجة السابق؟ تُهيأ قيمة المؤشر إلى 6 (لاحظ تحويل نوع 6 من int إلى مؤشر)، وهذه عملية تُجرى على مستوى الآلة غالبًا ويكون تمثيل قيمة المؤشر بالبتات غير مشابه لما قد يكون تمثيل الرقم 6، كما تُسند القيمة الست عشرية FF بعد التهيئة إلى الكائن الذي يشير إليه المؤشر. تُكتب القيمة 0xFF على الرقم الصحيح ذو الموضع 6، إذ يعتمد الموضع 6 على تفسير الآلة له على الذاكرة. قد تحتاج لهذا النوع من الأشياء وقد لا تحتاج إليها إطلاقًا، ولكن لغة سي تعطيك الخيار، ومن الواجب معرفتها إذ أنه من الممكن كتابتها على نحوٍ خاطئ غير مقصود مما سيتسبب بنتائج مفاجئة جدًا. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book. اقرأ أيضًا المقال التالي: التعامل مع المحارف والسلاسل النصية في لغة سي C المقال السابق: مدخل إلى المصفوفات في لغة سي C مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C البنية النصية لبرامج سي C -
 تستخدم لغة سي المصفوفات Arrays مثل سائر اللغات الأخرى لتمثيل مجموعة من متغيرات ذات خصائص متماثلة، إذ يكون لهذه المجموعة اسمًا واحدًا وتُحدّد عناصرها عن طريق دليل Index. إليك مثالًا للتصريح عن مصفوفةٍ ما: double ar[100]; في هذا المثال اسم المصفوفة هو ar ويمكن الوصول لعناصر المصفوفة عن طريق دليل كلٍّ منها كما يلي: ar[0] وصولًا إلى ar[99] لا غير، كما يوضح الشكل 1: شكل 1 مصفوفة ذات 100 عنصر يمثّل كلّ عنصر من عناصر المصفوفة المئة متغيّرًا منفصلًا من نوع double، ويُرمز لكل عنصر من أي مصفوفة في لغة سي بدءًا من الدليل 0 وصولًا إلى الدليل الذي يساوي حجم المصفوفة المُصرّح عنه ناقص واحد، ويعدّ البدء بالترقيم من 0 مفاجئًا لبعض المبتدئين فركّز على هذه النقطة. عليك أن تنتبه أيضًا إلى أن المصفوفات لا تقبل حجمًا متغيّرًا عند التصريح عنها، إذ يجب أن يكون الرقم تعبيرًا ثابتًا يمكن معرفة قيمته الثابتة وقت تصريف البرنامج compile time وليس وقت التشغيل run time. يوضح المثال التالي طريقة خاطئة للتصريح عن مصفوفة باستخدام الوسيط x: f(int x){ char var_sized_array[x]; /* هذه الطريقة ممنوعة*/ } وهذا ممنوع لأن قيمة x غير معروفة عند تصريف البرنامج، فهي قيمة تُعرف عند تشغيل البرنامج وليس عند تصريفه. من الأسهل لو كان مسموحًا استخدام المتغيرات لتحديد حجم المصفوفات وبالأخص البعد الأوّل لها، ولكن هذا الأمر لم تسمح به سي القديمة أو سي المعيارية، إلا أن هناك مصرّف قديم جدًا للغة سي اعتاد السماح بهذا. المصفوفات متعددة الأبعاد يمكن التصريح عن المصفوفات متعددة الأبعاد Multidimensional arrays على النحو التالي: int three_dee[5][4][2]; int t_d[2][3] تُستخدم الأقواس المعقوفة بعد كلٍّ من المصفوفات السابقة، وإذا نظرت إلى جدول الأسبقية في مقال العوامل في لغة سي C، فستلاحظ أن قراءة القوسين [] تكون من اليسار إلى اليمين وبذلك تكون نتيجة التصريح مصفوفةً تحتوي على خمس عناصر باسم three_dee، ويحتوي كل عنصر من عناصر هذه المصفوفة بدوره على مصفوفة بحجم أربعة عناصر وكل عنصر من هذه المصفوفة الأخيرة يحتوي على مصفوفة من عنصرين، وجميع العناصر من نوع int، وبهذه الحالة فنحن صرحنا عن مصفوفة مصفوفات، ويوضح الشكل 2 مثالًا على مصفوفة ثنائية البعد باسم t_d في مثال التصريح. شكل 2 هيكل مصفوفة ثنائية البعد ستلاحظ في الشكل السابق أن t_d[0] عنصرٌ واحدٌ متبوعٌ بعنصر t_d[1] دون أي فواصل، وكلا العنصرين يمثّلان مصفوفةً بحدّ ذاتهما بسعة ثلاث أعداد صحيحة. يأتي العنصر t_d[1][0] مباشرةً بعد العنصر t_d[0][2]، ومن الممكن الوصول إلى t_d[1][0] بالاستفادة من عدم وجود أي طريقة للتحقق من حدود المصفوفة باستخدام التعبير t_d[0][3] إلا أن هذا غير محبّذ أبدًا، لأن النتائج ستكون غير متوقعة إذا تغيّرت تفاصيل التصريح عن المصفوفة t_d. حسنًا، لكن هل هذا الأمر يؤثر على سلوك البرنامج عمليًّا؟ في الحقيقة لا، إلا أنه من الجدير بالذكر أن موقع تخزين العنصر الواقع على أقصى اليمين ضمن المصفوفة "يتغير بسرعة"، ويؤثر ذلك على المصفوفات عند استخدام المؤشرات معها، ولكن يمكن استخدامها بشكلها الطبيعي عدا عن تلك الحالة، مثل التعابير التالية: three_dee[1][3][1] = 0; three_dee[4][3][1] += 2; التعبير الأخير مثيرٌ للاهتمام لسببين، أولهما أنه يصل إلى قيمة العنصر الأخير من المصفوفة والمصرّح أنها بحجم [2][4][5]، والدليل الذي نستطيع استخدامه هو أقل بواحد دائمًا من العدد الذي صرّحنا عنه، أما ثانيًا، فنلاحظ أهمية وسهولة استخدام عامل الإسناد المُركّب في هذه الحالة. يفضّل مبرمجو لغة سي المتمرسون هذه الطريقة المختصرة، إليك كيف سيبدو الأمر لو كان التعبير مكتوبًا بلغة أخرى لا تسمح باستخدام هذا العامل: three_dee[4][3][1] = three_dee[4][3][1] + 2; ففي هذه الحالة يجب أن يتحقق القارئ أن العنصر على يمين عامل الإسناد هو ذات العنصر على يسار عامل الإسناد، كما أن الطريقة المُختصرة أفضل عند تصريفها، إذ يُحسب دليل العنصر وقيمته مرةً واحدة، مما ينتج شيفرةً برمجيةً أقصر وأسرع. قد ينتبه بعض المصرّفات طبعًا إلى أن العنصرين على طرفَي عامل الإسناد متساويين ولن تلجأ للوصول للقيمة مرتين، ولكن هذه الحالة لا تنطبق على جميع المصرّفات، وهناك العديد من الحالات أيضًا التي لا تستطيع فيها المصرفات الذكية هذه باختصار الخطوات. على الرغم من تقديم لغة سي دعمًا للمصفوفات متعددة الأبعاد، إلا أنه من النادر أن تجدها مُستخدمةً عمليًّا، إذ تُستخدم المصفوفات أحادية البعد أكثر في معظم البرامج، وأبسط هذه الأسباب هو أن السلسلة النصية String تُمثّل بمصفوفة أحادية البعد، وقد تلاحظ استخدام المصفوفات ثنائية البعد في بعض الحالات، ولكن استخدام المصفوفات ذات أبعاد أكثر من ذلك نادرة الحدوث، وذلك لكون المصفوفة هيكل بيانات غير مرن بالتعامل، كما أن سهولة عملية إنشاء ومعالجة هياكل البيانات وأنواعها في لغة سي تعني إمكانية استبدال المصفوفات في معظم البرامج متقدمة المستوى، وسننظر إلى هذه الطرق عندما ننظر إلى المؤشرات. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: المؤشرات Pointers في لغة سي C المقال السابق: مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C الدوال في لغة C البنية النصية لبرامج سي C
تستخدم لغة سي المصفوفات Arrays مثل سائر اللغات الأخرى لتمثيل مجموعة من متغيرات ذات خصائص متماثلة، إذ يكون لهذه المجموعة اسمًا واحدًا وتُحدّد عناصرها عن طريق دليل Index. إليك مثالًا للتصريح عن مصفوفةٍ ما: double ar[100]; في هذا المثال اسم المصفوفة هو ar ويمكن الوصول لعناصر المصفوفة عن طريق دليل كلٍّ منها كما يلي: ar[0] وصولًا إلى ar[99] لا غير، كما يوضح الشكل 1: شكل 1 مصفوفة ذات 100 عنصر يمثّل كلّ عنصر من عناصر المصفوفة المئة متغيّرًا منفصلًا من نوع double، ويُرمز لكل عنصر من أي مصفوفة في لغة سي بدءًا من الدليل 0 وصولًا إلى الدليل الذي يساوي حجم المصفوفة المُصرّح عنه ناقص واحد، ويعدّ البدء بالترقيم من 0 مفاجئًا لبعض المبتدئين فركّز على هذه النقطة. عليك أن تنتبه أيضًا إلى أن المصفوفات لا تقبل حجمًا متغيّرًا عند التصريح عنها، إذ يجب أن يكون الرقم تعبيرًا ثابتًا يمكن معرفة قيمته الثابتة وقت تصريف البرنامج compile time وليس وقت التشغيل run time. يوضح المثال التالي طريقة خاطئة للتصريح عن مصفوفة باستخدام الوسيط x: f(int x){ char var_sized_array[x]; /* هذه الطريقة ممنوعة*/ } وهذا ممنوع لأن قيمة x غير معروفة عند تصريف البرنامج، فهي قيمة تُعرف عند تشغيل البرنامج وليس عند تصريفه. من الأسهل لو كان مسموحًا استخدام المتغيرات لتحديد حجم المصفوفات وبالأخص البعد الأوّل لها، ولكن هذا الأمر لم تسمح به سي القديمة أو سي المعيارية، إلا أن هناك مصرّف قديم جدًا للغة سي اعتاد السماح بهذا. المصفوفات متعددة الأبعاد يمكن التصريح عن المصفوفات متعددة الأبعاد Multidimensional arrays على النحو التالي: int three_dee[5][4][2]; int t_d[2][3] تُستخدم الأقواس المعقوفة بعد كلٍّ من المصفوفات السابقة، وإذا نظرت إلى جدول الأسبقية في مقال العوامل في لغة سي C، فستلاحظ أن قراءة القوسين [] تكون من اليسار إلى اليمين وبذلك تكون نتيجة التصريح مصفوفةً تحتوي على خمس عناصر باسم three_dee، ويحتوي كل عنصر من عناصر هذه المصفوفة بدوره على مصفوفة بحجم أربعة عناصر وكل عنصر من هذه المصفوفة الأخيرة يحتوي على مصفوفة من عنصرين، وجميع العناصر من نوع int، وبهذه الحالة فنحن صرحنا عن مصفوفة مصفوفات، ويوضح الشكل 2 مثالًا على مصفوفة ثنائية البعد باسم t_d في مثال التصريح. شكل 2 هيكل مصفوفة ثنائية البعد ستلاحظ في الشكل السابق أن t_d[0] عنصرٌ واحدٌ متبوعٌ بعنصر t_d[1] دون أي فواصل، وكلا العنصرين يمثّلان مصفوفةً بحدّ ذاتهما بسعة ثلاث أعداد صحيحة. يأتي العنصر t_d[1][0] مباشرةً بعد العنصر t_d[0][2]، ومن الممكن الوصول إلى t_d[1][0] بالاستفادة من عدم وجود أي طريقة للتحقق من حدود المصفوفة باستخدام التعبير t_d[0][3] إلا أن هذا غير محبّذ أبدًا، لأن النتائج ستكون غير متوقعة إذا تغيّرت تفاصيل التصريح عن المصفوفة t_d. حسنًا، لكن هل هذا الأمر يؤثر على سلوك البرنامج عمليًّا؟ في الحقيقة لا، إلا أنه من الجدير بالذكر أن موقع تخزين العنصر الواقع على أقصى اليمين ضمن المصفوفة "يتغير بسرعة"، ويؤثر ذلك على المصفوفات عند استخدام المؤشرات معها، ولكن يمكن استخدامها بشكلها الطبيعي عدا عن تلك الحالة، مثل التعابير التالية: three_dee[1][3][1] = 0; three_dee[4][3][1] += 2; التعبير الأخير مثيرٌ للاهتمام لسببين، أولهما أنه يصل إلى قيمة العنصر الأخير من المصفوفة والمصرّح أنها بحجم [2][4][5]، والدليل الذي نستطيع استخدامه هو أقل بواحد دائمًا من العدد الذي صرّحنا عنه، أما ثانيًا، فنلاحظ أهمية وسهولة استخدام عامل الإسناد المُركّب في هذه الحالة. يفضّل مبرمجو لغة سي المتمرسون هذه الطريقة المختصرة، إليك كيف سيبدو الأمر لو كان التعبير مكتوبًا بلغة أخرى لا تسمح باستخدام هذا العامل: three_dee[4][3][1] = three_dee[4][3][1] + 2; ففي هذه الحالة يجب أن يتحقق القارئ أن العنصر على يمين عامل الإسناد هو ذات العنصر على يسار عامل الإسناد، كما أن الطريقة المُختصرة أفضل عند تصريفها، إذ يُحسب دليل العنصر وقيمته مرةً واحدة، مما ينتج شيفرةً برمجيةً أقصر وأسرع. قد ينتبه بعض المصرّفات طبعًا إلى أن العنصرين على طرفَي عامل الإسناد متساويين ولن تلجأ للوصول للقيمة مرتين، ولكن هذه الحالة لا تنطبق على جميع المصرّفات، وهناك العديد من الحالات أيضًا التي لا تستطيع فيها المصرفات الذكية هذه باختصار الخطوات. على الرغم من تقديم لغة سي دعمًا للمصفوفات متعددة الأبعاد، إلا أنه من النادر أن تجدها مُستخدمةً عمليًّا، إذ تُستخدم المصفوفات أحادية البعد أكثر في معظم البرامج، وأبسط هذه الأسباب هو أن السلسلة النصية String تُمثّل بمصفوفة أحادية البعد، وقد تلاحظ استخدام المصفوفات ثنائية البعد في بعض الحالات، ولكن استخدام المصفوفات ذات أبعاد أكثر من ذلك نادرة الحدوث، وذلك لكون المصفوفة هيكل بيانات غير مرن بالتعامل، كما أن سهولة عملية إنشاء ومعالجة هياكل البيانات وأنواعها في لغة سي تعني إمكانية استبدال المصفوفات في معظم البرامج متقدمة المستوى، وسننظر إلى هذه الطرق عندما ننظر إلى المؤشرات. ترجمة -وبتصرف- لقسم من الفصل Arrays and Pointers من كتاب The C Book اقرأ أيضًا المقال التالي: المؤشرات Pointers في لغة سي C المقال السابق: مفهوم النطاق Scope والربط Linkage على مستوى الدوال في لغة C مفهوم التعاود Recursion وتمرير الوسطاء إلى الدوال في لغة سي C الدوال في لغة C البنية النصية لبرامج سي C